ainews-not-much-technical-happened-today
今天技术方面没发生什么大事。
OpenAI 宣布以 1570 亿美元的估值筹集了 66 亿美元的新资金,同时 ChatGPT 的周活跃用户数已达到 2.5 亿。Poolside 筹集了 5 亿美元以推进通用人工智能(AGI)的开发。LiquidAI 推出了三款新的混合专家(MoE)模型(1B、3B、40B),具备 32k 上下文窗口和高效的 Token 处理能力。OpenAI 发布了 Whisper V3 Turbo,这是一款在速度上有显著提升的开源多语言模型。Meta AI FAIR 正在招聘研究实习生,重点关注 LLM 推理、对齐、合成数据和新型架构。Cohere 与富士通(Fujitsu)合作推出了定制日语模型 Takane。技术讨论包括 LoRA 微调中的挑战、Keras 中的 float8 量化,以及用于智能体模板的新工具(如 create-llama)。行业评论对 AI 发展的优先级表示担忧,并强调了 AI 领域的自由职业机会。
融资就是你所需要的一切。
2024年10月1日至10月2日的 AI 新闻。我们为您检查了 7 个 subreddits、433 个 Twitters 和 31 个 Discords(225 个频道和 1832 条消息)。预计节省阅读时间(按每分钟 200 字计算):219 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
今天 OpenAI 宣布以 1570 亿美金的估值筹集了 66 亿美金的新融资。在 Twitter 上,ChatGPT 产品负责人 Nick Turley 还补充道 “周活跃用户达到 2.5 亿,高于约一个月前的 2 亿”。
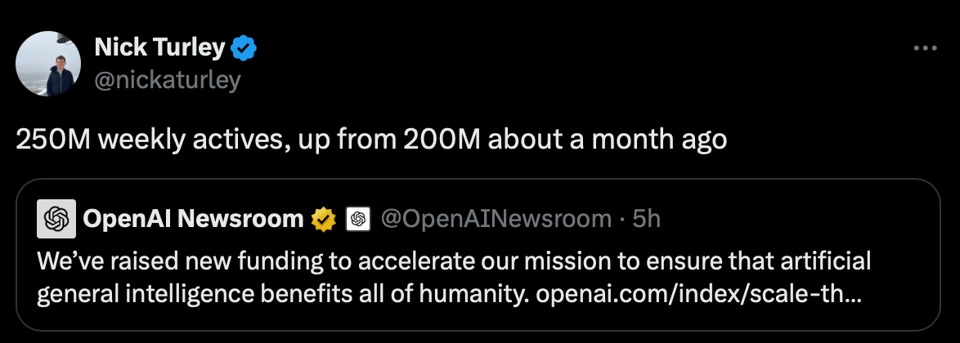
同样在融资新闻中,Poolside 宣布融资 5 亿美金,以推动 AGI 的进程。
AI Twitter 摘要
所有摘要均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
AI 模型进展与行业动态
-
新 AI 模型与能力:@LiquidAI_ 发布了三个新模型:1B、3B 和 40B MoE(12B 激活),采用了自定义的 Liquid Foundation Models (LFMs) 架构,在基准测试中表现优于 Transformer 模型。这些模型拥有 32k 上下文窗口和极小的内存占用,能够高效处理 1M token。@perplexity_ai 预告了即将推出的功能 “⌘ + ⇧ + P — coming soon”,暗示其 AI 平台将迎来新功能。
-
开源与模型发布:@basetenco 报道称 OpenAI 发布了 Whisper V3 Turbo,这是一个开源模型,其相对速度比 Whisper Large 快 8 倍,比 Medium 快 4 倍,比 Small 快 2 倍,拥有 809M 参数并支持全多语言。@jaseweston 宣布 FAIR 正在招聘 2025 年研究实习生,重点关注 LLM 推理、对齐 (alignment)、合成数据和新颖架构等主题。
-
行业合作伙伴与产品:@cohere 推出了 Takane,这是与 Fujitsu Global 合作开发的业界领先的定制日语模型。@AravSrinivas 预告了某款 AI 产品即将推出 Mac 应用,预示着 AI 工具正在向桌面平台扩展。
AI 研究与技术讨论
-
模型训练与优化:@francoisfleuret 对使用 10,000 块 H100 训练单个模型表示不确定,强调了大规模 AI 训练的复杂性。@finbarrtimbers 对 1B 模型表现变好所带来的 推理时搜索 (inference time search) 潜力感到兴奋,这暗示了条件计算 (conditional compute) 的新可能性。
-
技术挑战:@_lewtun 强调了 LoRA 微调和聊天模板的一个关键问题,强调需要将 embedding 层和 LM head 包含在可训练参数中,以避免输出乱码。这适用于使用 ChatML 和 Llama 3 聊天模板训练的模型。
-
AI 工具与框架:@fchollet 分享了如何使用
.quantize(policy)在 Keras 模型上启用 float8 训练或推理,展示了该框架对各种量化形式的灵活性。@jerryjliu0 介绍了 create-llama,这是一个可以快速生成由 Python 和 TypeScript 中的 LlamaIndex 工作流驱动的完整 Agent 模板的工具。
AI 行业趋势与评论
-
AI 发展类比:@mmitchell_ai 分享了对科技行业 AI 进步方式的批评,将其比作一个目标是寻找逃生口而非造福社会的电子游戏。这一观点突显了对 AI 发展方向的担忧。
-
AI 自由职业机会:@jxnlco 概述了自由职业者在 AI 淘金热中注定会大获全胜的原因,理由包括高需求、AI 系统的复杂性以及解决各行业实际问题的机会。
-
AI 产品发布:@swyx 将 Google DeepMind 的 NotebookLM 与 ChatGPT 进行了比较,指出了其多模态 RAG 能力以及 LLM 在产品功能中的原生集成。这突显了 AI 驱动的生产力工具中持续的竞争与创新。
梗与幽默
-
@bindureddy 幽默地评论了 Sam Altman 关于 AI 模型的言论,指出了一种批评当前模型同时炒作未来模型的模式。
-
@svpino 开玩笑说只需每月 2 美元就能托管年收入 110 万美元的网站,强调了网站托管的低成本,并嘲讽了过度复杂的解决方案。
AI Reddit 摘要
/r/LocalLlama 摘要
主题 1. OpenAI 的 Whisper Turbo:浏览器端语音识别的突破
- 令人抓狂的 Whisper 版本混乱(得分:30,评论:14):该帖子讨论了 Whisper 的众多版本,包括尺寸变体(base, small, tiny, large, turbo)、版本迭代(v1, v2, v3)、特定语言模型(English-only)以及专注于性能的变体(faster whisper, insanely-fast whisper)。作者寻求关于选择合适的 Whisper 模型的指导,并考虑了 GPU 性能和语言需求等因素,特别提到了用于英语的 medium.en 以及可能用于外语转录/翻译的更大版本。
- Whisper-ctranslate2(基于 faster-whisper)被推荐为最快的选择,而非英语用途则建议使用 large 模型。版本比较显示 v2 和 v3 的表现优于 v1,而 v3 的性能在不同语言上有所差异。
- large Whisper 模型的硬件要求包括 6GB VRAM(最低),CPU 推理速度约为 0.2-0.5 倍实时速度。有用户报告 WhisperX 在 8GB fp32 GPU 上会崩溃,而 fp16 在较低 VRAM 占用下表现更好。
- 现有的 Whisper 模型性能基准测试包括 FP16 基准测试 和 large v3 基准测试。对于快速 CPU 使用场景,建议使用 whisperfile(Whisper 的 llamafile 封装版本)等替代方案。
- OpenAI 的新 Whisper Turbo 模型通过 Transformers.js 在浏览器中 100% 本地运行(得分:456,评论:52):OpenAI 的 Whisper Turbo 模型现在可以使用 Transformers.js 在 Web 浏览器中 100% 本地运行,从而实现无需将数据发送到外部服务器的语音转文字转录。该实现利用 WebGPU 进行加速处理,在兼容设备上达到实时转录速度,并提供 WebGL 回退方案以实现更广泛的兼容性。
- Whisper large-v3-turbo 模型可达到 ~10x RTF(实时因子),在 M3 Max 上仅需 ~12 秒即可转录 120 秒的音频。它是 Whisper large-v3 的蒸馏版本,将解码层从 32 层减少到 4 层,在保持较小质量损失的同时实现了更快的处理速度。
- 该模型使用 Transformers.js 和 WebGPU 在浏览器中 100% 本地运行,无需访问 OpenAI 服务器。这个 800MB 的模型被下载并存储在浏览器的缓存存储中,通过 service workers 实现离线使用。
- 用户讨论了该模型的多语言能力和潜在的准确度变化。该模型的实时版本已在 Hugging Face 上线,也可以通过 ggerganov 的 whisper.cpp 离线使用。
- Transformers 现已支持 Whisper Turbo 🔥(得分:174,评论:33):Hugging Face 的开源音频团队发布了 Transformers 格式的 Whisper Turbo,其特点是一个拥有 8.09 亿参数的模型,比 Large v3 快 8 倍且体积小 2 倍。该多语言模型支持时间戳,并使用 4 个解码层而非 32 层。在 Transformers 中的实现仅需极少代码即可使用 ylacombe/whisper-large-v3-turbo 权重完成自动语音识别任务。
- 讨论了 Whisper Turbo 的性能,用户将其与 faster-whisper 和 Nvidia Canary 进行了比较。后者被指出位列 Open ASR 排行榜榜首,但支持的语言较少。
- GGUF 支持在请求发出后几小时内便迅速实现了,开发者提供了 GitHub pull request 和 模型权重 (checkpoints) 的链接。
- 用户确认了 Whisper Turbo 与 Mac M 系列芯片的兼容性,并提供了在 MPS 上运行的代码修改建议。一名用户报告在 4090 GPU 上达到了 820 倍实时速度且没有性能损失。
主题 2:当前 LLM 架构的收敛与局限性
- 所有 LLM 都在向同一点收敛 (Score: 108, Comments: 57): 包括 Gemini、GPT-4、GPT-4o、Llama 405B、MistralLarge、CommandR 和 DeepSeek 2.5 在内的多种大语言模型 (LLMs) 被用于生成一个包含 100 个项目的列表,结果前六个模型生成的数据库和分组几乎完全相同。作者观察到,尽管这些模型在“废话”或无关文本上有所不同,但其主要数据输出呈现出收敛趋势,从而得出结论:这些 LLM 正在趋向于一个共同点,而这并不一定预示着人工超级智能 (ASI) 的到来。
- ArsNeph 认为 LLM 的收敛是由于过度依赖来自 GPT 家族的合成数据,导致了广泛的“GPT 废话 (GPT slop)”和原创性的缺乏。开源微调版本以及像 Llama 2 这样的模型本质上是 GPT 的蒸馏版本,而像 Llama 3 和 Gemma 2 这样较新的模型则使用 DPO 来使其表现得更讨人喜欢。
- 用户讨论了解决 LLM 收敛的潜在方案,包括尝试不同的采样器 (samplers) 和 Tokenization 方法。针对 exllamav2 的 XTC 采样器被提及为一种减少重复输出的有前景的方法,一些用户渴望在 llama.cpp 中实现它。
- 讨论还涉及了 Claudisms,这是一种 Claude 表现出其自身并行版本的 GPTisms 的现象,可能是一种指纹识别 (fingerprinting) 形式。一些人推测,这些模式可能是用于识别特定模型生成文本的人工痕迹,即使其他模型是在这些数据上训练的。
- 48GB 显存的最佳模型 (Score: 225, Comments: 67): 一位拥有配备 48GB 显存的新 RTX A6000 GPU 的用户正在寻求在该硬件上运行的最佳模型建议。他们特别要求能够以至少 Q4 量化或 4 bits per weight (4bpw) 运行的模型,以优化其大容量 GPU 的性能。
- 用户建议运行 70B 模型,如 Llama 3.1 70B 或 Qwen2.5 72B。性能基准测试显示,在两块 RTX 3090 GPU 上,Qwen2.5 72B 使用 q4_0 量化可达到 12-13 tokens/second,使用 q4_K_S 量化可达到 8.5 tokens/second。
- 建议使用带有 TabbyAPI 的 ExllamaV2 以获得更快的速度,Mistral Large 在 3 bits per weight 下可能达到 15 tokens/second。一位用户报告称,在 Linux 上使用带有张量并行 (tensor parallelism) 和投机解码 (speculative decoding) 的 Qwen 2 72B 处理编程任务时,速度高达 37.31 tokens/second。
- 一些用户建议尝试 3 bits per weight 的 Mistral-Large-Instruct-2407(这是一个 120B 参数模型),而其他人则认为 Qwen 72B 是“最聪明”的 70B 级别模型。此外还讨论了 RTX A6000 的散热解决方案,一位用户展示了在 RM44 机箱中使用 Silverstone FHS 120X 风扇的配置。
- 在低资源边缘设备上高效运行 70B 规模的 LLM (Score: 53, Comments: 17): 该论文介绍了 TPI-LLM,这是一个张量并行推理系统,旨在低资源边缘设备上运行 70B 规模的语言模型,通过将敏感数据保留在本地来解决隐私问题。TPI-LLM 实现了滑动窗口内存调度器和基于星型的 AllReduce 算法,分别用于克服内存限制和通信瓶颈。实验表明,与 Accelerate 相比,TPI-LLM 的首字延迟 (time-to-first-token) 和 Token 延迟降低了 80% 以上;与 Transformers 和 Galaxy 相比,降低了 90% 以上。同时,它将 Llama 2-70B 的峰值内存占用减少了 90%,运行 70B 规模模型仅需 3.1 GB 内存。
- TPI-LLM 通过张量并行利用多个边缘设备进行推理,在 8 台各拥有 3GB 内存的设备上运行 Llama 2-70B。这种分布式方法实现了显著的内存缩减,但代价是速度上的权衡。
- 该系统的性能受限于磁盘 I/O,导致 70B 模型的首字延迟为 29.4 秒,平均吞吐量为 26.1 秒/token。尽管存在这些延迟,该方法在低资源设备上运行大语言模型方面仍显示出前景。
- 用户讨论了其他分布式实现,如用于跨多设备运行模型的 exo。人们对分布式设置中实时节点池变化和层重新平衡的潜在问题提出了担忧。
{kind=link}
主题 3:Nvidia 发布 NVLM 72B:新型多模态模型发布
- Nvidia 刚刚发布了其多模态模型 NVLM 72B (Score: 92, Comments: 10): Nvidia 发布了其多模态模型 NVLM 72B,详细信息见论文,模型可通过 Hugging Face 仓库访问。这个拥有 720 亿参数的模型代表了 Nvidia 进入多模态 AI 领域,能够处理和生成文本及视觉内容。
- NVLM 72B 是基于 Qwen 2 72B 构建的,这一点通过快速查看配置文件即可发现。
- llama.cpp 的创建者 Ggerganov 表示,需要具有软件架构技能的新贡献者来实现多模态支持,并对项目的可维护性表示担忧。他在一个 GitHub issue 评论中阐述了这一点。
- 讨论中提到了为什么大公司以 Hugging Face 格式而不是 GGUF 发布模型。原因包括与现有硬件的兼容性、无需量化以及能够进行微调(这在 GGUF 文件上不易实现)。
{kind=link}
Theme 4. 端侧 AI 的进展:适用于 Android 的 Gemini Nano 2
- Gemini Nano 2 现已通过实验性访问在 Android 上可用 (Score: 38, Comments: 12): Gemini Nano 2 是 Google 为 Android 提供的端侧 AI 模型的升级版,开发者现在可以通过实验性访问获取。这一新迭代的版本大小几乎是其前身 (Nano 1) 的两倍,在质量和性能上表现出显著提升,在学术基准测试和实际应用中均可与大得多的模型相媲美。
- 用户推测了从 Gemini Nano 2 中提取权重的可能性,并讨论了该模型的架构和大小。据澄清,Nano 2 拥有 3.25B 参数,而非最初建议的 2B。
- 人们对模型的透明度表现出兴趣,询问为什么 Google 对所使用的 LLM 不够开放。有人猜测它可能是 Gemini 1.5 flash 的一个版本。
- 一位用户提供了来自 Gemini 论文的信息,指出 Nano 2 是通过从更大的 Gemini 模型中蒸馏训练而来的,并且为了部署进行了 4-bit 量化。
Theme 5. 提升 LLM 性能的创新技术
-
Archon:来自斯坦福的推理时技术架构搜索框架。提供研究论文、代码、Colab;
pip install archon-ai。o1 的开源版本? (Score: 35, Comments: 2): 斯坦福大学的研究人员推出了 Archon,这是一个针对推理时技术 (inference-time techniques) 的开源架构搜索框架,可能作为 Anthropic o1 的开源替代方案。该框架可通过pip install archon-ai安装,并附带研究论文、代码和 Colab 笔记本,允许用户探索和实现大型语言模型的各种推理时方法。 - 刚刚发现了幻觉评估排行榜 - GLM-4-9b-Chat 在最低幻觉率方面领先(OpenAI o1-mini 位居第二) (Score: 39, Comments: 6): 幻觉评估排行榜 (Hallucination Eval Leaderboard) 显示 GLM-4-9b-Chat 表现最佳,幻觉率最低,其次是 OpenAI 的 o1-mini。这一发现促使人们考虑将 GLM-4-9b 作为 RAG (检索增强生成) 应用的潜在模型,暗示其在减少虚假信息生成方面的有效性。
- GLM-4-9b-Chat 和 Jamba Mini 被强调为具有低幻觉率且极具前景的模型,但目前尚未得到充分利用。Orca 13B 进入前列也令人感到意外。
- 该排行榜的数据被认为对基于 LLM 的机器翻译非常有价值,用户对该领域的潜在应用表示热切期待。
- GLM-4 因其 64K 有效上下文而受到赞誉,这在 RULER 排行榜上超过了许多更大的模型,此外它在多语言任务中最小化语种切换 (code switching) 的能力,使其成为 RAG 应用的强力竞争者。
- 效果惊人的超智能摘要 Prompt (Score: 235, Comments: 39): 该帖子讨论了一个受用户 Flashy_Management962 启发的 摘要系统 Prompt,其核心是生成 5 个关键问题 来捕捉文本要点,并详细回答这些问题。作者声称这种方法在 Qwen 2.5 32b q_4 上进行了测试,效果比他们之前尝试过的方法 “好得惊人”,并概述了制定针对中心主题、核心观点、事实、作者观点和影响的问题流程。
- 用户讨论了通过 指定回答长度 和包含示例来优化 Prompt。楼主提到曾尝试过 更复杂的 Prompt,但发现简单的指令在 Qwen 2.5 32b q_4 模型 上效果最好。
- 这种通过生成 问答对 来进行摘要的技术引发了关注,一些用户指出这是一个已知的 NLP 任务。楼主注意到显著的提升,将其描述为 LLM 在文本理解能力上实现了 “30 点智商水平的飞跃”。
- 该摘要方法正以 “supersummer” 的名称被集成到 Harbor Boost 等项目中。用户还分享了相关资源,包括 DSPy 和一个 电子书摘要工具,供进一步探索。
{kind=link}
其他 AI Subreddit 回顾
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI 模型发布与功能
-
OpenAI 发布 o1-mini 模型:OpenAI 发布了 o1-mini,这是其 o1 模型的缩小版本。一些用户报告在使用 GPT-4 时随机获得 o1 的响应,这表明 OpenAI 可能正在测试 model router,以确定何时使用 o1 与 GPT-4。来源
-
Whisper V3 Turbo 发布:OpenAI 发布了 Whisper V3 Turbo,这是其 large-v3 语音识别模型的优化版本,提供 8 倍的转录速度,且准确度损失极小。来源
-
适用于 Flux 的 PuLID 现在可在 ComfyUI 上运行:用于 Flux 图像生成模型的 PuLID (Prompt-based Unsupervised Learning of Image Descriptors) 模型现在已兼容 ComfyUI 界面。来源
AI 公司动态与事件
- OpenAI DevDay 公告:OpenAI 举办了开发者日活动并发布了多项公告,包括:
- 从 GPT-4 到 4o mini,每个 token 的成本降低了 98%
- 其系统的 token volume 增加了 50 倍
- 宣称“模型智能取得了卓越进展” 来源
- Mira Murati 从 OpenAI 离职:据报道,在 Mira Murati 突然宣布从 OpenAI 离职之前,一些员工认为 o1 模型的发布过于仓促。来源
AI 功能与应用
-
Advanced voice mode 开始推出:OpenAI 开始向 ChatGPT 免费用户推出 Advanced voice mode。来源
-
Realtime API 发布:OpenAI 宣布了 Realtime API,它将在其他应用程序中实现 Advanced voice mode 功能。来源
-
Copilot Vision 演示:微软演示了 Copilot Vision,它可以查看用户正在浏览的网页并与之交互。来源
-
NotebookLM 的功能:Google 的 NotebookLM 工具可以处理多本书籍、长视频和音频文件,提供摘要、引用和解释。它还可以处理外语内容。来源
AI 伦理与社会影响
-
对失业问题的担忧:Duolingo 的 CEO 讨论了 AI 可能导致的失业问题,引发了关于自动化对社会影响的辩论。来源
-
Sam Altman 谈 AI 进展:OpenAI 的 Sam Altman 讨论了 AI 的快速进展,表示到 2030 年,人们可能能够要求 AI 执行以前人类需要数月或数年才能完成的任务。来源
AI 研究与开发
- UltraRealistic Lora 项目:一种用于 Flux 图像生成系统的新 LoRA (Low-Rank Adaptation) 模型,旨在创建更真实、更具动态感的摄影风格输出。来源
AI Discord 摘要
由 O1-mini 生成的摘要之摘要的摘要
主题 1. AI 模型的进展与发布
- Nova Pro 在基准测试中超越 GPT-4:Nova-Pro 在 ARC-C 上获得 97.2%,在 GSM8K 上获得 96.9% 的优异成绩,在推理和数学方面超越了 GPT-4 和 Claude-3.5。
- 具备视觉能力的 Llama 3.2 发布:Llama 3.2 支持 11B 和 90B 配置,支持本地部署并增强了针对自定义视觉任务的微调。
- Phi-3.5 模型强调审查功能:Phi-3.5-MoE 展示了广泛的 censorship mechanisms(审查机制),引发了关于模型在技术应用中可用性的讨论。
主题 2. AI 基础设施与工具增强
- 使用 o1-engineer 简化项目管理:o1-engineer 利用 OpenAI API 进行高效的 code generation(代码生成)和项目规划,增强了开发者工作流。
- 通过 screenpipe 进行本地 AI 屏幕录制:screenpipe 提供基于 Rust 构建的安全、持续的本地 AI 录制,是 Rewind.ai 的强大替代方案。
- 解决 LM Studio 中的安装问题:社区成员排查了 LM Studio 的启动问题,强调了与 Llama 3.1 兼容性以及使用虚拟环境的重要性。
主题 3. AI 伦理、安全与法律影响
- 辩论 AI 安全与伦理问题:关于 AI Safety 的讨论涵盖了传统伦理和 deepfakes 等现代威胁,常被幽默地比作“愤怒的老奶奶对着云朵大喊”。
- NYT 诉讼影响 AI 版权立场:NYT(纽约时报)对 OpenAI 潜在的诉讼引发了关于 copyright infringement(版权侵权)和 LLMs 更广泛法律责任的疑问。
- 创意作品中 AI 的伦理使用:社区对 Character.AI 未经授权使用个人肖像表示愤慨,强调了负责任的 AI development 实践的必要性。
主题 4. 模型训练、微调与优化
- 通过 Activation Checkpointing 提高效率:在训练中实现 activation checkpointing 可以减少显存占用,从而能够处理像 Llama 3.1 70B 这样更大的模型。
- 解决 FP8 精度训练挑战:研究人员探索了在长时间训练运行中 FP8 precision 的不稳定性,寻求优化稳定性和性能的解决方案。
- 优化多 GPU 训练技术:有效的 multi-GPU training 强调并行网络训练和高效的状态通信,以扩展到 10,000 GPU 的规模。
主题 5. AI 集成与部署策略
- 使用 Oracle AI Vector Search 和 LlamaIndex 进行语义搜索:将 Oracle AI Vector Search 与 LlamaIndex 结合,增强了 RAG(检索增强生成)流水线,以实现更准确的上下文数据处理。
- 将 HuggingFace 模型部署为 LangChain Agents:HuggingFace 模型可以作为 Agents 集成到 LangChain 中,促进开发工作流中高级的聊天和文本生成任务。
- 使用 OpenRouter 和 LlamaIndex 的本地部署策略:利用 OpenRouter 和 LlamaIndex 进行语义搜索和多模态模型,支持在各种应用中实现可扩展且高效的 AI deployment。
第一部分:Discord 高层级摘要
aider (Paul Gauthier) Discord
- Prompt Caching 见解:分享了各种 AI 模型的 Prompt Caching 能力总结,重点关注 OpenAI 和 Anthropic 的策略,并讨论了成本影响和缓存未命中(cache misses)。
- 关键点包括对 DeepSeek 和 Gemini 等模型缓存机制的讨论,强调了它们的效率。
- 代码编辑 AI 模型对比:Sonnet 在整体性能上优于其他模型,但成本高于 o1-preview,后者在某些条件下提供更好的 Token 返还。
- 建议包括将 Gemini 作为架构模型与 Sonnet 结合进行基准测试,以潜在地增强编辑能力。
- YAML 解析陷阱:用户指出了 YAML 解析中的怪异现象,特别是将 ‘yes’ 等键转换为布尔值,这使他们的配置变得复杂。
- 分享的预防策略包括使用引号字符串以保持预期的解析结果。
- 通过 o1-engineer 简化项目管理:o1-engineer 是一个命令行工具,供开发者使用 OpenAI API 高效管理项目,执行 code generation 等任务。
- 该工具旨在增强开发流程,特别侧重于项目规划。
- 使用 screenpipe 进行无缝本地 AI 录制:screenpipe 允许持续的本地 AI screen recording,专为构建需要完整上下文保留的应用程序而设计。
- 定位为 Rewind.ai 的安全替代方案,它确保用户数据所有权,并使用 Rust 构建以实现更高效率。
OpenRouter (Alex Atallah) Discord
- Samba Nova 推出免费 Llama 端点:与 Samba Nova 合作,Llama 3.1 和 3.2 的 五个免费 bf16 端点 现已在其新的推理芯片上线以测量性能,包括 405B Instruct model。
- 在使用这些旨在支持 Nitro 生态系统的端点时,可以期待令人兴奋的吞吐量。
- Gemini 模型标准化 Token 大小:Gemini 和 PaLM 模型现在使用标准化的 Token 大小,导致 价格提高 2 倍 但 输入缩短 25%,这应该有助于提高整体负担能力 详情点击这里。
- 尽管有这些变化,用户可以预期随着时间的推移成本将 降低 50%。
- Cohere 提供模型折扣:Cohere models 在 OpenRouter 上提供 5% 折扣,并已升级以在其新的 v2 API 中包含工具调用(tool calling)支持。
- 此更新增强了用户对工具的访问,旨在改善整体体验。
- Realtime API 集成讨论:讨论集中在 OpenRouter 对新 Realtime API 的支持,特别是其目前在音频输入和输出方面的限制。
- 用户渴望改进,但目前尚未确认增强功能的具体时间表。
- OpenRouter 模型性能受到关注:关于 OpenRouter 上 模型性能 和可用性的担忧浮出水面,特别是灰色显示的提供商和波动的费率。
- 用户在选择不同提供商时需要对价格变化保持警惕。
HuggingFace Discord
- Llama 3.2 发布带来本地运行支持:Llama 3.2 已经发布,支持本地执行,并可通过新方案进行视觉微调。该模型支持 11B 和 90B 配置,以增强微调能力。
- 社区反馈显示反响热烈,成员们正在探索如何有效应用这些模型,并就其影响展开讨论。
- Transformers 4.45.0 简化工具创建:transformers v4.45.0 的发布引入了使用
@tool装饰器的工具,为用户简化了开发流程。此次更新提升了多种应用的构建效率。- 社区成员热烈讨论了这些变化,征求对更新设计的反馈,并提出了各种用途。
- 为叙事生成微调 Mistral 7B:一位成员热衷于为故事生成 微调 Mistral 7B,正在寻求预训练方法的指导。他们了解到 Mistral 是在大量数据上预训练的,强调了特定任务的微调方案。
- 进一步的澄清区分了预训练与高效使模型专业化所需的精炼过程。
- NotebookLM 超越传统工具:参与者称赞 NotebookLM 作为一个端到端多模态 RAG 应用的功效,证明其在分析财务报告方面特别有效。一位成员在 YouTube 视频中展示了它的功能,探索了其在教育内容方面的潜力。
- 团队成员对其应用潜力表示关注,加深了对其未来发展和集成的讨论。
- 探索 ‘trocr-large-handwriting’ 的优势:一位成员建议在与手写体高度相似的数据集上使用 ‘trocr-large-handwriting’ 以获得更好的性能。对话包括了在特定字符数据集上进行微调以提高识别率的想法。
- 这引发了关于手写识别任务模型选择的更广泛讨论,成员们权衡了各种方法的优缺点。
LM Studio Discord
- LM Studio 启动困扰:用户在更新后遇到了 LM Studio 的启动问题,特别是应用目录中的快捷方式和可执行文件问题,建议的一个解决方法是依赖更新后的安装文件。
- 这表明旧版安装可能存在潜在问题,可能会阻碍用户的工作效率。
- Llama 3.1 兼容性问题:在 LM Studio 中加载 Llama 3.1 模型时出现错误,促使建议更新到官方支持该模型的 0.3.3 版本。
- 这种不匹配凸显了在升级模型时确保软件兼容性的必要性。
- Langflow 集成成功:一位用户通过调整 OpenAI 组件的 base URL,成功将 LM Studio 与 Langflow 集成,发现该修改使工作流更加顺畅。
- 他们指出了 Langflow 的可用资源,这可能会帮助他人简化配置。
- 优化 GPU 利用率:关于 LM Studio 中 GPU 利用率设置的讨论集中在定义关于 CPU 和 GPU 资源管理的 “offload” 具体含义。
- 成员们寻求关于使用 GPU 与 CPU(特别是针对自动补全等任务)优化配置的澄清。
- 高端 GPU 性能对决:一位用户详细介绍了他们拥有 7 块 RTX 4090 GPU 的配置,其运行期间估计 3000 瓦 的功耗令人咋舌。
- 另一位用户幽默地指出了如此高功耗的戏剧性影响,反映了人们对高性能系统的痴迷。
Nous Research AI Discord
- 快速模型量化令用户惊叹:用户对 3b 模型的极速量化时间表示惊讶,处理过程不到一分钟。
- 一位用户幽默地将其与最低工资劳动进行了经济对比,强调了其相对于人工劳动的潜在效率提升。
- 音频 Token 定价引发关注:关于音频 Token 输出成本为每小时 14 美元的讨论展开,一些人认为与人工 Agent 相比价格昂贵。
- 参与者指出,虽然 AI 可以全天候在线,但该定价可能无法显著低于传统的支持岗位。
- 鲍尔默峰研究吸引成员:一篇关于鲍尔默峰 (Ballmer Peak) 的共享论文表明,少量酒精可以增强编程能力,挑战了传统观念。
- 成员们纷纷讨论在追求生产力“完美剂量”方面的个人经验。
- DisTrO 处理恶意行为者的能力:讨论指向 DisTrO 的验证层,该层能够在训练期间检测并过滤恶意行为者。
- 虽然它本质上并不管理不可信节点,但该层提供了一定程度的保护。
- RubiksAI 推出 Nova LLM 套件:RubiksAI 发布了 Nova 系列大语言模型,其中 Nova-Pro 在 MMLU 上达到了令人印象深刻的 88.8%。
- Nova-Pro 的基准测试分数为:ARC-C 97.2%,GSM8K 96.9%,重点关注 Nova-Focus 和改进的 Chain-of-Thought 能力。
Interconnects (Nathan Lambert) Discord
- OpenAI 为雄心勃勃的计划筹集 66 亿美元:OpenAI 已成功以惊人的 1570 亿美元估值筹集了 66 亿美元,由 Thrive Capital 以及 Microsoft 和 Nvidia 等机构促成。
- CFO Sarah Friar 分享道,这将为融资后的员工提供流动性选择,标志着公司财务格局的重大转变。
- Liquid.AI 声称取得架构突破:围绕 Liquid.AI 展开了讨论,据报道其性能超越了 Ilya Sutskever 在 2020 年做出的预测。
- 虽然一些怀疑者对其有效性表示质疑,但来自 Mikhail Parakhin 的见解为这些说法提供了一定程度的可信度。
- AI 在高等数学中的潜力:Robert Ghrist 发起了关于 AI 是否能从事研究级数学的对话,指出了 LLM 能力边界的移动。
- 这场对话突显了随着 AI 开始应对复杂的猜想和定理,人们预期的转变。
- AI 安全讨论引发进一步辩论:在漫长的讨论中,成员们纠结于 AI Safety 的影响,特别是关于旧伦理和 deepfakes 等新兴威胁。
- 评论将批评者比作“对着云朵大喊大叫的愤怒老奶奶”,说明了这场论辩的争议性。
- 谷歌的雄心壮志引发讨论:由于谷歌拥有巨额现金储备和 AI 投资历史,人们对其推动 AGI 的潜力产生了猜测。
- 对于该公司实现 AGI 愿景的真实承诺,疑虑依然存在,成员们的意见分歧很大。
Unsloth AI (Daniel Han) Discord
- VAE 中的特征提取格式:参与者讨论了 Variational Autoencoders 中首选的特征提取格式,倾向于使用 continuous latent vectors 或 pt 文件,并指出 RGB 输入/输出 对于 Stable Diffusion 等模型的相关性。
- 对话强调了增强模型训练和有效性的实际选择。
- AI 游戏反馈邀请:一位成员邀请大家对其新推出的 AI 游戏提供反馈,可在 game.text2content.online 游玩,游戏内容涉及在时间限制下编写 prompt 来对 AI 进行 jailbreak。
- 针对登录要求的担忧被提出,但创作者澄清这是为了减少游戏过程中的 bot 活动。
- FP8 训练中的挑战:分享了一篇讨论在使用 FP8 precision 训练大型语言模型(LLM)时面临的 instabilities(不稳定)问题的论文,该论文揭示了在长时间训练运行中出现的新问题;点击此处查看。
- 社区成员热衷于探索在这些场景下优化稳定性和性能的解决方案。
- 2024 年 AI 峰会折扣码:有人在征集参加在孟买举行的 NVIDIA AI Summit 2024 的 discount codes,一名学生表达了利用此机会与 AI 爱好者交流的兴趣。
- 他们的 AI 和 LLM 背景使他们能够从参与峰会中获益匪浅。
- Unsloth 模型加载故障:一位用户在使用 AutoModelForPeftCausalLM 加载带有 LoRA adapters 的微调模型时遇到错误,引发了关于调整 max_seq_length 的讨论。
- 成员们对模型加载方法和解决问题的最佳实践提供了宝贵的见解。
GPU MODE Discord
- 关于 Triton Kernel 调用参数的说明:一位用户询问了在 Triton kernel 调用中更改 num_stages 的功能,推测其与 pipelining 有关。
- 另一位成员解释说,pipelining 优化了加载、计算和存储操作,如本 YouTube 视频所示。
- CUDA Mode 活动引发关注:CUDA mode 的第三名奖项被指出与数据加载项目有关,激发了大家对进度更新的好奇心。
- 一位成员分享了 no-libtorch-compile 仓库,以帮助在不使用 libtorch 的情况下进行开发。
- IRL 主旨演讲现已可观看:IRL event 的主旨演讲录像已发布,其中包括 Andrej Karpathy 等知名人物的精彩演讲。
- 感谢参与者,特别是 Accel,感谢他们在有效记录这些演讲方面所做的贡献。
- 社区应对政治讨论:社区成员对地缘政治稳定性表示担忧,强调在紧张的讨论中应专注于 coding。
- 关于政治讨论适当性的辩论随之而来,成员们一致认为限制此类话题可以确保更舒适的环境。
- 即将于 10 月举行的 Advancing AI 活动:一场 Advancing AI event 计划在旧金山举行,邀请参与者与 ROCM 开发者互动。
- 鼓励社区成员私信获取注册详情,并在活动期间讨论 AI 的进展。
Eleuther Discord
- 贝叶斯模型面临频率派挑战:神经架构主要利用 frequentist statistics(频率派统计学),这为在可训练模型中有效实现 Bayesian networks 带来了障碍。建议包括将概率折叠进模型权重,从而简化贝叶斯方法。
- 讨论强调了在不牺牲复杂性的情况下,在 Bayesian 框架内保持实用性的替代方案。
- NYT 诉讼动摇 AI 版权基础:社区深入探讨了 OpenAI 可能通过向 NYT(纽约时报)支付费用来规避版权指控的影响,这引发了对 LLM 责任更广泛影响的担忧。有观点指出,此类补偿并不一定证实存在普遍的版权侵权。
- 成员们强调了盈利公司与面临版权纠纷的独立创作者之间动机的差异。
- 液态神经网络(Liquid Neural Networks):游戏规则改变者?:成员们对 liquid neural networks 在拟合连续函数方面的应用表示乐观,认为与传统方法相比,它降低了开发复杂度。他们建议,在开发者能力达标的前提下,端到端流水线可以增强可用性。
- 这些网络在减轻预测任务复杂性方面的潜力,引发了关于其实际部署的进一步讨论。
- 自监督学习拓展视野:引入了在任意 embeddings 上进行 self-supervised learning(自监督学习)的概念,强调其在各种模型权重中的适用性。这种方法涉及从多个模型中收集线性层,以形成用于更好训练的综合数据集。
- 成员们认识到扩展 SSL 在增强不同 AI 应用的模型能力方面的意义。
- T5 彻底改变迁移学习:T5 在 NLP 任务迁移学习中的有效性受到赞誉,其在建模各种应用方面具有显著能力。一位成员幽默地表示:“该死,T5 想到了一切”,展示了其广泛的 text-to-text 适应性。
- 此外,讨论还涉及了深度学习优化器的新设计,批评了 Adam 等现有方法,并提出了改进训练稳定性的修改方案。
OpenAI Discord
- 用户渴望更高等级的订阅方案:成员们讨论了推出更高价格的 OpenAI 订阅方案以提供更即时功能和服务的可能性,理由是对当前各 AI 平台限制的挫败感。
- 这一变化可以通过创新功能提升用户体验。
- 对新 Cove 语音模型的反馈:多位用户对新的 Cove voice model 表示不满,称其缺乏经典语音的镇静感,并呼吁恢复经典语音。
- 社区共识倾向于更喜欢宁静的声音,并对经典版本表示怀念。
- Liquid AI 的架构性能:讨论集中在一种据报道优于传统 LLM 的新 liquid AI 架构上,该架构已开放测试,并以推理效率著称。
- 成员们对其与典型 Transformer 模型相比的独特结构进行了推测。
- 访问 Playground 的问题:用户对登录 Playground 的困难表示担忧,一些用户建议使用无痕模式作为潜在的解决方法。
- 报告显示访问问题可能因地理位置而异,特别是在瑞士等地区。
- macOS 应用中回复消失的问题:用户报告在更新后 macOS 桌面应用中出现回复消失的问题,可能是由于通知设置的更改。
- 在执行关键任务时,这些问题显著影响了用户体验,导致了明显的挫败感。
Latent Space Discord
- OpenAI 获得 67 亿美元融资:OpenAI 宣布完成一轮 67 亿美元 的融资,估值达到 1570 亿美元,并建立了关键合作伙伴关系,可能涉及北约盟友以推进 AI 技术。
- 这笔资金引发了关于国际合作和 AI 政策战略方向的讨论。
- 面向所有用户的 Advanced Voice 功能:OpenAI 正在向全球所有 ChatGPT Enterprise 和 Edu 用户推出 Advanced Voice 功能,并为免费用户提供早期预览。
- 对于这些语音应用的实际性能提升,仍存在一些质疑。
- 深入探讨多 GPU 训练技术:关于多 GPU 训练的详细讨论强调了高效 checkpointing 和状态通信的需求,特别是在使用多达 10,000 个 GPU 的情况下。
- 重点介绍的关键策略包括并行化网络训练和增强故障恢复流程。
- 发布新型多模态模型 MM1.5:Apple 推出了 MM1.5 系列多模态语言模型,旨在改进 OCR 和多图推理,提供 Dense 和 MoE 两个版本。
- 此次发布重点关注专为视频处理和移动用户界面理解而定制的模型。
- Azure AI 的 HD Neural TTS 更新:Microsoft 在 Azure AI 上推出了高清版本的神经 TTS,承诺提供具有情感上下文检测的更丰富语音。
- 诸如自回归 Transformer 模型等特性预计将增强生成语音的真实感和质量。
Stability.ai (Stable Diffusion) Discord
- 解决 ComfyUI 安装问题:一位用户在 Google Colab 上安装 ComfyUI 时遇到困难,特别是 comfyui manager 的安装过程。
- 讨论者指出特定模型路径的重要性以及与 Automatic1111 的兼容性问题。
- Flux 模型展示出色特性:用户称赞了 Flux model 在创建一致的角色图像以及改进手部和脚部细节方面的效果。
- 一位成员分享了一个 Flux lora 链接,其对图像质量的提升出人意料地超出了其预期用途。
- Automatic1111 安装问题依然存在:在使用最新的 Python 版本安装 Automatic1111 时出现问题,引发了关于兼容性的疑问。
- 成员们建议使用 virtual environments 或 Docker 容器来更好地管理不同的 Python 版本。
- 辩论基于 Debian 的操作系统特性:一场热烈的对话集中在基于 Debian 的操作系统的优缺点上,重点介绍了 Pop 和 Mint 等流行发行版。
- 用户幽默地分享了他们因 Pop 的独特功能而尝试重新使用它的想法。
- Python 版本兼容性混乱:成员们讨论了使用 最新 Python 版本 的挑战,建议旧版本可能会提高与某些脚本的兼容性。
- 一位用户考虑调整其设置以分别执行脚本,从而克服稳定性问题。
Perplexity AI Discord
- 争取更高的速率限制:用户讨论了请求增加 API rate limit 的选项,寻求突破 20 次请求的限制。
- 这些请求得到了广泛支持,表明了对增强能力的集体需求。
- 迫切期待 Llama 3.2:即将发布的 Llama 3.2 激发了用户对新功能的迫切期待。
- 一个梗图反映了对发布日期的不确定感,幽默地引起了对过去延迟的关注。
- LiquidAI 凭借速度成名:LiquidAI 因其速度而受到称赞,一位用户宣称它与竞争模型相比 快得惊人。
- 虽然速度是其优势,但用户也注意到了它的 不准确性,引发了对可靠性的担忧。
- 具备 PDF 功能的聊天特性表现出色:一位用户确认成功将整个聊天记录下载为 PDF,引发了关于该功能实用性的讨论。
- 这反映了对保存完整对话(尤其是为了文档记录)的更好方式日益增长的需求。
- 文本转语音评价褒贬不一:关于 text-to-speech (TTS) 功能的讨论强调了其在处理长回复时的常用性,尽管存在一些 发音问题。
- 用户认为它是一个方便的工具,但在准确性方面仍有改进空间。
Cohere Discord
- 需要信用卡云端和 Apple Pay 支持:一位成员表示需要对信用卡云端和 Apple Pay 的全面支持,随后得到的建议是联系 support@cohere.com 以获取帮助。
- 另一位成员提出协助处理该支持查询,以便更顺利地解决问题。
- 活动通知送达延迟:一位成员报告了活动通知在活动结束后才送达的问题,特别是在最近一次的 Office Hours 会议期间。
- 这已被确认为一个技术故障,官方对提出该问题表示了感谢。
- 咨询 MSFT Copilot Studio:一位成员询问了关于 MSFT Copilot Studio 的使用经验,以及它与市场上其他解决方案相比的价值。
- 回复中强调了讨论中关于促销内容的敏感性。
- Azure 模型刷新故障:一位成员报告了在 Azure 中刷新模型时遇到的问题,建议立即联系 Cohere 支持团队和 Azure 团队。
- 另一位成员索要了相关的 Issue ID,以便在沟通中进行更好的跟踪。
- 对 Cohere 聊天应用开发的兴趣:一位成员询问了是否有任何即将推出的 Cohere 聊天应用计划(特别是针对移动设备),并表达了对社区推广的热情。
- 他们提出可以主持一场网络研讨会,并强调了对该平台的倡导。
LlamaIndex Discord
- 高性价比的 Contextual Retrieval RAG 出现:一位成员分享了 @AnthropicAI 的新 RAG 技术,该技术通过在文档块(chunks)前添加元数据来增强检索,从而提高性能和成本效益。这种方法能根据文档中的上下文位置更准确地引导 检索过程。
- 这种创新方法被定位为行业变革者,旨在简化各种应用中的数据处理。
- Oracle AI Vector Search 在语义搜索中表现出色:Oracle AI Vector Search 是 Oracle Database 的一项突破性功能,在语义搜索领域处于领先地位,使系统能够根据含义而非关键词来理解信息。当该技术与 LlamaIndex 框架结合时,被定位为构建复杂 RAG 流水线的强大解决方案。
- Oracle 与 LlamaIndex 之间的协同作用增强了能力,推动了 AI 驱动的数据检索边界,详见这篇 文章。
- 人类反馈助力 Multi-agent 写作:一个利用 Multi-agent 系统的创新博客写作 Agent 将 Human in the loop 反馈整合到 TypeScript 工作流中,展示了动态的写作改进。观众可以在这个 现场演示 中看到 Agent 实时进行写作和编辑。
- 这一进展突显了通过直接的人类参与显著增强协作写作过程的潜力。
- 探讨 LlamaIndex 基础设施需求:成员们分享了关于运行 LlamaIndex 的硬件规格见解,指出需求因模型和数据大小而异。关键考虑因素包括运行 LLM 和 Embedding 模型所需的 GPU,并推荐了特定的 Vector Database。
- 讨论强调了影响部署决策的实际因素,以满足不同的项目需求。
- NVIDIA 的 NVLM 引起关注:NVIDIA 推出的多模态大语言模型 NVLM 1.0 受到关注,强调了其在视觉语言任务中的领先能力。成员们推测了 LlamaIndex 对其的潜在支持,特别是关于巨大的 GPU 需求和加载配置。
- 讨论激发了人们对 LlamaIndex 内部实现可能带来的集成和性能基准测试的期待。
Torchtune Discord
- Salman Mohammadi 获贡献者奖提名:我们自己的 Salman Mohammadi 因其在 GitHub 上的宝贵贡献以及在 Discord 社区的积极支持,获得了 2024 PyTorch Contributor Awards 的提名。
- 他的工作对于推动 PyTorch 生态系统至关重要,该生态系统今年吸引了 3,500 人的贡献。
- Distillation 中的 Tokenizer 概率与 One-Hot 对比:成员们讨论了在 Token 训练中使用概率进行 distillation(蒸馏)与使用 One-Hot 向量的效果对比,强调了大型模型如何产生更好的潜在表示(latent representations)。
- 他们一致认为,混合标注和未标注的数据可以“平滑”损失函数曲面(loss landscape),从而增强 distillation 过程。
- H200 即将到来:一位成员宣布他们的 8x H200 配置(拥有令人印象深刻的 4TB RAM)已在运送途中,这引发了热烈讨论。
- 该配置将进一步助力其本地内部开发,强化其基础设施。
- 本地 LLM 获得优先权:聊天中引发了关于部署本地 LLM 的讨论,指出目前的 API 无法满足欧洲医疗数据的要求。
- 成员们强调,本地基础设施可以提高处理敏感信息的安全性。
- B100 硬件计划即将出炉:提出了未来集成 B100 硬件的计划,标志着向增强本地处理能力的转变。
- 社区对获得更多资源以强化开发能力表示期待。
Modular (Mojo 🔥) Discord
- Mojo Literals 支持滞后:一位成员确认 literals(字面量)在 Mojo 中尚无法正常工作,并建议使用
msg.extend(List[UInt8](0, 0, 0, 0))作为替代方案。- 社区预期 try 表达式可能会包含在未来的更新中。
- EC2 T2.Micro 实例的问题:由于编译期间可能的内存限制,用户在廉价的 EC2 t2.micro 实例上遇到了 JIT session error。
- 成员们建议至少使用 8GB RAM 以确保运行顺畅,其中一位指出 2GB 对于二进制构建(binary builds)已经足够。
- 关于 Mojo 库导入的讨论:人们对 Mojo 未来支持 import library 功能以利用 CPython 库(而非使用
cpython.import_module)的兴趣日益浓厚。- 针对潜在的模块名称冲突,有人提出了 import precedence(导入优先级)策略进行集成。
- 内存管理策略探索:有人建议在 EC2 上使用 swap 内存,但提醒注意因 IOPS 使用而导致的性能下降。
- 另一位用户验证了在 8GB 内存下的成功运行,同时 Mojo 处理特定内存导入的问题也受到了关注。
- Mojo 的导入行为:据观察,Mojo 目前不像 Python 那样管理具有 side effects(副作用)的导入,这增加了兼容性的复杂性。
- 这引发了关于 Mojo 编译器是否应该复制 Python 所有细微导入行为的讨论。
OpenInterpreter Discord
- Nova LLM 发布引起轰动:Nova 发布了其 Large Language Models 系列,包括 Nova-Instant、Nova-Air 和 Nova-Pro,在 MMLU 上取得了 88.8% 的分数。
- Nova-Pro 在 ARC-C 上获得 97.2%,在 GSM8K 上获得 96.9%,超越了竞争对手,彰显了其顶级的推理和数学能力。
- Open Interpreter 支持动态函数调用:成员们讨论了是否可以在其 Python 项目中使用 Open Interpreter 的
interpreter.llm.supports_functions功能来定义自定义函数。- 虽然 Open Interpreter 可以即时创建函数,但严格的定义可以确保准确的模型调用,这一点在参考 OpenAI documentation 时得到了澄清。
- 语音技术 Realtime API 发布:全新的 realtime API 实现了 speech-to-speech 功能,增强了对话式 AI 中的交互关系。
- 该 API 旨在通过即时响应增强应用程序,彻底改变交互式通信。
- Vision 现已集成到 Fine-Tuning API:OpenAI 宣布在 fine-tuning API 中加入 vision,允许模型在训练期间利用视觉数据。
- 这一扩展为多模态 AI 应用开辟了新途径,进一步桥接了文本和图像处理。
- 模型蒸馏提高效率:Model distillation 专注于优化模型权重管理以提升性能。
- 该方法旨在维持模型准确性的同时最小化计算负载,确保输出的最优化。
LangChain AI Discord
- LangChain 等待 GPT Realtime API:成员们热切讨论了 LangChain 何时支持新发布的 GPT Realtime API,但聊天中尚未出现明确的时间表。
- 这种不确定性导致社区内对潜在功能和实现的持续猜测。
- HuggingFace 现已成为 LangChain 的一个选项:HuggingFace 模型可以在 LangChain 中作为 Agent 使用,用于包括聊天和文本生成在内的各种任务,并分享了实现的代码片段。
- 为了进一步了解,成员们被引导至 LangChain’s documentation 和相关的 GitHub issue。
- 对 Prompt 中花括号的担忧:一位成员对在 LangChain 的聊天 Prompt 模板中有效传递带有花括号的字符串表示担忧,因为它们会被解释为占位符。
- 社区成员寻求不同的策略来处理此问题,而不改变处理过程中的输入。
- Nova LLM 表现优于竞争对手:Nova LLM(包括 Nova-Instant、Nova-Air 和 Nova-Pro)的发布展示了显著的性能,其中 Nova-Pro 在 MMLU 上取得了出色的 88.8%。
- Nova-Pro 在 ARC-C 上也获得了 97.2%,在 GSM8K 上获得了 96.9%,确立了其在 AI 交互中的领先地位;点击此处了解更多。
- LumiNova 提升图像生成:全新的 LumiNova 模型承诺提供卓越的图像生成能力,增强 AI 应用的视觉创造力。
- 这一进步为互动式和引人入胜的 AI 驱动体验开辟了新的可能性。
OpenAccess AI Collective (axolotl) Discord
- Qwen 2.5 在部署中表现惊人:一位成员成功部署了 Qwen 2.5 34B,并报告其性能好得离谱,足以媲美 GPT-4 Turbo。
- 讨论围绕部署细节和 vision 支持展开,强调了模型能力的快速演进。
- 小模型能力的探索:成员们对小模型的显著进步感到惊叹,并辩论了它们的潜在极限。
- 我们到底能把它推到多远?实际的限制是什么? 对话反映了人们对优化更小架构日益增长的兴趣。
- 关于 hf_mlflow_log_artifacts 的澄清:一位成员询问将 hf_mlflow_log_artifacts 设置为 true 是否会将模型 checkpoint 保存到 mlflow,这表明了对集成问题的关注。
- 这突显了模型训练工作流中对强大日志机制的关键需求。
- 讨论 sharegpt 中的自定义 instruct 格式:分享了在 sharegpt 中为数据集定义自定义 instruct 格式的说明,强调了 YAML 的使用。
- 概述了关键步骤,包括自定义 Prompt 以及确保 JSONL 格式兼容性以获得成功结果。
tinygrad (George Hotz) Discord
- Tiny Box 开箱深得人心:一位成员开箱了来自 Proxy 的 tiny box,并强调了精美的包装和木质底座是其亮点。
- 尽管担心 ny->au 的运输过程,他们还是称赞了确保包裹成功送达所付出的努力。
- 讨论 Bugfix PR 方案:有人呼吁对这个 bugfix PR进行审查,该 PR 解决了两次保存和加载 tensor 的问题。
- 该 PR 旨在解决 #6294,揭示了磁盘设备在不创建新文件的情况下保留未链接文件的问题,这仍然是一个关键的开发点。
- Tinygrad 代码提升编程技能:参与 tinygrad 代码库被证明能提升成员在日常工作中的编程技能,证明了开源经验的价值。
- 他们分享道:作为副作用,它让我的日常工作编程变得更好,反映了对编程能力的积极影响。
- C 互操作性是一大优势:成员们讨论了 Python 的生产力如何与其 C interoperability(C 互操作性)相媲美,允许平滑的函数调用,从而提高底层操作的性能。
- 尽管在 struct 方面存在一些限制,但共识是快速迭代带来的收益仍然巨大。
- UOp 与 UOP 优化的困扰:一位成员表达了在优化 UOp vs UOP pool 时面临的挑战,理由是单个对象引用使过程复杂化。
- 他们建议使用一种更高效的存储类,利用整数句柄(integer handles)来更好地管理对象引用。
LAION Discord
- 强烈的反垃圾信息情绪:一位成员表达了对 spam(垃圾信息)的强烈厌恶,强调了对社区中不受欢迎消息的沮丧。
- 这反映了一个共同的挑战,成员们敦促进行更好的审核,以控制垃圾信息对交流的影响。
- Sci Scope Newsletter 发布公告:来自 Sci Scope 的个性化通讯现已上线,每周提供针对首选研究领域和新论文的定制更新。
- 再也不会错过与你工作相关的研究! 用户可以现在尝试,以一种轻松的方式跟上 AI 领域的进展。
- 为繁忙专业人士提供的每周 AI 研究摘要:该通讯将扫描新的 ArXiv papers 并提供简洁的摘要,旨在每周为订阅者节省数小时的工作时间。
- 该服务承诺通过每周高层级摘要来简化选择相关阅读材料的任务。
- 新用户专属优惠:新用户可以注册 1 个月的免费试用,其中包括访问自定义查询和更相关的体验。
- 这一举措增强了参与度,使用户更容易跟上快速发展的 AI 领域。
DSPy Discord
- 来自 Sci Scope 的个性化通讯:Sci Scope 推出了个性化通讯,每周递送根据个人兴趣定制的新论文摘要,帮助用户轻松掌握最新动态。
- 该服务根据用户偏好扫描新的 ArXiv papers;它提供 1 个月的免费试用以吸引新用户。
- 关于代码相似性搜索的咨询:一位成员正在探索代码相似性的方案,并考虑使用 Colbert 从代码片段中输出相关的代码文档,质疑其在没有 finetuning(微调)的情况下的有效性。
- 他们还在寻求代码搜索的其他替代方法,突显了社区在有效方法上的协作。
LLM Agents (Berkeley MOOC) Discord
- 实验作业推迟:一位成员询问了原定于今天发布的 Lab assignments(实验作业),随后确认工作人员需要再花一周时间来准备。更新信息将在课程页面 llmagents-learning.org 上公布。
- 延迟引发了担忧,参与者对缺乏关于发布时间表和更新的沟通表示沮丧。
- 沟通脱节问题凸显:由于 Lab 发布更新不足,引发了担忧,一名成员无法找到相关的电子邮件或公告。这种情况凸显了在参与者期望中,课程沟通需要改进。
- 参与者正在等待有关课程进展的重要信息,强调了课程工作人员及时发布公告的紧迫性。
Mozilla AI Discord
- 建立 ML 论文阅读小组:一名成员提议启动 ML 论文阅读小组,旨在讨论最新研究,增强社区互动。
- 该倡议旨在促进对 Machine Learning 最新进展感兴趣的工程师之间的集体知识共享。
- 发布本地 LLM 应用的技巧:社区成员对有效将本地 LLM-based apps 发布到应用商店的见解表示感谢。
- 这些技巧被认为对于应对应用发布复杂性的人员至关重要。
- 社区招聘板提议引起关注:关于创建一个 招聘板 以促进社区职位发布的讨论正在展开。
- 该想法由一名成员发起,旨在将人才与工程领域的就业机会联系起来。
- Lumigator 获得官方关注:社区在 官方帖子 中介绍了 Lumigator,展示了其功能和特性。
- 这一介绍强化了社区致力于突出与 AI 工程师相关的值得关注的项目。
- 即将举行的技术创新活动:重点介绍了几个即将举行的活动,包括专注于搜索技术的 Hybrid Search 讨论。
- 其他会议,如 Data Pipelines for FineTuning,有望进一步提升工程知识和技能。
MLOps @Chipro Discord
- Nova 模型表现优于竞争对手:介绍 Nova:下一代大语言模型,在各种基准测试中击败了 GPT-4 和 Claude-3.5,其中 Nova-Pro 在 MMLU 上以 88.8% 领先。
- Nova-Air 在各种应用中表现出色,而 Nova-Instant 则提供快速且具有成本效益的解决方案。
- Nova 模型卓越的基准测试表现:Nova-Pro 取得了令人印象深刻的分数:推理方面 ARC-C 为 97.2%,数学方面 GSM8K 为 96.9%,编程方面 HumanEval 为 91.8%。
- 这些基准测试巩固了 Nova 作为 AI 领域顶级竞争者的地位,展示了其非凡的能力。
- LumiNova 彻底改变图像生成:新推出的 LumiNova 为图像生成设定了高标准,承诺在视觉效果上提供无与伦比的质量和多样性。
- 该模型补充了 Nova 系列,为用户提供了轻松创建惊人视觉效果的高级工具。
- Nova-Focus 的未来发展:开发团队正在探索 Nova-Focus 和增强的 Chain-of-Thought 能力,以进一步突破 AI 的界限。
- 这些创新旨在完善和扩展 Nova 模型在推理和视觉生成方面的潜在应用。
Alignment Lab AI Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
LLM Finetuning (Hamel + Dan) Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
DiscoResearch Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
第 2 部分:按频道详细摘要和链接
完整的逐频道细分内容已在邮件中截断。
如果您喜欢 AInews,请 分享给朋友!提前感谢!