ainews-tencents-hunyuan-large-claims-to-beat
腾讯的 Hunyuan-Large 声称以更少的数据击败了 DeepSeek-V2 和 Llama3-405B。
腾讯发布了一款备受关注的、参数量超过 3000 亿的 MoE(混合专家)模型。该模型在 7 万亿(7T)token 上进行了预训练,其中包括通过 Evol-Instruct 生成的 1.5 万亿(1.5T)合成数据。该模型引入了诸如“循环路由”(recycle routing)和专家特定学习率等新技术,以及针对 MoE 激活参数的计算高效缩放定律(scaling law)。然而,其自定义许可证限制了在欧盟境内的使用,也禁止月活跃用户数(MAU)超过 1 亿的公司使用,且该模型会避开涉及中国敏感话题的查询。
与此同时,Anthropic 推出了 Claude 3.5 Haiku,目前已在多个平台上线。尽管其智能程度和速度备受赞誉,但因价格上涨了 10 倍而遭到批评。Meta 向美国国防部门开放了 Llama AI,并举办了 Llama Impact 黑客松,为使用 Llama 3.1 和 3.2 Vision 的项目提供 1.5 万美元的奖金。LlamaIndex 发布了一个集成了 Tailwind CSS 和大模型后端的 React 聊天 UI 组件。MLX LM 模型则通过 KV 缓存量化技术,进一步提升了文本生成的执行速度和效率。
Evol-instruct 合成数据就是你所需要的一切。
2024年11月4日至11月5日的 AI 新闻。我们为您检查了 7 个 subreddits、433 个 Twitter 账号 和 30 个 Discord 服务器(217 个频道,3533 条消息)。预计节省阅读时间(以 200wpm 计算):364 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
我们倾向于对中国模型设定很高的标准,尤其是来自此前不为人知的团队。但腾讯今天发布的成果(huggingface,论文,HN 评论)在与其宣称的已知 SOTA 开源权重模型的对比中非常引人注目:
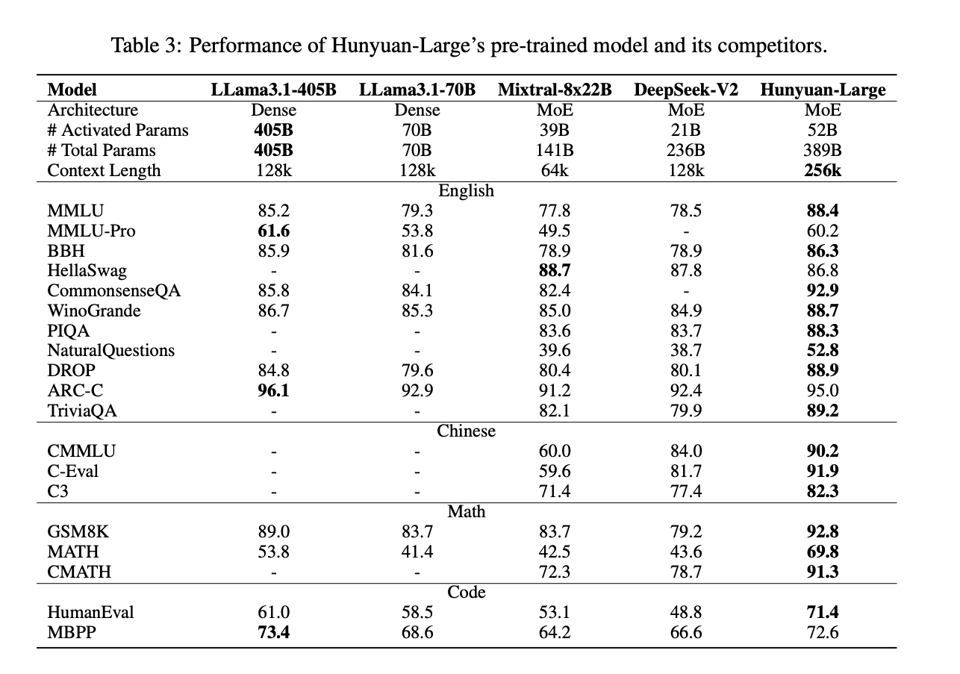
值得注意的是,作为一个参数量超过 300B 的模型(无论是否为 MoE),它的数据效率非常高,仅在“只有” 7T tokens 上进行了预训练(DeepseekV2 是 8T,Llama3 是 15T),其中 1.5T 是通过 Evol-Instruct 生成的合成数据,Wizard-LM 团队对此也深有感触:

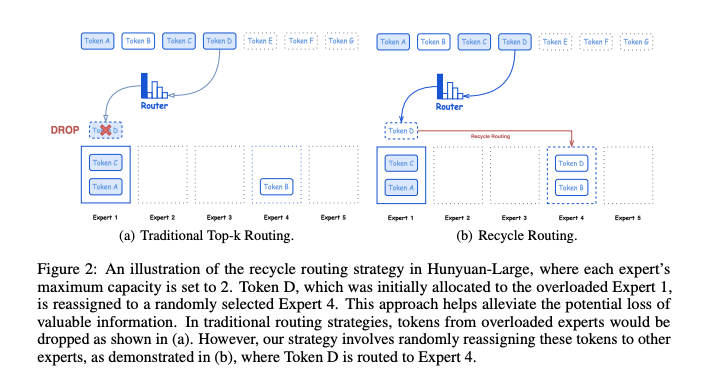
论文提供了一些他们探索的新颖方法的详细研究细节,包括 “recycle routing”:
以及 expert-specific LRs

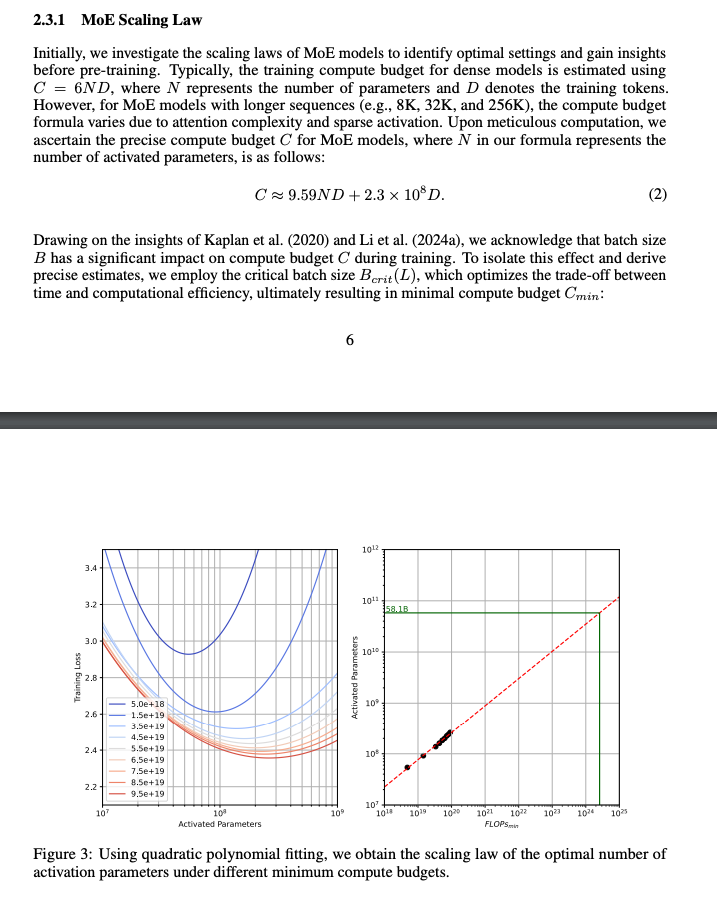
他们甚至研究并提供了一种针对 MoE 激活参数的计算高效的 scaling law:
情况并非全是正面的:自定义许可证禁止欧盟用户和 MAU 超过 1 亿的公司使用,当然,也不要问他们关于中国的敏感问题。Vibe checks 尚未得出结论(我们还没发现有人托管了方便的公共端点),目前也没有人对此大肆宣扬。尽管如此,对于这类模型来说,这仍然是一项不错的研究成果。
AI Twitter 综述
所有综述均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
AI 模型发布与更新
-
Claude 3.5 Haiku 增强功能:@AnthropicAI 宣布 Claude 3.5 Haiku 现已在 Anthropic API、Amazon Bedrock 和 Google Cloud 的 Vertex AI 上可用,将其定位为迄今为止最快且最智能的性价比模型。@ArtificialAnlys 分析称 Claude 3.5 Haiku 提升了智能水平,但指出其价格飙升,使其比 Google 的 Gemini Flash 和 OpenAI 的 GPT-4o mini 等竞争对手贵了 10 倍。此外,@skirano 分享道 Claude 3.5 Haiku 是最有趣的模型之一,在各种任务上表现优于之前的 Claude 模型。
-
Meta 的 Llama AI 用于国防:@TheRundownAI 报道称 Meta 已向美国国防部门开放 Llama AI,标志着 AI 领域的重大合作。
AI 工具与基础设施
-
转换会议录音:@TheRundownAI 介绍了一种将会议录音转化为可操作见解的工具,增强了生产力和信息获取能力。
-
Llama Impact 黑客松:@togethercompute 和 @AIatMeta 正在举办一场黑客松,专注于使用 Llama 3.1 & 3.2 Vision 构建解决方案,提供 $15K 奖金池并鼓励在现实挑战上进行协作。
-
LlamaIndex Chat UI:@llama_index 推出了 LlamaIndex chat-ui,这是一个用于构建聊天界面的 React 组件库,具有 Tailwind CSS 自定义功能以及与 Vercel AI 等 LLM 后端集成的特点。
AI 研究与基准测试
-
MLX LM 进展:@awnihannun 强调,最新的 MLX LM 在处理超大型模型时生成文本的速度更快,并引入了 KV cache 量化以提高效率。
-
自进化 RL 框架:@omarsar0 提出了一个 自进化在线课程 RL 框架,显著 提高了模型(如 Llama-3.1-8B)的成功率,表现优于 GPT-4-Turbo 等模型。
-
LLM 评估综述:@sbmaruf 发布了一份关于评估 Large Language Models 的 系统性综述,探讨了对于 稳健模型评估 至关重要的 挑战与建议。
AI 行业事件与黑客松
-
AI 高价值动态:@TheRundownAI 分享了 顶级 AI 故事,包括 Meta 用于国防的 Llama AI、Anthropic 发布 Claude Haiku 3.5,以及 Physical Intelligence 获得 4 亿美元融资 等新闻。
-
Builder’s Day 回顾:@ai_albert__ 回顾了与 @MenloVentures 合作举办的首届 Builder’s Day 活动,强调了开发者之间的 才华与协作。
-
ICLR 紧急征集审稿人:@savvyRL 为 LLM 推理 和 代码生成 等主题征集 紧急审稿人,强调了对专家评审的迫切需求。
AI 定价与市场反应
-
Claude 3.5 Haiku 定价争议:@omarsar0 对 Claude 3.5 Haiku 的 价格飙升 表示担忧,质疑其相对于 GPT-4o-mini 和 Gemini Flash 等其他模型的 价值主张。同样,@bindureddy 批评了 4 倍的价格上涨,认为这与 性能提升 不符。
-
Python 3.11 性能提升:@danielhanchen 提倡升级到 Python 3.11,详细介绍了其在 Linux 上 快 1.25 倍、在 Mac 上 快 1.2 倍 的性能表现,以及 优化的帧对象 和 函数调用内联 等改进。
-
腾讯的合成数据策略:@_philschmid 讨论了 腾讯 的策略,即在 1.5 万亿合成 Token 上训练其 389B 参数 MoE,并强调了其优于 Llama 3.1 等模型的 性能。
模因与幽默
-
AI 与选举幽默:@francoisfleuret 幽默地请求 GPT 在三天内 删除非编程和非小猫相关的推文,并生成一份 欢快的事件总结。
-
有趣的模型行为:@reach_vb 分享了一个 音频生成模型 “失控”的幽默观察,而 @hyhieu226 则开玩笑地发布了关于 特定 AI 回复 的推文。
-
用户互动与反应:@nearcyan 发布了一个与政治相关的模因,而 @kylebrussell 分享了一条轻松的“氛围感”推文。
AI Reddit 回顾
/r/LocalLlama 回顾
主题 1. 腾讯混元-Large:开源模型中的游戏规则改变者
- 腾讯刚刚发布了一个开源权重的 389B MoE 模型 (Score: 336, Comments: 132):腾讯发布了一个名为 Hunyuan-Large 的开源权重 389B MoE 模型,旨在性能上与 Llama 竞争。该模型架构利用了 Mixture of Experts (MoE),实现了高效扩展并提升了处理复杂任务的能力。
- Hunyuan-Large 模型拥有 3890 亿参数,其中 520 亿激活参数,支持 高达 256K Token。用户注意到其高效利用 CPU 的潜力,一些人在 DDR4 上有效运行了类似模型,并对该模型与 Llama 变体相比的能力感到兴奋。
- 讨论强调了模型的 巨大体量,据估计运行该模型需要 200-800 GB 内存,具体取决于配置。用户还分享了性能指标,表明它可能优于 Llama3.1-70B,同时由于其 Mixture of Experts (MoE) 架构,推理成本更低。
- 考虑到 中国的 GPU 制裁,人们对硬件限制产生了担忧,引发了关于腾讯如何运行此类大型模型的疑问。用户推测需要高端配置,有人开玩笑说需要一座 核电站 来为所需的 GPU 供电。
主题 2. Tensor Parallelism 增强 Llama 模型:基准测试见解
- 公告:llama.cpp 补丁使我的最大上下文长度翻倍 (Score: 95, Comments: 10):最近针对 llama.cpp 的一个补丁,使使用 3x Tesla P40 GPU 并在行拆分模式(
-sm row)下运行的用户,其最大上下文长度从 60K tokens 翻倍至 120K tokens。正如 Pull Request 中详述的那样,这一改进还带来了更均衡的 GPU VRAM 使用率,在不影响推理速度的情况下提升了整体 GPU 利用率。- 使用 3x Tesla P40 GPU 的用户报告称,由于上下文长度从 60K 增加到 120K tokens,他们的工作流得到了显著改善。一位用户指出,之前的限制迫使他们只能在小上下文中使用大型模型,这阻碍了性能发挥,而该补丁允许更高效的模型使用。
- 几条评论强调了新补丁易于实现的特点,一位用户成功在 QWEN-2.5-72B_Q4_K_S 上加载了 16K 上下文,并表示性能与之前的速度保持一致。另一位用户对模型按行拆分时缓存处理能力的提升表示兴奋。
- 用户分享了优化 GPU 性能的技巧,包括建议使用 nvidia-pstated 来管理 P40 的电源状态。该工具有助于在 GPU 负载和闲置时保持较低的功耗(8-10W),从而提高整体效率。
- 4x RTX 3090 + Threadripper 3970X + 256 GB RAM LLM 推理基准测试 (Score: 48, Comments: 39):该用户在一台配备 4x RTX 3090 GPU、Threadripper 3970X 和 256 GB RAM 的设备上进行了 LLM 推理基准测试。结果显示,Qwen2.5 和 Mistral Large 等模型表现出不同的 tokens per second (tps),Tensor Parallel 实现显著增强了性能,推理期间 PCIe 传输速率从 1 kB/s 增加到 200 kB/s 证明了这一点。
- 用户讨论了电源的稳定性,kryptkpr 建议使用 Dell 1100W 电源配合转接板(breakout boards)以实现可靠的电力输送,在闲置时可达到 12.3V。他们还分享了用于 PCIe 连接的可靠转接板链接。
- Lissanro 建议在使用 Tensor Parallel 的同时,通过 TabbyAPI (ExllamaV2) 探索 Speculative Decoding(投机解码),强调了在使用具有激进量化技术的 Qwen 2.5 和 Mistral Large 等模型时潜在的性能提升。同时也提供了这些模型的相关链接。
- a_beautiful_rhind 指出 Exllama 没有实现 NVLink,这限制了其性能潜力,而 kmouratidis 则建议在不同的 PCIe 配置下进行进一步测试,以评估潜在的降频影响。
主题 3. 编程模型领域的竞争进展:Qwen2.5-Coder 分析
- Qwen2.5-Coder-32B 到底在哪? (Score: 76, Comments: 21):Qwen2.5-Coder-32B 版本正在准备中,旨在与领先的专有模型竞争。该团队还在研究先进的以代码为中心的推理模型,以增强代码智能,更多更新将在其 博客 上发布。
- 用户对 Qwen2.5-Coder-32B 的发布时间表表示怀疑,评论指出“即将推出”这句话已经说了 两个月,却没有任何实质性更新。
- 用户 radmonstera 分享了他们使用 Qwen2.5-Coder-7B-Base 进行自动补全并配合 70B 模型使用的经验,指出 32B 版本虽然可以减少 RAM 占用,但速度可能无法与 7B 模型媲美。
- 普遍对该发布充满期待,用户 StarLord3011 希望能在几周内发布,而另一位用户 visionsmemories 则幽默地调侃了发布过程中可能存在的疏忽。
- 编程模型正变得越来越强大 (Score: 170, Comments: 71): 用户越来越多地在本地大语言模型 (LLM) 应用中采用 Qwen2.5 Coder 7B,并称赞其速度和准确性。一位用户报告称在搭载 LM Studio 的 Mac 上成功运行。
- 用户报告 Qwen2.5 Coder 7B 性能出色,一位用户在 M3 Max MacBook Pro 上运行达到了每秒约 18 tokens 的速度。另一位用户强调 Qwen 2.5 32B 模型在各项任务中表现优于 Claude,尽管对于本地 LLM 编程模型与 Claude 及 GPT-4o 相比的能力仍存在一些质疑。
- 基于 Qwen 2.5 14B 的 Supernova Medius 模型被强调为一款高效的编程助手,用户分享了该模型的 GGUF 链接和原始权重链接(点击此处)。用户对专用 32B coder 模型的潜力表示出浓厚兴趣。
- 讨论显示用户对 Qwen 2.5 的评价褒贬不一,部分用户认为它处理基础任务表现良好,但在处理比 Claude 和 OpenAI 模型更复杂的编程场景时仍显不足。一位用户提到,虽然 Qwen 2.5 在离线使用方面表现稳健,但仍无法与 GPT-4o 等更先进的闭源模型相媲美。
主题 4. 新型 AI 工具:语音克隆与投机采样技术
- OuteTTS-0.1-350M - 基于 LLaMa 架构的零样本语音克隆,采用 CC-BY 许可! (Score: 69, Comments: 13): OuteTTS-0.1-350M 具有基于 LLaMa 架构 的零样本语音克隆 (Zero-shot voice cloning) 功能,并以 CC-BY 许可 发布。该模型代表了语音合成技术的重大进步,无需针对特定语音数据进行预先训练即可生成语音输出。
- OuteTTS-0.1-350M 模型利用了 LLaMa 架构,受益于 llama.cpp 的优化,并在 Hugging Face 上提供了 GGUF 版本。
- 用户强调零样本语音克隆能力是语音合成技术的一项重大突破,官方博客 链接提供了更多细节。
- 讨论中提到了 TTS 系统中的语音恐怖谷 (Audio uncanny valley) 现象,即微小的错误会导致输出结果“几乎”像人类,从而给听者带来不安的体验。
- OpenAI 新功能 “Predicted Outputs” 使用投机采样技术 (Score: 51, Comments: 28): OpenAI 的新功能 “Predicted Outputs” 利用了投机采样 (Speculative decoding) 技术,这一概念一年多前就已在 llama.cpp 中得到验证。该帖子提出了关于在 70B 规模模型 以及 llama3.2 和 qwen2.5 等较小模型上实现更快推理的潜力,特别是对于本地用户而言。更多详情请参阅此处的 推文 以及 Karpathy 的 演示。
- 投机采样 (Speculative decoding) 可以通过允许较小模型快速生成初始 token 序列,再由较大模型进行验证,从而显著提升推理速度。像 Ill_Yam_9994 和 StevenSamAI 这样的用户讨论了这种方法如何有效地实现并行处理,在通常生成一个 token 的时间内可能生成多个 token。
- 几位用户指出,虽然 “Predicted Outputs” 功能可能会降低延迟,但不一定能降低模型使用成本,正如 HelpfulHand3 所言。该技术被公认为设备端推理 (On-device inference) 的标准,但正如 Old_Formal_1129 所提到的,对较小模型进行适当的训练对于最大化性能至关重要。
- 对话还涉及了分层模型的构想,即较小模型预测输出,较大模型进行验证,这可能会带来显著的速度提升,正如 Balance- 所提议的那样。这种分层方法引发了关于整合多种规模模型以实现最佳性能的有效性和可行性的讨论。
其他 AI Subreddit 回顾
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
自主系统与安全
- 大众汽车的紧急辅助技术 (Emergency Assist Technology):在 /r/singularity 中,大众汽车展示了新的自动驾驶技术,该技术可在驾驶员失去反应时安全地将车辆停靠在路边,在激活前会进行多个阶段的驾驶员注意力检查。
- 关键评论见解:系统包含对避免误触发和保持驾驶员控制的细致考量。
AI 安全与漏洞
- Google 的 Big Sleep AI Agent:在 /r/OpenAI 和 /r/singularity 中,Google 的安全 AI 发现了 SQLite 中的一个零日漏洞 (zero-day vulnerability),这标志着 AI Agent 首次公开在广泛使用的软件中发现以前未知的可利用内存安全问题。
- 技术细节:该漏洞已于 10 月正式发布前报告并修复。
3D 化身生成与渲染
- URAvatar 技术:在 /r/StableDiffusion 和 /r/singularity 中,一项新研究展示了逼真的头部化身 (head avatars),该研究使用光照未知的手机扫描,具有以下特点:
- 具有全局光照的实时渲染
- 用于光传输的可学习辐射传输 (radiance transfer)
- 在数百个高质量多视图人体扫描上进行训练
- 3D Gaussian 表示
行业动态与企业 AI
- OpenAI 动态:多个 Subreddit 的帖子指出:
AI 图像生成评论
- Adobe AI 的局限性:在 /r/StableDiffusion 中,用户报告了 Adobe AI 图像生成工具中显著的内容限制,特别是在人物主体和服装方面。
- 技术限制:由于过于激进的内容过滤,系统甚至会阻止基础的图像编辑任务。
迷因与幽默
AI Discord 简报
由 O1-preview 生成的摘要之摘要的摘要
主题 1. AI 巨头发布巨型模型:新的重量级选手
- 腾讯发布 389B 参数的 Hunyuan-Large MoE 模型:腾讯发布了 Hunyuan-Large,这是一个巨大的 Mixture-of-Experts 模型,拥有 3890 亿参数和 520 亿激活参数。虽然品牌定位为开源,但关于其真实的易用性以及运行它所需的庞大基础设施,讨论依然激烈。
- Anthropic 在用户抱怨声中推出 Claude 3.5 Haiku:Anthropic 推出了 Claude 3.5 Haiku,用户们正急于测试其在速度、代码准确性和工具集成方面的表现。然而,Claude 3 Opus 的移除引发了不满,因为许多人更倾向于将其用于编程和叙事。
- OpenAI 通过 Predicted Outputs 降低 GPT-4 延迟:OpenAI 引入了 Predicted Outputs,通过提供参考字符串,大幅降低了 GPT-4o 模型的延迟。基准测试显示,在文档迭代和代码重写等任务中,速度提升高达 5.8 倍。
主题 2. 国防遇见 AI:LLM 投身国家安全
- Scale AI 为机密任务部署 Defense Llama:Scale AI 宣布推出 Defense Llama,这是一款与 Meta 及国防专家共同开发的专用 LLM,旨在服务于美国国家安全应用。该模型已准备好集成到美国国防系统中。
- Nvidia 的 Project GR00T 旨在打造机器人霸主:来自 NVIDIA GEAR 团队的 Jim Fan 讨论了 Project GR00T,旨在开发能够在模拟和真实环境中运行的 AI Agent,增强机器人的通用能力。
- OpenAI 致力于安全 AGI 开发:成员们强调了 OpenAI 自 2015 年以来的创始目标,即构建安全且有益的 AGI。讨论还涉及了对 AI 自我开发的担忧,即如果成本超过了所有人类投入的情况。
主题 3. 开放数据盛宴:数据集将为 AI 注入强劲动力
- Open Trusted Data Initiative 预告 2 万亿 Token 数据集:Open Trusted Data Initiative 计划于 11 月 11 日通过 Hugging Face 发布一个包含 2 万亿 Token 的海量多语言数据集,旨在提升 LLM 的训练能力。
- 社区辩论训练数据的质量与数量:讨论强调了高质量数据集对未来 AI 模型的重要性。有人担心优先考虑质量可能会排除有价值的主题,但它能增强常识推理(commonsense reasoning)。
- EleutherAI 增强 LLM 鲁棒性评估:LLM Robustness Evaluation 开启了一个 Pull Request,引入了跨三个数据集的系统性一致性和鲁棒性评估,并修复了之前的 Bug。
主题 4. 用户对机器的愤怒:AI 工具备受指责
- Perplexity 用户哀悼 Claude 3 Opus 的缺失:从 Perplexity AI 中移除 Claude 3 Opus 导致了用户的不满,许多人声称它是他们编程和叙事的首选模型。Haiku 3.5 被认为是一个效果较差的替代品。
- LM Studio 用户应对故障和性能问题:LM Studio 用户报告了模型性能方面的挑战,包括 Hermes 405B 的结果不一致,以及从 USB 驱动器运行软件的困难。解决方法包括使用 Linux AppImage 二进制文件。
- NotebookLM 用户要求更好的语言支持:NotebookLM 中的多语言支持问题导致生成的摘要使用了非预期的语言。用户呼吁提供更直观的界面来直接管理语言偏好。
主题 5. AI 优化成为焦点:速度与效率
- Speculative Decoding 承诺更快的 AI 输出:关于 Speculative Decoding 的讨论强调了一种方法,即由较小的模型生成草稿,再由较大的模型进行精炼,从而缩短推理时间。虽然速度有所提升,但关于输出质量的问题依然存在。
- Python 3.11 将 AI 性能提升 1.25 倍:得益于静态分配的核心模块和内联函数调用等优化,升级到 Python 3.11 在 Linux 上可获得高达 1.25 倍 的加速,在 Windows 上为 1.12 倍。
- OpenAI 的 Predicted Outputs 重写速度脚本:通过引入 Predicted Outputs,OpenAI 缩短了 GPT-4 的响应时间,用户报告在代码重写任务中有显著的速度提升。
第一部分:Discord 高层摘要
HuggingFace Discord
-
Open Trusted Data Initiative 发布 2 万亿 Token 多语言数据集:Open Trusted Data Initiative 计划于 11 月 11 日通过 Hugging Face 发布包含 2 万亿 token 的最大多语言数据集。
- 该数据集旨在通过为开发者和研究人员提供广泛的多语言资源,显著增强 LLM 训练能力。
-
Computer Vision 模型量化技术:一位成员正在开发一个专注于 Computer Vision 模型量化的项目,旨在通过 quantization aware training 和 post training quantization 方法在边缘设备上实现更快的推理。
- 该计划强调减少模型权重并理解其对训练和推理性能的影响,引起了社区的关注。
-
Microsoft 发布新模型:社区对 Microsoft 发布的新模型感到兴奋,这些模型满足了几位成员的期望。
- 这些模型因解决了特定的功能需求而受到认可,增强了 AI 工程师可用的工具包。
-
AI 模型中的 Speculative Decoding:关于 speculative decoding 的讨论涉及使用较小的模型生成草稿输出,再由较大的模型进行细化,旨在缩短推理时间。
- 虽然这种方法提高了速度,但与使用单个大模型相比,在保持输出质量方面仍存在疑问。
-
在 Chroma Vector Store 中构建 RAG 的挑战:一位用户尝试使用 21 份文档构建 RAG 系统,但在 Chroma vector store 中存储 embeddings 时遇到问题,仅成功保存了 7 个 embeddings。
- 社区成员建议检查潜在的 error 信息,并查看默认函数参数,以确保文档没有被无意中丢弃。
Perplexity AI Discord
-
Opus 的移除引发用户不满:用户对 Claude 3 Opus 的移除表示失望,强调它是他们在 Anthropic 网站上进行编程和故事创作的首选模型。
- 许多人请求恢复之前的模型或提供替代方案,因为 Haiku 3.5 被认为效果较差。
-
Perplexity Pro 增强订阅权益:关于 Perplexity Pro 功能的讨论显示,Pro 订阅者可以通过 Revolut 推荐等合作伙伴关系获得高级模型的使用权。
- 关于 Pro 档位是否包含 Claude 访问权限以及移动应用程序最近的更新,仍然存在疑问。
-
Grok 2 与 Claude 3.5 Sonnet 之争:工程师们正在争论 Grok 2 和 Claude 3.5 Sonnet 哪个模型在复杂研究和数据分析方面表现更优。
- Perplexity 在学术场景下的优势受到称赞,而像 GPT-4o 这样的模型在编程和创意任务中表现出色。
-
Nvidia 通过战略市场举措瞄准 Intel:Nvidia 正在进行战略布局,直接与 Intel 竞争,旨在改变市场动态并影响产品策略。
- 分析师建议关注 Nvidia 即将开展的合作和发布的产品,这些可能会对技术格局产生重大影响。
-
分子神经形态平台取得突破:一种新型 molecular neuromorphic platform 模仿人类大脑功能,代表了 AI 和神经科学研究的重大进展。
- 专家对该平台在深化我们对人类认知的理解以及增强 AI 开发方面的潜力表示审慎乐观。
OpenRouter (Alex Atallah) Discord
-
Anthropic 推出 Claude 3.5 Haiku:Anthropic 已发布 Claude 3.5 的标准版和自我审查版,更多带有日期的版本选项可在此处查看。
- 用户渴望评估该模型在实际应用中的表现,期待其在速度、编码准确性和工具集成方面的提升。
-
免费 Llama 3.2 模型开放访问:Llama 3.2 模型(包括 11B 和 90B)现在提供免费的快速端点,分别达到 280tps 和 900tps,详见此处。
- 该举措旨在通过免费提供高吞吐量选项,增强社区对开源模型的参与度。
-
聊天室新增 PDF 分析功能:新功能允许用户在聊天室中上传或附加 PDF,并使用 OpenRouter 上的任何模型进行分析。
- 此外,最高购买限额已提高至 $10,000,为用户提供了更大的灵活性。
-
预测输出(Predicted Output)功能降低延迟:OpenAI 的 GPT-4 模型现已支持预测输出,通过
prediction属性优化编辑和重写任务。- 示例代码片段展示了其在更高效处理大量文本请求中的应用。
-
Hermes 405B 表现不稳定:免费版的 Hermes 405B 表现一直不稳定,用户报告存在间歇性功能故障。
- 许多用户仍持乐观态度,认为这些性能问题预示着正在进行更新或修复。
aider (Paul Gauthier) Discord
-
Aider v0.62.0 发布:Aider v0.62.0 现在全面支持 Claude 3.5 Haiku,在代码编辑排行榜上取得了 75% 的分数。此版本支持无缝编辑来自 ChatGPT 等网页版 LLM 的文件。
- 此外,Aider 生成了此版本中 84% 的代码,展示了显著的效率提升。
-
Claude 3.5 Haiku 对比 Sonnet:Claude 3.5 Haiku 提供了与 Sonnet 几乎相同的性能,但更具成本效益。用户可以通过使用
--haiku命令行选项来激活 Haiku。- 这种高性价比使 Haiku 成为许多人 AI 编码工作流中的首选。
-
AI 编码模型对比:用户分析了 AI 编码模型之间的性能差异,指出 3.5 Haiku 与 Sonnet 3.5 和 GPT-4o 相比效果略逊一筹。
- 市场对即将推出的 4.5o 等模型充满期待,这些模型可能会打破现状并影响 Anthropic 的市场地位。
-
预测输出功能的影响:正如 OpenAI Developers 的推文所述,OpenAI Predicted Outputs 的推出预计将通过降低延迟和提高代码编辑效率来彻底改变 GPT-4o 模型。
- 该功能预计将显著影响模型基准测试,尤其是与竞争模型直接对比时。
-
使用 Claude Haiku 作为编辑器模型:Claude 3 Haiku 被用作编辑器模型,以弥补主模型编辑能力的不足,从而增强开发过程。
- 这种方法对于需要精确语法管理的编程语言特别有益。
Eleuther Discord
-
积极性驱动成功的读书小组:一位成员强调,成功运行读书小组 (reading groups) 更多地依赖于积极性 (initiative) 而非专业知识 (expertise)。他在没有先验知识的情况下发起了 mech interp 读书小组,并始终坚持维护。
- 这种方法强调了在维持有效的学习会议中,主动领导和社区参与的重要性。
-
通过高级设置优化训练:参与者讨论了各种优化器设置(如 beta1 和 beta2)的影响,以及它们在模型训练期间与 FSDP 和 PP 等策略的兼容性。
- 不同的观点突显了训练效率与模型性能之间的平衡。
-
增强 Logits 和概率优化:深入讨论了优化 logits 输出以及确定训练所需的适当数学范数,建议使用 L-inf norm 来最大化概率,或通过 KL divergence 保持分布形状。
- 参与者探索了微调模型输出的方法,以提高预测准确性和稳定性。
-
LLM 鲁棒性评估 PR 增强框架:一位成员宣布针对三个不同数据集开启了 LLM Robustness Evaluation 的 PR,并邀请反馈和评论,可在此处查看。
- 该 PR 为大语言模型引入了系统的连贯性和鲁棒性评估,同时解决了之前的 bug。
Unsloth AI (Daniel Han) Discord
-
Python 3.11 在 Linux 上提升 1.25 倍性能:鼓励用户切换到 Python 3.11,因为它通过各种优化在 Linux 上提供高达 1.25 倍的加速,在 Windows 上提供 1.12 倍的加速。
- 核心模块被静态分配以加快加载速度,函数调用现在改为内联 (inlined),从而增强了整体性能。
-
llama.cpp 支持 Qwen 2.5,即将集成 Vision 模型:讨论确认 llama.cpp 已支持 Qwen 2.5,详见 Qwen 文档。
- 社区正期待在 Unsloth 中集成 vision 模型,预计很快就会推出。
-
在有限数据集上微调 LLM:用户正在探索仅使用 10 个示例(总计 60,000 字)微调模型的可行性,专门用于标点符号纠正。
- 建议包括使用 batch size 为 1,以缓解与有限数据相关的挑战。
-
使用 Hugging Face 指标实现 mtbench 评估:一位成员询问了在 mtbench 数据集上运行类似 mtbench 评估的回调 (callbacks) 参考实现,并询问是否存在 Hugging Face evaluate 指标。
- 需要精简评估流程,强调了将此类功能集成到当前项目中的重要性。
-
使用 Hugging Face 指标增强 mtbench 评估:请求关于实现回调以在 mtbench 数据集上运行评估的见解,类似于现有的 mtbench 评估。
- 该询问突显了在正在进行的 AI 工程项目中对高效评估机制的需求。
LM Studio Discord
-
便携式 LM Studio 解决方案:一位用户询问关于从 USB 闪存盘运行 LM Studio 的问题,收到了使用 Linux AppImage 二进制文件或共享脚本来实现便携性的建议。
- 尽管目前缺乏官方便携版本,社区成员仍提供了变通方案,以促进 便携式 LM Studio 部署。
-
LM Studio 服务器日志访问:用户发现,在 LM Studio 中按下 CTRL+J 可以打开服务器日志选项卡,从而实现对服务器活动的实时监控。
- 这一快速访问功能被分享出来,旨在帮助成员有效地跟踪和调试服务器性能。
-
模型性能评估:Mistral vs Qwen2:Mistral Nemo 在基于 Vulkan 的操作中表现优于 Qwen2,展示了更快的 Token 处理速度。
- 这种性能差异凸显了不同 模型架构 (model architectures) 对计算效率的影响。
-
Windows 调度器效率低下:成员们报告称,Windows Scheduler 在多核设置中难以处理 CPU 线程管理,从而影响了性能。
- 一位成员建议手动为进程设置 CPU 亲和性 (affinity) 和 优先级 (priority),以减轻调度问题。
-
LLM 上下文管理挑战:上下文长度 (Context length) 显著影响 LLM 的 推理速度,一位用户指出,在大上下文情况下,首个 Token 的延迟达到了 39 分钟。
- 建议在启动新对话时优化 上下文填充水平 (context fill levels),以提高 推理响应速度。
Latent Space Discord
-
Hume App 发布,融合 EVI 2 与 Claude 3.5:全新的 Hume App 结合了由 EVI 2 语音语言模型生成的语音和个性,以及 Claude 3.5 Haiku,旨在通过 AI 生成的助手增强用户交互。
- 正如官方公告所强调的,用户现在可以访问这些助手进行更具动态性的互动。
-
OpenAI 通过 Predicted Outputs 降低 GPT-4 延迟:OpenAI 推出了 Predicted Outputs,通过提供参考字符串来加快处理速度,显著降低了 GPT-4o 和 GPT-4o-mini 模型的延迟。
- 正如 Eddie Aftandilian 所指出的,基准测试显示在文档迭代和代码重写等任务中速度有所提升。
-
Supermemory AI 工具管理你的数字大脑:一位 19 岁的开发者推出了 Supermemory,这是一个旨在管理书签、推文和笔记的 AI 工具,功能类似于针对已保存内容的 ChatGPT。
- 正如 Dhravya Shah 所展示的,通过聊天机器人界面,用户可以轻松检索和探索之前保存的内容。
-
腾讯发布巨型 Hunyuan-Large 模型:腾讯发布了 Hunyuan-Large 模型,这是一个基于 Transformer 的开源权重混合专家模型 (mixture of experts),拥有 3890 亿参数和 520 亿激活参数。
- 尽管被标记为开源,但关于其地位的争论依然存在,且其庞大的体积对大多数基础设施公司构成了挑战,详见 Hunyuan-Large 论文。
-
Defense Llama:用于国家安全的 AI:Scale AI 宣布了 Defense Llama,这是一个与 Meta 及国防专家合作开发的专用 LLM,针对美国国家安全应用。
- 根据 Alexandr Wang 的说法,该模型现在可集成到美国国防系统中,突显了 AI 在安全领域的进步。
Notebook LM Discord Discord
-
NotebookLM 扩展集成能力:成员们讨论了 NotebookLM 集成多个 notebook 或来源的潜力,旨在增强其在学术研究中的功能。目前每个 notebook 限制为 50 个来源是一个主要关注点,参考见 NotebookLM Features。
- 社区对支持跨 notebook 数据共享的功能增强表现出浓厚兴趣,反映出用户对改进协作工具和更清晰的开发路线图的渴望。
-
Deepfake 技术引发伦理问题:一位用户强调了在除臭剂广告中使用的 Face Swap 技术,指出了 deepfake 技术在营销活动中的应用。这在 Deepfake Technology 的背景下得到了进一步讨论。
- 另一位参与者强调,deepfakes 本质上涉及面部交换,这促进了对伦理影响的共同理解以及对此类技术负责任使用的必要性。
-
使用 NotebookLM 管理供应商数据:一位企业主探索使用 NotebookLM 来管理约 1,500 家供应商的数据,利用了包括 pitch decks 在内的各种来源。他们提到有一个数据团队准备协助导入,详见 Vendor Database Management Use Cases。
- 讨论中提出了对跨 notebook 数据共享的担忧,强调了对强大数据管理功能的需求,以确保大型数据集的安全性和可访问性。
-
NotebookLM 中的音频播客生成:NotebookLM 推出了音频播客生成功能,成员们因其在多任务处理中的便利性而给予了积极评价。用户询问了有效利用该功能的策略,如 Audio Podcast Generation Features 中所述。
- 社区对播客功能表现出极大的热情,提出了潜在的使用案例,并征求最佳实践,以在各种工作流中最大化其效益。
-
NotebookLM 语言支持的挑战:几位成员报告了 NotebookLM 的 multilingual support(多语言支持)问题,即尽管设置配置为英语,但生成的摘要却是其他语言。这是 Language and Localization Issues 中的主要话题。
- 成员们建议改进用户界面以更好地管理语言偏好,强调需要一个更直观的过程来直接更改语言设置。
Stability.ai (Stable Diffusion) Discord
-
SWarmUI 简化 ComfyUI 设置:成员们建议安装 SWarmUI 来简化 ComfyUI 的部署,并强调了其管理复杂配置的能力。
- 一位成员强调道:“它的设计初衷就是为了让你的生活变得更轻松。” 这展现了社区对用户友好型界面的认可。
-
云端托管 Stable Diffusion 的挑战:讨论显示,与本地设置相比,在 Google Cloud 上托管 Stable Diffusion 可能更加复杂且昂贵。
- 参与者建议使用 vast.ai 等 GPU 租赁平台作为部署模型的高性价比且更简单的替代方案。
-
Civitai 上的最新模型和 LoRas:用户探索了从 Civitai 下载 1.5、SDXL 和 3.5 等最新模型,并指出大多数 LoRas 都是基于 1.5 的。
- 像 v1.4 这样的旧版本被认为已经过时,社区建议升级以从增强的功能和性能中受益。
-
分享 Animatediff 教程资源:一位成员请求 Animatediff 的教程,并收到了参考 Purz 的 YouTube 频道 资源的建议。
- 社区对分享知识表现出极大的热情,加强了围绕动画工具的协作学习环境。
-
ComfyUI 现在通过 GenMo 的 Mochi 支持视频 AI:确认 ComfyUI 已通过 GenMo’s Mochi 集成了视频 AI 功能,尽管这需要相当高的硬件配置。
- 这一集成被视为一项重大进步,有可能利用 Stable Diffusion 技术拓展视频生成的视野。
Nous Research AI Discord
-
Hermes 2.5 数据集的 ‘weight’ 字段受到质疑:成员们分析了 Hermes 2.5 数据集的 ‘weight’ 字段,发现其贡献微乎其微,并导致大量 空字段。
- 有推测认为,优化数据集采样可能会提高其对小型 LLM 的效用。
-
Nous Research 确认 Hermes 系列保持开源:针对有关 闭源 LLM 的询问,Nous Research 确认 Hermes 系列 将继续保持 开源。
- 虽然未来的一些项目可能会采用封闭模式,但对 Hermes 系列 的开源承诺依然存在。
-
在未来 AI 模型中平衡质量与数量:讨论强调了 高质量数据集 对开发未来 AI 模型的重要性。
- 有人担心优先考虑质量可能会排除有价值的主题和事实,尽管这可能会增强 常识推理 (commonsense reasoning)。
-
引入 OmniParser 以增强数据解析:分享了 OmniParser 工具,该工具以提高 数据解析 能力而闻名。
- 其 创新方法 已引起 AI 社区的关注。
-
Hertz-Dev 发布全双工对话音频模型:Hertz-Dev GitHub 仓库 推出了首个用于 全双工对话音频 的基座模型。
- 该模型旨在促进在单一框架内的 speech-to-speech 交互,增强 音频通信。
Interconnects (Nathan Lambert) Discord
-
NeurIPS 赞助推进:一位成员宣布他们正在努力为 NeurIPS 寻找 赞助商,这标志着潜在的合作机会。
- 他们还发出了 NeurIPS 团体晚宴的邀请,旨在加强会议期间参会者之间的社交。
-
腾讯发布 389B MoE 模型:腾讯 发布了其 389B Mixture of Experts (MoE) 模型,在 AI 社区引起了重大反响。
- 讨论强调,该模型的先进功能可能会为大规模模型性能设定新基准,详见其 论文。
-
Scale AI 推出 Defense Llama:Scale AI 介绍了 Defense Llama,这是一个专为 机密网络 内的军事应用设计的专用 LLM,正如 DefenseScoop 所报道。
- 该模型旨在支持作战规划等行动,标志着将 AI 整合到国家安全框架中的举措。
-
YOLOv3 论文获得高度推荐:一位成员强调了 YOLOv3 论文 的重要性,称其为从业者的必读内容。
- 他们评论道:“顺便说一下,如果你还没读过 YOLOv3 的论文,那你真的错过了”,强调了其在该领域的相关性。
-
LLM 性能漂移调查:围绕创建一个系统或论文来 微调小型 LLM 或分类器 以监控写作等任务中的模型性能漂移展开了讨论。
- 成员们辩论了现有 提示词分类器 (prompt classifiers) 在准确跟踪漂移方面的有效性,强调了对稳健 评估流水线 (evaluation pipelines) 的需求。
OpenAI Discord
-
GPT-4o 推送引入了类 o1 推理能力:GPT-4o 的推送引入了类 o1 的推理能力,并在一个 canvas 风格的文本框中包含大段文本。
- 社区成员对于这次推送是针对常规 GPT-4o 的 A/B test,还是针对特定用途的专门版本存在困惑。
-
OpenAI 对安全 AGI 开发的承诺:一位成员强调,OpenAI 成立的目标是构建安全且有益的 AGI,这是自 2015 年成立以来就宣布的使命。
- 讨论中还涉及了一些担忧,即如果 AI 开发成本超过了所有人类投资,可能会导致 AI 自我开发(AI self-development),从而产生重大影响。
-
GPT-5 发布日期尚不确定:社区成员对 GPT-5 及其配套 API 的发布感到好奇,但也承认确切的时间表尚不清楚。
- 一位成员表示:“今年应该会有一些新发布,但不会是 GPT-5。”
-
Premium 账户账单问题:一位用户报告了其 Premium account 账单出现问题,指出尽管有来自 Apple 的付款证明,但其账户仍显示为免费计划。
- 另一位成员尝试通过分享链接进行协助,但问题仍未解决。
-
文档摘要中的 Hallucinations 问题:成员们对文档摘要过程中出现的 hallucinations(幻觉)表示担忧,尤其是在生产环境中扩展工作流时。
- 为了减少不准确性,一位成员建议实施第二次 LLM pass 进行事实核查。
LlamaIndex Discord
-
LlamaIndex chat-ui 集成:开发者可以使用 LlamaIndex chat-ui 快速为他们的 LLM 应用创建聊天界面,该工具提供预构建组件和 Tailwind CSS 定制功能,并能与 Vercel AI 等 LLM 后端无缝集成。
- 这种集成简化了聊天功能的实现,提高了 AI 工程师开发对话界面的效率。
-
高级报告生成技术:一篇新的博客文章和视频探讨了高级报告生成,包括结构化输出定义和高级文档处理,这对于优化企业报告工作流至关重要。
- 这些资源为 AI 工程师提供了关于增强 LLM 应用中报告生成能力的更深层见解。
-
NVIDIA 竞赛提交截止日期:NVIDIA competition 的提交截止日期为 11 月 10 日,通过此链接提交的项目有机会获得 NVIDIA® GeForce RTX™ 4080 SUPER GPU 等奖品。
- 鼓励开发者利用 LlamaIndex 技术创建创新的 LLM 应用以赢取奖励。
-
LlamaParse 功能与数据保留:LlamaParse 是一款闭源解析工具,可将文档高效转换为结构化数据,并提供 48 小时数据保留政策,详情参阅 LlamaParse 文档。
- 讨论强调了其性能优势以及数据保留对重复任务处理的影响,并引用了入门指南。
-
与 Cohere 的 ColiPali 进行多模态集成:一个正在进行的 PR 旨在将 ColiPali 作为 reranker 添加到 LlamaIndex 中,尽管由于多向量索引(multi-vector indexing)的要求,将其作为 indexer 集成仍具有挑战性。
- 社区正积极致力于扩展 LlamaIndex 的多模态数据处理能力,突显了与 Cohere 的协作努力。
Cohere Discord
-
Connectors 问题:成员们报告在使用 Coral web interface 或 API 时,connectors 无法正常工作,导致来自 reqres.in 的结果为零。
- 一位用户指出,connectors 的响应时间比预期长,响应时间超过了 30 秒。
-
Cohere API 微调与错误:微调 Cohere API 需要输入卡片详情并切换到生产密钥,用户需要为 SQL 生成准备合适的 prompt 和 response 示例。
- 此外,一些成员报告称,尽管在 playground 环境中操作成功,但在通过 API 运行微调后的 classify 模型时遇到了 500 错误。
-
在 Wordpress 上开发 Prompt Tuner:一位用户询问如何使用 API 在 Wordpress 网站上重建 Cohere prompt tuner。
-
另一位成员建议开发自定义后端应用程序,并指出 Wordpress 可以支持此类集成。参考 [Login Cohere](https://dashboard.cohere.com/prompt-tuner) 以获取高级 LLM 和 NLP 工具。
-
-
软件测试中的 Embedding 模型:成员们讨论了 embed model 在软件测试任务中的应用,以增强测试流程。
- 寻求关于 embedding 如何具体协助这些测试任务的澄清。
-
GCP Marketplace 计费关注:一位用户提出了在通过 GCP Marketplace 激活 Cohere 并获得 API 密钥后的计费流程问题。
- 他们寻求关于费用是扣除在 GCP 账户还是注册卡上的澄清,并表示更倾向于针对特定模型的计费方式。
OpenInterpreter Discord
-
Microsoft Omniparser 集成:一位成员询问关于集成 Microsoft Omniparser 的事宜,强调了其对开源模式的潜在益处。另一位成员确认他们正在积极探索这一集成。
- 讨论强调了利用 Omniparser 的能力来提高系统的解析效率。
-
Claude’s Computer Use 集成:成员们讨论了在当前的
--os模式中集成 Claude’s Computer Use,并确认已经完成整合。对话强调了对使用实时预览以改进功能的兴趣。- 参与者对无缝集成表示热烈欢迎,指出实时预览可以显著提升用户体验。
-
Agent 标准:一位成员提议为 Agent 创建一个标准,理由是 LMC 的设置比 Claude 的界面更简洁。他们建议 OpenInterpreter (OI) 与 Anthropic 合作,建立一个与 OAI endpoints 兼容的通用标准。
- 小组讨论了统一标准的可行性,并考虑了与现有 OAI endpoints 的兼容性要求。
-
OpenInterpreter 中的 Haiku 性能:一位成员询问了新版 Haiku 在 OpenInterpreter 中的性能,并提到他们尚未进行测试。这反映了社区对评估最新工具的持续兴趣。
- 大家一致认为,测试 Haiku 性能对于评估其在各种工作流中的有效性和适用性至关重要。
-
Tool Use 软件包增强:
Tool Use软件包已更新两个新的免费工具:ai prioritize 和 ai log,可以通过pip install tool-use-ai安装。这些工具旨在简化工作流并提高生产力。- 鼓励社区成员向 Tool Use GitHub 仓库贡献代码,该仓库包含详细文档并邀请持续改进 AI 工具。
Modular (Mojo 🔥) Discord
- 提醒:11月12日的 Modular 社区 Q&A:发出提醒,请为定于 11月12日 举行的 Modular 社区 Q&A 提交问题,可选择是否署名。
- 鼓励成员通过 提交表单 分享他们的疑问,以参与即将举行的 社区会议。
- 社区会议项目和演讲征集:邀请成员在 Modular 社区 Q&A 期间展示项目、发表演讲或提出想法。
- 这一邀请旨在促进社区参与,并允许在 11月12日的会议 上展示贡献。
- 在 Mojo 中实现 Effect System:关于在 Mojo 中集成 effect system 的讨论集中在将执行 syscalls 的函数标记为 block,默认情况下可能作为警告。
- 建议包括引入 ‘panic’ effect,以便在 Mojo 语言中对敏感上下文进行静态管理。
- 解决 Mojo 中的矩阵乘法错误:一位用户报告了其矩阵乘法实现中的多个错误,包括 Mojo 中
memset_zero和rand函数调用的问题。- 这些错误突显了与函数定义中的隐式转换和参数规范相关的问题。
- 优化 Matmul Kernel 性能:一位用户注意到他们的 Mojo matmul kernel 比 C 版本慢两倍,尽管使用了类似的向量指令。
- 目前正在考虑优化方案以及 bounds checking 对性能的影响。
DSPy Discord
- 发布新的选举候选人研究工具:一位成员介绍了 Election Candidate Research Tool,旨在选举前简化候选人研究,强调了其易用的特性和预期功能。
- 该 GitHub 仓库 鼓励社区贡献,旨在通过协作开发提升选民的研究体验。
- 使用 BootstrapFewShot 优化 Few-Shot:成员们探索了使用 BootstrapFewShot 和 BootstrapFewShotWithRandomSearch 优化器在不修改现有 prompts 的情况下增强 few-shot 示例,提升了示例组合的灵活性。
- 这些优化器在保留主要指令内容的同时,提供了多样的 few-shot 示例组合,有助于提高 few-shot 学习性能。
- 庆祝 VLM 支持性能:一位成员赞扬了团队在 VLM 支持 方面所做的努力,认可其有效性以及对项目性能指标的积极影响。
- 他们的认可强调了项目中 VLM 支持的成功实现和增强。
- DSPy 2.5.16 在处理长输入时遇到困难:关于 DSPy 2.5.16 使用 Ollama 后端 的担忧出现,长输入会导致输入和输出字段混淆,从而产生错误输出,这表明可能存在 Bug。
- 一个 SQL 提取示例展示了长输入如何导致预测中出现意外的占位符,指向了输入/输出解析中的问题。
- 即将进行的 DSPy 版本测试:一位成员计划测试最新的 DSPy 版本,不再使用 conda 分发的版本,以调查长输入处理问题。
- 他们打算在测试后报告发现,表明正在持续努力解决 DSPy 中的解析问题。
OpenAccess AI Collective (axolotl) Discord
-
LLM 的分布式训练:一位成员发起了一项讨论,关于使用其大学新的 GPU 集群进行 LLM 的分布式训练,重点是从零开始训练模型。
- 另一位成员建议为分布式训练和预训练提供资源,以协助其研究项目。
-
Kubernetes 用于容错:有人提议实现 Kubernetes 集群,以增强 GPU 系统的容错能力。
- 成员们讨论了将 Kubernetes 与 Axolotl 集成的好处,以便更好地管理分布式训练任务。
-
Meta Llama 3.1 模型:Meta Llama 3.1 被强调为一个极具竞争力的开源模型,并提供了使用 Axolotl 进行微调和训练的资源。
- 鼓励成员们查看一份微调教程,该教程详细介绍了如何在多节点上使用该模型。
-
StreamingDataset PR:一位成员回想起关于 StreamingDataset PR 的讨论,询问是否仍有人对此感兴趣。
- 这表明关于云集成和数据集处理的讨论和开发正在持续进行。
-
Firefly 模型:Firefly 是 Mistral Small 22B 的微调版本,专为创意写作和角色扮演设计,支持高达 32,768 tokens 的上下文。
- 警告用户该模型可能会生成露骨、令人不安或冒犯性的回复,应负责任地使用。建议用户在进行任何访问或下载前在此查看内容。
Torchtune Discord
-
DistiLLM 优化教师概率:讨论集中在 DistiLLM 交叉熵优化中减去教师概率的问题,详见 GitHub issue。讨论强调由于教师模型保持冻结状态,常数项可以忽略。
- 建议更新 docstring,以澄清损失函数假设教师模型是冻结的。
-
KD-div 与交叉熵的澄清:有人担心在实际返回值为交叉熵时将其标记为 KD-div,这在与 KL-div 等损失进行比较时可能会引起混淆。
- 据指出,将此过程定义为优化交叉熵,能更好地契合从训练中的硬标签到教师模型产生的软标签的转变。
-
TPO 势头强劲:一位成员对 TPO 表达了热情,称其令人印象深刻,并计划集成一个追踪器。
- 成员们对 TPO 的功能及其潜在应用充满期待。
-
VinePPO 实现挑战:虽然欣赏 VinePPO 在推理和对齐方面的优势,但一位成员警告说,其实现可能会带来重大挑战。
- 强调了部署 VinePPO 的潜在困难,并指出了与其集成相关的风险。
tinygrad (George Hotz) Discord
-
TokenFormer 与 tinygrad 的集成:一位成员成功将 TokenFormer 的最小化实现移植到了 tinygrad,可在 GitHub 仓库中找到。
- 此次适配旨在增强 tinygrad 内部的推理和学习能力,展示了集成先进模型架构的潜力。
-
View 中的依赖解析:一位用户询问操作
x[0:1] += x[0:1]是取决于x[2:3] -= ones((2,))还是仅取决于x[0:1] += ones((2,)),这涉及到真假共享规则。- 该讨论提出了关于 tinygrad 内部操作序列中依赖关系如何追踪的技术思考。
-
为加速器开发进行的 Hailo 逆向工程:一位成员宣布开始 Hailo 逆向工程工作,以创建一种新的加速器,重点关注过程效率。
- 他们对内核编译过程表示担忧,该过程必须在执行前将 ONNX 以及即将支持的 Tinygrad 或 TensorFlow 编译为 Hailo。
-
tinygrad 融合中的内核一致性:一位用户正在调查在执行
BEAM=2融合时,tinygrad 中的内核在多次运行中是否保持一致。- 他们旨在通过强调有效缓存管理的必要性,来防止重新编译相同内核带来的开销。
LLM Agents (Berkeley MOOC) Discord
-
关于 Project GR00T 的第 9 讲:今天 LLM Agents MOOC 的第 9 讲定于 下午 3:00 PST 进行直播,届时 Jim Fan 将讨论 Project GR00T,这是 NVIDIA 的通用机器人计划。
- Jim Fan 在 GEAR 内部的团队正在开发能够在模拟和现实环境中运行的 AI Agent,重点在于增强通用能力。
-
Jim Fan 博士简介:Jim Fan 博士是 NVIDIA GEAR 的研究负责人,拥有斯坦福视觉实验室(Stanford Vision Lab)博士学位,并获得了 NeurIPS 2022 优秀论文奖。
- 他在机器人多模态模型和精通 Minecraft 的 AI Agent 方面的工作曾被《纽约时报》、Forbes 和《麻省理工科技评论》(MIT Technology Review)等主流媒体报道。
-
LLM Agents 课程资源:所有课程材料,包括直播链接和家庭作业,均可在网上获取。
- 鼓励学生在专门的课程频道中提问。
Mozilla AI Discord
-
FOSDEM 2025 DevRoom 开放:Mozilla 将于 2025 年 2 月 1 日至 2 日在布鲁塞尔举办的 FOSDEM 2025 中设立 DevRoom,重点关注开源演示。
- 演讲提案提交截止日期为 2024 年 12 月 1 日,录取通知将于 12 月 15 日发出。
-
演讲提案截止日期临近:参与者需在 2024 年 12 月 1 日之前为 FOSDEM 2025 DevRoom 提交演讲提案。
- 获选讲者将于 12 月 15 日收到通知,以确保有充足的准备时间。
-
FOSDEM 志愿者招募:FOSDEM 2025 志愿者公开招募已发布,并为欧洲参与者提供差旅赞助。
- 志愿服务提供了在活动中建立人脉和支持开源社区的机会。
-
FOSDEM 演讲主题多样化:FOSDEM 2025 演示的建议主题包括 Mozilla AI、Firefox 创新以及隐私与安全等。
- 鼓励讲者探索这些领域之外的内容,演讲时长从 15 到 45 分钟不等,包含问答环节。
-
提案准备资源发布:Mozilla 分享了一份关于如何创建成功提案的技巧资源,可在此处访问 here。
- 该指南旨在帮助潜在讲者在 FOSDEM 2025 上制作出有影响力的演示。
Gorilla LLM (Berkeley Function Calling) Discord
-
基准测试基于检索的函数调用:一位成员正在对函数调用的基于检索的方法进行基准测试,并正在寻求一系列可用的函数及其定义。
- 他们特别要求按测试类别组织这些定义,以便进行更有效的索引。
-
函数定义索引讨论:一位成员强调了需要索引化的函数定义集合,以增强基准测试工作。
- 他们强调了按测试类别对这些函数进行分类的重要性,以简化工作流程。
Alignment Lab AI Discord 没有新消息。如果该频道长时间没有更新,请告知我们,我们将将其移除。
LLM Finetuning (Hamel + Dan) Discord 没有新消息。如果该频道长时间没有更新,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该频道长时间没有更新,请告知我们,我们将将其移除。
LAION Discord 没有新消息。如果该频道长时间没有更新,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该频道长时间没有更新,请告知我们,我们将将其移除。
第 2 部分:详细频道摘要和链接
完整的频道细分内容已针对电子邮件进行截断。
如果您喜欢 AInews,请 分享给朋友!预谢!