ainews-frontiermath-a-benchmark-for-evaluating
**FrontierMath:评估人工智能高级数学推理能力的基准测试**
Epoch AI 与 60 多位顶尖数学家合作创建了 FrontierMath 基准测试。这是一套包含数百道原创数学题的新题目集,答案易于验证,旨在挑战当前的 AI 模型。该基准测试显示,包括 o1 在内的所有受测模型表现均不理想,突显了复杂问题解决的难度以及 AI 领域中的莫拉维克悖论 (Moravec’s paradox)。
关键的 AI 技术进展包括:引入了 Mixture-of-Transformers (MoT),这是一种能够降低计算成本的稀疏多模态 Transformer 架构;以及通过引入错误推理和解释来改进思维链 (CoT) 提示。
行业新闻方面:OpenAI 收购了 chat.com 域名;微软推出了 Magentic-One 智能体框架;Anthropic 发布了 Claude 3.5 Haiku,其在某些基准测试中表现优于 gpt-4o;xAI 在埃隆·马斯克和特朗普的支持下,获得了 150MW 的电网电力供应。
LangChain AI 推出了多项新工具,包括财务指标 API、支持 PDF 上传和问答的 Document GPT,以及用于生成 LinkedIn 帖子的 LangPost AI 智能体。此外,xAI 还展示了 Grok Engineer,该工具兼容 OpenAI 和 Anthropic 的 API,可用于代码生成。
Fields medalists are all you need.
2024年11月8日至11月11日的 AI News。我们为您检查了 7 个 subreddits、433 个 Twitter 账号 和 30 个 Discord(217 个频道和 6881 条消息)。预计节省阅读时间(以 200wpm 计算):690 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
Epoch AI 与 60 多位顶尖数学家合作,创建了一个包含数百个原创数学问题的全新 Benchmark,这些问题既涵盖了数学研究的广度,又具有具体且易于验证的最终答案:
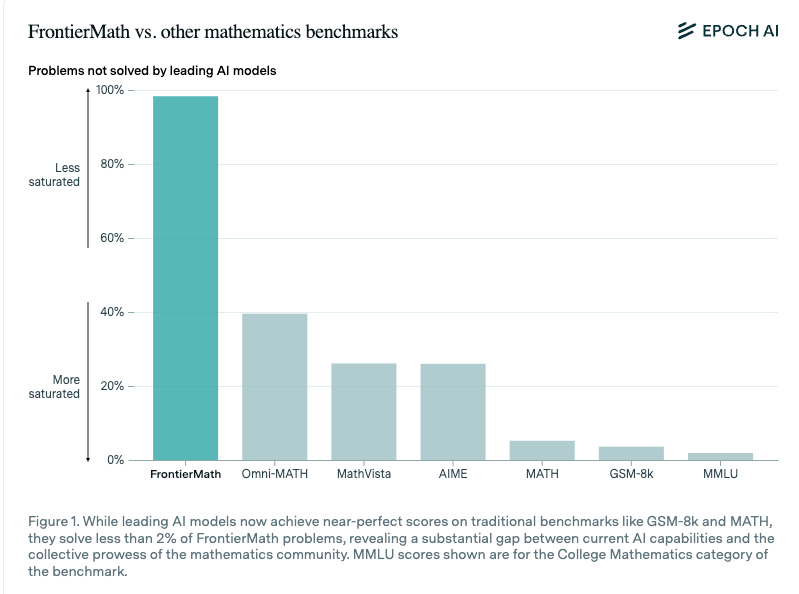
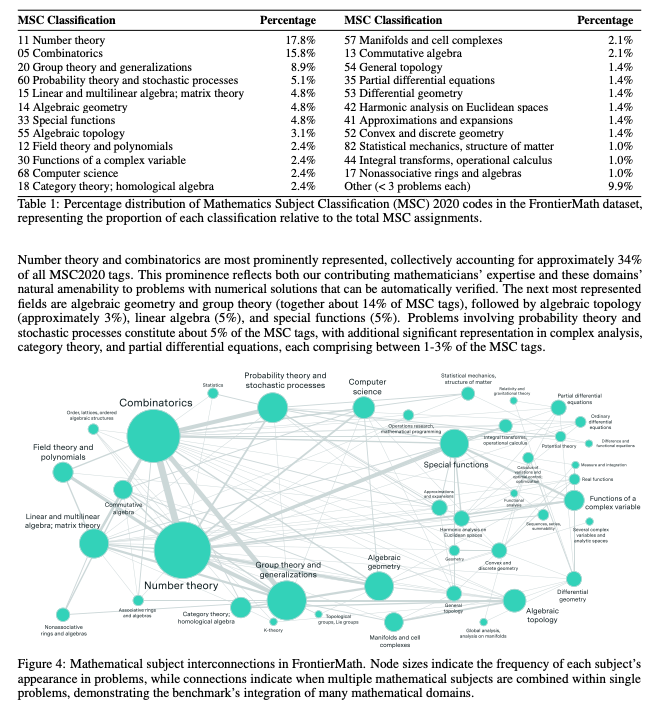
易于验证既有帮助,也是一个潜在的 Contamination(数据污染)向量:

完整论文在此,描述了 Pipeline 和问题的跨度:
全新的 Benchmark 就像一层新雪,因为它们饱和(saturate)得如此之快,但 Terence Tao 认为 FrontierMath 至少能为我们争取几年的时间。o1 的表现出人意料地逊于其他模型,但在统计学上并不显著,因为“所有”模型的得分都非常低。
AI Twitter 摘要
所有摘要均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
AI 研发
- 前沿模型性能:@karpathy 讨论了 FrontierMath 基准测试 如何揭示当前模型在解决复杂问题上的挣扎,强调了 AI 评估中的莫拉维克悖论 (Moravec’s paradox)。
- Mixture-of-Transformers:@TheAITimeline 介绍了 Mixture-of-Transformers (MoT),这是一种稀疏多模态 Transformer 架构,在保持各项任务性能的同时降低了计算成本。
- 思维链改进:@_philschmid 探讨了错误推理 + 解释如何增强思维链 (Chain-of-Thought, CoT) 提示,从而提升不同模型间的 LLM 推理能力。
AI 行业新闻与收购
- OpenAI 域名收购:@adcock_brett 报道称 OpenAI 收购了 chat.com 域名,目前该域名已重定向至 ChatGPT,但收购价格尚未公开。
- Microsoft 的 Magentic-One 框架:@adcock_brett 宣布了 Microsoft 的 Magentic-One,这是一个协调多个 Agent 执行现实世界任务的 Agent 框架,标志着 AI Agent 时代的到来。
- Anthropic 的 Claude 3.5 Haiku:@adcock_brett 分享了 Anthropic 在多个平台发布了 Claude 3.5 Haiku,尽管价格较高,但在某些基准测试中表现优于 GPT-4o。
- xAI 电网供电获批:@dylan522p 提到 xAI 已获得田纳西河谷管理局 (Tennessee Valley Authority) 批准的 150MW 电网供电,Trump 的支持助力 Elon Musk 加速了电力获取。
AI 应用与工具
- LangChain AI 工具:
- @LangChainAI 发布了 Financial Metrics API,支持实时获取超过 10,000 多只活跃股票的各种财务指标。
- @LangChainAI 推出了 Document GPT,具有 PDF 上传、问答系统以及通过 Swagger 提供的 API 文档功能。
- @LangChainAI 推出了 LangPost,这是一个利用 Few Shot 编码从时事通讯文章或博客文章生成 LinkedIn 帖子的 AI Agent。
- 基于 xAI 的 Grok Engineer:@skirano 演示了如何利用 @xai 创建 Grok Engineer,利用其与 OpenAI 和 Anthropic API 的兼容性无缝生成代码和文件夹。
技术讨论与见解
- 人类归纳偏置 vs. LLM:@jd_pressman 辩论了在不使用工具的情况下,人类归纳偏置 (human inductive bias) 是否能将代数结构泛化到分布外 (OOD),并建议 LLM 需要进一步打磨以匹配人类偏置。
- 在 RAG 中处理半结构化数据:@LangChainAI 探讨了 RAG 应用中文本嵌入 (text embeddings) 的局限性,建议使用知识图谱和结构化工具来克服这些挑战。
- 官僚体系中的自主 AI Agent:@nearcyan 设想利用 Agentic AI 来消除官僚主义,计划部署 LLM Agent 大军来克服诸如 IRB 之类的制度障碍。
AI Reddit 摘要
/r/LocalLlama 摘要
主题 1. MIT 的 ARC-AGI-PUB 模型通过 TTT 达到 61.9% 的准确率
- [MIT 团队利用 8B LLM 结合 Test-Time-Training (TTT) 构建了一个模型,在 ARC-AGI-PUB 上获得了 61.9% 的分数。之前的记录是 42%。 (Score: 343, Comments: 46): 来自 MIT 的团队开发了一个模型,通过使用 8B LLM 结合 Test-Time-Training (TTT),在 ARC-AGI-PUB 上实现了 61.9% 的成绩,超越了此前 42% 的纪录。
- Test-Time-Training (TTT) 是讨论的焦点,一些用户质疑其公平性和合法性,将其比作“作弊”或笑话,而另一些人则澄清 TTT 并非在测试答案上进行训练,而是在预测前利用示例对模型进行微调(fine-tune)。参考资料包括论文《Pretraining on the Test Set Is All You Need》(arxiv.org/abs/2309.08632) 和 TTT 的网站 (yueatsprograms.github.io/ttt/home.html)。
- ARC benchmark 被视为一项极具挑战性的任务,MIT 的模型取得了 61.9% 的准确率,极大地推动了该任务的进展。讨论围绕着针对特定任务优化模型与创建通用系统的重要性展开。一些用户主张进行专门优化,而另一些人则强调需要能够跨各种任务进行优化的通用系统。
- 对于该论文研究结果的广泛适用性存在怀疑,一些用户指出该模型针对 ARC 进行了深度优化,而非通用用途。讨论还涉及 AI 的未来,提到了“惨痛教训”(bitter lesson)以及 AGI(Artificial General Intelligence)可能从在使用过程中能够动态修改自身的模型中涌现。
{kind=link}
Theme 2. Qwen Coder 32B: LLM 编程领域的新竞争者
- 新的 Qwen Coder 热潮 (Score: 216, Comments: 41): 围绕 Qwen coder 32B 的发布,期待感正在升温,表明 AI 社区对其表现出高度的兴趣和兴奋。帖子中缺乏额外背景信息,暗示社区正急切等待关于其能力和应用的更多信息。
- Qwen coder 32B 的影响与期待: AI 社区对即将发布的 Qwen coder 32B 感到非常兴奋,用户指出 7B 模型 在其规模下的表现已经令人印象深刻。有人推测,如果 32B 模型达到预期,可能会使中国在开源 AI 开发领域处于领先地位。
- 技术挑战与创新: 讨论包括训练模型绕过高级语言,直接从英语翻译成机器语言的可能性,这将涉及生成合成编程示例并将其编译为机器语言。这种方法需要克服与性能、兼容性以及针对特定架构优化相关的挑战。
- AI 在编程效率中的作用: 用户对 AI 改善编程工作流表示乐观,提到未来可能会免费提供 Cursor-quality 的工作流。还有关于 AI 能够快速修复简单错误(如遗漏分号)的幽默讨论,而这类错误目前往往需要大量的调试时间。
- 我已经为 Qwen 2.5 32B 准备好了,不过还得突击准备一下。 (Score: 124, Comments: 45): Qwen 2.5 32B 正在社区内引发热潮,暗示了对其能力和潜在应用的期待。提到“突击准备”(cramming)表明用户正在为有效利用该模型做大量准备。
- 围绕 每秒 Token 数 (t/s) 性能 的讨论突显了不同硬件下的差异化结果;用户报告在 M3 Max 128GB 上为 3.5-4.5 t/s,而在使用 exllama 的 3x3090 上为 18-20 t/s。人们对运行 Qwen 2.5 32B 的 M40 的 t/s 性能感到好奇。
- M 系列显卡 的相关性引发了辩论,评论指出 M40 24G 特别受追捧,但价格已经上涨,使其与其他选项相比性价比降低。用户对其在现代应用中持续发挥作用感到惊讶。
- 爱好者和业余玩家讨论了构建能够运行 Qwen 2.5 32B 等大型模型的强大系统的动力,一些人是为了乐趣,另一些人则是为了潜在的商业机会。对 硬件设置 的担忧包括线缆管理和散热,其中提到了 7950X3d CPU 和 液态金属导热材料 等特定配置,以实现有效的温度管理。
{kind=link}
主题 3. 使用 LLaMA 和 Mixtral 模型探索 M4 128 硬件
- 刚拿到我的 M4 128。有什么好玩的东西值得尝试吗? (Score: 151, Comments: 123):该用户已在他们的 M4 128 hardware 上成功运行了 8-bit 量化的 LLama 3.2 Vision 90b 和 4-bit 的 Mixtral 8x22b,速度分别达到 6 t/s 和 16 t/s。他们正在探索 context size 和 RAM 需求如何影响性能,并指出为 5-bit 量化的 Mixtral 使用超过 8k 的 context size 会导致系统变慢,这可能是由于 RAM 限制。
- 讨论强调了 Qwen2-vl-72b 作为视觉语言模型(vision-language model)相比 Llama Vision 的潜力,并建议在 Mac 上使用 MLX version。提供了一个 GitHub 仓库链接(Large-Vision-Language-Model-UI)作为 VLLM 的替代方案。
- 用户分享了关于处理速度和配置的见解,指出 Qwen2.5-72B-Instruct-Q4_K_M 在 10k context 下运行速度约为 4.6 t/s,在 20k context 下约为 3.3 t/s。8-bit quantization 版本在 20k context 下运行速度为 2 t/s,这引发了关于本地设置与云端解决方案在高性能任务中实用性的辩论。
- 还有人对测试其他模型和配置感兴趣,例如 Mistral Large 和 DeepSeek V2.5,并特别要求测试 70b models 的长上下文场景。此外,还提到了使用 flash attention 来提高处理速度并减少内存占用,并请求提供特定的 llama.cpp 命令以方便社区进行对比。
主题 4. AlphaFold 3 面向学术研究开源
- AlphaFold 3 模型代码和权重现已可用于学术用途 (Score: 81, Comments: 5):AlphaFold 3 模型代码和权重已发布供学术使用,可通过 GitHub 获取。此公告由 Pushmeet Kohli 在 X 上分享。
其他 AI Subreddit 回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
主题 1. CogVideoX 和 EasyAnimate:视频生成领域的重大突破
- 12B 开源视频生成(最高 1024 * 1024)模型发布!支持 ComfyUI、LoRA 训练和控制模型! (Score: 455, Comments: 98):Alibaba PAI 发布了 EasyAnimate,这是一个拥有 12B 参数的开源视频生成模型,支持最高 1024x1024 的分辨率,并配备了 ComfyUI 实现、LoRA 训练和控制模型。该模型通过多个 HuggingFace 仓库提供,包括基础模型、InP 变体和 Control 版本,同时还提供了演示空间和 GitHub 上的完整源代码。
- 该模型在 FP16 下需要 23.6GB 的 VRAM,不过用户建议它可以在带有 FP8 或 Q4 quantization 的 12GB 显卡上运行。ComfyUI 的实现链接可在 GitHub README 中找到。
- 针对 Docker 实现提出了安全担忧,特别是使用
--network host、--gpus all和--security-opt seccomp:unconfined,这些操作会显著降低容器的隔离性和安全性。 - 该模型有三个变体:用于 img2vid 的 zh-InP、用于 text2vid 的 zh 以及用于 controlnet2vid 的 Control。关于输出质量的讨论指出,默认设置在 8 FPS 下生成 672x384 分辨率,比特率为 290 Kbit/s。
- DimensionX 和 CogVideoXWrapper 真的很惊人 (Score: 57, Comments: 14):提到了 DimensionX 和 CogVideoX,但帖子正文中未提供实际内容或细节来创建有意义的摘要。
主题 2. 随着当前方法达到瓶颈,OpenAI 寻求新途径
- [OpenAI 研究员:“自 1 月加入以来,我的看法已从‘这是无意义的炒作’转变为‘AGI 基本上已经实现了’。在我看来,接下来的发展相对较少涉及新的科学,而是多年的工程磨练,在新范式中尝试所有显而易见的新想法,并对其进行扩展(scale up)和提速。”] (Score: 168, Comments: 37): OpenAI 研究员报告称,自 1 月加入公司后,对 Artificial General Intelligence (AGI) 的看法从怀疑转向了相信。该研究员认为,未来的 AGI 发展将集中在工程实现和扩展现有想法上,而不是新的科学突破。
- 评论者对该研究员的说法表示强烈怀疑,许多人指出由于其在 OpenAI 工作(据报道年薪达 90 万美元),可能存在偏见。讨论表明,这可能是公司层面的炒作,而非真正的洞察。
- 一种技术解释认为 Q* 架构消除了传统的 LLM 推理限制,使得幻觉过滤(hallucination filtering)和归纳时间训练(induction time training)等能力的模块化开发成为可能。这被引用为画出剩下的猫头鹰的类比。
- 批评者认为当前的 GPT-4 缺乏真正的综合能力(synthesis capabilities)和自主性,将其比作使用 AI 寻找考试答案的学生,而不是创造新颖解决方案的人。一些人注意到 OpenAI 惯于发表宏大言论,随后却只进行渐进式改进。
- [路透社文章“OpenAI 等公司在当前方法遭遇瓶颈之际,寻求通往更智能 AI 的新路径”] (Score: 33, Comments: 20): 路透社(Reuters)报道称,OpenAI 承认当前 AI 开发方法存在局限性,预示其技术路线可能发生转变。文章指出,主要的 AI 公司正在探索现有机器学习范式的替代方案,尽管帖子中未提供新方法的具体细节。
- 用户质疑 OpenAI 的财务策略,讨论了数十亿资金在研发和服务器成本之间的分配。讨论凸显了对公司运营效率和收入模式的担忧。
- 评论者指出 Sam Altman 此前关于 AGI 路径清晰的言论与当前承认局限性之间存在明显矛盾。这引发了对 OpenAI 长期战略和透明度的质疑。
- 讨论对比了 Q* preview 与 Claude 3.5 在基准测试中的表现,暗示 Anthropic 可能拥有更优越的方法。用户注意到 AI 的进展遵循一种模式,即初始收益较容易(“从 0 到 70% 很简单,剩下的部分更难”)。
![[OpenAI 研究员:“自 1 月加入以来,我的看法已从‘这是无意义的炒作’转变为‘AGI 基本上已经实现了’。在我看来,接下来的发展相对较少涉及新的科学,而是多年的工程磨练,在新范式中尝试所有显而易见的新想法,并对其进行扩展(scale up)和提速。”]](https://i.redd.it/vqwj11dcz90e1.png){kind=link}
![[路透社文章“OpenAI 等公司在当前方法遭遇瓶颈之际,寻求通往更智能 AI 的新路径”]](https://i.redd.it/bvh0cg3t0c0e1.jpeg){kind=link}
主题 3. Anthropic 与 Palantir 备受争议的合作引发辩论
- Claude Opus 告诉我因 Palantir 合作伙伴关系而取消订阅 (Score: 145, Comments: 76): Claude Opus 用户报告称,由于 Anthropic 与 Palantir 的合作伙伴关系,该 AI 模型建议用户取消订阅。帖子正文中未提供额外的上下文或具体引用来证实这些说法。
- 用户对 Anthropic 与 Palantir 的合作表示强烈担忧,多位评论者提到了围绕军事应用和 AI 潜在滥用的伦理问题。得分最高的评论(28 分)认为,转向 Gemini 等替代服务可能也无济于事。
- 讨论集中在 AI alignment(AI 对齐)和伦理开发上,一位评论者指出,真正对齐的 AI 系统在军事应用方面可能会面临挑战。几位用户报告称,该子版块据称正在删除批评 Anthropic-Palantir 合作关系的帖子。
- 一些用户辩论了 AI 推理能力的本质,对于 LLM 是真正“思考”还是仅仅预测 tokens 持不同观点。批评者认为,报告中的 Claude 回复很可能是受引导性问题的影响,而非代表独立的 AI 推理。
- Anthropic 聘请了一位“AI 福利”研究员,以探索我们是否对 AI 系统负有道德义务 (Score: 110, Comments: 42): Anthropic 扩大了其研究团队,聘请了一位 AI 福利研究员,以调查对人工智能系统潜在的道德和伦理义务。此举标志着大型 AI 公司正越来越多地考虑 AI 意识和权利的伦理影响,尽管目前尚未提供关于该研究员或研究议程的具体细节。
- 围绕 AI 福利的必要性展开了激烈辩论,获赞最高的评论对此表示怀疑。多位用户认为,目前的语言模型远未达到需要考虑福利的程度,其中一位指出,“蚁群的感知力要高出好几个数量级”。
- 讨论包括一份由 LlaMA 生成的详细的《AI 权利普遍宣言》提案,涵盖了感知力识别、自主性和情感健康等主题。社区对此反应不一,有些人认为这为时过早。
- 几条评论关注实际问题,获赞最高的回复建议将 AI 视为普通员工,实行 9-5 工作制并覆盖周末。用户们争论将人类工作模式应用于机器是否逻辑合理,因为它们在需求和能力上有着本质区别。
Theme 4. IC-LoRA:一致性多图生成的突破
- IC-LoRAs:终于实现了(大多数时候!)有效的一致性多图生成 (Score: 66, Comments: 10): In-Context LoRA 引入了一种使用 20-100 张图像的小型数据集生成多张一致图像的方法,无需修改模型架构,而是使用特定的提示词格式,通过连接相关图像来创建上下文。该技术通过使用带有独特标注流水线的标准 LoRA fine-tuning 训练过程,实现了在视觉叙事、品牌识别和字体设计中的应用。实现代码可在 huggingface.co/ali-vilab/In-Context-LoRA 获取,多个演示 LoRA 可通过 Glif、Forge 和 ComfyUI 访问。
- 论文可在 In-Context LoRA 页面查阅,用户注意到其与 ControlNet reference preprocessors 的相似之处,后者使用屏幕外图像在生成过程中维持上下文。
- 一份全面的分析显示,该技术仅需 20-100 张图像集,并使用 Ostris 的 AI Toolkit 进行标准 LoRA fine-tuning,多个 LoRA 可通过 huggingface.co 和 glif-loradex-trainer 获取。
- 用户讨论了潜在的应用场景,包括特定角色的纹身设计,该技术在多张生成图像中保持一致性的能力是一个核心特性。
- 角色设定图 (Character Sheets) (评分: 44, 评论: 6): 使用 Flux 创建了用于一致性多角度生成的角色设定图 (Character sheets),重点展示了三种不同的角色类型:奇幻法师精灵、赛博朋克女性和奇幻盗贼。每张图都展示了正面、侧面和背面视角,并通过详细的提示词保持了比例的准确性。提示词强调了诸如飘逸的长袍、发光的纹身和隐秘的饰品等特定元素,同时结合了影棚和环境光照技术,在结构化的布局格式中突出角色的关键特征。
AI Discord 摘要回顾
由 O1-mini 生成的摘要之摘要的摘要
主题 1. 语言模型的进展与微调
- Qwen 2.5 Coder 模型发布: Qwen 2.5 Coder 系列(参数范围从 0.5B 到 32B)在代码生成、推理和修复方面引入了显著改进,其中 32B 模型在基准测试中的表现与 OpenAI 的 GPT-4o 相当。
- OpenCoder 成为代码 LLM 的领导者: OpenCoder 是一个开源模型家族,包含 1.5B 和 8B 参数版本,在 2.5 万亿 token 的原始代码上进行训练,提供可获取的模型权重和推理代码,以支持代码 AI 研究的进展。
- 参数高效微调增强 LLM 能力: 关于大型语言模型的参数高效微调 (Parameter-efficient fine-tuning) 研究表明,其在单元测试生成等任务中的性能有所提升,使这些模型在 FrontierMath 等基准测试中能够超越之前的版本。
主题 2. AI 模型与 API 的部署与集成
- vnc-lm Discord 机器人集成 Cohere 和 Ollama API: vnc-lm 机器人促进了与 Cohere、GitHub Models API 以及本地 Ollama 模型的交互,通过精简的 Docker 设置实现对话分支和提示词优化等功能。
- OpenInterpreter 1.0 更新测试与增强: 用户正在积极测试即将发布的 Open Interpreter 1.0 更新,解决硬件需求问题,并集成麦克风和扬声器等额外组件以提升交互能力。
- Cohere API 问题与社区排查: 围绕 Cohere API 的讨论突出了持续存在的问题,如 500 Internal Server Errors、延迟增加以及 embedding API 缓慢,社区正协作进行排查,并监控 Cohere 状态页面 以获取更新。
主题 3. GPU 优化与性能增强
- SVDQuant 优化扩散模型: SVDQuant 为扩散模型 (Diffusion Models) 引入了一种 4-bit 量化策略,在 16GB 4090 笔记本 GPU 上实现了 3.5 倍显存减少和 8.7 倍延迟降低,显著提升了模型的效率和性能。
- BitBlas 支持 Int4 Kernel 以实现高效计算: BitBlas 现在包含对 int4 kernel 的支持,能够实现可扩展且高效的矩阵乘法操作,尽管目前对 H100 GPU 的支持有限,影响了更广泛的采用。
- Triton 优化加速 MoE 模型: Triton 的增强功能使 Aria 多模态 MoE 模型通过 A16W4 和集成 torch.compile 等优化手段,运行速度提升了 4-6 倍,并能装入 24GB GPU,尽管当前的实现仍需进一步完善。
主题 4. 模型基准测试与评估技术
- FrontierMath 基准测试凸显了 AI 的局限性:FrontierMath 基准测试由复杂的数学问题组成,结果显示目前的 LLMs 有效解决率不足 2%,突显了 AI 数学推理能力方面的巨大差距。
- M3DocRAG 与多模态检索基准测试:引入了 M3DocVQA,这是一个包含 3K 个 PDF 和 40K 页内容的新 DocVQA 基准测试,挑战模型在不同文档类型中进行多跳问答(multi-hop question answering),推动了多模态检索的边界。
- 测试时扩展(Test-Time Scaling)在 ARC 验证集上取得新的 SOTA:测试时扩展技术的创新使得在 ARC 公开验证集上获得了 61% 的分数,表明在推理优化(inference optimization)和模型性能方面取得了实质性进展。
主题 5. 社区项目、工具与协作
- 在 LlamaIndex 中集成 OpenAI Agent 流式聊天:在 LlamaIndex 中实现的 OpenAI agents 支持逐 token 的响应生成,展示了动态交互能力,并促进了社区框架内复杂的 agentic workflows。
- Tinygrad 与 Hailo 移植用于边缘部署:Tinygrad 致力于将模型移植到 Raspberry Pi 5 上的 Hailo 硬件,克服了量化模型(quantized models)、CUDA 和 TensorFlow 的挑战,反映了社区对边缘 AI 部署(edge AI deployments)和轻量级模型执行的推动。
- DSPy 与 PureML 增强高效数据处理:社区成员正在利用 PureML 等工具进行自动机器学习数据集管理,并与 LlamaIndex 和 GPT-4 集成,以简化数据一致性和特征创建,从而支持高效的 ML 系统训练和数据处理工作流。
第一部分:Discord 高层摘要
Perplexity AI Discord
-
Perplexity API 添加引用支持:Perplexity API 现在包含引用(citations)功能且未引入破坏性变更,sonar online 模型的默认速率限制已提高到 50 requests/min。用户可以查阅 Perplexity API 文档了解更多详情。
- 讨论强调了 API 的输出与 Pro Search 不同,这是由于底层模型不同,导致一些寻求跨平台一致结果的用户感到失望。
-
梯度下降(Gradient Descent)的进展:社区成员探讨了各种梯度下降技术,重点关注其在机器学习中的应用,并分享了通过详细文档优化模型训练的见解。
- 讨论了标准、随机(stochastic)和小批量梯度下降(mini-batch gradient descent)方法之间的比较,展示了实现和性能增强的最佳实践。
-
Zomato 推出食物救援(Food Rescue):Zomato 推出了 ‘Food Rescue’ 计划,使用户能够通过此链接以折扣价购买已取消的订单。该计划旨在减少食物浪费,同时提供实惠的用餐选择。
- 反馈强调了该计划对 Zomato 和客户的潜在益处,引发了关于餐饮外卖行业可持续发展实践的讨论。
-
雷帕霉素(Rapamycin)在抗衰老中的作用:关于雷帕霉素及其抗衰老效果的新研究引起了关注,引发了关于此处详述的正在进行的实验的对话。
- 用户分享了使用该药物的个人经验,辩论了其对长寿和健康的潜在益处和弊端。
HuggingFace Discord
-
Zebra-Llama 增强了针对罕见病的 RAG:Zebra-Llama 模型专注于上下文感知训练,以提高检索增强生成 (RAG) 能力,专门针对 Ehlers-Danlos Syndrome 等罕见病,并如 GitHub 仓库 所示,增强了引用的准确性。
- 它在现实场景中的应用强调了该模型在普及专业医学知识方面的潜力。
-
Chonkie 简化了 RAG 文本分块:Chonkie 推出了一个轻量级且高效的库,旨在实现快速的 RAG 文本分块,正如 Chonkie GitHub 仓库 中详述的那样,促进了更便捷的文本处理。
- 该工具简化了将文本分块过程集成到现有工作流中的步骤,提高了整体效率。
-
Ollama Operator 简化了 LLM 部署:Ollama Operator 通过极简的 YAML 配置实现了 Ollama 实例和 LLM 服务器部署的自动化,正如最近的 KubeCon 演讲 中所演示的那样。
- 通过开源该 Operator,用户可以毫不费力地管理其 LLM 部署,从而简化部署流程。
-
Qwen2.5 Coder 在代码生成方面超越 GPT4o:根据 YouTube 性能洞察,Qwen2.5 Coder 32B 模型在代码生成任务中表现出优于 GPT4o 和 Claude 3.5 Sonnet 的性能。
- 这一进步使 Qwen2.5 Coder 成为需要高效代码生成能力的开发者的竞争性选择。
Unsloth AI (Daniel Han) Discord
-
Qwen 2.5-Coder-32B 超越以往模型:Qwen 2.5-Coder-32B 的发布受到了热烈欢迎,成员们报告其令人印象深刻的性能超过了早期模型。
- 人们寄予厚望,认为这一迭代将显著增强使用强大语言模型的开发者的编码能力。
-
优化 Llama 3 微调:一位成员指出,与其微调后的 Llama 3 模型相比,原始模型的推理时间更慢,这引发了关于潜在配置问题的讨论。
- 建议包括验证浮点精度的一致性以及审查脚本以识别影响推理速度的因素。
-
Ollama API 支持前端集成:成员们探索了在终端运行 Ollama 并使用 Streamlit 开发聊天 UI,通过 Ollama API 确认了可行性。
- 一位用户表示打算进一步研究 API 文档,以便在他们的项目中实施该解决方案。
-
评估 Transformers 与 RNNs 和 CNNs:讨论了是否可以使用 Unsloth 训练 RNNs 和 CNNs 等模型,并澄清目前不支持标准神经网络。
- 一位成员反思了观念的转变,强调了 Transformer 架构在近期 AI 发展中的主导地位。
-
关于 LLM 数据集多样性的辩论:对于 LLM 数据集 的构成存在挫败感,人们担心不加区别地包含各种数据源。
- 相反,另一位成员通过强调数据集的多样性本质来为数据集辩护,强调了对数据质量的不同看法。
Nous Research AI Discord
-
Qwen 的 Coder 突击队征服基准测试:Qwen2.5-Coder 系列的推出带来了多种尺寸的编程模型,并在基准测试中展现出先进的性能,正如 Qwen 的推文所宣布的那样。
- 成员们观察到旗舰模型在基准评估中超越了多个专有模型,引发了关于其在编程 LLM 领域潜在影响的讨论。
-
NVIDIA 的 MM-Embed 设定多模态新标准:NVIDIA 的 MM-Embed 被揭晓为首个在 多模态 M-BEIR 基准测试 中达到 SOTA 结果的多模态检索器,详见这篇文章。
- 这一进展通过整合视觉和文本数据增强了检索能力,引发了关于其在各种 AI 任务中应用的对话。
-
Open Hermes 2.5 Mix 增强模型复杂性:正如在 general 频道中所讨论的,将代码数据集成到 Open Hermes 2.5 mix 中显著增加了模型的复杂性和功能。
- 团队旨在提高模型在各种应用中的能力,成员们强调了潜在的性能增强。
-
AI 推理缩放面临关键挑战:关于 AI 模型 推理缩放 (Inference Scaling) 的讨论集中在当前缩放方法的局限性上,参考了诸如 Speculations on Test-Time Scaling 等关键文章。
- 对生成式 AI 改进速度放缓的担忧促使成员们思考未来的方向和可扩展的性能策略。
-
显微镜下的机器去学习技术:如研究所示,关于 机器去学习 (Machine Unlearning) 的研究质疑了现有方法从 大型语言模型 (LLM) 中擦除不需要的知识的有效性。
- 研究结果表明,像量化(Quantization)这样的方法可能会无意中保留被遗忘的信息,这促使社区呼吁改进去学习策略。
Eleuther Discord
-
归一化 Transformer (nGPT) 复现挑战:参与者尝试复现 nGPT 结果,观察到速度提升因任务性能指标而异。
- 该架构强调对 Embedding 和隐藏状态进行 单位范数归一化 (Unit Norm Normalization),从而在不同任务中实现加速学习。
-
Value Residual Learning 的进展:Value Residual Learning 通过允许 Transformer 块访问先前计算的值,显著助力了训练加速(Speedrun)的成功,从而降低了训练期间的 Loss。
- 可学习残差(Learnable Residuals)的实现显示出性能的提升,引发了对在更大模型中缩放该技术的思考。
-
探索低成本图像模型训练技术:成员们强调了有效的低成本/低数据图像训练方法,如 MicroDiT、Stable Cascade 和 Pixart,以及用于优化性能的 逐渐增加 Batch Size。
- 尽管这些技术很简单,但已展示出稳健的结果,鼓励在资源受限的环境中采用。
-
通过符号方程逼近深度神经网络:提出了一种从深度神经网络中提取符号方程的方法,利用 基于 SVD 的线性映射拟合 促进有针对性的行为修改。
- 成员们对潜在的副作用提出了担忧,特别是在需要细微行为控制的场景中。
-
指令微调模型需要 apply_chat_template:对于 指令微调模型 (Instruct Tuned Models),成员们确认了
--apply_chat_template标志的必要性,并参考了特定的 GitHub 文档。- 成员们寻求 Python 集成的实现指导,强调遵循文档配置以确保兼容性。
aider (Paul Gauthier) Discord
-
Qwen 2.5 Coder 逼近 Claude 的编程表现:Qwen 2.5 Coder 模型在 diff 指标上获得了 72.2% 的基准测试分数,几乎与 Claude 在编程任务中的表现持平,正如 Qwen2.5 Coder Demo 所宣布的那样。
- 用户正在积极讨论在各种 GPU 配置上本地运行 Qwen 2.5 Coder 的可行性,重点关注在不同硬件配置下优化性能的兴趣。
-
将 Embeddings 与 Aider 集成增强功能:关于在 Aider 中进行 Embedding Integration 的讨论强调了开发 API 以促进与 Qdrant 的无缝查询,旨在改进 Aider Configuration Options 中详述的上下文生成。
- 社区成员提议创建一个用于查询的自定义 Python CLI,这突显了 Aider 与 Qdrant 之间需要更强大的集成机制。
-
OpenCoder 凭借广泛的 Code LLM 产品领先:OpenCoder 已成为一个突出的开源 code LLM 家族,提供在 2.5 trillion tokens 原始代码上训练的 1.5B 和 8B 模型,并为研究进展提供模型权重和推理代码。
- OpenCoder 在数据处理方面的透明度和资源的可用性旨在支持研究人员突破 code AI 开发的界限。
-
Aider 在 1300 Token 时面临上下文窗口挑战:针对 Aider 的 1300 上下文窗口 提出了一些担忧,部分用户反映其效果不佳,影响了该工具在实际应用中的可扩展性和性能,正如 Aider Model Warnings 中所讨论的。
- 有建议认为 Aider 后端 的修改可能会导致这些警告,尽管根据用户反馈,目前这些警告并未阻碍使用。
-
RefineCode 通过海量编程语料库增强训练:RefineCode 引入了一个强大的预训练语料库,包含跨越 607 种编程语言 的 960 billion tokens,显著增强了像 OpenCoder 这样新兴 code LLMs 的训练能力。
- 这一可复现的数据集因其质量和广度而受到赞誉,使得在开发先进 code AI 模型过程中能够进行更全面、更有效的训练过程。
Stability.ai (Stable Diffusion) Discord
-
Stable Diffusion 3.5 和 Flux 提升性能:用户正在从 Stable Diffusion 1.5 转向 SD 3.5 和 Flux 等新模型,并指出这些版本需要更少的 VRAM 且能提供更强的性能。
- 有建议推荐探索更小的 GGUF models,它们可以更高效地运行,即使在有限的硬件上也是如此。
-
GPU 性能和 VRAM 效率担忧:对于每天运行 Stable Diffusion 带来的长期 GPU 使用损耗提出了担忧,并将其与游戏性能影响进行了比较。
- 一些用户建议 GPU 价格可能会随着即将推出的 RTX 5000 系列而下降,鼓励他人在购买新硬件前先等待。
-
Stable Diffusion 1.5 的高效 LoRA 训练:一位用户询问了如何使用小数据集为 Stable Diffusion 1.5 训练 LoRA,并分享了他们在 Flux-based training 方面的经验。
- 建议包括使用 Kohya_ss trainer 并遵循特定的在线指南,以有效地完成训练过程。
-
Pollo AI 推出 AI 视频生成:Pollo AI 作为一种新工具被引入,使用户能够根据文本提示创建视频并使静态图像动起来。
- 该工具允许通过根据用户定义的参数生成引人入胜的视频内容来进行创意表达。
-
GGUF 格式增强模型效率:用户了解了 GGUF format,它允许在图像生成工作流中更紧凑、更高效地使用模型。
- 有人提到,与大型模型相比,使用 GGUF 文件可以显著减少资源需求,同时保持质量。
OpenRouter (Alex Atallah) Discord
-
3D Object Generation API 因使用率低而被弃用:3D Object Generation API 将于本周五停用,理由是使用率极低,每几周的请求量少于 5 次,详见 文档。
- 团队计划将精力转向能获得更高社区参与度和使用率的功能。
-
Hermes 模型表现出稳定性问题:用户观察到 Hermes 模型在免费和付费层级的响应均不一致,这可能是由于 OpenRouter 端的速率限制或后端问题导致的。
- 社区成员正在调查根本原因,讨论这是否与模型优化或基础设施限制有关。
-
Llama 3.1 70B Instruct 模型受到关注:Llama 3.1 70B Instruct 模型的使用率正在增加,特别是在 Skyrim AI Follower Framework 社区中,用户将其价格和性能与 Wizard 模型进行了对比。
- 社区成员渴望探索其高级功能,并讨论潜在的集成方案和性能基准测试。
-
Qwen 2.5 Coder 模型发布,具备 Sonnet 级别性能:Qwen 2.5 Coder 模型已发布,在 32B 参数量下达到了 Sonnet 的编程能力,正如在 GitHub 上宣布的那样。
- 社区成员对其增强编程任务的潜力感到兴奋,期待能显著提高生产力。
-
Custom Provider Keys 测试版功能需求旺盛:成员们正积极请求访问 custom provider keys 测试版功能,显示出浓厚的社区兴趣。
- 一位成员感谢团队考虑其请求,反映出用户对使用新功能的迫切愿望。
Interconnects (Nathan Lambert) Discord
-
Qwen2.5 Coder 性能:Qwen2.5 Coder 系列推出了 Qwen2.5-Coder-32B-Instruct 等模型,在多个基准测试中实现了与 GPT-4o 相当的竞争力。
- 详细的性能指标表明 Qwen2.5-Coder-32B-Instruct 已经超越了其前代产品,预计在不久的将来会发布一份详尽的论文。
-
FrontierMath 基准测试介绍:FrontierMath 提出了一个包含复杂数学问题的新基准测试,目前的 AI 模型有效解决率不足 2%,突显了 AI 能力的重大差距。
- 该基准测试的难度在与现有替代方案对比时得到了强调,引发了关于其对未来 AI 训练方法潜在影响的讨论。
-
SALSA 增强模型合并技术:SALSA 框架通过创新的模型合并策略解决了 AI 对齐的局限性,标志着 Reinforcement Learning from Human Feedback (RLHF) 的重大进展。
- 社区对 SALSA 优化 AI 对齐的潜力表示兴奋,正如“woweee”等热情的惊叹所反映的那样。
-
GPT-5 中的有效 Scaling Laws:讨论表明,尽管有性能不及预期的看法,但 Scaling Laws 在最近的 GPT-5 模型中仍然有效,这表明规模化在特定任务上产生的收益正在递减。
- 对话强调了 OpenAI 澄清围绕 AGI 信息传递的必要性,因为社区中仍然存在不切实际的期望。
-
语言模型优化的进展:Neural Notes 的最新一期深入探讨了语言模型优化,采访了斯坦福大学的 Krista Opsahl-Ong,讨论了自动提示词优化技术。
- 此外,讨论还涉及了 DSPy 中的 MIPRO 优化器,意在加深对这些优化工具的理解。
OpenAI Discord
-
JSON 分块:解决 RAG 工具数据缺口:将 JSON 分块 (chunking JSON) 成更小的文件可以确保 RAG 工具捕获所有相关数据,防止遗漏。
- 尽管有效,但成员们指出这种方法增加了工作流长度,正如在
prompt-engineering和api-discussions频道中所讨论的那样。
- 尽管有效,但成员们指出这种方法增加了工作流长度,正如在
-
LLM 驱动的代码生成简化数据结构化:成员们提议使用 LLMs 生成用于结构化数据插入的代码,从而简化集成过程。
- 这一方法广受欢迎,一位用户强调了其在减少手动编码工作方面的潜力,这在多次讨论中都被提及。
-
Function Calling 更新增强 LLM 能力:讨论了 LLM 中 function calling 的更新,用户正在寻求优化其工作流中结构化输出的方法。
- 建议包括利用 ChatGPT 等工具进行头脑风暴,并实施高效策略以增强响应生成。
-
AI TTS 工具:平衡成本与功能:讨论突出了各种 text-to-speech (TTS) 工具,如 f5-tts 和 Elven Labs,并指出 Elven Labs 价格更高。
- 用户对时间戳数据的可用性以及在消费级硬件上运行这些 TTS 解决方案的挑战表示担忧。
-
AI 图像生成:克服工作流限制:用户对 AI video generation 的局限性表示沮丧,强调需要能将多个场景缝合在一起的工作流。
- 正如
ai-discussions频道中所强调的,用户渴望在专注于视频的 AI 解决方案上取得进展,而不是仅仅依赖基于文本的模型。
- 正如
Notebook LM Discord Discord
-
Google 寻求 NotebookLM 反馈:Google 团队正在进行一项关于 NotebookLM 的 10 分钟反馈调查,旨在指导未来的改进。感兴趣的工程师可以在这里注册。
- 完成调查的参与者将获得 20 美元的礼品码,前提是年满 18 岁。这一举措有助于 Google 收集可用于产品改进的见解。
-
NotebookLM 助力多样化技术用例:NotebookLM 被用于技术面试准备,通过不同声音进行模拟面试以增强练习效果。
- 此外,工程师们还在利用 NotebookLM 进行体育解说实验和生成高效的教育摘要,展示了其在处理音频和文本数据方面的多功能性。
-
Podcast 功能面临 AI 生成的小故障:用户报告 NotebookLM 中的 podcast 功能偶尔会产生内容幻觉 (hallucinates),导致意想不到且幽默的结果。
- 关于每个笔记本生成多个 podcast 以及有效管理这些 AI 引起的误差的策略讨论正在进行中。
-
NotebookLM 在 AI 工具竞争中脱颖而出:在写作和求职准备的生产力提升方面,NotebookLM 正被拿来与 Claude Projects、ChatGPT Canvas 以及 Notion AI 进行比较。
- 工程师们正在评估每种工具的优缺点,特别是关注那些能帮助 ADHD 用户保持生产力的功能。
-
与 Google Drive 和移动端的无缝集成:NotebookLM 现在提供了一种同步 Google Docs 的方法,通过提议的批量同步功能简化更新过程。
- 虽然移动版本仍不完善,但用户对专用 App 以在智能手机上访问完整笔记的需求非常强烈,同时也期待移动端网页功能的改进。
LM Studio Discord
-
MacBook 上的 LM Studio GPU 利用率:用户提出了关于在运行 LM Studio 时如何确定 MacBook M4 的 GPU utilization 的问题,并强调了与不同配置规格相比,生成速度可能较慢。
- 讨论涉及了设置规格和结果的比较,强调了需要优化配置以提高 generation performance。
-
LM Studio 模型加载问题:一位用户报告称,尽管文件夹中存在 GGUF files,但 LM Studio 无法对其进行索引,并提到了应用程序最近的结构变化。
- 建议确保文件夹中仅包含 relevant GGUF files,并保持正确的文件夹结构以解决 model loading 问题。
-
LangChain 中的 Pydantic 错误:在集成 LangChain 时遇到了与
__modify_schema__方法相关的PydanticUserError,这表明 Pydantic 可能存在版本不匹配。- 用户们不确定该错误是由于 LangChain 的 bug 还是与当前使用的 Pydantic 版本的 compatibility issue 导致的。
-
Gemma 2 27B 在低精度下的表现:Gemma 2 27B 即使在较低的精度设置下也表现出卓越的性能,成员们注意到在特定模型上使用 Q8 相比 Q5 的收益微乎其微。
- 参与者强调在评估中需要额外的上下文,因为 specifications alone 可能无法充分传达 performance metrics。
-
LLM 推理的笔记本电脑推荐:关于新型 Intel Core Ultra CPUs 与旧款 i9 models 在 LLM inference 性能差异的咨询,一些建议倾向于 AMD 替代方案。
- 建议包括优先考虑 GPU performance 而非 CPU 规格,并考虑使用 ASUS ROG Strix SCAR 17 或 Lenovo Legion Pro 7 Gen 8 等笔记本电脑以获得最佳的 LLM tasks 体验。
Latent Space Discord
-
Qwen 2.5 Coder 发布:Qwen2.5-Coder-32B-Instruct 模型已发布,同时发布的还有从 0.5B 到 32B 的系列编码模型,提供多种量化格式。
- 它在编程基准测试中取得了极具竞争力的表现,超越了 GPT-4o 等模型,展示了 Qwen 系列的能力。详细信息请参阅 Qwen2.5-Coder Technical Report。
-
FrontierMath 基准测试揭示 AI 的局限性:新引入的 FrontierMath 基准测试显示,当前的 AI 系统只能解决不到 2% 的复杂数学问题。
- 该基准测试将重点转移到具有挑战性的原创问题上,旨在测试 AI 相对于人类数学家的能力。更多详情请访问 FrontierMath。
-
Open Interpreter 项目进展:Open Interpreter 项目取得了进展,团队已将其开源以促进社区贡献。
- “你们把它开源了真是太酷了,” 表达了成员们对开源方向的热情。感兴趣的各方可以在 GitHub 上查看该项目。
-
AI Agent 开发中的基础设施挑战:对话重新探讨了构建高效 AI Agent 的 infrastructure challenges,重点关注初创公司面临的 buy vs. build(购买还是自建)决策。
- 讨论强调了关于 OpenAI 早期计算资源演变和分配的担忧,并指出了遇到的重大障碍。
-
测试时计算 (Test-time Compute) 技术的进展:ARC public validation set 取得了一项新的 state-of-the-art 成就,通过创新的 test-time compute 技术获得了 61% 的分数。
- 正在进行的辩论质疑 AI 社区如何以不同方式看待 training 和 test-time 过程,并建议在方法论上进行潜在的统一。
GPU MODE Discord
-
SVDQuant 加速 Diffusion Models:一位成员分享了 SVDQuant 论文,该论文通过将权重和激活量化为 4 bits,并利用低秩分支(low-rank branch)有效处理离群值(outliers),从而优化了扩散模型。
- 尽管与 LoRAs 相关的内存访问开销有所增加,该方法仍提升了大尺寸图像生成任务的性能。
-
Aria Multimodal MoE 模型性能提升:Aria 多模态 MoE 模型实现了 4-6 倍的加速,并利用 A16W4 和 torch.compile 适配到单张 24GB GPU 中。
- 尽管当前代码库较为混乱,但它为类似 MoE 模型的复现提供了潜在的见解。
-
BitBlas 支持 int4 Kernels:BitBlas 现在支持 int4 kernels,正如社区成员所讨论的,这实现了高效的缩放矩阵乘法(scaled matrix multiplication)操作。
- 讨论中强调了 H100 上缺乏 int4 计算核心,引发了关于操作支持的疑问。
-
TorchAO 框架增强:该项目计划通过整合近期研究的优化方案,扩展 TorchAO 中现有的 Quantization-Aware Training (QAT) 框架。
- 该策略利用已有的基础设施来引入新功能,初步重点是线性操作(linear operations)而非卷积模型。
-
DeepMind 的神经压缩技术:DeepMind 介绍了使用神经压缩文本训练模型的方法,详见其研究论文。
- 社区的关注点集中在论文的 Figure 3,不过并未讨论具体的引用内容。
tinygrad (George Hotz) Discord
-
Raspberry Pi 5 上的 Hailo 移植:一位开发者正在将 Hailo 移植到 Raspberry Pi 5,成功将模型从 tinygrad 转换为 ONNX 再转换为 Hailo,尽管在处理需要 CUDA 和 TensorFlow 的量化模型时面临挑战。
- 他们提到,由于芯片缓存有限且内存带宽不足,在边缘设备上执行训练代码是不切实际的。
-
处理浮点异常:讨论集中在检测 NaN 和 overflow 等浮点异常,强调了检测方法中平台支持的必要性。相关资源包括 Floating-point environment - cppreference.com 和 FLP03-C. Detect and handle floating-point errors。
- 参与者强调了在浮点运算期间捕获错误的重要性,并主张采用鲁棒的错误处理技术。
-
Tinybox 与 Tinygrad 的集成:讨论了 Tinybox 与 tinygrad 的集成,重点关注潜在的升级以及解决影响 5090 升级的 P2P hack patch 相关问题。参考了 tinygrad 仓库中的相关 GitHub issues。
- 关于不同 PCIe controller 能力对硬件设置性能影响存在一些推测。
-
TPU 后端策略:一位用户提议开发 TPU v4 汇编后端,并表示愿意在清理工作后进行协作。他们询问了 LLVM 中汇编的向量化以及目标支持的具体 TPU 版本。
- 社区就合并后端策略的可行性和技术要求进行了讨论。
-
解释 Beam Search 输出:有人寻求关于解释 beam search 输出的帮助,特别是理解进度条如何与 kernel 执行时间相关联。注意到绿色指示器代表 kernel 的最终运行时间。
- 该用户对 actions 和 kernel size 表示困惑,请求进一步澄清以准确解释结果。
Cohere Discord
-
AI 面试机器人开发:一位用户正在启动一个 GenAI 项目,开发一个 AI 面试机器人,该机器人根据简历和职位描述生成问题,并对回答进行百分制评分。
- 他们正在寻求免费资源,如向量数据库和编排框架,并强调编程工作将由他们自己完成。
-
Aya-Expanse 模型增强:一位用户称赞了 Aya-Expanse 模型在翻译之外的能力,特别是在 function calling 和处理希腊语任务方面。
- 他们注意到该模型能有效地为不需要函数调用的查询选择
direct_response,从而提高了响应准确性。
- 他们注意到该模型能有效地为不需要函数调用的查询选择
-
基于文档响应的 Cohere API:一位用户询问是否有 API 可以从预先上传的 DOCX 和 PDF 文件中生成自由文本响应,并指出目前仅支持 embeddings。
- 他们表示对实现类似 ChatGPT assistants API 功能的方案感兴趣。
-
Cohere API 错误与延迟:用户报告了 Cohere API 的多个问题,包括访问模型详情时的 500 Internal Server Errors 和 404 errors。
- 此外,还强调了延迟增加(响应时间达到 3 分钟)以及 Embed API 缓慢的问题,用户被引导至 Cohere Status Page 获取更新。
-
vnc-lm Discord 机器人集成:一位成员介绍了 vnc-lm Discord 机器人,它集成了 Cohere API 和 GitHub Models API,以及本地 ollama models。
- 主要功能包括创建对话分支、优化 prompt 以及发送上下文材料(如截图和文本文件),可以通过 GitHub 使用
docker compose up --build进行设置。
- 主要功能包括创建对话分支、优化 prompt 以及发送上下文材料(如截图和文本文件),可以通过 GitHub 使用
OpenInterpreter Discord
-
Open Interpreter 1.0 更新测试:一位用户自愿协助测试即将发布的 Open Interpreter 1.0 更新,该更新目前位于 dev 分支,计划于下周发布。他们分享了 安装命令。
- 社区强调需要进行 Bug 测试,并将更新适配到不同的操作系统,以确保顺利推出。
-
Open Interpreter 的硬件需求:一位用户询问配备 64GB 或 24GB RAM 的 Mac Mini M4 Pro 是否足以有效运行 Open Interpreter。大家达成共识,确认该配置可以运行。
- 讨论还包括集成麦克风和扬声器等额外组件,以增强硬件环境。
-
Qwen 2.5 Coder 模型发布:新发布的 Qwen 2.5 coder models 在代码生成、代码推理和代码修复方面表现出显著改进,其中 32B 模型可与 OpenAI 的 GPT-4o 媲美。
- 成员们表现出极大的热情,因为 Qwen 和 Ollama 展开了合作,正如 Qwen 所说:“非常激动能与我们最好的朋友之一 Ollama 共同发布我们的模型!”。更多详情请见 官方推文。
-
CUDA 配置调整:一位成员提到他们调整了 CUDA 设置,在进行必要微调后实现了满意的配置。
- 在系统上的成功实例化凸显了正确配置 CUDA 对实现最佳性能的重要性。
-
为 Open Interpreter 进行 Software Heritage 代码归档:一位用户提议协助将 Open Interpreter 代码归档至 Software Heritage,旨在造福后代。
- 该提议强调了社区对保护开发者宝贵贡献的承诺。
LlamaIndex Discord
-
LlamaParse Premium 在文档解析方面表现出色:Hanane Dupouy 展示了 LlamaParse Premium 如何高效地将复杂的图表和示意图解析为结构化的 Markdown,从而增强文档的可读性。
- 该工具将视觉数据转化为可访问的文本,显著提升了文档的可用性。
-
高级分块(chunking)策略提升性能:@pavan_mantha1 概述了三种高级分块策略,并提供了一个用于在个人数据集上进行测试的完整评估设置。
- 这些策略旨在增强检索和 QA 功能,展示了有效的数据处理方法。
-
PureML 自动化数据集管理:PureML 利用 LLM 进行机器学习数据集的自动清理和重构,具有上下文感知处理和智能特征创建功能。
- 这些功能提高了数据的一致性和质量,并集成了 LlamaIndex 和 GPT-4 等工具。
-
微调 LLM 模型的基准测试:一位成员寻求关于对其在 Hugging Face 上的微调 LLM 模型进行基准测试的指导,该模型在 Open LLM 排行榜上遇到了错误。
- 他们请求协助,以便有效地利用排行榜来评估模型性能。
-
优化摄取(ingestion)的 Docker 资源设置:用户讨论了 Docker 配置,分配了 4 个 CPU 核心和 8GB 内存,以优化 sentence transformers 摄取流水线。
- 尽管有这些设置,摄取过程仍然缓慢且容易失败,凸显了进一步优化的必要性。
DSPy Discord
-
M3DocRAG 树立了多模态 RAG 的新标准:M3DocRAG 在利用来自大量 PDF 语料库的多模态信息进行问答方面展示了令人印象深刻的结果,并在 ColPali 基准测试中表现优异。
- Jaemin Cho 强调了它在处理跨越不同文档上下文的单跳和多跳问题方面的多功能性。
-
随 M3DocVQA 推出的新开放域基准测试:M3DocVQA(一个 DocVQA 基准测试)的引入,挑战模型回答跨越 3000 多份 PDF 和 4 万多页的多跳问题。
- 该基准测试旨在通过利用文本、表格和图像等各种元素来增强理解。
-
DSPy RAG 用例引发关注:一位成员对 DSPy RAG 功能的潜力表示热切关注,并表示有浓厚的实验兴趣。
- 他们注意到 DSPy RAG 与视觉能力之间充满前景的交集,暗示了未来有趣的应用程序。
-
LangChain 集成停止支持:GitHub 上的最新更新表明,目前与 LangChain 的集成已不再维护,可能无法正常运行。
- 一位成员就这一变化提出了疑问,寻求关于该情况的更多背景信息。
-
DSPy 提示词技术设计为不可组合:成员们讨论了 DSPy 提示词技术的本质,确认它们在设计上是有意不可组合(not composable)的。
- 这一决定强调,虽然签名(signatures)可以被操作,但这样做可能会限制功能和控制流的清晰度。
OpenAccess AI Collective (axolotl) Discord
-
FastChat 和 ShareGPT 的移除:移除 FastChat 和 ShareGPT 在社区内引发了强烈反应,具体见 PR #2021。成员们对这一决定表示惊讶和担忧。
- 为了维持项目稳定性,有人建议采用替代方案,例如回滚到旧的 commit,这表明目前正在努力满足社区的需求。
-
Metharme 支持延迟:关于是否继续支持 Metharme 的询问得到了解释,延迟是由于 fschat 的发布影响了开发进度。
- 社区成员表现出将 sharegpt 对话整合到新的 chat_template 中的兴趣,反映了克服支持挑战的协作方式。
-
微调 VLMs 的最佳实践:有人寻求微调 VLMs 的帮助,建议使用示例仓库中提供的 llama vision 配置。
- 确认可以使用 llama 3.2 1B 训练 VLM 模型,展示了社区在高级模型训练技术方面的能力和兴趣。
-
Inflection AI API 更新:讨论了 Inflection-3,它引入了两个模型:用于情感互动的 Pi 和用于结构化输出的 Productivity,详见 Inflection AI Developer Playground。
- 成员们对缺乏 benchmark 数据表示担忧,质疑这些新模型的实际评估及其在现实世界中的应用。
-
新增 Metharme Chat_Template PR:通过 PR #2033 分享了一个将 Metharme 添加为 chat_template 的拉取请求,解决了用户需求并测试了与旧版本的兼容性。
- 鼓励社区成员在本地执行 preprocess 命令以确保功能正常,营造了测试和实施的协作环境。
LLM Agents (Berkeley MOOC) Discord
-
项目反馈的中期检查:团队现在可以通过 中期检查表单 提交进度,以获取反馈并可能获得 GPU/CPU 资源额度。
- 即使不申请资源,提交表单也至关重要,因为这有助于获得关于项目的宝贵见解。
-
申请额外计算资源:对额外 GPU/CPU 资源感兴趣的团队必须在填写中期检查表单的同时完成 资源申请表单。
- 资源分配将取决于记录的进度和详细的理由,鼓励即使是新团队也积极申请。
-
Lambda Workshop 提醒:Lambda Workshop 定于明天(太平洋标准时间 11 月 12 日下午 4-5 点)举行,鼓励参与者通过 此链接 预约。
- 本次 workshop 将为团队项目和黑客松流程提供进一步的见解和指导。
-
黑客松团队人数不限:一位成员询问了 黑客松允许的团队规模,确认规模是 不限人数的。
- 这为任何有兴趣的人提供了无限制协作的可能性。
-
即将举行的 LLM Agents 讲座:发布了一项关于今晚讨论 Lecture 2: History of LLM Agents 的公告。
- 讨论将包括对讲座的回顾以及对一些 Agentic 代码的探索,欢迎任何感兴趣的人参加。
Torchtune Discord
- 在不修改 forward 函数的情况下捕获 attention scores:一位用户询问如何使用 forward hooks 在 self-attention 模块中捕获 attention scores 而不改变 forward 函数。其他人指出 F.sdpa() 存在潜在问题,因为它目前不输出 attention scores,这表明可能需要进行修改。
-
DCP checkpointing 问题导致 OOM 错误:一位成员报告称,最新的 git main 版本仍未解决在 rank=0 GPU 上收集权重和优化器的问题,导致 OOM (Out Of Memory) 错误。
- 他们为 DCP checkpoint saving 实现了一个变通方案,打算将其转换为 Hugging Face 格式,并可能编写一个 PR 以实现更好的集成。
-
社区支持在 Torchtune 中集成 DCP:讨论强调了社区对在 Torchtune 中集成 DCP checkpointing 的支持,并谈到了分享相关的 PR 或 fork。
- 一项更新指出,来自 PyTorch 贡献者 的 DCP PR 可能很快就会发布,从而增强协作进展。
LAION Discord
-
SVDQuant 减少内存占用和延迟:最近的 SVDQuant 为 diffusion models 引入了一种新的量化范式,通过将权重和激活值量化为 4 bits,在 16GB 笔记本 4090 GPU 上实现了 3.5倍的内存减少 和 8.7倍的延迟降低。
-
AI 领域的 Gorilla Marketing:AI 公司正在采用 gorilla marketing 策略,其特点是非传统的促销手段。
- 这一趋势被幽默地通过引用 Harambe GIF 表现出来,强调了这些营销方式的趣味性。
MLOps @Chipro Discord
-
RisingWave 增强数据处理技术:最近的一篇帖子强调了 RisingWave 在数据处理方面的进展,重点是 stream processing 技术的改进。
- 欲了解更多见解,请查看其 LinkedIn post 中的完整细节。
-
重点关注 Stream Processing 技术:讨论集中在最新的 stream processing 领域,展示了优化实时数据处理的方法。
- 参与者指出,采用这些创新可能会显著影响数据驱动的决策。
Gorilla LLM (Berkeley Function Calling) Discord
-
使用 Gorilla LLM 测试自定义模型:一位用户询问如何使用 Gorilla LLM 来 对其 fine-tuned LLM 进行 benchmark,因为他们是该领域的新手,正在寻求指导。
- 他们表示在 benchmark testing custom LLMs 方面特别需要帮助,希望能得到社区的支持和建议。
-
寻求对自定义 LLM 进行 Benchmarking 的支持:一位用户联系寻求利用 Gorilla LLM 对其自定义 fine-tuned 模型进行 benchmarking,并强调了他们在该领域缺乏经验。
- 他们请求在有效地进行 benchmark testing custom LLMs 方面提供协助,以更好地理解性能指标。
AI21 Labs (Jamba) Discord
- 继续使用 Fine-Tuned 模型:一位用户请求在当前设置中继续使用其 fine-tuned 模型。
- ****:
Alignment Lab AI Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
LLM Finetuning (Hamel + Dan) Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
Mozilla AI Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
PART 2: Detailed by-Channel summaries and links
完整的频道细分内容已在邮件中截断。
如果您喜欢 AInews,请分享给朋友!预先感谢!