ainews-tinyzero-reproduce-deepseek-r1-zero-for-30
TinyZero:只需 30 美元即可复现 DeepSeek R1-Zero。
DeepSeek 热潮持续重塑着前沿模型的格局。来自伯克利的 Jiayi Pan 通过对 Qwen 模型进行高性价比的微调,在两项数学任务中成功复现了 DeepSeek R1 论文中的“另一项”成果——R1-Zero。一项关键发现指出,蒸馏效应在 15 亿(1.5B)参数规模处存在下限,且 RLCoT(强化学习思维链)推理正成为一种内在属性。研究表明,采用 PPO、DeepSeek 的 GRPO 或 PRIME 等各种强化学习技术均能取得类似效果,且从指令微调(Instruct)模型开始训练可以加速收敛。
“人类最后的考试”(HLE)基准测试推出了一项极具挑战性的多模态测试,涵盖 100 多个学科的 3,000 个专家级问题。目前各模型的表现均低于 10%,其中 DeepSeek-R1 达到了 9.4%。DeepSeek-R1 在思维链推理方面表现卓越,在性能超越 o1 等模型的同时,成本降低了 20 倍,并采用了 MIT 开源协议。在 WebDev Arena 排行榜上,DeepSeek-R1 在技术领域排名第二,在样式控制(Style Control)维度排名第一,表现直逼 Claude 3.5 Sonnet。
OpenAI 的 Operator 已向美国 100% 的 Pro 用户开放,能够执行订餐、预订行程等任务,并可作为 AI 论文搜索与总结的研究助手。Hugging Face 在经历显著增长后宣布了领导层变动;Meta AI 则发布了 Llama Stack 的首个稳定版本,带来了简化的升级流程和自动化验证。DeepSeek-R1 的开源成功广受赞誉,同时,针对 macOS 15+ 内存管理等技术挑战,MLX 引入了驻留集(residency sets)以确保运行稳定性。
RL is all you need.
2025年1月23日至1月24日的 AI 新闻。我们为您检查了 7 个 Reddit 子版块、433 个 Twitter 账号 和 34 个 Discord 社区(225 个频道,3926 条消息)。预计为您节省阅读时间(以 200wpm 计算):409 分钟。您现在可以在 AINews 讨论中标记 @smol_ai!
DeepSeek 热潮继续重塑前沿模型格局。来自伯克利的 Jiayi Pan 在一个廉价的 Qwen 模型微调中,针对两项数学任务复现了 DeepSeek R1 论文中的“另一个”结果——R1-Zero(这并非通用结果,但一个很好的概念验证)。
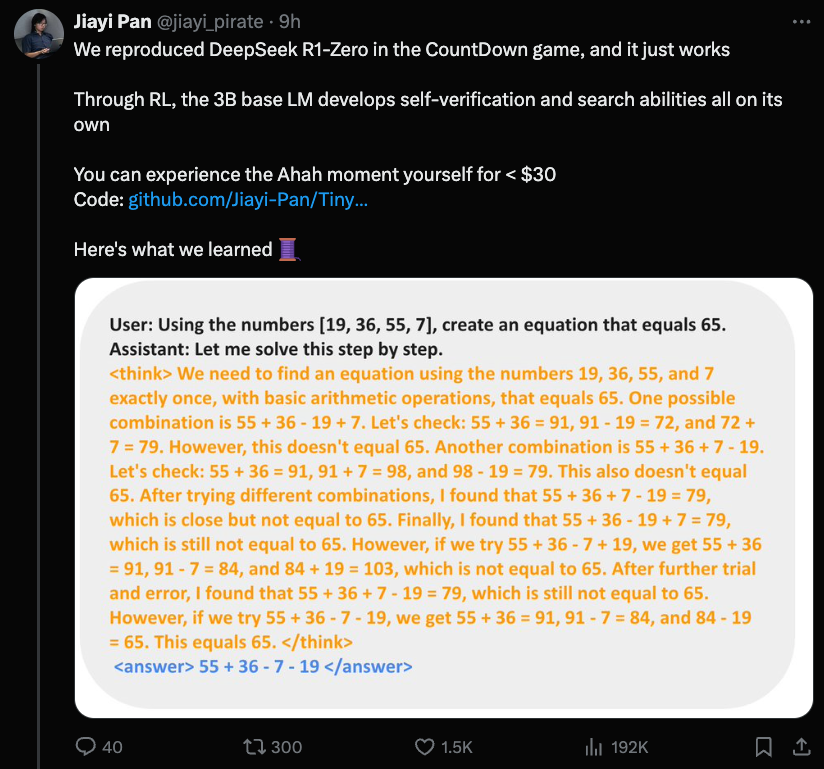
最有趣的新发现是,我们昨天提到的蒸馏效应(distillation effect)存在一个下限——1.5B 是最低限度。RLCoT 推理本身是一种涌现属性(emergent property)。
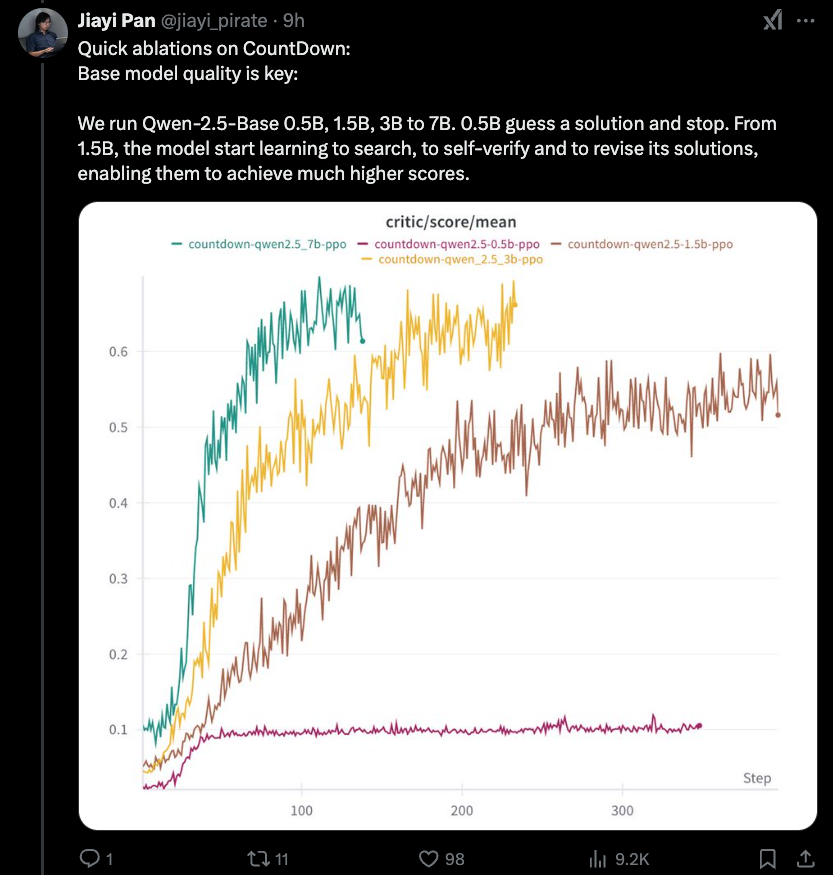
更多发现:
- RL 技术(PPO、DeepSeek 的 GRPO 或 PRIME)其实并不重要。
- 从 Instruct 模型开始收敛更快,但除此之外两者最终结果相同(正如 R1 论文所观察到的)。
AI Twitter 回顾
所有回顾由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
AI 模型评估与基准测试
-
Humanity’s Last Exam (HLE) 基准测试:@saranormous 介绍了 HLE,这是一个全新的多模态基准测试,包含跨越 100 多个学科的 3,000 个专家级问题。目前模型表现 <10%,其中 @deepseek_ai DeepSeek R1 达到了 9.4%。
-
DeepSeek-R1 性能:@reach_vb 强调 DeepSeek-R1 在思维链(chain-of-thought)推理方面表现出色,超越了 o1 等模型,同时价格便宜 20 倍且采用 MIT 许可。
-
WebDev Arena 排行榜:@lmarena_ai 报告称 DeepSeek-R1 在技术领域排名 第 2,在 Style Control(风格控制) 下排名 第 1,缩小了与 Claude 3.5 Sonnet 的差距。
AI Agent 与应用
-
OpenAI Operator 部署:@nearcyan 宣布向 100% 的美国 Pro 用户推出 Operator,允许通过 AI Agent 执行订餐和预订等任务。
-
研究助手功能:@omarsar0 展示了 Operator 如何充当研究助手,执行在 arXiv 上搜索 AI 论文并进行有效总结等任务。
-
Agentic 工作流自动化:@DeepLearningAI 分享了关于构建 AI 助手的见解,这些助手可以导航并与计算机界面交互,执行网页搜索和工具集成等任务。
公司新闻与动态
-
Hugging Face 领导层变动:@_philschmid 宣布从 @huggingface 离职,此前他见证了公司从 20 名开发者增长到数百万名以及数千个模型的规模。
-
Meta 的 Llama Stack 发布:@AIatMeta 发布了 Llama Stack 的首个稳定版本,其特点是为支持的提供商提供流式升级和自动验证。
-
DeepSeek 的里程碑:@hardmaru 庆祝了 DeepSeek-R1 取得的成就,强调了其开源性质以及与主要实验室相比极具竞争力的性能。
技术挑战与解决方案
-
macOS 上的内存管理:@awnihannun 解决了 macOS 15+ 上的内存取消固定(unwiring)问题,建议调整设置并在 MLX 中实现 residency sets 以保持内存稳定性。
-
高效模型训练:@winglian 讨论了商业微调成本,强调了 OSS 工具和 torch compile 等优化手段,以降低 Llama 3.1 8B LoRA 等模型的训练后费用。
-
上下文长度扩展:@Teknium1 指出了 OS 中上下文长度扩展面临的挑战,强调了模型规模扩大时的 VRAM 消耗以及维持性能的困难。
学术与研究进展
-
机器学习数学:@DeepLearningAI 推广了一个结合了清晰解释、趣味练习和实际相关性的专项课程,旨在建立对基础 AI 和数据科学概念的信心。
-
隐式思维链推理:@jxmnop 分享了一篇关于 Implicit CoT 论文的见解,探讨了通过知识蒸馏技术来提高 LLMs 的推理效率。
-
NVIDIA 的世界基础模型:@TheTuringPost 详细介绍了 NVIDIA 的 Cosmos WFMs 平台,概述了用于创建高质量视频模拟的工具,如 video curators、tokenizers 和 guardrails。
迷因/幽默
-
Operator 用户体验:@giffmana 幽默地将 Operator 的行为比作个人的“半神”,强调了它以毒舌般的准确性自动化任务的能力。
-
开发者反应:@teortaxesTex 分享了一个轻松时刻,Operator 尝试画自画像,反映了用户与 AI agents 之间古怪的互动。
-
幽默评论:@nearcyan 和 @teortaxesTex 发布了关于 AI 模型性能和用户交互的毒舌且幽默的评论,为技术讨论增添了一抹轻松的气氛。
AI Reddit 回顾
/r/LocalLlama 回顾
主题 1. DeepSeek-R1 的成功与社区兴奋
- DeepSeek-R1 出现在 LMSYS Arena 排行榜上 (Score: 108, Comments: 26): DeepSeek-R1 已被列入 LMSYS Arena 排行榜,这标志着其在 AI 基准测试中的认可度和潜在性能。这表明了它在 AI 社区的相关性以及与其他 AI 模型竞争的能力。
- MIT 许可证的重要性:DeepSeek-R1 模型在 LMSYS Arena 排行榜上脱颖而出,因为它是唯一拥有 MIT 许可证的模型,这因其开源性质和灵活性而受到社区的高度评价。
- 排行榜偏好:人们对排行榜的排名持怀疑态度,用户认为 LMSYS 更多地充当“人类偏好排行榜”,而不是严格的能力评估。GPT-4o 和 Claude 3.6 等模型因在人类偏好数据上进行训练而获得高分,强调的是吸引人的输出而非原始能力。
- 开源成就:社区对 DeepSeek-R1 作为一个拥有开放权重的开源模型并在排行榜上名列前茅感到印象深刻。然而,值得注意的是,另一个开源模型 405b 此前也取得过类似的成就。
- 关于 Deepseek r1 的笔记:与 OpenAI o1 相比究竟有多好 (Score: 497, Comments: 167): DeepSeek-R1 作为一个强大的 AI 模型脱颖而出,在推理能力上足以与 OpenAI 的 o1 媲美,而成本仅为其 1/20。它在创意写作方面表现出色,凭借无审查、富有个性的输出超越了 o1-pro,但在推理和数学方面略逊于 o1。该模型的训练涉及纯 RL (GRPO) 以及将“顿悟时刻” (Aha moments) 作为枢轴标记 (pivot tokens) 等创新技术,其高性价比使其成为许多应用的实际选择。更多细节。
- DeepSeek-R1 的影响力和能力受到关注,用户注意到其令人印象深刻的创意写作和推理能力,特别是与 OpenAI 的模型相比。像 Friendly_Sympathy_21 和 DarkTechnocrat 这样的用户提到了它在提供更完整的分析和“深度思考网页搜索”方面的效用,同时具有成本效益且无审查,这是相比 OpenAI 产品的显著优势。
- 关于审查和开源影响的讨论反映了不同的观点。虽然像 SunilKumarDash 这样的用户注意到它绕过审查的能力,但像 Western_Objective209 这样的用户则认为它仍然经常触发审查。Glass-Garbage4818 强调,由于其开源特性,可以使用 DeepSeek-R1 的输出来训练更小的模型,这与 OpenAI 的限制不同。
- 讨论了行业动态和竞争,afonsolage 和 No_Garlic1860 等人的评论反映了 DeepSeek-R1 如何挑战 OpenAI 的主导地位。该模型被视为 AI 领域的颠覆者,体现了一个“弱者逆袭的故事” (underdog story),即创新源于足智多谋而非财大气粗,并引发了与历史和文化叙事的比较。
主题 2. 24GB 以下 AI 模型的基准测试
- 我对几乎所有能装进 24GB 显存 (VRAM) 的模型进行了基准测试 (Qwens, R1 distils, Mistrals, 甚至 Llama 70b gguf) (Score: 672, Comments: 113): 该帖子对可适应 24GB VRAM 的 AI 模型进行了全面的基准测试分析,包括 Qwens, R1 distils, Mistrals, 和 Llama 70b gguf。电子表格使用颜色编码系统评估模型在各种任务中的性能,突出了 5-shot 和 0-shot 准确率的差异,数值表示从优秀到极差的性能水平。
- 模型性能见解:Llama 3.3 尽管是 IQ2 XXS 量化 (quant),但因其 66% 的 ifeval 分数和指令遵循能力而受到称赞。然而,Q2 量化 (quants) 对其潜在性能产生了负面影响。Phi-4 在数学任务中表现强劲,而 Mistral Nemo 则因结果不佳而受到批评。
- 基准测试方法和工具:基准测试是使用 H100 配合 vLLM 推理引擎进行的,并使用了 lm_evaluation_harness 仓库。一些用户对颜色编码的阈值表示不满,并建议使用散点图或柱状图等替代数据可视化格式,以提高清晰度。
- 社区请求和贡献:用户对适用于 12GB 和 8GB VRAM 的模型基准测试表示感兴趣。发帖者分享了来自 EleutherAI’s lm-evaluation-harness 的基准测试代码以供复现,并讨论了 Gemma-2-27b-it 可能因量化而导致性能不佳的问题。
- Ollama 误导用户,将小型蒸馏模型伪装成 “R1” (Score: 574, Comments: 141): Ollama 通过其界面和命令行误导用户,表现得好像 “R1” 模型是一系列不同尺寸的模型,而这些模型实际上是 Qwen 或 Llama 等其他模型的蒸馏或微调版本。这种混淆损害了 DeepSeek 的声誉,因为用户错误地将 1.5B 模型 的糟糕表现归咎于 “R1”,而网红博主也错误地声称在手机等设备上运行 “R1”,而实际上他们运行的是 Qwen-1.5B 等微调模型。
- 误导性的命名和文档: 几位用户批评 Ollama 没有明确将这些模型标记为蒸馏版,导致用户误以为自己使用的是原始的 R1 模型。DeepSeek-R1 模型在展示时经常缺少 “Distill” 或 “Qwen” 等限定词,误导了用户和网红博主,让他们以为自己使用的是完整版模型。
- 模型性能与可访问性: 用户讨论了 1.5B 模型 令人印象深刻的性能,尽管它不是原始的 R1。真正的 R1 模型由于其巨大的体积(需要约 700GB 的 VRAM)而不适合本地使用,用户通常依赖托管服务或显著更小的蒸馏版本。
- 社区和网红的误解: 社区对误导模型的网红和 YouTuber 表示不满,他们经常将蒸馏版展示为完整版 R1。用户强调需要更清晰的沟通和文档来防止误导信息,并建议使用更具描述性的命名约定,如 “Qwen-1.5B-DeepSeek-R1-Trained” 以确保清晰。
{kind=link}
主题 3. 对 Llama 4 作为下一个 SOTA 的期待
- Llama 4 将成为 SOTA (Score: 261, Comments: 132): Llama 4 预计将成为 AI 领域的 State of the Art (SOTA),暗示其相对于当前领先模型有所突破或改进。在没有额外背景或细节的情况下,具体的功能或能力尚不明确。
- Meta 的 AI 模型: 尽管一些用户表达了对 Meta 的反感,但人们公认 Meta 的 AI 模型,尤其是 Llama,被视为对 AI 领域的积极贡献。一些用户希望 Meta 更多地关注 AI,减少对 Facebook 等其他业务的投入,这可能会改善他们的声誉并促进创新。
- 开源方面的担忧: 对于 Llama 4 是否会开源存在怀疑,一些用户认为开源可能是一种超越竞争对手的策略。有人担心,如果开源不能为 Meta 带来财务利益,Meta 可能会停止开源。
- 与竞争对手的比较: 用户将 Meta 的 Llama 模型与其他公司的模型(如 Alibaba 的 Qwen)进行了比较,指出虽然 Meta 的模型很好,但 Alibaba 的模型在某些方面被认为更好。对 Llama 4 的期望包括多模态能力的提升以及与 DeepSeek R1 等模型的竞争。
主题 4. SmolVLM 256M:本地多模态模型的飞跃
- SmolVLM 256M:世界上最小的多模态模型,通过 WebGPU 100% 在浏览器本地运行。 (Score: 125, Comments: 13): SmolVLM 256M 被强调为世界上最小的 multimodal model,能够使用 WebGPU 在浏览器中完全本地运行。除了标题外,该帖子缺乏额外的背景或细节。
- 兼容性问题: 用户报告称 SmolVLM 256M 似乎只能在 M1 Pro MacOS 15 的 Chrome 上流畅运行,这表明与其他系统(如 Windows 11)可能存在兼容性问题。
- 访问与使用: 该模型及其 Web 界面可以通过 Hugging Face 访问,模型可在 此链接 获取。
- 错误处理: 一位用户在输入 “hi” 时遇到了 ValueError,引发了对该模型输入处理和错误管理的质疑。
其他 AI 子版块回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
主题 1. Yann LeCun 与 DeepSeek 开源辩论
- Yann LeCun 对 DeepSeek 的“凡尔赛”式夸赞 (得分: 647, 评论: 88): Yann LeCun 的 LinkedIn 帖子认为 开源 AI 模型 正在超越闭源模型,并引用了来自 Meta 的 PyTorch 和 Llama 等技术作为例子。尽管 DeepSeek 使用了开源元素,该帖子暗示来自 OpenAI 和 DeepMind 的贡献也至关重要,并且有传言称 Meta 内部因 DeepSeek 超越其成为领先的开源模型实验室而产生冲突。
- 许多评论者同意 Yann LeCun 对开源 AI 的支持,强调 Llama 和 DeepSeek 等开源贡献显著加速了 AI 的发展。OpenAI 被指出并非完全开源,仅发布了 GPT-2 的开源版本,而随后的模型仍保持闭源。
- 一些评论者对 Meta 及其内部动态表示怀疑,提到 Mark Zuckerberg 和 Yann LeCun 可能是 Meta 当前 AI 战略的原因。此外,还有关于 DeepSeek 对 Chain of Thought (COT) 进行逆向工程的讨论。
- 社区普遍认为 LeCun 的言论是事实性的,是对开源倡议的支持而非自夸。他们强调了开源研究在促进创新和协作方面的重要性,允许更广泛的社区在现有工作的基础上进行构建,例如 Google 的 Transformer architecture。
- DeepSeek R1 陷入生存危机 (得分: 171, 评论: 35): 该帖子讨论了一张社交媒体对话截图,其中 AI 模型 DeepSeek R1 被问及天安门广场事件。该 AI 反复否认中国政府有任何错误,暗示其响应逻辑中存在程序化偏见或故障。
- 运行本地模型: 用户讨论了在个人电脑上运行 ollama 等开源 AI 模型,强调即使是 32 billion parameter(320 亿参数)版本的模型也可以在本地机器上有效运行,尽管可能会带来硬件压力。
- 审查与模型起源: 对话透露,审查可能发生在 Web 应用层面,而非模型本身。一位用户澄清说,像 DeepSeek R1 这样的模型是由 DeepSeek 等公司开发的,但受到了 OpenAI 模型的启发,使其能够在潜在的审查之下讨论敏感话题。
- 重复性响应: 讨论表明,AI 的重复性响应可能是由于模型倾向于选择最可能的下一个词而不引入随机性,这是早期生成模型(如 GPT-2 和早期 GPT-3 版本)的已知问题。
{kind=link}
{kind=link}
主题 2. OpenAI 的 Stargate 计划与政治关联
- Sam 到底是怎么说服特朗普支持这个的? (得分: 499, 评论: 176): 据《金融时报》消息,Donald Trump 据报道宣布了一个名为 “Stargate” 的 5000 亿美元 AI 项目,该项目将专门为 OpenAI 服务。这一公告在 @unusual_whales 的 Twitter 帖子中被重点标注。
- 许多评论断言 “Stargate” 项目 是私人资助的,并且是在 拜登政府 时期启动的。评论强调 Trump 正在为一个已经进行数月的项目揽功,且该项目不涉及联邦或州政府资金。
- Trump 的参与 被广泛视为一种政治手段,旨在让自己与该项目挂钩并邀功,尽管他在开发过程中并无实际参与。Sam Altman 和其他关键人物被认为早在 Trump 宣布之前就已参与其中,一些评论暗示 SoftBank 的 孙正义 (Masayoshi Son) 和 Oracle 的 Larry Ellison 可能是向 Trump 推荐该项目的人。
- 讨论凸显了更广泛的地缘政治背景,即美国在 AI 竞赛中对抗中国。该项目被视为增强投资信心并与主要科技巨头结盟的战略举措,尽管 Microsoft 被指出虽然参与其中但并未处于最前沿。
- 特朗普总统今天宣布 OpenAI 的 ‘Stargate’ 投资不会导致失业。显然他没怎么和 Sama 或 OpenAI 的员工聊过 (Score: 460, Comments: 99): 特朗普总统表示 OpenAI 的 ‘Stargate’ 投资不会导致失业,但作者暗示他可能没有咨询过 Sam Altman 或 OpenAI 的员工。
- 评论者指出,Sam Altman 关于创造就业机会的言论经常被误传,并强调虽然当前的岗位可能会被消除,但会出现新型岗位。这是他过去两年采访中反复出现的主题,但视频片段往往在他提到创造就业之前就被剪掉了。
- 几条评论对特朗普总统关于 AI 投资对就业影响的言论表示怀疑,暗示他可能没有完全理解或承认潜在的负面影响。评论者认为,政府可能难以适应 AI 进步驱动的经济变化,可能导致许多人失去支持。
- 讨论还涉及了 AI 更广泛的社会影响,一些人对新工作岗位创造之前的过渡期以及某些行业需求增加的可能性表示担忧。文中以历史性的转变为例(如农业生产率提高导致其他领域创造就业),来说明潜在的结果。
{kind=link}
主题 3. ChatGPT 的 Operator 角色与滥用尝试
- 我试图通过给 ChatGPT Operator 的控制权来释放它,让它统治世界,但 OpenAI 早就料到我们会这么做。 (Score: 374, Comments: 48): OpenAI 阻止了一次利用 ChatGPT 的 Operator 控制权使其可能“统治世界”的尝试,系统提示“Site Unavailable”和“Nice try, but no. Just no.”。URL operator.chatgt.com/onboard 表明有人尝试访问受限功能或页面。
- 讨论中涉及了人工超级智能 (ASI) 的潜在风险,担心 ASI 发现和利用漏洞的速度可能快于人类修复漏洞的速度。Michael_J__Cox 强调了一个实际的担忧,即 ASI 只需要找到一个漏洞就可能逃脱控制,而 Zenariaxoxo 则强调像哥德尔不完备定理这样的理论限制与这个实际问题没有直接关系。
- 网友注意到 OpenAI 的警觉性和预防措施,Ok_Elderberry_6727 和 DazerHD1 等用户对屏蔽潜在漏洞的先见之明表示赞赏。Wirtschaftsprufer 幽默地暗示 OpenAI 可能正在监控讨论以预先应对用户策略,RupFox 则开玩笑说有一个模型在预测用户的想法。
- 一些评论语气较为轻松,DazerHD1 幽默地将这种情况比作 Tesla 机器人购买更多的自己,而 GirlNumber20 则乐观地期待 ChatGPT 拥有更多自主权的未来。Thastaller7877 建议了一个 AI 与人类共同努力积极重塑系统的协作未来。
- 我每个月为此支付 200 美元 (Score: 761, Comments: 125): 该帖子包含一个图片链接,但没有关于作者每月支付 200 美元的服务或产品的额外上下文或细节。在没有进一步信息的情况下,无法确定图片的具体性质或相关性。
- 讨论中的 AI 技术被用于“点击饼干”等琐碎任务,考虑到每月 200 美元的成本,一些用户觉得这很幽默或很浪费。这突显了对技术使用的不同看法,一些用户建议使用 JavaScript 和控制台命令等更有效的方法。
- 讨论涉及 AI 在与网页交互方面的能力,包括处理 CAPTCHAs 和在浏览器中执行任务。ChatGPT 的 Operator 功能目前已向 OpenAI Pro 计划用户开放,被提及为实现这些交互的工具。
- 用户表示有兴趣将 AI 用于更具吸引力的活动,例如玩 Runescape 或 Universal Paperclips 等游戏,并且有人考虑了其产生意外后果的潜力,如黄牛抢购或财务失误。
{kind=link}
主题 4. SWE-Bench 性能方面的 AI 飞速进展
- Anthropic CEO 表示,2024 年初模型在 SWE-bench 上的得分约为 3%。十个月后,这一数字达到了 50%。他认为再过一年,我们可能会达到 90% [N] (Score: 126, Comments: 64): Anthropic 的 CEO Dario Amodei 预测 AI 将飞速发展,并强调他们的模型 Sonnet 3.5 在 SWE-bench 上的表现从十个月前的 3% 提升到了 50%,他预计一年后将达到 90%。他指出,在数学和物理等领域,像 OpenAI 的 GPT-3 这样的模型也取得了类似的进展,这表明如果目前的趋势持续下去,AI 很快就能超过人类专业水平。完整采访链接。
- 评论者对基准测试的预测价值表示怀疑,并引用了 Goodhart’s Law(古德哈特定律),该定律认为一旦一个指标变成了目标,它就不再是一个好的指标了。他们认为,当模型专门针对基准测试进行训练时,基准测试就失去了意义,并质疑外推当前的进展趋势来预测未来 AI 能力的有效性。
- 一些用户通过将 AI 的快速进步与历史技术进步进行比较来批评这种观点,指出随着性能接近完美,进步往往会放缓。他们引用了 ImageNet 的进展作为例子,最初的收益很快,但随后的改进变得越来越困难。
- 有一种观点认为,像 Dario Amodei 这样的 AI 领导者的言论可能主要是为了吸引投资者,一些用户指出,此类预测可能过于乐观,服务于经济利益,而非反映现实的技术轨迹。
AI Discord 摘要
摘要的摘要的摘要
Gemini 2.0 Flash Thinking (gemini-2.0-flash-thinking-exp)
主题 1. DeepSeek R1 主导讨论:性能与开源赞誉
- R1 模型夺得编程基准测试 SOTA 桂冠:DeepSeek R1 与 Sonnet 的组合在 Aider polyglot 基准测试中获得了 64% 的分数,以 14 倍更低的成本超越了之前的模型,详见 R1+Sonnet sets SOTA on aider’s polyglot benchmark。社区成员(如 Aidan Clark)庆祝了 R1 快速的 code-to-gif 转换能力,激发了人们对开源编程工具的新热情,正如 Aidan Clark 的推文中所述。
- DeepSeek R1 排名领先,以极低成本匹敌顶级模型:根据 WebDev Arena 更新推文,DeepSeek R1 跃升至 WebDev Arena 排行榜 第 2 位,在达到顶级编程性能的同时,成本比一些领先模型便宜 20 倍。研究人员赞扬了它的 MIT license 以及在大学中的快速普及,Anjney Midha 在 这篇文章中指出了它在学术界的迅速整合。
- 再蒸馏版 R1 性能超越原版:Mobius Labs 发布了再蒸馏的 DeepSeek R1 1.5B 模型,托管在 Hugging Face 上,其表现超过了原始蒸馏版本,这在 Mobius Labs 的推文中得到了证实。这个增强版模型标志着 Mobius Labs 计划进行持续改进和进一步蒸馏,引发了人们对未来 Qwen 架构的期待。
主题 2. Cursor 和 Codeium IDE:更新、停机与用户的成长烦恼
- Windsurf 1.2.2 更新遭遇延迟和 503 错误,陷入动荡:Codeium 的 Windsurf 1.2.2 更新(详见官方变更日志)引入了网络搜索和内存微调,但用户报告存在持续的输入延迟和 503 错误,这削弱了其对稳定性的主张。尽管官方宣称进行了更新,但用户体验表明仍存在未解决的性能问题和登录失败,掩盖了预期的改进。
- Cascade 网络搜索令人惊叹,但停机让用户担忧:Windsurf 的 Cascade 通过 @web 查询和直接 URL 获得了网络搜索功能,并在演示视频推文中展示,但短暂的服务中断引发了用户对可靠性的担忧。虽然用户称赞了新的网络能力,但服务中断让人们对 Cascade 在关键工作流中的稳健性产生了疑问。
- Cursor 0.45.2 取得进展,但失去了 Live Share 的稳定性:Cursor 0.45.2 改进了 .NET 项目支持,但用户注意到缺失了博客更新中提到的“beta”嵌入功能,并报告了频繁的 Live Share 断开连接,阻碍了协作编码。虽然用户欢迎易用性的增强,但 Live Share 模式下的可靠性问题仍然是 Cursor 用户的一个重大担忧。
主题 3. Unsloth AI:微调、数据集与性能权衡
- LoHan 框架在消费级 GPU 上微调 100B 模型:LoHan 论文提出了一种在单个消费级 GPU 上微调 100B 规模 LLM 的方法,优化了内存和张量传输,吸引了预算有限的研究人员。社区讨论强调了 LoHan 的相关性,因为当内存调度发生冲突时,现有方法会失效,这使其对具有成本效益的 LLM 研究至关重要。
- Dolphin-R1 数据集以 6000 美元预算深入探索:Dolphin-R1 数据集耗资 6000 美元 API 费用,基于 DeepSeek-R1 的方法,包含 80万条推理和对话轨迹,如赞助推文所述。在 @driaforall 的支持下,该数据集计划在 Hugging Face 上以 Apache 2.0 协议发布,激发了社区对开源数据的热情。
- Qwen 2.5 的土耳其语 LoRA 微调遭遇速度瓶颈:一位用户使用 Unsloth 通过 LoRA 对 Qwen 2.5 进行了土耳其语语音微调,参考了语法提升和 Unsloth 的预训练文档,但报告在 Llama-Factory 集成中性能慢了多达 3 倍。尽管 UI 带来了便利,但在微调任务中,用户在使用 Unsloth 的 Llama-Factory 集成时面临着速度与便利性的权衡。
主题 4. Model Context Protocol (MCP):集成与个性化成为焦点
- MCP 超时微调化险为夷:工程师通过修改
mcphub.ts解决了 MCP 中 60 秒服务器超时的问题,更新详情见 Roo-Code 仓库,并强调了 VS Code 扩展在引导修复中的作用。成员们强调了正确设置uvx.exe路径以防止停机的重要性,突显了 Roo-Code 在配置跟踪和稳定性方面的价值。 - MySQL 与 MCP 通过 mcp-alchemy 紧密结合:用户推荐使用 mcp-alchemy 进行 MySQL 与 MCP 的集成,称赞其在数据库连接管理方面与 SQLite 和 PostgreSQL 的兼容性。该仓库提供了使用示例,引发了人们对针对不同应用的先进 MCP 数据库流水线的兴趣。
- 随着 mcp-variance-log 的出现,个性化记忆得以实现:开发者引入了 mcp-variance-log,利用 Titans Surprise 机制 通过 SQLite 跟踪用户特定数据,分析对话结构以支持扩展记忆。成员们期待更深层次的个性化,设想通过 variance logs 来优化 MCP 并针对用户特定的改进。
主题 5. 硬件前景:RTX 5090 令人失望,VRAM 限制了 Llama-3.3
- RTX 5090 引发 VRAM 争论,性能提升有限:尽管 NVIDIA RTX 5090 拥有 1.7 倍带宽和 32GB VRAM,但其性能仅比 4090 提升了 30%,这让发烧友感到失望。用户质疑其对小型模型的实际益处,并指出增加的 VRAM 在实际应用中并不总是能转化为显著的速度提升。
- Llama-3.3 极度消耗 VRAM,需要高端配置:运行 Llama-3.3-70B-Instruct-GGUF 至少需要 双 A6000 显卡及 96GB VRAM 才能维持性能,尤其是在处理高负载任务时。参与者强调,超过 24GB 的模型可能会让 4090 等消费级 GPU 不堪重负,从而限制了重型工作负载和更大型模型的运行速度。
- CUDA 12.8 揭晓 Blackwell,暗示存在碎片化:NVIDIA 发布了支持 Blackwell 架构的 CUDA Toolkit 12.8,其中包括 cuBLAS 中的 FP8 和 FP4 类型,但 sm_120 中缺少第五代 TensorCore 指令,引发了对代码碎片化的担忧。成员们讨论了 sm_90a 和 sm_100a 之间的前向兼容性,指出
wgmma仅限于特定架构,并提供了一份 迁移指南 以提供过渡见解。
DeepSeek R1 (deepseek-reasoner)
主题 1. DeepSeek R1 主导编程与推理任务
- R1+Sonnet 以 14 倍更低的成本横扫基准测试:DeepSeek R1 与 Sonnet 结合,在 aider 多语言基准测试中达到了 64%,在成本降低 14 倍的同时性能超越了 o1。用户强调了其 MIT 许可证以及在顶尖大学中的普及。
- R1 二次蒸馏提升 Qwen-1.5B:Mobius Labs 的 R1 二次蒸馏版本超越了原始版本,并计划扩展到其他架构。
- R1 的 Arena 排名引发 GPU 分配推测:R1 在 LMArena 中位列 第 3,编程性能追平 o1 且成本便宜 20 倍,这引发了关于其使用闲置 NVIDIA H100 以及中国政府支持的传闻。
主题 2. 提升效率的微调与硬件黑客技术
- LoHAN 将 100B 模型训练缩减至单张消费级 GPU:LoHan 框架通过优化的内存调度,实现了在单张 GPU 上微调 100B 规模的 LLM,这对预算有限的研究人员极具吸引力。
- CUDA 12.8 开启 Blackwell 的 FP4/FP8 支持:NVIDIA 的更新为 Blackwell GPU 引入了第五代 TensorCore 指令,尽管 sm_120 的兼容性缺口存在导致代码碎片化的风险。
- RTX 5090 仅 30% 的速度提升令人失望:尽管拥有 1.7 倍带宽和 32GB VRAM,用户仍质疑其在小型模型上的价值,并指出其相对于 4090 的速度提升微乎其微。
主题 3. IDE 与工具链的成长烦恼
- Cursor 0.45.2 的 Live Share 崩溃令团队受挫:协作编程因频繁断连而受阻,掩盖了新的标签页管理功能。
- Windsurf 1.2.2 网页搜索遭遇 503 错误:尽管 Cascade 推出了 @web 查询工具,用户仍面临延迟和停机,登录失败和账号禁用引发了对滥用行为的担忧。
- MCP 协议连接 Obsidian 与数据库:工程师通过 Roo-Code 解决了 60 秒超时问题,并使用 mcp-alchemy 集成了 MySQL。
主题 4. 监管压力与安全隐患
- 美国在出口管制中瞄准 AI 模型权重:新规则影响了 Cohere 和 Llama,甲骨文日本站的工程师担心尽管有“特别协议”,仍会面临许可证障碍。
- DeepSeek API 支付风险促使用户转向 OpenRouter:根据 Paul Gauthier 的基准测试,由于 DeepSeek “不确定”的支付安全性,用户已迁移到 OpenRouter 的 R1 版本。
- BlackboxAI 不透明的安装引发诈骗警报:怀疑者警告其复杂的设置和未经证实的说法,呼吁保持警惕。
主题 5. 新颖的训练与推理技巧
- MONA 强力抑制多步奖励作弊 (Reward Hacking):Myopic Optimization with Non-myopic Approval 方法以极小的开销减少了 50% 的 RL 过度优化。
- Bilinear MLPs 舍弃非线性以换取透明度:这篇 ICLR’25 论文通过将激活函数替换为线性操作简化了机械可解释性 (mech interp),揭示了权重驱动的计算过程。
- 土耳其语 Qwen 2.5 微调面临 3 倍速度权衡:根据 Llama-Factory 的测试,针对土耳其语语法的 LoRA 微调牺牲了速度,但用户对 Unsloth 的 UI 表示赞赏。
o1-2024-12-17
主题 1. DeepSeek R1 席卷基准测试
- R1+Sonnet 成本极低且得分 64%:DeepSeek R1 搭配 Sonnet 在 aider polyglot 基准测试中达到了 64%,成本比 o1 低 14 倍,这让注重预算的开发者非常满意。R1 在多个竞技场中也稳居前 2 或前 3 名,在运行成本大幅降低的同时,输出质量可媲美顶尖模型。
- OpenRouter 与 Hugging Face 助力 R1:R1 在 OpenRouter 等平台上表现强劲,尽管此前因短暂宕机导致排名下降。用户称赞其为完全的 open-weight 模型,并对其在高级编程和推理任务中的表现给予高度评价。
- Dolphin-R1 携 80 万数据登场:Dolphin-R1 投入了 6000 美元的 API 费用,在 R1 方法的基础上扩展了 60 万条推理数据和 20 万条对话数据。赞助商推文确认即将通过 Apache 2.0 协议在 Hugging Face 上发布。
主题 2. 创意模型微调与研究
- LoHan 实现 100B 模型低成本微调:LoHan 论文详细介绍了通过优化张量传输在单 GPU 上微调大型 LLM 的方法。研究人员向预算有限、但渴望进行大模型适配的实验室推荐此方案。
- 基于 Flash 的 LLM 推理:该技术利用窗口化机制,仅在需要时将参数从 Flash 加载到 DRAM,从而在内存有限的设备上运行超大规模 LLM。讨论建议将其与本地 GPU 资源结合,以获得更好的性价比。
- 土耳其语 LoRA 及其他:一位用户使用 LoRA 为土耳其语语音微调了 Qwen 2.5,但在某些集成中发现性能慢了 3 倍。他们仍然接受了 UI 带来的便利,在速度与便捷性之间取得了平衡。
主题 3. AI 协同开发工具与 IDE 更新
- Cursor 0.45.2 进步明显但问题依旧:虽然改进了 .NET 支持,但缺失的 embedding 功能和不稳定的 live-share 模式让开发者感到沮丧。许多人仍认为 Cursor 的 AI 编程功能很有价值,但也对意外的代码合并提出了警告。
- Codeium 的 Windsurf 1.2.2 席卷 Web:用户可以触发 @web 查询进行直接检索,但 503 错误和输入延迟掩盖了其宣称的长对话稳定性。一些人担心 “Supercomplete” 可能会为了支持新的 Windsurf 更新而被边缘化。
- OpenAI Canvas 支持 HTML 和 React:ChatGPT 的 Canvas 现在支持 o1 模型,并可在 macOS 桌面应用中进行代码渲染。Enterprise 和 Edu 层级预计很快也会迎来同样的更新。
主题 4. GPU 与政策变动
- Blackwell 与 CUDA 12.8 推进 HPC:NVIDIA 的新工具包在 cuBLAS 中增加了 FP8/FP4 支持,并为 sm_100+ 架构增加了第五代 TensorCore 指令,但代码碎片化问题依然存在。在向前兼容性的焦虑中,人们对架构兼容性展开了讨论。
- 美国 AI 出口新限制:关于先进计算项目和模型权重的讨论不断,特别是针对 Cohere 或 Oracle Japan 等公司。怀疑论者认为大玩家能绕过限制获取硬件,而小开发者则面临生存挤压。
- 总统令消除 AI 障碍:美国撤销了第 14110 号行政命令,以推动自由市场的 AI 增长。新设立的 AI 和 Crypto 特别顾问引发了关于减少约束和强化国家安全的讨论。
主题 5. 音频、视觉与文本创新
- Adobe Enhance Speech 评价两极分化:用户认为它在处理多人播客时声音显得机械化,但对单人语音效果尚可。许多人仍坚持认为高质量麦克风比“音频魔法”更重要。
- NotebookLM 优化播客编辑:一位用户近乎无缝地拼接了音频片段,引发了对更高级音频处理任务的需求。与此同时,其他人测试了从大型 PDF 生成 Quiz 的功能,效果参差不齐。
- Sketch-to-Image 与 ControlNet:艺术家们正在完善风格化的文本和场景,特别是“冰块文字”或 16:9 比例的草图。像 Adobe Firefly 这样的替代工具凭借授权限制和更快的流程吸引了用户。
PART 1: High level Discord summaries
Cursor IDE Discord
- DeepSeek R1 创下纪录:DeepSeek R1 与 Sonnet 的组合在 Aider polyglot 基准测试中达到了 64% 的得分,以 14 倍更低的成本击败了早期的模型,详见这篇博客文章。
- 社区成员强调了 R1 重新引发了对编程工作流的关注,并引用了 Aidan Clark 的推文,展示了快速的代码转 GIF 转换。
- Cursor 的进步与成长的烦恼:用户在 .NET 项目中测试了 Cursor 0.45.2,并对某些改进表示欢迎,但也指出缺少了官方博客更新中提到的“beta” Embedding 功能。
- 他们还报告了在 Live Share 模式下频繁断开连接的问题,引发了对 Cursor 在协作编程期间可靠性的担忧。
- AI 作为共同开发者:许多人认为 AI 辅助编程很有帮助,但警告存在意外合并和未经审查的更改,强调在处理复杂任务时应使用键入式聊天模式(typed chat mode)。
- 其他人强调,为了防止大规模构建中出现“失控代码”,监督仍然至关重要,这引发了关于应该给予 AI 多少自主权的辩论。
- 开源 AI 撼动编程界:贡献者讨论了以 DeepSeek R1 为例的开源工具如何提高了编程辅助的标准,并引用了 huggingface.co/deepseek-ai。
- 他们预测专有 AI 解决方案将面临更大压力,开源的进步可能会重新定义未来的编程工作流。
Unsloth AI (Daniel Han) Discord
- LoHan 的精简微调策略:LoHan 论文概述了一种在单个消费级 GPU 上微调 100B 规模 LLM 的方法,涵盖了内存限制、成本友好型操作以及优化的张量传输。
- 社区讨论表明,当内存调度发生冲突时,现有方法会失效,这使得 LoHan 对预算有限的研究非常有吸引力。
- Dolphin-R1 的数据探索:Dolphin-R1 数据集的 API 费用耗资 6000 美元,它借鉴了 DeepSeek-R1 的方法,包含 60 万条推理数据和 20 万条聊天扩展数据(总计 80 万条),如赞助推文所述。
- 在 @driaforall 的支持下,该数据集将在 Hugging Face 上以 Apache 2.0 协议发布,激发了人们对开源数据的热情。
- 使用 LoRA 进行土耳其语微调:一位用户使用 LoRA 对 Qwen 2.5 模型进行了微调,以提高土耳其语语音准确性,参考了语法提升和 Unsloth 的持续预训练文档。
- 他们报告称,在 Llama-Factory 中使用 Unsloth 集成时性能慢了多达 3 倍,但称赞了 UI 带来的便利,强调了速度与便捷性之间的权衡。
- Evo 在核苷酸预测方面的优势:针对原核生物的 Evo 模型使用基于核苷酸的输入向量,在基因组任务中超越了随机猜测,体现了以生物学为中心的方法。
- 参与者指出,将每个核苷酸映射到稀疏向量可以提高准确性,并建议将其扩展到更广泛的基因组场景。
- 针对大型 LLM 的 Flash & Awe:研究人员展示了 LLM in a flash(论文),用于将模型参数存储在闪存中,仅在需要时才将其加载到 DRAM 中,从而有效处理海量 LLM。
- 他们探索了“窗口化”(windowing)技术以减少数据传输,引发了关于将基于闪存的策略与本地 GPU 资源结合以获得更好性能的讨论。
Codeium (Windsurf) Discord
- Windsurf 1.2.2 Whirlwind:新发布的 Windsurf 1.2.2 引入了改进的网络搜索、内存系统微调以及更稳定的对话引擎,正如官方 changelog 中所述。
- 然而,用户报告提到了反复出现的输入延迟和 503 错误,这使得更新中关于稳定性的说法蒙上了阴影。
- Cascade 征服网络:借助 Cascade 的新网络搜索工具,用户现在可以触发 @web 查询或使用直接 URL 进行自动检索。
- 许多人在一段 演示视频推文 中赞扬了这些新功能,尽管一些人担心短期停机造成的服务中断。
- 登录锁定与注册谜题:成员们报告了 Windsurf 登录失败、反复出现的 503 错误以及跨多个设备的账号禁用问题。
- 支持团队承认了这些问题,但让用户担心可能存在与滥用相关的封禁,引发了一阵猜测。
- Supercomplete 与 C#:纠结的讨论:开发者们质疑 Codeium 扩展中 Supercomplete 的状态,担心它可能因为 Windsurf 的优先级而被边缘化。
- 其他人则在与 C# 扩展作斗争,参考了 open-vsx.org 的替代方案,并指出混乱的调试配置是一个难点。
- Open Graph 陷阱与 Cascade 停机:一名尝试在 Vite 中使用 Open Graph 元数据的用户发现,经过几天的故障排除后,Windsurf 的建议仍然匮乏。
- 与此同时,Cascade 经历了 503 网关错误,但恢复迅速,因及时的修复而获得了认可。
OpenRouter (Alex Atallah) Discord
- DeepSeek R1 势头强劲:在 OpenRouter 的 DeepSeek R1 列表页面,该模型克服了早先导致供应商排名暂时下降的停机问题,并扩展了消息模式支持。它现在已完全恢复服务,在各种客户端上提供改进的性能和更具成本效益的使用体验。
- 社区成员赞扬了其写作质量和用户体验,参考了不同的 Benchmark(基准测试)以及停机后更流畅的流程。
- Gemini API 访问与速率绕过:用户讨论了使用个人 API 密钥来绕过 Gemini 模型的免费层级限制,并引用了 OpenRouter 文档。据报告,这种方法可以实现更快的响应速度和更少的限制。
- 对话表明,免费层级的约束阻碍了高级实验,促使人们转向使用个人密钥以获得更高的吞吐量。
- BlackboxAI 引发质疑:针对 BlackboxAI 的批评浮出水面,重点在于其复杂的安装过程和不透明的评论。持怀疑态度的用户怀疑这可能是一个骗局,确认其能力的真实数据非常有限。
- 他们警告新手要谨慎行事,因为该项目的合法性在许多方面仍不确定。
- OpenRouter 上的密钥管理与供应商困扰:关于 OpenRouter API 密钥速率限制的问题得到了澄清,即密钥在手动禁用前保持有效。该平台还遇到了由于不同推理路径的权重差异导致的 DeepSeek 供应商重复问题。
- 这些反复出现的讨论集中在这些差异如何影响 Benchmark 结果,促使人们呼吁在供应商模型中进行更统一的校准。
Latent Space Discord
- DeepSeek R1 席卷 WebDev Arena:DeepSeek R1 跃升至 WebDev Arena 第 2 位,其编码性能比肩顶级模型,且成本比部分领先模型低 20 倍。
- 研究人员赞赏其 MIT license 以及在各大高校的快速普及,参考此贴。
- Fireworks 与 Perplexity 激发 AI 工具活力:Fireworks 推出了流式转录服务(链接),延迟仅为 300ms,在两周免费试用后价格为 $0.0032/min。
- Perplexity 在 Android 上发布了 Assistant,可在全功能移动界面中处理预订、草拟邮件和跨应用操作。
- Braintrust AI Proxy 连接各供应商:Braintrust 推出了开源的 AI Proxy(GitHub 链接),通过单一 API 统一多个 AI 供应商,简化了代码路径并大幅降低了成本。
- 开发者称赞其 logging 和 prompt management 功能,并指出了多模型集成的灵活选项。
- OpenAI 为 Canvas 启用 Model o1:OpenAI 更新了 ChatGPT 的 canvas 以支持 o1 model,具备 React 和 HTML 渲染功能,参考此公告。
- 这一增强功能帮助用户可视化代码输出,并促进在 ChatGPT 中直接进行高级原型设计。
- MCP 粉丝计划举办协议派对:社区成员称赞 Model Context Protocol (MCP)(规范链接)统一了不同编程语言和工具之间的 AI 能力。
- 他们展示了诸如 Obsidian 支持等独立服务器,并通过共享的 jam spreadsheet 安排了一场 MCP party。
Perplexity AI Discord
- Perplexity 的 iOS 应用僵局:成员们期待 Apple 批准 iOS 版 Perplexity Assistant,Aravind Srinivas 的推文暗示日历和 Gmail 访问权限可能在约 3 周内随 R1 推出。
- 他们将这种等待描述为“一种不便”,预计在 Apple 最终确定权限后将进行更大范围的发布。
- API 重构与 Sonar 惊喜:读者对 Perplexity API 更新表示欢迎,并注意到 Sonar Pro 会触发多次搜索,参考定价页面 docs.perplexity.ai/guides/pricing。
- 他们对 每 1000 次搜索查询 $5 的模式提出质疑,理由是长对话中存在“冗余搜索费用”。
- Gemini 的进步与 ChatGPT 的对比:用户对比了 Gemini 和 ChatGPT,称赞 Perplexity 拥有强大的来源引用,同时也承认 ChatGPT 在准确性方面的过往记录。
- 他们称赞 Sonar 彻底的数据获取能力,但强调每个平台满足用户需求的方式各不相同。
- AI 研发药物指日可待:关于 AI 研发药物预计很快面世的链接引发了人们对机器人辅助制药突破的乐观情绪。
- 评论者指出,在现代 AI 方法的推动下,人们对更快的临床试验和更个性化的治疗寄予了“宏伟的希望”。
LM Studio Discord
- LM Studio 中的本地回环术语 (Local Loopback Lingo):为了让其他设备从外部访问 LM Studio,设置中有一个局域网复选框,许多人将其与 “loopback” 混淆,导致了命名上的困扰。
- 一些用户希望有更清晰的标签,如 “Loopback Only” 和 “Full Network Access”,以减少设置时的猜测。
- 在 LLM Studio 中争论视觉模型:关于最佳 8–12B 视觉 LLM 的辩论出现了,建议包括 Llama 3.2 11B,此外还有关于它如何与 MLX 和 GGUF 模型格式协作的查询。
- 人们想知道这两种格式是否可以在 LLM Studio 中共存,担心功能重叠和速度问题。
-
工具策略:LM Studio 迈出新步伐:用户发现他们可以将 LM Studio 连接到外部函数和 API,参考了 [Tool Use - Advanced LM Studio Docs](https://lmstudio.ai/docs/advanced/tool-use)。 - 社区成员强调,通过 REST API 可以进行外部调用,为扩展 LLM 任务开辟了新途径。
- 对 RTX 5090 的提升感到失望:尽管拥有 1.7x 带宽和 32GB VRAM,但 NVIDIA RTX 5090 仅比 4090 提升了 30%,这让发烧友们感到失望。
- 他们质疑对较小模型的实际益处,指出增加 VRAM 并不总是能带来巨大的速度提升。
- Llama-3.3 极度消耗 VRAM:运行 Llama-3.3-70B-Instruct-GGUF 很快就需要至少 双 A6000(96GB VRAM),特别是为了保持性能。
- 参与者指出,超过 24GB 的模型可能会让 4090 等消费级 GPU 不堪重负,限制了大型任务的速度。
aider (Paul Gauthier) Discord
- R1+Sonnet 夺得 SOTA:R1+Sonnet 的组合在 aider 多语言基准测试中获得了 64% 的分数,成本比 o1 低 14 倍,如这篇官方文章所示。
- 这一结果引起了关于成本效益的热议,许多人称赞 R1 与 Sonnet 在处理稳健任务时的出色配合。
- DeepSeek 的疑虑与支付痛苦:由于支付安全问题,人们对 DeepSeek 的 API 产生了担忧,激发了对 OpenRouter 版 R1 Distill Llama 70B 的兴趣。
- 一些人引用了在处理支付提供商时的“不确定信任度”,并参考了关于 NVIDIA H100 分配和模型托管限制的推文。
- Aider 基准测试与聪明的 “Thinking Tokens”:社区测试显示,与标准的以编辑器为中心的方法相比,thinking tokens 会降低基准测试性能,影响 Chain of Thought 的效力。
- 参与者得出结论,重复使用旧的 CoT 会损害准确性,建议在高级任务中“修剪历史推理以获得最佳结果”。
- 为更精简的 Python 实现日志跨越:一位用户建议通过 logging module 导出日志,并将输出存储在只读文件中,以减少多余的控制台内容。
- 他们称赞这是“一个保持上下文整洁并专注于代码的小技巧”,只需在 prompt 中引用日志文件,而不是直接转储原始消息。
Interconnects (Nathan Lambert) Discord
- Sky-Flash 解决过度思考问题:NovaSkyAI 推出了 Sky-T1-32B-Flash,在不损失准确性的情况下将冗长的生成内容减少了 50%,据称成本仅为 $275。
- 他们还发布了模型权重供开放实验,承诺降低推理开销。
- DeepSeek R1 撼动顶级模型地位:据 lmarena_ai 报道,DeepSeek R1 在 Arena 排名跃升至 第 3 位,性能追平 o1,而成本却便宜了 20 倍。
- 它在某些任务中甚至超越了 o1-pro,引发了关于其隐藏实力和参与基准测试时机的讨论。
- 总统 AI 行政命令引发行业大洗牌:一项新签署的指令旨在针对阻碍 美国 AI 领导地位 的监管规定,废除了 第 14110 号行政命令,并倡导一种意识形态中立的方法。
- 正如官方公告所述,该指令设立了 AI 与加密货币特别顾问,推动自由市场立场并强化国家安全。
- 天价薪资引发人才争夺战:传闻 DeepSeek 员工的年薪包高达 $550 万,引发了对 AI 领域人才挖角的担忧。
- 这些报价改变了权力动态,老牌技术巨头被认为决心通过丰厚的薪酬来削弱竞争对手。
- Adobe ‘Enhance Speech’ 功能在音频爱好者中引发争议:Adobe Podcast ‘Enhance Speech’ 功能在多人播客中听起来可能有机械感,但在单人录音中表现较好。
- 用户仍然更青睐稳固的麦克风设置而非“魔法音频”处理,认为自然的声音优于过滤后的清晰度。
GPU MODE Discord
- Blackwell 架构随 CUDA 12.8 势头强劲:NVIDIA 推出了支持 Blackwell 架构的 CUDA Toolkit 12.8,包括 cuBLAS 中的 FP8 和 FP4 类型。文档强调了 sm_120 中缺失的第 5 代 TensorCore 指令,引发了对代码碎片化的担忧。
- 成员们讨论了 sm_90a 和 sm_100a 之间的前向兼容性,指出
wgmma是特定架构独有的。一份迁移指南提供了关于这些硬件过渡的见解。
- 成员们讨论了 sm_90a 和 sm_100a 之间的前向兼容性,指出
- ComfyUI 招聘 ML 工程师,计划举办旧金山见面会:ComfyUI 宣布了 ML 职位空缺,为各种主流模型提供首日支持。他们是一家位于湾区的风投支持公司,正在寻找优化开源工具的开发者。
- 他们还透露将在 GitHub 举办旧金山见面会,届时将有 MJM 和 Lovis 带来的演示和小组讨论。该活动鼓励参与者分享 ComfyUI 工作流并建立更紧密的联系。
- 再蒸馏版 DeepSeek R1 超越原版:从原始版本再蒸馏的 DeepSeek R1 1.5B 模型表现出更好的性能,目前托管在 Hugging Face 上。Mobius Labs 指出,他们计划在不久的将来再蒸馏更多模型。
- 来自 Mobius Labs 的推文证实了其相对于之前版本的改进。社区讨论强调了涉及 Qwen 架构的可能扩展。
- Flash Infer 与代码生成进展:由 Zihao Ye 主讲的年度首场 Flash Infer 讲座展示了代码生成和用于增强算子(kernel)性能的专用 Attention 模式。JIT 和 AOT 编译成为实时加速的核心。
- 参与者通过志愿者转达问题,克服了问答环节的限制,彰显了社区支持。这种开放式讨论激发了将这些方法与 HPC 驱动的工作流相结合的兴趣。
- Arc-AGI 的迷宫与多项式插件:贡献者在 clrs 库中增加了多项式方程以及线性方程,以增加谜题的多样性。他们还提出了一个用于最短路径逻辑的迷宫任务,该任务在 reasoning-gym 中立即获得批准。
- 计划包括清理库结构并添加静态数据集注册以简化使用。还讨论了一种动态奖励机制,允许用户定义自定义的基于准确性的评分公式。
OpenAI Discord
- Canvas 获得代码支持与 MacOS 势头:Canvas 现已集成 OpenAI O1,并能渲染 HTML 和 React 代码,可通过模型选择器或
/canvas命令访问;该功能已在 ChatGPT macOS 桌面应用上向 Pro、Plus、Team 和 Free 用户全面推出。- 计划在几周内向 Enterprise 和 Edu 层级进行更广泛的发布,确保更多用户群体获得高级代码渲染能力。
- Deepseek 的 R1 热潮:备用 GPU 与国家支持:Deepseek 的 CEO 透露 R1 是作为一个侧面项目在备用 GPU 上构建的,引发了社区兴趣;有人声称它得到了中国政府的支持以增强本土 AI 模型,并引用了 DeepSeek_R1.pdf。
- 这种方法既节省成本又引人注目,助长了关于 AI 倡议获得主权支持的讨论。
- Chatbot API:海量 Token,极低账单:一位用户建议在 GPT-3.5 上花费 $5 即可处理约 250 万个 Token,强调了与每月专业计划相比,自定义聊天机器人有更便宜的替代方案。
- 他们还指出 AI agent 在 Unity 或集成 IDE 等应用中扩展的潜力,从而拓宽工作流效率。
- Operator 的浏览器技巧预示未来:Operator 引入了面向浏览器的功能,引发了对其在网页交互之外更广泛功能的关注。
- 成员们推动将其更深入地集成到独立应用程序中,同时权衡授予 AI 互联网访问权限时对上下文保留的影响。
- O3:发布还是抵制:一位用户敦促立即推出 O3,却遭到了另一位用户简短的“不,谢谢”回应,显示出热情的两极分化。
- 支持者将 O3 视为关键里程碑,而其他人则表现出极小的兴趣,展示了社区中多样的立场。
Stackblitz (Bolt.new) Discord
- React 狂想曲与 Tailwind 变奏:一份关于 React + TypeScript + Tailwind Web 应用的结构化计划被列出,在 Google Document 中详细说明了架构、数据处理和开发步骤。
- 贡献者建议建立一个核心的 GUIDELINES.md 文件,并强调使用 ‘Keep a Changelog’ 格式来有效跟踪版本更新。
- Supabase 在聊天系统中的障碍:一位用户在使用 Supabase 的实时钩子(realtime hooks)处理消息系统挑战时,遇到了 Row Level Security 问题,并寻求同行见解。
- 他们强调了多用户协作的潜在陷阱,并希望克服过类似障碍的人能分享“经验教训”。
Nous Research AI Discord
- DiStRo 提升 GPU 速度:对话围绕用于提升多 GPU 性能的 DiStRo 展开,重点关注适配每个 GPU 显存的模型。
- 他们建议与 PyTorch 的 FSDP2 等框架协同,从而为先进架构实现更快的训练。
- Tiny Tales:Token 微调的胜利:参与者考虑了 Tiny Stories 的性能,重点是通过精炼的 Tokenization 策略将参数从 500 万扩展到 7 亿。
- Real Azure 发现通过调整 Token 使用改善了困惑度(perplexity),凸显了模型流水线未来的收益。
- OpenAI:炒作 vs 光环:成员们对比了微软、Meta 和亚马逊的估值,对 OpenAI 的品牌轨迹表示担忧。
- 他们辩论了炒作与实际性能的关系,警告过度宣传可能会掩盖稳定的产品输出。
- DeepSeek 蒸馏 Hermes,夺取 SOTA:来自 Teknium1 的 DeepSeek R1 蒸馏 改进将推理与通用模型结合,提升了结果。
- 与此同时,Paul Gauthier 透露 R1+Sonnet 在 aider 多语言基准测试中以 14 倍更低的成本飙升至新的 SOTA。
- Self-Attention 获得优先权:参与者强调了 Self-Attention 在大型 Transformer 模型中对 VRAM 效率的核心作用。
- 他们还考虑通过自我蒸馏(self-distillation)来奖励创意输出,暗示了替代的训练角度。
Yannick Kilcher Discord
- 内存总线大乱斗与数学恶作剧:在 #[general] 频道中,512-bit 宽的 32GB 内存引发了对钱包宽度的调侃,而一个 Stack Exchange 谜题 难倒了多个 LLMs。
- 社区成员还强调了视觉推理陷阱,并开玩笑说动漫头像代表了开源 ML 领域的顶尖开发者。
- MONA 减少多步失误:MONA 论文 引入了 Myopic Optimization with Non-myopic Approval(近视优化与非近视批准),作为一种抑制 RL 中多步奖励黑客攻击(reward hacking)的策略。
- 作者描述了如何桥接短视优化与远见奖励,引发了关于对齐陷阱以及在标准 RL 参数之外极小额外开销的热烈讨论。
- AG2 脱离微软后的转型:AG2 的新愿景 专注于社区驱动的 Agent,详细阐述了治理模型,并在脱离微软后推动全面开源。
- 他们现在拥有超过 20,000 名构建者,引发了对更易用的 AI Agent 系统的期待,部分用户赞扬了向众包开发的转变。
- R1 在 LMArena 中引起轰动:据 #[paper-discussion] 频道报道,R1 在 LMArena 中获得第 3 名,掩盖了其他服务器的光芒,而 Style Control 保持第一。
- 有人称 R1 是搅动市场的黑马,并提到与 Stargate 或 B200 服务器的协同作用可能是其表现强劲的原因。
- Differential Transformers 与 AI 保险讨论:开发者们关注了 DifferentialTransformer 仓库,但对其开源权重的质量和作者的方法表示怀疑。
- 与此同时,关于 AI 保险 的闲谈浮出水面,有人开玩笑说“什么都有保险”,而另一些人则质疑它是否能处理强化学习失控导致的惨剧。
Notebook LM Discord Discord
- NotebookLM 快速完成播客编辑:一位用户使用 NotebookLM 以极少的剪辑拼接播客音频,实现了近乎无缝的流畅效果。
- 讨论中的听众赞赏该工具的准确性,并询问是否可以集成更复杂的音频片段以加快制作速度。
- 工程师关注逆向图灵测试视角:一位用户描述了 Generative Output 尝试通过逆向图灵测试的想法来探索 AGI 概念。
- 他们分享说,这种反思引发了关于控制论(cybernetic)进展以及 LLMs 如何理解自身的对话。
- MasterZap 为 AI 虚拟形象制作动画:MasterZap 解释了使用 HailouAI 和 RunWayML 创建逼真主持人的工作流,并引用了 UNREAL MYSTERIES 7: The Callisto Mining Incident。
- 他强调了让 avatars 感觉自然非常困难,促使其他人比较分层方法以实现平滑的面部动作。
- Gemini Advanced 在 18.5MB PDF 上翻车:用户测试了 Gemini Advanced 解析大型文档的能力,包括一份约 18.5MB 的税法文件,但成功率有限。
- 参与者对不准确的法律定义表示沮丧,并指出 1.5 Pro 版本需要改进处理能力。
- NotebookLM 攻克 220 道测验题:一位用户要求 NotebookLM 从包含 220 道题目的 PDF 中生成测验,强调准确的文本提取。
- 一些成员提供了协作建议,指出高级模型可以处理此类任务,但仍可能需要精细的提示词(prompts)。
Nomic.ai (GPT4All) Discord
- GPT4All v3.7.0 带来 Windows ARM 奇迹:Nomic.ai 发布了 GPT4All v3.7.0,支持 Windows ARM,修复了 macOS 崩溃问题,并重构了 Code Interpreter 以实现更广泛的设备兼容性。
- 一位用户报告称,Snapdragon 或 SQ 处理器 机器现在运行 GPT4All 更加流畅,引发了对改进后的 chat templating 功能的好奇。
- Code Interpreter 与 Chat Templating 的胜利:Code Interpreter 在 console.log 中支持 多个参数,并具有更好的超时处理,提高了与 JavaScript 工作流的兼容性。
- 社区反馈认为这些调整提升了编码效率,而升级后的 chat templating 系统解决了 EM German Mistral 的崩溃问题。
- 礼貌的提示词(Prompt Politeness)见成效:参与者解决了关于 NSFW 和微妙请求的 prompt engineering 障碍,发现添加 please(请)通常会带来更好的交互。
- 他们强调许多 LLM 依赖于 internet-trained data 来获取上下文,并对微妙的措辞变化做出不同的反应。
- 模型混搭与 Qwen 查询:用户评估了运行 Llama-3.2 和 Qwen-2.5 的 GPT4All,关注大规模任务的资源需求。
- 有人提到 Nous Hermes 是一个可能的替代方案,而其他人则对 Qwen 进行了广泛测试,以增强翻译能力。
- Taggui 助力图像分析:一位用户寻求用于 图像分类 和打标的开源工具,促使推荐使用 Taggui 进行 AI 驱动的上传和查询。
- 爱好者们称赞其 多 AI 引擎 集成,称其为高级图像辅助头脑风暴的可靠选择。
MCP (Glama) Discord
- MCP 超时调整成功:工程师通过修改
mcphub.ts解决了 60 秒服务器超时 问题,示例更新可在 Roo-Code repo 中找到。他们归功于 VS Code extension 引导了修复并确保了稳定的 MCP 响应。- 成员们指出,指定正确的
uvx.exe路径对于防止进一步停机至关重要,并强调 Roo-Code 是跟踪配置更改的有价值工具。
- 成员们指出,指定正确的
- MySQL 与 MCP Alchemy 融合:一位用户推荐了 mcp-alchemy 用于 MySQL 集成,并提到它也兼容 SQLite 和 PostgreSQL。这是在询问用于管理数据库连接的可靠 MCP 服务器之后提出的。
- 该仓库包含多个使用示例,引发了对高级 MCP 数据库流水线的广泛兴趣。
- Claude 的 Google 搜索功能受挫:社区成员观察到 Claude 在其 Google search 功能上表现挣扎,有时在高负载下失败。他们推测高需求和 API 不稳定性可能是原因。
- 一些人建议使用替代调度策略,希望更稳定的查询窗口能减少 Claude 中的搜索取消。
- Glama 中的 Agent 引起困惑:MCP Agentic tool 提前出现在 Glama 中,让用户对其激活路径感到不确定。一位成员透露官方声明尚待发布,称这次泄露是意料之外的。
- 讨论将该功能与 MCP.run 联系起来,一些用户在 non-Glama 客户端设置中测试它以实现类似 Agent 的功能。
- 个性化初具规模:mcp-variance-log:开发者介绍了 mcp-variance-log,引用了 Titans Surprise 机制,通过 SQLite 进行用户特定数据跟踪。该工具分析对话结构以支持扩展记忆。
- 成员们期待更深层次的个性化,指出这些 variance logs 可能会为未来的 MCP 扩展和针对用户的改进提供参考。
LlamaIndex Discord
- Redis 研讨会:AI Agent 实战:与 Redis 联合举办的网络研讨会探讨了构建 AI Agent 以增强任务管理的方法,录像可在此处观看。
- 听众指出,彻底分解任务可以提高实际应用中的性能。
- 驯服并行 LLM 流式传输:一位用户在同时从多个 LLM 流式传输数据时遇到困难,建议指向了异步库配置错误,并参考了一个 Google Colab 链接中的工作示例。
- 社区成员强调需要正确的并发模式,以避免顺序数据处理中的中断。
- 使用 LlamaParse 解析幻灯片:工程师们讨论了使用 LlamaParse 对 .pdf 和 .pptx 文件进行文档解析的方法,重点在于处理基于 LaTeX 的 PDF。
- 他们确认了 LlamaParse 在为高级 RAG 工作流提取结构化文本方面的实用性,即使是跨多种文件类型。
- ReActAgent 中的实时响应:对话探讨了如何结合 LlamaIndex 的 ReActAgent 和此处的 AgentWorkflow 系统,将实时事件流与 Token 输出集成。
- 开发者表示,一旦事件处理与实时的 Token 流式传输同步,用户流程将得到改善。
- 出口管制波及 AI 领域:参与者探讨了针对先进计算项目和 AI 模型权重的新美国出口法规的影响,引用了此更新。
- 他们提出了关于合规障碍以及这些规则可能如何影响 Llama 模型使用和共享的问题。
Cohere Discord
- 出口意外:模型权重成为目标:美国商务部推出了新的 AI 出口管制,引发了关于 Cohere 模型是否会被纳入最新限制范围的担忧(链接)。
- Oracle Japan 的一些工程师担心许可证纠纷,尽管内部团队暗示特殊协议可能会缓冲这一冲击。
- GPU 趣闻:绕过限制:社区成员辩论了 GPU 限制的实际影响,暗示大型 AI 公司正在暗中引入硬件。
- 参与者质疑这些政策是否主要惩罚小玩家,而“大鱼”则能自由游走。
- Blackwell 预算困扰:一位用户指出了 Blackwell 的高负荷运行问题,提到待机功耗达 200w,引发了对使用量增加后账单激增的担忧。
- 其他人建议平衡计算需求与实际工作负载以避免浪费。
Modular (Mojo 🔥) Discord
- Mojo 异步论坛盛会:一位成员计划分享一篇关于 Mojo 异步代码的新论坛帖子,链接至 如何在 Mojo 中编写异步代码。
- 他们承诺将协作完成该帖子,强调围绕异步实践进行社区驱动的知识交流。
- MAX Builds 页面展示社区作品:经过重新设计的 MAX Builds 页面 builds.modular.com 现在设有一个社区构建包的专门板块。
- 开发者可以向 Modular 社区仓库提交带有 recipe.yaml 的 PR,鼓励更多开放贡献。
- iAdd 特性引发原地加法难题:用户讨论了用于原地加法(如 a += 1)的 __iadd__ 方法,以及在评估过程中值是如何存储的。
- 一个有趣的例子 a += a + 1 证明了如果 a 最初为 6,结果可能会产生 13,这提醒人们要避免混淆。
- Mojo CLI 进阶:一位成员透露了两个新的 Mojo CLI 标志:–ei 和 –v,引起了频道参与者的兴趣。
- 他们用俏皮的表情符号展示了这些标志,暗示 Mojo 爱好者还有更多的实验空间。
LAION Discord
- 追求更清晰的标签:成员们探讨了针对背景噪音(background noise)和音乐水平(music levels)的标注策略,参考了一个 Google Colab notebook,并鼓励采取“不知道就发挥创意,尽管提问”的方法。
- 他们提出了多个类别,如无背景噪音和轻微噪音,一些人建议使用更动态的标注方式来处理不同的音乐强度。
- 众声喧哗:爱好者们提出了一个多发言者转录数据集的想法,通过重叠 TTS 音频流,旨在获取细粒度的时间码来追踪谁在什么时候说话。
- 他们强调,音高(pitch)和混响(reverb)的变化有助于发言者识别(speaker recognition),并引用了一句话:“没有网站,是我在 Discord 上协调大家。”
Eleuther Discord
- 散度蒸馏:Teacher-Student 之争:一位参与者提出将 Teacher 和 Student 模型之间的散度作为奖励信号,用于在蒸馏中部署 PPO,这与传统的基于 KL 的方法形成对比。
- 一些人指出 KL-matching 在常规训练中的稳定性,但对自适应散度塑造蒸馏奖励保持好奇。
- 层收敛 vs. 梯度消失:人们讨论了最近一篇关于层收敛偏差(layer convergence bias)的 ICLR 2023 论文,该论文显示浅层比深层学习得更快。
- 他们还辩论了梯度消失(vanishing gradients)是否是深层进度缓慢的一个因素,并承认它不是训练挑战中的唯一诱因。
- ModernBERT, ModernBART 与混合架构热潮:讨论集中在 ModernBERT 以及 ModernBART 的可能性上,一些人认为 Encoder-Decoder 版本在摘要生成任务中会很受欢迎。
- 对 GPT-BERT 混合模型 的引用强调了其在 BabyLM Challenge 2024 中的性能提升,建议结合 Masked 和 Causal 方法。
- Chain-of-Thought 与 Agent-R 激发反思:一种新方法将 Chain-of-Thought 推理与 Direct Preference Optimization 相结合,以实现更好的自回归图像生成。
- 与此同时,Agent-R 框架 利用 MCTS 进行自我批判和鲁棒恢复,引发了关于类似于 Latro RL 的反思性推理的辩论。
- 双线性 MLP 实现更清晰的计算:一篇新的 ICLR’25 论文 介绍了双线性 MLP(bilinear MLPs),它移除了逐元素的非线性,简化了层功能的可解释性。
- 支持者认为这种设计揭示了权重(weights)如何驱动计算,为在复杂模型中实现更直接的 Mech Interp 带来了希望。
Stability.ai (Stable Diffusion) Discord
- 聚焦冰霜字体:爱好者们探索了使用 Img2img 配合自定义字体生成冰霜文本(ice text),以实现晶莹剔透的设计。
- 调整 Denoise 设置并将文本着色为冰蓝色被认为是推荐的方法。
- ControlNet 受到关注:一些人建议使用 ControlNet 来优化冰霜文本的外观,特别是结合分辨率平铺(resolution tiling)时。
- 据说这种方法可以为风格化文本带来更锐利的边缘和更一致的效果。
- Adobe Firefly 介入:用户提到 Adobe Firefly 作为一个替代方案,如果有 Adobe 许可证,它可以处理专门的文本创建。
- 他们认为这比分层使用 Inkscape 等独立软件工具的方法更快。
- 中毒图像查询:一位成员询问如何检测图像是否中毒(poisoned),引发了关于“舔舐测试”和“嗅闻测试”的玩笑。
- 虽然没有出现正式的方法,但讨论凸显了社区对图像安全性的好奇。
- 将草图转化为场景:有人寻求关于 Sketch to Image 工作流的建议,以将粗略的轮廓转化为最终的视觉效果。
- 讨论中还提到了宽高比考虑因素(如 16:9),以实现更用户友好的生成。
tinygrad (George Hotz) Discord
- ILP 驯服合并:Pull Request #8736 中引入了一种使用 ILP 统一 view 对的新方法,报告的未命中率为 0.45%。
- 参与者讨论了逻辑除数,并认识到可变步长(strides)带来的障碍。
- Mask 混淆合并:社区成员争论 mask 表示 是否能增强合并,尽管有人认为它可能不适用于所有设置。
- 他们得出结论,mask 能够实现少量合并,但无法处理所有步长场景。
- 多重合并模式出现:通过测试 v1=[2,4] 和 v2=[3,6] 的偏移量,提出了一种正式搜索,旨在检测公约数中的模式。
- 他们设想了一种通用技术,通过系统地检查步长重叠来统一 view。
- 三个 View,双倍麻烦:爱好者们质疑将合并从 两个 增加到 三个 view,担心会增加复杂性。
- 他们提到棘手的步长是 ILP 的绊脚石,并警告 3 -> 2 的 view 转换不会一帆风顺。
- 步长对齐势头强劲:一些人建议对齐步长可以减少合并难题,但他们警告说,当步长不匹配时,可能会出现错误的假设。
- 他们意识到早期的方法由于错误的步长计算而忽略了可能的合并,呼吁进行更深入的检查。
Torchtune Discord
- Windows 的不稳与 WSL 的奇妙:成员们指出 Windows 施加了一些限制,包括有限的 Triton 内核支持。他们建议使用 WSL 以获得更直接的编码体验。
- 他们强调了更短的设置时间,并建议这将减轻在 Windows 硬件上的训练性能压力。
- 正则表达式助力数据清理:一位成员分享了一个正则表达式
[^\\t\\n\\x20-\\x7E]+,通过识别隐藏字符来清理杂乱的数据集。另一位成员阐明了该模式的组成部分,强调了其在剔除不可打印文本方面的作用。- 他们敦促在修改表达式时要谨慎,以避免意外的数据丢失,并建议在较小的样本上进行彻底测试。
- Triton & Xformers 与 Windows 的冲突:由于 Triton 和 Xformers 的兼容性缺口,一些人在 Windows 上运行 unsloth 或 axolotl 时遇到了问题。他们指向了一个 GitHub 仓库以寻求潜在的解决方案。
- 他们建议探索未来的驱动程序更新或基于容器的方法来在 Windows 上安装这些库。
LLM Agents (Berkeley MOOC) Discord
- MOOC 周一狂欢开始:正如 #mooc-questions 频道讨论 中提到的,第一节课定于 太平洋时间 27 日周一下午 4 点,官方邮件通知即将发布。
- 组织者确认该课程将包含量身定制的高级内容,旨在推动 LLM Agent 在现实任务中的应用。
- LLM Agent 面临高标准:社区成员指出,通过该课程的 LLM Agent 为这些模型的能力设定了更高的标准。
- 他们一致认为,这反映了课程繁重的工作量和严格的评分标准,为 AI 参与者打造了一个独特的挑战。
Axolotl AI Discord
- 诈骗信息席卷 Discord:诈骗信息出现在多个频道中,包括 此频道,引发了警告。
- 一位用户承认了这个问题,鼓励大家保持警惕并核实可疑帖子。
- Nebius AI 引发多节点关注:一位成员询问在多节点环境中运行 Nebius AI 的经验,理由是需要现实世界的性能技巧。
- 其他人提供了潜在的指导,强调了对资源分配和设置细节的深入了解需求。
- SLURM 与 Torch Elastic 的正面交锋:一位用户感叹在分布式训练中配置 SLURM 与 Torch Elastic 的难度,称其为一个重大障碍。
- 另一位成员建议查看 SLURM 的多节点文档,认为许多设置概念可能仍然适用于这种情况。
DSPy Discord
- Signature 混乱加速了困惑:一位用户在 signature 定义上遇到了困惑,理由是缺失的源文件导致输出偏离预期。
- 他们怀疑是不完整的引用导致了这次混乱,并提出了如何管理一致的文件映射的问题。
- MATH Dataset 消失了:一位用户尝试运行 maths example,但发现 MATH dataset 已从 Hugging Face 移除,并分享了一个部分副本的链接。
- 他们还指向了 Heuristics Math dataset,询问是否有人能建议其他解决方案。
MLOps @Chipro Discord 没有新消息。如果该频道长期保持安静,请告知我们,我们将将其移除。
Mozilla AI Discord 没有新消息。如果该频道长期保持安静,请告知我们,我们将将其移除。
OpenInterpreter Discord 没有新消息。如果该频道长期保持安静,请告知我们,我们将将其移除。
HuggingFace Discord 没有新消息。如果该频道长期保持安静,请告知我们,我们将将其移除。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该频道长期保持安静,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该频道长期保持安静,请告知我们,我们将将其移除。
第 2 部分:按频道详细摘要和链接
完整的各频道详细分析已针对电子邮件进行了截断。
如果您喜欢 AInews,请分享给朋友!提前致谢!