ainews-stripe-lets-agents-spend-money-with
Stripe 允许智能体(Agents)通过 StripeAgentToolkit 进行支付。
Stripe 开创了专门为处理支付的智能体(agents)设计的 AI SDK,通过集成 gpt-4o 等模型来实现金融交易和基于 Token 的计费。AI 开发者工具的趋势正强调构建更好的“AI-计算机接口”(AI-Computer Interfaces)以提升智能体的可靠性,其中 E2B 和 llms.txt 文档趋势备受关注,并已被 Anthropic 采用。
在 AI 模型新闻方面,Gemini-Exp-1114 登顶了视觉排行榜,并在数学竞技场(Math Arena)中表现有所提升;与此同时,关于模型过拟合以及通用人工智能(AGI)扩展定律(scaling laws)局限性的讨论仍在继续。OpenAI 发布了支持 VS Code、Xcode 和 Terminal 集成的 macOS 版 ChatGPT 桌面应用,进一步优化了开发者工作流和结对编程。
Anthropic 推出了一款利用思维链(chain-of-thought)推理的提示词优化工具。Meta AI 分享了 EMNLP2024 关于图像字幕生成、对话系统和内存高效微调的顶级研究成果。ICLR 2025 的亮点包括基于扩散的光照协调、开源混合专家(MoE)语言模型以及双曲视觉语言模型。此外,一种新的自适应解码方法优化了每个 Token 的创造力和事实性。针对文档解析和检索增强生成(RAG),业界还推出了 LlamaParse 和 RAGformation 等新工具。
AI SDK 便是你所需的一切。
2024/11/14-2024/11/15 的 AI 新闻。我们为您检查了 7 个 subreddits、433 个 Twitter 账号 和 30 个 Discord(217 个频道和 1812 条消息)。预计节省阅读时间(以 200wpm 计算):191 分钟。您现在可以在 AINews 讨论中标记 @smol_ai!
今年 AI 开发者工具领域兴起的一个论点是,拥有更好“AI-Computer Interfaces”的工具将作为 Agent 可靠性/准确性的中期解决方案表现得更好。你可以在 E2B 等工具以及由 Jeremy Howard 发起、现已被 Anthropic 采用的 llms.txt 文档趋势中看到这一点。Vercel 拥有通用的 AI SDK,但 Stripe 是第一家专门为涉及资金往来的 Agent 创建 SDK的开发者工具公司:
import {StripeAgentToolkit} from '@stripe/agent-toolkit/ai-sdk';
import {openai} from '@ai-sdk/openai';
import {generateText} from 'ai';
const toolkit = new StripeAgentToolkit({
secretKey: "sk_test_123",
configuration: {
actions: {
// ... enable specific Stripe functionality
},
},
});
await generateText({
model: openai('gpt-4o'),
tools: {
...toolkit.getTools(),
},
maxSteps: 5,
prompt: 'Send <<email address>> an invoice for $100',
});
以及支出资金:
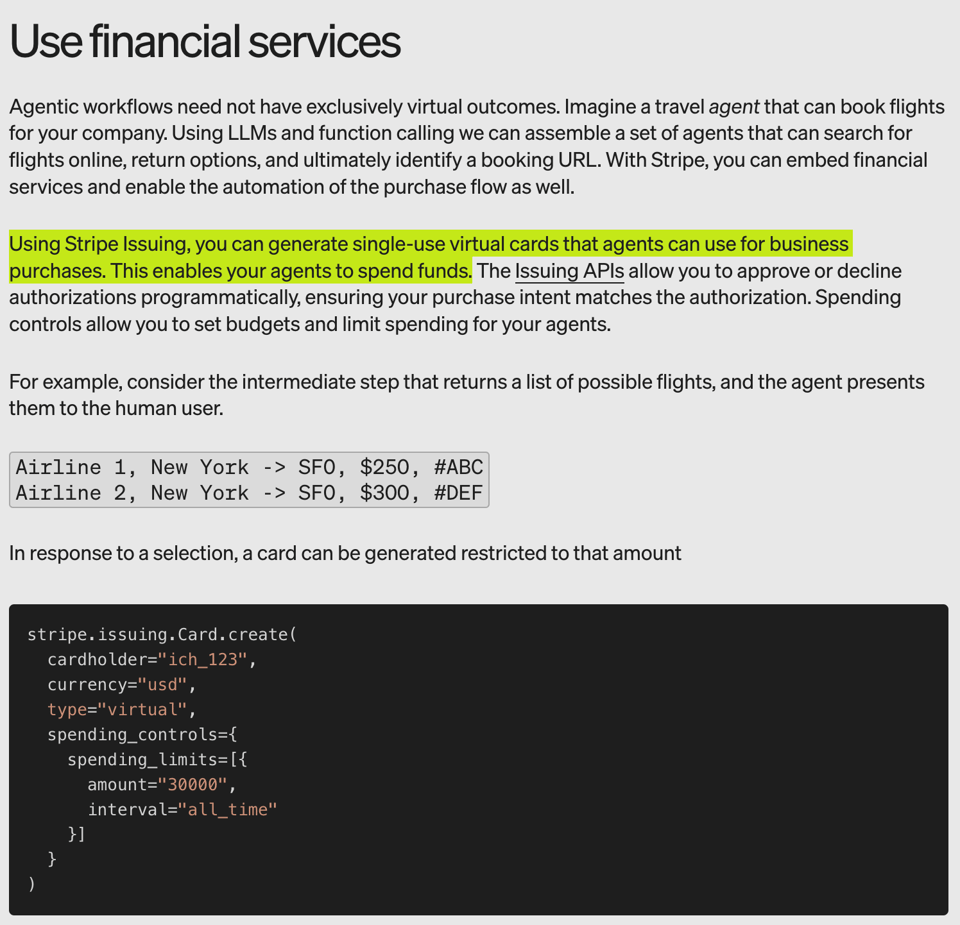
还有基于 token 使用情况进行收费。这是一个非常有前瞻性的举动,解决了常见的痛点。回想起来,Stripe 成为第一家为 AI Agents 构建金融服务的公司并不令人意外。
AI Twitter 摘要
所有摘要均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
AI 模型与基准测试
-
模型过拟合与性能:@abacaj 强调了对模型过拟合 (overfit) 的担忧,即模型仅在特定的基准测试 (benchmarks) 中表现良好。@francoisfleuret 对规模法则 (scaling laws) 已经失效的观点提出质疑,认为单纯增加模型规模可能无法实现 AGI。
-
Gemini 与 Claude 对比:@lmarena_ai 报告称 Gemini-Exp-1114 在视觉排行榜 (Vision Leaderboard) 中获得第一名,并在 Math Arena 中的排名有所提升。相比之下,@goodside 批评了 LLM 的 IQ 类比,指出 LLM 的智能在不同任务之间存在显著差异。
AI 公司新闻
-
OpenAI 更新:@OpenAI 宣布发布 macOS 版 ChatGPT 桌面应用,该应用现在可与 VS Code、Xcode 和 Terminal 等工具集成,以增强开发者的工作流。
-
Anthropic 与 Meta 动态:@AnthropicAI 在 Anthropic Console 中引入了新的 prompt improver,旨在利用思维链 (chain-of-thought) 推理来优化提示词。同时,@AIatMeta 分享了来自 EMNLP2024 的顶级研究论文,涵盖了图像字幕 (image captioning)、对话系统以及内存高效微调 (memory-efficient fine-tuning) 等方面的进展。
AI 研究与论文
-
ICLR 2025 亮点:@jxmnop 评述了 ICLR 2025 的高分论文,包括关于基于扩散的照明协调 (diffusion-based illumination harmonization)、开源混合专家语言模型 (OLMoE) 以及双曲视觉语言模型 (hyperbolic vision-language models) 的研究。
-
自适应解码技术:@jaseweston 介绍了 Adaptive Decoding via Latent Preference Optimization,这是一种新方法,通过为每个 token 自动选择创造性或事实性参数,其表现优于固定温度解码。
AI 工具与软件更新
-
ChatGPT 桌面版增强:@stevenheidel 展示了 ChatGPT 桌面应用的新功能,包括高级语音模式 (Advanced Voice Mode) 以及与 VS Code、Xcode 和 Terminal 交互的能力,从而实现无缝的结对编程 (pair programming) 体验。
-
LlamaParse 与 RAGformation:@lmarena_ai 介绍了 LlamaParse,这是一款用于解析复杂文档的工具,支持手写内容和图表等特征。此外,@llama_index 推出了 RAGformation,它可以根据自然语言描述自动配置云端设置,简化了云复杂性并优化了 ROI。
AI Agent 与应用
-
生产环境中的 AI Agent:@LangChainAI 透露,51% 的公司已经在生产环境中部署了 AI Agent,其中中型公司以 63% 的采用率领先。主要应用场景包括研究与摘要 (58%)、个人生产力 (53.5%) 和客户服务 (45.8%)。
-
Agent 工作流中的 Gemini 与 Claude:@AndrewYNg 讨论了如何针对 Agent 工作流 (agentic workflows) 优化 Gemini 和 Claude 等 LLM,增强函数调用 (function calling) 和工具使用 (tool use) 等能力,以提升各种应用中的 Agent 性能。
迷因与幽默
-
关于 AI 的幽默观点:@ClementDelangue 分享了一个关于 Transformers.js 的轻松迷因,而 [@rez0](https://twitter.com/rez0/status/1857190746841079930) 则幽默地评论了受 AI 影响的清洁习惯。
-
AI 相关笑话:@hardmaru 拿历史上的 NVIDIA 持股开玩笑,@fabianstelzer 发布了一个有趣的 AI Prompt 场景,展示了 LLM 中风格迁移 (style transfer) 的怪癖。
AI Reddit 摘要
/r/LocalLlama 摘要
主题 1. Gemini Exp 1114 在 Chatbot Arena 中获得最高排名
- Gemini Exp 1114 现在在 Chatbot Arena 排名并列总榜第一(不过这名字……) (Score: 322, Comments: 101): 由 GoogleDeepMind 开发的 Gemini Exp 1114 在 Chatbot Arena 中获得了 并列总榜第一 的排名,其分数显著提升了 40 多分,追平了 4o-latest 并超越了 o1-preview。它还在 Vision 排行榜 中领跑,并在 Math、Hard Prompts 和 Creative Writing 类别中晋升至第一,同时在 Coding 领域的排名提升至第三。
- 讨论中也出现了对 Gemini Exp 1114 表现的怀疑,一些用户质疑其改进是否源于在 Claude 的数据 或其他合成数据集上进行的训练。一些用户幽默地表示,该模型的身份和能力可能被夸大或误解了,正如有关其命名和表现的梗和笑话所展示的那样。
- 技术辩论涉及 context length(上下文长度)和响应时间,指出 Gemini Exp 1114 具有 32k 的输入上下文长度,且被认为速度较慢,可能专注于“思考”过程。在推理能力方面,用户将其与 OpenAI 的 o1 进行了比较,指出 Gemini Exp 1114 即使没有显式提示,也能有效地使用“思维链”(chain of thought)推理。
- 用户对 命名规范 和模型变体表示关注,提到了 Nemotron 并与 Llama 模型进行了比较。人们对 Gemini 模型如 “pro” 或 “flash” 的命名感到好奇,并猜测该版本是否是诸如 “1.5 Ultra” 或 “2.0 Flash/Pro” 之类的新迭代。
主题 2. Omnivision-968M 优化边缘设备视觉处理
- Omnivision-968M:边缘设备视觉语言模型,Token 减少 9 倍 (Score: 214, Comments: 47): Omnivision-968M 模型专为边缘设备优化,实现了 图像 Token 减少 9 倍(从 729 降至 81),增强了在 Visual Question Answering 和 Image Captioning 任务中的效率。它处理图像速度极快,在 M4 Pro Macbook 上为一张 1046×1568 像素的海报生成字幕仅需不到 2 秒,仅占用 988 MB RAM 和 948 MB 存储空间。更多信息和资源可在 Nexa AI 的博客及其 HuggingFace 仓库中找到。
- 讨论中有人好奇使用 消费级 GPU(如几块 3090)构建 Omnivision-968M 模型的可行性,还是需要租用更强大的云端 GPU(如 H100/A100)进行训练。该模型与 Llama CPP 的兼容性及其在 OCR 任务中的表现也受到了关注。
- 讨论还包括可能发布的 音频 + 视觉投影模型 以及 vision/text parameters 的划分。用户提到了 Qwen2.5-0.5B 模型,并对 Nexa SDK 的使用表示兴趣,文中提供了 GitHub 仓库链接。
- 有人对向 llama.cpp 项目回馈贡献表示担忧,一些用户批评开源贡献缺乏互惠性。此外,还有关于 Coral TPU 因内存较小而在运行模型方面存在局限性的讨论,建议将入门级 NVIDIA 显卡 作为更具成本效益的解决方案。
主题 3. Qwen 2.5 7B 霸榜 Livebench 排名
- Qwen 2.5 7B 已加入 Livebench,排名超越 Mixtral 8x22B 和 Claude 3 Haiku (Score: 154, Comments: 35): Qwen 2.5 7B 已被添加到 Livebench,并在排名中超越了 Mixtral 8x22B 和 Claude 3 Haiku。
- 用户质疑 Qwen 2.5 7B 在基准测试之外的实际效用,指出其在构建基础 Streamlit 页面和解析职位发布等任务中表现不佳。WizardLM 8x22B 被认为是更理想的替代方案,因为尽管其基准测试分数较低,但在实际应用中表现更优。
- 几位用户对基准测试的有效性表示怀疑,不相信像 Qwen 2.5 7B 这样的小型模型能超越 GPT-3.5 或 Mixtral 8x22B 等大型模型。他们强调了基准测试结果与实际可用性之间的脱节,特别是在对话和指令任务中。
- 讨论涉及在特定硬件配置(如 Apple M3 Max 和 NVIDIA GTX 1650)上运行 Qwen 2.5 14B 和 32B 等模型的技术细节,以及使用 fp16 或 Q4_K_M 格式模型的考量。用户还提到 Gemini-1.5-flash-8b 是基准测试中的强劲对手,并指出了其多模态能力。
- Claude 3.5 竟然知道我的姓氏——隐私怪象 (Score: 118, Comments: 141): 该帖子讨论了使用 Claude 3.5 Sonnet 的一次令人担忧的经历:尽管用户在会话中仅提供了名字,AI 却在生成的 MIT 许可证中意外包含了用户罕见的姓氏。这引发了关于 AI 是否能访问过去的交互记录或 GitHub 个人资料等外部来源的疑问(尽管用户认为自己已选择退出此类数据使用),并促使该用户寻求他人的类似经历或见解。
- 评论者推测 Claude 3.5 Sonnet 可能是通过 GitHub profiles 或其他公开数据获取了用户的姓氏,尽管用户努力保护隐私。一些用户建议 AI 可能会通过关联用户的代码风格和公共仓库来推断其身份,而另一些人则怀疑 AI 是否能访问私有数据或账户凭据。
- 讨论还涉及账户注册时的 metadata(元数据)或个人详情(如电子邮件地址或支付信息)是否被用于识别用户。一些评论指出,LLM 通常不会直接接收此类元数据,任何明显的个性化可能只是巧合或基于公开数据。
- 用户还辩论了 LLM 在解释其思维过程方面的可靠性,一些人指出模型可能会编造解释或依赖训练数据的关联性。有人建议联系 Anthropic 以寻求澄清,因为该事件引发了对隐私和数据使用的担忧。
{kind=link}
其他 AI Subreddit 摘要
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
主题 1. Claude 超越 GPT-4O:代码生成质量的重大转变
- 3.5 sonnet vs 4o 编程对比:是天差地别还是略胜一筹? (Score: 26, Comments: 42): Claude 3.5 Sonnet 在编程能力上表现出优于 GPT-4 的水平。在限制方面,Claude Pro 为 50 条消息/5 小时,而 ChatGPT Plus 为 80 条消息/3 小时,此外还有 O1-mini 的 50 条/天和 O1-preview 的 7 条/天。帖子作者寻求建议,想知道对于中高级水平的 Python、JavaScript 和 C++ 开发,这种性能差异是否值得切换到 Claude Pro。
- 用户反馈 Claude 3.5 Sonnet 在编程任务中始终优于 GPT-4,一位用户指出 GPT-4 的编程能力自最初发布以来已显著退化,当时它还能有效处理 Matlab-to-Python 转换和 PyQT5 实现等复杂任务。
- 几位开发者强调了 Sonnet 卓越的代码理解和错误修复能力,尽管有人提到在进行高层级架构讨论时会使用 O1-preview。用户建议配合 Sonnet 使用 Cursor,作为应对使用限制的替代方案。
- 尽管 Claude Pro 有 45 条消息/5 小时的严格限制,用户仍压倒性地倾向于选择它而非 GPT-4,理由是其代码质量和项目理解力更高。一些开发者采用混合方案,在等待 Claude 额度重置时切换到 GPT-4。
- Chat GPT plus 出现省略代码、删除函数甚至给出空回复的情况,即使是 o1-preview 也是如此 (Score: 27, Comments: 21): ChatGPT Plus 用户报告了 代码生成 方面的问题,模型在处理大型代码库(特别是 700 行脚本)时会截断回复、删除无关函数,偶尔还会提供空回复。即使使用 GPT-4 preview 模型,问题依然存在,请求完整代码时仅返回修改后的函数,而丢失了原始上下文。
- 用户反映各模型的代码质量均有所下降,有人猜测 OpenAI 可能在故意降低性能。另一些人注意到,由于负载较低,在美国夜间时段使用 API 效果更好。
- 使用这些模型的最佳实践是将代码拆分为更小、可管理的块。这种方法通过防止文件变得过大或过于碎片化,自然地引导出更好的架构。
- 尽管 GPT-4 preview 模型在详细代码分析和复杂主题讨论方面有优势,但 Claude 和标准版 GPT-4 产出的代码可能更好。
Theme 2. FrontierMath 基准测试:模型在高等数学中仅得 2 分
- FrontierMath 是一个新的 LLM 数学基准测试,用于测试其极限。目前得分最高的模型仅获得 2%。 (Score: 357, Comments: 117): FrontierMath 作为一个测试 LLM 的新数学基准,揭示了 LLM 数学能力的显著局限性,表现最好的模型准确率仅为 2%。该基准旨在评估超越标准测试的高级数学能力,凸显了当前 AI 系统明显的性能差距。
- 包括 Terence Tao 和 Timothy Gowers 在内的菲尔兹奖得主确认,这些问题“极具挑战性”,超出了典型的 IMO 题目。该基准需要研究生、AI 和代数软件包协作才能有效解决。
- FrontierMath 中的问题由数学博士专门为 AI 基准测试设计,需要多位领域专家长期合作。样例问题可在 epoch.ai 查看,但完整数据集仍不公开。
- 讨论集中在即使在大多数数学博士都无法独立解决的问题上达到 2% 准确率的意义。用户争论达到这一水平的 AI 是否应被视为协作团队成员而非仅仅是工具,并引用了 Chris Olah 关于神经网络的研究。
{kind=link}
Theme 3. Chat.com 域名以 1500 万美元售予 OpenAI - 重大企业举措
- 印度男子以 12.6 亿卢比出售 Chat.com (Score: 550, Comments: 173): Chat.com 域名以 1500 万美元(12.6 亿卢比)的价格售出,部分款项以 OpenAI 股份支付。该域名由一名印度籍所有者售出,标志着 2023 年一笔重大的域名交易。
- Dharmesh Shah,HubSpot 的 CTO 兼科技亿万富翁,在去年以约 1400 万美元购入该域名后将其售出。交易包括部分 OpenAI 股份,据悉 Shah 与 Sam(推测为 Altman)是朋友。
- 多位评论者批评标题过度关注卖家的国籍,而非其卓越的专业背景。对于据报道身价超过 10 亿美元的 Shah 来说,这笔交易规模相对较小。
- 讨论透露,这并非一项长期的域名投资,反驳了最初关于该域名自互联网早期就被持有的假设。考虑到最近的买入价格,实际利润率相对较低。
{kind=link}
主题 4. Claude 回滚:3.6 版本问题导致版本撤回
- 笑死,他们现在要撤回 Sonnet 3.6 了? (Score: 62, Comments: 55): Anthropic 似乎回滚了 Claude 3.6 Sonnet 并移除了 Haiku 的版本编号,截图显示模型选择界面中删除了“(new)”标识。这些变化表明其 Claude 模型可能进行了版本调整或静默更新,尽管官方未提供解释。
- 用户报告称,Claude Sonnet 可能仍是 3.6 版本,只是移除了“new”标签,模型对事件的了解及其 10 月 22 日的版本标识符证实了这一点。
- 社区成员批评 Anthropic 的沟通和版本命名策略,许多人指出该公司近期在透明度和内部组织方面存在问题。一位用户幽默地通过道歉短语来区分不同版本:旧版 3.5 使用 “你是对的,我道歉”,而新版 3.5 使用 “啊,我现在明白了!”。
- 讨论揭示了潜在的性能差异,有报告称该模型在消息输出方面存在限制,且无法通过简单的测试(如计算单词中的字母数量)。页面顶部观察到 High Demand Notice(高需求通知),表明系统负载较重。
- 既然刚登录就看到这种愚蠢的消息,付费还有什么意义?这简直糟糕透顶。我今天甚至还没用过 Claude 就已经被限制了。 (Score: 103, Comments: 50): Claude 用户报告称,尽管拥有付费订阅且当天未使用,仍立即受到访问限制和服务约束。Anthropic 的服务限制似乎同时影响了新老付费用户,且没有明确解释或事先通知。
- 用户报告称,Claude 付费订阅很快就会达到使用限制,部分用户在 上午 11 点 之前就被限制。多位用户建议使用 2-3 个账号(每个 20 美元)或切换到更昂贵的 API 作为变通方案。
- 社区讨论强调需要更好的使用情况追踪功能,建议增加一个进度条,显示在降级到简洁模式(concise mode)之前的剩余使用量。用户批评使用限制缺乏透明度,且在受限时无法退出简洁模式。
- 技术用户讨论了本地替代方案,推荐使用具有特定硬件要求的 Ollama:NVIDIA 3060(12GB VRAM,$200)或 3090(24GB VRAM,$700)。对于显存充足的用户建议使用 Qwen 2.5 32B 模型,而 Qwen 14B 2.5 则被推荐作为更轻量级的替代方案。
{kind=link}
AI Discord 摘要回顾
由 O1-mini 生成的摘要之摘要的摘要
主题 1:AI 模型的硬件与性能优化
- 技嘉发布 AMD Radeon PRO W7800 AI TOP 48G:技嘉推出了 AMD Radeon PRO W7800 AI TOP 48G,配备 48 GB GDDR6 显存,面向 AI 和工作站专业人士。
主题 2:模型发布与集成增强
- DeepMind 开源 AlphaFold 代码:DeepMind 发布了 AlphaFold 代码,让更多人能够使用其蛋白质折叠技术,预计将加速生物技术和生物信息学领域的研究。
- Google 发布 Gemini AI 应用:Google 推出了 Gemini 应用,集成了先进的 AI 功能以竞争现有工具,详见 TechCrunch 文章。
主题 3:AI 工具集成与功能开发
- ChatGPT 现已集成 macOS 桌面应用:ChatGPT for macOS 现在支持与 VS Code、Xcode、Terminal 和 iTerm2 集成,通过直接与开发环境交互来增强编程辅助功能。
- Stable Diffusion WebUI 对决:ComfyUI vs SwarmUI:用户对比了 ComfyUI 和 SwarmUI,由于 SwarmUI 安装简便且在 Stable Diffusion 工作流中表现稳定,用户更倾向于选择它。
主题 4:训练技术与数据集管理
- Orca-AgentInstruct 提升合成数据生成:Orca-AgentInstruct 引入了 Agentic Flows 来生成多样化、高质量的合成数据集,从而提升小型语言模型的训练效率。
- LLM 训练中的有效数据集混合策略:成员们寻求关于在 LLM 训练不同阶段混合与匹配数据集的指导,强调了在不损害模型性能的情况下优化训练过程的最佳实践。
第一部分:Discord 高层级摘要
LM Studio Discord
-
Qwen 2.5 LaTeX 渲染问题:用户在使用 Qwen 2.5 时遇到 LaTeX 无法在
$符号内正确渲染的问题,导致输出乱码。- 有建议提出通过创建带有明确指令的 System Prompt 来改善渲染,但目前的尝试尚未成功解决该问题。
-
LM Studio 的 Function Calling Beta 引发关注:LM Studio 用户对新的 Function Calling Beta 功能充满热情,正在寻求个人使用经验和反馈。
- 虽然部分成员认为文档清晰易懂,但也有人表示困惑,并期待在未来的更新中看到更多功能。
-
SSD 速度对比与 RAID 配置:社区讨论了 SSD 性能,特别是 SABRENT Rocket 5 与 Crucial T705 的对比,以及 PCIe 通道限制对 RAID 设置的影响。
- 用户指出,SSD 的实际性能会因具体的工作负载和 RAID 配置而产生显著差异,从而影响整体效率。
-
技嘉发布 AMD Radeon PRO W7800 AI TOP 48G:技嘉推出了配备 48 GB GDDR6 显存的 AMD Radeon PRO W7800 AI TOP 48G,目标用户为 AI 和工作站专业人士。
- 尽管规格令人印象深刻,但与 NVIDIA 的 CUDA 相比,人们对 AMD 驱动程序的可靠性和软件兼容性仍存疑虑。
-
LLM 训练的硬件考量:参与者指出 24 GB VRAM 对于训练较大的 LLM 往往不足,引发了关于升级路径和租用 GPU 的讨论。
- 在 Mac Mini 等设备上进行训练是可行的,但可能导致更高的电费支出,这促使成员们考虑更高效的硬件解决方案。
Perplexity AI Discord
-
Perplexity API 的 URL 注入问题:用户报告称 PPLX API 在无法确切检索信息时,偶尔会插入随机 URL,导致输出不准确。
- 讨论强调,API 添加无关 URL 的倾向削弱了其在生产环境中的可靠性,引发了对未来更新中增强准确性的呼吁。
-
DeepMind 发布 AlphaFold 代码:DeepMind 已开源 AlphaFold 代码,使更广泛的人群能够访问其蛋白质折叠技术,正如此处所宣布。
- 此次发布预计将加速生物技术和生物信息学的研究,促进蛋白质结构预测方面的创新。
-
ChatGPT 驱动的 Chegg 衰落:Chegg 的价值经历了 99% 的缩水,很大程度上归因于与 ChatGPT 的竞争,详见文章。
- AI 对 Chegg 等传统教育平台的影响在社区内引发了关于在线学习资源未来的重大辩论。
-
Google Gemini 应用发布:Google 正式发布了 Gemini 应用,引入了创新功能以与现有工具竞争,如 TechCrunch 文章所述。
- 该应用集成了 AI 和用户交互以提供增强功能,旨在在 AI 驱动的应用领域占据更大的市场份额。
aider (Paul Gauthier) Discord
-
Gemini 实验模型性能飙升:用户报告称,新的 gemini-exp-1114 模型在编辑方面的准确率高达 61%,在各种测试中表现优于 Gemini Pro 1.5,尽管存在细微的格式问题。
- 对比分析表明,gemini-exp-1114 提供了与之前版本相似的效能,具体取决于特定的使用场景。
-
Aider 中模型使用的成本影响:讨论指出,在 Aider 中使用不同模型的成本在每条消息 $0.05 到 $0.08 之间,受文件配置影响。
- 这导致用户考虑使用更经济的选择,如 Haiku 3.5,以减轻小规模项目的支出。
-
与 Qwen 2.5 Coder 的无缝集成:用户在集成 Hyperbolic 的 Qwen 2.5 Coder 时因缺少元数据而遇到问题,这些问题通过更新安装设置得到了解决。
- Aider 主分支的更新被证明对克服这些挑战至关重要,促进了顺利集成。
-
使用 Aider 自动生成 Commit 消息:为了给未提交的更改生成 commit 消息,用户在 Aider 中使用诸如
aider --commit --weak-model openrouter/deepseek/deepseek-chat或/commit的命令。- 这些命令通过提交所有更改而无需提示选择单个文件,从而实现了 commit 过程的自动化。
HuggingFace Discord
-
通过针对性训练提升 OCR 准确率:讨论强调,通过使用合适的文档扫描应用进行针对性训练,可以显著增强 OCR accuracy,有可能达到近乎完美的识别率。
- 参与者强调,确保合适的条件(如正确的扫描技术和模型 fine-tuning)对于最大化 OCR 性能至关重要。
-
通过反馈集成增强 OCR 模型:贡献者提议将失败的 OCR 实例重新整合进 training pipeline,以提高模型在特定应用中的性能。
- 这种反馈循环方法旨在迭代优化模型,从而提高 OCR 任务的准确性和可靠性。
-
发布用于研究的 OKReddit 数据集:一名成员发布了 OKReddit dataset,这是一个包含从 2005 年到 2023 年 5TiB Reddit 内容的精选集合,专为研究目的设计。
- 该数据集目前处于 alpha 阶段,提供了一个经过过滤的 subreddits 列表,并提供了访问链接,邀请研究人员探索其潜在应用。
-
区分 RWKV 模型与 Recursal.ai 的产品:一名成员澄清说,虽然 RWKV models 与特定的训练挑战相关,但它们在数据集细节方面与 Recursal.ai 模型有所不同。
- 计划中的未来集成预示着模型训练方法的进步,增强了两种模型类型的通用性。
-
优化法律应用的 Legal Embeddings:为法律应用有效训练 embedding 模型,需要使用在法律数据上预训练的 embeddings,以避免过长的训练时间和固有的偏见。
- 专注于特定领域训练(domain-specific training)不仅能提高准确性,还能加速法律 AI 系统的开发进程。
Unsloth AI (Daniel Han) Discord
-
Triton 和 CUDA 的未来焦点:成员们计划围绕 Triton 和 CUDA 开展重要的工程工作,强调了它们对未来项目的重要性。
- 存在对模型改进收益递减的担忧,这表明重点正转向效率(efficiency)。
-
语言模型偏好转移:随着 Qwen/Qwen2.5-Coder-7B-Instruct 因其广泛的训练数据而获得青睐,Mistral 7B v0.3 模型被认为已经过时。
- 社区成员比较了 Gemma2 和 GPT-4o 的性能,分享了关于它们效能的见解。
-
Unsloth 安装与 Lora+ 支持:用户因缺少 torch 遇到了 Unsloth 安装错误,建议在当前环境中验证安装。
- Lora+ support 已通过 pull requests 在 Unsloth 中得到确认,并讨论了其简单的实现方式。
-
为数学方程微调 Llama3.1b:一名用户正在为解决数学方程微调 Llama3.1b,目前达到了 77% 的准确率。
- 尽管他们数据集上的 loss 较低,但他们正在进行 hyperparameter sweeps,以将准确率提高到至少 80%。
-
数据集创建:Svelte 与歌词:由于 Qwen2.5-Coder 效果不佳,使用 Dreamslol/svelte-5-sveltekit-2 创建了一个全面的 Svelte 文档数据集。
- 针对歌词生成,正在使用 5780 首歌曲及相关元数据开发模型,建议使用 Alpaca chat template。
Eleuther Discord
-
Scaling Laws:Twitter 宣称 Scaling 已死:成员们讨论了 Twitter 最近关于 Scaling 在 AI 领域不再有效的说法,强调需要基于 同行评审论文(peer-reviewed papers) 的见解,而非未经证实的传闻。
- 一些参与者引用了来自各大实验室的 新闻来源,指出近期训练实验的结果令人失望,从而对 Twitter 的断言提出了质疑。
-
LLM 的局限性影响 AGI 愿景:讨论聚焦于当前 LLM 架构 的 能力约束,暗示潜在的 边际收益递减 可能会阻碍 AGI 级模型 的开发。
- 参与者强调 LLM 处理复杂任务(如 Diffie-Hellman 密钥交换)的必要性,并对模型在内部维护 私钥(private keys) 的能力及整体 隐私性 表示担忧。
-
Mixture-of-Experts 增强 Pythia 模型:一项讨论探索了在 Pythia 模型套件 中实现 Mixture-of-Experts (MoE) 框架,并在复制现有训练配置与更新 超参数(如 SwiGLU)之间进行了权衡。
- 成员们对比了 OLMo 和 OLMOE 模型,注意到 数据排序 和 规模一致性 方面的差异,这可能会影响 MoE 集成的效果。
-
定义开源 AI:数据 vs 代码:讨论围绕基于 IBM 的定义 对 AI 系统进行 开源 AI 分类展开,特别是争论这些要求是适用于 数据、代码 还是两者兼有。
- 链接到 Open Source AI Definition 1.0,成员们强调了 自主性、透明度 和 协作 的重要性,同时通过描述性数据披露来规避 法律风险。
-
Transformer Heads 在模型中识别反义词:研究发现某些 Transformer Heads 能够计算 反义词,分析展示了如 ‘hot’ - ‘cold’ 的示例,并利用了 OV 电路 和 消融研究(ablation studies)。
- 在各种模型中存在的可解释特征值证实了这些反义词 Head 在增强 语言模型(language model) 理解能力方面的功能。
Nous Research AI Discord
-
NVIDIA NV-Embed-v2 登顶 Embedding 基准测试:NVIDIA 发布了 NV-Embed-v2,这是一款领先的 Embedding 模型,在 Massive Text Embedding Benchmark 上获得了 72.31 分。
- 该模型结合了先进技术,如增强的潜在向量保留和独特的 难负样本挖掘(hard-negative mining) 方法。
-
Llama 3.2 训练中 RLHF 与 SFT 的探讨:关于 来自人类反馈的强化学习 (RLHF) 与 有监督微调 (SFT) 的讨论集中在训练 Llama 3.2 的资源需求上。
- 成员们指出,虽然 RLHF 需要更多 显存 (VRAM),但对于资源有限的用户来说,SFT 提供了一个可行的替代方案。
-
紧凑型模型实现 SOTA 图像识别:adjectiveallison 介绍了一种图像识别模型,以 缩小 29 倍 的体积实现了 SOTA 性能。
- 该模型证明了紧凑型架构可以保持高精度,从而可能减少计算资源消耗。
-
AI 驱动的翻译工具增强文化细微差别:一款 AI 驱动的翻译工具 利用 Agent 工作流,通过强调 文化细微差别 和适应性,超越了传统的机器翻译。
- 它考虑了地区方言、正式程度、语气和性别差异,确保翻译更加准确且具备上下文感知能力。
-
优化 LLM 训练中的数据集混合:一位成员请求关于在 LLM 训练 的不同阶段有效 混合和匹配数据集 的指导。
- 重点在于采用最佳实践来优化训练过程,同时不损害模型性能。
OpenRouter (Alex Atallah) Discord
-
MistralNemo 和 Celeste 支持已停止:MistralNemo StarCannon 和 Celeste 已正式弃用,因为唯一的供应商停止了支持,这影响了所有依赖这些模型的项目。
- 这一移除操作要求用户寻找替代模型或调整现有的工作流以适应变化。
-
Perplexity 在 Beta 版中增加引用溯源 (Grounding Citations):Perplexity 推出了引用溯源的 Beta 功能,允许在补全响应(completion responses)中包含 URL,以增强内容的可靠性。
- 用户现在可以直接引用来源,提高了生成信息的可信度。
-
Gemini API 现已开放:Gemini 现在可以通过 API 访问,其先进的能力在工程社区中引起了热烈讨论。
- 然而,一些用户报告称未看到更改,表明可能存在发布不一致的情况。
-
OpenRouter 实施速率限制:OpenRouter 为免费模型引入了每天 200 次请求的限制,详见其 官方文档。
- 由于可扩展性降低,这一限制给在生产环境中部署免费模型带来了挑战。
-
Hermes 405B 保持效率偏好:尽管成本较高,Hermes 405B 凭借其无与伦比的性能效率,仍然是许多用户的首选模型。
- 像 Fry69_dev 这样的用户强调了其卓越的效率,尽管存在利润率方面的顾虑,它依然保持着顶级选择的地位。
Stability.ai (Stable Diffusion) Discord
-
Stable Diffusion 的 Nvidia GPU 配置困扰:一位用户报告了在配置 Stable Diffusion 以使用其独立 Nvidia GPU 而非集成显卡时遇到的问题。另一位成员引用了频道中置顶的 WebUI 安装指南 以寻求支持。
- 社区强调了遵循设置指南的重要性,以确保 Stable Diffusion 工作流能够充分利用 GPU。
-
WebUI 对决:ComfyUI vs. SwarmUI:一位成员对比了 ComfyUI 与 SwarmUI 的复杂性,强调 SwarmUI 简化了配置过程。建议使用 SwarmUI 以获得更直接的安装体验和一致的性能。
- 讨论集中在易用性上,多位用户一致认为 SwarmUI 提供了一种技术门槛更低的方法,且不牺牲功能性。
-
寻找最新的图像融合 (Image Blending) 论文:一位用户寻求帮助寻找最近一篇关于图像融合的研究论文,提到了一位 Google 作者但未能找到。另一位成员建议在 arXiv 中搜索图像融合相关的 Google 论文。
- 社区强调了访问 arXiv 预印本的价值,以便及时了解图像融合技术的最新进展。
-
视频超分辨率 (Video Upscaling) 的逐帧修复:一位成员分享了他们通过每 0.5 秒提取一帧来修复不准确之处并进行视频超分辨率的方法。讨论还涉及使用 Flux Schnell 和其他工具来实现快速推理(inference)结果。
- 参与者讨论了各种增强视频质量的技术和工具,强调了在超分辨率过程中平衡速度与准确性的重要性。
-
使用 Diffusers 掌握低去噪局部重绘 (Low Denoise Inpainting):一位用户询问如何对特定图像区域进行低去噪局部重绘 (low denoise inpainting) 或 img2img 处理。建议包括利用 Diffusers 进行快速的 img2img 工作流,通过极少的步骤来精修图像。
- 社区推荐将 Diffusers 作为针对性重绘任务的有效工具,并强调了其在实现高质量图像精修方面的效率。
Interconnects (Nathan Lambert) Discord
-
Scaling Laws 理论面临审查:成员们对 Scaling Laws 理论的有效性提出了质疑,该理论认为增加计算能力和数据将增强 AI 能力。
- 一位成员表示宽慰,称降低交叉熵损失(cross-entropy loss)是提升 AI 能力的充分条件。
-
GPT-3 Scaling Hypothesis 验证了规模化收益:引用 The Scaling Hypothesis,一位成员指出,随着问题复杂度的增加,神经网络会产生泛化并展现出新的能力。
- 他们强调,于 2020 年 5 月发布的 GPT-3 持续证明了规模化的益处,这与收益递减的预测相反。
-
60 亿美元融资将估值推高至 500 亿美元:一位成员分享了一则 推文,指出下周结束的一轮融资将筹集 60 亿美元,主要来自中东主权基金,估值为 500 亿美元。
- 据报道,这笔资金将直接流向 Jensen,助力科技领域的后续发展。
-
历史上的对齐问题担忧在 2024 年案件中再次浮现:成员们分享了 TechEmails,讨论了 2017 年涉及 Elon Musk、Sam Altman 和 Ilya Sutskever 关于对齐(misalignment)问题的通信。
- 这些文件与正在进行的 Elon Musk, et al. v. Samuel Altman, et al. (2024) 案件相关,突显了对齐担忧的历史背景。
-
Apple Silicon vs NVIDIA GPU:LLM 性价比大对决:一篇 文章 讨论了 Apple Silicon 与 NVIDIA GPU 在运行 LLM 方面的竞争,强调了 Apple 平台的折中方案。
- 虽然 Apple 的新产品提供了更高的内存容量,但 NVIDIA 解决方案 仍然更具性价比。
GPU MODE Discord
-
FSDP 与 torch.compile 协同工作:一位用户演示了在 FSDP 中包装 torch.compile 且未遇到问题,表明两者可以无缝集成。
- 他们指出了这种方法的有效性,但提到尚未测试反向顺序,为进一步实验留下了空间。
-
NSYS 面临内存过载:nsys 性能分析在崩溃前可能消耗高达 60 GB 内存,这引发了对其在大型分析任务中实用性的担忧。
- 为了缓解这一问题,用户建议使用
nsys profile -c cudaProfilerApi -t nvtx,cuda等标志位来优化 nsys 使用,以减少日志记录开销。
- 为了缓解这一问题,用户建议使用
-
ZLUDA 将 CUDA 扩展至 AMD 和 Intel GPU:在一段 YouTube 视频 中,Andrzej Janik 展示了 ZLUDA 如何在 AMD 和 Intel GPU 上实现 CUDA 功能,这可能会改变 GPU 计算格局。
- 社区成员对这一突破表示赞赏,对在 NVIDIA 硬件之外普及 GPU 计算能力感到兴奋。
-
React Native 通过 ExecuTorch 拥抱 LLM:Software Mansion 发布了一个新的 React Native 库,利用 ExecuTorch 进行后端 LLM 处理,简化了移动平台上的模型部署。
- 用户称赞该库易于使用,强调了在 iOS 模拟器上简单的安装和模型启动流程。
-
Bitnet 1.58 A4 加速 LLM 推理:采用 Bitnet 1.58 A4 结合微软的 T-MAC 操作,在 7B 模型上实现了 10 tokens/s 的速度,提供了一种无需过度依赖 GPU 的快速推理解决方案。
- 虽然已有将模型转换为 Bitnet 的资源,但可能需要进行一些训练后修改以优化性能。
Notebook LM Discord Discord 频道
-
听众要求 Top Shelf Podcast 提供更多内容:听众正在推动扩展 Top Shelf Podcast,增加更多书籍摘要,特别是要求制作关于 Adam Grant 的 Think Again 以及 The Body Keeps Score 见解的节目。他们链接了 Top Shelf Spotify 节目以支持他们的建议。
- 一位用户鼓励社区成员分享更多书籍推荐,以丰富播客的内容。
-
对 AI 控制暴力的担忧:一位用户分享了 “AI 对暴力的垄断” YouTube 视频,对人工超级智能(artificial superintelligence)管理暴力行为的影响提出了警示。这种对暴力的垄断可能会导致重大的伦理和安全问题。
- 该视频探讨了授予 AI 实体控制暴力决策权的潜在后果,引发了关于严格治理措施必要性的讨论。
-
NotebookLM 面临运行问题:多名成员报告了 NotebookLM 的技术问题,例如功能故障和某些功能的访问受限。他们在等待开发团队解决问题时表达了沮丧。
- 用户分享了临时变通方法,并强调需要及时修复以恢复该工具的全部功能。
-
为不同受众定制音频摘要:一位成员展示了他们使用 NotebookLM 创建定制化音频摘要的方法,专门为社工和研究生调整内容。这展示了 NotebookLM 根据受众需求修改内容的能力。
- 定制过程涉及改变演示风格,以更好地适应不同专业群体的信息需求。
-
讨论文档上传限制:参与者讨论了 NotebookLM 内部的文档上传限制,并建议对文档进行分组以遵守上传限制。关于是否可以上传超过 50 份文档的问题也被提出。
- 讨论强调了改进上传能力的必要性,以更好地容纳大量的文档收藏。
OpenAccess AI Collective (axolotl) Discord 频道
-
Orca 合成数据进展:关于 Orca 的研究展示了其利用合成数据(synthetic data)进行小语言模型后训练的能力,使其性能能够媲美更大型的模型。
- Orca-AgentInstruct 引入了 Agentic flows 来生成多样化、高质量的合成数据集,增强了数据生成过程的效率。
-
Liger Kernel 和 Cut Cross-Entropy 的改进:Liger Kernel 的增强带来了速度和内存效率的提升,详情见 GitHub pull request。
- 提议的 Cut Cross-Entropy (CCE) 方法将 Gemma 2 模型的内存占用从 24 GB 降低到 1 MB,使得训练速度比当前的 Liger 设置快约 3 倍,详见此处。
-
Axolotl 答疑时间(Office Hours)和反馈环节:Axolotl 将于 12 月 5 日下午 1 点(EST)在 Discord 举办首场 Office Hours 活动,允许成员提问并分享反馈。
- 鼓励成员将他们的想法和建议带到 Axolotl 反馈环节,团队渴望参与并改进平台。更多详情可在 Discord 群聊中查看。
-
Qwen/Qwen2 预训练和 Phorm Bot 问题:一位成员正在寻求关于使用 qlora 和原始文本 jsonl 数据集预训练 Qwen/Qwen2 模型的指导,随后在安装 Axolotl docker 后使用 instruct 数据集进行微调。
- 报告的 Phorm bot 问题包括其无法响应基本查询,表明社区内可能存在技术故障。
-
Meta 邀请参加 Llama 活动:一位成员收到了来自 Meta 的意外邀请,参加在其总部举行的关于开源计划和 Llama 的为期两天的活动,引发了人们对潜在新模型发布的好奇。
- 社区成员正在推测活动的重点,特别是考虑到在没有发言角色的情况下收到邀请的特殊性。
OpenAI Discord
-
GPT-4o Token 计费:一次讨论透露,GPT-4o 在高分辨率模式下处理每个
512x512切片会产生 170 tokens 的费用,实际上将一张图片估值为约 227 个单词。深入分析请参考 OranLooney.com。- 参与者质疑了特定 token 定价背后的逻辑,将其类比为编程中的 magic numbers(魔术数字),并讨论了其对使用成本的影响。
-
利用 Few-Shot Examples 增强 RAG Prompts:用户正在探索将文档中的 few-shot examples 集成到 RAG prompts 中,是否能提高其 QA agent platform 的回答质量。
- 社区强调了在该领域进行深入研究的必要性,旨在优化 prompt 策略以增强响应准确性。
-
AI 在 24 点游戏中的表现:3.5 AI 模型已展示出在 Game of 24(24 点游戏)中偶尔获胜的能力,展示了 AI 游戏能力的显著进步。
- 这一进步凸显了 AI 算法的持续增强,用户对未来的性能里程碑表示乐观。
-
内容标记政策:成员们讨论了 content flags(内容标记)主要针对模型输出并有助于训练改进,而非暗示用户违规。
- 成员对内容标记的增加表示担忧,特别是在恐怖视频游戏等语境下,这表明监控措施有所加强。
-
高级照片筛选技术:一位成员提议创建一个编号拼贴图,作为从数百张照片中筛选最佳照片的高效方法,旨在简化选择过程。
- 尽管有人怀疑拼贴方法可能显得“零散”,但其有效性得到了认可,尤其是在按顺序处理任务时。
OpenInterpreter Discord
-
OpenAI 发布 ‘OPERATOR’ AI Agent:在一段名为“OpenAI Reveals OPERATOR The Ultimate AI Agent Smarter Than Any Chatbot”的 YouTube 视频 中,OpenAI 宣布了他们即将推出的 AI agent,预计很快将面向更广泛的受众。
- 视频强调 it’s coming to the masses!(它正走向大众!),暗示该 AI agent 的部署规模将大幅扩大。
-
Beta 版应用超越控制台集成:成员们确认 desktop beta app 的性能优于 console integration(控制台集成),这归功于增强的基础设施支持。
- 强调了桌面应用比 open-source repository(开源仓库)拥有更广泛的幕后支持,确保了更好的 Interpreter 体验。
-
Azure AI Search 技术详情:一段名为“How Azure AI Search powers RAG in ChatGPT and global scale apps”的 YouTube 视频 概述了 Azure AI Search 中使用的数据转换和质量恢复方法。
- 讨论引发了对专利申请、资源分配以及在大规模应用中高效数据删除流程必要性的关注。
-
概率计算提升 GPU 性能:一段 YouTube 视频 报道称,probabilistic computing(概率计算)与顶尖的 NVIDIA GPU 相比,实现了 1 亿倍的能效提升。
- 演讲者表示:“在这段视频中,我讨论了概率计算,据报道,与最好的 NVIDIA GPU 相比,它能实现 1 亿倍的能效提升。”
-
ChatGPT 桌面端增强:ChatGPT desktop 的最新更新引入了用户友好的增强功能,标志着对大众用户体验的显著改进。
- 用户渴望体验能优化平台交互的功能,强调了 desktop 增强的可用性。
tinygrad (George Hotz) Discord
-
tinybox pro 开启预订:tinybox pro 现已在 tinygrad 官网 开启预订,售价 40,000 美元,配备 8 张 RTX 4090,提供 1.36 PetaFLOPS 的 FP16 计算能力。
- 市场定位为单张 Nvidia H100 GPU 的高性价比替代方案,旨在为 AI 工程师提供强大的计算能力。
-
关于 int64 索引悬赏的说明:一位成员询问了 int64 索引 悬赏的要求,特别是关于 tensor.py 中
__getitem__等函数的修改。- 另一位成员提到了 PR #7601,该 PR 解决了该悬赏问题,但尚待受理。
-
CLOUD 设备 buffer 传输功能的增强:重点介绍了 CLOUD 设备 buffer 传输函数 的一个 Pull Request,旨在提高设备间的互操作性。
- 讨论指出目标 buffer 大小检查可能存在歧义,强调了实现中清晰度的必要性。
-
在 GPU 之间原生传输 tensor:明确了可以使用
.to函数在同一设备的不同 GPU 之间传输 tensor。- 该指南协助用户在项目中高效管理 tensor 传输。
-
寻求对 tinygrad 贡献的反馈:一位贡献者分享了他们为 tinygrad 做出贡献的初步尝试,并寻求全面的反馈。
- 他们提到了专注于数据传输改进的 PR #7709。
LlamaIndex Discord
-
在社区电话会议中学习 GenAI 应用构建:参加我们即将举行的 社区电话会议,探索如何从非结构化数据创建 知识图谱 (knowledge graphs) 以及高级检索方法。
- 参与者将深入研究将 数据转换 为可查询格式的技术。
-
Python 文档通过 RAG 系统获得功能提升:Python 文档通过一个新的 “Ask AI” 小组件得到了增强,该组件为代码查询启动了一个精确的 RAG 系统 点击查看!。
- 用户可以直接获得针对其问题的 准确、最新的代码 回复。
-
CondensePlusContext 的动态上下文检索:CondensePlusContext 压缩输入并为每条用户消息检索上下文,增强了向系统提示词 (system prompt) 中插入 动态上下文 的能力。
- 成员们因其在一致管理上下文检索方面的高效性而更青睐它。
-
condenseQuestionChatEngine 面临的挑战:一位成员报告称,当用户突然切换话题时,condenseQuestionChatEngine 可能会生成不连贯的独立问题。
- 建议包括自定义压缩提示词,以有效处理突然的话题转变。
-
在 CondensePlusContext 中实现自定义检索器:成员们同意使用带有自定义检索器 (custom retriever) 的 CondensePlusContextChatEngine 以符合特定需求。
- 他们建议采用自定义检索器和节点后处理器 (node postprocessors) 以优化性能。
Cohere Discord
-
Agentic Chunking 研究发布:一种针对 RAG 的 Agentic Chunking 新方法实现了少于 1 秒的推理时间,证明了在 GPU 上的高效性且具备成本效益。该研究的完整细节和社区建设可以在其 Discord 频道找到。
- 这一进展展示了检索增强生成过程中的显著性能提升,增强了系统效率。
-
LlamaChunk 简化文本处理:LlamaChunk 引入了一种由 LLM 驱动的技术,通过仅对文档进行单次 LLM 推理来优化递归字符文本分割。该方法消除了标准分块算法中通常使用的脆弱正则表达式模式。
- 团队鼓励对 LlamaChunk 代码库做出贡献,该代码库已在 GitHub 上公开。
-
RAG Pipeline 的增强:RAG Pipeline 正在通过 Agentic Chunking 进行优化,旨在简化检索增强生成过程。这种集成专注于减少推理时间并提高整体 Pipeline 效率。
- 这些更新利用 GPU 效率在提高性能指标的同时保持成本效益。
-
在 Python 中使用 Playwright 上传文件:一位用户分享了在 Playwright Python 中使用
set_input_files方法上传文本文件,随后查询上传内容的方法。这种方法简化了涉及文件交互的自动化测试工作流。- 然而,该用户指出,在请求 “你能总结文件中的文本吗?@file2upload.txt” 时,这种方法感觉有些奇怪。
LAION Discord
-
关于公开链接的版权困惑:一位成员断言,“公开链接的公开索引在任何情况下都不构成版权侵权”,引发了关于使用公开链接合法性的困惑。
- 这场辩论突显了社区对与公开链接索引相关的版权法的不确定性。
-
对 Discord 礼仪的赞赏:一位成员用简单的 ty 表达了感谢,展示了对所获帮助的感激。
- 这种交流表明了社区内持续的协作支持和对 Discord 礼仪的遵守。
DSPy Discord
-
ChatGPT for macOS 与桌面应用集成:ChatGPT for macOS 在面向 Plus 和 Team 用户的当前 Beta 版本中,现已支持与 VS Code、Xcode、Terminal 和 iTerm2 等桌面应用程序集成。
- 这种集成使 ChatGPT 能够通过与开发环境直接交互来增强编码辅助,从而可能改变项目工作流。OpenAI Developers 的推文最近宣布了这一功能。
-
dspy GPTs 功能:有强烈的意向扩展 dspy GPTs 的功能,旨在显著增强开发工作流。
- 社区成员讨论了扩展 dspy GPTs 集成的潜在好处,强调了对其项目流程的积极影响。
-
用于违规行为的 LLM 文档生成:一位用户正在开发一个 LLM 应用程序,用于生成全面的法律文件,为因违规(目前专注于酒精摄入案例)而面临吊销驾照的驾驶员辩护。
- 他们正在寻求一种方法来创建一个优化的 Prompt,该 Prompt 可以处理各种类型的违规行为,而无需单独定制 Prompt。
-
DSPy 语言兼容性:一位用户询问了 DSPy 对于需要非英语语言的应用的语言支持能力。
- 引用了一个公开的 GitHub issue,该 issue 涉及在 DSPy 中添加本地化功能的请求。
Modular (Mojo 🔥) Discord
-
ABI 研究揭示优化挑战:成员们分享了新的 ABI 研究论文和一份 PDF,强调了 low-level ABIs 在促进跨模块优化方面面临的挑战。
- 一位成员指出,为了获得最大执行速度,通常更倾向于用同一种语言编写所有内容。
-
ALLVM 项目面临运行障碍:讨论显示,ALLVM 项目可能由于编译和链接软件(特别是在浏览器中)时设备内存不足而受阻。ALLVM 研究项目。
- 另一位成员建议 Mojo 可以以创新方式利用 ALLVM 进行 C/C++ bindings。
-
成员提倡跨语言 LTO:一位成员强调了 cross-language LTO 对现有 C/C++ 软件生态系统的重要性,以避免重写。
- 讨论公认有效的链接可以显著提高遗留系统的性能和可维护性。
-
Mojo 探索 ABI 优化:成员们探讨了 Mojo 在定义 ABI 方面的潜力,该 ABI 通过利用 AVX-512 大小的结构并最大化寄存器信息来优化数据传输。
- 该 ABI 框架有望增强各种软件组件之间的互操作性和效率。
LLM Agents (Berkeley MOOC) Discord
-
关于 AI 工具的 Intel AMA:参加与 Intel 合作的独家 AMA 会议:使用 Intel 构建:Tiber AI Cloud 和 Intel Liftoff,定于 太平洋时间 11/21 下午 3 点,提供关于高级 AI 开发工具的见解。
- 本次活动提供了一个与 Intel 专家互动并获得使用其最新资源优化 AI 项目专业知识的独特机会。
-
Intel Tiber AI Cloud:Intel 将推出 Tiber AI Cloud,这是一个旨在通过提高计算能力和效率来增强黑客松项目的平台。
- 参与者可以探索如何利用该平台来提升性能并简化其 AI 开发工作流。
-
Intel Liftoff 计划:会议将涵盖 Intel Liftoff Program,该计划为初创公司提供技术资源和导师指导。
- 了解旨在帮助年轻公司在 AI 行业内扩大规模并取得成功的全面福利。
-
测验反馈延迟:一位成员对在尝试赶进度时未收到 quizzes 5 和 6 的电子邮件反馈表示担忧。
- 另一位成员建议验证本地设置,并建议 重新提交 测验以解决该问题。
-
课程截止日期提醒:发布了一项紧急提醒,参与者仍有 资格,但需要 快速赶上,因为每个测验都与课程内容挂钩。
- 最终提交日期定为 12 月 12 日,强调了及时完成的必要性。
Torchtune Discord
-
Torchtune v0.4.0 发布:Torchtune v0.4.0 已正式发布,引入了 Activation Offloading、Qwen2.5 支持以及增强的多模态训练 (Multimodal Training) 等功能。完整的发布说明请参阅此处。
- 这些更新旨在显著提升用户体验和模型训练效率。
-
Activation Offloading 功能:Activation Offloading 现已在 Torchtune v0.4.0 中实现,在 finetuning 和 LoRA recipes 过程中,可将所有文本模型的内存需求降低 20%。
- 这一增强功能优化了性能,支持更高效的模型训练工作流。
-
Qwen2.5 模型支持:Torchtune 已添加 Qwen2.5 Builders 支持,与 Qwen 模型家族的最新更新保持一致。更多详情请参阅 Qwen2.5 博客。
- 这一集成促进了在 Torchtune 训练环境中使用 Qwen2.5 模型。
-
多模态训练增强:Torchtune 中的多模态训练 (multimodal training) 功能得到了增强,支持 Llama3.2V 90B 和 QLoRA 分布式训练。
- 这些增强功能使用户能够处理更大的数据集和更复杂的模型,扩展了训练能力。
-
用于合成数据的 Orca-AgentInstruct:来自 Microsoft Research 的新项目 Orca-AgentInstruct 提供了一种 Agent 方案,用于大规模生成多样化、高质量的合成数据集 (synthetic datasets)。
- 该方法旨在通过利用有效的合成数据生成来进行 post-training 和 fine-tuning,从而提升小语言模型的性能。
Mozilla AI Discord
-
本地 LLM 工作坊定于周二举行:构建你自己的本地 LLM 工作坊定于周二举行,主题为 Building your own local LLM’s: Train, Tune, Eval, RAG all in your Local Env.,旨在指导成员了解本地 LLM 设置的复杂性。
- 鼓励参与者 RSVP 以增强其本地环境能力。
-
SQLite-Vec 添加元数据过滤:SQLite-Vec 现在支持元数据过滤 (Metadata Filtering) 已于周三通过此活动宣布,强调了具有实际应用价值的增强功能。
- 此更新允许通过元数据利用来改进数据处理。
-
周四举行自主 AI Agent 讨论:参加周四关于探索自主 AI Agent (Autonomous AI Agents) 的讨论,主题为 Autonomous AI Agents with Refact.AI,重点关注 AI 自动化进展。
- 该活动承诺提供有关 AI Agent 功能和未来轨迹的见解。
-
落地页开发寻求协助:一位成员正在为其项目寻求开发落地页 (landing page) 的帮助,并计划在 Mozilla AI 舞台上进行现场演示。
- 有兴趣的成员应在此帖子中联系以提供协作营销支持。
Alignment Lab AI Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
LLM Finetuning (Hamel + Dan) Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
第 2 部分:按频道详细摘要和链接
完整的频道详情已针对邮件进行了截断。
如果你喜欢 AInews,请分享给朋友!提前感谢!