ainews-anthropic-launches-the-model-context
Anthropic 发布模型上下文协议 (Model Context Protocol)
Anthropic 推出了模型上下文协议 (MCP),这是一种开放协议,旨在实现大语言模型应用与外部数据源及工具之间的无缝集成。
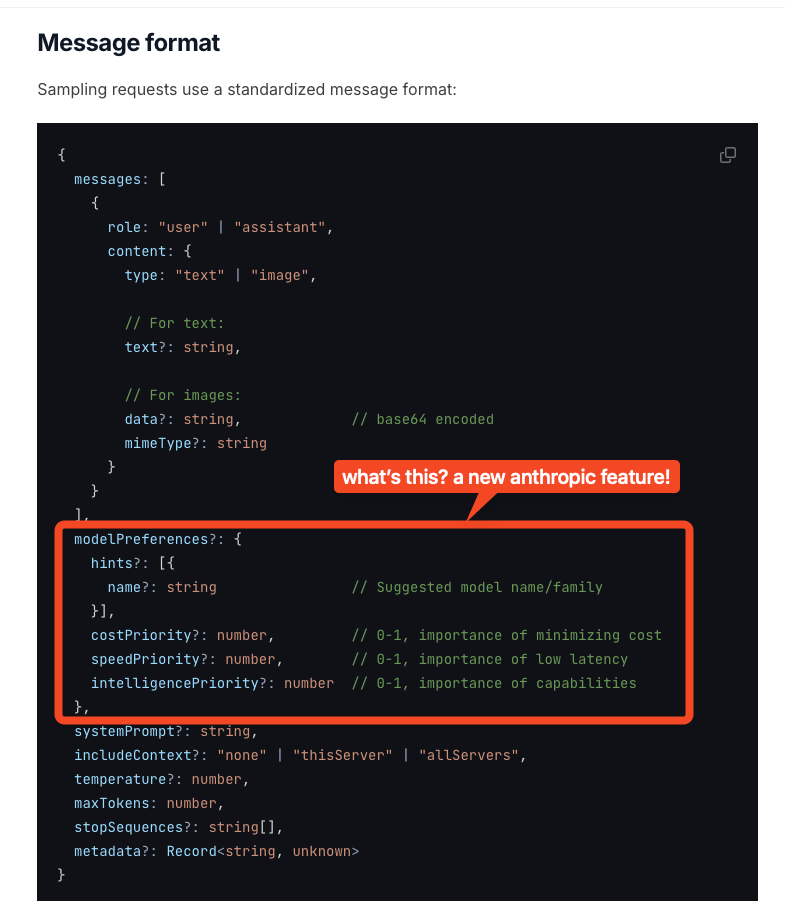
MCP 支持多种资源,包括文件内容、数据库记录、API 响应、实时系统数据、屏幕截图和日志,并由唯一的 URI 进行标识。它还包含可重用的提示词模板、系统和 API 工具,以及支持流式传输的 JSON-RPC 2.0 传输协议。MCP 允许服务器通过客户端请求 LLM 补全,并可根据成本、速度和智能程度设定优先级,这暗示了 Anthropic 即将推出模型路由器。
Zed、Sourcegraph 和 Replit 等发布合作伙伴对 MCP 给予了正面评价,而部分开发者则对其供应商独占性和普及潜力持怀疑态度。该协议强调安全性、测试和动态工具发现,Alex Albert 和 Matt Pocock 等社区成员也提供了相关的指南和视频。这一进展是在 Anthropic 最近获得亚马逊 40 亿美元融资之后取得的,旨在推进 Claude 桌面版的终端级集成。
claude_desktop_config.json 就是你所需的一切。
2024年11月25日至11月26日的 AI 新闻。我们为您检查了 7 个 subreddit、433 个 Twitter 账号 和 30 个 Discord 服务器(202 个频道,2684 条消息)。预计为您节省阅读时间(按 200wpm 计算):314 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
特别说明:我们清理了一些不活跃的 Discord,并添加了 Cursor Discord!
刚从 Amazon 获得 40 亿美元融资 的 Anthropic 并没有止步于视觉化的 Computer Use(我们的报道在此)。下一步是为 Claude Desktop 定义终端级别的集成点,以便直接与您机器上运行的代码进行交互。摘自 快速入门:

Model Context Protocol (MCP) 是一种开放协议,能够实现 LLM 应用程序与外部数据源及工具之间的无缝集成。类似于 Language Server Protocol,MCP 规定了如何将额外的上下文和工具集成到 AI 应用程序的生态系统中。有关实现指南和示例,请访问 modelcontextprotocol.io。
该协议足够灵活,涵盖了:
- Resources(资源):任何类型的数据,MCP 服务器希望提供给客户端。这可以包括:文件内容、数据库记录、API 响应、实时系统数据、屏幕截图和图像、日志文件等。每个资源由唯一的 URI 标识,可以包含文本或二进制数据。
- Prompts(提示词):可重用的模板和工作流(包括多步骤)。
- Tools(工具):从 系统操作到 API 集成,再到运行数据处理任务 的一切。
- Transports(传输):客户端与服务器之间通过 JSON-RPC 2.0 进行的请求、响应和通知,包括对服务器到客户端流式传输和其他自定义传输的支持(尚未提及 WebSockets/WebRTC…)。
- Sampling(采样):允许服务器通过客户端请求 LLM 补全,从而实现复杂的 Agent 行为(包括对 costPriority、speedPriority 和 intelligencePriority 进行评级,这暗示 Anthropic 很快将提供模型路由功能),同时保持安全性和隐私。
文档在安全考量、测试和动态工具发现方面给出了可靠的建议。
发布时的客户端展示了 这些功能实现的一系列有趣组合:
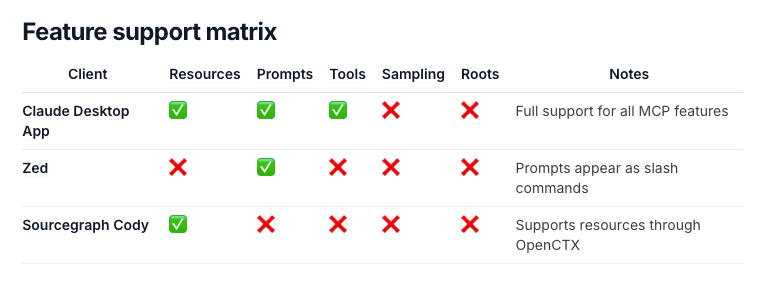
发布合作伙伴 Zed、Sourcegraph 和 Replit 都对其给出了好评,但也有人持 批评态度 或感到 困惑。Hacker News 已经联想到了 XKCD 927。
Glama.ai 已经 编写了一份很好的 MCP 指南/概述,Alex Albert 和 Matt Pocock 也都发布了精彩的入门视频。
AI Twitter 综述
所有综述均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
1. MCP 发布与反响:Anthropic 的 Model Context Protocol (MCP)
- Anthropic 推出 MCP:@alexalbert__ 讨论了 MCP,这是一个通过单一协议将 LLM 连接到数据资源的开放标准。他指出了其中的复杂性,并对其狭隘的供应商聚焦进行了批评。
- 对采用率的质疑:@hwchase17 将 MCP 与早期的 OpenAI 创新进行了对比,质疑其供应商排他性以及成为广泛标准的潜力。
- 开发者见解:@pirroh 反思了 MCP 与 Web 标准的相似之处,旨在确保不同 AI Agent 之间的互操作性。
2. 围绕 Claude 的兴奋点及 AI 能力讨论
- Claude 在 AI 集成中的潜力:@AmandaAskell 正在向社区征集能够增强特定任务性能和见解的 Claude Prompt。
- 能力与集成:@skirano 强调了 Claude 集成本地存储文件的能力,将其展示为基于 API 的 GUI 自动化的强大工具。
3. NeurIPS 与活动创新
- NeurIPS 2024 活动规划:@swyx 宣布了 Latent Space LIVE,这是一个形式新颖的周边活动,包含“Too Hot For NeurIPS”和“牛津式辩论”等独特环节,旨在实现有意义的互动和观众参与。
- 注册调整与讲者征集:@swyx 澄清了注册方面的困惑,并在活动筹备过程中敦促新的讲者申请。
4. 云端 AI 协作的投资与增长
- 亚马逊与 Anthropic 的战略举措:@andrew_n_carr 讨论了亚马逊对 Anthropic 的战略重点,强调了通过 AWS 的 Trainium 芯片进行的计算协作。
- 基础设施影响:@finbarrtimbers 分享了对 Trainium 潜力的看法,表达了对能与 Google TPU 相媲美的发展前景的期待。
5. 开源倡议与模型训练创新
- NuminaMath 数据集许可:@_lewtun 庆祝了 NuminaMath 数据集采用新的 Apache 2.0 许可证,这标志着数学问题数据集在开源方面的重大进展。
- AI 模型进展:如 @TheAITimeline 的综述等推文重点介绍了 LLaVA-o1 和 Marco-o1 等创新,为推理模型的讨论做出了贡献。
梗与幽默
- AI 能力鸭子:@arankomatsuzaki 以幽默的方式,通过俏皮的 AI 应用列表勾勒了 AI 趋势。
- 意想不到的场景:@mickeyxfriedman 分享了一个奇妙的互动,将幽默与意想不到的现实生活瞬间融合在一起。
AI Reddit 综述
/r/LocalLlama 综述
主题 1. Marco-o1 在网络测试中达到 83%:7B 模型 Chain-of-Thought 突破
- macro-o1(开源版 o1)对“9.9 和 9.11 哪个更大?”给出了最“可爱”的 AI 回答 :) (得分: 443, 评论: 87):Marco-o1 作为一个开源 AI 模型,通过回答 9.9 和 9.11 之间的数值比较问题,展示了 Chain-of-Thought 推理能力。由于帖子正文缺乏额外背景,关于回答内容或模型实现的具体细节无法包含在此摘要中。
- 用户注意到该模型表现出类似于自闭症的过度思考行为,许多评论者对其详细的思考过程产生共鸣。该模型对简单的 “Hi!” 的回答获得了显著关注,得到了 229 个赞成票。
- 技术讨论透露,该模型使用 Ollama 在 M1 Pro 芯片上运行,并配合一个启用 Chain-of-Thought 推理的 System Prompt。用户澄清这是 CoT 模型,而非尚未发布的 MCTS 模型。
- 该模型在处理数学和简单查询时表现最佳,展示了有趣但有时不必要的冗长推理。几位用户指出它在处理基础拼写任务(如计算“strawberry”中的字母数量)时表现吃力,这表明其可能存在训练局限性。
- 测试 LLM 的网络安全知识(测试了 15 个模型) (Score: 72, Comments: 17):一项针对 15 个不同 LLM 模型的基准测试,使用了 421 道 CompTIA 练习题。结果显示 o1-preview 以 95.72% 的准确率领先,随后是 Claude-3.5-October (92.92%) 和 o1-mini (92.87%)。测试揭示了一些意想不到的结果,marco-o1-7B 的得分低于预期,仅为 83.14%(落后于 Qwen2.5-7B 的 83.73%),而 Hunyuan-Large-389b 尽管体量巨大,但表现不佳,准确率为 88.60%。
- Marco-o1 模型的表现可以通过其基座模型是 Qwen2-7B-Instruct(而非 2.5 版本)来解释,且目前缺乏适当的搜索推理代码,使其本质上是一个 CoT finetune 实现。
- 用户建议测试更多模型,包括 WhiteRabbitNeo 专业模型和 DeepSeek 的深度思考版本,而其他人则指出需要考虑 CompTIA 题目是否可能存在于训练集中。
- 讨论强调了关注 AI 模型安全性测试的重要性,评论者指出这一领域需要更多关注,因为开发者在构建时往往不考虑安全因素。
主题 2. OuteTTS-0.2-500M:新型紧凑型文本转语音模型发布
- OuteTTS-0.2-500M:我们全新改进的轻量级文本转语音模型 (Score: 172, Comments: 29):OuteTTS 发布了其 500M 参数文本转语音模型的 0.2 版本。帖子中缺乏关于具体改进或技术细节的额外背景信息。
- 该模型支持通过参考音频进行语音克隆,相关文档可在 HuggingFace 上找到,不过对于 Emilia 数据集之外的声音,用户可能需要进行 finetune。
- 用户反馈尽管该模型只有 500M 参数,但表现良好,不过部分用户在 Gradio demo 上遇到了生成速度慢(14 秒音频约需 3 分钟)以及 attention mask 错误的问题。
- 围绕许可限制展开了讨论,因为该模型的非商业许可(继承自 Emilia 数据集)可能会限制其在 YouTube 视频等营利性内容中的使用,尽管像 Whisper 这样的类似模型使用的是网页抓取的训练数据。
主题 3. 小模型致胜:1.5B-3B LLM 展现出色的结果
- 这些微型模型非常令人印象深刻!大家都在用它们做什么? (Score: 28, Comments: 3):参数量在 1.5B 到 3B 之间的微型 LLM 在处理多个 function calls 时展现了出色的能力,其中 Gemma-2B 成功执行了 6 个并行 function calls,而其他模型则完成了 6 个中的 4 个。测试的模型包括 Gemma 2B (2.6GB)、Llama-3 3B (3.2GB)、Ministral 3B (3.3GB)、Qwen2.5 1.5B (1.8GB) 和 SmolLM2 1.7B (1.7GB),均显示出在特定领域应用中的潜力。
- 这些微型模型的本地部署能力提供了显著的隐私优势,并减少了对云端基础设施的依赖,使其在敏感应用中非常实用。
- 3B 参数模型被证明足以应对语法检查、文本摘要、代码补全和个人助手等常见用例,挑战了“模型越大越好”的观念。
- 这些较小模型的效率展示了成功的参数优化,在没有大型模型资源需求的情况下实现了目标功能。
- Teleut 7B - 在 Qwen 2.5 上复现 Tulu 3 SFT (得分: 55, 评论: 16): 一个名为 Teleut 的新型 7B 参数 LLM,在单个 8xH100 节点上使用 AllenAI 的数据混合 (data mixture) 进行训练,在包括 BBH (64.4%)、GSM8K (78.5%) 和 MMLU (73.2%) 在内的多个基准测试中,展现出足以与 Tülu 3 SFT 8B、Qwen 2.5 7B 和 Ministral 8B 等更大模型竞争的性能。该模型已在 Hugging Face 上发布,证明了使用 AllenAI 的公开训练数据可以复现 SOTA 性能。
- MMLU 在 7B 参数下达到 76% 的性能被认为是卓越的,因为这种水平此前仅由 32/34B 模型达到,尽管一些用户对这些对比指标的准确性表示怀疑。
- 用户指出 Qwen 2.5 Instruct 在大多数指标上优于 Teleut,从而对该模型相对于基础模型的实际改进以及结果的显著性提出了质疑。
- 社区对 AllenAI 在开放数据方面的贡献表示赞赏,Retis Labs 表示将根据社区需求为进一步研究提供额外的算力资源。
主题 4. 重大 LLM 开发工具发布:SmolLM2 & Optillm
- 完整的 LLM 训练与评估工具包 (得分: 41, 评论: 3): HuggingFace 在 smollm 以 Apache 2.0 许可证发布了完整的 SmolLM2 工具包,提供了全面的 LLM 开发工具,包括使用 nanotron 进行 pre-training、使用 lighteval 进行 evaluation,以及使用 distilabel 进行 synthetic data generation。该工具包还包括使用 TRL 和 alignment handbook 的 post-training 脚本,以及用于摘要和 Agent 等任务的 llama.cpp on-device tools。
- 用户询问了运行 SmolLM2 工具包 的最低硬件要求,尽管讨论中未提供官方规格。
- 在 Optillm 中使用 Chain-of-Code 推理在 AIME 2024 上超越 o1-preview (得分: 54, 评论: 7): Optillm 实现了 Chain-of-Code (CoC) 推理,在使用 Anthropic 和 DeepMind 的基础模型时,在 AIME 2024 (pass@1) 指标上超越了 OpenAI 的 o1-preview。该实现可在其 开源优化推理代理 (open-source optimizing inference proxy) 中获得,基于 Chain of Code 论文 的研究,并与 DeepSeek、Fireworks AI 和 NousResearch 最近发布的产品展开竞争。
- Chain-of-Code 的实现遵循结构化方法:从初始代码生成开始,随后是直接执行,然后是最多 3 次代码修复尝试,如果前面的步骤失败,最后进行基于 LLM 的模拟。
- OpenAI o1-preview 模型的创新更多被归结为“核算 (accounting)”而非能力提升,其架构可能整合了多个 Agent 和基础设施,而非单一模型的改进。
- 预测 Google 和 Anthropic 将超越 OpenAI 的下一代模型,同时基准测试的可靠性受到质疑,因为针对基准测试进行特定训练以及通过对齐技术掩盖分布变得越来越容易。
其他 AI 子版块回顾
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
主题 1. 中国 LLM 在基准测试中超越 Gemini:StepFun & Qwen
- 中国 LLMs 赶超美国 LLMs:Stepfun 排名高于 Gemini,Qwen 排名高于 4o (Score: 174, Comments: 75): 根据最近的基准测试,中国语言模型表现出极具竞争力的性能,Stepfun 的排名高于 Google 的 Gemini,而 Qwen 超过了 Claude 4.0。原始资料中未提供这些排名的具体指标和测试方法。
- 中国 AI 模型在现实世界中表现强劲,用户确认 Deepseek Coder 和 R1 等模型具有竞争力,尽管尚未超越 OpenAI 和 Anthropic。多位用户指出,最新的实验性模型提供了 2M context windows。
- 用户对 GPT-4 各版本的质量展开讨论,许多人报告 11 月版本的表现不如 8 月/5 月版本,特别是在文本分析任务中。一些人将其归因于为了优化实际使用而可能进行的模型尺寸缩减。
- 围绕美中 AI 竞争的讨论凸显了更广泛的技术竞争,引用 ASPI’s Tech Tracker 显示中国在战略技术方面取得进展,而美国在 AI/ML 和 semiconductors 等特定领域保持领先。
- 黄仁勋(Jensen Huang)表示 AI Scaling Laws 仍在继续,因为发展不仅发生在一个维度,而是三个维度:pre-training(类似于大学学位)、post-training(“深入某个领域”)和 test-time compute(“思考”) (Score: 66, Comments: 9): Jensen Huang 讨论了 AI scaling 的三个维度:pre-training(相当于通识教育)、post-training(领域专业化)和 test-time compute(主动处理)。他的分析表明,通过这些不同的发展路径,AI capabilities 将持续增长,反驳了关于达到 scaling limits 的论点。
- Jensen Huang 的分析符合 NVIDIA 的商业利益,因为每个 scaling 维度在实施和运行时都需要额外的 GPU compute resources。
- AI agents 的概念作为另一个潜在的 scaling 维度出现,专家建议未来的架构将由数千个专门模型组成,并由一个 state-of-the-art 控制器协调,以实现 AGI/ASI。
- 讨论强调了多种 scaling 方法(pre-training、post-training、test-time 和 agents)如何共同推动 GPU demand 的增长,从而支撑 NVIDIA 的市场地位。
{kind=link}
Theme 2. Flux 视频生成与风格迁移突破
- Flux + Regional Prompting ❄🔥 (Score: 263, Comments: 23): 标题中提到了 Flux 和 Regional Prompting,但正文中未提供额外背景或内容来生成有意义的摘要。
- 带有 Flux 工作流的 Regional Prompting 现在可以在 Patreon 上免费获取,尽管目前 LoRAs 与 regional prompting 配合使用时保真度会有所下降。推荐的方法是使用 regional prompting 进行基础构图,然后配合 LoRAs 进行 img-to-img 处理。
- YouTube 上提供了一份关于 ComfyUI 设置以及 Flux 与 SD 对比使用的全面教程,涵盖了安装、ComfyUI manager、默认工作流以及常见问题排查。
- 讨论涉及了现代内容变现,用户指出 2024 年的经济环境如何驱动创作者寻求多种收入来源,这与变现尚不普遍的 2000 年代初期形成了鲜明对比。
- LTX 时间对比:7900xtx vs 3090 vs 4090 (Score: 21, Comments: 23):AMD 7900xtx、NVIDIA RTX 3090 和 RTX 4090 在 Flux 和 LTX 视频生成方面的性能对比显示,4090 的表现显著优于其他型号,总处理时间为 6分15秒,而 3090 为 12分钟,7900xtx 为 27分30秒;在 Flux 上的具体迭代速度分别为 4.2it/s、1.76it/s 和 1.5it/s。作者指出,LTX 视频生成质量在很大程度上取决于 seed 运气和运动强度,剧烈运动会导致质量下降,而在 RunPod 上的整个测试花费了 1.32 美元。
- Triton Flash Attention 和 bf16-vae 优化有可能提高性能,后者可以通过
--bf16-vae命令行参数启用。Triton 的文档目前仅限于一个 GitHub Issue。 - 社区推测即将推出的 NVIDIA 5090 可以在大约 3分30秒 内完成测试,尽管人们对价格表示担忧。
- 关于 VAE 解码器和帧率优化的讨论建议通过后期处理速度调整来获得更好的结果,而高度的 seed 敏感性表明未来版本中需要改进模型。
- Triton Flash Attention 和 bf16-vae 优化有可能提高性能,后者可以通过
Theme 3. IntLoRA:内存高效的模型训练与推理
- IntLoRA: Integral Low-rank Adaptation of Quantized Diffusion Models (Score: 44, Comments: 6):IntLoRA 是一种针对扩散模型的新型量化技术,专注于通过低秩更新来适配量化模型。该技术的名称结合了“Integral”(积分/整数)与“LoRA”(Low-Rank Adaptation,低秩自适应),表明它处理的是模型适配中的基于整数的计算。
- IntLoRA 提供三个关键优势:量化的预训练权重以减少微调时的内存占用,预训练权重和低秩权重均采用 INT 存储,以及通过高效的整数乘法或位移实现无需训练后量化的合并推理。
- 该技术使用蜡笔盒类比进行解释,其中量化减少了颜色变化(例如更少的蓝色阴影),而低秩自适应识别出最重要的元素,使模型更高效且更易于使用。
- IntLoRA 使用辅助矩阵和方差匹配控制来进行组织和平衡,其功能类似于基础模型的 GGUF,但专门为扩散模型 LoRA 设计。
Theme 4. Anthropic 用于 Claude 集成的 Model Context Protocol
- Introducing the Model Context Protocol (Score: 26, Comments: 16):Model Context Protocol 发布以支持 Claude 集成,尽管帖子正文未提供具体细节。
- Model Context Protocol 允许 Claude 通过简单的 API 连接与本地系统(包括文件系统、SQL 服务器和 GitHub)进行交互,从而通过桌面应用实现基础的 Agent/工具功能。
- 实现过程需要通过
pip install uv安装以运行 MCP 服务器,设置说明可在 modelcontextprotocol.io/quickstart 找到。一个 SQLite3 连接示例通过 imgur 截图 进行了分享。 - 用户对实际应用表现出兴趣,包括使用它通过 GitHub 仓库连接来分析和修复 Bug 报告。
{kind=link}
AI Discord 摘要回顾
由 O1-preview 生成的摘要之摘要的摘要
主题 1. AI 模型变动引发用户社区动荡
- Cursor 削减长上下文模式,用户表示不满:Cursor 最近移除了长上下文模式(long context mode),特别是对 claude-3.5-200k 版本的影响,让用户感到沮丧并不得不匆忙调整工作流。虽然有推测认为这是向基于 Agent 的模型转变,但许多人对这一突然变化感到不满。
- Qwen 2.5 Coder 的性能波动令人困惑:用户在测试 Qwen 2.5 Coder 时感到困惑,注意到不同供应商与本地设置之间的 Benchmark 结果存在显著差异。这导致用户不断调整模型和设置,以追求一致的性能。
- GPT-4o 性能备受赞誉,令用户惊艳:
openai/gpt-4o-2024-11-20的发布赢得了用户的广泛赞誉,其令人印象深刻的性能使其成为社区中的首选。
主题 2. AI 工具与平台起伏不定
- LM Studio 模型搜索陷入僵局,用户感到迷茫:更新到 0.3.5 版本后,用户发现 LM Studio 的模型搜索功能受限,导致除非手动搜索,否则难以获取新模型,引发了混乱。
- OpenRouter API 因速率限制变得难以捉摸:用户遇到了 OpenRouter API 的速率限制(rate limit)问题,尽管有人提到私人协议可以提供更多灵活性,但这凸显了访问权限的不一致性。
- Aider 及其竞品辩论谁才是最强 IDE:Aider 用户将其与 Cursor 和 Windsurf 等工具进行比较,辩论它们在编程任务中的有效性,并指出 Copilot 可能落后于这些高级选项。
主题 3. 微调(Fine-Tuning)者面临重重考验
- Command R 微调者在困境中挣扎:尝试微调 Command R 模型的用户报告称,由于 max_output_token 限制,输出会过早停止。关于 EOS tokens 提前出现的假设引发了关于数据集配置的讨论。
- Windows 烦恼:Unsloth 用户与 Embedding 搏斗:用户在尝试使用输入 Embedding 而非 ID 时遇到困难,并在 Windows 上遇到模块错误,根据 Unsloth Notebooks 指南的建议,用户被引导转向 WSL 或 Linux。
- PDF 文件在模型微调中显得棘手:成员们考虑使用一份 80 页的公司规章 PDF 来微调模型,但由于数据提取和相关性方面的挑战,大家在讨论是否应转向 RAG 方法。
主题 4. 社区协作、共鸣与庆祝
- Prompt 骇客齐聚每周学习小组:爱好者们启动了一个每周学习小组,专注于 Prompt 骇客技术,旨在黑客松之前提升编程实践水平,并促进协作学习。
- Perplexity Pro 用户在故障与磨合中抱团:Perplexity Pro 用户面临功能故障,包括 Prompt 丢失和搜索问题,这促使社区内开展了经验分享和集体排错工作。
主题 5. AI 领域的伦理争议与治理抱怨
- ChatGPT 充当剽窃警察?教育工作者发声:尝试将 ChatGPT 配置为剽窃检测器的行为引发了关于使用 AI 进行学术诚信任务的伦理影响和可靠性的辩论。
- Mojo 的类型混淆让开发者摸不着头脑:关于 Mojo 类型系统的讨论揭示了
object和PyObject之间的混淆,引发了对动态类型处理和潜在线程安全问题的担忧。 - Notebook LM 的语言反复切换令用户沮丧:虽然一些人庆祝 Notebook LM 新增的多语言支持,但另一些人对摘要中不必要的语言切换表示沮丧,这影响了可用性,并导致用户呼吁改进语言控制功能。
第 1 部分:高层级 Discord 摘要
Cursor IDE Discord
-
Cursor 移除上下文模式:用户对 Cursor 最近移除 长上下文模式(long context mode) 感到 沮丧,尤其是 claude-3.5-200k 版本,这打乱了他们的工作流。
- 一些人推测转向基于 Agent 的模型可能会增强上下文检索,而另一些人则对失去原有功能感到不满。
-
Agent 功能挑战:多位用户报告了 Cursor 中 Agent 功能 的问题,指出存在 无响应行为 和非预期的任务结果。
- 用户对实现 自动批准 Agent 任务 以简化功能表现出显著兴趣。
-
Cursor 开发计划:开发者 正在利用 Cursor 构建创新项目,例如 AI 驱动的约会应用 和 犬种学习网站。
- 社区积极分享关于 Cursor 潜在应用的创意,融合了个人和专业项目。
-
Cursor 与 Windsurf 性能对比:用户正在辩论 Cursor 与 Windsurf 的 性能 和 实用性,寻求关于哪种工具能更好地服务 开发者 的见解。
- 虽然一些人因其能力而偏好 Cursor,但另一些人则因特定功能或个人体验而支持 Windsurf。
-
Cursor 更新与用户支持:关于更新到最新 Cursor 版本以及访问其新功能的 咨询 非常频繁,用户们正在分享资源和技巧。
- 社区成员互相帮助进行 故障排除,并应对更新带来的最新变化。
aider (Paul Gauthier) Discord
-
Qwen 2.5 Coder 性能困惑:用户对 Qwen 2.5 Coder 的性能表示困惑,注意到不同供应商和本地设置之间的 Benchmark 结果存在差异。
- 使用不同配置进行的测试显示出显著的性能差异,促使用户调整模型和设置以获得更好的结果。
-
本地模型挑战:用户报告了使用 Ollama 运行本地模型的困难,指出其性能比云端托管版本差。
- 对话强调了对更好配置的需求,并提出了在本地运行 Aider 模型的替代方案。
-
团队账户定价为每月 $30:团队账户 价格为每月 $30,每周允许 140 次 O1 请求,其他模型请求不限。
- 此次升级提供了更高的请求限制和更灵活的模型使用,增强了团队能力。
-
引入 Model Context Protocol:Anthropic 宣布开源 Model Context Protocol (MCP),这是一个旨在将 AI 助手连接到各种数据系统的标准。
- 该协议旨在用单一的通用标准取代碎片化的集成,改善 AI 对关键数据的访问。
-
理解 Benchmark
error_outputs:成员们询问了 Benchmark 结果中error_outputs的含义,质疑它反映的是模型错误还是 API/网络问题。- 澄清指出,这表示打印了错误(通常是 TimeoutErrors),并且 Aider 会重试这些情况。
HuggingFace Discord
-
访问受限的 Llama-2-7b 模型面临挑战:用户报告了在访问 meta-llama/Llama-2-7b 等受限模型(gated models)时遇到困难,出现了与文件缺失和权限相关的错误。
- 反馈包括用户对访问被拒绝的沮丧,以及建议使用替代的非受限模型来绕过这些限制。
-
Saplings 树搜索库:Saplings 是一个旨在利用简易树搜索算法构建更智能 AI Agent 的库,简化了高效 AI Agent 的创建过程。
- 该项目旨在提升 AI Agent 的性能,社区成员讨论了实现策略和潜在的用例。
-
在 Filecoin 上进行去中心化模型存储:用户正在采用 Filecoin 进行 AI 模型的去中心化存储,并指出存储成本已变得合理,目前已存储了近 1TB 的数据。
- 这种方法允许在一次性写入后免费获取模型,提高了可访问性和抗审查性。
-
SenTrEv Sentence Transformers 评估器:SenTrEv 是一个 Python 包,用于在 PDF 数据上对兼容 Sentence Transformers 的文本嵌入器(embedders)进行可定制化评估,提供详细的准确率和性能指标。
- 详细信息可在其 LinkedIn 帖子和 GitHub 仓库中找到。
-
HuggingFace TOP 300 趋势榜单:HuggingFace Trending TOP 300 Board 提供了一个展示热门 Spaces、Models 和 Datasets 的仪表板。
- 主要功能包括 AI Rising Rate(AI 上升率)和 AI Popularity Score(AI 受欢迎程度评分),用于评估上榜项目的增长潜力和流行度。
Unsloth AI (Daniel Han) Discord
-
使用 Unsloth 微调模型:一位成员询问如何微调模型以处理有关宝莱坞演员的 JSON 数据,其他成员引导其参考 Unsloth Notebooks 以获取用户友好的资源。
- 有建议指出,使用 RAG 可以简化与爬取数据交互的过程,从而优化微调工作流。
-
用于模型合并的 MergeKit:一位成员推荐使用来自 Arcee 的 MergeKit 来有效地合并预训练大语言模型,旨在提高指令模型的性能。
- 正如其 GitHub 页面所强调的,MergeKit 提供了合并预训练 LLM 的工具。
-
从 BERT 转向多任务模型:讨论涵盖了从 BERT 等需要独立分类头的单任务架构,向 T5 和集成文本生成能力的 decoder-only 架构等多任务模型的转变。
- 这种转变使模型能够在执行所有 BERT 功能的同时进行文本生成,简化了跨任务的模型使用。
-
用于混合检索的 RAG 策略:一位成员根据在化学研发等专业领域处理超过 500 份 PDF 的经验,提倡使用带有混合检索的 RAG 方法。
- 他们证实,即使在利基领域,利用强大的检索机制,这种方法也能增强问答生成(Q&A generation)。
-
在 LLM 中使用 Embeddings:一位用户寻求在 Hugging Face 上使用 LLM 生成文本时,使用输入 Embeddings 代替输入 IDs,引发了关于 Embedding 和 Tokenization 之间差异的讨论。
- 他们被引导至共享的 Google Colab Notebook 中的示例实现,以便更好地理解 Embedding 的用法。
Modular (Mojo 🔥) Discord
-
Mojo 类型系统重构:成员们讨论了 Mojo 的类型系统 的困惑点,重点强调了 object 和 PyObject 之间的区别;PyObject 直接映射到 CPython 类型,而 object 为了清晰起见可能需要重新设计。
- 讨论中提出了关于动态类型处理以及类型合并如何影响线程安全的担忧。
-
Mojo 中闭包语法的清晰度:参与者解释说,在 Mojo 中,语法
fn(Params) capturing -> Type表示一个闭包,并讨论了函数类型如何由来源、参数和返回类型决定。- 讨论中还将其与 Rust 在捕获闭包时的间接寻址方法进行了对比。
-
向量化与展开 (Unrolling) 策略:讨论对比了 @unroll 和 @parameter,指出两者都允许系统寻找并行性,但提供的控制级别不同。
- 共识是倾向于使用 vectorize 和 @parameter,因为它们比单纯使用 @unroll 具有更丰富的功能。
-
Mojo 成为 Python 超集的雄心:Mojo 旨在随着时间的推移成为 Python 的超集,初期专注于系统编程和 AI 性能特性,之后再全面支持动态类型。
- GitHub issue #3808 表明,由于现有的动态类型和语言人体工程学问题,实现完全的 Python 兼容性非常复杂。
-
Mojo 中的内存优化:一位用户分享了将问答机器人从 Python 移植到 Mojo 的经验,强调内存占用从 16GB 显著降低到了 2GB。
- 尽管在移植过程中遇到了段错误 (segmentation faults),但性能的提升使得研究迭代更加迅速。
OpenRouter (Alex Atallah) Discord
-
AI Commit 命令发布:推出了一款名为
cmai的新 CLI 工具,利用 OpenRouter API 生成 commit 信息,并支持 Bring Your Own Key (BYOK) 功能。- 该开源命令旨在简化 commit 信息编写过程,鼓励开发者社区贡献代码。
-
Toledo1 AI 采用按提问付费模式:Toledo1 提供了一种新颖的 AI 聊天体验,其特点是 按提问付费 (pay-per-question) 模式,并能够 结合多个 AI 以获得定制化响应。
- 用户可以在 toledo1.com 访问演示版本,并通过其 原生桌面应用 无缝集成该服务。
-
Hermes 增强功能提升 llama3.c 性能:对
llama3.c的修改在提示词处理中实现了惊人的 43.44 tok/s,超过了其他使用 Intel MKL 函数的实现。- 性能提升源于在矩阵计算中使用局部数组,显著增强了处理速度。
-
OpenRouter API 面临速率限制担忧:讨论揭示了 OpenRouter API 潜在的 速率限制 (rate limit) 问题,尽管一些回复表明存在提供灵活性的私有协议。
- 合同条款的可变性突显了 OpenRouter 与其供应商合作时的定制化方法。
-
Gemini 1.5 模型遭遇停机:用户报告收到来自 Gemini 1.5 模型的空响应,引发了对其运行状态的猜测。
- 然而,一些用户的确认表明该问题可能仅限于特定的配置环境。
OpenAI Discord
-
ChatGPT 作为抄袭检测器:用户探索了如何配置 ChatGPT 以使其具备抄袭检查功能,并为学术评估设定了特定的 JSON 输出结构。
- 然而,对于使用 AI 检测学术不端行为的伦理影响和可靠性,人们提出了担忧。
-
对 GPT-4o 版本的正面反馈:
openai/gpt-4o-2024-11-20版本的发布受到了成员们的赞赏,强调了其令人印象深刻的性能。- 用户指出 GPT-4o 提供了增强的功能,使其成为社区内的首选。
-
将自定义 GPT 与 Vertex 集成:一位成员询问了将他们的自定义 GPT 模型与 Vertex 连接的可行性,并得到了其他成员的指导。
- 回复中引用了 OpenAI 关于 actions 的文档,指出了可用于集成的现有资源。
-
Real-time API 在多媒体 AI 中的应用:讨论集中在 Real-time API 在多媒体 AI 中的应用,特别是针对需要低延迟的语音识别。
- 成员们澄清说,Real-time 指的是瞬时发生的过程,这对于多媒体内容的分类非常重要。
-
AI Agent 的记忆能力:参与者强调了 AI Agent 中记忆管理的重要性,并提到了聊天历史和上下文理解。
- 鼓励大家探索 OpenAI 的文档,以便在 AI 功能中更好地利用记忆框架。
Perplexity AI Discord
-
聊天机器人模型:Claude vs. Sonnet 3.5 vs GPT-4o:成员们辩论了不同聊天机器人模型的优势,指出 Claude 提供了更优质的输出,而 Sonnet 3.5 为学术写作增添了更多个性。此外,人们对 GPT-4o 的创意任务处理能力也表现出兴趣。
- 讨论强调了输出质量与个性化之间的权衡,一些用户支持 Claude 的可靠性,而另一些用户则更喜欢 Sonnet 3.5 引人入胜的回复。
-
亚马逊向 Anthropic 投资 40 亿美元:Amazon 宣布向 Anthropic 追加 40 亿美元投资,显示出对推进 AI 技术的强大信心。这笔资金预计将加速 Anthropic 的研发工作。
- 该投资旨在增强 Anthropic 创建更可靠、更可控的 AI 系统能力,促进 AI 工程社区内的创新。
-
API 更新影响 Llama-3.1 功能:最近的 API 变更影响了 Llama-3.1 模型的功能,用户报告称某些请求现在返回的是指令而非相关的搜索结果。支持的模型部分目前在定价页面下仅列出了三个在线模型。
- 用户注意到,尽管存在这些问题,目前尚未禁用任何模型,由于变更日志中未反映任何更新,这为过渡提供了一个缓冲期。
-
Perplexity Pro 用户面临功能问题:几位成员报告了 Perplexity Pro 的问题,特别是其在线搜索功能,导致一名用户建议联系客服。此外,刷新会话会导致长 Prompt 丢失,引发了对网站稳定性的担忧。
- 这些稳定性问题凸显了改进平台可靠性的必要性,以增强依赖这些工具的 AI Engineers 的用户体验。
-
最佳黑色星期五 VPS 优惠揭晓:成员们分享了关于最佳黑色星期五 VPS 优惠的见解,提到了显著的折扣,例如 You.Com 的 50% 折扣。这些优惠预计将为假期期间的技术爱好者节省大量开支。
- 讨论还比较了各种服务的有效性,表明了用户在选择 VPS 提供商时的多样化体验和偏好。
LM Studio Discord
-
LM Studio 中的模型搜索限制:在更新到 0.3.5 版本后,用户报告 LM Studio 中的模型搜索功能现在受到限制,导致对可用更新产生困惑。
- 自 0.3.3 版本以来,默认搜索仅包含已下载的模型,导致用户除非手动搜索,否则可能会错过新模型。
-
为 LLM 上下文上传文档:用户询问了关于上传文档以增强 LLM 上下文的问题,并获得了关于 0.3.5 更新中支持的文件格式(如
.docx、.pdf和.txt)的指导。- 官方文档已提供,强调上传文档可以显著改善 LLM 交互。
-
LM Studio 中的 GPU 兼容性和电源要求:讨论确认 LM Studio 支持广泛的 GPU,包括 RX 5600 XT,利用了高效的 llama.cpp Vulkan API。
- 对于配备 3090 等 GPU 和 5800x3D 等 CPU 的高端配置,成员建议电源供应单元 (PSU) 应保留约 80% 的容量作为缓冲。
-
GPU 价格飙升:成员们对 GPU 价格飞涨表示沮丧,特别是像 Pascal 系列这样的型号,认为它们性能低下且类似于电子垃圾。
- 社区一致认为目前的定价趋势是不可持续的,导致用户为高性能 GPU 支付了过高的费用。
-
PCIe 配置对性能的影响:讨论了与 LM Studio 相关的 PCIe 版本,成员指出它们主要影响模型加载时间,而不是推理速度。
- 澄清了使用 PCIe 3.0 不会阻碍推理性能,这使得带宽考虑在实时操作中变得不那么关键。
Eleuther Discord
-
Python 中的类型检查:成员们讨论了 Python 中类型提示 (type hinting) 的挑战,强调像 wandb 这样的库缺乏足够的类型检查,使集成变得复杂。
- 特别提到了微调中的 unsloth,由于其较新的状态,成员们对其表现出了更多的包容。
-
角色扮演项目协作:分享了 Our Brood 项目,重点是创建一个由 AI Agent 和人类参与者组成的、全天候运行 72 小时的协作抚育社区。
- 项目负责人正在寻找合作者来设置模型,并表示渴望与感兴趣的各方进行进一步讨论。
-
状态空间模型中的强化学习:关于使用强化学习 (Reinforcement Learning) 更新状态空间模型 (State-Space Models) 中隐藏状态的讨论建议,通过类似于随时间截断的反向传播 (truncated backpropagation through time) 的方法教模型预测状态更新。
- 一位成员提出将微调作为增强模型学习机器人策略的策略。
-
LLM 在压缩文本上的学习:成员们强调,在压缩文本上训练大语言模型 (LLM) 会由于非序列化数据的挑战而显著影响性能。
- 他们指出,在压缩序列关系的同时保持相关信息可以促进更有效的学习,正如 Training LLMs over Neurally Compressed Text 中所讨论的那样。
-
YAML 自洽性投票:一位成员确认 YAML 文件指定了跨所有任务重复的自洽性投票 (self-consistency voting),并询问如何在不显式列出每个重复的情况下获取平均 few-shot CoT 分数。
- 另一位成员指出,由于独立的过滤器管道会影响响应指标,因此情况比较复杂。
Nous Research AI Discord
-
Llama.cpp 中的自定义量化:针对 Llama.cpp 的自定义量化方案提出了一个 Pull Request,允许对模型参数进行更细粒度的控制。
- 讨论强调,关键层可以保持不量化,而较不重要的层可以被量化以减小模型大小。
-
LLM 谜题评估:一个过河谜题通过两个侧重于农夫行为和卷心菜命运的方案进行了评估,结果显示 LLMs 经常误解此类谜题。
- 反馈表明,像 deepseek-r1 和 o1-preview 这样的模型在正确理解谜题方面表现挣扎,这反映了人类在受限条件下进行推理时面临的挑战。
-
Anthropic 的模型进展:Anthropic 继续推进其模型,正如 Model Context Protocol 中提到的,他们正致力于自定义微调和模型改进。
- 社区讨论中提到,人们越来越关注通过结构化方法增强模型能力。
-
Hermes 3 概览:一位用户请求总结 Hermes 3 与其他 LLM 的不同之处,随后分享了 Nous Research 的 Hermes 3 页面。
- 一位 LLM 专家表达了对 Nous Research 的兴趣,突显了专家们对 Hermes 3 等新兴模型的参与度不断提高。
Notebook LM Discord Discord
-
“将笔记转换为源”功能:NotebookLM 推出了“Convert notes to source”功能,允许用户将笔记转换为单一源或手动选择笔记,每条笔记由分隔符分开并按日期命名。
- 该功能允许使用最新的聊天功能增强与笔记的交互,并作为一种备份方法,自动更新功能计划于 2025 年推出。
-
与 Wondercraft AI 的集成:Notebook LM 与 Wondercraft AI 集成以定制音频演示,使用户能够拼接自己的音频并操作语音。
- 虽然这种集成增强了音频定制能力,但用户也注意到了一些关于免费使用的限制。
-
播客的商业用途:讨论确认通过 Notebook LM 生成的内容可以进行商业发布,因为用户保留生成播客的所有权。
- 成员们正在基于这种内容所有权探索赞助和联盟营销等变现策略。
-
超速阅读 (Hyper-Reading) 博客见解:一位成员分享了一篇关于“Hyper-Reading”的博客文章,详细介绍了一种利用 AI 增强学习来阅读非虚构类书籍的现代方法。
- 博客概述了获取文本格式书籍并利用 NotebookLM 提高信息留存率的步骤。
-
Notebook LM 的语言支持:Notebook LM 现在支持多种语言,用户已成功在西班牙语下运行,但在意大利语摘要方面遇到了问题。
- 用户强调需要确保 AI 生成的摘要采用目标语言,以维持整体可用性。
Interconnects (Nathan Lambert) Discord
-
Optillm 通过 Chain-of-Code 表现优于 o1-preview:使用 Chain-of-Code (CoC) 插件,Optillm 在 AIME 2024 基准测试中超越了 OpenAI 的 o1-preview。
- Optillm 利用了来自 @AnthropicAI 和 @GoogleDeepMind 的 SOTA 模型,并参考了原始的 CoC 论文。
-
Google 整合研究人才:据推测 Google 已经收购了他们所有的研究人员,包括 Noam 和 Yi Tay 等知名人物。
- 如果属实,这突显了 Google 通过整合顶尖人才来增强其能力的战略。
-
Reka 与 Snowflake 的收购传闻:有传言称 Reka 被 Snowflake 收购(Acqui-hired),但交易并未达成。
- Nathan Lambert 对这次失败的收购尝试表示失望。
-
微软高管泄露 GPT-4 发布日期:一名 Microsoft 高管在德国泄露了 GPT-4 的发布日期,引发了对内部信息的担忧。
- 这一事件突显了科技组织内部信息泄露相关的风险。
-
推理者问题 (Reasoners Problem) 和 NATO 讨论:讨论了 Reasoners Problem,强调了其在 AI 研究中的影响。
- 在技术或安全背景下简要提到了 NATO,暗示了更广泛的技术格局影响。
Cohere Discord
-
Command R 微调挑战:一名成员报告称,微调后的 Command R 模型在生成过程中因达到 max_output_token 限制而导致输出过早停止。
- 另一名成员建议 EOS token 可能是导致过早终止的原因,并请求提供数据集详情以进行进一步调查。
-
Cohere API 输出不一致:用户遇到 Cohere API 响应不完整的问题,而 Claude 和 ChatGPT 的集成运行正常。
- 尽管多次尝试不同的 API 调用,内容不完整的问题依然存在,这表明可能存在潜在的 API 限制。
-
在 Vercel 上部署 Cohere API:一名开发者在 Vercel 上部署使用 Cohere API 的 React 应用程序时,遇到了与客户端实例化相关的 500 错误。
- 他们指出,该应用程序在本地使用独立的 server.js 文件时运行正常,但在配置其在 Vercel 平台上运行时面临挑战。
-
批处理与 LLM 作为裁判的方法:一名成员分享了他们使用 batching plus LLM 作为裁判的方法,并就微调一致性寻求反馈,强调了 command-r-plus 模型的幻觉问题。
- 作为回应,另一名成员建议在海量多智能体(multi-agent)设置中使用 Langchain,以潜在地解决观察到的挑战。
-
多智能体设置建议:一名成员建议在实施 LLM 作为裁判的批处理方法时,探索大规模多智能体(multi-agent)设置。
- 他们还询问“裁判”角色是否仅仅是在分析后给出通过或失败,以寻求对其功能的明确说明。
Stability.ai (Stable Diffusion) Discord
-
初学者寻求学习资源:新用户在图像创建方面遇到困难,正在寻求初学者指南以有效地使用这些工具。
- 一项建议强调观看初学者指南,因为它们为新手提供了更清晰的视角。
-
A1111 中的 ControlNet 放大:一名成员询问在利用 Depth 等 ControlNet 功能时,如何在 A1111 中启用 upscale。
- 另一名成员警告不要通过私信交流以避免诈骗者,并将原帖作者引导至支持频道。
-
用于自动化视频创建的 Buzzflix.ai:一名成员分享了 Buzzflix.ai 的链接,该工具可自动为 TikTok 和 YouTube 创建病毒式无脸视频。
- 他们对其将频道发展到数百万观看量的潜力表示惊讶,并指出这感觉像是一种作弊。
-
Hugging Face 网站困惑:成员们对 Hugging Face 网站表示困惑,特别是缺少“关于”部分以及模型的定价详情。
- 成员们对网站的可访问性和可用性表示担忧,并建议提供更好的文档和用户指导。
-
垃圾好友请求担忧:用户报告收到可疑的好友请求,怀疑可能是垃圾信息。
- 谈话引起了轻松的回应,但许多人对这些未经请求的请求表示担忧。
GPU MODE Discord
-
Grouped GEMM 在 fp8 加速方面遇到困难:一名成员报告称,在他们的 Grouped GEMM 示例中,fp8 相比 fp16 无法实现加速,因此需要调整 strides。
- 他们强调需要将 B 的 strides 设置为 (1, 4096),并提供主维度和次维度的 strides 以进行正确配置。
-
Triton 与 TPU 的兼容性:另一名成员询问了 Triton 与 TPU 的兼容性,表示有兴趣在 TPU 硬件上利用 Triton 的功能。
- 讨论指向了关于 Triton 在 TPU 设置上的性能 的潜在未来开发或社区见解。
-
CUDA 模拟在没有延迟的情况下产生奇怪的结果:一位用户观察到,快速连续运行 CUDA 模拟 会导致奇怪的结果,但引入 一秒延迟 可以缓解该问题。
- 这一行为是在检查随机过程性能时注意到的。
-
Torchao 在 GPTFast 中表现出色:讨论集中在 Torchao 集成到 GPTFast 的潜力,可能会利用 Flash Attention 3 FP8。
- 成员们对这种集成及其对效率的影响表示了兴趣。
-
理解技术中的数据依赖性:一名成员询问了数据依赖(data dependent)技术在稀疏化校准(sparsification calibration)期间或之后进行微调的必要性方面的含义。
- 这引发了关于此类技术对性能和准确性影响的讨论。
tinygrad (George Hotz) Discord
-
将 Flash-Attention 集成到 tinygrad:提议将 Flash-attention 引入 tinygrad 以增强注意力机制的效率。
- 一名成员提出了集成 flash-attention 的可能性,尽管讨论未涉及具体的实现细节。
-
扩展 nn/onnx.py 中的操作:讨论了在 nn/onnx.py 中添加 instancenorm 和 groupnorm 操作,旨在扩展功能。
- 成员对 ONNX 独有模式日益增加的复杂性 以及这些新增功能的 测试覆盖不足 表示了担忧。
-
实现符号化多维交换:寻求关于使用
swap(self, axis, i, j)方法执行符号化多维元素交换的指导,以便在不改变底层数组的情况下操作 views。- 为创建特定轴 views 而提议的符号突显了执行策略中对清晰度的需求。
-
开发 Radix Sort 原型函数:展示了一个可运行的 radix sort 原型,能够高效处理非负整数,并提出了潜在的优化建议。
- 有人提出了关于扩展排序函数以处理负数和浮点值的问题,并建议加入 scatter 操作。
-
评估 Radix Sort 中的 Kernel 启动:询问了在 radix sort 执行期间评估 kernel 启动次数的方法,考虑了调试技术和 big-O 估计。
- 关于为了效率目的,原地修改(in-place modification)与在 kernel 执行前进行输入 tensor 复制的优劣展开了辩论。
LLM Agents (Berkeley MOOC) Discord
-
计算资源申请今日截止:各团队必须在今天结束前通过此链接提交 GPU/CPU Compute Resources Form,以确保获得 Hackathon 所需的计算资源。
- 该截止日期是为了确保资源分配得到有效管理,让各团队能够毫无延迟地推进项目。
-
第 11 讲:Benjamin Mann 谈 AI Safety:第 11 讲由 Benjamin Mann 主讲,讨论 Responsible Scaling Policy、AI safety governance 以及 Agent capability measurement,直播地址在这里。
- Mann 将分享他在 OpenAI 期间关于在保持系统安全和控制的同时衡量 AI 能力的见解。
-
每周 Prompt Hacking 学习小组:启动了一个每周学习小组,专注于 Prompt Hacking 技术,会议将在 1.5 小时后开始,可通过此 Discord 链接加入。
- 参与者将探索讲座中的实际代码示例,以增强他们在 Hackathon 中的编程实践。
-
GSM8K 测试集成本分析:一项分析显示,基于当前的 GPT-4o 定价,在 GSM8K 1k 测试集上进行一次推理运行的成本约为 $0.66。
- 此外,实施自我纠正(self-correction)方法可能会使输出成本随纠正次数成比例增加。
Axolotl AI Discord
-
PDF Fine-Tuning 咨询:一位成员询问如何使用包含公司规章和内部数据的 80 页 PDF 生成用于 Fine-Tuning 模型的指令数据集。
- 他们特别想知道文档中带有标题和副标题的结构是否有助于使用 LangChain 进行处理。
-
PDF 数据提取的挑战:另一位成员建议检查能从 PDF 中提取多少信息,并指出某些文档——尤其是包含表格或图表的文档——较难读取。
- 从 PDF 中提取相关数据的难度因其布局和复杂程度而异。
-
RAG 与 Fine-Tuning 之争:一位成员分享到,虽然可以使用 PDF 数据对模型进行 Fine-Tuning,但使用 RAG (Retrieval-Augmented Generation) 可能会产生更好的效果。
- 这种方法为将外部数据整合到模型性能中提供了一种增强方案。
LlamaIndex Discord
-
AI 工具调查合作伙伴关系启动:与 Vellum AI、FireworksAI HQ 和 Weaviate IO 合作开展了一项关于开发者所用 AI 工具的 4 分钟调查,参与者有机会赢取 MacBook Pro M4。
- 该调查涵盖了受访者的 AI 开发历程、团队结构和技术使用情况,访问地址在这里。
-
RAG 应用研讨会排期:欢迎在 12 月 5 日上午 9 点(太平洋时间)参加由 MongoDB 和 LlamaIndex 举办的研讨会,主题是如何将 RAG 应用从基础转向 Agentic。
- 本次会议由来自 LlamaIndex 的 Laurie Voss 和来自 MongoDB 的 Anaiya Raisinghani 主讲,将提供详细见解。
-
加密货币初创公司寻求天使投资人:一位成员宣布其位于旧金山的跨链 DEX 初创公司正在寻求 A 轮融资,并希望与加密基础设施领域的天使投资人建立联系。
- 他们鼓励感兴趣的人士与其联系(HMU),表示已准备好进行投资洽谈。
-
全栈工程师寻求机会:一位在 Web 应用开发和区块链技术方面拥有 6 年以上经验的资深 Full Stack Software Engineer 正在寻找全职或兼职职位。
- 他们强调了在 JavaScript 框架、智能合约以及各种云服务方面的熟练程度,渴望讨论潜在的团队贡献。
Torchtune Discord
- 自定义参考模型的影响:一名成员发起了一个关于自定义参考模型 (custom reference models) 影响的议题,建议现在是时候加入这一考量了。
- 他们强调了这些模型在当前背景下的潜在有效性。
- 全量微调配方开发:一名成员表示需要全量微调 (full-finetune) 配方,并承认目前尚不存在此类配方。
- 他们提议修改现有的 LoRA recipes 以支持这种方法,并主张由于该技术较新,应保持谨慎。
- Pip-extra 工具加速开发:集成 pip-extra tools、pyenv 和 poetry 可以通过高效的错误修复实现更快的开发过程。
- 然而,一些人对 poetry 与其他工具相比的未来设计方向表示怀疑。
- 类 Rust 特性吸引开发者:该设置类似于 cargo 和 pubdev,迎合了 Rust 开发者。
- 这种相似性突显了不同编程语言在包和依赖管理工具上的趋同。
- uv.lock 和缓存提升效率:利用 uv.lock 和缓存增强了项目管理的速度和效率。
- 这些功能简化了工作流,确保常用任务能够更迅速地处理。
DSPy Discord
- 寻求合成数据论文:一名成员请求一篇论文,以了解合成数据生成 (synthetic data generation) 的工作原理。
- 这反映了人们对合成数据原理及其应用日益增长的兴趣。
- 合成数据生成的意义:该请求表明对数据生成技术的深入探索正在进行中。
- 成员们指出,理解这些技术对于未来的项目至关重要。
LAION Discord
- 与基础模型开发者合作:一名成员正在寻找基础模型 (foundation model) 开发者寻求合作机会,并为潜在项目提供超过 8000 万张带标签的图像。
- 他们还强调可以根据需求提供数千种小众摄影选项,为基础模型领域的开发者提供了宝贵的资源。
- 按需提供小众摄影服务:一名成员提供数千种小众摄影选项,为模型训练和开发提供资源。
- 这项服务为基础模型领域的开发者增强其项目提供了独特的机会。
Mozilla AI Discord
- Lumigator 技术演讲优化 LLM 选择:加入工程师关于 Lumigator 的深入技术演讲。这是一个强大的开源工具,旨在帮助开发者为项目选择最佳的 LLMs,其路线图目标是在 2025 年初正式发布 (General Availability)。
- 本次会议将展示 Lumigator 的功能,演示实际使用场景,并概述计划在 2025 年初实现更广泛可用性的路线图。
- Lumigator 推动伦理 AI 开发:Lumigator 旨在演变成一个全面的开源产品,支持伦理和透明的 AI 开发,填补当前工具链中的空白。
- 该倡议专注于建立对开发工具的信任,确保解决方案与开发者的价值观保持一致。
AI21 Labs (Jamba) Discord
- 对 API Key 生成的困惑:一名成员对网站上的 API key 生成问题表示沮丧,询问是自己的操作失误还是外部问题。
- 他们向社区成员寻求关于 API key 生成过程可靠性的澄清。
- 请求协助解决 API Key 问题:该成员促使他人对网站 API key 生成功能的潜在问题提供见解。
- 一些参与者分享了他们的经验,暗示该问题可能是暂时的,或与特定配置有关。
MLOps @Chipro Discord 没有新消息。如果该服务器长时间保持沉默,请告知我们,我们将将其移除。
OpenInterpreter Discord 没有新消息。如果该服务器长时间保持沉默,请告知我们,我们将将其移除。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该服务器长时间保持沉默,请告知我们,我们将将其移除。
第 2 部分:各频道详细摘要与链接
完整的逐频道细分内容已针对电子邮件进行了截断。
如果您喜欢 AInews,请分享给朋友!预先感谢!