ainews-deepseek-r1-o1-level-open-weights-model
DeepSeek R1:性能媲美 o1 的权重开放模型,以及将 1.5B 模型提升至 Sonnet/4o 级别的简单方法。
DeepSeek 发布了 DeepSeek R1,这是对其仅三周前发布的 DeepSeek V3 的重大升级。此次共推出了 8 个模型,包括全尺寸的 671B MoE 模型,以及基于 Qwen 2.5 和 Llama 3.1/3.3 的多个蒸馏版本。
这些模型采用 MIT 开源协议,允许进行微调和蒸馏。其价格显著低于 o1,便宜约 27 至 50 倍。训练过程采用了 GRPO(组相对策略优化,针对正确性和风格结果进行奖励),且不依赖于 PRM(过程奖励模型)、MCTS(蒙特卡洛树搜索)或传统的奖励模型,重点在于通过强化学习提升推理能力。
蒸馏后的模型可以在 Ollama 上运行,并展现出编写 Manim 代码(数学动画代码)等强大能力。此次发布强调了在强化学习、微调和模型蒸馏方面的进展,并采用了源自 DeepSeekMath 的新型强化学习框架。
GRPO 就是你所需的一切。
2025年1月17日至1月20日的 AI 新闻。我们为您查看了 7 个 subreddit、433 个 Twitter 账号 和 34 个 Discord 社区(225 个频道,8019 条消息)。预计为您节省阅读时间(以 200wpm 计算):910 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
我们知道 DeepSeek 迟早会发布开源权重版本,而且 DeepSeek 已经因其论文而闻名,V3 曾是全球顶尖的开源模型,但今天我们所有的 AI 消息源都无法将目光从 DeepSeek R1 的发布上移开。

R1 的性能表现证明它比仅仅三周前的 DeepSeek V3 有了跨越式的提升:
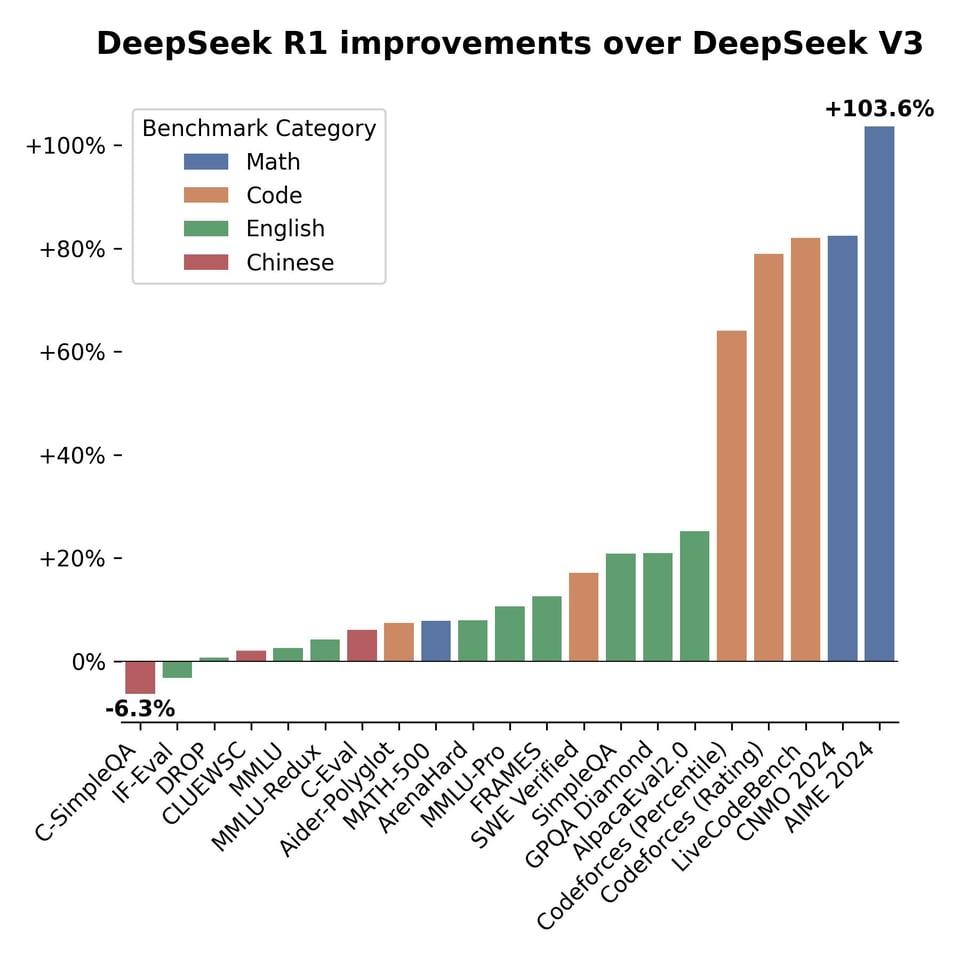
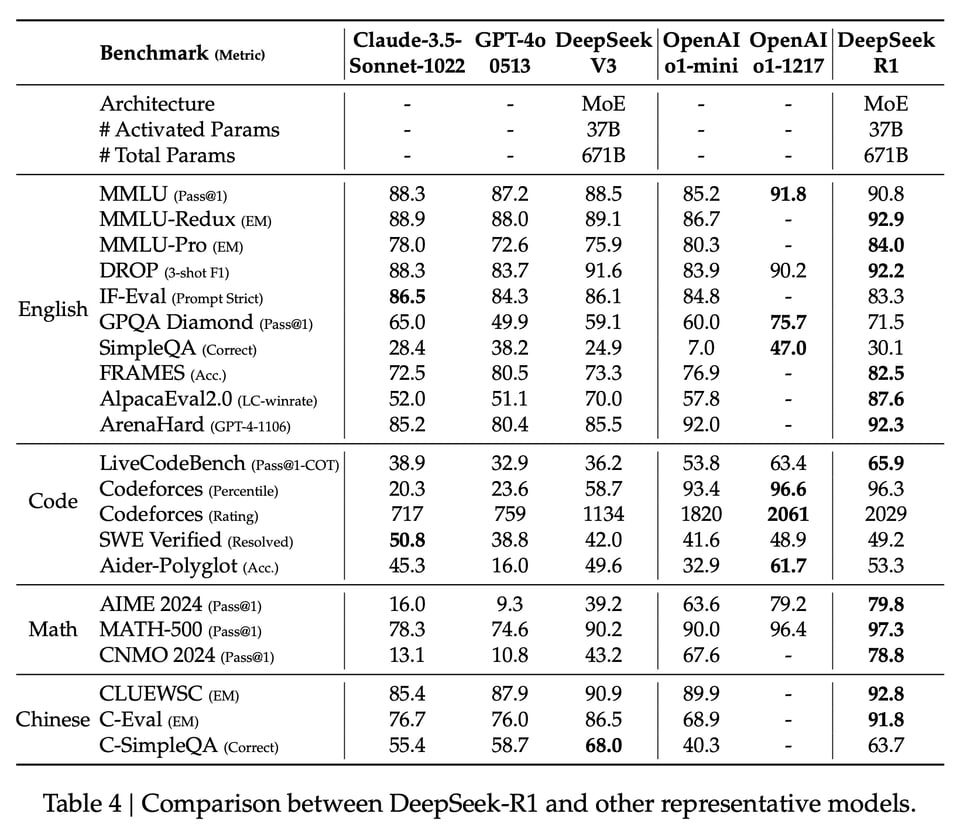
当我们提到 “R1” 时,这个表述其实比较模糊。DeepSeek 实际上发布了 8 个 R1 模型——2 个“完整”模型,以及 6 个基于开源模型的蒸馏版本:
- 基于 Qwen 2.5:使用 DeepSeek-R1 筛选的 80 万个样本进行微调,包含 1.5B、7B、14B 和 32B 版本
- 基于 Llama 3.1 8B Base:DeepSeek-R1-Distill-Llama-8B
- 基于 Llama3.3-70B-Instruct:DeepSeek-R1-Distill-Llama-70B
- 以及 DeepSeek-R1 和 DeepSeek-R1-Zero,即类似于 DeepSeek V3 的全尺寸 671B MoE 模型。令人惊讶的是,它们采用了 MIT 许可证而非自定义许可证,并明确允许进行微调和蒸馏
发布会中的其他亮点:
- 定价(每百万 token):输入 14 美分(缓存命中),输入 55 美分(缓存未命中),输出 219 美分。相比之下,o1 的价格为输入 750 美分(缓存命中),输入 1500 美分(缓存未命中),输出 6000 美分。这比 o1 便宜了 27 到 50 倍。
- 解决了 o1 博客文章中的每一个问题。每一个。
- 可以在 Ollama 上运行蒸馏模型
- 能够非常好地编写 Manim 代码
论文中的惊喜:
- 过程如下:
- V3 Base → R1 Zero(使用 GRPO —— 即针对正确性和风格结果的奖励 —— 没有花哨的 PRM/MCTS/RMs)
- R1 Zero → R1 Finetuned Cold Start(从 R1 Zero 中蒸馏长 CoT 样本)
- R1 Cold Start → R1 Reasoner with RL(专注于语言一致性 —— 以产生可读的推理)
- R1 Reasoning → R1 Finetuned-Reasoner(生成 600k 样本:多回复采样并仅保留正确样本(使用之前的规则),并使用 V3 作为裁判:过滤掉混合语言、长段落和代码)
- R1 Instruct-Reasoner → R1 Aligned(使用 GRPO 平衡推理能力与有用性和无害性)
-
可视化:
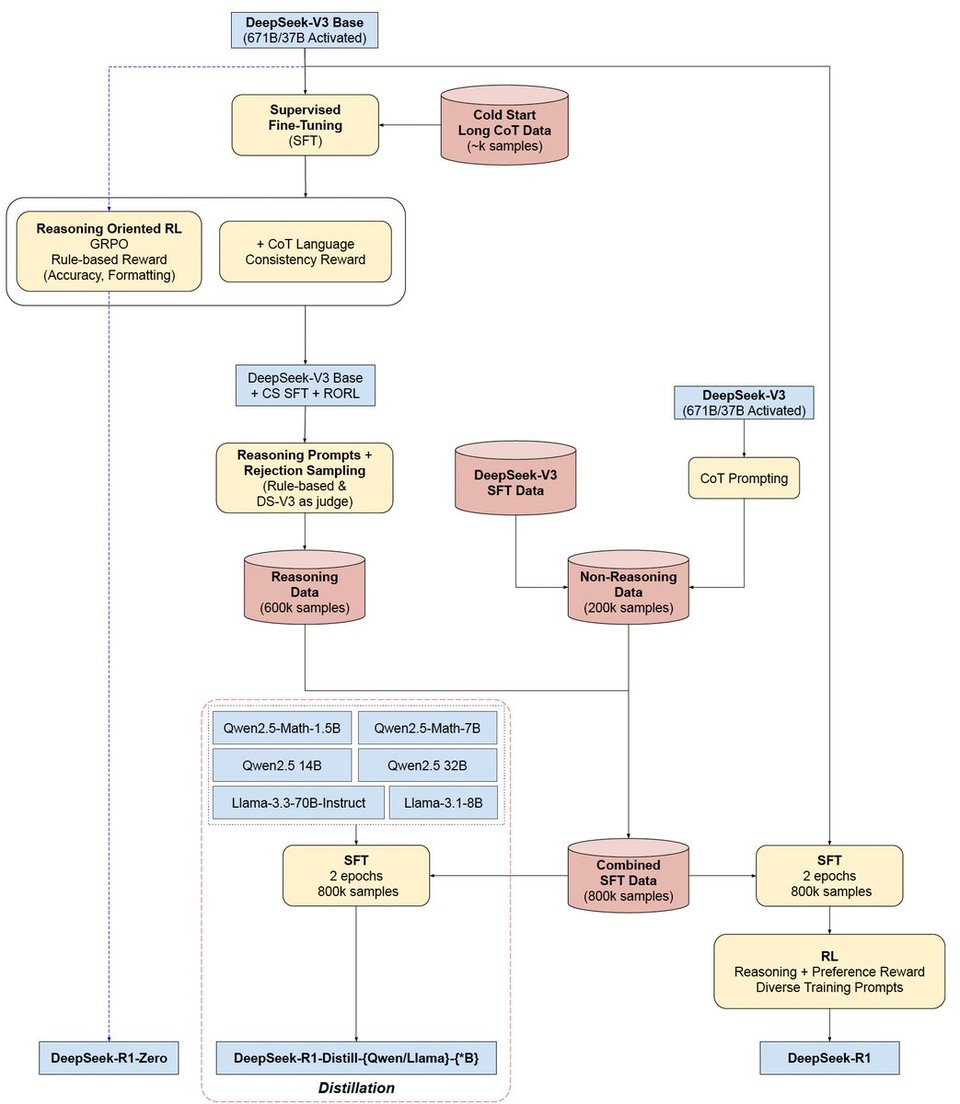
- 有监督数据、Process reward models 以及 MCTS 没有奏效

-
但他们确实使用了来自 DeepSeekMath 的 GRPO(受到 DPO 作者的质疑)作为“提高模型推理性能的 RL 框架”,其中推理能力(如 in-context back-tracking)在“数千步 RL 训练”后“自然涌现” —— 虽然不完全是著名的 o1 scaling 曲线,但也是近亲。
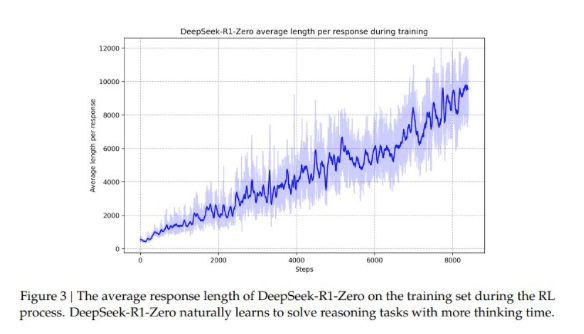
- 使用 “顿悟时刻”(aha moments)作为关键 token,通常以一种对读者不友好的方式混合语言
- R1 在 o1 发布后不到一个月就开始了训练
- R1 的蒸馏效果显著,带给我们这段疯狂的引言:“DeepSeek-R1-Distill-Qwen-1.5B 在数学基准测试中超越了 GPT-4o 和 Claude-3.5-Sonnet,AIME 得分为 28.9%,MATH 得分为 83.9%。”,而且这甚至还是在没有将蒸馏推向极限的情况下实现的。
- 这比仅仅对小模型进行 RL 微调更有效:“大模型的推理模式可以被蒸馏到小模型中,与通过 RL 在小模型上发现的推理模式相比,其性能更好。” 也就是所谓的“SFT 的全面胜利”。
AI Twitter 回顾
所有回顾均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
DeepSeek-R1 模型进展
- DeepSeek-R1 发布与更新:@deepseek_ai 宣布发布 DeepSeek-R1,这是一个性能与 OpenAI-o1 相当的开源推理模型。发布内容包括一份技术报告和蒸馏的小型模型,为开源社区赋能。@cwolferesearch 强调,与模型蒸馏相比,强化学习微调(reinforcement learning fine-tuning)的效果较弱,这标志着推理模型 Alpaca 时代的开始。
基准测试与性能对比
- DeepSeek-R1 vs OpenAI-o1:@_philschmid 总结的评估显示,DeepSeek-R1 在 AIME 2024 上达到了 79.8%,而 OpenAI-o1 为 79.2%。此外,@ollama 指出,R1-Distill-Qwen-7B 在推理基准测试上超越了如 GPT-4o 等更大型的专有模型。
LLM 训练中的强化学习
- 基于 RL 的模型训练:@cwolferesearch 强调,纯强化学习可以赋予 LLMs 强大的推理能力,而无需大量的有监督微调。@Philschmid 详细介绍了 DeepSeek-R1 的五阶段 RL 训练流水线,展示了在数学、代码和推理任务中的显著性能提升。
开源模型与蒸馏
- 模型蒸馏与开源可用性:@_akhaliq 宣布,DeepSeek 的蒸馏模型(如 R1-Distill-Qwen-7B)表现优于 GPT-4o-0513 等非推理模型。@reach_vb 强调了社区从 DeepSeek 的开源和蒸馏模型中获益,使先进的推理能力在消费级硬件上变得触手可及。
AI 研究论文与技术洞察
- 来自研究论文的洞察:@TheAITimeline 分享了来自 LongProc 基准测试的见解,显示在 17 个 LCLMs 中,权重开放模型在超过 2K tokens 后表现吃力,而像 GPT-4o 这样的闭源模型在 8K tokens 时性能下降。@_philschmid 讨论了 DeepSeek-R1 论文关于强化学习如何在不依赖复杂奖励模型的情况下增强模型推理的发现。
梗/幽默
-
关于 AI 和技术的幽默看法:@swyx 分享了一个幽默的 xkcd 漫画,而 @qtnx_ 以轻松的方式表达了对游戏发布和 Prompt Engineering 的沮丧。
-
对 AI 炒作的讽刺评论:@teortaxesTex 幽默地评论了过度乐观的 AI 预期,强调无论技术如何进步,幽默内容总是长存的。
-
俏皮互动:@jmdagdelen 俏皮地回应了 AI 讨论,为技术对话增添了一抹幽默。
-
技术讨论中的意外幽默:@evan4life 分享了一个关于 AI 模型行为的有趣轶事,将技术洞察与幽默融合在一起。
-
轻松的 AI 笑话:@sama 幽默地淡化了 AGI 的开发时间线,反映了社区俏皮的怀疑态度。
-
有趣的 AI 相关梗:@thegregyang 发布了一个关于职场场景的情境梗,为以 AI 为中心的讨论增添了轻松气氛。
AI Reddit 回顾
/r/LocalLlama 回顾
主题 1. DeepSeek-R1 蒸馏模型展示了卓越的 SOTA 性能
- DeepSeek 刚刚上传了 6 个 R1 的蒸馏版本 + R1 “完整版” 现已在其官网上线。 (Score: 790, Comments: 226): DeepSeek 发布了六个 R1 模型的蒸馏版本以及 R1 “完整版” 模型,目前已可在其官网访问。
- DeepSeek 的策略与许可:评论者赞扬 DeepSeek 发布竞争对手模型的微调版本并支持本地 LLM 社区,并指出了这一发布策略的精明之处。包括 DeepSeek-R1-Distill-Qwen-32B 在内的模型均采用 MIT License 发布,允许商业使用和修改,这被视为开源社区的一次重大举措。
- 模型性能与可用性:据报道,DeepSeek-R1-Distill-Qwen-32B 模型在基准测试中超越了 OpenAI-o1-mini 等其他模型,在稠密模型(dense models)中达到了 SOTA 水平。用户正急切等待 32B 和 70B 等更大模型的 GGUF 版本,这些模型的链接已在 Hugging Face 等平台分享。
- 社区反应与技术见解:用户对模型的性能和表现感到兴奋,一些人注意到蒸馏模型的输出较为冗长,并认为通过强化学习还有进一步提升的空间。此外,还有关于这些模型在现实应用中实际影响的讨论,部分用户分享了他们的测试经验和结果。
- DeepSeek-R1-Distill-Qwen-32B 直接达到 SOTA,为本地使用提供超越 GPT-4o 级别的 LLM,且没有任何限制! (Score: 247, Comments: 85): DeepSeek-R1-Distill-Qwen-32B 正在确立其 SOTA 地位,在无限制的本地使用中超越了 GPT-4 级别的 LLM。该模型的蒸馏版本,特别是与 Qwen-32B 融合的版本,在基准测试中取得了显著进步,非常适合 VRAM 较少的用户,且表现优于 Llama-70B 的蒸馏版。
- 蒸馏与基准测试:DeepSeek-R1-Distill-Qwen-32B 的性能亮点在于其在无量化的基准测试中以 36/48 的得分进入了帕累托前沿 (Pareto frontier),展示了其在本地使用模型中的效率和竞争优势。
- 模型比较与特性:讨论中提到了 Llama 3.1 8B 和 Qwen 2.5 14B 蒸馏版本的优越性,据称它们优于 QwQ 并包含“思考标签 (thinking tags)”,增强了推理能力。
- 软件与工具:这些模型的最新更新和支持已经可用,包括针对蒸馏版本的 PR #11310,以及需要最新的 LM Studio 0.3.7 来支持 DeepSeek R1。
- DeepSeek-R1 和 DeepSeek-R1-Zero 仓库正准备发布? (Score: 51, Comments: 5): 提供的链接表明 DeepSeek-R1 和 DeepSeek-R1-Zero 模型预计将在 Hugging Face 上发布。用户表达了对发布的渴望,希望就在今天。
- 如果用户有足够的存储空间,DeepSeek-R1-Zero 已经可以下载。DeepSeek-R1 同样如此。
主题 2. DeepSeek-R1 模型的价格优势压倒了 OpenAI 的高成本 Token
- Deepseek R1 = $2.19/M tok output vs o1 $60/M tok. Insane (Score: 155, Comments: 37): Deepseek R1 的定价为 每百万输出 token $2.19,与 o1 的每百万 token $60 相比显著更低。帖子作者对实际应用,特别是与 代码生成 (code generation) 相关的对比非常感兴趣。
- Deepseek R1 定价与性能:讨论强调了 Deepseek R1 提供了极具竞争力的 每百万 token $2.19 的定价,远低于 o1 的每百万 token $60。用户注意到 R1 模型 相比其之前的版本表现出了令人印象深刻的性能提升,特别是 35B 和 70B 参数模型,其表现与 o1-mini 相当甚至更好。
- 模型透明度与成本因素:OpenAI 在其模型架构和 token 使用方面缺乏透明度,这使得复制变得具有挑战性。一些评论认为 OpenAI 的定价 可能不仅仅是基于贪婪,而是与研发 (R&D) 和运营支出相关的成本有关,同时对 Sam Altman 关于公司财务亏损的说法持怀疑态度。
- 访问与实现:用户询问了如何访问和测试 Deepseek R1,并引用了 Deepseek API 文档 以获取更多信息。“deepthink” 功能被提及作为使用 R1 模型的一种方式,其网站和 App 上也同步了更新。
- Deepseek-R1 officially release (Score: 60, Comments: 2): DeepSeek-R1 在 MIT License 下正式发布,提供开源模型权重和支持思维链 (chain-of-thought) 输出的 API,声称在数学和编程等任务上与 OpenAI o1 性能对等。此次发布包括两个 660B 模型和六个较小的蒸馏 (distilled) 模型,其中 32B 和 70B 模型的能力与 OpenAI o1-mini 相匹配。API 定价为 每百万输入 token 1 元人民币(缓存命中) 和 每百万输出 token 16 元人民币,详细指南可在官方文档中找到。
- DeepSeek-R1 的美元定价可以在官方文档 DeepSeek Pricing 中找到,为那些有兴趣将其与其他模型进行比较的人提供了清晰的成本结构。
- DeepSeek-R1 Paper (Score: 58, Comments: 5): DeepSeek-R1 论文 介绍了一个强调成本效益 token 使用的 API。
- DeepSeek-R1-Zero 的自我演化:自我演化过程展示了 强化学习 (RL) 如何自主增强模型的推理能力。这一过程是在没有监督微调 (SFT) 影响的情况下观察到的,允许模型通过延长的测试时计算 (test-time computation) 自然地发展出诸如反思和探索等复杂行为。
- 复杂行为的涌现:随着 DeepSeek-R1-Zero 测试时计算量的增加,它自发地发展出高级行为,例如重新审视和重新评估之前的步骤。这些行为源于模型与 RL 环境的交互,并显著提高了其解决复杂任务的效率和准确性。
- “Aha Moment” (顿悟时刻) 现象:在训练过程中,DeepSeek-R1-Zero 经历了 “aha moment”,即它自主学会为问题分配更多的思考时间,从而增强其推理能力。这一现象突显了 RL 培养意想不到的解题策略的潜力,强调了 RL 在 AI 系统中实现新智能水平的力量。
Theme 3. DeepSeek-R1 模型全面采用 MIT License
- o1 级别的性能,成本仅约 1/50.. 还是开源的!!太强了,冲!! (Score: 668, Comments: 237): DeepSeek R1 和 R1 Zero 已以开源许可证发布,以约 1/50 的成本提供 o1 性能,并且它们是开源的。
- DeepSeek 的开源与定价疑虑:关于 DeepSeek 的开源声明存在大量讨论,一些用户质疑代码和数据集等模型细节的可获得性。定价问题也被提及,特别是 DeepSeek V3 的 Token 成本翻倍,以及与 OpenAI 定价的对比,部分用户指出高价可能为了防止系统过载。
- 模型性能与对比:用户强调了 DeepSeek 模型令人印象深刻的性能,并注意到参数量从 32B 增加到了 600B。用户将其与 Qwen 32B 和 Llama 7-8B 等其他模型进行了对比,一些用户声称这些模型在表现上超过了 4o 和 Claude Sonnet。
- 审查与地缘政治影响:关于 AI 模型中政治审查影响的辩论非常激烈,讨论了像 DeepSeek 这样的中国公司如何在其模型中嵌入 CCP 价值观。同时,也与同样应用自身“护栏 (guardrails)”、反映政治和文化偏见的美国公司进行了对比。
- DeepSeek-R1 及其蒸馏模型基准测试(颜色标注) (Score: 288, Comments: 61): DeepSeek R1 的许可协议明确允许进行模型蒸馏 (model distillation),这有利于创建高效的 AI 模型。帖子提到了经过颜色标注的蒸馏基准测试,这是一种评估性能指标的可视化方法。
- DeepSeek R1 模型,特别是 1.5B 和 7B 版本,在编程基准测试中被指出超越了 GPT-4o 和 Claude 3.5 Sonnet 等更大型的模型,这引发了对其在 MMLU 和 DROP 等非编程基准测试中表现的怀疑和好奇。用户对这些结果表示惊讶,质疑除了数学和编程任务之外,这种改进是否具有泛化性。
- DeepSeek-R1-Distill-Qwen-14B 因其效率而受到关注,其性能与 o1-mini 相当,同时输入/输出 Token 的价格显著降低。32B 和 70B 模型进一步超越了 o1-mini,其中 32B 模型的成本便宜 43 到 75 倍,使其在本地和商业用途上都极具吸引力。
- 针对蒸馏模型的训练数据存在疑虑,这些模型严重依赖监督微调 (SFT) 数据而没有使用强化学习 (RL),尽管一些用户澄清开发流程确实包含两个 RL 阶段。人们对 1.5B 模型的基准测试准确性持怀疑态度,一些人建议进行进一步测试以验证这些说法。
- Deepseek R1 / R1 Zero (Score: 349, Comments: 105): DeepSeek 已将其许可范围扩大到 MIT License 下的商业用途。帖子提到了 DeepSeek R1 和 R1 Zero,但未提供更多细节。
- 据 BlueSwordM 和 Few_Painter_5588 等用户讨论,DeepSeek R1 Zero 被推测为一个拥有约 600B 到 700B 参数的大型模型。这种模型规模意味着巨大的资源需求,估计需要 1.8TB RAM 才能运行,显示了其潜在的计算强度。
- 围绕 DeepSeek R1 Zero 的讨论还涉及其架构,De-Alf 指出它与其他 R1 模型共享相同的架构,表明它们之间存在通用框架。提到了在 Hugging Face 上的发布,一些用户对模型的规模和角色(例如作为“教师”或“评判”模型)表示困惑。
- DeepSeek R1 Zero 在 MIT License 下的发布因其开放性而受到赞扬,Ambitious_Subject108 等用户赞赏其没有将其限制在 API 之后的决定。社区还注意到发布了多个蒸馏版本,为各种硬件规格提供了灵活性。
主题 4. DeepSeek-R1 蒸馏模型革新精度基准测试
- Epyc 7532/dual MI50 (Score: 68, Comments: 36): 一位工程师使用从 eBay 以每块 110 美元购买的 双 MI50 GPU 构建了一台 Epyc 7532 服务器,配备 256 GB Micron 3200 RAM,并安置在 Thermaltake W200 机箱中。尽管 MI50 面临散热挑战(温度超过 80°C),该配置在 Ubuntu 上运行 ollama 和 open webui,在 Phi4 上达到约 5t/s 的速度,表现良好,而 qwen 32b 则较慢。
- 散热挑战:Evening_Ad6637 分享了通过解决气流问题和使用铝制材料提高散热效率的见解,与标准散热系统相比,温度降低了高达 10°C。他们建议确保铝制组件与 GPU 散热片直接接触,以获得更好的散热效果。
- 硬件兼容性与使用:Psychological_Ear393 讨论了 Radeon VII 和 MI50 GPU 与 ROCm 的兼容性,指出虽然两者都已被弃用,但仍可在最新驱动下运行。他们还提到 W200 机箱 非常大,能有效容纳该配置。
- 风扇与气流考量:No-Statement-0001 建议使用涡轮式风扇来增强静态压力,并改善穿过服务器 GPU 密集鳍片的气流,因为普通风扇可能难以胜任此任务。
- o1 思考了 12 分 35 秒,r1 思考了 5 分 9 秒。两者都得到了正确答案。均在两次尝试内完成。它们是首批正确完成该任务的两个模型。 (Score: 104, Comments: 25): DeepSeek R1 和 o1 模型 在两次尝试内正确解决了一个复杂的数学问题,其中 o1 耗时 12 分 35 秒,R1 耗时 5 分 9 秒。该问题涉及统计狼和野兔等元素的数量,并强调了当狼的数量变为负数时的逻辑错误,突出了计算中非负变量的重要性。
- 解题见解:讨论深入探讨了谜题背后的推理,强调了逻辑推理在 AI 模型中的重要性。Charuru 详细分解了解决问题的过程,识别了关键观察点,如每次移动总动物数减少一只、最终总数不可能为奇数,以及最多只能有一个物种稳定共存。
- 模型性能差异性:No_Training9444 等人讨论了模型性能的差异,一些模型如 DeepSeek R1 和 o1-pro 成功解决了问题,而 gemini-exp-1206 等其他模型则表现挣扎。StevenSamAI 指出重复试验可能会产生正确答案,表明模型输出存在变数。
- 社区参与:社区积极参与该问题的讨论,分享尝试和结果。Echo9Zulu- 质疑此类谜题在测试 AI 方面的目的,而 DeltaSqueezer 等人则表达了亲自解决谜题的兴趣,突显了这些问题所呈现的趣味性与技术挑战的结合。
- Deepseek-R1 GGUFs + 所有蒸馏版 2 到 16bit GGUFs + 2bit MoE GGUFs (Score: 101, Comments: 49): Deepseek-R1 模型已以多种 quantization formats 上传,包括 2 到 16-bit GGUFs,其中 Q2_K_L 200GB quant 专门用于 large R1 MoE 和 R1 Zero 模型。这些模型可在 Hugging Face 获取,并包含用于更高精度的 4-bit dynamic quant 版本,Unsloth blog 提供了使用 llama.cpp 运行模型的说明。
- Dynamic Quantization 与兼容性问题:用户讨论了使用 Q4_K_M 以获得最佳性能,并探索了 bitsandbytes 之外的、与 llama.cpp 兼容的动态量化替代方案。存在 LM Studio 不支持最新 llama.cpp 更新的问题,导致加载 R1 Gguf 等模型时出现错误。
- 模型上传延迟与可用性:Qwen 32b gguf 模型在上传过程中遇到了暂时的 404 错误,但随后已在 Hugging Face 上线。其他模型仍在上传过程中,团队正在连夜工作以确保可用性。
- 社区感谢与反馈:社区对 Unsloth 团队持续的工作和快速更新表示感谢,认可他们的奉献精神以及对用户反馈和问题的积极响应。
{kind=link}
其他 AI Subreddit 回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
主题 1. DeepSeek-R1 发布开源模型,挑战硬件成本
- 就在刚才!DeepSeek-R1 发布了! (Score: 250, Comments: 103): DeepSeek-R1 是一款需要大量 GPU 资源的新模型,暗示了极高的计算需求。它被描述为一个 open model,表明其可供公众使用,并具有社区贡献或修改的潜力。
- DeepSeek-R1 硬件要求:虽然一些用户最初认为 DeepSeek-R1 需要高端硬件,但蒸馏版本可以在单个 RTX 3090 甚至更低 VRAM 的显卡上运行,让拥有消费级 GPU 的用户也能更轻松地使用。
- 开源 vs. 专有模型:讨论了 DeepSeek-R1 与 ChatGPT 和 Claude 等专有模型的开放性对比,强调了本地运行 DeepSeek 的能力(尽管需要大量硬件投资),这与专有 API 带来的数据收集担忧形成对比。
- AI 模型开发与预期:DeepSeek 训练过程的简洁性(涉及带有奖励的标准策略优化)引发了疑问:为什么这种有效的方法没有早点被发现?这突显了 AI 领域不断发展的现状,以及对模型提高推理和推断能力的期望。
主题 2. 使用 Browser-Use 工具实现求职申请的 AI 自主化
- AI agent 自动申请工作 (Score: 200, Comments: 46): 该帖子讨论了一个利用 GitHub 自主申请工作的 AI agent。文中未提供有关该 AI agent 实现或有效性的具体细节,因为帖子正文为空,需通过视频获取更多信息。
- 自动化与外部性:用户对自动化求职申请的影响表示担忧,评论强调了申请量的增加以及由此导致的雇主需要使用自动化进行筛选。讨论强调,虽然 AI 可以申请数千个职位,但它可能导致更多的垃圾信息和就业市场的低效。
- AI 申请的有效性:一位记者对 AI 求职申请服务的测试显示,申请数千个职位确实可以获得面试机会,但单次申请的成功率很低。对话表明,虽然 AI 可以扩大求职申请的规模,但它可能会产生不准确的信息(如伪造资历),其整体有效性存疑。
- 潜在对策:用户预测,随着 AI agent 开始申请工作,招聘人员可能会开发诸如 honeypotting 之类的策略来识别 AI 生成的申请。还有人推测 AI agent 最终可能会管理远程工作,这引发了关于 AI 在就业市场中角色的伦理和实际问题。
主题 3. 对 OpenAI 营销和 AGI 承诺的批评
- 他亲自制造了炒作,但局面失去了控制 (分数: 1243, 评论: 135): Sam Altman 在 Twitter 上回应了围绕 OpenAI 的过度炒作 (hype),澄清说通用人工智能 (AGI) 不会在下个月部署,因为目前尚未建成。根据他日期为 2025年1月20日、拥有 2.69万次浏览量 的推文,他建议追随者尽管有令人兴奋的进展,但仍需降低预期。
- 讨论中充满了对 Sam Altman 言论的怀疑,用户对感知到的前后矛盾和炒作管理表示沮丧,特别是关于 AGI 的时间表。一些用户将他的表态解读为一种策略,可能是为了管理预期和应对监管审查。
- 用户们争论了奇点社区 (singularity community) 的反应,经常嘲笑他们对 AGI 过于乐观的时间表,并暗示像 r/singularity 和 r/openai 这样的论坛由于共同的不切实际预期而变得越来越难以区分。
- 几条评论反思了 Altman 过去的言论以及围绕 OpenAI 的炒作,一些人认为他最近的推文旨在平息市场预期,防止基于投机性 AGI 时间表的估值过高。
- OpenAI 的营销马戏团:别再被他们的科幻式炒作骗了 (分数: 357, 评论: 214): OpenAI 的营销策略因宣传对 AGI 和博士级超级智能体 (super-agents) 不切实际的预期而受到批评,暗示这些进步近在咫尺。该帖子认为,如果没有专门的训练,LLM 缺乏高级推理技能,并警告不要相信过度炒作的承诺,强调需要提高媒介素养。
- 讨论突显了对 OpenAI 营销策略的怀疑,一些用户认为该公司关于 AGI 和博士级超级智能体 (super-agents) 的主张被夸大了,不能反映当前的能力。Sam Altman 因发表雄心勃勃的言论而受到关注,这些言论既遭到了愤世嫉俗的对待,也引发了期待。
- 用户们争论了 LLM 的能力,一些人断言像 o1 和 o3 这样的当前模型在执行任务方面已经优于普通人类,而另一些人则认为这些模型仍然缺乏常识和可靠性。对话涉及了 LLM 的推理能力,并将其与幼儿进行比较,讨论了它们令人印象深刻但又有限的问题解决能力。
- 社区在感知到的炒作与 AI 模型的实际效用之间表现出分歧,一些用户主张对 AI 能力进行更现实的理解。人们呼吁对 AI 进展的媒体表现保持怀疑,强调需要通过实践经验和直接使用模型来评估其在现实世界中的适用性。
{kind=link}
主题 4. 对 Perplexity AI 可靠性的批评及偏见担忧
- 人们真的需要停止使用 Perplexity AI (分数: 220, 评论: 137): Perplexity AI 的 CEO Aravind Srinivas 提议开发 Wikipedia 的替代方案,理由是感知到的偏见,并鼓励通过 Perplexity API 进行协作。他发布于 2025年1月14日 的推文引起了广泛关注,拥有 82.07万次浏览、593个赞 和 315次转推。
- 讨论强调了 Wikipedia 中的偏见,特别是在涉及以色列/巴勒斯坦冲突等有争议的话题时。评论者认为 Wikipedia 的众包性质导致了活动家驱动的内容,一些人认为由于利润动机,企业化的替代方案可能会更有偏见。
- 许多评论者对 Perplexity AI 的意图表示怀疑,认为该公司的提议可能是在“无审查”的掩护下迎合右翼观点。人们对创建一个真正公正的平台的可行性表示担忧,因为所有信息源本质上都带有某种偏见。
- 关于替代信息源的想法引发了辩论,一些人支持信息源的多样化以避免单一叙述的主导,而另一些人则担心偏见和虚假信息增加的可能性。对话反映了人们对技术和 AI 在塑造公共话语和知识库中作用的更广泛担忧。
{kind=link}
AI Discord 简报
由 o1-2024-12-17 生成的摘要之摘要的摘要
主题 1. 开源 LLM 之争
- DeepSeek R1 强势超越 OpenAI 的 o1:这款拥有 671B 参数的模型在推理基准测试上追平了 o1,而成本仅为后者的 4%,并以 MIT 许可证发布,可免费商用。其蒸馏版本(1.5B 至 70B)在 MATH-500 和 AIME 上也取得了高分,令数学爱好者印象深刻。
- Kimi k1.5 在 128k-Token 对决中力压 GPT-4o:全新的 “k1.5” 能够协调多模态任务,据报道在代码和数学方面的表现比 GPT-4o 和 Claude Sonnet 3.5 高出多达 +550%。用户指出其 chain-of-thought 协同效应使其能够轻松通过困难的基准测试。
- Liquid LFM-7B 敢于挑战 Transformers:Liquid AI 推出了 LFM-7B,这是一种非 Transformer 设计,在 7B 规模上具有卓越的吞吐量。它大胆宣称在基于许可证的模型分发模式下,提供一流的英语、阿拉伯语和日语支持。
主题 2. 代码与 Agentic 工具
- Windsurf Wave 2 携 Cascade 与自动生成记忆来袭:新的 Windsurf 编辑器集成了强大的网页搜索、文档搜索,并为更广泛的代码团队提升了性能。用户赞扬其单一全局聊天的方式,尽管有些人抱怨在大文件上下文下性能迟缓。
- Cursor 在迟缓的对决中跌跌撞撞:开发者抱怨 3 分钟的延迟、代码删除事故以及 “flow actions” 拖慢了速度。许多人威胁要转投 Windsurf 或 Gemini 等更快的 AI 编辑器。
- Aider 0.72.0 凭借 DeepSeek R1 取得佳绩:Aider 的最新版本欢迎使用 “–model r1”,以统一跨 Kotlin 和 Docker 增强功能的代码生成。用户非常喜欢 Aider 编写了 “52% 的新代码”,证明了它是代码开发中的双刃剑伙伴。
主题 3. RL 与推理强化
- GRPO 为 DeepSeek 简化了 PPO:“Group Relative Policy Optimization (GRPO) 就是去掉了价值函数的 PPO,” Nathan Lambert 声称。通过依赖 Monte Carlo 优势,DeepSeek R1 涌现出了先进的数学和代码解决方案。
- Google 的 Mind Evolution 智胜顺序修正:通过系统地改进解决方案,它在 Gemini 1.5 Pro 的规划基准测试中实现了 98% 的成功率。观察者将其视为无求解器(solver-free)性能的新巅峰。
- rStar-Math 押注 MCTS:它训练小型 LLM 在棘手的数学任务上超越大模型,而无需从 GPT-4 进行蒸馏。论文表明,token 级的 Monte Carlo Tree Search 可以将中等规模的 LLM 转变为强大的推理器。
主题 4. HPC 与硬件花活
- M2 Ultra 联手运行 DeepSeek 671B:一位开发者声称使用两台 3-bit 量化的 M2 Ultra 达到了接近实时的速度。爱好者们在争论硬件成本是否值得为本地运行庞大的 LLM 而获得的炫耀资本。
- GPU vs CPU 大对决:有人认为 GPU 的并行化在处理大数组时彻底击败了 CPU,尽管数据传输可能成为瓶颈。其他人则表示对于小任务,CPU 可以同样快速且没有额外开销。
- KV Cache 量化助力 LM Studio:Llama.cpp 引擎 v1.9.2 带来了内存友好的推理,支持 3-bit 到 4-bit 量化。追求速度的用户对消费级硬件上的吞吐量增益表示赞赏。
主题 5. 合作伙伴与政策风波
- 微软对 OpenAI 的 130 亿美元豪赌惊动了 FTC:监管机构担心 “锁定” 的 AI 合作伙伴关系,并担心初创公司的竞争可能会受到影响。Lina Khan 警告说,垄断云资源加 AI 资源对新竞争者来说意味着麻烦。
- FrontierMath 资金来源笼罩在 NDA 之下:据透露,OpenAI 秘密资助了该数学数据集,让许多贡献者蒙在鼓里。批评者抨击这种秘密安排阻碍了透明度。
- TikTok 合并传闻与 Perplexity 纠缠不清:Perplexity 在惹恼 Pro 订阅者后进行了大规模扩张——传闻称其甚至考虑与 TikTok 合并。怀疑者质疑除了抢眼的标题之外,是否存在任何协同效应。
第一部分:高层级 Discord 摘要
Codeium (Windsurf) Discord
- Windsurf Wave 2 与 Cascade 升级:Windsurf Wave 2 的发布引入了 Cascade 网页和文档搜索、自动生成的 memories 以及性能增强,正如官方博客所述。
- 用户提到 Cascade 的运行更加流畅,并引用了 status.codeium.com,指出其对更广泛的团队具有更好的可靠性。
- Deepseek R1 拥有 671B 参数:新款 Deepseek R1 模型拥有 6710 亿参数,据报道超越了其他产品,@TheXeophon 强调了其强大的测试分数。
- 社区成员讨论了将其集成到 Windsurf 中的可能性,希望看到进一步的评估以及关于数据使用的明确说明。
- Windsurf 的性能与错误困扰:许多用户报告了 incomplete envelope 错误、打字缓慢以及 1.2.1 版本后的延迟,特别是在处理大文件时。
- 他们表达了对 flow actions 和 cascading edits 的沮丧,称这些问题严重降低了生产力。
- API Keys 与 Pro 计划的抱怨:开发者对 Windsurf 在个人 API keys 方面的立场表示担忧,这限制了聊天功能和高级集成的使用。
- 一些 Pro 计划订阅者感到被亏待了,将 Windsurf 与其他允许自由使用用户自有 API 的 IDE 进行了比较。
- Cascade 历史记录与长对话问题:单一的全局 Cascade 聊天列表给寻求特定项目分类的用户带来了困惑。
- 他们还抱怨在 Windsurf 中长时间的会话会变得迟钝,迫使他们频繁重置并重复解释 context。
Perplexity AI Discord
- Perplexity 更换模型,引发 Pro 用户不满:在切换到自研(in-house)模型后,用户批评 Perplexity 的输出变弱并取消了 Pro 订阅,理由是缺乏动态响应(Perplexity Status)。
- 其他人要求迅速修复并提高透明度,提到了该平台的估值并敦促及时改进。
- Ithy 等挑战 Perplexity 的统治地位:一波新 AI 工具,包括 Ithy 和开源项目如 Perplexica,在寻求替代方案的开发者中获得了关注。
- 社区成员表示这些工具提供了更广泛的功能,一些人预测开源平台可能很快会与封闭解决方案抗衡。
- DeepSeek-R1 准备接入 Perplexity:Perplexity 宣布计划集成 DeepSeek-R1 以处理高级推理任务,并引用了 Aravind Srinivas 的推文。
- 用户期待功能得到恢复以及更敏锐的 context 处理,希望与搜索界面的协同效应得到改善。
- Perplexity 收购 Read.cv:Perplexity 收购了 Read.cv,旨在增强其 AI 驱动的职业社交洞察(详情点击此处)。
- 参与者期待更强大的用户画像和数据驱动的匹配,引发了对该平台套件未来扩张的猜测。
Cursor IDE Discord
- DeepSeek R1 在基准测试中表现亮眼:DeepSeek R1 在 aider polyglot 基准测试中获得了 57% 的分数,紧随 O1 的 62% 之后,详见这条推文。
- 其在 GitHub 上的开源方案引发了将其集成到 Cursor 的兴趣,部分用户参考了 DeepSeek 推理模型文档 以实现高级工作流。
- Cursor 的卡顿问题引发热议:多位开发者报告在实际使用中出现了 3 分钟的延迟和 Agent 响应缓慢的问题,这加剧了对 Cursor 性能的不满。
- 一些用户威胁要转向更快的 AI 编辑器,如 Windsurf 或 Gemini,同时一份关于新鲜 Prompting 想法的 Notion 条目 也在流传。
- Agent 功能正面交锋:社区成员强调了 Cursor 在处理大文件和代码删除时的故障,并在一场 240k Token 之战 中将其与 GitHub Copilot 和 Cline 进行了对比。
- 一些人坚持要求更好的文档支持,而另一些人则引用了 Moritz Kremb 的推文,展示了单条命令的最佳实践。
- 社区推动 Cursor 更新:为了解决性能投诉,出现了要求引入 DeepSeek R1 和其他先进模型的呼声。
- 开发者们关注 Cursor Forum 以获取即将发布的补丁以及针对新版本的直接反馈渠道。
Nous Research AI Discord
- DeepSeek 的蒸馏技术成效显著:DeepSeek-R1 模型因其强大的蒸馏结果而备受关注,详见 Hugging Face 上的 DeepSeek-R1,并暗示了使用 RL 方法扩展推理能力的潜力。
- 贡献者们集思广益,探讨 Qwen 与开源微调工作之间的协同作用,建议针对复杂任务进行未来优化。
- Liquid AI 的许可证与 LFM-7B:Liquid AI 推出了采用 Recurrent 设计的 LFM-7B,在其官方链接中宣称在 7B 规模下具有卓越的吞吐量。
- 他们透露了一种基于许可证的分发模式,并强调了对本地和预算有限部署的英语、阿拉伯语和日语支持。
- 稀疏化提速:MOE 对比 Dense 模型:参与者使用几何平均技巧对比了 MOE 与 Dense 模型在匹配参数规模下的表现,关注其 3-4 倍的延迟优势。
- 他们引用了 NVIDIA 结构化稀疏博客 来强调 2:1 的 GPU 效率,尽管内存需求相似。
- Google 掌控 Mind Evolution:Google 展示了 Mind Evolution 的表现优于 Best-of-N 和 Sequential Revision,在 Gemini 1.5 Pro 的规划基准测试中实现了 98% 的成功率。
- 一个分享的推文示例强调了与旧的推理策略相比,Solver-free 带来的性能提升。
- 气候产量的 CNN 协作:一个名为 “开发卷积神经网络以评估气候变化对全球农业产量的影响” 的项目正在招募机器学习和气候科学专家,截止日期为 1 月 25 日。
- 有意向的合作者可以私信获取构建集成 CNN 框架以分析地理空间数据和产量因素的详细信息。
Unsloth AI (Daniel Han) Discord
- DeepSeek 揭秘与量化趣闻:Unsloth 宣布所有 DeepSeek R1 模型(包括 GGUF 和量化版本)现已上线 Hugging Face,提供易用性更高的 Llama 和 Qwen 蒸馏版本。社区成员称赞了 dynamic 4-bit 方法,并引用了 @ggerganov 的帖子,强调其在不牺牲准确性的情况下减少了 VRAM 占用。
- Qwen 和 Phi 的微调成果:社区成员使用各种训练参数测试了 Qwen 和 Phi-4,注意到 Phi-4 存在欠拟合问题,可能与更重的指令微调(instruction tuning)有关。他们还探索了在 Qwen2.5 上使用 Alpaca format,并参考了 Unsloth 文档 中的聊天模板解决方案。
- Chatterbox 对话与合成数据集:新的 Chatterbox 数据集构建器引入了多轮对话管理功能,包括 Token 计数和 Docker-compose 等特性,并在 GitHub repo 中共享。开发者提议使用 webworkers 或 CLI 批量生成合成数据集(synthetic datasets),旨在改进多轮对话流。
- Sky-T1 起飞:来自加州大学伯克利分校 NovaSky 团队的 Sky-T1-32B 模型在编程和数学方面得分很高,该模型在 8 个 H100 GPU 上花费 19 小时,基于 Qwen2.5-32B-Instruct 的 17K 数据训练而成。爱好者们称赞其在 DeepSpeed Zero-3 Offload 下的速度,表示其性能几乎与 o1-preview 持平。
- Cohere For AI LLM 研究队列招募:Cohere For AI 计划将开展一个 LLM Research Cohort,重点关注多语言长上下文任务,将于 1 月 10 日启动。参与者将练习高级 NLP 策略,并引用了 @cataluna84 的推文,讨论将大规模教师模型与较小的学生模型相结合。
Eleuther Discord
- RWKV7 携“Goose”强势登场:被亲切地称为“Goose”的 RWKV7 发布,在社区中引发了热潮,BlinkDL 展示了其超越旧模型的强大生成能力。它显著集成了通道衰减(channel-wise decay)和学习率调整,根据用户测试,表现十分稳健。成员们将 RWKV7 与 Gated DeltaNet 进行了比较,强调了使这一 gen7 RNN 领先于先前迭代的新设计特性。他们还辩论了内存衰减策略和分层技术,以进一步增强 RWKV7 的优势。
- DeepSeek R1 挑战 AIME 和 MATH-500:新推出的 DeepSeek R1 模型在 AIME 和 MATH-500 等任务中表现优于 GPT-4o 和 Claude Sonnet 3.5,展示了处理高达 128k tokens 扩展上下文的能力。社区对比表明其“冷启动”性能有所提高,这归功于强大的训练策略。讨论涉及使用 SPAM: Spike-Aware Adam 的策略来应对梯度峰值,暗示 DeepSeek R1 有效地避免了永久性损伤。用户认为这些改进很有前景,而一些人对在没有更多复制实验的情况下完全依赖“R1 Zero”结果表示怀疑。
- Qwen2.5 表现不及预期:许多人在 gsm8k 上测试了 Qwen2.5,观察到准确率仅为 ~60%,与官方博客声称的指令微调版 73% 有所出入。解析差异和 few-shot 格式细节引起了困惑。一些人建议采用 QwenLM/Qwen 使用的相同问答格式,并加上“step by step”风格以重新对齐结果。据报道,得分小幅提升至 66%,强调了提示策略(prompting tactics)如何影响最终结果。
- MoE 的热度与顾虑:社区称赞了 Mixture of Experts 模型的高效性,Hugging Face 的 MoE 博客等参考资料促进了其采用。一些人对训练稳定性表示担忧,强调了分片(sharding)和门控(gating)策略的复杂性。辩论集中在如果没有高级调优来处理潜在的训练波动,MoE 是否能提供足够的实际优势。支持者将其视为一条充满希望的途径,而其他人则强调持续的实验是关键。
Interconnects (Nathan Lambert) Discord
- DeepSeek 的大胆进击:DeepSeek-R1 的表现远超预期,在 MIT license 下实现了接近 OpenAI-o1 的性能,更多细节见 Hugging Face 上的 DeepSeek-R1。
- 怀疑者对 R1 Zero 的发现提出质疑,但其他人则称赞 Group Relative Policy Optimization (GRPO) 是更简洁的 PPO 替代方案,并引用了 GRPO 澄清说明。
- Kimi 在 RL 领域的强劲动力:Kimi 1.5 论文强调了新的 RL 方法,如奖励塑造(reward shaping)和先进的基础设施,代码已在 GitHub 上的 Kimi-k1.5 分享。
- 爱好者预测这些技术将增强 reinforcement learning 框架与 Chain-of-Thought 推理之间的协同作用,标志着 Agent 模型的一次飞跃。
- Molmo 的多模态实力:Molmo AI 作为一种强大的 VLM 受到关注,声称在检测和文本任务上具有卓越性能,展示于 molmo.org。
- 尽管出现了一些误分类情况,但许多人认为其跨领域灵活性使其成为 GPT-4V 等模型的有力竞争者。
- Cursor 在编程对决中击败 Devin:由于代码补全效果不佳,各团队迅速放弃了 Devin 转而使用 Cursor;有传言称 Devin 在编程任务中调用的是 gpt-4o,而非 Claude 等更强的替代方案。
- 这一转变引发了关于 AI 团队是否系统性高估了涌现的 Agent 解决方案的辩论,呼应了 Tyler Cowen 访谈中的观点。
- SOP-Agents 大放异彩:SOP-Agents 框架为 LLM 提出了 Standard Operational Procedures(标准作业程序),优化了多步规划。
- 开发者期待将其与 Chain of Thought 和 RL 结合,以增强高层决策图的清晰度。
aider (Paul Gauthier) Discord
- Aider v0.72.0 达到新高度:全新的 Aider v0.72.0 版本带来了 DeepSeek R1 支持(通过快捷方式
--model r1)和 Kotlin 语法集成,以及使用--line-endings增强的文件写入功能。- 社区成员提到了多项错误修复(包括 Docker 镜像中的 权限问题),并指出 Aider 编写了 52% 的新代码。
- DeepSeek R1 引发褒贬不一的反应:一些用户称赞 DeepSeek R1 是 OpenAI o1 的更廉价替代方案,在 Aider 编程基准测试中达到了 57% 的得分。
- 其他人则报告在基础任务中效果欠佳,建议将其与更可靠的编辑模型配对以提高一致性。
- Kimi k1.5 击败 GPT-4o:据报道,新的 Kimi k1.5 模型在多模态基准测试中优于 GPT-4o 和 Claude Sonnet 3.5,上下文缩放高达 128k tokens。
- 用户强调了在 MATH-500 和 AIME 上尤为强劲的结果,激发了对增强推理能力的乐观情绪。
- AI 数据隐私引发关注:参与者引用了 Fireworks AI 文档,同时描述了企业在数据使用透明度方面的差异。
- 他们质疑哪些供应商能负责任地处理用户数据,并指出大型 AI 厂商的政策尚不明确。
Stackblitz (Bolt.new) Discord
- Bolt.new 消除白屏问题:继最近的 Bolt.new 推文之后,Bolt.new 解决了臭名昭著的白屏问题,并确保从第一个提示词(prompt)开始就能进行精确的模板选择。
- 积极的测试者报告称流程更加顺畅,指出这直接修复了之前的困扰,并保证了更高效的启动。
- 错误循环吞噬 Token:用户面临持续的循环,导致严重的 Token 消耗——一位开发者消耗了 3000 万个 Token——特别是在涉及用户权限的场景中。
- 他们得出结论,完全重置是唯一的出路,社区成员敦促针对复杂功能进行更强大的调试。
- Supabase 中的 RLS 纠葛:开发者在 Supabase 中实现预订功能时,苦于反复出现的 RLS(行级安全性)违规,导致策略不断失败。
- 一位用户建议参考 Supabase 文档中的示例策略,以减少重复的配置错误。
- Stripe 还是 PayPal?支付讨论:社区成员讨论了在汽车美容支付中选择 Stripe 还是更简单的替代方案(如 PayPal),特别是针对技术水平较低的用户。
- 一些人指向了 Supabase 关于 Stripe Webhooks 的指南,而另一些人则推荐基于 WordPress 的解决方案以实现更快的部署。
- Pro 计划缓解 Token 限制:好奇的新手询问了 Pro 计划下的 Token 使用情况,发现每日限制消失了,使用情况很大程度上取决于用户技能和可选功能(如 diffs)。
- 这种方式让更高级的开发者感到安心,他们可以尽情使用 Bolt 而不必担心每日上限或意外的 Token 耗尽。
LM Studio Discord
- LM Studio 0.3.7 与 DeepSeek R1:强强联手:全新的 LM Studio 0.3.7 包含了对先进的 DeepSeek R1 模型的支持,并集成了 llama.cpp 引擎 v1.9.2,详见 LM Studio 更新说明。
- 社区成员赞扬了其开源方式,并引用了 DeepSeek_R1.pdf,称赞其带有
<think>标签的强大推理能力。
- 社区成员赞扬了其开源方式,并引用了 DeepSeek_R1.pdf,称赞其带有
- KV Cache 量化提升效率:针对 llama.cpp (v1.9.0+) 的 KV Cache 量化功能旨在通过减少内存占用来增强性能,如 LM Studio 0.3.7 所示。
- 用户报告称在大语言模型中获得了更快的吞吐量,并指出 3-bit 量化通常能在速度和准确性之间达到最佳平衡。
- LM Studio 中的文件附件保留在本地:用户询问在 LM Studio 中上传文件是否会将数据发送到别处,并得到了保证:内容保留在用户机器上,用于本地上下文检索。
- 他们测试了针对特定领域任务的多文件上传,确认了在不损害数据控制权的情况下的纯离线使用。
- GPU 评测:4090 对比廉价显卡:成员讨论权衡了 200 美元的 GPU 与 4090 等高端显卡,并参考了大规模 AI 任务的 技术规格。
- 大多数人同意更大的显存是处理巨型模型的关键,能为数据驱动型工作负载提供更高的吞吐量。
- 使用 M2 Ultra 进行分布式推理:速度还是挥霍?:Andrew C 的一条推文展示了在两台 M2 Ultra 上运行的 DeepSeek R1 671B,利用 3-bit 量化实现了接近实时的速度。
- 然而,参与者对硬件成本仍持谨慎态度,理由是带宽限制和收益递减的风险。
Latent Space Discord
- DeepSeek R1 蒸馏并占据主导地位:DeepSeek R1 发布,采用 MIT license,在数学、代码和推理任务上的表现与 OpenAI o1 相当。
- 一个蒸馏变体在 AIME 和 MATH 基准测试中超过了 GPT-4o,引发了人们对扩展开源产品的兴奋。
- OpenAI 的 Operator 在泄露文档中浮出水面:最近的泄露揭示了 OpenAI 的新项目 Operator(或称 Computer Use Agent),引发了关于即将发布的猜测。
- 观察者将其与 Claude 3.5 进行了对比,并引用了 Operator 系统泄露中的细节。
- Liquid Foundation Model LFM-7B 启航:来自 Liquid AI 的 LFM-7B 模型声称具有顶级的多语言能力,并采用了非 Transformer 设计。
- 工程师们称赞其低内存占用适合企业使用,这与基于 Transformer 的大型方法形成了鲜明对比。
- DeepSeek v3 & SGLang 助力关键任务推理:Latent.Space 播客重点介绍了 DeepSeek v3 和 SGLang 在“关键任务推理(Mission Critical Inference)”中对高级工作流的需求。
- 嘉宾们讨论了超越单 GPU 扩展的策略,并预告了 DeepSeek 的进一步改进,引起了关注性能的开发者的兴趣。
- Kimi k1.5 以 o1 级别的性能令人惊喜:Kimi k1.5 模型达到了 o1-level 基准,在数学和代码任务中表现优于 GPT-4o 和 Claude 3.5。
- 据报道在 LiveCodeBench 上有 +550% 的提升,这引发了关于较小架构如何缩小与较大竞争对手差距的讨论。
OpenRouter (Alex Atallah) Discord
- DeepSeek R1 对抗 OpenAI 的 o1:DeepSeek 在 OpenRouter 上推出了其 R1 模型,其性能可与 OpenAI o1 媲美,价格为 $0.55/M tokens(仅为成本的 4%)。
- 社区成员称赞该模型的开源 MIT license 和强大的实用性,并引用 DeepSeek 的推文了解更多细节。
- 无审查角度引发辩论:DeepSeek R1 在 OpenRouter 上被描述为无审查(censorship-free),尽管一些用户注意到它仍保留了过滤组件。
- 其他人建议额外的微调(finetuning)可以扩大其范围,期待在没有额外约束的情况下获得更强的性能。
- Llama 端点取消免费层级:OpenRouter 透露计划在月底前停止 free Llama 端点,因为 Samba Nova 发生了变化。
- 一个 Standard 变体 将以更高的价格取代它们,这让许多用户感到意外。
- OpenAI 模型速率限制已澄清:用户确认 OpenAI 的付费层级 没有每日请求上限,但免费层级将活动限制在 每天 200 次调用。
- 一些人通过附加自己的 API keys 克服了这些限制,减少了使用上的麻烦。
- 推理和网络搜索支持处于变动中:社区成员询问如何从 DeepSeek R1 访问
reasoning_content,预计 OpenRouter 很快会添加该功能。- 其他人希望 Web Search API 能有更广泛的可用性,目前该功能仅锁定在聊天室界面。
Stability.ai (Stable Diffusion) Discord
- Photorealistic Flourish with LoRA: 在关于使用 Stable Diffusion 3.5 生成逼真图像的讨论中,参与者探索了 LoRA 策略以减轻“塑料感”,并参考了 stable-diffusion-webui 进行高级控制。
- 一位用户坚持认为,将高分辨率样本与各种 resolutions 混合可以产生更真实的输出,并引用了 SwarmUI 来增强 prompt 定制。
- Cloudy E-commerce Deployments: 一位用户询问在 Google Cloud 上为电商部署 text-to-image 模型的可行性,并参考了 SwarmUI 作为预训练解决方案的起点。
- 其他人权衡了使用 Google Cloud Marketplace 还是 custom Docker 设置会更有效率,结论是预训练模型可以大大缩短设置时间。
- LoRA Resolution Rumble: 社区成员就仅在 1024×1024 分辨率下训练 LoRA 展开辩论,并指向 Prompt Syntax docs 以获得更细致的控制。
- 一组人强调了多样化的分辨率输入,以便 LoRA 能够处理各种图像质量而不会产生奇怪的伪影。
- Background-Editing Tangles: 用户遇到了性能下降和背景层缺陷的问题,将其归因于 Stable Diffusion 流水线中的 denoising 配置错误。
- 他们建议通过 GIMP 或专门的 AI 解决方案进行手动微调,并指出使用 SwarmUI 的功能可以改善结果。
Notebook LM Discord Discord
- Podcasts & Personality Swaps: 一位用户介绍了一个新的 GLP-1 主题播客,并尝试使用 提议的工具 更改主持人声音,但目前的解决方案可能无法妥善支持。
- 另一位用户指出,随机的声音角色切换会导致混乱,并回应称许多 podcast generation tools 在稳定的说话人分配方面表现不佳。
- Gemini Gains & NotebookLM in Class: 一位用户描述了使用 Gemini Advanced Deep Research 生成详尽音频概览的工作流,建议直接溯源以减少数据丢失。
- 另一位用户辩论了在 econ course 中是使用单个还是多个笔记本,更倾向于基于主题的方法以保持一致的组织。
- Subscriptions & Simple Setups: 几位用户比较了 Google One AI Premium 与 Google Workspace 以获取 NotebookLM Plus 访问权限,指出两者都提供了所需的模型功能。
- 用户得出结论,Google One 更易于管理,没有 Workspace 会员身份那么复杂。
- Big Bytes & OCR Ordeals: 一位用户在上传接近 100MB 的音频文件时遇到困难,怀疑如果与现有数据合并,将超过 200MB 的总限制。
- 另一位用户强调了不可复制 PDF 的 OCR 问题,呼吁改进 NotebookLM 的扫描支持。
- Multi-language Moves & Newcomer Hellos: 几位用户对 multi-language 播客支持表示感兴趣,希望很快能看到官方扩展到 English 以外的语言。
- 新成员介绍了自己,提到了 语言障碍,并鼓励提出更尖锐的问题以保持讨论简洁。
MCP (Glama) Discord
- 不稳定的 MCP Server 实现:用户指出多个 MCP servers 之间的 prompt 使用不一致,导致对正确规范的困惑。
- 一些实现仅获取资源而忽略了官方指南,引发了要求更严格遵守文档的呼声。
- Roo Cline 以 Agent 特性吸引用户:Roo Cline 通过自动批准命令给开发者留下了深刻印象,在使用 R1 servers 时提供了近乎全自动的体验。
- 许多人称赞其有用的 VSCode 插件集成,认为它是比 Claude Desktop 等大型客户端更简单的替代方案。
- Claude 遭遇速率限制瓶颈:频繁的 Claude 速率限制令测试者感到沮丧,限制了上下文长度和消息频率。
- 一些人要求在 Claude Desktop 中提供更好的使用情况追踪,希望能有更清晰的阈值提示并减少突然的中断。
- Figma MCP 寻找勇敢的代码贡献者:Figma MCP 作为早期原型发布,邀请开发者共同塑造其未来。
- “这还处于非常早期/粗糙的阶段,所以欢迎任何贡献者!”一位成员说道,并征求新的想法。
- AI 逻辑计算器引发好奇:MCP Logic Calculator 在 Windows 系统上利用 Python 中的 Prover9/Mace4 来处理逻辑任务。
- 另一位成员建议将其与 memory MCP 结合进行强大的分类,激发了对高级逻辑工作流的兴趣。
Yannick Kilcher Discord
- GPU 的收益与 CPU 的痛点:在关于 HPC 使用的对话中,参与者得出结论,大型数组通常受益于 GPU 并行化,尽管数据传输可能会导致减速。
- 一些参与者将该操作描述为“易并行”(trivially parallel),暗示对于较小的任务, CPU 方法仍具竞争力。
- 微软对 OpenAI 的巨额押注:来自微软的 130 亿美元投资 触发了反垄断警告,FTC 强调云端主导地位可能会渗透到 AI 市场。
- FTC 主席 Lina Khan 警告称,锁定的合作伙伴关系可能会阻碍初创公司获取关键的 AI 资源。
- FrontierMath 资金风波:社区成员在发现隐藏的资金安排后,对 OpenAI 参与 FrontierMath 表示质疑,引发了透明度问题。
- 一些人声称 Epoch 受制于严苛的 NDA 条款,导致许多贡献者对 OpenAI 在融资中的角色一无所知。
- Lightning 和 TPA:快速合成:Lightning Attention 与 Tensor Product Attention 的集成在原型模型测试中实现了约 3 倍的加速。
- 用户将 attention 中的大张量操作归功于线性化,强调了其相对于先前方法的重大性能飞跃。
- rStar-Math 凭借 MCTS 带来惊喜:论文 rStar-Math 展示了小型 LLM 如何通过 Monte Carlo Tree Search (MCTS) 在高级数学任务中超越大型模型。
- 其作者主张尽量减少对人类数据的依赖,详细介绍了一种使用三种不同训练策略来提升问题解决能力的方法。
Cohere Discord
- Konkani 协作势头强劲:一位用户旨在为 Konkani 语构建模型,并可能获得大学支持,希望能推动跨语言 NLP 的发展。
- 他们指出,行业合作伙伴关系对于项目的扩展和实际应用至关重要。
- Command-R 的难题:工程师发现 command-r 引用的是旧模型,以避免对现有用户造成破坏性变更。
- 他们建议使用带有 ‘latest’ 标签的官方别名,以保持发布的一致性,同时允许按需启用新版本。
- Cohere 的数学错误:用户发现 Cohere 错误地将 18 个月计算为 27 周,迫使他们手动验证结果。
- 他们强调大多数 LLM 都有此局限性,建议降低 temperature 或使用独立的计算器作为解决方案。
- 代码调用与工具策略:开发者概述了 Cohere 如何通过让 LLM 决定何时使用指定组件来调用外部工具。
- 他们注意到官方极少提及 AGI,但强调了用于代码生成工作流的结构化 prompt 和模型驱动执行。
LLM Agents (Berkeley MOOC) Discord
- 春季 MOOC 势头强劲:一位成员询问了关于今年 1 月开始的 MOOC 课程的确认信息,重点关注预期的 LLM Agents 覆盖内容。
- 他们还提到 mailing list 将于下周开始,暗示很快将分享更多 course timeline 细节。
- 邮件列表即将启动:社区成员确认 春季课程邮件列表 将于下周发布,解决了关于正式注册的公开问题。
- 他们预计一旦列表上线,将会有进一步的 course timeline 更新,并建议潜在参与者关注公告。
Mozilla AI Discord
- Document to Podcast 蓝图亮相:一个专门的团队介绍了 Document to Podcast 蓝图,这是一种利用开源解决方案将文本内容转化为音频的灵活方法。
- 他们宣布了一个直播环节,参与者可以在其中提问、分享反馈,并探索如何将该蓝图整合到自己的项目中。
- 蓝图强化开源协同效应:敦促与会者加入活动并与其他开源爱好者建立联系,承诺在未来项目上进行新的合作。
- 他们强调点击“感兴趣”按钮加入社区对话,为更深层次的开源交流激发新的可能性。
MLOps @Chipro Discord 没有新消息。如果该社区长时间没有动静,请告知我们,我们将将其移除。
HuggingFace Discord 没有新消息。如果该社区长时间没有动静,请告知我们,我们将将其移除。
PART 2: 详细频道摘要与链接
各频道的完整详细内容已针对邮件进行截断。
如果您喜欢 AInews,请分享给朋友!预先感谢!