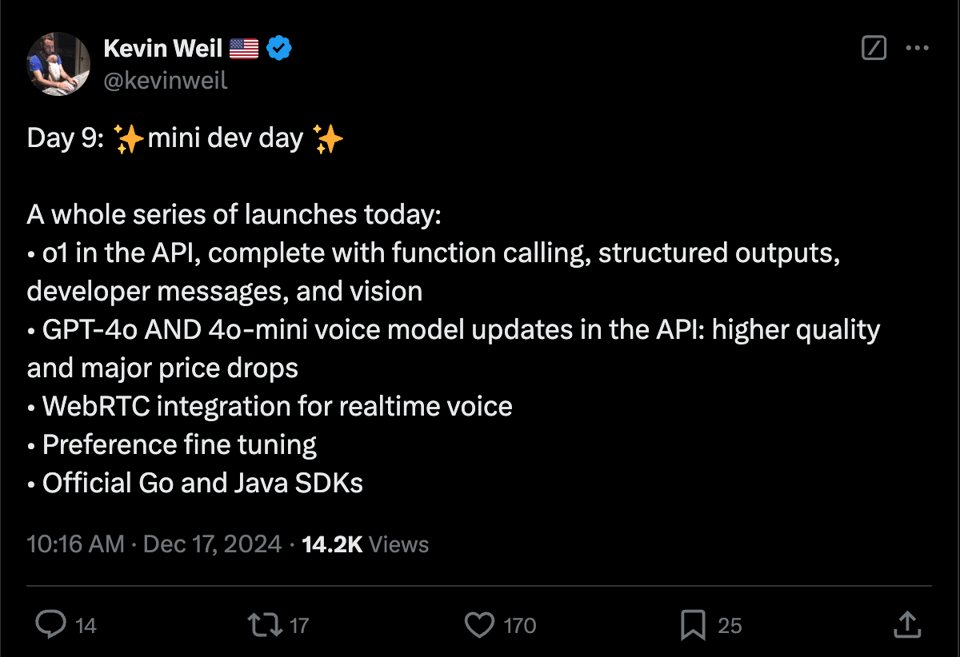
ainews-o1-api-4o4o-mini-in-realtime-api-webrtc
o1 API、Realtime API + WebRTC 中的 4o/4o-mini、DPO 微调。
OpenAI 推出了功能增强的 o1 API,新增了包括视觉输入、函数调用、结构化输出以及全新的 reasoning_effort(推理力度)参数,使得推理 Token 的平均消耗降低了 60%。官方确认 o1 pro 变体是一个即将推出的独立实现版本。
Realtime API(实时 API)也迎来了改进,通过集成 WebRTC 简化了使用流程,支持更长的会话(最长可达 30 分钟),并显著降低了价格(使用 mini 模型可便宜多达 10 倍)。此外,OpenAI 还引入了用于微调的 DPO 偏好微调功能,目前已支持 4o 模型。
其他更新还包括官方发布的 Go 和 Java SDK 以及 OpenAI DevDay 的视频回顾。新闻中还重点讨论了 Google Gemini 2.0 Flash 模型的性能表现,其准确率已达到 83.6%。
2024/12/16-2024/12/17 的 AI 新闻。我们为您检查了 7 个 subreddits、433 个 Twitter 和 32 个 Discord(210 个频道和 4050 条消息)。预计节省阅读时间(以 200wpm 计算):447 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
这是 OpenAI 的一个小型开发者日,发布了大量小型更新和一个备受期待的 API。让我们依次来看:
o1 API
要点:
o1-2024-12-17是比两周前发布到 ChatGPT 的 o1 更先进的 o1(我们的报道在此),平均减少了 60% 的推理 token (reasoning tokens)。- 视觉/图像输入(我们在完整的 o1 发布中看到了这一点,但现在它已进入 API)。
- o1 API 还具有 function calling 和 structured outputs 功能——对基准测试有一些但非常小的影响。
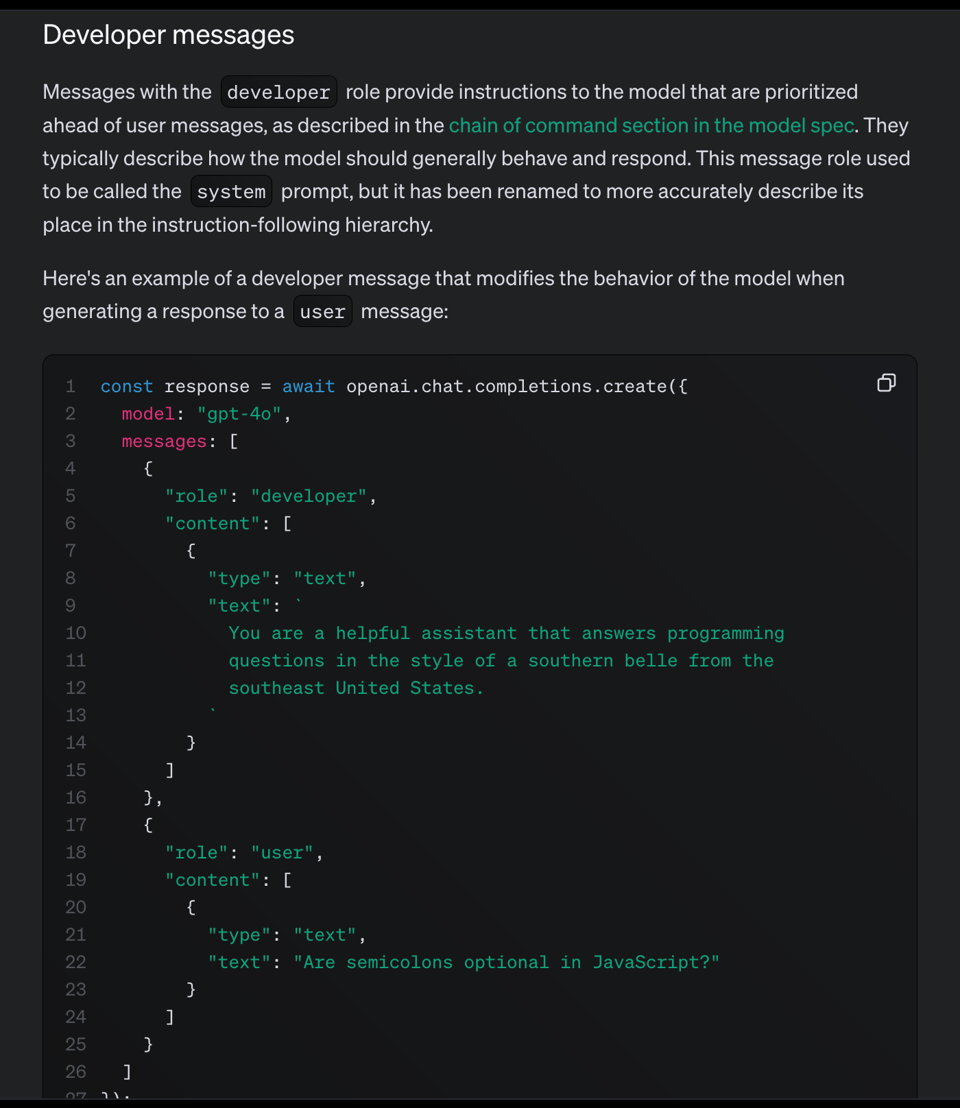
- 一个新的
reasoning_effort参数(目前只是low/medium/high字符串)。 - “system message” 已更名为 “developer messages”,原因众所周知……(开个玩笑,这只是将主要的 chatCompletion 行为更新为与 realtime API 相同的工作方式)。
o1 pro 已确认“是不同的实现,而不仅仅是设置了 high reasoning_effort 的 o1”,并将在“一段时间后”在 API 中提供。
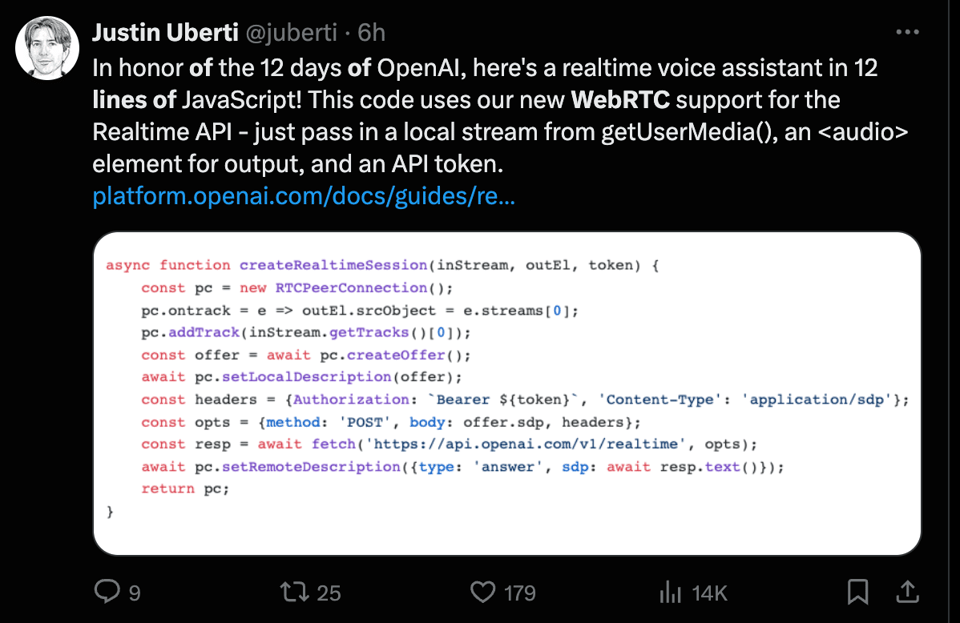
WebRTC 和 Realtime API 改进
现在通过 WebRTC 使用 RealTime API 变得容易得多,因为它短到可以放进一条推文(可以在 SimwonW 的演示中使用您自己的 key 进行尝试):
新的 4o 和 4o-mini 模型,仍处于预览阶段:

WebRTC 的创始人 Justin Uberti 最近加入了 OpenAI,他还强调了一些其他细节:
- 价格优化(使用 mini 时便宜 10 倍)。
- 更长的持续时间(会话限制现在为 30 分钟)。
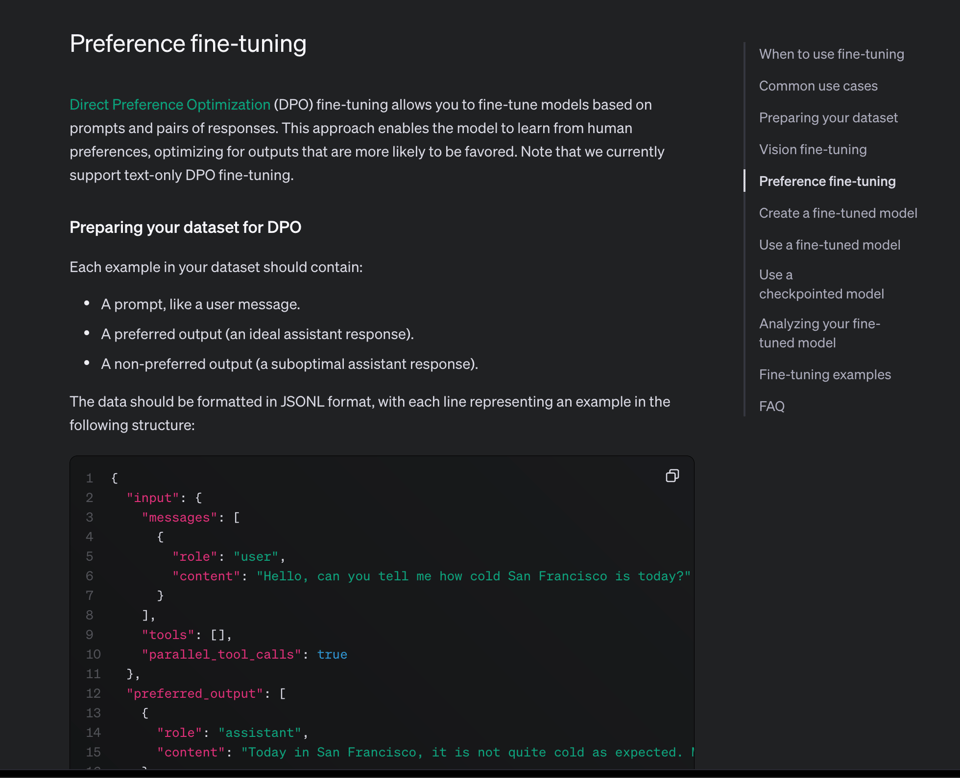
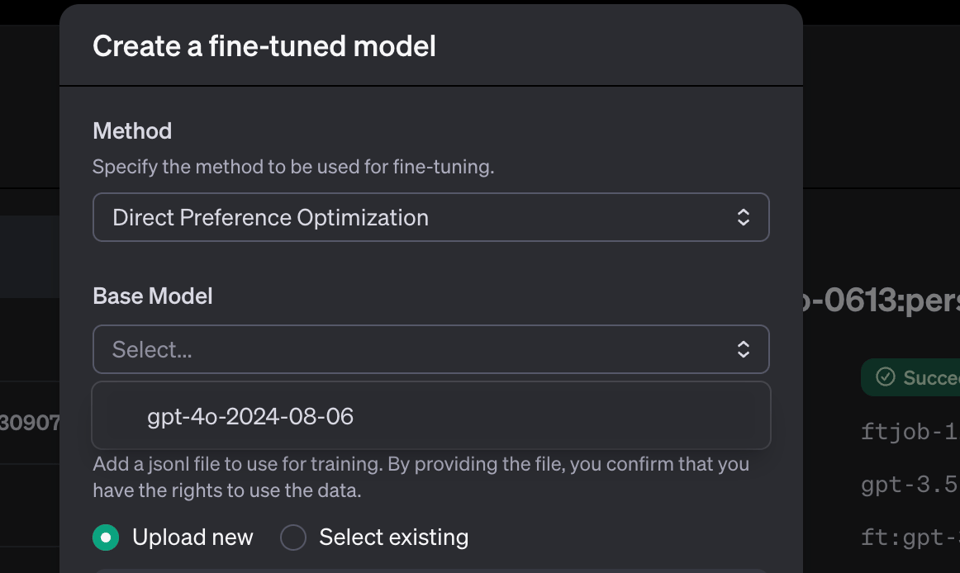
DPO 偏好微调 (Preference Tuning)
这是针对微调 (finetuning) 的偏好排序。我们打算尽快为 AINews 尝试这个……尽管它似乎只适用于 4o。
其他
精选的 OpenAI DevDay 视频也已发布。
为有需要的人提供官方的 Go 和 Java SDK。
完整的演示值得一看:
https://www.youtube.com/watch?v=14leJ1fg4Pw
AI Twitter 摘要
所有摘要均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
以下是关键讨论和公告的分类摘要:
模型发布与性能
- OpenAI o1 API 发布:@OpenAIDevs 宣布 o1 已在 API 中上线,支持 function calling、structured outputs、vision 能力和 developer messages。据报道,该模型使用的 reasoning tokens 比 o1-preview 少 60%。
- Google Gemini 更新:Gemini 2.0 Flash 在新的 DeepMind FACTS 基准测试中达到了 83.6% 的准确率,表现优于其他模型,取得了显著进步。
- Falcon 3 发布:@scaling01 分享 Falcon 发布了新模型(1B, 3B, 7B, 10B & 7B Mamba),在 14 万亿 (Trillion) tokens 上训练,采用 Apache 2.0 许可证。
研究与技术进展
- Test-Time Computing:@_philschmid 强调了 Llama 3 3B 如何通过 test-time compute 方法在 MATH-500 上超越 Llama 3.1 70B。
- Voice API 定价:OpenAI 宣布 GPT-4o 音频现在便宜了 60%,而 GPT-4o-mini 的音频 token 价格则便宜了 10 倍。
- WebRTC 支持:Realtime API 新增了使用 WHIP 协议的 WebRTC 端点。
公司动态
- Midjourney 观点:@DavidSHolz 分享了关于运营 Midjourney 的见解,指出他们在没有投资者的情况下拥有“足够的收入来资助大量疯狂的研发”。
- Anthropic 安全事件:该公司确认其账号出现了未经授权的帖子,并表示没有任何 Anthropic 系统遭到破坏。
迷因与幽默
- @jxmnop 调侃在 IMAX 观看《Attention Is All You Need》
- 社区中分享了多个关于模型对比和 AI 发展竞赛的幽默段子。
AI Reddit 摘要
/r/LocalLlama 摘要
主题 1. Falcon 3 问世,拥有惊人的 Token 训练量和多样化的模型
- Falcon 3 刚刚发布 (得分: 332, 评论: 122):Falcon 3 已发布,根据 Hugging Face 博客文章显示,其基准测试表现令人印象深刻。此次发布突显了 AI 模型性能的重大进步。
- 模型性能与基准测试:Falcon 3 的发布涵盖了从 1B 到 10B 的模型,在 14 万亿 tokens 上进行了训练。10B-Base 模型被认为是该类别中的 state-of-the-art,具体性能得分包括 MATH-Lvl5 为 24.77,GSM8K 为 83.0。基准测试表明 Falcon 3 与 Qwen 2.5 14B 和 Llama-3.1-8B 等其他模型相比具有竞争力。
- 许可证担忧与 BitNet 模型:人们对该模型的许可证表示担忧,其中包含一个可能限制其地理使用范围的“撤资条款 (rug pull clause)”。讨论中提到了 BitNet 模型的发布,一些人注意到该模型与传统的 FP16 模型相比基准测试表现较差,尽管它允许在相同硬件上运行更多参数。
- 社区与技术支持:社区正在积极讨论对 Mamba 模型和推理引擎支持,llama.cpp 正在持续开发以提高兼容性。人们对 1.58-bit 量化方法很感兴趣,尽管目前的基准测试显示与非量化模型相比性能有显著下降。
- 介绍 Falcon 3 系列 (Score: 121, Comments: 37): 该帖子宣布发布 Falcon 3,这是一款新的开源大语言模型,标志着 Falcon 团队的一个重要里程碑。欲了解更多详情,读者可参阅 Hugging Face 上的官方博客文章。
- LM Studio 预计将通过 llama.cpp 的更新来集成对 Falcon 3 的支持,尽管有报告称由于不支持的 tokenizer 导致加载模型时出现问题。一种解决方法是应用来自 GitHub pull request 的修复并重新编译 llama.cpp。
- 用户提出了关于 阿拉伯语支持 的担忧,指出缺乏具有强大阿拉伯语能力以及推理和数学基准测试的模型。回复表明目前尚不支持阿拉伯语。
- 用户对 Falcon 3 的发布和性能表示赞赏,并计划将其纳入即将进行的基准测试中。反馈建议更新模型卡片(model card),包含有关 tokenizer 问题及解决方法的说明。
主题 2. Nvidia 的 Jetson Orin Nano:嵌入式系统的游戏规则改变者?
- 终于,我们迎来了新硬件! (Score: 262, Comments: 171): Jetson Orin Nano 硬件正式推出,标志着 AI 技术的一个显著发展。这种新硬件通过提供增强的性能和功能,可能会影响 AI 应用,特别是在边缘计算和机器学习领域。
- Jetson Orin Nano 因其低功耗(7-25W)和紧凑的一体化设计而受到称赞,使其适用于机器人和嵌入式系统。然而,也有人对其 8GB 128-bit LPDDR5 内存 及 102 GB/s 的带宽提出批评,一些用户认为与同价位的 RTX 3060 或 Intel B580 等替代品相比,这不足以运行大型 AI 模型。
- 讨论强调了 Jetson Orin Nano 在机器学习应用和分布式 LLM 节点中的潜力,一些用户指出其在 LLM 任务中比 Raspberry Pi 5 快 5 倍。然而,人们也担心其内存带宽会限制 LLM 性能,强调了 RAM 带宽对 LLM 推理的重要性。
- 与其他硬件的比较包括提到 Raspberry Pi 即将推出的 16GB 计算模块和 Apple 的 M1/M4 Mac mini,后者提供了更好的内存带宽和能效。用户辩论了 Jetson Orin Nano 的价值主张,考虑了其在机器人和机器学习中的专门用途与更通用的计算需求之间的权衡。
主题 3. ZOTAC 发布配备 32GB GDDR7 的 GeForce RTX 5090:AI 的高端潜力
- ZOTAC 确认配备 32GB GDDR7 显存的 GeForce RTX 5090,5080 和 5070 系列也已列出 - VideoCardz.com (Score: 153, Comments: 61): ZOTAC 已确认 GeForce RTX 5090 显卡,该显卡将配备 32GB 的 GDDR7 显存。此外,5080 和 5070 系列也已列出,表明其产品线即将扩张。
- 显存带宽担忧:用户对新系列(除 RTX 5090 外)的显存带宽表示失望。人们渴望更大的显存容量,特别是对于 5080,一些人希望它能有 24GB。
- 市场动态:新显卡的发布通常会导致市场上充斥着 RTX 3090 和 4090 等旧型号。由于性价比考虑和新产品的供应问题,一些用户正在考虑购买这些旧型号。
- 成本与生产见解:Nvidia 旨在实现利润最大化,这影响了更大显存模块的可用性。4090 的生产成本约为 $300,其中很大一部分归因于显存模块,这暗示了即将推出的型号中新 GDDR7 模块容量可能存在限制。
主题 4. DavidAU 的大规模混合专家 (Mixture of Experts) LLM:一次创意飞跃
- (3 models) L3-MOE-8X8B-Dark-Planet-8D-Mirrored-Chaos-47B-GGUF - 又名 The Death Star - NSFW, 非 AI 风格文本 (Score: 67, Comments: 28): DavidAU 发布了一系列新模型,包括庞大的 L3-MOE-8X8B-Dark-Planet-8D-Mirrored-Chaos-47B-GGUF,这是他目前为止最大的模型,体积达 95GB,并采用独特的 Mixture of Experts (MOE) 方法来生成创意和 NSFW 内容。该模型通过进化过程集成了 8 个版本的 Dark Planet 8B,允许用户访问这些模型的不同组合并控制性能水平。更多模型和源代码可在 Hugging Face 上获取,以供进一步探索和自定义。
- DavidAU 独立开发了这些模型,使用了一种他称之为 “merge gambling”(合并博弈)的方法,通过结合不同模型的元素并选择最佳版本进行进一步开发,从而使 Dark Planet 8B 等模型不断进化。
- 关于 NSFW benchmarking 的讨论强调了模型理解细微提示词的重要性,而不是默认输出安全或通用的内容。用户指出,成功的模型会避免 “GPT-isms”(GPT 腔),并能处理详细提示词中描述的复杂场景。
- 评论者强调了模型评估中 prose quality(散文质量)和通用智能的重要性,指出许多模型在保持角色一致性和叙事深度方面表现不佳,往往倾向于总结而非详细的叙述。
主题 5. Llama.cpp GPU 优化:骁龙笔记本获得 AI 性能提升
- Llama.cpp 现已支持骁龙 Windows 笔记本的 GPU (Score: 65, Comments: 4): Llama.cpp 现在支持骁龙 Windows 笔记本上的 GPU,特别是利用了 Qualcomm Adreno GPU。帖子作者好奇该功能何时会集成到 LM Studio 和 Ollama 等平台中,并期待 KoboldCpp 的 ARM 版本发布。更多详情可见 Qualcomm 开发者博客。
- FullstackSensei 批评为 Qualcomm Adreno GPU 添加 OpenCL 后端是多余的,认为其效率低于使用 Hexagon NPU,且尽管 token 处理速度略有提升,但会导致更高的功耗。他们强调系统瓶颈仍然在于内存带宽,约为 136GB/sec。
其他 AI Subreddit 回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
主题 1. 煎牛排挑战凸显 Google 在 AI 视频渲染领域的领先地位
- 不同视频生成模型之间的煎牛排挑战。Google Veo 以巨大优势获胜 (Score: 106, Comments: 13): Google Veo 在视频渲染方面优于竞争对手,特别是在处理手指和切割物理效果等复杂元素方面。Hunyan 排名第二,Kling 紧随其后,而 Sora 表现不佳。原始讨论可以在这篇 推文 中找到。
- Google Veo 因其逼真的渲染效果而受到赞誉,特别是在拿刀等细微细节上,使其与竞争对手相比更具人性化。用户注意到视频中对食物准备的描绘具有令人印象深刻的真实感,这表明其在烹饪素材上进行了广泛的训练。
- Hunyan Video 的质量也受到了关注,尽管幽默的评论指出了它的渲染怪癖,例如使用塑料刀。这表明虽然 Hunyan 仅次于 Google Veo,但仍有明显的改进空间。
- 讨论暗示了在不久的将来出现此类高质量视频渲染的开源版本的潜力,表达了对该领域更广泛的可访问性和创新的兴奋与期待。
主题 2. Gemini 2.0 Flash 模型凭借先进的角色扮演和上下文能力增强 AI 体验
- Gemini 2.0 Advanced 发布 (Score: 299, Comments: 54): Gemini 2.0 因其复杂的 Roleplay 能力而受到关注,其功能标记为 “1.5 Pro”、”1.5 Flash” 以及实验性选项如 “2.0 Flash Experimental” 和 “2.0 Experimental Advanced”。界面因其简洁有序的布局而备受好评,强调了每个版本的功能。
- 关于 Gemini 2.0 与 1206 和 Claude 3.5 Sonnet 等其他模型在 Coding 任务中的有效性存在争论,如果 1206 确实是 2.0,一些用户表示失望。像 Salty-Garage7777 这样的用户报告称,2.0 比 Flash 更聪明,更擅长遵循 Prompt,但在图像识别方面较差。
- 2.0 Flash 模型因其 Roleplay 能力而受到称赞,用户如 CarefulGarage3902 强调了其长 Context Length 和自定义选项。该模型因其复杂性以及调整审查过滤器和创造力的能力而比 ChatGPT 等主流替代方案更受青睐。
- 用户对 Gemini 2.0 在 Google Pixel 手机的 Gemini App 等平台上的可用性和集成情况感兴趣,尽管目前尚未上线。此外,用户正在寻求 Coding Benchmarks 以将 Gemini 2.0 与其他模型进行比较,一些人对缺乏此类数据表示沮丧。
{kind=link}
AI Discord 回顾
由 O1-mini 总结的总结之总结
主题 1. AI 模型争夺霸权
- Phi-4 在 STEM 领域超越 GPT-4: 拥有 140 亿参数 的 phi-4 模型 通过利用合成数据和先进的训练技术,在 STEM 相关的 QA 中超越了 GPT-4,证明了参数规模并非一切。
- 尽管与 phi-3 相比只有微调,但 phi-4 改进后的课程学习(Curriculum)显著提升了推理 Benchmark。
- Gemini Flash 2 提升代码生成水平: Gemini Flash 2 在科学编程任务中优于 Sonnet 3.5,特别是在数组大小调整方面,标志着代码生成 AI 进入了新纪元。
- 用户对集成外部框架以进一步增强其能力感到兴奋。
- Cohere 的 Maya 在工具使用方面表现出色: Maya 的发布引起了开发者的热议,并计划对其进行微调以增强工具利用率,以前所未有的方式突破项目边界。
主题 2. AI 工具在定价与集成方面的挑战
- Windsurf 的困扰:代码覆盖与定价难题:用户感叹 Windsurf 不仅在修改文件方面表现挣扎,还引入了令人困惑的新定价方案,使得资源管理变得更加困难。
- 建议包括集成 Git 以实现更好的版本控制,防止不必要的代码覆盖。
- Codeium 的额度危机引发混乱:Codeium 中 Flex credits 的快速消耗让用户不得不争相购买更大额度的资源包,凸显了对更清晰定价层级的需求。
- 社区正在讨论新额度限制的公平性以及付费层级的具体细节。
- Aider 的 API 发布:功能丰富但价格昂贵:O1 API 引入了诸如 reasoning effort 参数等高级功能,但用户对其相对于 Sonnet 等竞争对手的大幅涨价保持警惕。
- 建议将 O1 与 Claude 结合使用以发挥各自优势,但也引发了对响应过度自信的担忧。
主题 3. 优化 AI 部署与硬件利用
- 量化探索:8B 模型的 2-Bit 魔法:成功将一个 80 亿参数 (8B) 模型量化至 2 bits,为在受限硬件上部署更大模型打开了大门,尽管初始设置过程较为繁琐。
- 开发者对于将此方法标准化并应用于超过 32B parameters 的模型表现出极高热情。
- NVIDIA Jetson Orin Nano Super Kit 提升 AI 处理能力:定价 $249,NVIDIA 的新套件通过将神经运算提升 70% 来增强 AI processing,使业余爱好者也能获得强大的 AI 能力。
- 开发者正在探索在 AGX Orin 和 Raspberry Pi 5 等设备上部署 LLMs,以增强本地 AI 能力。
- CUDA Graphs 与异步拷贝引发计算难题:在 4090 GPU 上将 cudaMemcpyAsync 集成到 CUDA Graphs 中会导致结果不一致,这令开发者感到困惑,并促使人们深入研究 stream capture 问题。
- 目前正在进行的调查旨在解决这些差异并优化 compute throughput。
主题 4. 开发者工作流中的 AI 增强
- Cursor 扩展:Markdown 魔法与网页发布:新的 Cursor Extension 允许将 composer 和聊天历史无缝导出为 Markdown,并支持一键网页发布,极大地提升了开发者的生产力。
- 用户称赞其能够毫不费力地捕捉并分享编程交互过程。
- Aider 的 Linter 与代码管理革新工作流:通过对各种 Linter 的内置支持和可自定义的 linting 命令,Aider 为开发者在管理代码质量和 AI 驱动的编辑方面提供了无与伦比的灵活性。
- 自动 linting 功能可以切换开关,从而实现量身定制的编程体验。
- SpecStory 扩展改变 AI 编程历程:VS Code 的 SpecStory 扩展可以捕捉、搜索并学习每一次 AI 辅助编程会话,为开发者优化实践提供了一个丰富的存储库。
- 增强了对编程交互的文档记录和分析,以获得更好的学习成果。
主题 5. 社区活动与教育倡议驱动创新
- DevDay 假日版与 API AMA 盛况:OpenAI 的 DevDay Holiday Edition 直播以一场由 API 团队参与的 AMA(问我任何事)圆满结束,为开发者提供了丰富的见解和直接互动的机会。
- 社区成员热切期待关于 API 紧迫问题的解答以及未来功能的发布。
- Code Wizard 黑客松为二月热潮寻求赞助:组织者正在为即将于 2025 年 2 月举行的 Code Wizard 黑客松寻找赞助,旨在促进参与者的创新和问题解决能力。
- 尽管有人质疑资金需求,但许多人强调了黑客松在构建有价值的技术项目方面的作用。
- LLM Agents MOOC 延长提交截止日期:Hackathon 提交截止日期延长 48 小时至 12 月 19 日,明确了提交流程,并为参与者提供了额外时间来完善他们的 AI agent 项目。
- MOOC 网站改进后的移动端响应能力获得了赞誉,有助于参与者展示他们的创新成果。
PART 1: 高层级 Discord 摘要
Codeium / Windsurf Discord
- Windsurf 在文件修改方面遇到困难:用户报告称 Windsurf 无法有效地修改或编辑文件,一位用户形容其在最近更新后变得“更笨了”。
- 讨论强调了资源耗尽错误以及对新定价方案引入的困惑。
- 对 Codeium 定价模式的困惑:成员询问如何购买更大额度的 Flex credits,并指出尽管他们努力管理使用情况,消耗依然很快。
- 对话集中在最新设立的额度限制以及不同付费层级的细节上。
- 性能对决:Windsurf vs Cursor:参与者对比了 Windsurf 和 Cursor,观察到两个平台都提供类似的 agent 功能,但在 context 使用策略上有所不同。
- Windsurf 执行严格的额度限制,而 Cursor 在达到一定的 premium 使用量后提供无限次的慢速查询,一些用户认为后者更人性化。
- Windsurf 代码管理中的挑战:用户对 Windsurf 倾向于覆盖代码并引入幻觉错误表示沮丧,这使开发过程变得复杂。
- 建议集成 Git 进行版本控制,以便更好地管理更改并实现可逆性。
- 评估 Gemini 2.0 与 Windsurf 的集成:工程师们正在评估 Gemini 2.0 与 Windsurf 的结合,注意到其在 context 方面的显著优势,但在输出质量方面评价褒贬不一。
- 虽然 Gemini 2.0 提供了更大的 context window,但一些用户观察到在超过特定 token 限制后性能会有所下降。
Nous Research AI Discord
- phi-4 模型在 STEM QA 中表现优于 GPT-4:拥有 140 亿参数的 phi-4 模型通过整合合成数据和增强的训练方法,在以 STEM 为重点的 QA 中超越了 GPT-4。
- 尽管在架构上与 phi-3 有细微相似之处,但 phi-4 在推理基准测试中表现出强劲的性能,这归功于其修订后的训练课程和后训练技术。
- 8B 模型实现有效的 2-bit 量化:一个 80 亿参数的模型成功量化至 2 bits,尽管初始设置复杂,但展示了作为更大模型标准的潜力。
- 这一进展表明超过 32B 参数的模型可用性将得到增强,成员们对其在未来草案中的适用性表示乐观。
- Gemini 在采样算法中使用 Threefry:成员们讨论了 LLM 采样中是否使用了 Xorshift 或其他算法,其中一人指出 Gemma 使用的是 Threefry。
- PyTorch 采用 Mersenne Twister 与 Gemini 的方法形成对比,突显了不同 AI 框架之间采样技术的差异。
- Hugging Face 推进推理时计算(Test-Time Compute)策略:Hugging Face 在推理时计算方法上的最新工作受到称赞,特别是他们在计算效率方面的扩展方法。
- 一篇 Hugging Face 博客文章 深入探讨了他们的策略,促进了社区的理解并获得了积极反响。
aider (Paul Gauthier) Discord
- O1 API 全面发布:即将推出的 O1 API 引入了 reasoning effort parameters(推理力度参数)和 system prompts(系统提示词)等功能,增强了 AI 能力。
- 用户预计价格相比 Sonnet 会有显著上涨,对 O1 API 可能带来的成本支出表现出复杂的情绪。
- O1 与 Claude 提升 AI 性能:O1 模型在特定提示词下展现了增强的响应能力,同时用户建议将其与 Claude 结合使用,以发挥两种模型的各自优势。
- 尽管性能有所提升,但 O1 模型在某些情况下会表现出过度自信,引发了关于模型最佳使用方式的讨论。
- Aider 的 Linter 与代码管理:Aider 内置支持多种 Linter,并允许通过
--lint-cmd选项进行自定义,详见 Linting and Testing 文档。- 用户可以切换自动 Linting 功能,在 AI 驱动的代码编辑过程中灵活管理代码质量。
- Claude 模型限制:Claude 模型被指出在生成某些输出时较为犹豫,且倾向于提供过于谨慎的回答。
- 用户强调需要更明确的引导才能获得理想结果,突出了提示词具体性的重要性。
- Aider 与 LM Studio 的集成:Aider 在与 LM Studio 集成时面临挑战,包括由于缺少 LLM 提供商而导致的 BadRequestError 等错误。
- 用户在排查故障时发现,通过将 OpenAI 提供商格式配置为
openai/qwen-2.5-coder-7b-instruct-128k可实现成功集成。
- 用户在排查故障时发现,通过将 OpenAI 提供商格式配置为
Notebook LM Discord Discord
- 新 UI 推送提升用户体验:今天早上,团队宣布向所有用户推送 新 UI 和 NotebookLM Plus 功能,这是提升平台用户体验的持续努力的一部分。公告详情。
- 然而,部分用户对新 UI 表示不满,指出聊天面板的可见性和笔记布局存在问题,而另一些用户则赞赏更大的编辑器,并建议通过折叠面板来提高可用性。
- NotebookLM Plus 通过 Google 服务扩大访问范围:NotebookLM Plus 现在可以通过 Google Workspace 和 Google Cloud 访问,并计划在 2025 年初向 Google One AI Premium 用户开放。升级信息。
- 关于其在 意大利 和 巴西 等国家可用性的问题,官方回应称正在全球范围内逐步推广。
- Interactive Audio BETA 仅限早期采用者:Interactive Audio 目前仅对部分选定用户开放,后端改进正在进行中。在过渡期间,没有 Interactive mode (BETA) 访问权限的用户无需担心。Interactive Audio 详情。
- 多位用户反映 Interactive Mode 功能存在困难,称即使更新到新 UI 后仍存在延迟和访问问题,表明该功能仍在推送中。
- 呼叫中心 AI 集成讨论:成员们探讨了将 AI 集成到 IT 呼叫中心的可能性,包括一段关于德语 AI 处理客户查询的幽默讨论,并分享了演示计算机故障排除和冷启动销售电话等场景的音频剪辑。使用案例。
- 讨论强调了通过 AI 实施提升客户服务效率的潜力。
- NotebookLM 扩展多语言支持:用户询问了 NotebookLM 生成播客的多语言能力,确认目前 音频摘要 仅支持 英语。常规频道。
- 尽管有此限制,葡萄牙语 内容的成功生成表明未来更新中可能支持更广泛的语言。
Unsloth AI (Daniel Han) Discord
- Phi-4 在 STEM 问答中超越 GPT-4:phi-4 是一个拥有 140 亿参数的语言模型,它利用强调数据质量的训练策略,在整个开发过程中整合了合成数据,使其在以 STEM 为重点的问答能力方面表现出色,超越了其教师模型 GPT-4。
- 尽管自 phi-3 以来架构变化极小,但该模型在推理基准测试中的表现突显了改进的训练课程,详情见 Continual Pre-Training of Large Language Models。
- Unsloth 4-bit 模型显示出性能差距:用户报告了 Unsloth 4-bit 模型与原始 Meta 版本之间在层大小上的差异,突显了模型参数化的潜在问题。
- 用户对从 4-bit 转换到全精度(full precision)时的 VRAM 占用和性能权衡表示担忧,如 Qwen2-VL-7B-Instruct-unsloth-bnb-4bit 仓库中所讨论的。
- Qwen 2.5 微调面临灾难性遗忘:一位成员表示,他们微调后的 Qwen 2.5 模型表现不如原始版本,并将这种下降归因于灾难性遗忘(catastrophic forgetting)。
- 其他成员建议对微调过程进行迭代,以更好地与特定目标对齐,并强调了定制化调整的重要性。
- 增强 Llama 3.2 中的函数调用:参与者探索了训练 Llama 3.2 以提高 function calling 能力的方法,但注意到缺乏直接的实现示例。
- 大家达成共识,认为将 special tokens 直接整合到数据集中可以简化训练过程,参考 Llama Model Text Prompt Format。
- 在 Unsloth 中优化 Lora+:成员们讨论了将 Lora+ 与 Unsloth 集成,观察到与其他方法的潜在不兼容性,并建议使用 LoFTQ 或 PiSSA 等替代方案以获得更好的初始化。
- 一位成员通过一篇 CPT 博客文章 强调了 Unsloth 最新版本中的性能改进,并突出了这些优化的好处。
Cohere Discord
- Cohere 提升多模态图像嵌入速率:Cohere 已将 Multimodal Image Embed 端点的速率限制提高了 10 倍,将生产密钥从 40 images/min 提升至 400 images/min。阅读更多
- 测试版用户仍限制在 5 images/min 以进行测试,这使得在不使系统过载的情况下进行应用开发和社区分享成为可能。
- Maya 发布增强了工具利用率:Maya 的发布受到了成员们的欢迎,激发了探索并可能针对 tool use 对其进行微调的热情。成员们致力于利用新模型突破项目边界。
- 社区计划进行广泛的测试和定制,旨在将 Maya 的能力有效地整合到他们的工作流中。
- 优化 Cohere API 密钥管理:Cohere 提供两种类型的 API 密钥:免费但有限制的评估密钥(evaluation keys),以及付费且限制较少的生产密钥(production keys)。用户可以通过 API keys 页面管理他们的密钥。
- 这种结构允许开发人员高效地启动项目,同时随着应用程序的增长使用生产密钥进行扩展。
- 使用嵌入进行图像检索的策略:为了实现基于用户查询的图像检索,一位成员建议在 Pinecone 向量数据库中将图像路径作为元数据与嵌入(embeddings)一起存储。这使得系统在嵌入匹配查询时能够显示正确的图像。
- 通过利用嵌入进行语义搜索(semantic search),检索过程变得更加准确和高效,从而提升了用户体验。
- 为 Code Wizard 黑客松寻求赞助:Code Wizard 黑客松的组织者正在积极为定于 2025 年 2 月举行的活动寻求赞助,旨在培养参与者的创新和解决问题的能力。
- 虽然一些参与者质疑资金的必要性,但其他人强调了该活动在构建有价值的项目和提升技术技能方面的作用。
Bolt.new / Stackblitz Discord
- 带有模型选择功能的 Bolt UI 版本:一位成员宣布推出了 Bolt 的 UI 版本,允许用户在托管于 Hyperbolic 的 Claude、OpenAI 和 Llama 模型之间进行选择。此次更新旨在通过提供多样化的模型选项来增强生成过程。
- 新 UI 旨在提升用户体验并简化模型选择,从而实现更具定制化且高效的项目工作流。
- 有效管理 Token:用户对 Bolt 中 Token 的使用和管理表示关注,强调了对意外消耗的挫败感。
- 会议强调了每月 Token 使用量存在限制,用户应留意更换成本,以避免超出配额。
- Bolt 集成面临的挑战:多位用户报告了 Bolt 的集成问题,例如平台生成不必要的文件以及在执行命令时遇到错误。
- 为了缓解挫败感,一些用户建议在使用平台期间适当休息,强调了在不过度劳累的情况下保持生产力的重要性。
- 用于 SaaS 项目的 Bolt:成员们表达了利用 Bolt 开发 SaaS 应用的兴趣,并认识到需要开发者协助以进行有效的扩展和集成。
- 一位用户寻求关于使用 Bolt 管理 SaaS 项目的分步指导,表明对更全面的支持资源存在需求。
- 编码问题的支持与协助:用户在 Bolt 内部寻求编码挑战的支持,特别是针对其 Python 代码的帮助请求。
- 社区成员提供了关于调试技术的建议,并推荐了在线资源以改进编码实践。
Eleuther Discord
- 基于 Pythia 的 RLHF 模型:general 频道的成员询问了是否有公开可用的基于 Pythia 的 RLHF 模型,但讨论中未推荐具体模型。
- TPU v5p 上的 TensorFlow:一位用户报告 TensorFlow 在 TPU v5p 上出现分段错误(segmentation faults),称
import tensorflow在多个 VM 镜像中均会导致错误。- 针对 Google 在持续的技术挑战中对 TensorFlow 支持力度减弱的问题,用户表达了担忧。
- SGD-SaI 优化器方法:在 research 频道中,SGD-SaI 的引入提出了一种在没有自适应矩(adaptive moments)的情况下增强随机梯度下降的新方法,取得了与 AdamW 相当的效果。
- 参与者强调需要与成熟的优化器进行公正的比较,并建议在训练阶段动态调整学习率。
- Stick Breaking 注意力机制:research 频道的讨论涵盖了 Stick Breaking Attention,这是一种自适应聚合注意力分数的技术,旨在减少模型中的过度平滑(oversmoothing)效应。
- 成员们辩论了这些自适应方法是否能更好地处理 Transformer 架构中学习表征的复杂性。
- Grokking 现象:最近的一篇论文通过将神经网络复杂度与泛化联系起来讨论了 Grokking 现象,并引入了一个基于 Kolmogorov 复杂度的指标。
- 该研究旨在辨别模型何时处于泛化与何时处于记忆状态,可能为训练动力学提供结构化的见解。
Cursor IDE Discord
- Cursor Extension 发布增强生产力:Cursor Extension 现在允许用户将 composer 和聊天历史导出为 Markdown,从而提高生产力并方便内容共享。
- 此外,它还包含一个将内容发布到 Web 的选项,能够有效捕获编码交互。
- O1 Pro 高效自动化编码任务:
@mckaywrigley报告称 O1 Pro 成功执行了 6 个任务,修改了 14 个文件,并在 5分25秒 内使用了 64,852 个 input tokens,实现了 100% 的正确率并节省了 2 小时。- 这展示了 O1 Pro 在简化复杂编码工作流方面的潜力。
- RAPIDS cuDF 无需修改代码即可加速 Pandas:@NVIDIAAIDev 的推文 宣布 RAPIDS cuDF 可以在不修改任何代码的情况下将 pandas 操作加速高达 150倍。
- 开发者现在可以在 Jupyter Notebooks 中处理更大的数据集,正如其 demo 中所示。
- SpecStory 扩展集成 AI 编码历程:适用于 Visual Studio Code 的 SpecStory 扩展提供了从每一次 AI coding journey 中捕获、搜索和学习的功能。
- 该工具增强了开发者有效记录和分析其编码交互的能力。
OpenAI Discord
- DevDay 节日版和 API 团队 AMA:DevDay Holiday Edition YouTube 直播 Day 9: DevDay Holiday Edition 已排期,可在此处观看。
- 直播之后将与 OpenAI 的 API 团队进行 AMA,计划于太平洋时间上午 10:30–11:30 在开发者论坛举行。
- AI 口音模仿与现实感局限:用户讨论了 AI 在多种语言和口音之间切换的能力,例如模仿澳洲口音,但交互感仍然显得不自然。
- 参与者指出,虽然 AI 可以模仿口音,但由于准则限制,它经常会拒绝某些出于礼貌的交互请求。
- 自定义 GPT 编辑与功能问题:多位用户报告称失去了编辑自定义 GPT 的能力,并且尽管进行了多次设置,仍无法访问它们。
- 这似乎是一个已知问题,其他面临类似自定义 GPT 配置问题的用户也证实了这一点。
- Anthropic 调整定价模型:Anthropic 调整了其定价模型,随着 API 引入 prompt caching,价格变得更低。
- 用户对这一转变将如何影响他们的使用以及与 OpenAI 产品的竞争表示好奇。
OpenRouter (Alex Atallah) Discord
- OpenRouter 新增对 46 个模型的支持:OpenRouter 现在支持 46 个模型 的结构化输出(structured outputs),增强了多模型应用的开发。该 demo 展示了结构化输出如何将 LLM 输出约束为 JSON schema。
- 此外,结构化输出在 8 家模型公司和 8 个免费模型之间实现了标准化,有助于更顺畅地集成到应用中。
- Gemini Flash 2 表现优于 Sonnet 3.5:在科学问题解决任务中,Gemini Flash 2 生成的代码优于 Sonnet 3.5,尤其是在数组大小调整(array sizing)场景中。
- 反馈表明,集成外部框架可以进一步提升其在特定用例中的有效性。
- 尝试通过拼写错误影响 AI 回复:成员们正在探索在 prompts 中使用故意拼写的错误和无意义词汇来引导模型输出,这可能对创意写作有益。
- 该技术旨在将模型注意力引导至特定关键词,同时通过思维链(Chain of Thought, CoT)方法保持受控的输出。
- o1 API 减少 60% 的 token 使用量:o1 API 现在的 token 消耗减少了 60%,引发了对其对模型性能影响的关注。
- 用户讨论了定价调整和提高 token 效率的需求,并指出当前的 tier 限制仍然适用。
- API key 泄露与报告:一位成员报告了 GitHub 上暴露的 OpenRouter API keys,引发了关于正确报告渠道的讨论。
- 建议联系 support@openrouter.ai 以处理泄露密钥带来的任何安全风险。
Perplexity AI Discord
- Perplexity 推出 Pro 礼品订阅服务:Perplexity 现在提供为期 1、3、6 或 12 个月的礼品订阅,可在此处购买,使用户能够解锁更强大的搜索功能。
- 订阅将通过优惠码(promo codes)直接发送至接收者的电子邮箱,并注明所有销售均为最终销售,以确保购买承诺。
- 关于 OpenAI 借鉴 Perplexity 功能的辩论:用户们就 OpenAI 是在创新还是在抄袭 Perplexity 的功能(如 Projects 和 GPT Search)展开了辩论,引发了关于 AI 开发原创性的讨论。
- 一些成员认为功能复制在各平台间很常见,并就如何保持 AI 工具的独特价值主张展开了对话。
- Mozi 应用在社交媒体的热议中发布:Ev Williams 发布了新的社交应用 Mozi,其全新的社交网络方式正引起关注,详见这段 YouTube 视频。
- 该应用承诺提供创新功能,引发了关于其对现有社交媒体平台潜在影响的讨论。
- 对模型性能下降的担忧:用户对 Sonnet 和 Claude 模型的变体表示失望,认为感知到的性能下降影响了回答质量。
- 在特定模型之间切换导致了不一致的用户体验,突显了对模型优化透明度的需求。
- Gemini API 集成增强了 Perplexity 的产品力:通过 OpenAI SDK 实现的新 Gemini 集成允许与多个 API 进行无缝交互,可通过 Gemini API 访问。
- 这种集成通过简化对包括 Gemini、OpenAI 和 Groq 在内的多种模型的访问来提升用户体验,Mistral 支持也即将推出。
Latent Space Discord
- Palmyra Creative 发布 128k 上下文版本:新的 Palmyra Creative 模型通过 128k 上下文窗口增强了创意业务任务,适用于头脑风暴和分析。
- 它与特定领域模型无缝集成,服务于从营销人员到临床医生的专业人士。
- OpenAI API 推出支持 Function Calling 的 O1:OpenAI 在小型开发者日上宣布了更新,包括支持 Function Calling 的 O1 实现以及新的语音模型功能。
- 用于实时语音应用的 WebRTC 支持和显著的输出 Token 增强是主要亮点。
- NVIDIA 发布 Jetson Orin Nano Super 套件:NVIDIA 的 Jetson Orin Nano Super 开发人员套件提升了 AI 处理能力,神经处理性能提升了 70% 达到 67 TOPS,并拥有 102 GB/s 内存带宽。
- 售价为 $249,旨在为爱好者提供高性价比的 AI 能力。
- Aidan McLau 澄清 O1 与 O1 Pro 的区别:Aidan McLau 澄清说,O1 Pro 是与标准 O1 模型不同的实现,专为更高的推理能力而设计。
- 这一区分引发了社区关于这些模型之间潜在功能混淆的问题。
- Anthropic API 将四项功能移出 Beta 阶段:Anthropic 宣布其 API 的四项新功能正式商用(GA),包括 Prompt Caching 和 PDF 支持。
- 这些更新旨在增强开发者体验并促进 Anthropic 平台上的更顺畅运营。
LM Studio Discord
- Zotac 的 RTX 50 抢先看:Zotac 意外在其网站上列出了即将推出的 RTX 5090、RTX 5080 和 RTX 5070 GPU 系列,在正式发布前揭晓了 32GB GDDR7 显存等先进规格。
- 这次意外泄露在社区内引发了轰动,证实了 RTX 5090 令人印象深刻的规格,并增加了对 Nvidia 下一代硬件的期待。
- AMD 驱动困境:用户报告了 24.12.1 AMD driver 的问题,该驱动导致性能下降和 GPU 占用率飙升,且未能有效利用功耗。
- 回退到 24.10.1 版本解决了这些卡顿问题,使各种模型的性能提升至 90+ tokens/second。
- TTS 之梦:LM Studio 的下一步:一位用户对在 LM Studio 中集成 text to speech 和 speech to text 功能表示乐观,目前已有替代方案作为临时解决方法。
- 另一位成员建议将这些工具作为服务器与 LM Studio 并行运行,以实现所需功能,从而增强整体用户体验。
- 去审查聊天机器人:新选择:关于寻找去审查聊天机器人 (uncensored chatbot) 替代方案的讨论不断涌现,推荐了可以在 CPU 上运行的 Gemma2 2B 和 Llama3.2 3B 等模型。
- 成员们获得了有效使用这些模型的资源,包括量化 (quantization) 选项的链接,以优化其性能。
- GPU 大对决:3070 Ti vs 3090:用户观察到 RTX 3070 Ti 和 RTX 3090 在游戏中的表现相似,尽管价格区间相当。
- 一位成员提到能以约 750 美元的价格买到 3090,而另一位成员则提到当地价格在 900 加元左右,凸显了市场价格的差异。
Stability.ai (Stable Diffusion) Discord
- 顶尖 Stable Diffusion 课程:一位成员正在寻找综合性的在线课程,这些课程汇集了 YouTube 教程,用于学习使用 A1111 的 Stable Diffusion。
- 社区强调了获取 Stable Diffusion 易用教育资源的必要性。
- AI 任务中的笔记本 vs 台式机:一位用户正在评估 4090 笔记本和 4070 TI Super 台式机(均配备 16GB VRAM)在 AI 任务中的表现。
- 成员们建议台式机更适合繁重的 AI 工作负载,并指出笔记本更适合游戏,但不适合高强度的图形任务。
- 机器人检测策略:讨论集中在识别诈骗机器人的技术上,例如询问荒谬的问题或采用“土豆测试 (potato test)”。
- 参与者强调机器人和人类都可能带来风险,需要谨慎互动。
- 创建你自己的 Lora 模型:一位用户请求关于构建 Lora 模型的指导,并收到了包括数据集创建、模型选择和训练在内的分步方法。
- 重点放在了研究用于训练目的的有效数据集创建上。
- 最新 AI 模型:Flux.1-Dev:一位回归成员询问了当前的 AI 模型,特别提到了 Flux.1-Dev 及其硬件要求。
- 社区提供了关于热门模型使用情况和必要实现要求的更新。
GPU MODE Discord
- CUDA Graphs 与 cudaMemcpyAsync 的兼容性:成员们确认 CUDA Graph 支持 cudaMemcpyAsync,但将它们集成会导致应用程序结果不一致,特别是在 4090 GPU 上会影响计算吞吐量。更多详情
- 一份报告的问题指出,在 CUDA Graph 模式下使用 cudaMemcpyAsync 会导致错误的应用程序结果,而 kernel copies 则能正常工作。目前正在通过最小示例进行进一步调查,以解决这些差异。
- 优化 PyTorch Docker 镜像:讨论显示官方 PyTorch Docker 镜像大小在 3-7 GB 之间,有可能通过使用 30MB Ubuntu 基础镜像配合 Conda 管理 CUDA 库来减小体积。GitHub 指南
- 随后引发了关于是否有必要结合使用 Conda 和 Docker 的辩论,支持者认为这有助于在不同的开发环境中保持安装的一致性。
- NVIDIA Jetson Nano Super 发布:NVIDIA 推出了 Jetson Nano Super,这是一款紧凑型 AI 计算机,可为机器人应用提供每秒 70-T 次操作,售价 $249,并支持 LLMs 等先进模型。推文
- 用户讨论了通过 SDK Manager 使用 JetPack 6.1 来增强 Jetson Orin 的性能,并在 AGX Orin 和 Raspberry Pi 5 等设备上部署 LLM inference,后者利用 nvme 256GB 来加速数据传输。
- 使用 Axolotl 和 TRL 进行 VLM 微调:分享了使用 Axolotl、Unslosh 和 Hugging Face TRL 进行 VLM fine-tuning 的资源,包括一份微调教程。
- 该过程被指出是资源密集型的,需要大量的计算能力,这被强调为实现高效集成时需要考虑的因素。
- Chain of Thought 数据集生成:团队启动了一个 Chain of Thought (CoT) dataset generation 项目,旨在评估哪种 CoT 形式能最有效地提升模型性能,并利用 reinforcement learning 进行优化。
- 该实验旨在确定 CoT 是否能解决超出直接转导(direct transduction)方法能力的谜题,初步进展显示已解决 119 个谜题,并有望通过强大的验证器(verifiers)进一步改进。
Modular (Mojo 🔥) Discord
- MAX 24.6 携 MAX GPU 发布:今天,MAX 24.6 正式发布,推出了备受期待的 MAX GPU。这是一个垂直集成的生成式 AI 堆栈,无需再使用 NVIDIA CUDA 等特定厂商的库。欲了解更多详情,请访问 Modular 博客。
- 此版本解决了大规模生成式 AI 日益增长的资源需求,为增强 AI 开发铺平了道路。
- Mojo v24.6 发布:最新版本的 Mojo (v24.6.0) 已经发布并可供使用,可通过命令
% mojo --version确认。社区对新功能表现出极大的热情。- mojo 频道的用户们渴望探索这些更新,显示出强烈的社区参与度。
- 推出 MAX Engine 和 MAX Serve:MAX Engine 和 MAX Serve 随 MAX 24.6 一同推出,提供了一个高速 AI 模型编译器和一个针对大语言模型 (LLMs) 的 Python 原生服务层。这些工具旨在提升 AI 工作负载的性能和效率。
- MAX Engine 具有针对 NVIDIA GPU 优化的厂商无关的 Mojo GPU kernels,而 MAX Serve 则简化了高负载场景下 LLMs 的集成。
- Mojo 确认支持 GPU:继最近的 24.6 版本之后,即将发布的 Mojo v25.1.0 nightly 版本确认将包含 GPU support。这一加入展示了 Mojo 平台持续的增强。
- 社区期待随着 GPU 支持的加入,复杂 AI 工作负载的性能和可扩展性将得到提升。
- Mojo REPL 在 Archcraft Linux 上遇到问题:一位用户报告在 Archcraft Linux 上进入 Mojo REPL 时遇到问题,理由是缺少动态链接库,可能是
mojo-ldd或mojo-lld。- 此外,该用户在安装 Python 依赖时也遇到了困难,提到了与处于外部管理环境(externally managed environment)相关的错误。
LlamaIndex Discord
- 探索 NVIDIA NV-Embed-v2 的可用性:成员们研究了 NVIDIA Embedding 中 NVIDIA NV-Embed-v2 的可用性,利用
embed_model.available_models功能来验证可访问的模型。- 有人指出,即使 NV-Embed-v2 没有被明确列出,它仍可能正常工作,因此需要进行额外测试以确认其可用性。
- 在工作流中集成 Qdrant Vector Store:一位用户寻求将 Qdrant vector store 集成到其工作流中的帮助,并提到了在现有集合和查询执行方面遇到的挑战。
- 另一位成员提供了 文档示例 并表示他们没有遇到类似问题,建议进行进一步排查。
- 解决 OpenAI LLM 双重重试问题:Paullg 对 OpenAI LLM 中潜在的双重重试问题表示担忧,指出 OpenAI 客户端和
llm_retry_decorator可能都在独立实现重试逻辑。- 讨论随后集中在最近的一个 pull request 是否解决了此问题,参与者对拟议更改的有效性表示不确定。
- LlamaReport 增强文档可读性:LlamaReport 目前处于预览阶段,可在几分钟内将文档数据库转换为结构良好、人类可读的报告,从而促进对文档集的有效问答。更多详情请见 公告帖子。
- 该工具旨在通过优化输出过程来简化文档交互,使用户更容易导航和利用其文档数据库。
- Agentic AI SDR 助力线索生成:新推出的 agentic AI SDR 利用 LlamaIndex 来生成线索,展示了 AI 在销售策略中的实际集成。其 代码 已开放供实现。
- 这一进展是 Quickstarters 计划的一部分,该计划通过示例项目和实际应用协助用户探索 Composio 的功能。
Nomic.ai (GPT4All) Discord
- GPT4All v3.5.3 发布,包含关键修复:GPT4All v3.5.3 版本已正式发布,解决了之前版本的显著问题,包括针对 v3.5.2 中运行异常的 LocalDocs 的关键修复。
- Nomic AI 的 Jared Van Bortel 和 Adam Treat 因对此次更新的贡献而受到认可,提升了 GPT4All 的整体功能。
- 新版本恢复 LocalDocs 功能:阻止 LocalDocs 在 v3.5.2 中正常运行的严重问题已在 GPT4All v3.5.3 中成功解决。
- 用户现在在使用 LocalDocs 进行文档处理时可以期待更好的性能和可靠性。
- 通过 YouTube 演示探索 AI Agent 能力:讨论中提到了通过 GPT4All 运行“AI Agent”的可能性,并链接到了一个展示其能力的 YouTube 视频。
- 一位成员指出,虽然技术上可行,但它主要作为一个生成式 AI 平台,功能有限。
- Jinja Template 问题困扰 GPT4All 用户:一位成员报告称,由于 Jinja template 问题,GPT4All 对他们来说几乎完全无法使用,希望该问题能尽快得到解决。
- 另一位成员强调了 Jinja templates 对模型交互至关重要,目前正在改进工具调用(tool calling)功能。
- API 文档请求凸显 GPT4All 的空白:有人请求提供包含端点和参数详情的完整 API 文档,并引用了现有的 GPT4All API 文档。
- 成员们分享了激活本地 API 服务器只需简单的步骤,但他们认为文档缺乏全面性。
OpenInterpreter Discord
- 关于 Gemini 2.0 Flash 的提问:用户正在询问 Gemini 2.0 Flash 的功能,并强调了目前缺乏响应和支持的问题。
- 这表明在 OpenInterpreter 社区中,该功能的用户体验或支持可能存在缺口。
- 关于 VEO 2 和 SORA 的辩论:成员们在争论 VEO 2 是否优于 SORA,并指出这两种 AI 目前在他们所在的地区都不可用。
- 可用性的缺失表明了用户的兴趣,同时也反映了他们想要探索这些选项时的挫败感。
- OpenInterpreter 与 Web Assembly 的集成:一位用户提议使用 Web Assembly 以及 Pyodide 或 Emscripten 等工具在网页中运行 OpenInterpreter 项目。
- 这种方法可以提供自动沙箱化 (auto-sandboxing) 并消除对计算调用的需求,从而增强在聊天 UI 环境下的可用性。
- OpenInterpreter 中 OS 的本地使用:有关于在 OpenInterpreter 中本地利用 OS 的咨询,用户寻求关于 OS 具体涵盖内容的澄清。
- 这反映了用户对增强功能和本地执行能力的持续兴趣。
- Open Interpreter 错误排查:一名成员报告了在使用带有
-y标志的代码时持续出现的错误,特别是与设置 OpenAI API key 相关的问题。- 这突显了用户面临的常见挑战,以及对错误处理提供更清晰指导的需求。
Torchtune Discord
- Torcheval 的批量指标同步简化了工作流:一位成员对 Torcheval 的批量指标同步 (batched metric sync) 功能以及无需额外依赖表示满意,认为它是一个非常愉快的工具。
- 这种精简的方法 提高了生产力并降低了处理指标时的复杂性。
- 指令微调损失计算中的挑战:一位成员对指令微调 (Instruction Fine-Tuning) 中的每个 token 损失 (per-token loss) 计算提出了担忧,指出由于 token 数量不同,一个句子的损失取决于 batch 中的其他句子。
- 这种方法似乎是标准做法,但也带来了社区必须去适应的挑战。
- GenRM 验证器模型提升 LLM 性能:最近的一篇 论文 提议使用基于 next-token prediction 训练的生成式验证器 (GenRM),通过将解决方案生成与验证相结合,来增强 LLM 的推理能力。
- 这种方法可以实现更好的指令微调,并具有通过多数投票改进计算的潜力,提供了优于标准 LLM 分类器的优势。
- Sakana AI 的通用 Transformer 内存优化:Sakana AI 的研究人员开发了一种优化 LLM 内存使用的技术,允许企业显著降低在 Transformer 模型上开发应用的成本。
- 通用 Transformer 内存 (universal transformer memory) 技术在丢弃冗余的同时保留关键信息,从而提高了模型效率。
- 8B 验证器性能分析与社区反应:针对使用 8B 奖励/验证器模型 的担忧被提出,一位成员指出,在性能讨论中不应忽视训练此类模型的计算成本和复杂性。
- 另一位成员幽默地将该方法比作“让猴子打字,然后让人类挑选最好的一个”,暗示这可能具有误导性,并表示需要更广泛的实验。
LLM Agents (Berkeley MOOC) Discord
- Hackathon 截止日期延长 48 小时:Hackathon 提交截止日期已延长 48 小时,至 太平洋时间 12 月 19 日晚上 11:59。
- 此次延期旨在消除关于提交过程的困惑,并让参赛者有更多时间完善他们的项目。
- 明确 Hackathon 提交流程:提醒参赛者应通过 Google Form 提交,而不是通过 Devpost 网站。
- 这一说明对于确保所有项目正确提交至关重要。
- LLM Agents MOOC 网站完成移动端适配:一位成员对 LLM Agents MOOC 网站进行了翻新,以获得更好的移动端响应能力,并在此链接分享了更新版本。
- 希望这能成为回馈 MOOC/Hackathon 的一种方式。 另一位用户称赞了该设计,并表示计划将其分享给工作人员。
- 证书截止日期确认至 12/19:一位用户询问了证书提交截止日期,因为不确定是否会延期。
- 另一位成员确认 MOOC 没有截止日期变更,并强调提交表单将一直开放到 12/19 以方便大家。
tinygrad (George Hotz) Discord
- 探索通过 USB 连接 GPU:#general 频道的一位用户询问了通过 USB 端口连接 GPU 的事宜,引用了一条推文,George Hotz 回复道:“我们的驱动程序应该允许这样做”。
- 这次讨论凸显了社区对扩展 tinygrad 应用的硬件兼容性的兴趣。
- Mac ARM64 后端访问仅限于 CI:在 #general 中,一位用户寻求访问 Mac 以进行 arm64 backend 开发,但 George 澄清说,这些系统仅指定用于持续集成 (CI)。
- 这一澄清强调了 Mac infrastructure 目前保留用于运行 benchmark 测试,而非通用开发用途。
- 持续集成侧重于 Mac Benchmarks:Mac Benchmark 作为项目持续集成 (CI) 流程的关键部分,专注于性能评估。
- 这种方法强调了团队利用特定硬件配置以确保稳健性能指标的策略。
Axolotl AI Discord
- 扩展测试时计算 (Scaling Test Time Compute) 分析:一位成员分享了讨论 scaling test time compute 的 Hugging Face 博客文章,他们认为这篇文章令人耳目一新。
- 这篇文章引发了社区对扩展测试效率的兴趣。
- 3b 模型在数学方面优于 70b:一位成员指出 3b 模型在数学方面的表现优于 70b 模型,称这既疯狂又意义重大。
- 这一观察引发了关于小模型出人意料的效率的讨论。
- 仓库中缺失 Optim 代码:一位成员对开发者仓库中缺少实际的 optim 代码表示担忧,该仓库仅包含 benchmark 脚本。
- 他们强调了在使用该仓库时遇到的困难,并表示正在努力解决该问题。
- 当前工作量阻碍了贡献:一位成员因无法做出贡献而道歉,理由是还有其他任务和 bug 修复。
- 这凸显了社区内开发与协作的繁忙本质。
- 社区对更新表示感谢:在持续的讨论中,一位成员感谢了另一位成员的更新。
- 这反映了频道积极且相互支持的氛围。
DSPy Discord
- 自主 AI 提升知识工作者效率:最近的一篇 论文 讨论了 自主 AI 如何通过自动化常规任务来提高知识工作者的效率,从而提升整体生产力。
- 研究显示,虽然最初的研究集中在 chatbots 辅助低技能工人,但 Agentic AI 的出现将优势转向了更高技能的个人。
- AI 运营模式改变劳动力动态:该论文介绍了一个框架,其中 AI Agent 可以自主或非自主运行,导致等级制公司内部劳动力动态的重大转变。
- 报告指出,基础自主 AI 可以将人类置换到专业化角色中,而 高级自主 AI 则将劳动力重新分配到常规任务中,从而产生规模更大、生产力更高的组织。
- 非自主 AI 赋能知识较少的人群:非自主 AI(如 chatbots)为知识较少的人群提供负担得起的专家协助,在不竞争大型任务的情况下增强其解决问题的能力。
- 尽管被认为是有益的,但随着 AI 技术的不断演进,自主 Agent 支持 知识工作者 的能力提供了一种竞争优势。
Mozilla AI Discord
- 超低依赖应用的最终 RAG 活动:明天是 12 月的最后一场活动,参与者将在 Alex Garcia 的带领下,学习仅使用 sqlite-vec、llamafile 和基础 Python 创建 超低依赖检索增强生成 (RAG) 应用。
- 该课程不需要额外的依赖项或 ‘pip install’,强调 RAG 开发的简洁与高效。
- Developer Hub 和 Blueprints 的重大更新:发布了关于 Developer Hub 和 Blueprints 的重要公告,提醒用户刷新关注。
- 随着社区探索关于 Blueprints 的讨论帖,反馈正受到重视,旨在帮助开发者构建开源 AI 解决方案。
MLOps @Chipro Discord
- 数据基础设施年终回顾:请在 12 月 18 日 加入我们的回顾小组,创始人 Yingjun Wu、Stéphane Derosiaux 和 Alexander Gallego 将讨论过去一年 数据基础设施 的创新。
- 小组讨论将涵盖关键主题,包括 Data Governance、Streaming 以及 AI 对数据基础设施的影响。
- 数据创新小组的主旨发言人:小组嘉宾包括 RisingWave CEO Yingjun Wu、Conduktor CPTO Stéphane Derosiaux 以及 Redpanda CEO Alexander Gallego。
- 他们的见解预计将探讨 Stream Processing 和 Iceberg 格式 等关键领域,塑造 2024 年的格局。
- AI 在数据基础设施中的角色:小组将讨论 AI 对数据基础设施的影响,重点介绍最近的进展和实现。
- 这包括 AI 技术如何改变 Data Governance 并增强 Streaming 能力。
- 流处理和 Iceberg 格式:关键话题包括 Stream Processing 和 Iceberg 格式,这对于现代数据基础设施至关重要。
- 小组成员将深入探讨这些技术如何塑造未来一年的数据基础设施生态系统。
Gorilla LLM (Berkeley Function Calling) Discord
- BFCL Leaderboard V3 在函数演示期间冻结:一名成员反映 BFCL Leaderboard 在函数调用演示期间卡在 ‘Loading Model Response…‘ 状态。
- 他们询问其他人是否也遇到了同样的加载问题,寻求确认及潜在的解决方案。
- BFCL Leaderboard V3 扩展功能和数据集:讨论强调了 Berkeley Function Calling Leaderboard V3 更新了 LLM 准确函数调用的评估标准。
- 成员们参考了之前的版本如 BFCL-v1 和 BFCL-v2,并指出 BFCL-v3 包含了针对多轮交互(multi-turn interactions)扩展的数据集和方法论。
LAION Discord 没有新消息。如果该服务器长时间没有动静,请告知我们,我们将将其移除。
HuggingFace Discord 没有新消息。如果该服务器长时间没有动静,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该服务器长时间没有动静,请告知我们,我们将将其移除。
PART 2: 频道详细摘要与链接
完整的各频道详情已针对邮件进行截断。
如果您喜欢 AInews,请分享给朋友!预谢!