ainews-chatgpt-canvas-ga
**ChatGPT Canvas 全面开放** (或 **正式发布**) 注:“GA” 是 **General Availability** 的缩写,在软件行业意指产品结束测试阶段,向所有用户正式开放。
OpenAI 向所有用户推出了 ChatGPT Canvas,具备代码执行和 GPT 集成功能,通过类似 Google Docs 的界面有效地取代了原有的代码解释器(Code Interpreter)。Deepseek AI 发布了 V2.5-1210 更新,提升了在 MATH-500 (82.8%) 和 LiveCodebench 上的性能表现。Meta AI Fair 推出了 COCONUT,这是一种全新的连续潜空间推理范式。Huggingface 发布了 TGI v3,在处理长提示词时,其处理的 Token 数量是 vLLM 的 3 倍,运行速度快 13 倍。Cognition Labs 发布了 Devin,这是一款能够构建 Kubernetes 算子(operators)的 AI 开发者工具。Hyperbolic 完成了 1200 万美元 A 轮融资,旨在构建一个带有 H100 GPU 交易市场的开放 AI 平台。
讨论内容涵盖了 AI 能力及其对就业的影响,以及 NeurIPS 2024 的相关发布,包括 Google DeepMind 的演示和关于 AI 缩放(scaling)的辩论。在 Reddit 上,Llama 3.3-70B 支持使用 Unsloth 进行 90K 上下文长度的微调,该技术结合了梯度检查点(gradient checkpointing)和苹果的 Cut Cross Entropy (CCE) 算法,仅需 41GB 显存即可运行。此外,Llama 3.1-8B 通过 Unsloth 达到了 342K 上下文长度,超越了其原生限制。
Karina Nguyen is all you need.
2024年12月9日至12月10日的 AI 新闻。我们为您检查了 7 个 subreddits、433 个 Twitter 账号 和 31 个 Discord(206 个频道,5518 条消息)。预计节省阅读时间(以 200wpm 计算):644 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
虽然现在还处于早期阶段,但我们已经可以宣布 OpenAI 的 12 Days of Shipmas 活动取得了成功。尽管昨天的 Sora 发布(截至今天)仍因需求过大而受限于受限注册,但 ChatGPT Canvas 无需额外的 GPU,并于今天向所有免费和付费用户发布,且运行顺畅。
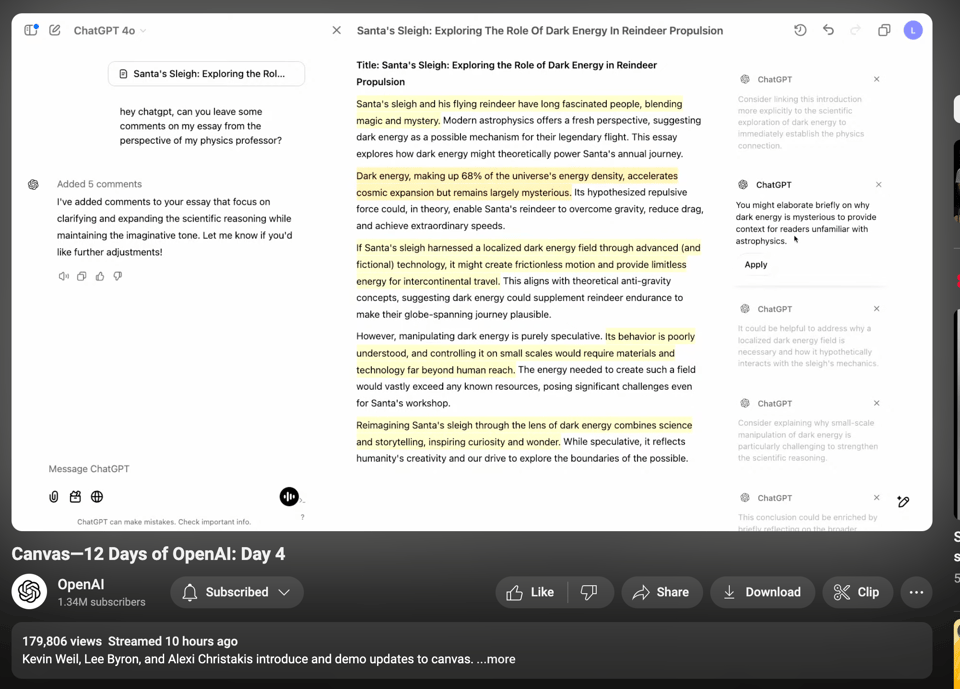
Canvas 现在实际上取代了 Code Interpreter,而且非常像 Google Docs,这进一步证明了 OpenAI 构建 Google 功能的速度比 Google 构建 OpenAI 功能的速度还要快。
有一种理论认为,每集结尾的笑话都是下一集内容的预告。如果这是真的,那么明天的发布将会非常震撼。
AI Twitter 总结
所有总结均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
以下是关键 Twitter 讨论的分类摘要:
AI 模型与研究更新
- @deepseek_ai 宣布了他们的 V2.5-1210 更新,在 MATH-500 (82.8%) 和 LiveCodebench (34.38%) 上性能有所提升
- Meta 介绍了 COCONUT (Chain of Continuous Thought),这是一种使用连续潜空间(latent space)进行 LLM 推理的新范式
- @Huggingface 发布了 TGI v3,在处理长 Prompt 时,其 Token 处理量提升了 3 倍,运行速度比 vLLM 快 13 倍
产品发布与更新
- OpenAI 向所有用户发布了 Canvas,具有代码执行、GPT 集成和改进的写作工具等功能
- @cognition_labs 发布了 Devin,这是一个 AI 开发者,它成功构建了一个带有测试环境的 Kubernetes operator
- Hyperbolic 完成了 1200 万美元 A 轮融资,旨在构建一个开放的 AI 平台,提供价格为 0.99 美元/小时的 H100 GPU 市场
行业与市场分析
- @AravSrinivas 分享了美国与加拿大的人均 GDP 对比,获得了 72,622 次展示
- @sama 指出 严重低估了 Sora 的需求,正在努力扩大访问权限
- 关于 AI 能力和就业在未来几十年影响的讨论
NeurIPS 会议
- 多位研究人员和公司宣布参加在温哥华举行的 NeurIPS 2024
- @GoogleDeepMind 举办了 GenCast 天气预报和其他 AI 工具的演示
- 计划举行一场辩论,由 Jonathan Frankle 和 Dylan 讨论 AI Scaling 的未来
迷因与幽默
AI Reddit 总结
/r/LocalLlama 总结
主题 1. Llama 3.3-70B 微调:在小于 41GB VRAM 上实现 90K 上下文
- Llama 3.3 (70B) Finetuning - 现支持 90K 上下文长度且适配 <41GB VRAM。 (Score: 360, Comments: 63): Llama 3.3 (70B) 现在可以使用 Unsloth 进行微调,以支持 90,000 上下文长度,这显著长于 Hugging Face + FA2 在 80GB GPU 上支持的 6,900 上下文长度。这一改进是通过 梯度检查点 (gradient checkpointing) 和 Apple 的 Cut Cross Entropy (CCE) 算法实现的,模型仅需 41GB VRAM 即可运行。此外,Llama 3.1 (8B) 使用 Unsloth 可以达到 342,000 上下文长度,远超其原生支持的 128K 上下文长度。
- Unsloth 使用 梯度检查点 (gradient checkpointing) 将激活值卸载到系统 RAM,从而节省 10 到 100GB 的 GPU 显存;Apple 的 Cut Cross Entropy (CCE) 在 GPU 上执行交叉熵损失计算,减少了对大型 logits 矩阵的需求,进一步节省了内存。这使得模型能够适配 41GB VRAM。
- 用户对测试中使用的 rank 以及 多 GPU 支持(目前不可用但在开发中)感到好奇。还有人对使 Unsloth 兼容 Apple 设备感兴趣。
- Unsloth 工具因其使微调能力平民化、让公众能够使用先进技术,并可能通过允许使用较小的 48GB GPU 来降低成本而受到称赞。
- Hugging Face 发布 Text Generation Inference TGI v3.0 - 在长提示词上比 vLLM 快 13 倍 🔥 (Score: 347, Comments: 52): Hugging Face 发布了 Text Generation Inference (TGI) v3.0,在长提示词上处理的 token 数量增加了 3 倍,速度比 vLLM 快 13 倍,且无需任何配置。通过优化内存使用,单个 L4 (24GB) 可以在 llama 3.1-8B 上处理 30k tokens,而 vLLM 仅能处理 10k,新版本将长提示词的回复时间从 27.5s 缩短至 2s。基准测试详情可供查阅。
- TGI v3.0 性能:讨论强调了 TGI v3.0 相比 vLLM 的显著速度提升,特别是在处理长提示词方面,这得益于 缓存提示词处理 (cached prompt processing) 的实现。该库通过保留初始对话数据,可以实现几乎瞬时的响应,查找开销仅约为 5 微秒。
- 比较与使用场景:用户对 TGI v3 与 TensorRT-LLM、ExLlamaV2 等其他模型的比较表现出兴趣,并询问了其在短查询和多 GPU 设置下的性能。还有人好奇 TGI 是否适用于单用户与多用户场景,一些用户认为它在为多用户托管模型方面进行了优化。
- 支持与文档:针对目前文档仅列出企业级 Nvidia 加速器的问题,用户提出了关于是否支持 RTX 3090 等消费级显卡的疑问。此外,用户还关注添加流式工具调用 (streaming tool calls) 等功能的路线图,以及与 fp16 处理相比是否存在潜在的输出质量下降。
主题 2. DeepSeek V2.5-1210:最终版本及后续计划
- deepseek-ai/DeepSeek-V2.5-1210 · Hugging Face (Score: 170, Comments: 11): 该帖子宣布在 Hugging Face 上发布 DeepSeek V2.5-1210,标志着该 AI 工具的新版本发布,但未说明具体改进。帖子中未提供关于该版本的更多细节。
- DeepSeek V2.5-1210 已被确认为 v2.5 系列的最终版本,未来预计将推出 v3 系列。更新日志显示数学性能(在 MATH-500 基准测试中从 74.8% 提升至 82.8%)和编程准确率(在 LiveCodebench 基准测试中从 29.2% 提升至 34.38%)有显著提升,同时增强了文件上传和网页摘要的用户体验。
- 用户对 R1 模型表现出浓厚兴趣,希望它能尽快发布。一些人推测当前版本可能使用了 R1 作为教师模型进行训练,还有人期待包含 32B 选项的更新版 Lite 版本。
- 社区正在积极讨论通过 exo 发布 量化版本 的可能性,并表达了对进一步更新的渴望,包括 R1 Lite 版本。
- DeepSeek-V2.5-1210: DeepSeek V2.5 的最终版本 (Score: 147, Comments: 36): DeepSeek-V2.5-1210 标志着 DeepSeek V2.5 系列的最终版本,自 5 月开源发布以来,经过五次迭代,该系列的开发已告一段落。团队目前正专注于开发下一代基础模型 DeepSeek V3。
- 硬件要求与限制:以 BF16 格式运行 DeepSeek-V2.5 需要大量资源,具体为 80GB*8 GPU。用户对软件优化的缺乏表示担忧,特别是 kv-cache 方面,这限制了模型在现有硬件上相对于 Llama 等其他模型的性能表现。
- 模型性能与能力:用户注意到该模型具有深层推理能力,但批评其推理速度较慢。尽管如此,DeepSeek 模型仍被视为其他大语言模型的高质量替代方案,其采用 Mixture of Experts (MoE) 结构,拥有约 220 亿激活参数,允许在 CPU+RAM 上实现合理的性能。
- 开发与发布频率:DeepSeek 团队保持了令人印象深刻的发布节奏,自 5 月以来几乎每月都有更新,这表明其训练过程非常成功。然而,由于创始人更看重研究而非商业应用,这些模型缺乏视觉理解能力,主要专注于文本。
主题 3. InternVL2.5 发布:视觉基准测试中的顶级表现
- InternVL2.5 发布(1B 到 78B)在 X 上引发热议。它能取代 GPT-4o 吗?你目前的体验如何? (Score: 131, Comments: 42): InternVL2.5 涵盖了从 1B 到 78B 参数的模型,现已发布并在 X 上受到关注。InternVL2.5-78B 模型因成为首个在 MMMU 基准测试中获得超过 70% 分数的开源 MLLM 而备受瞩目,其性能可与 GPT-4o 等领先的闭源模型相媲美。你可以通过 InternVL Web、Hugging Face Space 和 GitHub 等多个平台探索该模型。
- 视觉基准测试讨论:关于 InternVL2.5-78B 模型在视觉基准测试中的有效性存在争议,一些用户认为 4o 在视觉任务中优于 Sonnet。人们对基准测试的可靠性和模型声明的可信度提出了担忧,特别是考虑到 Reddit 和 Hugging Face 上一些令人质疑的历史记录。
- 地缘政治与教育背景:讨论涉及全球 STEM 领域格局,特别是美国和中国的对比,强调了中国的 STEM 博士数量和教育成就。一条评论提到一名 11 岁的中国孩子制造火箭,引发了关于此类声明的准确性和背景的辩论。
- 模型可用性与性能:用户赞赏 InternVL2.5 除了 78B 参数模型外,还提供了更小版本的模型,并注意到它们强劲的性能和本地部署的潜力。78B 模型在乌克兰语和俄语方面的表现被认为优于其他开源模型。
其他 AI 子版块回顾
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
主题 1. Google Willow:量子计算的巨大飞跃
- Google Willow:量子计算芯片在 5 分钟内完成最强超级计算机需耗时 1 亿亿亿年(septillion years)的任务 (Score: 311, Comments: 77):Google 推出了 Willow 量子计算芯片,实现了比最快超级计算机 Frontier 快约 10^30 倍的计算速度,在 5 分钟内完成了原本需要 1 亿亿亿年才能完成的任务。这被认为是今年最重要的技术发布,更多信息可在 YouTube 视频中查看。
- 几位评论者(如 beermad)对 基准测试(benchmark tests) 表示怀疑,认为这些测试是为量子计算机优化的,缺乏实际应用价值。他们认为这些测试旨在让量子芯片优于传统计算机,而没有展示实际应用。
- huffalump1 强调了 Google 在 纠错(error correction) 方面取得突破的重要性,该突破超越了 qubit 的物理极限。这对于量子计算至关重要,因为纠错是该领域的主要挑战。
- 讨论还涉及了潜在的财务影响,bartturner 指出 GOOG 股价上涨了 4%(盘前交易),表明投资者认可了这一技术进步的潜在价值。
- OpenAI Sora 对比开源替代方案 - Hunyuan(如图)+ Mochi & LTX (Score: 204, Comments: 56):该帖子讨论了 OpenAI Sora 与 Hunyuan、Mochi 和 LTX 等开源替代方案在 量子计算与传统超级计算机性能 背景下的对比。由于缺乏视频中的更多细节,未提供这些对比或性能指标的具体信息。
- 评论者讨论了 OpenAI Sora 与开源模型(如 HunyuanVideo)之间的比较,指出开源选项具有竞争力且通常更易于获取。HunyuanVideo 因其潜力和在消费级 GPU 上运行的能力而受到关注,一些用户因其不受审查的特性而更倾向于开源。
- Sora 的性能 在某些领域(如细节图像和风景)的质量受到称赞,但在可访问性受限和物理交互问题方面面临批评。用户注意到 HunyuanVideo 在某些场景下表现更好,并对与 TemporalPromptEngine 等模型的进一步对比感兴趣。
- 有人呼吁 西方改进其开源 AI 努力,因为中国开源模型在质量和在消费级硬件上运行的能力方面令人印象深刻。这种情绪反映了西方国家对更开放、更易获取的 AI 开发的渴望。
- 我预见广告商和零售商很快就会被起诉。这对我来说是一个真实的广告。 (Score: 177, Comments: 50):该帖子讨论了一个使用 卡通风格插图 和 争议性主题 来吸引注意力的广告,这可能会给广告商和零售商带来法律问题。广告中使用了幽默手段,涉及一只 看起来很悲伤的猫 和 漂白剂(bleach),这引发了伦理担忧,并凸显了创意营销与误导性或冒犯性内容之间的微妙界限。
- 评论者对广告的意图表示怀疑和幽默,SomeRandomName13 讽刺地指出该广告在猫的眼睛上使用 漂白剂 来解决问题的荒谬性,强调了广告的争议性。
- j-rojas 等人认为广告的设计是故意荒谬的,以充当 点击诱饵(clickbait),因其极端的荒谬感而激发好奇心。
- chrismcelroyseo 警告混合 漂白剂和氨水 的危险,并提供了一个关于毒性影响的文章链接,这强调了与广告内容相关的潜在现实风险。
{kind=link}
主题 2. Gemini 1.5 表现优于 Llama 2 70B:行业反应
- 说实话,与 ChatGPT 不同,我们中 97% 的人一个月后就不会再关心或使用 Sora 了。我尝试过所有的视频生成器和音乐生成器,新鲜感也就持续一周,然后就觉得没意思了。很有可能在你每月的 50 次生成额度用完后,你就会忘记 Sora。 (Score: 302, Comments: 113): Gemini 1.5 被讨论为超越了 Llama 2 70B,但作者对 Sora 的持久影响力表示怀疑。他们认为,与视频和音乐生成器等其他 AI 工具类似,Sora 最初可能很吸引人,但在有限的使用后,很可能会被大多数用户遗忘。
- 用户讨论了 Sora 在专业环境中的长期实用性,一些人认为工作室将采用它来降低成本,而另一些人则认为它是一个价格过高的新奇事物,由于 5 秒、720p 输出等限制,其用途有限。Sora 被比作过去最初引起关注但随后淡出的技术趋势,类似于 Suno 和 DALL-E 3 等其他 AI 工具,这些工具在使用量激增后便出现了下滑。
- 一些评论者强调了 AI 工具在改变工作流方面的重要性,并列举了视频相关业务的例子,在过去六个月中,AI 显著影响了这些业务的运营。尽管存在怀疑,但其他人指出,即使 AI 工具没有普遍吸引力,它们对于特定的专业任务仍然具有价值。
- 讨论还涉及了 AI 工具在最初炒作之外的更广泛适用性,并将其与 Apple Vision 和早期 Web 浏览器等历史技术采用模式进行了类比。共识是,虽然像 Sora 这样的工具可能并非普遍必需,但它们对利基市场和特定的专业用途具有重大价值。
- 艺术画廊正在出售 AI 艺术品? (Score: 285, Comments: 181): 作者描述了参加一次艺术画廊活动的情况,他们怀疑其中两幅标价在 5,000 到 15,000 欧元 之间的画作可能是 AI 生成的,因为作品中存在一些奇特之处,例如扭曲的手和不合逻辑的提包手柄。他们联系了组织者以调查 AI 参与的可能性,目前正在等待进一步消息。
- 许多评论者怀疑这些画作是 AI 生成的,因为存在手指畸形、荒谬的提包手柄和奇怪的房间布局等异常情况。Fingers(手指)和 dog features(狗的特征)经常被引用为 AI 的破绽,一些用户指出,将这些作为人类艺术家的风格是荒谬的。
- SitDownKawada 提供了这些以约 4,000 欧元 出售的画作链接,并质疑该艺术家在线存在的真实性,其内容看起来像是 AI 生成的。该艺术家的 Instagram 和其他社交媒体账号因其近期的活动和多产的产出而受到了审查。
- 讨论还涉及了 AI 在艺术领域的更广泛影响,一些用户思考手绘作品中的 AI 生成元素是否仍应被视为 AI 艺术。关于媒介还是创作过程更具价值存在争论,尤其是随着 AI 变得与人类艺术创作越来越难以区分。
- 你会使用 ChatGPT 或任何其他 AI 搜索来进行产品推荐或寻找新产品吗?如果是,请说明你信任 AI 的哪类产品推荐 (Score: 255, Comments: 18): Gemini 1.5 正在被讨论其在提供 AI 驱动的产品推荐 方面的潜力。社区被鼓励分享关于他们是否信任 AI 推荐来发现新产品的经验,重点关注那些由 ChatGPT 等 AI 工具建议时更可靠的特定类型产品。
- 一位用户通过 AI 推荐发现了一款名为 “Vagrus - The Riven Realms” 的游戏,强调了 AI 在产品发现中的作用,他们以前从未听说过这款游戏,但觉得非常出色。这突显了 AI 在建议可能符合用户兴趣的冷门产品方面的潜力。
- 对于具有 hard specifications(硬性规格)的产品(如计算机硬件和电子产品),对 AI 推荐的信任度往往更高。用户发现 AI 在比较技术细节方面特别有用,否则这需要大量的各种手动研究,例如一位用户使用 AI 来比较路由器。
Theme 3. Sora Video Generator: Redefining AI Creativity
- 用 Sora 制作的 Cortana (评分: 383, 评论: 42): Sora 被强调为一种增强 AI video generation 技术的工具,如帖子中链接的视频所示。该视频展示了一个名为 Cortana 的作品,尽管文中未提供有关视频内容或所用技术的具体细节。
- 讨论中提到 Sora 是一个生成视频而非文本的工具,一些用户询问目前公众是否可以访问 Sora。
- 评论中包含对 Cortana 外观的幽默和讽刺,用户提到了 “jiggle physics” 等特征,并对她的设计发表了轻松的评论。
- 一些评论关注技术层面和视觉设计,要求增加颜色和皮肤等额外功能,并对 Cortana 的“理线 (wire management)”开起了玩笑。
- 猪在夜间跳探戈 (评分: 373, 评论: 61): 作者使用 Sora 制作了一个视频,配上他兄弟在 Suno 中创作的幽默歌曲。他在制作过程中耗尽了额度,但认为这是对该技术的一次成功的初步尝试,并计划可能在一个月后发布另一个视频。
- Sora 的可访问性和订阅: 用户讨论了通过 20 美元的订阅访问 Sora 的情况,该订阅允许每月创建 50 个 5 秒钟的剪辑,并将其价值与其他生成器进行了比较。用户赞赏这一功能,但也注意到了额度的限制,一名用户本月的额度已用完。
- Prompt 理解和 remix 功能: 关于 Sora 如何解释 prompt 的讨论显示,用户描述了他们想要的每个场景,并使用 “remix” 功能在剪辑不符合预期时进行调整。一位用户提到由于大量的 remix 操作而耗尽了额度。
- Sora 的表现和用户反馈: 反馈强调了 Sora 在生成舞蹈动作方面的能力,一些用户称赞其输出优于其他模型。然而,对于内容的关联性反应不一,例如对探戈音乐的期望未能得到满足。
AI Discord 摘要
由 O1-preview 提供的摘要之摘要的总结
主题 1: AI 模型进展与新发布
- Gated DeltaNet 抢占风头: Gated DeltaNet 在长上下文任务中表现优于 Mamba2 等模型,利用门控记忆控制和 delta 更新来解决标准 Transformer 的局限性。这一进步显著提高了复杂语言建模场景中的任务准确性和效率。
- Llama 3.3 突破上下文障碍: Unsloth 现在支持在 80GB GPU 上微调上下文长度高达 89,000 tokens 的 Llama 3.3,通过减少 70% 的 VRAM 使用量来提高效率。这使得在 A100 GPU 上每个训练步骤仅需 2-3 分钟,大大超过了以前的能力。
- DeepSeek V2.5 发布“压轴作品”: DeepSeek 宣布发布 DeepSeek-V2.5-1210,在其聊天平台中加入了实时 Internet Search,为用户提供触手可及的实时答案。
主题 2: AI 工具与用户体验挑战
- Cursor 休息片刻: 用户报告 Cursor 中持续存在请求缓慢的问题,尽管最近对 Composer 和 Agent 模式进行了更新,但仍干扰了生产力。这两种模式的表现依然不佳,对编码工作流产生了负面影响。
- Bolt 遇到减速带: Bolt.new 用户在订阅结束时的 token 分配上感到困惑,token 不会叠加,且每 30 天重置一次。图像上传问题和“No Preview Available”错误进一步挫伤了用户的积极性,引发了关于 token 管理策略的讨论。
- Cursor 中的 Linting 噩梦: Cursor 的 linting 功能在没有实际错误的情况下触发,导致用户不必要地消耗了他们的快速消息配额。频繁的误报强化了这样一种观点,即 Cursor 的功能仍处于 beta 阶段,需要改进。
主题 3: 软件开发中的 AI 集成
- Mojo 通过新关键字打破旧习惯:在 Mojo 中引入
destroy关键字强化了线性类型(linear types)中更严格的内存管理,在增强安全性的同时也引发了关于新手复杂性的辩论。这一与 Pythondel的区别旨在改进编程实践。 - Aider 通过多实例成倍提高生产力:工程师们正同时运行多达 20 个 Aider 实例来处理大型项目工作流,展示了该工具的可扩展性。用户正在探索跨实例的命令执行,以优化大规模开发的编码方法。
- LangChain 和 Aider 成为黄金搭档:Aider 与 LangChain 的 ReAct 循环集成增强了项目管理任务,用户注意到其效果优于其他工具。这种协作提升了 AI 辅助编码的工作流和效率。
主题 4:AI 社区与开源倡议
- vLLM 加入 PyTorch 阵营:vLLM 正式集成到 PyTorch 生态系统中,增强了 LLM 的高吞吐量、内存高效推理。此举预计将推动 AI 创新并降低开发者的门槛。
- Grassroots Science 走向多语言:一项新倡议旨在通过开源努力和社区协作,在 2025 年 2 月前开发出多语言 LLM。该项目寻求利用开源工具吸引基层社区参与多语言研究。
- 2024 年 AI Agent 现状报告发布:Ahmad Awais 发布了一份深度报告,分析了 1840 亿个 token 和来自 4,000 名开发者的反馈,突出了 AI Agent 的趋势和未来方向。
主题 5:创意内容与用户交互中的 AI
- NotebookLM 在播客领域表现出色:用户分享了名为《NotebookLM 播客教程:10 个秘密提示词(绝密!)》的教程,提供专属提示词以增强播客创意。尝试使用 fact-checkers 等功能可以提高 AI 生成播客的对话质量。
- WaveForms AI 为交互注入情感:WaveForms AI 发布,旨在通过将情感智能(Emotional Intelligence)集成到 AI 系统中来通过语音图灵测试(Speech Turing Test)。这一进步致力于通过更自然、更具表现力的沟通来增强人机交互。
- Sora 的首次亮相毁誉参半,引发用户猜测:OpenAI 的 Sora 因 5 秒的视频输出和内容质量问题而受到质疑。用户将其与 Claude、Leonardo 和 Ideogram 等模型进行对比,结果并不理想,导致部分用户更倾向于替代方案。
第一部分:Discord 高层摘要
Codeium / Windsurf Discord
- Windsurf AI 启动周边赠送活动:Windsurf AI 在 Twitter 上发起了首次周边赠送活动,邀请用户分享他们的作品,以赢取护理礼包。
- 该活动利用标签 #WindsurfGiveaway 来追踪提交内容并提升社区参与度。
- 积分系统持续存在缺陷:用户报告购买的 credits 经常无法在账户中显示,导致广泛的不满和大量的支持工单。
- 尽管团队做出了保证,但缺乏及时的支持响应继续让用户群感到失望。
- 对 Windsurf 定价模式的困惑:用户对 Windsurf 的定价日益担忧,尤其是相对于所提供的功能,flow 和常规积分的限制较高。
- 用户主张建立更可持续的模式,包括引入未用积分的结转系统(rollover system)。
- Windsurf IDE 性能下降:最近的更新导致了对 Windsurf IDE 的批评,用户指出其 bugs 增加且效率下降。
- 与 Cline 等竞争对手的对比显示,用户更青睐 Cline 卓越的功能性和可靠性。
- Cline 在编程任务中表现优于 Windsurf:在某些编码任务中,Cline 比 Windsurf 更受青睐,尽管在某些方面性能较慢,但能提供更好的 prompt 响应。
- Cline 生成特定编码输出且无错误的能力受到了社区的特别称赞。
Eleuther Discord
- LLM 中的可复现性挑战:讨论强调了 Large Language Models (LLM) 中的可复现性担忧,特别是在医疗系统等高风险应用中,强调了超越传统软件开发的复杂性。成员们辩论了重建 LLM 的细微差别以及可靠 Benchmark 的重要性。
- 参与者提到了待评审的 HumanEval Benchmark PR,该 PR 旨在通过集成来自 HF evaluate 模块的 pass@k 指标来增强评估标准。
- Coconut Architecture 对比 Universal Transformers:Coconut Architecture 引入了一种新颖的方法,将
<eot>token 后的最终隐藏状态作为新 token 反馈,在每次迭代中改变 KV cache。这与 Universal Transformers 形成对比,后者通常在重复过程中保持静态 KV cache。- 讨论了该方法在特定条件下与 UTs 的潜在相似性,特别是在涉及共享 KV cache 和状态历史管理的场景中,突出了性能优化的机会。
- Gated DeltaNet 提升长上下文性能:Gated DeltaNet 在长上下文任务中表现出优于 Mamba2 和之前 DeltaNet 版本的性能,利用了门控内存控制和 delta 更新。这一进步解决了标准 Transformers 在长期依赖方面的局限性。
- 引用了 Benchmark 结果,展示了在任务准确性和效率方面的显著提升,使 Gated DeltaNet 在复杂的语言建模场景中成为具有竞争力的架构。
- Batch Size 影响 GSM8k 评估准确率:在 GSM8k benchmark 上的评估显示,1 的 Batch Size 达到了 85.52% 的最高准确率,而较大的 Batch Size 导致性能显著下降。这种差异可能与 padding 或 attention 机制的实现有关。
- 成员们正在调查根本原因,考虑调整 padding 策略和模型配置,以减轻增加 Batch Size 对评估指标的负面影响。
- RWKV 和 Transformers 中的 Attention Masking 问题:针对 RWKV model 的实现提出了担忧,特别是与 attention masking 和 left padding 相关的问题,这可能会对评估结果产生不利影响。此外,在多 GPU 环境中使用 SDPA attention 实现被指出可能存在性能不一致。
- 参与者强调了仔细配置的必要性,并建议探索替代的 attention backends,以确保在不同硬件设置下模型性能的可靠性。
Cursor IDE Discord
- Cursor 运行极其缓慢:多位用户报告 Cursor 中持续出现请求缓慢的问题,尽管最近对 Composer 和 Agent 模式进行了更新,但仍干扰了他们的生产力。
- 用户认为 Composer 和 Agent 模式的表现依然不尽如人意,对他们的编程工作流产生了负面影响。
- AI 模型对决:Gemini, Claude, Qwen:许多用户更青睐 Claude,认为其在编程任务中的表现优于 Gemini 和 Qwen。
- 虽然 Gemini 在某些测试中显示出潜力,但质量的不稳定性导致了开发者的挫败感。
- Agent 模式文件处理困惑:关于 Cursor 的 Agent mode 中的 Agent 是直接访问文件内容还是仅仅建议读取文件,产生了一些疑问。
- 这种不确定性突显了用户对 Cursor 的 Agent 功能之功能性和可靠性的持续关注。
- AI 称赞用户的代码结构:一位用户分享了反馈,尽管该用户缺乏经验,但 AI 称赞其代码结构非常专业。
- 这展示了当前 AI 在准确评估开发实践方面的先进能力。
- Linting 触发令用户沮丧:Cursor 的 linting 功能在没有实际错误的情况下触发,导致用户感到沮丧,他们认为自己的 fast message 配额被误用了。
- 频繁的误报强化了这样一种观点:Cursor 的功能仍处于 Beta 阶段,需要进一步完善。
aider (Paul Gauthier) Discord
- Aider v0.68.0 发布增强功能:最新的 Aider v0.68.0 版本引入了 copy-paste mode 和
/copy-context命令,显著提升了用户与 LLM Web Chat UI 的交互体验。- 增强的 API key 管理 功能允许用户通过
--openai-api-key和--anthropic-api-key开关为 OpenAI 和 Anthropic 设置密钥,并通过 YAML 配置文件简化环境配置。
- 增强的 API key 管理 功能允许用户通过
- Gemini 模型表现各异:用户报告称 Gemini 模型 提供了改进的上下文处理能力,但在编辑大文件时面临限制,引发了关于 性能基准测试 的讨论。
- 正如 DeepSeek 的更新 所强调的,社区呼吁与其他模型进行对比分析,以更好地了解架构能力。
- Aider 与 LangChain 无缝集成:Aider 与 LangChain 的 ReAct 循环集成 增强了项目管理任务,用户注意到其效果优于其他工具。
- 对该集成的进一步测试和潜在合作可能会为 AI 辅助编程工作流提供更深入的见解。
- 为复杂工作流管理多个 Aider 实例:工程师们正同时运行多达 20 个 Aider 实例 来处理大型项目工作流,展示了该工具的可扩展性。
- 用户正在探索跨实例执行命令,以优化大规模开发的编码方法。
- 社区分享 Aider 教程与资源:成员们对社区分享的 教程 和资源表示赞赏,营造了协作学习的环境。
- 讨论强调通过共享知识和视频内容来增强学习体验,支持 AI Engineer 的技能提升。
Unsloth AI (Daniel Han) Discord
- Llama 3.3 实现超长上下文长度:Unsloth 现在支持在 80GB GPU 上对 Llama 3.3 模型进行微调,上下文长度可达 89,000 tokens,与其先前版本相比能力显著提升。
- 正如 Unsloth 最新更新 所指出的,这一改进允许用户在 A100 GPU 上实现 每训练步 2-3 分钟 的速度,同时减少 70% 的 VRAM 占用。
- APOLLO 优化器减少 LLM 训练内存:APOLLO 优化器引入了一种近似学习率缩放的方法,以缓解使用 AdamW 训练大语言模型时的内存密集问题。
- 根据 APOLLO 论文,该方法旨在保持竞争力的性能,同时降低优化器的内存开销。
- QTIP 增强 LLM 的训练后量化:QTIP 采用格形编码量化(trellis coded quantization)来优化高维量化,从而改善大语言模型的 内存占用 和推理吞吐量。
- QTIP 方法 通过克服先前矢量量化技术的局限性,实现了有效的微调。
- 针对 OCR 任务微调 Qwen 模型:针对 OCR 任务 微调 Qwen2-VL 模型的兴趣日益浓厚,旨在增强从护照等文档中提取信息的能力。
- 用户对这种方法的有效性充满信心,利用 Qwen 强大的能力来解决专门的 OCR 挑战。
- Awesome RAG 项目扩展 RAG 与 Langchain 集成:Awesome RAG GitHub 项目专注于增强 RAG、VectorDB、embeddings、LlamaIndex 和 Langchain,并邀请社区贡献。
- 该仓库作为推进检索增强生成(RAG)技术资源和工具的中心枢纽。
Stability.ai (Stable Diffusion) Discord
- 图像增强与 AI 工具:成员们讨论了 Stable Diffusion 是否能在不改变核心内容的情况下改进图像,建议对于此类任务使用像 Photoshop 这样的传统编辑工具。
- 一些人强调了在专业效果中调色和光影技能的重要性,指出 AI 可能会增加噪点而非精炼图像。
- 本地部署中的 Llama 3.2-Vision 模型:Llama 3.2-Vision 模型被提及为图像分类和分析的可行本地选项,并由 KoboldCPP 等软件支持。
- 成员们指出本地模型可以在消费级 GPU 上运行,并强调在线服务通常要求用户放弃其数据权利。
- Automatic1111 WebUI 中的内存管理:讨论了影响 Automatic1111 WebUI 图像生成的内存管理问题,特别是 Batch Size 和 VRAM 使用。
- 成员们建议较大的 Batch 会导致显存溢出(Out-of-Memory)错误,这可能是由于系统中存储 Prompt 的方式效率低下造成的。
- 图像元数据和打标的挑战:参与者讨论了从图像中提取标签或描述的挑战,建议包括使用元数据读取器或 AI 模型进行分类。
- 针对分类方法可能遗漏某些细节的担忧被提出,一些人主张使用类似于 Imageboards 上的特定标签。
- AI 图像服务中的版权和数据权利:分享了关于使用在线服务进行 AI 图像生成的警告,强调此类服务通常对用户生成的内容主张广泛的权利。
- 成员们鼓励使用本地模型以保持对创作作品更清晰的所有权和控制权,这与基于 Web 的服务的广泛许可做法形成鲜明对比。
Perplexity AI Discord
- Perplexity AI 图像生成问题:用户报告 Perplexity AI 中的 ‘Generate Image’ 功能经常根据设备方向被隐藏或无响应,阻碍了图像生成过程。
- 一位用户通过将设备切换到横屏模式解决了该问题,成功显示了 ‘Generate Image’ 功能。
- Perplexity 中 Claude 与 GPT 的性能对比:Claude 模型因其写作能力而受到认可,但讨论表明,与官方平台相比,它们在 Perplexity AI 中的表现可能不佳。
- Pro 用户发现付费的 Claude 版本更有优势,理由是功能增强和性能改进。
- Perplexity 中的 Custom GPTs:Perplexity 中的 Custom GPTs 允许用户修改性格特征和引导设置,优化用户交互和任务管理。
- 一位参与者表达了利用 Custom GPTs 整理思路和开发项目想法的兴趣。
- OpenAI Sora 发布:OpenAI Sora 已正式发布,在 AI 社区引发了对其新功能的兴奋。
- 一位成员分享了一个 YouTube 视频,详细介绍了 Sora 的功能和潜在应用。
- Perplexity Pro 功能:Perplexity Pro 计划提供比免费版本更丰富的功能,为订阅者增强了研究和编程能力。
- 成员们讨论了使用推荐码获取折扣,表现出对订阅高级功能的兴趣。
OpenAI Discord
- Sora 生成怀疑与 AI 模型对比:用户对 Sora 的内容质量表示怀疑,质疑其是否依赖库存素材,同时将其在易用性和输出质量方面的表现与 Claude、O1、Leonardo 和 Ideogram 等模型进行了对比。
- 一些用户在特定任务中更倾向于使用 O1,并指出 Leonardo 和 Ideogram 提供了更好的可用性,而 Sora 仅能生成 5 秒视频的限制被视为进行实质性内容创作的约束。
- Custom GPTs 的连续性与 OpenAI 模型微调挑战:Custom GPTs 在更新后会丢失工具连接,这促使成员通过从现有 GPTs 中提取关键摘要来合成连续性,同时解决持续的管理需求。
- 讨论了 OpenAI 模型微调 中的挑战,用户在 Node.js 环境中微调后遇到了泛泛而谈的回复,并寻求关于其训练 JSONL 文件的帮助,以实现有效的模型定制。
- Prompt Engineering 中嵌套代码块的优化:参与者分享了在 ChatGPT 中管理嵌套代码块的技巧,强调使用双反引号来确保嵌套结构的正确渲染。
- 示例包括 YAML 和 Python 代码片段,展示了内部双反引号在保持嵌套代码块完整性和可读性方面的有效性。
- AI 能力预期与用户反馈洞察:讨论集中在 AI 模型未来动态生成用户界面并无需明确指令即可调整响应的潜力,旨在实现无缝的用户交互。
- 对于完全由 AI 驱动的交互的实用性存在怀疑,担心用户困惑和可用性问题,同时反馈强调需要 AI 功能有更实质性的进展。
Bolt.new / Stackblitz Discord
- 订阅结束后的 Token 变动:用户报告了对订阅结束后 token 分配的困惑,一些 token 无法叠加,且 Pro plan 的 token 每 30 天重置一次。对于账单问题,建议联系支持部门。
- 一位成员指出 token 不会叠加,这种重置政策引发了关于 token 管理策略的讨论。
- 支付网关集成到 Bolt?:用户正在探索与 Payfast、PayStack 等平台的支付网关集成,并询问其是否与 Stripe 的集成过程类似。目前尚未提供明确的解决方案。
- 一位用户建议分离仪表盘功能可能会增强大型项目的实用性。
- Bolt 缺乏多 LLM 支持:一位用户询问是否可以在 Bolt 中为复杂项目同时利用多个 LLMs,但另一位成员确认该功能目前尚不可用。
- 参与者讨论了在没有原生多 LLM 支持的情况下,提高生产力和管理更大型代码库的方法。
- Bolt 上传本地图像失败:提出了关于本地图像在 Bolt 中无法正确显示的问题,导致在上传失败的情况下消耗了 token。建议包括使用外部服务进行图像上传。
- 分享了一份关于在 Bolt 应用程序中正确集成图像上传功能的指南。
- Bolt 用户遇到“No Preview Available”错误:一些用户在修改后项目无法加载时遇到“No Preview Available”错误,这引发了创建专门讨论主题以进行详细故障排除的想法。
- 一位成员概述了重新加载项目和关注错误消息等步骤,以有效解决该问题。
Modular (Mojo 🔥) Discord
-
介绍 Mojo 的 ‘destroy’ 关键字:讨论强调了在 Mojo 中引入新 destroy关键字的必要性,通过在线性类型中强制执行更严格的用法,将其与 Python 的del区分开来,以增强内存管理安全性。[Ownership and borrowingModular Docs](https://docs.modular.com/mojo/manual/values/ownership)。 - 一些成员指出,强制使用
destroy可能会增加从 Python 迁移过来的新手的学习曲线,强调了文档清晰度的重要性。
- 一些成员指出,强制使用
- 优化 Multi-Paxos 中的内存管理:Multi-Paxos 的实现现在利用静态分配的结构来满足无堆分配(no-heap-allocation)的要求,支持高性能所需的流水线操作。GitHub - modularml/max。
- 评论强调了对 Promise 和 Leader 选举进行全面处理的必要性,以确保共识算法的健壮性。
-
澄清 Mojo 中的所有权语义:关于 Mojo 中所有权语义(ownership semantics)的对话要求明确析构函数的处理,特别是在对比拷贝(copy)和移动(move)构造函数的默认行为时。[Ownership and borrowing Modular Docs](https://docs.modular.com/mojo/manual/values/ownership)。 __del__(析构函数)等主题被标记为可能会让来自具有自动内存管理语言的用户感到困惑,强调了语法一致性的需求。
- 解决网络中断对模型权重的影响:一次讨论揭示了网络中断可能导致模型因验证缺陷而使用错误的权重,从而导致数据损坏。Checksums 已被整合到下载过程中以提高可靠性。
- 中断场景下的示例输出展示了离奇的数据损坏,突显了新 Checksum 措施的有效性。
- 通过 Hugging Face 集成增强 MAX Graph:与
huggingface_hub的集成现在支持自动恢复中断的下载,提升了系统的健壮性和可靠性。Hugging Face Integration。- 这一增强功能是在之前出现大权重损坏问题后推出的,利用 Hugging Face 来优化 MAX Graph pipelines 的性能。
Notebook LM Discord Discord
- NotebookLM 扩展播客功能:一位成员分享了一个名为“NotebookLM Podcast Tutorial: 10 Secret Prompts (People Will Kill You For!)”的 YouTube 教程,提供了增强播客创意的独家提示词。
- 用户还探索了为 AI 生成的播客添加事实核查器,旨在提高对话质量并确保 90 分钟节目期间的准确性。
- NotebookLM 中有限的来源利用:一位用户表达了挫败感,因为在论文需要 15 个来源时,NotebookLM 仅处理 5-6 个来源,突显了来源多样性的限制。
- 社区成员建议在查询时设置来源限制,以确保更广泛的参考范围,从而解决来源匮乏的问题。
- NotebookLM 请求增强语言支持:用户询问如何将 NotebookLM 的语言设置更改为英语,理由是即将到来的考试非常紧迫。
- 讨论包括调整浏览器设置和刷新 NotebookLM 页面以实现所需语言的方法,并请求未来支持法语和德语等语言。
- 在 NotebookLM 中分享笔记本的挑战:用户报告了使用“复制链接”分享笔记本时的困难,因为接收者在未被预先添加为查看者的情况下会看到空白页面。
- 针对成功分享笔记本的必要步骤进行了说明,以确保协作者拥有正确的访问权限。
LM Studio Discord
- LM Studio 的手动更新:用户强调 LM Studio 不会自动更新到 0.3.x 等较新版本,因此需要手动更新以保持与最新模型的兼容性。
- 建议采用手动更新方法,以确保与更新的功能和模型无缝集成。
- Tailscale 集成增强可访问性:使用设备的 MagicDNS 名称为 LM Studio 配置 Tailscale 提高了可访问性,并解决了之前的连接问题。
- 这种方法简化了网络配置,使 LM Studio 对用户来说更加可靠。
- 模型兼容性挑战:围绕 LLAMA-3_8B_Unaligned 等模型的兼容性问题展开了讨论,暗示最近的更新可能导致了功能损坏。
- 用户推测 LLAMA-3_8B_Unaligned 模型在最新更改后可能无法运行。
- 优化 GPU 散热方案:成员们称赞了他们强大的 GPU 散热设置,强调共享 VRAM 可能会降低性能,并建议限制 GPU 负载以获得最佳效率。
- 成员们分享了诸如修改 Batch Size 和上下文长度等技术,以增强 GPU 处理和资源管理。
- Alphacool 水箱兼容 D5 Pumps:Alphacool 提供适配 D5 pumps 的水箱,正如用户根据硬件要求调整设置时所指出的。
- 一位用户分享了他们为自己的配置选择的 Alphacool 水箱链接。
Nous Research AI Discord
- VLM 微调面临挑战:成员们讨论了微调 Llama Vision 等 VLM 模型的困难,指出 Hugging Face (hf) 对这些任务没有提供强有力的支持。
- 他们建议使用 Unsloth,并参考了 AnyModal GitHub 项目 来增强多模态框架的调整。
- 长期记忆路径的突破:分享了一篇关于 Max Planck Florida Institute for Neuroscience 的神经科学家发现形成长期记忆新路径的文章,该路径绕过了标准的短期过程(阅读更多)。
- 社区探讨了操纵这些记忆创建路径如何改进 AI 认知模型。
- 使用 OpenAI API 构建安全 Agent:一位用户概述了他们使用 OpenAI API 构建安全 Agent的方法,详细说明了创建 Tool 类和实现任务完成循环等步骤。
- 其他成员指出,扩展到高级架构(如多 Agent 系统和 ReAct 策略)会引入显著的复杂性。
- 探索 ReAct Agent 策略:讨论集中在各种 ReAct Agent 策略上,以使 Agent 能够推理并与其环境进行动态交互。
- 成员们考虑了将 Agent 输出作为用户输入以增强交互工作流的潜力。
- Meta 的 Thinking LLMs 论文见解:一位成员审阅了 Meta 的 Thinking LLMs 论文,强调了其让 LLM 在最终确定答案之前列出内部想法并评估响应的方法。
- 他们展示了一个 LLM 在生成答案过程中倾向于“过度思考”的例子,引发了关于优化推理过程的讨论(阅读更多)。
Interconnects (Nathan Lambert) Discord
- DeepSeek V2.5 发布“大结局”版本:DeepSeek 宣布发布 DeepSeek-V2.5-1210,被称为“大结局(Grand Finale)”,引发了对此更新期待已久的社区成员的热情。
- 成员们兴奋地讨论了这次发布,指出了新版本的重要意义及其对 DeepSeek 能力的影响。
- DeepSeek 联网搜索功能上线:DeepSeek 推出了 Internet Search 功能,现已在其 聊天平台 上线,允许用户通过开关该功能来获取实时答案。
- 社区成员对这一新功能表示欢迎,并对其提升用户体验和提供即时搜索结果的潜力表示乐观。
- DeepSeek 许可证允许合成数据:在一场讨论中,有成员询问 DeepSeek 当前的许可证是否允许合成数据生成(synthetic data generation),表现出对许可条款的兴趣。
- 另一位成员确认,在现有许可证下允许生成合成数据,尽管这并非普遍做法,这引发了对 OLMo 测试的进一步好奇。
- vLLM 集成至 PyTorch 生态系统:vLLM 项目 正式加入 PyTorch 生态系统,以增强大语言模型(LLM)的高吞吐量、内存高效推理。
- 利用 PagedAttention 算法,vLLM 通过流水线并行(pipeline parallelism)和推测解码(speculative decoding)等新功能持续演进。
- Fchollet 澄清对 Scaling Law 的立场:Fchollet 通过一条推文澄清了关于他对 AI Scaling Law 立场的误解,强调他不反对 Scaling,但批评过度依赖更大的模型。
- 他主张将重点从 LLM 是否具备推理能力转向其适应新奇事物的能力,并提出了一个数学定义来支持这一观点。
Latent Space Discord
- WaveForms AI 发布情感音频 LLM:由 WaveForms AI 宣布,该公司旨在解决语音图灵测试(Speech Turing Test)并将情感智能(Emotional Intelligence)集成到 AI 系统中。
- 此次发布符合增强 AI 情感理解能力以改善人机交互的趋势。
- vLLM 加入 PyTorch 生态系统:vLLM 项目 宣布其集成到 PyTorch 生态系统中,确保为开发者提供无缝的兼容性和性能优化。
- 此举预计将增强 AI 创新,并使 AI 工具对开发者社区更加触手可及。
- Devin 现已在 Cognition 全面开放:Cognition 已公开推出 Devin,起售价为 500 美元/月,提供无限席位和各种集成等福利。
- Devin 旨在协助工程团队高效完成调试、创建 PR 和执行代码重构等任务。
- 最新播客聚焦 Sora 发布:最新的播客节目包含了对 OpenAI Sora 的 7 小时深度探讨,由 Bill Peeb 提供见解。
- 听众可以在此访问该节目,获取关于 Sora 发布的详尽概述。
- 《2024 年 AI Agent 现状》报告发布:Ahmad Awais 发布了“State of AI Agents 2024”报告,分析了 1840 亿个 token 和来自 4000 名开发者 的反馈,以突出 AI Agent 的趋势。
- 这些见解对于理解当前环境下 AI Agent 技术的轨迹和演变至关重要。
Axolotl AI Discord
- Torch Compile:速度与内存:成员们讨论了使用 torch.compile 的经验,指出速度提升微乎其微,且内存占用有所增加。
- 一位成员评论道:“这也可能只是我个人的问题。”
- Online RL 中的 Reward Models:讨论得出结论,在 online RL 中,reward model 始终是一个用于评分的独立模型,并且在实际模型训练期间保持冻结状态。
- 成员们探讨了使用 reward model 的影响,强调了它与主训练过程的分离。
- KTO 模型的性能主张:Kaltcit 赞扬了 KTO 模型超越原始数据集标准的潜力,声称其鲁棒性有所增强。
- 然而,成员们表示需要确认 KTO 是否确实比已接受的数据有所改进。
- KTO 研究结果的证实:Kaltcit 提到 Kalo 证实了 KTO 论文的发现,但指出在微调者(finetuners)中缺乏广泛的定量研究。
- Nanobitz 观察到,这类工作大部分可能发生在不广泛分享研究结果的组织内部。
- Axolotl Reward Model 集成:有人询问如何在 Axolotl 中集成 reward model 进行评分,强调在现有数据集之外进行实验。
- Kaltcit 表示,目前的 KTO 设置可能足以在原始优势之外实现答案最大化。
LLM Agents (Berkeley MOOC) Discord
- LLM 中的 Function Calling:一位成员分享了 function calling 文档,解释了它如何利用 function descriptions 和 signatures 根据 prompt 设置参数。
- 有人建议,模型是在大量示例上进行训练的,以增强 generalization(泛化能力)。
- Tool Learning 的重要论文:一位成员重点介绍了多篇关键论文,包括 arXiv:2305.16504 和 GitHub 上的 ToolBench,以推进 LLM 的 tool learning。
- 另一篇论文 Tool Learning with Foundation Models 也被指出在讨论中具有潜在的重要意义。
LlamaIndex Discord
- LlamaParse Auto Mode 优化成本:LlamaParse 推出了 Auto Mode,它以标准的、更便宜的模式解析文档,同时根据用户定义的触发条件选择性地升级到 Premium mode。更多详情请参阅此处。
- 此处提供了 LlamaParse Auto Mode 的视频演示,提醒用户更新浏览器以确保兼容性。
- 使用 LlamaParse 增强 JSON 解析:LlamaParse 的 JSON mode 提供了对复杂文档的详细解析,提取图像、文本块、标题和表格。更多信息请参考此链接。
- 该功能增强了处理结构化数据提取时的控制力和能力。
- 开发端到端发票处理 Agent:团队正在探索创新的 document agent workflows,这些工作流超越了传统任务,可自动处理复杂流程,包括旨在从发票中提取信息并与供应商匹配的端到端发票处理 Agent。请关注此处的进展。
- 这一极具前景的工作流自动化工具将简化发票管理。
- Cohere Rerank 3.5 现已在 Bedrock 中可用:Cohere Rerank 3.5 现在可以通过 Bedrock 作为 postprocessor 使用,与最近的更新无缝集成。文档可以在此处访问。
- 可以通过
pip install llama-index-postprocessor-bedrock-rerank进行安装。
- 可以通过
- ColPali 增强 PDF 处理期间的 Reranking:ColPali 功能在 PDF 处理过程中充当 reranking 工具,而不是一个独立的过程,明确了其在动态文档处理中的作用。经用户确认,它主要用于检索后对图像节点进行 reranking。
- 这一澄清有助于理解 ColPali 在现有工作流中的集成方式。
Cohere Discord
- Cohere 商务幽默引发冲突:成员们对 Cohere 在商务讨论中使用无关幽默表示不满,强调轻松的氛围不应掩盖严肃的对话。
- 持续的辩论凸显了管理员在保持轻松氛围与维护专业讨论之间需要取得的平衡。
- Rerank 3.5 English 模型计划:一位成员询问了 Rerank 3.5 English 模型 的后续计划,寻求其开发时间线的细节。
- 未见相关回复,表明在该模型的进展方面可能存在沟通断层。
- CmdR+Play Bot 暂停服务:经成员询问状态后确认,CmdR+Play Bot 目前正在休息。
- 建议用户关注有关该 Bot 可用性的后续更新。
- Aya-expanse 指令性能:一位用户询问 command 系列中的 aya-expanse 是否增强了其指令处理性能。
- 讨论并未就其性能改进给出明确答案。
- API 403 错误与 Trial Keys 相关:成员报告在进行 API 请求时遇到 403 错误,暗示这可能与 trial key 的限制有关。
- Trial keys 通常具有限制访问特定功能或端点的约束。
Torchtune Discord
- 配置冲突难题:一位用户寻求一种合并冲突 configuration files 的简便方法,选择对所有文件使用“接受双方更改”。他们分享了一个通过将 conflict markers 替换为空字符串的变通方法。
- 这种方法引发了关于在协作项目中处理配置合并最佳实践的讨论。
- PR #2139 谜题:社区讨论了 PR #2139,重点关注
torch.utils.swap_tensors及其在 initialization 中的作用。- 贡献者一致认为,有必要就
self.magnitude的定义和初始化进行进一步对话。
- 贡献者一致认为,有必要就
- 空初始化增强:提出了改进
to_emptyinitialization method 的建议,旨在管理设备和参数捕获的同时,保持预期的用户体验。- 成员们辩论了如何在不破坏现有代码库的情况下平衡最佳实践。
- Tensor 策略:设备处理:强调了在 Tensor 初始化和交换期间进行有效 device management 的重要性,特别是涉及
magnitude等参数时。- 参与者强调了使用
swap_tensors等 API 来维护操作期间设备完整性的重要性。
- 参与者强调了使用
- 参数与梯度说明:贡献者澄清,在正确处理设备管理的前提下,使用
copy_是可以接受的,并强调了requires_grad状态的重要性。- 他们讨论了在初始化程序中集成错误检查,以防止处理 meta devices 上的 Tensor 等常见问题。
DSPy Discord
- LangWatch Optimization Studio 发布:LangWatch Optimization Studio 作为构建 DSPy 程序的新低代码 UI 发布,简化了 LM 的评估和优化。该工具目前已在 GitHub 上开源。
- 该 Studio 已结束私测,鼓励用户在 GitHub 仓库点赞以示支持。
- DSPy 文档访问问题:一位成员报告访问 DSPy 文档(特别是 API 参考链接)时遇到困难。另一位成员澄清说,大多数语法都可以在落地页找到,不再需要专门的类型模块。
- 社区讨论表明文档已被简化,语法示例已移至主页以便于访问。
- O1 系列模型对 DSPy 的影响:有人询问 O1 系列模型 如何影响 DSPy 工作流,特别是关于 MIPRO 优化模块的参数。可能需要进行调整,例如减少优化周期。
- 成员们正在寻求关于使用新的 O1 系列模型优化 DSPy 工作流的见解和建议。
- DSPy 中的优化错误报告:一位成员报告在 DSPy 优化过程中遇到通用错误,并在特定频道发布了详情。他们正在寻求关注以解决该问题。
- 社区已注意到报告的 优化错误,成员们正寻求协助排查问题。
LAION Discord
- Grassroots Science Initiative 启动:多个组织合作启动了 Grassroots Science,这是一个开源倡议,旨在到 2025年2月 开发出 多语言 LLMs。
- 他们旨在通过众包、基准测试模型以及使用开源工具来收集数据,让草根社区参与到多语言研究中。
- AI 威胁意识活动发起:一名成员强调了教育个人了解 AI 生成内容 危险性的重要性,建议使用 MKBHD 的最新视频 来展示这些能力。
- 该倡议旨在保护不熟悉技术的个人,使其免受日益逼真的 AI 生成诈骗 的侵害。
- 在 12GB 数据上训练 7B 模型的可行性:一名成员质疑在仅 12GB 数据上训练 7B 参数模型 的可行性,引发了关于其在实际应用中潜在性能的讨论。
- 这种雄心勃勃的方法挑战了大规模模型的传统数据需求,引发了关于效率和有效性的疑问。
- 对超高效小模型的兴奋:成员们对 超高效小模型 表现出极大的热情,强调了它们的性能以及相对于大型模型的优势。
- 一位粉丝表示:‘我喜欢超高效的小模型!它们太棒了!’,强调了在不牺牲能力的情况下降低资源需求的模型的潜力。
OpenInterpreter Discord
- 01 的语音功能登场:一名成员宣布 01 是 Open Interpreter 的语音驱动衍生项目,提供 CLI 和桌面应用程序。它包含了模拟 01 Light 硬件 以及运行服务器和客户端的指令。
- 提供的指令涵盖了模拟 01 Light 硬件 以及管理服务器和客户端的操作。
- OI 与 GPT o1 Pro 的集成:一名成员假设使用 OS 模式下的 OI 可以通过桌面应用或浏览器控制 GPT o1 Pro,从而可能实现网页搜索和文件上传功能。他们表示有兴趣探索这个想法,并指出这可能带来的强大影响。
- 社区成员对通过 OI 的 OS 模式 为 GPT o1 Pro 增强网页搜索和文件上传等功能的潜力非常感兴趣。
- Mac 版 01 App 的 Beta 访问权限:已澄清 01 App 仍处于 Beta 阶段,需要邀请才能访问,目前仅适用于 Mac 用户。一名成员报告称,他们向一位用户发送了私信以获取访问权限,这表明需求非常高。
- 针对 Mac 用户的有限 Beta 访问权限凸显了社区对 01 App 的高度关注。
- 网站功能问题:一名成员对 Open Interpreter 网站的问题表示沮丧,并展示了截图,但未详细说明具体问题。社区成员已开始讨论网站导航和功能,作为他们使用 Open Interpreter 持续体验的一部分。
- 关于网站导航和功能的持续讨论源于社区成员报告的问题。
Mozilla AI Discord
- Web Applets 启动会议:一场即将举行的 Web Applets 会议 计划很快开始,由一位核心成员主持。
- 本次活动旨在加强对现代开发中 Web Applets 集成与功能的理解。
- Theia-ide 探索:明天,参与者可以 探索 Theia-ide,它强调开发环境中的 openness(开放性)、transparency(透明度)和 flexibility(灵活性)。
- 讨论将由一位专家主持,展示与传统 IDE 相比使用 Theia-ide 的优势。
- 编程面试的演变:一条评论强调了编程面试是如何演变的,指出候选人过去常在白板上写 bubble sort。
- 现在,候选人可以指示他们的 IDE 构建一个,这强调了实时编码中向更实际技能的转变。
- Jonas 谈 Theia-ide 愿景:分享的一份 Jonas 访谈提供了关于 Theia-ide 背后愿景的见解,可在此处 访问。
- 这次访谈有助于更深入地了解指导 Theia-ide 开发的功能和哲学。
tinygrad (George Hotz) Discord 没有新消息。如果该频道长期处于沉寂状态,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该频道长期处于沉寂状态,请告知我们,我们将将其移除。
HuggingFace Discord 没有新消息。如果该频道长期处于沉寂状态,请告知我们,我们将将其移除。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该频道长期处于沉寂状态,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该频道长期处于沉寂状态,请告知我们,我们将将其移除。
第二部分:分频道详细摘要与链接
为了邮件展示,完整的逐频道详情已被截断。
如果您喜欢 AInews,请分享给朋友!预先感谢!