ainews-project-stargate-500b-datacenter-17-of-us
星际之门项目(Project Stargate):耗资 5000 亿美元的数据中心(占美国 GDP 的 1.7%)以及 Gemini 2 Flash Thinking 2。
星际之门项目 (Project Stargate) 是一个由 OpenAI 和 软银 (Softbank) 领导,并得到 甲骨文 (Oracle)、安谋 (Arm)、微软 (Microsoft) 和 英伟达 (NVIDIA) 支持的美国“AI 曼哈顿计划”。该项目的规模据称可与当年的曼哈顿计划相媲美,经通胀调整后的成本达 350 亿美元。尽管微软作为独家计算合作伙伴的角色有所削弱,但该项目态度严肃,只是目前尚不具备即时实用性。
与此同时,Noam Shazeer 披露了 Gemini 2.0 Flash Thinking 的第二次重大更新,实现了现已可用的 100 万 token 超长上下文。此外,AI Studio 推出了全新的 代码解释器 (code interpreter) 功能。
在 Reddit 上,基于 Qwen 32B 蒸馏而成的 DeepSeek R1 已在 HuggingChat 上免费发布,引发了关于私有化部署、性能问题和量化技术的讨论。DeepSeek 首席执行官 梁文锋 强调,尽管面临出口限制,他们仍专注于 通用人工智能 (AGI) 基础研究、高效的 MLA 架构,并致力于 开源开发。这使 DeepSeek 成为闭源 AI 趋势的一个潜在替代方案。
孙正义 (Masa Son) 与 Noam Shazeer 就是你所需要的一切。
2025/1/20-2025/1/21 的 AI 新闻。我们为你检查了 7 个 subreddits、433 个 Twitter 账号 和 34 个 Discord 社区(225 个频道,4353 条消息)。预计节省阅读时间(以 200wpm 计算):450 分钟。你现在可以标记 @smol_ai 来进行 AINews 讨论!
像这样的日子总是让人纠结——一方面,显而易见的重磅新闻是 Project Stargate 的宣布,这是一个由 OpenAI 和 Softbank 领导,并得到 Softbank、OpenAI、Oracle、MGX、Arm、Microsoft 和 NVIDIA 支持的美国“AI 曼哈顿计划”。作为规模参考,实际的曼哈顿计划经通胀调整后的成本为 350 亿美元。
尽管这在一年前就有传闻,但 Microsoft 作为 OpenAI 独家算力合作伙伴角色的削弱因其缺席而显得尤为突出。与任何引人注目的公关噱头一样,人们应该警惕 AI-washing,但该项目非常严肃,应予以重视。
然而,这并不是你今天就能用上的新闻,而这正是我们这份本地 AI 报纸的目标。
幸运的是,Noam Shazeer 为你带来了第二个 Gemini 2.0 Flash Thinking,它在 2.0 Flash 上又有了巨大飞跃,并且拥有你今天就可以使用的 1M 长上下文(我们明天将在 AINews 和 Smol Talk 中启用):
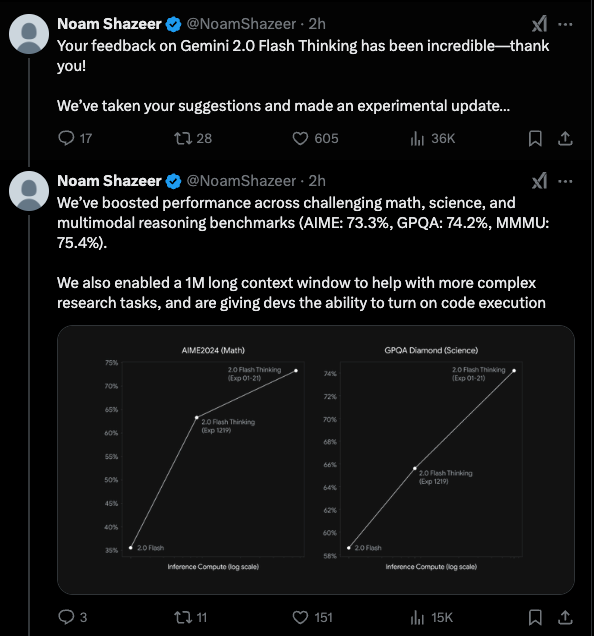
AI Studio 也获得了一个 code interpreter。
AI Twitter 回顾
所有回顾均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
待完成
AI Reddit 回顾
/r/LocalLlama 回顾
主题 1:DeepSeek R1:发布、性能与战略愿景
- DeepSeek R1 (Qwen 32B Distill) 现已在 HuggingChat 上免费可用! (得分: 364, 评论: 106): DeepSeek R1,一个 Qwen 32B 的蒸馏版本,现在可以在 HuggingChat 上免费访问。
- 托管与访问关注:用户讨论了自行托管 DeepSeek R1 以避免登录 HuggingChat 的选项,一些人对需要账号才能评估模型表示沮丧。有人建议使用虚拟邮箱创建账号来绕过这一限制。
- 性能与技术问题:有报告称存在模型无响应等性能问题,并讨论了使用 quantization(例如 FP8、8-bit)和 system prompts 对模型性能的影响。一些用户注意到 DeepSeek R1 在规划方面优于代码生成,其他人分享了像 cot_proxy 这样的工具来管理模型的“思考”标签。
- 模型比较与偏好:用户将 DeepSeek R1 与 Phi-4 和 Llama 70B 等其他模型进行了比较,一些用户在数学和细微理解等特定任务上更倾向于蒸馏模型。人们有兴趣探索 Qwen 14B 等其他变体,并期待 R1 Lite 以获得更好的连贯性。
- 深入探究 DeepSeek 的宏伟使命(CEO 梁文锋访谈) (Score: 124, Comments: 27):由 CEO 梁文锋领导的 DeepSeek 脱颖而出,其核心在于专注于基础 AGI 研究而非快速商业化,旨在将中国在全人工智能领域的角色从“搭便车者”转变为“贡献者”。他们的 MLA architecture 大幅降低了内存占用和成本,推理成本显著低于 Llama3 和 GPT-4 Turbo,体现了他们对高效创新的承诺。尽管面临美国芯片出口限制等挑战,DeepSeek 仍致力于开源开发,利用自下而上的组织结构和本土年轻人才,这可能使他们成为 AI 闭源趋势中的有力替代方案。
- DeepSeek 对 AGI 的关注:评论者强调,DeepSeek 对 AGI 而非利润的承诺值得关注,有人将其方法比作 OpenAI 的早期阶段。对于 DeepSeek 是否能长期保持这种开源精神,还是最终会像其他科技巨头一样转向闭源模型,存在一些怀疑。
- 领导力与认可:梁文锋的领导力受到关注,文中特别提到了他与中国总理李强的会面,这表明了高层的认可与支持。这次会面凸显了 DeepSeek 日益增长的影响力以及对中国 AI 发展的潜在影响。
- 年轻人才与创新:评论者赞扬了 DeepSeek 团队的创造力和创新精神,指出团队由年轻的应届博士组成,尽管在加入公司前并不出名,但已取得了重大成就。这凸显了利用年轻人才实现 AI 突破性进展的潜力。
- DeepSeek-R1-Distill-Qwen-1.5B 在浏览器中通过 WebGPU 100% 本地运行。据报道,在数学基准测试中表现优于 GPT-4o 和 Claude-3.5-Sonnet(AIME 为 28.9%,MATH 为 83.9%)。 (Score: 72, Comments: 17):DeepSeek-R1-Distill-Qwen-1.5B 完全使用 WebGPU 在浏览器内运行,据报道在数学基准测试中超过了 GPT-4o 和 Claude-3.5-Sonnet,在 AIME 上达到 28.9%,在 MATH 上达到 83.9%。
- ONNX 作为 LLM 的文件格式被讨论,一些用户指出它提供了性能优化,在特定硬件上可能比 safetensors 和 GGUF 等其他格式快 2.9 倍。然而,普遍共识是,这些只是被不同硬件/软件设置所青睐的不同数据格式。
- DeepSeek-R1-Distill-Qwen-1.5B 因在 WebGPU 上完全在浏览器内运行并在基准测试中优于 GPT-4o 而受到关注,在线演示和源代码可在 Hugging Face 和 GitHub 上获得。然而,一些用户认为尽管其基准测试结果令人印象深刻,但在实际应用中仍不及 GPT-4o。
主题 2. 新的 DeepSeek R1 工具增强了易用性和速度
- 以 3-10 倍速度在 Huggingface 上部署任何 LLM (Score: 109, Comments: 13):该图片展示了 Huggingface 上“专用部署”的数字化仪表盘,显示了两个模型部署卡。“deepseek-ai/DeepSeek-R1-Distill-Llama-70B” 模型正在使用四块 NVIDIA H100 GPU 进行 52% 的量化,而 “deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B” 模型在一块 NVIDIA H100 GPU 上运行,两者最近都处于活跃状态并准备好接收请求。
- avianio 推出了一项部署服务,声称比 HF Inference/VLLM 速度提高 3-10 倍,设置时间约为 5 分钟,利用 H100 和 H200 GPU。该服务支持约 100 种模型架构,未来计划支持多模态,并提供经济高效、无日志的私有部署,在高流量场景下价格为 每百万 tokens 0.01 美元。
- siegevjorn 和 killver 对 3-10 倍速度的说法提出质疑,要求澄清比较指标和硬件一致性。killver 特别询问该说法在相同硬件上是否有效。
- omomox 估计部署 4x H100 的成本约为 20 美元/小时,强调了用户潜在的成本考虑。
- 在 open webui 中获得更好的 R1 体验 (Score: 117, Comments: 41): 该帖子介绍了一个简单的 open webui function,用于 R1 模型,通过将
<think>标签替换为<details>和<summary>标签,使 R1 的思考过程可以折叠,从而提升用户体验。此外,它还按照 DeepSeek 的 API documentation 的建议,在多轮对话中移除旧的思考内容。该功能旨在用于本地 R1 (-distilled) 模型,不兼容 DeepSeek API。更多详情可以在 GitHub 找到。- OpenUI vs. LMstudio: 用户对 OpenUI 和 LMstudio 进行了对比,表达了希望 OpenUI 能像 LMstudio 一样响应迅速的愿望。然而,作者强调 webui 提供了更大的灵活性,允许用户自由修改输入和输出。
- DeepSeek API 支持: 一些用户请求在 open webui function 中增加对 DeepSeek API 的支持,表明了对本地使用之外更广泛兼容性的兴趣。
- VRAM 限制与解决方案: 用户讨论了在 8GB 等有限 VRAM 下使用模型的挑战,并分享了 Hugging Face 上的 DeepSeek-R1-Distill-Qwen-7B-GGUF 等资源,以潜在地解决这些限制。
{kind=link}
主题 3. DeepSeek R1 与竞争对手的效率和性能对比
- 我计算了 R1 与 o1 的实际成本,以下是我的发现 (Score: 58, Comments: 17): 该帖子通过对比 Token 生成和定价,分析了 R1 与 o1 模型的成本效益。R1 生成的 reasoning tokens 是 o1 的 6.22 倍,而 o1 每百万 output tokens 的价格是 R1 的 27.4 倍。因此,考虑到 Token 效率,R1 实际上比 o1 便宜 4.41 倍,尽管由于对 token-to-character 转换的假设,实际成本可能会略有波动。
- 包括 UAAgency 和 inkberk 在内的几位评论者批评了成本对比中使用的方法论,认为分析可能存在偏差,或者基于无法准确反映实际使用情况的假设。Dyoakom 和 pigeon57434 强调了 OpenAI 可能缺乏透明度,质疑该公司提供的示例是否具有代表性。
- dubesor86 提供了详细的测试结果,指出 R1 生成的 reasoning tokens 并没有达到 o1 的 6.22 倍。在他们的测试中,R1 产生的 thought tokens 多出约 44%,根据 API 使用数据,R1 的实际成本比 o1 便宜 21.7 倍,这与原帖的结论形成了对比。
- BoJackHorseMan53 建议不要仅仅依赖假设,并建议通过 API 运行实际查询来确定真实的成本差异,强调了通过实际测试验证假设的重要性。
- DeepSeek-R1 PlanBench 基准测试结果 (Score: 56, Comments: 2): 截至 2025 年 1 月 20 日的 PlanBench benchmark 结果对比了 Claude-3.5 Sonnet, GPT-4, LLaMA-3.1 405B, Gemini 1.5 Pro 和 Deepseek R1 等多种模型在 “Blocksworld” 和 “Mystery Blocksworld” 领域的表现。关键指标包括 “Zero shot” 得分、性能百分比以及每 100 个实例的平均 API 成本,其中 Claude-3.5 Sonnet 在 600 个问题中答对 329 个,达到了 54.8% 的成功率。
{kind=link}
主题 4. 对 LLM 中“陷阱测试”的批评及竞争背景
- 简直无法使用 (Score: 95, Comments: 102): 对 LLM “陷阱”测试的批评 重点展示了一个语言模型在计算 “strawberry” 中字母 ‘r’ 出现次数时的结构化响应。该模型的分析和指令式方法包括写出单词、识别并计数 ‘r’,并强调存在 2 个小写 ‘r’。
- 模型差异与性能:评论者讨论了不同的模型架构和预训练数据如何导致性能差异,较小模型的表现通常与 R1 等大型模型的结果背道而驰。Custodiam99 提到即使是 70b 模型 在实际中也可能无法使用,而 Upstairs_Tie_7855 等其他人则报告同一模型效果出色。
- 量化与设置的影响:几位用户强调了使用正确的量化设置和系统提示词(system prompts)以获得准确结果的重要性。Youcef0w0 指出,当缓存类型低于 Q8 时模型会崩溃,而 TacticalRock 则强调应根据文档使用正确的量化和温度(temperature)设置。
- 实际应用与局限性:讨论揭示了模型并非 AGI,而是需要正确使用才能有效解决问题的工具。ServeAlone7622 建议了一套使用推理模型的详细流程,而 MixtureOfAmateurs 和 LillyPlayer 则展示了模型在特定提示词下的挣扎以及在某些任务上的过拟合现象。
{kind=link}
其他 AI Subreddit 回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
主题 1. OpenAI 5000 亿美元投资:与 Oracle 和 Softbank 合作
- 特朗普将宣布由 OpenAI 领导的合资企业获得 5000 亿美元投资 (Score: 595, Comments: 181): 唐纳德·特朗普 计划宣布对一个由 OpenAI 领导的项目进行 5000 亿美元的投资。目前尚未提供该合资企业及其目标的具体细节。
- 对投资来源的误解:许多评论者澄清说,这 5000 亿美元投资 来自私营部门,而非美国政府。这项投资涉及 OpenAI、SoftBank 和 Oracle,共同组建名为 Stargate 的合资企业,初始承诺投资 1000 亿美元,四年内可能增长至 5000 亿美元。
- 对基础设施和选址的担忧:评论者对美国电网处理 AI 基础设施需求的能力表示担忧,建议未来依赖 核反应堆。由于德克萨斯州电网孤立且不可靠,该项目选择 德克萨斯州 受到了质疑。
- 怀疑态度与政治担忧:有人怀疑投资是否会兑现,并批评其政治影响,一些人认为这符合 法西斯主义 倾向。这一宣布被比作之前的投机项目,如“基础设施周”和 威斯康星工厂。
- Sam Altman 在整个 AI 基础设施协议宣布期间的表情 (Score: 163, Comments: 51): 该帖子缺乏关于 Sam Altman 在 AI 基础设施协议宣布期间表情的具体细节或背景,未提供进一步的信息或见解。
- 围绕 Sam Altman 的举止 的讨论突显了人们对其焦虑和压力的感知,评论建议他经常看起来就是这样。用户将他的表情比作“福奇脸(Fauci face)”或“黛博拉·伯克斯(Debra Birx)”,并推测他在职位上所面临的压力。
- 几条评论幽默地提到了 Elon Musk 以及像 普京 这样的地缘政治人物,暗示 Altman 可能因内部和外部政治动态而承受巨大压力。人们将其与寡头管理和“坠楼政治(defenestration politics)”进行了比较。
- 对话中包含了对 Altman 表情的轻松和讽刺性评论,用户开玩笑地将其归因于像个“等着见金主的男宠”,或者担心 Musk 的反应,这表明社区对 Altman 的看法混合了幽默与批判。
主题 2. OpenAI 的新模型 Operator
- Exa CEO 拥有关于 OpenAI 新模型的内幕消息 (Score: 215, Comments: 105): Exa 的 CEO 声称拥有关于 OpenAI 新模型能力的内幕消息,特别是质疑这些模型作为 operator 的潜在有效性。该帖子未提供更多细节或背景。
- 讨论重点是对 AGI 炒作和 OpenAI 新模型的怀疑,几位用户质疑这些说法的现实性,并将其与之前过度炒作的技术(如 3D printers)进行类比。用户对 o3 等模型在现实世界中的表现(与其 benchmark 结果相比)表示怀疑,强调了炒作与实际应用之间的差距。
- 几条评论探讨了当前 AI 模型的局限性,重点关注它们无法处理需要实时学习和复杂推理的任务,例如视频理解和对 3D spaces 的理解。Altruistic-Skill8667 预测,实现 AGI 将需要 compute power 和 online learning 的重大进步,潜在的时间表可能会延长到 2028 年或 2029 年。
- 一些用户对 AI 进步的社会政治影响表示担忧,认为 AGI 可能被用来在寡头政权下奴役工人阶级。一些评论还涉及政府和技术寡头在塑造 AI 未来方面的作用,并对比了美国和中国在技术控制和监管方面的差异。
主题 3. Anthropic 的 ASI 预测:2-3 年时间线的影响
- Anthropic CEO 现在确信 ASI(而非 AGI)将在未来 2-3 年内到来 (Score: 173, Comments: 115): Anthropic 的 CEO Amodei 预测,Artificial Superintelligence (ASI) 可能会在未来 2-3 年内实现,并超越人类智能。该公司计划为 Claude 发布具有增强记忆和双向语音集成功能的高级 AI 模型,以应对与 OpenAI 等公司的竞争。
- 讨论突显了对 2-3 年内实现 ASI 预测的怀疑,一些研究人员和评论者认为 AI 模型需要重大改进,而当前的 AI 系统距离实现 AGI 仍有很大差距。Dario Amodei 的背景是 AI 研究,其可信度得到了认可,但关于他的预测是否现实仍存在争议。
- 强调了 narrow AI 和 general AI 之间的区别,当前的 AI 系统在特定任务中表现出色,但缺乏 AGI 的综合能力。评论者指出,尽管取得了进步,AI 系统在处理许多对人类来说很简单的任务时仍然很吃力,通往 AGI 和 ASI 的路径仍不明确。
- 资金和商业动机受到质疑,一些人认为宣布 ASI 即将到来可能是为了配合融资活动的战略时机。关于 Anthropic 当前融资活动的评论支持了这一观点。
{kind=link}
AI Discord 简报
由 o1-preview-2024-09-12 生成的摘要之摘要的摘要
主题 1. DeepSeek R1 震撼 AI 界
- DeepSeek R1 赶超竞争对手:开源的 DeepSeek R1 性能比肩 OpenAI 的 o1,其高性价比和易用性令社区兴奋。用户反馈其在 coding 和 reasoning 任务中表现强劲,benchmarks 显示其超越了其他模型。
- 跨平台集成热潮:尽管偶尔会出现小问题,开发者们仍争先恐后地将 DeepSeek R1 集成到 Cursor、Codeium 和 Aider 等工具中。讨论集中在成功案例和挑战上,特别是关于工具兼容性和性能方面。
- 审查与无审查版本引发辩论:虽然有人称赞 DeepSeek R1 的安全特性,但也有人抱怨过度审查阻碍了实际使用。一个 uncensored version 正在流传,引发了关于安全与可用性之间平衡的辩论。
主题 2. OpenAI 的 Stargate 项目志存高远
- OpenAI 宣布 5000 亿美元 Stargate 投资计划:OpenAI 与 SoftBank 和 Oracle 共同承诺向 AI 基础设施投资 5000 亿美元,并将其命名为 Stargate 项目。该计划旨在巩固美国的 AI 领导地位,被比作“阿波罗计划”。
- 社区热议 AI 军备竞赛:惊人的投资额引发了关于 AI 军备竞赛和地缘政治影响的讨论。一些人担心,将 AI 发展定义为竞争可能会导致意想不到的后果。
- Mistral AI 开启重大 IPO 进程:与收购传闻相反,Mistral AI 宣布了 IPO 计划并向亚太地区扩张,引发了对其盈利能力和战略的猜测。
主题 3. 新模型与新技术突破边界
- Liquid AI 的 LFM-7B 引起轰动:Liquid AI 的 LFM-7B 声称在 7B 模型中表现顶尖,支持包括英语、阿拉伯语和日语在内的多种语言。其对本地部署(local deployment)的关注让寻求高效、私有 AI 解决方案的开发者感到兴奋。
- Mind Evolution 进化 AI 思维:一篇新论文介绍了 Mind Evolution,这是一种进化搜索策略,在规划任务上实现了超过 98% 的成功率。这种方法击败了 Best-of-N 等传统方法,标志着 LLM inference 扩展的一次飞跃。
- SleepNet 和 DreamNet 构想更佳 AI:创新模型 SleepNet 和 DreamNet 提议在训练中加入“睡眠”阶段,模仿人类的学习过程。这些方法旨在平衡探索与精准度,激发了关于新型 AI 训练技术的讨论。
主题 4. 用户与 AI 工具中的 Bug 和限制搏斗
- Windsurf 用户遭遇延迟风暴:沮丧的 Windsurf 用户报告了 prompt 延迟和类似 “incomplete envelope: unexpected EOF” 的错误,迫使一些人转向 Cursor 等替代方案。社区在寻求解决方案的同时,对生产力受损表示不满。
- Flow Actions 限制困扰程序员:Codeium 的 Flow Actions 限制阻碍了工作流,用户抱怨反复出现的瓶颈。虽然出现了一些战略性使用的建议,但许多人仍在等待官方解决方案。
- Bolt 用户因 Bug 损失 Token:开发者哀叹由于 Bolt 上的 Bug 代码导致 token 损失,主张通过免费调试来减轻损失。有人感叹:“我已经数不清浪费了多少 token 了!”,凸显了对成本的担忧。
主题 5. AI 在创意和技术领域不断扩大的角色
- DeepSeek R1 精通数学辅导:用户利用 DeepSeek R1 进行 数学辅导,称赞其分步解决方案以及对特殊教育需求的支持。其速度和本地部署使其成为教育工作者的宠儿。
- 生成式 AI 塑造创意产业:相关文章 引发了关于 AI 对艺术和音乐影响的辩论,一些人担心 AI 可能会取代人类创作者。另一些人则认为,人类技能对于有效引导 AI 输出仍然至关重要。
- Suno 因 AI 音乐面临版权诉讼:AI 音乐生成器 Suno 面临来自德国 GEMA 的新法律挑战,被指控使用未经授权的录音进行训练。该诉讼加剧了行业内关于 AI 生成内容合法性的辩论。
第一部分:高层级 Discord 摘要
Unsloth AI (Daniel Han) Discord
- DeepSeek-R1 具有误导性的深度:DeepSeek-R1 模型的最大 token 长度被发现是 16384 而不是预期的 163840,这引发了代码部署中的 bug 担忧。
- 一篇关于 RoPE factors 和模型 embeddings 的推文引发了进一步讨论,成员们认为模型的使用并不完整。
- LoRA Llama 3 微调策略:Gautam Chutani 的一篇 Medium 文章展示了基于 LoRA 的 Llama 3 微调,并集成了 Weights & Biases 和 vLLM 进行推理服务。
- 他强调通过 LoRA 注入来减少 GPU 开销,社区评论指出这是一种比高端基准微调更节省资源的替代方案。
- Chinchilla 的精确计算:Chinchilla 论文建议模型大小和训练 tokens 按比例增长以达到最高效率,这重塑了数据规划策略。
- 参与者认为 Chinchilla optimal 方法避免了只关注狭窄的参数段,强调全参数参与是更安全的策略。
- 合成数据与混合数据的收益:一些人提倡使用合成数据以实现更紧密的评估对齐,而另一些人则在 Unsloth 中应用混合格式数据集以扩大训练覆盖范围。
- 与会者指出动态调整可以减轻过拟合,但在涉足现实世界材料之外时,特定领域的关联性仍存疑。
- 开源 UI 的快速推进:OpenWebUI、Ollama 和 Flowise 成为下一个集成目标,而 Kobold 和 Aphrodite 通过 Kobold API 保持活跃。
- Invisietch 确认了一个长长的待办事项列表,包括用于创建合成数据集的 CLI,旨在建立统一的后端 API 以简化流程。
Cursor IDE Discord
- OpenAI 的 Stargate 项目宏大登场:OpenAI 宣布了一项名为 Stargate Project 的 5000 亿美元投资计划,旨在与软银等合作在美国建设新的 AI 基础设施,详情见此处。
- 社区成员对其战略影响议论纷纷,想知道日本的大额投资是否会助长新一轮的 AI 竞争。
- DeepSeek R1 的进展与 Cursor 的痛点:DeepSeek R1 可以通过 OpenRouter 集成到 Cursor 中,尽管一些用户发现这种变通方法有限制,更愿意等待原生支持。
- 基准测试讨论引用了 Paul Gauthier 的推文,提到在 aider polyglot 测试中获得了 57% 的分数,引发了关于 DeepSeek R1 与其他 LLM 之间即将到来的竞争的辩论。
- Cursor 0.45 回滚反应:由于索引问题,Cursor 团队不断回滚 v0.45.1 更新,迫使开发者恢复到早期版本,参考 Cursor Status。
- 一些用户对不稳定性感到沮丧,并提到官方声明极少,使他们的工作流程变得复杂,暗示他们可能会探索 Codefetch 等替代代码编辑器。
- Claude 3.5 与 DeepSeek 竞争:Claude 3.5 的性能有所提高,引发了与 DeepSeek R1 的直接对比,并促使了关于速度和准确性提升的讨论。
- Anthropic 对未来更新的沉默引发了对其下一个版本的猜测,因为其光芒被竞争对手的势头所掩盖。
Codeium (Windsurf) Discord
- Windsurf 的困扰与延迟激增:多位用户抱怨 Windsurf 持续出现延迟问题,尤其是在进行代码提示(code prompts)时,部分用户遇到了 ‘incomplete envelope: unexpected EOF’ 错误。
- 尽管调整本地设置等潜在解决方案尚未产生确定的修复效果,但一些用户由于这些 Bug 考虑切换到 Cursor。
- DeepSeek R1 在基准测试中占据主导地位:根据 Xeophon 的推文,社区成员对 DeepSeek R1 在各项性能测试中超越 OpenAI o1-preview 感到兴奋。
- 随后的另一条 推文 强调 R1 已处于领先地位,尽管对其在 Codeium 内的工具调用(tool-call)兼容性仍存疑问。
- Flow Actions 削弱生产力:许多人发现 Flow Actions 的限制干扰了他们的工作流,并提到全天都会反复遇到瓶颈。
- 社区成员建议通过策略性使用和部分重置来缓解这一限制,但官方修复方案仍不确定。
- Codeium 功能热潮:一名用户请求在 Codeium 中增加对 DeepSeek R1 的支持,同时呼吁为 JetBrains IDE 用户提供更好的微调(fine-tuning)和稳健的更新。
- 其他人提到需要通过 Codeium 的功能请求页面 改进重命名建议,并重点介绍了用于命令行自动补全的 Termium。
aider (Paul Gauthier) Discord
- Aider v0.72.0 发布助力开发:Aider v0.72.0 更新包括通过
--model r1或 OpenRouter 支持 DeepSeek R1,此外还增加了 Kotlin 语法支持和新的--line-endings选项,解决了 Docker 镜像权限和 ASCII fallback 修复问题。- 社区成员指出,Aider 为此版本的发布贡献了 52% 的自身代码,并发现配合 GPT-4o 使用
examples_as_sys_msg=True可以获得更高的测试分数。
- 社区成员指出,Aider 为此版本的发布贡献了 52% 的自身代码,并发现配合 GPT-4o 使用
- DeepSeek R1 成为强有力的挑战者:用户称赞 DeepSeek R1 的多语言处理能力,引用了这条推文,称其几乎与 OpenAI o1 持平,且采用 MIT 许可证分发。
- 对话暗示出于成本原因正从 Claude 转向 DeepSeek R1,并参考 GitHub 上的 DeepSeek-R1 获取更多技术细节。
- OpenAI 订阅与 GPU 成本引发辩论:一些成员报告了 OpenAI 订阅退款情况,并权衡了 DeepSeek 的性价比,提到了关于定价不确定性的 OpenAI CEO 文章。
- 欧洲用户还发现了更便宜的 RTX 3060 和 3090 GPU,并查阅了 Fireworks AI 文档 以了解 AI 驱动工作流中的隐私考量。
- 使用 DeepSeek R1 升级 Space Invaders:一段 实况编程视频 展示了由 DeepSeek R1 驱动的改进版 Space Invaders 游戏,证明了其在 Aider LLM 排行榜上名列第二。
- 用户强调其在价格更低的情况下几乎等同于 OpenAI o1,这激发了人们对受益于 R1 编程专注性的游戏和开发场景的兴趣。
LM Studio Discord
- DeepSeek 在数学领域的强势进军:DeepSeek R1 成为数学辅导的强力选择,提供逐步解决方案并支持特殊教育需求,例如 Andrew C 的推文中提到在 M2 Ultras 上运行 671B 版本。
- 一位用户赞扬了该模型的速度和本地部署能力,并参考了 DeepSeek-R1 GitHub 仓库以了解高级使用场景。
- 本地模型魔法与 OpenAI 衔接:爱好者们讨论了在 4090 GPU 和 64GB RAM 等强力家用配置上运行 LLM,参考 LM Studio Docs 和 Ollama 的 OpenAI 兼容性博客,将本地模型与 OpenAI API 桥接。
- 其他人强调了量化(Q3、Q4 等)对性能权衡的重要性,并探索了像 Chatbox AI 这样的解决方案来统一本地和在线使用。
- NVIDIA DIGITS 争议与 DGX OS 困境:用户感叹高昂的成本(128GB 约 3000 美元)以及 NVIDIA DIGITS 支持的不确定性,指向 NVIDIA DIGITS 文档以获取旧版见解。
- 讨论指出 DGX OS 与旧版 DIGITS 的相似之处,有人建议将 NVIDIA TAO 作为现代替代方案,尽管这在以容器为中心的发布方面引发了混乱。
- GPU 发热头疼与未来计划:一些人提到高性能 GPU 产生的过热问题,开玩笑说由于持续燃烧不需要清洁,并参考二手销售以寻求潜在的成本节约。
- 其他人计划采用无 GUI 方法以优化性能,重点是通过更轻量化的配置来减轻高级 ML 任务中的散热压力。
Nous Research AI Discord
- Liquid AI 的 LFM-7B 在本地部署中崛起:Liquid AI 推出了 LFM-7B,这是一款非 Transformer 模型,声称在 7B 级别拥有顶级性能,扩展了包括英语、阿拉伯语和日语在内的语言覆盖范围(链接)。
- 社区成员赞扬了其本地部署策略,一些人认为该模型的自动架构搜索是一个潜在的差异化优势。
- Mind Evolution 驱动 LLM 推理:一篇关于 Mind Evolution 的新论文展示了一种进化方法,在 TravelPlanner 和 Natural Plan 等任务中超越了 Best-of-N,使用 Gemini 1.5 Pro 实现了超过 98% 的成功率(arXiv 链接)。
- 工程师们讨论了该方法的迭代生成和 Prompt 重组,将其描述为扩展推理计算的精简路径。
- DeepSeek-R1 Distill 模型评价褒贬不一:用户试用了 DeepSeek-R1 Distill 进行量化调整和性能分析,参考了一个接近 8B 参数的 Hugging Face 仓库。
- 一些人称赞其推理输出,而另一些人则认为它在处理日常 Prompt 时过于冗长,但它仍是高级思考时间的亮点。
- SleepNet 与 DreamNet 带来“夜间”训练:SleepNet 和 DreamNet 提出了模拟“睡眠”的有监督加无监督循环来优化模型状态,详见 Dreaming is All You Need 和 Dreaming Learning。
- 它们使用 Encoder-Decoder 方法在离线阶段重新访问隐藏层,引发了关于综合探索的讨论。
- Mistral 对 Ministral 3B 和 Codestral 2501 的思考:Mistral 预告了 Ministral 3B 和 Codestral 2501,在紧张的 AI 竞争格局中引发了对其权重许可计划的猜测。
- 观察者们想知道 Mistral 的方法(类似于 Liquid AI 的架构实验)是否能为更小规模的部署开辟出专门的利基市场。
Stackblitz (Bolt.new) Discord
- Bolt 更大胆的代码包含功能:Bolt 的最新更新消除了白屏故障,并包含了完整代码交付的修复,确保从第一个 prompt 开始就能实现精准设置,详见此公告。
- 工程师们欢迎这一全面的转变,称“不再有偷懒的代码!”,并赞扬了新项目更流畅的启动体验。
- Prismic 困境与静态解决方案:一位用户在为管道网站集成 Prismic CMS 时遇到问题,引发了先构建静态网站以获得面向未来的灵活性的建议。
- 社区成员倾向于极简方法,其中一人指出“简单网站的 CMS 开销”过于复杂。
- Firebase vs Supabase 对决:一位用户主张将 Supabase 换成 Firebase,称其为开发者更简单的路径。
- 其他人同意 Firebase 简化了初始设置,强调了它如何加速快速概念验证。
- Token 纠纷:开发者报告称由于 Bolt 上的错误代码导致损失了 tokens,主张通过免费调试来遏制这些损失。
- 成本担忧飙升,一位用户宣称“我已经数不清浪费了多少 tokens 了!”
- Next.js & Bolt:结构性联系:一位社区成员尝试使用 Bolt 将 WordPress 博客集成到 Next.js 中,但发现框架更新速度快于 AI 工具。
- 意见不一,有人认为 Bolt 可能无法紧跟 Next.js 的快速变化。
Perplexity AI Discord
- Sonar 凭借速度和安全性崛起:Perplexity 发布了用于生成式搜索的 Sonar 和 Sonar Pro API,具有实时网络分析功能,并展示了 Zoom 的大规模采用,同时在 SimpleQA 基准测试中表现优于成熟的引擎。
- 社区成员赞赏其实惠的分级定价,并指出没有用户数据被用于 LLM 训练,暗示了更安全的企业级用途。
- DeepSeek vs O1 传闻:多位成员询问 DeepSeek-R1 是否会取代 Perplexity 中缺席的 O1,引用了关于高级推理能力的公开暗示。
- 其他人称赞 DeepSeek-R1 免费且性能顶尖,称其为“最佳替代方案”,而一些人对 O1 的计划前景仍持怀疑态度。
- Claude Opus:退役还是坚挺?:一些用户宣称 Claude Opus 已退役,取而代之的是
Sonnet 3.5,质疑其在创意任务中的可行性。- 其他人强调 Opus 在复杂项目中继续表现出色,坚持认为尽管有传言称其将被取代,但它仍然是该系列中最先进的。
- Sonar Pro 分级与域名过滤测试版:贡献者强调了 Sonar 和 Sonar Pro 的新使用分级,指出 search_domain_filter 是第 3 级的测试功能。
- 许多用户寻求从 API 输出中获得直接的 token 使用情况洞察,而一些人则推动在欧洲数据中心进行符合 GDPR 标准的托管。
Interconnects (Nathan Lambert) Discord
- DeepSeek R1 横扫基准测试:1月20日,中国的 DeepSeek AI 发布了 R1,在 ARC-AGI 公开评估中达到了 20.5%。
- 它在联网任务中表现优于 o1,完整的发布细节见此处。
- Mistral 的重大 IPO 举措:与收购传闻相反,Mistral AI 宣布了 IPO 计划,并为亚太市场开设了新加坡办公室。
- 成员们对 Mistral 的盈利能力进行了推测,引用此更新作为其大胆战略的证明。
- Stargate 凭借 5000 亿美元承诺激增:OpenAI、SoftBank 和 Oracle 在 Stargate 旗下联手,承诺在四年内投入 5000 亿美元以加强美国的 AI 基础设施。
- 他们将这项宏大的投资比作 Apollo 计划等历史性壮举,旨在巩固美国在 AI 领域的领导地位。
- Anthropic 谋划 Claude 的下一步:在达沃斯,CEO Dario Amodei 预告了 Claude 的语音模式和可能的网页浏览功能,详见此 WSJ 采访。
- 他暗示将发布更强大的 Claude 版本,社区正在讨论更新发布的频率。
- Tulu 3 RLVR 引发好奇:关于 Tulu 3 的 RLVR 的一个海报项目引起了关注,承诺提供强化学习的新方法。
- 爱好者们计划将其与 open-instruct 框架合并,预示着模型使用方式将发生更广泛的变革。
MCP (Glama) Discord
- Tavily Search MCP 服务器飙升:新的 Tavily Search MCP 服务器上线,为 LLM 提供了优化的网页搜索和内容提取功能,支持 SSE、stdio 和基于 Docker 的安装。
- 它使用 Node 脚本进行快速部署,为 MCP 生态系统提供了更广泛的服务器选择。
- MCP Language Server 对决:开发者们测试了 isaacphi/mcp-language-server 和 alexwohletz/language-server-mcp,旨在大型代码库中实现 get_definition 和 get_references。
- 他们注意到第二个仓库可能不太成熟,但社区仍渴望实现类似 IDE 的 MCP 功能。
- Roo-Clines 变得更加丰富:成员们支持将 roo-code 工具添加到 roo-cline 中,以处理扩展的语言任务,包括在大型项目中的代码操作。
- 他们设想更深层次的 MCP 协同效应来简化代码管理,建议在单一 CLI 生态系统中进行高级编辑。
- LibreChat 引发抱怨:一位用户抨击 LibreChat 配置复杂且 API 支持不可预测,尽管他们很欣赏其精美的 UI。
- 他们还哀叹缺乏使用限制,并将其与 Sage 或内置 MCP 服务器等更严格的平台进行了比较。
- Anthropic 模型与 Sage 的对决:关于 Anthropic 模型 r1 的可行性爆发了激烈的讨论,一些人猜测他们“很可能”能让它运行起来。
- 其他人则倾向于在 macOS 和 iPhone 上使用 Sage,相比不确定的 Anthropic 集成,他们更喜欢少出点麻烦。
OpenRouter (Alex Atallah) Discord
- Llama 在 Samba Nova 的最后时刻:由于 Samba Nova 的变更,免费 Llama 端点将于本月结束,直接用户访问权限将被移除。
- Samba Nova 将切换到具有新定价的 Standard 变体,引发了关于付费使用的讨论。
- DeepSeek R1 获得网页搜索与自由表达:DeepSeek R1 模型在 OpenRouter 上启用了网页搜索 Grounding,保持了无审查的方式,价格为每输入 token $0.55。
- 社区对比显示其性能接近 OpenAI 的 o1,Alex Atallah 的帖子中提到了关于微调 (fine-tuning) 的讨论。
- Gemini 2.0 Flash:64K Token 奇迹:新发布的 Gemini 2.0 Flash Thinking Experimental 01-21 提供 100 万上下文窗口以及 64K 输出 token。
- 观察者注意到在其 10 分钟的发布过程中存在一些命名上的小瑕疵;它仍可通过 AI Studio 使用,无需分级密钥。
- 巧妙的推理内容技巧出现:一位用户揭露了一种通过巧妙的 prompt 前缀从 DeepSeek Reasoner 中诱导推理内容的方法。
- 人们对残留 CoT 数据导致的 token 堆积表示担忧,促使了更好的消息处理策略。
- Perplexity 的 Sonar 模型备受关注:Perplexity 推出了具有网页搜索扩展功能的新 Sonar LLM,详见此推文。
- 虽然有些人对潜在的集成感到兴奋,但其他人对模型的实用性表示怀疑,并敦促为 OpenRouter 的支持进行投票。
Cohere Discord
- 提升 GPT-2 收益:工程师们讨论了调整 GPT-2 重新训练的
max_steps,建议将其翻倍以进行两个 epoch,从而防止快速学习率衰减 (rapid learning rate decay),并参考了 Andrew Karpathy 的方法。- 他们还警告说,草率的更改可能会浪费资源,建议在做出微调 (fine-tuning) 决策前进行透彻的了解。
- 实时问答中的 RAG 启示:一场关于 RAG 和模型工具使用 (tool use) 的实时问答定于东部时间周二上午 6:00 在 Discord Stage 举行,鼓励开发者分享经验。
- 参与者计划应对集成新实现中的挑战,旨在营造一个激发共享见解的协作环境。
- Cohere CLI:Transformer 的终端对话:新的 Cohere CLI 允许用户从命令行与 Cohere 的 AI 聊天,已在 GitHub 上展示。
- 社区成员赞扬了它的便利性,一些人强调了基于终端 (terminal-based) 的交互如何加速迭代开发。
- Cohere For AI:社区动力源:爱好者们互相敦促加入 Cohere For AI 倡议,进行开放的机器学习协作,参考了 Cohere 官方研究页面。
- 他们还提到试用密钥每月提供 1000 次免费请求,为渴望测试 AI 解决方案的新手提供了一个友好的空间。
- LLM 输出中的数学缺陷:成员们指出 Cohere 错误地将 18 个月计算为 27 周,对 LLM 的数学可靠性表示怀疑。
- 他们将此归因于分词 (tokenization) 问题,称其为一种普遍的缺陷,如果不加以解决,可能会导致项目失败。
Notebook LM Discord Discord
- 课堂征服:大学课程中的 NotebookLM:成员们建议按主题而非单个来源来组织 NotebookLM,以确保数据一致性 (data consistency),并指出 1:1 的笔记本与来源设置最适合单文件的播客生成 (podcast generation)。
- 他们强调这能消除杂乱并促进更顺畅的协作,有可能改变学术环境中的学习习惯和资源共享。
- 视频胜利:AI eXplained 的电影化展开:AI eXplained 频道发布了关于 AI 生成视频 (AI-generated videos) 的新视频,重点介绍了剧本创作和动画制作方面的进展。
- 早期观众提到,这些方法引发了重塑电影行业的兴趣浪潮,并预测视听 AI 领域将有更多突破。
- Gemini 收益:面向开发者的 Code Assist:社区成员推荐使用 Gemini Code Assist 来获取更深层的代码库洞察,称其在针对性代码查询方面比 NotebookLM 更准确。
- 他们指出,除非有非常具体的指令引导,否则 NotebookLM 可能会出错,这引发了关于代码分析方法和可靠性的讨论。
- 神圣摘要:教会服务中的 NotebookLM:一位参与者利用 NotebookLM 解析大量的布道讲稿,目标是一份 250 页 的合集,甚至是一个 2000 页 的圣经研究。
- 他们称其为处理大型宗教文本的游戏规则改变者,赞扬其在连接技术与信仰方面的效用。
- 工具宝库:插件与应用增强 NotebookLM:用户交流了关于插件的建议,包括 OpenInterX Mavi 和 Chrome Web Store 扩展程序,以增强功能。
- 他们测试了保留常用提示词 (prompts) 以提高工作效率的方法,并对未来更深度的 NotebookLM 集成表示期待。
Stability.ai (Stable Diffusion) Discord
- 使用 ControlNet 制作连贯漫画:成员们探索了使用 ControlNet 驱动的 AI 漫画分镜,以保持场景细节的一致性,通过单独生成每一帧来保持角色稳定。他们发现这种方法仍然会产生不同的结果,需要频繁重新生成以维持连贯性。
- 他们还辩论了高级提示词或额外的训练数据是否能改善结果,一些人认为一旦 Stable Diffusion 更加成熟,未来会有改进潜力。
- AI 艺术争议持续:贡献者注意到创意社区对 AI 渲染艺术品 (AI-rendered artwork) 的抵制情绪增强,强调了对可信度和尊重原创风格的质疑。他们引用了关于 AI 艺术是取代还是延伸了手工创作的广泛辩论。
- 其他人提出了关于使用公共仓库训练数据的伦理担忧,并提到了要求确保原创作者获得署名的准则呼吁。
- Stable Diffusion AMD 设置障碍:个人分享了在 AMD 硬件上运行 Stable Diffusion 的困难,指出驱动问题和性能较慢。他们参考了 Discord 中的置顶说明作为变通方法,但承认需要更强大的官方支持。
- 一些人通过更新库取得了成功,但其他人仍面临意外黑屏或渲染不完整的问题,需要手动重置 GPU。
- 手动 vs. AI 背景调整:爱好者们辩论了是使用 GIMP 进行直接的背景编辑,还是依赖 Stable Diffusion 进行自动增强。他们报告称手动编辑提供了更受控的结果,特别是对于个人摄影中敏感细节的处理。
- 一些人认为 AI 解决方案在处理细微任务时仍缺乏精细度,而另一些人则认为如果模型获得更多专业训练,前景广阔。
GPU MODE Discord
- 进化思维与驯服 GRPO:用于扩展 LLM 推理的 Mind Evolution 策略在 TravelPlanner 和 Natural Plan 上的成功率飙升至 98% 以上,详见 arXiv 论文。
- 一个简单的本地 GRPO 测试正在进行中,未来计划通过 OpenRLHF 和 Ray 进行扩展,并将 RL 应用于数学数据集。
- TMA 在 Triton 中占据核心地位:社区成员研究了 Triton 中的 TMA 描述符,利用
fill_2d_tma_descriptor并面对导致崩溃的 autotuning 陷阱。- 分享了一个带有 TMA 的 persistent GEMM 工作示例,但由于 autotuner 支持有限,目前仍需手动配置。
- Fluid Numerics 启动 AMD MI300A 测试:Fluid Numerics 平台推出了其 Galapagos 集群的订阅服务,该集群配备了用于 AI/ML/HPC 工作负载的 AMD Instinct MI300A 节点,并提供了 访问申请链接。
- 他们鼓励用户测试软件并对比 MI300A 与 MI300X 的性能,邀请进行广泛的基准测试。
- PMPP 书籍新增更多 GPU 精华内容:建议重读最新版的 PMPP Book,因为它更新了 2022 年版中缺失的内容,并增加了新的 CUDA 材料。
- 成员们推荐使用 Cloud GPUs 或 Lightning AI 等 cloud GPU 选项来进行书中练习的动手实践。
- Lindholm 的统一架构遗产:工程师 Lindholm 最近从 Nvidia 退休,他于 2024 年 11 月关于其 unified architecture(统一架构)的深度演讲可通过 Panopto 观看。
- 参与者了解了他富有影响力的设计原则以及直到两周前退休为止所做出的贡献。
Eleuther Discord
- GGUF 在竞争格式中脱颖而出:社区注意到 GGUF 是消费级硬件首选的量化方案,引用 LLM 推理后端基准测试 展示了其强大的性能优势。
- 他们对比了 vLLM 和 TensorRT-LLM 等工具,强调初创公司通常选择 Ollama 等简单的后端,以实现开箱即用的本地化部署。
- R1 之谜与 Qwen 特性:成员们对 R1 进行了细致研究,讨论了其对 PRMs 的使用,并思考了 4bit/3bit 与 f16 对 MMLU-PRO 性能的影响。
- 他们还考虑将 Qwen R1 模型转换为 Q-RWKV,关注 math500 等测试以确认转换效果,并探讨了在多次生成响应时如何最好地估算 pass@1。
- Titans 解决深度网络内存问题:Titans 论文(arXiv:2501.00663)提出将短期记忆与长期记忆结合以增强序列任务,该研究基于循环模型(recurrent models)和 attention。
- 一位用户询问:“在如此大的数据集上微调模型是否更快?”,而其他人则在权衡扩展数据规模是否优于增量方法。
- 转向(Steering)方案依然匮乏:目前还没有一个开源库在 LLM 的 SAE-based 转向领域占据主导地位,尽管 steering-vectors 和 repeng 等项目显示出潜力。
- 他们还提到了 representation-engineering,注意到其自顶向下的方法,但强调了目前普遍缺乏统一的方法论。
- NeoX:维度争议下的 HF 格式转换:
convert_neox_to_hf.py中的一个 RuntimeError 揭示了维度不匹配问题([8, 512, 4096] vs 4194304),这可能与多节点设置和 model_parallel_size=4 有关。- 针对 3x 中间层维度设置产生了疑问,而共享的配置提到 num_layers=32、hidden_size=4096 和 seq_length=8192 影响了导出过程。
Latent Space Discord
- OpenAI 为 Stargate 项目注资 5000 亿美元:OpenAI 公布了 The Stargate Project,承诺在未来四年内投资 5000 亿美元,旨在建设美国的 AI 基础设施,首期投入 1000 亿美元。
- 包括 SoftBank 和 Oracle 在内的主要支持者正大举押注这一倡议,强调在美国创造就业机会和保持 AI 领导地位。
- Gemini 2.0 获得实验性更新:针对 Gemini 2.0 Flash Thinking 的反馈促使 Noam Shazeer 引入了反映用户驱动改进的新变化。
- 这些调整旨在完善 Gemini 的技能集,并增强其对实际使用情况的响应能力。
- DeepSeek 发布低推理成本的 V2 模型:新发布的 DeepSeek V2 以降低运营成本和显著的性能提升脱颖而出。
- 其架构在社区中引起了轰动,展示了一种挑战既有模型的全新方法。
- Ai2 ScholarQA 助力文献综述:Ai2 ScholarQA 平台提供了一种提问方式,可以汇总多篇科学论文的信息,提供对比见解。
- 该工具旨在通过按需提供更深入的引用和参考资料来简化严谨的研究。
- 随着 WandB 达到 SOTA,SWE-Bench 飙升:WandB 宣布其 SWE-Bench 提交结果现已被公认为 State of the Art (SOTA),引起了人们对该基准测试重要性的关注。
- 该公告强调了性能指标方面的竞争驱动力,并促进了对高级测试的进一步探索。
OpenAI Discord
- DeepSeek R1 与 Sonnet 对决:成员们讨论了在拥有 32 GB RAM 和 16 GB VRAM 的系统上本地运行蒸馏至 Qwen 32B Coder 的 DeepSeek R1,通过将繁重计算卸载到 CPU 来实现可行性能。
- 他们报告 R1 在编码方面的 失败率为 60%,但仍优于 4O 和 Sonnet(失败率为 99%),尽管在 Ollama 上的稳定性仍不确定。
- Generative AI 席卷创意产业:一篇 Medium 文章 强调了 Generative AI 创作艺术的能力,引发了它可能取代人类创作者的担忧。
- 其他人则认为,人类技能对于有效塑造 AI 输出仍然至关重要,使艺术家能够参与到流程中。
- 内容合规性讨论:有人指出 DeepSeek 会避开关于 CCP 的批评性或幽默输出,这让人想起早期的 GPT 合规性问题。
- 用户质疑这些限制是否限制了表达或阻碍了开放式辩论。
- Archotech 猜测四起:一位用户沉思 AI 是否会进化成 Rimworld 风格的 archotechs,暗示了意想不到的能力和产物。
- 他们建议,随着 AI 公司不断训练更大的模型,“我们可能会意外产生高级实体”。
- GPT 宕机和响应延迟:频繁出现的 ‘Something went wrong’ 错误中断了与 GPT 的对话,尽管重新开启会话通常能解决问题。
- 几位成员注意到了性能迟缓,将缓慢的回复描述为集体恼火的源头。
Yannick Kilcher Discord
- Neural ODEs 激发 RL 策略:在 #general 频道,成员们表示 Neural ODEs 可以通过用层来建模函数复杂度来改进机器人技术,并引用了 Neural Ordinary Differential Equations 论文。
- 他们还讨论了较小的模型如何通过 RL 中重复的随机初始化发现高质量的推理,指出噪声和不规则性有助于探索。
- GRPO 获得支持:在 #paper-discussion 频道,DeepSeek 的 GRPO 被称为去掉了价值函数的 PPO,依靠 Monte Carlo 优势估计来进行更简单的策略微调,正如官方推文所示。
- 一份最近的出版物强调了减少的开销,同时该小组还通过从 50 多名志愿者中招募 12 人来解决审稿人短缺的问题。
- Suno 应对版权指控:在 #ml-news 频道,AI 音乐生成器 Suno 正面临来自 GEMA 的另一起版权诉讼,此前已有来自主要唱片公司的诉讼,详情见 Music Business Worldwide。
- 估值 5 亿美元的 Suno 及其竞争对手 Udio 被指控在未经授权的录音上进行训练,引发了行业关于 AI 生成内容合法性的辩论。
Modular (Mojo 🔥) Discord
- C 与 Python 之争:成员们就 C 的严谨性和 Python 更快速的内存管理见解展开辩论,并参考了未来在 JS 或 Python 中的应用。
- 一位参与者强调先学习 C 可以为职业转型打下更深的基础,但观点差异很大。
- 论坛与 Discord 的抉择:许多人敦促明确在 Discord 与论坛上发布项目的区别,理由是在快速聊天的环境中难以检索重要的讨论。
- 他们建议使用论坛进行深入更新,同时保留 Discord 用于快速反馈。
- Mojo 的 .gitignore 魔法:贡献者注意到 Mojo 的
.gitignore仅排除.pixi和.magic文件,这显得非常简洁。- 没有人提出异议,团队对这种精简的默认配置表示赞赏。
- Mojo 与 Netlify 不兼容?:有人提出了关于在 Netlify 上托管使用
lightbug_http的 Mojo 应用的问题,并参考了 Rust 应用的成功经验。- 成员表示 Netlify 缺乏对 Mojo 的原生支持,并参考了构建时可用软件以了解可能的功能。
- Mojo 的域名困境:一位用户询问 Mojo 是否会从 Modular 独立出来,并像其他语言一样申请
.org域名。- 开发者确认目前没有此类计划,确认其目前仍保留在 modular.com 下。
LlamaIndex Discord
- LlamaIndex Workflows 在 GCloud Run 上飞跃:一份新指南解释了如何在 Google Cloud Run 上启动用于 ETL 和查询任务的双分支 RAG 应用程序,详细介绍了通过 LlamaIndex 实现的 serverless 环境和事件驱动设计。
- 成员们指出三大特性——双分支架构、serverless 托管和事件驱动方法——是简化 AI 工作负载的关键。
- Chat2DB GenAI 聊天机器人攻克 SQL:贡献者重点介绍了开源的 Chat2DB 聊天机器人,解释了它如何让用户使用 RAG 或 TAG 策略以日常语言查询数据库。
- 他们强调了其多模型兼容性,支持 OpenAI 和 Claude,这使其成为数据访问的灵活工具。
- LlamaParse 拯救 PDF 提取:参与者推荐使用 LlamaParse 进行 PDF 解析,称其为全球首个用于 LLM 用例的 genAI 原生文档平台。
- 他们赞扬了其强大的数据清洗功能,并将其视为解决棘手的可选文本 PDF 的方案。
- 无痕模式解决文档故障:一位用户报告称,在普通浏览器会话中查看 LlamaIndex 文档时,页面会不断滚动回顶部。
- 他们确认 Microsoft Edge 的无痕模式解决了该故障,表明插件冲突可能是原因。
- 带有 Gemini 的 CAG 遭遇 API 壁垒:有人询问如何将 Cached Augmented Generation (CAG) 集成到 Gemini 中,结果得知模型级访问权限至关重要。
- 他们发现目前没有供应商提供对 API 如此深度的控制,目前该想法陷入停滞。
Nomic.ai (GPT4All) Discord
- ModernBert 实体出现:一位用户展示了在 ModernBert 中识别实体的语法,为旅游主题提供了分层文档布局,并寻求 embeddings 的最佳实践。
- 他们寻求关于围绕基于实体的任务构建这些文档的建议,希望能优化整体性能。
- Jinja 宝库成为焦点:一位参与者请求关于 Jinja 模板高级功能的强大资源,引发了社区的广泛关注。
- 其他人也加入进来,指出改进模板逻辑可以简化各种项目中的动态渲染。
- LMstudio 咨询找到了归宿:另一位用户寻求关于 LMstudio 的指导,在努力寻找专用 Discord 链接的同时询问当前频道是否合适。
- 他们还提到了 Adobe Photoshop 的问题,引发了关于非官方支持渠道的调侃。
- Photoshop 与非法幽默:简短的交流暗示了一个关于 Adobe Photoshop 的可能非法的问题,引发了关于此类询问性质的玩笑。
- 讨论简短地转向了在公共论坛分享可疑请求的更广泛担忧。
- Nomic 税收与实习生征税:成员们开玩笑说要增加 Nomic 的税收,其中一位参与者声称他们应该是这些资金的接收者。
- 引用 这个 GIF 突显了对话的俏皮基调。
LAION Discord
- Bud-E 支持 13 种语言:LAION 透露 Bud-E 已扩展至英语之外,支持 13 种语言(未指明完整列表),并利用 fish TTS 模块实现语音功能。
- 团队暂时“冻结”了现有的项目路线图,以强调 音频 和 视频 数据集的集成,导致开发进度略有延迟。
- Suno Music 的音频力量:Suno Music 功能允许用户通过录制自定义音频输入来创作自己的歌曲,吸引了寻求快速实验的移动端创作者。
- 成员们对广泛的易用性表示兴奋,强调了该平台多样化创作工作流的潜力。
- BUD-E 与 School-BUD-E 成为焦点:LAION 宣布 BUD-E 1.0 版本是一款 100% 开源的语音助手,适用于通用和教育用途,包括用于课堂的 School Bud-E。
- 这一里程碑促进了普及化访问并鼓励 AI 驱动的教育科技 (ed-tech),并在展示 BUD-E 功能的 教程视频 中进行了演示。
- BUD-E 的多平台灵活性:工程师们称赞 BUD-E 提供了与自托管 APIs 和本地数据存储的兼容性,确保了隐私和易于部署。
- 根据 LAION 的博客文章,桌面和网页变体满足了广泛的用户需求,扩大了全球范围内的免费教育覆盖。
LLM Agents (Berkeley MOOC) Discord
- 声明表单困惑:一位成员询问是否需要在 12 月提交后再次填写声明表单(Declaration Form),澄清现在只有新成员必须提交。
- 工作人员为错过最初截止日期的人重新开放了表单,确保之前的提交者无需额外步骤。
- 赞助商提供黑客松风格的项目:一位参与者询问企业赞助商是否会在下一期 MOOC 中提供类似实习的任务,并参考了上学期的黑客松作为灵感。
- 组织者表示,赞助商主导的演讲可能会暗示实习机会,尽管尚未透露正式安排。
- MOOC 教学大纲预计于 1 月 27 日发布:一位成员想知道新的 MOOC 教学大纲何时发布,工作人员指出 1 月 27 日 是可能的日期。
- 他们正在先确定演讲嘉宾,但承诺在那天之前提供一份初步大纲。
tinygrad (George Hotz) Discord
- BEAM 拖慢了 YoloV8:一位用户报告说,在 BEAM 下使用
python examples/webgpu/yolov8/compile.py运行 YoloV8 使吞吐量从 40fps 锐减至 8fps,引发了对 bug 的担忧。- George Hotz 指出 BEAM 不应降低性能,并建议调查代码路径中潜在的异常。
- WebGPU-WGSL 障碍减慢了 BEAM:另一位用户怀疑 WGSL 转换为 SPIR-V 可能会增加开销,从而削弱实时推理速度。
- 他们还强调 BEAM 需要精确的后端支持,引发了关于 WebGPU 特定硬件优化的疑问。
Torchtune Discord
- Torchtune 的 ‘Tune Cat’ 势头强劲:一位成员称赞了 Torchtune 软件包,并引用了一个 GitHub Issue,该议题提议增加
tune cat命令以简化使用。- 他们形容源代码 读起来非常愉悦,表明了极佳的用户体验。
- TRL 的命令导致终端信息膨胀:一位成员开玩笑说 TRL 的帮助命令延伸到了 三个 终端窗口,远超典型的帮助输出。
- 他们建议,对于需要所有技术细节的用户来说,这种详尽的性质可能仍然至关重要。
- LLMs 探索不确定性与内部推理:讨论集中在模型应该量化不确定性以增强可靠性的观点上,同时 LLMs 在回答之前似乎会进行自己的 Chain of Thought (CoT)。
- 这两点都强调了向更好解释性迈进的趋势,并有迹象表明存在用于深度推理的隐蔽 CoT 步骤。
- 通过 LLM 步骤提示与 Distillation 推进 RL:有人建议为 RL-LLM 引入思考步骤提示 (thinking-step prompts),为标准的基于目标的指令增加结构。
- 另一位成员提议在模型 Distillation 之上应用 RL 技术,预期即使是较小的模型也能获得进一步的提升。
DSPy Discord
- 动态 DSPy:RAG 与实时数据的邂逅:一位用户询问 基于 DSPy 的 RAG 如何管理不断变化的信息,暗示了实时更新对于低开销知识检索流水线的重要性。
- 他们建议未来的工作可以集中在缓存机制和增量索引上,使 DSPy 在处理动态工作负载时保持敏捷。
- 悬而未决的问题与语法错误:另一个帖子提出了 DSPy 中的一个开放性问题 (open problem),强调了对长期存在的技术问题的持续关注。
- 还出现了一个语法错误(‘y=y’ 应该使用数字),凸显了社区对细节的关注以及在消除小问题方面的积极参与。
Mozilla AI Discord
- ArXiv 作者呼吁更好的数据:题为 Towards Best Practices for Open Datasets for LLM Training 的论文在 ArXiv 上发表,详细介绍了开源 AI 数据集面临的挑战,并为公平性和透明度提供了建议。
- 社区成员称赞了该蓝图在提供公平竞争环境方面的潜力,强调更强大的开源数据生态系统将推动 LLM 的进步。
- Mozilla 与 EleutherAI 宣布数据治理峰会:Mozilla 与 EleutherAI 合作举办了一场数据集召集会议,重点关注开源数据的负责任管理和治理。
- 关键利益相关者讨论了最佳策展实践,强调了通过协作式社区参与推进 LLM 开发的共同目标。
AI21 Labs (Jamba) Discord
- AI 在网络安全领域从炒作转向实战:一位成员回忆起 AI 曾只是网络安全领域的一个流行词,并提到他们在一年前进入该领域。
- 他们对 AI 深度集成到安全流程中感到兴奋,憧憬着实时威胁检测和自动化事件响应。
- 安全团队拥抱 AI 辅助:讨论强调了人们对 AI 如何增强安全团队能力(特别是在处理复杂告警方面)日益增长的兴趣。
- 爱好者们期待 AI 提供更敏锐的分析工具,使分析师能够专注于关键任务并减少手动开销。
MLOps @Chipro Discord 没有新消息。如果该频道长时间没有活动,请告知我们,我们将将其移除。
Axolotl AI Discord 没有新消息。如果该频道长时间没有活动,请告知我们,我们将将其移除。
OpenInterpreter Discord 没有新消息。如果该频道长时间没有活动,请告知我们,我们将将其移除。
HuggingFace Discord 没有新消息。如果该频道长时间没有活动,请告知我们,我们将将其移除。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该频道长时间没有活动,请告知我们,我们将将其移除。
第 2 部分:按频道详细摘要与链接
完整的逐频道详情已因邮件篇幅原因截断。
如果您喜欢 AInews,请分享给朋友!预先感谢!