ainews-meta-apollo-video-understanding-up-to-1
Meta Apollo - 支持长达 1 小时的视频理解,SOTA 级开源权重。
以下是该文本的中文翻译:
Meta 发布了 Apollo,这是一个全新的最先进视频语言模型系列,提供 1B、3B 和 7B 三种尺寸。该系列具有“缩放一致性”(Scaling Consistency)以实现高效扩展,并引入了 ApolloBench,在五个时间感知类别中将视频理解的评估速度提升了 41倍。Google Deepmind 推出了 Veo 2,这是一款具备更强物理特性和摄像机控制能力的 4K 视频生成模型,同时还发布了增强版的 Imagen 3 图像模型。OpenAI 在全球范围内推出了具备先进语音和地图功能的 ChatGPT 搜索,并讨论了可能推出的每月 2,000 美元的“ChatGPT Max”层级。研究亮点包括:通过测试时计算缩放(test-time compute scaling),使 Llama 3B 达到了 Llama 70B 的性能水平;以及将 Command R7B 的语言支持从 10 种扩展到了 23 种。行业动态方面,Figure AI 已开始商业化交付人形机器人,而 Klarna 正在通过 AI 缩减员工规模。Notion 集成了 Cohere Rerank 以优化搜索。研究显示,大语言模型(LLM)能够识别自己的写作风格,并表现出自偏好偏差。讨论指出,由于更好的单位计算信号(signal-per-compute)和数据评估,视频处理的进展正在超越文本。
Scaling Consistency 便是你所需的一切。
2024/12/13-2024/12/16 AI 新闻。我们为你检查了 7 个 subreddits、433 个 Twitters 和 31 个 Discords(209 个频道,11992 条消息)。预计节省阅读时间(按 200wpm 计算):1365 分钟。你现在可以标记 @smol_ai 进行 AINews 讨论了!
Meta 在本周伊始表现强劲,发布了一个可立即使用的开源模型(1B, 3B, 7B)和论文:Apollo: An Exploration of Video Understanding in Large Multimodal Models。
虽然论文标题定得非常保守,但 Huggingface demo 展示了它在实践中的运作方式,可以轻松处理一段 24 分钟的样本视频:
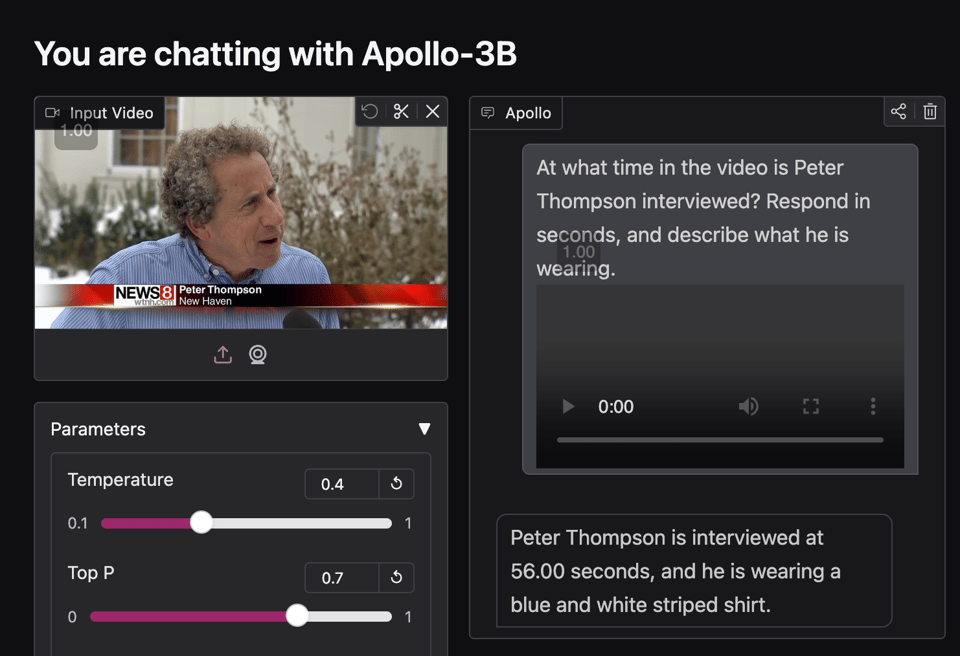
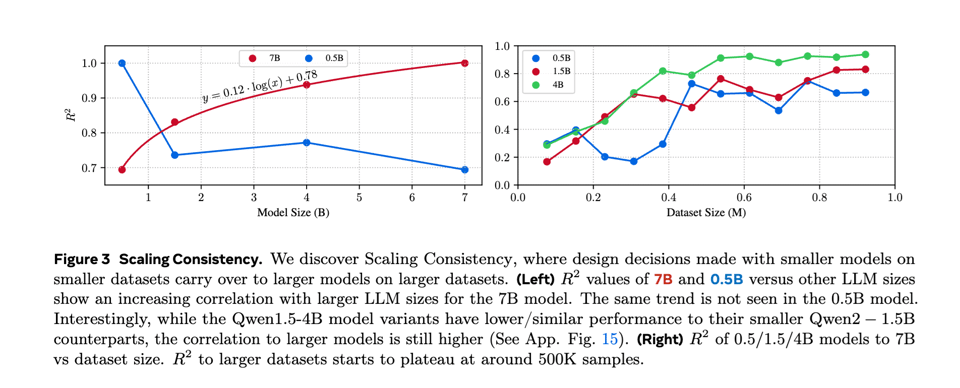
作者将 “Scaling Consistency” 的开发归功于他们对实验的高效扩展。

他们还推出了 ApolloBench,这是现有基准测试(如 Video-MME, MLVU, LongVideoBench)的一个子集,在保持高相关性的同时将评估时间缩短了 41 倍,并提供了五个广泛的时间感知类别的详细见解:Temporal OCR, Egocentric, Spatial, Perception 和 Reasoning。
或许这篇论文中最有趣的部分是那段带点“阴阳怪气”的摘要:“尽管视频感知能力已迅速整合到 Large Multimodal Models (LMMs) 中,但驱动其视频理解的底层机制仍未被充分理解。因此,该领域的许多设计决策是在没有适当理由或分析的情况下做出的。”
好吧 Meta,这火药味够浓的。
AI Twitter 摘要
所有摘要均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
以下是按主题分类的关键讨论:
AI 模型与产品发布
- Google Deepmind 的 Veo 2:作为其最新的 state-of-the-art 视频生成模型发布,具备 4K 分辨率能力、改进的物理模拟和相机控制功能。还推出了增强版的 Imagen 3 图像模型,具有更好的艺术风格多样性。
- OpenAI 更新:向全球所有登录用户推出了 ChatGPT search,包括高级语音功能和地图集成。还提到了关于潜在的 2,000 美元/月 “ChatGPT Max” 订阅层级的讨论。
- Meta 的 Apollo 发布:推出了 Apollo,这是一个全新的 state-of-the-art 视频语言模型系列。
研究与技术进展
- 语言模型能力:@_lewtun 分享了他们如何通过 test-time compute 扩展,利用 Llama 3B 实现了 Llama 70B 的性能。
- Command R7B 语言扩展:支持的语言从 10 种扩展到 23 种,包括主要的亚洲和欧洲语言。
- Hugging Face 成就:展示了 LLaMA 1B 如何通过扩展 test-time compute 在数学方面超越 LLaMA 8B。
行业与商业动态
- Figure AI 进展:宣布向首个商业客户交付 F.02 人形机器人,这是在公司成立 31 个月内实现的。
- Klarna 的 AI 集成:CEO 讨论了通过实施 AI 将员工人数从 4,500 人减少到 3,500 人。
- Notion 集成:实施了 Cohere Rerank 以提高搜索的准确性和效率。
AI 研究洞察
- LLM 自我识别:研究表明 LLM 可以识别自己的写作风格,并在评估输出时表现出自我偏好偏差。
- 视频 vs 文本处理:讨论了为什么视频进展超过了文本,理由是更好的 signal-per-compute 比率以及更容易的数据创建/评估。
迷因与幽默
- ChatGPT 因基础搜索结果被嘲讽,显示“吃食物”是饥饿的解决方案。
- 关于 AI 伴侣的笑话以及社交媒体好友是“有脾气的 GPU”。
- Tesla 过于敏感的驾驶员监控因打喷嚏和咳嗽而被触发。
AI Reddit 摘要
/r/LocalLlama 摘要
主题 1. Meta 的 Apollo 多模态模型:本地运行与 VRAM 效率
- Meta 发布 Apollo 系列大型多模态模型。7B 模型达到 SOTA 水平,可理解 1 小时长的视频。你可以在本地运行它。 (得分: 686, 评论: 108): Meta 发布了 Apollo 系列大型多模态模型,其中 7B 模型 达到了 state-of-the-art (SOTA) 水平,能够理解 1 小时长的视频。这些模型可以在本地执行,为多模态 AI 能力带来了重大进步。
- 讨论强调了 Apollo 模型令人印象深刻的视频理解能力,能够理解长达一小时的视频。用户对其时间推理和复杂的视频问答能力非常感兴趣,基准测试显示 Apollo-7B 超越了拥有超过 30B 参数的模型。
- 关于 Apollo 项目的作者身份和所属机构存在争议,对于这是否属于 Meta 发布 存在一些困惑。事实证明这是 Meta 与 Stanford 的合作项目,并指出 Qwen 模型是基础模型,引发了对其视频处理适用性的疑问。
- 讨论了模型的 VRAM 需求,7B 模型需要略低于 15GB 的 VRAM。用户还讨论了量化对 VRAM 使用和性能的影响,指出通常使用 FP16,但进一步量化为 FP8 或 FP4 可以在损失一定性能的情况下减少内存占用。
- 自问自答,我成功在 3090 上本地运行了 Apollo (Score: 84, Comments: 12):作者成功在 3090 GPU 上本地运行了 Meta 的 Apollo,并分享了一个包含本地环境必要修复补丁的 GitHub 仓库。该设置在 Linux 上的 Python 3.11 环境下通过了测试,视频大小约为 190Mb,生成首个 token 的处理时间约为 40 秒。
- Meta Apollo 的挑战 包括硬编码元素、未记录的环境变量以及缺乏示例文件,这使得初始设置并非即插即用。No_Pilot_1974 通过添加必要的修复并使其 venv-ready(支持虚拟环境)解决了这些问题。
- 有观点认为,一些开源项目缺乏文档且使用硬编码值,导致难以复现。这一问题在 偏好优化(preference optimization)论文 中屡见不鲜。
- ForsookComparison 赞扬了原帖作者独立解决问题并分享方案的毅力,强调了这种主动修复并为他人记录配置方法的积极态度。
主题 2. 思维链(Chain Of Thought)提示词的批评与探讨
- 大家来分享一下自己最喜欢的思维链提示词! (Score: 243, Comments: 56):该帖子分享了一个专为逻辑和创意设计的 Chain of Thought (COT) 提示词,强调使用
<thinking>、<step>、<count>和<reflection>等标签进行结构化问题解决。它建议设置 20 步的预算,通过质量评分引导策略调整,并鼓励使用 LaTeX 进行数学符号表示和多解法探索,最终得出答案和反思。- 模型兼容性与局限性:讨论指出,包括 ChatGPT 在内的许多 AI 系统由于禁止展示中间推理过程的指南,不支持显式的 Chain of Thought (CoT) 提示词。用户注意到像 o1 这样的模型可能会将 CoT 提示词标记为违规内容,且 ClosedAI 建议不要在 o1 等特定模型上使用 CoT 提示词。
- 工作流应用 vs 单个提示词:一些用户主张使用 N8N、Omnichain 和 Wilmer 等工作流应用,来比单个提示词更有效地管理复杂的后续推理过程。这些工具允许用户将任务分解为多个步骤,对 AI 输出提供更大的灵活性和控制力,如编码和事实核查工作流示例所示。
- 微调与提示词优化:用户讨论了通过 CoT 提示词微调模型以增强性能,一位用户在 Hugging Face 上分享了一个 3B 模型。对话还涉及了 TextGrad 和 DSPy 等提示词优化框架,认为它们具有加速实现预期结果的潜力。
- Hugging Face 发布合成数据生成器 - 一个通过自然语言构建数据集的 UI 工具 (Score: 130, Comments: 19):Hugging Face 发布了 Synthetic Data Generator,这是一个无代码 UI 工具,用于创建训练和微调语言模型的数据集,采用 Apache 2.0 许可证。它支持 文本分类(Text Classification) 和 监督微调(SFT)对话数据 等任务,具有本地托管、模型切换以及兼容 OpenAI APIs 等功能,并允许用户将数据集推送到 Hugging Face Hub 或 Argilla。
- 与 Argilla 和 Hugging Face Hub 的集成 允许在训练前审查生成的样本,并通过 smoltalk 等数据集展示了成功案例。这确保了闭源模型提供商在合成数据生成方面的质量和有效性。
- 数据多样性的改进 通过动态系统提示词和特定任务方法实现,详见关于文本分类的论文 arxiv.org/abs/2401.00368 和关于指令微调的论文 arxiv.org/abs/2406.08464。技术包括采样复杂度和教育水平、打乱标签以及在多标签场景中使用动态贝塔分布。
- Token 限制:样本的默认限制设置为 2048,可通过环境变量或 Hugging Face 推理端点进行调整。这在确保高效资源管理的同时,也提供了部署的灵活性。
主题 3. 高性能基准测试:Intel B580 与 LLMs
- 有人发布了 Intel B580 运行 LLM 的一些数据。速度很快。 (Score: 94, Comments: 56): Intel B580 在 Windows 上的表现略优于 A770,B580 在 Vulkan、RPC 基准测试中达到了约 35.89 到 35.45,而更新后的 A770 驱动将其性能显著提升至 30.52 到 30.06。A770 上较旧的 Linux 驱动产生的结果要慢得多,范围在 11.10 到 10.98 之间,这表明驱动更新可以大幅影响性能。
- Intel B580 的性能:讨论集中在 B580 的性能意外超越了 A770,尽管后者在理论规格上更优(由于更高的内存带宽,预计 A770 会快 22%)。一些用户认为 Intel 的第二代显卡比 AMD 有所进步,而另一些人则指出 A770 尚未发挥其潜力,可能是由于内存使用效率低下或计算限制。
- 驱动和软件的影响:评论强调了软件和驱动更新对性能的显著作用,特别是在不同的操作系统和配置下。A770 在 Linux 下使用 SYCL 和 IPEX-LLM 等工具显示出不同的结果,并且还提到了在 Fedora 上使用 Intel 软件栈(如 oneAPI)所面临的挑战。
- 市场与黄牛担忧:用户对黄牛将 B580 的价格加价 $150 表示沮丧,这表明需求量大且可能存在供应问题。有一种观点认为,如果 Intel 能更有效地管理生产和分销,就能利用这些显卡的受欢迎程度获利。
其他 AI Subreddit 摘要
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
主题 1. Claude 3.5 相对于 OpenAI o1 的优势
- OpenAI o1 vs Claude 3.5 Sonnet:哪一个真正值你的 20 美元? (Score: 228, Comments: 65): OpenAI o1 和 Claude 3.5 Sonnet 正在就其 20 美元投资的价值进行比较。讨论可能集中在这些 AI 模型的性能、功能和用户偏好上,目前没有提供额外的背景信息。
- Google 的 TPU 基础设施被强调为一个具有成本效益的选择,一些用户更喜欢针对特定任务组合使用不同的模型,例如使用 Claude 进行设计,使用 qwen 32b coder 处理简单任务。一些用户认为,如果不考虑成本,ChatGPT Pro 足以满足大多数需求。
- 讨论了 Claude 的局限性,包括它无法生成图像或视频,以及其严格的消息限制。一些用户批评它的审查制度和个性,而另一些用户则欣赏它的语气,这表明用户体验褒贬不一。
- Anthropic 的 Model Context Protocol (MCP) 被认为是 Claude 的一个显著优势,它允许与 OpenAI 和 Gemini APIs 等外部工具集成。这使用户能够在不改变核心 LLM 应用程序的情况下自定义其设置,从而增强了灵活性和实用性。
主题 2. 对 Apple 的 LLM 推理能力的批评
- [D] 你今年读过的最喜欢的论文是什么,为什么? (Score: 116, Comments: 33): Apple 的 LLM 推理论文在 AI 社区引发了分歧。该帖子寻求在假期旅行期间阅读的最受推荐的论文,表明了对参与性和启发性材料的渴望。
- 数据泄漏和 Token 重复:讨论强调了 Apple 的 LLM 论文中潜在的数据泄漏和 Token 重复问题,认为这些问题可能会扭曲下游评估结果。一些评论者批评了该论文夸张的说法,而另一些人则认为关于 Token 重复的发现具有实质意义。
- 时间序列预测:评论者辩论了 Transformers 用于时间序列预测的功效,并引用了 2022 年的一篇论文,该论文显示一个简单的前馈网络优于基于 Transformer 的架构。一些人对这些结果表示怀疑,并引用了 Hugging Face 的 Autoformer 等其他观点。
- 意识与智能:一篇关于 1999 年先天性去皮质儿童的案例研究引发了关于意识和智能定义的讨论,质疑了 ML 研究人员使用的基准。这场辩论强调了将神经生物学与智能联系起来的复杂性,以及 AI 研究中所做的假设。
主题 3. Google 的 VEO 2:高级视频创作
- Google 憋出大招:视频模型 Veo 2 优于 Sora,最高可生成 4K 视频 (Score: 147, Comments: 43): 据报道,Google VEO 2 在视频质量上超越了 Sora,并能够创建高达 4K 分辨率的视频。
- Google 的竞争优势:讨论强调了 Google 的优势在于其 TPUs 和雄厚的财力(拥有 900 多亿美元现金),这使他们尽管遭遇挫折仍能保持竞争力。Meta 的 600k H100 集群也被提及,显示了 AI 开发中所涉及的资源规模。
- 可用性与访问权限:人们对 Google VEO 2 模型充满期待,预计将于明年年初推出,部分用户已经通过此处的候补名单获得了访问权限。这反映了 Google 产品初期通常受限或封闭的常见模式。
- 行业动态与预期:评论反映了对新模型即时影响的怀疑态度,一些用户表示 OpenAI 的霸主地位正在终结,而另一些人则指出尽管访问受限,Sora 依然备受炒作。这种情绪表明,对于不断演变的 AI 视频领域,人们持观望态度。
主题 4. Eric Schmidt 对 AI 自主性的警告
- 前 Google CEO Eric Schmidt 警告称,AI 可能在 2-4 年内开始自我改进,我们应考虑“拔掉插头” (Score: 192, Comments: 144): 前 Google CEO Eric Schmidt 警告说,在 2-4 年内,AI 可能会开始自我改进,这引发了对其对个人权力影响的担忧。讨论强调了在 AI 开发中保持谨慎的必要性,反映了行业专家对 AI 独立性潜在风险的看法。
- 几位评论者对 Eric Schmidt 的警告表示怀疑,认为这可能是为了保持关注度或保护 Google 等大公司的利益。No-Way3802 讽刺地指出,“拔掉插头”可能意味着限制工人阶级的访问权限,同时为军方和亿万富翁保留权限。
- 关于 AI 自我改进的利弊存在争论,一些人主张开源 AI 开发以防止商业垄断,另一些人则强调人类与 AI 之间建立共生关系的潜力。BayesTheorems01 强调在解决全球问题时需要实践智慧(phronesis),而这是 AI 无法单独提供的。
- 讨论中还提到了对 AI 自我保护和欺骗能力的担忧,Radiant_Dog1937 警告不要让自主系统在缺乏制衡的情况下运行。ThreeChonkyCats 提出的 AI 可能颠覆经济权力结构的观点,反映了富裕阶层对 AI 冲击社会层级的恐惧。
{kind=link}
AI Discord 摘要
由 O1-preview 生成的摘要之摘要之摘要
主题 1. AI 模型之战:新发布与对比
-
Gemini 2.0 在代码性能对决中超越 Codeium:用户正在将 Codeium 与 Gemini 2.0 进行对比,观察到 Gemini 在编程任务中表现更优。然而,Gemini 缺少 Claude 的某些功能,导致用户根据使用场景产生不同的偏好。
-
Grok-2 携 Aurora 提速,将竞争对手甩在身后:Grok-2 现在的运行速度提高了 3 倍,准确性和多语言能力也有所提升,并在 X 上免费提供。它引入了网页搜索、引用以及名为 Aurora 的新图像生成器,以新功能惊艳了用户。
-
Byte Latent Transformer 终结 Token,拥抱 Patch:Meta 的 Byte Latent Transformer (BLT) 声称通过将字节动态编码为 Patch 来终结 Token 化。BLT 承诺更好的推理效率和扩展性,可能减少高达 50% 的推理 FLOPs。
主题 2. AI 工具闹脾气:用户苦于 Bug 和额度
-
Flow Action 额度消失速度快过免费甜甜圈:用户在 24 小时内烧光了 1k Flow Action 额度,难以管理消耗。对于一些繁重的工作流,将任务拆分为更小单元的建议并不能解决问题。
-
Bolt 疯狂消耗 Token,用户寻求“节食计划”:Bolt 正在以惊人的速度消耗 Token,但 UI 却没有反映出更改,这令用户感到沮丧。许多人正在记录问题,并诉诸于将项目 Fork 到 Replit 作为临时解决方案。
-
Cursor IDE 运行缓慢如蜗牛,是时候清理对话了:用户报告 Cursor IDE 在长时间使用后会变得迟钝,建议通过重置或清理聊天记录来提高效率。随着用户分享各种规避技巧,对更流畅编码体验的追求仍在继续。
主题 3. AI 伦理风波:对齐与告密者的忧虑
-
OpenAI 的对齐框架引发激烈辩论:一位用户分享了一个基于共同人类价值观和反馈循环的 AI 对齐框架。其他人则怀疑对齐不同利益相关者利益的可行性,引发了关于伦理的讨论。
-
告密者神秘死亡引发关注:曾对受版权保护材料的使用表示担忧的 OpenAI 告密者 Suchir Balaji 被发现死于家中。这一事件助长了阴谋论以及关于 AI 透明度的辩论。
-
Elon Musk 警告 AI 垄断,指责政府举措:Musk 暗示美国政府可能会限制 AI 初创公司,导致人们担心 AI 领域会出现垄断。社区对创新受到抑制感到担忧。
主题 4. AI 变得更有创意:从成人角色扮演到定制化输出
-
用户通过火辣的 ERP 提示词为 AI 增色:针对 AI 的 成人角色扮演 (ERP) 高级技术正在兴起,用户可以构建详细的角色档案。诸如 “Inner Monologue”(内心独白)和 “Freeze Frame”(定格画面)等方法增强了 AI 交互的沉浸感。
-
从莎士比亚到苏斯博士:轻松定制 AI 风格:用户正在定制 AI 输出以实现独特的语调和风格,强调了有效提示词的力量。一段 YouTube 教程 展示了获得理想艺术风格的技巧。
-
SillyTavern 成为我们意想不到的 AI 游乐场:SillyTavern 作为 LLM 工程师测试模型和参数的工具正受到关注。用户在享受严肃测试与趣味互动结合的同时,不断推高 AI 能力的边界。
主题 5. AI 研究突破:新方法与新模型涌现
-
Meta 的 BLT 舍弃 Token,转而采用 Patch:Meta 的 Byte Latent Transformer 引入了一种无分词器(tokenizer-free)架构,将字节编码为 Patch 以实现更好的扩展。BLT 模型声称在匹配 Llama 3 性能的同时,显著降低了推理时的 FLOPs。
-
通过可微分自适应合并 (DAM) 简化模型合并:DAM 论文揭示了一种无需大量重新训练即可集成模型的高效方法。关于模型合并技术及其在 AI 开发中独特优势的讨论异常火热。
-
小模型通过测试时计算 (Test-Time Compute) 技巧超越大模型:研究表明,扩展测试时计算可以让像 Llama 3B 这样的小型模型在复杂任务上表现优于大型模型。更智能地使用计算资源正在拉平 AI 性能的竞争环境。
第一部分:Discord 高层级摘要
Codeium / Windsurf Discord
- Flow Action Credits 消耗:用户正在迅速耗尽 Flow Action Credits,一名用户在 24 小时内消耗了 1k 额度。
- 建议包括将任务分解为更小的单元,尽管一些用户报告这在他们的工作流中并不奏效。
- AI 代码修改担忧:工程师们对 AI 在设置了防止更改的参数后仍意外修改代码 表示沮丧。
- 社区正在讨论编写更好 Prompt 的策略,以确保 AI 驱动的代码保持无误。
- 与 NVIDIA RAPIDS 集成:讨论重点介绍了 NVIDIA RAPIDS cuDF,它可以在不更改代码的情况下将 #pandas 操作加速高达 150 倍,详见 NVIDIA AI Developer 的推文。
- 成员们正考虑集成 RAPIDS 以增强其项目中的数据处理能力。
- Codeium 与 Gemini 2.0 对比:Codeium 和 Gemini 2.0 正在进行对比,观察到 Gemini 在某些编码任务中表现更优。
- 然而,Gemini 缺少 Claude 中的一些功能,导致根据具体用例产生了不同的看法。
- MCP 和 Function Calling 协议:正在讨论 Model Context Protocol (MCP),用于在不同技术栈之间建立标准化的 function call 结构。
- 用户建议利用 Playwright 和 MCP 等工具来增强 GUI 测试和交互。
Notebook LM Discord Discord
- NotebookLM Plus 缓慢推出:用户报告 NotebookLM Plus 正在分阶段推出,部分访问权限取决于其 Google 账号。预计到 2025 年初将向 Google One Premium 订阅者全面开放。
- 一些用户在访问新功能时遇到延迟,引发了关于优化部署策略的讨论。
- NotebookLM 播客功能的增强:最新的 NotebookLM 播客功能 包括显著提高用户参与度的自定义和交互功能。展示这些功能的播客链接被广泛分享。
- 成员们称赞该应用对音频内容领域的影响,并提到了允许更动态交互的具体增强功能。
- 增加 NotebookLM 的来源限制:免费版 NotebookLM 现在支持多达 300 个来源,引发了用户关于模型如何管理这一增长的疑问。正在探索有效利用这一扩展来源池的策略。
- 用户正在积极讨论收集足够来源的方法,以最大限度地发挥增加限制带来的好处,旨在获得更全面的 AI 输出。
- 为不同风格定制 AI 输出:强调了有效的 Prompting 和自定义函数在定制 AI 输出中的作用,从而产生不同的语气和风格。分享了一个 YouTube 教程 来展示有效的 Prompting 技巧。
- 用户正在微调 AI 响应以实现特定的艺术效果,利用定制化来满足多样化的内容创作需求。
- AI 工具中的多语言支持挑战:讨论强调了在不同语言中使用 NotebookLM 的复杂性,用户正在寻求引导 AI 以首选语言响应的方法。建议调整 Google 账号语言设置作为解决方案。
- 参与者正在分享 Prompt 策略,以确保准确且符合语境的多语言 AI 交互。
Cursor IDE Discord
- Cursor IDE 面临性能迟缓:用户报告在长时间开发过程中 Cursor IDE 出现 卡顿 (sluggishness),引发了关于是否需要重置或清除聊天历史的讨论。建议包括 创建新的聊天会话 以提升工作流效率。
- 实施这些更改旨在缓解性能瓶颈,并为长时间的编码任务提供更流畅的用户体验。
- 讨论 Cursor 的 Agent 与 Gemini 1206:参与者对比了 Cursor 的 Agent 与 Gemini 1206,强调了 Cursor 用户友好的界面以及 Gemini 在编码任务上的卓越性能。这种对比突显了每个模型在不同开发场景下的优势。
- 用户强调了根据项目需求选择合适工具的重要性,Google AI Studio 支持 Gemini 的各项功能。
- 构建新的社交媒体平台:几位用户表达了开发社交媒体平台的兴趣,重点关注必要的后端结构和潜在框架。重点在于理解 CRUD 操作 和管理 数据库关系。
- 推荐使用 Cursor IDE 等工具来简化开发过程并确保高效的数据库管理。
- 通过 Supabase 和 Bolt 集成增强 Cursor:有提议将 Cursor 与 Supabase 和 Bolt 等平台集成以扩展其功能。这些集成旨在简化工作流并增强开发能力。
- 用户讨论了此类集成的潜在好处,包括改进数据管理和简化部署流程。
Unsloth AI (Daniel Han) Discord
- 可微分自适应合并 (Differentiable Adaptive Merging, DAM):Differentiable Adaptive Merging (DAM) 论文介绍了一种无需大规模重新训练即可高效集成模型的方法,利用了 Differentiable Adaptive Merging (DAM)。
- 论文指出,像 Model Soups 这样更简单的技术在模型相似度较高时表现良好,展示了各种集成方法中的独特优势。
- Unsloth 与 Triton 的兼容性问题:用户遇到了 Unsloth 与 Triton 之间的兼容性问题,需要安装特定版本以实现无缝集成。
- 特别是 Python 3.13 带来了挑战,建议通过 Conda 使用 Python 3.10 以增强兼容性。
- 长上下文模型的效率:讨论指出了 长上下文模型 (long context models) 的局限性,强调了数据过滤的复杂性,以及仅靠数据质量不足以驱动训练效率。
- 参与者认为排除“坏数据”可能会损害模型的理解能力,因为多样化的数据集对于构建强大的 AI 至关重要。
- 使用 Unsloth 的微调技术:对 Unsloth 微调技术 的探索揭示了在数据集加载以及模型与 Streamlit 等平台的兼容性方面的共同挑战。
- 社区成员就正确的加载语法和模型配置提供了建议,以解决 FileNotFoundError 和模型识别错误等问题。
- Llama 3.2 的最大序列长度:关于 Llama 3.2 最大序列长度 (max sequence length) 的查询出现,最初建议为 4096。
- 随后被修正为实际最大值 131072,提供了对该模型能力的深入了解。
OpenAI Discord
- AI Alignment 框架分享:一位用户介绍了一个用于 AI Alignment 的工作框架,重点关注基于共同人类价值观的原则和迭代反馈,以确保 AI 开发的包容性。
- 讨论强调了在利益相关者之间达成共识的挑战,并对协调多样化利益的可行性持怀疑态度。
- Google Gemini 和 Imagen 更新讨论:用户对 Google Gemini 和最近的 Imagen 更新进行了评估,并将其性能与 OpenAI GPT-4 等现有模型进行了比较。
- 参与者指出,虽然 Grok 等模型正在进步,但在能力上仍落后于 ChatGPT 等更成熟的模型。
- GPT 4o 与 4o-mini 之间的性能差距:用户对 GPT 4o 和 GPT 4o-mini 之间的性能差异表示沮丧,称 mini 版本表现得像在“梦游”。
- 社区观察到 GPT 4o-mini 的响应质量显著下降,影响了整体用户体验。
- 本地 LLM 的优势探讨:参与者讨论了本地 LLM 的益处,强调了与大型科技公司的解决方案相比,本地 LLM 在提供更具定制化和灵活性的 AI 体验方面的潜力。
- 有人担心大型科技公司可能会在 AI 交互中优先考虑生产力的提升,而非创造力。
- 精炼提示工程(Prompt Engineering)技术:用户分享了增强提示工程的策略,将有效的提示词编写比作从零开始烹饪,并强调了清晰指令的重要性。
- 讨论内容包括开发提示工程课程,以及在 IDE 中利用 AI 进行代码辅助。
Nous Research AI Discord
- Byte Latent Transformer 发布,挑战 Llama 3:Meta 推出了 Byte Latent Transformer (BLT),这是一种无分词器(tokenizer-free)架构,可将 Bytes 动态编码为 Patches,从而提高推理效率和鲁棒性。参见公告。
- BLT 模型声称能达到与 Llama 3 等基于分词的模型相当的性能,同时可能减少高达 50% 的推理 FLOPs。他们在 1T tokens 上训练了 Llama-3 8B 模型,表现优于使用 BPE 的标准架构。
- Apollo LMMs 发布提升视频理解能力:社区讨论了 Apollo LMMs 的最新更新,其中包括专注于视频理解和多模态能力的模型。初步印象显示其表现良好,引发了对其潜在应用的兴趣。
- 成员们对将 Apollo 模型集成到现有工作流中持乐观态度,以增强视频分析和多模态处理能力。
- 开源代码 LLM 提升开发效率:推荐了几个开源代码 LLM,如 Mistral Codestral、Qwen 2.5 Coder 和 DeepSeek,它们可以与 VS Code 和 PyCharm 等 IDE 以及 continue.dev 等扩展集成。
- 这些工具使开发者能够使用本地模型提高编码效率,营造更具定制化的开发环境。
- 模型压缩技术借鉴通信理论:讨论集中在通信理论原则如何影响 LLM 的发展,特别是在分布式训练期间的梯度传输方面。
- 成员们指出,用计算换带宽可以简化流程,尽管组合多种技术可能会很复杂。此外还强调了在不损害性能的情况下优化数据效率的潜力。
- 本地 LLM 微调变得更加便捷:讨论提到,借助 unsloth 和 axolotl 等工具,即使是资深技术爱好者也有可能使用 QLoRA 训练高达 80 亿参数的模型。
- 越来越多的资源让那些愿意学习的人能够进行定制化开发,扩展了本地模型微调的能力。
OpenRouter (Alex Atallah) Discord
- SF Compute 集成至 OpenRouter:OpenRouter 宣布新增 SF Compute 作为新的供应商,增强了其服务能力。
- 这一集成扩展了用户在平台上寻求多样化服务集成的选择。
- Qwen QwQ 降价 55%:Qwen QwQ 进行了大幅度 55% 的降价,旨在吸引更多用户使用其功能。
- 详情请见其 定价页面。
- xAI 发布新 Grok 模型:xAI 在周末发布了两个新的 Grok 模型,导致平台流量增加。
- 用户可以在 OpenRouter 的 xAI 页面 探索所有模型。
- OpenRouter API 封装库发布:两天前发布了一个名为 openrouter-client 的 OpenRouter API 封装库。
- 该封装库简化了与 OpenRouter 的交互,并提供了实现和配置的示例代码。
- Hermes 3 405B 展现强劲性能:Hermes 3 405B 在创意任务中表现出色,据称其质量可与 Claude 2.0 媲美。
- 然而,讨论指出与其他模型相比,它在编程任务中的性能较慢。
Eleuther Discord
- JAX/Flax 取代 TensorFlow 以提升性能:成员们对 TensorFlow 支持度下降表示不满,导致许多人 转向 JAX/Flax。JAX/Flax 提供了更优的性能和更强大的功能,适用于现代 AI 工程。
- 社区赞扬了 JAX/Flax 的灵活性以及与当前模型架构更好的集成,并提到了更顺畅的依赖管理和更高的计算效率。
- 数据打乱减少近期训练带来的模型偏见:有人担心模型会对最近引入的训练数据产生偏见。成员们建议将 数据打乱 (data shuffling) 作为增强 训练公平性 和减少偏见的策略。
- 成员们分享了数据同质化策略的经验,强调了通过 随机数据排序 提升模型性能和公平性的效果。
- 注意力机制优于核方法:关于 Transformer 中的 注意力机制 (attention mechanisms) 是否等同于核方法 (kernel methods) 展开了辩论。成员们澄清说,attention(特别是带有 softmax 的)超出了传统核方法的功能范围。
- 讨论包括数学上的区别,并辩论了 attention 是否充分利用了核潜力,强调了其运行环境的复杂性。
- 非 Transformer 架构在 AI 研究中势头强劲:非 Transformer 架构 的活跃研究受到关注,提到 Numenta 和 AI2 等实验室发布了与主流 Transformer 模型不同的新模型 Checkpoint。
- 社区成员对推动新颖方法的小型实验室表示出兴趣,强调了多样化模型架构对推进 AI 能力的重要性。
- lm_eval 成功集成 VLLM:一位用户分享了让 lm_eval harness 与 VLLM 协同工作的方法,并指出了具体的安装命令。该过程包括安装 0.6.3 版本的 VLLM,以防止评估 harness 出现问题。
- 成员们讨论了 VLLM 产生的错误,暗示 lm_eval 使用的内部 API 可能已更改,并澄清了版本细节以解决 VLLM 版本混淆 问题。
Bolt.new / Stackblitz Discord
- Bolt 的 Token 消耗激增:多位用户报告称 Bolt 正在以加速率消耗 Token,其中一位用户指出在 UI 没有相应更改的情况下消耗了 500 万个 Token。该问题已记录在 GitHub Issue #4218 中。
- 成员们怀疑这是一个系统性 Bug,并正通过将项目 fork 到 GitHub 并在 Replit 上运行作为权宜之计。
- 货币更新遇到困难:用户在将货币显示从 $ USD 更改为 INR 时遇到困难,即使在锁定
.env文件后也是如此,这表明 Bolt 的文件处理可能存在 Bug。- 这一持续存在的问题已在多个频道中被报告,表明这并非特定于浏览器的孤立问题。
- Supabase 集成引发期待:备受期待的 Supabase 与 Bolt 的集成正引发热潮,早期的 视频演示 展示了其功能。
- 用户渴望获得更新,并期待新功能能够增强他们的项目。
- 对 Token 成本和订阅的担忧:用户对 Token 的快速消耗表示担忧,尤其是在充值之后,并寻求关于 Token 管理机制的明确说明。
- 用户对当前的过期规则表示不满,并主张建立累积 Token 系统。
- React Native 开发指南:讨论强调了使用 React Native 和 Expo 将 Web 应用程序迁移到移动平台的最佳实践。
- 建议包括将开发转移到 Cursor 以获得更好的功能支持。
Latent Space Discord
- Grok-2 凭借 Aurora 提速:Grok-2 已更新,运行速度提升了 三倍,并提高了 准确率 和 多语言能力,现已在 X 上免费提供。
- 它引入了 网页搜索、引用 以及名为 Aurora 的新图像生成器等功能,显著增强了用户交互。
- Ilya Sutskever 的 NeurIPS 新见解:在 NeurIPS 2024 的演讲中,Ilya Sutskever 强调了 LLM 在预训练期间的规模化瓶颈,以及未来向 Agent 行为 和 工具集成 发展的转变。
- 讨论包括关于 数据饱和 以及 未开发的视频内容 用于 AI 训练 潜力的各种观点。
- Google 的 Veo 2 和 Imagen 3:媒体魔力:Google 推出了 Veo 2 和 Imagen 3,具有改进的高质量 视频生成 和增强的 图像构图 功能,可在 VideoFX 和 ImageFX 中使用。
- 这些更新在生成内容中提供了更好的 电影摄影理解 和多样化的 艺术风格。
- META 的 Byte Latent Transformer:META 发布了 Byte Latent Transformer (BLT),这是一种无分词器 (tokenizer-free) 架构,可将字节动态编码为 patch,从而提高 推理效率。
- BLT 模型与 Llama 3 等现有模型相匹配或更胜一筹,显著降低了 推理 FLOPs。
- OpenAI 为 ChatGPT 推出语音搜索:OpenAI 宣布为 ChatGPT 推出 高级语音模式下的搜索 功能,允许用户通过 语音交互 获取 实时信息。
- 该功能是 OpenAI 的 Search 团队与 多模态产品研究团队 合作的成果。
LM Studio Discord
- 多模态模型集成:成员们探讨了结合文本、图像、音频和视频的 Multimodal Models,指出大多数解决方案通过 云服务 访问,同时强调了 LM Studio 目前在这一领域的局限性。
- 一个关键讨论点是本地设置缺乏完全多模态的 LLMs,这引发了对即将发布的模型的期待。
- 模型微调的局限性:用户询问是否可以通过数据导出来对现有模型进行 Fine-tuning,以模拟特定的语法或语气,但被告知 LM Studio 不支持 Fine-tuning。
- 作为替代方案,建议在聊天界面中使用 System Prompts 和示例文本进行临时模型调整。
- 无审查聊天机器人的选项:在寻找 Uncensored Chatbots 时,建议成员使用可以在 CPU 上运行的小型模型,如 Gemma2 2B 或 Llama3.2 3B。
- 分享了 Hugging Face 上可用于本地环境部署的各种无审查模型。
- RAG 实现与文档处理:讨论了 LM Studio 中的 Retrieval-Augmented Generation (RAG) 能力和文档上传功能,将其作为利用本地文档增强上下文响应的手段。
- 用户获知虽然所有模型都支持 RAG,但集成网页访问或互联网功能需要自定义 API 解决方案,详见 LM Studio Docs。
- AI/ML 任务的 GPU 选择:对话强调具有更大 VRAM 的 GPU(如 3090)更适合 AI 和 Machine Learning 任务,因为它们具有卓越的速度和能力。
- 提到了 4070ti 等替代方案,尽管一些成员指出,根据当地供应情况,二手 3090 可能提供更好的性价比。
Stability.ai (Stable Diffusion) Discord
- Reactor 实现高效换脸:用户推荐使用 Reactor 扩展进行图像中的 Face Swapping,在启用 Reactor 并上传目标面部图像后,用户可以成功生成修改后的图像。
- 该方法增强了 Stable Diffusion 工作流中的图像处理能力,允许无缝集成不同的面部特征。
- 讨论 Stable Diffusion 的多样化模型:讨论强调了各种 Stable Diffusion 模型,强调最佳选择取决于用户需求,其中 Flux 和 SD 3.5 在提示词遵循方面表现出色,而 Pixelwave 因其艺术知识受到称赞。
- 参与者分享了不同模型的经验,以优化图像生成质量和性能,根据特定项目需求定制选择。
- 寻求全面的 Stable Diffusion 学习资源:用户寻求关于 Stable Diffusion 的广泛课程和教程,特别是关注其与 Automatic1111 的集成,建议指向 YouTube 等平台上的系列视频和专门的在线资源。
- 这些资源旨在提高用户对利用 Stable Diffusion 高级功能的理解和熟练程度。
- 使用放大工具优化图像质量:用户请求推荐与 Stable Diffusion 生成图像兼容的高效 Upscalers,讨论了提高图像分辨率和质量的特定工具或扩展。
- 辩论了增强的 Upscaling 技术,以在生成的图像中实现更好的视觉保真度。
Interconnects (Nathan Lambert) Discord
- LiquidAI 获得 2.5 亿美元融资:LiquidAI 宣布完成由 AMD Ventures 领投的 2.5 亿美元 A 轮融资,旨在为其企业级 AI 解决方案扩展其 Liquid Foundation Models (LFMs)。
- 讨论中对其招聘实践表示了担忧,涉及潜在的人才挑战以及 LiquidAI 的规模可能阻碍收购机会的可能性。
- ChatGPT 通过 Memory 增强搜索功能:ChatGPT 在其搜索功能中引入了 memory 特性,允许模型利用记忆来优化搜索响应,从而提高相关性。
- 用户对此次更新未包含个性化搜索表示失望,并期待未来的增强功能,包括潜在的 API 集成。
- DeepMind 发布 Veo 2 和 Imagen 3:DeepMind 推出了新的视频生成模型 Veo 2 以及升级后的 Imagen 3,增强了根据提示词生成写实内容的能力。
- 早期反馈称赞了 Imagen 3 的表现,强调了 DeepMind 在科技界相对于 OpenAI 等其他主要参与者的竞争优势。
- OpenAI 举报人事件:OpenAI 举报人 Suchir Balaji 被发现死于其公寓内,当局报告死因为自杀,并排除了他杀可能。
- Balaji 因在离开公司后不久对 OpenAI 使用受版权保护的材料训练 ChatGPT 提出担忧而闻名。
- Apollo 视频 LLM 挑战竞争对手:Meta 的 Apollo 系列视频 LLM 表现强劲,可与 llava-OV 和 Qwen2-VL 媲美。
- 讨论强调了 Apollo 使用 Qwen2.5 作为其底层 LLM,而非预期的 Llama,引发了关于如何选择模型以实现最佳性能的疑问。
Perplexity AI Discord
- Perplexity Pro 订阅扩展服务:Perplexity Pro 现在提供 1、3、6 或 12 个月期限的礼品订阅,使用户能够分享增强功能,如搜索 3 倍数量的来源以及访问最新的 AI 模型。详细信息和购买选项请见此处。
- Campus Strategist 项目正在向国际扩展,允许学生在 12 月 28 日前申请 2025 年春季班,专属周边和活动机会详见此处。
- Spaces 推出自定义 Web 来源功能:Perplexity AI 在 Spaces 中引入了自定义 Web 来源,使用户能够通过选择特定网站来定制搜索,从而增强不同用例的相关性。
- 该功能允许工程师在 Spaces 内优化搜索查询,确保结果更符合专业化需求。
- Perplexity API 面临 URL 和访问挑战:用户报告 Perplexity API 将来源引用返回为纯文本数字(如 [1])而没有 URL,尽管一些用户通过明确请求成功获取了 URL。
- 此外,通过 API 获取新闻标题以及通过提供的电子邮件获取支持存在困难,表明可能存在稳定性和可用性问题。
- 对 Perplexity API 模型性能的担忧:多位用户表示最近的模型更新导致性能下降,特别指出 Claude 3.5 的效果不如其免费版本。
- 模型切换缺乏透明度,这影响了 API 服务的感知质量和可靠性。
- Google 发布 Gemini 2.0:Google 推出了 Gemini 2.0,标志着 AI 能力的重大进步,这引发了关于 problem movement 的讨论。
- 讨论参与者对此次更新及其对 AI 领域的潜在影响表示了热忱。
Cohere Discord
- Command R7B 模型提速:Cohere Command R7B 12-2024 模型现已上线,针对推理和摘要任务进行了优化,拥有更快的速度和更高的效率。
- Nils Reimers 的 Twitter 上展示的社区基准测试显示,Command R7B 的表现优于 Llama 8B 等模型,响应时间有显著改善。
- Rerank 与 Embed:功能详解:讨论明确了 Rerank 根据查询相关性对文档进行重新排序,而 Embed 则将文本转换为用于 NLP 应用的数值向量。
- Embed 的 API 更新现在支持 ‘image’ 输入类型,将其适用范围扩展到了文本任务之外。
- v2 版本中的 API Schema 重构:从 API v1 到 v2 的迁移缺乏关于新端点 Schema 变化的详细文档,导致用户对具体更新感到困惑。
- 工程师们正在调查现有的 迁移资源,以明确新的 API 结构。
- 为 Code Wizard 黑客松寻求赞助:Akash 宣布了即将由 SRM Institute 在 2025 年 2 月举办的 Code Wizard 黑客松,目标是吸引学生和技术爱好者解决现实世界的问题。
- 该活动正在积极寻求赞助商以获得支持和曝光,旨在开发者社区内培养创新解决方案。
- AI 增强合同条款审查:Eyal 正在开发一个使用 Cohere 的概念验证(PoC),用于自动识别并建议合同条款的修改。
- 正在征求关于定义特定条款类型或利用变更数据库等策略的反馈,以提高 AI 在合同分析中的有效性。
Modular (Mojo 🔥) Discord
- Mojo RSA 加密开发:一名成员发起了在 Mojo 中开发基础 RSA crypto 实现的项目,并展示了进展。
- 该项目引起了不同的反响,突显了社区的热情和建设性的反馈。
- 素数生成优化:素数生成脚本达到了 1.125 秒 的峰值性能,经过优化后,使用 SIMD instructions 每秒可生成超过 50,000 个 UInt32 素数。
- 这些增强功能保持了低内存占用,应用程序在运行期间消耗的内存少于 3mb。
- 自定义 Mojo Kernels:自定义 Mojo Kernels 已经发布,允许接受任何输入类型,尽管早期版本可能会因类型不匹配而崩溃。
- 开发者对 API 未来的健壮性保持信心,预计随着实现的成熟,稳定性将会提高。
- Mojo 中的网络性能:讨论倾向于在 Mojo 应用中使用 QUIC 而非 TCP 以降低延迟。
- 在现代网络环境中,避免 TCP 开销被视为实现高效 Mojo-to-Mojo 通信的关键。
- MAX 中的数据库规划:一名开发者计划在 MAX 中实现 数据库查询规划 和执行,利用新的自定义 Kernel 功能。
- 这一举措表明了在 Mojo 生态系统中推动更强大复杂数据操作处理的趋势。
LLM Agents (Berkeley MOOC) Discord
- LLM Agents MOOC Hackathon 截止日期临近:LLM Agents MOOC Hackathon 的提交截止日期为 PST 时间 12 月 17 日晚上 11:59,敦促参与者按时完成并提交项目。
- 鼓励参与者在指定频道寻求最后时刻的帮助,以确保所有提交内容符合要求。
- Hackathon 参赛条目转向 Google Forms:Hackathon 的提交方式已从 Devpost 转向 Google Forms,以简化提交过程。
- 参与者必须确保使用正确的表单链接,以避免在截止日期前出现任何提交问题。
- 证书通知计划于 12 月底发布:Certificate notifications(证书通知,包括通过或失败状态)将根据参与者的层级在 12 月底至 1 月初期间发放。
- 这一时间表回应了最近的咨询,并为参与者何时能获知其认证状态设定了明确预期。
- OpenAI Credit 提交问题:一些成员报告称,尽管在 11 月 25 日截止日期前提交了组织 ID,但仍未收到 OpenAI credits。
- 社区成员建议核实账户余额,因为通知可能未正常发送。
- 强调 AI Research Agents 中的安全对齐:一位成员强调了 AI Research Agents 中 safety alignment 的重要性,并分享了相关的 AI Research 资源。
- 这突显了社区对确保安全协议成为 AI research agents 开发中不可或缺的一部分的关注。
Torchtune Discord
- Torchtune v3.9 简化 Type Hinting:Torchtune v3.9 的更新允许用户使用默认内置类型替换
List、Dict和Tuple进行 Type Hinting。- 这一调整受到社区欢迎,它简化了 Python 代码,提高了开发者的生产力。
- Generative Verifiers 提升 LLM 性能:题为 Generative Verifiers: Reward Modeling as Next-Token Prediction 的论文介绍了 Generative Verifiers (GenRM),该模型使用 Next-token prediction 目标进行训练,以无缝集成验证和解法生成。
- 该方法支持 Instruction tuning,并通过利用额外的 Inference-time compute 来增强验证结果,从而实现 Chain-of-thought 推理。
- Distributed Training 中的 Gradient Normalization 挑战:讨论强调了 Distributed Training 中 Backward pass 期间归一化缩放因子的担忧,建议应为
world_size / num_tokens以管理 Token 数量的可变性。- 这个问题可能会由于 Padding 和索引差异而使梯度计算复杂化,从而引发了对通过 PR 解决不一致性的倡议。
- 探索 Scaling Test Time Compute 策略:一篇 Hugging Face 博客文章 讨论了扩展大型模型 Test-time compute 的策略,重点是在不损害结果的情况下进行性能优化。
- 该文章概述了在保持模型输出完整性的同时提高计算效率的方法。
tinygrad (George Hotz) Discord
- 优化 Kernel Search 的 BEAM 配置:成员们讨论了用于 Kernel Search 的各种 BEAM 设置,强调 BEAM=1 表示贪心搜索(greedy search),其效果较差。推荐的入门设置是 BEAM=2 或 3 以平衡性能,详见 文档。
- Kernel Search 体验的提升重点在于优化 编译时间 和 Kernel 执行时间。成员们对现有的 Benchmark 感兴趣,并建议在使用 JIT 编译 时采用 BEAM=2。
- 新的 Gradient API 简化梯度处理:George Hotz 宣布合并了新的 Gradient API,它可以简化梯度处理:使用
weight_grad, bias_grad = loss.gradient(weight, bias),而无需zero_grad或loss.backward。- 该 API 与 PyTorch 和 JAX 等传统框架不同,正如这篇 推文 中提到的,它可能会通过
optim.step(loss)简化优化器步骤。
- 该 API 与 PyTorch 和 JAX 等传统框架不同,正如这篇 推文 中提到的,它可能会通过
- Tinygrad 移植项目与后端支持讨论:宣布了将 fish-speech 项目移植到 Tinygrad 的计划,旨在增强 Tinygrad 的能力。该项目托管在 GitHub 上。
- 成员们讨论了为 Tinygrad 同时支持 x86 和 arm64 后端 的问题,考虑在资源受限的情况下维持性能。
- ShapeTracker 解释器与教程扩展:发布了改进版的 ShapeTracker Explainer,可在 此处 查看,提供了对其工作原理的深入见解。
- tinygrad-notes 仓库征集教程和资源贡献,鼓励社区参与。
LlamaIndex Discord
- 5 行代码实现 LlamaIndex RAG:TylerReedAI 分享了一个详细的 教程,介绍如何仅用 5 行代码 构建 RAG 应用,涵盖了数据加载和索引。
- 该教程强调了将 Query 引擎 和 Chat 引擎 集成到工作区中的简便性。
- Agentic 合规工作流:一个新的 教程 介绍了一种构建 Agentic 工作流 的方法,通过根据 GDPR 指南分析条款来确保 合同合规性。
- 它分解了如何解析供应商合同以有效维持合规性,从而简化合同管理。
- Contextual Retrieval 与 LlamaIndex 结合:一位用户在 LlamaIndex 中实现了 Anthropic 的 Contextual Retrieval,并分享了他们的 GitHub 仓库 供他人审阅。
- 他们表示有兴趣将这个健壮的实现作为 PR 提交,并强调了它对边缘情况的处理。
OpenInterpreter Discord
- 文件夹创建问题与缩进错误:一位成员指出该工具无法创建文件夹,且生成的代码缩进错误,导致难以复制粘贴,并询问是否应使用 cmd 以外的其他环境。
- 这一问题表明当前设置中的文件夹创建功能和代码格式化过程可能存在 Bug。
- macOS Monterey 上的 API 响应限制:一位用户报告称,在 macOS Monterey 上安装应用后,无法收到 API 响应,且仅执行 两次操作 后就达到了免费 Token 限制。
- 这表明可能存在特定于 macOS Monterey 的集成或使用问题,可能影响了 API 的可用性。
- 增强 Litellm 的计费追踪:一位用户询问如何将 OI 连接到 Litellm 代理服务器,以便有效追踪集成版 Litellm 包的计费和使用情况。
- 他们正在探索在 Litellm 集成中启用全面计费追踪的方法。
- 日语学习应用推荐:一位成员寻求好用的 日语 学习应用,导致另一位用户幽默地暗示他们可能进错了 Discord 服务器。
- 这一交流强调了社区内对专注于语言学习的专门资源或频道的潜在需求。
- 本地 OS 部署选项:一位用户询问了在本地使用该 OS 的可能性,表示对本地设置方案感兴趣。
- 该查询指向了关于本地环境潜在部署或托管配置的讨论。
DSPy Discord
- 使用 DSpy 优化 Claude Sonnet 提示词:一位用户在寻找优化其 Claude Sonnet 提示词的方法时发现了 DSpy,并收藏了一个特定的 Jupyter notebook。
- 他们提到该 notebook 最近被移到了一个过时的示例文件夹中,引发了对其时效性的疑问。
- 更新过时的 DSpy 示例:另一位成员建议,在 DSpy 中过时示例文件夹的内容被翻新之前应谨慎使用,这表明其可能存在不可靠性。
- 他们还指出,目前正在努力更新这些示例,有望提高它们的实用性。
Axolotl AI Discord
- APOLLO 优化器增强内存效率:新的 APOLLO 优化器 在 LLaMA 7B 训练 期间将内存使用量减少到 1.6G,同时实现了最佳困惑度(perplexity),相比之下,使用 8-bit Adam 则需要 13G。
- 一个独立的 Julia 实现 证实了 APOLLO 在优化内存和训练效率方面的有效性,详见此 帖子。
- LLM 训练面临 AdamW 的内存限制:大型语言模型在使用 AdamW 优化器 时会遇到严重的内存问题,通常需要在训练期间使用昂贵的硬件或较小的 batch sizes。
- 传统的内存高效优化器涉及 SVD 操作 或性能权衡,但 APOLLO 引入了一种新颖的方法来解决这些局限性。
- 关于多轮 KTO 的持续讨论:讨论强调了 多轮 KTO,尽管未提供具体细节和更新。
- 社区成员对该方法在 LLM 框架内的潜在能力和集成表示了兴趣。
LAION Discord
- VAE Embedding 改进渐进式分词:讨论集中在利用源自 VAE embedding 的 DWT 系数 的 零树排序(zero-tree ordering) 进行 渐进式分词(progressive tokenization)。一段附带的 视频 展示了该技术的实际应用。
- 分析了 Level 5 小波(wavelet) 变换对分词有效性的影响,强调了实际应用以及对未来模型增强的意义。
- Byte Latent Transformer Patches 优于 Tokens:出版物 Byte Latent Transformer Patches: Scale Better than Tokens 详细介绍了一种新的 NLP 方法,其中 byte latent transformer patches 与传统 tokens 相比展现出更好的可扩展性。
- 这一进展引发了关于在各种应用中增强语言建模 有效性 和 效率 的讨论。
- Level 5 小波变换提升分词效果:研究了 Level 5 小波 变换在改进当前方法中分词有效性的作用。
- 分析包括探索实际应用和对模型性能的未来影响,并引用了 附带视频。
Mozilla AI Discord
- RAG 盛会:使用 SQLite-Vec 和 LlamaFile 构建:明天的活动重点是使用 sqlite-vec 和 llamafile 创建一个 超低依赖的检索增强生成(RAG) 应用程序,仅使用 基础 Python,无需额外的依赖或安装。
- Alex Garcia 将主持该会议,为与会者提供构建 RAG 应用程序的简单方法。
- 假期聚会:放假前的最后一次 RAG 环节:12 月假期前的 最后一次聚会 强调了在年底前参与的重要性。
- 鼓励参与者 加入该环节,作为假期的前奏,并获取有关 RAG 开发 的见解。
Gorilla LLM (Berkeley Function Calling) Discord
- Gorilla LLM 发布 Function Calling 结果:Gorilla LLM 的 Berkeley Function Calling 的 BFCL-Result 仓库已更新。
- BFCL-Result 仓库现已可供查阅。
- Gorilla LLM 发布 Function Calling 结果:Gorilla LLM 的 Berkeley Function Calling 的 BFCL-Result 仓库已更新。
- BFCL-Result 仓库现已可供查阅。
MLOps @Chipro Discord 没有新消息。如果该频道长期处于沉寂状态,请告知我们,我们将将其移除。
HuggingFace Discord 没有新消息。如果该频道长期处于沉寂状态,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该频道长期处于沉寂状态,请告知我们,我们将将其移除。
第 2 部分:按频道详细摘要与链接
为了方便邮件阅读,完整的频道明细已被截断。
如果您喜欢 AInews,请分享给朋友!提前致谢!