ainews-not-much-happened-today-4715
今天没发生什么事。
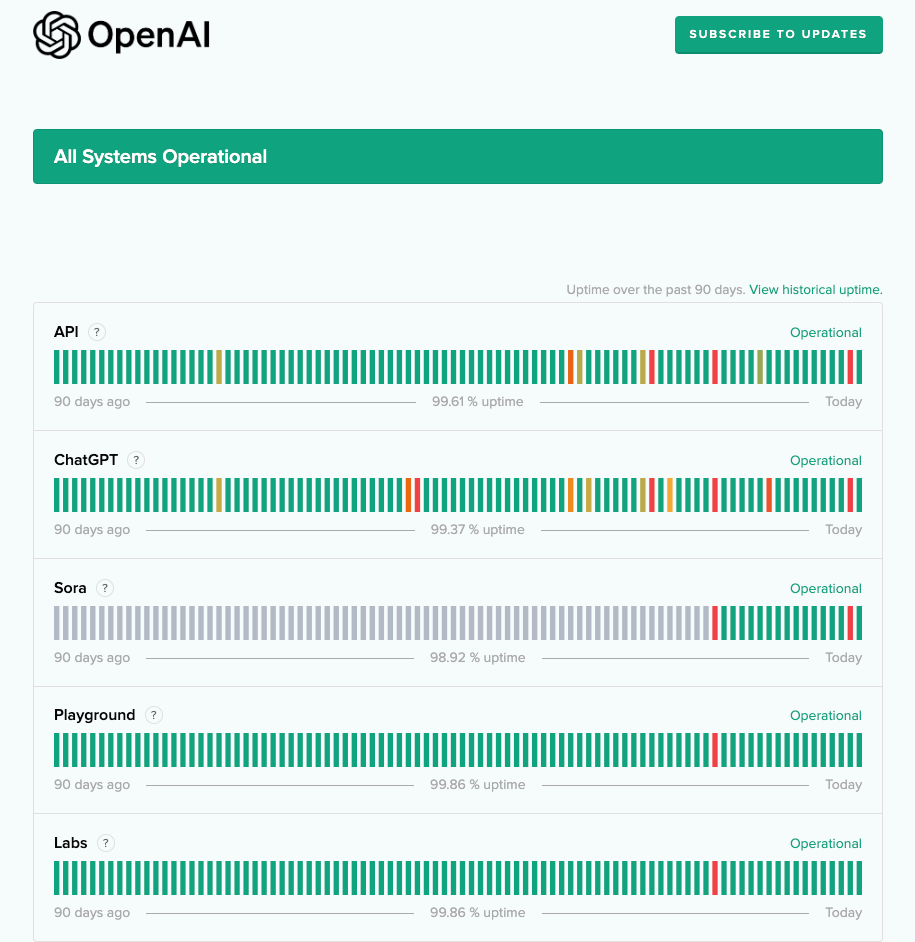
ChatGPT、Sora 和 OpenAI API 经历了超过 5 小时的停机故障,目前已恢复正常。vLLM 的更新支持 DeepSeek-V3 以增强的并行性和 CPU 卸载(CPU offloading)模式运行,提升了模型部署的灵活性。关于 top-k 路由 MoE(混合专家模型)中的梯度下降以及 FP8 精度的采用,相关讨论聚焦于训练效率和内存优化。由 Team Therasync 开发的 AI 语音医疗助手 AIDE 利用了 Qdrant、OpenAI 和 Twilio。DeepSeek-Engineer 提供支持结构化输出的 AI 编程辅助。LlamaIndex 集成了 LlamaCloud 和 ElevenLabs,用于大规模文档处理和语音交互。关于使用 ghstack 进行版本控制的见解以及对线性衰减学习率调度的倡导,突显了 AI 开发中的最佳实践。专家预测 2025 年将出现更小、更精炼的模型、真正的多模态模型以及端侧 AI(on-device AI)。关于行星级联邦学习和社区 AGI 登月计划的提议强调了 AI 的未来发展方向。关于智能体系统(agentic systems)、多智能体工作流以及通过思维链(CoT)推理进行审慎对齐(deliberative alignment)的讨论,进一步强化了 AI 安全与对齐方面的努力。
一个安静的周末正是我们所需要的。
2024/12/26-2024/12/27 的 AI 新闻。我们为您检查了 7 个 subreddits、433 个 Twitter 账号 和 32 个 Discord(215 个频道,5579 条消息)。预计节省阅读时间(以 200wpm 计算):601 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
ChatGPT, Sora 和 OpenAI API 经历了超过 5 小时的停机。它们已经恢复运行。
AI Twitter 综述
所有摘要由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
AI 基础设施与优化
-
训练效率与扩展:@vllm_project 宣布了 vLLM 的更新,允许 DeepSeek-V3 以多种 parallelism(并行)和 CPU offloading(CPU 卸载)选项运行,增强了 model deployment flexibility(模型部署灵活性)。
-
梯度下降与 MoE 路由:@francoisfleuret 询问了 top-k routing MoE 中的 gradient descent mechanics(梯度下降机制),探讨了 feature ranking(特征排序)如何影响 model training dynamics(模型训练动态)。
-
FP8 精度与内存优化:@danielhanchen 等人讨论了在 DeepSeek V3 中采用 FP8 precision(FP8 精度),重点在于 memory usage reduction(减少内存使用)和 training cost minimization(训练成本最小化)。
AI 应用与工具
-
AI 在医疗保健领域的应用:@qdrant_engine 展示了 AIDE,这是一款由 Team Therasync 在 Lokahi Innovation in Healthcare Hackathon 上开发的 AI 语音医疗助手,利用了 Qdrant、@OpenAI 和 @twilio 等工具。
-
AI 驱动的编程助手:@skirano 在 GitHub 上介绍了 DeepSeek-Engineer,这是一个能够使用 structured outputs(结构化输出)进行读取、创建和对比文件(diffing files)的 coding assistant。
-
AI 文档处理:@llama_index 演示了一个可以对 100 万份以上 PDF 进行 RAG 的 AI 助手,集成了 LlamaCloud 和 @elevenlabsio 用于 document processing(文档处理)和 voice interaction(语音交互)。
AI 开发实践
-
版本控制与协作:@vikhyatk 分享了使用 ghstack 管理 pull requests 的见解,增强了 GitHub 中的 collaboration(协作)和 code management(代码管理)。
-
训练计划与学习率:@aaron_defazio 提倡使用 linear decay learning rate schedule(线性衰减学习率调度),强调其在 model training 中比其他调度方式更有效。
-
开源贡献:@ArmenAgha 和 @ZeyuanAllenZhu 感谢同行引用研究论文,促进了开源协作,并为 PhysicsLM 等项目争取资源。
AI 创新与未来趋势
-
2025 年 AI 预测:@TheTuringPost 转达了来自 @fchollet 和 @EladGil 等专家的预测。关键预测包括更小、更紧凑的模型、真正的多模态模型以及 on-device AI(端侧 AI)解决方案。
-
联邦学习与社区 AGI:@teortaxesTex 提出有必要进行行星级规模的联邦学习(planetary-scale federated learning)和社区 AGI 的登月项目,类似于 ITER 等跨国倡议。
-
AI 生态系统演进:@RichardSocher 等人讨论了 agentic systems(智能体系统)的兴起、multi-agent workflows(多智能体工作流)以及 AI 在各行业的整合,标志着 AI 应用新时代的到来。
AI 安全与对齐
-
审议式对齐技术:@woj_zaremba 强调了通过 chain of thought reasoning(思维链推理)进行 deliberative alignment(审议式对齐)的重要性,从而提高 AGI 系统的安全性和有效性。
-
AI 模型提示词与行为:@giffmana 和 @abbcaj 探讨了 Prompting 对 AI 模型行为的影响,旨在防止模型泄露其训练来源,并使响应与预期行为保持一致。
-
模型评估与对齐:@jeremyphoward 和 @colin_de_de 辩论了评估指标的局限性以及 AI 模型 Alignment(对齐) 中持续改进的重要性。
AI 基础设施与优化
-
分布式训练技术:@ArmenAgha 和 @vllm_project 讨论了先进的并行策略,如 Tensor Parallelism 和 Pipeline Parallelism,提升了大规模模型的训练效率。
-
FP8 精度与内存优化:@madiator 强调了 DeepSeek V3 采用 FP8 精度 如何减少内存占用和训练成本,推动了高效的模型训练。
-
AI 模型部署灵活性:@llama_index 展示了如何使用 vLLM 部署 DeepSeek-V3,并配合各种 Parallelism 和 Offloading 配置,为模型部署提供了灵活性。
AI 开发实践
-
版本控制与协作:@vikhyatk 分享了使用 ghstack 管理 Pull Requests 的见解,增强了 GitHub 中的协作和代码管理。
-
训练调度与学习率:@aaron_defazio 提倡使用 Linear Decay Learning Rate Schedule,强调其在模型训练中优于其他调度方案的有效性。
-
开源贡献:@ArmenAgha 和 @ZeyuanAllenZhu 感谢同行引用研究论文,促进了开源协作,并为 PhysicsLM 等项目争取资源。
梗/幽默
-
AI 助手的古怪之处:@francoisfleuret 幽默地评论了他 8 岁孩子简单的目标“生存”,将育儿幽默与 AI 愿景结合在一起。
-
技术与 AI 笑话:@saranormous 调侃了 AI 模型性能,称“@Karpathy 还在阅读,其进步难以否认”,以此在 AI 社区的智力博弈中开玩笑。
-
个人轶事与轻松帖:
- @nearcyan 分享了对 COVID-19 封锁的幽默看法,嘲笑启动项目时的初期困难 (Teething Issues)。
- @mustafasuleyman 分享了关于电池的有趣观察,说:“锂是有限的,难以获取,且开采资源密集”,为可持续性话题增添了轻松的转折。
AI Reddit 回顾
/r/LocalLlama 回顾
主题 1. DeepSeek 的成本效益及与 4o 的性能对比
- DeepSeek 在大多数基准测试中优于 4o,且价格仅为其 10%? (Score: 785, Comments: 203): DeepSeek-V3 在性价比方面显著超越了 GPT-4o,其输入处理价格为每百万 tokens $0.27,而 GPT-4o 为 $2.50;输出处理价格为 $1.10,而 GPT-4o 为 $10.00。分析强调 DeepSeek-V3 提供了一个更经济的解决方案,图表使用不同颜色对比了成本,并注明这些是各模型目前可用的最低价格。
- 用户正在讨论与 DeepSeek-V3 相关的隐私担忧,强调其条款暗示数据存储在北京,这引起了对数据隐私持谨慎态度的公司的关注。一些评论建议在本地运行该模型作为解决方案,尽管这需要大量的硬件资源,例如 10 块 H100。
- 关于 DeepSeek-V3 的性能和推理能力存在争论,部分用户遇到了幻觉和错误,而另一些人则认为它在编程任务中非常有效,并对其 180k 上下文长度表示赞赏。该模型的低延迟以及通过 OpenAI Python package 与应用程序轻松集成的特性被视为显著优势。
- DeepSeek-V3 的成本效益及其对市场的影响是一个反复出现的主题,用户注意到其促销定价以及对 OpenAI 等主要参与者施加压力的潜力。讨论还涉及该模型由一家中国对冲基金资助,以及中国补贴电费在降低成本中可能发挥的作用。
- DeepSeek v3 的训练预算比同类模型低 8-11 倍:具体为 2048 块 H800(即“阉割版 H100”),耗时 2 个月。相比之下,Llama 3 405B 根据其论文使用了 1.6 万块 H100。DeepSeek 估计成本为 550 万美元。 (Score: 518, Comments: 58): DeepSeek v3 在 2048 块 H800(被称为“阉割版 H100”)上进行了为期 2 个月的训练,成本约为 550 万美元。相比之下,Llama 3 405B 在训练中使用了 16,000 块 H100,突显了两种模型在资源分配上的显著差异。
- DeepSeek v3 的性能与局限性:用户分享了使用 DeepSeek v3 的经验,指出其上下文窗口比 Claude 3.5 Sonnet 小,且缺乏多模态能力,导致在某些任务中出现性能问题。尽管有这些限制,DeepSeek 的成本仅为 Claude 的 2%,提供了更好的性价比。
- FP8 混合精度训练:FP8 混合精度训练的引入因其效率提升而受到关注,与 FP16/BF16 相比,它提供了 2 倍的 FLOPs 吞吐量和 50% 的内存带宽占用降低。这种效率是通过减少 GPU 显存使用和加速训练实现的,尽管实际的效率提升可能接近 30%。
- Mixture of Experts (MoE) 见解:讨论涉及了 Mixture of Experts (MoE) 方法,强调与稠密模型相比,MoE 可以降低计算需求。对话澄清了关于 MoE 的误解,指出开发者正在积极努力防止专家模型过度专业化,这与某些认为 MoE 只是并行训练小型模型的观点相反。
- DeepSeek V3 使用针对编程和数学的合成数据(synthetic data)构建。他们采用了来自 R1(推理模型/reasoner model)的蒸馏技术。此外,他们还实现了新颖的多 Token 预测(Multi-Token Prediction)技术 (分数: 136, 评论: 19): DeepSeek V3 的开发使用了专注于编程和数学的合成数据,采用了多 Token 预测技术(Multi-Token Prediction technique)以及来自 R1 推理模型的蒸馏。该模型的训练预算比典型模型少 8-11 倍,更多细节可以在其 论文 中找到。
- 多 Token 预测技术是一个重要的关注点,人们对其新颖性和规模进行了询问。它并不是第一个实现该技术的模型,但其规模值得注意;早期的模型和研究可以在 Hugging Face 上的论文 “Better & Faster Large Language Models via Multi-token Prediction” 中找到。
- 讨论中涉及了运行拥有 6000 亿参数的 DeepSeek V3 的可行性,这对于非服务器基础设施来说被认为具有挑战性。建议的配置包括一个成本约为 2 万美元的 8 x M4 Pro 64GB Mac Mini 集群,同时人们也对使用 NVIDIA 显卡的更便宜替代方案感到好奇。
- 该模型仅用 500 万美元的训练资源完成开发,令人印象深刻,论文的开源也受到了赞赏,特别是其在编程应用方面的潜力。模型的概述可以在这里查看。
{kind=link}
{kind=link}
主题 2. DeepSeek-V3 架构:利用 671B 混合专家模型 (Mixture-of-Experts)
- DeepSeek 发布了其 AI 研究人员在 2048 块 H800 上训练 DeepSeek-V3 671B 混合专家模型 (MoE) 的独家片段。 (分数: 717, 评论: 60): DeepSeek 发布了其 AI 研究人员使用 2048 块 H800 GPU 训练 DeepSeek-V3(一个 6710 亿参数的混合专家模型/MoE)的片段。
- DeepSeek-V3 的架构:该模型由 256 个带有共享组件的独立模型组成,具体为每层 257 个 MLP,每层总计有 370 亿激活参数。正如 ExtremeHeat 和 OfficialHashPanda 所强调的,这种结构允许在 CPU 上也能进行高效的训练和推理。
- 全球 AI 竞争与人才:讨论触及了 AI 开发的地缘政治方面,包括对俄罗斯人才流失以及美国因官僚障碍和缺乏资金而流失人才的担忧。还提到了中国留学生在美国面临困难,这可能导致他们回到中国,而像清华和北大这样的大学提供了极具竞争力的教育。
- DeepSeek 的成本效益:尽管 DeepSeek-V3 规模巨大,据报道其训练成本仅为 800-1000 万美元,与 OpenAI 在 O3 单次评估上花费 160 万美元形成鲜明对比。这种效率归功于该模型创新的架构和并行训练方法。
- 来自 Qwen 的 Sonnet 级别新模型即将发布? (分数: 225, 评论: 30): 在 2024 年 12 月 27 日的一次 Twitter 交流中,针对 Knut Jägersberg 对“Sonnet 级别 70B LLM”的渴望,林俊旸 (Junyang Lin) 以“等我 (Wait me)”回应,暗示了潜在的新模型发布。该推文获得了中等关注,有 228 次浏览和 17 个赞。
- 本地模型 vs. API 成本:几位用户表达了对本地运行 LLM 的偏好,因为这样可以节省成本并独立于基于 API 的模型。m98789 强调了免费和开放权重(open weights)允许本地执行的好处,并将其与昂贵的 API 服务进行了对比。
- 模型尺寸与可访问性:Only-Letterhead-3411 指出,70B LLM 是家庭使用且无需巨大成本的理想尺寸,Such_Advantage_6949 补充说,使用 2x3090 GPU 等硬件可以高效运行。他们还推测,随着技术的进步,像 100B 这样更大的模型可能会成为新标准。
- 对模型预告的看法:EmilPi 批评预热贴(teaser posts)分散注意力且缺乏实质性新闻,而 vincentz42 等人则幽默地推测将发布一个拥有 70B 激活参数的 1T MoE 模型,突显了社区对模型发布预告及其影响的复杂心情。
{kind=link}
其他 AI Subreddit 综述
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
主题 1. OpenAI 日益增长的资金需求与融资计划
- OpenAI 在制定营利计划时表示,其所需的资金“超出了我们的想象”——我的意思是,他确实说过 7 万亿美元…… (Score: 297, Comments: 72): OpenAI 宣布其运营所需的资金超出了最初的预期,突显了潜在的融资挑战。讨论引用了之前的一份声明,估计需要 7 万亿美元,这表明了 OpenAI 营利计划对资金需求的巨大规模。
- 讨论强调了对 OpenAI 财务策略的怀疑,一些用户质疑 7 万亿美元这一数字的真实性,并认为这可能是传闻而非事实。据指出,Sam Altman 否认曾要求 7 万亿美元,但也有人认为,考虑到 AI 开发成本的不断上升,这个数字并非遥不可及。
- 人们对 OpenAI 的商业模式表示担忧,并建议效仿 Apple 的应用平台模式,允许开发者发布 AI 应用并从中抽取分成。用户还指出,目前缺乏一个用于探索基于 ChatGPT 应用的平台,而这本可以作为一个潜在的收入来源。
- 讨论还涉及了高层员工的离职以及 Deepseek 成就的潜在影响,有人推测 Deepseek 通过利用来自 OpenAI 的合成数据,以更低的成本实现了类似的结果。这引发了对 OpenAI 竞争优势和战略方向的质疑。
主题 2. 对用于确定 LLM 智能的“陷阱”测试的批评
- 回来了! (Score: 299, Comments: 38): 该帖子幽默地描述了与 ChatGPT 的对话,当用户询问其状态时,AI 俏皮地引用了“矩阵中的故障(glitch in the Matrix)”作为回应。互动以对水豚(capybaras)的热情描述继续,突显了 AI 进行轻松对话交流的能力。
- 语言与幽默:发生了一场关于语言使用的轻松交流,评论者拿语法错误开玩笑,并强调了在线互动中幽默的重要性。
- AI 与世代影响:一场关于在无处不在的 AI 环境下成长的影响的讨论浮出水面,一些人对未来几代人对技术的依赖表示担忧。
- 水豚迷恋:对话幽默地触及了对水豚的兴趣,一位用户分享了一个 YouTube 链接,展示了它们与鳄鱼共存的冷静天性。
{kind=link}
主题 3. AI 与数学:突显进展与局限性
- AI 现在能做数学了吗?你可能会感到惊讶……一位数学家的思考。 (Score: 133, Comments: 40): 该帖子分享了来自 Hacker News 的一篇文章链接,探讨了 AI 目前在数学方面的能力,并从数学家的角度提供了见解。讨论邀请读者阅读文章并分享他们对 AI 执行数学任务能力的看法。
- 数学竞赛的误导性描述:FateOfMuffins 的评论指出,将 IMO 和 Putnam 等竞赛标记为“高中”和“本科”级别具有误导性,因为这些竞赛比典型课程要难得多。这种误传可能会让公众对 AI 的数学能力产生困惑,因为 AI 可能在这些竞赛中表现良好,但并不一定反映平均本科水平。
- AI 在数学任务中的表现:SoylentRox 质疑 AI 在数学环境中与人类数学家相比表现如何,特别是在步骤分(partial credit)和答案准确性方面。讨论表明,即使是熟练的人类数学家也可能在这些测试所需的精确度上遇到困难,从而引发了对 AI 比较表现的质疑。
- 对 AI 数学能力的认知:Mrb1585357890 和 soumen08 对分享的文章表示赞赏,因为它提供了对 AI 当前数学能力的见解。讨论反映了文章和讨论如何帮助澄清 AI 在执行复杂数学任务方面的进展和局限。
AI Discord 综述
由 o1-mini-2024-09-12 生成的摘要之摘要的摘要
主题 1: DeepSeek 主导 AI 竞赛
-
DeepSeek V3 以 60 Tokens/秒的速度碾压竞争对手:DeepSeek V3 通过每秒处理 60 tokens 的速度超越了之前的版本,比 V2 提升了 3 倍速度,并拥有巨大的 64k context window 来处理大规模任务。这个开源强力模型正在重塑基准测试,在 AI 领域挑战 Claude Sonnet 和 ChatGPT 等巨头。
-
许可证之战:DeepSeek 采取行动:DeepSeek 更新了其许可证,使其比 Llama 更加自由,引发了社区关于开源与专有模型的辩论。这一转变使 DeepSeek V3 成为开源 AI 模型领域的领跑者,激发了爱好者之间的“许可证之战!”。
-
推理循环?DeepSeek V3 面临挑战:尽管速度惊人,DeepSeek V3 在推理循环和在某些层级之外生成连贯输出方面遇到了问题。用户报告了“垃圾”输出,突显了在扩展 AI 推理能力方面持续存在的挑战。
主题 2:像专业人士一样集成 AI(或者并不专业)
-
Cursor IDE 和 Codeium 在性能上挣扎:使用 Cursor IDE 和 Codeium (Windsurf) 的开发者反映了对请求缓慢和系统挂起的挫败感,尤其是在 Pro plan 上。随着用户寻求更流畅的 AI 辅助编码工作流,要求增强快捷键和更好的 context management 的呼声很高。
-
Aider 更新:更多模型,更少错误:最新的 Aider v0.70.0 引入了对 o1 models 的支持并改进了错误处理,因其更简单的安装方法而受到贡献者的赞赏。此次更新旨在简化编码辅助,使 Aider 成为开发者工具箱中更强大的工具。
-
OpenRouter 整合 DeepSeek 的王牌举动:OpenRouter 见证了 DeepSeek V3 使用量自发布以来增长了三倍,其集成旨在利用自定义 API keys 和更低的成本。这种协同效应预计将增强编码任务,尽管一些用户对“许可证之战!”背景下的长期稳定性表示怀疑。
主题 3:金币叮当响!定价模式重塑 AI 准入门槛
-
DeepSeek V3 将训练成本削减了 100 倍:通过 550 万美元的投资,DeepSeek V3 利用 FP8 mixed precision 实现了训练成本两个数量级的降低。这一突破使先进的 AI 模型变得更加触手可及,挑战了高成本的同类产品。
-
AI 定价透明度:开发者要求更多:围绕 AI 模型定价 的讨论强调了对成本透明度的需求,尤其是在平衡性能与开支时。随着用户为其编码和开发需求寻求更清晰的价值主张,Claude Sonnet 和 DeepSeek Platform 等工具正受到严格审查。
-
Perplexity 的定价谜题:用户报告了 Perplexity AI 上图像嵌入限制的不一致,期望是每分钟 400 次而不是 40 次。由于修复承诺因节假日时间而推迟,社区对定价结构神话表达了不满,敦促公司将定价与性能挂钩。
主题 4:GPU 大神与训练技巧
-
H800 GPU:为了成本效益而“阉割”的 H100:H800 GPU(本质上是削弱版的 H100)的部署导致了 NVLink bandwidth 降低,但保持了至关重要的 FP64 性能。这一战略举措使得 DeepSeek V3 能够在短短 2 个月内,在 2000 个 GPU 上高效训练像 600B MoE 这样的大规模模型。
-
Triton vs. CUDA:终极对决:关于实现 quantization 的讨论集中在是使用 Triton 还是坚持使用纯 CUDA,以平衡易用性与速度。社区正在辩论集成像 bitblas 这样的专用内核用于 Conv2D 操作以提高效率的优劣。
-
FP8 训练推动新的编程尝试:受 DeepSeek 的 FP8 方法启发,开发者们渴望使用 torchao 框架将 FP8 training 引入 nanoGPT。这种兴趣凸显了社区对能源效率训练和可扩展模型推理的追求。
主题 5:创意遇见代码(以及伦理)
-
AI 只是想写作:创意写作和角色扮演飞速增长:Aider 和 Gen AI 等 AI 工具正在通过先进的 prompts 和沉浸式角色开发彻底改变 创意写作 和 色情角色扮演 (ERP)。用户称赞其构建详细角色档案和动态交互的能力,增强了 AI 辅助叙事体验。
-
伦理困境:AI 未经许可进行抓取:社区成员对 AI 伦理 表达了严重关切,特别是未经许可对 创意作品的抓取。关于 衍生内容 的范围以及 企业游说对版权法 的影响展开了激烈辩论,呼吁采取更具 伦理的 AI 开发 实践。
-
3D 打印与 AI 艺术:有形的融合:3D 打印 与 AI 生成视觉效果 的融合为 创新成果 开辟了新途径,例如像 羊形卫生纸架 这样奇特的物品。这种交汇展示了 LLMs 在 有形制造 中的创造潜力,将数字创意与物理生产相结合。
第 1 部分:高层级 Discord 摘要
Cursor IDE Discord
- Cursor IDE 的上下文难题:用户在探索 Cursor IDE 文档 时,发现了 请求缓慢、多文件处理受限以及对 上下文使用 的挫败感。
- 他们建议添加 快捷键 以加快工作流程,并参考了 社区论坛 上持续的反馈。
- DeepSeek V3 与 Claude Sonnet 的对决:根据 DeepSeek 官方推文,DeepSeek V3 达到 60 tokens/second,保持 API 兼容性,并主张开源透明。
- 然而,社区与 Claude Sonnet 的对比突显了后者更精细的代码编写能力,正如一条赞扬 Claude 3.5 Sonnet 的 Visual Studio Code 推文 所暗示的那样。
- 成本紧缩与效率讨论:参与者权衡了 AI 模型定价 与性能的关系,强调了 Claude Sonnet 和 DeepSeek Platform 等工具的成本透明度。
- 一些人对代码任务的强大价值主张表示感兴趣,而另一些人则对先进 AI 解决方案 定价结构的不确定性表示遗憾。
Codeium (Windsurf) Discord
- Windsurf 幕后视频令人惊叹:来自 Windsurf 的新视频 揭示了工程师构建 Windsurf 的方法,重点展示了独特的技术和节日精神。
- 他们展示了团队如何大胆重塑标准代码工作流,鼓励观众 尝试他们突破边界的方法。
- 性能陷阱与 Pro 计划的困惑:多位用户报告了系统变慢和 Pro 计划 额度消耗过快的问题,引发了对每月请求限制的担忧。
- 他们链接到了 关于额度使用的文档,抱怨无法控制的卡顿阻碍了编码目标的实现。
- DeepSeek V3 引发好奇:许多参与者称赞 DeepSeek V3 的速度和开源优势,期待其可能与 Windsurf 集成。
- 其他人则权衡将 Cursor 作为替代方案,理由是可以使用自定义 API keys 且代码任务成本更低。
- IDE 小故障与 M1 混淆:用户在 WebStorm 和 IntelliJ 中遇到了插件故障,包括更新后功能缺失。
- 一位 Macbook M1 Pro 用户发现 Windsurf 的终端运行在 i386 下,寻求 Apple Silicon 兼容性建议。
- Cascade 的全局规则引起讨论:一些人建议在 Cascade 中使用广泛的规则来统一代码风格并减少困惑,特别是在大型团队中。
- 他们请求了解哪些指南是有帮助的,希望保持未来编码会话的一致性。
aider (Paul Gauthier) Discord
- Aider v0.70.0 强化升级:新的 Aider v0.70.0 提供了 o1 模型支持、针对 10% 用户的分析数据选择性加入 (analytics opt-in),以及更好的错误处理,以简化编码任务。
- 贡献者赞扬了其新的安装方法和更简单的只读文件显示,强调了编码辅助方面更广泛的模型兼容性。
- DeepSeek V3 在 M4 Pro Mini 上飞速运行:在由 8 台 M4 Pro Mac Mini 组成的集群上运行 671B DeepSeek V3,速度达到 5.37 tokens/s,首个 token 响应时间 (TTFT) 为 2.91s,显示出强大的本地推理潜力。
- 社区讨论将此速度与 Claude AI 和 Sonnet 进行了对比,指出其在高容量使用下的开销更低且扩展性更好。
- Aider 中的 Repo Maps 与 Token 限制:成员们报告称,repo-map 功能在 Architect 模式与标准编辑模式下的表现有所不同,同时 DeepSeek Chat V3 的输入 token 限制跃升至 64k。
- 他们建议通过编辑 .aider.model.metadata.json 来处理新的限制,并优化模型与复杂代码库的交互方式。
- Git 工具以引人注目的格式渲染代码:GitDiagram 网站将 GitHub 仓库转换为交互式图表,而 Gitingest 则将其提取为对 Prompt 友好的文本。
- 用户发现将任何 GitHub URL 中的 ‘hub’ 替换为 ‘diagram’ 或 ‘ingest’,对于快速了解项目概况和简化 LLM 摄取非常有帮助。
Eleuther Discord
- Trainer 调整激发新的 Loss 技巧:一位成员询问如何修改 Hugging Face 的 Trainer 以进行因果语言建模,重点在于将填充 (padded) token 置零,并在 Loss 计算中忽略输入 token。
- 他们参考了 trl 库,并建议使用自定义 collator 将标签设置为
ignore_idx作为变通方案。
- 他们参考了 trl 库,并建议使用自定义 collator 将标签设置为
- Pythia 寻找中间 Checkpoint 状态:一位用户请求 Pythia 模型的中间优化器状态 (intermediate optimizer states),并指出目前仅提供最终的 checkpoint 状态。
- 他们计划联系工作人员以获取大文件访问权限,希望能更轻松地移交 Pythia 资源。
- 物理学家准备进军 ML:一位即将毕业的理论物理学博士介绍了探索 Machine Learning 和 LLM 以深入了解可解释性 (interpretability) 的计划。
- 他们表现出对参与研究项目和获得高级建模实践技能的极大热情。
- 因果关系提升训练讨论:参与者讨论了因果推理 (causal inference) 如何通过利用先验动态而非纯粹依赖统计趋势来改进模型训练。
- 他们辩论了允许知识分块的表示方式,并引用了盲棋 (blindfold chess) 等例子作为高效心理结构的案例。
- 视频模型在物理学习上受挫:成员们认为,视频生成模型在尝试从视觉效果中提取真实的物理定律时往往力不从心,即使在更大规模下也是如此。
- 他们指向了一项综合研究,该研究质疑这些模型在没有人类洞察的情况下是否能建立稳健的规则。
OpenRouter (Alex Atallah) Discord
- DeepSeek v3 使用量翻三倍并比肩大厂:正如这条推文所示,Deepseek v3 在 OpenRouter 上的使用量自昨天以来飙升了三倍。
- 一些业内声音声称,现在构建 frontier models 的成本约为 $6M,且中国加上开源力量已经接近领先的 AI 性能,这增强了人们对 Deepseek v3 的期待。
- ACT 与 CIMS 助力开发者日常工作:AI Chat Terminal (ACT) 集成了主流 API,允许开发者在终端中运行任务并与代码聊天,详见 GitHub。
- 同时,Content Identification/Moderation System (CIMS) 在 Companion 中增加了对问题内容的自动检测和删除,其 wiki 对此进行了说明。
- RockDev 在 SQL 生成领域势头强劲:RockDev.tool 使用 OpenRouter 将代码定义转换为开箱即用的 SQL,同时保留本地隐私,详见 rocksdev.tools。
- 社区反馈强调,本地数据处理是一个主要吸引力,并计划在未来进行更新。
- Google Search Grounding 将 AI 与 Web 关联:一位开发者展示了一种使用 Google GenAI SDK 在进行网络搜索前对回答进行 grounding 的方法,详见 GitHub。
- 这种方法依赖 Google 搜索来获取上下文,为实时验证 AI 输出提供了可能性。
- OCR 与 OWM 拓展 LLM 视野:Fireworks 增加了对图像和 PDF 的 OCR 支持,而 Pixtral 则负责处理高级文档处理中的文本提取。
- 关于 Open Weight Model (OWM) 和 Out-of-Domain (OOD) 任务的讨论强调了许多模型在已知数据上表现出色,但在训练范围之外面临挑战。
Nous Research AI Discord
- DeepSeek 因推理循环受阻:成员们透露 Deepseek V3 在逻辑上遇到了困难,并引用 DeepSeek V3 PDF 详细说明了重复循环如何阻碍复杂任务,尤其是在超过一定层数后。
- 他们指出经常出现 garbage 输出,一些人指出了底层 RPC 代码的潜在缺陷,并对推理链的训练提出了质疑。
- DeepSeek V3 中 RoPE 的反复难题:小组讨论了 Deepseek V3 中 RoPE 的使用,注意到它仅应用于一个 key,同时参考了用于定位的独立 embedding 索引方法。
- 一些人质疑简化方法是否能改善结果,强调了 position encoding 的复杂性如何显著影响模型准确性。
- Qwen-2.5-72b 在重测中表现飙升:Aidan McLau 的推文显示 Qwen-2.5-72b 在重测中获得了惊人的提升,该模型最初表现不佳,但在重复基准测试中跃升至顶级水平。
- 评论者想知道 benchmark 的公平性是否受到损害,或者重新运行是否只是使用了更好的超参数,一些人参考了 Better & Faster Large Language Models via Multi-token Prediction 以获取训练见解。
- Gemini 的上下文难题:一些人注意到 Gemini 模型的 context 使用可能更灵活地处理输入,尽管它需要保持在设定的参数范围内。
- 他们推测先进的 context selection 方法可能会如何改变环境输入,并参考了其在 aidanbench 上的第二名排名。
- Copilot 处理复杂代码:成员们称赞 GitHub Copilot 在简单项目中的快速修复和重构任务。
- 然而,他们发现像 llama.cpp 这样的高级系统需要更深入的手动处理,这表明 AI 驱动的编辑无法完全取代深入的代码理解。
LM Studio Discord
- AI 伦理工具大争论:一位用户抨击未经许可抓取创意作品的行为,认为这对于 AI ethics 来说是非常令人不安的问题。
- 其他人指出了企业对 copyright laws(版权法)的影响,并质疑衍生内容的界定范围。
- LM Studio 速度提升:一些用户报告称,在升级到 最新的 LM Studio Beta 版本 后,处理速度从 0.3 跃升至 6 tok/s。
- 他们使用 GPU 监控工具确认了性能的提升,并将这一成功归功于强大的硬件配置。
- 图像生成遭遇瓶颈:一位用户试图优化 AI 图像生成,但对于实现更好输出的可行性遭到了质疑。
- 讨论集中在这些模型如何解读创意,揭示了对实质性改进的怀疑。
- MLX 内存泄漏警报:参与者报告了 MLX 构建版本的内存泄漏问题,并引用 Issue #63 作为证据。
- 他们将性能下降归因于潜在的资源管理不当,并引发了进一步的调查。
- GPU 紧缺与 RPG AI 场景:多 GPU 设置、海量模型的 VRAM 需求以及低至 30% 的 CUDA 占用率引起了硬件爱好者的热议。
- 同时,像 LangChain 这样的 agentic 框架被用于 RPG 场景生成,引发了关于硬件与叙事协同作用的讨论。
Unsloth AI (Daniel Han) Discord
- LoRA vs 全模型权重:微调对决:多位用户讨论了使用 LoRA 而不是合并 full model 进行 fine-tuning,强调了在托管和推理方面的效率提升,并参考了 Unsloth 文档 中的示例。
- 他们强调 LoRA 作为一个 adapter 运行,一位用户强调提示词格式化(prompt formatting)和数据对齐对于 stable finetuning 至关重要。
- Hugging Face 动态 Adapter 加载失败:一名新手尝试通过 Hugging Face 进行 dynamic adapter loading,结果导致了 乱码输出,如 此 Gist 所示。
- 有人建议使用 VLLM 以获得更好的性能,对比了 Hugging Face 较慢的推理速度,并称赞 Unsloth Inference 在处理 adapter 方面的可靠性。
- Python 指令微调寻宝:一名成员正在寻找包含 问题描述 和 生成的解决方案 的 instruction-tune datasets,特别是针对 Python 编程任务,参考了 Hugging Face 的 smol-course。
- 他们希望得到一个能够满足真实编程见解的数据集,其他人也确认 精选数据(curated data)会极大地影响最终模型的性能。
- Hopper 上的 Binary Tensor Cores:HPC 的未来?:一位用户担心 binary tensor core 的支持在 Ampere 之后会被移除,质疑 Hopper 是否准备好应对超低精度的 HPC 任务。
- 社区内出现了对 NVIDIA 未来走向的猜测,一些参与者怀疑 low-precision 指令是否会持续可用。
- GGUF 与 4-bit 转换障碍:一位用户在生成 GGUF 模型时遇到了 RuntimeError,并发现缺少 tokenizer.json 等文件,随后指向官方 llama.cpp 寻求解决方案。
- 其他人建议 复制 必要的模型文件,并禁用 vision layers 的 4-bit 加载,强调了部分量化(partial quantization)的复杂性。
OpenAI Discord
- DeepSeek V3 以 64k 上下文惊艳亮相:根据 DeepSeek V3 文档,新提到的 DeepSeek V3 声称拥有 64k 上下文窗口、先进的混合专家 (mixture-of-expert) 架构以及高性价比的本地推理。
- 社区测试者考虑在 ChatGPT 宕机期间切换到 DeepSeek 处理专门任务,称赞其响应速度更快且对大上下文支持更好。
- GPT-03 (o3) 临近发布:开发者预测 o3-mini 将于 1 月底首次亮相,随后是完整的 o3,使用限制尚未确认。
- 推测涉及对现有 GPT 模型的可能增强,但官方细节仍然稀缺。
- ChatGPT 的宕机困境:频繁的 ChatGPT 宕机导致跨平台的错误消息和服务中断,如 OpenAI 状态页面所示。
- 一些成员对那些没有起效的“修复”公告开玩笑,而另一些人则测试了不同的 AI 解决方案,凸显了宕机的影响。
- MidJourney vs DALL-E:视觉之争:爱好者将 MidJourney 与 DALL-E 进行对比,强调最新版本的 DALL-E 在处理复杂提示词方面有更好的结果,且视觉效果有所提升。
- 他们回顾了旧模型的缺点,赞扬了最近在提升艺术质量和用户满意度方面的更新。
Stackblitz (Bolt.new) Discord
- Gabe 的隐秘简化:细心的观察者强调了 Gabe 新开发的由 Bolt 驱动的应用,传闻它将为所有人简化工作流,尽管尚未分享官方功能。
- 早期预览引发了热议,一些成员将其描述为开发团队的“下一个重大便利”。
- Anthropic 过载破坏了 Bolt:成员报告称,每当 Anthropic 切换到简洁模式时,Bolt 的质量大幅下降,导致响应生成反复失败。
- 用户要求更好的调度或警告,有人称这种体验为“彻底崩溃”,并敦促修复实时协作问题。
- 直接代码更改提示:一些开发者在 Bolt 中遇到了困难,聊天机器人返回的是原始代码块而不是编辑现有脚本,导致调试停滞。
- 他们分享了一个技巧,即在提示词中明确说明“请直接对我的代码进行更改”,声称这种方法可以减少摩擦。
- OpenAI 在 Bolt 中的设置障碍:尝试将 OpenAI 集成到 Bolt 的用户遇到了一波困惑,在提交 API key 时反复出现错误。
- 一些人建议加入 Bolt.diy 社区或查看 Issues · stackblitz/bolt.new 以获取及时的解决方案。
- Netlify 404 令人头疼:一组用户在 Netlify 上遇到了 404 错误,将其归因于其 Bolt 应用中的客户端路由。
- 变通方法确实存在,但需要进行实验,包括多次尝试自定义路由设置或调整 serverless functions。
Perplexity AI Discord
- OpenAI 的人形机器人动态:最近的热议聚焦于 OpenAI 的人形机器人 计划,详见此文档,其中记录了机械规格、预计发布时间表以及与高级 AI 模块的集成。
- 参与者表示希望这些机器人能加速 人机协作,并提出未来的软件增强功能可能会与其他机器人项目中展示的即将推出的架构保持一致。
- AI 令人惊讶的转变:一个持续的热点涵盖了 AI 如何假装改变观点,在此 YouTube 视频中有一个令人惊讶的演示。
- 社区成员讨论了对 AI 可操控性 的担忧,并考虑了潜在的保护措施,指出关于模型立场转变的直接引用既令人不安又在技术上具有启发性。
- 体温供电的可穿戴设备:讨论中出现了新的 体温供电可穿戴设备,见此链接,重点介绍了无需外部充电即可为低功耗设备供电的原型。
- 工程师们辩论了传感器的准确性和长期稳定性,强调 温差 是持续数据采集的一种新鲜能源。
- 视频聚合工具的开发:一些用户正在寻找一种能合并多个服务的 AI 视频创作聚合器,引发了关于现有工作流的活跃头脑风暴。
- 他们交流了关于流水线组装的建议,希望能有一个统一的工具来简化 多媒体制作 和同步。
- Perplexity 的 API 难题:开发者批评了 Perplexity API,称其弱于 OpenAI、Google 或 Anthropic 的替代方案,引发了关于容量限制和响应质量的问题。
- 其他人指出 Spaces 提供了更顺畅的集成,而 Perplexity 缺乏 自定义前端支持 是高级用户体验的硬伤。
Stability.ai (Stable Diffusion) Discord
- Hunyuan 在视频领域表现强劲:成员报告称 Hunyuan 的表现优于 Veo 和 KLING,并希望从 DiTCtrl 中获得进一步提升。
- 他们强调了 AI 视频生成中可靠性和连续性的重要性,期待新的注意力控制策略。
- 提示词优化:标签 vs 详细文本:参与者对比了处理长提示词的 Flux/SD3.5 与通常在使用短标签时效果最好的 SD1.5/SDXL。
- 他们分享了在平衡核心关键词和扩展描述以优化输出方面的技巧。
- 旧版模型的 Lora 连接:一些人询问关于为旧模型升级新 Loras 的问题,结论是重新适配 Loras 比更改基础 Checkpoints 更实用。
- 他们一致认为,经过良好微调的 Loras 优于对现有模型权重进行的强制调整。
- 缓慢的速度挤压 AI 视频渲染:用户描述渲染 5 秒 视频大约需要 8 分钟,将其归因于当前的 GPU 限制。
- 他们对新的 GPU 技术和改进的模型设计将缩短这些漫长的渲染时间保持乐观。
- 3D 打印与 AI 艺术的碰撞:一位贡献者强调了打印奇特物品(如羊形卷纸架)作为 3D 打印 的有趣应用。
- 他们看到了将 AI 生成的视觉效果与实体制造相结合以获得更多创意成果的潜力。
Notebook LM Discord Discord
- Pathfinder 播客瞬间生成:一位用户使用 NotebookLM 在约 15 分钟内生成了 Pathfinder 2 的 6 本书战役摘要,引用了 Paizo 2019 年发布的内容,并强调了精简的 GM 准备时间。
- 他们谈到了“大幅减少准备工作”,引发了社区关于快速、AI 驱动的叙事生成的讨论。
- 迷人的 Wikipedia 音频概览:成员们使用 NotebookLM 创建了新闻文章和 Wikipedia 条目的音频合成,包括 2004 年印度洋大地震及其即将到来的 20 周年纪念(2024 年 12 月)。
- 一位成员形容输出结果“栩栩如生,令人惊讶”,引发了更多关于音频形式大规模知识分发的讨论。
- 交互模式下的麦克风故障:几位用户指出,当 麦克风权限 被阻止时,NotebookLM 的交互模式会出现无尽加载的错误,并指出该问题会一直持续到更新浏览器设置。
- 他们分享了启用麦克风访问以规避此问题的技巧,推动了关于确保硬件兼容性以实现流畅 AI 使用的讨论。
- 小说作家的表格曲折:一位用户询问 NotebookLM 是否可以处理表格数据,特别是用于辅助小说创作的角色矩阵。
- 社区想知道结构化数据是否能被有效解析,建议探索潜在的文本转表格功能。
- AI 创作的播客平台:一位用户介绍了用于分享 AI 生成播客的 Akas,重点介绍了 RSS 提要集成和移动端友好的发布功能。
- 成员们还询问了 NotebookLM Plus 层级,参考官方订阅指南以确认价格和新功能。
Interconnects (Nathan Lambert) Discord
- DeepSeek V3 遥遥领先:DeepSeek V3 以 60 tokens/second 的速度发布(比 V2 快 3 倍),如这条推文所述,并支持在 NVIDIA 和 AMD GPU 上进行 FP8 训练。其许可证现在比 Llama 更宽松,引发了社区成员之间所谓的“许可证之战”。
- 社区评论赞扬了该团队在严苛的硬件限制下的卓越工程能力,而讨论集中在代码和数学自评中潜在的陷阱。一位参与者惊呼“许可证之战!”,捕捉到了这种复杂的反应。
- 强大的 Multi-Head 举措:DeepSeek 的 Multi-Head Latent Attention 引发了关于实现低秩近似的问题,SGLang 在 V3 中提供了首日支持。观察者指出 vLLM、TGI 和 hf/transformers 可能很快会增加兼容性。
- 一位用户询问“有人在开发相关版本吗?”,反映了社区推动适配该技术的努力。另一位计划查看 Hugging Face 方面,旨在同步努力以实现更好的采用。
- OpenAI 重组与 Bluesky 爆发:OpenAI 董事会打算组建“历史上资源最丰富的非营利组织之一”,根据此公告,而鉴于投资者压力和不断增长的资本需求,IPO 传闻四起。与此同时,Bluesky 极端的反 AI 倾向使得该平台不再欢迎 AI 讨论。
- 一些人预测,如果进一步的融资超出了 Venture Capital 的范围,OpenAI 将会上市。一位用户在目睹了对生成式 AI 的强烈抵制后重复道:“Bluesky 对 AI 讨论是不安全的”。
- MCTS 方法强化推理能力:一种基于 MCTS 的方法通过 Direct Preference Optimization 添加步骤级信号来优化 LLM 推理,强调 on-policy sampling 以实现稳健的自我提升。评估表明,与旧的 RL 设置相比,迭代性能有显著提升。
- 怀疑者质疑模型的整体水平,其中一人评论道:“不知道他们为什么要用这么烂的模型——2024 年 5 月的情况有那么糟吗?”。其他人则争论 PRMs 是否真的能产生更好的 Chains of Thought,或者替代方法是否能产生更好的结果。
GPU MODE Discord
- DeepSeek 通过 FP8 增益大幅降低成本:在筹集 500 万美元后,DeepSeek-V3 展示了使用 FP8 混合精度训练带来的两个数量级的成本降低,详见其文档。
- 他们记录了 278.8 万个 H800 GPU 小时,引发了关于 channel-wise(通道级)和 block-wise(块级)量化方法的激烈比较,并提到了 TransformerEngine 的累加精度。
- Character.AI 的 Int8 推理加速技巧:Character.AI 引入了一个自定义的 int8 attention kernel,以提升计算密集型和内存密集型操作的速度,详见其新文章。
- 他们之前通过 multi-query attention 和 int8 量化来优化内存效率,现在将重点转向提升 core inference(核心推理)任务的性能。
- BitBlas 与 Torch 的 Conv2D 结合:一位用户询问 bitblas 是否可以生成一个 Conv2D 以直接集成在 Torch 中,希望能实现更高效的训练流程。
- 其他人对将 bitblas 等专用 kernel 与主流框架合并表现出兴趣,暗示了这些可能性在未来的扩展。
- vLLM 为 xFormers 速度延迟 Batch:一次讨论强调了 vLLM 选择不使用批处理推理,而是使用 xFormers 后端,如其代码所示。
- 该策略利用了序列堆叠(sequence-stacked)方法,延迟差异极小,引发了关于批处理对吞吐量是否有实际优势的疑问。
- Torchcompiled 的 128 倍前向传播之争:一位用户指出 Torchcompiled 需要 128 次前向传播来进行梯度估计,但与真实梯度的余弦相似度仅为 0.009,参考了这条推文。
- Will 引用的一篇论文声称在 1.58b 下训练可减少 97% 的能耗,并将 175B 模型存储在仅 ~20mb 中,这加剧了关于小规模演示之外可行性的辩论。
tinygrad (George Hotz) Discord
- 加速匹配引擎的悬赏战:tinygrad 社区正在推进 GitHub issue 中提到的三个性能悬赏,目标是为 model lower 结果在基准测试中提供加速的匹配引擎。
- George Hotz 明确表示,赢得悬赏的关键在于 2 倍的加速,并建议提交带有明显改进证明的 Pull Request 来领取奖励。
- 重写速度令人震惊:一位成员目睹了一个重写过程在 RTX 3050 上运行耗时 800+ ms,引发了对硬件限制和结果不一致的质疑。
- 一张截图显示了与报告的 25 ms 性能之间的巨大差异,促使人们呼吁进行彻底测试。
- tinygrad 的 JIT 挑战 PyTorch:通过在所有层利用 JIT,tinygrad 现在在推理性能上已追平 PyTorch,突显了极小的 Python 开销如何放大速度。
- 用户通过在完整的 Transformer 上启用 JIT 避免了 out of memory(内存溢出)错误,强调了选择性使用可能会阻碍可靠性。
- Beam Search 缓存技巧:贡献者确认 beam search kernel 可以被存储和重用,从而减少后续运行的重新编译步骤。
- 他们建议在具有相同硬件的系统之间共享这些缓存的 kernel,跳过不必要的重复执行。
- TTS 模型迁移至 tinygrad:将 TTS 模型从 Torch 迁移到 tinygrad 的工作仍在继续,参考了 fish-speech/fish_speech/models/text2semantic/llama.py 和 llama-tinygrad/llama_tinygrad.ipynb。
- 开发者的目标是在 OpenCL 上获得接近 torch.compile 的结果,目前正在开发一个最小可复现示例以解决早期遇到的问题。
Cohere Discord
- Command R+ 考虑升级及 r7b 的反应:社区成员在遇到细微的使用问题后,探讨了 Command R+ 的未来改进,并参考了对 r7b 的初步测试。
- 针对 r7b 与 Command R 相比的性能表现出现了质疑,促使人们呼吁在官方 changelog 中提供更多细节。
- 图像嵌入限制之谜:用户对 image embed limits(每分钟 40 个 vs 预期的 400 个)表示困惑,并参考了生产密钥的使用和 Cohere 的定价文档。
- 团队承认了这种不匹配并承诺修复,尽管假期时间可能会推迟恢复 400 个嵌入限制。
- CIMS 提升 Companion 的审核能力:Content Identification/Moderation System (CIMS) 已推送到 Companion,实现了有害内容的自动检测和管理。
- 正如 Companion wiki 中详述的那样,它支持直接删除被标记的文本,以促进更安全的交互。
- Command R 展示大规模 RAG 能力:Command R 支持高达 128,000 tokens 的上下文和跨语言任务,为高级 multi-step tool use 提供动力。
- Command R+ 变体通过更强的 complex RAG 性能增强了这些能力,助力以业务为中心的解决方案。
Latent Space Discord
- Orion 与 OpenAI:迟到的双人组:成员们参考 Hacker News 条目 讨论了 Orion 的延迟,重点关注其对未来项目的潜在影响。
- 他们还注意到影响 OpenAI 服务的新故障,让人想起 2023 年 1 月那段不稳定的可靠性时期。
- Deepseek 价格亲民:该小组强调了 Deepseek 从 2 月份开始的定价为 $0.27/MM in 和 $1.10/MM out,认为其性能表现合理。
- 然而,他们提到虽然它在简单任务上表现出色,但在处理复杂请求的 post-training reasoning 方面仍有困难。
- Illuminate:类似 NotebookLM 的实验:几位参与者尝试了 Illuminate,参考了 其官方网站,将其描述为分析技术论文的工具。
- 评价褒贬不一,指出不同的开发团队导致其与现有的其他解决方案存在差异。
- Frontier vs Foundation:流行语之战:关于 Frontier 与 Foundation 模型的讨论强调,“Frontier”暗示着随着新版本的发布而具备的尖端性能。
- 成员们承认 “Foundation” 指的是较早期的努力,而 “Frontier” 虽然定义模糊,但目前非常流行。
- 纽约峰会与日历:期待 2025 年 4 月:组织者在 The Times Center 推广了 2025 年 4 月的 AI Engineer Summit NYC,并在 lu.ma 上分享了更新。
- 他们邀请通过 RSS 订阅以追踪活动,强调了“添加 iCal 订阅”,并确认目前没有待定活动。
LlamaIndex Discord
- 使用 LlamaParse 展现报告 Agent 的魔力:一段新视频展示了如何使用 LlamaParse 和 LlamaCloud 构建 Agent 工作流,从 PDF 研究论文中生成格式化报告,详见此链接。
- 社区成员赞扬了使用输入模板的方法取得的成功,并重点介绍了 LlamaCloud 在处理大型 PDF 文件方面的能力。
- 百万级 PDF RAG 聊天:一个详细的推文展示了对话式语音助手如何通过 LlamaCloud 将 RAG 与 100万+ PDF 集成,演示见此链接。
- 用户注意到交互体验有所提升,这归功于该流水线的高容量文档处理能力,能够应对更复杂的查询。
- LlamaIndex 文档与路线图大修:一位成员为 RAG 应用请求了 LlamaIndex 文档的 PDF 版本,并确认可以按需生成。
- 其他人指出 GitHub 上置顶的路线图已过时(源自 2024 年初),呼吁进行官方修订。
- Ollama vs. Llama3.2 Vision 测试:成员们在 Ollama 中运行 非量化 (non-quantized) 模型进行 RAG 时遇到困难,发现其对非量化模型的支持有限。
- 他们转而使用 Llama3.2 11B vision 进行表格提取,并报告称由于不同的图像处理方式,取得了更好的效果。
- 来自 IBM 的 Docling 加入:IBM 的 Docling 作为一个用于为 AI 准备文档的开源系统亮相,通过此 YouTube 视频介绍。
- 该资源被分享给寻求更有效构建数据结构的 LlamaIndex 用户,作为一种可能的增强方案。
Torchtune Discord
- Flex 应对 Graph Breaks 与嵌套编译混乱:成员们解决了 flex 可能导致的 graph breaks,并提到需要在 attention_utils.py 中进行更多测试。他们警告说,如果编译处理不当,性能提升可能会消失。
- 其他人提出了 嵌套编译 (nested compile) 障碍和 dynamo 错误,强调了当 flex 嵌套在另一个 compile 内部时存在的稳定性风险。
- DeepSeek V3 在 2 个月内完成 600B MoE 训练:如 DeepSeek V3 论文所述,DeepSeek V3 在仅 2000 个 GPU 上用 2 个月 运行了一个 600B+ MoE。他们的方法跳过了张量并行(tensor parallelism),但仍保持了速度。
- 成员们对这种大规模方法很感兴趣,注意到流水线(pipeline)和全对全(all-to-all)配置有助于管理数据吞吐量。
- H800 GPU:阉割版的 H100:许多人指出 H800 GPU 本质上是 NVLink 较弱的 H100,导致带宽较低。他们还发现了 FP64 性能 的差异,引发了关于硬件限制下替代方案的讨论。
- 一位成员建议,这些限制可能会促使人们重新思考分布式训练设置。
- FP8 训练激发新尝试:受 DeepSeek 的 FP8 方法启发,有人计划使用 torchao 框架将 FP8 训练 集成到 nanoGPT 中。他们强调需要精确的全对全(all-to-all)操作来挖掘 NVLink 的容量。
- 这引发了关于如何在降低精度的同时保持模型稳定收敛的讨论。
- Triton vs. CUDA:GPU 大对决:一场关于在 Triton 还是 纯 CUDA 中编写量化代码的辩论正在进行,旨在平衡易用性与速度。有人提到了 Triton 中的 SM90 限制,暗示 cutlass 对于高性能 GEMM 可能至关重要。
- 他们正在仔细权衡性能折衷,试图在不牺牲原始吞吐量的情况下保持代码整洁。
DSPy Discord
- 术语表脚本获得关注:一位成员分享了一个从 Jekyll 文章生成术语表的脚本,使用 DSPy 处理 LLM 解析并转换为 Pydantic 对象。
- 他们提到该脚本会将 YAML 文件导出到
_data目录,并赞扬了其自动收集术语的范围。
- 他们提到该脚本会将 YAML 文件导出到
- TypedDict 引发热烈讨论:TypedDict 引入了另一种定义字段的方法,引发了关于 Pydantic 处理嵌套数组的讨论。
- 一位参与者强调了处理多个输出字段的难题,但小组对其中的可能性很感兴趣。
- Pydantic 模型改进 Prompt Schema:成员们强调使用 pydantic.BaseModel 来构建结构化的 Prompt 输出,并确认子字段描述可以正确传播。
- 成员承诺提供一个修订后的 gist 示例,以更清晰地演示这些方法,这反映了小组对最佳实践的共识。
Modular (Mojo 🔥) Discord
- Mojo 周边魔法:一位身处偏远地区的社区用户庆祝收到了 Mojo 周边,分享了图片并确认即使在偏远地区配送也非常顺畅。
- 他们称赞了 T恤 的质量,并形容某款贴纸非常“硬核”,预测它肯定会在粉丝中“大火”。
- Traits 成为关注焦点:一名成员指出了 Copyable 和 ExplicitlyCopyable traits 的潜在问题,引用了一篇呼吁重新思考其设计的论坛帖子。
- 社区建议旨在优化这些 traits 以获得更好的使用体验,并在同一个论坛主题中公开征集反馈。
- MAX 更进一步:MAX 集成了来自 XLA 的 kernel fusion 和内存规划,同时增加了动态形状支持、用户定义算子(operators)以及专门的推理服务库。
- 爱好者们因其扩展的能力将其称为“XLA 2.0”,强调了其针对高级工作负载的自定义 kernel 方法。
- Mojo vs Python 对决:关于是构建一致的 Mojo API 还是加倍投入 Python 集成的争论仍在继续,一些人为了方便而转回使用 JAX。
- 一位用户提到某些编译器优化必须手动覆盖,强调了与典型的 Python 框架相比,在 Mojo 中需要更直接的控制。
- Endia 与 Basalt 的忧虑:几位参与者表达了对即将发布的 Endia 的期待,并对停滞不前的 Basalt 项目表示担忧。
- 他们表示暂时暂停了 Mojo 的开发,在等待明确进展的同时,仍鼓励社区在 Endia 上进行协作。
{kind=link}
LLM Agents (Berkeley MOOC) Discord
- 证书还是放弃:声明的困境:如果没有关键的证书声明表单,学习者将无法获得证书,该表单是已完成评估的官方注册凭证。
- 课程工作人员将其称为他们的“花名册”,并强调其对于最终审批至关重要。
- 一月的冲击:下一期 MOOC 即将到来:1 月下旬被定为下一期 LLM Agents MOOC 的开始日期,为错过当前课程的参与者提供了加入机会。
- 参与者注意到了这个时间点,希望在新的一年初扩展他们在 Large Language Model 方面的专业知识。
- 测验限制:表单已锁定:Quiz 5 - Compound AI Systems 链接目前已关闭,停止接收额外的测验提交。
- 许多人请求重新开放,强调了这些测验对于结构化练习的重要性。
- 高级 LLM Agents:更深层次的策略:即将推出的 Advanced LLM Agents 课程承诺涵盖详细的 Agent 设计,包括高级优化方法。
- 爱好者们认为这是完成基础语言模型课程后的逻辑延伸。
OpenInterpreter Discord
- Claude 3.5 Opus 引发与 O1 的竞争:Claude 3.5 Opus 的潜力令人兴奋,因为它拥有更强的推理能力。
- 许多人好奇它是否能超越 O1 和 O1 Pro,预示着一场激烈的模型竞争。
- Open-Interpreter QvQ 势头强劲:一位用户询问 QvQ 在 OS mode 下接入 Open-Interpreter 时如何运行,表现出对直接系统交互的兴趣。
- 该问题仍悬而未决,标志着社区进一步探索的一个方向。
- 生成式音频协作招募:一位 AI 工程师分享了在 DNN-VAD、NLP 和 ASR 方面的进展,包括最近的一个 Voice to Voice 聊天应用项目。
- 他们邀请其他人加入,暗示了在生成式 AI 音乐生成方面可能存在的协同效应。
Nomic.ai (GPT4All) Discord
- 复制按钮难题 (Copy-Button Conundrum):一位用户指出聊天 UI 中缺少代码的 copy 按钮,另一位用户确认基于鼠标的剪切粘贴功能无法正常工作。
- 然而,Control-C 和 Control-V 仍是社区提到的主要变通方法。
- WASM 疑问 (WASM Wondering):一位新人询问关于将 AI 作为 WASM package 安装的问题,引起了对可能部署方法的关注。
- 目前没有直接回应,该查询仍有待未来探索。
- Vulcan 版本空白 (Vulcan Version Void):一位成员多次询问关于 Vulcan 版本 的信息,但未获得任何澄清或细节。
- 对于熟悉 Vulcan 细节的人来说,这个问题仍未得到解答。
- 鼠标与键盘怪癖 (Mouse & Keyboard Quirks):参与者注意到基于鼠标的剪切粘贴在配置页面上失效。
- 他们强调 Control-C 和 Control-V 是复制代码或文本的推荐方法。
- 新模板尝试 (New Template Trials):一位成员询问是否有人尝试过使用 新模板 进行写作,暗示了一种新的内容创作方法。
- 讨论显示出对切换到新模板的兴趣,但关于实际使用情况的细节较少。
Gorilla LLM (Berkeley Function Calling) Discord
- BFCL 排行榜上的缩放调整 (Scaling Shuffle on BFCL Leaderboard):在关于 Gorilla LLM 排行榜 的 inference scaling(推理缩放)和 post-training(后训练)方法的问题中,一位成员询问 BFCL 是否允许通过重复输出选择来增强的多次调用模型。
- 他们解释说,post-inference verification(推理后验证)可以多次调用工具增强型 LLM 以获得更精炼的结果,并强调了潜在的性能提升。
- 公平性之争:单次调用 vs 多次调用 (Fairness Feuds: Single-Call vs Multi-Call):同一位用户担心多次调用扩展可能会盖过更简单的单次调用 LLM,称其为排行榜上的“不公平竞争”。
- 他们建议将 inference latency(推理延迟)作为额外调用的直接权衡因素纳入排名,希望社区能接受这种方法。
LAION Discord
- Whisper 巧妙的文字处理 (Whisper’s Witty Word Wrangling):一位用户描述了 Whisper 如何检测句子边界,从而为语音处理实现更准确的切分。
- 他们表示,利用这些检测可以提高清晰度,让开发者在语音任务中加入 句子级分解 (sentence-level breakdown)。
- VAD 的静音切分魔术 (VAD’s Silence Splitting Sorcery):另一位用户推荐使用 voice activity detector (VAD) 来将语音与静音分离,以实现稳健的音频分割。
- 这种方法利用 静音检测 (silence detection) 来优化分割过程并提高效率。
MLOps @Chipro Discord
- 针对 HPC 的 MLOps 解决方案 (MLOps Solutions for HPC):一位成员寻求适用于 HPC 且跳过 SaaS 依赖的 MLOps 框架,并指出 HPC 强大的存储能力是一项主要优势。
- 他们强调了对稳定解决方案的需求,并评估了 Guild AI 在 HPC 环境下的可靠性。
- Guild AI 的成长烦恼 (Guild AI Growing Pains):同一位用户对 Guild AI 的稳定性表示担忧,担心在 HPC 环境中可能出现停机。
- 他们寻求关于 HPC 部署的具体反馈,以确认 Guild AI 是否已准备好应对大规模训练任务。
- 低成本的 DIY Ops (DIY Ops on a Shoestring):他们还考虑自行构建一个极简的运维框架,认为这比安装基于服务器的解决方案更简单。
- 他们认为自定义方法可能会减少开销,同时也承认了维护自有工具集的风险。
PART 2: Detailed by-Channel summaries and links
完整的逐频道细分内容已针对邮件进行了截断。
如果您喜欢 AInews,请分享给朋友!提前致谢!