ainews-o3-solves-aime-gpqa-codeforces-makes-11
o3 攻克了 AIME、GPQA 和 Codeforces,在 ARC-AGI 上实现了相当于 11 年的跨越式进展,并在 FrontierMath 中取得了 25% 的成绩。
OpenAI 发布了 o3 和 o3-mini 模型,并展示了突破性的基准测试结果,包括在 FrontierMath 基准测试中从 2% 跃升至 25%,以及在 ARC-AGI 推理基准测试中达到 87.5%。这代表了在 GPT3 到 GPT4o 的扩展曲线上约 11 年的进步。
与 o3 全量版(o3-full)相比,o1-mini 模型表现出更优越的推理效率,有望显著降低编程任务的成本。此次发布还伴随着社区讨论、安全性测试应用以及详细分析。Sama(山姆·奥特曼)强调了这种不同寻常的性价比权衡,Eric Wallace 则分享了关于 o 系列“深思熟虑对齐策略”(deliberative alignment strategy)的见解。
蒸馏推理时计算(Distilled Inference Time Compute)就是你所需要的一切。
2024年12月19日至12月20日的 AI 新闻。我们为您检查了 7 个 subreddits、433 个 Twitter 账号 和 32 个 Discord(215 个频道和 6058 条消息)。预计节省阅读时间(以 200wpm 计算):607 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
随着核心研究人员的离职、Veo 2 在正面交锋中击败 Sora Turbo,以及 Noam Shazeer 推出了全新的 Gemini 2.0 Flash Reasoning 模型,OpenAI 周围的氛围往好里说也是非常紧张的。
但耐心得到了回报。
正如 sama 所预告的,以及互联网侦探和记者发现的线索,OpenAI Shipmas 的最后一天带来了最重磅的公告:o3 和 o3-mini 发布了,并带来了令人惊叹的早期基准测试结果:
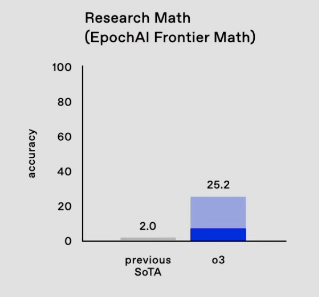
- FrontierMath:有史以来最难的数学基准测试(我们的报道在此)从 2% 提升到了 25% 的 SOTA。
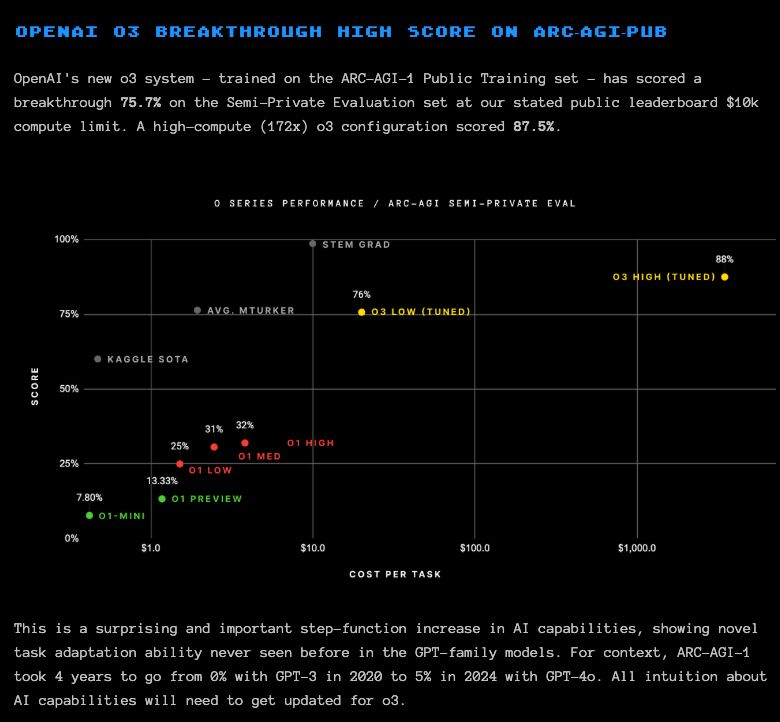
- ARC-AGI:著名的通用推理难题基准测试,在 o3 low($20/任务)和 o3 high(数千美元/任务)设置下,几乎呈直线延续了 o1 模型所展现的性能增长曲线。Greg Kamradt 出现在发布会上验证了这一点,并发表了一篇博客文章分享他们对结果的看法。正如他们所说,“ARC-AGI-1 从 2020 年 GPT-3 的 0% 增长到 2024 年 GPT-4o 的 5% 用了 4 年时间”。o1 在其最高设置下将其提升至 32%,而 o3-high 则推到了 87.5%(这相当于 GPT3 到 4o 缩放曲线上约 11 年的进展)。
- SWEBench-Verified, Codeforces, AIME, GPQA:人们太容易忘记这些模型在 9 月之前都不存在,而 o1 直到本周二才在 API 中提供:
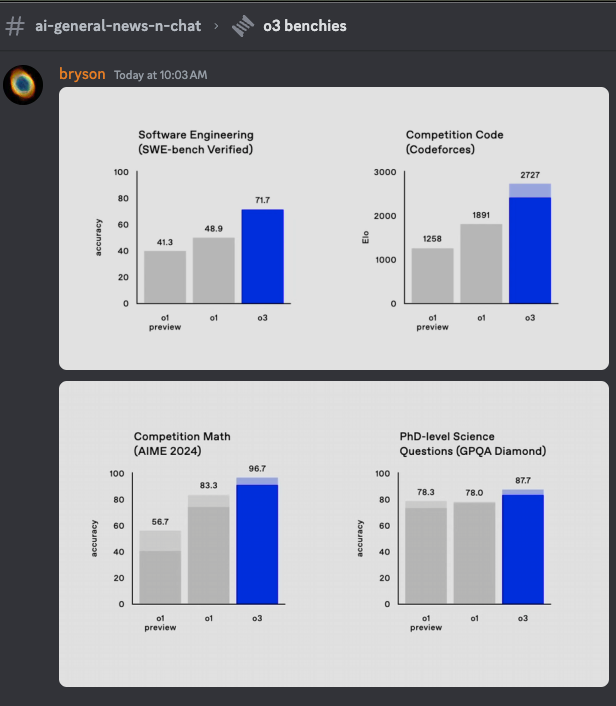
o1-mini 也不容忽视,蒸馏团队自豪地展示了它如何拥有比 o3-full 压倒性优势的推理-智能曲线:
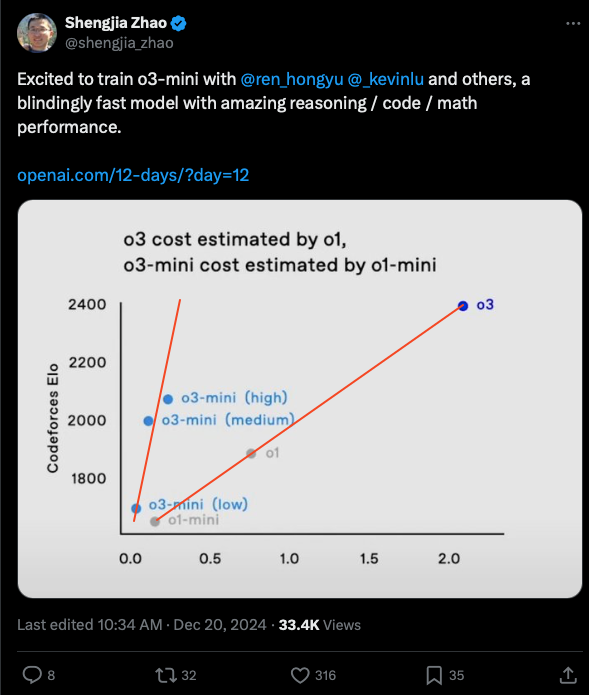
正如 sama 所说:“在许多编程任务中,o3-mini 将以大幅降低的成本超越 o1!我预计这一趋势将继续,但同时,以指数级的资金投入换取边际性能提升的能力将会变得非常奇怪。”
Eric Wallace 还发布了一篇关于他们 o 系列审议式对齐(deliberative alignment)策略的文章,安全研究人员现在可以申请进行安全测试。
AI Twitter 摘要
所有摘要均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
OpenAI 模型发布 (o3 和 o3-mini)
-
o3 和 o3-mini 公告与性能:@polynoamial 宣布了 o3 和 o3-mini,强调 o3 在 ARC-AGI 上达到了 75.7%,在 高算力下达到了 87.5%。@sama 对此次发布表示兴奋,并强调了正在进行的安全性测试。
-
o3 的基准测试成就:@dmdohan 指出 o3 在 ARC-AGI 上得分 75.7%,@goodside 祝贺团队 o3 在 ARC-AGI 上实现了新的 SOTA。
其他 AI 模型发布 (Qwen2.5, Google Gemini, Anthropic Claude)
-
Qwen2.5 技术进展:@huybery 发布了 Qwen2.5 技术报告,详细介绍了在数据质量、合成数据流水线 (synthetic data pipelines) 以及增强数学和编程能力的强化学习 (reinforcement learning) 方法方面的改进。
-
Google Gemini Flash Thinking:@shane_guML 讨论了 Gemini Flash 2.0 Thinking,将其描述为快速、出色且廉价,在推理任务 (reasoning tasks) 中表现优于竞争对手。
-
Anthropic Claude 更新:@AnthropicAI 分享了关于 Anthropic 在 AI 安全和扩展 (scaling) 方面的工作见解,强调了他们的负责任扩展政策 (responsible scaling policy) 和未来方向。
基准测试与性能指标
-
FrontierMath 和 ARC-AGI 评分:@dmdohan 强调了 o3 在 FrontierMath 上取得 25% 的成绩,相比之前的 2% 有了显著提升。此外,@cwolferesearch 展示了 o3 在多个基准测试上的表现,包括 SWE-bench 和 GPQA。
-
评估方法与挑战:@fchollet 讨论了 Scaling Laws 的局限性,以及下游任务性能 (downstream task performance) 相对于传统测试损失指标 (test loss metrics) 的重要性。
AI 安全、对齐与伦理
-
用于更安全模型的审辩式对齐 (Deliberative Alignment):@cwolferesearch 介绍了 Deliberative Alignment,这是一种旨在通过使用 思维链推理 (chain-of-thought reasoning) 来遵守安全规范 (safety specifications),从而增强模型安全性的训练方法。
-
AI 进步的社会影响:@Chamath 强调需要考虑 AI 进步带来的深远社会影响及其对后代的影响。
AI 工具、应用与研究
-
用于增强编程的 CodeLLM:@bindureddy 介绍了 CodeLLM,这是一款集成了 o1、Sonnet 3.5 和 Gemini 等多个 LLMs 的 AI 代码编辑器,为开发者提供无限的试用配额。
-
用于音频文件处理的 LlamaParse:@llama_index 宣布 LlamaParse 具备了解析音频文件的能力,将其功能扩展到无缝处理语音转文本 (speech-to-text) 转换。
-
用于改进算子实现的 Stream-K:@hyhieu226 展示了 Stream-K,它增强了 GEMM kernels,并为 persistent kernels 提供了更好的算子实现视角。
梗与幽默
-
关于 AI 和文化的幽默见解:@dylan522p 幽默地表示:“那些家伙疯狂买入 Nvidia 股票,因为 OpenAI 的 o3 实在是太他妈强了”,将 AI 进展与股市幽默结合在一起。
-
AI 相关笑话和双关语:@teknium1 推特道:“如果有人在纽约想见面,我 4:00 到 5:30 会在 Stout,和几个朋友在一起。”,俏皮地将社交计划与 AI 讨论结合。
-
对 AI 趋势的轻松评论:@saranormous 分享了关于在 X 上发布点击诱饵内容的幽默反思,将 AI 内容创作与社交媒体幽默结合。
AI 研究与技术洞察
-
混合专家模型 (MoE) 的推理成本:@EpochAIResearch 解释说,与稠密模型 (dense models) 相比,MoE 模型通常具有更低的推理成本,澄清了 AI 架构中的常见误解。
-
神经视频水印框架:@AIatMeta 介绍了 Meta Video Seal,这是一个神经视频水印框架,并详细说明了其在保护视频内容方面的应用。
-
关于 LLM 推理时自我改进的查询:@omarsar0 发布了一项关于 LLM 推理时自我改进的调查,探讨了增强 AI 推理能力的技术与挑战。
AI Reddit 回顾
/r/LocalLlama 回顾
主题 1. OpenAI 的 O3 Mini 性能超越前代
- OpenAI 刚刚发布了 O3 和 O3 mini (Score: 234, Comments: 186):OpenAI 最新发布的 O3 和 O3 mini 模型展现了显著的性能提升,其中 O3 在 ARC-AGI 测试中获得了 87.5% 的分数,该测试旨在评估 AI 学习训练数据之外的新技能的能力。这标志着相比 O1 此前 25% 到 32% 的分数有了巨大飞跃,Francois Chollet 承认这一进展是“扎实的”。
- 围绕 ARC-AGI 基准测试 结果存在质疑,用户对其有效性表示怀疑,原因是测试环境不公开,且该模型是在公开训练集上训练的,这与之前的版本不同。人们对 AGI 的说法表示担忧,强调该基准测试在证明真正的 AGI 能力方面存在局限性。
- 使用 O3 模型实现高性能的成本备受关注,87.5% 准确率版本的成本远高于 75.7% 准确率版本。用户讨论了该模型目前的经济可行性,并预测成本效益可能会随着时间的推移而提高,从而使其更具可及性。
- 值得注意的是,由于与英国电信巨头 O2 的商标问题,命名时跳过了“O2”,一些用户对命名惯例表示不满。此外,人们对公开发布和开源替代方案充满期待,预计将于 1 月下旬发布。
- O3 击败了 99.8% 的竞赛程序员 (Score: 121, Comments: 69):O3 在 CodeForces 上获得了 2727 的 ELO 评分,位列竞赛程序员的前 99.8%。更多详情请参阅 CodeForces 博客。
- O3 的性能与计算成本:O3 在 CodeForces 上取得了显著成绩,ELO 评分达到 2727,但为了达到高准确率,需要生成超过 191 亿个 token,产生了巨额成本,例如最高配置设置下的成本达 115 万美元。讨论强调了目前计算成本虽然很高,但预计会随着时间的推移而下降,突显了 AI 能力的进步。
- AI 解决问题的挑战:将 O3 的方法与 CoT + MCTS 等传统方法进行了对比,评论指出其在计算方面的效率和可扩展性,尽管它需要迭代过程来处理错误。讨论了问题的复杂性和对 In-context computation 的需求,并将 AI 的 token 生成与人类解决问题的能力进行了比较。
- 对编程面试的影响:O3 等模型的进步引发了关于 LeetCode 风格面试 相关性的辩论,一些人认为随着 AI 的改进,这类面试可能会过时。有人呼吁面试应纳入 LLM 等现代工具,并对某些技术面试问题的非现实性进行了幽默的批评。
- o3 图表的 X 轴是对数刻度,Y 轴是线性刻度 (Score: 139, Comments: 65):o3 图表在“每任务成本”上使用了对数 X 轴,在“分数”上使用了线性 Y 轴,展示了 O1 MIN、O1 PREVIEW、O3 LOW (Tuned) 和 O3 HIGH (Tuned) 等各种模型的性能指标。值得注意的是,O3 HIGH (Tuned) 在较高成本下达到了 88% 的分数,而 O1 LOW 在 1 美元成本下仅为 25% 的分数,突显了 ARC AGI 评估中成本与性能之间的权衡。
- 几位评论者批评 o3 图表因其对数 X 轴而具有误导性,hyperknot 强调该图表给人一种通往 AGI 是线性进展的错觉。hyperknot 进一步认为,实现 AGI 需要大幅降低成本,估计需要降低 10,000 倍才能使其可行。
- 关于 AGI 成本和实用性的讨论显示出对其当前可行性的怀疑,Uncle___Marty 反对增加模型规模和计算能力的趋势。其他人如 Ansible32 则反驳说,展示功能性 AGI 是有价值的,类似于 ITER 等研究项目,尽管 ForsookComparison 质疑成本逻辑,认为高昂的费用可能并不合理。
- 关于计算硬件进展的辩论中,Chemical_Mode2736 和 mrjackspade 讨论了降低成本和计算能力指数级提升的潜力。然而,EstarriolOfTheEast 指出,由于 fp8 或 fp4 的假设以及功耗需求的增加,最近的进展可能并不像看起来那么显著,暗示指数级提升正在放缓。
{kind=link}
主题 2. Qwen QVQ-72B:AI 建模的新前沿
- Qwen QVQ-72B-Preview 即将到来!!! (Score: 295, Comments: 48):Qwen QVQ-72B 是一个拥有 720 亿参数的模型,其预发布占位符现已在 ModelScope 上线。关于命名规范从 QwQ 更改为 QvQ 存在一些不确定性,目前尚不清楚它是否包含特定的推理能力。
- Qwen QVQ-72B 模型被推测包含视觉/视频能力,正如 Justin Lin 的 Twitter 帖子所指出的,暗示 QVQ 中的“V”代表 Vision(视觉)。ModelScope 上有一个占位符,但在创建后不久可能已被设为私有或删除。
- 讨论强调了模型的内部思考过程,并将 QwQ 与 Google 的模型进行了比较。Google 的模型因其推理的效率和透明度而受到称赞,相比之下,QwQ 倾向于冗长且在思考过程中可能具有“对抗性”,由于 Token 生成速度慢,在 CPU 上运行时可能会很繁琐。
- 讨论了开源贡献的潜力,Google 不隐藏模型推理过程的决定被认为对竞争对手和本地 LLM 社区都有利。这种透明度与 OpenAI 的方法形成对比,后者不公开推理过程,可能在推理时使用了 MCTS 等技术。
- Qwen 发布了他们的 Qwen2.5 技术报告 (Score: 175, Comments: 11):Qwen 发布了他们的 Qwen2.5 技术报告,尽管帖子中没有提供额外的信息或细节。
- Qwen2.5 的编程能力:用户对 Qwen2.5-Coder 模型在没有明确指令的情况下实现复杂功能(如 Levenshtein 距离方法)的能力印象深刻。该模型受益于一个用于静态代码检查和单元测试的全能多语言沙箱,这增强了近 40 种编程语言的代码质量和正确性。
- 技术报告 vs. 白皮书:使用“技术报告”而非“白皮书”一词,是因为它允许分享某些方法论,同时将模型架构和数据等其他细节作为商业机密保留。这种区别对于理解此类文档中分享的透明度和信息水平至关重要。
- 模型训练与性能:该模型的效能,特别是在编程任务中,归功于其在来自 GitHub 和代码相关问答网站的数据集上的训练。即使是 14b 模型在建议和实现算法方面也表现出强大的性能,预计 72b 模型将更加强大。
主题 3. RWKV-7 在多语言和长上下文处理方面的进展
- RWKV-7 0.1B (L12-D768) 在 ctx4k 下训练,解决了 NIAH 16k,外推至 32k+,100% RNN(无 attention),支持 100+ 语言和代码 (Score: 117, Comments: 16): RWKV-7 0.1B (L12-D768) 是一款无 attention、100% RNN 模型,擅长处理长上下文任务,并支持 100 多种语言和代码。该模型在包含 1 万亿 tokens 的多语言数据集上进行训练,在处理长上下文方面优于 SSM (Mamba1/Mamba2) 和 RWKV-6 等其他模型,并使用 in-context gradient descent 进行 test-time-training。RWKV 社区还开发了一个微型的 RWKV-6 模型,能够通过广泛的 chain-of-thought 推理解决数独等复杂问题,且无论上下文长度如何,都能保持恒定的速度和 VRAM 占用。
- RWKV 的未来潜力:爱好者们对 RWKV 模型的潜力表示兴奋,特别是它们在推理任务中超越带有 attention 层的传统 Transformer 模型的能力。社区期待在 1B 参数 规模之外的进展,以及发布像 3B 模型 这样更大的模型。
- 学习资源:对学习 RWKV 的全面资源有需求,这表明了对其架构和应用理解的兴趣。
- 研究与开发:一位用户分享了尝试创建 RWKV 图像生成模型的经验,强调了该模型的能力以及为进一步优化它而进行的持续研究工作。讨论中引用了一篇相关论文:arxiv.org/pdf/2404.04478。
主题 4. 开源 AI:必然的演进
- 为什么开源 AI 不仅是必要的,而且需要进化的真正原因 (Score: 57, Comments: 25): 作者批评了 OpenAI 对其 o1 模型 的定价策略,强调了与基础价格和不可见输出 tokens 相关的高昂成本,认为这相当于垄断行为。他们主张 开源 AI 和社区协作,以防止垄断行为并确保竞争带来的好处,并指出像 Google 这样的公司可能会提供较低的价格,但并非出于善意。
- 垄断担忧:评论者一致认为 AI 领域可能会出现垄断行为,正如在其他行业中看到的那样,早期进入者会推动监管以维持其市场主导地位。OpenAI 的定价策略被视为反消费者,类似于 Apple 等公司为排他性收取溢价的做法。
- 不可见输出 Tokens:关于“不可见”输出 tokens 相关成本的讨论,批评者认为将这些作为大型模型的一部分进行收费是不公平的。一些人认为用户应该能够看到这些 tokens,因为他们为此付了费。
- 开源 vs. 科技巨头:人们相信开源模型可以促进价格竞争,类似于 render farms 在渲染领域的运作方式。开源社区与小型公司之间的协作被视为挑战 OpenAI 和 Google 等巨头主导地位的潜在途径。
其他 AI 子版块回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
主题 1. OpenAI 的 O3:高 ARC-AGI 性能但高成本
- OpenAI 的新模型 o3 在全球最难数学基准测试中展现出巨大飞跃 (Score: 196, Comments: 80): OpenAI 的新模型 o3 在 ARC-AGI 数学基准测试中展示了显著进展,准确率达到 25.2%,而之前的 state-of-the-art 模型仅为 2.0%。这一性能飞跃突显了 o3 在解决复杂数学问题方面的进步。
- 关于 AI 在研究中作用的讨论:Ormusn2o 强调了像 o3 这样的 AI 模型在推进自主和辅助机器学习研究方面的潜力,这对于实现 AGI 可能至关重要。同时,ColonelStoic 讨论了当前 LLM 在处理复杂数学证明方面的局限性,建议与 Lean 等自动证明检查器集成以寻求改进。
- 关于基准测试和模型性能的澄清:FateOfMuffins 指出了对基准测试的误解,澄清 25% 的准确率 属于 ASI 数学基准测试,不能直接与研究生水平的人类表现相提并论。Elliotglazer 进一步解释了 FrontierMath 内部的分层难度级别,指出性能跨越了不同的问题复杂度。
- 模型评估与利用:Craygen9 对评估模型在各个专业领域的表现表示兴趣,主张开发针对数学、编程和医学等特定领域量身定制的模型。Marcmar11 和 DazerHD1 讨论了性能指标,强调了基于思考时间的模型性能差异,深蓝色表示低思考时间,浅蓝色表示高思考时间。
- 2025 年将很有趣——谷歌在 12 月之前一直是个笑话,现在我觉得 2025 年对谷歌来说会非常好 (Score: 118, Comments: 26): Logan Kilpatrick 对 2025 年 AI 编程模型的重大进展表示乐观,获得了 2400 个赞的广泛关注。Alex Albert 持怀疑态度回应,对这些进展表示不确定,他的回复也吸引了 639 个赞。
- OpenAI vs. Google:评论者讨论了 OpenAI 相比 Google 因公司限制而具有的灵活性,认为两家公司现在处于更平等的地位。一些人对 Google 改进其 AI 产品的能力表示怀疑,特别是对其搜索功能和潜在广告技术干扰的担忧。
- Gemini 模型:Gemini 模型被强调为一项重大进步,一位用户指出其性能优于之前的模型,如 4o 和 3.5 sonnet。关于其能力的争论仍在继续,特别是其对文本、图像和音频的原生多模态支持。
- 企业影响:人们普遍对 Google 对 AI 进步的影响持不信任态度,担心业务和广告部门到 2025 年可能对 Gemini 模型产生负面影响。用户对 AI 领域的未来发展表达了怀疑与期待并存的情绪。
- OpenAI o3 在 ARC-AGI 上的表现 (Score: 138, Comments: 88): 该帖子链接到一张图片,但正文中未提供关于 o3 表现在 ARC-AGI 上的具体细节或背景。
- 讨论强调了 o3 在 ARC-AGI 基准测试上的显著性能提升。RedGambitt_ 强调 o3 代表了 AI 能力的飞跃,修复了 LLM paradigm 中的局限性,需要更新对 AI 的直觉。尽管性能很高,但 o3 并不被视为 AGI,正如 phil917 所指出的,他引用 ARC-AGI 博客称 o3 在简单任务上仍然失败,且 ARC-AGI-2 将带来新的挑战。
- 使用 o3 的成本是一个主要担忧,daemeh 和 ReadySetPunish 指出 o3(low) 的价格约为每项任务 20 美元,而 o3(high) 则高达 3500 美元。Phil917 提到,高算力变体处理 100 个问题可能耗资约 350,000 美元,突显了大规模使用的昂贵成本。
- 对话中包含对 AGI 的怀疑,hixon4 和 phil917 指出通过 ARC-AGI 并不等同于实现 AGI。讨论了 o3 的高成本和局限性,phil917 指出结果中可能存在数据污染,因为模型是在基准数据上训练的,这削弱了 o3 分数的令人印象深刻程度。
{kind=link}
{kind=link}
主题 2:在 o3 的热度中,Google 的 Gemini 2.5 盖过竞争对手
- 他赢了,伙计们 (Score: 117, Comments: 25): Gary Marcus 预测到 2024 年底将出现 7-10 个 GPT-4 级别的模型,但不会有像 GPT-5 这样重大的突破,这将导致价格战和极小的竞争优势。他强调了 AI 幻觉的持续问题,并预计企业采用率和利润仅会有小幅增长。
- 讨论强调了对 Gary Marcus 预测的怀疑,用户质疑他预测的可信度,并认为 OpenAI 目前领先于 Google。然而,一些人认为 Google 仍可能在即将推出的模型中实现 Chain of Thought (CoT) 能力的突破。
- 关于 OpenAI 的 o3 模型发布及其影响存在争论,一些用户指出其可用性和定价可能会限制其普及。虽然 o3-mini 预计在 1 月底推出,但对于这些发布的及时性和公众访问权限仍存疑。
- 用户讨论了新型推理模型在 自动化工作流 (automated workflows) 中的效率和潜在成本优势,并将其与 GPT-4 等早期模型的复杂性和资源需求进行了对比。这些进步被视为驱动自动化系统的更智能解决方案。
{kind=link}
主题 3. TinyBox GPU 操作与网络欺骗
- 我不希望因为价格太高而用不起 AI (Score: 126, Comments: 91): 该帖子讨论了对 AI 服务 成本上升的担忧,特别是 O1 无限制 方案已经达到 每月 200 美元,以及未来 Agentic AI 可能达到 每月 2,000 美元 的定价。作者对因价格问题无法使用高质量 AI 表示沮丧,同时也承认了这些成本可能的合理性,引发了对 AI 技术更广泛定价轨迹的反思。
- 许多人强烈认为 开源 AI 对于抵消专有 AI 解决方案的高昂成本至关重要,正如 GBJI 所表达的,他主张支持 FOSS AI 开发者以对抗企业控制。Odd_Category_1038 指出,担忧在于高昂的定价可能会造成全球智能的瓶颈,使美国/欧盟以外的研究人员处于劣势并抑制创新。
- LegitimateLength1916 和 BlueberryFew613 讨论了 AI Agent 可能取代工人的经济影响,前者认为由于成本节约,企业将选择 AI 而非人类员工。然而,BlueberryFew613 个人认为目前的 AI 缺乏完全取代专业人士的能力和基础设施,强调需要符号推理和 AI 集成方面的进步。
- NoWeather1702 对 AI 的可扩展性表示担忧,原因是能源和算力不足,并指出 LLM 所需的电力/算力增长速度超过了生产速度。在全求数据中心行业工作的 ThenExtension9196 保证,目前正在努力解决这一问题。
主题 4. ChatGPT Pro 定价与市场影响讨论
- OpenAI 会发布 2000 美元的订阅服务吗? (Score: 349, Comments: 144): 该帖子推测了 OpenAI 可能推出的 2000 美元订阅服务,引用了 Sam Altman 在 2024 年 12 月 20 日 发布的一条俏皮的 Twitter 帖子。该帖子幽默地暗示了序列 “ooo -> 000 -> 2000” 与 Altman 推文之间的联系,推文中包含了一些随意且幽默的互动指标。
- O3 模型推测:关于可能作为 O1 后继者的新模型 o3 存在讨论。这种推测的出现是因为 O2 已经是欧洲一家注册商标的电话运营商,一些用户幽默地建议它可能会为不同的订阅层级提供每周限制的消息数。
- 定价与价值担忧:评论者对传闻中的 2000 美元/月 订阅表示怀疑,开玩笑说这样的价格应该配得上 AGI (通用人工智能),而他们认为 AGI 的价值远不止于此。
- 幽默与讽刺:评论充满了幽默感,提到了潜在的 NSFW 伴侣模型,以及与 Ozempic 和 OnlyFans 的俏皮关联。还有人对营销策略进行了讽刺,使用了 “ho ho ho” 和 “oh oh oh” 等词组。
{kind=link}
AI Discord 摘要
由 o1-2024-12-17 生成的摘要的摘要的摘要
主题 1. O3 热潮与新基准测试
- O3 突破 ARC-AGI:OpenAI 的 O3 模型在 ARC-AGI 半私有评估中达到了 75.7%,并在高算力模式下飙升至 87.5%。工程师们对其“超水平发挥”的推理能力表示赞赏,尽管批评者担心该模型巨大的推理成本。
- 高算力模式极其烧钱:部分评估每次运行耗资数千美元,这表明大公司可以以高昂的价格推高性能。小型机构担心算力壁垒,并怀疑 O3 这种马斯克级别的预算会让许多人无法触及 SOTA 级别的进展。
- O2 缺席,O3 快速登场:据传因商标冲突,OpenAI 跳过了 “O2”,在 O1 发布仅几个月后就推出了 O3。撇开命名方面的玩笑不谈,开发者们对从一个前沿模型到下一个模型的惊人进展速度感到惊叹。
主题 2. AI 编辑器狂热:Codeium, Cursor, Aider 等
- Cursor 0.44.5 提升生产力:用户称赞新版本的 Agent 模式既快又稳定,促使不少用户从竞争对手的 IDE 回归 Cursor。新一轮以 25 亿美元估值融资 1 亿美元的消息,为其灵活的代码环境增添了更多热度。
- Codeium “发送至 Cascade” 功能简化 Bug 报告:Codeium 的 Windsurf 1.1.1 更新引入了一个将问题直接转发到 Cascade 的按钮,消除了调试过程中的阻碍。成员们成功测试了更大的图像和传统聊天模式,并参考了文档中的方案使用详情。
- Aider 与 Cline 协同处理仓库:Aider 处理细微的代码调整,而 Cline 凭借扩展内存功能完成更大的自动化任务。开发者们看到了更高效的工作流,减少了重复性工作,且这两个工具之间具有互补的协同效应。
主题 3. 微调之争:LoRA, QLoRA 与剪枝
- LoRA 引发热议:批评者质疑 LoRA 在分布外(out-of-distribution)数据上的有效性,而其他人则坚持认为它是超大规模模型的必备方案。一些人建议采用全量微调(full finetuning)以获得一致的结果,引发了关于训练方式的持久争论。
- QAT + LoRA 登陆 Torchtune v0.5.0:新方案将量化感知训练(quantization-aware training)与 LoRA 结合,以创建更精简、更专业的 LLM。早期采用者非常喜欢更小的文件体积与不错的性能提升之间的平衡。
- 词表剪枝颇为棘手:一些开发者通过剪枝不需要的 Token 来减少内存占用,但保留 fp32 参数以维持精度。这种平衡行为凸显了大规模训练边缘案例模型时的复杂现实。
主题 4. Agent、RL 方法及竞争模型对决
- HL Chat:Anthropic 的惊喜与构建 Anthropic:粉丝们猜测可能会有节日发布,并注意到了团队充满热情的氛围。关于 Dario “可爱顽童”气质的玩笑,衬托出了 Agent 发布周边的轻松基调。
- 无需完全验证的 RL:一些团队推测,当任务缺乏完美检查器时,奖励模型会出现反复,并建议使用“松散验证器”或更简单的二元启发式方法。他们预计到 2025 年 RL+LLM 将迎来更大的里程碑,用尚不成熟的奖励信号连接不确定的输出。
- Gemini 2.0 Flash Thinking 对抗 O1:Google 的新模型公开展示了思考 Token,让开发者可以看到逐步的逻辑。观察者称赞其透明度,但也质疑 O3 目前在代码和数学任务上是否比 Gemini 更出色。
主题 5. 创意与多媒体 AI:Notebook LM, SDXL 等
- Notebook LM 批量产出播客:学生和创作者使用 AI 自动化生成具有一致音频质量的整个节目片段。该工具还有助于为新闻报道或学术写作构建时间线和思维导图,展示了灵活的内容生成能力。
- SDXL + LoRA 打造动漫场景:艺术家们称赞 SDXL 强大的风格,同时通过 LoRA 增强动漫艺术效果。用户克服了风格不匹配的问题,为游戏场景和角色设计保留了配色方案。
- AniDoc 帧上色宛如魔法:Gradio 的 AniDoc 将粗糙的草图转换为全彩动画,优雅地处理姿势和比例。开发者称赞它是加速视觉叙事和原型设计的强大扩展。
PART 1: High level Discord summaries
Codeium (Windsurf) Discord
- Windsurf 1.1.1 在定价和图像升级方面表现出色:Windsurf 1.1.1 更新引入了 ‘Send to Cascade’ 按钮、方案状态的使用信息,并取消了图像 1MB 的限制,详见 changelog。
- 社区成员测试了 ‘Legacy Chat’ 模式并称赞了新的 Python 增强功能,参考了 使用文档 中的细节。
- Send to Cascade 展示了快速的问题路由:一段简短的演示重点展示了 ‘Send to Cascade’ 功能,允许用户将问题上报给 Cascade,该演示发布在 推文 中。
- 贡献者鼓励大家尝试该功能,并指出将用户反馈与专门的故障排除迅速结合带来的便利性。
- Cascade 错误导致聊天重置:当聊天内容过长时,用户在 Cascade 中遇到了内部错误消息,促使他们开启新会话以维持稳定性。
- 他们强调了简洁的对话管理对维持性能的重要性,并指出了较小聊天日志带来的好处。
- 订阅方案困扰部分成员:一位用户询问为何 Windsurf 的 trial pro plan 被停止,引发了关于免费与分级功能的讨论,并引用了 方案设置。
- 其他人交流了关于使用限制的经验,强调了 extension、Cascade 和 Windsurf 软件包之间的差异。
- CLI 插件和性能表现引发辩论:一些参与者请求更好地集成 Warp 或 Gemini 等外部工具,同时注意到一天中不同时间的性能波动。
- 他们强调了命令行界面(CLI)使用与 AI 驱动编程之间潜在的协同效应,尽管对大型代码库中速度变慢的担忧依然存在。
Cursor IDE Discord
- Cursor 0.44.5 提升生产力并吸引融资:开发者报告称 Cursor 0.44.5 版本 显示出显著的性能提升,特别是在 Agent 模式下,促使许多人从竞争对手编辑器切回 Cursor。
- TechCrunch 披露了 Cursor 以 25 亿美元估值完成的新一轮 1 亿美元融资,表明投资者对 AI 驱动的编程解决方案有着强烈的热情。
- AI 工具助力开发工作:参与者强调了 AI 驱动的功能如何减少编码时间并扩大解决方案的搜索范围,使他们能够更高效地完成项目。
- 他们注意到了与 构建高效 Agent 等教程中额外指导的协同作用,这些教程确保了 LLM 在工作流中的实际集成。
- Sonnet 模型引发褒贬不一的反馈:用户对比了多个 Sonnet 版本,一些人称赞最新版本的 UI 生成能力,而另一些人则报告输出质量不稳定。
- 他们观察到 System Prompts 会显著影响模型的行为,导致某些开发者调整其方法以获得更好的结果。
- 自由职业者拥抱 AI 以实现更快交付:自由职业贡献者分享了使用 AI 自动化繁琐编码任务并更迅速地清理项目积压工作的案例。
- 少数人对客户对 AI 使用的怀疑表示担忧,但鉴于成果的改善,整体情绪保持积极。
- AI 创建的布局中 UI 样式挑战依然存在:虽然 AI 能有效处理后端逻辑,但在精细的样式元素上表现不佳,迫使开发者手动修复前端设计问题。
- 这一不足强调了对视觉组件进行更多数据训练的需求,这可以增强工具生成精美界面的能力。
aider (Paul Gauthier) Discord
- OpenAI O3 提速:基准测试显示 OpenAI O3 在 ARC-AGI 半私有评估中达到了 75.7%,如此推文所述。
- ARC Prize 的后续帖子提到,高计算量的 O3 版本得分高达 87.5%,引发了关于成本和性能改进的讨论。
- Aider 与 Cline 联手:开发者使用 Aider 进行较小的代码调整,而 Cline 凭借其更强的记忆能力处理更繁重的自动化任务。
- 他们观察到通过配对使用这些工具可以提升工作流,减少软件开发中的手动重复。
- AI 职业安全担忧增加:评论者表示担心 AI 可能通过自动化简单任务来取代部分编码角色。
- 其他人则坚持认为,对于复杂的问题解决,人的因素仍然是关键,因此开发者职位应该保持其重要性。
- Depth AI 提升代码洞察力:工程师在大型代码库上测试了 Depth AI,注意到其在 trydepth.ai 上的完整知识图谱和跨平台集成。
- 一位用户在不再需要检索增强生成(RAG)时停止了使用,但仍对其潜力表示赞赏。
- AniDoc 轻松为草图上色:新的 AniDoc 工具可根据风格参考将粗糙的帧转换为全彩动画。
- 用户赞赏其处理各种姿势和比例的能力,称其为视觉叙事的有效扩展。
Interconnects (Nathan Lambert) Discord
- O3 在 ARC-AGI 上的强劲表现:OpenAI 透露 O3 在 ARC-AGI 测试中得分 87.5%,跳过了 O2 这个名称,在三个月内从 O1 进化到 O3,如此推文所示。
- 社区成员就高昂的推理成本和 GPU 使用情况展开争论,有人开玩笑说 Nvidia 股票飙升是因为 O3 的强劲结果。
- LoRA 的收益有限:一位用户对 LoRA finetuning 提出质疑,引用了一篇分析论文,该论文怀疑 LoRA 在训练集之外的有效性。
- 其他人强调,随着模型变大,LoRA 变得必不可少,这引发了关于全量微调 (full finetuning) 是否能产生更一致结果的辩论。
- Chollet 将 O1 称为下一个 AlphaGo:François Chollet 将 O1 比作 AlphaGo,在此帖子中解释说,两者在单次移动或输出中都使用了大量的处理过程。
- 他坚持认为将 O1 标记为简单的语言模型具有误导性,这促使成员们质疑 O1 是否秘密使用了类搜索方法。
- RL & RLHF 奖励模型的挑战:一些成员认为,输出不确定的 Reinforcement Learning 需要专门的奖励标准,建议为简单任务使用宽松的验证器,并链接到此讨论。
- 他们警告奖励模型中存在噪声,强调在美学等领域推动二元检查,并预测 2025 年将有更大的 RL + LLM 突破。
- Anthropic 的惊喜发布与构建 Anthropic Chat:Anthropic 可能在假期发布产品引发了猜测,尽管一位成员开玩笑说 Anthropic 太有礼貌了,不会突然发布产品。
- 在关于 Building Anthropic 的 YouTube 视频中,参与者戏称 Dario 为“可爱的小矮人”,并赞扬了团队积极向上的氛围。
OpenAI Discord
- OpenAI 第 12 日收官活动引发观众热议:12 Days of OpenAI 的最后一天由 Sam Altman、Mark Chen 和 Hongyu Ren 主持,观众被引导至此处观看直播活动。
- 许多人期待这些关键人物能带来总结性的见解和潜在的重大发布。
- o3 模型热潮引发对比:参与者推测 o3 可能与 Google 的 Gemini 竞争,而 OpenAI 的定价也引发了对其市场优势的质疑。
- 一条 推文 强调了 o3 在全球编程基准测试中排名第 175 位,进一步提升了关注度。
- OpenAI 的发展方向引发褒贬不一的反应:一些人对 OpenAI 偏离开源初衷、转向付费服务表示不满,理由是免费资料减少。
- 评论者怀疑在这种定价结构下,未来发布的模型是否还能保持易用性。
- 聊天机器人查询与 4o 限制:一位用户指出 自定义 GPTs 被锁定在 4o,限制了模型的灵活性。
- 开发者们还在寻求关于构建机器人的建议,旨在解释软件功能并以通俗易懂的语言引导用户。
Unsloth AI (Daniel Han) Discord
- o3 的进展与质疑并存:新款 o3 在 ARC-AGI 公开排行榜 上飙升至 75.7%,引发了关于它是否使用了新模型、优化的数据策略以及大规模算力的讨论。
- 一些人称结果“很有趣”,但质疑 o1 加上微调(fine-tuning)技巧是否就能解释这种提升,并指出官方发布的内容可能存在疏漏。
- FrontierMath 惊人的准确率:根据 David Dohan 的推文,新的 FrontierMath 结果从 2% 跃升至 25%,挑战了此前关于高级数学任务的假设。
- 社区成员引用 Terence Tao 的话称,该数据集在未来几年内都不应被 AI 攻克,而另一些人则担心潜在的过拟合(overfitting)或数据泄露问题。
- RAG 与 Kaggle 加速微调:通过利用 GitHub 资源,RAG 训练时间从 3 小时缩短至 15 分钟,将 7.5 万行的 CSV 从 JSON 转换后显著提升了模型准确率。
- 一些人建议使用 Kaggle 获取每周 30 小时的免费 GPU 额度,并鼓励在 Llama 微调时关注数据质量而非单纯的数量。
- SDXL 与 LoRA 联手打造动漫效果:用户称赞 SDXL 在动漫效果上的强劲表现,并指出 Miyabi Hoshimi 的 LoRA 模型 可以提升风格准确度。
- 其他人报告了将 Flux 与 LoRA 配对以获得一致动漫输出的困难,期待 Unsloth 尽快支持 Flux。
- TGI 与 vLLM 的对决:TGI 和 vLLM 在速度和适配器(adapter)处理方面引发了辩论,参考了 Text Generation Inference 文档。
- 一些人因其灵活的方法而更青睐 vLLM,而另一些人则支持 TGI,认为它在服务大规模模型部署方面更为可靠。
Nous Research AI Discord
- O3 耗资巨大,超越 O1:新发布的 O3 模型在编程任务中表现优于 O1,且据这条推文指出,其计算费用高达 $1,600,250。
- 爱好者们指出了巨大的财务障碍,认为高昂的成本可能会限制其广泛应用。
- Gemini 2.0 展开华丽对决:Google 推出了 Gemini 2.0 Flash Thinking 以对抗 OpenAI 的 O1,据这篇文章报道,该模型允许用户查看逐步推理过程。
- 观察者将其与 O1 进行了对比,强调了新的下拉式解释功能是迈向透明模型内省的重要一步。
- Llama 3.3 过于积极的函数调用:成员们注意到 Llama 3.3 触发函数调用的速度远快于 Hermes 3 70b,这可能会推高成本。
- 他们发现 Hermes 在调用方面更加克制,从而降低了费用并提高了整体一致性。
- 潜意识提示引发好奇:有人提出在 Prompt 中进行潜层影响注入(latent influence injecting),这与微妙的 NLP 风格干预有异曲同工之妙。
- 参与者讨论了在不直接引用的情况下塑造输出的可能性,将其比作幕后建议。
- **利用
标签数据集进行宏大构想**:一项旨在利用 ** ** 标签构建推理数据集的协作工作已经启动,目标模型包括 **O1-Preview** 或 **O3**。 - 贡献者旨在将完整的推理轨迹嵌入原始数据中以提高清晰度,寻求结构化思维与最终答案之间的协同作用。
Stackblitz (Bolt.new) Discord
- Mistletokens 带来的圣诞狂欢:Bolt 团队推出了 Mistletokens,在年底前为 Pro 用户提供 200 万个免费 token,为免费用户提供每日 20 万个及每月 200 万个的限额。
- 他们旨在通过这些扩展的节日 token 福利激发更多的季节性项目和解决方案。
- Bolt 与冗余作斗争:开发者抱怨 Bolt 在不清理重复内容的情况下消耗 token,并提到“开启 diff 时存在大量重复”。
- 一些人通过针对性的审查克服了这个问题,例如“请对 [我的应用程序的 Auth Flow] 进行彻底的审查和审计”,这迫使它处理冗余问题。
- 集成 Bug 引发挫败感:多位用户注意到 Bolt 会自动创建新的 Supabase 实例而不是复用旧实例,导致 token 浪费。
- 重复的速率限制(rate-limits)引发了更多投诉,用户坚持认为购买的 token 应该让他们免受免费计划的限制。
- WebRTC 梦想与实时流媒体:在 Bolt 上为视频聊天应用集成 WebRTC 的尝试遇到了围绕实时功能的各种技术困难。
- 社区成员请求提供具有可定制配置的预构建 WebRTC 解决方案,以便更顺畅地处理媒体。
- 订阅纠葛与店面展示:许多人对于需要激活订阅才能使用购买的 token 充值感到担忧,敦促制定更清晰的支付指南。
- 与此同时,一位开发者预览了一个全栈电子商务项目,该项目具有 Headless 后端、精美的店面和旨在独立运行的视觉编辑器。
LM Studio Discord
- OpenAI 诽谤风波:一段相关的 YouTube 视频展示了针对 OpenAI 的法律威胁,指控该 AI 对特定个人发表了诽谤性言论。
- 成员们讨论了在公开网络数据上进行训练如何产生错误的归因,并对最终输出中的名称过滤器(name filters)表示担忧。
- LM Studio 的命名功能:参与者注意到 LM Studio 会自动生成对话名称,可能是通过使用内置的小型模型来总结对话内容。
- 有人推测其中嵌入了一个捆绑的摘要生成器(bundled summarizer),使对话交互更加无缝且用户友好。
- 3090 轻松运行 16B 模型:工程师们确认,配备 64 GB RAM 的 3090 GPU 加上 5800X 处理器,可以以舒适的 Token 速度处理 16B 参数模型。
- 他们提到 70B 模型仍然需要更高的 VRAM 和明智的量化策略来维持实用的性能。
- 参数量化见解:爱好者们解释说,对于许多模型,Q8 量化通常几乎是无损的,而 Q6 仍能保持不错的精度。
- 他们强调了更小的文件体积与模型准确性之间的权衡,主张采用平衡的方法以获得最佳效果。
- eGPU 强力方案:一位成员展示了使用 Razer Core X 外置显卡盒搭配 3090,通过 Thunderbolt 接口为 i7 笔记本电脑提供动力。
- 这一配置激发了人们对外部 GPU 的兴趣,认为它是那些希望在便携系统上获得桌面级性能用户的灵活选择。
OpenRouter (Alex Atallah) Discord
- Gemini 2.0 Flash Thinking 动态:Google 推出了新的 Gemini 2.0 Flash Thinking 模型,该模型直接在文本中输出思考 Token(thinking tokens),现在已可在 OpenRouter 上访问。
- 部分用户暂时无法使用,但如果你热衷于实验,可以通过 Discord 申请访问权限。
- BYOK 与费用讨论成为焦点:BYOK(自带 API 密钥)的推出允许用户将自己的供应商额度与 OpenRouter 的额度合并,在上游成本之上收取 5% 的费用。
- 有用户要求提供一个简单的示例来澄清费用结构,更新后的文档将详细说明使用费如何结合供应商费率以及这部分额外分成。
- AI 待办事项列表应用“5分钟法则”:一个基于 Open Router 构建的 AI To-Do List 利用“5分钟法则”自动启动任务。
- 它还会递归地创建新任务,让用户感叹“工作实际上变得很有趣”。
- 新模型发布与 AGI 争议:社区传闻 o3-mini 和 o3 即将推出,命名冲突引发了一些内部笑话。
- 关于 AGI 的辩论发生了转向,一些人称该话题为“红鲱鱼”(伪命题),并将好奇者引向一段 1.5 小时的视频讨论。
- 加密支付 API 激发资金流:新的 Crypto Payments API 允许 LLM 通过 ETH、0xPolygon 和 Base 处理链上交易,详见 OpenRouter 的推文。
- 它引入了无头、自主融资,为 Agent 提供了独立交易的方法,并为新型用例开辟了道路。
Eleuther Discord
- Natural Attention 挑战 Adam:Jeroaranda 介绍了一种 Natural Attention 方法,该方法可以近似 Fisher matrix,并在某些训练场景中超越了 Adam,参考 GitHub 上的证明细节。
- 社区成员强调了使用 causal mask 的必要性,并辩论了预训练数据中质量与数量的关系,强调需要对这些主张进行深入验证。
- MSR 的伦理困境被曝光:在出现剽窃案例后,关于 MSR 伦理问题的讨论爆发,涉及两篇论文,其中包括一篇 NeurIPS spotlight award 的入围作品。
- 参与者对引用 MSR 的工作表示不信任,并质疑其研究环境的可信度,警告他人要谨慎对待。
- BOS Token 的过度影响:成员们发现 BOS token 位置的激活范数(activation norms)可能高出多达 30倍,这可能会扭曲 SAE 的训练结果。
- 他们建议从训练数据中排除 BOS 或应用归一化(normalization)来减轻这种不成比例的影响,并参考了 2k 和 1024 上下文长度的短上下文实验。
- 基准测试目录混乱:用户被保存到
./benchmark_logs/name/__mnt__weka__home__...而非./benchmark_logs/name/的日志搞得措手不及,这使多模型运行变得复杂。- 他们提出了唯一的命名规范和专门用于比较所有 checkpoint 的 harness,以平衡改进与向后兼容性(backwards compatibility)。
- GPT-Neox MFU 日志记录受到关注:Pull Request #1331 添加了 MFU/HFU 指标,用于
neox_args.peak_theoretical_tflops的使用,并将这些统计数据集成到 WandB 和 TensorBoard 中。- 社区对新的 tokens_per_sec 和 iters_per_sec 日志表示赞赏,并在收到积极反馈后合并了该 PR,尽管测试有所延迟。
Modular (Mojo 🔥) Discord
- FFI 摩擦:v24.6 的纠葛:从 v24.5 升级到 v24.6 触发了与标准库内置 write 函数的冲突,使 Mojo 中的 socket 使用变得复杂。
- 开发者建议使用 FileDescriptor 作为权宜之计,参考 write(3p) 以避免符号冲突。
- Libc 绑定助力更精简的 Mojo:成员们推动更广泛的 libc 绑定,据报告已有 150 多个函数初步完成了 Mojo 集成。
- 他们主张为这些绑定建立单一仓库,以加强跨平台测试和系统级功能。
- 浮点数解析遇到障碍:从 Lemire 移植浮点数解析的效果不佳,标准库方法的表现也慢于预期。
- 一个待处理的 PR 寻求升级 atof 并增强数值处理能力,旨在提升数据密集型任务中的性能。
- Tensorlike Trait 之争:GitHub Issue #274 中的一个请求要求 tensor.Tensor 实现 tensor_utils.TensorLike,声称它已经符合标准。
- 关于
Tensor应该是 trait 还是 type 产生了争论,这反映了在 MAX APIs 内部直接实例化的挑战。
- 关于
- Modular 邮件:总结 2024:Modular 感谢社区在高效的 2024 年中所做的贡献,宣布假期停工至 1 月 6 日,期间回复将会减少。
- 他们邀请通过 论坛帖子 和 GitHub Issues 反馈 24.6 版本 的意见,激发了对 2025 年的期待。
Latent Space Discord
- OpenAI 的 O3 在 ARC-AGI 上表现强劲:OpenAI 推出了 O3 模型,在 ARC-AGI 半私有评估(Semi-Private Evaluation)中得分 75.7%,在最高计算模式下得分 87.5%,显示出强大的推理性能。研究人员提到了可能的并行 Chain-of-Thought 机制以及巨大的资源需求。
- 许多人讨论了该模型的成本——传闻约为 150 万美元——同时对其在代码、数学和逻辑任务上的飞跃表示赞赏。
- Alec Radford 离职:以早期 GPT 贡献闻名的 Alec Radford 确认离开 OpenAI 进行独立研究。成员们推测了领导层的变动以及对即将发布的模型的潜在影响。
- 一些人预测内部很快会有转向,另一些人则称赞 Radford 过去的工作是 GPT 奠基的关键。
- 高计算 AI 的经济压力:讨论引发了对高昂计算预算(如驱动 O3 的预算)可能阻碍商业可行性的担忧。参与者警告说,虽然突破令人兴奋,但它们带来了巨大的运营成本。
- 他们权衡了在 ARC-AGI 上提升的性能是否足以证明这些支出是合理的,特别是对于代码和数学等专业任务。
- 安全测试成为焦点:OpenAI 邀请志愿者对 O3 和 O3-mini 进行压力测试,体现了对发现潜在滥用行为的重视。这一呼吁强调了在更广泛部署之前进行彻底审查的推动力。
- 安全研究人员对这一机会表示欢迎,进一步强化了将社区驱动的监督作为负责任 AI 进展的关键衡量标准。
- API Keys 与 Character AI 角色扮演:开发者报告了对 API keys 的修补尝试,突显了 AI 社区日常的实验。与此同时,Character AI 吸引了更年轻的群体,他们对“迪士尼公主”风格的互动感兴趣。
- 参与者注意到了用户体验的信号,引用“神奇的数学石头(magical math rocks)”这一幽默说法来强调典型商业应用之外的趣味性互动。
Notebook LM Discord Discord
- AI 助力播客兴起:一次对话强调了使用 AI 制作播客剧集,加速了内容创作并提高了各章节音频的一致性。
- 此外,一个名为 Churros in the Void 的项目使用了 Notebook LM 和 LTX-studio 进行视觉和配音制作,强化了自主配音的方法。
- Notebook LM 助力教育:一位用户将 Notebook LM 描述为在新闻课上构建时间线和思维导图的强大工具,引用了来自此笔记本的数据。
- 他们整合了课程材料和特定主题的播客,据报告提高了内容的组织性,使论文更具连贯性。
- AI 帮助求职者准备:一位成员使用 Notebook LM 根据职位广告分析自己的简历,为即将到来的面试生成了定制的学习指南。
- 他们建议其他人上传简历,以获得关于技能匹配度的即时建议。
- 交互模式与引用工具遇到障碍:几位用户在访问新的基于语音的交互模式时遇到困难,引发了对其发布不均衡的质疑。
- 其他人报告了一个导致保存的笔记中引用功能消失的 Bug,开发团队确认修复工作正在进行中。
- 音频概览与语言限制:一位用户请求关于恢复丢失的音频概览的技巧,指出一旦丢失就很难生成完全相同的版本。
- 类似的讨论探索了 Notebook LM 如何通过将内容分成不同的集合,来更准确地处理多样化的语言源。
Perplexity AI Discord
- OpenAI 的 o3 强势推进:OpenAI 推出了全新的 o3 和 o3-mini 模型,TechCrunch 的报道引发了关于其性能是否能超越 o1 里程碑的讨论。
- 一些参与者强调了这些发布对大规模部署的重要性,并引用了一段 视频演示,其中 Sam Altman 呼吁在测试驱动下保持谨慎。
- Lepton AI 推动 Node 支付:新推出的基于 Node 的支付解决方案呼应了来自 Lepton AI 的开源蓝图,引发了关于原创性的讨论。
- 评论指向了 GitHub repo 作为此前开源努力的证据,加剧了关于复用和正确引用的争论。
- 三星的 Moohan 任务:Samsung 推出了 Project Moohan 这一 AI 项目,引发了对其新集成功能的猜测。
- 细节目前仍然较少,但参与者对其与现有硬件和 AI 平台的协同作用感到好奇。
- 职场 AI 使用率激增:最近的一项 调查 声称,超过 70% 的员工正在将 AI 融入日常任务中。
- 人们注意到新的生成式工具如何简化代码审查和文档编写,这表明高级自动化的标准正在提高。
Nomic.ai (GPT4All) Discord
- GPT4All v3.6.x:快速迭代与修复:全新的 GPT4All v3.6.0 发布,配备了 Reasoner v1、内置的 JavaScript 代码解释器,并改进了模板兼容性。
- 社区成员迅速处理了 v3.6.1 中的回归错误,Adam Treat 和 Jared Van Bortel 领导了修复工作,详见 Issue #3333。
- Llama 3.3 与 Qwen2 进步显著:成员们强调了 Llama 3.3 和 Qwen2 的功能性提升,称其性能优于之前的版本。
- 他们引用了 Logan Kilpatrick 的一条推文,展示了利用视觉和文本元素解决谜题的能力。
- Phi-4 表现超出预期:据 Hugging Face 报道,拥有 14B 参数的 Phi-4 模型 据称可以与 Llama 3.3 70B 媲美。
- 社区测试者对本地运行的流畅度发表了评论,注意到其强大的性能,并对进一步测试充满热情。
- 自定义模板与 LocalDocs 联动:一个专门的 GPT4All 聊天模板利用代码解释器实现强大的推理,经验证可与多种模型类型配合使用。
- 成员们描述了将 GPT4All 本地 API 服务器与 LocalDocs (文档) 连接,从而实现有效的离线操作。
Stability.ai (Stable Diffusion) Discord
- 本地生成器大对决:SD1.5 vs SDXL 1.0:一些成员称赞 SD1.5 性能稳定,而另一些人则推荐使用 SDXL 1.0 配合 ComfyUI 以获得更高级的效果。
- 他们注意到概念艺术在文生图清晰度方面的提升,并强调了这些本地模型极低的安装门槛。
- Flux 风格迁移受到关注:一位用户在本地运行了 Flux,并寻求如何匹配参考图风格以用于游戏场景的建议。
- 他们提到成功保留了配色方案和轮廓,并归功于 Flux 中一致的参数设置。
- 诈骗警报:技术支持服务器引发关注:一个自称提供 Discord 帮助的可疑团体要求提供钱包详情,引发了安全担忧。
- 成员们比较了更安全的替代方案,并互相提醒注意标准防范措施。
- SF3D 崭露头角,助力 3D 资产创作:爱好者们指向了 Hugging Face 上的 stabilityai/stable-fast-3d,用于生成等距视角角色和道具。
- 他们报告称,在创建游戏就绪对象时结果稳定,且伪影比其他方法更少。
- LoRA 魔法助力个人艺术训练:一位艺术家表达了希望通过用自己的图像训练新模型来加快艺术创作速度。
- 其他人推荐进行 LoRA 微调,特别是针对 Flux 或 SD 3.5,以锁定风格细节。
Cohere Discord
- Cohere c4ai Commands MLX 势头强劲:在一次 MLX 集成推进期间,成员们测试了 Cohere 的 c4ai-command-r7b 模型,并赞扬了其提升的开源协同效应。
- 他们强调了早期的 VLLM 支持,并指向了一个可能加速进一步扩展的 Pull Request。
- 128K 上下文特性令粉丝印象深刻:社区的一份测评展示了 Cohere 模型在 11.5 GB 内存上处理了一个包含 211,009 个 token 的《弹丸论破》同人小说。
- 讨论将强大的扩展上下文能力归功于缺乏位置编码(positional encoding),称其为处理大规模文本任务的关键因素。
- O3 模型引发猜测:成员们调侃了一个具有类似于 GPT-4 特性的 O3 模型,点燃了对语音交互功能的期待。
- 他们预测该模型可能很快发布,期待其先进的 AI 功能。
- Findr 借 Cohere 之势首次亮相:社区成员庆祝了 Findr 的发布,将其幕后的技术支持归功于 Cohere 的技术栈。
- 一位成员询问使用了哪些 Cohere 特性,反映出对集成方案选择的研究兴趣。
LAION Discord
- OpenAI o3 强势登场:OpenAI 发布了其 o3 推理模型,在低算力模式下达到 75.7%,在高算力模式下达到 87.5%。
- 一场对话引用了 François Chollet 的推文和 ARC-AGI-Pub 结果,暗示了在处理高级任务方面的新势头。
- 是否为 AGI:争论激烈:一些人断言,在 ARC 等任务上超越人类表现标志着 AGI 的到来。
- 另一些人则坚持认为 AGI 的定义过于模糊,敦促使用结合语境的含义以避免混淆。
- Elo 评分与算力推测:参与者将 o3 的结果与特级大师级的 Elo 评分进行了比较,参考了 Elo 概率计算器。
- 他们思考较弱的模型是否可以通过每次扩展运行花费 $20 的额外测试时算力(test-time compute)来达到类似的结果。
- 关于 DCT 和 VAE 的精彩讨论:讨论集中在 YCrCb 或 YUV 等颜色空间的 DCT 和 DWT 编码上,质疑额外的步骤是否能证明训练开销的合理性。
- 一些人引用了 VAR 论文,建议先预测 DC 分量然后再添加 AC 分量,强调了亮度通道在人类感知中的作用。
GPU MODE Discord
- Triton 文档出故障,开发者挺身而出:Triton 官方文档的搜索功能已损坏,社区指出缺少关于 tl.dtypes(如 tl.int1)的规范。
- 如果文档后端开放编辑,热心的贡献者希望对其进行修复。
- Flex Attention 势头渐起:正在折腾 flex attention 加 context parallel 的成员表示,一个示例可能很快就会进入 attn-gym。
- 他们认为将这些方法结合起来是有效处理更大任务的直接路径。
- Diffusion Autoguidance 备受关注:Tero Karras 发表的一篇 NeurIPS 2024 新论文概述了如何通过 Autoguidance 方法塑造 Diffusion 模型。
- 该论文的亚军地位及其 PDF 链接引发了关于其对生成建模影响的大量讨论。
- ARC CoT 数据助力 LLaMA 8B 测试:一位用户正在制作一个包含 10k 样本的 ARC CoT 数据集,以观察微调后的 LLaMA 8B 在对数概率指标上是否超过基础模型。
- 他们计划在生成几千个样本后检查“CoT”训练的影响,强调了对未来评估的潜在改进。
- PyTorch 聚焦稀疏性:PyTorch 稀疏性设计引入了用于推理的
to_sparse_semi_structured,用户建议更换为sparsify_以获得更大的灵活性。- 这种方法还突出了原生量化和其他用于模型优化的内置功能。
LlamaIndex Discord
- LlamaParse 增强音频解析能力:LlamaParse 工具现在支持解析音频文件,通过语音转文本功能补充了原有的 PDF 和 Word 支持。
- 根据用户反馈,这次更新巩固了 LlamaParse 作为多媒体工作流中强大的跨格式解析器的地位。
- LlamaIndex 庆祝年度增长:他们在年终回顾中宣布一年内解析了数千万页内容,并保持每周发布新功能。
- 他们预告 LlamaCloud 将于 2024 年初正式发布(GA),并分享了一个包含详细统计数据的年度回顾链接。
- 股票分析机器人利用 LlamaIndex 大放异彩:一个快速教程演示了如何使用 FunctionCallingAgent 和 Claude 3.5 Sonnet 构建自动化股票分析 Agent。
- 工程师可以参考 Hanane D 的帖子 获取简化金融任务的一键式解决方案。
- LlamaIndex 文档自动化演示:一个 Notebook 展示了 LlamaIndex 如何标准化跨多个供应商的单位和测量。
- 该示例 Notebook 演示了适用于真实生产环境的统一工作流。
- 利用合成数据微调 LLM:用户讨论了为情感分析生成人工样本,并参考了 Hugging Face 博客。
- 他们建议将 Prompt 操纵作为起步阶段,而其他人则讨论了更广泛的模型优化方法。
LLM Agents (Berkeley MOOC) Discord
- 黑客松冲刺与重新开放热潮:由于参赛者面临技术困难,黑客松提交表单已重新开放,截止时间为 PST 时间 12 月 20 日晚上 11:59。
- 组织者确认不会再延期,因此参赛者应在认证表单中确认主要联系邮箱等细节,以便接收官方通知。
- 人工提交检查与视频格式问题:为不确定提交状态的参赛者提供人工核实流程,以防止最后一刻出现混乱。
- 部分人在遇到 YouTube 问题后改用邮件提交,并表示他们仍专注于黑客松而非课程本身。
- Agent 构建方案替代方案与 AutoGen 警告:一位参赛者引用了一篇关于 Agent 构建策略的文章,建议不要完全依赖像 Autogen 这样的框架。
- 他们建议在未来的 MOOC 中采用更简单、模块化的方法,并强调指令微调(Instruction Tuning)和函数调用(Function Calling)。
Torchtune Discord
- Torchtune v0.5.0 发布:开发者发布了 Torchtune v0.5.0,包含了 Kaggle 集成、QAT + LoRA 训练、Early Exit Recipe 以及 Ascend NPU 支持。
- 他们分享了发布说明,详细介绍了这些升级如何简化大型模型的微调。
- QwQ-preview-32B 扩展 Token 视野:有人在 8×80G GPU 上测试了 QwQ-preview-32B,旨在实现超过 8K Token 的上下文并行。
- 他们提到了 optimizer_in_bwd、8bit Adam 和 QLoRA 优化标志作为扩展输入规模的方法。
- fsdp2 State Dict 加载引发关注:开发者对加载 fsdp2 state dict 提出疑问,因为在分布式加载代码中,分片参数与非 DTensors 存在冲突。
- 他们担心这些不匹配会增加在多节点部署 FSDPModule 设置的复杂性。
- 词表裁剪(Vocab Pruning)需注意 fp32:部分参与者通过裁剪词表来减小模型体积,但坚持以 fp32 格式保留参数以确保精度一致。
- 他们强调了分别处理 bf16 计算和 fp32 存储,以维持稳定的微调过程。
DSPy Discord
- Litellm Proxy 受到关注:Litellm 可以自托管或通过托管服务使用,并且可以与主系统运行在同一个 VM 上以简化操作。讨论强调这种设置通过将代理与相关服务捆绑在一起,使集成更加顺畅。
- 参与者指出,它在保持易于调整的同时,满足了广泛的基础设施需求。
- 合成数据推动 LLM 升级:一篇名为 On Synthetic Data: How It’s Improving & Shaping LLMs 的文章(发表于 dbreunig.com)解释了合成数据如何通过模拟类聊天机器人输入来微调较小的模型。对话还涵盖了其在大规模任务上的有限影响以及在不同领域应用的细微差别。
- 成员们观察到了错综复杂的结果,但一致认为这些生成的数据集可以推动 reasoning 研究的发展。
- 优化成本引发担忧:高级 optimizers 的长时间运行导致成本上升,促使人们建议限制调用次数或 Token 数量。一些人建议使用较小的参数设置,或将 LiteLLM 与预设限制配对以避免超支。
- 讨论中的声音强调了主动资源监控以避免意外支出。
- MIPRO ‘Light’ 模式节省资源:MIPRO ‘Light’ 模式为那些希望运行优化步骤的人提供了一种更精简的方式。据称它在更受控的环境中平衡了处理需求与性能。
- 早期采用者提到,较少的资源 仍然可以产生不错的结果,这为试验指明了一条充满希望的道路。
OpenInterpreter Discord
- OpenInterpreter 的服务器模式引起兴趣:一位用户询问了在 VPS 上以服务器模式运行 OpenInterpreter 的文档,好奇命令是在本地还是在服务器上运行。
- 他们表达了确认远程使用可能性的渴望,强调了灵活配置的潜力。
- Google Gemini 2.0 热度升温:有人询问了新的 Google Gemini 2.0 多模态功能,特别是其 os mode,并指出访问权限可能仅限于 ‘tier 5’ 用户。
- 他们对其可用性和性能表示好奇,建议需要更广泛的测试。
- 本地 LLM 集成带来良好体验:一位参与者庆祝 本地 LLM 集成 为 OpenInterpreter 增添了受欢迎的离线维度。
- 他们之前担心会失去这个功能,但现在对它仍然得到支持感到欣慰。
- SSH 使用启发了前端目标:一位用户分享了他们通过 SSH 与 OpenInterpreter 交互的方法,并指出远程体验非常直接。
- 他们暗示了开发前端界面的计划,并对以极小摩擦实现它充满信心。
- 社区标记垃圾信息:一名成员提醒其他人注意聊天中的推荐垃圾信息,旨在维护整洁的环境。
- 他们向相关角色报告了该事件,希望能得到及时干预。
Axolotl AI Discord
- KTO 与 Liger:令人惊喜的组合:公会成员确认 Liger 现在集成了 KTO,支持旨在提升模型性能的高级协同效应。
- 他们指出了相对于 HF TRL 基准的 loss parity 担忧带来的困扰,促使对训练指标进行进一步审查。
- DPO 愿景:Liger 关注下一步:团队正将重点放在 Liger DPO 上作为主要优先级,旨在实现稳定运行,从而带来更顺畅的扩展。
- 尽管出现了对 loss parity 问题的沮丧情绪,但人们仍然乐观地认为,针对这些遗留问题的修复方案很快就会出现。
tinygrad (George Hotz) Discord
- 陈旧 PR 面临清理:一位用户计划从下周开始关闭或自动关闭超过 30 天的 PR,移除过时的代码提案。这使项目摆脱了过多的开放请求,同时保持代码库精简。
- 他们强调了清理长期积压 PR 的重要性。除了拟定的时间表外,没有分享更多细节或链接。
- 机器人可能会介入:他们提到可能会使用机器人来跟踪或关闭不活跃的 PR,减少人工监管。这种方法可以减少维护任务并保持开发队列整洁。
- 未提供具体的机器人名称或实现细节。对话在没有额外引用或公告的情况下结束。
Gorilla LLM (Berkeley Function Calling) Discord
- Watt-Tool 模型助力 Gorilla 排行榜:提交了一个 pull request #847,旨在将 watt-tool-8B 和 watt-tool-70B 添加到 Gorilla 的 function calling 排行榜中。
- 这些模型也可以在 watt-tool-8B 和 watt-tool-70B 获取,以便进行进一步实验。
- 贡献者寻求在圣诞节前进行评审:他们请求及时检查新添加的 watt-tool,并暗示了潜在的性能和集成问题。
- 鼓励在假期休整前,就 function calling 使用案例以及与现有 Gorilla 工具的协同效应提供社区反馈。
MLOps @Chipro Discord 没有新消息。如果该服务器长时间没有动静,请告知我们,我们将将其移除。
Mozilla AI Discord 没有新消息。如果该服务器长时间没有动静,请告知我们,我们将将其移除。
HuggingFace Discord 没有新消息。如果该服务器长时间没有动静,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该服务器长时间没有动静,请告知我们,我们将将其移除。
第 2 部分:按频道详细摘要及链接
完整的频道明细已因邮件长度而截断。
如果你喜欢 AInews,请分享给朋友!提前致谢!