ainews-moondream-202519-structured-text-enhanced
Moondream 2025.1.9:在 2B 模型中实现结构化文本、增强 OCR 与视线检测功能。
Moondream 发布了新版本,提升了显存(VRAM)效率,并增加了结构化输出和视线检测功能,标志着视觉模型实用性迈向了新前沿。Twitter 上的讨论聚焦于推理模型的进展(如 OpenAI 的 o1)、模型蒸馏技术,以及 vdr-2b-multi-v1 和 LLaVA-Mini 等新型多模态嵌入模型,这些技术显著降低了计算成本。关于生成对抗网络(GANs)和去中心化扩散模型的研究展示了更高的稳定性和性能。MLX 和 vLLM 等开发工具迎来了更新,提升了便携性和开发者体验;同时,LangChain 和 Qdrant 等框架助力实现智能数据工作流。公司动态方面,GenmoAI 宣布了新职位及团队扩张。“效率技巧即一切(Efficiency tricks are all you need)。”
效率技巧就是你所需要的一切。
2025年1月9日至1月10日的 AI 新闻。我们为您检查了 7 个 subreddits、433 个 Twitter 账号 和 32 个 Discord 服务器(219 个频道和 2928 条消息)。预计节省阅读时间(以 200wpm 计算):312 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
Moondream 因其小巧、轻便、快速且达到 SOTA 水平的视觉能力而备受关注,并在昨天发布了一个出色的一新版本,标志着 VRAM 占用的新效率前沿(比单纯的参数量更具实际意义):
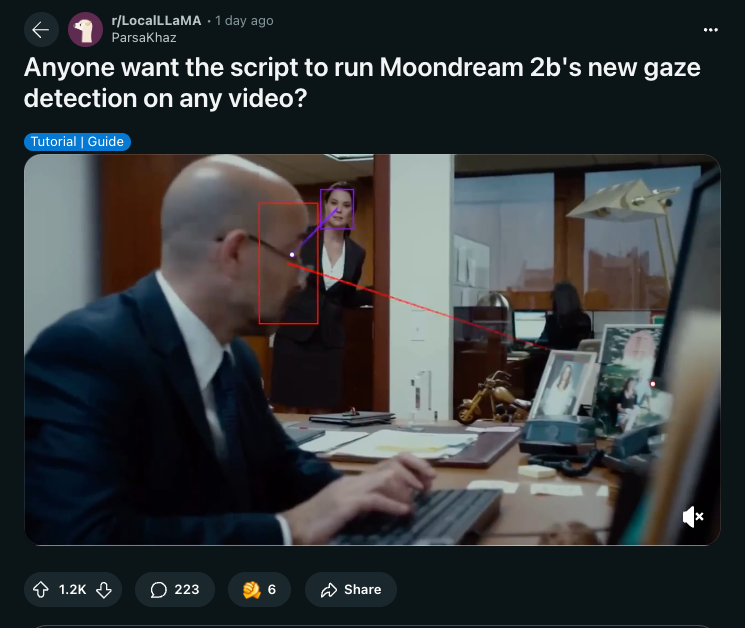
它现在还提供结构化输出和视线检测(gaze detection),这让富有创意的 Redditor 们想出了如下脚本:
如果您错过了,Vik 还在 Vision Latent Space Live 的 Best of 2024 活动中发表了关于 Moondream 的演讲:
https://www.youtube.com/watch?v=76EL7YVAwVo
AI Twitter 回顾
所有摘要均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
AI 模型与研究
-
推理模型与蒸馏技术:@_philschmid 和 @saranormous 讨论了推理模型的进展,如 @OpenAI 的 o1,详细介绍了构建此类模型的步骤。此外,@jxmnop 强调了模型蒸馏(distillation)的有效性,并指出其在缺乏理论解释的情况下取得了令人惊讶的性能提升。
-
多模态与嵌入模型:@llama_index 推出了 “vdr-2b-multi-v1”,这是一个 2B 参数的多模态、多语言嵌入模型,在多种语言中实现了 95.6% 的平均 NDCG@5。@reach_vb 展示了 LLaVA-Mini,它减少了 77% 的 FLOPs,并能在单个 GPU 上实现 3 小时视频处理。
-
GAN 与扩散模型的创新:@iScienceLuvr 和 @multimodalart 分享了关于现代 GAN 基准和去中心化扩散模型(Decentralized Diffusion Models)的研究,强调了它们与传统方法相比的稳定性与性能。
-
自注意力与训练技术:@arohan 讨论了用于长度泛化(length generalization)的 stick-breaking attention,而 @addock_brett 预测 2025 年将是物理 AI(Physical AI)之年,并对训练优化和模型架构进行了反思。
AI 工具与开发
-
开发框架与 API:@awnihannun 宣布了 MLX 的更新,通过支持多种语言和平台增强了可移植性。@vllm_project 为 vLLM 引入了 nightly builds 和 原生 MacOS 支持,通过更快的安装提升了开发者体验。
-
AI 集成与流水线:@LangChainAI 和 @virattt 演示了使用 LangChain 和 Qdrant 等工具构建 LLM 驱动的数据流水线和 AI 驱动的数据工作流,实现了智能语义搜索和 Agent 式文档处理。
-
模型导出与接口:@awnihannun 提供了在 MLX 中将函数从 Python 导出到 C++ 的指南,促进了跨语言模型部署。@ai_gradio 展示了 qwen 与 anychat 的集成,以极少的代码增强了开发者部署能力。
公司公告与更新
-
公司角色与扩张:@russelljkaplan 宣布了他的新角色 “认知专家” (cognition guy),而 @ajayj_ 欢迎新团队成员加入 GenmoAI 的旧金山办公室。
-
产品发布与增强:@TheGregYang 发布了 Grok iOS 应用,@c_valenzuelab 在 RunwayML 上推出了 新的牛仔系列。@everartai 推出了 角色微调 (character finetuning) 服务,展示了在 极少输入图像 情况下卓越的 流水线一致性 (pipeline consistency)。
-
招聘与就业趋势:@cto_junior 讨论了 Microsoft 的招聘趋势,而 @bindureddy 预测 Salesforce 和其他大型科技公司将由于 AI 驱动的生产力提升 而 停止招聘工程师。
数据集与基准测试
-
新数据集发布:@iScienceLuvr 和 @miivresearch 宣布了 去中心化扩散模型 (Decentralized Diffusion Models),并发布了 HtmlRAG 和其他 多模态数据集 的 代码 与 项目页面。
-
基准测试与评估:@swyx 分享了关于 MMLU/GPQA 知识 的见解,强调了对像 @ExaAILabs 这样的 神经搜索引擎 的需求。@FinBarrTimbers 讨论了在 机器人 (robotics) 领域之外缺乏持久的 认知基准测试 (cognitive benchmarks)。
AI 伦理、政策与社会
-
AI 的社会影响与伦理:@fchollet 和 @sama 辩论了 AI 自动化社会 中 工作的未来 以及 AI 治理 的 伦理影响,包括对 政策限制 和 AGI 定义 的担忧。
-
AI 的地缘政治影响:@teortaxesTex 和 @ClementDelangue 强调了 开源 AI 所掌握的 地缘政治力量,以及 中国 等国家在 AI 领域 的 战略举措。
-
AI 安全与监管担忧:@DeepLearningAI 和 @Nearcyan 对 AI 欺骗行为、公共安全 以及针对潜在 AI 驱动灾难 进行 妥善准备的必要性 提出了担忧。
个人动态与公告
-
职业变动与角色:@russelljkaplan 分享了对他新角色的兴奋,而 @megansirotanggalenuyen_ 庆祝入选 福布斯 30 Under 30。
-
职场经历:@vikhyatk 表达了对他所在大学行政部门的担忧,@sarahookr 提供了关于 洛杉矶灾情 (LA devastation) 的个人更新。
-
学习与发展:@qtnx_ 提到了 在 JAX 中学习 RL,@aidan_mclau 讨论了 AI 资本使用 以及 亿万富翁在 AI 开发中 面临的挑战。
梗/幽默
-
对 AI 和技术的幽默看法:@nearcyan 和 @teortaxesTex 分享了带有对 AI 提示工程 (prompt engineering)、科技公司行为 和 AI 炒作 的 讽刺评论 的推文,为技术讨论注入了轻松的评论。
-
随性且有趣的言论:@richardMCNgo 和 @teortaxesTex 发布了与 AI 进展 和 科技文化 相关的 笑话 和 双关语,为工程师受众提供了轻松时刻。
AI Reddit 回顾
/r/LocalLlama 回顾
主题 1. Moondream 2b 的视线检测引发热议
- 有人想要在任何视频上运行 Moondream 2b 新的视线检测(gaze detection)脚本吗? (Score: 1123, Comments: 207): 该帖子讨论了一个用于在任何视频上运行 Moondream 2b 视线检测的脚本发布。帖子正文中没有提供额外的细节或背景。
- 兴趣与热情:许多用户,包括 That_Neighborhood345 和 ParsaKhaz,对视线检测脚本的发布表示了浓厚的兴趣,像 ParsaKhaz 这样的人甚至表示,如果大家感兴趣,他们愿意清理并发布自己的脚本。这表明社区对实验和利用视线检测技术有着显著的兴趣。
- 监控担忧:几位用户,如 ArsNeph 和 SkullRunner,表达了对视线检测技术可能被滥用于监控和侵犯隐私的担忧。他们列举了像中国的社会信用体系和企业微观管理等例子,认为这项技术可能会被滥用来监控个人的专注度和活动。
- 技术可行性与用例:aitookmyj0b 指出,利用基础的 OpenCV processing 实现视线检测是可行的,这表明该技术对于感兴趣的人来说已经触手可及。然而,ArsNeph 认为该技术在合法的眼动追踪应用中缺乏精确度,强调其主要用途是作为监控软件,而非用于有益的目的。
主题 2. Transformers.js 通过 WebGPU 将 LLM 带入浏览器
- 使用 Transformers.js 在浏览器中 100% 本地运行 WebGPU 加速的推理 LLM (Score: 379, Comments: 62): 演示了使用 Transformers.js 在浏览器中完全本地运行 WebGPU-accelerated LLMs。这展示了无需依赖服务器端处理即可实现浏览器内 AI 应用的潜力。
- 性能差异:用户报告了基于硬件的不同性能指标,例如 RTX 3090 达到了 55.37 tokens per second,而 MiniThinky-v2 在 MacBook M3 Pro Max 上达到了 ~60 tps。性能指标中缺乏特定硬件说明被指出是机器学习讨论中的一个常见问题。
- 技术探索与挑战:人们对探索 WebGPU 的技术能力及其在本地运行 AI 模型中的应用很感兴趣。用户讨论了创建一个浏览器扩展的可能性,该扩展利用推理 LLM 直接操作 DOM,并强调隐私和本地处理。
- 模型输出问题:一些用户强调了模型输出的问题,例如生成无意义的文本或错误的推理,比如模型错误地声称 “60 does not equal 60” 的例子。这突显了在本地 AI 应用中实现准确可靠输出的挑战。
主题 3. 拜登的 AI 芯片出口限制引发全球反应
- 拜登在最后冲刺中进一步限制 Nvidia AI 芯片出口,限制波兰、葡萄牙、印度或 Falcon 模型制造商阿联酋等美国盟友 (Score: 167, Comments: 107): Nvidia AI 芯片出口面临 Biden administration(拜登政府)的额外限制,影响了包括波兰、葡萄牙、印度和阿联酋在内的美国盟友。此举旨在限制 AI 技术的出口,特别是对涉及 Falcon 模型的国家产生了影响。
- 几位评论者批评 Biden administration 的政策低效且具有潜在危害,认为这可能导致中国与 Tier 2 国家之间加强合作,并可能无意中针对开源 AI 而非中国。人们还对全球技术发展和美国地缘政治地位受到的影响表示担忧。
- 对于用于 AI 芯片出口国家分类的分级系统(tier system)存在困惑和不满,用户质疑将葡萄牙和瑞士归入 Tier 2,而意大利等其他国家则处于 Tier 1 的决定。申根区(Schengen Area)被提及为一个潜在漏洞,可能允许各国规避限制。
- 讨论强调了由于这些限制,NVIDIA 替代方案获得关注的可能性,并对 Nvidia 的芯片制造地点提出了疑问,特别是关于台湾的 TSMC 及其对美中关系的影响。有人担心这些政策可能无法有效阻止中国等国家获得受限技术。
主题 4. NVIDIA 的 Project Digits 承诺 AI 民主化
-
**[Project Digits:NVIDIA 价值 3,000 美元的 AI 超级计算机如何实现本地 AI 开发民主化 Caveman Press](https://www.caveman.press/article/project-digits-nvidia-3000-ai-supercomputer-democratize-development)** (Score: 113, Comments: 75): NVIDIA 的 Project Digits 旨在通过提供价值 3,000 美元的 AI 超级计算机来实现本地 AI 开发的民主化。这一举措可以显著提高开发者和研究人员的可访问性,有可能改变本地计算能力。 - 社区对 NVIDIA Project Digits 的民主化主张表示怀疑,认为它主要实现了部署的民主化而非训练。一些用户认为,真正的民主化需要开源 CUDA,并指出 NVIDIA 的基准测试使用的是 fp4 精度,低于 fp32 或 fp16 等典型标准。
- 人们对超级计算机这一标签持怀疑态度,通过与现有的 GPU 和 RAM 带宽标准进行比较,认为 Digits 产品可能达不到预期。用户强调,已经存在具有更高 RAM 带宽和更宽 RAM 到 CPU 总线的竞争产品,例如具有 546 GB/s 的 Apple M4 Max 和具有 460 GB/s 的 AMD EPYC。
- 讨论还集中在 CUDA 在机器学习中的作用,一些人主张使用更多像 Triton 这样与供应商无关的解决方案。虽然 CUDA 在开发新的 ML 技术方面仍然盛行,但人们正在推动支持多个供应商的框架,正如 OpenAI 和 Triton 所见,后者因其易用性和性能而正受到关注。
其他 AI Subreddit 回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
主题 1. DALL-E 被放弃:OpenAI 的多模态困境
- OpenAI 是否完全放弃了 DALL·E?相同提示词下 DALL·E 和 Imagen3 的结果对比 (Score: 343, Comments: 136): OpenAI 可能已经停止了对 DALL·E 的更新,正如使用相同提示词对 DALL·E 和 Imagen3 进行图像生成结果对比所显示的那样。讨论暗示 DALL·E 的性能没有得到改进或维护,引发了人们对 OpenAI 在该项目上投入精力的质疑。
- 几位评论者推测了 OpenAI DALL·E 的未来,一些人认为随着图像生成领域竞争的加剧,OpenAI 可能会发布一个更新的或全新的模型,可能是多模态模型。Vectoor 和 EarthquakeBass 提到,过去版本的 DALL·E 在发布时具有开创性,但由于更新频率低,很快就落后了。
- 评论中对 DALL·E 3 的审美和技术表现提出了批评,COAGULOPATH 和 EarthquakeBass 指出它无法生成令人信服的写实图像,这可能是由于 OpenAI 保守的安全立场。Demigod123 建议,这种卡通风格可能是一种防止滥用的刻意选择。
- 讨论中提到了 Midjourney、Flux Schnell 和 Mystic 2.5 等替代方案,用户分享了他们生成的图像链接,强调了这些工具与 DALL·E 相比的能力。Bloated_Plaid 和 MehmetTopal 提供了视觉对比,表明其他工具目前可能提供更优的结果。
主题 2. 微软展望组织中的 AI Agent 群体
- 微软 CEO 表示,每位员工很快将管理一个“AI Agent 群体”,每个组织内部将拥有“数十万个”Agent (Score: 235, Comments: 154): Microsoft CEO 预测,每位员工很快将管理一个 AI Agent “群体”,每个组织内部将部署“数十万个”此类 Agent。这一表态暗示了工作环境中 AI 集成和自动化的显著增加。
- 对 AI Agent 管理的怀疑:许多评论者对管理 AI Agent “群体”表示怀疑,质疑处理大量需要人工干预的 Agent 的实用性和潜在混乱。一些人认为这是 Microsoft 在没有交付实质性成果的情况下过度炒作技术的又一个例子。
- 对就业和行业的影响:讨论强调了对失业的担忧,担心 AI 将取代很大一部分劳动力,尤其是 white-collar jobs。关于工作的未来存在争论,一些人建议将任务从“白领”vs“蓝领”转向“可自动化”vs“不可自动化”。
- 科技行业的战略手段:评论者将 AI 集成与之前的技术策略(如 Apple 的生态系统固守)进行了类比。人们认为科技公司将使用类似的策略来锁定客户,使得从其 AI 解决方案中迁移出来的成本高昂且复杂。
AI Discord 回顾
由 o1-mini-2024-09-12 生成的摘要之摘要
主题 1. AI 模型对决:PHI-4 超越微软及其他模型
-
Unsloth 的 PHI-4 在 Open LLM Leaderboard 上超越微软:来自 Unsloth 的 PHI-4 通过实施关键的错误修复和 Llamafication,在 Open LLM Leaderboard 上超越了 Microsoft 的基准,尽管量化变体有时会略胜非量化变体。
-
rStar-Math 将 Qwen2.5 和 Phi3-mini 推向新高度:Microsoft 的 rStar-Math 将 Qwen2.5 在 MATH 基准测试中的表现从 58.8% 提升至 90.0%,将 Phi3-mini 从 41.4% 提升至 86.4%,标志着小型 LLM 在数学推理方面取得了重大进展。
-
Llama 3.3 在低端硬件上表现挣扎,输出缓慢:爱好者报告称 Llama 3.3 70B Instruct 在低端硬件上表现迟缓,在 Ryzen 7 和 RX 7900GRE 等中等配置系统上,Token 输出速度仅为 0.5/sec,突显了对强大 GPU 显存或系统 RAM 的需求。
主题 2. AI 工具对决:Codeium、ComfyUI 和 Cursor IDE
-
Codeium 的私有化部署版本助力团队部署:Codeium 在其企业版套餐中推出了私有化部署版本,吸引了渴望可定制、内部 AI 架构的团队,同时也需要应对额度处理的复杂细节。
-
ComfyUI 通过 IP Adapter 魔力增强 AnimateDiff:社区对 AnimateDiff 的输出质量提出了批评,转而采用集成 IP Adapter 的 ComfyUI 工作流,以显著提升视频生成效果。
-
Cursor IDE 规则强化 Claude 的代码编写能力:开发者在 Cursor IDE 中使用 .CursorRules 来精确引导 Claude 的输出,显著减少了代码误改并确保了准确的功能实现。
主题 3. GPU 难题与内核灾难:Linux 上的 Stable Diffusion
-
Linux 用户在 AMD GPUs 上运行 Stable Diffusion 时遭遇内核恐慌:在 Linux 上使用 AMD GPUs 运行 Stable Diffusion 的尝试有时会触发内核恐慌 (Kernel Panic),但参考 AMD GPUs 安装 Wiki 提供的修复方案可以解决 Python 版本问题。
-
Stable SwarmUI vs A1111:用户界面之争:Discord 用户讨论了 A1111、SwarmUI 和 ComfyUI 的易用性,尽管 SwarmUI 的学习曲线被认为更陡峭,但其高级功能仍赢得了赞誉。
-
MicroDiT 通过 DCAE 集成实现复现与优化:MicroDiT 的成功复现提供了可下载的权重和推理脚本,为使用 DCAE 进行架构增强以提升性能铺平了道路。
主题 4. AI 社区动态:黑客松、招聘与融资热潮
-
oTTomator 的 AI Agent 黑客松触发 6000 美元奖金盛宴:OpenRouter 启动了 oTTomator AI Agent 黑客松,由赞助商 Voiceflow 和 n8n 提供总计 6,000 美元 的奖金,在 1 月 8 日至 1 月 22 日期间引发了激烈竞争。
-
Anthropic 在 AI 创投飙升之际获得 20 亿美元融资:根据 Andrew Curran 的报告,Anthropic 额外筹集了 20 亿美元,将其估值提升至 600 亿美元,并巩固了其在企业级 AI 解决方案领域的地位。
-
Nectar Social 提供 1 万美元悬赏以招揽 AI 人才:位于西雅图的 AI 初创公司 Nectar Social 正在招聘产品经理和 AI 工程师,提供高达 10,000 美元的推荐奖金,以吸引优秀人才加入其不断发展的社交电商平台。
主题 5. 高级 AI 技术:微调、解码与正则化难题
-
适配器并非儿戏:LoRA 精度至关重要:技术专家强调在实现 LoRA 适配器时使用 16-bit 模型的重要性,以防止输出质量下降,并主张将适配器与更高精度的基座进行合并。
-
Speculative Decoding 成为资源节约英雄:为了减少下一个 Token 生成过程中的计算负载,社区将 Speculative Decoding 视为一种极具前景的技术,类似于语言模型的 DLSS。
-
权重衰减之战:通过温和设置稳定 LLM:研究人员讨论了大型语言模型中极端权重衰减(例如 0.1)的影响,建议采用更温和的衰减以及诸如 abs(norm(logits) - 1.0) 之类的辅助损失函数,以防止模型崩溃并保持数值稳定性。
PART 1: High level Discord summaries
Stability.ai (Stable Diffusion) Discord
- GPU 性能与槽点:工程师们对比了 RTX 4070 与 3090 在 AI 视频任务中的表现,指出 3090 可以在约 2 分钟内渲染 480p 视频;根据此讨论,AMD 显卡上的 LTXV 表现出更多差异。
- 参与者交流了性能指标和优化技巧,倾向于使用专门的配置来实现更快的 image-to-video 工作流。
- AnimateDiff 动态:成员们批评 AnimateDiff 的输出效果欠佳,并参考了一个合并了 IP Adapter 以增强质量的 ComfyUI 工作流。
- 他们还讨论了一个测试多种方法的 image-to-video 对比选项,并指出某些步骤的运行时间仍然超出了预期。
- Discord 争议:用户举报了不当个人资料,并就加强监管以保持对话文明进行了争论。
- 担忧主要集中在如何平衡清理毒性内容与维持友好环境之间。
- 界面之争:对 A1111、SwarmUI 和 ComfyUI 的对比显示了对用户友好度的不同看法,SwarmUI 的功能记录在此 GitHub 指南中。
- 虽然 A1111 因简单易用受到称赞,但一些人更欣赏 ComfyUI 用于动画内容创作的高级流水线。
- 内核恐慌:基于 Linux 的 Stable Diffusion 偶尔会触发内核恐慌(kernel panics),为此参考了 AMD GPUs 安装维基。
- 指南和修复方案通常针对 Python 版本问题,为 Linux 上更顺畅的 AI 工作流提供备选方案。
Unsloth AI (Daniel Han) Discord
- Unsloth 的 PHI-4 实力超越 Microsoft:在官方 Open LLM Leaderboard 评分中,得益于 Bug 修复和 Llamafication,来自 Unsloth 的 PHI-4 刚刚超过了 Microsoft 的基准线。
- 社区成员称赞了这一改进,但指出量化变体有时比非量化配置表现更好。
- Adapter 态度:精度决定成败:专家强调在挂载 Adapter 时应使用 16-bit 模型以获得更好的吞吐量,并参考了一篇 LoRA 注意事项文章。
- 他们提到使用较低精度可能会降低结果质量,通常更倾向于与高精度基座模型进行合并。
- Chat Templates 调整 LLM 行为:贡献者讨论了
tokenizer_config.json中的 chat templates 如何塑造输入输出格式,从而显著影响 LLM 性能。- 他们强调从训练到生产保持模板一致性可以确保结果稳定,有人声称这能“决定部署成功与否”。
- Speculative Decoding:减少资源消耗的关键技巧:关于语言模型类 DLSS 优化的讨论引出了 speculative decoding,它被誉为一种资源友好型技术。
- 研究人员发现它在绕过 next-token generation 中沉重的计算负载方面很有前景。
- Mathstral 7B 等待更广泛支持:澄清了
mistralai/Mathstral-7B-v0.1模型目前不支持直接微调,因为它不是标准的基座模型或 PEFT 模型。- 参与者表示支持即将推出,引发了对未来模型合并和扩展的谨慎乐观。
Codeium (Windsurf) Discord
- 自托管 Codeium 增强部署控制:成员们注意到 Codeium 的自托管版本现已包含在企业版套餐中,吸引了渴望管理自己环境的团队的关注。
- 他们还提出了关于额度处理和 Windsurf 功能的问题,并指向了 价格页面 以获取官方指南。
- Windsurf 在多个发行版上的安装挑战:用户报告在 Mint, Ubuntu 24.04, Arch 和 Hyprland 上成功安装了 Windsurf,有时需要删除配置文件以解决奇怪的错误。
- 他们还讨论了在多台 PC 上共享 Cascade 聊天的愿望,虽然出现了云同步的建议,但目前尚未推出官方功能。
- Flow Credits 计费问题引发不满:几个人抱怨多次支付 Flow Credits 但从未看到到账,呼吁制定更清晰的使用政策。
- 他们还质疑 internal errors 是否计入额度,敦促开发者迅速修复这些扣费问题。
- Cascade 的无代码胜利与聊天管理愿景:一位用户强调了在几乎没有实际编码的情况下构建了公司网站,并赞扬了 Cascade 免费层级中的 unlimited 查询。
- 其他人仍然希望在多个设备上实现更好的 Cascade 聊天管理,表示需要官方的同步解决方案。
Cursor IDE Discord
- Cursor Rules 驯服混乱代码:开发者分享了如何使用 .CursorRules 通过结构化提示词优化 Claude 的输出,重点关注明确的目标以避免意外的文件更改。
- 他们报告称,精确选择的关键词显著减少了代码误改,强调了定义良好的提示词指令的重要性。
- Cursor Directory 受到关注:Cursor Directory 的关注度激增,突显了其收集各种框架的社区规则的能力。
- 用户赞赏这种集中分享规则的方式,指出在处理特殊配置时节省了时间和精力。
Stackblitz (Bolt.new) Discord
- 灵活的颜色提示词:社区强调在提示词中使用颜色名称和十六进制代码来指定 colors,以确保使用清晰。
- 一位成员用更精确的指南取代了模糊的请求(如 Just do blue and white),以控制跨应用的样式。
- 支付系统故障:一位用户发现他们的 payment system 无法运行,发布了项目链接并寻求帮助。
- 他们提到正在积极开发以恢复全部功能,并敦促测试人员提供反馈。
- 使用 Bolt.new 打开公共仓库:开发者宣布了 public repos 功能,允许用户在任何 GitHub URL 前加上 http://bolt.new 前缀以立即访问。
- 他们引用了一篇 X 帖子,展示了如何以最少的配置打开仓库。
- Bolt Token 过度消耗:多人报告在编辑或调试时 token 消耗过快,并遇到了重复尝试修复错误的情况。
- 他们对持续的资源消耗表示沮丧,希望能有更高效的方法。
- Supabase 迁移与 Netlify 故障:开发者提到,如果在更新过程中出现问题,回滚 Supabase migrations 会非常麻烦,从而影响应用程序的稳定性。
- 此外,一位用户提到 Netlify 加载速度缓慢,怀疑是免费层级限制或 Bolt 代码效率低下。
aider (Paul Gauthier) Discord
- Gemini 2.0 迈向移动端与语音交互:一位用户在处理杂务时,在 iOS 上测试了 Gemini 2.0 Flash Experimental 的语音模式,实时构思了一个应用想法,并在返回后生成了简洁的任务列表。
- 社区成员对 Gemini 2.0 自主提出项目标准的能力表示赞赏,称其为迈向无摩擦开发(frictionless development)的有力一步。
- Tier 5 密钥获取尝试与 Unify.ai 技巧:讨论集中在昂贵的 Tier 5 OpenAI 访问权限的替代方案上,并提到 Unify.ai 和其 GitHub 仓库 是灵活的多模型解决方案。
- 成员们权衡了订阅成本,并分享了使用 OpenRouter 和 Unify 来简化配置的经验。
- Aider 与 Claude 在编程领域展开对决:多位用户将 Aider 不稳定的文件编辑和偶尔的失误与 Claude 进行了对比,并提到了整个文件被删除的滑稽事件,引用了文件编辑问题文档。
- 一些人认为 DeepSeek 聊天过于容易分心且表现懒惰,而另一些人则认为如果谨慎管理以避免大规模代码删除,Aider 仍然是可用的。
- 更强大 AI Agent 的愿景:一位用户预测 AI 最终将创造出自身的改进迭代并最大限度地减少人工干预,但这一观点因对计算成本和运营开销的担忧而有所保留。
- 参与者强调了硬件和资源可用性的当前局限性,对自主 AI 能力的短期扩张既表达了乐观也保持了谨慎。
Notebook LM Discord Discord
- DeepResearch 在 NotebookLM 中取得进展:成员们建议将 DeepResearch 引用集成到 NotebookLM 中,旨在合并现有报告的输出,尽管目前还没有官方插件。
- 一些用户提到了通过“批量上传”工作路经将大型数据集导入 NotebookLM,这激发了人们对更强大协同效应的期待。
- AI 音频生成引发热潮:参与者探索了利用精选的 NotebookLM 来源构建播客,并将其与 Illuminate 结合使用,以获得音频灵活性和更好的来源针对性。
- 他们称赞了限制来源的提示词(source-limited prompts)在控制风格方面的作用,而其他人则提到 Jellypod 是一个具有更广泛自定义选项的潜在替代方案。
- 跨语言播客展示 NotebookLM 的灵活性:一些用户尝试在 NotebookLM 内部根据英文内容生成中文播客脚本,并应用口语化改写策略以实现自然流畅。
- 他们还测试了日文对话,指出准确的音译可能需要额外的检查,但这反映了用户对切换语言的适应度。
- 引用模式与系统提示词困惑:开发者在 NotebookLM 中引入了“仅限引用(quotation-only)”命令,确保直接从源文件中摘录内容,并对重要引用进行更严格的验证。
- 然而,Gemini 偶尔会返回不完整的引用,引发了关于在 NotebookLM Plus 中改进系统提示词(system prompts)以获得一致结果的讨论。
LM Studio Discord
- 通义千问(Qwen)奇特的聊天热潮:阿里巴巴推出了 Qwen Chat,这是一个为 Qwen 模型设计的新 Web UI,提供文档上传和视觉理解功能,并在其推文中进行了预告。
- 社区期待即将推出的网页搜索和图像生成等功能,将 Qwen Chat 视为不断发展的 LLM 生态系统中的关键竞争者。
- AMD 7900 的性能难题:用户通过一篇 reddit 帖子 将 AMD RX 7900XT 20GB 与 NVIDIA 3090 进行了对比,认为 7900XT 在处理 LLM 任务时可能面临显存带宽限制。
- 其他人则认为 7900XT 在本地推理方面表现尚可,尽管他们在某些基准测试中看到 3090 的表现更稳定。
- Llama 3.3 的内存乱象:爱好者报告称,Llama 3.3 70B Instruct 在 Ryzen 7 和 RX 7900GRE 等低端硬件上的输出速度极慢,仅为 0.5 token/sec。
- 他们强调需要大量的 GPU 显存或系统 RAM 来避免这些减速,并维持大规模的 token 吞吐量。
- NVIDIA DIGITS 引发好奇:社区讨论转向了 DIGITS,传闻它是 NVIDIA 工作流中用于训练和测试模型的强大解决方案。
- 用户对性能开销保持谨慎,但期待它能成为本地 LLM 工具箱中的一个强大补充。
OpenAI Discord
- O1 的“思考”特性与 A/B 测试暗示:一位参与者指出了 Model O1 独特的“思考”输出,暗示可能涉及不同的模型格式。
- 他们提出了并行运行 Model 4O 的可能性,反映了对比较多种性能方案的热情。
- Meta-Prompting 激发灵感:成员们强调了 Meta-Prompting 策略,提到调整系统消息可以生成更高级的响应。
- 他们强调,在编写提示词时,在开始阶段明确目标会带来更精准的 model outputs。
- Hassabis 的投资轮:小组为 Hassabis 的投资轮送上祝福,认可了新资金在 AI 追求中的重要性。
- 他们称赞了他的过往战绩,并指出支持性的资金可以推动该领域进一步的 R&D 工作。
Interconnects (Nathan Lambert) Discord
- ICLR:聚会热潮:与会者正在为 ICLR 做准备,交流旅行的兴奋感并实时计划潜在的聚会。
- 他们期待活跃的面对面交流,Philpax 很快将穿着浅褐色外套和黑色牛仔裤抵达,准备讨论新的模型突破。
- rStar 崛起:Qwen2.5 与 Phi3-mini 飙升:Microsoft 的 rStar-Math 将 Qwen2.5 在 MATH 基准测试上的表现从 58.8% 提升至 90.0%,将 Phi3-mini 从 41.4% 提升至 86.4%。
- 它目前在全美数学奥林匹克竞赛(USA Math Olympiad)中平均得分为 53.3%,引发了人们对 Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking 的关注以获取更深层的见解。
- NuminaMath 与质量难题:由于约 7.7% 的条目包含多个相互矛盾的解决方案,人们对 NuminaMath 的怀疑增加,这指向了更广泛的数据问题。
- 成员们还引用了 “Towards System 2 Reasoning in LLMs: Learning How to Think With Meta Chain-of-Thought”,并注意到第一作者在斯坦福大学的心理学背景引起了关注。
- 开源 AI:成本冲突:政策制定者对开源 AI 成本仅为 $5M 表示担忧,引发了对实际预算的困惑。
- 一条推文的成本明细排除了资本和数据支出,因误导 GPU 小时数统计而遭到批评。
- Anthropic 的早期角色塑造:在一次 Anthropic 沙龙上,Josh Batson 表示 Amanda Askell 将基础模型塑造为 Agent 的时间比一些人预期的要早。
- 关于角色对齐(character alignment)是训练后的附加组件还是内置过程引发了辩论,对 Anthropic Research Salon 的引用进一步推动了对话。
Eleuther Discord
- SmolLM 分片风暴:SmolLM Corpus 飙升至 320GB,分为 23698 个分片,承诺采用更高效的
.jsonl.zst格式,该格式要到本周晚些时候才能最终确定。- 成员们称赞其体积比 1TB 的未压缩数据集小得多,并提到 HPC 的便利性以及“减少迭代训练流水线的开销”。
- Modal 的强力举措:爱好者们探索了 Modal、Colab 和 Kaggle 等高性价比的训练和分析方案,重点关注 Modal 的每月额度是处理大型任务的可靠方式。
- 他们注意到 Modal 可以运行超出个人 GPU 容量的任务,并赞赏其对大规模推理的稳定支持。
- SciAgents 影响 AI 圈:SciAgents 论文 采用本体知识图谱和 multi-agent 方法来增强研究操作,将结构化数据与 Agent 协作交织在一起。
- 有些人认为这个概念并不是巨大的飞跃,但其他人喜欢这种编排方法,称其为高级学习工作流中一个很有前景的框架。
- Grokking 势头强劲:成员们剖析了 Grokking at the Edge of Numerical Stability,强调了深度网络中的延迟泛化和 softmax 崩溃。
- 他们强调,不足的 regularization 会导致模型崩溃,敦促尽早进行干预并“抑制失控的 logits”。
- 权重衰减与 Llama2 HPC 困境:几位研究人员讨论了 LLM 中极端的权重衰减(如 0.1),建议对注意力层和辅助损失(例如 abs(norm(logits) - 1.0))采用更温和的设置。
- 与此同时,尝试使用
model_parallel=2预训练 7B Llama2 在 batch size 为 1 时触发了 OOM 停滞,促使进行显存分析并对 6.7B 配置进行新测试。
- 与此同时,尝试使用
GPU MODE Discord
- WGMMA & Triton 试验:工程师们讨论了 WGMMA 需要在 4 个 warp 之间进行拆分,且最小 tile 为 64,并参考了 NVlabs 的 tiny-cuda-nn 以获取关于 fused MLP 的见解。他们还推荐使用 Proton 进行性能分析(profiling),并引用了一段有用的视频。
- 社区成员称赞使用 Proton 调试 Triton kernel 更加容易,同时也对典型 HPC 任务中使用片上(on-chip)MLP 表示疑问。
- MI210 占用率之谜:成员们研究了 MI210 和 RX 7900XTX 的 GPU occupancy,参考了一篇关于 block 级优化的资源。他们注意到可能达到 16-warps 的占用率,但在实际代码中看到了诸如 block 级资源使用等限制。
- 他们得出结论,达到更高的占用率通常需要多个 kernel,而 CDNA 架构细节揭示了实际的 block 限制和早期退出(early exit)行为。进一步的测试验证了 MI210 上独特的 block 调度方法。
- Nectar Social 的 1 万美元悬赏:Nectar Social 正在 Seattle 招聘 Staff Product Manager、LLM/AI Engineer 和 Infra Engineer,并提供高达 $10,000 的推荐奖金。他们强调了先前的初创公司经验,并表示愿意私下分享细节。
- 一家拥有 AMD 等 HPC 客户的欧洲咨询公司也在寻找精通 CUDA、HIP 和 OpenCL 的开发人员,参考了 LinkedIn 上的职位列表。他们还合作开发 rocPRIM 和 hipCUB 等库,旨在填补专业的 GPU 开发人员职位。
- ARC Prize 向非营利组织转型:正如 François Chollet 的推文所示,ARC Prize 正在转型为非营利基金会,并由新任主席指导 AGI 研究。他们还启动了一个 rejection sampling 基准实验,以建立基础指标。
- 社区成员探索了 text-domain 解决方案以缓解 GPU 限制,并分析了 Meta CoT paper (链接) 以寻求潜在的改进。作者强调了经典 CoT 方法的不足,引发了关于上下文推理的更广泛讨论。
- MicroDiT 结合 DCAE 的进展:MicroDiT 的复现圆满结束,提供了权重文件和推理脚本。他们对计算支持表示感谢,并旨在通过 DCAE 改进架构以获得更强的性能。
- 计划包括采用 MMDIT 以实现更好的 prompt 遵循能力,并寻求计算资助(compute grants)。有限的家用 GPU 容量阻碍了高级 AI 实验,促使人们寻找额外资源。
Nous Research AI Discord
- Microsoft 的 rStar-Math 助力 Qwen 展现统治力:Microsoft 推出了 rStar-Math,将 Qwen 2.5-Math-7B 在 MATH 基准测试中的表现从 58.8% 提升至 90.0%,并在 AIME 中获得 53.3% 的分数,位列高中生前 20%。
- 成员们讨论了数学能力对推理技能的重要性,一些人提醒说,数值上的突破并不总能保证更广泛的 LLM 可靠性。
- DistTrO 敞开大门:一位成员确认 DistTrO 已开源,引发了社区训练器的立即集成。
- 贡献者称赞 DisTrO 的分布式训练简便性,一些人强调其设置比早期的解决方案更顺畅。
- Carson Poole 的论文展示:Carson Poole 介绍了 ReLoRA 和 Sparse Upcycling,并引用了 2022 年 11 月和 2023 年 3 月的讨论。
- 他敦促成员访问他的个人网站,并提议在 Forefront.ai 或 Simple AI Software 上通过邮件协作进行更深入的探索。
- DeepSeek V3 的双重测试:成员们将 DeepSeek V3 官方 API 的重复输出与 Hyperbolic 等第三方提供商进行了对比,注意到答案质量存在显著差异。
- 一些人将这些不一致归因于激进的缓存(aggressive caching),引发了对更一致推理方法的兴趣。
- Qwen2.5 在 24 GB VRAM 上的内存迷宫:一位用户在 RTX 4090 上运行 Qwen2.5-32B-Instruct-AWQ 时遇到了显存溢出错误,尽管启用了 flash attention。
- 讨论转向了针对约 6K token 上下文的潜在内存使用优化,以及对开源 function calling 准确性基准测试的咨询。
Latent Space Discord
- Salesforce 令人惊讶的招聘冻结:Marc Benioff 确认 Salesforce 将在 2025 年停止招聘软件工程师,理由是 Agentforce 带来了 30% 的生产力提升。
- 社区成员认为这是资源分配的重大转变,有人推测 “AI 确实正在接管基础软件任务”。
- OpenAI 调整自定义指令:据报道,OpenAI 更新了其 advanced voice 工具集的自定义指令,来自 topmass 的推文展示了部分功能损坏以及新功能的迹象。
- 观察者认为这些改进可能会带来新的语音功能,一位用户将其描述为 “为更流畅的 AI 体验提供的强大增强”。
- Anthropic 获得 20 亿美元注资:根据 Andrew Curran 的报告,Anthropic 正在以 600 亿美元的估值筹集 20 亿美元,其 ARR 达到 8.75 亿美元。
- 参与者评论道 “风险投资对 AI 解决方案有巨大的胃口”,特别是随着 Anthropic 在企业合同中的吸引力持续扩大。
- Google 将 AI 整合进 DeepMind:Google 宣布计划将多个 AI 产品合并到 DeepMind 旗下,Omar Sanseviero 的推文展示了双方在 2025 年联手的计划。
- 评论者预见到公司结构可能存在重叠,称其为 “令人费解的重组,但希望能简化 LLM 产品线”。
OpenRouter (Alex Atallah) Discord
- 现金奖励助力黑客松热潮:oTTomator AI Agent Hackathon 提供 6,000 美元的赞助奖金,第一名奖励 1,500 美元,亚军奖励 150 美元,外加 10 美元的 OpenRouter API 额度,报名地址见 此处注册。
- 活动时间为 1 月 8 日至 1 月 22 日,社区投票时间为 1 月 26 日至 2 月 1 日,赞助商包括 Voiceflow 和 n8n,分别提供额外的 700 美元和 300 美元奖金。
- OpenRouter UI 在超过 1000 行时出现卡顿:用户报告称 OpenRouter UI 在聊天记录超过 1000 行后运行速度大幅下降,导致滚动和编辑变得非常痛苦。
- 他们提出了按成本排序和 Next.js 分页等改进方案,以解决这些性能陷阱。
- Gemini Flash 引发困惑:Gemini Flash 引擎在聊天室中可以工作,但通过 API 调用似乎无法运行,这让多位用户感到困惑。
- 另一位用户总体上赞扬了 Gemini,但也指出了需要立即改进的性能问题。
- O1 采用不寻常的响应格式:开发者注意到 O1 的响应 使用 ‘====’ 代替了 Markdown 的反引号,引发了对格式异常的担忧。
- 讨论范围涵盖了这一举措是为了减少 Token 使用量还是为了优化输出,引发了关于最佳实践的辩论。
- API 访问与 Hanami 测试:开发者询问了如何通过 OpenRouter 提供他们自己的 LLM API,并分享了请求处理方面的问题。
- 另一位用户测试了 Hanami 但遇到了奇怪的字符,强调了强大的工具兼容性的重要性。
Perplexity AI Discord
- CSV 导出功能受到关注:Perplexity 推出了将表格响应下载为 CSV 文件的功能,详见说明图片。
- 用户欢迎这一增强功能,认为它简化了数据工作流,并强调了在处理大型数据集时如何节省时间。
- Youzu.ai 室内设计取得进展:Youzu.ai 提供 AI 驱动的房间设计及直接购物选项,详见此 Medium 指南。
- 社区成员对其进行了测试,并赞赏其减少麻烦的潜力,同时征求关于实际使用的反馈。
- 丰田的火箭之约:来自丰田的一项新火箭风险投资表明,他们正在向标准汽车工程之外的领域进军。
- 爱好者们注意到了丰田成熟的专业知识与航空航天需求之间的协同作用,预测随后会有更多官方细节。
- NVIDIA 价值 3000 美元的家用超级计算机:NVIDIA 在 CES 2025 参考资料中宣布了一款未来的家用级超级计算机,价格为 3000 美元。
- 科技粉丝们辩论了先进的性能是否与其成本相符,认为这是在家中进行机器学习实验的一个契机。
- Ecosia 寻求与 Perplexity 合作:Ecosia 的一名产品经理在联系 Perplexity 洽谈潜在合作时遇到困难,并寻求联系方式的指导。
- 社区中的热心人士提供了直接沟通的建议,希望如果讨论能继续推进,双方能达成富有成效的联盟。
{kind=link}
Cohere Discord
- Cohere 的 ‘North’ 崛起,挑战 Copilot:Cohere 推出了 North 的早期访问版,这是一个安全的 AI 工作区,将 LLMs、search 和 agents 融合到一个界面中以提升生产力。
- 正如官方博客文章所述,他们认为它可以超越 Microsoft Copilot 和 Google Vertex AI。
- Command R+ 推动生成式收益:一位用户在探索 Cohere 生态系统中大型生成式模型的工作流时提到了 Command R+。
- 社区讨论强调了清晰的集成策略,并认识到需要结构良好的 prompts 来优化模型行为。
- v2 到 v3 Embeddings:升级疑问:关于如何从 embed-v2 过渡到 v3 而无需重新对海量数据集进行 embedding 的问题被提出,引发了对资源消耗的担忧。
- 成员们寻求一种高效的方法,在保持性能的同时最大限度地减少开销和潜在的停机时间。
- LLM 循环与滚动聊天:驯服 Token 溢出:报告显示 Cohere 的 LLM 可能会陷入重复循环,导致 Python ClientV2 设置中出现失控的 token 使用。
- 建议包括设置 max_tokens 限制,并采用滚动聊天历史(rolling chat history)技术来处理 4k token 限制内的扩展响应。
- Alignment Evals Hackathon 激发行动:宣布将于 25 日举行 Alignment Evals Hackathon,届时将提供社区驱动的评估(eval)和解释教程。
- 鼓励参与者分享见解和成果,推动对齐评估方法上的协作。
tinygrad (George Hotz) Discord
- Mock GPU 混乱与悬赏讨论:针对涉及 macOS 上 MOCKGPU 的 Pull Request #8505 请求进行重新测试,George Hotz 确认已为该修复准备好悬赏。
- 他提议通过 PayPal 或以太坊上的 USDC 支付,强调了处理 tinygrad 待办任务的决心。
- LLVM JIT 与 Autogen 结对:成员们提议合并他们的 LLVM JIT 和 LLVM Autogen 工作,并引用了多个版本文件的更改。
- 他们还辩论了前向与后向兼容性,一些人强调支持旧版 LLVM 以避免静默损坏(silent breakage)。
- 函数签名稳定性摩擦:有人担心 LLVM 函数签名的潜在静默更改会导致未定义行为。
- George Hotz 淡化了这一风险,指出更倾向于支持旧的 LLVM 版本以保持一致性。
- TinyGrad 博客与设备设置:一篇题为 TinyGrad Codebase Explained-ish 的博客文章介绍了 tinygrad 的文件布局,并对 tinygrad/ 目录之外测试较少的代码提出了警告。
- 一位用户询问如何在特定硬件上初始化权重,并得到了在创建 tensors 之前将
Device.DEFAULT设置为 METAL、CUDA 或 CLANG 的建议。
- 一位用户询问如何在特定硬件上初始化权重,并得到了在创建 tensors 之前将
Nomic.ai (GPT4All) Discord
- Llama 与 GPT4All 之争升温:他们强调 Llama.cpp Vulkan 与 GPT4All 内部机制不同,由于使用了 CUDA,在 Nvidia GPUs 上产生了巨大的速度差距。
- 参与者得出结论,如果性能满足日常目标,这种差异可以忽略不计,并参考了 nomic-ai/gpt4all 以获取更多背景信息。
- Chat Template 纠葛:一位用户在 GPT4All 上使用 TheBloke 的模型时遇到了 Chat Template 问题,尽管安装正确,但仍收到通用回复。
- 其他人建议查看 GitHub 上的模型特定说明,强调 chat prompts 在不同模型之间差异很大。
- 基于 Llama-3 的角色扮演推荐:对于动漫主题的角色扮演,成员们推荐了 Nous Hermes 2 或 llama3-8B-DarkIdol-2.2-Uncensored-1048K 作为可行的旧选项。
- 他们指出 Nomic 的即插即用方法简化了使用,特别是对于快速的脚本化对话。
- ModernBERT 部署困境:有人询问 Nomic AI 的 ModernBERT 是否支持 text-embedding-inference 或 vLLM。
- 目前还没有确切的答案,这让小组对官方部署渠道感到不确定。
- 图像模型希望点燃 GPT4All 讨论:一些人考虑将图像模型加入 GPT4All 以扩展模态覆盖范围。
- 对话在没有明确计划的情况下结束,但强调了用户对桥接文本与视觉的兴趣。
LlamaIndex Discord
- GitHub 总部大聚会:1 月 15 日,他们将在 GitHub HQ 举办一系列专家演讲,讨论 AI Agent 改进、快速推理系统以及使用 LlamaIndex 构建工作流。
- 该活动展示了先进的 Agentic 工作流,重点介绍了来自多位行业专家的真实案例。
- Agentic 文档工作流:一次大胆飞跃:一篇新的 博客文章 介绍了 Agentic Document Workflows (ADW),旨在将文档处理直接集成到业务流程中。
- 它强调 文档有多种格式,并为未来驱动的应用提供了一种流线型方法。
- Ollama 提速:Ollama 的最新更新将评估时间缩短至 3 秒以内,引发了用户的兴奋。
- 一位用户称其提升是令人难以置信的,反映了对更快模型推理的强烈热情。
- VectorStoreIndex:元数据的手动操作:一些成员讨论了在 Postgres JSON 字段中使用 VectorStoreIndex 按元数据键过滤节点,询问是否可以避免手动索引。
- 他们得出结论,由于 LlamaIndex 尚未处理所有相关的自动化,可能仍需要 手动索引。
- 驯服 TEI 和 QueryFusionRetriever 的怪癖:使用 本地 TEI 服务器 进行 Reranking 的兴趣有所增加,参考了 API 文档 和 源代码。
- 与此同时,用户在 QueryFusionRetriever 中遇到了 518 个 Token 处的 输入验证错误,并分享了代码片段以寻找解决方法。
Modular (Mojo 🔥) Discord
- Rust 语法简化多行:一位用户在为 multipaxos 构建 Actor 时称赞了 Rust 的多行语法,强调其类型检查更少。
- 他们表示函数参数可能变得繁琐,给理清所需类型的用户带来困惑。
- 重载解析变得冒险:一位用户警告说,在大型代码库中重新排列重载可能会导致新的障碍,建议采用 ‘happens after’ 注解方法。
- 他们补充说 TraitVariant 检查可能与实现 Trait 混淆,可能导致混乱的重载解析。
- Mojo 中的量子库进展:一位成员提到需要一个 类 Qiskit 的库,提到了对量子扩展的兴趣,并链接到了 MLIR 开发视频。
- 他们建议 MAX 随着发展可能很快就能处理量子任务。
- MAX 支持量子编程:讨论聚焦于 MAX 作为 Mojo 微调量子例程的合作伙伴,允许实时硬件调整。
- 人们表示,当 MAX 成熟时,它可以统一量子和经典逻辑。
- Quojo 提供量子选项:通过 GitHub 分享的 Quojo 库被提及为 Mojo 中的量子计算工具。
- 大家对推动量子编程发展的新兴开发者表示兴奋。
LLM Agents (Berkeley MOOC) Discord
- 黑客松时间表成型:黑客松网站 (链接) 分享了更新后的结果公布时间表,将最终结果推迟到 1 月下旬。
- 组织者表示,仍有几位评委需要完成评审,承诺在宣布获胜者之前进行彻底评估。
- 评委们欢欣鼓舞:评委们对 黑客松提交作品 给予了极高的评价,称其整体为令人印象深刻的作品。
- 他们强调了极高的创意水平和技术深度,增强了对最终裁决的期待。
OpenInterpreter Discord
- OpenInterpreter 1.0 在 Python 执行方面遇到困难:用户发现 OpenInterpreter 1.0 不能直接运行 Python 代码,导致对
--tools interpreter命令产生困惑。- 一位成员对代码执行的限制表示沮丧,引发了对如何处理代码块提供更清晰指令的请求。
- GPT-4o-mini 获得部分命令控制能力:讨论指出 GPT-4o-mini 在命令处理方面有所改进,特别是在分块打印文件内容时。
- 对话集中在通过更好的文件输出策略和微调命令执行来优化模型性能。
- 征集模型规格参数:一位成员询问了关于参数量和底层框架的更多技术细节,以便更好地理解性能指标。
- 这一询问强调了对完整文档的需求,因为参与者正在寻求关于模型构建模块的清晰说明。
LAION Discord
- TruLie 还是假象?数据之谜:一位用户询问了 TruLie 数据集,但未提供具体细节或引用,导致对话缺乏事实依据。
- 成员们对可能的研究应用表示好奇,但尚未出现直接的资源。
- Chirpy3D 取得进展:爱好者们讨论了 image-to-3D 的进展,重点介绍了用于连续鸟类生成的 Chirpy3D 和 Gaussian splats 方法,并引用了 Chirpy3D 作为示例。
- 他们提到了来自多个机构的合作,并指出 Hugging Face 上的 3D Arena 是 NeRF 库的资源。
- World Models 进化视觉效果:贡献者分享了使用物理感知网络生成更真实视频内容的 World Models。
- 虽然超出了纯粹的 image-to-3D 流程,但这一方向与构建复杂视觉系统的更广泛努力相一致。
- 寻求开放工具注册表:一位研究人员请求建立一个用于构建 Agent 的开放工具注册表,希望能收集小组的建议。
- 目前尚未出现直接线索,促使进一步尝试寻找完整的资源。
DSPy Discord
- 聊天机器人的 Chain-of-Thought 增强:一位用户询问如何将聊天机器人的 Chain-of-Thought 提升到简单的角色签名(persona signature)之外,寻求更深层次的对话风格和推理步骤。
- 该问题未得到解答,凸显了优化聊天机器人逻辑和用户交互的难度。
- 使用 DSPy 进行评估尝试:一篇关于构建自定义评估的文章,题为《构建自定义评估简介:为什么它很重要以及 DSPy 如何提供帮助》,被分享在这里,以强调 DSPy 在定制测试框架中的作用。
- 读者对开发新的评估方法表现出兴奋,并认可了 DSPy 在改进知识库(knowledge bank)解决方案方面的潜力。
- 人类学与技术:Drew 的路径:Drew Breunig 概述了他在文化人类学、软件和媒体方面的背景,提到了在 PlaceIQ 和 Precisely 从事数据完整性方面的工作。
- 他还与 Overture Maps Foundation 合作,扩大了跨不同行业的数据使用范围。
AI21 Labs (Jamba) Discord
- Python + Jamba 增强播客内容召回:一位用户利用 Jamba 的对话式 RAG 配合一个基础 Python 应用,通过转录文本检索过去播客的精彩片段,称其为正在进行中的有趣实验。
- 他们提到正在探索集成 AI 驱动召回的新方法,且没有遇到重大障碍,发现该系统对于归档节目笔记非常方便。
- AI 代码生成很棒… 但也会出错:一位用户对 AI 生成代码的能力赞不绝口,称赞其对 HTML 和 JavaScript 的处理,但也指出偶尔会出现愚蠢的错误。
- 他们测试了 PHP 任务以衡量 AI 的极限,结论是代码生成虽然有时令人费解,但依然很有帮助。
- PHP 在 Jamba 连接中表现稳健:另一位用户宣布忠于使用 PHP 进行 Web 和 IRC 机器人编码,并称连接到 Jamba 是一次真正的冒险。
- 他们喜欢它与 deepSeek 和 OpenAI API 的相似之处,这简化了编程任务并鼓励快速尝试。
Torchtune Discord
- ModernBERT 微调引起关注:有人提出了关于 微调 ModernBERT 的咨询,暗示了特定任务的改进,但尚未分享直接经验。
- 对话在没有后续跟进的情况下结束,观察者们希望有 技术示例 或演示来指明前路。
- Nectar Social 抛出 1 万美元推荐奖金:Nectar Social 正在寻求以 AI 为核心的人才,推荐奖金高达 $10,000,职位包括高级/资深产品经理和 LLM/AI 工程师。
- 他们强调了在 社交电商 领域的增长,拥有知名客户,并鼓励感兴趣的申请人私信(DM)了解详情。
MLOps @Chipro Discord 没有新消息。如果该频道长时间没有动静,请告知我们,我们将将其移除。
Axolotl AI Discord 没有新消息。如果该频道长时间没有动静,请告知我们,我们将将其移除。
Mozilla AI Discord 没有新消息。如果该频道长时间没有动静,请告知我们,我们将将其移除。
HuggingFace Discord 没有新消息。如果该频道长时间没有动静,请告知我们,我们将将其移除。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该频道长时间没有动静,请告知我们,我们将将其移除。
第 2 部分:频道详细摘要与链接
为了邮件展示,完整的频道分类详情已被截断。
如果您喜欢 AInews,请分享给朋友!预谢支持!