ainews-olmo-2-new-sota-fully-open-model
OLMo 2 —— 全新 SOTA 级完全开源大语言模型
AI2 已将 OLMo-2 更新至大致相当于 Llama 3.1 8B 的水平。该模型采用了 5万亿 (5T) token 进行训练,并应用了学习率退火技术和全新的高质量数据集 (Dolmino)。他们将其进步归功于 Tülu 3 及其“带可验证奖励的强化学习”(Reinforcement Learning with Verifiable Rewards)方法。
在 Reddit 上,Qwen2.5-72B-Instruct 模型在经过 AutoRound 4位量化后表现出近乎无损的性能;该模型目前已在 HuggingFace 上提供 4位和 2位版本,社区正围绕其 MMLU 基准测试和量化感知训练展开讨论。
此外,HuggingFace 发布了 SmolVLM,这是一款拥有 20亿 (2B) 参数的视觉语言模型,可在消费级 GPU 上高效运行。它支持在 Google Colab 上进行微调,并凭借可调节的分辨率和量化选项展示了强大的 OCR(光学字符识别)能力。
Reinforcement Learning with Verifiable Rewards is all you need.
2024/11/26-2024/11/27 的 AI 新闻。我们为您检查了 7 个 Reddit 社区、433 个 Twitter 账号 和 29 个 Discord 社区(197 个频道,2528 条消息)。为您节省了约 318 分钟 的阅读时间(以 200wpm 计算)。您现在可以标记 @smol_ai 进行 AINews 讨论!
AI2 以拥有完全开放的模型而闻名——不仅是开放权重,还包括开放数据、代码以及其他一切。我们上次在 2 月报道了 OLMo 1,4 月报道了 OpenELM。现在看来 AI2 已经将 OLMo-2 更新到了大致相当于 Llama 3.1 8B 的水平。
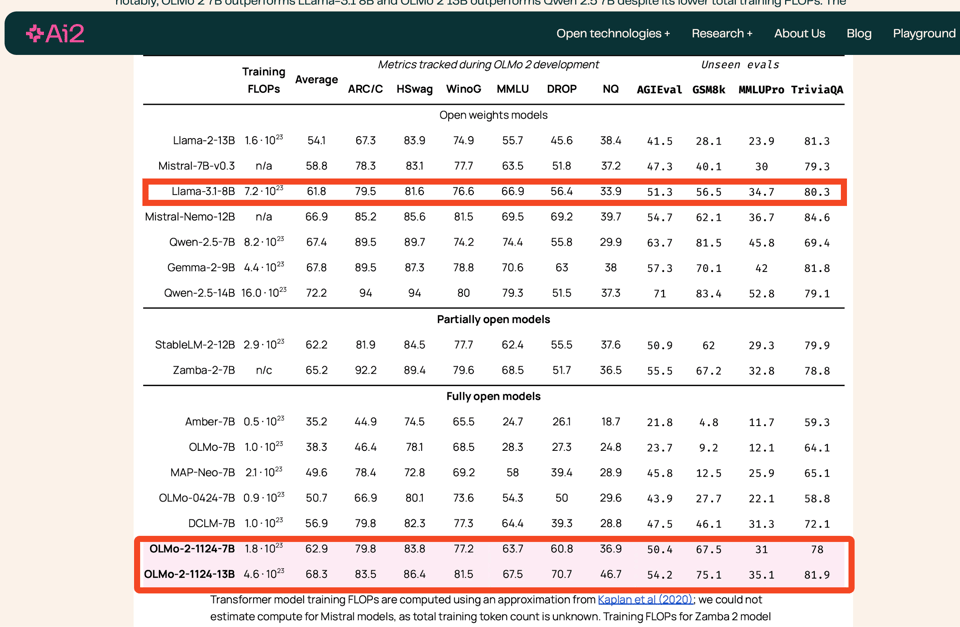
他们使用了 5T tokens 进行训练,特别采用了 learning rate annealing,并在 pretraining 结束时引入了新的高质量数据 (Dolmino)。完整的技术报告即将发布,因此我们了解的细节还不算多,但 post-training 归功于 Tülu 3,使用了他们上周刚刚宣布的 “Reinforcement Learning with Verifiable Rewards”(论文在此,推文在此)(当然也附带了 开源数据集)。

AI Twitter 回顾
所有总结均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
待完成
AI Reddit 回顾
/r/LocalLlama 回顾
主题 1. AutoRound 4-bit Quantization:Qwen2.5-72B 的无损性能
- 大模型的无损 4-bit Quantization,我们达到了吗? (评分: 118, 评论: 66): 在 Qwen2.5-72B instruct 模型上使用 AutoRound 进行 4-bit Quantization 的实验表明,即使没有优化 quantization 超参数,其性能也与原始模型持平。Quantized 模型已在 HuggingFace 上提供 4-bit 和 2-bit 版本。
- 讨论了 MMLU benchmark 测试方法,原帖作者确认了 0-shot 设置并引用了 Intel 的类似发现。批评者指出 MMLU 对大模型来说可能太“简单”了,建议尝试 MMLU Pro。
- Qwen2.5 模型表现出优于 Llama3.1 或 Gemma2 等其他模型的独特 quantization 韧性,用户推测其在训练时使用了 quantization-aware 技术。这在 Qwen Coder 的性能结果中尤为明显。
- 讨论集中在“无损”这一术语上,用户解释说 quantization 本质上是有损的(类似于 128kbps AAC 压缩),尽管性能影响因任务而异——对于简单查询影响极小,但对于代码重构等复杂任务可能影响显著。
主题 2. SmolVLM:在消费级硬件上运行的 2B 参数 Vision Model
- 隆重推出 Hugging Face 的 SmolVLM! (Score: 115, Comments: 12): HuggingFace 发布了 SmolVLM,这是一个 2B 参数的视觉语言模型,其 Token 生成速度比 Qwen2-VL 快 7.5-16 倍,在 Macbook 上可达 17 tokens/sec。该模型可以在 Google Colab 上进行微调,在消费级 GPU 上处理数百万个文档,尽管没有经过视频训练,但在视频基准测试中表现优于更大的模型。相关资源可在 HuggingFace 博客 和 模型页面 获取。
- SmolVLM 最少需要 5.02GB GPU RAM,但用户可以使用
size={"longest_edge": N*384}参数调整图像分辨率,并利用 bitsandbytes、torchao 或 Quanto 进行 4/8-bit 量化以降低内存需求。 - 该模型在关注特定段落时表现出强大的 OCR 能力,但在全屏文本识别方面表现欠佳,这可能是由于默认分辨率限制为 1536×1536 像素 (N=4) 导致的,为了获得更好的文档处理效果,可以将其增加到 1920×1920 (N=5)。
- 用户认为 SmolVLM 优于 mini-cpm-V-2.6,并指出了其准确的图像描述能力和更广泛的应用潜力。
- SmolVLM 最少需要 5.02GB GPU RAM,但用户可以使用
Theme 3. MLX LM 0.20.1 追平 llama.cpp Flash Attention 速度
- MLX LM 0.20.1 的速度终于可以与开启 flash attention 的 llama.cpp 媲美了! (Score: 84, Comments: 22): MLX LM 0.20.1 展示了显著的性能提升,4-bit 模型的生成速度从 22.569 提升至 33.269 tokens-per-second,达到了与开启 flash attention 的 llama.cpp 相当的速度。此次更新对 8-bit 模型也有类似的提升,生成速度从 18.505 增加到 25.236 tokens-per-second,同时保持 Prompt 处理速度在 425-433 tokens-per-second 左右。
- 用户讨论了 MLX 和 GGUF 格式之间的量化差异,指出 Qwen 2.5 32B 模型可能存在质量差异,且 8-bit MLX 版本相比 Q8_0 GGUF 具有更高的 RAM 占用(70+ GB)。
- llama.cpp 发布了其 speculative decoding server 实现,在 RAM 充足的情况下性能可能优于 MLX。讨论帖 提供了更多细节。
- 性能优化技巧包括使用命令
sudo sysctl iogpu.wired_limit_mb=40960增加 Apple Silicon 上的 GPU 内存限制,以允许高达 40GB 的 GPU 内存使用。
Theme 4. MoDEM:领域特定模型之间的路由表现优于通用模型
- MoDEM: Mixture of Domain Expert Models (Score: 76, Comments: 47): MoDEM 研究表明,在领域特定微调模型之间进行路由的表现优于通用模型。该系统通过将查询根据其专业领域定向到特定模型来取得成功。该论文提出了一种替代大型通用模型的方法,即使用微调的小型模型结合轻量级路由 (router),这对于计算资源有限的开源 AI 开发尤为重要。研究结果可在 arXiv 查看。
- 行业专业人士表示,这种架构在生产环境中已经很常见,特别是在数据网格 (data mesh) 系统中,一些实现在物流数字孪生等领域运行着数千个 ML 模型。该方法还包括决策器 (deciders)、排名系统和 QA 检查等额外组件。
- WilmerAI 展示了一个使用多个基础模型的实际实现:Llama3.1 70b 用于对话,Qwen2.5b 72b 用于代码/推理/数学,以及 Command-R 配合 离线维基百科 API 用于事实性回答。
- 讨论了技术限制,包括加载多个专家模型时的 VRAM 限制以及模型合并 (model merging) 的挑战。用户建议使用带有共享基础模型的 LoRAs 作为潜在解决方案,并参考了 Apple 的智能系统 (Apple Intelligence system) 作为示例。
其他 AI 子版块回顾
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
主题 1. Anthropic 为 Claude 发布 Model Context Protocol
- 介绍 Model Context Protocol (Score: 106, Comments: 37): Model Context Protocol (MCP) 似乎是一个用于文件和数据访问的协议,但帖子正文中未提供额外的上下文或详细信息来创建有意义的摘要。
- MCP 使 Claude Desktop 能够通过 API 与本地文件系统、SQL servers 和 GitHub 进行交互,从而促进 mini-agent/tool 的使用。实现该功能需要参考 快速入门指南 并运行
pip install uv来设置 MCP server。 - 用户反馈 文件服务器功能 的成功率参差不齐,特别是在 Windows 系统上存在问题。尽管日志显示服务器连接成功,但仍有几位用户遇到了连接问题。
- 该协议可通过桌面应用程序配合普通的 Claude Pro 账户 使用,无需额外的 API 访问权限。用户表示有兴趣将其用于 代码测试、错误修复 和 项目目录访问。
- MCP 使 Claude Desktop 能够通过 API 与本地文件系统、SQL servers 和 GitHub 进行交互,从而促进 mini-agent/tool 的使用。实现该功能需要参考 快速入门指南 并运行
-
Model Context Protocol (MCP) 快速入门 (Score: 64, Comments: 2): 关于 Model Context Protocol (MCP) 的帖子正文中似乎没有内容或文档。未提供可供总结的技术细节或快速入门信息。
- 有了 MCP,Claude 现在可以直接处理本地文件——无缝地创建、读取和编辑。 (Score: 23, Comments: 11): Claude 通过 MCP 获得了直接操作本地文件的能力,实现了文件创建、读取和编辑功能。帖子正文中未提供额外的上下文或细节。
- 用户对 Claude 通过 MCP 实现的新文件操作功能表示兴奋,尽管提供的实质性讨论较少。
- 一个 Mac 兼容版本 的功能通过 Twitter 链接 进行了分享。
主题 2. ChatGPT 和 Claude 的重大服务中断
- gpt 挂了吗? (Score: 38, Comments: 30): ChatGPT 用户报告了影响 Web 界面 和 移动端 App 的服务中断。此次停机导致用户无法通过任何方式访问平台。
- 包括 墨西哥 在内的不同地区的多个用户确认了 ChatGPT 停机,用户在对话中途收到错误消息。
- 用户无法从 ChatGPT 获取回复,一位用户分享了他们在对话过程中收到的错误消息 截图。
- 报告的广泛性表明这是一次 全球性的服务中断,而非局部问题。
- 不!!😿 (Score: 135, Comments: 45): Claude 的母公司 Anthropic 由于容量限制,正在限制对其 Sonnet 3.5 模型 的访问。帖子作者表达了失望,并希望有经济能力来维持对该模型的访问。
- 多名用户报告称,Pro 级别 对 Sonnet 3.5 的访问并不稳定,存在随机的额度限制和访问拒绝,导致一些用户转回使用 ChatGPT。一个 讨论 Opus 限制的帖子 被分享出来以记录这些问题。
- API 按需付费 (pay-as-you-go) 系统成为一种更可靠的替代方案,用户报告成本为 每个 prompt 0.01-0.02 美元,10 美元 可以维持一个多月。用户可以通过 LibreChat 等工具来实现这一点,以获得更好的界面。
- 对于免费用户来说,对 Sonnet 的访问似乎是 取决于账户 的,不同账户的可用性不一致。一些用户认为可能存在一种未公开的 分流指标 (triage metric) 来决定访问模式。
{kind=link}
{kind=link}
{kind=link}
主题 3. MIT 博士的开源 LLM 训练系列
-
**[D] Graduated from MIT with a PhD in ML Teaching you how to build an entire LLM from scratch** (Score: 301, Comments: 72): 一位 MIT PhD 毕业生创建了一个 15 部分的系列视频,教授如何在不使用库的情况下从头开始构建 Large Language Models。内容涵盖了从基础概念到实现细节,包括 tokenization、embeddings 和 attention mechanisms。该系列既提供了理论性的白板讲解,也提供了实际的 Python 代码实现,从 Lecture 1 的基础知识一直进展到 Lecture 15 中带有 key, query, and value matrices 的 self-attention 等高级概念。 - 多位用户对创作者的 credibility 提出了质疑,指出其 PhD 学位属于 Computational Science and Engineering 而非 ML,并指出其缺乏 LLM research 相关的发表论文。一些人推荐将 Andrej Karpathy’s lectures 作为更权威的替代方案,可通过 他的 YouTube 频道 观看。
- 讨论揭示了对 academic misrepresentation 的担忧,用户指出创作者的 NeurIPS 论文实际上是 workshop 论文而非主会论文,并对其近期发布的关于 Adam optimizer 等基础概念的帖子表示怀疑。
- 用户讨论了 MIT 背景在 LLM 领域的具体价值,一些人指出机构声望并不一定与每个子领域的专业知识挂钩。对话强调了学术资历如何可能被误用于营销目的。
Theme 4. Qwen2VL-Flux: New Open-Source Image Model
- Open Sourcing Qwen2VL-Flux: Replacing Flux’s Text Encoder with Qwen2VL-7B (Score: 96, Comments: 34): Qwen2vl-Flux 是一款新型开源图像生成模型,它将 Stable Diffusion 的 t5 text encoder 替换为 Qwen2VL-7B,以实现多模态生成能力,包括无需文本提示的直接图像变体生成、视觉-语言融合,以及用于精确风格修改的 GridDot 控制面板。该模型可在 Hugging Face 和 GitHub 上获取,集成了 ControlNet 用于结构引导,并提供智能风格迁移、文本引导生成和基于网格的 attention 控制等功能。
- 48GB+ 的 VRAM requirements 被强调为许多用户的主要限制,使得该模型在消费级硬件上难以运行。
- 用户询问了关于 ComfyUI 的兼容性以及使用自定义微调的 Flux 或 LoRA 模型的能力,表明了对集成到现有工作流中的浓厚兴趣。
- 社区反应显示出热情,但也对新模型发布的速度感到应接不暇,特别是提到了 Flux Redux 以及紧跟 SOTA 进展的挑战。
AI Discord 摘要
由 O1-preview 生成的摘要之摘要的总结
主题 1:AI 模型更新与发布
- Cursor 0.43 更新:新功能伴随 Bug 现身:Cursor IDE 的最新更新引入了全新的 Composer UI 和早期的 Agent 功能,但用户反馈缺少了“Add to chat”等功能,并遇到了阻碍生产力的 Bug。
- Allen AI 推出 OLMo 2,加冕开源模型冠军:Allen AI 发布了 OLMo 2,并称其为迄今为止最好的全开源语言模型,拥有 7B 和 13B 版本,训练数据量高达 5 万亿 Token。
- Stable Diffusion 3.5 迎来 ControlNets,艺术家们的福音:Stability.ai 为 Stable Diffusion 3.5 Large 增强了新的 ControlNets——Blur、Canny 和 Depth,可在 HuggingFace 下载并支持 ComfyUI。
主题 2:技术问题与性能增强
- Unsloth 修复 Qwen2.5 Tokenizer Bug,开发者欢呼:Unsloth 修复了 Qwen2.5 模型中的多个问题,包括 Tokenizer 问题,如 Daniel Han 的视频中所述,增强了兼容性和性能。
-
PyTorch 通过 FP8 和 FSDP2 提升训练速度,GPU 压力大减:PyTorch 的 FP8 训练更新显示,通过使用 FSDP2、DTensor 和
torch.compile,吞吐量提升了 50%,能够高效训练高达 405B 参数的模型。 - AMD GPU 表现滞后,ROCm 令用户愤怒:尽管 LM Studio 支持多 GPU,但用户报告称 AMD GPU 由于 ROCm 的性能限制而表现不佳,导致 AI 任务运行缓慢且令人沮丧。
主题 3:社区关注与反馈
-
Cursor 用户要求更好的沟通,渴望支持渠道:面对 Bug 和功能缺失,Cursor IDE 用户呼吁改进关于更新和问题的沟通,建议设立专门的支持频道来解决疑虑。
-
Stability.ai 支持陷入沉默,用户无助:用户对 Stability.ai 未回复邮件以及在支持和发票问题上缺乏沟通表示沮丧,对公司的参与度产生怀疑。
-
Cohere API 限制阻碍学生项目,寻求支持:一名开发葡萄牙语文本分类器的学生达到了 Cohere 的 API Key 限制且没有升级选项,引发社区建议其联系支持部门或探索开源替代方案。
主题 4:AI 应用进展
- AI 奏响旋律:MusicGen 实现续写:成员们讨论了能够续写音乐作品的 AI 模型,分享了 Hugging Face 上的 MusicGen-Continuation 等工具,以增强创意工作流。
- NotebookLM 将文本转为播客,内容创作者庆祝:用户利用 NotebookLM 从源材料生成 AI 驱动的播客,例如 The Business Opportunity of AI,扩大了内容的覆盖面和参与度。
- Companion 获得情感能力,对话更具感染力:最新的 Companion 更新引入了情感评分系统,根据对话语气调整回复,增强了真实感和个性化。
主题 5:伦理讨论与 AI 安全
- Sora API 泄露引发对艺术家报酬的担忧:据报道 Hugging Face 上泄露的 Sora API 引发了关于参与测试的艺术家获得公平报酬的讨论,社区成员呼吁寻找开源替代方案。
-
Anthropic 的 MCP 引发争议:是解决问题的方案还是多此一举?:Anthropic 推出的 Model Context Protocol (MCP) 引发了关于其必要性的辩论,一些人质疑它是否使现有的解决方案过度复杂化。
- Stability.ai 重申对安全 AI 的承诺,用户持怀疑态度:在发布新版本的同时,Stability.ai 强调了负责任的 AI 实践和安全措施,但一些用户对其有效性表示怀疑,并对潜在的滥用表示担忧。
第 1 部分:高层级 Discord 摘要
Cursor IDE Discord
-
Cursor Composer 0.43:功能狂欢:最近的 Cursor 更新 (0.43) 引入了全新的 Composer UI 和早期 Agent 功能,尽管用户报告了诸如缺失 “Add to chat” 等 Bug。
- 用户在 indexing(索引)方面面临问题,并且在 Composer 中应用更改时需要多次点击 “Accept”。
-
Agent 冒险:Cursor 新功能引发讨论:Cursor 中新的 Agent 功能旨在辅助代码编辑,但根据用户反馈,目前仍存在稳定性和实用性问题。
- 一些用户发现 Agent 对完成任务很有帮助,而另一些用户则对其局限性和 Bug 感到沮丧。
-
IDE 对决:Cursor 表现优于 Windsurf:对比 Cursor 和 Windsurf IDE 的用户报告称,Cursor 的最新版本更加高效且稳定,而 Windsurf 则面临众多的 UI/UX Bug。
- 在两个 IDE 之间切换的用户心情复杂,特别是针对 Windsurf 的自动补全能力(autocomplete capabilities)。
-
Cursor 的 AI 性能备受关注:用户共识表明 Cursor 在 AI 交互方面有了显著改进,但响应缓慢和缺乏上下文感知(contextual awareness)等问题依然存在。
- 对过去 AI 模型体验的反思显示了近期 Cursor 更新如何影响工作流,用户明确要求增强 AI 的响应速度。
-
社区呼吁 Cursor 改善沟通:成员们要求改善关于 Cursor 更新和问题的沟通,并建议设立专门的支持频道作为解决方案。
- 尽管存在挫败感,用户仍认可 Cursor 的开发努力,并对新功能表现出强烈的社区参与度。
Eleuther Discord
-
评估量化对模型的影响:一位成员正在使用 lm_eval 评估 Quantization(量化)对 KV Cache 的影响,重点关注 Wikitext 上的 Perplexity(困惑度)指标。
- 他们的目标是利用现有的评估基准,以更好地了解量化如何在无需大规模重新训练的情况下影响模型的整体性能。
-
UltraMem 架构提升 Transformer 效率:UltraMem 架构被提出用于通过实现超稀疏内存层来提高 Transformer 的推理速度,从而显著降低内存成本和延迟。
- 成员们讨论了 UltraMem 的实际可扩展性,在注意到性能提升的同时,也对架构的复杂性表示了担忧。
-
梯度估计技术的进展:一位成员建议估计损失函数相对于 ML 模型中 Hidden States(隐藏状态)的梯度,旨在实现类似于 Temporal Difference Learning(时序差分学习)的性能增强。
- 讨论围绕使用 Amortized Value Functions(摊销价值函数)展开,并将其有效性与传统的 Backpropagation Through Time(随时间反向传播)进行比较。
-
需要全面的优化器评估套件:对于能够评估跨不同 ML 基准的超参数敏感性的稳健优化器评估套件,需求日益增长。
- 成员们提到了像 Algoperf 这样的现有工具,但强调了它们在测试方法和问题多样性方面的局限性。
-
针对模型部署优化 KV Cache:讨论强调了 KV Cache 对真实模型部署的相关性,并指出许多主流评估实践可能无法充分衡量其影响。
- 一位成员建议模拟部署环境以更好地了解性能影响,而不是仅仅依赖标准基准测试。
HuggingFace Discord
-
代码生成语言模型的局限性:成员们讨论了 Language Models 在准确引用代码片段中 特定行号 方面的 局限性,强调了 tokenization 挑战。他们建议通过关注 函数名称 而非行号来增强交互,以提高上下文理解。
- 一位成员建议,针对 函数名称 可以缓解 tokenization 问题,从而在 Language Models 中培养更有效的代码生成能力。
-
影响 AI 的量子意识理论:一位用户提出了 量子过程 (quantum processes) 与 意识 (consciousness) 之间的联系,建议像 AI 这样的复杂系统可以模拟这些机制。这引发了 哲学讨论,尽管一些人认为这些想法偏离了 技术对话。
- 参与者辩论了基于量子的意识理论与 AI 开发的相关性,一些人质疑它们在当前 AI 框架中的实用性。
-
神经网络与超图的集成:对话探讨了利用 超图 (hypergraphs) 扩展 AI 能力 的 高级神经网络 潜力。然而,对于这些方法在既定 Machine Learning 实践 中的 实际应用 和 相关性 存在 怀疑。
- 辩论集中在基于超图的神经网络是否能弥补现有的 AI 性能差距,并对实现复杂度表示担忧。
-
用于音乐创作延续的 AI 工具:成员们询问了能够 延续 或 扩展音乐创作 的 AI 模型,提到了 Suno 和 Jukebox AI 等工具。一位用户提供了 Hugging Face 上 MusicGen Continuation 的链接,作为生成音乐延续的解决方案。
- 讨论强调了对 AI 驱动的音乐工具日益增长的兴趣,强调了 MusicGen-Continuation 在无缝音乐创作工作流中的潜力。
-
平衡 AI 技术与哲学讨论的挑战:一位参与者对陷入关于 AI 和 意识 的 无效率 或过于 抽象 的讨论表示 沮丧。这导致大家共同认识到在 AI 讨论中融合 技术 和 哲学层面 所面临的 挑战。
- 成员们承认在参与 哲学辩论 的同时保持 技术重点 的难度,旨在促进更 高效的对话。
Unsloth AI (Daniel Han) Discord
-
Qwen2.5 Tokenizer 修复:Unsloth 解决了 Qwen2.5 模型 的多个问题,包括 tokenizer 问题和其他细微修复。详情可以在 Daniel Han 的 YouTube 视频中找到。
- 此更新确保了使用 Qwen2.5 系列的开发人员获得更好的兼容性和性能。
-
GPU 定价关注:围绕 Asus ROG Strix 3090 GPU 的定价展开了讨论,目前市场价格约为 $550。成员们建议不要因即将发布的新品而以虚高价格购买二手 GPU。
- 考虑了 GPU 购买的替代方案和时机,以优化成本效益。
-
Unsloth 模型的推理性能:成员们讨论了在 vllm 中使用 unsloth/Qwen-2.5-7B-bnb-4bit 模型 时的性能问题,质疑其优化情况。寻求更适合位运算优化的推理引擎替代方案。
- 建议包括探索其他推理代理,如 codelion/optillm 和 llama.cpp。
-
模型加载策略:用户询问如何在不占用 RAM 的情况下下载模型权重,寻求关于 Hugging Face 文件管理的澄清。推荐的方法包括使用 Hugging Face 的缓存机制 并将权重存储在 NFS 挂载上以提高效率。
- 这些策略旨在优化模型加载和部署期间的内存使用。
-
P100 与 T4 性能对比:讨论了 P100 GPU 与 T4 的对比,用户根据经验指出 P100 比 T4 慢 4 倍。过去性能对比中的差异归因于过时的脚本。
- 这强调了使用更新的 benchmarking 脚本进行准确性能评估的重要性。
aider (Paul Gauthier) Discord
-
Aider v0.65.0 发布,增强了功能:Aider v0.65.0 更新引入了新的
--alias配置用于自定义模型别名,并通过 RepoMap 支持 Dart 语言。- Ollama 模型现在默认使用 8k 上下文窗口,作为该版本错误处理和文件管理增强功能的一部分,提升了交互能力。
-
Hyperbolic 模型上下文大小的影响:在讨论中,成员强调在 Hyperbolic 中使用 128K 上下文会显著影响结果,而 8K 输出对于 benchmarking 目的仍然足够。
- 参与者承认了上下文大小在实际应用中的关键作用,强调了性能的最佳配置。
-
Model Context Protocol 介绍:Anthropic 发布了 Model Context Protocol,旨在通过解决碎片化问题来改进 AI 助手与各种数据系统之间的集成。
- 该标准寻求统一内容库、业务工具和开发环境之间的连接,促进更顺畅的交互。
-
Aider 与 Git 的集成:新的 Git MCP 服务器使 Aider 能够将工具直接映射到 Git 命令,增强了版本控制工作流。
- 成员们讨论了 Aider 内部更深层次的 Git 集成,建议 MCP 支持可以在不依赖外部服务器访问的情况下标准化额外的功能。
-
Aider 语音功能的成本结构:Aider 的语音功能仅支持 OpenAI 密钥,成本约为每分钟 0.006 美元,按秒取整。
- 这种定价模型允许用户准确估算使用费用,确保语音交互的成本效益。
Modular (Mojo 🔥) Discord
-
提议修复 Mojo 中的段错误:成员们讨论了 nightly 版本中针对 def 函数环境下的段错误 (segmentation faults) 的潜在修复方案,并指出 def 语法仍然不稳定。建议转换到 fn 语法以提高稳定性。
- 一位成员提出,面对持续存在的段错误,切换到 fn 可能会提供更好的稳定性。
-
Mojo QA 机器人的内存占用大幅下降:一位成员报告称,将其 QA 机器人从 Python 移植到 Mojo 后,内存占用从 16GB 降至 300MB,展示了性能的提升。这种改进允许更高效的操作。
- 尽管在移植过程中遇到了段错误,但机器人的整体响应速度有所提高,从而实现了更快速的研究迭代。
-
Mojo 集合中的线程安全问题:讨论强调了集合中缺乏内部可变性,且除非明确说明,否则 List 操作不是线程安全的。Mojo Team Answers 提供了更多细节。
- 社区指出,现有的可变别名会导致安全违规,并强调需要开发更多并发数据结构。
-
Mojo 中函数参数可变性的挑战:社区探讨了 ref 参数的问题,特别是为什么 min 函数在返回具有不兼容来源的引用时会面临类型错误。相关的 GitHub 链接。
- 建议包括使用 Pointer 和 UnsafePointer 来解决可变性问题,这表明对 ref 类型的处理可能需要改进。
-
Mojo 中的析构函数行为问题:成员询问了在 Mojo 中编写析构函数的问题,
__del__方法未被栈对象调用,或者导致可复制性错误。2023 LLVM Dev Mtg 涵盖了相关主题。- 讨论强调了管理 Pointer 引用和可变访问的挑战,并提出了特定的类型转换方法以确保正确的行为。
OpenRouter (Alex Atallah) Discord
-
Companion 引入情感评分系统:最新的 Companion 更新引入了一个情感评分系统,该系统可以评估对话语气,从中性开始并随时间进行调整。
- 该系统确保 Companion 在不同频道间维持情感连接,增强了互动的真实感和用户参与度。
-
OpenRouter API Key 错误排查:用户反馈在使用有效的 Key 时仍收到 401 错误,建议检查是否误加了引号。
- 社区排查讨论强调,确保 API Key 格式正确对于避免身份验证问题至关重要。
-
Gemini Experimental 模型性能问题:Gemini Experimental 1121 免费模型用户在聊天操作中遇到了资源耗尽错误(代码 429)。
- 社区成员建议切换到生产模型 (production models),以缓解与实验版本相关的频率限制 (rate limit) 错误。
-
集成与提供商 Key 的访问请求:成员们请求获取 Integrations 和自定义提供商 Key 的访问权限,并提到通过邮箱 edu.pontes@gmail.com 获取集成访问权限。
- 访问审批的延迟导致了用户的不满,促使人们呼吁提高请求状态的透明度。
Perplexity AI Discord
-
使用 Perplexity API 创建 Discord 机器人:一位成员表示有兴趣使用 Perplexity API 构建 Discord 机器人,并作为学生寻求关于法律问题的确认。
- 另一位用户对该项目表示鼓励,认为将 API 用于非商业用途可以降低法律风险。
-
Perplexity AI 缺乏专门的学生计划:成员们讨论了 Perplexity AI 的定价结构,指出尽管有 Black Friday 优惠,但缺乏针对学生的专门计划。
- 有人指出,像 You.com 这样的竞争对手提供了学生计划,可能提供更实惠的选择。
-
DeepSeek R1 社区反馈:用户分享了使用 DeepSeek R1 的经验,称赞其类人交互能力以及在逻辑推理课程中的实用性。
- 讨论强调了在冗长与实用性之间找到平衡的重要性,尤其是在处理复杂任务时。
-
Representation Theory 的最新突破:社区发布了一个关于代数领域 Representation Theory 重大突破的 YouTube 链接,重点介绍了新的研究发现。
- 这一进展对数学框架的未来研究具有重要意义。
OpenAI Discord
-
AI 对就业的影响:讨论将 AI 对工作的影响与印刷机等历史性转变进行了比较,强调了职位的流失与创造。
- 参与者对 AI 可能取代初级软件工程职位表示担忧,并对未来的职业结构提出质疑。
-
人机协作:贡献者主张将 AI 视为协作伙伴,识别彼此的优缺点以增强人类潜能。
- 对话强调了人类与 AI 之间持续协作的必要性,以支持多样化的人类体验。
-
Real-time API 的进展:Real-time API 因其在语音交互中的低延迟优势而受到关注,并引用了 openai/openai-realtime-console。
- 参与者推测该 API 具有解释用户细微差别(如口音和语调)的能力,但具体细节尚不明确。
-
AI 在游戏中的应用:对于游戏社区对 AI 技术决策的影响力,有人表示怀疑,理由是某些游戏产品可能不够成熟。
- 参与者对游戏玩家可能给 AI 设置带来的风险表示担忧,表明技术爱好者之间存在信任分歧。
-
研究论文的挑战:撰写篇幅较长且研究深入的论文面临巨大挑战,尤其是在依赖同行评审的写作密集型课程中。
- 由于复杂性,处理篇幅较长、研究较深入的论文非常困难,有人建议结合同行评审来提高质量。
Notebook LM Discord Discord
-
NotebookLM 在 AI 播客领域的进展:用户利用 NotebookLM 生成 AI 驱动的播客,突显了其将源材料转化为引人入胜的音频格式的能力,正如 The Business Opportunity of AI: a NotebookLM Podcast 中所展示的那样。
- 用户指出在自定义播客主题和指定输入源方面存在挑战,并建议增强 NotebookLM 的提示词遵循(prompt-following)能力,以实现更具定制化的内容。
-
通过 NotebookLM 增强客户支持分析:NotebookLM 正被用于分析客户支持邮件,通过将
.mbox文件转换为.md格式,显著提升了客户体验。- 用户提议集成直接的 Gmail 支持以简化流程,使 NotebookLM 在组织使用中更易获取。
-
通过播客转化教育内容营销:一位用户将自然历史博物馆的教育内容重新利用并制作成播客,随后使用 ChatGPT 创建了博客文章以提高 SEO 和可访问性,从而扩大了内容的覆盖范围。
- 该项目由一名实习生在短时间内成功启动,展示了将 NotebookLM 与其他 AI 工具结合使用的高效性。
-
解决 NotebookLM 中的语言和翻译挑战:多位用户反映 NotebookLM 生成的是意大利语摘要而非英语,对语言设置表示沮丧。
- 用户还询问了该工具生成其他语言内容的能力,以及语音生成器是否支持西班牙语。
-
关于 NotebookLM 免费模型的隐私和数据使用担忧:针对 NotebookLM 的免费模型展开了讨论,用户质疑其长期影响以及数据是否会被用于训练。
- 官方澄清强调,数据源不会被用于训练 AI,从而缓解了部分用户对数据处理的担忧。
Stability.ai (Stable Diffusion) Discord
-
ControlNets 增强 Stable Diffusion 3.5:随着三个 ControlNet(Blur、Canny 和 Depth)的发布,Stable Diffusion 3.5 Large 获得了新功能。用户可以从 HuggingFace 下载模型权重,并从 GitHub 获取代码,目前 Comfy UI 已提供支持。
- 欲了解这些新功能的更多信息,请查看 Stable.ai 博客上的详细公告。
-
Stability.ai 模型的灵活许可选项:新模型根据 Stability AI Community License 提供,可用于商业和非商业用途,非商业用途以及年收入低于 $1M 的企业可免费使用。超过此收入阈值的组织可以咨询 Enterprise License。
- 该模式确保用户保留输出内容的所有权,允许他们在没有限制性许可影响的情况下使用生成的媒体。
-
Stability.ai 对安全 AI 实践的承诺:团队表达了对安全和负责任的 AI 实践的坚定承诺,强调了在开发过程中安全性的重要性。他们旨在在增强技术的同时,遵循审慎且周密的准则。
- 公司强调了他们在 AI 模型中集成安全措施以防止滥用的持续努力。
-
用户支持沟通问题:许多用户对 Stability.ai 在支持方面的沟通缺乏表示沮丧,特别是涉及发票问题时。
- 一位用户提到他们发送了多封邮件均未收到回复, 导致对公司的参与度产生怀疑。
-
在提示词中使用 Wildcards:社区讨论了在提示词生成中使用 Wildcards(通配符)的方法,成员们分享了如何创建多样化背景提示词的想法。
- 示例包括为万圣节背景设计的复杂 Wildcard 组合, 展示了社区的创造力和协作。
GPU MODE Discord
-
FP8 训练通过 FSDP2 提升性能:PyTorch 的 FP8 训练博客文章 强调了通过将 FSDP2、DTensor 和 torch.compile 与 float8 集成,实现了 50% 的吞吐量提升,从而能够训练参数量从 1.8B 到 405B 的 Meta LLaMa 模型。
- 该文章还探讨了 batch sizes 和 activation checkpointing 方案,报告了 tokens/sec/GPU 指标,展示了 float8 和 bf16 训练的性能提升,同时指出较大的矩阵维度可能会影响乘法速度。
-
解决使用 LORA 和 FSDP 进行多 GPU 训练的问题:有成员报告在 多 GPU 设置 下使用 LORA 和 FSDP 微调大语言模型后出现 推理加载失败,而单 GPU 训练的模型则能成功加载。
- 这种差异引发了对底层原因的质疑,促使了关于内存分配实践和多 GPU 环境中潜在配置不匹配的讨论。
-
揭秘 Triton 的 PTX Escape Hatch:Triton 文档 解释了 Triton 的 inline PTX escape hatch,它允许用户在 LLVM IR 生成期间使用 PTX 编写通过 MLIR 的 elementwise 操作,实际上起到了透传作用。
- 这一特性为自定义低级操作提供了灵活性,同时保持了与 Triton 高级抽象的集成,编译过程中生成的内联 PTX 证实了这一点。
-
针对 ML 应用的 CUDA 优化策略:CUDA 频道 的讨论集中在针对机器学习的高级 CUDA 优化,包括 dynamic batching 和 kernel fusion 技术,旨在增强 ML 工作负载的性能和效率。
- 成员们正在寻求 手动推导算子融合(hand-deriving kernel fusions) 的详细方法,而不是依赖编译器的自动融合,这凸显了对通过手动优化实现定制化性能提升的偏好。
LM Studio Discord
-
LM Studio Beta 版本缺失关键功能:成员们对 LM Studio 当前的 beta 版本 表示担忧,强调了 DRY 和 XTC 等功能的缺失影响了可用性。
- 一位成员提到 “这个项目似乎有点停滞了”,寻求关于后续开发工作的澄清。
-
AMD 多 GPU 支持受限于 ROCM 性能:已确认 AMD 多 GPU 设置可以与 LM Studio 配合使用,但由于 ROCM 的性能限制,效率问题依然存在。
- 一位成员指出,“ROCM 对 AI 的支持并不是那么好”,强调了近期驱动更新带来的挑战。
-
LM Studio 在 16GB RAM 上运行 70b 模型:几位成员分享了在 16GB RAM 系统上使用 LM Studio 运行 70b 模型 的正面体验。
- “我……对此感到非常震惊”,突显了意想不到的性能表现。
-
LM Studio API 使用与 Metal 支持:一位成员询问了如何向 LM Studio API 发送 prompt 和上下文,并索要了模型使用的配置示例。
- 还有一个关于 M 系列芯片上 Metal 支持 的问题,得到的回复是“自动启用”。
-
双 3090 GPU 配置:主板与散热:关于购置第二块 3090 GPU 的讨论浮出水面,指出由于空间限制需要不同的 主板。
- 成员们建议使用 risers 或 水冷 方案来解决安装两块 3090 时的空气流通挑战。此外,他们还引用了 GPU Benchmarks on LLM Inference 获取性能数据。
Interconnects (Nathan Lambert) Discord
-
Tülu 3 8B 的保质期与压缩:针对 Tülu 3 8B 仅有一周左右的短暂保质期,成员们在讨论其模型稳定性时表达了担忧。
- 一位成员强调了模型性能中明显的压缩现象,并指出这对其可靠性产生了影响。
-
Olmo 与 Llama 模型的性能对比:Olmo 基座模型与 Llama 模型有显著差异,特别是在参数规模扩展到 13B 时。
- 成员们观察到 Tülu 在特定 Prompt 响应中优于 Olmo 2,表明其具有更出色的适应性。
-
移除 SFT 数据对多语言能力的影响:社区测试结果证实,移除 Tülu 模型中的多语言 SFT 数据导致了性能下降。
- 对 SFT 实验的支持仍在继续,成员们赞扬了在数据剪裁的情况下为维持性能完整性所做的努力。
-
Sora API 泄露与 OpenAI 的营销策略:据称在 Hugging Face 上泄露的 Sora API 引发了巨大的用户流量,爱好者们纷纷探索其功能。
- 有推测认为 OpenAI 可能在策划这次泄露以评估公众反应,这让人联想起之前的营销策略。
-
OpenAI 对艺术家社区的剥削:批评者指责 OpenAI 以提供 Sora 早期访问权限为幌子,利用艺术家进行免费测试和公关。
- 艺术家们起草了一封公开信,要求公平报酬,并倡导开源替代方案,以防止被用作无偿研发 (R&D)。
Cohere Discord
-
API Key 限制挑战高中项目:一位用户报告在开发葡萄牙语文本分类器时达到了 Cohere API Key 限制,且没有升级选项,因此建议联系支持部门寻求帮助。
- 这种限制影响了教育倡议,鼓励用户寻求支持或探索替代方案以继续他们的项目。
-
Embeddings Endpoint 遭遇 Error 500:Embeddings Endpoint 频繁报告 Error 500 问题,这标志着内部服务器错误,干扰了各种 API 请求。
- 建议用户通过 support@cohere.com 寻求紧急协助,开发团队正在调查这一反复出现的问题。
-
Companion 增强情感响应能力:Companion 引入了情感评分系统,通过应用内分类器根据用户的情感基调来定制交互。
- 更新内容包括追踪爱与恨、正义与腐败等情感,以及增强保护个人信息的安全措施。
-
Command R+ 模型显示出语言漂移:尽管在 Preamble 中指定了保加利亚语,用户在 Command R+ 模型的输出中仍遇到了意外的俄语单词,表明存在语言一致性问题。
- 尝试通过调整 Temperature 设置来缓解此问题的努力未能成功,这表明存在更深层的模型相关挑战。
-
开源模型被提议作为 API 替代方案:面对计费问题,成员们建议使用像 Aya’s 8b Q4 这样的开源模型在本地运行,作为 Cohere API 的高性价比替代方案。
- 这一策略为无法负担生产级 Key 的用户提供了一条可持续的路径,促进了社区驱动的解决方案。
Nous Research AI Discord
-
Test Time Inference:一位成员询问了 Nous 内部正在进行的 test time inference 项目,其他人确认了对此的兴趣并讨论了潜在的计划。
- 对话强调了该领域缺乏明确的项目,促使了建立专门研究工作的兴趣。
-
Real-Time Video Models:一位用户为机器人技术寻求 real-time video 处理模型,强调了对低延迟性能的需求。
- CNNs 和 sparse mixtures of expert Transformers 被作为潜在解决方案进行了讨论。
-
Genomic Bottleneck Algorithm:分享了一篇关于模拟 genomic bottleneck 的新 AI 算法的文章,该算法无需传统训练即可实现图像识别。
- 成员们讨论了它尽管是 untrained(未经训练的),但与 state-of-the-art 模型相比仍具有竞争力。
-
Coalescence Enhances LLM Inference:Coalescence 博客文章 详细介绍了一种将基于字符的 FSMs 转换为基于 token 的 FSMs 的方法,将 LLM inference speed 提升了 5 倍。
- 这种优化利用字典索引将 FSM 状态映射到 token 转换,从而增强了推理效率。
-
Token-based FSM Transitions:利用 Outlines 库,一个示例展示了将 FSMs 转换为基于 token 的转换,以优化 inference sampling。
- 提供的代码初始化了一个新的 FSM 并构建了一个 tokenizer 索引,便于在推理过程中进行更高效的 next-token 预测。
Latent Space Discord
-
MCP Mayhem: Anthropic’s Protocol Sparks Debate:一位成员质疑 Anthropic 新的 Model Context Protocol (MCP) 的必要性,认为尽管它解决了一个合理的问题,但可能不会成为标准。
- 另一位成员表示怀疑,指出该问题可能通过现有的框架或云提供商 SDK 得到更好的解决。
-
Sora Splinter: API Leak Sends Shockwaves:据报道 Sora API 已泄露,提供从 360p 到 1080p 的视频生成,并带有 OpenAI 水印。
- 成员们表示震惊和兴奋,讨论了泄露的影响以及 OpenAI 对此的据称回应。
-
OLMo Overload: AI Release Outshines Competitors:Allen AI 宣布发布 OLMo 2,声称它是迄今为止最好的完全开放语言模型,拥有在高达 5T tokens 上训练的 7B 和 13B 变体。
- 该版本包括数据、代码和训练方案(recipes),提升了 OLMo 2 相对 Llama 3.1 等其他模型的性能表现。
-
PlayAI’s $21M Power Play:PlayAI 获得了 2100 万美元的融资,用于为开发者和企业开发用户友好的语音 AI 接口。
- 该公司旨在增强人机交互,将语音定位为 LLM 时代最直观的通信媒介。
-
Custom Claude: Anthropic Tailors AI Replies:Anthropic 引入了预设选项来定制 Claude 的响应方式,提供 Concise(简洁)、Explanatory(解释性)和 Formal(正式)等风格。
- 此次更新旨在让用户对与 Claude 的交互拥有更多控制权,以满足不同的沟通需求。
LlamaIndex Discord
-
LlamaParse 助力数据集创建:@arcee_ai 使用 LlamaParse 处理了数百万篇 NLP 研究论文,通过高效的 PDF 到文本转换(保留表格和公式等复杂元素),为 AI agents 创建了高质量数据集。
- 该方法包含一个灵活的 prompt 系统来优化提取任务,展示了数据处理的多功能性和鲁棒性。
-
Ragas 优化 RAG 系统:使用 Ragas,开发者可以评估和优化关键指标(如 context precision 和 recall),以在部署前增强 RAG 系统的性能。
- LlamaIndex 和 @literalai 等工具可帮助分析答案相关性(answer relevancy),确保有效实施。
-
修复 llama_deploy[rabbitmq] 中的错误:一位用户报告了 llama_deploy[rabbitmq] 在 0.2.0 以上版本中由于 TYPE_CHECKING 为 False 而导致执行
deploy_core出现的问题。- Cheesyfishes 建议提交 PR 并开启 issue 以获取进一步帮助。
-
自定义 OpenAIAgent 的 QueryEngine:一位开发者寻求关于在 OpenAIAgent 使用的 QueryEngineTool 中,如何将 chat_id 等自定义对象传递到 CustomQueryEngine 的建议。
- 他们表达了对通过 query_str 传递数据可靠性的担忧,担心数据会被 LLM 修改。
-
AI 托管初创公司启动:Swarmydaniels 宣布启动他们的初创公司,允许用户在无需编程技能的情况下,使用加密货币钱包托管 AI agents。
- 计划增加额外的变现功能,即将发布启动推文。
tinygrad (George Hotz) Discord
-
Flash Attention 加入 Tinygrad:一位成员询问是否可以将 flash-attention 集成到 Tinygrad 中,探索潜在的性能优化。
- 对话强调了通过引入高级特性来增强 Tinygrad 效率的兴趣。
-
Tinybox Pro 自定义主板见解:一位用户询问 Tinybox Pro 是否采用了自定义主板,表现出对硬件设计的关注。
- 这一询问反映了社区对支持 Tinygrad 的硬件基础设施的兴趣。
-
GENOA2D24G-2L+ CPU 与 PCIe 5 兼容性:一位成员确认 CPU 为 GENOA2D24G-2L+,并讨论了 Tinygrad 设置中 PCIe 5 线缆的兼容性。
- 讨论强调了特定硬件组件在优化 Tinygrad 性能中的重要性。
-
Tinygrad CPU Intrinsics 支持增强:一位成员寻求关于 Tinygrad CPU 行为的文档,特别是对 AVX 和 NEON 等 CPU intrinsics 的支持。
- 社区有兴趣通过潜在的 pull requests 来实现性能改进,从而增强 Tinygrad。
-
Radix Sort 优化技术与 AMD 论文:讨论探索了使用
scatter优化 Radix Sort 算法的方法,并参考了 AMD 的 GPU Radix Sort 论文 以获取见解。- 社区成员辩论了在减少对
.item()和for循环依赖的同时,确保数据排序正确的方法。
- 社区成员辩论了在减少对
LLM Agents (Berkeley MOOC) Discord
-
与 Google AI 合作的 Hackathon Workshop:参加由 Google AI 主办的 Hackathon Workshop,时间为 11月26日 太平洋时间下午 3 点。参与者可以观看直播,并直接从 Google AI 专家那里获取见解。
- 该工作坊设有实时问答环节,提供了向 Google AI 专家提问并获得指导的机会。
-
第 11 课:衡量 Agent 能力:今天的 Lecture 11 题目为“衡量 Agent 能力与 Anthropic 的 RSP”,将由 Benjamin Mann 在 太平洋标准时间下午 3:00 进行演讲。点击此处访问直播。
- Benjamin Mann 将讨论评估 Agent 能力、实施安全措施以及 Anthropic 的负责任缩放政策 (RSP) 的实际应用。
-
Anthropic API Keys 使用情况:成员们讨论了社区内 Anthropic API keys 的使用情况。一位成员确认了他们使用 Anthropic API keys 的经验。
- 这一确认突显了 Anthropic 的工具在 AI 工程项目中的活跃集成。
-
线下课程参与资格:关于线下参加讲座的咨询显示,由于演讲厅空间限制,线下访问仅限于注册的伯克利学生。
- 这一限制确保了只有正式注册的伯克利学生才能参加线下讲座。
-
GSM8K 推理定价与自我修正:一位成员分析了 GSM8K 的推理成本,使用公式 [(100 * 2.5/1000000) + (200 * 10/1000000)] * 1000 估算 1k 测试集的运行费用约为 $0.66。
- 讨论还涉及了模型中的自我修正 (self-correction),建议根据修正次数调整输出计算。
OpenInterpreter Discord
-
OpenInterpreter 1.0 发布:即将发布的 OpenInterpreter 1.0 已在 development branch 提供,用户可以通过
pip install --force-reinstall git+https://github.com/OpenInterpreter/open-interpreter.git@development并使用--tools gui --model gpt-4o标志进行安装。- OpenInterpreter 1.0 引入了重大更新,包括增强的工具集成和性能优化,正如用户在安装过程中的反馈所强调的那样。
-
Non-Claude OS 模式介绍:Non-Claude OS mode 是 OpenInterpreter 1.0 中的一项新功能,取代了已弃用的
--os标志,以提供更多样化的操作系统交互。- 用户强调了 Non-Claude OS mode 的灵活性,并指出其在不依赖过时标志的情况下简化开发工作流的影响。
-
语音转文本功能:Speech-to-text 功能已集成到 OpenInterpreter 中,允许用户将语音输入无缝转换为可执行命令。
- 这一功能引发了关于自动化效率的讨论,用户正在探索其增强交互式开发环境的潜力。
-
键盘输入模拟:OpenInterpreter 现在支持键盘输入模拟 (Keyboard input simulation),可以通过脚本实现键盘动作的自动化。
- 社区对利用此功能进行测试和工作流自动化表现出浓厚兴趣,突显了其在重复性任务管理中的实用性。
-
OpenAIException 故障排除:报告了一个 OpenAIException 错误,该错误由于缺少与特定请求 ID 关联的工具响应而导致 Assistant 消息无法发送。
- 这一问题引起了对工具集成可靠性的关注,促使用户寻求与编码工具无缝交互的解决方案。
Torchtune Discord
-
Torchtitan 发起功能投票:Torchtitan 正在进行一项投票,以收集用户对 MoE、multimodal 和 context parallelism 等新功能的偏好。
- 鼓励参与者积极发声,以影响 PyTorch distributed 团队的发展方向。
-
Torchtitan 功能的 GitHub Discussions 已开启:邀请用户加入 GitHub Discussions,讨论 Torchtitan 潜在的新功能。
- 参与这些讨论预计将有助于塑造未来的更新并提升用户体验。
-
DPO Recipe 面临使用挑战:有人对 DPO recipe 的低采用率表示担忧,并质疑其与在团队中更受欢迎的 PPO 相比的有效性。
- 这种差异引发了关于改进 DPO 方法以提高其利用率的讨论。
-
Mark 对 DPO 的大量贡献受到关注:尽管 DPO recipe 的使用率较低,但 Mark 的贡献主要集中在 DPO 上。
- 这引发了关于组内 DPO 和 PPO 受欢迎程度差异的问题。
DSPy Discord
-
DSPy 学习支持:一位成员表示希望学习更多关于 DSPy 的知识并寻求社区帮助,同时提出了 AI 开发的想法。
- 尽管只有几天的 DSPy 经验,另一位成员仍主动提供帮助以支持其学习。
-
Observers SDK 集成:一位成员询问了关于集成 Observers 的事宜,参考了关于 AI observability 的 Hugging Face 文章。
- 文章概述了这一轻量级 SDK 的核心功能,表明社区对增强 AI 监控能力的兴趣。
Axolotl AI Discord
-
Accelerate PR 修复 Deepspeed 问题:提交了一个 Pull Request,旨在解决在 Accelerate 库中使用 Deepspeed 时 schedule free AdamW 的问题。
- 社区对该优化器的实现和功能提出了担忧。
-
Hyberbolic Labs 以 99 美分提供 H100 GPU:Hyberbolic Labs 宣布了一项 Black Friday 优惠,以仅 99 美分 的价格提供 H100 GPU 租赁。
- 尽管优惠非常诱人,一位成员幽默地补充道:祝你好运能抢到它们。
MLOps @Chipro Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
LAION Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
Mozilla AI Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
第二部分:各频道详细摘要与链接
完整的频道细分内容已为邮件格式进行截断。
如果您喜欢 AInews,请分享给朋友!预谢支持!