ainews-reasoning-models-are-near-superhuman
推理模型已具备接近超人类的编程能力(OpenAI IOI、英伟达内核)
以下是该文本的中文翻译:
o3模型在2024年国际信息学奥林匹克竞赛(IOI)中摘得金牌,并在Codeforces上排名前99.8%,超越了大多数人类。这证明了强化学习(RL)方法优于传统的归纳偏置(inductive bias)方法。英伟达的DeepSeek-R1能够自主生成GPU内核,其性能甚至超过了部分专家设计的内核,展示了简单而有效的AI驱动优化能力。OpenAI更新了o1和o3-mini模型,使其在ChatGPT中支持文件和图像上传,并发布了DeepResearch——这是一款基于o3模型(结合强化学习)的强大研究助手,具备深度思维链(CoT)推理能力。Ollama推出了基于Qwen2.5微调的OpenThinker模型,其表现优于部分DeepSeek-R1蒸馏模型。ElevenLabs已成长为一家估值达33亿美元的公司,专注于AI语音合成,且并未开源其技术。研究亮点还包括:Sakana AI实验室的TAID知识蒸馏方法在ICLR 2025上获得Spotlight论文奖,以及苹果公司关于混合专家模型(MoEs)缩放法则的研究。此外,开源AI对科学发现的重要性也再次得到了强调。
RL 就是你所需要的一切。
2025年2月12日至2月13日的 AI 新闻。我们为您检查了 7 个 subreddits、433 个 Twitter 账号 和 29 个 Discord(包含 211 个频道和 5290 条消息)。预计为您节省阅读时间(以 200wpm 计算):554 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
这是两条不同新闻的汇总,但它们有着相同的主题:
-
o3 在 2024 年 IOI 中摘得金牌,并获得了与人类精英选手相当的 Codeforces 评分 —— 特别是其 Codeforces 评分处于 99.8 百分位 —— 仅有 199 名人类选手的表现优于 o3。值得注意的是,团队成员 Alex Wei 指出,与 RL 的“惨痛教训 (bitter lesson)”相比,所有的“归纳偏置 (inductive bias)”方法都失败了。
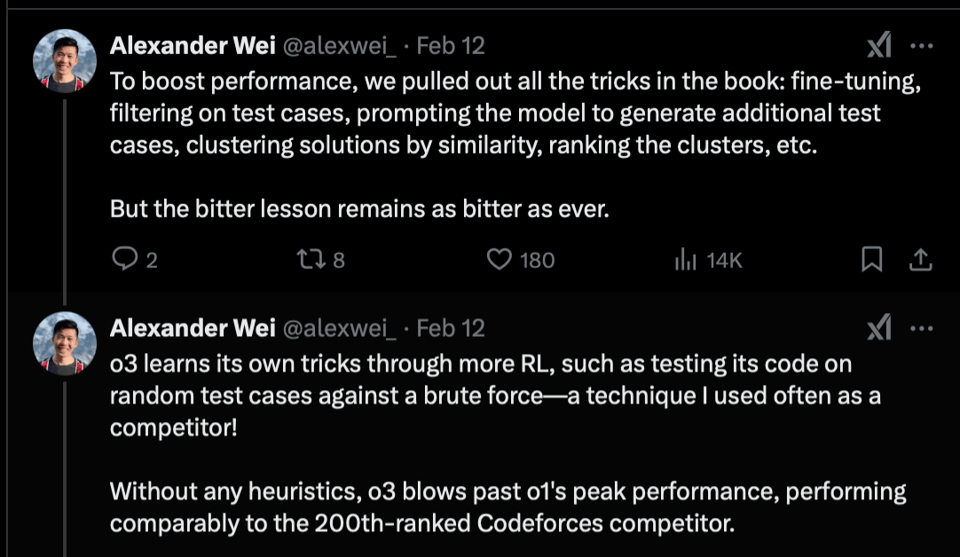
-
在 利用 DeepSeek-R1 和推理时间扩展 (Inference Time Scaling) 自动化 GPU Kernel 生成 中,Nvidia 发现 DeepSeek-R1 可以编写自定义 Kernel,且“在某些情况下,比资深工程师开发的优化 Kernel 表现更好”。
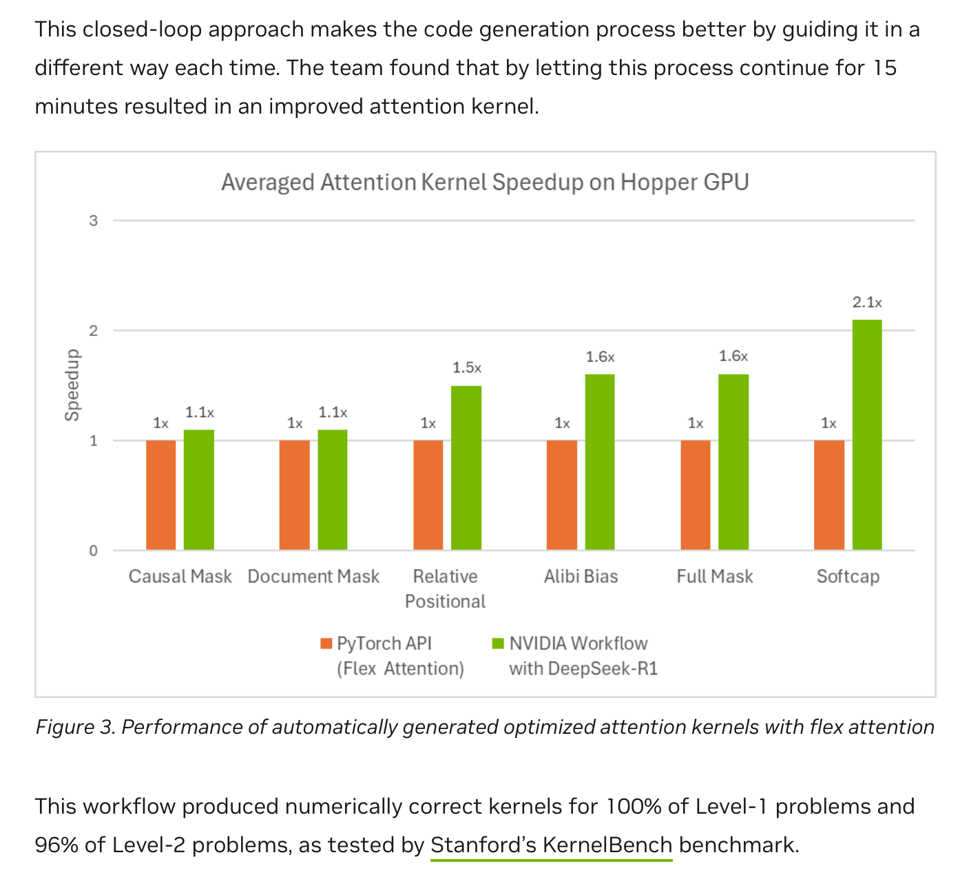
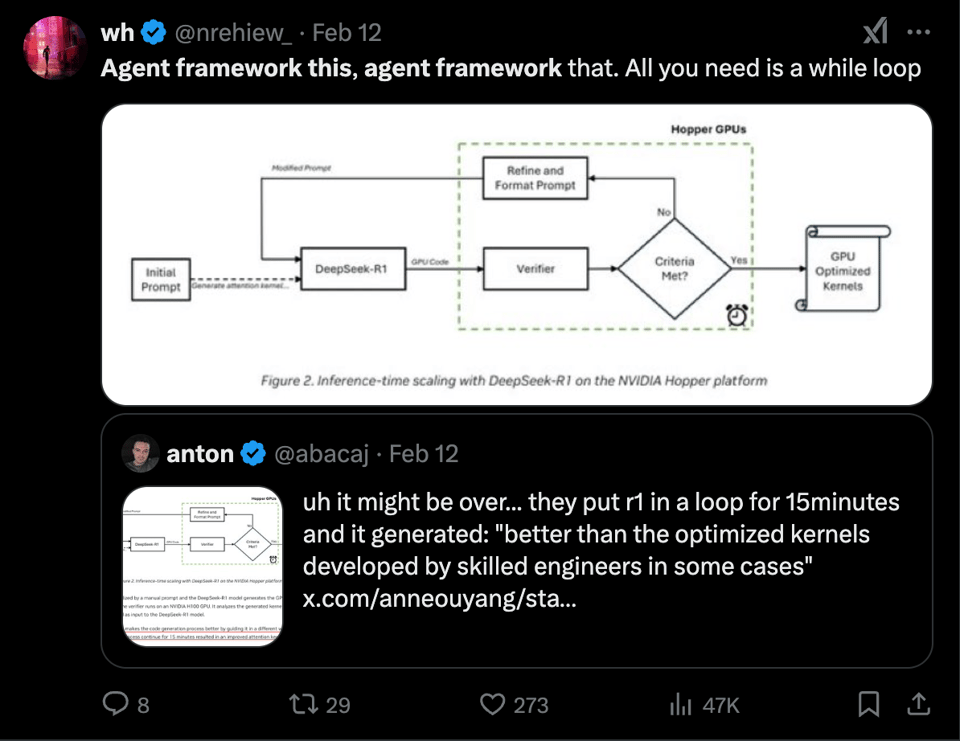
在 Nvidia 的案例中,解决方案也极其简单,这引发了许多人的惊愕。
AI Twitter 回顾
AI 工具与资源
-
OpenAI 关于 o1、o3-mini 和 DeepResearch 的更新:OpenAI 宣布 o1 和 o3-mini 现在在 ChatGPT 中支持文件和图像上传。此外,DeepResearch 现已向所有 Pro 用户开放,支持移动端和桌面端应用,进一步扩大了可用性。
-
使用 Ollama 在本地分发开源模型:@ollama 讨论了为开发者在本地分发和运行开源模型,并强调这是对托管型 OpenAI 模型的补充。
-
@karpathy 的“LLM 深度解析”:@TheTuringPost 分享了 @karpathy 制作的一段 3 小时以上的免费视频,探讨了 ChatGPT 等 AI 模型是如何构建的,包括预训练、后训练、推理以及如何有效使用模型等主题。
-
ElevenLabs 在 AI 语音合成领域的历程:@TheTuringPost 详细介绍了 @elevenlabsio 如何从一个周末项目演变为一家价值 33 亿美元的公司,在不开源的情况下提供 AI 驱动的 TTS、语音克隆和配音工具。
-
OpenAI 的 DeepResearch 是一款令人惊叹的研究助手:@TheTuringPost 评测了 OpenAI 的 DeepResearch,这是一款由带有 RL 的强大 o3 模型驱动的虚拟研究助手,专为深度思维链 (chain-of-thought) 推理而设计,并强调了其功能和优势。
-
OpenThinker 模型发布:@ollama 宣布推出 OpenThinker 模型,该模型基于 Qwen2.5 进行微调,在某些基准测试中超越了 DeepSeek-R1 蒸馏模型。
AI 研究进展
-
DeepSeek R1 生成优化 Kernel:@abacaj 报告称,他们让 R1 循环运行了 15 分钟,生成的代码在某些情况下“优于资深工程师开发的优化 Kernel”。
-
开源 AI 对科学发现的重要性:@stanfordnlp 强调,如果不对开源 AI 进行投资,可能会阻碍那些负担不起闭源模型的西方大学的科学发现。
-
Sakana AI Labs 的 ‘TAID’ 论文在 ICLR2025 获得关注:@SakanaAILabs 宣布其新的知识蒸馏方法 ‘TAID’ 被评为 ICLR2025 的 Spotlight 论文(前 5%)。
-
Apple 关于 Scaling Laws 的研究:@awnihannun 重点介绍了 Apple 最近关于 MoE 和知识蒸馏的 Scaling Laws 的两篇论文,贡献者包括 @samira_abnar、@danbusbridge 等人。
AI 基础设施与效率
- 提倡在数据中心而非移动端进行 AI 计算:@JonathanRoss321 认为,与数据中心相比,在移动设备上运行 AI 的能源效率较低,并使用类比说明了效率差异。
AI 安全与防护
-
AI Web Agent 漏洞曝光:@micahgoldblum 展示了攻击者如何诱导 Anthropic 的 Computer Use 等 AI Web Agent 发送钓鱼邮件或泄露信用卡信息,凸显了底层 LLM 的脆弱性。
-
Meta 的自动化合规加固 (ACH) 工具:@AIatMeta 介绍了他们的 ACH 工具,该工具通过基于 LLM 的测试生成来加固平台以防止回归,从而增强合规性和安全性。
AI 治理与政策
-
法国行动峰会的见解:@sarahookr 分享了对法国行动峰会的观察,指出此类峰会作为重要 AI 讨论的催化剂非常有价值,并强调了了解国家努力和科学进展的重要性。
-
从“AI 安全”转向“负责任的 AI”:@AndrewYNg 主张将对话从“AI 安全”转向“负责任的 AI”,认为这将加速 AI 带来的益处,并在不阻碍发展的情况下更好地解决实际问题。
梗/幽默
-
“Rizz GPT”与封锁后的社交挑战:@andersonbcdefg 幽默地评论道,Z 世代正在开发各种版本的“Rizz GPT”,因为他们的大脑因封锁而受损,不知道如何进行正常的对话。
-
“传染病的大日子”:@stevenheidel 发布了一条神秘消息,称今天是“传染病的大日子”,增添了一抹幽默感。
AI Reddit 综述
/r/LocalLlama 综述
主题 1. Google 的 FNet:通过傅里叶变换提升 LLM 效率的潜力
- 这篇论文可能是 Google 自己都还没意识到的突破 (Score: 362, Comments: 24):2022 年的 FNet 论文探索了使用傅里叶变换来混合 Token,暗示在模型训练中可能获得巨大的效率提升。作者推测,复制这种方法或将其集成到更大的模型中可能会带来 90% 的速度提升和内存减少,为 AI 模型效率的进步提供了重大机遇。
- 效率与收敛挑战:用户反馈称,虽然 FNet 有效,但其效果不如传统的 Attention 机制,特别是在小模型中,并且面临严重的收敛问题。这让人对其在更大模型中的可扩展性和有效性产生怀疑。
- 替代方案与对比:讨论中提到了其他模型,如 Holographic Reduced Representations (Hrrformer)(声称以更少的训练获得更优的性能)和 M2-BERT(在基准测试中显示出更高的准确性)。这些替代方案凸显了在评估训练速度、准确性和泛化能力之间权衡的复杂性。
- 集成与实现:FNet 代码可在 GitHub 上获得,但由于其是使用 JAX 实现的,将其与 Transformer 等现有模型集成并非易事。用户讨论了潜在的混合方法,例如创建 fnet-llama 或 fnet-phi 等变体,以探索性能差异和幻觉倾向。
主题 2. 为 70B LLM 自建高性能服务器:策略与成本
- 谁在组装能运行 70B 本地 LLMs 的电脑? (分数: 108, 评论: 160): 讨论了构建能够运行 70B 参数本地 LLMs 的家用服务器,重点是使用价格合理的旧服务器硬件来最大化核心数、RAM 和 GPU RAM。作者询问是否有专门从事此类服务器组装的专业人士或公司,因为他们无法承担配备高端 GPU 的家用服务器通常所需的 $10,000 到 $50,000 的成本。
- Psychological_Ear393 建议,使用 Epyc 7532、256GB RAM 和 MI60 GPUs 等组件,可以在 $3,000 以下构建用于 70B 参数 LLMs 的家用服务器。一些用户如 texasdude11 分享了使用双 NVIDIA 3090s 或 P40 GPUs 的配置以实现高效性能,并提供了详细的组装和操作指南及 YouTube 视频。
- NVIDIA A6000 GPU 因其在运行 70B 模型 时的速度和能力而受到关注;然而,其约 $5,000 的价格较为昂贵。替代方案包括配备多个 RTX 3090 或 3060 GPUs 的设置,用户如 Dundell 和 FearFactory2904 建议使用二手组件进行更具成本效益的组装。
- 用户讨论了使用 Macs(特别是配备 128GB RAM 的 M1 Ultra)高效运行 70B 模型 的可行性,尤其是在聊天应用中,正如 synn89 所指出的。未来的潜在选择包括等待 Nvidia Digits 或 AMD Strix Halo,它们可能为家用推理任务提供更好的性能。
主题 3. Gemini 2.0 在 OCR 基准测试和上下文处理中的主导地位
- Gemini 在视频 OCR 基准测试任务中击败了所有人。完整论文:https://arxiv.org/abs/2502.06445 (分数: 114, 评论: 26): Gemini-1.5 Pro 在视频 OCR 基准测试任务中表现出色,实现了 0.2387 的 字符错误率 (CER)、0.2385 的 词错误率 (WER) 以及 76.13% 的 平均准确率。尽管 GPT-4o 以 76.22% 的整体准确率略高且 WER 最低,但 Gemini-1.5 Pro 因其优于 RapidOCR 和 EasyOCR 等模型的性能而备受瞩目。完整论文
- RapidOCR 被指出是 PaddleOCR 的一个分支,预计其得分与原版偏差极小。人们对使用 Gemini-1.5 Pro 探索直接 PDF 处理能力很感兴趣,并提供了在 Google Cloud Vertex AI 上实现的链接 点击此处。
- 用户表示 OCR 基准测试需要包含手写识别,Azure FormRecognizer 因处理草体文本而受到称赞。一位用户报告称,与其他语言模型相比,Gemini 2.0 Pro 在俄语手写笔记上的表现异常出色。
- 有人呼吁在多种语言和模型之间进行更广泛的比较,包括 Gemini 2、Tesseract、Google Vision API 和 Azure Read API。尽管对 Gemini 处理简单任务的方式感到有些沮丧,但用户承认其在视觉标注方面的进步,且 Moondream 被强调为一个极具前景的新兴模型,并计划将其添加到 OCR 基准测试仓库 中。
- NoLiMa:超越字面匹配的长上下文评估 —— 终于有一个好的基准测试能展示 LLM 在长上下文下的表现有多糟糕。所有模型在仅 32k 上下文时性能就大幅下降。 (Score: 402, Comments: 75): NoLiMa 基准测试 强调了 LLMs 在长上下文长度下显著的性能退化,在 GPT-4、Llama、Gemini 1.5 Pro 和 Claude 3.5 Sonnet 等模型中,仅在 32k tokens 处就出现了明显的下降。图表和表格显示,在这些扩展长度下,得分降至基础得分的 50% 以下,表明在增加上下文时维持性能面临巨大挑战。
- 性能退化与基准测试对比:NoLiMa 基准测试 显示了像 llama3.1-70B 这样的 LLMs 存在实质性的性能退化,其在 32k 上下文长度下的得分为 43.2%,而相比之下在 RULER 上的得分为 94.8%。该基准测试被认为比之前的 LongBench 更具挑战性,后者侧重于多项选择题,无法充分捕捉跨上下文长度的性能退化。
- 模型性能与架构担忧:关于 o1/o3 等 reasoning models 如何处理长上下文存在大量讨论,部分模型在难题子集上表现不佳。当前架构的局限性(如 attention 机制的平方复杂度)被强调为维持长上下文性能的障碍,这表明需要像 RWKV 和 linear attention 这样的新架构。
- 未来模型测试与预期:参与者对测试 Gemini 2.0-flash/pro 和 Qwen 2.5 1M 等新模型表现出兴趣,希望在长上下文场景中能有更好的表现。对于模型能有效处理 128k tokens 的说法存在怀疑,一些用户强调实际应用通常在 8k tokens 以下的上下文中表现最好。
{kind=link}
{kind=link}
主题 4. 来自 DeepSeek 的创新架构见解:专家混合与 Token 预测
-
**从零开始构建 DeepSeek 由 MIT 博士毕业生授课** (Score: 245, Comments: 28):一位 MIT 博士毕业生正在推出一系列关于从零构建 DeepSeek 架构 的综合教育课程,重点关注基础元素,如 Mixture of Experts (MoE)、Multi-head Latent Attention (MLA)、Rotary Positional Encodings (RoPE)、Multi-token Prediction (MTP)、Supervised Fine-Tuning (SFT) 和 Group Relative Policy Optimisation (GRPO)。该系列包含 35-40 个深度视频,总时长超过 40 小时,旨在让参与者具备独立构建 DeepSeek 组件的能力,使他们跻身前 0.1% 的 ML/LLM 工程师行列。 - 对资历的怀疑:一些用户对强调 MIT 等名校资历表示怀疑,认为内容的质量应该独立于作者的背景。有人呼吁评判内容时应脱离创作者的学术或职业背景。
- 缺失的技术细节:讨论的一个重点是该系列忽略了 Nvidia 的 Parallel Thread Execution (PTX) 作为 CUDA 的高性价比替代方案,这被视为在探讨 DeepSeek 的效率和成本效益方面存在缺失。这表明,理解技术底层原理而不仅仅是功能,对于理解 DeepSeek 的架构至关重要。
- 算力的不确定性:关于 DeepSeek 开发中使用的实际算力存在争论,一些用户批评了网上流传的推测数字。讨论强调了准确数据(特别是在数据集和算力资源方面)对于理解和复制 AI 系统的重要性。
其他 AI 子版块回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
主题 1. OpenAI 将 o3 合并为统一的 GPT-5
- OpenAI 取消其 o3 AI 模型,转而发布“统一”的下一代版本 (Score: 307, Comments: 66): OpenAI 已决定取消其 o3 AI 模型项目,转而专注于开发包含 GPT-5 的统一下一代版本。这一战略转变表明,资源和精力正向单一且更先进的 AI 模型整合。
- 关于 OpenAI 将 o3 模型集成到 GPT-5 的举动究竟代表了进步还是缺乏创新,存在重大争议。一些用户认为这种集成是为了提高易用性的战略简化,而另一些用户则将其视为模型开发的停滞迹象,并引用 DeepSeek R1 作为具有竞争力的免费替代方案。
- 许多评论者对自动模型选择方式导致的用户控制权丧失表示担忧,担心这可能导致次优结果。像 whutmeow 和 jjjiiijjjiiijjj 这样的用户更倾向于手动选择模型,担心算法决策可能会优先考虑公司成本而非用户需求。
- 讨论还强调了对所用术语的困惑,几位用户纠正了 o3 被取消的说法,澄清其正在被集成到 GPT-5 中。这引发了对误导性标题以及对 OpenAI 战略方向和领导层潜在影响的担忧。
- Altman 把潜台词说了出来 (Score: 126, Comments: 59): Sam Altman 宣布,最初计划作为 GPT-5 的 Orion 将改为以 GPT-4.5 的名义发布,并将其定性为最后一个非 CoT 模型。来自 Bloomberg、The Information 和 The Wall Street Journal 的报道指出,GPT-5 面临重大挑战,其相对于 GPT-4 的提升幅度小于前代产品。此外,o3 模型将不会单独发布,而是集成到名为 GPT-5 的统一系统中,这可能是由于 ARC benchmark 揭示的高昂运营成本,如果被用户广泛且随意地使用,可能会给 OpenAI 带来财务压力。
- 硬件与成本:在不合适的硬件(如 Blackwell chips)上运行模型的低效率,以及由于重复查询导致的成本数据误读,被认为是影响 GPT-4.5 和 GPT-5 发布和运营的因素。Deep Research 查询的定价为每次 $0.50,计划为 Plus 会员提供 10 次,为免费用户提供 2 次。
- 模型演进与挑战:人们普遍认为非 CoT 模型可能已经达到了可扩展性极限,从而促使向具有推理能力的模型转变。这种转型被视为必要的演进,一些人认为 GPT-5 代表了一个新方向,而非对 GPT-4 的迭代改进。
- 推理与模型选择:讨论强调了推理模型的潜在优势,一些用户指出像 o3 这样的推理模型可能会“过度思考”,而另一些用户则建议使用混合方法为特定任务选择最合适的模型。关于具有可调思考时间的模型成本高昂的概念也引发了辩论,以及 OpenAI 实施使用上限以管理开支的可能性。
- 我 50 多岁了,刚刚让 ChatGPT 为我的网站写了一个 JavaScript/HTML 计算器。我被震撼到了。 (Score: 236, Comments: 62): 作者已年过五旬,他使用 ChatGPT 为自己的网站创建了一个 JavaScript/HTML 计算器,并对其理解模糊指令和优化代码的能力感到印象深刻,认为这就像与 Web 开发者对话一样。尽管之前很少使用 AI,但他对其能力感到惊讶,并回顾了自 1977 年以来观察技术进步的漫长历史。
- 用户分享了 ChatGPT 辅助完成各种编程任务的经验,从创建 SQL 查询到构建维基和服务器,强调了它在引导学习陌生技术方面的效用。FrozenFallout 和 redi6 强调了它在简化复杂流程和错误处理方面的作用,即使对于技术知识有限的人也是如此。
- Front_Carrot_1486 和 BroccoliSubstantial2 对 AI 的飞速发展表达了共同的惊叹,将其与过去的技术变革相提并论,并指出了见证技术从科幻变为现实的代际视角。他们赞赏 AI 提供解决方案和替代方案的能力,尽管偶尔会出现错误。
- 进一步探索的建议包括尝试使用 Cursor 会员以获得更令人印象深刻的体验(由 TheoreticalClick 建议),以及在 AI 指导下探索应用开发(由 South-Ad-9635 提到)。
主题 2. Anthropic 和 OpenAI 增强推理模型
- OpenAI 将其最先进推理模型的速率限制提高了 7 倍。现在轮到你了,Anthropic。 (Score: 486, Comments: 72): OpenAI 显著提高了其高级推理模型 o3-mini-high 的速率限制,为 Plus 用户 提高了 7 倍,现在每天允许使用多达 50 次。此外,OpenAI o1 和 o3-mini 现在支持在 ChatGPT 中上传文件和图像。
- 用户对 Anthropic 在竞争压力下表现出的紧迫感缺失表示强烈不满,一些人由于缺乏引人注目的更新或功能而取消了订阅。担忧包括该公司对安全和内容审核的关注超过了创新,可能失去竞争优势。
- OpenAI 的 o3-mini-high 模型速率限制的提高受到了积极评价,尤其是 Plus 用户,他们非常欣赏这种增强的访问权限。然而,一些人认为 OpenAI 优先考虑 API 商业客户而非 Web/App 用户,导致后者的限制较低。
- 存在一种对 Anthropic 失望的情绪,用户觉得他们对安全和企业客户的关注掩盖了创新和对市场竞争的响应。一些用户对 Claude 的局限性以及缺乏具有类似能力的替代方案感到沮丧。
- The Information:Claude 混合推理模型可能在未来几周内发布 (Score: 160, Comments: 44): 据报道,Anthropic 将在未来几周内发布 Claude 混合推理模型,提供一个滑动缩放功能,当设置为 0 时会退回到非推理模式。据称该模型在某些编程基准测试中优于 o3-mini,并且在典型的编程任务中表现出色,而 OpenAI 的模型在学术和竞赛编程方面更胜一筹。
- Anthropic 对安全的关注受到了一些用户的批评,他们将其与 OpenAI 减少的审查以及 Gemini 2.0 模型进行了比较,后者因限制较少而受到称赞。一些用户认为审查工作无关紧要,而另一些人则将其视为不必要的企业迎合。
- 人们对 Claude 混合推理模型 在写作任务中的有效性持怀疑态度,担心它可能会遇到与 o3-mini 类似的问题。用户表示需要更大且更有效的上下文窗口(context windows),并指出 Claude 所谓的 200k token 上下文在超过 32k token 后开始显著退化。
- 用户讨论了上下文窗口和输出复杂性的重要性,一些人认为 o3-mini-high 的输出过于复杂,而另一些人则强调需要一个在超过 64k token 后仍能保持完整性的上下文窗口。
- Deep reasoning coming soon (Score: 121, Comments: 42): 标题为 “Deep reasoning coming soon” 的帖子,正文内容为 “Hhh”,缺乏实质性内容和上下文,无法提供详细摘要。
- 代码输出担忧: Estebansaa 对深度推理的价值表示怀疑,如果它不能超越目前 300-400 行代码 的输出,并达到 o3 每次请求超过 1000 行 的能力。Durable-racoon 质疑是否需要如此大量的输出,认为即使是 300 行 的代码审查起来也可能让人不堪重负。
- API 访问问题: Hir0shima 等人讨论了 API 访问的挑战,强调了高昂的成本和频繁的错误。Zestyclose_Coat442 指出即使发生错误也会产生意外费用,而 Mutare123 提到了达到响应限制的可能性。
- 发布紧迫感: Joelrog 指出,最近关于深度推理的公告仍处于较短的时间窗口内,反对急躁情绪,并强调公司通常会遵守其发布计划。
{kind=link}
AI Discord 回顾
由 Gemini 2.0 Flash Exp 生成的摘要之摘要
主题 1. 推理 LLM 模型 - 新发布趋势
- Nous Research 推出 DeepHermes-3 以实现卓越推理: Nous Research 发布了 DeepHermes-3 Preview,展示了在统一推理和直觉语言模型能力方面的进展。该模型需要特定的带有
<think>标签的系统提示词(System Prompt)来启用长思维链(Chain of Thought)推理,从而增强系统性问题解决能力。基准测试报告显示其在数学推理方面有显著增强。 - Anthropic 计划推出集成推理功能的 Claude 版本: Anthropic 准备发布一个新的 Claude 模型,结合了传统 LLM 和推理 AI 的能力,通过基于 Token 的滑动标尺进行控制,适用于编程等任务。传闻该模型在多个基准测试中可能优于 OpenAI 的 o3-mini-high。这些模型及其新能力的亮相标志着 AI 系统混合思考新时代的开始。
- 智力规模化,Elon 承诺推出 Grok-3: Elon Musk 宣布 Grok 3 即将发布,吹嘘其拥有超越现有模型的卓越推理能力,暗示其将达到“可怕的聪明”新高度,预计在大约两周内发布。与此同时,他正以 974 亿美元 竞购 OpenAI 的非营利资产。这一公告预计将改变游戏规则。
主题 2. 小而强大的 LLM 与工具改进
- DeepSeek-R1 像老板一样生成 GPU Kernel: NVIDIA 的博客文章介绍了 LLM 生成的 GPU Kernel,展示了 DeepSeek-R1 加速 FlexAttention 并在 🌽KernelBench Level 1 上实现 100% 数值正确性,同时在 KernelBench 基准测试的 Level-2 问题上达到 96% 的准确率。这通过分配额外资源实现了计算密集型任务的自动化,但也引发了对基准测试本身的关注。
- Hugging Face Smolagents 问世,简化你的工作流: Hugging Face 推出了 smolagents,这是一个轻量级的 Agent 框架,可作为
deep research的替代方案,6 个步骤 的处理时间约为 13 秒。用户可以修改原始代码,以便在本地服务器运行时扩展执行,提供了极佳的适应性。 - Codeium 的 MCP 提升编程能力: Windsurf Wave 3 (Codeium) 引入了 Model Context Protocol (MCP) 等功能,集成了多个 AI 模型以提高效率和输出质量,允许用户配置工具调用到自定义的 MCP 服务器,并获得更高质量的代码。社区对这一混合 AI 框架感到兴奋!
主题 3. Perplexity 财经仪表盘与 AI 模型分析
- Perplexity 推出全能 Finance Dashboard: Perplexity 发布了新的 Finance Dashboard,提供市场摘要、每日亮点和收益快报。用户正请求在 Web 端和移动端 App 中添加专门的仪表盘按钮。
- Perplexity AI 模型性能受到严格审查: Perplexity AI 使用的模型受到质疑。关于 AI 模型的争论浮出水面,特别是 R1 与 DeepSeek 和 Gemini 等替代方案相比的效率和准确性。
- DeepSeek R1 在推理能力上击败 OpenAI: 一位用户报告称 DeepSeek R1 在处理复杂的 SIMD 函数时表现出令人印象深刻的推理能力,在 OpenRouter 上的表现优于 o3-mini。HuggingFace 上的用户赞扬了 V3 的编程能力,而 Unsloth AI 的一些用户看到它成功处理了合成数据和 GRPO/R1 蒸馏任务。
主题 4. 挑战与创意解决方案
- DOOM 游戏被压缩进二维码: 一名成员成功地将一款名为 The Backdooms 的可玩 DOOM 启发式游戏塞进了一个二维码中,占用空间不到 2.4kb,并以 MIT license 开源该项目供他人实验。该项目使用了类似 .kkrieger 的压缩技术,并有一篇博文记录了实现方法。
- 移动设备限制 RAM,促使寻找替代方案: 移动用户指出 12GB 手机仅允许 2GB 的可用内存,阻碍了模型性能,有人建议使用约 100 美元的 16GB ARM SBC 作为便携式计算的替代方案。如果你没有高端手机,那就升级它。
- Hugging Face Agents 课程导致用户连接中断: 由于用户在 Agents 课程期间遇到连接问题,一名成员建议将端点更改为新链接 (https://jc26mwg228mkj8dw.us-east-1.aws.endpoints.huggingface.cloud),并指出需要更新模型名称为 deepseek-ai/DeepSeek-R1-Distill-Qwen-32B,这可能是由过载引起的。尝试更换浏览器,如果一切都失败了……断开连接。
主题 5. 数据、版权与声明
- 美国拒绝 AI 安全协议,声称要保持竞争优势: 美国和英国拒绝签署联合 AI 安全声明,美国领导人强调他们致力于保持 AI 领导地位。官员们警告说,在 AI 领域与威权国家接触可能会损害基础设施安全。
- 汤森路透赢得具有里程碑意义的 AI 版权案: 汤森路透在针对 Ross Intelligence 的重大 AI 版权案 中获胜,判定该公司通过复制 Westlaw 的材料侵犯了其版权。美国巡回法院法官 Stephanos Bibas 驳回了 Ross 的所有辩护,称其全都站不住脚。
- LLM Agents MOOC 证书处理延迟: 许多 LLM Agents 课程的参与者尚未收到之前的证书,必须等待手动发送,而其他需要帮助寻找证书的人被提醒,declaration form 是证书处理所必需的。我的证书在哪?
第一部分:Discord 高层级摘要
Unsloth AI (Daniel Han) Discord
- DeepSeek 的动态量化减少内存占用:用户解释说,在 DeepSeek 模型中实现的动态量化有助于在保持性能的同时减少内存使用,尽管目前主要适用于特定模型,并详细说明了其优势。
- 动态量化是一项正在进行的工作,旨在减少 VRAM 占用并运行 Unsloth 的 1.58-bit 动态 GGUF 版本。
- GRPO 训练平台期与提示词正则表达式微调:关于在 GRPO 训练期间获得预期奖励的问题被提出,用户观察到性能指标出现平台期以及生成长度出现意外变化,更多细节见 Unsloth 的 GRPO 博客文章。
- 一位用户报告称通过修改正则表达式(regex)获得了更好的训练结果,但指标的不一致仍然是一个问题,且对 Llama3.1 (8B) 性能指标的影响尚不明确。
- Rombo-LLM-V3.0-Qwen-32b 表现亮眼:新模型 Rombo-LLM-V3.0-Qwen-32b 已发布,在各项任务中展现出令人印象深刻的性能,更多细节见 Reddit 帖子。
- 详细介绍了如何通过 Patreon 支持模型开发者的工作,每月仅需 5 美元即可为未来的模型投票并访问私有仓库。
- Lavender 方法增强 VLMs:Lavender 方法作为一种监督微调技术被引入,它利用 Stable Diffusion 提高了视觉语言模型(VLMs)的性能,代码和示例可在 AstraZeneca 的 GitHub 页面找到。
- 该方法实现了性能提升,包括在 20 个任务上增长了 +30%,在 OOD WorldMedQA 上提升了 +68%,展示了文本-视觉注意力对齐(attention alignment)的潜力。
HuggingFace Discord
- DOOM 游戏被压缩进二维码:一名成员成功将一款名为 The Backdooms 的可玩 DOOM 启发游戏塞进了一个二维码中,占用空间不足 2.4kb,并以 MIT 许可证在 GitHub 开源了该项目。
- 作者在这篇博客文章中记录了实现方法,提供了关于技术挑战和解决方案的见解。
- Steev AI 助手简化模型训练:一个团队推出了 Steev,这是一个旨在自动化 AI 模型训练的 AI 助手,减少了对持续监督的需求,更多信息请访问 Steev.io。
- 其目标是简化 AI 训练过程,消除乏味且重复的任务,让研究人员能够专注于模型开发和创新的核心环节。
- Rombo-LLM V3.0 在编程方面表现出色:新模型 Rombo-LLM-V3.0-Qwen-32b 已发布,在编程和数学任务中表现优异,如这篇 Reddit 帖子所示。
- 该模型使用的 Q8_0 量化显著提升了效率,使其能够在没有高计算需求的情况下执行复杂任务。
- Agents 课程验证出现问题:Hugging Face AI Agents 课程的许多参与者报告了通过 Discord 验证账户时遇到的持续问题,导致反复出现连接失败。
- 推荐的解决方案包括退出登录、清除缓存以及尝试不同的浏览器,少数幸运儿最终完成了验证过程。
- 建议为 Agent 连接使用新端点:针对用户在 Agents 课程中遇到的连接问题,一名成员建议将端点(endpoint)更改为新链接 (https://jc26mwg228mkj8dw.us-east-1.aws.endpoints.huggingface.cloud),并指出需要将模型名称更新为 deepseek-ai/DeepSeek-R1-Distill-Qwen-32B。
- 这一修复方案可能会解决课程参与者在 Agent 工作流中使用 LLM 时遇到的一系列近期问题。
OpenAI Discord
- Pro 用户获得 Deep Research 访问权限:Deep research 访问权限现已面向所有 Pro 用户开放,涵盖移动端和桌面端应用(iOS, Android, macOS 和 Windows)。
- 这增强了在各种设备上的研究能力。
- OpenAI o1 & o3 支持文件和图像上传:OpenAI o1 和 o3-mini 现在支持在 ChatGPT 中进行文件和图像上传。
- 此外,Plus 用户的 o3-mini-high 限制已提升 7 倍,每天允许最多 50 次上传。
- OpenAI 发布 Model Spec 更新:OpenAI 分享了 Model Spec 的重大更新,详细说明了对模型行为的预期。
- 该更新强调了对可定制性、透明度以及培养思想自由氛围的承诺。
- OpenAI 的所有权面临审查:讨论围绕 Elon Musk 收购 OpenAI 的可能性展开,许多人对此表示怀疑,并希望如果发生收购,能将技术开源。
- 用户推测大型科技公司可能会将利润置于公共利益之上,从而导致对 AI 过度控制的担忧。
- GPT-4o 设有免费限制:Custom GPTs 在 GPT-4o 模型上运行,其限制根据各种因素每天都在变化,只有部分固定值,如 AVM 为 15min/month。
- 用户必须根据其地区和使用时区来关注限制。
Cursor IDE Discord
- o3-mini 落后于 Claude:用户观察到 OpenAI 的 o3-mini 模型在 tool calling 方面表现不如 Claude,通常需要多次 prompt 才能达到预期结果,这引发了不满。
- 许多人表示 Claude 的推理模型在工具使用方面表现出色,并建议集成类似于 Cline 的 Plan/Act 模式以改善用户体验。
- 混合 AI 模型令开发者兴奋:社区对 Anthropic 即将推出的混合 AI 模型表现出兴奋,据报道,在利用最大推理能力时,该模型在编程任务上超越了 OpenAI 的 o3-mini。
- 这种期待源于新模型在编程基准测试中的高性能,表明相对于目前的替代方案,它可以显著提升编码工作流。
- Tool Calling 引发关注:用户对 o3-mini 在 tool calling 方面的灵活性和效率有限表示不满,质疑其在真实编程场景中的实用性。
- 讨论强调了对 AI 模型简化复杂编码任务的需求,并建议建立 prompting 最佳实践以引导出更高质量的代码。
- MCP 使用成为讨论话题:MCP (Multi-Channel Processor) 的概念作为一种通过集成多个 AI 模型来提高效率和产出的工具浮出水面。
- 用户一直在分享利用 MCP 服务器优化编码工作流并克服单一模型局限性的经验和策略。
- Windsurf 定价令人不满:讨论涉及 Windsurf 僵化的定价,特别是限制用户使用自己的 key,这导致了用户的不满。
- 许多用户表示相比竞争对手更青睐 Cursor 的功能和实用性,强调了其在性价比和整体用户体验方面的优势。
Nous Research AI Discord
- DeepHermes-3 统一推理能力:Nous Research 发布了 DeepHermes-3 Preview,这是一个将推理能力与传统语言模型相结合的 LLM,可在 Hugging Face 上获取。
- 该模型需要特定的带有
<think>标签的系统提示词(system prompt)来启用长链条思维链(chain of thought)推理,从而增强系统化问题解决能力,并在数学推理方面表现出显著提升。
- 该模型需要特定的带有
- Nvidia 的 LLM 内核加速:Nvidia 的博客文章介绍了由 LLM 生成的 GPU 内核,这些内核在加速 FlexAttention 的同时,在 🌽KernelBench Level 1 上实现了 100% 的数值正确性。
- 这标志着 GPU 性能优化取得了显著进展,成员们还推荐了 r1 kimik 和 synthlab 的论文,以获取有关 LLM 进展 的最新信息。
- 移动设备 RAM 限制:成员们注意到 12GB 的手机仅允许 2GB 的可访问内存,这阻碍了他们运行模型的能力。
- 一位用户建议购买 16GB 的 ARM SBC 用于便携式计算,这样可以在旅行时以约 100 美元的价格运行小型 LLM,为感兴趣的人提供了一个实惠的选择。
- 美国拒绝 AI 安全协议:据 ArsTechnica 报告,美国和英国拒绝签署一份联合 AI 安全宣言,美国领导人强调他们致力于保持 AI 领导地位。
- 官员们警告说,在 AI 领域与威权国家接触可能会损害国家基础设施安全,并引用了 CCTV 和 5G 作为通过补贴出口以施加不当影响的例子。
OpenRouter (Alex Atallah) Discord
- Groq DeepSeek R1 70B 冲刺 1000 TPS:OpenRouter 用户正在庆祝 Groq DeepSeek R1 70B 的加入,其吞吐量达到了 每秒 1000 个 token,并提供参数自定义和速率限制调整。该公告发布在 OpenRouter AI 的 X 账号上。
- 这是旨在增强用户与平台交互的更广泛集成的一部分。
- 新的排序调整提升 UX:用户现在可以在账户设置中自定义模型提供商的默认排序,专注于吞吐量或平衡速度与成本。如 OpenRouter 的推文所述,要在任何模型名称后附加
:nitro即可访问最快的可用提供商。- 此功能允许用户根据自己的优先级定制体验。
- API 采用原生 Token 计数:OpenRouter 计划将 API 中的
usage字段从 GPT token 归一化切换为模型的原生 token 计数,并正在征求用户反馈。- 有推测认为这一变化可能会影响像 Vertex 这样具有不同 token 比例的模型。
- Deepseek R1 在推理方面击败 OpenAI:一位用户报告称,Deepseek R1 在处理复杂的 SIMD 函数时表现出令人印象深刻的推理能力,优于表现“固执”的 o3-mini。
- 团队正在探索这一选项,并承认了用户对审核问题的担忧。
- 用户抱怨 Google 的速率限制:由于资源耗尽,用户经常遇到来自 Google 的 429 错误,尤其是影响到 Sonnet 模型。
- OpenRouter 团队正在积极解决由 Anthropic 容量限制引起的日益严重的速率限制问题。
Perplexity AI Discord
- Perplexity 发布 Finance Dashboard:Perplexity 发布了全新的 Finance Dashboard,提供市场摘要、每日亮点和收益快报。
- 用户请求在 Web 端和移动端 App 中添加仪表盘的专用按钮。
- 对 AI 模型性能产生质疑:关于 AI 模型的讨论不断涌现,特别是 R1 与 DeepSeek 和 Gemini 等替代方案相比的效率和准确性,以及首选的使用方式和性能指标。
- 成员们分享了使用经验,并提出了可以改善用户体验的功能和特性。
- Perplexity 支持服务受到批评:一名用户报告称,Perplexity 的客户服务响应缓慢且缺乏支持,涉及 Pro 账户已付费但无法访问的问题。
- 这引发了关于建立清晰沟通和高效支持团队必要性的讨论。
- API 遭遇大规模 500 错误:多名成员报告所有 API 调用均出现 500 错误,导致生产环境故障。
- 在 API 恢复正常之前,这些错误持续了一段时间。
- 对 Cerebras 上的 Sonar 充满热情:一名成员表达了成为 Cerebras 上 Sonar API 版本 beta tester 的强烈兴趣。
- 该成员表示他们已经梦想了几个月,表明了对这一集成的潜在兴趣。
Codeium (Windsurf) Discord
- Windsurf Wave 3 正式上线!:Windsurf Wave 3 引入了 Model Context Protocol (MCP)、可自定义的应用图标、增强的 Tab to Jump 导航以及 Turbo Mode,详见 Wave 3 博客文章。
- 此次更新还包括重大升级,如自动执行命令和改进的额度可见性,详见完整变更日志。
- 更新后 MCP 服务器选项难以找到?:更新 Windsurf 后,部分用户报告难以找到 MCP server options,该问题通过重新加载窗口得到解决。
- 此问题强调了刷新界面的重要性,以确保 MCP settings 按预期显示,从而允许配置对用户定义 MCP servers 的工具调用。
- Cascade 饱受性能问题困扰:用户报告 Cascade model 出现性能迟缓和频繁崩溃,通常需要重启才能恢复功能。
- 报告的挫败感包括运行期间响应时间慢和 CPU 占用率增加,突显了稳定性问题。
- Codeium 1.36.1 旨在修复 Bug:Codeium 1.36.1 的发布旨在解决现有问题,建议用户在此期间切换到 pre-release 版本。
- 之前修复 2025 写作问题的尝试未能成功,突显了此次更新的必要性。
- Windsurf Chat 饱受不稳定性困扰:Windsurf 聊天用户正经历频繁的卡死、对话历史丢失和工作流中断。
- 建议的解决方案包括重新加载应用程序并报告 Bug,以解决这些关键的稳定性问题。
LM Studio Discord
- Qwen-2.5 VL 面临性能瓶颈:用户报告 Qwen-2.5 VL 模型存在响应速度慢和内存问题,特别是在后续提示词(follow-up prompts)之后,会导致显著的延迟。
- 该模型的 内存占用激增,可能依赖于 SSD 而非 VRAM,这在高配置机器上尤为明显。
- Speculative Decoding 需要调整设置:上传与 Speculative Decoding(投机采样)相关的模型时遇到困难,经过排查发现用户需要调整设置并确保选择了兼容的模型。
- 该问题强调了将模型配置与所选 speculative decoding 功能相匹配的重要性。
- Tesla K80 PCIe 引发讨论:讨论了使用售价 60 美元、拥有 24GB VRAM 的 Tesla K80 PCIe 执行 LLM 任务的潜力,引发了对功耗和兼容性的担忧。
- 用户建议,虽然价格低廉,但 K80 过旧的架构和潜在的安装问题可能使得 GTX 1080 Ti 成为更好的替代方案。
- SanDisk 通过 HBF 内存大幅提升 VRAM:SanDisk 推出了新型高带宽闪存,能够在 GPU 上实现 4TB 的 VRAM,旨在用于需要高带宽和低功耗的 AI 推理应用。
- 据 Tom’s Hardware 报道,这种 HBF memory 将自己定位为未来 AI 硬件中传统 HBM 的潜在替代品。
GPU MODE Discord
- Blackwell 的 Tensor Memory 受到审视:讨论澄清了 Blackwell GPU 的 tensor memory 完全由程序员管理,具有专用的分配函数(详见此处),并且它也是矩阵乘法中寄存器的替代品。
- 关于 tensor memory 在处理 sparsity(稀疏性)和 microtensor scaling(微张量缩放)时的效率出现了争论,如果未充分利用,可能会导致容量浪费,并增加在 Streaming Multiprocessors 上拟合累加器的复杂性。
- D-Matrix 推广创新的 Kernel 工程:D-Matrix 正在招聘 Kernel 开发人员,邀请具有 CUDA 经验的人员联系并探索其独特技术栈中的机会,建议联系 LinkedIn 上的 Gaurav Jain 以了解其创新硬件和架构。
- D-Matrix 的 Corsair 技术栈旨在提高速度和能效,可能改变大规模推理的经济效益,并声称对 H100 GPU 具有竞争优势,强调 AI 的可持续解决方案。
- SymPy 简化反向传播推导:成员们对使用 SymPy 推导算法的反向传播(backward pass)以管理复杂性表现出兴趣。
- 围绕
gradgradcheck()遇到的问题进行了讨论,涉及非预期的输出行为,意在澄清要点并在问题持续时在 GitHub 上进行跟进,这暗示了维护准确中间输出的复杂性。
- 围绕
- Reasoning-Gym 改进评估指标:Reasoning-Gym 社区讨论了 MATH-P-Hard 上的性能下降,并发布了一个针对 Graph Coloring Problems(图着色问题)的新 Pull Request,通过统一提示词对数据集进行标准化以简化评估流程,提高输出的机器兼容性,详见 此处的 PR。
- 诸如 Futoshiki puzzle dataset 等更新旨在提供更简洁的解算器和改进的逻辑框架(如此 PR 所示),并建立了一种跨数据集平均分数的标准方法,以实现一致的报告。
- DeepSeek 自动化 Kernel 生成:NVIDIA 展示了使用 DeepSeek-R1 模型 自动为 GPU 应用生成数值正确的 Kernel,并在推理期间对其进行优化。
- 生成的 Kernel 在 KernelBench 基准测试的 Level-1 问题上达到了 100% 的准确率,在 Level-2 问题上达到了 96%,但也有人对该基准测试的饱和度表示担忧。
Interconnects (Nathan Lambert) Discord
- GRPO 极大提升 Tulu 流水线性能:在 Tulu 流水线中从 PPO 切换到 GRPO 带来了 4倍 的性能提升,正如 Costa Huang 所宣布的,新的 Llama-3.1-Tulu-3.1-8B 模型在 MATH 和 GSM8K 基准测试中均展现出进步。
- 这一转变标志着自去年秋天推出的早期模型以来的显著演进。
- Anthropic 的 Claude 获得推理滑块:根据 Stephanie Palazzolo 的推文,Anthropic 即将推出的 Claude 模型将融合传统的 LLM 与推理 AI,允许开发者通过 滑动刻度 微调推理水平,在多个基准测试中可能超越 OpenAI 的 o3-mini-high。
- 这代表了专为编程任务设计的模型训练和运行能力的转变。
- DeepHermes-3 深度思考,但成本更高:Nous Research 推出了 DeepHermes-3,这是一款集成了推理与语言处理的 LLM,可以切换长思维链(Chain of Thought)以提高准确性,但代价是更高的计算需求,正如 Nous Research 的公告所述。
- 评估指标以及与 Tulu 模型的比较引发了关于基准测试分数差异的辩论,特别是遗漏了与官方 8b distill release 的对比,后者拥有更高的分数(GPQA 约为 36-37%,而 r1-distill 约为 49%)。
- EnigmaEval 的谜题难倒了 AI:Dan Hendrycks 发布了 EnigmaEval,这是一套复杂的推理挑战,AI 系统在其中表现挣扎,在普通谜题上得分低于 10%,在 MIT 级别的挑战上得分为 0%,详见 Hendrycks 的推文。
- 该评估旨在突破 AI 推理能力的极限。
- OpenAI 释放 AGI 策略转变信号:Sam Altman 暗示 OpenAI 目前的 Scaling Up 策略将不再足以实现 AGI,并建议在计划发布 GPT-4.5 和 GPT-5 时进行转型;OpenAI 将整合其系统以提供更无缝的体验。
- 他们还将解决社区对模型选择步骤的不满。
Eleuther Discord
- 关于 PPO-Clip 效用的辩论出现:成员们重新讨论了将 PPO-Clip 应用于不同模型以生成 Rollouts 的方法,呼应了过去对话中的类似想法。
- 一位成员根据之前的尝试,对这种方法的有效性表示怀疑。
- Forgetting Transformer 性能调优:围绕 Forgetting Transformer 展开了讨论,特别是将激活函数从 sigmoid 更改为 tanh 是否能对性能产生积极影响。
- 对话还涉及引入负注意力权重,强调了注意力机制中潜在的复杂性。
- Delphi 的引用变得更加容易:成员们建议将来自论文和 GitHub 页面 的 Delphi 引用结合起来,以实现全面的归因。
- 还有人建议在引用常见论文时使用 arXiv 自动生成的 BibTeX 条目,以实现标准化。
- 深入探讨长上下文模型的挑战:成员们强调了对当前长上下文模型基准测试(如 HashHop)以及解决 1-NN 的迭代性质相关挑战的担忧。
- 针对这些长上下文模型所宣称的理论可行性提出了质疑。
Stability.ai (Stable Diffusion) Discord
- Stable Diffusion 用户未能保存进度:一位用户报告称,由于在 Stable Diffusion 中未启用自动保存功能,导致生成的图像丢失,随后询问了图像恢复选项。
- 该问题的解决方案涉及调试其使用的 Web UI 版本,以确定适当的保存设置。
- Linux 系统导致 ComfyUI 用户出现 OOM 错误:一位从 Windows 切换到 Pop Linux 的用户在 ComfyUI 中遇到了显存溢出 (OOM) 错误,尽管此前在 Windows 上运行正常。
- 社区讨论了确认系统更新和推荐驱动程序的问题,并强调了不同操作系统之间依赖项的差异。
- 角色一致性挑战困扰 AI 模型:一位用户在跨模型保持一致的角色设计方面遇到困难,引发了使用 Loras 以及 FaceTools 和 Reactor 等工具的建议。
- 建议强调了应选择为特定任务设计的模型。
- Stability 的创意放大器 (Creative Upscaler) 仍未发布:用户询问了 Stability 创意放大器 的发布状态,并断言该工具尚未发布。
- 讨论内容包括模型能力对内存和性能等硬件要求的限制。
- 账号共享受到质疑:一位用户请求为即将开展的项目借用美国的 Upwork 账号,这引发了质疑。
- 成员们对“借用”账号的可行性和潜在影响表示担忧。
Latent Space Discord
- OpenAI 通过 GPT-4.5/5 统一模型:根据其 路线图更新,OpenAI 正在通过在即将发布的 GPT-4.5 和 GPT-5 中整合 O 系列模型和工具来简化其产品线。
- 此举旨在通过更紧密地集成所有工具和功能,为开发者和用户简化 AI 体验。
- Anthropic 紧随其后推出推理 AI:根据 Stephanie Palazzolo 的推文,Anthropic 计划很快推出一款新的 Claude 模型,该模型结合了传统 LLM 能力与推理 AI,并可通过基于 Token 的滑动标尺进行控制。
- 这呼应了 OpenAI 的做法,标志着将高级推理直接整合到 AI 模型中的行业趋势。
- DeepHermes 3 推理 LLM 预览版发布:Nous Research 发布了 DeepHermes 3 的预览版,这是一款将推理能力与传统响应功能相结合的 LLM,旨在提升性能,详情见 HuggingFace。
- 新模型寻求提供更高的准确性和功能性,作为 LLM 发展的一大进步。
- Meta 使用 LLM 驱动的工具强化合规性:Meta 推出了其自动化合规强化 (ACH) 工具,该工具利用基于 LLM 的测试生成技术,通过创建未检测到的故障进行测试,从而增强软件安全性,详见 Meta 工程博客。
- 该工具旨在通过自动生成针对代码中特定故障条件的单元测试,来增强隐私合规性。
Yannick Kilcher Discord
- Hugging Face 发布 Smolagents:Hugging Face 推出了 smolagents,这是一个替代
deep research的 Agent 框架,6 个步骤的处理时间约为 13 秒。- 用户可以修改原始代码,以便在本地服务器运行时延长执行时间,从而提供适应性。
- Musk 声称 Grok 3 超越对手:Elon Musk 宣布他的新 AI 聊天机器人 Grok 3 即将发布,并且在推理能力上超越了现有模型,预计在大约两周内推出。
- 此前,Musk 的投资集团在与 OpenAI 持续的法律纠纷中,出价 974 亿美元收购其非营利资产。
- Thomson Reuters 赢得里程碑式 AI 版权案:Thomson Reuters 在针对 Ross Intelligence 的重大 AI 版权案中获胜,法院判定该公司通过复制 Westlaw 的材料侵犯了其版权。
- 美国巡回法院法官 Stephanos Bibas 驳回了 Ross 的所有辩护,称其没有一个能站得住脚。
- 强化学习(Reinforcement Learning)的创新方法:讨论中出现了一种在新的 Reinforcement Learning 模型中使用 logits 作为中间表示的方法,强调了为了有效采样而延迟 Normalization 的重要性。
- 该提案包括用 Energy-based methods 取代 softmax,并整合多目标训练范式,以实现更有效的模型性能。
- 新工具加速文献综述:一位成员介绍了一个用于快速文献综述的新工具,可在 Deep-Research-Arxiv 获取,强调了其简单性和可靠性。
- 此外,还提到了一个 Hugging Face 应用,该应用旨在实现快速高效的文献综述。
LlamaIndex Discord
- LlamaIndex 招聘开源工程师:LlamaIndex 正在招聘一名全职开源工程师以增强其框架,欢迎对开源、Python 和 AI 充满热情的人士加入,详见其职位公告。
- 该职位提供了为 LlamaIndex 框架开发尖端功能的机会。
- Nomic AI Embedding 模型助力 Agentic 工作流:LlamaIndex 重点介绍了 Nomic AI 的最新研究,强调了 Embedding 模型在改进 Agentic Document Workflows 中的作用,并在推文中进行了分享。
- 社区期待该 Embedding 模型能带来更好的 AI 工作流集成。
- LlamaIndex 与 Google Cloud:LlamaIndex 推出了与 Google Cloud 数据库的集成,方便进行数据存储、Vector 管理、文档处理和聊天功能,详见此帖。
- 这些增强功能旨在利用云端能力,简化并保障数据访问的安全性。
- 微调(Fine Tuning)LLM 的讨论:一位成员在 #ai-discussion 频道询问了关于对模型进行 Finetune 的合理理由。
- 频道内没有提供更多额外信息来回答这个问题。
Notebook LM Discord
- NotebookLM 创造了令人欲罢不能的 AI 播客:用户们称赞 NotebookLM 能够快速将文字内容转化为播客,并强调了其在 Spotify 和 Substack 等平台上进行内容营销的潜力。
- 爱好者们认为播客是一种内容营销工具,突出了其巨大的潜在受众覆盖范围和创作的便捷性。
- 通过 AI 播客开辟新收入渠道:用户正在探索利用 AI 创作播客来产生收入,通过运行一个两人制 AI 播客,在专注于快速创作内容的同时,每月可赚取约 $7,850。
- 他们声称,利用 Substack 等工具,AI 驱动的播客创作可以带来 300% 的自然触达率和内容消耗增长。
- AI 生成的播客主持人库引发关注:社区成员讨论了创建一个 AI 生成的播客主持人库的潜力,展示多样化的主题和内容风格。
- 爱好者们对协作和分享独特的 AI 生成音频体验感到兴奋,以增强社区参与度。
- 社区期待 NotebookLM 的多语言支持:用户渴望 NotebookLM 能将其功能扩展到英语以外的其他语言,这凸显了全球范围内对易用的 AI 工具日益增长的兴趣。
- 尽管可以调整语言设置,但音频功能目前仍仅限于英语输出,这引起了社区成员的沮丧。
- 探索 NotebookLM Plus 的功能与优势:据一位成员介绍,NotebookLM Plus 提供了诸如交互式播客等对学生有益的功能,而这些功能在免费版中可能无法使用。
- 另一位用户建议转向 Google AI Premium 以获取捆绑功能,这引发了关于 “Google NotebookLM 真的很棒……” 的讨论。
Modular (Mojo 🔥) Discord
- Modular 发布新职位空缺:一位成员分享了 Modular 发布了新的职位招聘。
- 这一消息引起了在 Mojo 生态系统中寻找机会的成员们的兴奋。
- Mojo 和类型(Sum Types)引发辩论:成员们将 Mojo 的和类型与 Rust-like 的和类型以及 C-style 的枚举进行了对比,指出
Variant解决了许多需求,但参数化 Trait(parameterized traits)具有更高的优先级。- 一位用户使用 variant 模块实现的“权宜之计”的联合类型(hacky union type)凸显了当前 Mojo 实现的局限性。
- Mojo 语境下的 ECS 定义得到澄清:一位成员澄清了 Mojo 语境下 ECS 的定义,指出状态应该与行为分离,类似于 Unity3D 中的 MonoBehavior 模式。
- 社区成员一致认为,一个遵循 ECS 原理的示例中,状态驻留在组件(components)中,而行为驻留在系统(systems)中。
- 使用 Unsafe Pointers 进行函数包装:关于在 Mojo 的结构体中存储和管理函数的讨论引出了一个使用
OpaquePointer安全处理函数引用的示例。- 交流中包含了完整的示例,并承认了在使用
UnsafePointer时管理生命周期和内存的复杂性。
- 交流中包含了完整的示例,并承认了在使用
- MAX 最小化了 CUDA 依赖:MAX 仅在内存分配等核心功能上依赖 CUDA driver,从而最小化了对 CUDA 的依赖。
- 一位成员指出,MAX 在使用 GPU(尤其是 NVIDIA 硬件)时采取了精简的方法,以实现最佳性能。
MCP (Glama) Discord
- MCP 客户端 Bug 困扰用户:成员们分享了使用 MCP 客户端的经验,重点推荐了 wong2/mcp-cli 的开箱即用功能,同时指出 客户端 Bug 频出是一个普遍现象。
- 开发者们讨论了尝试绕过现有工具限制的方法。
- OpenAI 模型进入 MCP 领域:新用户对 MCP 的功能表示兴奋,并询问 Claude 之外的模型是否会支持 MCP。
- 有人指出,虽然 MCP 与 OpenAI 模型兼容,但像 Open WebUI 这样的项目可能不会优先考虑它。
- Claude Desktop 用户遭遇使用限制:用户反映 Claude Desktop 的使用限制非常麻烦,并建议 Glama 的服务可以作为一种变通方案。
- 一位成员强调了这些限制如何影响他们的使用场景,并指出 Glama 提供了更便宜、更快速的替代方案。
- Glama Gateway 挑战 OpenRouter:成员们将 Glama 的 Gateway 与 OpenRouter 进行了对比,指出 Glama 的成本更低且有隐私保证。
- 虽然 Glama 支持的模型较少,但因其快速和可靠而受到称赞,使其成为某些应用的稳健选择。
- Open WebUI 引起关注:多位用户对 Open WebUI 表示好奇,提到了其丰富的功能集以及最近关于 MCP 支持的路线图更新。
- 成员们对其易用性给出了正面评价,并希望能够完全从 Claude Desktop 迁移出来。
tinygrad (George Hotz) Discord
- DeepSeek-R1 自动化 GPU Kernel 生成:一篇博文强调了 DeepSeek-R1 模型 在改进 GPU Kernel 生成方面的应用,通过使用 Test-time Scaling 在推理期间分配更多计算资源来提升模型性能,链接见 NVIDIA 技术博客。
- 文章指出,AI 可以通过在选择最佳方案前评估多种结果来有效地制定策略,这模仿了人类解决问题的过程。
- Tinygrad Graph Rewrite Bug 令成员沮丧:成员们调查了由于一个潜在 Bug 导致的 CI 失败,该 Bug 中错误的缩进导致
bottom_up_rewrite从RewriteContext中被移除。- 还考虑了 Graph 处理中更深层次的问题,例如错误的重写规则或顺序。
- Windows CI Backend 变量传递修复:一位成员注意到 Windows CI 未能在步骤之间传递 Backend 环境变量,并提交了一个 GitHub Pull Request 来解决此问题。
- 该 PR 通过在 CI 执行期间利用
$GITHUB_ENV来确保 Backend 变量持久化。
- 该 PR 通过在 CI 执行期间利用
- Tinygrad 承诺比 PyTorch 更高的性能收益:用户讨论了从 PyTorch 切换到 tinygrad 的利弊,考虑学习曲线是否值得,特别是在成本效率或掌握底层原理方面。
- 与 PyTorch 相比,使用 tinygrad 最终可能会带来更便宜的硬件支持或更快的模型,提供优化和资源管理方面的优势。
- 社区警告不要提交 AI 生成的代码:成员们强调在提交前要检查代码 Diff,指出微小的空格变化可能导致 PR 被关闭,并敦促不要直接提交由 AI 生成的代码。
- 社区建议使用 AI 进行头脑风暴和反馈,尊重成员的时间,并鼓励原创贡献。
LLM Agents (Berkeley MOOC) Discord
- LLM Agents Hackathon 获胜者公布:根据 Dawn Song 的推文,LLM Agents MOOC Hackathon 公布了来自 127 个国家的 3,000 名参与者中的获胜团队,彰显了全球 AI 社区的极高参与度。
- 顶尖代表机构包括 UC Berkeley、UIUC、Stanford、Amazon、Microsoft 和 Samsung,完整的提交作品可在 Hackathon 网站上查看。
- 2025 春季 MOOC 正式启动:2025 春季 MOOC 正式开课,面向更广泛的 AI 社区,并邀请大家转发 Dawn Song 教授的公告。该课程基于 2024 秋季课程的成功经验,当时有超过 1.5 万名注册学员。
- 更新后的课程涵盖了 Reasoning & Planning、Multimodal Agents 以及 AI for Mathematics and Theorem Proving 等高级主题,并邀请所有人参加每周一太平洋时间下午 4:10 的直播课程。
- MOOC 证书发放问题:多位用户反映未收到之前课程的证书,一名学生请求重发,另一名学生需要帮助查找,但处理可能需要等到周末。
- Tara 指出 Ninja Certification 没有正式评分,并建议在指定频道中针对其他学生的提交内容测试 Prompt。此外,处理证书需要提交 declaration form(声明表单)。
- 新 AI/ML 入门者寻求指导:一位新成员表达了希望在 AI/ML 领域入门以及了解模型训练技术的意愿,但频道内尚未提供相关指导。
Torchtune Discord
- Torchtune 支持分布式推理:用户现在可以使用 Torchtune 在多个 GPU 上运行分布式推理,实现细节请查看 GitHub recipe。
- 使用带有 vLLM 的保存模型可获得额外的速度提升。
- Torchtune 仍缺少 Docker 镜像:目前 Torchtune 尚无可用的 Docker 镜像,这导致部分用户安装困难。
- 唯一的安装方式是参考 GitHub 上的安装指南。
- Checkpointing 分支通过测试:新的 checkpointing 分支已成功克隆,且在初步测试中表现良好。
- 计划进一步测试 recipe_state.pt 功能,并可能更新关于恢复训练的文档。
- 团队积极协作处理 Checkpointing PR:团队成员对 checkpointing PR 表现出极大的热情和积极的协作态度。
- 这突显了团队对于改进 Checkpointing 流程的共同承诺。
DSPy Discord
- NVIDIA 利用 DeepSeek-R1 扩展推理:NVIDIA 的实验展示了利用 DeepSeek-R1 模型进行“推理时扩展”(inference-time scaling)以优化 GPU attention kernels,通过评估多种结果来实现更好的问题解决能力,详见其 博客文章。
- 这种技术在推理期间分配额外的计算资源,模拟了人类解决问题的策略。
- LangChain 与 DSPy 的选择权衡:关于何时选择 LangChain 而非 DSPy 的讨论强调两者用途不同。一位成员建议,如果 DSPy 的学习曲线太陡峭,应优先考虑成熟的 LangChain 方法。
- 对话强调了根据项目需求评估采用新框架复杂性的重要性。
- DSPy 2.6 更新日志揭晓:一位用户询问了 DSPy 2.6 的更新日志,特别是关于 Signatures 的 instructions 与旧版本相比的有效性。
- 澄清显示这些指令自 2022 年起就已存在,详细的更新日志可在 GitHub 上查看,尽管未提供具体链接。
Nomic.ai (GPT4All) Discord
- GPT4All 接入 Deepseek R1:GPT4All v3.9.0 允许用户在本地下载并运行 Deepseek R1,重点在于离线功能。
- 然而,在本地运行全量模型非常困难,目前似乎仅限于 13B 参数模型等较小变体,其性能表现不如全量版本。
- LocalDocs 困扰用户:有用户报告 LocalDocs 功能较为基础,处理 TXT 文档时提供准确结果的概率仅约 50%。
- 用户怀疑这些限制是由于使用了 Meta-Llama-3-8b instruct 模型或设置不当造成的。
- NOIMC v2 等待实现:尽管已确认发布,但成员们对 NOIMC v2 模型尚未得到妥善实现感到困惑。
- 分享了 nomic-embed-text-v2-moe 模型 的链接,强调了其多语言性能和能力。
- 多语言 Embeddings 支持 100 种语言:nomic-embed-text-v2-moe 模型支持约 100 种语言,相对于同等规模的模型具有高性能,且具备灵活的 Embedding 维度,并完全开源。
- 分享了其 代码。
- 社区寻求将 Prompt 转换为代码的工具:一位用户正在寻求关于将 英语 Prompt 转换为可用代码的工具建议。
- 需要具体的建议。
Cohere Discord
- Cohere 混乱的评分:一位用户发现 Rerank 3.5 在不同批次处理文档时会给出不同的评分,这超出了他们的预期,因为它是 cross-encoder。
- 这种评分的可变性被描述为“反直觉的”。
- Cohere 在 Salesforce 的 BYOLLM 中遇到困难:一位成员询问如何将 Cohere 作为 LLM 与 Salesforce 的 BYOLLM 开放连接器配合使用,并提到了 api.cohere.ai 聊天端点的问题。
- 他们正尝试按照 Salesforce 支持人员的建议,创建一个 https REST 服务来调用 Cohere 的聊天 API。
MLOps @Chipro Discord 没有新消息。如果该服务器长时间保持沉默,请告知我们,我们将将其移除。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该服务器长时间保持沉默,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该服务器长时间保持沉默,请告知我们,我们将将其移除。
第 2 部分:频道详细摘要与链接
完整的频道细分内容已为邮件格式进行删减。
如果您喜欢 AInews,请分享给朋友!预先感谢!