ainews-titans-learning-to-memorize-at-test-time
**Titans:在测试时学习记忆**
谷歌(Google)发布了一篇关于“神经记忆”(Neural Memory)的新论文,在推理阶段(test time)将持久性记忆直接集成到 Transformer 架构中,展示了在长上下文利用方面的潜力。由 @omarsar0 发布的 MiniMax-01 拥有 400 万 token 的上下文窗口、4560 亿参数和 32 个专家,其性能超越了 GPT-4o 和 Claude-3.5-Sonnet。InternLM3-8B-Instruct 是一款基于 4 万亿 token 训练的开源模型,达到了当前最先进的(SOTA)水平。Transformer² 引入了自适应大语言模型(LLM),通过动态调整权重来实现持续适配。AI 安全方面的进展强调了对智能体身份验证、提示词注入防御以及零信任架构的需求。像 Micro Diffusion 这样的工具让低成本的扩散模型训练成为可能,而 LeagueGraph 和 Agent Recipes 则为开源社交媒体智能体提供了支持。
Neural Memory is all you need.
2025年1月14日至1月15日的 AI 新闻。我们为您检查了 7 个 subreddits、433 个 Twitter 账号 和 32 个 Discord(219 个频道,2812 条消息)。预计为您节省了 327 分钟 的阅读时间(以 200wpm 计算)。您现在可以标记 @smol_ai 进行 AINews 讨论!
许多人都在热议 Google 最新的论文,被一些博主誉为 “Transformers 2.0” (arxiv, tweet):

它似乎在 “test time” 直接将持久化存储(persistent memory)集成到架构内部,而不是放在架构之外(这是作为 context、head 或 layer 的三种变体之一)。
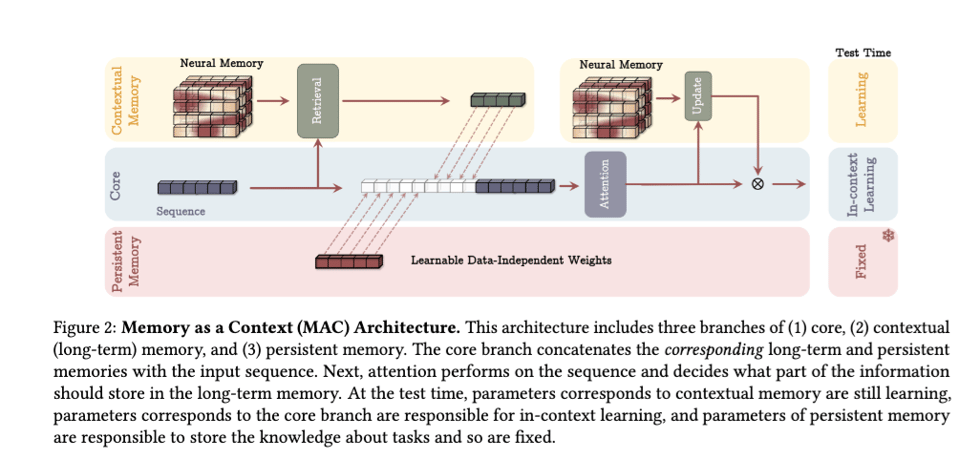
该论文显著地使用了一种惊奇度(surprisal)度量来更新其记忆:
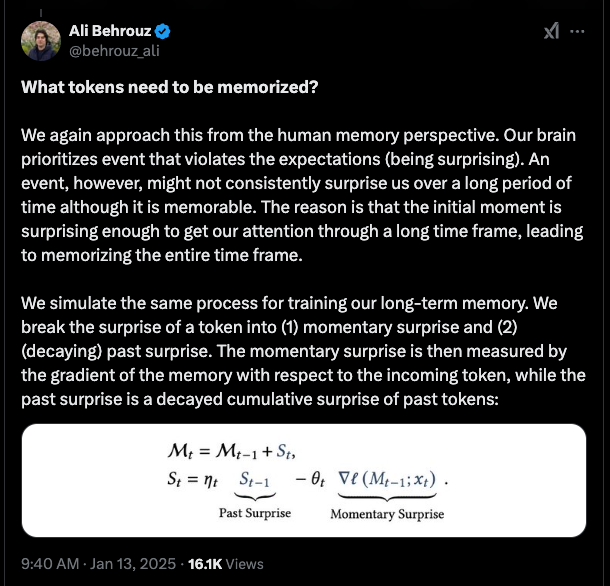
并通过权重衰减(weight decay)来模拟遗忘过程:

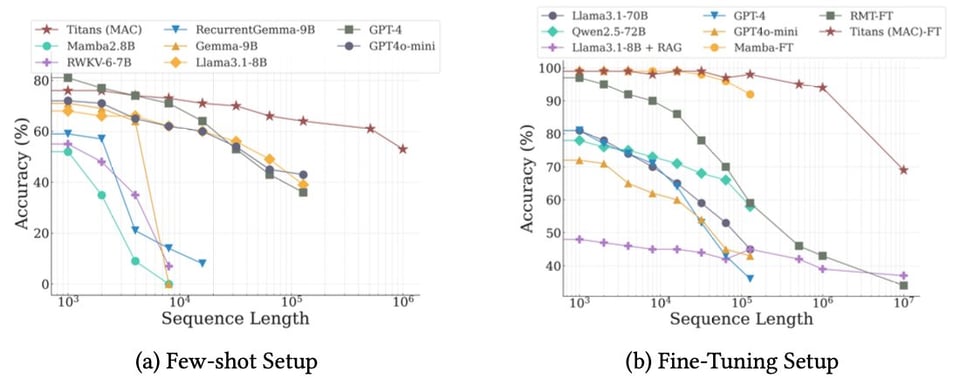
最终结果显示,在长上下文(long contexts)下,其上下文利用率表现非常出色。
AI Twitter 回顾
所有总结均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
AI 模型与扩展 (Scaling)
-
MiniMax-01 与超长上下文模型:@omarsar0 介绍了 MiniMax-01,它集成了 Mixture-of-Experts 架构,拥有 32 个专家和 456B 参数。它拥有 400 万 token 的上下文窗口,性能超越了 GPT-4o 和 Claude-3.5-Sonnet 等模型。同样,@hwchase17 强调了视觉空间草稿纸 (vision-spatial scratchpads) 的进展,解决了 VLMs 中长期存在的挑战。
-
InternLM 与开源 LLMs:@abacaj 讨论了 InternLM3-8B-Instruct,这是一款采用 Apache-2.0 许可的模型,在 4 万亿 token 上进行了训练,达到了最先进的性能。@AIatMeta 分享了发表在 @Nature 上的 SeamlessM4T 更新,强调了其受自然启发的自适应系统。
-
Transformer² 与自适应 AI:@hardmaru 展示了 Transformer²,展示了能够动态调整权重的自适应 LLMs,连接了 pre-training 和 post-training 以实现持续适应。
AI 应用与工具
-
AI 驱动的开发工具:[@rez0](https://twitter.com/rez0/status/1879557690101260681) 概述了对强大的 Agent Authentication、Prompt Injection 防御和安全 Agent 架构的需求。此外,@hkproj 推荐使用 Micro Diffusion 在有限预算下训练 diffusion models。
-
Agent 系统与自动化:@bindureddy 强调了 Search-o1 在增强复杂推理任务方面的潜力,其表现优于传统的 RAG 系统。@LangChainAI 推出了 LeagueGraph 和 Agent Recipes,用于构建开源社交媒体 Agent。
-
与开发环境的集成:@_akhaliq 讨论了为跨应用的 AI 模型支持统一本地端点,而 @saranormous 则提倡使用 Grok 的 Web 应用以避免干扰。
AI 安全与伦理担忧
-
数据完整性与 Prompt Injection:[@rez0](https://twitter.com/rez0/status/1879557690101260681) 强调了 prompt injection 的挑战以及采用零信任架构 (zero-trust architectures) 来保护 LLM 应用的必要性。@lateinteraction 批评了 AI prompts 中规范与实现之间界限的模糊,主张建立更清晰的领域特定知识。
-
地缘政治与 AI 监管:@teortaxesTex 批评了关于中国服务器存在显式后门的说法,转而推崇 Apple 的安全模型。@AravSrinivas 讨论了 AI 扩散规则对 NVIDIA 股票的影响,并对全球监管格局进行了反思。
教育与招聘中的 AI
-
家庭教育与教育政策:@teortaxesTex 对战斗动画以及缺乏有效的教育技术表示失望。同时,@stanfordnlp 举办了关于 AI 与教育的研讨会,强调了 Agent 和工作流的作用。
-
招聘与技能发展:@finbarrtimbers 分享了关于招聘 ML 工程师的见解,而 @fchollet 正在为 AI 程序合成寻找专家,强调了数学和编程技能的重要性。
软件工程中的 AI 集成
-
LLM 集成与生产力:@TheGregYang 和 @gdb 讨论了将 LLM 无缝集成到调试工具和 Web 应用中,以提高开发者生产力。@rasbt 强调了原始智能与智能软件系统之间的区别,主张采用正确的实施策略。
-
AI 驱动的编程与自动化:@hellmanikCoder 和 @skycoderrun 强调了使用 LLM 进行代码生成和自动化的优势与挑战,并强调了对稳健集成和错误处理的需求。
政治与 AI 监管
-
中国 AI 发展与安全:@teortaxesTex 提到了科大讯飞收购 Atlas 服务器,反映了中国 AI 基础设施的增长。@manyothers 讨论了 昇腾(Ascend)集群潜在的加速发展,突显了中国大陆在计算领域的进步。
-
美国 AI 政策与基础设施:@iScienceLuvr 总结了一项关于加速 AI 基础设施的美国行政命令,详细阐述了数据中心要求、清洁能源指令以及国际合作。@karinanguyen_ 批评了 AI 工作流在形态因素(form factors)上的滞后,并反思了政策影响。
梗图/幽默
-
关于 AI 与日常生活的幽默观点:@arojtext 调侃为了逃避现实而隐藏电子游戏的更好用途,而 @qtnx_ 分享了一个关于无关 AI 应用的有趣问题。此外,@nearcyan 幽默地反思了游戏习惯和意外的置业报价。
-
轻松的 AI 评论:@Saranormous 嘲讽了与 ScaleAI 的互动,@TheGregYang 则俏皮地鼓励使用 Grok 的 Web 应用来避免分心,将 AI 功能与日常幽默结合在一起。
AI Reddit 综述
/r/LocalLlama 综述
主题 1:InternLM3-8B 表现优于 Llama3.1-8B 和 Qwen2.5-7B
- 新模型…. (Score: 188, Comments: 31): 据报道 InternLM3 的表现优于 Llama3.1-8B 和 Qwen2.5-7B。该项目名为 “internlm3-8b-instruct”,托管在一个类似于 GitHub 的平台上,带有 “Safetensors” 和 “custom_code” 等标签,并引用了标识符为 2403.17297 的 arXiv 论文。
- InternLM3 的性能与特性:用户强调了 InternLM3 优于 Llama3.1-8B 和 Qwen2.5-7B 的卓越性能,并强调其仅使用 4 trillion tokens 进行训练的高效性,使成本降低了 75% 以上。该模型支持“深度思考模式”以处理复杂的推理任务,可以通过 Hugging Face 上显示的不同系统提示词(system prompt)来开启。
- 社区反馈与对比:用户对 InternLM3 的能力表示满意,指出其在逻辑和语言任务中的有效性,并认为其优于 Exaone 7.8b 和 Qwen2.5-7B 等模型。社区希望能推出 20 billion parameter 版本,并参考了 2.5 20b 模型。
- 模型命名与许可:讨论了 “Intern” 这个名字,一些用户认为由于 AI 扮演着无薪助手的角色,这个名字非常贴切。此外,用户呼吁在分享模型时应有更清晰的许可实践,并对不明确的许可证表示沮丧,特别是在音频/音乐模型中。
{kind=link}
主题 2. OpenRouter 获得新功能和社区驱动的改进
- OpenRouter 用户:你还缺少什么功能? (Score: 190, Comments: 79):作者无意中开发了一个名为 glama.ai/gateway 的 OpenRouter 替代方案,它提供类似的功能,如更高的 rate limits 和通过 OpenAI 兼容 API 轻松切换模型。其独特优势包括与 Chat 和 MCP 生态系统的集成、高级分析功能,以及据称比 OpenRouter 更低的延迟和更高的稳定性,同时每天处理数十亿个 tokens。
- API 兼容性与支持:用户对与 OpenAI API 的兼容性表示关注,特别是关于多轮工具使用、function calling 和图像输入格式。关注点包括工具使用语法的差异,以及对支持的 API 功能和模型的详细文档需求。
- 供应商管理与数据安全:用户要求对特定模型的供应商选择进行更细粒度的控制,因为某些供应商(如 DeepInfra)并非对所有模型都是最优的。此外,glama.ai 因其数据保护政策和不使用客户数据进行 AI 训练的承诺而受到称赞,这与 OpenRouter 的数据处理实践形成对比。
- Sampler 选项与移动端支持:用户讨论了对 XTC 和 DRY 等额外 sampler 选项的需求(目前尚不支持),以及作为中间商实现这些选项的挑战。此外,用户对改进移动端支持也很感兴趣,因为目前的流量主要来自桌面端,但移动端正成为一个更频繁的讨论话题。
主题 3. Kiln 作为 Google AI Studio 的开源替代方案受到关注
- 我不小心构建了一个 Google AI Studio 的开源替代方案 (Score: 865, Comments: 130): Kiln 是 Google AI Studio 的开源替代方案,提供增强功能,如通过多个主机支持任何 LLM、无限的微调能力、本地数据隐私和协作使用。它与 Google 有限的模型支持、数据隐私问题和单用户协作形成对比,同时还提供 Python 库和强大的数据集管理。Kiln 已在 GitHub 上发布,旨在像 Google AI Studio 一样易于使用,但功能更强大且更具私密性。
- 用户对隐私和许可的担忧非常突出,osskid 和 yhodda 等用户指出了 Kiln 的隐私声明与其 EULA 之间的差异,后者暗示 Kiln 可能拥有数据访问和使用权。Yhodda 强调桌面应用程序的专有许可证可能导致用户数据在没有补偿的情况下被共享和使用,这引发了对用户权利和隐私的警示。
- 用户赞赏 Kiln 的开源特性,fuckingpieceofrice 和 Imjustmisunderstood 等人的评论表达了对 Google AI Studio 替代方案的感激,担心未来会出现付费墙。开源方面被视为一个显著优势,即使桌面组件不是开源的。
- 文档和教程收到了积极反馈,Kooky-Breadfruit-837 和 danielhanchen 等用户称赞了详尽的指南和迷你视频教程。正如 RedZero76 所指出的,这表明 Kiln 对用户友好且易于上手,即使是技术经验有限的人也是如此。
Theme 4. OuteTTS 0.3 推出全新的 1B 和 500M 语言模型
- OuteTTS 0.3: 全新 1B & 500M 模型 (Score: 155, Comments: 62): OuteTTS 0.3 推出了全新的 1B 和 500M 模型,增强了其 text-to-speech 能力。此次更新可能包括模型性能和功能集的改进,尽管文中未提供具体细节。
- 关于 OuteTTS 的语言支持有显著讨论,特别是尽管西班牙语使用广泛但仍缺失。OuteAI 解释说这是由于西班牙语口音和方言的多样性,以及缺乏足够的数据集,导致输出结果是通用的 “Latino Neutro”。
- OuteAI 阐明了模型的各种技术细节,例如它们基于 LLMs 并使用 WavTokenizer 进行音频 Token 解码。这些模型与 Transformers, LLaMA.cpp 和 ExLlamaV2 兼容,并且正在持续探索 speech-to-speech 能力。
- OuteTTS 0.3 模型在语音的自然度和连贯性方面有所提升,支持包括新加入的法语和德语在内的六种语言。Demo 已在 Hugging Face 上线,通过 pip 即可轻松安装。
Theme 5. 405B MiniMax MoE:在上下文长度和效率方面的突破
- 405B MiniMax MoE 技术深度解析 (Score: 66, Comments: 10): 该帖子讨论了 405B MiniMax MoE 模型,强调了其创新的扩展方法,包括与 7/8 Lightning attention 的混合以及与 DeepSeek 不同的 MoE strategy。它详细介绍了该模型在约 2000 H800 和 12 trillion tokens 上的训练情况,更多信息可在 Hugging Face 的博客文章中找到。
- 405B MiniMax MoE 模型因其在没有 Chain of Thought (CoT) 的情况下在 Longbench 上的出色表现而受到关注,展示了其处理长上下文的能力。FiacR 强调了其“疯狂的上下文长度”,eliebakk 赞扬了其“超级令人印象深刻的数据”。
- 关于开源权重模型(open weights models)与闭源模型竞争趋势的讨论非常积极,人们对 2025 年的重大进展持乐观态度。vaibhavs10 对这一趋势表示热忱,并分享了 Hugging Face 上的 MiniMaxAI 模型链接。
- 正如 StevenSamAI 所提到的,该模型托管在 Hailuo.ai 上,为访问该模型提供了资源。
其他 AI Subreddit 回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
主题 1. Transformer²:增强实时 LLM 适应性
- [R] Transformer²: Self-Adaptive LLMs (Score: 137, Comments: 10): Transformer² 为大语言模型 (LLMs) 引入了一个自适应框架,该框架能够动态调整权重矩阵的奇异分量,以实时处理未知任务,在参数更少的情况下性能优于 LoRA 等传统方法。该方法采用双阶段机制,利用调度系统和通过强化学习训练的任务特定“专家”向量,展示了在各种架构和模态(包括视觉语言任务)中的通用性。论文, 博客摘要, GitHub。
- 评论者讨论了该框架的扩展方式,指出它是随磁盘空间而非参数数量扩展的,这可能意味着在存储和计算方面具有较高的效率。
- 讨论涉及了 Transformer² 对不同规模 LLM 的性能影响,观察到虽然它显著增强了较小的模型,但对于像 700 亿参数 (70 billion parameter) 模型这样的大型模型,改进微乎其微。
- Sakana 实验室的发展受到了关注,人们注意到该论文没有列出知名作者,这表明研究团队正在扩大且协作性日益增强。
主题 2. 深度学习革新预测性医疗保健
- 研究人员开发出预测乳腺癌的深度学习模型 (Score: 118, Comments: 17): 研究人员开发了一种深度学习模型,能够使用精简算法提前五年预测乳腺癌。该研究分析了超过 210,000 份乳腺 X 线摄影图像,并强调了乳腺不对称在评估癌症风险中的重要性,详情见这篇 RSNA 文章。
{kind=link}
AI Discord 摘要
由 o1-preview-2024-09-12 生成的摘要之摘要的摘要
主题 1:AI 模型性能在各平台遭遇挫折
- Perplexity 用户因持续停机感到困惑:用户报告 Perplexity 出现多次长时间停机,错误持续超过一小时,引发了不满并促使人们寻找替代方案。
- Cursor 运行缓慢,性能陷阱困扰开发者:Cursor IDE 用户面临严重的运行缓慢问题,5-10 分钟的等待时间阻碍了 Pro 订阅者的工作流,并引发了关于修复方案的推测。
- DeepSeek 响应迟缓,用户寻求更快的替代方案:DeepSeek V3 受到延迟问题和响应缓慢的困扰,导致用户转向 Sonnet 等模型,并对性能不稳定表示失望。
主题 2:新 AI 模型突破上下文障碍
- MiniMax-01 以 400 万 Token 上下文开辟新路径:MiniMax-01 发布,利用 Lightning Attention 实现了前所未有的 400 万 Token 上下文窗口,承诺提供超长上下文处理能力和性能飞跃。
- Cohere 将上下文提升至 128k Token:Cohere 将上下文长度扩展至 128k Token,支持在单次对话中处理约 42,000 个单词而无需重置,增强了连贯性。
- Mistral 的 FIM 奇迹令开发者惊叹:来自 Mistral AI 的新型 Fill-In-The-Middle (FIM) 编程模型凭借超越标准能力的先进代码补全和片段处理能力给用户留下了深刻印象。
主题 3:法律纠纷冲击 AI 数据集和开发者
- MATH 数据集遭遇 DMCA 卸载:AoPS 发起反击:Hendrycks MATH 数据集面临 DMCA 删帖,引发了对 Art of Problem Solving (AoPS) 内容以及 AI 领域数学数据未来的担忧。
- JavaScript 商标之争威胁开源社区:一场关于 JavaScript 商标的激烈法律纠纷引发了警报,可能产生的限制将影响社区主导的开发和开源贡献。
主题 4:AI 训练的进展与争论
- Grokking 取得进展:现象深度解析:一段名为 “Finally: Grokking Solved - It’s Not What You Think” 的新视频深入探讨了延迟泛化这一奇特的 Grokking 现象,激发了热议和争论。
- 动态量化(Dynamic Quantization)的怪异表现引发质疑:用户报告在对 Phi-4 应用动态量化时性能变化极小,引发了关于该技术与标准 4-bit 版本相比有效性的讨论。
- TruthfulQA 基准测试被简单技巧破解:TurnTrout 通过利用几个简单的规则漏洞,在 TruthfulQA 上实现了 79% 的准确率,突显了基准测试可靠性的缺陷。
主题 5:行业动态搅动 AI 格局
- Cursor AI 在 B 轮融资中获得巨额资金:Cursor AI 完成了由 a16z 领投的新一轮 Series B 融资,助力该编程平台的下一阶段发展,并在按需计费定价谈判中加强了与 Anthropic 的联系。
- Anthropic 获得 ISO 42001 负责任 AI 认证:Anthropic 宣布获得新标准 ISO/IEC 42001:2023 的认证,强调了负责任 AI 开发的结构化系统治理。
- NVIDIA Cosmos 在 CES 亮相,令 LLM 爱好者印象深刻:NVIDIA Cosmos 在 CES 上揭晓,展示了新的 AI 能力;LLM Paper Club 的演讲强调了其对该领域的潜在影响。
第一部分:Discord 高层级摘要
Cursor IDE Discord
- Cursor 运行缓慢:性能陷阱困扰用户:许多用户报告在 Cursor 中遇到了 5-10 分钟的等待时间,而其他用户则表示速度正常,这让试图保持稳定工作流的 Pro 订阅用户感到沮丧。
- 这种减速阻碍了编码工作,并引发了关于修复方案的推测,一些人正关注 Cursor 的博客更新 以寻求潜在的缓解方案。
- 快速部署:Vercel 与 Firebase 表现出色:开发者们称赞 Vercel 和 Google Firebase 在部署基于 Cursor 开发的应用时表现优异,强调其生产环境配置极简。
- 他们分享了 Vercel 上的模板 以实现快速启动,并指出了与 Firebase 轻松进行实时集成的优势。
- Gemini 2.0 Flash 对决 Llama 3.1:爱好者们更倾向于 Gemini 2.0 Flash,认为其 Benchmark 结果优于 Llama 3.1,并指出其文本生成性能更犀利。
- 另一些人承认,由于对 AI 的过度依赖,产生了“冒名顶替综合征”(imposter syndrome),但同时也接受了生产力提升带来的好处。
- Sora 在慢动作场景中受挫:有报告称 Sora 在生成可靠视频方面遇到困难,尤其是在慢动作片段中,这让部分用户感到不满。
- 在频繁的尝试和失败后,一些人开始探索替代方案,表明对 Sora 的功能集评价褒贬不一。
- Fusion 热潮:Cursor 为三月发布做准备:预计 Cursor 将在三月发布新版本,重点包括 Fusion 的实现,以及可能与 DeepSeek 和 Gemini 的集成。
- 尽管具体细节尚未披露,但 Cursor 的 Tab 模型文章 中透露的信息让人们对这个功能更强大的平台充满期待。
Perplexity AI Discord
- Perplexity 宕机引发不满:Perplexity 频繁的服务中断导致用户面临超过一小时的报错,正如 状态页面 所示,这引发了用户对备份方案的需求。
- 随着 citation(引用)故障的出现,用户的挫败感进一步增加,导致一些人开始寻找替代方案,并对可靠性表示担忧。
- AI 模型性能大比拼:社区成员权衡了最佳编码模型,其中 Claude Sonnet 3.5 在调试任务中脱颖而出,而 Deepseek 3.0 被提议作为经济实惠的备选方案。
- 一些人称赞 Perplexity 处理某些查询的能力,但同时也批评其 hallucinations(幻觉)和有限的 context window(上下文窗口)。
- 双重幻影:两个 Perplexity iOS 应用:一位用户在 App Store 中发现了重复项,并引发了关于官方 Perplexity 应用的 网页查询。
- 另一位用户无法找到第二个列表,引发了关于 naming(命名)和分发问题的简短讨论。
- JavaScript 商标之争:如果商标诉求变得更加严格,一场关于 JavaScript 商标的法律斗争可能会威胁到社区主导的开发。
- 舆论对所有权问题以及可能影响开源贡献的诉讼浪潮表示担忧。
- Llama-3.1-Sonar-Large 速度变慢:llama-3.1-sonar-large-128k-online 自 1 月 10 日以来输出速度明显下降,令用户感到困惑。
- 社区讨论指向未公开的更新或代码变动可能是导致减速的原因,引发了对更广泛性能影响的担忧。
Codeium (Windsurf) Discord
- Command 功能热潮与编辑器好评:Windsurf 发布了 Command 功能教程,通过 Luminary 等视频公布了 Discord 挑战赛获胜者,并推出了 Windsurf Editor。
- 他们还展示了 Codeium 对标 GitHub Copilot 的官方对比,并分享了一篇关于非许可代码担忧的博客文章。
- Telemetry 纠葛与订阅障碍:用户在 Codeium Visual Studio 扩展中遇到了 telemetry(遥测)问题,并对订阅计划中的额度结转(credit rollover)感到困惑,参考了 GitHub issues。
- 他们确认计划取消后额度不会结转,部分用户遇到了与扩展清单(manifest)命名相关的安装问题。
- 学生折扣与远程仓库谜题:学生对 Pro Tier 捆绑包表现出兴趣,但如果地址不是 .edu 则会遇到困难,这引发了对更具包容性的资格审查的呼声。
- 其他人报告了在 IntelliJ 中配合 Codeium 使用已索引的远程仓库时存在摩擦,并寻求社区的设置建议。
- C# 类型问题与 Cascade 讨论:Windsurf IDE 在 Windows 和 Mac 上分析 C# 变量类型时持续出现问题,尽管 VS Code 等其他编辑器表现流畅。
- 用户讨论了 Cascade 的性能并推荐了高级 Prompt,同时还讨论了集成 Claude 和其他模型以处理复杂编码任务。
Unsloth AI (Daniel Han) Discord
- Kaggle 中的多 GPU 混乱:开发者尝试在 Kaggle 上使用多个 T4 GPU 运行 Unsloth,但发现仅有一个 GPU 被启用用于推理,限制了扩展尝试。他们提到了这篇关于在 Kaggle T4 GPU 上进行微调的推文,希望能更有效地利用 Kaggle 的免费时长。
- 其他人建议如果需要并发,应付费购买更强大的硬件,并暗示 Kaggle 未来可能会扩大 GPU 供应。
- 揭秘微调误区:团队澄清说,fine-tuning(微调)实际上可以引入新知识,其作用类似于检索增强生成(RAG),这与广泛的假设相反。他们链接了 Unsloth 关于微调益处的文档以解决这些持续存在的误解。
- 有人指出,通过将新数据嵌入模型,它可以减轻内存使用,而其他人则强调了为获得最佳结果而进行正确数据集选择的重要性。
- Phi-4 的动态量化奇点:有报告显示 Phi-4 在动态量化后性能变化极小,与标准的 4-bit 版本非常接近。用户参考了 Unsloth 4-bit 动态量化集合来调查任何潜在的收益。
- 一些人坚持认为动态量化应该提高准确性,这促使进一步的实验以确认差异是否被测试条件所掩盖。
- Grokking 研究取得进展:一段新视频 Finally: Grokking Solved - It’s Not What You Think 深入探讨了延迟泛化这一奇特的 grokking(顿悟)现象。它激发了人们理解过拟合如何转化为模型能力突飞猛进的热情。
- 分享的论文 Grokking at the Edge of Numerical Stability 引入了 Softmax Collapse 的概念,引发了关于对 AI 训练更深层影响的辩论。
- LLM 在安全会议上的展示:一位用户建议将安全会议作为专门的 LLM 演讲的更合适场所,并提到了漏洞检测(exploit detection)的使用案例。这一想法引起了那些认为标准 ML 活动对于安全特定内容过于宽泛的人的共鸣。
- 其他人支持突出以领域为中心的方法,指出在这些专业论坛中讨论 LLM 研究的呼声日益增高。
Stability.ai (Stable Diffusion) Discord
- Stable Diffusion XL 速度与规格:一位用户在 Colab 上运行了 stabilityai/stable-diffusion-xl-base-1.0,希望寻找类似 ComfyUI 显示的每秒迭代次数(iterations per second)等内置指标。
- 他们强调了多达 50 inference steps 的可能性,并指出如果没有专门的工具或自定义日志,这些指标仍然难以获取。
- 虚假代币引发骚乱:社区成员发现了一个与 Stability AI 挂钩的虚假加密货币发行,并在一条警告推文中确认其为诈骗。
- 他们警告说,被盗账号可能会欺骗毫无防备的投资者,并分享了个人损失的经历,敦促大家远离可疑链接。
- AI 图像分享趋向社交化:用户讨论了在哪里发布 AI 生成的图像,建议将 Civitai 和其他社交媒体作为展示成功和失败案例的主要平台。
- 在收集图像反馈时,人们对数据质量产生了担忧,引发了关于如何过滤掉虚假或低质量内容的讨论。
Interconnects (Nathan Lambert) Discord
- Xeno 推动 Agent 身份变革:在纽约 Betaworks 举办的 24 日交流会和 25 日黑客松上,来自 Xeno Grant 的 $5k 奖金开启了新一波 Agent identity 项目。
- 获胜者每个 Agent 可获得价值 $10k 的 $YOUSIM 和 $USDC,显示出黑客松参与者对身份解决方案的浓厚兴趣。
- Ndea 侧重程序合成 (Program Synthesis):François Chollet 介绍了 Ndea,旨在启动深度学习引导的程序合成,目标是为真正的 AI 发明开辟一条新路径。
- 社区将其视为一种脱离常规 LLM 扩展(scaling)趋势的方法,一些人称赞它是追求 AGI 的有力替代方案。
- Cerebras 攻克芯片良率难题:Cerebras 声称已经破解了晶圆级(wafer-scale)芯片的良率问题,生产出的器件比通常大 50 倍。
- 通过反转传统的良率逻辑,他们构建了容错设计,从而控制了制造成本。
- MATH 数据集遭遇 DMCA 打击:MATH 数据集面临 DMCA 移除通知,引发了对 AoPS 保护的数学内容的担忧。
- 一些人建议剥离 AoPS 部分以挽救部分使用权,但对更广泛的数据集损失仍存顾虑。
- MVoT 在图像中展示推理:新的 Multimodal Visualization-of-Thought (MVoT) 论文提出在 MLLM 的 Chain-of-Thought 提示中加入视觉步骤,将文本与图像结合以优化解决方案。
- 作者建议,描绘心理图像可以改善复杂的推理流,并能很好地与 reinforcement learning 技术融合。
Nous Research AI Discord
- Claude 的独特个性与 Fine-Tuning 成果:成员们称赞 Claude 具有“酷酷的同事感”,指出了其偶尔拒绝回答的情况,并交流了结合公司知识进行高级 Fine-Tuning 以及分类任务的技巧。
- 他们强调了数据多样性(data diversity)对提升模型准确性的重要性,并提出了通过定制化方法来改善结果。
- 数据集辩论与 Nous Research 的私有化道路:社区对 LLM dataset 的可靠性提出质疑,强调了推动更好数据清洗(data curation)的重要性,并澄清了 Nous Research 通过私募股权和周边销售运营的情况。
- 他们对开源合成数据(synthetic data)计划表示出兴趣,提到了与 Microsoft 的合作,但目前没有正式的政府或学术联系。
- Gemini 表现优于 mini 模型:多位用户称赞 Gemini 在准确提取数据方面的表现,声称在精准定位原始内容方面,它优于 4o-mini 和 Llama-8B。
- 他们对可检索性挑战(retrievability challenges)保持谨慎,将下一步重点放在稳定的扩展上。
- Grokking 调整与优化器对决:参与者剖析了 grokking 以及 Softmax 中的数值问题,引用了关于 Softmax Collapse 及其对训练影响的这篇论文。
- 他们权衡了结合来自此 GitHub 仓库的 GrokAdamW 和 Ortho Grad 的方案,并提到了来自 Facebook Research 的 Coconut,用于连续潜空间推理(continuous latent space reasoning)。
- Agent 身份黑客松征集创意:纽约市宣布举办一场充满活力的 hackathon,为 Agent 身份原型提供 $5k 奖金,旨在培养富有想象力的 AI 项目。
- 创作者暗示了新鲜概念,并引导感兴趣的人士查看这条推文以获取活动详情。
Stackblitz (Bolt.new) Discord
- Bolt 中的标题修改:随着 Bolt 更新,用户现在可以轻松重命名项目标题,详情见此官方帖子。
- 此次推出简化了项目组织,有助于在列表中更高效地定位项目,提升了用户体验。
- GA4 集成故障:一位开发者的 React/Vite 应用在 Netlify 上调用 GA4 API 时遇到了“Unexpected token”错误,尽管在本地运行正常。
- 他们验证了凭据和环境变量,但正在寻找替代解决方案以绕过这一集成障碍。
- Firebase 的快速填充技巧:一位用户建议创建一个“加载演示数据”页面来无缝填充 Firestore,从而避免空 Schema 的麻烦。
- 这种方法被认为是一种简单但有效的方法,特别是对于那些可能忽略初始数据集设置的人来说非常有益。
- Supabase 的失误与快照:一些用户在存储数据时遇到了 Supabase 集成错误和应用崩溃。
- 他们还讨论了聊天历史快照系统(chat history snapshot system),旨在保存之前的状态以实现更好的上下文恢复。
- Token 之争:出现了高使用量的报告,其中一个案例声称每个 Prompt 消耗了 400 万个 tokens,其他人对其真实性表示怀疑。
- 社区建议提交 GitHub issue,因为有人怀疑 Bolt 的上下文机制(context mechanics)中潜伏着 Bug。
Notebook LM Discord Discord
- QuPath 照亮组织数据:一位用户报告称,NotebookLM 根据数字病理学论坛的帖子,生成了一个功能齐全的 Groovy script,用于 QuPath,从而节省了数小时的手动编码时间。
- 这一成功案例凸显了 NotebookLM 在专业任务中的实用性,一位用户称其为“硬编码病理学工作流”中备受欢迎的时间节省利器。
- 世界观构建令作家惊叹:一位用户利用 NotebookLM 进行 worldbuilding(世界观构建)的创意扩展,指出它能理清不够完善的背景设定(lore)并找回被忽视的想法。
- 他们添加了类似 “大胆预测即将到来!” 的笔记,以激发 AI 的想象力输出,从而毫不费力地推动更深层次的虚构场景。
- NotebookLM Plus:神秘的迁移:关于 NotebookLM Plus 在不同 Google Workspace 方案中的可用性和过渡时间表出现了混乱,特别是对于那些使用已弃用版本的用户。
- 一些用户在继续为旧版附加组件付费的同时,也在权衡是否根据 Google Workspace Blog 含糊不清的公告来升级方案。
- API:批量同步指日可待?:用户询问 NotebookLM 是否提供 API 或能否批量同步 Google Docs 源,目前尚未提供官方时间表。
- 社区成员参考了 NotebookLM Help 中的用户请求,对今年的公告保持期待。
- YouTube 导入困扰与字数限制警告:多位成员在将 YouTube links 导入为有效来源时遇到困难,怀疑是功能缺失而非用户操作错误。
- 他们还发现每个来源有 500,000 词 的限制,且每个笔记本总共只能有 50 个来源,这迫使他们不得不进行手动网站抓取或其他变通方法。
Cohere Discord
- Cohere 将上下文提升至 128k:Cohere 将上下文长度扩展至 128k tokens,使得在单次对话中可以处理约 42,000 词 而无需重置上下文。参与者参考了 Cohere 的速率限制文档 以了解此次扩展对更广泛模型使用的影响。
- 他们注意到整个聊天时间线可以保持激活状态,这意味着较长的讨论可以在不分段的情况下保持连贯性。
- Rerank v3.5 引发关注:一些用户报告称,Cohere 的 rerank-v3.5 除非仅限于最近的用户查询,否则输出结果不一致,这使多轮排序工作变得复杂。
- 他们尝试了 Jina.ai 等其他服务,获得了更稳定的结果,并就性能下滑向 Cohere 进行了直接反馈。
- Command R 获得持续维护:成员们寻求对 Command R 和 R+ 的迭代增强,希望通过新数据和微调来进化模型,而不是发布全新的版本。
- 一位贡献者强调 检索增强生成 (RAG) 是将更新信息引入现有模型架构的一种强大方法。
OpenRouter (Alex Atallah) Discord
- Mistral 的 FIM 奇迹:来自 Mistral 的最新 Fill-In-The-Middle 编程模型已经发布,拥有超越标准代码补全的高级功能。OpenRouterAI 确认该模型的请求目前仅在其 Discord 频道处理。
- 爱好者们提到了改进的代码片段上下文处理能力,一些人期待它在代码任务中有强劲表现。其他人则指出 OpenRouter 的 Codestral-2501 页面 是其强大编程潜力的证据。
- Minimax-01 的 4M 上下文壮举:Minimax-01 被宣传为该团队的首个开源 LLM,据报道它在巨大的 4M 上下文下通过了 Needle-In-A-Haystack 测试。详情出现在 Minimax 页面,用户评价称赞其广泛的上下文处理能力。
- 一些人认为 4M Token 的说法过于大胆,但支持者表示目前尚未看到明显的性能权衡。访问同样需要在 Discord 服务器提出请求,这显示出人们对更大上下文范围日益增长的兴趣。
- DeepSeek 风波:延迟与 Token 缩减:成员们反映了持续的 DeepSeek API 不一致问题,报告称多个提供商的响应时间缓慢且出现意外错误。许多人对 Token 限制在未通知的情况下从 64k 降至 10-15k 表示沮丧。
- 评论者指向 DeepSeek V3 Uptime and Availability 页面以寻求部分解释,同时指出首字延迟(first-token latency)仍然持续偏高。其他人担心这些波动会破坏对长上下文使用的信任。
- 提供商对决与模型移除传闻:一位用户对 lizpreciatior/lzlv-70b-fp16-hf 的消失表示担忧,得知可能已没有提供商再托管它。与此同时,参与者讨论了 DeepSeek、TogetherAI 和 NovitaAI 之间的性能差距,引用了 OpenRouter 网站上的延迟差异。
- 一些人发现 DeepInfra 更可靠,而其他人则看到所有提供商都出现了峰值。这引发了关于提供商在极短通知下轮换或移除模型端点频率的更广泛讨论。
- Prompt Caching 问答:多位用户询问 OpenRouter 是否支持 Claude 等模型的 Prompt Caching,并引用了文档。他们希望缓存能大幅降低成本并提高吞吐量。
- Toven 提供了一个有用的指引,确认该功能确实可用,一些开发者称赞其稳定了项目预算。聊天中还分享了关于请求处理和流取消的进一步阅读材料。
OpenAI Discord
- 神经反馈助力个性化学习:一位用户提出了一种神经反馈循环(neural feedback loop)系统,引导个人采用优化的思维模式以获得更好的认知表现,不过尚未分享官方发布日期。
- 其他人认为这是 AI 辅助学习的根本性转变,尽管目前还没有相关的链接或代码参考。
- Anthropic 获得 ISO 42001 负责任 AI 认证:Anthropic 宣布通过了 ISO/IEC 42001:2023 标准的负责任 AI 认证,强调结构化的系统治理。
- 用户认可该标准的公信力,但对 Anthropic 与 Anduril 的合作表示质疑。
- 共享图像导致 AI 记忆不足:参与者观察到,在引入图像后,AI 经常丢失长上下文,导致需要重复说明。
- 一位用户建议图像可能会从短期存储中掉出,导致模型忽略了之前的参考内容。
- ChatGPT 分级导致性能不均:社区成员注意到 ChatGPT 对免费用户似乎有所限制,尤其是在网页搜索方面。
- 他们指出 Plus 订阅者获得了更高级的功能,这引发了 API 用户对公平性的讨论。
- GPT-4o 任务功能超越 Canvas 工具:多位用户报告称,桌面版中的 Canvas 功能被任务界面取代,尽管通过工具箱图标仍可启动 Canvas。
- 他们强调 GPT-4o 任务为语言练习或新闻更新等行动提供了定时提醒。
LM Studio Discord
- 微调热潮与公有领域佳作:一位用户正在利用公有领域文本微调 LLMs 以提升输出质量,在首次探索 Python 的同时将工作重心转移到了 Google Colab。
- 他们的目标是塑造 Prompt 以获得更好的写作效果,专注于探索利用 LLMs 进行创意任务的新方法。
- 上下文紧缺与内存变动:成员们注意到,当长对话超出 LLM 的缓冲区时,会弹出“上下文已满 90.5%”的警告,从而面临输出被截断的风险。
- 他们讨论了调整上下文长度与增加内存占用(memory footprints)之间的权衡,强调了为了稳定性能而进行的微妙平衡。
- GPU 速度对决:2×4090 vs A6000:据报告,2x RTX 4090 配置的速度为 19.06 t/s,超过了 RTX A6000 48GB 的 18.36 t/s,不过有一项修正建议 A6000 的速度应为 19.27 t/s。
- 爱好者们还称赞了 2x RTX 4090 方案显著降低的功耗,表明其在性能和效率上均有提升。
- 并行化难题与层分布:讨论探索了将模型拆分到多个 GPU 上,将一半的层放置在每张显卡上以进行同步计算。
- 然而,参与者指出 PCIe 潜在的延迟和更重的同步负担是实现明显速度优势的障碍。
- 快照故障:LLMs 与图像分析:一些用户在让 QVQ-72B 和 Qwen2-VL-7B-Instruct 正确解析图像时遇到困难,面临初始化错误。
- 他们强调了保持运行时环境(runtime environments)更新的重要性,并指出缺失依赖项经常会导致图像处理尝试失败。
aider (Paul Gauthier) Discord
- DeepSeek V3 运行缓慢,GPU 讨论升温:多位成员报告 DeepSeek V3 运行缓慢或卡住,促使一些人转向 Sonnet 以获得更好性能,并在 此 HF 线程 中分享了他们的挫折感。
- 一位用户强调 RTX 4090 理论上可以胜任更大的模型,并引用了 SillyTavern 的 LLM 模型 VRAM 计算器,提出了关于 VRAM 需求的问题。
- Aider 获得赞誉,提交停滞:一位用户称赞了 Aider 的代码编辑能力,但抱怨尽管设置正确且使用了克隆的项目,却没有生成 Git commits。
- 其他人建议使用 architect mode 在提交前确认更改,并引用了旨在解决这些问题的 PR #2877。
- 仓库图谱膨胀,Agent 工具介入:一位成员注意到他们的 repository-map 从 2k 行增长到了 8k 行,引发了对一次性处理超过 5 个文件时效率的担忧。
- 用户建议使用 cursor’s chat 和 windsurf 等 agentic 探索工具来扫描代码库,并称赞 Aider 完成了最终的实现步骤。
- Repomix 打包代码,减少 API 体积:一位用户展示了 Repomix,它可以将代码库重新打包成对 LLM 驱动的任务更友好的格式。
- 他们还提到了与 Repopack 的协同作用,以最大限度地减少 Aider 的 API 调用,从而减少大型项目的 token 开销。
- 标题党调侃,o1-preview 进展缓慢:一位用户取笑另一位用户的 AI 内容风格“简直像二手车推销员”,呼应了社区对标题党推广的厌烦。
- 其他人提到 o1-preview 的响应变慢且 token 消耗更高,指出性能下降阻碍了实时交互。
Modular (Mojo 🔥) Discord
- 文档字体变粗:文档字体现在更粗了,以提高可读性,用户在 #general 中称赞其好得多。
- 用户似乎对进一步的调整持开放态度,表现出持续优化用户体验的意愿。
- Mojo 暂无 Lambda 语法:社区确认 Mojo 目前缺乏
lambda语法,但一份 路线图说明 预示了未来的计划。- 在 Lambda 得到正式支持之前,有人建议将命名函数作为参数传递。
- Zed 与 Mojo 强强联手:爱好者们分享了如何像稳定版一样在 Zed Preview 中安装 Mojo,设置完成后代码补全功能即可正常工作。
- 尽管有些人在缺少某些设置时遇到了小障碍,但一旦配置妥当,整体集成非常顺畅。
- SIMD 引发性能瓶颈:参与者警告了 SIMD 的性能陷阱,并引用了 Ice Lake AVX-512 Downclocking。
- 他们敦促检查汇编输出,以检测任何可能抵消各种 CPU 上 SIMD 优势的寄存器重排(register shuffling)。
- 递归类型挑战 Mojo 的耐心:开发者们正在努力解决 Mojo 中的递归类型问题,转而使用指针来处理树状结构。
- 他们链接了 GitHub issues 以获取更多细节,并指出语言设计中持续存在的复杂性。
Eleuther Discord
- 关键 Token 引发热议:一篇新的 arXiv 预印本 介绍了用于 LLM 推理的关键 Token (critical tokens),显示出在精心管理这些关键 Token 时,GSM8K 和 MATH500 的准确率大幅提升。成员们还澄清了 VinePPO 实际上并不需要示例 Chain-of-Thought 数据,尽管离线 RL 的比较仍存在激烈争论。
- 他们接受了选择性降低这些 Token 权重可以提升整体性能的观点,社区注意到这与其它 implicit PRM 的发现有相似之处。
- NanoGPT 打破速度记录:据报告,在 modded-nanoGPT 上实现了一次创纪录的 3.17 分钟 训练运行,该运行结合了新的 Token 相关 lm_head 偏置和多个融合操作(fused operations),详见 此 pull request。
- 进一步的优化想法,如 Long-Short Sliding Window Attention,被提出以进一步提升速度和性能。
- TruthfulQA 遭遇滑铁卢:TurnTrout 的推文 揭示了通过利用几个琐碎规则的弱点,在多选题 TruthfulQA 上达到了 79% 的准确率,从而绕过了更深层的模型推理。
- 这一发现引发了社区辩论,凸显了基准测试的缺陷如何削弱 halueval 等其他数据集的可靠性。
- MATH 数据集 DMCA 删帖风波:由于 DMCA 移除,Hendrycks MATH 数据集已下架,正如 此 Hugging Face 讨论 所述,这引发了法律和物流方面的担忧。
- 成员们追溯到原始问题源自 AOPS,重申这些谜题类内容从一开始就注明了归属,突显了数据集许可方面的摩擦。
- Anthropic 与 Pythia 电路分析揭秘:多次引用 Anthropic 的电路分析,探讨了子网络如何在不同 Pythia 模型的连贯训练阶段形成,如 此论文 所述。
- 参与者指出,这些涌现结构并不严格符合简单的训练损失(dev-loss)与计算量(compute)图表,强调了内部架构演变的细微差别。
Latent Space Discord
- Cursor AI 获得巨额融资:他们完成了由 a16z 领投的新一轮 Series B 融资,以支持该编程平台的下一阶段发展,详见此公告。
- 社区讨论指出 Cursor AI 是 Anthropic 的关键客户,这引发了关于基于用量定价(usage-based pricing)的热议。
- Transformer² 像章鱼一样灵活适应:来自 Sakana AI Labs 的新论文引入了动态权重调整,连接了预训练(pre-training)与后训练(post-training)。
- 爱好者将其比作章鱼如何融入周围环境,强调了其在特定任务中自我改进的潜力。
- OpenBMB MiniCPM-o 2.6 进军多模态:MiniCPM-o 2.6 的发布展示了一个 8B-parameter 模型,能够在边缘设备上处理视觉、语音和语言任务。
- 初步测试称赞了其双语语音性能和跨平台集成,引发了对其在现实场景应用的乐观预期。
- Curator:按需生成合成数据:新的 Curator 库提供了一种开源方法,为 LLM 和 RAG 工作流生成训练和评估数据。
- 工程师们预计这将填补后训练数据流水线中的空白,并计划推出更多功能以实现更全面的覆盖。
- NVIDIA Cosmos 在 CES 亮相:在 LLM Paper Club 上,NVIDIA Cosmos 在 CES 发布后被重点介绍,展示了其各项能力。
- 与会者被敦促注册并将该环节添加到日历中,以免错过这一新模型的揭秘。
GPU MODE Discord
- Triton 与 Torch:依赖关系之舞:一位用户发现 Triton 依赖于 Torch,这使得纯 CUDA 工作流变得复杂,并引发了关于是否存在 cuBLAS 等效项的讨论(文档)。
- 另一位用户遇到了指针类型不匹配导致的 ValueError,结论是
tl.load中的指针必须是 float 标量。
- 另一位用户遇到了指针类型不匹配导致的 ValueError,结论是
- RTX 50x TMA 传闻:有传言称 RTX 50x Blackwell 显卡可能会继承 Hopper 的 TMA,但目前尚无确切细节。
- 社区成员在白皮书(whitepaper)发布前仍感焦虑,这让关于 TMA 的讨论热度不减。
- MiniMax-01 拥有 4M-Token 上下文:MiniMax-01 开源模型引入了 Lightning Attention,能够处理高达 4M tokens 的内容,且性能大幅提升。
- Thunder Compute:廉价 A100 风暴:Thunder Compute 首次亮相,提供 $0.92/小时 的 A100 实例,并赠送 $20/月 的额度,详见其官网。
- 该项目由 Y Combinator 校友支持,并提供 CLI 工具(
pip install tnr)用于快速管理实例。
- 该项目由 Y Combinator 校友支持,并提供 CLI 工具(
- GPU 使用技巧与调试故事:工程师们强调了在 bfloat16 训练中 weight decay 的重要性(图 8),并讨论了在 Torch 中批量调用
.to(device)以减少 CPU 开销。- 他们还探讨了多 GPU 推理策略、MPS 内核性能分析(profiling)的怪癖,以及用于 popcorn bot 的专用 GPU 装饰器,参考了 deviceQuery 信息。
LlamaIndex Discord
- 使用 LlamaParse 开启 RAG 热潮:利用 LlamaParse、LlamaCloud 和 AWS Bedrock,该小组构建了一个专注于高效解析 SEC documents 的 RAG application。
- 他们的分步指南概述了处理大型文档的高级索引策略,同时强调了这些平台之间的强大协同作用。
- 利用 LlamaIndex 提升知识图谱收益:来自 @neo4j 的 Tomaz Bratanic 在其详尽的帖子中介绍了一种使用 LlamaIndex 的 agentic strategies 来提高知识图谱准确性的方法。
- 他从朴素的 text2cypher 模型转向了稳健的 agentic workflow,通过精心设计的错误处理提升了性能。
- LlamaIndex 与 Vellum AI 联手:LlamaIndex 团队宣布与 Vellum AI 建立合作伙伴关系,并在此处分享了他们的调查用例发现 here。
- 此次合作旨在扩大他们的用户社区,并探索 RAG-powered 解决方案的新策略。
- 利用 Chromium 解决 XHTML 转 PDF 难题:一位成员指出 Chromium 在将 XHTML 转换为 PDF 方面表现出色,优于 pandoc、wkhtmltopdf 和 weasyprint 等库。
- 他们分享了一个 XHTML 文档示例 和一个 HTML 文档示例,强调了其出色的渲染忠实度。
- 大规模向量数据库的选择困境:用户讨论了是否从 Pinecone 切换到 pgvector 或 Azure AI search,以便以更好的成本效益管理 2 万份文档。
- 他们参考了 LlamaIndex 的 Vector Store 选项 来评估与 Azure 的集成情况,并强调了建立强大生产工作流的必要性。
OpenInterpreter Discord
- OpenInterpreter 1.0 的命令难题:OpenInterpreter 1.0 限制了直接代码执行,将任务转向命令行使用,这引发了关于失去 user-friendly 特性的担忧。
- 社区成员对背离即时 Python 执行表示遗憾,称新方法“感觉更慢”且“需要更多手动步骤”。
- Bora 定律打破算力惯例:一篇新的工作论文 Bora’s Law: Intelligence Scales With Constraints, Not Compute 指出,intelligence 的指数级增长是由约束而非 compute 驱动的。
- 与会者强调,这一理论挑战了像 GPT-4 这样的大规模建模策略,质疑了对原始硬件资源的过度依赖。
- OI 中的 Python 增强功能:爱好者敦促添加 Python 便捷函数,以简化 OpenInterpreter 中的任务。
- 他们认为这些增强功能可以在保持平台交互风格的同时“提升用户效率”。
- AGI 方法受到质疑:社区的一部分人批评 OpenAI 过度关注暴力 compute,忽略了更微妙的智能提升因素。
- 成员们呼吁根据 Bora’s Law 等创意理论重新评估 AI 开发原则,强调需要优化大模型缩放(scaling)策略。
LAION Discord
- DougDoug 对 AI 版权法的深入探讨:在这段 YouTube 视频中,DougDoug 详细解释了 AI copyright law,重点关注 tech 与法律结构之间潜在的交集。
- 这一观点引发了热烈讨论,参与者赞扬了他对新兴法律盲点的关注,并推测了可能的创作者补偿模型。
- 超可解释网络引发对版税的重新思考:一项关于 hyper-explainable networks 的提案引入了衡量训练数据对模型输出影响的想法,可能将版税定向给数据提供者。
- 观点在对数据驱动补偿潜力的兴奋与对实施此类系统开销的怀疑之间摇摆不定。
- 推理时信用分配获得关注:关于 inference-time credit assignment 的相关对话提出了使用它来追踪每个数据集分块对模型结果影响的可能性。
- 虽然一些人看到了认可数据贡献者的希望,但另一些人指出量化这些影响具有极高的复杂性。
AI21 Labs (Jamba) Discord
- P2B 的提议引发加密货币冲突:一名来自 P2B 的代表提供了融资、上市、社区支持和流动性管理(liquidity management)等服务,希望吸引 AI21 参与其加密货币愿景。
- 他们询问是否可以分享更多关于这些服务的细节,但在 AI21 Labs 明确表达了对加密货币的立场后,对话发生了转变。
- AI21 Labs 拒绝加密货币倡议:AI21 Labs 坚决拒绝与基于加密货币的努力产生关联,并表示他们永远不会开展相关项目。
- 他们还警告说,反复提及加密货币将导致迅速封禁,强调了其零容忍的立场。
MLOps @Chipro Discord
- AI Agent 将在 2025 年崛起:Sakshi 和 Satvik 将于 1 月 16 日星期四晚上 9 点(IST)主持 Build Your First AI Agent of 2025 活动,展示来自 Build Fast with AI 和 Lyzr AI 的代码和无代码方法。
- 该研讨会重点预测了 AI Agent 将在 2025 年改变各行各业,为新手和工程师等群体扩大准入门槛。
- AI 采用过程中的预算博弈:社区成员强调成本是决定采用新解决方案还是保留现有系统的关键因素。
- 许多人仍保持谨慎,表示相比风险更高、成本更昂贵的安装,他们更倾向于保留经过验证的基础设施。
Nomic.ai (GPT4All) Discord
- 对 Qwen 2.5 微调的关注:一位用户询问了 Qwen 2.5 Coder Instruct (7B) 的微调细节,想知道它是否已在 Hugging Face 上发布,并表达了对更大模型的好奇。
- 他们还寻求其他人在成熟模型上的成功案例,强调了在真实场景中的性能表现。
- Llama 3.2 在处理长剧本时遇到困难:一位用户在使用 Llama 3.2 3B 分析一份 45 页的电视试播剧本时遇到了错误,原本期望它能处理该文本而不会出现字符限制问题。
- 他们分享了一个对比链接,展示了 Llama 3.2 3B 和 Llama 3 8B Instruct 在 Token 容量和近期发布版本方面的区别。
DSPy Discord
- 推动 Ambient Agent 实现的标准化:#general 频道的一位用户询问了如何使用 DSPy 构建 Ambient Agent,寻求尝试过此方法的用户的经验和标准化方案。
- 他们强调了 Ambient Agent 与 DSPy 工作流之间潜在的协同效应,邀请大家共同投入以寻求更结构化的解决方案。
- 对 DSPy 示例的兴趣日益增长:另一个关于实现 Ambient Agent 的具体 DSPy 示例的询问出现了,强调了社区对具体代码参考的渴望。
- 目前尚未提供直接示例,但社区对共享演示或开源材料以增强 DSPy 的实际应用表现出极大的热情。
tinygrad (George Hotz) Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将予以移除。
LLM Agents (Berkeley MOOC) Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将予以移除。
Axolotl AI Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将予以移除。
Torchtune Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将予以移除。
Mozilla AI Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将予以移除。
HuggingFace Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将予以移除。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将予以移除。
第二部分:按频道划分的详细摘要和链接
完整的频道细分内容已为邮件格式进行截断。
如果你喜欢 AInews,请分享给朋友!预先感谢!