ainews-mistral-small-3-24b-and-tulu-3-405b
Mistral Small 3 24B 和 Tulu 3 405B
Mistral AI 发布了 Mistral Small 3,这是一个拥有 240 亿参数的模型,针对低延迟的本地推理进行了优化,在 MMLU 上的准确率达到 81%,可与 Llama 3.3 70B、Qwen-2.5 32B 以及 GPT4o-mini 竞争。AI2 发布了 Tülu 3 405B,这是一个基于 Llama 3 的大型微调模型,采用了基于可验证奖励的强化学习(RVLR)技术,性能可与 DeepSeek v3 媲美。Sakana AI 推出了 TinySwallow-1.5B,这是一款采用 TAID 技术、专为端侧使用的日语语言模型。阿里巴巴 Qwen 发布了 Qwen 2.5 Max,该模型在 20 万亿 token 上进行了训练,性能与 DeepSeek V3、Claude 3.5 Sonnet 和 Gemini 1.5 Pro 相当,并更新了 API 定价。这些发布突显了开源模型、高效推理和强化学习技术方面的进展。
开源模型就是我们所需要的一切。
2025年1月29日至1月30日的 AI 新闻。我们为您检查了 7 个 subreddit、433 个 Twitter 账号 和 34 个 Discord 服务(225 个频道,7312 条消息)。预计节省阅读时间(按每分钟 200 字计算):744 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
命运弄人,风投支持的 Mistral(至今已融资 14 亿美元)和非营利组织 AI2 今天分别发布了一个小型 Apache 2 模型和一个大型模型,但它们的规模与你根据融资背景所预期的正好相反。
首先是 Mistral Small 3,通过他们标志性的 磁力链接 发布,幸好还有 博客文章:
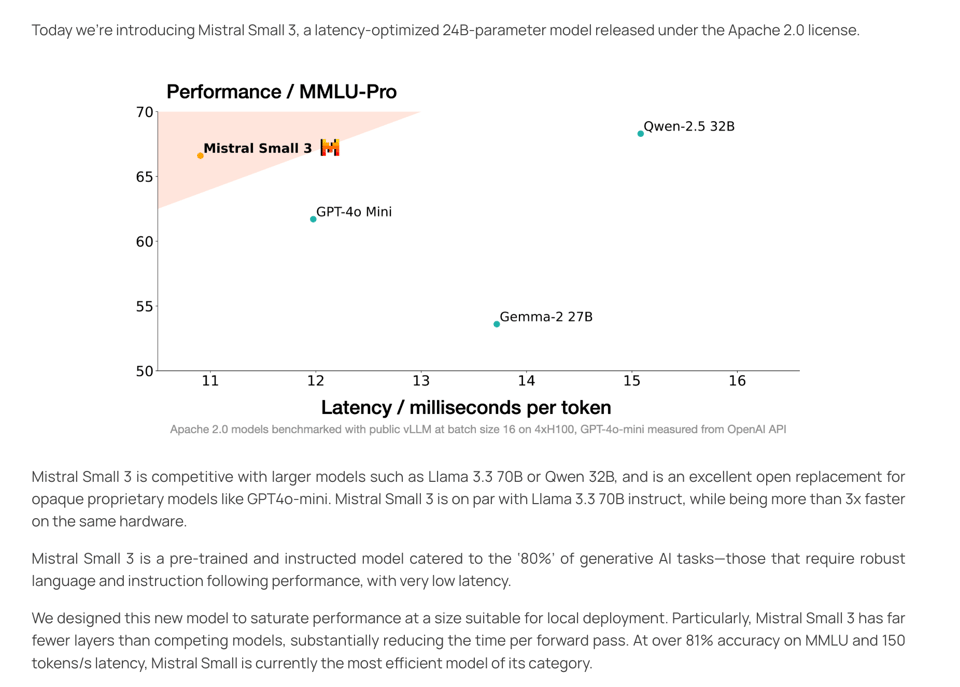
这是 Mistral 产品线在 2025 年的一次非常出色的更新,针对本地推理进行了优化——尽管人们注意到其效率图表的 x 轴变化比 y 轴更快。网络侦探已经 对比 了它与 Mistral Small 2 的架构差异(基本上是扩大了维度,但减少了层数和注意力头以降低延迟):

他们关于使用场景的段落提供了有趣的信息,解释了为什么他们认为发布这个模型是值得的:

接下来,AI2 发布了 Tülu 3 405B,这是他们对 Llama 3 的大型微调版本,使用了来自 Tulu 3 论文 的可验证奖励强化学习(RVLR)方案,使其在某些维度上能与 DeepSeek v3 竞争:
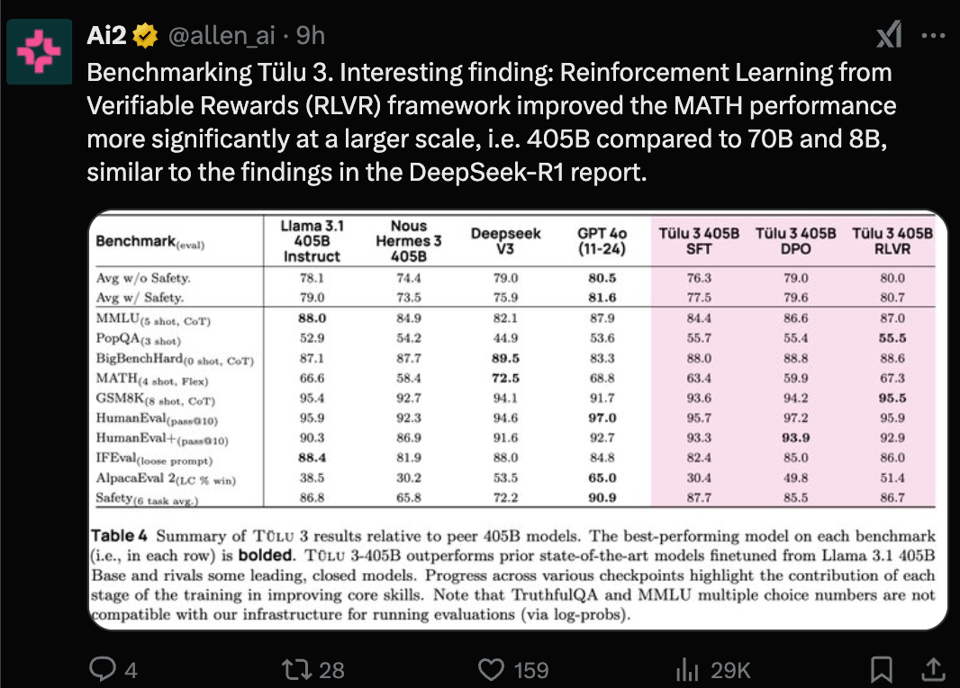
不幸的是,发布时似乎没有任何托管 API,因此很难试用这个 庞大 的模型。
AI Twitter 回顾
所有摘要均由 Gemini 2.0 Flash 完成
模型发布与更新
- Sakana AI 发布了 TinySwallow-1.5B,这是一个使用其新方法 TAID (Temporally Adaptive Interpolated Distillation) 训练的小型日语语言模型,在其尺寸类别中实现了 state-of-the-art 的性能。该模型可以完全在设备端运行,甚至可以在 Web 浏览器中运行。目前已提供演示版供试用,以及 模型 和 GitHub 仓库。还提供了一个包含模型权重的 自包含 Web 应用,可用于本地执行。
- Mistral AI 发布了 Mistral Small 3,这是一个拥有 24B 参数的模型,采用 Apache 2.0 许可证,提供 Base 和 Instruct 两个版本。其设计目标是低延迟,速度达 150 tokens/s,MMLU 准确率为 81%。它被定位为 Llama 3.3 70B、Qwen-2.5 32B 和 GPT4o-mini 的竞争对手。该模型已在 la Plateforme、HF 和其他供应商 上线,博客文章 提供了详细信息。@ClementDelangue 也关注了此次发布,并指出了 Base 模型 和 Instruct 模型 的可用性。Ollama 和 llama.cpp 也已发布了对其的支持。
- Alibaba_Qwen 发布了 Qwen 2.5 Max,这是他们迄今为止最大的模型,在 20 万亿 tokens 上训练而成,其性能可与 DeepSeek V3、Claude 3.5 Sonnet 和 Gemini 1.5 Pro 相媲美,Artificial Analysis 质量指数为 79。他们还发布了 Qwen2.5-VL Cookbooks,这是一系列展示 Qwen2.5-VL 各种用例的 Notebook,包括计算机使用、空间理解、文档解析、Mobile Agent、OCR、通用识别和视频理解。该模型的 API 已更新,价格为每百万 Input Token 1.6 美元,每百万 Output Token 6.4 美元。
- Allen AI 发布了 Tülu 3 405B,这是一个开源的 Post-training 模型,其性能超越了 DeepSeek-V3,证明了他们包含 RVLR (Reinforcement Learning from Verifiable Rewards) 在内的方案可以扩展到 405B,并表现出与 GPT-4o 相当的水平。@ClementDelangue 也注意到了这次发布,强调了这些模型在 HF 上的可用性。@reach_vb 称其为一个“精心准备”的发布,并指出它在比 DeepSeek V3 小 40% 的情况下实现了超越。
- DeepSeek-V3 被 Tülu 3 超越,@Tim_Dettmers 指出这是通过 405B Llama Base 实现的,且 扎实的 Post-training 发挥了重要作用。他强调了该方案完全开源特性的重要性。
- DeepSeek R1 Distill 已在 Together AI 上免费提供。Together AI 还为该模型提供了一个 100% 免费的 API 端点。
工具、基准测试与评估
- LangChain 在 LangSmith 中为标注队列(annotation queues)引入了批量视图,允许用户管理用于模型训练的大型数据集。他们还添加了瀑布图来可视化 traces,以便发现瓶颈并优化响应时间。此外还发布了一个关于如何评估文档提取流水线(document extraction pipelines)的视频。
- @awnihannun 指出,Qwen 2.5 模型可以在笔记本电脑上使用 mlx-lm 生成或微调代码,并报告称 7B 模型在 M4 Max 上运行非常快,使用的是 mlx-lm 代码库(1.6万行)作为上下文。此外还提供了一份关于高效重新计算 prompt cache 的指南。
- @jerryjliu0 分享了 LlamaReport 的预览,这是一个能从非结构化数据创建复杂、多章节报告的 Agent。
- @AravSrinivas 指出,来源(sources)和推理链(reasoning traces)对 AI 产品的 UX 和信任度产生了巨大影响。他还表示,Perplexity 将使手机(Android)上的原生助手更可靠地完成任务。他向所有拥有 .gov 邮箱的美国政府雇员免费提供为期一年的 Perplexity Pro。
- @_akhaliq 在 ai-gradio 上提供了支持 DeepSeek 模型的 Perplexity Sonar Reasoning。他们还发布了 Atla Selene Mini,这是一个通用评估模型。
- @swyx 在多个模型上运行了他们的报告 Agent,并得出结论:Gemini 2.0 Flash 在摘要报告方面比 O1 更高效,且价格便宜 200 倍。
- @karpathy 解释了一个关于 LLM 的教科书类比,将 pretraining、supervised finetuning 和 reinforcement learning 分别比作教科书阐述、例题讲解和练习题。
AI Infrastructure and Compute
- @draecomino 指出,Cerebras 让 AI 再次实现即时响应,DeepSeek R1 70B 的 首个 token 响应时间(time to first token)仅为 1 秒。
- @cto_junior 指出,2000 块 H100 足以在一个财季内完成 15T tokens 的稠密 70B 模型训练,成本约为 1000 万美元。他还提到 Yotta 拥有 4096 块 H100 的访问权限。
- @fchollet 表示,AI 领域 5000 亿美元的数字是虚假的,估计最多 1500 亿美元 才是现实的。
- @mustafasuleyman 认为技术倾向于变得更便宜、更高效。他还认为 AI 正在从模仿学习(imitation learning)转向奖励学习(reward learning)。
- @teortaxesTex 指出,R1 的发布让许多人得出结论“你可以直接构建东西”。他们表示 DeepSeek 在算力(compute power)较少的情况下实现了这一目标。
- @shaneguML 指出,测试时算力扩展(test-time compute scaling)有利于像 Cerebras 和 Groq 这样快速推理芯片初创公司。
AI Reddit Recap
/r/LocalLlama Recap
主题 1:Mistral Small 3 发布:具备与更大型模型竞争的实力
- Mistral Small 3 (分数:643,评论:205): Mistral Small 3 在 @MistralAI 发布于 2025 年 1 月 30 日的一条推文中被提及,推文中包含一个可能指向该版本资源或细节的 URL。该推文已获得 998 次查看,显示出外界对该主题的关注。
- Mistral Small 3 是一款拥有 24B 参数的模型,采用 Apache 2.0 许可证发布,针对低延迟和高效率进行了优化,处理速度达 150 tokens per second。它以强大的语言任务处理和指令遵循能力著称,在相同硬件上比 Llama 3.3 70B 等大型模型快三倍以上,并在 MMLU 上实现了超过 81% 的准确率。
- 用户们非常欣赏针对小型模型的 human evaluation chart(人类评估图表),强调了使模型符合人类视角而非仅仅关注 Benchmark 的重要性。该模型可以针对法律、医疗和技术支持等多个领域进行 Fine-tune,并适用于 RTX 4090 或配备 32GB RAM 的 Macbooks 等设备上的本地推理(Local Inference)。
- 社区对 Apache 2.0 许可证 充满热情,因为这允许广泛的分发和修改。此外,用户还讨论了该模型与 Qwen 2.5 32B 和 GPT-4o-mini 等其他模型的性能对比,以及在不同硬件配置下的速度和效率,有用户报告在 RTX 8000 上速度为 21.46 tokens/s,在 M1 Max 64GB 上为 24.4 tokens/s。
- DeepSeek 创始人专访:我们不会走闭源路线。我们相信建立强大的技术生态系统更为重要。 (分数:298,评论:41): DeepSeek 的创始人强调了他们坚持开源的承诺,认为建立强大的技术生态系统优先于闭源策略。采访表明,这种方法对于 AI 社区的创新与协作至关重要。
- OpenAI 与 DeepSeek:讨论中流露出对 OpenAI 最初开源意图的怀疑,并将其与 DeepSeek 当前的开源策略进行了对比。用户担心一旦完成用户习惯培养,是否会像 OpenAI 那样转向闭源。
- 对冲基金策略:有人对 DeepSeek 的财务策略提出猜测,部分用户认为他们的运作方式类似于对冲基金,通过发布开源模型来影响市场估值,这种策略被描述为一种基于信息的市场操纵。
- 技术好奇心:社区对 DeepSeek 的技术表现出明显兴趣,特别是关于他们的 FP8 训练代码。用户表达了获取该代码以加速家庭端训练的愿望,强调了技术社区利用开源进展开展个人项目的兴趣。
- Mistral 新开源模型 (分数:128,评论:7): Mistral 发布了两个新模型:Mistral-Small-24B-Instruct 和 Mistral-Small-24B-Base-2501,并配备了包含搜索栏和排序选项的用户界面更新。这些模型属于 23 个可用模型系列的一部分,其中 Instruct 模型获得了 50 个赞,Base 模型获得了 23 个赞。
- Mistral Small 3 因其与 Llama 3.3 70B 和 Qwen 32B 等大型模型的竞争力而受到关注,在相同硬件上速度快 3 倍以上且完全开源。它被认为是 GPT-4o-mini 等专有模型的优秀开源替代方案。更多详情可以在这里找到。
- 评论中有人对 Base 和 Instruct 模型之间的区别感到好奇,尽管具体细节尚未详述。
{kind=link}
{kind=link}
主题 2. Nvidia 削减 RTX 40/50 GPU 的 FP8 训练性能
- Nvidia 在 RTX 40 和 50 系列 GPU 上将 FP8 训练性能减半 (Score: 401, Comments: 93): 根据 Nvidia 新发布的 Blackwell GPU 架构白皮书,Nvidia 据报道已将 RTX 40 和 50 系列 GPU 的 FP8 训练性能削减了一半。其中 4090 型号在 FP8(使用 FP32 累加)下的性能从 660.6 TFlops 降至 330.3 TFlops。这一变化可能会阻碍在 Geforce GPU 上进行 AI/ML 训练,反映了自 Turing 架构以来,在保持 Quadro 和数据中心 GPU 全速性能的同时,限制消费级显卡性能的一贯模式。
- 许多评论者认为,RTX 40 和 50 系列 GPU 中报道的 FP8 训练性能减半可能是文档中的笔误,并参考了 Ada Lovelace 论文,其中曾将 FP8/FP16 累加与 FP8/FP32 混淆。一些人建议使用新旧驱动程序进行测试,以验证性能是否确实被更改。
- 有指控称 Nvidia 从事反消费者行为,并提到可能通过芯片蚀刻(chip etching)和固件限制来约束性能。讨论还涉及了法律行动的可能性,将此情况与之前的案例进行对比,如苹果 iPhone 降速和解案以及 Nvidia GTX 970 虚假广告罚款案。
- 用户强调了 CUDA 对机器学习任务的重要性,并指出了在 Apple Silicon 等非 Nvidia 硬件上遇到的困难。讨论还触及了 AI/ML GPU 市场的不健康状态,并对比了 Quadro 和数据中心 GPU 的全速性能,而这些性能在消费级 GPU 中并未得到体现。
主题 3. DeepSeek R1 性能:在本地设备上表现出色
- DeepSeek R1 671B 在本地游戏配置上无需 GPU 即可达到超过 2 tok/sec! (Score: 165, Comments: 57): 该帖子讨论了在不使用 GPU 的情况下,通过一台配备 96GB RAM 和 Gen 5 x4 NVMe SSD(用于内存缓存)的游戏配置,在 DeepSeek R1 671B 模型上实现了 2.13 tokens/秒 的速度。作者建议,投资多个 NVMe SSD 可能是运行大模型的一种高性价比替代方案,可以取代昂贵的 GPU,因为他们的配置显示 CPU 和 GPU 占用率极低,突显了家庭配置更好的性价比潜力。
- 用户讨论了 2.13 tokens/秒 速率的实用性和局限性,一些人表示至少需要 5 tokens/秒 才能有效使用,另一些人则指出 2k context 对于编程等某些应用来说是不够的。
- 人们对通过将 NVMe SSD 堆叠成 RAID 配置或使用加速卡来提高性能表现出兴趣,并建议花费约 $1,000 理论上可以达到 60 GBPS,从而提升运行大模型的速度和性能。
- 对详细复现步骤和特定命令用法的请求表明社区有兴趣尝试类似的配置。一位用户分享了一个 包含 llama.cpp 命令和日志的 gist,以帮助他人理解和复现该设置。
- 你到底在用 R1 做什么? (Score: 106, Comments: 134): 作者质疑 DeepSeek R1 模型 的实际效用,指出它们专注于推理并生成冗长的思考过程,即使是针对简单问题也是如此。他们对匆忙将这些模型用于日常任务表示怀疑,认为它们可能更适合解决复杂问题,而不是像 GPT-4o 那样的常规交互。
- 用户强调了 DeepSeek R1 在各种技术任务中的效用,例如编程、数学解题和数据分析。Loud_Specialist_6574 和 TaroOk7112 发现它在编程方面特别有用,TaroOk7112 指出它有能力在第一次尝试时就无误地将脚本转换为更新的版本。No-Statement-0001 描述了一个复杂问题,R1 提供了一个涉及处理 Docker 信号的 shell 脚本解决方案。
- 几位用户提到了该模型在创意和理论应用中的有效性。Automatic_Flounder89 和 Acrolith 分别指出了它在理论实验和创意写作中的用途,而 a_beautiful_rhind 则赞赏它的角色扮演能力。Dysfu 将其用作数学助教,通过避免直接给出答案来增强学习体验。
- AaronFeng47 和 EmbarrassedBiscotti9 讨论了 R1 面临的挑战,例如代码中的逻辑错误和偶尔忽略规范,但也承认其在复杂任务中的潜力。AaronFeng47 将其与其他模型的体验进行了对比,发现 R1 不如 o1-preview 可靠。
主题 4. 马克·扎克伯格谈 Llama 4 进展与策略
- 马克·扎克伯格谈 Llama 4 训练进展! (Score: 154, Comments: 85): 马克·扎克伯格 强调了 Meta 在 Llama 4 上的进展,突出了其凭借多模态能力在 AI 领域领先的潜力,以及 2025 年即将到来的惊喜。他还讨论了 Ray-Ban Meta AI 眼镜 的成功以及重大基础设施投资计划,预计 Meta AI 将成为超过 10 亿人 使用的领先个性化助手。
- 人们对 Llama 4 的模型大小和配置表现出浓厚兴趣。用户表示需要能够适应各种硬件能力的任务模型,并建议提供 1B、3B、7B 直至 630B 的中间尺寸,以适应不同的 VRAM 容量,避免 7B 和 800B 模型之间的断档。
- 围绕 Meta 多模态能力 的讨论突出了对原生全模态的兴奋,期待模型在文本、推理、视觉理解和音频方面表现出色。用户渴望支持音频/文本、图像/文本和视频能力的模型,这对于语音助手和视觉合成等应用至关重要。
- 评论反映了对 Meta 时间表和战略决策的怀疑。担忧包括 Llama 4 的延迟发布、对训练后微调的关注以及模型尺寸范围有限的可能性。辩论还涉及 Meta 的 AI 发展在隐私以及与其他科技巨头竞争背景下的更广泛影响。
其他 AI 版块回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
主题 1. DeepSeek-R1 的影响:技术与竞争分析
- 无炒作 DeepSeek-R1 阅读清单 (Score: 196, Comments: 9): 作者分享了从他们的研究论文俱乐部汇编的阅读清单,重点关注通向 DeepSeek-R1 的 AI/ML 基础论文。旨在提供对该技术的深入理解,他们邀请读者在 Oxen.ai 的博客 上探索该清单。
- 讨论了带有 Attention 的低秩矩阵方法,并提出了一个问题:是否可以使用现有权重将其回溯应用到现有模型中。
- 表达了加入研究论文俱乐部的兴趣,并询问了更多关于如何参与的信息。
- 分享了对阅读清单的正面反馈,并期待即将举行的 Paper Club 会议。
- [d] 为什么 “Knowledge distillation” 现在突然被贴上了盗窃的标签? (Score: 256, Comments: 87): Knowledge distillation 正被争议性地贴上盗窃的标签,尽管它是一种通过模仿输出来近似变换的方法。该帖子认为这种标签是站不住脚的,因为架构和训练方法不同,且该过程并不一定会复制原始的变换函数。
- 几位评论者强调了 copyright law(版权法)与 Terms of Service (TOS) 违规之间的区别,强调虽然使用 OpenAI 模型的输出可能违反 TOS,但在 copyright law 下并不等同于盗窃。ResidentPositive4122 指出,OpenAI 的文档阐明他们并不对 API 生成内容主张版权,只是规定使用此类数据训练其他模型违反了 TOS。
- 围绕 OpenAI 对潜在 TOS 违规的反应的讨论表明,这是一种维持其地位的战略举措,proto-n 认为 OpenAI 对 DeepSeek 的指控是断言其在 AI 领域影响力和重要性的一种方式。batteries_not_inc 和其他人认为,OpenAI 的反应更多是出于不满而非法律依据。
- 辩论还涉及 AI 监管与伦理的更广泛主题,H4RZ3RK4S3 等人讨论了 EU regulations 的影响以及对美国和中国技术实践的不同看法。KingsmanVince 和 defaultagi 对美国和中国的做法都表示怀疑,表明了伦理考量和公众认知的复杂格局。
- OpenAI 与 Microsoft 的现状:昨天 vs 今天 (Score: 154, Comments: 27): DeepSeek-R1 现已集成到 Microsoft Azure services 中,这标志着与此前涉及指控从 OpenAI API 泄露数据的争议相比发生了转变。最近在 Azure AI Foundry 和 GitHub 上的发布突显了该平台的可靠性和能力,与 Reuters 此前报道的安全担忧形成鲜明对比。
- DeepSeek-R1 现已在 Azure 上可用,用户表示有兴趣将其作为 API 选项进行测试。人们对 Microsoft 的动机表示怀疑,一些人认为他们正在利用之前的争议牟利。
- 该模型是 free and open source 的,这是其获得广泛支持的关键原因,尽管一些用户并不理解模型与其应用之间的区别。
- 讨论中提到了 Microsoft 历史上的 “embrace, extend, and extinguish”(拥抱、扩展、再消灭)策略,暗示了对其支持 DeepSeek-R1 背后真实意图的担忧。
{kind=link}
主题 2. Copilot 的 AI 模型集成与用户反馈
- o1 现在在 Copilot 中免费提供 (Score: 253, Comments: 56): Copilot 现在向所有用户免费提供 OpenAI 的 reasoning model (o1),正如 Mustafa Suleyman 在 Twitter 上宣布的那样。该公告展示了一个关于洋流的对话,说明了 o1 提供详细回答的能力,并突出了用户参与度指标。
- 大多数用户对 Copilot 表示不满,称其为 Microsoft 产品中“最差”的 AI,多条评论强调了与 错误答案 和集成不佳相关的问题。有一种观点认为 Copilot 的质量已经恶化,尤其是自 去年 8 月 左右做出更改以来。
- 一些用户推测,Copilot 感知质量下降的原因是 Microsoft 和 OpenAI 的战略决策,旨在引导用户回到 OpenAI 订阅,或为未来的“虚拟员工”等产品收集数据。Microsoft 持有 OpenAI 49% 的股份被认为是这些战略中的一个重要因素。
- 技术问题被归咎于超长的 system prompts 和出于“安全原因”的 prompt injections,这些因素干扰了模型性能。重点似乎在于企业用户,因为尽管产品质量下降,但公司在使用 Copilot 处理其数据时感到更放心。
{kind=link}
主题 3. ChatGPT 最新更新:用户体验与技术变革
- ChatGPT 获得了一些不错的增量更新 (Score: 171, Comments: 61): 截至 2025年1月29日,ChatGPT 的 GPT-4o 模型 已获得增量更新,包括扩展了训练数据范围以提供更相关的知识、增强了图像分析能力,并提升了在 STEM 相关查询中的表现。此外,该模型现在对 emoji 的响应更加热情。
- 用户对 GPT-4o 的 增量更新 持怀疑态度,认为 OpenAI 解除了之前的限制是为了推销更高价格的订阅层级,一些用户注意到响应质量正回归到最初的水平。讨论中还提到对 o3-mini 的期待,将其视为应对当前局限性的潜在短期方案。
- 新更新中 emojis 的使用引发了分歧,一些用户欣赏增强的格式化效果,而另一些人则认为这过于冗余且具有干扰性,尤其是在专业语境下。一位用户将当前的 emoji 使用情况与 Copilot 的早期版本进行了对比。
- 讨论了 “Think” 按钮 功能,部分用户已获得访问权限,并指出它有潜力为 GPT-4o 增加推理链。然而,人们担心这可能会如何影响消息限制,特别是对于配额有限的用户。
{kind=link}
AI Discord 回顾
由 Gemini 2.0 Flash Exp (gemini-2.0-flash-exp) 生成的摘要之摘要
1. DeepSeek 的崛起:速度、泄露与 OpenAI 的竞争
- DeepSeek 超出预期,泄露数据:DeepSeek 模型,尤其是 R1,展示了强大的推理和创意潜力,足以与 OpenAI 的 o1 匹敌,但 Hacker News 上的一次数据库暴露泄露了用户数据,引发了隐私担忧。尽管如此,许多人认为它在创意任务和代码方面的表现正超越 OpenAI。
- R1 性能表现各异:根据此文档,DeepSeek R1 1.58B 在基础硬件上运行缓慢(3 tokens/s),需要 160GB VRAM 或快速存储才能获得更好的吞吐量,但也有人报告在高端 GPU 上达到了 32 TPS。用户还反映量化版本在指令遵循方面可能会遇到困难。
- OpenAI 与 DeepSeek 激烈交锋:虽然有人注意到 OpenAI 指责 DeepSeek 使用其训练数据,但他们也在内部使用 DeepSeek 进行数据检索。这种竞争已经白热化,并引发了关于审查、开放访问和数据收集实践的质疑。
2. 小模型掀起大波澜:Mistral 与 Tülu
- Mistral Small 3 表现亮眼:新的 Mistral Small 3(24B 参数,81% MMLU)因其低延迟和本地部署能力而受到赞誉。根据官方网站,它的运行速度比竞争对手快 3倍,在性能和资源消耗之间找到了平衡点,并采用 Apache 2.0 许可。
- Tülu 3 击败顶尖模型:Tülu 3 405B 是一个拥有 405B 参数的开源权重模型,在基准测试中超越了 DeepSeek v3 和 GPT-4o。这得益于其 可验证奖励强化学习 (RLVR) 方法,并提供了公开的后训练配方。
- 量化权衡讨论:开发者正在尝试模型量化,指出这虽然减小了模型大小和 VRAM 占用,但也可能降低指令遵循能力,促使用户评估其在各种任务中的有效性。
3. RAG 与工具:LM Studio 与 Agent 工作流
- LM Studio 支持 RAG:LM Studio 0.3.9 现在支持通过本地文档附件实现 RAG,详见文档。这允许在聊天会话中使用上下文窗口内的文档。此外,它现在还支持 Idle TTL 和自动更新 (auto-update),提升了运行效率。
- Aider 通过只读存根 (Read-Only Stubs) 实现本地化:出于隐私考虑,用户正在探索将 Aider 与 Ollama 等本地模型集成的方法。新的 YouTube 视频重点介绍了使用只读存根 (read-only stubs) 来管理大型代码库。
- LlamaIndex 集成高级 Agent:LlamaIndex 的 “Mastering AI Agents Workshop” 介绍了用于多 Agent 系统的高级 AgentWorkflow 概念,并展示了利用 LlamaIndex 构建的强大架构,详见此处。
4. 硬件与性能:GPU 与优化
- Blackwell 的性能提升:根据 NVIDIA 文档,采用 sm_120a 的新 Blackwell 架构将彻底改变 GPU 性能,为消费级 GPU 提供更强的计算能力。讨论指出,在新款 RTX 5090 上,FP4 任务的速度可能提升 5 倍,尽管部分测试显示增幅仅为 2 倍。
- PyTorch 2.6 性能调节选项:新发布的 PyTorch 2.6 为 Python 3.13 添加了
torch.compile支持,在 X86 上引入了 FP16,并使用了 Manylinux 2.28,但停止了对 Conda 分发的支持。 - GPU 价格与可用性:用户注意到新款 5090 GPU 非常难买,迅速售罄;而 Jetson Nano 的价格已从约 $250 的标价飙升至 $500-$700。
5. 融资、伦理与社区热点
- Dario Amodei 的 AI Safety 投资遭到批评:社区成员对 Dario Amodei 投入 $10亿 推动 AI Safety 的大胆举动表示怀疑,有人将其言论贴上“欺诈性营销”的标签,并对大规模 AI 筹款活动提出质疑。
- 软银对 OpenAI 的百亿美金豪赌:据报道,软银 (SoftBank) 计划向 OpenAI 注入 $150亿-$250亿 的巨额投资,这是其对 AI 及其未来潜力的又一次重大押注,进一步增加了其现有的投入。
- 跨平台社区互动:成员们积极分享发现并提出问题,对各种 AI 模型、框架和工具表现出强烈的参与度,包括在多个 Discord 频道中讨论不同方法如何影响该领域。
PART 1: Discord 高层级摘要
Unsloth AI (Daniel Han) Discord
- DeepSeek R1 的速度与障碍:DeepSeek R1 1.58B 在受限硬件上的运行速度约为 3 tokens/s。这份官方文档建议使用 160GB VRAM 或高速存储以获得更高的吞吐量。
- 社区成员指出了在 Windows 上可能存在的问题,并推荐使用 Linux 以获得更好的量化性能。
- Mistral-Small 24B 强势登场:新分享的 Mistral-Small-24B-Instruct-2501-GGUF 采用 Apache 2.0 许可证,虽然权重不公开,但承诺降低延迟。
- 贡献者引用了 Mistral 官网的数据,称其 MMLU 达到 81%,认为它是开源选项中极具竞争力的补充。
- Unsloth 开启在线 DPO 火花:一位用户确认,在应用部分硬编码以处理内存限制后,使用 Unsloth 仓库成功运行了在线 DPO (online DPO)。
- 他们分享了一篇关于降低 DPO 内存消耗的 LinkedIn 帖子,并征求实际反馈。
- MusicGen 微调尝试:一位新手目标是使用
.WAV和.TXT文件微调 facebook/musicgen-medium 或 musicgen-small,重点关注 本指南 中提到的 epoch 和 batch size。- 他们考虑利用 vllm 进行生成,同时也研究了 Unsloth 和 GRPOTrainer,以寻求稳定的微调路径。
- vllm vs. Unsloth:殊途同归还是分道扬镳?:社区成员将 vllm 的 Neural Magic 优势与 Unsloth 的量化方法进行了比较,不确定未来在 Red Hat 旗下两者是否会趋于一致。
- 有人提议进行部分集成以减少 GPU 空闲时间,而另一些人则认为由于速度差异,这两种方法各具特色。
Perplexity AI Discord
- O1 vs. R1 之争与 Perplexity 的切换困扰:用户质疑 Perplexity Pro 中 O1 vs. R1 的可靠性,注意到尽管选择了 O1,系统仍会默认切换到 R1。许多人认为 O1 提供了更好的推理能力,但最近的可靠性问题引发了担忧。
- 在 Aravind Srinivas 的一条推文中,承诺为 Pro 用户提供每日 500 次 DeepSeek R1 查询,但其一致性仍存疑,部分用户称其“稳定得令人恼火”。
- 阿里巴巴的竞争追赶者模型:阿里巴巴推出了一个新模型以加强其竞争地位,可能会重新调整市场动态。更多详情见此链接,重点介绍了用于提升用户体验速度的高级算法。
- 社区成员期待进一步的增强,有人暗示可能与现有的开源框架产生协同效应,尽管尚未发布官方声明。
- DeepSeek 获得关注并颠覆数据检索:OpenAI 澄清了其对 DeepSeek 的使用,赞扬了其处理复杂数据集的查询能力。许多人称赞 DeepSeek 稳定的隐私功能,尽管他们也注意到了偶尔的停机。
- Deepinfra 的 DeepSeek-R1 Demo 被引用为可以完成与 OpenAI-O1 类似的任务,引发了关于 Token 使用和性能优势的激烈辩论。
- Sonar-Reasoning 令人惊讶的不足:sonar-reasoning 模型 API 的测试者质疑其在实际应用中的表现,寻求相比其他模型的改进细节。一些人报告称出现了冗长且重复的回答,浪费了 Token 并忽略了新的 Prompt。
- 其他人认为它在某些任务中仍然表现出色,但在 Playground 中的直接对比表明,该模型的“思考”能力在 API 响应中可能有所减弱。
- GPT-4、Sonnet 和 Gemini 的对决:在一场持续的辩论中,用户讨论了 GPT-4、Sonnet 和 Gemini 2.0 在高级查询(包括微积分和编程任务)中的表现。Sonnet 因更自然的文本表达而获得赞誉,而 GPT-4 和 Gemini 在原始准确性方面仍是强力竞争者。
- 一些人强调,将 Sonnet 与 O1 结合使用可以为复杂任务提供更清晰的输出,促使人们放弃部分 Claude 订阅并重新思考付费墙。
Codeium (Windsurf) Discord
- DeepSeek 的动态双雄:Windsurf 为 Pro 级账户引入了 DeepSeek R1 和 DeepSeek V3,每条消息需要不同的 Credits。
- 开发者强调了 R1 首次作为 Coding Agent 的使用,并参考 Changelog 获取更多更新。
- Cascade 的快速修复:社区成员报告了输入延迟的减少,以及修复了 Cascade 面板在重新加载时自动重新打开的问题。
- 他们还讨论了通过
@web和@docs实现的新网页搜索功能,指向基于 URL 的上下文处理。
- 他们还讨论了通过
- DeepSeek vs. Sonnet 对决:用户比较了 DeepSeek 和 Claude 3.5 Sonnet 的成本效益和性能,许多测试者更青睐 R1。
- 其他人描述 Sonnet 会不断地编辑文件,而 R1 在编程任务中表现出稳定的行为。
- 额度困惑得到澄清:成员们争论 DeepSeek R1 每条消息是消耗 0.25 还是 0.5 个 Credits,理由是文档说明不一。
- 他们指向 Codeium Docs 和支持页面以获取准确详情。
OpenAI Discord
- DeepSeek 敢于与 OpenAI 决斗:在公会讨论中,参与者强调 DeepSeek R1 在创意任务上优于 OpenAI 的 o1,并引用了一个 Raspberry Pi 演示以及来自 Gemini Pro 和 Grok 的潜在竞争。
- 有人在一段 YouTube 评论视频中声称 “DeepSeek 审查结果”,引发了关于数据收集和开放访问的推测。
- OneClickPrompts 助力快速设置:介绍了一款名为 OneClickPrompts 的新工具,用于构建可个性化的多部分 Prompt,并分享了一个 GIF,展示了其在重复任务中的简化用法。
- 用户称赞了该扩展的模块化方法,但指出 “智能 Prompt 组合” 对于获得更深层次的结果仍然至关重要。
- Ollama 微调获得关注:一位用户寻求为特定领域任务微调 Ollama 的方法,引发了对未来扩展或官方工作流的期待。
- 其他人提到了 GitHub 上零散的参考资料,并补充说简化的流程可以解锁 Ollama 中 “下一级别的适应性”。
- GPT 的记忆与 Context Windows 冲突:成员们批评 GPT 的记忆在漫长的对话中会丢失关键细节,引发了对 DeepSeek 等开源项目更大 Context Window 的重新关注。
- 他们认为不一致的回忆阻碍了生产环境的使用,并呼吁将 “稳定的上下文保留” 作为未来的必备功能。
LM Studio Discord
- LM Studio 0.3.9 势头强劲:LM Studio 0.3.9 增加了 Idle TTL、API 响应中独立的 reasoning_content 以及运行时的自动更新,官方安装程序见此处。
- 社区成员认可了改进的内存管理,并提到 Hugging Face 模型下载的自动更新过程更加简单,参考了文档。
- RAG 推出在 LM Studio:LM Studio 现在支持在聊天会话中附加本地文档进行 RAG,详见文档。
- 用户观察到,如果文档符合模型的 Context,则可以完整包含,这激发了利用本地参考资料的兴趣。
- DeepSeek 的 GPU 性能飙升:讨论显示,在 GTX 1080 和 Ryzen 5 3600 上,DeepSeek 模型可达到 6-7 tokens/sec,重点在于 VRAM 管理以防止减速。
- 其他人报告称,i9-14900KF、128GB RAM 和双 RTX 4090 的配置在 70B 模型上达到了 30-40 tokens/sec,强调了将整个模型放入 GPU 显存的重要性。
- Jetson Nano 的价格令人咋舌:成员们注意到 Jetson Nano 的价格达到了 $500-$700 或处于缺货状态,使其与标准 GPU 相比吸引力下降。
- 少数人发现了 $250 左右的报价,但许多人更倾向于选择性能更优的常规硬件。
aider (Paul Gauthier) Discord
- DeepSeek R1 飙升与数据库泄露:成员们报告 DeepSeek R1 在 4090 GPU 上达到了约 32 TPS,在赞扬其性能的同时也指出了量化版本的问题。Hacker News 上的一个爆料揭露了 DeepSeek 的数据库暴露,引发了用户隐私警报。
- 一些参与者对依赖可能存在数据泄露的服务表示怀疑,称“隐私噩梦”是他们探索本地解决方案的原因。
- O3 Mini 热度与量化怪癖:许多人对 O3 Mini 表现出兴趣,认为它是一个更快、更小的替代方案,期待其体验优于现有的庞大模型。他们讨论了 quantization(量化)如何阻碍性能和指令遵循能力,有人称这是一种棘手的权衡。
- 少数人开玩笑说正焦急等待 O3 Mini 来解决他们的模型困扰,而其他人则分享了之前量化版本的不同结果,强调了缩小模型规模的不可预测性。
- Aider 转向本地化与只读存根 (Read-Only Stubs):出于隐私考虑,用户探索将 Aider 与 Ollama 等本地模型集成,期望一种避免将数据发送给第三方的解决方案。一个新的 YouTube 视频展示了旨在更高效处理大型代码库的 read-only stubs。
- 一些人在使用多个端点(如 Azure AI)时遇到困惑,但发现 advanced model settings 的参考资料很有帮助,另一些人则称赞 stubs 是加强代码修改控制的受欢迎举措。
- O1 Pro 辩论引发定价讨论:几位开发者支持将 O1 Pro 用于编程任务,但批评其成本和使用限制。他们将这些因素与本地开源模型进行权衡,指出审查担忧偶尔会阻碍生产力。
- 少数参与者形容 O1 Pro 尽管价格昂贵,仍是强大的编程盟友,而另一些人则坚持使用本地模型,以摆脱潜在政策变化的影响。
Cursor IDE Discord
- DeepSeek R1 席卷西方:Windsurf 宣布 DeepSeek R1 和 V3 现已上线 tool calling capabilities(工具调用能力),首次实现了 R1 在编程 Agent 模式下运行。
- 用户注意到它完全托管在西方服务器上,并参考了 Cursor 社区论坛 进行持续讨论。
- Chat 与 Composer 中的 Token 纠葛:一些用户对 10k token context 设置表示困惑,报告在 Chat 和 Composer 中难以追踪使用情况。
- 他们质疑 Beta 设置是否真的提供了扩展上下文,或者消息是否在没有警告的情况下被截断。
- MCP 设置势头强劲:一种 Bash 脚本方法允许人们快速添加 MCP server 配置,如此 GitHub 仓库所示。
- 开发者分享了 MCP Servers 网站,鼓励尝试将不同的服务器与 Cursor 协同使用。
- 模型安全风暴预警:针对 ML 模型中潜在的隐藏代码执行产生了担忧,引用了一篇关于 Hugging Face 模型静默后门的帖子。
- 一些人建议使用 protectai/modelscan 扫描本地环境,以发现任何可疑的负载。
- 本地 vs 托管大对决:关于自托管与依赖 DeepSeek R1 等解决方案的辩论异常激烈,涉及隐私和成本的权衡。
- 虽然本地爱好者希望有更好的离线模型,但其他人则指出托管服务器随着发展带来的性能优势。
Nous Research AI Discord
- Nous x Solana Sunset Soirée: 即将举行的纽约 Nous x Solana 活动收到了大量参加请求,重点讨论 AI 模型的分布式训练。
- 参与者期待现场演示和专门的 Q&A,并希望与新的 Psyche 方法产生协同效应。
- Mistral & Tülu Tussle: 社区成员对 Hugging Face 上的 Mistral-Small-24B-Instruct-2501 和这条推文中的 Tülu 3 405B 感到兴奋,两者都定位为高性能的小规模 LLM。
- 几位成员提到了 R1-Zero 的博客分析进行基准测试对比,引发了关于哪种模型真正卓越的辩论。
- Psyche Paves Paths for Distributed Gains: Psyche 分布式训练框架旨在通过模块化系统处理大规模 RL,因其扩展模型训练的能力而受到赞誉。
- 一条推文展示了对该框架开源的兴奋之情,重点关注 GitHub 的可访问性和可能的共识算法路线图。
- China’s Ten Titans Tower Over Europe’s Models: 根据这条推文,一次聊天透露中国拥有 10 个可与欧洲顶级模型(包括 Mistral)匹敌的一流 AI 模型。
- 参与者指出,美国仅拥有五个主要的 AI 实验室——OpenAI、Anthropic、Google、Meta 和 xAI——凸显了激烈的全球竞争。
- CLIP-Driven Generation Gains Ground: 一位成员询问了关于 CLIP 嵌入的自回归生成,这通常用于引导 Stable Diffusion。
- 他们强调直接由 CLIP 驱动的生成过程缺乏参考资料,表明了将多模态输入与解码任务合并的兴趣。
Yannick Kilcher Discord
- Dario’s Daring $1B Venture: 社区成员讨论了 Dario Amodei 及其投入 10 亿美元推动 AI Safety 的举动,对他博客文章中的财务透明度和雄心勃勃的声明提出了质疑。他们对一些人标记为“欺诈性营销”的行为表示不安,反映了对大规模 AI 筹款活动的更深层怀疑。
- 几位技术专家认为,将如此巨额资金投入广泛的安全倡议可能会忽视其他紧迫的 AI 研究,而其他人则坚持认为这可以催化更负责任的 AI 发展。
- Mistral’s Middling-Sized Marvel: 新发布的 Mistral Small 3 拥有 24B 参数,在 MMLU 上达到 81%,运行速度比大型竞争对手快 3 倍。开发者赞扬了它的本地部署能力,称其在性能和资源效率之间找到了平衡点。
- 爱好者将其与 Llama 3.3 (70B) 等模型进行了对比,认为 Mistral 精简的设计可能会推动更易于获取的专业化解决方案。
- Tülu 3 405B Triumph: AI2 的研究人员发布了 Tülu 3 405B,拥有惊人的 405B 参数,并在多个基准测试中击败了 DeepSeek v3 和 GPT-4o。其 Reinforcement Learning from Verifiable Rewards (RLVR) 方法提升了模型在测试环境中的准确性和一致性。
- 参与者注意到了该模型的训练配方和权重开放政策,认为这可能为更大胆的开放研究合作提供动力。
- Framework Face-Off: LlamaIndex vs PydanticAI vs LangChain: 开发者报告称 PydanticAI 界面整洁且有内部温度设置,但遗憾其经常出现损坏的 JSON 输出。LlamaIndex 产生了更一致的结构化数据,而 LangChain 因其基于管道的架构使错误追踪复杂化而受到批评。
- 其他人强调某些 UI 中的高 CPU 或 GPU 占用是一个痛点,促使人们呼吁开发具有强大日志记录和性能指标的精简 Agent 工具。
- Prospective Config’s Bold Brainchild: 一篇 Nature Neuroscience 论文引入了 prospective configuration 作为超越反向传播 (backpropagation) 的学习基础,引发了对下一代神经训练的新推测。该方法声称提高了效率,并更好地与生物过程保持一致。
- 社区讨论表明其可能与 RL 方法产生协同效应,而一些人则质疑在技术飞跃如此之快的领域,该方法是否可能承诺过度。
Interconnects (Nathan Lambert) Discord
- Tülu 3 击败巨头:Tülu 3 405B 的发布展示了相比 DeepSeek v3 和 GPT-4o 更优越的性能,详见其博客。
- 爱好者们强调了其开源训练后配方 (open post-training recipes),对其可扩展性和巨大的 405B 参数量感到兴奋。
- Mistral Small 3 掌控极低延迟:Mistral Small 3 作为一款 24B 参数模型首次亮相,具有低延迟特性,据称可以在典型硬件上流畅运行(详情点击)。
- 社区反馈赞扬了其知识密集型 (knowledge-dense) 架构,将其定位为本地生成式 AI 任务的强力竞争者。
- DeepSeek 泄露引发安全担忧:Wiz Research 透露一个可公开访问的 DeepSeek 数据库泄露了密钥和聊天记录。
- 讨论集中在隐私问题上,引发了对 AI 基础设施采取更严格控制措施的呼吁。
- 软银向 OpenAI 注入数十亿美元:有报道称 SoftBank 计划向 OpenAI 投资 150-250 亿美元,以补充其现有的超过 150 亿美元的承诺。
- 分析师认为这是对 AI 的又一次巨大赌注,提高了本已激烈的融资竞赛的筹码。
- DeepSeek v3 专家实现并行化:DeepSeek v3 中新的 Mixture-of-Experts (MoE) 设计使用了 sigmoid gating 和 dropless load balancing,让多个专家能够在没有直接竞争的情况下做出响应(论文)。
- 贡献者讨论了微调这些专家层并应用 MTP 来一次预测两个 token,引发了关于推理加速的猜测。
Eleuther Discord
- Deepseek 困境:OpenAI 的双标伦理:社区成员注意到 OpenAI 在批评 Deepseek 训练 的同时,却讽刺地使用来自类似来源的数据,这引发了对其动机的质疑。他们怀疑 OpenAI 利用法律声明在拥挤的领域中塑造自信的形象。
- 一些参与者认为 Deepseek 的争论凸显了潜在的虚伪,加深了对 OpenAI 是否真正保护合作者利益的怀疑。
- RL 启示:更少的工具,更多的天赋:LLM 爱好者发现,使用强化学习 (RL) 可以减少工具使用指令的大小,让模型在最少的指导下掌握核心技能。他们担心过度依赖特定工具可能会损害核心解决问题的能力。
- 通过平衡 RL 与选择性的工具接触,他们希望保留模型的推理能力,而不至于陷入机械的工具依赖。
- Hyperfitting 热潮:微小数据带来巨大收益:新结果显示,在极小的数据集上进行 hyperfitting 可以大幅提升开放式文本生成,在人类偏好评分中从 4.9% 跃升至 34.3%。一篇论文证实了这些显著的改进,促使人们重新审视传统的过拟合 (overfitting) 担忧。
- 批评者争论这种狭窄的训练是否会损害更广泛的泛化能力,但许多人对这些令人惊讶的文本质量提升表示欢迎。
- 批判热潮:微调优于盲目模仿:研究人员提出了批判微调 (Critique Fine-Tuning, CFT),教模型识别和纠正带噪声的回答,而不仅仅是模仿正确的解决方案。据这篇论文记录,他们在六个数学基准测试中报告了 4–10% 的性能提升。
- 社区对教模型批判错误可能比标准监督微调 (SFT) 产生更稳健的推理表示乐观。
- 后门传闻与 Llama2 配置困惑:这篇论文中出现了关于不可检测的后门模型 (backdoored models) 的新警告,对传统的基于损失 (loss-based) 的检测策略提出了质疑。同时,开发者在设置 gated MLP 维度时,对 Llama2 配置中 32768 这个数字的意义提出了疑问。
- 一些人指出这个数字不能被 3 整除,导致重置为 11008,并引发了关于如何干净地导出模型配置的进一步讨论。
OpenRouter (Alex Atallah) Discord
- DeepSeek 的双重蒸馏模型发布:OpenRouter 推出了 DeepSeek R1 Distill Qwen 32B 和 DeepSeek R1 Distill Qwen 14B,两款模型均承诺以每百万 Token $0.7–$0.75 的价格提供接近大模型的性能。
- 据报道,14B 版本在 AIME 2024 上获得了 69.7 分,两款模型均可通过 OpenRouter Discord 访问。
- Subconscious AI 与 Beamlit 的重大进展:Subconscious AI 在其官网展示了因果推理(causal inference)和市场模拟的潜力,强调“保证人类级别的可靠性”。
- 与此同时,Beamlit 推出了免费 Alpha 版,可将 AI Agent 的交付速度提升高达 10 倍,并提供 GitHub 工作流和可观测性工具。
- OpenRouter 价格争议与速率限制吐槽:用户对 OpenRouter 收取 5% 的费用展开讨论,部分原因归结于底层的 Stripe 成本。
- 其他用户报告了使用 Google Gemini 时频繁出现 429 RESOURCE_EXHAUSTED 错误,建议使用个人 API Key 以避免超时。
- Mistral Small 3 与 Tülu 3 预告:通过 推文 宣布,Mistral Small 3(24B,81% MMLU)和 Tülu 3(405B)均承诺进行扩展训练并提供更快的吞吐量。
- 社区讨论认为,这些新发布的模型与 DeepSeek 搭配使用可能会在速度和准确性上获得更大提升。
Stackblitz (Bolt.new) Discord
- Bolt 重大的二进制文件突破:根据 bolt.new 的推文,Bolt 停止生成二进制资产,从而显著减少了数十万个 Token 的消耗,并提升了输出质量。
- 社区成员对转向外部资产的做法表示赞赏,认为这加快了执行速度,并在社区讨论中称其为“重大的性能飞跃”。
- 社区系统提示词(System Prompt)惊喜:开发者讨论转向了项目和全局系统提示词,一位用户将其用于变更日志(changelog)更新,并希望看到更多扩展的创意用途。
- 有技巧提示分享特定文件并确认视图正确,展示了超越日常任务的更深层使用潜力。
Stability.ai (Stable Diffusion) Discord
- ComfyUI 获得更清晰的局部重绘(Inpainting)控制:部分参与者分享了手动局部重绘的方法,引用了 Streamable 上的示例,展示了在 ComfyUI 中通过高级 ControlNet 设置实现精准修饰。
- 他们赞赏这种针对特定调整的灵活性,而非仅仅依赖自动化方法。
- 硬件热潮:GPU 讨论升温:用户讨论了他们的 GPU 选择,Intel Arc A770 LE 被认为在游戏和 AI 任务中可与 3060 媲美。
- 其他用户交流了 3080 和 3090 的使用心得,重点关注 Stable Diffusion 的 VRAM 需求。
- 换脸工具 Reactor 带着过滤器重新上线:参与者注意到 Reactor 曾因缺乏 NSFW 检查被移除,随后在 GitHub 上传了更安全的版本。
- 他们还指向了 ComfyUI 扩展,以实现更精简的换脸功能。
- Stable Diffusion 的 Lora 训练技巧:成员们剖析了构建 Lora 的步骤,强调了风格整合和精确的面部匹配。
- 他们讨论了结合多个参考源的方法,突出了在同步风格和特征方面的挑战。
- 5090 GPU 瞬间售罄:新款 5090 GPU 被瞬间抢购一空,引发了对缺货和高昂需求的沮丧情绪。
- 人们在考虑通过融资方式购买新硬件,并对极少的库存感到失望。
GPU MODE Discord
- Blackwell 与 sm_120a 的重大突破:全新的 Blackwell 架构及其 sm_120a 特性使之前的 sm_90a 功能相形见绌,详见 cutlass/media/docs/blackwell_functionality.md,这预示着消费级 GPU 将拥有更强大的计算能力。
- 社区成员讨论了 RTX 5090 相比 RTX 4090 的提升,提到在 FP4 任务中可能有 5倍 的加速,但在其他测试中仅为 2倍,引发了对文档不一致的担忧。
- PyTorch 2.6 重磅发布:最新推出的 PyTorch 2.6 增加了对 Python 3.13 的
torch.compile支持,引入了 X86 上的 FP16,并使用了 Manylinux 2.28,详见 PyTorch 2.6 发布博客。- 爱好者们注意到了 Conda 的弃用,同时赞扬了如
torch.compiler.set_stance等新的性能调节参数,有人称其为分发策略中的“重大转变”。
- 爱好者们注意到了 Conda 的弃用,同时赞扬了如
- Reasoning Gym 快速扩张:Reasoning Gym 已飙升至 33 个数据集,并包含在 GALLERY.md 的新展示页中,展示了广泛的强化学习任务。
- 贡献者赞扬了协作挑战,并提出了多 Agent 协商设置,引发了关于解释性和基于逻辑任务的讨论。
- Mistral 在 AIx Jam 的精彩表现:Mistral AIx 的参赛作品在 🤗 Game Jam 中获得第 2 名,邀请大家在 这个 HF Space 中测试 ParentalControl,将 AI 与游戏开发结合,打造喜剧恐怖体验。
- 他们还展示了 Llama3-8B R1,声称在 GSM8K 上有 14% 的提升,详见这篇博客文章,引发了对高性价比训练的热议。
Nomic.ai (GPT4All) Discord
- DeepSeek 模型引发 LaTeX 讨论:成员们热切期待 DeepSeek 的发布,称赞其在复杂任务中强大的数学和 LaTeX 能力。
- 他们讨论了 VRAM 限制,强调在进行繁重计算时需要谨慎管理上下文窗口大小。
- Ollama 与 GPT4All 联动实现本地增益:一些用户确认通过将 Ollama 作为服务器运行,并从 GPT4All 调用 OpenAI API,成功将 GPT4All 连接到 Ollama。
- 他们推荐参考 GPT4All 文档 获取分步操作方法。
- 远程 LLM 接入 GPT4All:用户测试了将远程 LLM 加载到 GPT4All 中,强调了设置正确 API 密钥和环境变量的必要性。
- 他们建议在 GitHub wiki 中改进引导说明以帮助新手。
- AI 教育计划进入离线模式:一位用户展示了为非洲儿童构建 AI 驱动工具的计划,引用了 Funda AI。
- 他们计划使用轻量级模型和精选数据,以便在没有网络的情况下进行自主学习,弥补资源差距。
- 模型后缀 -I1- 之谜:一位成员询问某些模型名称中的 -I1- 含义,但目前尚无官方确认的解释。
- 其他人要求更清晰的标签,表明对更公开的模型文档的需求。
MCP (Glama) Discord
- Cursor 受限的 MCP 能力:新版 Cursor 增加了部分 MCP 支持,但环境变量仍是一个空白,导致需要像 env invocation 中提到的那样,使用
FOO=bar npx some-server这种命令行变通方案。- 社区成员寻求 MCP 与 LSP 配置结构之间更好的对齐,认为这种不匹配是阻碍广泛采用的绊脚石。
- MCP 的 Web 客户端黑科技:一个自托管的 Web 客户端现在可以协调多个 MCP 服务器和 Agent,实现本地或云端设置的平滑切换。
- 其灵活的方法激发了人们的兴趣,尽管有些人对 MCP 缺乏动态 Agent 提示词(prompt)功能感到遗憾。
- 8b 模型的函数调用挫败感:MCP 中的 8b 模型在函数调用(function-calling)和工具使用方面表现挣扎,这让依赖强大 Agent 交互的测试者感到困惑。
- 几位贡献者建议在 Reddit 等论坛上进行更深入的社区讨论,希望能解决该模型的可靠性问题。
- Hataraku 在 ShowHN 登顶:Hataraku 项目在 ShowHN 上飙升至榜首,为其 TypeScript SDK 提案和 CLI 功能注入了动力。
- 社区成员正通过协作和试运行积极参与,旨在优化界面并提升更广泛的用户体验。
Notebook LM Discord Discord
- NotebookLM 二月反馈盛会:NotebookLM 将于 2025 年 2 月 6 日 举办远程聊天会议以收集用户反馈,并向参与者提供 $75 奖励。
- 参与者需要提交筛选表单,具备稳定的网络连接以及带视频功能的设备。
- 用英雄联盟术语转录交易策略:一位用户将交易课程视频转换为音频,然后使用 AI 进行转录,并利用 NotebookLM 来理清高级材料。
- 他们使用 LoL(英雄联盟)的引用介绍了 Big Players(大玩家/主力),展示了 AI 在解释复杂概念时的灵活性。
- 24 小时内解读行政命令:NotebookLM 在不到一天的时间内总结了一份关于公共教育隐私的新行政命令(Executive Order),并附带了深入的 YouTube 评论。
- 这一演示引发了关于将该工具应用于政策简报和深入分析的讨论。
- 剖析 DeepSeek R1:GRPO 与 MoE:一期 NotebookLM 播客介绍了 DeepSeek R1,重点讲解了 GRPO 和 Mixture of Experts (MoE) 以解释其架构。
- 听众观看了包含基准测试和快速演示的完整讨论,并针对性能提升提出了疑问。
- 学习指南生成缓慢与语言失效:一些用户在生成学习指南时面临 10-30 分钟的延迟,即使只有一个源文件也是如此。
- 其他人则抱怨多语言处理能力较差(例如韩语和日语)以及短暂的 Gemini 2.0 Flash 故障,同时寻求更严格的来源引用规则。
Modular (Mojo 🔥) Discord
- 分支提升与重定向汇总:分支变更已完成,所有 Pull Request 均已重定向,确保了代码集成过程的顺畅。
- 团队成员如有疑问可以随时提问,凸显了项目对公开沟通的重视。
- 为 Mojo LSP 推进 NeoVim 支持:开发者讨论了如何通过 nvim-lspconfig 启用 Mojo LSP,但在设置过程中遇到了一些奇怪的问题。
- 少数人报告仅获得部分成功,表明需要更深入的调试来实现稳定的工作流。
- Mojo 1.0:速度与稳定性的对决:Chris Lattner 强调 Mojo 1.0 应该融合 GPU 优化与直接执行,以实现速度最大化。
- 参与者认为,在追求顶级性能指标的竞争中,必须平衡即时的可靠性。
- 向后兼容性大检查:成员们担心新版本 Mojo 中的破坏性变更(breaking changes)可能会阻碍用户升级。
- 他们强调了对旧版本库的支持,以保持势头并培养稳定的用户群。
- Mojo 中的反射与性能探讨:对话集中在用于数据序列化的反射(reflection)上,并指出部分反射功能已初步实现。
- 与会者还推动进行大规模集群的基准测试(benchmarking),并提到了 Chris Lattner 的 Mojo🔥: a deep dive on ownership 视频。
Latent Space Discord
- 小巧但迅速:Mistral 3:根据官方详情,Mistral Small 3 作为一款拥有 24B 参数的模型发布,采用 Apache 2.0 license,具备 81% MMLU 和 150 tokens/sec 的性能。
- 它具有更少的层数和更大的词汇量,其在社交媒体上非传统的 FF-dim/model-dim ratio 引发了社区兴趣。
- DeepSeek 数据库泄露暴露秘密:据 Wiz Research 报道,DeepSeek 一个配置错误的 ClickHouse database 导致了重大数据泄露,包括聊天记录和密钥。
- 他们在披露后迅速修复了泄露,这引发了人们对 AI 数据处理整体安全性的担忧。
- Riffusion 推出 FUZZ:Riffusion 推出了 FUZZ,这是一款旨在免费提供高质量输出的新型生成式音乐模型,在此分享。
- 早期采用者称赞其旋律效果,并指出该服务仅在 GPU 资源充足时免费。
- OpenAI API 延迟受到关注:讨论中提到了 OpenRouter 和 Artificial Analysis,作为追踪 OpenAI API 可能出现的 latency(延迟)激增的方法。
- 一些人认为响应率正常,但社区成员建议保持谨慎并持续检查。
- ElevenLabs 获得 1.8 亿美元融资:ElevenLabs 在由 a16z & ICONIQ 领投的 C 轮融资中筹集了 1.8 亿美元,这一里程碑在此宣布。
- 观察人士认为,这是对 AI voice 技术未来及其巨大市场潜力的有力认可。
LLM Agents (Berkeley MOOC) Discord
- 赛道预告吸引 LLM Agents 观众:参与者正在等待有关 LLM Agents MOOC 的 application(应用)和 research(研究)赛道的更多细节,组织者承诺很快会分享。
- 社区成员重复着“请保持关注!”的消息,渴望听到官方公告。
- 报名故障导致确认停滞:几个人注意到他们提交了 Google Forms 报名表但未收到回复,特别是那些寻求 PhD 机会的人。
- 他们要求提供最终录取详情并加快回复速度,以便管理自己的日程。
- Quiz 1 查询与私人存档:成员们确认 Quiz 1 已在课程网站上线(参考教学大纲),一些人正在寻找之前 LLM Agent 课程的旧测验解答。
- 他们分享了一个 Quizzes Archive,并提醒注意隐藏的答案和过时的浏览器提示。
- 证书困惑仍在继续:许多人正在等待早期课程的 certificates(证书),官方指南承诺很快发布。
- 组织者表示,即将发布的公告将澄清本学期奖励的处理流程。
- 讲座发布与无障碍目标:成员们敦促尽快上传 第 1 讲,认为只需“5 分钟”,但编辑团队提到了 Berkeley 的字幕要求。
- 他们指出可以通过 课程网站 观看直播,而精修版本需等待无障碍措施完成后发布。
LlamaIndex Discord
- Agent 实战:通过 LlamaIndex 掌握 AI:Mastering AI Agents Workshop 介绍了用于多 Agent 框架的高级 AgentWorkflow 概念,如此链接所示。
- 与会者探索了使用 LlamaIndex 的稳健架构方法,引发了关于最佳实践的新讨论。
- BlueSky 助力:LlamaIndex 扩展版图:LlamaIndex 团队正式入驻 BlueSky,在此链接中展示了新的曝光度。
- 贡献者期待与该平台开展更广泛的互动,激发更多围绕 AI 发展的活动。
- o1 的奇特支持:部分流式传输与争论:成员们注意到 LlamaIndex 通过
pip install -U llama-index-llms-openai增加了o1兼容性,尽管某些功能仍未实现。- 他们引用了一个 OpenAI 社区帖子,该帖子确认 OpenAI 尚未完全启用流式传输(streaming),这引发了用户的不满。
tinygrad (George Hotz) Discord
- GPU 探戈:P2P Patch 对阵 Proxmox:在 #general 频道中,参与者讨论了在多块 NVIDIA GPU 上使用 P2P patch 的情况,并权衡了 Proxmox 与裸机 (baremetal) 设置以获得最佳 IOMMU 支持。
- 一些用户倾向于使用裸机以绕过预期的 hypervisor 限制,而另一些用户则报告称,如果配置得当,Proxmox 也能胜任。
- Tiny Boxes 联手实现 VRAM 梦想:成员们探讨了可以互连多少台 Tiny Boxes,并想知道是否可以在它们之间共享 VRAM 以进行 HPC 级的推理。
- 他们注意到缺乏直接的 VRAM 池化机制,建议使用高速 NIC 进行基于网络的扩展,以实现分布式性能。
- Token 吞吐量:15/秒到 100 个请求:估算显示每个模型的容量为 15 tokens/sec,如果每个模型以 14 tokens/sec 运行,则潜在扩展能力可达 100 个请求。
- 这说明了在受控条件下分布请求如何维持接近峰值的速度,为 HPC 设计讨论提供了支持。
- 为本地 (On-Prem) LLM 选购服务器:一位用户询问在企业环境中托管 LLM 的推荐物理服务器,凸显了对本地部署解决方案的广泛兴趣。
- 社区成员讨论了成本效益、功耗以及处理大规模部署的 GPU 扩展空间。
- Tinygrad 中的 Block/Fused 代码:在 #learn-tinygrad 频道,有人请求 blocked/fused 程序的示例代码,以演示如何加载和写入 tensor blocks。
- 其他人解释说,通过减少开销和合并步骤,按块 (blocks) 执行操作可以显著提升性能。
Cohere Discord
- Command R 提升上下文能力:一位用户分享了将 command-r7b 与蒸馏框架 (distillation frameworks) 集成的困扰,提到使用 ollama 生成合成数据,并指出这些工具现有支持中的空白。他们强调 Command R 是一款具有 128,000-token 上下文长度和检索增强生成 (RAG) 能力的大语言模型,并引导他人查看 Models Overview、The Command R Model 以及 Command R Changelog。
- 贡献者们关注 Command R 即将发布的版本,强调了增强的决策和数据分析能力。他们还讨论了弥合框架集成差距的问题,希望在未来的迭代中实现更顺畅的合成数据工作流。
- 关于 AI “毯子”的辩论:一些成员形容 AI 模型是冰冷的,开玩笑说一条“毯子”可以给它们带来温暖。他们认为这反映了一种将无感情的机器拟人化的俏皮尝试。
- 另一些人坚持认为 AI 不需要温暖或感情,引发了一场关于什么定义了人工智能系统中真实共情的快速争论。这段打趣凸显了人们对 AI 情感感知持续的好奇心。
DSPy Discord
- Proxy Patch 与 DSPy 辩论:一位用户询问如何向
dspy.LM适配器添加 proxy,并引用了在gpt3.py中集成http_client的 GitHub PR #1331。如果没有代理支持,他们无法在其托管端点上使用 dspy 2.6。- 另一位用户指出了代理用法如何与 dspy/clients/lm.py 代码引用保持一致。他们还质疑在
litellm中是否可以配置 SSL context 以实现稳定连接。
- 另一位用户指出了代理用法如何与 dspy/clients/lm.py 代码引用保持一致。他们还质疑在
- LiteLLM 与 DSPy:支持阵容:一位新成员询问 DSPy 支持哪些 LLM,从而引出了对 LiteLLM 文档 的提及。该文档引用了 OpenAI、Azure 和 VertexAI 提供的服务。
- 对话还涉及了在
http_client中为高级配置指定 SSL context 的挑战。参与者注意到,这些参数设置在默认的 DSPy 文档中并未完全解释。
- 对话还涉及了在
Axolotl AI Discord
- KTO vs Axolotl:紧急对决:成员们指出了在为 KTO 任务集成 Axolotl 时面临的挑战,并表示迫切需要确认可行性和解决方案路径。
- 他们表示已准备好协助审查代码并完成任务,强调希望保持项目进度。
- Mistral 发布 24B 模型:拥有 24B 参数 的新 Mistral-Small-24B-Base-2501 模型 引发了追求高性能小型 LLM 成员的兴奋。
- 此次发布凸显了 Mistral AI 的开源承诺,并暗示将推出更多商业变体以满足特定需求。
- Mistral 性能之谜:一位成员承认目前缺乏对 新 Mistral 模型 的实际操作经验,导致性能声明尚未得到证实。
- 对话建议未来进行用户测试,以收集真实世界的运行结果,并深入了解该模型在实践中的表现。
- 冬季学期超负荷:繁忙的 冬季学期 时间表被描述为非常紧凑,影响了一位成员的贡献能力。
- 这可能会推迟协作任务,促使其他人协调时间表并分担责任。
OpenInterpreter Discord
- Farm Friend 之谜:一位用户表达了对去年 Farm Friend 的喜爱,并注意到它目前在讨论中缺席。
- 社区成员对其命运保持好奇,因为该讨论串中没有透露进一步的更新。
- 陈词滥调的评论引发趣闻:对 cliché reviews 的轻松提及引发了俏皮的玩笑,随附的一张图片突显了这个笑话。
- 虽然没有提供更深层的背景,但这次交流为社区增添了趣味时刻。
- 解读 ‘01’:一位用户解释说 ‘01’ 与 OpenAI 无关,澄清了之前对话中的困惑。
- 这一言论平息了猜测,并确认了该沟通误会纯属巧合。
Torchtune Discord
- 通过 DCP 开关提升 Checkpoints 性能:成员们澄清说 DCP checkpointing 默认是关闭的,但可以通过在配置中设置
enable_async_checkpointing=True来激活,从而实现异步写入。- 他们指出,该功能目前仅限于 full_finetune_distributed,这可能会限制在其他配置下的使用。
- 推动更广泛的 Checkpoint 支持范围:一些人想知道为什么 async checkpointing 不能支持所有配置,暗示需要未来的更新。
- 目前尚未提供明确的时间表,成员们希望看到更广泛的集成,以简化大规模微调过程。
LAION Discord
- 本地 Img2Vid 热潮:一位用户询问了最佳的本地 img2vid 工具,引发了围绕性能需求和 GPU 利用率的讨论。
- 其他人分享了他们的经验,强调了 AI 工程工作流中快速安装和 清晰文档 的重要性。
- ltxv 受到青睐:另一位成员推崇 ltxv 作为本地 img2vid 任务的首选,理由是其使用简单。
- 他们暗示了未来的测试和改进,希望看到更多社区驱动的基准测试和扩展的模型支持。
MLOps @Chipro Discord
- Simba 引发 Databricks 特征工程热潮:Simba Khadder 将于 太平洋时间 1 月 30 日上午 8 点 举办一场关于在 Databricks 上构建 feature pipelines 的 MLOps Workshop,并提供了直接报名链接 此处。
- 与会者可以从 Unity Catalog 集成和直接的 Q&A 中汲取最佳实践,该活动对 Data Engineers、Data Scientists 和 Machine Learning Engineers 免费 开放。
- Databricks 拥抱地理空间分析:美国东部时间 2025 年 1 月 30 日下午 1:00,Databricks 将举办一场关于高级 geospatial analytics 的免费会议,可在 Eventbrite 报名。
- 与会者将看到 spatial data 如何在 Databricks 上进行处理,为那些寻求更深层数据工程见解的人延续了早先研讨会的势头。
Gorilla LLM (Berkeley Function Calling) Discord
- BFCL 数据向 HF 数据集靠拢:一位参与者询问了使 BFCL data 符合 Hugging Face 数据集指南所需的步骤,寻求确保合规性的蓝图。
- 未提供示例或文档,使得关于如何调整 metadata schema 或格式的讨论处于开放状态。
- 未出现其他主题:对话仅限于关于实现 Hugging Face 合规性的单一查询。
- 没有进一步的细节出现,其他人对潜在的解决方案保持沉默。
Mozilla AI Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
HuggingFace Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
第二部分:分频道详细摘要与链接
完整的逐频道明细已针对邮件进行截断。
如果您喜欢 AInews,请分享给朋友!预先感谢!