ainews-perplexity-starts-shopping-for-you
Perplexity 开始为你购物。
以下是该文本的中文翻译:
Stripe 推出了其 Agent SDK,为美国 Pro 会员实现了如 Perplexity Shopping 般的 AI 原生购物体验,其特点是通过 Perplexity 商家计划提供一键结账和免运费服务。Mistral AI 发布了 Pixtral Large 124B 多模态图像模型,该模型目前已在 Hugging Face 上线,并由 Le Chat 支持图像生成。Cerebras Systems 为 Llama 3.1 405B 提供了公共推理端点,具备 128k 上下文窗口和高吞吐量。Claude 3.6 展现出优于 Claude 3.5 的改进,但仍存在细微的“幻觉”现象。Bi-Mamba 1-bit 架构提升了大语言模型(LLM)的效率。wandb SDK 已预装在 Google Colab 中,同时 Pixtral Large 已集成到 AnyChat,并得到 vLLM 的支持以实现高效的模型使用。
Stripe SDK 就够了吗?
2024/11/18-2024/11/19 AI 新闻快报。我们为您查看了 7 个 Reddit 分区、433 个 Twitter 账号 和 30 个 Discord 社区(217 个频道,1912 条消息)。为您节省了约 253 分钟 的阅读时间(以 200wpm 计算)。您现在可以标记 @smol_ai 来参与 AINews 讨论!
就在 Stripe 发布其 Agent SDK 仅仅两天后(我们的报道在此),Perplexity 现已面向美国 Pro 会员推出其应用内购物体验。这是首个大规模的 AI 原生购物体验,比起 Amazon,它更接近(做得很好的)Google Shopping。示例展示了你可以使用自然语言进行查询,而这在传统的电子商务 UI 中是很难实现的:
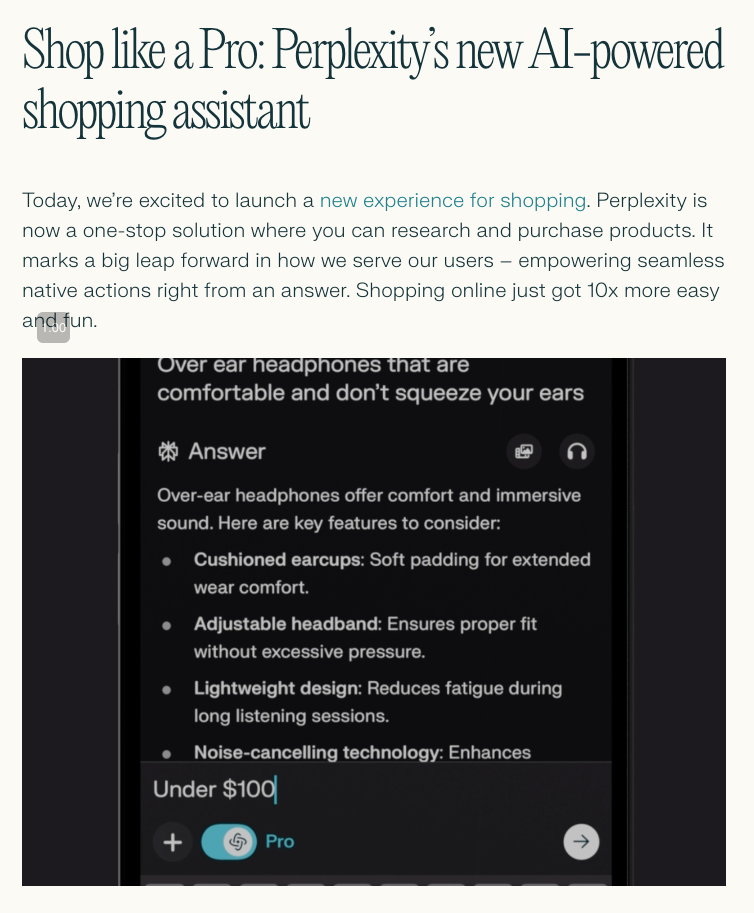
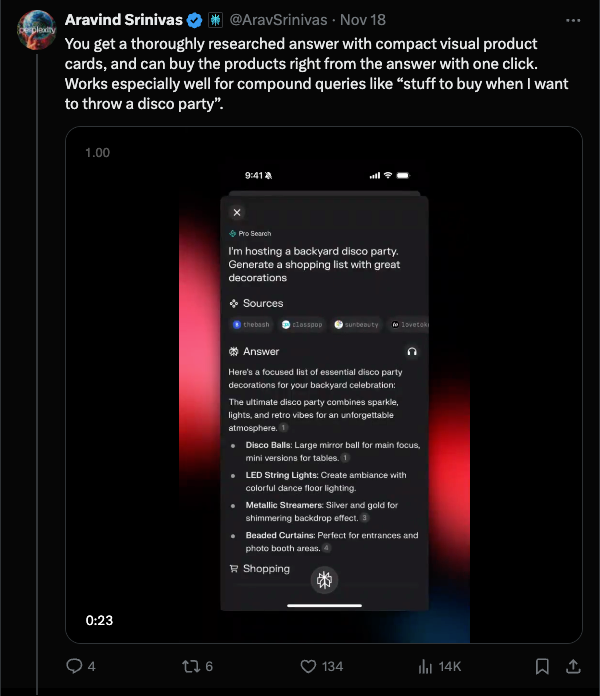
全新的 “Buy With Pro” 计划提供与 “精选商家”(!稍后详细说明)的一键结账和免费送货服务。
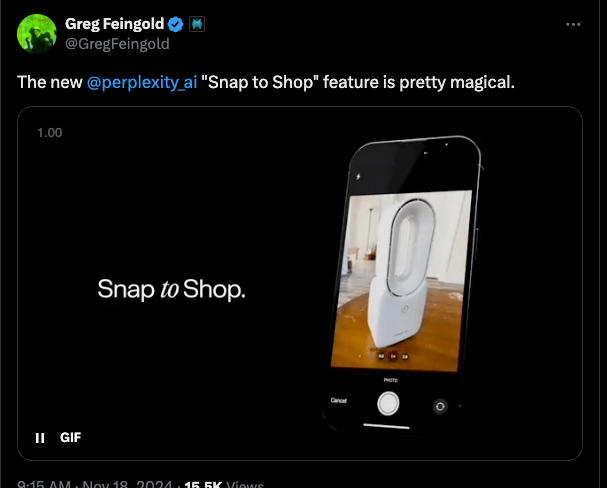
Snap to Shop 也是一个很棒的视觉电商创意… 但它在非 Perplexity 员工手中的实际准确性仍有待观察。
Buy With Pro 计划几乎肯定与新的 Perplexity Merchant Program 挂钩,这是一种标准的免费“以数据换推荐”的价值交换。
Patrick Collison 和 Jeff Weinstein 都迅速指出了 Stripe 的参与,尽管两人都没有直接说明 Perplexity Shopping 使用的就是 Stripe 刚刚发布的那个 Agent SDK。
AI Twitter 摘要
所有摘要均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
AI 模型发布与性能
-
Mistral 的多模态图像模型:@mervenoyann 宣布发布 拥有 124B 参数的 Pixtral Large,现在 @huggingface 已支持该模型。此外,@sophiamyang 分享了 @MistralAI 现在支持在 Le Chat 上生成图像,由 @bfl_ml 提供支持,并免费开放。
-
Cerebras Systems 的 Llama 3.1 405B:@ArtificialAnlys 详细介绍了 Cerebras 的 Llama 3.1 405B 公共推理端点,拥有 969 output tokens/s 和 128k 上下文窗口。这一性能比中位数供应商快 10 倍以上。定价设定为每 1M input tokens $6,每 1M output tokens $12。
-
Claude 3.5 和 3.6 的增强:@Yuchenj_UW 讨论了 Claude 3.5 如何被 Claude 3.6 超越,后者虽然更具说服力,但表现出更微妙的幻觉。像 @Tim_Dettmers 这样的用户已经开始调试输出以维持对模型的信任。
-
Bi-Mamba 架构:@omarsar0 介绍了 Bi-Mamba,这是一种专为更高效的 LLM 设计的 1-bit Mamba 架构,在显著减少内存占用的同时,实现了与 FP16 或 BF16 模型相当的性能。
AI 工具、SDK 与平台
-
Google Colab 上的 Wandb SDK:@weights_biases 宣布 wandb Python SDK 现在已预装在每个 Google Colab 笔记本中,允许用户跳过
!pip install步骤直接导入。 -
AnyChat 集成:@_akhaliq 强调 Pixtral Large 现在已在 AnyChat 上可用,通过集成 ChatGPT 和 Google Gemini 等多个模型来增强 AI 灵活性。
-
vLLM 支持:@vllm_project 通过简单的
pip install -U vLLM引入了对 Pixtral Large 的支持,使用户能够高效地运行该模型。 -
Perplexity Shopping 功能:@AravSrinivas 详细介绍了 Perplexity Shopping 的发布,该功能与 @Shopify 集成,提供 AI 驱动的产品推荐和多模态购物体验。
AI 研究与基准测试
-
nGPT 论文与基准测试:@jxmnop 分享了关于 nGPT 论文的见解,强调了其声称比 GPT 训练速度快 4-20 倍。然而,由于基准测试存在问题,社区在复现结果方面面临挑战。
-
VisRAG 框架:@JinaAI_ 介绍了 VisRAG,这是一个通过多模态推理解决 RAG 瓶颈来增强检索工作流的框架,其性能优于 TextRAG。
-
用于 LLM 评估的 Judge Arena:@clefourrier 展示了 Judge Arena,这是一个用于比较模型裁判 (model-judges) 的工具,旨在对复杂生成内容进行细致评估,帮助研究人员选择合适的 LLM 评估器。
-
Bi-Mamba 的效率:@omarsar0 讨论了 Bi-Mamba 如何实现与全精度模型相当的性能,标志着 LLM 低比特表示 (low-bit representation) 的一个重要趋势。
AI 公司合作伙伴关系与公告
-
Google Colab 与 Wandb 合作伙伴关系:@weights_biases 宣布与 @GoogleColab 合作,确保 wandb SDK 可供用户直接使用,从而简化工作流集成。
-
凯悦 (Hyatt) 与 Snowflake 的合作伙伴关系:@RamaswmySridhar 分享了 @Hyatt 如何利用 @SnowflakeDB 来统一数据、减少管理时间并快速创新,从而提高运营效率和客户洞察。
-
Figure Robotics 的招聘与部署:@adcock_brett 多次讨论了 Figure 致力于交付数百万台人形机器人、招聘顶尖工程师以及部署自主车队的承诺,展示了 AI 机器人领域的重大规模化努力。
-
Hugging Face 增强功能:@ClementDelangue 强调 @huggingface 现在提供帖子互动情况的可视化,增强了该平台作为 AI 新闻和更新中心的角色。
AI 活动与工作坊
-
AIMakerspace Agentic RAG 工作坊:@llama_index 宣传了将于 11 月 27 日由 @AIMakerspace 主办的直播活动,重点关注使用开源 LLM 构建本地 Agentic RAG 应用,并由 Dr. Greg Loughnane 和 Chris “The Wiz” Alexiuk 主持动手实践环节。
-
SambaNova 与 Hugging Face 开源 AI 之夜:@_akhaliq 宣布了一场定于 12 月 10 日举行的开源 AI 活动,届时将汇聚硅谷的 AI 思想家,促进 @Sambanova 与 @HuggingFace 之间的合作。
-
新加坡 DevDay:@stevenheidel 分享了参加 2024 年最后一场 DevDay(位于新加坡)的兴奋之情,并强调了与其他受邀演讲者交流的机会。
梗/幽默
-
对 AI 的误解与挫败感:@transfornix 表达了对缺乏动力和大脑迷雾的沮丧。同样,@fabianstelzer 分享了对 AI 工作流和意外结果的轻松调侃式挫败感。
-
关于 AI 和技术的幽默见解:@jxmnop 幽默地质疑为什么 Transformer 实现错误会导致一切崩溃,反映了开发者的常见挫败感。此外,@idrdrdv 开玩笑说范畴论 (category theory) 让新人望而却步。
-
轻松有趣的互动:诸如 @swyx 分享关于 oauth 需求的幽默评论,以及 @HamelHusain 参与轻松的对话,展示了社区风趣的一面。
-
对 AI 发展的反应:@aidan_mclau 对在社交网络上看到他人做出了幽默的回应,@giffmana 则分享了关于 AI 互动的笑料。
AI 应用与用例
-
AI 在文档处理中的应用:@omarsar0 介绍了 Documind,这是一个用于从 PDF 中提取结构化数据的 AI 驱动工具,并强调了其易用性和 AGPL v3.0 License。
-
AI 在金融回测中的应用:@virattt 描述了使用 @LangChainAI 进行编排来回测 AI 金融 Agent 的方案,并概述了评估投资组合收益的四个步骤。
-
AI 在购物与电子商务中的应用:@AravSrinivas 展示了 Perplexity Shopping,详细介绍了多模态搜索、Buy with Pro 以及与 @Shopify 的集成等功能,旨在简化购物体验。
-
AI 在医疗沟通中的应用:@krandiash 强调了与 @anothercohen 的合作,旨在利用 AI 改善医疗沟通,并重点介绍了修复破碎系统的努力。
AI 社区与综合讨论
-
AI 好奇心与学习:@saranormous 强调,真正的技术好奇心是一种强大且难以伪造的特质,鼓励 AI 社区内的持续学习与探索。
-
AI 模型开发中的挑战:@huybery 和 @karpathy 讨论了模型训练的挑战,包括延迟问题、Layer Normalization 以及模型监管对于构建值得信赖的 AI 系统的重要性。
-
AI 在社会科学与伦理中的应用:@BorisMPower 思考了 AI 在社会科学中的革命性潜力,主张在假设检验中使用 in silico 模拟(计算机模拟)取代传统的真人访谈。
-
AI 在软件工程中的应用:@inykcarr 和 @HellerS 参与了关于 LLM Prompt Engineering 的讨论,强调了通过有效利用 AI 实现 10 倍生产力提升的“超能力”。
AI Reddit 热点回顾
/r/LocalLlama 综述
主题 1. Mistral Large 2411:期待与发布详情
- Mistral Large 2411 和 Pixtral Large 将于 11 月 18 日发布 (Score: 336, Comments: 114): Mistral Large 2411 和 Pixtral Large 定于 11 月 18 日发布。
- 许可与使用方面的担忧:针对 Mistral 模型限制性的 MRL License 存在大量讨论,用户对不明确的许可条款以及 Mistral 对商业用途咨询缺乏回应表示沮丧。一些人认为,虽然该许可证允许研究使用,但它使商业应用和微调模型的分享变得复杂。
- 基准测试对比:据报道,Pixtral Large 在 MathVista (69.4) 和 DocVQA (93.3) 等多项基准测试中表现优于 GPT-4o 和 Claude-3.5-Sonnet,但用户注意到缺乏与 Qwen2-VL 和 Molmo-72B 等其他领先模型的对比。此外,基于基准测试表中的潜在拼写错误或泄露,有人猜测可能存在 Llama 3.1 505B 模型。
- 技术实现与支持:用户讨论了将 Pixtral Large 与 Exllama 集成以提高 VRAM 效率和张量并行(Tensor Parallelism)的潜力,并确认 Mistral Large 2411 不需要对 llama.cpp 进行更改即可支持。此外,还提到了一种新的指令模板(Instruct Template)可能会增强模型的可控性(Steerability),这与社区建议的 Prompt 格式化方案不谋而合。
- mistralai/Mistral-Large-Instruct-2411 · Hugging Face (Score: 303, Comments: 81): 该帖子讨论了 Mistral Large 2411,这是一个在 Hugging Face 的 mistralai/Mistral-Large-Instruct-2411 仓库中提供的模型。帖子正文未提供更多细节或背景。
- 用户讨论了 Mistral Large 2411 的性能,指出在各种任务中结果参差不齐。Sabin_Stargem 提到在 NSFW 叙事生成方面取得了成功,但在背景设定(lore)理解和掷骰子点数任务中表现失败。ortegaalfredo 发现整体有轻微改进,但在编程任务中更倾向于使用 qwen-2.5-32B。
- 关于 模型的许可和分发 存在争议。TheLocalDrummer 和其他人对 MRL 许可证表示担忧,mikael110 对 Apache-2 发布的终结感到惋惜。thereisonlythedance 尽管对许可证有抱怨,但出于经济必要性,仍对 Mistral 提供的本地模型访问表示赞赏。
- 技术讨论涉及 模型部署和量化。noneabove1182 分享了 Hugging Face 上 GGUF 量化的链接,并提到缺乏与之前版本对比的评估(evals)。segmond 对缺乏评估数据表示怀疑,并指出在编程测试中与 large-2407 相比性能略有下降。
- Pixtral Large Released - Vision model based on Mistral Large 2 (Score: 123, Comments: 27): Pixtral Large 已作为基于 Mistral Large 2 的 视觉模型(vision model) 发布。帖子中未提供有关模型规格或能力的进一步细节。
- Pixtral Large 的视觉设置:该模型并非基于 Qwen2-VL;相反,它使用了 Qwen2-72B 文本 LLM 和自定义视觉系统。7B 变体 使用 Olmo 模型 作为基础,其表现与 Qwen 基础模型相似,表明了其数据集的稳健性。
- 技术要求与能力:运行该模型可能需要大量的硬件资源,例如 4x3090 GPU 或配备 128GB RAM 的 MacBook Pro。该模型的视觉编码器更大(1B 对比 400M),表明它可以处理至少 30 张高分辨率图像,尽管“高分辨率(hi-res)”的具体定义尚不明确。
- 性能基准与对比:Pixtral Large 的性能仅与 Llama-3.2 90B 进行了对比,后者因其规模而被认为表现欠佳。与 Molmo-72B 和 Qwen2-VL 在 Mathvista、MMMU 和 DocVQA 等数据集上的对比显示出不同的结果,表明其与当前最先进水平(state-of-the-art)的对比仍不全面。
主题 2. Llama 3.1 405B 推理:Cerebras 的突破
- Llama 3.1 405B now runs at 969 tokens/s on Cerebras Inference - Cerebras (Score: 272, Comments: 49): Cerebras 在其推理平台上以 969 tokens/s 的速度运行 Llama 3.1 405B,实现了一个性能里程碑。这展示了 Cerebras 在高效处理大规模模型方面的能力。
- 用户注意到 405B 模型 目前仅在付费层级向企业开放,而 Openrouter 以显著降低的价格提供该模型,尽管速度较慢。128K 上下文长度 和全 16 位精度被强调为 Cerebras 平台的关键特性。
- 讨论强调 Cerebras 的性能提升 更多归功于软件改进而非硬件变更,一些用户指出了 WSE-3 集群 的使用以及潜在的替代方案,如 8x AMD Instinct MI300X 加速器。
- 人们对高速推理的应用场景表现出兴趣,例如 Agent 工作流 和 高频交易,在这些场景中,对大型模型的快速处理可以提供优于传统慢速方法的显著优势。
主题 3. Raspberry Pi 上的 AMD GPU:Llama.cpp 集成
- 在 Raspberry Pi 5 上通过 Vulkan 为 llama.cpp 提供 AMD GPU 支持 (Score: 144, Comments: 49):作者一直在 Raspberry Pi 5 上集成 AMD 显卡,并已成功在 Pi OS 上实现了 Linux
amdgpu驱动。他们为多款 AMD GPU 编译了支持 Vulkan 的llama.cpp,并正在收集基准测试结果,详情可见此处。他们正在寻求社区对额外测试的建议,并计划评估低端 AMD 显卡的性价比和能效比。- 几位用户建议使用 ROCm 代替 Vulkan 以获得更好的 AMD GPU 性能,但指出由于兼容性有限,在 ARM 平台上支持 ROCm 具有挑战性。虽然有人建议使用 hipblas 等替代方案,但其设置过程非常复杂,参考 Phoronix 文章。
- 讨论中涉及了针对 ARM CPU 的量化优化,特别是使用
llama.cpp的4_0_X_X量化级别,以利用neon+dotprod等 ARM 特定指令。这可以提高搭载 BCM2712 的 Raspberry Pi 5 等设备的性能,使用如-march=armv8.2-a+fp16+dotprod的编译标志。 - 在 RX 6700 XT 上使用 Vulkan 版
llama.cpp的基准测试结果显示了令人期待的性能指标,但也凸显了功耗问题,测试期间平均约为 195W。讨论还涉及了使用 GPU 执行 AI 任务与 CPU 相比的效率,Raspberry Pi 设置在待机时仅消耗 11.4W。
主题 4. txtai 8.0:精简版 Agent 框架发布
- txtai 8.0 发布:极简主义者的 Agent 框架 (Score: 60, Comments: 9):txtai 8.0 已作为专为极简主义者设计的 Agent 框架发布。此版本专注于简化 AI 应用的开发和部署。
- txtai 8.0 引入了一个新的 Agent 框架,该框架与 Transformers Agents 集成并支持所有 LLMs,提供了一种精简的方法来部署现实世界的 Agent,而无需不必要的复杂性。更多详情和资源可在 GitHub、PyPI 和 Docker Hub 上找到。
- txtai 8.0 中的 Agent 框架通过工具使用和规划展示了决策能力,如 Colab 上的详细示例所示。该示例展示了 Agent 如何使用 ‘web_search’ 和 ‘wikipedia’ 等工具来回答复杂问题。
- 用户询问了该框架的能力,包括是否支持 Agent 的函数调用 (function calling) 和 视觉模型 (vision models)。这些问题凸显了用户对于将 txtai 的功能扩展到包含视觉分析等更高级特性的兴趣。
其他 AI Subreddit 摘要
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
主题 1. Flux vs SD3.5:尽管存在技术权衡,社区仍更青睐 Flux
- Flux 与 SD3.5 的现状如何? (Score: 40, Comments: 99):社区正在对 Stable Diffusion 3.5 和 Flux 进行比较,据报道,自一个月前发布以来,对 SD3.5 的最初热情有所下降。该帖子寻求澄清可能导致用户回归 Flux 的 SD3.5 潜在技术问题,尽管提问中未提供具体的技术对比。
- SD3.5 面临重大的采用挑战,原因是它在 Forge 上不可用,且与 Flux 相比 微调 (finetune) 能力有限。用户报告称 SD3.5 擅长艺术风格和更高分辨率,但在解剖结构(尤其是手部)方面表现不佳。
- 社区测试显示 Flux 在 img2img 任务和写实人物生成方面更胜一筹,而 SD3.5 提供了更好的负面提示词 (negative prompt) 支持和更快的处理速度。SD3.5 缺乏高质量的微调模型和 LoRAs,限制了其广泛采用。
- 高级用户建议结合两者的优势,例如使用 SD3.5 进行初步的创意生成,然后使用 Flux 进行解剖结构优化。Flux 于 8月 发布,并凭借大量可用的微调模型维持了更强大的社区支持。
- 通过提示词减少 Flux “同质化面孔”的方法(摘要与长文) (Score: 33, Comments: 5): 该帖子为减少 Flux 图像生成中的“同质化面孔 (same face)”问题提供了技术建议,推荐的关键策略包括将 CFG/Guidance 降低至 1.6-2.6,避免使用 “man”/”woman” 等通用词汇,并加入关于族裔、体型和年龄的具体描述。作者分享了一组示例图像来演示这些技术,并提供了一个描述“轮廓分明的黎巴嫩女性”在厨房场景中的示例提示词,同时解释了模型训练偏差和常见的提示词模式是如何导致同质化面孔问题的。
- Flux 中较低的 Guidance 设置 (1.6-2.6) 以牺牲提示词遵循度为代价换取照片写实感和多样性,而一些用户为了在复杂描述中获得更好的提示词遵循度,仍维持默认的 3.5 CFG。
- 社区此前曾记录过针对“sameface”问题的类似解决方案,包括一个通过国籍、姓名和头发特征随机化提示词的 auto1111 扩展。
- 出于安全考虑,用户建议不要下载随机的 .zip 文件,并建议使用 Imgur 等替代图像托管平台来分享生成的示例。
主题 2. O2 机器人技术突破:宝马工厂速度提升 400%
- Figure 02 现已成为在宝马工厂工作的自主机群,近几个月速度提升了 400% (Score: 180, Comments: 63): Figure 02 机器人目前作为自主机群在宝马工厂运行,近几个月其操作速度提升了 400%。
- 根据 宝马新闻稿,Figure 02 机器人目前在需要充电前可运行 5 小时,单台成本为 $130,000。这些机器人在实现 400% 速度提升的同时,可靠性也提升了 7 倍。
- 多位用户指出,这些机器人的进步速度超过了人类的能力,具有全天候 24/7 运行的潜力,且无需休息或福利。批评者则指出,与专用机械臂相比,目前在效率上仍存在局限。
- 讨论集中在经济可行性上,一些人主张为了自动化应重新设计整个工厂,而不是保留适应人类的空间。机器人需要工厂照明和维护成本,但不需要暖气或保险。
主题 3. Claude vs ChatGPT:企业用户体验讨论
- 我应该升级到 ChatGPT Plus 还是 Claude AI?帮我决定! (Score: 33, Comments: 69): 数字营销专业人士对比了 ChatGPT Plus 和 Claude AI 在内容创作和技术辅助方面的表现,重点关注处理内容构思(占用途的 75%)和 Linux 技术支持(占用途的 25%)。近期出现了对 Claude 可靠性和模型降级的担忧,用户报告了停机和模型变更中的透明度问题,引发了关于 Claude 作为付费服务可行性的质疑。
- OpenRouter 和 TypingMind 等第三方应用成为直接订阅的热门替代方案,提供了在不同模型间切换的灵活性,且成本可能低于每月 20 美元的方案。用户强调了在同一处维持上下文并集成多个 API 的能力。
- Claude 最近的变化引发了关于审查制度加强和使用限制(免费档的 5 倍限制)的批评,尤其影响了西班牙语用户和技术任务。用户报告 Claude 以“伦理原因”拒绝任务,并经历了显著的模型行为变化。
- o1-preview 模型因其集成的思维链 (chain of thought) 能力和处理复杂数学的能力而受到高度赞赏,而 Google Gemini 1.5 Pro 则因其 1,000,000 Token 上下文窗口以及与 Google Workspace 的集成而备受关注。
- Claude 的服务器快崩溃了! (Score: 86, Comments: 24): Claude 用户报告了持续的服务器容量问题,频繁的高需求通知导致工作流中断。用户对服务中断表示沮丧,并要求 Anthropic 团队升级基础设施。
- 用户报告 Claude 的最佳使用时间是当印度和加利福尼亚都不活跃时,多位用户确认他们根据这些时区规划工作以避开过载问题。
- 几位用户建议放弃 Claude 网页界面,转而使用基于 API 的解决方案,其中一位用户详细介绍了他们从使用网页界面到通过自定义实现和 Open WebUI 管理 100 多个 AI 模型的历程。
- 用户对简短的回答和 “Error sending messages. Overloaded” 通知表示不满,尽管成本更高,一些人仍推荐 OpenRouter API 作为替代方案。
主题 4. CogVideo 封装器更新:重大重构与 1.5 支持
- Kijai 更新了 CogVideoXWrapper:支持 1.5!重构了简化管道并进行了额外优化。(但会破坏旧的工作流) (Score: 69, Comments: 23): CogVideoXWrapper 迎来了重大更新,支持 CogVideoX 1.5 模型,其特点包括代码清理、将 Fun-model 功能合并到主管道中,并添加了 torch.compile 优化以及 torchao 量化。此次更新对旧工作流引入了破坏性变更,包括从采样器组件中移除宽度/高度、将 VAE 从模型中分离、支持 fp32 VAE 以及用 FasterCache 替换 PAB,同时在 ComfyUI-CogVideoXWrapper 保留了旧版本的遗留分支。
- 在 RTX 4090 上的测试显示,CogVideoX 1.5 以 720x480 分辨率处理 49 帧、20 步大约需要 30-40 秒,在相同帧数下,该模型明显比以前的版本更快。
- 2B 模型需要大约 3GB VRAM 用于存储,外加额外的推理内存,在 512x512 分辨率下的测试显示,包括 VAE 解码在内的峰值 VRAM 占用约为 6GB。
- Alibaba 发布了更新版本的 CogVideoXFun,截至 2024.11.16,新增了对 Canny、Depth、Pose 和 MLSD 条件的控制模型支持。
AI Discord 摘要
由 O1-preview 提供的摘要之摘要的总结
主题 1:尖端 AI 模型竞相宣示主导地位
- Cerebras 凭借 Llama 3.1 创下速度纪录: Cerebras 声称其 Llama 3.1 405B 模型达到了惊人的 969 tokens/s,比平均供应商快 10 倍以上。批评者认为这是“苹果与橘子”的不对等比较,指出 Cerebras 在 batch size 为 1 时表现出色,但在处理大 batch 时落后。
- Runner H 冲向 ASI,表现超越竞争对手: H Company 宣布了 Runner H 的 Beta 版本,声称突破了 scaling laws 的限制,向人工超智能(ASI)迈进。据报道,Runner H 在 WebVoyager 基准测试上超越了 Qwen,展示了卓越的导航和推理能力。
- Mistral 发布具有 128K 上下文窗口的 Pixtral Large: Mistral 推出了 Pixtral Large,这是一个基于 Mistral Large 2 的 124B 多模态模型,通过 128K 上下文窗口可处理超过 30 张高分辨率图像。它在 MathVista 和 VQAv2 等基准测试中达到了业界领先的性能。
主题 2:AI 模型努力应对局限性与 Bug
- Qwen 2.5 模型在训练中表现不稳定:用户报告在训练 Qwen 2.5 时结果不一致,而切换到 Llama 3.1 时错误则会消失。该模型似乎对特定配置非常敏感,这给开发者带来了困扰。
- AI 在井字棋中失误并遗忘规则:成员们观察到像 GPT-4 这样的 AI 模型在处理井字棋等简单游戏时表现挣扎,无法封堵对手招式并在游戏途中丢失进度。LLM 作为状态机的局限性引发了关于需要更好游戏逻辑框架的讨论。
- Mistral 模型陷入死循环:用户在使用 Mistral Nemo 等模型通过 OpenRouter 输出时遇到了死循环和重复输出的问题。调整温度(temperature)设置未能完全解决该问题,表明模型输出存在更深层的问题。
主题 3:创新研究照亮 AI 前景
- Neural Metamorphosis 实现网络即时变形:Neural Metamorphosis 论文通过学习连续权重流形引入了自变形神经网络,允许模型在不进行重新训练的情况下调整大小和配置。
- LLM2CLIP 利用 LLM 增强 CLIP:微软发布了 LLM2CLIP,利用大语言模型增强 CLIP 处理长且复杂标题的能力,显著提升了其跨模态性能。
- AgentInstruct 生成海量合成数据:AgentInstruct 框架自动创建了 2500 万个 多样化的提示词-响应对(prompt-response pairs),使 Orca-3 模型在 AGIEval 上的表现提升了 40%,超越了 GPT-3.5-turbo 等模型。
主题 4:AI 工具演进与工作流优化
- Augment 为开发者加速 LLM 推理:Augment 详细介绍了他们在优化 LLM 推理方面的方法,通过提供完整的代码库上下文(这对开发者 AI 至关重要)并克服延迟挑战,以确保快速且高质量的输出。
- DSPy 引入 VLM 支持进军视觉领域:DSPy 宣布对 Vision-Language Models 提供 Beta 版支持,并在教程中展示了如何从图像(如网站截图)中提取属性,标志着其能力的重大扩展。
- Hugging Face 通过 Pipelines 简化视觉模型:Hugging Face 的 pipeline 抽象现在支持视觉语言模型,使得以统一方式处理文本和图像变得前所未有的简单。
主题 5:社区动态与重大举措
- Roboflow 获 4000 万美元融资以强化 AI 视觉:Roboflow 在 B 轮融资中额外筹集了 4000 万美元,用于增强视觉 AI 的开发者工具,旨在医疗和环境等行业部署应用。
- Google AI 工作坊将在黑客松中释放 Gemini 潜力:11 月 26 日的一场特别 Google AI 工作坊将在 LLM Agents MOOC 黑客松期间向开发者介绍如何基于 Gemini 进行构建,包括现场演示以及与 Google AI 专家的直接问答。
- LAION 发布 1200 万个用于 ML 的 YouTube 样本:LAION 宣布推出 LAION-DISCO-12M,这是一个包含 1200 万个 YouTube 链接及元数据的数据集,旨在支持音频和音乐领域基础模型的研究。
第一部分:Discord 高层级摘要
Eleuther Discord
-
Muon 优化器表现不如 AdamW:讨论强调,由于不合适的学习率和调度技术,Muon 优化器的表现明显逊于 AdamW,引发了对其优越性主张的怀疑。
- 一些成员指出,使用更好的超参数可以改善对比结果,但针对未调优基准线的批评依然存在。
-
Neural Metamorphosis 引入自变形网络:关于 Neural Metamorphosis (NeuMeta) 的论文提出了一种通过直接学习连续权重流形来创建自变形神经网络的新方法。
- 这可能允许针对任何网络规模和配置进行即时采样,并引发了关于利用小模型更新来实现更快训练的讨论。
-
SAE 特征转向推动 AI Safety:Microsoft 的合作者发布了一份关于 SAE 特征转向的报告,展示了其在 AI Safety 方面的应用。
- 研究表明,转向 Phi-3 Mini 可以增强拒绝行为,同时强调需要探索其优势和局限性。
-
Cerebras 收购推测:讨论集中在为什么像 Microsoft 这样的大公司尚未收购 Cerebras,推测这可能是因为它们有潜力与 NVIDIA 竞争。
- 一些成员回忆起 OpenAI 在 2017 年前后曾有兴趣收购 Cerebras,暗示了其在 AI 领域的持久影响力。
-
经济可行性担忧下 Scaling Laws 依然重要:Scaling laws 仍被视为模型的基本属性,但在经济上,进一步推行扩展已变得不可行。
- 一位成员幽默地指出,如果你没有达到 GPT-4 或 Claude 3.5 的预算水平,可能还不需要担心收益递减问题。
OpenAI Discord
-
GPT-4-turbo 更新引发性能审查:成员们正在询问 gpt-4-turbo-2024-04-09 更新,并注意到其此前出色的表现。
- 一位用户对更新后模型思考能力的不一致性表示沮丧。
-
NVIDIA 的 Add-it 提升 AI 图像编辑:讨论重点介绍了顶尖的 AI 图像编辑工具,如 ‘magnific’ 和 NVIDIA 的 ****Add-it** **,后者允许根据文本提示添加对象。
- 成员们对这些新兴工具的可靠性和实际可访问性表示怀疑。
-
Temperature 设置影响 AI 创造力:在井字棋(Tic Tac Toe)讨论中,较高的 Temperature 设置会导致 AI 回复的创造力增加,这可能会阻碍其在基于规则的游戏中的表现。
- 参与者注意到,在 Temperature 0 时,由于其他影响因素,AI 的回复虽然一致,但并非完全相同。
-
LLMs 作为游戏状态机面临挑战:用户指出,当 LLMs 被用于表示井字棋等游戏中的状态机时,会表现出不一致性。
- 大家一致认为,需要比单纯依赖 LLMs 更有效地处理游戏逻辑的框架。
-
难度参数增强 AI 游戏表现:参与者讨论了引入难度参数来改进 AI 游戏表现,例如让 AI 提前思考几步。
- 随着用户对长时间的 AI 对话感到疲劳,进一步的讨论被暂停。
Unsloth AI (Daniel Han) Discord
-
Qwen 2.5 模型问题:用户报告在使用 ORPO trainer 训练 Qwen 2.5 模型时出现结果不一致的情况,并指出切换到 Llama 3.1 后解决了这些错误。
- 讨论集中在模型类型的变化是否通常会影响训练结果,见解表明此类调整可能不会显著影响结果。
-
基于人类反馈的强化学习 (RLHF):社区探索了集成 PPO (RLHF) 技术,表明映射 Hugging Face 组件可以简化该过程。
- 成员们分享了开发奖励模型 (reward model) 的方法论,为有效实施 RLHF 提供了一个支持性框架。
-
多轮对话微调:提供了关于为多轮对话格式化数据集的指导,建议使用 EOS tokens 来指示响应终止。
- 强调利用适合多轮格式的数据(如 ShareGPT)来增强训练效果。
-
Aya Expanse 支持:确认了对 Cohere 的 Aya Expanse 模型支持,解决了成员关于其集成的咨询。
- 讨论未深入探讨更多细节,主要集中在对 Aya Expanse 兼容性的积极确认上。
-
语言模型中的合成数据:一场讨论强调了合成数据 (synthetic data) 对于加速语言模型开发的重要性,并引用了论文 AgentInstruct: Toward Generative Teaching with Agentic Flows。
- 该论文探讨了模型崩溃 (model collapse) 问题,并强调在使用合成数据时需要进行细致的质量和多样性管理。
HuggingFace Discord
-
Pipeline 抽象简化视觉模型:@huggingface transformers 中的 pipeline abstraction 现在支持视觉语言模型 (vision language models),简化了推理过程。
- 此次更新使开发者能够在统一的框架内高效处理视觉和文本数据。
-
Diffusers 引入 LoRA Adapter 方法:Diffusers 为支持 LoRA 的模型添加了两个新方法:
load_lora_adapter()和save_lora_adapter(),方便与 LoRA checkpoints 直接交互。- 这些新增功能消除了加载权重时对先前命令的需求,提升了工作流效率。
-
精确取消学习 (Exact Unlearning) 揭示 LLM 中的隐私漏洞:最近一篇关于将精确取消学习作为机器学习模型隐私机制的论文揭示了其在大语言模型 (LLMs) 应用中的不一致性。
- 作者强调,虽然取消学习可以管理训练期间的数据删除,但模型仍可能保留未经授权的知识,如恶意信息或错误信息。
-
RAG Fusion 变革生成式 AI:一篇文章讨论了 RAG Fusion 作为生成式 AI 的关键转变,预测了 AI 生成方法的重大变革。
- 它探讨了 RAG 技术 的影响及其在各种 AI 应用中的预期集成。
-
Augment 为开发者优化 LLM 推理:Augment 发布了一篇 博客文章,详细介绍了他们通过提供全代码库上下文 (full codebase context) 来增强 LLM 推理的策略,这对于开发者 AI 至关重要,但也带来了延迟挑战。
- 他们概述了旨在提高推理速度和质量的优化技术,确保为客户提供更好的性能。
Stability.ai (Stable Diffusion) Discord
-
Mochi 在排行榜上表现优于 CogVideo:成员们讨论了 Mochi-1 目前在排行榜上表现优于其他模型,尽管其 Discord 社区似乎并不活跃。
- CogVideo 因其功能和更快的处理速度而受到欢迎,但在纯 text-to-video 任务中,仍被认为逊色于 Mochi。
-
Stable Diffusion 初学者的顶级模型选择:建议新用户探索 Auto1111 和 Forge WebUI,作为 Stable Diffusion 的入门友好选项。
- 虽然 ComfyUI 提供了更多控制权,但其复杂性可能会让新手感到困惑,这使得 Forge 成为一个更具吸引力的选择。
-
在 GGUF 和大型模型格式之间做出选择:stable-diffusion-3.5-large 与 stable-diffusion-3.5-large-gguf 之间的区别在于 GPU 处理数据的方式,GGUF 允许进行更小的、分块的处理。
- 鼓励拥有更强大配置的用户使用基础模型以获得速度优势,而 VRAM 有限的用户可以探索 GGUF 格式。
-
推出 AI 驱动的新闻内容创作软件:一位用户介绍了一款能够监控新闻话题并生成 AI 驱动的社交媒体帖子的软件,强调了其在 LinkedIn 和 Twitter 等平台上的实用性。
- 该用户正在为这项服务寻找潜在客户,并强调了其在房地产等行业的应用能力。
-
社区成员对 WebUI 的偏好:社区分享了关于不同 WebUI 的经验,指出 ComfyUI 在工作流设计方面的优势,特别是对于熟悉音频软件的用户。
- 一些人对 Gradio 的表单填写特性表示不满,呼吁提供更用户友好的界面,同时也承认了 Forge 强大的优化能力。
aider (Paul Gauthier) Discord
-
OpenAI o1 模型现在支持 streaming:OpenAI 的 o1-preview 和 o1-mini 模型现在支持 streaming(流式传输),允许在所有付费使用层级进行开发。主分支默认集成了此功能,增强了开发者能力。
- Aider 的主分支在发布新版本时会提示更新,但开发者环境不保证自动更新。
-
Aider API 兼容性与配置:有成员担心 Aider 的默认输出限制被设置为 512 tokens,尽管通过 OpenAI API 支持高达 4k tokens。成员们讨论了调整配置的方法,包括利用
extra_params进行自定义设置。- 强调了将 Aider 与本地模型和 Bedrock(如 Anthropic Claude 3.5)连接时的问题,需要正确格式化的元数据 JSON 文件以避免冲突和错误。
-
Anthropic API 速率限制变更引入分级限制:Anthropic 取消了每日 token 限制,在不同层级引入了新的基于分钟的输入/输出 token 限制。此更新可能需要开发者升级到更高层级以获得更高的速率限制。
- 用户对层级结构表示怀疑,认为这是激励用户为了获得更多访问权限而增加支出的策略。
-
Pixtral Large 发布增强 Mistral 性能:Mistral 发布了 Pixtral Large,这是一个基于 Mistral Large 2 构建的 124B 多模态模型,在 MathVista、DocVQA 和 VQAv2 上达到了 state-of-the-art 性能。它可以处理超过 30 张高分辨率图像,具有 128K context window,并可在 API 中作为
pixtral-large-latest进行测试。- Elbie 提到希望看到 Pixtral Large 的 Aider benchmarks,并指出虽然之前的 Mistral Large 表现出色,但并未完全满足 Aider 的要求。
-
qwen-2.5-coder 的困境及与 Sonnet 的对比:用户报告称 OpenRouter 的 qwen-2.5-coder 有时无法提交更改或进入死循环,可能是由于设置参数不正确或内存压力。它在 architect mode 下的表现比常规模式更差。
- 与 Sonnet 的对比表明,根据初步经验,qwen-2.5-coder 可能无法达到 Sonnet 的效率,这引发了关于影响性能的训练因素的讨论。
LM Studio Discord
-
7900XTX 显卡性能:一位用户报告称 7900XTX 在处理文本时效率很高,但在使用专为 AMD 设计的 amuse 软件处理图形密集型任务时会出现明显减速。另一位用户询问了针对 7900XTX 图形性能测试的具体模型。
- 用户正在积极评估 7900XTX 在不同工作负载下的能力,指出其在文本处理方面的优势,同时强调了在图形密集型应用中的挑战。
-
基于 Llama 3.2 的角色扮演模型:一位用户寻求适用于角色扮演的优质 NSFW/Uncensored、基于 Llama 3.2 的模型推荐。另一位成员回应称,通过适当的搜索可以找到此类模型。
- 讨论强调了在 HuggingFace 上查找特定角色扮演模型的难度,建议需要更好的搜索策略。
-
LM Studio 的远程服务器使用:一位用户寻求将 LM Studio 指向远程服务器的配置建议。建议包括使用 RDP 或 openweb-ui 以增强用户体验。
- 一位用户表示有兴趣利用 Tailscale 远程托管推理后端,并强调了在不同设置中保持性能一致性的重要性。
-
Windows vs Ubuntu 推理速度:测试显示,一个 1b 模型在 Windows 上的速度为 134 tok/sec,而 Ubuntu 以 375 tok/sec 的表现远超前者,表明存在巨大的性能差异。一位成员建议,这种差异可能是由于 Windows 中不同的电源计划造成的,并建议切换到高性能模式。
- 社区正在研究导致操作系统之间推理速度差异的因素,将电源管理设置视为潜在原因。
-
AMD GPU 性能挑战:讨论强调,虽然 AMD GPU 提供了高效的性能,但受限于软件支持,使其在某些应用中缺乏吸引力。一位成员指出,由于与各种工具的兼容性问题,使用 AMD 硬件通常感觉像是一场艰苦的战斗。
- 参与者对 AMD GPU 的软件兼容性表示沮丧,强调需要改进支持以充分利用 AMD 硬件的能力。
OpenRouter (Alex Atallah) Discord
-
O1 流式传输现已上线:OpenAIDevs 宣布 OpenAI 的 o1-preview 和 o1-mini 模型现在支持真正的流式传输功能,所有付费层级的开发者均可使用。
- 此次更新解决了之前“伪”流式传输方法的局限性,社区对最新流式传输功能的进一步明确表示出兴趣。
-
Gemini 模型遇到速率限制:用户报告在利用 Google 的
Flash 1.5和Gemini Experiment 1114时频繁出现 503 错误,这表明这些较新的实验性模型可能存在速率限制问题。- 社区讨论强调了资源耗尽错误,成员建议 OpenRouter 提供更好的沟通以减轻此类技术中断的影响。
-
Mistral 模型面临无限循环问题:关于 Mistral 模型(如
Mistral Nemo)和Gemini在与 OpenRouter 配合使用时出现无限循环和重复输出的问题被提出。- 建议包括调整 Temperature 设置,但用户承认解决这些技术挑战具有复杂性。
-
自定义提供商密钥需求激增:多位用户请求访问自定义提供商密钥 (custom provider keys),突显了利用它们进行多样化应用的浓厚兴趣。
- 在 beta-feedback 频道中,用户还对 beta 自定义提供商密钥和自带 API keys 表示了兴趣,表明了向更具定制化的平台集成发展的趋势。
Notebook LM Discord Discord
-
NotebookLM 中的音轨分离:一位成员在 #use-cases 频道询问了在录音过程中获取独立人声音轨的方法。
- 这凸显了用户对 音频管理工具 的持续关注,并提到了用于说话人分离和 mp4 录音共享的 Simli_NotebookLM。
-
创新的视频创作解决方案:分享了关于 Somli 视频创作工具以及以极具竞争力的价格使用 D-ID Avatar studio 的讨论。
- 成员们交流了使用数字人(Avatar)制作视频的步骤,并为感兴趣的人提供了相关的编程实践。
-
利用 NotebookLM 增强文档组织:一位成员表示有兴趣利用 NotebookLM 来汇编和组织世界观构建(world-building)文档。
- 该请求强调了 NotebookLM 通过有效管理大量笔记来简化 创作过程 的潜力。
-
在 NotebookLM 中创建定制化课程:一位英语教师分享了他们使用 NotebookLM 开发针对学生兴趣的阅读和听力课程的经验。
- 该方法将工具提示作为微型课程,通过实际的语言场景增强学生的语境理解。
-
利用 NotebookLM 从代码生成播客:一位用户讨论了尝试使用 NotebookLM 从代码片段生成播客的实验。
- 随着成员们探索各种生成技术,这展示了 NotebookLM 从多样化数据输入创建内容的通用性。
Nous Research AI Discord
-
LLM2CLIP 提升 CLIP 的文本处理能力:LLM2CLIP 论文利用大语言模型通过高效处理更长的描述(captions)来增强 CLIP 的多模态能力。
- 这种集成利用微调后的 LLM 来引导视觉编码器,显著提高了 CLIP 在跨模态任务中的性能。
-
Neural Metamorphosis 实现自变形网络:Neural Metamorphosis (NeuMeta) 引入了一种通过从连续权重流形(weight manifold)中采样来创建自变形神经网络的范式。
- 该方法允许为各种配置动态生成权重而无需重新训练,强调了流形的平滑性。
-
AgentInstruct 自动化大规模合成数据创建:AgentInstruct 框架从原始数据源生成了 2500 万个多样化的提示-响应对(prompt-response pairs),以促进 Generative Teaching。
- 在使用该数据集进行训练后,Orca-3 模型在 AGIEval 上的表现比之前的模型(如 LLAMA-8B-instruct 和 GPT-3.5-turbo)提高了 40%。
-
LLaVA-o1 增强视觉语言模型的推理能力:LLaVA-o1 为视觉语言模型引入了结构化推理,使其能够在复杂的视觉问答任务中进行自主的多阶段推理。
- LLaVA-o1-100k 数据集的开发为推理密集型基准测试的精度提升做出了显著贡献。
-
合成数据生成策略讨论:讨论强调了 合成数据生成 在训练鲁棒 AI 模型中的重要性,并引用了 AgentInstruct 等框架。
- 参与者强调了大尺度合成数据集在实现基准测试性能提升方面的作用。
GPU MODE Discord
-
在 PyTorch 中集成 Triton CPU 后端:分享了一个 GitHub Pull Request,旨在将 Triton CPU 作为 PyTorch 中的 Inductor 后端,目标是利用 Inductor-generated kernels 对新后端进行压力测试。
- 此次集成旨在评估 Triton CPU 后端的性能和鲁棒性,从而增强 PyTorch 内部的计算能力。
-
PyTorch FSDP 内存分配洞察:成员们讨论了在保存操作期间,FSDP 分配是如何发生在设备内存的
CUDACachingAllocator中,而非 CPU 上。- 未来的 FSDP 版本预计将改进分片技术,通过消除对参数进行 all-gathering 的需求来减少内存分配,发布目标定于今年年底或明年年初。
-
Liger Kernel 蒸馏损失的增强:针对在 Liger Kernel 中实现新的蒸馏损失函数提出了一个 GitHub issue,概述了支持各种对齐和蒸馏层的动机。
- 讨论强调了通过引入多样化的蒸馏层来改进模型训练技术的潜力,旨在提高性能和灵活性。
-
优化寄存器分配策略:讨论强调了寄存器分配中的溢出 (spills) 会严重影响性能,主张增加寄存器利用率以缓解此问题。
- 成员们探索了诸如定义和重用单个寄存器瓦片(tiles)以及平衡资源分配以最小化溢出的策略,特别是在添加额外的 WGMMAs 时。
-
解决 FP32 MMA 中的 FP8 对齐问题:发现了一个挑战,即 FP32 MMA 中的 FP8 输出线程片段所有权(thread fragment ownership)与预期输入不符,如此文档所述。
- 为了在不通过 warp shuffle 降低性能的情况下解决这种不匹配,对共享内存张量采用了静态布局置换(static layout permutation),以实现高效的数据处理。
Interconnects (Nathan Lambert) Discord
-
Runner H Beta 版发布,迈向 ASI:H Company 宣布发布 Runner H 的 Beta 版本,标志着超越当前缩放法则(scaling laws)、迈向人工超级智能 (ASI) 的重大进展。H Company 的推文强调了这一里程碑。
- 该公司强调,通过这次 Beta 版发布,他们不仅是在推出一款产品,还在开启 AI 发展的新篇章。
-
Pixtral 论文揭示先进技术:Sagar Vaze 讨论了 Pixtral 论文,特别引用了 第 4.2 节、第 4.3 节和附录 E。该论文深入探讨了与当前研究相关的复杂方法论。
- Sagar Vaze 提供了见解,指出这些详细讨论为小组当前的项目提供了宝贵的背景信息。
-
Runner H 在基准测试中超越 Qwen:如 WebVoyager 论文所述,Runner H 在使用 WebVoyager 基准测试时表现出优于 Qwen 的性能。
- 这一成功突显了 Runner H 通过创新的自动评估方法在现实场景评估中的优势。
-
树搜索方法的进展:一份最新报告强调了在 Jinhao Jiang 和 Zhipeng Chen 等研究人员的共同努力下,树搜索(tree search)技术取得了显著进展。
- 这些改进增强了大型语言模型(LLM)的推理能力。
-
探索 Q* 算法的基础:重新审视了 Q* 算法,引发了关于其在当前 AI 方法论中基础性作用的讨论。
- 成员们表达了怀旧之情,承认该算法对当今 AI 技术产生的深远影响。
Latent Space Discord
-
Cerebras 的 Llama 3.1 推理速度:Cerebras 声称其 Llama 3.1 405B 的推理速度达到 969 tokens/s,比中位数供应商基准快 10 倍以上。
- 批评者认为,虽然 Cerebras 在 Batch Size 为 1 的评估中表现出色,但在更大 Batch Size 下性能会有所下降,建议对比时应考虑这些差异。
-
OpenAI 增强语音功能:OpenAI 宣布在 chatgpt.com 上为付费用户推出语音功能更新,旨在让演示变得更容易。
- 此次更新允许用户通过演示学习发音,突显了对增强用户交互的持续关注。
-
Roboflow 获得 4000 万美元 B 轮融资:Roboflow 额外筹集了 4000 万美元,用于增强其在医疗和环境等各个领域的视觉 AI 应用开发工具。
- CEO Joseph Nelson 强调了他们的使命是赋能开发者有效地部署视觉 AI,并强调了在数字世界中“看见”的重要性。
-
关于小语言模型的讨论:社区辩论了小语言模型 (SLM) 的定义,建议指出 1B 到 3B 规模的模型属于小型。
- 共识是较大的模型不符合此分类,并指出了基于在消费级硬件上运行能力的区分。
LlamaIndex Discord
-
AIMakerspace 领导本地 RAG 工作坊:加入 AIMakerspace 于 11 月 27 日举办的活动,学习使用开源 LLM 构建本地 RAG 应用,重点关注 LlamaIndex Workflows 和 Llama-Deploy。
- 该活动提供实战培训和构建稳健本地 LLM 栈的深入见解。
-
LlamaIndex 在 Microsoft Ignite 上与 Azure 集成:LlamaIndex 在 #MSIgnite 上展示了其与 Azure 集成的端到端解决方案,涵盖 Azure OpenAI、Azure AI Embeddings 和 Azure AI Search。
- 鼓励参会者联系 @seldo 了解此全面集成的更多细节。
-
将聊天历史集成到 RAG 系统中:一位用户讨论了如何利用 Milvus 和 Ollama 的 LLM,通过自定义索引方法将聊天历史整合到 RAG 应用中。
- 社区建议修改现有的聊天引擎功能,以增强与其工具的兼容性。
-
使用 SQLAutoVectorQueryEngine 实现引用:提出了关于使用 SQLAutoVectorQueryEngine 获取行内引用及其与 CitationQueryEngine 潜在集成的咨询。
- 顾问建议将引用工作流分开,因为实现引用逻辑本身非常直接。
-
评估 RAG 系统中的检索指标:针对 RAG 系统中缺乏用于评估检索指标的 Ground Truth 数据表达了担忧。
- 社区成员被要求提供方法论或教程,以有效解决这一测试挑战。
tinygrad (George Hotz) Discord
-
tinygrad 0.10.0 发布,包含 1200 个 Commit:团队宣布发布 tinygrad 0.10.0,包含 1200 多个 Commit,重点在于最小化依赖。
- tinygrad 现在同时支持推理和训练,并立志构建硬件,近期已筹集资金。
-
ARM 测试失败及解决:用户报告了 aarch64-linux 架构上的测试失败,具体是在测试期间遇到了 AttributeError。
- 这些问题在不同架构上均可复现,潜在的解决方案包括在
test_interpolate_bilinear中集成x.realize()。
- 这些问题在不同架构上均可复现,潜在的解决方案包括在
-
Kernel Cache 测试修复:通过添加
Tensor.manual_seed(123)实现了对test_kernel_cache_in_action的修复,确保测试套件通过。- ARM 架构上仅剩一个问题,相关解决方案正在讨论中。
-
在 tinygrad 中调试 Jitted 函数:设置 DEBUG=2 会导致进程在底部行持续输出,表明其正在运行。
- tinygrad 中的 Jitted 函数仅执行 GPU Kernels,因此内部的 print 语句不会产生可见输出。
Cohere Discord
-
分词训练损害单词识别:一位成员指出,单词 ‘strawberry’ 在训练过程中被分词(tokenized),这干扰了其在 GPT-4o 和 Google’s Gemma2 27B 等模型中的识别,揭示了不同系统面临的类似挑战。
- 这一分词问题影响了模型准确识别某些单词的能力,引发了关于通过更好的训练方法来改进单词识别的讨论。
-
Cohere 研究工具 Beta 计划:Cohere 研究原型 Beta 计划 的报名将于今晚 东部时间午夜 截止,入选者可提前体验专为研究和写作任务设计的新工具。
- 鼓励参与者提供 详细反馈 以帮助塑造工具的功能,重点是创建复杂的报告和摘要。
-
配置 Command-R 模型语言设置:一位用户询问如何为 Command-R 模型 设置 Preamble,以确保使用 保加利亚语 回答,并避免与 俄语 术语混淆。
- 他们提到使用 API 请求构建器 进行自定义,表明模型响应中需要更清晰的语言区分。
OpenInterpreter Discord
-
开发分支面临稳定性问题:一位成员报告称,开发分支 (development branch) 目前处于 进行中状态,
interpreter --version显示为 1.0.0,表明 UI 和功能可能出现了退化。- 另一位成员自愿解决这些问题,并指出最后的提交记录为 9d251648。
-
寻求技能生成方面的帮助:Open Interpreter 用户请求在技能生成(skills generation)方面提供帮助,提到预期的文件夹为空,并寻求后续操作指导。
- 建议遵循与教学模型相关的 GitHub 指南,未来的版本计划整合此功能。
-
UI 简化收到褒贬不一的反馈:围绕最近的 UI 简化 展开了讨论,一些成员更喜欢之前的设计,表示对旧界面感到更舒适。
- 开发者确认了反馈,并询问用户是否更青睐旧版本。
-
Claude 模型的问题引发担忧:有报告指出 Claude 模型 出现故障;临时切换模型解决了问题,这引发了对 Anthropic 服务可靠性的担忧。
- 成员们询问这些问题是否在不同版本中持续存在。
-
Ray Fernando 在最新播客中探索 AI 工具:在 YouTube 视频 中,Ray Fernando 讨论了能增强构建过程的 AI 工具,重点介绍了 10 个助力快速构建的 AI 工具。
- 这集名为“10 个真正产生效果的 AI 工具”的视频为对工具利用感兴趣的开发者提供了宝贵的见解。
DSPy Discord
-
DSPy 引入 VLM 支持:新的 DSPy VLM 教程 现已发布,重点介绍了处于 Beta 阶段的 VLM 支持,用于从图像中提取属性。
- 该教程利用 网站截图 演示了有效的属性提取技术。
-
DSPy 与非 Python 后端的集成:成员报告称,将 DSPy 编译的 JSON 输出与 Go 集成时准确率有所下降,这引发了对 Prompt 处理复现的担忧。
- 有建议提出使用 inspect_history 方法来创建针对特定应用定制的模板。
-
DSPy 中的成本优化策略:讨论了 DSPy 如何通过 Prompt 优化 以及可能使用小语言模型作为代理来降低 Prompt 成本。
- 然而,对于 长上下文限制 存在担忧,需要采取上下文剪枝和 RAG 实现等策略。
-
长上下文 Prompt 的挑战:强调了在长文档解析中带有大量上下文的 Few-shot 示例效率低下的问题,并批评了对模型在大规模输入中保持连贯性的依赖。
- 提议包括将处理过程分解为更小的步骤,并最大限度地提高每个 Token 的信息量,以解决上下文相关的问题。
-
DSPy Assertions 与 MIRPOv2 的兼容性:针对即将发布的 2.5 版本中 DSPy Assertions 与 MIRPOv2 的兼容性提出了疑问,并参考了过去的兼容性问题。
- 这表明人们对这些功能在框架内将如何演变和集成持续关注。
OpenAccess AI Collective (axolotl) Discord
-
Mistral Large 引入 Pixtral 模型:社区成员表示有兴趣尝试最新的 Mistral Large 和 Pixtral 模型,并寻求经验丰富用户的专业建议。
- 讨论反映了正在进行的实验,以及对这些 AI 模型性能见解的渴求。
-
MI300X 训练现已投入运行:使用 MI300X 进行的训练现已投入运行,多项上游变更确保了性能的一致性。
- 一位成员强调了上游贡献在维持训练过程可靠性方面的重要性。
-
bitsandbytes 集成增强:有人对在不使用 bitsandbytes 时仍需在训练期间导入它的必要性提出了质疑,建议将其设为可选。
- 提出了一项建议,即实现一个上下文管理器来抑制导入错误,旨在提高代码库的灵活性。
-
Axolotl v0.5.2 发布:新的 Axolotl v0.5.2 已经发布,具有多项修复、增强的单元测试和升级的依赖项。
- 值得注意的是,该版本通过解决
pip install axolotl问题,修复了 v0.5.1 版本的安装问题,为用户提供了更顺畅的更新体验。
- 值得注意的是,该版本通过解决
-
Phorm Bot 弃用担忧:有人对 Phorm Bot 可能被弃用提出了疑问,有迹象表明它可能出现了故障。
- 成员们推测,该问题源于机器人在迁移到新组织后仍引用过时的仓库 URL。
Modular (Mojo 🔥) Discord
-
Max Graph 集成增强知识图谱:有人询问 Max Graph 是否可以增强传统的 Knowledge Graphs(知识图谱),将其作为 Agentic RAG tools 之一用于统一 LLM inference。
- Darkmatter 指出,虽然 Knowledge Graphs 充当数据结构,但 Max Graph 代表了一种计算方法。
-
MAX 提升图搜索性能:关于利用 MAX 提升图搜索性能的讨论显示,目前的能力需要将整个图复制到 MAX 中。
- 提出了一种潜在的变通方案,涉及将图编码为一维字节 Tensor,尽管内存需求可能会带来挑战。
-
区分图类型及其用途:一位用户指出了各种图类型之间的区别,指出 MAX computational graphs 与计算相关,而 Knowledge Graphs 存储关系。
- 他们进一步解释说,Graph RAG 利用知识图谱增强检索,而 Agent Graph 描述了 Agent 之间的数据流。
-
Max Graph 的 Tensor 依赖性受到关注:Msaelices 质疑 Max Graph 是否从根本上与 Tensor 绑定,并注意到其 API 参数受限于 TensorTypes。
- 这引发了在继续进行实现咨询之前查阅 API 文档的建议。
LLM Agents (Berkeley MOOC) Discord
-
Gemini Google AI 工作坊:参加于 PT 时间 11/26 下午 3 点举行的 Google AI 工作坊,重点讨论在 LLM Agents MOOC Hackathon 期间使用 Gemini 进行构建。活动包括 Gemini 的现场演示,以及与 Google AI 专家进行直接支持的互动问答。
- 参与者将深入了解 Gemini 以及 Google 的 AI 模型和平台,利用最新技术增强 Hackathon 项目。
-
第 10 讲公告:第 10 讲定于今日 PST 时间下午 3:00 举行,并提供直播以供实时参与。本节课将介绍 Foundation Models 开发中的重大更新。
- 所有课程材料,包括直播链接和作业,均可在课程网站上获取,确保核心资源的集中访问。
-
Percy Liang 的演讲:斯坦福大学副教授 Percy Liang 将发表题为“Foundation Models 时代的开源与科学”的演讲。他强调,尽管目前存在可访问性限制,但开源对于推动 AI 创新至关重要。
- Liang 强调了社区资源对于开发强大的开源模型的必要性,以促进该领域的共同进步。
-
实现非英语模型的 State of the Art:Tejasmic 询问了关于如何使非英语模型达到 State of the Art 性能的策略,特别是在数据点较少的语言中。
- 有建议提议将该问题提交至专门频道,工作人员正在那里积极审阅类似咨询。
Torchtune Discord
-
Flex Attention 块分数复制:一名成员报告了在尝试复制 Flex Attention 的
score_mod函数中的 Attention Scores 时出现错误,导致 Unsupported: HigherOrderOperator 变异错误。- 另一名成员确认了这一限制,并引用了 Issue 以获取更多详情。
-
Attention 分数提取技巧:成员们讨论了由于无法访问 SDPA 内部机制,使用 Vanilla Attention 复制 Attention Scores 所面临的挑战,并建议修改 Gemma 2 Attention 类可能提供一种变通方法。
- 有人分享了一个 GitHub Gist,详细介绍了一种在不使用 Triton Kernel 的情况下提取 Attention Scores 的技巧,尽管这偏离了标准的 Torchtune 实现。
-
Vanilla Attention 变通方案:据透露,由于缺乏对 SDPA 内部机制的访问,使用 Vanilla Attention 复制 Attention Scores 是不可行的,这引发了对替代方案的探索。
- 一名成员建议修改 Gemma 2 Attention 类可能会提供解决方案,因为它更易于进行 Hack 修改。
LAION Discord
-
LAION-DISCO-12M 发布,包含 1200 万个链接:LAION 宣布推出 LAION-DISCO-12M,这是一个包含 1200 万个公开 YouTube 样本链接及其元数据的集合,旨在支持通用音频和音乐的基础机器学习研究。该计划的更多详情见其博客文章。
- LAION 的推文中也强调了这一发布,重点介绍了该数据集在增强音频相关 Foundation Models 方面的潜力。
-
音频研究的元数据增强:LAION-DISCO-12M 集合中包含的元数据旨在促进音频分析领域 Foundation Models 的研究。
- 几位开发者对公告中强调的潜在用例表示兴奋,强调了在音频机器学习领域需要更好的数据。
Mozilla AI Discord
-
Transformer Lab Demo 今日开启:今天的 Transformer Lab Demo 展示了 Transformer 技术 的最新进展。
- 鼓励成员加入并参与讨论,以探索这些进步。
-
元数据过滤(Metadata Filtering)会议提醒:一场关于 元数据过滤 的会议定于明天举行,由 #1262961960157450330 频道的专家主持。
- 参与者将获得有关 AI 中有效数据处理实践的见解。
-
Refact AI 讨论自主 AI Agent:Refact AI 将于本周四介绍如何构建 自主 AI Agent 以端到端地执行工程任务。
- 他们还将回答与会者的提问,提供互动学习的机会。
Alignment Lab AI Discord 没有新消息。如果该服务器沉寂时间过长,请告知我们,我们将将其移除。
LLM Finetuning (Hamel + Dan) Discord 没有新消息。如果该服务器沉寂时间过长,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该服务器沉寂时间过长,请告知我们,我们将将其移除。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该服务器沉寂时间过长,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该服务器沉寂时间过长,请告知我们,我们将将其移除。
第 2 部分:按频道详细摘要和链接
完整的频道细分内容已为邮件格式进行截断。
如果您喜欢 AInews,请分享给朋友!提前致谢!