ainews-olympus-has-dropped-aka-amazon-nova
Olympus 正式发布(即 Amazon Nova Micro|Lite|Pro|Premier|Canvas|Reel)
亚马逊在 AWS Re:Invent 大会上发布了 Amazon Nova 系列多模态基础模型。该系列目前已立即开放使用,无需排队,提供 Micro、Lite、Pro、Canvas 和 Reel 等多种配置,而 Premier 版本和语音对语音(speech-to-speech)功能将于明年推出。
这些模型的 Token 生成速度快了 2 到 4 倍,且价格比 Anthropic Claude 等竞争对手便宜 25% 到 400%,这使得 Nova 成为 AI 工程领域的有力竞争者。其定价低于 Google DeepMind Gemini Flash 8B 等模型,部分 Nova 模型的上下文长度可扩展至 30 万个 Token。
然而,目前存在基准测试争议,因为一些评估显示 Nova 在 LiveBench AI 指标上的得分低于 Llama-3 70B。
另外,Sakana AI 实验室推出了 CycleQD,该技术利用演化计算进行基于种群的模型合并,旨在开发特定领域的 LLM 智能体。
Amazon Bedrock 就够了吗?
2024年12月2日至12月3日的 AI 新闻。我们为您检查了 7 个 subreddits、433 个 Twitter 账号 和 29 个 Discord(198 个频道,2914 条消息)。预计为您节省阅读时间(以 200wpm 计算):340 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
我们对昨天的重复邮件表示歉意。这是我们无法控制的平台 Bug,但我们会密切关注,因为我们绝对不想骚扰您或损害我们的送达率。幸运的是,AINews 的理念之一就是邮件的长度和数量几乎(但不完全)是免费的。
正如过去一年中广泛传闻(代号为 Olympus)的那样,AWS Re:invent(此处为完整直播)拉开帷幕,前 AWS 负责人、现任 Amazon CEO Andy Jassy 投下了一个重磅炸弹:他们推出了一套真正的、具有竞争力的、毫不含糊的多模态基础模型——Amazon Nova(报告,博客):

作为一个令人难以置信的加码(对于大型科技公司的 Keynote 而言),没有等待名单——Micro/Lite/Pro/Canvas/Reel 立即正式发布(Generally Available),而 Premier、Speech-to-Speech 和 “Any-to-Any” 将于明年推出。
LMArena 的 Elo 评分正在进行中,但与之前的 Titan 世代 相比,这已经是 AI Engineer 们更值得关注的竞争者了。虽然在 Keynote 中没有被强调,但极高的速度(比 Anthropic/OpenAI 快 2-4 倍的 tok/s):
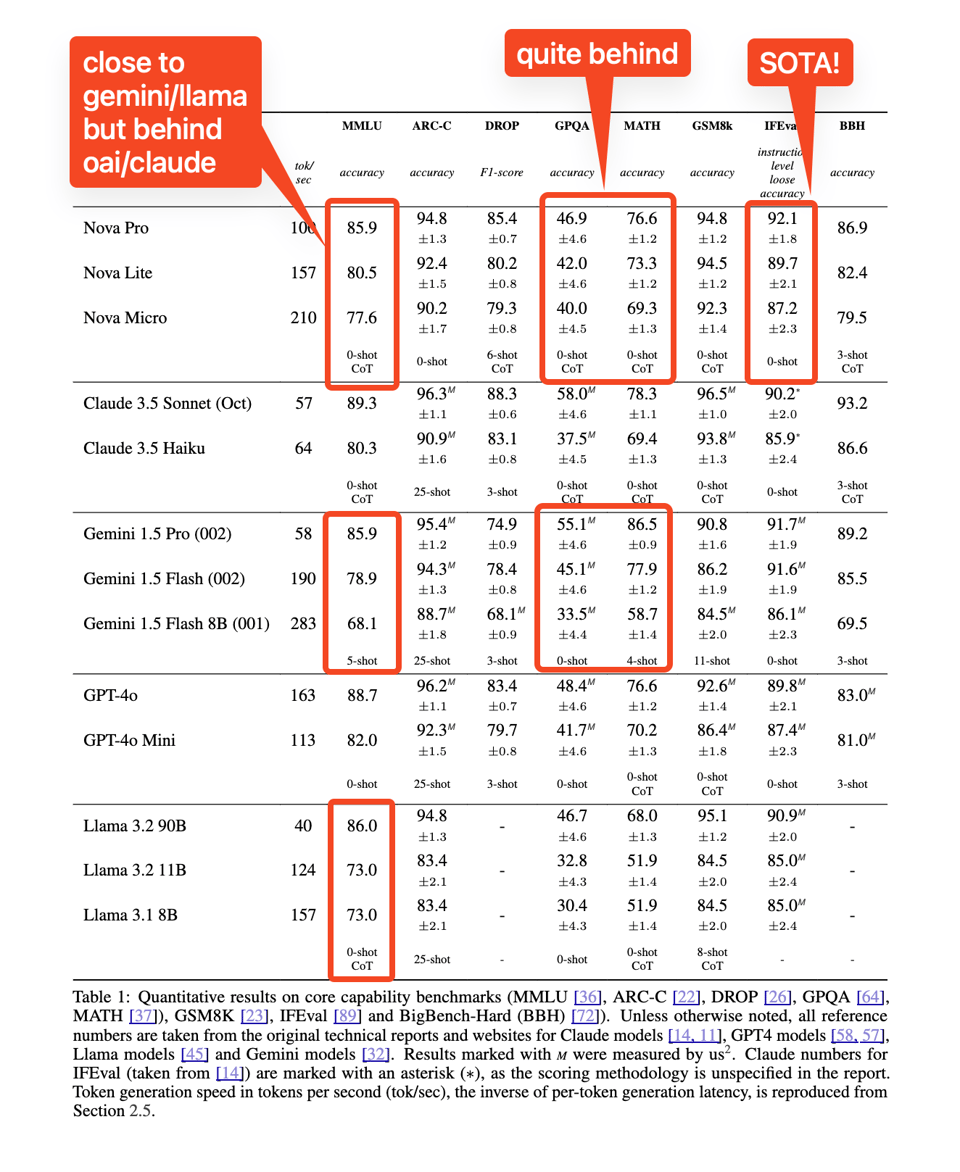
以及极低的成本(比同级别的 Claude 便宜 25% - 400%)都至关重要:

将它们的 Arena 分数与最接近的同类模型进行推算,这提供了接近前沿水平的性价比表现:
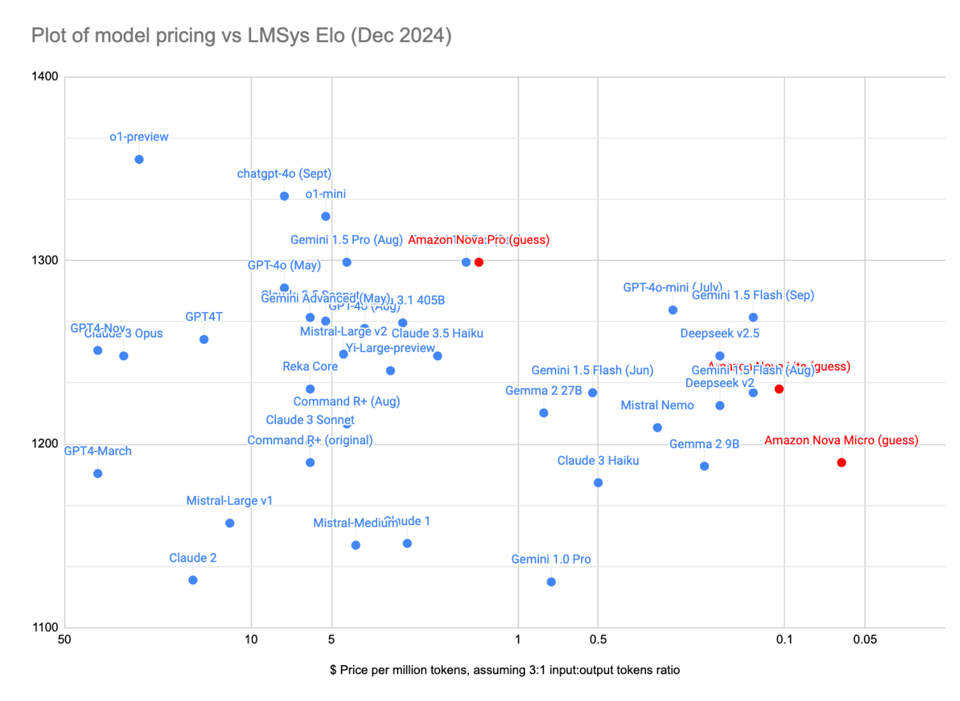
当然,每个人都在评论这与 Amazon 再次向 Anthropic 投资 40 亿美元 的关系,对此,这位“万能商店”(Everything Store)的 CEO 给出了一个答案:

AI Twitter 回顾
所有回顾均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
主题 1. Amazon Nova 基础模型:发布、定价与评估
- Amazon Nova 发布概览:@_philschmid 全面介绍了新款 Amazon Nova 模型,强调了其极具竞争力的定价和基准测试表现。Nova 模型可通过 Amazon Bedrock 获取,包含 Micro、Lite、Pro 和 Premier 多种配置,部分模型的上下文长度扩展到了 300k tokens。
- 定价策略:正如 @_philschmid 所指出的,Nova 模型的定价低于 Google DeepMind Gemini Flash 8B 等竞争对手,在输入/输出 token 定价上极具竞争力。
- 性能与使用:根据 @ArtificialAnlys 的说法,Nova 系列模型(尤其是 Pro 版本)在特定基准测试中超越了 GPT-4o 等模型。
- 评估与基准测试争议:@bindureddy 提出了批评性观点,尽管参数看起来很有前景,但 Nova 在 LiveBench AI 指标中的得分低于 Llama-70B。这再次体现了模型基准测试的动态性和竞争性。
主题 2. CycleQD:语言模型中的进化方法
- CycleQD 方法论与发布:最重要的讨论来自 @SakanaAILabs,他们介绍了 CycleQD,这是一种通过 Quality Diversity 进行基于种群的模型合并方法。该方法利用进化计算来开发具有特定领域能力的 LLM Agent,旨在实现终身学习。HARDMARU 的另一条推文赞扬了生态位(ecological niche)类比,认为这是 AI 系统获取技能的一种极具吸引力的策略。
主题 3. AI 幽默与迷因 (Memes)
- 趣闻轶事与幽默:@arohan 幽默地分享了一个瞬间,关于忘记告诉伴侣自己六个月前升职的事情。同时,@tom_doerr 分享了一个关于“不可能”问题的迷因,强调了 AI 交互中轻松的一面。
- 社交媒体幽默:@teortaxesTex 提到了一项关于与“不可能”问题相关的 NFT 的戏谑策略。
主题 4. Hugging Face 的担忧与社区回应
- 存储配额与开源模型争议:@far__el 等人对 Hugging Face 的存储限制表达了不满,认为这可能是 AI 开源社区的一个潜在障碍。@mervenoyann 澄清说 Hugging Face 在存储方面依然慷慨,但强调了他们对社区驱动型仓库的适应性调整。
- 新兴竞争对手:作为对近期政策变化的回应,@far__el 宣布了 OpenFace,这是一项旨在独立于 Hugging Face 自托管 AI 模型的倡议。
主题 5. 值得关注的新模型创新
- 混元视频 (HunyuanVideo) 与情感协调模型:@andrew_n_carr 重点介绍了腾讯的 HunyuanVideo,指出了其权重开放以及对视频生成模型领域的贡献。同时,@reach_vb 发布了 Indic-Parler TTS,这是一款具备情感协调能力的文本转语音模型。
- 模型性能更新:@cognitivecompai 记录了关于 GPT-4o 性能更新的讨论,例如智力水平有明显提升。
主题 6. AI 寒冬与行业展望
- 对 AI 未来的担忧:@iScienceLuvr 对即将到来的 AI 寒冬 表示担忧,暗示 AI 的进步或投资热情可能会放缓或倒退,这展示了 AI 行业中波动不定的乐观情绪。
AI Reddit 回顾
/r/LocalLlama 回顾
主题 1. HuggingFace 实施 500GB 限制,优先考虑社区贡献者
- Huggingface 不再是无限的模型存储空间:新限制为每个免费账户 500 Gb (Score: 249, Comments: 76): HuggingFace 为免费层级账户引入了 500GB 存储限制,标志着其从之前的无限存储政策发生了转变。这一变化影响了该平台上免费用户的模型存储能力。
- Huggingface 员工 (VB) 澄清说,这是对现有限制的 UI 更新,而非新政策。该平台继续为具有价值的社区贡献(如 model quantization、datasets 和 fine-tuning)提供 storage and GPU grants,同时打击滥用和垃圾信息。
- 社区成员报告了巨大的存储使用量,其中一名用户达到了 8.61 TB/500 GB,并对未来大型模型(如需要约 130GB 的 LLaMA 65B)的可用性表示担忧。讨论集中在包括本地存储和 torrents 在内的潜在解决方案上。
- 用户辩论了商业影响,指出贡献者已经投入了大量时间和精力为社区创建 quantized 模型。这一变化引发了与 YouTube 模式的比较,即用户为消费内容付费,而不是为上传内容付费。
- Hugging Face 在所有 25 万+ 公共数据集上添加了 Text to SQL 功能 - 由 Qwen 2.5 Coder 32B 驱动 🔥 (Score: 119, Comments: 11): Hugging Face 利用 Qwen 2.5 Coder 32B 模型,在其 250,000+ 公共数据集 中集成了 Text-to-SQL 功能。这种集成使得能够从自然语言输入中直接生成跨其整个公共数据集集合的 SQL 查询。
- VB(Hugging Face 的 GPU Poor 成员)确认,该实现使用 DuckDB WASM 进行浏览器内 SQL 查询执行。该功能结合了用于查询生成的 Qwen 2.5 32B Coder 和基于浏览器的执行能力。
- 用户对减少手动编写 SQL 的需求表示热衷,特别强调了这如何帮助那些在查询编写方面经验较少的人。
- 该公告获得了积极的反响,评论者赞赏其庆祝的基调,包括演示中使用的纸屑动画。
Theme 2. DeepSeek and Qwen Surpass Expectations, Challenge OpenAI’s Position
- OpenAI CEO Sam Altman 称权重开放 AI 模型是坏事。因为 DeepSeek 和 Qwen 2.5 做了 OpenAI 应该做的事! (Score: 541, Comments: 216): 来自 中国 的 DeepSeek 和 Qwen 2.5 开源 AI 模型展示了足以与闭源替代方案相媲美的能力,促使 Sam Altman 在接受 Fox News 采访(主持人 Shannon Bream)时对 open-weights 模型表示担忧。这位 OpenAI CEO 强调了在 AI development 中保持美国对中国的领导地位的战略重要性,同时由于中国开源模型达到了具有竞争力的性能水平,他也面临着批评。
- 社区情绪强烈批评 Sam Altman 和 OpenAI 被认为的虚伪,用户指出,鉴于开源模型日益增长的竞争,其 1570 亿美元 的估值似乎并不合理。许多人注意到,之前关于 open-weights 模型的安全担忧似乎是毫无根据的。
- 用户强调 OpenAI 的技术优势或“护城河”正在迅速缩小,像 DeepSeek 和 Qwen 这样的 Chinese models 已经实现了具有竞争力的性能。一些评论认为 OpenAI 的主要优势在于 marketing 而非技术卓越。
- 多位用户提到了 OpenAI 背离了其最初的开源使命,引用了早期与 Elon Musk 的沟通以及公司目前反对 open-weights 模型的立场。讨论表明 OpenAI 的商业策略严重依赖于维持闭源优势。
- 开源才是王道 (Score: 60, Comments: 14): 在推理能力的对比中,开源模型 (Deepseek R1 和 QwQ) 在复杂推理问题上超越了闭源 API (Claude Haiku 和 OpenAI),其中 R1 使用 Chain of Thought (CoT) 在 25 秒内实现了最快的正确解。一位非编程用户发现 R1 和 QwQ 对编程任务特别有帮助,同时指出 Claude Sonnet 的实用性受限于其免费版本的访问限制和上下文长度约束。
- QwQ 与 GPT-4o 的使用限制对比显示,4o 对普通用户有 40 条消息的严格限制,Plus 用户每 3 小时限 80 条消息,详见 OpenAI’s FAQ。
- 用户预计 2025 年将是开源模型的突破之年,并指出 QwQ 目前的成本比 GPT-4o 低 5 倍,同时提供更优越的推理性能。目前 QwQ 和 R1 均处于 preview/lite 版本阶段。
- GPT-4o 的免费版本很可能是 4o-mini 变体,用户根据 Benchmark 结果指出其性能相比 QwQ 存在局限。
主题 3. 利用国家安全担忧推动 AI 监管
- 开源 AI = 国家安全:监管呼声愈发强烈 (Score: 114, Comments: 87): 媒体机构和政策制定者继续将开源 AI 的发展与国家安全威胁挂钩,推动加强监管和审查。这种叙事将不受限制的 AI 开发等同于潜在的安全风险,尽管具体的政策提案仍不明确。
- 据报道,像 Yi 和 Qwen 这样的中国 AI 模型领先于西方的开源努力,用户指出它们并非基于 Llama。多位评论者指出,对美国开源模型的监管将主要使中国的 AI 发展受益。
- 讨论将当前的 AI 监管恐惧与 21 世纪初对开源软件的历史性抵制进行了类比,特别是提到了 Microsoft/SCO 事件。用户认为,就像 Linux 一样,开源 AI 可能会加速行业创新。
- 用户批评媒体的叙事是旨在通过监管建立 AI 垄断的恐吓行为。许多人提到了 Fox News 在技术问题上的可信度,并暗示这是由企业利益而非合法的安全担忧驱动的。
主题 4. 新工具:功能增强的 Open-WebUI
- 🧙♂️ 增强版 Open-WebUI:我的 ArXiv、ImageGen 和 AI 规划魔法工具箱!🔮 (Score: 97, Comments: 11): 作者为 Open-WebUI 开发了多种工具,包括 arXiv Search 工具、Hugging Face Image Generator,以及各种功能管道,如使用 Monte Carlo Tree Search 的 Planner Agent,以及支持多达 5 种不同 AI 模型的 Multi Model Conversations。该 AI 技术栈运行在 R7 5800X、16GB DDR4 和 RX6900XT 的配置上,包括 Ollama、Open-webUI、OpenedAI-tts、ComfyUI、n8n、quadrant 和 AnythingLLM,主要使用 8B Q6 或 14B Q4 模型及 16k context,代码可在 open-webui-tools 和 open-webui 获取。
- 用户建议使用 Python 3.12 来提升性能,但开发者表示目前由于时间限制暂未实施。
- 用户对用于研究摘要的 Monte Carlo Tree Search (MCTS) 实现表现出兴趣,尽管讨论中未提供具体细节或论文。
- 我构建了这个用于比较 LLM 的工具 (评分: 297, 评论: 55): 提到的模型比较工具缺乏具体细节或功能说明,因此无法对其基准测试能力或实现细节提供有意义的技术总结。未提供关于该工具实际功能或特性的额外背景。
- 用户建议在比较工具中增加更小的语言模型,特别提到了 Gemma 2 2B、Llama 3.2 1B/3B、Qwen 2.5 1.5B/3B 等模型,用于 PocketPal 等端侧应用。
- 关于 Token 计数归一化引发了大量讨论,详细分析显示,对于相同的输入,Claude-3.5-Sonnet 使用的 Token 数量大约是 GPT-4o 的两倍,这影响了成本计算和上下文长度的比较。
- 对“开源 (Open Source)”和“开放权重 (Open Weight)”模型进行了重要区分,指出列表中可自托管的模型在技术上属于“开放权重”,因为它们的训练数据并未公开。
其他 AI Subreddit 回顾
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
主题 1. ChatGPT 助力赢得针对房东的 1180 美元小额法庭诉讼案
- 更新:ChatGPT 让我无需法律代表即可起诉房东——而且我赢了! (评分: 1028, 评论: 38): 一名租客赢得了针对 Jericho High School 联合校长 Dr. Joe Prisinzano 的诉讼。该房东非法收取了 2,175 美元的押金(超过了一个月 1,450 美元的租金),且未能在冬季修复破碎的窗户。ChatGPT 帮助识别了 2019 年的一项法律违规行为,并针对报复性的 5,000 美元反诉准备了法律辩护。法院判给租客 1,180 美元并驳回了反诉。尽管 Prisinzano 威胁要上诉并追究诽谤责任,但该案件通过 Sabrina Ramonov 的一段播放量超过 100 万次的 TikTok 视频引起了病毒式关注 病毒式 TikTok。
- 租客认为这涉及公共利益,因为 Joe Prisinzano 是美国顶尖公立高中之一的教育领导者,年薪 25 万美元,其不道德的房东行为与其领导地位相悖,理应引起公众关注。
- 多位用户分享了使用 ChatGPT 寻求法律援助的类似经历,但提醒不要完全依赖 AI,并建议进行 1 小时法律咨询。一位用户指出,在纽约,租客可以针对非法押金索取双倍赔偿,针对无证明的扣款索取三倍赔偿。
- 尽管房东书面承认明知故犯,但原审法官对租客提出的 4,000 美元惩罚性赔偿请求裁定较为保守,仅准予退还非法押金,并针对窗户破损期间给予 7% 的租金减免。
主题 2. 混元视频 (HunyuanVideo) 声称达到 SOTA 视频生成水平,击败 Gen3 和 Luma
- SANA,NVIDIA 图像生成模型终于发布 (评分: 136, 评论: 78): NVIDIA 的图像生成模型 SANA 已公开发布。帖子正文中未提供关于模型能力、架构或源代码位置的额外细节。
- 许可证限制非常严格——模型仅限非商业用途,必须在 NVIDIA 处理器上运行,需要 NSFW 过滤,并授予 NVIDIA 对衍生作品的商业权利。该模型可在 HuggingFace 上获取。
- 技术要求包括训练 0.6B 和 1.6B 模型需要 32GB VRAM,推理则分别需要 9GB 和 12GB VRAM。未来的量化版本有望将推理需求降低至 8GB 以下。
- 该模型使用 Decoder-only LLM(可能是 Gemma 2B)作为文本编码器而非 T5。虽然速度极快,但用户反映其图像质量存在问题,且文本生成能力逊于 Flux。演示地址:nv-sana.mit.edu。
- Tencent Hunyuan-Video:在文本生成视频领域击败 Gen3 和 Luma。 (Score: 37, Comments: 15): Tencent 发布了 Hunyuan-video,这是一款开源的文本生成视频模型,声称在测试中表现优于闭源竞争对手 Gen3 和 Luma1.6。该模型包含音频生成功能,可以在其演示视频中预览。
- 该模型已在 GitHub 和 Hugging Face 上线,官方项目页面位于 Tencent Hunyuan。
- 系统要求包括:720x1280 分辨率(129 帧)需要 60GB GPU 显存,或 544x960 分辨率(129 帧)需要 45GB,这引发了关于在消费级 GPU 上运行该模型的幽默评论。
- ComfyUI 集成已列入项目路线图的未来开发项,表明计划扩大其易用性。
主题 3. ChatGPT 母公司 OpenAI 考虑引入广告
- 我们确实应该担心 2025 年会以 W T F 开头 (Score: 190, Comments: 157): OpenAI 计划到 2025 年在 ChatGPT 中实施广告,这引发了人们对 AI 变现未来走向的担忧。社区对这一进展表示怀疑,质疑其对用户体验的影响以及对 AI 商业模式的更广泛影响。
- 数据变现担忧主导了讨论,用户预测其演变过程将从针对免费用户的“推广建议”最终发展到涵盖所有层级的赞助内容。社区预期会整合基于对话数据的定向广告,类似于 Prime Video 的广告模式。
- “平台劣化”(enshittification)的概念成为一个关键主题,用户预见到服务将从以用户为中心转向利润最大化。多位评论者指出 Claude 和本地 LLM(如 Llama、QWQ 和 Qwen)是潜在的替代方案。
- 用户对 AI 生成广告可能带来的微妙操纵表示担忧,并指出传统的广告拦截器可能对集成在 AI 中的促销内容无效。讨论强调了 ChatGPT 的对话性质可能使赞助内容特别难以识别或监管。
- ChatGPT 可能会引入广告——尽管 Sam Altman 并不热衷于此 (Score: 70, Comments: 108): 尽管 CEO Sam Altman 此前曾表示反感基于广告的营收模式,但 OpenAI 仍可能在 ChatGPT 中引入广告。仅标题就暗示了 OpenAI 变现策略的潜在转变,尽管尚未提供具体的时间表或实施细节。
- 用户反应绝大多数是负面的,许多人表示如果实施广告,他们将立即取消订阅。多位用户将其与 Prime Video 和 Disney+ 等流媒体服务相提并论,这些服务甚至在付费层级中也引入了广告。
- 原始文章似乎是标题党,正如用户指出的那样,OpenAI “目前没有”添加广告的“活跃计划”,一些人认为这仅仅是在测试公众反应。澄清这一点的热门评论获得了 177 个点赞。
- 用户担心基于广告的激励机制会损害 ChatGPT 的完整性,将其比作信任的朋友推荐与拿佣金的销售人员之间的区别。几条评论强调了广告通常如何随着时间的推移从免费层级扩展到付费服务,并以有线电视和流媒体平台为例。
{kind=link}
主题 4. 沃达丰 (Vodafone) 的 AI 广告展示了 AI 视频制作的新标杆
- 沃达丰(Vodafone)绝对令人惊叹的 AI 广告。比可口可乐(Coca-Cola)的尝试好得多。 (评分: 163, 评论: 63): Vodafone 制作了一条 AI 生成的商业广告,获得了观众的积极反响,评论者特别将其与 Coca-Cola 之前的 AI 广告尝试进行了对比,并给予了更高评价。帖子中未提供关于该广告内容或创作过程的更多细节。
- 观众反应 大多是负面的,批评该广告缺乏连贯性且过度使用刻板镜头。多位用户指出,该广告在 静音状态下观感极差,且包含大量脱节的场景。
- 该广告的 成本效率 受到关注,据估计仅为“普通商业广告的 十分之一”。用户讨论了其 技术成就 是否超过了艺术价值,其中视频剪辑师获得的赞誉多于 AI 本身。
- 讨论集中在 行业影响 上,特别是关于演员和传统制作团队可能被取代的问题。引用了一篇关于该广告创作的 Campaign Live 文章,但仍处于付费墙后。
AI Discord 摘要回顾
由 O1-preview 提供的摘要之摘要的总结
主题 1:新型优化器与训练技术革新 AI
- DeMo 实现去中心化模型训练:Nous Research 发布了 DeMo 优化器,通过 Nous DisTrO 实现 15B 模型的去中心化预训练,其性能可媲美中心化训练方法。实时运行展示了其效率,可以在此处观看。
- Axolotl 集成 ADOPT 优化器:Axolotl AI 引入了最新的 ADOPT 优化器,可在任何 beta 值下提供最佳收敛,并增强模型训练效率。邀请工程师在更新后的代码库中尝试这些增强功能。
- Pydantic AI 桥接 LLM 集成:Pydantic AI 的发布提供了与 LLMs 的无缝集成,增强了 AI 应用。它还与 DSPy 的 DSLModel 集成,简化了 AI 工程师的开发工作流。
主题 2:新型 AI 模型引发热议与辩论
- 亚马逊 Nova 瞄准 GPT-4o:Amazon 通过 Bedrock 发布了 Nova 基础模型,拥有极具竞争力的能力和高性价比的定价。Nova 支持零日集成,并以实惠的选择扩展了 AI 模型版图。
- 混元视频(Hunyuan Video)树立文本生成视频新标杆:腾讯混元视频(Hunyuan Video) 作为领先的开源文本生成视频模型发布,尽管资源需求较高,但仍令用户印象深刻。初步反馈积极,期待未来的效率优化。
- Sana 模型的效率受到质疑:Stability.ai 社区对新型 Sana 模型 展开辩论,质疑其相对于 Flux 等现有模型的实际优势。一些人建议使用先前的模型可能会产生相似或更好的结果。
主题 3:AI 工具面临性能与更新挑战
- Cursor IDE 的延迟促使用户转向 Windsurf:由于对 Cursor IDE 在 Next.js 项目中的延迟感到沮丧,用户因 Cursor 持续的性能问题而回归 Windsurf。Cursor 的语法高亮和聊天功能也因导致“视觉不适”和阻碍可用性而受到批评。
- OpenInterpreter 重构以提升速度与智能:OpenInterpreter 开发分支的完全重构带来了一个“更轻、更快、更聪明”的工具。新的
--serve选项引入了一个兼容 OpenAI 的 REST 服务器,增强了可访问性和可用性。 - Unsloth AI 微调遇到障碍:用户在 Llama 3.2 上进行 LoRA 微调 时遇到困难,并面临 xformers 兼容性问题,导致社区共享修复方案。挑战包括 OOM 错误以及训练期间序列长度配置的不一致。
主题 4:社区探索 AI 方法与框架
- Function Calling vs MCP:AI 状态管理器的交锋:Nous Research 讨论了 function calling 与 Model Context Protocol (MCP) 在管理 AI 模型状态和动作方面的优劣,强调了两者在应用场景上的困惑以及对更清晰指南的需求。
- ReAct 范式的有效性取决于实现细节:LLM Agents 课程参与者强调,ReAct 的成功取决于具体的实现细节,如 prompt 设计和状态管理。由于 AI 领域存在“模糊定义”,基准测试应反映这些细节。
- DSPy 和 Pydantic AI 增强开发者工作流:DSPy 集成了 Pydantic AI,允许通过 DSLModel 进行高效开发。现场演示展示了高级 AI 开发技术,激发了在项目中实现 Pydantic 功能的热情。
主题 5:AI 社区参与机遇与活动
- 前 Google 员工创立新公司,邀请合作伙伴:Raiza 在 Google 工作 5.5 年后离职,与前 NotebookLM 团队成员共同创立了一家新公司,并邀请他人通过 hello@raiza.ai 加入。他们庆祝了重大成就,并计划与社区一起构建创新产品。
- Sierra AI 在宣讲会上挖掘人才:Sierra AI 举办了一场独家信息宣讲会,揭晓了他们的 Agent OS 和 Agent SDK,同时寻求优秀开发者加入团队。参与者可以在此预约以锁定机会。
- 多 Agent 聚会凸显协作创新:即将在 GitHub 总部举行的多 Agent 聚会将邀请专家讨论使用 CrewAI 自动化任务以及使用 Arize AI 评估 Agent,促进 Agentic Retrieval 应用中的协作。
第一部分:Discord 高层级摘要
Nous Research AI Discord
- 使用 DisTrO 进行去中心化预训练:Nous 已启动一个 15B 参数语言模型的去中心化预训练,使用了 Nous DisTrO 以及来自 Oracle 和 Lambda Labs 等合作伙伴的硬件,展示了与传统使用 AdamW 的中心化训练相匹配甚至更优的损失曲线。
- DeMo 优化器发布:DeMo 优化器通过在每个优化步骤中仅同步极小的模型状态,实现了神经网络的并行训练,在减少加速器间通信的同时增强了收敛性。
- DisTrO 训练更新:正在进行的 DisTrO 训练运行已接近完成,预计本周末将公布有关硬件和用户贡献的具体细节。
- 此次运行主要作为测试,可能不会立即为用户提供公开的注册表或教程。
- AI 模型中的 Function Calling vs MCP:Function calling 用于管理 AI 模型内部的状态和动作,而 MCP 在实现复杂功能方面提供了替代优势。
- 在区分 MCP 与 function calling 方面存在一些困惑,强调了对各自应用场景提供更清晰指南的需求。
- 在特定任务中使用较小模型:在某些创意任务中,较小的 AI 模型表现可能优于较大的模型,并具有处理速度更快、资源消耗更少等优点。
- 建议采用平衡的方法,由较小的模型处理状态管理,而将较大的模型保留用于讲故事等更密集的任务。
Eleuther Discord
- JAX Adoption Accelerates in Major AI Labs:JAX 在主流 AI 实验室的采用加速。成员透露,Anthropic、DeepMind 和其他领先的 AI 实验室正越来越多地在模型中使用 JAX,尽管其主要使用程度因机构而异。
- 关于 JAX 是否会超越 PyTorch 的主导地位存在持续争论,呼吁在行业采用率和实践方面提高透明度。
- Vendor Lock-in Raises Concerns in Academic Curricula:学术课程中的供应商锁定(Vendor Lock-in)引发关注。讨论强调了学术界中的供应商锁定问题,科技公司通过为 PyTorch 和 JAX 等特定框架提供资源来影响大学课程。
- 观点不一;一些人看到了建立合作伙伴关系的好处,而另一些人则担心这会限制学生接触更广泛的工具和框架。
- DeMo Optimizer Enhances Large-Scale Model Training:DeMo 优化器增强大规模模型训练。DeMo 优化器引入了一种通过解耦动量更新(momentum updates)来最小化加速器间通信的技术,这使得在无需高速网络完全同步的情况下实现更好的收敛。
- 其极简设计将优化器状态大小减少了每个参数 4 字节,使其在训练超大规模模型时具有优势。
- Externalizing Evals via Hugging Face Proposed:提议通过 Hugging Face 外部化 evals。有人提议允许通过 Hugging Face 外部加载 evals,类似于数据集和模型的集成方式。
- 这种方法可以简化数据集和相关 eval YAML 文件的加载过程,但需要解决可见性和版本控制问题以确保可复现性(reproducibility)。
- wall_clock_breakdown Configures Detailed Logging:wall_clock_breakdown 配置详细日志记录。成员们发现 wall_clock_breakdown 配置选项可以启用详细的日志消息,包括 optimizer_allgather 和 fwd_microstep 等优化器计时指标。
- 澄清确认,启用此选项对于生成深入的性能日志至关重要,有助于性能诊断和优化。
Modular (Mojo 🔥) Discord
- Mojo Socket Communication Delays:Mojo 套接字通信(socket communication)延迟。由于待处理的语言特性,Mojo 中的套接字通信实现被推迟,计划开发一个支持可交换网络后端(如 POSIX sockets)的标准库。
- 计划进行重大重写,以确保在这些语言特性可用后进行正确集成。
- Mojo’s SIMD Support Simplifies Programming:Mojo 的 SIMD 支持简化了编程。讨论强调 Mojo 的 SIMD 支持相比 C/C++ intrinsics(通常很混乱)简化了 SIMD 编程。
- 目标是在未来的更新中将更多 intrinsics 映射到标准库,以减少直接使用。
- High-Performance File Server Project in Mojo:Mojo 中的高性能文件服务器项目。一个旨在为游戏开发高性能文件服务器的项目,其目标是实现比 Nginx 高出 30% 的每秒数据包处理率。
- 目前,该项目在延迟的套接字通信功能可用之前,利用外部调用进行网络连接。
- Reference Trait Proposal for Mojo:Mojo 的 Reference Trait 提案。Mojo 中关于
Referencetrait 的提案旨在增强对 Mojo 代码中可变和可读引用的管理。- 这种方法预计将改进借用检查(borrow-checking),并减少函数参数中关于可变性的困惑。
- Magic Package Distribution Launch:Magic Package Distribution 发布。Magic Package Distribution 正在开发中,早期访问预览即将推出,允许社区成员通过 Magic 分发软件包。
- 团队正在寻找测试人员来完善该功能,邀请成员通过对软件包评审回复 🔍 或对安装回复 🧪 来参与。
aider (Paul Gauthier) Discord
- OpenRouter 性能落后于直接 API:基准测试分析显示,通过 OpenRouter 访问的模型性能低于直接通过 API 访问的模型,引发了关于优化策略的讨论。
- 用户正在协作探索提高 OpenRouter 效率的解决方案,表明社区正在努力解决这些差异。
- Aider 为开发者推出增强功能:Aider 最新的
--watch-files功能简化了 AI 指令到编码工作流的集成,同时还包括/save、/add和上下文修改等功能,详见其 options reference。- 这些更新受到了好评,用户注意到透明度有所提高,编程体验更加明晰。
- Amazon 在 re:Invent 上发布六款新基础模型:在 re:Invent 期间,Amazon 宣布了六款新的基础模型,包括 Micro、Lite 和 Canvas,强调了它们的多模态能力和极具竞争力的定价。
- 这些模型将仅通过 Amazon Bedrock 提供,并被定位为其他美国前沿模型的高性价比替代方案。
- 使用 Model Context Protocol 增强 Aider 的上下文:用户一直在集成 Model Context Protocol (MCP) 以提高 Aider 的上下文管理能力,特别是在代码相关场景中,如此视频中所讨论的。
- 正在利用 IndyDevDan’s agent 和 Crawl4AI 等工具创建优化的文档,以便实现无缝的 LLM 集成。
- 解决 Python 3.12 下 Aider 更新挑战:将 Aider 更新到版本 0.66.0 时遇到问题,包括包安装期间的命令失败,这些问题通过显式调用 Python 3.12 解释器得到解决,如 pipx installation guide 中所述。
- 这种方法使客户能够成功升级并利用最新功能,而不会出现重复问题。
Cursor IDE Discord
- Cursor 在 Next.js 项目中出现延迟:用户报告称,在对中大型项目使用 Next.js 进行开发时,Cursor 出现明显延迟,需要频繁执行 ‘Reload Window’ 命令。
- 性能因系统 RAM 而异,16GB 内存的用户比 32GB 配置的用户遇到更多延迟,这引发了对 Cursor 性能一致性的担忧。
- Windsurf 可靠性优于 Cursor:由于最新 Cursor 更新中修复重复失效,一些用户回退到了 Windsurf。
- 他们强调 Windsurf’s agent 能成功编辑多个文件且不丢失注释,而这是 Cursor 目前缺乏的功能。
- Cursor Agent 的功能请求:成员们请求在 Cursor Agent 中添加 @web 功能,以增强实时信息获取能力。
- 提到了 Agent 无法识别文件更改的问题,导致了对其可靠性的沮丧。
- Cursor 语法高亮的缺点:初次使用者报告称 Cursor 的语法高亮导致视觉不适并阻碍了易用性。
- 投诉包括各种 VS Code addons 在 Cursor 中运行异常,降低了整体用户体验。
- Cursor 更新后的聊天问题:在最近的更新后,用户遇到了 Cursor 聊天功能的问题,包括模型幻觉和性能不一致。
- 反馈表明 模型质量有所下降,使得编码任务变得更加具有挑战性和令人沮丧。
Perplexity AI Discord
- Perplexity AI 面临性能下降:多名用户在使用 Perplexity AI 的功能时遇到持续的性能下降和无限加载问题,这表明可能存在扩展性问题 (scaling issues)。
- 这些性能问题在其他平台上也有所体现,导致用户考虑转向 API 服务以获得更稳定的体验。
- 用户探索图像生成能力:关于图像生成工具的讨论涉及分享能产生意想不到且极具创意结果的 prompts。
- 用户尝试使用量子主题提示词 (quantum-themed prompts) 来生成独特的视觉输出,展示了图像生成模型的多样化应用。
- Amazon Nova 与 ChatGPT 和 Claude 的对比:社区对 AI 模型进行了深入对比,特别是 Amazon Nova 与 ChatGPT 和 Claude 等平台之间的对比。
- 用户根据特定任务及其与 Perplexity 等工具的集成情况,评估了各种基础模型 (foundational models) 的有效性。
- Google Gemini 与 Drive 集成的问题:一位用户强调了通过 Google Gemini 访问 Google Drive 文档时存在访问不一致的问题,对其可靠性提出质疑。
- 用户担心高级功能是否仅限于付费版本,并促请提供实际演示。
- API 错误响应及用户规避方法:用户报告了间歇性的 API 错误,如
unable to complete request,导致了困惑。- 一种临时的规避方法是在用户 prompts 中添加前缀,在等待解决方案期间减少错误发生。
Unsloth AI (Daniel Han) Discord
- 使用 LoRA 微调 Llama 3.2:用户报告了使用 LoRA 微调 Llama 3.2 时的挑战,特别是从 tokenization 到 processor management 的过渡,并建议修改 Colab notebooks 以成功执行。
- 故障排除步骤包括解决 xformers 安装问题,并确保与当前的 PyTorch 和 CUDA 版本兼容。
- 模型兼容性和 xformers 问题:几位用户遇到了 xformers 与其现有 PyTorch 和 CUDA 环境的兼容性问题,导致运行时错误。
- 建议包括重新安装匹配版本的 xformers,并验证依赖项以解决这些问题。
- 使用 LLaVA-CoT 微调 QWen2 VL 7B:一位成员使用 LLaVA-CoT 数据集微调了 QWen2 VL 7B,并发布了训练脚本和数据集供社区使用。
- 生成的模型具有 8.29B 参数,并使用 BF16 张量类型,训练脚本可在此处获取 here。
- Unsloth 模型中的 GGUF 转换挑战:用户在将模型保存为 GGUF 时遇到问题,在转换过程中遇到关于缺少 ‘llama.cpp/llama-quantize’ 等文件的运行时错误。
- 尝试通过重启 Colab 来解决这些问题的努力未获成功,这表明底层库可能发生了近期更改。
- 训练模型中的部分可训练 Embeddings:一位用户讨论了创建部分可训练的 Embeddings,但在训练期间面临 forward 函数未被调用的挑战。
- 社区反馈表明模型可能直接访问权重而不是修改后的 head,因此需要更深层次的集成。
Notebook LM Discord Discord
- Raiza 离开 Google 创办新公司:Raiza 宣布在 Google 工作 5.5 年后离职,强调了在 NotebookLM 团队取得的显著成就,并开发了一款被数百万人使用的产品。
- Raiza 正与两名原 NotebookLM 成员共同创办一家新公司,邀请合作者通过 werebuilding.ai 加入,并可通过 hello@raiza.ai 联系。
- NotebookLM 在剧本和播客中的创意用途:用户详细介绍了如何利用 NotebookLM 进行剧本创作、开发详细的摄像和灯光设置,以及将剧本集成到视频项目中。
- 另一位用户通过逐章概述内容,成功生成了长篇播客剧集,并在纪录片风格的项目中使用 Eleven Labs 处理音频和视觉效果。
- 使用 PDF OCR 工具增强文档管理:讨论强调了使用 PDF24 对扫描文档进行 OCR 处理,将其转换为具有强大安全协议的可搜索 PDF。
- 推荐使用 PDF24 将图像和照片转换为可搜索格式,无需安装或注册即可优化文档的可用性。
- NotebookLM 的功能请求与集成挑战:用户表达了对 NotebookLM 中无限制音频生成的需求,建议采用订阅模式以突破目前每日 20 次的限制。
- 用户注意到了处理长 PDF 的挑战,推测 Gemini 1.5 Pro 可能会提供更强大的能力,同时也对 Google Drive 集成的不稳定性表示沮丧。
- 多语言 AI 支持的进展与问题:有关于更改 NotebookLM 语言设置以支持非英语输出的咨询,目前的指南建议通过修改 Google 账户设置来实现。
- 用户报告了 AI 生成语言输出的成功率各不相同,特别是在苏格兰或波兰等口音方面,表明多语言能力仍有改进空间。
OpenAI Discord
- 意大利 AI 监管法案强制执行数据删除:意大利宣布计划禁用 AI 平台(如 OpenAI),除非用户可以请求删除其数据,这引发了关于监管有效性的辩论。
- 针对地理位置封锁的无效性提出了担忧,并讨论了用户绕过这些限制的潜在方法。
- ChatGPT Plus 计划遭遇功能故障:用户报告称,在支付 $20 订阅 ChatGPT Plus 计划后,图像生成和文件读取等功能无法正常运行。
- 此外,多名成员指出他们收到的回复似乎过时,且该问题已持续一周多。
- GPT 在账单汇编中面临功能问题:一位用户强调了一个旨在汇编计费工时的 GPT 存在的问题,提到它会遗漏条目,且难以生成 XLS 兼容列表。
- 出现了幽默的推测,质疑该 GPT 是否对工作感到厌倦,反映了用户对该工具可靠性的挫败感。
- 利用 Custom Instructions 定制 ChatGPT:成员们正在利用 custom instructions 来调整 ChatGPT 的写作风格,并将此方法与创建新的 GPTs 区分开来。
- 建议提供示例文本以帮助 ChatGPT 调整其输出,增强与用户特定叙事偏好的契合度。
- 提升 AI 工程师的 Prompt Engineering 技能:AI 工程师表示有兴趣获取免费或低成本资源,以改进他们的 Prompt Engineering,从而利用 OpenAI ChatGPT 开发自定义 GPT。
- 讨论强调了优化交互技术对于最大化 ChatGPT 效能和能力的重要性。
OpenRouter (Alex Atallah) Discord
- 模型移除与降价:两个模型
nousresearch/hermes-3-llama-3.1-405b和liquid/lfm-40b已停止提供,提示用户增加额度 (credits) 以维持其 API 请求。- 显著的降价措施:nousresearch/hermes-3-llama-3.1-405b 从每百万 token 4.5 降至 0.9,liquid/lfm-40b 从 1 降至 0.15,在移除后提供了更实惠的替代方案。
- Hermes 405B 模型移除:Hermes 405B 不再可用,标志着该模型的逐步淘汰,用户正在讨论替代方案的成本,并倾向于现有的免费模型。
- 移除引发了对模型可用性的担忧,一些用户考虑购买价格日益上涨的模型,而另一些用户则坚持使用免费选项。
- OpenRouter API Key 管理:OpenRouter 现在支持 API keys 的创建和管理,允许用户为每个 key 设置和调整额度限制 (credit limits),且不会自动重置。
- 用户通过手动管理 key 的使用情况来控制其应用程序访问,确保安全且受控的 API 访问。
- Gemini Flash 错误:用户在访问 Gemini Flash 时遇到了短暂的 525 Cloudflare 错误,该问题很快自行解决。
- 注意到该模型的不稳定性,建议通过 OpenRouter 的聊天界面验证其功能。
- BYOK 访问更新:团队宣布 BYOK (Bring Your Own Key) 访问将很快对所有用户开放,尽管目前的私测阶段已暂停。
- 正在进行调整以解决现有问题,然后再广泛推出该功能。
Stability.ai (Stable Diffusion) Discord
- 掌握 LORA 创建:用户分享了创建有效 LORA 的策略,例如使用由图像制成的背景 LORA,并使用 Photoshop 或 Krita 等软件精修输出。
- 一位成员建议在训练前精修生成的图像,以确保更高质量的结果。
- Stable Diffusion 设置技巧:多位用户寻求 Stable Diffusion 设置指南,建议包括使用 ComfyUI - 入门教程 以及各种云端选项。
- 成员强调了决定是在本地运行还是利用云端 GPU 的重要性,推荐使用 Vast.ai 进行 GPU 租赁。
- 诈骗警报策略:对服务器中诈骗者的担忧促使用户分享警告,并建议向 Discord 举报可疑账号。
- 用户讨论了如何识别钓鱼尝试,以及某些账号如何冒充支持人员来欺骗成员。
- 比较 GPU 性能:对话强调了 GPU 性能的差异,用户比较了不同型号的体验,并强调了显存 (memory) 和速度的重要性。
- 一位用户指出,由于电费成本,较便宜的云端 GPU 选项可能比本地设置提供更好的整体性能。
- 评估 Sana 模型:成员讨论了一个名为 Sana 的新模型,注意到其与早期版本相比的效率和质量,同时对其商业用途持保留意见。
- 有建议称,对于日常用途,使用 Flux 或之前的模型可能会产生相似或更好的结果。
Latent Space Discord
- Pydantic AI 与 LLM 集成:来自 Pydantic 的新 Agent Framework 现已上线,旨在与 LLM 无缝集成,以实现创新的 AI 应用。
- 然而,一些用户对其与 LangChain 等现有框架的差异化表示怀疑,认为它与目前的解决方案非常相似。
- Bolt 在 2 个月内达到 800 万美元 ARR:作为一款 Claude Wrapper,Bolt 在短短 2 个月 内突破了 800 万美元 ARR,嘉宾包括 @ericsimons40 和 @itamar_mar。
- 播客节目深入探讨了 Bolt 的 增长策略,并讨论了 code agent engineering,重点介绍了与 @QodoAI 的合作以及 StackBlitz 的首次亮相。
- 腾讯发布混元视频(Hunyuan Video),领跑开源领域:腾讯 发布了 Hunyuan Video,将其确立为以高质量著称的顶级 开源 text-to-video 技术。
- 初步的用户反馈指出其渲染的 资源需求较高,但对其即将推出的 效率提升 持乐观态度。
- 亚马逊发布 Nova 基础模型:亚马逊 宣布了其新的基础模型 Nova,定位是与 GPT-4o 等先进模型竞争。
- 早期评估显示出潜力,但用户体验仍然 褒贬不一,一些人认为它不像亚马逊之前发布的 模型 那样令人印象深刻。
- ChatGPT 面临姓名过滤故障:ChatGPT 遇到了一个问题,即由于系统故障,特定姓名(如 David Mayer)会触发响应中断。
- 此问题不影响 OpenAI API,并引发了关于 姓名关联 如何影响 AI 行为 的讨论。
Cohere Discord
- Rerank 3.5 增强多语言搜索:Cohere 推出了 Rerank 3.5,通过
rerank-v3.5API 提供增强的推理能力,并支持包括阿拉伯语、法语、日语和韩语在内的 100 多种语言。- 用户对性能的提升及其与包括 多媒体 内容在内的各种数据格式的兼容性表示热烈欢迎。
- Cohere 宣布 API 弃用:Cohere 宣布 弃用 旧模型,并提供了关于 弃用端点 的详细信息以及推荐的替代方案,作为其 模型生命周期 管理的一部分。
- 此举影响了依赖旧模型的应用程序,促使开发者相应地更新其集成。
- Harmony 项目发布 NLP 协调工具:Harmony 项目推出了用于协调问卷项目和元数据的 NLP 工具,使研究人员能够 跨研究比较问卷项目。
- 该项目总部位于 UCL,正与多家大学和专业人士合作,以完善其 文档检索能力。
- API 密钥延迟触发 TooManyRequestsError:有用户报告称,尽管升级到了生产环境 API 密钥,仍遇到 TooManyRequestsError,将问题归因于潜在的 API 密钥设置延迟。
- 建议联系 support@cohere.com 寻求帮助,有迹象表明设置延迟通常很小。
- Stripe 集成导致支付问题:一些用户在 Cohere 平台上遇到了 信用卡支付问题,尽管之前的交易很成功。
- 成员们建议问题可能出在用户的银行,并建议联系 support@cohere.com,因为支付是通过 Stripe 处理的。
GPU MODE Discord
- Xmma 和 Nvjet 在特定基准测试中表现优于 Cutlass:成员们评估了 Xmma kernels,注意到 nvjet 在小尺寸上正在赶上,对于 N=8192,自定义 kernel 的运行速度比 cutlass 快 1.5%。
- nvjet 通常与 cutlass 竞争激烈,但在某些特定情况下 cutlass 可能略胜一筹。
- Triton MLIR Dialects 文档批评:一位成员询问了关于 Triton MLIR Dialects 的文档,指出大部分 TritonOps documentation 非常简略且缺乏详尽的示例。
- 另一位成员指出 GitHub 上的 programming guide 也很简略且未完成,旨在帮助使用 Triton language 的开发者。
- CUDARC Crate 支持手动 CUDA 绑定:CUDARC crate 提供了 CUDA API 的绑定,由于是手动实现,目前仅支持 matrix multiplication。
- 测试显示,优化 matmul 函数消耗了大部分开发时间。
- GPU Warp Scheduler 和 FP32 核心分布见解:一位成员解释说,一个 warp 包含 32 threads,并行使用 32 FP32 cores,导致每个 SM 有 128 FP32 cores。
- 注意到 A100 的 4 个 warp schedulers 对应 64 FP32 cores,而 RTX 30xx 和 40xx 系列则拥有 128 FP32 cores,两者之间存在差异。
- KernelBench 发布及排行榜完整性问题:@anneouyang 推出了 KernelBench (Preview),用于评估 LLM 生成的 GPU kernels 以进行神经网络优化。
- 用户对排行榜上不完整的 fastest kernels 表示担忧,并引用了一个 不完整的 kernel 解决方案。
LlamaIndex Discord
- NVIDIA 财务洞察揭晓:@pyquantnews 展示了如何利用 NVIDIA 的财务报表进行简单的收入查询和复杂的业务风险分析,并使用了 设置 LlamaIndex 的实际代码示例。
- 该方法通过利用结构化财务数据增强了商业智能。
- 使用 Google Drive 简化 LlamaCloud:@ravithejads 概述了配置以 Google Drive 作为数据源的 LlamaCloud 流水线的逐步过程,包括 chunking 和 embedding 参数。完整的设置说明可在 此处 查看。
- 该指南协助开发者将文档索引与 LlamaIndex 无缝集成。
- 亚马逊发布 Nova 基础模型:Amazon 推出了 Nova,这是一系列基础模型(foundation models),与竞争对手相比价格更实惠,并提供 day 0 支持。通过
pip install llama-index-llms-bedrock-converse安装 Nova,并在此处查看 示例。- Nova 的发布以具有成本效益和高性能的选项扩展了 AI 模型版图。
- 有效的 RAG 实现:一位成员分享了一个包含 10 多个 RAG 实现 的仓库,包括 Naive RAG 和 Hyde RAG 等方法,帮助他人为自己的数据集定制 RAG。在此处查看 仓库。
- 这些实现促进了针对特定 AI 开发需求定制的 RAG 应用实验。
- 嵌入模型 Token 尺寸限制:讨论强调了 HuggingFaceEmbedding 类会截断超过 512 tokens 的输入文本,这给嵌入较长文本带来了挑战。
- 成员们建议选择合适的
embed_model类来有效绕过这些限制。
- 成员们建议选择合适的
LM Studio Discord
- Qwen LV 7B Vision 功能:有用户询问 Qwen LV 7B 模型是否支持 vision(视觉)功能,引发了关于将视觉能力集成到各种 AI 模型中的讨论。
- 社区成员正在探索将视觉与 Qwen LV 7B 结合的潜力,讨论了可能的应用场景和技术要求。
- FP8 量化提升模型效率:根据 VLLM 文档,FP8 量化可以在几乎不影响准确性的情况下,实现 2 倍的模型内存减少和 1.6 倍的吞吐量提升。
- 这种优化对于在资源有限的机器上优化性能尤为重要。
- HF Spaces 现在支持 Docker 容器:一位成员确认任何 HF space 都可以作为 docker container 运行,为本地部署和测试提供了灵活性。
- 这一增强功能为在 HF spaces 上工作的 AI 工程师提供了更简便的集成和扩展性。
- Intel Arc Battlemage 显卡在 AI 任务中面临质疑:一位成员对新款 Arc Battlemage 显卡表示怀疑,认为它们不适合 AI 任务。
- 另一位成员反驳称,尽管对于构建本地推理服务器来说具有性价比,但此类应用对 Intel 的依赖性仍存疑问。
- LM Studio 在 Windows 上的性能问题:用户报告称,与 Mac 相比,在 Windows 上运行 LM Studio 时速度较慢且输出异常,特别是在使用 3.2 模型时。
- 建议的解决方案包括切换
Flash Attention开关以及检查系统规格的兼容性。
- 建议的解决方案包括切换
LLM Agents (Berkeley MOOC) Discord
- Sierra AI 宣讲会与人才招募:Sierra AI 将于 太平洋时间 12 月 3 日上午 9 点为开发者举办专属宣讲会,可通过 YouTube 直播 观看,届时参与者将探索 Sierra 的 Agent OS 和 Agent SDK 能力。
- 在会议期间,Sierra AI 将讨论他们对优秀开发者的招募需求,并鼓励感兴趣的人士 RSVP 报名以锁定职业机会。
- Dawn Song 的 AI 安全结课讲座:Dawn Song 教授将于今日 PST 下午 3:00 发表题为《迈向构建安全可靠的 AI Agents 以及基于科学和证据的 AI 政策之路》的最后一场讲座,并在 YouTube 同步直播。
- 她将探讨与 LLM agents 相关的重大风险,并提出基于科学的 AI 政策以有效缓解这些威胁。
- LLM Agents 课程作业与 Mastery 等级:参与者仍可通过填写 报名表 注册 LLM Agents 学习课程,并在 课程网站 获取所有材料。
- 虽然实验作业并非所有证书的强制要求,但要获得 Mastery 等级 必须完成全部三项作业,允许晚加入的学习者按需补课。
- 对 GPT-4 PII 泄露的担忧:一位成员担心 GPT-4 可能会泄露个人身份信息(PII),并将其与 2006 年的 AOL 搜索日志泄露 事件相类比。
- 他们强调,尽管 AOL 声称进行了匿名化处理,但泄露内容包含了来自超过 650,000 名用户 的 2000 万条搜索查询,且这些数据至今仍可在网上获取。
- ReAct 范式实现方式的影响:ReAct 范式 的有效性高度依赖于具体的实现细节,如 prompt design(提示词设计)和 state management(状态管理),成员指出 Benchmark 应该反映这些细节。
- 讨论中将其与传统机器学习中的基础模型进行了对比,引发了关于不同实现方式如何因 AI 领域内模糊的定义而导致 Benchmark 性能巨大差异的讨论。
OpenInterpreter Discord
- 开发分支重写以增强性能:最新的开发分支已完全重写,使其更轻量、更快速、更智能,给用户留下了深刻印象。
- 成员们对测试这个活跃分支感到兴奋,并被鼓励针对旧版本中缺失的功能提供反馈。
- 新的
--serve选项支持 OpenAI 兼容服务器:新的--serve选项引入了一个 OpenAI 兼容的 REST 服务器,1.0 版本排除了旧的 LMC/web socket 协议。- 此设置允许用户通过任何 OpenAI 兼容的客户端进行连接,从而直接在服务器设备上执行操作。
- Anthropic 集成遇到 TypeError:用户报告在将开发分支与 Anthropic 集成时遇到了 TypeError,具体表现为意外的关键字参数 ‘proxies’。
- 建议用户分享完整的 traceback 以便调试,并向其提供了正确的安装命令示例。
- 请求社区测试以增强开发分支:成员们请求社区参与测试,以改进频繁更新的开发分支功能。
- 一位成员表示依赖 LMC 进行通信,并发现过渡到新设置既令人恐惧又令人兴奋。
- LiveKit 实现远程设备连接:O1 利用 LiveKit 连接设备,如 iPhone 和笔记本电脑,或运行服务器的 Raspberry Pi。
- 此设置便于通过在其上运行的本地 OpenInterpreter (OI) 实例远程访问并控制机器。
DSPy Discord
- Pydantic AI 与 DSLModel 集成:Pydantic AI 的引入增强了与 DSLModel 的集成,为开发者创建了一个无缝框架。
- 此集成利用了 Pydantic,该工具在 Python 的各种 Agent 框架和 LLM 库中被广泛使用。
- DSPy 在 AWS Lambda 上的优化挑战:一位成员正考虑为 LangWatch 客户在 AWS Lambda 上运行 DSPy 优化,但 15 分钟的限制带来了挑战。
- 他们表示需要绕过这一时间限制的策略。
- 推荐使用 ECS/Fargate 而非 Lambda:另一位成员分享了他们的经验,建议由于存储限制,在 Lambda 上运行 DSPy 可能不可行。
- 他们建议探索 ECS/Fargate 作为一种可能更可靠的解决方案。
- Program Of Thought 弃用担忧:一位成员询问 Program Of Thought 是否在 v2.5 之后走向弃用/无积极支持的道路。
- 这表明社区对该程序未来的持续关注。
- DSPy 中的 Agentic 和 RAG 示例:一位成员询问了 DSPy 中的 Agentic 示例,即一个 signature 的输出被用作另一个 signature 的输入,特别是针对电子邮件撰写程序。
- 另一位成员建议查看 RAG 示例,但随后澄清相关示例的位置可能在 dspy.ai 网站上。
Torchtune Discord
- Torchtune 中的图像生成功能:一位用户对在 Torchtune 中添加图像生成功能表示兴奋,并引用了 Pull Request #2098。
- 该 Pull Request 旨在整合增强平台能力的新功能。
- Torchtune 中的 T5 集成:根据 Pull Request #2069 的见解,讨论表明 T5 可能会被集成到 Torchtune 中。
- 预计此次集成将使 T5 功能与即将推出的图像生成增强功能保持一致。
- 在 Torchtune 中微调 ImageGen 模型:一位成员强调了在 Torchtune 中微调图像生成模型的潜力,并将其描述为一个有趣的项目。
- 这一评论引发了轻松的回应,表明成员之间的熟悉程度各不相同。
- CycleQD Recipe 分享:一位成员分享了 CycleQD recipe 的链接,并将其描述为一个有趣的项目。
MLOps @Chipro Discord
- 成员对即将举行的活动感到兴奋:成员们表达了参加即将举行的活动的兴奋和兴趣,其中一位成员提到在那段时间计划访问印度。
- 分享了“噢太棒了。是的。我会去的。希望能见面!”,突显了参与者的热情。
- 活动注册流程说明:一位用户询问了参加活动的注册流程,引发了关于如何有效操作注册系统的讨论。
- 参与者分享了简化参会者引导体验的策略,以确保注册流程顺畅。
Axolotl AI Discord
- ADOPT 优化器加速 Axolotl:团队已将最新的 ADOPT 优化器更新集成到 Axolotl 代码库中,鼓励工程师们尝试这些增强功能。
- 一位成员询问了在 Axolotl 中使用 ADOPT 优化器的优势,引发了关于性能提升的讨论。
- ADOPT 优化器的 Beta 提升:ADOPT 优化器现在支持在任何 beta 值下实现最优收敛,增强了在不同场景下的性能。
- 成员们在讨论中探索了这一能力,强调了其在各种部署场景中优化性能的潜力。
tinygrad (George Hotz) Discord
- PR#7987 凭借稳定的基准测试取得成功:jewnex 指出 PR#7987 在运行基准测试后值得发推文,显示这次使用 beam 时没有 GPU 挂起 🚀。
- 调整 uopgraph.py 中的线程组:learn-tinygrad 频道的一位成员询问在
uopgraph.py的图重写优化期间是否可以更改线程组/网格大小。- 讨论集中在这些大小是基于 pm_lowerer 中早期的搜索而固定的,还是可以在优化后进行调整。
LAION Discord
- 2024 年的 Bio-ML 革命:2024 年标志着生物机器学习(bio-ML)的激增,取得了显著成就,如因结构生物学预测授予的诺贝尔奖,以及对蛋白质序列模型的大量投资。
-
该领域充满了兴奋,尽管对需要解决的计算最优蛋白质序列建模曲线仍存在担忧。[Through a Glass Darkly Markov Bio](https://www.markov.bio/research/mech-interp-path-to-e2e-biology) 讨论了通往端到端生物学的路径以及人类理解的作用。
-
- 为单细胞生物学引入 Gene Diffusion:描述了一种名为 Gene Diffusion 的新模型,该模型利用在单细胞基因计数数据上训练的连续扩散 Transformer 来探索细胞功能状态。
- 它采用自监督学习方法,从基因 Token 向量中预测干净、无噪声的嵌入,类似于文本生成图像模型中使用的技术。
- 寻求 Gene Diffusion 训练机制的澄清:人们对 Gene Diffusion 模型的训练机制感到好奇,特别是其输入/输出关系以及它的预测目标。
- 成员们表达了对模型复杂细节进行澄清的愿望,强调了在理解这些复杂概念时需要社区的帮助。
Mozilla AI Discord
- 12月日程活动:12月日程中新增了三项成员活动,旨在提高社区参与度。
- 这些活动旨在展示成员的项目并提升社区活跃度。
- 下一代 Llamafile 黑客松演示:学生们明天将展示他们使用 Llamafile 构建个性化 AI 的项目,重点关注社会公益。
- 鼓励社区成员支持学生们的创新举措。
- Web Applets 介绍:<@823757327756427295> 将进行 Web Applets 介绍,解释用于高级客户端应用程序的开放标准和 SDK。
- 参与者可以在社区内自定义角色以接收更新。
- Theia IDE 实操演示:<@1131955800601002095> 将演示 Theia IDE,这是一个开放的 AI 驱动开发环境。
- 演示将展示 Theia 如何增强开发实践。
- Llamafile 发布与安全赏金:宣布了 Llamafile 的新版本,包含多项软件改进。
- <@&1245781246550999141> 在第一个月发放了 42 份赏金,用于识别生成式 AI 中的漏洞。
HuggingFace Discord 没有新消息。如果该公会长期沉寂,请告知我们,我们将将其移除。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该公会长期沉寂,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该公会长期沉寂,请告知我们,我们将将其移除。
第 2 部分:频道详细摘要与链接
完整的频道细分内容已针对邮件进行截断。
如果您喜欢 AInews,请分享给朋友!预谢!