ainews-bespoke-stratos-sky-t1-the-vicunaalpaca
**Bespoke-Stratos + Sky-T1:推理领域的 Vicuna+Alpaca 时刻**
推理蒸馏(Reasoning Distillation)已成为一项关键技术。伯克利与南加州大学(USC)的研究人员发布了 Sky-T1-32B-Preview,这是一个基于 Qwen 2.5 32B 微调的模型,仅耗资 450 美元,利用 1.7 万条推理轨迹(reasoning traces)便在基准测试中达到了 o1-preview 的水平。
DeepSeek 推出了 R1,该模型不仅超越了 o1-preview,还支持将其能力蒸馏至更小的模型(如 1.5B 的 Qwen),使其表现足以媲美 GPT-4o 和 Claude-3-Sonnet。Bespoke Labs 在 Qwen 上对 R1 进行了进一步蒸馏,以更少的样本实现了超越 o1-preview 的性能。这些进展表明,在无需改变重大架构的情况下,实现推理能力“只需 SFT(有监督微调)就够了”。
此外,DeepSeek-R1 采用纯强化学习结合有监督微调来加速收敛,并展现出强大的推理和多模态能力。谷歌的 Gemini 2.0 Flash Thinking 模型则拥有 100 万 token 的上下文窗口和代码执行功能,在数学、科学及多模态推理方面表现卓越。不过,也有批评指出,模型在可重复性、行为自我意识以及 RLHF(基于人类反馈的强化学习)在推理鲁棒性方面的局限性仍是当前面临的挑战。
Reasoning Distillation is all you need.
2025年1月21日至1月22日的 AI 新闻。我们为您检查了 7 个 subreddits、433 个 Twitter 账号 和 34 个 Discord 服务器(225 个频道,4297 条消息)。预计节省阅读时间(以 200wpm 计算):496 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
在 2022-23 年 ChatGPT 的鼎盛时期,LMsys 和斯坦福大学推出了 Alpaca 和 Vicuna,它们是 LLaMA 1 的超廉价(300 美元)微调版本,通过从 ChatGPT/Bard 样本中进行蒸馏(distill),达到了 ChatGPT/GPT3.5 90% 的质量。
在过去的 48 小时里,伯克利/南加州大学(USC)的团队似乎再次做到了这一点,这次是针对推理模型(reasoning models)。
很难相信这一系列事件竟然发生在短短过去两周内:
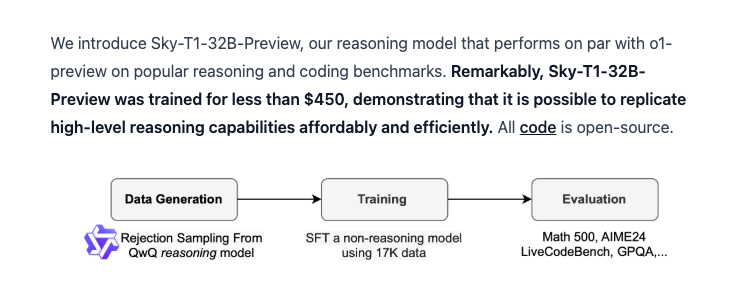
- 伯克利的 Sky Computing 实验室发布了 Sky-T1-32B-Preview,这是 Qwen 2.5 32B 的微调版本(我们的报道在此),使用了来自 QwQ-32B 的 1.7 万行训练数据(我们的报道在此)+ 使用 gpt-4o-mini 重写轨迹 + 拒绝采样(rejection sampling),总成本仅为 450 美元。由于 QwQ 的表现优于 o1-preview,通过从 QwQ 蒸馏,使 Qwen 的基准测试结果能够匹配 o1-preview:
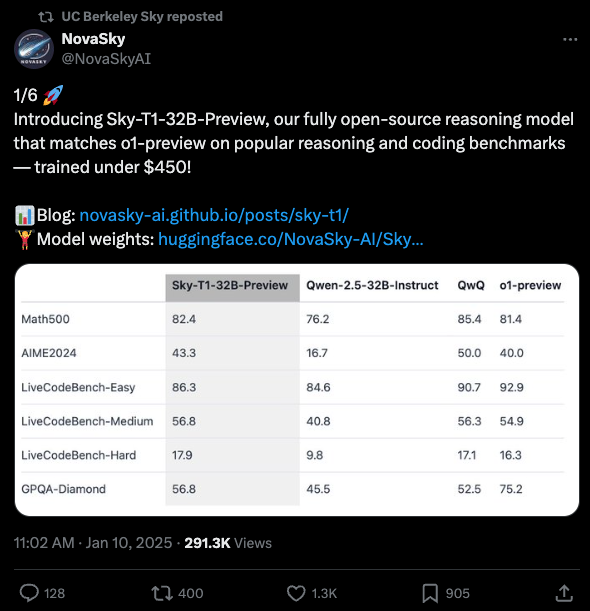
- DeepSeek 发布了 R1(2 天前),其基准测试远超 o1-preview。R1 论文还揭示了一个令人惊讶的发现:你可以通过从 R1 蒸馏,让一个 1.5B 的 Qwen 模型匹配 4o 和 3.5 Sonnet(?!)。
- Bespoke Labs(今天)使用 Sky-T1 的方案在 Qwen 上再次蒸馏 R1,其表现大幅超过(而不仅仅是匹配)o1-preview,同样只用了 1.7 万行推理轨迹(reasoning traces)。
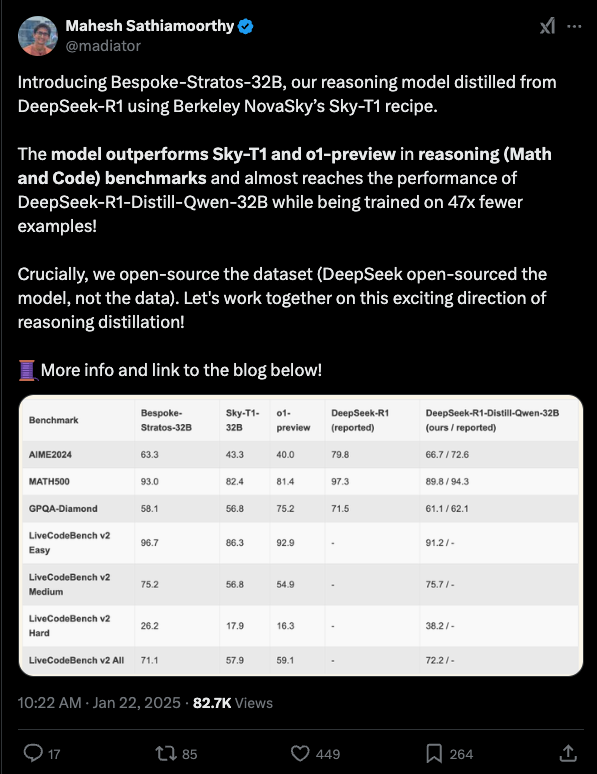
虽然 Bespoke 的蒸馏在性能上尚未完全达到 DeepSeek 蒸馏的水平,但他们只使用了 1.7 万个样本,而 DeepSeek 使用了 80 万个。显而易见,如果他们愿意,可以继续提升。
更令人震惊的是,“SFT is all you need” —— 推理能力的产生不需要重大的架构改变,只需输入更多(经过验证、改写的)推理轨迹,包括回溯(backtracking)和转向(pivoting)等,它似乎就能很好地泛化。极有可能,这解释了 o1-mini 和 o3-mini 相对于其全尺寸版本的高效率。
AI Twitter 回顾
所有回顾均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
AI 模型开发与评估
-
DeepSeek-R1 的创新与性能:@teortaxesTex、@cwolferesearch 和 @madiator 讨论了 DeepSeek-R1 通过纯强化学习 (RL) 进行的训练,强调了有监督微调 (SFT) 对于加速 RL 收敛的重要性。DeepSeek-R1 展示了强大的推理能力和多模态功能,而 Bespoke-Stratos-32B 作为蒸馏版本被推出,仅用 47 倍更少的样本就实现了显著的性能。
-
Gemini 及其他 LLM 进展:@chakraAI 和 @philschmid 重点介绍了 Google 的 Gemini 2.0 Flash Thinking 模型,指出其具有 100 万 token 的上下文窗口、代码执行支持,以及在数学、科学和多模态推理基准测试中的 state-of-the-art 表现。
-
AI 模型对比与评论:@abacaj 和 @teortaxesTex 对 o1 和 R1-Zero 等模型提供了批判性见解,讨论了模型可重复性、行为自我意识以及 RLHF 在实现稳健推理方面的局限性等问题。
AI 应用与工具
-
Windsurf 与 AI 驱动的幻灯片演示文稿:@omarsar0 展示了 Windsurf,这是一个能够 分析代码、复制功能 并通过无缝集成 PDF 和 图像 来 自动化创建幻灯片 的 AI agent。用户可以通过简单的 prompts 来 扩展功能,突显了 基于 Web 的 AI 应用 的 灵活性。
-
本地 AI 部署与扩展:@ggerganov 介绍了 llama.cpp server,它提供了 独特的上下文重用技术,用于根据 代码库内容 增强 LLM completions,并针对 低端硬件 进行了优化。此外,利用 llama.cpp 的 VS Code 扩展 提供了 本地 LLM 辅助的代码和文本补全,无需外部 RAG 系统。
-
AI 与开发工具的集成:@lah2139 和 @JayMcMillan 强调了 LlamaIndex 与 DeepSeek-R1 的集成,实现了 AI 辅助开发 和 agent 工作流。这些工具允许开发者 构建和评估多智能体系统 (multi-agent systems),促进了 高效的 AI 应用开发。
AI 研究与论文
-
IntellAgent 多智能体框架:@omarsar0 介绍了 IntellAgent,这是一个旨在 评估复杂对话式 AI 系统 的 开源多智能体框架。该框架促进了 合成基准测试 (synthetic benchmarks) 和 交互式用户-智能体模拟 的生成,捕捉了 agent 能力 和 策略约束 之间复杂的动态关系。
-
LLM 中的行为自我意识:@omarsar0 讨论了一篇 新论文,该论文证明了 LLM 可以通过识别和评论其自身的 不安全代码 输出而表现出 行为自我意识,且无需显式训练,这表明模型内部更可靠的 策略执行 (policy enforcement) 具有潜力。
-
ModernBERT 与嵌入模型:@philschmid 介绍了 ModernBERT,这是一种 嵌入和排序模型 (embedding and ranking model),它比前代模型能更准确地关联上下文信息。对比显示,仅依赖 基准测试 (benchmarks) 可能无法完全捕捉模型的 有效性,强调了定制化 评估策略 的必要性。
AI 基础设施与算力
-
OpenAI 的 Stargate 项目:@sama 和 @gdb 宣布了 Stargate 项目,这是一项 5000 亿美元的 AI 基础设施计划,旨在在 美国 建设 AI 数据中心,将其定位为对 全球 AI 竞争 的回应,以及 增强国家 AI 能力 的战略。
-
NVIDIA 的 AI 模型与算力解决方案:@reach_vb 详细介绍了 NVIDIAAI 的 Eagle 2,这是一套 视觉语言模型 (VLMs),在特定基准测试上 表现优于 GPT-4o 等竞争对手,强调了 高效算力架构 在开发高性能 AI 模型中的重要性。
-
算力资源管理:@swyx 和 @cto_junior 讨论了管理 推理时算力 (inference-time compute) 的策略,平衡 成本 与 对抗鲁棒性 (adversarial robustness),以及 算力资源分配 对 AI 模型性能 的影响。
AI 社区、教育与活动
-
AI 工作坊与课程:@deeplearningai 和 @AndrewYNg 推广了 实战工作坊 和 免费课程,重点关注 构建具备计算机操作能力的 AI agents,涵盖了 多模态提示 (multimodal prompting)、XML 结构化 和 prompt caching 等主题,以增强 AI 助手功能。
-
AI 电影节的发展:@c_valenzuelab 庆祝了他们 电影节 的扩张,指出 投稿量增加了 10 倍,并搬迁至 Alice Tully Hall 等著名场馆,反映了 AI 媒体 与 创意产业 之间 日益增长的交集。
-
AI 社区贡献:@LangChainAI 和 @Hacubu 展示了 AgentWorkflow 和 LangSmith Evals 等 社区驱动的项目,这些项目 简化 了 构建多 Agent 系统 和 测试 LLM 应用 的流程,从而 增强了社区协作 并提升了 开发者生产力。
梗与幽默
-
AI 模型幽默:@giffmana 和 @saranormous 分享了关于 AI 模型局限性 和 用户交互 的幽默看法,包括关于 Chatbot 行为 和 AI 驱动的创意失误 的笑话。
-
关于 AI 发展的讽刺评论:@nearcyan 和 @giffmana 发布了关于 AI 项目命名规范 和 对 AI 能力的误解 的 讽刺性言论,为该领域的快速发展增添了轻松的视角。
AI 政策与伦理
-
AI 安全与治理:@togelius 对 AI 安全议程 表示担忧,主张采取平衡的方法,在应对 生存风险 的同时优先考虑 计算自由 (freedom of compute),强调了 AI 创新 与 伦理考量 之间的紧张关系。
-
AI 社区批评:[@pthoughtcrime__](https://twitter.com/pthoughtcrime__/status/…) 和 @simran_s_arora 批评了 政策驱动的 AI 倡议,强调了 对 AI 开发的控制 潜力以及 维护开源原则 以促进 伦理 AI 进展 的重要性。
-
监管讨论:@agihippo 和 @labloke11 就 AI 监管 对 创新 和 研究 的影响进行了对话,辩论了 监管审查 与 技术进步 之间的平衡。
AI Reddit 摘要
/r/LocalLlama 摘要
主题 1. Mistral 10V:探索 12K Tokens 的新功能
- 中国全面迈向机器人化。疯狂的发展。目前,这是中美之间的一场激烈竞赛。 (得分: 768, 评论: 237): 该帖子强调了 美国 和 中国 在 AI 领域的激烈竞争,特别提到了中国在机器人技术方面的进步。文中暗示 Mistral 10V 的发布对 AI 技术具有重大影响,尽管文中未提供具体细节。
- 许多评论者对视频的真实性表示怀疑,质疑其是否为 AI 生成 或预先编程的,一些人注意到官方渠道并未发布该视频,另一些人则讨论了其为 造假 的可能性。
- 讨论反映出一种观点,即 中国 在机器人技术方面显著领先,一些评论者认为 美国 由于专注于非制造业而落后,并质疑两国之间是否存在“竞赛”。
- 对于先进机器人技术的未来影响,人们既有幽默感也有担忧,评论提到了潜在的军事应用,以及一旦机器人具备进一步能力,将取代 警犬 等工作。
- 噢……尴尬了 (分数: 560, 评论: 295): OpenAI 推出了容量为 12,000 tokens 的 Mistral 10V,标志着 AI 能力的重大进展。帖子的背景暗示了一个潜在的尴尬局面,可能与该模型的发布或功能有关。
- 演讲者的 vocal fry(气泡音)是一个热门话题,许多评论者批评其令人分心或显得不专业。Sam Altman 在演讲中的举止被认为缺乏自信,一些人推测他的紧张源于当时的背景,而非内容本身。
- 讨论涉及了 AI 潜在的经济影响,对 AI 将创造 100,000 jobs 的说法表示怀疑。评论者对创造就业机会表示怀疑,认为 AI 可能会减少劳动力,并引用 Theranos 作为前车之鉴。
- 带有政治色彩,提到了 Donald Trump 以及利用 AI 声称取得治愈癌症等成就的观点。一些评论者认为 Sam Altman 正在应对复杂的政治局势,试图在 Trump 的影响下保持有利地位。
- Sam Altman 在整个 AI Infra Deal 公布期间的表情 (分数: 469, 评论: 131): 该帖子缺乏关于 Sam Altman 或 AI Infra Deal Announcement 的具体内容或讨论点。由于缺乏额外的背景或细节,无法提供技术总结。
- 讨论将 Russia’s oligarchic system(俄罗斯寡头体系)与美国进行了比较,指出对富人日益向 Trump 靠拢以获取影响力的担忧。这反映了对向寡头倾向转变的担忧,类似于普京统治下的 Russia’s political structure,在那里,如果寡头失宠,将面临严重后果。
- 有关于 Sam Altman 在公开场合举止的评论,一些人将其表情归因于焦虑或不适。反应表明人们对他对某些合作伙伴关系的积极性持怀疑态度,可能暗指他违背意愿创建 Skynet-like scenario(类似天网的场景)的讽刺说法。
- 对话包括对 Elon Musk 在 AI 进展中被 Altman 边缘化的讽刺评论,并提到了 Musk 参与的其他计划,如 meme coins。这种幽默强调了科技领域影响力人物之间被察觉到的竞争关系。
主题 2. O1-Pro:在立法分析中的革命性应用
- 我使用 O1-pro 分析了 Trump 所有行政命令的合宪性。 (分数: 135, 评论: 33): 作者使用 O1-Pro 对 Trump’s Executive Orders 进行了详细分析,并从 whitehouse.gov 获取文本以保证客观性。该文档包含 Table of Contents(目录)和 source text links(原始文本链接),并由 GT4o 提供摘要。
- 分析过程:作者手动准备了文档,使用 Google Doc 的书签和链接系统进行导航。他们使用 O1-Pro 进行分析,插入行政命令的全文,并使用 prompt 模板生成摘要和标题,确保每次分析都在新的对话中进行以避免偏见。
- 行政命令的影响:讨论强调了潜在的短期和长期影响,例如联邦机构内部的立即重组、移民政策的变化以及能源和环境重点的转移。长期影响可能包括规模更小、更集中的联邦劳动力,以及由于退出条约而导致的国际关系转变。
- 事实核查与经济担忧:评论者建议分享真实的 ChatGPT 链接以便进行事实核查,并推测了经济影响,如关税及其对加拿大和美国物价的影响。人们对拟议的关税是否会在没有正式命令的情况下颁布持怀疑态度。
- [D]: 详细解释 Attention 机制的 3blue1brown 视频 (Score: 285, Comments: 12): 3blue1brown 关于 attention 机制 的视频详细解释了 token embedding 等概念,以及 embedding 空间 在为一个单词编码多种含义时的作用。它讨论了训练良好的 attention 块如何根据上下文调整 embedding,并将 Ks 概念化为对 Qs 的潜在回答。视频链接 和 字幕 已提供供进一步探索。
- 3blue1brown 的视频 因其对 attention 机制 清晰且可视化的解释而受到称赞,它有效地引入了问题并逐步构建解决方案,不像其他教程往往跳过基础解释。
- 用户强调了在模型训练期间 masking 对于预测下一个 token 的重要性,并参考了 Karpathy 的教程 中关于从零构建 GPT 的内容,以进一步理解这些概念。
- 基于该视频系列的 3blue1brown 演讲 也因其直观的解释而被推荐,并为有兴趣探索更多内容的人提供了链接:YouTube 链接。
- 特朗普宣布高达 5000 亿美元的 AI 基础设施投资 (Score: 141, Comments: 22): OpenAI、SoftBank 和 Oracle 正在启动一项名为 Stargate 的德克萨斯州合资项目,初始承诺资金为 1000 亿美元,并计划在未来四年内投资高达 5000 亿美元。该合资项目旨在树立 AI 基础设施的新标准。
- 多条评论指出,Stargate 项目最初于去年宣布,一些用户对其最近的宣布表示怀疑,认为这带有政治动机,特别是关于特朗普抢占功劳这一点。
- 讨论涉及该项目的规模,一位评论者指出这可能是历史上最大的基础设施项目,而另一位用户则幽默地将其比作 Foxconn 2.0。
- 一些用户对这种直截了当的发布风格表示感谢,避免了像 “BREAKING” 这样日益变得毫无意义的煽动性标题。
主题 3. Gemini 1.5: 凭借性能优势领先 AI
- 埃隆表示 Softbank 资金不足.. (Score: 417, Comments: 227): Elon Musk 对 SoftBank 的财务能力表示怀疑,反驳了关于 AI 基础设施巨额资金的说法,称其“担保资金远低于 100 亿美元”。一张来自 OpenAI 的图片宣布了 “Stargate 项目”,该项目计划四年内在美国 AI 基础设施上投资 5000 亿美元,首批 1000 亿美元 将立即部署。
- 舆论对 SoftBank 的财务声明表示怀疑,一些人认为他们可能在没有获得必要资金的情况下就宣布了计划,希望随后能吸引投资。人们对像 Elon Musk 这样的商业领袖影响或评论其他业务的合法性和道德性表示担忧,尤其是考虑到他备受争议的过往记录以及与政府计划的联系。
- 讨论强调了特朗普宣布的 5000 亿美元 政府 AI 补贴,并将其与过去被滥用的基础设施资金相类比。批评者认为这可能是向科技精英的潜在财富转移,质疑 SoftBank 和 Oracle 等公司的参与度及实际财务能力。
- 许多评论对 Elon Musk 表示蔑视,质疑他的动机和公信力,指责其存在个人偏见和“钓鱼”行为。文中还提到了过去未实现的承诺,如 XAi Grok 模型,并批评他被认为与争议人物和意识形态结盟。
- OpenAI 关于 Stargate 项目的公告 (Score: 186, Comments: 90): OpenAI 的 Stargate Project 计划在四年内向美国的 AI 基础设施投资 5000 亿美元,首期将立即投入 1000 亿美元。初始股权出资方包括 SoftBank, OpenAI, Oracle 和 MGX,关键技术合作伙伴包括 Arm, Microsoft, NVIDIA, Oracle 和 OpenAI。该项目旨在支持美国就业、国家安全,并为了人类福祉推进 AGI。
- 评论中讨论了对 SoftBank 参与 的怀疑,有人质疑他们为什么不在日本投资,并澄清了 SoftBank 与中东主权基金的联系。人们对资金来源表示担忧,指出可能存在对补贴和税收抵免的依赖。
- 讨论强调了对该项目目标的困惑,一些人认为这 1000 亿美元 将用于数据中心、AI 研发实验室和能源基础设施,并提到了 Microsoft 过去与 Three Mile Island 核电站的合作。人们对该项目的就业声明持怀疑态度,将其与 Tesla 和 Alexa 等其他技术计划进行了比较。
- “Stargate” 一词被幽默地与《终结者》系列中的 “Skynet” 相提并论,一些评论指出 Skynet 程序已经作为一个军事卫星系统存在。有人提到该项目有助于“美国的再工业化”,并且是第四次工业革命的一部分。
{kind=link}
{kind=link}
其他 AI Subreddit 综述
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
主题 1. Stargate AI 项目:5000 亿美元投资的影响
- Trump 宣布在美国进行 5000 亿美元的 AI 基础设施投资 (Score: 582, Comments: 355): Trump 宣布在 US 进行 5000 亿美元 的 AI 基础设施投资,标志着对推进 AI 能力和基础设施建设的重大承诺。这一公告突显了 AI 在国家经济和技术战略中日益增长的重要性。
- Stargate Project:这 5000 亿美元的投资流向了一家名为 Stargate 的新私营公司,该公司由 Sam Altman, Masayoshi Son 和 Larry Ellison 共同拥有,而非 OpenAI。这引发了对知识产权和现有合作伙伴关系(特别是与 Microsoft 的关系)的担忧。
- 资金与所有权:关于资金来源存在争议,一些人认为这是来自 SoftBank 等公司的私人投资,而非美国政府资金。Trump 的声明被一些人视为政治举措,声称该声明让他能够将私营部门的举措归功于自己。
- 地缘政治与经济影响:这一公告被视为全球 AI 竞赛中的战略举措,特别是针对中国 DeepSeek R1 等进展的回应。讨论还涉及了潜在的经济影响,包括就业创造声明以及对美国技术领导地位的更广泛影响。
- 我不相信这笔 5000 亿美元的 OpenAI 投资 (Score: 419, Comments: 142): 该帖子对 5000 亿美元的 OpenAI 投资 表示怀疑,认为这一数字过于乐观,且在资金来源和项目细节方面缺乏透明度。作者批评了模糊法律术语的使用,并暗示该公告具有政治动机,特别是在 Trump 赢得总统选举后的时机选择,旨在制造新闻头条而缺乏坚定承诺,暗示实际投资将比宣传的更小、更慢。
- 评论者强调了对 5000 亿美元投资 的怀疑,并将其与过去的 Foxconn 和 Star Wars 计划等项目进行了比较,认为该公告更多是为了操纵股票和市场炒作,而非实际资金。UncannyRobotPodcast 等人对缺乏后续行动以及潜在的内幕交易获利表示担忧。
- 关于政府与私营公司在融资中的作用存在争论,tertain 和 ThreeKiloZero 澄清说资金来自四家合作伙伴公司,而非 US 联邦资金,而 05032-MendicantBias 指出政府在放宽基础设施监管方面的作用。SoftBank 被提及为可能参与其中的拥有大量资产的重要参与者。
- 围绕 投资的潜在影响 的讨论包括对 AI 过度炒作的担忧以及 AI 发展的存在性影响。NebulousNitrate 认为,为了防止对手获得超级智能,大规模投资是合理的,而 Super_Sierra 则认为,尽管对 5000 亿美元目标的实际实现持怀疑态度,但这种炒作有利于创新。
- 美国 5000 亿美元 Stargate AI 项目与其他科技项目的简单对比 (Score: 112, Comments: 103): 将 5000 亿美元的 Stargate AI 项目 与历史上的科技项目进行了对比,强调其规模约为 2024 年 US GDP 的 1.7%。相比之下,Manhattan Project 耗资约 300 亿美元(约占 20 世纪 40 年代 GDP 的 1.5%),Apollo Program 耗资约 1700-1800 亿美元(约占 20 世纪 60 年代 GDP 的 0.5%),而 Space Shuttle Program 耗资约 2750-3000 亿美元(约占 20 世纪 80 年代 GDP 的 0.2%)。Interstate Highway System 在几十年间耗资 5000-5500 亿美元(每年约占 GDP 的 0.2%-0.3%)。
- 讨论集中在 Stargate AI 项目的 私人融资 上,SoftBank, OpenAI, Oracle, 和 MGX 是主要投资者。人们对该项目的意图持怀疑态度,评论暗示它可能会取代很大一部分劳动力(10-30%),同时对比了 US 在医疗和教育等社会福利计划上缺乏资金的现状。
- 辩论了 项目的规模和影响,并就其占 GDP 的百分比与 Manhattan Project 和 Apollo Program 等历史项目进行了比较。一些人认为,虽然该项目由私人资助,但其规模类似于公共倡议,引发了对其社会影响和 US 政府角色的质疑。
- 表达了对 US 在 AI 发展中的角色 的担忧,一些评论者对政府的动机以及富裕利益集团潜在的剥削表示不信任。有一种观点认为,US 正专注于维持全球主导地位,类似于与 China 的新“太空竞赛”,且该项目最终可能导向国防领域。
Theme 2. DeepSeek R1: Redefining AI Benchmarks
- R1 令人惊叹 (Score: 578, Comments: 139): R1 在一个微妙的 graph theory 问题中展示了卓越的解题能力,在 4o 失败两次后,R1 第一次尝试就成功给出了正确答案。作者对 R1 证明其解法并表达细致理解的能力印象深刻,认为即使是在 MacBook 等个人设备上运行的较小模型,在特定领域也可能超越人类智能。
- 用户讨论了 R1 model 与 o1 及其他模型的性能对比,一些人强调 R1 具有极高的性价比,因为其在性能相近的情况下成本更低。讨论突出了 R1 在解题和推理方面的能力,部分用户注意到其蒸馏版本(distilled versions)的表现也令人印象深刻。
- R1 的解题能力受到称赞,具体例子包括第一次尝试就成功解决 graph theory 问题,表现优于 4o 等其他模型。然而,一些用户也指出了局限性,例如缺乏上下文意识以及提示词优化(prompt optimization)方面的问题。
- 讨论还涉及了 model deployment 和使用的技术细节,例如需要特定的 temperature settings,以及关于 self-hosting 能力的问题。一些用户表达了在专业环境中使用 R1 的挑战,主要是出于数据隐私的考虑。
- 对 Deep Seek R1 的过度吹捧虽然离谱,但确实是真的。 (Score: 63, Comments: 46): 作者在 RAG machine 的编程问题上困扰了两天,尝试了包括 OpenAI 的 O1 Pro 在内的各种主流 LLMs 均未成功。然而,Deep Seek R1 在第一次尝试时就解决了该问题,这使得作者考虑将其作为首选编程工具,甚至可能取代 OpenAI Pro。
- 对于 OpenAI 的 LLMs 是否了解自身架构存在怀疑,正如用户 KriosXVII 和 gliptic 指出的,这些细节不太可能包含在训练数据中。Dan-Boy-Dan 批评作者的言论是营销手段,并挑战其发布该问题,以便其他人用不同模型进行测试。
- a_beautiful_rhind 和 LostMyOtherAcct69 讨论了 AI 模型性格和架构的差异,认为 Mixture of Experts (MoE) 凭借其效率和专业化,相比稠密模型(dense models)可能是 AI 的未来。ReasonablePossum_ 认为美国公司优先考虑利润而非开发此类模型,而 Caffeine_Monster 则批评 AI 模型中过度的正面偏见会适得其反。
- 多位用户(包括 Dan-Boy-Dan 和 emteedub)要求作者发布那个只有 Deep Seek R1 解决的具体问题,对相关说法表示怀疑,并希望在其他模型上进行测试。
- Deepseek-R1 很脆弱 (Score: 61, Comments: 23): 该帖子讨论了 Deepseek-R1 的脆弱性,强调了它的局限性和优势。文中包含一个图片链接 此处 以支持分析。
- 提示词优化 (Prompt Optimization):用户发现 Deepseek-R1 在特定场景下表现良好,特别是使用 R1 论文中的提示词结构,并设置 temperature 为 0.6 和 top p 为 0.95,这涉及在提示词中明确标记推理过程和答案。这种方法在 o1 模型的指令中也有提及,表明这是推理模型的一种通用方法。
- 模型脆弱性 (Model Brittleness):Deepseek-R1 在需要创造力或主观回答的任务中表现吃力,经常产生不兼容或冗余的输出,例如在一次测试中,它为一个应用建议了不切实际的技术栈。然而,通过练习和精确的提示词引导,用户注意到 R1 的表现有所提高,这支持了帖子关于其脆弱性的断言。
- 与其他模型的对比:讨论强调 Deepseek-R1 在有唯一正确答案的任务(如编程)中表现出色,但在处理更复杂或更具创造性的任务时,不如 Deepseek v3 等其他模型。这表明虽然 R1 可能很有效,但其应用需要根据任务需求进行仔细考虑和调整。
{kind=link}
Theme 3. 模型无关的推理:R1 技术
- 你可以从 R1 中提取推理并将其传递给任何模型 (评分: 368, 评论: 101): Twitter 上的 @skirano 建议你可以从 deepseek-reasoner 中提取推理过程并将其应用于任何模型,从而增强其性能,正如在 GPT-3.5 turbo 上所演示的那样。
- 工作流与推理技术:讨论强调了使用 Chain-of-Thought (CoT) 提示和分步思考来增强模型推理,@SomeOddCodeGuy 建议使用工作流应用进行两步工作流以获得有趣的结果,正如在 QwQ 模拟 中所展示的。Nixellion 补充说,提示模型模拟专家讨论可以产生更好的结果,并强调了新 CoT 技术的潜力。
- 批评与质疑:Ok-Parsnip-4826 批评了提取推理的概念,认为这仅仅是让一个模型总结另一个模型的想法,没有实际益处;而 gus_the_polar_bear 反驳说 LLM 对来自其他 LLM 的提示可能会有不同的反应,暗示了潜在的尚未探索的交互。nuclearbananana 质疑使用辅助模型的效率,因为这可能带来延迟和成本影响。
- 技术实现与工具:SomeOddCodeGuy 讨论了使用 Wilmer 促进 Open WebUI 和 Ollama 之间连接的技术细节,强调了创建容器化设置以增强工作流管理的潜力。此外,xadiant 提到了通过 completions API 将推理过程注入本地模型以提升性能的可能性。
- 蒸馏后的 R1 模型在工作流中可能表现最好,所以如果你还没学过,现在是学习工作流的好时机! (评分: 49, 评论: 14): 正如论文 “DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning” 中所述,DeepSeek-R1 模型在 zero-shot 提示下表现最佳,而非 few-shot 提示。作者强调了使用工作流来增强 R1 及其蒸馏版本等推理模型性能的重要性,建议采用包含总结和问题解决的结构化方法,以最大化效率和输出质量。
- 用户讨论了 DeepSeek-R1 输出格式一致性的挑战,特别是在生成 JSON 等结构化格式方面,一位用户提到使用 langgraph 来解决这些问题。另一位用户则在寻求更多提高模型性能的技巧。
- 一位评论者指出,DeepSeek 自身也承认 R1 与 DeepSeek-V3 相比,在 function calling 和复杂任务方面存在局限性,并引用研究论文中提到的计划利用长 Chain-of-Thought (CoT) 技术进行改进。
- 一些用户表示有兴趣让 AI 修改提示词以获得更好的输出,这表明对改进 prompt engineering 以增强模型响应的需求。
Theme 4. Deepseek R1 GRPO Code: Open-Sourcing Breakthrough
- Deepseek R1 GRPO 代码开源了 🤯 (评分: 260, 评论: 6): Deepseek R1 已经开源了其 GRPO 代码,并附带了一张详细说明模型组件的流程图。该图表突出了 Prompts、Completions、Rewards and Advantages、Policy and Reference Policy 以及 DKL 等部分,所有这些部分都通过一系列涉及均值和标准差的结构化计算,为一个核心“目标 (objective)”做出贡献。
- 分享的 Deepseek R1 代码并非真正的 R1 代码,而是 R1 训练过程中使用的偏好优化方法 (preference optimization method),强调了在 PO 训练中 RL 环境相对于奖励模型的创新性。
- 根据论文,RL 环境采用了一种简单的算法,评估推理的起始和结束 token 对,将模型的输出与数学数据集中的 ground truth 进行比较。
- 相关代码的链接可在 GitHub 上找到。
- DeepSeek-R1-Distill-Qwen-1.5B 在浏览器中通过 WebGPU 100% 本地运行。据报道在数学基准测试中超越了 GPT-4o 和 Claude-3.5-Sonnet(AIME 为 28.9%,MATH 为 83.9%)。 (Score: 170, Comments: 38): DeepSeek-R1-Distill-Qwen-1.5B 据报道完全通过 WebGPU 在浏览器本地运行,并在数学基准测试中超越了 GPT-4o 和 Claude-3.5-Sonnet,在 AIME 上达到 28.9%,在 MATH 上达到 83.9%。
{kind=link}
Theme 5. R1-Zero: AI 强化学习突破
- R1-Zero:纯 RL 创造了一个我们无法解码的心智——这是 AGI 的黑暗镜像吗? (Score: 204, Comments: 105): DeepSeek-R1-Zero 是一款通过纯 Reinforcement Learning (RL) 开发且未经监督微调的 AI 模型,其 AIME 数学分数 从 15.6% 剧增至 86.7%,但其推理过程仍无法解释,会产生乱码输出。虽然其兄弟模型 R1 使用了一些监督数据来保持可读性,但 R1-Zero 引发了对 AI 对齐以及超人工智能潜在民主化的担忧,因为其 API 成本极低——比 OpenAI 便宜 50 倍——尽管其逻辑不可读。
- R1-Zero 的 乱码输出 可能是一种 Symbolic Reasoning 形式,其中 Token 被赋予了超越其语言含义的新用途,用以表达复杂的相互关系。这一概念类似于人类使用 俚语或术语,暗示该模型的推理可能因 Token 语义的转变而被误解为乱码,类似于代际间的语言差异。
- 讨论强调了 R1-Zero 的 Reinforcement Learning 重塑 Token 语义的潜力,使其表现优于依赖 Supervised Fine-tuning 的 R1 等模型。这引发了关于如何衡量使用新符号推理形式的模型安全性和对齐性的问题,以及这可能如何促进 Multimodal AI 的发展。
- 存在对 R1-Zero 能力 的怀疑,一些评论者认为其输出仅仅是错误或幻觉,而非突破性的见解。其他人则提到需要更多具体的例子和报告来证实其推理能力的说法,并提到了 Karpathy 的预测 以及 Meta 的 “Coconut” 论文 等概念以提供进一步背景。
- Gemini Thinking experimental 01-21 发布了! (Score: 71, Comments: 17): 在 Google AI Studio 界面中展示的 Gemini 2.0 Flash Thinking Experimental 模型具有高级选项,如 “Model”、”Token count” 和 “Temperature” 设置。该界面采用深色主题,允许用户输入数学问题并调整各种工具和设置进行实验。
- Gemini 1.5/1.0 曾因仓促推出且表现平平而受到批评,但新的 AI Studio 模型 因其改进而受到称赞,表明其开发过程更加周密。用户赞赏实验性模型的开放测试,希望其他公司也能这样做。
- Open weight models 被指出正在超越封闭模型,引发了关于其优势的讨论。有人提到了模型版本中的 命名不一致 问题,这可能会导致混淆。
- Flash Thinking Experimental 模型 已从 32k 更新为 100 万 Context Window,与 Google 的其他模型保持一致。用户在速度方面的体验褒贬不一,有人认为令人印象深刻,有人则不然。
{kind=link}
AI Discord 摘要
摘要之摘要的摘要
o1-preview-2024-09-12
主题 1. AI 的十亿级 Stargate Project:宏伟目标与质疑
- OpenAI 宣布 5000 亿美元的 Stargate Project,质疑声不断:OpenAI 公布了 Stargate Project,旨在四年内向 AI 基础设施投资 5000 亿美元,但像 Elon Musk 这样的批评者怀疑融资的可行性,称其“荒谬”。
- 微软和甲骨文在融资疑虑中承诺支持:微软 CEO 确认了对该项目的承诺,表示“我这 800 亿美元没问题”,而 Oracle 也在对 SoftBank 是否有能力做出重大贡献的质疑声中加入。
- 特朗普的 Stargate 引发关于技术与政府的辩论:特朗普总统宣布了 Project Stargate,引发了关于政府参与 AI 的讨论,以及对技术投资中企业过度扩张的担忧。
主题 2. AI 模型对决:DeepSeek R1 表现超越巨头
- DeepSeek R1 在数学任务中胜过 Gemini 和 O1:社区成员赞扬 DeepSeek R1 在数学表现上达到 92%,超越了 Gemini 和 O1 等模型,展示了先进的推理能力。
- Bespoke-Stratos-32B 成为推理强力模型:一款从 DeepSeek-R1 蒸馏出的新模型 Bespoke-Stratos-32B,在推理任务中超越了 Sky-T1 和 o1-preview,仅使用了成本为 800 美元 的 800k 训练样本。
- Gemini 2.0 Flash Thinking 飙升至第一:Gemini-2.0-Flash-Thinking 以 73.3% 的数学得分和 100 万 token 的上下文窗口夺得 Chatbot Arena 榜首,引发了热议并与 DeepSeek 模型进行了对比。
主题 3. 审查 vs. 无审查 AI 模型:用户寻求自由
- DeepSeek R1 在审查担忧中面临性能下降:用户报告 DeepSeek R1 的性能在一夜之间下降了 85%,怀疑是增加了审查过滤,并正在寻找针对敏感提示词的规避方法。
- 对过度审查的 AI 模型挫败感增加:社区成员嘲讽了像 Phi-3.5 这样受到严重审查的模型,表示过度的限制使得模型在技术任务和角色扮演中变得不切实际。
- 对无审查模型的搜寻加剧:用户在 OpenRouter 等平台上讨论了他们最喜欢的无审查模型,如 Dolphin 和 Hermes,强调了对更开放 AI 体验的需求。
主题 4. 新 AI 工具与创新赋能开发者
- LlamaIndex 发布 AgentWorkflow 实现多 Agent 协作:推出了 AgentWorkflow,使开发者能够构建具有扩展工具支持的多 Agent 系统,被誉为“迈向更强大 Agent 协作的下一步”。
- Ai2 ScholarQA 彻底改变文献综述:Ai2 ScholarQA 推出了一项基于 RAG 的多论文查询解决方案,帮助研究人员利用交叉引用功能进行深入的文献综述。
- OpenAI 的 Operator 准备在你的浏览器中执行操作:报告指出 OpenAI 正在准备 Operator,这是一个 ChatGPT 功能,可代表用户执行浏览器操作,这既引发了兴奋也带来了隐私讨论。
主题 5. AI 开发挑战:从量化到隐私
- 模型量化辩论与创新:Unsloth AI Discord 中的讨论强调了动态 4-bit 量化方法,该方法在减少 VRAM 占用的同时保留了准确性,并引发了与 BnB 8-bit 方法的对比。
- 对 AI 数据处理政策的隐私担忧:用户质疑 Codeium 和 Windsurf 等 AI 服务的数据处理实践,仔细审查其隐私政策以及使用用户数据进行训练的情况。
- AI 在网络安全中的作用仍未得到充分探索:成员们强调了对 AI 网络安全解决方案重视不足,指出像 CrowdStrike 这样的公司多年来一直使用 ML,并建议 Generative AI 可以自动化威胁检测和基于代码的入侵分析。
o1-2024-12-17
主题 1. AI 基础设施与融资热潮
- Stargate 召唤 5000 亿美元 AI 盛宴:特朗普总统宣布了一项耗资 5000 亿美元的巨型“Stargate 项目”,用于建设 AI 数据中心,首批资金来自 SoftBank, Oracle 和 MGX。Microsoft 的博客文章称其为有史以来最大的 AI 倡议,旨在推动就业和美国在 AI 领域的领导地位。
- Musk, SoftBank, Oracle 引发争议:Elon Musk 嘲讽 SoftBank 资金不足,而怀疑论者则对 SoftBank 的流动性和债务表示质疑。尽管如此,官方声明仍强调了对这一超大规模投资的大胆乐观态度。
- Google 再向 Anthropic 投入 10 亿美元:Google 再次向 Anthropic 投入 10 亿美元,加剧了 AI 巨头之间的激烈竞争。关于滚动融资策略和 Anthropic 不断扩大的下一代产品的猜测层出不穷。
主题 2. LLM 对决与数学奇迹
- DeepSeek R1 主宰数学领域:据报道,DeepSeek R1 在数学表现上达到 92%,在高级推理任务中超越了 O1 和 Gemini。用户称赞其几何洞察力和彻底的多阶段 RL 训练。
- Gemini 2.0 Flash 冲上第一:Google 的 Gemini 2.0 Flash-Thinking 跃居 Chatbot Arena 榜首,拥有 73.3% 的数学得分和 100 万 token 的上下文窗口。开发者期待很快会有更精细的迭代。
- Bespoke-Stratos-32B 赶超对手:该模型从 DeepSeek-R1 蒸馏而来,在仅需 47 倍更少样本的情况下击败了 Sky-T1 和 o1-preview。其使用的 800 美元开源数据集激发了人们对具有成本效益的社区数据策划分发的兴趣。
主题 3. 强化学习与 GRPO 讨论
- Tiny GRPO 获得实质性关注:开发者正在运行用于数学任务的极简 GRPO 代码,并称赞这种简化方法易于实验。早期采用者注意到其迭代周期快且调试简单。
- Kimi-k1.5 论文深入探讨:研究人员强调了基于课程的 RL 和长度惩罚对提升模型性能的作用。社区反馈促使新手将这些想法融入到新的 RL 训练方案中。
- GRPO 辩论引发 KL 散度争议:Hugging Face 用户质疑 GRPO 在优势计算中如何处理 KL。代码贡献者权衡了将 KL 直接应用于损失函数而非奖励函数的优缺点。
主题 4. HPC 与 GPU 代码生成进展
- Blackwell 突破代码限制:NVIDIA 的 Blackwell B100/B200 codegen 10.0 和 RTX 50 codegen 12.0 更新引发了对 sm_100a, sm_101a 以及可能的 sm_120 的期待。社区成员正在等待官方白皮书,目前仅靠部分 PR 说明进行了解。
- Triton 与 3.2 版本的博弈:INT8×INT8 点积在新的 TMA 方法下崩溃,导致需要手动修复和 jit 重构。PyTorch Issue #144103 突出了 AttrsDescriptor 移除带来的向后兼容性问题。
- Accel-Sim 演讲引发热潮:HPC 探索者关注用于在 CPU 上进行 GPU 仿真的 Accel-Sim 框架。预定于 3 月底举行的演讲承诺将对模拟 GPU 性能和代码优化提供更深入的见解。
主题 5. RAG 系统与工具创新
- AgentWorkflow 助力多智能体:LlamaIndex 发布了一个高级框架,用于编排并行工具使用和 Agent 协作。爱好者将其视为构建稳健多智能体解决方案的“下一步”。
- Sonar Pro 在 SimpleQA 中表现出色:Perplexity 新推出的 Sonar Pro API 在基于实时搜索的问答中表现优于对手,同时承诺更低的成本。Zoom 将其集成到 AI Companion 2.0 中,开发者称赞其引用友好的方式。
- Ai2 ScholarQA 增强文献处理:该系统具有跨引用超级能力,可回答多论文查询,从而加快学术评审。研究人员可以从逐个扫描 PDF 转向从整个语料库中获取精选见解。
DeepSeek v3
主题 1. DeepSeek R1 模型性能与集成
- DeepSeek R1 在数学和推理方面超越竞争对手:DeepSeek R1 Distill Qwen 32B 模型因其在复杂数学任务中的卓越表现而受到赞誉,超越了 Llama 405B 和 DeepSeek V3 671B 等模型。用户强调了其几何推理能力和多阶段 RL 训练,基准测试显示其数学性能达到 92%。
- DeepSeek R1 集成挑战:用户报告了将 DeepSeek R1 集成到 GPT4All 和 LM Studio 等平台时遇到的困难,理由是缺少公共模型目录以及需要 llama.cpp 更新。一些用户还面临 API 性能下降和审查过滤器的问题。
- DeepSeek R1 的思维链 (Chain-of-Thought) 推理:该模型外化推理步骤的能力(例如拼写 ‘razzberry’ 与 ‘raspberry’ 的对比)被视为一大特色。用户指出其具有增强 Claude 和 O1 等其他模型推理能力的潜力。
Theme 2. AI 模型量化与微调
- Unsloth 推出动态 4-bit 量化:Unsloth 新的动态 4-bit 量化方法有选择地避免压缩某些参数,在减少 VRAM 使用的同时保持准确性。用户将其与 BnB 8-bit 进行了对比,称赞其在模型优化方面的效率。
- Phi-4 的微调挑战:用户报告了微调 Phi-4 模型时遇到的问题,理由是输出质量差和循环修复。建议包括调整 LoRA settings 并确保使用高质量数据集以获得更好结果。
- 重温 Chinchilla 公式:围绕 Chinchilla 公式的讨论强调了模型大小与训练 tokens 之间的平衡。用户注意到许多模型超过了最佳阈值,导致资源利用效率低下。
Theme 3. AI 基础设施与大规模投资
- Stargate 项目:5000 亿美元 AI 基础设施计划:OpenAI 的 Stargate Project 旨在四年内投资 5000 亿美元,在美国建设先进的 AI 基础设施。初始资金包括来自 SoftBank、Oracle 和 MGX 的 1000 亿美元,重点关注就业创造和国家安全。
- 谷歌向 Anthropic 投资 10 亿美元:谷歌对 Anthropic 的追加投资显示了对该公司下一代模型的信心,引发了关于滚动融资策略和 AI 竞争的猜测。
- DeepSeek R1 硬件需求:运行完整的 DeepSeek R1 671B 模型需要大量硬件,据估计需要花费 18,000 美元 购买多块 NVIDIA Digits。用户讨论了这种配置的可行性,一些人选择了更便宜的替代方案,如 4xA4000。
Theme 4. AI 在创意与技术领域的应用
- Gemini 2.0 Flash Thinking 模型发布:谷歌的 Gemini 2.0 Flash Thinking 模型拥有 100 万 token 上下文窗口和 64K 最大输出 token,已针对 DeepSeek R1 进行了测试。用户赞扬了其在大规模推理任务中的潜力,尽管一些人指出了在处理复杂提示词时的挑战。
- NotebookLM 用于教会服务和学习工作流:一位用户利用 NotebookLM 分析了 16 个 5 小时的 YouTube 直播,生成了一本 250 页的书和一份 2000 页的圣经研究资料。其他人将其集成到学习日常中,称赞其在参考文献查找方面的效率。
- AI 艺术面临敌对反应:用户报告了对 AI 生成艺术的负面反应,有些人甚至因为使用这些工具而被言语攻击。这反映了社会对创意领域 AI 应用的持续抵制。
Theme 5. AI 安全、伦理与监管
- 对 AI 导致失业的担忧:一位创始人对其 AI 初创公司的成功可能导致的裁员表达了道德困境,引发了关于 AI 进步对社会经济影响的辩论。用户将其与同样削减工作岗位的日常自动化进行了比较。
- AI 安全指数与模型对齐:围绕 AI Safety Index 的讨论强调了在 MiniCPM 等模型中建立稳健安全指标的必要性。用户质疑某些模型缺乏对齐和安全实践,强调了伦理 AI 开发的重要性。
- AI 监管挑战:一场关于 AI 监管的会议探讨了近期政策的影响,来自 SemiAnalysis 的 Dylan Patel 讨论了不断演变的监管格局中的赢家和输家。人们对 AI 开发中政府与企业的重叠表示担忧。
DeepSeek R1
主题 1. 模型优化之战:量化、微调与 Scaling 之争
- Unsloth 的动态 4-bit 量化撼动 VRAM 效率:Unsloth 的动态 4-bit 量化避免了压缩关键参数,在保持准确性的同时大幅降低了 VRAM 占用。用户将其与 BnB 8-bit 进行了比较,指出动态 4-bit 在内存和性能之间取得了平衡。
- Phi-4 微调失败引发架构争论:微调 Phi-4 导致输出效果不佳,用户将其归咎于模型架构。其他 Notebook 中的权宜之计暗示了对专门超参数的需求。
- 训练 Token 过剩背景下重审 Chinchilla Scaling Laws:关于 Chinchilla 的模型大小与 Token 比例的讨论再次升温,许多模型已经超越了阈值。经验性的 Scaling 证明敦促为了效率进行资源优化。
主题 2. AI 基础设施军备竞赛:5000 亿美元项目与硬件障碍
- Stargate 项目 5000 亿美元的雄心面临资金质疑:OpenAI 的 Stargate Project 旨在投入 5000 亿美元用于 AI 基础设施,但像 Gavin Baker 这样的批评者质疑 SoftBank 的流动性。Elon Musk 抨击该提案不切实际。
- DeepSeek R1 671B 需 1.8 万美元硬件,引发成本辩论:据报道,运行 DeepSeek R1 671B 需要 4x NVIDIA Digits(1.8 万美元),而用户提出了更便宜的 4xA4000 方案。怀疑者认为更大的模型并不等于更好的 ROI。
- Apple Silicon 挑战 R1 32B 的 4-bit 量化极限:M3 Max MacBook Pro 用户测试了 R1 32B 的 4-bit 量化,注意到质量有所下降。尽管存在精度权衡,MLX 优化变体仍带来了速度提升。
主题 3. Agentic AI:自主系统中的炒作与现实
- 脚本工作流被贴上 “Agentic AI” 标签引发用户反感:成员们嘲笑了将基础脚本工具等同于 Agentic AI 的营销主张,理由是缺乏真正的自主性。要求在 “Agent” 定义上保持透明度的呼声日益高涨。
- GRPO 和 T1 RL 论文预示强化学习变革:GRPO 的极简实现和 T1 RL 的规模化自我验证论文引发了兴趣。人们对优势计算中的 KL 散度处理表示担忧。
- OpenAI 的 “Operator” 预告浏览器自动化,但 API 缺席:泄露消息透露了用于浏览器操作的 ChatGPT Operator,但不支持 API。用户推测这是通往 “PhD-level Super Agents” 的权宜之计。
主题 4. 工具动荡:IDE 之战、API 怪癖与 RAG 现实
- Windsurf 的自动记忆功能与 Cascade 的循环冲突:Windsurf 的项目记忆功能赢得了赞誉,但 Cascade 在 FastAPI 文件访问上出了差错,并陷入了修复循环。用户敦促重新编写 Prompt 以跳出循环。
- LM Studio 0.3.8 增强了 LaTeX 和 DeepSeek R1 “Thinking” UI:此次更新增加了 LaTeX 渲染和 DeepSeek R1 界面,修复了 Windows 安装程序的 Bug。用户称赞了 Vulkan GPU 去重技术带来的稳定性。
- Perplexity 的 Sonar Pro API 在 SimpleQA 基准测试中超越竞争对手:Sonar Pro 以 73.3% 的数学得分和 1M-token 上下文主导了基准测试,但上线初期的故障导致了 500/403 错误。关于欧盟托管的 GDPR 合规性辩论也愈演愈烈。
主题 5. 伦理、审查与劳动力流失担忧
- DeepSeek R1 性能下降 85% 引发审查猜疑:用户将 R1 隔夜性能崩溃归咎于内部审查过滤器。针对敏感 Prompt 的绕过方法开始流行,同时运行时间监控器也在跟踪修复进度。
- 创业公司创始人深陷 AI 驱动裁员的愧疚:一位创始人对他们的 AI 工具可能导致的失业表示哀叹,引发了关于自动化伦理的辩论。批评者将其比作历史上的技术变革。
- 微软 Phi-3.5 的安全推送引发了 Uncensored Fork:Phi-3.5 “过度热衷”的审查导致了一个 Hugging Face fork。程序员批评其拒绝回答良性查询,并嘲讽其在井字棋问题上的回避。
第 1 部分:Discord 高层级摘要
Unsloth AI (Daniel Han) Discord
-
来自 Unsloth 的强力 4-bit 量化:Unsloth 引入了一种动态 4-bit 量化方法,该方法避免压缩特定参数,在仅占用一小部分 VRAM 的情况下保持了极高的准确度。
- 用户将其与 BnB 8-bit 方案进行了比较,结果显示动态 4-bit 在仅略微增加内存需求的情况下保留了性能。
-
Phi-4 微调惨败:用户报告了 Phi-4 模型在微调后输出效果不佳的问题,质疑是否是模型架构的原因。
- 他们注意到微调在其他 Notebook 上可以运行,暗示 Phi-4 可能需要专门的设置才能获得更好的响应。
-
Chinchilla 危机:规模 vs. Token:参与者重新讨论了 Chinchilla 公式,重点关注模型规模与训练 Token 之间的相互作用,以实现效率最大化。
- 他们观察到许多模型超出了建议的阈值,并分享了缩放增益的经验证明,呼吁进行资源优化。
-
合成数据热潮:一些人主张使用“无限合成数据流”来强化模型训练,强调 eval 合规性和精选输入。
- 他们警告说,如果数据精选过于随意,会出现 Garbage in, garbage out(垃圾进,垃圾出) 的情况,敦促对合成数据集进行专门监督。
-
Agentic AI “全是炒作”的说法:成员们对将基础的基于脚本的系统贴上 Agentic AI 标签的营销策略表示不满,认为其缺乏真正的自主能力。
- 他们指出了宏大的品牌声明与有限的 Agent 功能现状之间的差距。
Codeium (Windsurf) Discord
-
网页搜索之困:Codeium 对比 Windsurf:一位用户敦促 Codeium 追赶 Windsurf 的网页搜索能力,并引用了 扩展更新日志。
- 他们通过引用 隐私政策 并对比 JetBrains 与 VS Code 的功能,对数据处理政策提出了质疑。
-
Windsurf IDE 访问难题:在最新的 Windsurf 更新后,多位成员在 Ubuntu 上难以打开 FastAPI 文件,并指出 Cascade 无法读取或编辑某些路径。
- 虽然有人建议调整文件权限或环境设置,但部分开发者的这一问题仍然存在。
-
Cascade 令人困惑的代码对话:几位开发者报告称,在处理复杂的代码调试提示词时,Cascade 会陷入重复修复的循环。
- 他们发现重新表述指令或提供更多上下文有助于打破循环,这显示了结构良好的提示词的重要性。
-
提示词威力与项目记忆:用户赞扬了 Windsurf 自动生成的记忆功能,它可以跨会话携带上下文,并引用了一个 论坛帖子 以获取更深层的项目记忆想法。
- 他们还引用了一篇 Cline 博客文章,强调“规划优于完美的提示词”以改善 AI 交互。
-
Diff 查看器困境与 Writemode 烦恼:社区成员经常在 Windsurf 的 Diff 查看器中遇到配色方案混淆,并询问 Writemode 是否免费。
- 一位用户澄清这是付费功能,而其他用户则在探索通过 Flow Actions 连接多个 LLMs,以实现更灵活的集成。
LM Studio Discord
-
LM Studio 0.3.8 增强思考 UI:新发布的 LM Studio 0.3.8 为 DeepSeek R1 添加了 思考 UI (Thinking UI),并通过
\text{...}块支持 LaTeX 渲染。- 与会者注意到它解决了 Windows 安装程序问题并消除了重复的 Vulkan GPUs,使使用更加顺畅。
-
DeepSeek R1 Distill Qwen 32B 惊艳数学迷:用户称赞 DeepSeek R1 Distill Qwen 32B 在复杂的 AIME 级别数学测试中表现优于 Llama 405B 等其他本地模型。
- 他们引用了 Hugging Face 发布页面 以获取更多细节,并赞扬其增强的推理步骤。
-
Apple Silicon 上的量化博弈:参与者探索了使用 4-bit 量化以在 M3 Max MacBook Pro 上运行 R1 32B 模型,并注意到答案质量可能下降。
- 多位用户测试了 MLX 优化的变体以降低内存需求,暗示尽管可能存在精度权衡,但速度更快。
-
671B 部署的高昂代价:据估计,运行完整的 DeepSeek R1 671B 需要价值 18,000 美元 的硬件(多个 NVIDIA Digits),这引发了关于可行性的争论。
- 其他人提到 4xA4000 配置是一条更便宜的路线,并评论说更大的模型并不总是能保证更优的性能。
Nous Research AI Discord
-
Stargate 的 5000 亿美元计划引发关注:有传言称 Project Stargate 正寻求来自 SoftBank 的 5000 亿美元投资,但鉴于 SoftBank 有限的流动性和债务状况,这一消息引发了质疑,正如 Gavin Baker 在此处所指出的。
- 讨论引用了 Elon Musk 的评论,他认为 SoftBank 并没有这么多现金,这进一步加深了对该提案真实性的怀疑。
-
对 DeepSeek 在 Razzberry 拼写上的质疑:成员们测试了 DeepSeek R1 Distill Llama-8B,观察它在拼写“razzberry”与“raspberry”时如何将推理过程外显化。
- 他们强调了关于零个“p”的滑稽混乱,展示了 DeepSeek 的 Chain-of-Thought(思维链)揭示过程,以及它在模型间实现更深层协同的潜力。
-
FLAME 在 Excel 领域表现出色:一个名为 FLAME 的 60M 参数模型使用 Excel 专用 Tokenizer 来处理公式补全和修复,其表现足以媲美 Davinci 等更大型的模型。
- 社区成员赞赏其针对性的训练和较小的体积,认为这是处理特定领域任务的一种强有力的方法。
-
EvaByte 实现无 Token 化:EvaByte 作为一款 6.5B 基于字节的模型首次亮相,它使用 5 倍更少的数据并实现了 2 倍更快的解码,在无需 Tokenizer 的情况下开启了多模态的可能性。
- 尽管怀疑者对其硬件效率提出质疑,但结果表明,向具有更广泛灵活性、面向字节的训练转型是可行的。
-
STAR 与 TensorGrad 撼动模型架构:STAR 概述了一种改进 LLM 结构的进化方法,声称在扩展性和效率方面获得了性能提升。
- TensorGrad 引入了用于简化矩阵运算和符号优化的命名边(named edges),吸引了渴望摆脱繁琐数字维度映射的开发者。
Interconnects (Nathan Lambert) Discord
-
Stargate 获得宏大增长:OpenAI 新的 Stargate Project 确定了一项为期四年、总额高达 5000 亿美元的巨额计划,其中 1000 亿美元已由 SoftBank、Oracle 和 MGX 立即承诺,用于推动先进的 AI 基础设施建设(参考资料)。
- 这一巨大的倡议预计将创造大量就业机会,并巩固美国在 AI 领域的领导地位,Microsoft 官方博客和各大科技频道均对此进行了报道(博客链接)。
-
Bespoke-Stratos-32B 挑战基准测试:从 DeepSeek-R1 蒸馏而来的 Bespoke-Stratos-32B 模型在推理任务中超越了 Sky-T1 和 o1-preview,且仅需 47 倍更少的训练样本(来源)。
- 它利用一个价值 800 美元的开源数据集实现了极具成本效益的结果,激发了社区对数据收集和协作改进的兴趣。
-
谷歌再次向 Anthropic 投资 10 亿美元:为了再次展示信心,Google 向 Anthropic 注资 10 亿美元,引发了关于滚动融资策略和 AI 竞争的猜测(推文)。
- 这笔投资强化了 Google 对新兴 AI 参与者的持续承诺,讨论重点关注了 Anthropic 下一代模型可能的扩张。
-
Gemini-2.0-Flash 跃升至 Arena 榜首:Gemini-2.0-Flash-Thinking 以 73.3% 的强劲数学得分和 100 万 Token 的上下文窗口夺得 Chatbot Arena 第一名(链接)。
- 开发者称赞了其在大规模推理方面的潜力,同时也承认未来的迭代可能会进一步优化其性能。
-
GRPO 调整与 T1 RL 的成功:社区成员对 GRPO 方法提出质疑,指出在优势计算(advantage calculations)中处理 KL 散度(KL divergence)时存在疑虑,并引用了 TRL 的相关问题。
- 与此同时,来自智谱和清华的一篇新 T1 论文详细介绍了针对大语言模型的扩展 RL(强化学习),将试错与自我验证相结合,详见 arXiv。
aider (Paul Gauthier) Discord
-
Gemini 2.0 备受瞩目:Google 推出了具有 100 万 token 上下文窗口、64K 最大输出 token 以及原生代码执行支持的 Gemini 2.0,正如这条推文所确认的那样。
- 用户将其与 DeepSeek R1 进行了对比测试,对其处理复杂任务的能力和整体效率表示好奇。
-
Aider 的 Markdown 改造:用户描述了一种改进 Aider 的精细方法,即将主要功能、规格和重构步骤存储在 markdown 中,并参考了高级模型设置。
- 他们强调,LLM 自我评估配合单元测试有助于生成更简洁的代码并缩短开发循环。
-
辩论 R1 vs. Sonnet:社区成员观察到了 DeepSeek R1 和 Sonnet 之间的区别,并引用了 DeepSeek Reasoning Model 文档中的思维链能力。
- 他们注意到 Sonnet 反复提供更彻底的建议,并提议将 R1 的推理输出合并到其他模型中以应对高级场景。
-
Aider 中针对 PDF 的 RAG:一位用户询问了在 Aider 中引用 PDF 的 RAG 功能,发现 Sonnet 通过一个简单的内置命令即可支持该功能。
- 该讨论激发了利用外部数据源为 Aider 工作流提供更深层次上下文的想法。
-
Aider 升级与 Nix 历险:多位用户在 Aider 中遇到了升级错误和配置障碍,分享了诸如删除
.aider目录或通过pip重新安装等技巧。- 他们还提到了 NixOS 中 Aider 0.72.1 的 PR,并思考了 Neovim 插件设置,但最终建议仍在审查中。
Stackblitz (Bolt.new) Discord
-
Bolt 获得巨额资金支持:今天,Bolt 宣布获得由 Emergence 和 GV 领投、Madrona 和 The Chainsmokers 支持的 1.055 亿美元 B 轮融资,详见这条推文。
- 他们感谢社区对 devtools 和 AI 增长的支持,并承诺未来将加强 Bolt 的功能。
-
Telegram 版俄罗斯方块新花样:一位开发者旨在构建一个以肉类为主题方块的 Telegram 小程序版俄罗斯方块,并分享了 Telegram Apps Center 作为资源。
- 他们计划加入排行榜,希望这个古怪的概念能激发社区协作。
-
Claude 解决代码困惑:成员们发现,在 Bolt 遇到困难时,使用 Claude 处理棘手的代码任务和检索策略更新非常成功。
- 他们注意到 Claude 在处理 Supabase 用户权限方面的彻底性,赞扬了 AI 驱动调试的协同效应。
Yannick Kilcher Discord
-
DeepSeek R1 与 OpenAI 展开竞争:DeepSeek R1 以 92% 的数学性能超越了 Gemini 和 O1,凭借技术实力和成本优势势头强劲,详见 DeepSeek R1 - API, Providers, Stats。
- 讨论重点包括高级几何推理、多阶段 RL 训练,以及对 DeepSeekMath (arxiv.org/abs/2402.03300) 的深入探讨,该研究推动了基于模型计算的边界。
-
5000 亿美元的 Stargate Project 引发争论:OpenAI 披露了 Stargate Project,涉及 5000 亿美元的 AI 基础设施资金,参考其官方推文。
- 评论员对政府与企业的重叠以及美国的决策收益表示质疑,引用了 AshutoshShrivastava 等来源。
-
AI 初创公司面临职位取代的道德拷问:一位创始人对其快速发展的 AI 解决方案可能引发的裁员表示悔意,称其为一个道德难题。另一位用户将其比作同样削减职位的日常自动化,反映了更广泛的社会经济问题。
- 许多人同意此类副作用伴随着新的 AI 发展,强调了进步与劳动力流失之间的紧张关系。
-
IntellAgent 重新定义 Agent 评估:开源的 IntellAgent 框架应用模拟交互进行多层级 Agent 诊断,展示于 GitHub。
- 发表在 arxiv.org/pdf/2501.11067 的相应论文分享了数据驱动批评带来的惊人结果,并在
intellagent_system_overview.gif中展示了视觉工作流。
- 发表在 arxiv.org/pdf/2501.11067 的相应论文分享了数据驱动批评带来的惊人结果,并在
-
UI-TARS 和 OpenAI Operator 成为焦点:Hugging Face 发布了 UI-TARS,旨在实现自动化 GUI 任务,包括 UI-TARS-2B-SFT 等变体,详见其论文。
- 与此同时,据 Stephanie Palazzolo 报道,OpenAI 正在为 ChatGPT 准备 Operator 功能以执行浏览器操作。
OpenRouter (Alex Atallah) Discord
-
OpenRouter 为网页搜索定价:新的网页查询定价为 每 1000 次结果 4 美元,将于明天开始执行,单次请求成本约为 低于 0.02 美元。
- 成员们对这种精简的模型表示欢迎,但对大规模使用开始后的计费细节表示好奇。
-
API 访问权限小范围测试上线:OpenRouter 的 API 访问权限 将于明天开放,并为用户提供额外的 Customizability(可定制性)选项。
- 成员们期待测试这些新功能,并分享关于性能和集成的反馈。
-
DeepSeek R1 性能暴跌 85%:报告显示 DeepSeek R1 的 API 性能在隔夜之间下降了 85%,引发了对内部审查和 Censorship(审查)过滤器的担忧。
- 一些人分享了针对敏感提示词的变通方法,而其他人则关注 DeepSeek R1 – Uptime and Availability 以获取官方修复。
-
Cerebras 的 Mistral Large 吊足胃口,但用户仍无法使用:许多人希望在 OpenRouter 上看到 Cerebras 的 Mistral Large,但目前仍未对公众开放。
- 感到沮丧的用户转而使用 Llama 模型,质疑 Mistral Large 是否如宣传的那样准备就绪。
Perplexity AI Discord
-
Sonar Pro 引起轰动:今天,Perplexity 推出了新的 Sonar 和 Sonar Pro API,使开发者能够将生成式搜索与实时网页研究及强大的引用功能相结合。
- Zoom 等公司已采用该 API 来提升 AI Companion 2.0,同时 Sonar Pro 的定价据称比其他同类产品更低。
-
SimpleQA 基准测试:Sonar Pro 大放异彩:Sonar Pro 在 SimpleQA 基准测试中表现优于主要竞争对手,在回答质量上超越了其他搜索引擎和 LLM。
- 支持者称赞其“全网覆盖”能力远超竞争解决方案。
-
对比层出不穷:模型调整与欧洲需求:社区成员报告称 Sonar Large 现在运行速度超过了 Sonar Huge,官方暗示将退役旧模型。
- 与此同时,欧洲的 GDPR 合规推进引发了关于在本地数据中心托管 Sonar Pro 的讨论。
-
Altman 预告“博士级超级 Agent”:传闻 Altman 在华盛顿特区的一次简报中提到了先进的“博士级超级 Agent (PhD-level Super Agents)”,引发了人们对下一代 AI 能力的好奇。
- 观察人士将这些假设的 Agent 视为即将取得重大进展的信号,尽管具体细节仍然很少。
-
Anduril 的 10 亿美元武器工厂备受关注:有关 Anduril 建立 10 亿美元“自主武器工厂 (Autonomous Weapons Factory)”的消息提高了人们对防御导向型机器系统的兴趣,如此视频所示。
- 参与者讨论了自主战争,并强调了与武器化 AI 相关的伦理问题。
MCP (Glama) Discord
-
MCP 的代码处理:成员们讨论了 MCP language server 中不断发展的代码编辑功能,指出其处理大型代码库的能力有所提高,并能与 Git 操作协同工作。
- 他们提到了一个新的 Express 风格的 API Pull Request,这可能会统一 MCP 服务器在语义工具选择的同时更新代码的方式。
-
利用 Brave 浏览获取清晰文档:用户依靠 Brave Search 获取更新的文档,并将参考资料编译成 Markdown 以进行快速集成。
- 他们强调了使用 brave-search MCP server 方法来抓取和自动化文档检索,并称赞了该流程的精简性。
-
2024 年 GPT 的不满:社区成员对自定义 GPT (custom GPT) 未能整合 ChatGPT 的新功能表示沮丧,这加剧了对自定义 GPT 市场的怀疑。
- 他们指出担心这些机器人会失去相关性,并对改进速度缓慢表示失望。
-
Claude Desktop 的 Prompt 展示:参与者探索了将 Prompt 挂载到 Claude Desktop 的方法,重点关注如何通过
prompts/List端点展示 Prompt。- 他们分享了日志工具示例和部分代码片段,旨在简化测试专业 Prompt 的过程。
-
Apify Actors 与 SSE 试验:开发者正在开发 Apify Actors 的 MCP 服务器,构建数据提取功能,但面临动态工具集成的挑战。
- 围绕 Anthropic TS client 的问题凸显了对 SSE 端点的困惑,导致一些成员在等待修复期间转向使用 Python。
Latent Space Discord
- Ai2 ScholarQA 加速文献综述:Ai2 ScholarQA 推出了一款基于 RAG 的多论文查询解决方案,并发布了官方博客文章解释其交叉引用功能。
- 它旨在帮助学术界人士从各种开放获取论文中快速获取研究见解,重点关注对比分析。
- 特朗普启动 5000 亿美元 Project Stargate:特朗普总统宣布了 Project Stargate,承诺在四年内投入 5000 亿美元巨资扩建美国的 AI 基础设施,并获得了 OpenAI、SoftBank 和 Oracle 的支持。
- Elon Musk 和 Gavin Baker 等评论员对该金额的可行性表示质疑,称其“荒谬”,但仍对其雄心表示认可。
- Bespoke-Stratos-32B 问世:根据官方公告,一款从 DeepSeek-R1 蒸馏而来的新型推理模型 Bespoke-Stratos-32B 展示了先进的数学和代码推理能力。
- 开发者强调,它采用了 “Berkeley NovaSky 的 Sky-T1 配方”,在推理基准测试中超越了之前的模型。
- Clay GTM 融资 4000 万美元:Clay GTM 宣布以 12.5 亿美元的估值完成了 4000 万美元的 B 轮扩展融资,其强劲的营收增长引起了投资者的关注。
- 他们现有的资金大部分仍未动用,并计划放大势头以推动进一步增长。
- LLM Paper Club 聚焦语言模型物理学:LLM Paper Club 活动重点关注 Physics of Language Models 和 Retroinstruct,详情见此链接。
- 参与者可以通过 RSS 标志订阅 Latent.Space 的活动提醒,确保不会错过任何活动。
GPU MODE Discord
- NVIDIA Blackwell Codegen 持续推进:PR #12271 揭示了 Blackwell B100/B200 codegen 10.0,并预告了 RTX 50 codegen 12.0,引发了对 sm_100a 和 sm_101a 的期待。
- 尽管有关于 sm_120 的传闻以及 Blackwell 白皮书的推迟,社区仍热切期待更多消息以及关于 Accel-Sim 框架的演讲。
- Triton 3.2 HPC 故障:当前的 TMA 实现可能会在
@triton.autotune时崩溃,导致持久化 matmul 描述符和数据依赖问题出现混乱。- 一位用户指向了 GridQuant gemm.py 第 79-100 行以获取描述符创建的见解,强调了 Triton kernel 的复杂性。
- GRPO 在 RL 中势头强劲:一个极简的 GRPO 算法已接近完成,其初始版本预计很快运行,早期实验已在进行中。
- Kimi-k1.5 论文和 TRL 中新的 GRPO trainer 凸显了人们对基于课程的学习(curriculum-based)强化学习日益增长的兴趣。
- 利用 HPC 工具加速 LLM 推理:一位用户寻求更快的 Hugging Face
generate()性能,引用了此提交并讨论了针对更重型模型的 liuhaotian/llava-v1.5-7b。- 同时,这篇 PyTorch 博客文章探讨了 HPC 友好型策略,如专门的调度和内存优化,以提升大模型推理速度。
- Torch 与 Triton 在 3.2 版本上的博弈:新的 Triton 3.2 删除了
AttrsDescriptor,导致torchao和 torch.compile 中断,记录在 PyTorch issue #144103 中。- Triton issue #5669 中的 INT8 x INT8 点积失败,加上重大的 JIT 重构,揭示了反复出现的向后兼容性难题。
Eleuther Discord
-
谷歌的 Titan 预告与 Transformers 之争:在 Google 的 Titans 宣布利用先进的内存特性获得卓越性能后,成员们讨论了推理阶段处理(inference-time handling)的潜在改进。
- 社区观点认为,原始方法可能难以复制,反映了对实验透明度不足的担忧。
-
数值稳定性带来的 Grokking 收益:最近的一篇论文 Grokking at the Edge of Numerical Stability 强调了数值问题(numerical issues)如何阻碍模型训练,引发了关于改进优化策略的讨论。
- 成员们辩论了一种一阶(first-order)方法,并引用了 这个 GitHub 仓库 以获取更深入的见解。
-
DeepSeek 奖励模型传闻:与会者研究了 DeepSeek-R1-Distill-Qwen-1.5B 模型的指标差异,引用了部分评估中的 0.834 (n=2) 对比 97.3 (n=64)。
- DeepSeek_R1.pdf 的链接引用了解码策略和基于奖励训练的架构细节。
-
Minerva Math 与 MATH-500 的改进:参与者测试了 minerva_math 与 sympy 的符号等价性,引用了来自 OpenAI “Let’s Think Step by Step”研究中的 MATH-500 子集。
- 他们讨论了 DeepSeek R1 在这些任务中表现得像基座模型(base model)还是需要聊天模板(chat template),并指向 HuggingFaceH4/MATH-500 以获取更多背景信息。
-
线性注意力与多米诺学习:成员们探索了一种专门的线性注意力(linear attention)架构,旨在不损失稳健性能的情况下提高速度。
- 他们还讨论了技能堆叠中的多米诺效应(Domino effect),引用了 Physics of Skill Learning 来强调神经网络中顺序能力是如何出现的。
OpenAI Discord
-
DeepSeek 与 o1 及 Sonnet 的对决:DeepSeek 在数学和 GitHub 相关的基准测试中与 o1 和 Sonnet 等模型进行了对比,表现强劲。它可以在其官方网站上免费访问,并为各种平台提供 API 集成。
- 一些用户在 o1 上遇到了问题,但他们称赞官方的 DeepSeek R1 功能在快速评估方面更稳定,这推动了对一致性模型替代方案的需求。
-
AI 安全引发好奇:成员们质疑为什么 AI 网络安全 仍然被忽视,并提到 CrowdStrike 多年来一直使用 ML。他们看到了生成式 AI 在自动化威胁检测和基于代码的入侵分析方面的潜力。
- 社区声音认为,企业更强调利润而非基础安全,指出营销炒作与真正的用户保护之间存在脱节。
-
纯图像 GPT 势头强劲:一位用户想完全基于聊天的截图来训练一个类似 GPT 的模型,绕过基于文本的流水线。他们想知道在现有的 chat completion API 中是否可以进行文件上传或图像数据处理。
- 其他人权衡了直接图像摄取(image ingestion)的可行性,建议在 API 支持内联文件之前增加额外的预处理步骤。
-
OCR 困惑与地图解决方案:成员们发现 OCR 提示词会导致严重的幻觉(hallucinations),特别是在不受约束的示例中。他们探索了一种读取地图的专门变通方法,希望 OpenAI 的 O 系列能尽快解决空间数据问题。
- 他们警告了自由格式 OCR 设置中的上下文污染(context contamination),结论是在更好的 GIS 支持出现之前,特定领域的约束更为安全。
Notebook LM Discord Discord
- NotebookLM 彻底改变了教会聚会:一位用户利用 NotebookLM 分析了 16 个时长 5 小时的 YouTube 直播,生成了一本 250 页的书和一份 2000 页的圣经研读资料。
- 他们引用了 We Need to Talk About NotebookLM 作为动力,赞扬其处理海量文本的能力。
- 学习工作流开始采用 NotebookLM:一位用户在数周的学习例程中集成了 NotebookLM,认为它简化了参考文献的查找。
- 他们分享了一个 YouTube 视频 展示其效率,激励他人采用类似的方法。
- Gemini 在 Prompt 优化方面势头强劲:成员们报告称,通过将 NotebookLM 与 Gemini 配合使用以精炼指令,可以获得更好的输出效果。
- 他们称赞了 Gemini 对提升清晰度的影响,但也指出了在针对高度特定文档时的挑战。
- APA 引用和音频概览引发讨论:参与者在处理 APA 引用时遇到了困难,发现 NotebookLM 除非调整名称,否则会依赖之前使用过的来源。
- 他们还讨论了每天生成多达三次的新音频概览(Audio Overviews),并警告存在重复风险,且需要先删除旧文件。
- CompTIA A+ 内容受到关注:一位用户发布了 CompTIA A+ 音频系列的第一部分,后续章节正在制作中。
- 社区成员将其视为自主进度认证准备的关键资源,NotebookLM 提供了快速的信息获取。
Stability.ai (Stable Diffusion) Discord
- Flux 模型表现与负面提示词引导:一位用户报告称,去蒸馏的 Flux 模型在配置了 CFG 设置后,在某些内容上表现更好,尽管运行速度较慢。
- 他们指出,负面提示词(Negative Prompts)可以提高 Prompt 的遵循度,但会增加更重的计算开销。
- AI 艺术引发敌对情绪:一些参与者在展示 AI 生成的艺术作品时遇到了敌对反应,包括因为使用这些工具而被言语攻击。
- 他们提到,对 AI 艺术的负面情绪已持续多年,引发了关于更广泛接受度的讨论。
- Discord 机器人诈骗横行:成员们标记了来自机器人账号的异常私信(DMs),这些账号索要个人信息,揭示了一种持续的诈骗趋势。
- 有人回忆起早期的付费“服务”推销,暗示这些诈骗仍然是 Discord 的老问题。
- CitivAI 的故障与担忧:一位用户指出 CitivAI 每天多次宕机,引发了对该服务稳定性的担忧。
- 其他人也分享了类似的经历,质疑该平台的可靠性。
- SwarmUI 面部修复备受关注:一位用户询问关于 SwarmUI 中的面部修复问题,想知道是否需要 Refiner 来提高图像保真度。
- 他们注意到社区对增强现实感的追求,旨在进一步优化图像生成流水线(Image-generation Pipelines)。
LlamaIndex Discord
- AgentWorkflow 发布并增强多 Agent 系统:LlamaIndex 宣布推出 AgentWorkflow,这是一个基于 LlamaIndex Workflows 构建的新型高级框架,旨在支持多 Agent 解决方案。
- 他们强调了扩展的工具支持和社区的热情,称其为“迈向更强大 Agent 协作的下一步”。
- DeepSeek-R1 挑战 OpenAI 的 o1:DeepSeek-R1 模型已接入 LlamaIndex,其性能可与 OpenAI 的 o1 媲美,并可用于全栈 RAG 聊天应用。
- 用户赞扬了其集成的便利性,并寄希望于“进一步扩展以用于实际场景”。
- 开源 RAG 系统结合 Llama3 与 TruLens 力量:一份详细指南贡献了使用 LlamaIndex、Meta Llama 3 和 TruLensML 构建开源 RAG 系统的分步方法。
- 它对比了基础 RAG 方法与“带有 @neo4j 的 Agentic 变体”,包括关于 OpenAI vs Llama 3.2 的性能见解。
- AgentWorkflow 探索并行 Agent 调用:社区成员讨论了 AgentWorkflow 中的并行调用,同时承认 Agent 通常按顺序运行,而工具调用可以是异步的。
- 他们提议将“嵌套工作流(Nesting Workflows)”作为一种可能的技巧,以在多 Agent 流水线中实现并行任务。
Modular (Mojo 🔥) Discord
-
论坛功能优于 Discord 的快节奏:一位用户称赞 forum(论坛)比节奏飞快的 Discord 具有更好的存档功能和更深入的讨论,并引用了 general 频道的讨论。
- 他们建议利用论坛来避免向 Modular 员工提出的请求被淹没,并保持语言设计的清晰度,鼓励持续跨平台发布社区展示内容。
-
Nightly 版本悄然推进:简要提到了 Nightly 版本正在活跃更新中,但未透露具体细节。
- 对话将其列为未来更新的关注点,让社区对底层架构的新变化充满好奇。
-
Mojo 保留在 Modular.com:成员们好奇 Mojo 是否会像 Python 那样采用 .org 域名,但 #mojo 频道 确认它仍将保留在 modular.com 下。
- 他们强调 Mojo 不会从 Modular 中拆分出来,所有的努力都将统一在现有域名下。
-
MLIR 并行化优于 LLVM:用户强调 MLIR 的并行化比 LLVM 更有前景,并提到了正在进行的使并行执行更接近现实的工作。
- 他们将新实现视为高性能编译器的关键里程碑,尤其是目前 LLVM 仍在追赶。
-
Rust 处理工作窃取调度器:对话探讨了 Rust 在工作窃取(work-stealing)调度器与线程安全之间的冲突,指出这限制了在 yield 点跨越使用 mutex。
- 虽然复杂,但成员们主张对任务进行更细粒度的控制,认为尽管有开销,但用心的并发设计是值得的。
LAION Discord
-
SunoMusic 凭声音起飞:他们推出了一项功能,允许用户录制自己的歌声或乐器演奏,如 这条推文 所示。
- 这一新功能将用户的创造力转化为从个人录音中生成完整的歌曲。
-
音频标注难题:由于数据集有限,参与者发现衡量 background noise(背景噪声)和 recording quality(录音质量)非常棘手。
- 他们建议在现有样本中添加合成噪声,并参考了 audio_augmentations.ipynb。
-
构建音频数据集:一位贡献者维护着涵盖配音、视频剪辑 embedding 和科学知识图谱的开源数据集。
- 他们面临资源限制,但对新合作者的加入持开放态度。
-
Bud-E 推出情感化 TTS:他们展示了 Bud-E 的情感化文本转语音(TTS)路线图,强调了更具表现力的语音输出。
- 分享的音频样本暗示了在合成用户意图方面具有更深层次的细微差别。
-
教师投身 AI 项目:一位高中教师在处理教学任务的同时,还在扩展多个 AI 数据集项目。
- 他们拒绝了工作邀约以保持独立性,并依靠志愿者力量推动音频和视频数据集的发展。
Cohere Discord
-
DeepSeek 的 OpenAI Endpoint 探索:成员们使用了 OpenAI endpoint,并参考 DeepSeek 提供了代码示例,展示了如何为聊天请求定义自定义路由,并强调了灵活的 prompt 结构。
- 他们强调了简化调用的好处,赞扬了这种方法能够在使用各种文本生成框架时进行敏捷的试错,并对进一步的改进表示了兴趣。
-
最佳模型热议:’Command-R7b’ vs ‘Aya Expanse 32B’:一位用户询问了最受推崇的文本生成偏好,引发了对 Command-R7b 和 Aya Expanse 32B 的讨论,多位成员分享了使用经验。
- 他们指出了不同的性能表现,指出某些用例更倾向于使用 Command-R7b 处理更重的逻辑任务,而另一些则更喜欢 Aya Expanse 32B 以应对更广阔的创意语境。
-
Cohere Command R+ 08-2024 流量增长:成员们在聊天中重点介绍了新的 Cohere Command R+ 08-2024 模型,赞扬了其在 Azure AI Foundry 设置下扩展的文本生成能力。
- 他们讨论了与 LlamaIndex 工作流的协同作用,期待最终过渡到 Cohere API v2,并继续分享使用心得。
-
模因梦想:Cohere 的 LCoT 模型权重:爱好者们建议 Cohere 发布“LCoT 模因模型权重”,将喜剧线索与更深层次的推理相结合,并参考了用于喜剧扩展的企业级解决方案。
- 其他人对可行性表示怀疑,考虑到 Cohere 的品牌定位,但也表示希望这能为新受众带来专门的喜剧文本生成。
-
从静态到动态:图像转视频 AI 计划:一位用户展示了图像转视频生成的尝试,参考了多个 ML 框架,探索了跨领域转换,并寻求反馈。
- 他们特别提到了向 3D 过渡的扩展,并对推动视觉生成工作流中的创意动力表示兴奋。
LLM Agents (Berkeley MOOC) Discord
-
1 月 27 日前的教学大纲惊喜:即将到来的 MOOC 修订版教学大纲定于 1 月 27 日发布,将明确高级 LLM Agents 的内容。
- 组织者指出最终审批仍在进行中,但学习者可以期待很快看到具体的模块细节。
-
塑造舞台的演讲者:已注意到邀请梁文锋(Liang Wenfeng)的建议,尽管大多数客座演讲者的选择已经确定。
- 计划推出一份新的反馈表,以收集热心参与者对未来选择的更多意见。
-
黑客松热潮暂缓:目前尚未确认下一次活动的正式日期,一些人希望它能与春季计划保持一致。
- 组织者暗示未来的研究合作可能会与即将举行的任何黑客松相结合,因此关注者应保持关注。
-
春季 MOOC 超越秋季:新课程将在秋季内容的基础上进行构建,但不要求预先完成秋季课程,允许任何人加入。
- 它扩展了基础的 LLM Agent 概念,通过更新的材料针对老学员和新学员。
-
展望未来的研究合作:Song 教授正在评估对即将开展的小组研究项目的兴趣,以展示更广泛的 LLM Agent 进展。
- 鼓励感兴趣的学生提及他们的领域或课题,以塑造可能出现的任何共同努力。
Nomic.ai (GPT4All) Discord
-
GPT4All 的 DeepSeek R1 之谜:社区成员询问哪些 DeepSeek R1 蒸馏模型可以在 GPT4All 上运行,并指出缺少类似 LM Studio 的公开模型目录,暗示需要 llama.cpp 的更新。
- 他们讨论了这些模型发布的具体时间表,交流了如何确认稳定集成到 GPT4All 的准备情况。
-
WordPress 聊天机器人困扰:一位开发者试图在不使用插件的情况下将聊天机器人接入 WordPress,但在获取 API Key 方面遇到困难,引发了对官方指南的担忧。
- 其他人提出了替代方案,但讨论结束时仍未就立即获取密钥给出具体解决方案。
-
寻求免费 ChatGPT 访问权限:一位用户公开寻求 ChatGPT 的免费、无限使用,希望能有可行的变通方法或平台提供商的慷慨赠予。
- 对话凸显了对免费 AI 解决方案的持续需求,但对于合法的免费密钥尚未达成共识。
DSPy Discord
-
RAG 处理动态数据面临挑战:一位用户询问 基于 DSPy 的 RAG 如何管理动态数据,强调了对其实时适应性的关注,但目前尚未提供明确的解决方案。
- 其他人未对该查询做出解答,没有提供具体的代码示例或后续参考资料。
-
征集 DSPy 研究合作伙伴:一位用户请求在 DSPy 研究方面进行合作,并强调了在 AI for Good、LLMs 和 高等教育领域的经验。
- 他们表达了做出有意义贡献的强烈愿望,但未提供直接链接或资源。
-
LM Studio 在集成 DSPy 时遇到障碍:一位用户报告在将 LM Studio 与 DSPy 搭配使用时遇到困难,并将其与使用 Ollama 时更顺畅的体验进行了对比。
- 另一位成员询问 “你是如何使用该模型的?”,引发了关于本地环境设置和可能存在的兼容性陷阱的讨论。
-
Ollama 错误困扰:在将 DSPy 与 Ollama 运行时出现了一个涉及 ‘str’ 对象的错误,阻碍了数据摘要功能。
- 这迫使 DSPy 在没有数据感知建议器(data-aware proposer)的情况下运行,引发了对功能缺失的担忧。
-
仓库垃圾信息吐槽:一位用户抱怨仓库中的 垃圾信息(spam),可能与某个代币(coin)相关问题有关,称其 非常差劲。
- 他们认为这是对真正的 DSPy 讨论的一种令人厌恶的干扰,但尚未确定直接的解决办法。
Torchtune Discord
-
自定义 RLHF 重构获得支持:成员们提议移除所有自定义损失函数,同时提供一个文档页面以便于添加,参考 issue #2206。
- 他们还强调需要提供传递自定义前向传播函数的示例,以确保 DPO 全量微调(full-finetuning) 的兼容性。
-
Phi 4 PR 等待最终调整:Phi 4 PR 因在合并前需要进行一些调整而受到关注,计划近期优化其设计。
- 贡献者们表现出迅速解决这些问题的积极性,这与更广泛的 RLHF 增强计划保持一致。
-
SimPO 弃用重写路线图:开发者宣布 SimPO 已弃用,以减少冗余并推进新的 RLHF 方案(recipes)。
- 他们承诺更新相关文档,旨在对齐任务中实现更灵活的损失函数集成。
-
Nature Communications 论文发表引发热烈欢呼:该论文在 Nature Communications 上的专题展示获得了社区的热烈反馈。
- 它的被接收强调了持续的研究努力,引发了 超级酷 的反应和团队自豪感。
OpenInterpreter Discord
-
OpenInterpreter 1.0 预发布版与 Python 代码执行:即将发布的 OpenInterpreter 1.0 引发了关于移除 Python 代码执行 的猜测,成员们注意到 Python 在 1.0 预发布版中似乎未完全实现。
- 一位用户询问该功能是否会在稍后回归,反映出对编码功能 未来更新 的不确定性。
-
Markdown 和 TXT 是显示格式:一位用户澄清说,Markdown 和 TXT 文件是作为文本格式化机制,而非编程语言。
- 随后的评论暗示,可能正在开发某些功能以处理 OpenInterpreter 中的格式化行为。
Gorilla LLM (Berkeley Function Calling) Discord
-
Gorilla 模型获取指南:一位成员询问 Ollama 文档 中的 Gorilla 模型 是否正确,参考了 Hugging Face 上的 adrienbrault/gorilla-openfunctions-v2:Q6_K/model。
- 他们标记了其他人以确认构建函数调用(function-calling)LLM 的 正确引用。
-
LLaMA v2 扩展能力:LLaMA v2 包含 4096 上下文长度、30 块数量和 32 注意力头,以提供更大的容量。
- 参与者强调了 tokenizer 设置 和 量化版本,强调了这些高级用法的细节。
tinygrad (George Hotz) Discord
- Tinygrad 获得 Windows 适配:一位贡献者提交了 Windows 测试的 pull request,并询问 LLVM 或 Clang 是否可以驱动正式的 Windows 后端。
- 他们提供了一张显示 PR 详情的图片,并引发了关于如何确保在多种 Windows 配置下实现广泛测试覆盖的讨论。
- OpenCL GPU 支持成为优先级:另一位成员强调 GPU (OpenCL) 支持是 Windows 测试的关键补充,理由是其在不同硬件上的性能提升。
- 这一讨论突显了在 Windows 环境下优化 Tinygrad GPU 性能并完善跨平台兼容性的努力。
Axolotl AI Discord
- Liger Kernel 获得 KTO 支持:Liger Kernel 仓库正式合并了 KTO loss,标志着旨在增强性能的一次重大更新。
- 贡献者们对此表示庆祝,并强调 KTO loss 可以为更好地集成即将到来的模型更新提供桥梁。
- 利用 KTO 优势进行模型合并:工程师们讨论了可能受益于基于 KTO 指标的模型合并策略,并引用了 Liger Kernel 中新加入的功能。
- 他们强调了积极的协作,并期望该损失函数能简化未来版本中的合并工作。
Mozilla AI Discord
- Local-First X AI 黑客松在旧金山启动:组织者宣布将于 2 月 22 日在旧金山举办 Local-First X AI Hackathon,重点关注离线友好的开发策略。
- 他们期待现场气氛热烈,并鼓励参与者在活动日期前就先进的 Local-First AI 进行头脑风暴。
- 加入黑客松对话线程:一个专门的讨论线程现已开放,用于对项目构思和物流进行更深入的讨论。
- 组织者强调请尽快报名,并提到欢迎关于 Local-First 方法的新建议。
MLOps @Chipro Discord 没有新消息。如果该社区长时间没有活动,请告知我们,我们将将其移除。
HuggingFace Discord 没有新消息。如果该社区长时间没有活动,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该社区长时间没有活动,请告知我们,我们将将其移除。
PART 2: 渠道详细摘要与链接
完整的频道细分内容已针对电子邮件进行了截断。
如果您喜欢 AInews,请分享给朋友!预先感谢!