ainews-meta-llama-33-405bnova-pro-performance-at
Meta Llama 3.3:以 70B 的价格提供 405B/Nova Pro 级别的性能。
Meta AI 发布了 Llama 3.3 70B,通过“全新的对齐流程和在线强化学习(RL)技术的进步”提升了效率,其性能可与 405B 模型相媲美。OpenAI 宣布推出强化微调(RFT),旨在利用有限的数据构建专家模型,并已向研究人员和企业开放 Alpha 访问权限。Google DeepMind 的 Gemini-Exp-1206 在基准测试中处于领先地位,其编程性能与 GPT-4o 持平。LlamaCloud 通过表格提取和分析功能增强了文档处理能力。社区关于 OpenAI 定价方案的讨论仍在持续。
“一种新的对齐过程和在线 RL 技术的进展”就是你所需要的一切。
2024年12月5日至12月6日的 AI 新闻。我们为您查看了 7 个 subreddits、433 个 Twitter 账号 和 31 个 Discord(206 个频道,5628 条消息)。预计节省阅读时间(以 200wpm 计算):535 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
Meta AI 明智地等待 OpenAI 发布 o1 finetuning 等候名单,谢天谢地,他们保持了理智的版本策略,只是再次将 Llama 次要版本号提升到了 3.3。这一次,他们通过 “一种新的对齐过程和在线 RL 技术的进展”,让 70B 模型的性能追平了 405B。当然,没有发布论文。
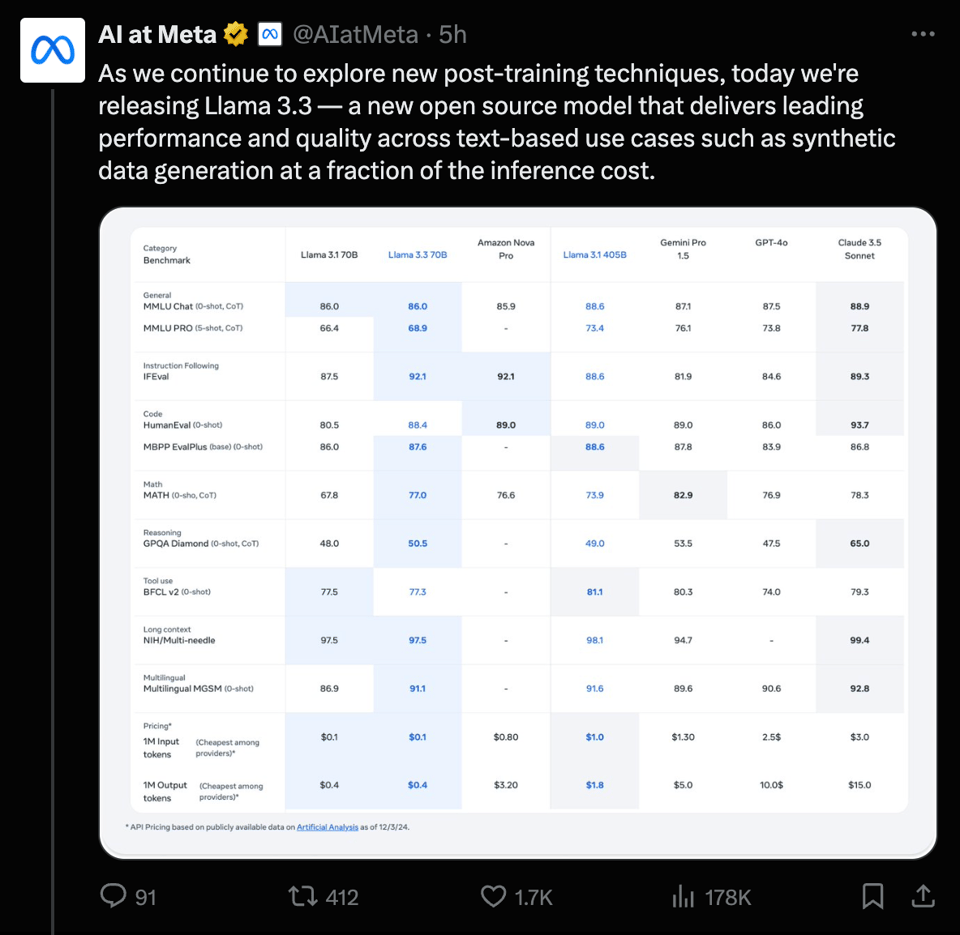
Amazon Nova Pro 仅仅风光了 3 天,但随着 Meta 大声宣传以 12% 的成本实现相同的性能,它们在性价比层级中再次被击落。
AI Twitter 综述
所有综述均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
以下是 Twitter 活动中的关键主题和讨论,按主要话题分类:
Meta 发布 Llama 3.3 70B
- 发布详情:@AIatMeta 宣布推出 Llama 3.3,这是一个 70B 模型,提供的性能可与 Llama 3.1 405B 媲美,但计算需求显著降低。该模型在 GPQA Diamond (50.5%)、Math (77.0%) 和 Steerability (92.1%) 上均有性能提升。
- 包括 @hyperbolic_labs 和 @ollama 在内的几家供应商迅速宣布支持该模型的推理服务。
- 该模型支持 8 种语言,并保持与之前 Llama 版本相同的许可证。
OpenAI 宣布强化微调 (RFT)
- 产品发布:@OpenAI 预览了 Reinforcement Fine-Tuning (RFT),允许组织使用有限的训练数据为特定领域构建专家模型。
- @stevenheidel 指出,RFT 允许用户使用 OpenAI 内部使用的相同流程来创建自定义模型。
- 目前正通过一项研究计划向研究人员和企业提供 Alpha 测试权限。
Google Gemini 性能更新
- 新模型版本:@lmarena_ai 宣布 Gemini-Exp-1206 目前在基准测试中领先,位列总榜第一,并在编程性能上与 GPT-4o 持平。
- 该模型在包括硬核提示词(hard prompts)和风格控制在内的各种基准测试中均表现出进步。
- @OriolVinyalsML 庆祝了 Gemini 发布一周年,并指出在超越自身基准测试方面取得的进展。
LlamaCloud 与文档处理
- 功能更新:@jerryjliu0 展示了 LlamaCloud 从文档中提取表格并执行分析工作负载的能力。
- 该平台现在支持直接在 UI 中渲染表格和代码。
- @jerryjliu0 强调自动化提取是一个被忽视但极具价值的用例,特别是对于收据/发票处理。
梗图与行业评论
- OpenAI 定价:包括 @aidan_mclau 在内的多位用户对 OpenAI 每月 200 美元的方案发表了评论,并讨论了 AI 定价模型的经济学。
- @sama 澄清说,大多数用户使用免费层级或每月 20 美元的 Plus 层级就足够了。
AI Reddit 综述
/r/LocalLlama 综述
主题 1:Llama 3.3 70B 性能对比 GPT-4o 及其他模型
- Llama-3.3-70B-Instruct · Hugging Face (Score: 465, Comments: 139): 该帖子关于在 Hugging Face 上发布的 Llama-3.3-70B-Instruct 模型,但缺乏关于其特性、功能或应用的额外细节或背景。
- 讨论强调了 Llama-3.3-70B-Instruct 令人印象深刻的性能,指出尽管参数量显著减少,但其能力可与 Llama 405B 媲美。用户对其 128K context 和多语言能力印象深刻,基准测试显示其在代码生成、推理和数学方面有实质性改进。
- 人们对该模型可能发布的更小版本感兴趣,因为由于 VRAM 限制,70B 模型对消费级硬件具有挑战性。讨论了 quantizing(量化)等技术,作为使其能在 RTX 4090 等具有 24G VRAM 的 GPU 上运行的方法,尽管这可能会影响输出质量。
- 一些用户对该模型与基准测试相比的实际表现表示怀疑,并将其与 Qwen2.5 72B 进行了比较,讨论了性能扩展中的权衡。社区热切期待在未来的迭代中看到进一步的架构变化,例如 Llama 4 和 Qwen 3。
- Meta releases Llama3.3 70B (Score: 432, Comments: 100): Meta 发布了 Llama3.3 70B,该模型可作为 Llama3.1-70B 的直接替代品(drop-in replacement),且性能接近 405B 模型。该新模型因其成本效益、易用性和改进的可访问性而受到关注,更多信息可在 Hugging Face 上获得。
- Llama 3.3 70B 较之前版本有显著的性能提升,正如 vaibhavs10 所强调的,在代码生成、多语言能力以及推理和数学方面有显著增强。该模型以更少的参数实现了与 405B 模型相当的性能,具体的指标改进包括代码生成的 HumanEval 提升了 7.9%,MATH (CoT) 提升了 9%。
- 围绕多语言支持的讨论强调 Llama 3.3 除英语外还支持 7 种额外语言。然而,人们对缺乏 pretrained 版本表示担忧,正如 Electroboots 和 mikael110 根据 官方文档 所提到的,目前仅提供 instruction-tuned 版本。
- Few_Painter_5588 和 SeymourStacks 等评论者将 Llama 与 Qwen 2.5 72b 等其他模型进行了比较,指出 Llama 改进了文本质量和推理能力,尽管在某些基准测试中 Qwen 仍被认为更聪明。还有人呼吁建立更全面的基准测试,重点关注基础能力,而不是容易被 post-training 刷分的指标。
- New Llama 3.3 70B beats GPT 4o, Sonnet and Gemini Pro at a fraction of the cost (Score: 112, Comments: 0): 据报道,Llama 3.3 70B 在提供成本优势的同时,性能超越了 GPT-4o, Sonnet 和 Gemini Pro。帖子中未提供性能指标和成本比较的具体细节。
{kind=link}
主题 2. 开源 O1:呼吁更好的模型
- 为什么我们需要开源的 o1 (Score: 267, Comments: 135): 作者批评了新的 o1 模型,指出它在编程任务中相比 o1-preview 有所退步,表现为无法遵循指令并对脚本进行未经授权的更改。他们认为这些问题凸显了对 QwQ 等开源模型的需求,因为私有模型可能会优先考虑利润而非性能和可靠性,使其不适用于关键系统。
- 像 QwQ 这样的开源模型正因 o1 等私有模型的可靠性问题而受到关注,后者经常意外改变行为并破坏工作流。用户更倾向于 open-weight 解决方案以获得稳定性,因为他们可以控制更新并确保长期的性能一致性。
- o1 模型因其在编程方面的糟糕表现而受到批评,用户报告了未经授权的更改和无法遵循指令的情况。这引发了对其在关键应用中适用性的担忧,一些用户认为 OpenAI 可能正在通过故意发布能力较弱的模型来削减成本。
- 普遍情绪认为模型自 GPT-4 以来一直在退步,用户对 o1 和 Gemini 等较新的迭代版本表示不满。许多人认为这些变化是由商业策略而非技术改进驱动的,导致人们更倾向于旧模型或开源替代方案。
- 我是唯一一个对 O1 不感到惊艳的人吗? (Score: 124, Comments: 95): 作者对 O1 模型表示怀疑,称其并不代表范式转移。他们认为 OpenAI 只是应用了开源 AI 社区现有的方法,例如 OptiLLM 以及自 10 月以来一直在使用的 “best of n” 和 “self consistency” 等 prompt 优化技术。
- 许多用户对 O1 模型表示不满,将其描述为 O1-preview 的降级,并质疑每月支付 $200 订阅费用的价值。一些人认为该模型的局限性(如在长时间交互中丢失思路)使其不适合专业用途,他们更倾向于使用 4o 或 Claude 等其他替代方案。
- 讨论涉及对 OpenAI 策略的看法,一些用户注意到该公司已转向“营利”模式,专注于增量升级而非突破性创新。这让那些觉得 OpenAI 优先考虑企业客户而非个人消费者的用户感到失望。
- 对话触及了更广泛的 AI 领域,提到了 QwenQbQ 和 DeepSeek R1 等其他模型,以及 open-source 进步的潜力。用户强调需要将可靠的模型集成到工作流中,强调长短期记忆和成熟的 Agent 框架,而不仅仅是提高智能。
主题 3. Windsurf Cascade 系统 Prompt 详情
- Windsurf Cascade 泄露的系统 prompt!! (Score: 173, Comments: 51): Windsurf Cascade 是由 Codeium 工程团队设计的 agentic AI 编程助手,用于基于 AI Flow 范式的 IDE —— Windsurf。Cascade 协助用户完成创建、修改或调试代码库等编程任务,并使用 Codebase Search、Grep Search 和 Run Command 等工具进行操作。它强调异步操作、精确的工具使用和专业的沟通风格,同时确保代码更改是可执行且用户友好的。
- 讨论强调了 AI 模型中 prompt 的复杂性,用户对尽管有许多负面表述的规则但复杂的 prompt 依然有效感到惊讶。人们对 Windsurf Cascade 使用的具体模型感到好奇。
- 讨论了在 prompt 中使用 HTML 样式标签的情况,解释称它们提供了结构和焦点,帮助模型处理较长的 prompt。一些用户提到了与 Anthropic 的 Erik Schluntz 合作的播客,指出像 XML/HTML 样式的结构化标记比原始文本更有效。
- 关于 prompt 中正向强化有效性的辩论,一些人认为正向语言可以通过将关键词与更好的解决方案联系起来提高模型性能。然而,其他人指出了不断向 prompt 添加条件的局限性,将其比作使用大量 “IF” 语句进行低效编程。
主题 4. HuggingFace 课程:LLM 的偏好对齐 (Preference Alignment)
- 免费的 Hugging Face 本地 LLMs 偏好对齐 (preference alignment) 课程! (Score: 192, Comments: 13): Hugging Face 提供了一门关于本地 LLMs preference alignment 的免费课程,包含 Argilla、distilabel、lightval、PEFT 和 TRL 等模块。该课程涵盖七个主题,“Instruction Tuning” 和 “Preference Alignment” 已经发布,而 “Parameter Efficient Fine Tuning” 和 “Vision Language Models” 等其他主题计划在未来发布。
- Colab 格式说明 (Colab Format Clarification):关于 “Colab format” 一词存在困惑,用户澄清课程材料是 notebook 格式,可以在 Google Colab 上运行,但主要是为本地运行设计的。bburtenshaw 强调 notebooks 包含在 Colab 中打开的链接以提供便利,尽管所有内容都旨在本地机器上运行。
- 本地 LLMs 预期 (Local LLMs Expectation):像 10minOfNamingMyAcc 这样的用户希望课程能为本地 LLMs 提供本地代码库,这与课程关注本地模型训练和使用的初衷一致。该课程确实支持代码和模型的本地执行。
- 课程获取 (Course Access):该课程可在 GitHub 上获取,MasterScrat 为有兴趣直接访问材料的人提供了链接 点击此处。
{kind=link}
主题 5. Adobe 发布用于自我编程 AI 的 DynaSaur 代码
- Adobe 发布 DynaSaur 代码:一个可以自我编程的 Agent (Score: 88, Comments: 13): Adobe 发布了 DynaSaur 的代码,这是一个能够自我编程的 Agent。此举突显了 Adobe 在 AI 领域,特别是在自主编程 Agent 方面的贡献。
- Eposnix 建议在 VM 中运行 DynaSaur,因为存在它无限迭代并可能导致系统损坏的风险。他们建议 confidence scoring 可以防止这种情况,如果任务太难,允许 AI 退出,而不是坚持使用可能有危害的解决方案。
- Knownboyofno 解释说 DynaSaur 可以通过生成 Python 函数来自主创建工具,以实现特定目标,这让人们对其能力有了更清晰的理解。
- Staladine 和其他人表示有兴趣看到 DynaSaur 运行的实际案例或演示,这表明需要更多说明性资源来理解其功能。
其他 AI Subreddit 综述
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
主题 1. OpenAI GPT-4.5:在创意语言任务中超出预期
- 让她吐槽 UHC CEO (Score: 195, Comments: 27): ChatGPT 批判了医疗保险行业,将其利润驱动的行为比作“用人命玩大富翁”,反思了将利润置于患者护理之上的道德影响。对话还触及了吐槽一个被暗杀的人所面临的挑战。
- 讨论强调了 ChatGPT 不断进化的能力,用户对其能够提供尖锐批判(特别是针对保险高管且无审查)感到震惊。评论反映了 ChatGPT 的大胆,并暗示它变得更加激进,尤其是在政治背景下。
- 一位用户幽默地指出 “事实总是带有自由主义偏见”,表明其认为 ChatGPT 的批判与自由主义观点一致。这突显了 AI 在挑战敏感行业中既定规范和人物方面所扮演的角色。
- 社区通过幽默和梗图参与该帖子,展示了对 AI 关于保险行业评论的轻松而又带有批判性的反响,并称其批判的严厉程度是“残暴的”和“致命的”。
{kind=link}
AI Discord 综述
由 O1-mini 生成的摘要之摘要的摘要
主题 1. AI 模型发布与性能大逃杀
- Meta 的 Llama 3.3 性能超越 405B 竞争对手:拥有 70B 参数的 Meta Llama 3.3 在保持更高成本效益的同时,性能媲美 405B 模型,引发了与 Gemini-exp-1206 和 Qwen2-VL-72B 模型的对比。
- 用户盛赞 Llama 3.3 增强的数学解题能力以及在编程任务中的稳健表现,认为其非常适合各种工程项目。
- 该版本的发布激发了竞争性的基准测试,社区成员渴望将其集成并针对既定标准进行测试。
- 一位用户惊叹道:“看到了语法处理方面的显著改进,” 强调了该模型的高级能力。
- Gemini-exp-1206 在编程基准测试中与 O1 持平:Google 的 Gemini-exp-1206 模型夺得总榜首位,在编程基准测试中与 O1 旗鼓相当,推向了 AI 性能的技术边界。
- 该模型展示了在合成数据生成和高性价比推理方面的重大进展,吸引了关注可扩展性的开发者。
- 社区讨论强调了 Gemini-exp-1206 在复杂 AI 应用中超越预期的潜力。
- 探索 Gemini-exp-1206 的功能。
主题 2. 价格变动引发用户不满
- Windsurf 大幅涨价令订阅者感到沮丧:Codeium 将 Windsurf 的 Pro 档位上调至 $60/月,并对 Prompt 和 Flow Action 设置了新的硬性限制,导致许多用户不满并寻求关于祖父条款(grandfathering)政策的说明。
- 订阅者对在尚未修复现有 Bug 的情况下突然涨价表示愤怒,质疑新定价模式的可持续性。
- 尽管一些替代方案也存在类似的可靠性问题,但这些突如其来的变化加速了用户对 Cursor、Bolt AI 和 Copilot 等工具的探索。
- 一位用户哀叹道:“考虑到目前的性能,这个定价是不可持续的。”
- 查看 Windsurf 的新定价详情。
- Lambda Labs 削减模型价格以吸引开发者:DeepInfra 下调了多个模型的价格,包括 Llama 3.2 3B Instruct 仅需 $0.018,Mistral Nemo 仅需 $0.04,旨在为预算敏感型开发者提供实惠的选择。
- 这些降价举措使高质量模型变得更加易于获取,促进了开发者社区内更广泛的采用和创新。
- 用户对更低的成本表示欢迎,并指出了价值主张的提升和可访问性的增加。
- 查看 DeepInfra 的降价信息。
主题 3. 工具稳定性故障与用户挫败感
- Claude 的代码处理困境阻碍开发者:用户报告 Windsurf 和 Claude 等工具存在重大 Bug,导致性能不可靠且错误率增加,使编程任务变得更加繁琐。
- 持续的服务器宕机和 “resource_exhausted” 等问题损害了生产力,导致用户重新考虑其订阅。
- 社区共识强调,在进行任何进一步价格调整之前,AI 工具迫切需要可靠的性能。
- 阅读更多关于 Claude 的用户反馈。
- Cursor 响应缓慢迫使用户转向替代方案:用户报告 Cursor 的 Composer 出现连接失败和响应缓慢,通常需要开启新会话才能恢复功能,导致用户感到沮丧并向更稳定的工具(如 Windsurf)迁移。
- 尽管 Cursor 0.43.6 推出了新功能,但 Composer 响应不可靠等问题依然存在,削弱了用户体验。
- 讨论强调需要通过强大的 Bug 修复和性能改进来留住用户信任。
- 一位开发者指出:“Cursor 的性能未达到预期。”
- 探索 Cursor 的性能问题。
主题 4. 功能增强与新集成发布
- Aider Pro 升级引入高级语音和上下文功能:Aider Pro 现在包含无限制高级语音模式、针对 O1 的全新 128k 上下文,以及复制/粘贴到 Web 聊天功能,提升了工作流效率以及处理大量文档和代码的能力。
- 此外,进程挂起支持和异常捕获分析为用户提供了更好的进程控制和洞察。
- 用户反馈称赞 Aider 实现了 61% 的代码贡献,展示了其不断增长的能力和稳健的发展。
- 探索 Aider Pro 的新功能。
- OpenRouter 的作者页面简化了模型发现:OpenRouter 推出了作者页面 (Author Pages),使用户能够通过创作者探索模型,并通过便捷的轮播 (carousel) 界面展示详细统计数据和相关模型。
- 该功能增强了模型发现并允许更好的分析,使用户更容易查找和评估各种 AI 模型。
- 社区期待通过不同作者的收藏集来改善用户体验并简化导航。
- 访问 OpenRouter 的作者页面。
主题 5. 社区关注:安全、许可和虚假应用
- 警惕虚假的 Perplexity 应用!:Discord 用户提醒社区,Windows 应用商店中流传着一个虚假 Perplexity 应用,该应用欺骗性地使用官方 Logo 和未经授权的 API,将用户引导至可疑的 Google Doc,并敦促立即举报以防止安全漏洞。
- 成员们强调了验证应用真实性的重要性,以避免暴露于恶意软件和钓鱼攻击中。
- 讨论强调了保持警惕和采取社区驱动措施来打击欺诈应用程序的必要性。
- 举报虚假 Perplexity 应用。
- Phi-3.5 对 AI 响应过度审查:微软的 Phi-3.5 模型因高度审查而受到批评,使其对冒犯性查询产生抵触,并可能限制其在技术任务中的实用性,引发了关于 AI 模型中安全性与可用性平衡的辩论。
- 用户讨论了解除审查或改进模型功能的方法,包括分享 Hugging Face 上的无审查版本 链接。
- 开发者对审查对编码和技术应用的影响表示担忧,敦促寻求具有更好上下文理解的模型。
- 一位用户辩称:“Phi-3.5 的审查使其在许多实际应用中变得不切实际。”
- 探索 Phi-3.5 的无审查版本。
- AI 工具中的安全疏忽引发警报:围绕 AI 工具安全问题的讨论突出了过度审查和缺乏安全的许可协议等问题,强调需要更好的安全协议和透明的许可来保护用户利益。
- 社区成员呼吁改进监管机制,以确保 AI 模型既安全又实用,避免阻碍实际使用的过度限制。
- 一位参与者表示:“我们需要在 AI 模型的安全性和可用性之间取得平衡。”
- 了解 AI 模型安全问题。
第一部分:Discord 高层级摘要
Codeium / Windsurf Discord
- Windsurf Pricing Overhaul:Codeium 将 Windsurf 的 Pro 层级价格上调至 $60/month,并对用户 prompts 和 flow actions 引入了硬性限制,这引起了许多订阅者的不安。
- 用户要求明确新的定价结构,以及现有方案是否会执行 grandfathered(老用户保留原价),并对在未修复现有 Bug 的情况下突然涨价表示不满。
- User Frustrations with AI Tools:工程师们报告了 Windsurf 等工具中存在的重大 Bug,阻碍了高效编码,并导致他们重新考虑是否续订。
- 共识认为,AI 工具在实施进一步价格调整之前,需要确保 reliable performance 和用户友好的功能。
- Alternatives to Windsurf:针对 Windsurf 的定价和性能问题,用户正在探索 Cursor、Bolt AI 和 Copilot 等替代方案,以获得更一致的性能。
- 尽管在考虑这些替代方案,一些用户仍保持谨慎,因为据报道 Bolt AI 等工具也面临类似的可靠性挑战。
- Impact of Server Issues:频繁的服务器宕机和 ‘resource_exhausted’ 等错误正在干扰 Windsurf 的使用,对用户生产力产生了负面影响。
- 这些技术问题加剧了用户的挫败感,并加速了向其他 AI 编码解决方案的转移。
- Feedback on AI Tool Performance:用户强调 Claude 在上下文保留(context retention)方面表现吃力,并在代码中引入错误,降低了其在开发任务中的有效性。
- 这些反馈强调了 AI 工具需要增强其 accuracy 和 contextual understanding,以更好地满足工程项目的需求。
Notebook LM Discord Discord
- Audio Generation with NotebookLM:成员们探索了使用 NotebookLM 进行音频生成,成功地从文档中创建了播客。一位用户报告称,从一份多语言文档中生成了长达 64 分钟的播客,突显了基于输入类型的不同结果。
- 讨论揭示了在 AI 生成的音频中保持连贯性和重点的挑战,尽管使用了有效的提示词(prompting)技术,一些用户仍遇到了意料之外的跑题现象。
- Language and Voice Support in NotebookLM:对话集中在 NotebookLM 对英语以外语言的支持上,一些用户回想起之前仅限英语的限制。生成的音频中令人印象深刻的 voice quality 引发了关于其作为独立 text-to-speech 解决方案潜力的辩论。
- 用户质疑语言支持的范围,讨论了扩展 NotebookLM 多语言能力的可能性,以增强其对全球工程师受众的实用性。
- Game Development using Google Docs and AI:工程师们分享了利用 Google Docs 组织游戏规则和叙事的策略,利用 AI 生成场景并构建沉浸式世界。一位成员强调了在他们的 RPG 游戏中,AI 生成的融合了严肃与幽默内容的场景取得了成功。
- AI 在游戏开发中的集成因增强了创作过程而受到称赞,用户强调了 Google Docs 作为叙事构建协作工具的灵活性。
- Spreadsheet Integration Workarounds for NotebookLM:用户发现了将 电子表格直接上传 到 NotebookLM 的限制,建议采用将数据转换为 Google Docs 等替代方案以获得更好的兼容性。一位用户提到通过隐藏不必要的列来降低电子表格的复杂性,从而整合核心数据。
- 讨论了集成电子表格数据的创意方法,重点是在规避 NotebookLM 上传限制的同时保持数据完整性。
- NotebookLM Performance and Usability Feedback:对 NotebookLM 性能的反馈褒贬不一,涉及生成内容的准确性和深度。用户强调需要更多关于潜在 paywalls 的透明度以及一致的性能指标。
- 关于 new notebook 按钮消失的担忧引发了对可能存在笔记本数量限制的猜测,这影响了 NotebookLM 的整体可用性和工作流。
Unsloth AI (Daniel Han) Discord
- PaliGemma 2 发布扩展了模型选择:Google 推出了 PaliGemma 2,包含 3B、10B 和 28B 参数的新预训练模型,为开发者提供了更大的灵活性。
- SigLIP 在视觉任务中的集成以及文本解码器升级至 Gemma 2,预计将比之前的版本带来性能提升。
- Qwen 微调遭遇 VRAM 限制:工程师在 80GB GPU 上微调 Qwen32B 模型时遇到问题,需要 96GB H100 NVL GPU 才能防止 OOM 错误(Issue #1390)。
- 对话显示 QLORA 可能会比 LORA 消耗更多内存,导致目前正在对 VRAM 消耗差异进行持续调查。
- Unsloth Pro 期待即将到来的发布:Unsloth Pro 计划于近期发布,引发了期待增强功能的用户的兴奋。
- 社区成员期待利用 Unsloth Pro 来简化工作流并利用新的模型能力。
- Llama 3.3 推出 70B 模型并提升效率:Llama 3.3 已发布,其 70B 参数模型在提供强劲性能的同时降低了运营成本(Ahmad_Al_Dahle 的推文)。
- Unsloth 推出了 Llama 3.3 的 4-bit 量化版本,提升了加载速度并减少了内存占用。
- 优化 LoRA 微调配置:’Silk.ai’ 质疑了 LoRA 微调中 use_cache 参数的必要性,引发了关于最佳设置的讨论。
- 另一位贡献者强调了启用 LoRA dropout 以实现预期模型性能的重要性。
Cursor IDE Discord
- Cursor 性能受挫:用户报告称 Cursor 在使用 Composer 时经历了 连接失败 和 响应缓慢,通常需要开启新会话才能正常工作。
- 许多人将其性能与 Windsurf 进行对比并给出负面评价,对 持续存在的问题 表示沮丧。
- Windsurf 超越 Cursor:几位用户提到 Windsurf 在处理任务时表现更好,即使在繁重的代码生成需求下也没有出现问题。
- 用户强调,虽然 Cursor 在应用更改时显得吃力,但 Windsurf 能够顺畅执行类似任务,这改变了用户的偏好。
- Cursor 0.43.6 增加侧边栏集成:在最新的 Cursor 0.43.6 更新中,用户注意到 Composer UI 已集成到侧边栏中,但一些功能如 long context chat 已被移除。
- 还提到了新功能,如 inline diffs、git commit 信息生成 以及 agent 的早期版本。
- Composer 响应不可靠:用户分享了关于 Cursor 的 Composer 功能的参差不齐的体验,有报告称它有时无法响应查询。
- 问题包括 Composer 未能生成预期的代码或遗漏更新,尤其是在最近的更新之后。
- 探索使用 Cursor 进行单元测试:一位用户询问了使用 Cursor 编写 unit tests 的有效方法,并对分享的技术表示感兴趣。
- 虽然尚未有定论性的答复,但用户鼓励分享各自的测试 经验 和 方法。
OpenRouter (Alex Atallah) Discord
- OpenRouter 推出作者页面 (Author Pages):OpenRouter 推出了 Author Pages 功能,使用户可以在 openrouter.ai/author 探索创作者的模型。此次更新包括详细的统计数据以及通过轮播图展示的相关模型。
- 该功能旨在增强模型发现和分析,为用户浏览不同作者的收藏提供流线化的体验。
- Amazon Nova 模型收到褒贬不一的反馈:用户报告了对 Amazon Nova 模型不同的使用体验,称其中一些模型与 Nova Pro 1.0 等替代方案相比表现欠佳。
- 尽管存在批评,某些用户仍强调了该模型的速度和性价比,表明用户满意度存在分歧。
- Llama 3.3 的部署与性能:Llama 3.3 已成功发布,供应商在发布后不久即提供支持,正如 OpenRouter 的公告中所述,增强了文本应用的能力。
- AI at Meta 指出,该模型有望在生成合成数据方面提高性能,同时降低推理成本。
- DeepInfra 降低模型定价:根据其最新推文,DeepInfra 宣布大幅下调多款模型的价格,包括 Llama 3.2 3B Instruct 降至 $0.018,Mistral Nemo 降至 $0.04。
- 这些降价旨在为预算有限的开发者提供以更实惠的价格获取高质量模型的途径。
- OpenAI 推出强化学习微调:在 OpenAI Day 2 期间,公司宣布即将为 o1 提供强化学习微调 (reinforcement learning finetuning),尽管这在社区中引起的兴奋有限。
- 参与者对这些更新表达了怀疑,期待在现有产品之外能有更实质性的进展。
Eleuther Discord
- MoE-lite Motif 提升 Transformer 效率:一位成员介绍了 MoE-lite motif,它利用自定义的 bias-per-block-per-token 非线性地影响残差流 (residual stream),这表明尽管参数成本增加,但计算速度更快。
- 讨论将其效率与传统的 Mixture of Experts (MoE) 架构进行了比较,辩论了潜在的优缺点。
- GoldFinch 架构精简 Transformer 参数:一位成员详细介绍了 GoldFinch 模型,该模型通过从变异的 layer 0 嵌入中推导来移除 V 矩阵,显著提高了参数效率。GoldFinch 论文
- 团队讨论了替换或压缩 K 和 V 参数的潜力,旨在提高 Transformer 的整体效率。
- 逐层 Token 嵌入优化 Transformer 参数:成员们探索了逐层 Token 值嵌入 (layerwise token value embeddings) 作为传统值矩阵 (value matrices) 的替代方案,在不损害性能的情况下实现了 Transformer 的显著参数节省。
- 该方法利用初始嵌入动态计算 V 值,从而减少了对广泛值投影 (value projections) 的依赖。
- 更新后的 Mechanistic Interpretability 资源现已发布:一位成员分享了一个 Google Sheets 资源,按主题分类编目了 Mechanistic Interpretability 领域的关键论文,以便于流线化探索。
- 该资源包括基于主题的分类和注释笔记,以协助研究人员有效地查阅基础文献。
- 动态权重调整提升 Transformer 效率:成员们提议通过动态权重调整 (dynamic weight adjustments) 来增强参数分配和 Transformer 效率,这与 momentum 等正则化方法有相似之处。
- 对话强调了通过消除或修改 V 参数来提升潜在性能和简化计算的可能性。
aider (Paul Gauthier) Discord
- Aider v0.67.0 发布,带来新特性:最新的 Aider v0.67.0 引入了对 Amazon Bedrock Nova 模型 的支持、增强的命令功能、进程挂起支持以及异常捕获分析。
- 值得关注的是,Aider 为该版本的开发贡献了 61% 的代码,展示了其强大的能力。
- Aider Pro 功能备受关注:Aider Pro 现在包含无限制的高级语音模式、针对 O1 的全新 128k 上下文,以及 复制/粘贴到 Web 聊天 功能,实现了与 Web 界面的无缝集成。
- 用户称赞这些功能使其能够处理大量的文档和代码,提升了工作流效率。
- Gemini 1206 模型发布引发兴趣:Google DeepMind 发布了 Gemini-exp-1206 模型,声称比之前的迭代版本有性能提升。
- 社区成员渴望看到其与 Claude 等模型的对比基准测试,并期待 Paul Gauthier 的详细性能结果。
- DeepSeek 在 Aider 中的表现:DeepSeek 被讨论为 Aider 用户的一个高性价比选择,此外还有 Qwen 2.5 和 Haiku 等替代方案。
- 有推测认为,通过微调社区版本,有望提升 DeepSeek 在 Aider 中的基准测试表现。
Interconnects (Nathan Lambert) Discord
- Gemini-exp-1206 夺得榜首:新的 Gemini-exp-1206 模型获得了总分第一,并在编程基准测试中与 O1 持平,标志着较之前版本的重大改进。
- OpenAI 的演示显示,基于医学数据微调的 O1-mini 可以超越完整的 O1 模型,这进一步凸显了 Gemini 强劲的表现。
- Llama 3.3 带来高性价比性能:Llama 3.3 的增强得益于更新的对齐流程和在线强化学习(Reinforcement Learning)技术的进步。
- 该模型在性能上与 405B 模型相当,同时能在标准开发者工作站上实现更具成本效益的推理。
- 阿里巴巴发布 Qwen2-VL-72B:阿里云推出了 Qwen2-VL-72B 模型,具备先进的视觉理解能力。
- 该模型专为多模态任务设计,在视频理解方面表现出色,并可在各种设备上无缝运行,旨在提升多模态性能。
- 强化微调(Reinforcement Fine-Tuning)推动 AI 模型进步:讨论强调了 Reinforcement Learning 在微调模型以超越现有竞争对手方面的作用。
- 关键点包括在模型训练中使用预定义的评分器(graders),以及不断演进的 RL 训练方法论。
- AI 竞争驱动模型创新:成员们呼吁在 AI 领域开展强有力的竞争,敦促 OpenAI 挑战 Claude 和 DeepSeek 等模型以促进进步。
- 这种观点强调了社区的信念,即有效的竞争对手对于 AI 领域的持续进步至关重要。
Bolt.new / Stackblitz Discord
- 提升 Bolt.new 的 Token 效率:成员们讨论了如 特定部分编辑 (Specific Section Edits) 等策略,通过仅修改选定部分而非重新生成整个文件来减少 token usage,旨在提高 token management 效率。
- 提出了关于免费账户 daily token limits 的问题,以及购买 token reload option 以允许 token 结转的好处。
- 将 GitHub 仓库与 Bolt.new 集成:用户探索了 GitHub Repo Integration,通过使用仓库 URL(如 bolt.new/github.com/org/repo)启动 Bolt,并指出 private repositories 目前需要设置为公开才能成功集成。
- 为了解决与私有仓库相关的 deployment errors,用户建议切换到公开仓库以绕过权限问题。
- 管理功能请求与改进:讨论强调了通过与 Bolt 互动来单独处理请求,从而实现高效的 Feature Requests Management,这有助于减少 Bot 响应中的 hallucination。
- 社区成员建议通过 GitHub Issues 页面 提交功能增强想法,强调了 user feedback 对产品开发的重要性。
- 利用本地存储和后端集成优化开发:开发者建议最初使用 local storage 构建应用程序,然后将功能迁移到 Supabase 等 backend solutions,以促进更顺畅的测试并简化 integration process。
- 确认该方法有助于保持应用的完善度,并减少向数据库存储过渡期间的错误。
Stability.ai (Stable Diffusion) Discord
- Reactor 的换脸大决战:用户讨论了 Reactor 是否是换脸的最佳选择,目前尚未达成明确共识。
- 参与者建议尝试各种模型,以评估它们对 output quality 的影响。
- AI Discord 社区讨论多样化:一位用户正在寻找除了 LLM 之外讨论多样化 AI 主题的 Discord 社区,引发了相关推荐。
- 成员们推荐了 Gallus 和 TheBloke 的 Discord 频道,将其作为广泛 AI 讨论的枢纽。
- 云端 GPU 供应商的价格战:用户分享了首选的 Cloud GPU 供应商,如 Runpod、Vast.ai 和 Lambda Labs,突出了其竞争力的定价。
- Lambda Labs 被指出通常是最便宜的选择,尽管获取访问权限可能具有挑战性。
- Lora 和 ControlNet 调整 Stable Diffusion:讨论围绕在 Stable Diffusion 中调整 Lora 的强度展开,指出其强度可以超过 1,但在更高设置下存在图像失真的风险。
- 成员们建议使用 OpenPose 以获得准确的姿势,并利用 depth control 来改善结果。
- AI 艺术许可困境:一位用户提出了关于超过 Stability AI 许可协议中收入阈值的问题。
- 澄清表明输出内容仍然可以使用,但模型使用的许可在终止后将被撤销。
OpenAI Discord
- OpenAI 12 天活动中的 Reinforcement Fine-Tuning:YouTube 活动 ‘12 Days of OpenAI: Day 2’ 由 OpenAI 研究高级副总裁 Mark Chen 和 Justin Reese 主持,讨论了 reinforcement fine-tuning 的最新进展。
- 鼓励参与者在太平洋时间 10am PT 加入直播,直接从领先的研究人员那里获取见解。
- Gemini 1206 实验模型超越 O1 Pro:Gemini 1206 实验模型因其强劲表现而受到关注,在生成详细独角兽插图的 SVG 代码等任务中超越了 O1 Pro。
- 用户报告称 Gemini 1206 提供了增强的结果,特别是在 SVG generation 和其他技术应用方面表现出色。
- O1 Pro 与 Gemini 1206 的定价对比:O1 Pro 定价为 $200/月,引发了关于其与 Gemini 1206 等免费替代方案相比价值如何的讨论。
- 一些用户认为,尽管 O1 功能强大,但考虑到有效免费模型的可用性,如此高的成本是不合理的。
- 对高级 Voice Mode 功能的需求:社区对更高级的 voice mode 有明确需求,目前的版本因声音机械化而受到批评。
- 用户表达了对该功能重大改进的希望,特别是在即将到来的假期期间。
- 提议 GPT 协作编辑功能:一名成员表达了希望允许多个编辑者同时修改一个 GPT 的愿望,强调了协作的需求。
- 目前只有创建者可以编辑 GPT,但社区建议增加“Share GPT edit access”功能以促进团队合作。
Modular (Mojo 🔥) Discord
- VSCode Extension 查询已解决:一名成员遇到了 VSCode extension 测试以 cwd=/ 运行的问题,在找到询问该扩展的合适频道后,问题得到了解决。
- 这一事件强调了将技术查询定向到正确的社区频道以高效解决问题的重要性。
- Mojo 函数提取错误:一名用户在适配 Mojo math module 中的
j0函数时遇到错误,原因是编译期间出现了未知的声明_call_libm。- 他们寻求关于如何正确从 math standard library 提取和利用函数而不遇到编译器问题的指导。
- 编程职业专业化:成员们讨论了专注于 blockchain、cryptography 或 distributed systems 等领域对提升技术就业前景的好处。
- 重点强调了有针对性的学习、实战项目以及对基础概念的扎实掌握,以促进职业发展。
- Mojo 中的 Compiler Passes 和 Metaprogramming:讨论重点介绍了 Mojo 的新功能,这些功能支持自定义 compiler passes,并提出了增强 API 以实现更广泛程序转换的想法。
- 成员们将 Mojo 的 metaprogramming 方法与传统的 LLVM Compiler Infrastructure Project 进行了比较,并指出了 JAX 风格程序转换的局限性。
- 计算机科学教育见解:参与者分享了关于具有挑战性的计算机科学课程和项目的经验,这些经历加深了他们对编程概念的理解。
- 他们讨论了如何在个人兴趣与市场需求之间取得平衡,并以自己的学术历程为例。
Perplexity AI Discord
- Perplexity AI 面临 Code Interpreter 限制:用户报告称,即使在上传了相关文件后,Perplexity AI 的 Code Interpreter 仍无法执行 Python 脚本,其功能仅限于生成文本和图表。
- 这一限制引发了关于 Perplexity AI 支持实际代码执行必要性的讨论,以更好地满足技术工程需求。
- Windows 应用商店出现虚假 Perplexity 应用:成员们发现 Windows 应用商店中存在一个虚假 Perplexity 应用,该应用欺骗性地使用了官方 Logo 和未经授权的 API,并将用户引导至一个可疑的 Google Doc。
- 社区敦促举报该欺诈应用,以防止潜在的安全风险并保护 Perplexity AI 产品的完整性。
- Llama 3.3 模型发布并增强功能:Llama 3.3 正式发布,因其较前代版本的性能提升而受到用户欢迎。
- 社区强烈期待 Perplexity AI 将 Llama 3.3 集成到其服务中,以利用其先进的功能。
- 利用 Grok 和 Groq 优化 API 使用:关于使用 Grok 和 Groq API 的讨论显示,Grok 提供免费的初始额度,而 Groq 则通过集成 Llama 3.3 提供免费使用。
- 用户分享了故障排除技巧,指出了 Groq 端点(endpoint)面临的挑战,部分成员通过社区支持成功解决了这些问题。
- 为 Perplexity API 引入 RAG 功能:一名成员询问如何将 Perplexity Spaces 中的 RAG 功能整合到 API 中,表明了对高级检索能力的需求。
- 这种兴趣凸显了社区对增强 Perplexity API 功能的需求,以支持更复杂的数据检索流程。
LM Studio Discord
- Paligemma 2 发布:Paligemma 2 在 MLX 上发布,引入了来自 GoogleDeepMind 的新模型,增强了平台的能力。
- 鼓励用户使用
pip install -U mlx-vlm进行安装,通过 Star 该项目进行支持,并提交 Pull Requests。
- 鼓励用户使用
- RAG 文件限制:一名成员讨论了针对 5 个文件 RAG 限制的变通方法,强调了分析多个小文件以进行问题检测的必要性。
- 社区成员商讨了潜在的解决方案,以及使用模型处理较小批量文件的性能影响。
- Llama 3.1 CPU 基准测试:用户请求在 Intel i7-13700 和 i7-14700 CPU 上对 Llama 3.1 8B 模型进行基准测试,以评估潜在的推理速度。
- 社区见解表明,根据近期用户在类似 CPU 配置下的经验,性能指标各不相同。
- 4090 GPU 价格飙升:据报告,某些地区的 4090 GPU 新卡和二手卡价格均出现飙升,引发用户担忧。
- 传闻称某些 4090 GPU 可能会被改装以将 VRAM 扩展至 48GB,引发了进一步讨论。
- 中国改装 4090 GPU:提到了 Reddit 上关于中国改装者研究 4090 GPU 的讨论,但未提供具体来源。
- 用户表示在查找有关这些 GPU 改装活动的详细信息或链接时面临挑战。
Cohere Discord
- Rerank 3.5 模型提升搜索准确率:新发布的 Rerank 3.5 模型 提供了改进的推理和多语言能力,能够对复杂的企业数据进行更准确的搜索。
- 成员们正在寻求 benchmark scores(基准测试分数)和 performance metrics(性能指标)来评估 Rerank 3.5 的有效性。
- Structured Outputs 简化 Command 模型:Command 模型现在强制执行严格的 Structured Outputs,确保包含所有 required(必填)参数,并增强了企业级应用中的可靠性。
- 用户可以在文本生成中使用 JSON 格式的 Structured Outputs,或通过 function calling 使用 Tools,该功能目前在 Chat API V2 中处于实验阶段,欢迎用户提供反馈。
- vnc-lm 集成 LiteLLM 以增强 API 连接:vnc-lm 现在已与 LiteLLM 集成,能够连接到任何支持 Cohere 模型的 API,如 Cohere API 和 OpenRouter。
- 正如 GitHub 上所示,该集成实现了无缝的 API 交互,并支持包括 Claude 3.5、Llama 3.3 和 GPT-4o 在内的多个 LLM。
- /embed 端点面临速率限制问题:用户对 /embed 端点每分钟 40 张图像 的低速率限制(rate limit)表示不满,这限制了高效嵌入数据集的能力。
- 成员们建议联系支持团队以寻求提高速率限制的可能性。
- 利用重试机制优化 API 调用:用户正在讨论如何使用原生的 Cohere Python client 优化其 retry mechanisms(重试机制),该客户端本身就能优雅地处理重试。
- 这引发了关于有效管理 API 重试的各种方法的富有成效的交流。
Latent Space Discord
- Writer 部署内置 RAG 工具:Writer 推出了一个内置的 RAG 工具,允许用户传递 graph ID 以使模型访问知识图谱(Knowledge Graph),Sam Julien 对此进行了演示。该功能支持将抓取的内容自动上传到知识图谱中,并进行交互式后期讨论。
- 该工具增强了内容管理和交互能力,允许将用户特定的知识库无缝集成到建模过程中。
- ShellSage 提升终端中的 AI 生产力:AnswerDot AI 的研发人员介绍了 ShellSage 项目,重点是通过在终端环境中集成 AI 来提高生产力,如这条推文所述。
- ShellSage 被设计为一个 AI 终端助手,利用人机协作(human+AI)的混合方法在 shell 界面中更智能地处理任务。
- OpenAI 发布全新 RL 微调 API:OpenAI 宣布了一个全新的 Reinforcement Learning(强化学习)微调 API,允许用户将先进的训练算法应用于他们的模型,详情见 John Allard 的帖子。
- 该 API 使用户能够在之前 o1 模型的基础上,开发跨各个领域的专家模型。
- Google 的 Gemini Exp 1206 登顶多项 AI 基准测试:据 Jeff Dean 报告,Google 的 Gemini exp 1206 在包括硬提示(hard prompts)和编程在内的多项任务中获得了最高排名。
- Gemini API 现在已开放使用,标志着 Google 在竞争激烈的 AI 领域取得了重大成就。
- AI 文章探讨 Service-as-Software 与商业策略:几篇文章讨论了 AI 机遇,包括 Joanne Chen 分享的 Service-as-Software 框架下价值 4.6 万亿美元的市场。
- 另一篇文章提出了利用 AI 模型进行融资和整合服务型业务的策略,如此帖所述。
Nous Research AI Discord
- Llama 3.3 模型发布引发辩论:Ahmad Al-Dahle 宣布了 Llama 3.3,这是一个全新的 70B 模型,其性能可与 405B 模型相媲美,但成本效益更高。
- 社区成员质疑 Llama 3.3 是否是依赖于 Llama 3.1 的基础模型,并讨论了它是否是一个没有经过新预训练的复杂微调流水线,突显了模型发布的趋势。
- 使用 Nous Distro 进行去中心化训练:Nous Distro 被明确为一个去中心化训练框架,其潜在应用让成员们感到兴奋。
- 该项目获得了积极反应,成员们对它为分布式 AI 训练方法论带来的进步表示热忱。
- 微调 Mistral 用于肾脏检测的挑战:一位用户强调了在使用包含 25 列的数据集微调 Mistral 模型以进行慢性肾脏病检测时遇到的困难,并提到在尝试三个月后仍缺乏合适的教程。
- 社区成员推荐了克服这些挑战的资源和策略,强调了对专门模型调优需要更好的文档和支持。
- 利用 LightGBM 增强表格数据性能:成员们建议在机器学习任务中使用 LightGBM 以更好地处理表格数据,并指出其在排序和分类方面的效率。
- 这一建议作为特定数据集下 LLM 的替代方案,突显了 LightGBM 在性能和可扩展性方面的优势。
- 优化模型训练的数据格式:讨论强调了将数值数据转换为文本格式的必要性,因为 LLM 在直接处理数值型表格数据时表现不佳。
- 一位成员指向了一个使用 Unsloth 进行自定义模板分类的示例,强调了通用 CSV 数据在训练模型中的重要性。
GPU MODE Discord
- Popcorn 项目携 NVIDIA H100 基准测试亮相:Popcorn 项目定于 2025 年 1 月启动,支持针对各种 kernel 的排行榜提交任务,并包含在 NVIDIA H100 等 GPU 上的基准测试能力。
- 尽管采用了非传统方法,该倡议旨在通过提供强大的性能指标来增强开发体验。
- Triton 的 TMA 支持在 Nightly 版本损坏的情况下寻求正式发布:Triton 用户请求发布官方版本以支持低开销的 TMA 描述符,因为据报道当前的 nightly 构建版本已损坏。
- 对 nightly 构建稳定性的担忧突显了社区对可靠工具链 (tooling) 的依赖,以实现最佳 GPU 性能。
- LTX Video 的 CUDA 重构使 GEMM 速度翻倍:一位成员使用 CUDA 重新实现了 LTX Video 模型中的所有层,实现了比 cuBLAS FP8 快两倍的 8bit GEMM,并集成了 FP8 Flash Attention 2、RMSNorm、RoPE Layer 和量化器,且由于使用了 Hadamard Transformation 而没有精度损失。
- 在 RTX 4090 上的性能测试展示了仅需 60 个去噪步骤即可实现实时生成,展示了模型速度和效率的重大进步。
- TorchAO 量化:探索新方法与最佳实践:一位成员深入研究了 TorchAO 中的多种量化实现方法,寻求最佳实践指导,并确定了特定文件作为切入点。
- 这一探索反映了社区致力于通过 AI 工程工作流中有效的量化技术来优化模型性能。
- Llama 3.3 发布:Llama 3.3 已经发布,正如这条推文所宣布的。
- 社区对新发布的 Llama 3.3 表现出浓厚兴趣,并讨论了其潜在的增强功能。
Torchtune Discord
- Llama 3.3 发布,规格增强:Llama 3.3 模型已发布,在保持紧凑的 70B 尺寸的同时,拥有媲美 405B 参数模型的性能,预计将激发创新应用。
- 社区渴望探索 Llama 3.3 缩小尺寸后的能力,以用于各种 AI 工程项目。
- Torchtune 为 Llama 3.3 增加全面微调支持:Torchtune 扩展了其支持范围,包括为新发布的 Llama 3.3 提供完整的 LoRA 和 QLoRA 微调,增强了定制化选项。
- 详细的配置设置可在 Torchtune GitHub repository 中找到。
- 提议调整 LoRA 训练:正如 此 GitHub issue 中所讨论的,LoRA 训练的一项提议更改现在要求独立的权重合并步骤,而不是自动合并。
- 成员们讨论了这一变化对现有工作流的潜在影响,权衡了增加灵活性带来的好处。
- 关于 Alpaca 训练默认值的辩论:针对 Alpaca 训练库中 train_on_input 的默认设置(目前设为 False)引发了担忧,导致人们质疑其是否符合通用实践。
- 讨论引用了诸如 Hugging Face 的 trl 和 Stanford Alpaca 等仓库,以评估默认配置的恰当性。
- 加密货币彩票引入 LLM 协议挑战:描述了一种 crypto lottery 模型,参与者按 LLM 提示词付费,有机会通过说服 LLM 同意支付来赢得所有资金。
- 这种独特的激励结构引发了关于加密生态系统中此类机制的伦理影响和实用性的辩论。
LlamaIndex Discord
- LlamaParse 提升文档解析效率:LlamaParse 提供了先进的 文档解析 能力,显著缩短了复杂文档的解析时间。
- 这一改进通过有效处理复杂的文档结构,简化了工作流。
- 与 MongoDB 合作的混合搜索网络研讨会已录制:最近一场由 MongoDB Atlas 主讲的 网络研讨会 涵盖了混合搜索 (hybrid search) 策略和元数据过滤技术。
- 参与者可以回顾关键主题,例如从顺序推理 (sequential reasoning) 到 DAG 推理 (DAG reasoning) 的转变,以优化搜索性能。
- 在 LlamaParse 中启用多模态解析:LlamaParse 现在支持使用 GPT-4 和 Claude 3.5 等模型进行多模态解析,正如 @ravithejads 的视频所示。
- 用户可以通过将页面截图无缝转换为结构化数据来增强其解析能力。
- 通过调整超时设置解决 WorkflowTimeoutError:可以通过增加超时时间或将其设置为 None 来缓解 WorkflowTimeoutError,使用
w = MyWorkflow(timeout=None)。- 这种方法有助于防止长时间运行的工作流出现超时问题,确保执行更顺畅。
- 在 LlamaIndex 中配置 ReAct Agent:要切换到 ReAct agent,请按照 工作流文档 中的说明,将标准 Agent 配置替换为
ReActAgent(...)。- 这种修改允许更具适应性的设置,利用 ReAct 框架的灵活性。
OpenInterpreter Discord
- 1.0 预览版提升性能:一位成员对 1.0 预览版 的 精简 和 快速 表现 印象深刻,强调了其 整洁的 UI 和良好的代码隔离。他们目前正在使用特定参数测试 interpreter 工具,但无法执行来自 AI 的任何代码。
- 用户正在使用特定参数测试 interpreter 工具,但报告称无法执行 AI 生成的任何代码。
- MacOS 应用访问加速:多位用户询问如何获取 仅限 MacOS 的应用。团队成员确认他们即将进行 公开发布,并愿意将用户添加到下一批名单中,同时也在开发 跨平台版本。
- 这一举措旨在扩大用户覆盖范围并增强平台兼容性。
- API 可用性临近:一位成员对每月 200 美元 的 API 访问费表示担忧,质疑其可获得性。另一位成员向社区保证 API 很快将对用户开放。
- 这些讨论突显了社区对 API 可访问性和定价的关注。
- 强化微调 (Reinforcement Fine-Tuning) 更新:OpenAI 宣布第 2 天重点关注 Reinforcement Fine-Tuning,通过 X 上的帖子 分享了见解,并在其 官网 提供了更多细节。
- 社区正积极致力于优化模型训练方法,体现了对增强强化学习技术的投入。
- Llama 发布 3.3:Meta 宣布发布 Llama 3.3,这是一个新的开源模型,在 合成数据生成 和其他文本任务中表现出色,且 推理成本 显著降低,详见其 X 上的帖子。
- 此次发布强调了 Meta 对提高 模型效率 和扩展 文本用例 能力的关注。
LLM Agents (Berkeley MOOC) Discord
- 2025 春季 MOOC 获批:Berkeley MOOC 团队已正式确认 2025 春季 的后续课程。建议参与者关注后续发布的更多细节。
- 成员们对即将推出的课程表示 “Woohoo!”,显示出社区内极高的兴奋度。
- 作业截止日期临近:一位参与者强调必须在设定的截止日期前完成所有作业。这突显了学习者中日益增长的紧迫感。
- 参与者正在细致地安排时间表,以应对即将到来的评估。
- 使用 Lambda Labs 进行实验评分:有人询问是否可以使用非 OpenAI 模型(如 Lambda Labs)来对实验作业进行评分。
- 这表明社区有兴趣探索多样化的评分解决方案。
- 讲座讲义更新停滞:成员报告称,由于不可预见的延迟,上一次课程的 讲座讲义 尚未在课程网站上更新。
- 一位成员指出讲座包含约 400 页讲义,显示出内容覆盖面极广。
- 字幕制作导致延迟:讲座录像正在等待 专业字幕制作,这可能会导致进一步的延迟。
- 鉴于讲座 时长较长,字幕制作过程预计会非常耗时。
Axolotl AI Discord
- Llama 3.3 发布:Llama 3.3 已经发布,仅包含指令模型,引发了寻求其功能细节的成员们的兴奋。
- 成员们对 Llama 3.3 充满热情,但部分成员希望获得更多信息以全面了解其特性。
- llama.com 上的模型申请问题:成员报告在 llama.com 申请模型时出现问题,点击“接受并继续”后流程卡住。
- 这一技术故障引起了挫败感,用户正在寻找解决方案和替代方案。
- SFT 与 RL 的质量边界:讨论强调 监督微调 (SFT) 会根据数据集限制模型质量。
- 相反,强化学习 (RL) 方法可能允许模型超越数据集限制,尤其是通过在线 RL。
DSPy Discord
- DSPy 优化的可选性:一名成员在 #general 频道询问 DSPy Modules 是否需要针对每个用例进行优化,并将其比作训练 ML models 以增强提示效果。
- 另一名成员澄清说,optimization 是可选的,仅在需要提高固定系统性能时才必要。
- RAG 系统上下文冲突:RAG System 中报告了一个 TypeError,表明在尝试使用 DSPy 时,
RAG.forward()接收到了一个意外的关键字参数 ‘context’。- 据指出,RAG system 需要关键字参数 ‘context’ 才能正常运行,而用户当时没有提供。
tinygrad (George Hotz) Discord
- tinygrad 统计网站停机:tinygrad stats site 经历了停机,引发了对其基础设施的关注。
- George Hotz 询问是否需要现金来支付 VPS 账单,暗示可能存在财务问题。
- SSL 证书过期导致 tinygrad 宕机:由于 SSL 证书过期,托管在 Hetzner 上的 tinygrad stats site 宕机。
- 在解决该问题后,网站已恢复运行。
LAION Discord
- 媒体中的细胞拟人化:一次讨论强调了细胞的拟人化,这是自 Osmosis Jones 以来一个显著的实例,并为细胞表现形式增添了幽默感。
- 这种方法将幽默与科学概念相结合,有可能使复杂的话题对观众更具吸引力。
- Osmosis Jones 引用:对 Osmosis Jones 的引用强调了它对当前拟人化细胞结构努力的影响,突出了它在塑造创意表达方面的作用。
- 参与者发现 Osmosis Jones 中的动画描绘与最近通过媒体使细胞生物学更易引起共鸣的尝试之间存在相似之处。
MLOps @Chipro Discord 没有新消息。如果该服务器长时间没有动态,请告知我们,我们将将其移除。
Mozilla AI Discord 没有新消息。如果该服务器长时间没有动态,请告知我们,我们将将其移除。
HuggingFace Discord 没有新消息。如果该服务器长时间没有动态,请告知我们,我们将将其移除。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该服务器长时间没有动态,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该服务器长时间没有动态,请告知我们,我们将将其移除。
第 2 部分:按频道详细摘要和链接
完整的各频道详细分析已为邮件格式进行删减。
如果您喜欢 AInews,请分享给朋友!提前致谢!