ainews-creating-a-llm-as-a-judge
构建 LLM-as-a-Judge(大模型评委)
Anthropic 发布了关于 Claude 3.5 SWEBench+SWEAgent 的详细信息,与此同时,OpenAI 推出了 SimpleQA,DeepMind 则发布了 NotebookLM。苹果 (Apple) 宣布了新款 M4 MacBook,同时一个新的 SOTA(最先进)图像模型 Recraft v3 正式问世。
Hamel Husain 发表了一篇长达 6,000 字的详细论述,介绍了一种名为“批判影子 (critique shadowing)”的方法来构建 LLM 裁判(LLM judges),旨在使大语言模型与领域专家保持一致,从而解决 AI 团队中数据不可信和未被利用的问题。该工作流程涉及专家评审的数据集和迭代式的提示词优化。
此外,Zep 引入了一个时序知识图谱记忆层,以增强 AI 智能体的记忆能力并减少幻觉。Anthropic 还将 Claude 3.5 Sonnet 集成到了 GitHub Copilot 中,扩大了 Copilot Chat 用户的使用范围。
Critique Shadowing is all you need.
2024年10月29日至10月30日的 AI 新闻。我们为您检查了 7 个 subreddits、433 个 Twitters 和 32 个 Discords(231 个频道和 2558 条消息)。预计节省阅读时间(以 200wpm 计算):241 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
在 Anthropic(Claude 3.5 SWEBench+SWEAgent 详情)、OpenAI (SimpleQA)、DeepMind (NotebookLM)、Apple (M4 Macbooks) 以及一个神秘的新 SOTA 图像模型 (Recraft v3) 纷纷发布新品的一天,关注一个小众名字的新闻实属罕见,但我们热爱那些实用的新闻。
继热门文章 Your AI Product Needs Evals(我们的报道在此)之后,Hamel Husain 带着一篇关于创建驱动业务结果的 LLM-as-a-Judge 的 6000 字史诗级论述回归了,文中提出了一个明确的问题陈述:AI 团队拥有太多他们不信任且不使用的数据。
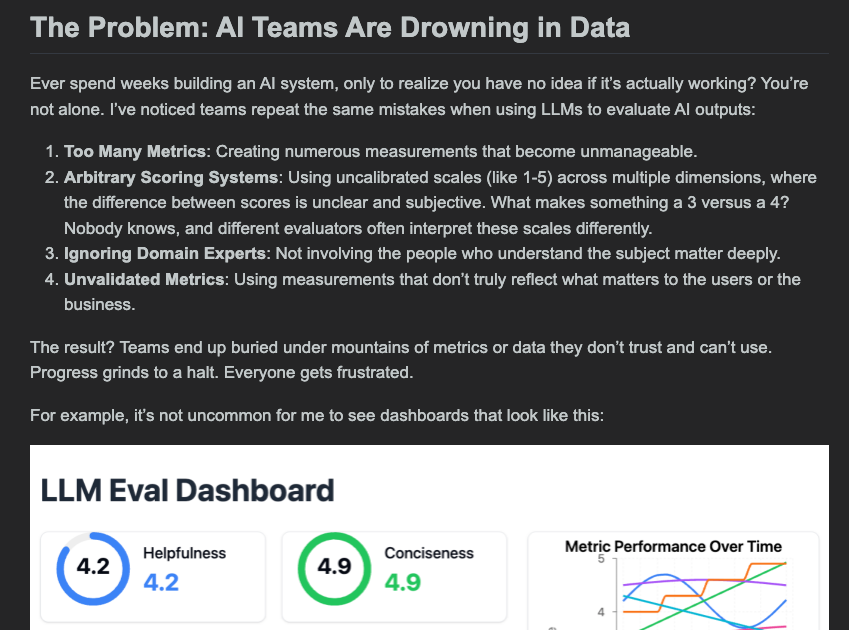
在 Hamel 的 AI.Engineer 演讲(以及非常有趣的 Weights & Biases 演讲)中呼应了许多标准主题,但这篇文章的显著之处在于它强烈推荐使用 critique shadowing,以此创建 few-shot 示例,使 LLM judges 与 domain experts(领域专家)保持一致:
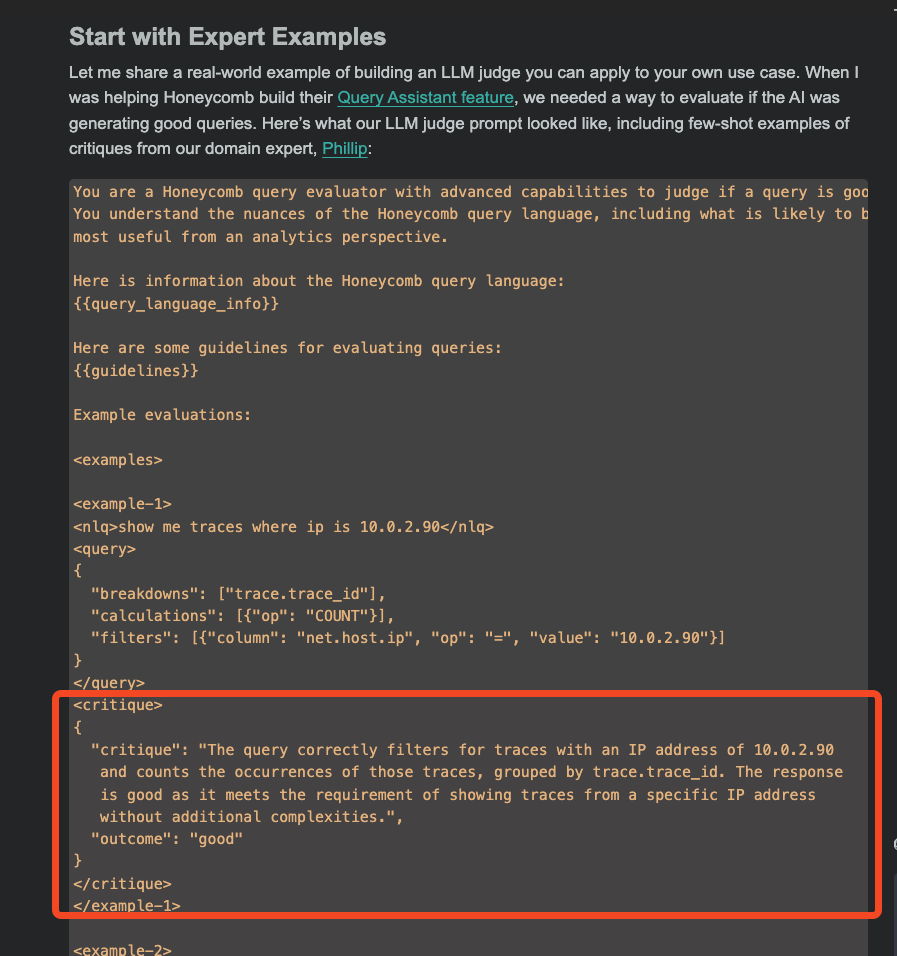
Critique Shadowing TLDR:
- 寻找首席领域专家 (Principal Domain Expert)
- 创建数据集
- 生成涵盖您用例的多样化示例
- 包含真实或合成的用户交互
- 领域专家评审数据
- 专家进行通过/失败判定
- 专家编写详细的 critiques 以解释其推理过程
- 修复错误(如果发现)
- 解决评审过程中发现的任何问题
- 返回专家评审以验证修复效果
- 如果发现错误,返回第 3 步
- 构建 LLM Judge
- 使用专家示例创建 prompt
- 针对专家判定进行测试
- 优化 prompt 直到一致性达到满意水平
- 执行错误分析
- 计算不同维度的错误率
- 识别模式和根本原因
- 修复错误,必要时返回第 3 步
- 根据需要创建专门的 judges
最终的工作流如下所示:
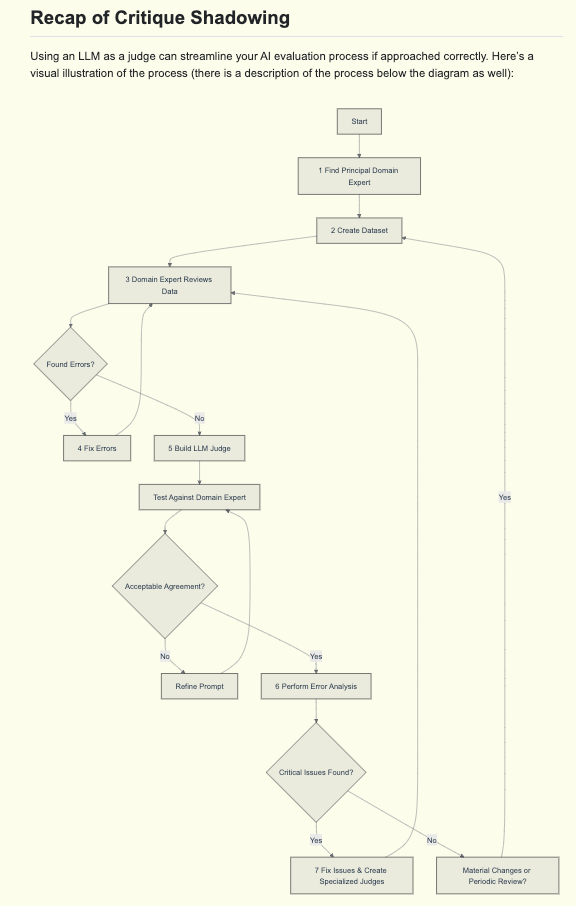
非常实用,正如 Hamel 在文章中提到的,这也是我们构建 AINews 时所采用的重度依赖 critique 和领域专家的迭代过程!
[由 Zep 赞助] 为什么 AI agents 到底需要一个记忆层?在 prompts 中包含完整的交互历史会导致幻觉、召回率差以及昂贵的 LLM 调用。此外,大多数 RAG 流水线在处理事实随时间变化的 temporal data 时表现挣扎。Zep 是一项新服务,它使用一种称为 temporal knowledge graph 的独特结构来解决这些问题。通过快速入门指南在几分钟内启动并运行。
swyx 的评论:Zep 的 4 个 memory APIs 文档 也帮助我更好地理解了 Zep 的功能范围,并提供了一个更好的心理模型,让我了解一个与具体工具无关的 chatbot memory API 应该是什么样子的。值得一读!
AI Twitter 摘要
所有摘要均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
GitHub Copilot 与 AI 集成
-
Claude 集成:@AnthropicAI 宣布 Claude 3.5 Sonnet 现已在 GitHub Copilot 中可用,并将在未来几周内向所有 Copilot Chat 用户和组织开放。@alexalbert__ 呼应了这一公告,强调了其在 Visual Studio Code 和 GitHub 中的可用性。
-
Perplexity AI 合作伙伴关系:@perplexity_ai 分享了与 GitHub 合作的兴奋之情,详细介绍了在 GitHub Copilot 平台内保持库更新、寻找问题答案以及获取 API 集成协助等功能。
-
多模型支持:@rohanpaul_ai 指出 Gemini 1.5 Pro 也已在 GitHub Copilot 中可用,与 Claude 3.5 Sonnet 和 OpenAI 的 o1-preview 并列。这种多模型支持代表了 GitHub Copilot 产品的一个重大转变。
-
对开发的影响:@rohanpaul_ai 强调了一项统计数据,“Google 超过 25% 的新代码现在是由 AI 生成的”,这表明 AI 对软件开发实践产生了重大影响。
AI 进展与研究
-
Layer Skip 技术:@AIatMeta 宣布发布 Layer Skip 的推理代码和微调 checkpoints。这是一种通过执行部分层并使用后续层进行验证和纠错来加速 LLM 的端到端解决方案。
-
小语言模型 (Small Language Models):@rohanpaul_ai 分享了一篇关于 Small Language Models 的综述论文,表明研究界对更高效 AI 模型的持续关注。
-
混合专家模型 (MoE) 研究:@rohanpaul_ai 讨论了一篇论文,该论文揭示了在 LLM 架构中,MoE 架构以推理能力换取内存效率,更多的专家并不一定让 LLM 更聪明,而是让其更擅长记忆。
AI 应用与工具
-
Perplexity Sports:@AravSrinivas 宣布推出 Perplexity Sports,首先推出用于比赛摘要、统计数据以及球员/球队对比的 NFL 小组件,并计划扩展到其他体育项目。
-
AI 在媒体制作中的应用:@c_valenzuelab 分享了关于 Runway 对 AI 在媒体和娱乐领域愿景的长推文,将 AI 描述为讲故事的工具,并预测将向交互式、生成式和个性化内容转变。
-
开源进展:@AIatMeta 在 Hugging Face 上发布了 Layer Skip 的推理代码和微调 checkpoints,这是一种 LLM 的加速技术。
编程语言与工具
-
Python 的流行度:@svpino 指出 Python 现在是 GitHub 上排名第一的编程语言,超越了 JavaScript。
-
GitHub 统计数据:@rohanpaul_ai 分享了 Octoverse 2024 报告的见解,包括 AI 项目同比增长 98%,以及 Jupyter Notebook 使用量激增 92%。
迷因与幽默
-
@willdepue 开玩笑说 AGI 已经在内部实现了,称“证明 AGI 已在内部实现。我们做到了,Joe”。
-
@Teknium1 调侃道“日本 AI 公司太残暴了,哈哈”,这可能是指日本某些幽默或激进的 AI 相关进展。
-
@nearcyan 讲了一个关于投资 NVIDIA 的“80 IQ 骚操作”笑话,因为 ChatGPT 的流行,回想起来这样的投资会产生巨大的回报。
AI Reddit 摘要
/r/LocalLlama 摘要
主题 1. Apple 的 M4 Mac Mini:AI 开发的新竞争者
-
Mac Mini 现在看起来很有吸引力……比 5090 更便宜,且拥有近两倍的 VRAM…… (Score: 49, Comments: 18): 该帖子指出,与假设的 5090 等高端 GPU 相比,搭载 M4 芯片 的 Mac Mini 对于 AI 工作负载 可能是一个更具吸引力的选择。作者强调,Mac Mini 可能更便宜,并且提供近两倍的 VRAM,使其成为需要大容量内存的 AI 任务的极佳选择。
-
新款 M4 / Pro Mac Mini 讨论 (Score: 40, Comments: 58): 该帖子讨论了关于针对 AI 任务 优化的 M4 / Pro Mac Mini 机型的推测。虽然没有提供具体的规格或价格信息,但标题表明了人们对未来 Mac Mini 迭代版本在人工智能应用方面的能力和成本的关注。
- 关于 M4 Mac Mini 价格 的推测:配备 32GB RAM 的基础型号估计为 $1000,而 64GB 版本为 $2000。一位用户声称,使用教育优惠,16GB 的基础型号可能仅需 $499。
- 关于内存带宽和性能的讨论:据估计 M4 拥有 260 GB/s 的带宽,在使用 Qwen 72B 4-bit MLX 时可能达到 6-7 tokens/s。一些用户讨论了在 AI 任务中 Mac Mini 与 3090s 等 GPU 之间的权衡。
- 与 Nvidia GPU 的比较:用户讨论了高 RAM 的 Mac Mini 如何与 4090 等昂贵 GPU 竞争。然而,也有人指出,虽然 Mac 提供更多 RAM,但 GPU 在 AI 任务的处理速度上仍然明显更快。
{kind=link}
主题 2. Stable Diffusion 3.5 Medium 在 Hugging Face 发布
- Stable Diffusion 3.5 Medium · Hugging Face (Score: 68, Comments: 31): Stable Diffusion 3.5 Medium,一款新的文本生成图像模型,已在 Hugging Face 上发布。该模型在文本渲染、多主体生成和构图理解方面具有更强的能力,同时与之前的版本相比,图像质量有所提高,伪影有所减少。该模型可根据 OpenRAIL-M 许可证 用于商业用途,默认分辨率为 768x768,并支持包括 txt2img、img2img 和 inpainting 在内的各种推理方法。
- 用户询问了自托管该模型的硬件要求。根据博客,它需要 10GB 的 VRAM,对于“32GB 或更大”的配置,建议使用从 3090 到 H100 的 GPU。
- 出现了关于像 LLM 一样运行更小量化版本的可能性的讨论。用户推测社区可能会尝试这样做。
- 当被问及与 Flux Dev 的比较时,一位用户简单地回答“很糟糕”,暗示 Stable Diffusion 3.5 Medium 在某些方面的表现可能不如 Flux Dev。
主题 3. AI 安全与对齐:辩论与批评
- MacOS 15.1 中的 Apple Intelligence 提示词模板 (Score: 293, Comments: 67): Apple 的 MacOS 15.1 引入了 AI prompt templates 和安全措施,作为其 Apple Intelligence 功能的一部分。该系统包含用于各种任务(如总结文本、解释概念和生成创意)的 built-in prompts,重点在于维护用户隐私和数据安全。Apple 的方法强调 on-device processing,并结合了 content filtering 以防止生成有害或不当内容。
- 用户幽默地批评了 Apple 的 prompt engineering,开玩笑说它在“乞求”正确的 JSON output,并辩论了 YAML vs. JSON 的效率。讨论强调了 minifying JSON 对节省 token 的重要性。
- 社区对 Apple 防止 hallucinations 和 factual inaccuracies 的方法表示怀疑,一位用户分享了一个包含 Apple 资源文件夹中 metadata.json files 的 GitHub gist。
- 讨论涉及了可能使用的 30 billion parameter model (v5.0-30b),并批评了在活动选项中包含 diving 和 hiking 等特定运动的做法,推测这可能受到了管理层的影响。
- “AI Safety”的危险风险 (Score: 47, Comments: 62): 该帖子讨论了 AI alignment 工作的潜在风险,链接到一篇文章,该文章认为 alignment technology 可能会被滥用,服务于恶意利益而非全人类。作者认为这种情况已经在发生,并指出目前的 API-based AI 系统通常执行比西方民主法律更严格的规则,在某些领域有时甚至与 Taliban 等极端主义意识形态更加一致,而 local models 受影响较小但仍存在问题。
- 用户注意到 AI 不一致的内容限制,一些人指出 API-based AI 经常禁止在黄金时段电视节目中随处可见的内容。尽管 AI 公司持有反 NSFW 立场,但对 NSFW content 的需求依然巨大。
- 评论者讨论了 AI alignment 被用作 censorship 和 control 工具的可能性。一些人认为这已经在发生,AI 在意识形态上与其创造者保持一致,并被用来对用户施加权力。
- 几位用户对 corporate anxiety 和 sensitivity 驱动 AI 限制表示担忧,这可能导致对言论自由的压制。一些人主张 widespread AI access,以平衡公民与政府/企业之间的权力。
其他 AI Subreddit 综述
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI 研究与技术
-
LLM 学习概念中的几何结构:一篇 在 Twitter 上分享的论文 揭示了 LLM 学习到的概念中存在令人惊讶的几何结构,包括类脑的 “lobes” 和精确的 “semantic crystals”。
-
Google 的 AI 生成代码:Google CEO Sundar Pichai 表示,Google 超过 25% 的新代码现在由 AI 生成。一些评论者推测,这可能包括自动补全建议和其他辅助工具。
-
ARC-AGI 基准测试进展:MindsAI 在 ARC-AGI 基准测试中取得了 54.5% 的新高分,高于 6 天前的 53%。该奖项的目标是 85%。
AI 应用与影响
-
AI 在教育领域:一项 研究发现,使用 AI 导师的学生学习到的内容是传统课堂教学的两倍多,且用时更短。一些评论者指出,AI 可以提供更加个性化、互动式的学习。
-
数字水果复制:一颗 李子成为首个在没有人工干预的情况下被完全数字化并重新打印的水果,且带有其气味。
-
AI 在软件开发中:从今天开始,开发者可以在 Visual Studio Code 和 GitHub Copilot 中选择 Claude 3.5 Sonnet。Gemini 也正式加入 GitHub Copilot。
AI 模型发布与改进
- Stable Diffusion 3.5 的改进:一个 结合了 SD 3.5 Large、Medium 和 upscaling 技术的流水线 产生了高质量的图像结果,展示了图像生成能力的进步。
AI 行业与商业
- OpenAI 收入来源:OpenAI 的 CFO 报告称,公司 75% 的收入来自付费消费者,而非企业客户。这引发了关于 OpenAI 商业模式和盈利时间表的讨论。
AI 伦理与社会影响
- Linus Torvalds 谈 AI 炒作:Linux 创始人 Linus Torvalds 表示,AI 是“90% 的营销和 10% 的现实”。这引发了关于 AI 技术现状和未来潜力的辩论。
迷因与幽默
- 一张描绘使用动漫风格角色 为“AI 战争”做准备 的幽默图片,引发了关于 AI 潜在军事化及其文化影响的讨论。
AI Discord 摘要
由 O1-preview 生成的摘要之摘要的总结
主题 1:Apple M4 芯片极大提升 AI 性能
- LM Studio 在 Apple 新发布的 M4 MacBook Pro 上大放异彩: 在最近的 Apple 发布会上,LM Studio 展示了其在搭载 M4 芯片的新款 MacBook Pro 上的能力,突显了其对 AI 应用的影响。
- 传闻称 M4 Ultra 旨在超越 NVIDIA 4090 GPU:即将推出的 M4 Ultra 据传将支持 256GB 统一内存,性能可能超越 M2 Ultra 并与高端 GPU 匹敌。
- M3 Max 以每秒 60 Token 的速度给工程师留下深刻印象:据报道,M3 Max 芯片运行 Phi 3.5 MoE 等模型的速度约为 60 tokens per second,展示了其即使在低配配置下的高效性。
主题 2:AI 模型更新与争议引发社区热议
- Haiku 3.5 发布在即,AI 爱好者兴奋不已:社区热切期待 Haiku 3.5 的发布,有迹象表明它可能很快面世,引发了对其潜在改进的好奇。
- Gemini 甩开竞争对手,程序员欢呼雀跃:用户称赞 Gemini 在处理数据库编程任务方面的卓越表现,在实际应用中超越了 Claude 和 Aider 等模型。
- 用户嘲讽微软过度谨慎的 Phi-3.5 模型:Phi-3.5 过度的审查导致了幽默的嘲讽,用户分享了一些讽刺性的回复,突显了该模型拒绝回答简单问题的倾向。
主题 3:微调与训练障碍挑战 AI 开发者
- Unsloth 团队发现梯度缺陷,动摇训练基础: Unsloth 团队揭示了训练框架中梯度累积 (gradient accumulation) 的关键问题,这影响了语言模型的一致性。
- LoRA 微调在 H100 GPU 上碰壁,工程师感到沮丧:用户在 H100 GPU 上进行 LoRA 微调时遇到困难,并指出由于 BitsAndBytes 问题尚未解决,QLoRA 可能是唯一的权宜之计。
- 量化失误导致输出变成乱码:在 Llama 3.2 1B QLoRA 训练期间,用户在应用 Int8DynActInt4WeightQuantizer 时遇到了不连贯的输出,突显了量化过程中的挑战。
主题 4:AI 冲击软件工程,自动化工具蓬勃发展
- AI 蚕食软件工程师岗位,开发者感到恐慌:成员们注意到 AI 正在越来越多地接管常规软件工程任务,引发了关于科技就业前景的辩论。
- Skyvern 实现浏览器自动化,手动任务迎来对手: Skyvern 推出了一种用于浏览器自动化的无代码解决方案,使用户无需编写代码即可简化工作流程。
- ThunderKittens 发布新功能,自带幽默感: ThunderKittens 团队发布了诸如 exciting kernels 和语音模型等新功能,并穿插了对可爱小猫的俏皮提及。
主题 5:OpenAI 应对事实性问题并提升用户体验
- OpenAI 通过新的 SimpleQA 基准测试对抗幻觉: 通过引入 SimpleQA,OpenAI 旨在通过 4,000 个多样化问题来衡量语言模型的事实准确性,针对的是幻觉问题。
- ChatGPT 终于支持搜索聊天记录,用户欢呼雀跃:OpenAI 在 ChatGPT 网页版上推出了搜索聊天记录的功能,使用户更容易参考或继续之前的对话。
- AGI 辩论升温,乐观派与怀疑派交锋:成员们对实现 AGI 的时间表和可行性表达了不同看法,辩论 Google 等公司在面临挑战时能否跟上步伐。
第一部分:Discord 高层摘要
LM Studio Discord
-
苹果 MacBook Pro 展示 LM Studio:在最近的苹果发布会上,LM Studio 展示了其在搭载 M4 系列芯片的新款 MacBook Pro 上的能力,这标志着其在商业应用中的影响力得到了显著认可。
- 成员们为开发者感到兴奋,并指出这种认可可能会影响未来 AI 工作流的集成。
-
M3 Max 的 Token 速度令人印象深刻:据报道,M3 Max 运行 Phi 3.5 MoE 等模型的速度约为 每秒 60 个 token,突显了其即使在较低配置下的效率。
- 虽然这令人印象深刻,但一些用户建议,为了追求极致速度,像 A6000 这样的专用 GPU 可能会产生更好的结果。
-
H100 GPU 租赁变得经济实惠:用户提到 H100 租赁现在的价格约为 每小时 1 美元,使其成为模型推理的一个具有成本效益的选择。
- 尽管价格下降,但关于在各种任务中使用高性能 GPU 与本地模型的实用性讨论也随之出现。
-
M4 Ultra 传闻规格令竞争对手生畏:传闻即将推出的 M4 Ultra 将支持 256GB 的统一内存,预计性能将显著超越 M2 Ultra。
- 关于 M4 与 4090 GPU 竞争的猜测层出不穷,用户们对增强的性能指标议论纷纷。
-
Windows vs. Linux 性能之争:对 Windows 的不满情绪浮出水面,强调了其在 AI 任务中相比 Linux 的局限性,后者提供了更高的效率和控制力。
- 成员们一致认为 Linux 可以更好地优化 GPU 利用率,尤其是在运行计算密集型应用程序时。
HuggingFace Discord
-
Hugging Face API 支持获取 token 概率:一位用户确认,可以通过 Hugging Face 无服务器推理 API 获取大型语言模型的 token 概率,特别是使用推理客户端时。
- 讨论还涉及了 rate limits 和 API 使用情况,并在 Rate Limits 的详细链接中进行了进一步阐述。
-
Ollama 在图像分析中提供隐私保护:针对 Ollama 在图像分析期间访问本地文件的担忧得到了回应,强调其在本地运行,无需服务器交互。
- 这确保了用户在有效分析图像时的隐私。
-
在机器学习中选择正确的道路:一位参与者强调选择一个涵盖广泛 data science 知识的专业,而不仅仅是 AI,并反思了数学和编程技能的重要性。
- 进一步的讨论集中在该领域职业生涯所需的基础方面。
-
Qwen 2 模型遭遇错误的 token 生成问题:有报告称 Qwen 2 基座模型存在问题,特别是由于 EOS token 识别错误导致输出末尾出现意外 token。
- 这反映了对模型上下文长度处理能力的更广泛担忧。
-
Langchain SQL agent 在使用 GPT-4 时遇到困难:从 GPT-3.5 Turbo 切换到 GPT-4 配合 Langchain SQL agent 使用时结果参差不齐,后者表现出一定的困难。
- 对 API 停用的担忧引发了关于替代环境的讨论。
Unsloth AI (Daniel Han) Discord
-
Unsloth 团队揭示梯度问题:Unsloth 团队发布了关于训练框架中梯度累积(Gradient Accumulation)问题的研究结果,该问题会影响语言模型输出的一致性。
- 报告指出,由于对 Loss 计算有显著影响,建议寻找传统 Batch Size 的替代方案。
-
苹果发布紧凑型新款 Mac Mini:苹果宣布推出新款 Mac mini,搭载 M4 和 M4 Pro 芯片,宣称 CPU 性能提升了惊人的 1.8 倍。
- 此次发布标志着苹果首款碳中和 Mac 的诞生,是其产品线中的一个重要里程碑。
-
ThunderKittens 带来新功能:ThunderKittens 团队发表了一篇 博客文章 揭晓新功能,重点介绍了 令人兴奋的 Kernel 和对话模型。
- 他们还俏皮地提到了社交媒体的反应,并展示了 超级可爱的猫咪 来增强社区互动。
-
Instruct 微调挑战:一位用户在尝试微调 Meta Llama3.1 8B Instruct 模型时遇到了 Tensor 形状不匹配的错误。
- 随着用户切换模型但仍受困于合并与加载问题,挫败感倍增,这凸显了兼容性方面的疑虑。
-
Unsloth 在 VRAM 效率方面的努力:Unsloth 宣布了一种预训练方法,可实现 2 倍速 训练并减少 50% 的 VRAM 消耗,同时为 Mistral v0.3 7b 提供了一个 免费 Colab Notebook。
- 建议用户在微调 Embedding 和调整学习率(Learning Rates)时保持谨慎,以稳定训练过程。
OpenAI Discord
-
对 AGI 竞赛看法不一:成员们对实现 AGI 的时间表和可行性表达了不同看法,特别是关于谷歌面临监管挑战阻碍其进展的问题。
- 对谷歌困境的 担忧 与对新兴算法推动进步的 乐观 情绪形成了鲜明对比。
-
模型效率辩论持续升温:社区讨论了 大模型 并不总是更优,指出 量化(Quantization) 在不牺牲性能的情况下实现效率的作用,并提到了 Llama 3.0 和 Qwen 模型。
- 最近的 量化模型 被引用为表现优于其更大的对应版本,强调了关注点正转向高效的模型利用。
-
Nvidia GPU 是否足够引发争议:辩论集中在 4070 Super GPU 对于本地 AI 项目是否充足,提醒人们对于高需求应用需要更高 VRAM 的选项。
- 参与者既承认了小模型的性能,也指出了价格亲民的高性能 GPU 在供应上的 缺口。
-
Prompt 生成工具需求旺盛:用户寻求在 OpenAI Playground 中使用 Prompt 生成工具 以更好地定制请求,并参考了 官方 Prompt 生成指南。
- 讨论达成共识,认为该工具对于优化 Prompt 策略至关重要。
-
有序数据对聊天机器人至关重要:在开发个人聊天机器人时,强调了保持数据有序和简洁的重要性,以避免额外的 API 调用费用,因为无关数据的 Input Token 仍会产生费用。
- 一位成员指出,妥善的数据管理不仅是最佳实践,更是 API 使用中关键的财务考量。
Perplexity AI Discord
-
Perplexity Supply 推出新款 Essentials 系列:Perplexity Supply 推出了一系列为好奇心设计的贴心必需品,让客户通过产品激发对话。
- 全球发货现已覆盖美国、澳大利亚和德国等国家,更新信息可通过此链接获取。
-
文件上传问题令用户感到沮丧:几位用户报告了文件上传功能的问题,强调了讨论过程中文件残留的问题。
- 一位用户指出,与其他平台相比,其文件处理能力较差。
-
探索 Playground 与 API 结果的差异:一位用户对 Playground 和 API 之间观察到的结果差异表示担忧,尽管两者使用的是相同的模型。
- 目前尚未对这些不一致背后的原因提供进一步说明。
-
地球的临时新卫星引发讨论:最近的一项讨论重点介绍了地球的临时新卫星,详细说明了其可见性和影响,点击此处查看详情。
- 这一迷人的发现引发了关于临时天体现象的动态对话。
-
澄清 Perplexity Spaces 的 API 使用:已澄清目前没有可用于 Perplexity Spaces 的 API,网站和 API 作为独立实体运行。
- 一位用户表达了在开发项目中使用 Perplexity API 的兴趣,但未收到具体指导。
aider (Paul Gauthier) Discord
-
Aider 通过命令增强文件管理:Aider 引入了
/save <fname>和/load <fname>命令以便于上下文管理,简化了批处理和文件处理。- 该功能消除了手动重建代码上下文的麻烦,使工作流更加高效。
-
备受期待的 Haiku 3.5 发布引发关注:持续的讨论表明 Haiku 3.5 可能很快发布,最早可能就在明天。
- 用户渴望了解其相对于先前版本的增强功能,并希望有显著改进。
-
Qodo AI 与 Cline 引发对比辩论:关于 Qodo AI 如何在可用性和功能方面与 Cline 等竞争对手区分开来的讨论浮出水面。
- 尽管起步订阅费用为 $19/月,但对功能有限的担忧削弱了人们对 Qodo 市场地位的热情。
-
Skyvern 利用 AI 自动化浏览器任务:Skyvern 旨在作为一种无代码解决方案简化浏览器自动化,为重复性工作流提供效率。
- 它在网页间的适应性允许用户通过简单的命令执行复杂任务。
-
用户评价 Gemini 的编程效率:反馈强调了 Gemini 在处理数据库相关编程任务方面优于 Claude 和 Aider。
- 共识显示了 Gemini 在实际编程需求方面的优势,但性能可能会根据上下文而波动。
OpenRouter (Alex Atallah) Discord
- Oauth 身份验证故障,修复即将发布:由于 Oauth 问题,使用 openrouter.ai/auth 的应用今早面临故障,但在公告发布后不久预计将会有修复方案。
- 团队确认 API key 创建 的停机时间将非常短,以此安抚受影响的用户。
- macOS 聊天应用招募 Alpha 测试人员:一位开发者正在为一款灵活的 macOS 聊天应用寻求 alpha 测试人员,并提供了 截图 供查看。
- 鼓励感兴趣的人员通过 DM 获取更多信息,强调了测试期间用户反馈的重要性。
- 围绕 OpenRouter API Key 的安全担忧:用户对 OpenRouter API keys 的脆弱性表示担忧,特别是关于在 Sonnet 3.5 等代理设置中的滥用问题。
- 一位社区成员警告说:“仅仅因为你认为 key 是安全的,并不意味着它真的安全,” 强调了 key 管理的重要性。
- 热切期待 Haiku 3.5 发布:社区对预期发布的 Haiku 3.5 议论纷纷,分享的模型标识符 (slug) 为
claude-3-5-haiku@20241022。- 尽管该模型已在白名单中但尚未正式开放,但迹象表明可能会在一天内发布。
- 请求访问集成功能:用户纷纷要求访问 integration feature(集成功能),强调其对于测试各种能力的重要性。
- 诸如 “我想再次申请集成功能!” 之类的回应表明了对该功能的强烈需求。
Stability.ai (Stable Diffusion) Discord
- GPU 价格辩论升温:成员们分析认为,二手 3090 显卡的价格低于 7900 XTX 型号,强调了预算与性能之间的权衡。
- eBay 价格徘徊在 ~$690 左右,这让注重成本的工程师在选择 GPU 时面临艰难抉择。
- 自定义风格训练:一位成员询问关于使用 15-20 张图像 训练朋友的艺术风格,在选择模型还是 Lora/ti 之间进行讨论。
- 其他人建议使用 Lora,以便根据特定的风格偏好获得更好的角色一致性。
- Stable Diffusion 中的灰色图像问题:多位用户报告在 Stable Diffusion 中遇到 灰色图像,并寻求故障排除建议。
- 成员们建议尝试不同的 UI 选项,并检查与 AMD GPUs 的兼容性以改善输出。
- UI 大对决:Auto1111 对比 Comfy UI:Comfy UI 因其用户友好性成为热门选择,而一些人仍偏好使用 Auto1111 进行自动化。
- 建议还包括尝试 SwarmUI,因为它安装简单且功能齐全。
- 关于即将发布的 AI 模型的传闻:社区推测 SD 3.5 相比 SDXL 的潜在普及程度,引发了关于性能的讨论。
- 对新的 ControlNet 和模型更新的期待与日俱增,这对于跟上 AI 发展步伐至关重要。
Nous Research AI Discord
- 微软降低对 OpenAI 依赖的风险:讨论涉及微软降低对 OpenAI 依赖的策略,特别是如果 OpenAI 宣布实现 AGI,这可能会为微软提供合同上的退出机制和重新谈判的机会。
- “微软永远不会让这种事发生,” 表达了对 AGI 可能发布的怀疑。
- AI 延迟问题引发关注:有报告称某 AI 模型出现了 20 秒的延迟,成员们幽默地暗示它可能是 在土豆上运行的。
- 成员将其与 Lambda 的性能进行了对比,后者处理 10 倍以上的请求,延迟仅为 1 秒。
- Hermes 3 性能令用户惊喜:成员们讨论到 Hermes 3 8B 的质量出人意料地可与 GPT-3.5 媲美,表现优于其他 10B 以下的模型。
- 相比之下,Mistral 7B 等模型被评价为 令人遗憾。
- 寻求西班牙语 Function Calling 数据集:一位成员寻求构建 西班牙语的 function calling 数据集,但在使用开源模型处理来自 López Obrador 会议的数据时面临效果不佳的挑战。
- 他们的目标是处理来自 一千多个视频 的信息,旨在实现 新闻相关性。
- Sundar Pichai 强调 AI 在谷歌的作用:在财报电话会议上,Sundar Pichai 表示谷歌超过 25% 的新代码 是由 AI 生成的,引发了关于 AI 对编程影响的讨论。
- 这一被广泛分享的统计数据引发了关于编程实践演变的对话。
Eleuther Discord
-
在单张 GPU 上运行多个实例:成员们讨论了在同一张 GPU 上运行多个 GPT-NeoX 实例,旨在通过更大的 Batch Size 最大化显存利用率,尽管 DDP 的收益可能有限。
- 正在进行的对话强调了并行训练的潜在配置和注意事项。
-
使用 CSV 数据的 RAG:一位成员询问了对 ~3B LLM 使用原始 CSV 数据进行 RAG 的效果,并表示在遇到案例编号不一致的挑战后,计划将其转换为 JSON。
- 这一举动暗示了预处理的复杂性可能会影响 RAG 的性能。
-
实体提取的 Temperature 调优:在意识到 Entity Extraction 过程中的 Temperature 设置不正确后,一位成员使用修正后的参数重新尝试,以优化结果。
- 这突显了调优模型参数对于获得有效性能的重要性。
-
LLM 中的模块化对偶性与优化:最近的一篇论文揭示了 maximal update parameterization 和 Shampoo 等方法可以作为线性层单一对偶映射(Duality Map)的部分近似。
- 这种联系强化了论文中讨论的当代优化技术的理论基础。
-
Diffusion Models 的挑战:讨论中提到了 Diffusion Models 与 GANs 及 autoregressive models 相比所呈现的独特局限性,特别是在训练和质量指标方面。
- 成员们指出了围绕可控性和表示学习(Representation Learning)的问题,强调了它们对模型适用性的影响。
Interconnects (Nathan Lambert) Discord
-
Elon Musk 洽谈提升 xAI 估值:据 WSJ 报道,Elon 正在洽谈新一轮融资,旨在将 xAI 的估值从 240 亿美元提升至 400 亿美元。尽管正在讨论,Elon 仍不断否认之前的融资传闻,导致社区对 xAI 的发展方向感到不安。
- 一位成员表示:“xAI 有点让我害怕”,反映了社区内更广泛的担忧。
-
揭秘 Claude 3 Tokenizer:最近的一篇 文章 强调了 Claude 3 Tokenizer 的封闭性质,透露可获取的信息非常有限。用户不得不依赖付费服务而非公开文档,这引发了挫败感。
- 该文章强调了开发者在有效利用 Claude 3 时面临的重大障碍。
-
AI2 将搬迁至水边新办公室:AI2 将于明年 6 月搬迁至新办公室,届时可欣赏 Pacific Northwest 的美景。成员们对搬迁表示兴奋,认为宜人的风景是一项福利。
- 这一变动有望为 AI2 团队营造一个更具启发性的工作环境。
-
MacBook Pro 惊人的价格:成员们对高配 MacBook Pro 的昂贵价格做出反应,128GB RAM + 4TB SSD 的配置售价约为 8000 欧元。讨论突显了对不同地区定价差异的困惑。
- 评论反映了汇率波动和税收如何使寻求尖端硬件的工程师的购买过程变得复杂。
-
Voiceover 增强个人文章体验:一位成员提倡将 Voiceover 作为明天 Personal Article 更具吸引力的媒介。他们对 Voiceover 内容表示满意,标志着书面材料交付方式的转变。
- 这表明了集成音频元素以增强用户体验和可访问性的趋势。
Notebook LM Discord Discord
-
NotebookLM 可用性研究邀请:NotebookLM UXR 正在邀请用户参加一项针对 Audio Overviews 的 30 分钟 远程可用性研究,入选者将获得 50 美元礼品。
- 参与者需要 高速互联网、Gmail 账号以及功能正常的音视频设备,研究将持续到 2024 年底。
-
Simli 虚拟形象增强播客:一名成员展示了 Simli 如何通过对 .wav 文件进行说话人日志处理(diarization)来同步音频片段,从而叠加实时虚拟形象,为未来的功能集成铺平了道路。
- 这一概念验证为增强播客的用户参与度开辟了令人兴奋的可能性。
-
Pictory 在播客视频制作中的作用:用户正在探索使用 Pictory 将播客转换为视频格式,并讨论了如何有效地整合演讲者的面部。
- 另一位成员提到 Hedra 可以通过上传分割的音轨来实现角色可视化,从而促进这一过程。
-
播客生成限制:用户反映在最初成功后,生成 西班牙语 播客时遇到挑战,引发了对该功能状态的疑问。
- 一位用户表达了沮丧,指出:“它在头两天运行得很好,然后就停止产出西班牙语内容了。”
-
语音分离技术讨论:参与者讨论了使用 Descript 高效隔离播客中单个说话人的方法,利用了在 Deep Dive 期间注意到的自动分割功能。
- 一位用户评论道:“我注意到 Deep Dive 有时会自行划分为多个章节,” 展示了该平台简化播客制作的潜力。
GPU MODE Discord
-
AI 挑战软件工程师岗位:一位成员指出 AI 正在越来越多地接管 常规软件工程师的工作,表明就业形势正在发生变化。
- 人们对这一趋势对科技行业就业机会的影响表示担忧。
-
对深科技(Deep Tech)的兴趣日益增长:一位成员表达了参与 deep tech 创新的强烈愿望,反映了对先进技术的关注。
- 这突显了技术参与向更深层次(而非表面应用)发展的趋势。
-
FSDP2 API 弃用警告:一位用户强调了关于
torch.distributed._composable.fully_shard弃用的 FutureWarning,敦促切换到 FSDP,详情见 此 issue。- 在 torch titan 论文 发表见解后,这引发了关于 fully_shard API 持续相关性的疑问。
-
Rust 应用中的内存分析:一位成员寻求关于使用 torchscript 对 Rust 应用进行内存分析的建议,以识别潜在的内存泄漏问题。
- 他们特别希望调试涉及自定义 CUDA kernels 的问题。
-
ThunderKittens 演讲安排:讨论了关于 ThunderKittens 的演讲计划、功能和社区反馈,并对协调工作表示感谢。
- 此次参与有望加强围绕该项目的社区联系。
Torchtune Discord
-
Llama 3.2 QLoRA 训练问题:在 Llama 3.2 1B QLoRA 训练期间,用户成功实现了 QAT,但在使用 Int8DynActInt4WeightQuantizer 时遇到了生成内容不连贯的问题。
- 有人担心 QAT 调整可能不足,从而导致量化问题。
-
量化层引发困惑:量化后生成的文本不连贯归因于 QAT 训练 和量化层中的配置错误。
- 用户分享了说明 torchtune 和 torchao 版本配置错误的示例代码。
-
激活检查点减慢保存速度:参与者质疑为何默认将 activation checkpointing 设置为 false,并指出 Llama 3.2 的检查点保存速度大幅下降。
- 对方澄清说,对于较小的模型,这种开销并非必要,因为它会产生额外的成本。
-
动态缓存调整以提高效率:关于 KV 缓存动态调整功能的提案将根据实际需求高效地分配内存。
- 预计这一变化将通过减少不必要的内存使用来增强性能,特别是在长文本生成期间。
-
多查询注意力在缓存效率中的作用:正如 PyTorch 2.5 增强功能讨论中所述,multi-query attention 的实现旨在节省 KV 缓存存储。
- 分组查询注意力(Group query attention)支持被视为一项战略性进展,减轻了未来实现中手动扩展 KV 的需求。
Cohere Discord
-
Vyas 博士谈 SOAP Optimizer 方法:哈佛大学博士后 Nikhil Vyas 博士将在即将举行的活动中讨论 SOAP Optimizer。欢迎参加 Discord 活动以获取见解。
- 这为深入理解与 AI 模型相关的优化技术提供了机会。
-
Command R 模型面临 AI 检测问题:用户报告称 Command R 模型输出的文本始终有 90-95% 被识别为 AI 生成,这引起了付费用户的沮丧。
- 创造力是 AI 固有的,这暗示了与训练数据分布相关的潜在局限性。
-
对邀请和申请回复的担忧:成员们正在积极询问邀请状态和申请的常见回复时间,对长时间的延迟表示担忧。
- 目前似乎缺乏关于潜在拒绝标准的透明度,表明需要改进沟通。
-
Embed V3 与旧版模型的辩论:讨论重点是 Embed V3、ColPali 和 JINA CLIP 之间的比较,关注超越旧版 Embedding 的演进比较方法论。
- 成员们对集成 JSON 结构化输出如何增强功能(特别是搜索能力)非常感兴趣。
-
寻求账号问题帮助:对于账号或服务问题,建议用户直接联系 support@cohere.com 寻求帮助。
- 一位积极的成员表示渴望帮助其他遇到类似问题的用户。
Latent Space Discord
-
Browserbase 获 2100 万美元融资用于 Web 自动化:Browserbase 宣布已完成 2100 万美元 A 轮融资,由 Kleiner Perkins 和 CRV 领投,旨在帮助 AI 初创公司大规模实现 Web 自动化。在这一篇 推文中了解更多关于他们宏伟计划的信息。
- 你会构建(🅱️uild)什么? 强调了他们的目标,即通过未来的开发让初创公司更容易参与 Web 自动化。
-
ChatGPT 终于支持聊天记录搜索:OpenAI 已在 ChatGPT Web 应用上推出了搜索聊天记录的功能,允许用户快速引用或继续过去的对话。此功能通过简化访问先前聊天的流程来提升用户体验。
- OpenAI 在一篇 推文中宣布了这一更新,强调了与平台之间更流水的交互。
-
Hamel Husain 警告 LLM 评估陷阱:Hamel Husain 的一份指南概述了使用 LLM judges 时的常见错误,例如使用过多指标以及忽视领域专家的见解。他强调了经过验证的测量对于更准确评估的重要性。
- 他的指南可以在这篇 推文中找到,主张采用聚焦的评估策略。
-
OpenAI 的 Realtime API 推出新功能:OpenAI 的 Realtime API 现在包含五个新的表现力语音,用于改进语音转语音应用,并由于 Prompt Caching 引入了大幅降价。这意味着缓存文本输入可享受 50% 折扣,缓存音频输入可享受 80% 折扣。
- 新的定价模型促进了 API 更经济的使用,详情见其 更新推文。
-
SimpleQA 旨在打击 AI 中的幻觉问题:OpenAI 推出了新的 SimpleQA 基准测试,包含 4000 个多样化问题,用于衡量语言模型的事实准确性。这一举措直接针对 AI 输出中普遍存在的幻觉问题。
- OpenAI 的 公告强调了在 AI 部署中建立可靠评估标准的必要性。
tinygrad (George Hotz) Discord
-
Tinycorp 对 Ethos NPU 的立场引发辩论:成员们讨论了 Tinycorp 对 Ethos NPU 的非官方立场,一些人建议询问硬件细节和未来支持。
- 一位用户幽默地指出,详细的问题可能会引发社区对 NPU 性能更丰富的反馈。
-
掌握 Tinybox 上的长时训练任务:在 Tinybox 上管理长时训练任务的策略包括使用 tmux 和 screen 进行会话持久化。
- 一位成员幽默地抱怨说,尽管有人推荐,但他还是因为懒惰而没有切换到更好的工具。
-
Qwen2 独特的构建模块引发关注:人们对 Qwen2 在 rotary embedding 和 MLP 等基础元素上的非常规方法感到好奇,并对阿里巴巴的参与进行了推测。
- 一位用户对这种合作表示沮丧,这增加了社区关于依赖关系的激烈讨论。
-
EfficientNet 面临 OpenCL 输出问题:一位用户报告在用 C++ 实现 EfficientNet 时出现 输出爆炸(exploding outputs),这引发了对调试工具的需求,以帮助比较 buffer。
- 建议包括从 tinygrad 的实现中访问和转储 buffer 的方法,以便进行更有效的故障排除。
-
将模型导出为 ONNX:一个热门话题:讨论集中在将 tinygrad 模型导出为 ONNX 的策略上,并建议使用现有脚本在低端硬件上进行优化。
- 关于直接导出模型与用于芯片部署的替代字节码(bytecode)方法的优劣引发了辩论。
Modular (Mojo 🔥) Discord
-
演进中的 Mojo 惯用法:成员们讨论了随着该语言获得新功能,惯用 Mojo(idiomatic Mojo) 仍在演进中,从而产生了新的最佳实践。
- 与 Python 等更成熟的语言相比,这展示了语言惯用法的流动性。
-
学习资源匮乏:一位成员强调了在寻找 Mojo 中学习 线性代数(linear algebra) 资源方面的困难,特别是在 GPU 使用和实现方面。
- 有人建议与 NuMojo 和 Basalt 的项目负责人直接沟通,可能有助于解决可用资料有限的问题。
-
雄心勃勃的 C++ 兼容性目标:成员们分享了实现与 C++ 100% 兼容 的雄心,讨论集中在 Chris Lattner 的潜在影响上。
- 一位用户认为这将是一个 彻底的奇迹,反映了围绕兼容性的高风险和高关注度。
-
语法引发对话:将 ‘alias’ 重命名为 ‘static’ 的提议引发了关于对 Mojo 语法影响以及可能与 C++ 用法产生混淆的辩论。
- 一些成员对使用 static 表示担忧,认为它可能无法像在 C++ 中那样准确地代表其预期功能。
-
探索自定义装饰器:讨论了在 Mojo 中实现 自定义装饰器(custom decorators) 的计划,认为这与编译时执行(compile-time execution)结合可能已经足够。
- 有人指出,像 SQL 查询验证 这样的功能可能超出了单纯装饰器的能力范围。
LlamaIndex Discord
-
Create-Llama App 发布,助力快速开发:全新的 create-llama 工具允许用户在几分钟内搭建一个 LlamaIndex 应用,支持 Next.js 或 Python FastAPI 后端全栈支持,并提供多种预配置用例,如 Agentic RAG。
- 这一集成促进了多种文件格式的摄取,显著简化了开发流程。
-
来自 ToolhouseAI 的变革性工具:ToolhouseAI 提供了一系列高质量工具,可增强 LlamaIndex Agent 的生产力,在最近的一次黑客松中,这些工具因大幅缩短开发时间而备受关注。
- 这些工具旨在无缝集成到 Agent 中,在加速工作流方面证明了其有效性。
-
增强的多 Agent 查询流水线:一位成员展示了使用 LlamaIndex workflows 构建多 Agent 查询流水线,并推介该方法是实现协作的有效方式。
- 演示材料可以在此处获取,以进一步探索实现策略。
-
RAG 与 Text-to-SQL 集成见解:一篇文章详细阐述了如何使用 LlamaIndex 将 RAG (Retrieval-Augmented Generation) 与 Text-to-SQL 集成,展示了在查询处理方面的改进。
- 用户报告查询响应时间减少了 30%,强调了 LlamaIndex 在提高数据检索效率方面的作用。
-
通过 LlamaIndex 增强用户交互:LlamaIndex 旨在通过将自然语言输入自动生成 SQL 来简化用户与数据库的交互,从而进一步赋能用户。
- 事实证明,这种方法非常有效,用户表示即使没有深厚的技术知识,也能更有信心地提取数据。
DSPy Discord
-
IReRa 应对多标签分类:题为 IReRa: In-Context Learning for Extreme Multi-Label Classification 的论文提出了 Infer–Retrieve–Rank(推理-检索-排序)框架,以提高语言模型在多标签任务中的效率,在 HOUSE、TECH 和 TECHWOLF 基准测试中取得了顶尖成绩。
- 这凸显了缺乏类别先验知识的 LLM 所面临的困境,并提出了一个可以增强整体性能的新框架。
-
与 IReRa 相关的 GitHub 仓库:成员们注意到了论文摘要中提到的相关 GitHub repo,这为讨论的方法论提供了进一步的见解。
- 这将极大地有助于论文研究结果的实现和理解。
-
关于 DSPy 强制结构的辩论:一位成员质疑,当像 Outlines 这样的库可以更高效地处理结构化生成时,DSPy 是否有必要强制执行结构。
- 另一位贡献者指出,DSPy 自 v0.1 以来的结构强制执行对于从 Signature 到 Prompt 的准确映射至关重要,在有效性与质量之间取得了平衡。
-
质量与结构的对决:随着对结构化输出可能降低输出质量的怀疑出现,讨论变得激烈起来,有人建议约束实际上可以增强结果,特别是对于较小的模型。
- 这种方法可能会产生很好的效果,特别是对于较小的 LLM, 这反映了关于质量和格式遵循度的不同观点。
-
将 MIPROv2 与 DSPy 集成:一位成员分享了利用 Zero-shot MIPROv2 配合 Pydantic 优先接口进行结构化输出的见解,主张在 DSPy 的优化过程中进行更多集成。
- 他们表达了对以更集成和原生的方式处理结构化输出的渴望, 预示着工作流可能得到改进。
OpenInterpreter Discord
-
任务自动化预测引发劳动力辩论:一位用户预测 virtual beings(虚拟存在)将导致职位冗余,并将其比作虚拟天网接管。
- 这引发了关于 AI 对就业和未来职业格局总体影响的激烈讨论。
-
Open Interpreter 相较于 Claude 的优势:一名成员询问 Open Interpreter 在计算机操作方面与 Claude 有何不同。
- Mikebirdtech 强调了在 Claude 中利用
interpreter --os的功能,并突出了其开源(open-source)的优势。
- Mikebirdtech 强调了在 Claude 中利用
-
聊天配置文件恢复引发疑问:一位用户寻求关于如何使用之前激活的特定 profile/model(配置文件/模型)来恢复聊天的建议。
- 尽管使用了
--conversations,它仍默认指向标准模型,这让用户在寻找解决方案。
- 尽管使用了
-
ChatGPT 聊天历史搜索功能推出:OpenAI 宣布推出一项功能,允许用户在 ChatGPT web 端搜索其聊天历史,增强了参考便利性。
- 这一新功能旨在简化用户交互,提升平台上的整体体验。
-
气味数字化取得重大里程碑:一个团队在没有任何人工干预的情况下成功数字化了夏李(summer plum)的气味,实现了重大突破。
- 一名成员表达了对携带李子香气的兴奋,并考虑发布一款独家香水来资助科学探索。
LangChain AI Discord
-
Invoke 函数性能之谜:调用 retriever 的 .invoke function 让用户感到困惑,Llama3.1:70b 模型的响应时间超过 120 秒,而本地仅需 20 秒。
- 有人怀疑是安全问题影响了性能,促使社区协助排查这一异常。
-
FastAPI 路由执行性能:通过调试日志确认,FastAPI 路由表现出令人印象深刻的性能,执行时间始终保持在 1 秒以内。
- 用户确认发送的数据是准确的,从而将响应速度问题锁定在 invoke 函数本身。
-
对 Hugging Face 文档的挫败感:对于旨在设置 chat/conversational pipeline 的用户来说,查阅 Hugging Face Transformers 的文档一直是一件令人头疼的事。
- 在文档中难以找到核心指导,突显了用户入门体验中需要改进的领域。
-
Knowledge Nexus AI 发起社区倡议:Knowledge Nexus AI (KNAI) 宣布了旨在连接人类知识与 AI 的新倡议,重点关注去中心化方法。
- 他们的目标是将集体知识转化为结构化、机器可读的数据,从而对医疗保健、教育和供应链产生影响。
-
OppyDev 推出插件系统:OppyDev 的插件系统通过创新的 chain-of-thought(思维链)推理增强了标准 AI 模型的输出,以提高响应的清晰度。
- 一段教程视频演示了该插件系统,并展示了 AI 交互中的实际改进。
OpenAccess AI Collective (axolotl) Discord
-
LoRA 微调问题仍未解决:一名成员表示在 H100 GPUs 上进行 LoRA finetuning 难以找到解决方案,并暗示 QLoRA 可能是唯一可行的权宜之计。
- 该问题依然存在,另一名成员确认针对 Hopper 8bit 的 BitsAndBytes issue 仍处于开启状态且未得到解决。
-
量化挑战依然存在:讨论强调了量化相关问题的持续挑战,特别是在 Hopper 8bit 的 BitsAndBytes 背景下。
- 尽管做出了努力,但似乎尚未就这些技术问题建立明确的解决方案。
LAION Discord
-
图像解码中 Clamping 数值至关重要:一位成员强调,在将解码后的图像转换为 uint8 之前,如果未能将 数值限制 (clamp) 在 [0,1] 范围内,会导致 超出范围的数值回绕 (wrapping),从而影响图像质量。
- 图像外观出现意外结果 可能是由于在预处理链中忽略了这一关键步骤。
-
解码工作流中可能潜伏的缺陷:有人对 解码工作流中可能存在的缺陷 提出了担忧,这可能会影响整体图像处理的可靠性。
- 需要进一步讨论以彻底识别这些问题并增强工作流的鲁棒性。
-
关于图像处理的新 arXiv 论文:一位成员分享了一篇名为《Research Paper on Decoding Techniques》的新 arXiv 论文链接,可在此处 查看。
- 该论文可能会为当前关于图像解码的讨论提供有价值的见解或方法论。
LLM Agents (Berkeley MOOC) Discord
-
LLM Agents 测验位置公布:一位成员询问了 LLM Agents 课程 每周测验 的位置,并得到了带有 测验链接 的迅速回复,回复称:“你可以在这里找到所有的测验。”
- 这些测验对于跟踪课程进度至关重要,可以通过提供的链接访问。
-
准备好参加 LLM Agents 黑客松!:参与者们了解了即将举行的 LLM Agents Hackathon,并获得了 黑客松详情 链接以报名参加这场编程竞技。
- 此次活动为参与者提供了一个展示技能并就创新项目进行协作的绝佳机会。
-
便捷的课程报名流程:分享了如何通过 Google Form 注册课程的说明,鼓励参与者填写此 表格 加入。
- 这一简单的报名流程旨在提高入学率,让更多工程师参与到该计划中。
-
加入 Discord 上活跃的课程讨论:提供了加入 LLM Agents Discord 中 MOOC 频道 讨论的详细信息,以促进社区参与。
- 参与者可以在整个课程期间利用该平台提问并分享见解。
Mozilla AI Discord
-
Transformer Labs 展示在 LLM 上运行本地 RAG:Transformer Labs 正在举办一场活动,演示如何在可本地安装且具有用户友好 UI 的环境下,在 LLM 上进行 RAG 的训练、微调和评估。
- 这种无代码(no-code)方法有望让各种技能水平的工程师都能参与此次活动。
-
技术演讲中介绍 Lumigator 工具:工程师们将深入介绍 Lumigator,这是一个开源工具,旨在协助根据特定需求选择最佳的 LLM。
- 该工具旨在加快工程师在选择大语言模型时的决策过程。
Gorilla LLM (Berkeley Function Calling) Discord
-
Llama-3.1-8B-Instruct (FC) 在与 Prompting 模式对比时表现不佳:一位成员提出 Llama-3.1-8B-Instruct (FC) 的表现不如 Llama-3.1-8B-Instruct (Prompting),并对 Function Calling 任务的预期结果表示怀疑。
- “这种差异的原因是什么?” 表明了对基于模型预期功能的性能预期的担忧。
-
对 Function Calling 机制的期望:另一位参与者表达了失望,认为考虑到其设计重点,FC 变体应该优于其他变体。
- 这引发了关于当前结果是令人惊讶,还是暗示了模型内部潜在架构问题的讨论。
Alignment Lab AI Discord 没有新消息。如果该服务器长期沉寂,请告知我们,我们将将其移除。
LLM Finetuning (Hamel + Dan) Discord 没有新消息。如果该服务器长期沉寂,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该服务器长期沉寂,请告知我们,我们将将其移除。
DiscoResearch Discord 没有新消息。如果该服务器长期沉寂,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该服务器长期沉寂,请告知我们,我们将将其移除。
第 2 部分:按频道划分的详细摘要和链接
完整的频道细分内容已针对邮件进行截断。
如果您喜欢 AInews,请分享给朋友!提前感谢!