ainews-state-of-ai-2024
2024年人工智能现状 / 2024年人工智能报告
Nathan Benaich 的第七年度《AI 现状报告》全面概述了人工智能研究和行业趋势,其中包括 BitNet 和合成数据辩论等亮点。Cerebras 正在筹备 IPO,反映了 AI 算力领域的增长。由 Daily 和 Pipecat 社区主办的黑客松专注于对话式语音 AI 和多模态体验,奖金总额达 2 万美元。
诺贝尔物理学奖和化学奖被授予了 AI 研究:杰弗里·辛顿 (Geoffrey Hinton) 和 约翰·霍普菲尔德 (John Hopfield) 因在神经网络和统计力学方面的贡献获奖;德米斯·哈萨比斯 (Demis Hassabis)、约翰·江珀 (John Jumper) 和 大卫·贝克 (David Baker) 则因 AlphaFold 和蛋白质结构预测获奖。Meta 发布了具备多模态能力的 Llama 3.2,并同步推出了教育资源和性能更新。专家指出,“这认可了深度神经网络对社会的影响”以及“AlphaFold 和机器学习驱动的蛋白质结构预测产生的巨大影响”。
204 张幻灯片足以让你跟上 AI 的步伐。
2024/10/9-2024/10/10 的 AI 新闻。我们为你检查了 7 个 subreddits、433 个 Twitter 账号 和 32 个 Discord(231 个频道,2109 条消息)。预计节省阅读时间(以 200wpm 计算):267 分钟。你现在可以标记 @smol_ai 进行 AINews 讨论!
这是一个年度回顾的季节,无论是 SWE-bench 的第一年(今天由 MLE-bench 庆祝),还是 Sequoia 的第三年,或者是 a16z 被 roon 嘲讽的两周年,但这里的重头戏是 Nathan Benaich 的 State of AI Report,现在已经进入第 7 年。
https://www.youtube.com/watch?v=CyOL_4K2Nyo
AI Engineers 可能想跳过摘要,直接查看幻灯片,这些幻灯片在一个地方汇总了我们在本通讯中涵盖的主题,尽管你需要深入挖掘才能找到参考文献:

研究(Research)和行业(Industry)部分将是最相关的,其中包含年度必读研究的有用单页摘要,例如 BitNet(我们的报道在此):

以及对合成数据(Synthetic Data)辩论双方公正的陈述:

尽管有些报道可能过于不加批判地接受了一些大胆的主张。
随着 Cerebras 准备 IPO,计算指数(Compute Index)很好地解释了为什么它是同类中第一个最终脱颖而出的:
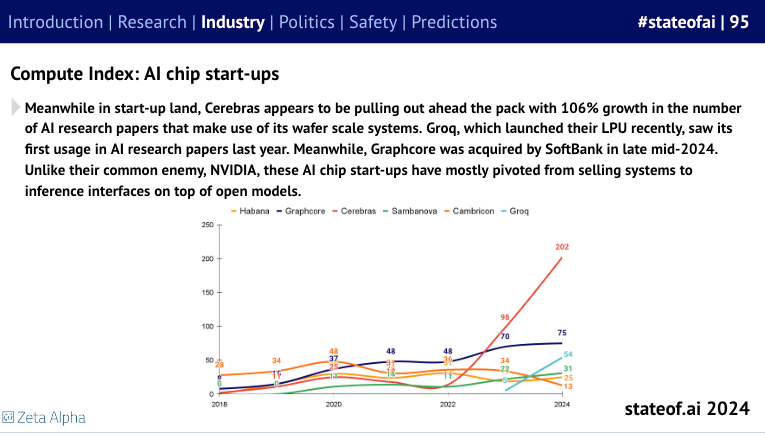
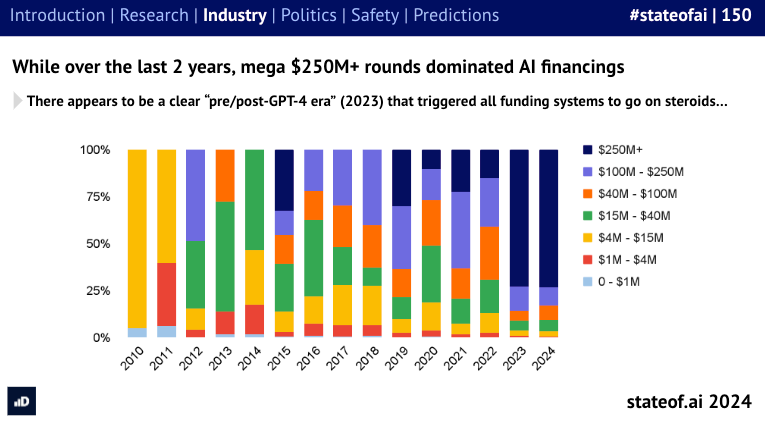
以及对融资概况的良好回顾:

由 Daily 为您呈现:如果您对对话式语音 AI(以及视频)感兴趣,请加入 Daily 团队和开源 Pipecat 社区,参加 10 月 19 日至 20 日在旧金山举行的 黑客松。为最佳语音 AI Agent、虚拟头像体验、多模态 AI UI、艺术项目以及我们共同构思的其他任何项目提供 20,000 美元的奖金。
Swyx 评论:他们刚刚宣布 Cartesia(我最近最喜欢的 TTS)和 GCP 已作为赞助商加入,而且 Product Hunt 也在举办远程赛道!如果你曾经想做任何语音 + 视频相关的事情,下周末这里就是你的不二之选!
AI Twitter 摘要
所有摘要均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
诺贝尔物理学奖和化学奖授予 AI 研究
-
物理学奖:Geoffrey Hinton 和 John Hopfield 因在神经网络和应用于 AI 的统计力学概念方面的贡献而获奖 @mark_riedl 指出,这认可了深度神经网络对社会的影响 @SerranoAcademy 强调了 Hopfield 网络和 RBMs 是关键贡献
-
化学奖:Demis Hassabis、John Jumper 和 David Baker 因 AlphaFold 和蛋白质结构预测而获奖 @ylecun 评论了 AlphaFold 和基于 ML 的蛋白质结构预测产生的巨大影响 @polynoamial 表示希望这只是 AI 辅助科学研究的开始
新 AI 模型发布与更新
-
Meta 发布了具有多模态能力的 Llama 3.2 @DeepLearningAI 宣布了关于 Llama 3.2 特性的免费课程 @AIatMeta 报告称 Llama 3.2 1B 在 Mac 上的运行速度达到 250 tokens/sec
-
Anthropic 更新了其 API 并增加了新功能 @alexalbert__ 宣布支持多个连续的用户/助手消息,以及一个新的
disable_parallel_tool_use选项
AI 开发与研究
-
EdgeRunner:3D mesh 生成的新方法 @rohanpaul_ai 总结了关键改进,如生成具有多达 4,000 个面的网格以及提高顶点量化分辨率
-
TurtleBench:评估 LLM 推理能力的新基准测试 @rohanpaul_ai 描述了它如何使用动态的、现实世界的谜题,侧重于推理而非知识召回
-
HyperCloning:模型间高效知识迁移的方法 @rohanpaul_ai 报告称,与随机初始化相比,其收敛速度快 2-4 倍
AI 工具与应用
-
Tutor CoPilot:用于提高辅导质量的 AI 系统 @rohanpaul_ai 分享道,它使学生的掌握程度整体提高了 4 个百分点,其中评分较低的导师提高了 9 个百分点
-
Suno AI 发布了新的音乐生成功能 @suno_ai_ 宣布能够用新的歌词或器乐间奏替换歌曲的特定部分
AI 行业与市场趋势
-
关于 AI 模型商品化(Commoditization)的讨论 @corbtt 认为开源模型在简单任务中正占据主导地位,并可能随着时间的推移扩展到更大的模型
-
关于基于 API 与自建 AI 初创公司未来的辩论 @ClementDelangue 认为,构建和优化自己模型的初创公司可能比依赖 API 的公司更具优势
梗与幽默
- 关于 AI 赢得未来诺贝尔奖的笑话 @osanseviero 调侃《Attention Is All You Need》的作者们应该获得文学奖 @Teknium1 讽刺道,到 2027 年 AI 模型将直接获奖
AI Reddit 摘要
/r/LocalLlama 摘要
主题 1. 大语言模型发布:Behemoth 123B
- Drummer’s Behemoth 123B v1 - 尺寸确实很重要! (Score: 48, Comments: 17): Drummer’s Behemoth 123B v1,一个大型语言模型,已在 Hugging Face 上发布。该模型拥有 1230 亿参数,强调了尺寸在 AI 模型性能中的重要性,表明它可能比小型模型提供更强大的能力。
- 用户将 Behemoth 123B 与其他模型进行了对比,其中 Magnum 72b 的性能受到称赞,而 Mistral Large 2 因指令遵循能力较差而受到批评。分享了 Behemoth 的 GGUF 版本 和 iMatrix 版本。
- 一位用户请求该模型的 exl2 5bpw 版本,另一位用户已开始处理,预计在量化和上传之前的测量过程需要 172 分钟。这突显了社区对于优化大模型以提高可访问性的兴趣。
- 讨论涉及了大模型与小模型之间的平衡,一些人主张更多关注 1B、3B、Gemmasutra 和 Llama 3.2 等较小模型。其他人则指出,最近的趋势显示 12B 以下的模型仍在持续发展。
Theme 2. Nvidia RTX 5090: 定价策略与 VRAM 担忧
- MLID $1999 - $2499 RTX 5090 定价 (Score: 107, Comments: 164): 根据 Moore’s Law Is Dead (MLID) 报道的一份泄露消息,即将推出的 NVIDIA RTX 5090 显卡预计定价在 $1999 到 $2499 之间。泄露信息显示,RTX 5090 将配备 32GB VRAM,与其前代产品相比,显存容量可能有显著提升。
- RTX 5090 的高昂价格引发了关于替代方案的讨论,许多人建议使用多个 3090 或 4090 作为更具成本效益的选择。用户指出,4x 3090s 将提供 96GB VRAM,价格与一台 5090 相当。
- 评论者回顾了过去的 GPU 定价,将 GTX 1080 的 $699 发布价格与当前趋势进行了对比。一些人将价格上涨归因于 NVIDIA 的市场主导地位和 AI 热潮,而另一些人则希望 AMD 能提供竞争。
- 据报道,5070 和 5080 型号分别配备 12GB 和 16GB VRAM,这被批评为不足,特别是与 4060 Ti 的 16GB 相比。这引发了对 3090 等旧款 24GB 显卡可能涨价的猜测。
- 8GB GDDR6 VRAM 现在仅需 $18 (Score: 227, Comments: 119): 8GB GDDR6 VRAM 的成本已大幅下降至仅 $18,引发了关于 GPU 定价结构的讨论。这种价格下降让人质疑高昂 GPU 成本的合理性,尤其是考虑到 VRAM 经常被认为是决定显卡整体价格的主要组成部分。
- Nvidia 对显存受限 GPU 的定价策略受到批评,人们呼吁在所有层级增加 VRAM(例如:5060 = 12GB, 5070/5080 = 16-24GB, 5090 = 32GB)。该公司对 CUDA 的垄断被认为是维持高价的关键因素。
- 讨论强调,如果制造商优先考虑消费者需求,推出 128GB+ VRAM 的平价 GPU 是有潜力的。AMD 也因未提供具有竞争力的价格而受到批评,其 48GB 显卡定价在 $2000 以上,与 Nvidia 的专业级选项类似。
- 一些用户指出,像 摩尔线程 (Moore Threads) 这样提供 ~$250 的 16GB GDDR6 显卡的中国 GPU 公司,是 Nvidia 市场主导地位的潜在未来挑战者。然而,硬件开发速度和软件成熟度被认为是立即产生竞争的障碍。
{kind=link}
{kind=link}
Theme 3. 使用 Llama 3 开发语音助手
- 我正在使用 Llama3 开发一款语音助手 (V.I.S.O.R.)! (Score: 45, Comments: 15):V.I.S.O.R. (Voice Assistant) 项目集成了 Llama3,支持 Android 和 桌面/服务器 平台,并在 Raspberry Pi 5 (8GB) 上进行了开发测试。主要功能包括便捷的模块创建、集成 WolframAlpha 和 Wikipedia 的聊天功能,以及用于复杂句子识别的自定义识别器;目前的挑战包括将命令识别与 Llama3 响应集成,以及实现用于个性化交互的用户画像。开发者正在寻求贡献与合作,长期目标是实现智能家居控制,并鼓励感兴趣的用户使用 Go 和 Android Studio 构建应用程序来尝试该项目。
- 开发者使用了来自 Hugging Face 的 Meta-Llama-3-8B-Instruct-Q4_K_M.gguf 模型。他们表示有兴趣在未来微调自定义模型并创建一个类似 JARVIS 的助手。
- 分享了 LLM 训练资源,包括 philschmid.de 和一篇关于为代码助手构建代码生成数据集工具的 Reddit 帖子。
- 该项目引起了潜在贡献者的兴趣,目前代码库包含用于 Android 应用的 1.1 万行 Java 代码和用于桌面/服务器组件的 7000 行 Go 代码。
主题 4. ARIA:新型开源多模态原生 Mixture-of-Experts 模型
- ARIA:一款开源多模态原生 Mixture-of-Experts 模型 (Score: 187, Comments: 40):ARIA 是一款新型多模态 Mixture-of-Experts (MoE) 模型,具有 39 亿激活参数和 64K 上下文窗口。该模型在视觉、语言和音频处理等各种任务中表现出强劲性能,同时通过其稀疏激活方法保持效率。ARIA 的架构每层包含 32 个专家,并采用原生 MoE 实现,与同等规模的密集模型相比,能够实现有效的扩展并提升性能。
- ARIA 是一款采用 Apache 2.0 协议的多模态 MoE 模型,在某些基准测试中表现优于 GPT4o, Gemini Flash, Pixtral 12B, Llama Vision 11B 和 Qwen VL。它拥有 3.9B 激活参数(总计 25.3B),64K token 上下文,并在四个阶段中基于 7.5T token 进行了训练。
- 该模型的架构包括一个具有三种分辨率模式的视觉编码器,以及一个每层包含 66 个专家的 MoE 解码器。用户报告其效果优于 Qwen72, Llama 和 GPT4o,并能在 2x3090 GPU 上成功运行(每个占用约 20GB VRAM)。
- 一些用户注意到尚未发布基础模型,并在 Hugging Face 上提交了 issue。该模型包含 vllm 和 LoRA 微调脚本,使其在批量视觉理解任务中具有潜在价值。
其他 AI Subreddit 热帖回顾
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI 研究与突破
-
Google DeepMind 的 AlphaFold 荣获诺贝尔化学奖:2024 年诺贝尔化学奖授予了 DeepMind 的 Demis Hassabis 和 John Jumper,以及 David Baker,以表彰他们在蛋白质结构预测方面的贡献。AlphaFold 被认为是对生物学和生物技术领域的开创性贡献。
-
Geoffrey Hinton 和 John Hopfield 荣获诺贝尔物理学奖:2024 年诺贝尔物理学奖授予了 Geoffrey Hinton 和 John Hopfield,以表彰他们在神经网络方面的研究工作。这一决定引发了一些争议,Jurgen Schmidhuber 对某些思想的归属权提出了批评。
-
OpenAI 在 AI 研究上的巨额投入:OpenAI 在 模型训练上花费了 30 亿美元,而推理服务(serving)花费了 20 亿美元,这表明其在研发新 AI 模型方面投入了巨大资金。
AI 安全与伦理担忧
-
Geoffrey Hinton 对 AI 安全表示担忧:Stuart Russell 报告称 Hinton 正在“整理后事”,因为他非常担心 AI 的发展,并暗示在 AI 引起重大变革前大约还有 4 年的时间线。
-
关于 AI 安全与利润动机的辩论:目前正在进行关于 AI 安全担忧与利润驱动开发之间平衡的讨论,包括 Hinton 在内的一些研究人员批评公司将利润置于安全之上。
AI 行业动态
-
OpenAI 的财务状况:对 OpenAI 财务状况的分析显示其 在研发上投入了巨额资金,引发了关于其商业模式可持续性和 AI 开发经济效益的讨论。
-
AI 取代人类角色:温网(Wimbledon)宣布计划 用 AI 技术取代全部 300 名司线员,凸显了 AI 自动化在各个领域的持续趋势。
更广泛的影响与讨论
-
关于 AI 研究中功劳归属的争论:Jurgen Schmidhuber 对诺贝尔奖决定的批评 引发了关于 AI 研究领域正确归属和认可的讨论。
-
关于 AGI 时间线的推测:多篇帖子和评论讨论了 AGI 开发的潜在时间线,一些研究人员和社区成员提出了仅需几年的较短时间线。
-
AI 对科学研究的影响:诺贝尔物理学奖和化学奖均授予了 AI 相关工作,凸显了 AI 在跨学科科学研究中日益增长的影响力。
AI Discord 精华回顾
由 O1-mini 生成的摘要之摘要
主题 1:模型微调(Fine-Tuning)提升性能
- 优化资源受限下的微调:工程师们讨论了在 VRAM 限制下如何通过调整 batch sizes 和 epochs 来有效地微调 Qwen 2.5 等模型。策略包括从默认设置开始,并根据训练期间的模型行为逐步进行微调。
- 解决 torch.compile 和量化挑战:用户指出了
torch.compile在 Windows 上导致TorchRuntimeError以及 int8 量化导致操作变慢的问题。解决方案包括修改 torch.compile 设置以及探索替代量化方法以保持性能。 - 无需提示词的思维链(CoT)推理:一项研究表明,LLM 可以通过改变 解码过程(decoding process) 而非依赖传统的提示词来产生 CoT 推理。这种方法展示了模型增强的 内在推理能力 和更高的回答置信度。
主题 2:新 AI 模型的发布与集成
- OpenRouter 发布免费 MythoMax API:OpenRouter 推出了免费的 MythoMax API,能够使用 int4 quantization 每周处理 10B tokens。自 2023 年 8 月成立以来,此次发布标志着一次重大升级,促进了对 MythoMax 能力的更广泛访问。
- Aria Multimodal MoE 表现优于竞争对手:Aria - Multimodal MoE 的发布引入了一个拥有 3.9B active parameters 的模型,并能够在 10 秒内为 256 帧生成字幕。工程师们称赞 Aria 的性能优于 Pixtral 12B 和 Llama Vision 11B 等模型,并强调了其先进的训练技术。
- Llama 3.2 模型在 Hugging Face 上发布:Llama 3.2 模型(包括 1B 和 3B 版本)已在 Hugging Face 上发布,以增强开发者资源。这些模型扩展了开发者的工具包,提供了更好的可访问性和更广泛的应用范围。
主题 3. AI 音频和播客创作的进展
- NotebookLM 支持更长的音频摘要:用户强调了对 NotebookLM 生成更长 audio summaries 的需求,目前时长可达 30 分钟。尽管存在对 hallucinations 的担忧,但输出质量仍然是学术和播客创作目的关注的重点。
- TTS Spaces Arena 发布并增强功能:TTS Spaces Arena 的创建旨在探索先进的 text-to-speech (TTS) 能力。开发者展示了提升用户交互并演示 TTS technologies 最新进展的新功能。
- Whisper 微调实现准确率突破:对 Whisper 的 fine-tuning 努力使转录准确率提高了 84%,特别是在 空中交通管制 (air traffic control) 应用中受益匪浅。这一里程碑强调了 Whisper 在有效解决 automatic transcription 挑战方面的潜力。
主题 4. 增强 AI 性能的硬件优化
- Llama 3.1 在 AMD MI300X GPU 上的基准测试:Llama 3.1 405B 在 8x AMD MI300X GPUs 上的 benchmarking 结果 展示了令人印象深刻的性能指标,显著优于 vLLM。在 Hot Aisle 的支持下,此次基准测试强调了在复杂任务中追求高效模型的趋势。
- GPU Mode 重构 TMA 接口以进行优化:TMA interface 正在进行重构,以提高性能并减少与 GEMM implementations 相关的开销,这些开销曾消耗高达 80% 的处理时间。虽然建议在 host 上预初始化描述符等变通方法,但它们增加了复杂性,且与 torch.compile 不兼容。
- NVIDIA RTX 4000 系列采用 PCIe Gen 5,取消 NVLink:新款 NVIDIA RTX 4000 series 在多 GPU 设置中转向 PCIe Gen 5,取消了 NVLink 支持。这一转变允许 GPU 在没有互连限制的情况下以更高速度运行,从而增强了 AI 应用的 multi-GPU performance。
主题 5. AI 伦理与社区趋势
- 关于 AGI 发展与伦理的辩论:成员们参与了关于 AGI 真实本质的讨论,强调它更多地与 learning 相关,而非仅仅是泛化。围绕 AI-generated content 和 censorship 的伦理考量非常突出,特别是在开发既能提供帮助又不会过度限制能力的工具方面。
- 从 Crypto 到 AI 的转型反映了更广泛的趋势:随着 FTX 的崩溃和 ChatGPT 的兴起,许多专业人士从 crypto 转向 AI,寻求具有更多 societal impact 的职位。这一趋势突显了 tech community 内部不断变化的优先级,即倾向于可持续且具有影响力的领域。
- 针对老龄化人口的陪伴型 AI 的伦理担忧:在老龄化人口中使用 AI for companionship 解决了劳动力短缺问题,但也引发了关于此类技术拟人化特征的 ethical concerns。平衡研究方向以纳入伦理影响仍然是开发者之间的一个关键话题。
PART 1: High level Discord summaries
Notebook LM Discord Discord
-
音频生成需要微调:用户强调了 NotebookLM 需要提供更长的音频摘要,部分用户生成的摘要达到了 30 分钟,而其他用户则被限制在 17 分钟。
- 尽管时长较短,但输出质量得到了认可,不过也有人对音频内容中的 hallucinations(幻觉)表示担忧。
-
NotebookLM 提供学术洞察:学者们正在探索 NotebookLM 在追踪文档主题方面的潜力,将其视为 Zotero 关键词搜索的替代方案。
- 然而,关于 hallucinations 影响准确性的担忧引发了关于是否应依赖传统学术方法的辩论。
-
使用 NotebookLM 创建播客:用户分享了生成播客的见解,强调需要精心制作源材料,例如专门的“Show Notes”。
- 一位用户通过输入多个来源实现了一个 21 分钟的播客,证明了内容的深度是可能的。
-
关于 AI 音频偏见的批判性对话:讨论中出现了关于 AI 生成音频中可能存在负面偏见的观点,并提到语调是多么容易被操纵。
- 有人担心,告知音频主持人可能会导致尴尬的输出,这展示了引导 AI 所面临的挑战。
-
用户参与激发讨论:社区成员继续致力于探索 NotebookLM 并提供反馈,分享来自各种内容创作项目的见解。
- 建议包括改进方法以提高用户对 NotebookLM 能力的理解,并解决技术问题。
Unsloth AI (Daniel Han) Discord
-
资源受限下的模型微调:用户讨论了微调模型的最佳设置,强调通过调整 batch size 和 epochs 来提高性能。许多人建议从默认值开始,并根据训练期间的模型行为进行逐步微调。
- 随后进行了关于 VRAM 限制的对话,建议使用较低的位精度(bit precision)作为解决方案,以防止训练期间崩溃,同时仍保持质量。
-
Qwen 2.5 面临内存障碍:用户报告了在 32k context 下微调 Qwen 2.5 的挑战,尽管训练阶段成功,但在评估期间经常遇到 out of memory (OOM) 错误。问题被认为与数据集上下文长度的不一致有关。
- 为了处理 eval memory issues,参与者讨论了调整最大序列长度并利用评估累积策略,特别是针对 H100 NVL GPUs 上的高上下文尺寸。
-
期待多模态模型支持:对于即将支持的 Llama3.2 和 Qwen2 VL 等多模态模型,社区反响热烈,预计这些模型将增强 OCR 能力。用户期待将这些模型集成到他们的工作流中以提高性能。
- 对话中还提到了社区对于新模型将如何塑造数据交互和输出质量的看法。
-
CoT 推理突破边界:一篇论文展示了 Chain-of-Thought (CoT) 推理源于 decoding process 的变化,而非仅仅依赖于传统的 prompts。这种方法展示了 LLMs 的内在推理能力。
- 尽管该论文发布已有一段时间,成员们一致认为,围绕其影响的讨论反映了 AI research 社区的快速演进,许多人承认该领域普遍存在快速变化。
OpenAI Discord
-
AGI 发展引发辩论:AGI 更多地与学习有关,而非仅仅是更通用,成员们讨论了不断进化的 AI 能力和模型训练挑战。
- 社区预见到模型适应性将有显著提升,尽管承认 AGI 尚未实现。
-
OpenAI 语音模型令人失望:成员们对 Advanced Voice Model 表示失望,指出它缺乏展示过的功能,如唱歌和视觉。
- 针对其不一致的语音模仿出现了担忧,突显了用户交互能力方面的局限性。
-
Vision O1 发布的不确定性:一位用户询问了即将推出的 Vision O1,但目前还没有关于该产品潜在发布的任何信息。
- 社区对该开发的进一步公告保持期待状态。
-
Mistral AI 的欧洲前景:围绕 Mistral AI 的讨论显示了对其 API 的热情,并认可了欧洲 AI 领域的进步。
- 成员们对竞争格局表达了乐观与谨慎并存的态度,特别是针对像 OpenAI 这样的美国公司。
-
改进 ChatGPT 提示词:用户分享了增强 ChatGPT 提示词的技巧,例如指示它“像朋友一样回应”以获得更具吸引力的互动。
- 注意到对角色描述的抵触;建议在询问中保持具体性以获得更好的回复。
OpenRouter (Alex Atallah) Discord
-
MythoMax API 免费发布:OpenRouter 推出了免费的 MythoMax API 端点 🎁,利用了带有 int4 quantization 的 TogetherCompute Lite。
- 这个 MythoMax API 每周可以处理 10B tokens,标志着自 2023 年 8 月成立以来的重大升级。
-
NotebookLM 播客热潮:一位用户赞扬了 NotebookLM Deep Dive 播客,并正在创建笔记本以便在移动端轻松访问论文摘要。
- 对话转向自动化,强调了像 ai-podcast-maker 和 groqcasters 这样的新工具,以增强播客管理。
-
Gemini 的审核困境:针对 Gemini 审核用户输入以及因行为可能导致封禁的问题提出了担忧。
- 澄清了 Gemini 拥有严格的过滤器,但 OpenRouter 并不执行封禁,这引发了关于审核标记的更深层讨论。
-
Claude 模型错误讨论:用户遇到 Claude 3.5 返回 404 错误,引发了对其原因和解决方案的推测。
- 普遍的理论认为,这些可能是由于与服务器过载相关的频率限制(rate limits)造成的,影响了部分用户,而其他用户的请求则成功了。
-
Grok 模型集成期望:围绕 Grok 模型 潜在集成的讨论浮出水面,对即将到来的会议充满热情。
- 成员们敦促其他人支持 Grok 集成线程,以表达对其工具包资源扩展的需求。
HuggingFace Discord
-
TTS Spaces Arena 推出新功能:TTS Spaces Arena 已创建,允许用户在热心开发者的推动下,通过令人兴奋的新功能探索 TTS 能力。
- 该项目增强了用户交互,并展示了 text-to-speech technologies 的进步。
-
Llama 3.1 在基准测试中表现出色:Llama 3.1 405B 在 8x AMD MI300X GPU 上的基准测试结果 显示了令人印象深刻的性能指标,显著优于 vLLM。
- 在 Hot Aisle 的支持下,该基准测试强调了在复杂任务中追求高效模型的趋势。
-
FluxBooru 12B 带来创新演示:FluxBooru 12B 演示 展示了生成式建模的前沿进展,增加了 AI 生成视觉内容的深度。
- 这一举措引发了关于通过新型 AI 应用增强视觉内容生成能力的持续讨论。
-
Whisper 微调实现显著的准确率提升:对 Whisper 的微调工作使转录准确率提高了 84%,特别是在空中交通管制应用中获益匪浅。
- 这一突破突显了 Whisper 在有效解决自动转录挑战方面的潜力。
-
开发者可访问 700 万张 Wikipedia 图像:包含 700 万张 Wikipedia 图像 的数据集现已开放免费使用,为研究人员和开发者获取多样化的视觉资源铺平了道路。
- 这一举措极大地增强了 AI 项目在无限制情况下的资源可用性。
GPU MODE Discord
-
TMA 接口重构进行中:团队正在积极重构 TMA interface,预计将带来增强和优化。
- 成员们鼓励关注更新,表明改进即将到来。
-
GEMM 实现性能问题:GitHub 上的一个未解决问题讨论了与 GEMM implementation 和 TMA 描述符相关的性能开销,据报道占用了高达 80% 的处理时间。
- 成员建议在 host 端预初始化描述符作为变通方案,尽管这种方法增加了复杂性且与 torch.compile 不兼容。
-
torch.compile 面临适配挑战:在 Windows 上报告的
torch.compile问题包括与 dynamic tensor subclasses 的兼容性问题,导致TorchRuntimeError。- 这些挑战影响了模型导出,人们呼吁解决这些兼容性问题以提高可用性。
-
int8 量化性能担忧:测试显示,即使应用了
torchao,使用 int8 quantization 也会导致操作变慢,每次迭代耗时 6.68 秒。- 尽管量化成功,但与编译相关的持续性能问题仍然存在且未得到解决。
-
Llama 3.1 在 AMD GPU 上的基准测试结果:对使用 8x AMD MI300X GPU 的 Llama 3.1 405B 推理性能进行了基准测试,支持性细节可在 基准测试文章 中找到。
- 该基准测试强调了实时推理与批量推理的使用场景,并得到了 Hot Aisle 的裸机支持。
Eleuther Discord
-
加密货币专业人士转向 AI:大量人员正从 crypto 转向 AI,特别是在 FTX 倒闭和 ChatGPT 出现之后。
- 这一转变反映了技术专家在工作中追求社会影响的更广泛趋势。
-
探索 Web5 概念:一位成员正在研究一种名为 Web5 的新网络范式,目前网上缺乏详尽的信息。
- 成员们开玩笑说,命名可能会继续升级,幽默地暗示未来会出现 Web8。
-
论文写作最佳实践:分享了关于如何有效构建研究论文的建议,重点关注 abstract 和 results 等部分的清晰度。
- 鼓励社区查看此 视频资源 以获取更多见解。
-
招聘人员对技术表现出兴趣:成员们报告了大量与技术角色相关的 recruiter 消息,特别是强调了 crypto startups 的机会。
- 成员对 ML roles 的回复率较低表示担忧,许多招聘人员专注于企业和金融职位。
-
LUMI 性能查询:出现了关于 neox on LUMI 性能基准的咨询,特别是关于 EAI 进行的测试。
- 成员们表现出分享见解的兴趣,以汇编有关 LUMI 能力的必要数据。
Perplexity AI Discord
-
Perplexity 的回答质量下降:用户对 Perplexity 的回答质量表示失望,报告称输出内容比以前更“简练”且信息量更少。有人担心 token 限制可能导致了深度的降低。
- 一位用户感叹道:“几个月来,我一直用变量输入运行相同的查询,并获得高质量的回答。现在,它只是一个段落的回复。”
-
AI 在视频生成方面面临挑战:讨论集中在 AI 生成连贯视频的可行性上,一些参与者表示完全自动化仍遥不可及。一位成员指出:“我不觉得 AI 目前完全有能力自动生成整个视频。”
- 参与者承认技术在不断发展,但对其目前的局限性保持怀疑。
-
Perplexity 的财务状况受到关注:多位用户对 Perplexity 在服务器和人员相关持续支出下的财务可持续性表示担忧。一位用户幽默地反映:“我的银行账户是 -$9”,这引发了关于财务压力的讨论。
- 这突显了对其服务长期可行性的更广泛担忧。
-
欺诈检测工具研究:一位成员分享了关于各种欺诈检测技术的见解,并指向了一个讨论当前提高 AI 应用准确性方法的 资源。分享的链接提供了关于不断发展的欺诈预防策略的全面视角。
- 这在开发能够在不确定性下做出更好决策的稳健 AI 系统方面可能发挥关键作用。
-
Exa vs. Perplexity AI 对决:成员们参与了 Exa 和 Perplexity AI 的对比讨论,重点关注它们各自的搜索查询效率。考虑因素包括 Exa 拥有更好的文档,以及 Perplexity 搜索结果更优的报告。
- 这场辩论表明这两个系统有不同的使用场景,并提醒人们需要足够的文档来提升用户体验。
aider (Paul Gauthier) Discord
-
SambaNova 与 Aider 结合: 成员们讨论了将 SambaNova 模型与 Aider 集成,并指出如果 API 兼容 OpenAI,则可以手动添加模型。成功添加
/model sambanova/Meta-Llama-3.1-405B-Instruct后引发了关于成本的讨论,凸显了定价透明度的缺失。- ‘Only 3 reflections allowed, stopping’ 成了 Aider 更新半途而废时的常见障碍,促使用户重试或手动编写代码。此问题源于 Aider 在有效处理复杂更改方面的局限性。
-
Deno 2 简化开发: Deno 2 已经发布,旨在简化 Web 开发并确保与 Node.js 和 npm 生态系统的兼容性。开发者可以期待零配置设置和增强 JavaScript 与 TypeScript 开发的一体化工具链。
- 增强的 Jupyter 支持 允许用户使用 JavaScript/TypeScript 代替 Python,并进一步允许通过
deno jupyter命令输出图像、图表和 HTML。
- 增强的 Jupyter 支持 允许用户使用 JavaScript/TypeScript 代替 Python,并进一步允许通过
-
Palmyra X 004 增强工作流: 新发布的 Palmyra X 004 模型有望改进企业工作流。用户对其自动化任务的功能以及在外部系统中有效集成数据的能力特别感兴趣。
- Ryan Dahl 展示了 Deno 2 中新的 notebook 支持,强调了使用
deno jupyter --install安装 Jupyter 内核,这标志着 Deno 用户的一次重大升级。
- Ryan Dahl 展示了 Deno 2 中新的 notebook 支持,强调了使用
-
小型模型中的 Function Calling 困境: 在 AI 中使用较小模型进行 Function Calling 时出现了挑战,讨论将其能力与 Claude 进行了对比。这些模型在生成 XML 输出方面的训练似乎较少,从而造成了障碍。
- 开发讨论引用了解决这些局限性的发布说明,促使社区努力分享资源以增强模型能力。
Nous Research AI Discord
-
GAIR-NLP 的 O1 复现之旅: O1 Replication Journey 报告详细介绍了 GAIR-NLP 复现 OpenAI O1 模型的工作,通过使用一种新颖的旅程学习范式,仅用 327 个训练样本 就实现了 8% 的性能提升。
- 这种透明的方法记录了成功与挑战,促进了社区参与模型复现工作。
-
Pyramid Flow 为视频生成奠定基础: Pyramid Flow 仓库介绍了一种通过 Flow Matching 实现的 Autoregressive Video Generation 方法,能够生成分辨率为 768p、帧率为 24 FPS 的高质量 10 秒视频。
- 预期的功能包括一份 技术报告 和新的模型检查点,标志着视频合成技术的进步。
-
模型合并策略前景广阔: 一项研究调查了模型大小与 Task Arithmetic 等模型合并 (model merging) 方法之间的相互作用,表明合并更强大的基础模型可以提升泛化能力。
- 研究结果表明,合并专家模型可以增强性能,为有效的合并技术提供了见解。
-
RNN 在长上下文中面临挑战: 研究强调了循环神经网络 (RNNs) 在处理长上下文时的局限性,包括状态崩溃 (state collapse) 和内存问题,这些在论文 Stuffed Mamba 中得到了检验。
- 提出的策略旨在增强 RNN 处理长序列的有效性,挑战了在扩展上下文处理中对 Transformer 模型的依赖。
-
思维链推理的革新: 关于 Chain-of-Thought (CoT) 推理 的最新发现表明,它可以从 LLMs 解码过程的方法论改进中产生,在不依赖提示词 (prompt) 的情况下提高推理能力,详见论文 Chain-of-Thought Reasoning Without Prompting。
- 研究强调 CoT 路径与更高的回答置信度相关,重塑了我们对 LLMs 内在推理能力的理解。
Cohere Discord
-
诺贝尔奖传闻:反应不一:瑞典皇家科学院因传闻将 2024年诺贝尔文学奖 授予 Attention Is All You Need 的作者而引发热议,在 Twitter 上引起了轰动。尽管如此,人们对这些说法的真实性持怀疑态度。
- 最终,参与者指出 The Guardian 确认该奖项实际上授予了韩国作家 韩江 (Han Kang),从而揭穿了早先的传闻。
-
Google Drive 连接困扰:据一名在企业和个人账户均遇到问题的成员报告,Google Drive 的 连接问题 正在增加。有人建议问题可能源于 Google 端,并敦促用户联系支持部门。
- 社区讨论了可靠连接对生产力的重要性,强调了在此类停机期间面临的挑战。
-
AI 应对情感挑战:开发者正在应对创建能够理解 情感语境 的 AI 的复杂性,并在影响训练数据的严格 审查政策 下开展工作。这项工作旨在为缺乏与患者直接互动的专业人士增强治疗体验。
- 新兴技术包括为输入分配 情感评分,力求获得更真实的 AI 响应,同时也承认用户不愿与 AI 界面进行有意义互动所带来的问题。
-
陪伴型 AI:一把双刃剑:对话探讨了 AI 在为 老龄化人口提供陪伴、解决劳动力短缺方面的潜力,但也引发了关于此类技术拟人化特征的重要伦理担忧。平衡研究方向涵盖了这些伦理影响。
- 随着成员们倡导负责任的 AI 发展,寻求支持以应对这些伦理挑战仍是一个关键话题。
-
个人 AI 项目的独立研究:一名成员澄清其正在进行的 个人 AI 项目 独立于任何大学机构,展示了一个往往被忽视的研究领域。这一启示引发了关于外部支持结构如何增强个人创新努力的讨论。
- 对话强调了建立协作学术环境以促进 AI 领域更多参与的必要性。
Interconnects (Nathan Lambert) Discord
-
LMSYS 转型为公司:成员们讨论了 LMSYS 转型为公司的激动人心消息,指出其重点从学术激励转向了潜在的财务收益。
- 一位成员更倾向于非营利地位,并补充说 “营利性更具可预测性”。
-
Aria - 多模态 MoE 引起轰动:Aria - Multimodal MoE 宣布发布,拥有 3.9B 激活参数,并能在 10 秒内为 256 帧生成字幕,性能令人印象深刻。
- 成员们强调了 Aria 优于 Pixtral 12B 和 Llama Vision 11B 等模型的表现。
-
关于 o1 推理树的辩论:针对 o1 在没有来自 PRM 的中间评分的情况下如何运作产生了疑虑,建议树剪枝(tree pruning)可以提高性能。
- 一名成员对实现细节表示困惑,表明需要进一步澄清。
-
ButtBench 对齐项目展示新 Logo:随着 ButtBench 对齐项目 发布官方 Logo,项目取得了令人兴奋的进展,尽管距离达到 人类水平表现 仍有很大差距。
- Luca Soldaini 评论道:“我们距离人类水平的表现还很远”,再次强调了该项目面临的挑战。
-
系统搭建看似简单:一位成员表示搭建系统不会太难,但对其中涉及的一些复杂性表示不确定。
- 这暗示虽然过程看起来很直接,但在实施过程中可能会出现错综复杂的情况。
Stability.ai (Stable Diffusion) Discord
-
探索 Deforum 的替代方案:成员们讨论了在 Deforum 被 Google Colab 禁用后寻找免费替代方案的问题,建议包括从 RunPod 租用 GPU,价格约为每小时 $0.3。
- 成本考量引发了关于使用外部 GPU 服务进行模型实验可行性的重要问题。
-
CogVideoX 在视频任务中表现出色:CogVideoX 已成为视频生成领域最佳的开源模型,可通过 Comfy UI 或 Diffusers 安装,满足了对动画工具的需求。
- 该模型展示了处理各种视频生成任务的强大能力,凸显了社区向开源解决方案的转变。
-
Flux 模型使用指南:一位用户请求协助使用 Flux checkpoint 设置网格生成,并说明他们正在使用 Flux 的开发版本。
- 这一咨询表明人们对利用 Flux 模型高级功能的兴趣日益浓厚,特别是关于与 Loras 集成的部分。
-
AI 重建产品的挑战:成员们分享了使用 AI 重建产品图像的见解,特别是使用工具将生成的产品融入背景而无需传统的合成方法,并参考了一个背景切换器的 workflow。
- 这种方法强调了 AI 在创意任务中的能力,激发了对产品设计自动化的热情。
-
在 Comfy UI 中优化 KJNodes:一位成员在 Comfy UI 中使用 KJNodes 进行网格生成,并推荐了用于标签添加和文本生成自动化的特定节点。
- 这一见解反映了用户不断探索 Comfy UI 功能以简化 workflow,从而提高图像处理的生产力。
Modular (Mojo 🔥) Discord
-
Rust’s Provenance APIs 得到验证:讨论集中在 Rust’s Provenance APIs,探讨它们如何可能使对 io_uring API 至关重要的
int -> ptr转换“合法化”,从而增强 buffer 管理能力。- 参与者建议使用编译器 builtin 进行指针跟踪,以简化操作并实现优化。
-
使用 io_uring 进行高效事件处理:io_uring API 通过使用
user_data字段促进了事件完成的指针管理,该字段可以保存索引或指向 coroutine context 的指针,从而增强状态处理。- 这种设计允许有效管理栈分配的 coroutines,是现代架构中一个值得注意的工程决策。
-
现代服务器寻址受限:讨论了当前计算中 48 位和 57 位寻址 的限制,指出理论上支持巨大的内存空间,但实际应用中经常遇到约束。
- 重点介绍了基于 CXL 的存储服务器,反映了未来解耦架构中“稀疏”内存使用的挑战。
-
一致性内存互连的历史问题:深入探讨揭示了 coherent memory interconnects 面临的历史挑战,其中缓存一致性算法的巨大压力导致利用率降低。
- 虽然存在像 IBM 互连这样的替代方案,但节点连接的实际限制阻碍了更广泛的实施。
-
分布式共享内存的相关性:强调了 distributed shared memory (DSM) 的持续重要性,尽管其具有复杂性,但它允许独立的内存在统一的地址空间下运行。
- IBM 的策略强调了计算节点之间物理接近的迫切需求,以提升性能指标。
LM Studio Discord
-
LMX 性能超越 Ollama:在相同设置下,LM Studio 中的 LMX 在 q4 模型上的运行速度记录显示平均比 Ollama 快 40%。
- 这一性能差距令成员们感到惊讶,他们原本预计新集成只会带来微小的提升。
-
GPU 加速配置步骤:一位成员详细介绍了配置 CUDA/Vulkan/ROCM 的步骤,以根据 GPU 类型优化 GPU 加速。
- 用户分享了通过更改设置来增强性能所需的调整。
-
支持 Llama 3.2 模型:具有视觉能力的 Llama 3.2 模型(如 11b 或 90b)需要在 vllm 或 transformers 中运行,且至少需要 24GB 的 VRAM。
- 目前,llama.cpp 或 MLX 尚不支持这些较大的模型。
-
NVIDIA RTX 4000 系列取消 NVLink 支持:全新的 NVIDIA RTX 4000 系列取消了 NVLink 支持,转而使用 PCIe Gen 5 来增强多 GPU 设置。
- 这一升级强调在没有互连限制的情况下以更高速度运行,引发了关于性能收益的讨论。
-
模型运行的 AVX2 要求:为了高效运行模型,必须使用兼容 AVX2 的 CPU,但该功能在虚拟机(VM)中的可用性引发了疑问。
- 用户建议通过 CPUID 或类似工具验证 Ubuntu VM 中 AVX2 的激活情况。
OpenAccess AI Collective (axolotl) Discord
-
Hugging Face Token 使用简化:要使用 Hugging Face 身份验证 Token,请在脚本中设置
HUGGINGFACE_HUB_TOKEN环境变量,或通过 Hugging Face CLI 登录以安全地保存 Token。- 此方法可防止将敏感信息直接嵌入脚本,从而提高安全性和易用性。
-
Axolotl 配置文件调整:成员们报告了 Axolotl 配置文件的问题,指出其中包含一些不寻常的字段和硬编码的 Token,应避免使用。
- 建议包括对敏感数据使用环境变量,并删除任何不必要的字段以简化配置。
-
使用 Axolotl 进行多 GPU 设置:要利用 Axolotl 使用多个 GPU,请配置
accelerate库进行分布式训练,并根据可用 GPU 数量调整进程数。- 通过环境变量(如
CUDA_VISIBLE_DEVICES)微调设置可以增强对 GPU 分配的控制。
- 通过环境变量(如
-
GPU 租赁查询的重要性:一位成员询问了提供 10xA100 或 10xH100 节点租赁的主机商,突显了对高性能 GPU 资源的迫切需求。
- 他们对 10x 配置的可行性表示担忧,质疑 CPU 是否支持那么多 PCI x16 lanes。
-
从 Jupyter 登录 Hugging Face:
huggingface_hub库中的notebook_login函数简化了在 Jupyter Notebooks 中安全使用 Hugging Face Token 的过程。- 另外,如果 Notebook 被广泛共享,将 Token 设置为环境变量会带来安全风险。
LlamaIndex Discord
-
LlamaIndex 语音 Agent 赋能交互:观看一段演示,其中 AI Agent 通过 LlamaIndex 和 OpenAI realtime API client 进行语音对话,展示了强大的交互能力。
- 该项目是开源的,允许社区创建自己的语音 Agent。
-
Argilla 提升数据集质量:Argilla 是一款用于生成和标注数据集的工具,现在支持 fine-tuning、RLHF,并与 LlamaIndex 无缝集成。
- 查看此处的演示 Notebook,了解它如何帮助提高数据质量。
-
AWS Bedrock 面临 API 维护问题:AWS Bedrock 用户报告了由于供应商 API 更改导致的维护复杂化,这使得 LlamaIndex 中的数据处理变得复杂。
- 社区强烈推动建立统一的 API 以简化集成工作流程。
-
Qdrant Node 使用需澄清:一位成员提出了关于在 Qdrant Database 中存储 JSON 数据的问题,揭示了在摄取过程中对 Node 和 Document 之间的误解。
- 社区澄清了 Node 和 Document 在很大程度上是语义化的且可互换的,允许从 JSON 创建自定义 Node。
-
Hugging Face Inference API 可访问性确认:讨论确认 LlamaIndex 支持通过 Inference API 和 Endpoint 模型访问 Hugging Face 模型推理端点。
- 共享了有用的文档链接以帮助用户进行实现。
Latent Space Discord
-
Sierra 估值达到 40 亿美元:Bret Taylor 的 AI 初创公司 Sierra 在一笔新交易后获得了惊人的 40 亿美元估值,其营收倍数极高,引发关注。
- 正如这篇 tweet 所分享的,这一估值引发了关于由 Taylor 这样声名显赫的领导者掌舵所带来优势的讨论。
-
UGround 实现类人 Agent:介绍 UGround,这是一个通用 Grounding 模型,允许 Agent 仅通过视觉感知来理解数字世界,在六个基准测试中提供 SOTA 性能。
- 这种方法简化了多模态 Agent 的创建,消除了对繁琐的文本观测的需求,详见这篇 详细解释。
-
2024 年 AI 现状报告发布:备受期待的 State of AI Report 2024 现已发布,全面概述了 AI 领域的研究、行业、安全和政治。
- Nathan Benaich 的 tweet 重点介绍了导演剪辑版以及配套的视频教程,以供进一步深入了解。
-
AMD 发布新款 AI 芯片:AMD 推出了 Instinct MI325X AI 芯片,计划于 2024 年底开始生产,直接对标 Nvidia 的产品。
- 此次发布旨在挑战 Nvidia 在快速增长的市场中 75% 的毛利率,该市场对先进的 AI 处理能力需求巨大,CNBC 文章 对此进行了报道。
-
Writer.com 开发具有竞争力的 AI 模型:AI 初创公司 Writer 发布了一款新模型,旨在与 OpenAI 等公司的产品竞争,其训练成本仅约 70 万美元,表现亮眼。
- 据 CNBC 报道,Writer 目前正以 19 亿美元的估值筹集高达 2 亿美元的资金,反映出投资者的浓厚兴趣。
LLM Agents (Berkeley MOOC) Discord
-
黑客松焦点引发关注:成员们讨论认为,ninja 和 legendary 级别的学生应优先提交黑客松作品,以提高整体质量和专注度。
- 这一决定旨在最大化提交期间的影响力和参与度。
-
Lab 1 下载问题浮现:有报告指出从邮件链接下载 Lab 1 时存在问题,用户经常得到 空文件。
- 成员们建议切换到 课程网站链接 以获得更好的可靠性。
-
征求 RAG 框架建议:一位成员寻求关于 最易用的 RAG 框架 的建议,表现出对集成便捷性和功能满意度的兴趣。
- 这一咨询表明了在项目中优化编码工作流的需求。
-
浏览器 Agent 引起热议:对话探讨了使用 Web 浏览器 Agent 的经验,特别强调了 Web Voyager 是一个非常有前景的工具。
- 这反映了对增强浏览器内 Agent 功能的兴趣。
-
头脑风暴频道受到关注:成员们在 <#1293323662300155934> 发起了头脑风暴会议,同意使用该频道进行协作式创意生成。
- 这一共识强调了对促进协作和创造性讨论的承诺。
Torchtune Discord
-
小模型预示潜在问题:一位成员对来自小模型的想法的可靠性提出了担忧,认为这些结果可能不会显著影响未来的概念。
- 他们指出,虽然这些论文处于种子阶段,但其实际影响力仍有待商榷。
-
混合优化受到质疑:讨论质疑了伴随成功的小模型而出现的混合优化在现实世界中的影响,暗示了其潜在的局限性。
- 成员们暗示,即使是有效的方法,在实践中表现出的差异也可能微乎其微。
-
SOAP 优于 AdamW 但面临现实问题:SOAP 优化器在 Alpaca 上的运行表现优于 AdamW,但在分布式上下文和 bf16 方面遇到了挑战。
- 一位成员指出,为了应对其复杂性,调整 AdamW 的学习率是必要的。
-
预条件化带来实现挑战:预条件优化器(Preconditioning optimizers)需要对权重和梯度矩阵进行精细管理,这增加了分布式设置的复杂性。
- 一位成员提到了 Facebook 研究仓库,以获取关于这些问题的见解。
-
Entropix 凭借独特方法获得关注:Entropix 方法通过避免输出具有高熵 Logits 的 Token,在一周内星标数飙升至 2k stars。
- 一位成员分享了项目更新,强调了其有效的 Token 预测策略。
OpenInterpreter Discord
-
OS 模式针对 MacOS 性能进行了完善:OS 模式似乎显著提升了专门针对 MacOS 的性能,并针对该平台优化了工具。
- mikebirdtech 强调,这将为 Mac 用户带来更好的使用体验。
-
AI Agent 在终端大放异彩:分享的 GitHub 仓库展示了一个直接在终端中利用本地工具和视觉能力的 AI Agent。
- 它可以运行 Shell 命令并执行代码,证明了其在辅助开发任务中的价值。
-
Calypso 凭借语音功能引起轰动:自主 AI 主播项目 Calypso 引起了热烈反响,其具备的精细语音能力让用户感到兴奋。
- 该项目旨在集成三个 AI 模型,目标是提供难以匹敌的逼真表现。
-
ElevenLabs Creator 计划定价公开:一项分析显示,ElevenLabs Creator 计划每月提供 100k 积分,每分钟音频成本约为 $0.18。
- 这一结构相当于每月约 2 小时的音频制作量,为音频服务用户提供了清晰的参考。
LAION Discord
-
视觉语言智能初具规模:最近一篇题为《视觉语言智能的火花》的论文提出了一种旨在实现高效细粒度图像生成的自回归 Transformer。
- 这种方法预示了 AI 中融合视觉与语言能力的良好趋势。
-
与视觉自回归模型的联系:讨论强调了与视觉自回归建模的相似之处,后者专注于通过下一尺度预测(next-scale prediction)实现可扩展的图像生成。
- 讨论中还提到了 Apple 的 Matryoshka 扩散模型,展示了类似的创新。
-
转向从粗到精的技术:一位成员评论道,图像有效的自回归方向应该是从粗到精,而不是传统的“从左上到右下”。
- 这一见解强调了以更有结构的方式生成图像。
-
带有梯度 Dropout 的创新自动编码器概念:提出的一种新颖想法涉及使用对潜变量向量(latent vector)进行“梯度 Dropout”(gradiated dropout)来训练图像-向量-图像自动编码器。
- 在这种方法中,Dropout 概率在各个元素间逐渐增加,从而产生有利于渐进式解码的潜变量。
DSPy Discord
-
对 DOTS 算法的兴奋:一位成员对 DOTS 论文 表达了热忱,强调其相对于静态方法论的动态推理(dynamic reasoning)方法,并计划通过 DSPy 框架实现 DOTS。
- 该实现将利用 Signatures 执行原子操作,并集成自定义模块以增强动态决策能力。
-
DOTS 24点游戏实现:分享了一个 DOTS 24点游戏脚本,并附带了 DOTS 论文 的引用,展示了 LLM 推理方面的创新点。
- 论文详细介绍了如何使用定制的动态推理轨迹而非静态推理动作来增强 LLM 的能力,这标志着一个重大的转变。
-
关于 DOTS 的 YouTube 资源:一位成员链接了一个 YouTube 视频,为 DOTS 算法的讨论提供了额外的见解。
- 该资源可能有助于理解 DOTS 算法在 LLM 社区内的实现及其更广泛的影响。
LangChain AI Discord
-
AI 聊天助手参加 Piñata 挑战赛:一位用户展示了他们的 AI Chat Assistant 项目,作为 Piñata Challenge 的一部分,旨在激励其他开发者。
- 他们鼓励社区成员如果产生共鸣就点赞该帖子,从而培养积极参与和反馈的文化。
-
通过点赞促进社区参与:呼吁用户如果产生共鸣就点赞该帖子,为有用的内容创建反馈闭环。
- 这种方法鼓励社区开发者之间的积极参与和欣赏。
tinygrad (George Hotz) Discord
-
关于 Hugging Face Diffusers 的咨询:一位用户询问频道中是否有人有使用 Hugging Face 的
diffusers的经验,引发了关于其功能和应用的讨论。- 这一咨询凸显了人们对生成式模型以及促进其实现的实用工具日益增长的兴趣,这是许多 AI 工程项目的核心。
-
对 Diffusion 模型技术的兴趣:对
diffusers的提及表明,人们对最先进技术(特别是与这些模型相关的图像生成和文生图艺术)的好奇心日益增加。- 参与者可能很快会分享他们在实验 Hugging Face 产品时,关于各种参数和数据集配置的经验。
Mozilla AI Discord
-
Llama 3.2 登陆 Hugging Face:Llama 3.2 现已在 Hugging Face 上发布 1B 和 3B 版本,以增强开发者资源。
- 此次发布专注于提高可访问性,并为用户提供更广泛的工具包来利用 Llama 模型。
-
Mozilla 加速器资助 14 个项目:Mozilla 新的加速器计划宣布资助 14 个创新项目,每个项目最高可获得 $100,000,以支持开源 AI 工作。
- 项目范围从药物研发计划到 Swahili LLM,旨在聚焦社区驱动的创新。
-
Lumigator MVP 为模型选择带来清晰度:Mozilla.ai 推出了 Lumigator MVP,旨在为开发者简化并清晰化模型选择过程。
- 通过提供特定任务的指标,Lumigator 帮助用户不仅是识别任何模型,而是识别最适合其特定项目需求的模型。
Gorilla LLM (Berkeley Function Calling) Discord
-
BFCL-V3 增强对缺失字段的处理:BFCL-V3 专注于改进模型在多轮对话中对缺失字段的响应,以创造更连贯的对话体验。
- 成员们期待 Gorilla LLM 优化此功能,这有望提升交互质量。
-
对即将推出的 Gorilla 功能的期待:讨论强调了成员们对 Gorilla LLM 即将推出的功能的期待,特别是在处理对话复杂性的背景下。
- 关于这些增强功能将如何影响用户交互存在很多讨论,这表明了向更强大的对话式 AI 的转变。
AI21 Labs (Jamba) Discord
-
AI21-Jamba-1.5-Mini 中的 CUDA 错误:一位用户在 Ubuntu 上的 Docker 环境(使用 CUDA 12.4)运行 Hugging Face 模型 AI21-Jamba-1.5-Mini 时,遇到了 CUDA 初始化错误:Cannot re-initialize CUDA in forked subprocess。
- 该用户的设置利用了
torch.multiprocessing的 ‘spawn’ 方法,并对如何解决其 Docker 环境特有的这一问题表示关注。
- 该用户的设置利用了
-
请求 CUDA 错误解决方案:用户寻求在模型执行期间修复 CUDA 错误 的指导,并强调了其 Docker 和 torch.multiprocessing 配置的重要性。
- 他们正在寻找针对其特定技术设置的解决方案。
Alignment Lab AI Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
LLM Finetuning (Hamel + Dan) Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
DiscoResearch Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
PART 2: 频道详细摘要与链接
完整的频道细分内容已在邮件中截断。
如果您喜欢 AInews,请分享给朋友!提前感谢!