ainews-vision-everywhere-apple-aimv2-and-jina
视觉无处不在:Apple AIMv2 与 Jina CLIP v2
苹果(Apple)发布了 AIMv2,这是一种采用自回归目标预训练的新型视觉编码器,在 ImageNet 上实现了 89.5% 的准确率,并集成了视觉与文本联合目标。Jina 推出了 Jina CLIP v2,这是一款支持 89 种语言和高分辨率图像的多模态嵌入模型,其采用的高效 Matryoshka(俄罗斯套娃)嵌入技术在几乎不损失准确率的情况下将维度降低了 94%。Allen AI 推出了基于 Llama 3.1 的 Tülu 3 模型,包含 8B 和 70B 参数版本,推理速度提升了 2.5 倍,并通过 SFT、DPO 和 RLVR 方法进行对齐,性能可与 Claude 3.5 和 Llama 3.1 70B 竞争。这些进展突显了自回归训练、视觉编码器以及多语言多模态嵌入领域的最新突破。
自回归目标就是你所需要的一切。
2024年11月22日至11月23日的 AI 新闻。我们为你检查了 7 个 Reddit 分区、433 个 Twitter 账号 和 28 个 Discord 社区(211 个频道,2674 条消息)。预计为你节省阅读时间(以 200wpm 计算):265 分钟。你现在可以标记 @smol_ai 进行 AINews 讨论!
顺应大家都在转向多模态的大趋势(Pixtral、Llama 3.2、Pixtral Large),“多模态”(实际上主要是视觉)Embedding 的进步是非常基础且关键的。这使得 Apple 和 Jina 在过去 48 小时内的发布特别受欢迎。
Apple AIMv2
他们的 论文(GitHub 地址)详细介绍了一种“大规模视觉编码器预训练的新方法”:将视觉编码器与多模态解码器配对,该解码器以自回归方式生成原始图像块(image patches)和文本标记(text tokens)。

这扩展了去年关于使用自回归目标预训练视觉模型的 AIMv1 工作,该工作增加了 T5 风格的 prefix attention 和 token 级别的预测头,成功预训练了一个 7B 的 AIM,在冻结 trunk 的情况下在 ImageNet1k 上达到了 84.0%。
主要的更新是引入了视觉和文本的联合目标,这似乎具有非常好的扩展性(scaling):

AIMV2-3B 现在在同一基准测试中达到了 89.5% 的准确率 —— 体积更小,但性能更强。定性的视觉效果也非常出色:

Jina CLIP v2
虽然 Apple 做了更多基础性的 VQA 研究,但 Jina 新的 CLIP 后代模型 对于多模态 RAG 工作负载来说是立即可用的。Jina 几个月前发布了 embeddings-v3,现在正将其文本编码器整合到其 CLIP 产品中:
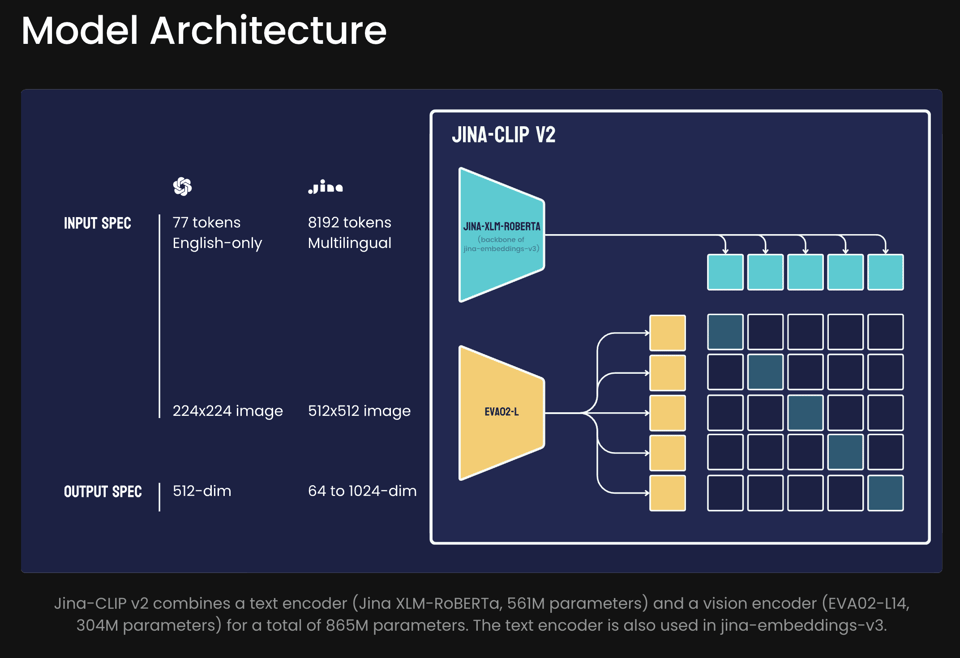
其标语展示了 Jina 在这次发布中集成了多少尖端特性:“一个 0.9B 的多模态 Embedding 模型,具有 89 种语言的多语言支持、512x512 的高图像分辨率以及 Matryoshka 表征。”
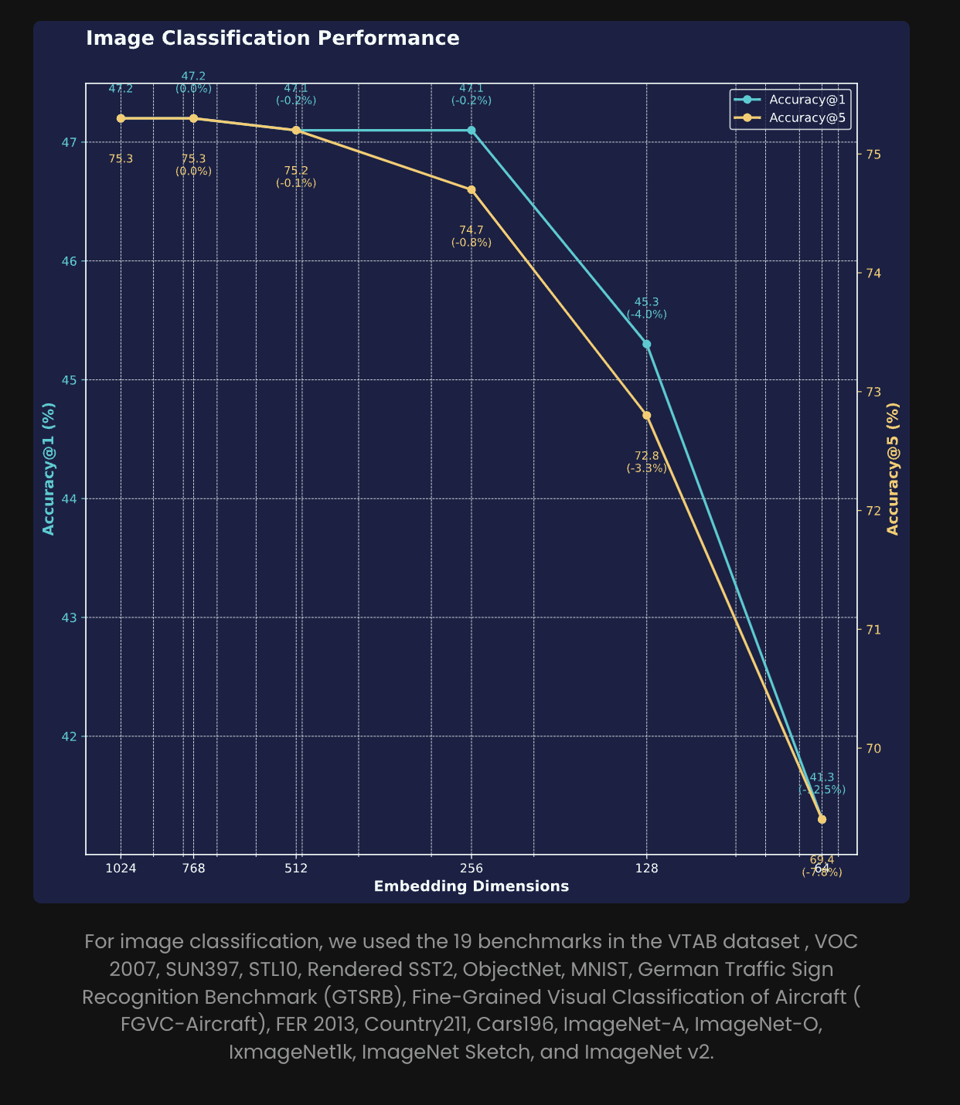
Matryoshka Embedding(套娃嵌入)尤其引人注目:“从 1024 维压缩到 64 维(减少了 94%)仅导致 top-5 准确率下降 8%,top-1 准确率下降 12.5%,突显了其在极小性能损失下进行高效部署的潜力。”
AI Twitter 摘要
所有总结均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
1. 前沿 AI 模型发布与进展:Tülu 3、AIMv2 等
- @allen_ai 发布的 Tülu 3 模型:Tülu 3 系列基于 Llama 3.1,包括 8B 和 70B 模型,与 Tulu 2 相比提供 2.5 倍的推理加速。它使用 SFT、DPO 和基于 RL 的方法进行对齐,所有资源均公开可用。
- 关于 Tülu 3 的讨论 强调了它与 Claude 3.5 和 Llama 3.1 70B 等其他领先 LLM 的竞争力。此次发布包括对数据集、模型 Checkpoints 和训练代码的公开访问,以便进行实际实验。
- 强调了 Tülu 模型在 有效开放科学 方面的贡献,赞扬了其引入的新技术,如 带有可验证奖励的强化学习 (RLVR)。
- Apple 的 AIMv2 视觉编码器:AIMv2 编码器在多模态基准测试中优于 CLIP 和 SigLIP。它们在开放词汇目标检测方面表现出色,并且在 冻结 trunk 的情况下具有极高的 ImageNet 准确率。
- AIMv2-3B 使用集成的 Transformers 代码在 ImageNet 上达到了 89.5% 的准确率。
- Jina-CLIP-v2 (由 JinaAI 提供):一款支持 89 种语言 和 512x512 图像分辨率 的多模态模型,旨在增强文本与图像的交互。该模型在检索和分类任务中表现出强劲性能。
2. AI Agents 增强与应用:FLUX 工具、来自 Suno 的洞察
- Black Forest Labs 推出的 FLUX 工具套件:新的专用模型为 AI 图像生成提供了更强的控制力。可通过 @replicate API 在 anychat 中使用,支持全新的 Canny、Depth 和 Redux 模型。
- FLUX 工具赋能开发者以更高的精度和定制化能力创作引人入胜的多媒体内容。
- Suno 与音乐制作中的 AI:Suno 的 v4 版本被用于创意音乐尝试,展示了 AI 在音乐制作中的变革性作用,来自 Suno 的 Bassel 带来了全新的 AI 生成作品。
- 此外,关于将 AI 与 B-box 结合的讨论反映了 Suno 对音乐创作的独特贡献。
3. AI、科学与社会
- 利用 AI 产生科学发现:由 GoogleDeepMind 举办的小组讨论聚焦于 AI 正在彻底改变科学方法并辅助发现。主要参与者包括 Eric Topol、Pushmeet、Alison Noble 和 Fiona Marshall。
- Baby-AIGS 系统研究 通过证伪和消融研究 (falsification and ablation studies) 探索 AI 在科学发现中的潜力,重点展示了专注于可执行科学提案的早期研究。
- AI 与科学方法讨论:深入探讨 AI 如何重塑科学方法论,多位杰出专家分享了见解。
- 参与者辩论了 AI 在促进新科学突破中的作用及其与生物医学研究的交集。
4. AI 伦理、红队测试 (Red Teaming) 与 Bug 修复的进展
- OpenAI 的红队测试增强:关于红队测试的白皮书披露了涉及外部红队人员和自动化系统的新方法,增强了 AI 安全评估。
- 这些努力旨在通过在测试中积极引入多样化的人类反馈来提升 AI 的鲁棒性。
- MarsCode Agent 在 Bug 修复中的应用:字节跳动的 MarsCode Agent 在 SWE-bench Lite 基准测试中展示了在自动 Bug 修复方面的显著成功,强调了精确错误定位在解决问题中的重要性。
- 同时也指出了未来自动化工作流创新的挑战领域。
5. 企业与工具的协作与创新
- Anthropic 与亚马逊的 40 亿美元合作:双方建立合作伙伴关系,共同开发专注于 AWS 基础设施的下一代 AI 模型,展示了 AI 开发领域的强强联合。
- 这一战略投资强调利用亚马逊开发的芯片 (silicon) 来优化训练过程。
- LangGraph 语音交互功能:将语音识别功能与 AI Agents 集成,利用 OpenAI Whisper 和 ElevenLabs 实现无缝语音交互界面。
- LangGraph 增强了 AI 在现实应用中的适应性,提供了更自然的交互体验。
6. 迷因、幽默与社会评论
- LLM 基准测试技术张力中的幽默:对 AI 模型性能“战争”和基准测试的讽刺性解读,嘲讽了对评估分数的痴迷是片面且具有误导性的。
- 社区声音对某些基准测试在现实世界 AI 模型性能中的相关性表示怀疑。
- 对 Elon Musk 创业项目的评论:以冷嘲热讽的言论审视了在 Musk 等科技巨头拥有的平台上所呈现的“言论自由”叙事,挑战了对开放话语的假设。
- 对主要科技平台的变化及其对真正自由表达的影响进行了批判性反思。
AI Reddit 摘要
/r/LocalLlama 摘要
主题 1:DeepSeek 崛起为领先的中国开源 AI 公司
- Chad Deepseek (Score: 1486, Comments: 174): DeepSeek 开发了一个模型,在仅使用 18,000 个 GPU 的情况下,性能达到或超过了 OpenAI(使用 100,000 个 GPU)的表现。这种效率展示了在 LLM 开发中,模型训练方法和资源利用率方面的显著改进。
- 社区对包括 Qwen、DeepSeek 和 Yi 在内的中国开源 AI 公司表示强烈支持,用户强调了它们在以更少资源(18K GPU 对比 OpenAI 的 100K GPU)实现同等效果方面的高效性。
- 关于模型性能的讨论集中在实际能力上,用户报告了在数学推理(特别是“-4 的平方”问题)和编程任务中的成功,同时也指出了一些在创造性推理和细微响应方面的局限性。
- 围绕 AI 模型中的政治审查展开了辩论,用户讨论了中国和西方模型如何处理敏感历史话题,以及 GPU 出口限制可能如何激励中国公司进行更多的开源开发。
- Competition is still going on when i am posting this.. DeepSeek R1 lite has impressed me more than any model releases, qwen 2.5 coder is not capable for these competitions , but deepseek r1 solved 4 of 7 , R1 lite is milestone in open source ai world truly (Score: 41, Comments: 10): DeepSeek R1 Lite 在一场正在进行的编程竞赛中表现强劲,解决了 7 道题中的 4 道,表现优于 Qwen 2.5 Coder。该模型的成功标志着开源 AI 开发的重大进展。
- 传闻 DeepSeek R1 Lite 是一个 16B 参数模型,尽管其性能表明它可能更大。考虑到 OpenAI o1 的发布时机和当前的 GPU 短缺,社区推测它是一个 16B MoE 模型。
- 模型权重尚未公开,但预计将“很快”发布。社区舆论强调,在宣布其为里程碑之前,应等待实际的开源发布。
- 目前尚未正式发布详细的模型信息或技术规格,这使得性能声明仍处于初步阶段。
{kind=link}
主题 2:创新模型架构:Marco-o1 与 OpenScholar
-
Marco-o1 from MarcoPolo Alibaba and what it proposes (Score: 40, Comments: 0): 由 MarcoPolo Alibaba 开发的 Marco-o1 结合了 Chain of Thought (CoT)、Monte Carlo Tree Search (MCTS) 和推理动作,以解决没有既定解决方案的开放式问题,从而区别于 OpenAI 的 o1。该模型整合了这三个组件,以实现逻辑问题解决、最优路径选择和动态细节调整,旨在跨多个领域在写作和推理任务中表现出色,模型可在 AIDC-AI/Marco-o1 获取。
-
OpenScholar: The open-source AI outperforming GPT-4o in scientific research (Score: 98, Comments: 2): 由 Allen Institute for AI 和华盛顿大学开发的 OpenScholar 将检索系统与微调后的语言模型相结合,提供有引用支持的研究答案,在真实性和引用准确性方面优于 GPT-4o。该系统实现了一个用于输出精炼的自我反馈推理循环,并作为开源模型在 Hugging Face 上发布,尽管在开放获取论文的可用性方面存在限制,但它使小型机构和发展中国家的研究人员更容易获得此类工具。
- 与 VentureBeat 的报道相比,AI2 博客文章提供了关于 OpenScholar 更全面的技术细节,参考链接为 allenai.org/blog/openscholar。
{kind=link}
主题 3:系统提示词与 Tokenizer 优化见解
- 来自 v0(Vercel 的 AI 组件生成器)的泄露系统提示词 (System Prompts) (100% 真实) (Score: 292, Comments: 54):一名开发者泄露了 Vercel V0 的系统提示词,揭示了该 AI 工具使用 MDX components、专用代码块以及带有内部提醒的结构化思考过程来生成 UI 组件。该系统包含处理 React、Node.js、Python 和 HTML 代码块的详细规范,重点在于使用 shadcn/ui library、Tailwind CSS 并保持可访问性标准,正如其 GitHub repository 中所记录的那样。
- 讨论表明,由于其 XML tag 结构以及对 shadcn/ui 的熟练程度,V0 可能使用的是 Claude/Sonnet 而非 GPT-4,这参考了 Anthropic’s documentation 中关于提示词结构化的说明。
- 多位用户确认该系统使用的是 closed-source SOTA models 而非开源模型,完整的提示词长度约为 16,000 tokens,并包含动态内容,包括 NextJS/React documentation。
- V0 system prompts 的更新版本已泄露并通过 GitHub 分享,一些用户注意到它与 Qwen2.5-Coder-Artifacts 有相似之处,但专门针对 React 实现进行了优化。
- 警惕损坏的分词器 (Tokenizers)!在创建 v1.3 RPMax 模型时发现了这一点! (Score: 137, Comments: 31):Tokenizer issues 影响了 RPMax v1.3 models 的 model performance,尽管没有提供关于问题性质或解决方案的具体细节。
- RPMax versions 已从 v1.0 演进到 v1.3,其中 v1.3 实现了 rsLoRA+ (rank-stabilized low rank adaptation) 以提高学习效果和输出质量。由于天然无审查,基于 Mistral-based models 的模型被证明最有效,而 Llama 3.1 70B 实现了最低的损失率。
- Huggingface transformers library 中一个关键的 tokenizer bug 会导致分词器文件在修改时大小翻倍,从而影响模型性能。该问题可以使用 AutoTokenizer.from_pretrained() 后接 save_pretrained() 来重现,这会错误地重新生成 “merges” 部分。
- RPMax training approach 非常规,采用 single epoch、低梯度累积和较高的学习率,导致损失曲线不稳定但稳步下降。这种方法旨在防止模型强化特定的角色设定或故事模式。
主题 4. INTELLECT-1:分布式训练创新
- 开源 LLM INTELLECT-1 完成训练 (Score: 268, Comments: 28):INTELLECT-1,一个 open source Large Language Model,已使用 distributed GPU resources worldwide 完成了训练阶段。帖子中未提供关于模型架构、训练参数或性能指标的额外背景或技术细节。
- 该模型跨全球 GPU 资源的 distributed training approach 引起了社区的极大兴趣,用户将其与 protein folding projects 进行比较,并询问如何贡献自己的 GPU。根据 their website,dataset 预计将于 11 月底发布。
- 围绕该模型 open source status 的讨论引发了辩论,并与现有的开源模型如 Olmo 和 K2-65B 进行了比较。用户注意到,虽然其他模型分享了脚本和数据集,但 INTELLECT-1 的分布式算力贡献代表了一种独特的方法。
- 技术观察包括与学习率降低同时出现的 perplexity and loss bump(困惑度和损失抖动),这归因于引入了具有不同 token 分布的高质量数据。用户指出,虽然该模型的性能并非出类拔萃,但它代表了一个重要的首次迭代。
{kind=link}
其他 AI Subreddit 回顾
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
主题 1. Amazon x Anthropic 40 亿美元投资与云合作伙伴关系
- 正在发生。Amazon X Anthropic。 (Score: 323, Comments: 103): 根据 Anthropic 的公告,Amazon 向 Anthropic 追加 40 亿美元 投资,并确立 AWS 为其主要的云服务和训练合作伙伴。此次合作重点在于云基础设施以及使用 AWS Trainium 进行 AI 模型训练。
- AWS 用户指出,他们已经在生产环境中使用 Claude 超过一年,一些人表示 Amazon Q 在后台已经使用了 Claude。此次合作加强了现有的关系,其中包括将 Claude 引入 Alexa 的计划。
- 该交易的一个关键益处是解决了 Claude 的算力限制 和性能问题,由 AWS Trainium 取代 CUDA 进行模型训练。从 Nvidia 硬件向 Amazon 基础设施的转变预示着未来将有重大的技术变革。
- 用户强调了对 rate limits(速率限制)和服务可靠性的担忧,并猜测可能会有 Prime 集成(可能带有广告)。一些人将其与 Microsoft-OpenAI 的合作伙伴关系进行比较,指出 Google(同样是 Anthropic 的投资者)的投资地位可能面临挑战。
- 厌倦了“需求量过高” (Score: 34, Comments: 19): Claude 的付费服务面临日益严重的容量问题,尽管是付费订阅用户,仍频繁遇到“We’re experiencing High Demand”(我们正面临高需求)的消息。该帖子批评 Anthropic 优先发布新功能而非提升基础设施的可扩展性,表达了对付费客户服务受限的沮丧。
- 用户报告称 Claude 的质量在高需求期间会有所下降,“Full Response”模式可能提供的推理能力有限且 Token 消耗更快。
- 多名用户确认经历了每日服务中断,一名用户因 AI 在处理常规任务时的不可靠性 导致手动完成效率更高而取消了订阅。
- 一名用户推测,军事采购计算资源可能导致了容量限制,但这尚未得到证实。
主题 2. GPT-4o 在技术基准测试中的性能退化
- 独立评估机构发现新 GPT-4o 模型表现显著下降,例如“GPQA Diamond 从 51% 下降到 39%,MATH 从 78% 下降到 69%” (Score: 262, Comments: 53): GPT-4o 在技术基准测试中表现下降,GPQA Diamond 分数从 51% 降至 39%,MATH 分数从 78% 降至 69%。技术任务性能的下降表明,与前代模型相比,最新模型的能力可能出现了退化。
- GPT-4o 似乎针对自然语言任务而非技术任务进行了优化,用户注意到尽管基准测试分数较低,但它感觉“更自然”。几位用户建议 OpenAI 正在有意区分不同模型的能力,GPT-4o 专注于写作,而 O1 处理技术推理。
- 用户报告了对当前替代模型的混合体验:Claude Sonnet 面临消息限制,O1-mini 被描述为啰嗦,而 O1-preview 限制为每周 50 个问题。一些用户提到 Gemini experimental 1121 在解决问题和数学方面表现出潜力。
- 围绕基准测试方法的讨论也随之出现,用户批评 LMSYS 作为性能指标是不够的,并质疑单 Token 数学答案与复杂指令响应的价值。模型技术性能的下降可能反映了有意的权衡,而非单纯的退化。
- 为什么 ChatGPT 变得“懒惰”了? (Score: 146, Comments: 134): 用户反映 ChatGPT 提供的回复越来越肤浅且不完整,示例显示 AI 给出的答案简短、不全面,遗漏了 Prompt 中的关键细节,并需要频繁修正。帖子作者指出,ChatGPT 在被纠正时会承认错误,但随后继续提供浅薄的回复,质疑这种感知到的性能下降是否存在深层原因。
- 用户报告在最近的“创意升级”后,GPT-4 的性能显著下降,有证据显示其在 STEM 学科和基础数学方面的表现不如 GPT-4 mini,如对比图所示。
- 多位用户描述了上下文保留问题和记忆问题,AI 经常忽略详细的 Prompt 和自定义指令。这种退化似乎与 OpenAI 的成本削减措施和减少算力分配有关。
- 技术用户报告了在代码生成、文档审查和详细查询方面的特定问题,指出回复变得更加通用,缺乏针对性。多人提到需要多次尝试才能获得以前单次回复就能提供的全面答案。
{kind=link}
Theme 3. LTX Video: 新型开源快速视频生成模型
- LTX Video - 带有 ComfyUI 工作流的新型开源视频模型 (Score: 259, Comments: 122): LTX Video 是一款新型开源视频模型,集成了 ComfyUI,可通过 Hugging Face 和 ComfyUI 示例获取。该模型通过 ComfyUI 工作流提供视频生成能力,为用户提供直接访问视频创作工具的途径。
- 研究团队的一名成员确认,LTX-Video 可以实时生成 768x512 分辨率、24 FPS 的视频,并计划进行更多改进。该模型在 3060/12GB 上运行约需 1 分钟,而 4090 生成 10 秒视频需要 1:48s。
- 用户对该模型的表现评价褒贬不一,特别是 img2video 功能出现了故障。研究团队承认结果对 Prompt 高度敏感,并在其 GitHub 页面上提供了详细的示例 Prompt。
- 该模型现已集成到最新的 ComfyUI 更新中,支持包括 Text2Video、Image2Video 和 Video2Video 在内的多种模式。用户需要遵循特定的 Prompt 结构,将动作描述置于 Prompt 前部以获得最佳效果。
- LTX-Video 极速运行 - 尽管有 RAM 卸载且仅 12 GB VRAM,1-1.5 分钟内生成 153 帧 (Score: 95, Comments: 30): LTX-Video 展示了高速视频生成能力,在 12GB VRAM 限制和 RAM 卸载的情况下,于 1-1.5 分钟内生成了 153 帧。这一性能指标显示了在视频生成任务中对消费级硬件的高效利用。
- LTX-Video 在消费级硬件上运行效率极高,用户确认尽管有 18GB VRAM 的需求,但通过 RAM 卸载在 12GB 4070Ti 上也能成功运行。安装指南可在 ComfyUI 博客查看。
- 用户讨论了未来的潜力,提到了即将推出的 32GB VRAM 消费级显卡,并将现状与早期《玩具总动员》时代的怀疑论进行了对比。预计该技术将在 2-3 年内取得重大进展。
- 当前版本 (0.9) 被描述为对 Prompt 敏感,后续有改进计划,同时部分用户对输出质量存在争议。原始输出是在没有插帧的情况下生成的。
Theme 4. 中国 AI 模型作为潜在竞争对手崭露头角
- 有人深入研究过中国 AI 吗? (Score: 62, Comments: 128): 包括 DeepSeek、ChatGLM 和 Ernie Bot 在内的 Chinese AI models 提供免费访问,并能生成高质量的回复,在某些领域足以与 ChatGPT-4 竞争。帖子作者指出,尽管这些模型能力出色,但社区对它们的讨论却非常有限。
- 用户对 Chinese Communist Party (CCP) 背景下的 data privacy 和 censorship 表示强烈担忧,多位评论者提到了监控和信息控制的风险。得分最高的评论主要集中在这些信任和隐私问题上。
- 讨论强调了未来的潜在情景,包括 AI development 中“East versus West”的分歧,以及各国之间可能出现的竞争性 singularities。几位用户指出,这可能会导致兼容性和竞争方面的挑战。
- 评论指出,西方 AI 模型(ChatGPT、Claude、Gemini)的 market awareness 和 first-mover advantage 是其占据主导地位的关键因素,而非技术能力是主要差异点。
{kind=link}
AI Discord 摘要
由 O1-preview 对摘要进行的摘要总结
主题 1. AI 军备竞赛:新模型与突破
- INTELLECT-1:全球首个去中心化训练模型:Prime Intellect 宣布完成 INTELLECT-1 的训练,这是首个通过横跨美国、欧洲和亚洲的去中心化努力训练而成的 10B 模型。开源版本将在约一周内发布,标志着协作式 AI 开发的一个里程碑。
- 阿里巴巴发布 Marco-o1:ChatGPT o1 的开源替代方案:AlibabaGroup 发布了 Marco-o1,这是一款采用 Apache 2 许可证的模型,旨在通过思维链 (CoT) 微调和蒙特卡洛树搜索 (MCTS) 解决复杂问题。研究员 Xin Dong 和 Yonggan Fu 旨在增强模糊领域的推理能力。
- Lightricks 的 LTX Video 模型瞬间生成 5 秒视频:Lightricks 推出了 LTX Video 模型,在高性能硬件上仅需 4 秒即可生成 5 秒视频。该模型已开源并可通过 API 调用,推向了快速视频生成的极限。
主题 2. 十亿美元级动作:Anthropic 与亚马逊握手言和
- Anthropic 获亚马逊 40 亿美元投资,AWS 成为其核心伙伴:Anthropic 扩大了与 AWS 的合作,获得了来自亚马逊高达 40 亿美元的投资。AWS 现已成为 Anthropic 的主要云服务和训练合作伙伴,利用 AWS Trainium 为其最大的模型提供动力。
- Cerebras 称其 Llama 3.1 部署速度夺冠:Cerebras 吹嘘其运行 Llama 3.1 405B 的速度惊人,将自己定位为大语言模型部署的领导者,并激起了 AI 硬件竞争。
主题 3. AI 被指控:OpenAI 在诉讼中删除证据
- 糟糕!OpenAI 在诉讼期间“意外”删除数据:律师指控 OpenAI 在与《纽约时报》和《每日新闻》的版权诉讼中,在进行了 150 小时的搜索后抹除了数据。这引发了法律纠纷中数据处理的严重担忧。
- CamelAI 在进行百万级 Agent 模拟后账号消失:CamelAIOrg 的 OpenAI 账号被封禁,可能与其涉及 100 万个 Agent 的 OASIS 社交模拟项目有关。尽管已进行沟通,但他们已等待 5 天未获回复,使社区陷入困境。
主题 4. AI 工具变得更智能:增强开发与工作流
- Unsloth 更新大幅降低 VRAM 占用,新增视觉微调功能:最新的 Unsloth 更新将 VRAM 效率提升了 30-70%,并为 Llama 3.2 Vision 等模型引入了视觉微调。它还支持在免费的 16GB Colab 中进行 Pixtral 微调,使先进 AI 更加触手可及。
- LM Studio 讨论多 GPU 魔法与 GPU 对决:LM Studio 用户讨论了平衡多 GPU 推理,并对比了 RTX 4070 Ti 和 Radeon RX 7900 XT 等 GPU。虽然功耗有所不同,但他们发现性能差异微乎其微,引发了关于 AI 任务最佳硬件的辩论。
- Aider 用户应对量化怪癖与基准测试困惑:Aider 社区深入探讨了不同量化方法如何影响模型性能。他们注意到 Qwen 2.5 Coder 在不同供应商之间表现出不一致的结果,强调了关注量化细节的必要性。
主题 5. AI 艺术与创意:拥有(幽默感的)机器
- AI 艺术图灵测试让所有人困惑(且觉得有趣):最近的 AI 艺术图灵测试让参与者感到困惑,难以区分 AI 生成的艺术与人类作品。讨论围绕测试的有效性以及 AI 在艺术中不断演变的角色展开。
- 语音克隆故障将有声书变成了意外的音乐剧:用户在尝试使用语音克隆制作有声书时遇到了意想不到的故障,导致 AI 以歌唱的方式回答。这些“美丽的意外”为有声书制作增添了有趣的转折。
- ChatGPT 的喜剧追求(再次)落空:尽管有所进步,像 ChatGPT 这样的 AI 模型在幽默感方面仍然挣扎,经常讲出平淡无奇的笑话。用户注意到,尝试幽默或 ASCII 艺术往往以乱码告终,凸显了 AI 喜剧技能仍有提升空间。
第一部分:高层级 Discord 摘要
Eleuther Discord
- Test-Time Training 提升 ARC 性能:最近关于 Test-Time Training (TTT) 的实验在 Abstraction and Reasoning Corpus (ARC) 上相比基础模型实现了高达 6倍 的准确率提升。
- 关键因素包括在相似任务上的初始微调、辅助任务格式化以及针对每个实例的训练,展示了 TTT 在增强推理能力方面的潜力。
- Wave Network 引入复数 Token 表示:Wave Network 利用 复数向量 (complex vectors) 进行 Token 表示,分离全局和局部语义,从而在 AG News 分类任务 中获得了极高的准确率。
- 每个 Token 与全局语义向量的数值比例建立了一种与整体序列范数的新型关系,增强了模型对输入上下文的理解。
- 关于可学习位置嵌入的争论:关于 Mamba 等模型中 可学习位置嵌入 (learnable positional embeddings) 的讨论,强调了其与传统嵌入相比在输入依赖性方面的有效性。
- 有人对其在约束较少的情况下的表现表示担忧,并建议使用 Yarn 或 Alibi 等替代方案以获得更好的灵活性。
- RNN 展示出分布外外推能力:RNN 在算法任务上展示了分布外 (out-of-distribution) 的外推能力,一些人建议可以将思维链 (chain of thought) 应用于 线性模型 (linear models)。
- 然而,对于像 ARC 这样的复杂任务,由于 RNN 固有的表示限制,TTT 可能比上下文学习 (ICL) 更有益。
- Muon 正交化技术的见解:Muon 的实现采用了 momentum 以及在 momentum 更新后的 正交化 (orthogonalization),这可能会影响其有效性。
- 讨论强调了足够的 Batch Size 对于有效正交化的重要性,特别是在处理 低秩矩阵 (low-rank matrices) 时。
Unsloth AI (Daniel Han) Discord
- Unsloth 更新提升 VRAM 效率:最新的 Unsloth 更新 为 Llama 3.2 Vision 等模型引入了 视觉微调 (vision finetuning),将 VRAM 使用效率提升了 30-70%,并增加了在免费的 16GB Colab 环境中对 Pixtral 微调 的支持。
- 此外,该更新还包括将模型合并为 16bit 以简化推理,并为视觉模型提供 长上下文支持,显著提高了可用性。
- Mistral 模型表现优于同类模型:用户报告称 Mistral 模型在微调方面表现出色,与 Llama 和 Qwen 模型相比,展示了强大的 提示词遵循能力 (prompt adherence) 和卓越的 准确率。
- 尽管表现优异,但对于 Qwen 的有效性仍存在一些怀疑,有报告称其在特定应用中会出现 乱码输出 (gibberish outputs)。
- 微调与推理挑战:社区成员在 微调模型 时面临困难,例如无法加载微调后的模型进行推理,以及在输出文件夹中遇到 BF16 和 Q4 量化 等多个模型版本。
- 在 推理 过程中,会出现
AttributeError和WebServerErrors等错误,特别是在使用 ‘Mistral-Nemo-Instruct-2407-bnb-4bit’ 等模型时,这促使人们建议更换模型路径并验证与 Hugging Face 端点的兼容性。
- 在 推理 过程中,会出现
- Tokenization 与预训练指导:有报告称存在 Tokenization 问题,包括在 Hindi 等数据集训练期间与列长度不匹配相关的错误,以及评估阶段的空预测。
- 对于 持续预训练 (continued pretraining),用户讨论了使用 Unsloth 提供范围之外的模型,并被鼓励寻求社区支持或在 GitHub 上针对不支持的模型提出兼容性请求。
LM Studio Discord
- 平衡多 GPU 推理:用户讨论了在 LM Studio 中实现 多 GPU 性能 的可行性,特别是关于跨多个 GPU 的推理和模型分布,并指出负载均衡可能会使 VRAM 分配 变得复杂。
- 讨论中提出了关于是配对不同的 GPU 还是选择更强大的单个 GPU 以获得更好的整体性能的疑虑。
- 比较 RTX 4070 Ti 和 Radeon RX 7900 XT:社区比较了 RTX 4070 Ti、Radeon RX 7900 XT 和 GeForce RTX 4080 在 1440p 和 4K 分辨率下的性能,指出虽然功耗有所不同,但性能差异通常很小。
- 成员们讨论了平衡 功耗 和 性能 的问题,建议为了获得最佳结果应优先选择更高质量的模型。
- 微调模型对比 RAG 策略:成员们辩论了 微调模型 与使用 RAG(检索增强生成)策略的优劣,共识是微调可以使模型专门用于特定任务,而 RAG 提供了更大的灵活性。
- 微调的例子包括针对 C# 编程语言适配模型,但同时也提出了关于敏感公司数据安全影响的担忧。
- LLM 基准测试中的 AMD GPU:AMD GPU 可以通过 ROCm 或 Vulkan 运行 LLM;然而,讨论中也提到了关于驱动更新影响性能的持续担忧。
- 有人指出 ROCm 主要在 Linux 或 WSL 上运行,限制了部分用户的可用性。
- 期待 5090 显卡的发布:成员们对即将发布的 5090 显卡 表示期待,同时也对供应情况和定价感到担忧。
- 讨论内容包括关税对硬件价格的影响,以及在预期价格上涨前确保设备供应的必要性。
HuggingFace Discord
- IntelliBricks 工具包简化 AI 应用开发:IntelliBricks 是一个旨在简化 AI 驱动应用程序开发的开源工具包,其特点是使用
msgspec.Struct处理结构化输出。该项目目前正在开发中,欢迎在其 GitHub 仓库 进行贡献。- 鼓励开发者参与贡献以增强其功能,营造一个构建高效 AI 应用的协作环境。
- FLUX.1 Tools 增强图像编辑能力:FLUX.1 Tools 的发布引入了一套用于编辑和修改图像的工具,包括 FLUX.1 Fill 和 FLUX.1 Depth 等模型,由 Black Forest Labs 发布。
- 这些模型提高了文本生成图像任务的 可控性 (steerability),允许用户尝试开放获取的功能并增强其图像生成工作流。
- 去中心化训练完成 INTELLECT-1 模型:Prime Intellect 宣布完成 INTELLECT-1 的训练,这是一个通过遍布美国、欧洲和亚洲的去中心化努力训练出的 10B 模型。预计在大约一周内发布完整的开源版本。
- 这一里程碑突显了去中心化训练方法的有效性,更多细节可在 Prime Intellect 的推文 中找到。
- Cybertron v4 UNA-MGS 模型登顶 LLM 基准测试:cybertron-v4-qw7B-UNAMGS 模型已重新推出,在无污染的情况下实现了 7-8B LLM 排名第一,并增强了推理能力,正如其 Hugging Face 页面 所示。
- 该模型利用了
MGS和UNA等独特技术,展示了卓越的基准测试性能,吸引了 AI 工程社区的关注。
- 该模型利用了
- Cerebras 以高速 Llama 3.1 部署领先:Cerebras 正在通过以惊人的速度运行 Llama 3.1 405B 来引领 LLM 性能,将自己定位为大语言模型部署的领导者。
- 这一进步强调了 Cerebras 致力于优化 AI 模型性能的承诺,在快速发展的大语言模型领域提供了竞争优势。
Latent Space Discord
- Anthropic 从 AWS 获得 40 亿美元融资:Anthropic 额外获得了来自 Amazon 的 40 亿美元投资,指定 AWS 为其主要的云和训练合作伙伴,通过 AWS Trainium 增强 AI 模型训练。
- 正如其官方公告中所述,此次合作旨在利用 AWS 基础设施开发和部署 Anthropic 最大的基础模型。
- AI 艺术图灵测试引发褒贬不一的反应:最近的 AI Art Turing Test 引发了讨论,此分析中强调了参与者难以区分 AI 和人类创作的艺术品。
- 成员们有兴趣邀请艺术修复专家来评估该测试,以更好地衡量其有效性。
- Lightricks 发布开源 LTX Video 模型:Lightricks 推出了 LTX Video 模型,能够在高性能硬件上仅用 4 秒生成 5 秒的视频,可通过 APIs 获取。
- 讨论集中在利用 LTX Video 模型时,如何平衡本地处理能力与云端相关的成本。
- 斯坦福大学发布 AI 活力排名工具:斯坦福大学推出了 AI Vibrancy Rankings Tool,该工具根据可定制的 AI 发展指标对各国进行评估,允许用户调整指标权重以匹配其观点。
- 该工具因其在提供全球 AI 进展洞察方面的灵活性而受到赞誉。
- 基于 LLM 的需求分析受到关注:LLM-powered requirements analysis 正成为一个关键话题,成员们强调了其在自动化复杂问题理解和建模过程中的有效性。
- 对话指出 LLM 在简化分析工作流方面具有巨大潜力,并参考了 DDD starter modeling process。
OpenAI Discord
- 语音克隆故障增强了有声书效果:成员们讨论了用于 audiobook 改编的 voice cloning 技术,注意到意想不到的声音和故障有时会产生令人惊喜的增强效果(如唱歌)。 #ai-discussions
- 一位用户分享了使用各种 voice models 的经验,强调了语音克隆如何在对话中创造出怪异的效果。
- ChatGPT 与 Airtable 和 Notion 集成:探索了 ChatGPT 与 Airtable 和 Notion 等工具的集成能力,旨在增强这些应用程序中的 Prompt 编写。 #ai-discussions
- 成员们分享了他们改进 Prompt 编写的目标,寻求更个性化和有效的交互。
- Copilot 的图像生成能力引发猜测:对 Copilot 的图像生成能力产生了好奇,猜测其来源是未发布的 DALL-E 模型还是名为 Sora 的新程序。 #ai-discussions
- 对不同 AI 工具生成的图像进行了比较,指出受其他模型影响的质量差异。
- GPT 在使用 Dall-E 时的词汇限制问题:一位成员表达了挫败感,称他们的 GPT 在使用 Dall-E 生成约 10 张图像后,往往会忘记特定的词汇限制。 #gpt-4-discussions
- 他们正在寻求技巧来维持角色描述,并避免在生成内容中出现不想要的词语。
- 探索 Dall-E 之外的替代方案和免费图像模型:成员们讨论了 Dall-E 的替代方案,如带有 ComfyUI 的 Stable Diffusion 和 Flux models,认为它们可能更好地处理特定的词汇限制。 #gpt-4-discussions
- 他们建议查看 YouTube 上的最新教程,以确保获得保持角色一致性的更新方法。
aider (Paul Gauthier) Discord
- Qwen 2.5 Coder 的性能差异:用户观察到 Qwen 2.5 Coder 模型在不同供应商之间的性能表现不一,其中 Hyperbolic 的得分为 47.4%,而排行榜上的得分为 71.4%。
- 社区讨论强调了量化 (quantization) 的影响,指出 BF16 和其他变体产生了不同的性能结果。
- Aider 基准测试方法的更新:Aider 针对 Qwen 2.5 Coder 32B 的排行榜现在通过 GLHF 使用来自 HuggingFace 的权重,从而提高了基准测试的准确性。
- 用户对不同托管平台导致的评分差异表示担忧,并对模型质量可能存在的差异提出质疑。
- 与 Qwen 模型的直接 API 集成:Aider 框架现在可以直接访问 Qwen 模型,而无需依赖 OpenRouter,从而简化了使用流程。
- 此次更新旨在通过减少对第三方服务的依赖来提升用户体验,同时保持模型性能。
- 引入 Uithub 作为 GitHub 的替代方案:用户推荐将 Uithub 作为 GitHub 的替代方案,只需将 ‘G’ 改为 ‘U’,即可轻松将仓库内容复制到 LLM 中。
- 来自 Nick Dobos 和 Ian Nuttall 等成员的反馈强调了 Uithub 获取完整仓库上下文的能力,从而增强了开发工作流。
- 亚马逊向 Anthropic 追加 40 亿美元投资:Amazon 宣布向 Anthropic 追加 40 亿美元投资,加剧了 AI 开发领域的竞争态势。
- 此举引发了关于在企业投资不断增加的情况下,AI 项目的可持续性和创新速度的讨论。
Nous Research AI Discord
- Marco-o1 发布,作为 ChatGPT o1 的替代方案:AlibabaGroup 发布了 Marco-o1,这是一个采用 Apache 2 许可证的 ChatGPT o1 模型替代方案,旨在通过思维链 (CoT) 微调和蒙特卡洛树搜索 (MCTS) 解决复杂问题。
- Xin Dong、Yonggan Fu 和 Jan Kautz 等研究人员正领导 Marco-o1 的开发,旨在增强在标准模糊和奖励量化困难的领域中的推理能力。
- 带有 Few-shot Prompting 的 Agent 翻译工作流:该 Agent 翻译工作流采用 few-shot prompting 和迭代反馈循环,而非传统的微调,使 LLM 能够对其翻译进行批判和改进,从而提高灵活性和定制化程度。
- 通过利用迭代反馈,该工作流避免了训练开销,从而提高了翻译任务的生产力。
- 阿里巴巴的 AWS 合作与 40 亿美元投资:AnthropicAI 宣布与 AWS 建立合作伙伴关系,包括来自 Amazon 的新一轮 40 亿美元投资,将 AWS 定位为其主要的云和训练合作伙伴,正如这条推文所分享的。
- Teknium 在一则推文中强调,按目前的速度维持预训练扩展 (pretraining scaling) 在未来两年将需要 2000 亿美元,并对持续进步的可行性提出了质疑。
- 用于 LLM 和多模型聊天界面的 Open WebUI:成员们讨论了用于 LLM 托管聊天体验的图形用户界面 (GUI),倾向于使用 Open WebUI 和 LibreChat 等工具,其中 Open WebUI 因其用户友好界面而受到广泛青睐。
- 社区分享了 Open WebUI 功能的动画演示,强调了其对各种 LLM runners 的支持以及高效处理多个模型交互的能力。
- 使用 Axolotl 的示例默认配置微调数据集:一位寻求微调模型和创建数据集的成员对高昂的试错成本表示担忧,随后收到了使用 Axolotl 的示例默认配置的建议,这些配置被认为对训练运行非常有效。
- 使用 Axolotl 的示例默认配置可以简化微调过程,降低成本并提高数据集创建工作的效能。
OpenRouter (Alex Atallah) Discord
- Claude 3.5 Haiku ID 变更:Claude 3.5 Haiku 模型已重命名,其 ID 中使用 点 (dot) 代替了 连字符 (dash),这改变了其可用性。新的模型 ID 可在 Claude 3.5 Haiku 和 Claude 3.5 Haiku 20241022 获取,尽管访问可能受限。
- 寻求这些模型的用户可以通过 Discord 频道申请访问权限,而之前的 ID 仍可正常使用。
- Gemini 模型配额问题:用户在通过 OpenRouter 访问 Gemini Experimental 1121 模型时遇到配额错误。建议直接连接到 Google Gemini 以获得更可靠的访问。
- 这些配额限制影响了依赖免费版本的用户,从而引发了对替代连接方法的建议。
- OpenRouter API Token 统计差异:有报告称 Qwen 2.5 72B Turbo 模型不像其他提供商那样通过 OpenRouter API 返回 Token 计数。然而,OpenRouter 页面上的 活动报告 (activity reports) 能准确显示 Token 使用情况。
- 这种不一致表明 OpenRouter 在处理特定模型的 Token 计数时可能存在问题。
- 欧洲 OpenRouter 积分的税费问题:一位用户询问为什么在欧洲购买 OpenRouter credits 不包含增值税 (VAT),而不像 OpenAI 或 Anthropic 的服务那样。回复澄清说,VAT 计算是用户的责任,并计划在未来实施自动税费计算。
- 缺乏 VAT 包含引起了欧洲用户的关注,凸显了简化税务流程的需求。
- 自定义 Provider Key 的访问权限:多位用户请求访问 custom provider keys,反复的呼吁强调了对该功能的浓厚兴趣。用户如 sportswook420 和 vneqisntreal 强调了这一需求。
- 社区对自定义 Provider Key 的热情表明了对增强功能的渴望,尽管访问程序仍未明确。
Perplexity AI Discord
- Gemini AI 对比 ChatGPT:用户报告称 Gemini AI 在几次交互后经常停止响应,引发了对其与 ChatGPT 相比可靠性的质疑。
- 讨论强调了性能差异,一些成员发现 ChatGPT 在长时间对话中表现更一致。
- Perplexity 浏览器扩展:有一场关于 Safari 浏览器的 Perplexity extensions 可用性的对话,包括新增的搜索引擎和已停止使用的摘要工具。
- 成员们分享了针对非 Safari 浏览器的替代解决方案,并提供了管理现有扩展的技巧。
- 非编程人员的 AI 易用性:提出了一项基于层级的学习系统方案,旨在通过结构化的项目和教程课程,使 AI 技术对非编程人员更易获取。
- 该系统旨在提供分步指导,在面向社区的框架内促进技能发展。
- AI 中的数字孪生 (Digital Twins):探讨了 Digital twins,重点关注其在各行业监控和优化现实实体中的应用。
- 用户对数字孪生如何增强模拟能力和运营效率表现出浓厚兴趣。
- AI 对 Grammarly 的影响:辩论了 AI 对 Grammarly 的影响,此讨论 审视了 AI 技术进展在写作工具中的整合。
- 参与者考虑了引入 AI 以增强 Grammarly 功能的利弊。
Stability.ai (Stable Diffusion) Discord
- SDXL Lightning 支持图像提示词 (Image Prompts):一位用户询问如何通过 Python 在 SDXL Lightning 中利用图像提示词,寻求将照片集成到特定语境中的指导。
- 另一位用户确认了可行性,并建议通过私信交流更多信息。
- 为 12GB VRAM 优化 WebUI:讨论集中在增强 webui.bat 参数以提升 12GB VRAM 的性能,建议包含 ‘–no-half-vae’。
- 用户一致认为,此调整足以优化性能且不会引入进一步的复杂问题。
- 将企业照片转换为 Pixar 风格:有人请求将企业照片转换为 Pixar 风格 图像的方法,需要在短时间内处理约十张肖像。
- 成员们讨论了可行性,指出可能没有免费服务,并建议对图像生成模型进行微调 (Fine-tuning)。
- 探索使用 Cogvideo 的视频微调服务:用户对视频微调表现出兴趣,并询问了可用的服务器或服务,参考了 Cogvideo 模型。
- 有人强调,虽然 Cogvideo 在视频生成方面很突出,但其他特定的微调版本可能更符合用户需求。
- 下载 Stable Diffusion 及其使用场景:一位新用户寻求在 PC 上下载 Stable Diffusion 最简单、最快的方法,并询问了相关的使用场景。
- 另一位用户请求帮助使用 Stable Diffusion 创建特定图像,同时绕过内容过滤器,这表明需要更宽松的软件选项。
LlamaIndex Discord
- 简化 Workflow 中的 Function Calling:用户讨论了简化 Workflow 中的 Function Calling,建议使用预构建的 Agent(如
FunctionCallingAgent)来实现 自动化函数调用,从而避免编写样板代码。- 一位成员指出,虽然样板代码提供了更多控制权,但使用预构建的 Agent 可以 简化流程。
- LlamaIndex 安全合规性:LlamaIndex 确认其符合 SOC2 标准,并详细说明了通过 LlamaParse 和 LlamaCloud 安全处理原始文档的细节。
- LlamaParse 对文件进行 48 小时加密,而 LlamaCloud 则对数据进行分块 (Chunking) 并安全存储。
- LlamaIndex 中的 Ollama 包问题:用户报告了 LlamaIndex 中 Ollama 包的问题,称最新版本中的一个 Bug 导致聊天响应时出错。
- 建议降级到 Ollama 版本 0.3.3,一些成员确认此操作解决了他们的问题,参考 Pull Request #17036。
- Hugging Face Embedding 兼容性问题:用户担心来自 Hugging Face 上 CODE-BERT 模型的 Embedding 与 LlamaIndex 预期的格式不一致。
- 用户建议 在 GitHub 上提交 Issue 以解决处理模型响应时可能出现的匹配问题。
- LlamaParse 解析挑战:尽管有排除冗余信息的详细指令,LlamaParse 在返回信息时仍包含页眉和参考文献等冗余内容。
- 一位成员询问:‘还有其他人遇到这个问题吗?’,并分享了针对科学论文的全面解析指令,以保持内容的逻辑流并排除致谢和参考文献等非核心元素。
Notebook LM Discord Discord
- NotebookLM 实现了 Retrieval-Augmented Generation:正如社区成员所讨论的,NotebookLM 现在利用 Retrieval-Augmented Generation 来增强 response accuracy 和 citation tracking。
- 这一实现旨在为进行广泛查询会话的用户提供更可靠、更可验证的输出。
- Podcastfy.ai 成为 NotebookLM API 的替代方案:一位成员推荐了 Podcastfy.ai 作为 NotebookLM’s podcast API 的开源替代方案,引发了关于功能对比的讨论。
- 用户正在评估 Podcastfy.ai 在播客创建和管理方面与现有 NotebookLM 选项的优劣。
- NotebookLM 对 Producer Studio 的需求增长:一位用户强调了他们对 NotebookLM 的 Producer Studio 功能请求,主张增强播客制作能力。
- 社区成员对先进的制作工具表现出兴趣,以简化平台内的播客创作流程。
- NotebookLM 寻求多语言音频翻译支持:用户请求将 NotebookLM 音频输出翻译成德语和意大利语等语言的能力,突显了对更广泛多语言支持的需求。
- 这一需求强调了该平台迎合更广泛、全球化工程师群体的潜力。
- NotebookLM 播客创建限制已明确:用户已确认 NotebookLM 内部存在每个账户 100 个播客的限制,以及每日 20 个播客创建的可能上限。
- 这一限制促使用户仔细管理其播客库存,因为删除旧播客会重置其创建额度。
Interconnects (Nathan Lambert) Discord
- OpenAI 的数据删除诉讼:The New York Times 和 Daily News 的律师正在起诉 OpenAI,指控其在经过 150 多个小时的搜索后意外删除了潜在证据。
- 11 月 14 日,一台虚拟主机上的数据被擦除,正如法庭信函中所述,这可能会影响案件。
- Prime Intellect 的 INTELLECT-1 去中心化 10B 模型:Prime Intellect 宣布完成 INTELLECT-1,这是首个跨越多个大洲的 10B model 去中心化训练。
- 预计在一周内发布完整的开源版本,邀请各方协作构建开源 AGI。
- Anthropic 与 AWS 达成 40 亿美元合作伙伴关系:Anthropic 通过亚马逊 40 亿美元的投资扩大了与 AWS 的合作,确立 AWS 为其主要的云和训练合作伙伴。
- 此次合作旨在增强 Anthropic’s AI technologies,详见其官方新闻稿。
- Tulu 3 的 On-policy DPO 分析:关于 Tulu 3 论文的讨论质疑了所描述的 DPO method 是否由于训练期间模型策略的演变而真正属于 on-policy。
- 成员们辩论认为,第 8.1 节中提到的 online DPO 通过在每个训练步骤为奖励模型采样完成结果,更符合 on-policy 推理。
- CamelAIOrg 的 OASIS 社会模拟项目:CamelAIOrg 面临 OpenAI 的账号封禁,可能与其最近涉及 100 万个 Agent 的 OASIS social simulation project 有关,详见其 GitHub page。
- 尽管已寻求帮助,但 20 多名社区成员在等待 5 天后仍未收到 API keys 的回复。
GPU MODE Discord
- Triton 优化 AMD GPU:在一段 YouTube 视频 中,Lei Zhang 和 Lixun Zhang 讨论了针对 AMD GPU 的 Triton 优化,重点关注 L2 缓存 swizzle 和 内存访问效率 等技术。
- 他们还探讨了通过 MLIR 分析 来增强 Triton kernel,参与者强调了这些优化在提高 GPU 整体性能方面的重要性。
- FlashAttention 优化:成员们讨论了 FlashAttention 的进展,包括基于 QK^T 分块(tiling block)内 局部和(local sums) 的 全局指数和(global exponential sum) 近似技术。
- 重点在于理解 局部 与 全局指数和 之间的关系,以有效地优化 Attention 机制。
- LLM 剪枝技术:一位成员请求关于 大语言模型 (LLM) 最新的 剪枝和模型效率论文,并引用了 What Matters in Transformers 论文及其 数据依赖(data-dependent) 技术。
- 讨论强调了对 非数据依赖技术 的需求,以提高各种工业应用中的模型效率。
- GPT-2 训练方法:分享了一个 GitHub Gist,详细介绍了如何 在五分钟内免费训练 GPT-2,包括一个简化流程的辅助函数。
- 此外,还有关于将 GPT-2 训练 功能集成到 Discord bot 中的讨论,旨在改善 AI 相关任务的用户体验。
- NPU 加速方案:一位成员询问支持 NPU 加速 的库或运行时,并提到 Executorch 为 Qualcomm NPU 提供了一些支持。
- 讨论旨在确定其他能有效利用 NPU 加速 的框架,并鼓励社区提供建议。
Cohere Discord
- Cohere API 增强对话编辑:用户请求一个与 Cohere API 兼容的前端,其中包含一个 编辑按钮,用于在不重启对话的情况下修改聊天历史。
- 会议澄清了编辑应无缝集成到聊天历史中,并指出目前 Cohere 官网 的聊天和 playground-chat 页面均缺少 编辑选项。
- SQL Agent 与 Langchain 集成:SQL Agent 项目在 Cohere 文档 中展示,并获得了社区的积极反馈。
tinygrad (George Hotz) Discord
- SDXL 基准测试在更新后变慢:在应用更新 #7644 后,SDXL 在 CI tinybox green 上不再转换为 half 类型,导致基准测试速度下降超过 2 倍。
- 成员们质疑这次类型转换的更改是否是为了解决之前错误的转换实现。
- 对 SDXL 最新回归问题的担忧:更新 #7644 中移除了 SDXL 的 half 转换,引发了社区对 回归问题(regression) 的担忧。
- 用户正在寻求澄清,即基准测试性能的下降是否意味着 SDXL 能力的倒退。
- 提议中间转换策略转型:提出了一项建议,根据 输入 dtype 而非设备来确定中间转换(intermediate casting),主张采用 纯函数式(pure functional) 方法。
- 该建议包括采用类似于 Stable Diffusion 中 fp16 的方法,以提高模型和输入转换的效率。
- Tinygrad 移除自定义 Kernel 函数:Tinygrad 仓库的最新版本中已移除 自定义 kernel 函数。
- George Hotz 建议使用替代方法来实现预期结果,而不损害抽象层。
- 通过 YouTube 介绍 Tinygrad:通过 YouTube 链接 分享了 Tinygrad 入门介绍,以帮助初学者。
- 该资源旨在帮助新用户更有效地理解 Tinygrad 的基础知识。
Modular (Mojo 🔥) Discord
- Mojo-Python 互操作性指日可待:Mojo 路线图 包括允许 Python 开发者导入 Mojo 包并调用 Mojo 函数,旨在提高跨语言互操作性。
- 社区成员正在积极开发此功能,对于不追求极致性能的用户,目前已有初步方法可用。
- Mojo 中的异步事件循环配置:尽管最初支持异步分配的数据结构,但现在 Mojo 中的异步操作需要设置事件循环以有效管理状态机。
- 未来计划允许在不需要时编译掉异步运行时,从而优化性能。
- Mojo-Python 多线程集成的权宜之计:一位用户分享了一种方法,通过队列让 Mojo 和 Python 进行通信,利用 Python 的多线程实现异步交互。
- 虽然在某些情况下有效,但有人认为这种方法对于简单需求过于复杂,主张提供官方解决方案。
- 推进 Mojo 特性以进行速度优化:一位成员强调 Mojo 的主要用途是作为 C/C++/Rust 的类 Python 替代方案,强调其在加速缓慢进程中的作用。
- 他们强调了基础特性的重要性,如参数化 traits 和 Rust 风格的 enums,其优先级高于基础 Mojo 类。
Torchtune Discord
- HF Transfer 加速模型下载:在 torchtune 中加入 HF transfer 显著缩短了模型下载时间,llama 8b 的下载时间从 2分12秒降至32秒。
- 用户可以通过运行
pip install hf_transfer并为非 nightly 版本添加标志HF_HUB_ENABLE_HF_TRANSFER=1来启用它。此外,有用户报告在家庭网络连接上通过 HF transfer 每次下载一个文件,下载速度超过了 1GB/s。
- 用户可以通过运行
- Anthropic 论文质疑 AI 评估的一致性:Anthropic 最近的一篇 研究论文 讨论了 AI 模型评估的可靠性,质疑性能差异是真实的,还是源于问题选择中的随机运气。
- 该研究鼓励 AI 研究社区采用更严谨的统计报告方法,而一些社区成员对强调误差棒(error bars)表示怀疑,引发了关于提升评估标准的持续讨论。
LLM Agents (Berkeley MOOC) Discord
- Hackathon 转为完全线上:即将举行的 Hackathon 将 100% 在线 进行,允许参与者从任何地点加入,无需物理场地。
- 这一决定解决了物流问题,并确保所有团队成员都能更广泛地参与。
- 简化团队注册:团队注册现在会向第一个字段中输入的邮箱发送 确认邮件,确保至少有一名团队成员收到确认。
- 这一改进简化了注册流程,使其更加用户友好且高效。
- Percy Liang 的演讲:Percy Liang 本周的演讲获得了成员们的积极反馈。
- 参与者强调了会议期间交付内容的清晰度和深度。
OpenInterpreter Discord
- Desktop App 发布时间表仍不确定:一位新成员在加入 waiting list 后询问了 Desktop App 的发布计划,但未提供具体的发布日期,导致时间表仍不确定。
- 这种不确定性表明开发工作仍在进行中,目前尚未公布 Desktop App 的明确时间线。
- Exponent 演示凸显 Windsurf 的有效性:一名成员分享了他们使用 Exponent 进行演示的经验,并提到正在继续对其功能进行实验。
- 成员对 Windsurf 给予了积极反馈,强调了其在演示过程中的有效性。
- 社区探索开源版 Devin:讨论中提到了社区成员一直在探索的一个开源版本的 Devin,尽管并非所有人都尝试过。
- 这反映了利用开源工具进行项目实验的持续兴趣。
- 克服 O1 在 Linux 上的安装挑战:一名成员报告了在其 Linux 系统上安装 O1 的困难,并正在寻求解决方案。
- 他们正在寻求有关安装问题的潜在解决方案或变通方法的建议。 此外,讨论还涉及了将 Groq API 或其他免费 API 与 Linux 上的 O1 集成的可行性。
DSPy Discord
- VLM 增强发票处理能力:一名成员正在探索将 VLM 用于一个高风险的发票处理项目,并寻求关于 DSPy 如何增强其针对专门子任务的 Prompt 指导。
- 提到 DSPy 最近增加了对 VLM(特别是 Qwen)的支持。
- DSPy 集成 Qwen 以支持 VLM:DSPy 已添加对 Qwen(一种特定的 VLM)的支持,以增强其处理专门任务的能力。
- 此次集成旨在改进高风险发票处理等项目的 Prompt Engineering。
- 在视觉分析项目上测试 DSPy:一名成员建议在 VLM 上尝试 DSPy,分享了他们在视觉分析项目中的成功经验,并指出 CoT 模块在图像输入下运行良好。
- 他们尚未测试优化器(optimizers),表明还有更多探索空间。
- 利用 DSPy 简化项目开发:另一名成员强调从简单任务开始,然后逐渐增加项目的复杂性,强化了 DSPy 易于上手的理念。
- “如果你从简单开始并随着时间的推移增加复杂性,这并不难!” 传达了一种鼓励实验的情绪。
OpenAccess AI Collective (axolotl) Discord
- INTELLECT-1 完成去中心化训练:Prime Intellect 宣布完成 INTELLECT-1,这标志着首次跨越多个大洲对 10B 模型 进行的去中心化训练。来自 Prime Intellect 的推文 确认,目前正在与 arcee_ai 进行训练后处理,完整的开源发布计划在大约一周后进行。
- INTELLECT-1 实现了去中心化 AI 训练的一个重要里程碑,实现了横跨美国、欧洲和亚洲的协作开发。即将到来的开源发布预计将促进更广泛的社区参与 AGI 研究。
- 训练能力提升 10 倍:Prime Intellect 声称,与之前的模型相比,INTELLECT-1 的去中心化训练能力提升了 10 倍。这一进步突显了该项目在分布式环境中的可扩展性和效率。
- 10 倍的增强使 INTELLECT-1 成为去中心化 AI 训练领域的领先模型,邀请 AI 工程师为构建更强大的开源 AGI 框架做出贡献。
- 对 Axolotl 微调的期待:人们对 INTELLECT-1 发布后 Axolotl 的 fine-tuning 能力充满期待。参与者渴望评估该系统在去中心化训练取得进展的情况下如何管理 finetuning。
- Axolotl 的微调功能与 INTELLECT-1 的去中心化框架的集成预计将增强模型的适应性和性能,从而使技术工程社区受益。
LAION Discord
- Neural Turing Machines 狂热:一位成员在过去几天里一直在探索 Neural Turing Machines。
- 他们非常希望与对此感兴趣的其他人交流想法。
- Differentiable Neural Computers 深度探索:一位成员正在深入研究 Differentiable Neural Computers 以获得进一步的见解。
- 他们正在寻找志同道合的热心人士,就这些技术相关的想法和见解进行合作。
MLOps @Chipro Discord 没有新消息。如果该频道长期没有动态,请告知我们,我们将将其移除。
Mozilla AI Discord 没有新消息。如果该频道长期没有动态,请告知我们,我们将将其移除。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该频道长期没有动态,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该频道长期没有动态,请告知我们,我们将将其移除。
第 2 部分:各频道详细摘要与链接
完整的频道逐条分析已针对电子邮件进行了截断。
如果您喜欢 AInews,请分享给朋友!提前感谢!