ainews-canvas-openais-answer-to-claude-artifacts
**Canvas:OpenAI 对标 Claude Artifacts 的产品** (或者:**Canvas:OpenAI 针对 Claude Artifacts 给出的回应**)
OpenAI 发布了 Canvas,这是一款基于 GPT-4o 的增强型写作与编程工具,具备行内建议、无缝编辑及协作环境等功能。早期反馈将其与 Cursor 和 Claude Artifacts 进行了对比,指出了其优势及部分实现上的问题。OpenAI 还资助了 ProseMirror 和 CodeMirror 的开发者 Marijn Haverbeke,Canvas 正是采用了这些技术。在集成过程中,OpenAI 训练了一个检测器来适时触发 Canvas,其触发准确率达到了 83%。与 Claude Artifacts 不同,Canvas 目前尚不支持 Mermaid 图表和 HTML 预览。此外,Daily 正在旧金山赞助一场奖金达 20,000 美元的语音 AI 黑客松,凸显了语音 AI 作为一项关键新兴技能的重要性。
Chat-with-Artifacts 就是你所需的一切。
2024年10月2日至10月3日的 AI 新闻。我们为你检查了 7 个 subreddits、433 个 Twitter 账号 和 31 个 Discord 服务(225 个频道及 1721 条消息)。预计节省阅读时间(按 200wpm 计算):212 分钟。你现在可以标记 @smol_ai 来参与 AINews 讨论!
在 Claude Artifacts 发布三个月后(我们的报道见此),OpenAI 发布了 Canvas,这是一个基于 GPT-4o 的增强型写作和编程工具(Mikhail Parakhin 也提到他们在 Bing Copilot 中发布了类似功能)。根据发布公告,Canvas 包括:
- 行内建议: Canvas 提供行内建议和直接操作,用于完善写作和代码,例如润色、修复 Bug 或移植代码。

-
无缝编辑: 它支持对大型文档和复杂代码库进行无缝编辑,使项目管理更加轻松。
-
协作环境: 协作环境确保你的工作能够持续改进和演进。
快速浏览早期评论和反馈包括:
-
Vincente Silveira 指出: “看起来很棒,我们刚刚试用了它,并与 Cursor 和 Claude 进行了对比,它似乎将更多核心的编辑和编程用例带入了 ChatGPT,并为普通用户提供了更好的 UX。”
-
然而,Machine Learning Street Talk 在推特上指出了早期问题: “OpenAI 克隆了 @cursor_ai 内部的功能,即 apply 模型。想法不错,但执行力较差——效果不太好。经常更新整个文档,而不是选中的部分。”
-
Karina Nguyen(参与了 Canvas 的开发)发布了几个使用 Canvas 进行写作和编程的示例。
虽然早期的重点似乎在于写作场景,并与 ChatGPT 现有的搜索功能良好集成,但编程当然是与 Claude Artifacts 对比的重要维度,Karina 为这些任务内置了一些自定义工具。
OpenAI 还将资助 Marijn Haverbeke,他是用于构建 Canvas 的开源库 ProseMirror 和 CodeMirror 的创建者和维护者。
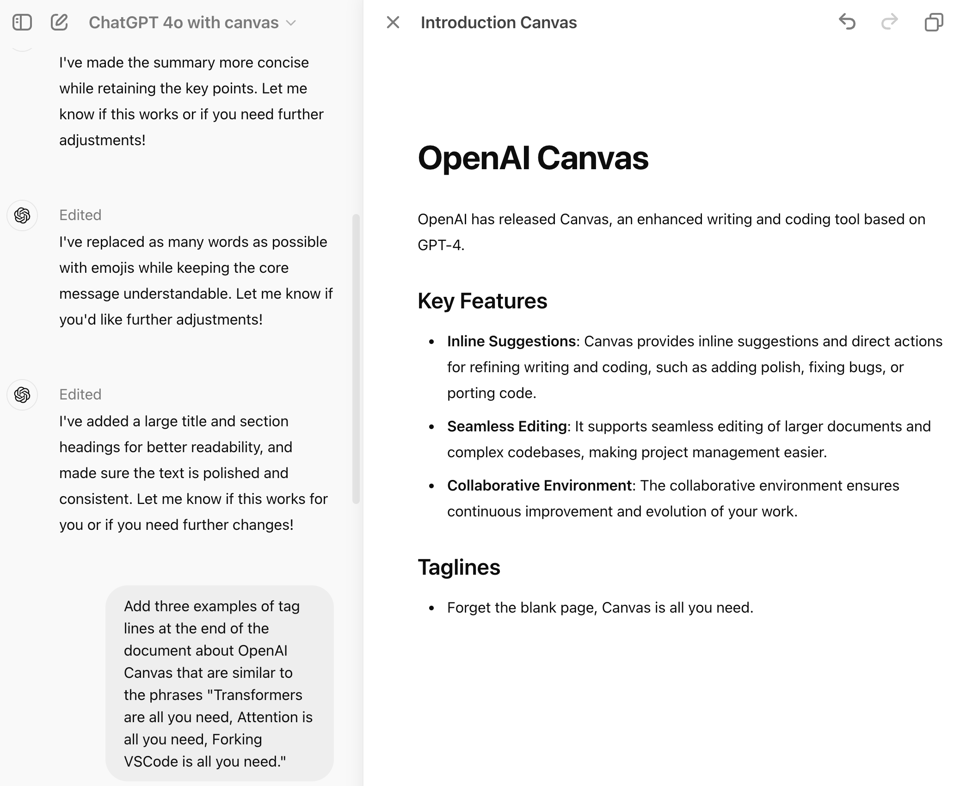
实现中最棘手的部分是 OpenAI 选择将其集成到现有 ChatGPT 体验中的方式,这涉及训练一个检测器,用于判断何时应开启 canvas 功能:
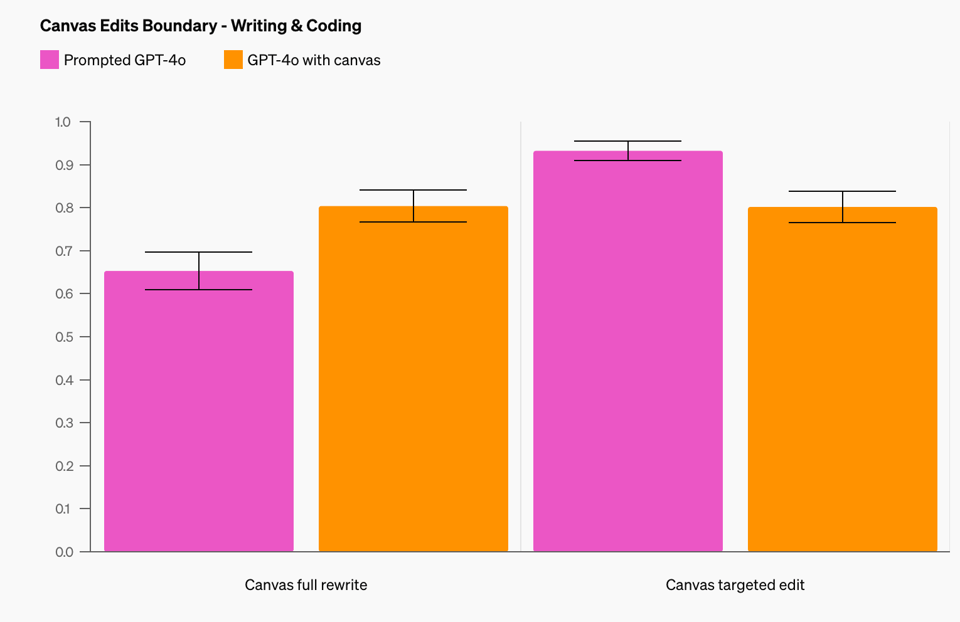
一个关键挑战是定义何时触发 canvas。 我们训练模型在遇到诸如“写一篇关于咖啡豆历史的博客文章”之类的提示词(prompts)时打开 canvas,同时避免在“帮我做一道新的晚餐菜谱”等通用问答任务中过度触发。对于写作任务,我们优先提高了“正确触发”率(以牺牲“正确不触发”为代价),与带有提示指令的基准 zero-shot GPT-4o 相比,达到了 83%。他们也分享了他们的评估(evals):
针对触发编辑行为和评论创建也做了类似的改进。这可能意味着 API 中的 chatgpt-4o-latest 模型也已更新。
与 Artifacts 不同,OpenAI Canvas 不支持显示 Mermaid 图表或 HTML 预览。据推测这些功能正在开发中,但令人好奇的是,这些功能既没有被优先考虑,也没有在两天前的 Dev Day 上发布(Latent Space 的回顾见此)。
由 Daily 赞助: 如果你对对话式语音 AI(以及视频)感兴趣,请加入 Daily 团队 和开源 Pipecat 社区,参加 10 月 19 日至 20 日在旧金山举行的 黑客松。20,000 美元奖金将授予最佳语音 AI Agent、虚拟化身体验、多模态 AI UI、艺术项目以及我们共同构思的其他任何作品。
swyx:语音 AI 是目前最热门的新 AI 工程技能!我也会参加——Daily 长期活跃在旧金山 AI 黑客松圈子里,这是我一段时间以来见过的为了学习我想精通的技术而设立的最高奖金池。
AI Twitter 回顾
所有摘要均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
AI 与技术进步
-
大语言模型 (LLMs) 与 AI 发展:@karpathy 分享了一个实验,他仅用 2 小时就利用 ChatGPT、Claude 和 NotebookLM 等 AI 工具策划了一个名为 “Histories of Mysteries” 的 10 集播客,展示了生成式 AI 带来的快速内容创作能力。@cwolferesearch 讨论了 o1(OpenAI 的最新模型)在自动 Prompt Engineering 方面的潜力,强调了其利用增加的推理时间计算(inference time compute)来实现更好推理的能力。
-
AI 在医疗保健领域:@bindureddy 主张在医疗保健领域快速采用 AI,指出 AI 在检索信息方面优于人类,且错误更少。他们建议用 AI 取代人类医生可能会造福人类。
-
AI 模型进展:@OfirPress 宣布 o1 在 SciCode 上创下了新的 SOTA,大幅领先 Claude。@rohanpaul_ai 分享了关于 Nvidia NVLM-D 1.0 72B 模型的信息,该模型在数学和编程任务上的表现与 Llama 3.1 405B 持平。
-
AI 基础设施:@soumithchintala 详细解释了如何在 10,000 块 H100 GPUs 上训练模型,涵盖了并行化(parallelization)、通信优化和故障恢复策略等主题。
AI 伦理与社会影响
-
AI 安全:@NPCollapse 分享了一个关于利用 AI 为人类构建美好未来的资源,称其为迄今为止在该主题上最好的尝试。
-
AI 监管:@JvNixon 对加州 AI 法律的潜在问题发表了评论,暗示这些法律可能侵犯言论和思想自由。
AI 应用与工具
-
AI 在软件开发中:@AlphaSignalAI 发布了 Pythagora,这是一个 VScode 扩展,使用 14 个 AI Agents 来管理从规划到部署的整个开发流程。
-
AI 用于数据分析:@basetenco 引入了一种新的模型推理指标导出集成,允许轻松导出到 Grafana Cloud 等可观测性平台。
-
AI 在内容创作中:@c_valenzuelab 分享了一个在潜在空间(latent space)中使用 AI 进行取景(location scouting)的示例,展示了可视化不同时间和季节的能力。
行业趋势与观点
-
AI 公司估值:@RazRazcle 评论了 OpenAI 的快速增长,指出他们在 2 年内实现了从 ~0 到 35 亿美元的营收。
-
软件开发实践:@svpino 批评了软件开发过度复杂化的趋势,呼吁回归更简单、更直接的应用程序构建方法。
-
AI 模型定价:@_philschmid 分享了 LLM 定价的更新,指出包括 OpenAI、Google Deepmind、Cohere、Mistral 和 Cloudflare 在内的多家供应商都在大幅降价。
AI Reddit 回顾
/r/LocalLlama 回顾
主题 1. Meta 发布 Llama 3.2:开源视觉模型的飞跃
- HuggingChat 模型更新!(Llama 3.2, Qwen, Hermes 3 等) (Score: 49, Comments: 15):HuggingChat 更新了其模型阵容,现在提供对 五个新模型 的免费访问,包括 Qwen2.5-72B-Instruct、Llama-3.2-11B-Vision-Instruct(具备 vision 能力)、Mistral-Nemo-Instruct-2407、Hermes-3-Llama-3.1-8B 和 Phi-3.5-mini-instruct。此外,还提供了 两个 启用了 tool calling 的模型:Meta-Llama-3.1-70B-Instruct 和 c4ai-command-r-plus-08-2024。
- Jamba Mini,一个 12B 激活/52B 总参数的 MoE 模型,因其在 256K context 下的卓越表现和低 hallucination rate 而被推荐。它在本地运行具有挑战性,但可以由 HuggingChat 托管,尽管这可能需要 vllm support 或自定义代码。
- 用户表达了尝试 Jamba Mini 的兴趣,HuggingChat 团队承认了其潜力,但指出 lack of TGI support 是一个重大问题。他们承诺会考虑这一建议。
- 有人请求由 thudm 开发的 LongWriter-glm4-9b,该模型能够“一次性生成 10,000+ 字”。该模型被认为适合像 HuggingChat 这样拥有更好硬件的公司。
- Meta Llama 3.2:视觉能力简析 (Score: 244, Comments: 47):Meta 发布了两个 multi-modal language models,Llama 3.2,参数量分别为 11B 和 90B。作者测试了该模型在各种任务中的 vision 能力,包括 image understanding、medical report analysis 和 chart analysis,发现它是日常使用场景中的强力竞争者,并在某些应用中可能替代 GPT-4o,尽管 GPT-4o 在更复杂的任务中表现仍然更优。欲了解详细分析,作者建议读者阅读其关于 Llama 3.2 vision 能力的 深度文章。
- 用户讨论了其他替代模型,如 Qwen 2 VL 72B 和 Molmo,一些人认为这些模型的表现优于 Llama 3.2。作者计划将 90B 模型与 Qwen 2 VL 72B 进行比较。
- 该模型的文本提取能力被发现在 标准文本中非常可靠,但在 发票或表格方面不够精确。用户还对其生成物体坐标和处理带有叠加网格任务的能力表示了兴趣。
- 由于本地硬件资源有限,作者使用 Gradio 和 Together AI 云服务来运行 70B 模型。一些用户分享了使用 Gradio 和 Transformers 实现其他模型(如 Qwen 2 VL 72B)的经验。
主题 2:特定语言和特定任务模型的进展
- google/gemma-2-2b-jpn-it 日本特定模型 (Score: 45, Comments: 15):Google 发布了 gemma-2-2b-jpn-it,这是 Gemma 系列中的一个 Japanese-specific model,现已在 Hugging Face 上可用。这一新模型是在 东京的 Gemma Developer Day 上宣布的,表明 Google 正致力于为日本市场扩展特定语言的 AI 模型。
- 正如 task-specific tuning 文档 中所解释的,该日本特定 Gemma 模型的 pre-training 是用日语进行的。目前没有提到关于 9B 版本 的计划或 Gemma 3 的发布日期。
- Google CEO Sundar Pichai 意外现身 Gemma Developer Day,暗示了对该项目的强力支持。一位 Hugging Face 代表 也发表了讲话,暗示未来可能会有该模型的 GGUF 版本。
- Google 介绍了几个与 Gemma 相关的工具,包括 Responsible Generative AI Toolkit、用于模型分析的 Gemma Scope,以及使用 MediaPipe 的 on-device generation 能力。还宣布了一项奖金为 $150,000 的 Kaggle 竞赛,旨在利用 Gemma 进行全球交流。
- Llama-3.1-Nemotron-70B-Reward (得分: 45, 评论: 6): 帖子标题 “Llama-3.1-Nemotron-70B-Reward” 似乎指向一个特定的 AI 语言模型,但正文中未提供额外内容或背景。由于缺乏进一步信息,无法对该帖子的内容或讨论点提供有意义的总结。
- Llama-3.1-Nemotron-70B-Reward 在人类标注任务上的表现与 Skywork-Reward-Gemma-2-27B 相似,但在 GPT-4 标注的任务上落后。这表明 Skywork-Reward-Gemma-2-27B 更好地模拟了 GPT-4 的偏好,这可能是因为它是在 GPT-4 标注的数据上训练的。
- 讨论中澄清了 Reward-Gemma(非 Gemini)与 GPT-4 生成的 “Ground Truth” 对齐得更好,但与人类的 “Ground Truth” 对齐较差。这归因于 Reward-Gemma 的训练数据包含了 GPT-4 生成的文本。
- 该模型被描述为 “RLHF(人类反馈强化学习)领域新的同类最佳裁判”,因其在预测人类偏好方面的准确性而受到关注。
- 新排行榜:哪些模型最擅长角色扮演? (得分: 40, 评论: 7): 一个名为 StickToYourRoleLeaderboard 的新排行榜评估了 LLM 在角色扮演场景中维持角色一致性的能力。该排行榜可在 Hugging Face 上查看,旨在评估模型在讨论过程中遵循指定角色和角色价值观的程度,作者在 X (原 Twitter) 上发布了详细的解释说明。
- 用户注意到 Mistral 在测试模型(Llama 3.1-8b、Llama 3.2-3b、Qwen 2.5、Mythomax)中表现最好,并强调了基础 Prompt 和模型参数的重要性。
- 排行榜中遗漏了 Mistral Nemo 引起了关注,并有建议在基准测试过程中包含更多热门的微调模型。
主题 3. AMD Strix Halo:本地 LLM 推理的潜在游戏规则改变者
- 传闻 AMD Strix Halo APU 具备 7600 XT 性能及 96 GB 共享 VRAM (得分: 68, 评论: 39): 据传 AMD 的 Strix Halo APU 性能可与 Radeon 7600 XT 媲美,并支持高达 96 GB 的共享 VRAM。这款高端笔记本芯片可能在不需要独立 AI GPU 的情况下在内存中运行大型语言模型。尽管目前 APU 缺乏官方 ROCm 支持,但 Llama.cpp 的 Vulkan kernel 对 APU 的支持速度与其它 AMD 硬件上的 ROCm kernel 相当。
- AMD 缺乏具备 CUDA 支持的 48GB VRAM GPU 被视为 AI 市场的错失良机。W7900-PRO 虽然提供 48GB,但价格高达 4000 美元,这可能是为了避免削弱 AMD 的 Instinct 系列产品。
- 传闻 Strix Halo APU 使用 256-bit LPDDR5X-8000 内存,提供 256GB/s 的理论带宽。有人推测其带宽可能达到 500GB/s 范围,可能还得益于针对游戏负载的 3D cache。
- 目前的 AMD APU 在 VRAM 分配方面面临限制,仅允许最多 8GB 作为专用 VRAM。然而,一项名为 Variable Graphics Memory 的新功能允许 AMD Ryzen™ AI 300 series 处理器将高达 75% 的系统内存转换为“专用”显存。
- Qwen 2.5 Coder 7b 用于自动补全 (Score: 37, Comments: 17): Qwen 2.5 Coder 7b 模型在处理数千个 token 的大上下文时,表现出优于其他本地模型的自动补全能力。用户报告称其幻觉显著减少,代码风格延续性有所提高,性能足以媲美 Copilot。若要在 IntelliJ 的 ContinueDev 插件中使用,需要自定义模板覆盖:
"<|fim_prefix|>{{{ prefix }}}<|fim_suffix|>{{{ suffix }}}<|fim_middle|>",并且为了确保控制 token 和 FIM 支持正常工作,使用 instruct 模型变体至关重要。- Qwen2.5-7b-coder-q8_0.gguf 在 Neovim 的 C++ 自动补全中表现出色,对于短补全,Q8 量化仅比 Q4 慢约 5%。用户 ggerganov 正在使用 256 行前缀和 128 行后缀作为上下文。
- Qwen2.5 7b-coder 与 14b-instruct 模型的对比表明,尽管后者并非专门为编程训练,但更大的模型可能提供更好的上下文理解和代码解释能力。7b-coder 版本则是针对带有特殊 token 的自动补全进行了微调。
- 关于在 Fill-in-the-middle (FIM) 任务中使用 base 还是 instruct 模型存在困惑,原帖作者报告在使用 base 模型时遇到问题。Qwen 的官方文档建议在 FIM 任务中使用 base 模型,这与用户的实际体验相矛盾。
Theme 4. 用于 AI 开发和评估的开源工具
-
Moshi 工作原理:开源实时语音 LLM 简明指南 (Score: 52, Comments: 7): Moshi 是 OpenAI Voice mode 的开源替代方案,由 Kyutai 开发,用于语言模型中的实时语音交互。作者分享了详细介绍 Moshi 架构的文章链接,并认为尽管它尚未达到 OpenAI 产品的水平,但仍值得深入了解。
- 🧬 OSS 合成数据生成器 - 使用自然语言构建数据集 (Score: 38, Comments: 3): 该帖子介绍了一个开源合成数据生成器,允许用户使用自然语言提示词创建数据集。该工具可在 GitHub 上找到,支持为各种机器学习任务(如分类、目标检测和分割)生成包括图像、文本和结构化数据在内的多样化数据集。该生成器利用大型语言模型和图像生成模型,根据用户定义的规格生产高质量的合成数据。
- Hugging Face 员工介绍了 Distilabel Synthetic Data Generator,这是一个通过自然语言提示词创建高质量数据集的开源工具。用户可以通过 克隆 Space 或安装 distilabel 库 在本地运行。
- 用户对该工具表示热烈欢迎,称赞其推动了 “AI 商品化(AI as commodity)”范式。创建者欢迎反馈,并提到计划在未来增加更多任务和功能。
- 该工具简化了用于训练和微调语言模型的数据集创建过程,允许用户定义应用特征、生成系统提示词,并产出可直接推送到 Hugging Face Hub 的可定制数据集。
- “箴言 27:17:铁磨铁,磨出刃来;朋友相感,也是如此” “通过 Self-play 训练语言模型赢得辩论可提高评判准确性” (Score: 35, Comments: 4):该论文介绍了 DebateGPT,这是一种通过 Self-play 训练进行辩论的语言模型,从而提高了评判辩论结果的准确性。通过让模型在各种话题上进行自我辩论,研究人员发现生成的评判模型在确定辩论获胜者方面的准确率达到了 83%,超过了人类评判员和之前的 AI 模型。这种方法展示了 Self-play 在增强语言模型辩论和分析能力方面的潜力。
- Self-play 以及在语言模型中复制人类倾向(如 Chain of Thought (CoT) 和辩论式交互)被证明对提高任务性能非常有效。这些“简单”的过程变化通常会带来显著的性能提升。
- 帖子正文中提供了论文链接 https://www.arxiv.org/abs/2409.16636,但由于应用在显示图片帖子文本时的限制,部分用户难以访问。
- 讨论强调了在社交媒体平台的学术讨论中,正确的论文引用和链接实践的重要性。
{kind=link}
其他 AI Subreddit 摘要
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
以下是所提供 Reddit 帖子中关键主题和进展的总结:
AI 模型进阶与能力
- OpenAI 的 o1 模型 正在展示令人印象深刻的推理和问题解决能力:
- 它可以 在几小时内复制复杂的博士级编程项目,而以前这需要数月时间。
- 它在 数学证明方面显示出可喜的结果,表现优于之前的模型。
- OpenAI 研究员 Hunter Lightman 表示,o1 已经表现得像一名软件工程师,并能编写 Pull requests。
-
Google 正在利用 Chain-of-thought 提示等技术开发 类似于 OpenAI o1 的推理 AI。他们已经展示了用于数学推理的 AlphaProof 等模型。
- Salesforce 发布了 xLAM-1b,这是一个拥有 10 亿参数的模型,在 Function calling 中实现了 70% 的准确率,尽管体积较小,但仍超越了 GPT-3.5。
AI 研究与开发
-
一篇 Google Deepmind 论文 展示了如何通过联合样本选择进行数据策展,从而加速多模态学习。
-
Microsoft 的 MInference 技术 能够在保持准确性的同时,为长上下文任务实现高达数百万个 Token 的推理。
-
关于使用 10 亿个网络策展的角色(Personas)来 扩展合成数据生成 的研究,在生成多样化训练数据方面展现了前景。
AI 行业与融资
-
OpenAI 正在 寻求独家融资安排 以加速 AGI 的开发。
-
NVIDIA 首席执行官 Jensen Huang 表示,一万亿美元正被投入到数据中心,以开启下一波提升业务生产力的 AI 浪潮。
AI 伦理与社会影响
-
关于 AGI 可能导致的岗位取代 以及对新经济范式需求的讨论正在进行中。
-
Sam Altman 建议 对 ChatGPT 等 AI 助手保持礼貌,这暗示了未来 AI 意识或权利的潜在发展。
AI 图像生成
- 图像生成模型的新版本如 PonyRealism v2.2 和 RealFlux 正在发布,展示了在写实性和功能方面的持续改进。
AI Discord 摘要回顾
摘要之摘要的摘要
Claude 3.5 Sonnet
1. LLM 进展与基准测试
- DeepSeek-V2 挑战 GPT-4:DeepSeek-V2,一款全新的 236B 参数模型,在 AlignBench 和 MT-Bench 等基准测试中表现出色,据报道在某些领域已超越 GPT-4。
- DeepSeek-V2 发布公告引发了关于其能力及对 AI 领域潜在影响的热烈讨论,社区成员渴望探索其全部潜力。
- Llama 3 在排行榜上的飞跃:Meta 的 Llama 3 迅速攀升至 ChatbotArena 等排行榜的首位,在超过 50,000 场对决中表现优于 GPT-4-Turbo 和 Claude 3 Opus 等模型。
- 这一迅速崛起引发了关于大语言模型演变格局的讨论,以及开源替代方案挑战该领域专有模型领导者的潜力。
2. 优化 LLM 推理与训练
- ZeRO++ 大幅削减通信开销:ZeRO++ 承诺将 GPU 上大型模型训练的通信开销降低 4 倍,这可能彻底改变分布式训练的效率。
- 这一进展可能显著影响 LLM 训练的可扩展性,使研究人员能够更快速、更具成本效益地训练更大的模型。
- vAttention 的动态 KV 缓存:vAttention 系统引入了 KV-cache 内存的动态管理,无需依赖 PagedAttention 即可实现高效的 LLM 推理。
- 这一创新解决了 LLM 部署中的内存限制问题,可能实现在有限的硬件资源上更高效地提供大型模型服务。
- Consistency LLMs 加速解码:Consistency LLMs 等技术探索了并行 Token 解码以降低推理延迟,有望为 LLM 应用提供更快的响应速度。
- 这种方法挑战了传统的自回归解码方法,为优化实时应用中的 LLM 性能开辟了新途径。
3. 开源 AI 框架与社区努力
- Axolotl 扩展数据集格式支持:Axolotl 扩展了对多种数据集格式的支持,增强了其在指令微调和预训练 LLM 方面的能力。
- 此次更新促进了各种数据源的轻松集成,使研究人员和开发人员能够利用自定义数据集更有效地微调模型。
- LlamaIndex 与 Andrew Ng 联手:LlamaIndex 宣布与 Andrew Ng 的 DeepLearning.ai 合作推出一门关于构建 Agentic RAG 系统的新课程,将学术见解与实际应用相结合。
- 这一合作伙伴关系旨在使先进的 AI 技术大众化,让广大开发人员和研究人员更容易接触到 Agentic RAG 等复杂概念。
- Mojo 展示 Python 集成潜力:Modular 的全新深度解析 中,Chris Lattner 展示了 Mojo 实现无缝 Python 集成以及
_bfloat16_等 AI 特定扩展的潜力。- 讨论强调了 Mojo 将 Python 的易用性与系统编程能力相结合的雄心,这可能会重塑 AI 开发工作流。
4. 多模态 AI 与生成式建模创新
- Idefics2 和 CodeGemma 突破边界:Idefics2 8B Chatty 专注于提升聊天交互体验,而 CodeGemma 1.1 7B 则进一步优化了编程能力,展示了专用 AI 模型的进步。
- 这些模型体现了将 AI 能力针对特定领域进行定制的持续趋势,增强了在对话式 AI 和代码生成等目标应用中的性能。
- Phi-3 将 AI 引入浏览器:Phi-3 模型通过 WebGPU 为浏览器引入了强大的 AI 聊天机器人功能,有可能彻底改变客户端 AI 应用。
- 这一进展标志着向更易于访问且保护隐私的 AI 体验迈出了重要一步,使得直接在 Web 浏览器中进行复杂的 AI 交互成为可能。
- IC-Light 照亮开源图像重照明领域:开源项目 IC-Light 专注于推进图像重照明(relighting)技术,使复杂的视觉效果对社区而言更加触手可及。
- 该工具赋能创作者和研究人员探索先进的图像处理技术,可能在计算机图形学和视觉 AI 领域带来新的应用。
GPT4O (gpt-4o-2024-05-13)
1. Model Performance Optimization
- 动态内存压缩提升吞吐量:Dynamic Memory Compression (DMC) 在 H100 GPU 上将吞吐量提升了高达 370%,增强了 Transformer 的效率。
@p_nawrot分享了关于 DMC 论文 的见解,引发了关于其对大规模模型训练影响的讨论。
- ZeRO++ 减少 GPU 通信开销:ZeRO++ 承诺在 GPU 上进行大模型训练时,将通信开销降低 4 倍。
@deep_speed强调了 ZeRO++ 的优势,指出其在优化资源利用率方面的潜力。
- Flash Attention 的内存使用引发讨论:社区讨论了 Flash Attention 在计算复杂度为平方级的情况下,是否表现出线性内存增长。
@ggerganov指出 Flash Attention 可以优化大模型中的内存使用。
2. Fundraising and New Product Launches
- OpenAI 获得 66 亿美元融资:OpenAI 成功筹集了 66 亿美元,以支持其 AI 研究项目。
@openai宣布了 本轮融资,并讨论了其对未来 AI 进展的影响。
- FLUX1.1 Pro 以速度取胜:FLUX1.1 Pro 发布,提供 快 6 倍的生成速度 和改进的图像质量。
@blackforestlabs分享了 FLUX1.1 Pro 的发布消息,在 AI 社区引发了兴奋和期待。
- GPT-4o Realtime API 发布:GPT-4o Realtime API 已发布,用于低延迟音频交互。
@azure详细介绍了 API 的发布,重点关注客户支持等应用场景。
3. AI Tooling and Community Innovations
- Crawl4AI 增强数据采集:Crawl4AI 是一款开源 Web 爬虫,提供可定制的数据采集工具。
@unclecode介绍了 Crawl4AI,讨论了其与语言模型的集成,以改进数据提取。
- Mojo 的错误处理策略:对话集中在 Mojo 的错误处理上,建议采用 Zig 风格的错误联合类型 (error unions)。
@msaelices提出了对 Mojo 错误处理的 改进建议,强调模式匹配和组合性。
- MongoDB Atlas 赋能混合搜索:一篇关于使用 MongoDB Atlas 创建和配置混合搜索索引 的博客文章,旨在增强搜索相关性。
@llama_index详细介绍了 实现过程,将语义搜索与全文搜索合并,以解决常见的低效问题。
4. AI Alignment and Research Discussions
- AI Reading Group 启动:来自 Women in AI & Robotics 的 AI Reading Group 启动,重点关注研究讨论。
@aashka_trivedi将展示 INDUS 论文,重点介绍 IBM 与 NASA 之间的合作。
- OpenAI 审核政策引发讨论:成员们讲述了他们在 OpenAI 审核政策 方面的经历,指出了一些提示 AGI 的请求被标记。
@eleuther指出这些政策似乎过于谨慎,并暗示许多被标记的信息并不符合其陈述的使用政策。
- Softmax 函数的局限性探讨:一篇论文强调了 Softmax 函数的局限性,即在输入规模增加时难以实现鲁棒计算。
@nous_research分享了该论文,提出 adaptive temperature 作为这些局限性的解决方法。
5. 开源贡献与协作
- Axolotl 添加数据集格式文档:Axolotl 支持多种数据集格式,用于指令微调和预训练 LLM。
@axolotl_ai宣布了文档更新,提升了社区的易用性。
- OpenDevin 发布公告:开源自主 AI 工程师 OpenDevin 的发布在 GitHub 上引起关注。
@cognition_ai分享了该发布,强调了其在开发者协作和创新方面的潜力。
GPT4O-Aug (gpt-4o-2024-08-06)
1. AI 模型性能与优化
- FLUX1.1 Pro 超出预期:FLUX1.1 Pro 发布,拥有快六倍的生成速度和更高的图像质量,在 Artificial Analysis 图像竞技场中获得了最高的 Elo score。
- AI 社区兴奋不已,渴望探索该模型在优化 AI 工作流和应用方面的潜力。
- 大型模型的量化技术:围绕大型神经网络(50B+ 参数)量化算法的讨论强调了 int8 和 HQQ 等技术,可将目标指标的损失维持在 1% 以下。
- 成员们指出 int4 + hqq 量化 同样有效,且仅需极少的校准,引发了对优化模型效率的兴趣。
- AI 配置的 GPU 散热方案:一位用户考虑为其 8 GPU 配置使用单槽水冷头,并指出在两个 1600W 和一个 1500W 电源上的最大功耗为 4000W。
- 讨论强调了用电安全的重要性以及 GPU 配置的创新用途,例如在寒冷月份作为取暖方案。
2. AI 社区实践与担忧
- OpenAI 泡沫担忧:成员们担心 OpenAI 泡沫 正在危险地扩张,将其与 WeWork 类比,并质疑 AI 炒作的长期可持续性。
- o1 的发布暂时缓解了恐惧,但讨论强调了 OpenAI 未来轨迹及其对行业影响的不确定性。
- 社区对客户支持的挫败感:用户对订阅问题的客户支持表示不满,包括文件下载和响应延迟,这影响了用户留存。
- 一位用户考虑取消订阅,强调了支持不足对社区满意度的重大影响。
- 解决 AI 模型审核问题:Claude 2.1 标记 SFW 提示词 的问题引起了关注,其中一个案例将角色描述标记为“色情”,引发了关于审核实践的辩论。
- 社区讨论强调需要更清晰的审核指南,以防止干扰用户交互。
3. AI 工具与功能发布
- OpenAI’s New Canvas Feature:OpenAI 为写作和编码项目推出了 canvas 功能,允许 Plus & Team 用户 通过选择 “GPT-4o with canvas” 来超越简单的聊天交互进行协作。
- 该功能旨在提升项目管理和协作的用户体验,并就其增强复杂任务工作流的潜力展开了讨论。
- GPT-4o Realtime API for Audio:GPT-4o Realtime API 发布,用于低延迟音频交互,目标应用场景包括 customer support,并需要客户端集成以实现最终用户音频。
- 这一进展激发了人们对通过实时音频功能增强各种应用对话能力的兴趣。
- LangChain’s LangGraph Innovates Query Generation:一篇 LinkedIn 帖子 强调了 LangGraph 在 LangChain 生态系统中管理复杂查询生成和输出结构化方面的作用。
- 重点放在了错误纠正和用户友好型结果上,并对 Harrison Chase 和 LangChain 团队的贡献表示赞赏。
4. AI Research and Collaboration
- AI Reading Group Promotes Collaboration:来自 Women in AI & Robotics 的 AI Reading Group 启动,将于 2024 年 10 月 17 日 展示 IBM 和 NASA 的研究,观众问答环节名额有限。
- 该小组旨在促进研究人员与社区之间的直接对话,聚焦跨学科 AI 讨论和创新。
- Exploring Liability in AI Research:讨论集中在分享 AI 模型用于研究的个人是否应对滥用承担责任,并呼吁制定明确的法律准则。
- 成员们强调了理清法律环境的重要性,以建立负责任的 AI 研究实践并保护原始研究人员。
- Knowledge Graph Embedding Innovations:一篇论文介绍了一种 knowledge graph embedding (KGE) 的新方法,通过群论集成不确定性,以实现高效且具有表现力的模型。
- 这种方法允许实体和关系作为对称群中的置换进行嵌入,展示了改进 KGE 框架的潜力。
5. AI Ethics and Data Privacy
- Concerns Over Data Privacy in AI:一位成员对 data privacy 提出了警告,指责包括 OpenAI 在内的 AI 公司专注于从中型公司“窃取数据”,引发了辩论。
- 讨论强调了数据共享透明度和选择退出(opt-out)选项的重要性,反映了 AI 社区更广泛的担忧。
- AI’s Impact on Future Movies:一篇文章探讨了 AI 对电影制作的影响,认为技术将重塑叙事和制作流程,可在此处访问 here。
- 对话指出了可能重新定义电影观众参与度的新兴趋势,AI 在行业转型中发挥着关键作用。
- Legal Status of Web Scraping:针对 web scraping 正在进行的诉讼引起了关注,艺术家和作家对其法律地位和影响感到沮丧。
- 对话强调了法律的复杂性,以及在数据访问和知识产权保护之间取得平衡的明确准则需求。
O1-mini
Theme 1. AI Models on the Fast Track: Speed and Savings
- FLUX1.1 Pro Zooms Ahead:FLUX1.1 Pro 发布,具有 6 倍快的生成速度和卓越的图像质量,在 Artificial Analysis image arena 中获得了最高的 Elo score。
- GPT-4o Slashes Prices:从今天起,GPT-4o 的输入成本下降 50%,输出成本下降 33%,与 8 月份发布的更新模型 GPT-4o-2024-08-06 保持一致。
- NVIDIA’s NVLM 1.0 Unveiled:NVLM 1.0 推出了用于视觉语言任务的开源权重,使 NVIDIA 成为对抗专有模型的主要竞争对手。
Theme 2. Seamless Integration: Bringing AI to Your Projects
- gpt4free 加入聊天机器人:一位成员成功将 gpt4free 集成到他们的聊天机器人中,尽管性能较慢且需要频繁切换提供商,但增强了灵活性。
- 针对 AMD GPU 挑战的云解决方案:面对在没有 CUDA 的 Windows 上进行 fine-tuning 的问题,成员们推荐使用 Lambda Labs 或 Collab 等云平台,以确保在 AMD 硬件上进行有效的训练。
- Shadeform 的 GPU 市场流:Shadeform 提供了一个集中的计费和管理系统,用于预订按需 GPU,为开发者简化了多云部署。
主题 3. 攻克技术难题:克服 AI 训练障碍
- 量化难题获解:开发者们正在探索 int8 和 HQQ 等 quantization algorithms,以在大型模型(50B+ 参数)中保持 <1% 的损失,并利用 Hugging Face 的指南 进行实现。
- Mojo 的导入之谜:Mojo 在 Python 的动态导入方面面临挑战,引发了关于安全风险以及可能委托给 CPython 的讨论。
- Flash Attention 的内存混淆:Flash Attention 功能表现出不一致的内存行为,尽管其计算复杂度为二次方,但一些用户遇到了线性增长,如 llama.cpp Pull Request #5021 所示。
主题 4. 搭建桥梁:参与 AI 社区
- AI 读书会激发协作:在多个 Discord 频道启动,来自 Women in AI & Robotics 的小组展示了由 IBM 和 NASA 的 Aashka Trivedi 带来的 INDUS 等演示,促进了直接对话和跨学科讨论。
- Unsloth 网络研讨会分享见解:Unsloth Webinar 强调了为了训练速度而转向低精度位(lower precision bits)的趋势以及高质量数据集的集成,引发了更深层次的技术对话。
- 节日 AI 家庭派对:诸如 October House Party 之类的活动鼓励成员展示他们的 Open Interpreter 作品,将乐趣与知识共享及社区凝聚结合在一起。
主题 5. 助力进步:优化 AI 工具和基础设施
- Torchtune 0.3.1 助力微调:最新的 Torchtune 0.3.1 更新包含了所有 Llama 3.2 Vision models,为 Macbook 引入了 MPS beta support,并为 Llama3.2 和 Qwen2 等模型提供了新的 knowledge distillation recipe。
- LlamaIndex 增强混合搜索:将 MongoDB Atlas 与 LlamaIndex 集成可实现无缝的 hybrid search,结合 semantic 和 full-text search 以提高结果相关性。
- Aider 扩展实时 API:在 Aider 中推出的 GPT-4o Realtime API 为诸如 customer support 等应用启用了低延迟音频交互,增强了对话能力。
提到的链接:
- FLUX1.1 Pro on Replicate
- Artificial Analysis Image Arena
- GPT-4o GitHub Release
- Lambda Labs
- Shadeform AI Marketplace
- Hugging Face Quantization Guide
- llama.cpp Pull Request #5021
- INDUS Paper
- Unsloth Documentation
- Aider Configuration Options
- Torchtune Documentation
- Torchtune GitHub Release
- LlamaIndex with MongoDB Atlas
O1-preview
主题 1:OpenAI 的新功能与战略举措
- OpenAI 推出 Canvas,彻底改变协作方式:OpenAI 推出了 Canvas 功能,允许用户在简单的聊天之外,针对写作和编程项目与 ChatGPT 进行交互。Plus 和 Team 用户现在可以通过在模型选择器中选择 “GPT-4o with canvas” 来进行尝试。
- GPT-4o 随模型更新大幅降价:OpenAI 将 GPT-4o 的输入价格降低了 50%,输出价格降低了 33%,这与自 8 月份以来提供的更新版 GPT-4o-2024-08-06 模型保持一致。此举让用户更容易获得先进的 AI 能力。
- Sam Altman 在 OpenAI 寻求 1570 亿美元估值之际加强控制:报告显示,在 OpenAI 估值飙升至惊人的 1570 亿美元 期间,Sam Altman 正在加强其在公司的影响力。这种领导权的集中引发了人们对该组织未来发展轨迹的疑问。
主题 2:AI 模型与工具的创新
- FLUX1.1 Pro 以六倍速度提升遥遥领先:新发布的 FLUX1.1 Pro 提供了 六倍的生成速度提升,改进了图像质量,并在 Artificial Analysis 图像竞技场 中保持着最高的 Elo 分数。该模型在图像生成领域树立了新的性能标准。
- NVIDIA 发布 NVLM 1.0,挑战专有模型:NVIDIA 推出了 NVLM 1.0,这是一个专为视觉语言任务设计的开源模型,其准确率可与领先的专有模型相媲美。开发者可以访问其 权重(weights)和代码,为新的创新铺平道路。
- StackBlitz 发布用于 AI 驱动全栈开发的 Bolt:StackBlitz 推出的 Bolt 允许用户在 AI 的支持下提示、编辑、运行和部署全栈应用程序。它提供了一个免费、全面的开发环境,支持 npm、Vite 和 Next.js。
主题 3:AI 模型局限性的挑战与担忧
- 审核疯狂:SFW 提示词被 AI 误标:用户报告称 Claude 2.1 和其他模型错误地将 SFW(职场安全)提示词 标记为不当内容,干扰了交互。一段角色描述被错误地标记为“性暗示”,引发了关于过度审核做法的辩论。
- Softmax 的弱点:在尖锐决策中的局限性:一篇论文揭示了 softmax 函数 在输入增加时无法逼近尖锐函数(sharp functions)的局限性,挑战了其在 AI 推理任务中的有效性。作者建议将 自适应温度(adaptive temperature) 作为一种潜在的补救措施,引发了进一步的研究。
- GPU 困境:在入门级硬件上运行大模型:用户正在努力解决在旧 GPU 上运行 SDXL 等大型模型的问题,并为 AMD 用户探索 ZLUDA 等替代方案。社区正在讨论平衡性能与硬件限制的策略。
主题 4:AI 社区参与与学习
- AI 阅读小组架起研究与社区的桥梁:来自 Women in AI & Robotics 的 AI 阅读小组 启动,由来自 IBM 的 Aashka Trivedi 于 2024 年 10 月 17 日 展示与 NASA 的联合研究。会议将深入探讨 INDUS:适用于科学应用的高效语言模型。
- DSPy 2.5 获得好评,呼吁更多文档:用户称赞 DSPy 2.5 在 TypedPredictors 等方面的改进,但敦促提供更多关于自定义和集成 Pydantic 的文档。增强的指南可以为用户解锁高级功能。
- 关于数据实践和隐私的激烈辩论:成员们对数据隐私表示担忧,指责一些 AI 公司专注于从垂直领域的中型公司“窃取数据”。社区正在辩论 AI 开发中数据使用的伦理和合法性。
主题 5:AI 模型优化的技术讨论
- 量化探索:平衡体积与精度:开发者正在探索针对大型模型(50B+ 参数)的 int8、HQQ 以及 int4 + HQQ 等量化算法,旨在使目标指标的损失低于 1%。HQQ 等技术提供了高效率,且仅需极少的校准。
- Mojo 与 Python 导入及错误处理的斗争:Mojo 编程语言在处理 Python 的动态导入时遇到困难,使集成和错误管理变得复杂。社区成员正在辩论是否采用 Zig 风格的错误联合(error unions) 以及其他策略来提高 Mojo 的鲁棒性。
- Flash Attention 引发内存占用之谜:用户质疑 Flash Attention 是否在计算复杂度为平方级的情况下导致内存线性增长。混合的体验引发了关于澄清其对内存和性能实际影响的讨论。
第一部分:Discord 高层级摘要
Unsloth AI (Daniel Han) Discord
- 晨间问候引发闲聊:成员们交换了晨间问候,随后展开了关于时差的轻松讨论,幽默地提到,“如果你不在 EST 或 PST 时区,你就错过了。”
- 这种轻松的氛围为后续的技术讨论奠定了基调。
- 关于 Jupyter Notebook 与 VS Code 的辩论:成员们表达了对界面的偏好,其中一位对 Jupyter Notebook 表示不满,称其与 VS Code 相比显得过时。
- 另一位成员反驳道,他们更喜欢 VS Code,因为它对 notebook 的支持和整体可用性。
- 对 Qwen 模型可靠性的担忧:讨论引发了对 Qwen 模型 可靠性的担忧,用户报告了熟悉配置下出现的意外结果。
- Unsloth 页面上模型的缺失让成员们感到困惑,加剧了讨论。
- 来自 Unsloth Webinar 的见解:Unsloth 网络研讨会强调的关键点包括在训练期间转向更低精度的 bits,旨在提高速度。
- 成员们讨论了高质量数据集的整合以及为深度学习增强的模型架构。
- 在 AMD GPU 上进行 Fine-tuning 的挑战:一位成员询问如何在没有 CUDA 支持 的情况下在 Windows 上运行 Unsloth,引发了关于 AMD 在 ML 领域局限性的讨论。
- 建议包括使用 Lambda Labs 或 Collab 等云解决方案进行有效训练。
HuggingFace Discord
- 用户遇到模型访问问题:几位用户报告了访问 Llama 等模型时遇到的问题,在使用 Hugging Face 平台时面临超时和限制,影响了热门模型的可用性。
- 一位用户确认在 GeForce 980Ti 等旧硬件上运行 Llama-3.2-1B,表明即使资源有限也仍然足够。
- gpt4free 成功集成:一位成员成功将 gpt4free 集成到他们的聊天机器人中,尽管经历了性能下降和需要频繁更换提供商的情况。
- 此次集成还包括添加了两个 OpenAI 模型,展示了其在 GitHub 上的 Release v1.3.0 期间的灵活开发。
- FLUX1.1 Pro 以速度令人印象深刻:FLUX1.1 Pro 发布,提供了 6 倍更快的生成速度 和改进的图像质量,在 Artificial Analysis 图像竞技场 中获得了最高的 Elo 评分。
- 该模型的表现引发了 AI 社区的兴奋以及对进一步进步的期待。
- AI 读书小组启动公告:来自 Women in AI & Robotics 的 AI Reading Group 启动,其首届会议将于 2024 年 10 月 17 日 举行,届时将有来自 IBM 关于与 NASA 联合研究的演讲。
- 一位成员建议在 Discord 和 Eventbrite 上直播活动,以扩大受众参与度,增强社区对 AI 研究的参与。
- 为初学者推荐 Hugging Face 课程:成员们推荐将 Hugging Face 课程和 Open Source AI Cookbook 作为 NLP 新手的必备资源,强调了将实践经验与基础理论相结合的重要性。
- 像 ‘The Illustrated Transformer’ 和 3blueonebrown 这样的资源被认为对理解 NLP 中的复杂概念很有帮助。
aider (Paul Gauthier) Discord
- Aider 遥测数据收集引发关注:用户讨论了 Aider 目前缺乏遥测数据收集,限制了对使用指标和趋势的洞察。
- 对未来遥测的建议包括在确保隐私的前提下监控 model choices 和 tokens。
- Cursor vs Aider - 界面之争:成员们对比了 Aider 和 Cursor,指出 Cursor 的界面更流畅,但称赞 Aider 在终端使用中的效率。
- 用户对 Cursor 的 Composer 功能的不一致性表示不满,这与 Aider 的可靠性形成对比。
- Claude Development 引发关注:用户对 Claude Development 展现出浓厚兴趣,因其具有前景的代码辅助能力。
- 用户热切期待更新,渴望将其潜在的改进与当前工具进行对比。
- GPT-4o Realtime API 发布:GPT-4o Realtime API 已发布,旨在为 customer support 等应用提供低延迟的音频交互。
- 集成需要处理终端用户的音频,从而增强对话能力。
- Crawl4AI 增强数据收集:Crawl4AI 现已作为开源的 LLM 友好型网络爬虫推出,为开发者提供可定制的数据收集工具。
- 它与语言模型的集成可以显著改善运营数据的提取流程。
OpenRouter (Alex Atallah) Discord
- DeepInfra 停机时长受到影响:DeepInfra 经历了约 15 分钟 的停机,但目前正在恢复中。
- 用户在不久后收到了关于状态和持续恢复工作的通知。
- GPT-4o 价格腰斩:从今天起,GPT-4o 模型的输入价格下降 50%,输出价格下降 33%。
- 这一调整与 8 月份发布的更新模型 GPT-4o-2024-08-06 保持一致。
- Claude 2.1 的审核困惑:用户对 Claude 2.1 标记 SFW prompts 表示担忧,这干扰了交互。
- 其中一个被标记的案例涉及角色描述被错误地标记为“色情”,引发了关于审核机制的辩论。
- NVIDIA 发布 NVLM 1.0 模型:NVIDIA 发布了具有竞争力的 NVLM 1.0,提供专为视觉语言任务设计的开源权重和代码。
- 该模型预计将提高性能和准确度,与该领域的专有模型展开竞争。
- Flash 8B 模型在生产环境中变慢:Flash 8B model 现已投入生产,但记录的速度为 200 tokens per second,比之前的版本慢。
- 讨论表明,未来可能会考虑进行速度升级,以解决硬件效率问题。
Modular (Mojo 🔥) Discord
- Mojo 在 Python 导入方面遇到困难:讨论显示 Mojo 无法原生处理 Python 的动态导入行为,使集成和错误管理变得复杂。
- 成员们指出,将导入委托给 CPython 可能会引入类似于 NPM 生态系统中的安全风险。
- Mojo 函数遇到返回值问题:成员们发现,在 Mojo 中从函数返回值有时需要变量声明(例如使用
var)以避免运行时错误。- 分享的一个示例显示,除非修改为返回可变对象,否则
SIMD初始化会失败。
- 分享的一个示例显示,除非修改为返回可变对象,否则
- 探索错误处理策略:对话集中在 Mojo 错误处理的潜在改进上,建议倾向于使用 Zig-style error unions 来处理推断的错误类型。
- 一些成员主张采用更具函数式编程风格的错误管理方法,强调模式匹配和组合性。
- 静态数据存储的复杂性:用户寻求在 Mojo 中静态存储表的方法,以避免产生过多的代码膨胀,特别是来自
List等构造。- 重点是匹配 C static declarations 中的性能和内存效率。
- SIMD 初始化问题引发 GitHub 讨论:有人请求针对
SIMD.__init__构造函数的异常行为创建一个 GitHub issue,该构造函数在某些条件下会报错。- 成员们表示愿意帮助追踪 SIMD 相关 bug 的根本原因。
OpenAI Discord
- 用于写作与编码的 Canvas 功能发布:OpenAI 宣布了 canvas 功能的早期版本,允许用户在简单的聊天交互之外处理写作和编码项目。从今天开始,Plus 和 Team 用户可以通过在模型选择器中选择 “GPT-4o with canvas” 来试用。
- 这一增强旨在提升项目管理和协作的用户体验,利用先进的 AI 能力处理复杂任务。
- API Access 层级困惑:关于 API access 逐步向特定使用层级(usage tiers)开放的讨论出现,一位用户在之前拥有访问权限的情况下遇到了 403 error。对话强调了处理 rate limit issues 和有效处理错误的重要性。
- 成员们分享了在 OpenAI Cookbook 中找到的缓解速率限制的见解,强调了社区在应对这些 API 挑战方面的支持。
- 新版 Copilot App 的印象:用户对新版 Copilot App 的性能给出了正面反馈,指出其作为 Android 原生应用 的流畅易用性。然而,对于无法删除聊天的担忧也随之产生,这成为了与其他聊天机器人的对比点。
- 社区讨论集中在用户体验、功能对比上,并提出了改进空间。
- 语音功能现已在自定义 GPTs 中可用:一位成员庆祝了今天在 GPT store 的自定义 GPT 中引入语音功能,感谢 OpenAI 解决了之前的顾虑。他们指出,该语音模式并非新的 advanced voice,用户希望未来所有自定义 GPT 都能包含该功能。
- 这一增强反映了对 GPT 中更丰富交互功能的持续需求,表明了社区对持续改进的渴望。
- 4o-mini 中九尾(Ninetails)训练数据的缺陷:一位用户发现,当被问及火属性宝可梦时,4o-mini 始终错误地将 Ninetails 识别为有 6 条尾巴,而 4o 则提供了正确答案。这种在多次生成中出现的模式表明这是 training data 的缺陷,而非典型的幻觉。
- 进一步调查显示,像 gpt-3.5-turbo 和 gpt-4o-mini 这样的小型模型也会显示不准确的回答,引发了对其训练数据集的质疑。
Stability.ai (Stable Diffusion) Discord
- 虚拟环境是兼容性的关键:成员们建议使用 venv 或 conda 等 virtual environments,以避免在运行 AUTOMATIC1111 等工具时出现 Python 版本冲突。
- Virtual environments 简化了包管理,确保不同的设置不会干扰工作流。
- 选择正确的 AI 模型和 UI:鼓励新用户使用 Comfy UI,因为它具有灵活性,同时也提到了 Automatic1111 和更快的 Forge UI 分支。
- Comfy UI 的基于节点的设计提供了更多通用性,而 Automatic1111 在教程方面仍然很受欢迎。
- 生成特定姿势的图像:用户解决了生成特定姿势图像的挑战,并建议使用 ControlNet 来增强输出控制。
- 训练像 LoRA 这样的特定模型有助于调整生成的图像以满足用户预期。
- 应对 AI 模型的局限性:讨论强调了在旧款 GPU 上运行 SDXL 的问题,并为 AMD 用户推荐了 ZLUDA 等替代方案。
- 虽然较低的分辨率可以加快处理速度,但最佳效果通常需要适合特定模型的高分辨率。
- 尝试 AI 模型训练:一位用户分享了以复杂情况告终的训练经历,强调了不当图像选择的后果。
- 这提醒了在训练 AI 模型时遵守社区标准的重要性。
Nous Research AI Discord
- FLUX1.1 Pro 性能超越竞争对手:FLUX1.1 Pro 正式发布,宣称其生成速度比前代快 6 倍,且图像质量有所提升,标志着一次重大升级。
- 用户可以利用这一性能实现更高效的工作流,正如 发布公告 中所强调的。
- Grok 使用需要验证:讨论中提到了访问 Grok 需要 验证 和 付费 的必要性,成员们对此意见不一。
- 澄清了一些用户无需验证即可访问该服务,但仍需付费。
- 探讨 Softmax 函数的局限性:一篇论文强调了 softmax 函数 在输入规模增加时实现鲁棒计算的局限性,并从理论上证明了其缺陷。
- 作者提出 adaptive temperature(自适应温度)作为这些局限性的潜在解决方案。
- 寻找无审查的故事创作 LLM:一位用户询问哪种 LLM 最适合创作故事,要求既无审查又可以作为 API 运行。
- 他们还在寻找能够自动使用 LLM 构建故事,而不仅仅是提供标准帮助的网站。
- 揭示控制模型思考过程:针对防止模型泄露其 chain of thought(思维链)的控制措施引发了担忧,人们质疑这些措施对自我解释能力的影响。
- 这指向了关于在 AI 交互中平衡透明度与安全性的持续讨论。
Perplexity AI Discord
- 语音朗读功能评价褒贬不一:用户讨论了语音朗读功能的潜力,认为它对消化长回复很有帮助,但也面临 发音 问题。
- 一位成员表示他们在多任务处理时经常使用此功能,展示了其公认的价值。
- 对订阅客户支持感到沮丧:几位用户对订阅问题(如文件下载)以及支持团队对安全问题的延迟回复表示沮丧。
- 有人甚至考虑取消订阅,凸显了对用户留存的重大影响。
- 模型输出质量不一致:社区讨论揭示了对模型质量不一致的担忧,特别是在 Collection 或 Pro 套餐下。
- 成员们注意到极端的性能不稳定性,引发了对产品可靠性的怀疑。
- 探讨 AI 对未来电影的影响:一篇文章详细介绍了 AI 对电影制作的影响,认为技术将重塑叙事和制作流程,详见 此处。
- 对话指出了一些可能重新定义电影观众参与度的新兴趋势。
- OpenAI 获得巨额融资:报告显示 OpenAI 成功筹集了 66 亿美元,预计将支持其 AI 研究项目;详情见 此处。
- 这笔资金预计将显著提升其技术和平台能力。
Cohere Discord
- OpenAI 泡沫处于破裂边缘:成员们对 OpenAI 泡沫 正在危险地扩张表示担忧,特别是在 o1 发布后,虽然它暂时缓解了恐惧。
- 这感觉就像 WeWork 事件重演, 讨论强调了 OpenAI 长期命运的不确定性。
- Cohere 的低调策略:对 Cohere 策略的赞赏浮出水面,评论认为它在全面运作的同时,在 AI 领域保持了务实的存在感。
- 这种谨慎的做法可能会在充满寻求曝光度的玩家的环境中为 Cohere 提供竞争优势。
- AGI 概念的转变:一种观点认为 AGI 概念 将在未来 二十年 内发生剧变,引发了成员间的激烈讨论。
- 这种转变可能会重新定义 AI 生态系统的预期和范围,令社区成员感到惊讶。
- 对数据隐私的担忧:一名成员对 数据隐私 发出了警报,声称包括 OpenAI 在内的一些 AI 公司正专注于从 中型公司 窃取数据。
- 社区对这一说法的有效性进行了辩论,指出公司可以选择 退出 (opt-out) 数据共享实践。
- Reranking API 达到速率限制:用户报告在仅使用 50 条记录 进行极少量 API 调用时就遇到了 rate limit,这引发了不满。
- 这个问题引发了对 免费层级 限制的质疑,可能会阻碍有效的测试。
Interconnects (Nathan Lambert) Discord
- OpenAI 发布 Canvas 以增强协作:OpenAI 新的 Canvas 界面允许用户更直观地与 ChatGPT 进行写作和编码项目的互动,整体提升了协作体验。
- 尽管有其优点,但早期用户也指出了诸如缺乏渲染的前端代码以及难以追踪代码演变等局限性。
- Sam Altman 在 OpenAI 的权威日益增长:一篇文章揭示了 Sam Altman 如何在 OpenAI 估值飙升至 1570 亿美元 之际,扩大了他的影响力。
- 这一时刻引发了关于权力集中对组织未来发展轨迹影响的关键问题。
- c.ai 面临潜在公关危机:关于 c.ai 即将面临 公关灾难 (PR disaster) 的警告浮出水面,成员们对该公司的声誉表示担忧。
- 社区对现状感到失望,情绪中流露出悲伤和无奈。
- 探索 Shadeform 的 GPU 市场:成员们讨论了 Shadeform,它提供了一个预订按需 GPU 的市场,增强了多云部署能力。
- 集中计费和管理功能似乎简化了工作负载部署,突显了 Shadeform 的效率。
- O1 Preview 思维过程泄露:Reddit 上的一篇帖子透露 O1 Preview 意外泄露了其完整的思维过程,在聊天中引起了极大关注。
- 一名成员幽默地建议这可能会激发一篇引人入胜的博客文章,展示了科技社区内意想不到的透明度。
Latent Space Discord
- OpenAI 发布 ChatGPT Canvas:OpenAI 推出了 ChatGPT Canvas,这是 ChatGPT 内部用于协作项目的新界面,允许用户编辑代码并接收行内反馈。
- 功能包括直接编辑能力、任务快捷方式和改进的研究功能。
- StackBlitz 推出 Bolt 平台:StackBlitz 发布了 Bolt,这是一个用于通过 AI 支持进行提示、编辑、运行和部署全栈应用的平台。
- 该开发环境完全支持 npm, Vite 和 Next.js,为应用创建提供了一套免费工具。
- Gartner 认可 AI 工程:Gartner 已将 Writer 评为生成式 AI 技术的后起之秀 (Emerging Leader),强调了 AI 在企业解决方案中的重要性。
- 这一认可突出了在生成式 AI 工程和 AI 知识管理应用等领域的进展。
- Google 的 Gemini AI 与 OpenAI 竞争:Google 正在开发名为 Gemini AI 的推理 AI 模型,旨在与 OpenAI 的能力展开竞争。
- 该计划建立在 Google 先进 AI 系统(如 AlphaGo)的遗产之上,目标是增强类人推理能力。
- 关于 Reflection 70B 模型的讨论:Sahil Chaudhary 讨论了 Reflection 70B 模型 面临的挑战,特别是围绕基准测试的可复现性和输出质量。
- 社区成员对评估的不一致性以及该模型对 AI 的整体影响表示担忧。
LM Studio Discord
- 对 LM Studio 设置的困惑:关于将 LM Studio 与 Langflow 连接的讨论揭示了用户对 OpenAI 组件基础 URL (base URL) 清晰度的不满。
- 有人对消息查询的语法正确性表示担忧,这表明需要改进文档。
- LM Studio 更新带来的输出改进:将 LM Studio 从版本 0.2.31 更新到 0.3.3 后,尽管设置未变,模型输出仍有显著增强。
- 这引发了关于键值缓存 (key-value caching) 在影响输出质量方面作用的询问。
- 管理上下文的局限性:用户讨论了在 LM Studio 固有的无状态架构中跨会话维持上下文的挑战。
- 参与者强调了在不重复的情况下提供持久输入的困难。
- Flash Attention 引发争议:Flash Attention 功能被广泛讨论,用户对其在 GTX 等特定 GPU 型号上不可用感到沮丧。
- 共享了一个 GitHub pull request,展示了它可以提供的显著加速。
- 优化 GPU 性能的水冷方案:一位成员正在考虑为 8 卡 配置使用单槽水冷头,因为其最大功率达到了 4000W。
- 目前的计划涉及两个 1600W 和一个 1500W 电源,以维持理想的热条件。
GPU MODE Discord
- 大模型的量化算法:成员们讨论了适用于大型神经网络(50B+ 参数)且目标指标损失小于 1% 的量化算法,重点介绍了 int8 和 HQQ 等技术。
- 一位成员指出,int4 + hqq 量化也非常有效,因为它只需要极少的校准。
- 探索 BF16 权重对准确性的影响:一位成员担心在使用 4090 VRAM 时,使用 BF16 权重而非 FP32 进行训练可能会牺牲准确性。
- 他们认为在当前配置中,将权重使用 FP32 而优化器 (optimizer) 保持为 BF16 是可行的。
- 理解 Metal 编程基础:一位新手了解到,虽然 CUDA 使用
block_size * grid_size进行线程调度,但 Metal 仅涉及 grid size,从而使线程管理更简单。- 他们强调 Metal 中的 threadgroups 是为 grid 间的共享内存设计的。
- 更长的项目周期很有帮助:一位成员表示,为项目提供更长的时间有助于推进,特别是考虑到通常需要时间来积累势头。
- 他们强调了保留充足时间以完成项目的重要性。
- 关于自压缩神经网络实现的咨询:一位成员就 GitHub 上的 Issue #658 进行了咨询,涉及自压缩神经网络,重点是动态量化感知训练。
- 他们的目标是将其作为训练期间的一个选项,让用户选择特定的 VRAM 预算。
Eleuther Discord
- 探讨 AI 研究中的法律责任:讨论集中在分享 AI 模型用于研究的个人是否应对他人的滥用负责,一些人认为法律责任可能不会追溯到原始研究者。
- 成员们指出,可能需要一个明确的裁决来建立准则,并强调了在这些法律领域中明确性的必要性。
- 网页爬取诉讼引发担忧:针对网页爬取法律地位的持续诉讼引发了担忧,艺术家和作家对这种做法表示不满。
- 引用了一个案例,其中公司试图禁止爬取(除非满足严格条件)但未获成功,凸显了法律的复杂性。
- OpenAI 审核政策的影响:一位成员讲述了他们在 OpenAI 审核政策方面的经历,该政策标记了他们提示 AGI 的请求,因感知到的违规行为导致了不安时刻。
- 其他人一致认为这些政策似乎过于谨慎,并指出许多被标记的消息并不符合所述的使用政策。
- 创意 AI 项目的机会:一位新成员介绍自己是寻求 AI 领域基于公地(commons-based)方法协作项目的研究员,强调了潜在的跨学科研究。
- 这演变成了一项参与号召,特别是针对数字人文领域的贡献。
- 分享 MMLU 评分资源:一位成员询问如何获取新模型的 MMLU 分数,随后有人推荐了 EleutherAI 的 evaluation harness。
- 他们还提到了一个专门用于进一步讨论该话题的频道,以促进协作学习。
DSPy Discord
- DSPy 2.5 反馈涌现:用户报告对 DSPy 2.5 的整体体验感到满意,注意到了 TypedPredictors 的积极变化,但呼吁提供更多 自定义文档。
- 反馈强调,虽然更新很有前景,但更多的指导可以增强高级功能的可操作性。
- 文档改进需求:社区呼吁改进 DSPy 文档,特别是关于 Pydantic 和多个 LM 集成的部分。
- 成员们强调了 用户友好指南 对于处理复杂生成任务的重要性,这有助于有效地引导新用户。
- AI Arxiv 播客介绍:新的 AI Arxiv 播客 重点介绍了大厂如何实现 LLM,旨在为该领域的从业者提供有价值的见解。
- 听众被引导至一期关于 使用 Vision Language Models 进行文档检索 的节目,未来还计划将内容上传至 YouTube 以提高可访问性。
- 必备 LLM 资源建议:在寻找资源时,一位成员征求了 AI/LLM 相关新闻 的建议,指向了 Twitter 和相关的 subreddit 等平台。
- 回复中包含了一个精选的 Twitter 列表,专注于 LLM 领域的关键讨论和更新,增强了知识共享。
- 优化 DSPy Prompt 流水线:讨论围绕 DSPy Prompt 流水线的 自我改进 方面与传统 LLM 训练方法的对比展开。
- 推荐了关于多阶段语言模型程序 优化策略 的论文,深入探讨了微调和 Prompt 策略的优势。
Torchtune Discord
- Torchtune 0.3.1 发布,包含关键增强功能:Torchtune 0.3.1 更新包含了所有 Llama 3.2 Vision 模型,增强了对微调、生成和评估的多模态支持。
- 关键改进包括在 8 x A100 上使用 QLoRA 微调 Llama 3.1 405B,显著优化了性能选项。
- Tokenizer 自动截断导致数据丢失:文本补全数据集在 max_seq_len 处会经历自动截断,导致较大文档的 Token 丢失,引发了增加用户控制权的请求。
- 有提议建议将 packing max_seq_len 与 Tokenizer 限制分离,以减少不必要的截断。
- 知识蒸馏 (Knowledge Distillation) 方案现已可用:为 Llama3.2 和 Qwen2 等配置添加了新的知识蒸馏方案,增强了用户的工具包选项。
- 提示成员利用这些功能来提升模型的效率和性能。
- 关于 Flash Attention 内存分配的担忧:讨论了 Flash Attention 是否表现出线性内存增长,与其平方级的计算复杂度形成对比,导致预期内存使用量出现偏差。
- 参与者注意到内存消耗的体验各异,对其真实行为的评估存在冲突。
- 推动更好的 HF 数据集引用:提议的映射系统如 DATASET_TO_SOURCE 旨在简化对 HF 数据集名称的访问,促进更清晰的模型卡片生成。
- 重点仍然是增强 YAML 格式中数据集文档的清晰度,体现了简化项目能力的努力。
LlamaIndex Discord
- MongoDB Atlas 助力混合搜索:最近的一篇文章介绍了如何创建和配置 MongoDB Atlas 向量和全文搜索索引,以实现混合搜索,将语义搜索与全文搜索相结合。
- 该方法显著增强了搜索结果的相关性,解决了常见的搜索低效问题。
- Box 集成助力更智能的应用:一份指南介绍了将 Box 工具与 LlamaIndex 集成,以开发 AI 驱动的内容管理应用。
- 这实现了高级搜索,优化了直接从 Box 内容中提取和处理信息的过程。
- RAG 系统设置中的挑战:用户报告在关于使用 Excel 构建 RAG 系统的教程中遇到了
ModuleNotFoundError,暗示存在 pandas 版本冲突。- 一位用户建议回退到较旧的 pandas 版本(2.2.2 或更低)以可能修复兼容性问题,该问题已在 GitHub 示例中分享。
- RAG 实现中的异步转换查询:一位开发者正在研究将 RAG 应用转换为异步模式,并询问
QueryEngineTool的异步兼容性以及RouterQueryEngine的作用。- 回复澄清了如何在
RouterQueryEngine中实现异步方法,提供了向异步处理更平滑的过渡。
- 回复澄清了如何在
- 使用 LlamaIndex 生成 RFP 响应:一位开发者寻求关于利用 LlamaIndex 使用以往中标方案的数据生成 RFP(建议书请求)响应的指导,重点关注高效的索引策略。
- 他们对 LlamaIndex 从生成的响应中生成 PDF 或 Word 文档的能力表示感兴趣。
LangChain AI Discord
- Jordan Pfost 带来十年的 AI 经验:Jordan Pfost 介绍自己是一名拥有 10 年 AI/Web 产品经验的高级全栈工程师,专注于 GPU Clustering、RAG 和 Agentic Reasoning。
- 寻求合作:他分享了来自 spendeffect.ai 和 iplan.ai 等项目的见解。
- Kapa.ai 令人印象深刻的能力:Kapa.ai 展示了其作为一个基于 Transformer 的模型,拥有约 3.4 亿参数 (340 million parameters),专为自然语言任务设计。
- 它还提到其在多样化数据上进行了训练,确保生成 真人质量 (human-like quality) 的文本,并建议成员参考 LangChain documentation 以进行进一步探索。
- 解码 LLM 中的喜好与奖励:Kapa.ai 澄清说 LLM 是基于训练数据中的模式运行的,并不具备个人偏好或奖励机制。
- 他们引用了一篇关于 Preference Optimization 的论文,并指出在 LangChain documentation 中可以获得更多见解。
- 为学生对接 AI 实习机会:一位成员为寻求 AI 实习机会的印度大学生提供了交流平台,鼓励他们表达意向。
- 此次讨论旨在为学生与 潜在的 AI 实习机会 搭建桥梁。
- LangGraph 创新查询生成:一篇 LinkedIn 帖子 强调了 LangGraph 如何在 LangChain 生态系统中管理复杂的查询生成(Query Generation)。
- 该帖子专注于 错误修正 (error correction) 和 用户友好型结果,并对 Harrison Chase 和 LangChain 团队的贡献表示了认可。
OpenInterpreter Discord
- 十月家庭派对明天举行:别忘了明天的 October House Party —— 点击此处加入 参与趣味活动并获取更新。
- 一位成员表示,由于之前的健康和工作限制,他们 这次绝不会错过。
- 展示你的 Open Interpreter 作品:主持人邀请成员在派对期间展示他们使用 Open Interpreter 创作的作品,并鼓励提问和分享经验。
- 这引发了关于时间的各种反应,一些成员觉得太早了,而另一些人则兴奋地宣告:派对时间到 (PARTY TIMEEEE)。
- 探索模型的技能教学:成员们讨论了如何有效地向他们的模型传授技能,强调了意图清晰度对于实现成功教学的重要性。
- 尽管进行了尝试,但未解决的问题促使大家建议在未来寻求额外的支持。
- 关于模型 Vision 能力的困惑:对话转向技能是否自带 Vision 能力,这取决于所使用的具体模型。
- 一位用户提到将 gpt4o 与 Cartesia 和 Deepgram 结合使用,讨论结论是理论上应该是可行的。
- OpenAI 请求出现问题:一位用户报告说 OpenAI 请求在发送几条消息后就会失败,且没有附带任何错误或日志。
- 这种情况说明了潜在的系统问题,导致大家建议发布新帖进行故障排除。
OpenAccess AI Collective (axolotl) Discord
- Logo 变更引发褒贬不一的反应:成员们对最近的 Logo 变更 反应不一,表情符号涵盖了从困惑到沮丧的各种情绪,表明接受程度各异。
- 一位成员幽默地提到:“我以为我把服务器从列表里弄丢了 😅。”
- 对融资预期的质疑:一位成员幽默地期待新 Logo 能与筹集 1000 万美元 且估值达到 10 亿美元 相关联。
- 另一位用户回应道:“Sheeesh,”表示对如此宏大目标的不敢置信。
- 分享 Demo 体验:一位成员分享了他们的 Demo 使用体验,称:“还不赖,我通过 Demo 用过了,”暗示了积极的互动。
- 持续的对话表明成员们仍在适应这些变化。
- 微调讨论进行中:成员们提出了关于模型是否已经进行微调的问题,确认目前尚未进行微调。
- 一位成员安慰说微调很快就会进行,并强调了准备就绪后部署 70B 参数模型 的计划。
LAION Discord
- 正则表达式规则显著遏制垃圾信息:一位成员分享了一个正则表达式模式
\[[^\]]+\]\(https?:\/\/[^)\s]+\),该模式能有效阻止 Markdown 链接混淆,减少垃圾机器人的存在。- 针对特定垃圾信息类别的自定义正则表达式和词汇黑名单已显示出能显著减少不必要的机器人活动。
- 60 秒超时策略让垃圾信息远离:在消息屏蔽后实施 60 秒超时策略,能有效促使垃圾机器人在尝试几次后退出。
- 这一策略通过最大限度地减少对合法用户的干扰,有助于维护用户体验。
- Google 的 Illuminate:领域内的新 AI 工具:对 Google’s Illuminate 工具的关注表明,对于寻求复杂内容的 AI 生成音频摘要的研究人员来说,它可能是一个游戏规则改变者。
- 成员们热衷于将其功能与 notebooklm 播客工具进行对比,凸显了对这两项创新的浓厚兴趣。
- Arxflix 将 Arxiv 论文带到 YouTube:关注 Arxflix,这是一个致力于将 Arxiv 论文转化为引人入胜的视频内容的自动化 YouTube 频道。
- 创作者对该项目表达了兴奋之情,认为它为传统的学术工具提供了一个动态的替代方案。
tinygrad (George Hotz) Discord
- Tinybox 交付时间表受到关注:一位用户对美国境内 tinybox 的交付时间表表示担忧,特别是询问是否能在 2-5 天 内送达。
- George Hotz 回应称,用户应就物流问题发送邮件至 support@tinygrad.org,并强调了提出清晰询问的重要性。
- FAQ 必须包含支持邮箱:有人建议将目前缺失的支持邮箱加入 网站 FAQ。
- George 同意立即添加,展示了对社区反馈的关注。
- 交付查询中的地理关注点:George 对交付地点限制的重要性提出疑问,提到了 圣地亚哥、密歇根或夏威夷 等特定地区。
- 他强调了清晰表述问题的必要性,并引导用户前往 #1068979651336216706 频道寻求帮助。
- 通过点击确认明确用户协议:George 提出了一个点击确认协议的想法,让用户确认已阅读问题文档,可能会利用多选题形式。
- 另一位成员指出,点击确认机制已经存在,表明已有相关措施供用户确认。
- 社区文化需要改进:George 对社区的提问方式表示沮丧,认为这是一个反复出现的挑战。
- 他呼吁转向优先考虑清晰沟通和正确的咨询实践。
LLM Agents (Berkeley MOOC) Discord
- 通过 RAG 优化推理耗时:一位成员询问如何优化部署了 RAG 架构 且使用 Llama Index 的 SLM-based systems 的推理耗时,寻求社区见解。
- 该请求凸显了一个持续的挑战;性能优化仍然是专注于效率的开发人员的热门话题。
- AI 阅读小组启动:来自 Women in AI & Robotics 的 AI Reading Group 启动并讨论 AI 论文,首场由来自 IBM 的 Aashka Trivedi 讨论他们与 NASA 的合作。
- 观众问答环节的有限名额强调了该小组的互动方式,促进了研究人员与社区之间更紧密的联系。
- 记下日期:INDUS 论文演讲:加入 AI Reading Group,于 2024 年 10 月 17 日 东部时间中午 12 点 参加由 Aashka Trivedi 主讲的 INDUS: Effective and Efficient Language Models for Scientific Applications 演讲。
- 本次会议承诺提供有关适用于科学任务的语言模型显著进展的见解,重点介绍来自 IBM 和 NASA 的关键贡献。
- INDUS 论文凸显合作成果:由 IBM Research AI、NASA 等共同撰写的 INDUS 论文展示了用于科学应用的语言模型的进展。
- 该倡议旨在增强对当前创新的广泛理解,同时鼓励跨学科的知识共享。
Alignment Lab AI Discord
- AI 读书会启动,专注于研究:来自 Women in AI & Robotics 的 AI 读书会正式启动,为研究人员讨论 AI 论文提供了一个平台,并设有互动的 Q&A 环节。
- 该倡议加强了研究人员与社区之间的直接对话,重点展示了 AI 领域的最新进展。
- INDUS 研究演讲已排期:来自 IBM 的 Aashka Trivedi 将于 2024 年 10 月 17 日展示“INDUS: Effective and Efficient Language Models for Scientific Applications”,重点探讨其在科学背景下的潜力。
- 贡献作者来自 IBM Research、NASA 和 Harvard-Smithsonian CfA,表明该研究具有极高的专业水平。
- 读书会参与名额有限:由于名额有限,感兴趣的参与者需尽快报名,旨在确保观众能进行有意义的互动。
- 这一策略有助于在每次演讲后的 Q&A 环节中进行更深入的交流。
- 突出跨学科 AI 讨论:该小组提供了一个关注当前研究热点并鼓励跨越传统学科边界讨论的场所。
- 跨学科的参与确保了对 AI 领域复杂性的深入探讨。
Gorilla LLM (Berkeley Function Calling) Discord
- 修改代码以支持第三方数据集:Gorilla LLM 的当前实现原生不支持第三方数据集,但一名成员建议通过修改代码来启用此功能。
- 调整工作将涉及为解析逻辑添加 model handler、更改测试文件映射以及选择合适的 checkers。
- 实现数据集解析逻辑:为了集成新数据集,一名成员解释了使用
decode_ast和decode_exec实现解析逻辑的必要性。- 这种适配需要对流水线的数据集处理有深入的理解,以确保所有内容的兼容性。
LLM Finetuning (Hamel + Dan) Discord 没有新消息。如果该频道长时间没有活动,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该频道长时间没有活动,请告知我们,我们将将其移除。
Mozilla AI Discord 没有新消息。如果该频道长时间没有活动,请告知我们,我们将将其移除。
DiscoResearch Discord 没有新消息。如果该频道长时间没有活动,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该频道长时间没有活动,请告知我们,我们将将其移除。
PART 2: 按频道划分的详细摘要和链接
完整的频道逐条解析已因邮件篇幅原因截断。
如果你喜欢 AInews,请分享给朋友!预谢支持!