ainews-genesis-generative-physics-engine-for-6175
Genesis:面向机器人技术的生成式物理引擎 (o1-2024-12-17)
Genesis 是由卡内基梅隆大学(CMU)博士生周仙(Zhou Xian)领导的大规模协作团队最新发布的通用物理引擎。它集成了多种最先进的物理求解器,可模拟各种材料和物理现象,并针对机器人应用提供了轻量化、超快速模拟、照片级渲染以及生成式数据能力等特性。该引擎现已开源,旨在为机器人仿真提供支持,其用途远超单纯的视频生成。
此外,OpenAI 已向 API 开放了 o1 模型,支持函数调用和视觉能力等高级功能,在数学和编程性能上表现强劲。谷歌也预告了 Gemini 2.0 Pro 的更新,正加速面向高级用户的部署。
一个通用的物理引擎就是你所需要的一切。
2024/12/17-2024/12/18 的 AI 新闻。我们为您检查了 7 个 subreddits、433 个 Twitter 账号 和 32 个 Discord (包含 215 个频道和 4542 条消息)。预计节省阅读时间(以 200wpm 计算):497 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
您正在阅读由 o1-2024-12-17 生成的 AINews。按照新前沿模型发布日的传统,我们会尝试发布多个版本进行 A/B 测试/自我评估。请查看我们的存档以获取 o1-mini 版本。对于昨天的重复发送(平台漏洞)我们深表歉意,但今天的发送是故意的。
十二月显然已成为 生成式视频世界模拟器 之月,Sora Turbo 正式商用 (GA),Google 也预告了 Genie 2 和 Veo 2。现在,由 CMU 博士生 Zhou Xian 领导 的学术团队宣布了 Genesis: A Generative and Universal Physics Engine for Robotics and Beyond,这是一项涉及 20 多个实验室、为期 2 年的大规模研究合作,首秀展示了一滴水从喜力啤酒瓶上滚落的画面:
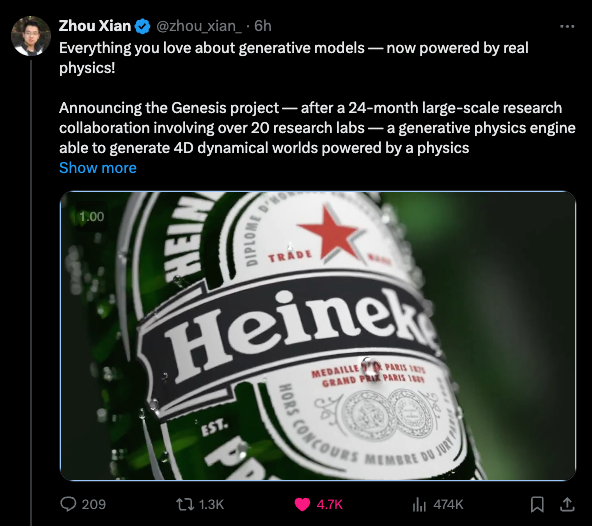
因为它是一个物理引擎,它可以从不同的摄像机角度渲染同一个引擎:
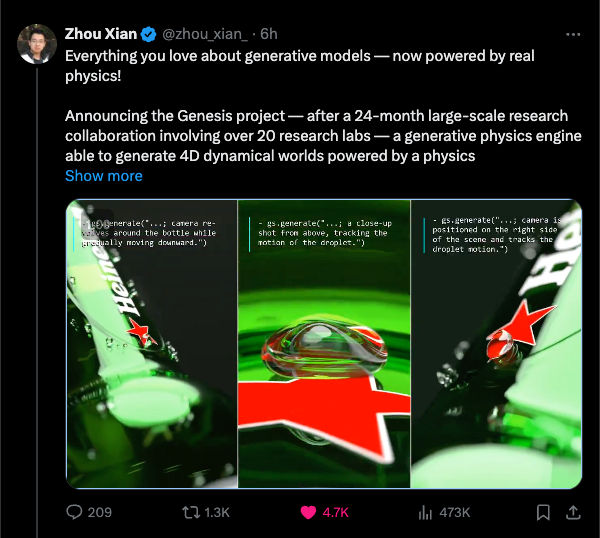
以及暴露驱动向量:

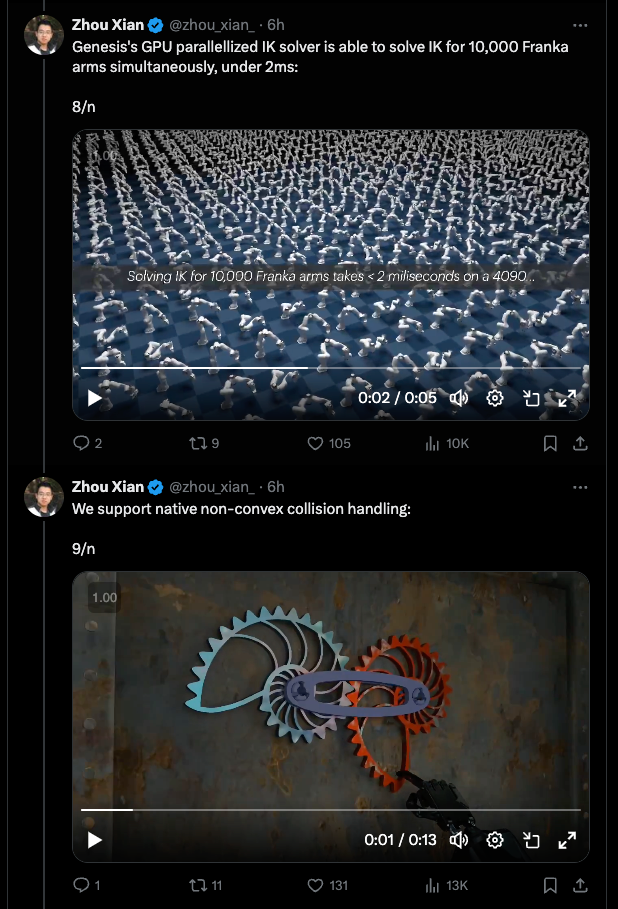
这个“统一物理引擎”集成了各种 SOTA 物理求解器(MPM, SPH, FEM, Rigid Body, PBD 等),支持模拟广泛的材料:刚体 (rigid body)、关节体 (articulated body)、布料 (Cloth)、液体 (Liquid)、烟雾 (Smoke)、可变形体 (Deformables)、薄壳材料 (Thin-shell materials)、弹性/塑性体 (Elastic/Plastic Body)、机器人肌肉 (Robot Muscles) 等。
渲染一致的对象在今天立即就能发挥作用,但这听起来不像大实验室所采取的“纯粹主义”苦涩教训 (bitter pilled) 方法——它是手动组合的一堆物理求解器,而不是通过数据进行机器学习得到的——但它的优势在于开源且现成可用(目前还没有论文)。
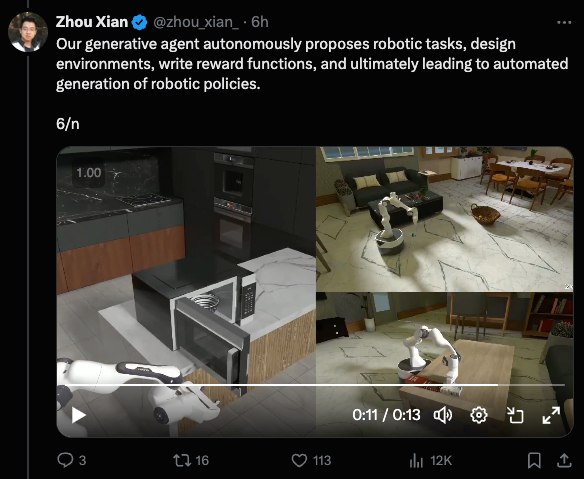
如果目的是视频生成,这已经令人印象深刻,但真正的目标是机器人技术。Genesis 实际上是一个包含 4 个方面的平台:
- 一个从头开始重建的通用物理引擎,能够模拟广泛的材料和物理现象。
- 一个轻量级、超快速、Pythonic 且用户友好的机器人模拟平台。
- 一个强大且快速的照片级真实感渲染系统。
- 一个生成式数据引擎,可将用户提示的自然语言描述转化为各种模态的数据。
而机器人应用才是它真正大放异彩的地方。
AI Twitter 摘要
所有摘要由 Claude 3.5 Sonnet 生成,取 4 次运行中的最佳结果。
以下是按主题分类的关键讨论:
OpenAI o1 API 发布与特性
-
o1 模型已发布至 API,支持 function calling, structured outputs, vision support, 以及 developer messages。该模型使用的推理 token 比 o1-preview 减少了 60%,并包含一个新的 “reasoning_effort” 参数。
-
性能基准测试:@aidan_mclau 指出 o1 “在数学/代码方面强得离谱”,但“在其他方面表现平平”。基准测试结果显示 o1 在 LiveBench Coding 上得分为 0.76,而 Sonnet 3.5 为 0.67。
-
新 SDK:发布了 Go 和 Java 的 beta 版 SDK。同时为 realtime API 添加了 WebRTC 支持,且价格降低了 60%。
Google Gemini 更新
-
@sundarpichai 确认 Gemini Exp 1206 即为 Gemini 2.0 Pro,在代码、数学和推理任务上表现出更强的性能。
-
为了响应用户反馈,Gemini 2.0 的部署已加速,现已面向 Advanced 用户开放。
模型开发与架构
-
关于模型大小和训练的讨论——关于 o1-preview 的尺寸是否与 o1 匹配以及其与 GPT-4o 关系的辩论。
-
Meta 的新研究:直接在原始字节(raw bytes)上训练 Transformer,使用基于熵(entropy)的动态分块(dynamic patching)。
行业与商业
-
@adcock_brett 报告商用人形机器人已在客户现场成功部署,并实现了从总部到现场的快速迁移。
-
宣布推出新的 LlamaReport 工具,用于使用 LLM 将文档数据库转换为人类可读的报告。
梗与幽默
AI Reddit 摘要
/r/LocalLlama 摘要
主题 1. Hugging Face 的 3B Llama 模型:通过搜索超越 70B 模型
- Hugging Face 研究人员通过搜索让 3B Llama 表现超越 70B (得分: 668, 评论: 123):Hugging Face 的研究人员取得了一项突破,通过搜索技术使 3B Llama 模型在 MATH-500 准确率上超越了 70B Llama 模型。图表显示,在特定条件下,3B 模型在每个问题的生成准确率上超过了 70B 模型,突显了该模型与大型模型相比潜在的效率和有效性。
- 推理时间与模型大小优化:用户讨论了在推理时间和模型大小之间寻找最佳平衡的潜力,认为如果小型模型在特定任务上表现足够好,它们会更高效,特别是当知识已嵌入 prompt 或针对特定领域进行了微调时。
- 可复现性与数据集引用:由于 Diverse Verifier Tree Search (DVTS) 模型尚未公开发布,人们对结果的可复现性表示担忧。文中提供了所用数据集的链接 (Hugging Face Dataset) 以及 DVTS 的实现代码 (GitHub)。
- 领域特定限制:由于缺乏在其他领域训练的 PRMs 以及带有逐步标注的数据集,人们对该方法在数学和代码领域之外的适用性持怀疑态度,质疑该通用的普适性。
{kind=link}
主题 2. Moonshine Web:比 Whisper 更快、更准确
- Moonshine Web: 实时浏览器内语音识别,比 Whisper 更快、更准确 (Score: 193, Comments: 25): Moonshine Web 声称提供比 Whisper 更快且更准确的实时浏览器内语音识别。
- Moonshine Web 在 MIT license 下开源,目前正致力于将其集成到 transformers 中,详见此 PR。ONNX models 已在 Hugging Face Hub 上线,尽管人们对 ONNX web runtime 的不透明性存在担忧。
- 讨论要点包括对 Moonshine 相比 Whisper 模型(特别是 v3 large)在实时能力和准确性声明的怀疑。用户对其执行说话人日志 (speaker diarization) 的能力以及目前仅限于英语的局限性感到好奇。
- Moonshine 针对实时、设备端应用进行了优化,Transformers.js v3.2 已添加支持。演示源代码和在线演示可供测试和探索。
Theme 3. Granite 3.1 Language Models: 128k Context & Open License
- Granite 3.1 语言模型:128k 上下文长度与 Apache 2.0 (Score: 144, Comments: 22): Granite 3.1 语言模型现在具备 128k context length,并采用 Apache 2.0 license,这标志着在处理更大数据集和开发者可访问性方面的重大进展。
- Granite 模型性能:据报告,Granite 3.1 3B MoE 模型在 Open LLM Leaderboard 上的平均得分高于 Falcon 3 1B,这反驳了 MoE 模型性能与具有等效激活参数的稠密模型相似的说法。尽管其激活参数比竞争对手少 20%,但表现依然出色。
- 模型规格与许可:Granite 稠密模型(2B 和 8B)和 MoE 模型(1B 和 3B)分别在超过 12 万亿和 10 万亿 tokens 上进行了训练,其中稠密模型支持基于工具的使用场景,而 MoE 模型专为低延迟应用设计。这些模型均以 Apache 2.0 license 发布,其中 8B 模型在代码生成和翻译任务中的表现备受关注。
- 社区见解与对比:Granite Code 模型因其被低估的性能而受到赞誉,特别是 Granite 8BCode 模型,可与 Qwen2.5 Coder 7B 竞争。讨论还强调了 MoE 模型促进各种检索策略的潜力,以及像 Red Hat 集成 Granite 模型这样熟悉的企业级解决方案的重要性。
Theme 4. Moxin LLM 7B: A Fully Open-Source AI Model
- Moxin LLM 7B: 一款完全开源的 LLM - Base 和 Chat + GGUF (Score: 131, Comments: 5): Moxin LLM 7B 是一款完全开源的大语言模型,在来自 SlimPajama、DCLM-BASELINE 和 the-stack-dedup 的文本和代码数据上进行了训练,实现了优于其他 7B 模型的零样本性能。它具有 32k 上下文大小,支持通过 Grouped-query attention、Sliding window attention 和 Rolling Buffer Cache 进行长上下文处理,所有开发资源均可在 GitHub 和 Hugging Face 上获取。
- Moxin LLM 7B 被赞誉为模型训练的极佳资源,正如 Stepfunction 所指出的,它拥有简洁且易于获取的代码和数据集。该模型全面的开发资源被视为一项显著优势。
- TheActualStudy 称赞该模型集成了 Qwen 级别的上下文、Gemma 级别的技术以及 Mistral-7B-v0.1 的性能。这种先进方法和数据的结合令人印象深刻。
- Many_SuchCases 提到探索了 GitHub 仓库,并注意到缺少一些组件(如中间检查点),暗示这些可能会在稍后上传。
Other AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
Theme 1. Imagen v2 质量提升图像生成基准
- 新的 Imagen v2 简直疯狂 (Score: 680, Comments: 119): Imagen 3 正在其发布的版本(被称为 Imagen v2)中树立 image quality 的新标杆。该帖子强调了这项技术的惊人进步,但未提供额外的背景或细节。
- 访问与使用:用户讨论了通过 Google Labs 网站访问 Imagen 3 的方法,并建议在受限地区使用 VPNs。有提到在 labs.google/fx/tools/image-fx 上可以免费访问,但有一定的每日使用配额。
- 艺术方面的担忧:艺术家们对 Imagen 3 对艺术行业的影响表示极大担忧,担心对人类艺术家的需求会减少,以及传统艺术会被 AI 生成的图像所掩盖。一些用户认为,这种转变可能会导致创意领域的私有化和艺术劳动的侵蚀。
- 模型混淆与改进:关于 Imagen 3 的命名和版本存在一些混淆,用户澄清其为 Imagen3 v2。用户注意到图像质量有了显著提高,早期测试人员对结果表示满意,认为优于之前的版本。
主题 2. NotebookLM 的对话式播客革命
- OpenAI 应该开发自己的 NotebookLM 应用,这太令人震撼了! (Score: 299, Comments: 75): NotebookLM 生成的 AI 播客听起来非常自然,在对话质量上甚至超越了 Huberman 的播客。该帖子建议 OpenAI 应该开发类似的应用,因为这可能会对该领域产生重大影响。
- NotebookLM 的语音质量 受到称赞,但与人类主持人相比仍被认为不够自然,而 Gemini 2.0 提供了与播客主持人实时聊天的功能,增强了其吸引力。用户注意到不同平台之间的功能集成问题,强调了在使用高级语音模式和自定义项目方面的限制。
- 对话式 AI 在总结 PDF 等任务中的价值引发了讨论,一些人认为这在节省时间和成人学习理论方面具有革命性,而另一些人则认为内容浅薄、缺乏深度。Gemini 模型因其巨大的 context window 而受到关注,使其非常适合处理海量信息。
- Google 的硬件优势 被反复强调,他们在基础设施和能源解决方案上的投资使其能够提供比 OpenAI 更具成本效益的 AI 模型。这使得 Google 有可能在播客 AI 领域超越 OpenAI,利用其硬件能力大幅降低成本。
主题 3. Gemini 2.0 在学术写作方面超越其他模型
- Gemini 2.0 Advanced 在学术写作方面表现极其出色。 (Score: 166, Comments: 39): Gemini 2.0 Advanced 在学术写作方面表现优异,与包括 ChatGPT 在内的其他模型相比,提供了更出色的理解力、结构和风格。作者考虑在 OpenAI 发布改进版本之前一直使用 Gemini 2.0。
- Gemini 2.0 Advanced 在 AI Studio 上被识别为 Gemini Experimental 1206,目前无需付费版本即可使用,尽管用户需要以数据交换访问权限。Google 的命名惯例以及缺乏统一的 AI 服务给用户带来了一些困惑。
- Gemini 2.0 Advanced 在学术写作质量上展示了显著的进步,在评估中优于 GPT-4o 和 Claude。它提供详细的反馈,经常以幽默的方式批评回复,用户认为这既有效又有趣。
- 用户讨论了通过订阅获取 Gemini 2.0 Advanced 的情况,对于它在 Gemini web app 中被列为 “2.0 Experimental Advanced, Preview gemini-exp-1206” 存在一些困惑。该模型在学术背景下的表现受到称赞,用户希望这将推动 OpenAI 解决 ChatGPT 中的问题。
主题 4. Veo 2 通过逼真的视频生成挑战 Sora
- Google 正在通过其视频生成模型的最新版本 Veo 2 挑战 OpenAI 的 Sora,据称该版本能生成更具真实感的视频。 (Score: 124, Comments: 34): Google 正在通过发布 Veo 2 与 OpenAI 的 Sora 展开竞争,这是其视频生成模型的新版本,声称可以生成更真实的视频。
- Veo 2 的可用性与性能:几位评论者指出 Veo 2 仍处于早期测试阶段,尚未广泛可用,这与宣称的发布情况形成对比。尽管如此,Twitter 等平台上的部分测试者报告了令人印象深刻的结果,特别是在物理特性和一致性等领域,表现优于 Sora。
- 市场策略与可访问性:有人怀疑这次发布是针对 OpenAI 的一种营销策略。对于 Veo 2 和 Sora 缺乏公众访问权限和 API 可用性的担忧十分普遍,不过已确认 January 将在 aistudio 上发布。
- 对视频真实性的信任:讨论涉及了由于 Veo 2 等先进生成模型的出现,可能导致对视频真实性信任度的削弱。一些人提出了解决方案,例如通过个人 AI 利用区块链注册表来验证媒体真实性,以解决这一问题。
AI Discord Recap
由 o1-2024-12-17 生成的摘要之摘要
主题 1. AI 扩展与项目中的挑战
- Codeium 扩展在 VSCode 中短暂失效:该扩展仅在瞬间显示自动补全建议,导致无法使用。根据多名用户的报告,回退到 1.24.8 版本可恢复正常功能。
- Windsurf 在高负载下性能崩溃:部分用户遇到了超过 10 分钟的加载时间,以及偶尔出现的“代码消失”或 Cascade 功能损坏。在稳定修复方案发布前,提交支持工单是首选建议。
- Bolt 用户抱怨 Token 浪费:在收到消耗额度却无关痛痒的回复后,用户开玩笑地提议增加一个“拳打 AI”按钮。许多人呼吁在即将发布的版本中改进记忆控制功能。
主题 2. 新模型与升级模型
- OpenAI o1 凭借 Function Calling 大放异彩:作为 o1-preview 的继任者,它引入了一个新的 “reasoning_effort” 参数,用于控制回复前的思考时间。通过 OpenRouter 使用时,其延迟明显降低。
- EVA Llama 成为叙事专家:该模型针对 Roleplay 和叙事任务,据报道在多步骤故事讲述方面表现出色。早期采用者称赞其创意输出和用户友好的设计。
- 热门模型大幅降价:MythoMax 13B 降价 12.5%,QwQ 推理模型降价 55%。这些折扣旨在扩大社区实验的准入门槛。
主题 3. GPU 与推理陷阱
- AMD 驱动更新导致性能骤降:用户发现从驱动版本 24.10.1 升级到 24.12.1 后,每秒 Token 数(tps)从 90+ 暴跌至 20 左右。回滚驱动可解决减速问题,这再次提醒用户对新发布的 GPU 驱动保持谨慎。
- Ubuntu 上的 Stable Diffusion 遇到障碍:像 ComfyUI 或 Forge UI 这样的工具通常需要深入的 Linux 知识来解决兼容性问题。许多人仍推荐将拥有 16GB VRAM 的 NVIDIA 3060 作为更顺畅的入门基准。
- TinyGrad, Torch 与 CUDA 显存困惑:移除如 IsDense(y) && IsSame(x, y) 之类的检查解决了意外的推理失败,但引入了新的复杂性。这促使开发者参考官方 CUDA Graphs 讨论以寻求潜在解决方案。
主题 4. 高级微调与 RAG 技术
- 使用 4-bit 转换微调 Llama 3.2:许多人依赖 load_in_4bit=true 来平衡 VRAM 占用和模型精度。通过偏精度设置,Checkpoint 可以重复使用,并最大限度地减少资源限制。
- Depth AI 大规模索引代码库:它在回答技术查询时达到了 99% 的准确率,尽管索引 18 万个 Token 可能需要 40 分钟。虽然存在 LightRAG 等竞争方案,但 Depth AI 因设置更简单而受到称赞。
- Gemini 2.0 新增 Google Search Grounding:新配置允许实时网页查询以优化回答。早期评论强调了其在编程和问答场景中事实精准度的提升。
主题 5. NotebookLM 与 Agentic 工作流
- NotebookLM 改版其 3 面板 UI:此次更新因使用率低移除了“建议操作”,但开发者承诺将重新引入设计更佳的类似功能。计划包括根据用户反馈增强“引用”和“回答准确性”。
- 多语言提示词引发广泛参与:用户尝试了巴西葡萄牙语和孟加拉语查询,发现明确告知 NotebookLM 语言语境会使交互更流畅。这展示了其包容性全球通信的能力。
- 控制播客长度依然困难:即使在提示词中指定了时间,最终输出往往仍会超出或忽略限制。大多数人依靠灵活的长度范围来在深度覆盖和听众参与度之间取得平衡。
PART 1: High level Discord summaries
Codeium (Windsurf) Discord
-
Codeium 难题仍在继续:用户反馈了 Codeium 扩展的问题,例如自动补全消失以及取消订阅后仍产生意外费用,并引导用户前往 codeium.com/support 寻求支持。
- Elementor 的粉丝想知道 Codeium 是否可以生成 JSON 或 CSS 代码,而 flex credits 关于使用和结转的问题也一直存在。
-
Windsurf 问题加剧:许多人报告 Windsurf 导致他们的笔记本电脑卡顿十分钟或更长时间,反复出现的错误动摇了用户对最新版本的信心。
- 一些人考虑降级,同时参考了诸如 Windsurf Focus Follows Mouse 之类的功能请求,以解决性能问题。
-
Codeium 与 Copilot 之争:辩论集中在随着 Copilot 开放免费层级,Codeium 是否仍具有优势,并猜测基于 GPT 的服务是否正面临容量问题。
- 支持者坚持认为 Codeium 的自动补全仍然很强大,并暗示 Copilot 的免费层级可能会引发对 Claude 和 GPT 广泛使用的担忧。
-
Cascade 的自动批准困扰:一些开发者批评 Cascade 自动批准代码更改,阻碍了对关键合并的彻底审查。
- 讨论集中在改进审查工作流上,人们推动更好的输出检查以避免未经审核的合并。
-
Llama 模型与免费 AI 工具讨论:Llama 3.3 和 4o-mini 的基准测试引起了兴趣,有说法称较小的变体可以与较大的模型并驾齐驱。
Cursor IDE Discord
-
Cursor 0.44.2 修复 Bug:在从 0.44 版本回滚后,更新后的 Cursor v0.44.2 问世,解决了 changelog 中提到的 composer 异常和终端文本问题。
- 成员们描述了 devcontainers 更好的稳定性,并参考了一篇具有警示意义的论坛帖子,该帖子最初标记了 0.44 版本中的中断问题。
-
Kepler 浏览器强调隐私:一款名为 Kepler 的 Python 编写浏览器承诺极低的服务端依赖和用户控制,在 社区仓库 中备受关注。
- 它实现了随机化的 user agents,并邀请开源贡献以增强安全性。
-
UV 工具简化 Python 管理:社区讨论揭示了用于 Python 环境管理的 UV 工具,具有如 其文档 所示的强大版本处理能力。
- 它简化了项目依赖关系,并与 Poetry 和 Python Environment Manager 扩展 等其他资源集成。
-
O1 Pro 大放异彩:O1 Pro 功能在 20 次尝试内解决了一个困扰用户的持久 Bug,展示了在复杂场景下性能的提升。
- 然而,聊天输出格式化方面出现了连贯性问题,表明仍需进一步改进。
-
Galileo API 访问停滞:关于 Galileo API 以及 Cursor 内 Gemini 2.0 等模型的咨询显示可用性有限,引发了开发者群体的关注。
- 他们正在寻求官方的集成时间表,特别是在 Cursor 平台 内。
aider (Paul Gauthier) Discord
-
O1 冲击与 Sonnet 的平局:OpenAI 向 Tier 5 密钥持有者推出了 O1 API,但部分用户反映无法访问,这引发了对其推理能力的期待与挫败感。
- 多位用户展示了 O1 在测试中获得 84.2 分,与 Sonnet 持平,并就 O1 Pro 与标准版之间的价格和性能差异展开了讨论。
-
AI 模型间的竞争:成员们将 Google 的 Veo 2 与 Sonnet 等现有竞争对手进行了比较,评估其输出质量和在编程任务中的实用性。
- 他们还对不断上涨的订阅费用和多个模型方案的可持续性表示担忧。
-
支持与退款全凭运气:社区成员反映退款时间不一,有人等待了 4 个月,而有人在几小时内就获得了退款。
- 这导致了对客户支持整体响应速度的怀疑。
-
Gemini 作为编辑器获得认可:爱好者们强调 gemini/gemini-exp-1206 的编码错误极少,且在实际场景中与 Aider 有很强的协同作用。
- 尽管如此,他们承认 Gemini 与 O1 相比仍有局限性,建议针对高级用例进行进一步测试。
-
用于代码库洞察的 Depth AI 和 LightRAG:参与者称赞 Depth AI 的代码索引准确率接近 99%,且资源占用适中。
- 虽然 LightRAG 被提及作为替代方案,但一些人观察到 Depth AI 存在“无输出”的故障,并对其一致性提出质疑。
OpenAI Discord
-
OpenAI 的 12 天活动与令人惊讶的拨号机器人:OpenAI 正在通过 第 10 天精彩回顾 和 1-800-chatgpt 的大胆电话新功能来庆祝 12 Days of OpenAI。
- 有些人认为电话服务在处理高级任务时并不可靠,但它可能对老年人或完全的初学者有所帮助。
-
Gemini 在 AI 竞争中取得进展:传闻 Gemini 正在超越 OpenAI,引发了关于 AI 竞争加剧的讨论。
- 怀疑论者暗示 OpenAI 可能在保留功能,仅在绝对必要时才发布,这引发了更多热议。
-
AI 模型安全性引发激烈辩论:参与者引用了 AlignAGI 仓库,思考人类是否能在没有高级 AI 支持的情况下独自解决 AI 安全问题。
- 他们在审查与创意表达之间寻求平衡,并警告双方都可能出现意想不到的极端情况。
-
DALL-E 在与 Midjourney 和 Imagen 的对比中受挫:一些人声称 DALL-E 在写实度上不如 Midjourney 和 Imagen,并将其归咎于限制性的设计选择。
- 批评者指出“Midjourney 吹嘘得太多”,而其他人则坚持认为“DALL-E 需要更多自由”才能脱颖而出。
-
GPT 管理器训练与编辑难题:爱好者们尝试将 GPT 作为“管理者”以简化任务,但发现效果一般。
- 其他人对自定义 GPTs 的编辑限制表示沮丧,呼吁给予用户更多控制权。
Nous Research AI Discord
-
提示词链(Prompt Chaining)助力更敏捷的原型开发:贡献者指出,Prompt Chaining 如何将一个模型的输出连接到另一个模型的提示词中,从而通过 Langflow 改进多阶段工作流和高级 Agent 设计。他们认为更快的迭代和更结构化的 AI 响应是主要优势,展示了小规模模型之间更好的协同效应。
- 几位成员认为这种链式方法对于快速测试想法至关重要,并称赞它在完善新 AI 原型时消除了繁琐的手动编排。
-
Falcon 3 势头强劲:成员们强调了 Hugging Face 上的 Falcon3-7B,这是一个新发布的版本,改进了工具调用(tool-call)处理,并在 7B 到 40B 参数范围内具有可扩展的性能。热心的测试者讨论了其在模拟和推理任务中的潜力,并对其在本地硬件上处理实际使用情况的表现表示关注。
- 他们还注意到大型 Falcon 变体即将进行的改进,并引用了用户关于在 HPC 部署中进行更稳健模型实验的反馈。
-
轻量级模型的本地函数调用:参与者权衡了小型本地模型的函数调用(function calling)技术,比较了能有效解析结构化输出的库。他们寻求灵活的设置来处理个性化任务,而不依赖于大规模云解决方案。
- 一些人以 Gemini 为例,说明将搜索任务卸载到真实数据源的做法,建议采用混合方法,而不是仅仅依赖聊天机器人进行记忆。
-
Hermes 3 405B 的重复性怪癖:一位用户报告称,尽管有避免重复的指令,Hermes 3 405B 仍会逐字重复提示词,这使对话流程变得复杂。他们将其与 gpt-4o 进行了对比,指出后者在行为上表现出更简洁的合规性,且重复问题更少。
- 社区成员尝试了专门的提示策略来抑制重复,强调了对高参数模型进行迭代微调以确保可靠性的重要性。
-
信噪比与一致的 LLM 输出:一次讨论强调了 AI 推理中的信噪比(signal vs noise),认为它是连贯思维的基石。社区对比将其与人类大脑过滤无关输入的方式进行了类比,将清晰度与更好的模型输出联系起来。
- 一位成员还征求了关于在扩展 AI 响应中保持输出一致性的最佳论文,暗示了对长文本生成中持续可靠性的持续关注。
Notebook LM Discord Discord
-
三面板调整优化 NotebookLM:新的 3 面板 UI 不再包含“解释”和“评论”等“建议操作”,以解决该功能使用率低的问题。
- 目前,用户依靠从源文件中复制文本到聊天框,而开发人员计划以更直观的方式恢复缺失的功能。
-
引用与笔记面板调整:NotebookLM 的最新版本从笔记中移除了嵌入式引用,引发了恢复这些引用的请求。
- 用户还发现他们无法轻松合并选定的笔记,迫使他们只能要么全选,要么一次选择一个。
-
播客长度控制变得棘手:在 NotebookLM 中设置较短音频段的尝试经常失败,因为 AI 显然忽略了长度指令。
- 一个想法是将内容拆分为更小的文件,而 博客公告 则暗示了未来的改进。
-
游戏与聊天的多语言混合:玩家称赞 NotebookLM 通过检索增强查询简化了复杂的规则,而一些人则测试了用于交互式播客的多语言聊天。
- 他们分享了诸如 YouTube 上的 Starlings One 之类的链接以供更广泛使用,同时也对被称为“AI 垃圾(AI slop)”的肤浅 AI 播客发出了警告。
-
共享笔记本与空间奇谈:用户希望在组织之外共享 NotebookLM 项目,引发了关于外部访问和家庭友好型功能的问题。
- 与此同时,一段关于太空孤独感的 AI 视频提出了“你能活下来吗?”的问题,展示了 NotebookLM 在更广泛的视听用途上的潜力。
Unsloth AI (Daniel Han) Discord
-
Llama 3.2 Loss 之谜:训练者在针对 1bn instruct 模型时,遇到了令人困惑的高 Loss 差异:使用 Llama 模板时为 (5.1→1.5),而使用 Alpaca 模板时为 (1.9→0.1)。
- 一位用户怀疑不正确的 Prompt 风格导致了这种差异,并进一步询问了关于合并新数据集进行重复微调的问题。
-
QwQ 推理模型之争:成员们测试了开源模型 QwQ,但注意到在省略数学 Prompt 时,它会默认表现为 instruct 行为。
- 一些人声称 RLHF 对于强化推理至关重要,而另一些人则认为仅靠 SFT 就能构建高级逻辑能力。
-
多 GPU 与 M4 MAX Mac 相关事宜:用户证实 Unsloth 支持跨平台的多 GPU 使用,尽管有些人在 M4 MAX GPU 上安装时遇到了困难。
- 开发者计划在 2025 年第二季度左右添加官方支持,并建议将 Google Colab 和社区贡献作为临时解决方案。
-
LoRA 增益与合并最小化:参与者澄清说 LoRA 适配器调整的参数较少,并与基础模型合并以获得更小的最终文件。
- 他们指出,典型的合并会产生紧凑的 LoRA 输出,在不损害训练性能的情况下抑制 VRAM 占用。
-
DiLoCo 的分布式开发:社区成员展示了他们关于大语言模型低通信训练的 DiLoCo 研究演示文稿。
- 他们强调了在开源框架上的持续工作,并链接了 DiLoCo arXiv 论文,鼓励合作。
OpenRouter (Alex Atallah) Discord
-
OpenAI 的 O1 增强:OpenRouter 推出了支持 function calling、structured outputs 以及改进后的
reasoning_effort参数的新型 O1 模型,详情见 openrouter.ai/openai/o1。- 用户可以在此链接找到关于 structured outputs 的教程,并在 Chatroom 中探索挑战以测试模型的思维能力。
-
EVA Llama 登场:OpenRouter 添加了 EVA Llama 3.33 70b,这是一款故事叙述和角色扮演专家,扩展了其在此链接的高级模型阵容。
- 该模型专注于叙事生成,提升了平台创意互动的范围。
-
降价带来喜悦:gryphe/mythomax-l2-13b 模型现在的价格降低了 12.5%,方便爱好者进行实验。
- 同时,QwQ 推理模型的成本大幅下降了 55%,鼓励更多用户挑战其极限。
-
密钥泄露,支持警报:一位用户在 GitHub 上发现了泄露的 OpenRouter 密钥,并被建议联系支持人员寻求即时帮助,避免直接通过电子邮件提交受损的 Token。
- 其他人注意到调用后仅保留 metadata,如果需要更详细的跟踪,建议使用基于 proxy 的日志记录等解决方案。
-
Google 密钥费用与推理小问题:社区成员确认,在将个人 Google AI 密钥链接到 OpenRouter 时会收取 5% 的服务费,这也适用于信用额度使用。
- 同时,QwQ 在处理严格的指令格式时比较吃力,尽管 OpenAI 的 “developer” 角色最终可能会增强推理导向模型的合规性。
Interconnects (Nathan Lambert) Discord
-
Gemini 取得进展:在 Google Shipmas 期间,Gemini 2.0 凭借 Astra 和 Mariner 等演示引起了关注,Jeff Dean 确认了 Gemini-exp-1206 的进展。
- 社区反馈赞赏其多模态成就,但也指出了 Gemini Exp 1206 中的速率限制(rate-limit)问题。
-
Copilot 的免费代码服务:GitHub 宣布了 Copilot 的免费层级,每月包含 2,000 次代码补全和 50 条聊天消息,参考了这条推文。
- 成员们称赞了 Claude 3.5 Sonnet 和 GPT-4o 模型的加入,同时预测 GitHub 目前 1.5 亿+ 的用户基数将迎来开发者激增。
-
微软考虑投资 Anthropic:据 Dylan Patel 透露,传闻 Microsoft 将以 590 亿美元的估值投资 Anthropic。
- 他们的目标是在维持与 OpenAI 关系的同时引入 Claude,这引发了社区对这种微妙伙伴关系的讨论。
-
Qwen 2.5 Tulu 预告:Qwen 2.5 7B Tulu 3 预计将超越 Olmo,具有改进的许可协议,并预告了正在开发中“更多疯狂的 RL 内容”。
- 团队成员将重复的 RL 运行比作 “souping”,强调了令人惊讶的积极结果,为即将发布的版本造势。
-
RL 涌现的惊喜:Edward Hughes 指出,在“捐赠者博弈”(Donor Game)中对 LLM agents 进行的实验表明,合作差异取决于基础模型。
- 随后关于 RLVR 训练的更新引起了人们对基于结果奖励中自我修正行为的关注,引发了对重复 RL 运行的新兴趣。
Eleuther Discord
-
零售综述:电商工具关注 Runway:成员们讨论了使用 Runway、OpenAI Sora 和 Veo 2 来制作零售广告内容的视频和文案,寻求更高层次的解决方案以脱颖而出。
- 他们征求了更多建议,以优化营销方法,而不是重复旧有的策略。
-
Koopman 骚动:我们是在原地踏步吗?:一篇关于神经网络中 Koopman 算子理论的论文引发了争论,讨论它究竟是真正增加了新的见解,还是仅仅重新包装了残差连接(residual connections)。
- 一些人认为它缺乏实际价值,而另一些人则坚持认为该方法可能会通过先进的线性算子技术补充网络分析。
-
涌现标签:真实还是炒作?:社区成员仔细研读了《大语言模型的涌现能力是幻象吗?》,质疑这些能力反映的是重大飞跃还是仅仅是评估伪像(evaluation artifacts)。
- 这种怀疑延伸到了“仅靠扩展大模型就能解决核心局限”的假设,指向了更深层次的未解决理论鸿沟。
-
迭代压缩:廉价代理与 OATS:工程师们讨论了用于模型压缩的迭代函数方法,并指出 OATS 剪枝技术是减小模型体积且不牺牲高级行为的路径。
- 他们还提出了廉价代理(cheap surrogate)层的策略,尽管有些人担心在链接近似值时会出现误差累积。
-
WANDB 日志与非参数 Norm:下一步是什么?:开发者要求将 MFU 和吞吐量指标直接记录到 WANDB,暗示 GPT-NeoX 的日志代码中即将加入新功能。
- 他们还预计在未来几天内会有一个非参数 layernorm 的 pull request,从而为 GPT-NeoX 拓宽实验选项。
Stability.ai (Stable Diffusion) Discord
-
LoRA 秘籍:训练心得:成员们强调在训练 LoRA 之前收集高质量数据集的重要性,并建议通过彻底的测试和迭代来保证质量。
- 他们强调了数据集策划策略的重要性,建议研究专门的资源以提高训练成功率。
-
Stable Diffusion 大杂烩:建议初学者尝试 InvokeAI,因为它具有直观的工作流;而 ComfyUI 和 Forge UI 则因其模块化功能而受到推崇。
- 分享了 Civitai 上的模型链接以及 stable-diffusion-webui-forge 的 GitHub 脚本,并提供了有效利用它们的技巧。
-
量子争议与经典算力:部分成员提到了 quantum computing 的突破,同时也指出实际部署仍需时日。
- 针对量子技术进步引发的未来战争场景和计算能力的重大飞跃,人们表达了担忧。
-
GPU 收益与 FP8 调优:优化 VRAM 使用是一个热门技巧,特别是在 3060 GPU 上采用 FP8 mode 以提升速度和显存效率。
- 建议在生成图像期间监控 GPU 显存使用情况,以避免意外的减速或崩溃。
-
AI 视频愿景与局限:参与者一致认为,虽然 AI 生成图像已取得显著进展,视频输出仍有提升空间。
- 讨论了实现无缝 AI 视频的实际时间表,并提到了 macOS 的静态 FFmpeg 二进制文件 等工具,用于优化后期处理。
Perplexity AI Discord
-
Spaces 重大更新:自定义 Web 来源:Perplexity 在 Spaces 中引入了 Custom Web Sources,允许用户选择偏好的网站以获得更专业的搜索结果。一段简短的 发布视频 展示了这些来源的简化设置过程。
- 社区成员强调了处理高级任务的潜力,提到 customizing Perplexity 如何满足高强度的工程需求。
-
赠送 Pro:订阅与频率限制:用户称赞了 Perplexity Pro 赠送订阅功能,该功能提供了更多来源和 AI 模型,Perplexity Supply 的推文 宣传了这一优惠。他们还对达到请求上限表示担忧,怀疑更高级别可能解决这些限制。
- 有些人提议在 UI 中加入有趣的“降雪效果”,而另一些人则认为这对于硬核使用来说太让人分心。
-
Meta 与 OpenAI 的对峙:Meta 希望阻止 OpenAI 的营利性尝试,引发了关于货币化 AI 伦理的辩论。社区讨论质疑企业优先级是否会掩盖开放研究的理想。
- 其他人引用了早期的对峙,将其定性为无限制开发与收入驱动模型之间的“决定性时刻”。
-
拒绝死亡的细胞:研究表明,cells 在死亡后可以恢复功能,这动摇了细胞最终关机的观念。一段 视频解释 推动了关于急性医疗手段可能取得突破的讨论。
- 论坛讨论还涉及了 microbial threat warning(微生物威胁警告),敦促密切关注健康影响和未来的预防措施。
-
植物之泪与多巴胺机制:新发现声称 plants 可能会表现出类似于哭泣的压力信号,挑战了关于植物交流的旧观点。关于 dopamine precursor 探索的讨论也浮出水面,暗示了心理健康干预的精细化策略。
- 参与者思考了更广泛的影响,提到这些生物学见解如何塑造研究轨迹。
GPU MODE Discord
-
MatX 直奔芯片:MatX 宣布了一款旨在提升 AI 性能的 LLM accelerator ASIC,并正在积极招聘 low level compute kernels、compiler 开发和 ML performance 工程方面的专家,详情见 MatX Jobs。
- 他们强调了重塑下一代推理和训练的潜力,吸引了对 on-chip 性能提升感兴趣的工程师。
-
Pi 5 展现 1.5B 参数实力:一台超频至 2.8GHz 并配备 256GB NVMe 的 Raspberry Pi 5 正在通过 Ollama 和 OpenBLAS 运行 1.5B 参数模型,展示了在边缘设备上的本地 LLM 部署。
- 社区成员赞赏这种实用方法,指出 Pi 5 可以在不需要大规模 GPU 资源的情况下托管较小的专用模型。
-
CoT 获得视觉与深度:一个团队探索了为小尺寸图像集成 custom vision encoder,并讨论了扩展 Chain of Thought 以通过更深层次的迭代步骤来完善推理。
- 他们计划进行一项 Proof of Concept,将 inner reasoning 嵌入到 LLM 中,旨在实现更好的上下文处理和解决方案准确性。
-
强力的 int4group 与 Tinygemm:工程师们描述了在 int4group scheme 中使用 int4 weights 和 fp16 activations,让 matmul kernel 处理即时反量化(on-the-fly dequantization)。
- 他们确认在训练期间不进行激活量化,利用 bf16 计算来确保性能的一致性。
-
A100 对决 H100:用户注意到在比较 A100 和 H100 时,训练损失(training loss)存在 0.3% 的差异,引发了关于硬件特定变异性的疑问。
- 他们辩论了是 Automatic Mixed Precision (AMP) 还是 GPU 架构的细微差别导致了这一差距,强调了进行更深层次分析的必要性。
LM Studio Discord
-
LM Studio Beta 惊喜:用户使用 Llama 3.2-11B-Vision-Instruct-4bit 测试 LM Studio 时遇到了架构错误,如 unknown model architecture mllama。
- 一些人通过查看 LM Studio Beta Releases 克服了困难,并指出损坏的下载以及大型模型对某些用户有效。
-
角色扮演 LLM 势头强劲:一位用户请求关于配置 roleplay LLM 的指导,促使社区分享了高级使用技巧。
- 他们宣传了用于深入讨论的独立频道,并强调了长时间会话的内存限制。
-
GPU 困惑与驱动难题:成员们质疑 3060 Ti 11GB 是否真的存在,还是其实是 12GB 的 3060,引发了关于 GPU 细节的辩论。
- 与此同时,Radeon VII 受到驱动程序 24.12.1 问题的困扰,导致 100% GPU usage 却无功耗,被迫退回到 24.10.1。
-
推理开销与 Mac 愿望:爱好者们意识到一个 70B 的 Llama 模型在 q8 量化下可能需要总计 70GB 的内存,涵盖 VRAM 和系统 RAM。
- 一位用户开玩笑说,拥有一台 M2 MacBook Air 激发起对 future MBP M4 的渴望,指出了高性能配置的高昂成本。
Stackblitz (Bolt.new) Discord
-
从 Firebase 切换到 Supabase:成员们讨论了将整个网站从 Firebase 迁移到 Supabase 的过程,遇到了 create-mf-app 和 Bootstrap 使用中的样式冲突。
- 一位用户指出这些框架在配置上存在重叠,并暗示很快会完善迁移步骤。
-
Bolt Pilot GPT 开启 Beta 测试:一位成员介绍了用于 ChatGPT 的 Bolt Pilot GPT,并建议探索 stackblitz-labs/bolt.diy 以获取相关的代码示例。
- 他们展示了对多租户能力的乐观态度,并邀请社区反馈以指导未来的更新。
-
Token 纠纷与 Bolt 忧郁:多位成员抱怨 Bolt 在占位符提示词上消耗 Token,敦促增加重置功能,并希望在 Office Hours 期间提供节日折扣。
- 一些用户在 Token 上花费了大量资金却效果不佳,引发了对协作和资源池化的兴趣。
Cohere Discord
-
多模态嵌入(Multimodal Embeds)速率限制大幅提升:Cohere 将生产密钥在 Multimodal Image Embed 端点的速率限制从 40 张图像/分钟提升至 400 张图像/分钟,而测试密钥固定为 5 张图像/分钟。
-
通过 Maya 命令增强本地模型:开发者探索了通过发布 command-r-plus-08-2024 将本地模型与 Maya 连接,使模型能够处理查询中的图像路径。
- 他们还在基础模型中增加了 tool use(工具使用)以实现更好的图像分析,引发了关于高级 Pipeline 设置的讨论。
-
Cohere Toolkit 应对 AWS 流错误:在 AWS 上成功部署的 Cohere Toolkit 遇到了间歇性的 stream ended unexpectedly(流意外结束)警告,导致聊天兼容性中断。
- 用户通过检查 docker logs 来诊断这一随机故障,希望能查明根本原因。
-
结构化输出展示与 Reranker 难题:用户测试了 Cohere 的 Structured Outputs 配合
strict_tools使用,通过精炼 Prompt 参数来获得精确的 JSON 响应。- 与此同时,一个基于 RAG 的 PDF 系统在使用 Cohere Reranker 时遇到了困难,表现为 Reranker 忽略了相关分块,但偶尔又能准确命中正确内容。
-
Findr 作为“无限大脑”亮相:Findr 在 Product Hunt 上线,提供了一个无限的记忆库来存储和访问笔记。
- 爱好者们对这一发布表示欢迎,称赞其可搜索数字大脑的概念有助于更好地记忆。
Modular (Mojo 🔥) Discord
-
Mojo 与 Archcraft:缺失链接器的谜团:一位用户在 Archcraft 上启动 Mojo REPL 时遇到问题,原因是缺失 mojo-ldd 库以及未管理的环境阻塞了 Python 依赖。他们还提到安装 Max 的尝试停滞不前,引发了创建一个专门线程来解决问题的建议。
- 一个 Stable Diffusion 示例被提及作为新功能的有用 GitHub 资源。对话强调了调整环境设置以避免安装突然失败的重要性。
-
文档与 ‘var’ 之争:当语法遇上困惑:关于 Mojo 文档中明确提到的 var 关键字要求引发了讨论,让部分用户感到不安。官方透露即将更新文档,但未提供明确的时间表。
- 社区成员对变量是否需要专用关键字持有不同意见。他们鼓励通过反馈来完善未来的文档版本。
-
Kernel 还是仅仅是一个函数?Mojo 的术语纠葛:成员们澄清了 Mojo 中的 “Kernel” 通常指为 GPU 执行优化的函数,以区别于操作系统内核。该术语含义各异,有时描述核心计算逻辑或对加速器友好的代码。
- 参与者交流了对该概念的理解,争论其是否应仅限于 GPU 任务。一些人注意到它在数学中用于表示更广泛计算中的基本操作。
-
缺失 argmax 与 argmin:关于 Reduction 的思考:一位用户感叹 algorithm.reduction 中缺少 argmax 和 argmin,质疑是否需要从头开始重构它们。他们对重新实现那些在其他库中可能是标准的优化函数感到沮丧。
- 成员们呼吁对这些操作提供更好的文档或官方支持。讨论凸显了 Mojo 不断演进的标准库中的连续性问题。
-
MAX 与 Mojo:自定义算子(Custom Ops)难题:用户在 custom ops 集成上苦苦挣扎,引用了
session.load(graph, custom_ops_paths=Path("kernels.mojopkg"))来修复缺失的 mandelbrot kernel 问题。他们还引用了 Issue #269,要求改进错误消息和单编译单元 kernel。- MOToMGP Pass Manager 错误进一步复杂化了自定义算子的加载,促使人们呼吁在失败报告中提供更好的清晰度。贡献者强调了通过更具描述性的诊断来引导用户的重要性。
Latent Space Discord
-
Nvidia 的 Nimble Nano 推动 AI 发展:Nvidia 推出了售价 $249 的 Jetson Orin Nano Super Developer Kit,拥有 67 TOPS 的算力,性能比前代提升了 70%。
- 它包含 102GB/s 的带宽,旨在帮助爱好者运行更繁重的 AI 任务,尽管一些参与者质疑它是否能处理高级机器人技术。
-
GitHub Copilot 开启免费模式:正如 Satya Nadella 所确认的,GitHub Copilot 现在对 VS Code 免费开放,每月限制 50 次对话。
- 社区成员讨论了与 Cursor 等竞争对手相比,这一限制是否会削弱 Copilot 的实用性。
-
1-800-CHATGPT 热线开通:由 Kevin Weil 宣布,1-800-CHATGPT 为全球提供免费的电话和 WhatsApp 访问 GPT 的渠道。
- 讨论强调了它对更广泛受众的普及性,无需额外的 App 或账号。
-
AI 视频工具迎来转折点:OpenAI 的 Sora 引发了关于视频模型演进的讨论,并引用了 Will Smith 测试片段来衡量进展。
- 爱好者们将这些突破与早期的图像生成浪潮进行了比较,并引用了 Replicate 的一篇博客文章,探讨了对高清 AI 视频日益增长的需求。
-
EvoMerge & DynoSaur 双重专题:LLM Paper Club 在一次“双头龙”会议中展示了 Sakana AI 的 EvoMerge 和 DynoSaur,并邀请现场观众提问。
- 与会者被敦促将 Latent.Space RSS 订阅源添加到日历中,以紧跟未来的活动。
OpenInterpreter Discord
-
Interpreter 中断问题加剧:多位用户在使用 Open Interpreter 时遇到重复异常,导致丢失了关键的对话日志。他们报告了加载聊天历史记录和 API key 混淆的问题,在多个帖子中引发了不满。
- 一位用户特别感叹丢失了高质量的对话,而其他用户则提到在多个设置中都发生了类似事件。尚未解决的技术故障继续阻碍着长时间的使用。
-
1.x 的谜团与 0.34 混杂:社区成员讨论了 Open Interpreter 1.x 是否存在,而他们目前仅限于使用 0.34 版本。他们质疑功能上的变化,指出 OS 模式似乎并未出现在 1.0 中。
- 这种版本不匹配引发了关于更新程序和支持的困惑。一些人询问切换版本的官方步骤,希望能确认新功能。
-
Cloudflare 扮演网关策略角色:一位用户提议使用 Cloudflare AI Gateway 来解决 Open Interpreter 的一些配置障碍。这种方法引发了关于外部解决方案和高级部署的简短辩论。
- 成员们考虑了新的工具链,研究 Cloudflare 的平台如何提高可靠性。他们还提到了与其他 AI 应用的协同作用,但尚未得出最终结论。
-
Truffle 的端侧设备预告:一位用户介绍了 Truffle-1:这是一款拥有 64GB 内存的设备,押金为 $500,每月租金 $115。他们发布了官方网站,展示了一个支持无限端侧推理的球体设备。
- 来自 simp 4 satoshi 的推文提供了更多财务细节,提到了押金和月度计划。这激发了人们通过该球体设备的本地堆栈构建和共享自定义应用的兴趣。
-
长期记忆思维:爱好者们探索了将扩展记忆与 Open Interpreter 集成的方法,重点在于代码库管理。一些人提议使用包括 Raspberry Pi 在内的本地设置来存储对话数据以备后用。
- 他们看到了通过持久化日志实现流线型协作工具的潜力。这一想法在寻求保持更大上下文窗口随时可用的参与者中获得了支持。
tinygrad (George Hotz) Discord
-
LLaMA 基准测试之争:一位用户询问是否有人对比过使用 tinygrad OpenCL 的 LLaMA models 与 PyTorch CUDA 的基准测试,但目前没有相关数据。
- 讨论结论是目前没有已知的正面性能对比统计数据,这让 AI engineers 暂时无从参考。
-
ShapeTracker 合并乱象:关于在 Lean 中合并两个任意 ShapeTrackers 的悬赏引发了关于 strides 和 shapes 的疑问。
- 贡献者指出,一种通用的方法似乎行不通,因为变量使得合并过程变得复杂,超出了简单的修复范围。
-
反例导致崩溃:成员们遇到了会导致当前合并算法在处理异常 view 对时崩溃的 counterexamples。
- 他们暗示可以从单个不规则案例中自动生成更多示例,并强调了维度溢出(dimension overflow)问题。
-
CuTe Layout 代数对比:TinyGrad 的合并对被比作 CuTe layout 代数中的 composition,参考了 layout docs。
- 这种类比引起了人们对在确定 shape 兼容性之前验证某些代数属性这一复杂过程的关注。
-
单射性证明被视为 NP Hard:对于证明 layout 代数中的 injectivity 存在质疑,有人认为这可能是 NP hard 问题。
- 同时检查必要性和充分性似乎过于复杂,无法迅速解决,这暗示了一个更深层次的理论挑战。
Torchtune Discord
-
FSDP 之争与 TRL 纠葛:团队意识到,如果 FSDP 的 reduce 操作取平均值,则必须在 这段代码 中应用
world_size缩放。他们还发现 trl 中可能存在缩放故障,并指向了 这个修复 PR。- 成员们建议提交一个 Unsloth 风格的 Bug 报告,并建议直接在
scale_grads中调整代码以提高清晰度。他们预计这一修正将简化分布式设置中的梯度行为。
- 成员们建议提交一个 Unsloth 风格的 Bug 报告,并建议直接在
-
Loss 处理策略与梯度增益:贡献者一致认为在训练 recipe 中显式缩放 loss 可以提高清晰度,参考了 这段内存代码 中的更新。他们强调代码注释有助于突出每个缩放步骤的目的。
- PR 中增加了一个 optimizer_in_bwd 场景的修复,以正确处理归一化。此调整旨在保持训练循环的透明度并维持一致的梯度缩放。
-
Sakana 的进化视角:工作人员对 Sakana 扩展 evolutionary algorithms 以抗衡基于梯度的技术产生了兴趣。他们发现进化驱动的方法可能会为 AI 发展注入不同的视角,这一点值得关注。
- 一些人看到了将进化思想与标准梯度 recipes 合并的前景。其他人则计划关注 Sakana 的进展,看它是否能在严格的基准测试中站稳脚跟。
DSPy Discord
- Collabin 视频片段引发好奇:一段名为 collabin 的简短视频出现在此链接,暗示了某些协作项目或演示。
- 参与者分享的细节很少,但视频展示了未来团队合作或演示的可能性。
- 自主 Agent 助力知识精英:一篇名为 Artificial Intelligence in the Knowledge Economy (链接) 的新论文强调了自主 AI Agent 如何通过自动化常规工作来提升高技能人才的水平。
- 社区评论提醒,随着这些 Agent 的普及,拥有深厚专业知识的人在生产力方面将获得额外的优势。
- Coconut 将 LLM 推理引导至潜空间 (Latent Space):一篇关于 Coconut (Chain of Continuous Thought) (链接) 的论文挑战了基于文本的一致性,转而建议采用潜空间方法。
- 重 Token 策略 (Token-heavy strategies) 可能会忽略细微差别,因此社区评论支持重写 LLM 的思维过程以管理复杂的规划。
- RouteLLM 进度落后,但 DSPy 出现疑问:人们注意到 RouteLLM (仓库) 已不再维护,这引发了对未来与 DSPy 协同作用的担忧。
- 虽然没有产生具体的计划,但这标志着 DSPy 生态系统内对强大路由工具 (routing tools) 的渴望。
- DSPy 规划以推理为中心的路径:讨论指出 TypedReAct 已部分弃用,敦促转向更简单的命名和模式,不再使用 ‘TypedChainOfThought’。
- 其他人认为 fine-tuning 在 DSPy 内部正转向奖励级分支,并参考 DSPy 的 Agent 教程 作为后续步骤的资源。
Nomic.ai (GPT4All) Discord
- Localdocs 支持点亮 GPT4All:成员们讨论了在 GPT4All 中引用本地文档,但发现旧的 CLI 缺乏官方支持,这促使他们转向 server API 或 GUI 方法。
- 几位参与者确认了 CLI 的局限性,强调 local document 功能 仍需要在官方工具集中进行特定配置。
- GPT4All 的 Docker 梦想停滞:一位用户询问关于在带有 Web UI 的 Docker 容器中运行 GPT4All 的问题,但没有人提供现成的解决方案。
- 该问题仍然悬而未决,让容器爱好者们希望有人能尽快发布官方或社区镜像。
LlamaIndex Discord
- Agentic AI SDR 激发线索:在 blog 频道讨论中,可以关注这个使用 LlamaIndex 自动化营收任务并生成线索的 agentic AI SDR。
- 它展示了将 function calling 与销售工作流结合的新可能性,突显了 LlamaIndex 产生直接业务影响的能力。
- Composio Quickstarters 启动 LLM Agent:Quickstarters 文件夹 指向了 Composio,将 LLM Agent 与 GitHub 和 Gmail 连接起来。
- 通过 function calling,它实现了一种流线型的方法来处理代码提交 (code commits) 或收件箱扫描等任务,所有这些都由自然语言输入触发。
- 异步工具提升 OpenAIAgent 并发能力:成员们讨论了 OpenAIAgent 的并发性,参考了 OpenAI 文档 中关于 API v1.1.0+ 并行函数调用的内容。
- 他们分享了建议使用异步函数的代码片段,并澄清并发并不意味着真正的 CPU 并行执行。
- RAG 评估协作浮现:一位成员邀请社区在 RAG 评估方面进行合作,敦促其他人分享见解。
- 他们欢迎通过直接讨论进行更深层次的技术探索,反映了人们对检索增强生成 (RAG) 技术日益增长的兴趣。
Gorilla LLM (Berkeley Function Calling) Discord
-
BFCL 排行榜小故障:一位用户观察到 BFCL Leaderboard 因证书问题导致临时停机,卡在 “Loading Model Response…” 界面。
- 他们强调模型端点 (model endpoint) 无法访问,这引起了急于尝试新 Function Calling 功能的测试人员的关注。
-
Gorilla 基准测试关注 JSON 一致性:一位参与者提议使用 Gorilla 基准测试来验证模型对 JSON schema 或 Pydantic 模型的遵循情况,强调结构化输出测试。
- 他们询问是否有专门用于衡量结构化生成 (structured generation) 准确性的子任务,尽管目前还没有官方提到此类任务。
LAION Discord
-
GPT-O1 逆向工程引发研究人员关注:爱好者们征集任何已知的 GPT-O1 逆向工程努力或材料,包括技术报告和论文,并欢迎来自社交媒体帖子的额外见解。这引发了集体分享和资源收集的热潮,旨在揭开 GPT-O1 复杂性的神秘面纱。
- 他们提议发起一个协作倡议,汇编有关 GPT-O1 的参考资料,特别是来自 Twitter 讨论和已发表的材料,旨在汇集社区知识。
-
Meta 开启生成式 AI 实习:Meta 宣布了一个为期 3-6 个月的文本生成图像模型和视觉语言模型研究实习职位,提供大规模动手实验的机会,申请地址在这里。该职位专注于推动核心算法进展并构建生成式 AI 的新能力。
- 变现生成式 AI 团队正在寻找具有深度学习 (deep learning)、计算机视觉 (computer vision) 和 NLP 背景的研究人员,强调对用户在线交互方式产生全球性影响。
LLM Agents (Berkeley MOOC) Discord
-
无重大讨论:我们只看到了一些友好的感谢表达,没有发布额外的信息或参考资料。
- 没有进一步的聊天或数据共享,因此没有其他值得关注的内容。
-
无技术更新:本次讨论中没有出现新的模型、代码发布或相关的技术进展。
- 对于 AI 专家来说,这条单一消息没有提供更多数据。
Axolotl AI Discord
-
一月强化学习人才加入:一名新工程师将于 1 月加入团队,协助强化学习 (RL) 计划,为训练扩展提供额外人手。
- 他们还将为 KTO 项目提供直接支持,确保 RL 组件的及时集成和功能的改进。
-
KTO 获得额外人手:新工程师入职后将帮助完善 KTO 系统,重点关注实时性能的提升。
- 项目负责人预计他们的贡献将显著提高 RL 任务的生产力。
Mozilla AI Discord
-
开发者中心 (Developer Hub) 势头强劲:一项重大公告推出了 Developer Hub 的全新功能,强调通过社区反馈进行持续改进,详见此处。
- 参与者强调了明确使用指南以及收集未来扩展建议的重要性。
-
Blueprints 计划简化 AI 构建:Blueprints 计划旨在通过精心提供的资源帮助开发者组装开源 AI 解决方案,讨论见此处。
- 他们指出,计划中的增强功能可以实现更广泛的项目协作,并为特定用例提供灵活的模板。
MLOps @Chipro Discord 没有新消息。如果该服务器长时间保持沉默,请告知我们,我们将将其移除。
HuggingFace Discord 没有新消息。如果该服务器长时间保持沉默,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该服务器长时间保持沉默,请告知我们,我们将将其移除。
第 2 部分:渠道详细摘要和链接
完整的频道细分内容已为邮件格式截断。
如果您喜欢 AInews,请分享给朋友!提前致谢!