ainews-the-ai-search-wars-have-begun-searchgpt
AI 搜索大战已经打响——SearchGPT、Gemini Grounding 及更多内容。
ChatGPT 在所有平台上推出了搜索功能,该功能采用了经过微调的 GPT-4o 版本,并结合了合成数据生成以及来自 o1-preview 的模型蒸馏技术。此项功能还包括一个由 Sam Altman 推广的 Chrome 浏览器扩展程序,但目前仍存在“幻觉”问题。
此次发布正值 Gemini 在经历延迟后推出“搜索接地”(Search Grounding)功能之际。值得注意的是,由于针对 OpenAI 的诉讼,《纽约时报》 并非其合作伙伴。随着 Perplexity(面向消费者)和 Glean(面向企业级 B2B)等选手的加入,AI 搜索领域的竞争愈发激烈。
此外,Claude 3.5 Sonnet 在 SWE-bench Verified 基准测试中创下了新纪录,同时还推出了一项名为 SimpleQA 的新幻觉评估基准。其他亮点还包括拥有 6.6 亿参数的 Universal-2 语音转文本模型,以及在 NVIDIA Isaac 模拟中训练的人形机器人神经全身控制器 HOVER。此外,还展示了使用 LangChain 和 LangGraph 的 AI 对冲基金团队。本期新闻由 RAG++ 课程赞助,该课程汇集了来自 Weights & Biases、Cohere 和 Weaviate 的专家。
一个 AI 搜索框就够了。
2024/10/30-2024/10/31 的 AI 新闻。我们为你检查了 7 个 subreddits、433 个 Twitter 账号 和 32 个 Discord 社区(231 个频道,2468 条消息)。预计节省阅读时间(按 200wpm 计算):264 分钟。你现在可以标记 @smol_ai 进行 AINews 讨论了!
继 7 月份以 SearchGPT 之名预热后,ChatGPT 今天终于在所有平台推出了搜索功能,纯属巧合地与 Gemini 在经历了一次不幸的延迟后推出 Search Grounding 撞期。此次发布包含一个简单的 Chrome Extension,@sama 正在 Twitter 和今天的 Reddit AMA(别费劲看了)上亲自推广:
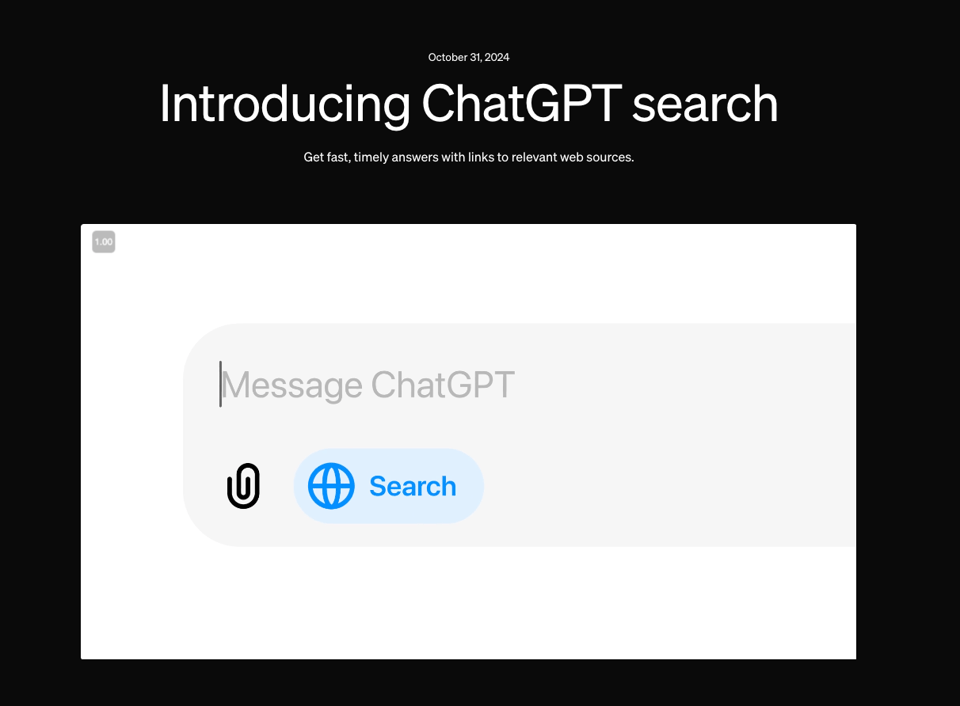
该功能拥有一系列天气、股票、体育、新闻和地图合作伙伴——值得注意的是,你永远不会通过 ChatGPT 看到《纽约时报》的文章,因为 NYT 选择起诉 OpenAI 而不是与其合作。合作伙伴大概对这个功能感到满意,但引用来源有一个陷阱——你必须额外点击一次才能看到它们,而大多数人不会这么做。
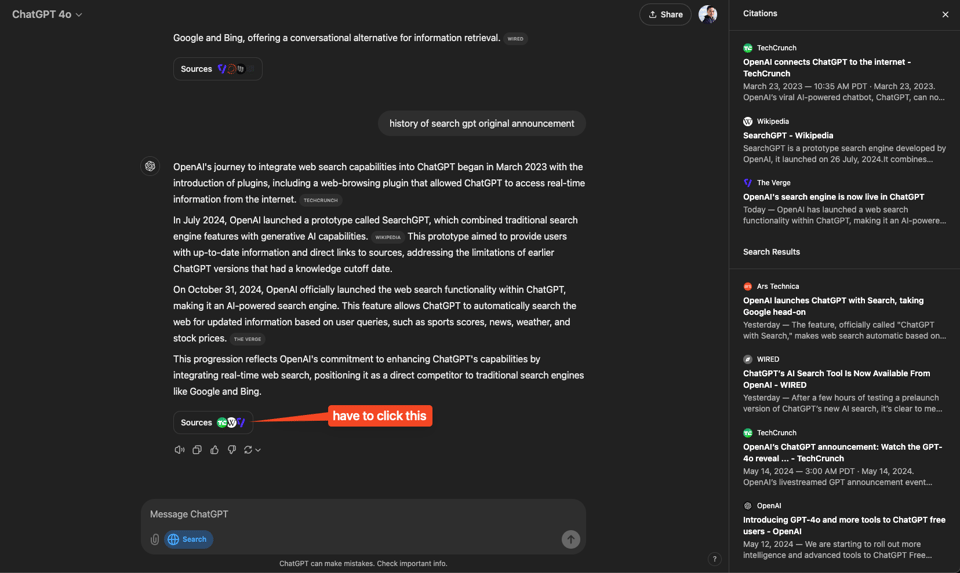
ChatGPT 搜索使用了一个“经过微调的 GPT-4o 版本,通过新型合成数据生成技术进行后训练,包括从 OpenAI o1-preview 蒸馏输出”,然而它已经被发现存在 Hallucinations(幻觉)。
这场消费级 AI 领域挑战搜索领头羊(Perplexity)的新攻势,反映了 B2B AI 领域(Dropbox Dash)挑战其搜索领头羊(Glean)的更广泛趋势。
看来现在正是通过今天的 AINews 赞助商来温习 AI 搜索技术的好时机!
由 RAG++ 课程赞助:超越基础的 RAG 实现,探索混合搜索和高级 Prompting 等进阶策略,以优化性能、评估和部署。向来自 Weights & Biases、Cohere 和 Weaviate 的行业专家学习如何克服常见的 RAG 挑战并构建强大的 AI 解决方案,利用 Cohere 平台为参与者提供的额度进行实践。

AI Twitter 摘要
所有摘要均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
AI 模型发展与基准测试
-
Claude 3.5 Sonnet 性能表现:@alexalbert__ 宣布 Claude 3.5 Sonnet 在 SWE-bench Verified 上达到了 49%,超越了此前 45% 的 SOTA 记录。该模型采用极简的 prompt 结构,在处理多样化编程挑战时极具灵活性。
-
SimpleQA 基准测试:@_jasonwei 推出了 SimpleQA,这是一个包含 4,000 个多样化事实寻求问题的全新幻觉评估基准。目前的顶尖模型如 Claude 3.5 Sonnet 在这一极具挑战性的基准测试中准确率低于 50%。
-
Universal-2 语音转文本模型:@svpino 分享了 Universal-2 的细节,这是一款拥有 660M 参数的下一代 Speech-To-Text 模型。它在专有名词识别、字母数字准确性以及文本格式化方面表现出显著提升。
-
HOVER 神经全身控制器:@DrJimFan 展示了 HOVER,一个用于控制人形机器人的 1.5M 参数神经网络。它在 NVIDIA Isaac 仿真环境中训练,可以根据各种高级运动指令进行提示,并支持多种输入设备。
AI 工具与应用
-
AI 对冲基金团队:@virattt 使用 LangChain 和 LangGraph 构建了一个由 AI Agent 组成的对冲基金团队,包括基本面分析师、技术分析师和情绪分析师。
-
NotebookLM 与 Illuminate:@GoogleDeepMind 开发了两款 AI 工具,用于文章叙述、故事生成以及创建多发言人的音频讨论。
-
LongVU 视频语言模型:@mervenoyann 分享了 Meta 的 LongVU 细节,这是一款新的视频 LM,能够通过使用 DINOv2 进行下采样并融合特征来处理长视频。
-
AI 运维工程师:@svpino 讨论了由 @resolveai 开发的 AI 系统,该系统可处理警报、执行根因分析并解决生产环境中的故障。
AI 研究与趋势
-
视觉语言模型 (VLMs):@mervenoyann 总结了 VLMs 的趋势,包括交织的文本-视频-图像模型、多视觉编码器以及 zero-shot 视觉任务。
-
推测性知识蒸馏 (SKD):@_philschmid 分享了来自 Google 的一种新方法,用于解决 on-policy 知识蒸馏的局限性,在蒸馏过程中同时使用教师模型和学生模型。
-
QTIP 量化:@togethercompute 推出了 QTIP,这是一种新的量化方法,为 LLM 实现了最先进的质量和推理速度。
-
可信执行环境 (TEEs):@rohanpaul_ai 讨论了将 TEEs 用于保护隐私的去中心化 AI,解决了在不可信节点间处理敏感数据的挑战。
AI 行业新闻与公告
-
OpenAI 新员工:@SebastienBubeck 宣布加入 OpenAI,强调了公司对安全 AGI 开发的关注。
-
Perplexity Supply 发布:@perplexity_ai 推出了 Perplexity Supply,为充满好奇心的人们提供优质商品。
-
GitHub Copilot 更新:@svpino 指出 GitHub Copilot 正在快速发布新功能,这可能是为了应对来自 Cursor 的竞争。
-
Meta 的 AI 投资:@nearcyan 报告称 Meta 目前在 VR 上投入 40 亿美元,在 AI 上投入 60 亿美元,利润率为 43%。
AI Reddit 摘要
/r/LocalLlama 摘要
主题 1:苹果在 MacBook Pro 广告中展示 LMStudio:本地 LLM 走向主流
- MacBook Pro M4 Max;高达 526 GB/s 的内存带宽。 (Score: 195, Comments: 87):新款 MacBook Pro M4 Max 芯片拥有 高达 526 GB/s 的内存带宽,显著增强了本地 AI 性能。内存带宽的这一大幅提升预计将极大提高 AI 相关任务的速度和效率,特别是对于设备端机器学习和数据处理操作。
- 苹果在他们的新 Macbook Pro 广告中展示了这张截图 (Score: 726, Comments: 116):苹果新款 MacBook Pro 广告中出现了一张 LMStudio 的截图,这是一个用于运行 本地大语言模型 (LLMs) 的流行开源工具。这一举动表明苹果正在承认并可能在背书 本地 AI 采用 的增长趋势,突显了其硬件在本地运行复杂 AI 模型的能力。
- LMStudio 通过苹果的广告获得了主流认可,用户对其功能和易用性表示赞赏。一些人对其开源状态以及与 Kobold 和 Ollama 等替代方案的对比展开了讨论。
- AI 社区的增长受到关注,并讨论了其规模和影响。AMD 也展示了 LM Studio 的基准测试,表明本地 AI 工具在更广泛的行业内得到采用。
- 用户推测新款 Apple M4 芯片 运行大语言模型的性能,预期能以 8+ tokens/sec 的速度运行 70B+ 模型。据报道,目前的 M2 Ultra 芯片已能达到类似的性能。
{kind=link}
Theme 2. Meta 的 Llama 4:在 10 万余张 H100 GPU 上训练,将于 2025 年发布
- 十月 AI 重大事件回顾 (Score: 99, Comments: 20):2023 年 10 月见证了几个重要 AI 模型的发布,包括用于图像创作的 Flux 1.1 Pro、Meta 用于视频生成的 Movie Gen,以及提供三种尺寸开源版本的 Stable Diffusion 3.5。推出的著名多模态模型包括 DeepSeek-AI 的 Janus AI、Google DeepMind 和 MIT 拥有 10.5B 参数 的 Fluid 文本转图像模型,以及 Anthropic 的 Claude 3.5 Sonnet New 和 Claude 3.5 Haiku,展示了各种 AI 能力的进步。
- Flux 1.1 Pro 引发了关于开源潜力的讨论,用户推测如果公开释放,它可能会变得“无敌”。对话演变为关于 AI 智能极限 的辩论,特别是在语言模型与图像生成方面的对比。
- Stable Diffusion 3.5 的发布被强调为本地、非 API 驱动图像生成的重大进展。用户对该开源模型的可访问性表现出极大热情。
- 讨论涉及 AI 模型的未来,预测独立的图像模型可能很快会被集成了视频能力的 多模态模型 所取代。一些用户推测,AI 可以在 两年内 通过“点击按钮”创建完整的漫画。
- Llama 4 模型正在超过 10 万张 H100 的集群上训练:2025 年初发布,具备新模态、更强推理和更快速度 (Score: 573, Comments: 157):据报道,Meta 的 Llama 4 模型正在一个超过 100,000 张 H100 GPU 的庞大集群上进行训练,并计划于 2025 年初发布。根据一条推文和 Meta 2024 年第三季度财报,新模型预计将具备 新模态、更强的推理能力 以及 显著提升的速度。
- 用户对 Llama 4 的潜力感到兴奋,希望它能达到或超越 GPT-4/Turbo 的能力。一些人推测了模型尺寸,希望有从 9B 到 123B 参数的选项,以适应各种硬件配置。
- 讨论集中在用于训练的庞大 100,000 张 H100 GPU 集群上,并对功耗(估计为 70 MW)进行了辩论,并将其与工业设施进行了比较。一些人称赞了 Meta 对开源 AI 开发的投入。
- 用户将 Llama 与 Mistral 和 Nemotron 等其他模型进行了比较,讨论了相对性能和使用场景。一些人希望 Llama 4 在基准测试分数之外,还能提高易用性和可训练性。
Theme 3. 本地 AI 替代方案挑战云端 API:Cortex 和 Whisper-Zero
- Cortex: Local AI API Platform - a journey to build a local alternative to OpenAI API (Score: 66, Comments: 29): Cortex 是一个本地 AI API 平台,旨在通过多模态支持提供 OpenAI API 的替代方案。该项目专注于创建一个自托管解决方案,提供与 OpenAI API 类似的功能,包括文本生成、图像生成和语音转文本功能。Cortex 旨在让用户更好地控制其数据和 AI 模型,同时为习惯于使用 OpenAI API 的开发人员提供熟悉的接口。
- Cortex 与 Ollama 的不同之处在于它使用 C++(而非 Go)并以通用文件格式存储模型。它的目标是与 OpenAI API 规范实现 1:1 等效,重点关注多模态和有状态操作。
- 该项目被设计为 OpenAI API 平台的本地替代方案,计划支持多模态任务和实时功能。它将与本地实时语音 AI Ichigo 集成,并推动 llama.cpp 的前向分支以支持多模态语音。
- 一些用户表示怀疑,认为 Cortex 只是“另一个 llama-cpp 封装器”。开发人员澄清说,它不仅仅是一个简单的封装器,其目标是统一各种引擎,并处理跨不同硬件和 AI 模型的复杂多模态任务。
- How did whisper-zero manage to reduce whisper hallucinations? Any ideas? (Score: 72, Comments: 49): Whisper-Zero 是 OpenAI 的 Whisper 语音识别模型的修改版本,声称可以减少语音识别中的幻觉。帖子作者正在寻求有关 Whisper-Zero 如何实现这一改进的信息,特别是在处理静音和背景噪声方面,这些是原始 Whisper 模型容易产生幻觉的领域。
- Whisper 继承了 YouTube 自动字幕的问题,包括在静音期间添加“[APPLAUSE]”等幻觉。用户报告该模型有时会添加随机句子或“卡在”重复单词上,尤其是在静音期间。
- “消除幻觉”的说法受到了质疑,有人建议可能使用了降噪预处理。一些用户指出,在某些任务(包括带口音的语音识别)中,Large-V3 的表现不如 Large-V2。
- 用户对“无幻觉”的说法表示怀疑,指出 10-15% 的 WER 改进并不等同于零幻觉。其价格(每小时转录 0.6 美元)也被批评为比免费替代方案昂贵。
Theme 4. Optimizing LLM Inference: KV Cache Compression and New Models
-
[R] Super simple KV Cache compression (Score: 39, Comments: 5): 研究人员发现了一种通过压缩 KV Cache 来提高 LLM 推理效率的简单方法,详见其论文《A Simple and Effective L2 Norm-Based Strategy for KV Cache Compression》。他们的方法利用了 KV Cache 中 Token Key 投影的 L2 范数与其接收到的注意力分数之间的强相关性,从而在不影响性能的情况下实现缓存压缩。
-
Introducing Starcannon-Unleashed-12B-v1.0 — When your favorite models had a baby! (Score: 41, Comments: 8): Starcannon-Unleashed-12B-v1.0 是一款新的合并模型,结合了 nothingiisreal/MN-12B-Starcannon-v3 和 MarinaraSpaghetti/NemoMix-Unleashed-12B,可在 HuggingFace 上获取。该模型声称提高了输出质量和处理更长上下文的能力,可配合 ChatML 或 Mistral 设置使用,运行在 koboldcpp-1.76 后端。
其他 AI Subreddit 回顾
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI 模型进展与能力
-
OpenAI 的 o1 模型:Sam Altman 宣布 OpenAI 的 o 系列推理模型正处于“非常陡峭的改进轨迹上”。即将推出的 o1 功能包括 function calling、developer messages、streaming、structured outputs 和 image understanding。完整的 o1 模型仍在开发中,但将“很快”发布。
-
Google 的 AI 代码生成:据报道,AI 现在编写了 Google 超过 25% 的代码。这突显了 AI 在大型科技公司软件开发中日益增长的作用。
-
Salesforce 的 xLAM-1b 模型:一个拥有 10 亿参数的模型,在 function calling 方面达到了 70% 的准确率,超越了 GPT 3.5,尽管其体积相对较小。
-
Phi-3 Mini 更新:Rubra AI 发布了更新后的 Phi-3 Mini 模型,具备 function calling 能力,可与 Mistral-7b v3 竞争。
AI 工具与界面
-
Invoke 5.3:新版本包含一个“Select Object”工具,允许用户挑选出图像中的特定对象并将其转换为可编辑图层,这在图像编辑工作流中非常有用。
-
Wonder Animation:一款可以将任何视频转换为带有 CG 角色的 3D 动画场景的工具。
AI 伦理与社会影响
-
AI alignment:关于将 AI 与人类价值观对齐的挑战以及高度先进的 AI 系统潜在影响的讨论。
-
混合现实概念:一段展示混合现实技术潜在应用场景的视频,展示了 AI 与增强现实的交汇。
AI Discord 回顾
由 O1-mini 生成的摘要之摘要的摘要
主题 1. 为你的 AI 加速:模型获得速度提升
- Meta 的 Llama 3.2 获得加速!:Meta 发布了量化版 Llama 3.2 模型,通过使用 Quantization-Aware Training(量化感知训练),将推理速度提升了 2-4 倍,并将模型体积缩减了 56%。
- SageAttention 超越 FlashAttention:SageAttention 分别比 FlashAttention2 和 xformers 实现了 2.1 倍和 2.7 倍的性能提升,增强了 Transformer 的效率。
- BitsAndBytes 原生量化发布:Hugging Face 集成了 bitsandbytes 的原生量化支持,引入了 8-bit 和 4-bit 选项,以优化模型存储和性能。
主题 2. 新型 AI 模型登场
- SmolLM2 凭借 11T Token 起飞:SmolLM2 系列发布,模型参数范围从 135M 到 1.7B,在高达 11 万亿 (11 trillion) Token 的数据集上进行训练,并根据 Apache 2.0 协议完全开源。
- Recraft V3 在设计语言方面占据主导地位:Recraft V3 声称在设计语言方面具有优越性,表现优于 Midjourney 和 OpenAI 等竞争对手,推向了 AI 生成创意的边界。
- Hermes 3 与 Llama 3.1 展开竞争:Hermes 3 在角色扮演数据集微调方面表现出色,通过系统提示词保持强大的角色设定,并证明在对话一致性上优于 Llama 3.1。
主题 3. 智能构建:高级 AI 工具和框架
- HuggingFace 发布原生量化:集成 bitsandbytes 库实现了 8-bit 和 4-bit 量化,增强了 Hugging Face 生态系统内模型的灵活性和性能。
- Aider 通过自动补丁增强编程:Aider 现在可以自动生成错误修复和文档,允许开发人员一键应用补丁,从而简化代码审查并提高生产力。
- OpenInterpreter 添加自定义配置文件:用户可以通过 Python 文件在 Open Interpreter 中创建可定制的配置文件 (Profiles),从而为各种应用实现量身定制的模型选择和上下文调整。
主题 4. 部署困境:导航 AI 基础设施
- 多 GPU 微调即将推出:Unsloth AI 暗示将在年底前推出多 GPU 微调功能,最初将专注于 Vision 模型,以增强整体模型支持。
- 网络问题正在调查中:OpenRouter 正在解决云提供商之间导致 524 错误的偶发性网络连接问题,目前的持续改进已初见成效。
- Unsloth 的 Docker 镜像收到反馈:社区对 Unsloth Docker 镜像的测试和反馈强调了用户见解对于优化容器易用性和性能的重要性。
主题 5. 更智能的搜索:信息检索中的 AI 增强
- ChatGPT 搜索功能大幅增强:OpenAI 升级了 ChatGPT 的网页搜索,能够通过相关链接提供更快、更准确的答案,显著提升了用户体验。
- Perplexity AI 推出图片上传功能:在 Perplexity AI 中上传图片的能力被视为一项重大改进,尽管用户对更新后缺失的功能表示担忧。
- WeKnow-RAG 结合网页与知识图谱:WeKnow-RAG 将网页搜索和知识图谱 (Knowledge Graphs) 集成到 Retrieval-Augmented Generation (RAG) 系统中,增强了 LLM 响应的可靠性并对抗事实错误。
第一部分:高层级 Discord 摘要
HuggingFace Discord
- Llama 3.2 模型加速:Meta 新推出的 Llama 3.2 1B 和 3B 量化版本利用 Quantization-Aware Training,将推理速度提升了 2-4 倍,并将模型大小缩减了 56%。
- 社区讨论强调了这种增强如何在不牺牲质量的情况下实现更快的性能。
- 原生量化支持发布:Hugging Face 已通过 bitsandbytes 库集成了原生量化支持,增强了模型的灵活性。
- 新功能包括 8-bit 和 4-bit 量化,简化了模型存储并提升了使用性能。
- 阅读研究论文的有效策略:成员们分享了阅读论文的不同目标,重点在于实现与保持更新,其中一位提到:我不认为我曾经从论文中实现过什么。
- 讨论了一种结构化的三步阅读法,并指出其在掌握复杂学术内容方面的高效性。
- AI 工具自动生成 Bug 修复:开发了一款 AI 工具来自动生成补丁,允许开发者在提交 PR 时一键应用修复。
- 该工具不仅提高了代码质量,还通过及早发现问题节省了代码审查的时间。
- SD3Transformer2DModel 导入故障排除:一位成员在 VSCode 中导入
SD3Transformer2DModel时遇到问题,而导入另一个模型却成功了,这表明可能存在特定模块的复杂情况。- 社区参与了协作式故障排除,展示了该群体在技术背景下解决问题的承诺。
Nous Research AI Discord
- Flash-Attn 现在可在 A6000 上运行:一位成员成功在 A6000 上通过 CUDA 12.4 和 PyTorch 2.5.0 运行了 flash-attn 2.6.3,通过手动构建解决了之前的问题。
- 他们注意到 pip 安装会导致链接错误,但新设置看起来很有前景。
- Perplexity 推出新供应线:Perplexity 推出了 Perplexity Supply,旨在为好奇的人们提供优质产品。
- 这引发了关于与 Nous 竞争的讨论,表明需要增强他们自己的产品。
- AI 助手的未来:围绕 AI 助手通过本地和云端集成的混合方式管理多项任务展开了讨论。
- 成员们辩论了本地计算资源是否足以支持全面的 AI 功能和可用性。
- Hermes 3 相比 Llama 3 表现出色:Hermes 3 因其在角色扮演数据集上的微调而表现优异,通过系统提示词(system prompts)比 Llama 3.1 更能忠实于角色设定。
- 用户发现 ollama 对测试模型很有帮助,提供了简单的自定义命令。
- SmolLM2 系列展示轻量级能力:SmolLM2 系列包含 135M、360M 和 1.7B 参数规模,专为设备端任务设计,且非常轻量。
- 与 SmolLM1 相比,1.7B 变体在指令遵循和推理方面有所改进。
Unsloth AI (Daniel Han) Discord
- 多 GPU 微调的预计到达时间:成员们急于了解多 GPU 微调的上线时间,有迹象表明可能在年底前“很快(soon (tm))”推出。
- 重点仍在于与视觉模型相关的增强和整体模型支持。
- 关于量化技术的辩论:讨论围绕 30 亿参数以下最适合微调的 Language Models 展开,建议包括 DeBERTa 和 Llama。
- 积极辩论了量化中潜在质量损失与速度提升之间的权衡。
- Unsloth 框架展现前景:成员们赞扬了 Unsloth 框架高效的微调能力,强调了其用户友好的体验。
- 关于其在层冻结等高级任务中的灵活性查询得到了支持这些功能的保证。
- 运行推理时的内存问题:一位用户指出在使用 ‘unsloth/Meta-Llama-3.1-8B’ 进行多次推理运行后,GPU 内存使用量增加,引发了对内存累积的警报。
- 尝试使用 torch.cuda.empty_cache() 清理内存未能解决问题,表明存在更深层次的内存管理问题。
- 社区测试 Unsloth Docker 镜像:一位成员分享了他们的 Unsloth Docker Image 链接,以征求社区反馈。
- 讨论强调了社区见解对于改进 Docker 镜像和容器可用性的重要性。
Perplexity AI Discord
-
Grok 2 模型评价褒贬不一:用户对新的 Grok 2 模型 表达了喜爱与沮丧并存的情绪,特别是关于其在 Perplexity iOS 应用中对 Pro 用户的可用性。
- 一些人评论说它缺乏有用的性格特征,导致用户体验参差不齐。
-
Perplexity Pro 订阅问题持续存在:几位用户报告了 Pro 订阅 的持续问题,包括订阅状态无法识别。
- 尽管已付费,但由于来源输出有限,用户感到沮丧,并对服务质量提出了质疑。
-
用户喜爱图片上传功能:在 Perplexity 中上传图片的能力被赞誉为一项重大增强,改善了用户交互。
- 然而,在最近的更新后,对性能质量和缺失功能的担忧依然存在。
-
对 Perplexity 搜索功能的困惑:讨论显示出对 搜索功能 清晰度的困惑,用户注意到其主要侧重于标题。
- 由于响应在没有开发者提前沟通的情况下被重定向到 GPT,挫败感进一步加剧。
-
用户在 Perplexity 和 ChatGPT 之间进行比较:成员们比较了 Perplexity 和 ChatGPT,审视了各自的功能以及感知的优缺点。
- 总的来说,一些人认为 ChatGPT 在某些语境下表现更好,引发了对 Perplexity 有效性的质疑。
OpenAI Discord
-
与 OpenAI 高管的 Reddit AMA:一场与 Sam Altman、Kevin Weil、Srinivas Narayanan 和 Mark Chen 的 Reddit AMA 定于 太平洋时间上午 10:30 举行。用户可以提交问题进行讨论,详情见此处。
- 此次活动为社区提供了一个与 OpenAI 领导层直接交流的渠道。
-
翻新后的 ChatGPT 搜索功能:ChatGPT 升级了其搜索功能,能够通过相关链接提供更快、更准确的答案。有关此增强功能的更多信息请点击此处。
- 这一重大改进预计将显著提升用户体验。
-
关于 GPT-4 训练频率的见解:参与者讨论道,重大的 GPT-4 更新通常需要 2-4 个月 的时间进行训练和安全测试。一些成员主张根据用户反馈进行更频繁的小型更新。
- 这种意见分歧说明了对产品开发周期的不同看法。
-
打造 D&D DM GPT:一个令人兴奋的项目正在进行中,旨在创建一个 D&D DM GPT,通过 AI 集成增强桌面游戏体验。
- 该倡议旨在在 D&D 会话中创建一种更具互动性的叙事机制。
-
辩论 AI 生成约束:围绕将 AI 生成 仅限制在反映用户行为结果的范围内展开了讨论。成员们强调需要明确如何启用与用户交互保持一致的 交互式 AI。
- 寻求进一步阐述如何最好地定义这些限制,以优化模型的上下文。
OpenRouter (Alex Atallah) Discord
- OpenAI Speech-to-Speech API 可用性:用户对新的 OpenAI Speech-to-Speech API 表示好奇,但目前还没有预估的发布日期。
- 这种不确定性引发了热烈讨论,参与者们正急切等待其部署的具体细节。
- Claude 3.5 的简洁模式(Concise Mode)引发争论:关于 Claude 3.5 新的“简洁模式” 出现了激烈的辩论,一些用户认为其回复受到了过度限制。
- 参与者表达了不同的使用体验,许多人无法察觉到 API 功能上的显著差异。
- 澄清 OpenRouter 积分定价:用户详细分析了 OpenRouter 积分 的定价,指出在扣除手续费后,1 美元大约可兑换 0.95 个积分。
- 免费模型有 每天 200 次请求的限制,而付费使用费率则根据模型和需求而有所不同。
- Gemini API 通过 Google Grounding 增强搜索:Gemini API 现在支持 Google Search Grounding,集成了类似于 Vertex AI 中的功能。
- 用户提醒定价可能高于预期,但他们承认其在增强技术相关查询方面的潜力。
- 网络连接问题正在调查中:两个云服务商之间偶尔出现的 网络连接问题 正在调查中,这些问题导致了 524 错误。
- 最近的改进看起来很有希望,随着有关请求超时问题的更多细节浮出水面,团队旨在提供进一步的更新。
aider (Paul Gauthier) Discord
- Aider 自动读取文件:Aider 现在会在执行每个命令时自动读取文件的磁盘版本,允许用户在无需手动添加的情况下查看最新更新。像 Sengoku 这样的扩展可以进一步自动化开发环境中的文件管理。
- 这增强了交互效率,使用户管理代码资源变得更加容易。
- 对 Haiku 3.5 的期待:讨论围绕着 Haiku 3.5 的预期发布展开,推测其将在今年晚些时候发布,但不会立即推出。社区的强烈情绪表明,该版本的发布将引起巨大的轰动。
- 这种渴望意味着用户对该版本的改进抱有很高的标准。
- Continue 作为一个极具前景的 AI 助手:用户非常欣赏 Continue,这是一个适用于 VS Code 的 AI 代码助手,可与 Cursor 的自动补全功能相媲美。其用户友好的界面因通过可定制的工作流提高编码效率而受到称赞。
- 该工具强化了向更集成开发环境发展的趋势。
- Aider 的分析功能:Aider 引入了分析功能,收集匿名用户数据以提高整体可用性。鼓励用户加入分析将有助于识别热门功能并协助调试工作。
- 用户反馈可以显著塑造 Aider 的未来迭代。
- Aider 与 Ollama 的性能波动:一些用户在将 Aider 与 Ollama 集成时面临性能问题,特别是较大的模型尺寸会导致响应缓慢。用户呼吁建立一个强大的配置来优化无缝功能。
- 性能方面的挑战凸显了对提高兼容性和效率的迫切需求。
Eleuther Discord
-
开源 Value Heads 咨询:成员们表示难以找到开源 Value Heads,这表明社区面临共同的挑战。
- 这为寻求这些资源的成员提供了协作和知识共享的机会。
-
Universal Transformers 利用不足:尽管有其优势,Universal Transformers (UTs) 通常需要像 long skip connections 这样的修改,导致其未被充分探索。
- 涉及 chaining halting 的复杂性影响了其更广泛的应用采用,引发了对其具体实现的质疑。
-
Deep Equilibrium Networks 面临质疑:Deep Equilibrium Networks (DEQs) 具有潜力,但在稳定性和训练复杂性方面存在困难,导致人们对其功能产生怀疑。
- 对 DEQs 中 fixed points 的担忧强调了它们与更简单的模型相比,在实现参数效率方面面临的挑战。
-
Timestep Shifting 承诺优化:Stable Diffusion 3 中关于 timestep shifting 的新进展为优化模型推理中的计算提供了方法。
- 社区的努力体现在旨在数值求解离散 schedule 的 timestep shifting 共享代码中。
-
Gradient Descent 与 Fixed Points 探索:在探索对神经网络中 fixed points 的影响时,调整 Gradient Descent 中的 step sizes 被证明至关重要。
- 讨论指出了与 recurrent structures 相关的挑战,以及它们在应用中表现出有用的 fixed points 的潜力。
Latent Space Discord
-
Jasper AI 加倍投入企业级市场:Jasper AI 报告称过去一年企业营收翻了一番,目前服务于 850 多家客户,其中包括 20% 的世界 500 强企业。他们推出了 AI App Library 和 Marketing Workflow Automation 等创新功能,以进一步协助营销团队。
- 这一增长与企业营销中对 AI 采用的日益关注相吻合,许多团队将采用策略视为竞争工具。
-
OpenAI 的搜索功能获得提升:OpenAI 增强了 ChatGPT 的网页搜索功能,允许为用户提供更准确、更及时的响应。这次更新使 ChatGPT 在不断发展的 AI 搜索领域中能够很好地应对新兴竞争。
- 用户已经开始注意到差异,报告强调了与之前版本相比,信息检索精度的提高。
-
ChatGPT 与 Perplexity 争夺搜索霸权:随着两个平台都升级了功能,关于 ChatGPT 与 Perplexity 搜索结果质量的辩论随之而来。用户注意到 ChatGPT 在更有效地提供相关信息方面具有优势。
- 这种竞争凸显了搜索引擎对用户满意度日益增长的关注,推动了跨平台的进一步创新和增强。
-
突破性 AI 工具的崛起:Recraft V3 声称在设计语言方面表现出色,超越了 Midjourney 和 OpenAI 的产品。此外,开源模型 SmolLM2 在高达 11 万亿 tokens 的海量数据上进行了训练。
- 这些进步反映了 AI 能力的竞争马拉松,推向了设计和自然语言处理的边界。
-
AI 监管呼声日益高涨:Anthropic 最近的博客主张对 AI 进行有针对性的监管,强调了及时立法响应的必要性。他们的评论为关于 AI 治理和伦理的讨论做出了有意义的贡献。
- 随着对 AI 社会影响的担忧日益增加,这篇文章引发了关于监管如何塑造未来技术格局的对话。
LM Studio Discord
-
venvstacks 简化了 Python 安装:
venvstacks简化了基于 Python 的 Apple MLX 引擎的交付,无需单独安装。该工具已在 PyPi 上发布,可通过$ pip install --user venvstacks安装,目前已开源并在技术博客文章中提供了文档说明。- 该集成支持 LM Studio 内部的 MLX engine,提升了用户体验。
-
LM Studio 庆祝支持 Apple MLX:最新的 LM Studio 0.3.4 版本带来了对 Apple MLX 的支持,以及在博客文章中详细介绍的集成式可下载 Python 环境。
- 成员们强调,venvstacks 对于实现 Python 依赖项的无缝用户体验至关重要。
-
M2 Ultra 的 T/S 性能令人印象深刻:用户报告 M2 Ultra 的性能达到 8 - 12 T/S,并推测 12 - 16 T/S 的提升可能不会产生特别重大的影响。传闻称即将推出的 M4 芯片可能会挑战 4090 显卡,引发了广泛关注。
- 社区成员在分享经验的同时,正热切期待更多的性能基准测试。
-
Mistral Large 受到欢迎:用户对 Mistral Large 的满意度持续增加,分享了其在生成连贯输出方面的能力和有效性。
- 然而,由于 36GB 统一内存 的限制,运行更大模型的能力受到了一定影响。
-
理解 API 请求中的系统提示词 (system prompts):讨论了系统提示词的重要性,澄清了 API 负载中的参数会覆盖 UI 设置。这提供了灵活性,但也使得一致的使用变得至关重要。
- 成员们强调了理解这一点对于优化与 LM Studio API 交互的重要性。
GPU MODE Discord
-
Tensor 数据类型转换详解:讨论集中在 Tensor 数据类型上,特别是 f32、f16 和 fp8,研究了转换中随机舍入 (stochastic rounding) 的影响。
- 探索包括了位 (bits) 与标准浮点格式之间转换的考量。
-
探索 Int8 Tensor Core WMMA 指令的形状:一位成员指出,int8 Tensor Core wmma 指令的形状与 LLM 中的内存处理有关,特别是当 M 固定为 16 时。
- 这引发了关于当 M 较小时实现方式的疑问,暗示了可能的内存优化策略。
-
学习 Triton 及可视化修复更新:一位成员对修复其 Triton 学习过程中可视化功能的补丁表示感谢,这有助于参与 Trion puzzle。
- 他们回归 Triton 反映了对该领域重新燃起的兴趣,以及对讨论的积极参与。
-
ThunderKittens 库提供用户友好的 CUDA 工具:ThunderKittens 旨在创建易于使用的 CUDA 库,处理 95% 的复杂性,同时允许用户在剩余的 5% 中使用原始 CUDA / PTX。
- Mamba-2 kernel 通过集成自定义 CUDA 来处理复杂任务,展示了其可扩展性,突显了该库的灵活性。
-
深度学习效率指南评论:一位成员分享了他们的深度学习效率指南,涵盖了相关的论文、库和技术。
- 反馈包括对编写稳定算法章节的建议,反映了社区对知识共享的承诺。
Cohere Discord
-
Cohere API 前端选项受到好评:成员们讨论了与 Cohere API key 兼容的各种 Chat UI 前端选项,确认 Cohere Toolkit 符合需求。
- 一位用户分享了构建应用程序的见解,指出该工具包在快速部署方面的支持。
-
Chatbot 可能取代浏览器:一位成员分享了专注于模拟 ChatGPT browsing 过程的研发工作,旨在分析其输出过滤机制。
- 该倡议引发了热烈讨论,进一步探讨了 ChatGPT 的算法与传统 SEO 方法的区别。
-
申请审核流程正在进行中:团队重申 application acceptances 正在处理中,确保对每份提交进行彻底审查。
- 他们强调,具有具体 Agent 构建经验的候选人是选拔的关键。
-
微调问题正在解决:在用户对持续存在的问题表示担忧后,团队成员正通过计划更新来解决 fine-tuning 问题。
- 随着测试即将探索 ChatGPT 的 browsing 能力,这对于进一步开发仍然至关重要。
-
Cohere-Python 安装问题已解决:有成员提出了使用
poetry安装 cohere-python 包的相关问题,大家分享了经验并寻求帮助。- 问题很快得到解决,社区内的协作排查受到了好评。
Interconnects (Nathan Lambert) Discord
-
创意写作竞技场首次亮相:一个专注于原创性的新类别 Creative Writing Arena 在首次亮相中获得了约 15% 的选票。关键模型排名发生显著变化,ChatGPT-4o-Latest 升至第一。
- 该类别的引入突显了 AI 生成内容向增强艺术表达的转变。
-
SmolLM2:开源奇迹:SmolLM2 模型 拥有 1B 参数,并在 11T tokens 上进行了训练,现已在 Apache 2.0 协议下完全开源。
- 团队旨在通过发布所有数据集和训练脚本来促进协作,推动社区驱动的创新。
-
在 ARC 上评估模型受到关注:在 ARC 上评估模型正变得流行,反映了社区内评估标准的提高。
- 参与者指出,这些评估表明了强大的基础模型性能,并正在成为一种主流方法。
-
Llama 4 训练引入大型集群:Llama 4 模型正在一个超过 100K H100 的集群上进行训练,展示了 AI 能力的重大进步。此外,还通过 招聘链接 发布了针对 reasoning(推理)和 code generation(代码生成)研究员的职位空缺。
- 正如 Mark Zuckerberg 在 META 财报电话会议上指出的,这种强大的训练基础设施强化了竞争精神。
-
播客迎来“围巾头像男”:围巾头像男加入了播客,在成员中引起了轰动,有人幽默地回复道:Lfg! 这突显了社区对知名嘉宾登场的热情。
- NatoLambert 回忆了他们作为 OG Discord 好友的历史,强调了该社区内长期的联系。
Stability.ai (Stable Diffusion) Discord
-
Inpaint 工具证明非常有用:用户讨论了 inpaint 工具 是修正图像和构图元素的宝贵方法,使得更容易达到预期效果。
- Inpainting 可能比较棘手,但它通常成为完善图像的必要手段,增强了用户对自己能力的信心。
-
对 Stable Diffusion 基准测试的兴趣:成员们对 Stable Diffusion 的最新基准测试(Benchmarks)感到好奇,特别是关于企业级 GPU 与个人 3090 配置的性能对比。
- 一位用户指出,使用云服务可能会加快生成过程。
-
关于模型偏差的讨论:用户观察到一个趋势,即最新的模型经常生成带有红鼻子、红脸颊和红耳朵的图像,引发了关于根本原因的争论。
- 出现了围绕 VAE 问题和训练数据不足(特别是来自 anime 资源的数据)影响这些结果的推测。
-
寻求社区帮助进行项目:一位用户在制作宣传视频(promo video)时寻求帮助,促使大家建议在相关论坛发布信息以获得更多专业知识。
- 这些回应凸显了社区内分享知识和资源的强大协作努力。
-
图像处理中的个人偏好:一位成员分享了他们的工作流偏好,指出他们更倾向于将 img2img 和 upscale 步骤分开,而不是依赖集成解决方案。
- 这种方法允许在最终定稿前对图像进行更深思熟虑的精修。
Modular (Mojo 🔥) Discord
-
11 月 12 日社区会议预告:下一次社区会议定于 11 月 12 日举行,届时将分享 Evan 的 LLVM 开发者大会演讲中的见解,重点关注 Mojo 中的 linear/non-destructible 类型。
- 成员可以通过 Modular Community Q&A 提交会议问题,社区演讲还有 1-2 个名额开放。
-
关于 C-style Macros 的辩论:一场讨论强调引入 C-style Macros 可能会造成混乱,主张将自定义 Decorators 作为一种更简单的替代方案。
- 成员们对在引入 Decorator 功能的同时保持 Mojo 的简洁性表示关注。
-
编译时 SQL 查询验证:虽然详细的 DB schema 验证可能需要更多处理,但利用 Decorators 在编译时进行 SQL 查询验证具有潜力。
- 针对以这种方式验证查询的可行性提出了疑虑。
-
用于提高效率的自定义字符串插值器:在 Mojo 中引入类似于 Scala 中的自定义字符串插值器(custom string interpolators),可以简化 SQL 字符串的语法检查。
- 实现此功能可能会避免与传统 Macros 相关的复杂问题。
-
静态 MLIR Reflection vs Macros:关于静态 MLIR Reflection 的讨论表明,它在类型操作能力方面可能超越传统的 Macros。
- 在有效利用此功能的同时,保持简洁性对于避免 Language Server Protocols 出现问题仍然至关重要。
DSPy Discord
- 分享了硕士论文图表:一位成员分享了为其硕士论文创作的图表,并表示这可能对他人有用。
- 遗憾的是,未提供关于该图表的更多细节。
- 通过 GitHub 提升 CodeIt:分享了一个名为“CodeIt Implementation: Self-Improving Language Models with Prioritized Hindsight Replay”的 GitHub Gist,其中包含详细的实现指南。
- 对于从事相关研究工作的人员来说,这一资源可能特别有价值。
- WeKnow-RAG 融合 Web 与知识图谱:WeKnow-RAG 将 Web 搜索和知识图谱集成到“检索增强生成 (RAG)”系统中,增强了 LLM 响应的可靠性,详见 arXiv 论文。
- 这一创新系统解决了 LLM 容易生成事实错误内容的问题。
- XMC 项目探索 In-Context Learning:xmc.dspy 展示了针对极端多标签分类 (XMC) 的有效 In-Context Learning 策略,能够以极少的示例高效运行,更多信息请访问 GitHub。
- 这种方法可以显著提高分类任务的效率。
- DSPy 名称的由来:dspy 这个名字最初在 PyPI 上不得不通过
pip install dspy-ai来绕过占用。正如 Omar Khattab 所述,得益于社区的努力,在处理了一个用户相关的请求后,最终实现了简洁的pip install dspy。- 这说明了社区参与在项目发展中的重要性。
OpenInterpreter Discord
- Open Interpreter 配置文件自定义:用户可以通过指南在 Open Interpreter 中创建新配置文件,允许通过 Python 文件进行自定义,包括模型选择和上下文窗口调整。
- 配置文件支持多种优化变体,通过
interpreter --profiles访问,增强了用户的灵活性。
- 配置文件支持多种优化变体,通过
- 桌面客户端更新与活动:讨论了桌面客户端的更新,将社区的 House Party 定位为获取最新公告和 Beta 测试访问权限的主要来源。
- 成员们强调,以往的参与者已经获得了早期访问权限,这暗示了未来的发展动向。
- ChatGPT 搜索获得升级:OpenAI 改进了 ChatGPT 的网页搜索功能,提供快速、及时的回答以及相关链接,旨在提高响应的准确性。
- 这一进步提升了用户体验,使回答更具上下文相关性。
- Meta 发布机器人创新成果:在 Meta FAIR 上揭晓了三项机器人技术进展,包括 Meta Sparsh、Meta Digit 360 和 Meta Digit Plexus,详见帖子。
- 这些开发项目旨在提升开源社区的能力,展示了触觉技术方面的创新。
- 对 Anthropic API 集成的担忧:针对 Open Interpreter 0.4.x 版本中影响本地执行和 Anthropic API 集成的最新更新,出现了一些不满情绪。
- 有建议提出将 Anthropic API 集成设为可选,以增强社区对本地模型的支持。
tinygrad (George Hotz) Discord
-
对 NPU 性能的质疑:关于微软笔记本电脑中 NPU 性能 的疑虑依然存在,讨论暗示 Qualcomm 和 Rockchip 是获得更好体验的替代方案。
- 成员们在评估这些替代方案的同时,也对当前厂商提供的产品持怀疑态度。
-
导出 Tinygrad 模型遇到 Buffer 问题:成员在导出源自 ONNX 的 Tinygrad 模型 时遇到挑战,在
jit_cache中发现了BufferCopy对象而非CompiledRunner。- 建议过滤掉这些对象,以避免在调用
compile_model()时出现运行时问题。
- 建议过滤掉这些对象,以避免在调用
-
逆向工程 Hailo 指令集:一位成员寻求使用 IDA 等工具对 .hef 文件中的 Hailo Chip 指令集(op-codes)进行逆向工程,并对缺乏通用编码接口感到沮丧。
- 他们在导出为 ONNX 还是直接进行逆向工程之间权衡。
-
Lazy.py 中的 Tensor 赋值困惑:一位成员质疑在创建 disk tensor 时先调用
Tensor.empty()再调用assign()的必要性,对其运作方式表示困惑。- 他们还强调了在推理过程中使用
assign向 KV cache 写入新键值对的用法,暗示其具有更广泛的功能。
- 他们还强调了在推理过程中使用
-
Assign 方法是怎么回事?:另一场讨论关于在不追踪梯度时,创建新张量与使用
assign方法之间似乎没有本质区别。- 参与者指出需要明确该方法的效用和行为差异。
LlamaIndex Discord
-
自动化研究论文报告生成器上线:LlamaIndex 正在创建一个 自动化研究论文报告生成器,它可以从 arXiv 下载论文,通过 LlamaParse 进行处理,并在 LlamaCloud 中进行索引,从而进一步简化报告生成,如这条推文所示。更多细节请参见其概述该功能的博客文章。
- 用户热切期待这一功能对论文相关工作流的影响。
-
Open Telemetry 增强 LlamaIndex 体验:Open Telemetry 现已与 LlamaIndex 集成,增强了直接进入可观测性平台的日志追踪(logging traces),详见此文档。如这条推文所述,这一集成增强了开发者在复杂生产环境中导航的遥测策略。
- 此举简化了复杂应用程序的监控指标。
-
Llamaparse 在 Schema 一致性方面存在困难:成员们对 llamaparse 将 PDF 文档解析为不一致的 Schema 表示担忧,这使得导入 Milvus 数据库变得复杂。对于管理多 Schema 数据的用户来说,标准化解析输出仍然是首要任务。
- JSON 输出的一致性对于更顺畅的数据处理和用户体验至关重要。
-
呼吁 Milvus 字段标准化:用户对多个文档输出中多样的字段结构表示担忧,这使导入 Milvus 数据库变得复杂。他们正在探索实现 标准化解析输出 的方法。
- 缺乏统一性可能会阻碍跨不同数据集的集成工作。
-
自定义 Retriever 查询得到增强:关于如何在查询基础查询字符串之外的自定义 Retriever 时添加额外的 元信息(meta information) 展开了讨论。用户争论创建自定义 QueryFusionRetriever 是否是有效管理这些额外数据的解决方案。
- 优化检索策略可以提高数据查询的效率。
LAION Discord
-
寻找营养数据集:由于 OpenFoodFacts 数据集 的不足,一位成员正在寻找包含详细营养信息(包括条形码和饮食标签)的数据集。
- 他们的目标是找到一个结构更完整的数据集,以满足开发食品检测模型的需求。
-
对 Patch 伪影的挫败感:成员们对自回归图像生成中出现的 Patch 伪影 表示沮丧,并表达了对矢量量化(vector quantization)替代方案的需求。
- 尽管他们不喜欢 Variational Autoencoders (VAEs),但由于在生成清晰图像方面面临挑战,他们感到不得不考虑使用它。
-
关于图像生成替代方案的讨论:有建议指出,即使不使用 VAE 生成图像,仍然会导致 Patch 的使用,其功能与 VAE 非常相似。
- 这引发了关于不依赖传统方法的图像生成方法所面临的固有挑战的更广泛讨论。
Gorilla LLM (Berkeley Function Calling) Discord
-
参数类型错误引起困惑:一位成员报告遇到了参数类型错误,模型在评估过程中返回了 string 而不是预期的 integer。
- 该 Bug 直接影响了模型的整体性能,是社区内关注的一个重要问题。
-
如何评估自定义模型:有人询问如何在 Berkeley Function Calling 排行榜上评估 finetuned models,特别是关于处理单次和并行调用的问题。
- 明确这一主题对于确保正确理解现有的评估方法至关重要。
-
命令输出问题引发困惑:一位成员分享说运行
bfcl evaluate后显示没有模型被评估,从而对该命令的有效性提出了质疑。- 得到的指导是检查评估结果的存放位置,这暗示了在使用该命令时缺乏清晰度。
-
正确的命令序列对评估至关重要:会议明确了在运行评估命令之前,必须使用
bfcl generate后跟模型名称来获取响应。- 这一细节对于参与者正确遵循评估流程至关重要。
-
确认 Generate 命令中的模型名称:成员们确认生成命令中的
xxxx指的是模型名称,强调了准确命令语法的重要性。- 查阅 setup instructions 对于确保正确执行命令至关重要。
OpenAccess AI Collective (axolotl) Discord
-
SageAttention 超越 FlashAttention:新推出的 SageAttention 方法显著增强了 Transformer 模型中注意力机制的量化,其 OPS 分别比 FlashAttention2 和 xformers 高出 2.1 倍 和 2.7 倍,详见此 研究论文。这一进展还提供了优于 FlashAttention3 的准确性,暗示了在高效处理更长序列方面的潜力。
- 此外,SageAttention 对未来 Transformer 模型架构的影响可能非常重大,填补了性能优化方面的关键空白。
-
对 Axolotl Docker 标签的困惑:用户对
winglian/axolotl和winglian/axolotl-cloud的 Docker 镜像发布策略 提出了疑虑,特别是关于main-latest等动态标签是否适合稳定的生产环境使用。用户强调需要更清晰的发布策略文档,因为反映 main-YYYYMMDD 的标签暗示的是每日构建版本而非稳定版本。- 这一讨论强调了随着用户寻求生产环境的可靠部署,对版本控制清晰度的需求日益增长。
-
H100 兼容性即将到来:一位成员报告称 H100 兼容性 即将推出,并引用了一个相关的 GitHub pull request,该 PR 重点介绍了 bitsandbytes 库即将进行的改进。此次兼容性更新有望增强在现有 AI 工作流中的集成。
- 社区成员对这一兼容性可能为他们的项目带来的性能提升和新应用表示期待。
-
bitsandbytes 更新讨论:最新的讨论集中在预期的 H100 兼容性 对 bitsandbytes 库的影响,社区成员热衷于分享关于其潜在益处的见解。对该更新的热情表明了他们正在进行的创新项目正处于关键时刻。
- 随着改进的展开,成员们探讨了新兼容性可能带来的性能升级和众多应用场景。
LangChain AI Discord
-
自定义模型创建是关键:一位成员强调,唯一的选择是创建完全自定义的模型,并引导他人参考 Hugging Face 文档 以获取指导。
- 成员们承认了利用这些资源的重要性,并指出大量示例可以辅助开发过程。
-
使用 Ollama 构建你自己的聊天应用:一位成员分享了一篇关于使用 Ollama 构建聊天应用的 LinkedIn 帖子,强调了其灵活性。
- 该帖子强调了 Ollama 提供的 定制化 和 控制力 的优势,这对于有效的聊天解决方案至关重要。
-
关于聊天应用核心功能的讨论:成员们讨论了集成到聊天应用中的关键功能,强调了 安全性 和增强的 用户体验。
- 他们指出,加入 实时消息 等功能可以显著提高用户满意度。
Alignment Lab AI Discord
-
Steam 礼品卡分享:一位成员分享了一个购买 50 美元 Steam 礼品卡 的链接,可在 steamcommunity.com 获取。这对于希望进行游戏或在项目中使用游戏引擎的工程师来说可能感兴趣。
- 礼品卡可以作为一种有趣的激励方式或 团队建设活动 的工具,鼓励工程社区内的创造力。
-
Steam 礼品促销重复:有趣的是,同一个 50 美元 Steam 礼品卡 链接也在另一个频道中被分享,再次强调了其在 steamcommunity.com 的可用性。
- 这种重复可能表明成员们对参与游戏内容或奖励有浓厚兴趣。
LLM Agents (Berkeley MOOC) Discord
-
对 LLM Agents 的兴趣被激发:参与者表示有兴趣通过 Berkeley MOOC 学习 LLM Agents。
- evilspartan98 强调了这次机会,可以加深对语言处理中基于 Agent 模型(agent-based models)的理解。
-
Berkeley MOOC 的参与度:Berkeley MOOC 中正在进行的讨论表明,成员们对 LLM Agents 未来影响的关注度日益增加。
- 集体参与强调了大家对探索该领域创新框架和应用的共同热情。
LLM Finetuning (Hamel + Dan) Discord 没有新消息。如果该社区沉寂时间过长,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该社区沉寂时间过长,请告知我们,我们将将其移除。
Torchtune Discord 没有新消息。如果该社区沉寂时间过长,请告知我们,我们将将其移除。
Mozilla AI Discord 没有新消息。如果该社区沉寂时间过长,请告知我们,我们将将其移除。
DiscoResearch Discord 没有新消息。如果该社区沉寂时间过长,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该社区沉寂时间过长,请告知我们,我们将将其移除。
第二部分:按频道详细摘要和链接
完整的逐频道明细已在邮件中截断。
如果你喜欢 AInews,请分享给朋友!预先感谢!