ainews-deepseek-1-on-us-app-store-nvidia-stock
DeepSeek 登顶美国 App Store,英伟达股价暴跌 17%。
DeepSeek 在 2025 年出人意料地登上了主流新闻,产生了重大的文化影响。DeepSeek-R1 模型采用了庞大的 6710 亿参数 MoE(混合专家)架构,并展现出与 OpenAI o1 相当的思维链(CoT)能力,且成本更低。DeepSeek V3 模型利用 fp8 精度,在训练 2360 亿参数模型时,速度比其前代产品快了 42%。Qwen2.5 多模态模型支持图像和视频,参数规模从 30 亿到 720 亿不等,具备强大的视觉和智能体(agentic)能力。LangChain 与 LangGraph 的集成使 AI 聊天机器人具备了记忆和工具使用能力,包括 DeFi Agent(去中心化金融智能体)等应用。相关讨论强调了英伟达(NVIDIA)在硬件加速方面的作用,同时也对因 DeepSeek 的高效和市场恐慌导致的股价下跌表示担忧。尽管效率有所提升,但在推理扩展和 MoE 设计改进的推动下,计算需求预计仍将增长。
DeepSeek is all you need.
2025年1月24日至1月27日的 AI 新闻。我们为您检查了 7 个 subreddit、433 个 Twitter 账号 和 34 个 Discord 服务器(225 个频道和 11316 条消息)。预计节省阅读时间(以 200wpm 计算):1229 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
我们一直努力保持新闻报道的技术性,但在极少数情况下,主流/非技术性新闻的影响力如此之大,以至于它也出现在了这里。
今天就是这样的日子。
以及 sama:
最终,大部分讨论都非常无益,看起来就像这个版本的变体:

我们主要报道 DeepSeek 进入主流新闻的文化时刻,这从未出现在我们对 2025 年的预测中。
AI Twitter 回顾
所有摘要均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
AI 模型发布与增强
-
DeepSeek-R1 和 V3 的效率:@teortaxesTex 讨论了 V3 如何展示出比之前的 67B 模型快 42% 的速度来训练 236B 模型的能力,并利用 fp8 精度为更大型的模型保持速度。@nptacek 强调 DeepSeek-R1 需要大量的 GPU,并重点介绍了其具有 671B 参数的 MoE 架构。@carpeetti 赞扬了 DeepSeek-R1 的思维链 (CoT) 能力,能以极低的成本媲美 OpenAI 的 o1。
-
Qwen2.5 模型:@mervenoyann 宣布发布 Qwen2.5-VL,这是一款能够处理图像和视频的多模态模型,版本包括 3B、7B 和 72B 参数。@omarasar0 详细介绍了 Qwen2.5 强大的视觉能力和 Agent 特性,支持长视频理解和结构化数据输出。
-
LangChain 和 LangGraph 集成:@LangChainAI 分享了使用 LangGraph 构建 AI 聊天机器人的教程,实现了记忆和工具集成。他们还展示了 DeFi Agent 等应用,可自动化 Aave 协议操作。
计算与硬件
-
NVIDIA 的影响:@teortaxesTex 对在 32K Ascend 910C 集群上进行训练表示担忧,暗示可能会做空 NVIDIA 股票。@samyj19 和 @ykylee 讨论了 DeepSeek-R1 的推理速度优化,利用 NVIDIA H800 GPU 来提升性能。
-
算力需求:@finbarrtimbers 认为,尽管 DeepSeek 效率很高,但由于推理侧扩展 (inference scaling),算力需求仍将增加。@cwolferesearch 分析了 DeepSeek-v3 的 Mixture-of-Experts (MoE) 设计,强调了其在效率和性能方面的改进。
AI 竞争与市场反应
-
股市反应:@MiddleOpenAI 报道称,在 DeepSeek 取得进展后,由于市场恐慌,NVIDIA 的股价大幅下跌 -17%。@arthurrapier 同样表达了对 NVIDIA 看跌信号的担忧,而 @DanHendrycks 等人则强调了由于芯片供应链依赖而导致的战略脆弱性。
-
竞争格局:@scaling01 批评了市场对 DeepSeek 的反应,认为 DeepSeek 的效率挑战了高利润模型背后的假设。@janusflow 指出 DeepSeek 的发布对技术生态系统具有颠覆性,引发了市场波动。
AI 应用与用例
-
Agent 能力:@teortaxesTex 介绍了 Grace, Kane 和 Flows,这些 AI Agent 能够在电脑和智能手机上执行命令,展示了实时交互和多步推理能力。
-
历史研究与药物研发:@omarsar0 探讨了 LLMs 在历史研究中的应用,例如转录早期现代意大利语和生成历史解读。此外,还讨论了通过幻觉特性与药物研发的结合。
-
视频与图像处理:@mervenoyann 展示了 DeepSeek 的 Janus-Pro 用于多模态图像生成,超越了 DALL-E 等模型。@chethaan 强调了 NVIDIA 的 Cosmos Tokenizer 用于物理 AI 训练,增强了图像和视频的 Token 化。
技术讨论与创新
-
强化学习与训练效率:@teortaxesTex 强调了强化学习 (RL) 在 DeepSeek 模型中的重要性,突出了 DeepSeek Zero 范式中独立的并行工作。@lateinteraction 讨论了并没有所谓的秘密革命性技术,将成功归功于工程精度。
-
量化技术:@danielhanchen 详细介绍了 DeepSeek R1 量化至 1.58bit 的过程,通过动态量化在保持可用性的同时实现了 80% 的体积缩减。这一创新使模型能够在更普及的硬件上运行。
-
Mixture-of-Experts (MoE) 模型:@cwolferesearch 解释了 DeepSeek-v3 的 MoE 架构,包含共享专家和多 Token 预测,提升了训练效率和模型性能。
AI 业务与市场反应
-
开源 vs. 闭源模型:@ClementDelangue 倡导开源 AI,表示:“AI 不是一场零和博弈。开源 AI 是惠及所有人的浪潮!” @cwolferesearch 也表达了类似观点,赞扬了 DeepSeek 开源模型的透明度和成本效益。
-
投资策略:@swyx 建议不要做空 NVIDIA,认为 DeepSeek 的进步推动了算力需求而非减少。相反,@scaling01 基于 DeepSeek 对 AI 算力经济学的影响提出了做空策略。
-
招聘与人才获取:@AlexAlbert__ 等人提到了 Anthropic 等 AI 公司的招聘机会,强调需要多元化的技术背景来驱动未来的 AI 创新。
AI Reddit Recap
/r/LocalLlama Recap
主题 1. DeepSeek 登顶美国 App Store:市场影响
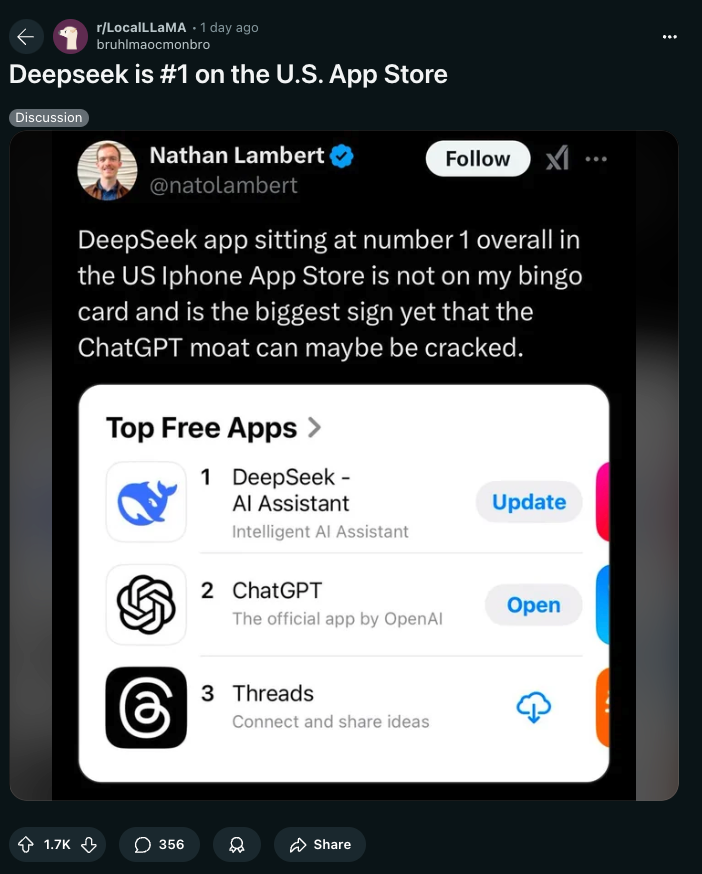
- Deepseek 登顶美国 App Store (Score: 1618, Comments: 341): Deepseek 已在 U.S. App Store 的“免费应用排行榜”中位列第一,超越了 ChatGPT 和 Threads 等知名应用。这一排名突显了其作为智能 AI 助手的竞争优势,并对其在面对成熟 AI 工具时的市场地位产生了影响。
- 舆论对 Deepseek 的竞争优势持怀疑态度,并担心它会因为潜在的国家安全风险而面临与 TikTok 类似的命运。一些用户对高流量导致的服务器宕机表示沮丧,而另一些用户则质疑与 ChatGPT 和 Perplexity 等其他 AI 模型相比,它能为普通用户提供哪些独特价值。
- 讨论强调了 Deepseek 的开源特性,用户指出其模型权重和训练方法可能会发布,从而使其更易于获取。一些用户讨论了本地运行 Deepseek 的可行性,并提到了可以在消费级硬件上运行的蒸馏模型 (distilled models),尽管完整模型需要大量资源。
- 评论反映了关于 AI 发展中全球竞争的更广泛对话,一些用户批评了“护城河”的概念,并强调多个国家都能开发出具有竞争力的软件。此外,还有关于美国技术竞争方式的看法,以及 Deepseek 的开源方法对国际动态影响的辩论。
- OpenAI 员工对 Deepseek 的反应 (Score: 1239, Comments: 256): OpenAI 员工 Steven Heidel 批评了与 DeepSeek 相关的数据隐私问题,暗示美国人正在为了免费服务将数据交给 CCP。讨论强调,与 OpenAI 的模型不同,DeepSeek 可以在没有互联网连接的情况下本地运行。
- 开源与本地运行:许多评论者强调 DeepSeek 是开源的,可以在本地或云端硬件上运行,这解决了对数据隐私和对外国实体依赖的担忧。TogetherAI 被提及为一个托管该模型的服务,且不使用数据进行训练,为本地运行提供了替代方案。
- 审查与模型透明度:舆论对 AI 模型的透明度持怀疑态度,一些用户注意到 DeepSeek 在对齐 CCP 叙事方面表现出审查倾向,这强调了对像 HuggingFace 正在开发的这类真正开放模型的需求。
- 硬件与可访问性:关于运行 DeepSeek 等大型模型的硬件要求的讨论强调,虽然个人可能缺乏资源,但资金充足的初创公司可能负担得起必要的基础设施。一些用户提到了具体的硬件配置,例如使用 30 块 3090/4090 或 9 块 80 GB 大显存 GPU 来满足模型的需求。
- 1.58bit DeepSeek R1 - 131GB 动态 GGUF (Score: 552, Comments: 125): 该帖子讨论了 DeepSeek R1 671B MoE 模型的 dynamic quantization(动态量化)至 GGUF 格式的 1.58bits,通过仅将 MoE 层量化为 1.5bit,同时保持 attention 和其他层为 4 或 6bit,有效地将磁盘占用减少到 131GB。这种方法防止了产生乱码和无限重复的问题,在 2x H100 80GB GPU 上实现了 140 tokens/s 的处理速度,并成功在特定条件下生成了一个 Flappy Bird 游戏。更多资源和细节可以在 Hugging Face 和 Unsloth 博客上找到。
- 量化策略:成功量化 DeepSeek R1 671B MoE 模型 的关键是仅将 MoE 层量化为 1.5bit,同时保持其他层具有更高的精度(4 或 6 bits),这符合 BitNet 论文 的原则,即建议保留某些层的高精度以优化性能。这种方法防止了计算成本过高的问题,并保持了模型执行复杂任务的能力,例如生成 Flappy Bird 游戏。
- 兼容性与实现问题:用户讨论了在不同设置下运行模型的挑战并寻求指导,例如 Ollama、LM studio 和 llama.cpp,强调了理解具体实现和兼容性问题的重要性。还有关于硬件要求的咨询,一位用户指出 24GB GPU(如 RTX 4090) 应该能达到 1 到 3 tokens/s 的速度。
- 社区反馈与性能预期:社区对该模型的性能给出了显著的正面反馈,用户对其能力表示惊讶,特别是生成无错的 Flappy Bird 游戏的能力。用户还讨论了潜在的性能指标,例如在不同硬件配置上的推理速度,并对基准测试以及与 Q2KS 等其他模型的比较表示了兴趣。
{kind=link}
{kind=link}
主题 2. Deepseek 如何降低 95-97% 的成本
- Deepseek 究竟为何如此便宜? (Score: 386, Comments: 334): Deepseek 通过采用避免 RLHF (Reinforcement Learning from Human Feedback)、利用 quantization 以及实施 语义输入 HTTP 缓存 等策略,实现了 95-97% 的成本削减。然而,关于 R1 是否经过量化存在困惑,引发了关于潜在补贴或 OpenAI/Anthropic 是否过度收费的问题。
- 讨论强调了 Deepseek 的成本节约策略,重点是将 MoE (Mixture of Experts)、FP8 精度和 multi-token prediction (MTP) 作为关键因素。这些技术选择,加上廉价的电力和较低的研发成本,使其与 OpenAI/Anthropic 相比实现了显著的成本降低。一些用户怀疑存在政府补贴或亏本经营以获取市场份额。
- 也有人对 Deepseek 运营的真实成本和效率持怀疑态度,一些评论者质疑其定价模型的财务透明度和可持续性。有人担心他们是否在使用更便宜的 Nvidia H800 芯片,以及 OpenAI/Anthropic 是否因为潜在不可持续的商业模式而过度收费。
- Deepseek 模型的开源性质(可在 Huggingface 等平台获取)被视为一种竞争优势,允许广泛采用和托管的灵活性。然而,一些用户对这些模型的运行质量和性能表示怀疑,报告了翻译能力方面的问题,并质疑 Deepseek 声明的可信度。
主题 3. 本地 LLM 兼容性新工具:“Can You Run It?”
- 有人需要为开源 LLM 创建一个“你能运行它吗?”工具 (Score: 298, Comments: 64): 一位非技术用户表达了对类似于 System Requirements Lab 的工具的需求,用于开源 LLM(如 Deepseek, LLaMA, 和 Mistral),以确定这些模型是否可以在其硬件上运行。他们提议建立一个系统,用户可以输入电脑配置,从而获得直观的性能评估和优化建议,例如使用量化版本以更好地兼容低端系统。
- 提到了几种用于确定 LLM 是否可以在特定硬件上运行的工具和资源,包括 Vokturz’s can-it-run-llm 和 NyxKrage’s LLM-Model-VRAM-Calculator。这些工具帮助用户计算 VRAM 需求并评估模型与系统的兼容性。
- 社区成员分享了估算硬件需求的经验法则,例如 每 1B 参数 1GB 和 每 1K 上下文 1GB,并推荐在低端系统上使用 llama 3.2 或 Qwen 2.5 以获得最佳性能。他们还讨论了量化和上下文长度对性能及内存占用的影响。
- 用户(如 Solid_Owl 和 Shark_Tooth1)对易于使用、开源且能保护隐私并保持模型需求更新的工具有需求,他们表达了对隐私的担忧,并寻求针对本地 LLM 使用的可靠性能预期工具。
- 我为开源 LLM 创建了一个“你能运行它吗”工具 (Score: 261, Comments: 50): 我为开源 LLM 创建了一个 “你能运行它吗”工具,该工具提供 tk/s 预估,以及在 GPU 上运行模型(包含 80% 层卸载 和 KV 卸载 等选项)的说明。该工具已在 Linux 单 Nvidia GPU 环境下测试,现征求其他系统(包括多 GPU 设置)的反馈,以识别潜在问题。GitHub 链接。
- Mac 兼容性:Environmental-Metal9 调整了针对 macOS 的计算,报告了 M1 Max 上性能预估的差异。他们提出通过 Pull Request 或 Pastebin 贡献 Mac 支持 的补丁。
- 用户界面建议:包括 Catch_022 和 MixtureOfAmateurs 在内的用户建议通过创建带有 GUI 的便携式可执行文件 或将其托管为 网站 来简化工具的可用性,从而消除安装 Python 的需求。
- Web 界面与变现:Whole-Mastodon6063 为该工具开发了 Web 应用界面,mxforest 建议通过在线托管并投放广告来获取潜在收益,Ok-Protection-6612 和 femio 支持通过赞助进行变现的想法。
主题 4. Qwen 3.0 MOE: 新兴推理模型
- Qwen3.0 MOE? 新的推理模型? (Score: 239, Comments: 34): Binyuan Hui 的一条推文暗示了 Qwen3.0 MOE 和一个潜在的 新推理模型,预示着即将发布的公告或活动。该推文暗示了 AI 领域的重大进展,尽管未提供具体细节。
- Qwen2.5-VL 已确认是即将发布的版本之一,并在 Hugging Face 上创建了合集。这表明除了视觉模型之外,可能很快会有包括 Qwen MoE 和 Qwen 3.0 在内的更新。
- DeepSeek 被提及为处理巨大算力需求的合作伙伴,一些用户希望看到采用 Apache/MIT 许可证 的新推理模型。人们对各种模型尺寸和功能充满期待,包括音频模型和像 Qwen 2.5 100B+ 这样的大规模模型。
- 由于临近 春节假期,发布公告的时机受到质疑,人们对发布前的炒作持怀疑态度。
{kind=link}
其他 AI 子版块回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
主题 1. Nvidia 股票波动:DeepSeek 高效模型的影响
- Nvidia 泡沫破裂 (评分: 627, 评论: 245): Nvidia 的股价经历了显著下跌,五天内下跌了 $17.66 (12.68%),从 2023 年 1 月 24 日的峰值 $142.02 跌至 1 月 27 日的 $121.56。该公司的市值 (market cap) 据报道为 $2.97 万亿,市盈率 (P/E ratio) 为 48.07,52 周波动范围在 $60.70 至 $153.13 之间。
- 许多评论者将股价下跌视为买入机会,多人表示相信 Nvidia 将会反弹。itsreallyreallytrue 和 AGIwhen 认为,尽管 DeepSeek 声称降低了 GPU 需求,但由于其在 AI 基础设施中的关键作用,对 Nvidia GPU 的需求依然强劲。
- 讨论中表现出对 DeepSeek 的主张及其对 Nvidia 股价影响的怀疑,TheorySudden5996 和 Agreeable_Service407 指出,尽管效率可能提升,但对 GPU 的需求仍然巨大。DerpDerper909 认为,即使效率有所提高,Nvidia 也会从小型公司开发 AI 模型门槛降低中受益。
- Cramer4President 等人批评了基于短期股票表现就认为“泡沫破裂”的观点,主张从更长的时间跨度来看待。OptionsDonkey 和 Legitimate-Arm9438 强调 Nvidia 的长期价值依然强劲,认为目前的下跌是暂时波动而非根本性问题。
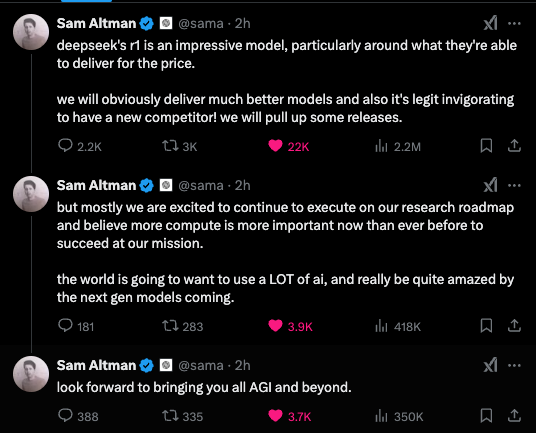
- 这是关于 DeepSeek 的吗?你认为他真的担心吗? (评分: 540, 评论: 203): Sam Altman 强调了与复制现有成功想法相比,创建创新且具有风险的项目的挑战,并强调了认可个人研究人员突破性工作的重要性。他最后总结道,这些努力代表了“世界上最酷的事情”。
- 对 Sam Altman 言论的批评:许多评论者批评了 Sam Altman 对个人研究人员的强调,认为突破往往是协作努力的结果。Neofelis213 强调了“孤独研究者”的迷思,并指出像 Sam Altman 和 Elon Musk 这样的人物往往掩盖了技术进步的实际贡献者。
- 历史背景与贡献:讨论集中在 Transformer 架构和 LLM 的起源上,用户指出 Google 发表了奠基性论文《Attention Is All You Need》,OpenAI 在此基础上进行了构建。coloradical5280 等人强调了这些发展的协作性质,以及 Ilya Sutskever 等关键人物在技术演进中的作用。
- 伦理与版权担忧:一些评论提到了在训练 AI 模型中使用受版权保护材料的伦理影响,Riegel_Haribo 提到了 AI 训练中涉及的大规模版权侵权。这引发了关于使用公共数据的合法性和公平性的辩论,并引用了 Aaron Swartz 被起诉等历史案例。
- “每个模型都有审查”是一个无知的论点 (Score: 179, Comments: 146): 该帖子批评了西方对 DeepSeek 和 ChatGPT 审查制度的看法,认为虽然两者都有审查,但 CCP 的审查危害更大,因为它压制了对威权权力的批评。作者强调,与西方替代方案不同,Chinese AI models 普遍受到政府审查,并强调了 CCP 统治下中国公民受到的剥削,许多人年收入不足 $4,000 且缺乏免费医疗。该帖子谴责西方人为了廉价的中国产品而忽视这些问题。
- 几位评论者认为,审查制度和威权主义并非中国独有,因为美国也从事类似的做法,包括在 Gemini 和 ChatGPT 等 AI models 中进行审查,以及对无证劳工的依赖。他们认为,西方 AI models 也受到审查以保护政治利益,且美国自身也存在贫富差距和剥削问题。
- 讨论强调了 AI 技术的剥削性质,指出数据集通常是利用未支付报酬的知识产权汇编而成的,而创建和维护这些技术所涉及的劳动价值被低估。评论者批评了在谴责中国做法的同时忽视西方国家类似问题的虚伪行为,例如 Lockheed Martin 在政府支出中的角色,以及像 Larry Ellison 这样的亿万富翁在 AI 监控中的作用。
- 一些评论者对审查制度对 AI 发展的影响表示怀疑,认为像 HuggingFace 上的开源项目可以绕过审查。他们指出,随着 R1 等模型被逆向工程,AI 的快速进步削弱了审查的力量,因为更多的模型是在本地开发的,且限制更少。
{kind=link}
{kind=link}
Theme 2. DeepSeek R1’s Coding Efficiency vs OpenAI O3
- DeepSeek R1 比 o1 便宜 25 倍,且在相同成本下,其编码基准测试表现优于“未发布”的 o3。DeepSeek 正在让 OpenAI 感到压力。 (Score: 355, Comments: 111): DeepSeek R1 的定位是比 OpenAI 的 o1 模型便宜 25x,并在相同成本下展示了优于“未发布”的 o3 的编码性能。图形数据突显了 DeepSeek R1 在编码基准测试中 15.8% 的优异表现得分,强调了其成本效益以及相对于其他模型的竞争优势。
- 几位评论者对 DeepSeek R1 性能声明的可信度表示质疑,指出数据中存在问号,且需要第三方验证。人们对论文的方法论以及缺乏关于训练硬件的可验证信息表示担忧。
- 人们对 DeepSeek 推广的频率和性质表示怀疑,认为可能存在蓄意的宣传活动或“astroturfing(草根营销)”。评论者将其与 Claude 和 Gemini 等其他模型的推广进行了比较,指出存在类似的激进营销模式。
- 一些用户对 AI 领域竞争的加剧表示支持,希望能有更多像 Meta 和 Claude 这样的参与者。然而,其他人对关于 DeepSeek 的大量宣传帖子感到沮丧,质疑其与 OpenAI 和 Claude 等成熟模型相比的实际效用和性能。
{kind=link}
Theme 3. Debates on DeepSeek vs ChatGPT: A Censorship Perspective
- 受 Octopus 启发的 Logarithmic spiral manipulator 可以操纵多种物体 (Score: 537, Comments: 41): 帖子标题讨论了一种受 Octopus 启发的 Logarithmic spiral manipulator,它能够处理各种物体。关于 AI 在政治审查中的伦理影响并未被直接提及,这表明主题与标题之间可能存在混淆。
- 技术起源: Logarithmic spiral manipulator 技术由 University of Science and Technology of China 开发,并在中国进行了测试。这澄清了关于起源的任何困惑,因为一些评论误将其归功于日本。
- 设计与构造: 该机械手似乎由 3D printed pieces 构造而成,并通过两侧的两条线进行操作,强调了软件在其功能中的重要作用。人们对软件是否会 Open Source 表现出浓厚兴趣,这可能会使其更易于使用。
- 公众反应与幽默: 讨论中包含了幽默和反乌托邦式的反应,提到了 Robot tentacles 及其在 War and entertainment 场景中的潜在用途。这突显了围绕先进机器人技术的复杂情感和想象力推测。
AI Discord 摘要回顾
由 o1-preview-2024-09-12 生成的摘要之摘要的总结
主题 1. DeepSeek R1 模型颠覆 AI 格局
- DeepSeek R1 缩减至 1.58-Bit,威力不减!:社区对 DeepSeek R1 在 1.58-bit 量化下运行 感到惊叹,其体积从 720GB 缩减至 131GB,却保留了完整的推理能力。
- DeepSeek R1 正面挑战 OpenAI O1:用户将 DeepSeek-R1 与 OpenAI 的 O1 进行对比,指出 R1 在 aider’s polyglot 等基准测试中的表现与 O1 持平甚至超越。
- DeepSeek 的亮相震动科技市场:据报道,DeepSeek 的 R1 导致美国科技股下跌 6000 亿美元,引发了关于中国 AI 实力崛起的讨论;详情见 这段 Bloomberg 视频。
主题 2. Qwen2.5 模型打破上下文壁垒
- Qwen2.5 发布 100 万 Token 上下文——越大越好吗?:阿里巴巴发布了具有惊人的 100 万 Token 上下文长度 的 Qwen2.5 模型,引发了关于如此长上下文实用性的辩论。
- Qwen2.5-VL 擅长 OCR——手写识别不在话下!:全新的 Qwen2.5-VL-72B-Instruct 以其先进的 OCR 能力给用户留下深刻印象,包括手写分析和强大的视觉内容解析。
- Qwen2.5-VL 对标 DALL-E 3:视觉语言模型之战:用户将 Qwen2.5-VL 的视觉理解能力与 DALL-E 3 等模型进行对比,强调了其在金融和商业任务中处理结构化数据输出的能力。
主题 3. AI 工具进阶,融入开发者工作流
- RAG 策略引发开发者讨论:开发者深入研究检索增强生成(RAG)方法,讨论向量数据库和嵌入模型,如 voyage-code-3。
- 代码库索引:过于简陋的方法?:一些用户批评代码库索引工具未能充分利用项目文件,并引用了 Cursor 的文档,而另一些人则认为在正确配置下它们非常有用。
- AI 结对编程随 Aider 和 CodeGate 起飞:CodeGate 集成 允许开发者直接在终端进行结对编程,通过 AI 辅助增强编码工作流。
主题 4. OpenRouter 扩展新模型与供应商
- Liquid AI 在 OpenRouter 上引起轰动:Liquid AI 将 多语言模型 LFM 40B, 7B 和 3B 引入 OpenRouter,声称在主要语言中拥有顶尖性能。
- DeepSeek Nitro:够快但不够强?:DeepSeek R1 的 Nitro 变体 承诺更快的响应速度,但用户反馈其在实际场景中的表现并未超越标准版 R1。
- OpenRouter 用户自带密钥 (BYOK):讨论强调在 OpenRouter 中使用个人 API 密钥以缓解速率限制并控制支出,使用时会收取 5% 的费用。
主题 5. 全球 AI 政策与投资加剧竞争
- 中国 1 万亿元豪赌 AI 引发全球竞赛:据 此处 报道,中国宣布对 AI 投资 1 万亿元(约 1370 亿美元),引发了关于美国能否跟上步伐的疑问。
- 大国竞争背景下的美国 AI 政策辩论:讨论强调美国正考虑在大国竞争的旗帜下资助 AI,这与 CHIPS Act 等历史性产业政策有异曲同工之妙。
- DeepSeek 的崛起引起地缘政治关注:DeepSeek 模型的成功加剧了对中国在 AI 领域影响力日益增长的担忧,促使人们分析 AI 在国家竞争力中的作用。
第一部分:高层级 Discord 摘要
Unsloth AI (Daniel Han) Discord
- DeepSeek R1 升级:社区成员展示了运行在 1.58-bit 量化下的 DeepSeek R1,具备完全正常的推理能力,引用了这条推文,并强调模型体积从 720GB 缩减至 131GB。
- 他们将 DeepSeek-R1 与 OpenAI 的 o1 模型进行了对比,指出用户对本地使用和开源协作处理高级推理任务的兴趣日益浓厚。
- Qwen2.5 百万 Token 发布:聊天集中在阿里巴巴的 Qwen2.5,Qwen 推文中透露了 100 万 Token 的上下文长度,并提到了 14B 参数的指令微调版本。
- 成员们讨论了扩展的上下文长度是否名副其实,并对充足 VRAM 支持下的大规模本地推理(local inference)表示乐观。
- SmoLlm 微调受到关注:多位用户测试了使用 Unsloth 进行 SmoLlm 微调,并成功通过 ollama 部署,默认温度(temperature)为
0.8,这在讨论线程中得到了澄清。- 他们强调了与个人工作流的平滑集成,称其 “无需显式温度设置即可正常工作”,并确认已准备好用于本地代码审查任务。
- 数据集格式化的细节:用户分享了关于使用 ‘instruction’、’input’ 和 ‘output’ 字段构建训练数据的技巧,参考了 Wikimedia 数据集和个人论坛收藏的示例。
- 他们指出字段名称不匹配会导致 Unsloth 在微调期间报错,强调需要一致的问答格式以确保模型行为正确。
Cursor IDE Discord
- 速度困扰还是速度提升?关注 Cursor IDE:用户报告了请求时间缓慢以及在 Cursor 上使用 Claude 时的一些摩擦,Fast and Slow Requests – Cursor 中描述了非高峰时段的部分修复方案。
- 他们还称赞了 DeepSeek R1 在某些任务中的表现,并提到可以使用 Spark Engine 作为补充,以减少请求时间和成本。
- Claude vs DeepSeek:代码洞察之战:DeepSeek R1 擅长规划任务,而 Claude 则能产生更高级的响应,如 DeepSeek R1 - API 文档所示。
- 社区讨论指出,在简单任务中使用 DeepSeek 可以节省费用,但用户在处理繁重的代码生成和调试时仍依赖 Claude。
- 代码库索引:过于简陋?:一些用户认为 Cursor 的代码库索引(codebase indexing)没有利用所有项目文件,如 Context / Codebase Indexing – Cursor 所示。
- 其他人则为其辩护,认为索引可以改进代码建议,并建议调整设置以获得更好的效果。
- RAG 策略引发开发者对话:关于检索增强生成(RAG)方法的讨论包括向量库和嵌入(embedding)方法,例如这篇博客文章中描述的 voyage-code-3。
- 参与者强调,结构良好的嵌入和检索可以减少错误,并提高代码密集型项目的输出质量。
- 告别 Claude:替代方案层出不穷:一些用户权衡在简单场景下用 DeepSeek 替换 Claude,同时也探索了 GitHub Copilot 和 Spark Engine。
- 观点各异,但对话指向结合各平台的优势以实现平衡的工作流。
Codeium (Windsurf) Discord
- Windsurf 1.2.2 发布,带来更流畅的 Cascade:团队推出了 Windsurf 1.2.2,其特点是增强了 Cascade 内存并修复了对话卡顿问题,详见 Windsurf Editor Changelogs。Cascade 现在支持网页查询或直接 URL 输入,使 Prompt 交互更加动态。
- 尽管有了这些修复,一些用户仍然遇到 internal error 激增,干扰了日常编码任务,引发了对进一步稳定性更新的呼吁。
- 性能受损且免费额度大幅削减:各频道频繁出现的错误和延迟导致了用户沮丧和额度损失,削弱了对 Windsurf 的信任。如 Pricing 所示,免费计划现在仅提供 5 个高级模型额度(从 50 个下调)。
- 社区反馈强调,这些变化限制了新用户的上手,并阻碍了调试(debugging)环节。
- DeepSeek 的首次亮相仍不确定:讨论表明,DeepSeek 集成到 Codeium 不会很快到来,这引发了对其错过低成本运营优势的担忧。一些用户公开表示,如果近期不公布时间表,将放弃 Windsurf。
- 他们还质疑 DeepSeek 在工具调用(tool calls)方面的可靠性,希望 Codeium 能尽快解决这些疑虑。
- Git 来救场:成员们建议使用 Git 进行版本控制,以防 Cascade 和 Windsurf 更新触发意外错误。他们引用了 Learn Git Branching 等资源来保持代码稳定并维护进度。
- 标记里程碑和回滚到之前提交(commits)等最佳实践,有助于在 AI 驱动的更改失败时防止重大损失。
Perplexity AI Discord
- Perplexity 的 R1 推出引发骚动:R1 在 Perplexity Pro 上取代了 O1 和 Grok 等旧宠,将每日查询限制为 10 次,引发了用户抗议。
- 一些用户威胁要转向 DeepSeek 或 ChatGPT,理由是性能欠佳且使用条款不明,而另一些人则通过 此参考资料 要求退款。
- DeepSeek 的数据困境引发分歧:DeepSeek 由于中国所有权引发了隐私担忧,用户担心数据从美国路由到中国的做法。
- 社区反馈毁誉参半,一些人看到了 DeepSeek R1 模型的潜力,但对敏感查询的数据主权(data sovereignty)表示怀疑。
- 十亿级构想:5000 亿美元的 AI 转型:据 此来源 称,一笔传闻中的 5000 亿美元 交易可能会重塑 AI,引发了对自动化和机器学习未来方向的推测。
- 贡献者认为这种可能性是高级研究资金的一个重大转折点,与过去推动 新 AI 框架(AI frameworks) 的繁荣期相似。
- 初创公司的 2 亿美元之路与标普指数飙升:一位成员展示了如何通过 Wingify 方法 实现 2 亿美元 的初创公司退出,重点在于资源化扩展和投资者关系。
- 他们还注意到 S&P 500 指数创下收盘历史新高,他们认为这为渴望复制这一成功的雄心勃勃的创始人增添了动力。
Nous Research AI Discord
- Nous Psyche Nudges Collaboration:Nous 在 Solana 上推出了 Nous Psyche,这是一个利用异构计算 (heterogeneous compute) 的开源生成式 AI 协作训练网络,代码已在 GitHub 上共享。
- 他们计划于 30 日与 Solana Foundation 合作举办测试网活动,并在其博客中引用了神话灵感来团结开发者。
- DeepSeek R1 蒸馏 (Distillation) 取得进展:研究人员引用了 Distilling System 2 into System 1 论文 (arXiv),为 R1 蒸馏模型提出了新的改进方案。
- 他们还指出与 Bespoke-Stratos-17k 的潜在协同作用,以优化数据集的覆盖范围和处理。
- LLM Live2D 桌面助手亮相:新款 LLM Live2D Desktop Assistant 支持 Windows 和 Mac,具有语音触发功能,并可通过屏幕感知实现完整的计算机控制。
- 其方法融合了系统剪贴板检索和交互式命令,为用户的日常任务提供了一个生动的角色界面。
- Qwen2.5-VL 突破 OCR 障碍:新款 Qwen2.5-VL-72B-Instruct 模型展示了先进的 OCR 能力,包括手写分析和强大的视觉内容解析。
- 社区成员称赞其在图像上的强大文本识别能力,标志着多模态 (multi-modal) 任务的一次重大飞跃。
- 类人 LLM 论文引发伦理辩论:论文 Enhancing Human-Like Responses in Large Language Models 探讨了提升 AI 自然语言理解 (natural language understanding) 和情感智能 (emotional intelligence) 的精细技术。
- 该研究强调了在用户参与度方面的提升,同时也引发了对偏见的担忧,呼吁更深入地审视人机交互动态。
OpenAI Discord
- Canvas 与 O1 联动:OpenAI 发布了一项新更新,使 ChatGPT Canvas 能够与 OpenAI o1 配合使用,并在所有层级用户的 macOS 桌面应用上渲染 HTML 和 React 代码。
- 他们预告了即将面向 Enterprise 和 Edu 用户发布的版本,预示着专业环境下的功能扩展。
- DeepSeek 震撼科技市场:DeepSeek R1 与 O1 和 GPT-4o 正面交锋,因其代码生成准确性和成本优势而广受赞誉。
- 据称其首次亮相导致美国主要科技股蒸发了近 6000 亿美元,引发了关于 AI 竞赛中更大颠覆的猜测。
- O3 Mini 发布在即:社区传闻指出 O3 Mini 可能很快发布,尽管有人担心它可能只是 O1 Mini 的小幅升级,缺乏真正的多模态 (multimodal) 功能。
- Sam Altman 的一条推文承诺为 Plus 层级提供每日 100 次查询,暗示即将扩大 operator 访问权限。
- Token 的 Tiktoken 问题:用户报告了关于 Tiktoken 将 token 拆分为单个字符的不确定性,导致在某些输入中产生混淆。
- 这引发了关于特殊 token 限制的讨论,并指向了可能解释 Tiktoken 不规则合并规则的研究。
- LangChain 的 ChatPrompt 与向量存储 (Vector Stores):成员们探索了将向量存储 (vector store) 文档输入到 LangChain 的 ChatPromptTemplate 中,并指出官方指导有限。
- 他们考虑将标准 prompt 路径作为备选方案,等待更稳健配置的成功案例。
aider (Paul Gauthier) Discord
- DeepSeek 因攻击受阻:恶意攻击冲击了 DeepSeek API,导致间歇性停机和响应时间变慢,这一点已由 DeepSeek Service Status 和用户报告确认。
- 一些人注意到对基于 R1 的产品需求激增,而另一些人则在推测这些攻击的严重程度,并探索 OpenRouter 替代方案。
- LLM 推理提供商:盈利还是陷阱?:推理提供商的盈利能力取决于高利用率以抵消固定成本,成员们权衡了不同服务之间的各种定价模型。
- 一些人认为低使用率会导致利润微薄,从而引发了关于与 DeepSeek-R1-Nitro 等高流量发布版本协同效应的讨论。
- R1 与 O1 的竞争升级:一项新的基准测试暗示,DeepSeek 的 R1 搭配 Sonnet 在某些场景下可能优于 O1,这一结论得到了 R1+Sonnet 在 aider 的多语言基准测试中创下 SOTA 数据支持。
- 怀疑者坚持认为 O1 Pro 在编程任务中表现更佳,而一些人则将希望寄托在 Unsloth AI 的推文中提到的 R1 1.58-bit 格式上。
- Qwen2.5 与 Janus-Pro 强势登场:Alibaba Qwen2.5-1M 和 Janus-Pro 因其 100 万 token 的上下文能力而备受关注,这在 Qwen 的推文和 Janus-Pro 的提及中得到了强调。
- 评论者认为它们是 O1 的强力竞争对手,并引用了 DeepInfra 上与 DeepSeek-R1 的对比。
- Aider 与 CodeGate(及 Rust)结盟:CodeGate 集成 授权 Aider 用户直接在终端进行结对编程,通过 API key 在 OpenAI 和 Ollama 之间切换。
- 其他人在 Aider 中测试了新的 Rust crates 以增强上下文,并注意到 architect mode 会隐藏编辑器模型的响应,导致他们请求 GitHub 上的 bug 修复。
LM Studio Discord
- DeepSeek Distill 备受好评:参与者测试了 DeepSeek R1 Distill 的 Q3 和 Q4 量化版本,赞扬其强大的知识保留能力以及在 LLM Explorer 目录上的表现。
- 他们观察到高参数模型可以提升编程任务,但需要仔细规划并发和 VRAM 以实现流畅推理。
- Chatter UI 困惑:成员报告了将 Chatter UI 连接到 LM Studio 时的问题,将故障追溯到 ChatterUI GitHub 仓库中的错误 URL 和端口冲突。
- 他们敦促验证本地主机地址并对齐 LM Studio 识别的端点以稳定请求。
- Apple M3 Max 的 Token 速度:一些用户估计 DeepSeek-R1 在配备 48GB RAM 的 Apple M3 Max 上达到了每秒 16–17 个 token,强调了硬件限制。
- 讨论集中在芯片架构的效率限制上,一些人考虑在 llama.cpp 中使用负载均衡方法以增加速度。
- MoE 策略:爱好者们研究了针对特定任务的 Mixture of Experts (MoE) 解决方案,注意到在代码生成工作流中潜在的性能提升。
- 他们强调了内存考量,并指向 MoE 资源以获取实践见解和部署策略。
OpenRouter (Alex Atallah) Discord
- Liquid AI 进驻 OpenRouter:Liquid AI 通过 OpenRouter 推出了新模型 LFM 40B、LFM 3B 和 LFM 7B,扩展了多语言覆盖范围。
- 他们将 LFM-7B 视为企业级聊天的首选,强调了其在主要语言中极高的性能尺寸比(performance-to-size ratio)。
- DeepSeek Nitro:极速捷径还是令人失望?:DeepSeek R1 的 Nitro 变体已发布,声称响应速度更快,详见公告。
- 一些用户反映其在实际表现中未能超越标准版 R1,反馈暗示沉重的用户需求导致了系统压力。
- Amazon Nova 突然崩溃:Amazon Nova 模型目前处于宕机状态,因为 Amazon Bedrock 将激增的使用量误判为密钥泄露,导致了误导性的 400 状态码。
- 团队正在加紧解决这一上游问题,预计服务稳定后将发布官方更新。
- DeepSeek 的超载考验:频繁的 503 错误和缓慢的响应时间困扰着 DeepSeek R1,这指向了高流量以及潜在的恶意活动。
- DeepSeek 限制了新用户注册并面临可靠性担忧,凸显了应对极高用户负载的挑战。
- BYOK 势头强劲:OpenRouter 的讨论强调了使用 BYOK 来缓解速率限制(rate limits)并控制费用,使用费为 5%。
- 社区成员一致认为,接入个人密钥可以帮助避开瓶颈,尽管一些人担心成本管理的复杂性。
Yannick Kilcher Discord
- Janus 领跑:DeepSeek 推出了 Janus Pro 模型,号称拥有先进的推理性能且无需高端 GPU,引发了关于超越美国基准测试新前沿的猜测。
- 参与者称赞了 Janus Pro 改进的多模态理解能力,引用了题为 Janus-Series: Unified Multimodal Understanding and Generation Models 的白皮书,并讨论了其改变科技市场情绪的潜力。
- Qwen2.5-VL 的视觉探索:阿里巴巴 Qwen 发布了 Qwen2.5-VL-72B-Instruct 以庆祝农历新年,重点强调了长视频理解和先进的视觉识别。
- 讨论强调了其处理金融和商业任务中结构化数据输出的能力,而一篇博客文章详细介绍了其上下文长度达到 1M tokens,适用于更广泛的企业用例。
- GPRO 在 PPO 中崭露头角:一场激烈的对话围绕 GPRO 消除 Value Function 和 Generalised Advantage Estimation (GAE) 展开,声称它可能解决 PPO 中的 stuck loss 和早期收敛问题。
- 用户指出 GAE 对折扣和(discounted sum)的依赖阻碍了某些场景下的扩展,而 GPRO 的全局归一化奖励保持了训练稳定,引发了对其与开源 RL 库集成的兴趣。
- DSL 梦想与 PydanticAI 现身:一位成员探索了使用 PydanticAI 在生产级生成式应用中实现结构化输出,建议它可以与 LlamaIndex+LangChain 集成。
- 他们还讨论了构建一个将自然语言转换为 DSL 的健身记录应用,参考了 Microsoft ODSL 论文 以寻求部分解决方案,并强调了语音到 DSL 流水线的挑战。
Interconnects (Nathan Lambert) Discord
- DeepSeek 的双重重击:R1 与 Janus Pro:DeepSeek 全新的 R1 模型因其权重开放(open-weight)的方法引发了巨大轰动,在推理和性能基准测试中以极低的训练成本匹配或超越了一些成熟的 LLM。行业传闻指向 Janus Pro (7B) 在 Hugging Face 上的发布,强调了其透明度以及在文本和图像方面的先进能力。
- 怀疑论者质疑 R1 的泛化和推理极限,而其他人则称赞其在数学和编程任务中的显著飞跃。因此,像 Meta 这样的大型企业已经建立了“作战室(war rooms)”,以分析 DeepSeek 的训练配方(training recipes)和成本效率。
- Qwen2.5-VL 点亮视觉语言融合:阿里巴巴的 Qwen2.5-VL 首次亮相,具备强大的多模态能力,支持长视频理解和精确重定位。观察者将其与过去的重大发布进行了比较,指出视觉语言模型在感知和竞争方面可能发生的转变。
- 开发者强调了在精选任务上的显著性能提升,引发了对实际应用场景的推测。官方演示和提交(例如 Qwen2.5-VL GitHub)展示了先进的图像到文本协同作用和长上下文处理能力的融合。
- Nous Psyche 遭黑客攻击与 Solana 设置:Nous Research 推出了 Nous Psyche,这是一个基于 Solana 的协作训练网络,旨在推动开放超级智能计划。尽管这一概念令人兴奋,但黑客攻击的消息动摇了人们对其安全措施的信任。
- 讨论还涉及了在推进复杂生成模型方面,开放实验室与资金充足的封闭实验室之间的广泛问题。这次黑客攻击强调了将区块链生态系统与 AI 训练结合时,严格安全保障的重要性。
- Tulu 3 vs Tulu 4 与偏好微调的困扰:爱好者们重新审视了 Tulu3,注意到尽管通常倾向于在策(on-policy)方法,但在偏好微调(preference tuning)中使用了离策(off-policy)数据。这标志着在完善基于偏好的训练流水线方面仍存在持续的复杂性。
- 对 Tulu4 的期待与日俱增,用户希望它能解决 Tulu3 面临的挑战。讨论突显了将偏好微调扩展到更广泛应用中尚未解决的挑战。
- 中国数千亿 AI 政策及其全球影响:中国宣布投入 1 万亿元人民币(1370 亿美元)用于 AI,引发了关于研发(R&D)快速扩张的激烈推测。参与者注意到这与美国的《芯片法案》(CHIPS Act)等工业政策有相似之处,但质疑美国是否准备好匹配如此大规模的 AI 资金。
- 随着共和党人可能在大国竞争的理想下资助 AI,国防相关的视角也随之出现。对于工程师来说,这些政策可能会提供更多尖端硬件和激励措施,从而加剧全球 AI 竞赛。
Latent Space Discord
- DeepSeek R1 引发热议:成员们注意到其项目报告中提到的 $5M 训练成本(参考 DeepSeek V3),并提到了作为确认的图片附件。DeepSeek R1 声称能以极低的成本与 o1 等老牌闭源模型竞争,这引发了人们对开源竞争力的讨论。
- 社区讨论强调了 R1+Sonnet 在 aider 的 polyglot 基准测试中取得的新 SOTA 声明,而暗示强劲结果的推文让许多人对其更深层次的推理能力感到好奇。
- Qwen2.5-VL 与 DALL-E 3 的对决:阿里巴巴发布了 Qwen2.5-VL,这是一款旨在在视觉理解和定位方面超越 DALL-E 3 的多模态模型,详见其官方公告。该模型在特定基准测试中也与 Stable Diffusion 展开竞争,并在其 Qwen 集合中强调了先进的图像生成功能。
- 用户对比了 GenEval 和 DPG-Bench 上的指标,指出 DeepSeek 的 Janus-Pro-7B 也在多模态领域参与竞争,这引发了关于这些新模型的成本效益和实际应用性的更广泛讨论。
- Operator 与推理模型掀起波澜:参与者称赞 Operator 能够快速生成初始代码库,但也对其处理复杂站点和视频采样率的能力表示担忧,如此视频演示所示。与此同时,关于 R1 等推理模型的讨论表明,它们在编程任务及其他领域具有先进的 Agent 能力。
- 一些人归功于 function calling 基准测试指出了多步约束,为 DeepSeek R1 等模型在集成到开发流水线时如何处理复杂工作流提供了视角。
- Model Context Protocol (MCP) 势头强劲:成员们对 MCP 作为跨工具集成 AI 功能的统一方法表现出热情,参考了用 Go、Rust 甚至 assembly 构建的服务器,详见 MCP server 仓库。他们比较了如何通过 mcp-obsidian 等插件将其与 Obsidian 互连,用于转录和文档记录。
- MCP party 的计划鼓励社区反馈和协同,并呼吁查阅最新规范和教程,凸显了对一致的跨应用协议的浓厚兴趣。
- Latent Space 发布新播客:简要提到 Latent Space 播客发布了新的一集,在此分享。
- 社区对这一更新表示欢迎,期待能进一步深入探讨这些新兴 AI 技术和协作计划。
Eleuther Discord
- 层收敛与 Tokenization 策略:在 一篇 ICLR 2023 论文 中,成员们观察到 Layer Convergence Bias 如何使浅层比深层学习得更快。
- 另一组人对 Armen Aghajanyan 论文 中提出的新 Causally Regularized Tokenization 表示赞赏,并指出其在 LlamaGen-3B 中提升了效率。
- DeepSeek R1 与 GRPO 的差距:参与者对 DeepSeek 声称 R1 使用廉价芯片的说法表示质疑,参考了约 160 万美元 的训练成本以及开源细节的匮乏。
- AlphaZero 的演进与好奇心驱动的 AI:采用者认可 AlphaZero 的精简设计,但指出实际设置中很少直接跳到其技术。
- 一些人提到了 empowerment 概念(维基百科条目)和好奇心驱动的方法,认为它们是未来大规模训练的灵活方法。
- Scaling Laws 与 20-Token 技巧:一项 Chinchilla 库分析 表明,20-tokens-per-parameter 规则几乎与完全优化的 Chinchilla 设置相匹配。
- 社区成员将此与 tokens-per-parameter 比率中的平坦极小值联系起来,表明微小的偏差可能不会大幅损害性能。
- 可解释性与多轮 Benchmark:一些用户强调训练中的 verified reasoning 是可解释性的新优先级,关注 LLM 如何推理而不仅仅是输出。
- 同时,scbench、zeroSCROLLS 和 longbench 等框架正在被集成,尽管它们的多轮特性可能需要不同的实现策略。
Stackblitz (Bolt.new) Discord
- System Prompt 的运用:现在可以在 Bolt 的项目或全局层级设置 system prompt,让你从一开始就注入首选的库和方法。
- 社区成员正在交流塑造 Bolt 行为的最佳方式,并呼吁分享高级使用技巧以实现更顺畅的开发。
- 结构化与拆分策略:成员们辩论了过于僵化的规划对创造力的影响,提到了重启循环以及在拆分复杂组件时对灵活方法的需求。
- 一位用户推荐使用 NEXTSTEPS.md 大纲的系统化方法,并指出结构化迁移如何帮助保持清晰度而不扼杀新想法。
- 作为安全网的指南:遵守 GUIDELINES.md 提高了稳定性,确保每个组件按顺序构建并与妥善管理的上下文窗口集成。
- 参与者将避免混乱合并归功于这些护栏,稳定的文档实践为持续进展铺平了道路。
- Bolt 的计费与错误困扰:一些人抱怨大量的 Token 使用和频繁的 rate limits,并提到退款和成本差异问题。
- 错误消息和网络故障让他们不得不寻求专业帮助,因为 Bolt 有时在没有交付结果的情况下消耗了大量 Token。
- Supabase 角色权限的突破:一位用户克服了复杂的 Supabase 策略,构建了包括超级管理员和管理员在内的多个登录角色,解决了递归陷阱。
- 同时也探索了与 Netlify 和 GitHub 的集成,尽管私有仓库目前仍无法访问,这促使对 Bolt 的核心功能进行进一步修改。
MCP (Glama) Discord
- MCP Client 投诉与语音聊天抱怨:开发者们正在努力解决无需重启即可动态更新 MCP client 工具的问题,并呼吁在 multimodal-mcp-client 中提供更清晰的语音集成文档。
- 许多关注点集中在 server config 的改进以及减少对私有 API 的依赖上,特别是针对 Kubernetes 部署。
- Variance Log 工具捕捉异常:MCP Variance Log 方案将低概率对话事件收集到 SQLite database 中,用于用户数据分析。
- 采用者指出 Titans Surprise mechanism 是该方法的灵感来源,可以增强 Agent 工作流中的长期记忆。
- KoboldCPP 与 Claude 建立新连接:如 GitHub 所示,一个新的 KoboldCPP-MCP Server 促进了 Claude 与其他 MCP 应用之间的 AI 协作。
- 社区成员指出,这为更同步的任务和更深层次的 AI 到 AI 交互铺平了道路。
- Inception Server 运行并行 LLM 任务:MCP Inception server 允许使用各种参数进行并发查询,详见 其仓库。
- 开发者计划通过爬虫扩展加密货币相关功能,暗示了更多的使用场景。
- Shopify 商家与 Claude 对话:一个 MCP server for Shopify 使用 Claude 进行店铺分析,如 此仓库 所示。
- 目前的端点集中在产品和订单上,为商家提供了一条直接获取 AI 驱动数据洞察的途径。
Notebook LM Discord Discord
- HeyGen 场景与 ElevenLabs 音调:一位用户展示了使用 HeyGen 和 RunWayML’s Act-One 制作逼真数字人视频的工作流,视频看起来像是在倾听,链接至 UnrealMysteries.com。
- 他们还展示了一个名为 “Thomas” 的 ElevenLabs 语音,带有一种 HAL 的氛围,增添了独特风格。
- NotebookLM 用于播客摘要:一位用户使用 NotebookLM 将每周新闻压缩成播客格式,并称赞其快速摘要的能力。
- 其他人希望有更强大的 Prompt 来改进音频内容创作并提升工具的能力。
- 混合 HeyGen 与 MiniMax:成员们尝试了混合内容,结合 HeyGen 静态图像和来自 MiniMax 的见解来制作长视频。
- 他们观察到,相比单独使用其中一种技术,这种方式能产生更具吸引力的叙事,引发了进一步的创作尝试。
- NotebookLM 的限制与困惑:成员们在 UI 更改后遇到了 NotebookLM 中链接源丢失的问题,引发了对引用丢失的担忧。
- 另一位用户发现了 1000 条笔记 的限制,呼吁为高级用法提供更清晰的文档。
- 语言切换与 PDF 页码争议:一些人在默认语言设置上遇到困难,通过切换 notebooklm.google/?hl=es 等 URL 来获得更好的控制。
- 其他人注意到部分 PDF 页面无法生成见解,指出 NotebookLM 中的页面引用存在不一致。
Stability.ai (Stable Diffusion) Discord
- Hunyuan-Video 在 12GB VRAM 上取得成功:hunyuan-video 模型在低至 12GB VRAM 的环境下也能有效运行,提供本地图生视频(image-to-video)处理能力,吸引了众多开发者。
- 社区成员赞扬了其在日常实验中的易用性,并参考 Webui Installation Guides 进行高级调整。
- Kling AI 缺乏图生视频功能:用户注意到 Kling AI 在图像质量上与 hunyuan 接近,但目前尚不支持视频转换。
- 他们认为对于完整的流水线(pipeline)来说,缺失该功能令人遗憾,一些人希望后续更新能尽快解决这一差距。
- 面向新图像创作者的 Forge 与 Swarm:对于寻求更简单本地 AI image generation 工具的新手来说,Forge 和 Swarm 成为了热门选择。
- 资深用户推荐使用 ComfyUI 以获得更大的灵活性,但他们提醒初学者注意其额外的复杂性。
- Stable Diffusion 倾向于 32GB RAM 或更高配置:运行 Stable Diffusion 最好配备 32GB RAM 的系统,而 64GB 能确保更流畅的体验。
- 使用 RTX 4090 或 AMD 7900XTX 的成员报告称,在升级内存后,硬件冲突明显减少。
- Deepseek 需要高达 1.3TB 的 VRAM:Deepseek 系列(包括 V3 和 R1)在全精度下需要超过 1.3TB 的 VRAM,这远超消费级设备的承载能力。
- 只有拥有 A100 或 H100 等多 GPU 集群的用户才能处理这些模型,迫使其他用户只能寻找更小的替代方案。
GPU MODE Discord
- DeepSeek 通过 TinyZero 和 Open R1 实现双重突破:TinyZero 项目以简洁、易获取的方式复现了 DeepSeek R1 Zero,并为贡献者提供了图像和详细信息。同时,Hugging Face 的 Open R1 提供了 DeepSeek-R1 的完全开源版本,鼓励协作开发。
- 这两个仓库都邀请社区参与,展示了在 HPC 背景下对可复现研究的强力推动。
- 解决 HPC 中的 NCCL 超时问题:多位成员报告了在多节点训练期间遇到 NCCL timeouts,并询问调试的最佳实践。他们对 GPU 任务进行了性能分析(profiling),并考虑使用高级策略来处理大规模设置中的超时问题。
- 社区记录了包括 CUDA 版本不匹配在内的常见陷阱,强调了对强大 HPC 调试工具的需求。
- Adam Paszke 的 Mosaic GPU DSL 魔法:著名的 Adam Paszke 在 YouTube 直播中讨论了他的 Mosaic GPU DSL,重点关注底层 GPU 编程。社区成员可以在 GitHub 上找到补充材料,并加入 Discord 进行主动学习。
- 该讲座承诺将深入探讨用于 GPU 优化的布局系统(layout systems)和分块(tiling)技术。
- JAX 在旧款 GPU 上运行 FP8:一项 GitHub discussion 透露,JAX 可以在 sm<89 的 Nvidia GPU 上使用 fp8,突破了典型的硬件限制。PyTorch 用户报告在旧款 GPU 上运行失败,引发了对 JAX 变通方案的好奇。
- 这一差距激发了人们对 JAX 究竟如何绕过标准限制的兴趣,促使对库内部机制的进一步探索。
- Arc-AGI 扩展迷宫任务与 FSDP:Arc-AGI 环境在 reasoning-gym 中增加了多项式方程、迷宫任务和更多示例,并参考了来自 CLRS 的算法。同时,Tiny-GRPO 引入了 FSDP support,大幅降低了 VRAM 占用并提升了效率。
- 成员们还提出了关于家庭关系数据和 GSM8K 模板的想法,计划推送到 HF hub 以方便用户下载。
Modular (Mojo 🔥) Discord
- Mojo 文档消失后重新上线:由于 Cloudflare 托管问题,Mojo 文档突然离线,引发了用户的不满。
- 开发团队表示歉意,并确认文档已恢复上线,并更新了来自 Mojo GitHub changelog 的参考内容。
- 新 GPU Package API 登陆 Nightly 版本:用户确认 GPU package API 文档已在 nightly 版本中上线,为 Mojo 提供了高级 GPU 功能。
- 他们对这一更新表示欢迎,认为这是一项重大改进,并指出了 changelog 中的最新更新。
- CSS Struct Fluent API 引发警告:一位开发者构建了一个
struct,使用链式调用 API (fluent API) 风格生成 CSS,但在 Zed Preview 中遇到了未使用值的警告。- 他们尝试使用
_ =来消除警告,但希望能有一种更优雅的解决方案来保持代码清晰。
- 他们尝试使用
- List 与 Representable Trait 的纠缠:一位用户在将
List[Int]传入函数时遇到了困难,发现编译器无法将 Int 识别为 Representable。- 他们指出了 int.mojo 和 List module 中可能存在的条件一致性 (conditional conformance) 问题。
- Unsafe Pointers 与函数指针 FFI 障碍:在使用 UnsafePointer 时,发现值结构体 (value structs) 中的对象标识 (object identity) 会发生偏移,导致指针独立移动时产生困惑。
- 他们还指出,Mojo 中的函数指针 FFI 仍然不够可靠,仅部分兼容 C ABI,且文档有限。
LlamaIndex Discord
- Presenter 亮相与多 Agent 魔法:LlamaIndex 推出了 Presenter,这是一个多 Agent 工作流,可以在一个流水线中创建包含 Mermaid 图表、脚本生成和报告生成的视觉丰富型幻灯片。
- 社区成员赞扬了 Presenter 易于访问的结构,展示了这些参考案例如何演变成协调复杂步骤的高级演示文稿构建 Agent。
- 文档钻取与 Google 风格的收益:MarcusSchiesser 发布了一个完全开源的模板,用于多步文档研究 Agent,其灵感来自 Google 的深度研究 (deep research) 方法。
- 用户提到该模板处理复杂研究工作流的能力,并指出它解决了高级项目中对集成分析与引用的普遍需求。
- Scaleport 的快速理赔处理:Scaleport AI 与一家旅游保险公司达成合作伙伴关系,利用 LlamaIndex 自动从医疗报告中进行理赔评估,并使用 OCR 进行数据提取。
- 社区成员强调了其显著的时间节省,并指出这些方法展示了如何通过 AI 驱动的风险分析来实现更高效的保险流程。
- DeepSeek 与 LlamaIndex 的巧妙集成:LlamaIndex 现在已集成 DeepSeek-R1 API,支持在统一环境中使用 deepseek-chat 和 deepseek-reasoner 进行高级调用。
- 开发者肯定了这种协同效应的提升,并参考 DeepSeek 文档 启用了 API-key 导入和无缝模型使用。
Cohere Discord
- 日本监管自由:Cohere 保持不受影响:Cohere 发现,针对高级计算的日本 AI 新规在 2025 年 5 月之前不太可能对他们产生影响,因为他们的语言模型不在关键限制范围之内。
- 这些规则专门针对强大的芯片和扩展,目前 Cohere 未受波及,而他们的法律团队正在密切关注相关修订情况。
- 仪表盘困境:Cohere 即将进行 UI 重构:社区反馈指出 Cohere dashboard 上存在令人困惑的界面元素,特别是镜像按钮布局。
- 建议的改进包括为 Discord 和邮件支持提供更大的行动号召(CTA)按钮,用户也敦促采用更精简的设计方案。
- 纯粹文本:Cohere 不提供 TTS 或 STT:Cohere 正式确认其专注于大语言模型,不提供内置的文本转语音(TTS)或语音转文本(STT)功能。
- 这一明确表态结束了关于音频功能的猜测,重申了 LLM 支持是该平台的核心优势。
- ChatCohere 代码纪事:分步 LLM 设置:开发者展示了如何定义 ChatCohere,使用
bind_tools绑定工具,然后通过结构化消息调用 LLM 以执行高级任务。- 一些人提到将逆向规划作为最后一步检查,并强调 Cohere 坚持基于文本的解决方案,而非 TTS 或 STT 集成。
- 工具层级:Cohere 的多步方法:Cohere 的文档详细介绍了从用户提示词检索到最终文本生成的阶段性多步(multi-step)流程。
- 社区成员称赞了这种系统化的分解,强调了顺序推理如何细化复杂的输出,并确保在每个阶段提取相关数据。
Nomic.ai (GPT4All) Discord
- 开源图像分析获得关注:人们正在寻找处理图像提示词的开源模型,并转向 Taggui 等框架进行打标签。他们很难找到一个在打标签和响应生成方面都表现出色的确定选项。
- 一些人主张采用不需要高级配置的更简单设置。另一些人指出市场缺乏明确的领先者,这促使了更多的实验。
- DeepSeek R1 模型初期遇挫:多位用户报告了 DeepSeek R1 存在推理不完整和聊天模板错误的问题。他们提到在没有补丁的情况下很难在本地稳定运行。
- 基准测试暗示其结果与 LLAMA 相当,但尚未有人确认其输出完全可靠。一些人呼吁在实际场景中信任该模型之前进行更多测试。
- 本地文档分析引起好奇:爱好者们希望通过探索 PDFGear 等工具进行本地文本索引来保持数据私密性。他们的目标是在不依赖云服务或上传的情况下查询个人文档。
- 关于如何处理复杂的 PDF 和大量文本,意见不一。人们要求提供详细的示例和更简单的流水线来简化这些流程。
- GPT4All 等待 DeepSeek R1 支持:社区成员询问 DeepSeek R1 何时能以官方、易于安装的方式进入 GPT4All。贡献者表示集成仍在进行中,但未给出确切的发布时间表。
- 他们希望实现一键设置,不需要大量的后期手动调整。有人暗示修复方案已接近完成,但尚未发布官方声明。
LLM Agents (Berkeley MOOC) Discord
- MOOC 周一狂欢:Advanced LLM Agents MOOC 将于 1 月 27 日 4:00PM PST 开始,持续至 4 月 28 日,通过 课程网站 提供每周 直播 和资源。
- 参与者可以 在此注册 并在 YouTube 上观看回放,对于非伯克利学生,没有紧迫的截止日期,也不提供线下参加机会。
- 证书与困惑交织:成员反映 Fall’24 MOOC 证书 仍未发放,工作人员宣布即将发布消息并请大家耐心等待。
- 一些人还提到在报名后未收到 确认邮件,纷纷表示 “在同一条船上…”,而工作人员承诺很快会有官方更新。
- 黑客松与无线下聚会:爱好者询问了 黑客松机会,工作人员指出虽然兴趣浓厚,但本学期尚无最终计划。
- 其他人寻求线下访问权限,但获悉只有伯克利正式学生才允许进入现场,因此其他所有人只能依赖虚拟平台。
- Substack 谜团浮现:在 #mooc-readings-discussion 中出现了一个令人好奇的 Substack 链接,但提供的上下文很少。
- 社区对此保持观望,等待后续对该共享资源的进一步说明。
tinygrad (George Hotz) Discord
- 梯度引导取得进展:关于
Tensor.gradient用法的困惑爆发,文档称 ‘计算 targets 相对于 self 的梯度’,但上下文暗示其含义是 ‘计算 self 相对于 targets 的梯度’,引发了讨论。- 参与者提议修改文档以确保准确性,并指出 tensor.py 可能需要为未来的参考提供进一步的澄清。
- STRIDE 与 FLIP 之争:建议将 STRIDE 更名为 FLIP 以避免名称过于通用,旨在提高代码库的清晰度。
- 贡献者支持这一转变,理由是残留的旧引用会使更新复杂化并减慢功能集成。
- 周一疯狂:第 55 次会议:计划于圣地亚哥时间周一早上 6 点举行,Meeting #55 计划讨论最近的多梯度设计、公司更新以及 resnet 和 bert 等项目。
- 参与者期望解决新的项目悬赏(bounties),意在细化即将到来的任务和截止日期。
- BobNet 命名困惑:在 GitHub 引用 暗示使用了 bounding box 后,围绕 BobNet 产生了疑问,然而代码只是普通的 feed-forward。
- 成员强调了命名清晰度的重要性,指出标题与功能之间的不匹配可能会误导新用户。
- Tinygrad 中的格式化之争:用户讨论了官方格式化工具,一些人引用了 Black,而另一些人则指向了 pre-commit config 中的 Ruff。
- 达成的共识是 Ruff 有效地规范了格式,敦促贡献者遵循推荐的方法。
Torchtune Discord
- Torchtune 中的联邦学习热潮:贡献者提议为 Torchtune 联邦学习创建 每个节点 N 个分片,在每个分块训练完成后将权重与保存的 optimizer state 合并。
- 一些人询问如何 “在没有过度中断的情况下” 简化训练,而另一些人则讨论了与 torch distributed 和 raylib 方法的潜在协同作用。
- 部分参数大乱斗:社区成员辩论了应用 opt-in backward hooks 的 性能提升,以便某些参数在梯度准备就绪后立即更新。
- 他们还权衡了一种仅使用独立更新器优化 output projection 的策略,并对并行运行多个优化器的复杂性表示担忧。
- EBNF 胜过 Regex:在一名成员声称 regex “看起来像格式错误的 tokenizer”后,社区转向使用 EBNF grammars 以获得更好的可读性。
- 一些人发现 EBNF 虽然更冗长但更容易理解,直接引用称赞其 “在保持鲁棒性的同时具有人类可读性。”
- Deepseek 惊艳的 Janus 系列:一位用户批评 Deepseek 更新过于频繁,并引用了这份关于 Janus-Series: Unified Multimodal Understanding and Generation Models 的 报告。
- 其他人则在调侃这些多模态功能的潜在影响范围,其中一人在与过时模型的持续对比中打趣道 “他们需要冷静一下”。
OpenInterpreter Discord
- OpenInterpreter 1.0 保留 Python 解释器:OpenInterpreter 项目在昨天提交了一个 commit,计划发布集成 Python 解释器的 1.0 版本,并根据其 GitHub 仓库 的确认,在重大发布前将网站保持在极简状态。
- 他们承诺在正式发布后进行更大规模的更新,社区反馈主要集中在用户交互的扩展上。
- DeepSeek R1 触发 400 错误:一位用户报告了 Deepseek_r1 模型的 400 错误,该模型通过指向 https://api.deepseek.com 的
api_base进行配置,由于模型不存在而产生 BadRequestError。- 对话指出在 OpenAIException 下出现了 invalid_request_error,这给尝试在工作流中运行
$ interpreter -y --profile deepseek.yaml的用户带来了困惑。
- 对话指出在 OpenAIException 下出现了 invalid_request_error,这给尝试在工作流中运行
- DeepSeek 在测试中媲美 OpenAI-o1:社区成员注意到 DeepSeek-R1 和较小的 Distill-Qwen-1.5B 模型在数学和代码任务上的表现与 OpenAI-o1 持平,参考了 deepseek-r1 库信息。
- 他们还强调了 DeepSeek 在 OS 模式下的 tool-calling 要求以及集成 vision model 可能存在的问题,旨在优化高级场景下的使用。
- 结合 Ollama 和 Llamafile 的本地使用:通过使用 Ollama 和 Llamafile 展示了完全在本地资源上运行 Open Interpreter 的努力,响应了官方 本地运行指南 中的
interpreter --local命令。- 讨论集中在多模型设置中是否有必要启用 vision model,并呼吁明确在组合框架中的使用方法。
- DSH - AI Terminal 邀请贡献者:一个名为 DSH - Ai terminal 的项目正在寻求对其开源应用的改进,参考了 其 GitHub 仓库。
- 开发者被鼓励为该项目点亮 star 并分享用户反馈,以增强其未来的功能。
LAION Discord
- DeepSeek R1 受到审视:初步的 benchmark 表明 DeepSeek R1 与 o1-mini 和 Claude 3.5 Sonnet 相当,这与它在挑战性 LLM 基准测试中媲美 o1 的说法相矛盾,详见 此处。
- 参与者质疑其在奥数级 AIW 问题上的有效性,并引用了 这篇论文 来衡量其真实能力。
- 流水线获得音频升级:有人建议使用 audio widgets 来比较增强效果,并集成了来自 DeepSeq 或 O1 等库的失真处理。
- 贡献者强调了交互式功能对于检查和优化音频变化的便利性,目标是改进流水线。
- 测试流水线发布:一位用户分享了一个 开发阶段的流水线,展示了在繁忙的旅途后的初步进展。
- 他们邀请大家对流水线的功能特性提供反馈,重点是如何更好地探索音频增强能力。
DSPy Discord
- GitHub 垃圾内容增加:一位成员指出随机垃圾信息淹没了 GitHub 仓库,掩盖了关于项目 bug 和功能的有价值报告。
- 这引发了挫败感,其他人讨论了可能的过滤器和更警觉的分流(triaging)机制来遏制这些杂乱内容。
- 语言界限:自然语言 vs 代码:一位用户询问是否有可靠的方法来检测文本是自然语言还是结构化代码(如 HTML 或 Python)。
- 他们提出了使用专门的分类器来清晰分类文本格式的想法。
- DSPy + DeepSeek 的困境:一位参与者尝试为 70B COT 示例优化 dspy + deepseek,但无法明确简化流程的具体步骤。
- 其他人就运行时间和内存限制提出了疑问,强调了大规模优化的复杂性。
- BSR 六小时停滞:一位用户运行 BSR 示例六小时未见收敛,引发了对该方法实用性的质疑。
- 这引发了关于替代策略的辩论,或者这种超长运行时间是否值得其产出。
- 针对 FastAPI 的 PyPI 压力:一位开发者需要 PyPI 上更新的 RC 版本以匹配现代 FastAPI 依赖项,因为过时的包导致安装失败。
- 他们指出主分支在三周前已有一个修复补丁,敦促维护者发布新版本。
Axolotl AI Discord
- Deepseek 亮相与 GRPO 猜想:成员们询问了 Deepseek 算法 以及是否有人在进行复现,并提到了 trl 中与 grpo 可能存在的联系。
- 一位参与者建议它可能指的是 grpo,这表明人们对高级 RL 方法重新产生了兴趣,尽管目前尚未得到官方确认。
- H200 vs 5090 GPU 的博弈:一位用户在权衡购买 2x 5090s 还是 1x H200,并指出 H200 拥有更多 RAM,但性能收益尚不确定。
- 他们提到了成本和速度方面的担忧,希望能获得关于哪种配置能更好支持重型 AI 工作负载的真实反馈。
- RL 框架支持停滞不前:一位成员指出 trl 缺乏在线 RL 训练器(online RL trainers),表达了对更广泛 RL 库集成的渴望。
- 然而,另一条回复坚持认为这极有可能不会发生,加剧了对扩展 RL 支持的疑虑。
Gorilla LLM (Berkeley Function Calling) Discord
- Gorilla 提示词窥探:用户询问了 Berkeley Function Call Leaderboard 上不支持函数调用的模型的系统提示词,随后有人引用了 Gorilla GitHub 代码 (第 3-18 行)。
- 该仓库专注于针对函数调用(function calls)训练和评估 LLM,并为非函数版本提供了所需的系统消息。
- Gorilla 排行榜资源现身:Gorilla 函数调用排行榜的代码 被分享作为相关系统提示词的所在地。
- 它包含了受函数启发(function-inspired)的提示词定义,可以为寻求非函数用法参考的用户提供指导。
MLOps @Chipro Discord
- 2025 水晶球与实时数据盛会:在 1 月 28 日,一场名为 2025 Crystal Ball: Real-Time Data & AI 的活动将邀请 Rayees Pasha (RisingWave Labs)、Sijie Guo (StreamNative) 和 Chang She (LanceDB) 参加,重点讨论实时数据如何提升 AI,详见 此 Meetup 链接。
- 他们强调,如果没有低延迟的数据流水线(data pipelines),AI 的潜力就无法得到充分利用,并指出 Apache Iceberg 是助力各行业新兴分析的关键方法。
- 行业领袖预测 2025 创新方向:专家小组成员预测,到 2025 年,实时数据流(real-time data streaming)将塑造 AI 的新工作流,在运营效率和快速决策方面赋予显著优势。
- 他们计划解决从消费者应用到企业用例中不断演变的数据基础设施障碍,强调流技术与 AI 日益增长的需求之间的协同作用。
Mozilla AI Discord
- 论文阅读俱乐部再次聚首:论文阅读俱乐部(Paper Reading Club)本周回归并安排了会议,详见 Discord 活动链接。与会者可以期待对 AI 研究的深入探讨,重点关注能引起工程受众共鸣的高级论文。
- 组织者鼓励参与者加入并分享想法,在社区环境中进行活跃的前沿讨论。
- Discord 活动激发社区参与:除了论文阅读俱乐部,本周还重点推出了各种 Discord 活动,以保持成员对新活动的参与度。用户受邀加入正在进行的对话,获得交流技术见解的机会。
- 负责人提醒大家查看公告频道以获取实时更新,强调了在这些协作聚会中积极参与的重要性。
HuggingFace Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
第二部分:分频道详细摘要与链接
完整的频道细分内容已针对电子邮件进行了截断。
如果您喜欢 AInews,请分享给朋友!提前感谢!