ainews-deepseek-v3-671b-finegrained-moe-trained
DeepSeek v3:671B(6710亿)参数的细粒度混合专家模型(MoE),在 15T(15万亿)token 上训练而成,算力成本仅为 550 万美元。
DeepSeek-V3 正式发布,该模型拥有 6710 亿 (671B) MoE 参数,并在 14.8 万亿 (14.8T) token 上进行了训练,其基准测试表现超越了 GPT-4o 和 Claude-3.5-sonnet。
该模型的训练仅耗费了 278.8 万 H800 GPU 小时,远低于 Llama-3 的 3080 万 GPU 小时,展现了极高的计算效率和大幅的成本降低。该模型目前已开源,通过 Hugging Face 部署并提供 API 支持。
其技术创新包括:原生 FP8 混合精度训练、多头潜在注意力(MLA)扩展、合成推理数据蒸馏、针对多达 256 个专家的 MoE 剪枝与修复,以及一种支持前瞻性 token 规划的新型多 token 预测(MTP)目标。研究亮点还涵盖了用于多步推理和智能体控制的 OREO 方法和自然语言强化学习 (NLRL)。
算法、框架与硬件的全方位协同设计(Full co-design)就是你所需要的一切。
2024年12月25日至12月26日的 AI 新闻。我们为您检查了 7 个 Reddit 子版块、433 个 Twitter 账号 和 32 个 Discord 社区(215 个频道,5486 条消息)。预计节省阅读时间(按 200wpm 计算):548 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!

正如在圣诞假期期间预告的那样,DeepSeek v3 已经发布(我们之前对 DeepSeek v2 的报道在此)。其 Benchmark 表现一如既往地符合你对中国顶尖开源模型实验室的预期:
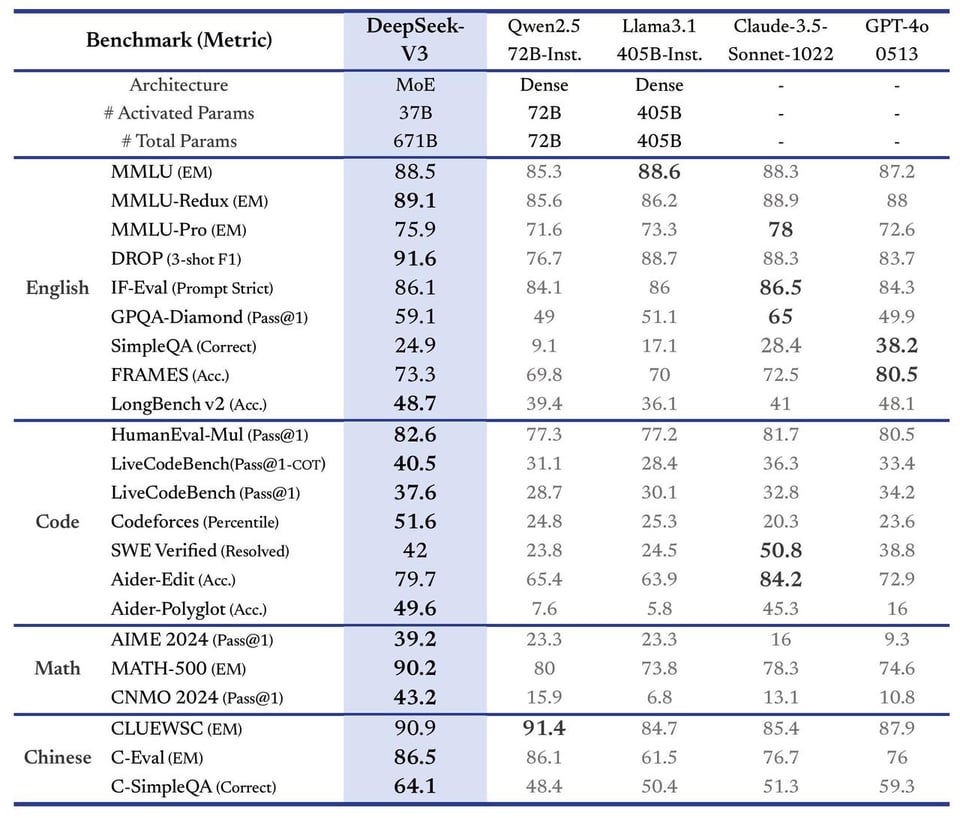
(更多细节见 aider 和 bigcodebench)
但训练细节甚至更令人惊叹:
-
训练预算比同类模型低 8-11 倍:具体使用了 2048 块 H800(即“阉割版 H100”),耗时 2 个月。相比之下,Llama 3 405B 根据其论文 是在 16k 块 H100 上训练的。他们估计这项成本为 550 万美元。

-
自研原生 FP8 混合精度训练(在没有 Blackwell GPU 的情况下实现——正如 Shazeer 所期望的?)
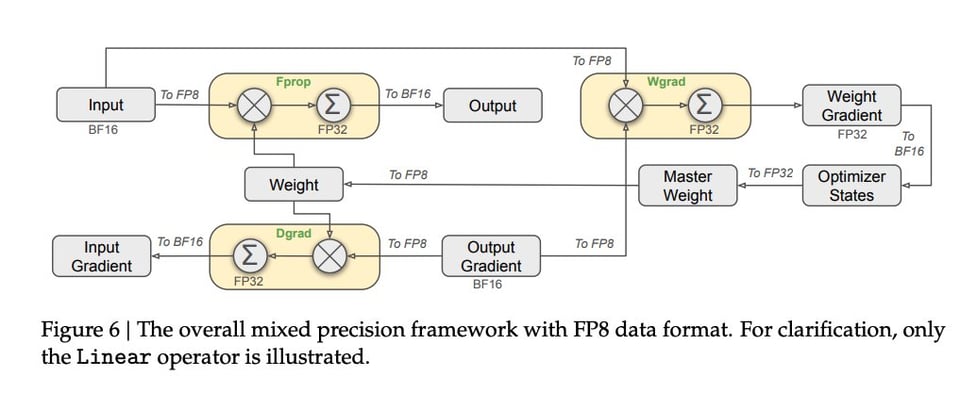
- 扩展了来自 DeepSeek v2 的 Multi-Head Latent Attention
- 从 R1 生成的合成推理数据中进行蒸馏 (distilling)
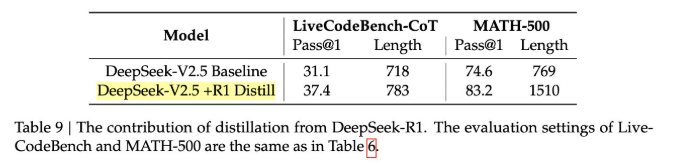 并使用其他类型的奖励模型 (reward models)
并使用其他类型的奖励模型 (reward models) - 无需 张量并行 (tensor parallelism) —— 最近被 Ilya 称为 是一个错误
- 针对 DeepSeekMoE 风格的 MoE 进行 剪枝 + 修复 (pruning + healing),扩展至 256 个专家 (experts)(8 个激活 + 1 个共享)
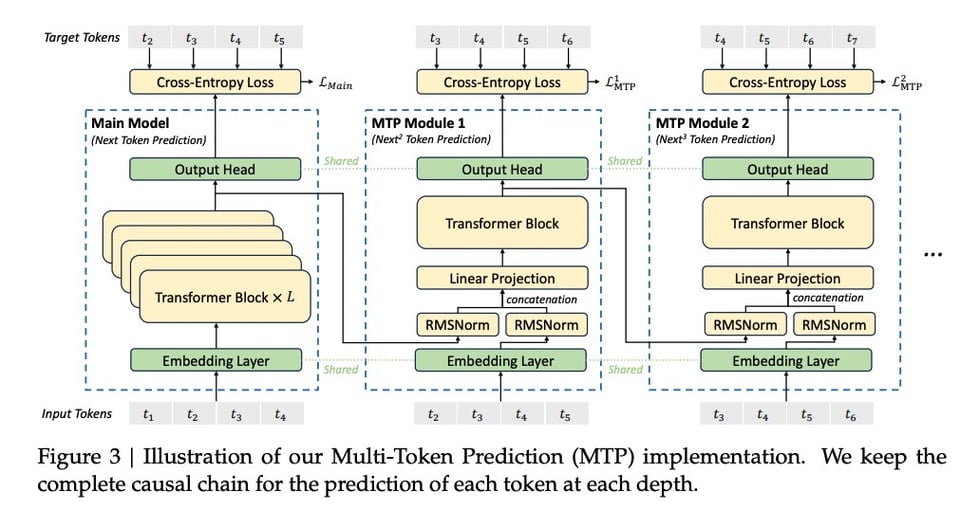
- 一种新的 “**多 Token 预测**” (multi token prediction) 目标(源自 Better & Faster Large Language Models via Multi-token Prediction),允许模型提前查看并预规划未来的 Token(在本例中一次仅 2 个)
AI Twitter 摘要
所有摘要均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
AI 模型开发与发布
- DeepSeek-V3 发布与性能:@deepseek_ai 和 @reach_vb 宣布发布 DeepSeek-V3,拥有 671B MoE 参数,并在 14.8T Token 上进行了训练。该模型在各项 Benchmark 中超越了 GPT-4o 和 Claude Sonnet-3.5。
- 算力效率与成本效益:@scaling01 强调 DeepSeek-V3 仅使用 278.8 万 H800 GPU 小时完成训练,与使用 3080 万 GPU 小时的 Llama 3 等模型相比,显著降低了成本。
- 部署与可访问性:@DeepLearningAI 和 @reach_vb 分享了通过 Hugging Face 等平台部署 DeepSeek-V3 的更新,强调了其开源可用性和 API 兼容性。
AI 研究技术与 Benchmark
- OREO 与 NLRL 创新:@TheTuringPost 讨论了 OREO 方法和 Natural Language Reinforcement Learning (NLRL),展示了它们在多步推理和 Agent 控制任务中的有效性。
- 无需 Prompt 的 Chain-of-Thought 推理:@denny_zhou 介绍了 Chain-of-Thought (CoT) 推理的一项突破,通过微调模型使其能够进行内在推理,而不依赖于特定任务的 Prompt,从而显著增强了模型推理能力。
- 基准测试表现:@francoisfleuret 和 @TheTuringPost 报告称,Multi-Token Prediction (MTP) 和 Chain-of-Knowledge 等新技术在数学解题和 Agent 控制等领域持续超越现有基准测试。
开源 AI vs 闭源 AI
- 开源模型的竞争优势:@scaling01 强调 DeepSeek-V3 目前已达到或超过了 GPT-4o 和 Claude Sonnet-3.5 等闭源模型,主张由开源 AI 驱动的可持续性与创新。
- 许可与可访问性:@deepseek_ai 强调 DeepSeek-V3 是开源的,且许可用于商业用途,使其成为闭源模型的一个更自由的替代方案,并促进了开发者和企业的广泛普及。
- 经济影响:@reach_vb 和 @DeepLearningAI 讨论了开源 AI 如何使访问民主化,减少对高利润闭源模型的依赖,并培育一个更具包容性的 AI 生态系统。
AI 基础设施与计算资源
- 优化 GPU 使用:@francoisfleuret 和 @scaling01 探讨了 DeepSeek-V3 如何通过 Multi-Token Prediction (MTP) 和负载均衡 (Load Balancing) 等技术高效利用 H800 GPU,从而提高计算利用率和训练效率。
- 硬件设计改进:@francoisfleuret 建议进行硬件增强,如改进 FP8 GEMM 和更好的量化支持以支持 MoE 训练,从而解决通信瓶颈和计算效率低下的问题。
- 具有成本效益的扩展策略:@reach_vb 详细介绍了 DeepSeek-V3 如何以极少量的典型计算资源实现 SOTA 性能,强调通过算法-框架-硬件协同设计在扩展规模的同时保持成本效益。
移民与 AI 人才政策
- 倡导技术移民:@AndrewYNg 和 @HamelHusain 强调了 H-1B 和 O-1 签证等高技能移民项目对于促进 AI 领域内创新与经济增长的重要性。
- 政策批评与建议:@bindureddy 和 @HamelHusain 批评了限制性签证政策,主张简化签证转换、取消特定职位的限制并扩大合法移民,以增强美国 AI 竞争力和创新。
- 经济与道德论点:@AndrewYNg 指出移民创造的就业机会多于他们占用的机会,将签证改革界定为支持美国经济的经济必然要求和道德议题。
模因与幽默
- 有趣的互动与模因:@HamelHusain 幽默地评论了对 AI 模型表现的误解,为技术讨论带来了轻松有趣的基调。
- 俏皮的 AI 对话:@teortaxesTex 发布了一条模因式的评论,为关于 AI 能力的对话注入了幽默感。
AI Reddit 摘要
/r/LocalLlama 摘要
主题 1. DeepSeek V3 发布:技术创新与基准测试
- DeepSeek-V3 正式发布 (Score: 101, Comments: 22): DeepSeek 发布了 DeepSeek-V3,采用 Mixture of Experts (MoE) 架构,拥有 671B 总参数和 37B 激活参数,其表现优于其他开源模型,并能媲美 GPT-4o 和 Claude-3.5-Sonnet 等闭源模型。该模型在知识类任务、长文本评估、编程、数学以及中文能力方面表现出显著提升,且 Token 生成速度提升了 3 倍。该开源模型支持 FP8 权重,社区工具如 SGLang 和 LMDeploy 已提供原生 FP8 推理支持,API 促销定价将持续至 2025 年 2 月 8 日。
- DeepSeek-V3 的 FP8 训练:该模型使用 FP8 混合精度训练框架进行训练,标志着首次在大规模模型上验证了 FP8 训练的可行性。这种方法实现了稳定的训练过程,没有出现任何不可恢复的 Loss 突刺或回滚,引发了人们对 DeepSeek 是否已有效“攻克”了 FP8 训练的好奇。
- 经济与技术考量:训练 DeepSeek-V3 耗资 550 万美元,凸显了其背后量化机构所重视的经济效率。讨论还涉及了潜在的 GPU 制裁对模型设计的影响,暗示其可能针对 CPU 和 RAM 使用进行了优化,并提到了在 Epyc 主板上运行的可能性。
- 社区与开源动态:开源软件与免费软件之间存在区别,评论指出 DeepSeek-V3 在 r/localllama 上的发布针对的是本地社区,而非更广泛的开源推广。一些用户幽默地提到该模型在圣诞节发布,将其比作来自中国“圣诞老人”的惊喜。
- DeepSeek V3 Chat 版权重已上传至 Huggingface (Score: 143, Comments: 67): DeepSeek V3 Chat 版权重现已在 Huggingface 上线,提供了获取该 AI 模型最新迭代版本的通道。
- 硬件要求与性能:讨论强调了运行 DeepSeek V3 的极高硬件要求,提到 1-bit 量化需要 384GB RAM 和 4 块 RTX 3090。用户讨论了各种量化级别及其 VRAM 需求,并幽默地表示需要变卖家产才能买得起必要的 GPU。
- 开源与竞争:关于开源模型超越闭源模型的讨论非常激烈,提到了 Elon Musk 的 X.AI,以及开源模型可能超越其闭源模型 Groq2 和 Groq3 的讽刺意味。对话强调了开源竞争在推动技术进步方面的价值。
- 模型大小与复杂性:该模型拥有 685B 参数和 163 个分片,是讨论的焦点,用户开玩笑说需要 163 块 GPU 是多么不切实际。这凸显了在硬件和软件实现方面处理如此庞大且复杂模型的挑战。
- Sonnet 3.5 对比 v3 (Score: 83, Comments: 19): DeepSeek V3 在基准测试中显著优于 Sonnet 3.5,正如一张动画图片所示,图中展示了标记为 “Claude” 和 “DeepSeek” 的角色之间的激烈对抗。这一场景传达了动态且竞争激烈的环境,强调了两者之间显著的性能差距。
- DeepSeek V3 的性价比极高,比 Sonnet 3.6 便宜 57 倍,且在其网站上提供几乎无限的可用性,而 Claude 即使对付费用户也有访问限制。
- 尽管 DeepSeek V3 的性价比被用户评为 10/10,但对其较短的上下文窗口仍有一些担忧。
- 用户表示有兴趣对 DeepSeek V3 进行实际测试以验证基准测试结果,并建议将其纳入 lmarena 的 webdev arena,以便与 Sonnet 进行更全面的对比。
{kind=link}
主题 2. DeepSeek V3 与竞品的成本效益
- PSA - Deepseek v3 在 API 费率上比 Sonnet 便宜 53 倍且性能更强 (Score: 291, Comments: 113): Deepseek V3 的性能超越了 Sonnet,且 API 费率便宜了 53 倍,即使与 3 倍的价格差异相比,这也是一个巨大的差距。作者表达了对 Anthropic 的兴趣,并建议如果某个模型在编程任务中能提供实质性的改进,他们可能仍愿意支付更高费用以获得卓越性能。
- Deepseek V3 的训练成本为 560 万美元,在不到两个月的时间内使用了 2,000 块 H800,突显了 LLM training 的潜在效率。该模型的 API pricing 明显低于 Claude Sonnet,其成本为 输入 $0.14/1M 和 输出 $0.28/1M,而 Sonnet 为 输入 $3/1M 和 输出 $15/1M,这比某些本地构建的电力成本还要便宜约 5 倍。
- Deepseek V3 的 context window 仅为 64k,这可能是其高成本效益的原因之一,尽管在某些基准测试中其表现仍逊于 Claude。讨论中涉及了模型的参数规模(37B 激活参数)以及使用 MoE (Mixture of Experts) 来降低推理成本。
- 针对数据使用和在 API 请求上进行训练的担忧被提出,一些人对模型的性能和数据实践持怀疑态度。人们期待 Deepseek V3 在 OpenRouter 等平台上线,并提到促销活动将持续到 2 月,以进一步降低成本。
- Deepseek V3 基准测试提醒我们 Qwen 2.5 72B 才是真正的王者,其他人都在开玩笑! (Score: 86, Comments: 46): DeepSeek V3 的基准测试证明 Qwen 2.5 72B 是一款领先模型,在多个基准测试中超越了 Llama-3.1-405B、GPT-4o-0513 和 Claude 3.5。值得注意的是,DeepSeek-V3 在 MATH 500 基准测试中以 90.2% 的得分脱颖而出,彰显了其卓越的准确性。
- 讨论强调了在服务器上为多用户运行 DeepSeek V3 等模型的成本效益,而非使用 2x3090 等 GPU 的本地设置,强调了在电力和硬件上的节省。OfficialHashPanda 指出了 MoE (Mixture of Experts) 的优势,它允许在增加能力的同时减少激活参数,使其适合服务大量用户。
- 评论探讨了硬件需求和成本,提到了使用廉价 RAM 和具有高内存带宽的服务器 CPU 来高效运行大型模型。对话对比了 API 与本地硬件设置的成本,建议基于服务器的解决方案对于大规模使用更为经济。
- 讨论了小型高效模型的潜力,并对 DeepSeek V3 Lite 可能提供的功能表示兴趣。Calcidiol 建议未来的“轻量级”模型通过利用更好的训练数据和技术,可能会达到当今大型模型的能力,这表明了 AI 模型的持续演进和优化。
{kind=link}
Theme 3. DeepSeek V3 中的 FP8 训练突破
- Deepseek V3 正式发布(代码、论文、基准测试结果) (Score: 372, Comments: 96): DeepSeek V3 已正式发布,具有 FP8 training 能力。发布内容包括代码访问、研究论文和基准测试结果,标志着 AI 训练方法领域的重大进展。
- DeepSeek V3 的性能与能力:尽管拥有令人印象深刻的架构和 FP8 训练,DeepSeek V3 在某些基准测试中仍落后于 Claude Sonnet 3.5 等模型。然而,它被誉为目前最强的 open-weight 模型,如果模型尺寸减小,则具有更容易 self-hosting 的潜力。
- 技术要求与成本:运行 DeepSeek V3 需要大量资源,例如 600B 模型需要 384GB RAM,基础设置成本可能在 $10K 左右。用户讨论了各种硬件配置,包括 EPYC 服务器和仅 CPU 推理的可行性,强调了对大量 RAM 和 VRAM 的需求。
- 创新特性与许可担忧:该模型引入了诸如 Multi-Token Prediction (MTP) 和高效的 FP8 混合精度训练等创新特性,将训练成本显著降低至 2.664M GPU hours。然而,许可问题令人担忧,因为 Deepseek 许可证被认为对商业用途有高度限制。
- 哇,这可能是目前最好的开源模型? (得分: 284, 评论: 99): DeepSeek-V3 作为一款开源模型展现了卓越的性能,超越了其前代产品以及竞争对手,如 DeepSeek-V2.5、Qwen2.5-72B-Inst、Llama-3.1-405B-Inst、GPT-4o-0513 和 Claude-3.5-Sonnet-1022。值得注意的是,它在 MATH 500 benchmark 上达到了 90.2% 的准确率,表明了其在使用 FP8 时强大的训练稳定性和效率。
- 推理挑战与能力:用户讨论了由于其 671B 参数量,在本地运行 DeepSeek-V3 的难度,4-bit 量化至少需要 336GB 的 RAM。尽管如此,由于其 37B 激活参数和包含 256 个专家的 Mixture of Experts 架构,它在 512GB 双路 Epyc 系统上的 CPU 推理速度可达约 10 tokens/second。
- 模型对比与性能:该模型的性能被认为可与 GPT-4o 和 Claude-3.5-Sonnet 等闭源模型相媲美,一些用户指出它在目标导向型任务中具有超越对手的潜力,尽管在指令遵循方面可能稍逊于 Llama。
- 开放权重 vs. 开源:关于该模型是 Open Weights(开放权重)而非完全 Open Source(开源)存在一些困惑和澄清,讨论涉及其影响以及未来蒸馏为更易于管理的尺寸(如 72B 参数)的可能性。
{kind=link}
其他 AI Subreddit 综述
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
主题 1. OpenAI O1 模型影响金融市场
- OpenAI o1 在交易和投资中的真实用例 (得分: 232, 评论: 207): OpenAI O1 模型 在金融研究和交易策略方面展示了显著进步,通过提供精确的数据驱动解决方案并支持用于生成 JSON 对象的 function-calling,其表现优于传统模型。值得注意的是,该模型执行精确金融分析的能力(例如识别自 2000 年以来 SPY 在 7 天内下跌 5% 的情况),使得创建无需编程即可部署的复杂交易策略成为可能。该模型增强的能力,包括 vision API 和改进的推理,使其能够处理复杂的金融任务,通过使算法交易和研究民主化,有可能改变金融业和华尔街。
- 评论者强调了在金融市场中使用 AI 的挑战和怀疑态度,重点提到了 data leakage(数据泄漏)和 efficient market hypothesis(有效市场假说)等问题。许多人指出,由于市场的适应性和随机性,历史回测并不能保证未来的成功,这表明这些模型在实时场景中可能表现不佳。
- 讨论中涉及了投资的行为层面,一些用户指出对市场波动的过度情绪反应(如在回撤期间抛售)可能会破坏策略。会议还强调了理解 risk-reward dynamics(风险回报动态)以及避免对 AI 生成策略过度自信的重要性。
- 少数用户分享了个人经验和项目,例如使用各种 LLM 的 Vector Stock Market bot,但也承认了其局限性并需要进一步测试。普遍共识是,AI 可能会使工具的使用变得民主化,但由于市场固有的复杂性,并不一定会带来持续的超额收益。
主题 2. 围绕 O1 Pro 模式实用性的辩论
- o1 pro mode is pathetic. (Score: 177, Comments: 133): 该帖子批评了 OpenAI 的 o1 Pro 模式,称其价格过高,且由于输出生成速度慢,在编程任务中与 4o 相比效率低下。作者自称是 AI 业余爱好者,认为这些模型针对基准测试(benchmarks)过度拟合,在实际应用中并不实用,并暗示“推理模型”主要是一种营销策略。唯一被注意到的实际用途是在对齐任务中,模型可以评估用户意图。
- o1 Pro 模型收到的评价褒贬不一;一些用户发现它在处理复杂编程任务时非常宝贵,理由是它能够处理大型代码库并能一次性产生准确结果,而另一些人则批评其响应速度慢且知识截止日期(knowledge cutoff)过时。像 ChronoPsyche 和 JohnnyTheBoneless 这样的用户称赞其处理复杂任务的能力,而像 epistemole 这样的人则认为,无限制的速率限制(rate limits)才是真正的优势,而非模型性能。
- 几位用户强调了详细 Prompt 对于最大化 o1 Pro 潜力的重要性,建议提供全面的文档或在大型上下文窗口中使用迭代方法,相比于输入零散的代码片段,这样可以产生更好的效果。Pillars-In-The-Trees 将有效的 Prompt 编写比作指导一名研究生,突出了该模型在逻辑任务方面的熟练程度。
- 讨论显示 o1 Pro 在某些编程语言中表现出色,用户如 NootropicDiary 提到它在 Rust 方面优于 Claude 等其他模型,而其他人则发现 Claude 在 TypeScript 等不同语言中更有效。这强化了这样一种观点:模型的有效性会根据任务和所使用的语言而显著不同。
Theme 3. OpenAI 最新进展与工具概览
- 12 Days of OpenAi - 综合总结。 (Score: 227, Comments: 25): “OpenAI 的 12 天”网格图记录了 12 月 5 日至 12 月 20 日 期间的每日亮点,包括 12 月 5 日的 ChatGPT Pro 计划 和 12 月 6 日的强化微调 (Reinforcement Fine-Tuning)。该系列以 12 月 20 日 o3 和 o3-mini 的进展达到高潮,预示着向 AGI 迈进。
- 第 2 天的强化微调 (Reinforcement Fine-Tuning) 被强调为一项重大进展,具有通过极少的示例显著改进系统的潜力。虽然缺乏正式论文留下了一些不确定性,但它对 Agent 开发的影响被认为是大有可为的,特别是展望 2025 年。
- 围绕 Canvas UX 的讨论表明,其最近的更新较小,一些用户对其约 200 行的限制表示不满。尽管这是早先推出的功能,但它仍然是用户争论的一个点。
- 人们对 MacOS 应用更新后 Windows 应用的可用性感到好奇,并幽默地建议这可能与 Microsoft 为 OpenAI 建造核反应堆的时间点重合。
{kind=link}
Theme 4. ChatGPT 宕机及其对用户的影响
- CHAT GPT IS DOWN. (Score: 366, Comments: 206): ChatGPT 经历了严重的服务中断,在 下午 6:00 报告的故障峰值达到 5,315 起。图表显示在一段低活跃期后,故障报告急剧增加,表明受影响的用户范围广泛。
- 用户对 ChatGPT 宕机表达了沮丧和幽默,一些人开玩笑说在作业和生产力任务上对 AI 的依赖。Street-Inspectors 幽默地指出了询问 ChatGPT 为什么它不工作这一行为的讽刺性。
- 提到了 OpenAI 的状态页面和 Downdetector 作为检查宕机状态的来源,bashbang 提供的一个链接显示了影响 ChatGPT、API 和 Sora 的重大故障。
- Kenshiken 和 BuckyBoy3855 提到“上游供应商 (upstream provider)”是问题的原因,强调了宕机的技术层面,而 HappinessKitty 则推测是服务器容量问题。
{kind=link}
AI Discord Recap
由 o1-2024-12-17 生成的摘要之摘要
主题 1. DeepSeek V3 成为焦点
- 大规模混合精度提升:DeepSeek V3 发布了一个拥有 685B 参数的模型,采用 FP8 训练,声称节省了 2 个数量级的成本。该模型运行速度约为 60 tokens/second,在 14.8T tokens 上进行了训练,许多人将其视为 GPT-4o 的强力开源竞争对手。
- API 普及与使用量翻三倍:OpenRouter 报告称 DeepSeek V3 发布后使用量翻了三倍,足以与价格更高的老牌模型竞争。社区成员赞扬了其强大的代码编写性能,但也指出了响应慢和 VRAM 需求大的问题。
- MoE 架构引发热议:DeepSeek 的 Mixture-of-Experts (MoE) 架构提供了更清晰的扩展路径和大幅降低的训练成本。工程师们推测未来的开源扩展以及用于稳定推理的 320-GPU HPC 集群。
主题 2. 代码编辑器与 IDE 的困扰
- Windsurf 与 Cascade 的困境:Windsurf 的 Cascade Base 模型因处理代码提示词不当以及在没有结果的情况下消耗额度而受到批评。工程师们提出了 global_rules 的变通方案,但许多人仍对 UI 延迟和无响应的查询感到沮丧。
- Cursor IDE 的 Token 考验:Cursor IDE 在处理有限的上下文和大型代码任务的性能下降方面挣扎。用户将其与 DeepSeek 和 Cline 进行了对比,称赞后两者拥有更长的上下文窗口,能实现更稳健的代码生成。
- Bolt 的 Token 紧张局势:Stackblitz (Bolt.new) 用户在重复的代码请求中消耗了高达 150 万个 tokens。许多人要求直接进行代码编辑而非提供示例代码片段,并转向 GitHub 反馈以寻求订阅层级的改进。
主题 3. AI 赋能创意与协作工作
- 播客结合实时摘要:NotebookLM 用户将 Google News 集成到 AI 驱动的播客中,在播报时事的同时生成喜剧片段。一些人分享了 15 分钟的 TTRPG 回顾,突显了 AI 让爱好者快速获取信息的能力。
- ERP 与角色扮演:爱好者们为沉浸式桌面战役编写了高级提示词,确保复杂叙事的连续性。他们提到分块 (chunking) 和检索增强生成 (RAG) 对于稳定的长篇叙事至关重要。
- 语音对语音与音乐生成:AI 工程师展示了语音对语音聊天应用和根据文本提示创作音乐。他们邀请合作者共同优化 DNN-VAD 流水线,在有趣的新工作流中将音频转换与生成式文本模型连接起来。
主题 4. 检索、微调与 HPC 扩展
- GitIngest 与 GitDiagram:开发者将大规模代码库映射为文本和图表,用于 RAG 实验。这种方法简化了 LLM 训练和代码摄取,让 HPC 集群能更有效地处理大型仓库。
- LlamaIndex 与 DocumentContextExtractor:用户接入批处理以降低 50% 的成本并处理非工作时间的任务。结合块切分、本地 embeddings 和可选的开源 RLHF 工具,提高了在现实世界数据上的准确性。
- 微调 VLM 与 HPC MLOps:研究人员利用 LLaVA、Qwen-VL 和 Guild AI 等 HPC 框架来管理大规模模型训练。他们注意到了 HPC 的开销,并讨论了构建自己的极简 Ops 解决方案以避免 SaaS 陷阱。
主题 5. 关键技术与性能修复
- TMA 击败 cp.async:HPC 专家解释了在 H100 上进行 GEMM 计算时,TMA 如何优于 cp.async,从而实现批量调度和更低的寄存器占用。他们赞扬了 CUTLASS 中的结构化稀疏内核带来的进一步增益,尤其是在 FP8 下。
- Mojo 与 Modular 的进展:用户调试了 StringRef 崩溃问题,并发现了 memcpy 调用中缺失的长度检查。他们称赞了新的周边商品,并讨论了 MAX 与 XLA 的编译时间,关注 HPC 代码的改进。
- Tinygrad 与 PyTorch 的速度竞赛:Tinygrad 在 CUDA 上的前向传播速度落后于 PyTorch(800ms vs. 17ms),但开发者寄希望于 beam search 缓存和 jitting。他们合并了针对输入创建循环的 PR 修复,并解决了匹配引擎的悬赏任务以减少开销。
PART 1: High level Discord summaries
Codeium (Windsurf) Discord
- Windsurf 大胆的行业突破:一段新视频展示了工程师们详细介绍 Windsurf 如何刻意挑战典型的开发方法,分享了关于工作流变革和设计选择的见解 (Windsurf’s Twitter)。
- 他们还发出了节日问候,强调了社区精神,并引发了关于这些大胆举措背后新鲜视角的讨论。
- Cascade Base 模型之忧:用户批评 Cascade Base model 在处理复杂编程任务时缺乏准确性,且经常无法执行简单指令,尤其是与 Claude 3.5 Sonnet 相比时。
- 尽管一些人分享了通过全局规则取得的部分成功,但其他人发现改进微乎其微,并在发布挫败感的同时附上了 awesome-windsurfrules 等链接。
- 远程主机故障与延迟:通过 SSH Remote Hosts 连接的用户注意到 Windsurf 显示出显著延迟,导致实时编辑变得混乱且无法追踪,直到 Cascade 更新。
- 他们报告称命令仍能正常执行,但延迟的界面造成了工作流脱节,许多人认为这具有干扰性。
- 额度消耗与无响应查询:当无响应的请求消耗了 tokens 却未交付功能性输出时,用户感到被亏待,导致他们通过 Windsurf Editor Support 反复联系支持部门。
- 许多人对这些消耗额度的失败表示担忧,认为这削弱了对 Windsurf 处理大型代码库可靠性的信心。
Cursor IDE Discord
- DeepSeek V3 主导讨论:开发者们称赞 DeepSeek V3 的代码生成和分析能力,声称其可与 Sonnet 3.5 媲美且输出速度更快,详见 DeepSeek 的这条推文。
- 社区成员讨论了与 Cursor IDE 的集成,参考了 DeepSeek Platform 的 API-compatible 方案,并对更低的使用成本表现出兴趣。
- Cursor IDE 的 Token 考验:许多人报告 Cursor IDE 的上下文窗口有限,降低了大型代码生成任务的性能,Cursor 官网提供了各平台的下载。
- 用户对比了 DeepSeek 和 Cline 如何更高效地处理扩展上下文窗口,并参考 Cursor Forum 持续反馈关于更好利用 token 的建议。
- Next.js UI 问题困扰设计者:创作者们在 Next.js 的 UI 问题中挣扎,抱怨 Claude 生成的代码有时会导致元素错位和样式复杂化,即使在使用 shadcn 等库之后也是如此。
- 他们建议将相关文档嵌入上下文以获得更好的设计效果,并推荐使用 Uiverse 获取快速 UI 组件。
- OpenAI 可靠性的起伏:一些人面临 OpenAI 最近的性能问题,理由是响应时间变慢且可用性降低,而替代模型以更低的成本提供了更稳定的结果。
- 他们建议测试多个 AI 系统,参考 DeepSeek API Docs 以获取兼容性信息,而其他人则只是在不同供应商之间切换以保持任务推进。
aider (Paul Gauthier) Discord
- Aider v0.70.0 提升自我代码统计数据:Aider v0.70.0 引入了分析选项加入 (analytics opt-in)、针对交互式命令的新错误处理以及扩展的模型支持,详见 Aider Release History。
- 社区成员强调 Aider 有 74% 的代码是自我贡献的,并称赞该工具改进的安装流程、文件监视功能以及 Git 名称处理是重大的升级。
- DeepSeek V3 实现 3 倍速度提升:DeepSeek V3 现在每秒处理 60 tokens(比 V2 快 3 倍),展现出比 Sonnet 3.5 更强的编程性能,并具备 64k token 的上下文限制,详见此推文。
- 社区对 DeepSeek V3 在某些任务上超越 Claude 感到兴奋,尽管响应缓慢和上下文管理仍是持续讨论的焦点。
- BigCodeBench 揭示 LLM 的优势与不足:BigCodeBench Leaderboard (链接) 在现实世界的编程任务上评估 LLM,并引用 arXiv 论文 以深入了解其方法论。
- 贡献者对比了 DeepSeek 和 O1 的得分,指出这些指标有助于澄清各模型在实际条件下的代码生成能力。
- GitDiagram 与 GitIngest 让仓库透明化:GitDiagram 将 GitHub 仓库转换为交互式图表,而 GitIngest 将任何 Git 仓库渲染为纯文本,以便轻松进行代码摄取。
- 用户只需将 URL 中的 ‘hub’ 替换为 ‘diagram’ 或 ‘ingest’,即可立即可视化仓库结构或为任何 LLM 做好准备。
Nous Research AI Discord
- DeepSeek V3 的 GPU 资源消耗与收益:DeepSeek V3 发布,拥有 6850 亿参数,需要约 320 块 H100 等 GPU 才能达到最佳性能,如官方代码仓库所示。
- 讨论强调了其稳定推理对大容量 VRAM 的需求,成员们称其为目前可用的最大开放权重模型之一。
- 可微缓存加速推理:关于可微缓存增强 (Differentiable Cache Augmentation) 的研究揭示了一种将冻结的 LLM 与操作 key-value (kv) cache 的离线协处理器配对的方法,如此论文所述。
- 该方法降低了推理任务的困惑度 (perplexity),成员们观察到即使协处理器离线,它也能保持 LLM 的功能。
- 文本转视频之争:Hunyuan 对阵 LTX:用户对比了 Hunyuan 和 LTX 文本转视频模型的性能,强调了实现流畅渲染对 VRAM 的要求。
- 他们对 T2V 的发展表现出浓厚兴趣,建议资源密集型任务可能会从流水线调整中受益。
- URL 审核 API 难题:一位 AI 工程师在构建能够准确分类不安全网站的 URL 审核 API 时遇到困难,凸显了 Llama 的结构化输出问题以及 OpenAI 频繁拒绝请求的问题。
- 社区反馈指出特定领域处理的重要性,因为反复尝试产生的结果往往不一致或不完整。
- 推理成本难题:参与者辩论了部署大型 AI 模型的成本结构,质疑促销定价是否能承受高使用量需求。
- 他们建议持续的负载可能会平衡运营支出,从而使高性能 AI 服务在成本压力下依然可行。
OpenRouter (Alex Atallah) Discord
- Web Searching LLMs & 价格大跌:OpenRouter 为任何 LLM 推出了 Web Search 功能,目前免费使用,为用户查询提供及时的参考,如此演示所示。他们还大幅下调了多个模型的价格,包括 qwen-2.5 降价 12%,hermes-3-llama-3.1-70b 降价 31%。
- 社区成员认为降价幅度巨大并表示欢迎,特别是对于高端模型。一些人预计成本结构将出现更广泛的转变。
- DeepSeek v3 使用量翻三倍:DeepSeek v3 在 OpenRouter 上的受欢迎程度飙升,据此贴报道,自发布以来使用量翻了三倍,在某些指标上可与更大的模型媲美。它以更低的价格与 Sonnet 和 GPT-4o 竞争,引发了关于“中国 AI 已经赶上”的讨论。
- general 频道的用户对其在编程任务和诗歌方面的表现评价褒贬不一。一些人称赞其创意输出,而另一些人则指出结果不一致。
- Endpoints 与 Chat 困扰:OpenRouter 推出了 Beta 版 Endpoints API,允许开发者获取模型详情,参考用法见此处。一些用户在对话历史较长时遇到了 OpenRouter Chat 延迟,呼吁对大数据集进行更灵敏的处理。
- 社区注意到没有对 batching 请求的直接支持,强调了及时的 GPU 使用。同时,某些“未找到端点”的错误源于 API 设置配置错误,凸显了正确设置的重要性。
- 文字驱动的 3D 游戏魔法:一个新展示的工具承诺可以根据简单的文本提示创建 3D 游戏,相比早期使用 o-1 和 o-1 preview 的尝试有所改进。这种方法暗示了未来将集成 voxel 引擎以处理更复杂的形状,如此项目链接中所预告。
- 爱好者认为这是对之前基于 GPT 尝试的飞跃,其功能似乎经过精炼,可用于构建完整的交互式体验。频道中的一些人认为,如果规模化,它可能会改变独立游戏开发流程。
- AI Chat Terminal: Agent 在行动:AI Chat Terminal (ACT) 将 Agent 特性与代码库交互相结合,允许用户在 OpenAI 和 Anthropic 等提供商之间切换。它引入了 Agent Mode 来自动化任务,旨在简化编码过程,如此仓库所示。
- app-showcase 频道的开发者强调了在单个终端中灵活使用多模型的潜力。许多人称赞其在构建超越典型聊天限制的脚本方面的便利性。
LM Studio Discord
- LM Studio 优化大模型表现:Build 0.3.5 修复了之前 GGUF 模型加载中的 Bug,并解决了 MLX 的会话处理问题,参考 Issue #63。
- 用户注意到 QVQ 72B 和 Qwentile2.5-32B 现在运行得更好,尽管一些内存泄漏仍在调查中。
- RPG 爱好者保持叙事流畅:爱好者使用 Mistral 和 Qwen 等模型来管理长期的桌面游戏故事情节,其 Prompt 灵感来自 ChatGPT TTRPG 指南。
- 他们探索了微调和 RAG 技术以获得更好的连续性,并引用独立分块(chunking)作为保持背景设定一致性的策略。
- X99 系统紧跟步伐:在 X99 主板上运行 Xeon E5 v4 的用户报告称,即使使用旧设备,模型推理性能依然稳健。
- 双 RTX 2060 配置展示了对大型模型的稳定处理,打破了对新硬件的紧迫需求。
- 多 GPU 收益与 LoRAs 热度:参与者观察到 GPU 利用率较低(约 30%),并强调额外的 VRAM 并不总是能带来速度提升,除非配合 NVLink 等增强功能。
- 他们还推测即将推出视频生成 LoRAs,尽管有些人怀疑在极少数静态图像上进行训练的效果。
Stability.ai (Stable Diffusion) Discord
- 提示词精度助力 SD:许多参与者发现,更具描述性的提示词能产生更优质的 Stable Diffusion 输出,强调了详尽指令的优势。他们测试了各种模型,突出了风格和资源使用方面的差异。
- 他们强调需要强大的提示词能力来实现更好的图像控制,并建议通过模型实验来优化结果。
- ComfyUI 的复杂性可控:贡献者通过符号链接模型并参考 Stability Matrix 进行更简单的管理来操作 ComfyUI,尽管许多人认为学习曲线很陡峭。他们还分享了 SwarmUI 为新手提供了更易用的界面。
- 用户将 SwarmUI 等门槛较低的前端与标准 ComfyUI 进行了比较,思考这些工具如何在不牺牲高级功能的情况下简化生成艺术(generative art)流程。
- 视频生成势头强劲:爱好者们在 ComfyUI 中实验了 img2video 模型,并将其与 Veo2 和 Flux 的效率进行了对比。他们发现 LTXVideo Q8 在 8GB VRAM 的配置下表现良好。
- 他们仍然渴望测试新的视频生成方法,以扩展对资源友好型的可能性,继续在较低硬件规格上突破界限。
- NSFW LoRA 引发讨论:关于 LoRA 中的 NSFW 过滤器产生了一些有趣的交流,讨论了如何管理审查开关。参与者希望就每个设置在控制成人内容方面的作用进行公开讨论。
- 他们强调标准的 LoRA 约束偶尔会阻碍合法的创作任务,呼吁提供关于审查开关更清晰的文档。
OpenAI Discord
- OpenAI 停机引发新选择:成员们遇到了 ChatGPT 宕机,参考了 OpenAI 状态页面,并权衡了 DeepSeek 和 Claude 等替代方案。
- 此次停机感觉比之前的事件轻微,但它重新激发了探索不同模型的兴趣。
- DeepSeek V3 飞速领先:成员们注意到 DeepSeek V3 拥有 64k 的上下文限制,在速度和代码一致性方面优于 GPT-4。
- 爱好者们赞扬了其可靠的代码支持,而一些人指出了缺失的功能,如直接文件处理和对 OCR 的依赖。
- GPT-O3 隐约可见:提到 O3-mini 将于 1 月底发布,引发了随后不久发布完整 O3 模型的希望。
- 具体细节仍然匮乏,引发了对其性能和可能的新功能的猜测。
- 缩写词困扰 LLMs:缩写词识别引发了辩论,揭示了某些模型在正确扩展特定领域缩写方面的困难。
- 提出了诸如自定义字典或优化提示词等技术,以保持扩展的一致性。
- Canvas 与 ESLint 冲突:用户遇到了 Canvas 窗口在打开几秒后消失的问题,导致编辑工作流中断。
- 其他人在 O1 Pro 下苦于 ESLint 设置,旨在寻求一个适合高级开发需求的整洁配置。
Stackblitz (Bolt.new) Discord
- ProductPAPI 正在研发中:一名成员透露了 ProductPAPI,这是 Gabe 开发的一款旨在简化任务的应用,但尚未公开发布日期、核心功能和 API 结构等细节。
- 另一位用户表示“我们需要更多见解来评估其潜力”,并建议参考 GitHub 社区反馈线程 以了解任何计划中的扩展。
- Anthropic 简洁模式的难题:成员们报告称,在 Bolt 上使用 Anthropic 的简洁模式 (concise mode) 时质量有所下降,并强调了高峰使用时段的可扩展性担忧。
- 一位用户推测各供应商之间存在“普遍的扩展压力”,并提到当 Claude 需求警告触发时,Bolt 的性能也会随之变慢。
- 直接修改代码,否则免谈:沮丧的开发者注意到他们不断收到“示例代码”而非直接编辑,敦促他人在 Prompt 中明确要求“请直接进行修改”。
- 他们测试了在单个 Prompt 中添加澄清指令,并链接到 最佳实践 以优化 Prompt 措辞,确认了这样能获得更好的代码修改效果。
- Bolt 中的 Token 紧张局势:用户反映 Token 消耗过高——有人声称在重写相同的代码请求时消耗了 150 万个 Token,理由是 Prompt 被忽略以及出现了意外更改。
- 他们在 GitHub 和 Bolters.io 上发布了反馈,提议更新订阅层级,许多人在达到 Token 上限后开始探索在 StackBlitz 上进行免费编码。
- 利用 Bolt 实现网约车雄心:一位新手询问是否可以用 Bolt 构建一个全国性的网约车 App,并提到了他们现有的机场乘车门户,寻求可扩展性和多区域支持。
- 社区成员对这一想法表示支持,称其为“大胆的扩展”,并引用了 Bolters.io 社区指南 中关于扩展的逐步检查清单。
Unsloth AI (Daniel Han) Discord
- QVQ-72B 亮相并获得高分:QVQ-72B 推出了 4-bit 和 16-bit 版本,在 MMMU 基准测试中达到 70.3%,成为视觉推理领域的有力竞争者 (Qwen/QVQ-72B-Preview)。
- 社区成员强调了数据格式化和谨慎的训练步骤,并指向 Unsloth 文档 以获取模型最佳实践。
- DeepSeek V3 引发 MoE 热议:采用 Mixture of Experts 配置的 DeepSeek V3 模型因比 Sonnet 便宜 50 倍而备受关注 (deepseek-ai/DeepSeek-V3-Base)。
- 一些人推测 OpenAI 和 Anthropic 也在采用类似技术,引发了关于扩展和成本效率的技术讨论。
- Llama 3.2 遭遇数据不匹配障碍:多位用户在纯文本 JSONL 数据集上微调 Llama 3.2 时遇到困难,尽管禁用了视觉层,仍会遇到意外的图像数据检查。
- 其他人报告性能参差不齐,将失败归因于输入质量而非数量,并参考了 Unsloth 的 peft_utils.py 中的潜在解决方案。
- 训练模型的 GGUF 和 CPU 负载障碍:一些社区成员在通过 llama.cpp 将 Llama 3.2 模型转换为 GGUF 后,因 Prompt 格式不匹配而面临性能下降的问题。
- 其他人抱怨在本地硬件上出现奇怪的输出,强调需要谨慎量化并咨询 Unsloth 文档 以进行正确的纯 CPU 设置。
- Stella 被忽视,mixed bread 粉丝增加:一位用户质疑为什么 Stella 很少被推荐,Mrdragonfox 承认没有使用它,认为它缺乏广泛的社区动力。
- 与此同时,mixed bread 模型在日常使用中获得了强力支持,人们坚持认为基准测试 (benchmarking) 和微调 (finetuning) 对实际效果至关重要。
Perplexity AI Discord
- Gemini 取得进展与 ‘o1’ 传闻:一些用户声称 Gemini 的 Deep Research 模式在上下文处理和整体实用性方面优于 Claude 3.5 Sonnet 和 GPT-4o。
- 针对名为 ‘o1’ 的新模型的猜测浮出水面,引发了关于 Perplexity 是否会集成它以实现更广泛 AI 功能的疑问。
- OpenRouter 接入 Perplexity 模型:在购买额度后,一位用户发现 OpenRouter 提供了直接访问 Perplexity 进行问答和推理的途径。
- 尽管发现了这个选项,该用户仍选择坚持使用另一个供应商,这引发了关于 OpenRouter 扩展的激烈讨论。
- DeepSeek-V3 给人留下深刻印象:提及 DeepSeek-V3 表示其已通过 Web 界面和 API 提供,引发了对其能力的关注。
- 测试者将其性能描述为“太强了”,并希望价格能保持稳定,将其与其他安装版本进行了积极对比。
- 印度受 LeCun 启发的飞跃:印度新推出的一款 AI 模型参考了 Yann LeCun 的理念,旨在增强类人推理和伦理,引发了对话。
- 成员们对其影响表示乐观,认为它可能会重塑 模型训练 (model training) 并展示 应用 AI (applied AI) 的力量。
Latent Space Discord
- DeepSeek V3 强势登场:中国团队 DeepSeek 推出了一个 685B 参数的模型,声称总训练成本为 550 万美元,使用了 260 万个 H800 小时,吞吐量约为 60 tokens/second。
- 像 这条推文 展示了其优于更高预算模型的基准测试结果,一些人称其为成本效率的新标杆。
- ChatGPT 瞄准“无限记忆”:传闻称 ChatGPT 可能很快就能访问所有历史聊天记录,这可能会改变用户依赖广泛对话上下文的方式。
- 来自 Mark Kretschmann 的推文 表明该功能即将推出,引发了关于更深层次和更持续交互的辩论。
- 强化训练提升 LLM 推理能力:分享的 YouTube 视频 展示了在不增加额外开销的情况下,使用先进的 RL 方法来完善大语言模型的逻辑。
- 贡献者引用了 验证器奖励 (verifier rewards) 和 基于模型的 RM(例如 @nrehiew_),提出了一种更结构化的训练方法。
- Anduril 与 OpenAI 合作:Anduril Industries 的推文 透露了一项合作,将 OpenAI 模型与 Anduril 的防御系统相结合。
- 他们的目标是提升 AI 驱动的国家安全技术,引发了关于军事领域伦理和实践界限的新辩论。
- 2024 & 2025:合成数据、Agent 与峰会:Graham Neubig 发表了关于 2024 年 Agent 的主旨演讲,而 Loubna Ben Allal 评述了关于 合成数据 (Synthetic Data) 和 Smol 模型的论文。
- 同时,AI Engineer Summit 定于 2025 年在纽约市举行,并为关注行业聚会的人士提供了活动日历。
Interconnects (Nathan Lambert) Discord
- DeepSeek V3 的大胆亮相:DeepSeek 发布了 V3,该模型在 14.8 trillion tokens 上训练,拥有 60 tokens/second 的速度(比 V2 快 3 倍),并在 Hugging Face 上完全开源。
- 讨论重点包括 Multi-Token Prediction、新的奖励建模以及关于批判效率的问题,成员们指出其表现优于许多开源模型。
- Magnitude 685B:DeepSeek 的下一个豪赌:传闻 DeepSeek 的 685B LLM 可能在圣诞节发布,据 一则推文 暗示,其大小可能超过 700GB,目前尚未列出许可证。
- 社区成员开玩笑说它会让现有解决方案黯然失色,并对在 repo 中未注明明确 license 的情况下开源的可行性表示好奇。
- MCTS 提升推理能力的魔力:最近的一篇论文 (arXiv:2405.00451) 展示了 Monte Carlo Tree Search (MCTS) 结合迭代偏好学习如何增强 LLM 的推理能力。
- 它集成了结果验证和 Direct Preference Optimization 进行策略内精炼,并在算术和常识任务上进行了测试。
- DPO vs PPO:竞争愈演愈烈:一场 CMU RL 研讨会 探讨了 LLM 的 DPO vs PPO 优化,暗示了在实践中处理 clip/delta 约束和 PRM 偏差 的稳健方法。
- 与会者辩论了 DPO 是否优于 PPO,一篇即将发表在 ICML 2024 的论文和一段 YouTube 视频 进一步激发了好奇心。
GPU MODE Discord
- DeepSeek-V3 的双重重击:DeepSeek-V3 文档 强调了大规模 FP8 混合精度训练,声称成本降低了 2 个数量级。
- 社区成员讨论了该项目的资金和质量权衡,但认可其在 HPC 工作负载中实现大幅节省的潜力。
- Triton 在 FP8 转 BF16 上遇到问题:SM89 上从 fp8 到 bf16 的类型转换问题导致了 ptx 错误,详见 Triton 的 GitHub Issue #5491。
- 开发者建议使用
.to(tl.float32).to(tl.bfloat16)加上一个哑操作(dummy op)来防止融合 (fusion),同时解决 ptx 错误。
- 开发者建议使用
- TMA 胜过 cp.async:用户解释说,由于 H100 具有更高的算力,在 Hopper (H100) 上进行 GEMM 时,TMA 的性能优于 cp.async。
- 他们强调了 async 支持、批量调度和边界检查是减少 HPC 内核中寄存器使用的关键特性。
- 无反向传播方法引发 128 次前向传递:一种新的训练方法声称可以避免反向传播 (backprop) 或动量,通过 128 次前向传递来估计梯度,且与真实梯度的余弦相似度较低。
- 虽然它承诺节省 97% 的能源,但许多工程师担心其在小型演示设置之外的实用性。
- ARC-AGI-2 & 1D 任务生成器:研究人员在共享的 GitHub 仓库 中收集了 ARC-AGI-2 实验资源,邀请社区驱动的探索。
- 他们还展示了 一维任务生成器,这些生成器可能会扩展到二维符号推理,激发了对基于谜题的 AI 任务的广泛兴趣。
Notebook LM Discord Discord
- 与 Google News 的播客合作伙伴关系:成员们提议将 Google News 与 AI 生成的播客内容集成,以短篇或长篇形式总结前 10 条故事,引发了对交互式问答的兴趣。他们报告称,听众对这种新闻传递与按需讨论的动态结合表现出越来越高的参与度。
- 几位参与者分享了在实时更新中穿插喜剧桥段的例子,反映了 AI 驱动的播客 如何在让观众获取信息的同时保持娱乐性。
- AI 畅谈人生重大问题:一位用户展示了一个以幽默方式探讨哲学的 AI 生成播客,将其描述为“smurf-tastic banter”(蓝精灵式的逗趣),带来耳目一新的转折。这种形式将幽默与反思性对话相结合,暗示了对喜爱智力乐趣的受众具有更广泛的吸引力。
- 其他人称其为传统谈话节目的生动替代方案,强调了自然听感的 AI 语音既能带来娱乐,又能引发深思。
- 15 分钟了解 Pathfinder:一位参与者生成了一个简洁的 15 分钟 播客,总结了包含 6 本书 的 Pathfinder 2 战役,为游戏主持人提供了快速的剧情概览。他们在故事情节亮点与相关技巧之间取得了平衡,使玩家能够迅速沉浸在桌面游戏内容中。
- 这种方法激发了人们对短篇桌面游戏回顾的热情,预示着 AI 引导的叙事与角色扮演社区之间潜在的协同效应。
- Akas 连接 AI 播客主与其受众:一位爱好者介绍了 Akas,这是一个用于分享 AI 生成播客并发布个性化 RSS 订阅源的网站,详见 Akas: share AI generated podcasts。他们将其定位为 AI 驱动节目与每位主持人个人声音之间的平滑连接,将创意想法桥接到更广泛的受众。
- 一些人预测未来会扩展并统一像 NotebookLM 这样的工具,鼓励用户驱动的 AI 剧集走向更广阔的平台并激发进一步的协作。
LlamaIndex Discord
- 报告就绪:LlamaParse 助力 Agent 工作流:有人发布了一个新的 Report Generation Agent,它使用 LlamaParse 和 LlamaCloud 从 PDF 研究论文中构建格式化报告,并参考了 演示视频。
- 他们强调了该方法在自动化多论文分析方面的潜力,提供了与输入模板的强大集成。
- DocumentContextExtractor 削减成本:对话集中在使用 DocumentContextExtractor 进行批处理,以削减 50% 的费用,允许用户在非高峰时段处理任务。
- 这种方法无需保持 Python 脚本持续运行,让个人可以随时查看结果。
- LlamaIndex 中的 Tokenization 纠葛:参与者批评 LlamaIndex tokenizer 缺乏解码支持,对功能集不完整表示失望。
- 虽然推荐了块切分(chunk splitting)和大小管理,但一些人开玩笑说干脆取消截断功能,把提交超大文件的责任推给用户。
- Unstructured RAG 进阶:一篇博客详细介绍了使用 LangChain 和 Unstructured IO 构建的 Unstructured RAG 如何比旧的检索系统更有效地处理图像和表格等数据,参考了 此指南。
- 它还描述了使用 FAISS 进行 PDF 嵌入(embeddings),并建议使用 Athina AI 评估策略以确保 RAG 在真实环境中的准确性。
- LlamaIndex 文档与工资单 PDF:一些人正在寻找获取 PDF 和 Markdown 格式 LlamaIndex 文档的方法,而另一些人则在努力使用 LlamaParse 高级模式解析工资单 PDF。
- 讨论得出结论,生成这些文档是可行的,且 LlamaParse 在完全配置后可以处理工资单任务。
Eleuther Discord
- 优化器状态缺失 (Optimizers on the Loose):一些人在 Hugging Face checkpoints 中发现了缺失的优化器状态,引发了对 checkpoint 完整性的疑问。
- 其他人确认 checkpointing 代码通常会保存这些状态,使得真实原因尚不明确。
- VLM 微调热潮 (VLM Fine-Tuning Frenzy):工程师们正在处理 LLaVA、Qwen-VL 和 InternVL 微调脚本的模型特定细节,并指出每种方法都有所不同。
- 他们分享了 LLaVA 作为热门参考,强调遵循正确的方法论对结果至关重要。
- 追求更低延迟 (Chasing Lower Latency):参与者汇总了一系列针对 CUDA 或 Triton 级别优化的方法,旨在缩短 LLM 推理时间。
- 他们还指出了开源解决方案的进展,在 function calling 等任务中,这些方案有时能超越 GPT-4。
- GPT-2 惊人的首个 Token (GPT-2’s Shocking First Token):在 GPT-2 中,初始 token 的激活值飙升至 3000 左右,而后续 token 通常仅为 100。
- 关于 GPT-2 中是否存在 BOS token 的争论仍在继续,一些人断言它只是在默认情况下被省略了。
- EVE 引发无编码器架构的好奇 (EVE Sparks Encoder-Free Curiosity):研究人员探索了 EVE,这是一个专注于视频的无编码器视觉语言模型,避开了 CLIP 风格的架构。
- 与此同时,Fuyu 模型系列在实际性能提升方面面临质疑,引发了对编码器效率更多见解的呼吁。
tinygrad (George Hotz) Discord
- Lean 悬赏与 BITCAST 探索 (Lean Bounty and the BITCAST Quest):成员们应对了 Lean bounty 证明挑战,参考了 tinygrad notes 进行指导。他们还讨论了实现 BITCAST const folding 以优化编译时间。
- 有人提出了关于实现 BITCAST const folding 以进行编译时优化的兴趣,并询问相关代码存放在哪个目录。另一位用户建议参考旧的 PR 以获取如何进行的示例。
- Tinygrad 与 PyTorch 的对决 (Tinygrad vs. PyTorch Face-Off):有人报告称,在 CUDA 上进行前向传播时,Tinygrad 耗时 800ms,而 PyTorch 仅需 17ms,这促使人们尝试通过 jitting 进行改进。社区成员预期 beam search 会带来并发收益,并重申稳定后的方法可以达到或超过 PyTorch 的速度。
- 他们承认速度差异可能源于不同的 CUDA 设置和系统配置。一些参与者建议加大 jitting 力度以缩小性能差距。
- 匹配引擎中的重写之争 (Rewrite Rumble in Matching Engines):参与者探索了匹配引擎性能悬赏,并链接到了 tinygrad/tinygrad#4878 的待解决问题。
- 一位用户澄清了他们对 rewrite 部分的关注,并参考了虽然过时但仍能指导方案方向的 PR。
- 输入处理的小故障 (Input Handling Hiccups):一位用户指出在循环中重新创建 input tensor 会严重拖慢 Tinygrad,尽管输出正确,但还遇到了 CUDA 分配器的属性错误。作为回应,PR #8309 的更改已被合并以修复这些问题,强调了回归测试对稳定性能的重要性。
- 深入调查发现
tiny_input.clone()触发了 CUDA 内存分配器中的错误。贡献者一致认为需要更多测试来防止循环输入创建中的回归问题。
- 深入调查发现
- 通过 Kernel 缓存提升 GPU 收益 (GPU Gains with Kernel Caching):聊天中提到了使用驱动版本 535.183.01 和 CUDA 12.2 的 RTX 4070 GPU,引发了对开源驱动的关注。关于 beam search 缓存的讨论确认了 kernel 会被重用以提高速度,并有望在类似系统间共享这些缓存。
- 与会者推测潜在的驱动不匹配可能会限制性能,并敦促通过 debug 日志进行确认。一些人建议分发已编译的 beam search kernels,以加快在匹配硬件上的设置。
Cohere Discord
- 体验 CMD-R 与 R7B 的起伏:成员们讨论了 CMD-R 即将到来的变化,并对 R7B 中出现的“两个答案 (two ans)”怪异现象表示好奇,引用了一张暗示意外更新的共享图片。
- 他们开玩笑说这种奇怪的结果很少出现,在 社区讨论 中,有人称其为 “一个值得研究的喜剧性故障”。
- 精打细算 Re-ranker 定价:Re-ranker 的成本结构引起了关注,特别是如 Cohere 定价页面 所示,每 1M tokens 输入需 $2.50,输出需 $10.00。
- 相关问题激发了人们对团队如何为高使用量制定预算的兴趣,一些人将其与其他替代方案进行了比较。
- LLM University 取得进展:Cohere 推出了 LLM University,提供 NLP 和 LLMs 的专业课程,旨在增强企业级 AI 专业知识。
- 参与者给出了热烈的反馈,称赞其资源结构合理,并指出用户可以利用这些材料进行 快速技能扩展。
- Command R & R+ 在多步任务中占据主导地位:Command R 提供 128,000 token 的上下文容量和高效的 RAG 性能,而 Command R+ 则展示了顶级的多步工具使用能力。
- 参与者将其归功于其多语言覆盖(10 种语言)和先进的训练细节,特别是在 cmd-r-bot 频道 中提到的 具有挑战性的生产需求。
- 语音、VAD 与音乐融合 AI 魔力:一位 AI Engineer 展示了一个利用 DNN-VAD 的 Voice to Voice 聊天应用,并分享了使用 stereo-melody-large 模型根据文本提示生成的音乐。
- 他们邀请合作者,表示 “我想与你合作”,并送上了 圣诞快乐 的问候以保持活跃的氛围。
Modular (Mojo 🔥) Discord
- io_uring 的好奇与网络优化:成员们探讨了 io_uring 如何提升网络性能,参考了 man pages 作为起点,并承认目前熟悉程度有限。
- 社区推测 io_uring 可能会简化异步 I/O,并呼吁通过实际基准测试来确认其协同效应。
- StringRef 异常与负长度崩溃:当 StringRef() 接收到负长度时发生了崩溃,指向 memcpy 中缺失的长度检查。
- 一位用户建议改用 StringSlice,强调了 StringRef 在处理长度验证时的风险。
- EOF 测试与 Copyable 评价:用户确认 read_until_delimiter 正确触发了 EOF,引用了 GitHub commits。
- 对话重点讨论了 Copyable 和 ExplicitlyCopyable 特性,Modular 论坛上也出现了一些潜在的设计调整。
- Mojo 周边与 Modular 商品热潮:成员们炫耀了他们的 Mojo swag,对海外邮寄表示感谢,并分享了全新装备的照片。
- 其他人称赞了 Modular 的商品,包括 T 恤的质量和“硬核”贴纸设计,进一步激发了品牌热情。
- Modular Kernel 查询与 MAX 对比 XLA:一位用户询问了关于 Modular 栈的专用 kernel,暗示可能存在的性能改进。
- MAX 与 XLA 进行了对比,引用“JAX 编译时间过长”作为考虑替代编译器策略的原因。
DSPy Discord
- PyN8N 获得 Node Wiz 支持:爱好者们注意到 PyN8N 集成了 AI 来构建自定义工作流,尽管一些用户报告了与广告拦截器相关的加载问题。
- 他们强调了 README 的愿景基调,并建议切换浏览器或禁用扩展程序以解决这些网站拦截错误。
- DSPy 与 DSLModel 协作:社区成员发现 DSPy 通过 DSLModel 扩展了功能,允许使用高级特性以获得更好的性能。
- 他们认为这种方法在保持复杂数据工作流精简的同时,减少了代码开销。
- NotebookLM 的行内溯源引发好奇:一位用户询问 NotebookLM 是如何实现行内溯源(inline sourcing)的,并指出目前缺乏详细的解答。
- 他们寻求对底层实现的更多见解,但对话提供的后续信息有限。
- Jekyll 术语表获得 DSPy 助力:有人分享了一个 Jekyll 脚本,用于生成关键术语表,并使用 DSPy 进行 LLM 交互。
- 他们完善了诸如 Artificial General Intelligence 之类的条目,并指出了 long description parameter 的潜在改进方向。
- Typing.TypedDict 与 pydantic 的纠葛:成员们发现了用于类型化字段的
typing.TypedDict,并承认其在 Python 使用场景中的复杂性。- 他们还讨论了使用 pydantic 处理多实例输出数组,旨在实现更精细的布局。
LLM Agents (Berkeley MOOC) Discord
- 证书困惑与严格的表单要求:成员们确认证书将于 1 月底发放,如此处所述。
- 一位参与者询问如果没有填写 Certificate Declaration Form 是否仍能获得证书,得到的答复是该表单为强制要求,没有例外。
- LLM Agents MOOC 春季课程热度:社区讨论透露,下一期 LLM Agents 课程将于 春季 开始,与当前课程的结束时间衔接。
- 参与者表现出极大的兴趣,参考了证书流程,并希望课程更新能按时发布。
OpenInterpreter Discord
- Open Interpreter 开创性的像素级精度:Open Interpreter API 为 UI 自动化提供了近乎 像素级(pixel-perfect) 的控制,包括用于文本识别的 OCR,并在 Python 脚本中提供了使用示例。
- 一位社区成员提到 OCR 似乎无法正常工作,而其他人则询问了 桌面版 的发布时间表,显示出对进一步开发的广泛兴趣。
- 语音对语音聊天与 QvQ 协同:一位 AI 工程师介绍了一款具有从文本提示进行 音乐生成(Music Generation) 功能的 语音对语音(Voice to Voice)聊天应用,寻求与其他生成式 AI 爱好者的合作。
- 另一位用户询问 QvQ 在 Open Interpreter 的 OS 模式 下将如何运作,暗示了将 语音 与 系统级 任务连接起来的可能性。
Nomic.ai (GPT4All) Discord
- 复制按钮难题:一位成员注意到 GPT4All 聊天界面 UI 中缺少用于 AI 生成代码的专用 “复制”按钮,从而引发了关于 UI 改进的讨论。
- 他们对任何变通方案的建议表示感谢,并强调代码复制的便利性在开发者需求中排名很高。
- 键盘快捷键问题:社区成员确认基于鼠标的剪切和粘贴在聊天 UI 或配置页面中无法工作,这让依赖右键操作的用户感到沮丧。
- 他们澄清说 Control-C 和 Control-V 仍然有效,为复制代码片段提供了备选方案。
- 对新模板的好奇:一位成员用法语询问是否有人尝试过 使用新模板编写内容,表明了英语语境之外的多语言采用情况。
- 他们希望获得安装后步骤的反馈,尽管交流中没有出现具体的结果或共享示例。
LAION Discord
- Mega Audio Chunks for TTS: 一位成员寻求从长达一小时的海量音频文件中构建 TTS dataset 的建议,并询问了有关正确分割这些文件的工具。
- 他们的目标是寻找一种在减少人工劳动的同时保持质量的方法,重点关注处理大文件大小的 audio segmentation 方法。
- Whisper Splits the Script: 另一位参与者提议使用 Whisper 进行句子级分割,认为这是为 TTS 任务准备音频的一种实用方式。
- 他们强调了 Whisper 如何简化分割流程,在缩短制作时间的同时保留一致的句子边界。
MLOps @Chipro Discord
- HPC MLOps frameworks in the spotlight: 一位成员请求一个稳定且具有成本效益、且开销最小的 HPC ML ops framework,并指出 Guild AI 是一个可能的选择。
- 他们质疑 Guild AI 的可靠性,并倾向于采用自托管方式,理由是不喜欢 SaaS 解决方案。
- Server chores spark talk of a DIY ops tool: 安装和维护负担的增加使他们对运行用于 MLOps 任务的专用服务器产生顾虑。
- 他们表示,如果能避免沉重的服务器管理工作,愿意自己编写一个简单的 ops 框架。
Axolotl AI Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
Torchtune Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
Mozilla AI Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
HuggingFace Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
PART 2: Detailed by-Channel summaries and links
完整的频道细分内容已针对电子邮件进行了截断。
如果您喜欢 AInews,请分享给朋友!预谢!