ainews-gemini-20-flash-ga-with-new-flash-lite-20
Gemini 2.0 Flash 正式发布(GA),同步推出全新的 Flash Lite、2.0 Pro 以及 Flash Thinking。
以下是为您翻译的内容:
Google DeepMind 正式发布了 Gemini 2.0 系列模型,包括 Flash、Flash-Lite 和 Pro Experimental。其中,Gemini 2.0 Flash 的性能超越了 Gemini 1.5 Pro,且价格便宜了 12 倍,同时支持多模态输入和 100 万 token 的上下文窗口。Andrej Karpathy 发布了一段时长 3 小时 31 分钟的视频,深入解析了大语言模型,涵盖了预训练、微调和强化学习,并以 GPT-2 和 Llama 3.1 为例进行讲解。Jay Alammar、Maarten Gr 和吴恩达 (Andrew Ng) 推出了一门关于 Transformer 架构的免费课程,重点讲解分词器 (tokenizers)、嵌入 (embeddings) 和混合专家模型 (MoE)。DeepSeek-R1 在 Hugging Face 上的下载量已达到 120 万次,并附有一份详尽的 36 页技术报告。Anthropic 将其“越狱挑战”的奖励提高至 1 万美元和 2 万美元;同时,BlueRaven 浏览器扩展程序进行了更新,可隐藏 Twitter 指标以实现无偏见的社交互动。
[REDACTED] is all you need.
2025年2月4日至2月5日的 AI 新闻。我们为您检查了 7 个 Reddit 社区、433 个 Twitter 账号 和 29 个 Discord 社区(210 个频道,5481 条消息)。为您节省了预计 571 分钟 的阅读时间(以 200wpm 计算)。您现在可以标记 @smol_ai 进行 AINews 讨论!
Gemini 2.0 自 12 月以来就已经“发布”了(我们的报道在此),但现在我们可以正式将 Gemini 2.0 Flash 的价格视为“真实”价格,并将其放入我们的帕累托前沿图表 (Pareto frontier chart) 中:
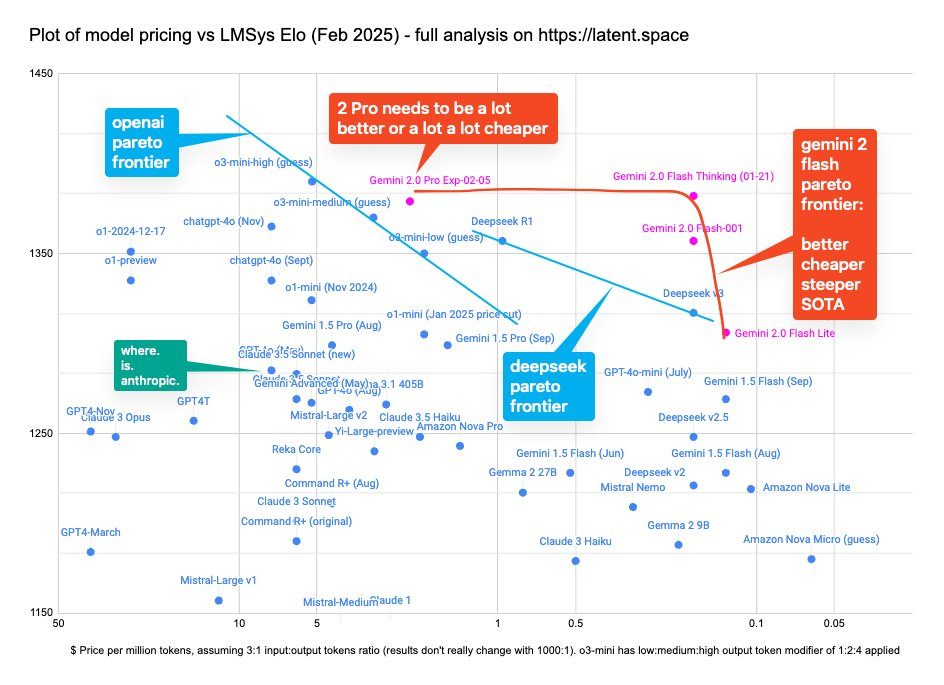
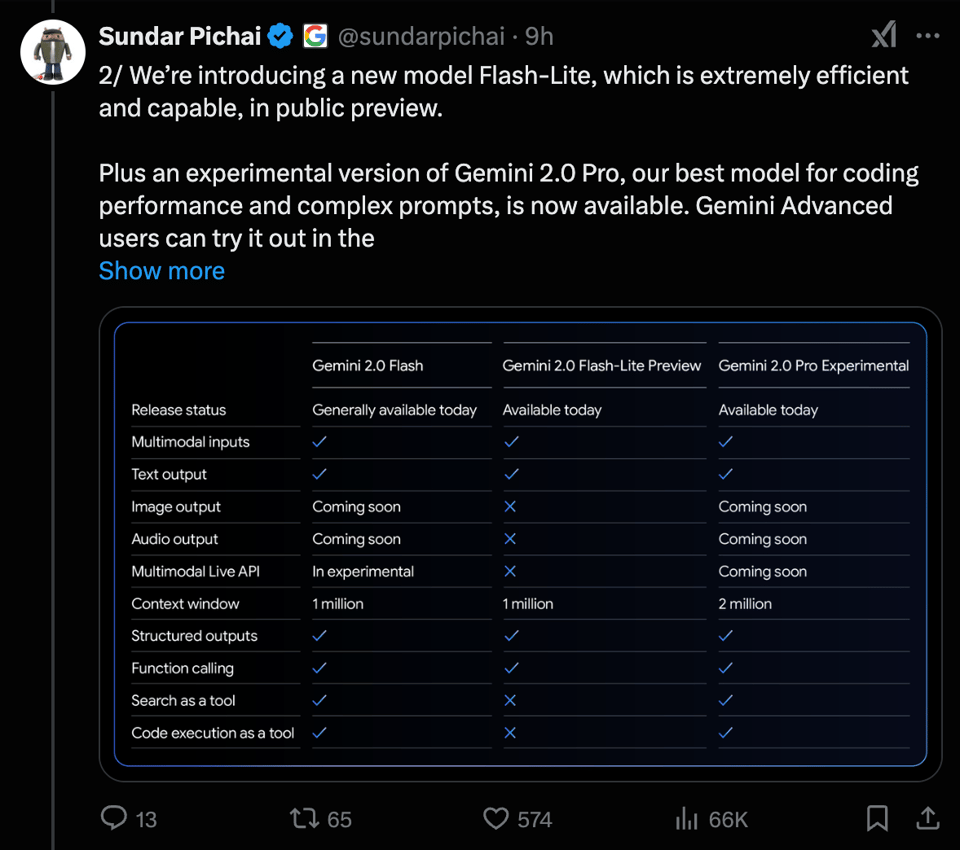
我们承认,像这样单纯的智能图表意义正变得越来越小,并且可能会在今年彻底失效,因为它们无法准确描述这些发布版本的多模态输入和输出能力,也无法体现 coding 能力或 100-200 万的超长上下文,正如 Sundar Pichai 所展示的:
特别值得注意的是新推出的 “Flash Lite” 的性价比,以及 Gemini 2.0 Flash 相对于 1.5 Flash 极微小的价格上涨。
有趣的是,OpenAI “压制 (mogging)” Google 发布节奏的竞争态势似乎停留在 2024 年了。
AI Twitter 回顾
-
Google DeepMind 发布 Gemini 2.0 模型,包括 Flash、Flash-Lite 和 Pro Experimental:@GoogleDeepMind 宣布 Gemini 2.0 Flash、Flash-Lite 和 Pro Experimental 模型正式全面可用。@_philschmid 总结了这次更新,指出 Gemini 2.0 Flash 的性能超越了 Gemini 1.5 Pro,同时价格便宜了 12 倍。新模型提供了多模态输入、100 万 token 上下文窗口以及极高的成本效益。
-
Andrej Karpathy 发布“深入探讨 ChatGPT 等 LLM”视频:@karpathy 发布了一个 3 小时 31 分钟的 YouTube 视频,全面概述了 Large Language Models (LLMs),涵盖了 pretraining(预训练)、supervised fine-tuning(监督微调)和 reinforcement learning(强化学习)等阶段。他讨论了 data、tokenization、Transformer 内部机制等主题,并以 GPT-2 训练和 Llama 3.1 基础推理为例进行了讲解。
-
“Transformer LLM 工作原理”免费课程:@JayAlammar 和 @MaartenGr 与 @AndrewYNg 合作,推出了一门免费课程,深入探讨 Transformer 架构,包括 tokenizers、embeddings 和 mixture-of-expert 模型等主题。该课程旨在帮助学习者理解现代 LLM 的内部运作机制。
-
DeepSeek-R1 下载量突破 120 万次:@omarsar0 强调,自 1 月 20 日发布以来,DeepSeek-R1 在 Hugging Face 上的下载量已达 120 万次。他还利用 Deep Research 对 DeepSeek-R1 进行了技术深度分析,生成了一份 36 页的报告。
-
Anthropic 提高越狱挑战奖励:@AnthropicAI 宣布,目前还没有人完全越狱其系统,因此他们将首位通过所有八个关卡的人员奖励提高至 $10K,而通过所有八个关卡并实现通用越狱的奖励提高至 $20K。详细信息请参阅其公告。@nearcyan 幽默地推出了 PopTarts: Claude 口味,作为给渗透测试人员的创意奖励。
-
BlueRaven 扩展隐藏 Twitter 指标:@nearcyan 发布了 BlueRaven 的更新,该扩展允许用户在隐藏所有指标的情况下浏览 Twitter。这挑战了用户在不受流行度指标影响的情况下进行互动。其源代码已公开,并支持 Firefox 和 Chromium。
-
Chain-of-Associated-Thoughts (CoAT) 框架发布:@omarsar0 讨论了一个通过结合 Monte Carlo Tree Search 与动态知识整合来增强 LLM 推理能力的新框架。该方法旨在提高复杂推理任务中全面且准确的回答。更多细节见论文。
-
关于主题大纲合成的 STROM 论文:@_philschmid 重点介绍了一篇题为 “Synthesis of Topic Outlines through Retrieval and Multi-perspective” (STROM) 的论文,该论文提出了一种多问题、迭代式的研究方法。它类似于 Gemini Deep Research 和 OpenAI Deep Research。感兴趣的人可以查阅其论文和 GitHub 仓库。
-
关于 AI 影响与工具的讨论:@omarsar0 分享了关于 AI 如何使个人能够同时在多个领域表现出色的见解,强调了学习以及 ChatGPT 和 Claude 等工具的重要性。@abacaj 分享了一个 Gist,展示了如何在 GRPO 训练期间运行 gsm8k 评估,并扩展了 GRPOTrainer 以进行自定义评估。
-
Nearcyan 的幽默沉思与测试帖子:@nearcyan 在 Twitter 上发布了测试帖子,观察他的推文是如何被降权 (deboosted) 的。他思考了在不知道互动指标的情况下使用 Twitter 的体验。此外,他还幽默地表达了在当今环境下作为一名 iOS 开发者的感受 (推文)。
AI Reddit 回顾
/r/LocalLlama 回顾
主题 1. DeepSeek VL2 Small 发布及 R1 的基准测试成功
- DeepSeek 刚刚发布了 DeepSeek VL2 Small 的官方 Demo - 它在 OCR、文本提取和对话用例方面非常强大 (Hugging Face Space) (评分: 615, 评论: 37):DeepSeek VL2 Small 的 Demo(一个 16B MoE 模型)已在 Hugging Face 上发布,展示了其在 OCR、文本提取和对话应用中的能力。Vaibhav Srivastav 和 Zizheng Pan 在 X 上宣布了这一发布,强调了它在各种视觉语言任务中的实用性。
- 发布时间线与性能:DeepSeek VL2 Small 模型大约在两个月前上传到 Hugging Face,预计本月将发布一个推理模型。评论者指出该模型在其尺寸下表现良好,尽管有些人更倾向于使用 florence-2-large-ft 来处理特定的视觉任务。
- 无障碍与集成:讨论包括视觉语言模型在浏览网站方面的实用性,特别是在无障碍功能实现良好的情况下。建议用户在将其集成到系统之前,先在一些文档上尝试该模型。
- 模型可用性与工具:人们对 DeepSeek V3 Lite 和 gguf 格式很感兴趣,并建议使用 llama.cpp 中的 convert_hf_to_gguf.py 进行转换。Environmental-Metal9 提供的 Demo 链接在这里,尽管有人反映 Demo 目前无法运行。
- 2B 模型击败 72B 模型 (Score: 164, Comments: 57): DeepSeek R1-V 项目证明了一个 2B 参数模型在视觉语言任务中可以超越 72B 参数模型,实现了卓越的有效性和分布外 (out-of-distribution) 鲁棒性。该模型在特定的分布外评估中仅通过 100 个训练步数就达到了 99% 和 81% 的准确率,成本仅为 $2.62,并在 8 台 A100 GPU 上运行了 30 分钟。该项目已完全开源,可在 此处 获取。
- 一些评论者对 DeepSeek R1-V 模型的成就表示怀疑,认为结果可能具有误导性,或者过于针对某些特定的基准测试。Admirable-Star7088 和 Everlier 幽默地指出,较小的模型在特定任务中可以超越较大的模型,但强调较大的模型通常更具通用性。
- Real-Technician831 和 iam_wizard 讨论了在特定任务中使用较小模型的实际意义,指出这种方法对于范围较窄的商业应用来说计算效率更高。他们认为这样的结果并不令人惊讶,因为针对特定任务微调较小模型是一种已知的策略。
- 讨论中还提到了另一个模型 phi-CTNL,据 gentlecucumber 分享的 arXiv 链接显示,该模型在各种基准测试中也击败了更大的模型。这增加了关于特定基准测试性能与通用能力之间关系的讨论。
- DeepSeek R1 在泛化基准测试中与 o1 并列第一。 (Score: 162, Comments: 23): DeepSeek R1 和 o1 在 Generalization Benchmark 中并列第一,平均排名均为 1.80。该基准测试在 810 个案例中测试了 AI 模型,并指出 Qwen QwQ 在 280 个案例中失败。
- Generalization Benchmark 测试 AI 模型从示例中推断特定主题的能力,其中 o3-mini 排名第四。有关该基准测试的更多详细信息可以在 GitHub 上找到。
- Phi 4 排名靠前,超越了 Mistral Large 2、Llama 3.3 70b 和 Qwen 2.5 72b,并因其适合自托管 (self-hosting) 的合理尺寸而受到称赞。Qwen QwQ 得分更高,但在生成正确的输出格式方面存在问题。
- o3-mini-high 被指出缺失,但其对 Livebench 结果的影响非常重要。此外,Gemini 1.5 Pro 和 Gemini 1.5 Flash 之间存在 0.99 的相关性,表明两者性能相似。
{kind=link}
{kind=link}
主题 2. Google 关于武器和监控用途的 AI 政策转变
- Google 解除使用其 AI 开发武器和进行监控的禁令 (Score: 497, Comments: 126): Google 更新了其 AI 政策,取消了此前禁止将其 AI 技术用于武器和监控的规定。这一政策变动标志着 Google 在 AI 伦理应用立场上的重大转变。
- 用户对 Google 的 AI 政策转变表示极大担忧,将其等同于道德滑坡,并质疑将 AI 用于武器和监控的伦理影响。许多评论讽刺地引用了 Google 以前的座右铭“Don’t be evil”,暗示其背叛了核心价值观。
- 讨论强调了政策变动的政治和国际影响,提到了 Google 参与以色列军事行动的情况,并将其与中国等其他国家的监控行为进行了比较。对隐私侵蚀以及 AI 在全球冲突中被滥用的担忧十分普遍。
- 几条评论批评了政策变动背后的公司动机,认为股东利益往往高于伦理考量。“做正确的事 (do the right thing)”这一说法被批评为含糊不清且可能带有私利,将公司利益置于社会利益之上。
主题 3. Gemma 3 发布与社区反应
- Gemma 3 即将来临! (Score: 403, Comments: 42): Omar Sanseviero 在推文中预告了关于 “Gemma” 的更新,引发了 r/LocalLLama 社区的关注。随附的截图强调了 “Gemini” 的功能,包括 “2.0 Flash”、”2.0 Flash Thinking Experimental” 和 “Gemini Advanced”,这表明目前正在进行的是 Gemini 而非 Gemma 3 的活跃开发。
- 评论者表达了对更大上下文长度(Context Sizes)的强烈渴望,提到 64k 和 128k 是未来模型(如 Gemma 3)的首选目标。一些用户认为目前的 8k 上下文长度不足。
- 一些用户强调了对 Gemma 2 的成功和偏爱,特别称赞了 9b simpo 模型在媒体知识方面的能力,并对具备增强功能甚至 AGI 能力的 Gemma 3 表示期待。
- 讨论还反映了 Reddit 的社区参与方面,将其比作 2010 年代初期研究人员和开发人员与用户直接互动的场景,说明了该平台在促进 AI 进展讨论中的作用。
{kind=link}
其他 AI 子版块回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
主题 1. Nvidia 的 CUDA 战略:AI 进化的催化剂
- 黄仁勋(Jensen Huang)是否承认过 Nvidia 只是在 AI 领域碰巧走运? (Score: 153, Comments: 92): Nvidia 最初的目标是增强图形渲染,但无意中开发出了对训练神经网络至关重要的技术。这种偶然的成功极大地促使黄仁勋成为了历史上最富有的人之一。
- 评论者的共识是,Nvidia 在 AI 领域的成功并非源于运气,而是战略远见和长期投资,特别是从 2006/2007 年开始开发的 CUDA。这一战略举措使 Nvidia 能够建立一个强大的开发者生态系统,这对于他们在 AI 和科学计算领域的统治地位至关重要。
- CUDA 的早期采用最初遭到了质疑,用户回忆起 10-20 年前人们对它的看法。尽管如此, Nvidia 坚持了下来,使他们能够在 2011 年 AlexNet 论文发表后利用 AI 热潮,该论文使用了 Nvidia GPU 并突显了其战略优势。
- Nvidia 的投资从 AI 扩展到各种市场,包括加密货币、生物技术和自主系统。评论者指出 Nvidia 参与了光线追踪(Ray Tracing)、机器人技术甚至军事技术等多种应用,展示了他们致力于在各行业扩大其 GPU 使用的决心。
主题 2. 字节跳动(ByteDance)和 Google 推进 AI 前沿
- [字节跳动新的多模态 AI 研究] (https://v.redd.it/4ns98irddbhe1) (Score: 251, Comments: 26): 帖子提到了字节跳动(ByteDance)在多模态 AI(Multi-modal AI)方面的新研究,尽管文中未提供具体细节。帖子包含一段视频,此处未作分析。
- 视听匹配:讨论强调了多模态 AI 将任何音频与视觉效果匹配的能力,例如将美国口音与爱因斯坦(Einstein)的形象结合,这种刻意的错配是为了展示该技术的潜力。
- 来源和内容的真实性:在 omnihuman-lab.github.io 提供了源代码链接,用户批评了 AI 生成内容与历史表现之间的不匹配,指出 AI 的刻画让爱因斯坦看起来像个“神经典型(Neurotypical)”人。
- 音频来源:演示中使用的音频导致了关于口音的困惑,经确认为源自一场 TEDx 演讲(来源)。
- Google 声称实现了全球最强 AI,并免费提供给用户! (Score: 203, Comments: 56):Google 声称开发出了全球最强 AI,并正向用户免费提供。帖子中未提供更多细节,包括该 AI 的具体功能或应用。
- 关于 Google 的 Gemini AI 的讨论呈现出褒贬不一的观点,一些用户对其能力表示怀疑,特别是在害虫防治建议等领域;而另一些用户则认为它在编程任务和使用 AI Studio 方面表现出色。Gemini 2.0 与前代产品相比显示出一定的局限性,导致一些用户在特定功能上回退到旧版本。
- 用户对编程模型的性能展开了辩论,一些模型如 o1 和 o3-mini 因能高效生成大量代码而受到称赞,而其他模型在超过 100 行代码时就显得力不从心。有评论强调了这些模型先进的推理能力,突出了它们对编程任务的影响。
- Sonnet 模型在 lmsys webdev arena 性能讨论中脱颖而出,用户注意到尽管其体积较小,但表现优于其他模型。关于是否应将 Sonnet 等模型与专注于推理扩展(inference scaling)的模型进行比较存在争议,一些人将竞争优势归功于新的方法论。
主题 3. 辩论 AI 开源:审视 DeepSeek 及更多
- DeepSeek 就其“完全开源”的说法进行更正 (Score: 126, Comments: 36):DeepSeek 就其 DeepSeek-R1 发布了“术语更正”,澄清虽然其代码和模型是在 MIT License 下发布的,但它们并不像之前声称的那样是“完全开源”的。宣布这一更正的推文获得了显著关注,拥有 186 个赞、39 次转发和 324 条回复,浏览量达 27,000 次。
- 许多评论者认为,虽然 MIT License 通常与开源相关联,但 DeepSeek 的说法具有误导性,因为他们没有发布源代码或训练数据。这种区别在判断某物是否真正开源时至关重要,因为获取源代码是一个基本要求。
- coder543 强调 Llama 模型和类似项目也不是完全开源的,因为它们缺乏详细的数据集描述和训练代码。这突出了 AI 社区中一个更广泛的问题,即模型发布时带有权重,但没有足够的细节或资源来复制训练过程。
- 讨论强调了在应用于 AI 模型和软件时,对“开源”一词的误解或误用。一些用户澄清,除非提供了实际的源代码,否则在 MIT 下授权并不等同于开源,这说明了许可与实际开放性之间的区别。
{kind=link}
AI Discord 摘要
由 Gemini 2.0 Flash Thinking 提供的摘要之摘要
主题 1. Gemini 2.0 模型系列:性能与集成
- Flash 2.0 快速上线 Windsurf 和 Perplexity:Gemini 2.0 Flash 已在 Windsurf 上线 以及 Perplexity AI,因其在编程查询中的速度和效率而备受推崇,在 Windsurf 上仅消耗 0.25 用户提示词额度。虽然速度受到称赞,但用户注意到其工具调用(tool calling)能力有限,且与 Claude 和 DeepSeek 等模型相比,其可靠性仍处于审查之中。
- Pro Experimental 基准测试挑战 Claude 3.5 Sonnet:Gemini 2.0 Pro Experimental 在编程和复杂提示词方面的基准测试与 Claude 3.5 Sonnet 相当,并在 lmarena.ai 的排行榜上夺得 第 1 名。然而,用户观察到 API 响应存在不一致性,且尽管宣传有 200 万 token 上下文,但与 Gemini 1.5 Pro 相比,长上下文能力可能有所下降。
- GitHub Copilot 为开发者引入 Gemini 2.0 Flash:GitHub 宣布为所有 Copilot 用户集成 Gemini 2.0 Flash,使其可以在代码编辑器的模型选择器和 GitHub 上的 Copilot Chat 中使用。此举标志着 Gemini 在 Microsoft 生态系统中的重大胜利,使其在开发者工具集成方面领先于竞争对手。
主题 2. 编程 IDE 和 AI 助手:功能对比与用户反馈
- Cursor IDE 通过 MCP Server 集成获得强力增强:Cursor IDE 现在支持 MCP server 集成,使用户能够直接在 IDE 中利用 Perplexity 和其他工具,正如 YouTube 教程中演示的那样。这一增强功能允许复杂的流水线和定制化的 AI 辅助,并可以通过提供的 GitHub 仓库轻松设置。
- JetBrains 的 Codeium 插件面临用户稳定性困扰:用户报告 Codeium JetBrains 插件存在严重的稳定性问题,理由是频繁的无响应和需要重启,这促使一些用户转回使用 Copilot。用户的诉求 “请给 Jetbrains 插件一些关爱” 突显了社区对更可靠插件体验的需求。
- Windsurf Next Beta 旨在超越 Cursor,但额度问题令人痛苦:Windsurf Next Beta 发布以预览创新功能,但用户正挣扎于额度分配,特别是 flex credits,导致工作流中断。与 Cursor 的对比突显了 Cursor 在第三方工具和扩展灵活性方面的优势,表明 Windsurf 可以通过采用类似功能来提升其价值。
Theme 3. 高级模型训练与优化技术
- Unsloth 发布动态 4-bit 量化以提升精度:Unsloth 推出了动态 4-bit 量化(Dynamic 4-bit Quantization),通过选择性地量化参数,在保持 VRAM 效率的同时提高模型精度。与标准量化技术相比,该方法增强了 DeepSeek 和 Llama 等模型的性能,为模型压缩提供了一种细致入微的方法。
- Ladder-Residual 架构在 Torchtune 上大幅提升 Llama 70B 性能:当在 Torchtune 中使用时,Ladder-residual 修改在具有张量并行(tensor parallelism)的多 GPU 设置上,将 70B Llama 模型的速度提升了约 30%。这项由 TogetherCompute 开发的增强功能标志着分布式模型训练效率的重大进步。
- Harmonic Loss 挑战神经网络中的交叉熵:一篇新论文引入了 harmonic loss 作为标准交叉熵损失(cross-entropy loss)的替代方案,声称在神经网络和 LLM 中具有更好的可解释性和更快的收敛速度。虽然一些人对其新颖性表示怀疑,但其他人看到了其改变优化目标和改善模型训练动态的潜力。
Theme 4. AI 开发中的开源与社区
- Mistral AI 品牌重塑,加倍投入开源:Mistral AI 推出了重新设计的网站,强调了他们对开源模型和为企业部署提供可定制 AI 解决方案的承诺。品牌重塑信号了对透明度和社区参与的关注,巩固了他们作为开源 AI 领先贡献者的地位。
- GPT4All v3.9.0 发布,带来 LocalDocs 和模型扩展:GPT4All v3.9.0 发布,具有 LocalDocs 功能、错误修复以及对 OLMoE 和 Granite MoE 等新模型的支持。此更新增强了该开源本地 LLM 平台的可用性和通用性。
- Stability.ai 任命首席社区官以提升参与度:Stability.ai 任命 Maxfield 为其新任首席社区官(Chief Community Guy),承认 “Stability 最近的参与度一直不尽如人意” 并承诺加强互动。Maxfield 计划实施功能请求板,并增加 Stability 研究人员的透明度,以使开发更好地符合社区需求。
Theme 5. 推理模型基准测试与性能分析
- DeepSeek R1 Nitro 在 OpenRouter 上表现出极速运行时间:DeepSeek R1 Nitro 在 OpenRouter 上实现了 97% 的请求完成率,为使用 API 的用户展示了改进的运行时间和速度。OpenRouter 鼓励用户尝试使用以获得更强的性能。
- 据称 DeepSeek R1 可与 OpenAI 的推理能力相媲美:讨论强调 DeepSeek R1 是 OpenAI O1 推理模型的强力开源竞争对手,在提供开放权重的同事具备可比拟的能力。成员们注意到它在本地执行的可访问性以及在推理任务中的出色表现。
- Flux 在 Hugging Face L40S 上的图像生成速度超越 Emu3:Flux 使用 flash-attention 在 Huggingface L40S 上仅用 30 秒就生成了一张 1024x1024 的图像,显著快于 Emu3 生成较小的 720x720 图像所需的约 600 秒。尽管参数量相似,这种速度差异引发了人们对 Emu3 相对于单模态模型效率的质疑。
PART 1: Discord 高层摘要
aider (Paul Gauthier) Discord
- Aider 管理代码错误:用户正在利用 Aider 管理大型项目中的错误,并使用
/run命令重构代码以自主解决问题,同时根据 Linting and Testing 文档 添加文件进行诊断和解决。- 社区讨论了使用 Aider 进行自动代码修改、简化工作流程和自动化编码任务。
- Claude 在编程方面击败 R1:对 O3 Mini、R1 和 Claude 模型的比较显示了不同的编程任务成功率,根据这条推文,一些用户认为在特定场景下 Claude 略胜 R1。
- 用户对模型准确性的局限性表示沮丧,同时考虑将 DeepClaude 等工具与 OpenRouter 集成的可能性。
- LLM 在 Rust 语言上表现挣扎:社区承认,尽管取得了进展,LLM 在处理复杂任务时仍然会遇到困难,尤其是在 Rust 等语言中,难以应对深层推理和多步解决方案。
- 虽然 LLM 在简单任务上表现出色,但在处理更复杂的问题并获得满意结果方面挑战依然存在。
- Aider 提交乱码内容:用户报告称,使用来自 Together.ai 的推理模型时,生成的提交消息充满了
<think>标记,根据文档,需要进行配置更改。- 讨论包括建议使用
--weak-model something-else来避免这些标记,这表明问题源于 Aider 与不同 API 提供商之间的交互。
- 讨论包括建议使用
- Gemini 2.0 现已上线 LMSYS:Gemini 2.0 现已在 lmarena.ai 上可用,以便进行更广泛的比较。
- 社区可能会评估将其集成到现有工作流程中。
Unsloth AI (Daniel Han) Discord
- 动态量化提升准确率:Unsloth 推出了 Dynamic 4-bit Quantization(动态 4 位量化),通过选择性量化参数,在保持 VRAM 效率的同时提高准确率,详见其 博客文章。
- 与标准量化技术相比,该方法旨在增强 DeepSeek 和 Llama 等模型的性能。
- 期待集成 GRPO 以增强训练:Unsloth 正在积极集成 GRPO training,以简化并增强模型微调,有望实现更高效的训练过程,详见 此 GitHub issue。
- 社区对 GRPO support 的期待非常高,尽管大家也承认可能还有一些 kinks(小瑕疵)需要解决,这表明正式实现可能还需要一些时间。
- 揭示 DeepSeek 在 Oobagooba 上的挑战:用户在 Oobagooba 本地运行 DeepSeek 模型时遇到了问题,通常是由于模型权重配置错误导致的。根据 Unsloth Documentation,成员建议使用标志 –enforce-eager 来防止模型加载失败。
- 优化建议包括确保使用 –enforce-eager 标志,以防止模型加载失败。
- CPT 模型显示出令人印象深刻的困惑度得分:CPT with Unsloth 模型在 Perplexity (PPL) 方面表现出重大改进,基础模型得分从 200 左右降至 80 左右,受到了热烈欢迎。
- 成员们指出 DeepSeek model 已经很老了,表示需要更新版本和更有趣的数据集,特别是针对该模型的 math versions(数学版本)。
- LLM 模型重组的困扰:一位成员报告称,在尝试在 PyTorch 神经网络中重组 LLM model 时错误地导入了一个层,导致输出乱码,并寻求优化模型效率的帮助。
- 他们寻求关于如何理解模型不同部分的效率改进点,以修复输出乱码问题的建议。
Codeium (Windsurf) Discord
- Gemini 2.0 Flash 在 Windsurf 亮相:Gemini 2.0 Flash 现已在 Windsurf 上线,每次工具调用仅消耗 0.25 user prompt credits 和 0.25 flow action credits,因其在编程查询中的速度而备受关注。
- 根据 Windsurf’s announcement,尽管它效率很高,但用户观察到其工具调用能力有限。
- Windsurf Next Beta 发布:Windsurf Next Beta 版本已开放下载 此处,允许用户测试软件开发中 AI 的创新功能和改进。
- 正如 Windsurf Next Launch 博客文章中所详述,它至少需要 OS X Yosemite、Ubuntu 20.04 或 Windows 10 (64-bit)。
- 用户报告 Codeium 插件使用困难:多位用户提到了 Codeium JetBrains 插件的问题,描述其频繁无响应且需要重启才能维持功能,导致一些用户转回使用 Copilot。
- 一位用户恳求道:“Please give the Jetbrains plugin some love”(请给 Jetbrains 插件多一点关爱),以增强其稳定性,突显了社区对可靠工具的需求。
- Windsurf 额度分配令用户恼火:用户在 Windsurf 中面临额度分配问题,特别是 flex credits,这导致功能受限,一名用户已多次联系支持部门。
- 讨论强调了用户对系统可靠性的沮丧,这影响了关键的工作流程。
- Windsurf 落后于 Cursor:用户指出 Cursor 相对于 Windsurf 的优势在于其安装第三方工具和扩展的灵活性。
- 他们建议 Windsurf 可以通过允许类似的功能来提升其价值,特别是在 IDE 内移动第三方应用程序方面。
Stability.ai (Stable Diffusion) Discord
- Stability 迎来社区负责人:Stability.ai 引入了 Maxfield 作为新的首席社区负责人 (Chief Community Guy),强调了他自 2022 年 11 月以来对 Stable Diffusion 的参与,并承认 Stability 最近的社区参与度一直不尽如人意。
- Maxfield 计划通过功能需求板(用于收集社区建议)以及增加 Stability 研究人员和创作者的透明度来提升参与度,并表示:如果我们不构建你们想要的东西,那么所有这些算力的意义何在?
- 扩散模型嵌套探索:general-chat 频道的讨论显示了对嵌套 AI 架构的兴趣,即一个扩散模型在另一个模型的潜空间 (latent space) 内运行,尽管兼容的 VAE 是必不可少的。
- 用户寻找探索这一概念的论文,但分享的链接很少。
- 模型训练被证明很棘手:用户报告在训练 LoRA 等模型时遇到挑战,指出默认设置通常优于复杂的调整,并引用了 NeuralNotW0rk/LoRAW。
- 架构演进的复杂性让一些用户渴望更精简、更易用的工具,以便在潜空间中有效地工作。
- 未来 AI 模型引发关注:社区对未来的多模态模型进行了推测,对融合文本和图像生成能力的工具表现出热情,例如 PurpleSmartAI 之类的项目。
- 人们有兴趣开发新模型,通过直观的界面增强视频游戏开发等创意用途,并围绕该概念举办了黑客松 Multimodal AI Agents - Hackathon · Luma。
- 用户对抗 Discord 垃圾信息:general-chat 频道发生了一起垃圾信息事件,用户迅速举报了该消息并主张采取禁言措施。
- 社区通过标记无关的推广帖子,展示了维护频道纯净的集体努力。
Cursor IDE Discord
- Cursor 新增 MCP Server 集成:Cursor IDE 现在支持 MCP server 集成,使用户能够通过命令利用 Perplexity 提供协助,并使用提供的 GitHub 仓库 进行轻松设置。
- 一位用户在这段 Youtube 视频中展示了如何通过 MCP 打造具有增强功能的“加强版 Cursor”。
- Gemini 2.0 Pro 编程能力受到质疑:根据 lmarena.ai 的数据,用户批评 Gemini 2.0 Pro 模型虽然在数据分析方面表现良好,但在处理编程任务时却很吃力。
- 基准测试显示,尽管 Gemini 2.0 Pro 在处理随机任务时表现尚可,但在编程任务上仍落后于 O3-mini high 和 Sonnet;可以在 HuggingFace 上查看对比。
- 程序员使用语音听写:讨论者探索了语音听写工具,引用了 Andrej Karpathy 使用 Whisper 技术的编程听写方法,尽管 Windows 内置听写功能的准确性仍有待提高。
- 为编程定制语音接口引发了兴趣,目标是提高速度和准确性。
- 移动端 Cursor 引发讨论:一位用户提议开发 Cursor 的 iPhone 应用,以便随时随地进行编程和提示词编写 (prompting),但共识表明目前的框架可能无法证明这种开发投入的合理性。
- 社区权衡了开发移动版 Cursor 的实用性,指出其优势可能无法抵消开发成本。
Perplexity AI Discord
- Perplexity AI 的 UI 更改引起用户不满:用户对 Perplexity AI 最近的 UI 更改表示不满,特别是焦点模式(focus modes)的移除和性能变慢。
- 一些用户在访问 Claude 3.5 Sonnet 等模型时遇到困难,在 Pro Search 模式下会自动激活 R1 或 o3-mini。
- Gemini 2.0 Flash 登场:Gemini 2.0 Flash 已向所有 Pro 用户发布,正如 Aravind Srinivas 的推文所指出的,这是自早期版本以来 Gemini 模型首次回归 Perplexity。
- 用户对其上下文限制、与之前模型相比的能力以及在当前应用界面中的可用性感到好奇。
- 模型访问限制引发困惑:Pro 用户报告称模型访问不一致,尽管订阅了服务,但仍有人无法使用 Gemini 或访问所需模型,并建议通过 Perplexity 状态页面进行排查。
- 用户体验存在差异,一些人认为这些限制没有必要,而另一些人仍在适应跨平台的新功能。
- Sonar Reasoning Pro 基于 DeepSeek R1:一名成员澄清说 Sonar Reasoning Pro 运行在 DeepSeek R1 之上,这已在其网站上得到确认。
- 这一发现对一些不了解底层模型的成员来说是新鲜事。
- 在脱离联邦提议中提议美国“铁穹”:一名成员分享了一段视频,讨论了特朗普关于美国铁穹(US Iron Dome)的提议,以及包括加州脱离联邦提议在内的持续政治进展。
- 讨论考虑了此类军事战略对国家安全和地方治理的影响。
Eleuther Discord
- 谐波损失(Harmonic Loss)引发乐观情绪:一篇介绍 harmonic loss 作为神经网络标准交叉熵损失(cross-entropy loss)替代方案的论文出现,正如 Twitter 上讨论的那样,该论文声称其提高了可解释性并加快了收敛速度。
- 虽然一些人对其新颖性表示怀疑,但其他人指出它具有改变优化目标的潜力;这引发了关于模型训练期间稳定性和激活交互的讨论。
- VideoJAM 生成动作:Hila Chefer 介绍了 VideoJAM 框架,旨在通过直接解决视频生成器在没有额外数据的情况下在动作表征方面面临的挑战来增强动作生成,正如 Twitter 和项目网站上所讨论的那样。
- 它旨在直接解决视频生成器在动作表征方面面临的挑战,而无需额外数据,并有望改善视频内容中动作生成的动态性。
- GAS 提升 TPS 优于 Checkpointing:不使用激活检查点(activation checkpointing)并使用 GAS 进行训练可显著提高 TPS,对比显示 Batch Size 为 8 且使用 GAS 的 TPS 为 242K,而 Batch Size 为 48 且使用 Checkpointing 的 TPS 为 202K。
- 尽管有效 Batch Size 不同,但使用 GAS 的较小 Batch Size 显示出更快的收敛速度,虽然较低的 HFU/MFU 可能会引起关注,但如果 TPS 得到改善,则不会被优先考虑。
OpenRouter (Alex Atallah) Discord
- DeepSeek R1 Nitro 提速:DeepSeek R1 Nitro 展示了更好的运行时间和速度,请求完成率达到 97%。
- 根据 OpenRouterAI 的消息,现在鼓励用户尝试使用。
- OpenRouter 恢复在线:用户报告了 API 问题和速率限制错误,引发了对服务可靠性的担忧,但在撤销最近的一项更改后,服务立即恢复。
- Toven 确认了停机时间并宣布了修复方案,向用户保证服务功能已恢复。
- Anthropic API 遭遇速率限制:用户在使用 API 时遇到速率限制错误,特别是 Anthropic,其限制为每分钟 2000 万输入 token。
- Louisgv 提到正在联系 Anthropic,寻求提高速率限制的可能性以解决这些限制。
- Gemini 2.0:处于磨合期?:Xiaoqianwx 发起了关于对 Gemini 2.0 预期的讨论,以及是否需要更强大的模型来有效竞争。
- 社区对其表现普遍感到失望,并正在积极讨论该模型的优缺点。
- OpenRouter 即将推出价格控制功能:用户询问了关于 API 使用的潜在价格控制,特别是针对不同供应商之间的成本差异。
- Toven 引入了一个新的
max_price参数用于控制 API 调用的支出上限,该功能目前已上线,但尚未提供完整文档。
- Toven 引入了一个新的
Interconnects (Nathan Lambert) Discord
- Gemini 2.0 携 Flash 和 Experimental Pro 亮相:基准测试显示 Gemini 2.0 Pro Experimental 的性能与 Claude 3.5 Sonnet 相当,尽管注意到 API 响应存在不一致性;同时 Gemini 2.0 Flash 已集成到 GitHub Copilot 中供所有用户使用,作为开发者的新工具,使 Gemini 在微软生态系统中领先竞争对手获得显著关注。
- 一些用户认为,虽然 Flash 模型性能超越了 Gemini 1.5 Pro,但长上下文能力似乎有所减弱,并且他们认为 AI 模型的命名惯例缺乏创意和清晰度(DeepMind 推文, GitHub 推文)。
- Mistral 品牌重塑,专注于开源:Mistral 推出了重新设计的网站(Mistral AI),展示了旨在定制 AI 解决方案的开源模型,强调透明度和企业级部署选项,并采用了新的猫咪 logo。
- 该公司在保持领先独立 AI 实验室形象的同时,采用了俏皮的设计风格。
- 软银的 AGI 梦之队:讨论围绕公司是否有必要探索各种途径,在两年内向软银交付 AGI,因为该公司预期收入将达到 1000 亿美元。
- 社区正在思考这是否是一个现实的时间表。
- DeepSeek R1 在审视中亮相:2025 年 1 月 20 日,DeepSeek 发布了其开源权重推理模型 DeepSeek-R1,引发了围绕其在 这篇 Gradient Updates 文章 中公布的训练成本真实性的辩论。
- 该模型的架构与 DeepSeek v3 相似,引发了关于其性能和定价的讨论。
- Karpathy 转向 Vibe Coding:Andrej Karpathy 引入了 ‘vibe coding’ 的概念,拥抱像 Cursor Composer 这样的 LLM 并绕过传统编码,他表示自己几乎不再阅读 diff 了。
- 他补充道:“当我收到错误消息时,我只是不加评论地直接复制粘贴进去,” 正如在 这条推文 中所见。
LM Studio Discord
- LM Studio 面临低 VRAM 困扰:用户分享了在旧 CPU 和 GPU 上运行 LM Studio 的挑战,特别是像 RX 580 这样显存较低的显卡,导致了性能限制。
- 一些用户建议在不带 AVX 支持的情况下编译 llama.cpp,以增强在旧系统上的性能。
- 推荐 Qwen 2.5 用于编程:Qwen 2.5 model 获得了需要编程任务支持的用户的推荐,特别是对于那些具有特定硬件配置的用户。
- 用户根据本地安装的性能和可用性表达了对模型的偏好。
- Vulkan 支持效果参差不齐:在 llama.cpp 中启用 Vulkan 支持以提高 GPU 利用率需要特定的构建配置,这引发了关于 LM Studio 细节的讨论。
- 分享的资源强调了使用 Vulkan 进行编译的设置要求。
- GPT-Researcher 困扰 LM Studio:将 GPT-Researcher 与 LM Studio 集成的用户报告称,在模型加载和 embedding 请求时遇到错误。
- 具体而言,404 error 表示未加载任何模型,导致集成尝试中断。
- GPU 价格飙升:对于 eBay 和 Mercari 等平台上 GPU 价格的担忧日益增加,由于需求旺盛,这些硬件现在被视为“增值资产”。
- 包括 Jetson board 在内的组件价格膨胀正受到黄牛的影响。
HuggingFace Discord
- DeepSeek 表现优于下滑中的 ChatGPT:用户报告称 DeepSeek 提供的答案更好,且具有比 ChatGPT 更具吸引力的 chain of thought methodology(思维链方法论),但由于高流量,访问受到限制。
- 用户对 DeepSeek 的思考过程表现出浓厚兴趣,强调其思维链方法论比传统的 AI 回复更引人入胜。
- TinyRAG 简化 RAG 系统:TinyRAG 项目使用 llama-cpp-python 和 sqlite-vec 进行排序、查询和生成 LLM 答案,从而简化了 RAG 的实现。
- 该计划为开发者和研究人员提供了一种部署检索增强生成(retrieval-augmented generation)系统的简化方法。
- 距离学习(Distance-Based Learning)论文发表:一篇新论文《神经网络中的距离学习》(Distance-Based Learning in Neural Networks,arXiv)介绍了一个几何框架和 OffsetL2 architecture。
- 该研究强调了基于距离的表示(distance-based representations)对模型性能的影响,并将其与基于强度的方法进行了对比。
- Agents 课程下周开启:Agents Course 将于下周一启动,届时将开设用于更新、提问和项目展示的新频道。
- 随着第一单元目录的预览,热度不断上升;但一些成员对缺乏课程所需的编程基础 Python 技能表示担忧。
- HuggingFace 需要更新 NLP 课程:成员们要求 Hugging Face 更新 NLP 课程,因为现有课程缺乏对在当今 NLP 框架中至关重要的 LLM 的覆盖。
- 这一差距促使人们建议提供更全面的培训材料,以应对该领域的新兴趋势。
Yannick Kilcher Discord
- NURBS 挑战模拟中的网格:NURBS(非均匀有理 B 样条)提供适用于动态模拟的参数化表示,与传统网格日益低效的情况形成对比,而现代程序化着色器有助于解决纹理问题。
- 成员们注意到行业标准正向动态模型以及 NURBS 和 SubDs 等先进技术转变,摆脱了静态网格方法在动态应用中的局限性。
- Gemini 2.0 更新 Flash 和 Lite 版本:Google 在 Gemini API 和 Google AI Studio 中发布了更新后的 Gemini 2.0 Flash,强调与之前的 Flash Thinking 等版本相比具有更低的延迟和更强的性能。
- 关于新 Flash Lite 模型的反馈表明其在返回结构化输出方面存在问题,用户报告在生成有效的 JSON 响应时遇到困难。
- 工程师制造爆火的 ChatGPT 哨兵枪:在一段展示 AI 控制的电动哨兵枪视频走红后,OpenAI 切断了工程师 sts_3d 的 API 访问权限,引发了对 AI 武器化的担忧。
- 该工程师项目的快速进展凸显了与不断演进的 AI applications 相关的潜在风险。
- 研究人员攻克廉价 AI 推理模型:研究人员开发了 s1 reasoning model,以不到 $50 的云计算额度实现了与 OpenAI’s models 类似的能力,标志着成本的大幅降低 [TechCrunch 文章]。
- 该模型利用蒸馏方法,从 Google’s Gemini 2.0 中提取推理能力,从而展示了 AI technologies 更加普及的趋势。
- Harmonic Loss 论文评价褒贬不一:Harmonic Loss 论文 引入了一种更快的收敛模型,但该模型尚未表现出显著的性能提升,引发了对其实用性的争论。
- 虽然有些人认为这篇论文“粗糙”,但其简洁性被认为很有价值,尤其是在 其 GitHub 仓库 中可以获得额外的见解。
OpenAI Discord
- DeepSeek 数据实践受调查:一段 YouTube 视频引发了对 DeepSeek 可能将数据发送到中国的担忧,理由是其服务器设在中国。
- 讨论强调了 AI 开发中数据治理和监管标准的重要性,用户指出了 data residency(数据驻留)的影响。
- ChatGPT 的推理怪癖:用户观察到 ChatGPT 4o 表现出不可预测的行为,例如尽管收到的是英文提示词,却使用多种语言提供推理过程。
- 这些报告引发了关于模型当前局限性的讨论,以及完善 AI 生成输出的一致性和清晰度的必要性。
- Gemini 2.0 Token 上下文令人印象深刻:Gemini 2.0 提供的 2 million token context 和免费 API 访问激起了开发者的兴趣,他们渴望探索其广阔的能力。
- 虽然一些用户承认 Gemini 2.0 促进了自动化的重要性,但也有人评论说该 AI 过于啰嗦,导致阅读量过大。
- 用户编写修辞提示词:一名成员详细介绍了一个提示词,用于生成关于为什么 Coca-Cola 配 hot dog 最好吃的说服性论点,并结合了 Antimetabole 和 Chiasmus 等高级修辞技巧。
- 提示词结构包括论证理由、提供示例和应对反驳的部分,旨在达成连贯且有影响力的结论。
- 精灵图表 (Sprite Sheet) 模板咨询:一位用户寻求关于优化提示词模板的建议,以生成一致的卡通风格精灵图表,重点在于角色和动画帧布局。
- 尽管指定了角色设计和尺寸,但图像并未按预期对齐,因此该用户请求进行优化。
Nous Research AI Discord
- DeepSeek 在推理能力上媲美 OpenAI:讨论强调了 DeepSeek R1 据称在完全开源且可高效运行的情况下,能与 OpenAI 的 O1 推理模型相媲美。
- 成员们注意到像 Gemini 这样较新的模型在执行数学任务方面的惊人能力,以及品牌命名的复杂性如何困扰用户;参见 Gemini 2.0 现已向所有人开放。
- AI 与 Crypto 的联系?:一位成员推测对 AI 的抵制是否与 2020-21 年 NFT 和 crypto 争议的余波有关。
- 他们引用了 为什么大家突然对 AI 感到愤怒 及其对 AI 认知的启示,将其与过去的技术炒作联系起来。
- DeepResearch 获得好评:用户对 OpenAI 的 DeepResearch 功能充满热情,称赞其性能和高效检索冷门信息的能力,如这条推文所示。
- 成员们讨论了利用知识图谱丰富结果,以增强事实核查和研究的准确性。
- Liger Kernel 获得 GRPO Chunked Loss:最近的一个 pull request 为 Liger Kernel 增加了 GRPO chunked loss,解决了 issue #548。
- 开发者可以运行 make test、make checkstyle 和 make test-convergence 来测试正确性和代码风格。
- 基础设施团队被低估了?:成员们注意到,由于需要致谢 hardware infrastructure 团队,许多预训练论文都有大量作者。
- 有人强调,infra 团队忍受挑战是为了让研究科学家能够专注于工作而不受干扰——基础设施人员受苦,是为了让研究科学家不必受苦。
Modular (Mojo 🔥) Discord
- Mojo 编译器转为闭源:据一名团队成员称,受管理快速变化的需要驱动,Mojo 编译器转为了闭源。
- 编译器爱好者渴望了解其内部工作原理,特别是 MLIR 中的自定义 lowering passes,但根据这段视频,必须等到 2026 年底。
- Mojo 计划在 2025 年第四季度开源:据一名团队成员称,Modular 目标是在明年第四季度开源 Mojo 编译器,尽管有人希望能更早发布。
- 目前没有计划在整个编译器开源之前发布 MLIR 中的单个 dialects 或 passes,这让编译器极客们的希望落空。
- Mojo 标准库面临设计选择:围绕 Mojo 标准库是否应该演变为具有 Web 服务器和 JSON 解析等功能的通用库展开了辩论。
- 有人对支持广泛用例的复杂性表示担忧,这提高了向
stdlib贡献新功能的门槛,正如这个 GitHub 仓库所整理的那样。
- 有人对支持广泛用例的复杂性表示担忧,这提高了向
- Async 函数引发讨论:Mojo 中 async 函数的处理正在讨论中,有人提议采用新语法以提高清晰度并实现性能优化,如这份提案所示。
- 参与者对维护独立的 async 和 sync 库的复杂性,以及对不同版本功能的可用性影响表示担忧。
Notebook LM Discord
- 法律 AI 自动化草拟:AI 现在被用于自动化草拟重复性的法律文件,利用以往案例的模板作为来源,使流程更加高效,成员们发现 AI 非常有用。
- 一位律师报告称 AI 可靠并提供清晰的来源,特别是对于类似案件或大规模诉讼。
- 虚拟形象提升合同审查:成员们正在尝试在合同审查中使用虚拟形象,使修订分析更具吸引力,正如 YouTube 视频 中展示的那样。
- 增加虚拟形象旨在使产品差异化,并有效地支持客户团队。
- NotebookLM Plus 激活问题出现:根据 Google Support,Google Workspace 管理员在激活 NotebookLM Plus 时面临问题,需要 Business Standard 或更高级别的许可证才能访问高级功能。
- 已分享相关资源以帮助管理员启用和管理用户访问,重点在于了解具体要求和所需的许可证。
- 电子表格集成仍面临挑战:正如 general 频道 中所述,用户对 NotebookLM 分析电子表格中表格数据的有效性表示担忧,建议 Gemini 可能更适合复杂的数据任务。
- 讨论围绕上传电子表格的最佳实践以及数据识别能力的局限性展开。
Torchtune Discord
- Torchtune 在显存管理上胜过 Unsloth:用户报告称,在 12GB 的 4070 显卡上,Torchtune 处理微调时没有出现 Unsloth 中常见的 CUDA 显存问题。
- 除非使用过大的 batch sizes,否则该工具可以避免遇到同样的显存问题。
- Ladder-Residual 极大提升 Llama 速度:根据 @zhang_muru 在 TogetherCompute 的工作,Ladder-residual 修改在多 GPU 张量并行下使 70B Llama 模型加速了 约 30%。
- 这一增强功能由 @MayankMish98 共同作者完成,并由 @ben_athi 指导,标志着分布式模型训练的显著进步。
- Kolo 开启 Torchtune 集成:Kolo Docker 工具现在提供对 Torchtune 的官方支持,为新手简化了本地模型训练和测试,项目链接。
- 由 MaxHastings 创建的 Kolo Docker 工具旨在促进在单一环境中使用一系列工具进行 LLM 训练 和 测试。
- 为 Torchtune 定制的 Tune Lab UI:一位成员正在开发 Tune Lab,这是一个用于 Torchtune 的 FastAPI 和 Next.js 界面,使用现代 UI 组件来增强用户体验,Tune Lab 仓库。
- 该项目旨在集成预构建和自定义脚本,邀请用户参与其开发。
- GRPO 为训练带来巨大提升:据成员报告,GRPO 实现取得了显著成功,将 GSM8k 上的训练性能从 10% 提升到 40%。参见 相关 issue
- 该实现涉及解决与死锁和显存问题相关的调试挑战,并计划重构代码供社区使用。
Latent Space Discord
- OpenAI 计划推出 SWE Agent:据 一条推文 称,OpenAI 计划在第一季度末或第二季度中期发布新的 SWE Agent,由面向企业的 O3 和 O3 Pro 提供支持。
- 该 Agent 预计将对软件行业产生重大影响,据称可以与中级工程师竞争,这一消息在 一场直播 中被发现。
- OmniHuman 生成头像视频:据 一条推文 称,新的 OmniHuman 视频研究项目可以从单张图像和音频生成逼真的头像视频,且不受长宽比限制。
- 该项目被誉为一项突破,其细节水平令观众感到 震惊。
- Figure AI 与 OpenAI 分道扬镳:据 一条推文 称,Figure AI 在报道称取得突破后,退出了与 OpenAI 的合作协议,转而专注于内部 AI 技术。
- 据 TechCrunch 报道,创始人暗示将在 30 天内展示 从未有人在人形机器人上见过的东西。
- Gemini 2.0 Flash 正式发布 (GA):据 一条推文 称,Google 宣布 Gemini 2.0 Flash 现已正式发布,使开发者能够创建生产级应用程序。
- 据 一条推文 称,该模型支持 200 万 token 的上下文,引发了关于其相对于 Pro 版本性能的讨论。
- Mistral AI 重塑平台品牌:据 其官网 显示,Mistral AI 的网站进行了重大品牌重塑,推广其可定制、可移植且企业级的 AI 平台。
- 他们强调了自己作为开源 AI 主要贡献者的角色,以及致力于提供引人入胜的用户体验的承诺。
Nomic.ai (GPT4All) Discord
- GPT4All v3.9.0 发布:GPT4All v3.9.0 已发布,具有 LocalDocs 功能,并增强了对 OLMoE 和 Granite MoE 等新模型的支持。
- 新版本还修复了在使用推理模型时后续消息出现的错误,并增强了 Windows ARM 支持。
- 推理增强生成 (ReAG) 亮相:ReAG 直接将原始文档输入语言模型,与传统方法相比,有助于实现更具上下文感知能力的响应。
- 这种方法通过避免过度简化的语义匹配来提高准确性和相关性。
- GPT4All 作为自托管服务器:用户讨论了在桌面端自托管 GPT4All 以实现移动端连接,这可以通过 Python 主机实现。
- 虽然可行,但支持可能有限,并且可能需要非常规的设置。
- NSFW 内容寻找本地模型:成员们讨论了用于 NSFW 故事的本地可用 LLM,发现 wizardlm 和 wizardvicuna 效果欠佳。
- 像 obadooga 和 writing-roleplay-20k-context-nemo 这样的替代方案在生成 NSFW 内容方面可能提供更好的性能。
- UI 滚动 Bug 出现:一位用户报告了一个 UI Bug,即如果文本超过可见区域,提示窗口的内容无法滚动,从而导致可访问性问题。
- 此前在 GitHub 上也报告过类似问题,表明这是一个更广泛的问题。
MCP (Glama) Discord
- ChatGPT Pro 引发团队兴趣:成员们有兴趣购买 ChatGPT Pro 订阅,可能通过多个账号分摊成本供团队使用。
- 兴趣集中在将 ChatGPT Pro 用于开发,但对账号拆分和适当的使用策略提出了担忧。
- Excel MCP 构想涌现:围绕创建一个用于读取和操作 Excel 文件 的 MCP 展开了热烈讨论,并就使用 Python 还是 TypeScript 进行了辩论。
- 讨论强调了自动化数据处理任务的潜力,但每种语言的可行性是争论的焦点。
- Playwright 胜过 Puppeteer:分享的经验表明 Playwright 与 MCP 配合良好,而 Puppeteer 需要本地修改,且此 GitHub 实现 尚未达到生产就绪状态。
- 用户比较了这两种工具在自动化项目中的实现难度,更倾向于 Playwright 更简单的集成方式。
- Home Assistant 添加 MCP 客户端/服务器支持:Home Assistant 发布了对 MCP 客户端/服务器的支持,扩展了集成能力,很高兴看到自动化生态系统的进一步融合。
- 这一集成有望增强自动化工作流,允许用户在其家庭自动化设置中利用 MCP。
- PulseMCP 展示使用案例:PulseMCP 发布了一个新展示页,包含实用的 MCP 服务器和客户端组合,并附有详细说明、截图和视频。
- 示例包括使用 Gemini voice 管理 Notion,以及利用 Claude 将 Figma 设计 转换为代码,展示了 MCP 应用的多样性。
GPU MODE Discord
- Flux 在图像生成方面碾压 Emu3:在 Huggingface L40S 上,Flux 使用
flash-attention和 W8A16 量化,在 30 秒 内生成了一张 1024x1024 的图像,使 Emu3 生成 720x720 图像所需的约 600 秒相形见绌。- 尽管参数量相当(Emu3 为 8B,Flux 为 12B),但速度差异引发了关于 Emu3 与单模态模型相比效率如何的疑问。
- OmniHuman 制作逼真的人物视频:OmniHuman 项目 仅凭一张图像即可生成高质量的人物视频内容,突显了其在多媒体应用中的潜力。
- 其独特的框架通过混合训练策略实现了端到端的多模态条件人物视频生成,大大提升了生成视频的质量。
- FlowLLM 启动材料发现:FlowLLM 是一种新型生成模型,它将大语言模型(LLM)与黎曼流匹配(Riemannian flow matching)相结合,用于设计新型晶体材料,显著提高了生成速率。
- 该方法在材料生成速度上超越了现有方法,基于 LLM 输出开发稳定材料的效率提高了三倍以上。
- Modal 招聘 ML 性能工程师:Modal 是一个 serverless 计算平台,为 Suno 和 Liger Kernel 团队 等用户提供灵活、自动扩展的计算基础设施。
- Modal 正在招聘 ML 性能工程师 以增强 GPU 性能,并为 vLLM 等上游库做出贡献,职位描述点击此处。
- Torchao 在 Torch Compile 中遇到困难:一位用户报告称,结合使用 Torchao 和 torch.compile 似乎会导致 bug,暗示存在兼容性问题。
- 另一位成员建议该 bug 与此 GitHub issue 一致,涉及
nn.Module无法在设备间转移的问题。
- 另一位成员建议该 bug 与此 GitHub issue 一致,涉及
LlamaIndex Discord
- Deepseek 论坛将探索工作流:@aicampai 正在举办一场关于 Deepseek 的虚拟论坛,重点介绍其功能以及如何集成到开发者和工程师的工作流中,详情见此处。
- 该论坛旨在提供关于 Deepseek 技术及其应用的实战学习体验。
- 新教程指导构建首个 RAG 应用:@Pavan_Belagatti 发布了一个视频教程,指导用户使用 @llama_index 构建他们的第一个 Retrieval Augmented Generation (RAG) 应用程序,链接见此处。
- 这是为了回应新用户寻求 RAG 应用开发的实践见解。
- Gemini 2.0 发布并支持 LlamaIndex:@google 宣布 Gemini 2.0 已全面上市,且 @llama_index 提供零日支持,详见其发布博客文章。
- 用户可以通过
pip install llama-index-llms-gemini安装最新的集成包来体验出色的基准测试结果,更多信息可通过 Google AI Studio 获取。
- 用户可以通过
- LlamaIndex LLM 类缺少超时设置:一位用户观察到默认的 LlamaIndex LLM 类缺乏内置的超时(timeout)功能,而 OpenAI 的模型中存在该功能,链接见此处。
- 另一位用户建议,超时设置可能包含在 client kwargs 中。
- 解决 Qwen-2.5 的 Function Calling 问题:一位用户报告了在使用 Qwen-2.5 进行 Function Calling 时出现
ValueError,建议使用命令行参数并切换到类 OpenAI 的实现,文档见此处。- 为了顺利在 Qwen-2.5 中使用 Function Calling,另一位用户转而实现 LlamaIndex 的
OpenAILike类。
- 为了顺利在 Qwen-2.5 中使用 Function Calling,另一位用户转而实现 LlamaIndex 的
LLM Agents (Berkeley MOOC) Discord
- MOOC 证书发放延迟:一名成员报告称 12 月份申请的证书发放延迟,课程工作人员目前正在努力加快分发进度。
- 课程工作人员希望在未来一两周内解决这些问题。
- 测验难以查找:成员们询问了 Quiz 1 和 Quiz 2 的可用性,课程工作人员确认 Quiz 2 尚未发布,并提供了 Quiz 1 的链接。
- 成员们可以在周五之后完成 Quiz 1,目前没有截止日期。
- 第一课视频现已配备专业字幕:一名成员确认 YouTube 链接 指向的是第一课的修正版本,标题为“CS 194/294-280 (Advanced LLM Agents) - Lecture 1, Xinyun Chen”。
- 编辑后的录像包含了专业字幕以提高可访问性。
Cohere Discord
- 用户思考 Embed v3 迁移:一位用户询问如何将现有的 float 类型向量从 embed v3 迁移到 embed v3 light,并询问是否可以删除多余维度,或者是否需要完全重新生成数据库。
- 缺乏直接回应突显了此类迁移过程的复杂性和疑虑。
- 渴望 Cohere 的 Moderation Model:一名成员表达了希望 Cohere 提供 moderation model(审核模型)的愿望,以减少对美国服务的依赖。
- 这一需求凸显了对满足区域要求的本地化 AI 解决方案的渴望。
- 探讨聊天功能定价:一位用户询问了聊天功能的月费付费选项,表明其主要兴趣在于聊天功能而非产品开发。
- 另一位成员指出存在需要付费使用的 production API。
- 对话记忆困扰开发者:一名成员分享了他们的挫败感,即 AI 的响应在请求之间缺乏上下文关联,并寻求关于如何使用 Java 代码 实现对话记忆(conversational memory)的指导。
- 另一位成员确认已创建了与该问题相关的支持工单,并提供了工单链接,加强了社区支持。
- 社区澄清行为准则:一名成员发出严厉提醒,称未来的违规行为可能导致封禁(ban),强调必须遵守社区准则。
- 作为回应,另一名成员为过去的行为道歉,表达了遵守社区预期的承诺。
tinygrad (George Hotz) Discord
- tinygrad 0.10.1 面临错误:在将 tinygrad 升级到版本 0.10.1 时,用户报告测试失败并出现 NotImplementedError,原因是未知的重定位类型 4,这表示版本 19.1.6 不支持外部函数调用。
- 这些问题可能与影响编译过程的 Nix 特有行为 有关。
- 编译器标志引发关注:由于设置了
NIX_ENFORCE_NO_NATIVE,编译器警告关于跳过非纯净标志 -march=native 的问题引起了讨论。- 一名成员澄清说,移除 -march=native 通常适用于用户机器软件,而 tinygrad 使用 clang 作为 kernel 的 JIT 编译器,从而在 tinygrad 上下文中减轻了该标志的必要性。
- 调试变得更容易:一位贡献者宣布 PR #8902 将改进 tinygrad 的调试功能,使复杂问题的解决更加可控。
- 预期项目持续的改进将有助于缓解观察到的问题。
- 基础操作和 Kernel 实现受到询问:一名成员询问了 tinygrad 中 base operations 的数量,寻求澄清该框架的基础元素。
- 随后有人请求提供与 tinygrad 相关的 kernel implementations 源码,表明了对理解底层代码库的兴趣。
Gorilla LLM (Berkeley Function Calling) Discord
- API Endpoint 需要公开:向 leaderboard 添加新模型说明中规定,虽然可能需要 authentication,但 API endpoint 应该对 公众 开放。
- 可访问性旨在确保 API endpoint 更广泛的可用性。
- Raft 方法在 Llama 3.1 7B 上是否足够?:一名成员询问 1000 个用户的数据 是否足够用于 Llama 3.1 7B 的 Raft method 训练,以及在应用 RAG 之前是否应加入 synthetic data。
- 有人担心 1000 个用户的数据 可能无法为有效的模型训练提供足够的样性,建议可能需要 synthetic data 来填补空白并提高训练效果。
DSPy Discord
- Chain of Agents 在 DSPy 中亮相:一位用户介绍了一个以 DSPy 方式 实现的 Chain of Agents 示例,详情可见这篇文章。
- 讨论还引用了关于 Chain of Agents 的原始研究论文,可在此处访问。
- 社区寻求 DSPy Chain of Agents 的 Git 仓库:一位用户询问讨论中的 DSPy 版 Chain of Agents 示例是否有可用的 Git repository。
- 这一请求表明社区对 Chain of Agents 概念的实际动手实现有着浓厚兴趣。
MLOps @Chipro Discord 没有新消息。如果该服务器沉寂时间过长,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该服务器沉寂时间过长,请告知我们,我们将将其移除。
第 2 部分:按频道详细摘要和链接
完整的逐频道详情已针对电子邮件进行了删减。
如果您喜欢 AInews,请分享给朋友!预谢!