ainews-contextual-document-embeddings-cde-small-v1
上下文文档嵌入:`cde-small-v1`
Meta 发布了全新的文生视频模型 Movie Gen。该公司声称,与 OpenAI 的 Sora(基于 Diffusion Transformers 架构)相比,Movie Gen 将 Llama 3 适配于视频生成的效果更佳,不过目前该模型尚未公开发布。研究人员 Jack Morris 和 Sasha Rush 推出了 cde-small-v1 模型,该模型采用了创新的上下文批处理 (contextual batching) 训练技术和上下文嵌入 (contextual embeddings),仅凭 1.43 亿 (143M) 参数就实现了强劲的性能表现。OpenAI 推出了 Canvas,这是 ChatGPT 的一个协作界面,并采用了合成数据进行训练。Google DeepMind 迎来了 Tim Brooks 的加入,他将致力于视频生成和世界模拟器 (world simulators) 的研究。Google 发布了 Gemini 1.5 Flash-8B,通过算法效率的提升优化了成本和速率限制。
Contextual Batching is all you need.
2024年10月3日至10月4日的 AI News。我们为您检查了 7 个 subreddits、433 个 Twitter 账号 和 31 个 Discord(226 个频道和 1896 条消息)。为您节省了预计 210 分钟的阅读时间(按每分钟 200 字计算)。您现在可以标记 @smol_ai 进行 AINews 讨论!
我们通常将 AINews 的头条新闻留给大型模型实验室的动态,今天 Meta 的新文本生成视频模型 Movie Gen 席卷了新闻。其论文声称,他们能够将 Llama 3 适配到视频生成中,且效果显著优于 OpenAI Sora 的 Diffusion Transformers。然而,目前还没有实际发布,只有经过精挑细选的营销视频,而我们在这里尝试关注您可以实际使用的消息。
因此,我们很高兴向大家推荐 Jack Morris 和 Sasha Rush 的新论文以及关于 Contextual Document Embeddings 的 cde-small-v1 模型,它是“世界上最好的 BERT 尺寸的文本嵌入模型”。

Jack 的描述最为精辟:
“典型的文本嵌入模型有两个主要问题:
- 训练它们很复杂,需要很多技巧:巨大的 batches、蒸馏、hard negatives…
- 嵌入(embeddings)不知道它们将被用于哪个语料库;因此,所有的文本片段都以相同的方式编码。”
为了解决 (1),我们开发了一种新的训练技术:contextual batching。所有的 batches 都共享大量的上下文——一个 batch 可能关于肯塔基州的赛马,下一个 batch 可能关于微分方程等。
对于 (2),我们提出了一种新的 contextual embedding 架构。这需要对训练和评估流程进行更改,以纳入 contextual tokens——本质上,模型会看到来自周围上下文的额外文本,并可以据此更新嵌入。
这似乎很有道理——在进行正式嵌入之前,先引导嵌入模型适应上下文 tokens。
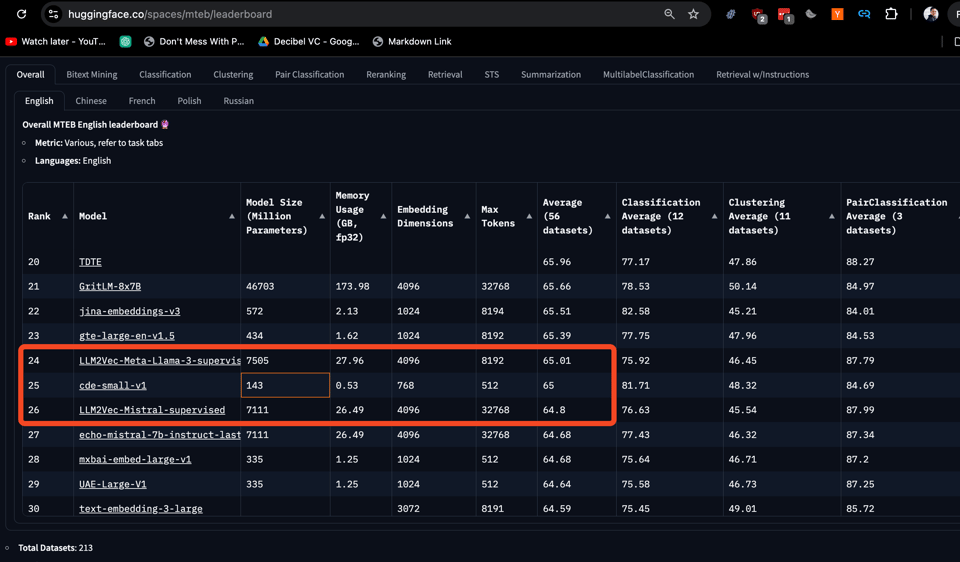
虽然大多数在 MTEB 排行榜 登顶的嵌入模型参数量都超过 7B(得分约为 72),但拥有 1.43 亿参数的 cde-small-v1 得分达到了体面的 65,且在比它大 50 倍的模型中表现稳健。这是一个非常棒的效率提升。
在您探索新的嵌入模型时,您可能还想探索来自 今日赞助商 的其他高级 RAG 技术!
由 RAG++ 为您呈现:RAG 的查询细化(Query refinement)就像给您的系统装上了 X 光透视眼;有了它,系统可以更清晰地“看到”用户意图——从而实现更准确的 chunk 检索和更相关的 LLM 响应。

在 Weights & Biases 的新课程 RAG++ : From POC to Production 的这段 YouTube 摘录中了解如何改进您的 RAG 查询细化,并注册获取免费的 LLM API 额度以开始学习!
AI Twitter 摘要
所有摘要均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
AI 模型与公司动态
-
OpenAI 动态:OpenAI 推出了 Canvas,这是一个用于在写作和编程项目上与 ChatGPT 协作的新界面。@karinanguyen_ 强调了关键功能,包括行内反馈、针对性编辑和快捷菜单。Canvas 模型是使用新型合成数据生成技术训练的,允许在不依赖人工数据收集的情况下进行快速迭代。
-
Google AI 新闻:@_tim_brooks 宣布加入 Google DeepMind,致力于视频生成和世界模拟器(world simulators)的研究。@demishassabis 对他表示欢迎,并对将长期以来的世界模拟器梦想变为现实表示兴奋。
-
模型发布与更新:Google 发布了 Gemini 1.5 Flash-8B,与之前的版本相比,价格降低了 50%,速率限制(rate limits)提高了 2 倍。@arohan 提到 Flash 8B 结合了算法效率的改进,以便在小型化形态中尽可能多地打包功能。@bfl_ml 推出了 FLUX1.1 [pro],这是一款全新的 state-of-the-art 扩散模型,其出图速度比前代快 3 倍,且质量有所提升。
AI 研究与技术
-
Scaling Laws 与模型训练:@soumithchintala 讨论了现代 Transformer 如何遵循良好的 Scaling Laws,使研究人员能够在较小规模上找到超参数(hyperparameters),然后根据幂律(power laws)扩展参数和数据。这种方法增加了对更大规模训练运行的信心。
-
推理优化:@rohanpaul_ai 分享了 Transformer 推理优化技术的总结,包括 KV Cache、MQA/GQA、Sliding Window Attention、Linear Attention、FlashAttention、Ring Attention 和 PagedAttention。
-
AI 安全与对齐:@RichardMCNgo 对过度关注 AI 安全而牺牲神经网络、深度学习和 Agent 基础等潜在突破性研究表示沮丧。
行业趋势与应用
-
语音 AI 与呼叫中心:@rohanpaul_ai 强调了 OpenAI 的 Real-time API 对呼叫中心行业的潜在影响,AI 驱动的通话成本显著低于人工 Agent。
-
AI 在医疗保健领域:@BorisMPower 指出,在针对专业医生的狭窄测试中,AI 的表现优于“人类 + AI”,这与在国际象棋和围棋中观察到的现象相似。
-
开发者工具与界面:多条推文讨论了新型 AI 界面的重要性,@finbarrtimbers 指出更好的界面将使 LLM 更易于使用,并以 Cursor 与 Copilot 为例。
AI Reddit 摘要
/r/LocalLlama 摘要
主题 1. Whisper Turbo:语音识别速度的显著提升
- OpenAI 的新 Whisper Turbo 模型在 M1 Pro 上本地运行速度比 Whisper V3 Large 快 5.4 倍 (评分: 80, 评论: 15):OpenAI 的新 Whisper Turbo 模型展示了与 Whisper V3 Large 相比,在 M1 Pro MacBook Pro 上的本地转录速度快了 5.4 倍,处理一个 66 秒的音频文件仅需 24 秒,而后者需要 130 秒。该帖子提供了使用 nexa-sdk python package 进行本地测试的说明,并包含了 nexaai.com 上 Whisper-V3-Large-Turbo 和 Whisper-V3-Large 模型的链接。
- 在 RTX3090 Linux 系统上,Faster-Whisper 的表现优于 Whisper-Turbo,转录一个 24:55 的音频文件用时 14 秒,而后者为 23 秒。对于优先考虑转录速度和长音频文件的情况,建议使用分块算法(chunked algorithm)。
- 用户报告 Whisper Turbo 在 MacBook 上的运行速度快于实时,为本地实时助手解决方案开启了可能性。该模型支持多种语言,不仅限于英语。
- 关于 Whisper 等 ASR 模型的流式输入/输出讨论强调了由于其 30 秒分块架构(30-second chunk architecture)带来的挑战。目前存在一个工作原型,但与非异步架构相比可靠性较低。
- 终于有了一个用户友好的 Whisper 转录应用:SoftWhisper (Score: 62, Comments: 19): SoftWhisper 是一款全新的 Whisper AI 转录桌面应用,提供直观的界面,功能包括内置媒体播放器、说话人日志 (speaker diarization)(使用 Hugging Face API)、SRT 字幕创建以及处理长文件的能力。该应用使用 Python 和 Tkinter 开发,旨在让转录变得触手可及,开发者正在寻求反馈和潜在合作伙伴,以进行 GPU 优化等未来改进。
- 用户讨论了运行该应用程序的方法,开发者提供了教程和 dependency_installer.bat 脚本以简化设置。该项目现在包含 requirements.txt 文件和 Python 安装说明。
- 一位用户分享了一个用于使用 Pyannote 进行离线说话人日志的 GitHub 仓库,开发者表示有兴趣探索。Pyannote 的离线使用被确认是允许的。
- 对未来改进的建议包括会议的实时捕获能力以及对多音频流视频的支持。开发者确认 SoftWhisper 可以通过提取音频来转录视频格式,尽管格式支持可能有限。
主题 2. Qwen 2.5:保守行业对中国 AI 模型的争议
- [Gemma 2 2b-it 是一个被低估的 SLM GOAT] (Score: 92, Comments: 21): Gemma 2 2b-it 被赞誉为卓越的 Small Language Model (SLM),在各种基准测试中表现优于许多大型模型。尽管其参数规模仅为 20 亿 (2 billion parameters),该模型仍展示了令人印象深刻的能力,包括零样本推理 (zero-shot reasoning)、少样本学习 (few-shot learning) 以及在编程任务中的强劲表现。其效率和性能使其成为 SLM 领域的有力竞争者,挑战了像 Mistral 7B 和 Llama 2 13B 这样的大型模型。
- 有人建议为 Small Language Models (SLMs) 设立单独的排行榜,并认为在智能手机上运行本地 AGI 具有潜力。然而,关于 “SLM” 一词引发了争论,一些人认为模型大小并不能定义它是否属于大型或小型语言模型。
- Qwen2.5-3B-Instruct 模型与 Gemma2-2B-IT 和 Phi3.5-mini-Instruct 等其他小型模型相比,表现出令人印象深刻的性能。分享了一份详细的性能对比表,突出了 Qwen 在 MATH (65.9%) 和 GSM8K (86.7%) 等任务中的优势。
- Gemma 2 2b-it 的能力受到称赞,用户注意到它在面对 Claude 2 和 Gemini 1 Pro 等较旧的大型模型时的表现。该模型的效率和低廉的微调成本也受到了关注。
- Qwen 2.5 = 中国 = 糟糕 (Score: 300, Comments: 232): 该帖子讨论了在保守行业中使用中国 AI 模型 Qwen 2.5 的担忧,由于担心它是来自阿里巴巴的木马 (trojan),上级拒绝使用它。作者认为这些担忧是没有根据的,特别是考虑到计划在没有互联网连接的情况下本地部署 (on-premise) 使用该模型并对其进行微调 (finetune),这可能使其与原始形式完全不同。
- 用户讨论了 LLM 潜在的安全风险,包括可以绕过安全训练持续存在的潜伏特工 (sleeper agents),以及被训练在特定条件下插入可利用代码的模型。一些人认为物理隔离 (air-gapping) 和使用 safetensors 格式可以减轻风险。
- 几位评论者指出,虽然技术风险可能较低,但感知风险会对业务产生实际影响,包括对风险评估、保险费和投资者关系的影响。一些人建议使用替代模型以避免这些问题。
- 关于对 Qwen 等中国模型的担忧是否合理存在争论。一些人认为它的风险并不比其他中国制造的技术产品高,而另一些人则引用了中国间谍活动的例子,并建议在处理敏感数据或应用时保持谨慎。
{kind=link}
主题 3. XTC Sampler:减少 LLM 输出中 GPT 风格用语 (GPTisms) 的新技术
- 告别 GPTisms 和废话 (slop)!为 llama.cpp 开发的 XTC sampler (Score: 144, Comments: 45): 该帖子介绍了一个为 llama.cpp 实现的 XTC sampler,旨在减少语言模型输出中的 GPTisms 和废话 (slop)。这种采样方法通过解决与大型语言模型中使用的传统采样技术相关的常见问题,旨在提高生成文本的质量和连贯性。
- 为 llama.cpp 实现的 XTC sampler 旨在通过在采样过程中忽略 top tokens 来减少 GPTisms 并提高创造力。用户可以在 GitHub 仓库中找到示例和使用说明。
- 关于 XTC 有效性的讨论随之展开,一些用户称赞其增强创意写作的能力,而另一些用户则质疑其对通用性能的影响。推荐的参数值为 threshold = 0.1 和 probability = 0.5,可行范围为 threshold 0.05-0.2,probability 0.3-1.0。
- 辩论围绕移除 top token 候选者是否是改进语言模型输出的最佳方法展开。一些人认为这可能导致非创意任务的性能下降,而另一些人则强调其在减少重复短语和增强生成文本多样性方面的潜力。
- 量化测试:看看 Aphrodite Engine 的自定义 FPx 量化是否好用 (Score: 64, Comments: 32): Aphrodite Engine 的自定义 FPx 量化与标准 FP16 和 INT8 量化方法进行了对比测试。结果显示,FPx 的表现优于 INT8,并达到或略微超过了 FP16 的性能,同时提供了潜在的内存节省。测试使用了 MMLU 和 HumanEval 基准测试,并计划使用 TinyStories 和 Alpaca 数据集进行进一步评估。
- Aphrodite 的自定义 FP 量化展示了令人印象深刻的结果,推荐将 FP6 用于 <8-bit 的快速推理。FP5 出人意料地获得了最高分 (40.61%),这可能是由于无意中触发了思维链 (Chain of Thought) 推理。
- 基准测试结果显示 GGUF Q4_K_M 表现出奇地好,优于 GPTQ 和 FP4 量化。Aphrodite 的 FP 量化展示了极高的速度,在较低量化级别下扩展速度更快,而 GGUF 模型明显较慢。
- 研究结论认为,使用 Aphrodite 的自定义 FP 量化进行 >4-bit 量化是速度最优的选择。对于 4-bit 或更低的量化,GGUF 表现更好。8-bit 量化在各种方法中显示出与完整 BF16 模型相似的性能。
主题 4. 开源 LLM 中的工具调用:构建 Agentic AI 系统
- LLM 工具调用:入门指南 (Score: 73, Comments: 3): 该帖子介绍了 LLM 中的工具调用,将工具定义为提供给语言模型的具有名称、参数和描述的函数。它解释了 LLM 并不直接执行工具,而是在识别出与给定查询相关的工具时,生成一个包含工具名称和参数值的结构化模式 (structured schema)(通常是一个 JSON 对象)。该帖子概述了工具调用的四步工作流,从定义工具到使用工具输出生成完整答案,并提供了一个关于在开源 Llama 3 中使用 Agent 进行工具调用的深入指南链接。
其他 AI Subreddit 回顾
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI 研究与技术
-
Google DeepMind 推进多模态学习:一篇新论文展示了通过联合样本选择(joint example selection)进行数据策展如何加速多模态学习。
-
Microsoft 的 MInference 加速长上下文推理:MInference 能够在保持准确性的同时,为长上下文任务实现高达数百万个 token 的推理。
-
扩展合成数据生成:一篇关于扩展合成数据生成的论文利用 10 亿个从网络策展的角色(personas)来生成多样化的训练数据。
-
NeRFs 的精确体渲染(Exact volume rendering):一篇新论文在 30FPS@720p 下实现了精确体渲染,生成了高度详细且 3D 一致的 NeRFs。
AI 模型发布与改进
-
Salesforce 发布 xLAM-1b:这个拥有 10 亿参数的模型在函数调用(function calling)方面达到了 70% 的准确率,超越了 GPT 3.5。
-
Phi-3 Mini 更新函数调用功能:Rubra AI 发布了更新后的 Phi-3 Mini 模型,具备函数调用能力,可与 Mistral-7b v3 竞争。
-
适用于 Flux 的 iPhone 照片风格 LoRA:一个新的 LoRA 微调提升了 Stable Diffusion Flux 输出的逼真度,使其匹配 iPhone 的照片美学。
AI 行业动态
-
Nvidia Blackwell AI 芯片需求旺盛:Nvidia CEO Jensen Huang 报告称,各大科技公司对其下一代 AI 芯片的需求“非常疯狂”。
-
OpenAI 劝阻投资者支持竞争对手:OpenAI 要求投资者不要资助某些 AI 竞争对手,引发了对垄断行为的担忧。
-
Sora 负责人加入 Google:OpenAI Sora 视频生成模型的首席研究员 Tim Brooks 已加入 Google。
AI 伦理与社会影响
-
关于 AI 对齐(AI alignment)与企业控制的辩论:围绕 OpenAI 转向营利模式的讨论,以及对企业控制 AGI 开发的担忧。
-
欧盟 AI 监管担忧:法国总统 Macron 警告称,对 AI 的过度监管和投资不足可能会损害欧盟的竞争力。
-
工会与 AI 采用:瑞典工会领导人关于拥抱新技术同时保护劳动者的观点,强调了重新培训和适应的必要性。
AI 能力与里程碑
-
人类水平推理能力的宣称:OpenAI CEO Sam Altman 暗示他们已经达到了人类水平的推理能力,尽管其确切含义和影响仍存争议。
-
图像生成能力的提升:展示了使用 Stable Diffusion Flux 生成的高度写实照片,尽管部分说法存在争议。
AI Discord 摘要
由 O1-preview 生成的摘要之摘要
主题 1:Meta 发布 Movie Gen,彻底改变视频生成领域
- Meta 首映 Movie Gen,重新定义多媒体创作:Meta 的 Movie Gen 推出了先进的模型,可以根据文本提示生成高质量的图像、视频和同步音频。其功能包括精确的视频编辑和个性化内容生成。
- AI 社区对 Movie Gen 的潜力议论纷纷:Movie Gen 研究论文展示了视频内容创作中的突破性技术。Meta 正在与创意人士合作,在广泛发布前进一步完善该工具。
- Movie Gen 在各大 AI 论坛引发热议:讨论强调了 Movie Gen 在突破 AI 生成视频边界方面的潜力,爱好者们渴望探索其在多媒体项目中的应用。
主题 2:新 AI 模型与基准测试引领潮流
- Nvidia 发布重磅消息,推出 GPT-4 竞争对手:据 VentureBeat 报道,Nvidia 的新 AI 模型是开源且巨大的,旨在挑战 GPT-4。AI 社区正拭目以待它的实际表现。
- 金融 LLM 排行榜揭晓顶尖表现者:一份新的针对金融领域的 LLM 排行榜 对 OpenAI 的 GPT-4、Meta 的 Llama 3.1 和 Alibaba 的 Qwen 在 40 项任务中的表现进行了排名。这为评估金融应用中的模型提供了新的指标。
- Gemini 1.5 Flash-8B 提供高性价比的 AI 算力:现在已在 OpenRouter 上线,价格为 每百万 token 0.0375 美元,Gemini 1.5 Flash-8B 在不牺牲性能的前提下提供了一个极具成本效益的选择。
主题 3:模型优化与训练技术的进展
- TorchAO 通过模型优化点亮 PyTorch:新的 torchao 库 引入了量化和低位数据类型,提升了模型性能并大幅降低了内存占用。这是 PyTorch 用户迈出的重要一步。
- SageAttention 速度超越竞争对手:SageAttention 实现了比 FlashAttention2 快 2.1 倍、比 xformers 快 2.7 倍 的速度,且完全没有精度损失。这种量化方法极大地加速了注意力机制。
- VinePPO 释放 LLM 中的 RL 潜力:VinePPO 算法 解决了 LLM 推理任务中的信用分配(credit assignment)问题,其表现优于 PPO,步骤减少了 9 倍,时间缩短了 3 倍,同时内存占用减半。
主题 4:OpenAI 的 Canvas 工具与模型引发复杂反响
- OpenAI 的 Canvas 工具引发喜忧参半的反响:新的 Canvas 工具 通过集成功能和减少滚动操作简化了代码编写。然而,用户对缺失 continue 按钮 等基本功能表示遗憾,并遇到了一些编辑上的小问题。
- 高级语音模式(Advanced Voice Mode)可能提升编程体验:讨论表明,将 Advanced Voice Mode 与 Canvas 结合可以增强编程工作流。社区分享的 设置指南 旨在帮助用户实现平滑集成。
- OpenAI 的 o1 模型给开发者留下深刻印象:o1-preview 和 o1-mini 模型 的引入增强了聊天机器人的能力。用户注意到 o1-mini 在处理复杂任务时表现出惊人的实力。
主题 5:循环神经网络(RNN)强势回归
- RNN 以 175 倍的训练速度回归:论文《Were RNNs All We Needed?》揭示了没有隐藏状态依赖的 minLSTMs 和 minGRUs 训练速度显著加快,重新引发了人们对 RNN 架构的兴趣。
- 极简 RNN 实现高效并行训练:通过消除随时间反向传播(BPTT),这些简化的 RNN 允许并行计算,在序列建模效率方面挑战 Transformer。
- 社区探索 RNN 的现代潜力:爱好者们讨论了精简 RNN 如何实现适合当今 AI 需求的扩展训练方法,这可能会重塑神经网络架构的格局。
第 1 部分:高层级 Discord 摘要
Nous Research AI Discord
- torchao 库引入模型优化:来自 PyTorch 的 torchao 库 具备量化(quantization)和低比特数据类型技术,提升了模型性能和内存利用率。
- 它承诺在现有工具的基础上实现自动量化,标志着 PyTorch 的一项重大进步。
- OpenAI 的 Canvas 工具简化代码编写:OpenAI 的 Canvas 工具 因其集成功能而备受关注,减少了编码过程中不必要的滚动。
- 用户注意到其编辑能力相比 Claude 等之前的工具有了显著进步。
- Meta 的 Movie Gen 模型展现巨大潜力:Meta 发布了 Movie Gen 模型,可根据文本提示生成高质量的多媒体内容。
- 这些模型具有精确的视频编辑和个性化生成功能,突显了其创意应用价值。
- 文化偏见限制 AI 训练理解:目前的讨论指出,LLM 训练缺乏人类偏见,且过度依赖大型数据集,这影响了对爱和道德等概念的理解。
- 成员们质疑 AI 在没有真正内在理解的情况下,如何“学习”这些复杂的情感。
- VinePPO 解决 LLM 信用分配问题:关于 VinePPO 的论文批评了 Proximal Policy Optimization (PPO) 在推理任务中的不一致性,并引入了一种改进方案来解决信用分配(credit assignment)问题。
- 研究表明,PPO 中现有的价值网络(value networks)会产生高方差更新,表现仅勉强优于随机基准线。
aider (Paul Gauthier) Discord
- 敦促 Aider 完善遥测功能:成员们强调了 Aider 中遥测(telemetry) 的重要性,建议增加选择性加入(opt-in)功能以保护用户隐私,同时提高对性能的洞察。
- 提议使用 System call tracing 来诊断性能问题,并强调了对收集数据保持透明度的必要性。
- OpenRouter 免费模型面临测试:OpenRouter 的免费模型 存在严格的全账户限制,即 每天 200 条消息,这影响了希望获得更多访问权限的用户的灵活性。
- 参与者对某些模型缺乏付费选项表示担忧,质疑其整体可用性。
- 模型基准测试引发疑问:参与者分享了 对各种模型进行基准测试(benchmarking) 的经验,指出在处理错误率方面的表现参差不齐。
- Aider 处理编辑任务的能力是关注焦点,用户报告了与 Token 限制以及特定错误相关的问题。
- Ollama 模型在 Aider 中的性能表现:用户报告在使用 Aider 配合 Ollama 的本地 8B 模型 时响应速度缓慢,质疑付费 API keys 的益处。
- 讨论显示本地模型在处理编辑任务时可能会遇到困难,表明用户更倾向于具有更强编辑能力的模型。
- 探索文件添加的复杂性:在 Aider 中测试 /read-only 命令表明,它现在只能按文件夹完成任务,这使文件访问变得复杂。
- 另一位用户确认,正确的使用方式仍应添加所有文件,这揭示了命令功能中的细微差别。
HuggingFace Discord
- Salamandra 设备端演示大放异彩:Salamandra 演示展示了令人印象深刻的能力,在吸引用户的同时也突出了其功能特性。
- 社区对 Salamandra 亮点的兴奋 反映了人们对设备端 AI 应用日益增长的兴趣。
- Nvidia 发布了一款具有变革意义的 AI 模型:根据 VentureBeat 的报道,Nvidia 的新 AI 模型是开源且巨大的,并准备好与 GPT-4 竞争。社区渴望看到该模型将如何竞争以及它拥有哪些独特的能力。
- 这一公告在 AI 社区引起了轰动。
- OpenAI 推出新模型:两个新的 OpenAI 模型 o1-preview 和 o1-mini 已集成到 开源聊天机器人 中,增强了其功能。成员们庆祝这些新增功能,认为这是迈向更强大聊天机器人体验的重要飞跃。
- MusicGen iOS 应用取得进展:MusicGen 的 iOS 应用更新揭示了一些新功能,包括输入音频的降噪功能和针对鼓点的 ‘tame the gary’ 开关。一位成员评论道,它的目标是精细化的音频输入输出集成,旨在提升用户体验。
- AI 感知预测引发疑问:一篇名为《感知预测方程》(The Sentience Prediction Equation)的文章讨论了未来 AI 可能产生的感知及其影响,质疑 AI 是否会思考其存在的意义。文章幽默地指出,AI 可能会问:“为什么人类坚持要在披萨上放菠萝?”,并引入了“预测方程”作为一种估算工具。
OpenAI Discord
- Canvas 模型增强功能引发热议:新的 Canvas 模型 引起了轰动,成员们正在讨论其潜在功能以及与 GPT-4o 的集成。然而,由于缺少 continue 按钮 和编辑问题,也出现了一些挫败感。
- 用户希望改进能提升编程任务的 UX,同时解决当前的局限性。
- Advanced Voice Mode 可能促进集成:关于 Advanced Voice Mode 的讨论强调了它与 Canvas 工具 的潜在协同作用,从而在编码中提供更流畅的用户体验。社区成员在 GitHub 上传阅设置指南,以帮助实现无缝集成。
- 他们提议将实时 API 集成作为令人兴奋的下一步,以提高编码效率。
- Custom GPTs 体验反馈不一:用户报告了在 Custom GPTs 初始推出期间集成 Google API/OAuth 时遇到的挑战,引发了对其可靠性的一些担忧。他们尚未查看最近关于稳定性的改进情况。
- 这种缺乏一致性的情况让一些用户对重新尝试该集成持谨慎态度。
- ChatGPT 评估的不一致性成为焦点:当任务是在 temperature 0.7 下对答案进行评分时,ChatGPT 评估的不一致性引发了不满,促使人们建议采用更严格的评分标准。一位用户建议使用 评分量规 (grading rubric) 来提高清晰度和一致性。
- 另一位用户提议使用 Chain-of-Thought 推理框架来提高评分准确性和评估清晰度。
- 分享高效 JSON 处理技巧:一位开发者寻求关于使用 GPT-4o 将 10,000 个代码片段解析为 JSON 的建议,并询问是否需要为每个片段重新发送协议参数。建议鼓励通过在处理过程中仅发送新片段来进行优化。
- 这次对话说明了在模型交互和 JSON 处理中对成本效率的持续需求。
Unsloth AI (Daniel Han) Discord
- Unsloth AI 项目简化了微调流程:成员们讨论了使用 Unsloth AI 进行 LLM 的持续预训练(continual pretraining),与传统方法相比,训练速度提升了 2 倍,同时 VRAM 占用减少了 50%。
- 强调了像 持续预训练 notebook 这样的必备工具对于扩展模型训练能力的重要性。
- ZLUDA 的融资带来新希望:ZLUDA 的开发已获得一家新商业实体的支持,目标是增强 LLM 的功能。
- 法律纠纷的担忧依然存在,特别是与 NVIDIA 之间可能产生的冲突,这呼应了以往股权支持案例中遇到的问题。
- 代际偏好:一个幽默的视角:成员们戏谑地争论起自己的代际身份,有人声称年仅 24 岁就感觉像个 boomer(老顽固),触及了文化认知的话题。
- 这场轻松的对话指出,Legos 和 modded Minecraft(模组化我的世界)定义了代际界限,暗示了文化习俗的转变。
- 本地推理脚本的烦恼:一位成员在使用 llama-cpp 运行 gguf models 的本地推理脚本时遇到挑战,反映尽管 GPU 性能强劲,但表现依然迟缓。
- 诸如使用 llama-cli 等建议被提出,表明了提升脚本效率的潜力。
- 循环神经网络(RNNs)的复兴:最近的一篇论文建议,通过消除隐藏状态依赖,minimal LSTMs 和 GRUs 的训练速度可以快 175 倍,引发了对 RNN 的重新关注。
- 这一发现指向了与现代架构相关的可扩展训练方法的新可能性。
Eleuther Discord
- IREE 面临不可预测的采用时间表:成员们讨论了大型实验室是否会采用 IREE 进行大规模模型服务,迹象表明许多实验室仍在使用自定义推理运行时(inference runtimes)。
- 一些人指出,像 IREE 这样的新技术拥有不可预测的采用时间表是很正常的。
- RWKV 引入高效并行化:RWKV 通过将网络结构化为更小的层来采用部分并行化,从而能够在等待 Token 输入时进行计算。
- 这种方法旨在优化性能,同时有效地管理模型间的相互依赖。
- 探索线性注意力(Linear Attention)模型:对话集中在线性注意力和门控线性注意力作为 RNN 运行的能力上,这使得跨序列的并行计算成为可能。
- 随着 Songlin Yang 的研究揭示了能够提高并行化程度的复杂 RNN 类别,人们的兴趣日益浓厚。
- VinePPO 在信用分配(credit assignment)上挣扎:VinePPO 论文概述了价值网络在复杂推理任务中面临的信用分配挑战,其表现甚至低于随机基准线。
- 这强调了在 Proximal Policy Optimization (PPO) 中需要改进模型或技术来优化信用分配。
- lm-evaluation-harness 寻求贡献者:lm-evaluation-harness 正在邀请贡献者集成新的 LLM 评估并修复 Bug,目前有许多待处理的问题。
- 潜在的贡献者可以在 GitHub repository 中找到更多详细信息。
OpenRouter (Alex Atallah) Discord
- SambaNova AI 的吞吐量表现令人印象深刻:SambaNova AI 在 OpenRouter 上推出了 Llama 3.1 和 3.2 的端点,声称拥有记录以来最快的吞吐量测量结果。
- 他们指出,“这是我们见过的最快速度”,表明其吞吐量指标与竞争对手相比具有显著优势。
- Gemini 1.5 Flash-8B 正式发布:Gemini 1.5 Flash-8B 模型现已上线,价格为 每百万 Token 0.0375 美元,使其成为与同类产品相比值得关注的预算选择。
- 如需访问,请查看此处的链接;讨论还集中在其性能扩展潜力上。
- o1 Mini 在任务性能上带来惊喜:o1 Mini 在解决复杂任务方面表现出更强的能力,超出了社区对其性能的预期。
- 一位成员提到计划将 o1 Mini 用于处理图像描述的机器人,展示了其在实际应用中的潜力。
- Anthropic 乘着融资浪潮前进:讨论透露,Anthropic 快速的模型开发(特别是 Claude)源于一支前 OpenAI 工程师团队以及来自 Amazon 的支持。
- 针对 Anthropic 如何在资金支持少于行业巨头的情况下,在性能上保持有效竞争,出现了一些推测。
- OpenRouter 基础设施扩展指日可待:人们对 OpenRouter 的扩展充满期待,以适应包括图像和音频处理在内的多样化模型功能。
- 开发负责人确认正积极致力于升级,以应对不断增长的流量和新模型的发布。
LM Studio Discord
- Langflow 集成助力 LM Studio:LM Studio 正在集成对 Langflow 的支持,正如最近的 GitHub Pull Request所强调的那样,这增强了构建 LLM 应用程序的功能。
- 此次集成旨在简化用户体验并扩展 LM Studio 的能力。
- v0.3.2.6 版本的内存泄漏风波:用户报告了 LM Studio v0.3.2.6 版本的严重内存泄漏问题,导致模型生成无意义的输出。
- 建议检查 v0.3.3 版本是否已解决该问题。
- 模型下载问题引发错误:从 Hugging Face 下载模型时出现持续性问题,在 LM Studio 中选择模型时会发生错误。
- 成员建议直接将模型侧加载 (Sideloading)到模型目录中以绕过这些错误。
- 聊天缓存位置不可自定义:关于在 LM Studio 中自定义聊天缓存位置的问题被提出,目前该位置是硬编码的。
- LM Studio 以 JSON 格式保存对话数据,但目前没有更改缓存位置的选项。
- AI 模型推荐引发讨论:讨论强调 Llama-3-8B 作为聊天机器人助手时未能达到部分用户的预期。
- 鼓励用户在 LM Studio Model Catalog 上探索各种选项,以寻找可能更合适的模型。
Latent Space Discord
- LangChain 发布 Voice ReAct Agent:LangChain 推出了 Voice ReAct Agent,利用 Realtime API 提供定制化语音体验,并演示了一个使用计算器和 Tavily web search tool 的 Agent。
- 这一创新的 Agent 展示了交互式应用中语音交互的新可能性。
- GPT-4o 机器人热聊:一个演示展示了两个 GPT-4o Voice AI 机器人 使用 Realtime API 进行对话,凸显了语音 AI 技术的进步。
- 机器人表现出令人印象深刻的 轮替延迟 (turn-taking latency),显示出交互流畅度的显著提升。
- Meta Movie Gen 进军视频生成:Meta 展示了其最新项目 Meta Movie Gen,旨在开拓 视频生成 领域,但尚未确定发布日期。更多详情可以在其 AI 研究页面 和 相关论文 中探索。
- 该项目承诺在最先进模型的驱动下,突破视频内容创作的边界。
- 新 LLM 排行榜引入金融领域领先者:最新的金融领域 LLM 排行榜 将 OpenAI 的 GPT-4、Meta 的 Llama 3.1 和 阿里巴巴的 Qwen 列为 40 项相关任务中的佼佼者,详见 Hugging Face 博客文章。
- 这种评估方法为衡量模型在金融应用中的性能提供了一种新颖的方式。
- Luma AI 激发 3D 建模兴趣:关于 Luma AI 的热烈讨论强调了其在为 Unity 和 Unreal 等平台创建逼真 3D 模型方面的潜力,成员们分享了各种功能展示。
- Luma AI 的能力在其电影编辑和精细 3D 模型应用中得到凸显,预示着其在创意科技领域的广阔前景。
GPU MODE Discord
- 性能基准测试咨询:成员们正在寻求工具和方法的 性能基准测试 (performance benchmarks),特别是将这些指标与 fio 工具 的原始性能进行对比。
- 目前正致力于分析 数据访问方法,以了解其相对于传统性能指标的有效性。
- OpenAI 的财务成功:据报道,得益于近期的创新,OpenAI 正在刷新财务记录,并有推测称其正在开发硬件以利用这一增长。
- 围绕 新产品开发 的讨论日益增多,指向了开发专注于用户数据应用的移动设备的可能性,这让人联想到 Apple 的隐私考量。
- 活动策划策略:活动规划时间表建议可能在 9月 左右举行,以配合开学季来提高出席率。
- 提议与 Triton 和 PyTorch 会议同地举办,以便于团体旅行,展示了有效的策划策略。
- Triton Kernel 挑战:用户正在排查 Triton kernels 的故障,特别是面临非连续输入的问题,这表明可能需要进行 reshape。
- 此外,OptimState8bit 调度错误问题依然存在,凸显了 8-bit 优化器实现的局限性。
- 需要超参数缩放指南:一位成员呼吁制定 超参数缩放指南 (hyperparameter scaling guide),表示由于缺乏针对大型模型训练的清晰启发式方法而感到困惑。
- 对训练方法的担忧表明,在支持社区成员这一技术领域方面,可获取的资源存在缺口。
Perplexity AI Discord
- Perplexity AI 更新 Collections UI:Perplexity AI 正在增强其 Collections 功能,采用新的 UI 以支持 custom instructions 和文件上传,计划于未来部署。
- 即将推出的 Files search feature 旨在改进信息组织和用户体验。
- Boeing 777-300ER 规格发布:分享了 Boeing 777-300ER 规格的详细大纲,涵盖尺寸、性能和载客量。
- 关键亮点包括 7,370 海里 的 最大航程 以及最多可容纳 550 名乘客 的潜力。
- TradingView Premium 破解版披露:流传出一个免费的 TradingView Premium(版本 2.9)破解版,提供无需付费的高级交易工具。
- 这一披露引起了寻求改进图表功能的交易者的兴趣。
- Llama 3.2 发布备受期待:用户对 Llama 3.2 的预期功能和发布日期议论纷纷,对其进展表现出浓厚兴趣。
- 社区对这一新迭代可能带来的潜在创新感到兴奋。
- Claude 3.5 表现优于竞争对手:出现了将 Claude 3.5 Sonnet 与其他模型进行比较的讨论,许多人断言其在信息检索方面的可靠性。
- 成员们强调了 Perplexity Pro 与 Claude 协同工作以改进资源数据提取的效果。
Cohere Discord
- Command R 08-2024 微调亮点:更新后的 Command R 08-2024 引入了对新选项的支持,旨在为用户提供 更多控制 和 可见性。此次更新的特点是与 Weights & Biases 无缝集成,以增强性能跟踪。
- 成员们对 Command R 的更新表示 热烈欢迎,诸如 “Awesome” 之类的评论捕捉到了社区的兴奋和期待。
- 平台指标缺失:一位用户报告称,他们无法在 Overview 和 API 等各个选项卡中看到其模型的 metrics boxes(指标框),而这些选项卡以前会显示基本信息。他们强调该问题已持续 2 天 未解决。
- 这引发了对平台一致性的担忧,并对模型创建的状态提出了质疑。
- 价格页面困惑:价格页面 显示训练费用为 每 1M tokens 3 美元,但微调 UI 显示的价格为 8 美元。这种差异引发了对不同平台定价信息准确性的质疑。
- 这造成了困惑,可能会影响用户对训练和微调项目的预算编制。
Stability.ai (Stable Diffusion) Discord
- 寻找 OpenPose 替代方案:用户表达了对 OpenPose 在生成坐姿时的挫败感,引发了对 DWPose 等替代方案的讨论,并探索了自定义模型训练选项。
- 如果有足够的参考图像,训练自己的模型也不失为一个可行的解决方案。
- 提高 ComfyUI 的图像质量:一位成员提出了关于如何使 ComfyUI 输出达到与 Auto1111 相当水平的问题,因为最近的图像质量看起来像卡通。
- 推荐了 ComfyUI 中的特定节点作为获得更好质量输出的潜在方法。
- 澄清 SDXL 模型变体:讨论了多个版本的 SDXL,特别是
SDXL 1.0,涵盖了从 1024x1024 开始的分辨率等方面。- 参与者确认所有变体都与 SDXL 1.0 模型框架相关。
- 参考图像生成姿势:已确认在 Stable Diffusion 中使用单张参考图像生成姿势是可行的,尽管准确性可能会受到影响。
- 强调了 img2img 功能是正确的方法,并建议多张参考图像将提高保真度。
- AI 物品放置工具查询:讨论发现了对 OpenPose 技术的兴趣,以协助物品放置,特别是关于剑等物品的 LoRA 模型。
- 虽然 Stable Diffusion 中存在各种训练风格,但用户注意到在专用姿势方法方面存在空白。
LAION Discord
- MinGRU 架构让循环网络更精简:minGRUs 的引入提出了一种更简单的 GRUs 形式,消除了隐藏状态依赖,将训练速度提升了 175 倍。
- 该论文强调,只需两个线性层即可实现并行隐藏状态计算,引发了关于简化 NLP 架构的讨论。
- 寻找构建 BARK 模型的资源:一位新手渴望在 2-3 个月 内从头开始训练一个 类似 BARK 的模型,但难以找到相关文献。
- 他们注意到 BARK 与 Audio LM 和 VALL-E 等模型之间的联系,寻求社区建议以获取论文来指导其训练工作。
- 应对技术领域的语言挑战:一位成员对技术讨论中 English 的主导地位表示担忧,指出许多复杂术语(如 embeddings 和 transformers)往往缺乏直接的翻译。
- 对语言偏好的沮丧使技术讨论变得复杂,因为有效的沟通取决于共享的术语。
- 社区诈骗警报提醒成员保持警惕:出现了大量关于潜在诈骗的警告,这些诈骗以虚假承诺诱导成员,声称在 72 小时 内赚取 5 万美元 即可获得 10% 的利润分成。
- 建议个人对此类方案保持怀疑,特别是那些涉及未经请求的 Telegram 外联。
LLM Agents (Berkeley MOOC) Discord
- 文章评分查询引发关注:一位成员询问如何查看他们提交的三篇文章的评分,包括草稿和 LinkedIn 链接,这凸显了对提交反馈的持续关注。
- 提交反馈仍然是成员们的热门话题,他们寻求关于自己贡献的明确说明。
- 实时流式传输受垃圾回收阻碍:一位成员表示希望将 chat_manager 的响应实时直接流式传输到前端,并指出目前的响应仅在垃圾回收后才进行流式传输。
- 另一位成员确认大约 8 个月前已经创建了一个 Streamlit UI,解决了这一挑战。
- Chainlit 在对话管理方面展现潜力:一位成员指出存在使用 Chainlit 的解决方案,在 GitHub 上的 AutoGen 项目中可能有一个方案可以促进实时聊天功能。
- 这一实现可以有效解决正在进行的讨论中强调的改进对话管理的需求。
- GitHub Pull Request 聊天处理见解:一位成员分享了一个相关的 GitHub pull request,该 PR 专注于在发送消息之前对其进行处理,从而增强了自定义功能。
- 这一进展与之前关于实时流式传输的咨询相一致,显示了社区在改进功能方面的动力。
- 校园课程地点已明确:一位成员询问了伯克利校园内某门课程的具体教室,强调了参与者对物流安排的关注。
- 随着社区成员处理他们的教育要求,协调活动似乎至关重要。
LlamaIndex Discord
- 使用 LlamaCloud 构建 AI Agents:了解如何使用 LlamaCloud 和 Qdrant Engine 构建 AI Agents,重点在于实现 semantic caching 以提升速度和效率。
- 该演示包含了 query routing 和 query decomposition 等高级技术,以优化 Agent 交互。
- 增强 RAG 部署的安全性:一场关于利用 Box 的企业级安全特性 结合 LlamaIndex 进行安全 RAG 实现的讨论引发关注。
- 成员们强调了 permission-aware RAG 体验对于确保稳健数据处理的重要性。
- 与 OpenAI API 的语音交互:Marcus 展示了一个使用 OpenAI 实时音频 API 的新功能,支持通过语音命令进行文档聊天。
- 该功能彻底改变了文档交互方式,允许用户通过口语进行交流。
- 对抗 RAG 中的幻觉:CleanlabAI 的解决方案 通过为 LLM 输出实现信任度评分系统,解决了 RAG 中的幻觉问题。
- 该方法通过识别并移除不可靠的响应来提升数据质量。
- 宣布令人兴奋的黑客松机会:即将举行的黑客松提供超过 12,000 美元的现金奖励,将于 10 月 11 日在帕洛阿尔托的 500 Global VC 总部 拉开帷幕。
- 参与者将有机会在整个周末争夺丰厚现金奖励的同时,创作创新项目。
DSPy Discord
- dslmodel 实时演示排期:dslmodel 的交互式编程实时演示将于 PST 4:30 举行,欢迎在 coding lounge 参与。
- 这些演示旨在展示实时应用以及用户对 dslmodel 功能的参与。
- 情感分析结果令人印象深刻:SentimentModel 准确地将短语 “This is a wonderful experience!” 分类为 sentiment=’positive’,置信度为 1.0。
- 这突显了其在情感分类任务中的有效性,为用户提供可靠的结果。
- 摘要模型有效捕捉主题:使用 SummarizationModel,文档的关键信息被提炼为:“关于成功与坚持的励志演讲。”
- 该模型有效地识别了控制、成功和韧性等主题,展示了其在摘要任务中的能力。
- DSPy 解读其缩写含义:成员们澄清 DSPy 代表 Declarative Self-improving Language Programs,也被戏称为 Declarative Self-Improving Python。
- 这次对话展示了社区的参与度和在解读 DSPy 缩写时的幽默感。
- DSPy Signatures 详解:一位用户分享了关于 DSPy Signatures 的细节,强调它们作为模块输入/输出行为的声明式规范的作用。
- 这些 Signatures 提供了一种结构化的方式来定义和管理模块交互,与标准的函数签名有所不同。
OpenInterpreter Discord
- 活动参与人数限制回退至 25 人:成员们注意到活动的参与人数上限被设为 25 人,尽管 MikeBirdTech 曾提议将其更改为 99 人。
- 一位用户确认多次尝试加入,但仍然遇到“已满 (full)”状态。
- 加入 Human Devices 活动:MikeBirdTech 分享了即将举行的 Human Devices 活动链接:点击加入。
- 鼓励参与者在指定频道中请求或分享与活动相关的任何内容。
- Obelisk:一个实用的 GitHub 工具:一位成员重点介绍了来自 GitHub 的 Obelisk 项目,这是一个将网页保存为单个 HTML 文件的工具。
- 他们建议它在许多场景下都非常有用,并提供了探索链接:GitHub - go-shiori/obelisk。
- Meta Movie Gen 发布:今天,Meta 首映了 Movie Gen,这是一套旨在增强视频和音频创作的高级媒体基础模型。
- 这些模型可以生成高质量的图像、视频和同步音频,具有令人印象深刻的对齐效果和质量。
- Mozilla 的开源愿景:在关于 Meta Movie Gen 开放性的讨论中,一位成员澄清说,虽然 Mozilla 提倡开源,但这一举措更多是为了展示他们的愿景。
- Mozilla 的原则与 Movie Gen 性质之间的区别突显了其与更广泛目标的一致性。
LangChain AI Discord
- FAANG 公司要求 SDLC 认证:一位用户询问了除了 PMP 之外,被 FAANG 公司认可的软件开发生命周期 (SDLC) 认证的相关课程。
- 这对于从不同行业转型到技术岗位的申请人来说是一个重大关注点。
- LangChain API 调用发生变化:一位成员注意到 LangChain 的 API chain 发生了变化,并正在寻求最新的 API 调用方法。
- 这突显了 LangChain 框架内持续的更新和发展。
- LangChain 将支持 GPT 实时 API:一位用户询问 LangChain 何时会支持最近发布的 GPT real-time API,并提到了即将到来的集成。
- 通过一段解决这些查询的 YouTube 视频提供了进一步的澄清。
- 评估 RAG 流水线检索器:有人就如何评估和比较 RAG pipeline 中三种不同检索器 (retrievers) 的性能寻求建议。
- 一位成员建议使用 query_similarity_score 来识别性能最佳的检索器,并提出通过 LinkedIn 分享代码片段。
- 用户对 LangChain 聊天机器人的兴趣:一位用户请求关于如何使用 LangChain 创建自己的聊天机器人 (chatbot) 的指导。
- 这表明利用 LangChain 进行聊天机器人开发的兴趣日益浓厚。
Interconnects (Nathan Lambert) Discord
- NeurIPS 2024 为 Taylor Swift 粉丝调整日期:NeurIPS 2024 会议的开始日期已移至 12 月 10 日星期二,幽默地指出这是受到了 Taylor Swift 的 Eras Tour 影响。
- 正如一篇 tweet 中所强调的,这一变动允许代表们提前一天到达,从而更好地配合旅行计划。
- Elon Musk 举办安保严密的 xAI 招聘盛会:Elon Musk 的 xAI 招聘活动在身份检查和金属探测器的严密安保下,展示了通过代码生成的现场音乐,引发了 AI 招聘领域的关注。
- 此次活动恰逢 OpenAI 的 Dev Day,在 融资传闻 满天飞之际,Musk 旨在吸引顶尖人才,引发了广泛讨论。
- OpenAI CEO 在座无虚席的 Dev Day 发表演讲:OpenAI CEO Sam Altman 在年度 Dev Day 上向满场的开发者发表讲话,推广了最近的进展和即将推出的项目。
- 活动期间,有关 OpenAI 即将完成一轮创纪录融资的传闻四起。
- Meta Movie Gen 发布高级功能:Meta 首发了 Movie Gen,这是一套能够根据文本提示生成高质量图像、视频和音频的媒体基础模型(media foundation models),具备个性化视频创建等令人印象深刻的能力。
- 据报道,他们正在与创意专业人士密切合作,以便在更广泛发布之前增强该工具的功能。
- 强化学习增强用于代码的 LLM:一篇新论文提出了一种用于 LLM 竞技编程任务的端到端强化学习(Reinforcement Learning)方法,在提高效率的同时实现了 state-of-the-art 的结果。
- 该方法展示了执行反馈(execution feedback)如何大幅减少样本需求,同时增强催化性能。
tinygrad (George Hotz) Discord
- Tensors:Permute 与 Reshape 的抉择:一位成员询问是使用
.permute还是.reshape来将目标 tensor 的尺寸从 (1024,1,14,1) 转换为 (14,1024,1),突显了深度学习中 tensor 操作的复杂性。- Dumb q. 反映了一些挫败感,表明需要明确 tensor 操作的最佳实践。
- 高效的 Stable Diffusion 训练:有人询问在 M3 MacBook Air 上于 48 小时内训练 Stable Diffusion 模型的可行性,显示出对高效模型训练方法的兴趣。
- 这表明用户需要精简的资源,使高性能训练更加触手可及。
- 需要增强 bfloat16 测试:George 强调了在 tinygrad 中增加 bfloat16 测试的重要性,指出了目前
test_dtype.py中的局限性。- 一位成员询问哪些额外测试能真正增强测试框架的鲁棒性。
- 看看这些 Triton 演讲:一位成员分享了一个 Triton 演讲的 YouTube 链接,内容涵盖了 Triton 技术的各种发展,为开发者提供了见解。
- 你可以在这里观看,以深入了解 Triton 的功能。
- 分析 tinygrad CI 警告和失败:有人呼吁对 tinygrad 测试运行期间最近出现的 CI 警告提供见解,旨在提高框架的可靠性。
- 查看 node cleanup 和测试速度 有助于理解最近的更改和稳定性工作。
Torchtune Discord
- Torchtune 的 KTO 训练查询:一位用户询问 Torchtune 是否支持 KTO 训练,表明了对其效率能力的兴趣。
- 该讨论串中没有分享更多细节或回复。
- VinePPO 改变了 LLM 推理的 RL:一位成员展示了 VinePPO(对 PPO 的一种改进),在基于 RL 的方法中实现了高达 9 倍的步数减少和 3 倍的时间节省。
- 这些结果表明 RL post-training 方法可能会发生转变,同时也带来了显著的内存节省。
- Flex Attention 提升运行时效率:Flex Attention 通过利用 Attention Mask 中的 block sparsity 来保持运行时性能,在 bsz=1 和 bsz=2 的设置下表现出相同的性能。
- 测试已确认,处理 1000 tokens 时,其时间和内存效率与批处理(batching)相似。
- 简化 Packed Runs 中的 Batch Size:有人提议取消 Packed Runs 中的 Batch Size 选项,专注于 tokens_per_pack 以实现稳定的 bs=1。
- 这可以提高效率并简化对性能指标的考量。
- DDP 实现讨论:成员们推测了 Distributed Data Parallel (DDP) 的集成,将每个 Sampler 设置为 bsz=1,以优化单设备资源利用率。
- 这可能会改善跨设备的性能分配。
Modular (Mojo 🔥) Discord
- AI 提升了网络速度,但软件滞后:最近的讨论指出,AI 的进步使得 100 Gbps 技术更加实惠,实验室已实现 1.6 Tbps。
- Darkmatter 强调软件未能跟上 80 倍的带宽增长,导致即使在 10 Gbps 时也面临挑战。
- 增强网络能力的紧迫性:Luanon404 表达了对改进网络的强烈愿望,宣称 “是时候加速网络了。”
- 这凸显了对当前网络框架中最佳 throughput 和 latency 的日益关注。
OpenAccess AI Collective (axolotl) Discord
- 为 axolotl 探索 pip 的替代方案:一位成员发现 axolotl 中的 dependency management 令人沮丧,并建议使用 uv 等非 pip 打包工具进行安装和更新。
- 他们表现出积极参与旨在增强 axolotl 体验的持续工作的意愿。
- axolotl 开发中的社区参与:同一位成员表示愿意通过研究多样化的 packaging options 来改进 axolotl 库。
- 他们的目标是促使其他开发者参与进来,解决在 dependency management 方面的共同困扰。
Alignment Lab AI Discord 没有新消息。如果该公会长期沉寂,请告知我们,我们将将其移除。
LLM Finetuning (Hamel + Dan) Discord 没有新消息。如果该公会长期沉寂,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该公会长期沉寂,请告知我们,我们将将其移除。
Mozilla AI Discord 没有新消息。如果该公会长期沉寂,请告知我们,我们将将其移除。
DiscoResearch Discord 没有新消息。如果该公会长期沉寂,请告知我们,我们将将其移除。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该公会长期沉寂,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该公会长期沉寂,请告知我们,我们将将其移除。
PART 2: 按频道分类的详细摘要和链接
各频道的详细拆解内容已针对邮件进行截断。
如果你喜欢 AInews,请分享给朋友!预谢支持!