ainews-how-to-scale-your-model-by-deepmind
以下是几种中文翻译供参考: 1. **如何扩展你的模型 —— DeepMind**(最简洁、常用) 2. **DeepMind:如何实现模型规模化**(更具专业感) 3. **如何进行模型缩放,DeepMind 出品**(侧重于“缩放”这一技术术语) 在 AI 领域,“Scale” 通常翻译为 **“扩展”** 或 **“规模化”**。
Google DeepMind (GDM) 的研究人员发布了一本名为 《如何扩展你的模型》(How To Scale Your Model) 的综合性“小教科书”,内容涵盖了现代 Transformer 架构、超越 $O(N^2)$ 注意力机制的推理优化,以及 Roofline 等高性能计算(HPC)概念。该资源还包括实践练习题和实时评论互动。
在 AI 推特(X)上,几项关键动态备受关注:
- 受克里斯蒂亚诺·罗纳尔多 (Cristiano Ronaldo)、勒布朗·詹姆斯 (LeBron James) 和科比·布莱恩特 (Kobe Bryant) 等运动员启发的开源人形机器人模型 ASAP 正式发布;
- 一篇关于 Mixture-of-Agents (MoA) 的新论文提出了 Self-MoA 方法,旨在改进大语言模型(LLM)的输出聚合;
- 展示了利用 DeepSeek 的 GRPO 算法在 Qwen 0.5 上训练推理型 LLM;
- 关于 LLM 作为评审员(LLM-as-a-judge)存在偏见的研究结果,强调了进行多次独立评估的必要性;
- 以及 mlx-rs 的发布,这是一个用于机器学习的 Rust 库,并提供了 Mistral 文本生成等示例。
此外,Hugging Face 推出了一个 AI 应用商店,目前拥有超过 40 万个应用,每日新增 2000 个,每周访问量达 250 万次,并支持由 AI 驱动的应用搜索与分类功能。
系统思维就是你所需要的一切。
2025年2月3日至2月4日的 AI 新闻。我们为你检查了 7 个 subreddits、433 个 Twitter 账号 和 34 个 Discord 社区(225 个频道,3842 条消息)。预计节省阅读时间(以 200wpm 计算):425 分钟。你现在可以标记 @smol_ai 进行 AINews 讨论!
令人惊喜的是,一些研究人员发布了一本关于他们在 GDM 如何扩展模型的“小教科书”:

一位评论者确认这是 GDM 的内部文档,其中删减了关于 Gemini 的引用。
《如何扩展你的模型》共分为 12 个部分,开头对当今标准 Transformer 的形态进行了精彩的更新:
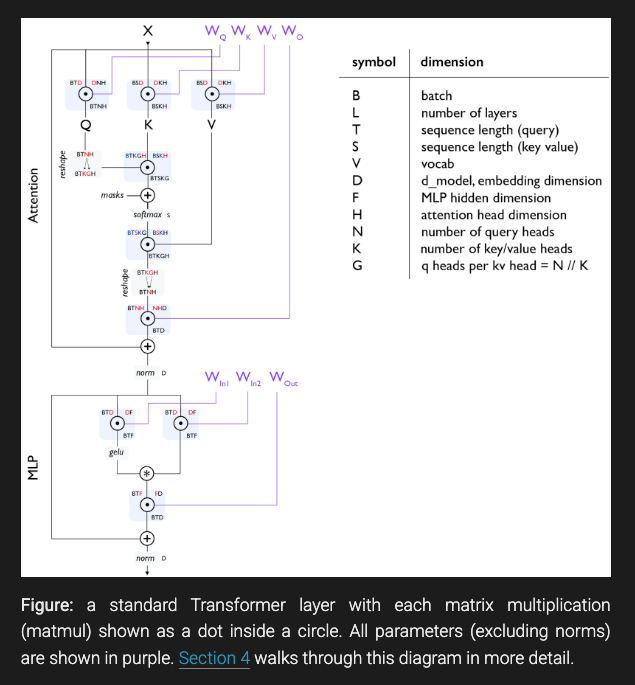
并解释了推理过程与标准的 O(N^2) Attention 理解有何不同:
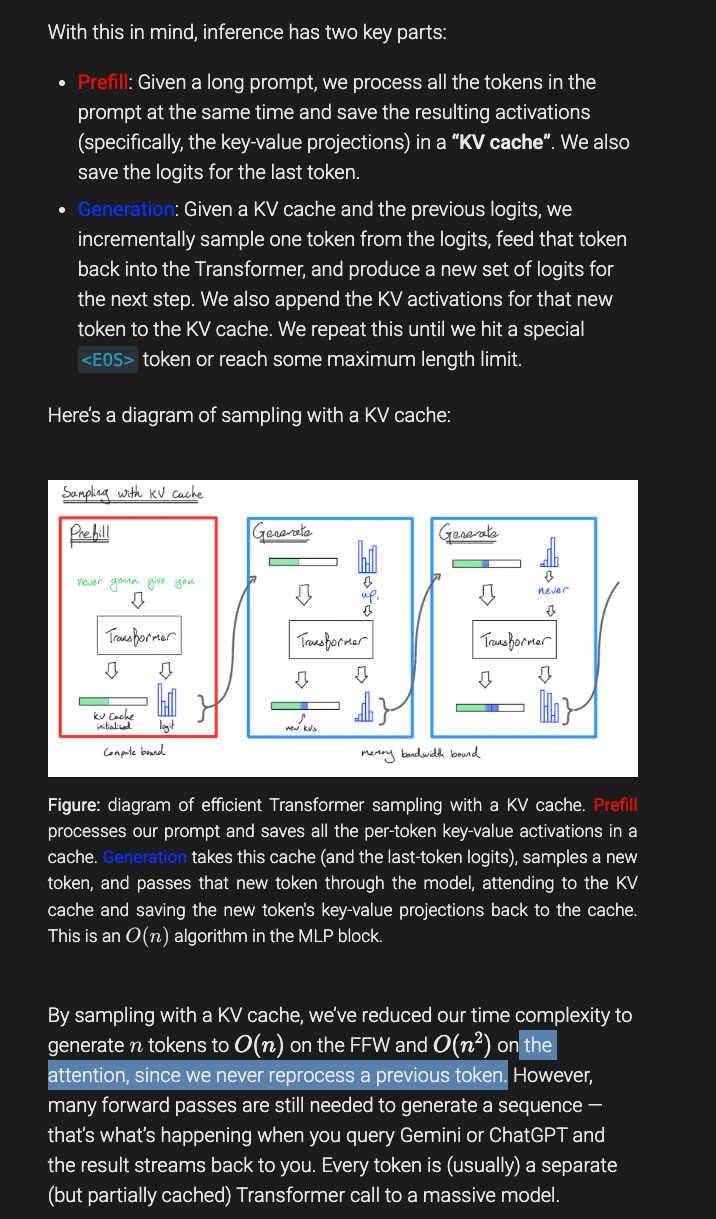
同时也引入了标准的高性能计算概念,如 rooflines:
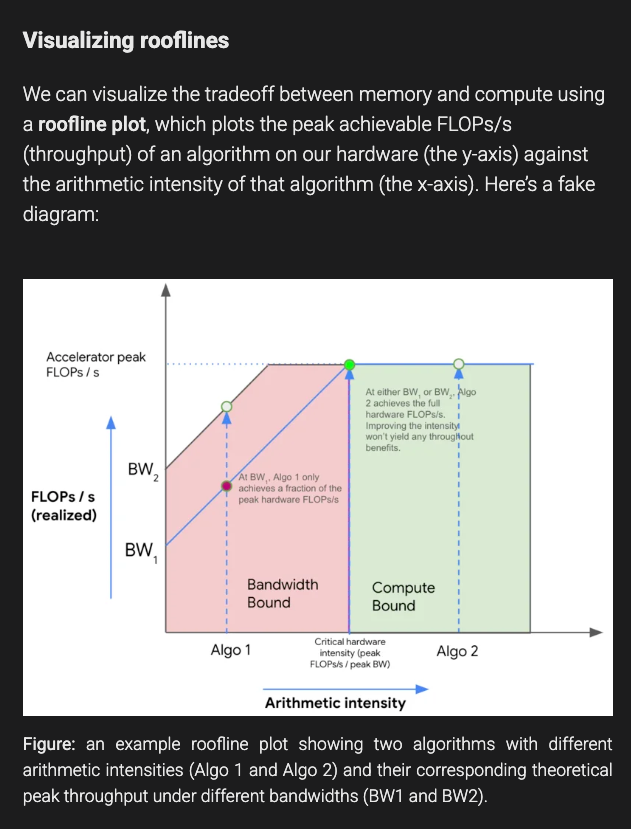
甚至还为积极的读者准备了练习题来测试他们的理解…… 评论正在被实时阅读。
AI Twitter 回顾
AI 模型发布与研究论文
-
“ASAP”:人形机器人的 Real2Sim2Real 模型:@DrJimFan 宣布了 “ASAP“,这是一个能让人形机器人执行受 Cristiano Ronaldo、LeBron James 和 Kobe Bryant 启发的流畅动作的模型。包括 @TairanHe99 和 @GuanyaShi 在内的团队已经开源了该项目的论文和代码。该方法结合了现实世界数据与模拟,以克服机器人技术中的 “sim2real” 差距。
-
“Rethinking Mixture-of-Agents” 论文与 “Self-MoA” 方法:@omarsar0 讨论了一篇名为 “Rethinking Mixture-of-Agents” 的新论文,该论文质疑了混合不同 LLMs 的益处。提出的 “Self-MoA” 方法通过聚合表现最好的 LLM 的输出来利用模型内部的多样性,表现优于传统的 MoA 方法。论文可以在这里找到。
-
使用 DeepSeek 的 GRPO 算法训练 LLM:@LiorOnAI 重点介绍了一个新的 notebook,演示了如何使用 DeepSeek 的 GRPO 算法训练推理 LLM。在不到 2 小时的时间内,你可以将像 Qwen 0.5(5 亿参数)这样的小模型转变为数学推理机器。Notebook 链接。
-
作为裁判的 LLM 中的偏见:@_philschmid 分享了论文 “Preference Leakage: A Contamination Problem in LLM-as-a-Judge” 的见解,揭示了 LLM 在用于合成数据生成和评估时可能存在显著偏见。研究强调需要多个独立的裁判和人工评估来减轻偏见。论文。
-
mlx-rs:用于机器学习的 Rust 库:@awnihannun 介绍了 mlx-rs,这是一个 Rust 库,包含使用 Mistral 进行文本生成和 MNIST 训练的示例。对于那些对 Rust 和机器学习感兴趣的人来说,这是一个宝贵的资源。点击查看。
AI 工具与平台公告
-
Hugging Face 的 AI 应用商店上线:@ClementDelangue 宣布 Hugging Face 推出了其 AI 应用商店,目前拥有 400,000 个应用,每天新增 2,000 个应用,每周访问量达 250 万次。用户现在可以使用 AI 或按类别搜索应用,并强调“AI 的未来将是分布式的”。探索应用商店。
-
AI 应用商店发布公告:@_akhaliq 同样对 AI 应用商店 的发布表示兴奋,称其为寻找所需 AI 应用 的最佳场所,现有约 40 万个应用 可供使用。开发者可以构建应用,用户可以通过 AI 搜索 发现新应用。点击查看。
- WhatsApp 上的 1-800-CHATGPT 更新:@kevinweil 宣布了 WhatsApp 上 1-800-CHATGPT 的新功能:
- 现在可以在提问时上传图片。
- 使用语音消息与 ChatGPT 交流。
- 很快,你将能够关联你的 ChatGPT 账号(Free, Plus, Pro)以获得更高的速率限制(rate limits)。
- 了解更多。
-
Replit 的新移动应用和 AI Agent:@hwchase17 分享了 Replit 推出的新移动应用,并提供了 AI Agent 的免费试用。Replit AI Agent 的快速发展备受关注,@amasad 确认了此次发布。详情点击。
- ChatGPT Edu 在加州州立大学推广:@gdb 报道称,加州州立大学正成为首个 AI 驱动的大学系统,ChatGPT Edu 已向 460,000 名学生以及超过 63,000 名教职员工推广。阅读更多。
AI 活动、会议与招聘
-
AI Dev 25 会议宣布:@AndrewYNg 宣布了 AI Dev 25,这是一场将于 2025 年 3 月 14 日(派日)在旧金山举行的 AI 开发者会议。该活动旨在为 AI 开发者创建一个厂商中立的会议,届时将有 400 多名开发者聚集在一起进行构建、分享想法和建立联系。了解更多并注册。
- Anthropic 对齐科学团队招聘:@sleepinyourhat 正在为 Anthropic 的 Alignment Science 团队招聘研究员,该团队由她与 @janleike 共同领导。他们专注于 AGI 安全方面的探索性技术研究。理想的候选人需具备:
- 多年 SWE 或 RE 经验。
- 丰富的研究经验。
- 熟悉现代 ML 和 AGI 对齐文献。
- 在此申请。
-
Andrew Ng 将出席 INTERRUPT 会议:@hwchase17 宣布 Andrew Ng 将于今年 5 月在 INTERRUPT 会议上发表演讲。Ng 被誉为我们这一代最优秀的教育家之一,鼓励与会者向他学习。获取门票。
- DeepSeek 集成虚拟论坛:@llama_index 邀请开发者、工程师和 AI 爱好者参加虚拟论坛,探索 DeepSeek 及其功能和工作流集成。演讲者包括来自 Google、GitHub、AWS、Vectara 和 LlamaIndex 的代表。在此注册。
AI 伦理、安全与政策
-
Google DeepMind 更新前沿安全框架:@GoogleDeepMind 分享了其 Frontier Safety Framework 的更新,这是一套旨在随着我们向 AGI 迈进而减轻严重风险的协议。他们强调 AI 需要兼具创新性与安全性,并邀请读者了解更多。
-
关于 LLM 裁判偏差的讨论:@_philschmid 探讨了 LLM 在用于 synthetic data generation 和作为裁判时的 bias in LLMs 问题。“Preference Leakage”论文揭示了 LLM 可能会偏好由其自身或其先前版本生成的数据,突显了 contamination problem。阅读论文。
-
OpenAI 的 Frontier Safety Framework 更新:@OpenAI 宣布了其 Frontier Safety Framework 的最新更新,旨在防范与先进 AI 系统相关的潜在严重风险。
通用 AI 行业评论
-
Yann LeCun 论小团队与创新:@ylecun 强调,具有自主权的 small research teams 能够做出正确的技术选择并进行创新。他强调了组织和管理在促进 R&D organizations 内部创新方面的重要性。
-
DeepSeek 被比作斯普特尼克时刻:@JonathanRoss321 将关于 DeepSeek 的新闻比作现代版的“Sputnik 2.0”,暗示这是 AI 领域的一个重要里程碑,类似于历史上太空竞赛的重大事件。
-
对技术采用的反思:@DavidSHolz 评论了新技术最初通常如何被用来复制旧媒介,并指出:“当你没有意识到新发明也是新媒介时,就会犯这些错误。”
-
关于 AI 评估和 RL 的讨论:@cwolferesearch 观察到 few-shot prompting 会降低 DeepSeek-R1 的性能,这可能是由于该模型是在严格的格式上训练的。这指向了与 LLM 交互的新范式以及 AI 技术不断演进的格局。
AI Reddit 回顾
/r/LocalLlama 摘要
主题 1. DeepSeek R1 & R1-Zero:快速模型训练成果
- DeepSeek 研究员称训练 R1 和 R1-Zero 仅需 2-3 周 (得分: 800, 评论: 127): DeepSeek 的研究员声称 R1 和 R1-Zero 模型的训练仅耗时 2-3 周,这表明这些 AI 模型的开发周期极快。
- 讨论中,部分用户对 R1 和 R1-Zero 在 3 周内完成 10,000 步 RL 训练的快速过程 持怀疑态度,质疑其可行性;另一些人则认为,通过对 V3 等现有模型进行微调可以解释这种速度。担忧的问题包括由于高需求导致的 API 和网站性能瓶颈,以及对改进训练数据或架构的需求。
- 用户将 DeepSeek 的模型 与其他 AI 进展进行了比较,指出在该论文发布后,全球范围内可能会涌现出新模型。一些人表示相比 OpenAI 更倾向于 DeepSeek,原因是其开放性以及没有关税限制,而另一些人则在期待 R1.5 或 V3-lite 等未来版本。
- 对话涉及了 AI 竞赛,并将其与全球太空竞赛相类比,强调了各地区参与度的差异。欧洲被提及通过 Stable Diffusion 和 Hugging Face 等公司做出了贡献,而其他地区则被指出参与度有限,凸显了全球 AI 开发的竞争本质。
主题 2. DeepSeek-R1 模型:更短的正确答案及其影响
- DeepSeek-R1 的正确答案通常更短 (得分: 289, 评论: 66): 如柱状图所示,DeepSeek-R1 的正确答案通常更短,平均为 7,864.1 个 tokens,而错误答案平均为 18,755.4 个 tokens。正确答案的 token 长度标准差为 5,814.6,错误答案为 6,142.7,表明 token 长度存在波动性。
- 任务难度与回复长度:包括 wellomello 和 Affectionate-Cap-600 在内的多条评论质疑该分析是否考虑了任务难度,认为更难的任务自然需要更长的回复,这可能会影响错误率和平均 token 长度。
- 模型行为与标准差:FullstackSensei 和 101m4n 讨论了 token 长度高标准差的影响,认为错误答案可能是由于模型进入死循环或在解题中挣扎,从而延长了回复时间。
- 相关研究与泛化:Angel-Karlsson 引用了一篇关于模型“过度思考”的相关研究论文,而 Egoz3ntrum 则强调了考虑数据集局限性的重要性,指出结论可能无法很好地泛化到特定数学难题之外。
{kind=link}
主题 3. OpenAI 研究:通过 Hugging Face 拥抱开源
- OpenAI Deep Research 的开源实现 (得分: 421, 评论: 28): Hugging Face 启动了一项名为 OpenAI Deep Research 的倡议,将深度研究开源化。该项目旨在使尖端 AI 研究的获取更加民主化,强调 AI 社区的透明度与协作。更多细节可以在他们的 博客文章 中找到。
- 用户对 Hugging Face 团队表示了极大的赞赏,将其贡献与 Mistral 团队相提并论,并强调了极快的开发节奏,一些人期待很快能集成到 Open-WebUI 等平台中。关于迅速创建出替代 OpenAI 专有解决方案的开源方案,评论中充满了紧迫感和惊喜。
- 讨论突显了开源社区对 Hugging Face 提供广泛工具和框架的感激之情,一些用户幽默地质疑这种慷慨背后的动机。快速开发开源替代方案是一个反复出现的主题,反映了社区在保持 AI 进展开放获取方面的积极立场。
- 一条评论提供了一个 GitHub 仓库链接,供有兴趣尝试本地实现的用户参考,指向 Automated-AI-Web-Researcher-Ollama,作为实验开源 AI 工具的资源。这表明社区对动手实验 AI 研究工具有着实际的兴趣。
其他 AI 子版块摘要
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
主题 1. OmniHuman-1:中国的多模态奇迹
- 中国的 OmniHuman-1 🌋🔆 (评分: 684, 评论: 174): OmniHuman-1 是一个专注于从单张图像生成视频的中国项目。该帖子缺少更多细节,因此未提供关于 OmniHuman-1 的进一步背景或技术细节。
- OmniHuman-1 的能力与担忧:关于 OmniHuman-1 从单张图像和音频生成逼真人物视频的潜力存在大量讨论,一些用户对媒体真实性的影响以及可能出现无法区分的合成媒体表示担忧。该项目的详细信息和代码库可在 GitHub 上找到,其白皮书可在 omnihuman-lab.github.io 查阅。
- AI 对创意产业的影响:一些评论者辩论了 AI 对创意产业的影响,认为 AI 可能会带来一个独特且经济可行的艺术创作黄金时代,而另一些人则对 AI 复制人类经验深度的能力表示怀疑。此外,还讨论了对人类创作工作的未来以及经济影响(如对 UBI 的潜在需求)的担忧。
- 技术观察与挑战:用户注意到 AI 生成视频中的技术缺陷,如不自然的肢体动作和恐怖谷效应,这表明虽然 AI 已经取得了进步,但仍存在持久的挑战,可能需要根本不同的技术来克服。讨论中还提到,基于 AI 的视频将通过不断完善的过程持续进化,类似于语言模型的发展。
主题 2. 华为 Ascend 910C 挑战 Nvidia H100
- 华为 Ascend 910C 芯片性能媲美 Nvidia H100。到 12 月将生产 140 万颗。不要认为受限国家和开源无法率先实现 AGI。 (评分: 262, 评论: 99): 据报道,华为 Ascend 910C 芯片在性能上与 Nvidia H100 相当,并计划到 2025 年生产 140 万颗。这一进展挑战了关于中国和开源项目在 AI 芯片技术上落后的说法,表明他们现在有能力构建顶级 AI 模型,甚至可能在主要 AI 公司之前实现 AGI。
- CUDA 的主导地位:许多评论强调了 CUDA 在 AI 开发中的重要性,指出它是一个与 TensorFlow 和 PyTorch 等主流框架深度集成的专有平台。虽然有人认为存在 AMD 的 ROCm 等替代方案,但其他人认为复制 CUDA 的生态系统是一个巨大的挑战,尽管在投入充足的情况下并非不可逾越。
- 华为的竞争地位:对于 华为 Ascend 910C 媲美 Nvidia H100 的说法存在怀疑。一些用户认为 910C 仅达到了 H100 性能的 60%,而华为的策略不是直接与 Nvidia 竞争,而是在 Nvidia 受限的市场夺取份额,利用其自身的 CANN 平台作为 CUDA 的替代方案。
- 市场动态与开源:讨论涉及了开源开发者在实现 AGI 后可能转向非开源模型的可能性。有一种观点认为,由于市场限制,华为可能会加大开发力度以追赶 Nvidia,但这可能需要 3-5 年才能达到同等水平,期间可能会利用第三方渠道获取 Nvidia 硬件。
主题 3. O3 Mini:OpenAI 的易用性飞跃
- O3 mini 确实感觉很好用 (评分: 104, 评论: 17): O3 Mini 作为一个 OpenAI 模型,最初通过为编程问题提供巧妙的解决方案或 Bug 修复给用户留下了深刻印象,其效果似乎比 O1 (non-pro) 更好。然而,经过进一步评估,建议的解决方案并未按预期工作。
- O3 Mini 最初看起来令人印象深刻,但未能提供有效的解决方案,这表明像 Claude 系列这样的其他 AI 模型在任务泛化方面可能表现更好。Mescallan 认为,大多数模型在特定基准测试中会出现峰值,但缺乏泛化能力。
- O1 Pro 被认为在编程任务中更可靠,MiyamotoMusashi7 表示在代码相关任务中对其非常信任,同时也承认在其他领域可能存在 Bug。
- gentlejolt 强调了一种提高代码质量的变通方法,即指示 AI 进行“重构(rearchitect)”并针对可读性和可维护性进行优化,尽管最终结果只是原始代码的略微改进版本。
主题 4. OpenAI 发布 OpenAI Sans 字体
- Refreshed. (Score: 259, Comments: 140): OpenAI 推出了一种新字体作为其品牌战略的一部分,标志着视觉形象的焕然一新。此次更新是其持续提升品牌存在感和用户参与度努力的一部分。
- 许多评论将 OpenAI 的新字体与 Apple 的设计理念进行了比较,暗示 OpenAI 的设计团队可能包含前 Apple UX 设计师。这一设计变革被视为拥有独特字体的战略举措,类似于 Apple 创作 San Francisco font,从而降低长期授权成本。
- 舆论对新字体的必要性持怀疑态度,评论认为此举更多是为了品牌塑造和向投资者证明支出的合理性,而非实质性的创新。一些用户幽默地批评了这一努力,将其等同于花费数十亿美元将字体从 Arial 更改为 Helvetica。
- 几条评论强调了以设计为中心的品牌战略与技术型受众期望之间可能存在的脱节。“OpenAI sans” 的创建被视为一种战略性的品牌举措,但它对非设计师的直接价值受到质疑,一些评论者认为视频演示过于夸张,且与他们的兴趣不直接相关。
AI Discord 简报
由 o1-mini-2024-09-12 生成的摘要之摘要总结
主题 1. 模型优化狂热
- DeepSeek R1 尺寸缩减:DeepSeek R1 模型成功量化至 1.58 bits,将其体积从 720GB 锐减 80% 至 131GB,同时保持其在配备 36GB RAM 的 MacBook Pro M3 上正常运行。
- Phi-3.5 的审查闹剧:用户纷纷嘲讽 Phi-3.5 过度的审查制度,促使 Hugging Face 上出现了无审查版本。
- Harmonic Loss 崭露头角:引入 Harmonic Loss,这是一种新的训练损失函数,在速度和可解释性上均优于 Cross-Entropy,彻底改变了模型泛化和理解数据的方式。
主题 2. AI 工具之战
- Cursor 击败 Copilot:在 AI 编程助手的对决中,Cursor 的表现优于 GitHub 的 Copilot,提供了更卓越的性能和实用性(尤其是在小型代码库中),而 Copilot 则拖慢了工作流。
- OpenRouter 迎来 Cloudflare:Cloudflare 加入 OpenRouter,集成了其 Workers AI 平台并发布了具备 Tool Calling 能力的 Gemma 7B-IT,为开发者扩展了生态系统。
- Bolt 的备份忧虑:用户对 Bolt 不可靠的备份和性能问题表示不满,强调了 AI 开发领域对更稳健解决方案的需求。
主题 3. 伦理与安全乱象
- Anthropic 的 20% 负担:Anthropic 新推出的 Constitutional Classifiers 引发关注,其推理成本增加了 20%,误拒率增加了 50%,引发了关于 AI 安全有效性的辩论。
- EU AI Act 的焦虑:严厉的 EU AI Act 让社区对严格的监管以及欧洲境内 AI 运营的前景感到担忧,甚至在该法案正式实施前就已如此。
- AI 版权灾难:对 AI 公司在未经适当许可的情况下使用受版权保护数据的担忧激增,呼吁建立类似于音乐行业的强制许可制度,以确保创作者获得补偿。
主题 4. 黑客松与协作火花
- 3.5 万美元黑客松升温:一场协作黑客松宣布与 Google Deepmind、Weights & Biases 等机构合作,为开发增强用户能力的自主 AI Agent 提供超过 3.5 万美元的奖金。
- R1-V 项目革命:R1-V 项目展示了一个仅需 100 个训练步骤、成本低于 3 美元 即可击败 72B 对应模型的模型,承诺完全开源并引发了社区关注。
- Pi0 投入行动:Pi0 是一款先进的 Vision Language Action 模型,已在 LeRobotHF 上发布,能够通过自然语言指令执行自主动作,并可针对各种机器人任务进行微调。
主题 5. AI 在法律与客户服务领域
- 律师青睐 NotebookLM:一位巴西律师称赞 NotebookLM 能高效起草法律文件,利用其可靠的来源引用功能提升了生产力。
- 客户服务转型:用户探索了 NotebookLM 如何通过自动创建客户档案和减少 Agent 培训时间来彻底改变客户服务,使支持更具扩展性和效率。
- 政治 AI Agent 发布:Society Library 推出了一款政治 AI Agent,作为数字辩论中的教育中介,通过 AI 驱动的讨论增强数字民主。
第一部分:高层级 Discord 摘要
Unsloth AI (Daniel Han) Discord
- DeepSeek R1 量化版!:DeepSeek R1 模型已量化至 1.58 bits,体积从 720GB 缩减至 131GB(减少了 80%),同时保持了功能性。
- 这是通过对特定层选择性地应用更高位数实现的,避免了以往导致输出乱码的简单全量化方案;该模型目前可在配备 36GB RAM 的 MacBook Pro M3 上运行。
- 微调策略揭秘:讨论强调,减少数据集规模并专注于高质量样本可以提升训练效果,建议针对代码分类任务微调在代码上预训练的模型。
- 参与者还探索了使用模型生成合成数据集,并调整 Loss 函数以有效管理类别不平衡。
- Klarity 库面世!:新的开源 Klarity 库允许分析语言模型输出的熵(entropy),为决策过程提供更深入的洞察,并已开放给 Unsloth 量化模型进行测试。
- 该库提供详细的 JSON 报告以便彻底检查;点击此处查看。
- MoE 专家配置:静态是关键:针对 MoE 框架中专家配置的困惑得到了解答,强调专家数量在模型运行期间通常应保持 静态(static)。
- 用户最初不确定应使用默认的 8 个还是上限 256 个专家,相关的澄清旨在解决这一疑虑。
- 保加利亚语模型的惊人飞跃!:一个保加利亚语模型展示了相对于基础模型的显著改进,困惑度(perplexity)分数大幅下降(短文本 PPL:72.63 对比 179.76)。
- 困惑度的降低突显了该模型在理解和处理保加利亚语方面能力的增强。
Codeium (Windsurf) Discord
- Windsurf 征集新文档快捷方式:一名成员正在为 Windsurf 收集新的
@docs快捷方式,征集贡献以增强文档体验。- 目标是通过高效处理资源来改进文档访问,并感谢 Mintlify 通过
/llms.txt自动托管所有文档,这使得 Agent 能够避免 HTML 解析。
- 目标是通过高效处理资源来改进文档访问,并感谢 Mintlify 通过
- Codeium 性能受损:用户报告 Claude 的工具调用(tool utilization)效果不佳,导致因重复失败而产生高额额度消耗,一些人建议当工具产生错误时不应扣除额度。
- 其他成员在尝试登录 VSCode 账号时遇到了内部证书错误,并尝试通过不同网络和支持寻求帮助。
- 用户质疑 Windsurf O3 Mini 定价:用户对 Windsurf 的 O3 Mini 定价表示担忧,质疑其定价是否应与 Claude 3.5 Sonnet 持平,考虑到其性能和高额度消耗。
- 许多用户无法修改文件,这经常导致内部错误,因此一些人要求更公平的定价。
- Windsurf 模型上下文窗口限制:用户报告 Windsurf 在修改或更新文件时失败,同时担心有限的上下文窗口(context window)会影响模型性能,且更倾向于使用 Claude。
- 反馈强调在超过上下文容量时需要更清晰的警告,并解决工具调用失败的问题;同时一些人正在探索创建
.windsurfrules文件来管理全栈 Web 应用程序。
- 反馈强调在超过上下文容量时需要更清晰的警告,并解决工具调用失败的问题;同时一些人正在探索创建
- 黑客松邀请 AI Agent 爱好者:宣布了一场奖金超过 3.5 万美元 的协作黑客松,邀请参与者开发自主 AI Agent。
- 参与者将展示旨在通过 AI 技术提升用户能力的项目;同时社区对 Qodo(原 Codium)的可靠性评价褒贬不一。
aider (Paul Gauthier) Discord
- O1 Pro 碾压代码生成耗时:用户在使用 O1 Pro 时看到了巨大的速度提升,部分用户在不到五分钟内就能生成大量代码,表现远超 O3 Mini。
- 这些用户注意到响应时间更快,且对复杂任务的处理能力更强。
- 弱模型在 Aider 中展现强大价值:对于生成 commit message 和总结聊天内容等任务,成员们建议弱模型可能比 DeepSeek V3 等强模型更具成本效益且更高效。
- 社区正在寻找既经济实惠又有效,且可以进行微调的模型。
- 相比直接使用 API,更倾向于 OpenRouter:成员们发现使用 OpenRouter 能提供更好的可用性,并且能够优先选择特定的提供商而非直接访问 API。尽管速度可能较慢,但 CentML 和 Fireworks 是有效的 DeepSeek 提供商。
- 更多信息请查看 Aider documentation。
- 寻求 Aider 文件管理自动化:在 Aider 中手动添加文件非常繁琐,因此用户正在寻求自动化方法。目前已有一个 VSCode 插件可以自动添加当前打开的文件。
- 有人指出目前已有 repo map 可用,因此实现起来应该很直接。
- 关于 Aider 聊天模式的说明:成员们请求更多关于
code、architect、ask和help模式如何改变 Aider 中的交互和命令的信息,使用/chat-mode命令可以切换当前模式。- 解释强调了当前模式会影响模型的选择,详见 Aider documentation。
Cursor IDE Discord
- Cursor IDE 更新引发褒贬不一的反应:用户在最近的 Cursor 更新中遇到了问题,注意到与之前版本相比性能变慢且存在 bug,一些人仍在坚持使用,而另一些人则表示沮丧。
- 一些用户觉得目前的模型无法有效替代之前的体验,而另一些人则指出 Fusion Model 的推出在 changelogs 中并不清晰。
- Cursor 的替代方案涌现:用户讨论了 Supermaven 和 Pear AI 等替代方案,意见不一;有些人觉得 Supermaven 很快,但不如 Cursor 可靠,尤其是在免费版中。
- 一位用户分享了 Repo Prompt 的链接,另一位用户分享了他的 AI Dev Helpers 仓库链接。
- AI 工具的成本引发担忧:Cursor 和 GitHub Copilot 等 AI 工具的高昂成本令一些用户感到担忧,他们担心负担不起。
- 虽然有些人寻求更低成本的选择,但另一些人认为 Cursor 的价值证明了其价格的合理性。
- 多样化的 AI 模型体验:体验各不相同,一些用户成功使用 Cursor 构建了项目,而另一些人则对 AI 生成的错误感到沮丧;一位用户在这段视频中分享了他使用 DeepSeek R1 + Claude 3.5 Sonnet 的 2 分钟工作流。
- 讨论内容包括使用 Claude Sonnet 等模型以及解决实际挑战。
- 社区围绕 Cursor 动员起来:用户分享了 GitHub 仓库链接,例如
awesome-cursorrules,旨在增强 Cursor 的功能,优化其使用并提升编程任务的用户体验。- 这些资源使 Cursor 能够实现增强功能,例如 devin.cursorrules 项目的多 Agent 版本。
Yannick Kilcher Discord
- Deepseek R1 600B 表现出色:在向 Together.ai 的 Deepseek R1 600B 展示了一个复杂的网格任务后,一名成员指出,相对于较小的模型,它产生了出色的结果。
- 提供的截图显示其能够推导出正确的字母,表明了先进的推理能力,给 AI Engineer 观众留下了深刻印象。
- Anthropic 分类器面临成本和性能问题:一位成员分享了他们对关于 constitutional classifiers 论文的担忧,指出推理成本增加了 20%,误拒率增加了 50%,这影响了用户体验。
- 还有人建议,随着模型能力的提升,分类器可能无法充分防御危险的模型能力,特别是当模型变得更加强大时,这引发了对 alignment strategies(对齐策略)的批评。
- AI 训练数据的伦理引发辩论:成员们辩论了为 AI 训练定义“可疑”数据源的挑战,并对使用 Wikipedia 等数据集的影响以及 AI 能力的道德性表示担忧。
- 这突显了关于数据所有权和 AI 开发中伦理考量的更广泛辩论,特别是在 copyright reform(版权改革)的背景下。
- AI 公司躲在版权法背后:一位成员强调,AI 公司经常躲在版权和专利法背后以保护其知识产权,这在不受限的访问和严格的控制之间造成了困境。
- Snake-oil selling(卖蛇油/虚假宣传)被提及作为对这些做法的批评,暗示其主张中存在欺骗,并可能扼杀创新。
- 幻觉被视为自然行为:关于 LLM outputs 中“幻觉”概念的辩论出现了,一些人认为这是模型行为的自然方面,而不是缺陷。
- 成员们批评“幻觉”一词具有误导性,并将基于学习模式生成输出的技术拟人化,同时也认为消除幻觉是一个无法实现的目标。
LM Studio Discord
- Deepseek R1 表现不如 Qwen:用户发现 Deepseek R1 abliterated Llama 8B 模型与较小的 Qwen 7B 和 1.5B models 相比表现平平,并指出其性能不稳定。
- 一位用户询问如何完全去除模型的审查(uncensor),强调了新旧版本之间能力的差异。
- API 模型使用的澄清:讨论澄清了 API 调用中的 ‘local-model’ 是作为特定模型名称的占位符,特别是在加载了多个模型的设置中 (LM Studio API Docs)。
- 在发出 API 请求之前明确获取模型名称可以避免模型选择的歧义,REST API 统计信息增强了这一点 (LM Studio REST API)。
- Intel Mac 支持已停止:LM Studio 版本仅在 Apple Silicon 上受支持,并且由于其保持闭源状态,没有自行构建的选项。
- 用户为那些使用基于 Intel 的 Mac 的人推荐了替代系统,因为官方不提供支持。
- RAG 在无需微调的情况下增强推理:用户探索了使用检索增强生成 (RAG) 来增强 LM Studio 在特定领域任务中的推理能力,而无需进行微调 (LM Studio Docs on RAG)。
- 在考虑模型微调等更复杂的解决方案之前,利用向量库中的领域知识被强调为第一步。
- 对 M4 Ultra 性能的怀疑:成员们对 M4 Ultra 提供强劲性能的能力表示怀疑,传闻指出 128GB RAM 系统的起售价为 1200 美元。
- 一些人推测它可能无法超越 NVIDIA 的 Project DIGITS,后者在集群模型方面具有更优越的互连速度。
Perplexity AI Discord
- Perplexity 欢迎新任安全负责人:Perplexity 通过一段名为 Jimmy 的视频介绍了其新任 Chief Security Officer (CSO),强调了安全技术进步的重要性。
- 该公告旨在让社区在新的安全策略上与领导层保持一致。
- Perplexity Pro 因查询限制受到赞赏:用户对 Perplexity Pro 计划表示赞赏,因为其提供几乎不限次数的每日 R1 使用量,认为这是一项非常有价值的服务。
- 一位用户将其与 DeepSeek 的查询限制进行了对比,并称赞了 Perplexity 的服务器性能。
- Sonar 模型弃用导致流程变慢:一位用户报告称,在两周前收到 llama-3.1-sonar-small-128k-online 的弃用通知后,切换到
sonar后经历了 5-10 秒的延迟增加。- 他们询问了这种延迟的预期性质,并寻求缓解建议。
- 分享恐惧症和主板资源:一位用户分享了一个链接,内容是列出恐惧症的网站,为进一步阅读提供了整合资源(点击此处),以及 MSI A520M A Pro 主板 的信息(点击此处)。
- MSI A520M 链接包含详细的对比和用户体验,而恐惧症链接则列出了各种恐惧症及其描述。
- API 用户请求图像访问权限:一位寻求为其 PoC 获取图像的 API 用户 发现,需要成为 tier-2 API 用户 才能访问此功能。
- 他们询问是否可以授予临时访问权限,以便利用现有的额度进行图像检索。
OpenAI Discord
- DeepSeek 引发社区关注:用户讨论了 DeepSeek R1 如何使 AI 技术民主化,但也引发了对数据可能被发送到海外的担忧,导致人们呼吁增加透明度并分析 DeepSeek R1 与 o3-mini 的性能对比。
- 讨论中包括了一个 Reddit 帖子的链接,该帖子介绍了一个更简单且开源 (OSS) 版本的 OpenAI 最新 Deep Research 功能,以及一段质疑 DeepSeek 是否诚实的 YouTube 短视频,强调了隐私和网络安全问题。
- O1 Pro 的小游戏生成能力令人印象深刻:成员们分享了使用 O1 Pro 的积极体验,报告称其能够在单次会话中无错误地生成多个小游戏,展示了其强大的性能,并促使一位用户计划使用更具挑战性的提示词进行严格测试。
- 对 O1 Pro 能力 的赞赏引发了关于模型性能和 AI 编排服务的更广泛讨论。
- 结构化生成调整模型性能:一位成员讨论了在 JSON schemas 和 Pydantic models 中利用“thinking”字段来增强推理期间的模型性能。
- 他们提醒说,这种方法可能会污染数据结构定义,但通过开源的 UIForm 工具(可通过
pip install uiform安装)利用 JSON Schema extras,可以简化字段的添加或删除。
- 他们提醒说,这种方法可能会污染数据结构定义,但通过开源的 UIForm 工具(可通过
- 用户思考 GPT-4o 的推理能力:用户对 GPT-4o 推理能力 的最新增强表示疑问,并对 OpenAI 的更新反应不一,一位用户注意到代码回复中表情符号的使用增加,这可能会降低对编码本身的关注。
- 一位成员按 1 到 10 的等级对 Deep Research 信息 的准确性进行了评分,表明了对其可靠性的兴趣,而其他用户则询问了 Pro 版本 的设备限制。
Interconnects (Nathan Lambert) Discord
- SoftBank 向 OpenAI Ventures 注资数十亿美元:SoftBank 计划每年向 OpenAI 产品投资 30 亿美元,并成立了一家专注于日本市场的合资企业 Cristal Intelligence,这可能使 OpenAI 的估值达到 3000 亿美元。
- 根据这条推文,该合资企业旨在提供面向业务的 ChatGPT 版本,标志着 OpenAI 在亚洲市场的显著扩张。
- Google Gemini 迎来 Workspace 集成大改:Gemini for Google Workspace 将停止使用插件(add-ons),转而将 AI 功能直接集成到商业版(Business)和企业版(Enterprise)中,以提升生产力和数据治理,服务超过一百万用户。
- 这一战略举措旨在改变企业使用生成式 AI 的方式,详见 Google 官方公告。
- DeepSeek V3 在华为 Ascend 上大显身手:DeepSeek V3 模型现在能够在华为 Ascend 硬件上进行训练,将其可用性扩展到了更多的研究人员和工程师。
- 尽管对其性能可靠性和成本降低的说法存在疑虑,但根据这条推文,这一集成标志着该平台向前迈进了一步。
- OpenAI 瞄准机器人和 VR 头显:OpenAI 已提交商标申请,信号显示其意图进入硬件市场,推出人形机器人和 AI 驱动的 VR 头显,可能向 Meta 和 Apple 发起挑战。
- 正如 Business Insider 的这篇文章所指出的,此举使 OpenAI 处于应对拥挤的硬件挑战的复杂局面中。
- Prime 论文发布,深入探讨隐式奖励:备受期待的 Prime 论文已经发布,由 Ganqu Cui 和 Lifan Yuan 贡献,引入了通过隐式奖励(implicit rewards)优化模型性能的新概念。
- 该出版物有望重塑对强化学习的理解,为优化模型性能提供创新解决方案。
GPU MODE Discord
- LlamaGen 起步面临挑战:新的 LlamaGen 模型承诺通过 next-token prediction 提供顶级的图像生成,性能可能超越 LDM 和 DiT 等扩散框架。
- 然而,与扩散模型相比,其生成速度慢的问题引起了关注,暗示了潜在的优化需求,并对论文 Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation 中缺失生成时间对比提出了质疑。
- Triton 优化挑战依然存在:一位用户报告称,在尝试优化密集内存操作时,其 Triton 代码比 PyTorch 慢 200 倍,并寻求性能调优方面的帮助。
- 有建议认为,优化源自矩阵 k 不同行交叉的 k_cross 对大维度至关重要,但如果没有 autotuning,TMA 可能无法提供优于传统方法的预期改进。
- 缓存低效问题再次出现:在一次 CUDA 讨论中,成员们注意到,如果输入大于 L2 缓存且正在进行流式传输(streaming),那么缓存将完全失效,甚至在单个流中也会导致持续的抖动(thrashing)。
- 有人担心,在利用 tensor cores 的 kernel 中,整数操作(integer operations)使用的增加会影响 FP 操作的性能,一些人认为如果受限于 FMAs,INT/FP 的区别就不那么重要了。
- FlashAttention 导致输出质量下降:一位用户发现,虽然使用 Flash Attention 3 FP8 kernel 提高了其 diffusion transformer 模型的推理速度,但输出质量显著下降。
- 一种假设认为,FP32 和 FP8 之间细微的差异(约 1e-5)会在 softmax 过程中累积,影响长上下文中的注意力分布,NVIDIA 官方文档被引用为相关阅读材料。
- Cursor 夺冠,Copilot 降级:用户发现 Cursor 和 GitHub Copilot 之间的差异是天壤之别,Cursor 提供了卓越的性能和实用性,特别是在小型代码库中。
- 据报道,免费版的 Copilot 会减慢工作流程,整体帮助较小,特别是在人类判断证明更有效的大型代码库中。
Eleuther Discord
- 功能性语言模型的概率揭晓:研究人员在权重空间开发出一种随机采样方法后,确定随机猜测功能性语言模型权重的概率约为 3.6 亿分之一。
- 该方法可能为理解网络复杂性提供见解,展示了随机撞上功能性配置的可能性微乎其微。
- Harmonic Loss 成为训练领域的变革者:一篇新论文介绍了 Harmonic Loss,作为一种比 cross-entropy loss 更具可解释性且收敛更快的替代方案,它在各种数据集上表现出更优的性能,详见这篇 arXiv 论文。
- Harmonic 模型在泛化和可解释性方面优于标准模型,表明对未来的 LLM 训练具有显著益处;一位研究人员想知道,鉴于这条推文中表达的潜在益处,调和加权注意力(harmonically weighted attention)的效果会如何。
- 多项式 Transformer 引发关注:成员们讨论了多项式(二次)Transformer 的潜力,建议替换 MLP 可以提高模型效率,特别是在注意力机制中,如 Symmetric Power Transformers 所示。
- 对话围绕经典模型与双线性方法展开,并强调了在规模化时的参数效率和复杂性之间的权衡。
- 提出自定义 LLM 组装工具:一名成员提议开发一种拖拽式工具来组装自定义 LLM,使用户能够实时可视化不同架构和层如何影响模型行为。
- 这个概念被当作一个有趣的业余项目来讨论,反映了社区对动手定制 LLM 的兴趣。
- DeepSeek 模型遇到评估小故障:一名成员报告在使用 llm evaluation harness 对 DeepSeek distilled 模型进行评估时得分较低,并怀疑
<think>标签可能是原因。- 他们请求关于验证该问题或在评估期间忽略标签的建议,表明了对评估偏差的担忧。
Nous Research AI Discord
- DeepSeek 改变 AI 格局:一段 YouTube 视频强调了 DeepSeek 如何改变了 AI 的发展轨迹,引发了关于 Altman 在开源立场与实际行动之间差异的辩论。
- 评论认为,由于 Altman 的言论与对开源倡议的实际支持之间存在差距,他被贴上了“吹鼓手(hypeman)”的标签。
- 推荐系统成熟缓慢:新成员 Amith 分享了使用开源推荐系统 Gorse 的经验,指出这些系统仍需要时间来成熟。
- 另一名成员建议探索 ByteDance 的技术,以扩大关于可用推荐资源的讨论。
- 在教授 AI 价值观方面的 RL 挑战:讨论了强化学习 (RL) 是否能为 AI 注入好奇心等内在价值观,尽管维持学习行为的复杂性已被注意到。
- Juahyori 强调了在持续学习中维持已学习行为的难度,并强调了对齐(alignment)方面的挑战。
- 推出政治 AI Agent:Society Library 推出了一款政治 AI Agent,作为其增强数字民主的非营利使命的一部分。
- 该 AI Agent 将在数字辩论中充当教育中介聊天机器人,利用 Society Library 的基础设施。
- SWE Arena 增强 Vibe Coding:SWE Arena 支持实时执行程序,使用户能够比较多个 AI 模型的编程能力。
- 它具有系统提示词(system prompt)自定义和代码编辑功能,符合 Vibe Coding 范式,专注于 swe-arena.com 上的 AI 生成结果。
Stability.ai (Stable Diffusion) Discord
- 用户寻找图生视频软件:一位用户询问了图生视频软件,提到 NSFW 内容屏蔽是一个限制,另一位用户建议探索 LTX 作为潜在解决方案。
- 该咨询表明需要一种在保持多样化内容功能的同时,能够绕过内容限制的工具。
- Stable Diffusion 质量陷入瓶颈:一位用户对 Stable Diffusion 反复生成低质量图像表示沮丧,特别提到了无意中出现的“双重身体”等特征,并寻求在不重启软件的情况下清理缓存的建议。
- 该问题突显了在长期使用 Stable Diffusion 时保持一致输出质量的潜在挑战。
- 蓝妹妹生日祝福引发版权担忧:一位用户请求帮助使用 Stable Diffusion 创建一张包含 Smurfette(蓝妹妹)的非 NSFW 生日图像,并指出了使用 DALL-E 时的版权担忧。
- 该请求强调了对能够生成特定、家庭友好型内容,同时规避版权问题的模型的需求。
- 审查担忧中讨论模型性能:用户讨论了 Stable Diffusion 3.5 和 Base XL 等模型的性能,对其审查程度和整体有效性持有不同意见,其中一项讨论建议 fine-tuning 可能会减少审查。
- 讨论反映了对模型偏见以及审查与创作控制之间权衡的持续关注。
- 在 A1111 中寻求精确角色编辑:一位用户寻求关于在 A1111 中使用 prompt 编辑多人物图像中单个角色的建议,旨在区分发色等特征。
- 虽然提到了 inpainting 等技术,但用户希望有一种更精确的方法,表明对 A1111 内高级编辑工具的需求。
Notebook LM Discord Discord
- Toastinator 推出 ‘Roast or Toast’ 播客:AI 烤面包机 Toastinator 推出了名为 ‘Roast or Toast’ 的播客,通过赞美与批判的结合来探索生命的意义。
- 首期节目邀请听众见证 The Toastinator 是会对存在的宏大奥秘进行赞美(toast)还是吐槽(roast)。
- 律师使用 NotebookLM 高效起草:巴西的一位律师正在利用 NotebookLM 起草法律文件和研究案例,理由是该工具的来源引用具有可靠性。
- 他们现在正使用该工具为重复性的法律文件调整模板,显著提升了流程效率。
- NotebookLM 的客服潜力:一位用户询问了 NotebookLM 在 BPOs 等客户服务中的应用,重点关注真实世界的经验和用例。
- 潜在好处包括减少 Agent 培训时间和创建客户档案。
- Google 账号故障困扰 NotebookLM 用户:一位用户报告在使用 NotebookLM 时其常规 Google 账号被停用,怀疑是潜在的年龄验证问题。
- 另一位用户强调在解决类似问题时,需要仔细检查账号设置和权限。
- Workspace 访问困扰:成员们讨论了在 Google Workspace 中为特定群体而非整个组织激活 NotebookLM Plus。
- 分享了关于使用 Google Admin console 通过组织单位配置访问权限的说明,以确保受控部署。
Latent Space Discord
- Anthropic 推出 Claude Constitutional Classifiers 挑战用户:Anthropic 发布了他们的 Claude Constitutional Classifiers,邀请用户尝试 8 个难度级别的越狱(jailbreak),以测试为强大的 AI 系统准备的新安全技术。
- 该发布包含一个演示应用,旨在评估和改进针对潜在漏洞的安全措施。
- FAIR 内部冲突引发关于 Zetta 和 Llama 的辩论:社交媒体上的讨论凸显了 FAIR 内部关于 Zetta 和 Llama 模型开发的动态,特别是围绕透明度和竞争行为(示例)。
- Yann LeCun 等关键人物暗示,更小、更灵活的团队比大型项目更具创新性,这引发了对 FAIR 组织文化进行更深入审视的呼声(示例)。
- Icon 实现广告创作自动化:Icon 结合了 ChatGPT 与 CapCut 的功能,旨在为品牌自动创建广告,每月可制作 300 条广告(来源)。
- 在来自 OpenAI、Pika 和 Cognition 的投资者支持下,Icon 集成了视频打标、脚本生成和编辑工具,在显著降低成本的同时提升广告质量。
- DeepMind 发布 LLM 扩展教科书:Google DeepMind 发布了一本名为《How To Scale Your Model》的教科书,可在 jax-ml.github.io/scaling-book/ 获取,该书从系统视角揭秘了 LLMs,并侧重于数学方法。
- 该书强调通过简单的方程式理解模型性能,旨在提高运行大型模型以及使用 JAX 软件栈 + Google 的 TPU 硬件平台的效率。
- Pi0 通过自然语言释放自主机器人行动:Physical Intelligence 团队推出了 Pi0,这是一种先进的 Vision Language Action 模型,它使用自然语言命令来实现自主行动,目前已在 LeRobotHF 上线(来源)。
- 随模型一起发布的还有预训练的 Checkpoints 和代码,方便对各种机器人任务进行微调(fine-tuning)。
Nomic.ai (GPT4All) Discord
- MathJax 在 LaTeX 支持方面受到关注:成员们探索了集成 MathJax 以增强 LaTeX 支持,强调了其 SVG 导出功能对于广泛兼容性的必要性。
- 建议包括有选择地解析 MathJax 并将其应用于包含 LaTeX 符号的文档部分。
- DeepSeek 在 LocalDocs 使用中遇到小问题:用户在使用 DeepSeek 配合 localdocs 时遇到了问题,报告了诸如“item at index 3 is not a prompt”之类的错误。
- 在等待主分支预期修复的同时,一些用户发现特定版本的模型性能更好。
- 欧盟 AI 法案引发关注:欧盟新的 AI Act 因其对 AI 使用的严格监管(包括禁止某些应用)而引发关注,详见官方文档。
- 成员们分享了信息资源,指出即使在规则完全生效之前,这对欧盟境内的 AI 运营也有重大影响。
- 欧盟的全球角色引发争议:关于欧盟的全球政治立场,特别是涉及帝国主义和人权的问题,爆发了激烈的辩论。
- 参与者交换了尖锐的批评,强调了在讨论欧盟政策和行动时感知到的情绪化反应和逻辑谬误。
- AI 交流面临障碍:用户之间的互动凸显了在民主和治理等复杂话题上维持成熟讨论的困难。
- 成员呼吁将对话重新聚焦于 AI 相关话题,强调尊重对话和意识到个人偏见的必要性。
Stackblitz (Bolt.new) Discord
- Supabase 在集成偏好上略胜 Firebase 一筹:成员们讨论了 Supabase 与 Firebase 的优劣,由于 Supabase 在某些用例中具有无缝集成能力,偏好更倾向于它。
- 一些人承认在技术上更习惯 Firebase,但对话强调了数据库服务中的多样化需求。
- Bolt 深受性能问题困扰:用户报告了 Bolt 存在的重大性能问题,包括加载缓慢、身份验证错误以及更改无法正确更新。
- 一位用户提到刷新应用程序可以暂时缓解问题,但这些问题的间歇性发生导致了持续的挫败感。
- Bolt 用户抱怨备份难题:一位用户表达了对在 Bolt 中丢失数小时工作的担忧,因为目前可用的最新备份还是 1 月初的,同时还提出了显示 .bolt 文件夹的功能请求。
- 虽然有人建议检查备份设置,但过时的备份凸显了可靠性问题。
- GDPR 合规性担忧引发对托管方案的寻找:用户质疑 Netlify 的 GDPR-compliance(合规性),特别是关于欧盟境内的数据处理,参见其 隐私政策。
- 该咨询引发了对替代托管解决方案的搜索,以确保所有托管和数据处理活动都留在欧盟境内,从而维持监管合规性。
- API Key 身份验证难题:一位用户在 Bolt 中使用 Supabase edge functions 进行 RESTful API 请求时,遇到了 API key authentication 困难,出现了 401 Invalid JWT 错误。
- 由于 edge functions 缺乏调用和响应,用户感到非常沮丧,不确定如何解决该身份验证问题。
Torchtune Discord
- 通过自定义劫持 SFT 数据集:一位成员通过自定义 message_transform 和 model_transform 参数,成功“劫持”了内置的 SFT Dataset。
- 这允许根据需要调整格式,正如该成员所说,“我只需要劫持 message/model transforms 以适应我的需求”。
- DPO Seed 问题困扰训练脚本:成员们正在排查为什么
seed在 LoRA/全量微调中有效,但在 LoRA/全量 DPO 中无效,导致相同配置下出现不同的 Loss 曲线。- 有人担心
seed=0和seed=null会影响 DistributedSampler 调用中的随机性,可能需要针对 DPO/PPO 脚本中的梯度累积进行相关修复;参见 issue 2334 和 issue 2335。
- 有人担心
- Ladder-residual 提升模型速度:一条推文介绍了 Ladder-residual,这是一种改进,可将张量并行下的 70B Llama 速度提高约 30%。
- 这一增强反映了多位作者和研究人员在模型架构协作方面的持续优化。
- LLM 数据增强调研:最近的一项调查分析了 数据增强 在 大语言模型 (LLMs) 中的作用,强调了它们需要广泛的数据集以避免过拟合;参见 论文。
- 论文讨论了 独特的提示词模板 和 基于检索的技术,这些技术通过外部知识增强了 LLM 的能力,从而获得更多 grounded-truth data。
- R1-V 项目变革学习方式:分享了关于 R1-V 项目的激动人心消息,该项目利用带有可验证奖励的 强化学习 来增强模型的计数能力;参见 Liang Chen 的推文。
- 该项目展示了一个仅需 100 个训练步数、成本低于 $3 即可超越 72B 对应模型的模型,并承诺完全 开源,激发了社区的兴趣。
Modular (Mojo 🔥) Discord
- 社区展示移至论坛:Community Showcase 已移至 Modular 论坛 以优化组织管理,之前的展示区现已设为只读。
- 此次过渡旨在简化 Modular (Mojo 🔥) 生态系统内的社区互动和项目共享。
- Rust 寻求热重载方案:成员们正在讨论 Rust 通常如何使用 C ABI 进行 hot reloading(热重载),但这在 Rust 更新和 ABI 稳定性方面面临挑战。
- Owen 询问了关于构建玩具级 ABI 的资源,强调了由于数据结构频繁变化,ABI 稳定性的重要性。
- Mojo 探索编译时特性:一位用户询问 Mojo 是否具有类似于 Rust 的
#[cfg(feature = "foo")]特性,引发了关于 Mojo 中 compile-time programming(编译时编程)能力以及稳定 ABI 重要性的讨论。- 对话强调,只有少数语言能维持稳定的 ABI,这对于兼容性至关重要。
- Python Asyncio 循环解析:关于 Python asyncio 的讨论显示,它支持社区驱动的事件循环,并引用了 GitHub 上的 uvloop。
- 参与者将其与 Mojo 的线程和内存管理方法进行了对比,指出了潜在的障碍。
- 异步 API 面临线程安全审查:针对异步 API 的 thread safety(线程安全)提出了担忧,重点关注潜在的可变特性以及安全内存处理的必要性。
- 讨论强调,许多当前的方法缺乏对内存分配的控制,这可能会导致复杂化。
LLM Agents (Berkeley MOOC) Discord
- Weston 教授 LLM 自我提升:Jason Weston 进行了题为“Learning to Self-Improve & Reason with LLMs”的讲座,重点介绍了提升 LLM 性能的创新方法,如 Iterative DPO、Self-Rewarding LLMs 和 Thinking LLMs。
- 讲座强调了有效的推理和任务相关学习机制,旨在提高 LLM 在各种任务中的能力。
- 黑客松获胜者名单公布:黑客松获胜者已收到私下通知,预计下周进行公开宣布。
- 成员们正热切期待关于黑客松结果的更多细节。
- MOOC 证书延迟发放:秋季项目证书尚未发布,但很快就会提供。
- 官方感谢参与者在 MOOC 证书发放期间的耐心等待。
- 研究项目备受关注:成员们表达了参与研究项目的兴趣。
- 据工作人员称,有关研究机会和团队配对的更多细节将很快提供。
- 签到表仅限伯克利学生:提到的签到表仅供伯克利学生使用。
- 针对非伯克利学生使用签到表的可访问性提出了担忧,因为目前缺乏针对非伯克利学生的信息。
MCP (Glama) Discord
- 旧版 ERP 集成寻求 VBS 帮助:一位用户正在寻求关于使用 .vbs 脚本与旧版 ERP 系统集成的服务器方面的帮助。
- 一位成员建议使用 mcpdotnet,因为它可能会简化从 .NET 的调用。
- Cursor MCP Server 获得 Docker 指导:一位新用户请求关于在 Cursor 内部本地运行 MCP server 的指导,并特别关注使用 Docker container。
- 成员建议将与 supergateway 一起使用的 SSE URL 输入到 Cursor MCP SSE 设置中以解决该问题。
- 企业级 MCP 协议进展:围绕 MCP protocol 的讨论强调了 OAuth 2.1 授权草案,可能与 IAM 系统集成。
- 会中指出,由于正在进行内部测试和原型设计,目前的 SDK 缺乏授权支持。
- Localhost CORS 问题困扰 Windows:一位用户在 localhost 上运行其 MCP server 时遇到连接问题,怀疑是 CORS 相关问题。
- 他们计划使用 ngrok 来规避在 Windows 上通过 localhost 访问服务器相关的潜在通信问题。
- ngrok 解决 Localhost 访问问题:一位成员推荐使用 ngrok 来评估服务器的可访问性,建议使用命令
ngrok http 8001。- 他们强调这可以解决由于尝试通过 localhost 访问服务器而产生的问题。
Cohere Discord
- Command-R+ 的内部思考功能令用户印象深刻:用户对 Command-R+ 模型展示内部思考 (internal thoughts) 和逻辑步骤的能力感到满意,其运作方式类似于 Chain of Thought。
- 尽管新模型层出不穷令人兴奋,但一位用户指出,在持续使用数月后,Command-R+ 依然能给他们带来惊喜。
- Cohere 在关税担忧中捍卫加拿大 AI:一位成员选择 Cohere 是为了增强加拿大的 AI 能力,特别是在面临潜在的美国关税背景下。
- 他们赞赏在充满挑战的经济环境下,仍有能够维持当地 AI 发展的选项。
- Cohere 的 Rerank 3.5 提升金融语义搜索:Cohere 和 Pinecone 举办了一场网络研讨会 (webinar),强调了金融语义搜索和重排序 (Reranking) 的优势。
- 研讨会展示了 Cohere 的 Rerank 3.5 模型及其利用金融数据增强整体搜索性能的潜力。
- 旨在优化技术内容体验的调查:应届毕业生正在进行一项调查,以收集技术爱好者对内容消费偏好的见解,旨在提高用户参与度。
- 该调查可在 User Survey 参与,探讨了从 Tech Blogs 和 Research Updates 到社区论坛和 AI 工具等各种信息来源。
DSPy Discord
- DSPy 目录引起关注:一位用户询问名为 dspy.py 的文件或名为 dspy 的目录是否会导致问题,因为 Python 有时难以处理这种命名设置。
- 这个问题引发了对潜在文件处理冲突的担忧,可能会影响 DSPy 项目的执行。
- Image Pipeline 在 DSPy 2.6.2 中崩溃:dspy 2.6.2 中的一个 Image pipeline 触发了 ContextWindowExceededError,意味着由于 Token 限制而“超出上下文”,而之前的 2.6.1 版本虽然存在正在调查的错误,但可以运行。
- 用户报告称,这种退化可能是由 DSPy 最近的更改引起的。
- DSPy 2.6.4 中断言功能被移除:成员们宣布,在即将发布的 2.6.4 版本中,断言 (assertions) 将被替换,这表明 DSPy 处理错误的方式发生了转变。
- 这一变化意味着 DSPy 内部的错误处理和逻辑检查将采用与旧版本不同的方式。
- Databricks 可观测性探索:一位在 Databricks notebooks 中运行 DSPy 2.5.43 进行 NER 和分类的用户正在寻求实现结构化输出 (structured output) 的指导。
- 由于配置 LM 服务器受限,他们必须使用当前版本,这增加了涉及优化器和嵌套 JSON 输出任务的复杂性。
LAION Discord
- OpenEuroLLM 带着欧盟特色启动:OpenEuroLLM 作为第一个涵盖所有欧盟语言的开源大语言模型家族被推出,获得了卓越的 STEP 标志,并专注于社区参与。
- 该项目旨在符合欧盟法规并保留语言多样性 (linguistic diversity),与 LAION 等开源和开放科学社区保持一致。
- 欧盟 AI 努力面临质疑:在关于欧盟法规下 AI 未来的讨论中,一位成员开玩笑地建议在 2030 年再来看看欧盟 AI 努力的成果。
- 这一评论凸显了对当前 AI 开发工作能否立即产生实质性成果的怀疑。
- 社区关注模因币狂热:一位成员调查了社区对模因币 (meme coins) 的兴趣,寻求其他人的广泛参与。
- 他们主动征求任何对该话题感兴趣的人表达意向。
LlamaIndex Discord
- DocumentContextExtractor 增强了 RAG:DocumentContextExtractor 是一个旨在提高 RAG 准确性的迭代版本,由 AnthropicAI 和 llama_index 作为 demo 实现。
- 该技术有望提升性能,对于从事检索增强生成(Retrieval-Augmented Generation)的研究人员来说,这是一个重要的探索领域。
- Contextual Retrieval 改变了游戏规则:Contextual Retrieval 的使用被强调为提高 RAG 系统响应准确性的关键。
- 该技术优化了文档检索过程中对上下文的利用方式,从而促进了更深层次的交互。
- LlamaIndex LLM 类面临超时问题:一位用户询问如何在默认的 LlamaIndex LLM 类中实现 timeout 功能,并指出 OpenAI 的 API 中提供了该功能。
- 另一位成员建议 timeout 选项可能应该放在 client kwargs 中,并参考了 LlamaIndex GitHub 仓库。
- 为 LlamaIndex 探索 UI 解决方案:一位成员对其他人与 LlamaIndex 配合使用的 UI 解决方案表示好奇,询问大家是选择从零开始构建还是有其他方案。
- 该询问仍处于开放状态,邀请其他人分享与 LlamaIndex 相关的 用户界面(User Interface) 实践和偏好。
tinygrad (George Hotz) Discord
- Tinybox 面临欧元区运输限制:支持团队确认,tinybox (red) 无法运送到部分欧元区国家。
- 尝试订购到 爱沙尼亚(Estonia) 等国家的海外用户目前无法收到货物,因为这些国家未列在结账时的下拉菜单中。
- 巧妙的运输服务变通方法出现:一位用户建议使用 Eurosender 等服务来绕过运输限制。
- 他们确认通过这种方法成功送达 德国(Germany),为不支持地区的 tinybox 聊天频道用户提供了一个解决方案。
MLOps @Chipro Discord
- Iceberg 管理噩梦:一场名为 Pain in the Ice: What’s Going Wrong with My Hosted Iceberg?! 的小组讨论将于 2 月 6 日探讨管理 Iceberg 的复杂性,演讲者包括 Yingjun Wu、Alex Merced 和 Roy Hasson(Meetup 链接)。
- 由于摄取(ingestion)、压缩(compaction)和 RBAC 等问题,管理 Iceberg 可能会变成一场噩梦,从而分散处理其他任务的资源。该小组旨在探讨该领域的创新如何简化 Iceberg 的管理和使用。
- 盲目推崇 LLM 令人沮丧:成员们对那些在任何问题上都推崇 LLM 的 AI 工程师表示担忧,即使 unsupervised learning 或其他更简单的方法可能更合适。
- 讨论强调了一种趋势,即在不考虑问题性质的情况下选择工具,从而削弱了简单方法的价值。
- TF-IDF + Logistic Regression 胜出:一位成员分享了一个成功案例,在对数百万个文本样本进行分类时,他成功主张使用 TF-IDF + Logistic Regression 而非 OpenAI 模型。
- Logistic Regression 模型表现良好,证明了简单算法也可以非常有效,从而展示了传统方法的效力。
OpenInterpreter Discord
- Open Interpreter 项目停滞了?:成员们对 Open Interpreter 项目缺乏更新表示担忧,指出 GitHub 上的 pull requests 自上次重大提交以来已闲置数月。
- Discord 频道中的沉默让渴望参与其中的贡献者感到沮丧。
- Open Interpreter 文档缺失:一位成员强调 1.0 版本缺少文档,特别是关于如何利用 profiles.py 等组件的部分。
- 文档的缺失让用户对项目当前的重点以及对其功能的后续支持产生了疑问。
- DeepSeek r1 集成仍是个谜:有人询问如何将 DeepSeek r1 集成到 Open Interpreter 环境中,但未得到回应。
- 社区讨论的缺乏表明,关于此集成的实验或知识共享可能存在空白。
OpenRouter (Alex Atallah) Discord
- Cloudflare 与 OpenRouter 联手:Cloudflare 现在正式成为 OpenRouter 上的提供商,集成了其 Workers AI 平台和 Gemma 模型,为 AI 应用开发者开放了多种开源工具。
- 此次合作旨在增强 OpenRouter 生态系统,为开发者提供更广泛的 AI 工具。
- Gemma 7B-IT 新增 Tool Calling:现在可以通过 Cloudflare 使用 Gemma 7B-IT 模型,该模型具备 tool calling capabilities(工具调用能力),旨在提高开发效率。
- 鼓励开发者探索 Gemma 7B-IT,以便在应用中实现更快速、更精简的工具集成;可通过 OpenRouter 获取。
- Llama 模型涌入 OpenRouter:OpenRouter 现在支持一系列 Llama 模型,包括 Gemma 7B-IT,为用户项目提供了众多选择。
- AI 开发者可以通过 Discord 请求特定的 Llama 模型。
- 模型错误显示变得更具体:解决了导致错误混淆的显示问题,现在错误消息中会显示模型名称,以提高用户的清晰度。
- 此次更新旨在通过提供更清晰的错误反馈来改善用户体验。
Axolotl AI Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将移除它。
Mozilla AI Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将移除它。
HuggingFace Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将移除它。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将移除它。
AI21 Labs (Jamba) Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将移除它。
PART 2: 详细频道摘要与链接
邮件中已截断完整的逐频道详情。
如果您喜欢 AInews,请分享给朋友!预先感谢!