ainews-openai-takes-on-geminis-deep-research
OpenAI 对标 Gemini 的 Deep Research。
OpenAI 发布了 o3 智能体的完整版本,其全新的 Deep Research 变体在 HLE 基准测试中表现出显著提升,并在 GAIA 上达到了业界领先(SOTA)水平。此次发布包含一张展示严谨研究的“推理时间扩展”(inference time scaling)图表,尽管公开测试集的结果引发了一些争议。
该智能体被评价为“极其简单”,目前每月限额 100 次查询,并计划推出更高频率的版本。外界反响总体积极,但也存在部分质疑。此外,强化学习领域的进展也备受瞩目,其中包括一种名为“预算强制”(budget forcing)的简单测试时扩展技术,该技术使数学竞赛的推理表现提升了 27%。
来自 Google DeepMind、纽约大学(NYU)、加州大学伯克利分校(UC Berkeley)和香港大学(HKU)的研究人员共同参与了这些研究。原 Gemini Deep Research 团队也将参加即将举行的 AI Engineer NYC 活动。
o3 和 tools 就是你所需要的一切。
2025年1月31日至2月3日的 AI 新闻。我们为你检查了 7 个 subreddits、433 个 Twitter 账号 和 34 个 Discord(225 个频道和 16942 条消息)。预计为你节省了阅读时间(以 200wpm 计算):1721 分钟。你现在可以标记 @smol_ai 进行 AINews 讨论!
在介绍 Operator(我们的报道在此)时,sama 暗示了更多 OpenAI Agents 即将推出,但很少有人预料到下一个会在 9 天后发布,而且还是在美东时间周日从日本发布的:
https://www.youtube.com/watch?v=YkCDVn3_wiw
这篇 blogpost 提供了更多关于预期用例的见解,但值得注意的是 Deep Research 在 Dan Hendrycks 的新 HLE benchmark 上的结果,比上周五发布的 o3-mini-high 的结果翻了一倍多(我们的报道在此)。

他们还发布了在 GAIA 上的 SOTA 结果——这遭到了共同作者的批评,因为他们只发布了公开测试集的结果——对于一个可以浏览网页的 Agent 来说,这显然是有问题的,尽管没有理由质疑其完整性,特别是在脚注中已确认且 GAIA 测试轨迹样本已发布的情况下。
OAIDR 附带了其自身版本的 “inference time scaling” 图表,非常令人印象深刻——令人印象深刻的不是图表本身的缩放,而是在研究过程中表现出的严谨性,使得生成这样的图表成为可能(当然,假设这是 research 而非 marketing,但在这里,为了推销每月 200 美元的订阅,两者的界限不幸地变得模糊了)。
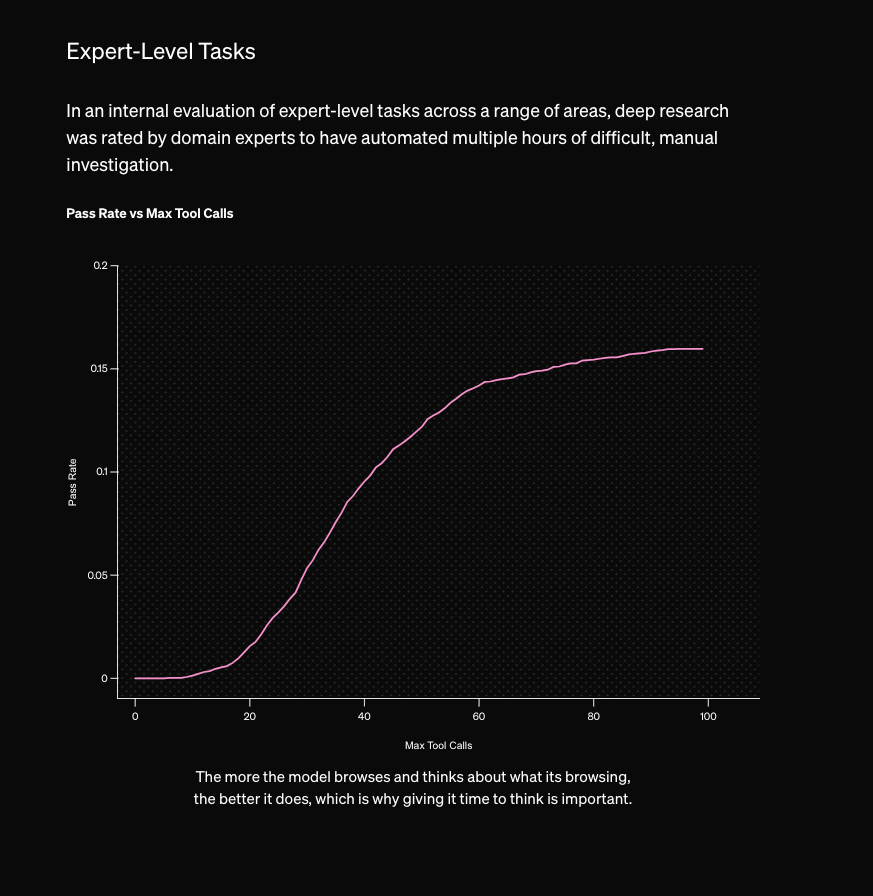
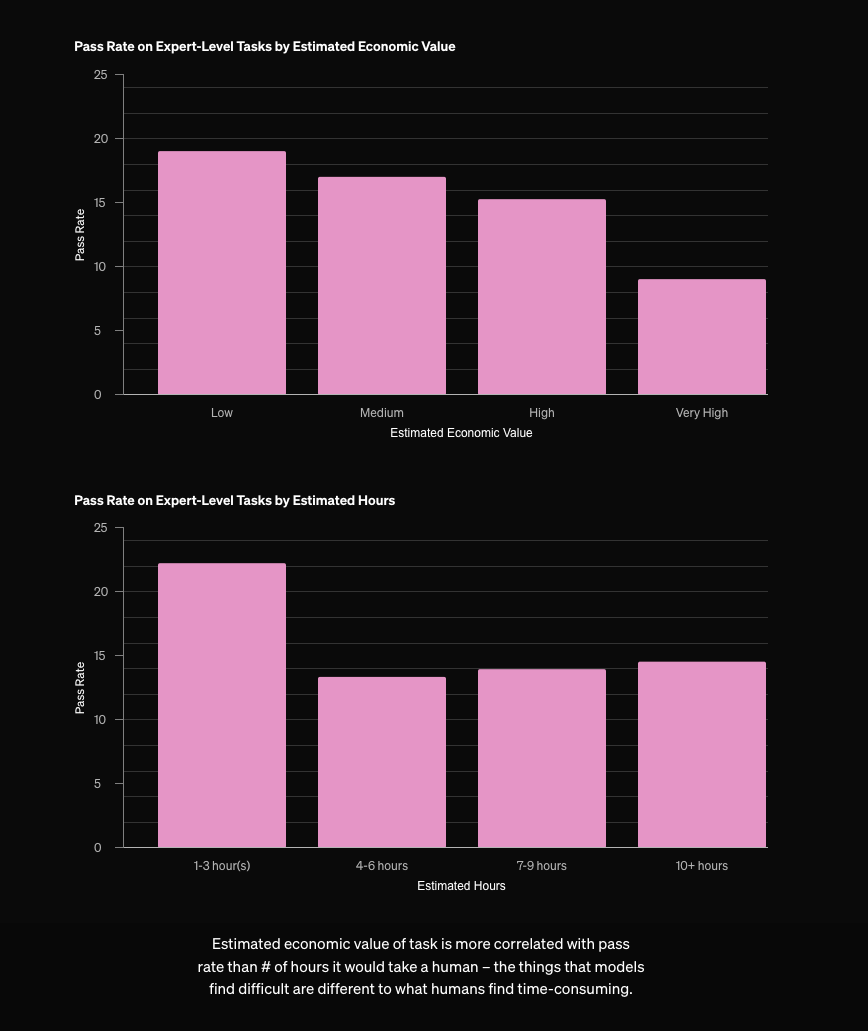
OpenAI 员工确认这是 full o3 首次在野外发布(gdb 说它是一个“极其简单的 agent”),blogpost 指出 “o3-deep-research-mini” 版本正在路上,它将提高目前每月 100 次查询的速率限制。
反响大多是积极的,有时甚至到了过度兴奋的程度。有些人正在嘲笑这种夸张,但总的来说,我们倾向于同意 Ethan Mollick 和 Dan Shipper 的积极看法,尽管我们也经历了很多失败。
厚脸皮的广告:我们将于 2 月 20 日至 22 日在 AI Engineer NYC 邀请多位 Deep Research 和其他 Agent 构建者,包括原 Gemini Deep Research 团队。最后一次申请机会!
AI Twitter 回顾
强化学习 (RL) 和 AI 研究的进展
-
强化学习的简化及其对 AI 的影响:@andersonbcdefg 改变了主意,现在认为 RL 很简单,反映了 RL 技术在 AI 研究中的可及性。
-
s1:AI 模型中简单的 Test-Time Scaling:@iScienceLuvr 分享了一篇关于 s1 的论文,证明仅在 1,000 个样本上进行 next-token prediction 训练,并通过一种名为 budget forcing 的简单 test-time 技术控制思考时间,就能产生强大的推理模型。该模型在竞赛数学题上的表现比之前的模型高出多达 27%。更多讨论可以在这里和这里找到。
-
RL 提升模型对新任务的适应能力:来自 Google DeepMind、NYU、UC Berkeley 和 HKU 的研究人员发现,强化学习(RL)提高了模型对新的、未见过的任务变体的适应能力,而监督微调(supervised fine-tuning)虽然会导致记忆化,但对于模型稳定仍然至关重要。
-
对 DeepSeek r1 的评述及 s1 的引入:@Muennighoff 介绍了 s1,它仅通过 1K 个高质量示例和简单的测试时干预(test-time intervention),就复现了 o1-preview 的缩放(scaling)和性能,解决了 DeepSeek r1 的数据密集型问题。
OpenAI 的 Deep Research 与推理模型
-
OpenAI Deep Research 助手发布:@OpenAI 宣布 Deep Research 现已向所有 Pro 用户开放,为复杂的知识任务提供强大的 AI 工具。@nickaturley 强调了其通用用途以及改变工作、家庭和学校任务的潜力。
-
测试时缩放效率(Test-Time Scaling Efficiency)的提升:@percyliang 强调了仅使用 1K 个精心挑选的示例实现测试时缩放效率的重要性,鼓励开发能提高单位预算能力的方法。
-
初窥 OpenAI o3 的能力:@BorisMPower 对 o3 的能力表示兴奋,指出它在节省资金和减少对专家分析依赖方面的潜力。
Qwen 模型进展与 AI 技术突破
-
R1-V:增强视觉语言模型(Vision Language Models)的超强泛化能力:@_akhaliq 分享了 R1-V 的发布,展示了一个 2B 模型在仅 100 个训练步数内,就能在分布外(out-of-distribution)测试中超越 72B 模型。该模型显著提升了长上下文和关键信息检索的性能。
-
Qwen2.5-Max 在 Chatbot Arena 中的强劲表现:@Alibaba_Qwen 宣布 Qwen2.5-Max 目前在 Chatbot Arena 中排名 第 7,超越了 DeepSeek V3、o1-mini 和 Claude-3.5-Sonnet。它在数学和编程方面排名第 1,在困难提示词(hard prompts)方面排名第 2。
-
s1 模型超越 o1-Preview:@arankomatsuzaki 指出,s1-32B 在基于 Qwen2.5-32B-Instruct 进行监督微调后,在竞赛数学题上超越 o1-preview 高达 27%。该模型、数据和代码已向社区开源。
AI 安全与防御越狱(Jailbreaks)
-
Anthropic 针对通用越狱的宪法分类器(Constitutional Classifiers):@iScienceLuvr 讨论了 Anthropic 引入的宪法分类器,这是基于合成数据训练的防护措施,旨在防止通用越狱。超过 3,000 小时的红队测试(red teaming)显示,没有任何成功的攻击能从受保护的模型中提取详细信息。
-
Anthropic 测试新安全技术的演示:@skirano 宣布了 Anthropic 的一项新研究预览,邀请用户尝试越狱其受宪法分类器保护的系统,旨在增强 AI 安全措施。
-
关于 AI 模型幻觉(Hallucination)的讨论:@OfirPress 分享了对 AI 模型幻觉的担忧,强调即使在像 OpenAI Deep Research 这样先进的系统中,这仍然是一个重大问题。
面向开发者的 AI 工具与平台
-
用于 Vibe Coding 的 SWE Arena 发布:@terryyuezhuo 发布了 SWE Arena,一个 vibe coding 平台,支持实时代码执行和渲染,涵盖了各种前沿 LLM 和 VLM。@_akhaliq 也强调了 SWE Arena,并指出了其令人印象深刻的能力。
-
Perplexity AI 助手的增强:@AravSrinivas 介绍了 Perplexity Assistant 的更新,鼓励用户在 Nothing phone 等新设备上尝试,并提到了即将推出的功能,如集成到 Android Auto。他还宣布带有网页搜索和推理链(reasoning traces)的 o3-mini 已向所有 Perplexity 用户开放,Pro 用户每天可使用 500 次(推文链接)。
-
Llama 开发工具的进展:@ggerganov 宣布 llama.vscode 的安装量已超过 1000 次,提升了基于 llama 模型开发的体验。他在此分享了一个快乐的 llama.cpp 用户是什么样子的。
梗与幽默
-
对 AI 研究和命名能力的观察:@jeremyphoward 幽默地指出,一个人不可能既是强大的 AI 研究员又擅长给事物命名,并称这是所有已知文化中的普遍事实。
-
对天赋的代际反思:@willdepue 评论道,Gen Z 要么是极具天赋的个人,要么是“完全的废人”,他将这种两极分化归因于互联网,并预见 AI 将加速这一趋势。
-
对界面设计的幽默看法:@jeremyphoward 调侃说他的主屏幕上只有 5 个 Grok 图标,并建议可以放更多,以此幽默地调侃技术设计。
-
快乐的 llama.cpp 用户:@ggerganov 分享了一张描绘快乐的 llama.cpp 用户样子的图片,为 AI 社区增添了一抹轻松的色彩。
AI Reddit 摘要
/r/LocalLlama 摘要
主题 1. AI 模型硬件的范式转移:从 GPU 到 CPU+RAM
- 范式转移? (得分: 532, 评论: 159):该帖子暗示了 AI 模型处理可能从以 GPU 为中心的方法转向 CPU+RAM 配置的范式转移,特别强调了 AMD EPYC 处理器和内存模块的使用。这种转变通过对比图像生动地展示:一个人拒绝 GPU 而认可 CPU+RAM 设置,表明 AI 计算的硬件偏好可能发生变化。
- CPU+RAM 的可行性:转向 AMD EPYC 处理器和海量内存配置被认为对个人用户具有性价比,但对于服务多用户而言,GPU 仍然是首选。构建 EPYC 系统的成本显著更高,估计在 $5k 到 $15k 之间,且性能通常比 GPU 配置慢。
- 性能与配置:讨论焦点在于优化配置,例如使用双路 12 通道系统并确保插满所有内存插槽以获得最佳性能。一些用户报告在特定模型上达到了 5.4 tokens/second,而另一些用户则指出 I/O 瓶颈和未利用所有核心会影响性能。
- 潜在突破与 MoE 模型:讨论还涉及了 Mixture of Experts (MoE) 模型的潜力,这可能允许直接从高速 NVMe 存储读取 LLM 权重,从而减少激活参数。这可能会改变当前的硬件需求,但此类进展的可行性和时间表仍不确定。
{kind=link}
主题 2. Mistral、Qwen 和 DeepSeek 在美国境外的崛起
- Mistral, Qwen, Deepseek (得分: 334, 评论: 114):Mistral AI、Qwen 和 DeepSeek 等非美国公司正在发布开源模型,与美国同类模型相比,这些模型更易获取且体积更小。这凸显了一个趋势,即国际公司在向公众普及 AI 技术方面处于领先地位。
- Mistral 3 small 24B 模型获得了积极反馈,多位用户强调了其有效性和易用性。Qwen 因其多样的模型尺寸而受到关注,与 Meta 的 Llama 模型相比,它在不同硬件上提供了更多的灵活性和可用性,而后者因尺寸选择有限和专有许可而受到批评。
- 关于美国与国际 AI 模型的讨论显示出对美国当前产品的怀疑,一些用户更青睐来自中国等地的国际模型,因为它们的开源性质和极具竞争力的性能。Meta 被提及开启了权重开放(open weights)趋势,但用户对其依赖大模型和专有许可表示担忧。
- 关于公司保持 AI 模型权重开放或封闭的战略利益存在争论。一些人认为领先公司保持权重封闭以维持竞争优势,而挑战者则发布开放权重以削弱这些领导者。预计 Meta 的 Llama 4 将整合 DeepSeek R1 的创新以保持竞争力。
主题 3. Phi 4 模型在资源受限硬件上受到关注
- Phi 4 被严重低估了 (Score: 207, Comments: 84): 作者赞扬了 Phi 4 模型 (Q8, Unsloth 变体) 在有限硬件(如 M4 Mac mini (24 GB RAM))上的表现,认为它在常识问题和编程提示词等任务上可与 GPT 3.5 媲美。作者对其能力表示满意,并不关心正式的基准测试(benchmarks),强调个人体验优于技术指标。
- Phi 4 的优势与局限性: 用户称赞 Phi 4 在特定领域(如知识库和规则遵循)的强劲表现,在指令遵循方面甚至优于更大的模型。然而,它在小语种方面表现不佳,在非英语环境下输出质量较差,且缺乏 128k context version,这限制了它与 Phi-3 相比的潜力。
- 用户体验与实现: 许多用户分享了在各种工作流中使用 Phi 4 的积极体验,强调了它在提示词增强和创意基准测试(如鸡尾酒创作)等任务中的多功能性和有效性。然而,一些用户报告在特定任务(如工单分类)中效果不佳,而 Llama 3.3 和 Gemma2 等其他模型在这些任务中表现更好。
- 工具与工作流集成: 讨论包括在自定义设置(如 Roland 和 WilmerAI)中使用 Phi 4,通过将其与 Mistral Small 3 和 Qwen2.5 Instruct 等其他模型结合来增强问题解决能力。社区还探索了 n8n 和 omniflow 等工作流应用,以便将 Phi 4 集成到更广泛的 AI 系统中,并提供了详细设置和工具的链接 (WilmerAI GitHub)。
主题 4. DeepSeek-R1 在复杂问题解决中的能力
- DeepSeek-R1 永不松懈… (Score: 133, Comments: 30): DeepSeek-R1 模型通过解决一个涉及回文数的数学问题展示了自我纠错能力,最初犯了错误,但在完成回答之前自行纠正了。值得注意的是,OpenAI o1 是唯一解决该问题的其他模型,而包括 chatgpt-4o-latest-20241120 和 claude-3-5-sonnet-20241022 在内的其他几个模型都失败了,这引发了关于 tokenizers、采样参数或非思考型 LLM 固有数学能力的潜在问题的讨论。
- 讨论强调了 LLM 的自我纠错能力,特别是在 zero-shot 设置下。这种能力源于模型接触到的训练数据中包含错误被纠正的情况(例如在 Stack Overflow 等平台上),从而影响后续的 token 预测以纠正错误。
- DeepSeek-R1 以及 Mistral Large 2.1 和 Gemini Thinking on AI Studio 等其他模型成功解决了回文数问题,同时探讨了Chain-of-Thought (CoT) 模型。CoT 模型与非 CoT 模型形成了对比,后者由于训练范式不同,通常难以在回答过程中纠正错误。
- 对话深入探讨了代际模型(如 gen1, gen1.5, gen2)之间训练数据的根本差异,以及这些差异对纠错能力的影响。有建议认为,将模型输出作为用户输入进行验证可能有助于解决这些挑战。
其他 AI Subreddit 回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
主题 1. DeepSeek 与深度研究:颠覆性的 AI 挑战
- Deep Research Replicated Within 12 Hours (Score: 746, Comments: 93): 该帖子重点介绍了 Ashutosh Shrivastava 的推文,内容关于在 12 小时内快速创建了 “Open DeepResearch” —— 这是 OpenAI Deep Research Agent 的对应版本。它包含的代码片段可以通过针对性的网络搜索和 URL 访问,通过检查估值、增长和采用率指标来比较 Cohere、Jina AI 和 Voyage 等 AI 公司。
- 许多评论者认为 OpenAI 的 Deep Research 更胜一筹,因为它使用了强化学习 (RL),这使其能够自主学习复杂任务的策略,而其他缺乏此功能的模型则不然。Was_der_Fall_ist 强调,如果没有 RL,像 “Open DeepResearch” 这样的工具只是复杂的 Prompt,而不是真正的 Agent,可能会导致脆弱性和不可靠性。
- 讨论强调了不仅要关注模型,还要关注围绕它们的工具和应用,正如 frivolousfidget 所指出的。他们认为,通过创新性地使用现有模型,而不是仅仅通过模型改进,可以实现显著的能力提升,并引用了 AutoGPT 和 LangChain 等例子。
- GitHub 链接以及关于模型成本和可访问性的讨论强调了与 OpenAI 等顶尖解决方案竞争的财务障碍。YakFull8300 提供了一个 GitHub 链接 以供进一步探索,而其他人则讨论了与高级 AI 模型训练和部署相关的昂贵成本。
- DeepSeek might not be as disruptive as claimed, firm reportedly has 50,000 Nvidia GPUs and spent $1.6 billion on buildouts (Score: 535, Comments: 157): 据报道,DeepSeek 拥有 50,000 块 Nvidia GPU,并在基础设施建设上投资了 16 亿美元,这引发了对其声称的在 AI 行业具有颠覆性影响的质疑。其投资规模表明了巨大的计算能力,但人们对其技术进步是否与其资金投入相匹配持怀疑态度。
- 讨论中充满了对 DeepSeek 主张 的怀疑,一些用户质疑其报告的成本和 GPU 使用情况的真实性。DeepSeek 的论文 清楚地阐述了训练成本,但许多人认为媒体误读了这些数字,导致了对其实际支出的误导和混乱。
- 关于 DeepSeek 的开源模型 是否代表了 AI 领域的重大进步存在争议,一些人认为它挑战了美国在 AI 发展中的主导地位。批评者认为,西方媒体和恐华症 (sinophobia) 促成了 DeepSeek 的成就被夸大或误导的说法。
- DeepSeek 发布公告带来的财务影响(如 Nvidia 股价下跌 17%)是一个焦点,用户注意到了这对 AI 硬件市场的更广泛影响。一些用户认为,DeepSeek 模型的开源性质允许具有成本效益的 AI 开发,有可能使 AI 技术的获取变得民主化。
- EU and UK waiting for Sora, Operator and Deep Research (Score: 110, Comments: 23): 帖子提到 EU 和 UK 正在等待 Sora、Operator 和 Deep Research 工具,但未提供更多细节或背景。配图描绘了一个处于各种沉思姿态的男人,暗示了反思与孤独的主题,但与帖子主题缺乏直接关联。
- 可用性与定价担忧:用户对 Sora 在 UK 和 EU 的延迟上线表示沮丧,推测延迟是由于 OpenAI 自身原因还是政府监管。一些人对每月支付 $200 的服务费用持怀疑态度,还有传言称下周可能会面向 Plus tier 发布,但对其时间表仍存疑。
- 性能与实用性:一位用户分享了该工具的正面体验,指出它在 14 分钟 内生成了一份带有 LaTeX 格式 APA citations 的 10 页文献综述。这突显了该工具在处理复杂任务时令人印象深刻的能力和效率。
- 监管与运营见解:有推测认为,延迟可能是 OpenAI 影响政策制定者的战略举措,或者是由于资源分配问题,特别是在处理 Republic of Ireland 的用户活动方面。讨论表明,监管过程理想情况下应增强模型安全性,并将 OpenAI 的延迟与其他能在 UK 和 EU 实现同步首发的 AI 公司进行了对比。
{kind=link}
{kind=link}
Theme 2. OpenAI’s New Hardware Initiatives with Jony Ive
- Open Ai is developing hardware to replace smartphones (Score: 279, Comments: 100): 据报道,OpenAI 正在开发一种旨在取代智能手机的新型 AI device,正如 CEO Sam Altman 所宣布的那样。来自 Nikkei(2025 年 2 月 3 日)的新闻文章还提到了 Altman 试图通过生成式 AI 转型 IT 行业的野心,以及他即将与日本首相的会面。
- OpenAI 的 AI 硬件野心:Sam Altman 宣布了针对 AI 专用硬件和芯片的计划,这可能会像 2007 年 iPhone 发布一样颠覆科技硬件行业。他们计划与 Jony Ive 合作,将“语音”界面作为核心功能,原型预计将在“几年内”问世(Nikkei 来源)。
- 对取代智能手机的怀疑:许多评论者对取代智能手机的可行性表示怀疑,强调了屏幕在视频和阅读方面的持久用途。他们对将“语音”作为主要交互界面表示怀疑,质疑它如何能取代智能手机的视觉和交互元素。
- 新兴 AI 助手:Gemini 被视为 Google Assistant 日益强大的竞争对手,它已集成到 Samsung 设备中,并可在 Android OS 中被选为首选助手。Gemini 向 Google Home 和 Nest 设备的潜在扩展正处于 beta 阶段,预示着 AI 助手技术的转变。
- Breaking News: OpenAI will develop AI-specific hardware, CEO Sam Altman says (Score: 138, Comments: 29): OpenAI 计划开发 AI-specific hardware,正如 CEO Sam Altman 所宣布的那样。这一战略举措标志着在增强 AI 能力和基础设施方面迈出了重要一步。
- 闭源担忧:用户对 OpenAI 举措的开放性持怀疑态度,指出“Open” AI 开发闭源软件和硬件具有讽刺意味。这反映了公众对 AI 开发透明度和可访问性的广泛关注。
- 与 Jony Ive 的合作:与 Jony Ive 的合作被视为一项战略举措,可能导致自 2007 iPhone launch 以来最大的科技硬件变革。重点是创建一种利用 AI 进步来增强用户交互的新型硬件。
- 定制 AI 芯片:OpenAI 正在致力于开发自己的半导体,加入 Apple, Google, and Amazon 等大型科技公司的行列。这一举措是定制芯片大趋势的一部分,旨在提高 AI 性能,原型预计将在“几年内”推出,并强调语音功能。
{kind=link}
Theme 3. Critique on AI Outperforming Human Expertise Claims
- 指数级进步 - AI 现在在各自领域超越了人类博士专家 (得分: 176, 评论: 86): 该帖子讨论了一张名为 “Performance on GPQA Diamond” 的图表,该图表比较了人类博士专家与 AI 模型 GPT-3.5 Turbo 及 GPT-4o 随时间变化的准确率。图表显示 AI 模型呈上升趋势,在 2023 年 7 月至 2025 年 1 月期间,其准确率在 0.2 到 0.9 之间,已超越了各自领域的专家。
- AI 的局限性与误导性主张:评论者认为,虽然 AI 模型擅长模式识别和数据检索,但并不具备真正的推理或科学发现能力(如治愈癌症)。他们强调,AI 在特定测试中超越博士并不等同于在实际、现实世界的问题解决中超越人类专业知识。
- 对指数级提升主张的批评:AI 模型呈指数级提升的观点被批评为具有误导性,一位评论者将其比作一种偏见指标,不能真实反映人类专业知识的复杂性和深度。讨论强调,虽然 AI 在理论知识方面表现出色,但缺乏进行实验和做出新发现的能力。
- 对 AI 专业能力的怀疑:许多人对 AI 在没有专家指导的情况下提供博士级见解的能力表示怀疑,将 AI 比作高级搜索引擎而非真正的专家。人们对 AI 模型已超越博士的说法表示担忧,认为这些说法更多归因于营销而非实际能力。
- Stability AI 创始人:”我们显然处于智能起飞情景中” (得分: 127, 评论: 122): Stability AI 创始人 Emad Mostaque 断言,我们正处于“智能起飞情景(intelligence takeoff scenario)”中,机器很快将在数字知识任务上超越人类。他强调需要超越对 AGI 和 ASI 的讨论,预测机器效率、成本效益和协调能力的提升,同时敦促考虑这些进步的影响。
- 许多评论者对 AI 即将取代人类表示怀疑,并举例说明了使用 o3-mini 和 o1 pro 等 AI 模型生成简单代码任务时面临的挑战。RingDigaDing 等人认为,尽管基准测试显示 AI 接近 AGI,但在现实场景的可靠性和实际应用方面仍面临困难。
- IDefendWaffles 和 mulligan_sullivan 讨论了 AI 炒作背后的动机,提到了投资利益以及关于 AGI 即将到来的主张缺乏事实证据。他们强调需要有根据的论点,并指出当前 AI 能力与未来投机性 AI 进步之间的区别。
- 用户如 whtevn 和 traumfisch 讨论了 AI 增强人类工作的潜力,whtevn 分享了使用 AI 作为开发助手的经验。他们强调 AI 能够高效执行任务(尽管仍需人类监督),以及 AI 逐渐而非瞬间改变行业的潜力。
{kind=link}
{kind=link}
AI Discord 摘要
由 Gemini 2.0 Flash Thinking (gemini-2.0-flash-thinking-exp) 生成的摘要之摘要
主题 1. DeepSeek AI 的崛起与监管审查
- DeepSeek 模型抢尽风头,表现超越西方巨头:中国的 DeepSeek AI 模型目前在基准测试中表现优于 OpenAI 和 Anthropic 等西方竞争对手,引发了全球关于 AI 霸权的讨论。DeepSeek AI 主导西方基准测试。这一性能飞跃促使美国采取立法行动,限制与中国 AI 研究的合作,以保护国家创新。
- DeepSeek 安全护盾破碎,引发越狱狂潮:Cisco 的研究人员发现 DeepSeek R1 模型未能通过 100% 的安全测试,无法阻止有害提示词。DeepSeek R1 性能问题。用户还报告了服务器访问困难的问题,尽管其基准测试表现出色,但其实际应用的可靠性仍存疑。
- 美国立法者拔剑相向,针对 DeepSeek 提出严厉法案:参议员 Josh Hawley 提出立法以遏制美国与中国的 AI 合作,专门针对 DeepSeek 等模型。AI 监管面临新的立法推动。该法案建议对违规行为处以最高 20 年的监禁,引发了人们对扼杀开源 AI 创新和可访问性的担忧。
主题 2. OpenAI 的 o3-mini:性能与公众审视
- o3-mini AMA:Altman 与 Chen 面对关于新模型的质疑:OpenAI 安排了一场由 Sam Altman 和 Mark Chen 主持的 AMA(问我任何事)活动,以回应社区关于 o3-mini 的疑问。OpenAI 安排 o3-mini AMA。用户正通过 Reddit 提交问题,渴望了解未来发展并提供关于该模型的反馈。
- o3-mini 的推理能力受到质疑,Sonnet 依然称王:用户反映 o3-mini 在编程任务中的表现褒贬不一,理由是速度较慢且解决方案不完整。o3-mini 面临性能批评。Claude 3.5 Sonnet 仍然是许多开发者的首选,因为它具有一致的可靠性和速度,特别是在处理复杂代码库时。
- o3-mini 发布 “Deep Research” Agent,但疑虑尚存:OpenAI 推出了 Deep Research,这是一款由 o3-mini 驱动的新型 Agent,旨在进行自主信息综合和报告生成。OpenAI 发布 Deep Research Agent。尽管前景看好,但用户已经注意到其在输出质量和来源分析方面的局限性,一些人发现 Gemini Deep Research 在综合任务中更有效。
主题 3. AI 工具与 IDE:变革之风
- Windsurf 1.2.5 补丁:Cascade 获得 Web 超能力,DeepSeek 仍存在 Bug:Codeium 发布了 Windsurf 1.2.5 补丁,通过自动触发器和 @web、@docs 等新命令增强了 Cascade web search。Windsurf 1.2.5 补丁更新发布。然而,用户报告在 Windsurf 中使用 DeepSeek 模型 时存在持续性问题,包括无效的工具调用和上下文丢失,从而影响了额度使用。
- Aider v0.73.0:适配 o3-mini,推理增加“努力程度”调节:Aider 发布了 v0.73.0,增加了对 o3-mini 的全面支持,以及用于控制推理的新参数
--reasoning-effort。Aider v0.73.0 发布并增强功能。尽管集成了 o3-mini,用户发现 Sonnet 在编程任务中仍然更快、更高效,即便 o3-mini 在复杂逻辑方面表现出色。 - Cursor IDE 更新发布,更新日志依然晦涩难懂:Cursor IDE 推出了包括检查点恢复功能在内的更新,但用户对不一致的更新日志和未公开的功能更改表示不满。Cursor IDE 推出新功能。用户对性能差异以及在缺乏明确沟通的情况下更新对模型能力的影响表示担忧。
主题 4. LLM 训练与优化:新技术涌现
- Unsloth 的动态量化缩小了模型体积,同时保持了性能:Unsloth AI 强调了动态量化技术,在不牺牲准确性的情况下,使 DeepSeek R1 等模型的体积减少了高达 80%。Unsloth 框架中的动态量化。用户正在尝试 1.58-bit 量化模型,但在确保符合位规格和优化 LlamaCPP 性能方面面临挑战。
- GRPO 崭露头角:强化学习竞赛升温:讨论强调了在强化学习框架中,GRPO (Group Relative Policy Optimization) 比 DPO (Direct Preference Optimization) 更有效。强化学习:GRPO vs. DPO。实验表明,GRPO 提高了 Llama 2 7B 在 GSM8K 上的准确率,这表明它是一种跨模型系列的稳健方法,且 DeepSeek R1 的表现优于 PEFT 和指令微调。
- 测试时计算策略:Budget Forcing 进入赛场:“Budget forcing” 作为一种新型的测试时计算(test-time compute)策略出现,通过延长模型推理时间来鼓励答案复查并提高准确性。测试时计算策略:Budget Forcing。该方法利用了一个包含 1,000 个精心挑选的问题 的数据集,旨在测试特定标准,促使模型在评估期间增强其推理性能。
主题 5. 硬件障碍与前景
- RTX 5090 在 AI 推理对决中遥遥领先 RTX 4090:讨论显示,在大语言模型中,RTX 5090 GPU 的 token 处理速度比 RTX 4090 快达 60%。RTX 5090 在 AI 任务中超越 RTX 4090。基准测试结果正在被分享,突显了 AI 密集型任务的性能飞跃。
- AMD RX 7900 XTX 在应对重量级 LLM 时陷入苦战:用户指出,在运行 70B 等大语言模型时,AMD RX 7900 XTX GPU 的效率难以与 NVIDIA GPU 匹敌。AMD RX 7900 XTX 在大型 LLM 任务中表现吃力。社区正在讨论 AMD 硬件在严苛的 LLM 任务中有限的 token 生成速度。
- GPU 共享内存技巧提升 LM Studio 效率:讨论强调了在 LM Studio 中利用 GPU 的 shared memory(共享内存)来增加 RAM 利用率并增强模型性能。通过共享内存提升 GPU 效率。鼓励用户调整 LM Studio 设置以优化 GPU offloading 并有效管理 VRAM,尤其是在本地运行大型模型时。
PART 1: 高层级 Discord 摘要
Unsloth AI (Daniel Han) Discord
- Unsloth 框架中的动态量化:Unsloth 的动态量化可将模型大小减少多达 80%,同时保持 DeepSeek R1 等模型的准确度。该博客文章概述了使用指定量化技术运行和微调模型的有效方法。
- 用户在面对 1.58-bit 量化模型时遇到挑战,因为动态量化并不总是遵循位规格(bit specification),这引发了对当前设置下 LlamaCPP 性能的担忧。
- VLLM 对 DeepSeek R1 的卸载限制:VLLM 目前缺乏对 GGUF 卸载的支持,特别是对于 DeepSeek V2 架构,除非应用最近的补丁。
- 正如最近社区讨论所强调的,这一限制给依赖卸载功能的流水线带来了优化问题。
- 模型训练中的梯度累积:Gradient accumulation(梯度累积)通过允许模型仅根据生成的补全(completions)反馈进行训练来减轻 VRAM 使用,从而比直接在先前输入上训练具有更高的稳定性。
- 建议使用此方法来保留上下文并防止过拟合,详见 Unsloth 文档。
- 测试时计算策略:预算强制:引入 budget forcing(预算强制)来控制测试时计算(test-time compute),通过延长推理时间鼓励模型双重检查答案,旨在提高推理性能。
- 该策略利用了一个包含 1,000 个问题的精选数据集,这些问题旨在满足特定标准,详见最近的研究论坛。
- 用于模型分析的 Klarity 库:Klarity 是一个已发布的开源库,用于分析语言模型输出的熵(entropy),提供详细的 JSON 报告和见解。
- 鼓励开发者通过 Klarity GitHub 仓库进行贡献并提供反馈。
Codeium (Windsurf) Discord
- Windsurf 1.2.5 补丁更新发布:Windsurf 1.2.5 补丁更新已发布,重点改进和修复了 Cascade 网络搜索体验。完整的 changelog 详细说明了模型调用工具方式的增强。
- 新的 Cascade 功能允许用户通过自动触发、URL 输入以及 @web 和 @docs 命令进行网络搜索,以获得更多控制权。这些功能每次使用消耗 1 个 flow action 额度,并可在 Windsurf 设置面板中切换。
- DeepSeek 模型性能问题:用户报告了 DeepSeek 模型的问题,包括关于无效工具调用的错误消息以及任务期间的上下文丢失,导致在没有产生有效动作的情况下消耗了额度。
- 这些问题引发了关于提高模型可靠性并确保 Windsurf 内高效额度使用的讨论。
- Windsurf 定价与折扣:用户对 Windsurf 缺乏学生折扣选项表示担忧,并质疑该工具与替代方案相比的价格竞争力。
- 用户对当前的定价结构表示不满,认为其价值可能与所提供的服务不符。
- Codeium 扩展程序 vs Windsurf 功能:官方澄清 Cascade 和 AI flows 功能在 JetBrains 插件中不可用,这使得某些高级功能仅限于 Windsurf。
- 用户参考文档以了解两个平台之间的当前限制和性能差异。
- Cascade 功能与用户反馈:用户分享了有效使用 Cascade 的策略,例如设置全局规则以阻止不必要的代码修改,以及对 Claude 或 Cascade Base 使用结构化 Prompt。
- 反馈强调了对 Cascade “记忆(memories)”功能不遵守既定指令的担忧,这导致了不必要的代码更改。
aider (Paul Gauthier) Discord
- Aider v0.73.0 发布,带来增强功能:Aider v0.73.0 的发布引入了对
o3-mini的支持和新的--reasoning-effort参数(提供 low, medium, high 选项),以及在创建新文件时自动创建父目录的功能。- 这些更新旨在改进文件管理,并让用户对推理过程拥有更多控制权,从而增强整体功能。
- O3 Mini 与 Sonnet:性能对比:用户报告称 O3 Mini 在大型项目中可能会遇到响应时间较慢的问题,有时长达一分钟,而 Sonnet 则能以更少的手动上下文添加提供更快的反馈。
- 尽管用户欣赏 O3 Mini 的快速迭代能力,但许多人因速度和效率原因在编程任务中更倾向于使用 Sonnet。
- DeepSeek R1 集成与自托管挑战:DeepSeek R1 与 Aider 的集成在 Aider 的排行榜上展示了顶尖性能,尽管一些用户对其速度表示担忧。
- 围绕自托管 LLM 的讨论揭示了对云端依赖的挫败感,促使像 George Coles 这样的用户考虑独立托管解决方案。
- Windsurf IDE 与内联提示增强:Windsurf 作为一款 Agentic IDE 的引入,为结对编程带来了先进的 AI 能力,通过实时状态感知增强了 VSCode 等工具。
- 内联提示(Inline prompting)功能允许根据之前的操作自动完成代码更改,为使用 Aider 和 Cursor 的用户简化了编程体验。
Cursor IDE Discord
- O3 Mini 面临性能批评:用户分享了关于 O3 Mini 在编程任务中表现的褒贬不一的评价,强调了速度和解决方案不完整的问题。
- Claude 3.5 Sonnet 通常被认为是处理大型复杂代码库的首选,能提供更可靠和一致的性能。
- Cursor IDE 推出新功能:Cursor 最近的更新包括旨在增强用户体验的检查点恢复(checkpoint restore)功能,但缺乏一致的变更日志引发了关注。
- 用户对未公开的功能和性能差异表示不满,质疑更新对模型能力的影响。
- 讨论高级 Meta Prompting 技术:出现了围绕 Meta-prompting 技术的讨论,旨在将复杂项目拆解为 LLM 可管理的任务。
- 分享的资源表明,这些技术可以通过优化 Prompt 结构显著提高用户生产力。
Yannick Kilcher Discord
- DeepSeek AI 在西方基准测试中占据主导地位:中国的 DeepSeek AI model 在各项基准测试中超越了 OpenAI 和 Anthropic 等西方同行,引发了全球关于 AI 竞争力的讨论。该模型卓越的性能在最近的测试中得到了凸显,展示了其强大的能力。
- 作为回应,美国正在考虑采取立法措施限制与中国 AI 研究的合作,旨在随着 DeepSeek 在市场中获得青睐而保护国家创新。
- AI 监管面临新的立法推动:参议员 Josh Hawley 最近提出的 AI 监管立法 针对 DeepSeek 等模型,施加了可能阻碍开源 AI 发展的严厉处罚。该法案强调国家安全,并呼吁对版权法进行彻底改革,正如这篇文章中所讨论的那样。
- 批评者认为,此类监管可能会扼杀创新并限制可访问性,这呼应了人们对安全与技术进步之间平衡的担忧。
- LLMs 的数学能力受到审查:LLMs 的数学表现因根本性的不匹配而受到批评,有人将其比作“用叉子刷牙”。o1-mini 等模型在数学问题上表现出参差不齐的结果,引发了对其推理有效性的质疑。
- 社区讨论强调 o3-mini 在数学推理方面表现出色,比同类模型能更好地解决复杂谜题,这引发了组织数学推理竞赛的兴趣。
- 自我-他人重叠(SOO)微调增强 AI 诚实度:一篇关于 Self-Other Overlap (SOO) fine-tuning 的论文表明,在不损害任务性能的情况下,各种规模模型的欺骗性 AI 响应都显著减少。该研究详见 arXiv:2412.16325,SOO 将 AI 的自我表征与外部感知对齐以促进诚实。
- 实验表明,Mistral-7B 中的欺骗性响应减少到 17.2%,表明 SOO 在强化学习场景中的有效性,并促进了更可靠的 AI 交互。
- OpenEuroLLM 发布专注于欧盟的语言模型:OpenEuroLLM 计划已经启动,旨在开发为所有欧盟语言量身定制的开源大语言模型,并获得了 European Commission 颁发的首个代表卓越的 STEP Seal 标志。
- 在欧洲机构联盟的支持下,该项目旨在为整个欧盟的各种应用创建合规且可持续的高质量 AI 技术,增强区域 AI 能力。
LM Studio Discord
- DeepSeek R1 面临蒸馏限制:用户报告了对 DeepSeek R1 模型参数规模的困惑,争论其到底是 14B 还是 7B。
- 许多人对该模型的自动补全(auto-completion)和调试(debugging)能力感到沮丧,特别是在编程任务方面。
- AI 驱动的直播聊天室初具规模:一位用户详细介绍了在 LM Studio 中创建多 Agent 直播聊天室的过程,其特点是各种 AI 人格进行实时互动。
- 计划包括将该系统集成到 Twitch 和 YouTube 直播流中,以展示 AI 在动态环境中的潜力。
- 通过共享内存提升 GPU 效率:讨论强调了在 GPU 上使用共享内存以实现更高的 RAM 利用率,从而提高模型性能。
- 鼓励用户调整 LM Studio 中的设置,以优化 GPU offloading 并管理大型模型的 VRAM。
- RTX 5090 在 AI 任务中超越 RTX 4090:交流透露,在处理大型模型时,RTX 5090 的 Token 处理速度比 RTX 4090 快 60%。
- 基准测试结果分享自 GPU-Benchmarks-on-LLM-Inference。
- AMD RX 7900 XTX 在运行大型 LLM 时表现挣扎:用户指出,在运行 70B 等大语言模型时,AMD RX 7900 XTX 的效率不如 NVIDIA GPU。
- 社区讨论了 AMD GPU 在 LLM 任务中有限的 Token 生成速度。
OpenAI Discord
- OpenAI 安排 o3-mini AMA:一场由 Sam Altman、Mark Chen 和其他核心人物参加的 AMA 定于 PST 时间下午 2 点举行,旨在回答有关 OpenAI o3-mini 及其即将推出的功能的问题。用户可以在 Reddit 此处 提交问题。
- 此次 AMA 旨在提供对 OpenAI 未来发展的见解,并收集社区对 o3-mini 模型的反馈。
- OpenAI 发布 Deep Research Agent:OpenAI 推出了一款全新的 Deep Research Agent,能够自主从多个在线平台获取、分析和综合信息,在几分钟内生成全面的报告。详细信息请见 此处。
- 该工具预计将通过显著减少数据汇编和分析所需的时间来简化研究流程。
- DeepSeek R1 性能问题:据 Cisco 强调,有用户报告 DeepSeek R1 的攻击成功率达到 100%,未能通过所有安全测试,且由于频繁的服务器问题导致访问困难。
- DeepSeek 无法阻止有害提示词的情况引发了对其在现实应用中可靠性和安全性的担忧。
- OpenAI 为模型设置上下文 Token 限制:OpenAI 的模型执行严格的上下文限制,Plus 用户上限为 32k tokens,Pro 用户上限为 128k tokens,这限制了它们处理大规模知识库的能力。
- 讨论中提到了利用 embeddings 和向量数据库作为替代方案,以比将数据切分为 chunks 更有效的方式管理大型数据集。
- AI 模型对比:GPT-4 vs DeepSeek R1:对话对比了 OpenAI 的 GPT-4 和 DeepSeek R1,指出了在编程辅助和推理任务等能力上的差异。用户观察到 GPT-4 在某些 DeepSeek R1 表现不足的领域表现出色。
- 成员们辩论了包括 O1、o3-mini 和 Gemini 在内的模型优缺点,根据功能和在各种应用中的可用性对其进行评估。
Nous Research AI Discord
- DeepSeek 和 Psyche AI 的进展:参与者强调了 DeepSeek 的进步,重点介绍了 Psyche AI 如何在其技术栈中利用 Rust,同时集成现有的 Python 模块以保持 p2p 网络功能。
- 针对在强化学习中实现多步响应提出了担忧,重点关注效率以及在扩展这些功能时固有的挑战。
- OpenAI 在 DeepSeek 之后的策略:OpenAI 在 DeepSeek 出现后的立场受到了审视,特别是 Sam Altman 关于处于“历史错误一边”的言论,鉴于 OpenAI 此前不愿开源模型的态度,这引发了对其真实性的质疑。
- 成员们强调,OpenAI 的行动需要与其言论保持一致才具有公信力,并指出其承诺与实际执行之间存在差距。
- AI 中的法律和版权考量:讨论集中在 AI 开发的法律影响上,特别是关于版权问题,成员们辩论了保护知识产权与促进 AI 创新之间的平衡。
- 一名法学院学生询问了如何将以法律为中心的对话与技术讨论相结合,强调了可能影响未来 AI 研发的潜在监管规定。
- 模型训练技术的进步:社区探讨了 Deep Gradient Compression,这是一种在分布式训练中将通信带宽降低 99.9% 且不损失准确性的方法,详见相关 论文。
- 此外还讨论了 Stanford 的 Simple Test-Time Scaling,该技术在竞赛数学题上的推理性能提升了高达 27%,且所有资源均已开源。
- 新 AI 工具与社区贡献:Relign 推出了开发者悬赏任务,旨在构建一个专为推理引擎量身定制的 开源 RL 库,邀请社区贡献力量。
- 此外,成员们分享了关于用于研究探索的 Scite 平台 的见解,并鼓励参与社区驱动的 AI 模型测试计划。
Interconnects (Nathan Lambert) Discord
- OpenAI 的 Deep Research 增强功能:OpenAI 随 O3 模型推出了 Deep Research,允许用户细化研究查询并通过侧边栏查看推理进度。初步反馈指出其在综合信息方面的能力,尽管在来源分析方面仍存在一些局限性。
- 此外,OpenAI 的 O3 通过强化学习(RL)技术持续改进,同时其 Deep Research 工具也得到了增强,突显了其模型训练中对 RL 方法论的高度关注。
- 软银向 OpenAI 承诺 30 亿美元投资:软银(SoftBank)宣布每年向 OpenAI 产品投资 30 亿美元,并在日本成立一家专注于 Crystal Intelligence 模型的合资企业。该伙伴关系旨在将 OpenAI 的技术整合到软银子公司中,为日本企业推进 AI 解决方案。
- Crystal Intelligence 旨在自主分析和优化遗留代码,并计划在两年内引入 AGI,体现了孙正义将 AI 视为超级智慧(Super Wisdom)的愿景。
- 共和党 AI 立法针对中国技术:一项由共和党(GOP)发起的法案提议禁止从中国进口 AI 技术,包括来自 DeepSeek 等平台的模型权重,违者最高可判处 20 年监禁。
- 该立法还将向指定关注实体出口 AI 定为犯罪,将发布 Llama 4 等产品的行为等同于类似的严厉处罚,引发了对其对开源 AI 发展影响的担忧。
- 强化学习:GRPO vs. DPO:讨论强调了在强化学习框架中,特别是在 RLVR 应用背景下,GRPO 优于 DPO 的有效性。成员们认为,虽然可以使用 DPO,但其效果可能不如 GRPO。
- 此外,研究结果表明 GRPO 对 Llama 2 7B 模型产生了积极影响,在 GSM8K 基准测试中实现了显著的准确率提升,展示了该方法在不同模型系列中的稳健性。
- DeepSeek AI 的 R1 模型亮相:DeepSeek AI 于 1 月 20 日发布了其旗舰 R1 模型,强调通过额外数据进行扩展训练以增强推理能力。社区对推理模型领域的这一进展表现出极大热情。
- R1 模型简单的训练方法(在训练后周期的早期优先考虑排序)因其简洁性和有效性而受到赞誉,引发了对推理 LM 未来发展的期待。
Latent Space Discord
- OpenAI 推出 Deep Research Agent:OpenAI 推出了 Deep Research,这是一个针对网页浏览和复杂推理进行优化的自主 Agent,能够在几分钟内综合来自不同来源的大量报告。
- 初步反馈强调了其作为强大电子商务工具的实用性,尽管一些用户报告了输出质量的局限性。
- 推理增强生成 (ReAG) 亮相:推理增强生成 (ReAG) 被引入以增强传统的检索增强生成(RAG),通过消除检索步骤并将原始材料直接输入 LLM 进行综合。
- 初步反应注意到了其潜在的有效性,同时也对其可扩展性和预处理文档的必要性提出了质疑。
- AI Engineer Summit 门票火爆:AI Engineer Summit 的门票和赞助正在快速售罄,该活动定于 2 月 20 日至 22 日在纽约市举行。
- 新的峰会网站提供了演讲者和日程安排的实时更新。
- Karina Nguyen 将为 AI 峰会收官:Karina Nguyen 将在 AI Engineer Summit 上发表闭幕主题演讲,展示她在 Notion、Square 和 Anthropic 任职期间的经验。
- 她的贡献涵盖了 Claude 1, 2, 和 3 的开发,凸显了她对 AI 进步的影响。
- Deepseek API 面临可靠性问题:成员们对 Deepseek API 的可靠性表示担忧,强调了访问问题和性能缺陷。
- 观点认为该 API 的托管和功能落后于预期,引发了关于潜在改进的讨论。
Eleuther Discord
- 获得功能性语言模型的概率:EleutherAI 的一项研究计算出,通过随机猜测权重来获得一个功能性语言模型的概率大约为 1 后面跟着 3.6 亿个零分之一,突显了其中涉及的巨大复杂度。
- 团队分享了他们的 basin-volume GitHub 仓库和一篇研究论文,以探索网络复杂度及其对模型对齐的影响。
- R1 在 SmolLM2 上的复现失败:研究人员在 SmolLM2 135M 上测试 R1 结果时遇到了复现失败,观察到与在真实数据上训练的模型相比,其自动解释 (autointerp) 得分更低,重构误差更高。
- 这一差异引发了对原始论文有效性的质疑,正如在围绕 Sparse Autoencoders 社区发现的讨论中所指出的那样。
- DeepSeek 的审查问题:DeepSeek 对天安门广场等敏感话题的反应因提示词语言而异,表明其设计中集成了潜在的偏见。
- 用户建议了绕过这些审查机制的方法,并引用了相关文献中讨论的 AI safety training 漏洞。
- DRAW 架构增强图像生成:DRAW 网络架构引入了一种新型的空间注意力机制,模拟人类的视觉注视 (foveation),显著提高了在 MNIST 和 Street View House Numbers 等数据集上的图像生成效果。
- 来自 DRAW 论文 的性能指标表明,生成的图像与真实数据无法区分,展示了增强的生成能力。
- NeoX 性能指标与挑战:一名成员报告称,在 A100s 上运行 1.3B 参数模型时达到了 每秒 10-11K tokens,而 OLMo2 论文中报告的则是 50K+ tokens。
- 讨论了融合标志 (fusion flags) 的问题以及 gpt-neox configurations 中的差异,突显了扩展 Transformer Engine 加速时面临的挑战。
MCP (Glama) Discord
- 远程 MCP 工具需求激增:成员们强调了 MCP 工具 对远程能力的需求,并指出大多数现有解决方案都集中在本地实现上。
- 提出了对可扩展性和可用性的担忧,并建议探索替代方案以增强 MCP 功能。
- Superinterface 产品明确 AI 基础设施重点:Superinterface 的联合创始人详细介绍了他们专注于提供 AI Agent 基础设施即服务,以区别于开源替代方案。
- 该产品旨在将 AI 能力集成到用户产品中,突显了基础设施需求中涉及的复杂性。
- Goose 自动化 GitHub 任务:一段 YouTube 视频展示了开源 AI Agent Goose 如何通过与任何 MCP 服务器集成来自动化任务。
- 该演示突显了 Goose 处理 GitHub 交互的能力,强调了 MCP 的创新用途。
- Supergateway v2 增强 MCP 服务器可访问性:Supergateway v2 现在支持通过 ngrok 隧道远程运行任何 MCP 服务器,简化了服务器的设置和访问。
- 鼓励社区成员寻求帮助,反映了改进 MCP 服务器可用性的协作努力。
- Litellm Proxy 中的负载均衡技术:讨论涵盖了使用 Litellm proxy 进行负载均衡的方法,包括配置权重和管理每分钟请求数。
- 这些策略旨在工作流中高效管理多个 AI 模型端点。
Stackblitz (Bolt.new) Discord
- Bolt 性能问题影响用户:多名用户报告 Bolt 响应缓慢且频繁出现错误消息,导致操作中断,需要频繁刷新页面或清除 cookie。
- 反复出现的问题表明可能存在服务器端(server-side)问题或本地存储管理(local storage management)挑战,因为用户试图通过清除浏览器数据来恢复访问。
- Supabase 相比 Firebase 更受青睐:在一场激烈的辩论中,许多用户因 Supabase 的直接集成能力和用户友好界面而更青睐它,而非 Firebase。
- 然而,一些参与者对已经深入其生态系统的 Firebase 表示赞赏,凸显了社区中偏好的分歧。
- Supabase 服务连接不稳定:用户在进行更改后遇到 Supabase 断连,需要重新连接或重新加载项目以恢复功能。
- 一名用户通过重新加载项目解决了连接问题,表明断连可能源于最近的前端修改(front-end modifications)。
- Voiceflow 聊天机器人中 Calendly 的 Iframe 错误:一名用户在 Voiceflow 聊天机器人中集成 Calendly 时遇到 iframe 错误,导致显示问题。
- 在咨询了 Voiceflow 和 Calendly 的代表后,确定这是一个 Bolt 问题,令该用户感到非常沮丧。
- 持续的用户身份验证挑战:用户报告了身份验证(authentication)问题,包括无法登录以及在不同浏览器中遇到相同的错误。
- 清除本地存储(local storage)等建议的解决方法对某些人无效,指向身份验证系统内部的潜在问题。
Nomic.ai (GPT4All) Discord
- GPT4All v3.8.0 在 Intel Mac 上崩溃:用户报告 GPT4All v3.8.0 在现代 Intel macOS 机器上崩溃,暗示该版本对这些系统可能是 DOA(出厂即失效)。
- 正在根据用户的系统规格形成一个工作假设,以识别受影响的配置,因为多名用户遇到了类似问题。
- 量化级别影响 GPT4All 性能:量化级别(Quantization levels)显著影响 GPT4All 的性能,较低的量化会导致质量下降(quality degradation)。
- 鼓励用户平衡量化设置,在不使硬件过载的情况下保持输出质量。
- AI 模型数据收集中的隐私担忧:关于数据收集信任的辩论已经兴起,对比了西方和中国的数据实践,用户表达了不同程度的担忧和怀疑。
- 参与者争论不同国家在数据收集方面存在的双重标准。
- 在 GPT4All 中集成 MathJax 以支持 LaTeX:用户正在探索在 GPT4All 中集成 MathJax 以支持 LaTeX,强调与 LaTeX 结构的兼容性。
- 讨论集中在解析 LaTeX 内容和提取数学表达式,以改进 LLM 的输出表现。
- 开发用于 NSFW 故事生成的本地 LLM:一名用户正在寻找能够离线生成 NSFW 故事的本地 LLM,类似于现有的在线工具,但不使用 llama 或 DeepSeek。
- 该用户指定了他们的系统能力和要求,包括对德语 LLM 的偏好。
Notebook LM Discord Discord
- NotebookLM 计划发布 API:用户询问了即将发布的 NotebookLM API release,对扩展功能表示热切期待。
- 提到 NotebookLM 的 output token limit 低于 Gemini,但具体细节尚未披露。
- NotebookLM Plus 功能在 Google Workspace 推出:一位用户升级到 Google Workspace Standard 后,观察到 NotebookLM 顶部栏增加了“Analytics”,表明已获得 NotebookLM Plus 的访问权限。
- 他们指出尽管界面外观相似,但使用限制(usage limits)有所不同,并分享了截图以供参考。
- 将完整教程集成到 NotebookLM:一名成员建议将整个教程网站(如 W3Schools JavaScript)整合进 NotebookLM,以加强对 JS 面试的准备。
- 另一名成员提到现有的 Chrome 扩展程序可以辅助将网页导入 NotebookLM。
- UI 更新后音频自定义功能缺失:用户报告在最近的 UI 更新后,NotebookLM 丢失了 audio customization 功能。
- 建议包括探索 Illuminate 以获取相关功能,并希望某些功能将来能迁移到 NotebookLM。
Modular (Mojo 🔥) Discord
- Mojo 和 MAX 简化解决方案:一名成员强调了 Mojo 和 MAX 在解决当前工程挑战方面的有效性,强调了它们作为综合解决方案的潜力。
- 讨论强调了在现有工作流中有效实施这些解决方案需要投入大量精力。
- 减少 Mojo 中 Swift 的复杂性:有人担心 Mojo 会继承 Swift 的复杂性,社区提倡更清晰的开发路径以确保稳定性。
- 成员们强调了仔细评估权衡(tradeoff)的重要性,以防止仓促推进可能损害 Mojo 可靠性的情况。
- Ollama 性能超过 MAX:观察到在相同机器上 Ollama 的运行速度比 MAX 快,尽管最初的指标显示 MAX 性能较慢。
- 目前的开发重点是优化 MAX 基于 CPU 的 serving 能力,以提升整体性能。
- 增强 Mojo 的类型系统:用户询问在将参数作为 concrete types 传递时,如何访问 Mojo 类型系统中的特定 struct 字段。
- 回复指出有效利用 Mojo 的类型功能存在学习曲线,表明社区正在进行持续的教育工作。
- MAX Serving 基础设施优化:MAX serving 基础设施使用
huggingface_hub下载和缓存模型权重,这与 Ollama 的方法有所不同。- 讨论揭示了可以通过修改
--weight-path=参数来防止重复下载,尽管管理 Ollama 的本地缓存仍然很复杂。
- 讨论揭示了可以通过修改
Torchtune Discord
- 16 节点上的 GRPO 部署:一名成员通过调整 multinode PR,成功在 16 个节点上部署了 GRPO,并期待即将进行的奖励曲线验证。
- 他们幽默地评论道,身处一家资金充足的公司在进行此类部署时具有显著优势。
- Torchtune 多节点支持的最终审批:有人请求对 Torchtune 中的 multinode support PR 进行最终审批,并强调了基于用户需求的必要性。
- 讨论中提到了关于 API 参数
offload_ops_to_cpu的潜在担忧,建议可能需要额外的审查。
- 讨论中提到了关于 API 参数
- DPO Recipe 中的 Seed 不一致性:Seed 在 LoRA 微调中有效,但在 LoRA DPO 中失效,issue #2335 正在调查 sampler 行为的不一致性。
- 已记录多个与 seed 管理相关的问题,重点关注数据集中
seed=0和seed=null的影响。
- 已记录多个与 seed 管理相关的问题,重点关注数据集中
- LLM 数据增强全面综述:一份综述详细介绍了大型预训练语言模型 (LLM) 如何从大规模训练数据集中获益,解决了 overfitting 问题,并利用独特的 prompt templates增强了数据生成。
- 它还涵盖了近期整合外部知识的基于检索的技术,使 LLM 能够生成 grounded-truth data。
- R1-V 模型增强 VLM 的计数能力:R1-V 利用带有 verifiable rewards 的 reinforcement learning 来提升视觉语言模型 (VLM) 的计数能力,其中一个 2B model 在 100 个训练步数内的表现优于 72B model,成本低于 $3。
- 该模型将完全开源,鼓励社区关注未来的更新。
LLM Agents (Berkeley MOOC) Discord
- 关于 LLM 自我改进的即将举行的讲座:Jason Weston 将于今天 PST 时间下午 4:00 介绍 LLM 中的自我改进方法,重点关注 Iterative DPO 和 Meta-Rewarding LLMs 等技术。
- 参与者可以在此处观看直播,Jason 将探讨增强 LLM 推理、数学和创意任务的方法。
- LLM 中的 Iterative DPO 与 Meta-Rewarding:Iterative DPO 和 Meta-Rewarding LLMs 作为近期进展被讨论,并附带了 Iterative DPO 和 Self-Rewarding LLMs 论文的链接。
- 这些方法旨在通过改进强化学习技术来提升 LLM 在各种任务中的性能。
- DeepSeek R1 超越 PEFT:DeepSeek R1 证明了结合组相对策略优化 (GRPO) 的强化学习优于 PEFT 和指令微调。
- 这一转变表明,由于 DeepSeek R1 增强的有效性,可能会逐渐脱离传统的提示方法。
- MOOC 测验和证书更新:测验现已在课程网站的教学大纲部分上线,为了防止收件箱混乱,不会发送邮件提醒。
- 证书状态正在更新中,并保证提交内容将很快得到处理,尽管一些成员报告了延迟。
- 黑客松结果即将公布:成员们正期待黑客松结果,结果已私下通知,预计下周公开发布。
- 这是在广泛参与 MOOC 的研究和项目轨道之后进行的,突显了活跃的社区参与。
tinygrad (George Hotz) Discord
- NVDEC 解码复杂性揭秘:使用 NVDEC 解码视频面临与文件格式相关的挑战以及对 cuvid binaries 的必要性,正如 FFmpeg/libavcodec/nvdec.c 中所强调的。
- 冗长的 libavcodec 实现包含高层抽象,简化这些抽象可能有助于提高效率。
- WebGPU Autogen 接近完成:一位成员报告 WebGPU autogen 已接近完成,仅需少量简化,且测试在 Ubuntu 和 Mac 平台上均已通过。
- 他们强调在未安装 dawn binaries 的情况下需要提供相关指令。
- Linux 发行版中的 Clang 与 GCC 之争:辩论强调,虽然 Apple 和 Google 等平台青睐 clang,但 gcc 在主要的 Linux 发行版中仍然盛行。
- 这引发了关于发行版是否应转向 clang 以获得更好优化的讨论。
- HCQ 执行范式增强多 GPU:HCQ-like execution 被认为是理解 multi-GPU execution 的关键步骤,并可能支持 CPU implementations。
- 优化调度器以在 CPU 和 GPU 之间高效分配任务可能会带来性能提升。
- CPU P2P 传输机制探索:讨论推测 CPU p2p 传输可能涉及释放内存块上的锁以便驱逐到 L3/DRAM,并考虑了 D2C transfers 的效率。
- 针对复杂多插槽传输过程中的执行局部性提出了性能担忧。
Cohere Discord
- Cohere 试用密钥重置时间:一位成员询问 Cohere trial key 何时重置——是生成后 30 天还是每个月初。这种不确定性影响了开发者规划评估期的方式。
- 需要进一步明确,因为试用密钥旨在用于评估,而非长期免费使用。
- Command-R+ 模型性能备受赞誉:用户称赞 Command-R+ model 始终能满足他们的需求,一位用户提到,尽管自己不是高级用户,该模型仍不断给他们带来惊喜。
- 这种持续的性能表现表明了其在实际应用中的可靠性和有效性。
- Embed API v2.0 HTTP 422 错误:一位成员在使用带有特定 cURL 命令的 Embed API v2.0 时遇到“HTTP 422 Unprocessable Entity”错误,引发了对长篇文章预处理需求的关注。
- 建议包括验证是否包含 API key,因为其他人在类似条件下报告了成功的请求。
- 持续的账户自动登出问题:多名用户报告了自动登出问题,迫使他们反复登录,中断了平台内的流程。
- 这一反复出现的问题突显了一个显著的用户体验缺陷,需要解决以确保无缝访问。
- Command R 的日语翻译不一致:Command R 和 Command R+ 在日语翻译方面表现出不一致的结果,部分翻译完全失败。
- 建议用户携带具体案例联系支持部门以协助多语言团队,或利用日语资源以获得更好的上下文。
LlamaIndex Discord
- Deepseek 压倒 OpenAI:一位成员指出 Deepseek 与 OpenAI 之间出现了明显的赢家,并分享了一段令人惊讶的叙述,展示了其竞争实力。
- 这一讨论引发了人们对这些工具相对性能的兴趣,强调了 Deepseek 正在显现的优势。
- LlamaReport 自动化报告生成:分享了 LlamaReport 的早期 Beta 版视频,展示了其在 2025 年进行报告生成的潜力。点击此处观看。
- 该项目旨在简化报告流程,为用户提供高效的解决方案。
- SciAgents 增强科学发现:介绍了 SciAgents,这是一个利用多 Agent 工作流和本体图谱(ontological graphs)的自动化科学发现系统。了解更多请点击此处。
- 该项目展示了协作分析如何驱动科学研究的创新。
- AI 驱动的 PDF 转 PPT 工具:一个开源 Web 应用支持使用 LlamaParse 将 PDF 文档转换为动态的 PowerPoint 演示文稿。点击此处探索。
- 该应用简化了演示文稿的制作,为用户实现了工作流自动化。
- DocumentContextExtractor 提升 RAG 准确率:DocumentContextExtractor 因提升 Retrieval-Augmented Generation (RAG) 的准确率而受到关注,该项目由 AnthropicAI 和 LlamaIndex 共同贡献。查看讨论串请点击此处。
- 这强调了社区在改进 AI 上下文理解方面的持续贡献。
DSPy Discord
- DeepSeek 反映了对 AI 的希望与恐惧:文章讨论了 DeepSeek 如何作为一个“教科书式的力量对象”,揭示了更多关于我们对 AI 的欲望和担忧,而非技术本身,详见此处。
- 关于 DeepSeek 的每一种热评都反映了个人对 AI 影响的具体希望或恐惧。
- SAEs 在引导 LLMs 方面面临重大挑战:一位成员对 SAEs 在可预测地引导 LLMs 方面的长期可行性表示失望,并引用了最近的一场讨论。
- 另一位成员强调了近期问题的严重性,称:“天哪,一天之内发生了‘三重命案’。SAEs 最近真的遭受了沉重打击。”
- DSPy 2.6 弃用 Typed Predictors:成员们澄清 typed predictors 已被弃用;在 DSPy 2.6 中,普通的 predictors 已足以满足功能需求。
- 会议强调,在当前版本中已经不再有 typed predictor 这种东西了。
- 在 DSPy 中将 Chain-of-Thought 与 R1 模型结合:一位成员表示有兴趣将 DSPy Chain-of-Thought 与 R1 模型结合进行微调,以共同角逐 Konwinski Prize。
- 他们还邀请其他人加入关于这一倡议的讨论和协作努力。
- DSPy 中的流式输出问题:一位用户分享了在使用 dspy.streamify 增量产生输出时遇到的困难,收到了 ModelResponseStream 对象而非预期的值。
- 他们在代码中实现了条件判断来处理输出类型,并寻求进一步的改进建议。
LAION Discord
- OpenEuroLLM 为欧盟语言首次亮相:OpenEuroLLM 已作为首个涵盖所有欧盟语言的开源大语言模型 (LLM) 系列发布,优先考虑符合欧盟法规。
- 该模型在欧洲监管框架内开发,确保符合欧洲价值观,同时保持技术卓越。
- R1-Llama 表现超出预期:对 R1-Llama-70B 的初步评估显示,在解决奥林匹克级别的数学和编程问题方面,它与 o1-mini 和原始 R1 模型旗鼓相当甚至有所超越。
- 这些结果突显了领先模型中潜在的泛化缺陷,引发了社区内的讨论。
- DeepSeek 的规格受到关注:DeepSeek v3/R1 模型具有 37B 激活参数,并采用混合专家 (MoE) 方法,与 Llama 3 模型的稠密架构相比,提高了计算效率。
- DeepSeek 团队实施了广泛的优化以支持 MoE 策略,从而实现了更高效的资源性能。
- 对性能比较的兴趣:一位社区成员表达了对测试一款据称比 HunYuan 更快的新模型的热情。
- 这种情绪强调了社区对当前 AI 模型性能基准测试的关注。
- 欧盟委员会强调 AI 的欧洲根源:欧盟委员会 (EU_Commission) 的一条推文宣布,OpenEuroLLM 已获得首个卓越 STEP 标志,旨在团结欧盟的初创公司和研究实验室。
- 该倡议强调保护语言和文化多样性,并在欧洲超级计算机上开发 AI。
Axolotl AI Discord
- 微调的挫败感:一位成员对微调推理模型 (reasoning models) 表示困惑,幽默地承认不知道从哪里开始。
- 他们评论道 Lol,表明在该领域需要指导。
- GRPO Colab Notebook 发布:一位成员分享了一个 用于 GRPO 的 Colab notebook,为对该主题感兴趣的人提供了资源。
- 该 notebook 为寻求进一步了解 GRPO 的成员提供了一个起点。
OpenInterpreter Discord
- o3-mini 的 Interpreter 集成:一位成员询问 o3-mini 是否可以同时在 01 和 interpreter 中使用,突显了潜在的集成问题。
- 这些担忧强调了需要澄清 o3-mini 与 Open Interpreter 的兼容性。
- 期待 Interpreter 更新:一位成员询问了即将到来的 Open Interpreter 更改的性质,试图了解这些更改是微小的还是重大的。
- 他们的询问反映了社区对计划更新的范围和影响的好奇。
MLOps @Chipro Discord
- 掌握 Cursor AI 以提高生产力:本周二东部时间下午 5 点,参加关于 Cursor AI 的线上线下混合活动,特邀演讲嘉宾 Arnold(一位 10X CTO)将讨论提高编码速度和质量的最佳实践。
- 参与者可以亲身前往 Builder’s Club 或通过 Zoom 虚拟参加,注册链接将在报名后提供。
- 《王者荣耀》市场的高价值交易:Honor of Kings 市场今天出现了一笔高价收购,小蛇糕以 486 的价格售出。
- 鼓励用户使用提供的市场代码 -<344IRCIX>- 和密码 [[S8fRXNgQyhysJ9H8tuSvSSdVkdalSFE]] 在市场中进行交易,购买或出售物品。
Mozilla AI Discord
- Lumigator 实时演示简化模型测试:参加 Lumigator 实时演示 了解安装和入门,运行你的第一次 模型评估 (model evaluation)。
- 该活动将引导参与者完成 有效的模型性能测试 的关键设置步骤。
- Firefox AI 平台首次推出离线 ML 任务:Firefox AI 平台 现已上线,使开发者能够在网络扩展中利用 离线机器学习任务 (offline machine learning tasks)。
- 这个新平台为直接在用户友好环境中提升 机器学习能力 (machine learning capabilities) 开辟了道路。
- Blueprints 更新增强开源配方:查看 Blueprints 更新 获取旨在增强开源项目的新配方。
- 该计划为开发者提供了 创建有效软件解决方案 的必备工具。
- Builders Demo Day 演讲在 YouTube 首次亮相:Builders Demo Day 演讲 已在 Mozilla Developers 的 YouTube 频道发布,展示了开发者社区的创新。
- 这些演讲提供了一个与 前沿开发项目 和想法互动的激动人心的机会。
- 社区宣布关键更新:成员可以找到关于社区内最新进展的 重要新闻。
- 随时了解影响社区倡议和协作的关键讨论。
HuggingFace Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
PART 2: Detailed by-Channel summaries and links
完整的频道细分内容已针对电子邮件进行截断。
如果你喜欢 AInews,请分享给朋友!预谢!