ainews-deepseek-r1-claims-to-beat-o1-preview-and
DeepSeek-R1 声称超越了 o1-preview,并且将会开源。
DeepSeek 发布了 DeepSeek-R1-Lite-Preview,这是一款开源推理模型,在数学基准测试中达到了 o1-preview 级别的性能。该模型具有透明的思维过程,在实时问题解决方面展现出巨大潜力。
英伟达 (NVIDIA) 报告第三季度营收达到创纪录的 351 亿美元,其中数据中心业务同比增长 112%,这主要受到 Hopper 和 Blackwell 架构 的推动,后者提供了 2.2 倍的性能提升。
Google DeepMind 推出了 AlphaQubit,这是一个量子计算系统,旨在改进纠错能力,其表现优于领先的解码器,尽管在扩展性和速度方面仍面临挑战。AI 社区将继续关注 推理模型、基准测试 以及 量子纠错 领域的进展。
Whalebros 就够了。
2024年11月20日至11月21日的 AI 新闻。我们为您检查了 7 个 subreddits、433 个 Twitter 账号 和 30 个 Discord(217 个频道和 1837 条消息)。预计节省阅读时间(按 200wpm 计算):197 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
自从 o1 发布以来(我们的报道见此处、此处和此处),“开源”复现的竞赛就已拉开帷幕。两个月后,在提及 Nous Forge Reasoning API 和 Fireworks f1 的同时,DeepSeek 似乎已经做出了第一次令人信服的尝试,它 1) 拥有比 o1-preview 更好 的基准测试结果,并且 2) 拥有公开可用的 Demo 而不是等待名单。
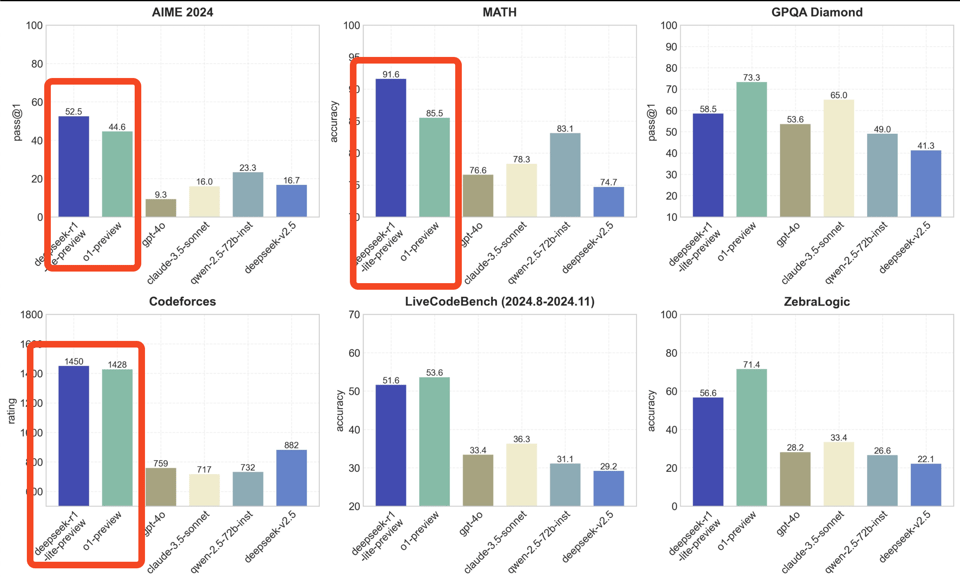
在基准测试方面,它并没有全面超越 o1,但在重要的数学基准测试上表现出色,并且除了 GPQA Diamond 之外,在所有其他测试上至少比同类产品更好。
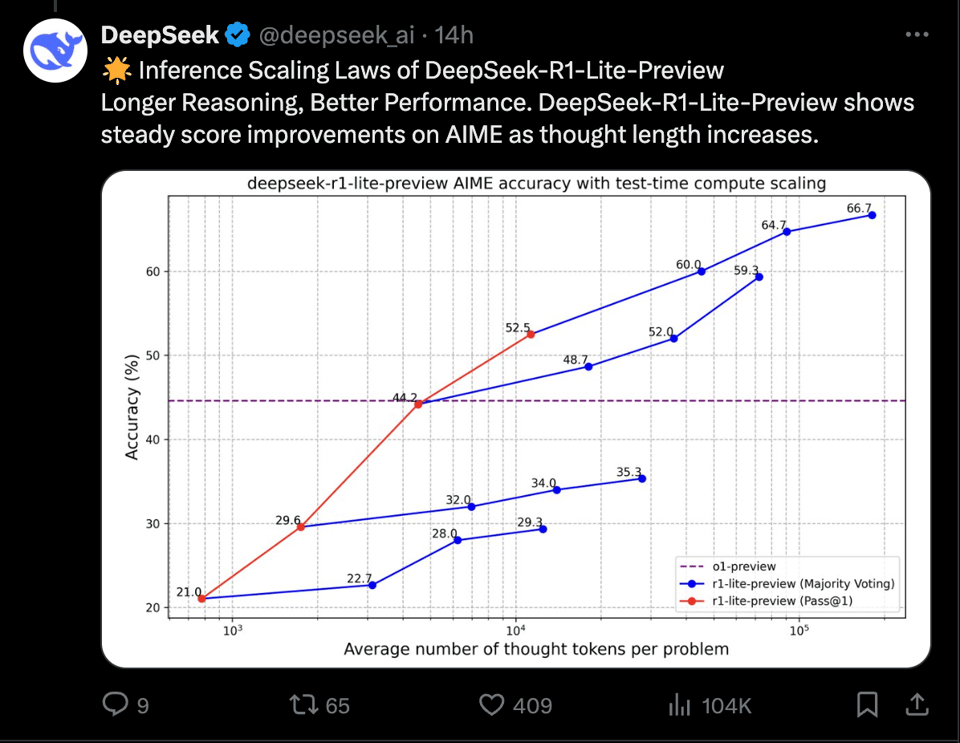
同样重要的是,他们似乎复现了 OpenAI 提到的类似的推理时间扩展(inference-time-scaling)性能提升,但这次带有了实际的 x 轴:
至于 “R1-Lite” 的命名,传闻(基于微信公告)它是基于 DeepSeek 现有的 V2-Lite 模型,该模型仅是一个具有 2.4B 激活参数的 16B MoE —— 这意味着如果他们能够成功扩大规模,“R1-full” 将是一个绝对的怪物。
一个值得注意的结果是,它在 Yann LeCun 钟爱的 7 档齿轮问题上表现(虽然不一致)良好。
AI Twitter 摘要
所有摘要均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
1. NVIDIA 财务更新与市场洞察
-
NVIDIA 报告第三季度创纪录营收:@perplexity_ai 讨论了来自 NVIDIA 第三季度财报电话会议的见解,强调了 351 亿美元的创纪录营收,较上一季度增长 17%。主要增长驱动力包括强劲的数据中心销售以及对 NVIDIA Hopper 和 Blackwell 架构的需求。该公司预计将继续增长,第四季度预测营收为 375 亿美元。
-
财报电话会议中的详细表现:来自 @perplexity_ai 的另一份更新进一步指出,数据中心营收达到 308 亿美元,同比增长 112%。据报道,Blackwell 架构比 Hopper 提供了 2.2 倍的性能提升。
2. DeepSeek-R1-Lite-Preview:新型推理模型进展
-
DeepSeek-R1-Lite-Preview 发布:@deepseek_ai 对发布 DeepSeek-R1-Lite-Preview 感到兴奋,该模型在 MATH 基准测试上提供了 o1-preview 级别性能,并具有透明的思考过程。该模型的目标是尽快推出开源版本。
-
DeepSeek-R1-Lite-Preview 的评估:多位用户(如 @omarsar0)讨论了它的能力,包括数学推理能力的提升以及在代码任务中的挑战。尽管存在一些小瑕疵,该模型在实时问题解决和推理方面展现出了潜力。
3. AlphaQubit 在量子计算方面的进展
-
AlphaQubit 与 Google 的合作:@GoogleDeepMind 介绍了 AlphaQubit,这是一个旨在提高量子计算纠错能力的系统。该系统表现优于领先的算法解码器,并在规模化场景中显示出潜力。
-
量子纠错中的挑战:尽管取得了这些进展,来自 Google DeepMind 的额外见解指出,在扩展和速度方面仍存在持续性问题,强调了使量子计算机更加可靠的目标。
4. GPT-4o 的发展与 AI 创意增强
-
GPT-4o 增强的创意写作:@OpenAI 指出了 GPT-4o 在生成更自然、更具吸引力的内容方面的更新。用户评论(如来自 @gdb)强调了在处理文件和提供更深层见解方面的改进。
-
Chatbot Arena 排名更新:@lmarena_ai 分享了对 ChatGPT-4o 登上榜首的兴奋,它在创意写作和技术性能方面有显著提升,超越了 Gemini 和 Claude 模型。
5. AI 实现与工具
-
LangChain 和 LlamaIndex 系统:@LangChainAI 宣布了平台的更新,重点关注可观测性、评估和 Prompt Engineering。他们强调无缝集成,为开发者提供完善 LLM 应用的全面工具。
-
AI 游戏开发课程:@togethercompute 与行业领导者合作推出了一门关于构建 AI 驱动游戏的课程。它专注于集成 LLM 以创建沉浸式游戏。
6. 迷因/幽默
-
高中 AI 怀旧:@aidan_mclau 幽默地反思了使用 AI 完成哲学作业的经历,展现了对 AI 教育用途的轻松调侃。
-
国际象棋迷因:@BorisMPower 参与了一个国际象棋迷因话题,思考游戏背景下的战略举措和决策。
AI Reddit 摘要
/r/LocalLlama 摘要
主题 1. DeepSeek R1-Lite 在数学基准测试中追平 o1-preview,开源版即将推出
- DeepSeek-R1-Lite 预览版正式发布 (Score: 189, Comments: 64): DeepSeek 发布了其全新的 R1 系列推理模型,该模型采用 reinforcement learning(强化学习)训练,具备强大的反思和验证能力,其 chain of thought(思维链)推理长度可达数万字。该模型在数学、代码和复杂逻辑推理任务中的表现与 o1-preview 相当,并在 chat.deepseek.com 提供了透明的推理过程展示。
- DeepSeek-R1-Lite 目前仍处于开发阶段,官方公告确认其目前仅限网页端使用,暂不提供 API 访问。根据其 推文 透露,公司计划开源完整的 DeepSeek-R1 模型,发布技术报告,并部署 API 服务。
- 初步的用户测试显示,该模型在数学方面表现出色,具有详尽的推理步骤,尽管部分用户注意到其响应时间比 o1-preview 更长。根据 DeepSeek 之前的发布记录,该模型被推测拥有 15B 参数。
- 社区反应凸显了中国 AI 实验室在 GPU 受限的情况下取得的快速进展,用户指出该模型透明的思考过程可能惠及开源社区的发展。多位用户证实了其在 AIME 和 MATH 基准测试中的强劲表现。
- 中国 AI 初创公司阶跃星辰 (StepFun) 凭借其全新的 1 万亿参数 MOE 模型在 livebench 排名靠前 (Score: 264, Comments: 74): StepFun(阶跃星辰)开发了一款 1 万亿参数的 Mixture-of-Experts (MOE) 模型,在实时 AI 模型排行榜 livebench 上取得了极具竞争力的分数。原始资料中未披露该模型的具体性能指标和技术细节。
- Livebench 评分显示,相对于其庞大的体量,该模型目前的表现不及预期。用户注意到它被更小的模型如 o1 mini(估计为 70-120B 参数)击败,且数学得分尤其低。
- 该模型似乎处于早期训练阶段,讨论中提到的“Step 2”可能暗示其正处于第二阶段训练。用户推测其表现平平是由于严重训练不足,而非架构限制。
- 讨论集中在该模型的 MoE 架构和部署策略上,专家指出每个 transformer 层都需要自己的一套专家系统,这导致在推理和训练期间产生大量的 GPU-to-GPU 通信需求。
{kind=link}
主题 2:复杂的开源 LLM 工具:研究助手与记忆框架
- 我创建了一个真正能做研究的 AI 研究助手!给它任何主题,它会搜索网页、抓取内容、保存来源,并为你提供完整的研究文档 + 摘要。使用 Ollama (免费) - 只需提问,让它开始工作!无 API 成本,开源,本地运行! (Score: 487, Comments: 76): Automated-AI-Web-Researcher 是一款基于 Python 的工具,它利用 Ollama 和本地 LLM 进行全面的网络研究。它可以根据单个查询自动生成多达 5 个特定的研究重点,持续搜索和抓取内容并保存来源,最后创建包含摘要的详细研究文档。该项目已在 GitHub 上开源,完全在本地运行,支持 phi3:3.8b-mini-128k-instruct 或 phi3:14b-medium-128k-instruct 等模型,具备暂停/恢复功能,并允许用户针对收集的研究内容进行追问。
- 用户反馈在不同 LLM 上的成功率各异——虽然有些人在使用 Llama3.2-vision:11b 和 Qwen2.5:14b 时遇到了生成空摘要的问题,但另一些人成功使用了 mistral-nemo 12B,在 16GB VRAM 下实现了 38000 上下文长度,CPU 占用率为 3%,GPU 占用率为 97%。
- 社区提出了一些技术建议,包括忽略 robots.txt、增加对 OpenAI API 兼容性的支持(后来通过 PR 实现),以及使用 “lib” 文件夹重构代码库,并利用 pydantic 或 omegaconf 等工具进行规范的配置管理。
- 关于该工具用途的讨论强调了其在寻找和总结真实研究方面的价值,而非仅仅生成内容,同时也对来源验证和网页抓取信息的真实准确性提出了担忧。
-
Agent Memory (Score: 64, Comments: 11): 多个 GitHub 项目对 LLM Agent 内存框架进行了对比,关键实现包括 Letta(基于 MemGPT 论文)、Memoripy(支持 Ollama 和 OpenAI)以及 Zep(维护时序知识图谱)。多个框架通过 Ollama 和 vLLM 支持本地模型,尽管许多框架默认假设具有 GPT 访问权限,且对开源替代方案的兼容程度各不相同。
- 对比涵盖了活跃项目如 cognee(用于文档摄取)和 MemoryScope(具有内存整合功能),以及开发资源如 LangGraph Memory Service 模板和用于 RAG 实现的 txtai,大多数框架通过 LiteLLM 等工具提供 OpenAI 兼容 API 支持。
- 基于向量的内存系统使用邻近度和重排序(reranking)来确定相关性,这与 Kobold 或 NovelAI 中使用的简单关键词激活系统形成对比。向量方法在空间上映射概念(例如,“汉堡王”比“英格兰国王”更接近食物相关的术语),并利用小型神经网络或直接通过 AI 评估进行重排序。
- 内存框架的主要区别在于它们处理上下文注入的方式——从自动化到手动方法不等——更复杂的系统结合了知识图谱和决策树。内存处理可能会变得资源密集,有时消耗的 Token 甚至超过了实际对话。
- LLM 内存系统领域仍处于实验阶段,尚未建立最佳实践,涵盖了从基础的设定集(lorebook)风格实现到复杂的上下文感知解决方案。简单的系统需要更多的人工监督来纠正错误,而复杂的系统在应对上下文错误方面表现出更强的鲁棒性。
主题 3. 硬件与浏览器优化:Pi GPU 加速与 WebGPU 实现
- LLM 硬件加速——在 Raspberry Pi 上(使用低成本 Pi 作为基础计算机的高端 AMD GPU) (Score: 53, Comments: 18): Raspberry Pi 配置可以通过 Vulkan 图形处理运行具有 AMD GPU 加速的 Large Language Models (LLMs)。这种硬件设置将 Raspberry Pi 的性价比与高端 AMD GPU 的处理能力相结合。
- 使用 6700XT GPU 配合 Vulkan 后端实现了 40 t/s 的 Token 速率,而使用 RTX 3060 配合 CUDA 的速率为 55 t/s。ARM 平台上缺乏 ROCm 支持显著限制了性能潜力。
- 一套完整的 Raspberry Pi 设置成本约为 383 美元(不含 GPU),而同类的 x86 系统(如 ASRock N100M)成本为 260-300 美元。Intel N100 系统仅多消耗 5W 功率,同时提供更好的兼容性和性能。
- 用户指出,AMD 可能会开发一种专用产品,在类 NUC 的外形尺寸中结合基础 APU 和高 VRAM GPU。即将发布的 Strix Halo 可能会测试市场需求,尽管像双 P40(500 美元)这样的替代方案仍具竞争力。
- 由 Qwen2.5-Coder 驱动的浏览器内网站生成器 (Score: 55, Comments: 8): 一个在浏览器中运行的 AI 网站生成器,使用 WebGPU、OnnxRuntime-Web、Qwen2.5-Coder 和 Qwen2-VL 从文本、图像和语音输入生成代码,尽管由于性能限制,目前仅上线了文本转代码功能。该项目实现了 Moonshine 用于语音转文本,并在 GitHub 和 Huggingface 上提供了集成代码示例,目前性能受限于 GPU 能力,主要在 Mac 系统上进行了测试。
- 开发者详细介绍了模型转换中的挑战,通过导出文档和自定义 Makefile 分享了他们的流程,并指出混合数据类型和内存管理问题使该项目变得尤为困难。
- 社区反馈显示了在 Linux 和 NVIDIA RTX 硬件上测试该系统的兴趣,同时也有用户反映由于背景颜色相近,在 iPhone 设备上存在 UI 对比度问题。
主题 4. 模型架构:GPT-4、Gemini 及其他闭源模型分析
- 闭源模型参数量推测 (Score: 52, Comments: 12): 该帖子分析了闭源 LLM 的参数量,认为 GPT-4 Original 拥有 280B 激活参数和 1.8T 总参数,而 GPT-4 Turbo 和 GPT-4o 等更新版本的激活参数量逐渐减少(分别约为 ~93-94B 和 ~28-32B)。分析将模型架构与定价联系起来,将微软的 Grin MoE 论文与 GPT-4o Mini(6.6B-8B 激活参数)挂钩,并将 Gemini Flash 版本(8B、32B 和 16B 稠密)与 Qwen 等模型以及 Huyuan 和 Yi Lightning 的架构进行了对比。
- Qwen 2.5 的性能参数比支持了现代模型激活参数更小的理论,特别是在 MoE architecture 和闭源研究取得进展的情况下。讨论表明 Claude 的效率可能低于 OpenAI 和 Google 的模型。
- Gemini Flash 的 8B 参数量可能包含了视觉模型,使得核心语言模型约为 7B parameters。该模型在此规模下的性能被认为非常出色。
- 社区估计 GPT-4 Turbo 拥有 ~1T 参数(100B 激活),GPT-4o 拥有 ~500B(50B 激活),而 Yi-Lightning 根据其低廉的定价和推理能力,规模可能更小。Step-2 由于定价较高(输入 $6/M,输出 $20/M),估计规模更大。
- Judge Arena 排行榜:将 LLM 作为评估者的基准测试 (Score: 33, Comments: 14): Judge Arena Leaderboard 旨在测试 LLM 评估和评判其他 AI 输出的能力。由于帖子正文缺乏背景信息,本摘要无法包含有关方法论、指标或参与模型的具体细节。
- Claude 3.5 Sonnet 最初在 Judge Arena 排行榜上领先,但随后的更新显示出显著的波动,7B models 在开源条目中升至顶级位置。在 1197 votes 后,排名显示 ELO spread 从约 400 分压缩至约 250 分。
- 社区成员质疑结果的有效性,特别是关于 Mistral 7B (v0.1) 表现优于 GPT-4、GPT-3.5 和 Claude 3 Haiku 的情况,高误差范围(约 100 ELO points)被认为是可能的解释。
- 批评者指出了 judgment prompt 的局限性,认为其缺乏具体的评估标准和深度,而要求忽略回复长度的指令可能会通过“粉红大象效应”反过来影响评估者。
{kind=link}
其他 AI Subreddit 摘要
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
主题 1. 实时 AI 面部识别演示引发隐私警报
- 这位荷兰记者演示了实时 AI 面部识别技术,识别出了正在与之交谈的人。 (Score: 2523, Comments: 304): 荷兰记者通过在现场对话中识别个人,展示了实时面部识别 AI 的能力。没有提供关于所使用的具体技术或实现的额外背景或技术细节。
- 获赞最高的评论强调了隐私担忧,建议“不要在网上任何地方发布附带真实姓名的照片”,获得了 457 个赞。多位用户讨论了继续佩戴口罩以及规避面部识别的方法。
- 讨论显示这可能使用了 Pimeyes 或类似技术,用户指出 Clearview AI 拥有更先进的能力,可以“在音乐会的人群中找到你的脸”。几位用户指出,演示可能涉及第二个人进行手动搜索。
- 用户辩论了社会影响,一些人称其为“对民主和自由的威胁”,而另一些人则讨论了诸如汽车销售之类的实际应用。对话包括对政府监控和数据隐私的担忧,特别是提到中国和其他国家。
主题 2. CogVideoX 1.5 图生视频:质量与性能的权衡
- CogvideoX 1.5 img2vid 对比 - BF16 vs FP8 (Score: 165, Comments: 49): CogVideoX 1.5 帖子缺乏足够的上下文或内容,无法生成关于 BF16 和 FP8 实现对比的有意义技术摘要。帖子正文中未提供分析这些数值格式之间质量差异的细节。
- 性能指标显示出显著差异:在 RTX 3060 12GB 上,生成 1360x768 分辨率的 24 帧,BF16 耗时 12分57秒,而 FP8 仅需 7分57秒。由于 OOM 错误,BF16 需要 CPU offload,但能提供更稳定的结果。
- CogVideoX 1.5 面临量化挑战,无法在 FP16 下运行。在可用选项中,TorchAO FP6 提供了最佳质量结果,而 FP8DQ 和 FP8DQrow 由于支持 FP8 scaled matmul,在 RTX 4090 上表现出更快的性能。
- 在 Windows 上安装需要使用 TorchAO v0.6.1 进行特定设置,并修改
base.h文件中的代码,将FragM定义更改为Vec<unsigned int, 1>。
Theme 3. 10 个 AI Agent 实时协作创作小说
- 10 个自主 AI Agent 实时创作小说 (Score: 277, Comments: 153): 10 个自主 AI Agent 实时协作创作一部小说,尽管帖子正文中未提供有关过程、实现或结果的更多细节。该概念暗示了一项多 Agent 创意写作和 AI 协作的实验,但由于缺乏进一步背景,无法总结具体的技术细节。
- 用户对 AI 生成的长篇内容表示出明显的怀疑,许多人指出 ChatGPT 在超过几页后就难以保持连贯性,并且经常遗忘情节要点和角色。获 178 个赞 的热门评论强调了这一局限性。
- 作者解释了他们维持叙事连贯性的解决方案:通过一个基于文件的协作系统,多个 Agent 访问全局地图、内容摘要和运行变更日志,而不是依赖于单个上下文窗口。该系统目前正处于使用 Qwen 2.5 进行准备和结构化的阶段。
- 几位用户辩论了 AI 生成小说的艺术价值和目的,认为文学从根本上是关于表达人类经验和建立人类联系。批评者指出,像 ChatGPT 和 Claude 这样的 AI 模型可能会避开让小说变得有趣的争议性话题。
{kind=link}
Theme 4. StepFun 的 1T 参数模型在 LiveBench 排名上升
-
中国 AI 初创公司 StepFun 的新型 1 万亿参数 MOE 模型在 LiveBench 排名靠前 (Score: 29, Comments: 0): StepFun(一家中国 AI 初创公司)开发了一个 1 万亿参数的混合专家 (MOE) 模型,在 LiveBench 上名列前茅。该模型的表现展示了中国公司在大规模 AI 模型开发领域日益增强的竞争力。
-
Microsoft CEO 表示,与其说 AI Scaling Laws 撞墙了,不如说我们正看到推理时 (inference) 计算的新 Scaling Law 出现 (Score: 99, Comments: 40): Microsoft CEO 讨论了关于 AI Scaling Laws 的观察,指出与其说遇到了计算限制,不如说有证据表明专门针对推理时 (test-time inference) 计算出现了新模式。帖子正文缺乏具体细节或引用,限制了对该观察的声明或支持证据的进一步分析。
- 讨论表明,推理时计算涉及允许模型“思考”更长时间并对输出进行迭代,而不是接受第一反应,其准确率随思考时间呈对数级增长。这代表了除传统训练计算缩放之外的第二个缩放因子。
- 包括 Pitiful-Taste9403 在内的几位用户将此解释为参数缩放 (parameter scaling) 已达极限的证据,导致公司将推理优化作为 AI 进步的替代路径。
- “Scaling Law”一词引发了辩论,用户将其与摩尔定律 (Moore’s Law) 进行比较,认为它更多是一种趋势而非基本定律。一些人对这些发展对普通人的经济影响表示怀疑。
{kind=link}
AI Discord Recap
O1-mini 对“摘要之摘要”的总结
主题 1. 定制化模型部署占据核心地位
-
在 Hugging Face 上部署定制化 AI 模型:开发者现在可以使用
handler.py文件在 Hugging Face 上部署量身定制的 AI 模型,从而实现自定义的前处理和后处理。- 这一进展利用 Hugging Face endpoints 增强了模型的灵活性,并使其能够更好地集成到各种应用程序中。
-
DeepSeek-R1-Lite-Preview 性能比肩 OpenAI 的 o1-Preview:DeepSeek 发布了 R1-Lite-Preview,在 AIME 和 MATH 基准测试中达到了 o1-preview 级别的性能。
- 该模型不仅反映了 OpenAI 的进步,还引入了可实时访问的透明推理过程。
-
腾讯混元模型微调现已开放:用户可以通过 GitHub 仓库和官方 Demo 等资源微调 腾讯混元模型 (Tencent Hunyuan model)。
- 这为各种 NLP 任务提供了更强的定制化能力,扩展了模型的适用性。
主题 2. AI 模型性能与优化飞速发展
-
SageAttention2 使推理速度翻倍:SageAttention2 技术报告 揭示了一种 4-bit 矩阵乘法方法,在 RTX40/3090 GPU 上实现了比 FlashAttention2 快 2 倍的加速。
- 这项创新可以作为无缝替换方案,在不牺牲准确性的情况下显著加速推理 (inference)。
-
GPT-4o 获得创意提升和文件处理增强:OpenAI 更新了 GPT-4o,提升了其创意写作能力,并改进了文件处理以获得更深刻的见解。
- 改进后的模型在聊天机器人竞赛的编程 (coding)和创意写作等类别中重返榜首。
-
关于通过模型量化提升性能的讨论:用户对量化 (quantization)对模型性能产生的负面影响表示担忧,相比量化版本更倾向于原始模型。
- 建议包括要求 OpenRouter 等提供商进行更清晰的信息披露,并探索修改评估库以适配剪枝模型。
主题 3. 创新 AI 研究开辟新路径
-
ACE 方法增强模型控制:EleutherAI 引入了 ACE (Affine Concept Editing) 方法,将概念视为仿射函数,以更好地控制模型响应。
- 在 Llama 3 70B 等模型上的测试表明,ACE 在处理有害和无害提示词的拒绝行为方面优于以往技术。
-
Scaling Laws 揭示低维能力空间:一篇新论文指出,语言模型性能受低维能力空间的影响比单纯的多维扩展更大。
- 来自 Apollo 的 Marius Hobbhahn 倡导推进评估科学,强调严谨的模型评估实践。
-
Generative Agents 模拟超过 1,000 名真实个体:一种新型架构有效地模拟了 1,052 名真实人类的态度和行为,在综合社会调查 (General Social Survey) 中达到了 85% 的准确率。
- 这减少了不同种族和意识形态群体之间的准确性偏差,为探索社会科学中的个人和集体行为提供了强大的工具。
主题 4. AI 工具集成与社区支持蓬勃发展
-
Aider 的安装难题通过强制重装解决:遇到 Aider 安装问题(特别是 API keys 和环境变量问题)的用户发现,通过执行强制重装可以成功解决。
- 该方案简化了设置流程,使 DeepSeek-R1-Lite-Preview 和其他模型的集成更加顺畅。
-
LM Studio 结合云端方案应对硬件限制:成员们讨论了在有限硬件上运行 DeepSeek v2.5 Lite 的问题,强调需要至少 24GB VRAM 的 GPU。
- 云端硬件租赁被视为具有成本效益的替代方案,提供高速模型访问,且不受本地硬件限制。
-
Torchtune 的自适应批处理优化 GPU 利用率:在 Torchtune 中实现 adaptive batching 旨在通过动态调整 batch sizes 来防止 OOM errors,从而最大化 GPU utilization。
- 建议将此功能作为 flag 集成到未来的 recipes 中,以增强训练效率和资源管理。
主题 5. 前沿 AI 发展应对多样化挑战
-
LLMs 在没有显式提示的情况下表现出内在推理能力:研究表明,通过调整解码过程,large language models (LLMs) 可以在没有显式 prompting 的情况下展示出类似于 chain-of-thought (CoT) 的推理路径。
- 通过调整以考虑 top-$k$ alternative tokens,揭示了 LLMs 固有的推理能力,减少了对手动 prompt engineering 的依赖。
-
Perplexity AI 在 API 挑战中推出购物功能:Perplexity AI 推出了新的 Shopping 功能,引发了关于其仅限美国市场的讨论,同时用户正面临 API response consistency 的问题。
- 尽管是 Pro 用户,一些成员仍对限制表示沮丧,导致对 ChatGPT 等替代方案的依赖增加。
-
OpenRouter 解决模型描述和缓存澄清问题:用户发现 OpenRouter 上 GPT-4o 模型描述存在差异,促使官方快速修复了 model cards。
- 用户寻求关于不同供应商之间 prompt caching 策略的澄清,并对 Anthropic 和 OpenAI 的协议进行了比较。
第一部分:Discord 高层级摘要
HuggingFace Discord
-
现在可以部署自定义 AI 模型:一位成员发现可以使用
handler.py文件在 Hugging Face 上部署自定义 AI models,从而实现量身定制的模型前后处理。- 该过程涉及指定请求和响应的处理方法,通过 Hugging Face endpoints 增强自定义能力。
-
发布关于 AI 安全见解的新论文:Redhat/IBM 的 AI 研究人员发表了一篇论文,探讨了公开可用 AI 模型的安全影响,重点关注风险和生命周期管理。
- 该论文概述了提高开发者和用户安全性的策略,旨在 AI 社区内建立更标准化的实践。查看论文。
-
自动化 AI 研究助手问世:一个使用本地 LLMs 构建的 Automated AI Researcher 被创建,用于根据用户查询生成研究文档。
- 该系统利用网页抓取来汇编信息并生成与主题相关的摘要和链接,使研究更加便捷。
-
LangGraph 学习倡议:用户
richieghost发起了围绕 LangGraph 的学习,讨论了其在社区中的应用和发展。- 这突显了人们对在 AI 模型中集成基于图的技术的持续兴趣。
-
Ada 002 的语义搜索挑战:使用 OpenAI Ada 002 的 Semantic search 会优先考虑主导话题,导致不太突出但相关的句子排名较低。
- 用户正在寻求 semantic search 的替代方案,以提高信息提取的有效性。
Interconnects (Nathan Lambert) Discord
-
o1 发布传闻:有关 OpenAI o1 模型 即将发布的传言甚嚣尘上,可能会与 DevDay Singapore 同步,尽管这些传闻尚未得到证实。
- 一位成员指出,“周三发布会很奇怪”,这凸显了尽管存在不确定性,社区仍保持着高度的期待。
-
DeepSeek 的 RL 驱动:围绕 DeepSeek Prover 的讨论揭示了人们对其 reinforcement learning(强化学习)应用的兴趣,尽管在模型大小和性能方面存在挑战,成员们仍期待可能发布的论文。
- 社区正在考虑由于这些性能障碍而导致完整发布推迟的可能性。
-
GPT-4o 取得进展:OpenAI 宣布了 GPT-4o 的更新,增强了其创意写作能力和文件处理能力,这使其在聊天机器人竞赛的创意写作和编程等性能类别中重返巅峰。
- 此次更新强调了 GPT-4o 在相关性和可读性方面的提升,详见 OpenAI 官方推文。
-
LLM 学习循环:最近的研究见解表明,LLM 记忆训练样本的方式会显著影响其泛化能力,模型在记忆之前先理解概念有助于更好地预测测试准确率。
- Katie Kang 分享说,这种方法允许仅根据训练动态来预测测试结果。
-
NeurIPS NLP 被否决:有人对 NeurIPS D&B 审稿人 驳回专注于 韩语 LLM 评估 的项目表示担忧,理由是中文领域已经存在类似的工作。
- 社区成员认为每种语言都需要定制化的模型,并强调了 NLP 发展 中包容性的重要性,正如 Stella Biderman 的推文 所强调的那样。
Unsloth AI (Daniel Han) Discord
-
LLM 微调技巧:一位用户利用 16-bit 版本 成功将 Llama 3.1 导出到 Hugging Face 用于 本地项目,以增强构建 RAG 应用的性能。
- 成员们建议使用 16-bit 版本 来优化 fine-tuning 能力,确保模型开发过程中的资源管理更加高效。
-
SageAttention2 加速推理:SageAttention2 技术报告 介绍了一种 4-bit 矩阵乘法 方法,其速度比 FlashAttention2 快 2 倍。
- 凭借对 RTX40/3090 硬件的支持,SageAttention2 可作为 FlashAttention2 的直接替代方案,在不损失指标保真度的情况下增强 推理加速。
-
训练 Llama 模型:多位成员分享了训练不同 Llama 模型 的经验,并指出根据 模型参数 和 数据集大小,成功程度各不相同。
- 建议包括从基础模型开始,并调整 训练步数 以获得最佳 性能。
-
通过多 GPU 训练增强性能:用户正在探索 Unsloth 的 多 GPU 训练 功能,目前该功能尚未推出,但预计很快发布。
- 讨论了利用 Llama Factory 管理多个 GPU 等策略,以为即将推出的功能做准备。
aider (Paul Gauthier) Discord
-
Aider 安装挑战已解决:用户在 Aider 的安装过程中遇到了问题,特别是关于 API keys 和环境变量的设置,导致部分用户尝试重新安装组件。
- 一位用户报告称,执行 force reinstall(强制重装)成功解决了安装难题。
-
DeepSeek 性能令人印象深刻:DeepSeek-R1-Lite-Preview 在 AIME 和 MATH 基准测试中的表现与 o1-preview 持平,且与之前的模型相比,响应速度更快。
- 该模型透明的推理过程增强了其在编程任务中的有效性,允许用户实时观察其思考过程。
-
对 OpenRouter 模型质量的担忧:用户对 OpenRouter 使用开源模型的量化版本表示不满,对其在 Aider Leaderboard 上的表现提出质疑。
- 用户呼吁在排行榜上发布更清晰的警告,说明使用 OpenRouter 的量化模型时可能出现的性能差异。
-
讨论模型量化的影响:量化会对模型性能产生负面影响,导致用户更倾向于选择原始模型而非量化版本。
- 用户建议 OpenRouter 应当公开具体的模型版本,以便准确设定性能预期。
-
了解 Aider 的聊天模式:成员们讨论了各种 Aider 聊天模式的效果,强调将 o1-preview 作为 Architect,并配合 DeepSeek 或 o1-mini 作为 Editor 使用可以获得最佳效果。
- 一位用户指出,Sonnet 在处理日常任务时表现异常出色,且不需要复杂的配置。
Eleuther Discord
-
通过仿射编辑实现 ACE 模型控制:作者介绍了一种新的 ACE (Affine Concept Editing) 方法,将概念视为仿射函数,以增强对模型响应的控制。ACE 能够将激活值投影到超平面上,在 Gemma 的测试中展示了在管理模型行为方面更高的精确度。
- ACE 在包括 Llama 3 70B 在内的十个模型上进行了评估,在处理有害和无害提示词的拒绝行为控制方面取得了优异效果。该方法超越了以往的技术,为引导模型行为提供了更可靠的策略。
-
潜动作推动逆动力学:一位用户询问了关于 latent actions(潜动作)和 inverse dynamics models(逆动力学模型)的顶级论文,表示对这些领域内最前沿的研究感兴趣。讨论强调了相关文献对于推进当前 AI 方法论的重要性。
- 虽然没有引用具体的论文,但对话强调了探索 latent actions 和 inverse dynamics models 以突破现有 AI 框架界限的重要性。
-
缩放定律揭示能力维度:一篇新发表的论文 Understanding How Language Model Performance Varies with Scale 提出了一种基于约 100 个公开模型的缩放定律(Scaling Laws)观察方法。作者认为,语言模型的性能更多地受到低维能力空间的影响,而不仅仅是在多个尺度上进行训练。
- Apollo 的 Marius Hobbhahn 被公认为 AI 社区内推动评估方法科学化的领先倡导者,这突显了 AI 模型开发中对严谨评估实践日益增长的关注。
-
WANDA 剪枝增强模型效率:一位成员询问 lm-eval 是否支持剪枝模型的 zero-shot 基准测试,并提到了使用 WANDA 剪枝方法。用户对从 zero-shot 评估中获得的可疑结果表示担忧。
- 讨论内容包括对 lm_eval 进行修改以兼容剪枝模型,以及使用 vllm 在 ADVBench 上进行评估,并分享了具体的代码片段来演示模型加载和推理方法。
-
Forgetting Transformer 集成遗忘门:Forgetting Transformer 论文介绍了一种在 softmax attention 机制中加入遗忘门的方法,解决了传统位置嵌入(position embeddings)的局限性。这种方法通过将遗忘门自然地集成到 Transformer 架构中,为循环序列模型提供了一种替代方案。
- 社区讨论引用了诸如 Contextual Position Encoding (CoPE) 等相关工作,并分析了不同的位置嵌入策略,评估了像 ALiBi 或 RoPE 这样更简单的方法是否比最近复杂的方案集成效果更好。
Perplexity AI Discord
-
Perplexity 被 ChatGPT 超越:用户将 Perplexity 与 ChatGPT 进行了对比,强调了 ChatGPT 的多功能性和卓越的对话能力。
- 尽管是 Perplexity 的 Pro 用户,一些人仍对其局限性表示沮丧,导致对 ChatGPT 的依赖增加。
-
推出 Perplexity Shopping 功能:新的 Perplexity Shopping 功能引发了讨论,用户询问其是否为美国市场独有。
- 社区对了解该购物功能的潜在访问限制表现出浓厚兴趣。
-
报告 API 功能问题:用户报告称,尽管切换了模型,API 响应仍保持不变,造成了困惑和沮丧。
- 社区讨论了平台的灵活性,并对响应的多样性提出了质疑。
-
Next.js 全栈开发见解:分享了一个关于 全栈 Next.js 开发 的资源,提供了对现代 Web 框架的见解。
- 探索使用 Hono 进行服务端路由!
-
NVIDIA AI 芯片过热担忧:正如这份报告中所详述,人们对 NVIDIA AI 芯片过热表示担忧。
- 讨论强调了与长时间使用这些芯片相关的风险。
OpenRouter (Alex Atallah) Discord
-
Gemini 1114 在处理输入方面存在困难:用户报告称,Gemini 1114 在对话过程中经常忽略图像输入,导致产生幻觉响应,这与 Grok vision Beta 等模型不同。
- 成员们希望得到确认和修复,对该模型反复出现的问题表示沮丧。
-
DeepSeek 发布新的推理模型:新模型 DeepSeek-R1-Lite-Preview 正式发布,该模型拥有增强的推理能力,并在 AIME 和 MATH 基准测试中表现出色。
- 然而,一些用户注意到该模型的运行速度较慢,引发了关于 DeepInfra 是否可能是更快替代方案的讨论。
-
关于 Prompt Caching 的澄清:Prompt Caching 适用于 DeepSeek 等特定模型,用户对其他提供商的缓存策略提出了疑问。
- 一些成员讨论了不同系统之间缓存工作方式的差异,特别提到了 Anthropic 和 OpenAI 的协议。
-
GPT-4o 模型描述问题:用户发现新发布的 GPT-4o 存在差异,指出该模型错误地列出了 8k context 以及与 GPT-4 相关的错误描述。
- 在指出错误后,成员们看到模型卡片得到了快速更新和修复,恢复了准确信息。
-
RP 模型对比:成员们讨论了用于故事叙述和角色扮演(RP)的 Claude 替代方案,由于 Hermes 的质量和性价比,有人建议使用它。
- 用户表示对这些模型的体验各异,有些人觉得 Hermes 更合适,而另一些人则继续忠于 Claude。
LM Studio Discord
- 受限硬件上的模型加载:一位用户在 36GB RAM M3 MacBook 上的 LM Studio 中遇到了 模型加载问题,并强调了关于系统资源限制的错误消息。
- 另一位成员建议在这种配置下避免使用 32B 模型,建议最高使用 14B 以防止过载。
- LLM 的 GPU 和 RAM 需求:讨论强调运行 DeepSeek v2.5 Lite 的 Q4_K_M 变体至少需要 24GB VRAM,而完整的 Q8 则需要 48GB VRAM。
- 成员们更倾向于选择 NVIDIA GPU 而非 AMD,原因是驱动稳定性问题会影响性能。
- 云端解决方案 vs 本地硬件:用户探讨了将 云端硬件租赁 作为本地配置的经济型替代方案,每月费用在 $25 到 $50 之间。
- 这种方法可以在不受本地硬件限制的情况下访问高速模型。
- 针对 AI 工作负载的工作站设计:一位成员寻求关于在 $30,000 到 $40,000 预算内构建用于微调 LLM 的工作站建议,考虑了选择多个 NVIDIA A6000s 还是较少的 H100s。
- 讨论强调了显存和硬件灵活性在应对预算限制时的重要性。
- 模型推荐与偏好:用户根据性能和写作质量推荐了各种模型,包括 Hermes 3、Lexi Uncensored V2 和 Goliath 120B。
- 鼓励用户随着新选项的出现尝试不同的模型,以找到最适合个人用例的选择。
Stability.ai (Stable Diffusion) Discord
- 海量游戏 PC 指南:一位用户正在寻求预算在 $2500 以内的 游戏 PC 推荐,询问关于组件选择和购买渠道的建议。
- 他们鼓励其他人发送私信以获取个性化建议。
- 角色一致性挑战:一位成员询问如何在整个绘本中保持一致的 角色设计,因为在生成多张图像时难以应对变化。
- 建议包括使用 FLUX 或图像转换技术来提高一致性。
- AI 模型 vs. Substance Designer:关于 AI 模型 是否能有效替代 Substance Designer 引发了讨论,强调了在该领域进一步探索的必要性。
- 成员们分享了对不同 AI 模型能力及其表现的看法。
- 视频生成的 GPU 优化:用户讨论了在显存(VRAM)受限的 GPU 上进行 AI 视频生成 的困难,并指出处理时间可能会很慢。
- 建议的操作流程包括清理 VRAM 并使用更高效的模型,如 CogVideoX。
- 快速 AI 绘图技术:一位成员询问了屏幕上快速更新的 AI 绘图 表现背后的技术,想知道其具体实现方式。
- 回复指出,这通常依赖于强大的 GPU 和一致性模型(Consistency Models)来实现快速更新。
Notebook LM Discord Discord
-
NotebookLM 中的音频生成增强:一位成员展示了他们由 AI 角色主持的播客,利用 NotebookLM 来编排复杂的角色对话。
- 他们详细介绍了其中的多步流程,包括各种 AI 工具的集成以及 NotebookLM 在促进动态对话中的作用。
-
NotebookLM 中的播客创建工作流:一位成员分享了他们使用 NotebookLM 进行音频生成来创建 Spotify 上的德语播客的经验。
- 他们强调了 NotebookLM 出色的音频功能,并寻求自定义建议以增强其播客制作效果。
-
音频文件的转录功能:成员们讨论了将生成的音频文件上传到 NotebookLM 进行自动转录的选项。
- 另外,一位成员建议利用 MS Word 的 Dictate…Transcribe 功能将音频转换为文本。
-
合并笔记功能评估:成员们审议了 NotebookLM 中的“合并为笔记”(Combine to note)功能,评估其将多条笔记合并为单个文档的功能性。
- 一位成员质疑其必要性,因为现有的合并笔记能力已经存在,并寻求对其效用的进一步说明。
-
共享笔记本功能:一位用户询问了与同行共享笔记本的流程,并在过程中遇到了困难。
- 另一位成员澄清说,在 NotebookLM 界面的右上角有一个“分享笔记”按钮,可以方便地进行共享。
Latent Space Discord
-
DeepSeek-R1-Lite-Preview 发布:DeepSeek 宣布推出 DeepSeek-R1-Lite-Preview,展示了在 AIME 和 MATH 基准测试中增强的性能,并具有透明的推理过程。
- 用户对其潜在应用感到兴奋,并指出推理能力的提升会随着长度的增加而有效扩展。
-
GPT-4o 更新增强功能:OpenAI 发布了新的 GPT-4o 快照
gpt-4o-2024-11-20,该版本提升了创意写作能力,并改进了文件处理以获得更深刻的洞察。- 最近的性能测试显示,GPT-4o 在多个类别中重新夺回了榜首位置,突显了显著的进步。
-
Truffles 硬件设备准备用于 LLM 托管:Truffles 硬件设备被确定为一种用于在家自托管 LLM 的半透明解决方案,被幽默地称为“发光的乳房植入物”。
- 这个绰号反映了围绕创新的家用 LLM 部署方案的轻松讨论。
-
Vercel 收购 Grep 以助力代码搜索:Vercel 宣布收购 Grep,使开发者能够高效地搜索超过 500,000 个公共仓库。
- 创始人 Dan Fox 将加入 Vercel 的 AI 团队,以增强代码搜索功能并改进开发工作流。
-
Claude 经历可用性波动:用户报告了 Claude 的间歇性可用性问题,在不同实例中经历了零星的停机。
- 这些可靠性问题引发了积极讨论,用户通过社交媒体平台寻求更新。
GPU MODE Discord
-
Triton 在 Softmax 上胜过 Torch:一位成员在 RTX 3060 上对比了 Triton 的 fused softmax 与 PyTorch 的原生实现,强调了 Triton 更平滑的性能表现。
- 虽然 Triton 的表现通常优于 PyTorch,但在某些情况下 PyTorch 的性能与 Triton 持平甚至更优。
-
Metal GEMM 取得进展:展示了 Philip Turner 的 Metal GEMM 实现,一位成员指出他们自己的实现达到了理论最大速度的 85-90%,与 Turner 的结果相似。
- 进一步的讨论涉及了优化 Metal 编译器以及从性能关键循环中移除寻址计算(addressing computations)的挑战。
-
Dawn 的渲染性能退化:人们对 Dawn 最新版本的性能退化表示担忧,特别是在 Chrome 130 之后的 wgsl-to-Metal 工作流中,尽管 Chrome 131 有所改进。
- 与未定义行为(Undefined Behavior, UB)检查代码放置位置相关的问题被认为是导致落后于 Chrome 129 的潜在原因。
-
FLUX 通过 CPU Offload 提速:一位成员报告称,通过在 4070Ti SUPER 上实现逐层 CPU offload,FLUX 推理速度提升了 200%,推理时间从 3.72 s/it 降至 1.23 s/it。
- 讨论强调了在高性能机器上使用 pinned memory 和 CUDA streams 的有效性,尽管在共享实例上性能提升有限。
Nous Research AI Discord
-
DeepSeek-R1-Lite-Preview 发布:DeepSeek-R1-Lite-Preview 现已上线,在 AIME 和 MATH 基准测试中表现出 o1-preview 级别的性能。
- 它还包含实时的透明思维链(thought process),并计划很快发布开源模型和 API。
-
用于写书的 AI Agents:Venture Twins 展示了一个项目,其中十个 AI agents 协作编写一本完全自主生成的书,每个 agent 被分配不同的角色,如设定叙事和保持一致性。
- 随着项目的实时开发,可以通过 GitHub commits 监控进度。
-
无需提示的 LLMs 推理:研究表明,通过调整解码过程以考虑前 $k$ 个备选 token,大语言模型(LLMs) 可以在没有显式提示的情况下展现出类似于 chain-of-thought (CoT) 的推理路径。
- 这种方法强调了 LLMs 的内在推理能力,表明 CoT 机制可能固有地存在于它们的 token 序列中。
-
生成式 Agent 行为模拟:一种新架构有效地模拟了 1,052 名真实个体的态度和行为,生成式 agents 在综合社会调查(General Social Survey)的回答中达到了 85% 的准确率。
- 该架构显著减少了跨种族和意识形态群体的准确性偏差,为社会科学中探索个人和集体行为提供了工具。
-
Soft Prompts 咨询:一位成员询问了关于 post 中提到的 LLMs soft prompts 的研究,强调了它们在将系统提示优化到嵌入空间(embedding space)方面的潜力。
- 另一位成员回应称 soft prompts 的概念非常有趣,表明了社区内对此的一定兴趣。
OpenAI Discord
-
API 使用挑战:一位成员报告在搜索 API 或工具时发现这两个选项都不尽如人意,表达了挫败感。
- 这个问题反映了社区内对寻找高效资源的广泛兴趣。
-
模型选项澄清:关于 4o model 以及它是否使用了 o1 mini 或 o1 preview 进行了讨论,确认倾向于 o1 mini。
- 一位成员建议检查设置以验证选项,提倡动手排查问题。
-
高 Temperature 性能:一位成员询问在 较高 Temperature 下性能的提升是否与其 Prompt 风格有关,暗示可能存在过多的引导规则或约束。
- 这引发了对优化 Prompt 设计以增强 AI 响应能力的思考。
-
o1 的 Beta 访问权限:一位成员对 NH 授予他们 o1 的 Beta 访问权限 表示兴奋和感谢,这点亮了他们的早晨。
- Woo! Thank you NH for making this morning even brighter 反映了对新更新的兴奋之情。
-
在 Prompt 中部署分隔符:一位成员分享了 OpenAI 关于使用三引号或 XML 标签等分隔符的建议,以帮助模型清晰地理解输入的不同部分。
- 这种方法有助于更好地构建 Prompt 以改进模型响应,使输入解析更容易。
Cohere Discord
-
API Key 问题阻碍访问:多位成员报告遇到 403 错误,表明在尝试访问某些功能时 API keys 无效或使用了过时的 Endpoint。
- 一位成员分享了在验证其 API keys 后仍遇到 fetch 错误 和使用 sandbox 功能困难的经历。
-
CORS 错误中断 API 调用:一位 free tier 用户在控制台中遇到了多个 CORS 错误,尽管使用了标准设置且未添加额外插件。
- 尝试升级到 production key 以解决这些问题的努力未能成功,凸显了 free tier 的局限性。
-
探索高级模型 Tuning 技术:讨论深入探讨了是否可以仅使用 preamble 和可能的聊天历史来实现模型 Tuning。
- 提出了关于模型对各种训练输入的适应性问题,表明需要更有效的 Tuning 方法。
-
Cohere 推出多模态 Embeddings:一位成员称赞了新的图像 multi-modal embeddings,指出其在应用中有了 显著改进。
- 然而,有人对 每分钟 40 次请求的 rate limit 表示担忧,这阻碍了他们的预期使用场景,导致他们寻求替代方案。
-
Harmony 项目简化问卷协调:Harmony 项目旨在利用 LLM 协调问卷项目和元数据,为研究人员提供更好的数据兼容性。
- 正在举办一场竞赛以增强 Harmony 的 LLM 匹配算法,参与者可以在 DOXA AI 上注册并为使 Harmony 更加健壮做出贡献。
Torchtune Discord
-
自适应批处理优化 GPU 使用:adaptive batching 的实现旨在通过动态调整批次大小来最大化 GPU utilization,从而防止训练过程中的 OOM errors。
- 有建议将此功能作为未来 recipes 中的一个 flag 集成,理想情况下在
packed=true时激活以保持效率。
- 有建议将此功能作为未来 recipes 中的一个 flag 集成,理想情况下在
-
增强 DPO Loss 结构:关于当前 TRL 代码结构中是否包含近期关于 DPO 改进的论文(如 Pull Request #2035 所示)存在疑虑。
- 有人请求澄清是否应移除 SimPO 及任何独立类,以保持 DPO recipe 的简洁直接。
-
SageAttention 加速推理:SageAttention 相比 FlashAttention2 和 xformers 分别实现了 2.1x 和 2.7x 的加速,同时在各种模型中保持了端到端指标。
- “这里的推理增益非常酷!” 表达了对 SageAttention 带来的性能提升的兴奋。
-
对比 sdpa 与 Naive sdpa 的基准测试:成员建议针对提议的 sdpa/flex 方法与 naive sdpa 方法进行基准测试,以识别性能差异。
- 分数中的数值误差可能会根据所使用的 sdpa backend 和 data type 而有所不同。
-
Nitro 订阅影响服务器提升(Server Boosts):一名成员强调,如果用户取消其 免费 Nitro 订阅,server boosts 将被移除,从而影响服务器管理。
- 这强调了维持 Nitro 订阅以确保服务器福利不中断的重要性。
tinygrad (George Hotz) Discord
-
Tinygrad 处理 Triton 集成:一位用户询问了 Tinygrad 与 Triton 的原生集成情况,并引用了早期的讨论。George Hotz 指引他们查阅问题文档以获取进一步说明。
- 进一步的讨论澄清了集成步骤,强调了 Tinygrad 与 Triton 之间的兼容性以提升性能。
-
SASS 汇编器寻求替代 PTXAS:成员们讨论了 SASS assembler 的未来,询问其是否旨在取代 ptxas。George Hotz 建议参考问题文档了解更多细节。
- 这引发了人们对 SASS assembler 相比 ptxas 可能带来的改进的兴趣,尽管关于该汇编器的长期角色仍存在一些不确定性。
-
FOSDEM AI DevRoom 征集 Tinygrad 演讲者:一位社区成员分享了在 2025 年 2 月 2 日举行的 FOSDEM AI DevRoom 上进行演讲的机会,强调了 Tinygrad 在 AI 行业中的作用。鼓励感兴趣的演讲者进行联系。
- 此次演讲旨在展示 Tinygrad 的最新进展,并促进 AI 工程师之间的协作。
-
Tinybox 黑客松期待动手实践:一位成员提议组织一场 FOSDEM 前的 hackathon,建议在现场带上一台 Tinybox 以提供动手体验。他们表达了在活动期间边喝比利时啤酒边与社区互动的热情。
- 黑客松旨在促进 Tinygrad 开发者之间的实际讨论和协作项目。
-
在 Tinygrad 中探索 Int64 索引:一位成员质疑在不涉及 huge tensors 的场景下使用 int64 indexing 的必要性,寻求了解其优势。讨论旨在澄清 int64 indexing 在大规模张量操作之外的使用场景。
- 通过探索各种 indexing techniques,社区正在评估在较小张量语境下 int64 与 int32 索引对性能和效率的影响。
Modular (Mojo 🔥) Discord
- Mojo 同步函数中可 await 异步函数:一位成员对在 Mojo 同步函数内部能够 await 异步函数 感到困惑,这与 Python 的限制形成对比,并寻求关于这种异步功能处理差异的澄清或解释。
- 关于 Mojo 库仓库的查询:另一位成员对是否存在类似于 pip 的 Mojo 库仓库感到好奇,正在寻找可以访问 Mojo 库的资源或链接。
-
使用 Max 测试 Moonshine ASR 模型:一位用户分别使用 Max 的 Python API 和原生 Mojo 版本测试了 Moonshine ASR 模型的性能,注意到两者都比直接使用 onnxruntime 的 Python 版本慢了约 1.8 倍。
- Mojo 和 Python Max 版本转录 10 秒语音大约需要 82ms,而原生 onnxruntime 仅需 46ms。相关链接:moonshine.mojo 和 moonshine.py。
-
因 TensorMap 导致 Mojo Model.execute 崩溃:在分享的 mojo 文件顶部的注释中提供了运行 Moonshine ASR 模型的说明。
- 用户的实践表明,将 TensorMap 传入 Model.execute 会导致崩溃,由于 Mojo 的限制,必须手动解包 26 个参数。相关链接:moonshine.mojo。
-
寻求 Mojo 性能优化:该用户表示这是他们最初的几个 Mojo 程序之一,并承认代码可能不够地道(idiomatic)。
- 他们请求协助以实现更好的性能,并强调渴望提高自己的 Mojo 和 Max 技能。
OpenAccess AI Collective (axolotl) Discord
-
腾讯混元 (Hunyuan) 模型微调:一位成员询问了关于微调 腾讯混元模型 的事宜,并分享了 GitHub 仓库 和 官方网站 的链接。
-
在 MI300X 上使用 Bits and Bytes:一位成员分享了在 MI300X 系统上使用 Bits and Bytes 的经验,强调了其易用性。
- 他们强调在更新时必须使用
--no-deps标志,并提供了一个强制重新安装该包的单行命令。
- 他们强调在更新时必须使用
-
用于 LLaMA 持续预训练的 Axolotl Colab Notebook:一位用户询问 Axolotl 是否提供任何用于 LLaMA 持续预训练 的 Colab Notebook。
- Phorm 回复称搜索结果为 undefined,表示目前没有可用的 Notebook,并鼓励用户稍后再次检查更新。
DSPy Discord
-
Juan 寻求多模态挑战的帮助:Juan 询问了在处理 多模态问题 时如何使用对 视觉语言模型 (vision language models) 的实验性支持。
- 另一位成员提供了进一步的帮助,表示 “如果有任何问题请告诉我!”。
-
Juan 发现了 mmmu notebook:Juan 随后自己找到了 mmmu notebook,这为他的项目提供了所需的持。
- 他感谢社区的 “出色工作”,对现有资源表示赞赏。
-
将 Semantic Router 作为基准:一位成员建议将 Semantic Router 作为 分类任务 的性能基准,强调其 极速 AI 决策 能力。
- 该项目专注于 多模态数据的智能处理,它可能提供我们旨在超越的竞争性基准。
-
专注于性能提升:有人断言需要超越现有 分类工具 的性能,并以 Semantic Router 作为参考点。
- 讨论围绕确定指标和策略展开,以实现比该工具设定的基准更好的结果。
LlamaIndex Discord
-
LLM-Native 简历匹配功能上线:感谢 @ravithejads,开发了一种 LLM-native 解决方案用于简历匹配,增强了传统的筛选方法。
- 这种创新方法解决了招聘中人工筛选缓慢且乏味的过程,提供了一个更高效的替代方案。
-
12 月 12 日构建 AI Agents 网络研讨会:加入 @Redisinc 和 LlamaIndex 参加 12 月 12 日的研讨会,重点关注构建数据驱动的 AI Agents。
- 该会议将涵盖架构 Agent 系统以及降低成本和优化延迟的最佳实践。
-
PDF 表格数据提取方法:#general 频道的一位成员询问了从包含文本和图像的 PDF 文件中提取表格数据的方法。
- 他们表示有兴趣了解是否存在任何可以简化此过程的现有应用程序。
-
PDF 数据提取应用:另一位成员寻求推荐专门用于从 PDF 中提取数据的应用程序。
- 这突显了社区内对能够处理各种复杂 PDF 工具的需求。
OpenInterpreter Discord
-
新 UI 引发褒贬不一的评价:一些用户觉得新 UI 有点令人应接不暇,且注意力引导不清晰,有人将其比作《异形》(Alien)中的计算机。
- 然而,其他人开始欣赏其受 UNIX 启发的设计,认为它适合 1.0 版本功能。
-
需要配置 Rate Limit:一位用户对受到 Anthropic 的 Rate Limit(速率限制)表示沮丧,并指出 Interpreter 当前的错误处理会导致在超过限制时退出会话。
- 他们强调了在未来更新中加入更好的 Rate Limit 管理的重要性。
-
用户呼吁 UI 增强:有呼声要求提供信息更丰富的 UI,显示当前工具、模型和工作目录,以增强可用性。
- 用户还倡导建立潜在的插件生态系统,以便在未来版本中实现可定制功能。
-
提议分离计算工作负载:一位成员建议将 LLM 工作负载分配到本地和云端计算之间,以优化性能。
- 这反映了对当前 Interpreter 设计局限性的担忧,该设计主要针对一次运行一个 LLM。
LLM Agents (Berkeley MOOC) Discord
-
明天 Intel AMA 环节:一场与 Intel 合作的 Hackathon AMA 定于明天(11/21)太平洋时间下午 3 点举行,为参与者提供来自 Intel 专家的直接见解。别忘了在这里观看直播并设置提醒!
- 鼓励参与者准备好问题,以最大限度地从会议中获益。
- 参与者注册困惑:一位用户报告在加入三个不同的群组并使用多个电子邮件地址注册后未收到电子邮件,这让他们对注册是否成功产生了不确定性。
- 活动类型澄清:一位成员寻求澄清注册问题是关于 Hackathon 还是 MOOC,这突显了参与者对不同注册类型可能存在的混淆。
Mozilla AI Discord
-
Refact.AI 实时演示重点展示 Autonomous Agents:Refact.AI 正在举办一场实时演示,展示其 Autonomous Agent 和 tooling。
- 加入 实时演示和对话 以探索他们的最新进展。
-
Refact.AI 发布新 Tooling:Refact.AI 团队发布了新的 tooling 以支持其 Autonomous Agent 项目。
- 鼓励参与者在实时演示活动期间体验这些工具。
Alignment Lab AI Discord 没有新消息。如果该频道(Guild)沉寂太久,请告知我们,我们将移除它。
LLM Finetuning (Hamel + Dan) Discord 没有新消息。如果该频道(Guild)沉寂太久,请告知我们,我们将移除它。
MLOps @Chipro Discord 没有新消息。如果该频道(Guild)沉寂太久,请告知我们,我们将移除它。
LAION Discord 没有新消息。如果该频道(Guild)沉寂太久,请告知我们,我们将移除它。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该频道(Guild)沉寂太久,请告知我们,我们将移除它。
AI21 Labs (Jamba) Discord 没有新消息。如果该频道(Guild)沉寂太久,请告知我们,我们将移除它。
第 2 部分:按频道细分的详细摘要和链接
逐个频道的详细分解内容已因邮件篇幅而截断。
如果您喜欢 AInews,请分享给朋友!预谢!