ainews-bitnet-was-a-lie
BitNet 是个谎言吗?
由 Chris Re 领导的研究小组修改了量化扩展定律(Scaling laws for quantization)。通过对 465 次以上的预训练运行进行分析,他们发现量化带来的收益在 FP6 精度时趋于平缓。
第一作者 Tanishq Kumar 强调,更长的训练时间和更多的数据会增加模型对量化的敏感性,这解释了 Llama-3 等模型在量化时面临的挑战。QLoRA 的作者 Tim Dettmers 警告称,通过低精度量化获取效率提升的时代正在终结,这标志着行业重心正从单纯的规模扩张转向优化现有资源。
此外,阿里巴巴发布了 Qwen 2.5-Coder-32B-Instruct,其在编程基准测试中已达到或超越了 GPT-4o 的水平。同时,像 DeepEval 这样用于大语言模型(LLM)测试的开源项目也正受到广泛关注。
精度(量化)的 Scaling Laws 就是你所需要的一切。
2024/11/11-2024/11/12 AI 新闻回顾。我们为你检查了 7 个 Reddit 子版块、433 个 Twitter 账号 和 30 个 Discord 社区(包含 217 个频道和 2286 条消息)。预计为你节省了 281 分钟 的阅读时间(以 200wpm 计算)。你现在可以标记 @smol_ai 来参与 AINews 讨论!
在日益增多的后 Chinchilla 论文中,对量化的热情在今年夏天达到了顶峰。BitNet 论文(我们的报道在此)提出了一种极端的量化方案,即三进制(-1, 0, 1),又称 1.58 bits。Chris Re 团队的一组研究生现已针对量化修改了 Chinchilla Scaling Laws,通过 465 次以上的预训练运行发现,量化带来的收益在 FP6 处趋于平缓。
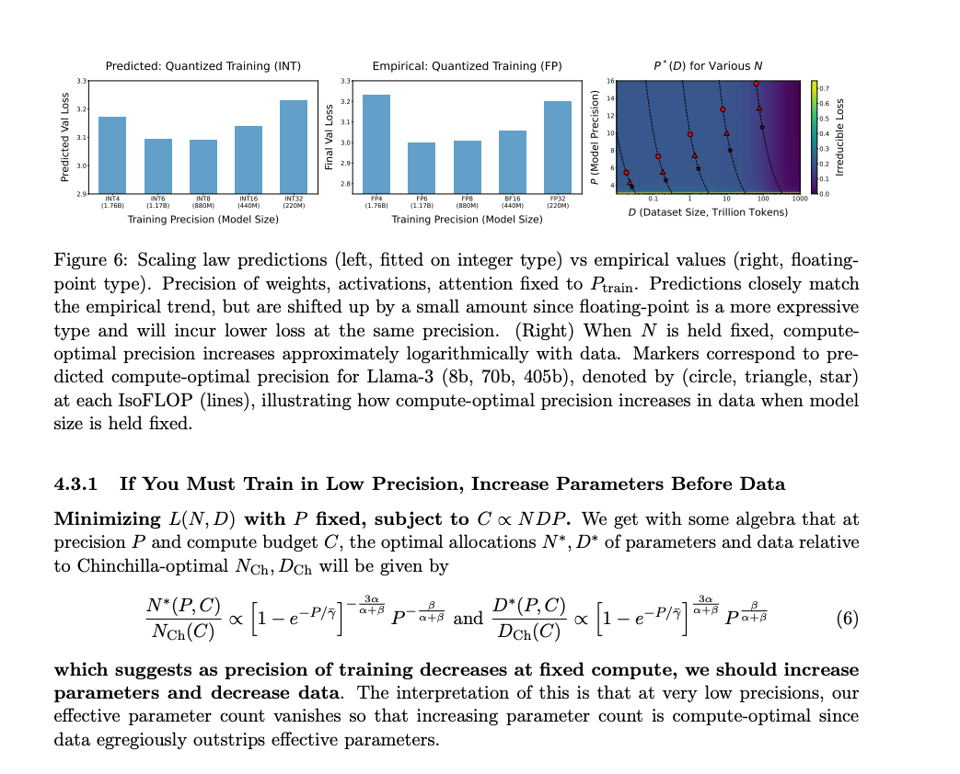
第一作者 Tanishq Kumar 指出:
- 预训练时间越长/看到的数据越多,模型在推理阶段对量化就越敏感,这解释了为什么 Llama-3 可能更难量化。
- 事实上,这种性能损失退化大致遵循预训练期间 token/参数比率的幂律。因此,如果你要部署量化模型,可以提前预测临界数据量,超过这个量后的更多数据预训练反而会有害。
- 直观理解可能是:随着训练数据增加,更多的知识被压缩进权重中,给定的扰动对性能造成的损害就会越大。
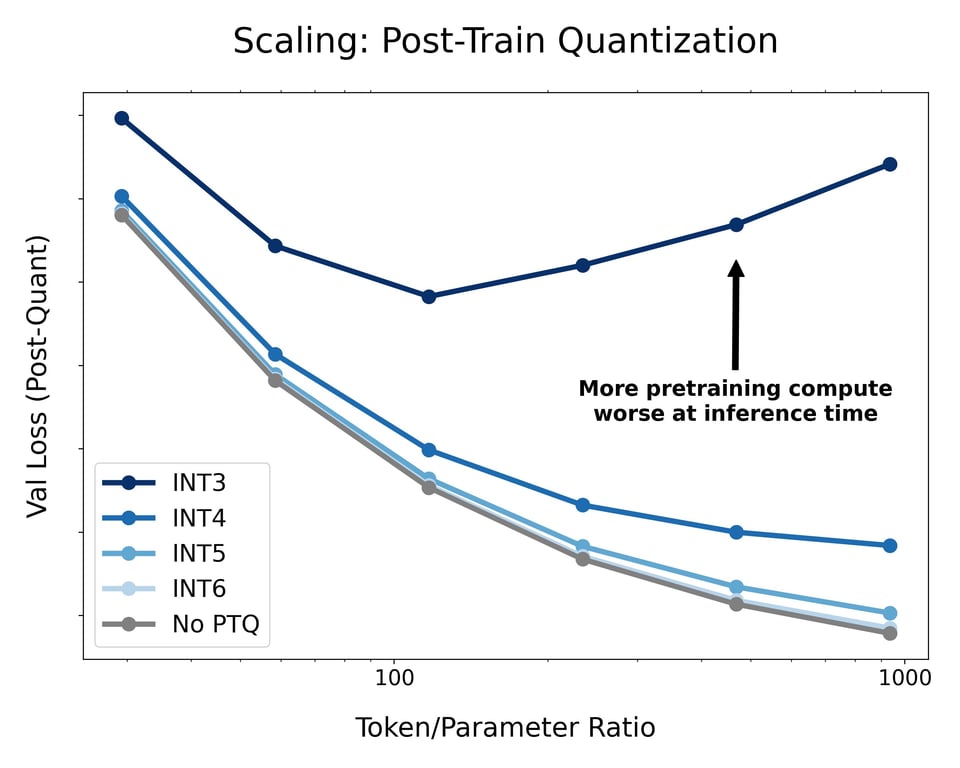
下图是一个固定的语言模型,在高达 30B tokens 的各种数据预算下进行了显著的过度训练,随后进行了训练后量化(PTQ)。这证明了更多的预训练 FLOPs 并不总是能让生产环境中的模型表现更好。
QLoRA 作者 Tim Dettmers 更加尖锐地指出了量化缩放“免费午餐”的终结:“可以说,AI 的大部分进步源于计算能力的提升,而这主要依赖于低精度加速(32 -> 16 -> 8 bit)。现在这已走向尽头。结合物理限制,这为‘规模终结’创造了完美的风暴。 根据我个人的经验(大量失败的研究),你无法在效率上投机取巧。如果量化失败了,那么稀疏化(sparsification)也会失败,其他效率机制同样如此。如果这是真的,我们现在已经接近极限了。” 鉴于此,他认为只有三条出路……这一切意味着范式将很快从 Scaling 转向“利用现有资源能做些什么”。我认为“如何利用 AI 帮助人们提高生产力”是未来最好的心态。
[由 SambaNova 赞助] 本周花几个小时在 SambaNova 的极速 AI 黑客松(Lightning Fast AI Hackathon) 中构建一个 AI Agent 吧!他们将为最快、最流畅、最有创意的 Agent 提供总计 10,000 美元的奖金。比赛将于 11 月 22 日结束 —— 现在就开始构建吧!
Swyx 评论:对于构建你一直想要的快速 AI Agent 来说,1 万美元的线上黑客松奖金非常丰厚!
AI Twitter 回顾
所有摘要均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
AI 模型与工具
-
Qwen 2.5-Coder-32B-Instruct 性能:@Alibaba_Qwen 发布了 Qwen 2.5-Coder-32B-Instruct,它在多个编程基准测试中匹配或超越了 GPT-4o。早期测试者称其结果“与 o1-preview 难分伯仲” (@hrishioa),并注意到它在代码生成和推理方面的竞争性表现。
-
开源 LLM 倡议:@reach_vb 强调,随着像 Qwen2.5-Coder 这样的开源模型出现,智能正变得廉价到难以计量,并突出了它们在 Hugging Face 等平台上的可用性。此外,@llama_index 介绍了 DeepEval,这是一个用于 LLM 驱动应用单元测试的开源库,可与 Pytest 集成用于 CI/CD 流水线。
-
AI Infrastructure and Optimization: @Tim_Dettmers 讨论了 AI 模型中 quantization 的局限性,指出我们正接近效率极限。他概述了三条前行路径:扩展数据中心 (scaling data centers)、通过动态性进行扩展 (scaling through dynamics) 以及知识蒸馏 (knowledge distillation)。
-
Developer Tools and Automation: @tom_doerr 分享了多个工具,例如允许使用自然语言指令执行操作的 Composio,以及命令行网页抓取工具 Flyscrape。@svpino 介绍了用于 LLM 应用基准测试的 DeepEval,强调了其与 Pytest 的集成以及对 14 种以上指标的支持。
-
AI Research and Benchmarks: @fchollet 对比了程序合成 (program synthesis) 与测试时微调 (test-time fine-tuning),强调了它们在函数重用方面的不同方法。@samyaksharma 分享了关于 Agentic AI 系统的见解,重点关注生产力提升而非仅仅是技术进步。
AI Governance and Ethics
-
AI Safety and Policy: @nearcyan 反思了 AI 对编程自动化的影响,对界面创新缺乏表示遗憾。@RichardMCNgo 讨论了将 AI Safety 整合到政府计划中,并质疑这些计划是会奏效还是会产生危害。
-
AI Alignment and Regulation: @latticeflowai 推出了 COMPL-AI,这是一个评估 LLM 对齐是否符合欧盟 AI 法案 (EU’s AI Act) 的框架。@DeepLearningAI 也强调了在 AI 治理方面的努力,强调了监管合规性的重要性。
AI Applications
-
Generative AI in Media and Content Creation: @skirano 在 @everartai 上推出了生成式广告,能够创建兼容 Instagram 和 Facebook 等平台的广告格式图像。@runwayml 提供了 Runway 工具中摄像机放置的技巧,强调了摄像机角度如何影响叙事。
-
AI in Data Engineering and Analysis: @llama_index 展示了 PureML,它使用 LLM 自动清理和重构 ML 数据集,增强了数据一致性和特征创建。@LangChainAI 推出了用于 RAG 应用数据切块 (chunking) 以及识别 Agent 故障的工具,提高了数据检索和 Agent 的可靠性。
-
AI in Healthcare and Biological Systems: @mustafasuleyman 分享了关于 AI2BMD 的工作,旨在通过 AI 驱动的分析来理解生物系统并设计新的生物材料和药物。
Developer Infrastructure and Tools
-
Bug Tracking and Error Monitoring: @svpino 介绍了 Jam 等工具,这是一个用于详细错误报告的浏览器扩展,声称可以将 bug 修复时间缩短 70% 以上。@tom_doerr 介绍了专为开发者量身定制的错误跟踪和性能监控工具。
-
Code Generation and Testing: @jamdotdev 在错误报告工具上进行了合作,而 @svpino 强调了使用 DeepEval 对 LLM 驱动的应用进行单元测试的重要性。
-
API Clients and Development Frameworks: @tom_doerr 介绍了一款用于管理 REST、GraphQL 和 gRPC 请求的桌面 API 客户端,提升了开发效率。此外,像 Composio 这样的工具支持基于自然语言的操作,简化了工作流自动化。
AI Research and Insights
-
LLM Training and Optimization: @Tim_Dettmers 讨论了数据中心扩展的终结以及 quantization 的极限,认为未来的进步可能更多地依赖于知识蒸馏 (knowledge distillation) 和模型动态性 (model dynamics)。
-
AI 协作与生产力:@karpathy 沉思于一个 IRC 成为主导协议的平行宇宙,强调了信息交换向 与 AI 进行实时对话 的转变。
-
AI 教育与学习:@DeepLearningAI 推广了他们的 Data Engineering 证书,其中包含 模拟对话,以演示 数据工程 中的 利益相关者需求收集。
迷因与幽默
-
AI 与技术笑话:@JonathanRoss321 幽默地建议在阿西莫夫定律中增加 第四条法则,即 机器人不能让机器人相信它们是人类。@giffmana 分享了对 ASPX 网站 的挫败感,表达了对 过时技术 的幽默 抱怨。
-
轻松的 AI 评论:@Sama 开玩笑说 AI 通过 LLM 自动化接管生活。@Transfornix 戏称 rotmaxers 害怕“真正的那个”。
-
幽默的互动与反应:@richardMCNgo 以幽默的方式表达了对文化和历史的 隐喻性反思。@lhiyasut 对“ai”在不同语言中的含义发表了机智的评论。
社区与活动
-
AI 会议与聚会:@c_valenzuelab 宣布在 伦敦开设办公室,并列举了全球各地的众多 社区聚会,包括 多伦多、洛杉矶、上海 等,旨在培养 全球 AI 社区。
-
播客与讨论:@GoogleDeepMind 推广了他们 由 AI 专家参与的播客,讨论了 AI 助手(AI assistants)的未来 及其带来的 伦理挑战。@omaarsar0 与 @lexfridman 和 @DarioAmodei 等 AI 思想领袖 进行了 讨论。
-
教育内容与研讨会:@lmarena_ai 鼓励参与他们的 OSS fellowship,而 @shuyanzhxyc 邀请个人 加入他们在杜克大学的实验室,该实验室专注于 Agentic AI 系统。
AI Reddit 回顾
/r/LocalLlama 回顾
主题 1. Qwen2.5-Coder 32B 发布:社区反响与技术解析
- 新的 Qwen 模型登上 Aider 排行榜!!! (Score: 648, Comments: 153): 新的 Qwen 模型已添加到 Aider Leaderboard,这标志着 AI 模型性能的进步,并可能在领域内树立新的基准。
- 讨论重点关注 Hugging Face 上的 Qwen2.5-Coder 模型,用户将其性能与 GPT-4o 等其他模型进行了比较,并对其在 Coding 任务中的能力表示出浓厚兴趣。32B 版本被认为表现尤为强劲,一些用户发现它在特定任务中优于 GPT-4o。
- 围绕本地运行这些模型存在技术考量,讨论涉及了高效处理 32B 和 72B 等模型尺寸所需的 PC 规格和量化技术。用户讨论了 multi-shot inferencing 的优势,以及为了实现实用的 Token 生成速度对高内存带宽的需求。
- 对话还涉及了模型许可以及开源社区对这些发布的反应,部分模型遵循 Apache License,另一些则引发了关于可访问性和社区驱动开发的讨论。用户对这些模型的潜力感到兴奋,尤其是在自托管环境中,以及相比之前版本的改进。
- Qwen/Qwen2.5-Coder-32B-Instruct · Hugging Face (Score: 486, Comments: 134): Qwen/Qwen2.5-Coder-32B-Instruct 已在 Hugging Face 发布,引发了关于其能力和潜在应用的讨论。重点在于其技术规格以及在各种编程和指令任务中的表现。
- 讨论强调了 Qwen2.5-Coder-32B-Instruct 模型的性能和效率,一些用户注意到,尽管其计算资源可能少于其他模型,但结果令人印象深刻。14B 版本也被提及,认为其效果几乎同样出色,且对于标准硬件配置的用户来说更易获取。
- 用户讨论了运行这些模型的技术要求和性能基准,强调需要大量的 RAM 和 VRAM,并建议资源有限的用户使用较小的模型或量化版本(如 14B 或 7B)。分享了具体的基准测试和性能指标(如 Token 评估速率),以展示模型的能力。
- 资源链接如 Qwen2.5-Coder-32B-Instruct-GGUF 和一篇博客文章提供了额外的背景信息。用户还讨论了 OpenVINO 转换的可用性,以及模型量化对性能和可用性的影响。
- 我的测试提示词,以前只有初代 GPT-4 能答对。之后的模型都没成功过,直到 Qwen-Coder-32B。在 RTX 4090 上运行 Q4_K_M,它第一次尝试就成功了。 (Score: 327, Comments: 108): Qwen-Coder-32B 成功地在第一次尝试中处理了一个复杂的测试提示词,这是以前只有初代 GPT-4 才能实现的壮举。该测试是在 RTX 4090 GPU 上使用 Q4_K_M 量化版本进行的。
- 平台与配置:平台和配置显著影响模型性能,VLLM 和 Llama.cpp 等平台之间存在差异。Temperature 设置和自定义 UI 设置也会影响输出,正如 LocoMod 在其使用 HTMX 进行动态 UI 修改的个性化实现中所讨论的那样。
- 模型性能与比较:Qwen-Coder-32B 模型显示出可观的前景,优于经常在复杂提示词上失败的 7B 等较小模型。用户注意到 32B 处理多种编程语言的能力,而其他人则怀念初代 GPT-4 在能力被削减之前的卓越表现。
- 技术规格与基准测试:RTX 4090 的基准测试显示,在特定配置下可达到 41 tokens/second,突显了硬件在实现高效性能方面的重要性。用户分享了他们的配置,包括 双 3090 和 双 P40,分别达到了 22 tokens/second 和 7 tokens/second,说明了基于硬件和配置的性能差异。
{kind=link}
主题 2. ExllamaV2 通过 Pixtral 引入视觉模型支持
- ExllamaV2 在 v0.2.4 中发布了对 Pixtral 的支持 (Score: 29, Comments: 2): ExllamaV2 发布了 v0.2.4 版本,支持视觉模型 Pixtral,这标志着其首次涉足视觉模型支持。Turboderp 建议未来扩展多模态(multimodal)功能,可能允许将 Qwen2.5 32B Coder 等模型与来自 Qwen2 VL 的视觉功能集成,从而增强开源模型的吸引力。欲了解更多详情,请参考 release notes 以及 GitHub 上相关的 API 支持讨论。
- Qwen2.5-Coder 系列:强大、多样、实用。 (Score: 58, Comments: 8): Qwen2.5-Coder 32B 被推测是一款既强大又实用的 multi-modal AI 模型,暗示了在多样化应用方面的潜在进步。由于缺乏正文内容,该模型的具体细节和特性尚未得到确认。
- 通义(Tongyi)官网承诺提供一种支持一键生成网站和视觉应用的“代码模式”,但尽管之前已有公告,该功能尚未上线。用户报告称,虽然该模型可以生成代码(例如 HTML 贪吃蛇游戏),但无法渲染输出结果。
主题 3. 探索 Binary Vector Embeddings:速度与压缩的权衡
- 二进制向量嵌入(Binary vector embeddings)非常酷 (Score: 314, Comments: 20): Binary vector embeddings 在提供 32 倍压缩和约 25 倍检索加速的同时,实现了超过 95% 的检索准确率,使其在数据密集型应用中具有极高的效率。更多详情请参阅博客文章。
- Binary Vector Embeddings 因其效率和速度而备受关注,通过 Numpy 的 bitwise_count() 等工具可以简化实现,从而在 CPU 上实现快速执行。讨论强调了在廉价 CPU 上使用 xor + popcnt 等简单操作实现二进制量化(binary quantization)的便利性。
- 模型训练与兼容性 对于有效的二进制量化至关重要,像 MixedBread 和 Nomic 这样的模型是专门为压缩友好型操作而训练的。这一方法得到了 Cohere 文档的支持,该文档强调模型需要在包括 int8 和 binary 在内的不同压缩格式下表现良好。
- 压缩中的权衡 非常显著,正如 pgVector 维护者所讨论的,用户报告了取决于位多样性(bit diversity)的不可预测损失。衡量这些损失的复杂性表明,需要进行仔细评估以确定数据流水线(data pipeline)是否适合二进制量化。
- 这是否是开放 AI 的黄金时代 - SD 3.5, Mochi, Flux, Qwen 2.5/Coder, LLama 3.1/2, Qwen2-VL, F5-TTS, MeloTTS, Whisper 等 (Score: 74, Comments: 28): 该帖子讨论了 开源 AI 模型的重大进展,重点介绍了近期发布的 Qwen 2.5/Coder, LLama 3.1/2 和 SD 3.5。它强调了开源与闭源 AI 模型之间差距的缩小,并引用了推理服务的价格优势(约 每百万 token 0.2 美元)以及 Groq 和 Cerebras 等专用硬件提供商的潜力。作者认为开源模型目前正超越闭源模型,尽管面临潜在的监管挑战,但前景光明。
- 硬件要求与性能:用户讨论了 AI 模型在各种 GPU 上的性能,提到了使用 RTX 4070 Super 和 RTX 3080 运行 Mochi 1 并生成视频片段。据报道,RTX 4070 Super 在 ComfyUI 中生成一段视频需要 7.5 分钟,而为了获得更高质量的输出,用户倾向于选择像 3090 这样拥有 24GB VRAM 的显卡。
- 开源与闭源模型的能力:讨论强调了 Qwen 模型 的编程能力,并指出了开源与闭源模型之间的差距。Qwen 2.5 Coder 14B 在 Aider 基准测试中超越了 Llama3 405b,而像 Qwen 2.5 Coder 3B 这样的小型模型对于本地任务非常有用,这表明了对开源进展的乐观态度。
- 未来前景与发展:关于开源模型的当前阶段存在争论,一些人认为它们已接近闭源模型但尚未超越。随着消费级硬件的改进,社区期待进一步的突破,用户对阿里巴巴新发布的 Easy Animate(需要 12GB VRAM)表现出浓厚兴趣。
主题 4. Qwen 2.5 技术基准:硬件与平台策略
- qwen-2.5-coder 32B 在 3xP40 和 3090 上的基准测试 (Score: 49, Comments: 22): qwen-2.5-32B 的基准测试显示,3090 GPU 在 32K context 下达到了显著的 28 tokens/second,而单个 P40 GPU 可以处理 10 tokens/second。3xP40 配置在 Q8 quantization 下支持 120K context,但性能并非线性扩展,其中 row split mode 显著提升了生成速度。将 P40 的功耗限制从 160W 调整到 250W 对性能影响微乎其微,而 3090 在 350W 功耗下的生成速度表现更优,达到 32.83 tokens/second。
- VLLM 对 P40 GPU 的兼容性有限,用户推荐 llama.cpp 作为这些 GPU 的最佳选择。据指出,MLC 在 P40 上的表现比 GGUF Q4 差约 20%,且缺乏 flash attention,这进一步增强了用户对 llama.cpp 的偏好。
- 围绕 Q4、Q8 和 fp8/16 等 quantization levels 的讨论显示性能差异极小,正如 Neural Magic 博客文章中所详述的那样。用户强调了对 kv cache 进行量化以减少内存占用且无明显质量损失的好处。
- P40 GPU 功耗被有效管理在 120W 左右,超过 140W 几乎没有收益。用户报告在水冷 3090 上达到 36 tokens/second,并强调 P40 在价格低于 $200 时是一个极具性价比的选择。
- 分布在 4 台 M4 Pro Mac Mini 上的 LLM + Thunderbolt 5 互连 (80Gbps) (Score: 58, Comments: 30): 讨论了在通过带宽为 80Gbps 的 Thunderbolt 5 互连的 四台 M4 Pro Mac Mini 配置上运行 Qwen 2.5。重点在于跨此硬件配置分布 LLM 的潜力。
- 讨论集中在 M4 Pro Mac Mini 与 M2 Ultra 和 M4 Max 等替代方案相比的性价比和配置上。一台顶配的 M4 Pro Mini 售价约 $2,100,两台配置可提供 128GB VRAM,而售价 $4,999 的 M4 Max 虽然价格更高,但提供了两倍的内存带宽和 GPU 核心。
- 用户辩论了 Mac Mini 与传统配置(如搭载 4x3090 GPU 的 ROMED8-2T 主板)的实用性,理由是前者易于使用且发热量更低。能够避免 Linux、CUDA 错误和 PCIe 常见问题的潜力被视为一个显著优势。
- 存在对性能宣称的怀疑,包括对模型细节的疑问,例如它是 tensor parallel 还是所使用的模型精度类型(例如 fp16, Q2)。在考虑从现有设备切换之前,强调需要证明 Mac Mini 在以合理速度进行 fine-tuning 方面的能力。
其他 AI Subreddit 摘要
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
主题 1. Claude 3.5 Opus 即将推出:Anthropic CEO 确认
- Anthropic CEO on Lex Friedman, 5 hours! (Score: 184, Comments: 49): Anthropic CEO Dario Amodei 做客 Lex Fridman 播客 进行了一场 5 小时的对话 可在 YouTube 观看。讨论确认了 Claude Opus 3.5 仍在持续开发中,但未提供具体的发布时间表。
- 用户对 Anthropic 声称没有“削弱 (nerfing)” Claude 表示怀疑,指出性能变化可能是通过“根据当前负载通过提示词分配不同的思考预算 (thinking budget)”而非修改权重来实现的。
- 知名嘉宾 Chris Olah 和 Amanda Askell 因其在机械可解释性 (mechanistic interpretability) 和哲学思考方面的专业知识而受到关注,引发了观众的极大兴趣。
- 社区对 Lex Fridman 最近的内容方向表示担忧,用户注意到他正从技术主题转向与政治人物的争议性关联,甚至被称为“普京辩护者”。
- Opus 3.5 is Not Die! It will be still coming out conform by anthropic CEO (Score: 62, Comments: 63): 根据公司 CEO 的说法,Anthropic 的模型 Opus 3.5 仍在开发中。该帖子缺乏关于发布时间表或模型能力的额外背景或具体细节。
- 用户讨论了 Opus 3.5 的潜在定价,预期在 $100/M tokens 左右,类似于 GPT-4-32k 的 $120/M tokens。如果该模型能提供卓越的 one-shot 性能(特别是在编程任务中),多位用户表示愿意支付溢价。
- 社区对之前 Reddit 上关于 Opus 3.5 被取消或合并到 3.5 Sonnet 的猜测产生了怀疑。用户指出,以 Sonnet 的价格运行更大的模型对 Anthropic 来说在财务上是不可持续的。
- 竞争压力被提及,Qwen 正在赢得市场份额。用户还批评了 CEO 的沟通风格,认为他在讨论模型开发状态时言辞闪烁且显得局促。
Theme 2. Qwen2.5-Coder-32B Matches Claude: Open Source Milestone
- Open source coding model matches with sonnet 3.5 (Score: 100, Comments: 33): 开源编程模型宣称性能可与 Claude Sonnet 3.5 媲美,尽管帖子正文未提供更多背景或证据。
- LM Studio 使得在本地运行该模型变得触手可及,为自动化任务提供网络连接,并提供各种量化选项,如 17GB 的 Q3。该模型在 VRAM 中运行效果最佳,而非从 RAM 运行。
- Qwen2.5-Coder-32B 模型在 24GB 显卡上配合 Q4 量化 运行效果良好,可在 Hugging Face 获取。用户指出它比 Haiku 更具成本效益,成本约为其一半。
- 用户对微调 (fine-tuning) 能力表现出兴趣,以匹配特定的编程风格和项目结构,并可选择通过 OpenRouter 以极具竞争力的价格进行托管。该模型在其 32B 规模下表现出了令人印象深刻的性能。
- Every one heard that Qwen2.5-Coder-32B beat Claude Sonnet 3.5, but…. (Score: 61, Comments: 42): 如对比统计图表所示,Qwen2.5-Coder-32B 在编程基准测试中超越了 Claude Sonnet。图片展示了两个模型之间的性能指标,突显了 Qwen 在更低运营成本下的竞争能力。
- Qwen2.5-Coder-32B 作为开源模型因其出色的性能受到赞誉,通过 deepinfra.com 的定价为 每百万 token $0.18,而 Claude Sonnet 的输入/输出费率为 $3/$15。
- 实际测试显示,Qwen 在特定开发任务中表现出色,但与 Claude 相比,在处理复杂逻辑和设计任务时仍显吃力。该模型的 32B 尺寸 允许在本地计算机运行,但 Q3 量化 可能会影响其在复杂任务上的表现。
- 中国政府对 AI API 提供了大量补贴,这解释了其低廉的 token 成本;而 Anthropic 最近提高了 Haiku 3.5 的价格,理由是智能水平有所提升。用户指出,这降低了使用闭源模型的动力。
{kind=link}
Theme 3. ComfyUI Video Generation: New Tools & Capabilities
- [mochi1 文本转视频(内置 ComfyUI 且速度极快)] (评分: 51, 评论: 6): Mochi1 是一款 text-to-video 模型,集成了 ComfyUI 工作流功能用于视频生成。该工具强调操作速度,尽管帖子中未提供具体的性能指标或技术细节。
- 用户指出原帖包含重复链接且缺乏适当的工作流文档,批评该帖子宣称“包含工作流(Workflow Included)”具有误导性。
- [使用 ComfyUI、Cogvideox 模型和 DimensionX lora 制作。全自动 AI 3D 动画。我热爱比利时漫画,想用 AI 展示一个如何增强它们的例子。很快会有完整的 3D 建模吗?等待更多 lora 来创建一个完整的移动端 App。感谢 @Kijaidesign] (评分: 83, 评论: 10): 使用 ComfyUI 和 Cogvideox 模型配合 DimensionX lora 创作了比利时漫画的 3D 运动动画。创作者的目标是在更多 lora 模型发布后,开发一款使用 AI 增强比利时漫画的移动应用程序。
- 用户询问了工作流以及在动画过程中使用 After Effects 的可能性,表现出对技术实现细节的浓厚兴趣。
- 评论者预见了自动化分镜动画(panel-to-panel animation)的潜力,其具有能够适应不同漫画布局和构图的动态相机移动(camera movements)。
主题 4. Reddit 上的 AI 内容生成:增长趋势与担忧
- 还记得那个 50k 点赞的帖子吗?原作者承认 100% 是 ChatGPT 写的 (评分: 1349, 评论: 163): 据称 ChatGPT 生成了一个获得 50,000 个点赞的 Reddit 热门帖子,原作者随后确认内容完全由 AI 生成。源材料中未提供关于该特定帖子内容的更多上下文或细节。
- 用户指出了 AI 生成内容的几个写作风格特征,特别是使用 em-dashes 和在典型 Reddit 帖子中少见的正式格式。结构化、冗长的格式被认为是 AI 创作的关键迹象。
- 讨论集中在 Reddit 上检测 AI 内容日益增长的挑战,用户对平台被 AI 生成的帖子主导表示担忧。几位评论者提到,尽管注意到一些可疑元素,最初还是被骗了。
- 一名正确识别该帖子为 AI 生成的用户最初因其怀疑态度被点赞降级(downvoted)和批评,这突显了社区检测 AI 内容的能力参差不齐。原帖获得了 50,000 个点赞,而这一真相揭露获得的关注显著较少。
- 死网理论(Dead Internet Theory):r/ChatGPT 上的这个帖子获得了 50k 点赞,随后原作者承认是 ChatGPT 写的 (评分: 130, 评论: 48): 当 r/ChatGPT 上一个达到 50,000 个点赞的热门帖子被揭露为 AI 生成内容时,死网理论(Dead Internet Theory)获得了更多可信度,原作者随后承认 ChatGPT 撰写了整个提交内容。这一事件说明了人们对 AI 生成内容在没有明确披露其人工来源的情况下主导社交媒体平台的担忧。
AI Discord 摘要回顾
由 O1-mini 总结的总结之总结
AI 语言模型争夺霸主地位
- Qwen2.5 Coder 超越 GPT-O 和 Claude 3.5: Qwen2.5 Coder 32B 在复杂任务上的表现达到 73.7%,超过了 GPT-O,而 Claude 3.5 Sonnet 为 84.2%。用户称赞其开源能力,同时也注意到其持续的改进。
- Phi-3.5 的过度审查引发辩论: Microsoft 的 Phi-3.5 模型因严厉的审查面临批评,导致 Hugging Face 上出现了无审查版本。用户幽默地嘲讽了 Phi-3.5 过度的限制,强调了这对其在技术任务中实用性的影响。
- OpenAI o1 模型发布备受期待: OpenAI 正准备在年底前全面发布 o1 推理模型,匿名见解进一步点燃了社区的热情。对开发团队专业知识的推测增加了期待感。
Optimization Techniques Revolutionize Model Training
- Gradient Descent Mechanics Unveiled:在 Eleuther Discord 中,工程师们讨论了使用 Gradient Descent 缩放更新以及 second-order information 对实现最优收敛的作用。讨论引用了关于特征学习和核动力学(kernel dynamics)的最新论文。
- LoRA Fine-Tuning Accelerates Inference:Unsloth AI 成员利用 LoRA fine-tuned models(如 Llama-3.2-1B-FastApply),通过原生支持实现加速推理。示例代码展示了通过减小模型大小来提高执行速度。
- Line Search Methods Enhance Learning Rates:Eleuther 参与者探索了 line search techniques,以便在 Loss 趋于发散时动态恢复最佳 Learning Rate。研究结果表明,线搜索产生的速率约为更新范数(norm of the update)的 1/2,这暗示了某种一致的模式。
Deployment and Inference Get a Boost with New Strategies
- Speculative Decoding Boosts Inference Speed:成员们分享了 Speculative Decoding 以及使用 FP8 或 int8 precision 作为提升 Inference speed 的策略。来自 qroq 和 Cerebras 等供应商的自定义 CUDA kernels 提供了更高的性能增益。
- Vast.ai Offers Affordable Cloud GPU Solutions:Vast.ai 被推荐为实惠的云端 GPU 供应商,对于 A100 和 RTX 4090 等 GPU,价格范围在每小时 $0.30 到 $2.80 之间。用户建议不要使用旧款 Tesla 显卡,而应选择更新的硬件以保证可靠性。
- Multi-GPU Syncing Poses Challenges:Interconnects 和 GPU MODE 中的讨论强调了在 multi-GPU setups 中使用 Pytorch 的 SyncBatchNorm 等工具同步均值和方差参数的复杂性,这在 liger 等框架中构成了实现挑战。
APIs and Tools Streamline AI Development
- Cohere API Changes Cause Headaches:由于 /rerank 端点中 return_documents 字段的移除,Cohere Discord 的用户面临 UnprocessableEntityError。团队成员正在努力恢复该参数,Cohere 的支持团队正在处理此问题。
- Aider Integrates LoRA for Faster Operations:在 aider Discord 中,成员讨论了利用 LoRA fine-tuned models(如 Llama-3.2-1B-FastApply),通过 Aider 的原生支持实现加速推理。示例代码演示了加载 Adapter 以提高速度。
- NotebookLM Enhances Summarization Workflows:Notebook LM Discord 的参与者探索了使用 NotebookLM 来总结超过 200 封 AI newsletter 邮件,从而简化信息消化流程。讨论中提到了音频文件上传失败等技术问题,指向了潜在的技术故障。
Scaling Laws and Datasets Challenge AI Research
- Scaling Laws Reveal Quantization Limits:在 Eleuther 和 Interconnects Discord 中,研究人员讨论了一项研究,该研究表明在更多 Token 上训练的模型需要更高的精度进行 Quantization,从而影响了可扩展性。人们对 LLaMA-3 模型在这些定律下的表现表示担忧。
- Aya_collection Dataset Faces Translation Inconsistencies:Cohere 用户发现 aya_collection 数据集在 19 种语言的翻译中存在差异,英语有 249716 行,而阿拉伯语和法语为 124858 行。translated_cnn_dailymail 中的特定不匹配问题被重点指出。
- Data-Parallel Scaling Bridges Theory and Practice:Eleuther Discord 上的讨论强调了在 data-parallel scaling 中桥接理论与应用的实际挑战,并引用了文档。诸如“有效的东西不被允许发表”之类的引言凸显了出版限制。
PART 1: High level Discord summaries
Eleuther Discord
-
探索 Gradient Descent 机制:一场讨论探讨了 Gradient Descent 更新机制,重点关注更新投影和范数如何影响 模型权重变化。
- 参与者辩论了相对于输入变化缩放更新的重要性,以及 二阶信息 在实现 最优收敛 中的作用。
-
Muon 优化的重要性:研究了 Muon 作为优化器的角色,强调了它与 Feature Learning 的交互以及对 网络训练动力学 的影响。
- 建议包括探索 Muon 与其他理论框架(如 Kernel Dynamics)以及现有 Feature Learning 文献之间的联系。
-
填补 Scaling Laws 的空白:一位成员分享了关于 填补 Scaling Laws 缺失部分 的见解,强调了弥合理论与 应用 之间差距的实际挑战。
- 那些有效的东西是不允许发表的,突显了有效应用研究成果所面临的挑战。
-
使用 Line Searches 优化 Learning Rates:有人推测 Line Searching 是一种在训练期间恢复 最优 Learning Rates 的方法,特别是在 Loss 接近发散时。
- 一位贡献者引用了研究结果,指出 Line Searches 产生的速率约为 更新范数的 1/2,表明可能存在一致的模式。
-
建议 Text-MIDI 多模态数据集:一位参与者提议实现一个 Text-MIDI 多模态数据集,考虑到现有的录音和元数据集合。
- 他们承认 版权限制,建议仅将 MIDI 文件 开源。
Perplexity AI Discord
-
Perplexity 面临持续技术问题的困扰:用户报告了 Perplexity AI 平台的 持续技术问题,特别是影响长对话线程且仍未解决的 隐藏消息 Bug。
- 这些持续存在的问题已经出现了一个多月,尽管修复了其他次要 Bug,但仍严重 影响了用户体验。
-
关于 Perplexity Pro 订阅到期的不确定性:一位用户询问了他们的 Perplexity Pro 免费一年到期后的续订情况,并质疑其对 R1 设备 的影响。
- 社区确认订阅在试用期后不会保持免费,用户将恢复到 受限的免费搜索。
-
Perplexity 模型对决:GPT-O 位居榜首:讨论表明 GPT-O 在 Perplexity AI 中的表现优于其他模型,尤其是在特定任务中。
- 相反,尽管 o1 具有专业化性质,但被认为 应用有限。
-
Mac App UI 问题困扰 Perplexity 用户:用户报告了 Perplexity 应用 Mac 版本 的 UI 问题,强调了 缺少滚动条 阻碍了导航。
- 其他投诉包括持续的 Google 登录问题 以及缺少 Web App 中可用的功能。
-
社区寻求 Pplx API DailyBot 编辑器的解决方案:一位成员请求关于实现 Pplx API DailyBot 自定义命令编辑器 的指导,寻求项目启动的初步步骤。
- 另一位用户分享了使用带有 Webhooks 的 CodeSandBox VM 的变通方法,但社区正在探索更好的 替代解决方案。
Unsloth AI (Daniel Han) Discord
-
Qwen 2.5 Coder 微调资源发布:一个新的针对 Qwen 2.5 Coder (14B) 模型的 微调 notebook 现已在 Colab 上线,支持免费微调,VRAM 占用减少 60%,并将上下文长度从 32K 扩展至 128K。
- 用户可以访问 Qwen2.5 Coder Artifacts 和 Unsloth 版本 来解决 token 训练问题并提升模型性能。
-
更快速推理的优化策略:成员们分享了提升推理速度的技术,包括 Speculative Decoding、利用 FP8 或 int8 精度,以及实现 自定义优化的 CUDA kernel。
- qroq 和 Cerebras 等供应商已经开发了 自定义硬件 解决方案来进一步提升性能,尽管这可能会影响吞吐量。
-
LoRA 微调与 Unsloth 的集成:用户讨论了利用 Unsloth 的原生支持,使用经过 LoRA 微调的模型(如 Llama-3.2-1B-FastApply)来加速推理。
- 提供的示例代码演示了如何使用 Unsloth 加载 adapter,由于模型尺寸较小,执行速度得到了提升。
-
模型 Checkpoint 和 Adapter 使用最佳实践:使用 PeftModel 类成功实现了在基础模型之上集成 adapter 模型进行推理,强调了在加载模型时指定 checkpoint 路径的重要性。
- 最佳实践包括先构建 adapter 并确保正确的 checkpoint 路径,以促进准确的模型增强和部署。
-
管理模型训练期间的 RAM 使用:一名用户报告在运行 Gemma 2B 时 RAM 消耗增加,这可能是由于评估过程加剧了内存需求。
- 另一名成员询问了评估实践,建议关闭评估可能会减轻内存占用过高的问题。
aider (Paul Gauthier) Discord
-
Qwen 2.5 Coder 性能:Qwen 2.5-Coder-32B 在复杂任务中表现出 73.7% 的性能,落后于 Claude 3.5 Sonnet 的 84.2%。
- 用户指出 Qwen 模型仍然会出现占位符响应,这可能会阻碍编码效率和完整性。
-
Aider 安装与使用:Aider 安装 需要 Python 3.9-3.12 和 git,用户可参考 官方安装指南 获取帮助。
- 讨论强调了简化安装流程以提升 AI 工程师用户体验的重要性。
-
模型对比:将 Qwen 2.5-Coder 的性能与 DeepSeek 和 GPT-4o 等模型进行了对比,在不同任务中表现各异。
- 排行榜分数表明,调整模型配置可以优化特定编码任务的性能。
-
Aider 配置警告:当 Ollama server 未运行或未设置 API base 时,用户会遇到 Aider 配置警告,导致出现通用警告而非具体错误。
- 社区建议包括验证模型名称以及解决 Litellm 持续存在的 bug 以消除虚假警告。
-
OpenRouter API 使用:有报告称 OpenRouter API 存在问题,例如由于模型名称无法识别,基准测试脚本无法连接到 llama-server。
- 解决方案涉及调整
.aider.model.metadata.json文件,该文件主要影响成本报告,必要时可以忽略。
- 解决方案涉及调整
Interconnects (Nathan Lambert) Discord
-
Qwen 2.5 Coder 突破 23.5T Tokens:Qwen 2.5 Coder 已在惊人的 23.5 trillion tokens 上进行了预训练,使其成为首个突破 20 trillion token 门槛的开源权重模型,正如 #news 频道中所强调的。
- 尽管取得了这一成就,用户仍对在本地运行 Qwen 2.5 的挑战表示担忧,理由是需要像 128GB MacBook 这样的高规格硬件才能处理完整的 BF16 精度。
-
Scaling Laws 挑战 LLaMA-3 Quantization:#reads 频道讨论的一项研究表明,随着模型在更多 token 上进行训练,它们在进行 quantization 时需要更高的精度,这给 LLaMA-3 模型带来了重大挑战。
- 研究表明,预训练数据的持续增加可能会对 quantization 过程产生不利影响,引发了对未来 AI models 可扩展性和性能的担忧。
-
Dario Amodei 预测 2027 年实现人类水平 AI:在 #news 频道的一档播客中,Dario Amodei 讨论了在各种 AI 模态中观察到的 scaling 现象,预测 human-level AI 将在 2026-2027 年出现。
- 他强调了 AI systems 在规模扩大时道德考量和细微行为的重要性,并指出了实现这些进步过程中潜在的不确定性。
-
Nous Research 推出 Forge Reasoning API Beta:Nous Research 在 #news 频道发布了 Forge Reasoning API Beta,旨在增强适用于任何模型的 inference time scaling,特别针对 Hermes 70B 模型。
- 尽管发布前景看好,但人们对报告的 benchmarks 的一致性仍存在担忧,导致对该 API 性能指标可靠性的怀疑。
-
OpenAI 准备正式发布 o1 模型:正如 #news 频道所讨论的,人们对 OpenAI 计划在年底前正式发布 o1 reasoning model 的期待日益增加。
- 社区成员对 o1 背后的开发团队特别感兴趣,匿名消息来源引发了关于该模型能力和底层技术的猜测。
OpenRouter (Alex Atallah) Discord
-
Qwen 凭借 Coder 32B 实现飞跃:根据 OpenRouter 的推文,新发布的 Qwen2.5 Coder 32B 在多项编程 benchmarks 中超越了竞争对手 Sonnet 和 GPT-4o。
- 尽管有这些说法,一些成员对准确性提出了质疑,认为 MBPP 和 McEval 等测试可能无法完全反映真实性能。
-
Gemini 1.5 Flash 提升性能:Gemini 1.5 Flash 已获得包括 frequency penalty、presence penalty 和 seed 调整在内的更新,根据 OpenRouter 的官方更新,提升了其在各种任务中的能力。
- 用户注意到性能有所提高,尤其是在 temperature 0 时,并推测 Google AI Studio 上部署了一个实验版本。
-
Anthropic 的工具尚未兼容:讨论显示,Anthropic’s computer use tool 目前在 OpenRouter 中缺乏支持,需要特殊的 beta header。
- 成员们对未来的兼容性表示出兴趣,以增强其项目中的集成和功能。
-
OpenRouter 引入价格调整:OpenRouter 澄清说,通过积分支付 token 可能会产生约 5% 的额外费用,如其 服务条款 中所述。
- 这一更新引发了用户关于价格透明度以及与直接使用模型进行对比的询问。
-
Beta 测试者寻求自定义 Provider Keys:多位用户请求访问 custom provider keys 进行 beta 测试,以便更好地管理 Google 的 rate limits。
- 强烈的兴趣凸显了社区对增强功能和项目优化的渴望。
OpenAI Discord
-
Qwen2.5-Coder 展示开源实力:新款 Qwen2.5-Coder 模型因其 开源代码能力 受到关注,为对抗 GPT-4o 等模型提供了竞争优势。
- 模型及其演示可在 GitHub、Hugging Face 和 ModelScope 上获取。
-
KitchenAI 项目寻求开发者贡献:开源项目 KitchenAI 正式发布,旨在创建 可共享的运行时 AI cookbooks,并邀请开发者参与贡献。
- 团队正在 Discord 和 Reddit 上开展推广活动,以吸引感兴趣的贡献者。
-
优化 GPT 模型的 Prompt Engineering:讨论集中在提高 提示词清晰度 以及利用 Token 计数 来优化 GPT 模型的输出。
- 分享了一份 Prompt Engineering 指南,以帮助成员提升其提示词设计技能。
-
评估 TTS 替代方案:关注 f5-TTS:成员们探索了各种 文本转语音 (TTS) 解决方案,其中 f5-tts 因其在消费级 GPU 上的表现而获得推荐。
- 讨论还包括在处理有关时间戳数据能力的问题时,建议关注 高性价比的解决方案。
Modular (Mojo 🔥) Discord
-
WSL2 中的 CUDA 驱动限制:Windows 上的 Nvidia CUDA 驱动 在 WSL2 中被存根(stubbed)为 libcuda.so,这可能会限制通过 Mojo 使用完整的驱动功能。
- 成员们指出,如果 MAX 依赖于宿主 Windows 驱动,这种存根驱动可能会使 WSL 内的支持变得复杂。
-
CRABI ABI 提案增强语言互操作性:由 joshtriplett 提出的
CRABI实验性特性门控提案 旨在为 Rust、C++、Mojo 和 Zig 等高级语言之间的互操作性开发一种新的 ABI。- 参与者讨论了与 Lua 和 Java 等语言的集成挑战,表明需要更广泛的采用。
-
通过正确的 URL 修复 Mojo 安装问题:一位用户通过修正
curl命令的 URL 解决了 Mojo 安装 问题,确保了安装成功。- 这强调了在安装软件包时准确输入 URL 的重要性。
-
Mojo 的 Benchmark 模块面临性能限制:Mojo 中的 Benchmark 模块 通过管理设置(setup)和清理(teardown)以及处理吞吐量测量的单位,方便了快速编写基准测试。
- 然而,该模块存在一些限制,例如在热循环(hot loops)中存在 不必要的系统调用,这可能会影响性能。
-
动态模块导入受限于 Mojo 的编译结构:由于 Mojo 的编译结构将所有内容捆绑为常量和函数,目前不支持模块的 动态导入。
- 引入 JIT 编译器是一个潜在的解决方案,但对于二进制文件大小以及与预编译代码的兼容性仍存在担忧。
tinygrad (George Hotz) Discord
-
Hailo 模型量化挑战:一位成员详细说明了运行 Hailo 需要进行八位量化(eight-bit quantization)的复杂性,这增加了训练过程的难度,并且需要编译好的 .so 文件才能让 CUDA 和 TensorFlow 正常工作。
- 由于这些要求,Hailo 的环境搭建非常繁琐。
-
ASM2464PD 芯片规格确认:讨论确认了 ASM2464PD 芯片支持通用 PCIe,可通过多个供应商获得,且不限于 NVMe。
- 成员们对该芯片为实现最佳性能而产生的 70W 功耗需求表示担忧。
-
开源 USB4 转 PCIe 转换器进展:GitHub 上分享了一个开源的 USB4/Thunderbolt to M.2 PCIe 转换器设计,展示了显著进展并获得了硬件开发的资金支持。
- 设计者概述了下一阶段的开发预期,以实现有效的 USB4 到 PCIe 的集成。
-
使用 Opus 编解码器优化音频录制:成员们讨论了使用 Opus 编解码器进行音频录制,因为它能够在不牺牲质量的情况下减小文件体积。
- 然而,有人指出 Opus 在浏览器兼容性方面存在问题,凸显了技术局限性。
-
开发 Tinygrad 的 Distributed Systems 库:一位用户提议为 Tinygrad 构建一个 Distributed Systems 库,专注于 dataloaders 和 optimizers,而不依赖于 MPI 或 NCCL 等现有框架。
- 目标是从零开始创建基础网络功能,同时保持 Tinygrad 现有的接口。
Notebook LM Discord Discord
-
NotebookLM 可总结 AI 通讯邮件:一位成员建议使用 NotebookLM 来总结超过 200 封 AI newsletter 邮件,以避免手动复制粘贴内容。
- 提到了 Gmail 中的 Gemini 按钮可能有助于总结,但指出其并非免费。
-
围绕 NotebookLM 的非官方 API 质疑:用户讨论了一个每月 30 美元的非官方 API,并对其合法性表示怀疑 NotebookLM API。
- 担忧包括缺乏商业信息和示例输出,导致一些人将其标记为诈骗。
-
集成 KATT 用于播客事实核查:一位用户讨论了将 KATT (Knowledge-based Autonomous Trained Transformer) 集成到其播客的事实核查器中,导致单集节目变长。
- 他们将这种集成描述为痛苦的,因为它结合了传统方法和新的 AI 技术。
-
NotebookLM 音频文件上传问题:用户对无法向 NotebookLM 上传 .mp3 文件表示沮丧,并得到了通过 Google Drive 进行正确上传程序的指导。
- 一些人注意到其他文件类型上传没有问题,表明可能存在技术故障或转换错误。
-
在 NotebookLM 中将笔记本导出为 PDF:用户正在询问未来是否有计划将笔记或笔记本导出为 .pdf,并寻求用于笔记本自动化的 API。
- 虽然有人提到使用 PDF 合并工具等替代方案,但他们更渴望原生导出功能。
Latent Space Discord
-
Magentic-One 框架发布:推出了 Magentic-One 框架,展示了一个旨在处理复杂任务并在效率上超越传统模型的多 Agent 系统。
- 它使用一个编排器 (orchestrator) 来指导专业 Agent,并在各种基准测试中表现出竞争力 来源。
-
Context Autopilot 介绍:Context.inc 推出了 Context Autopilot,这是一款能像用户一样学习的 AI,展示了在信息工作方面的尖端能力。
- 分享了一个实际演示,表明在增强 AI 工作流中的生产力工具方面具有前景 视频。
-
Writer C 轮融资公告:Writer 宣布了 2 亿美元的 C 轮融资,估值为 19 亿美元,旨在增强其 AI 企业解决方案。
- 这笔资金将支持扩展其生成式 AI 应用,并得到了知名投资者的显著支持 Tech Crunch 文章。
-
Supermaven 加入 Cursor:Supermaven 宣布与 Cursor 合并,旨在开发先进的 AI 代码编辑器,并就新的 AI 工具功能展开合作。
- 尽管处于过渡期,Supermaven 插件仍将继续维护,表明了对提高生产力的持续承诺 (博客文章)。
-
Dust XP1 和日活跃使用率:分享了关于如何使用 Dust XP1 创建高效工作助手的见解,在客户中实现了令人印象深刻的 88% 日活跃使用率 (Daily Active Usage)。
- 本集涵盖了早期的 OpenAI 历程,包括关键的合作。
GPU MODE Discord
-
GPU 显存与速度的权衡:关于从 RTX 2060 Super 升级到 RTX 3090 的讨论,权衡了 GPU 显存与处理速度之间的平衡,以及购买旧的二手 Tesla 卡的选项。
- 共识倾向于选择更新的硬件以获得更高的可靠性,特别建议个人开发者不要购买旧款 GPU。
-
Vast.ai 作为云端 GPU 供应商:Vast.ai 被推荐为一种经济实惠的云端 GPU 选择,目前 A100 和 RTX 4090 等 GPU 的价格在每小时 $0.30 到 $2.80 之间。
- 用户指出,虽然 Vast.ai 提供了具有成本效益的解决方案,但其租赁 GPU 的模式引入了一些潜在用户应考虑的特殊问题。
-
Surfgrad:基于 WebGPU 的 Autograd 引擎:Surfgrad 是一个基于 WebGPU 构建的 autograd 引擎,在 M2 芯片上实现了高达 1 TFLOP 的性能,详见 优化 WebGPU Matmul 内核。
- 该项目强调内核优化,并作为那些希望在 autograd 库开发中探索 WebGPU 和 TypeScript 的人员的教育工具。
-
高效深度学习系统资源:分享了由 HSE 和 YSDA 提供的 Efficient Deep Learning Systems 课程材料,提供了旨在优化 AI 系统效率的全面资源。
- 参与者强调了该仓库在增强对深度学习中高效系统架构和资源管理的理解方面的价值。
-
Liger 中的多 GPU 同步:讨论了在 liger 的多 GPU 设置中同步均值和方差参数的挑战,参考了 PyTorch 的 SyncBatchNorm 操作。
- 成员们表示,在 liger 中复制 SyncBatchNorm 行为将非常复杂且不直接,突显了其中涉及的复杂性。
Cohere Discord
- Cohere API /rerank 问题:由于 return_documents 字段被移除,用户在使用 /rerank 端点时遇到了 UnprocessableEntityError。
- 开发团队承认了这一非预期的变更,并正在努力恢复 return_documents 参数,因为多位用户在更新 SDK 后报告了相同的问题。
- Command R 的开发状态:针对 Command R 可能停用的担忧,官方保证目前没有退役该模型的计划。
- 建议成员使用最新的更新(如 command-r-08-2024),以从增强的性能和成本效益中获益。
- aya_collection 数据集不一致性:发现了 aya_collection 数据集的不一致性,特别是在 19 种语言的翻译质量方面,其中英语有 249716 行,而阿拉伯语和法语为 124858 行。
- translated_cnn_dailymail 数据集中突显了具体的翻译不匹配问题,英语句子与阿拉伯语和法语的对应部分在比例上不一致。
- 森林火灾预测 AI 项目:一位成员介绍了他们使用 Catboost & XLModel 的森林火灾预测 AI 项目,强调了模型在 AWS 上部署的可靠性需求。
- 建议包括采用最新版本的 Command R 以获得更好的性能,并建议联系销售团队以获取额外的支持和更新。
- 研究原型 Beta 测试:一个支持报告创建等研究和写作任务的研究原型已开放限量 beta 测试注册,链接在这里。
- 参与者需要提供详细且建设性的反馈,以帮助在早期测试阶段完善工具的功能。
HuggingFace Discord
- 经济型 AI 家用服务器亮相:一段 YouTube 视频 展示了如何使用单块 3060 GPU 和一台 Dell 3620 搭建高性价比的 AI 家用服务器,并演示了在 Llama 3.2 模型上的出色性能。
- 该方案为运行 LLM 提供了一个低成本选择,使工程师无需巨额硬件投资即可接触先进的 AI 技术。
- 图神经网络主导 NeurIPS 2024:NeurIPS 2024 重点关注了 Graph Neural Networks 和几何学习,提交论文约 400-500 篇,超过了 ICML 2024 的提交数量。
- 关键主题包括扩散模型 (diffusion models)、Transformer、Agent 和知识图谱 (knowledge graphs),并在理论上强调了等变性 (equivariance) 和泛化性 (generalization),详见 GitHub 仓库。
- Qwen2.5 Coder 超越 GPT4o 和 Claude 3.5:在最近的评估中,Qwen2.5 Coder 32B 的表现优于 GPT4o 和 Claude 3.5 Sonnet,相关分析见此 YouTube 视频。
- 社区认可 Qwen2.5 Coder 的快速进步,将其定位为编程 AI 领域的强力竞争者。
- 高级电子商务 Embedding 模型发布:新的电子商务 Embedding 模型已发布,其性能超越 Amazon-Titan-Multimodal 高达 88%,可在 Hugging Face 上获取并集成到 Marqo Cloud。
- 详细的功能和性能指标可以在 Marqo-Ecommerce-Embeddings 集合中找到,有助于开发强大的电子商务应用。
- 讨论创新的图像去噪技术:论文 Phase Transitions in Image Denoising via Sparsity 现已在 Semantic Scholar 上线,提出了解决图像处理挑战的新方法。
- 该研究为提升图像去噪方法做出了贡献,解决了保持图像质量的关键问题。
LlamaIndex Discord
-
PursuitGov 使用 LlamaParse 增强 B2G 服务:通过采用 LlamaParse,PursuitGov 在一个周末内成功解析了 400 万页 文档,显著增强了其 B2G 服务。
- 这一转变使复杂文档格式的准确率提升了 25-30%,使客户能够从公共部门数据中挖掘隐藏的机会。
-
集成 ColPali 进行高级重排序:一位成员分享了使用 ColPali 作为重排序器 (re-ranker) 的见解,以在多模态索引 (multimodal index) 中实现高度相关的搜索结果。
- 该技术利用 Cohere 的多模态嵌入 (multimodal embeddings) 进行初始检索,整合文本和图像以获得最佳结果。
-
Cohere 的新多模态嵌入功能:团队讨论了 Cohere 的多模态嵌入,强调了其有效处理文本和图像数据的能力。
- 这些嵌入正与 ColPali 集成,以增强搜索相关性和整体模型性能。
-
自动化 LlamaIndex 工作流流程:一位成员对繁琐的发布过程表示不满,旨在实现更多自动化,并分享了一个 LlamaIndex v0.11.23 的 GitHub pull request。
- 他们强调需要简化工作流,以减少人工干预并提高部署效率。
-
优化 FastAPI 的流式响应:围绕使用 FastAPI 的 StreamingResponse 展开了讨论,担心事件流延迟可能是由于协程调度 (coroutine dispatching) 问题引起的。
- 成员们建议使用高级流式传输技术,例如使用
llm.astream_complete()将每个 token 作为流事件写入,以增强性能。
- 成员们建议使用高级流式传输技术,例如使用
LAION Discord
-
AI 公司拥抱大猩猩式营销 (Gorilla Marketing):一位成员指出 AI 公司非常喜欢大猩猩式营销,这可能是指非传统的促销策略,并分享了一个有趣的大猩猩挥舞美国国旗的 GIF。
- 这突显了 AI 行业内独特且富有创意的营销策略的使用。
-
寻求目标检测项目帮助:一位成员详细介绍了一个涉及使用 Python Django 进行空调目标检测的项目,旨在识别空调类型和品牌。
- 他们寻求帮助,表明在开发此识别功能方面需要支持。
-
为代码生成模型引入 GitChameleon:新数据集 GitChameleon: Unmasking the Version-Switching Capabilities of Code Generation Models 引入了 116 个基于特定库版本的 Python 代码补全问题,并配有可执行的单元测试,以严格评估 LLM 的能力。
- 这旨在解决现有基准测试忽略软件库演进的动态特性且未评估实际可用性的局限性。
-
激动人心的 SCAR 概念检测发布:SCAR 是一种在 LLM 中进行精确概念检测和引导的方法,它以监督方式使用 Sparse Autoencoders 学习单语义特征 (monosemantic features)。
- 它为毒性、安全性和写作风格等概念提供了强大的检测能力,并可在 Hugging Face 的 transformers 中进行实验。
-
NVIDIA 关于噪声频率训练的论文:NVIDIA 的论文提出了一个概念,即在正向加噪步骤中,高空间频率比低频率加噪更快。
- 在反向去噪步骤中,模型被显式训练为从低频到高频工作,提供了一种独特的训练方法。
Gorilla LLM (Berkeley Function Calling) Discord
- 为自定义模型重写测试用例:一位成员询问在修改 handler 后,如何为自定义模型重写或重新运行测试用例。
- 另一位成员建议删除
result文件夹中的结果文件,或更改constant.py中的路径以保留旧结果。
- 另一位成员建议删除
- Qwen-2.5 输出中的无效 AST 错误:一位成员描述了在微调 Qwen-2.5 1B 模型时遇到的问题,尽管模型输出有效,但仍会导致 INVALID AST 错误。
- 成员们讨论了一种特定的错误输出格式,其中包含一个未匹配的反括号,这表明存在语法问题。
- 对 JSON 结构输出的困惑:一位成员对模型输出 JSON 结构 而非预期的函数调用格式表示困惑。
- 其他成员澄清说,QwenHandler 理想情况下应该将 JSON 结构转换为函数形式,从而引发了关于输出预期的讨论。
- 评估量化微调模型:一位成员提出了关于评估量化微调模型的问题,特别是关于它们在 vllm 上的部署。
- 他们提到在模型服务中使用特定参数,如
--quantization bitsandbytes和--max-model-len 8192。
- 他们提到在模型服务中使用特定参数,如
LLM Agents (Berkeley MOOC) Discord
- LLM Agents MOOC 黑客松启动:LLM Agents MOOC 黑客松于 太平洋时间 11/12 下午 4 点开始,通过实况 LambdaAPI 演示 协助参赛者开发项目。
- 共有约 2,000 名创新者报名参加了 Applications 和 Benchmarks 等赛道,活动由 rdi.berkeley.edu/llm-agents-hackathon 主办。
- LambdaAPI 演示支持黑客松项目:LambdaAPI 提供了实操演示,指导黑客松参与者构建高效的 LLM Agent 应用。
- 这些演示提供了可操作的工具和技术,帮助开发者完善其项目实现。
- NVIDIA 的具身智能引发伦理辩论:NVIDIA 关于具身智能 (Embodied AI) 的演讲引发了关于是否赋予类人 AI 系统道德权利的讨论。
- 参与者强调了对规范对齐 (Normative Alignment) 关注的缺失,并对 AI 进步的伦理边界提出了质疑。
- AI 权利与规范对齐担忧:社区对 AI 开发中缺乏规范对齐讨论表示不安,尤其是在 NVIDIA 分享见解之后。
- 辩论集中在 AI 权利的伦理影响上,强调了对全面对齐策略的需求。
OpenAccess AI Collective (axolotl) Discord
- FOSDEM AI DevRoom 定于 2025 年举行:AIFoundry 团队正在筹备计划于 2025 年 2 月 2 日举行的 FOSDEM AI DevRoom,重点关注 ggml/llama.cpp 及相关项目,旨在团结 AI 贡献者和开发者。
- 他们正在邀请底层 AI 核心开源项目维护者提交提案,截止日期为 2024 年 12 月 1 日,并为引人入胜的主题提供潜在的差旅补贴。
- Axolotl 微调利用 Alpaca 格式:一位用户阐明了使用 Axolotl 进行微调的设置过程,强调使用 Alpaca 格式的数据集进行训练预处理。
- 有人指出 tokenizer_config.json 缺少 chat template 字段,需要进一步调整以完成完整配置。
- 通过聊天模板增强 Tokenizer 配置:一位成员分享了一种通过复制特定 JSON 结构将 chat template 合并到 tokenizer config 中的方法。
- 他们建议修改 Axolotl 内的设置,以确保在未来的配置中自动包含聊天模板。
- 在微调中集成默认系统提示词:发出了一个提醒,指出共享模板缺少 Alpaca 的默认系统提示词,这可能需要调整。
- 用户被告知可以在 ### Instruction 之前包含条件语句,以有效地集成所需的提示词。
DSPy Discord
-
注解增强 dspy.Signature:成员们讨论了在 dspy.Signature 中使用 annotations(注解)的情况,澄清了虽然 基础注解 可以工作,但使用 list[MyClass] 等 custom types(自定义类型)也具有潜力。
- 一位成员确认字符串形式在此用途下不起作用,建议优先使用 显式类型定义。
-
为临床实体实现自定义签名:一位成员分享了在输出中使用 字典列表 实现 custom signature(自定义签名)的成功案例,展示了对 临床实体 的提取。
- 该实现包括对输入和输出字段的 详细描述,表明了定义 复杂数据结构 的 灵活方法。
OpenInterpreter Discord
-
Linux Mint 在虚拟机中运行困难:在 Virtual Machine Manager 中安装 Linux Mint 后,用户报告网络无法正常工作。
- 不过,有人尝试在一个名为 Boxes 的应用中安装 Linux Mint。
-
Microsoft Copilot 沟通故障:与 Microsoft Copilot 的反复交互显现出挫败感,因为命令未按要求进行配置。
- 用户强调没有创建桥接,但他们设法自行创建了一个。
-
OS X 上的 Interpreter CLI Bug:有报告称 OS X 上的 Interpreter CLI 存在文件持久化并意外退出的问题。
- 用户对这些问题在 developer branch(开发分支)上频繁发生表示担忧。
Torchtune Discord
- PyTorch 团队将发布 DCP PR:whynot9753 宣布 PyTorch 团队可能会在明天发布一个 DCP PR。
- ****:
AI21 Labs (Jamba) Discord
- 请求继续使用微调模型:一位用户请求继续使用他们的 fine-tuned models(微调模型)。
- 请求继续使用微调模型:一位用户请求继续使用他们的 fine-tuned models(微调模型)。
Alignment Lab AI Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
LLM Finetuning (Hamel + Dan) Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
Mozilla AI Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
第 2 部分:按频道详细摘要和链接
完整的各频道详情已针对邮件进行了删减。
如果您喜欢 AInews,请分享给朋友!预谢!