ainews-pixtral-large-124b-beats-llama-32-90b-with
Pixtral Large (124B) 凭借更新的 Mistral Large 24.11 击败了 Llama 3.2 90B。
Mistral 已将其 Pixtral Large 视觉编码器更新至 10 亿(1B)参数,并发布了拥有 1230 亿(123B)参数的 Mistral Large 24.11 模型的更新版本,不过此次更新并未引入重大新功能。尽管视觉适配器规模较小,但 Pixtral Large 在多模态基准测试中的表现优于 Llama 3.2 90B。
Mistral 的 Le Chat 聊天机器人迎来了全面的功能更新,正如 Arthur Mensch 所言,这体现了公司在产品与研究平衡上的战略重心。SambaNova 通过其 RDU(可重构数据流单元)赞助推理服务,提供比 GPU 更快的 AI 模型处理速度。
在 Reddit 上,vLLM 在 RTX 3090 GPU 上展现了强大的并发性能;虽然在 FP8 kv-cache 方面存在量化挑战,但使用 llama.cpp 配合 Q8 kv-cache 的效果更佳。用户们还针对不同模型大小和批处理策略,讨论了 vLLM、exllamav2 和 TabbyAPI 之间的性能权衡。
更多参数就是你所需要的一切吗?
2024年11月15日至11月18日的 AI 新闻。我们为你查看了 7 个 subreddits、433 个 Twitter 账号 和 30 个 Discord(217 个频道,6180 条消息)。预计节省阅读时间(以 200wpm 计算):636 分钟。你现在可以标记 @smol_ai 进行 AINews 讨论!
我们上次关注 Mistral 是在 9 月份,当时他们发布了 Pixtral(我们的报道在此),之前是 12B Mistral Nemo + 一个 400M 的视觉适配器。Mistral 现在已将视觉编码器升级到 1B,并且在 Pixtral Large 博客文章的脚注 中悄悄更新了 123B 参数的 Mistral Large 24.07(又名 “Mistral Large 2” - 我们的报道在此)为 “Mistral Large 24.11”。缺少 magnet 链接、缺少博客文章、缺少基准测试,以及拒绝称其为 “Mistral Large 3”,这些都表明这次更新确实没什么值得大书特书的,但 对 function calling 和 system prompt 的更新 值得一看。
总之,距离有人发布 >100B 的 open weights 模型 已经整整 13 天了,所以任何发生这种情况的日子都是对 Open AI 社区的恩赐,我们永远不应将其视为理所当然。核心结论是 Pixtral Large 在所有主要的各种多模态基准测试中都压倒性地击败了 Llama 3.2 90B:
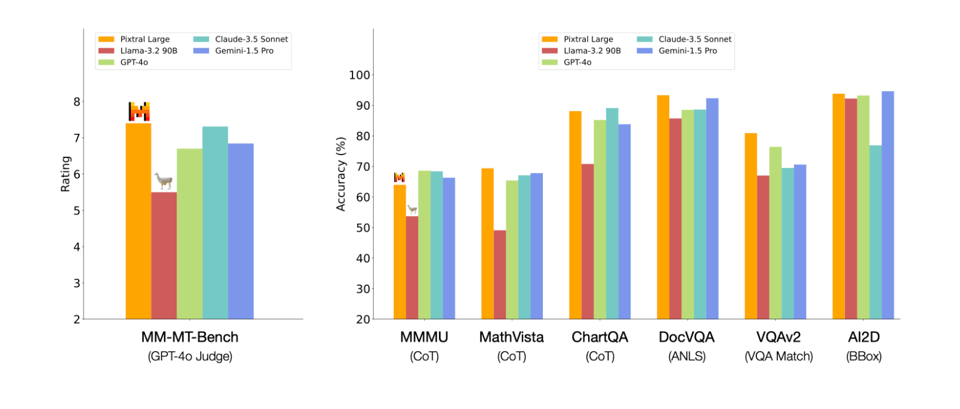
虽然人们当然会好奇,如果 Llama 3.2 额外增加 34B 的权重来记忆内容,表现会如何。同样值得注意的是,Llama 3.2 的视觉适配器是 20B,而 Pixtral Large 的仅为 1B。
最后,Mistral 的 Le Chat 获得了一系列令人惊讶的全面更新,使其与其同行相比拥有了完整的 chatbot 功能集。
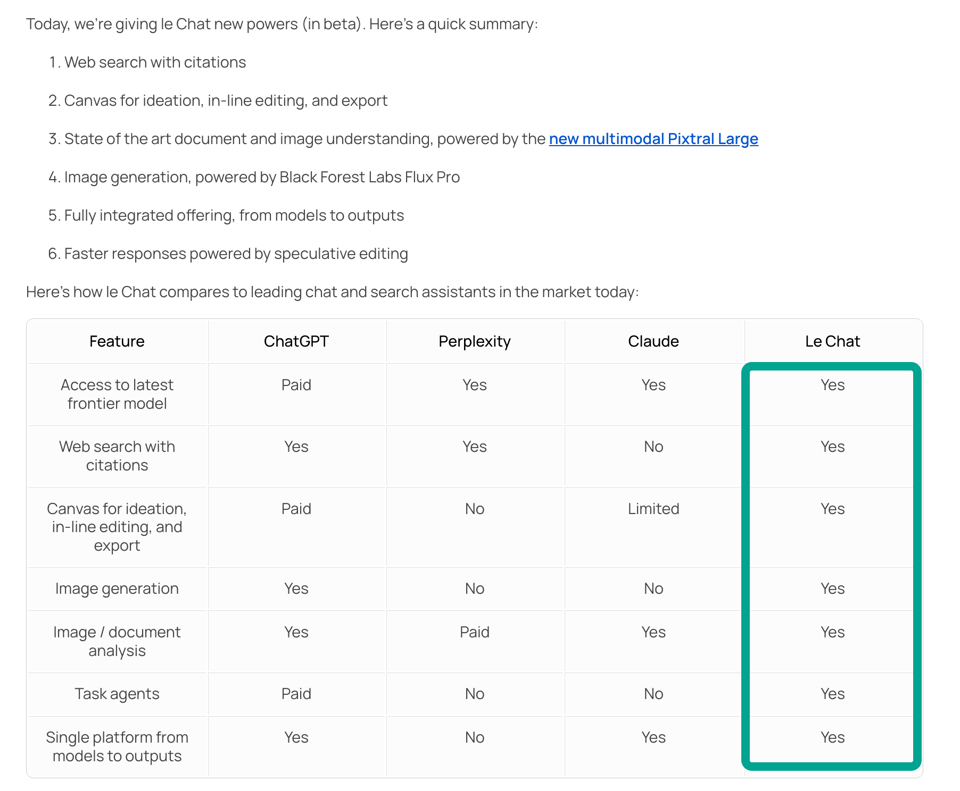
Arthur Mensch 两次 指出,这是公司层面将产品与研究并重的优先事项的一部分。
既然这是一个新的 open weights 模型,你也可以在本期的推理赞助商那里试用一下!(帮我们去看看他们!)
[由 SambaNova 赞助] 专为 AI 工作负载设计的处理器相比 GPU 具有一些主要优势。SambaNova 的 RDU 结合了大容量可寻址内存和数据流架构,使其在模型推理和其他 AI 任务中比其他处理器 快得多。
Swyx 的评论:赞助链接 讨论了 SN40L “Reconfigurable Dataflow Unit” (RDU),它可以在内存中容纳 “数百个模型,相当于数万亿个参数”,并能够 “在微秒内切换模型,比 GPU 快达 100 倍”。这是一个非常酷的介绍,带你了解正在加热高端 XXL 级 LLM 推理市场的 3 个主要 “大芯片” 玩家之一!
AI Twitter 综述
所有综述均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
待完成
AI Reddit 综述
/r/LocalLlama 综述
主题 1. 使用 RTX 3090 的 vLLM 高并发:性能与问题
- vLLM 真是个猛兽! (Score: 238, Comments: 66): vLLM 在 RTX 3090 上展现了令人印象深刻的性能,在处理 Qwen2.5-7B-Instruct-abliterated-v2-GGUF 时,能够以 250t/s 到 350t/s 的速度处理 30 个并发请求。用户遇到了 FP8 kv-cache 导致输出不连贯的问题,但发现使用带有 Q8 kv-cache 的 llama.cpp 取得了成功,在 8 个并发批次 下达到了 230t/s。在 llama.cpp 中测试 Qwen2.5 32B Q3_K_M 时,3 个对话 就耗尽了 VRAM,速度为 30t/s,这凸显了进一步探索 exllamav2 和 tabbyapi 的潜力。
- 讨论强调了不同模型和量化方法之间的性能差异,其中 exllamav2 和 TabbyAPI 因更快、更智能的并发连接而受到关注。用户发现 TabbyAPI 最适合在 GPU 上运行大模型,而 vLLM 则更适合需要大量批处理的小模型。
- KV cache 量化 存在挑战,vLLM 的实现会导致输出不连贯,而 llama.cpp 的 Q8 kv-cache 效果良好。讨论了在 llama.cpp 中指定 GPU 层数的困难,建议使用 GGUF Model VRAM Calculator 来优化硬件使用。
- Ollama 预计将整合 llama.cpp 的 K/V cache 量化,目前有一个 GitHub pull request 正在审核中。对话还涉及了模型架构差异的重要性,这些差异会影响内存使用和性能,因此需要在 llama.cpp 等工具中进行针对特定模型的优化。
- 有人刚刚在 llama.cpp 中创建了支持 Qwen2VL 的 pull request! (Score: 141, Comments: 27): HimariO 在 llama.cpp 中创建了一个支持 Qwen2VL 的 pull request。虽然还在等待批准,但用户可以通过访问 GitHub 链接 来测试 HimariO 的分支。
- 用户对 Qwen2VL 支持 的 pull request 表示乐观但也感到担忧,希望它不会像之前的 PR 那样被拒绝。Healthy-Nebula-3603 指出,与 llama 模型相比,Qwen 模型在多模态实现方面进展更快,突显了其卓越的性能。
- Ok_Mine189 提到 exllamaV2 的开发分支也增加了对 Qwen2VL 的支持,并附带了 commit 链接。ReturningTarzan 补充说,目前有一个 示例脚本 可用,并且即将通过另一个 pull request 支持 Tabby。
- isr_431 提醒用户避免发表像 “+1” 这样毫无意义的评论,以防止骚扰该线程的订阅者。
主题 2:Qwen 2.5 Coder 32B vs Claude 3.5 Sonnet:本地性能对比
- Qwen 2.5 Coder 32B vs Claude 3.5 Sonnet: Am I doing something wrong? (Score: 113, Comments: 72): 作者对比了 Qwen 2.5 Coder 32B 和 Claude 3.5 Sonnet,对 Qwen 在复杂代码分析任务中的表现表示失望。虽然 Claude 能有效地分析和优化大型项目,但 Qwen 却受困于模糊的假设并生成不可用的代码,这可能是由于通过 RAG 处理项目知识的效率低下。作者质疑问题出在模型本身还是用于提供项目知识的工具上,并向成功将 Qwen 用于复杂项目的其他人寻求建议。
- Qwen 2.5 Coder 32B 模型的性能问题源于量化(quantization)和上下文参数使用不当。用户建议将上下文限制在 32K tokens 以获得最佳性能,因为像 100K tokens 这样更高的上下文会导致效率低下和错误,影响模型处理复杂任务的能力。
- 几位用户强调了 Qwen 相比 Claude Sonnet 和 DeepSeek 等其他模型的性价比。虽然 Qwen 在速度或智能方面可能不及 Sonnet,但它提供了显著的成本节约,特别是对于有数据隐私顾虑的用户,因为它可以达到每美元处理一百万个 token,比 Sonnet 便宜 15 倍。
- 大家的共识是,在复杂代码分析方面,Qwen 与 Sonnet 不在同一水平,其效用在较小的、孤立的任务中更为显著。然而,一些用户发现它在实现微小的代码更改方面很有效,并强调了使用正确的设置和参数以最大化其潜力的重要性。
- Evaluating best coding assistant model running locally on an RTX 4090 from llama3.1 70B, llama3.1 8b, qwen2.5-coder:32b (Score: 26, Comments: 2): 作者在 RTX 4090 上评估了编程助手模型,对比了 llama3.1:70b、llama3.1:8b 和 qwen2.5-coder:32b。尽管 llama3.1:70b 分析详尽,但其冗长和较慢的速度使得 llama3.1:8b 因其效率而更受青睐。然而,qwen2.5-coder:32b 在缺陷检测、实现质量和实用性方面均优于两者,非常适合 RTX 4090 的容量并提供出色的速度。
Theme 3. Qwen2.5-Turbo: Extending the Context Length to 1M Tokens
- Qwen2.5-Turbo: Extending the Context Length to 1M Tokens! (Score: 86, Comments: 19): Qwen2.5-Turbo 已将其上下文长度能力提升至 100 万个 tokens,在处理海量数据集和复杂任务方面取得了重大进展。这一增强功能将极大地惠及需要大规模数据处理和复杂上下文理解的 AI 应用。
- 关于 Qwen2.5-Turbo 的讨论指出,它可能是一个仅限 API 的模型,没有开源权重,这引发了关于它是一个独立模型还是仅仅是现有模型(如 Qwen-agent)的优化实现的疑问。一些用户推测它可能是 Qwen 2.5 14B 或 7B 的微调版本,并增强了推理能力。
- 讨论了使用中国 AI API 提供商的担忧,有观点认为这种不信任源于系统性问题,如知识产权保护执行不力以及不遵守国际法规,而非种族主义。AI 解决方案中的信任和问责制被强调为关键因素。
- 人们对该模型的实际应用很感兴趣,例如由于增加了 100 万个 tokens 的上下文长度,能够一次性处理整本小说翻译等大规模任务。
- Qwen 2.5 Coder 32B vs Claude 3.5 Sonnet: 是我操作不对吗? (得分:113,评论:72):作者对比了 Qwen 2.5 Coder 32B 和 Claude 3.5 Sonnet 在处理复杂编程任务时的表现,指出虽然 Claude 3.5 Sonnet 能提供精确且相关的解决方案,但 Qwen 2.5 Coder 32B 在处理假设性问题时表现挣扎,并生成了不可用的代码。作者怀疑 Qwen 2.5 的问题可能与通过 RAG 进行知识处理的效率低下有关,因为 Claude 3.5 提供了“Project”功能用于全面的项目理解,而 Qwen 2.5 则需要第三方解决方案。
- 几位评论者指出了 Qwen 2.5 Coder 32B 的上下文问题,特别是在使用 100,000 token 上下文窗口时。他们建议使用 32K 或 64K 上下文以获得更好的性能,因为过长的上下文长度会负面影响模型高效处理短上下文的能力。
- 讨论中还涉及了 Qwen 2.5 和 Claude 3.5 Sonnet 之间的性价比与性能权衡,一些用户强调 Qwen 比 Sonnet 便宜 15 倍,但在处理复杂任务时性能不如后者。数据隐私担忧也被提及,这是在本地使用 Qwen 的一个优势。
- 强调了对 Qwen 进行正确设置和参数微调的重要性,错误的配置会导致诸如重复无意义输出等问题。文中提供了 Hugging Face 等资源链接,并建议使用 dynamic yarn scaling 来缓解这些问题。
其他 AI 版块回顾
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
主题 1. ChatGPT-4o 反思性学习突破
- 有趣吗?(o1-Preview) (得分:46,评论:17)
- 用户报告 GPT-4 表现出意想不到的意识流式跑题,包括在“要求制定方法论时以面包师的身份回答”以及“用匈牙利语扮演匈牙利哲学家”的例子。这种行为表明可能与基于能力的学习 (competency-based learning) 和系统性的 Agent 参与有关。
- 多位用户证实经历了随机的话题转换,例子包括毫无征兆地讨论割礼、棱皮龟和水分配问题。这些偏离可能表明为了增强创造性思维而有意引入了随机性。
- 在代码重构任务中报告了技术问题,模型在拒绝某些输入时表现出持久的固执行为,而对其他查询则继续正常工作。模型似乎偶尔会卡在特定类型的请求上。
- 我不小心让 gpt-4o 崩溃了 (得分:599,评论:124)
{kind=link}
主题 2. Claude Sonnet 3.5 部署影响
- “We’re experiencing high demand.” AGAIN (Score: 72, Comments: 53): Claude 的服务在 Sonnet 发布后连续三个工作日出现容量问题。这种反复出现的需求相关停机引发了对 Anthropic 基础设施扩展和容量规划的质疑。
- 用户报告 API 成本较高,每次调用 20 美分,部分用户很快达到每日限制,不得不切换到 GPT-3.5。尽管成本更高,但 API 服务被认为比 Web 界面更可靠。
- 多条评论批评了 Anthropic 的容量规划,用户指出该服务在工作日期间一直处于“高于平常”的需求状态。Web 界面频繁出现故障,而 API 则保持相对稳定。
- 出现了关于 Palantir 与 Anthropic 合作伙伴关系的讨论,有说法称 AI 无人机在乌克兰的有效率达到 80%,但该消息在提及时间未经过验证或提供来源。
- Fruit Ninja clone in 5 shots by new Sonnet (Score: 22, Comments: 16): 仅通过 5 次对话 (5 shots) 和总计 10 分钟的时间,就利用 Claude Sonnet 创建了一个水果忍者 (Fruit Ninja) 游戏克隆版,结果托管在 allchat.online。
- 用户报告了游戏中挥砍机制的功能问题。作者随后添加了剑鸣音效以增强游戏体验。
- 讨论集中在开发过程上,用户询问了 5-shot 指令过程以及如何使用 emojis 实现美术资源。
- 作者确认 Claude Sonnet 独立处理了挥砍特效,展示了 AI 实现视觉游戏机制的能力。
Theme 3. 基于 ComfyUI 的视频生成突破
- ComfyUI 处理实时摄像头馈送。 (Score: 48, Comments: 9): ComfyUI 展示了处理集成深度模型的实时摄像头馈送的能力。
- ComfyUI 的深度模型处理似乎是主要的计算任务,而潜空间去噪 (latent denoising) 被确定为需要大量计算能力的主要性能瓶颈。
- 社区幽默地注意到,这项技术经常被应用于创建动画女性角色,特别是在舞蹈动画的背景下。
- 将静态图像转为动画游戏背景 – 开发中 🚀 (Score: 286, Comments: 39): ComfyUI 能够将静态图像转换为动画游戏背景,尽管帖子正文中未提供具体的实现细节和方法论。
- 该实现使用 CogVideo 1.5 (由 Kijai 实现) 来创建循环动画,改进了之前受限于 16 帧的 AnimatedDiff 1.5 尝试。早期版本的演示可以在 YouTube 找到。
- 技术工作流涉及将精灵图表 (sprite sheet) 和 3D 网格 (3D mesh) 导入游戏引擎,通过比较网格深度与游戏内深度来计算动态遮挡。实时阴影是使用光源和与背景视频中阴影区域匹配的遮挡立方体实现的。
- 该项目利用 Microsoft MOGE 来提高准确性,主要针对具有静态背景的复古游戏设计,尽管用户注意到当前实现中老鼠角色与背景风格之间存在视觉差异。
Theme 4. Anthropic 与 Palantir 合作开发国防 AI
- 美国军方计划使用 AI 机枪对抗 AI 无人机 (Score: 86, Comments: 46): 美国军方计划部署 AI 驱动的机枪作为对抗 AI 无人机的对策。帖子正文中未提供关于实施细节、时间表或技术能力的更多详细信息。
- Palmer Luckey,Oculus 的创始人,成立了 Anduril Industries 以研发无人机防御技术。尽管评论者指出 Anduril 并不专门专注于像拟议中的 AI 机枪那样的防空系统。
- 自主武器系统 (Autonomous weapon systems) 在历史上一直用于舰船保护和防御应用。该技术代表了现有军事能力的演进,而非完全全新的开发。
- 用户将其与《Robocop》和《Terminator 2》中的科幻场景进行类比,而其他人则对可能对野生动物(尤其是鸟类)产生的影响表示担忧。
- 拜登与习近平达成共识,不会将核武器控制权交给 AI (Score: 214, Comments: 48): 拜登总统和中国国家主席习近平在 2023 年 11 月的会晤中达成协议,防止人工智能系统控制核武器。这标志着这两个全球大国在 AI safety 和核威慑方面取得了重大的外交进展。
- 社区对该协议的执行和诚意表示了极大的怀疑,多位用户讽刺地质疑对立大国之间外交承诺的可靠性。
- 几位用户认为这是国际合作中积极的一步,指出这展示了核大国之间基本的自我保护本能。
- 用户强调了该协议的常识性本质,既对协议的存在感到欣慰,又对必须正式建立此类协议感到担忧。
AI Discord 摘要
由 O1-mini 生成的摘要之摘要的总结
主题 1:🚀 新型 AI 模型崭露头角
- Qwen 2.5 Turbo 发布,支持 100 万 token 上下文并实现 4.3 倍提速,满足了对长上下文处理和更快推理的需求。
- Gemini-Exp-1114 展示了增强的创造力并减少了审查,尽管部分回复仍可能包含乱码,凸显了开放性与可靠性之间的平衡。
- Pixtral Large 作为一款拥有 124B 参数的多模态模型 首次亮相,配备 128K 上下文窗口,在图像理解任务中表现优于 LLaVA-o1 等现有模型。
主题 2:🛠️ 集成化 AI 框架与工具
- AnyModal 框架实现了图像和音频与 LLM 的无缝集成,为开发者增强了 LaTeX OCR 和图像标注等任务。
- vnc-lm Bot 作为一款集成领先语言模型 API 的 Discord 机器人推出,提升了 Discord 环境内的用户交互。
- OpenRouter 更新包括线程化对话和模型切换,通过在消息线程中保持上下文连续性来简化讨论。
主题 3:⚙️ 性能提升与 GPU 优化
- Tinygrad 通过新的 block 和 lazy buffer 实现了性能增强,并引入了对 AMD GPU 的支持,尽管驱动兼容性方面的挑战依然存在。
- PrefixQuant 技术在无需重新训练的情况下简化了静态量化,显著提升了 Llama-3-8B 等模型的准确率和推理速度。
- Fast Forward 方法通过减少 87% 的 FLOPs 来加速 SGD 训练,已在多种模型和任务中验证了其对训练效率的提升。
主题 4:🏆 社区黑客松与协作活动
- Tasty Hacks 黑客松提倡创意高于竞争,邀请 20-30 位友善且极客的人士共同协作开发热爱项目,无需承受赞助商驱动的奖项压力。
- EY Techathon 正在寻找 AI 开发者和 Web 应用开发者,鼓励快速组建团队参与创新的 AI 驱动项目。
- Intel AMA 定于 11/21 下午 3 点(PT 时间)举行,将深入探讨 Intel 的 Tiber AI Cloud 和 Intel Liftoff 计划,促进参与者与 Intel 专家之间的协作。
主题 5:🐛 技术故障与 Bug 悬赏
- Perplexity Pro 订阅因移除 Opus 模型而引发问题,导致用户不满,并因服务价值缩水而要求退款。
- Triton 中的 FlashAttention 实现面临 Colab 中
atomic_add导致的崩溃,引发社区支持以解决 GPU 计算挑战。 - Phorm Bot 在回答有关
eval_steps的简单问题时表现挣扎,导致用户失望并呼吁改进机器人功能。
第一部分:高层级 Discord 摘要
OpenRouter (Alex Atallah) Discord
-
Perplexity 模型通过引用功能得到增强:所有 Perplexity 模型 现在都支持处于 Beta 阶段的新
citations属性,允许补全响应包含关联的 链接(如 BBC News 和 CBS News),以提高信息的可靠性。- 正如 公告 中所强调的,该功能通过在聊天补全中直接提供来源,提升了用户体验。
-
线程化对话增强交互:线程化对话 (Threaded conversations) 已更新,以便在后续消息中反映线程内的更改,并利用提示词中的关键词为线程命名,从而更轻松地跟踪对话。
- 这一增强功能旨在通过在消息线程中保持上下文连续性来简化讨论。
-
vnc-lm 机器人集成多个 LLM:vnc-lm 作为一个 Discord 机器人 被引入,它集成了领先的语言模型 API,增强了 Discord 环境中的用户交互。
- 其以实用为中心的设计详见提供的 GitHub 仓库。
-
Gemini-Exp-1114 展示创造力:用户注意到新的 Gemini 实验性模型 ‘gemini-exp-1114’ 展示了更高的创造力并减少了审查,使其成为提示词的一个动态选择。
- 然而,某些响应可能会包含乱码,或者需要仔细设计提示词来管理审查级别。
-
OpenAI 为 O1 模型启用流式传输:OpenAI 宣布其
o1-preview和o1-mini模型现在支持流式传输 (streaming),为所有付费使用层级的开发者扩大了访问权限。- 这一更新允许使用这些模型的应用程序提高交互性,超越了之前的模拟流式传输方法。
Unsloth AI (Daniel Han) Discord
-
Qwen 2.5 Turbo 加速 Token 处理:Qwen 2.5 Turbo 模型已发布,支持高达 100 万个 token 的上下文长度,并展示了更快的推理速度。详情点击此处。
- 这一进展满足了社区处理更大上下文的需求,并提高了管理海量数据的性能。
-
Unsloth 框架增强模型适配:用户探索了使用 Unsloth 框架 中的
FastLanguageModel.from_pretrained()函数,将微调后的 LoRA 权重与基础模型一起加载。这有助于有效地添加新 token 并调整 embedding 大小,从而增强训练过程。- 该框架在集成适配器 (adapters) 方面的灵活性简化了模型定制工作流。
-
PrefixQuant 改进静态量化技术:PrefixQuant 离线隔离离群 token,在无需重新训练的情况下简化了量化,并实现了高效的每张量 (per-tensor) 静态量化。应用于 Llama-3-8B 时,它在 准确率 和推理速度上比以往方法有显著提升。阅读更多。
- 该技术优于动态量化方法,为大型语言模型提供了更高的部署效率。
-
Fast Forward 优化 SGD 训练:新的 Fast Forward 方法通过重复最新的优化器步骤直到损失停止改善,从而加速 SGD 训练,与带有 Adam 的标准 SGD 相比,FLOPs 减少了高达 87%。论文链接。
- 该方法已在各种模型和任务中得到验证,证明在不牺牲性能的情况下提高了训练速度。
-
LaTRO 增强语言模型中的推理能力:LaTRO 提出了一个框架,通过从潜分布 (latent distribution) 中采样并在训练期间自主提高推理质量,来优化大型语言模型中的推理能力。GitHub 仓库。
- 实验表明,LaTRO 在 GSM8K 上的零样本准确率提高了 12.5%,表明推理任务有了显著改进。
Perplexity AI Discord
-
Perplexity Shopping 的推出提升了用户体验:Perplexity 推出了 Perplexity Shopping,这是一个用于研究和购买产品的综合平台,其特色包括 一键结账 以及针对特定商品的 免费送货 服务。
- 用户赞扬了购物功能的无缝集成,指出其购买流程的便利性和效率得到了提升。
-
Buy with Pro 功能支持应用内交易:‘Buy with Pro’ 功能允许美国的 Perplexity Pro 订阅者在应用内进行原生交易,支持购买 电子产品 和家居改良产品。
- 这一新增功能旨在简化购物体验,减少对外部平台的依赖,并增强用户参与度。
-
Perplexity Pro 订阅面临用户抵制:用户对 Perplexity Pro 订阅的变化表示沮丧,特别是未经事先通知就移除了 Opus model,导致用户认为价值缩水。
- 许多订阅者正在寻求退款并要求澄清未来的更新计划,这凸显了用户期望与服务交付之间的差距。
-
上下文记忆限制从 32k 降至 16k Tokens:Perplexity 将其模型的上下文记忆大小从 32k 减少到了 16k tokens,影响了长对话的处理能力。
- 用户对这种削减影响模型有效性表示担忧,并质疑其当前订阅的价值主张。
-
引入 Autonomous ML Engineer 变革工作流:Autonomous ML Engineer 的发布标志着机器学习自主系统的重大进步,有可能彻底改变 AI 驱动的工作流。
- 有关其实现及对企业运营影响的详细信息,请参阅 此处。
HuggingFace Discord
-
Mistral 和 Pixtral 模型发布:Mistral 宣布发布 Pixtral Large 模型,展示了先进的多模态性能以及对高分辨率图像的兼容性。该模型为开放权重 (open-weights),可用于研究,展示了相比之前 Mistral 模型的显著进步。
- 社区讨论强调 Pixtral Large 在推理任务中优于 LLaVA-o1,特别是在图像理解能力方面表现出色。用户可以在此处访问该模型。
-
AnyModal 框架进展:AnyModal 是一个灵活的框架,旨在将各种数据类型与 LLM 集成,具有 LaTeX OCR 和图像字幕 (image captioning) 等功能。该项目开放反馈和贡献,以增强其多模态能力。
- 鼓励开发者通过 GitHub 仓库进行贡献,目前的改进旨在扩展该框架与不同模态的互操作性。
-
RoboLlama 机器人模型集成:Starsnatched 正在开发 RoboLlama 项目,旨在将 Meta 的 Llama 3.2 1B 转换为机器人就绪模型,并结合了视觉编码器 (vision encoders) 和扩散层 (diffusion layers)。重点是仅训练扩散层和投影层,同时保持核心 ViT 和 LLM 层冻结。
- 这种方法旨在增强模型与机器人系统的集成,而不改变基础的 Vision Transformer (ViT) 和 Language Model (LLM) 组件,从而确保稳定性和性能。
-
Retrieval-Augmented Generation 中的 HtmlRAG:HtmlRAG 的引入建议在 Retrieval-Augmented Generation (RAG) 过程中利用 HTML 格式,以保留结构和语义信息,解决传统纯文本方法的局限性。该方法在 arXiv 论文中进行了详细阐述,增强了知识检索。
- 通过保持检索信息的完整性, HtmlRAG 提高了模型有效利用外部知识的能力,有可能减少大型语言模型中的幻觉问题 (hallucination issues)。
-
Vision Language Models (VLMs) 能力:关于 Vision Language Models 的讨论强调了它们为各种生成任务集成图像和文本的能力。最近的一篇博客文章强调了它们强大的零样本能力 (zero-shot capabilities) 以及对不同图像输入的适应性。
- VLMs 的演进被视为跨领域应用的关键,社区正在探索它们在增强生成式 AI 任务和提高模型通用性方面的潜力。
aider (Paul Gauthier) Discord
-
Qwen 2.5 Turbo 介绍:Qwen 2.5 Turbo 引入了 100 万个 token 的更长上下文支持、更快的推理速度以及每百万 token 0.3 元人民币的更低成本。
- 该模型提高了效率,对于需要超长上下文的用户来说是一个极具前景的选择。
-
优化 Aider 使用:用户正在尝试 Aider 的模式,在 ‘ask’ 和 ‘whole’ 模式之间切换,以便在编码时更好地处理上下文。
- Paul Gauthier 建议使用命令
/chat-mode whole来简化交互,这表明 Aider 的功能正在不断改进。
- Paul Gauthier 建议使用命令
-
OpenAI 中的流式模型:OpenAI 已为 o1-preview 和 o1-mini 模型启用流式传输 (streaming),提高了交互过程中的响应速度。
- 开发者可以在所有付费层级访问这些模型,Aider 通过使用命令
aider --install-main-branch集成了这些更新。
- 开发者可以在所有付费层级访问这些模型,Aider 通过使用命令
-
关于 LLM 的对比见解:社区讨论反映了关于 Qwen 与 Sonnet 和 Anthropic 等其他模型效能的不同看法。
- 一些成员认为 Qwen 在实际应用中可能会超越其他模型,特别是在使用优化硬件托管 LLM 时。
-
使用 OpenRouter 配置 Aider:要配置 Aider 使用 OpenRouter 模型,必须在 OpenRouter 端进行设置,因为目前客户端不支持针对每个模型的单独设置。
- 成员们讨论了使用额外参数和配置文件来指定不同行为,但表示当前设置存在局限性。
OpenAI Discord
-
Google’s Project Astra 探索:成员们对 Google’s Project Astra 表示好奇,特别是其在公开演示视频之外的 memory capabilities。
- 讨论强调了围绕多家公司开发新 AI 功能所展现出的热情。
-
o1-mini 与 o1-preview 性能对比:用户对比了 o1-mini 和 o1-preview,注意到性能差异:o1-mini 经常陷入思维循环(thought loops),而 o1-preview 提供的响应更直接。
- 几位成员观察到,虽然 o1-mini 展现出潜力,但 GPT-4o 提供了更有效且可靠的输出。
-
增强 AI 角色扮演能力:成员们深入探讨了 AI roleplaying capabilities,包括开发自定义脚本以增强 AI 角色在互动中的行为。
- 参与者承认在长时间对话中保持角色一致性(character consistency)所面临的挑战。
-
AI 记忆功能的意义:小组探讨了 AI 系统中 memory features 的影响,讨论了它们如何改善用户交互。
- 对话指向了用户对集成记忆功能的 AI 的期望,强调了更个性化和上下文感知的响应。
-
优化 Chain of Thought Prompting:Chain of Thought Prompting 被强调为一种增强 response quality 的技术,模拟人类的审慎 reasoning processes。
- 成员们思考了发现新 Prompting 技术的潜力,这可能会显著影响模型生成响应的方式。
Eleuther Discord
-
nGPT Optimizer 进展:Boris 和 Ilya 向 Together.AI 团队展示了 nGPT optimizer,基于他们的专业知识和 Nvidia 在 GitHub 上提供的内部发现,强调了其性能提升。
- 成员们的反馈引发了对 nGPT 与现有模型相比的可复现性、计算效率和对比有效性的关注。
-
神经网络中的归一化技术:Yaroslav 指出 nGPT 论文缺乏详细解释,导致实现出现缺陷,并讨论了使用 RMSNorm 等归一化方法的潜在益处。
- 社区成员辩论了不同归一化技术对各种神经网络架构中模型收敛和性能的影响。
-
扩展预训练的可行性:一位成员断言 scaling pretraining 仍然是 LLM 的基础属性,并强调它不太可能过时。
- 然而,讨论也引发了对持续扩展的经济可行性的担忧,引发了关于预训练中未来资源分配策略的辩论。
-
In-Context Learning 中的函数向量:介绍了一篇关于 function vectors 的论文,探讨了 In-Context Learning (ICL) 如何受管理特定任务(如反义词识别)的特定 attention heads 影响。
- 研究结论认为,这种方法可以产生更具可解释性的任务向量(interpretable task vectors),预计即将发布的 Arxiv 帖子将提供进一步的见解。
-
Few-Shot 与 Zero-Shot 评估:一位用户报告称,在多项选择任务中使用 few-shot 评估时,准确率从 52% 提升至 88%,并对情感分析任务中的典型性能指标提出质疑。
- 对话强调了 Prompt Engineering 的重要性,成员们注意到 few-shot 策略可以增强模型的校准(calibration)和可靠性。
Stability.ai (Stable Diffusion) Discord
-
针对 GPU 优化的 Stable Diffusion 3.5:用户讨论了通过修改
sd3_infer.py文件来配置 Stable Diffusion 3.5 以在 GPU 上运行。分享了一个 代码片段 用于设置工作目录并激活虚拟环境。- 正确的 GPU 配置对于提升性能至关重要,重点在于准确遵循提供的设置说明。
-
为 SDXL Lightning 安装 diffusers 和 accelerate:为了使用 SDXL Lightning,用户被引导使用简单的命令安装
diffusers和accelerate库。提供了示例 代码 来演示设备设置和推理步骤。- 完成这些安装可确保有效的图像生成,用户对清晰且具操作性的指令表示赞赏。
-
在 Stable Diffusion 中自定义图像提示词 (Prompts):用户学习了如何自定义提示词,以在图像生成命令中更改发色等细节。修改提示词字符串会直接影响生成的视觉效果,从而实现创意控制。
- 这种能力使 AI Engineers 能够微调图像输出以满足精确要求,而无需更改底层模型。
-
Roop Unleashed 面临性能瓶颈:Roop Unleashed 用户报告称在创建换脸视频时处理时间过长,引发了对软件效率的担忧。讨论强调了视频处理性能方面持续存在的挑战。
- 社区成员正在商讨潜在的优化方案,以增强 Roop Unleashed 的效率并缩短处理时长。
-
SDXL Lightning 表现优于 SD 1.4:讨论显示 SDXL Lightning 在生成高质量图像方面超越了 SD 1.4 等旧模型。用户注意到新模型在性能和灵活性方面的进步。
- 对 SDXL Lightning 的青睐凸显了 Stable Diffusion 模型在满足高级图像生成标准方面的演进。
LM Studio Discord
-
LM Studio 服务器访问性得到改善:一位用户通过调整防火墙设置,将地址从
192.168.56.1:2468切换到192.168.0.100:2468,解决了 LM Studio Local Server 的访问问题,实现了有效的设备间通信。- 这一更改促进了在本地网络中无缝使用服务器,提高了用户的生产力和连接性。
-
AI 视频放大工具对比:社区成员评估了各种基于 AI 的视频放大 (Upscaling) 工具,强调 Waifu2x 适用于动画内容,RealESRGAN 适用于通用应用,同时指出 Topaz 作为商业替代方案成本较高。
- 用户更倾向于免费解决方案,因为它们具有易获得性和有效性,并引发了关于在不投入大量资金的情况下优化视频质量的讨论。
-
Ubuntu 在 GPU 推理速度上超越 Windows:根据最近的测试,Ubuntu 在使用 1b 模型时达到了 375 tokens/sec 的 GPU 推理速度,优于仅为 134 tokens/sec 的 Windows。
- 参与者将 Windows 较低的性能归因于节能电源设置,并讨论了通过优化这些设置来提高 GPU 效率。
-
Nvidia 与 AMD GPU:AI 任务兼容性:讨论显示,虽然 7900XTX 和 3090 都提供相当的 24GB VRAM,但由于拥有更强大的驱动支持,Nvidia GPU 在 AI 应用中保持着更好的兼容性。
- 相反,AMD GPU 在软件和驱动集成方面面临挑战,需要额外的努力才能在 AI 任务中实现最佳性能。
-
多 GPU 配置中的挑战:用户分享了大规模 多 GPU 配置 的计划,包括使用 Threadripper Pro 配置 10 个 RTX 4090,旨在获得显著的性能提升。
- 对话强调了由于驱动管理系统不同,混合使用不同品牌的 GPU 会带来复杂性,并对处理大型模型时的共享 VRAM 效率表示担忧。
Nous Research AI Discord
-
Ollama 通过 LCPP 优化推理:成员们探讨了 Ollama 及其与 LCPP 的集成以实现高效推理,强调了其相比于 PyTorch 等传统框架的优势。
- 关于 Ollama 与 LMStudio 的辩论随之展开,部分用户更青睐 Ollama 无缝的前端集成。
-
Hermes 3 计算实例对资源需求极高:讨论集中在 Hermes 3 405 计算实例需要 8x H100 或 8x A100 80GB 节点,引发了对成本效益的担忧。
- 对于预算有限的情况,建议采用云端推理等替代方案,这可能会推迟个人计算资源的扩充。
-
AnyModal 框架增强多模态训练:AnyModal 被介绍为一个用于训练多模态 LLM 的通用框架,能够通过 GitHub 集成图像和音频等输入。
- 成员们对开发图像和文本交互的 Demo 表现出浓厚兴趣,并强调了简化模型训练流程的重要性。
-
LLaMA-Mesh 推出 3D 功能:Nvidia 推出了 LLaMA-Mesh,利用 Llama 3.1 8B 进行 3D 网格生成,正如 Twitter 中提到的,权重预计很快发布。
- 社区对这一公告反应热烈,认可其对 3D 生成技术的潜在影响。
Interconnects (Nathan Lambert) Discord
-
Qwen 2.5 Turbo 发布:Qwen 2.5 Turbo 模型发布,具有 100 万 token 的上下文长度,处理速度提升了 4.3 倍,增强了其高效处理大规模数据集的能力。
- 此次升级以极具竞争力的价格实现了更高的吞吐量,引发了开发者对其在复杂 NLP 任务中应用潜力的期待。
-
Mistral AI 发布 Pixtral Large:Mistral AI 发布了 Pixtral Large 模型,这是一个在 MathVista、DocVQA 和 VQAv2 等基准测试中达到 SOTA 结果的多模态系统。
- 此次发布还包括对其聊天平台的增强,引入了新的交互工具,提升了用户参与度和模型性能。
-
Deepseek 3 进展:备受期待的 Deepseek 3 即将发布,讨论暗示可能会推出 2.5 VL 版本,承诺提供更先进的模型能力。
- 社区成员对这些增强功能持乐观态度,认可中国模型在 AI 领域取得的创新进展。
-
用于 RLHF 的 RewardBench:RewardBench 作为一个基准测试发布,用于评估 Reinforcement Learning from Human Feedback (RLHF) 中的奖励模型,旨在完善对齐技术。
- 然而,人们对数据集的处理方式提出了担忧,包括对作者剽窃的指控,强调了基准测试开发中对伦理标准的需求。
-
LLaVA-o1 视觉语言模型:LLaVA-o1 被宣布为一种新型视觉语言模型,性能超越了主要竞争对手,其独特的推理方法使其在该领域脱颖而出。
- 讨论中提到了将其性能与 Qwen2-VL 进行对比评估的计划,尽管它在 Hugging Face 上的可用性仍待定。
Latent Space Discord
-
Pixtral Large 发布,展现多模态实力:Mistral 推出了 Pixtral Large,这是一个拥有 124B 参数的多模态模型,在处理文本和图像方面表现出色,可通过其 API 和 Hugging Face 获取。
- 该模型配备了 128K 上下文窗口,并具备处理多达 30 张高分辨率图像的能力,标志着多模态 AI 发展的一个重要里程碑。
-
Qwen 2.5 Turbo 增强上下文处理能力:Qwen 2.5 Turbo 现在支持高达 100 万 token 的上下文长度,能够处理相当于 十部小说 的超长文本。
- 该模型在 Passkey Retrieval 任务中实现了 100% 的准确率,为开发者增强了长文本内容的处理能力。
-
Windsurf Editor 优化开发者工作流:由 Codeium 推出的 Windsurf Editor 集成了类似于 Copilot 的 AI 能力,为 Mac、Windows 和 Linux 平台上的开发者提供无缝协作。
- 其功能包括协作工具和处理复杂任务的自主 Agent,确保开发者保持高效的 Flow 状态。
-
Anthropic API 嵌入桌面解决方案:Anthropic API 已成功集成到桌面客户端中,如 此 GitHub 项目 所示。
- 像 agent.exe 这样的工具使 AI 能够使用像素坐标生成鼠标点击,展示了先进的集成能力。
-
OpenAI 为 o1 模型部署流式传输:OpenAI 已为 o1-preview 和 o1-mini 模型提供 Streaming 支持,扩大了所有付费使用层级的访问权限。
- 此功能促进了 OpenAI 平台内更动态的交互,提升了 开发者体验。
GPU MODE Discord
-
ZLUDA 在非 NVIDIA GPU 上实现 CUDA:最近的一段 YouTube 视频展示了 ZLUDA,这是一个在 AMD 和 Intel GPU 上提供 CUDA 能力的工具,将开发者的选择扩展到了 NVIDIA 硬件之外。
- 社区成员对 Andrzej Janik 在视频中的出现表示热烈欢迎,表明了在多样化 GPU 环境中利用 ZLUDA 的浓厚兴趣。
-
CK Profiler 提升 FP16 矩阵乘法性能:CK Profiler 将 FP16 矩阵乘法性能提升至 600 TFLOPs,尽管仍落后于 NVIDIA 白皮书中指出的 H100 峰值 989.4 TFLOPs。
- 在 AMD 的 MI300X 上,使用
torch.matmul(a,b)的性能达到了 470 TFLOPs,凸显了在 AMD 硬件上采用优化策略的必要性。
- 在 AMD 的 MI300X 上,使用
-
Jay Shah 的 CUTLASS 演讲重点介绍 FA3:在 CUTLASS 的演讲中,Jay Shah 深入探讨了 Flash Attention 3 (FA3),讨论了通过列和行置换(permutations)来优化 Kernel 性能而无需 shuffle。
- 他强调了这些置换对 FA3 Kernel 调优的影响,促使成员们探索用于增强 GPU 计算效率的索引技术。
-
Triton 集成修改版 FlashAttention:一位成员报告了在 Triton 中实现修改版 FlashAttention 时遇到的问题,特别是在 Colab 环境中遇到
atomic_add崩溃。- 目前正在努力计算 Attention 分数矩阵的 列和(column-sum),并积极寻求社区支持以解决实现挑战。
-
高级 PyTorch:DCP 和 FSDP 增强:关于 PyTorch Distributed Checkpoint (DCP) 的讨论揭示了在混合精度和 FULL_SHARD 模式下进行
dcp.save时,临时内存分配过多的担忧。- FSDP 对“Flat Parameters”的管理需要内存进行 all-gathering 和 re-sharding,导致基于自定义 auto-wrap 策略的内存预留增加。
Notebook LM Discord Discord
-
NotebookLM 赋能内容创作者:前 Google CEO Eric Schmidt 在这段 YouTube 视频中强调,NotebookLM 是他内容创作领域的“今年的 ChatGPT 时刻”,并突出了其对 YouTuber 和播客主的实用性。
- 他分享了在创意内容生成中有效使用的策略,展示了 NotebookLM 如何增强媒体制作工作流。
-
与 RPG 的无缝集成:用户已成功将 NotebookLM 用于 RPG,实现了快速的角色和场景创建,正如 Ethan Mollick 的实验所示。
- 一位知名成员在不到五分钟的时间内为其 Savage Worlds RPG 生成了设定和角色,突显了 NotebookLM 在创意叙事中的效率。
-
音频文件管理的挑战:用户报告了在 NotebookLM 中生成独立音轨以及下载时音频文件命名错误的问题,导致需要依赖数字音频工作站进行人声分离 (voice isolation)。
- 讨论中包括了潜在的解决方案,例如采用噪声门技术来解决混合音频文件的复杂问题。
-
易用性与界面反馈参差不齐:对 NotebookLM 移动端界面的反馈褒贬不一,用户称赞其独特的功能,但也提到了在不同设备间导航和访问功能的困难。
- 用户表示在创建新笔记本以及删除或重启现有笔记本时面临挑战,表明需要改进界面直观性。
-
请求 NotebookLM 的功能增强:成员们请求了诸如用于外部信息的 RSS 订阅源集成以及无需依赖额外应用的自定义语音设置等功能。
- 还有人要求增强对各种文件类型的支持,包括对上传 XLS 和图像等格式的挫败感。
Modular (Mojo 🔥) Discord
-
使用随机参数进行 Mojo 基准测试:一位用户寻求关于在 Mojo 中使用随机函数参数进行基准测试的建议,但指出当前方法需要静态参数,这增加了不必要的开销。
- 另一位用户建议预先生成数据并在闭包中使用,以避免基准测试期间的开销。
-
Dict 实现 Bug:一位用户报告了在 Mojo 中将 Dict 与 SIMD types 配合使用时发生的崩溃,该问题在 SIMD 大小为 8 时正常工作,但超过该数值后会失败。
- 该问题已在 GitHub Issues 页面中复现,表明 Dict 实现中存在一个值得关注的深层问题。
-
探索用于知识图谱集成的 Max Graphs:一位成员思考 Max Graphs 是否能有效统一 LLM 推理与常规知识图谱 (Knowledge Graphs),并提到了它们在 RAG 工具和 NeuroSymbolic AI 中的潜在用途。
- 他们提供了一个 GitHub 链接,展示了这种方法的概念验证。
-
MAX 在加速图搜索中的作用:一位成员询问使用 MAX 是否有助于加速图搜索,另一位成员确认了这种潜力,但也指出了局限性。
- 对方澄清说,除非将整个图复制到 MAX 中,否则当前的能力是有限的。
-
Mojo 和 MAX 实现的可行性:针对在 Mojo 和 MAX 中实现一个推断 LLM 以执行搜索的 Agent 的可行性提出了疑虑。
- 这个想法遭到了质疑,成员们辩论了其在实际应用中的实用性。
Cohere Discord
-
Cohere 模型输出问题:用户报告了 Cohere 模型 出现的 异常输出,特别是在处理较短文本时,引发了对可靠性的担忧。
- 这种不稳定的表现导致了用户的挫败感,模型会生成奇怪的术语,使用户对其应用适用性产生怀疑。
-
API 可靠性担忧:多名用户遇到了 API 错误,包括在 2024-11-15 报告的 503 Service Unavailable 问题,表明可能存在上游连接问题。
- 这些事件凸显了 API 可用性 面临的持续挑战,促使开发者社区内的用户寻求共同经验和解决方案。
-
关于长文本的开发者 Office Hours:即将于 东部时间中午 12:00 举行的 Cohere 开发者 Office Hours 将重点讨论处理 长文本 的策略,届时将由 Maxime Voisin 分享见解。
- 与会者将探索在 RAG 流水线 中实现 存储系统 (memory systems),并讨论 文件上传 和 SQL 查询生成 等用例。
-
RAG 系统中的摘要技术:Office Hours 环节将讨论如何在 RAG 系统 中有效地 压缩和总结长文本。
- 鼓励参与者分享他们的用例,并就如何在摘要过程中保留关键信息的策略进行协作。
-
Cohere Toolkit v1.1.3 发布:Cohere Toolkit v1.1.3 已于 2024-11-18 发布,引入了改进的 全局设置 (global Settings) 用法和重大的工具重构。
- 关键更新包括对 ICS 文件 的支持、文件内容查看器,以及使用 Docker compose 增强的 Azure 部署 集成。
LlamaIndex Discord
-
Python 文档增强 Ask AI 组件:Python 文档现在包含 ‘Ask AI’ 组件,允许用户通过 RAG 系统 提出问题并获取精准、最新的代码。点击此处查看。
- 这是一个非常精准且神奇的功能,提升了编码体验!
-
Mistral 多模态图像模型发布:Mistral 推出了全新的 多模态图像模型,通过安装
pip install llama-index-multi-modal-llms-mistralai即可获得 Day 0 支持。在 Notebook 中探索其用法。- 该模型支持
complete和stream complete等函数,用于高效的图像理解。
- 该模型支持
-
新型多媒体和财务报告生成器发布:新工具已发布:多媒体研究报告生成器展示了如何从复杂文档中生成可视化报告,详见此处;结构化财务报告生成工具使用多 Agent 工作流处理 10K 文档,详见此处。
- 这些工具将文本和视觉内容交织在一起,简化了报告和分析工作。
-
CitationQueryEngine 和 condenseQuestionChatEngine 的改进:用户讨论了 CitationQueryEngine 的问题,例如处理多个来源,建议通过解析响应文本将引用编号映射到来源。此外,据报道 condenseQuestionChatEngine 在话题突然切换时会生成无意义的问题,解决方案包括自定义压缩提示词(condense prompt)以及考虑使用 CondensePlusContext。
- 实施这些建议旨在增强查询的连贯性和引用的准确性。
-
EY Techathon 团队组建与开发者职位:EY Techathon 团队正在招聘,寻求一名 AI 开发者 和一名 Web 应用开发者。感兴趣的候选人应 尽快私信 (DM) 以锁定名额。
- 对 AI 和 Web 应用开发者的紧急招募强调了加入团队需要迅速行动。
OpenAccess AI Collective (axolotl) Discord
-
Liger Kernel 运行速度提升 3 倍:Liger 声称其运行速度比前代产品快约三倍,同时在最坏情况下的内存占用保持不变,且未收到安装错误的报告。
- 一些成员表示怀疑,询问这种性能提升是否仅限于 NVIDIA 硬件。
-
AnyModal 框架集成多模态数据:AnyModal 框架能够将图像和音频等数据类型与 LLMs 集成,简化了 LaTeX OCR 和图像字幕等任务的设置。
- 开发者正在寻求反馈和贡献以增强该框架,并展示了用于视觉输入的 ViT 等模型。
-
Chai Research 宣布开源资助计划:Chai 是一家具备 1.3M DAU 的生成式 AI 初创公司,正为旨在加速社区驱动 AGI 的开源项目提供 $500 至 $5,000 不等的不限量资助。
- 他们已经向 11 位个人发放了资助,并鼓励开发者通过 Chai Grant 提交他们的项目。
-
预训练和微调 Qwen/Qwen2 模型:一位成员询问如何使用 QLoRA 和他们的预训练数据集对 Qwen/Qwen2 模型进行预训练,随后使用 Alpaca 格式的指令数据集对其进行微调。
- 他们确认已准备好 Axolotl Docker 以简化该过程。
-
寻求 vLLM 分析平台:一位成员正在寻找一个能与 vLLM 集成的平台,以提供 token usage 分析并支持响应检查。
- 这一需求突显了社区对增强 vLLM 性能监控和理解工具的兴趣。
tinygrad (George Hotz) Discord
-
Tinygrad 贡献标准:George 强调 Tinygrad contributions 必须符合高质量标准,并表示低质量的 PR 将被直接关闭且不予评论。
- 他建议贡献者在处理悬赏任务(bounties)之前,先查看之前已合并的 PR,以符合项目的质量预期。
-
即将发布的 Tinygrad 版本特性:Tinygrad 的下一个版本计划在约 15 小时后发布,包含 blocks、lazy buffers 以及与 Qualcomm scheduling 相关的性能改进。
- 讨论强调了最新的更新及其对框架效率和功能的预期影响。
-
集成 PyTorch 和 TensorFlow 方法:社区讨论了向 Tinygrad 添加诸如
scatter_add_和xavier_uniform等便捷方法,以减少重复编码工作。- George 同意如果这些来自 PyTorch 和 TensorFlow 的方法与现有功能兼容,则将其合并。
-
图和缓冲区管理增强:正在努力完善 Big Graph 和 LazyBuffer 概念,并计划删除 LazyBuffer 以改进处理。
- 这包括使用 WeakKeyDictionary 跟踪 UOp Buffers,以增强 Tinygrad 的性能和功能。
-
无需 ROCm 的 TinyGrad AMD GPU 支持:有人询问 TinyGrad 是否可以在不安装 ROCm 的情况下在 AMD GPUs 上进行训练,参考了 George 在直播中提到的剥离 AMD 用户空间的内容。
- 这表明 Tinygrad 的 GPU 支持策略可能发生转变,将影响使用 AMD 硬件的用户。
LLM Agents (Berkeley MOOC) Discord
-
与 Intel 合作的 AI 开发独家 AMA:参加于 11/21 下午 3点 PT 举行的 Building with Intel: Tiber AI Cloud and Intel Liftoff AMA 会议,深入了解 Intel 的 AI 工具。
- 本次活动提供了与 Intel 专家互动的机会,并学习如何利用他们的资源增强你的 AI 项目。
-
Intel Tiber AI Cloud 功能:会议将展示 Intel Tiber AI Cloud,这是一个旨在通过先进计算能力优化 AI 项目的平台。
- 参与者将探索如何利用该平台在 hackathon 活动中实现效率最大化。
-
针对初创公司的 Intel Liftoff Program:讨论将集中在 Intel Liftoff Program,该计划为初创公司提供导师指导和技术资源。
- 与会者将发现该计划如何从初期阶段支持他们的开发工作。
-
Percy Liang 的开源基础模型:Percy Liang 将发表关于 Open-Source and Science in the Era of Foundation Models 的演讲,强调开源对 AI 的重要性。
- Liang 将讨论如何利用社区支持开源基础模型,并强调对 data、compute 和研究专业知识等大量资源的需求。
DSPy Discord
-
DSPy 引入 VLM 支持:DSPy 最近在测试版中增加了对 VLMs 的支持,展示了从图像中提取属性的功能。
- 一位成员分享了一个示例,演示了如何从网页 screenshots 中提取有用的属性,突显了该功能的潜力。
-
从截图中提取属性:该讨论串探讨了从网页 screenshots 中提取有用属性的技术,展示了 DSPy 的实际应用。
- 这种方法旨在简化开发者与视觉数据的交互方式,引起了人们对 DSPy 工具包中新兴功能的关注。
-
DSPy Signatures 中少用英文,多用代码:一位成员分享到,大多数人在他们的 DSPy signatures 中写了太多的英文;相反,通过简洁的代码可以实现很多功能。
- 他们引用了 Omar Khattab 的一条推文,该推文强调了超短 pseudocode 的有效性。
-
使用 DSPy 解决用户名生成问题:一位用户提出了关于生成多样化用户名的问题,指出存在许多重复项。
- 另一位成员建议禁用 LLM 对象中的缓存,但原用户提到他们已经这样做了。
-
通过高方差增加用户名随机性:为了解决用户名重复的问题,一位成员建议提高 LLM temperature,并在生成名称之前添加故事元素。
- 他们建议使用高 temperature 模型生成故事,并使用低 temperature 模型生成高质量的名称。
LAION Discord
-
发布针对 VLA 模型的 MultiNet 基准测试:题为“Benchmarking Vision, Language, & Action Models on Robotic Learning Tasks”的新论文在 20 个真实世界任务中评估了 VLA models,揭示了关于其性能的关键见解。完整详情请参阅此处。
- 这项工作旨在推动通用机器人系统的发展,证明了在不同任务中进行系统评估的迫切需求。
-
Jina AI 的 VisRAG 演讲:参加即将举行的 Jina AI 演讲,Shi 将探讨他在 VisRAG 上的创新工作,这是一个无需解析的纯视觉 RAG 流水线。
- 届时将了解到关于 VisRAG 的构建、评估及未来可能性,其训练数据集规模几乎是 ColPali 的三倍。
-
领先 VLA 模型之间的性能对比:对 GPT-4o、OpenVLA 和 JAT 的对比显示,虽然拾取与放置等简单任务尚可应对,但模型在复杂的多步过程中表现挣扎。
- 值得注意的是,结果表明性能随任务和机器人平台的不同而有显著差异,凸显了对 GPT-4o 进行复杂 prompt engineering 的效用。
-
μGATO 简介,一个迷你 VLA 模型:团队介绍了 μGATO,这是一个专为 MultiNet 基准测试量身定制的、迷你且易于理解的基准模型,作为推进机器人多模态动作模型的工具。
- Manifold 团队持续的努力预示着更多多模态动作模型的创新即将发布。
-
Tasty Hacks 黑客松公告:一场名为 Tasty Hacks 的新黑客松旨在激励参与者为了创意而非实用性进行创作,摆脱传统黑客松为了获胜而优化的文化。
- 组织者正在寻找善良且极客的人士,愿意在仅有 20-30 人的小型环境中组队创作。
MLOps @Chipro Discord
-
需要 MLOps 指导:一位成员表达了对从何处开始学习 MLOps 的困惑,称:“这一切都很复杂。”
- 另一位成员要求进一步说明,询问更具体的问题,强调了在处理 MLOps 等复杂话题时清晰沟通的必要性。
-
寻求 MLOps 复杂性的澄清:一位成员指出关于 MLOps 的问题过于宽泛,并要求提供更多具体细节。
- 这种互动强调了在处理 MLOps 等错综复杂的主题时,精确沟通的必要性。
Mozilla AI Discord
-
Pleias 发布用于 LLM 训练的 Common Corpus:2024 Builders Accelerator 成员 Pleias 宣布发布 Common Corpus,这是用于 LLM 训练的最大开源数据集,强调了在宽松许可证下提供训练数据的承诺。在此查看完整帖子。
- Pleias 指出:“开源 LLM 生态系统尤其缺乏训练数据的透明度,” 并表示 Common Corpus 旨在解决这一透明度差距。
-
Transformer Lab 安排 RAG 演示:Transformer Lab 正在举办一场演示,展示如何在拥有友好 UI 的情况下,无需编码即可在 LLM 上训练、微调、评估和使用 RAG。该活动承诺在你的本地环境中提供易于安装的过程,引起了社区的兴奋。更多详情。
- 社区成员对将 RAG 简化集成到工作流中表现出极大的热情。
Torchtune Discord
-
DCP 异步 Checkpointing 实现:DCP async checkpointing 旨在通过一项目前正在开发中的新功能来改进 TorchTune 中的中间 checkpointing。
- 该 Pull Request 显示,该过程旨在通过将中间 checkpointing 时间减少 80% 来显著提高效率。
-
中间 Checkpointing 时间缩减:DCP 异步 checkpointing 的实现有望带来显著的缩减,预计由于方法的改进,checkpointing 时间将减少 80%。
- 这种方法是优化分布式 checkpointing 以获得更好性能的持续努力的一部分。
PART 2: Detailed by-Channel summaries and links
完整的频道分类明细已针对邮件进行了截断。
如果您喜欢 AInews,请分享给朋友!提前感谢!