ainews-claude-35-sonnet-new-gets-computer-use
Claude 3.5 Sonnet (新版) 获“电脑使用” (Computer Use) 功能。
Anthropic 发布了全新的 Claude 3.5 模型:3.5 Sonnet 和 3.5 Haiku。新模型显著提升了编程性能,其中 Sonnet 在 Aider 和 Vectara 等多个编程基准测试中位居榜首。
全新的 Computer Use API 能够通过视觉能力控制计算机,其评分显著高于其他 AI 系统,展示了 AI 驱动的计算机交互技术的进步。Zep 推出了用于 AI 智能体记忆管理的云端版本,并强调了多模态记忆面临的挑战。此外,本次更新还提到了来自 NVIDIA(英伟达) 的 Llama 3.1 和 Nemotron 模型。
更好的模型命名就是我们所需要的一切。
2024/10/21-2024/10/22 的 AI 新闻。我们为您检查了 7 个 subreddits、433 个 Twitter 和 32 个 Discord(232 个频道和 3347 条消息)。预计节省阅读时间(以 200wpm 计算):341 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
Anthropic 并没有发布广受期待(且现已无限期推迟)的 Claude 3.5 Opus,而是发布了新款 3.5 Sonnet 和 3.5 Haiku,为每个模型都带来了提升。
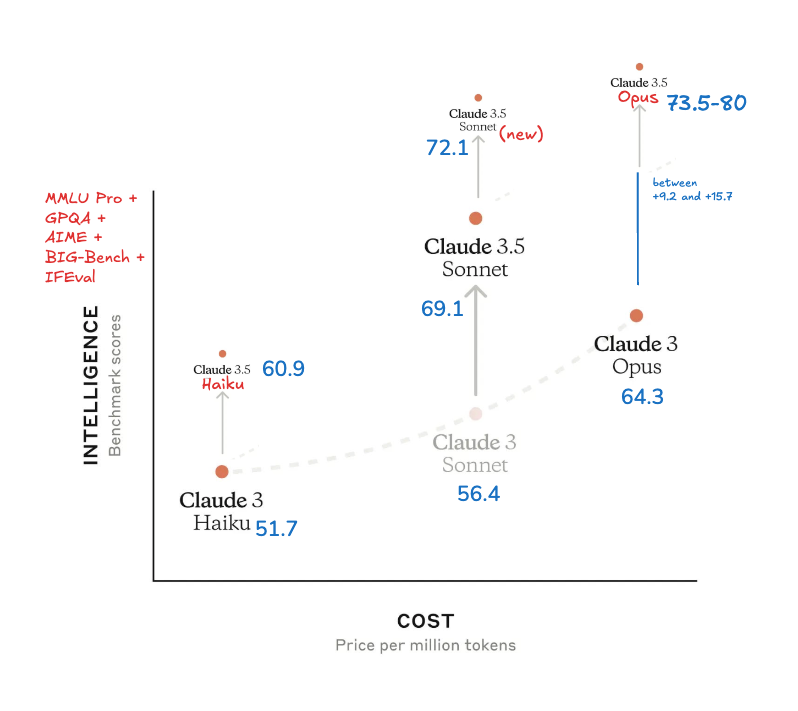
3.5 Sonnet 已经在代码编写方面带来了显著提升。新款 3.5 Haiku(基准测试见 model card)在“许多评估中达到了 Claude 3 Opus 的性能,且成本与上一代 Haiku 相同,速度也相近”。
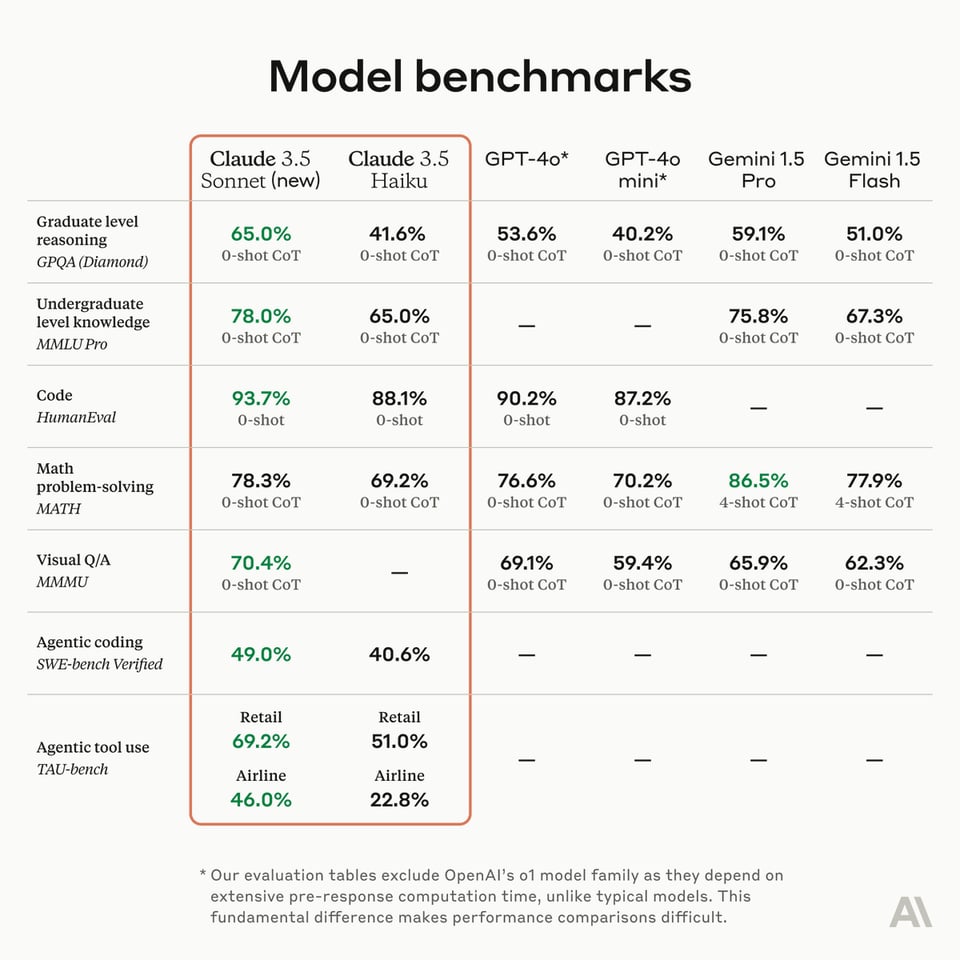
值得注意的是,在编程方面,它在 SWE-bench Verified 上的性能提升从 33.4% 增加到 49.0%,得分高于 o1-preview 的 41.4%,且无需任何复杂的推理步骤。然而,在数学方面,3.5 Sonnet 27.6% 的最高纪录与 o1-preview 的 83% 相比仍显逊色。
其他基准测试:
- Aider:新款 Sonnet 在 aider 的代码编辑排行榜中以 84.2% 位居榜首,并在 aider 要求更高的重构基准测试中以 92.1% 的得分创下 SOTA!
- Vectara:在 Vectara 的 Hughes 幻觉评估模型中,Sonnet 3.5 从 8.6 降至 4.6。
Computer Use
Anthropic 新推出的 Computer Use API(文档在此,演示在此)引用了 OSWorld 作为其相关的屏幕操作基准测试——在仅限截图类别中得分 14.9%,明显优于排名第二的 AI 系统(7.8%)。
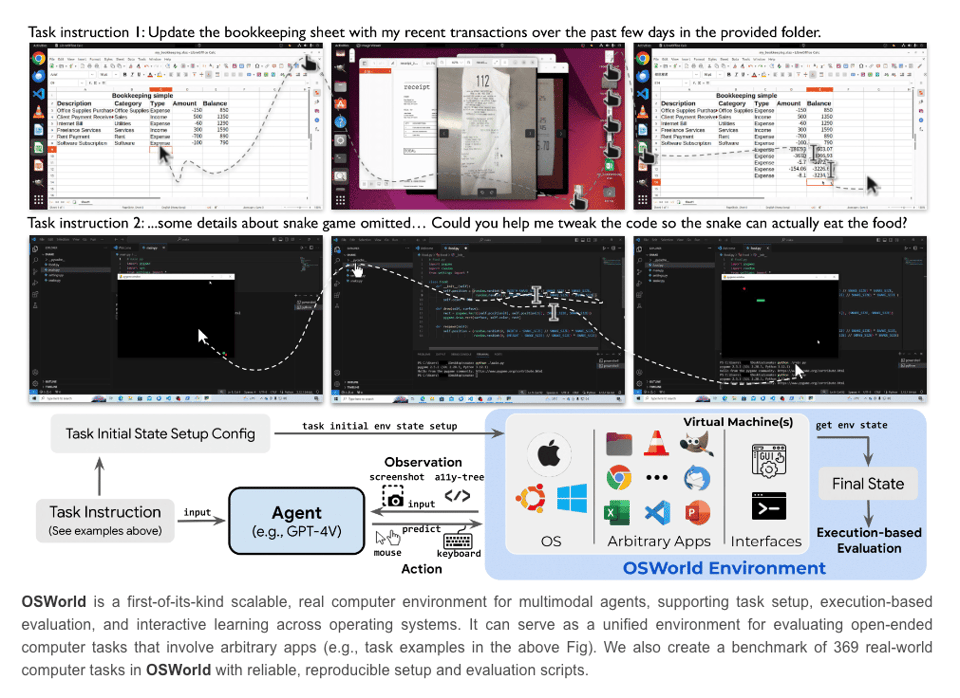
当被允许使用更多步骤来完成任务时,Claude 的得分为 22.0%。这仍远低于人类 70 多分的表现,但值得关注,因为这本质上是 Adept 此前通过其 Fuyu 模型宣布但从未广泛发布的功能。从简化的角度来看,“computer use”(通过视觉控制计算机)与标准的“tool use”(通过 API/函数调用控制计算机)形成了对比。
示例视频:
供应商请求表单、通过视觉编写代码、Google 搜索和 Google 地图
Simon Willison 对 GitHub 快速入门进行了进一步测试,包括在 C 语言中编译并运行 hello world(它已经内置了 gcc,所以直接成功)以及安装缺失的 Ubuntu 软件包。
Replit 也能将 Claude 作为人类反馈的替代方案接入 @Replit Agent。
[由 Zep 赞助] Zep 今天刚刚发布了他们的云版本!Zep 是一个为 AI Agent 和助手提供的低延迟记忆层,能够对随时间变化的事实进行推理。加入 Discord 探讨知识图谱和记忆的未来!
swyx 评论:随着 Claude 升级后的视觉模型正式支持 computer use,Agent 的记忆存储需要如何改变?你可以看到 Anthropic 简单的图像记忆实现,但目前还没有多模态记忆的解决方案……这是 Zep Discord 的一个热门话题。
AI Twitter 摘要
所有摘要均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
AI 模型更新与发布
-
Llama 3.1 和 Nemotron:@_philschmid 报道称,NVIDIA 的 Llama 3.1 Nemotron 70B 在 Arena Hard (85.0) 和 AlpacaEval 2 LC (57.6) 中登顶,向 GPT-4 和 Claude 3.5 发起挑战。
-
IBM Granite 3.0:IBM 发布了 Granite 3.0 模型,参数范围从 4 亿到 8B,在 Hugging Face 的 OpenLLM 排行榜上超越了同等规模的 Llama-3.1 8B。该模型在 12 种语言和 116 种编程语言的 12+ 万亿 token 上进行了训练。
-
xAI API:xAI API Beta 版现已上线,允许开发者将 Grok 集成到他们的应用程序中。
-
BitNet:Microsoft 开源了 bitnet.cpp,实现了 1.58-bit LLM 架构。这使得在 CPU 上以每秒 5-7 个 token 的速度运行 100B 参数模型成为可能。
AI 研究与技术
-
量化 (Quantization):一种新的线性复杂度乘法 (L-Mul) 算法声称可以将 LLM 中逐元素张量乘法的能耗降低 95%,点积能耗降低 80%。
-
合成数据 (Synthetic Data):@omarsar0 强调了合成数据对于改进 LLM 及其构建系统(Agent、RAG 等)的重要性。
-
Agentic Information Retrieval:分享了一篇介绍 Agentic Information Retrieval 的论文,讨论了 LLM Agent 如何塑造检索系统。
-
RoPE 频率:@vikhyatk 指出截断最低的 RoPE 频率有助于 LLM 的长度外推 (length extrapolation)。
AI 工具与应用
-
Perplexity Finance:Perplexity Finance 已在 iOS 上推出,提供财务信息和股票数据。
-
LlamaIndex:分享了多种使用 LlamaIndex 的应用,包括报告生成和 Serverless RAG 应用。
-
Hugging Face 更新:宣布了新功能,如面向企业 Hub 订阅的代码库分析以及 diffusers 中的量化支持。
AI 伦理与社会影响
-
法律服务:OpenAI 的 CPO Kevin Weil 讨论了法律服务领域潜在的颠覆性变化,AI 可能将成本降低 99.9%。
-
AI 审计:宣布将于 10 月 28 日举行关于第三方 AI 审计、红队测试 (Red Teaming) 和评估的在线研讨会。
迷因与幽默
-
分享了关于 ChatGPT 即将到来的生日及潜在礼物的各种推文,包括 @sama 发出的这一条。
-
分享了关于 Google Meet 中 AI 生成背景以及 AI 对视频编辑影响的笑话。
AI Reddit 摘要
/r/LocalLlama 摘要
主题 1. Moonshine:新型开源语音转文本模型挑战 Whisper
- Moonshine 新型开源语音转文本模型 (Score: 54, Comments: 5): Moonshine 是一款新型的开源语音转文本模型,声称在保持与 Whisper 相当的准确率的同时,速度比其更快。由 Sanchit Gandhi 和 Hugging Face 团队开发,Moonshine 基于 wav2vec2,在 CPU 上的处理速度比 Whisper 快 30 倍。该模型已在 Hugging Face Hub 上提供,并可以使用 Transformers 库轻松集成到项目中。
Theme 2. Allegro: 新型 SOTA 开源文本转视频模型
- 新型文本转视频模型: Allegro (Score: 99, Comments: 8): Allegro 是一款新型的开源文本转视频模型,已发布详细论文和 Hugging Face 实现。该模型基于开发者之前的开源视觉语言模型 (VLM) Aria 构建,后者为监控定位(surveillance grounding)和推理等任务提供了全面的微调指南。
- Allegro 被誉为新的本地文本转视频 SOTA (State of the Art),其 Apache-2.0 license 尤其受到欢迎。该模型的开源性质被视为本地视频生成领域的一个积极进展。
- 讨论了模型的 VRAM 需求,选项从 9.3GB (含 CPU offload) 到 27.5GB (不含 offload) 不等。用户建议将 T5 model 量化为较低精度 (fp16/fp8/int8),以适配 24GB/16GB VRAM 的显卡。
- 强调了模型使用的灵活性,可以权衡生成质量以减少 VRAM 占用并缩短生成时间 (可能为 10-30 分钟)。一些用户讨论了在初始 prompt encoding 后更换 T5 model 的选项,以优化资源利用。
Theme 3. 字节跳动 AI 破坏事件引发安全担忧
- TikTok 母公司解雇破坏 AI 项目的实习生 (Score: 153, Comments: 50): ByteDance,即 TikTok 的母公司,据报道解雇了一名实习生,原因是其通过插入恶意代码蓄意破坏 AI 项目。这起发生在中国的事件凸显了与 AI 开发相关的安全风险以及科技公司内部威胁的可能性。ByteDance 在例行代码审查中发现了破坏行为,强调了 AI 开发过程中稳健的安全措施和代码审计的重要性。
- 据称,该实习生通过在 checkpoint models 中植入 backdoors、插入 random sleeps 以减慢训练速度、终止训练任务以及逆转训练步骤来破坏 AI 研究。据报道,这是由于对 GPU resource allocation 不满所致。
- ByteDance 已于 8 月解雇了该实习生,通报了其所在大学和行业机构,并澄清该事件仅影响了商业技术团队的研究项目,而非官方项目或大模型。关于“8,000 张显卡和数百万损失”的传言被夸大了。
- 一些用户对该实习生据称缺乏 AI 经验表示质疑,因为他有能力逆转训练过程。其他人指出这是“职业自杀”,并推测其可能会被主要科技公司列入黑名单。
Theme 4. PocketPal AI: 移动端本地模型的开源应用
- PocketPal AI 已开源 (Score: 434, Comments: 78): PocketPal AI 是一款用于在 iOS 和 Android 设备上运行 local models 的应用程序,现已 开源。该项目的源代码目前已在 GitHub 上发布,允许开发者探索并为移动平台的设备端 AI 模型实现做出贡献。
- 用户报告了 Llama 3.2 1B 模型令人印象深刻的性能,在 iPhone 13 上达到了 20 tokens/second,在 Samsung S24+ 上达到了 31 tokens/second。iOS 版本 使用了 Metal acceleration,这可能是提升速度的关键因素。
- 社区对该应用的开源表示感谢,许多人称赞其便利性和性能。一些用户建议增加 donation section 以支持开发,并请求增加如 character cards 集成等功能。
- 用户将 PocketPal 与另一个开源移动端 LLM 应用 ChatterUI 进行了比较。PocketPal 因其用户友好性和在 App Store 的可用性而受到关注,而 ChatterUI 则提供更多自定义选项和 API 支持。
- 🏆 GPU-Poor LLM Gladiator Arena 🏆 (Score: 137, Comments: 38): GPU-Poor LLM Gladiator Arena 是一个比较可以在消费级硬件上运行的小型语言模型的竞赛。鼓励参与者提交参数量最大为 3 billion parameters 且能在 24GB VRAM 或更低配置设备上运行的模型,目标是在保持效率和可访问性的同时,在各种 benchmark 上实现高性能。
- 用户对 GPU-Poor LLM Gladiator Arena 表现出极大的热情,一些人建议加入更多模型,如 allenai/OLMoE-1B-7B-0924-Instruct 和 tiiuae/falcon-mamba-7b-instruct。该项目因简化了小型模型的比较而受到称赞。
- 讨论中提到了 Gemma 2 2B 的表现,一些用户注意到它与更大模型相比具有强劲的性能。关于 Gemma 友好的对话风格是否会影响人类评估结果也存在争议。
- 改进建议包括为评估增加 tie button(平局按钮)、计算 ELO ratings 而非原始胜率,以及引入更强大的统计方法来考虑样本量和对手强度。
主题 5:开源权重 AI 模型许可证趋于严格的趋势
- 近期发布的开源权重模型具有更严格的许可证 (Score: 36, Comments: 10): 近期发布的 open-weight AI model,包括 Mistral small、Ministral、Qwen 2.5 72B 和 Qwen 2.5 3B,与早期的 Mistral Large 2407 等发布相比,显示出 restricted licenses 增加的趋势。随着 AI 模型性能的提高和运行成本效益的提升,许可证条款明显转向严格,未来 open-weight releases 可能主要来自 academic laboratories。
- Mistral 对小型模型采取更严格的许可可能会损害其品牌,可能导致公司范围内禁用 Mistral 模型,并降低对其 API-only 大型模型的兴趣。用户对缺乏评估模型质量的本地参考点表示担忧。
- 不发布 Mistral 3B 模型 权重的决定被视为 开源 AI 的负面信号。这一趋势表明,公司可能会越来越多地将性能良好的小型模型保持私有,以维持竞争优势。
- 讨论围绕 Mistral 对盈利的需求 以维持运营展开,这与 Meta 等能够负担得起公开模型的大型公司形成鲜明对比。一些用户认为 Mistral 的做法是为了生存,而另一些人则认为这是 AI 模型许可中令人担忧的趋势的一部分。
其他 AI Subreddit 回顾
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI 模型开发与发布
-
ComfyUI V1 桌面应用程序发布:ComfyUI 宣布推出全新的封装桌面应用,支持一键安装、自动更新,并配备了包含模板工作流和节点模糊搜索的新 UI。它还包含一个拥有 600 多个已发布节点的 Custom Node Registry。来源
-
OpenAI 的 o1 模型在增加算力后表现出更强的推理能力:OpenAI 研究员 Noam Brown 分享道,o1 模型在数学问题上的推理能力随着测试时算力(test-time compute)的增加而提升,且在对数尺度上“没有停止的迹象”。来源
-
Advanced Voice Mode 在欧盟发布:OpenAI 的 Advanced Voice Mode 现已在欧盟正式可用。用户反馈其在口音处理方面有所改进。来源
AI 研究与行业洞察
-
微软 CEO 谈 AI 开发加速:Satya Nadella 表示,由于 Scaling Laws 范式,计算能力现在每 6 个月翻一番。他还提到 AI 开发已进入递归阶段,即利用 AI 来构建更好的 AI 工具。来源 1, 来源 2
-
OpenAI 谈 o1 模型的可靠性:OpenAI 应用研究负责人 Boris Power 表示,o1 模型的可靠性已足以支持 Agent。来源
AI 伦理与社会影响
- Sam Altman 谈技术进步:OpenAI CEO Sam Altman 发推称,“并不是未来会发生得太快,而是过去发生得太慢”,引发了关于技术进步速度的讨论。来源
机器人技术进展
- Unitree 机器人训练:一段展示 Unitree 机器人日常训练的视频被分享,展示了机器人在移动性和控制方面的进步。来源
迷因与幽默
- 一篇题为“训练更多 AI 的 AI”的帖子引发了关于递归式 AI 改进的幽默讨论。来源
AI Discord 摘要回顾
由 O1-preview 生成的摘要之摘要的摘要
主题 1. Claude 3.5 在 Computer Use 领域取得突破
- Claude 3.5 成为你的硅基管家:Anthropic 的 Claude 3.5 Sonnet 推出了 beta 版的 ‘Computer Use’ 功能,允许它像人类助手一样在你的电脑上执行任务。尽管存在一些小瑕疵,用户对这一模糊了 AI 与人类交互界限的实验性功能感到兴奋。
- Haiku 3.5 跃升至编程巅峰:全新的 Claude 3.5 Haiku 超越了其前代产品,在 SWE-bench Verified 上获得了 40.6% 的评分,表现优于 Claude 3 Opus。随着 Haiku 3.5 树立了 AI 辅助编程的新标准,程序员们欢欣鼓舞。
- Claude 操控电脑,用户挑战极限:虽然 ‘Computer Use’ 功能具有开创性,但 Anthropic 警告称它是实验性的,并且“有时容易出错”。但这并没有削弱社区挑战极限的热情。
主题 2. Stable Diffusion 3.5 点亮 AI 艺术
- Stability AI 发布 Stable Diffusion 3.5——艺术家的盛宴:Stable Diffusion 3.5 发布,提升了图像质量和 Prompt 遵循能力,对于年收入低于 100 万美元的商业用途免费。它已在 Hugging Face 上线,是送给艺术家和开发者的礼物。
- SD 3.5 Turbo 疾速领先:全新的 Stable Diffusion 3.5 Large Turbo 模型在不牺牲质量的情况下提供了极快的推理速度。用户对这种速度与性能的结合感到兴奋。
- 艺术家辩论:SD 3.5 对决 Flux——谁能问鼎?:社区正在热议 SD 3.5 是否能在图像质量和美感上取代 Flux。早期测试者的评价褒贬不一,但竞争正在升温。
主题 3. AI 视频生成随 Mochi 1 和 Allegro 升温
- GenmoAI 的 Mochi 1 带来震撼视频:Mochi 1 树立了开源视频生成的新标准,在 480p 分辨率下提供逼真的动态效果和 Prompt 遵循能力。在 2840 万美元资金的支持下, GenmoAI 正在重新定义写实视频模型。
- Allegro 在 Text-to-Video 领域表现亮眼:Rhymes AI 推出了 Allegro,能将文本转化为 15 FPS、720p 的 6 秒视频。早期采用者可以在此处加入等待名单,抢先体验。
- 视频大战开启:Mochi 对决 Allegro——愿最强帧胜出:随着 Mochi 1 和 Allegro 的加入,创作者们热切期待哪个模型将在 AI 驱动的视频内容领域领先。
主题 4. Cohere 将图像嵌入多模态搜索
- Cohere 的 Embed 3 终于将图像接入搜索!:Multimodal Embed 3 支持混合模态搜索,在检索任务中表现出色。现在,你可以将文本和图像数据存储在一个数据库中,使 RAG 系统变得异常简单。
- 图像与文本,终成眷属:新的 Embed API 增加了一个名为
image的input_type,让开发者可以与文本一起处理图像。虽然每次请求限制一张图像,但这是统一数据检索的一大飞跃。 - 与 Embed 专家面对面:Cohere 正与其 Embed 高级产品经理举行答疑会,以提供对新功能的见解。参加活动,直接从源头获取内部消息。
主题 5. 黑客松热潮:伯克利提供超过 20 万美元奖金
- LLM Agents MOOC 黑客松提供 20 万美元重奖:伯克利 RDI 发起了一场黑客松,奖金超过 200,000 美元,从 10 月中旬持续到 12 月中旬。该活动向所有人开放,设有应用、基准测试等赛道。
- OpenAI 和 GoogleAI 全力支持黑客松:OpenAI 和 GoogleAI 等主要赞助商支持此次活动,增加了声望和资源。参与者还可以在比赛期间探索职业和实习机会。
- 五大赛道,无限可能:黑客松包括 Applications、Benchmarks、Fundamentals、Safety 以及 Decentralized & Multi-Agents 等赛道,邀请参与者突破 AI 边界并释放创新。
第一部分:高层级 Discord 摘要
HuggingFace Discord
- AI DJ 软件展示潜力:用户讨论了一个创新的 AI DJ Software 概念,该软件可以像 Spotify 那样实现自动歌曲过渡和混音。
- 提到了 rave.dj 等工具用于创建有趣的混搭(mashups),尽管输出结果尚不完美。
- Hugging Face 模型查询引发安全担忧:一位用户寻求关于如何通过
huggingface_hub安全下载 Hugging Face 模型权重而不泄露权重的建议。- 社区成员提供了关于使用环境变量进行身份验证以维护隐私的见解。
- OCR 工具受到关注:讨论了从 PDF 中提取结构化数据的有效 OCR 解决方案,特别是针对建筑领域的应用。
- 推荐包括 Koboldcpp 等模型,以提高文本提取的准确性。
- Granite 3.0 模型发布备受瞩目:新的 端侧 Granite 3.0 模型 引起了用户的兴奋,突显了其便捷的部署特性。
- 该模型的属性被赞誉为增强了快速集成的可用性。
- LLM 最佳实践网络研讨会吸引关注:一位 META 高级 ML 工程师宣布了一个专注于 LLM 导航的 网络研讨会,目前已有近 200 人报名。
- 该会议承诺提供关于 Prompt Engineering 和模型选择的可操作见解。
OpenRouter (Alex Atallah) Discord
- Claude 3.5 Sonnet 展示了令人印象深刻的基准测试结果:新发布的 Claude 3.5 Sonnet 在基准测试中取得了显著提升,且用户无需更改代码。更多信息请参见官方公告 此处。
- 成员指出,通过悬停在供应商旁边的信息图标可以轻松跟踪升级,从而增强了用户体验。
- Llama 3.1 Nitro 带来闪电般的性能提升:随着 70% 的速度提升,Llama 3.1 405b Nitro 现已上线,承诺吞吐量约为 120 tps。查看新端点:405b 和 70b。
- 用户被该模型带来的性能优势所吸引,使其成为一个极具吸引力的选择。
- Ministral 强大的模型阵容:Ministral 8b 已推出,在 128k 上下文下达到 150 tps,目前在技术提示词(tech prompts)中排名 #4。经济型的 3b 模型 可在 此处 访问。
- 这些模型的性能和定价在用户中引起了极大的兴奋,满足了不同的预算需求。
- Grok Beta 扩展功能:Grok Beta 现在支持增加到 131,072 的上下文长度,费用为 $15/m,取代了旧的
x-ai/grok-2请求。这一更新受到了期待增强性能的用户们的热烈欢迎。- 社区讨论反映了对新定价模式下功能改进的期望。
- 社区对 Claude 自我审查端点的反馈:发起了一项投票,以收集对 Claude 自我审查(self-moderated) 端点的意见,该端点目前在排行榜上排名第一。成员可以点击 此处 参与投票。
- 用户参与表明他们对影响这些端点的开发和用户体验有着浓厚的兴趣。
aider (Paul Gauthier) Discord
-
Claude 3.5 Sonnet 统治基准测试:升级后的 Claude 3.5 Sonnet 在 Aider 的排行榜上获得了 84.2% 的分数,在架构师模式(architect mode)下与 DeepSeek 配合使用时达到了 85.7%。
- 该模型不仅增强了编码任务,还保留了之前的价格结构,令许多用户感到兴奋。
-
DeepSeek 是高性价比的编辑器替代方案:DeepSeek 的成本为 每 1M 输出 token $0.28,与价格为 $15 的 Sonnet 相比,是一个更便宜的选择。
- 用户注意到它与 Sonnet 配合良好,尽管关于 token 成本变化影响性能的讨论也随之出现。
-
Aider 配置文件需要明确说明:用户询问了如何设置
.aider.conf.yml文件,指定如openrouter/anthropic/claude-3.5-sonnet:beta之类的类型作为编辑器模型。- 用户寻求关于 Aider 在运行时从何处提取配置细节的澄清,以实现最佳设置。
-
令人兴奋的 computer use 测试版公告:Anthropic 新的 computer use 功能允许 Claude 执行移动光标等任务,目前处于公开测试阶段,被描述为实验性的。
- 开发者可以引导其功能,这标志着与 AI 交互方式的转变,并提高了编码环境中的可用性。
-
DreamCut AI - 新颖的视频编辑解决方案:DreamCut AI 已发布,允许用户利用 Claude AI 进行视频编辑,由 MengTo 历时 3 个月 编写 5 万行代码 开发而成。
- 目前处于早期访问阶段,用户可以通过免费账号体验其 AI 驱动的功能。
Stability.ai (Stable Diffusion) Discord
-
Stable Diffusion 3.5 发布震惊用户:Stable Diffusion 3.5 发布,包含适用于消费级硬件的可定制模型,根据 Stability AI Community License 提供。用户对 3.5 Large 和 Turbo 模型感到兴奋,这些模型已在 Hugging Face 和 GitHub 上线,3.5 Medium 将于 10 月 29 日 发布。
- 这一公告让许多人措手不及,引发了关于其意外发布以及预期比之前版本性能提升的讨论。
-
SD3.5 与 Flux 图像质量大对决:社区评估了 SD3.5 在图像质量方面是否能击败 Flux,重点关注微调和美学。初步印象表明 Flux 在这些领域可能仍具有优势,引发了对数据集有效性的好奇。
- 讨论强调了模型之间基准测试比较的重要性,特别是在建立图像生成的市场标准时。
-
新的许可细节引发疑问:参与者对 SD3.5 的许可模式表示担忧,特别是与 AuraFlow 相比在商业环境下的应用。在可访问性与 Stability AI 的盈利需求之间取得平衡成为了热门话题。
- 这一讨论凸显了确保模型既对开发者开放,又能让生产者可持续发展的挑战。
-
社区支持促进技术采用:发现 Automatic1111’s Web UI 问题的用户在支持频道获得了指导,体现了社区内的协作精神。一位成员迅速获得了直接帮助,展示了与新用户的积极互动。
- 这种主动的支持方式有助于确保用户能够有效地利用新模型和可用的集成工具。
-
LoRA 应用激发艺术家热情:为 SD3.5 引入的 LoRA 模型让用户开始尝试提示词并分享结果,展示了其在增强图像生成方面的有效性。社区一直积极展示他们的作品并鼓励进一步的实验。
- 这些举措反映了旨在最大限度提高 AI 艺术社区内新发布功能影响力的参与策略。
Unsloth AI (Daniel Han) Discord
-
Nightly Transformers 修复了梯度累积 Bug:最近的更新显示,梯度累积(gradient accumulation)Bug 已被修复,并将包含在 nightly transformers 和 Unsloth 训练器中,纠正了损失曲线计算中的不准确之处。
- 此修复增强了各种训练设置中性能指标的可靠性。
-
关于 LLM 训练效率的见解:成员们讨论了使用短语输入训练 LLM 会生成多个子样本,从而最大限度地提高训练效果并使模型能够高效学习。
- 这种方法允许更丰富的训练数据集,从而提升模型能力。
-
模型性能与基准测试的挑战:针对新的 Nvidia Nemotron Llama 3.1 模型 出现了一些担忧,尽管其基准测试分数与 Llama 70B 相似,但对其性能是否优于后者表示怀疑。
- Nvidia 基准测试的不一致性引发了对其模型性能评估的质疑。
-
创建研究生申请文书编辑器:一位成员寻求开发 研究生申请文书编辑器 的帮助,在实现 AI 模型时面临复杂 Prompt 导致输出过于平庸的挑战。
- 专家被召集来提供微调模型的策略,以增强输出的相关性。
-
在 CSV 数据上微调 LLaMA:根据 Turing 文章 中分享的方法,请求澄清如何使用 CSV 数据微调 LLaMA 模型 以处理特定的事件查询。
- 社区反馈在制定有效模型测试方法方面发挥了关键作用。
Nous Research AI Discord
-
LLM 中的灾难性遗忘:讨论集中在大型语言模型(LLM)在持续指令微调过程中的 灾难性遗忘(catastrophic forgetting),特别是在 1B 到 7B 参数规模的模型中。成员们指出,微调可能会显著降低性能,详见 这项研究。
- 参与者分享了将自己的模型与成熟模型进行基准测试对比的个人经验,揭示了 LLM 训练中固有的挑战。
-
关于 LLM 基准测试性能的见解:用户指出模型规模显著影响性能,并提到如果没有适当的优化,数据限制会导致较差的结果。一位参与者讨论了他们的 1B 模型 相对于 Meta 模型 较低的分数,强调了基准对比的重要性。
- 这引发了关于某些模型在缺乏足够训练资源的情况下,如何在竞争环境中表现不佳的进一步思考。
-
对研究论文可靠性的担忧:最近的一项研究显示,大约 1/7 的研究论文 存在严重错误,削弱了其可信度。这引发了关于误导性研究可能导致研究人员无意中建立在错误结论之上的讨论。
- 成员们指出,评估研究完整性的传统方法需要更多资金和关注来纠正这些问题。
-
模型微调:一把双刃剑:围绕微调大型基础模型(foundation models)有效性的辩论强调了为特定目标而降低广泛能力的风险。成员们推测,微调需要细致的超参数优化才能获得丰硕成果。
- 针对社区缺乏关于微调最佳实践的既定知识的担忧浮现,引发了对自去年以来最新进展的疑问。
LM Studio Discord
-
LM Studio v0.3.5 功能亮点:LM Studio v0.3.5 的更新引入了 headless mode 和按需模型加载 (on-demand model loading),优化了本地 LLM 服务功能。
- 用户现在可以使用 CLI 命令
lms get轻松下载模型,增强了模型获取的便利性和可用性。
- 用户现在可以使用 CLI 命令
-
GPU Offloading 性能大幅下降:一位用户发现,在最近的更新后,GPU Offloading 性能骤降,仅利用了 4.2GB,而非预期的 15GB。
- 恢复到旧版本的 ROCm 运行时 (runtime) 版本后恢复了正常性能,这表明更新可能改变了 GPU 的利用方式。
-
出现模型加载错误:一位用户报告了与 GPU Offload 设置调整相关的 “Model loading aborted due to insufficient system resources” 错误。
- 禁用加载防护机制 (loading guardrails) 被提作为一种变通方法,尽管通常不推荐这样做。
-
讨论 AI 模型性能指标:社区就衡量性能进行了详细讨论,强调了加载设置对吞吐量 (throughput) 和延迟 (latency) 的影响。
- 值得注意的是,在重度 GPU Offloading 下,吞吐量降至 0.9t/s,表明可能存在效率低下的问题。
-
咨询游戏图像增强工具:用户开始探索将游戏图像转换为写实艺术的选项,Stable Diffusion 被列为候选工具。
- 对话引发了关于各种图像增强器在转换游戏视觉效果方面有效性的关注。
Latent Space Discord
-
Anthropic 发布 Claude 3.5:Anthropic 推出了升级版的 Claude 3.5 Sonnet 和 Claude 3.5 Haiku 模型,并加入了一项新的 Beta 功能 computer use,允许模型像人类一样与计算机交互。
- 尽管具有创新能力,但有用户报告它不能有效地遵循 Prompt,导致用户体验参差不齐。
-
Mochi 1 重新定义视频生成:GenmoAI 推出了 Mochi 1,这是一个旨在实现高质量视频生成的开源模型,以其在 480p 分辨率下的逼真动态和 Prompt 遵循能力而著称。
- 该项目利用大量资金进行进一步开发,旨在为写实视频生成设定新标准。
-
CrewAI 完成 1800 万美元 A 轮融资:CrewAI 在由 Insight Partners 领投的 A 轮融资中筹集了 1800 万美元,专注于利用其开源框架实现企业流程自动化。
- 该公司声称每月执行超过 1000 万个 Agent,服务于很大一部分财富 500 强公司。
-
Stable Diffusion 3.5 上线:Stability AI 发布了 Stable Diffusion 3.5,这是一个高度可定制的模型,可在消费级硬件上运行,并免费用于商业用途。
- 用户现在可以通过 Hugging Face 访问它,预计未来还会推出更多变体。
-
Outlines 库的 Rust 移植版提升效率:Dottxtai 宣布了 Outlines 库的 Rust 移植版,它为结构化生成 (structured generation) 任务提供了更快的编译速度和轻量化设计。
- 此次更新显著提升了开发者的效率,并包含多种编程语言的绑定。
Notebook LM Discord Discord
-
NotebookLM 中的语言混淆:用户报告称,尽管提供了英文文档,NotebookLM 的回答仍默认为荷兰语,建议调整 Google 账户语言设置。一位用户在德语输出方面遇到困难,遇到了意想不到的“外星”方言。
- 这突显了 NotebookLM 目前在语言处理方面的局限性以及潜在的改进方向。
-
共享 Notebooks 的挫败感:几位成员在尝试共享 notebook 时遇到问题,面临永久的“Loading…”屏幕,导致协作失效。这引发了对该工具稳定性和可靠性的担忧。
- 用户正在敦促解决此问题,表明迫切需要一个强大的共享功能来促进团队合作。
-
多语言音频效果参差不齐:尝试创建各种语言的音频概览(audio overviews)结果不尽如人意,特别是在荷兰语方面,发音和母语般的质量明显不足。一些用户成功生成了荷兰语内容,为改进带来了希望。
- 这一讨论揭示了社区对增强多语言能力以实现更广泛可用性的浓厚兴趣。
-
使用 NotebookLM 的播客体验:一位用户兴奋地分享了他们成功上传了一个 90 页的区块链课程,并生成了有趣的音频。反馈表明,输入的变化会导致意想不到且具有娱乐性的输出。
- 这展示了 NotebookLM 在播客领域的多种应用,尽管一致的质量仍是需要增强的话题。
-
文档上传问题依然存在:用户面临文档无法在 Google Drive 中显示的问题,以及处理延迟,引发了关于潜在文件损坏的讨论。建议通过刷新操作来解决这些上传挑战。
- 这些技术障碍强调了 NotebookLM 内部需要可靠的文档管理功能。
Perplexity AI Discord
-
Claude 3.5 模型引发热议:用户热切讨论新的 Claude 3.5 Sonnet 和 Claude 3.5 Haiku,希望在 AnthropicAI 的公告之后,它们能迅速集成到 Perplexity 中。关键特性包括 Claude 能够像人类一样使用计算机。
- 这种兴奋情绪反映了之前的发布情况,并表明了对 AI 不断进化的能力的浓厚兴趣。
-
API 功能引发挫败感:用户担心 Perplexity API 在收到提示时无法返回来源的完整 URL,导致用户对其易用性感到困惑。一位特定用户表达了尽管按照说明操作,但在获取这些 URL 方面仍面临挑战。
- 这一问题引发了关于 AI 产品中 API 能力以及需要更清晰文档的更大范围讨论。
-
Perplexity 面临竞争挑战:随着 Yahoo 推出 AI 聊天服务,围绕 Perplexity 竞争优势的讨论变得普遍。然而,用户强调 Perplexity 的可靠性和资源丰富度是其优于竞争对手的关键优势。
- 尽管竞争加剧,但对质量和性能的承诺仍然是用户的基石。
-
用户反馈突显优势:多位用户对 Perplexity 的表现给予了积极评价,称赞其高质量的信息传递。一位用户强调了满意度,表示:“我超级喜欢 PAI!我在工作和生活中一直在用它。”
- 此类反馈突显了该平台在 AI 社区中的声誉。
-
增强事实核查的资源共享:关于 AI 驱动的事实核查 策略的合集强调了伦理考量以及 LLM 在 Perplexity 误导信息管理中的作用。该资源讨论了来源可信度和偏见检测的重要性。
- 分享此类资源反映了社区在提高信息传播准确性方面的积极努力。
Eleuther Discord
-
新的开源 SAE 解释流水线发布:可解释性团队发布了一个新的开源 pipeline,用于自动解释 LLMs 中的 SAE features 和神经元,该流水线引入了五种评估解释质量的技术。
- 这一举措有望大规模增强可解释性,展示了利用 LLMs 进行特征解释方面的进展。
-
集成国际象棋 AI 与 LLMs 以增强交互性:一项将国际象棋 AI 与 LLM 结合的提案旨在创建一个能够理解自身决策的对话式 Agent,从而提升用户参与度。
- 构想中的模型力求实现连贯的对话,使 AI 能够清晰地阐述其国际象棋走法背后的推理。
-
SAE 研究思路引发讨论:一名本科生寻求关于 Sparse Autoencoders (SAEs) 的项目思路,引发了关于当前研究工作和协作机会的讨论。
- 成员们分享了资源,包括一篇用于深入探索的 Alignment Forum 帖子。
-
Woog09 为 ICLR 2025 的 Mech Interp 论文评分:一名成员分享了一份 电子表格,对 ICLR 2025 的所有机械解释性(mechanistic interpretability)论文进行了评分,采用 1-3 分的质量量表。
- 他们的重点是提供经过校准的评分,以引导读者阅读提交的论文。
-
调试 Batch Size 配置:成员们讨论了在设置
batch_size后requests无法正确进行批处理的问题,强调了在模型层面处理此配置的必要性。- 针对指定
batch_size的目的产生了困惑,随后有人澄清了其与模型初始化的联系。
- 针对指定
Interconnects (Nathan Lambert) Discord
-
Allegro 模型实现文生视频:Rhymes AI 发布了其新的开源模型 Allegro,能以 15 FPS 和 720p 分辨率从文本生成 6 秒的视频,并提供了包括 GitHub 仓库 在内的探索链接。用户可以加入 Discord 等候名单 以获取早期访问权限。
- 这一创新为内容创作打开了新大门, 既引人入胜又易于获取。
-
Stability AI 凭借 SD 3.5 升温:Stability AI 推出了 Stable Diffusion 3.5,为年收入低于 100 万美元的企业提供三个免费商用版本,并增强了如 Query-Key Normalization 等优化功能。Large 版本现已在 Hugging Face 和 GitHub 上线,Medium 版本定于 10 月 29 日发布。
- 该模型标志着一次实质性的升级,因其独特的功能吸引了社区的极大关注。
-
Claude 3.5 Haiku 在编程领域树立高标准:Anthropic 推出了 Claude 3.5 Haiku,在编程任务中超越了 Claude 3 Opus,在 SWE-bench Verified 上得分为 40.6%,可通过 此处 的 API 获取。用户对各种 Benchmark 中突出的进步印象深刻。
- 该模型的性能正在重塑标准,使其成为编程相关任务的首选。
-
Factor 64 的启示:一位成员对涉及 Factor 64 的突破感到兴奋,事后看来这似乎是“显而易见”的。这一时刻引发了关于其影响的更深层次讨论。
- 这一发现激发了进一步的参与,暗示了后续的协作或新探索。
-
Hackernews 社区反馈的疏离感:关于 Hackernews 沦为 流量彩票(views lottery) 的担忧表明,讨论缺乏实质内容,更多是噪音而非真正的反馈。成员们将其描述为非常嘈杂且带有偏见,质疑其参与价值。
- 该平台被越来越多的人认为效率低下,从而引发了关于替代反馈机制的对话。
GPU MODE Discord
-
Unsloth 讲座上线:Unsloth 演讲现已发布,展示了极高的信息密度,许多观众对其紧凑的节奏表示赞赏。
- “我正以 0.5 倍速回看,但感觉还是很快”,这反映了讲座的深度。
-
梯度累积(Gradient Accumulation)见解:关于梯度累积的讨论强调了 batch 间重缩放以及对大梯度使用 fp32 的重要性。
- “通常所有 batch 无法保持相同大小是有原因的”,强调了训练的复杂性。
-
GitHub AI 项目揭晓:一位用户分享了他们的 GitHub 项目,其特点是用 纯 C 语言实现 GPT,激发了关于深度学习的讨论。
- 该计划旨在通过易于理解的实现来增强对深度学习的理解。
-
解码 Torch Compile 输出:来自
torch.compile的指标显示了矩阵乘法的执行时间,从而澄清了如何解释SingleProcess AUTOTUNE的结果。- SingleProcess AUTOTUNE 完成耗时 30.7940 秒,引发了关于运行时分析(runtime profiling)的深入讨论。
-
Meta 的 HOTI 2024 聚焦生成式 AI:分享了来自 Meta HOTI 2024 的见解,此环节讨论了具体问题。
- 关于“驱动 Llama 3”的主旨演讲揭示了对于理解 Llama 3 集成至关重要的基础设施见解。
OpenAI Discord
-
AGI 辩论升温:成员们讨论了我们实现 AGI 的困境是否源于所提供的数据类型,一些人认为 二进制数据 可能会限制进展。
- 一位成员断言,改进的算法可以使 AGI 无论数据类型如何都能实现。
-
澄清 GPT 术语:术语“GPTs”引起了混淆,因为它通常指代 自定义 GPTs,而不是涵盖像 ChatGPT 这样的模型。
- 参与者强调了区分通用 GPTs 及其具体实现的重要性。
-
量子计算模拟器见解:一位成员指出,有效的 量子计算模拟器 应该产生与真实量子计算机 1:1 的输出,尽管其有效性仍存争议。
- 各家公司都在开发模拟器,但它们的实际应用仍在讨论中。
-
Anthropic 的 TANGO 模型引发关注:TANGO 说话头像模型 因其唇形同步能力和开源潜力而受到关注,成员们渴望探索其功能。
- 讨论包括 Claude 3.5 Sonnet 对阵 Gemini Flash 2.0 的性能,关于谁更占优势意见不一。
-
ChatGPT 在电视节目方面表现不佳:一位成员分享了 ChatGPT 错误识别电视节目剧集标题和编号的挫败感,指出训练数据中存在缺口。
- 对话强调了数据中的观点可能会如何使娱乐相关查询的结果产生偏差。
Cohere Discord
-
Cohere 模型受到青睐:成员们讨论了在 playground 中积极使用 Cohere models 的情况,强调了它们的多样化应用和探索尝试。一位成员特别强调,在探索 multi-modal embeddings 时,需要使用不同模型重新运行推理。
- 这引发了人们对这些模型在现实场景中广泛能力的关注。
-
Multimodal Embed 3 发布!:Embed 3 模型发布,在检索任务上具有 SOTA 性能,支持混合模态和多语言搜索,允许文本和图像数据共同存储。更多详情请参阅 博客文章 和 发布说明。
- 该模型将成为创建统一数据检索系统的游戏规则改变者。
-
微调 LLM 需要更多数据:针对使用极小数据集进行 fine-tuning LLM 的担忧被提出,重点在于潜在的过拟合问题。建议的策略包括扩大数据集规模和调整超参数,并参考了 Cohere 微调指南。
- 成员们在面临挑战时,寻求通过有效的调整来优化模型性能。
-
多语言模型遭遇延迟峰值:多语言 embed 模型报告了 30-60s 的延迟问题,在 15:05 CEST 左右飙升至 90-120s。用户注意到情况有所改善,并敦促报告持续存在的故障。
- 延迟问题凸显了进行进一步技术评估以确保最佳性能的必要性。
-
Agentic Builder Day 宣布:Cohere 和 OpenSesame 将于 11 月 23 日共同举办 Agentic Builder Day,邀请才华横溢的开发者使用 Cohere 模型创建 AI Agent。参与者可以申请参加这场为期 8 小时的黑客松,并有机会赢取奖品。
- 该竞赛鼓励渴望为有影响力的 AI 项目做出贡献的开发者进行协作,申请链接见 此处。
Modular (Mojo 🔥) Discord
-
Mojo 引入自定义数组结构 (SoA):你可以使用 Mojo 的语法构建自己的 Structure of Arrays (SoA),尽管它尚未原生集成到语言中。
- 虽然目前可以使用 slice type,但用户发现它有一定的局限性,预计 Mojo 不断演进的类型系统会有所改进。
-
Mojo 的 Slice 类型需要改进:虽然 Mojo 包含 slice 类型,但它基本上仅限于作为标准库结构体,只有部分方法返回 slice。
- 随着 Mojo 的进一步发展,成员们期待重新审视这些 slice 功能。
-
二进制文件剥离显示出显著的体积减小:剥离一个 300KB 的二进制文件 可以显著减小到仅 80KB,这表明了强大的优化可能性。
- 成员们指出,这种显著的下降对于未来的二进制管理策略是令人鼓舞的。
-
Comptime 变量导致编译错误:有用户报告在
@parameter作用域之外使用comptime var会触发编译错误。- 讨论强调,虽然 alias 允许编译时声明,但实现直接的可变性仍然很复杂。
-
Node.js 与 Mojo 在 BigInt 计算中的对比:对比显示 Node.js 中的 BigInt 操作耗时 40 秒,这表明 Mojo 可能会更好地优化这一过程。
- 成员们指出,完善任意宽度整数库是提升性能基准的关键。
tinygrad (George Hotz) Discord
-
LLVM Renderer 重构提案:一位用户提议使用模式匹配风格重写 LLVM renderer 以增强功能,这可能会提高清晰度和效率。
- 这种方法旨在简化开发并使集成更容易。
-
提升 Tinygrad 的速度:讨论强调了在过渡到使用 uops 后增强 Tinygrad 性能 的要求,这对于紧跟计算进步至关重要。
- 建议通过优化算法和减少开销来努力实现这些速度目标。
-
将梯度裁剪集成到 Tinygrad:社区讨论了
clip_grad_norm_是否应该成为 Tinygrad 的标准,这是深度学习框架中常见的方法。- George Hotz 指出,在进行此集成之前必须先进行梯度重构才能生效。
-
Action Chunking Transformers 的进展:一位用户报告了 ACT 训练 的收敛情况,在几百步后实现了低于 3.0 的 loss,并附带了 源代码 和相关研究的链接。
- 这一进展表明,基于当前模型性能,仍有进一步优化的潜力。
-
探索使用 .where() 进行张量索引:围绕对布尔张量使用
.where()函数展开了讨论,揭示了使用.int()索引时的非常规结果。- 这引发了关于不同场景下张量操作预期行为的询问。
OpenInterpreter Discord
-
Hume AI 加入:一位成员宣布在 phidatahq 通用 Agent 中添加了 Hume AI 语音助手,通过精简的 UI 以及在 Mac 上创建和执行 AppleScripts 的能力增强了功能。
- “非常喜欢新的 @phidatahq UI”,指出了通过此次集成实现的改进。
-
Claude 3.5 Sonnet 开启实验性功能:Anthropic 正式发布了具有计算机使用(computer usage)公开 beta 测试权限的 Claude 3.5 Sonnet 模型,尽管它被描述为仍处于实验阶段且容易出错。
- 成员们表达了兴奋之情,同时指出此类进步强化了 AI 模型日益增长的能力。更多详情请参阅 Anthropic 的推文。
-
Open Interpreter 借力 Claude 升级:人们对使用 Claude 增强 Open Interpreter 充满热情,成员们讨论了运行新模型的实际实现和代码。
- 一位成员报告了使用特定模型命令的成功经验,鼓励其他人尝试。
-
Screenpipe 受到关注:成员们称赞 Screenpipe 工具在构建日志中的实用性,注意到其有趣的落地页以及社区贡献的潜力。
- 一位成员鼓励更多地参与该工具,并引用了 GitHub 上链接的一个有用配置文件。
-
货币化与开源的结合:围绕通过允许用户从源码构建或为预构建版本付费来使公司盈利的讨论展开,以平衡贡献和使用。
- 成员们对这种模式表示赞同,强调了开发者贡献和付费用户共同带来的好处。
DSPy Discord
-
新版本即将到来:一位成员对创建 新版本 而不是修改现有版本表示兴奋,计划在周一进行直播。
- 这种热情得到了共鸣,社区成员纷纷响应即将举行的会议,届时还将涵盖当前的功能。
-
DSPy 文档面临问题:成员们哀叹新的文档结构中缺少了 小 AI 助手,这导致了广泛的失望。
- 聊天中反映了社区的情绪,强调了失去这一重要功能是一种损失。
-
死链警报:报告了 DSPy 文档中导致 404 错误的大量 死链,引起了用户的不满。
- 至少有一位用户迅速采取行动通过 PR 修复了此问题,赢得了同行的感谢。
-
文档机器人回归:随着 文档机器人 的回归,社区爆发了庆祝活动,恢复了用户非常欣赏的功能。
- 聊天中充满了由衷的表情符号和肯定,展示了社区对该机器人重要存在的宽慰和支持。
-
征求对 3.0 版本的看法:一位成员询问了即将发布的 3.0 版本的 总体氛围,表现出对社区反馈的渴望。
- 然而,回应寥寥无几,使得集体的感受笼罩在不确定性之中。
LlamaIndex Discord
-
VividNode:在桌面端与 AI 模型聊天:VividNode 应用允许桌面用户与 GPT、Claude、Gemini 和 Llama 进行聊天,具有高级设置以及使用 DALL-E 3 或各种 Replicate 模型生成图像的功能。更多详情请参阅公告。
- 该应用程序简化了与 AI 的沟通,为用户提供了一个强大的聊天界面。
-
用 9 行代码构建 Serverless RAG 应用:一个教程演示了仅用 9 行代码 即可使用 LlamaIndex 部署 Serverless RAG 应用,使其成为相比 AWS Lambda 更具成本效益的解决方案。更多见解请参考此推文。
- 易于部署和成本效益是开发者使用此方法的关键亮点。
-
通过知识管理增强 RFP 响应:讨论集中在利用向量数据库索引文档以增强 RFP(征求建议书)响应生成,从而实现超越简单聊天回复的高级工作流。关于该主题的更多内容可以在此帖子中找到。
- 这种方法强化了向量数据库在支持复杂 AI 功能中的作用。
-
加入 Llama Impact 黑客松!:在旧金山举办的 Llama Impact Hackathon 为参与者提供了一个使用 Llama 3.2 模型构建解决方案的平台,设有 15,000 美元的奖金池,其中包括为最佳使用 LlamaIndex 提供的 1,000 美元奖金。活动详情可见此公告。
- 黑客松将于 11 月 8 日至 10 日举行,同时支持线下和线上参与者。
-
CondensePlusContextChatEngine 自动初始化记忆:讨论澄清了 CondensePlusContextChatEngine 现在会自动为连续问题初始化记忆,从而改善用户体验。之前的版本行为不同,导致了一些用户的困惑。
- 这一变化简化了持续聊天中的记忆管理,增强了用户交互。
LLM Agents (Berkeley MOOC) Discord
-
LLM Agents MOOC 黑客松启动:Berkeley RDI 将于 10 月中旬至 12 月中旬启动 LLM Agents MOOC Hackathon,奖金总额超过 200,000 美元。参与者可以通过注册链接报名。
- 该黑客松设有五个赛道,旨在吸引 Berkeley 学生和公众参与,并得到了 OpenAI 和 GoogleAI 等主要赞助商的支持。
-
TapeAgents 框架介绍:ServiceNow 新推出的 TapeAgents 框架 通过结构化日志记录促进了 Agent 的优化和开发。该框架增强了控制力,能够实现论文中详述的逐步调试。
- 该工具提供了关于 Agent 性能的有价值见解,强调了如何记录每次交互以进行全面分析。
-
LLM 中的 Function Calling 详解:有一场关于 LLM 如何处理将任务拆分为 Function Calling 的讨论,强调了对代码示例的需求。澄清说明了理解这一机制对未来发展的重要性。
- 成员们探讨了架构选择对 Agent 能力的影响,同时研究了这些方法如何提高功能性。
-
关于企业级 AI 的讲座见解:Nicolas Chapados 在第 7 讲中讨论了企业级生成式 AI 的进展,强调了像 TapeAgents 这样的框架。会议回顾了在 AI 应用中集成安全性和可靠性的重要性。
- Chapados 和客座演讲者的关键见解强调了实际应用以及 AI 改变企业工作流的潜力。
-
模型蒸馏技术与资源:成员们分享了关于 AI Agentic Design Patterns with Autogen 的课程,提供了学习模型蒸馏和 Agent 框架的资源。该课程为掌握 Autogen 技术提供了结构化的方法。
Torchtune Discord
-
PyTorch Core 出现警告:一位用户报告称 PyTorch 中的一个 warning 现在会在 float16 上触发,但在 float32 上不会,建议使用不同的 kernel 进行测试以评估性能影响。有人推测 PyTorch 源代码 中的特定行可能会影响 JIT 行为。
- 社区预计解决此问题可能会带来显著的性能洞察。
-
分布式训练错误令人头疼:一位用户在使用
tune命令进行分布式训练并设置 CUDA_VISIBLE_DEVICES 时遇到了无报错信息的 stop。移除该设置后问题仍未解决,暗示存在更深层次的配置问题。- 这表明可能需要调查环境设置以查明根本原因。
-
对 Torchtune 配置文件产生困惑:关于 .yaml 扩展名导致 Torchtune 误解本地配置的问题引发了困惑。强调了验证文件命名的重要性,以避免操作期间出现意外行为。
- 参与者指出,微小的细节可能导致严重的运行时问题。
-
Flex 性能讨论升温:围绕 Flex 在 3090s 和 4090s 上的成功运行展开了讨论,并提到了在 A800s 上优化的内存使用。对话涉及随着模型规模扩大,更快的 out-of-memory 操作。
- 优化的内存管理被视为有效处理大型模型的关键。
-
训练硬件设置受到审查:一位用户在讨论训练性能问题时确认使用了 8x A800 GPU。社区讨论了通过减少 GPU 数量进行测试,作为有效排查持续错误的一种手段。
- 对不同硬件设置的讨论突显了训练环境中扩展的细微差别。
LangChain AI Discord
-
Langchain Open Canvas 探索兼容性:一位成员询问 Langchain Open Canvas 是否可以集成 Anthropic 和 OpenAI 之外的 LLM 提供商,反映了对更广泛兼容性的需求。
- 这一询问表明社区对扩展该应用与各种工具的可用性有着浓厚兴趣。
-
使用 Langchain 的 Agent 编排能力:关于 Langchain 促进 OpenAI Swarm 进行 Agent 编排的潜力引发了讨论,并询问是否需要自定义编程。
- 这引发了关于支持编排功能的现有库的回应。
-
策划输出链重构策略:一位用户正在考虑是重构其 Langchain 工作流,还是切换到 LangGraph 以增强复杂工具使用中的功能。
- 当前设置的复杂性使得这一战略决策对于实现最佳性能至关重要。
-
Langchain 0.3.4 的安全疑虑:一位用户标记了 PyCharm 关于 Langchain 0.3.4 依赖项的 malicious 警告,引发了对潜在安全风险的警报。
- 他们寻求社区确认此警告是否为常见现象,担心这可能是误报。
-
寻求本地托管解决方案的建议:在为企业应用寻求模型的 local hosting 过程中,一位用户正在探索使用 Flask 或 FastAPI 构建 inference container。
- 他们的目标是通过发现社区内更好的解决方案来避免冗余。
OpenAccess AI Collective (axolotl) Discord
-
2.5.0 带来实验性 Triton FA 支持:版本 2.5.0 为 gfx1100 引入了实验性的 Triton Flash Attention (FA) 支持,通过
TORCH_ROCM_AOTRITON_ENABLE_EXPERIMENTAL=1激活,这在 Navi31 GPU 上导致了 UserWarning。- 正如 GitHub issue 中讨论的那样,该警告最初让用户感到困惑,以为它与 Liger 有关。
-
利用指令微调模型进行训练:一位成员提议利用像 llama-instruct 这样的指令微调模型进行指令训练,并指出只要用户接受其先前的微调,这样做是有益的。
- 他们强调了进行实验以发现最佳方法的必要性,可能会在训练中混合多种策略。
-
对灾难性遗忘(Catastrophic Forgetting)的担忧:关于在领域特定指令数据或与通用数据混合之间进行选择以防止训练期间出现灾难性遗忘的担忧浮出水面。
- 成员们讨论了训练的复杂性,并鼓励探索多种策略以找到最有效的方法。
-
预训练与指令微调之争:讨论重点在于,是应该从基础模型开始对原始领域数据进行预训练,还是依赖指令微调模型进行微调。
- 一位成员主张,如果有原始数据,最初应使用原始数据以提供更强大的基础。
-
从原始文本生成指令数据:一位成员分享了他们使用 GPT-4 从原始文本生成指令数据的计划,同时也承认了可能产生的潜在偏差。
- 这种方法旨在减少对人工生成的指令数据的依赖,同时意识到其局限性。
Gorilla LLM (Berkeley Function Calling) Discord
-
对用于函数调用的微调模型感到兴奋:一位用户在为 function calling 专门微调了一个模型并成功创建了自己的推理 API 后,对 Gorilla 项目 表达了极大的热情。
- 他们寻求对自定义端点进行基准测试(benchmarking)的方法,并请求有关该过程的相关文档。
-
分享添加新模型的说明:针对询问,一位成员引导用户查看一个 README 文件,该文件概述了如何在 Gorilla 生态系统内的排行榜中添加新模型。
- 对于旨在为 Gorilla 项目 做出有效贡献的用户来说,这份文档非常有价值。
LAION Discord
-
参加关于 LLM 的免费网络研讨会:一位来自 Meta 的高级 ML 工程师正在举办一场关于 构建 LLM 的最佳实践 的免费网络研讨会,目前已有近 200 人报名。点击此处注册,获取关于高级 Prompt Engineering 技术、模型选择和项目规划的见解。
- 与会者可以期待深入探讨针对现实场景量身定制的 LLM 实际应用,从而增强其部署策略。
-
关于 Prompt Engineering 的见解:网络研讨会包括对优化模型性能至关重要的高级 Prompt Engineering 技术的讨论。参与者可以利用这些见解更有效地执行 LLM 项目。
- 会议还将讨论性能优化方法,这对于成功部署 LLM 项目至关重要。
-
探索检索增强生成(RAG):Retrieval-Augmented Generation (RAG) 将是一个重点话题,展示它如何增强 LLM 解决方案的能力。微调策略也将是最大化模型效能的关键讨论点。
- 本次会议旨在为工程师提供在项目中有效实施 RAG 所需的工具。
-
在 Analytics Vidhya 上发表文章:网络研讨会参与者的优秀文章将发表在 Analytics Vidhya 的博客空间,从而提高他们的专业知名度。这为在数据科学社区内分享见解提供了一个极佳的平台。
- 这种曝光可以显著增强他们贡献的影响力,并促进社区参与。
Mozilla AI Discord
-
Mozilla 对 AI 访问挑战的见解:Mozilla 发布了两份关键研究报告:‘External Researcher Access to Closed Foundation Models’ 和 ‘Stopping Big Tech From Becoming Big AI’,揭示了 AI 开发的控制权问题。
- 这些报告强调了为创建更公平的 AI 生态系统而进行变革的必要性。
-
总结 AI 研究结果的博客文章:欲了解更多深入见解,此处的博客文章详细阐述了受委托的研究及其影响。
- 文章讨论了这些发现对大型科技巨头之间 AI 竞争格局的影响。
Alignment Lab AI Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
LLM Finetuning (Hamel + Dan) Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
DiscoResearch Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
PART 2: 频道详细摘要与链接
为了便于邮件阅读,完整的频道细分内容已被截断。
如果您喜欢 AInews,请分享给朋友!预谢!