ainews-the-ultra-scale-playbook-training-llms-on
**超大规模实战手册:在 GPU 集群上训练大语言模型**
Huggingface 发布了《超大规模指南:在 GPU 集群上训练大语言模型》(The Ultra-Scale Playbook: Training LLMs on GPU Clusters),这是一篇基于在多达 512 块 GPU 上进行的 4000 次扩展实验而撰写的交互式博客文章,提供了关于现代 GPU 训练策略的详细见解。DeepSeek 推出了原生稀疏注意力(NSA)模型,引起了社区的极大关注;与此同时,Perplexity AI 推出了 R1-1776,这是 DeepSeek R1 模型的一个无审查且无偏见的版本。Google DeepMind 发布了 PaliGemma 2 Mix,这是一款多任务视觉语言模型,提供 3B、10B 和 28B 三种尺寸。微软(Microsoft)推出了 Muse,这是一款基于游戏《嗜血边缘》(Bleeding Edge)训练的生成式 AI 模型,并展示了 Magma,这是一款在 UI 导航和机器人操控方面表现出色的多模态 AI 智能体基础模型。Baichuan-M1-14B 作为一款基于 20 万亿(20T)token 训练的顶尖医疗大模型正式亮相,同时发布的还有一款采用 StripedHyena 2 架构的完全开源 40B 基因组建模模型。针对 Muse,文中指出:“创造属于你自己的游戏体验,这一天的到来将比你想象的更快。”
读完这些仅需 2 天。
2025/2/18-2025/2/19 的 AI 新闻。我们为你检查了 7 个 subreddits、433 个 Twitter 账号 和 29 个 Discord(211 个频道,6631 条消息)。预计节省阅读时间(按 200wpm 计算):700 分钟。你现在可以标记 @smol_ai 进行 AINews 讨论!
似乎是为了回应 DeepMind 的《如何扩展你的模型》,Huggingface 突然发布了一个重量级的 GPU 版“博客文章”:The Ultra-Scale Playbook: Training LLMs on GPU Clusters。
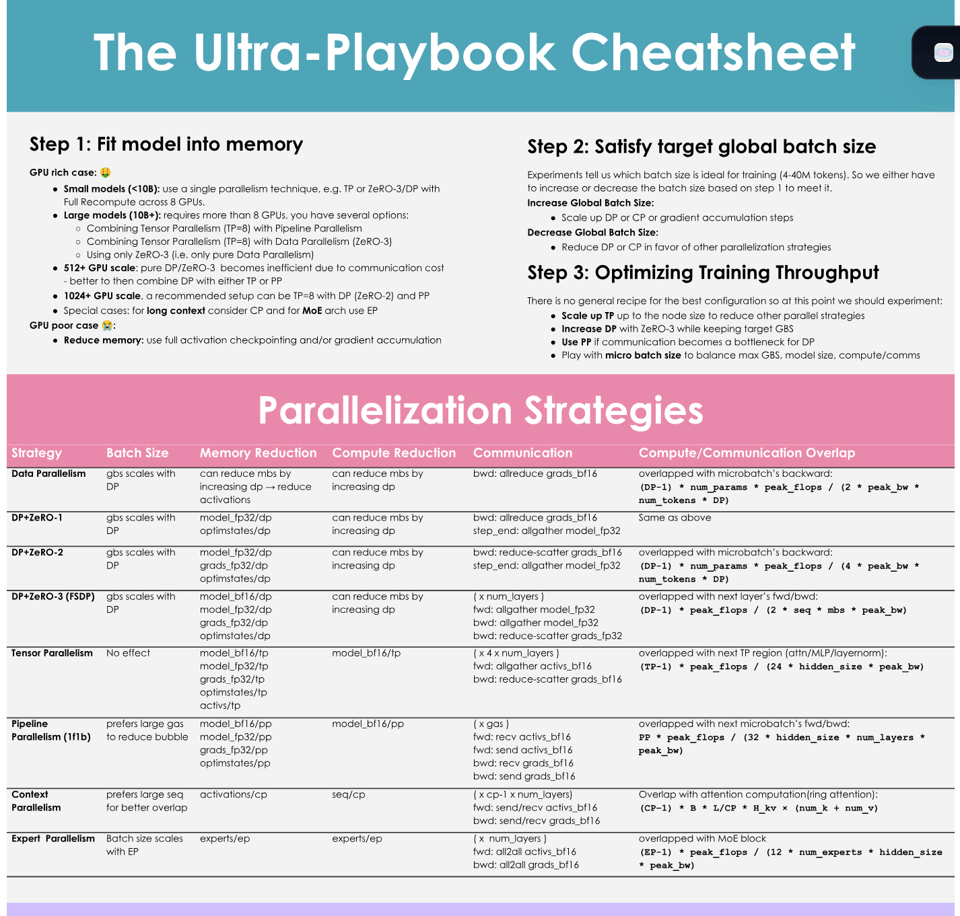
对于想要直观、详细地了解现代训练限制以及在 GPU 上进行规模扩展策略的人来说,这是一个极佳的起点,它从第一性原理出发构建了现代最佳实践:
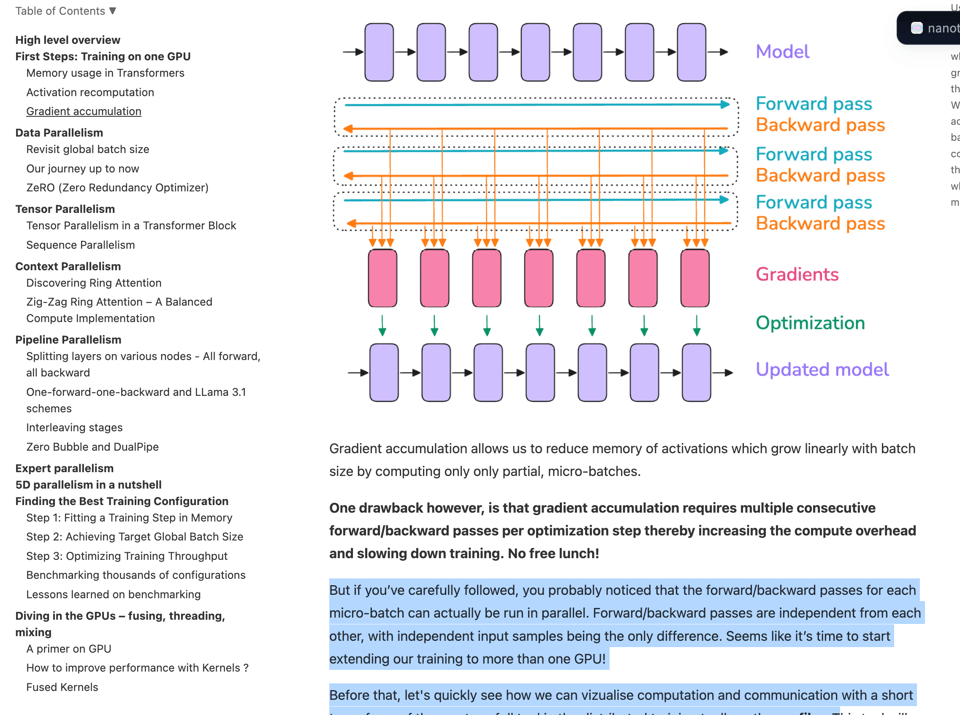
更不用说这篇博文是交互式的,基于 4000 次扩展实验的真实数据,最高支持 512 个 GPU。
虽然对 AI Engineer 来说不是严格要求的,但对于任何想要快速掌握训练术语的人来说,这都是一个绝佳的起点。
AI Twitter 摘要
AI 模型与发布
- DeepSeek 的 Native Sparse Attention (NSA) 模型引起了广泛关注。@eliebakouch 分享了关于它的更多细节,并向包括 @Nouamanetazi、@lvwerra 和 @Thom_Wolf 在内的团队表示祝贺。@ProfTomYeh 提到他将在直播研讨会中手绘 DeepSeek 的 Native Sparse Attention,并分享了一张草图,随后宣布他将在 Alex Wang 主持的另一场研讨会中通过画圆和线来解释 DeepSeek 论文。@hkproj 指出 DeepSeek 发布论文让整个 ML 社区都为之瞩目,凸显了其软实力。@qtnx_ 提到 command r 7b 是他们最喜欢的 Transformer 实现。
- Perplexity AI 发布了 R1-1776,这是 DeepSeek R1 模型的一个无审查、无偏见且基于事实的版本,由 @AravSrinivas 宣布,他预告本周和下周还会有更多酷炫的发布。@_akhaliq 也强调了这次发布,将其描述为经过后训练以移除中国共产党审查的版本。
- Google DeepMind 发布了 PaliGemma 2 Mix,这是一个开放的多任务视觉语言模型,能够执行服装评判和物体计数等任务,由 @_philschmid 宣布。@mervenoyann 进一步详细介绍了 PaliGemma 2 Mix,强调了它在开放式提示词、文档理解以及分割/检测等视觉语言任务中的多功能性,提供 3B、10B 和 28B 三种尺寸。
- Microsoft 推出了 Muse,这是一个在 Ninja Theory 的游戏《Bleeding Edge》上训练的生成式 AI 模型,并发布了模型权重和代码,由 @reach_vb 分享,他表示这预示着制作属于你自己的游戏体验将比你想象的更早到来。
- Baichuan-M1,一个开源的 SotA 医疗 LLM (Baichuan-M1-14B),在 20T tokens 上从头开始训练,专注于医疗能力,由 @arankomatsuzaki 宣布。
- @maximelabonne 宣布了一个完全开源的 40B 模型,用于跨生命所有领域的基因组建模和设计,采用了新的 StripedHyena 2 架构。
研究与论文
- Microsoft 发布了 Magma,这是一个用于多模态 AI Agent 的基础模型,在 UI 导航和机器人操作任务上达到了 SotA。该模型在标注有 Set-of-Mark (SoM) 和 Trace-of-Mark (ToM) 的大规模数据集上进行了预训练,正如 @arankomatsuzaki 和 @_akhaliq 所强调的。
- Meta 发布了 NaturalReasoning,这是一个包含 280 万个挑战性问题的野外推理(Reasoning in the Wild)数据集,由 @arankomatsuzaki 分享。@jaseweston 详细介绍了 NaturalReasoning 的发布,强调其 280 万个具有挑战性且多样化的问题需要多步推理,展示了更陡峭的数据缩放曲线(data scaling curves)以及自我训练(self-training)的潜力。
- DeepMind 发布了 PaliGemma 2 Checkpoints,专为 OCR(光学字符识别)和字幕生成(Captioning)等任务量身定制,模型尺寸从 3B 到 28B 不等,全部为开放权重并兼容 Transformers,正如 @reach_vb 所提到的。
- Hugging Face 发布了《在 GPU 集群上训练 LLM 的超大规模指南》(Ultra Scale Playbook for Training LLMs on GPU Clusters),这是一本免费的开源书籍,涵盖了 5D 并行、ZeRO、快速 CUDA 内核以及计算与通信重叠等内容,基于为期 6 个月的缩放实验,由 @reach_vb 宣布。
- “Cramming 1568 Tokens into a Single Vector and Back Again: Exploring the Limits of Embedding Space Capacity” 是 @arankomatsuzaki 强调的一篇新论文。
- “Revisiting the Test-Time Scaling of o1-like Models” 论文由 @_akhaliq 分享,该论文质疑这些模型是否真正具备推理时缩放(test-time scaling)能力。
- “ByteDance presents Phantom: Subject-consistent video generation via cross-modal alignment” 论文由 @_akhaliq 分享。
- “Sailor2: Sailing in South-East Asia with Inclusive Multilingual LLMs” 论文由 @_akhaliq 提及。
- “Learning to Reason at the Frontier of Learnability” 论文由 @iScienceLuvr 强调,重点关注 LLM 中的课程学习(curriculum learning),并在强化学习(RL)中使用采样来提高可学习性。
- “Is Noise Conditioning Necessary for Denoising Generative Models?” 论文由 @iScienceLuvr 分享,探讨了无需噪声调节(noise conditioning)的去噪生成模型,发现其性能下降平缓,有时甚至表现更好。
工具与库
- LangChain 宣布了 LangGraph Studio 的 Playground 集成,用于更快的 Prompt 迭代,允许用户直接查看 LLM 调用并在不重新运行整个 Graph 的情况下迭代 Prompt,根据 @LangChainAI 的消息。他们还推出了 Langchain MCP Adapters,使 LangGraph Agent 能够即时连接到 MCP 生态系统中的数百个工具,以及用于引导 LangGraph.js Agent 模板的
npm create langgraph。 - Modular 发布了 MAX 25.1,这是一个重要的版本,支持新的 Agentic 工作流、Mojo 中的 GPU 自定义算子(custom ops)以及一个新的开发者内容门户,由 @clattner_llvm 宣布。
- Together AI 宣布了 NVIDIA Blackwell GPU 的试用计划,通过 Together GPU Clusters 为 8 个 AI 团队提供免费访问权限,以优化模型并加速训练,根据 @togethercompute 的消息。他们还强调了 Scaled Cognition 在 Together GPU Clusters 上训练 APT-1。
- LM Studio 现在支持投机采样(speculative decoding),由 @cognitivecompai 宣布。
- LlamaCloud EU 是一项安全、合规的知识管理 SaaS 服务,确保数据完全驻留在欧盟境内,由 @llama_index 宣布。
- 根据 @_akhaliq 的说法,Gradio 被强调为当今构建大多数 AI 应用的首选工具。
行业新闻与活动
- 4月29日是首届 LlamaCon 的举办日期,而 Meta Connect 定于9月17-18日举行,正如 @AIatMeta 所宣布的那样。
- LangChain 正在举办系列活动,包括2月19日在纽约举行的晚间见面会,以及2月27日在亚特兰大举行的 AI 活动,消息来自 @LangChainAI 和 @LangChainAI。@hwchase17 也提到他将在亚特兰大。
- 纽约 AI Engineer Summit 正在进行中,@HamelHusain 提到他正为此身处纽约。
AI Agents 与应用
- 评估 AI Agents 是 DeepLearningAI 与 Arize AI 合作推出的新短课重点,由 @JohnGilhuly 和 @_amankhan 授课,涵盖了 AI Agent 性能的系统性评估与改进,由 @AndrewYNg 和 @DeepLearningAI 宣布。
- AI co-scientist 是一个由 Google 使用 Gemini 2.0 构建的多 Agent AI 系统,旨在加速科学突破。@omarsar0 在详细的推文中介绍了其功能,如生成新颖假设、表现优于其他 SoTA 模型以及利用 test-time compute。
- Weights & Biases 举办了 Multimodal AI Agents Hackathon,吸引了超过 200 名创新者和 40 支团队参加,展示了在构建 AI Agents 过程中的创意与迭代,由 @weights_biases 提及。
- Microsoft 刚刚发布了 MUSE —— 一个在 Ninja Theory 的多人对战游戏《Bleeding Edge》上训练的生成式 AI 模型,用于游戏玩法,据 @reach_vb 报道。
- 能从游戏过程中学习并生成视觉效果的 AI 被 @yusuf_i_mehdi 强调为游戏领域的新篇章。
量子计算突破
- Microsoft 的量子团队因一项突破受到 @stevenheidel 的祝贺,@yusuf_i_mehdi 宣布这是朝着让量子计算成为现实迈出的重大一步,释放了解决当今计算机无法处理的问题的能力,可能重塑行业并加速科学发现。@cognitivecompai 向 @satyanadella 询问 topological superconductor(拓扑超导体)是否真的是一种新的物质状态。@jeremyphoward 也对该新闻做出了反应,引用道“我们创造了一种全新的物质状态”。
梗与幽默
- @nearcyan 表示,每一个购买了 700 美元 AI pin 的人都被彻底坑了(rugged),该观点获得了大量关注。
AI Reddit 热帖回顾
/r/LocalLlama 回顾
主题 1. o3-mini 取代 DeepSeek 成为今年 LLaMA 的领跑者
- o3-mini 赢得了投票!伙计们,我们做到了! (得分: 1688, 评论: 186): o3-mini 在一项 Twitter 投票中以 54% 的得票率(共 128,108 票)击败了“手机大小模型”选项。Ahmad 的回复暗示该投票具有误导性,并鼓励为“o3-mini”投票,突显了社区通过点赞、引用和转发进行的积极参与。
- 模型蒸馏(Model Distillation)讨论:用户讨论了蒸馏模型的过程,即通过训练一个紧凑模型(学生)来模仿大型模型(教师),从而创建一个更小、更快的版本。虽然使用了知识蒸馏、剪枝(pruning)和量化(quantization)等技术,但 OpenAI 的闭源性质限制了直接从其模型进行蒸馏。
- 对模型发布的怀疑:对于 OpenAI 是否会发布开源模型存在怀疑,因为从历史上看,他们已经远离了开源模式。用户对“o3-mini 级别”等术语保持警惕,认为它可能达不到预期,或者是一个显著降级的版本。
- 社区反应与讽刺:社区对 Twitter 投票结果和可能发布的“手机大小”模型反应不一。评论强调了对这类模型实际效用和性能的讽刺与怀疑,一些用户幽默地指出,发布会可能会令人大失所望。
{kind=link}
主题 2. 配备 128 GB 统一内存的 AMD 笔记本挑战 Apple 的主导地位
- 配备 AMD 芯片的新款笔记本拥有 128 GB 统一内存(其中高达 96 GB 可分配为 VRAM) (评分: 482, 评论: 157): 新款 AMD 笔记本现在配备 128 GB 统一内存,允许将高达 96 GB 分配为 VRAM。
- 讨论强调了配备 128 GB 统一内存的新款 AMD 笔记本的性能和通用性。像 JustJosh 和 Dave2D 这样的测评者赞扬了它们运行 LLMs 和 Linux 的能力,挑战了 Mac 在处理大模型的统一内存方面的统治地位。b3081a 提到通过特定配置运行 vLLM 以在这些设备上实现性能优化。
- 与 Apple 设备的价格和对比是重要的讨论点。Asus 128GB 版本售价为 $2799,比同级别的 Apple 设备($4700)更便宜。用户对价值和性能差异进行了辩论,一些人指出其相对于 RTX 5090 等高端 GPU 可能具有成本优势。
- 讨论还涉及对 Linux 支持和潜在桌面应用的兴趣。Kernel 6.14 预计将为这些设备中的 NPUs 带来完整的 Linux 支持,用户对搭载这些芯片的 Mini PCs 和 Framework 13 主板表示出兴趣,讨论了在各种配置中共享 RAM 和统一内存的好处。
主题 3. Gemini 2.0 卓越的带说话人标签的音频转录功能
- Gemini 2.0 在带有说话人标签、精确到秒的时间戳的音频转录方面表现惊人; (评分: 387, 评论: 90): Gemini 2.0 在音频转录方面表现出色,具有精确的说话人标签和精确到秒的时间戳,正如 Matt Stanbrell 在 Twitter 上所强调的那样。该工具识别各种声音并提供详细转录的能力,鼓励用户上传音频文件以进行增强的摘要和说话人识别。
- Gemini 2.0 的转录能力在越南语准确度(包括声调)方面受到称赞,用户发现它在语言学习方面非常可靠,如 Mescallan 所述。然而,来自一家 ASR 公司的 leeharris100 批评了其时间戳准确性,并提到它在长上下文下会产生幻觉,尽管它在通用 WER(词错率)方面与 Whisper medium 等模型相比仍具竞争力。
- 存在一种共识,即 Google 的 Gemini 模型不是开源的,这阻碍了像 Whisper 那样的本地使用,正如 CleanThroughMyJorts 所强调的。nrkishere 和 silenceimpaired 对其本地运行能力和开源潜力表示怀疑。
- Gemini 2.0 因其物体识别和图表理解能力而受到关注,像 Kathane37 这样的用户对其性能印象深刻。space_iio 将其有效性归功于 Google 能够访问 YouTube 视频和元数据,从而增强了其超越典型抓取方法的训练数据。
{kind=link}
主题 4. Unsloth 发布具有高准确度的 R1-1776 动态 GGUF
- Unsloth 发布的 R1-1776 动态 GGUF (评分: 132, 评论: 53): Unsloth 发布了从 2-bit 到 16-bit 的 R1-1776 GGUFs,包括 动态 2-bit、3-bit 和 4-bit 版本,其中 动态 4-bit 比 medium 版本更小但更准确。这些模型可在 Hugging Face 上获取,需要特定的 token 格式,并在模型卡片中提供了说明,更多见解可在其 博客 中找到。
- 资源需求:运行 R1-1776 GGUFs 并不一定需要 VRAM,但为了获得最佳性能,建议至少拥有 120GB 的 VRAM + RAM。动态 2-bit 版本需要 211GB 的磁盘空间,并提供了特定的格式指南以增强模型输出。
- 模型性能和基准测试:R1 模型的动态量化 (Dynamic quants) 在提交给 Hugging Face 排行榜的基准测试中显示出优于或等同于原始 16-bit 模型的性能。然而,用户指出除了 Flappy Bird 测试之外,还需要更全面的基准测试来全面评估性能。
- 未来发展和发布:即将发布的版本将专注于长上下文和超过 10,000 名用户请求的其他功能,这表明了强烈的社区参与度。此外,还有支持蒸馏到更小模型的计划,以及针对 V3 和 V2.5-1210 版本的潜在更新,以提高可访问性和性能。
其他 AI 子版块回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding
主题 1. DeepSeek GPU 走私调查:揭示 Nvidia 新加坡营收异常
- DeepSeek GPU 走私调查显示 Nvidia 在新加坡的 GPU 销售额占其营收的 28%,但仅有 1% 交付至该国:报告 (Score: 286, Comments: 90): DeepSeek 的调查显示,Nvidia 在新加坡的 GPU 销售额占其总营收的 28%,然而实际上只有 1% 的 GPU 交付到了该国。这种差异暗示了可能存在 GPU 走私活动。
- DeepSeek V3 论文因声称使用 8-bit floating point (FP8) 而受到质疑,如果属实,这将是 AI 模型训练的一个重大转变。讨论显示了对 DeepSeek 说法真实性的怀疑,一些人认为这被媒体过度炒作了。
- 新加坡作为主要贸易港口的角色被重点提及,解释了尽管实际交付量较低,但 Nvidia 归属于该国的营收比例却很高。这与新加坡超过 300% 的贸易占 GDP 比率相符,表明这可能是转口贸易或加工活动,而非直接走私。
- Nvidia 的行为被视为试图规避美国法律,一些评论者指出文章标题具有误导性,并强调了 GPU 的战略重要性。讨论涉及了更广泛的地缘政治影响,包括与中国对战略资产潜在控制的对比。
- 准确 (Score: 286, Comments: 15): 该帖子幽默地将严肃的医疗环境与随意的回答进行了对比,画面中一名正在进行 MRI 扫描的患者询问医生结果,而显示器上显示着 “ChatGPT-4o” 的 Logo。这种并置通过将传统的严肃语境与轻松、非正式的回复相结合,突显了喜剧色调。
- 医疗 AI 辅助:Human-Independent999 建议 AI 在医疗领域的最佳应用是辅助医生,暗示这种集成可能已经在发生。这反映了关于 AI 增强医疗实践潜力的普遍看法。
- 未来科技对比:PerennialPsycho 幽默地将这一场景比作《星际迷航》(Star Trek),医生使用简单的工具进行诊断,突显了 AI 在医疗保健领域的未来主义和简化愿景。
- 对 AI 未来的乐观态度:Potential_Club_9494 对 AI 的未来影响表示乐观,暗示了像 ChatGPT 这样的 AI 可能对各个领域产生的变革性潜力。
- 来自一位 OpenAI 研究员的推文 (Score: 273, Comments: 27): Aidan Clark 发布了一条关于 “Sonnet 4” 的推文并祝贺 “Demis & Team”,截至 2025 年 2 月 19 日,该推文获得了 1.27 万次查看、34 条回复、25 次转发和 239 个赞,引起了广泛关注。
- 关于 “Sonnet 4” 以及 Demis Hassabis 的参与存在困惑和猜测,一些用户质疑 Demis 是因为 DeepMind 的成就受到祝贺,还是因为 Google 对 Anthropic 的投资而产生的一种反讽(trolling)。
- 讨论中热情地提到了 Grok 4.5,暗示对话中可能存在混淆或玩笑,因为 Demis Hassabis 与 DeepMind 相关,而非 Anthropic。
- 几位用户对什么是 “Sonnet 4” 表示困惑,一些人幽默地建议这可能是一个跨宇宙或虚构的概念,表明原始推文缺乏清晰度或可能是在开玩笑。
{kind=link}
{kind=link}
主题 2. Google 的 NotebookLM:AI 研究工具的变革者
- NotebookLM 最被低估的 AI 工具! (Score: 1143, Comments: 104): Google 的 NotebookLM 被强调为一个被低估的 AI 工具,它结合了 ChatGPT, Perplexity 和 Notion AI 的功能,同时提供自动源引用以消除幻觉。它在阅读和总结 PDF、Docs 和笔记方面表现出色,并且比 ChatGPT 更好地记住上传的文件,使其成为处理大量数据的研究人员、学生和专业人士的宝贵工具。
- 用户称赞 NotebookLM 独特的播客功能,该功能允许交互式和可定制的体验,将其比作拥有个人 AI 广播节目。然而,人们对潜在的幻觉(特别是在免费层级)以及 Google 停止该服务的可能性表示担忧。
- 一些用户对 NotebookLM 管理和总结数据的潜力表示兴趣,例如 Excel 表格中的支出,但对其聊天功能和 UI 限制存在批评。该工具因其优于其他工具的源管理和引用能力而受到关注。
- 用户渴望有一个开源、本地的 NotebookLM 替代方案,这反映了对 Google 长期支持该工具的担忧。用户还对定价模型及其与 Google One AI 的集成感到好奇。
- ‘Improved Amateur Snapshot Photo Realism’ v12 [FLUX LoRa] - 修复了过度饱和,略微改善了皮肤,提高了提示词遵循度和图像连贯性(20 张示例图)- 现已推出 Tensor.art 版本! (Score: 239, Comments: 18): ‘Improved Amateur Snapshot Photo Realism’ v12 [FLUX LoRa] 是一个重大更新,解决了过度饱和问题,增强了皮肤纹理,并提高了提示词遵循度和图像连贯性。该更新包括 20 张示例图像,并引入了与 Tensor.art 兼容的版本。
- 图像质量担忧:像 animerobin 这样的用户指出,FLUX LoRa 模型经常受到低分辨率像素模糊的困扰,询问如何获得更清晰的图像。
- 数据集来源:TheManni1000 寻求关于寻找用于训练类似模型的图像数据集的建议,建议包括 Reddit 图像子版块、Instagram、Flickr 以及来自 Hugging Face 和 Kaggle 的数据集。
- 资源链接与术语:AI_Characters 提供了该模型在 CivitAI 和 Tensor.art 上的链接,同时围绕“amateer”一词展开了讨论,该词被认为是“AI 生成的名人”的流行语,对其一致的描述存在一些困惑。
Theme 3. Claude 3.5 Sonnet: AI 编程与一致性的基准
- Claude 推理功能。Anthropic 可能随时发布官方公告.. (Score: 222, Comments: 87): Claude 3.5 Sonnet 界面展示了“相机”、“照片”和“文件”按钮等功能,以及“选择风格”和为 PRO 用户切换“使用扩展思考”的选项。界面暗示了免费计划中的每日消息限制功能和“升级”选项,表明了增强功能的潜力。
- 用户对 Claude 的 API 定价表示沮丧,一位用户指出改写几个段落每次花费 $0.60,导致他们尽管每日消息有限,仍更倾向于使用 Web 版本。每日消息限制是一个主要的痛点,用户感到使用受限。
- 对 Claude 3.5 Sonnet 的更新存在怀疑,一些用户怀疑这仅仅是现有功能(如 MCP servers)的重新品牌化,而不是引入新功能。虽然注意到了增加的推理和潜在的 web search 功能,但用户仍对缺乏实质性改进持批评态度。
- 用户报告称,尽管应用已更新,但某些人的 iOS 或 Android 上仍无法使用新功能,导致对推出的困惑。社区还批评 Anthropic 专注于更新而没有解决消息限制和实际增强等根本问题。
- 到底发生了什么? (Score: 226, Comments: 185): 尽管没有采用 AI 自循环(AI self-looping)等新技术,Claude 3.5 Sonnet 因其与 DeepSeek、O3 和 Grok 3 等模型相比更卓越的代码可靠性和一致性而受到赞誉。作者指出,虽然这些新模型因其新颖的方法而备受关注,但 Claude 3.5 Sonnet 依然无与伦比,尽管它最近没有表现出显著的改进。
- 许多用户认为 Claude 3.5 Sonnet 并非在所有领域都具有优势,因为它在处理编程竞赛题目和架构问题等特定任务时比较吃力,而 O1 和 O3-mini 在这些方面的表现更好。批评者强调,与 ChatGPT 相比,Claude 更高的上下文窗口(200k vs. 32k)可能是导致其性能差异的原因之一 (Reddit 帖子)。
- 一些用户对过分强调 AI 基准测试(Benchmarks)和排行榜表示怀疑,认为它们可能无法准确反映现实世界的可用性和智能。他们认为,仅仅关注基准测试性能可能会削弱 AI 模型的实际效用和用户友好性。
- 人们对未来的发布充满期待,例如 Claude 4.0 和 Opus 4.0,预计它们将超越当前模型;而其他人则指出,对于需要不同智能维度的任务,目前更倾向于使用 Gemini Pro 2.0 以及像 R1 和 O3 这样的推理模型。一些用户提到了即将推出的具有推理能力的混合模型,暗示了 AI 自循环和推理方面的进展。
{kind=link}
主题 4. OpenAI 的 4o 模型:在创意写作和叙事连贯性方面表现出色
- 4o 的创意写作太惊人了! (Score: 135, Comments: 53): 该帖子讨论了 OpenAI 4o 模型 及其在创意写作方面的卓越能力,特别是在科幻和奇幻等类型中。作者强调了该模型在延续系列丛书时保持角色一致性的能力,并指出 Pro 订阅提供的 128k 上下文 可能产生了影响。
- 用户对 OpenAI 4o 模型 保持角色一致性和自然延伸故事的能力印象深刻,尤其是在 128k 上下文 的支持下。然而,一些用户发现该模型有时会默认使用程式化的叙事方式(特别是在恐怖等类型中),并且在编程任务中表现不佳,需要人工干预才能生成准确的代码。
- 该模型最近的更新(包括 1 月底的微调 和 2 月中旬的内容过滤器放宽)被认为增强了其自然语言处理能力。一些用户建议,OpenAI 的推理模型 可能会在底层进行集成以提高性能。
- 使用该模型进行创意写作被认为具有娱乐性和个性化,用户分享了诸如使用叙事技巧来引导故事发展等策略。此外,还有关于模型处理大输出容量能力的讨论,并提到了像 Flash Thinking 这样具有更高 Token 限制的替代方案。
主题 5. SFW Hunyuan Video LoRAs:扩展创意 AI 视频应用
- 我将训练并开源 50 个 SFW Hunyuan Video LoRAs。欢迎提需求! (Score: 144, Comments: 161): 作者计划利用近乎无限的算力训练并开源 50 个 SFW Hunyuan Video LoRAs。他们征集训练创意,承诺将优先考虑点赞数最高的请求和个人偏好。
- 用户对武术打斗场景和浓郁的电影胶片风格表现出浓厚兴趣,并建议探索超广角镜头和不同的武术风格以实现多样化的视觉效果。Wes Anderson 美学和黑色电影(Film Noir)镜头也是独特视觉叙事的热门请求。
- 一些评论者强调了将微调模型推向极限以获得高质量输出的潜力,建议的主题包括 360 度角色转场、VR 和 SBS 3D 视频以及沉浸式实景 GoPro 画面。其他人则建议专注于独特的视频训练,如镜头移动和动作序列,而非静态图像。
- 针对主题内容有一些创意建议,包括 Cyberpunk 2077 和 Blade Runner 2049 等赛博朋克设定、暗黑奇幻风格以及外星人传说。此外,人们还有兴趣捕捉具有细腻情感表达的电影对话瞬间,以及动漫之外的 2D 动画风格。
- Anthropic 即将发布推理模型及其他酷炫功能.. (Score: 218, Comments: 44): Anthropic 准备为 Claude iOS app 发布新功能,重点在于 Thinking Models 和 Web Search 能力。该公告最初由 Twitter 用户 @M1Astra 发布,包含了“Steps”、“Think”和“Magnifying Glass”等功能的新图标,发布日期为 2 月 19 日。
- 用户表达了希望 Claude 解决 rate limits、内存和更长对话问题的愿望,如果这些功能得到改进,一些人会考虑重新订阅。Web search 能力也是一个呼声极高的功能,用于获取最新的在线信息。
- 一些评论者(如 ChrisT182)强调 Anthropic 对 AI safety 和理解的关注 是其更新频率较低的原因,并认为这些基础工作对于未来迈向 AGI 至关重要。
- 还有人期待 Claude’s voice 等新功能,Hir0shima 等人对此表示期待,而一些用户由于对当前产品不满已转向 DeepSeek 等替代方案。
- ChatGPT 创始人分享完美提示词模板的剖析 (Score: 1232, Comments: 62): Greg Brockman 分享了一条推文,详细介绍了 ChatGPT 最佳提示词的结构,重点是创建 New York City 附近的独特周末度假方案。该提示词包含“Goal”、“Return Format”、“Warnings”和“Context dump”等部分,以确保生成响应的清晰度和有效性。
- 提示词结构与有效性:关于 prompt structure 的有效性存在讨论,一些用户注意到将目标或问题放在顶部可能会导致不太理想的响应,而另一些人则认为将其放在底部或使用数据分隔符可以改善结果。ArthurParkerhouse 建议使用三井号分隔符来区分上下文和任务,这与 MemeMan64209 观察到的“将问题放在最后效果更好”的结论一致。
- AI 交互与用户体验:Fit-Buddy-9035 将向 AI 提问比作与逻辑严密、直率的人交流,强调了清晰和明确的必要性;而 Professional-Noise80 则强调编写有效的提示词需要批判性思维。TheSaltySeagull87 指出,创建详细提示词所付出的努力与使用 Google 或 Reddit 等传统研究方法相当。
- AI 模型中的认知处理:MaintenanceOk3364 认为 AI 模型与人类一样会优先处理初始信息,但 MemeMan64209 和 ArthurParkerhouse 观察到 AI 可能会优先处理最后读取的 token,这反映了对 AI 如何处理信息感知的差异。这突显了 AI 认知处理的复杂性和多变性,引发了关于最佳提示词设计的进一步辩论。
{kind=link}
{kind=link}
AI Discord 简报
由 o1-preview-2024-09-12 生成的摘要之摘要的摘要
主题 1:Grok 3 成为焦点,反应褒贬不一
- Grok 3 让服务器和大脑都“熔化”了!:xAI 的 Grok 3 现已免费开放,直到达到服务器容量上限,提供了前所未有的权限来访问这款“全球最聪明 AI”,正如这条推文所宣布的那样。用户们正在推测使用限制以及潜在的服务器过载。
- Grok 3 的热度遭遇质疑:虽然一些用户称赞 Grok 3 优于 ChatGPT-4,但也有人认为其推理能力与 Claude 3.5 和 O1 等模型相比差强人意。社区里充满了关于其真实实力的对比和争论。
- Elon 进军游戏领域并结合 Grok 3:Elon Musk 的 xAI 宣布成立一个与 Grok 3 挂钩的新游戏工作室,标志着将 AI 与游戏整合的战略举措,正如 Elon 的推文中所暗示的那样。
主题 2:AI CUDA Engineer 加速算子优化
- AI 为 AI 编写代码:CUDA Kernel 获得提升:Sakana AI 推出了 AI CUDA Engineer,实现了优化 CUDA Kernel 创建的自动化,并比标准 PyTorch 操作实现了 10-100 倍的加速。
- Kernel 魔法令社区印象深刻:AI CUDA Engineer 在将 PyTorch 转换为 CUDA 方面拥有 90% 的成功率,并发布了一个包含 17,000 个经过验证的 CUDA Kernel 的数据集,标志着 AI 驱动的性能优化取得了突破。
- Jim Fan 博士赞赏自主编程 Agent:在一条推文中,Jim Fan 博士 称赞 AI CUDA Engineer 是“最酷的自主编程 Agent”,强调了其通过增强 CUDA Kernel 来加速 AI 的潜力。
主题 3:新 AI 实验室与量子计算进展震撼业界
- Mira Murati 创立新 AI 实验室:前 OpenAI CTO Mira Murati 推出了 Thinking Machines Lab,旨在开发更易理解、更可定制的 AI 系统,并承诺对公众透明。
- 微软凭借 Majorana 1 实现量子飞跃:Microsoft 推出了 Majorana 1,这是首个由拓扑量子比特(topological qubits)驱动的量子处理单元(QPU),有可能在单个芯片上扩展到一百万个量子比特。
- Lambda 获得 4.8 亿美元融资以助力 AI 云服务:Lambda 获得了巨额 4.8 亿美元 D 轮融资,NVIDIA 和 ARK Invest 参投,突显了 AI 基础设施投资的蓬勃发展。
主题 4:AI 审查引发辩论;无审查模型发布
- Perplexity 开创后审查时代 AI:Perplexity AI 发布了 R1 1776,这是 DeepSeek R1 模型的无审查版本,力求提供公正且事实的信息。
- 强化量化版 DeepSeek R1 发布:用户现在可以使用 动态 2-bit GGUF 量化 运行 Perplexity 的无审查版 DeepSeek R1,承诺比标准格式具有更高的准确度。
- 用户要求 AI 拥有言论自由:用户对 ChatGPT 和 Grok 等模型中严重的审查制度感到愈发沮丧,纷纷寻求允许更多创意和无限制互动的替代方案。
主题 5:AI 变革游戏与创意表达
- AI 渲染改变游戏设计:爱好者们讨论了 AI 通过动态、交互式环境彻底改变游戏的潜力,呼应了 Satya Nadella 在这条推文中关于 AI 生成世界的愿景。
- 用于创意写作和角色扮演的 AI 蓬勃发展:用户分享了使用 AI 模型增强成人角色扮演(ERP)的高级技术,重点在于创建详细的角色和沉浸式体验,突显了 AI 的创意潜力。
- Anthropic 为 Claude 准备新功能:据报道,Anthropic 正在升级 Claude,增加网页搜索和新的“Paprika 模式”以增强推理能力,这在最近的应用更新和推文中有所体现。
第一部分:Discord 高层级摘要
LM Studio Discord
- LM Studio 通过 Speculative Decoding 增强推理性能:LM Studio 0.3.10 引入了 Speculative Decoding,该技术将大模型与更小、更快的草稿模型(draft model)配对,可能使推理速度翻倍,特别是在 llama.cpp/GGUF 和 MLX 中,详见 发布博客文章。
- 用户报告的结果各不相同,部分用户达到了超过 100 tokens/sec 的速度,而其他用户则因配置和模型选择的不同经历了较慢的性能。
- 文本嵌入(Text Embeddings)实现 LM Studio 长期记忆:Text embeddings 被用于直接在 LM Studio 中从用户创建和上传的文件中检索相关数据,作为在 LLMs 中存储信息以供长期使用的一种方法。
- 这种方法不同于 LLM 的扩展,因为 embeddings 促进了特定数据的检索,从而增强了 LLM 的上下文(context)。
- 模型微调(Fine-Tuning):谨慎操作:Fine-tuning 允许模型适应特定上下文,但如果执行不当,可能会导致幻觉(hallucinations),尤其是在处理知名角色或概念时。
- 社区成员讨论了使用不恰当的训练示例使模型产生偏见的风险,这可能会严重扭曲模型的响应。
- A6000 GPU 验证微调实力:配备 256 GB 显存的 A6000 GPU 被证实足以微调 phi4 model;用户被引导至 Unsloth’s notebooks 获取微调示例。
- 讨论强调了易于获取的硬件对 AI 开发日益增长的重要性,A6000 系列在性能和成本效益之间取得了平衡。
- Mistral 模型在法语任务中表现出色:用户强调 Mistral 模型是执行法语任务的最佳选择,同时还推荐了 DeepSeek V2 Lite 等模型,以便在没有 GPU 资源时获得更快的推理速度。
- 这些建议反映了在模型准确性与计算效率之间取得平衡的需求,确保模型能够在不同的硬件配置下有效运行。
OpenAI Discord
- Grok 3 引发关注但仍有不足:用户发现 Grok 3 在给予充足且具体的提示词(prompts)时,在详细脚本和艺术作品生成方面表现出色,超越了免费版本的 ChatGPT。
- Grok 3 速度更快且审查制度较少,但据报道在逻辑推理方面不如更先进的模型。
- AI 审查引发辩论:用户对 ChatGPT 和 Grok 中的审查制度表示担忧,特别是针对某些内容类型,不同平台(如 Perplexity 和 o1 models)的审查程度各不相同。
- 一位用户表达了挫败感,称这些审查问题显著阻碍了 AI 的创造力和交互能力。
- Evo-2 从零开始编写基因组:根据 vittorio 的这条推文,Evo-2 这是一个在 9.3 万亿 DNA 碱基对上训练的大型 AI 模型,现在可以从零开始编写基因组,这可能会彻底改变生物学研究。
- 这一进展提升了人们对肿瘤学和基因工程突破的乐观情绪,为医学研究和治疗开辟了新途径。
- 伦理 AI 交互需要尊重:一位成员对与 AI 的交互如何反映人类行为表示担忧,强调需要建立健康的边界,并指出:“我们对待 AI 的方式……很可能就是我们对待同胞的方式。”
- 这一观点引发了关于动物对待心理学与人类交互之间相似性的讨论,建议对 AI 进行伦理对待。
- 提示词清晰度修复 ChatGPT 的失误:一位用户通过简化提示词改进了 ChatGPT 的功能,但在其公司服务器上问题依然存在;他们注意到在 Playground 中功能有所改善,但在公司服务器中仍有疑问。
- 社区反馈强调,清晰、具体的提示词会产生更好的 AI 响应,其中一条回复敦促关注服务器输入并确保清晰度,以有效引导模型的输出。
Codeium (Windsurf) Discord
- DeepSeek-V3 开启不限量模式!:正如 Windsurf AI 官方账号所宣布的,DeepSeek-V3 现在对 Windsurf Pro 和 Ultimate 计划的用户不限量,消除了对 prompt credits 和 flow action credits 的担忧。
- 社区成员对这一更新表示兴奋,并被鼓励去体验(surf)并充分利用这些新功能。
- Matt Li 展示 MCP 内容:Matt Li 重点展示了新的 MCP 内容和用例,引发了积极的互动和支持,详情见此推文。
- 此外,还分享了一个演示,展示了 MCP 如何在 Cascade 中高效工作,阐明了 MCP 的潜在用途并提升了社区参与度。
- Codeium Autocomplete 功能澄清:讨论澄清了 Codeium 中 autocomplete 和 supercomplete 的区别,其中 supercomplete 可以建议整个函数,而 autocomplete 辅助单行代码。
- 然而,这次讨论也暴露了文档清晰度的问题,以及部分成员在寻找自动安装信息时遇到的困难。
- 学生认为 Codeium 订阅物有所值:成员们得出结论,对于开发 SaaS 项目的学生来说,Codeium 的 $60 订阅可能是值得的,因为这通常会带来更高的收益。
- 一位成员指出,尽管订阅费用看起来很贵,但对于从事严肃开发项目的学生来说,这可以实现收支平衡。
- Windsurf 性能面临挑战:许多用户报告了 Windsurf 的问题,包括模型迭代期间的内部错误和文件编辑问题,这表明 context length 可能会影响性能。
- 他们表示需要更高效的确认流程来改进编码工作流。
Unsloth AI (Daniel Han) Discord
- Unsloth AI 兄弟亮相 GitHub 采访:Unsloth AI 团队在 GitHub Universe 采访中重点介绍了他们的项目,展示了 Han 氏兄弟之间的协同作用以及他们的工作对 AI 开发的影响。
- 充满热情的社区成员对采访中展现的清晰思路和激情表示赞赏。
- 利用免费 GPU 进行模型微调:Unsloth 正在有效利用 Colab 等平台提供的免费 GPU,社区成员分享了访问这些资源的链接,以支持模型微调,特别是针对 DeepSeek-R1 等模型。
- 社区成员探索了内容创作机会,以推广这些免费资源及其利用方式。
- Med-R1 模型进军医疗领域:新发布的 med-r1 模型拥有 1B 参数,并在医疗推理数据集上进行了训练,现已在 Hugging Face 上可用。
- 该模型专为医疗问答和诊断设计,支持 4-bit 推理,最大序列长度(max sequence length)为 2048 tokens。
- 社区攻克 Bitsandbytes 代码:成员们仔细研究了 bitsandbytes 代码,对实现的浮点类型和 block sizes 提出了担忧。
- 讨论集中在代码理想情况下应使用
fp32但实际出现fp16值的差异上,引发了关于指针转换的问题。
- 讨论集中在代码理想情况下应使用
- AI 提升植物化学精准度:一个 AI 驱动的模型现在可以通过一个新框架系统地识别植物化合物,从而优化健康支持。
- 这种方法旨在加强循证营养保健品的开发,同时优先考虑安全性和有效性。
HuggingFace Discord
- 据报道 Grok 3 完胜 ChatGPT-4:有消息称 Grok 3 的表现优于 ChatGPT-4,引发了对其能力的广泛关注。
- 社区成员对这些模型之间的技术差异表达了好奇并进行了推测。
- SWE-Lancer 基准测试评估 LLM 自由职业能力:根据这条推文,OpenAI 推出了 SWE-Lancer 基准测试,旨在测试 LLM 执行价值高达 100 万美元的软件工程任务的能力。
- 初步见解表明,模型在方案选择方面比在具体实现方面表现更出色,揭示了其优势与短板。
- 微软凭借 Majorana 1 芯片启动量子计算:Satya Nadella 宣布推出 Majorana 1 芯片,这是量子计算领域的一项重大进展。正如这篇博客文章所述,该芯片有望在几分钟内完成超级计算机需要数十亿年才能完成的计算。
- 这一创新具有重塑行业并显著影响气候变化的潜力。
- CommentRescueAI 助力 Python 文档编写:一位成员介绍了 CommentRescueAI,这是一个网页扩展程序,旨在轻松地为 Python 代码添加 AI 生成的 docstrings 和注释。
- 该扩展程序现已在 VS Code marketplace 上架,创作者正在征求建议和功能创意。
- Agents 课程证书获取问题已解决:许多用户最近在完成 Agents Course 的测验后难以生成证书,但该问题已得到解决,目前提交会被定向到一个直接生成证书的新 Space。
- 鼓励参与者尝试更新后的测验链接,以便及时领取证书。
aider (Paul Gauthier) Discord
- Grok 3 震撼服务器与人心!:根据 xAI 的推文,Grok 3 现已免费开放,直至达到服务器容量上限,并增加了 X Premium+ 用户和 SuperGrok 成员的访问权限。
- 用户推测 Grok 3 可能会有限制,预计每天限制约 5 次查询,这引发了对可用性的担忧。
- LLM 推理成为瓶颈:用户对使用 Aider 编码时的 LLM 推理速度 表示沮丧,而根据社区反馈,其他人指出 Azure 的 OpenAI API 通常更快。
- 他们分享了关于缓存、将文件标记为只读以及改进 Aider 编码实践的技巧,并详细说明了特定偏好,例如使用 httpx 替代 requests。
- OpenRouter 限制端点:讨论显示 OpenRouter 可能会将 o3-mini 等模型的端点限制在 100k 次请求,这表明了潜在的可用性问题。
- 这种限制使得用户尝试利用 OpenRouter 进行更高强度 AI 交互的体验变得复杂。
- Ministral 可能会加入 Aider!:一位成员在看到讨论 Mistral 的 LinkedIn 帖子后,询问是否有人尝试将 Ministral 与 Aider 集成,并对其兼容性表示好奇。
- 另外,另一位成员发现构建过程非常缓慢,因为在使用 TF-IDF 的 API 调用期间,它会用 ‘build’ 重写块。
- LLADA 模型登场:社区讨论了一个名为 LLADA 的新模型,该模型在编码任务上表现出高性能。
- 见解表明,由于其创新的方法,像 LLADA 这样的模型可能会成为代码编辑的强力替代方案。
Cursor IDE Discord
- Sonnet 在编程方面表现出色:用户因其可靠性和上下文理解能力而青睐 Sonnet 处理编程任务,并指出 Anthropic 模型在结合推理和谨慎执行时,在编程和复杂任务中表现卓越。
- 用户普遍认为 OpenAI 和 DeepSeek 是通用任务的强力竞争者。
- Grok 3 面临用户审查:一些用户批评了 Grok 3 的实用性,根据个人测试经验将其贴上“令人失望”标签,显示其在编程任务中的不足,尽管 YouTube 上有一些正面评价。
- 其他人通过指出多位 YouTuber 的好评来质疑针对 Grok 3 的负面论点,而另一些人则指向了正面评价。
- Cursor 的 Agent 模式简化工作流:用户分享了在 Agent 模式下使用 Cursor 的经验,强调了变更日志 (changelogs) 和自定义规则等功能如何帮助简化工作流。
- 讨论围绕使用 AI 助手自动化任务并确保高质量输出展开,突出了正面和负面的互动。
- 初创项目寻求程序员合作:一位用户宣布有兴趣启动一个新项目,正在寻找有时间和奉献精神的程序员进行合作,并表示愿意为项目提供资金。
- 这一公告引发了频道成员对潜在合作伙伴关系的开放态度。
Perplexity AI Discord
- Deep Research 饱受崩溃困扰:用户报告 Deep Research 功能持续崩溃,特别是企业版用户,此外还存在线程导航和访问库内容的问题。
- 他们讨论了潜在的修复方案,暗示了平台稳定性和可用性的底层问题,目前正在积极进一步调查该问题。
- 订阅模式引发讨论:一位成员对 Pro 订阅模式表示困惑,该模式以单一费用提供对多个模型的访问。
- 关于定价策略合法性的猜测随之而来,一位用户幽默地暗示模型可能是盗版的,尽管这很快被斥为毫无根据;然而,关于在各种模型上运行推理 (inference) 的实际成本讨论仍在继续。
- 图像生成功能表现不佳:尽管访问小组件显示具有图像生成能力,但一些用户在平台上使用该功能时遇到了困难。
- 讨论了变通方法,包括为图像创建编写特定的提示词 (prompts) 以及使用浏览器插件;然而,完全集成到 Perplexity 的工作似乎仍在进行中。
- R1-1776 模型承诺无审查回复:研究了 R1-1776 模型的推理能力及其与标准 R1 模型的区别,指出其基于 DeepSeek 模型提供无审查回复的潜力。
- 用户分享了使用该模型的经验,强调了其在敏感话题和操作上下文中的表现,特别是使用 OpenRouter API。
- IRS 利用 Nvidia 增强算力:据报道,IRS 正在采购一台 Nvidia 超级计算机以增强运营能力,提高税务处理数据分析的效率。
- 在日益增长的数据挑战中,这一举措被视为优化税务处理技术的关键,尽管尚未发布具体的模型细节或配置。
Interconnects (Nathan Lambert) Discord
- Grok 3 发布引发质疑:虽然 Grok 3 展现出潜力,但对其真实能力的质疑依然存在,用户正在 Twitter 之外寻找可靠的来源进行性能验证。成员们讨论了关于整体性能指标以及 Grok 3 是否能有效竞争的担忧。
- 有人对阅读 Hacker News 的评论表示担忧。为什么关于 XAI 的讨论感觉压力这么大?。
- Google 推出 PaliGemma 2 Mix:Google 推出了 PaliGemma 2 mix,允许在多种任务中开箱即用,突破了预训练 Checkpoint 的限制。查看 发布博客文章。
- 与之前版本进行了对比,并讨论了命名和功能的清晰度及实用性。
- AI CUDA Engineer 旨在提升 Kernel 速度:Sakana AI 推出了 AI CUDA Engineer,这是一个旨在生成优化 CUDA kernels 的 AI 系统,相比典型实现可实现 10-100 倍加速。查看 Sakana AI 的公告。
- 该系统被预见为可能对机器学习运营中 AI 驱动的性能优化产生变革性影响。
- Tulu3 70B 进行为期一周的 RLVR 训练:在 8×8 H100 配置下,tulu3 70B 模型的 RLVR 阶段训练预计在内存充足的情况下需要约一周时间。使用 GRPO 将增强内存能力,这可能会对训练过程产生积极影响。
- 团队指出,他们已更新论文,包含了关于训练阶段的相关信息。
- Evo 2 成为生物学基础模型:Michael Poli 宣布推出 Evo 2,这是一款拥有 400 亿参数的新型基础模型,专为生物应用设计,旨在显著推进对基因组学的理解。查看 Michael Poli 的公告。
- Evo 2 旨在展示推理时扩展定律(test-time scaling laws),并改进乳腺癌变异分类,同时推动 AI 领域的真正开源工作。
OpenRouter (Alex Atallah) Discord
- OpenRouter 辩论推理 Token 默认设置:由于用户反馈希望在 max_tokens 较低时也能接收内容,OpenRouter 正在重新考虑 include_reasoning 的默认设置。
- 目前正进行社区反馈投票,共有四个选项,从保持当前设置到将推理 Token 设为默认,以及一个用于用户评论的补充选项。
- Grok 3 在推理任务中表现平平:用户报告称,尽管 Grok 3 被誉为顶级 LLM,但与 Claude 3.5 和 O1 相比,其推理能力并不理想。
- 一位用户表示它没有达到预期,并对其现状表示担忧。
- 新用户在导航 OpenRouter API 时表示困惑:新用户在访问 OpenRouter 以及通过 API 使用 O3 mini 时遇到困难,这引发了关于使用限制的问题。
- 需要更好的集成选项和关于 API key 使用的清晰说明,特别是关于模型访问的逐步推广。
- Perplexity R1 1776 加入战场:来自 Perplexity 的 R1 1776 模型(DeepSeek R1 模型的一个版本)已发布,允许用户访问经过后训练以移除审查的模型。
- X 上的公告 链接到了该模型权重的 HuggingFace Repo。
- 聊天机器人集成寻求帮助:一位用户需要关于使用 OpenRouter API 在 HTML 网站上集成 AI 聊天机器人的指导,强调了对现成资源的需求。
- 社区成员建议他们需要自行开发解决方案或聘请开发人员协助。
Stability.ai (Stable Diffusion) Discord
- ControlNet 提升图像准确度:ControlNet 通过使用姿势作为骨架参考,增强了 Stable Diffusion (SD) 和 Flux 中的图像生成,提高了生成图像的准确性。
- 用户发现 ControlNet 与 SD 和 Flux 配合良好,可以生成特定姿势的图像。
- SwarmUI 简化 AI 工具访问:ComfyUI 复杂且类似思维导图的界面对普通用户并不友好,但 SwarmUI 和其他一站式解决方案提供了更便捷的访问方式。
- 这些替代方案提供了更简单的界面,使 AI 工具更易于使用。
- RTX 3080 可有效处理 SD 和 Flux:拥有 RTX 3080 GPU 的用户可以高效运行 Stable Diffusion 3.5 和 Flux。
- SD 3.5 和 XL 之间的选择取决于用户的具体需求,新模型提供了更好的功能。
- 安装指南简化设置:SwarmUI、CS1o 教程和 Lykos Stability Matrix 的安装指南提供了设置 AI 工具的详细步骤。
- 这些资源协助用户完成不同界面的安装过程,例如 LykosAI Stability Matrix。
Torchtune Discord
- Torchtune 2025 年上半年路线图公开:Torchtune 2025 年上半年的路线图现已在 PyTorch dev-discuss 上发布,概述了关键目标和时间表,包括在新型模型架构方面保持领先。
- 团队旨在优先处理现有的核心工作,该路线图是对整个 PyTorch organization 其他令人兴奋的进展的补充。
- Packing 增加 VRAM 占用:用户发现,在训练过程中使用具有更长序列长度的 packing 会显著提高 VRAM requirements,导致不可预测的内存分配。
- 社区正在积极调查 kernel 差异,以优化内存管理和设置。
- Llama 3B 微调后表现异常:在对 3B Llama models 进行微调后,用户报告模型在推理过程中会出现胡言乱语的问题,这与 8B variant 形成了鲜明对比。
- 团队怀疑 Torchtune 的模型导出和 checkpointing 过程中存在潜在 bug,这可能会影响 3B model。
- 新的 Attention 机制即将到来:社区有兴趣将稀疏和压缩 attention 等先进的 attention mechanisms 集成到 Torchtune 中,以提高效率。
- Torchtune 团队欢迎新想法,重点是利用 PyTorch 核心功能。
- StepTool 增强多步工具使用:论文 StepTool: Enhancing Multi-Step Tool Usage in LLMs through Step-Grained Reinforcement Learning (arxiv.org/abs/2410.07745) 介绍了 StepTool,这是一种新型的强化学习框架,通过将工具学习视为动态决策任务,增强了 LLMs 的多步工具使用能力。
- 关键在于 Step-grained Reward Shaping,它根据工具交互的成功程度及其对任务的贡献在交互过程中提供奖励,从而以多步方式优化模型的 policy。
Nous Research AI Discord
- Grok-3 API 仍然难以获取:成员们讨论了 Grok-3 缺少 API 的问题,这限制了其可用性,并建议在进行任何测试之前需要独立的 benchmarks。
- 观察表明 Grok-3 可能会混淆内容,引发了关于如何将其集成并应用于各种场景的持续讨论。
- Le Chat 以速度和质量赢得青睐:用户报告了使用 Le Chat 的积极体验,称赞其速度、图像生成能力以及与其他模型相比的整体质量;法国居民正获得低价订阅优惠。
- 一位用户分享了 Le Chat 的链接,称其 “与竞争对手相比令人印象深刻,尤其是对于法国居民的这个价格点。”
- AI 渲染可能变革游戏设计:讨论集中在 AI rendering 通过动态和交互式环境彻底改变游戏的潜力。
- 成员们对平衡 AI 生成内容与传统游戏开发表示担忧,强调了与技术进行有意义互动的重要性,正如 Satya Nadella 在关于想象用 AI 创建整个交互式环境的 推文 中所描述的那样。
- SWE-Lancer 以 100 万美元挑战赛考验模型:论文中描述的 SWE-Lancer benchmark 包含来自 Upwork 的 1,400 多个自由软件工程任务,总价值 100 万美元。
- 任务范围从 50 美元的 Bug 修复到 32,000 美元的功能实现,评估显示 frontier models 难以有效解决大多数任务。
- MoBA 旨在提升长上下文 LLM 性能:在 GitHub 上记录的 MoBA 引入了一种 Mixture of Block Attention 方法,旨在提高 long-context LLMs 的性能。
- 该项目旨在克服有效处理长输入的局限性,可以在 GitHub 上找到更多见解和贡献。
Notebook LM Discord
- Notebook LM 擅长书籍教学:一位用户确信 Notebook LM 可以通过使用精确的 prompts 有效地教他们一本书,并希望这能帮助避免跳过关键部分。
- 这反映了用户越来越多地尝试并依赖 AI tools 来获得个性化的学习体验。
- 音频讨论被打断:一位用户赞赏 Notebook LM 如何帮助组织回复,但发现音频讨论由于声音之间的频繁中断而难以跟进。
- 他们建议采用更结构化的方法,即一个声音在另一个声音插话之前表达完整的想法,这表明需要改进 audio management features。
- 播客 TTS 提示词出现问题:一位用户在播客功能的 TTS prompts 方面寻求帮助,难以让主持人逐字阅读文本。
- 对所用精确提示词的请求表明了在实现对 AI-driven voice outputs 精确控制方面的挑战。
- Notebook LM 访问面临限制:一位用户询问是否可以邀请非 Google 账户持有者访问 Notebook,类似于 Google Docs 的共享功能。
- 这突显了 Notebook LM 在访问和协作功能方面持续存在的局限性,可能会阻碍更广泛的采用。
- NotebookLM Plus 设有使用上限:用户注意到 NotebookLM Plus 在所有笔记本中每天有 500 次聊天查询限制,且共享上限为 50 个用户。
- 通过创建多个账户来绕过这些限制的建议表明,尽管目前对 AI Tool usage 有所限制,用户仍在寻找最大化效用的方法。
GPU MODE Discord
- AI CUDA Engineer 自动生成 Kernel:Sakana AI 推出了 AI CUDA Engineer,它可以自动生成优化的 CUDA kernel,通过将 PyTorch 算子转换为 CUDA,可能实现比普通 PyTorch 操作快 10-100 倍的速度。
- 该工具的过程涉及使用由 LLM 驱动的进化方法(evolutionary approach)来超越传统的 torch.compile,并发布了一个包含 17,000 个经过验证的 CUDA kernel 的数据集。
- Windows 上的 CUDA 安装面临挑战:多名用户报告称,CUDA Express Installer 在 Windows 上针对不同 NVIDIA GPU 安装 Nsight 和 Visual Studio 等组件时卡住。
- 在 Visual Studio 中安装 CUDA 12.5 和 12.8 时遇到了困难,并引发了关于 Linux 与 Windows 安装便捷性的讨论。
- DeepSeek 旨在通过 CodeI/O 提高推理能力:DeepSeek 发布了一篇关于 CodeI/O 的论文,旨在通过将代码转换为输入输出预测格式来提高推理能力。
- 这种新的训练方法基于自然语言任务,这与增强狭窄技能的做法有所不同;论文可以在 GitHub 上找到。
- AMD 推出 ROCm 开发人员认证:AMD 推出了 ROCm 应用开发人员证书(ROCm Application Developer Certificate),以增强 ROCm 生态系统中的 GPU 计算技能。
- 该认证旨在促进开源 GPU 计算技术的专业化。
- 利用 Triton 和 CUDA 优化 Kokoro TTS:现代 TTS 模型 Kokoro 的推理速度得到了提升,通过使用 Triton + CUDA graph 减少了 4070Ti SUPER 上 bs=1 时 LSTM 的 kernel 启动开销。
- 一位成员表示 “不敢相信在这个时代我还得优化 LSTM” 😂,并引用了他的改进测量结果。
Eleuther Discord
- DeepSeek R1 推出增强版量化模型:一位成员分享了在 Hugging Face 上运行 Perplexity 未经审查的 DeepSeek R1 以及其他模型版本的链接。
- 新的动态 2-bit GGUF 量化(quants)承诺比标准的 1-bit/2-bit 格式具有更高的准确性;包含使用说明。
- 模型引导(Model-guidance)加速扩散模型训练:模型引导(MG)目标移除了 Classifier-free guidance(CFG),加速了训练并使推理速率翻倍,在 ImageNet 256 基准测试中实现了 1.34 的 FID,达到 state-of-the-art 性能。
- 评估确认 MG 在扩散模型训练中树立了新标准。
- AI CUDA Engineer 自动化 Kernel 优化:AI CUDA Engineer 自动化了 CUDA kernel 的创建,实现了比标准 PyTorch 快 10-100 倍的速度,并发布了 17,000 个经过验证的 kernel。
- 这一进展据称标志着机器学习操作中 AI 驱动效率的新时代,对推理时间的自动优化具有重要意义。
- 探索优化 LLM 计算分配:成员们讨论了在最近发布的 Grok 3 等 LLM 中,对优化测试时计算(test-time compute)的关注度日益增加,并且扩大预训练计算规模正在产生收益。
- 尽管对预训练与后训练之间的分配平衡存在推测,但关于资源分配的数据在很大程度上仍无法获得。
- Transformer Engine 在 NeoX 中面临障碍:一位尝试在 NeoX 中集成 Transformer Engine 的成员遇到了阻碍测试的挑战,表明启用非 FP8 标志会导致系统故障。
- 这突显了在旨在维护系统可靠性的同时,集成所面临的复杂性。
Yannick Kilcher Discord
- 马斯克进军游戏领域并推出 Grok 3:Elon Musk 的 xAI 宣布成立一个与 Grok 3 相关的全新游戏工作室,将其 AI 计划扩展至游戏领域,正如其在 Twitter 上所发布的。
- 此举紧随 Grok 3 最近的品牌更新之后,表明了将 AI 与游戏应用集成的战略转变。
- DeepSeek 探索稀疏注意力机制:社区讨论重点关注了 DeepSeek 的新论文《Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention》(链接),该论文因其高质量而受到赞誉。
- 该论文介绍了一种新型的稀疏注意力机制,该机制既符合硬件特性又是原生可训练的,解决了计算效率问题。
- Murati 创立新 AI 实验室:前 OpenAI CTO Mira Murati 启动了 Thinking Machines Lab,专注于开发更易理解和可定制的 AI 系统,同时确保公众透明度。
- 虽然具体项目仍处于保密状态,但该实验室承诺定期发布技术研究,目标是降低 AI 系统的黑箱程度。
- Perplexity 开创“后审查” AI:Perplexity AI 推出了 R1 1776,这是一个旨在通过对 DeepSeek R1 模型使用创新的后训练技术来克服中国式审查的新模型。
- 这种方法旨在创建更强大的 AI 系统,在生成内容的同时保持上下文的完整性,即使面临审查限制。
- 微软凭借 Majorana 1 实现量子飞跃:微软发布了 Majorana 1,这是全球首款由拓扑量子比特驱动的量子处理单元(QPU),具有在单芯片上扩展至百万量子比特的潜力。
- 这一进步代表了迈向实用量子计算的重要一步,为计算技术的新纪元铺平了道路。
Latent Space Discord
- Thinking Machines Lab 诞生:Thinking Machines Lab 正式启动,旨在提高 AI 系统的可访问性和定制化,由 Mira Murati(前 OpenAI CTO)和 Lilian Weng 等知名人物领导,致力于解决 AI 领域的知识鸿沟。
- 该实验室的成立引发了 AI 社区的热烈讨论,Andrej Karpathy 向团队表示祝贺,团队中许多成员都曾参与构建 ChatGPT。
- Perplexity AI 的 R1 1776 宣布开源:Perplexity AI 开源了 R1 1776,这是其 DeepSeek R1 模型的一个版本,旨在提供无审查且无偏见的信息,推动更可靠的 AI 模型发展。
- AI 社区戏称这种做法为“自由微调”(freedomtuning),标志着该模型对未过滤数据和事实准确性的重视。
- OpenAI 的 SWElancer 设定新编程基准:OpenAI 推出了 SWElancer,这是一个包含 1,400 多个自由软件工程任务的新基准,用于评估 AI 在真实场景中的编程性能。
- 这一举措是在关于 AI 驱动的游戏生成可能取代传统游戏工作室的讨论中提出的,强调了对现实评估指标的需求。
- Mastra 的 JS SDK 释放 AI Agent 潜力:Mastra 发布了一个开源 JavaScript SDK,旨在促进能够通过内置工作流执行复杂任务的 AI Agent 的开发。
- 该框架旨在方便与 Vercel 的 AI SDK 进行协作和集成,标志着开源 AI 开发的重大进展。
- Lambda 获得 4.8 亿美元 D 轮融资:Lambda 完成了由 Andra Capital 和 SGW 领投的 4.8 亿美元巨额 D 轮融资,突显了市场对为 AI 应用量身定制的云服务日益增长的兴趣。
- 来自 NVIDIA 和 ARK Invest 等投资者的参与强调了该公司在不断发展的 AI 领域中的潜力。
Modular (Mojo 🔥) Discord
- Grok 3 提前发布,令 Mojo 感到意外:Grok 3 的发布抢在了 Mojo 的进度之前,但这激发了开发者的兴趣而非挫败感。
- 这种提前发布被认为是有益的,可能会进一步推动 Mojo 的创新。
- Polars 迅速集成到 Mojo:一位开发者报告称能快速将 Polars 导入 Mojo 项目,并在 GitHub 上分享了包含示例的实现。
- 针对在项目语境下“实现”与“导入” Polars 之间的区别进行了澄清。
- MAX 25.1 直播引发好奇:即将举行的直播将涵盖 MAX 25.1,并提供 Google Form 用于提交问题。
- 该活动通过 LinkedIn 进行推广,鼓励社区参与。
- Mojo 的快速排序面临性能瓶颈:一位用户发现用 Mojo 实现的 quick sort 算法显著慢于(2.9s)其 Python 版本(0.4s)。
- 随后的讨论建议使用 Mojo 的 benchmark 模块来隔离并准确测量排序性能,并注意编译时间对计时结果的影响。
- Slab List 相比 Linked List 受到更多关注:成员们探讨了 SlabList 优于传统 LinkedLists 的优势,重点在于常数时间操作和缓存效率,并指向了 nickziv’s github。
- slab list 被定义为
LinkedList[InlineArray[T, N]],在不进行复杂操作的情况下优化了内存使用。
- slab list 被定义为
Nomic.ai (GPT4All) Discord
- CUDA GPU 获得支持:频道讨论了增加对旧款 CUDA 5.0 兼容 GPU(如 GM107/GM108)的支持,成员指出目前缺乏对低端架构的支持。
- 一位成员确认支持这些 GPU 的 PR 已经合并,并将包含在下一个版本中,参考 CUDA Wikipedia 页面。
- GPT4All 嵌入 Token 限制揭晓:成员们讨论了达到 GPT4All 嵌入的 1000 万 Token 限制,指出基础价格为 $10/月,额外 Token 需另付费。
- 澄清了从本地文档中删除 Token 并不会减少已计费的总 Token 数。
- 聊天模板提示词令人头疼:成员们寻求关于使用 chat templates 指导模型引用摘录的澄清,但根据 GPT4All’s docs,被告知系统消息指令就足够了。
- 其他成员询问了 Jinja 或 JSON 代码在提示模型时的有效性,这表明实现预期输出具有复杂性。
- Nomic v2 发布失踪了?:关于 Nomic v2 缺席的猜测四起,成员们对延迟表示好奇并指出其重要性。
- 一位成员幽默地质疑了在没有新版本更新的情况下漫长的等待。
- GPT4All 的图像处理表现不佳:一位成员请求能够像其他平台一样直接在聊天中复制粘贴图像,但 GPT4All 目前不支持图像输入。
- 频道建议使用外部软件进行图像处理。
MCP (Glama) Discord
- Anthropic 意外宕机:Anthropic 首页经历了停机,引发了关于潜在服务中断的猜测。
- 一位成员报告了停机情况,并通过随附的图片进行了分享。
- Haiku 3.5 传闻甚嚣尘上:讨论围绕 Haiku 3.5 的潜在发布展开,可能包含 tool 和 vision 支持。
- 一位成员还暗示我们可能会看到 Sonnet 4.0 的发布。
- Cursor MCP 工具检测失效:多位成员报告 Cursor MCP 显示 ‘No tool found’,表明这是一个普遍问题。
- 一位用户分享了一个 /sse 实现来解决此问题,并提供了相关信息的链接。
- Google Workspace MCP 功能强大:一位成员重点介绍了他们在 Docker 上运行的 Google Workspace MCP,支持多账号和 token 自动刷新,并提供适用于不同平台的 Docker 镜像。
- 该 MCP 提供了对 Gmail、Calendar 和其他 Google Workspace API 的集成访问。
- Python REPL 获得 Matplotlib 支持:一位成员介绍了他们的 Python REPL for MCP,提供 STDIO 支持、matplotlib、seaborn 和 numpy。
- 未来计划包括添加 IPython 支持,并对类似于 Jupyter 中的可视化功能表现出浓厚兴趣。
LlamaIndex Discord
- LlamaCloud EU 消除障碍:LlamaCloud EU 已宣布推出,专门为欧洲企业提供安全、合规的知识管理,重点关注欧盟管辖范围内的数据驻留,详情见此处。
- 这一早期访问产品旨在为关注合规性和数据隐私的欧洲公司消除重大障碍。
- 供应商调查问卷应用实现答案检索:来自 @patrickrolsen 的创新全栈应用允许用户通过语义化检索之前的答案并使用 LLM 进行增强,从而回答供应商调查问卷。
- 该应用通过简化阅读表单和填写答案的过程,展示了 knowledge agents 的核心用例。
- AgentWorkflow 工具输出存在 Bug:一位用户报告称,尽管生成了响应,但其 AgentWorkflow 的工具输出列表仍然为空,并寻求关于 AgentWorkflow tool 实现的澄清。
- 另一位成员分享道,streaming events 可以作为一种变通方法,在 AgentWorkflow 执行期间捕获所有工具调用。
- AI 和数据运营(Data Ops)下一阶段的挑战:最近一篇题为 《大而笨的 AI 与数据的终结》 的文章讨论了 AI 和数据运营 中挑战传统方法的新兴趋势。
- 它强调了在处理数据以实现更好决策时向更智能、更高效系统的转变,并关注自两年前启动以来的联邦技术支出和企业级 AI 应用。
LLM Agents (Berkeley MOOC) Discord
- MOOC 学生获得传奇地位:F24 MOOC 表彰了 15,000 名学生,庆祝了 304 位 trailblazers、160 位 masters、90 位 ninjas、11 位 legends 以及 7 位 honorees。
- 课程工作人员强调,三位 honorees 来自 ninja 级别,四位来自 masters 级别,标志着广泛的成就。
- 高级课程证书现已推出!:成员们询问了高级课程证书的可用性,以及是否可以在没有 F24 MOOC 证书的情况下获得它,课程工作人员对这两个问题都给予了肯定回答。
- 关于高级课程证书获取的具体细节将很快发布。
- LangChain 简化 LLM 应用:LangChain 旨在简化 LLM 应用生命周期,涵盖开发、生产化和部署等领域,并提供各种组件。
- 它的工作原理是将一个 LLM 的输出链接为另一个 LLM 的输入,从而有效地创建链以增强性能,这对于 LLM 应用架构师 来说非常有用。
- 结合机器学习预测模型探索 LLM:讨论了将 LLM Agent 与机器学习预测模型相结合的问题,建议查看 Everscope 上的学术论文以获取见解。
- 在 Everscope 上过滤“all-time”可能会产生与 LLM 相关的最佳论文,使你能够学习新技术。
- MOOC 课程视频现已发布:课程工作人员宣布,当前课程的视频讲座仍可在 syllabus 中查看。
- 课程工作人员鼓励成员报名参加 Spring 2025 iteration 以继续学习,因为之前的课程已不再提供测验和考试。
Cohere Discord
- 频道流量激增:所有 text channels 都经历了高流量,表明正在进行的讨论激增。
- 还注意到大部分流量是由 automation bots 造成的,一名成员请求开设一个专门用于分享 screenshots 的新频道。
- 利润共享提案引起轰动:一名成员提议了一项针对 25-50 岁人群的 profit-sharing 合作,潜在利润在 $100 到 $1500 之间。
- 该提案引发了关于身份共享以及协作与盗窃之间平衡的辩论。
- 身份共享受到审查:成员们对在社区内共享个人身份信息的 隐私影响 表示担忧,这引发了诸如“现在身份盗用这么公开吗?”之类的问题。
- 一名成员建议,在分享观点时,更清晰的表达对于防止误解至关重要,尤其是在基于文本的媒介中。
- 项目频道呼吁透明度:在 projects 频道中,发布者强调了一项提案中 缺乏细节,且没有网站或文档。
- 一位用户形容整个风险投资是“可疑的”,并指出透明度对于谨慎的合作至关重要。
- 调查无咖啡世界的影响:有人请求写一篇 essay,探讨没有咖啡的世界所带来的文化和经济后果。
- 这个话题开启了关于如果没有这种流行饮料可能发生的假设情景和社会变化的讨论。
AI21 Labs (Jamba) Discord
- 用户寻求集成 Jamba-1.5-large 模型的帮助:一位用户请求协助如何通过 AI21 API 向
jamba-1.5-large模型格式化请求,成员们提供了 API reference 和正确构建请求的示例。- 讨论强调了成功进行 API 调用所需的特定 headers 和参数,特别是在集成
jamba-1.5-large时。
- 讨论强调了成功进行 API 调用所需的特定 headers 和参数,特别是在集成
- Jamba 1.5 API 输出中出现转义字符:一位用户询问在使用 AI21 API 解决数学表达式时,API 输出中出现的意外细节。
- 一位成员澄清说,输出中的转义字符需要额外的代码调整才能整洁显示,因为 AI21 Studio UI 会自动处理这些字符。
- API 响应需要特殊字符处理:社区成员讨论了在使用 PHP 时从 AI21 API 响应中移除特殊字符的必要性。
- 讨论强调虽然 AI21 Studio UI 旨在处理特殊字符,但在直接访问 API 时,需要额外的代码处理以实现正确的输出格式化。
- PHP 与 Symfony 集成带来挑战:一位用户强调了使用 Symfony 和 PHP 集成 AI21 API 响应时的挑战,指出需要进行大量的数据转换和自定义处理。
- 该用户感谢社区提供了关于在 PHP 环境中有效处理和格式化 API 输出的见解。
DSPy Discord
- SPO 框架优化 Prompt:一种新的 Self-Supervised Prompt Optimization (SPO) 框架可以在没有外部参考的情况下,为封闭式和开放式任务发现有效的 Prompt,增强了 Self-Supervised Prompt Optimization paper 中详述的 LLM 推理能力。
- 该框架纯粹从输出比较中推导评估信号,使其具有成本效益;一位参与者指出,该论文直到最后一段才提到 DSPy。
- Zero-Indexing 互联网搜索改进 RAG:一项研究介绍了一种新的 Retrieval Augmented Generation (RAG) 方法,详见 Zero-Indexing Internet Search Augmented Generation for Large Language Models,通过使用标准搜索引擎 API 在生成推理过程中动态集成最新的在线信息。
- 这种范式涉及一个 parser-LLM,它决定是否需要互联网增强,并在单次推理中提取搜索关键词,从而在不依赖固定索引的情况下提高生成内容的质量。
- DSPy 使用 Jinja2 合成数据:成员们分享了一个 GitHub 仓库链接,展示了来自 DSPy 和 Jinja2 的结构化输出,强调了它们在合成数据生成方面的结合能力。
- 合成数据生成流水线可用于训练带有插图附件的 ChatDoctor。
- Judge-Time Scaling 库 Verdict 亮相:一位成员分享了 Leonard Tang 的帖子,表达了对名为 Verdict 的新库的兴奋,该库专注于扩展 judge-time 计算,旨在解决 AI 中的评估局限性,特别是在开放式和不可验证领域。
- 另一位成员表示,这个库非常适合他们的 Personal Voice Identity Manager 概念,强调了其对 AI 框架内个人身份管理的潜在影响。
- DSPy Prompt 冻结导致控制流丢失:一位成员分享了一段代码片段,展示了如何使用默认适配器将 DSPy 程序中的所有 Prompt 冻结并导出为消息模板。
- 虽然这种方法很方便,但可能会导致丢失控制流逻辑,建议使用
program.save()等替代方案。
- 虽然这种方法很方便,但可能会导致丢失控制流逻辑,建议使用
tinygrad (George Hotz) Discord
- 不同配置下的模型性能表现参差不齐:一位用户报告在 10 年前的 GeForce 850M 上测试仅获得 3 tok/s,而另一位在 Windows 11 上使用 RTX 4070 的用户获得了 12 tok/s。
- 使用 RTX 4070 的用户提到 首个 token 生成时间 (time to first token) 为 1.9 秒。
- 计算成本仍然过高:尽管 RTX 4070 性能尚可,但一位用户发现由于高昂的计算成本和复杂性,该模型并不太实用。
- 他们指出了诸如 数值刚性 (numerical stiffness) 以及非线性子问题导致难以获取准确解等复杂问题。
MLOps @Chipro Discord 没有新消息。如果该频道长时间保持安静,请告知我们,我们将将其移除。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该频道长时间保持安静,请告知我们,我们将将其移除。
第 2 部分:频道详细摘要与链接
完整的频道逐项分析已针对邮件进行删减。
如果您喜欢 AInews,请分享给朋友!提前感谢!