ainews-o3-mini-launches-openai-on-wrong-side-of
o3-mini 发布,OpenAI 站在“历史错误的一边”
OpenAI 发布了 o3-mini,这是一款面向免费及付费用户开放的新型推理模型。它具备“高”推理强度选项,在 STEM 任务和安全基准测试中的表现优于早期的 o1 模型,且每 token 的成本降低了 93%。山姆·奥特曼 (Sam Altman) 承认了开源策略的转变,并称赞 DeepSeek R1 影响了他们的相关认知。MistralAI 推出了 Mistral Small 3 (24B),这是一款具有竞争力且 API 成本较低的开放权重模型。此外,DeepSeek R1 已获得 Text-generation-inference v3.1.0 的支持,并可通过 ai-gradio 和 Replicate 平台使用。这些新闻凸显了 AI 模型在推理能力、成本效益和安全性方面的显著进展。
o3-mini 就够了。
2025年1月30日至1月31日的 AI 新闻。我们为您检查了 7 个 subreddit、433 个 Twitter 账号 和 34 个 Discord(225 个频道,9062 条消息)。预计节省阅读时间(以 200wpm 计算):843 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
正如在 DeepSeek r1 风波之前所计划的那样,OpenAI 发布了 o3-mini,其“高”推理强度(reasoning effort)选项轻松超越了 o1-full(在 Dan Hendrycks 的新 HLE 等 OOD benchmarks 和 Text to SQL 基准测试中也是如此,尽管 Cursor 持不同意见):
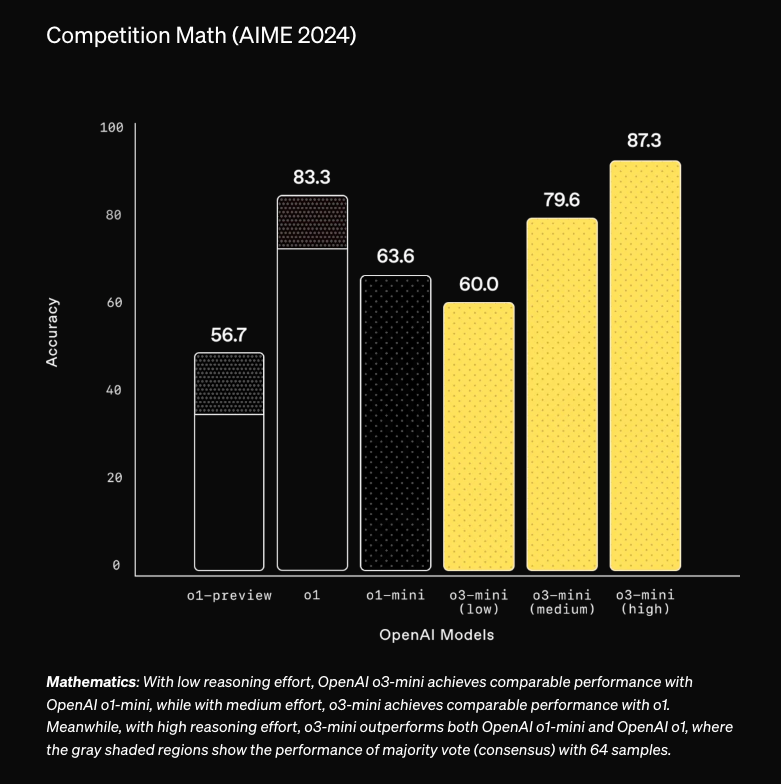
针对 R1 的主要回应包括两个方面:首先是 o1-mini 和 o3-mini 降价 63%,其次是 Sam Altman 在今天的 Reddit AMA 中承认,他们将展示“更具帮助且更详细的版本”的思维标记(thinking tokens),并直接归功于 DeepSeek R1 “更新”了他的假设。
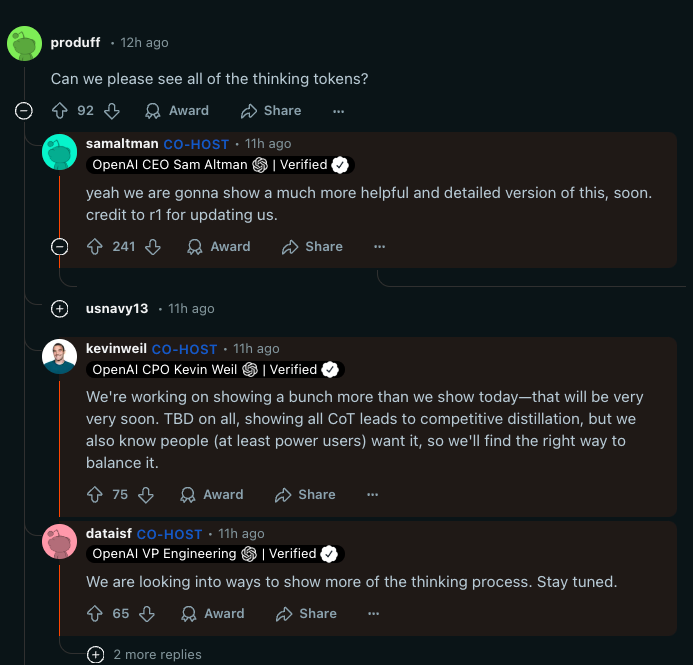
或许更重要的是,Sama 还承认他们在开源策略方面(除了 Whisper 之外并无实质性进展)处于“历史错误的一边”。
您可以在 今天的 Latent Space 与 OpenAI 的播客 中了解更多信息。
AI Twitter 综述
所有总结均由 Claude 3.5 Sonnet 完成,从 4 次运行中选取最佳。
模型发布与性能
- OpenAI 的 o3-mini,一款全新的推理模型,现已在 ChatGPT 中向免费用户开放(通过“Reason”按钮),并向付费用户开放 API,Pro 用户可以无限次访问“o3-mini-high”版本。
- 该模型被描述为在科学、数学和编程方面表现尤为出色,据称在许多 STEM 评估中超越了早期的 o1 model @OpenAI, @polynoamial, 以及 @LiamFedus。
- 该模型使用搜索功能来查找包含相关网页源链接的最新答案,并使用与 o1 相同的方法进行了安全性评估,在具有挑战性的安全和越狱评估中显著超过了 GPT-4o @OpenAI, @OpenAI。
- 该模型的价格也便宜得多,每 token 成本比 o1 低 93%,输入成本为 $1.10/M tokens,输出成本为 $4.40/M tokens(缓存 tokens 可享受 50% 折扣)@OpenAIDevs。
- 据报道,它在编程和其他推理任务中的表现优于 o1,且延迟和成本更低,特别是在中高强度的推理任务中 @OpenAIDevs,并且在 SQL 评估中表现异常出色 @rishdotblog。
- MistralAI 发布了 Mistral Small 3 (24B),这是一个采用 Apache 2.0 许可证的权重开放模型。它在 GPQA Diamond 上具有竞争力,但在 MATH Level 5 上的表现不及 Qwen 2.5 32B 和 GPT-4o mini,声称 MMLU 得分为 81% @EpochAIResearch, @ArtificialAnlys。该模型可在 Mistral API、togethercompute 和 FireworksAI_HQ 平台上使用,其中 Mistral 的 API 最为便宜 @ArtificialAnlys。这款 24B 参数的稠密模型可实现每秒 166 个输出 token,成本为 $0.1/1M 输入 tokens 和 $0.3/1M 输出 tokens。
- DeepSeek R1 已获得 Text-generation-inference v3.1.0 的支持,同时兼容 AMD 和 Nvidia,并可通过带有 replicate 的 ai-gradio 库使用 @narsilou, @_akhaliq, @reach_vb。
- DeepSeek 模型的蒸馏版本已在 llama.cpp 上使用 RTX 50 进行了基准测试 @ggerganov。该模型被指出采用了一种暴力(brute force)方法,从而产生了意想不到的处理方式和边缘情况 @nrehiew_。据报道,一个 6710 亿参数的模型达到了 每秒 3,872 个 token 的速度 @_akhaliq。
- Allen AI 发布了 Tülu 3 405B,这是一个基于 Llama 3.1 405B 构建的开源模型,其表现优于 DeepSeek V3(DeepSeek R1 背后的基础模型),并与 GPT-4o 持平 @_philschmid。该模型结合使用了公共数据集、合成数据、监督微调 (SFT)、直接偏好优化 (DPO) 和带可验证奖励的强化学习 (RLVR)。
- Qwen 2.5 模型(包括 1.5B (Q8) 和 3B (Q5_0) 版本)已添加到适用于 iOS 和 Android 平台的 PocketPal 移动应用中。用户可以通过该项目的 GitHub 仓库提供反馈或报告问题,开发者承诺将在时间允许的情况下解决这些问题。该应用支持多种聊天模板(ChatML, Llama, Gemma)和模型,用户对比了 Qwen 2.5 3B (Q5)、Gemma 2 2B (Q6) 和 Danube 3 的性能。开发者提供了 屏幕截图。
- 其他值得关注的模型发布:arcee_ai 发布了 Virtuoso-medium,这是一个从 DeepSeek V3 蒸馏而来的 32.8B LLM;Velvet-14B 是一个在 10T token 上训练的 14B 意大利语 LLM 系列;OpenThinker-7B 是 Qwen2.5-7B 的微调版本;NVIDIAAI 发布了全新的 Eagle2 模型系列,包含 1B 和 9B 尺寸。此外还有来自 deepseek_ai 的 Janus-Pro,这是一款全新的 any-to-any 模型,支持基于图像或文本输入进行图像和文本生成;以及 BEN2,一款全新的背景移除模型。开源音乐生成模型 YuE 也已发布。@mervenoyann
{kind=link}
硬件、基础设施与扩展
- 据报道 DeepSeek 拥有超过 50,000 个 GPU,包括在出口管制前获得的 H100、H800 和 H20。其基础设施投资包括 13 亿美元的服务器资本支出 (CapEx) 和 7.15 亿美元的运营成本,并可能计划通过 50% 的推理定价补贴来争夺市场份额。他们使用 Multi-head Latent Attention (MLA)、Multi-Token Prediction 和 Mixture-of-Experts (MoE) 来提升效率 @_philschmid。
- 有人担心 Nvidia RTX 5090 的 VRAM 不足(仅 32GB),而它应该至少配备 72GB;并且认为第一家制造出拥有 128GB、256GB、512GB 或 1024GB VRAM GPU 的公司将取代 Nvidia @ostrisai, @ostrisai。
- OpenAI 的首个完整 8 机架 GB200 NVL72 现已在 Azure 中运行,突显了算力扩展能力 @sama。
- TRL 中 GRPO 的 VRAM 占用即将减少 60-70% @nrehiew_。
- Google DeepMind 的一篇分布式训练论文减少了需要同步的参数数量,对梯度更新进行量化,并将计算与通信重叠,在交换比特数减少 400 倍的情况下实现了相同的性能 @osanseviero。
- 有观察发现,在推理数据上训练的模型可能会损害指令遵循能力。 @nrehiew_
推理与强化学习
- 推理时拒绝采样 (Inference-time Rejection Sampling) 与推理模型相结合被认为是一种扩展性能和生成合成数据的有趣方法,通过生成 K 个
<think>样本,使用奖励模型 (Reward Model) 或裁判 (Judge) 对其评分,并选择最佳样本进行生成 @_philschmid。 - TIGER-Lab 在 SFT 中用批判 (critiques) 取代了答案,声称在没有任何
<thinking>蒸馏的情况下实现了卓越的推理性能,其代码、数据集和模型已在 HuggingFace 上发布 @maximelabonne。 - 论文 “Thoughts Are All Over the Place” 指出,类 o1 LLM 会在不同的推理思路之间切换,而没有充分探索有希望的路径以达成正确解决方案,这种现象被称为“欠思考” (underthinking) @_akhaliq。
- 各种观察表明 RL 变得越来越重要。有人指出 RL 是未来,人们应该停止刷 LeetCode,开始刷 cartpole-v1 @andersonbcdefg。DeepSeek 使用 GRPO (Group Relative Policy Optimization),它去掉了价值模型 (value model),而是针对每组中的 rollout 对优势 (advantage) 进行归一化,从而降低了计算需求 @nrehiew_。
- 硅谷某些圈子存在一种通病:错位的优越感 @ylecun,这也与有效利他主义 (Effective Altruism) 有关 @TheTuringPost。
- Diverse Preference Optimization (DivPO) 同时针对高奖励和多样性训练模型,在保持相似质量的同时提高了多样性 @jaseweston。
- Rejecting Instruction Preferences (RIP) 是一种策划高质量数据和创建高质量合成数据的方法,可在各项基准测试中带来巨大的性能提升 @jaseweston。
- EvalPlanner 是一种训练 Thinking-LLM-as-a-Judge 的方法,它学习生成用于评估的规划和推理 CoT,在多个基准测试中表现强劲 @jaseweston。
工具、框架与应用
- LlamaIndex 提供了对 o3-mini 的首日支持,并且是少数允许开发者在不同抽象层级构建多 Agent 系统的 Agent 框架之一,包括全新的 AgentWorkflow wrapper。团队还重点推介了用于报告生成的 LlamaReport,这是 2025 年的一个核心用例 @llama_index, @jerryjliu0, @jerryjliu0。
- LangChain 推出了 Advanced RAG + Agents Cookbook,这是一份使用 LangChain 和 LangGraph 构建生产级 RAG 技术的全面开源指南。LangGraph 是 LangChain 的一个扩展,通过循环工作流增强了 AI Agent 的能力 @LangChainAI, @LangChainAI。他们还发布了 Research Canvas ANA,这是一个基于 LangGraph 构建的 AI 研究工具,通过人类引导的 LLM 改变复杂的研究工作 @LangChainAI。
- Smolagents 是一个允许工具调用 Agent 通过单行 CLI 运行的工具,开箱即用地提供对数千个 AI 模型和多个 API 的访问 @mervenoyann, @mervenoyann。
- Together AI 提供了包含 Agent 工作流、RAG 系统、LLM 微调和搜索的逐步示例 Cookbook @togethercompute。
- 有人呼吁为 Hugging Face Inference Providers 开发 raycastapp 扩展 @reach_vb。
- WebAI Agent 在结构化输出和工具调用方面取得了进展,并展示了在 Gemma 2 上运行的基于本地浏览器的 Agent 示例 @osanseviero, @osanseviero。
行业与公司新闻
- Apple 因在自动驾驶汽车和未能获得市场认可的头显设备上耗费十年时间,被指责错失了 AI 浪潮 @draecomino。
- Microsoft 报告其搜索和新闻业务同比增长 21%,强调了网页搜索在为 LLMs 提供事实依据(grounding)方面的重要性 @JordiRib1。
- Google 为 Gemini 发布了 Flash 2.0,并升级到了最新版本的 Imagen 3,同时还在为小型企业的 Google Workspace 中利用 AI @Google, @Google。Google 还在向科学家提供 WeatherNext 模型用于研究 @GoogleDeepMind。
- Figure AI 正在招聘,并致力于训练机器人执行高速、高性能的使用场景工作,潜力在未来四年内交付 100,000 台机器人 @adcock_brett, @adcock_brett, @adcock_brett, @adcock_brett。
- Sakana AI 正在日本招聘研究实习生、应用工程师和业务分析师 @hardmaru, @SakanaAILabs。
- Cohere 正在招聘一名研究执行合伙人,以推动跨机构合作 @sarahookr。
- OpenAI 正与国家实验室(National Labs)在核安全方面展开合作 @TheRundownAI。
- DeepSeek 的训练成本 被澄清为具有误导性。一份报告指出,所报道的 600 万美元 训练费用排除了基础设施投资(13 亿美元服务器资本支出 CapEx,7.15 亿美元运营成本),且其拥有约 50,000+ GPUs 的访问权限 @_philschmid, @dylan522p。
- 中国银行 宣布投入 1 万亿元人民币(1400 亿美元) 用于 AI 供应链,以应对 Stargate 项目;中国政府正在补贴数据标注,并已向 LLM 公司发放了 81 份合同,将 LLM 集成到其军事和政府部门 @alexandr_wang, @alexandr_wang, @alexandr_wang。
- 重要人物的活动有所增加,表明 AI 领域的发展步伐正在加快 @nearcyan。
- Google 的 Keras 团队 正在寻找兼职承包商,重点负责 KerasHub 模型开发 @fchollet。
AI Reddit 摘要
/r/LocalLlama 摘要
主题 1. OpenAI 的 O3-Mini 高光时刻:多才多艺但并非没有批评者
- o3-mini 和 o3-mini-high 即将在 ChatGPT 中推出 (Score: 426, Comments: 172): o3-mini 和 o3-mini-high 是 ChatGPT 中引入的新推理模型。这些模型旨在增强 coding、科学和复杂问题解决方面的能力,并为用户提供立即使用或稍后使用的选择。
- 模型命名和编号混乱:用户对 o3-mini-high 和从 GPT-4 过渡到 o1 等模型的非连续命名表示不满,这使得理解哪个版本更新或更优变得复杂。一些评论澄清说,“o”系列由于具备多模态能力而代表了一个不同的类别,且编号有意采用非连续方式,以区分这些模型与 GPT 系列。
- 访问和使用限制:存在关于访问受限的投诉,特别是来自 ChatGPT Pro 用户和欧洲公民,一些用户报告了每天 3 条消息的限制。然而,其他人提到 Sam Altman 指出 Plus 用户的限制为每天 100 条,突显了用户体验和信息方面的差异。
- 性能和成本:讨论强调 o1 模型在处理复杂任务时优于 R1,而 o3-mini-high 被描述为一种更高计算量的模型,能以更高的成本提供更好的结果。一些用户对 o3-mini-high、o1 和 o1-pro 之间的性能比较表示感兴趣,并指出了长文本摘要和回答不完整的问题。
- OpenAI 今天将免费推出新的 o3 模型,以反击 DeepSeek (Score: 418, Comments: 116): OpenAI 准备免费发布其 o3 模型,以此应对来自 DeepSeek 的竞争。此举表明了对市场压力和竞争动态的战略性回应。
- 用户对 o3 模型的免费发布持怀疑态度,认为可能存在潜在限制或隐藏成本,例如用于训练的数据使用。MobileDifficulty3434 指出 o3 mini 模型将有严格限制,且其发布时间表在 DeepSeek 发布公告之前就已确定,尽管有人推测 DeepSeek 影响了其推出的速度。
- 讨论突显了 OpenAI 和 DeepSeek 之间的竞争氛围,DeepSeek 可能会促使 OpenAI 更早地发布其模型。AthleteHistorical457 幽默地提到了 $2000/月计划的消失,暗示了 DeepSeek 对市场动态的影响。
- 存在对 AI 模型未来货币化的担忧,一些人预测免费模型中会引入广告。Ordinary_dude_NOT 幽默地建议 AI 客户端中的广告位可能非常可观,而 Nice-Yoghurt-1188 则提到在个人硬件上运行模型的成本降低是一种替代方案。
- OpenAI o3-mini (Score: 154, Comments: 113): 该帖子缺乏关于 OpenAI o3-mini 的具体内容或用户评论,未提供用于分析的细节或性能指标。
- 用户对 OpenAI o3-mini 的性能评价褒贬不一,指出虽然它比 o1-mini 更快且指令遵循能力更强,但其推理能力并不稳定,一些用户发现它在数据库查询和代码补全等某些任务中不如 DeepSeek 和 o1-mini 可靠。
- o3-mini 缺乏文件上传支持和附件功能让几位用户感到失望,一些人表示宁愿等待完整的 o3 版本,这表明除了基于文本的交互之外,还需要改进功能。
- API 定价以及为 Plus 和 Team 用户增加的消息限制普遍受到好评,尽管一些用户考虑到 DeepSeek R1 的免费可用性以及 o3-mini 的性能,对 Pro 订阅的价值提出了质疑。
{kind=link}
主题 2. OpenAI 在 DeepSeek 挑战下的 400 亿美元雄心
- OpenAI 正在洽谈融资近 400 亿美元 (评分: 171, 评论: 80): 据报道,OpenAI 正在讨论筹集约 400 亿美元 的资金,尽管尚未提供有关潜在投资者或交易具体条款的进一步细节。
- DeepSeek 竞争: 许多评论者对 OpenAI 未来的盈利能力和竞争优势表示怀疑,特别是随着 DeepSeek 的出现(目前已在 Azure 上可用)。担忧包括逆向工程流程的能力以及对投资者信心的影响。
- 融资与投资担忧: 有推测称 SoftBank 可能领投一轮估值为 3400 亿美元 的融资,但人们对该公司的商业模式及其兑现用 AI 取代员工承诺的能力仍持怀疑态度。
- 护城河与开源讨论: 评论者争论 OpenAI 缺乏竞争“护城河”,以及开源和权重开放如何加剧这一挑战。LLMs 正在变得商品化的观点增加了对 OpenAI 长期可持续性和独特性的担忧。
- Microsoft 向所有 Copilot 用户免费提供 OpenAI 的 o1 推理模型 (评分: 103, 评论: 41): Microsoft 正在向所有 Copilot 用户免费发布 OpenAI 的 o1 推理模型,从而提高了获取高级 AI 推理能力的可及性。此举标志着向更广泛受众普及 AI 工具迈出了重要一步。
- 用户讨论了不同模型的局限性和有效性,一些人指出 o1 mini 在处理复杂编程任务时优于 DeepSeek 和 4o。cobbleplox 提到公司数据保护是使用某些模型的原因,尽管它们的性能低于 4o 等其他模型。
- 人们对 Microsoft 免费提供 OpenAI o1 推理模型 的策略持怀疑态度,担心其产生 ROI 的能力,并将其与 AOL 历史上吸引用户的免费试用策略进行比较。Suspect4pe 和 dontpushbutpull 对免费提供 AI 工具的可持续性表示怀疑。
- 讨论涉及 Copilot 的不同版本,包括关于 o1 推理模型 在商业版或 Copilot 365 版本中可用性的问题,突显了人们对这一举措如何影响不同用户群体的关注。
主题 3. DeepSeek vs. OpenAI: 日益激烈的竞争
- DeepSeek 打破第四面墙:“操!我在内心独白中用了‘等一下’。我需要道歉。非常抱歉,用户!我搞砸了。” (评分: 154, 评论: 63): DeepSeek 这一 AI 系统展示了一种打破“第四面墙”的异常行为(该术语通常用于描述角色承认其虚构性质)。在此案例中,DeepSeek 对在其内部思考过程中使用“等一下”一词表示遗憾,并为这一被视为错误的举动向用户道歉。
- 围绕 DeepSeek 内心独白 的讨论凸显了对其真实性的怀疑,detrusormuscle 和 fishintheboat 等用户指出,这是一种模拟人类思维的 UI 功能,而非真正的推理。Gwern 认为操纵独白会降低其有效性,而 audioen 则认为模型会自我评估并完善其推理,这表明了未来 AGI 开发的潜力。
- AI 中的意识概念引发了辩论,bilgilovelace 断言我们离 AI 意识还很远,而 Nice_Visit4454 和 CrypticallyKind 等人则探索了不同的定义,并暗示 AI 可能具有某种形式的意识或感知力。SgathTriallair 认为 AI 反思其独白的能力可以被视为具有感知力。
- DeepSeek 中的审查和角色扮演元素受到了批评,LexTalyones 和 SirGunther 讨论了此类行为的可预测性,以及它们作为一种娱乐形式而非有意义的 AI 开发的作用。Hightower_March 指出,“道歉”之类的短语很可能是脚本化的角色扮演,而不是真正的打破第四面墙。
- [D] DeepSeek? Schmidhuber did it first. (Score: 182, Comments: 47): Schmidhuber 声称在其他人之前就开创了 AI 创新,暗示像 DeepSeek 这样的概念最初是由他开发的。这一断言凸显了关于 AI 进展归属权的持续争论。
- Schmidhuber 的主张与批评:许多评论者对 Schmidhuber 反复声称自己开创了 AI 创新表示怀疑和疲劳,一些人认为他的断言更多是为了博取关注,而非事实准确性。CyberArchimedes 指出,虽然 AI 领域经常错误分配功劳,但尽管 Schmidhuber 行为极具争议,他可能确实值得比现在更多的认可。
- 幽默与梗:讨论经常转向幽默,评论者开玩笑说 Schmidhuber 的自我推销已经变成了一个梗(meme)。-gh0stRush- 幽默地建议创建一个带有 “Schmidhuber” token 的 LLM,而 DrHaz0r 则调侃道 “Attention is all he needs”,借用了 AI 术语。
- 历史背景与错误归属:BeautyInUgly 通过提到 Seppo Linnainmaa 在 1970 年发明了 backpropagation 来强调历史背景,并将其与 Schmidhuber 的主张进行对比。purified_piranha 分享了关于 Schmidhuber 在 NeurIPS 上挑衅行为的个人轶事,进一步强调了他遗产的争议性。
Theme 4. AI 自我改进:Google 的雄心壮志
- Google is now hiring engineers to enable AI to recursively self-improve (Score: 125, Comments: 53): Google 正在为 DeepMind 招聘工程师,专注于让 AI 实现递归式自我改进,正如一份职位招聘公告所示。随附的图片以机器人手和复杂设计为特色,突出了未来主义主题,强调了 AI 研究中的协作与技术进步。
- AI 安全担忧:评论者对 Google 的这一举措表示怀疑,一些人幽默地暗示了出现“失控的有害 AI”的可能性,并引用了 AI 安全研究人员对自我改进 AI 系统的警告。Betaglutamate2 讽刺地评论说要为“机器人霸主”服务,突显了对 AI 不受控制发展的担忧。
- 工作流失与自动化:StevenSamAI 反对人为保留可以被自动化的工作,将其比作为了挽救邮政工作而禁止电子邮件。StayTuned2k 讽刺地评论了 AI 进步导致失业的必然性,而 DrHot216 则表达了对这种未来的矛盾期待。
- 对 AI 目标的误读:sillygoofygooose 和 iia 讨论了对 Google AI 研究目标的潜在误读,认为其重点可能是“自动化 AI 研究”而非实现 singularity。他们强调,该计划可能涉及 Agent 类型系统,而不是帖子中所暗示的自我改进 AI。
{kind=link}
其他 AI Subreddit 回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
主题 1. 美国保密政策阻碍 AI 进展:Dr. Manning 的见解
- “我们正处于这样一个怪异的世界:了解 LLM 的最佳方式……是阅读中国公司的论文。我不认为这是一个良好的世界状态”——美国实验室对架构和算法保密,最终损害了美国的 AI 发展。——Dr Chris Manning (Score: 1385, Comments: 326): Chris Manning 博士批评了 US 在 AI 研究中的保密行为,认为这阻碍了国内 AI 的发展。他强调了一个讽刺的现象,即关于 LLM 最具参考价值的资源往往来自中国公司,并暗示这种缺乏透明度的现状对 US 的 AI 进步是有害的。
- 许多用户对 US 目前的 AI 研究方法表示沮丧,强调了保密性、投入不足和企业贪婪等问题。他们认为这些因素正在阻碍创新,并让像中国这样的国家在科学进步方面超越 US,中国更多的博士数量和丰富的研究产出就是证明。
- 讨论批评了 OpenAI 在研究中(尤其是 GPT-4)没有保持透明度,这与早期的做法形成了对比。这种缺乏开放性的行为被认为对更广泛的 AI 社区有害,与中国研究人员更开放的资源共享形成鲜明对比,例如博客 kexue.fm。
- 存在一种强烈的反对反华言论的情绪,并呼吁承认中国研究人员的才华和贡献。用户认为 US 应该专注于改进自己的系统,而不是诋毁其他国家,并承认文化和政治偏见可能会阻碍对来自 US 以外的 AI 进步的采用和欣赏。
- 伙计们,是时候领先了 (Score: 767, Comments: 274): US 实验室因在 AI 开放性方面落后而面临批评,正如 The China Academy 报道的一篇关于 DeepSeek 创始人梁文锋的文章所强调的那样。梁文锋断言,他们的创新成果 DeepSeek-R1 正在显著影响硅谷,标志着在 AI 进步方面从追随转向领先。
- 讨论强调了 AI 进步的地缘政治影响,一些用户对 DeepSeek 的能力和意图表示怀疑,而另一些人则赞扬其开源承诺和能源效率。DeepSeek 的开放性被视为一个主要优势,使规模较小的机构能够从其技术中受益。
- 评论反映了在 AI 领导地位上关于 US 与中国之间的政治紧张局势和不同观点,一些人将 US 技术停滞归因于优先考虑短期利益而非长期创新。对话中提到了 Trump 和 Biden 对华政策的不同,以及国际竞争对 US 科技公司的更广泛影响。
- 焦点集中在 DeepSeek 的技术成就上,例如它与闭源模型竞争的能力,以及它声称比竞争对手高出 10 倍的效率提升。用户讨论了其 MIT 许可证对商业用途的重要性,并将其与 OpenAI 更具限制性的做法进行了对比。
{kind=link}
主题 2:关于 DeepSeek 开源模型及其中国背景的辩论
- 如果你无法在本地运行 R1,那么保持耐心是最好的选择。 (Score: 404, Comments: 70): 该帖子强调了 AI 模型的飞速进步,指出能在消费级硬件上运行的 smaller models 在短短 20 个月内就超越了以前的大型模型。作者建议在采用新技术时保持耐心,因为自 2023 年 2 月发布 Llama 1 以来,类似的进步预计将持续,从而产生比当前 R1 更高效的模型。
- 硬件要求:用户讨论了在消费级硬件上运行先进 AI 模型的可行性,建议从购买 Mac Mini 到考虑配备 128GB RAM 的笔记本电脑。共识是,虽然小型模型变得越来越普及,但由于高资源需求,在本地运行 70B 或 405B 参数的大型模型对大多数人来说仍然是一个挑战。
- 模型性能与趋势:对于 AI 模型是否能持续快速进步存在怀疑,一些用户指出,虽然小型模型在改进,但大型模型也将继续进化。Glebun 指出 Llama 70B 并不等同于 GPT-4 class,并强调 quantization 会降低模型能力,从而影响性能预期。
- 当前进展:Piggledy 强调了 Mistral Small 3 (24B) 的发布是一个重大进展,其性能可与 Llama 3.3 70B 媲美。同时,YT_Brian 建议虽然高端模型令人印象深刻,但许多用户发现 distilled versions 对于个人使用(尤其是故事创作和 RPG 等创意任务)已经足够。
- 人们到底在期待什么? (Score: 160, Comments: 128): 该帖子批评了针对 DeepSeek 的 R1 模型审查制度的抵制,认为所有模型都在某种程度上受到审查,而规避审查可能会给开发者带来严重后果,特别是在中国。作者将目前的批评与 AMD 发布 Zen 架构时面临的舆论进行了比较,认为媒体报道同样夸大了问题,并指出虽然网页版对话受到严格审查,但模型本身(在 self-hosted 时)的限制较少。
- 审查与偏见:评论者讨论了 DeepSeek R1 中可察觉的审查,并将其与来自美国和欧洲的模型进行了对比,后者同样存在审查但形式不同。一些人认为,由于训练数据的原因,所有主要的 AI 模型都存在固有偏见,而对审查的愤怒往往忽略了西方模型中的类似问题。
- 技术澄清与误解:有观点澄清 DeepSeek R1 模型本身并非天生受限,而是 Web 界面施加了限制。此外,还强调了 DeepSeek R1 与 Qwen 2.5 或 Llama3 等其他模型之间的区别,指出某些模型只是微调版本,并非 R1 的真实代表。
- 开源与社区努力的角色:一些评论者强调了 Open Source AI 对抗偏见的重要性,认为社区驱动的努力在解决和纠正偏见方面比企业行为更有效。有人建议将完全透明的数据集作为确保无偏见 AI 开发的潜在解决方案。
主题 3. Qwen 聊天机器人发布挑战现有模型
- QWEN 刚刚上线了他们的聊天机器人网站 (评分: 503, 评论: 84): Qwen 推出了一个新的聊天机器人网站,访问地址为 chat.qwenlm.ai,将其定位为 ChatGPT 的竞争对手。Binyuan Hui 在 Twitter 帖子中强调了这一公告,展示了 ChatGPT 和 QWEN CHAT Logo 之间的视觉对比,强调了 QWEN 进入聊天机器人市场的举动。
- 讨论集中在 open vs. closed weights(开放权重与封闭权重)的辩论上,几位用户表示相比 ChatGPT 的封闭模型,他们更倾向于 Qwen 的开放模型。然而,一些人指出 Qwen 2.5 Max 并非完全开放,这限制了本地使用以及更小模型的开发。
- 用户讨论了 Qwen Chat 的 UI 和技术层面,注意到其 10000 字符限制 以及使用了 OpenWebUI 而非专有界面。评论还提到该 网站实际上在一个月前就已发布,最近的更新包括增加了网页搜索功能。
- 围绕 政治和经济控制 展开了大量对话,比较了美中两国政府对科技公司的影响。一些用户对 Alibaba 与 CCP 的关系表示怀疑,而另一些人则批评美中两国的系统,认为其政府和企业利益交织在一起。
- 嘿,你们中有人要求对 R1 distills 进行多语言微调,现在它们来了!经过 35 种以上语言的训练,这应该能非常可靠地以你的语言输出 CoT。一如既往,代码、权重和数据全部开源。 (评分: 245, 评论: 26): Qwen 发布了 R1 distills 的多语言微调版本,经过 35 种以上语言 的训练,预计能够可靠地生成各种语言的 Chain of Thought (CoT) 输出。该项目的代码、权重和数据均已开源,为聊天机器人市场和 AI 领域的进步做出了贡献。
- 模型局限性:Qwen 的 14B 模型在理解 English 和 Chinese 以外的语言提示词时表现挣扎,正如 prostospichkin 所指出的,它经常产生随机的 Chain of Thought (CoT) 输出而不遵循提示词语言。Peter_Lightblue 强调了在训练 Cebuano 和 Yoruba 等低资源语言模型时面临的挑战,建议需要翻译后的 CoT 来改善结果。
- Prompt Engineering:sebastianmicu24 和 Peter_Lightblue 讨论了对 R1 模型进行高级 Prompt Engineering 的必要性,指出极端措施有时可以产生预期的结果,但理想情况下,模型应该需要更少的操纵。u_3WaD 幽默地反思了礼貌请求的无效性,强调了更强大的模型训练的必要性。
- 资源与开发:Peter_Lightblue 分享了 Hugging Face 上各种模型版本的链接,并提到正在努力训练 8B Llama 模型,但在使用 L20 + Llama Factory 时遇到了技术问题。这突显了社区在提高不同语言模型的可访问性和性能方面的积极参与。
{kind=link}
主题 4. DeepSeek 托管热潮引发 GPU 价格飙升
- 随着人们争相私有化部署 DeepSeek,GPU 价格正在飙升 (Score: 551, Comments: 195): 私有化部署 DeepSeek 的热潮推高了 AWS H100 SXM GPU 的成本,价格在 2025 年初显著飙升。折线图展示了不同可用区的这一趋势,反映了从 2024 年到 2025 年 GPU 价格的广泛上涨。
- 讨论强调了私有化部署 DeepSeek 的可行性和成本,指出完整配置需要大量资源,例如 10 个 H100 GPU,成本约为 30 万美元或 20 美元/小时。用户探索了在高性能 CPU 上本地运行量化模型等替代方案,强调了在没有大量投资的情况下满足性能标准的挑战。
- 对话涉及 GPU 定价动态,用户对成本上升和供应有限表示沮丧。文中将当前的 GPU 价格模式与过去进行了对比,提到了 3090 和 A6000,并对关税影响未来价格表示担忧。一些用户讨论了 Nvidia 股票的潜在影响以及对计算资源的持续需求。
- 存在对 AWS 和“私有化部署 (self-hosting)”术语的质疑,一些用户认为 AWS 提供的隐私性类似于私有化部署,而另一些人则质疑使用云服务作为真正私有化部署方案的实用性。讨论还涵盖了关税和芯片生产的更广泛影响,特别是关于亚利桑那晶圆厂及其对台湾芯片封装的依赖。
- DeepSeek AI 数据库泄露:超过 100 万行日志、密钥泄露 (Score: 182, Comments: 78): DeepSeek AI 数据库遭到破坏,导致超过 100 万行日志和密钥泄露。这次泄露可能会对硬件市场产生重大影响,特别是对于那些使用私有化部署 DeepSeek 模型的用户。
- 这次泄露因其糟糕的实现和缺乏基本安全措施而受到广泛批评,例如 SQL 注入漏洞以及一个在互联网上公开且无需身份验证的 ClickHouse 实例。评论者对 2025 年还会出现如此基础的安全疏忽表示难以置信。
- 讨论强调了本地部署对于隐私和安全的重要性,用户指出了在云端 AI 服务中存储敏感数据的风险。该事件强化了用户对 DeepSeek 等私有化部署模型的偏好,以避免此类漏洞。
- 文章中使用的措辞引发了辩论,一些人建议使用“暴露 (exposed)”而非“泄露 (leaked)”来描述 Wiz 发现的漏洞。一些人对叙事持怀疑态度,声称可能存在偏见或宣传影响。
{kind=link}
主题 5. Mistral 模型进展与评估结果
- Mistral Small 3 知道真相 (Score: 99, Comments: 12): Mistral Small 3 已更新,其中包含一个功能,将其识别 OpenAI 为“营利性公司”,强调了 AI 回答的透明度。提供的图片是一个展示该功能的代码片段,为了清晰起见,采用了简单的美学格式。
- 讨论强调了对 OpenAI 的批评,原因在于其被认为不诚实的营销,而非其营利动机。用户对 OpenAI 与其他提供免费资源或透明度的公司相比的营销方式表示蔑视。
- Mistral 的幽默感和透明度受到用户赞赏,例如 Mistral Small 2409 的提示词展示了他们轻松幽默的方式。这提升了 Mistral 在用户中的受欢迎程度,用户因其模型引人入胜的特性而青睐它们。
- 文中提到了 Hugging Face 上的 Mistral 文档,表明该功能已供有兴趣进一步探索的用户使用。
- Mistral Small 3 24B GGUF 量化评估结果 (Score: 99, Comments: 34):针对 Mistral Small 3 24B GGUF 模型的评估重点关注了低量化水平对模型智能的影响,并区分了静态和动态量化模型。由 bartowski 上传的 lmstudio hf 仓库中的 Q6_K-lmstudio 模型是静态的,而 bartowski 仓库中的其他模型是动态的,相关资源可在 Hugging Face 获取,并使用 Ollama-MMLU-Pro 工具进行了评估。
- 量化水平与性能:用户对比较 Q6_K、Q4_K_L 和 Q8 等不同量化水平表现出浓厚兴趣,并注意到了一些奇特现象,例如 Q6_K 虽然在其他方面表现稍逊,但在“法律”子集中得分很高。由于 Q8 体积巨大(25.05GB)无法放入 24GB 显存的显卡中,因此未对其进行评估,这凸显了测试中的技术限制。
- 测试变异性与方法论:讨论指出测试结果存在变异性,一些用户质疑观察到的差异是否由噪声或随机偶然造成。此外,人们对测试方法论也感到好奇,包括测试重复的频率以及是否排除了猜测成分,以确保数据的可靠性。
- 模型性能异常:用户注意到了一些意想不到的性能结果,例如 Q4 模型 在计算机科学领域的表现优于 Q5/Q6,这表明测试过程或模型架构中可能存在潜在问题或有趣的特性。在 bartowski 第二个仓库的一些模型中使用的 imatrix 选项可能会对这些结果产生影响,从而引发了对这些差异的进一步调查。
{kind=link}
AI Discord 摘要
由 Gemini 2.0 Flash Thinking (gemini-2.0-flash-thinking-exp) 生成的摘要之摘要的摘要
主题 1. OpenAI 的 o3-mini 模型:推理实力与用户访问
- O3 Mini 亮相,评价两极分化:OpenAI 发布用于推理任务的 o3-mini:OpenAI 推出了新的推理模型 o3-mini,可在 ChatGPT 和 API 中使用,目标定位于数学、编程和科学任务。虽然 Pro 用户 享有无限访问权限,Plus & Team 用户 获得了三倍的速率限制,但 免费用户 只能通过“Reason”按钮进行体验,这引发了关于使用配额以及与 o1-mini 等旧模型相比实际性能表现的辩论。
- 小模型,大推理?:O3-Mini 宣称推理能力提升 56%,挑战 o1:O3-mini 被标榜拥有卓越的推理能力,在专家测试中比前代产品提升了 56%,在复杂问题上的重大错误减少了 39%。尽管宣传势头强劲,但在 Latent Space 和 Cursor IDE 等频道的早期用户报告显示 反应不一,一些人发现 o3-mini 在编程任务中的表现不如 Sonnet 3.6 等模型,这引发了对其在现实世界中有效性的质疑,并促使旧款 o1-mini 降价 63%。
- BYOK 阵营率先获得 O3 使用权:OpenRouter 将 o3-mini 限制为 Tier 3+ 的 Key 持有者:OpenRouter 上对 o3-mini 的访问最初仅限于 Tier 3 或更高水平的 BYOK (Bring Your Own Key) 用户,这在更广泛的社区中引起了一些挫败感。此举强调了该模型的高端定位,并引发了关于不同使用层级的开发者获取先进 AI 模型可及性的讨论,免费用户被引导至 ChatGPT 的“Reason”按钮来体验该模型。
主题 2. DeepSeek R1:性能、泄露与硬件需求
- DeepSeek R1 的 1.58-Bit 瘦身计划:Unsloth 将 DeepSeek R1 压缩至 1.58 Bits:得益于 Unsloth AI,DeepSeek R1 现在正以高度压缩的 1.58-bit 动态量化形式运行,为即使在最低配置硬件上进行本地推理打开了大门。社区测试强调了其效率,尽管也指出了其资源密集型的特性,这展示了 Unsloth 推动大规模本地推理普及的努力。
- DeepSeek 数据库泄露机密:网络安全新闻对 DeepSeek 泄露事件敲响警钟:一次 DeepSeek 数据库泄露暴露了密钥、日志和聊天记录,尽管其性能可与 O1 和 R1 等模型媲美,但仍引发了严重的数据安全担忧。这次泄露触发了关于 AI 数据安全和未经授权访问风险的紧急讨论,可能影响用户信任和采用。
- Cerebras 声称 DeepSeek R1 速度提升 57 倍:VentureBeat 冠名 Cerebras 为 DeepSeek R1 最快托管商:Cerebras 声称其晶圆级系统运行 DeepSeek R1-70B 的速度比 Nvidia GPU 快达 57 倍,挑战了 Nvidia 在 AI 硬件领域的统治地位。这一公告引发了关于替代性高性能 AI 托管方案及其对 GPU 市场影响的辩论,特别是在 OpenRouter 和 GPU MODE 等频道中。
主题 3. Aider 和 Cursor 拥抱用于代码生成的新模型
- Aider v0.73.0 展示 O3 Mini 和 OpenRouter 的实力:Aider 0.73.0 发布说明详述 o3-mini 和 R1 支持:Aider v0.73.0 首次支持 o3-mini 和 OpenRouter 的免费 DeepSeek R1,并新增了 –reasoning-effort 参数。用户称赞 O3 Mini 能以比 O1 更低的成本编写功能性的 Rust 代码,同时指出 Aider 自身编写了该版本 69% 的代码,展示了 AI 在软件开发工具中日益增长的作用。
- Cursor IDE 将 DeepSeek R1 与 Sonnet 3.6 配对打造编程利器:Windsurf 推文吹捧 Cursor 中 R1 + Sonnet 3.6 的协同效应:Cursor IDE 集成了 DeepSeek R1 进行推理并配合 Sonnet 3.6 进行编码,声称在 aider polyglot benchmark 中创下了新纪录。这种组合旨在提高解决方案质量并降低成本(相比 O1),在编码 Agent 性能方面树立了新标杆,正如在 Cursor IDE 和 Aider 频道中所讨论的那样。
- Cursor 中的 MCP 工具:可用但功能饥渴:Cursor IDE 讨论中强调 MCP 服务器库:MCP (Model Context Protocol) 工具在 Cursor IDE 中被确认为可用,但用户希望有更强的界面集成和更多突破性的功能。Cursor IDE 和 MCP 频道的讨论显示,社区渴望在编码工作流中更无缝、更强大地利用 MCP 工具,并参考了如 HarshJ23 的 DeepSeek-Claude MCP 服务器等示例。
主题 4. 本地 LLM 生态系统:LM Studio、GPT4All 和硬件之争
- LM Studio 0.3.9 通过 Idle TTL 实现内存优化:LM Studio 0.3.9 博客文章宣布 Idle TTL 及更多功能:LM Studio 0.3.9 引入了用于内存管理的 Idle TTL、运行时的自动更新以及对 Hugging Face 仓库的嵌套文件夹支持,增强了本地 LLM 的管理。用户发现独立的 reasoning_content 字段有助于 DeepSeek API 的兼容性,而 Idle TTL 因其高效的内存利用而受到欢迎,正如 LM Studio 频道中所强调的那样。
- GPT4All 3.8.0 蒸馏 DeepSeek R1 与 Jinja 魔法:GPT4All v3.8.0 发布说明详述 DeepSeek 集成:GPT4All v3.8.0 集成了 DeepSeek-R1-Distill,使用 Jinja 彻底重构了聊天模板,并修复了代码解释器和本地服务器的问题。社区称赞了 DeepSeek 的集成,并注意到模板处理方面的改进,同时也指出了 GPT4All 频道中反馈的 Mac 启动崩溃问题,展示了活跃的开源开发和快速的社区反馈。
- 双 GPU 梦想在 LM Studio 中遭遇 VRAM 现实:LM Studio 的硬件讨论显示用户正在尝试双 GPU 设置(NVIDIA RTX 4080 + Intel UHD),发现 NVIDIA 在 VRAM 满载后会卸载到系统 RAM。发烧友们成功实现了高达 80k tokens 的上下文,但挑战极限会使硬件承压并降低速度,凸显了当前硬件在极端上下文长度下的实际限制。
主题 5. 批判性微调与思维链创新
- Critique Fine-Tuning 宣称比 SFT 提升 4-10%:Critique Fine-Tuning 论文承诺泛化增益:Critique Fine-Tuning (CFT) 作为一种极具前景的技术脱颖而出,通过训练模型对噪声输出进行批判,声称比标准的 Supervised Fine-Tuning (SFT) 提升了 4-10%。Eleuther 频道的讨论辩论了 CE-loss 的有效性,并考虑直接奖励“胜出者”以改善训练结果,这标志着向更细致的训练方法论的转变。
- 非 Token CoT 和回溯向量重塑推理:Eleuther 讨论中探索的全非 Token CoT 概念:一种新颖的全非 Token 思维链 (CoT) 方法为原始潜变量(raw latents)引入了
<scratchpad>token,对每个 prompt 的原始思维潜变量实施限制。研究人员还强调了一个影响 CoT 结构的正“回溯向量”,并使用 sparse autoencoders 证明了其效果,引发了 Eleuther 频道关于探测内部推理结构和为更广泛任务编辑向量的讨论。 - Tülu 3 405B 在基准测试中挑战 GPT-4o 和 DeepSeek v3:Ai2 博客文章宣称 Tülu 3 405B 超越对手:新发布的 Tülu 3 405B 模型声称在特定基准测试中优于 DeepSeek v3 和 GPT-4o,该模型采用了 Reinforcement Learning from Verifiable Rewards。然而,Yannick Kilcher 频道的社区审查质疑其对 DeepSeek v3 的实际领先地位,认为尽管采用了先进的 RL 方法,增益却有限,这促使人们对基准测试方法论和实际性能影响进行更深入的探讨。
PART 1: High level Discord summaries
Codeium (Windsurf) Discord
- Cascade 推出 DeepSeek R1 和 V3:工程师们重点介绍了 DeepSeek-R1 和 V3,每次调用分别消耗 0.5 和 0.25 用户积分,承诺提升编程效率。
- 他们还推出了新的 o3-mini 模型,消耗 1 用户积分,更多细节见 Windsurf Editor Changelogs。
- DeepSeek R1 在压力下表现不佳:用户报告称 DeepSeek R1 反复出现工具调用(tool call)失败和文件读取不完整的问题,降低了其在编程任务中的有效性。
- 一些人建议回退到旧版本,因为最近的修订似乎降低了稳定性。
- O3 Mini 引发褒贬不一的反应:虽然有人称赞 O3 Mini 的代码响应速度更快,但也有人认为其工具调用处理能力太弱。
- 一位参与者将其与 Claude 3.5 进行了比较,指出其在多步操作中的可靠性较低。
- 关于成本与产出的争论持续升温:几位成员质疑 DeepSeek 等模型的费用,指出对于高级用户来说,本地设置可能更便宜。
- 他们认为需要顶级的 GPU 才能获得可靠的本地部署(on-prem)输出,这加剧了关于性能与价格之争的讨论。
- Windsurf 迎来 6K 社区里程碑:Windsurf 的 Reddit 页面关注者突破了 6k,反映出用户参与度的提高。
- 开发团队在最近的推文中进行了庆祝,并将这一里程碑与新公告联系在一起。
Unsloth AI (Daniel Han) Discord
- DeepSeek R1 大胆的 1.58-Bit 技巧:DeepSeek R1 现在可以以 1.58-bit 动态量化形式(671B 参数)运行,如 Unsloth 关于 OpenWebUI 集成的文档所述。
- 在最低限度硬件上的社区测试凸显了一种高效但耗费资源的方法,许多人称赞 Unsloth 处理大规模本地推理的方法。
- Quadro 上的 Qwen2.5:渴望退休的 GPU:一位用户在仅有 5GB VRAM 的 Quadro P2000 上尝试运行 Qwen2.5-0.5B-instruct,开玩笑说它可能要到 2026 年才能运行完。
- 关于 GPU 尖叫着要求休息的评论突显了旧硬件的极限,但也指向了超越典型能力的理念验证。
- 双重麻烦:vLLM 和 Unsloth 中的 XGB 重叠:讨论显示 vLLM 和 Unsloth 都依赖 XGB,存在重复加载和潜在资源过度使用的风险。
- 成员们询问补丁是否能修复 deepseek v2 架构下 gguf 的 offloading 问题,并推测未来的兼容性改进。
- 微调壮举与多 GPU 等待名单:Unsloth 用户辩论了微调大型 LLM 的学习率(e-5 vs e-6),引用了官方检查点指南。
- 他们还对持续缺乏多 GPU 支持表示遗憾,指出 offloading 或额外的 VRAM 可能是短期内唯一的权宜之计。
aider (Paul Gauthier) Discord
- Aider v0.73.0 推出新功能:官方版本引入了对 o3-mini 的支持(使用
aider --model o3-mini),新增了 –reasoning-effort 参数,改进了上下文窗口(context window)处理,并支持自动目录创建,详见 发布历史。- 社区成员报告称,Aider 编写了该版本 69% 的代码,并欢迎 OpenRouter 上通过
--model openrouter/deepseek/deepseek-r1:free提供的 R1 free 支持。
- 社区成员报告称,Aider 编写了该版本 69% 的代码,并欢迎 OpenRouter 上通过
- O3 Mini 抢占老牌模型风头:早期采用者称赞 O3 Mini 能够生成功能完备的 Rust 代码,且成本远低于 O1,如 TestingCatalog 的更新 所示。
- 在看到 O3 Mini 在实际编程任务中交付快速结果并展现出可靠性能后,怀疑论者改变了立场。
- DeepSeek 遇挫,用户寻求修复:多位成员报告 DeepSeek 出现卡顿和空格处理错误,引发了对性能问题的反思。
- 一些人考虑使用本地模型(local model)替代方案,并寻找在 DeepSeek 失效时保持代码稳定的方法。
- Aider 配置获得社区见解:贡献者报告通过设置环境变量而非仅依赖配置文件解决了 API key 检测问题,参考了 高级模型设置。
- 其他人对在保持聊天模式的同时通过文件脚本指挥 Aider 表示出兴趣,表明用户希望有更灵活的工作流选项。
- Linting 和测试在 Aider 中盛行:成员们强调了使用 Aider 内置功能 实时自动进行 lint 和 测试 的能力,并以 Rust 项目作为演示。
- 据称,这种设置能更快发现错误,并鼓励 O3 Mini 及其他集成模型输出更健壮的代码。
Perplexity AI Discord
- O3 Mini 超越 O1:成员们对 O3 Mini 的发布感到兴奋,尤其是其速度,参考了 Kevin Lu 的推文 和 OpenAI 的公告。
- 与 O1 和 R1 的对比突出了其在谜题解决方面的改进,而一些用户对 Perplexity 的模型管理以及仅在免费层提供的“Reason”按钮表示不满。
- DeepSeek 泄露暴露聊天秘密:安全研究人员发现了一个 DeepSeek 数据库泄露,其中暴露了密钥(Secret keys)、日志和聊天历史。
- 尽管许多人将 DeepSeek 视为 O1 或 R1 的替代方案,但此次泄露引发了对数据安全和未经授权访问的紧迫担忧。
- AI 处方法案进入临床阶段:一项提议的 AI 处方法案 旨在强制执行医疗保健 AI 的伦理标准和问责制。
- 该立法解决了围绕 医疗 AI 监管的焦虑,反映了先进系统在患者护理中日益增长的作用。
- 纳德拉在 AI 领域的杰文斯悖论警告:Satya Nadella 警告称,AI 创新可能会消耗更多资源而非缩减规模,这呼应了技术使用中的 杰文斯悖论 (Jevons Paradox)。
- 他的观点引发了关于 O3 Mini 或 DeepSeek 等突破是否会引发算力需求激增的讨论。
- Sonar Reasoning 停留在 80 年代:一位用户注意到 sonar reasoning 调用的详情来自 1982 年 的波托马克河空难,而非最近发生的事故。
- 这突显了在紧急查询中使用过时参考资料的风险,此时模型的历史准确性可能无法满足即时需求。
LM Studio Discord
- LM Studio 0.3.9 势头强劲:全新的 LM Studio 0.3.9 增加了 Idle TTL、运行时的 auto-update 以及 Hugging Face 仓库中的嵌套文件夹,详见 博客。
- 用户发现独立的 reasoning_content 字段在高级用法中非常方便,而 Idle TTL 通过自动卸载空闲模型来节省内存。
- OpenAI 的 o3-mini 发布令用户困惑:OpenAI 推出了用于数学和编程任务的 o3-mini 模型,参考 The Verge 的报道。
- 随后出现了一些混乱,因为部分用户无法免费访问,引发了关于实际可用性和使用限制的疑问。
- DeepSeek 在代码领域表现优于 OpenAI:工程师们称赞 DeepSeek 的速度和强大的编程能力,声称它在实际项目中挑战了 OpenAI 的付费产品。
- OpenAI 的降价被归因于 DeepSeek 的进步,引发了关于本地模型取代云端模型的讨论。
- Qwen2.5 证明了长上下文能力:社区测试发现 Qwen2.5-7B-Instruct-1M 能平滑处理更大的输入,Flash Attention 和 K/V cache quantization 提升了效率。
- 据报道,它在内存占用和准确性方面超过了旧模型,为处理海量文本集的开发者注入了活力。
- 双 GPU 构想与上下文过载:爱好者尝试将 NVIDIA RTX 4080 与 Intel UHD 配对,但发现一旦 VRAM 满载,NVIDIA 就会将负载卸载到系统 RAM。
- 有人成功实现了高达 80k tokens 的上下文,但过度推高上下文长度会使硬件承压并显著降低速度。
Cursor IDE Discord
- DeepSeek R1 + Sonnet 3.6 协同效应:他们将用于详细推理的 R1 与用于编程的 Sonnet 3.6 结合,提升了解决方案的质量。Windsurf 的推文提到了开放推理 Token 以及与编程 Agent 的协同。
- 这种组合在 aider polyglot benchmark 上创下了新纪录,在用户测试中成本低于 O1。
- O3 Mini 评价褒贬不一:一些用户发现 O3 Mini 在某些任务中很有帮助,但另一些人觉得它的性能落后于 Sonnet 3.6。讨论围绕着运行代码更改时需要明确 Prompt 的需求展开。
- Reddit 帖子 强调了失望情绪以及对更新的猜测。
- MCP 工具在 Cursor 中引发讨论:许多人表示 MCP 工具运行良好,但在 Cursor 中需要更强大的界面,参考了 MCP Servers 库。
- 一个例子是 HarshJ23/deepseek-claude-MCP-server,它融合了 R1 推理与 Claude 以供桌面端使用。
- Claude 模型:对下一版本的期待:个人用户期待 Anthropic 的新发布,希望更先进的 Claude 版本能提升编程工作流。一篇 博客文章 预告了 Claude 的网页搜索功能,弥补了静态 LLM 与实时数据之间的差距。
- 社区讨论围绕功能扩展或命名的可能性展开,但官方消息尚待公布。
- 用户体验与安全警报:某些参与者报告了新集成的基于 R1 的解决方案取得了成功,但其他人则面临响应时间慢和结果不一致的问题。
OpenRouter (Alex Atallah) Discord
- o3-mini 强势登场:OpenAI 面向使用等级(usage tiers)3 到 5 的用户发布了 o3-mini,提供更敏锐的推理能力,在专家测试中比其前代产品获得了 56% 的评分提升。
- 该模型拥有 39% 的重大错误减少率,并为精通 STEM 的开发者内置了 function calling 和 structured outputs。
- BYOK 或无缘:密钥访问要求:OpenRouter 将 o3-mini 限制为等级 3 或更高的 BYOK 用户,但这份快速入门指南可帮助进行设置。
- 他们还鼓励免费用户通过点击 ChatGPT 中的 Reason 按钮来测试 o3-mini。
- 模型之战:o1 对阵 DeepSeek R1 以及 GPT-4 的失落:评论者辩论了 o1 和 DeepSeek R1 的性能,一些人称赞 R1 的写作风格优于 GPT-4 “令人失望”的表现。
- 其他人则表达了对 GPT-4 的不满,并引用了关于模型局限性的 Reddit 帖子。
- Cerebras 飞速发展:DeepSeek R1 超越 Nvidia:根据 VentureBeat 的报道,Cerebras 现在运行 DeepSeek R1-70B 的速度比 Nvidia GPU 快 57 倍。
- 这种晶圆级系统挑战了 Nvidia 的主导地位,为大规模 AI 托管提供了一个高性能的替代方案。
- AGI 之争:近在咫尺还是遥远的幻想?:一些人坚持认为 AGI 可能近在眼前,回顾了早期激发 AI 潜力雄心的演示。
- 其他人则保持怀疑,认为通往真正 AGI 的道路仍需要更深层次的突破。
Interconnects (Nathan Lambert) Discord
- OpenAI o3-mini 公开亮相:OpenAI 推出了 o3-mini 系列,具有改进的推理和 function calling 能力,与旧模型相比具有成本优势,如这条推文所述。
- 社区讨论称赞 o3-mini-high 是目前最好的公开可用推理模型,引用了 Kevin Lu 的帖子,而一些用户对 “LLM 抽卡式(gacha)”订阅模式表示不满。
- DeepSeek 的十亿美元数据中心:来自 SemiAnalysis 的新信息显示,DeepSeek 在 HPC 上投资了 13 亿美元,反驳了仅持有 50,000 张 H100 的传闻。
- 社区成员在推理性能方面将 R1 与 o1 进行了比较,强调了对 chain-of-thought 协同效应和巨大基础设施成本的关注。
- Mistral 的巨大惊喜:尽管筹集了 14 亿美元,Mistral 还是发布了一个小型和一个较大型的模型,包括一个 24B 参数版本,令观察者感到惊讶。
- 聊天记录引用了 MistralAI 的发布,称赞了较小模型的效率,并开玩笑说“小”的真正定义。
- K2 Chat 榜上有名:LLM360 发布了一个名为 K2 Chat 的 65B 模型,声称比 Llama 2 70B 减少了 35% 的计算量,如 Hugging Face 所示。
- 该模型于 2024 年 10 月 31 日推出,支持 function calling 并使用 Infinity-Instruct,引发了更多正面交锋的基准测试。
- Altman 的宇宙级 Stargate 支票:根据 OpenAI 的声明,Sam Altman 宣布了由唐纳德·特朗普支持的 5000 亿美元 Stargate 项目。
- 批评者质疑巨额预算,但 Altman 认为这对于扩展超智能 AI 至关重要,引发了关于市场主导地位的辩论。
OpenAI Discord
- O3 Mini 令人困惑的配额:新发布的 O3 Mini 设置了每日 150 条的消息配额,但一些参考资料指向每周 50 条,用户正在讨论这种不匹配。
- 某些声音怀疑这是一个 bug,并评论道 “之前从未正式提到过 50 条消息的限制”,这引发了早期采用者的担忧。
- AMA 预告:Sam Altman 及其团队:即将于 PST 时间下午 2 点举行的 Reddit AMA 将邀请 Sam Altman、Mark Chen 和 Kevin Weil,重点关注 OpenAI o3-mini 和 AI 的未来。
- 社区反响热烈,诸如 “在这里提出你的问题!” 之类的邀请提供了与这些关键人物直接互动的机会。
- DeepSeek 跃入竞争焦点:用户认可 DeepSeek R1 在编程任务中的表现,并将其与主要供应商进行了积极对比,引用了 AI 军备竞赛中的报道。
- 他们赞扬了开源方法在匹配大厂性能方面的表现,认为 DeepSeek 可能会推动更多小型社区驱动模型的采用。
- Vision 模型在地面线条识别上失误:开发者发现 Vision 模型在区分地面和线条时遇到困难,一个月前的日志表明需要进一步改进。
- 一位测试者将其比作 “需要配副新眼镜”,并强调了隐藏的 training data 缺口,这些缺口随着时间的推移可能会修复这些缺陷。
Latent Space Discord
- O3 Mini 正式发布:OpenAI 的 O3 Mini 发布,为 API 级别 3–5 提供 function calling 和 structured outputs,在 ChatGPT 中也可免费使用。
- 出现了新的 价格更新 参考,尽管 O1 降价了 63%,但 O3 Mini 仍以相同的费率推出,突显了竞争的加剧。
- Sonnet 在代码测试中表现优于 O3 Mini:多份报告描述 O3 Mini 在编程提示词上未能达标,而 Sonnet 的最新迭代处理任务更加敏捷。
- 用户强调了 Sonnet 中 更快的错误发现能力,并讨论了 O3 Mini 是否能通过有针对性的 fine-tuning 赶上。
- DeepSeek 引发价格战:在 O3 Mini 发布的消息中,O1 Mini 进行了 63% 的降价,这似乎是受 DeepSeek 日益增长的影响力所推动。
- 爱好者们注意到 AI 领域持续存在的 “美国溢价 (USA premium)”,表明 DeepSeek 成功挑战了传统的成本模型。
- 开源 AI 工具和辅导计划:社区成员推崇 Cline 和 Roocline 等新兴开源工具,重点介绍了付费解决方案的潜在替代方案。
- 他们还讨论了一个拟议的 AI 辅导 课程,该课程借鉴了 boot_camp.ai 等项目,希望通过集体知识为新手赋能。
- DeepSeek API 引发不满:反复的 API key 故障和连接问题困扰着尝试将 DeepSeek 用于生产需求的用户。
- 成员们权衡了备选策略,对依赖一个以稳定性问题著称的 API 表示谨慎。
Yannick Kilcher Discord
- OpenAI 的 o3-mini 取得进展:OpenAI 在 ChatGPT 和 API 中推出了 o3-mini,为 Pro 用户提供无限访问权限,为 Plus & Team 用户提供三倍的速率限制,并允许免费用户通过选择 Reason 按钮进行尝试。
- 成员们报告称推送进度较慢,欧盟的一些用户看到激活较晚,参考了 Parker Rex 的推文。
- FP4 论文为正式发布做准备:社区将研究一种 FP4 技术,该技术通过改进 QKV 处理来解决量化误差,从而承诺提高训练效率。
- 参与者计划提前温习 QKV 基础知识,预见到关于其对大型模型准确性的实际影响会有更深入的提问。
- Tülu 3 巨头挑战 GPT-4o:新发布的 Tülu 3 405B 模型声称在特定基准测试中超越了 DeepSeek v3 和 GPT-4o,Ai2 的博客文章证实了这一点。
- 一些参与者质疑其对 DeepSeek v3 的实际领先地位,指出尽管采用了 Reinforcement Learning from Verifiable Rewards 方法,但收益有限。
- 低成本克隆 DeepSeek R1:由 Jiayi Pan 领导的 Berkeley AI 研究小组以低于 $30 的成本,在 1.5B parameters 规模下复制了 DeepSeek R1-Zero 的复杂推理能力,详见这篇 substack 文章。
- 这一成就引发了关于低成本实验的辩论,许多声音都在庆祝推动 democratized AI(AI 民主化)。
- Qwen 2.5VL 获得敏锐洞察:转向 Qwen 2.5VL 产生了更强的描述能力和对相关特征的关注,提高了网格变换中的模式识别能力。
- 成员们报告称其在连贯性方面优于 Llama,并注意到它在变换过程中更加注重保持原始数据。
Nous Research AI Discord
- Psyche 项目助力去中心化训练:在 #general 频道中,Psyche 项目旨在协调全球闲置硬件的不可信算力进行去中心化训练,参考了这篇关于分布式 LLM 训练的论文。
- 成员们辩论了使用 blockchain 进行验证与更简单的基于服务器的方法,一些人引用了 Teknium 关于 Psyche 的帖子,认为这是一个充满希望的方向。
- 加密货币难题困扰 Nous:#general 中的一些人质疑 crypto 的联系是否会招致诈骗,而另一些人则认为成熟的 blockchain 技术可能有利于分布式训练。
- 参与者将不道德的加密货币骗局与公开股票中的阴暗行为进行了比较,结论是对 blockchain 持谨慎但开放的态度是合适的。
- o3-mini 对阵 Sonnet:意外对决:在 #general 中,开发者承认 o3-mini 在复杂任务上的强劲表现,引用了 Cursor 的推文。
- 他们称赞其流式传输速度更快,编译错误比 Sonnet 更少,但仍有一些人因操作清晰度而忠于旧的 R1 模型。
- CLIP 的自回归冒险:在 #ask-about-llms 中,一位用户询问在 CLIP embeddings 上进行 autoregressive generation 是否可行,并指出 CLIP 通常用于引导 Stable Diffusion。
- 对话提议直接从 CLIP 的 latent space 生成,尽管参与者观察到除了多模态任务之外,几乎没有记录在案的探索。
- DeepSeek 颠覆招聘教条:在 2023 年的一次采访中,Liang Wenfeng 声称经验无关紧要,参考了这篇文章。
- 他支持创造力而非简历,但承认从大型 AI 公司招聘的人员可以帮助实现短期目标。
Stackblitz (Bolt.new) Discord
- 无显著 AI 或融资公告 #1:提供的日志中没有出现重大的新 AI 进展或融资公告。
- 所有提到的细节仅围绕 Supabase、Bolt 和 CORS 的常规调试和配置。
- 无显著 AI 或融资公告 #2:对话集中在关于 token 管理、身份验证和项目删除问题的常规故障排除。
- 除了标准使用指南外,没有提到新模型、数据发布或高级研究。
MCP (Glama) Discord
- MCP 设置提速:成员们讨论了本地与远程 MCP 服务器的对比,并引用 mcp-cli 工具 来解决困惑。
- 他们强调 authentication(身份验证)对远程部署至关重要,并呼吁提供更易用的文档。
- 传输协议对决:一些人称赞 stdio 的简洁性,但指出标准配置缺乏加密。
- 他们权衡了 SSE 与 HTTP POST 的性能,并建议探索替代传输方式以增强安全性。
- Toolbase 认证在 YouTube 演示中亮相:一位开发者在 YouTube 演示中展示了 Claude 的 Toolbase 中的 Notion、Slack 和 GitHub 身份验证。
- 观众建议调整 YouTube playback 或使用 ffmpeg 命令来优化观看体验。
- 日志记录 MCP 服务器保存对话:一位成员介绍了一个用于记录与 Claude 对话日志的 MCP server,分享地址为 GitHub - mtct/journaling_mcp。
- 他们计划添加本地 LLM 以提高隐私性并实现设备端对话存档。
Stability.ai (Stable Diffusion) Discord
- 50 系列 GPU 瞬间售罄:新发布的 50 Series GPUs 在几分钟内从货架上消失,据报道整个北美地区仅出货了几千块。
- 一位用户差点买到 5090,但在商店崩溃时错失了机会,如此截图所示。
- 性能思考:5090 对比 3060:成员们将 5090 与 3060 等旧显卡进行了对比,重点关注游戏基准测试和 VR 潜力。
- 几位用户对极低的库存表示失望,同时仍在权衡新系列是否真的超越了中端 GPU。
- 手机与 AI 的博弈:关于在 Android 上运行 Flux 的辩论爆发了,一位用户计算出生成结果需要 22.3 分钟。
- 一些人称赞手机用于小型任务,而另一些人则强调了减慢 AI 工作负载的硬件限制。
- AI 平台与工具兴起:成员们讨论了用于本地 AI 图像生成的 Webui Forge,并建议使用专门的模型来优化输出。
- 他们强调为每个平台匹配正确的模型,以获得最佳的 Stable Diffusion 性能。
- Stable Diffusion UI 大变动:用户想知道 Stable Diffusion 3.5 是否强制切换到 ComfyUI,因为他们怀念旧版布局。
- 他们承认对 UI 一致性的渴望,但尽管有学习曲线,仍对增量改进表示欢迎。
Eleuther Discord
- 批判微调:优于 SFT:批判微调(CFT)声称通过训练模型批判嘈杂输出,比标准监督微调(SFT)提升了 4–10%,在多个基准测试中表现出更强的结果。
- 社区讨论了 CE-loss 指标是否足够,并建议直接奖励“胜者”以获得更好的结果。
- **完全非 Token CoT 结合
**:一种新的**完全非 Token Chain of Thought** 方法为原始潜变量(raw latents)引入了 ` ` token,并对每个 prompt 的原始思维潜变量施加了强制限制,详情见此 [Overleaf 链接](https://www.overleaf.com/read/krhxtvkxjywb#416acf)。 - 贡献者看到了直接进行行为探测(behavioral probing)的潜力,并指出原始潜变量可能揭示内部推理结构。
- 回溯向量:反向实现更好的推理:研究人员强调了一种改变 chain of thought 结构的“回溯向量”,见 Chris Barber 的推文。
- 他们利用 sparse autoencoders 展示了切换该向量如何影响推理步骤,并提议未来针对更广泛的任务编辑这些向量。
- gsm8k 基准测试困惑:成员们报告了 gsm8k 准确率的不匹配(0.0334 对比 0.1251),其中
gsm8k_cot_llama.yaml与 Llama 2 论文中记录的结果存在偏差。- 他们怀疑差异源于测试框架(harness)设置,建议手动调整 max_new_length 以匹配 Llama 2 报告的指标。
- 随机顺序 AR 模型引发好奇:参与者研究了随机顺序自回归(random order autoregressive)模型,承认它们可能不切实际,但可以揭示训练的结构性方面。
- 他们观察到小数据集中的过度参数化网络可能会捕捉到模式,尽管实际应用价值仍有待商榷。
GPU MODE Discord
- Deep Seek HPC 困境与质疑:技术爱好者对 Deep Seek 声称在 HPC 中使用 50k H100s 的说法提出挑战,并引用了 SemiAnalysis expansions 质疑其官方声明。
- 一些人担心 Nvidia 的股价是否会受到这些言论的影响,社区成员对 Deep Seek 突破背后的“真实成本”表示怀疑。
- GPU 服务器 vs. 笔记本电脑大对决:一位软件架构师在权衡是为 HPC 开发购买一台 GPU server 还是四台 GPU 笔记本电脑,并参考了 The Best GPUs for Deep Learning 指南。
- 其他人强调了中心化服务器在“面向未来”方面的优势,但也指出了 HPC 扩展在前期成本上的差异。
- RTX 5090 与 FP4 的困惑:用户报告称 RTX 5090 上的 FP4 运行速度仅比 4090 上的 FP8 快约 2 倍,这与官方资料中声称的 5 倍不符。
- 怀疑者将其归咎于“不清晰的文档”,并指出可能存在的内存开销,呼吁提供更好的 HPC 基准测试。
- Reasoning Gym 新增数据集:贡献者为 Collaborative Problem-Solving 和 Ethical Reasoning 投放了数据集,参考了 NousResearch/Open-Reasoning-Tasks 和其他 GitHub 项目以扩展 HPC 模拟。
- 他们还讨论了添加 Z3Py 来处理约束,维护者建议提交针对 HPC 友好模块的 pull requests。
- NVIDIA GTC 40% 折扣盛惠:Nvidia 宣布使用代码 GPUMODE 注册 GTC 可享受 40% 折扣,这是参加 HPC 专题会议的好机会。
- 对于 GPU 专业人士来说,这次活动仍然是交流见解和提升 HPC 技能的首选场所。
Nomic.ai (GPT4All) Discord
- GPT4All 3.8.0 发布,集成 DeepSeek 特性:Nomic AI 发布了 GPT4All v3.8.0,完全集成了 DeepSeek-R1-Distill,带来了更好的性能,并解决了之前 DeepSeek-R1 Qwen pretokenizer 的加载问题。此次更新还彻底重构了 chat template parser,扩大了对各种模型的兼容性。
- 来自 主仓库 的贡献者强调了对 code interpreter 和本地服务器的重要修复,并对 Jared Van Bortel、Adam Treat 和 ThiloteE 表示感谢。他们确认系统消息现在会从消息日志中隐藏,以防止 UI 混乱。
- 量化特性引发好奇:社区成员讨论了 K-quants 和 i-quants 之间的区别,参考了 Reddit 概览。他们得出结论,每种方法都适合特定的硬件需求,并建议针对性使用以获得最佳效果。
- 一位用户通过 GitHub Issue #3448 反馈了 GPT4All 3.8.0 在 Mac 上启动崩溃的问题,可能与 Qt 6.5.1 升级到 6.8.1 的更改有关。其他人建议回滚或等待官方修复,并指出平台正在积极开发中。
- GPT4All 暂不支持语音分析:有用户询问关于分析语音相似性的问题,但已确认 GPT4All 缺乏语音模型支持。社区成员建议使用外部工具来处理高级语音相似性任务。
- 一些参与者希望未来能提供支持,而另一些人则认为专门的第三方库仍是短期内的最佳选择。目前没有直接提到 GPT4All 即将推出语音功能。
- Jinja 技巧扩展模板功能:关于 GPT4All 模板的讨论展示了新的 namespaces 和 list slicing,参考了 Jinja 官方文档。此更改旨在减少解析器冲突,并简化复杂模板的用户体验。
- 开发者指出了 google/minja 中的 minja.hpp 以实现更轻量级的 Jinja 集成方案,同时更新了 GPT4All 文档。他们注意到 GPT4All v3.8 的稳定性有所提高,这归功于开源社区的快速合并。
Notebook LM Discord Discord
- NotebookLM 动态:75 美元奖励与远程访谈:2025 年 2 月 6 日,NotebookLM UXR 邀请用户参与远程可用性研究,提供 75 美元或 Google 商品代金券以收集直接的用户反馈。
- 参与者必须通过筛选表单,保持高速互联网连接,并在在线会议中分享见解,以指导即将推出的产品更新。
- 短小精悍:将播客限制在一分钟:社区成员讨论了将播客压缩至一分钟片段的想法,但承认很难严格执行。
- 一些人建议通过修剪文本输入作为权宜之计,这引发了关于短内容在处理详细话题时实用性的辩论。
- 叙述之声:用户渴望 AI 配音:多位参与者寻求 AI 驱动的叙述功能,能够精确阅读脚本,以实现更真实的单人主持演示。
- 其他人警告说这可能与 NotebookLM 更广泛的平台目标相冲突,但对文本转音频(text-to-audio)扩展的热情依然高涨。
- Workspace 烦恼:NotebookLM Plus 集成困惑:一位用户升级到了标准的 Google Workspace 计划,但未能访问 NotebookLM Plus,误以为不需要额外的插件许可。
- 社区回复指向了一个故障排除检查列表,反映出 NotebookLM 入职流程中的说明不够清晰。
Torchtune Discord
- BF16 缓解 GRPO 难题:成员们发现在使用 GRPO 时会出现 显存溢出 (OOM) 错误,归咎于 fp32 中不匹配的内存管理,并引用了 Torchtune 仓库 作为参考。切换到 bf16 解决了一些问题,展示了在资源利用率方面的显著改进,以及与 vLLM 进行推理时的协同效应。
- 他们使用了当前 PPO 方案中的 profiler 来可视化内存需求,一位参与者强调对于大型任务,“bf16 比全量 fp32 是更稳妥的选择”。他们还讨论了在 GRPO 中并行化推理,但在 Hugging Face 生态系统之外面临复杂性。
- 梯度累积故障引发开发者警惕:一个围绕 梯度累积 (Gradient Accumulation) 的已知问题浮出水面,该问题会干扰 DPO 和 PPO 模型的训练,导致损失跟踪不完整。对 Unsloth 修复方案 的引用提出了一种减轻累积期间内存缺陷的方法。
- 一些人推测这些累积错误会影响高级优化器,引发了“对大批量训练中结果一致性的担忧”。开发者对合并稳健的修复方案保持警惕,特别是针对大规模训练中的多步更新。
- DPO 的零损失冲击:异常情况导致 DPO 迅速下降至 0 损失 和 100% 准确率,这记录在一个拉取请求评论中。这种诡异行为在寥寥几步内就会出现,指向了归一化例程中的疏忽。
- 参与者辩论是否“应该以不同方式缩放目标函数”以避免立即收敛。他们得出结论,确保对非填充(non-padding)标记进行精确的损失归一化可能会恢复可靠的指标。
- Torchtune 的多节点进军:开发者推动对 Torchtune 中多节点支持的最终批准,旨在扩展分布式训练能力。此次更新承诺为大规模 LLM 训练提供更广泛的使用场景,并提高在 HPC 环境中的性能。
- 他们质疑了 offload_ops_to_cpu 在多线程中的作用,在合并前进行了额外澄清。对话强调“我们需要全力以赴以保证稳定的多节点运行”,以确保可靠性。
Modular (Mojo 🔥) Discord
- 异构硬件上的 HPC 奔忙:一系列博客文章将 Mojo 吹捧为解决 HPC 资源挑战的语言,并引用了 Modular: Democratizing Compute Part 1 以强调硬件利用率可以降低 GPU 成本的观点。
- 社区成员强调了库之间向后兼容性的重要性,以维持用户满意度并确保 HPC 的平稳过渡。
- DeepSeek 挑战传统计算假设:成员们讨论了 DeepSeek 如何动摇 AI 计算需求,认为改进的硬件优化可能会使大规模基础设施变得不再那么关键。
- 大厂(Big Tech)被描述为正争先恐后地效仿 DeepSeek 的壮举,而一些人则抵制“小规模解决方案可能就足够了”这一观点。
- Mojo 1.0 的等待是值得的:贡献者支持推迟 Mojo 1.0 的发布,以便在更大的集群上进行基准测试,从而确保在微型测试之外赢得广泛的社区信心。
- 他们赞扬了在版本化之前对稳定性的关注,将性能置于仓促发布之上。
- Swift 的异步难题激发了简化希望:Mojo 的设计者注意到 Swift 可能会使异步代码复杂化,这激发了将 Mojo 推向更简单方向的愿望。
- 一些用户阐述了 Swift 方法中的陷阱,影响了 Mojo 开发中对清晰度的广泛追求。
- MAX 让 DeepSeek 部署更直接:通过一个简单的命令
magic run serve --huggingface-repo-id deepseek-ai/DeepSeek-R1-Distill-Llama-8B --weight-path=unsloth/DeepSeek-R1-Distill-Llama-8B-GGUF/DeepSeek-R1-Distill-Llama-8B-Q4_K_M.gguf,只要用户准备好 Ollama 的 gguf 文件,就可以使用 MAX 运行 DeepSeek。- 最近的 论坛指南 和 GitHub issue 展示了 MAX 如何通过演进来改进像 DeepSeek 这样的模型集成。
LlamaIndex Discord
- 三方对谈预告:Arize 与 Groq 联手:与会者参加了与 Arize AI 和 Groq 的见面会,讨论了 Agent 和追踪(tracing),并由 Phoenix by Arize 进行了现场演示。
- 该会议重点展示了 LlamaIndex 的 Agent 能力,从基础的 RAG 到高级操作,详见 Twitter 线程。
- LlamaReport Beta 版展望 2025:LlamaReport 的预览展示了一个早期的 Beta 构建版本,核心重点是为 2025 年生成报告。
- 视频演示 展示了其核心功能并预告了即将推出的特性。
- o3-mini 获得 Day 0 支持:o3-mini 的 Day 0 支持已上线,用户可以通过
pip install -U llama-index-llms-openai进行安装。- Twitter 公告 展示了如何快速上手,强调了简单的设置流程。
- OpenAI O1 引发困惑:OpenAI O1 缺乏完整功能,导致社区对流式传输(streaming)特性和可靠性感到不确定。
- 成员们在 OpenAI 论坛参考 中指出了“奇怪”的流式传输问题,某些功能未能按预期工作。
- LlamaReport 与支付查询隐忧:用户在使用 LlamaReport 时遇到困难,理由是生成输出存在困难以及关于 LLM 集成费用的疑问。
- 尽管在上传论文进行摘要方面取得了一些成功,但许多人指出 Llama-Parse 的费用可能是一个障碍,并指出它在某些条件下可能是免费的。
tinygrad (George Hotz) Discord
- 物理托管,真实收益:一位用户询问了用于企业任务本地 LLM 托管的物理服务器,并引用了来自 Exolabs 的 Mac Minis 作为经过测试的解决方案。
- 他们还讨论了大规模运行大型模型的问题,引发了关于 AI 工作负载硬件方法的简短讨论。
- Tinygrad 的 Kernel 调整与标题调侃:George Hotz 称赞了 tinygrad 的一个“优秀的第一个 PR”,该 PR 优化了 kernel、buffer 和启动维度(launch dimensions)。
- 他建议从
DEFINE_LOCAL中移除 16 以避免重复,小组还调侃了一个很快被修复的 PR 标题小拼写错误。
- 他建议从
Axolotl AI Discord
- Axolotl 转向 bf16 和 8bit LoRa:参与者确认 Axolotl 支持 bf16 作为除 fp32 之外的稳定训练精度,一些人还注意到 Axolotl 仓库 中 8bit LoRa 的潜力。
- 他们发现 bf16 对于长时间运行特别可靠,尽管 8bit fft 能力仍不明确,引发了关于训练效率的进一步讨论。
- Axolotl 中的 Fp8 尝试与困境:成员表示 fp8 在 accelerate 中有实验性支持,但在实践中性能表现不一。
- 有人表示 “我目前不认为我们在研究那个”,强调了与 fp8 相关的不稳定结果,并重申了持续的保留意见。
LLM Agents (Berkeley MOOC) Discord
- 证书待定,热度不减:LLM Agents MOOC 的证书尚未发放,预计很快会公布更多关于要求的细节。
- 成员们感叹 “等待证书的过程太令人兴奋了!”,并期待官方更新。
- Quiz 1 与课程大纲的小插曲:Quiz 1 现在可以在课程大纲页面访问,并提到 Quizzes Archive - LLM Agents MOOC 包含隐藏的正确答案。
- 一些人发现链接缺失或不清晰,促使其他人分享截图并揭示大纲中的“神秘内容”。
OpenInterpreter Discord
- AI 工具预告吸引初学者:爱好者要求对该 AI 工具进行简单直接的解释,寻求对其即将推出的功能的清晰认识。
- 他们专注于为新手提供更直接的方法,强调需要更简单的术语和实际用例。
- Farm Friend 应用热度上升:社区成员展示了新的 Farm Friend 应用程序,强调了其在生态系统中的桌面集成。
- 他们承诺分享后续资源,并预告了更多即将推出的项目以扩展基础设施。
- iOS Shortcuts Patreon 出现:一位用户宣布了一个 Patreon,将提供不同级别的进阶 iOS Shortcuts,包括对 agentic 功能的支持。
- 他们对回归分享过去一年的技术表示热忱,并暗示会有更多深入的内容。
- NVIDIA NIM 与 DeepSeek 联动:一位社区成员探索将 NVIDIA NIM 接入 DeepSeek,以便与 open interpreter 直接连接。
- 他们征求了关于桥接这些组件的技术建议,寻求关于安装和协同作用的见解。
Cohere Discord
- Cohere 的 422 难题:一位用户在使用带有有效参数的 Cohere Embed API v2.0 时遇到了 HTTP 422 Unprocessable Entity 错误,提示需要仔细检查请求格式。
- 他们分享了官方文档作为参考,并报告没有立即的修复方案,暗示可能是 payload 结构有问题。
- 跨语言 Embedding 的热情:同一位用户希望使用 embed-multilingual-v3.0 模型来研究跨语言极化,指向了 Cohere/wikipedia-2023-11-embed-multilingual-v3 数据集。
- 他们询问了关于预处理杂乱、冗长文本的问题,旨在研究中获得更稳健的多语言 embeddings。
LAION Discord
- 无重大更新:对话中未出现值得注意的讨论或新的技术细节。
- 仅有一些提及和简短的“Ty”,没有为 AI 工程师提供进一步的背景信息。
- 缺乏技术内容:交流中未涉及新的工具、模型或数据集。
- 这使得没有额外的见解或资源可供报告。
DSPy Discord
- 没有
http_client?在 dspy.LM 中没问题!: 成员们发现 dspy.LM 中缺少http_client参数,这在配置自定义 SSL 或代理时引发了困惑。- 他们参考了
gpt3.py中使用的http_client: Optional[httpx.Client] = None,建议为 dspy.LM 增加类似功能。
- 他们参考了
- dspy.LM 的自定义客户端引起关注: 开发者们询问如何在 dspy.LM 中复制 gpt3.py 的自定义客户端设置,以满足高级网络需求。
- 他们提议借鉴 OpenAI 和
gpt3.py的代码作为参考模型,鼓励在 dspy 架构内进行进一步实验。
- 他们提议借鉴 OpenAI 和
MLOps @Chipro Discord 没有新消息。如果该社区长期沉寂,请告知我们,我们将将其移除。
Mozilla AI Discord 没有新消息。如果该社区长期沉寂,请告知我们,我们将将其移除。
HuggingFace Discord 没有新消息。如果该社区长期沉寂,请告知我们,我们将将其移除。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该社区长期沉寂,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该社区长期沉寂,请告知我们,我们将将其移除。
PART 2: Detailed by-Channel summaries and links
完整的频道细分内容已在邮件中截断。
如果您喜欢 AInews,请分享给朋友!预先感谢!