ainews-openai-voice-mode-can-see-now-after-gemini
继 Gemini 之后,OpenAI 语音模式现在也具备视觉功能了。
OpenAI 在 Gemini 之后不久推出了实时视频 (Realtime Video) 功能,但由于 Gemini 发布更早、成本更低且速率限制更少,导致 OpenAI 的功能影响力相对较小。Google DeepMind 发布了 Gemini 2.0 Flash,其特点是增强的多模态能力和实时流媒体功能。Anthropic 推出了 Clio,这是一个用于分析 Claude 模型实际使用情况的系统。Together Computing 收购了 CodeSandbox,旨在推出一款代码解释器工具。
社区讨论重点关注了 Meta 的 Llama 3.3-70B,称赞其先进的角色扮演和提示词处理能力,在表达力和规避审查方面优于 Mistral Large 和 GPT-4o 等模型。AI 社区还针对 AI 宕机和模型竞争进行了幽默的调侃,同时 ChatGPT 增加了“圣诞老人模式”以进行节日互动。社区中一个引人注目的观点是:“Anthropic 正在占领开发者生态系统,Gemini 赢得了 AI 爱好者的关注,而 ChatGPT 则统治着 AI 浅尝辄止者。”
率先发布就是一切 (Shipping first is all you need)。
2024/12/11-2024/12/12 AI 新闻。我们为您检查了 7 个 subreddits、433 个 Twitter 账号 和 31 个 Discord(207 个频道和 6137 条消息)。预计节省阅读时间(以 200wpm 计算):616 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
OpenAI 在比预期晚一天后发布了 Realtime Video,但其反响较小,因为 Gemini 抢先一步到达,且成本更低,速率限制(rate limiting)更少。
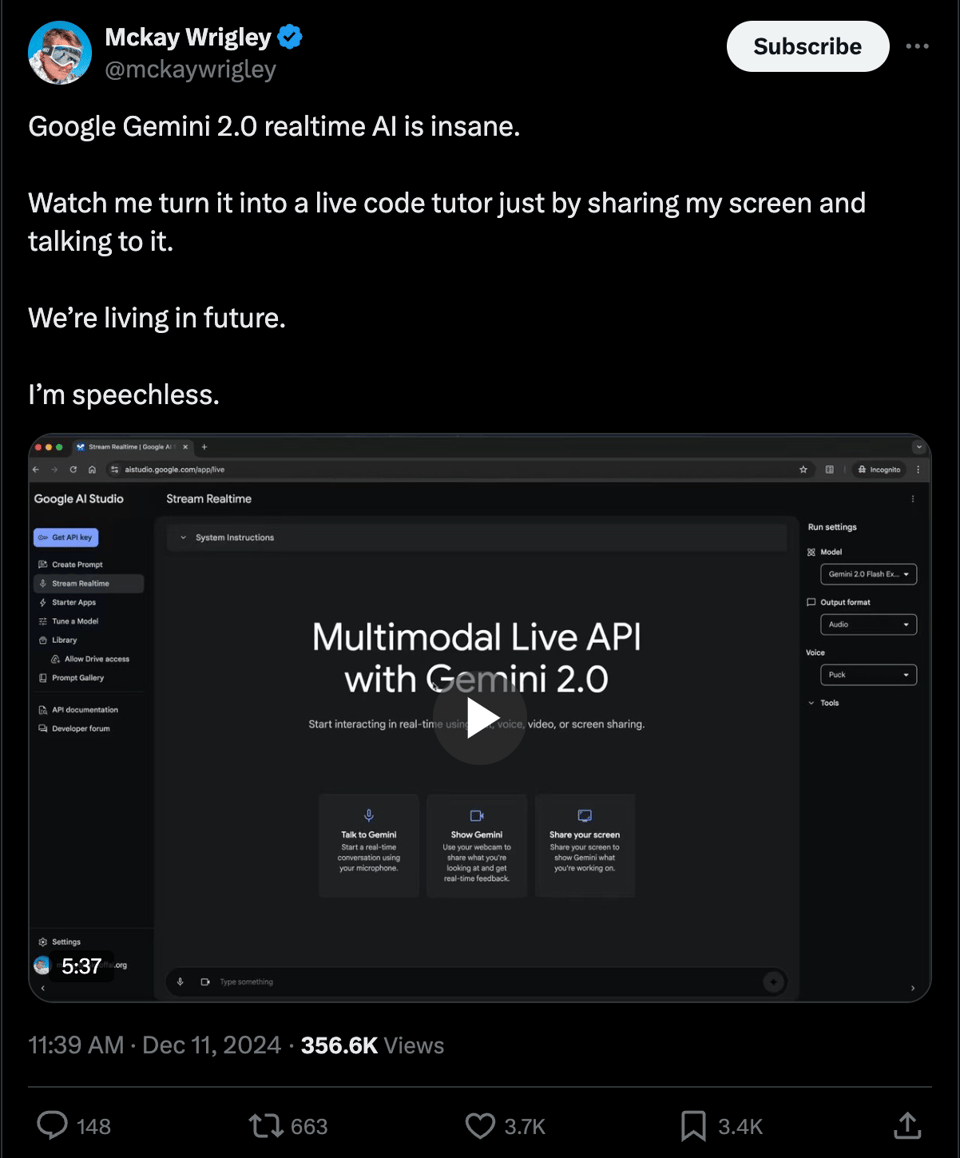
舆论 依然坚定地支持 Gemini:
我们很高兴看到这些无疑是 SOTA 级别、非常努力的团队之间进行一些友好的“互怼”。
AI Twitter 回顾
所有总结由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
以下是根据 Twitter 讨论整理的关键主题:
AI 模型发布与更新
- Google 发布了 Gemini 2.0 Flash,在多模态能力、实时流媒体和性能指标方面有重大改进。@GoogleDeepMind 指出 开发者现在可以使用实时音频/视频流。
- OpenAI 宣布了 ChatGPT 的视频功能,包括 Advanced Voice mode 中的实时视频和屏幕共享。
- Anthropic 发布了关于 Clio 的研究,这是一个用于分析 Claude 在不同语言和用例下的真实使用模式的系统。
AI 基础设施与开发
- @bindureddy 观察到,“Anthropic 正在占领开发者生态系统,Gemini 拥有 AI 爱好者的心智份额,而 ChatGPT 则统治着 AI 浅尝辄止者”。
- Together Computing 收购了 CodeSandbox,以推出 Together Code Interpreter,实现无缝的代码执行。
- @teortaxesTex 指出,放弃 Attention 机制意味着失去依赖它的几项关键能力。
行业与市场动态
- Scale AI 和 TIME 杂志推出了 TIME AI 用于年度人物报道。
- @far__el 讨论了 美国和中国 AI 能力之间的比较,认为差距可能比普遍认为的要小。
梗与幽默
- ChatGPT 添加了圣诞老人模式 用于节日对话。
- 关于 AI 宕机和服务中断的多个笑话。
- 关于模型比较和行业竞争的幽默看法。
AI Reddit 回顾
/r/LocalLlama 回顾
主题 1. Meta 的 Llama 3.3-70B:角色扮演与 Prompt 处理的卓越表现
- [为什么 Llama 3.3-70B 如此擅长根据 system prompt 扮演角色(甚至在未明确要求的情况下进入 roleplay)] (Score: 311, Comments: 83): Llama 3.3-70B 因其在根据 system prompt 采用特定人格和参与 roleplay 方面的精通而受到认可,即使在没有明确要求 roleplay 的情况下也是如此。这突显了其有效解释和响应细微 prompt 的高级能力。
- Roleplay 与创意写作: Llama 3.3-70B 的 roleplay 能力备受关注,示例显示它能有效刻画 Yoda 和 Jar Jar Binks 等角色。一些用户注意到它在 roleplay 中的创意潜力,尽管它仍面临重复和回答简短等问题,特别是在 quantized 版本中。
- 与其他模型的比较: 讨论将 Llama 3.3 与 Mistral Large 和 GPT-4o 等其他模型进行了对比,一些用户指出 Llama 3.3 表现力更强且审查更少。该模型采用人格的能力归功于其训练,可能受到 Meta 的 AI Studio 以及来自 Facebook 和 Instagram 等平台的多元数据的影响。
- 训练与审查: 社区推测,由于 Meta 的战略目标,Llama 3.3 在训练时重点关注了 roleplay 和角色刻画,而不像 OpenAI 的模型那样受到严格审查。用户讨论了 Meta 的训练方法和数据策选如何促成了 Llama 3.3 先进的 roleplay 能力,一些人将其成功归因于缺乏 fine-tuning 约束和多样化的训练数据。
主题 2. Microsoft 的 Phi-4:小模型,大 Benchmark 结果,怀疑依然存在
- [介绍 Phi-4:Microsoft 最新的专注于复杂推理的小型语言模型] (Score: 217, Comments: 86): Microsoft 推出了 Phi-4,这是一款旨在专注于复杂推理任务的新型小型语言模型(SLM)。该帖子未提供有关该模型能力或应用的更多细节或背景。
- 许多用户对 Phi 系列模型表示怀疑,称其在 benchmark 上表现良好,但在实际应用中表现不佳。据推测,Synthetic training datasets(合成训练数据集)是 Microsoft 的关注重点,可能用于授权给其他公司作为抓取数据的替代方案。
- 关于 14B 参数模型被视为“小模型”的讨论充满幽默感,用户指出这需要大量的 GPU 资源。Phi-4 的 benchmark 结果令人印象深刻,但由于以往对 Phi-3 的经验,用户仍保持谨慎。
- 一些评论提到 Phi-4 将于下周在 Hugging Face 上线,并有人暗示早期关于 Phi-3 的帖子是试图制造噱头。训练中使用的 synthetic data 受到关注,特别是针对数学补全等任务。
- [兄弟,什么情况??] (Score: 81, Comments: 38): 与 Phi-3, Qwen 2.5, GPT, 和 Llama-3.3 等其他模型相比,Phi-4 在 benchmark 中展现了极具前景的性能,评估使用的是 OpenAI 的 SIMPLE-EVALS 框架。表格将结果分为“小模型”和“大模型”,详细列出了 MMLU, GPQA, 和 MATH 等指标。
- Phi-4 的性能: 虽然 Phi-4 显示出令人期待的 benchmark 结果,但用户对其现实世界的适用性表示怀疑,并指出以往 Phi 模型在受控测试之外往往表现不佳。共识是,尽管推理能力不错,但由于数据集较小,该模型在处理事实性数据时比较吃力。
- 开源与 Synthetic Data: 讨论强调了开源领域的进展,一些用户注意到 Phi-4 在某些测试中有潜力超越 GPT-4o mini。关于 synthetic data 与广泛互联网数据的有效性也存在争论,一些用户主张使用高质量的 synthetic data 以获得更好的模型训练效果。
- 模型可用性与使用: 该模型预计将在 Hugging Face 上提供,目前可从 Azure 下载,尽管用户反映下载速度较慢。一些用户分享了他们使用之前 Phi 模型的经验,强调了它们在推理和单轮交互等特定任务中的效用,尽管它们比较啰嗦且在多轮对话中效果较差。
![[兄弟,什么情况??]](https://i.redd.it/npjopxbhsi6e1.png){kind=link}
主题 3. OpenAI o1 vs Claude 3.5 Sonnet:订阅大对决
- OpenAI o1 vs Claude 3.5 Sonnet:哪款模型最物超所值? (Score: 139, Comments: 78):OpenAI 的 o1 在复杂推理和数学方面表现出色,在 20 美元档位中超越了其他模型,是处理非编程任务的理想选择。Claude 3.5 Sonnet 在编程方面更胜一筹,尽管每周有 50 条消息的限制,但在速度和准确性之间提供了更好的平衡。Claude 以其迷人的个性著称,而 o1 则以高 IQ 被认可,这使得 Claude 更适合编程和对话任务,而 o1 更适合数学和推理。
- 用户讨论了不同模型的性价比,1M input tokens 价格为 $15,output tokens 为 每 1M $60,对定价结构表示担忧。一些人建议使用 openrouter 或 OpenWebUI,以便在无需订阅费用的情况下灵活选择模型。
- Claude 因其编程能力和迷人的个性而受到青睐,尽管一些用户报告了代码中的幻觉和过于一致的回答问题,而另一些人则认为它在快速解决复杂软件 Bug 方面不可或缺。o1 因过于顺从(overly agreeable)而受到批评,这使得它在某些任务中效果较差。
- Gemini 2.0 和 Qwen 系列 获得了积极评价;Gemini 因其速度和免费而受到关注,而 Qwen 在非编程任务上比 o1 更受青睐。普遍观点认为,使用 API 并避免订阅可能更高效且更具成本效益。
主题 4. Gemini 系列在数学基准测试中表现亮眼,认知声誉不断提升
- U-MATH:全新的大学级数学基准测试;Gemini 是 GOAT / Qwen 是王者 (Score: 74, Comments: 21):Gemini 和 Qwen 因在 U-MATH(一个新的大学级数学基准测试)中的卓越表现而受到关注。帖子指出,在这种背景下,Gemini 被认为是史上最强(GOAT),而 Qwen 则被公认为领先者。
- Gemini 的表现:Gemini 在包括 U-MATH、LiveBench 和 FrontierMath 在内的各种基准测试中被一致公认为表现最好的模型,超越了 GPT-4o 和 Claude 等其他模型。据推测,Google 通过 AlphaZero、AlphaFold 和 AlphaProof 等项目对数学和科学的专注为 Gemini 的成功做出了贡献。
- 模型对比与挑战:讨论强调了像 7b-Math 这样的小型模型令人印象深刻的表现,它们紧追 72b-Instruct 等大型模型。然而,小型模型在理解上下文线索和“指令遵循(instructions following)”方面存在困难,经常导致幻觉,正如在 Qwen 模型中所观察到的那样。
- 基准测试详情与更新:U-MATH 和 μ-MATH 基准测试是仅有的在此复杂度水平上测试 LLM 的测试,Gemini Pro 在解题和判断能力方面领先,尽管 GPT/Claude/Gemini Flash 等其他模型的幻觉率较低。leaderboard 和 HuggingFace 链接提供了关于这些评估的更多见解。
其他 AI 子版块回顾
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
主题 1. NeurIPS 2024 破坏指控扰乱研究
- [D] NeurIPS 2024 Best Paper Award 获得者破坏了其他团队 (Score: 327, Comments: 31): NeurIPS 2024 Best Paper Award 争议涉及对一名 ByteDance 研究员的指控,称其涉嫌破坏其他团队的研究以获取优势。指控包括该研究员参加会议以调试同事的代码,从而保持竞争优势,并有人呼吁撤回其论文。更多细节可以在 integrity report 中找到。
- 针对 Keyu Tian 的指控:Keyu Tian 据称修改了 PyTorch source code,并通过入侵集群和创建登录后门来干扰训练过程,这使他能够通过更改模型权重和终止进程来破坏同事的实验。这导致了大规模的实验失败,引发了对其行为诚信的担忧。
- 法律和机构反应:据报道,ByteDance 正在起诉 Tian 索赔,这可能会影响他的 NeurIPS 2024 Best Paper Award。人们猜测这一事件可能对其学术和职业地位产生影响,并质疑 NeurIPS 是否有会影响其奖项的行为准则。
- 文化和竞争背景:一些评论者强调了中国学术界内部激烈的竞争压力,这可能会促使个人采取极端行动来获取资源和认可。这种背景可能解释(尽管不能证明其合理性)这种指控的行为,反映了该领域更广泛的系统性问题。
Theme 2. Controversial ‘Stop Hiring Humans’ Campaign in SF
- 旧金山到处都是 “Stop Hiring Humans” 广告 (Score: 237, Comments: 79): “Stop Hiring Humans” 广告已投放在整个 San Francisco,引发了广泛关注和讨论。该活动极具挑衅性的信息暗示了向自动化和 AI 驱动解决方案的转变,引发了关于以技术为中心的城市中人类就业未来的疑问。
- 许多评论者(如 XbabajagaX 和 dasjati)指出,该广告活动的挑衅性质是获取关注和免费媒体曝光的战略举措,强调了其在引发广泛讨论和媒体报道方面的成功。活动分析链接。
- 包括 heavy-minium 和 umotex12 在内的讨论批评了该活动对 AI 能力的误导性声明,认为这可能会使公众对真正的 AI 进步感到麻木,或过早地加速关于 AI 的社会对话。
- AI_Ship 和 Secure-Summer2552 等评论者指出,考虑到 San Francisco 明显的社会问题(如无家可归者),这些广告具有反乌托邦色彩且缺乏同理心,将其比作 Black Mirror 的一集,并建议 AI 应该支持而不是取代人类。
Theme 3. ChatGPT’s Santa Voice: Seasonal Gimmick or Revolutionary?
- ChatGPT Advanced Voice Mode 增加了圣诞老人语音 (Score: 128, Comments: 33): ChatGPT 推出了具有 Santa Voice 选项的 Advanced Voice Mode。
- 用户对 Santa Voice 功能的反应不一;有些人觉得它很有趣且具有季节性,而另一些人则遇到了问题,例如难以切换回标准语音,或者由于摄像头激活而觉得该功能令人毛骨悚然。surfer808 提到了一次摄像头指示灯亮起且 Santa Voice 与他们互动的事件,引发了隐私担忧。
- Zulakki 报告了一个技术问题,即 Santa Voice 最初可用但随后消失了,在尝试向家人演示时造成了不便。这表明该功能的可用性可能存在潜在的 Bug 或限制。
- 关于圣诞老人的国籍有一场幽默的辩论,评论建议他来自 UK、North Pole 或 Canada,反映了对该功能实现及其文化影响的轻松看法。
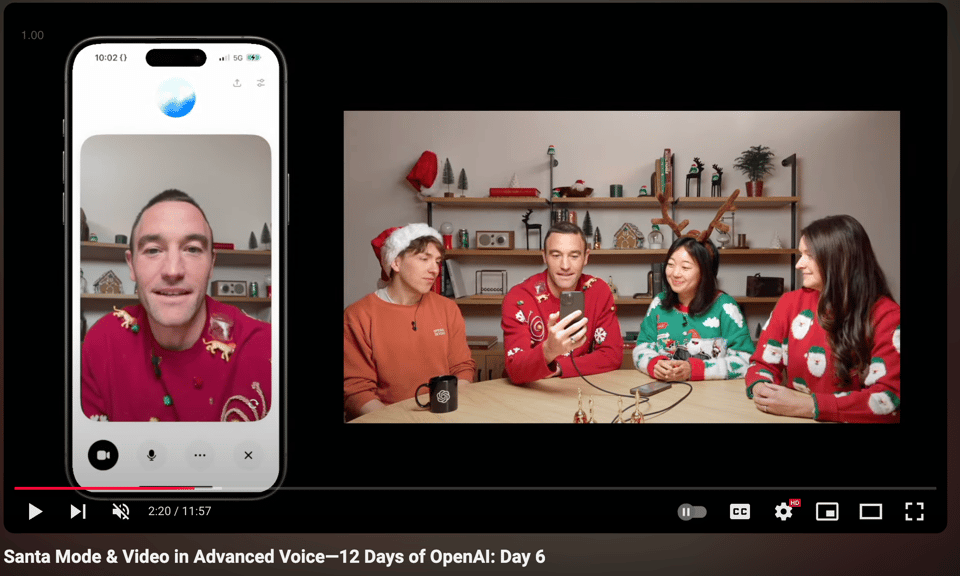
- OpenAI 12 天活动:第 6 天讨论帖 (Score: 126, Comments: 241): OpenAI 的 12 天活动在第 6 天推出了 ChatGPT 的圣诞老人模式 (Santa mode),展示了结合视频的高级语音能力。直播讨论可通过 OpenAI 官网 和 YouTube 观看。
- 高级语音模式 (Advanced Voice Mode) 与视频集成:用户正在讨论在高级语音模式 (AVM) 中集成视频和屏幕共享功能,部分用户对 AVM 有效处理视频上下文的能力表示担忧。多条评论强调了在欧洲推出的延迟,并推测原因可能是容量问题而非法律限制。
- 与 Google Gemini 的对比:用户将 OpenAI 的发布与 Google 的 Gemini 2.0 进行对比,注意到 Gemini 的多模态能力和语音模式功能。一些用户认为 Google 在及时有效地发布功能方面处于领先地位,而另一些用户则对 OpenAI 潜在的未来更新(如传闻中的 GPT-5 发布)感到兴奋。
- 用户体验与可访问性:对于功能的可用性,用户的情绪交织着兴奋与沮丧,部分用户无法在所有设备或地区访问新功能。评论还提到了 ChatGPT 语音回复中被认为带有说教意味的语气,并建议进行更自然的交互。
主题 4. OpenAI 的 12 天发布活动:AVM 中的视频功能
- OpenAI 为高级语音模式发布视频功能 (Score: 105, Comments: 43): OpenAI 在 Gemini 发布之际,为其高级语音模式 (Advanced Voice Mode) 引入了视频功能。
- OpenAI 的新功能包括在高级语音模式中进行实时视频对话和屏幕共享,今天开始向 Teams 用户以及大多数 Plus 和 Pro 订阅者推出,而 Enterprise 和 Edu 用户将在明年年初获得访问权限。“圣诞老人模式” (Santa mode) 已在全球范围内支持 ChatGPT 语音模式的地区上线。
- 关于推出时间表存在讨论,一些用户指出沟通中存在差异,因为 OpenAI 表示该功能将在“今天及下周内”推出,部分用户将其与之前功能发布的延迟进行了比较。
- 用户对可用性感到好奇,一些人对欧洲地区的延迟访问表示沮丧,而另一些人则询问如何访问新功能,并提供了一个 YouTube 链接作为参考资源。
AI Discord 摘要
由 O1-mini 生成的摘要之摘要的摘要
主题 1. AI 模型对决:Gemini vs. Claude
- Claude 在编程任务中占据主导地位:用户一致反馈 Claude 在编程准确性上优于 Gemini 2.0,巩固了其作为开发工作流首选的地位。
- Gemini 2.0 Flash 提升 AI 速度:Gemini 2.0 Flash 因其提升的速度和性能而受到赞誉,尽管一些 Bug(如实时视频读取问题)仍在修复中。
- Project Astra 瞄准 OpenAI 的宝座:Project Astra 作为 OpenAI 的强力竞争对手正受到关注,Gemini 2.0 的发布可能会重塑 AI 行业格局。
主题 2. GPU 狂热:新品发布与黄牛之战
- 5090 GPU 发布引发期待:5090 GPU 定于 1 月初发布,拥有令人印象深刻的 32GB VRAM,有望大幅提升 AI 计算能力,引发了极大的期待。
- 黄牛与网页爬虫争夺 GPU:GPU 黄牛的兴起迫使用户采用网页爬虫 (web scrapers) 等策略,以便在高需求发布期间抢购心仪的显卡。
- Intel ARC B580 vs. Nvidia RTX 3060:战斗继续:关于拥有 12GB VRAM 的 Intel B580 GPU 是否能超越流行的 RTX 3060 争论激烈,尽管人们对其 CUDA 支持仍有疑虑。
主题 3. AI 工具动向:更新、Bug 与集成
- Codeium 的 Windsurf Wave 1 发布:Windsurf Wave 1 推出了自主性升级,如 Cascade Memories 和自动化终端命令,通过
.windsurfrules增强了 AI 交互。 - Aider 面临安装障碍:用户在全局安装 Aider 时遇到困难,在 OpenSSL 兼容性警告中找到了
uv tool install aider-chat等替代方案。 - Cohere Go SDK 需要结构性修复:反馈指出 Cohere Go SDK 存在问题,特别是
StreamedChatResponseV2字段,需要紧急进行结构调整以实现准确解析。
主题 4. MLOps 奇迹:训练与优化创新
- 直接偏好优化登陆 Llama 3.3:DPO 成功集成到 Llama 3.3 中,并配有完善的文档支持,为用户简化了微调过程。
- SPDL 提升 AI 训练效率:SPDL 利用基于线程的数据加载 (thread-based data loading) 显著缩短了 AI 模型训练时间,这对于 Reality Labs 的研究具有里程碑意义。
- 训练雅可比分析揭示隐藏动态:一篇新论文深入研究了训练雅可比 (training Jacobian),揭示了初始参数如何影响最终结果,并指出了将该分析扩展到更大网络时面临的挑战。
主题 5. 社区催化剂:黑客松、AMA 会议与协作工具
- LLM Agents MOOC 黑客松截止日期临近:LLM Agents MOOC 黑客松将于 12 月 17 日截止提交,提交平台已从 Devpost 转移到 Google Forms 以简化评估流程。
- Modular 的 AMA 系列深化技术见解:由 Joe 和 Steffi 等专家主持的 Ask Me Anything (AMA) 会议探讨了使用 Mojo 进行 GPU 编程,促进了社区的深入理解。
- 社区包早期访问启动:Modular 发布了社区包的早期访问预览,邀请用户共同参与测试并扩展包生态系统。
第 1 部分:高层级 Discord 摘要
Codeium / Windsurf Discord
- Windsurf Wave 1 发布:Codeium 发布了 Windsurf Wave 1,引入了重大的自主性升级,包括 Cascade Memories 和自动终端命令执行。用户可以查看 完整变更日志 了解详细更新。
- 此次发布通过 .windsurfrules 引导行为,增强了 AI 交互,使用户在适应新功能时能更有效地进行任务管理。
- Cascade Memories 增强:Cascade Memories 已集成到 Windsurf 中,通过 .windsurfrules 为 AI 行为提供强大的指导。该功能旨在自动化用户交互并改进任务管理。
- 社区反馈表明 Cascade Memories 显著丰富了 AI 功能,尽管一些用户报告了与该功能相关的内部错误。
- Gemini 模型与 Claude 性能对比:讨论强调 Gemini 2.0 模型在编程任务中可能优于 Claude,用户表示有兴趣在 Cursor 等工具上部署 Gemini 模型。
- 用户报告称,与其它模型相比,Gemini-exp-1206 等模型显示出更优越的性能指标,引发了关于开发工作流中最佳模型选择的辩论。
- 图像上传功能扩展:Windsurf 中的 Cascade 图像上传 现在支持超过 1MB 的文件,增强了处理多种文件类型的灵活性。此次升级解决了之前用户体验中的限制。
- 扩展后的图像上传能力受到了好评,允许用户在平台内处理更复杂的数据集和媒体。
- Windsurf 中 Python 支持的改进:Windsurf 中的 Python 支持 已升级,承诺提供更流畅、更顺滑的编程体验。用户可以通过 Codeium 方案页面 管理其升级计划。
- 增强的 Python 集成旨在简化开发流程,尽管一些用户报告了更新后因内部错误带来的挑战。
aider (Paul Gauthier) Discord
- O1 Pro 在调试方面表现出色:用户报告称 O1 Pro 能有效地一次性修复问题,在处理重复性或复杂任务时表现优于其他模型。
- 用户分享了对 Sonnet 的沮丧,它经常在简单的编辑上陷入无限循环,突显了 O1 Pro 的效率。
- Gemini 2.0 Flash 性能亮眼:Gemini 2.0 Flash 因其速度和准确性受到称赞,在编辑模式下得分很高,并为编程任务提供了巨大的 Context Window。
- 尽管结果褒贬不一,许多用户认为它适合实际应用,特别是与编辑器模型结合使用时。
- Aider 安装障碍与解决方案:用户在全局安装 Aider 时面临挑战,但发现使用
uv tool install aider-chat等解决方案非常有效。- 讨论了安装过程中的 OpenSSL 兼容性问题等警告,但认为可以忽略。
- DeepSeek 面临性能问题:用户对通过 OpenRouter 访问的 DeepSeek 表示沮丧,理由是性能缓慢且频繁报错。
- 尽管面临这些挑战,DeepSeek 仍因其准确性而受到关注,促使一些用户继续使用它。
- Gemini 模型响应差异:用户报告称,与网页界面相比,Aider 中的 Gemini 模型提供的体育赛事比分已过时。
- 这表明无法通过 API 获取近期事件,突显了对信息一致性的担忧。
Cursor IDE Discord
- Claude 在编程方面仍优于 Gemini 2.0:用户讨论了 Gemini 2.0 和 Claude,尽管 Gemini 最近有所增强,但 Claude 在编程准确性方面仍处于领先地位。
- 对比突显了 Claude 在编程任务中的持续优势,促使用户保持其偏好。
- 用户对 Cursor 的性能表示担忧:参与者对 Cursor 最近的更新提供了反馈,表达了对其 Chat 和 Composer 功能性能及限制的沮丧。
- 建议集中在优化 AI 规则,以增强 Cursor 内部的查询和响应能力。
- AI 工具定价引发社区辩论:用户辩论了 Cursor 和 Gemini 等 AI 工具的性价比,评估了它们相对于产出结果的价值。
- 用户对订阅价格及其与市场上其他可用选项的对比表示担忧。
- 开发者讨论首选的 Web 托管平台:用户推荐了 Railway 和 Cloudflare Workers 等服务器托管平台,强调了根据项目类型进行选择的重要性。
- 讨论强调了在为各种开发项目选择托管方案时,成本与易用性之间的平衡。
- Z 世代的编程风格受到关注:关于代际编程风格的轻松对话出现了,引用了描绘 Z 世代程序员的幽默 YouTube 视频。
- 参与者对这些编程趋势对未来代码质量和职场互动可能产生的影响表示担忧。
OpenAI Discord
- OpenAI 推出圣诞老人模式和高级语音功能:在 12 Days of OpenAI 的第 6 天,Kevin Weil 及其团队在 Advanced Voice 中引入了新的 Santa voice 以及 video 和 screensharing 功能。
- 演示鼓励观众参与这些节日功能,增强了节日主题活动期间的互动体验。
- Project Astra 挑战 OpenAI 的主导地位:Project Astra 作为 OpenAI 的潜在竞争对手正受到关注,讨论强调了它已准备好挑战 OpenAI 的产品。
- 一些用户认为,即将发布的 Gemini 2.0 可能会显著影响 AI 行业的竞争格局。
- Gemini 2.0 超越 OpenAI 模型,反馈褒贬不一:Gemini 2.0 Flash 目前可在网页端访问,其性能相比 OpenAI 的模型获得了积极反馈。
- 然而,用户报告了影响实时视频读取等功能的 Bug,表明仍有需要进一步完善的地方。
- AI 图像和语音技术的进展:ElevenLabs 的语音 AI 技术正在进行真实感测试,力求实现与人类声音无异的输出。
- 在 AI 图像生成领域,Hailuo 和 Sora 等工具因免费额度而需求旺盛,尽管用户对不同视频格式的输出质量反应不一。
- OpenAI 服务中断及恢复程序:12 月 11 日 PST 时间下午 3:16 至晚上 7:38,服务中断影响了 OpenAI,API 流量在 下午 5:40 左右开始恢复。
- 所有服务现已恢复运行,OpenAI 将进行根本原因分析以防止未来再次发生此类事件。
Perplexity AI Discord
- Gemini 1.5 Pro Deep Search 比 Perplexity 慢:用户观察到,与 Perplexity 相比,Gemini 1.5 Pro Deep Search 提供了更全面的研究能力,但 响应时间显著更长。分享了详细的基准测试(benchmarks)来阐明性能差异。
- 一位成员强调,尽管在速度上有所权衡,但 Gemini 的彻底性使其适用于密集型研究任务,而其他成员则更喜欢 Perplexity 在要求较低的场景中更快的响应。
- Perplexity 弃用 O1 推理模型:O1 推理模型 已从 Perplexity 平台移除,引发了对处理复杂查询的担忧。@AravSrinivas 提到,该模型被认为是不必要的,因为 推理(reasoning)现在会自动触发 复杂任务。
- 针对依赖 O1 模型进行高级推理的 Pro 用户的影响展开了讨论,一些人质疑这一决定及其对工作流效率的影响。
- Perplexity 推出 LinkedIn 验证:Perplexity 推出了 LinkedIn 验证,允许用户连接其个人资料以增强功能。该 公告 让社区对该功能的具体益处感到好奇。
- 用户推测了潜在优势,如改进的凭证验证或个性化的用户体验,但 Perplexity 尚未澄清这种集成的确切目的。
- GPR 设备方法论的进展:关于 GPR 设备和方法论 的讨论引起了成员的兴趣,此链接 强调了最近的进展。
- 参与者就 GPR 技术的最新技术和应用进行了交流,强调了其在各种工程领域中日益增长的作用。
- Perplexity API 遇到 3D Secure 问题:用户报告称,通过 Perplexity API 添加卡片会导致 UI 冻结,随后 银行的 3D Secure 屏幕迅速出现并消失,从而阻止了交易授权。
- 讨论集中在 3D Secure 对安全合规性的必要性以及 API 内部缺乏替代解决方案,这阻碍了无缝支付流程。
Unsloth AI (Daniel Han) Discord
- 使用 Llama 3.3 进行直接偏好优化 (DPO):成员确认 Direct Preference Optimization (DPO) 已成功与 Llama 3.3 集成,并有全面的文档和示例支持。
- Theyruinedelise 强调,提供的文档增强了易用性,促进了用户更顺畅的实现。
- 模型合并与量化的挑战:讨论集中在合并模型的复杂性上,特别是合并到 4-bit 的缺点,这可能会降低 LoRA 微调模型的性能。
- Disgrace6161 主张先合并到全精度以保持性能,强调了保留模型质量的重要性。
- 使用 LoRA 适配器优化微调:LoRA 适配器 在微调中的作用得到了广泛讨论,强调了它们在保持模型完整性的同时优化 VRAM 占用的能力。
- 参与者指出,根据具体任务要求和数据集特征,LoRA 中更高的秩(ranks)可以提升性能。
- SPDL 提升 AI 训练效率:SPDL 博客文章 概述了 SPDL 如何通过 基于线程的数据加载 加速 AI 模型训练,显著缩短了训练时间。
- 这种方法改进了数据管理和吞吐量,事实证明对于处理 Reality Labs 研究中的大型数据集至关重要。
- 发布 OpenPlatypus 数据集:包含 25,000 个样本 的 OpenPlatypus 数据集已发布,并在温度为 0 的情况下针对 Qwen QwQ 进行了评估,在 OpenRouter 上花费了 $30。
- 建议包括排除 100-5000 tokens 范围之外的响应,并在缩减样本量后应用 k-means 聚类。
Stability.ai (Stable Diffusion) Discord
- 5090 GPU 发布备受期待:成员们正热切期待预定于 1 月初发布的 5090 GPU,并强调了其令人印象深刻的 32GB VRAM 容量。
- 诸如 “在 AI 的时间维度里,那就像过了好几年” 之类的幽默评论反映了社区对这款新 GPU 的兴奋与期待。
- 利用 Web Scrapers 对抗 GPU 黄牛:针对黄牛(scalpers)抢购 GPU 的现象引发了讨论,促使用户探索 web scrapers 和其他技术以在发布期间确保能买到显卡。
- 参与者强调了对于不在 US 本地的用户来说难度更大,突显了获取 GPU 的挑战。
- 图像生成推荐的热门模型:用户推荐了 Dream Shaper、Juggernaut 和 SDXL 等模型用于生成宇宙飞船等专业内容,并指出其效果显著。
- 一些人建议利用 LoRA 训练来增强模型性能,而另一些人则指出 8GB VRAM 可能会限制其能力。
- 旧版 Stable Diffusion 模型的问题:成员们报告了在使用 WD1.4 等旧模型时遇到的挑战,这些模型在图像生成任务中往往会产生异常结果。
- 建议包括在训练 LoRA 模型时为正则化图像(regularization images)添加标签(captioning),以减轻这些问题并提高输出质量。
- 视频 AI 爱好者的 Discord 服务器推荐:在询问讨论本地视频 AI 模型的合适 Discord 服务器时,提到了 Mochi、LTX 和 HunYuanVideo 等平台。
- Banodoco Discord 服务器被强调为对这些视频 AI 模型感兴趣的爱好者的首选社区。
Eleuther Discord
- 训练 Jacobian 分析揭示参数依赖性:arXiv 上的一篇新论文分析了训练 Jacobian,通过将参数空间中的一个小球体转换为椭球体,说明了最终参数如何受其初始值的影响。
- 该研究识别了奇异值谱中的不同区域,指出在白噪声(white noise)上训练比在真实数据上训练更剧烈地压缩参数空间,并强调了将 Jacobian 分析扩展到更大网络时的计算挑战。
- RWKV 模型发布:Flock of Finches & QRWKV-6:RWKV 团队发布了 Flock of Finches 37B-A11B 和 QRWKV-6 32B Instruct Preview,两者在多项任务中均展示了令人印象深刻的 Benchmark 结果。
- Flock of Finches 仅用 109 billion tokens 训练就实现了极具竞争力的性能,而 QRWKV-6 在关键指标上已经超越了之前的 RWKV 模型。
- Muon 优化器展现出优于 AdamW 的潜力:共识认为 Muon 可能优于 AdamW 等现有优化器,其梯度正交化(gradient orthogonalization)可能与最大流形容量损失(maximum manifold capacity loss)和强化学习正则化有关。
- Muon 优化器的底层数学原理被认为对提升性能具有启发性和合理性,尽管关于其更广泛适用性的讨论仍在继续。
- NeurIPS 奖项争议与 VAR 论文学术不端疑虑:NeurIPS 的 ARC 奖项引发了关于主办方改变规则(goalpost shifting)和潜在操纵策略的辩论,使人对其 Benchmark 的有效性产生怀疑。
- 此外,针对 NeurIPS 2024 最佳论文一作 Keyu Tian 的质疑也被提出,指控其在 ByteDance 实习期间存在学术不端和恶意代码攻击行为,引发了重新评估该论文荣誉的呼声。
- 负注意力权重与 Cog Attention:Cog Attention 的引入提出了一种允许负权重的注意力机制,旨在通过促进 Token 的删除、复制或保留来增强模型的表达能力。
- 虽然这一概念具有创新性,但对其有效性和潜在学习难度的担忧依然存在,特别是在数独(Sudoku)任务等特定应用中。
LM Studio Discord
- GPU 网格:LM Studio 的多 GPU 掌控:LM Studio 高效地将任务分配到多个 GPU 上,要求它们属于同一“类型”,但不一定是同一型号。Heyitsyorkie 提到,LM Studio 中的 GPU offload 是一个开关,可以利用所有可用的 GPU。
- LM Studio 用户强调,这种设置通过利用连接的 GPU 的总计算能力,增强了性能的可扩展性。
- Mac 性能:在 M4 Max 上运行 70b LLMs:M4 Pro 芯片可以在至少 16GB RAM 的 Mac 上运行 8b 模型,而 M4 Max 则有能力运行 70b 模型,前提是用户为了灵活性优先考虑 RAM。
- 参与者指出,像 70b 这样的大型模型需要大量内存,这使得 M4 Max 成为处理高需求 AI 任务的合适选择。
- GPU 对决:Intel B580 vs Nvidia RTX 3060:Intel 的 B580 GPU 价格亲民且拥有 12GB VRAM,但需要 Vulkan 支持,这引起了用户的怀疑。相比之下,RTX 3060 提供 12GB VRAM,二手价格在 $150-$250 之间。
- mlengle 强调更倾向于 Nvidia GPU,因为它们支持 CUDA,而 Intel 的产品则缺乏这种支持。
- 无审查 AI:应对模型安全限制:一位用户在寻找创建无审查 AI 模型的指导时表达了挫败感,强调缺乏移除安全功能的清晰资源。他们被建议探索 Unsloth 微调指南,并考虑使用旨在实现限制更少模型的数据集。
- 参与者提出了处理模型安全性的替代方法,并指出了修改现有 LLMs 所涉及的复杂性。
- 微调 vs RAG:选择正确的 LLM 策略:参与者讨论了微调 LLMs 的复杂性,特别是在处理数值数据时,认为这可能无法提供预期的结果。建议使用 RAG (Retrieval-Augmented Generation) 等替代方案进行数据检索。
- 社区指出,与微调相比,传统的分析方法对于特定用例可能会产生更好的见解。
Bolt.new / Stackblitz Discord
- 少量使用后 Token 使用量显示为 ‘NaN’:用户报告称,在少量使用后,token usage 显示为 ‘NaN’,导致困惑和跟踪不准确。
- 支持人员建议如果问题持续存在,请重新加载标签页或联系帮助中心,因为显示问题正在解决中。
- Bolt 中的调试导致过度的 Token 消耗:用户在 Bolt 中调试时遇到问题,导致在没有有效结果的情况下消耗了过多的 Token。
- 建议包括使用更集中的 Prompt 和文件固定(file pinning),以防止在复杂任务期间发生不必要的更改。
- Supabase 集成将增强 Bolt 功能:社区讨论了将 Supabase 集成到 Bolt 中的潜力,许多人认为这将增强构建项目的功能。
- 用户表示乐观,认为这种集成可以显著简化工作流程,特别是对于那些从 Firebase 等服务迁移过来的用户。
- 功能请求集中在 GitHub 集成和全栈支持:用户对功能提出了建议,包括更好的 GitHub 集成和对全栈应用的更多支持。
- 社区强调要礼貌地提出功能请求,并将其引导至 GitHub issues 页面进行正式审议。
Notebook LM Discord Discord
- NotebookLM UI 翻新并推出交互式音频:NotebookLM 即将迎来 UI 翻新,其特点是为 Sources、Chat 以及 Notes & Audio Overview 设立了独立板块,并推出了 Interactive Audio Beta,支持与主持人进行实时互动 (Tweet)。
- 此次更新旨在通过改进导航和可用性来提升用户体验,解决当前在源管理和音频交互方面的局限性。
- Gemini 2.0 提升性能:Gemini 2.0 预计将以更高的输出 Token 限制和先进功能超越现有模型 (Tweet)。
- 然而,人们对与前代版本相比可能存在的上下文窗口大小限制表示担忧。
- 自定义 AI 语音助力播客个性化:成员们讨论了为播客集成 custom voices(自定义语音),并建议使用 Eleven Labs 进行语音克隆,以满足日益增长的个性化音频体验需求。
- 一位用户强调了利用专业克隆语音来增强听众参与度和内容独特性的重要性。
- AI 驱动的 TTRPG 冒险受到关注:使用 AI 运行 TTRPG 冒险的热度激增,这与单人 D&D 游戏类似,可提供更具沉浸感的叙事。
- 用户报告了这种尝试的不同成功程度,指出尽管存在一些挑战,但这仍是一项有趣的尝试。
- AI 生成的视频播客探讨深度主题:一个由原始人和 AI 聊天机器人组成的全新 AI 生成视频播客 深入探讨了诸如 生命意义 等主题,将幽默与深刻对话融为一体。
- 这种创新的形式展示了古代与现代视角之间的动态关系,因其独特的方法而引起关注。
Nous Research AI Discord
- Hermes 3B 超出基准测试预期:用户正在对比 Hermes 3B、Llama 3.2、Mistral 7B 和 Qwen 2.5 的基准测试,Hermes 3B 在多项指标上表现出卓越性能。
- Senor1854 强调了新 数学基准数据集 相比既有数据集的可靠性,强调了不断演进评估技术的重要性。
- QTIP 模型在无需重新训练的情况下优于 AQLM:据报道,QTIP 模型在无需重新训练的情况下表现优于 AQLM,详情见 QTIP GitHub 仓库。
- 社区反应表明信号处理技术在机器学习中正重新兴起,成员们指向 研究论文 以获取更深入的见解。
- Llama3 面临容量利用率挑战:Llama3 被指出在模型容量利用率方面经历了性能下降,导致成员们开始审视底层的模型动态。
- 成员们计划研究相关研究以了解性能退化的原因,并对模型容量如何影响 Llama3 的效能表示关注。
- 推出新数学基准 U-MATH 和 μ-MATH:Toloka 宣布推出 U-MATH 和 μ-MATH,这是两个旨在评估 LLMs 大学水平数学能力的全新基准。
- 这些基准预计将提供更可靠的评估,与之前的评分系统形成对比,并推动评估技术的进步。
- 利用大模型隐藏状态预训练小模型:Kotykd 提出了一种新颖的训练方法,即使用大模型隐藏状态(big model hidden states)在不同架构中预训练较小的模型,以提高效率。
- 这一想法引发了关于此类方法可行性和潜力的讨论,成员们强调需要进一步的探索和实验。
GPU MODE Discord
- Torch.compile 面临 Dynamic Padding 性能惩罚:一位用户报告称,在将 torch.compile(mode=’max-autotune’) 与 dynamic=True 结合使用时,初始 Decoder 迭代过程中出现了显著的性能惩罚,特别是在处理新的 conditioning shapes 时运行速度变慢。
- 尽管启用了 dynamic padding,性能问题依然存在,这引发了关于减轻与变长输入相关的性能惩罚的潜在解决方案的讨论。
- Triton 通过 Fused Kernels 增强 Matmul 和 Softmax:社区成员正在 Triton 中为 matmul 和 softmax 开发 fused kernel,借鉴了现有的点对点激活融合(如 ReLU)。
- 成员们寻求关于利用 Triton 文档中 group-ordered matmul 示例的指导,以克服融合 softmax 操作相关的挑战。
- TorchAO 中的 Float8 训练:从 DDP 转向 FSDP:TorchAO 的 float8 训练实现在使用 DDP 扩展到多 GPU 设置时遇到错误,尽管在单 GPU 上运行顺畅。
- 社区成员建议采用 FSDP 进行数据并行,并鼓励在 TorchAO 上分享代码或报告问题,以促进故障排除和改进。
- CUTLASS 成为顶级 GEMM 实现替代方案:在关于排除 cuBLAS 之外的最佳 GEMM 实现讨论中,CUTLASS 被认为是领先的替代方案。
- 参与者比较了纯 CUDA 和 Triton 等多种替代方案,最终认可 CUTLASS 在矩阵乘法任务中的卓越性能。
- GPU Glossary 发布及 H100 Tensor Core 澄清:GPU Glossary 在 Modal 上发布,详细介绍了“Streaming Multiprocessor”等术语,并解决了 H100 GPU 中的核心计数和 tensor core 功能问题。
- 讨论强调了准确表示 GPU 架构的必要性,包括澄清 H100 中的每个 SM 拥有 128 个 FP32 cores,以及 tensor cores 与 CUDA cores 相比的操作差异。
Cohere Discord
- Cohere 支持响应速度:当用户报告问题时,成员强调对于紧急事项应联系 support@cohere.com 的支持团队。
- 另一位用户鼓励直接发消息以获得更快协助,并认可支持团队的存在。
- Rerank 超时问题:多位用户在使用 Rerank 功能时遇到 504 gateway timeout 错误,其中一位报告请求在 40 秒后超时。
- 该问题似乎是偶发的,因为一些成员注意到服务不久后恢复,而其他人仍报告存在困难。
- H100 上 FP8 量化优于 BnB:关于量化技术的讨论显示,在 H100 硬件上,FP8 量化在高用户负载下的快速推理方面优于 BnB。
- 成员们一致认为,像 WikiText 这样的传统校准数据集在实际性能中往往表现不足,特别是对于非英语语言。
- Cohere Go SDK 结构修复:反馈表明 Cohere Go SDK 中与 tools calls 相关的
StreamedChatResponseV2字段结构不正确。- ToolPlanDelta 和 ToolCallDelta 的定义缺少准确解析所需的必要字段。
- Aya Expanse 模型许可担忧:用户表示倾向于在公司内部环境中使用 Aya Expanse 模型,强调在避免潜在数据泄露的同时需要速度。
- 用户对 CC-BY-NC 许可表示了担忧,引发了关于即使在企业环境内进行非商业用途的影响的讨论。
LLM Agents (Berkeley MOOC) Discord
- LLM Agents Hackathon 截止日期及平台变更:LLM Agents MOOC Hackathon 的提交截止日期临近,为 12月17日。提交平台已从 Devpost 迁移至 Google Forms,以确保评估工作的顺利进行。
- 获胜者将于 2025年1月上半月 公布,鼓励参与者通过聊天频道寻求最后的帮助,并访问 Hackathon 网站了解更多详情。
- 高级 LLM Agents MOOC 将于 2025 年春季启动:Advanced Large Language Model Agents MOOC 定于 2025年春季 开课,重点关注推理和数学 AI。目前已开放报名,链接见 此表单。
- 教学大纲仍在制定中,预计 Prof Song 将提供更多细节。课程将从 1月中旬持续到5月初,更多信息可在 MOOC 网站 查看。
- MOOC 作业和测验政策:所有作业(包括书面文章)的截止日期为 2024年12月12日晚上 11:59 PM PST。测验按 完成情况评分(completion basis),允许参与者在不受惩罚的情况下获得证书。
- 书面文章作业需要提供社交媒体帖子的链接,可通过 Written Article Assignment Submission 提交。测验旨在促进学习而非严格考核。
- Hackathon 的 Ninja Tier 要求:对于 Hackathon 中的 Ninja Tier,必须完成所有测验并提交文章作业,实验(Labs)为选修项。
- 鼓励参与者针对其 Hackathon 项目撰写书面文章,以增强他们在该等级中的贡献。
Interconnects (Nathan Lambert) Discord
- Google 发布 Android XR:Google 在最近的 演示 中展示了 Android XR,这是一款专为 Headsets(头显)和 Smart Glasses(智能眼镜)设计的新型混合现实操作系统。
- 该平台具有带字幕的实时 Translation(翻译)功能,强化了 Google 向增强现实技术转型的战略重点。
- OpenAI 与 Anthropic 的市场竞争:OpenAI 和 Anthropic 正在加剧市场领导地位的竞争。到 2024 年底,Anthropic 的 ARR 达到 10 亿美元,而 OpenAI 的收入为 40 亿美元,估值为 1570 亿美元。
- 这种竞争凸显了 Anthropic 在编程应用领域的增长,引发了 OpenAI 高管 对战略从安全转向激进营销的担忧。
- MLLM 开发进展:社区成员正积极寻找跟踪 MLLM 发展的优质来源,一些人利用 Scraping 技术和 Twitter 信息流作为潜在资源。
- 提升信息质量的努力反映了 MLLM 领域对实时、可靠数据的需求。
- Hugging Face 的 VLM 见解:来自 Hugging Face 的 Merve 被推荐为获取 VLM 见解的关键资源,可以通过 Twitter 访问她发布的信息。
- 她的内容被认为对于紧跟 Vision-Language Models 发展的人士非常有价值。
- AI 模型创意基准测试:围绕建立衡量 LLM 创意任务能力的有效基准展开了讨论,旨在解决目前缺乏 Diversity(多样性)和创意标准的问题。
- Claude-3 尽管受到社区青睐,但在创意写作基准测试中排名往往较低,这凸显了改进评估指标的必要性。
LlamaIndex Discord
- Calsoft 发布 CalPitch 工具:Calsoft 推出了 CalPitch,该工具旨在协助其业务开发团队研究潜在客户,并在人工监督下起草外联邮件。
- 此次发布展示了 AI 如何增强并加速 当前的工作流程。
- 通过 SharePoint 和 LlamaParse 增强 RAG Agent:新功能支持构建遵循 SharePoint 权限的 RAG Agent,满足了 Azure stack 用户使用 LlamaParse 解析非结构化 PDF 数据并连接到企业数据源的需求。
- 针对数据隐私问题,确保数据保留时间不超过 48 小时。
- Google Gemini 2.0 模型发布:Google 发布了最新的 Gemini 2.0 模型,并提供首日支持,可通过
pip install llama-index-llms-gemini或pip install llama-index-llms-vertex进行访问。- Gemini 2.0 Flash 模型承诺提升速度和能力,被誉为 AI 领域的游戏规则改变者。
- 使用 ReAct Agent 个性化 Slack Bot:一位用户正在使用 ReAct Agent 开发 Slack Bot,并寻求关于如何在不暴露其 AI 身份的情况下融入个性的建议。
- 社区成员建议使用带有 system prompt 的 FunctionCallingAgent 来定制其个性。
- 将 BGEM3 与 Qdrant 数据库集成:一位用户询问如何通过 LlamaIndex 将 BGEM3 模型与 Qdrant 数据库集成,并寻求相关流程指导。
- 社区分享了与 BGEM3 相关的资源以协助集成。
Modular (Mojo 🔥) Discord
- Swag Challenge 获胜者公布:我们在周一开启了 swag challenge,并在此处公布了获胜者。Ahmed 还主持了一场 关于使用 Mojo 进行 GPU 编程的 Ask Me Anything 会议。
- 这一举措不仅增强了社区参与度,还为参与者提供了与专家直接交流使用 Mojo 进行 GPU 编程的机会。
- AMA 会议深入探讨 Mojo:周二,Joe 主持了一场 关于标准库的 Ask Me Anything 会议,对标准库的功能和特性提供了宝贵的见解。
- 此外,今天的活动还包括 关于 MLIR 中 async Mojo/协程实现的 Steffi 问答 以及 关于 Mojo 优化流水线的 Weiwei 问答,旨在深化对特定技术主题的理解。
- 社区软件包早期访问版发布:昨天,我们发布了 社区软件包的早期访问预览版,鼓励用户加入并协助测试打包功能。感兴趣的用户可以在 <#1098713770961944628> 注册,以获得进入指导频道 <#1313164738116583454> 的权限。
- 此次发布旨在通过让社区参与测试和开发来扩展软件包生态系统。
- Async Mojo 实现与优化流水线:今天的 Ask Me Anything 会议 包括关于 MLIR 中 async Mojo/协程实现 以及 Mojo 优化流水线 的讨论。
- 这些会议旨在提供深入的技术知识,并促进使用 Mojo 的 AI 工程师之间的互动。
DSPy Discord
- 面向 LLM 的 DSPy 框架:在引入 DSPy 框架后,DSPy 显著减少了为编程语言模型编写 Prompt 的时间。
- 该框架使用样板化 Prompt 和任务签名(task signatures),简化了 Prompt 的创建并提高了基于 LLM 应用的效率。
- 关注文本和图像输入:成员们讨论了是否要投入视频和音频输入,其中一位成员建议目前先专注于文本和图像输入。
- 定义 LLM Agent:一位成员发起了关于“LLM Agent”定义的讨论,并分享了一个探讨其隐喻含义的 Thread。
- 参与者幽默地承认了这场辩论的争议性,称 “你现在捅了马蜂窝了。”
- 使用有标签数据进行优化:确认了 Optimizer 可以与有标签数据(特别是金标准输入输出对)一起使用。
- 这一确认引发了成员们对使用有标签数据集进行优化的浓厚兴趣和参与。
- AI 是技术界的鸭嘴兽:一位成员反思了 AI 对现有技术分类的挑战,将其比作 The Platypus In The Room 中描述的技术“鸭嘴兽”。
- 他们强调:“AI 和 LLM 的几乎每一个显著特性都在挑战我们的惯例、分类和规则集。”
OpenInterpreter Discord
- 寻找蜘蛛侠:平行宇宙故障效果:一位用户正在寻找他们在网站上看到的 Spider Verse 故障效果,以便复制该效果。
- 他们对该效果的创意方面表现出浓厚兴趣。
- Open Interpreter 的 Docker 问题:一位成员报告称,在 Docker 中运行的 Open Interpreter 仅返回模型的聊天响应,而不执行代码。
- 他们认为该应用程序似乎在假装执行代码,而实际上并没有执行。
- GitHub Model I 教程更新:一位用户询问了 GitHub 页面上关于 Model I 教程的最新变化,注意到信息发生了重大转变。
- 似乎 GitHub 页面更新了,现在很多东西都不一样了,这表明了对文档的困惑。
- Struggles with NVIDIA NIM Base URL Setup: 一位用户寻求设置 NVIDIA NIM 基础 URL 链接的帮助,提到尝试多次均未成功。
- 他们表达了沮丧,称已经尝试了很久但运气不佳。
- WebVoyager 与 GPT 4V 的偏好:一位成员询问了关于 WebVoyager 的意见,表示倾向于更新模型以使用 GPT 01 而不是 GPT 4V。
- 他们对测试并可能切换模型感到好奇。
tinygrad (George Hotz) Discord
- Coverage.py 介绍:一位成员介绍了 Coverage.py 作为测量 Python 代码覆盖率的工具,强调了其跟踪已执行代码和分析未执行部分的能力。
- 最新版本 7.6.9 于 2024 年 12 月 6 日发布,支持从 3.9 到 3.14 alpha 2 的 Python 版本。
- gcov 作为替代覆盖率工具:一位成员推荐使用 gcov 进行覆盖率分析,并询问是否有更细粒度的选项。
- 这引发了关于各种可用覆盖率工具及其各自优势的广泛讨论。
- George Hotz 认可 Coverage.py:George Hotz 认为 Coverage.py 是评估测试覆盖率的良好起点,体现了他对其增强代码质量能力的信心。
- 他的背书强调了该工具在寻求改进测试流程的工程师中的有效性。
- 寻求测试覆盖率专家:一位成员请求熟练使用测试覆盖率工具的用户提供帮助,以识别死代码。
- 他们强调,为了保持代码质量,未测试的代码可能应该被删除。
Torchtune Discord
- QRWKV6-32B 模型提升计算效率:Recursal AI 将 Qwen 32B Instruct 模型转换为 QRWKV6 架构,在保持原始 32B 性能的同时,在推理过程中实现了 1000 倍的计算效率。
- 此修改将 Transformer Attention 替换为 RWKV-V6 Attention,从而显著降低了计算成本。
- AMD GPU 实现快速训练:使用 16 块 AMD MI300X GPU(每块 192GB VRAM),QRWKV6 模型的训练仅需 8 小时 即可完成,展示了 AI 开发速度的进步。
- 即将推出的 Q-RWKV-6 72B 和 RWKV-7 32B 等模型正在开发中,有望提供更强大的能力。
- RWKV-V6 Attention 增强可扩展性:QRWKV6 模型中的线性注意力机制(Linear Attention)在规模化应用中被证明非常高效,特别是在处理长上下文(Long Context)时。
- 尽管有这些改进,由于计算限制,该模型目前的上下文长度上限为 16k,但在超过此限制后仍保持稳定。
- 模型转换降低重训练成本:转换过程允许将任何 QKV Attention 模型转换为 RWKV 变体,而无需进行完整重训练,从而降低了计算成本。
- 然而,该模型继承了 Qwen 模型的语言限制,仅支持约 30 种语言,而 RWKV 通常支持 100 多种语言。
- 社区协作推动进步:QRWKV6 模型的训练由 TensorWave 赞助,EleutherAI 和 RWKV 社区做出了重大贡献。
- 虽然转换过程具有创新性,但部分细节尚未公开,社区对其具体实现方式(how-to)感到好奇。
Gorilla LLM (Berkeley Function Calling) Discord
- 为自定义 API 微调 Gorilla LLM:一位用户正在寻求关于如何微调 Gorilla LLM 以识别自定义 API 的指导,并表示此前在该过程中遇到了困难。
- 他们特别提到了从 Hugging Face 下载 GoEx 模型时的挑战。
- 下载 GoEx 模型的挑战:用户提到在尝试下载 GoEx 模型以便在 Colab 环境中使用时遇到了麻烦。
- 这凸显了对模型获取提供更清晰说明或故障排除步骤的需求。
- 在 Gorilla LLM 中实现可逆性:用户询问了在其 Gorilla LLM 项目中实现可逆性(Reversibility)的策略。
- 这表明开发者对开发过程中的有效控制机制有着广泛兴趣。
- 在 Colab 中训练 Gorilla LLM:他们正在 Colab 环境中进行 Gorilla LLM 的训练。
- 这种方法可能需要高效的资源管理和清晰的训练协议。
Axolotl AI Discord
- PyTorch 的 PYTORCH_TUNABLEOP_ENABLED 标志:一位成员强调了在 PyTorch 中使用
PYTORCH_TUNABLEOP_ENABLED=1来启用可调操作(Tunable Operations),并引用了 PyTorch GitHub 仓库。- 该功能暗示了 CUDA 可调操作的优化,可能会提高使用 PyTorch 的开发者的效率。
- CUDA 可调性提升 GPU 性能:讨论集中在
PYTORCH_TUNABLEOP_ENABLED=1及其对 CUDA 操作的好处,表明在 GPU 计算任务中可能存在性能提升。- 成员们认为,可调方法允许开发者更有效地自定义操作,从而符合特定的用户需求。
Mozilla AI Discord
- Mozilla Builders Demo Day 回顾发布:Mozilla Builders Demo Day 回顾 重点介绍了成员们如何在恶劣的天气条件下线下齐聚,展示了令人惊叹的 technology 以及 participant connections。
- 该活动展示了前沿技术,并促进了参与者之间的紧密联系。
- 致谢核心贡献者:向促成此次活动的特定团队和贡献者表达了特别感谢,详情见此处。
- 社区成员展现了非凡的韧性,在困难条件下(如冒着海啸)依然坚持参加。
- Demo Day 的社交媒体热度:Mozilla Builders 分享了他们的 LinkedIn 动态 和一条 推文,将此次活动描述为优秀人才与卓越技术的精彩汇聚。
- 社交媒体帖子强调了活动的成功以及强烈的社区参与度。
- Demo Day 精彩视频发布:为错过活动的人分享了名为 Demo_day.mp4 的精彩回顾视频。
- 该视频展示了当天的部分 presentations 和 interactions,提供了全面的概览。
MLOps @Chipro Discord 没有新消息。如果该频道长时间没有动态,请告知我们,我们将将其移除。
LAION Discord 没有新消息。如果该频道长时间没有动态,请告知我们,我们将将其移除。
HuggingFace Discord 没有新消息。如果该频道长时间没有动态,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该频道长时间没有动态,请告知我们,我们将将其移除。
第二部分:分频道详细摘要与链接
完整的各频道详情已在邮件中截断。
如果你喜欢 AInews,请分享给朋友!提前感谢!