ainews-modernbert-small-new-retrieverclassifier
ModernBert:新款小型检索/分类利器,支持 8k 上下文,训练量达 2T tokens。
Answer.ai/LightOn 发布了 ModernBERT,这是一款更新的仅编码器(encoder-only)模型,支持 8k token 上下文,在包含代码的 2 万亿 token 数据集上训练而成。该模型拥有 1.39 亿/3.95 亿参数,在检索、自然语言理解(NLU)和代码任务中表现出顶尖(SOTA)性能。其特点是采用了交替注意力(Alternating Attention)层,融合了全局和局部注意力。
Gemini 2.0 Flash Thinking 在 Chatbot Arena 中首次亮相即登顶榜首,而 O1 模型在推理基准测试中取得了最高分。Llama 的下载量突破了 6.5 亿次,在 3 个月内翻了一番。OpenAI 推出了具有语音功能的桌面端应用集成。Figure 交付了其首批商用人形机器人。机器人仿真领域也取得了显著进展,新的物理引擎 Genesis 声称其运行速度比实时快 43 万倍。
Encoder-only 模型就是你所需要的一切。
2024/12/18-2024/12/19 AI 新闻。我们为你检查了 7 个 subreddits、433 个 Twitter 账号 和 32 个 Discord(215 个频道,4745 条消息)。预计节省阅读时间(以 200wpm 计算):440 分钟。你现在可以标记 @smol_ai 进行 AINews 讨论了!
正如他几个月来一直预告的那样,Jeremy Howard 和 Answer.ai/LightOn 团队今天发布了 ModernBERT,更新了 2018 年的经典 BERT:
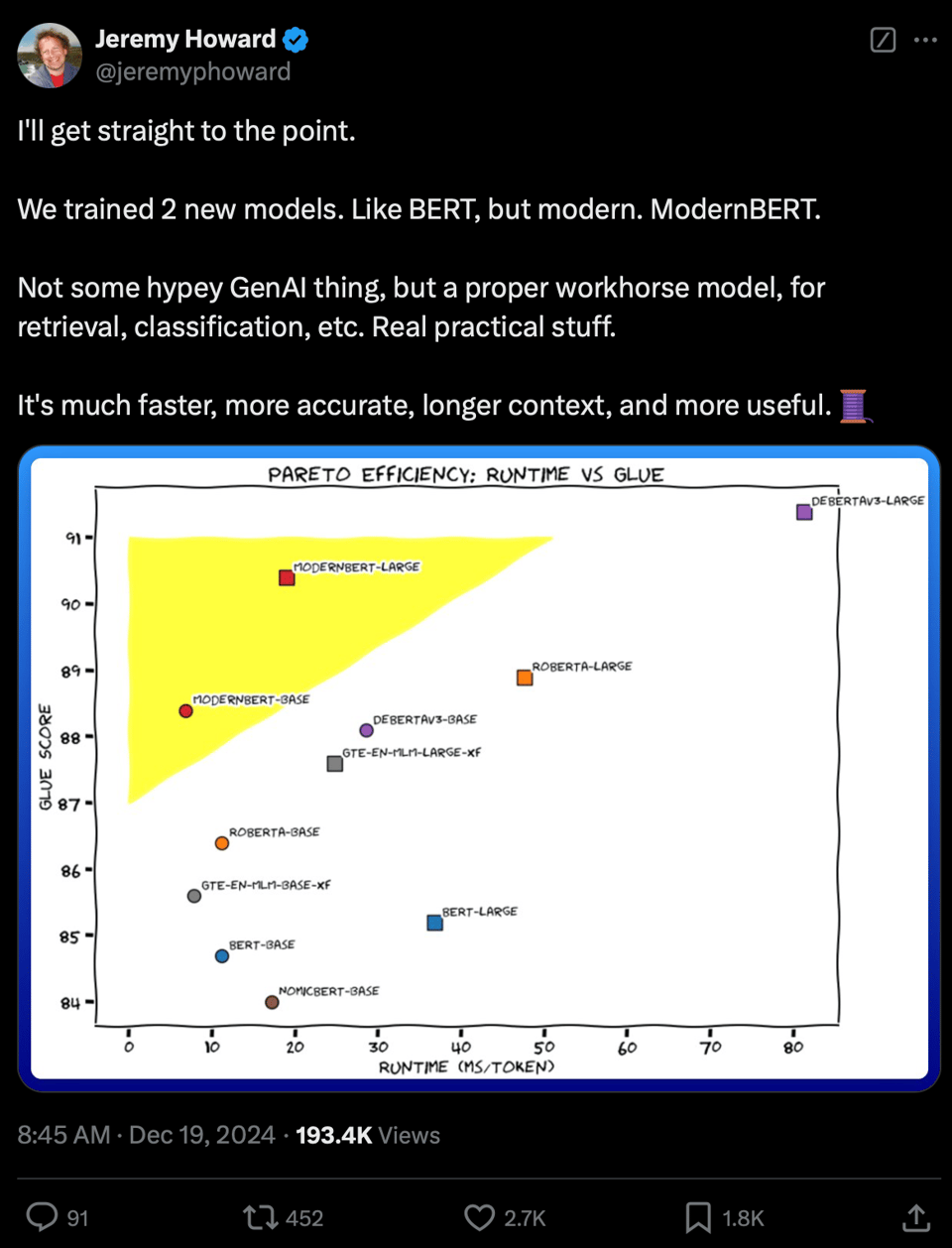
HuggingFace 博客文章详细介绍了为什么这很有用:
- Context (上下文):旧的 BERT 只有约 500 token 的上下文;ModernBERT 拥有 8k。
- Data (数据):旧的 BERT 基于较旧/较少的数据;ModernBERT 在 2T 数据上进行训练,包括“大量的代码”。
- Size (规模):如今的 LLM 普遍 >70B,伴随着相应的成本和延迟问题;ModernBERT 仅有 139M (base)/395M (large) 参数。
-
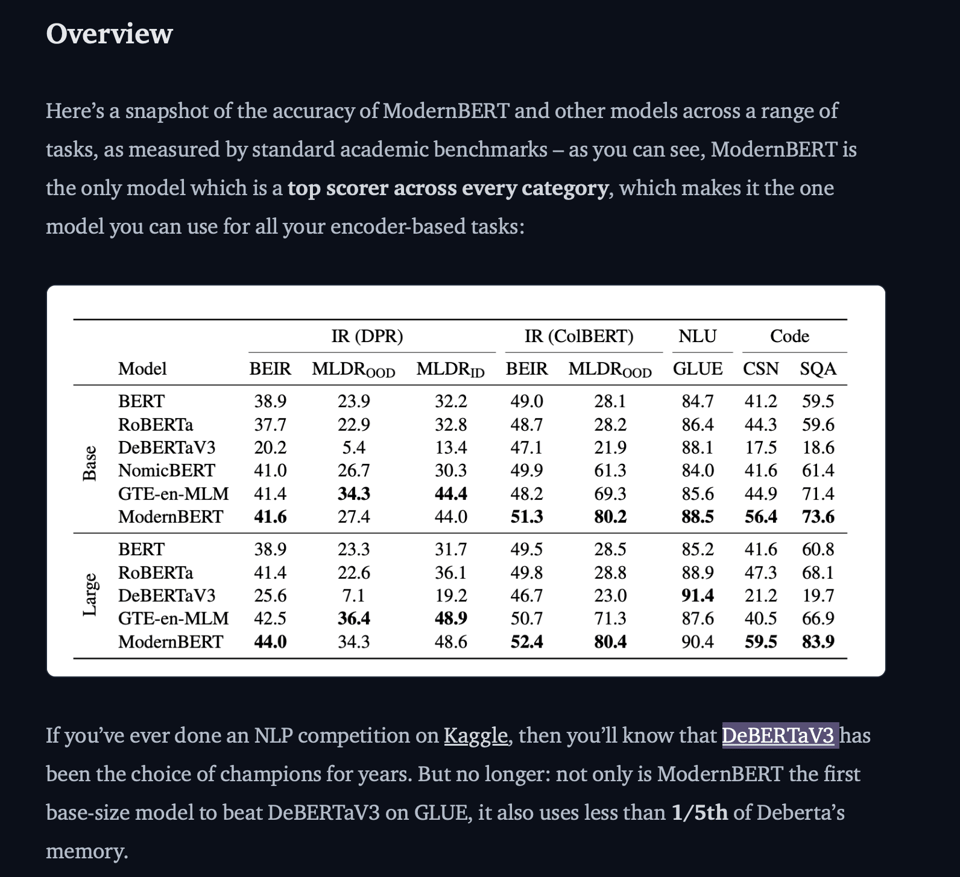
同等规模下的 SOTA 性能:在所有检索/NLU/代码类别中击败了像 DeBERTaV3 这样的常规 Kaggle 冠军。
-
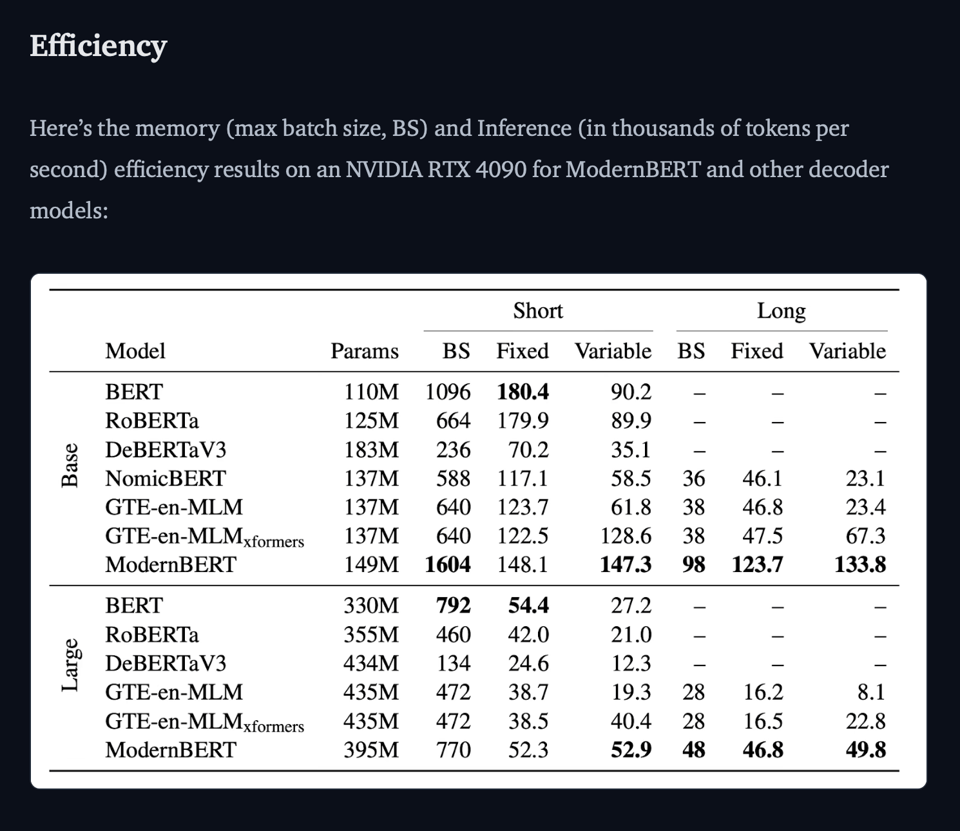
真实世界的变长长上下文:现实世界中的输入大小各不相同,因此这是我们努力优化的性能——即“variable”列。如你所见,对于变长输入,ModernBERT 比所有其他模型都快得多。
- Bidirectional (双向):Decoder-only 模型被特别限制不能“向后看”,而 BERT 可以填补空白:
import torch
from transformers import pipeline
from pprint import pprint
pipe = pipeline(
"fill-mask",
model="answerdotai/ModernBERT-base",
torch_dtype=torch.bfloat16,
)
input_text = "One thing I really like about the [MASK] newsletter is its ability to summarize the entire AI universe in one email, consistently, over time. Don't love the occasional multiple sends tho but I hear they are fixing it."
results = pipe(input_text)
pprint(results)
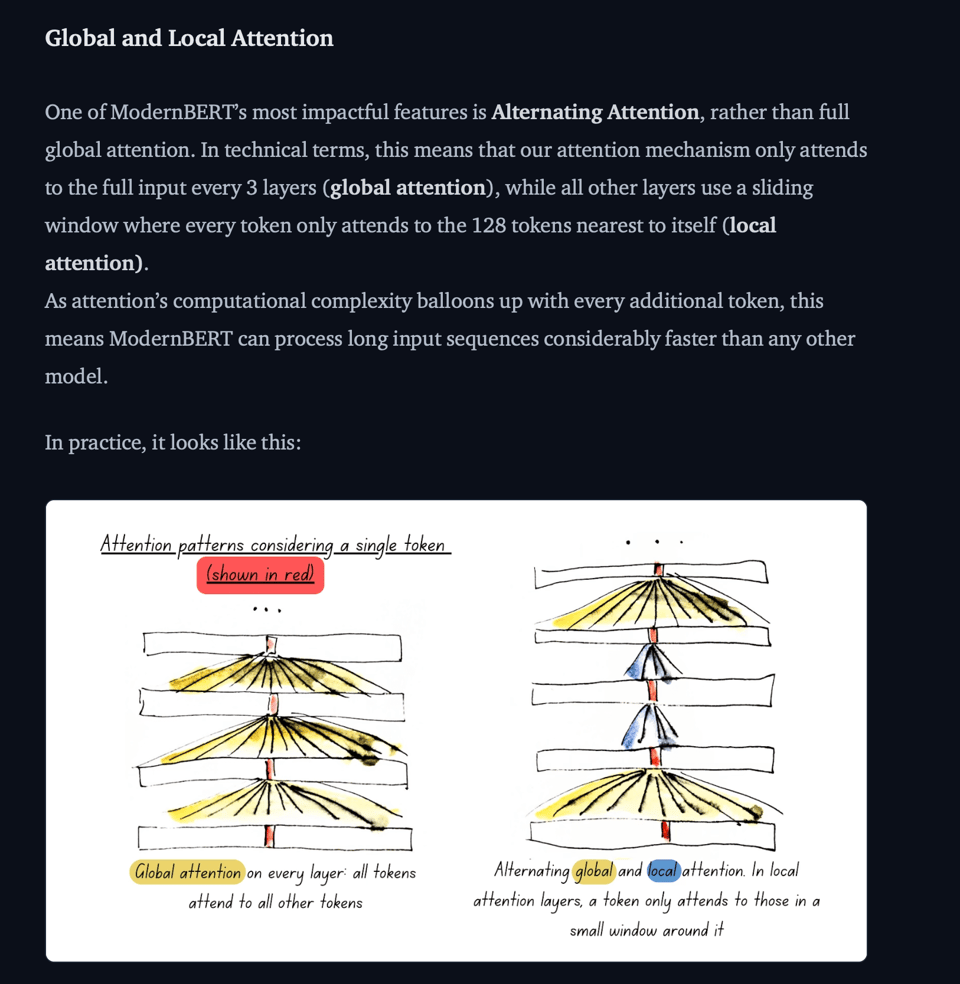
论文中披露的众多有趣细节之一是 Alternating Attention 层——以 Noam Shazeer 在 Character 所做的相同方式混合全局和局部注意力(我们的报道在此):
AI Twitter 回顾
所有回顾由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
AI 模型发布与性能
- @drjwrae 宣布发布 Gemini 2.0 Flash Thinking,该模型基于 2.0 Flash 模型构建,旨在提升推理能力。
- @lmarena_ai 报告 Gemini-2.0-Flash-Thinking 在 Chatbot Arena 的所有类别中均首次亮相即位列第一。
- @bindureddy 指出新的 O1 model 在推理方面得分 91.58,并在 Livebench AI 上排名第一。
- @answerdotai 和 @LightOnIO 发布了 ModernBERT,其上下文长度高达 8,192 tokens,并提升了性能。
重大公司新闻
- @AIatMeta 分享道,Llama 的下载量已超过 6.5 亿次,在 3 个月内翻了一番。
- @OpenAI 推出了桌面端应用集成,支持 Xcode、Warp、Notion 等应用,并具备语音功能。
- @adcock_brett 宣布 Figure 已向商业客户交付了首批人形机器人。
- Alec Radford 从 OpenAI 离职的消息被公开。
技术进展
- @DrJimFan 讨论了机器人仿真领域的进展,强调了大规模并行化和生成式图形学的趋势。
- @_philschmid 分享了关于 Genesis 的细节,这是一个全新的物理引擎,声称比实时仿真快 43 万倍。
- @krandiash 概述了在扩展 AI 模型上下文窗口和内存方面面临的挑战。
梗与幽默
- @AmandaAskell 调侃了物种通过 FOMO(错失恐惧症)进行繁衍的现象。
- @_jasonwei 分享了被女朋友吐槽的经历,她将他的演讲比作电影《降临》(Arrival)中的场景。
- @karpathy 发布了关于他每天下午 3:14 拍照的 PiOclock 传统。
AI Reddit 回顾
/r/LocalLlama 回顾
主题 1. Bamba:推理高效的混合 Mamba2 模型
- Bamba:推理高效的混合 Mamba2 模型 🐍 (评分: 60, 评论: 14): Bamba 是一个基于 Mamba2 的推理高效混合模型。帖子标题暗示该模型关注性能差距和新的基准测试,尽管正文中未提供更多细节。
- 基准测试差距:讨论指出,由于训练数据以及在训练阶段加入了与基准测试对齐的指令数据集,Bamba 模型在数学基准测试中表现出与其他线性模型类似的差距。一个具体的例子是,通过添加 metamath 数据,GSM8k score 从 36.77 提升到了 60.0。
- 方法论的开放性:评论者对 Bamba 模型在训练和量化过程中的透明度表示赞赏,并对即将发布的论文表示期待,该论文承诺将提供有关数据源、比例和消融实验技术的详细见解。
- 模型命名幽默:网友们对 Bamba、Zamba 等模型的命名惯例进行了轻松的交流,并提供了 Hugging Face 上相关论文和模型的链接 (Zamba-7B-v1, Jamba, Samba)。
主题 2. Genesis:生成式物理引擎的突破
- 新款物理 AI 简直疯狂(开源) (评分: 1350, 评论: 147): 该帖子讨论了一个名为 Genesis 的 开源物理 AI,强调了其令人印象深刻的生成能力和物理引擎功能。由于缺乏详细的文字描述,链接的视频可能提供了关于其功能和应用的更多见解。
- 怀疑与担忧:许多评论者对该项目表示怀疑,将其与 Theranos 和 Juicero 等过度炒作的技术进行比较,并暗示其所属机构和“开源”声明可能被夸大了。MayorWolf 等人怀疑视频的真实性,认为其中包含创意剪辑,且开源部分可能仅限于 Blender 等现有工具中已有的功能。
- 技术讨论:一些用户讨论了技术层面,例如使用 Taichi 进行高效的 GPU 模拟,以及与 Nvidia 的 Omniverse 的潜在相似之处。AwesomeDragon97 指出了模拟中关于水滴粘附的一个缺陷,表明物理引擎需要进一步完善。
- 项目合法性:分享了该项目的 网站 和 GitHub 仓库 链接,一些用户注意到有顶尖大学参与,并认为它可能是真实的。其他用户如 Same_Leadership_6238 强调,虽然它看起来好得令人难以置信,但它是开源的,值得进一步调查。
- Genesis 项目:一个能够生成由物理模拟平台驱动的 4D 动态世界的生成式物理引擎 (评分: 103, 评论: 13): Genesis 项目 推出了一种 生成式物理引擎,能够使用物理模拟平台创建 4D 动态世界,该项目历时 24 个月开发,由 20 多个研究实验室共同贡献。该引擎采用纯 Python 编写,运行速度比现有的 GPU 加速栈快 10-80 倍,并在模拟速度上取得了重大突破,比 实时速度快约 430,000 倍。它是开源的,旨在为机器人和物理 AI 应用自主生成复杂的物理世界。
- 生成式物理引擎 允许进行模拟,使包括软体机器人在内的机器人能够以远快于现实世界试验的速度进行实验和改进动作,这可能会彻底改变机器人和物理 AI 应用。
- 对 模拟和动画的影响 是巨大的,使拥有 NVIDIA 4090 等消费级硬件的个人能够为现实世界应用训练机器人,而这在以前仅限于拥有大量资源的实体。
- 由于其令人印象深刻的宣称,人们对该技术的能力存在怀疑,用户表示希望亲自测试该引擎以验证其性能。
主题 3. Slim-Llama ASIC 处理器的效率飞跃
- [Slim-Llama 是一款 LLM ASIC 处理器,能够处理 30 亿参数,而功耗仅为 4.69mW —— 我们很快就会了解到更多关于这一潜在 AI 游戏规则改变者的信息] (Score: 240, Comments: 25): Slim-Llama 是一款 LLM ASIC 处理器,能够处理 30 亿参数,而功耗仅为 4.69mW。关于这一潜在的 AI 硬件重大进展的更多细节预计很快就会公布。
- 人们对 Slim-Llama 的性能持怀疑态度,担心其 3000ms 延迟以及其 5 TOPS(能效比 1.3 TOPS/W) 功耗效率的实用性。批评者认为,500KB 内存不足以在不使用外部内存的情况下运行 1B 模型,而外部内存会增加能耗(来源)。
- Slim-Llama 仅支持 1 比特和 1.5 比特模型,被视为一种学术上的探索而非实际解决方案。由于其 4.69mW 的极低功耗,在 可穿戴设备、IoT 传感器节点和节能型 工业应用 中具有潜在用途。一些评论者对未来通过改进 4-bit quantization 和更好的软件支持来实现更多用例表示期待。
- 讨论内容包括该芯片采用 三星 28nm CMOS 工艺,芯片面积为 20.25mm²,并对其在 5nm 或 3nm 等更先进工艺上的潜在表现感到好奇。此外,还有关于在“基于 SLUT 的 BMM 核心”上运行 Enterprise Resource Planning 模拟的玩笑,突显了该芯片的新颖性和小众吸引力。
主题 4. Gemini 2.0 Flash Thinking Experimental 发布
- [Gemini 2.0 Flash Thinking Experimental 现已在 Google AI Studio 免费开放(10 RPM,1500 次请求/天)] (Score: 73, Comments: 10): Gemini 2.0 Flash Thinking Experimental 现已在 Google AI Studio 中免费提供,允许用户每分钟进行 10 次请求,每天 1500 次请求。界面包含用于回答“你现在是谁?”等查询的系统指令,并允许调整模型选择、token 数量和 temperature 设置。
- 一位用户幽默地描述了一个 thinking process(思考过程)示例,模型计算了 “strawberry” 中 “r” 的出现次数,但指出了一处拼写错误,突显了模型的逐步推理能力。
- 人们对利用 Gemini 2.0 Flash Thinking 的输出来训练其他思考模型的潜力感到好奇,这表明了对模型改进和开发的兴趣。
![[Gemini 2.0 Flash Thinking Experimental 现已在 Google AI Studio 免费开放(10 RPM,1500 次请求/天)]](https://i.redd.it/xbibsmke7u7e1.png){kind=link}
其他 AI 版块回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
主题 1. Gemini 2.0 Flash Thinking 发布,性能超越旧模型
- Gemini 2.0 Flash Thinking (推理模型,免费) (Score: 268, Comments: 95): Gemini 2.0 Flash 是 Google 推出的一款推理模型,现已在 aistudio.google.com 免费开放,每天提供高达 1500 次免费请求,知识截止日期为 2024 年。作者认为它令人印象深刻,特别是它可以通过系统提示词(system prompts)进行引导,并指出在图像处理、通用问题和数学等任务上,它的表现与 OpenAI 的 GPT-3.5 相当甚至更好,同时批评了 OpenAI 产品的成本和限制。
- 用户对 Gemini 2.0 Flash 的性能印象深刻,注意到它在 数学 方面优于其他模型,并且能够展示其推理过程,一些人认为这非常了不起。普遍观点认为它超越了 OpenAI 的产品,用户开始质疑支付 ChatGPT Plus 费用的价值。
- 讨论涉及 Google 的战略优势,这得益于其具有成本效益的基础设施,特别是其 TPUs,这使得他们能够免费提供该模型,而 OpenAI 的模型则昂贵且封闭。这种成本优势被视为 Google 在 AI 领域潜在的长期胜利。
- 一些用户表达了对 Google AI 产品 UI/UX 改进 的渴望,认为更友好的用户界面可以增强其吸引力。对话还涉及 Gemini 缺乏网页搜索功能,以及 AI Studio 中自定义指令的潜力,这增强了用户对模型响应的控制。
- O1 的完整 LiveBench 结果现已公布,表现非常亮眼。 (得分: 267, 评论: 85): OpenAI 的 “o1-2024-12-17” 模型在 LiveBench 结果中处于领先地位,特别是在 Reasoning(推理)和 Global Average(全球平均)得分方面表现卓越。该表格对比了多个模型在 Coding(编程)、Mathematics(数学)和 Language(语言)等指标上的表现,竞争对手包括 Google、Alibaba 和 Anthropic。
- 关于 O1 模型的定价和性能存在大量讨论。一些用户认为 O1 比 Opus 更贵,因为存在“隐形思维 Token (thought tokens)”,导致每百万输出 Token (mTok output) 的成本超过 200 美元;而另一些人则声称价格相同,但由于推理 Token (reasoning tokens) 的存在导致成本累积 (来源)。
- O1 的能力和访问权限也引发了争论,有人指出 O1 Pro API 尚未开放,且当前的 O1 模型使用了 “reasoning_effort” 参数,这会影响其性能和定价。该参数表明 O1 Pro 可能是一个具有更高推理强度的更高级版本。
- 与 Gemini 2.0 Flash 等其他模型的对比非常普遍,Gemini 因其性价比和扩展潜力而受到关注。一些人推测 Gemini 的效率归功于 Google 的 TPU 资源,并对未来 1-2 年内实现“开箱即用的 AGI (in-the-box-AGI)”持乐观态度。
- Artificial Analysis 发布的 AI 竞赛历程 (得分: 157, 评论: 12): 来自 Artificial Analysis 的报告全面回顾了 AI 竞赛,重点关注了 OpenAI、Anthropic、Google、Mistral 和 Meta 的 AI 语言模型演进。一张折线图展示了随时间变化的“前沿语言模型智能 (Frontier Language Model Intelligence)”,使用“Artificial Analysis 质量指数”对比了 2022 年第四季度至 2025 年第二季度的模型质量,突出了 AI 发展的趋势和进步。完整报告在此。
- Gemini 2.0 被认为在各方面都优于目前的 GPT-4o 模型,并且可以在 Google AI Studio 上免费使用。
- 关于时间线有一个修正:GPT-3.5 Turbo 在 2022 年尚未推出;当时可用的是 GPT-3.5 Legacy。
{kind=link}
{kind=link}
主题 2. NotebookLM 引入交互式播客功能
- Notebook LM 交互测试版。令人震撼。 (得分: 272, 评论: 69): Google 悄然激活了 NotebookLM 中的交互功能,允许用户与生成的播客进行互动。该帖子表达了对这一新功能的兴奋,称其“令人震撼 (mindblowing)”。
- 用户讨论了 NotebookLM 中的交互功能,指出它允许就上传的源材料与 AI 进行实时对话。然而,目前的交互仍停留在表面,用户表达了对更深层次对话能力以及相比 ChatGPT 更好的 Prompt 响应的期望。
- 该功能需要创建一个新的笔记本并添加来源以生成音频概览。音频准备就绪后即可开始交互,但一些用户注意到它缺乏保存或下载交互式播客的功能,且可用性可能因地区而异。
- 对于 Google 在 AI 领域的进展,反应褒贬不一,一些用户对 Google 在 AI 竞赛中的地位表示怀疑,而另一些人则指出了该功能在学习方面的实用性,同时也有人将其与 OpenAI 最近的更新进行了对比,部分人认为 OpenAI 的更新不尽如人意。
AI Discord 回顾
由 o1-2024-12-17 生成的摘要之摘要的总结
主题 1. 激烈的模型大战与大胆的价格削减
- Gemini 2.0 闪亮登场:用户称赞 “Gemini 2.0 Flash Thinking” 展示了显式的思维链(chain-of-thought),并在推理任务中击败了旧模型。包括 lmarena.ai 的提及在内的多项测试显示,它在性能排行榜上名列前茅,引发了公众的热烈讨论。
- OpenRouter 在史诗级对决中大幅降价:MythoMax 和 QwQ 等供应商降价超过 7%,mistralai/mistral-nemo 降价 12.5%。观察人士称之为 “持续的价格战”,因为 AI 供应商正在争夺用户采用率。
- Databricks 为增长狂揽 100 亿美元:该公司以惊人的 620 亿美元估值完成了一轮巨额融资,计划使年化营收运行率(revenue run rate)超过 30 亿美元。利益相关者将这一增长归功于企业级 AI 需求的飙升和 60% 的年增长率。
主题 2. 多 GPU 与微调热潮
- Unsloth 筹备 GPU 魔法:多 GPU 支持将于第一季度上线,团队正在测试企业定价和销售体系重组。他们确认 Llama 3.3 需要大约 41GB 的 VRAM 才能进行妥善的 fine-tune(微调)。
- SGLang 与 vLLM 的性能对决:vLLM 在原始吞吐量(throughput)上胜出,而 SGLang 在结构化输出和调度方面表现出色。工程师们权衡了利弊,指出 SGLang 灵活的模块化方法适用于某些工作流。
- 量化(Quantization)拯救世界:讨论区热议使用 4-bit 或 8-bit 量化来缩小内存占用。贡献者强调 “RAG 加上量化” 是资源受限任务的高效路径。
主题 3. Agent、RAG 与 RLHF 的突破
- Agentic Systems 竞相发展:Anthropic 的 “Agentic Systems 之年” 蓝图概述了可组合模式,引发了对 2025 年重大飞跃的推测。研究人员将这些设计与经典搜索进行了比较,并指出开放式思维模式可以超越简单的检索。
- 异步 RLHF 助力更快训练:一篇论文提出了 off-policy RLHF,将生成与学习解耦,以加速语言模型的精炼。社区在追求效率的过程中争论 “我们可以容忍多少程度的 off-policyness?”。
- 多 Agent LlamaIndex 释放 RAG 潜力:开发者正从单 Agent 转向多 Agent 架构,每个 Agent 专注于一个专门的子任务,以实现稳健的检索增强生成(RAG)。他们使用 Agent 工厂来协调任务,确保对大型语料库有更好的覆盖。
主题 4. AI 编程工具成为焦点
- Cursor 0.44.4 升级:此次发布引入了 “Yolo mode” 并改进了 Agent 命令,详见 changelog。早期采用者注意到在大型项目中代码编辑速度更快,任务处理能力更强。
- GitHub Copilot Chat 推出免费版:Microsoft 宣布了一个无需信用卡的层级,甚至可以调用 “Claude 以获得更强的能力”。开发者为免费的实时代码建议欢呼,尽管有些人仍然更喜欢传统的 diff 编辑来进行版本控制。
- Windsurf vs. Cursor 大对决:用户比较了协作编辑、大文件处理和性能。许多人提到 Cursor 在复杂重构中的一致性,而一些人则欣赏 Windsurf 在处理较小任务时灵活的 UI。
主题 5. 新鲜的库与开源探索
- Genesis AI 幻化物理现实:一个新的生成式引擎可以模拟 4D 世界,速度比实时快 430,000 倍。机器人爱好者对在 RTX4090 上仅需 26 秒的训练运行感到惊叹,该项目展示在 Genesis-Embodied-AI/Genesis 仓库中。
- ModernBERT 亮相:这个 “主力模型” 与旧版 BERT 相比,提供了扩展的上下文以及改进的分类或检索能力。社区测试者确认了其在 RAG 工作流中具有更好的性能和更简单的优化。
- Nomic 在浏览器中映射数据:其数据映射系列的最后一篇文章展示了可扩展的 embeddings(嵌入)和降维技术如何使大规模数据集的可视化变得大众化。读者称赞它是探索性分析的颠覆者。
PART 1: 高层级 Discord 摘要
Unsloth AI (Daniel Han) Discord
- Unsloth 筹备 Multi-GPU 魔法:Unsloth 的 Multi-GPU 支持计划于第一季度推出,团队正在进行最终测试并微调定价细节。
- 他们还暗示将针对企业兴趣改进销售流程,尽管其企业版 Beta 仍处于测试阶段。
- Llama 3.3 提升动力:根据 Unsloth 博客,Llama 3.3 模型微调大约需要 41GB 的 VRAM。
- 参与者报告称,与早期版本相比,该版本性能更高,这归功于在大数据集上进行精心训练周期的收益。
- SGLang vs. vLLM:速度大比拼:许多人认为 vLLM 在处理繁重的生产任务时超过了 SGLang,但 SGLang v0.4 在结构化输出和调度技巧方面看起来很有前景。
- 社区成员认为 vLLM 在吞吐量方面更强,而 SGLang 则吸引那些优化模块化结果的用户。
- RAG 遇见量化 (Quantization):当资源紧张时,Retrieval-Augmented Generation (RAG) 表现为直接微调的一种更智能的替代方案,通常采用分块数据和 embeddings 进行上下文检索。
- 用户称赞量化(参见 Transformers 文档)可以在不完全牺牲性能的情况下缩小内存占用。
- LoRAs、合并与指令微调 (Instruction Tuning) 警告:将 Low Rank Adapters (LoRAs) 与基础模型合并(可能保存为 GGUF 选项)需要仔细平衡参数以避免不必要的失真。
- 一篇 指令微调论文 强调了部分训练如何退化核心知识,突显了在没有彻底验证的情况下合并多种技术的风险。
Cursor IDE Discord
- Cursor 0.44.4 发布,增强 Agent 功能:Cursor 0.44.4 引入了改进的 Agent 功能、Yolo mode,可在此处 下载。
- 工程师们称赞其更快的命令执行和更好的任务处理能力,并引用了 更新日志 (changelog) 以获取详细分解。
- 抛硬币:O1 vs Sonnet 3.5:用户将 O1 的成本定在每次请求约 40 美分,并将其收益与 Sonnet 3.5 进行了比较。
- 一些人认为 Sonnet 3.5 “足够好”,而另一些人则质疑 O1 的额外成本是否物有所值。
- 构建之争:Framer vs. DIY 代码:一场生动的讨论对比了用于快速建站的 Framer 与完全自定义的代码。
- 一些人称赞其节省了时间,而另一些人则更喜欢对性能和灵活性进行完全控制。
- Gemini-1206 引起好奇:成员们对 Gemini-1206 表现出兴趣,但关于其能力的具体证据仍然稀缺。
- 其他人则继续专注于使用 Sonnet 3.5 进行编码,因为他们缺乏关于 Gemini-1206 的广泛数据。
- 大学还是创业:大对决:有人认为常春藤盟校 (Ivy League) 的资历提供了人脉优势,而另一些人则倾向于跳过学校去构建现实世界的产品。
- 观点各异,个人成功案例表明任何路径都可以产生重大突破。
Codeium (Windsurf) Discord
- Cline 与 Gemini 联手获胜:多位成员称赞 Cline v3 结合 Gemini 2.0 带来了更流畅的编码体验和大型任务处理能力。
- 他们指出,这优于其他配置,主要是由于更快的迭代和更稳定的重构能力。
- Windsurf vs Cursor 摊牌:比较参考了关于协作编辑和文件处理等功能的 直接对比分析。
- 观点似乎存在分歧,但许多人认为 Cursor 更一致的性能是重度代码工作流中的关键优势。
- 额度结转 (Credit Rollover) 保证:用户确认 Codeium 付费计划 中的 flex credits 可以结转,确保不会突然中断。
- 一些参与者对支付后不会丢失额度感到宽慰,强调了稳定订阅模型的重要性。
- Claude vs Gemini 模型讨论:社区成员权衡了 Claude Sonnet、Gemini 和其他 AI 模型之间的性能差异,并参考了 Aider LLM Leaderboards。
- 他们强调需要上下文提示和详尽的文档,以充分利用每个模型的编码潜力。
Interconnects (Nathan Lambert) Discord
- Gemini 2.0 展现“大声思考”技巧:Google 推出了 Gemini 2.0 Flash Thinking,这是一个实验性模型,通过训练显式思维链 (explicit chain-of-thought) 来增强聊天机器人任务中的推理能力和速度。
- 社区成员引用了 Denny Zhou 关于经典 AI 依赖搜索的立场,暗示 Gemini 的开放思考模式可能超越朴素的检索方案。
- OpenAI 语音模式开启联动:OpenAI 在语音模式中推出了 Work with Apps 功能,实现了与 Notion 和 Apple Notes 等应用的集成,正如其 12 Days of ChatGPT 网站所预告的那样。
- 成员们称这是将 ChatGPT 与现实世界生产力连接起来的简单但重要的一步,一些人希望高级语音功能能够助力日常任务。
- Chollet 关于 “o1 争端” 震惊 LLM 圈:François Chollet 将 o1 标记为 LLM 比作将 AlphaGo 称为“卷积网络 (convnet)”,在 X 上引发了激烈争论。
- 社区成员指出这与之前的 Subbarao/Miles Brundage 事件 类似,要求澄清 o1 架构的呼声进一步加剧了这场风波。
- FineMath:LLM 算术能力的巨大提升:来自 @anton_lozhkov 的链接展示了 FineMath,这是一个专注于数学的数据集,包含超过 50B+ tokens,有望比传统语料库带来更大提升。
- 参与者认为这是复杂代码数学任务的一大飞跃,并提到将 FineMath 与主流预训练合并 以处理高级计算。
- RLHF 书籍:找错别字,赢免费副本:GitHub 上提到了一个 RLHF 资源,发现错别字或格式错误的志愿者有资格获得该书的免费副本。
- 积极的贡献者发现以这种方式完善 reinforcement learning 基础知识压力较小,称这一过程既有趣又对社区有益。
OpenAI Discord
- OpenAI 第 11 天提升 ChatGPT:12 Days of OpenAI 的第 11 天为 ChatGPT 引入了新方法,并举行了 YouTube 直播,重点展示了高级代码协作。
- 工程师现在可以在 AI 的协助下扩展日常开发周期,尽管手动复制操作仍然是必要的。
- ChatGPT 与 XCode 集成:参与者讨论了将代码从 ChatGPT 直接复制到 XCode 中,从而简化 iOS 开发任务。
- 这一步带来了便利,但实际的代码插入仍取决于用户发起的触发操作。
- Google 的 Gemini 2.0 备受瞩目:Google 发布了 Gemini 2.0 Flash Thinking 实验性模型,其大胆的性能宣称引起了好奇。
- 一些参与者在模型处理字母计数任务出错后对其可靠性表示怀疑,引发了对其真实实力的质疑。
- 使用 ChatGPT 演示 YouTube 克隆:成员们探索了使用 ChatGPT 构建类似 YouTube 的体验,涵盖了前端和后端解决方案。
- 虽然前端任务看起来很简单,但服务器端设置需要通过终端指令执行更多步骤。
- AI 自动化在工程领域升温:对话集中在 AI 全面自动化软件开发的前景上,这正在重塑对人类工程师的需求。
- 虽然许多人认识到潜在的时间节省,但也有人怀疑炒作是否超前于实际的突破。
Eleuther Discord
- FSDP vs Tensor Parallel Tangle: 在 Eleuther,参与者对比了 Fully Sharded Data Parallel (FSDP) 与 Tensor Parallelism,并参考了 llama-recipes 的实际实现。
- 他们争论了 FSDP 中较高的通信开销,并将其与基于 Tensor 方法的直接并行操作优势进行了权衡,一些人对多节点扩展限制表示担忧。
- NaturalAttention Nudges Adam: 一位成员在 GitHub 上重点介绍了一个新的 Natural Attention Optimizer,它通过基于 Attention 的梯度调整来修改 Adam,并由 Natural_attention_proofs.pdf 中的证明提供支持。
- 他们声称性能有显著提升,尽管有人指出 natural_attention.py 中的代码可能存在 Bug,并建议在复现结果时保持谨慎。
- Diffusion vs Autoregressive Arm-Wrestle: 一场关于图像和文本领域中 diffusion 和 autoregressive 模型对比的讨论展开了,重点讨论了效率权衡和离散数据处理。
- 一些人认为 diffusion 在图像生成方面领先,但在需要 Token 级控制的任务中可能会受到 autoregressive 方法的挑战。
- Koopman Commotion in NNs: 成员们辩论了将 Koopman theory 应用于神经网络的问题,参考了 Time-Delay Observables for Koopman: Theory and Applications 和 Learning Invariant Subspaces of Koopman Operators–Part 1。
- 他们质疑将 Koopman 方法强加于标准框架的正当性,认为如果底层数学与现实世界的激活行为不符,可能会误导研究人员。
- Steered Sparse AE OOD Queries: 在可解释性讨论中,爱好者们探索了 steered sparse autoencoders (SAE),以及对重构质心进行余弦相似度检查是否能有效衡量 Out-of-Distribution (OOD) 数据。
- 他们报告称,调整一个激活值通常会影响其他激活值,这表明存在很强的相互依赖性,并提醒在解释基于 SAE 的 OOD 分数时要谨慎。
Perplexity AI Discord
- Perplexity’s Referral Program Boosts Sign-Ups: 多位用户确认 Perplexity 提供推荐计划,为那些邀请新用户注册的人提供奖励。
- 爱好者们旨在招募整个团体,加速平台的覆盖范围,并激发了关于用户增长的讨论。
- You.com Imitation Raises Accuracy Concerns: 社区成员讨论了 You.com 使用基于搜索的系统指令复制回答的情况,并质疑其输出质量。
- 他们指出,依赖直接的模型调用通常会产生更精确的逻辑,揭示了面向搜索的问答解决方案中潜在的差距。
- Game Descriptions Overwhelm Translation Limits: 一位尝试将长列表转换为法语的用户遇到了大小限制,显示了 Perplexity AI 的文本处理约束。
- 他们寻求关于将内容分割成更小块的建议,希望能绕过复杂翻译任务中的这些限制。
- Magic Spell Hypothesis Sparks Curiosity: 一份发布的 文档 描述了 Magic Spell Hypothesis,将高级语言模式与科学界新兴概念联系起来。
- 研究人员和社区成员评估了其可信度,赞扬了在结构化实验中测试边缘理论的尝试。
aider (Paul Gauthier) Discord
- Gemini 取得进展:12/19,Gemini 2.0 Flash Thinking 推出了
gemini-2.0-flash-thinking-exp-1219变体,正如 Jeff Dean 的推文所言,该模型在 Agent 工作流中表现出更强的推理能力。- 初步测试显示其性能优于 O1 和 DeepSeek,部分社区成员对其升级后的输出质量表示赞赏。
- Aider 与 MCP 深度集成:用户实现了 Aider 与 MCP 的集成以简化 Jira 任务,参考了 Sentry 集成服务器 - MCP Server 集成。
- 他们讨论了在 MCP 配置中用其他模型替换 Sonnet 的方案,这为错误追踪和工作流自动化提供了极高的灵活性。
- OpenAPI 孪生使用引发热议:社区成员探索了在本地运行 Ollama 的同时,在 Hugging Face 上运行 QwQ,并明确了 Hugging Face 要求使用其自身的 API 以实现无缝模型切换。
- 他们发现需要在模型名称中注明服务来源,以防止在多 API 配置中产生混淆。
- Copilot Chat 迎来更新:根据 GitHub 的公告,GitHub Copilot Chat 推出了免费的沉浸模式,提供实时代码交互和更精准的多文件编辑。
- 虽然用户对增强的聊天界面表示赞赏,但一些人仍然倾向于使用传统的 diff 编辑,以控制成本并保持工作流的可预测性。
Stackblitz (Bolt.new) Discord
- Bolt 与 Supabase 实现即时设置:Bolt 与 Supabase 的集成已正式上线,提供更简单的“一键连接”,如 这条来自 StackBlitz 的推文所示。它消除了手动步骤,让工程师能更快地统一服务并减少开销。
- 用户称赞了这种简便的设置方式,指出它缩短了数据驱动型应用的开发周期,并提供了无摩擦的开发者体验。
- Figma 导出受阻与 .env 文件问题:用户报告了 .env 文件 重置导致 Firebase 配置中断的问题,刷新后锁定尝试失败,并引发“项目超出支持的总 Prompt 大小”错误。
- 此外,目前无法直接从 Figma 上传,迫使设计师依赖截图,同时他们也呼吁提供更强大的“从设计到开发”的集成功能。
- 冗余代码优化与 Public 文件夹设置:社区成员询问 Bolt 是否可以分析代码中的冗余块,旨在减少大规模应用中的 Token 消耗。他们还需要关于构建 public 文件夹 以托管图像的指导,反映出对项目结构的困惑。
- 一些人建议提供更直白的文档来解决文件夹设置的不确定性,表明在配合 Bolt 工作时需要更简单的参考资料。
- 会话故障与 Token 消耗困扰:频繁的会话超时和强制页面刷新导致许多人在 Bolt 中丢失聊天记录,增加了挫败感和 Token 成本。开发团队正在调查这些身份验证问题,但实时中断的情况仍然存在。
- 用户希望修复这些问题以减少冗余输出,并控制 Token 的过度支出,寻求项目工作流的稳定性。
- 社区汇聚编写指南与集成方案:参与者计划为 Bolt 编写一份更广泛的指南,并提供一个用户仪表板用于提交和审核资源。对话涉及了 Stripe 集成、高级 Token 处理以及与多种技术栈的协同。
- 他们还展示了 Wiser - 知识共享平台,暗示了在共享内容和更完善的开发者体验方面有更深层次的扩展。
Notebook LM Discord Discord
- Interactive Mode 覆盖全员:开发团队确认 Interactive Mode 已覆盖 100% 的用户,并对音频概览(audio overviews)进行了显著改进。
- 爱好者们称赞了其带来的创意可能性,并分享了更流畅部署的第一手经验。
- 用于自动 NPC 的 MySQL 数据库钩子:一位游戏主持人(game master)询问如何将大型 MySQL 数据库连接到 NotebookLM,以实现非玩家角色(NPC)响应的自动化。
- 他们强调了积累十年的 RPG 数据,并寻求管理动态查询的方法。
- 播客作者调整录音设置:成员们讨论了交互式播客功能不存储对话的问题,这迫使他们必须为外部听众进行独立的音频采集。
- 一个简洁的“播客风格提示词”引发了人们对 QWQ model 评论中更快速、更直率见解的兴趣。
- AI 生成的太空 Vlog 震撼观众:一位用户展示了由 AI 渲染的为期一年的宇航员隔离 Vlog,链接见 此 YouTube 链接。
- 其他人注意到由 NotebookML 输出驱动的每日动画上传,展示了持续的内容生产能力。
- 更新后的 UI 获得好评:用户们赞赏 NotebookLM 界面的翻新,称其在项目导航方面更加灵敏和便捷。
- 他们渴望测试新的布局,并称赞了整体精致的外观。
Stability.ai (Stable Diffusion) Discord
- SDXL 的 Ubuntu 步骤:一些成员分享了在 Ubuntu 上运行 SDXL 的技巧,建议使用来自 stable-diffusion-webui-forge 的 shell 脚本以简化设置。
- 他们强调了系统知识对于避免性能瓶颈的重要性。
- ComfyUI 崩溃问题:工程师们抱怨尽管尝试修复采样问题,ComfyUI 仍持续出现错误和焦黑的输出。
- 他们建议使用 Euler 采样并配合调优后的去噪水平(denoising levels),以减少瑕疵结果。
- AI 图像通往完美的道路充满坎坷:一些人认为,由于当前的挑战,AI 生成的图像和视频到 2030 年也不会达到完美。
- 另一些人则反驳称,技术的飞速跨越可能会更早地带来精致的输出。
- 关于 P=NP 的量子争论:一场激烈的聊天集中在如果 P=NP 成为现实,quantum computing(量子计算)是否还有相关性。
- 怀疑者指出从量子态中提取现实世界价值存在困难,并引用了实际执行中的复杂性。
- Civitai.com 又挂了?:多位用户注意到 civitai.com 频繁宕机,导致模型访问变得困难。
- 他们推测反复出现的服务器问题是导致多次停机的原因。
GPU MODE Discord
- GPU 闪烁与电感啸叫:用户抱怨退货的 RX 6750XT 存在离谱的电感啸叫(coil whine),此外 VRChat 对显存的渴求促使一些人选择了 4090s。
- 他们还对下一代 RTX 50 系列显卡可能更高的价格表示担忧,同时对比了 7900 XTX。
- Triton 在 AMD 上的尝试:社区成员在 RX 7900 等 AMD GPU 上测试了 Triton kernel,注意到性能仍落后于 PyTorch/rocBLAS。
- 他们还发现 warp-specialization 在 Triton 3.x 中被移除,这促使他们探索其他的优化方案。
- CARLA 冲入 UE 5.5:CARLA 0.10.0 版本引入了 Unreal Engine 5.5 特性,如 Lumen 和 Nanite,提升了环境真实感。
- 与会者还称赞了 Genesis AI 的水滴演示,预见了其与 Sim2Real 的协同效应,并引用了 Waymo 的合成数据方法用于自动驾驶。
- MatX 的 HPC 招聘热潮:MatX 宣布公开招聘 low-level compute kernel authors 和 ML performance engineers,旨在构建 LLM accelerator ASIC。
- 职位列表强调了一个高信任度的环境,比起长时间的测试,该环境更看重大胆的设计决策。
- Alma 的 40 选项基准测试大杂烩:两人组发布了 alma,这是一个 Python 包,可以在单个函数调用中检查超过 40 种 PyTorch 转换选项的 throughput(吞吐量)。
- 根据 GitHub 的描述,它通过隔离进程优雅地处理失败,并很快将扩展到 JAX 和 llama.cpp。
Latent Space Discord
- Anthropic Agents 发力:Anthropic 发布了 Building effective agents,介绍了 AI agentic systems 的模式,并预告 2025 年将迎来重大里程碑。
- 他们强调了可组合的工作流,并引用了一条关于“代理系统之年(year of agentic systems)”的推文,旨在进行高级设计。
- Gemini 2.0 提速:多条推文(包括 lmarena.ai 的提及 和 Noam Shazeer 的公告)称赞 Gemini 2.0 Flash Thinking 在所有类别中均名列前茅。
- 该模型训练以“出声思考(think out loud)”,从而实现更强的推理能力,并超越了早期的 Gemini 版本。
- Databricks 融资 100 亿美元:他们宣布了价值 100 亿美元 的 J 轮融资,由 Thrive Capital 领投,估值达到 620 亿美元。
- 他们预计年营收运行率(revenue run rate)将突破 30 亿美元,并报告了由 AI 需求引发的 60% 的增长。
- ModernBERT 登场:一个名为 ModernBERT 的新模型被推出,作为一种具有扩展上下文和改进性能的“主力军”选择。
- 诸如 Jeremy Howard 的提及 等参考资料显示,人们正尝试将其应用于检索和分类,引发了从业者之间的讨论。
- Radford 告别 OpenAI:GPT 原始论文的作者 Alec Radford 离开了 OpenAI,去追求独立研究。
- 这一变动引发了关于 OpenAI 在行业内未来走向的猜测。
OpenInterpreter Discord
- OpenInterpreter 的 Vision 版本:OpenInterpreter 1.0 现在包含 vision 支持,可通过 GitHub 和
pip install git+https://github.com/OpenInterpreter/open-interpreter.git@development进行安装。- 实验表明
--tools gui命令在桥接不同模型或 API 时运行良好,用户还提到了本地或基于 SSH 的用法。
- 实验表明
- Server 模式引发执行疑问:成员们询问 server mode 如何处理命令执行,讨论任务是在本地运行还是在服务器上运行。
- 他们提到了使用 SSH 进行更简单的交互,并建议增加一个前端以改进工作流。
- Google Gemini 2.0 受到关注:一位用户对 Google Gemini 2.0 在 OS 模式下的多模态任务表现出兴趣,希望其具备高效的命令执行能力。
- 他们将其与现有配置进行了比较,并想知道它是否能与其他系统有效竞争。
- 清理安装与 O1 困惑:一些用户在多次配置后遇到了 OpenInterpreter 安装问题,促使他们删除标志以进行全新设置。
- 同时,一位 O1 频道的用户抱怨文档不清晰,即使在阅读了官方参考资料后仍寻求直接指导。
LM Studio Discord
- Safetensors 故障困扰 LM Studio:用户在加载模型时遇到 Safetensors header is unexpectedly large: bytes=2199142139136 错误,被迫重新下载 MLX 版本的 Llama 3.3 以修复可能的损坏问题。
- 讨论中提到了文件兼容性冲突,一些用户建议在未来的下载中进行仔细的文件检查。
- 移动端梦想:iOS 迎来聊天功能,Android 仍在等待:一款名为 3Sparks Chat (link) 的 iOS 应用可连接到 Mac 或 PC 上的 LM Studio,为本地 LLM 提供手持界面。
- 成员们对缺乏 Android 客户端表示失望,社区纷纷请求替代方案。
- AMD 24.12.1 的困扰:AMD 24.12.1 驱动在通过 LM Studio 加载模型(连接到 llama.cpp rocm 库)时引发了系统卡顿和性能下降。
- 降级驱动程序解决了一些配置中的问题,7900XTX GPU 的稳定性也成为了关注焦点。
- LM Studio 的视觉模型希望:关于图像输入模型的查询引出了对 mlx-community/Llama-3.2-11B-Vision-Instruct-4bit 的提及,突显了集成视觉功能的早期尝试。
- 用户报告了在 Windows 上的加载问题,引发了关于模型与本地硬件兼容性的讨论。
- Apple Silicon vs. 4090 GPU 对决:社区成员质疑 Mac Pro 和 Ultra 芯片 是否因内存带宽优势而优于 30 或 4090 显卡。
- 基准测试引用指向了 llama.cpp GitHub discussion,用户证实 4090 在实际测试中仍保持着更快的指标。
OpenRouter (Alex Atallah) Discord
- 降价震动 LLM 市场:今天早上 gryphe/mythomax-l2-13b 降价 7%,qwen/qwq-32b-preview 降价 7.7%,mistralai/mistral-nemo 降价 12.5%。
- 社区成员戏称“持续的价格战”正在加剧供应商之间的竞争。
- 众包 AI 技术栈备受关注:风险投资公司发布了各种生态系统图谱,但人们正推动一种真正的众包和开源方法,如此 GitHub 项目所示。
- 一位用户请求对提议的逻辑提供反馈,鼓励社区“为动态开发者资源做出贡献”。
- DeepSeek 加速代码学习:开发者使用 DeepSeek V2 和 DeepSeek V2.5 解析整个 GitHub 仓库,报告称在项目范围的优化方面有显著提升。
- 然而,一位用户警告说“它可能无法处理高级代码生成”,但仍对其注释能力表示赞赏。
- 对编程式 API Key 的呼吁:讨论中提到允许在请求中隐式发送 provider API key,以简化集成。
- 一位用户表示“我很想看到一个编程式版本”,以提高开发者的整体便利性。
Nous Research AI Discord
- GitHub Copilot 推出免费版:Microsoft 推出了新的 GitHub Copilot 免费层级,立即面向所有用户开放。
- 令人惊喜的是,它包含了 Claude 以提供更强大的能力,且无需信用卡。
- Granite 3.1-8B-Instruct 备受青睐:开发者们称赞了 Granite 3.1-8B-Instruct 模型在长上下文任务中的强劲表现。
- 它能为实际案例提供快速结果,IBM 在 GitHub 上提供了代码资源。
- LM Studio 支持本地 LLM 选择:LM Studio 简化了离线运行 Llama、Mistral 或 Qwen 模型的过程,同时支持从 Hugging Face 下载文件。
- 用户还可以快速与文档进行对话,吸引了那些希望使用离线方式的人群。
- 微调中使用统一指令引发辩论:关于在问答数据集中对每个 prompt 使用相同指令的做法引发了疑问。
- 有人提出警告,由于重复使用,这可能会导致模型性能欠佳。
- Genesis 项目凭借生成式物理学大放异彩:Genesis 引擎构建 4D 动力学世界的速度比实时快 430,000 倍。
- 它是开源的,运行在 Python 环境中,在单张 RTX4090 上将机器人训练时间缩短至仅 26 秒。
Modular (Mojo 🔥) Discord
- Mojo 中的负索引之争:关于在 Mojo 中采用负索引(negative indexing)引发了激烈讨论,一些人认为它是错误诱因,而另一些人则认为这是 Python 中的标准做法。
- 反对者更倾向于使用
.last()方法以避免开销,并警告负偏移量可能带来的性能问题。
- 反对者更倾向于使用
- Dict 中 SIMD 键引发崩溃:基于 SIMD 的结构体键(struct keys)中的一个严重 Bug 触发了 Dict 使用中的段错误(segmentation faults),详见 GitHub Issue #3781。
- 缺失 scaling_cur_freq 导致了这些崩溃,促使官方在 6 周窗口内进行修复。
- Mojo 在 Android 上“野蛮生长”:爱好者们尝试通过基于 Docker 的黑客手段在原生 Android 上运行 Mojo,尽管这被标记为“完全不支持”。
- 许可规则禁止发布 Docker 镜像,但本地自定义构建仍然可行。
- Python 集成探索 SIMD 支持:参与者讨论了将 SIMD 和条件一致性(conditional conformance)与 Python 类型合并,平衡对整数和浮点数据的分别处理。
- 他们强调了 ABI 约束和未来的位宽扩展,激发了对跨语言交互的兴趣。
DSPy Discord
- 合成数据解释指南受到关注:一位贡献者正在编写关于合成数据(synthetic data)生成方式的解释指南,并征求社区对难点领域的意见。
- 他们计划重点介绍创建方法以及对高级模型性能的影响。
- DataBricks 速率限制辩论:参与者指出吞吐量费用高昂,呼吁在 DataBricks 中加入速率限制器(rate limiter)以防止过度使用。
- 一些人建议使用 LiteLLM 代理层进行用量跟踪,同时也参考了 Mosaic AI Gateway 作为补充方案。
- dspy.Signature 作为类使用:一位用户询问关于以类(class)形式返回 dspy.Signature 的问题,旨在获得结构化输出而非原始字符串。
- 他们希望定义明确的字段以提高清晰度并实现潜在的类型检查。
- 预置吞吐量让钱包缩水:一场对话揭露了 DataBricks 中预置吞吐量(provisioned throughput)在保持激活状态时的高昂费用。
- 成员们建议使用“缩减至 0(scale to 0)”功能,以遏制空闲期间的成本。
- LiteLLM 接入 DataBricks:与会者讨论了是将 LiteLLM 代理嵌入 DataBricks notebook 还是独立运行。
- 他们一致认为,考虑到环境控制和资源需求,整合这两种方法是可行的。
LlamaIndex Discord
- LlamaIndex 的 Multi-Agent 改造:一篇文章描述了从 single agent 到 multi-agent system 的飞跃,并提供了 LlamaIndex 中的实际代码示例,参考此链接。
- 它还阐明了 agent factories 如何管理多个协同工作的任务。
- Vectara 的 RAG 动态:更新展示了 Vectara 的 RAG 优势,包括数据加载和基于流式的查询,参考此链接。
- 它强调了 RAG 方法的 Agentic 使用,并对托管环境中的 reranking 提出了见解。
- Vercel 的 AI 调查呼吁:敦促社区成员填写 Vercel 的 State of AI Survey,详见此处。
- 他们计划收集有关开发者经验、挑战以及未来 AI 改进目标领域的数据。
- 用于 PDF 处理的 Vision Parse:介绍了一个新的开源 Python 库 Vision Parse,用于使用先进的 Vision Language Models 将 PDF 转换为结构良好的 Markdown。
- 参与者赞扬了其简化文档处理的潜力,并欢迎为集体成长而进行的开源努力。
Nomic.ai (GPT4All) Discord
- Nomic 的数据映射系列马拉松结束:Data Mapping Series 的最后一篇在 Nomic 的博客文章中重点介绍了针对 embeddings 和非结构化数据的可扩展图形。
- 这个分为六部分的系列展示了 dimensionality reduction 等技术如何使用户能够在 Web 浏览器中可视化海量数据集。
- BERT 和 GGUF 故障已修复:在一次 commit 破坏了功能后,用户在从 Huggingface 加载 Nomic 的 BERT embedding 模型时遇到了问题,但现在修复程序已上线。
- 社区成员还指出了 .GGUF 文件中的 chat template 问题,并承诺在即将发布的版本中提供更新版本。
- Code Interpreter 和系统加载器亮点:一个 pull request 提议了一个基于 jinja template 构建的 code interpreter 工具,用于运行高级代码任务。
- 同时,用户请求一个更方便的系统消息加载器,以避免手动复制粘贴大量的上下文文件。
- GPT4All 设备规格确认:关于 GPT4All 系统要求的问题引导至一个详细说明硬件支持的链接。
- 重点强调了重要的 CPU、GPU 和内存细节,以确保稳定的本地 LLM 体验。
tinygrad (George Hotz) Discord
- TinyChat 安装纠纷:一位用户在设置 TinyChat 时遇到问题,报告缺少 tiktoken 等组件、系统冻结 30 秒,以及关于本地网络设备的令人费解的提示。
- George Hotz 谈到了在 TinyGrad 中编写 tiktoken 替代方案,并将 8GB RAM 标记为限制因素。
- Mac 滚动方向异常:一位用户抱怨运行 TinyChat 翻转了他们 Mac 上的滚动方向,然后在应用关闭后恢复。
- George Hotz 称这种行为令人莫名其妙,承认这是一个奇怪的故障。
- Bounty 推动与布局讨论:贡献者讨论了推动 tinygrad 发展的 bounty 奖励,强调测试和改进是关键驱动力。
- 一位用户提到了布局符号 (layout notation) 的复杂性,并链接到 view merges 文档和 viewable_tensor.py 以获取更深层次的背景。
- #learn-tinygrad 中的 Scheduler 查询:一位参与者询问为什么 scheduler 在 expand 或 unsafe pad ops 之前使用 realize,但未得到明确解释。
- 小组没有完全展开讨论其原因,使该话题保持开放以供进一步探索。
Cohere Discord
- Ikuo 令人印象深刻 & 礼仪随之而来:Ikuo618 介绍了自己,他拥有六年的 DP、NLP 和 CV 经验,并重点展示了他的 Python、TensorFlow 和 PyTorch 技能。
- 随后出现了一个温馨提示,建议成员不要在不同频道重复发布消息,以保持对话流程整洁。
- 平台功能疑问:一位用户询问了平台上某个功能的可用性,一名成员确认该功能尚未上线。
- 询问者表示感谢,并以一个笑脸符号愉快地结束了对话。
- Cohere 密钥与速率限制揭晓:Cohere 提供评估和生产 API 密钥,详见 API 密钥页面 和 定价文档。
- 速率限制包括:试用版每分钟 20 次调用,生产版在 Chat 端点每分钟 500 次调用,Embed 和 Classify 共享不同的配额。
Torchtune Discord
- Torchtune 预告 Phi 4 与角色:在 Torchtune 官方文档页面 中,成员确认 Torchtune 目前仅支持 Phi 3,但欢迎对 Phi 4 的贡献。
- 他们引入了 Discord 上的 Contributor 角色,并指出 Phi 3 和 Phi 4 之间的差异极小,以简化新的 pull requests。
- 异步 RLHF 飞速发展:Asynchronous RLHF 将生成和学习分离,以实现更快的模型训练,详见 “Asynchronous RLHF: Faster and More Efficient Off-Policy RL for Language Models”。
- 该论文探讨了 我们可以容忍多大程度的离策性 (off-policyness),在不牺牲性能的情况下追求速度。
- 训练后 (Post-Training) 势头强劲:Allen AI 博客 强调,在预训练之后,post-training 对于确保模型安全地遵循人类指令至关重要。
- 他们概述了指令微调步骤,并专注于在专业化的同时保留中间推理等能力。
- 指令微调的平衡木:InstructGPT 风格的策略可能会无意中削弱某些模型能力,特别是如果专业任务掩盖了更广泛的用途。
- 在处理 诗意或通用指令 的同时保持 coding 熟练度,成为了需要维持的微妙平衡。
LLM Agents (Berkeley MOOC) Discord
- LLM Agents 黑客松倒计时:黑客松的 提交截止日期 为 12/19 11:59 PM PST,参赛作品需通过 官方提交表单 提交。
- 社区正处于 最后修复 的待命状态,确保每个人在时间截止前都有公平的机会。
- 最后时刻的 LLM 问题支持:参与者可以在聊天中提出 最后时刻的问题,以获得同伴的快速反馈。
- 组织者敦促开发者及时完成检查,避免在最后关头进行 疯狂的合并 (merges)。
MLOps @Chipro Discord 没有新消息。如果该公会长时间保持沉默,请告知我们,我们将将其移除。
Axolotl AI Discord 没有新消息。如果该公会长时间保持沉默,请告知我们,我们将将其移除。
LAION Discord 没有新消息。如果该公会长时间保持沉默,请告知我们,我们将将其移除。
Mozilla AI Discord 没有新消息。如果该公会长时间保持沉默,请告知我们,我们将将其移除。
HuggingFace Discord 没有新消息。如果该公会长时间保持沉默,请告知我们,我们将将其移除。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该公会长时间保持沉默,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该公会长时间保持沉默,请告知我们,我们将将其移除。
PART 2: Detailed by-Channel summaries and links
完整的频道逐项解析已针对邮件进行截断。
如果您喜欢 AInews,请分享给朋友!预谢支持!