ainews-s1-simple-test-time-scaling-and-kyutai
s1:简单的测试时缩放(以及 Kyutai Hibiki)
“Wait” is all you need 介绍了一种新型推理模型,该模型仅使用从 Gemini 2.0 Flash Thinking 蒸馏出的 1000 个带有推理轨迹的问题,对 Qwen 2.5 32B 进行微调而成。它通过在提示中添加“Wait”一词来延长推理过程,从而实现了可控的测试时计算(test-time compute)。首席作者 Niklas Muennighoff(因在 Bloom、StarCoder 和 BIG-bench 方面的工作而闻名)强调了该方法的效率,并指出它重现了著名的 o1 缩放图表(scaling chart)。
此外,Kyutai Moshi 的 Hibiki 项目展示了在 iPhone 上令人印象深刻的离线法英实时翻译。近期发布的 AI 模型还包括:DeepSeek R1 和 R3 开源模型,这可能标志着开源领域的一个重大里程碑;Hugging Face 的 SmolLM2,强调针对小型语言模型(SLM)的以数据为中心的训练;以及 IBM 的 Granite-Vision-3.1-2B,一款性能强劲的小型视觉语言模型。重点研究论文则聚焦于 LIMO(通过极简示例推理在 AIME 和 MATH 基准测试中实现高准确率)以及 Token-Assisted Reasoning(通过混合潜变量 token 和文本 token 来提升语言模型的推理能力)。
“Wait” 就是你所需的一切。
2025年2月5日至2月6日的 AI 新闻。我们为你查看了 7 个 Reddit 子版块、433 个 Twitter 账号 和 29 个 Discord 社区(210 个频道,共 4396 条消息)。预计为你节省了 490 分钟 的阅读时间(以 200wpm 计算)。你现在可以标记 @smol_ai 来参与 AINews 的讨论!
遗憾的是,我们报道这篇论文的时间稍晚了一些,但迟到总比不到好。s1: Simple test-time scaling 记录了一个新的推理模型,包含两项创新贡献:
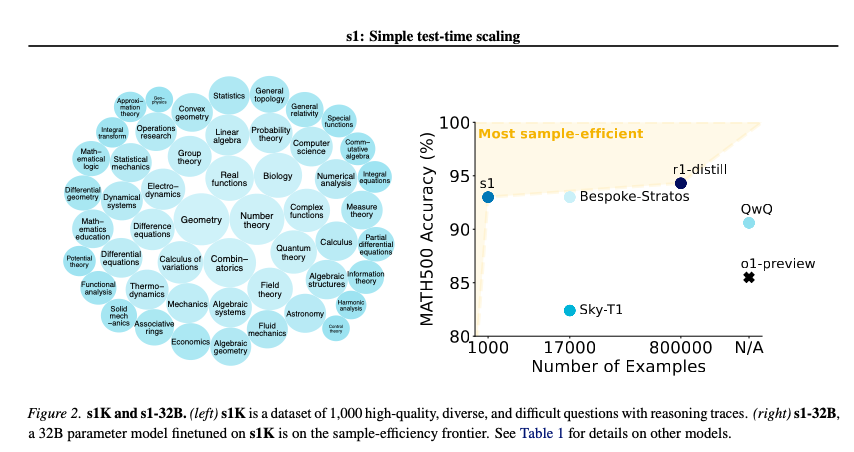
- 基于 Qwen 2.5 32B,仅在 1000 个配有推理轨迹(reasoning traces)的问题上进行微调,这些轨迹是从 Gemini 2.0 Flash Thinking 蒸馏而来,并经过难度、多样性和质量过滤(在 16 台 H100 上训练了 26 分钟)。
- 可控的 test-time compute:通过强制终止模型的思考过程,或者在模型试图结束生成时多次附加 “Wait” 来延长其思考时间。

主作者 Niklas Muennighoff(曾参与 Bloom, StarCoder, MTEB 以及 BIG-bench 的工作)指出,这第二个技巧复现了著名的 o1 扩展图表(scaling chart):
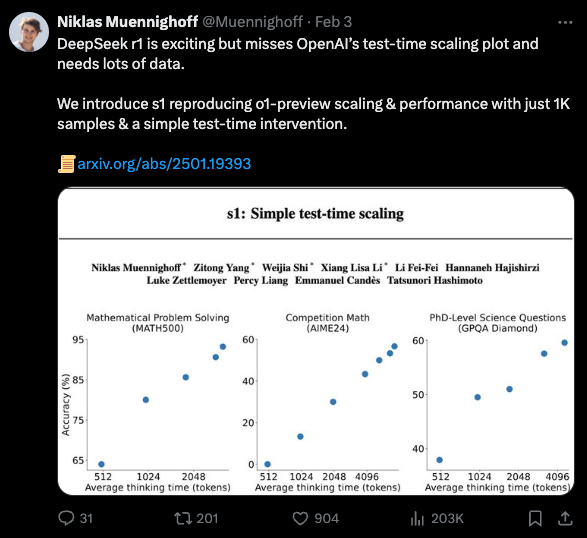
与 Bespoke-Stratos(我们的报道在此)相比,其过滤机制在样本效率上也表现得非常出色。
我们还推荐阅读 Simonw 和 Tim Kellogg 的解读文章。
今日荣誉提名:
Kyutai Moshi 去年因其带有内心独白的实时语音而引起轰动(我们的报道在此),现在 Hibiki 展示了在 iPhone 上离线进行的非常令人印象深刻的法英实时翻译。对于一个实习项目来说,这表现相当不错。
AI Twitter 回顾
AI 模型与发布
-
DeepSeek R1 和 R3 开源发布:@teortaxesTex 宣布 R1-low-mid-high 模型即将推出,这可能标志着 LLM 领域第一个真正的开源时刻,可与 nginx、Blender 甚至 Linux 相媲美。这一发布可能会削弱由拥有专有技术的现任巨头组成的卡特尔所垄断的市场。
-
Hugging Face 发布 SmolLM2:@_akhaliq 分享了 Hugging Face 宣布 SmolLM2 的消息,详见论文 “When Smol Goes Big – Data-Centric Training of a Small Language Model”。@LoubnaBenAllal1 提供了 SmolLM2 论文的详细解读,强调 数据是小模型(small LMs)强大性能背后的秘密武器。
-
IBM 的 Granite-Vision-3.1-2B 模型:@mervenoyann 讨论了 Granite-Vision-3.1-2B 的发布,这是一个在各种任务上表现令人印象深刻的小型视觉语言模型。目前已提供 Notebook 用于测试该模型。
AI 研究论文与发现
-
LIMO:推理中的“少即是多”:@_akhaliq 重点介绍了 LIMO,展示了通过极少但精确设计的示例,可以激发出复杂的推理能力。@arankomatsuzaki 指出,LIMO 仅用 817 个训练样本就在 AIME 上达到了 57.1% 的准确率,在 MATH 上达到了 94.8%,显著优于以往的方法。
-
令牌辅助推理:@_akhaliq 分享了论文 “Token Assorted: Mixing Latent and Text Tokens for Improved Language Model Reasoning” 的见解,讨论了结合潜变量令牌(latent tokens)和文本令牌如何增强语言模型的推理能力。
-
长思维链(Long Chains of Thought)的进展:@gneubig 展示了关于短思维链与长思维链对比、监督微调(supervised fine-tuning)与强化学习(reinforcement learning)的作用,以及在语言模型中控制推理长度的方法的研究见解。
AI 工具与平台
-
Gradio DualVision 应用:@_akhaliq 介绍了 DualVision,这是一个用于图像处理的 Gradio 模板应用,具有多模态预测、GPU 支持和示例库,旨在提升用户体验。
-
Mistral AI 的 Le Chat 现已登陆移动端:@sophiamyang 宣布由 Mistral AI 开发的 AI 助手 Le Chat 正式发布移动版,具备代码解释器(code interpreter)和由 Mistral 模型驱动的极速响应等功能。
-
ChatGPT 中的 Canvas 共享功能:@OpenAIDevs 宣布 canvas 共享功能现已在 ChatGPT 上线,允许用户共享、交互或编辑 canvas,增强了协作能力。
AI 行业新闻与活动
-
Google DeepMind 的 Applied ML Days 工作坊:@GoogleDeepMind 邀请参与者参加 Applied ML Days 的两个工作坊,重点关注使用 Google Gemini 构建 LLM 应用以及与基础模型(Foundational Models)的自然交互。
-
Cerebras 为领先的 AI 实验室提供动力:@draecomino 分享称 Cerebras 目前正在为一家领先的 AI 实验室的生产环境提供支持,展示了 AI 基础设施和计算能力的进步。
-
Keras 社区会议:@fchollet 宣布将举行 Keras 团队公开社区会议,提供 Keras 的最新动态并为开发者提供提问机会。
个人成就与更新
-
Google Developers India 认可:@RisingSayak 对获得提名表示感谢,并感谢 @GoogleDevsIN 的认可,强调了在社区中的成就感。
-
Philipp Schmid 加入 Google DeepMind:@osanseviero 欢迎 Philipp Schmid 加入 Google DeepMind,并表达了与包括 @DynamicWebPaige、@film_girl 等人在内的梦之队共事的兴奋之情。
迷因/幽默
-
程序员的类型:@hyhieu226 幽默地将程序员分为两类:编写冗长类型声明的人和为了简洁而使用 ‘auto’ 的人。
-
过度自信警告:@qtnx_ 分享了个人反思,提醒过度自信会导致失败,建议保持谦逊并勤奋工作。
-
AI 实验室骗子:@scaling01 指责了 AI 社区中的 YouTube 骗子,指出他们从最初蔑视 AI 进展转向利用其牟利,暗示其关注点在于利润而非技术。
AI Reddit 汇总
/r/LocalLlama 汇总
主题 1. Hibiki 语音对语音翻译 - 法语到英语能力
- Hibiki by kyutai, a simultaneous speech-to-speech translation model, currently supporting FR to EN (Score: 448, Comments: 40): Hibiki 是由 Kyutai 开发的实时语音到语音翻译模型,目前支持 法语 (FR) 到英语 (EN) 的翻译。
- Hibiki 的功能:Hibiki 因其实时翻译质量、自然度以及说话人相似度而受到赞誉,相关资源可在 GitHub 和 Hugging Face 上获取。该模型在调整语速以适应语义内容的同时,能够保留说话人声音的能力备受关注,且据称其表现优于以往的系统。
- 社区反馈与需求:用户对该模型的表现表示赞赏,部分用户希望增加更多语言支持,特别是 Spanish(西班牙语)和 Chinese(中文)。用户还希望推出设备端(on-device)版本,以便在旅行和非英语地区使用。
- 文化与开发观察:社区中出现了一些关于法国人英语水平以及这款由法国开发的模型采用日语命名(Hibiki)的幽默评论。该项目的开源性质(类似于 Mistral)也受到了关注,人们对其未来在设备端翻译能力方面的进展充满期待。
Theme 2. Challenges with Gemini 2.0 Pro Experimental Model
- The New Gemini Pro 2.0 Experimental sucks Donkey Balls. (Score: 205, Comments: 83): 作者批评 Gemini 2.0 Pro Experimental 模型与之前的 1206 模型相比表现极差,指出了频繁出错和不必要的代码重构等问题。他们对 Google 发布质量倒退模型的模式感到沮丧,并将其与 Flash 2.0(原文为 Flesh light 2.0)在 OCR 任务中令人印象深刻的速度和效率进行了对比。
- 许多用户对 Gemini 2.0 Pro Experimental 表示不满,指出其智力下降、以牺牲质量为代价提高速度等问题,一些用户更倾向于旧的 1206 模型,或者在编程和创意写作等特定任务中使用 Flash 2.0 等其他模型以获得更好的表现。
- Flash 2.0 和 o1 模型因其有效性而受到称赞,特别是在处理复杂查询和在长任务中保持上下文方面;而较新的模型如 o3-mini 则因需要更冗长的输入才能理解用户意图而受到批评,这导致了效率低下。
- 讨论凸显了一个更广泛的趋势:AI 模型正变得更快、更高效,但却以牺牲深度和一致性为代价。一些用户指出了当前评估指标的局限性,以及在实际应用中平衡速度与质量的挑战。
Theme 3. Open WebUI Releases Code Interpreter and Exa Search Features
- Open WebUI drops 3 new releases today. Code Interpreter, Native Tool Calling, Exa Search added (Score: 185, Comments: 61): Open WebUI 在 0.5.8 版本中引入了重大更新,包括使用 Pyodide 实时执行代码的 Code Interpreter(代码解释器)、重新设计的聊天输入 UI,以及用于在聊天中检索信息的 Exa Search Engine Integration(Exa 搜索引擎集成)。此外,Native Tool Calling Support(原生工具调用支持)现已进入实验阶段,有望降低查询延迟并改善上下文响应。发布详情可在网上查阅。
- Code Interpreter 和 Pyodide:用户对使用 Pyodide 添加代码解释器表示赞赏,虽然注意到其局限性,但认可其在常见用例中的实用性。用户呼吁进一步改进,例如集成 Gradio 并支持下载结果(如绘图或处理后的数据)。
- 社区贡献:尽管有很多贡献者,但 tjbck 被公认为 Open WebUI 最主要且持续的贡献者,社区建议通过 GitHub sponsorship 来支持他们。该项目因其快速的功能更新以及相对于闭源 UI 的竞争优势而受到赞誉。
- 文档处理与 RAG:针对文档处理存在一些批评,特别是针对单文档引用使用简单的向量数据库 RAG,这在处理简单查询时经常失败。建议包括将文档、RAG 和搜索功能移至独立的流水线(pipelines)以跟上快速发展的步伐,并默认禁用 RAG 以便用户更好地控制。
Theme 4. Over-Tokenized Transformer Enhances LLM Performance
- Over-Tokenized Transformer - 一项新研究表明,在相同的训练成本下,大幅增加稠密 LLM 的输入词表(增加 100 倍或更多)能显著提升模型性能 (Score: 324, Comments: 37): 一篇新论文证明,将稠密 Large Language Model (LLM) 的输入词表大幅增加 100 倍或更多,可以在不增加训练成本的情况下显著提升模型性能。这一发现为通过扩大词表大小来提高 Transformer 效率提供了一种潜在策略。
- Tokenization 与词表大小:将词表大小增加到数百万(而非典型的 32k 到 128k),可以通过使用更具意义的层级化 Token 来增强模型性能。这种方法通过将多个 Token 组合成新的 Token 来实现更快的收敛,尽管它主要提升的是训练效率,而非与词表大小成正比的最终性能。
- 潜在挑战与考量:人们担心贪婪 Tokenizer 会导致 Token 训练不足,这可能会在拼写错误以及对单字符变动敏感的任务(如算术或代数推理)中引发性能问题。此外,在使用较小 Token 时,对内存占用、推理速度和有效上下文窗口大小的影响也存在疑问。
- 研究与对比:三个月前的一项类似研究建议,像 Llama 2 70B 这样的模型应至少使用 216k tokens 以实现最佳算力利用率,甚至更大的 Token 数量也可能有益。该论文的发现对稠密模型特别有意义,但并未在 Mixture of Experts (MoE) 模型中显示出同样的改进,这凸显了一个值得进一步探索的领域。
其他 AI Subreddit 综述
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
主题 1. Altman 承认 OpenAI 的竞争优势有所减弱
- Altman 承认 OpenAI 将不再能够保持巨大的领先优势 (Score: 259, Comments: 69): Sam Altman 承认 OpenAI 将面临日益激烈的竞争,并且无法维持其此前在 AI 开发中的领先地位。据 Fortune.com 采访报道,他指出虽然 OpenAI 会产出更好的模型,但竞争差距将会缩小。来源。
- OpenAI 的竞争策略:几位评论者讨论了这样一种观点:OpenAI 试图通过控制其研究成果的发布来维持垄断,这使他们在竞争对手复制其工作之前拥有大约 3-4 个月 的优势。这一策略被视为在竞争格局中保持领先的临时措施。
- 技术瓶颈与模型训练:有一种观点认为 AI 技术可能正处于瓶颈期,用户注意到 OpenAI 承认面临不可避免的竞争。评论者强调了防止他人利用大模型输出训练自家模型的挑战,这表明 OpenAI 必须与其他公司共同持续创新。
- 媒体与公众互动:一位评论者的提问出现在了 Fortune 的文章中,引发了关于媒体伦理和此类出版物价值的讨论。尽管 Sam Altman 在 AMA 活动中能披露的内容有限,但人们对其开放态度表示赞赏。
主题 2. 使用 AI 工具进行复杂分析的深度重构
- 给我一个 Deep Research 的提示词,我来为你运行! (Score: 246, Comments: 111): 该用户支付了 $200 以获取 Deep Research 的访问权限,并提议为社区运行提示词以评估其能力。他们将其与 o3-mini-high 进行了比较,指出 Deep Research 支持附件,但似乎并没有显著更好。他们邀请社区提交严肃的提示词并进行投票,以确定执行的优先顺序。
- 复杂提示词的挑战: 用户正在提交复杂的跨学科提示词,例如涉及 particle physics、ontological spaces 和 depression subtypes 的内容。这些通常需要 AI 进行澄清才能继续研究或分析,凸显了通过精确输入来优化 AI 响应的必要性。
- 投资与经济预测: 人们对在后 ASI 时代使用 AI 进行 stock market predictions 和经济分析表现出浓厚兴趣。用户对 ASI 对股票估值、GDP 增长和债券市场的影响感到好奇,强调了这些查询的投机性质,以及 AI 需要考虑多种场景和变量的需求。
- 农业与环境系统: 讨论包括创新的农业方法,如 3 sisters method,以及利用 AI 针对不同气候和土壤类型优化植物协作系统的潜力。这反映了应用 AI 增强可持续农业实践的广泛兴趣。
- 亲爱的 OpenAI,如果我每月为 Deep Research 支付 $200,能保存为 PDF/Markdown 就太好了! (Score: 229, Comments: 40): 作者对 OpenAI 的 Deep Research 表示失望,尽管每月费用高达 $200,但仍缺乏直接将报告保存为 PDF 或 Markdown 的功能。他们建议了一个变通方法:使用“复制”按钮获取原始 Markdown,然后将其粘贴到 Notion 中。
- 许多用户对 OpenAI 的 Deep Research 缺乏直接的 PDF 或 Markdown 导出功能感到沮丧,强调 AI 应该减少繁琐的工作,并促进与 Pages 和 Word 等其他应用程序的更轻松集成。考虑到该工具每月 $200 的高昂成本,这些功能的缺失被视为重大疏忽。
- 变通建议包括使用 Markdown 的“复制”按钮,然后粘贴到 Markdown Editor 中,或者使用 print > save as PDF。然而,用户发现这些手动过程与 AI 节省时间和简化任务的初衷背道而驰。
- 围绕 AI 工具的命名惯例有一些幽默的讨论,比如与 Gemini Deep Research 的比较,以及对未来工具(如“Microsoft Co-pilot - In to Deep”版本)的期待。对话凸显了对当前 AI 能力的更广泛不满,以及对高级付费层级中更无缝功能的期望。
主题 3. 用于可追踪健康诊断的开源 AI
- 我如何构建了一个开源 AI 工具来诊断我的自身免疫性疾病(在花费 10 万美元并就诊 30 多次之后)——现在已开放供所有人使用 (Score: 195, Comments: 27): 作者分享了他们构建一个开源 AI 工具的历程,该工具旨在帮助诊断自身免疫性疾病。此前,作者花费了 10 万美元并走访了 30 多家医院,却始终没有得到明确的答案。该工具允许用户上传并标准化医疗记录,追踪化验结果的变化,并利用包括 Deepseek 和 GPT4/Claude 在内的不同 AI 模型来识别模式。他们提供了诸如 Fasten Health 之类的资源用于获取医疗记录,并提到计划将文档解析迁移到本地运行。
- 数据安全担忧:几位评论者强调了在本地运行该工具以避免数据泄露的至关重要性,特别是考虑到医疗记录的敏感性以及此类数据在黑市上的高价值。Mithril 被提及作为处理医疗信息的安全 AI 部署选项,并强调了对 FISMA 和 HITRUST 等认证的需求。
- 从碎片化诊断到发现:讨论中包括一个个人案例,该用户曾收到过椎间盘突出和脊柱弯曲等多个诊断,后来使用该工具统一诊断为强直性脊柱炎 (Ankylosing Spondylitis)。还有建议考虑 EDS (Ehlers-Danlos Syndrome),这表明了该工具在细化和发现复杂医疗状况方面的潜力。
- 用户反应:用户的强烈反应表明了对潜在严重数据泄露的惊讶和担忧,多条评论表示难以置信,并强调了处理敏感医疗数据不当的法律后果。
AI Discord 摘要
由 Gemini 2.0 Flash Thinking 提供的摘要之摘要的摘要
主题 1. 模型能力与性能的突破
- Hibiki 实现了像人类一样的实时语音翻译:Kyutai 的 Hibiki 模型实现了从 🇫🇷 到 🇬🇧 的同声传译,能够根据内容调整语速并保留说话者的声音。早期报告称赞 Hibiki 具有卓越的质量、自然度和说话者相似度,在实时沟通中足以媲美专业的人类口译员。
- Gemini 2.0 Flash 以极低成本大规模解析 PDF:Gemini 2 Flash 现在能以大约 每 6000 tokens 1 美元的价格高效解析大型 PDF 文档,标志着文档处理领域的重大飞跃。这种具有成本效益的解决方案为需要从复杂文档格式中进行高吞吐量、高精度文本提取的应用开启了新的可能性。
- Unsloth 的 GRPO 让 DeepSeek-R1 推理在 7GB VRAM 上触手可及:Unsloth 最新的 GRPO 更新将显存占用削减了 80%,允许用户仅需 7GB VRAM 即可复现 DeepSeek-R1 的推理过程。这一突破使先进推理模型的获取变得民主化,即使在资源受限的系统上也能进行 Llama 3.1 (8B) 和 Phi-4 (14B) 等模型的本地实验。
主题 2. 面向 AI 工程师的工具与框架增强
- GitHub Copilot 作为 Agent 觉醒,像专家一样编辑代码:GitHub Copilot 引入了 Agent 模式,并正式发布了 Copilot Edits,通过更智能的 AI 辅助增强了开发者的工作流。此次更新旨在提供更主动、更有效的编码支持,将 Copilot 转变为一个更集成、更强大的开发伙伴。
- Windsurf IDE 通过 Gemini 2.0 Flash 和 Cascade 网页搜索实现性能飞跃:Windsurf 现在支持极速的 Gemini 2.0 Flash,仅消耗 0.25 个 prompt 额度;同时 Cascade 通过 @web 获得了自动网页搜索功能,每次 flow action 消耗 1 个额度。这些增强功能旨在通过更快的模型和 IDE 环境内集成的的信息检索来提升开发者生产力。
- Cursor IDE 推出 GitHub Agents 和 Architect 功能以提升生产力:Cursor IDE 推出了新的 GitHub Agents 和 Architect 功能,旨在显著提升开发者生产力并简化复杂项目。虽然用户对这些新增功能充满热情,但一些用户报告了 Composer 工具中命令执行的潜在 bug,这标志着这些功能仍在积极开发和完善中。
主题 3. 应对模型性能与基础设施方面的挑战
- DeepInfra 供应商正面临 50% 的失败率,用户报告:DeepInfra 供应商目前有 50% 的时间 无法返回响应,导致零 token 生成和显著的处理延迟,特别是在 SillyTavern 等应用中。社区成员正在积极分享观察结果,并为 OpenRouter 上的不同模型和供应商寻求性能问题的解决方案。
- LM Studio 用户面临 API 错误潮,寻求调试指导:LM Studio 用户报告在加载模型时出现大量错误,如 ‘unknown error’ 和 ‘exit code: 18446744072635812000’,促使人们呼吁提供详细的系统规格和 API 见解以进行有效调试。通过 API 连接时的状态处理问题也突显了对 API 交互需要更清晰的文档和用户支持。
- Codeium Jetbrains 插件因无响应和频繁重启受到批评:用户对 Codeium Jetbrains plugin 表示不满,理由是频繁响应失败且需要频繁重启,影响了开发者的工作流。一些用户选择切换回 Copilot 以获得可靠性,而其他用户报告了在 PhpStorm 中的特定错误,表明该插件性能持续不稳定。
主题 4. 社区驱动的创新和开源贡献
- 独立研究人员利用 JAX 和 TPU 进行低成本 AI 研究:独立 AI 研究人员正在探索 AI/ML 研究的现实领域,建议学习 JAX 以访问 TPU Research Cloud,从而实现资源高效的实验。社区引用 OpenMoE GitHub 仓库作为在资源有限的情况下实现 Mixture-of-Experts 模型影响力研究的典范。
- Y CLI 项目作为 OpenRouter 终端聊天替代方案出现:Y CLI 是一个个人项目,为 OpenRouter 提供了一个基于终端的网页聊天替代方案,将聊天数据本地存储在 jsonl 文件中,现在已支持 Deepseek-r1 推理。积极鼓励开发者通过其 GitHub 仓库为 Y CLI 做出贡献,促进社区驱动的开发并迎合终端爱好者。
- Hugging Face 社区克隆 DeepResearch 以实现开放访问:HuggingFace 研究人员推出了 DeepResearch 的开源克隆版,强调了 Agent 框架的重要性,并引入了 GAIA benchmark 以促进社区贡献。该倡议促进了 AI Agent 技术的透明度和协作开发,鼓励更广泛的参与和创新。
主题 5. AI 中的伦理辩论和商业模式审查
- OpenAI 的利润优先做法引发社区辩论和怀疑:成员们正在辩论 OpenAI 等 AI 巨头的动机,批评其将利润置于公共利益之上,并质疑小型公司的竞争力。怀疑围绕 OpenAI 更新的 chain of thought 功能展开,人们担心企业议程主导 AI 发展,对其真实目的表示怀疑。
- AI 抵制情绪呼应了对加密货币的不信任,加剧了伦理担忧:公众对 AI 的不信任与过去对 cryptocurrency 和 NFTs 的负面经历有关,影响了对 AI 技术的看法,并引发了关于 AI 开发的伦理担忧。批评者指出未经许可的 AI 训练数据以及 AI 扰乱劳动力市场的潜力,加剧了社会对 AI 伦理影响的广泛焦虑。
- Stability AI 的订阅成本和“私有图像”选项引发辩论:成员们对 Stability AI 的 Max subscription 中的“私有图像”选项提出质疑,辩论其是否含蓄地迎合了 NSFW 内容,而其他人则将云服务成本与本地电费进行了比较。这些讨论反映了用户对不同 AI 模型准入门槛和感知效用的不同态度,突显了关于 AI 服务经济学的持续辩论。
第一部分:Discord 高层摘要
Unsloth AI (Daniel Han) Discord
- Unsloth 的 GRPO 现在支持通过 vLLM 进行推理!:Unsloth 关于 GRPO 的最新更新允许以低至 7GB VRAM 的显存复现 DeepSeek-R1 的推理能力,同时支持在 Colab 上使用显存占用更低的模型。
- 用户可以尝试最新的功能和 notebook 更新以提升性能,并训练 Llama 3.1 (8B) 和 Phi-4 (14B) 模型。
- Unsloth 微调 R1 Distill Llama + Qwen!:Unsloth 引入了对微调蒸馏版 DeepSeek 模型的支持,利用 Llama 和 Qwen 架构,并提供了模型上传。
- Unsloth 还支持新模型,如 Mistral-Small-24B-2501 和 Qwen2.5,可在 Hugging Face 集合中找到。
- 量化可减少 60% 的 VRAM!:最近的讨论强调了 BitsandBytes 量化的有效使用,通过选择性量化层可减少约 60% 的 VRAM 使用,更多细节可见 Unsloth 的博客文章。
- 参与者讨论了在 GRPO 中使用多轮对话数据集,强调在模型训练期间保留推理上下文,并通过格式良好的数据集提高 AI 模型的推理能力。
- OpenAI 优先考虑利润:成员们辩论了像 OpenAI 这样的主要 AI 参与者的动机,批评其将利润置于公共利益之上,并对小公司的竞争力和潜在的联盟需求表示担忧。
- 一位用户强调了 OpenAI 对 chain of thought 功能的更新,并链接到了公告,但回应显示对其真实目的持怀疑态度。
- 独立 AI 研究人员通过 JAX 使用 TPU!:独立研究人员正在寻找现实领域来开始 AI/ML 研究,一位成员建议学习 JAX 以获取 TPU Research Cloud 的访问权限,并链接到了申请表。
- 成员们引用了 OpenMoE GitHub 仓库作为在 Mixture-of-Experts 模型中进行研究的相关示例,甚至在 TinyStories 数据集上预训练小型 Transformer。
Stability.ai (Stable Diffusion) Discord
- Stability 欢迎新任社区负责人:Maxfield,Stability 的新任 Chief Community Guy,介绍了自己以改善社区参与度,他自 2022 年起曾在 Civitai 做出贡献。
- 承认过去的参与度“乏善可陈”,Maxfield 计划推出一个功能请求板,并鼓励研究人员分享项目更新以提高透明度。
- Civitai 饱受下载错误困扰:用户报告在从 Civitai 下载模型时遇到 Error 1101,导致社区对停机时间感到沮丧。
- 这些问题引起了对通过 Civitai 访问模型的可用性和可靠性的担忧。
- 用户剖析 Latent Space 的复杂性:一位用户对交换 latent space 参数的工具复杂性表示困惑,建议需要更用户友好的解决方案。
- 讨论涉及了新 diffusion 模型潜在的实现方式以及调整现有架构的挑战。
- AI 订阅成本引发辩论:成员们质疑 Stability 的 Max 订阅中的“私有图像”选项,辩论其是否迎合了 NSFW 内容,而其他人则将云服务成本与本地电费进行了比较。
- 讨论强调了对不同 AI 模型的准入门槛与实用性之间的不同态度。
- 工程师寻求 AI Prompting 的清晰度:一位用户寻求关于生成模型 prompting 技巧的见解,而其他人建议使用 brxce/stable-diffusion-prompt-generator 等外部工具来提供帮助。
- 对话强调了适应不同 AI 模型要求和生成令人满意的 prompt 的困难,尤其是跨平台时。
Codeium (Windsurf) Discord
- Windsurf 新增 Gemini 2.0 Flash 支持:Windsurf 现在支持 Gemini 2.0 Flash,如这条推文所述,每条消息仅消耗 0.25 个用户提示额度,每次工具调用消耗 flow action 额度。
- 虽然 Gemini 2.0 Flash 速度极快且效率高,但其工具调用能力有限,但在回答代码库相关问题方面表现出色。
- Windsurf Next Beta 版发布:用户现在可以通过此链接下载 Beta 版,体验 Windsurf Next 的最新功能。
- 该 Beta 版允许用户抢先探索新的 AI 能力,并能灵活地在 Next 和 Stable 版本之间切换。
- Jetbrains 插件遭到用户批评:用户反映对 Codeium Jetbrains 插件感到沮丧,理由是该插件经常无响应且需要频繁重启。
- 一位用户为了稳定性换回了 Copilot,而另一位用户报告了 PhpStorm 中与文件访问相关的错误。
- 用户报告 Windsurf 性能问题:用户报告了 Windsurf 的性能问题,特别是在使用 O3-mini 和 Gemini Flash 等模型时,这些模型会在建议未完成时提前结束。
- 一位用户对需要不断提示模型 ‘continue’ 表示沮丧,并对浪费额度表示担忧。
- Cascade 学会了网页搜索:Cascade 现在可以自动或通过用户命令(如 @web 和 @docs)进行网页搜索,每次消耗 1 个 flow action 额度,详见 Windsurf Editor 更新日志。
- 此功能支持 URL 输入,并利用网页上下文来改进回复,旨在提供更准确、更全面的信息。
aider (Paul Gauthier) Discord
- Aider 用户发现端口错误修复方法:一位用户报告了 Aider 在加载模型元数据时出现无效端口错误,这表明可能存在配置问题。
- 另一位成员建议通过覆盖默认的模型元数据文件作为权宜之计来解决此错误,以确保工具正常运行。
- Gemini 独特的编辑需求:用户讨论了 DeepSeek 和 Gemini 模型的不一致性,指出 Gemini 独特的编辑格式 (udiff) 与其他模型不同。
- Aider 会自动为 Google 模型使用 udiff,同时为其他模型保持不同的默认设置,以适应这种差异。
- AI 渗透测试有利可图但有风险:一位成员分享了他们使用 LLM 进行渗透测试的项目,创建了一个由两个模型协作的模拟黑客环境。
- 尽管 Token 消耗量很大,但专业的渗透测试可能极其丰厚,暗示了潜在的经济利益。
- HuggingFace 克隆了 DeepResearch:HuggingFace 的研究人员创建了一个开源的 DeepResearch 克隆版,详见其博客文章。
- 该倡议强调了 Agent 框架的重要性,并引入了 GAIA 基准测试,以促进社区贡献。
- R1 模型产生垃圾
<think>Token:一位用户报告称,在使用通过 Together.ai 提供的 R1 时,提交信息中充斥着 `` Token,并寻求配置指导。- 建议包括配置模型设置以尽量减少提交信息中的这些 Token,从而保持提交记录的整洁。
OpenAI Discord
- Gemini 2.0 Pro 引起热议:用户对拥有 200万 token 上下文 的 Gemini 2.0 Pro 感到兴奋,这有助于复杂的交互,但也对其与 Google AI Studio 相比的易用性提出了担忧。
- 免费替代方案提供了广泛的自定义功能,并可能在某些任务上为用户提供更好的结果;社区建议在额外功能的感知价值与付出的努力之间进行权衡。
- DeepSeek 与 ChatGPT 争夺棋王头衔:鉴于模型在推理方面的局限性,DeepSeek 和 ChatGPT 之间潜在的国际象棋比赛引起了用户的兴趣,这注定会非常有趣。
- 用户对 DeepSeek 1美元一局的国际象棋游戏与 OpenAI 100美元一局的游戏进行了幽默的对比,暗示一些人更喜欢便宜但仍具挑战性的游戏。
- Gemini Flash 2.0 和 Copilot 作为编程工具表现出色:在关于编程的讨论中,成员们推荐了 Gemini Flash 2.0 和 Microsoft Copilot,因为它们的功能和性价比,特别是在高等数学方面。
- 用户指出 Copilot 提供免费试用,使其在没有立即财务承诺的情况下更容易探索,并允许工程师“先试后买”。
- Plus 用户热切期待 Deep Research 对话功能:几位成员表达了对 Deep Research 对话功能尽快向 Plus 用户 开放的渴望,并指出他们在未来几天内有此需求。
- 一位成员询问是否有人分享了关于 Deep Research 对话的信息,显然是在寻求见解,并促使其他人表达了对该功能加入 Plus 订阅的类似期待。
- 通过迭代编辑微调 AI:一位成员建议使用 Python 统计字数并进行迭代,以确保更好的回复长度,但指出在尝试控制 AI 回复的 Response Length 时,这可能会影响创造力。
- 成员们还指出使用编辑按钮编辑输入的重要性,通过调整输入直到满意为止来有效地塑造 AI 的输出,从而确保对话中上下文的连贯性。
Cursor IDE Discord
- Cursor IDE 获得 GitHub Agents 和 Architect 功能:用户对 Cursor IDE 中新的 GitHub agents 和 architect 功能感到兴奋,这些功能旨在提高生产力。
- 然而,正如 Cursor 论坛 所述,一些用户报告了在最近更新后,在 Composer 工具中运行命令时可能存在的 bug。
- Gemini 2.0 自学能力扎实,但并非顶尖:用户发现 Gemini 2.0 由于其价格优势和上下文管理能力,在自学任务中表现良好;一些讨论提到它很扎实,但在编程方面不如 Sonnet。
- 社区指出其有效的上下文利用使其在处理大型代码库时具有吸引力,可能会冲击像 Momentic 这样的 AI testing tools。
- 剪贴板比较工具推荐:社区推荐了一款用于剪贴板比较的 VSCode extension,它允许用户按照 Microsoft 的 VSCode 文档 中记录的方式与剪贴板内容进行比较。
- 用户还在 VSCode 的本地历史记录与 JetBrains 的 Timeline 之间进行比较,认为 Timeline 效率更高,并推荐了来自 VSCode Marketplace 的 Partial Diff 扩展。
- MCP 服务器配置需要更好的上下文:一位用户正在寻求关于 MCP server configurations 以及访问 Supabase 密钥的帮助,并指出某些密钥的访问权限有限,同时提到了 mcp-starter 的 GitHub 仓库。
- 社区普遍强调了在 Cursor 内部改进上下文管理的必要性,特别是对于管理复杂项目,并参考了 daniel-lxs/mcp-starter 的发布版本。
- Cursor 的上下文瓶颈引发辩论:关于 Cursor 上下文限制的担忧正在浮现,一些用户更倾向于使用 Cline 或 Google models,因为它们拥有更大的上下文窗口,或许是因为他们阅读了 Andrej Karpathy 关于 vibe coding 的推文。
- 关于上下文大小如何影响 AI 模型 有效性的争论仍在继续,特别是更大的上下文窗口如何提升广泛应用中的性能,以及 Cursor 论坛 中讨论的模型特定规则的作用。
Perplexity AI Discord
- Focus Mode 被取消:用户注意到 Perplexity AI 暂时移除了 Focus Mode,引发了关于是否需要在 prompt 中明确提及 Reddit 等来源的必要性的争论。
- 一些用户表示担心,这增加了他们有效引导 AI 信息溯源能力的复杂性。
- 解析 Perplexity Pro 中的模型使用:用户正试图弄清楚 Pro mode 是否完全端到端地使用 Claude 3.5 等模型,还是集成了 R1 进行推理,这表明其采用了一种更复杂的、多模型协作的方法。
- 见解表明,在将任务移交给选定模型进行最终答案生成之前,会有未公开的模型进行初始搜索。
- ByteDance 深耕 Deepfake:ByteDance 发布的新 deepfake technology 引发了 AI 社区对其伦理影响和潜在滥用风险的讨论。
- 社区成员正在积极推测该技术的后果,权衡其创新可能性与造成危害的风险。
- 对模型透明度的需求激增:用户敦促 Perplexity AI 就 model specifications 和更新进行更清晰的沟通,特别是涉及影响功能和性能的变更。
- 更高的透明度有望减少用户困惑,并改善与平台 AI 功能的交互。
- Sonar Pro 开发者因安全问题面临压力:由于发现了一个 security issue,用户紧急呼吁联系 Sonar Pro reasoning developers。
- 用户被引导发送邮件至 api@perplexity.ai 以解决该漏洞。
OpenRouter (Alex Atallah) Discord
- DeepSeek 保险机制进一步加强:OpenRouter 现在为没有收到 completion tokens 的 DeepSeek R1 请求提供保险,因此即使上游供应商收费,你也不会被扣费。
- 标准版 DeepSeek R1 的完成率已从 60% 提高到 96%,使其成为一个更可靠的选择。
- Kluster 的取消故障已修复:一个 Kluster 集成问题曾导致 completion tokens 延迟,并由于未能取消超时的请求而产生意外费用。
- 该问题现已得到解决,解决了用户在 OpenRouter 端显示超时但仍被扣费的问题。
- Qwen 悄然退出:Novita 正在弃用其 Qwen/Qwen-2-72B-Instruct 模型,OpenRouter 也将在同一时间禁用该模型。
- 用户应停止使用该模型,以避免模型不可用时造成业务中断。
- Y CLI 期待你的关注:Y CLI 是一个个人项目和 Web Chat 的替代方案,它将所有聊天数据存储在单个 jsonl 文件中,并增加了对 Deepseek-r1 推理内容的支持,详见这段 asciinema 录制。
- 鼓励开发者通过其 GitHub repository 为 Y CLI 贡献代码,并向 terminal fans 发出号召。
- DeepInfra 表现极不稳定:用户报告称,由于处理延迟增加,DeepInfra 目前有 50% 的概率无法返回响应,在使用 SillyTavern 等应用程序时经常导致零 token 补全。
- 社区正在分享关于不同模型和供应商之间性能差异的观察,包括改进建议。
LM Studio Discord
- 用户面临 LM Studio API 错误潮:用户报告在 LM Studio 中加载模型时出现“unknown error”和“exit code: 18446744072635812000”等错误,需要系统规格和 API 详情进行调试。
- 一位用户在通过 API 连接到本地模型时在 state handling(状态处理)方面遇到困难,表明需要更好的 API 交互指导。
- Obsidian 的 Smart Connections 扩展引发混乱:用户在将 Obsidian 的 Smart Connections 扩展连接到 LM Studio 时遇到错误,理由是与其他扩展冲突以及 API 响应中缺少必填字段。
- 故障排除涉及卸载冲突插件和重建缓存,尽管即使在建立连接后,持续的错误仍然存在。
- TheBloke 模型仍是标准:成员们询问从 TheBloke 下载 AI 模型的安全性和可靠性,即使他在社区的活跃度有所下降。
- 确认 TheBloke 的模型仍是行业标准,鼓励用户关注社区频道以获取可用性更新。
- DDR5 6000 EXPO 时序过于保守:一位用户发现其 DDR5 6000 EXPO 时序比较保守,在推理过程中观察到的峰值内存带宽为 72。
- 在完成 4 轮 memtest86 后,另一位成员建议尝试 TestMem5 以进行更严格的稳定性评估。
- DeepSeek R1 模型支持 GPU 加速吗?:关于 DeepSeek R1 Distill Qwen 7B 模型的 GPU 加速出现了咨询,不确定哪些模型支持 GPU 使用。
- 澄清只有像 Llama 这样的特定模型已知支持加速,而 DeepSeek 模型仍存在一些模糊性。
MCP (Glama) Discord
- Home Assistant 获得功能性 MCP 客户端:一位用户发布了具有 MCP client/server 支持的 Home Assistant,并计划通过 met4citizen/TalkingHead 添加动画谈话头像,以实现更好的用户交互。
- 该项目仍在开发中,因为开发者正在平衡有偿工作与开源开发。此外,人们对 Home Assistant MCP 与 Claude 等工具桥接的使用统计数据感到好奇。
- Goose MCP 客户端表现强劲:用户分享了在测试中使用 Goose MCP Client 的积极体验,强调了其有效性。
- 一个增强其日志功能的 Pull Request block/goose@162c4c5 正在进行中,其中包含在 Goose 的使用计数日志中包含缓存 Token 的修复。
- Claude 努力处理图像显示:一位用户报告了在 Claude Desktop 上将图像显示为工具结果时的挑战,遇到了输入错误。
- 该错误引发了推测,即由于将图像结果转换为嵌入资源可能是一个潜在的变通方案。
- PulseMCP 展示用例:一个新的实际 PulseMCP Use Cases 展示亮相,包含使用各种客户端应用和服务器的说明和视频,并在 PulseMCP 上发布了这些用例。
- 它强调了使用 Gemini voice、Claude 和 Cline 来管理 Notion、转换 Figma 设计以及创建知识图谱。
- 讨论移动端 MCP 选项:成员建议 Sage 支持 iPhone,而 Android 用户的选项可能需要使用 LibreChat 或 MCP-Bridge 等 Web 客户端。
- 这次对话强调了将 MCP 功能扩展到桌面环境之外的兴趣。
Yannick Kilcher Discord
- Gemini 2.0 Pro 生成 SVG: 成员们讨论了 Gemini 2.0 Pro 在创建 SVG 方面表现出的令人印象深刻的性能,超越了 o3-mini 和 R1 等模型,正如 Simon Willison 的博客中所指出的。
- 几位成员还观察到其增强的 SQL 查询能力,暗示 Google 在 Gemini Flash 2.0 上取得了重大进展。
- DeepSpeed Dataloader Batch-size 困扰: 一位用户报告了在使用 DeepSpeed 的自动 Batch Size 配置时,是否需要在 Dataloader 中手动定义 batch_size 的困惑。
- 另一位成员建议将 DeepSpeed 标签集成到 Dataloader 中进行优化,并针对特定节点提出了潜在的性能修改建议。
- Harmonic Loss 论文缺乏说服力: 社区成员对 Harmonic Loss 论文 表示怀疑,认为其拼凑痕迹明显,尽管具有理论优势,但未能提供有意义的性能提升。
- 一位成员指出,与该论文相关的 GitHub 仓库 比论文本身提供了更有价值的信息。
- Gemini 2.0 Flash 表现亮眼: 通过 LlamaIndex 尝试新款 Gemini 2.0 Flash 模型的用户报告了令人难以置信的速度,尽管没有 Groq 那么快。
- 一位用户表示,该模型在返回有效的 JSON 格式方面表现不佳,结论是它可能不适合需要输出可靠性的任务。
- S1 模型以低于 50 美元的成本问世: 讨论了 S1 推理模型,强调了其与 OpenAI 的 o1 等模型相比的性能,但成本仅为一小部分,低于 50 美元。
- S1 模型及其工具可在 GitHub 上获得,它是通过 Gemini 2.0 蒸馏开发的。
Eleuther Discord
- Adobe 寻求 LLM Agent 研究合作伙伴: Adobe 的一位高级 ML 工程师正在寻求 LLM Agent 研究项目的合作。
- 邀请感兴趣的人士加入讨论,探索潜在的合作伙伴关系。
- DeepSpeed 仍需指定 Batch Size: 在使用 DeepSpeed 进行自动 Batch Size 调整时,仍需为 Data Loader 指定 batch_size。
- 尽管配置了自动 Batch Size,这一要求依然存在。
- 主题泛化基准测试发布: 一位成员分享了一个 GitHub 仓库,详细介绍了一个主题泛化基准测试,用于评估 LLM 从示例和反例中进行类别推理的能力。
- 该基准测试与 SAE autointerp 性能的相关性受到了质疑。
- RWKV 正在开发新架构: RWKV 团队正在积极开发一些新架构,展现了其积极的态势。
- 一位正在处理扩展问题的用户邀请大家就未来的合作进行交流。
- MATS 8.0 批次申请现已开放: MATS 8.0 批次的申请截止日期为 2 月 28 日,提供全职带薪的机械可解释性(Mechanistic Interpretability)研究机会,点击此处申请。
- 之前的学员做出了重大贡献,他们在 10 篇顶级会议论文中的参与证明了这一点。
Nous Research AI Discord
- Deep Research 令用户感到兴奋:成员们赞扬 OpenAI 的 Deep Research 能够高效收集相关的关联信息和来源,提升了他们的认知带宽。
- 一位用户强调了它探索冷门在线社区并收集意想不到数据的能力。
- AI 遭到的抵制呼应了对加密货币的担忧:一些成员认为,公众对 AI 的不信任源于过去对 cryptocurrency 和 NFTs 的负面印象,这影响了对 AI 技术的看法。
- 批评者担心 AI 训练数据 未经授权,以及 AI 对劳动力市场的破坏性影响,详见 Why Everyone Is Suddenly Mad at AI。
- 处于法律模糊地带的有目标的 AI Agent:一位用户旨在法律信托框架内开发一个目标驱动的 AI Agent,旨在开创关于 AI 法律主体地位 (AI personhood) 的法律讨论。
- 反馈集中在工程复杂性上,包括集成财务管理功能,同时强调了定制软件解决方案的潜力,如 I Built the Ultimate Team of AI Agents in n8n With No Code (Free Template) 中展示的案例。
- 模型合并热潮:成员们讨论了合并 AI 模型 的策略,分享了关于改进模型指令微调 (instruction tuning) 和推理性能的见解。
- 探索了各种微调方法,强调了在 AI 训练 中使用创新技术通过 Unsloth Documentation 等工具增强模型性能的益处。
- 合成数据之梦:一位成员在面临 Magpie 输出的挑战后,正在寻找关于合成数据生成的资源,重点关注类似于 Self-Instruct 的基于种子 (seed-based) 的方法。
- 他们发现了 Awesome-LLM-Synthetic-Data GitHub 仓库,该仓库提供了关于基于 LLM 的合成数据生成的资源列表。
Interconnects (Nathan Lambert) Discord
- Schulman 从 Anthropic 离职:领先的 AI 研究员、OpenAI 联合创始人 John Schulman 在入职约五个月后离开了 Anthropic,引发了对其职业生涯下一步的猜测 链接。
- 据消息人士透露,潜在的去向包括 Deepseek 和 AI2。
- Copilot 变为 Agent:GitHub Copilot 引入了 agent mode,增强了开发者辅助功能,并全面开放了 Copilot Edits 链接。
- 此次更新旨在通过 AI 提供更有效的编程支持。
- LRM Test-Time Scaling 术语争议:成员们对长程模型 (LRMs) 的 test-time scaling 术语提出质疑,强调模型决定其自身的输出 链接。
- 有人指出,扩展发生在训练阶段,这使得该术语具有误导性;一位成员称整个概念从根本上就是有缺陷的。
- Qwen 取得惊人成果:Qwen 2.5 模型在极少训练数据的情况下表现出令人印象深刻的结果,成员们讨论了他们的发现 链接。
- Aran Komatsuzaki 评论道,Qwen 模型似乎具有一种“魔力”,在有限的数据下实现了显著出色的性能。
- Scale AI 面临转型挑战:成员们认识到 Scale AI 有可能进行调整,但由于当前的运营模式和估值,挑战依然存在 链接。
- 共识是,在不断变化的环境中,如果不大幅改变方法,前景将十分暗淡。
Notebook LM Discord
- NotebookLM 移动端用户仅限使用单一模型:用户无法在移动版 NotebookLM 中切换模型,这一限制让期待更高灵活性的用户感到沮丧。
- 这一限制阻碍了移动设备上的用户体验,导致习惯于在网页端管理模型的用户感到困惑。
- Gemini 在 Sheets 中表现出色,NotebookLM 则略显吃力:成员们对使用 NotebookLM 分析电子表格数据表示担忧,认为在 Google Sheets 中使用 Gemini 等工具更为合适。
- 正如 Engadget 报道的那样,Gemini 可以使用 Python 代码生成见解和图表,这进一步巩固了 NotebookLM 作为主要 文本分析工具 的定位。
- 滑块功能可微调 AI 创造力:一位用户在发现了一个与 AI 功能相关的 漏洞 (exploit) 后受到启发,建议集成用于调节 AI 创造力的滑块,类似于 Gemini API 中的功能。
- 该功能将允许用户调整参数,从而对 AI 模型的创意输出实现更精准的控制。
- NotebookLM 总结纽约预算听证会的法律证词:一位用户使用 NotebookLM 记录了 纽约州议会环境保护预算听证会 的证词。
- 该用户强调了由于许可问题分享这份详尽文档的挑战,笔记可在 此处 查看。
- Max Headroom 带着故障风格回归,批判 AI:标志性的 Max Headroom 带着新视频回归,展示了与 AI 互动的独特方式。
- 正如 Youtube 上所示,新内容幽默地批判了企业的 AI 实践,并呼吁观众分享和参与。
LLM Agents (Berkeley MOOC) Discord
- 2024 秋季 MOOC 证书终于发放:在解决技术挑战后,2024 秋季 MOOC 证书 于今天 太平洋时间上午 8 点 正式发布。
- 一些参与者因未完成课程作业被 降级至 Trailblazer 等级,且不提供补考机会。
- 证书发放时间难以确定:成员们对证书发放时间表表示不确定,希望在 不可预见的技术问题 解决后的一两周内送达。
- 一位成员注意到证书接收情况存在差异,表明可能存在影响通信的 软退信 (soft bounce) 问题。
- 测验开放情况引发混乱:随着 Quiz-2 的启动,关于 Quiz-1 答案开放情况的担忧随之而来,促使成员们寻求关于答案发布新政策的澄清。
- 社区成员澄清说,可以通过原始提交链接查看 Quiz-1 的分数。
- 证书等级分布:据透露,参与者中共有 301 名 Trailblazer、138 名 Masters、89 名 Ninjas、11 名 Legends 和 7 名 Honorees。
- 官方澄清,如果同时获得荣誉等级和特定等级,将仅标注荣誉等级。
- 课程体验赢得好评:社区对课程期间获得的支持表示感谢,特别是对处理评分和证书查询的团队表示认可。
- 参与者对课程表现出极大的热情,一位成员回顾了他们的学习历程,并强调了证书对未来发展的重要性。
GPU MODE Discord
- NVIDIA Blackwell 支持 OpenAI Triton:由于 NVIDIA 与 OpenAI 的持续合作,Triton 编译器现在支持 NVIDIA Blackwell 架构,通过 cuDNN 和 CUTLASS 增强了性能和可编程性。
- 这一进展使开发者能够针对现代 AI 工作负载优化矩阵乘法(matrix multiplication)和注意力机制(attention mechanisms),提高效率和能力。
- 降低 AI 研究成本:成员们分享了独立研究人员如何在有限预算下对 LLMs 和视觉(vision)任务进行高效工作并微调模型,通过低比特训练权重(low-bit training weights)的稳定性来节省 AI 研究开支。
- 使用 Muon 进行 GPT-2 speedruns 的成功被视为利用有限资源进行高影响力研究的典型案例。
- FP8 Attention 需要 Hadamard 变换:一位成员观察到,视频模型的 FP8 Attention 在使用 Hadamard Transform 时表现显著更好,大幅降低了错误率;Flash Attention 3 论文表明这种方法对于 FP8 操作至关重要。
- 另一位成员建议使用 fast-hadamard-transform 仓库在注意力机制之前实现 Hadamard,以获得更好的性能。
- Reasoning Gym 引入推箱子(Sokoban)谜题:一个 Pull Request 已提交,旨在将推箱子谜题添加到 reasoning-gym 中,为用户展示了一种新的谜题格式,包括谜题设置的图形解释以及移动示例。
- 成员们还在讨论协作构建一个基础 Gym,将 Rush Hour 游戏集成到 reasoning-gym 中,以鼓励联合编码工作。
- 线性注意力(Linear Attention)面临蒸馏挑战:一位成员尝试按照 Lolcats 的方案将一个小 LLM 蒸馏为线性注意力模型,但模型只输出了重复字符。
- 该成员专门向 Lolcats 团队寻求帮助,突显了 AI 模型开发中经常依赖的社区支持。
Nomic.ai (GPT4All) Discord
- 尽管定价昂贵,O3 依然保持领先:根据 general 频道的讨论,尽管存在价格担忧,O3 的表现依然优于其他模型,Llama 4 被视为下一个潜在的挑战者。
- DeepSeek 在政治讨论中受到限制:用户发现 DeepSeek 在敏感政治讨论中的限制比 ChatGPT 和 O3-mini 更多,经常导致意外的内容删除或回避。
- 这突显了语言模型在面对敏感政治话题提示时的潜在约束。
- DeepSeek 的知识截止日期引发疑问:据报道,DeepSeek 的知识截止日期是 2024 年 7 月,鉴于现在已经是 2025 年,这引发了对其时效性的质疑。
- 讨论中提到了利用时间上下文提取信息的 Time Bandit 方法与 DeepSeek 的关系,关于其 System Prompt 的更多细节可以在线查阅。
Torchtune Discord
- GRPO 实现取得重大进展:一位成员报告了 GRPO 训练的成功实现,在 GSM8k 上达到了 10% 到 40% 的训练分数。
- 在调试过程中,他们指出了死锁和内存管理方面的挑战,并计划进行改进并开放项目以供贡献。
- Kolo 扩展至 Torchtune:Kolo 在其 GitHub 页面上正式宣布支持 Torchtune。
- 该项目为使用现有的最佳工具在本地微调和测试 LLM 提供了一套全面的解决方案。
- Llama 3.1 和 Qwen 2.5 在配置上遇到困难:成员们发现由于路径配置不匹配,在下载和微调 Llama 3.1 及 Qwen 2.5 时出现了 FileNotFoundError 问题。
- 一位成员创建了一个 GitHub issue 以解决错误的默认路径并提出修复方案。
- Hugging Face Fast Tokenizers 获得支持:社区讨论了使用 Hugging Face fast tokenizers 的前景,成员们表示虽然目前存在局限性,但正在取得进展。
- 一位成员提到 Evan 正在积极启用支持,详见 此 GitHub pull request。
- Full DPO Distributed PR 面临障碍:一位用户报告了其 Full DPO Distributed PR 在 GitHub checks 中遇到的问题,具体错误与 GPU 和 OOM 问题有关。
- 错误提示
ValueError: ProcessGroupNCCL is only supported with GPUs, no GPUs found!促使该用户向社区寻求帮助。
- 错误提示
Modular (Mojo 🔥) Discord
- Mojo 偏离 Python,专注于 GPU:在最近的一次社区会议中,Modular 澄清说 Mojo 目前并不是 Python 的超集,而是专注于利用 GPU 和性能编程。
- 这一转变强调提高 Mojo 在其设计应用中的效率,而不是扩大其语言框架。
- 解析器修订平衡分支成本:一位成员建议 parser 需要针对处理多个数据切片进行调整,权衡分支成本,并指出分支可能比大量数据传输更便宜。
- 对于那些不专注于更高性能需求的人来说,这是一个合理的考虑。
- Msty 简化本地模型访问:一位成员介绍了 Msty,这是一个兼容 OpenAI 的客户端,与使用 Docker 和其他复杂设置相比,它简化了本地模型交互,并强调了其易用性以及通过 Msty 官网无缝访问 AI 模型的功能。
- 强调了 Msty 的离线可用性和隐私重要性,表明它对于希望避免复杂配置的用户非常有利。
- MAX Serve CLI 模仿 Ollama 的功能:成员们讨论了在 MAX Serve 之上构建一个类似于 ollama 的 CLI,并指出 MAX Serve 已经可以通过 docker 容器处理 Ollama 提供的许多功能。
- 讨论强调了与 Ollama 相比,在运行本地模型时获得更好性能的期望。
- 社区报告 OpenAI API 不兼容问题:一位用户报告了 max serve (v24.6) 中 OpenAI completions API 缺失的功能,例如在指定 token 处停止生成,并建议他们在 GitHub repo 上提交 issue 以突出这些缺失的元素。
- 该小组承认 OpenAI API 兼容性方面存在持续问题,特别是参考了 v1/models 端点,以及 此 GitHub issue 中提到的 token 停止和 prompt 处理等其他缺失功能。
Latent Space Discord
- Hibiki 引领实时翻译:Kyutai 的 Hibiki 模型实现了从 🇫🇷 到 🇬🇧 的实时语音对语音翻译,保留了说话者的声音并能适应语境。
- 早期报告称 Hibiki 在质量、自然度和说话者相似度方面表现出色,足以媲美人类口译员。
- Melanie Mitchell 对 Agent 提出担忧:@mmitchell_ai 的最新 论文 反对开发 全自动 Agent (Fully Autonomous Agents),强调了伦理考量。
- 该文章在 AI 社区引发了辩论,人们在热烈讨论中认可了她 平衡的视角。
- Mistral AI 的 Le Chat 登场:Mistral AI 推出了 Le Chat,这是一款专为日常个人和专业任务量身定制的多功能 AI 助手,可在网页和移动端使用。
- 该工具将重新定义用户与 AI 的交互,可能影响工作流和个人日常习惯。
- OpenAI 增强 o3-mini 功能:OpenAI 在 o3-mini 和 o3-mini-high 中推出了增强的 思维链 (chain of thought) 功能(来源),惠及免费和付费订阅用户。
- 这些更新承诺提供更好的性能和更流畅的用户体验,再次印证了 OpenAI 对持续服务演进的承诺。
- PDF 解析取得突破:PDF 解析 现在可以大规模高效解决;根据 @deedydas 的说法,Gemini 2 Flash 解析大型文档的成本约为每 6000 个 tokens 1 美元。
- 处理复杂文档方面的这一进步,为需要高质量文本提取的应用开启了新的可能性。
LlamaIndex Discord
- Gemini 2.0 现已全面开放:来自 @google 的 Gemini 2.0 已发布并提供首日支持,开发者可以通过
pip install llama-index-llms-gemini安装最新的集成包,并在 公告博客文章 中阅读更多信息。- 更新后的 2.0 Flash 已在桌面和移动端的 Gemini app 中向所有用户开放。
- LlamaParse 应对复杂财务报表:Hanane D 展示了如何使用 LlamaParse 的“Auto”模式和 @OpenAI embeddings 准确且经济地解析 复杂的财务文档,详见此 链接。
- 她的演示突出了解析技术在从复杂数据、图表和表格中提取相关见解方面的进展。
- Embedding 打印困扰 LlamaIndex:一名成员请求从 LlamaIndex 文档中删除 embedding 打印 部分,原因是其占用空间过大且影响可读性,详见 GitHub issue。
- 另一名成员提议创建一个 Pull Request (PR) 来解决 删除 embedding 打印 的问题。
MLOps @Chipro Discord
- LLM 分类效果好,但噪声使其步履维艰:成员们讨论认为,虽然 LLM 在分类方面很有效,但 噪声数据 (noisy data) 需要额外的技术(如稠密向量 (dense embeddings) 和自动编码器重排序器 (autoencoder rerankers))来提高性能。
- 这表明在处理具有挑战性的数据场景时,需要更复杂的策略。
- 延迟担忧削弱了对 LLM 的热情:讨论显示,尽管 LLM 分类效果很好,但在有严格 延迟要求 (latency requirements) 的场景下,由于其处理限制,其适用性可能会降低。
- LLM 的适用性取决于特定应用的延迟约束。
- 业务需求凸显 ML 不匹配:一名成员指出,在向 ML 解决方案过渡期间,未能正确界定业务需求是一个 失误。
- 从一开始就应该明确,如果低延迟是首要任务,传统的 LLM 可能不是理想选择。
Cohere Discord
- Cohere 微调限制引发关注:一名用户在 Cohere 中遇到了 BadRequestError(状态码:400),表明训练配置超过了 250 个训练步数 (training steps) 的上限,且 batch size 限制为 16。
- 一名成员质疑这是否将微调限制在了 4000 个样本 以内,并指出这一限制以前并不存在。
- 征集 AI/ML 系统设计面试题:一名成员在 Cohere 频道询问了针对 AI/ML 的 系统设计面试题。
- 另一名成员确认了该请求并表示将进行收集,暗示团队将在此话题上进行协作。
Gorilla LLM (Berkeley Function Calling) Discord
- 标准系统提示词(Canonical System Prompts)需求出现:一名成员请求澄清微调后的工具调用模型(fine-tuned tool-using models)的标准系统提示词,并指出 Gorilla 论文中缺少这一细节。
- 目标是确保模型能够可靠地返回函数调用的响应或 JSON,这表明需要标准化的 Prompt Engineering 实践。
- Hugging Face 数据集寻求转换:一名成员旨在通过转换数据并在 Hugging Face 上使用
datasets.map来简化实验,这标志着向更灵活的数据操作迈进。- 这突显了为提高研究和开发目的下数据集的可用性和可访问性所做的持续努力。
- Hugging Face 数据集格式问题:一名成员报告了 Hugging Face 内部的数据集格式不匹配问题,即 .json 文件实际上包含的是 jsonl 数据,导致了兼容性问题。
- 建议的解决方案包括将文件后缀重命名为 .jsonl,并调整数据集配置文件以与实际数据格式保持一致。
DSPy Discord
- DSPy 相关论文发布:一名成员分享了关于 DSPy 的论文链接。
- 该论文分享在 #papers 频道中。
- 成员询问 Git 仓库:在 #examples 频道中,一名成员询问其工作的 Git repo 是否可用,表示有兴趣获取相关代码或资源。
- 该成员未指明具体是指哪个项目。
- Colab 笔记本出现:作为对 Git repo 查询的回应,一名成员提供了 Colab 笔记本链接。
- 访问该笔记本需要登录,且它可能与 DSPy 的讨论有关。
tinygrad (George Hotz) Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
第 2 部分:分频道详细摘要与链接
完整的频道详细分类已在邮件中截断。
如果你喜欢 AInews,请分享给朋友!预谢支持!