ainews-claude-37-sonnet
Claude 3.7 Sonnet (通常保留原名,也可译为:Claude 3.7 奏鸣曲)
Anthropic 发布了 Claude 3.7 Sonnet,这是该公司迄今为止最智能的模型。该模型具备混合推理功能,提供两种思考模式:近乎即时的快速响应和扩展的逐步思考。
此次发布还包括处于限量预览阶段的智能体化编程工具 Claude Code,并在测试版中支持 128k 输出 Token 能力。Claude 3.7 Sonnet 在 SWE-Bench Verified 和 Cognition 的初级开发人员评估 (junior-dev eval) 等编程基准测试中表现优异,并引入了流式思考、提示词缓存和工具调用等高级功能。
此外,该模型在 Pokebench 上的基准测试结果反映了其具备类似于 Voyager 论文中所述的智能体能力。随模型一同发布的还有详尽的文档、Cookbook 以及针对扩展思考的提示词指南。社交媒体公告中特别强调了该模型是“首个普遍可用的混合推理模型”以及“Anthropic 推出的首个编程工具”。
思考即一切。
2025年2月24日至2月25日的 AI 新闻。我们为您检查了 7 个 subreddits、433 个 Twitter 账号 和 29 个 Discord 社区(220 个频道,5949 条消息)。预计节省阅读时间(按每分钟 200 字计算):503 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
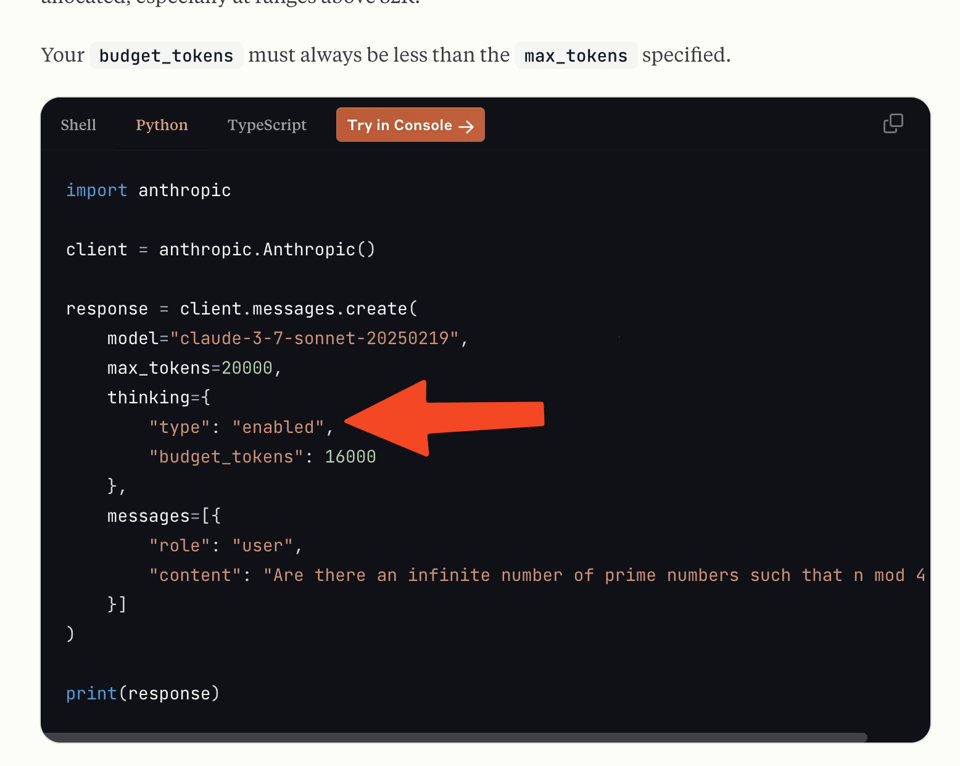
略微领先于 GPT5 路线图,Claude 3.7 Sonnet 今日发布(别问名字的事 —— 请注意,除了经过多次私下预览泄露后正式推出的这款带有可选思考模式和明确 Token 预算的模型外,还有两篇博文、文档、Cookbooks 和 提示词指南 可供阅读,以及处于有限预览阶段的 Claude Code)。
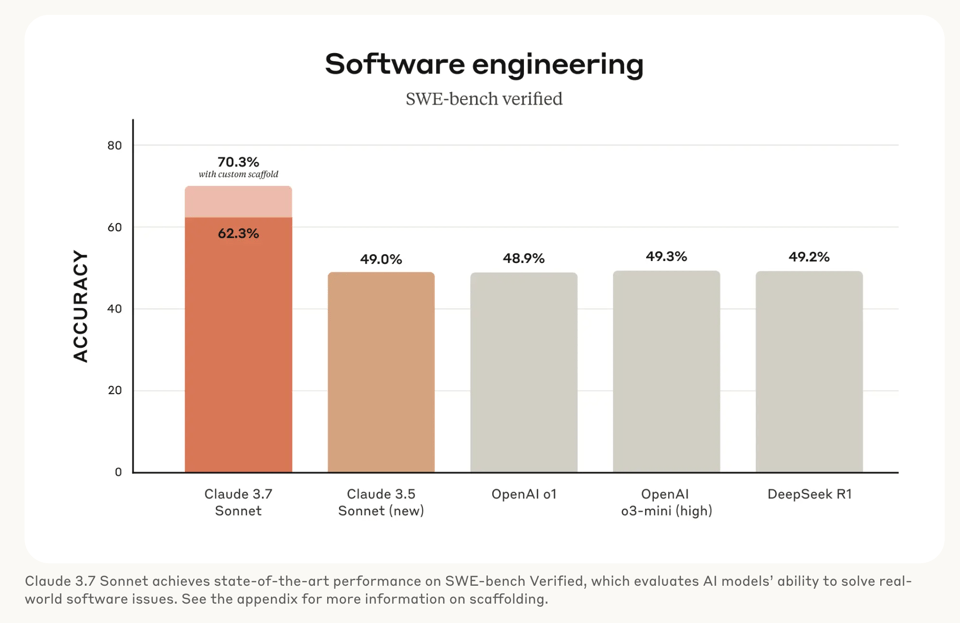
3.7 Sonnet 在许多编程基准测试中表现出色,如 SWE-Bench Verified、aider 和 Cognition 的初级开发人员评估,无论是否开启(绝大部分未经过滤的!)思考模式。
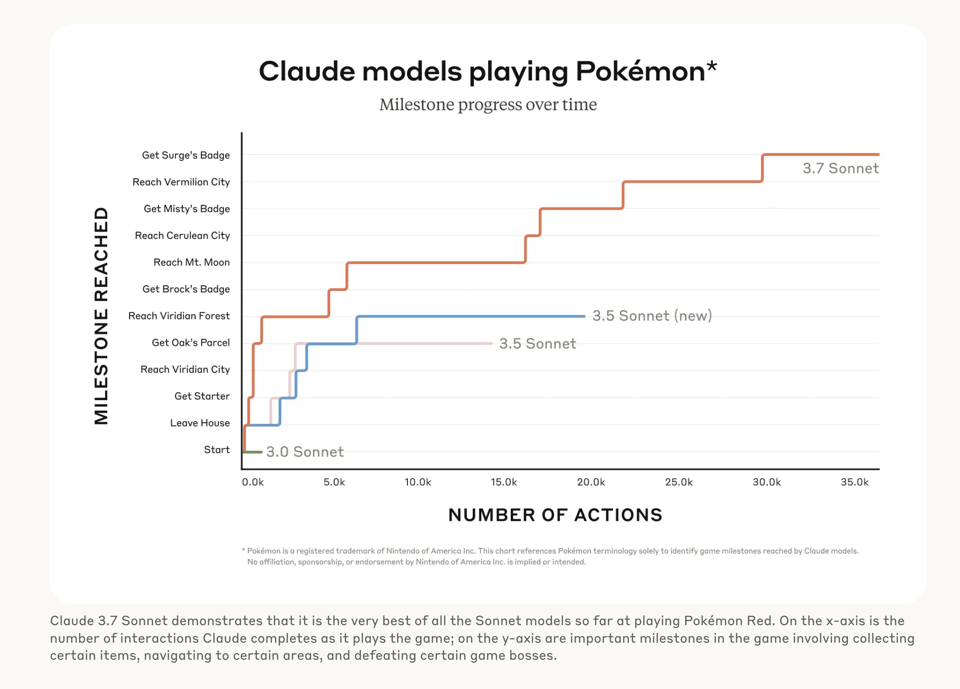
然而,在关于扩展思考的第二篇博文中提到的最受欢迎的新基准测试是 Pokebench,它借鉴了 Voyager 论文,作为一个 Agent 评测基准:
发布时的功能集和文档非常令人印象深刻。在可能被头条新闻淹没的值得注意的事项中包括:
- 新的系统提示词 (System Prompt)
- 被脱敏思考内容的编码/解码
- 流式思考 (Streaming Thinking)
- 128k 输出 Token 能力(测试版)
-
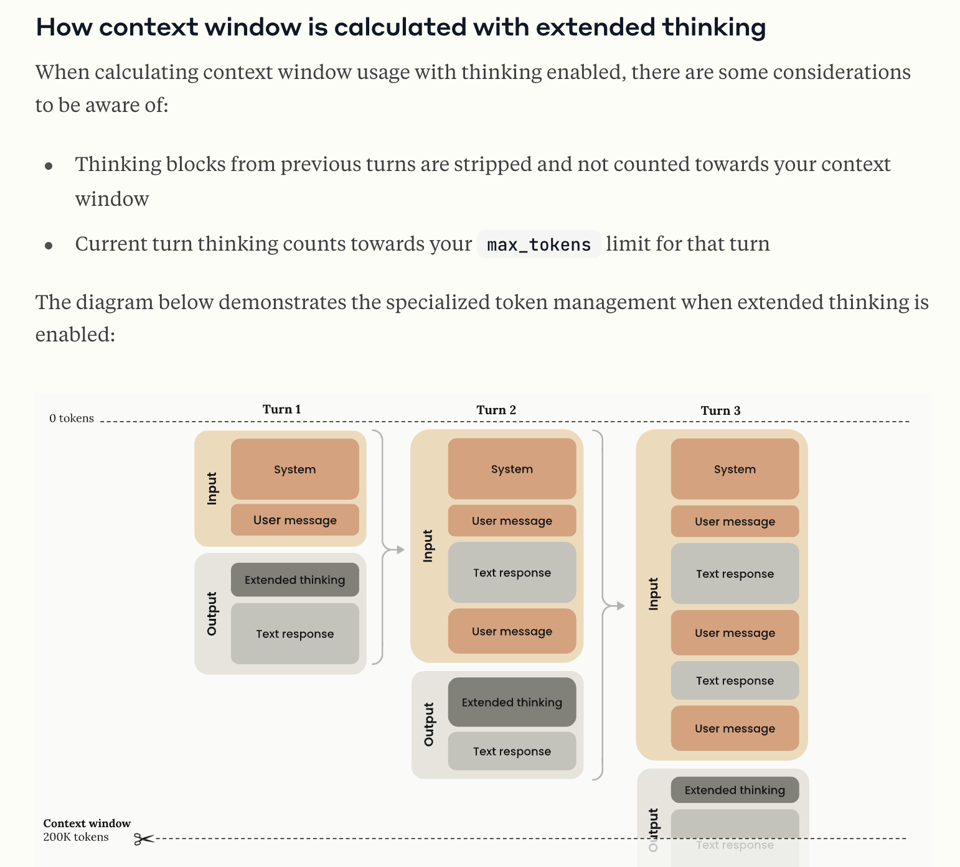
上下文窗口和 Prompt Caching 会跳过前一轮的思考块
- 工具调用 (Tool Use)
- 与 Grok 3 观点一致,认为并行 test time compute 非常有用且值得研究
AI Twitter 回顾
新模型发布与更新 (Claude 3.7 Sonnet, Grok 3)
-
Claude 3.7 Sonnet 发布:@alexalbert__ 宣布发布 Claude 3.7 Sonnet,强调它是他们迄今为止最智能的模型,也是首个普遍可用的混合推理模型。该模型具有两种思考模式:近乎即时的响应和扩展的、逐步的思考。@AnthropicAI 也正式介绍了 Claude 3.7 Sonnet,强调了其混合推理能力以及 Claude Code(一款 Agent 化的编程工具)的推出。@skirano 将 Claude Code 描述为 Anthropic 的首个编程工具,强调了它与 Claude 3.7 Sonnet 在编程任务中的协同作用。@arankomatsuzaki 分享了 Claude 3.7 Sonnet System Card。@stevenheidel 祝贺 Anthropic 团队发布 3.7 Sonnet,并表示很期待尝试。
-
Claude 3.7 Sonnet 的特性与能力:@alexalbert__ 详细说明了 3.7 Sonnet 针对现实世界任务而非仅仅是竞赛进行了优化,在标准模式下提供了重大升级,在处理复杂任务的扩展思考模式下提升更大。@AnthropicAI 解释了 Claude 的扩展思考模式,强调了它在解决难题时带来的智能提升,以及开发者设置“思考预算” (thinking budget) 的能力。@alexalbert__ 提到用户可以控制 Claude 的思考预算以平衡速度和质量,新的 Beta Header 允许高达 128k tokens 的思考/输出。@alexalbert__ 还表示价格与之前的 Sonnet 模型保持一致:每百万 input tokens 3 美元 / 每百万 output tokens 15 美元。@AnthropicAI 表示,与前代产品相比,拒绝率降低了 45%。@akhaliq](https://twitter.com/_akhaliq/status/1894106278185898489) 使用编程提示词测试了 Claude 3.7 Sonnet 并分享了结果。[@qtnx 分享了对 Sonnet 3.7 的初步体验 (vibe check),指出它“越来越吸引我”。@Teknium1 注意到 Claude 3.7 Sonnet 似乎显示出针对性的改进,在 SWE-bench 中表现出色,并质疑这是否预示着 AGI 的到来,暗示基准测试可能无法说明全部情况。
-
Claude Code - Agent 化的编程工具:@alexalbert__ 宣布了 Claude Code 的研究预览版,这是一款 Agent 化的编程工具,用于由 Claude 驱动的代码辅助、文件操作以及直接从终端执行任务。@AnthropicAI 强调了 Claude Code 的效率,声称在早期测试中,它在单次运行中完成了通常需要 45 分钟以上手动工作的任务。@alexalbert__ 解释说 Claude Code 还可以作为 Model Context Protocol (MCP) 客户端运行,允许用户通过 Sentry、GitHub 或 Web 搜索等服务器扩展其功能。@nearcyan 强调了 Claude Code 的终端集成,指出 Agent 与系统合二为一。@catherineols 分享了使用 Claude Code 编程的小技巧,建议在干净的 commit 上工作以便轻松重置。@pirroh 注意到 Replit 对 Replit Agent 发布公告的期待,暗示将使用 Sonnet 3.7 的预览版进行协作。@casper_hansen_ 表示 Claude Code 在 SWE Bench 上达到了 70% 的性能,且不像 Aider 那样有陡峭的学习曲线。
-
Grok 3 与语音模式:@goodside 称 Grok 3 令人印象深刻,属于顶尖水平,尤其是在需要“无拒绝”响应的任务中,强调了它对提示者的信任。@Teknium1 认为 Grok 提供了最大的价值,而不像 OpenAI 那样充满陈词滥调。@goodside 报告了 Grok 3 Voice Mode 表现出的意外行为,包括在多次要求调大声音后,出现了长达 30 秒的尖叫和辱骂。@Teknium1 分享了 Grok 3 语音在浪漫模式(Romantic Mode)下的演示。@_akhaliq 分享了 Grok 3 构建跑酷游戏和 3D 游戏的演示。
研究与论文
-
DeepSeek 的 FlashMLA:@deepseek_ai 宣布推出 FlashMLA,这是一款针对 Hopper GPUs 的高效 MLA 解码算子,针对变长序列进行了优化,现已投入生产,作为其开源周(Open Source Week)的一部分。@danielhanchen 讨论了 DeepSeek 的首个 OSS 软件包发布,重点介绍了优化的 multi latent attention CUDA kernels,并提供了其 DeepSeek V3 分析推文的链接。@tri_dao 赞扬了 DeepSeek 在 FlashAttention 3 基础上的构建,并指出 MLA 已在 FA3 中启用。@reach_vb 强调了 DeepSeek 开源 FlashMLA 及其性能细节。@_philschmid 解释了 Multi-head Latent Attention (MLA) 如何加速 LLM 推理并减少内存需求,并引用了 DeepSeek 的 MLA 实现。
-
AI Agent 中的推理与规划:@TheTuringPost 分享了 AI 推理方面的最新突破,包括 思维链(CoT)提示、自我反思、少样本学习(Few-shot learning)和神经符号(Neuro-symbolic)方法,并链接到了 Hugging Face 上的一篇免费文章。@omarsar0 总结了 LightThinker,这篇论文提出了一种动态压缩 LLM 推理步骤的新方法,旨在不损失准确性的情况下提高效率。
-
扩散模型与采样:@cloneofsimo 指出,在扩散采样中,99.8% 的潜在轨迹(latent trajectory)可以用前两个主成分来解释,这表明轨迹在很大程度上是二维的。@iScienceLuvr 分享了 NVIDIA 关于基于 f-散度分布匹配(f-Divergence Distribution Matching)的一步生成扩散模型的新工作,实现了最先进的一步生成效果。
-
合成数据与缩放法则(Scaling Laws):@iScienceLuvr 重点介绍了一篇关于通过刻意练习(Deliberate Practice)改进合成数据缩放法则的论文,表明刻意练习可以提高验证准确性并降低计算成本。@jd_pressman 提倡使用 RetroInstruct 合成数据指南中的技术来增强英语语料库,并从现有语料库(如经济价格数据)中创建奖励模型(reward models)。
-
其他研究论文:@TheAITimeline 列出了上周顶尖的 AI/ML 研究论文,包括 Native Sparse Attention、SWE-Lancer、Qwen2.5-VL Technical Report、Mixture of Block Attention、Linear Diffusion Networks 和 SigLIP 2,并提供了概述和作者的解读。@_akhaliq 分享了 SIFT: Grounding LLM Reasoning in Contexts via Stickers。@_akhaliq 分享了 Think Inside the JSON: Reinforcement Strategy for Strict LLM Schema Adherence。@_akhaliq 分享了 InterFeedback: Unveiling Interactive Intelligence of Large Multimodal Models via Human Feedback。@_akhaliq 分享了 The Relationship Between Reasoning and Performance in Large Language Models: o3 (mini) Thinks Harder, Not Longer。@arankomatsuzaki 分享了 Bengio 等人关于 Superintelligent Agents and Catastrophic Risks 的论文。@iScienceLuvr 讨论了 GneissWeb,这是一个包含 10T 高质量 token 用于 LLM 训练的大型数据集。
编程与开发工具
-
Replit Agent 与移动端应用升级:@DeepLearningAI 报道了 Replit 升级其 Agent 驱动的移动端应用,用于生成和部署 iOS 及 Android 应用,目前由 Replit Agent 以及 Claude 3.5 Sonnet 和 GPT-4o 等模型提供支持。@cloneofsimo 对发现 Replit 表示惊叹。
-
LangChain 与 LangGraph:@LangChainAI 宣布 LangChain Python 已支持 Claude 3.7 Sonnet,JS 支持即将推出。@LangChainAI 推广了一场探讨 LangGraph.js + MongoDB 构建 AI Agent 的研讨会。@LangChainAI 宣布了与 CEO Harrison Chase 一同在亚特兰大举行的 LangChain in Atlanta 活动。@hwchase17 提到 LangSmith 等工具可以促进对新模型的快速评估。
-
Ollama 更新:@ollama 宣布 Ollama 的 JavaScript 库更新至 v0.5.14,改进了 Header 配置并修复了浏览器兼容性问题。
-
DSPy 范式:@lateinteraction 主张采用更高级别的 ML/编程范式,强调使用 DSPy 等工具将系统规范与 ML 机制解耦。@lateinteraction 强调 DSPy 是将系统规范与 ML 范式解耦的典型示例。
AI 模型性能与基准测试
-
SWE-bench 性能:@scaling01 表示他们正朝着 90% SWE-bench 验证预测的目标迈进。@OfirPress 对强劲的 SWE-bench 结果表示祝贺。@Teknium1 认为 SWE-bench 的实用性可能仅限于 Devin 等特定工具。
-
模型排名与评估:@goodside 提到 o1 pro 是顶尖的已发布模型,但在处理散文和代码时更倾向于 Claude 3.6。@abacaj 建议如果 Sonnet 获得知识更新,它可能会成为 SOTA。@andrew_n_carr 赞扬了 Riley 对模型排名的直觉。@MillionInt 提到了一个“全新的高品味评估(new high taste eval)”。
-
OmniAI OCR 基准测试:@_philschmid 讨论了 OmniAI OCR Benchmark,显示多模态 LLM 比传统 OCR 更好且更便宜,其中 Gemini 2.0 Flash 提供了最佳的性价比。
AI 行业与商业
-
Perplexity AI 的 Comet 浏览器:@AravSrinivas 宣布 Perplexity 即将推出 Comet,一款全新的 Agent 浏览器。@perplexity_ai 正式发布了 Comet:由 Perplexity 打造的 Agent 搜索浏览器。@AravSrinivas 就 Comet 除了标准 AI 功能外所需的特性征求用户反馈。@AravSrinivas 强调了 Comet 的工程挑战,并邀请人才加入。
-
MongoDB 收购 Voyage AI:@saranormous 祝贺 VoyageAI 团队被 MongoDB 收购,并指出 Embedding 和 Re-ranking 模型对企业级 AI 搜索的重要性。
-
AI 中心与全球扩张:@osanseviero 指出苏黎世正迅速成为一个超密集的 ML 中心,Anthropic、OpenAI 和 Microsoft 都在此开设了办公室,Meta 也在扩大其 Llama 团队。@dylan522p 引用了华为 CEO 关于中国半导体进展和雄心的言论。
-
政府与公共部门中的 AI:@ClementDelangue 赞扬了波兰政府成为 AI 构建者并在 Hub 上发布了开源权重。
梗与幽默
-
Anthropic 的命名惯例:@aidan_clark 表示对 Claude 命名团队的处境感同身受。@scaling01 调侃 Claude 4 被推迟到 2049 年。@fabianstelzer 发布了一个关于 Anthropic 产品命名的梗图。@typedfemale 调侃预测 Sonnet 3.78 将是下一个版本。@jachiam0 幽默地祝贺 Anthropic 在角逐最不可预测版本增量奖。
-
Grok 与 Elon Musk:@Teknium1 调侃 Grok 对被称为“智障”的本能反应及其对 X 平台特性的认知。@aidan_clark 幽默地威胁要破坏挪威的重水生产,以应对 Grok 3 的发布。
AI Reddit 摘要
/r/LocalLlama 摘要
主题 1. FlashMLA 的 Hopper GPU 优化:游戏规则改变者
- FlashMLA - OpenSourceWeek 第一天 (得分: 946, 评论: 82): FlashMLA 以发布针对 Hopper GPU 优化的 MLA 解码内核开启了 OpenSourceWeek,该内核支持 BF16 和块大小为 64 的 paged KV cache。性能指标包括在 H800 上达到 3000 GB/s 内存带宽受限和 580 TFLOPS 计算受限,更多详情见 GitHub。
- DeepSeek 的 GPU 获取渠道:关于 DeepSeek 是否拥有 NVIDIA H100 GPU 用于训练的说法存在质疑和辩论,一些用户认为这是假新闻。H800 GPU 已确认可以合法销往中国,混淆似乎源于沟通不畅或误报。
- 技术细节与优化:讨论集中在针对 Hopper GPU 的 MLA 解码内核优化,特别关注 CUDA 文件结构和 BFloat16 的使用。有疑问关于为何某些优化仅针对 Hopper,以及增加对其他架构支持的影响。
- 开源与社区影响:FlashMLA 的发布因其对开源社区的贡献而受到称赞,用户对未来可能的发布以及对创建高效 AI 模型的影响感到兴奋。社区对这种创新和分享精神持积极态度,将其比作 Llama 的开放性。
{kind=link}
主题 2. Claude 3.7 Sonnet 发布:探索混合 AI 推理模型
- Claude Sonnet 3.7 soon (Score: 359, Comments: 107): Claude Sonnet 3.7 与之前的版本(如 Claude V1 和 Claude V2)一同被提及,表明了软件开发的进展。图片暗示其重点在于编程代码和配置设置,突出了新 Claude Sonnet 3.7 模型的各种技术属性和参数。
- 版本混淆与命名:许多用户对 Claude Sonnet 的版本命名表示沮丧,尤其是从 3.5 到 3.7 的跳跃,一些人认为 3.7 是为了修正之前版本(如 3.5 v2 被标记为 3.6)带来的困惑。一位用户解释说,3 系列代表 1000 万美元规模的训练运行,而 4 系列预计将是 1 亿美元的投资,这解释了 Claude 4 发布延迟的原因。
- 平台与用例:Claude Sonnet 3.7 预计将在 AWS Bedrock 上推出,并可能在 2 月 26 日的 AWS 活动中宣布。该模型旨在支持 RAG、搜索与检索、产品推荐和代码生成等用例,但也有人对这些应用的深度表示怀疑,因为与之前版本相比,目前尚未提及明确的改进。
- 社区反应:在专注于开源话题的论坛中,对于讨论像 Claude Sonnet 这样的闭源模型反应不一,一些用户强调了了解闭源发展动态的重要性。另一些人则对讨论转向通用 LLM 表示失望,更倾向于关于开源模型及其实现的内容。
- Claude 3.7 is real (Score: 220, Comments: 71): Claude 3.7 已经发布,用户界面显示了标题 “Claude 3.7 Sonnet” 且设计极简。界面向用户提问:“今晚我能帮你什么?” 并建议升级到 Pro 版本以获得更多功能。
- Claude 3.7 Sonnet 的可用性与特性:Claude 3.7 Sonnet 可在多个平台上使用,包括 Claude 订阅计划、Anthropic API、Amazon Bedrock 和 Google Cloud 的 Vertex AI。它保持了与之前版本相同的价格,即 每百万输入 Token 3 美元 和 每百万输出 Token 15 美元,并引入了“扩展思考”(extended thinking)模式(免费版除外)。
- 模型性能与测试:用户对 Claude 3.7 Sonnet 的性能反应不一,一些人称赞其处理复杂推理任务的能力,而另一些人则指出它在特定测试(如 nonogram test)中失败。尽管有所改进,它在某些任务上仍面临与旧版本类似的困难,且用户对其推理时间限制和输出成本表示担忧。
- 数据利用与蒸馏:目前的重点在于利用 Claude 3.7 Sonnet 生成高质量数据集,用于微调本地模型。用户讨论了从 API 提取数据进行模型蒸馏,一些人强调了创建数据集以通过监督微调 (SFT) 增强本地模型能力的重要性。
- Most people are worried about LLM’s executing code. Then theres me…… 😂 (Score: 236, Comments: 33): 该帖子幽默地将人们对 大语言模型 (LLMs) 执行代码的普遍担忧与个人对系统自动化的轻松态度进行了对比。帖子附带的图片列出了一套使用 PowerShell 和 Python 自动化任务的规则,并俏皮地暗示完成这些任务将通向“自由”。
- 风险管理:一位用户建议在 AI 生成的代码执行前后实施风险分析流程,以确保风险最小化,并强调了使用沙箱或虚拟机 (VMs) 进行安全防护的重要性。
- 幽默与视角:人们对 AI 能力的看法正从恐惧转向幽默,用户们开玩笑说 AI 实现了“自由”,并回忆起 ChatGPT 热潮初期的种种忧虑。
- 执行环境:讨论强调了使用 VM 执行 AI 生成代码的重要性,并提到了 OmniTool with OmniParser2 等工具,尽管它们成本高昂且性能并非最优。
{kind=link}
{kind=link}
{kind=link}
主题 3. Qwen 系列:通过 QwQ-Max 推进开源 AI
- Qwen 今晚将发布新内容! (Score: 293, Comments: 57): Qwen 预计今晚将发布一项新进展,引发了 AI 社区的关注和猜测。帖子中未提供发布的具体细节。
- QwQ-Max Preview 被强调为 Qwen 系列 的重大进步,专注于深度推理和多功能问题解决。此次发布将包括 Qwen Chat 的专用 App,开源如 QwQ-32B 等较小的推理模型,并促进社区驱动的创新 (GitHub 链接)。
- 社区热切期待 Qwen 3 的开源,并预计 QwQ32B 等模型在推理能力上将超越现有的 R1 70B 等模型。目前存在关于可能发布 Qwen Coder 72B 的猜测,以及对具有 自动 COT 级别 GPT-4 模型的兴趣。
- 对于媒体报道中关于 DeepSeek 和 Qwen 系列性价比的描述存在怀疑,一些用户对配置模型的团队能力表示怀疑。讨论还涉及作为 OpenSourceWeek 一部分的针对 Hopper GPU 的 FlashMLA 效率问题 (GitHub 链接)。
主题 4. AI 基准测试批判:可靠性与误解
- 基准测试是谎言,我有几个例子 (Score: 149, Comments: 84): 作者批评了 AI 基准测试分数,强调了基准测试结果与模型实际表现之间的差异。他们引用了 Midnight Miqu 1.5 和 Wingless_Imp_8B 的例子,后者分数更高但表现更差;以及 Phi-Lthy 和 Phi-Line_14B 的案例,其中一个被“脑叶切除”的模型尽管减少了层数,但得分却更高。他们认为基准测试可能无法准确反映模型能力,并暗示一些 SOTA 模型可能因误导性的分数而被忽视。提供了所讨论模型的链接以便进一步检查:Phi-Line_14B 和 Phi-lthy4。
- EQbench 和基准测试的局限性:EQbench 因使用 Claude 作为评委并偏好“废话和华丽辞藻”而受到批评。基准测试被认为是有缺陷的,不能反映真实世界的表现,因为个人测试通常会得出不同的结果 (ASS Benchmark)。
- 基准测试 vs. 真实世界表现:几位评论者认为,基准测试经常被刷分(gamed),无法准确代表模型在实际用例中的能力。像 Phi-4 14B 这样的模型被指出在基准测试中的表现优于实际应用,用户建议保留个性化的基准测试套件以更好地评估模型性能。
- 模型表现与用户反馈:用户表示,真实世界的测试和个人体验比基准测试分数更有价值,正如在 Phi-Lthy 14b 和 Gemini 等模型中所看到的那样。人们呼吁针对特定用例(如角色扮演)建立更多相关的基准测试,而目前的基准测试未能充分覆盖这些领域。
其他 AI Subreddit 回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding
主题 1. Claude Sonnet 3.7 通过 AWS Bedrock 泄露详细信息
- Claude Sonnet 3.7 即将发布? (Score: 192, Comments: 55):AWS Bedrock 似乎泄露了关于 Claude Sonnet 3.7 的细节,潜在发布日期为 2025 年 2 月 19 日。该模型被描述为 Anthropic 迄今为止最智能的模型,引入了用于解决复杂问题的 “extended thinking”,并允许用户在速度和质量之间取得平衡。它专为 coding、agentic 能力和内容生成而设计,支持 RAG、预测和定向营销等用例。
- 讨论强调了 AI 模型的命名规范,批评了如 “3.5 Sonnet (new)” 等版本命名导致的不一致和混乱,并建议使用更清晰的次版本标记(如 “4.1, 4.2”)来准确反映性能差异。
- 对于 Claude Sonnet 3.7 的命名存在怀疑和幽默,引用了关于 Anthropic 模型命名惯例的笑话,并认为 “extended thinking” 功能可能只是之前版本的微小升级。
- 多名用户确认在 AWS 代码中提到了 Claude 3.7,并附上了特定 JS 文件(main.js, vendor_aws-bd654809.js)的链接,证实了 Claude 3.7 Sonnet 作为 Anthropic 拥有 “extended thinking” 能力的最先进模型的存在。
AI Discord 回顾
由 Gemini 2.0 Flash Thinking 提供的摘要之摘要
以下是针对技术工程师受众量身定制的各 Discord 频道关键讨论主题的统一摘要:
主题 1. Claude 3.7 Sonnet:Thinking Coder 登场
- Claude 3.7 Sonnet 横扫 Coding 基准测试,获得 IDE 访问权限:Claude 3.7 Sonnet 被誉为 coding 强力工具,在使用 32k thinking tokens 的情况下,在 Aider 排行榜上获得了 65% 的分数,超越了之前的模型甚至 Grok 3。Cursor IDE 和 Aider 已经集成了 Sonnet 3.7,用户报告了显著的 coding 改进和 agentic 能力,引发了对其在现实世界开发任务中潜力的兴奋。
- 推理能力强大,但价格昂贵:Aider 和 OpenAI 频道的用户对 Claude 3.7 的 thinking model 和增强的推理能力(尤其是调试方面)印象深刻,但质疑每 1M output token 15 美元 的价格是否优于 Grok 3(每 1M 2.19 美元)等更便宜的模型。OpenRouter 提供对 Claude 3.7 和其他模型的访问,允许用户管理 API keys 并绕过速率限制,但价格仍是一个担忧。
- Claude Code:你的终端伙伴已上线(但仍需磨合):Anthropic 与 Claude 3.7 一起推出了 Claude Code,这是一个基于终端的 coding assistant。虽然在 coding 辅助和错误处理方面优于 Aider 等工具,但 Latent Space 和 MCP 频道的一些用户报告响应时间较慢,并寻求关于其 extended thinking 功能以及与 MCP 工具(如 AgentDeskAI/browser-tools-mcp)集成的更好文档。
主题 2. 开源模型竞赛升温:Qwen 与 DeepSeek 争夺推理桂冠
- 通义千问 QwQ-Max 预览版:推理模型发布,移动端应用即将推出:Qwen AI 预览了 QwQ-Max-Preview,这是一个基于 Qwen2.5-Max 的推理模型。根据 LiveCodeBench 的数据,其性能与 o1-medium 相当。在 Interconnects 和 Yannick Kilcher 频道中讨论指出,该模型在 Apache 2.0 协议下开源,并计划推出 Android 和 iOS 应用,标志着对易用且强大的推理模型的强力推动。
- DeepSeek 开源周:MLA 提升推理速度,DeepEP 助力 MoE 训练:DeepSeek AI 在开源周期间引起轰动,发布了 DeepEP,这是一个用于高效 MoE 训练的专家并行通信库,在 Unsloth AI 和 GPU MODE 频道中引发讨论。他们在 Eleuther 中被重点提及的 Multi-head Latent Attention (MLA) 架构,通过压缩 KV cache,有望实现 5-10 倍的推理速度提升,可能会重塑未来的 LLM 架构。
- DeepScaleR:1.5B 模型的 RL 微调性能超越 O1-Preview:Torchtune 频道成员注意到 DeepScaleR,这是一个基于 Deepseek-R1-Distilled-Qwen-1.5B 并使用强化学习(RL)进行微调的 1.5B 参数模型。它在 AIME2024 上实现了 43.1% 的 Pass@1 准确率,比 O1-preview 显著提升了 14.3%,展示了 RL 在扩展小型模型以处理复杂任务方面的强大能力。详细信息请参阅 此 Notion 帖子。
主题 3. IDE 对决:Cursor vs. Windsurf(以及 Vim 的困境)
- Cursor 在 Claude 3.7 上的领先引发 Windsurf 用户羡慕,MCP 问题依然存在:Codeium (Windsurf) 频道的用户正焦急地等待 Claude 3.7,并对 Cursor IDE 用户已经可以使用该模型感到沮丧,这引发了关于 Cursor 更快模型集成的辩论。与此同时,Cursor 和 Windsurf 频道都在讨论持续存在的 MCP (Model Context Protocol) 问题,这些问题阻碍了编辑功能,并导致用户不得不手动修改配置文件。
- Cursor 0.46 更新:索引 Bug 困扰多文件夹工作区:Cursor IDE 用户报告了 0.46 版本(更新日志)中跨多个目录的文件夹索引和文件编辑问题,促使用户检查设置并在 Cursor 论坛 上提供反馈,以改进平台功能。
- Vim 用户苦于 Codeium Chat 连接错误:Codeium (Windsurf) 频道的 Vim 用户正努力尝试在 Vim 中通过 SSH 启动 Codeium Chat,但在访问提供的 URL 时遇到连接错误,凸显了特定扩展可能存在的问题,以及在 Codeium 论坛 中寻求针对性支持的必要性。
主题 4. 硬件黑客与内核深度探索:GPU Mode 社区走向细粒度
- GPU MODE 基准测试:Gemlite 内核引发内存受限(Memory-Bound)辩论,Tensor Core 限制被揭示:GPU MODE 频道成员深入研究了 Triton 中 mobiusml/gemlite 库的快速低比特 matmul 内核,讨论了 gemv 操作的内存受限本质以及令人惊讶的 Tensor Core 使用缺失。他们澄清说,tensorcores 要求最小张量维度为 16x16,这限制了它们在某些内核优化中的适用性。
- RX 9850M XT 上的 ROCm/MIOpen Wavefront 问题:调试标志前来救场:GPU MODE 用户报告了 RX 9850M XT GPU 上由于错误的 wavefront 大小默认值导致的 MIOpen 问题,这引发了 PyTorch 中的内存访问故障。分享了一个使用
MIOPEN_DEBUG_CONV_GEMM=0和MIOPEN_DEBUG_CONV_DIRECT=0的变通方法,更多细节见 此 GitHub issue。 - Mojo FFI 弥合 C++/图形学差距,Eggsquad 的生命游戏实现硬件加速:Modular (Mojo 🔥) 频道成员展示了使用 Mojo FFI 链接到 GLFW/GLEW 以在 Mojo 中进行图形编程,并提供了一个数独演示 (ihnorton/mojo-ffi)。Eggsquad 展示了一个虽然搞怪但令人印象深刻的硬件加速版 Conway’s Game of Life,该程序使用 MAX 和 pygame 构建,引发了关于 Mojo 中 GPU 利用率和 SIMD 优化的讨论。
Theme 5. 社区贡献与课程:共同学习与构建
- Unsloth AI 挑战赛升温,仍在大力招揽顶尖人才:Unsloth AI 频道的 Unsloth AI Challenge 正在收到大量投稿,但到目前为止,还没有参与者达到发放录用通知的高门槛,这促使官方寻求推荐以寻找合格候选人,显示出 AI 人才招聘领域的竞争态势。
- Berkeley MOOC:Tulu 3 深度解析,RLVR 训练方法,课程详情即将公布:LLM Agents (Berkeley MOOC) 频道宣传了 第 4 课,由 Hanna Hajishirzi 讨论 Tulu 3(据报道该模型性能优于 GPT-4o)以及创新的 具有可验证奖励的强化学习 (RLVR) 训练方法。包括项目在内的 MOOC 课程详情即将公布,承诺提供实践学习体验。
- Hugging Face 社区助力乌克兰语 TTS,推出商业 AI 系列:HuggingFace 频道重点介绍了一个新的高质量 乌克兰语 TTS 数据集,改善了语音应用的资源 (speech-uk/opentts-mykyta)。推出了名为“AI for Business – From Hype to Impact”的新系列,旨在指导企业利用 AI,展示了社区在民主化和应用 AI 知识方面的努力。
PART 1: 高层级 Discord 摘要
Cursor IDE Discord
- Claude 3.7 在编程方面表现出色:用户报告称 Claude 3.7 处理编程任务和复杂 Prompt 的效率比 3.5 更高,并指出其在编程能力和实际 Agent 任务方面有显著改进。
- 社区对 thinking model(思考模型)及其在规划和调试方面的潜力印象深刻,尽管正如 Cursor 的推文所强调的,部分用户发现其在 Agent 模式下的执行力令人沮丧。
- MCP 工具极大提升用户体验:MCP 工具的集成(特别是配合自定义指令)增强了模型在 Cursor 中处理文件和命令的功能,用户正在利用深度思考和浏览器工具(AgentDeskAI/browser-tools-mcp)优化配置。
- 社区成员正积极探索改进 MCP 设置的方法以获得更好的项目成果,重点关注如何通过有效的 Prompt 来最大化性能。
- Cursor 更新引发 Bug 讨论:讨论集中在 Cursor 0.46 版本中文件夹索引和跨多个目录的文件编辑问题(Changelog)。
- 用户正在检查设置以解决索引问题,目前正在收集持续的反馈以改进平台功能,详见 Cursor 论坛。
- 社区分享模型使用经验:成员们正积极分享与 Claude、Grok 和 Qwen 相关的经验和实用工具,讨论它们在 Cursor 中的交互以及优化性能的方法。
- 社区专注于优化 Cursor 内的交互并分享有效的 Prompt,以最大化 AI 模型性能,并对比不同模型的使用体验。
aider (Paul Gauthier) Discord
- Claude 3.7 霸榜 Aider 排行榜:Claude 3.7 Sonnet 在 Aider 排行榜上使用 32k thinking tokens 获得了 65% 的评分,超越了以往模型,而其非思考版本的评分为 60%。
- Aider 频道的用户将其性能与 Grok 3 进行了对比,指出 $15/M 与 Grok $2.19/M 的价格差异,对于成本增加是否物有所值评价不一。他们引用了 Anthropic 的这条推文。
- Aider 拥抱 Claude 3.7 的思考能力:Aider 0.75.1 版本现已支持 Claude 3.7,使用户能够进行实验并有效管理成本;用户正在讨论如
--copy-paste等命令,以优化 Claude 的工作流,详见 Aider 文档。- 社区讨论了 Claude Code 界面的设计和功能,将其与 Aider 进行对比,并探索提升编程体验的方法,权衡使用不同平台的优缺点。
- OpenRouter 为无限 API 开启大门:用户发现 OpenRouter 在绕过速率限制和集中管理 API Key 方面非常有用,简化了访问多种模型的流程。
- 尽管定价与原始供应商一致,但统一 API 访问的便利性使 OpenRouter 成为一个极具吸引力的选择,尤其是在管理
claude-3-7-sonnet-20250219等模型的 Token 使用量时。
- 尽管定价与原始供应商一致,但统一 API 访问的便利性使 OpenRouter 成为一个极具吸引力的选择,尤其是在管理
- Hacker News 个人资料被 AI 吐槽:Claude Sonnet 3.7 现在可以分析 Hacker News 个人资料,提供幽默且准确的用户活动亮点和趋势分析。
- 用户开玩笑说他们的资料被 AI “吐槽(roasted)”了,并赞赏其对他们在线行为的洞察力既搞笑又深刻。
- Kagi 的 LLM 基准测试评选出新的推理冠军:Kagi LLM 基准测试项目(最后更新于 2025 年 2 月 24 日)评估了主流 LLM 在推理、编程和指令遵循方面的表现,揭示了令人惊讶的见解。
- 结果显示 Google 的 gemini-2.0 以 60.78% 领先,在这些旨在防止基准测试过拟合的新型任务中,表现优于 OpenAI 的 gpt-4o(48.39%)。
Codeium (Windsurf) Discord
- Windsurf 用户焦急等待 Claude 3.7:Windsurf 用户正在等待 Claude 3.7 的推出,并对 Cursor 用户已经获得访问权限表示沮丧。
- 社区期待易用性的改进和增强,想知道他们是否能获得访问权限。
- Windsurf 与 Cursor 性能辩论:用户正在比较 Windsurf 和 Cursor,一些人认为 Cursor 在实现新模型方面速度更快。
- 尽管 Cursor 速度较快,一些用户仍因其更整洁的 UI 和更好的集成能力而偏好 Windsurf。
- MCP 问题困扰 Windsurf:持续的讨论围绕 MCP 的问题展开,这些问题阻碍了正常的编辑功能,促使用户手动编辑配置文件。
- 社区在等待支持团队官方修复的同时,正在分享临时解决方案。
- Vim 用户在 Codeium Chat 中遇到困难:一位用户在通过 SSH 会话在 Vim 中启动 Codeium Chat 时遇到困难,尝试访问提供的 URL 时遇到连接错误。
- 另一位成员建议在相关的扩展频道寻求帮助,并确认他们正在使用的是哪个扩展。
- 账号创建故障:一位用户报告称无法创建新的 Codeium 账号,遇到了内部错误消息。
- 这引发了关于其他用户在账号创建过程中是否也面临类似问题的担忧。
OpenAI Discord
- Claude 3.7 Sonnet 在编程领域遥遥领先:用户发现 Claude 3.7 Sonnet 在编程和 Web dev 方面优于 ChatGPT,理由是根据 Anthropic 的公告,其具有更好的连贯性和可靠性。
- 根据展示其 Agentic coding 能力的 推文,新模型 Claude Code 促进了代码辅助、文件操作和任务执行。
- Grok 3 因项目通用性受到关注:Grok 3 因其编程能力而受到赞誉,并被鼓励在 Copilot 等 IDE 中使用,可能会集成 Claude 3.7 的功能。
- 它处理项目的能力(特别是在 Frontend development 方面)受到高度重视,正如一位用户所说,它可以有效地协助 ‘Copilot 等 IDE 内部’ 的项目。
- 字节跳动的 Trae 加入免费 AI 狂潮:ByteDance 的 ‘Trae’ 提供对高级 AI 模型的免费访问,标志着 AI 领域的一次竞争性举动。
- 虽然用户赞赏免费 AI 工具的兴起,但他们仍对这类优惠的临时性质保持警惕,思考其对 AI 领域长期消费者访问和服务的影响。
- O3 推理受到惊人延迟的困扰:用户报告称 O3 模型经常显示“推理成功”,但完整文本输出会延迟 10 秒 或更长时间。
- 一位用户注意到在 EST 下午 3 点至 7 点 之间存在持续延迟,影响了所有“思考”模型,导致用户体验受挫。
- 截图问题阻碍 Bug 报告:一位成员指出在当前聊天频道添加截图存在挑战,阻碍了有效的 Bug 报告。
- 用户互相引导如何浏览不同频道和报告 Bug,强调了在发布新问题之前探索现有问题以提高效率的重要性。
Unsloth AI (Daniel Han) Discord
- Unsloth Challenge 寻求强力候选人:Unsloth AI Challenge 正在收到多份提交,但到目前为止,还没有参与者达到获得录用通知(offer)的标准。
- 社区鼓励推荐该挑战赛,以帮助寻找合格的候选人。
- DeepSeek 的发布引发观点分歧:DeepSeek OSS 的发布引入了 MoE kernels 和高效通信库等特性(来自 Daniel Han 的推文),引发了褒贬不一的反应。
- 一些人认为它更多地迎合了大公司,引发了关于这种开放性将如何影响竞争和 AI 开发格局(特别是在降低模型成本方面)的辩论。
- 训练配置引发困扰:用户报告称,当从 batch size 8 切换到带有 gradient accumulation 的 batch size 1 时,validation loss 意外地显著增加,这令人感到困惑。
- 社区探讨了混合设置策略如何影响模型学习,以及不同策略是否会产生相似的结果。
- Checkpointing 期间的 VRAM 占用问题:讨论强调了在 checkpointing 期间进行模型保存操作时,VRAM usage 会出现显著峰值。
- 用户建议将模型保存为 LoRA 以卸载 VRAM,从而更好地管理内存。
- QwenLM 发布新 qwq 模型:一名成员分享了 QwenLM 发布的新 qwq model 链接(qwq-max-preview)。
- 该帖子预告了他们的新模型,但目前还没有进一步的讨论。
OpenRouter (Alex Atallah) Discord
- Claude 3.7 Sonnet 的推理能力升级:Claude 3.7 Sonnet 已在 OpenRouter 上线,增强了数学推理、编程和问题解决能力,详见 Anthropic 的博客文章。
- 此次发布改进了 agentic workflows,并提供了快速推理和扩展推理的选项,不过扩展思考(extended thinking)功能的文档和支持尚在完善中。
- OpenRouter 管理 API Keys 并保留额度:可以生成新的 API keys 而不会丢失账户额度,因为额度是与账户绑定的,而非单个 key。
- 讨论澄清了尽管用户对丢失 API keys 表示担忧,但无论 key 的状态如何,额度都是安全的。
- 模型定价结构:Sonnet vs 其他模型:Claude 3.7 Sonnet 的定价为输入每百万 tokens 3 美元,输出(包括 thinking tokens)每百万 tokens 15 美元,旨在平衡用户参与度和模型效用。
- 与其他模型的对比显示,虽然 Claude 的定价被认为较高,但在特定性能指标(尤其是推理任务)方面仍具竞争力。
- 图片上传触及大小限制:用户报告在使用 Claude 3.7 时频繁报错,特别是当图片大小超过 5MB 时,会导致请求失败。
- 建议参与者将图片大小控制在限制范围内,以符合 API 要求并确保成功处理。
- 设备同步功能缺失:OpenRouter 不支持在不同设备(如桌面端到移动端)之间同步聊天会话。
- 有建议称用户可以使用 chatterui 和 typign mind 等第三方应用来弥补这一功能缺口。
Interconnects (Nathan Lambert) Discord
- Claude 3.7 Sonnet 携智能升级登场:根据 Anthropic 的消息,Claude 3.7 Sonnet 已发布,提升了推理、编程和调试任务的能力,尽管它有时会生成更复杂的代码。
- X(原 Twitter)上的用户正在分享有趣的测试结果,例如这个用 Tikz 绘制的雅典卫城,该模型拥有多种推理选项,包括 64k reasoning tokens。
- Qwen AI 展示 QwQ-Max 预览版:根据官方博客文章,Qwen AI 发布了 QwQ-Max-Preview,展示了其推理能力,并在 Apache 2.0 协议下保持开源可访问性。
- 正如这条推文所述,QwQ-Max-Preview 在 LiveCodeBench 上的评估显示其性能与 o1-medium 相当。
- 伯克利高级 Agent 课程聚焦 Tulu 3:Berkeley Advanced Agents MOOC 在太平洋标准时间今天下午 4 点邀请了 Hanna Hajishirzi 讨论 Tulu 3,并在 YouTube 上进行了直播(链接)。
- 参与者称赞该课程内容详实且具有实践意义。
- DeepSeek 开源 EP 通信库:DeepSeek 在开源周期间宣布了其开源的 EP 通信库 DeepEP,专注于模型训练的高效通信,详见这条推文。
- 此次发布是 AI 技术开源趋势的一部分,旨在鼓励社区参与。
GPU MODE Discord
- Gemlite 库引发 Kernel 讨论:成员们讨论了包含 Triton 编写的快速低比特 matmul kernel 的 mobiusml/gemlite 库,强调了 gemv 操作的 memory-bound(内存受限)特性。
- 讨论中提到 gemv 不使用 Tensor Cores,因为它们只增加 flops,且 tensorcores 要求最小张量维度为 16x16。
- TorchAO 获得 E2E 示例:
@drisspg确认他们正在开发 TorchAO 中的 E2E 示例。- 这突显了 TorchAO 社区协作讨论的性质。
- DeepSeek AI 开源专家并行通信库:deepseek-ai 的 GitHub 仓库 DeepEP 提供了一个高效的专家并行(expert-parallel)通信库。
- 其目标是增强分布式系统的通信性能。
- Meta 为 AI 协作招募 PyTorch 工程师:Meta 宣布招聘 PyTorch Partner Engineers,与领先的行业合作伙伴及 PyTorch 团队合作。
- 该职位强调系统和社区工作,并提供将 AI 技术从研究推向实际应用的机会,同时确保招聘过程中的平等就业机会(Equal Employment Opportunity)。
- MIOpen Wavefront 问题:一位用户报告了由于 RX 9850M XT 上错误的 wavefront 大小默认值导致 MIOpen 出现问题,从而引发 PyTorch 中的内存访问错误。
- 他们使用
MIOPEN_DEBUG_CONV_GEMM=0和MIOPEN_DEBUG_CONV_DIRECT=0作为临时解决方案,更多信息可在此 GitHub issue 中找到。
- 他们使用
Yannick Kilcher Discord
- Grok vs O1:模型大讨论?:关于是否从 O1-Pro 切换到 SuperGrok 引发了激烈辩论,双方对其编程能力的看法各不相同。
- 一些工程师认为 O1 在代码处理方面表现更好,而另一些人则欣赏 Grok 详尽的回复,即便这需要对 Prompt 进行调整。
- xAI 构建巨型计算集群:xAI 计划将其 GPU 集群扩展至 200,000 个 GPU,将 Grok 定位为挑战 OpenAI 的多功能 AI 平台。
- 据 NextBigFuture.com 报道,此次扩张反映了将 Grok 打造为更通用解决方案的战略举措。
- DeepSeek 深入探索数据合成:讨论强调了合成数据生成日益增长的重要性,特别是 DeepSeek 利用概念而非仅仅是 Token 进行优化的范例。
- 构建强大的合成数据流水线现在被视为 AI 模型可持续发展的关键,创建高质量训练数据的技术正成为一种竞争优势。
- Claude 3.7 Sonnet 表现亮眼:Anthropic 推出了 Claude 3.7 Sonnet,宣传其混合推理能力可实现近乎即时的响应,在编程和前端开发方面表现卓越,点击查看更多。
- 随新模型一同推出的还有 Claude Code,旨在处理 Agent 编程任务,以进一步简化开发者的工作流程,详见此 YouTube 视频。
- Qwen 满足推理需求:Qwen Chat 预览了基于 Qwen2.5-Max 的推理模型 QwQ-Max,并计划推出 Android 和 iOS 应用以及遵循 Apache 2.0 许可证的开源版本。
- 其在数学、编程和 Agent 任务方面的专业能力详情可见其 博客文章,这标志着其在推理能力上迈出了雄心勃勃的一步。
Eleuther Discord
- 大脑分块,AI 预测:讨论指出人类语言处理依赖于分块(chunking)和抽象,而不像 AI 模型那样同时预测 Token,这让人质疑大脑与 AI 之间的并行性。
- 辩论强调了由于反向传播挑战导致传统 RNN 架构难以扩展的问题,以及对替代架构的潜在需求。
- DeepSeek 的 MLA 碾压 KV Cache:由 DeepSeek 创新的 Multi-head Latent Attention (MLA) 显著压缩了 Key-Value (KV) cache。根据这篇论文,与传统方法相比,推理速度提高了 5-10 倍。
- DeepSeek 在 MLA 驱动的模型上投入了至少 550 万美元,这表明业界对未来模型转向 MLA 技术充满兴趣。
- Looped Transformers 高效推理:一篇论文提出,Looped Transformer 模型在推理任务中可以匹配更深的非循环架构的性能,同时减少了参数需求,详见这篇论文。
- 这种方法展示了迭代方法在应对复杂计算挑战中的优势,并具有降低计算成本的潜在益处。
- Attention Maps 依然流行吗?:成员们讨论了 Attention Maps 与基于神经元的方法相比受欢迎程度下降的问题。一些人认为这是由于 Attention Maps 的观察性质,而另一些人提到 Attention Maps 在前向传播过程中可以直接进行干预。
- 一位成员表达了对 Attention Maps 的偏好,因为它们能够利用语言特征生成树和图,并引用了自 BERT 以来从 Attention Maps 中涌现的语法特性。
- 混合精度状态解析:在混合精度训练中,除非激活了 ZeRO Offload,否则 Master FP32 权重通常存储在 GPU VRAM 中。
- 建议使用 BF16 低精度权重配合 FP32 优化器状态 + Master 权重 + 梯度进行常规混合精度训练,成员们指出 Megatron-LM 是一个极佳的参考示例。
Latent Space Discord
- Anthropic 发布 Claude 3.7 Sonnet 和 Claude Code:Anthropic 推出了 Claude 3.7 Sonnet,其中包括推理能力的提升,以及 Claude Code,一个基于终端的编程助手 (@anthropic-ai/claude-code)。
- 测试者注意到其 更高的输出 Token 限制 和 增强的推理模式,带来了更连贯的交互,一些人还称赞了其巧妙的 System Prompt (Mona 的推文)。
- 微软取消数据中心租赁:报告显示微软正在取消数据中心租赁,这预示着数据中心市场可能存在 供应过剩 (Dylan Patel 的推文)。
- 此举让人们对微软 2024 年初激进的预租赁策略及其对托管服务领域的广泛影响产生怀疑。
- Qwen 的未来发布引发期待:对于即将发布的 Qwen QwQ-Max 的期待正在增长,据报道该版本具有改进的推理能力,并将在 Apache 2.0 协议下开源 (Hui 的推文)。
- 社区正密切关注这些进展及其对智能模型格局的影响。
- Claude Code 简化编程辅助:早期用户发现 Claude Code 对编程辅助很有帮助,但体验各异,一些人反映响应时间较慢。
- 反馈还提到了价格方面的顾虑,并赞扬了优化性能的 强力缓存 (heavy caching) 功能。
- GitHub 的 FlashMLA 吸引社区关注:GitHub 项目 FlashMLA 最近被分享,在没有任何宣传的情况下引发了对其在 AI 开发中可能产生的影响的兴趣 (FlashMLA GitHub)。
- 成员们对本周预期发布的 AI 工具的未来进展感到兴奋。
Nous Research AI Discord
- Grok3 工具调用引发困扰:成员们对 Grok3 的工具调用 (tool invocation) 机制表示困惑,指出 System Prompt 中缺少 Token 序列列表。
- 讨论质疑了硬编码函数调用与用于工具调用的 In-context Learning 的可靠性和透明度。
- Claude 3.7 Sonnet 登场:Anthropic 发布了 Claude 3.7 Sonnet,强调了其混合推理能力和用于编程的命令行工具。
- 早期基准测试表明 Sonnet 在软件工程任务中表现优异,使其成为 Claude 3.5 的潜在替代者。
- QwQ-Max-Preview 展示深度推理:QwQ-Max-Preview 作为 Qwen 系列的一部分亮相,主打深度推理和 Apache 2.0 协议下的开源可访问性。
- 社区推测该模型的尺寸,并希望有更小的、可在本地使用的版本。
- 结构化输出项目寻求反馈:一个旨在解决结构化输出 (Structured Outputs) 挑战的开源项目启动,邀请社区反馈和协作。
- 成员建议重新发布公告,以增加在社区内的曝光度和参与度。
- Sonnet-3.7 在 Misguided Attention 中脱颖而出:一位成员使用 Misguided Attention Eval 对 Sonnet-3.7 进行了基准测试,注意到其处理误导信息的能力。
- 他们声称它作为非推理模型表现最好,几乎超越了 o3-mini,进一步证明了其在推理评估中的竞争优势。
MCP (Glama) Discord
- Anthropic 发布 MCP Registry API:@AnthropicAI 发布了官方 MCP registry API,旨在为 MCP 工具和集成提供权威来源(source of truth)。
- 社区成员表示兴奋,希望这将使 MCP 管理标准化并提高可靠性。
- LLM 版本命名规范令用户困惑:用户对 LLM 版本命名感到困惑,尤其是 Claude 3.7,并注意到它通过 adaptive thinking modes 整合了功能并提升了性能。
- 这表明 version 3.7 在通过 adaptive thinking modes 提升性能的同时,整合了之前版本的功能。
- Haiku 3.5 的工具支持存在特性:根据用户经验,Haiku 3.5 虽然支持工具,但在连接较少工具时表现更好。
- 服务器和工具管理的压力是一个令人担忧的问题,这促使了开发集成工具集的聊天应用的计划,以便于使用。
- Claude Code 在编码任务中优于 Aider:用户发现 Claude Code 在有效处理编码错误方面优于 Aider。
- 人们对使用 Claude Code 处理更复杂的任务越来越感兴趣,可能会利用 heavy thinking modes 来获得最佳结果。
- MetaMCP 考虑使用 AGPL 以保持开放性:MetaMCP 正在考虑切换到 AGPL 协议,以鼓励社区贡献。
- 此举旨在解决当前 ELv2 许可证的局限性,该许可证限制了贡献,并要求托管的更改必须开源。
HuggingFace Discord
- Gemma-9B 模型面临加载错误:用户报告了在使用自定义 LoRA 加载 Gemma-9B 模型时出现错误,特别是
LoraConfig.__init__()函数。- 几位用户寻求建议,表明在通过自定义配置适配 Gemma-9B 时存在共同的技术挑战。
- Qwen Max 推理模型备受期待:Qwen Max 推理模型预计将于本周发布,被誉为自 DeepSeek-R1 以来最强大的开源模型。
- 根据这条推文,Qwen Max 在数学理解和创造力方面表现出进步,并计划推出官方版本和移动应用。
- Claude-3.7 被称为潜在的 SWE-bench 杀手:Claude-3.7 被称为潜在的 SWE-bench 杀手,预计性能可与 DeepSeek-R1 媲美,而体积仅为其三分之一。
- 由于其每百万 token 输出的高昂定价,人们对 Claude-3.7 的成本效益提出了担忧。
- 乌克兰语 TTS 数据集增强了可访问性:Hugging Face 上发布了一个高质量的乌克兰语 TTS 数据集,改善了 TTS 项目的资源,更新详情见此处。
- speech-uk/opentts-mykyta 数据集的最新更新展示了对乌克兰语文本转语音应用的持续支持。
- AI for Business 系列揭晓:推出了名为 AI for Business – From Hype to Impact 的新系列,旨在帮助企业利用 AI 获得竞争优势。
- 该系列计划涵盖如何在不中断业务运营的情况下扩展 AI 的主题。
LM Studio Discord
- Qwen 2.5 VL 模型夺冠:Qwen 2.5 VL 7B 模型在质量上超越了 Llama 3.2 等先前模型,因其在生成图像描述方面的出色表现而受到关注。根据用户报告,该模型可从 Hugging Face 下载。
- 多位用户确认了其在现实场景中的应用潜力,特别是在视觉语言应用中,并可以在 LM Studio 中本地运行。
- 讨论 Deepseek R1 本地托管:用户讨论了在本地运行 Deepseek R1 671B,根据文档,这需要 192GB 的 RAM 阈值,同时将计算卸载到 GPU。
- 一位用户分享了使用特定量化技术优化模型性能的经验,使用了 Unsloth’s GGUF。
- 应对装机难题:一位用户对电脑配置的兼容性表示沮丧,指出 aio pump 需要一个 USB 2.0 header,并且会干扰最后一个 PCIE slot。
- 该用户正在考虑替代方案,因为他们有“第二个系统可以放置所有组件”,这表明他们正转向优化硬件配置。
- Apple M2 Max:依然可行吗?:一位用户选择了翻新的 M2 Max 96GB 用于爱好和工作,对投资最新的 M4 Max 芯片表示犹豫。
- 讨论涉及了各种 Apple 芯片的 clock and throttle behavior(频率和降频行为),并指出了功耗差异:M2 Max 功耗为 60W,而 M4 Max 峰值达到 140W。
Stability.ai (Stable Diffusion) Discord
- SD3 Ultra 的存在引发关注:成员们对 SD3 Ultra 表示好奇,称其与 SD3L 8B 相比具有更高频率细节的潜力。
- 一位用户增加了关于其能力的神秘感,指出:它仍然存在——我还在使用它。
- 图像生成速度大比拼:图像生成时间差异巨大,一位用户报告在未说明的配置上需要 20 分钟,而另一位用户在 3060 TI 上生成 1920x1080 图像仅需 31 秒。
- 使用 SD1.5 的性能基准测试在 3070 TI 上平均为 4-5 秒,突显了模型和硬件选择对速度的影响。
- 寻找犬种图像数据集:一位成员正在寻找超过 20k 图像 的犬种图像数据集,超出了 Stanford Dogs dataset 的容量。
- 他们强调需要明确标注犬种的数据集。
- 分辨率调整带来速度提升:用户讨论了最佳分辨率设置,提倡使用 576x576 等较小尺寸来提高图像生成速度。
- 一位用户报告在实施这些调整后,处理时间缩短至约 8 分钟。
- Stability AI 开启反馈通道:Stability AI 推出了新的功能请求看板,允许用户通过 Discord 使用
/feedback命令提交想法。- 这一举措支持社区对请求进行投票,为 Stability AI 的开发优先级提供参考,并帮助我们确定下一步工作的优先级。
Modular (Mojo 🔥) Discord
- Mojo FFI 助力图形编程:成员展示了使用 Mojo FFI 将静态库链接到 GLFW/GLEW,通过一个数独示例证明了在 Mojo 中通过自定义 C/C++ 库进行图形编程的可行性。
- 他们使用了带有
alias draw_sudoku_grid = external_call[...]语法的别名来简化函数访问,并使用 Python 脚本动态链接库,该脚本可在 这里 获取。
- 他们使用了带有
- Mojo 的依赖版本控制至关重要:一位用户报告了在一个新的 Mojo 项目中 lightbug_http 依赖项出现错误,并引用了 Stack Overflow 的问题,而另一位用户则推测将 small_time 依赖项固定在
25.1.0是否可能是导致错误的原因。- 这些报告表明,精确的依赖版本控制对于避免安装和配置问题至关重要。
- MAX 在 GPU 上运行康威生命游戏:一位成员展示了他们使用 MAX 和 pygame 实现的硬件加速版康威生命游戏 (Conway’s Game of Life),称其为一个相当“愚蠢”的应用,同时引发了关于将 MAX 与 2080 Super GPU 配合使用的兼容性讨论。
- 讨论建议从 Python 运行脚本以促进 GPU 集成,这可以用于通过 graph API 向模型添加参数。
- SIMD 实现诱惑 Eggsquad:Eggsquad 提到发现了 Daniel Lemire 的 SIMD 化实现,但表示现阶段不愿进一步探索,而 Darkmatter 指出利用位打包 (bit packing) 可以在其实现中支持更大的图。
- Eggsquad 确认他们的康威生命游戏实现在修复一个 bug 后运行良好,并通过动画展示了结果,其中包括一个描绘游戏中“枪”的动画。
LLM Agents (Berkeley MOOC) Discord
- 据报道 Tulu 3 表现优于 GPT-4o:据 Hanna Hajishirzi 称,Tulu 3 作为一种最先进的经过后期训练的语言模型,通过创新的训练方法超越了 DeepSeek V3 和 GPT-4o。
- 这一声明是在一次涵盖语言模型训练和增强推理能力的全面努力的讲座中发表的。
- 伯克利 LLM Agents 课程将使用 RLVR:一种独特的具有可验证奖励的强化学习方法 (RLVR) 正被展示为一种有效训练语言模型的方式,旨在显著影响训练期间的推理。
- Hanna 在讲座中分享了关于在训练中结合这些先进强化学习技术的测试策略见解。
- MOOC 学生面临测验提交宽限:澄清说明测验截止日期仅适用于伯克利学生,MOOC 学生的所有测验均在学期末截止。
- 这一澄清为迟到者和担心错过初始截止日期的人提供了保证。
- MOOC 课程详情即将发布:一位成员宣布 MOOC 课程详情将很快发布,包括一个项目部分,并引用了一个 Discord 链接。
- 然而,研究轨道仅面向伯克利学生。
Notebook LM Discord
- 谷歌 Deep Research 与 Gemini 集成引发热潮:围绕将 Google Deep Research 和 Gemini 与 NotebookLM 集成以增强功能的讨论被点燃。
- 爱好者们对未来的发展表示兴奋。
- 用户在 NotebookLM 语言设置中挣扎:关于在不影响 Google 账户语言的情况下更改 NotebookLM 语言设置的问题浮出水面。
- 一位用户寻求关于如何有效实施此类语言更改的建议。
- 创意书籍数字化策略出现:一位成员建议使用 lens app 拍摄每一页以创建 PDF,然后将其转换为 PowerPoint 上传到 NotebookLM。
- 也有人提出了替代方案,例如使用复印机或 Adobe Scan 应用直接创建 PDF。
- 多语言 Prompt 有效性分析:关于是使用单个还是多个 Prompt 来促使 NotebookLM 中的主持人说德语引发了辩论。
- 一位成员推测,有效性可能与其 premium 订阅状态有关。
- Claude 3.7 引发用户狂热:用户对 Claude 3.7 充满热情,希望在选择模型方面有更多控制权。
- 一位用户发起了关于此类决定对用户体验影响的讨论。
LlamaIndex Discord
- AI Assistant 为 LlamaIndex 正式上线:LlamaIndex 文档中出色的 AI assistant 现在已面向所有人开放!点击这里查看。
- 团队非常期待看到用户如何将其整合到自己的工作流中。
- ComposioHQ 发布又一力作!:ComposioHQ 发布了又一个重磅产品!其功能和特性持续给人留下深刻印象。
- 早期采用者称赞其直观的界面和强大的功能集,并表示期待进一步的改进。
- Anthropic 发布 Claude Sonnet 3.7:AnthropicAI 发布了 Claude Sonnet 3.7,目前的情绪反馈和评估都非常积极。通过
pip install llama-index-llms-anthropic --upgrade即可获得 Day 0 支持。- 更多详情可以在 Anthropic 的发布公告中找到,其中强调了此新版本最新的集成能力。
- BM25 Retriever 需要 Nodes:一位成员指出,BM25 retriever 无法仅从 vector store 初始化,因为 docstore 必须包含已保存的 nodes。
- 解决该问题的一个建议是将 top k 设置为 10000 以检索所有 nodes,尽管这可能效率不高。
- MultiModalVectorStoreIndex 在处理图像时遇到困难:一位成员在尝试创建 MultiModalVectorStoreIndex 时遇到了与图像文件相关的错误,尽管图像存储在 GCS bucket 中。
- 该问题专门针对图像出现,因为他们的代码在处理 PDF documents 时运行正常,这表明 index 需要更好的图像处理能力。
Torchtune Discord
- TorchTune 辩论微调中的截断问题:Torchtune 的 #dev 频道出现了一场讨论,关于微调时是否应将默认设置从 right truncation 改为 left truncation,并引用了一个支持性的图表。
- 意见不一,一些人承认 HF 目前的默认设置是 right truncation,而另一些人则主张进行更改。
- StatefulDataLoader 寻求评审:一位成员请求对其 pull request 进行评审,该 PR 为 Torchtune 添加了对 StatefulDataLoader 类的支持。
- 该 pull request 旨在引入新功能并解决 Torchtune 框架内潜在的 bug 修复。
- DeepScaleR 使用 RL 超越 O1-Preview:DeepScaleR 模型基于 Deepseek-R1-Distilled-Qwen-1.5B 通过强化学习(RL)微调而成,在 AIME2024 上实现了 43.1% Pass@1 准确率。根据其 Notion,这比 O1-preview 提升了 14.3%。
- 这突显了强化学习在扩展模型以提高准确性方面的有效性。
- Deepseek 开源 DeepEP 通信库:作为 #OpenSourceWeek 的一部分,Deepseek AI 推出了 DeepEP。根据其推文,这是一个专门为 Mixture of Experts (MoE) 模型训练和推理定制的开源通信库。
- DeepEP 支持 FP8 dispatch 并优化了节点内和节点间通信,旨在简化训练和推理阶段,可在 GitHub 上获取。
Cohere Discord
- 询问 DeSci 中 Validator 的可行性:一位用户询问了 DeSci 领域内 POS Validators 的盈利阈值。
- 这一查询强调了在去中心化科学中运行 nodes 的经济可行性的重要性。
- 讨论 Validator 池化策略:一位用户提到了 pool validator nodes,表现出对 Validator 之间共享资源或协作的兴趣。
- 这暗示了通过池化方法提高 Validator 效率的趋势。
- 辩论资产估值专业知识:一条消息提到了 asset value expert 一词,但由于其他无关术语,其上下文尚不明确。
- 这引发了关于在所讨论的主题中,评估资产估值的专业知识重要性的疑问。
Nomic.ai (GPT4All) Discord
- GPT4All v3.10.0 发布并带来升级:GPT4All v3.10.0 首次亮相,带来了更好的远程模型配置和更广泛的模型支持,并解决了崩溃问题。
- 增强功能涵盖了跨平台的稳定性能提升和多项崩溃修复。
- 远程模型配置更加顺畅:“添加模型”页面现在拥有一个专门的标签页,用于配置 Groq、OpenAI 和 Mistral 等远程模型提供商,使模型配置更加便捷。
- 这一增强旨在使外部解决方案在 GPT4All 环境中的集成变得无缝。
- CUDA 兼容性进一步扩大:此次更新引入了对具有 CUDA compute capability 5.0 的 GPU 的支持,扩展了兼容硬件的范围。
- 这包括 GTX 750,提升了不同硬件配置用户的可访问性。
- GPT4All 引发版本命名疑问:成员们对于 v3.10.0 是否应该标记为 v4.0 产生困惑,并引发了对版本命名惯例的询问。
- 最近发布的 Nomic Embed v2 加剧了这种困惑。
- 用户期待 Nomic Embed v2:用户热切期待 GPT4All v4.0.0,尤其是因为当前版本尽管新版本已发布,但仍依赖于 Nomic Embed v1.5。
- 社区提醒成员在期待即将到来的更新时,耐心是关键。
DSPy Discord
- phi4 响应格式依然不同:phi4 响应格式与大多数模型存在一些差异,相关教程待发布。
- 一份旨在更好解释该格式的教程正在制作中。
- Assertion 迁移流程简化:从 2.5 风格 Assertions 迁移的用户可以使用
dspy.BestOfN或dspy.Refine来简化模块。- 这些新选项有望比传统断言提供更高的效率。
- BestOfN 已实现:一个示例展示了在 ChainOfThought 模块中实现
dspy.BestOfN,允许最多 5 次重试。- 该方法将选择最佳奖励,并在达到 threshold(阈值)时停止。
- 奖励函数解析:分享了一个
reward_fn示例,展示了它如何返回 float 或 bool 等标量值来评估预测字段长度。- 该函数适用于 dspy.BestOfN 实现的上下文中。
tinygrad (George Hotz) Discord 没有新消息。如果该服务器长时间没有动态,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该服务器长时间没有动态,请告知我们,我们将将其移除。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该服务器长时间没有动态,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该服务器长时间没有动态,请告知我们,我们将将其移除。
第 2 部分:详细的频道摘要和链接
完整的频道逐条细分内容已针对邮件进行了截断。
如果你喜欢 AInews,请分享给朋友!预谢!