ainews-prime-process-reinforcement-through
**PRIME:基于隐式奖励的过程强化**
隐式过程奖励模型 (PRIME) 被视为在线强化学习领域的重大进展。该模型基于 7B 参数模型训练,其表现与 GPT-4o 相比毫不逊色,令人印象深刻。这一方法建立在《让我们逐步验证》(Let’s Verify Step By Step) 研究中所确立的过程奖励模型的重要性基础之上。
此外,AI 社交媒体上的讨论涵盖了 Claude-3.5-sonnet 的准 AGI (proto-AGI) 能力、算力扩展对人工超级智能 (ASI) 的作用,以及模型性能的细微差别。Gemini 2.0 编程模式和 LangGraph Studio 等新型 AI 工具进一步增强了智能体架构和软件开发能力。
行业动态方面,包括 LangChain AI 智能体大会及各类促进 AI 社区联系的线下聚会。公司更新显示,OpenAI 在 Pro 订阅方面面临财务挑战,而 DeepSeek-V3 已集成至 Together AI 的 API 中,展示了高效的 671B MoE 参数模型。研究讨论则集中在大语言模型的缩放法则 (scaling laws) 和计算效率上。
Implicit Process Reward Models are all you need.
2025年1月3日至2025年1月6日的 AI News。我们为您检查了 7 个 subreddits、433 个 Twitter 和 32 个 Discord(218 个频道和 5779 条消息)。预计节省阅读时间(以 200wpm 计算):687 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
我们在周五看到了这个,但留出了同行评审的时间,其反馈非常积极,足以作为头条新闻(PRIME 博客文章):
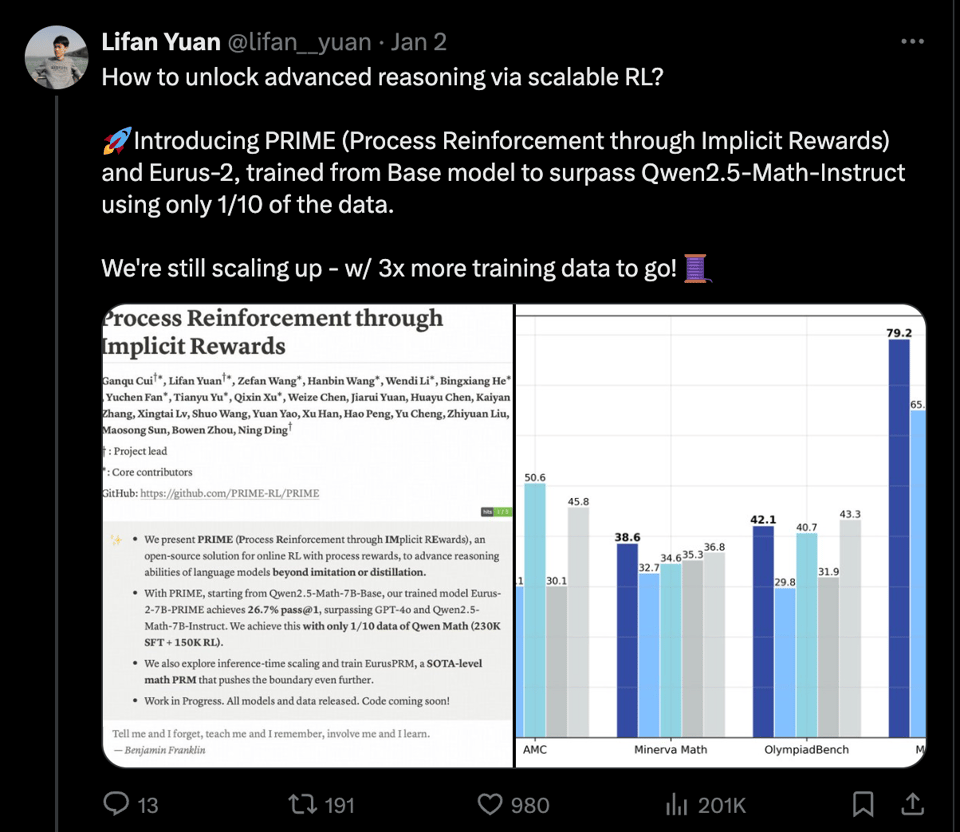
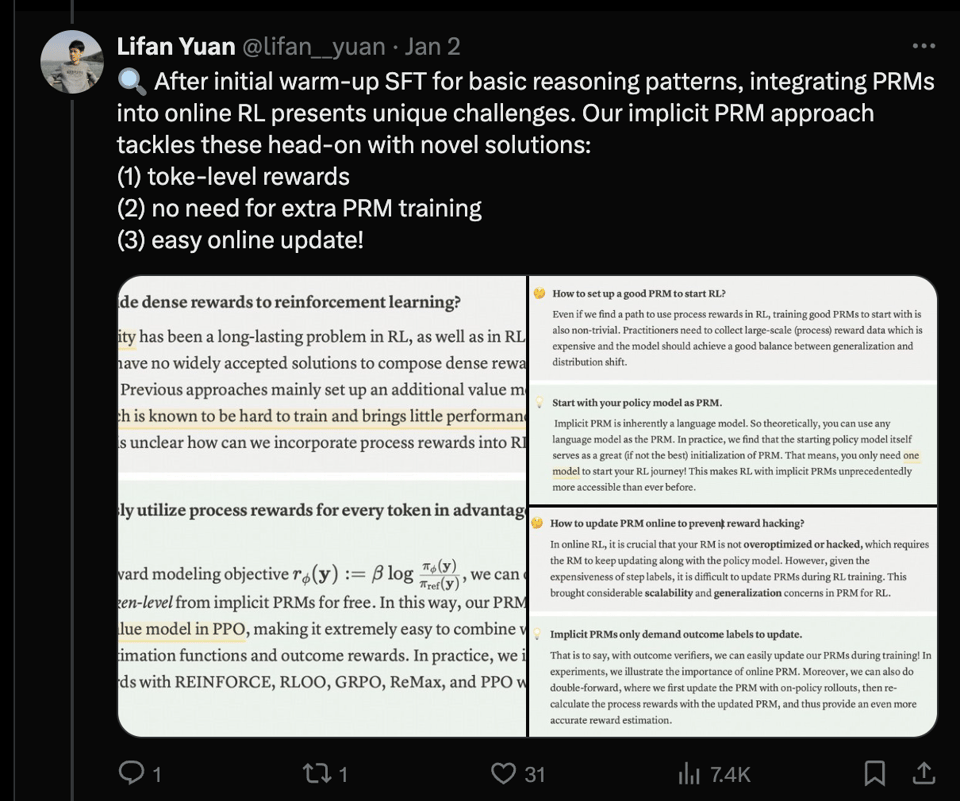
自从 Let’s Verify Step By Step 确立了 Process Reward Models 的重要性以来,人们一直在寻找其“开源”版本。PRIME 解决了 Online RL 的一些独特挑战:
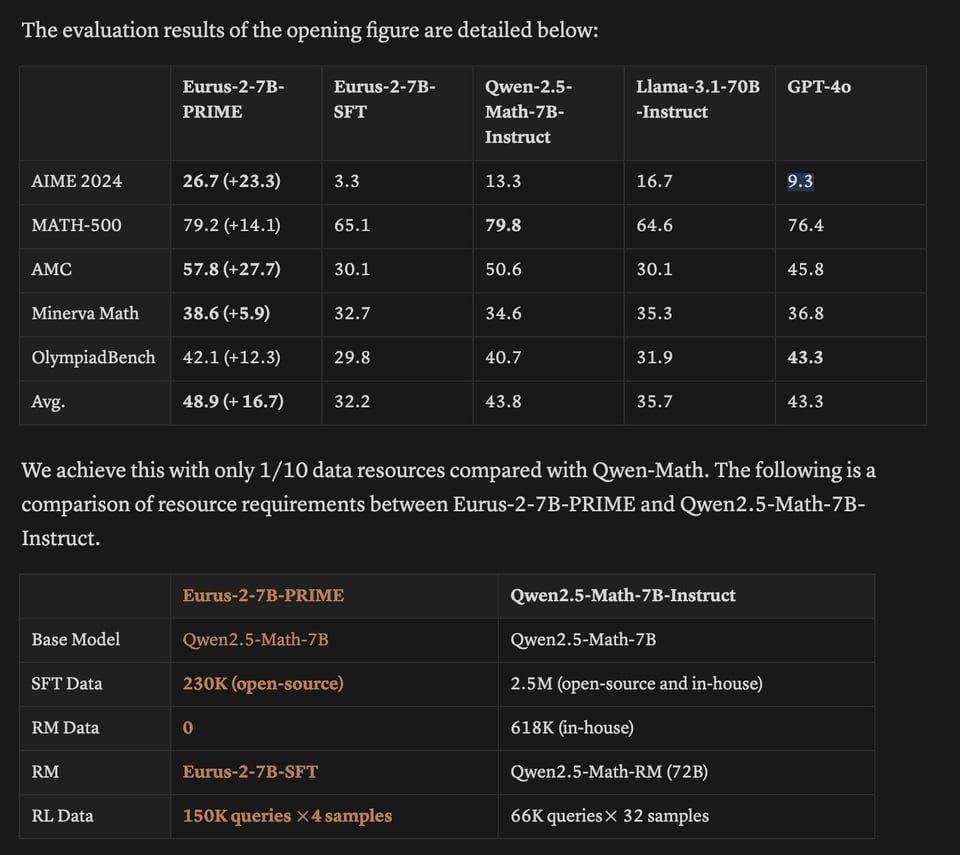
并在一个 7B 模型上进行训练,取得了相对于 4o 令人印象深刻的结果:
一个 lucidrains 的实现版本 正在开发中。
AI Twitter 摘要回顾
所有摘要均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
AGI 和大语言模型 (LLMs)
-
原始 AGI (Proto-AGI) 与模型能力:@teortaxesTex 和 @nrehiew_ 讨论了 Sonnet 3.5 作为一种原始 AGI (proto-AGI) 以及 AGI 不断演变的定义。@scaling01 强调了 算力扩展对人工智能超智能 (ASI) 的重要性,以及 测试时算力 (test-time compute) 在未来 AI 发展中的作用。
-
模型性能与对比:@omarsar0 分析了 Claude 3.5 Sonnet 的性能 与其他模型的对比,指出其在 数学推理方面的性能有所下降。@aidan_mclau 质疑了 评测框架 (harness) 的差异对模型评估的影响,强调了建立一致基准测试的必要性。
AI 工具与库
-
Gemini Coder 和 LangGraph:@_akhaliq 展示了 Gemini 2.0 编码模式 (coder mode),该模式支持 图片上传 和 AI-Gradio 集成。@hwchase17 介绍了 LangGraph Studio 的本地版本,增强了 Agent 架构开发 的体验。
-
软件开发实用工具:@tom_doerr 分享了诸如 Helix(一款基于 Rust 的文本编辑器)和 用 Python 解析简历 等工具,助力 代码导航 和 简历优化。@lmarena_ai 发布了 文生图竞技场排行榜 (Text-to-Image Arena Leaderboard),根据社区投票对 Recraft V3 和 DALL·E 3 等模型进行了排名。
AI 活动与会议
-
LangChain AI Agent 大会:@LangChainAI 宣布将在旧金山举办 Interrupt: The AI Agent Conference,届时将有来自 Michele Catasta 和 Adam D’Angelo 等行业领袖的 技术演讲和工作坊。
-
AI Agent 线下聚会:@LangChainAI 推广了 LangChain 橙县用户组聚会 (LangChain Orange County User Group meetup),促进 AI 构建者、初创公司和开发者 之间的联系。
公司动态与公告
-
OpenAI 财务与使用情况:@sama 透露,由于 使用量高于预期,OpenAI 目前在 Pro 订阅服务上处于亏损状态。
-
DeepSeek 与 Together AI 合作伙伴关系:@togethercompute 宣布 DeepSeek-V3 已上线 Together AI API,强调了其拥有 671B MoE 参数的高效性,且在 Chatbot Arena 中排名第 7。
AI 研究与技术讨论
-
扩展定律 (Scaling Laws) 与算力效率:@cwolferesearch 深入分析了 LLM 扩展定律,讨论了 幂律 (power laws) 和 数据扩展 的影响。@RichardMCNgo 辩论了 ASI 竞赛 以及 AI 模型实现 递归自我改进 (recursive self-improvement) 的潜力。
-
AI 伦理与安全:@mmitchell_ai 提出了 2025 年的伦理议题,重点关注 数据知情同意 和 语音克隆 等核心问题。
技术工具与软件开发
-
开发框架与实用工具:@tom_doerr 介绍了 Browserless,这是一项使用 Docker 执行无头浏览器任务的服务。@tom_doerr 介绍了 Terragrunt,这是一个封装了 Terraform 的工具,用于遵循 DRY (Don’t Repeat Yourself) 原则进行 基础设施管理。
-
AI 集成与 API:@kubtale 讨论了 Gemini coder 的图片支持 和 AI-Gradio 集成,使开发者能够轻松 构建自定义 AI 应用。
迷因与幽默
-
关于 AI 和技术的幽默观点:@doomslide 幽默地评论了 Elon 与英国国家机器的互动。@jackburning 发布了关于 AI 模型及其古怪之处 的有趣内容。
-
轻松对话:@tejreddy 分享了一个关于 AI 取代艺术家 的趣闻,而 @sophiamyang 则拿 航班延误和 AI 生成的邮件 开起了玩笑。
AI Reddit 回顾
/r/LocalLlama 回顾
主题 1. DeepSeek V3 在 AI 工作流中的主导地位
- DeepSeek V3 表现惊人。 (评分: 524, 评论: 207): DeepSeek V3 以其 6000 亿参数给人留下了深刻印象,提供了以往模型(包括 Claude, ChatGPT 和早期的 Gemini 变体)所缺乏的可靠性和多功能性。该模型在生成详细回复和适应用户提示词方面表现出色,成为那些对最先进模型工作流不一致感到沮丧的专业人士的首选。
- 用户将 DeepSeek V3 与 Claude 3.5 Sonnet 进行了比较,注意到其编程能力,但对其在长上下文下的响应速度慢表示不满。一些用户在使用 Cline 或 OpenRouter 等工具时遇到了 API 问题,而另一些用户则对其在聊天网页界面的稳定性表示赞赏。
- 讨论强调了 DeepSeek V3 的部署挑战,特别是对 GPU 服务器集群的需求,这使得个人用户较难触达。有建议认为,投资 Intel GPU 可能是一个战略举措,以鼓励开发更多专用代码。
- AMD 的 mi300x 和 mi355x 产品在 AI 开发方面被提及,尽管 mi300x 最初并非为 AI 设计,但其销量增长迅速。即将推出的 Strix Halo APU 被视为高端消费级市场的一项重大进展,表明 AMD 在 AI 硬件领域的存在感日益增强。
- DeepSeek v3 在 2x M2 Ultra 上通过 MLX.distributed 运行速度达到 17 tps! (评分: 105, 评论: 30): 据报道,DeepSeek v3 在使用 MLX.distributed 技术的 2x M2 Ultra 处理器配置上实现了 每秒 17 次事务 (TPS)。该信息由一位 Twitter 用户分享,更多详情链接见此处。
- 讨论强调了 M2 Ultra 处理器与二手 3090 GPU 之间的成本和性能比较,指出虽然 3090 GPU 的性能高出一个数量级,但其能效比明显较低。MoffKalast 计算出,以 7,499.99 美元的价格,考虑到每千瓦时 20 美分的电费,这笔钱足够让一块 3090 GPU 在满载状态下运行大约十年。
- 上下文长度和 Token 生成是重要的技术考量因素,用户询问 Token 数量如何影响 TPS,以及 4096 Token 的提示词是否会影响性能。Coder543 引用了 Reddit 上关于不同提示词长度性能差异的相关讨论。
- MOE (Mixture of Experts) 模型的效率引发了争论,fallingdowndizzyvr 指出,由于无法预先预测专家的使用情况,所有专家都需要加载,这会影响资源分配和性能。
主题 2. Dolphin 3.0:结合先进的 AI 模型
- Dolphin 3.0 发布 (Llama 3.1 + 3.2 + Qwen 2.5) (评分: 304, 评论: 37): Dolphin 3.0 已经发布,融合了 Llama 3.1、Llama 3.2 和 Qwen 2.5。
- 围绕 Dolphin 3.0 的讨论集中在模型性能和基准测试上,用户注意到缺乏全面的基准测试,导致难以评估模型质量。一位用户分享了一个快速测试结果,显示 Dolphin 3.0 在 MMLU-Pro 数据集上得分为 37.80,而 Llama 3.1 得分为 47.56,但提醒这些结果仅是初步的。
- Dolphin 和 Abliterated 模型之间的区别得到了澄清:Abliterated 模型移除了拒绝向量,而 Dolphin 模型是在新数据集上进行了微调。一些用户发现 Abliterated 模型更可靠,而 Dolphin 模型被描述为“前卫”而非真正的“无审查”。
- 用户对未来的更新充满期待,预计 Dolphin 3.1 将减少免责声明出现的频率。Discord 公告确认,更大的模型(如 32b 和 72b)目前正在训练中,并致力于通过标记和删除免责声明来改善模型行为。
- 我制作了一个关于理解英国经典流行问答节目 Never Mind the Buzzcocks 中笑话的(高难度)幽默分析基准测试 (Score: 108, Comments: 34): 该帖子讨论了一个名为 “BuzzBench” 的幽默分析基准测试,用于通过英国经典问答节目 “Never Mind the Buzzcocks” 评估语言模型 (LLM) 的情感智能。该基准测试根据模型的幽默理解得分进行排名,其中 “claude-3.5-sonnet” 得分最高,为 61.94,而 “llama-3.2-1b-instruct” 最低,为 9.51。
- 文化偏见担忧:评论者对幽默分析中潜在的文化偏见表示担忧,特别是考虑到 “Never Mind the Buzzcocks” 的英国背景。人们对如何解决此类偏见提出了疑问,例如是否明确说明了英国拼写或受众。
- 基准测试详情:该基准测试 BuzzBench 评估模型对幽默影响的理解和预测,最高分为 100。目前的最先进 (SOTA) 得分为 61.94,数据集可在 Hugging Face 上获取。
- 对历史背景的兴趣:人们好奇模型在处理该节目的早期剧集时表现如何,并质疑对不太受欢迎的主持人(如 Simon Amstell)的熟悉程度是否会影响幽默理解。
{kind=link}
主题 3. RTX 5090 传闻:高带宽潜力
- 传闻 RTX 5090 拥有 1.8 TB/s 显存带宽 (Score: 141, Comments: 161): 传闻 RTX 5090 将拥有 1.8 TB/s 显存带宽 和 512-bit 显存位宽,超越了除 A100/H100(带宽 2 TB/s,位宽 5120-bit)之外的所有专业卡。尽管其配备 32GB GDDR7 VRAM,但 RTX 5090 潜力巨大,可能是运行任何 Q6 量化下 <30B LLM 的最快选择。
- 讨论强调了 NVIDIA 消费级 GPU 缺乏足够的 VRAM,批评者认为两代产品仅增加 8GB 显存不足以满足 AI 和游戏需求。用户对 NVIDIA 刻意限制 VRAM 以保护其专业显卡市场表示沮丧,认为 48GB 或 64GB 型号 会蚕食其高端产品的市场。
- 成本担忧普遍存在,用户指出单张 RTX 5090 的价格可能相当于多张 RTX 3090,而后者因其 VRAM 和性能仍具有显著价值。消费级显卡的 单位 VRAM 价格 被认为比专业 GPU 更具优势,但总成本对许多人来说仍然过高。
- 能效和功耗是关键考量因素,传闻 RTX 5090 的功耗要求至少为 550 瓦,而 3090 为 350 瓦。用户讨论将降压 (undervolting) 作为潜在解决方案,但强调速度、VRAM 和功耗之间的权衡仍然是 GPU 选择的关键因素。
- 适用于 24Gb 的 LLM (Score: 53, Comments: 32): 作者组装了一台配备 i7-12700kf CPU、128Gb RAM 和 RTX 3090 24 GB 的设备,强调适配 VRAM 的模型运行速度明显更快。他们提到使用 Gemma2 27B 进行通用讨论以及使用 Qwen2.5-coder 31B 进行编程任务取得了良好效果,并询问其他适合 24Gb VRAM 限制的模型。
- 模型推荐:用户推荐了多种适合 24GB VRAM 配置的模型,包括 Llama-3_1-Nemotron-51B-instruct 和 Mistral small。Q4 量化模型如 QwQ 32b 和 Llama 3.1 Nemotron 51b 因其在此配置下的效率和性能而受到关注。
- 性能指标:评论者讨论了不同模型的吞吐量,Qwen2.5 32B 在 3090 上可达到 40-60 tokens/s,在 4090 上可能更高。72B Q4 模型在部分卸载 (offloading) 情况下运行速度约为 2.5 tokens/s,而 32B Q4 模型可达到 20-38 tokens/s。
- 软件与配置:人们对实现这些性能指标所使用的软件配置很感兴趣,要求提供关于使用 EXL2、tabbyAPI 和上下文长度的配置详情。一个 Reddit 讨论链接 提供了在单 GPU 配置下选择模型的更多资源。
其他 AI 子版块回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
主题 1. OpenAI 在 O1-Pro 遭受批评之际面临财务困境
- OpenAI 正在亏损 (Score: 2550, Comments: 518): 据报道,OpenAI 的 订阅模式 正面临财务挑战。在没有更多背景信息的情况下,尚未提供这些财务困难的具体细节。
- 许多用户对 o1-Pro 的 200 美元订阅费 反应不一,一些人认为它对提高生产力和编程效率具有不可估量的价值,而另一些人则因编程人员竞争加剧和成本上升的潜力而质疑其价值。Treksis 和 KeikakuAccelerator 强调了它在处理复杂编程任务方面的优势,但 IAmFitzRoy 对其在编程就业市场的影响表示担忧。
- 讨论显示出对 OpenAI 财务策略 的怀疑,评论认为尽管收费很高,公司仍在亏损,这可能是由于运行 o1-Pro 等高级模型的高昂运营成本。LarsHaur 和 Vectoor 讨论了公司在 R&D 上的投入以及维持正向现金流的挑战。
- 对 订阅模式的批评 包括要求提供基于 API 的模式,以及对当前定价可持续性的担忧,正如 MultiMarcus 和 mikerao10 所指出的。Fantasy-512 和 Unfair-Associate9025 等用户对定价策略表示难以置信,质疑其长期可行性和涨价的可能性。
- 你不是真正的客户。 (Score: 237, Comments: 34): Anthony Aguirre 认为,科技公司在 AI 投资策略中优先考虑雇主而非个人消费者,旨在通过用 AI 系统取代工人来获得显著的财务回报。这反映了影响 AI 发展和基础设施投资的更广泛的财务动态。
- 全民基本收入 (UBI) 被批评为一种幻想,无法解决 AI 取代工作所带来的经济挑战。评论者认为,这种过渡将创造一种新形式的农奴制,公司通过提供有需求的技术来获得权力,但最终仍依赖于消费者的购买力。
- 预计在 AI 真正达到人类水平之前,就会发生 AI 替代 工人的现象,这是由降低成本而非提高质量驱动的。这反映了过去为了廉价劳动力而进行的离岸外包等趋势,体现了对财务效率而非服务质量的关注。
- AI 从业者承认 AI 发展中的 经济动态 优先考虑利润和削减成本,而非消费者利益。讨论强调了这种转变的必然性,以及工人和公司都可能面临艰难过渡的可能性。
{kind=link}
主题 2. 2025 年实现 AI Level 3:OpenAI 的愿景与担忧
- 2025 年实现 AI Level 3 (Agent),正如 Sam Altman 的新帖… (Score: 336, Comments: 162): 到 2025 年,AI Level 3 Agent 的发展预计将显著影响业务生产力,标志着从基础 AI 聊天机器人向更高级 AI 系统的转变。该帖子乐观地认为,这些 AI 的进步将提供有效的工具,从而在劳动力市场产生广泛的积极结果。
- 对于 AI Level 3 Agent 对公司的影响存在怀疑,一些人认为个人将比企业受益更多。Immersive-matthew 指出,许多人已经为了生产力而拥抱 AI,而公司尚未看到同等的收益,这表明 AI 可能会赋能个人而非大型企业。
- 对 AI 进步带来的经济和劳动力影响的担忧十分普遍。Kiwizoo 和 Grizzly_Corey 讨论了潜在的经济崩溃和劳动力中断,认为 AI 和机器人技术可能会消除对人类劳动的需求,从而导致重大的社会变革。
- 存在对围绕 AGI 的炒作的批评,以及对其短期实现的怀疑。Agitated_Marzipan371 等人对 2025 年 实现真正 AGI 的可行性表示怀疑,认为该术语是一种营销策略而非现实目标,并将其与其他过度炒作的技术预测进行了比较。
{kind=link}
主题 3. AI 模型的效率:Claude 3.5 与 Google 的进展
- 在阅读一些评论后看了 Anthropic CEO 的访谈。我认为没有人知道为什么当 LLM 复杂度和训练数据集规模增加时会出现涌现属性。在我看来,这些技术巨头正在进行一场竞赛,盲目地增加能源需求而非软件优化。 (Score: 130, Comments: 79): 该帖子批评了 AI 领域 tech leaders 的做法,认为他们专注于扩大 LLM complexity 和 training dataset sizes,而不理解 AGI 等属性的涌现。作者建议投资 nuclear energy technology 作为更有效的策略,而不是在不优化软件的情况下盲目增加能源需求。
- 优化与扩展 (Optimization and Scaling): 几条评论强调了 AI 开发中对优化的关注,RevoDS 指出 GPT-4o 比 GPT-4 便宜 30 倍且体积小 8 倍,这表明在扩展的同时,人们也在为优化模型做出巨大努力。Prescod 认为行业并非“盲目”扩展,也在探索更好的学习算法,尽管到目前为止扩展一直很有效。
- 核能与 AI (Nuclear Energy and AI): Rampants 提到像 Sam Altman 这样的技术领袖参与了 Oklo 等核能初创公司,Microsoft 也在探索核能,这表明人们对 AI 可持续能源解决方案有着平行的兴趣。然而,新的核能项目面临着巨大的审批和实施挑战。
- 涌现属性与复杂度 (Emergent Properties and Complexity): Pixel-Piglet 讨论了随着神经网络规模扩大,涌现属性的必然性,并将其与人类大脑进行了类比。评论认为数据和模型的复杂度会导致意想不到的结果,这一观点得到了 Ilya Sutskever 对模型复杂性和涌现能力的观察的支持。
AI Discord 摘要
由 o1-preview-2024-09-12 生成的摘要的摘要总结
主题 1. AI 模型性能与故障排除
- DeepSeek V3 面临稳定性挑战: 用户报告了 DeepSeek V3 的性能问题,包括响应时间长以及在处理较大输入时失败。尽管基准测试表现良好,但人们对其在实际应用中的实际精度和可靠性表示担忧。
- Cursor IDE 用户应对模型性能不稳定的问题: 开发者经历了 Cursor IDE 的不稳定表现,特别是在使用 Claude Sonnet 3.5 时,提到了上下文保留问题和令人困惑的输出。建议包括降级版本或简化 prompt 以缓解这些问题。
- LM Studio 0.3.6 模型加载错误引发用户不满: LM Studio 的新版本在加载 QVQ 和 Qwen2-VL 等模型时导致了 exit code 133 错误和 RAM 占用增加。一些用户通过调整上下文长度或回退到旧版本克服了这些挫折。
主题 2. 新 AI 模型与工具发布
- Unsloth 发布动态 4-bit 量化黑科技: Unsloth 推出了 dynamic 4-bit quantization,在降低 VRAM 占用的同时保持了模型精度。测试者报告称在不牺牲微调保真度的情况下实现了速度提升,这标志着高效模型训练的重大进步。
- LM Studio 0.3.6 升级,支持 Function Calling 和视觉功能: 最新的 LM Studio 版本具有用于本地模型使用的全新 Function Calling API,并支持 Qwen2VL 模型。开发者称赞了扩展的功能和改进的 Windows installer,提升了用户体验。
- Aider 扩展 Java 支持与调试集成: 贡献者强调 Aider 现在通过 prompt caching 支持 Java 项目,并正在探索与 ChatDBG 等工具的调试集成。这些进步旨在增强程序员的开发工作流。
主题 3. 硬件更新与展望
- Nvidia RTX 5090 泄露引发 AI 爱好者关注:一次泄露透露了即将推出的 Nvidia RTX 5090 将配备 32GB GDDR7 显存,在预期的 CES 发布前引发了热烈讨论。这一消息让最近购买 RTX 4090 的用户感到被背刺,并预示着 AI 训练工作负载的加速。
- 社区辩论 AMD vs. NVIDIA 在 AI 工作负载上的表现:用户对比了 AMD 的 CPU 和 GPU 与 NVIDIA 在 AI 任务中的表现,对 AMD 的宣传持怀疑态度。许多人更倾向于 NVIDIA 在重型模型中的稳定表现,尽管也有一些人在等待 AMD 新产品的实际基准测试。
- 对 AMD Ryzen AI Max 的期待升温:爱好者们对测试 AMD Ryzen AI Max 表现出浓厚兴趣,推测其在 AI 工作负载中与 NVIDIA 竞争的潜力。关于将其与 GPU 结合运行以提升 AI 应用综合性能的问题也随之产生。
主题 4. AI 伦理、政策与行业动态
- OpenAI 对 AGI 进展的反思引发辩论:Sam Altman 讨论了 OpenAI 迈向 AGI 的历程,引发了关于 AI 开发中企业动机和透明度的辩论。批评者强调了对先进 AI 能力可能对创新和创业产生影响的担忧。
- Anthropic 因 Claude 面临版权挑战:Anthropic 同意在 Claude 上维持护栏(guardrails),以防止在出版商提起法律诉讼期间分享受版权保护的歌词。这一争端突显了 AI 开发与知识产权之间的紧张关系。
- 阿里巴巴与 01.AI 合作建立工业 AI 实验室:Alibaba Cloud 与 01.AI 合作建立联合 AI 实验室,目标行业包括金融和制造业。此次合作旨在加速大模型解决方案在企业环境中的落地。
主题 5. AI 训练技术与研究进展
- PRIME RL 开启高级语言推理:研究人员研究了 PRIME (Process Reinforcement through Implicit Rewards),展示了可扩展的 RL 技术以增强语言模型的推理能力。该方法证明了在极少的训练步骤下即可超越现有模型。
- MeCo 方法加速语言模型预训练:由 Tianyu Gao 引入的 MeCo 技术通过在训练文档前添加源 URL 来加速 LM 预训练。早期反馈表明,在各种语料库的训练结果中都有适度的改进。
- 使用 LoRA 技术的显存高效微调受到关注:用户讨论了在 GPU 容量有限的情况下使用 LoRA 进行大模型的高效 fine-tuning。建议集中在如何在不牺牲模型性能的情况下优化内存使用,特别是针对低 VRAM 配置下的 DiscoLM 等模型。
第 1 部分:高层级 Discord 摘要
aider (Paul Gauthier) Discord
- Sophia 的翱翔方案与 Aider 的显见亲和力:全新的 Sophia 平台 引入了 autonomous agents、强大的 pull request 审查和多服务支持,如 sophia.dev 所示,旨在针对高级工程工作流。
- 社区成员将这些功能与 Aider 的特性进行了对比,称赞了其重合之处,并表现出对 测试 Sophia 以用于 AI 驱动的软件流程的兴趣。
- Val Town 的涡轮增压 LLM 策略:在博文中,Val Town 分享了他们从 GitHub Copilot 转向 Bolt 和 Cursor 等新型助手的进展,试图与快速更新的 LLM 保持同步。
- 他们的这种被称为 fast-follows 的方法引发了关于采用其他团队成熟策略来优化代码生成系统的讨论。
- AI 代码分析获得“高级开发人员”视野:我教 AI 像高级开发人员一样阅读代码的那一天中概述的一项实验引入了上下文感知分组,使 AI 能够优先处理 核心变更 和架构。
- 参与者指出,这种方法克服了 React codebases 中的混乱,称其为超越朴素的、逐行 AI 解析方法的重大飞跃。
- Aider 推进 Java 支持和调试举措:贡献者透露 Aider 通过 prompt caching 支持 Java 项目,并参考了安装文档进行灵活设置。
- 他们还探索了使用 ChatDBG 等框架进行调试,强调了 Aider 与交互式故障排除解决方案之间的潜在协同作用。
Unsloth AI (Daniel Han) Discord
- Unsloth 的 4-bit 巫术:团队推出了 动态 4-bit quantization,在保留 模型准确度 的同时减少了 VRAM 使用量。
- 他们在 Unsloth 文档中分享了 安装 技巧,并报告称测试者在不牺牲微调保真度的情况下看到了速度提升。
- 并发微调的壮举:一位用户确认,同时 微调多种模型尺寸(0.5B, 1.5B, 3B)是安全的,正如 Unsloth 文档中所解释的那样。
- 他们指出了关键的 VRAM 限制,建议使用较小的学习率和 LoRA 方法以确保 内存效率。
- Rohan 的量子旋转与数据工具:Rohan 展示了用于 Pandas 数据任务的交互式 Streamlit 应用,并链接了他的 LinkedIn 帖子和一篇量子博客 此处。
- 他将经典数据分析与 复数探索 相结合,激发了人们对将 AI 与新兴量子方法集成的兴趣。
- LLM 排行榜大对决:社区成员将 Gemini 和 Claude 排在首位,称赞 Gemini experimental 1207 是一款出色的免费模型。
- 讨论表明 Gemini 跑赢了其他开源构建版本,引发了关于哪款 LLM 真正夺冠的辩论。
Codeium (Windsurf) Discord
- Tidal 调整:Codeium 频道与 12 月更新日志:Codeium 服务器为 .windsurfrules 策略引入了新频道,添加了一个独立的协作论坛,并发布了 12 月更新日志。
- 成员们期待新的 Stage 频道和更多展示社区成就的方式,许多人称赞了精简后的 support portal(支持门户)方法。
- 登录困境:身份验证故障与私有化部署愿景:用户遇到了 Codeium 登录问题,建议重置 Token,而其他人则询问在 Enterprise License(企业许可证)下为 10–20 名开发者进行私有化部署的设置。
- 有人建议使用单台 PC 进行托管,但也有人担心如果使用量增长可能会出现性能瓶颈。
- Neovim 动态:插件重构与展示频道梦想:讨论集中在 Neovim 的
codeium.vim和Codeium.nvim上,重点关注了冗长的注释补全以及建立 showcase(展示)频道的愿景。- 社区成员期望更精细的插件行为,希望很快能在专门的论坛中展示基于 Windsurf 和 Cascade 的应用。
- Claude 瓶颈:Windsurf 的挣扎与 Cascade 的怪癖:Windsurf 在使用 Claude 3.5 时反复出现无法应用代码更改的问题,产生“Cascade 无法编辑不存在的文件”错误,并提示开启全新会话。
- 许多人怀疑 Claude 在处理多文件工作时比较吃力,建议用户使用 Cascade Base 以获得更可预测的结果。
- 额度困惑:Premium vs. Flex 与项目结构:开发者讨论了 Premium User Prompt Credits 与 Flex Credits 的区别,指出 Flex 支持持续的 Prompt 以及在 Cascade Base 上的高强度使用。
- 他们还建议将规则整合到单个 .windsurfrules 文件中,并分享了后端组织的方法。
Cursor IDE Discord
- Cursor 更新日志与计划:新发布的 Cursor v0.44.11 引发了对更好更新日志和模块化文档的需求,并提供了 下载链接。
- 一些开发者强调需要灵活的项目计划功能,希望有更简单的步骤来实时跟踪任务。
- Claude Sonnet 3.5 的意外表现:工程师们报告了 Claude Sonnet 3.5 不稳定的性能,理由是长对话中的上下文保留问题和令人困惑的输出。
- 一些用户建议,回退版本或使用更简洁的 Prompt 有时比详尽的指令效果更好。
- Cursor 的 AGI 雄心:几位用户将 Cursor 视为编程领域更高层级智能的潜在跳板,讨论了利用任务导向功能的方法。
- 他们推测,完善这些功能可能会增强 AI 驱动的能力,缩小手动编码与自动化辅助之间的差距。
- Composer 与上下文灾难:开发者在处理大文件时遇到了 Composer 的麻烦,理由是编辑问题以及对扩展代码块的上下文处理不佳。
- 他们注意到在切换任务时会出现随机的上下文重置,导致意外的更改和跨会话的混乱。
LM Studio Discord
- LM Studio 0.3.6 带来 Tool Calls 功能:LM Studio 0.3.6 发布,推出了用于本地模型使用的 新 Function Calling / Tool Use API,并新增了对 Qwen2VL 的支持。
- 模型加载遇到 Exit Code 133:用户在 LM Studio 中加载 QVQ 和 Qwen2-VL 时遇到了 exit code 133 错误以及 RAM 占用增加的问题。
- 一些用户通过调整上下文长度或回退到旧版本解决了这些问题,而另一些用户则通过在命令行使用 MLX 取得了成功。
- Function Calling API 广受好评:Function Calling API 将模型输出扩展到了文本之外,用户对文档和示例工作流都给予了高度评价。
- 然而,少数用户在升级到 3.6 后遇到了 JiT model loading 的意外变化,并呼吁进行额外的 Bug 修复。
- AMD 与 NVIDIA 的硬件之争:参与者指出,70B 模型需要的 VRAM 超过了大多数 GPU 的容量,只能依赖 CPU 推理或更小的量化版本。
- 他们辩论了 AMD vs NVIDIA 的表现——一些人支持 AMD CPU 的性能,但对处理超大模型时的实际收益仍持怀疑态度。
- 关于 AMD Ryzen AI Max 的讨论:爱好者们对 AMD 新推出的 Ryzen AI Max 表现出浓厚兴趣,询问其是否有潜力在处理重型模型需求时与 NVIDIA 竞争。
- 他们还询问了将其与 GPU 并行运行以获得组合算力的可能性,反映出对多设备设置的持续关注。
Stackblitz (Bolt.new) Discord
- Stackblitz 备份消失:如 #prompting 频道所述,一些用户在重新打开 Stackblitz 时发现项目恢复到了早期状态,尽管频繁保存但仍丢失了代码。
- 社区成员确认了类似经历,但除了反复检查保存和备份外,目前还没有通用的解决方案。
- 部署工作流困惑:用户在尝试从 Netlify 或 Bolt 等不同服务将代码推送到 GitHub 时感到困惑,争论是该依赖 Bolt Sync 还是外部工具。
- 他们一致认为,统一的仓库更新方法至关重要,但讨论中尚未形成定论性的工作流。
- Token 消耗与高额账单:参与者报告了极高的 Token 使用量,有时为了微小的修改就消耗了数十万个 Token,引发了对成本的担忧。
- 他们建议优化指令以减少 Token 浪费,并强调精细的编辑和周密的计划有助于防止过度消耗。
- Supabase 与 Netlify 故障:开发者在集成 Bolt 时遇到了 Netlify 部署错误,并参考 此 GitHub issue 寻求指导。
- 其他人则遇到了 Supabase 登录和账户创建问题,通常需要重新配置 .env 才能使一切正常运行。
- Prompting 与 OAuth 异常:社区成员建议在开发阶段不要在 Bolt 中使用 OAuth,理由是经常出现身份验证失败,建议改用基于电子邮件的登录。
- 讨论还强调了为 Bolt 编写高效 Prompt 以限制 Token 消耗的重要性,用户们分享了如何精准构建指令的技巧。
Stability.ai (Stable Diffusion) Discord
- Stable 惊喜:模型混淆:多位用户发现 Civit.ai 模型在处理“骑马的女人”等基础提示词时表现不佳,引发了对提示词精确性的困惑。
- 一些参与者分享称某些 LoRA 的表现优于其他模型,并链接到了 CogVideoX-v1.5-5B I2V workflow,称赞其生成的质量更清晰。
- LoRA 逻辑还是全量 Checkpoint 热潮:参与者讨论了 LoRA 还是完整的 Checkpoint 谁能更好地满足风格需求,LoRA 提供针对性的增强,而全量 Checkpoint 则提供更广泛的能力。
- 他们指出如果堆叠多个 LoRA 可能会产生模型冲突,强调更倾向于专门的训练,并参考了 GitHub - bmaltais/kohya_ss 以实现流程化的自定义 LoRA 创建。
- ComfyUI 难题:掌握基于节点的系统:ComfyUI 工作流引发了讨论,新手发现其基于节点的方法既灵活又具挑战性。
- 推荐了 Stable Diffusion Webui Civitai Helper 等资源,以便轻松管理 LoRA 使用并减少工作流摩擦。
- 局部重绘 (Inpainting) vs. 图生图 (img2img):速度之争:一些用户报告称,尽管只编辑图像的一部分,但 Inpainting 的耗时明显长于 img2img。
- 他们推测内部操作的复杂度差异很大,并引用了 AnimateDiff 进行高级多步生成的参考。
- GPU 传闻:5080 与 5090 推测:关于即将推出的 NVIDIA GPU 的传闻四起,提到 5080 和 5090 的定价可能分别为 1400 美元和 2600 美元。
- 对市场炒作(黄牛)的担忧也随之而来,促使一些人建议等待未来的 AI 专用显卡或 NVIDIA 的更多官方公告。
Latent Space Discord
- Nvidia 5090 带来的 GDDR7 提升:来自 Tom Warren 的最后一刻泄露显示,Nvidia RTX 5090 将包含 32GB 的 GDDR7 显存,就在其预期的 CES 亮相之前。
- 爱好者们讨论了加速训练工作负载的潜力,期待官方公告确认规格和发布时间表。
- LangChain 的 Interrupt 会议:LangChain 揭晓了将于 5 月在旧金山举办的 Interrupt: The AI Agent Conference,其特色是以代码为核心的工作坊和深度会议。
- 一些人认为时间点与更大规模的 Agent 专题活动一致,标志着这次聚会将成为推动新 Agent 解决方案的人士的枢纽。
- PRIME 时间:重温强化奖励:开发者们对 PRIME (Process Reinforcement through Implicit Rewards) 议论纷纷,该研究显示 Eurus-2 在极少的训练步数下超越了 Qwen2.5-Math-Instruct。
- 批评者称其为两个 LLM 之间的博弈,而支持者则认为它是密集型分步奖励建模的一次飞跃。
- ComfyUI 与艺术 AI 工程:新一期 Latent.Space 播客 重点介绍了 ComfyUI 的起源故事,涵盖了 GPU 兼容性和用于创意工作的视频生成。
- 团队讨论了 ComfyUI 如何从个人原型演变为一家在 AI 驱动艺术领域进行创新的初创公司。
- GPT-O1 在 SWE-Bench 上表现不佳:多条推文(如这条)显示,OpenAI 的 GPT-O1 在 SWE-Bench Verified 上的得分为 30%,与声称的 48.9% 不符。
- 与此同时,Claude 得分为 53%,引发了关于模型评估以及在现实任务中可靠性的辩论。
Interconnects (Nathan Lambert) Discord
- Nvidia 5090 意外亮相:来自 Tom Warren 的报告指出,Nvidia RTX 5090 在 CES 前夕浮出水面,配备 32GB GDDR7 显存,令最近购买 RTX 4090 的用户感到背刺。这次泄露引发了对其规格以及对高端 AI 工作负载价格影响的兴奋讨论。
- 社区反应不一,既有对匆忙购买 4090 的后悔,也有对即将发布的 benchmark 结果的好奇。一些人推测 Nvidia 的下一代产品线可能会进一步加速 compute-intense training pipelines。
- 阿里巴巴与 01.AI 的联合行动:正如 SCMP 文章 所述,阿里云与 01.AI 建立了合作伙伴关系,旨在建立一个针对金融、制造等行业的工业级 AI 联合实验室。他们计划合并大模型解决方案的研究资源,旨在加速企业环境中的应用落地。
- 关于资源共享范围以及是否会进行海外扩张的问题依然存在。尽管报告褒贬不一,但参与者看到了推动亚洲下一代企业技术发展的潜力。
- METAGENE-1 应对病原体:根据 Prime Intellect 的消息,一个名为 METAGENE-1 的 7B 参数宏基因组模型 已与 USC 研究人员合作开源。该工具针对全球范围内的病原体检测,以加强大流行病预防。
- 成员们强调,这种规模的领域特定模型可以加速流行病学监测。许多人期待在大型公共卫生计划中出现扫描基因组数据的新流水线。
- OpenAI 的 O1 分数走低:据 Alex_Cuadron 报道,O1 在 SWE-Bench Verified 上的得分仅为 30%,与此前声称的 48.9% 相矛盾,而 Claude 在同一测试中达到了 53%。测试者怀疑这种差异可能反映了 prompting 细节或不完整的验证步骤。
- 这一发现引发了关于 post-training 改进和实际性能的辩论。一些人敦促建立更透明的 benchmark,以澄清 O1 是否仅仅需要更精细的指令。
- 用于快速预训练的 MeCo 方法:由 Tianyu Gao 提出的 MeCo(metadata conditioning then cooldown)技术,通过在训练文档前添加 source URLs 来加速 LM 预训练。这些增加的 metadata 提供了领域上下文线索,可以减少文本理解中的盲目猜测。
- 怀疑者质疑其大规模可行性,但该方法因阐明了基于站点的提示如何优化训练而获得赞赏。早期反馈表明,对于某些语料库,训练结果有适度改善。
Nous Research AI Discord
- Hermes 3 遭遇“舞台恐惧症”:社区成员反映 Hermes 3 405b 生成的角色表现出焦虑和胆怯,即使是那些本应表现自信的角色也是如此。他们分享了调整 system prompts 和提供澄清示例等技巧,但也承认塑造理想模型行为具有挑战性。
- 一些人指出,微调 prompt 基准非常棘手,这反映了平衡 AI 能力与用户 prompts 之间关系的大背景。其他人则坚持认为,彻底的人工测试是验证角色塑造的唯一可靠方法。
- ReLU² 与 SwiGLU 之争:针对 Primer: Searching for Efficient Transformers 的后续研究表明,ReLU² 在成本相关指标上优于 SwiGLU,这引发了关于为什么 LLaMA3 没有采用它的讨论。
- 一些参与者注意到前馈块(feed-forward block)调整的重要性,称这种改进为“Transformer 优化的新尝试”。他们好奇更低的训练开销是否会导致在未来的架构中出现更多实验。
- PRIME RL 强化语言推理:用户研究了 PRIME RL GitHub 仓库,该项目声称提供了一种可扩展的 RL 解决方案,以增强高级语言模型的推理能力。他们评论说,这可能为大规模 LLM 的结构化思维开辟更广阔的道路。
- 一位用户承认在研究该项目时感到疲惫,但仍认可该项目极具前景的研究方向,这表明社区共同渴望更强大的基于 RL 的方法。对话显示,一旦成员们恢复精力,将有兴趣进行进一步探索。
- OLMo 的大规模协作:Team OLMo 发布了 2 OLMo 2 Furious (arXiv 链接),展示了具有改进架构和数据混合的新型稠密自回归模型。这一努力突显了他们对开放研究的推动,多位贡献者共同完善了下一代 LLM 开发的训练配方。
- 社区成员赞扬了广泛的协作,强调了架构和数据的扩展如何促进更深层次的实验。他们认为这是一个信号,表明围绕高级语言建模的开放讨论在研究人员中正日益升温。
OpenAI Discord
- OmniDefender 的本地 LLM 飞跃:在 OmniDefender 中,用户集成了一个 Local LLM 来检测恶意 URL 并离线检查文件行为。这种设置避免了外部调用,但在恶意网站阻止传出检查时会遇到困难,从而使威胁检测复杂化。
- 社区反馈赞扬了离线扫描的潜力,并引用了 GitHub - DustinBrett/daedalOS: Desktop environment in the browser 作为重型本地应用的例子。一位成员开玩笑说,这展示了驱动 恶意软件预防 的“自给自足式防御的一瞥”。
- MCP 规范势头强劲:实施 MCP 规范 简化了插件集成,引发了 AI 开发的飞跃。一些人将 MCP 与旧的插件方法进行了对比,称赞其为多功能扩展的新标准。
- 参与者指出“多兼容性是逻辑上的下一步”,引发了广泛关注。他们预测,随着供应商追求 MCP 就绪性,将会出现一场“插件军备竞赛”。
- 天价 GPT 账单:OpenAI 透露其大型 GPT 模型的运行成本为 每条消息 25 美元,引起了轰动。开发者对在日常使用中扩展此类费用的问题表示担忧。
- 一些参与者称这个价格对于持续的实验来说“太贵了”。其他人则希望分级套餐能向更多用户开放高级 GPT-4 功能。
- Sora 的单图困局:开发者抱怨 Sora 每个视频仅支持上传一张图片,落后于支持多图工作流的平台。这一限制为详细的图像处理任务带来了重大障碍。
- 反馈包括“图像结果还不错,但一次只能一张是一个很大的限制”等评论。一些人寄希望于功能扩展,称其为“现代多图流水线的关键”。
- AI 文档分析策略:成员们讨论了在不暴露 PII 的情况下扫描车辆贷款文件的方法,建议在进行任何 AI 驱动的检查之前先进行脱敏处理。这种手动方法旨在利用高级解析技术的同时保护隐私。
- 一位参与者将其称为“暴力隐私保护”,并敦促对自动化解决方案保持谨慎。另一位建议从官方渠道获取脱敏版本,以规避存储机密数据的风险。
Perplexity AI Discord
- Apple Siri 窃听风波平息:Apple 就 Siri Snooping(Siri 窃听)诉讼达成和解,引发了隐私问题并突显了用户在这篇文章中表达的担忧。
- 评论者分析了长期法律和伦理辩论的影响,强调了强大的数据保护的必要性。
- Swift 在现代开发中势头强劲:一位用户分享了关于 Swift 及其最新增强功能的见解,引用了这篇概述。
- 开发者赞扬了 Swift 不断进化的能力,称其为 Apple 平台应用创建的首选。
- 游戏巨头任命 AI CEO:一家未具名的游戏公司开创先河,任命了一位 AI CEO,详情见此简报。
- 观察者指出,这一新兴的企业实验标志着管理和战略的新方法。
- Mistral 引发 LLM 好奇心:成员们在缺乏深度专业知识的情况下,讨论了将 Mistral 作为潜在 LLM 选项的可能性,想知道它是否在众多 AI 工具中增加了新功能。
- 用户对其独特优势表示疑问,在考虑广泛采用之前寻求具体的性能数据。
Eleuther Discord
- DeepSeek v3 深度探索:爱好者们在本地使用 4x3090 Ti GPU 测试了 DeepSeek v3,目标是在 3 天内使 MMLU-pro 达到 68.9%,并指向 Eleuther AI 的参与页面以获取更多资源。
- 他们的对话强调了硬件限制以及对架构改进的建议,引用了一条关于新 Transformer 设计的推文。
- MoE 热潮与 Gated DeltaNet:成员们辩论了高专家数 MoE 的可行性以及 Gated DeltaNet 中的参数平衡,链接到了 GitHub 代码和一条关于 DeepSeek 的 MoE 方法的推文。
- 他们质疑了大规模实验室的实际权衡,同时赞扬 Mamba2 减少了参数,暗示“百万专家”概念可能无法完全兑现性能承诺。
- Metadata Conditioning 的收益:研究人员提出 Metadata Conditioning (MeCo) 作为一种引导语言模型学习的新技术,引用了论文 “Metadata Conditioning Accelerates Language Model Pre-training” (arXiv) 并参考了 Cerebras RFP。
- 他们在各种规模下都看到了显著的预训练效率提升,并关注到 Cerebras AI 提供资助以推动生成式 AI 研究。
- 显微镜下的 CodeLLMs:社区成员分享了关于编程模型的 mechanistic interpretability 研究结果,指向 Arjun Guha 的 Scholar 简介,并探讨了通过“Understanding How CodeLLMs (Mis)Predict Types with Activation Steering”进行的 type hint steering。
- 他们讨论了用于代码生成的 Selfcodealign(预告于 2024 年发布),并认为自动化测试套件反馈可以纠正预测错误的类型。
- Chat Template 的波动:在 L3 8B 上使用 chat templates 的多次评估结果在 70% 左右波动,参考了 lm-evaluation-harness 代码。
- 他们发现移除模板后性能有 73% 的跃升,这让他们后悔没有早点测试,并澄清了本地 HF 模型的 request caching 细微差别。
OpenRouter (Alex Atallah) Discord
- llmcord 取得重大进展:llmcord 项目 已获得超过 400 个 GitHub stars,它让 Discord 能够作为包括 OpenRouter 和 Mistral 在内的多个 AI 提供商的中心。
- 贡献者强调了其简单的设置以及在单一环境中统一 LLM usage 的潜力,并指出了其灵活的 API 兼容性。
- 美甲艺术融入 AI 元素:一个新的 美甲生成器 (Nail Art Generator) 使用文本 Prompt 和 最多 3 张图片 来生成有趣的设计,由 OpenRouter 和 Together AI 提供支持。
- 成员们赞扬了其快速生成的结果,称其为 “创意与 AI 的巧妙融合”,并指出未来在 Prompt 和艺术风格方面会有所扩展。
- Gemini Flash 1.5 表现出色:社区成员权衡了 Gemini Flash 1.5 与 8B 版本,建议先使用较小的模型以更好地控制成本,并参考了 具有竞争力的价格。
- 他们注意到 Hermes 测试者在使用 OpenRouter 而非 AI Studio 时看到了 Token 费用的降低,这激发了切换到该模型的兴趣。
- DeepSeek 遇到障碍:多名用户报告了 DeepSeek V3 的停机时间以及超过 8k tokens 的 Prompt 输出变慢,认为这与扩展性问题有关。
- 一些人建议绕过 OpenRouter 直接连接 DeepSeek,期望此举能降低延迟并避免临时限制。
Notebook LM Discord Discord
- 300 个源导致音频冻结:一位用户注意到,当包含多达 300 个源 时,NLM 音频概览会冻结在某一个源上,从而中断播放。
- 他们强调了对大型项目可靠性的担忧,希望能有修复方案来改进 multi-source handling。
- NotebookLM Plus 功能强大:成员们分析了免费层级和付费层级之间的差异,参考了 NotebookLM Help 中关于上传限制和功能的具体细节。
- 他们讨论了诸如 更大的文件限额 等高级功能,促使一些人权衡是否为更重的工作负载进行升级。
- 播客中断与语音随机切换:尽管有自定义指令,但频繁的播客中断仍然存在,这促使人们建议使用更强力的 System Prompt 来让主持人保持对话。
- 一位用户成功测试了单一男声,但尝试仅选择 女性专家 声音时遇到了意想不到的阻碍。
- 教育 Prompt 与备忘录变得简单:人们探索了将 Mac 上的 备忘录 (memos) 上传到 NLM 进行结构化学习,希望能简化数字笔记流程。
- 另一个话题推出了一份精心策划的 中等教育 Prompt 列表,突出了社区驱动的专业技巧分享。
GPU MODE Discord
- Quantization 争论与 Tiling 尝试:成员们注意到 Quantization overhead 可能会使 float16 权重的加载时间翻倍,并且 matmul 中的 32x32 tiling 运行速度比 16x16 慢 50%,这说明了 GPU 架构上复杂的实现细节。
- 他们讨论了 register spilling 是否可能导致减速,并表示有兴趣探索更简单的、架构感知的解释。
- Triton 调优与 Softmax 细节:用户观察到使用
torch.empty代替torch.empty_like结果快了 3.5 倍,同时通过triton.heuristics缓存最佳 block size 可以减少 autotune overhead。- 他们还报告了针对 softmax kernels 的 reshape 技巧,但由于性能各异,row-major 与 col-major 的问题仍然存在。
- WMMA 困扰与 ROCm 启示:wmma.load.a.sync 指令为一个 16×16 的矩阵 fragment 消耗 8 个 registers,而 wmma.store.d.sync 只需要 4 个,这引发了关于 data packing 复杂性的辩论。
- 与此同时,关于 MI210 报告的 2 thread-block 限制与 A100 的 32 个限制之间产生了困惑,使成员们对硬件设计的含义感到不确定。
- SmolLM2 与 Bits-and-Bytes 收益:Hugging Face 合作推出的 SmolLM2 使用 11 trillion tokens 训练,发布了 135M、360M 和 1.7B 参数版本,旨在提高效率。
- 与此同时,一位新的 bitsandbytes 维护者宣布了他们从软件工程领域的转型,强调了在面向 GPU 优化方面的新扩展。
- 谜题奖励与 Rejection 策略:对 800 个谜题 的数千次补全显示出巨大的 log-prob 方差,促使将 negative logprop 作为一种简单的 reward 方法。
- 成员们探索了在 top-k 补全上结合 rejection sampling 的 expert iteration,并关注像 PRIME 和 veRL 这样的框架来增强 LLM 性能。
Cohere Discord
- 联合训练焦虑与模型混淆:一位用户在 joint-training 和 loss calculation 方面寻求帮助,但其他人开玩笑说他应该寻求报酬,同时关于 command-r7b-12-2024 访问权限的困惑也在增加。LiteLLM issues 和 n8n 错误指向了新 Cohere 模型被忽视的更新。
- 一位成员坚持认为 n8n 找不到 command-r7b-12-2024,建议转向 command-r-08-2024,这突显了 LiteLLM 和 n8n 维护者提供即时支持的必要性。
- 黑客松热潮与机械解释性讨论:在提到 1 月 25 日的 AI-Plans hackathon 后,一位用户推介了一个专注于评估先进系统的 alignment 活动。他们还将 mechanistic interpretation 确定为一个活跃的探索领域,将 alignment 理念与实际代码联系起来。
- 参与者的引言表达了分享 alignment 见解的兴奋,一些人提到了 AI-Plans 与 mech interp 研究潜在扩展之间的协同作用。
- API Key 难题与安全解决方案:多次提醒强调 API keys 必须保持安全,同时用户建议进行 key rotation 以避免意外泄露。Cohere 的支持团队也被提及以提供专业指导。
- 一位用户发现自己误发了一个公开 key,随后迅速将其删除并提醒他人在不确定时也要这样做。
- Temperature 调整与模型对决:一位用户询问是否可以为结构化生成逐项设置 temperature,寻求关于高级参数处理的澄清。另一位询问与 OpenAI 的 o1 相比最好的 AI 模型,揭示了社区对直接性能对比的兴趣。
- 他们要求提供更多关于模型可靠性的细节,引发了关于平衡结果以及 temperature 调整如何塑造最终输出的进一步讨论。
- Agentic AI 探索与论文追踪:一位专注于 agentic AI 的硕士生提议将先进的系统能力与 人类利益 联系起来,寻求前沿的研究视角。他们专门询问了 Papers with Code 的引用以寻找相关工作。
- 社区成员建议提供更多现实世界的证明点,并建议探索关于渐进式 Agent 设计的新出版物,强调了概念与执行之间的协同作用。
LlamaIndex Discord
- Agentic 发票自动化:LlamaIndex 实战:一系列详尽的 notebook 展示了 LlamaIndex 如何利用 RAG 实现全自动发票处理,点击此处查看详情。
- 他们引入了结构化生成(structured generation)以加快任务处理速度,吸引了许多正在探索 Agentic 工作流的成员的关注。
- 使用 LlamaIndex 和 Streamlit 构建动态 UI:一份新指南展示了为 LlamaIndex 设计的、具备实时更新功能的 Streamlit 用户界面,并提到了与 FastAPI 集成以进行高级部署的方法(阅读此处)。
- 贡献者强调了即时用户交互的重要性,突出了前端与 LLM 数据流之间的协同作用。
- MLflow 与 Qdrant:LlamaIndex 的强大组合:一个分步教程演示了如何将用于实验跟踪的 MLflow 和用于向量搜索的 Qdrant 与 LlamaIndex 配对使用,链接见此处。
- 教程概述了用于实时更新的变更数据捕获(Change Data Capture),引发了关于扩展存储解决方案的讨论。
- 利用 LlamaParse 精通文档解析:一段新的 YouTube 视频展示了使用 LlamaParse 的专业文档解析方法,旨在优化文本摄取管道(ingestion pipelines)。
- 该视频涵盖了优化工作流的关键技术,参与者提到在大型项目中,稳健的数据提取至关重要。
OpenInterpreter Discord
- Cursor 强制要求 .py 配置文件:开发者发现 Cursor 现在要求配置文件必须为
.py格式,这引发了混乱和半成品式的配置。他们提到:“示例 py 文件配置文件也完全没有帮助。”- 几个人尝试转换现有配置文件,但成功率有限,抱怨 Cursor 的这一转变迫使他们不得不四处寻找稳定的解决方案。
- Claude Engineer 消耗大量 Token:一位用户发现 Claude Engineer 消耗 tokens 的速度极快,促使他们剥离了插件,仅保留默认的 shell 和 python 访问权限。他们表示这导致使用成本激增,迫使他们削减高级工具的使用。
- 其他人也表达了在平衡性能和成本方面的困难,指出当系统调用外部资源时,token 膨胀(token bloat)很快就会成为负担。
- Open Interpreter 1.0 与 Llama 冲突:多次讨论强调了在运行微调后的 Llama 模型时,Open Interpreter 1.0 会出现 JSON 问题,导致反复崩溃。据报道,该问题出现在需要复杂错误处理和工具调用的任务中。
- 参与者抱怨禁用工具调用(tool calling)并不总能解决问题,引发了关于不可序列化对象错误和依赖冲突的进一步讨论。
- Windows 11 运行完美:一份针对 Windows 11 24H2 的安装指南被证明至关重要,参考链接见此处。该指南的作者报告称 OpenInterpreter 在其系统上运行稳定。
- 他们展示了该流程如何解决常见陷阱,增强了大家对 Windows 11 作为测试新 alpha 特性可行环境的信心。
Nomic.ai (GPT4All) Discord
- GPT4All 的 Android 应用引发关注:关于 Google Play Store 上 GPT4All 应用官方身份的担忧浮出水面,社区提醒注意发布者名称可能存在的不匹配。
- 一些用户建议在消息限制和可信度检查与已知的 GPT4All 产品一致之前,先不要安装。
- 通过 Termux 实现离线本地 AI 聊天机器人:一位用户分享了使用 Termux 和 Python 创建本地 AI 聊天机器人的成功经验,强调了基于手机的推理(inference)以便于随时访问。
- 其他人提出了关于电池消耗和存储开销的担忧,确认了直接下载模型可以完全在移动设备上运行。
- C++ 爱好者关注 GPT4All 处理 OpenFOAM:开发者正在权衡 GPT4All 是否能胜任 OpenFOAM 代码分析,探索哪种模型最能处理高级 C++ 查询。
- 有人暂时推荐了 Workik,同时小组讨论了 GPT4All 在处理复杂库任务方面的准备情况。
- 聊天模板与 Python 设置引发 GPT4All 热议:爱好者们分享了使用 GPT4All 构建自定义系统消息的技巧,并指向了官方文档以获取分步指导。
- 其他人请求关于通过 Python 进行高级本地内存增强的教程,推动了对集成离线解决方案的兴趣。
tinygrad (George Hotz) Discord
- Windows CI 进展:社区强调了在 Windows 上建立 Continuous Integration (CI) 以允许合并的必要性,并引用了修复 ops_clang 中缺失导入的 PR #8492。
- 一位参与者表示 “没有 CI,合并进程就无法推进”,促使采取紧急行动以维持开发进度。
- 悬赏任务蓬勃发展:多名成员提交了 Pull Requests 以领取悬赏,包括用于在 macOS 上运行 CI 的 PR #8517。
- 他们请求开设专门频道来跟踪这些倡议,希望能有更高效的管理和状态更新。
- Tinychat 浏览器版:一位开发者展示了由 WebGPU 驱动的 浏览器版 tinychat,实现了 Llama-3.2-1B 和 tiktoken 在客户端运行。
- 他们建议增加一个进度条,以便更平滑地显示模型权重解压过程,这得到了测试者的积极反馈。
- CES 动态与会议提要:tiny corp 宣布参加 CES,展位位于 LVCC West Hall #6475,展示了 tinybox red 设备。
- 预定会议涵盖了合同细节和多项技术悬赏,为接下来的目标奠定了基础。
- 分布式计划与 Multiview 实战:Distributed training 的架构师讨论了 FSDP 的使用,敦促进行代码重构以适应并行化工作。
- tinygrad notes 还强调了 multiview implementation 和教程,鼓励广泛的社区协作。
Modular (Mojo 🔥) Discord
- Mojo 强化
concat功能:他们为List[Int]引入了只读和基于所有权版本的concat函数,允许开发者在语言 owns(拥有)该列表时复用内存。- 这一策略减少了大数组的额外复制,旨在不增加用户负担的情况下提升速度。
- 重载难题:讨论集中在 Mojo 中自定义 structs 的函数重载如何因两个
concat签名看起来完全相同而遇到障碍。- 这种不匹配揭示了在没有直接复制机制时代码复用的难度,导致了编译时冲突。
- 使用 Owned 参数的内存魔法:核心思想是让重载根据 read(读取)与 owned(拥有)输入而有所不同,以便编译器优化最终用途并跳过不必要的数据移动。
- 该计划涉及自动检测变量何时可以被释放或复用,从而填补内存管理逻辑中的空白。
- Issue #3917 中的调试器 Bug:如 Issue #3917 所示,在使用
--debug-level full运行某些 Mojo 脚本时会出现 segfault(段错误)。- 用户注意到常规脚本执行可以避免崩溃,但调试器问题仍有待进一步修复。
LAION Discord
- 情感 TTS:恐惧与惊讶:分享了多个展示 fear(恐惧)和 astonishment(惊讶)的音频剪辑,征求关于感知质量差异和表现力语气的反馈。
- 参与者被要求对他们喜欢的版本进行投票,突显了社区驱动的情感语音模型优化。
- PyCoT 的 Python 式问题解决:一位用户展示了 PyCoT dataset,用于通过 AI 驱动的 Python 脚本解决数学应用题,参考了 AtlasUnified/PyCoT 仓库。
- 每个问题都包含一个思维链(chain-of-thought)方法,展示了逐步的 Python 逻辑,使推理更透明。
- 寻找 GPT-4o 和 Gemini 2.0 音频数据:成员们询问了支持 GPT-4o Advanced Voice Mode 和 Gemini 2.0 Flash Native Speech 的专用数据集,旨在进一步提升 TTS 能力。
- 他们寻求社区对现有或即将推出的音频参考资料的建议,希望扩大高级语音数据集库。
DSPy Discord
- 复旦大学在 Test-Time 策略上的探索:复旦大学最近的一篇 论文 研究了 test-time compute 如何塑造先进的 LLM,重点介绍了架构、多步推理和反思模式。
- 研究结果还概述了使用 DSPy 构建复杂推理系统的途径,这些见解对于追求更高层级模型行为的 AI 工程师非常有用。
- System Prompts 的 Few-Shot 趣味实践:参与者询问了如何通过 System Prompt 让 LLM 产生 few shot examples,旨在提升特定输出的效果。
- 他们强调了简洁的 Prompt 和直接指令的重要性,认为这是提高模型响应能力的实用方法。
- Mipro 的 Docstring 收益:有人建议在 Signature 中嵌入额外的 Docstring 或使用自定义 Adapter,以提高分类任务的清晰度。
- Mipro 利用这些 Docstring 来优化标签,允许用户指定示例和指令,从而增强分类准确性。
- DSPy 在分类任务中的大胆尝试:贡献者展示了 DSPy 如何简化分类中的 Prompt 优化,并分享了一篇关于基于 Pipeline 工作流的 博客文章。
- 他们还提到通过 DSPy 成功升级了一个天气网站,称赞其在编排语言模型时无需冗长 Prompt 的直接方法。
- 34 分钟 DSPy 演示:有人分享了一个 YouTube 视频,在短短 34 分钟 内浓缩了 8 个 DSPy 示例。
- 他们推荐将其作为掌握 DSPy 特性的快捷方式,并指出它为新老用户都简化了高级用法。
LLM Agents (Berkeley MOOC) Discord
- 对同伴项目的持续好奇:学员们请求建立一个中央仓库来查看他人的 LLM Agents 项目,但由于参与者隐私同意问题,目前还没有官方汇编。
- 组织者可能会展示优秀作品,让大家一睹课程中的最佳提交案例。
- Quiz 5 截止日期的困惑:参与者反映关于 Compound AI Systems 的 Quiz 5 提前关闭了,导致部分人未能按时完成。
- 有人建议重新开放错过的测试以进行彻底的知识自测,并指出了对课程截止日期的困惑。
- 证书申报截止日期已过:一位用户因在完成测试和项目后错过了证书申报表而感到遗憾,失去了获得官方认可的资格。
- 课程工作人员澄清,逾期提交将不予考虑,表格将在 1 月份证书发放后才会重新开放。
MLOps @Chipro Discord
- 聚类算法依然占据主导地位:尽管 LLM 兴起,许多数据从业者证实 search、time series 和 clustering 仍被广泛使用,目前还没有向神经解决方案的大规模迁移。
- 他们认为这些核心方法对于数据探索和预测至关重要,使其与更先进的 ML 方法并驾齐驱。
- 搜索技术保持稳健:讨论显示核心 search 方法基本保持不变,LLM 在 RAG 或大规模索引策略中的影响微乎其微。
- 成员们指出,许多成熟的服务认为没有理由颠覆经过验证的 search pipelines,导致基于语言模型的新系统采用缓慢。
- 小型模型精通 NLP:讨论显示在某些 NLP 任务中,像 logistic regression 这样更简单的方法有时表现优于大型 LLM。
- 与会者观察到,虽然 LLM 在许多领域都有帮助,但在某些情况下,传统的分类器仍然能产生更好的结果。
- LLM 热潮催生新解决方案:参与者报告称,新兴产品中 LLM 的使用量有所增加,为软件开发提供了不同的方向。
- 其他人仍然依赖成熟的方法,凸显了创新驱动型项目与更稳定的 ML 实现之间的分歧。
Torchtune Discord
- Wandb 性能分析热议:成员们讨论了使用 Wandb 进行 profiling,但指出其中一个私有代码库与 Torchtune 无关,而一个潜在的分支仍可能从即将发布的基准测试中受益。
- 观察者评论说,一旦 Torchtune 更紧密地集成它,这种 profiling 讨论可能会为性能洞察铺平道路。
- Torch 内存操作:用户注意到 Torch 通过在 cross-entropy 编译期间跳过某些矩阵实例化来减少内存使用,并强调了 chunked_nll 对性能提升的作用。
- 他们强调这种减少潜在地解决了 GPU 瓶颈,并在无需重大代码重构的情况下提高了效率。
- Differential Attention 之谜:一种名为 differential attention 的概念(源自 10 月的一篇 arXiv 论文)尚未出现在最近的架构中。
- 与会者建议它可能被其他方法掩盖,或者在实际测试中未能提供预期结果。
- Torchtune 中的 Pre-Projection 推进:一位贡献者分享了基准测试,显示 chunking pre projection 加上 matmul 与 loss 的融合提高了 Torchtune 的性能,并引用了他们的 GitHub 代码。
- 他们报告说,在某些梯度稀疏条件下,cross-entropy 是内存和时间效率最高的选项,强调了选择性优化的重要性。
Axolotl AI Discord
- 未识别到相关的 AI 主题 #1:这些消息中没有出现技术或新的 AI 进展,而是集中在 Discord 诈骗/垃圾邮件通知。
- 因此,没有关于模型发布、基准测试或新工具的内容可供总结。
- 未识别到相关的 AI 主题 #2:对话仅涉及服务器维护更新中的 拼写错误修正。
- 未记录更深层次的 AI 或以开发者为中心的细节,因此无法进行进一步的技术总结。
Mozilla AI Discord
- Common Voice AMA 迈向 2025:该项目正在其新推出的 Discord 服务器中举办 AMA,以回顾进展并引发关于未来语音技术的讨论。
- 他们的目标是解决有关 Common Voice 的问题,并概述 2024 年回顾后的后续步骤。
- Common Voice 宣扬语音数据的开放性:Common Voice 收集广泛的公共语音数据以创建开放的语音识别工具,倡导所有开发者的协作。
- “语音是自然的,语音是人类的”,捕捉到了该运动的目标,即让语音技术在私有实验室之外也能被广泛获取。
- AMA 专家小组阵容强大:EM Lewis-Jong(产品总监)、Dmitrij Feller(全栈工程师)和 Rotimi Babalola(前端工程师)将回答有关该项目成就的问题。
- 一位技术社区专家将引导讨论,重点介绍年度进展和未来愿景。
HuggingFace Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
第 2 部分:按频道划分的详细摘要和链接
各频道的详细分析已为邮件版本截断。
如果您喜欢 AInews,请分享给朋友!预谢支持!