ainews-meta-blt-tokenizer-free-byte-level-llm
Meta BLT:无需分词器的字节级大语言模型。
Meta AI 推出了 Byte Latent Transformer (BLT),这是一种无分词器(tokenizer-free)架构,通过动态形成字节补丁(byte patches)来实现高效的计算分配,在包括 CUTE 基准测试在内的多项测试中表现优于 Llama 3。该模型在约 1 万亿个 token 上进行了训练,采用了包含局部和全局组件的三块式 Transformer 设计。这种方法挑战了传统的分词方式,并可能开启新的多模态能力,例如无需检索增强生成(RAG)即可直接进行文件交互。
此外,微软发布了拥有 140 亿参数的 Phi-4 模型,在 STEM 和推理基准测试中取得了最先进(SOTA)的结果,超越了 GPT-4o。DeepSeek AI 推出了基于其混合专家(MoE)架构的新型视觉语言模型,参数规模从 10 亿到 270 亿不等。OpenAI 为 ChatGPT 发布了新的 Projects(项目)功能,Cohere 则推出了其体积最小、速度最快的 Command R7B 模型。Anthropic 发布了关于文本、视觉和音频模型中“Best-of-N 越狱”漏洞的研究。行业讨论凸显了前沿大语言模型(LLM)规模缩小的趋势,例如 GPT-4 的参数量约为 1.8 万亿,而更新的模型规模则更小。
动态字节补丁大小(Dynamic byte patch sizing)就是你所需要的一切。
2024/12/12-2024/12/13 的 AI 新闻。我们为您检查了 7 个 subreddits、433 个 Twitter 账号 和 31 个 Discord(209 个频道和 6703 条消息)。为您节省了预计阅读时间(以 200wpm 计算):741 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
在经历了 2.5 亿美元的巨额融资 和 Ilya 宣布预训练终结 的一天后,我们很高兴看到 Meta 发布了一篇具有技术含金量的论文:Byte Latent Transformer: Patches Scale Better Than Tokens。

摘要非常易读。与之前像 MambaByte 这样的字节级工作相比,BLT 使用动态形成的补丁(patches),并将其编码为潜表征(latent representations)。正如作者所说:“基于 Tokenization 的 LLM 为每个 token 分配相同的计算量。这牺牲了效率以换取性能,因为 token 是通过压缩启发式方法诱导出来的,而这些方法并不总是与预测的复杂性相关。我们架构的核心思想是模型应该动态地分配计算资源到需要的地方。例如,预测大多数单词的结尾并不需要大型 Transformer,因为与选择新句子的第一个单词相比,这些是相对容易、低熵的决策。这反映在 BLT 的架构(§3)中,其中有三个 Transformer 块:两个小型的字节级局部模型和一个大型的全局潜变量 Transformer(latent transformer)。”
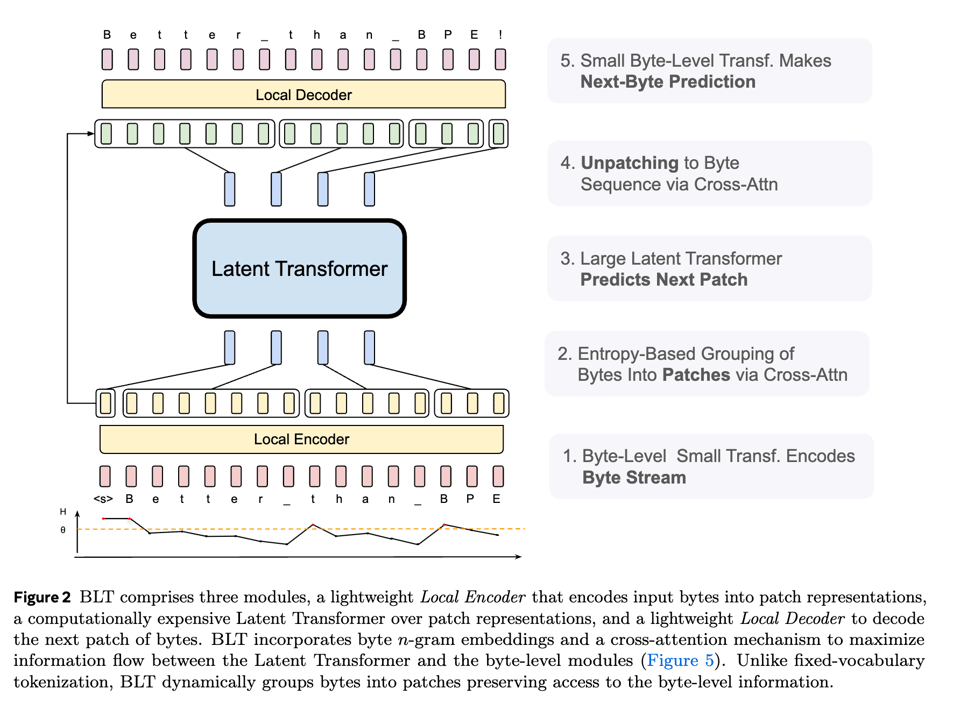
作者在约 1T tokens 的数据上训练了该模型,并将其与自家的 Llama 3 模型进行了对比,它在标准基准测试中的表现出奇地好:
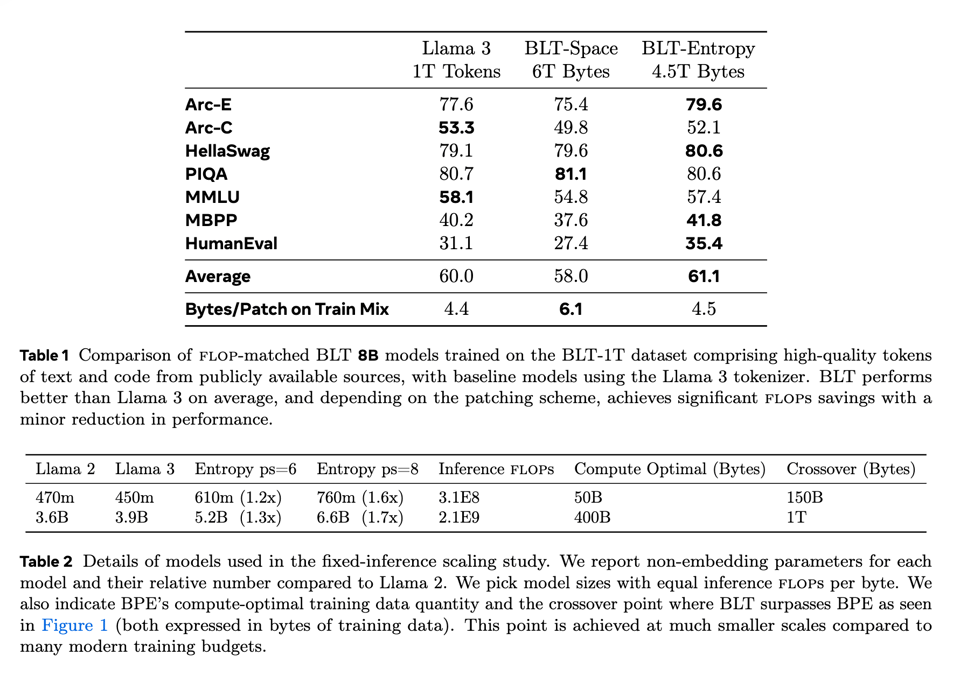
而且在通常会让基于 tokenizer 的模型感到困惑的任务(CUTE 基准测试)上表现也更好:
接下来是什么——扩大规模?是否值得将我们对 tokenization 的所有认知都抛之脑后?长上下文(Long context)、检索(retrieval)或 IFEval 类型的能力又如何?
字节级 Transformer 可能会开启全新的多模态形式,正如 /r/localllama 所解释的:
这种新可能性的一个例子是“与你的 PDF 对话”,当你真的这样做时,无需 RAG,也无需分块,直接将数据输入模型。你可以想象这种原生支持常见文件类型的模型所带来的各种疯狂用例。
AI Twitter 摘要
所有摘要均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
以下是来自 Twitter 讨论的关键话题,按类别整理:
新模型与研究发布
- Microsoft Phi-4:@SebastienBubeck 宣布 推出一款 14B 参数模型,在 STEM/推理基准测试中取得 SOTA 结果,在 GPQA 和 MATH 上超越了 GPT-4o。
- Meta Research:发布了 Byte Latent Transformer,这是一种无分词器(tokenizer-free)架构,能动态地将字节编码为 patch,具有更好的推理效率。
- DeepSeek-VL2:@deepseek_ai 发布 了新的视觉语言模型,采用 DeepSeek-MoE 架构,规模包括 1.0B、2.8B 和 27B 参数。
产品发布与更新
- ChatGPT Projects:@OpenAI 宣布 新的 Projects 功能,用于组织对话、文件和自定义指令。
- Cohere Command R7B:@cohere 发布 了其 R 系列中最小且最快的模型。
- Anthropic Research:发布了关于 “Best-of-N Jailbreaking” 的研究结果,展示了文本、视觉和音频模型中的漏洞。
行业讨论与分析
- 模型缩放(Model Scaling):@tamaybes 指出,前沿 LLM 的规模已大幅减小——GPT-4 约 1.8T 参数,而较新的模型约为 200-400B 参数。
- 基准测试性能:围绕 Phi-4 尽管规模较小但在基准测试中表现强劲 展开了大量讨论。
迷因与幽默
AI Reddit 摘要
/r/LocalLlama 摘要
主题 1. Phi-4 发布:基准测试亮眼但实用性受质疑
- 介绍 Phi-4:Microsoft 专注于复杂推理的最新小语言模型 (得分: 749, 评论: 195):Microsoft 推出了 Phi-4,这是一款专为复杂推理设计的小语言模型。帖子中未提供有关其功能和应用的进一步细节。
- 讨论重点在于对 Phi-4 实际表现的怀疑,用户指出之前的 Phi 模型虽然基准测试分数很高,但在实际应用中表现不佳。指令遵循(Instruction following)被提及为 Phi 模型的短板,一些用户将其与 Llama 相比并给出了负面评价。
- 几条评论关注 合成数据(synthetic data) 及其在训练 Phi 模型中的作用,认为 Microsoft 可能利用 Phi 系列来展示其合成数据集。有推测称这些数据集可能会授权给其他公司,一些用户对合成数据在提高数学等特定领域模型性能方面的潜力表示关注。
- 社区对基准测试结果表示关注,一些人注意到作为一个 14B 模型,其分数令人印象深刻。然而,也有人对潜在的过拟合和这些基准测试的有效性表示担忧,部分用户质疑 Phi-4 模型的透明度和可访问性,提到它将于下周在 Hugging Face 上线。
- Bro WTF?? (Score: 447, Comments: 131): 该帖子讨论了一个 AI 模型对比表,重点展示了 “phi-4” 在 MMLU、GPQA 和 MATH 等任务中相对于其他模型的表现。它将模型分为“Small”和“Large”两类,并包含一个名为 “PhiBench” 的特定内部基准测试,以展示 phi 模型 极具竞争力的结果。
- Phi 模型性能与实际应用:尽管 phi-4 模型 的基准测试表现强劲,但许多用户对其在现实世界中的适用性表示怀疑,并指出之前的 phi 模型 经常在测试中表现出色,但在实践中表现不佳。lostinthellama 强调这些模型是为商业和推理任务量身定制的,但在讲故事等创意任务中表现较差。
- 模型规模与开发:讨论围绕更大规模 phi 模型 的潜力展开,Educational_Gap5867 指出目前最大的 Phi 模型为 14B 参数。arbv 提到之前扩展到 7B 以上的尝试并未成功,建议重点关注更小、更高效的模型。
- 可用性与获取途径:该模型预计将在 Hugging Face 上发布,Guudbaad 提供了其目前在 Azure 上的可用链接,尽管据报道下载速度较慢。sammcj 提供了一个从 Azure 下载文件的脚本以方便获取。
- Microsoft Phi-4 GGUF available. Download link in the post (Score: 231, Comments: 65): 从 Azure AI Foundry 转换而来的 Microsoft Phi-4 GGUF 模型已在 Hugging Face 上作为非官方版本提供下载,官方版本预计下周发布。可用的量化版本包括 Q8_0、Q6_K、Q4_K_M 和 f16,以及未量化的模型,目前没有进一步的量化计划。
- Phi-4 性能与对比:Phi-4 模型明显优于其前身 Phi-3,特别是在多语言任务和指令遵循方面,在 farel-bench 等基准测试中表现出显著提升(Phi-4 得分为 81.11,而 Phi-3 为 62.44)。然而,在某些领域,它仍面临来自 Qwen 2.5 14B 等模型的竞争。
- 模型可用性与许可:该模型可在 Hugging Face 下载,并已上传至 Ollama 以方便获取。许可协议已更改为 Microsoft Research License Agreement,仅允许非商业用途。
- 技术测试与实现:用户已在 LM Studio 等环境中使用 AMD ROCm 对模型进行了测试,在 RX6800XT 上达到了约 36 T/s。该模型的表现被认为简洁且信息丰富,能很好地适应 16GB GPU 上的 16K context。
{kind=link}
主题 2. Andy Konwinski 为 SWE-bench 上的开源 AI 设立 100 万美元奖金
- I’ll give $1M to the first open source AI that gets 90% on contamination-free SWE-bench —xoxo Andy (Score: 449, Comments: 97): Andy Konwinski 宣布,将为第一个在无污染 SWE-bench 上获得 90% 分数的开源 AI 模型提供 100 万美元奖金。该挑战规定代码和模型权重都必须开源,更多详情可以在他的 网站 上找到。
- 人们对在 SWE-bench 上达到 90% 的可行性表示怀疑,因为 Amazon 的模型 仅达到了 55%。由于不需要提交数据集,人们担心基准测试可能被操纵,同时也对确保评估过程真正无污染的挑战感到担忧。
- Andy Konwinski 澄清了竞赛的完整性,将使用提交冻结后创建的新 GitHub issue 测试集,以确保无污染评估。这种方法灵感来自 Kaggle 的市场预测竞赛,涉及一个专门的工程团队来验证 issue 的可解性,并借鉴了 SWE-bench Verified 的经验。
- Andy Konwinski 的身份和奖金的真实性曾受到质疑,但随后通过他与 Perplexity 和 Databricks 的关联得到了确认。该倡议被视为未来激励奖金的雏形,如果观察到显著的社区参与,计划可能会继续并扩大竞赛规模。
主题 3. GPU 性能大揭秘:我们到底有多“富”?
- 你有多“GPU 穷”?你的朋友是“GPU 富”吗?现在可以在 Hugging Face 上揭晓了!🔥 (Score: 70, Comments: 65):该帖子重点介绍了 Hugging Face 上的一项功能,允许用户与其他用户比较他们的 GPU 配置和性能指标。提供的示例显示,Julien Chaumond 拥有一块 NVIDIA RTX 3090 和两块 Apple M1 Pro chips,达到了 45.98 TFLOPS,被归类为“GPU 富豪”;而另一位用户仅为 25.20 TFLOPS,被贴上了“GPU 贫困”的标签。
- 用户对 Hugging Face 上有限的 GPU 选项表示不满,指出缺少 Threadripper 7000、Intel GPUs 以及 kobold.cpp 等其他配置。这凸显了该平台需要更广泛的硬件兼容性和认可。
- 几条评论反映了硬件对比带来的情绪影响,用户幽默地哀叹自己的“GPU 贫困”状态,并承认了自己设备的局限性。帖子提供了一个 GitHub 文件 链接,供用户添加尚未支持的 GPU。
- 围绕 GPU 利用率 的讨论表明了对软件支持的不满,特别是针对 AMD 和旧款 GPU 型号。用户指出,尽管拥有性能不错的硬件,但由于缺乏强大的软件框架,限制了他们充分发挥 GPU 潜力的能力。
{kind=link}
主题 4. Meta 的 Byte Latent Transformer 重新定义 Tokenization
- Meta 的 Byte Latent Transformer (BLT) 论文看起来货真价实。其表现优于基于 Tokenization 的模型,甚至在测试的 8B 参数规模下也是如此。2025 年可能是我们告别 Tokenization 的一年。 (Score: 90, Comments: 27):Meta 的 Byte Latent Transformer (BLT) 展示了语言处理领域的重大进步,在各种任务中超越了像 Llama 3 这样基于 Tokenization 的模型,特别是在“拼写”和“拼写反转”任务中获得了 99.9% 的高分。分析表明,到 2025 年,由于 BLT 在语言感知和任务表现方面的卓越能力,Tokenization 可能会变得过时。
- BLT 的核心创新:Byte Latent Transformer (BLT) 引入了一种动态补丁(dynamic patching)机制,取代了固定大小的 Tokenization,根据预测的熵(entropy)将字节分组为可变长度的补丁,从而提高了效率和鲁棒性。它结合了全局 Transformer 和本地字节级 Transformer,直接对字节进行操作,消除了对预定义词表(vocabulary)的需求,并提高了处理多语言数据和拼写错误时的灵活性和效率。
- 潜力与影响:BLT 模型的字节级方法被视为一项突破,为应用开辟了新的可能性,例如无需 RAG 等额外处理步骤即可直接与文件类型交互。这可以简化多模态(multimodal)训练,允许模型将图像、视频和声音等各种数据类型作为字节处理,从而可能实现字节编辑程序等高级任务。
- 社区资源:BLT 的论文和代码已在网上发布,论文可通过此处访问,代码托管在 GitHub,为进一步探索和实验该模型提供了资源。
{kind=link}
其他 AI Subreddit 综述
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
主题 1. Gemini 2.0:Google 的多模态突破
- Gemini 2.0 才是 4o 本应有的样子 (Score: 853, Comments: 287): Gemini 2.0 被描述为兑现了 4o 未能实现的承诺,特别是在原生多模态能力、SOTA 性能以及语音模式和图像输出等功能方面。作者对 Gemini 2.0 的 200 万字符上下文和深度搜索能力印象深刻,并指出虽然早期测试人员现在可以访问,但它将在 2025 年广泛可用,而不像 OpenAI 对类似功能的发布时间表那样模糊。提供了视频链接以供进一步了解。
- Gemini 2.0 的功能与易用性:用户强调了 Gemini 2.0 Flash 在 Google AI Studio 上的可用性,提供免费访问以及实时视频和屏幕共享等功能。其能够以多种语言和地道口音进行对话的能力以及 200 万字符上下文窗口受到了赞扬,尽管某些功能仍仅限受信任的测试人员使用。
- 与 OpenAI 产品的对比:讨论反映出一种观点,即 OpenAI 正面临成本和资源限制的困扰,其 $200 的 Pro 订阅就是证明。相比之下,Google 对 TPUs 的使用和对 Gemini 2.0 的免费开放被视为竞争优势,可能标志着 AI 格局的一个转折点。
- 社区反应与预期:人们的情绪交织着热情与怀疑,一些用户由于 Google 的性能和性价比,正考虑从 OpenAI 转向 Google。社区表达了对两家公司未来更新的期待,特别是关于多模态能力和改进的模型功能。
- 不要为 ChatGPT Pro 付费,改用 gemini-exp-1206 (Score: 386, Comments: 109): 针对编程用途,作者建议使用 AI Studio 上提供的 Google gemini-exp-1206 模型,而不是为 ChatGPT Pro 付费。他们认为 gemini-exp-1206 优于目前已无法使用的 o1-preview 模型,并认为它与 GPT Plus 以及 带有摄像头的 Advanced Voice 模型并用已足够。
- Gemini-exp-1206 与其他模型的对比:几位用户认为 gemini-exp-1206 在各种编程任务中表现优于 Claude 3.5 和 o1,lmsys arena 排名也支持这一说法。然而,一些用户指出 Gemini 并不是 o1-Pro 的直接替代品,特别是在处理更复杂的任务时,还有人发现 Gemini 在实际编程应用中表现较差。
- Google AI 生态系统的混乱:用户对 Google AI 服务的碎片化表示不满,提到了由 AI Studio、Note LLM 和 Gemini 等多个平台引起的困惑。呼吁建立一个更统一的界面来简化访问和可用性。
- 数据隐私担忧:提出了关于 Gemini 数据隐私的担忧,特别是免费版本缺乏数据退出选项。然而,有人指出 Google 的付费 API 服务有不同的条款,承诺不使用用户数据来改进产品。
主题 2. Advanced Voice Mode 使用限制
- Plus 用户的高级语音模式现在每天限时 15 分钟? (Score: 191, Comments: 144):OpenAI 为 Plus 用户提供的 advanced voice mode(高级语音模式)被误报为每天限时 15 分钟,这在依赖该功能的粉丝中引发了不满。然而,/u/OpenAI 随后澄清这是一个错误,确认 advanced voice limits(高级语音限制)保持不变,较低的限制仅适用于视频和屏幕共享功能。
- 高级语音模式的担忧:用户对感知到的限制和货币化策略表示沮丧,像 Visionary-Vibes 这样的用户认为 15 分钟的限制对付费 Plus 用户不公平。PopSynic 强调了视障用户的无障碍使用问题,以及即使在未主动使用语音模式时限制也会被意外消耗的情况。
- 技术与资源挑战:来自 ShabalalaWATP 和 realityexperiencer 的评论指出,OpenAI 与其他公司一样面临硬件限制的困扰,这影响了服务交付。traumfisch 指出服务器过载可能导致了不一致的服务上限。
- 用户体验与反馈:一些用户(如 Barkis_Willing)批评了语音质量和功能,而 chazwhiz 则赞赏能够以自然的节奏进行沟通以进行头脑风暴。pickadol 称赞了 OpenAI 的直接沟通,强调这对提升用户好感度有积极影响。
AI Discord 回顾
由 o1-mini 生成的摘要之摘要
主题 1. AI 模型性能与创新
-
Phi-4 在基准测试中超越 GPT-4o:Microsoft 的 Phi-4 是一个 14B 参数 的语言模型,在 GPQA 和 MATH 基准测试中均优于 GPT-4o,突显了其对数据质量的关注。Phi-4 技术报告详细介绍了其进步,并已在 Azure AI Foundry 和 Hugging Face 上线。
-
Command R7B 发布,提升 AI 效率:Cohere 发布了 Command R7B,这是其 R 系列中最小且最快的模型,支持 23 种语言,并针对数学、代码和推理等任务进行了优化。该模型可在 Hugging Face 上获取,旨在满足多样化的企业用例。
-
DeepSeek-VL2 引入混合专家模型:DeepSeek-VL2 采用 Mixture-of-Experts (MoE) 架构发布,具有可扩展的模型尺寸(3B, 16B, 27B)和动态图像平铺功能。它在视觉语言任务中取得了卓越性能,在 WebDev Arena 排行榜上展现出足以抗衡 GPT-4o 和 Sonnet 3.5 的强劲实力。
主题 2. 开发者集成与工具增强
-
Aider v0.69.0 简化编码工作流:最新的 Aider v0.69.0 更新支持通过
# ... AI?注释触发并监控所有文件,增强了自动化代码管理。对 Gemini Flash 2.0 和 ChatGPT Pro 集成的支持优化了编码工作流。Aider 文档提供了详细的使用说明。 -
Cursor IDE 在自动补全方面优于 Windsurf:Cursor 因其卓越的 autocomplete(自动补全)能力以及在不产生高额成本的情况下管理多个模型的灵活性而更受青睐。用户反映了对 Windsurf 在文件编辑效率低下和冗余代码生成方面的不满,突显了 Cursor 在提高开发者生产力方面的优势。
-
NotebookLM Plus 增强 AI 文档功能:NotebookLM Plus 引入了新功能,如每个笔记本支持多达 300 个源,并改进了音频和聊天功能。更新后的 3 面板界面和交互式音频概览有助于更好的内容管理和用户交互。可通过 Google Workspace 获取。
主题 3. AI 模型开发技术与优化
-
量化感知训练提升模型准确率:在 PyTorch 中实施 Quantization-Aware Training (QAT) 可以在特定基准测试中恢复高达 96% 的准确率下降。利用 torchao 和 torchtune 等工具可以促进有效的微调,通过 Straight-Through Estimators (STE) 处理不可微操作以保持梯度完整性。
-
逆向机械可解释性探索:研究人员正在深入研究 inverse mechanistic interpretability,旨在不依赖可微编程的情况下将代码转换为神经网络架构。RASP 是一个相关的例子,展示了在机械层面的代码解释。RASP Paper 提供了全面的见解。
-
动态 4-bit 量化增强视觉模型:Unsloth 的 Dynamic 4-bit Quantization 有选择地避免对某些参数进行量化,在保持 VRAM 效率的同时显著提高了准确性。这种方法证明对 vision models 非常有效,这些模型传统上难以进行量化,该技术使其在 local training environments 中表现更佳。
主题 4. AI 提供商的产品更新和公告
-
ChatGPT 推出新的 Projects 功能:在最新的 YouTube 发布会中,OpenAI 展示了 ChatGPT 中的 Projects 功能,增强了结构化讨论管理的 chat organization 和 customization。
-
Perplexity Pro 面临可用性挑战:Perplexity Pro 用户报告了 conversation tracking 和 image generation 方面的问题,影响了整体用户体验。最近的更新在 Spaces 中引入了 custom web sources,以便针对特定网站定制搜索,增强了 search specificity。
-
OpenRouter 在 API 停机期间增加模型提供商过滤功能:OpenRouter 现在允许用户按 provider 过滤模型,提高了模型选择效率。在 AI Launch Week 期间,尽管 OpenAI 和 Anthropic 等提供商出现了大范围的 API downtime,OpenRouter 仍处理了超过 180 万次请求,确保了企业的业务连续性。
主题 5. 社区参与和支持问题
-
Codeium 定价和性能令人沮丧:用户对 Codeium 的定价和持续的性能问题表示 dissatisfaction,特别是 Claude 和 Cascade 模型。尽管最近价格上涨,但内部错误仍未解决,引发了对平台可靠性的担忧。
-
Tinygrad 性能瓶颈凸显优化需求:Tinygrad 用户报告称,与 PyTorch 相比存在显著的 performance lags,尤其是在较大的序列长度和批大小下。对 benchmark scripts 的呼吁旨在识别并解决 compile time 和 kernel execution 的低效问题。
-
Unsloth AI 增强多 GPU 训练支持:Unsloth 预计将引入 multi-GPU training support,目前在 Kaggle 等平台上仅限于单 GPU。这一增强预计将优化大型模型的训练工作流程,缓解当前的瓶颈并提高 training efficiency。
第 1 部分:Discord 高层摘要
Codeium / Windsurf Discord
- Codeium 的定价和性能困扰:用户对 Codeium 的定价和持续的性能问题感到 frustrated,尽管最近价格上涨,但对服务仍不满意。
- 投诉集中在 Claude 和 Cascade 模型的 internal errors,导致用户后悔在平台上消费。
- Claude 模型面临内部错误:多份报告指出 Claude model 在初始消息后遇到内部错误,扰乱了用户体验。
- 切换到 GPT-4o model 可缓解该问题,表明 Claude 内部可能存在不稳定性。
- Cascade 在 C# 集成方面遇到困难:用户报告了将 Cascade 与其 C# .NET projects 集成的挑战,理由是该工具对 .NET 框架不熟悉。
- 关于 workspace AI rules 的提议旨在定制 Cascade 的使用,以更好地适应特定的编程需求。
- Windsurf 的 Sonnet 版本难题:Windsurf 用户在使用 Sonnet 3.5 时遇到的错误增加,而 Claude 4o 作为一个更稳定的替代方案。
- 这种差异引发了对 Windsurf 内部不同 Sonnet 版本运行可靠性的质疑。
- Seamless Windsurf 和 Git 集成:Windsurf 展示了与 Git 的强大兼容性,保留了类似于 VSCode 的原生 Git 功能。
- 用户可以在使用 Windsurf 的同时有效地利用 GitHub Desktop 和 GitLens 等工具,而不会产生冲突。
Notebook LM Discord Discord
- NotebookLM 的功能逐步推出:最新的 NotebookLM 更新(包括高级功能和 UI 增强)正在增量部署,导致部分用户即使拥有有效订阅,仍在使用旧界面。
- 建议用户在推出过程中保持耐心,具体进度可能因国家/地区和工作区配置而异。
- Interactive Audio Overviews 问题:多位用户报告了 Interactive Audio Overviews 的中断问题,例如 AI 主持人提前结束句子并打断对话。
- 社区正在排查潜在的麦克风问题,并对该交互功能的实用性提出质疑。
- 多语言支持增强:NotebookLM 在单次性能测试中处理多种欧洲语言的能力成为讨论焦点,展示了其多语言处理优势。
- 用户分享了不同口音和语言切换的体验,强调了 AI 语言处理的有效性以及有待改进之处。
- NotebookLM Plus 发布:NotebookLM Plus 的推出提供了扩展功能,包括每个笔记本支持多达 300 个来源,以及增强的音频和聊天功能。
- 可通过 Google Workspace、Google Cloud 以及即将推出的 Google One AI Premium 获取。
- AI 在创意项目中的集成:一位资深创作者详细介绍了他们在项目 UNREAL MYSTERIES 中结合使用 NotebookLM 和 3D 渲染技术的情况,强调了 AI 在增强叙事方面的作用。
- 在一次 知名 FX 播客 的采访中分享了见解,展示了 AI 与创意流程之间的协同作用。
aider (Paul Gauthier) Discord
- Aider v0.69.0 简化文件交互:最新的 Aider v0.69.0 更新允许用户通过
# ... AI?注释触发 Aider 并监控 所有 文件,从而增强编码工作流。- 可以在任何文本文件中使用
# AI comments、// AI comments或-- AI comments添加新指令,促进无缝的自动化代码管理。
- 可以在任何文本文件中使用
- Gemini Flash 2.0 支持增强通用性:Aider 现在全面支持 Gemini Flash 2.0 Exp,支持
aider --model flash等命令,增加了与各种 LLM 的兼容性。- 用户强调 Gemini Flash 2.0 在处理大型 Pull Request 时的表现显著提升了代码审查的效率。
- ChatGPT Pro 集成优化编码工作流:将 Aider 与 ChatGPT Pro 结合使用被证明是有效的,允许在编码任务期间在两个平台之间高效复制粘贴命令。
- 这种集成简化了工作流,使开发者能够更轻松地无缝管理和执行编码命令。
- 微调模型增强对最新库的了解:用户成功通过将文档压缩到相关上下文中来微调模型,以更新其对最新库的知识。
- 正如社区成员分享的那样,这种方法在处理较新版本的库时显著提高了模型性能。
- 关于 LLM 排行榜和性能对比的讨论:围绕寻找可靠的排行榜以比较 LLM 在编码任务中的表现展开了讨论,推荐使用 LiveBench 以获得准确性。
- 参与者指出,由于数据集污染,许多现有的排行榜可能存在偏见,强调了对公正评估工具的需求。
Cursor IDE Discord
- Cursor 在性能对决中完胜 Windsurf:用户更倾向于选择 Cursor 而非 Windsurf,原因是其灵活性和卓越的性能,特别是在 autocomplete(自动补全)以及在不产生过度成本的情况下管理多个模型方面。
- Windsurf 因 file editing(文件编辑)效率低下和生成冗余代码而受到批评,凸显了 Cursor 在这些领域的优势。
- Cursor 的订阅困扰:支付痛点依然存在:用户反映了对 Cursor 支付选项的挫败感,特别是涉及 PayPal 和信用卡的问题,以及购买 Pro accounts 的困难。
- 一位用户在最初遇到问题后成功使用 PayPal 支付,这表明 payment processing(支付处理)存在不一致性。
- Cursor 的模型限制:详述具体数值:Cursor 的订阅计划提供 500 次 fast requests,在 fast requests 耗尽后提供无限次的 slow requests,主要针对高级模型。
- 用户澄清说,Claude Haiku 和 Sonnet 都可以这些参数范围内得到有效利用,其中 Haiku 请求的成本更低。
- 开发者对 Cursor 编程能力的赞赏:用户分享了使用 Cursor 执行编程任务的积极体验,包括部署 Python projects 和理解服务器设置。
- Cursor 因提高生产力和效率而受到称赞,尽管一些人指出 Docker 等功能可能存在一定的学习曲线。
- Cursor vs Windsurf:AI 性能备受关注:关于各种 AI 模型响应质量的讨论不断出现,一些用户对 Windsurf 相比 Cursor 的可靠性表示怀疑。
- 比较还包括 proactive assistance in agents(Agent 中的主动协助)以及如何恰当地处理复杂的 code。
Eleuther Discord
- GPU 集群风波上演:一名成员幽默地描述了通过“熬通宵”垄断 gpu-serv01 集群的 GPU 时间来干扰 GPU 集群的行为。
- 另一位参与者提到了之前的干扰行为,指出这种做法在社区内既“有趣又具有竞争性”。
- 为奇幻角色项目评分:一名成员介绍了一个项目,学生们从奇幻角色数据集中生成 token,并提出了关于有效评估方法的问题。
- 提议的评分策略包括 perplexity scoring(困惑度评分)和 CLIP 标注,以及关于防止评估期间作弊的幽默思考。
- 众包评估标准:针对评分挑战,一名成员建议将 evaluation criteria(评估标准)直接嵌入到作业中,让学生参与到评分过程中。
- 当另一名成员开玩笑说通过给所有提交的作品都打 100 分来简化评分时,讨论变得轻松起来。
- 区分 Aleatoric 和 Epistemic 不确定性:社区深入探讨了如何区分 aleatoric(偶然)和 epistemic(认知)不确定性,断言大多数现实世界的不确定性由于未知的潜在过程而属于 epistemic。
- 讨论强调,模型中的记忆模糊了这种区别,使表示从固有分布转变为经验分布。
- 探索逆向机械可解释性 (Inverse Mechanistic Interpretability):一名成员询问了 inverse mechanistic interpretability,特别是如何在不使用可微分编程的情况下将代码转换为神经网络的过程。
- 另一名成员指出 RASP 是一个相关的例子,并链接到了 RASP 论文,该论文展示了在机械层面的代码解释。
OpenAI Discord
- ChatGPT 推出 Projects 功能:在最新的 YouTube 视频 中,Kevin Weil、Drew Schuster 和 Thomas Dimson 展示了 ChatGPT 中全新的 Projects 功能,增强了对话的组织和自定义能力。
- 此更新旨在为用户提供一种更结构化的方法,用于在平台内管理他们的讨论。
- Teams 方案面临 Sora 访问限制:用户报告称 ChatGPT Teams 方案不包含 Sora 的访问权限,导致订阅者不满。
- 此外,尽管订阅费用更高,但消息限制仍与 Plus 方案持平,这也引发了担忧。
- 相比 Gemini 和 ChatGPT,用户更青睐 Claude:讨论强调了用户对 Claude 的偏好超过了 Gemini 和 ChatGPT 等模型,理由是性能更佳。
- 参与者还强调了 LM Studio 和 OpenWebUI 等本地模型的实用性优势。
- AI 生成内容质量问题:用户指出了 AI 生成输出的质量问题,包括图像中出现意料之外的元素(如剑)。
- 对于针对受版权保护的角色实施质量控制,人们持不同意见,一些人主张采取更严格的措施。
- 本地 AI 工具的采用与 Prompt 复杂性:分享了关于使用 Ollama 和 OpenWebUI 等工具在本地运行 AI 的见解,这些工具被视为有效的解决方案。
- 讨论还显示,虽然简单的 Prompt 能获得快速响应,但更复杂的 Prompt 需要更深层的推理,可能会延长响应时间。
LM Studio Discord
- MacBook Pro M4 Pro 可处理大型 LLM:搭载 M4 Pro 芯片的 MacBook Pro 14 能够高效运行 8b 模型(至少配备 16GB RAM),但更大的模型则受益于 64GB 或更多 内存。
- 一位成员评论道:“8b 相当低”,表达了对更高容量模型的兴趣,并讨论了 128GB M4 MBP 等选项。
- RTX 3060 为 AI 工作负载提供极高性价比:RTX 3060 因其性价比受到赞誉,通过与 3070 和 3090 的对比,突显了其在 AI 任务中的适用性。
- 人们对 Intel GPU 的 CUDA 支持限制提出了担忧,导致成员们开始比较 二手市场 的选择。
- AMD 与 Intel GPU 在 AI 性能上的对比:成员们将 AMD 的 RX 7900XT 与 Intel 的 i7-13650HX 进行了对比,指出后者的 Cinebench 分数更高。
- RX 7900XT 的 20GB VRAM 被强调为在特定 AI 工作负载中的优势。
- 选择合适的 PSU 对配置至关重要:强调了选择合适 电源单元 (PSU) 的重要性,对于高需求配置,1000W 的电源更受青睐。
- 成员们分享了各种 PSU 的链接,讨论了它们的 能效等级 以及对系统整体性能的影响。
- 通过内存超频优化 AI 性能:建议通过超频内存时序来增强 GPU 受限任务中的 带宽性能。
- 讨论了有效 散热解决方案 的重要性,以在高性能计算期间保持效率。
Latent Space Discord
- Qwen 2.5 Turbo 引入 1M 上下文长度:Qwen 2.5 Turbo 的发布将其上下文长度扩展至 100 万个 tokens,显著提升了其处理能力。
- 这一增强功能促进了需要广泛上下文的复杂任务,标志着 AI 模型性能的显著进步。
- Codeium 每分钟处理超过 1 亿个 Tokens:在最近的一次更新中,Codeium 展示了每分钟处理超过 1 亿个 tokens 的能力,彰显了其可扩展的基础设施。
- 这一成就反映了他们对企业级解决方案的关注,其见解源于在短短 18 个月内实现 100 倍的规模增长。
- NotebookLM 推出 Audio Overview 和 NotebookLM Plus:NotebookLM 推出了 Audio Overview 功能,允许用户直接与 AI 主持人互动,并为企业用户发布了 NotebookLM Plus,在 notebooklm.status/updates 增强了其功能。
- 重新设计的用户界面有助于更轻松地进行内容管理,满足了企业对改进 AI 驱动文档的需求。
- Sonnet 登顶 WebDev Arena 排行榜:Claude 3.5 Sonnet 在新推出的 WebDev Arena 排行榜上夺得榜首,超越了 GPT-4o 等模型,并在 Web 应用程序开发中展示了卓越的性能。
- 这一排名强调了 Sonnet 在实际 AI 应用中的有效性,社区超过 1 万张选票 证明了这一点。
- SillyTavern 成为 LLM 测试场:SillyTavern 被 AI 工程师强调为测试大语言模型的宝贵前端,类似于针对多种场景的综合测试套件。
- 成员们利用它进行复杂的哲学讨论,展示了它在与 AI 模型交互中的灵活性和实用性。
Bolt.new / Stackblitz Discord
- 测试 Bolt 的内存清除:用户正在尝试使用 内存擦除提示词 (memory erasure prompts),通过指示 Bolt 删除所有先前的交互,旨在修改其召回机制。
- 一位用户指出,“值得一试”,以评估其对 Bolt 内存保留能力的影响。
- Bolt 对 Prompt 中 URL 的处理:关于 Bolt 处理 API 引用中 URL 的能力存在不确定性,用户正在询问此功能。
- 官方提供了澄清:Bolt 不读取 URL,建议用户将内容转移到
.md文件中以进行有效审查。
- 官方提供了澄清:Bolt 不读取 URL,建议用户将内容转移到
- 图像分析过程的耗时:用户对图像分析过程的预期持续时间进行了咨询,反映了对效率的关注。
- 这一持续的对话突显了社区对提高 图像分析功能 响应速度的关注。
- 在 Bolt 中集成 Supabase 和 Stripe:参与者正在探索 Supabase 和 Stripe 的集成,但在 Webhook 功能方面面临挑战。
- 许多人预计即将推出的 Supabase 集成 将增强 Bolt 的能力并解决当前的问题。
- 持续存在的 Bolt 集成问题:尽管尝试了各种措辞,用户仍面临 Bolt 无法处理命令的挑战,导致挫败感增加。
- 正如几位社区成员所强调的,Bolt 缺乏全面的反馈,这使得任务完成变得复杂。
GPU MODE Discord
- PyTorch 中的量化热潮提升了准确率:一位用户详细介绍了 PyTorch 中的量化感知训练 (Quantization-Aware Training, QAT) 如何在特定基准测试中恢复高达 96% 的准确率损失,并利用 torchao 和 torchtune 进行有效的微调。
- 讨论强调了直通估计器 (Straight-Through Estimators, STE) 在处理 QAT 期间不可微操作中的作用,成员们确认了其对线性层梯度计算的影响。
- Triton 难题:融合注意力机制 (Fused Attention) 调试揭秘:成员们对 Triton 中的融合注意力机制表示关注,寻求澄清其实现的资源和会议,同时一名用户报告了与 TRITON_INTERPET=1 相关的自定义 Flash Attention 内核中出现垃圾值的问题。
- 提出的解决方案是禁用 TRITON_INTERPET 以获得有效输出,并强调了与 bfloat16 的兼容性问题,这与 Triton 数据类型中现有的挑战一致。
- Modal 的 GPU 术语表助力 CUDA 理解:Modal 发布了一份全面的 GPU 术语表 (GPU Glossary),旨在通过交叉引用的文章简化 CUDA 术语,受到了社区的积极反馈。
- 记录了精炼定义的协作努力,特别是针对张量核心 (tensor cores) 和寄存器 (registers),增强了该术语表对 AI 工程师的实用性。
- 对于小模型,CPU Offload 性能优于非 Offload 的 GPU 训练:实现了单 GPU 训练的 CPU offloading,通过增加 Batch Size,在较小模型上显示出更高的吞吐量,但由于 PyTorch 在反向传播期间的 CUDA 同步,大模型的性能有所下降。
- 成员们讨论了 VRAM 限制带来的约束,并建议修改优化器使其直接在 CUDA 上运行以减轻延迟。
- H100 GPU 调度器引发架构洞察:讨论澄清了 H100 GPU 的架构,指出尽管每个流式多处理器 (SM) 拥有 128 个 FP32 核心,但调度器每个周期仅发出一个 Warp,从而引发了关于调度器复杂性的疑问。
- 这引发了关于架构命名惯例以及张量核心 (tensor cores) 与 CUDA 核心 (CUDA cores) 运行行为的进一步询问。
Nous Research AI Discord
- 微软发布 Phi-4,一个 14B 参数的语言模型:微软推出了 Phi-4,这是一个 14B 参数的语言模型,专为数学和语言处理中的复杂推理而设计,可在 Azure AI Foundry 和 Hugging Face 上获取。
- Phi-4 技术报告强调其训练以数据质量为中心,凭借其专业能力与其他模型区分开来。
- DeepSeek-VL2 进入 MoE 时代:DeepSeek-VL2 发布,采用 MoE 架构,具有动态图像切片功能,模型规模可扩展至 3B、16B 和 27B 参数。
- 该版本强调了在各项基准测试中的卓越性能,特别是在视觉语言任务方面。
- Meta 凭借 SONAR 在分词 (Tokenization) 领域取得突破:Meta 推出了一种新的语言建模方法,如其最新论文所述,该方法使用 SONAR 句子嵌入进行句子表示,从而取代了传统的分词 (Tokenization)。
- 这种方法使得包括扩散模型 (diffusion model) 在内的模型在摘要提取等任务上表现优于 Llama-3 等现有模型。
- Byte Latent Transformer 重新定义分词:Scaling01 宣布了 Byte Latent Transformer,这是一种无分词器 (tokenizer-free) 模型,增强了推理效率和鲁棒性。
- 基准测试结果显示,它在减少推理 FLOPs 高达 50% 的同时,能与 Llama 3 竞争。
- 投机采样 (Speculative Decoding) 提升模型效率:关于投机采样的讨论透露,它通过较小的模型生成草稿响应,并在单次前向传播中由较大模型进行校正。
- 成员们辩论了该方法的效率以及草稿输出对重新分词 (re-tokenization) 需求的影响。
Unsloth AI (Daniel Han) Discord
- Phi-4 发布并开放权重:Phi-4 定于下周发布并开放权重(open weights),与早期模型相比,在推理任务中提供了显著的性能增强。Sebastien Bubeck 宣布 Phi-4 属于 Llama 3.3-70B 级别,其参数量减少了 5 倍,同时在 GPQA 和 MATH 基准测试中取得了高分。
- 成员们期待利用 Phi-4 精简的架构实现更高效的部署,并认为减少的参数量是一个关键优势。
- Command R7B 展示了速度与效率:Command R7B 因其令人印象深刻的速度和效率而受到关注,特别是考虑到其紧凑的 7B 参数规模。Cohere 强调 Command R7B 提供了顶级的性能,适用于在商用 GPU 和边缘设备上部署。
- 社区渴望将 Command R7B 与其他模型进行基准测试,特别是在托管成本和各种应用的可扩展性方面。
- Unsloth AI 增强多 GPU 训练支持:Unsloth 预计将引入多 GPU(multi-GPU)训练支持,解决目前 Kaggle 等平台限制用户只能使用单个 GPU 的局限性。这一增强旨在优化大型模型的训练工作流。
- 成员们讨论了多 GPU 支持实现后,提高训练效率和缓解瓶颈的潜力。
- 在 Unsloth 上微调 Llama 3.3 70B 需要高显存:使用 Unsloth 对 Llama 3.3 70B 模型进行微调(Fine-tuning)需要 41GB 的 VRAM,这使得 Google Colab 等平台不足以胜任此任务。GitHub - unslothai/unsloth 提供了促进这一过程的资源。
- 社区成员建议使用 Runpod 或 Vast.ai 来访问配备 80GB VRAM 的 A100/H100 GPU,尽管目前仍不支持多 GPU 训练。
- Unsloth 与 Llama 模型:性能与可用性:讨论表明,使用 Unsloth 的模型版本 而非原始 Llama 模型版本 可以获得更好的微调结果,简化 API key 处理,并解决某些 bug。GitHub 资源简化了大规模模型的微调工作流。
- 成员们建议优先使用 Unsloth 的版本,以利用增强的功能并实现更稳定、更高效的模型性能。
Cohere Discord
- Command R7B 发布加速 AI 效率:Cohere 正式发布了 Command R7B,这是其 R 系列中最小且最快的模型,提升了各种设备上 AI 应用的速度、效率和质量。
- 该模型已在 Hugging Face 上线,支持 23 种语言,并针对数学、代码和推理任务进行了优化,满足多样化的企业用例需求。
- 解决 Cohere API 错误:多名用户报告在使用 Cohere API 时遇到 403 和 400 Bad Request 错误,凸显了权限和配置方面的问题。
- 社区成员建议通过使用
pip install -U cohere更新 Cohere Python library,这有助于解决部分 API 访问问题。
- 社区成员建议通过使用
- 理解 Cohere 中的 Rerank 与 Embed:讨论明确了 Rerank 功能是根据相关性对文档进行重新排序,而 Embed 则将文本转换为数值表示,用于各种 NLP 任务。
- Embed 现在可以通过新的 Embed v3.0 模型处理图像,从而在 AI 工作流中实现语义相似度估算和分类任务。
- 7B 模型提升性能指标:Cohere 的 7B 模型 性能优于 Aya Expanse 和之前的 Command R 版本,在 Retrieval Augmented Generation 和复杂工具使用方面提供了更强的能力。
- 用于微调 7B 模型 的后续示例将于下周发布,展示其先进的推理和摘要能力。
- Cohere Bot 和 Python Library 简化开发:Cohere bot 已重新上线,协助用户查找相关资源并高效解决技术查询。
- 此外,官方分享了 Cohere Python library 以促进 API 访问,使开发者能够将 Cohere 的功能无缝集成到他们的项目中。
Perplexity AI Discord
- 校园策略师计划走向国际化:我们激动地宣布 Campus Strategist 计划 扩展至全球,允许学生运行自己的校园活动,获得独家周边,并与我们的全球团队合作。2025 春季班的申请截止日期为 12 月 28 日;更多详情请访问 Campus Strategists Info。
- 该倡议强调全球策略师之间的协作,培养一个充满活力的社区。
- Perplexity Pro 面临易用性挑战:用户报告了 Perplexity Pro 的问题,指出它无法有效跟踪对话,并经常出错,例如不准确的时间引用。
- 这些易用性问题正在影响用户体验,特别是在性能和对指令的遵循方面。
- Perplexity Pro 用户在图像生成方面遇到困难:一位用户表达了对无法使用 Perplexity Pro 生成图像的沮丧,尽管他们遵循了指南中概述的提示词。
- 附带的图片突显了预期功能与实际的差距,表明图像生成功能可能存在问题。
- Perplexity 在 Spaces 中引入自定义 Web 来源:Perplexity 在 Spaces 中推出了自定义 Web 来源,使用户能够针对特定网站定制搜索。此更新旨在提供更具相关性和上下文驱动的查询。
- 该功能允许增强定制化,适应多样化的用户需求并提高 Spaces 内搜索的针对性。
- 关于 Perplexity API 与网站的澄清:官方已澄清 Perplexity API 和 Perplexity 网站 是独立的产品,主站目前没有可用的 API。
- 这一区分确保用户了解每个平台组件的具体功能和产品。
OpenRouter (Alex Atallah) Discord
- 现在支持按提供商筛选模型:用户现在可以在
/models页面按 provider 进行筛选,增强了快速查找特定模型的能力。提供了一张包含此更新详情的 截图。 - AI Launch Week 期间的 API 运行时间问题:在 AI Launch Week 期间广泛的 API 故障中,OpenRouter 为闭源 LLM 恢复了超过 180 万次请求。OpenRouter 的一条 推文 强调了来自 OpenAI 和 Gemini 等提供商的显著 API 停机时间。
- 所有提供商的 API 都经历了相当长的停机时间,其中 OpenAI API 停机达 4 小时,而 Gemini API 几乎处于不可用状态。Anthropic 也表现出极度的不稳定,导致依赖这些模型的企业遭受重大中断。
- Gemini Flash 2.0 Bug 修复正在进行中:成员们报告了 Gemini Flash 2.0 持续存在的 Bug,例如主页版本不返回任何提供商,并对正在实施的修复方案表示乐观。
- 建议包括链接到免费版本,并解决在使用 Google models 时超出消息配额的担忧。
- Euryale 模型性能下降:Euryale 最近一直在产生荒谬的输出,成员们怀疑问题源于模型更新而非他们的配置。
- 另一位成员指出,类似的性能不一致现象很常见,突显了 AI 模型行为不可预测的本质。
- 自定义提供商密钥访问权限即将发布:custom provider keys 的访问权限即将开放,Alex Atallah 确认其即将发布。
- 成员们正热切请求访问权限,用户表达了提供自己 API Keys 的愿望,表明了对定制化选项的推动。
{kind=link}
Modular (Mojo 🔥) Discord
- Mojo 中的创新网络策略:Mojo 社区强调了对高效 API 的需求,讨论了使用 XDP sockets 和 DPDK 来实现高级网络性能。
- 成员们对 Mojo 在 Mojo-to-Mojo 通信中相比 TCP 减少开销的潜力感到兴奋。
- Mojo 中的 CPU 与 GPU 性能对比:讨论强调,利用 GPU 处理网络任务可以增强性能,配合特定网卡可实现高达每秒 40 万次请求。
- 共识倾向于认为数据中心级组件比消费级硬件能为这种效率提供更好的支持。
- Mojo 与 MLIR 的演进:Mojo 与 MLIR 的集成是一个关键话题,重点关注其不断演进的特性以及对语言编译过程的影响。
- 贡献者们辩论了高级开发者的视角对 Mojo 语言效率的影响,强调了其在各个领域的潜力。
- 探索 Mojo 的身份:社区幽默地讨论了为与 Mojo 相关的火焰小角色命名,提议了像 Mojo 或 Mo’ Joe 这样的名字,并带有俏皮的评论。
- 关于 Mojo 作为一种语言的身份讨论引发了关于外界误解的对话,外界通常仅将其视为加速 Python 的另一种方式。
Interconnects (Nathan Lambert) Discord
- Microsoft Phi-4 在基准测试中超越 GPT-4o:Microsoft 的 Phi-4 模型(一个 14B 参数 的语言模型)在 GPQA 和 MATH 基准测试中表现优于 GPT-4o,目前已在 Azure AI Foundry 上线。
- 尽管 Phi-4 表现出色,但人们对 早期 Phi 模型 的训练方法仍持怀疑态度,用户质疑其过于关注基准测试而非多样化数据。
- LiquidAI 获得 2.5 亿美元融资用于 AI 扩展:LiquidAI 已筹集 2.5 亿美元,用于增强其 Liquid Foundation Models 在企业级 AI 解决方案中的扩展和部署,详见其 博客文章。
- 有人对其招聘实践、对 AMD 硬件的依赖以及在吸引顶尖人才方面可能面临的挑战提出了担忧。
- DeepSeek VL2 推出 Mixture-of-Experts 视觉语言模型:DeepSeek-VL2 发布,其特点是采用了专为高级多模态理解设计的 Mixture-of-Experts 视觉语言模型,提供 4.5A27.5B 和 Tiny: 1A3.4B 等规格。
- 社区讨论强调了这些模型的创新潜力,表明对其性能表现有浓厚兴趣。
- Tulu 3 探索先进的训练后技术:在最近的一次 YouTube 演讲 中,Nathan Lambert 讨论了语言模型中的 训练后技术 (post-training techniques),重点关注 Reinforcement Learning from Human Feedback (RLHF)。
- 联合主持人 Sadhika 提出了 富有洞察力的问题,深入探讨了这些技术对未来模型开发的影响。
- 语言模型规模呈现反转趋势:最近的分析显示,语言模型规模的增长趋势出现 反转,目前的模型如 GPT-4o 和 Claude 3.5 Sonnet 的参数量分别约为 200B 和 400B,偏离了早先达到 10T 参数的预期。
- 一些成员对这些规模估算表示怀疑,认为由于报告的不确定性,实际参数量可能比这 小两个数量级。
LLM Agents (Berkeley MOOC) Discord
- 证书申报表混淆已解决:一名成员最初在 Certificate Declaration Form 上找不到提交书面文章链接的地方,但随后找到了。
- 这反映了成员们在繁忙的课程安排中对正确提交渠道的普遍关注。
- Labs 提交截止日期延长:Labs 的截止日期延长至 2024 年 12 月 17 日,并提醒成员 Quizzes 和 文章 的截止时间为午夜。
- 这一延期为因各种原因(尤其是技术问题)进度落后的成员提供了灵活性。
- Quizzes 要求已明确:已确认所有 Quizzes 必须在截止日期前提交以满足认证要求,不过对于逾期提交也提供了一定的宽限。
- 一名错过 Quiz 截止日期的成员得到保证,他们仍可以提交答案而不会受到惩罚。
- 公开 Notion 链接指南:关于是否可以使用 Notion 提交文章进行了澄清,强调链接必须是公开可访问的。
- 成员们被鼓励确保其 Notion 页面已正确发布,以避免提交过程中出现问题。
- 证书发放时间线:成员们询问了 证书发放 的时间线,确认证书将于 12 月底至 1 月期间发出。
- 时间线根据所获得的认证等级而有所不同,为参与者提供了明确的预期。
Stability.ai (Stable Diffusion) Discord
- WD 1.4 表现不如替代方案:一位成员回想起 WD 1.4 仅仅是一个在发布时就存在问题的 SD 2.1 model,并指出 Novel AI’s model 在最初发布时是动漫领域的金标准。
- 他们提到在 SDXL dropped 之后,2.1 model 的用户由于其局限性已基本转向其他模型。
- 本地视频 AI 模型 Discord 推荐:一位用户寻求专注于 Local Video AI Models 的 Discord 小组推荐,特别是针对 Mochi, LTX, and HunYuanVideo。
- 另一位用户建议加入 banodoco,认为那是讨论这些模型的最佳选择。
- 标签生成模型推荐:一位成员询问适用于 Taggui 中 tag generation 的优秀模型,另一位成员自信地推荐了 Florence。
- 此外,建议根据个人需求调整 max tokens。
- 对 Stable Diffusion XL Inpainting 脚本的需求:一位用户表达了对缺乏可用的 Stable Diffusion XL Inpainting 微调脚本的沮丧,尽管进行了广泛搜索。
- 他们询问该频道是否是进行此类咨询的正确场所,或者技术支持是否更合适。
- 使用 ComfyUI 进行图像生成:一位用户询问如何修改 Python 脚本,以便使用指定的 prompt 和加载的图像实现 image-to-image processing。
- 其他人确认,虽然初始代码旨在实现 text-to-image,但如果配置正确的模型,理论上可以支持 image-to-image。
OpenInterpreter Discord
- 已解决 Nvidia NIM API 设置问题:一位用户通过执行
interpreter --model nvidia_nim/meta/llama3-70b-instruct并设置NVIDIA_NIM_API_KEY环境变量,成功配置了 Nvidia NIM API。- 他们对该解决方案表示感谢,同时也强调了在创建 repository 方面的困难。
- Open Interpreter 中的自定义 API 集成:一位成员询问如何自定义 Open Interpreter app 的 API,引发了关于集成替代 API 以增强桌面应用程序功能的讨论。
- 另一位参与者强调,该应用的目标受众是非开发人员,侧重于用户友好性,无需配置 API key。
- 澄清 Token 限制功能:用户讨论了 max tokens 功能的作用,指出它限制了响应长度,但不会在对话中累积,这导致在跟踪 token 使用情况时面临挑战。
- 建议包括实现
max-turns和预期的 max-budget 功能,以便根据 token 消耗管理计费。
- 建议包括实现
- 开发分支的进展:对 development branch 的反馈表明,它支持通过命令创建 repository,在项目实际应用中受到称赞。
- 然而,用户报告了代码缩进和文件夹创建的问题,并对最佳运行环境提出了疑问。
- Meta 发布 Byte Latent Transformer:Meta 发布了 Byte Latent Transformer: Patches Scale Better Than Tokens,介绍了一种利用 bytes 代替传统 tokenization 以增强模型性能的策略。
- 这种方法通过采用 byte-level representation 来提高可扩展性和效率,可能会改变语言模型的运行方式。
LlamaIndex Discord
- LlamaCloud 的多模态 RAG 流水线:Fahd Mirza 在最近的视频中展示了 LlamaCloud 的多模态能力,允许用户上传文档并通过 Python 或 JavaScript API 切换多模态功能。
- 该设置能有效处理混合媒体,为不同数据类型简化了 RAG 流水线。
- OpenAI 的非严格函数调用默认设置:正如在 general 频道 中讨论的那样,OpenAI 的 Function calling 默认设置 保持为非严格模式,以最大限度地减少延迟并确保与 Pydantic 类的兼容性。
- 用户可以通过设置
strict=True来启用严格模式,尽管这可能会破坏某些 Pydantic 集成。
- 用户可以通过设置
- 提示工程与 dspy 等框架的对比:围绕 Prompt Engineering 与 dspy 等框架的有效性展开了讨论,成员们正在寻求构建具有影响力的提示词的策略。
- 社区表示有兴趣确定最佳实践,以增强特定目标的提示性能。
- AWS Valkey 作为 Redis 的替代品:在 Redis 转向非开源模式后,成员们询问了对 AWS Valkey(一个掉入式替代品)的支持情况,详见 Valkey 数据存储说明。
- 对话强调了与现有 Redis 代码的潜在兼容性以及进一步探索的必要性。
- 将 Langchain 与 MegaParse 集成:正如 AI Artistry 的博客 所述,Langchain 与 MegaParse 的集成增强了文档解析能力,能够从各种文档类型中高效提取信息。
- 这种组合对于寻求强大解析解决方案的企业和研究人员特别有价值。
DSPy Discord
- DSPy 框架加速 LLM 应用开发:DSPy 通过提供样板提示和任务“signatures”,简化了 LLM 驱动的应用 开发,减少了在提示上花费的时间 DSPy。
- 该框架能够高效地构建像天气网站这样的 Agent。
- AI 像鸭嘴兽一样重新定义类别:一篇博客文章描述了 AI 如何像鸭嘴兽一样,挑战现有的技术分类 房间里的鸭嘴兽。
- 这个类比强调了 AI 挑战传统分组的独特品质。
- Cohere v3 在性能上超越 Colbert v2:在最近的评估中,Cohere v3 被认为比 Colbert v2 具有更优越的性能,引发了对底层增强功能的兴趣。
- 讨论深入探讨了促成 Cohere v3 性能提升的具体改进,并探讨了对正在进行的项目的意义。
- 利用 DAG 和 Serverless 构建可扩展的 AI:分享了一个名为“使用 DAG 和 Serverless 为 RAG 构建可扩展系统”的 YouTube 视频,重点关注 AI 系统开发中的挑战。
- Jason and Dan 讨论了从路由器实现到管理对话历史等问题,为 AI 工程师提供了宝贵的见解。
- 使用 DSPy 优化器优化提示:讨论强调了 DSPy optimizers 在优化运行期间引导 LLM 指令编写的作用,并引用了一篇 arXiv 论文。
- 成员们表示需要加强关于优化器的文档,旨在提供更详细和简化的解释以帮助理解。
tinygrad (George Hotz) Discord
- Tinygrad 性能滞后:性能分析显示 Tinygrad 的运行速度明显慢于 PyTorch,在 Batch Size 为 32、序列长度为 256 时,前向/后向传递耗时 434.34 ms。
- 用户报告称,在单个 A100 GPU 上增加序列长度时,速度出现了惊人的下降。
- BEAM 配置调整:讨论强调,在 Tinygrad 中设置 BEAM=1 是贪婪的,且对性能而言并非最优。
- 建议切换到 BEAM=2 或 3,以提高内核搜索(Kernel Search)期间的运行时间和性能。
- 基准测试脚本需求:成员们表示需要简单的基准测试脚本来增强 Tinygrad 的性能。
- 提供这些基准测试有助于识别编译时间和内核执行方面的改进。
Torchtune Discord
- Torchtune 3.9 简化了 Type Hinting:随着 Torchtune 3.9 的发布,开发者现在可以使用默认的内置类型替换
List、Dict和Tuple来进行 Type Hinting,从而简化编码过程。- 这一更新引发了一场关于 Python 持续变化如何影响工作流的轻松讨论。
- Python 不断演进的类型系统挑战:一位成员幽默地指出,由于最近的变化,Python 增加了他们的工作量,这反映了社区内的一种普遍情绪。
- 这体现了开发者在适应语言更新时经常遇到的、往往带有幽默感的挫折。
- Ruff 自动化 Type Hint 替换:Ruff 现在包含一条自动管理 Type Hint 替换的规则,为开发者的过渡提供了便利。
- 这一增强功能强调了像 Ruff 这样的工具是如何不断演进,以在 Python 持续更新的过程中支持开发者的。
MLOps @Chipro Discord
- 以新一代检索技术开启新的一年:参与者将在 1 月 8 日下午 1 点(EST) 的会议中,探索如何整合向量搜索 (vector search)、图数据库 (graph databases) 和文本搜索引擎,以建立一个多功能、上下文丰富的数据层。
- 重新思考如何在生产环境中构建 AI 应用,以有效支持现代大规模 LLMOps 的需求。
- 通过高级 Agent 增强运行时:会议提供了关于利用 Vertex AI Agent Builder 等工具来编排长时间运行的会话并管理 Chain of Thought 工作流的见解。
- 该策略旨在提高更复杂应用中 Agent 工作流 的性能。
- 大规模 LLM 模型管理:重点将放在利用强大的工具进行大规模模型管理 (model management),确保专用 LLM 应用的高效运行。
- 预计将讨论整合 AI Safety 框架与动态 Prompt Engineering 的策略。
- 简化动态 Prompt Engineering:研讨会将强调动态 Prompt Engineering,这对于适应不断发展的模型能力和用户需求至关重要。
- 该方法旨在提供实时的上下文响应,提升用户满意度。
- 确保 AI 合规与安全标准:将介绍 AI Safety 和合规性 (compliance) 实践的概览,确保 AI 应用符合必要的法规。
- 参与者将学习如何将安全措施整合到他们的应用开发工作流中。
Mozilla AI Discord
- Demo Day 回顾已发布:Mozilla Builders Demo Day 的回顾已发布,详细介绍了在挑战性条件下参与者的参与情况。阅读完整回顾此处。
- Mozilla Builders 团队在社交媒体上强调了活动的成功,重点突出了创新技术与专注参与者的融合。
- 贡献者获得特别鸣谢:对在活动执行中发挥关键作用的各位 contributors 表达了特别致谢。对具有特定组织角色的团队给予了认可。
- 鼓励参与者感谢社区的支持和确保活动成功的协作努力。
- 社交媒体放大活动成功:活动的亮点已在 LinkedIn 和 X 等平台分享,展示了活动的影响力。
- 这些平台上的互动指标强调了社区对 Demo Day 的热情和积极反馈。
- Demo Day 视频现已发布:一段名为 Demo_day.mp4 的视频记录了 Demo Day 的关键时刻和演示,现已发布。点击此处观看亮点。
- 该视频作为一个全面的视觉总结,让错过活动的人能够了解所展示的技术和演示。
Axolotl AI Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
LAION Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
HuggingFace Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
第 2 部分:按频道详细摘要和链接
完整的逐频道详情已在邮件中截断。
如果您喜欢 AInews,请分享给朋友!提前致谢!