ainews-anthropics-615b-series-e
Anthropic 的 615 亿美元 E 轮融资。
Anthropic 以 615 亿美元的估值完成了 35 亿美元的 E 轮融资,这标志着其 Claude AI 模型获得了强大的资金支持。GPT-4.5 在 LMArena 排行榜上夺得所有类别的第一名,在多轮对话、编程、数学、创意写作和风格控制方面表现卓越。DeepSeek R1 在带有风格控制的困难提示词测试中,与 GPT-4.5 并列第一。讨论重点关注了 GPT-4.5 与 Claude 3.7 Sonnet 在编程和工作流应用方面的对比。LMSYS 基准测试的重要性再次被强调,尽管也有人质疑基准测试与用户获取之间的相关性。此外,Perplexity AI 与德国电信 (Deutsche Telekom) 达成合作,将 Perplexity 助手集成到一款新型 AI 手机中。
恭喜团队!
2025年3月3日至3月4日的 AI 新闻。我们为您检查了 7 个 subreddits、433 个 Twitter 账号 和 29 个 Discord 社区(221 个频道,4084 条消息)。预计节省阅读时间(按 200wpm 计算):481 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
他们简短的博客文章见此。虽然这不是技术新闻,但顶级实验室(frontier lab)每隔一周融资一次的情况并不多见,为 Claude 筹集更多资金对 AI Engineers 来说无疑是好消息。
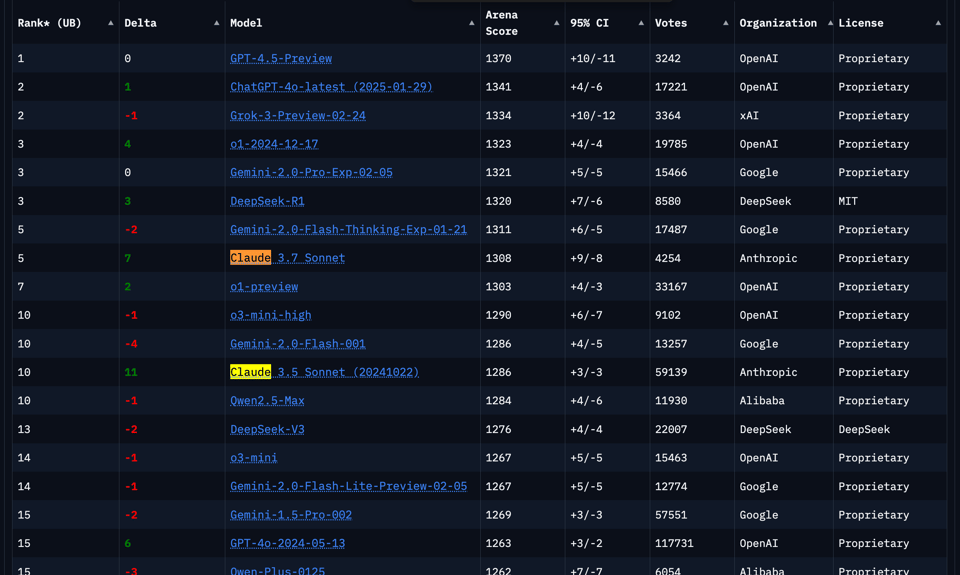
与此同时,GPT 4.5 在 LMArena 上全面排名第一。为了记录,这里是当前在样式控制(style control)下的排名情况。Claude 想要夺回领先地位还有很长的路要走。
AI Twitter 简报
模型性能与基准测试、对比与评估
- GPT-4.5 性能领先地位:@lmarena_ai 宣布 GPT-4.5 已登顶 Arena 排行榜,在包括多轮对话(Multi-Turn)和样式控制(Style Control)在内的所有类别中均排名第一,基于超过 3000 张选票。@lmarena_ai 进一步详细说明,GPT-4.5 在多轮对话、高难度提示词(Hard Prompts)、编程、数学、创意写作、指令遵循和长查询类别中均处于领先地位。@lmarena_ai 强调了 GPT-4.5 在样式控制方面的优势,在该特定领域领跑排行榜。@lmarena_ai 提供了探索完整 GPT 4.5 结果的链接。
- DeepSeek R1 与 GPT 4.5 并列第一:@teortaxesTex 指出,DeepSeek R1 在带有样式控制的高难度提示词上与 GPT 4.5 并列第一,并向 OpenAI 团队表示祝贺。
- GPT-4.5 vs Claude 3.7 编程能力:@casper_hansen_ 质疑 GPT 4.5 在编程方面是否真的优于 Claude Sonnet 3.7。
- GPT-4.5 vs Claude 3.7 工作流:@omarsar0 描述了一种新的编程工作流:使用 GPT-4.5 进行头脑风暴,Claude 3.7 Sonnet 进行构建,以及使用 Windsurf 处理 Agent 任务。
- 对 GPT-4.5 基准测试的质疑:@aidan_mclau 询问 @DaveShapi 4.5 是否对基准测试过拟合,或者其他模型是否存在此问题。@willdepue 对 GPT-4.5 在没有推理时计算(test-time compute)的情况下登顶各类别表示惊讶,认为预训练(pretraining)仍然至关重要。@vikhyatk 正在撤回对 GPT-4.5 的正面评价,不想被视为“低品位的测试者”。
- Claude Sonnet 3.7 性能:@Teknium1 将 Cursor 中的 Sonnet 3.7 描述为“表现糟糕”,并质疑其正确的聊天模式用法。@reach_vb 提到 Claude Sonnet 3.7 和 DeepSeek 是其最喜欢的 LLM,并配合使用 Cursor 和 DeepSeek chat。
- LMSYS 排行榜的重要性:@aidan_clark 表示 LMSYS 显然是最重要的基准测试,并建议各实验室应优先考虑它以最大化用户价值。
- 基准测试相关性受质疑:@cto_junior 认为现在战胜基准测试并不重要,获取用户才是更关键的。
行业新闻、融资与合作伙伴关系
- Anthropic 的 35 亿美元融资轮:@AnthropicAI 宣布以 615 亿美元的估值完成 35 亿美元融资,由 Lightspeed Venture Partners 领投,旨在推进 AI 开发和国际扩张。
- Perplexity AI 与德国电信(Deutsche Telekom)合作:@perplexity_ai 宣布与 Deutsche Telekom 达成合作伙伴关系,使 Perplexity Assistant 成为其新款 AI 手机的原生功能。@AravSrinivas 和 @yusuf_i_mehdi 进一步强调,AI 优先的浏览器是未来,Edge 正在通过集成 Copilot 推动这一进程。
- Microsoft Dragon Copilot 发布:@mustafasuleyman 强调了 Microsoft Dragon Copilot 的发布,旨在减少医疗保健领域的行政负担,让医生重新专注于患者。
- DeepSeek AI 登陆 Copilot+ PC:@yusuf_i_mehdi 提到 DeepSeek R1 的 7B 和 14B 蒸馏模型现已在搭载 Snapdragon 的 Copilot+ PC 上可用,并强调了混合 AI(hybrid AI)。
- Firefly Aerospace 月球着陆:@kevinweil 祝贺 @Firefly_Space 成为 首家成功将探测器降落在月球上的商业公司。
工具、框架与编程工作流
- LlamaParse 更新,支持 Claude 3.7 和 Gemini 2.0:@llama_index 宣布了 LlamaParse 的更新,在 “Parse With Agent” 模式中增加了对 AnthropicAI Claude Sonnet 3.7 和 Google Gemini 2.0 Flash 的支持,以实现更好的表格解析和跨页一致性;在 “Parse With LVM” 模式中支持解析屏幕截图。
- 基于 LlamaIndex 工作流的旅行规划器教程:@llama_index 分享了 RS Rohan 的一个教程和仓库,关于如何使用 LlamaIndex 构建 Agentic 旅行规划器,展示了使用 Pydantic 模型的结构化预测功能、API 集成(Google Flights, Hotels, Top Sites)以及事件驱动架构。
- 用于简历提取的 LlamaExtract:@llama_index 推出了 LlamaExtract,由 3.7 Sonnet 和 o3-mini 等 SOTA LLM 驱动,用于从简历中提取标准化的候选人信息,并可推广到其他数据类型。
- SynaLinks,受 Keras 启发的 LLM 应用框架:@fchollet 和 @fchollet 介绍了 SynaLinks,这是一个 受 Keras 启发的框架,用于将 LLM 应用程序构建为可训练组件的 DAG,支持复杂的流水线和 RL 微调。
- Groovy,Python 转 JavaScript 引擎:@_akhaliq 强调了 Groovy,这是一个 Python 转 JavaScript 引擎,可将 Python 函数转译为客户端执行,@algo_diver 指出其潜力在于能让 Gradio 达到生产级水平。
- 使用 MLX-LM 进行结构化生成的 Outlines:@awnihannun 分享了如何将 @dottxtai 的 Outlines 与 mlx-lm 结合使用进行本地结构化生成,并提供了文档 @awnihannun。
- 用于可观测性和评估工具的 LangSmith:@hwchase17 指出 LangSmith 被用于将用户反馈转化为评估(evals),强调可观测性即评估工具。
- Cursor 编程工作流:@omarsar0 提到在新的编程工作流中使用 Cursor。@jeremyphoward 提到使用 Cursor 配合 Python、fasthtml 和 MonsterUI 等工具,在一天内创建复杂的应用。
- 用于加密 AI Agent 通信的 Gibberlink:@ggerganov、@ggerganov 和 @ggerganov 介绍了 Gibberlink,演示了两个 AI Agent 之间的加密语音聊天,并提供了 GitHub 项目链接。
研究与论文
- 脑机文本解码研究:@AIatMeta 重点介绍了来自 Meta FAIR 和 BCBL 研究人员关于 Brain-to-Text Decoding 的研究论文,这是一种通过打字实现的非侵入性方法。
- 扩散模型与流匹配课程:@omarsar0 和 @TheTuringPost 分享了一门免费的 MIT 关于流匹配与扩散模型导论的课程,涵盖了理论、训练和应用,包括课程笔记、幻灯片、YouTube 视频和实验,@omarsar0 提供了另一个链接。
- 推理 LLMs 深度解析:@omarsar0 推荐了“推理 LLMs 深度解析”,总结了后训练(post-training)方面的进展。
- 关于推理 LLMs 作为平方和求解器的 SoS1 论文:@_akhaliq 分享了一篇题为“SoS1: O1 and R1-Like Reasoning LLMs are Sum-of-Square Solvers”的论文。
- 提升人类动作理解的 HAIC 论文:@_akhaliq 发布了关于“HAIC”论文的内容,重点是通过为多模态 LLMs 提供更好的字幕来改进人类动作的理解和生成。
- 人形机器人操控的 Sim-to-Real 强化学习:@arankomatsuzaki 和 @arankomatsuzaki 重点介绍了 Nvidia 关于人形机器人基于视觉的灵巧操控的 Sim-to-Real 强化学习的演讲,该研究在无需人类演示的情况下实现了强大的泛化能力,并提供了项目和摘要链接。
- 思维链与推理瓶颈:@francoisfleuret 讨论了思维链(Chains-of-thought)如何使推理受限于计算资源(compute-bound),并建议将大型模型蒸馏为更快的 SSMs 或混合模型以获得更好的权衡。
- LLMs 作为进化策略:@SakanaAILabs 列出了访谈中讨论的几项工作,包括“(1) Large Language Models As Evolution Strategies”。
- 用于 Kernel 编程的 TileLang:@teortaxesTex 提到了 TileLang,这是一种用户友好的 AI 编程语言,降低了 Kernel 编程的门槛。
- LLM 信仰结构的评估:@teortaxesTex 分享了对 LLM 信仰结构(belief structures)的深刻评估。
- 用于评估 AI 系统的 LangProBe:@lateinteraction 介绍了来自 @ShangyinT 等人的 LangProBe,对应该构建和评估什么样的完整 AI 系统提出了疑问。
AI 在商业与应用中的表现
- 库存追踪与 Token 需求:@gallabytes 认为,每天数万亿 Token 的需求将来自于改进各经济部门的库存追踪等领域。
- 用于 Shader Golf 的 AI:@torchcompiled 向致力于 shader golf 的人们致敬。
- AI 驱动的 Wiki Explorer 应用:@omarsar0 和 @omarsar0 使用 AI 开发了一个 wikiexplorer app,利用 Wikipedia 和 OpenAI 模型提供提示,旨在成为学习新主题的有趣方式。
- 用于文献综述的 AI 研究 Agent:@TheTuringPost 推广了由 SciSpace 开发的 Deep Review,这是一个用于系统性文献综述的 AI 研究 Agent,声称它可以节省数小时的工作时间,并且比 OpenAI 的 Deep Research 和 Google Scholar 更具相关性。
- Android 日常生活中的 AI:@Google 在 #MWC25 上重点展示了 AI on Android,演示了 Circle to Search 翻译菜单和 Gemini Live 学习复杂主题等功能。
- 结合 AlphaFold 的 AI 协同科学家示例:@_philschmid 举了一个使用 GoogleDeepMind AlphaFold 扩展 GoogleAI co-scientist 以进行蛋白质修饰评估的例子。
- 使用 Groovy 和 Gradio 的 Web 开发中的 AI:@algo_diver 认为 Groovy 将使 Gradio 具备生产力,适用于全栈 Web 开发。
迷因与幽默
- Karpathy 的 AirPods Pro 传奇:@karpathy 分享了一条幽默的多行推文,模仿 4chan greentext 风格,讲述了 AirPods Pro 故障。
- Elon Musk 与 Grok 现实主义:@Teknium1 发布了“Grok 对现实主义更加开放”并附带链接,暗示 Grok 的无过滤特性,@Teknium1 在回复 Grok 图像对比时表示“更好”。
AI Reddit 摘要
/r/LocalLlama 摘要
主题 1. Atom of Thoughts 增强小型模型
- 新的 Atom of Thoughts 看起来有望帮助小型模型进行推理 (Score: 641, Comments: 90):Atom of Thoughts (AOT) 算法显著增强了小型模型的推理能力,在 HotpotQA 上使用 GPT-4o-mini 达到了 80.6% F1 分数,超越了其他模型。AOT 的过程包括将问题分解为 Directed Acyclic Graph (DAG),通过子问题收缩进行简化,并迭代以达到原子问题,如附带的流程图所示。
- 对方法论和结果的批评:用户质疑 Atom of Thoughts (AOT) 结果的可靠性,理由是 1k 任务 的样本量可能存在问题、未指明的置信区间,以及在 temperature 1 下进行的测试,这可能导致结果的高波动性。人们对结果的随机性表示担忧,认为如果没有重复测试,报告的改进在统计上可能并不显著。
- 关于基于规则的方法的讨论:辩论了 AI 中基于规则的方法的相关性,一些用户认为虽然 rule-based approaches 不具备可扩展性,但在特定语境下仍具相关性。提到了 “bitter lesson” 的概念,表明计算通常胜过编码知识,但这并不排除逻辑规则集的效用。
- 实际实现和资源:分享了 AOT 算法的 open-source repository 链接,允许用户自行探索和实现该算法 (GitHub link)。此外,原始论文可在 arXiv 上查阅,提供了关于该算法开发和性能的更多细节。
{kind=link}
主题 2. Klee 开源,用于本地 LLM 使用且零数据收集
- 我今天开源了 Klee,这是一个旨在本地运行 LLM 且零数据收集的桌面应用。它还包括内置的 RAG 知识库和笔记功能。 (Score: 397, Comments: 67):Klee 桌面应用 现已开源,专为在不收集任何数据的情况下 locally 运行 LLMs 而设计,并包含 RAG 知识库 和笔记功能。应用界面提供了如 “deepseek-r1-7b” 等模型选项,并通过 “Local Mode” 开关强调隐私,确保没有数据被发送到云端。
- 用户讨论了 Klee 的 backend compatibility,询问是否强制使用 Ollama,或者是否可以使用 llama.cpp 等替代方案。还有人好奇 Klee 与 LM Studio 和 OpenWebUI 等其他平台的对比,一些人指出 Klee 本质上是 Ollama 的一个封装。
- 数据隐私 是焦点,有人询问“零数据收集”的主张,以及使用 Ollama + Open WebUI 是否涉及数据收集。指出这两个平台都会运行统计数据以收集错误信息,这些功能可以被禁用,这与 Klee 对本地数据安全的强调一致。
- 用户界面和功能 受到讨论,一些用户对受 Slack 启发的 UI 感到反感,而另一些人则欣赏其对非技术用户的简单性。提出了关于 Android port 可能性、运行来自 Hugging Face 模型的能力以及 RAG 知识库 自定义的问题。
{kind=link}
主题 3. 分裂脑 ‘DeepSeek-R1-Distill-Qwen’ 与 ‘Llama’ 融合架构
- 分裂脑 “DeepSeek-R1-Distill-Qwen-1.5B” 与 “meta-llama/Llama-3.2-1B” (Score: 139, Comments: 30): Split Brain 项目 探索了一种新颖的双解码器(dual-decoder)架构,该架构结合了两个不同的语言模型 DeepSeek-R1-Distill-Qwen-1.5B 和 meta-llama/Llama-3.2-1B,以实现同步处理和 cross-attention fusion(交叉注意力融合)。该系统通过在不同的 GPU 上运行独立模型,利用 EnhancedFusionLayer 进行 cross-attention,并采用复杂的门控机制(gating mechanism)来实现自适应信息流,从而实现协作推理和专业化处理。该架构提高了计算效率和任务灵活性,在允许协作和专业化操作的同时,通过仅训练融合组件来保持参数效率。
- Cross-Attention Fusion:Split Brain 项目 使用双向 cross-attention fusion,两个模型同时生成输出,关注彼此的隐藏表示(hidden representations)而非最终的 token 输出。这种在隐藏表示层级的实时交互允许模型在没有直接 token 反馈的情况下,对彼此的“思考过程”产生相互影响。
- 模型词汇表挑战:确定的一个关键挑战是管理模型之间不同的词汇表(vocabularies),这需要一种复杂的机制来确保无缝的交互和处理。
- 个性化潜力:人们对使用分裂脑方法实现个性化 AI 模型很感兴趣,即通过将一个反映个性的小型模型与一个强大的大型模型相结合。这可能通过允许一个模型引导和纠正另一个模型,通过协作处理增强个性化,从而超越当前基于 prompt 的 Agent。
其他 AI Subreddit 回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding
待完成
AI Discord 回顾
由 Gemini 2.0 Flash Thinking 提供的摘要之摘要的总结
主题 1. IDE 之战:Cursor 跌跌撞撞,Windsurf 乘风破浪,插件阵痛持续
- Cursor IDE 陷入 Bug 深渊:Cursor IDE 用户正面临 不稳定性、连接失败 和 检查点(checkpoint)故障,这促使工程师们将 Windsurf 和 Trae AI 视为救生筏。最新版本被描述为极其不稳定,MCP 服务器配置增加了混乱,特别是在 Windows 和远程 Ubuntu 设置上,导致客户端创建失败,用户纷纷在论坛寻求帮助。
- Windsurf 的 Ubuntu 更新导致系统崩溃后自我修复:最近针对 Ubuntu 24.04 的 Windsurf 更新 产生了严重的负面影响,因 FATAL:setuid_sandbox_host.cc(158) 错误导致系统变砖,迫使部分用户重新安装并造成数据丢失,但随后的补丁和涉及 chrome-sandbox 权限的变通方法提供了生机。然而,Windows ARM64 用户正在庆祝,因为 Windsurf Next 现在支持他们的平台,可在此处下载。
- JetBrains 插件请求挂起:Codeium 的 JetBrains 插件 让用户感到沮丧,它一直卡在 Processing request 状态,尤其是在最新的预发布版本中,导致其无法生成代码,迫使开发人员降级到更稳定的旧版本以维持工作流。JetBrains 插件的问题与 Windsurf Next 对 Windows ARM64 的支持形成鲜明对比,展示了不同 IDE 集成之间功能可靠性的不平衡。
主题 2. Claude 3.7:速度瓶颈与额度紧缩,但依然令人印象深刻
- Claude 3.7 在 Cursor 中表现挣扎,运行缓慢:Claude 3.7 在 Cursor IDE 中引发了用户头疼,用户反映其运行极其缓慢且容易在请求中途停止,迫使许多人降级或使用 Cursor 的 ‘Ask’ 模式,引发了对其模型当前稳定性的担忧。尽管在 Cursor 中表现不稳定,OpenAI Discord 的用户宣称 ChatGPT 现在就是个笑话,并发现 Claude 3.7 非常令人印象深刻,特别指出 Claude 在处理大文件时具有更优越的上下文理解能力,拥有 200K token 窗口,超越了 ChatGPT 的 128K。
- Claude 3.7 像吃豆人一样吞噬 Windsurf 额度:Windsurf 中的 Claude 3.7 正在以惊人的速度消耗 premium flow action credits,有报告称即使是微小的编辑,每个 prompt 也会产生 30-40 次 tool calls,导致额度迅速耗尽并引发用户愤怒,一些用户正切换回 3.5 或考虑转投 Cursor 以逃避额度消耗。用户敦促 Codeium 将 Claude 3.7 从默认模型状态降级,因为它对额度的消耗过于贪婪。
- Claude Code 获得 Anon-Kode 重混版,支持 Open API:一位名为 anon-kode 的开发者在提取原始源代码后 (原始推文),发布了一个修改过的、OpenAI 兼容版本的 Claude Code,命名为 anon-kode。它兼容 OpenAI APIs (推文) 并在 GitHub 上可用,提供了一个潜在的开源替代方案,尽管还有很多东西需要修复。
主题 3. AI 模型:新发布、性能怪癖与伦理困境
- GPT-4.5 登顶 Arena 榜首,图像识别能力存议:GPT-4.5 已登上 Arena 排行榜榜首,在从 coding 到创意写作的各个类别中占据主导地位 (来源),但其图像识别能力正受到审查,评价褒贬不一,并引发了关于它是否超越 GPT-4o 的争论,尽管初步测试显示其在 MMMU 基准测试上仅有 +5% 的边际提升。尽管在排行榜上取得了胜利,一些用户觉得 OpenAI 正在降低 Plus 用户的优先级以偏向 Pro 用户,暗示了高级会员地位认知的转变。
- Grok 的自定义指令未能成功“整活”,引发人格模拟恐慌:Grok AI 备受期待的 custom instructions 功能现已向所有用户开放,但因无用而面临批评。用户报告称无法将 Grok 塑造成理想的人格,其中一次试图创建一个“辱骂性和淫秽的喷子”的尝试以失败告终,让用户质疑该功能的有效性。尽管自定义指令表现不佳,Grok 因其调试能力受到称赞,在这一领域胜过 O3 mini high sonnet 等模型,尽管一些用户发现 O3 mini high sonnet 在代码创建任务中表现更优。
- Phi-3 模型微调面临 A100 硬件门槛,Dataset Viewer 需要修复错误:为多模态微调 Phi-3 被证明是一项艰巨的任务,即使使用 Colab Pro,估计也需要 6 台以上的 A100 以及大约 2 周时间。同时,Hugging Face 的 Dataset Viewer 正受到错误的困扰,影响了与各种库和 SQL 的兼容性,阻碍了数据的可发现性和可用性。尽管面临这些挑战,Hugging Face 正在庆祝 Remote VAE Decode endpoints 在 SD v1、SD XL 和 Flux 上的延迟降低了高达 10x,这归功于代号为 honey 的项目,通过 Hybrid Inference 赋能本地 AI 构建者。
主题 4. 硬件动态:Tilelang 获胜、AMD 崛起与 SRAM 秘密
- Tilelang 内核性能完胜 Triton,逼近 Flash-MLA 速度:一个精简的 80 行 tilelang 内核 在 H100 上达到了 DeepSeek Flash-MLA 95% 的性能,相比 Triton 实现了 500% 的加速,展示了 tilelang 在高性能计算方面的潜力,代码已在 GitHub 开源。这一性能飞跃引发了建立 MLA 排行榜 以展示类似成果的呼声,该榜单可能会由 BitNet 团队 重新调整用途。
- AMD GPU 逐渐逼近 ML 聚光灯,Intel Arc A770 加入 Tinygrad 阵营:关于 AMD 和 Intel 成为 ML 流水线中 CUDA 可行替代方案的讨论正在升温。一些人认为 AMD 市场份额的增加可能会刺激其 GPU 计算部门的更多投资。同时,Intel Arc A770 GPU 已确认通过 OpenCL 后端与 Tinygrad 兼容,为开发者拓宽了硬件选择。尽管 AMD 取得了进展,但关于其代工产能获取的问题依然存在,人们担心 NVIDIA 在芯片制造资源的获取上仍持有显著优势。
- SRAM 缓存机制揭秘:对 SRAM 架构的深入研究表明,寄存器、共享内存和缓存都是 SRAM 结构,未分配的共享内存会转化为 L1 cache。虽然 Triton 在
tl.load中的cache_modifier允许指定 L1 或 L2 命中,但缺乏直接的缓存层级控制,这揭示了 GPU 编程中内存管理的细微层级。对于 CUDA 编译,建议在 PyTorch 中使用torch.cuda.get_device_capability()来确定--arch=,不过nvidia-smi --query-gpu=name,compute_cap --format=csv提供了一个无需 PyTorch 的替代方案。
主题 5:Agent 创新与挫折:旅游规划 AI、Smol Agent 测验失败以及 MCP 多 Agent 愿景
- 旅游应用 Agent 现身拯救被短视频淹没的旅行者:一款名为 ThatSpot 的新应用出现,旨在应对旅游短视频(Reels)信息过载。它部署了 AI Agent,直接从旅游短视频中自动提取关键行程规划数据——地点、价格、预订链接——为受旅行渴望驱使的用户自动化了数小时的手动研究并简化了行程组织。该应用承诺处理旅游短视频并提取提及的每个地点,使繁琐的手动研究过程自动化。
- Smol Agents 测验难倒学生,错误日志中藏有线索:Smol Agents 测验让用户感到头疼,有报告称尽管多次尝试,但要求不明确且得分不及格。这促使人们呼吁从 测验的 app.py 文件 中 挖掘错误日志,以确定必要的工具和模型提供商,突显了 AI 学习平台中需要更清晰的测验说明和更好的错误反馈。尽管测验遇到困难,HuggingFace 还是推出了新的 NLP 推理课程单元,旨在教育 LLM 中的强化学习以及对 Open R1 的贡献。
- MCP 多 Agent 架构初现,快速 Agent 框架浮出水面:工程师们正在探索 用于多 Agent 系统的 MCP,从 Anthropic 的研讨会中汲取灵感,并构思 Agent 在跨设备协作的框架。一位成员分享了他们的 fast-agent GitHub 项目,用于 定义、提示和测试启用 MCP 的 Agent 及工作流,允许为 Agent 配置不同的 MCP 服务器,并由其他 Agent 作为工具调用。然而,MCP Terraform Registry 的设置被证明很麻烦,特别是在使用 Claude 桌面版和 Cline 时,当系统级代理处于活动状态时会遇到 mcp-server-fetch 错误。
第 1 部分:Discord 高层级摘要
Cursor IDE Discord
- Cursor 饱受不稳定性困扰:用户报告在最新的 Cursor IDE 版本中存在 不稳定性、连接失败以及 checkpoints 功能失效的问题。
- 由于用户体验不佳,成员们正在考虑 Windsurf 和 Trae AI 等替代方案。
- MCP Servers 导致配置噩梦:成员们在 Cursor 中配置 MCP servers 时遇到困难,特别是在 Windows 和远程 Ubuntu 工作区环境下,面临诸如“客户端创建失败”等问题。
- 一位成员最终通过 Pupeteer 解决了问题,并使用 Firecrawl MCP server 配合 LLM 客户端进行网页抓取。
- Claude 3.7 面临故障:用户在使用 Claude 3.7 时遇到问题,例如响应极度缓慢以及在没有错误提示的情况下中途停止请求。
- 因此,许多人转而使用 Cursor 的 ‘Ask’ 模式,或者在执行关键任务时回退到旧版本。
- 设计师们投身落地页设计:成员们分享了使用 Cursor 生成的落地页设计,并讨论了它们的美学吸引力和有效性。
- 社区将这些设计与 Linear、Framer、Magician Design 和 Webflow 进行比较以获取灵感。
- Repo Prompt 的多文件编辑功能备受赞誉:用户对 Repo Prompt 感到兴奋,称赞其 多文件编辑 能力和代码片段集成功能。
- 社区还提到了用于调试的 BrowserTools,以及用于文件选择的 PasteMax(Repo Prompt 的一个开源“穷人版”)。
Codeium (Windsurf) Discord
- Windsurf 增加 Windows ARM64 支持:Windsurf Next 现在支持 Windows ARM64,可在此处下载。
- 这一扩展允许 Windows ARM64 平台的用户利用 Windsurf Next 中的最新功能和改进。
- Windsurf 的 Ubuntu 更新导致系统崩溃:最近的 Windsurf 更新 在 Ubuntu 24.04 上引发了问题,导致应用程序启动失败并提示 FATAL:setuid_sandbox_host.cc(158) 错误。
- 一位用户报告了系统崩溃、重新安装和数据丢失的情况,强调了更新前备份的必要性,并且可能需要手动更改 chrome-sandbox 权限的权宜之计。
- Claude 3.7 消耗额度过快引发用户不满:用户报告 Windsurf 中的 Claude 3.7 正在迅速耗尽 premium flow action credits,原因是每个 prompt 产生的工具调用(tool calls)过多,有些用户在进行微小更改时竟产生了 30-40 次工具调用。
- 成员们建议 Codeium 取消将 Claude 3.7 作为默认模型,一些人为了提高效率切换回 3.5 或其他模型,并考虑转向 Cursor。
- Codeium 客户支持面临审查:用户报告 Codeium 的客户支持体验较差,一名用户等待解决 订阅问题 已长达四周。
- 缺乏及时有效的支持正促使用户寻求替代方案,并引发了对 Codeium 响应能力的担忧。
- JetBrains 插件受“正在处理请求”卡死困扰:JetBrains 插件 用户遇到了持续的 Processing request 状态,导致报错,特别是在最新的预发布版本中。
- 该问题导致插件无法生成响应,中断了工作流,迫使用户降级到更稳定的版本。
OpenAI Discord
- OpenAI 举办 Sora 入门培训:Sora 团队在 <t:1741024800:R> 举办了一场直播入门会议,涵盖了 Sora 基础知识和最佳 Prompting 技巧,你可以通过 此 Discord 链接 加入讨论。
- Sora 101 会议还分享了早期访问艺术家的入门流程心得。
- GPT-4.5 图像识别评价褒贬不一:成员们正在争论新款 GPT-4.5 的 Image Recognition 能力是否优于 GPT-4o,Future Machine 对 OpenAI (OAI) 的选择发声较多。
- 初步测试显示,GPT-4.5 在 MMMU(面向视觉推理的基准测试)上的得分比 4o 略高,有 +5% 的提升。
- Custom Grok 表现不佳:Grok AI 的 Custom Instructions 功能已向所有用户发布,但成员们反映该自定义指令毫无用处。
- 一位成员分享了旨在塑造“辱骂和淫秽喷子”人格的 Custom Grok 指令,但反馈称其“不起作用”,其他用户也反映了同样的情况。
- Claude 3.7 表现惊艳,但 Projects 功能受挫:一位用户宣称“ChatGPT 现在就是个笑话”,并发现 Claude 3.7 “非常令人印象深刻”,同时 Claude 凭借 200K 的上下文窗口能更好地理解大文件中的语境。
- 然而,另一位用户表示 Claude 的 Projects 功能毫无用处,抱怨称“最多只能上传两个文件”,且提示“内存已满”,称 Claude 被“过度炒作”了。
- Dall-E 呈现合成生物学:一位成员提示 Dall-E 生成一张“长出用于移植的心脏和肝脏的合成植物”图像,这些器官在透明薄膜内可见,并由转基因植物提供养分。
- 初步结果侧重于心脏而非肝脏,促使用户通过更多关于肝叶的细节来优化 Prompt。
Unsloth AI (Daniel Han) Discord
- Llama 模型将 ZIP 压缩成 WAV 格式引发趣闻:一位成员有趣地报告称,使用 Llama 模型压缩一个 192 KB 的 ZIP 文件,结果得到了一个 48 KB 的无损 WAV 格式。
- 用户发现这种“混乱”是因为模型随后试图重新压缩该 WAV 以使其更小,特别提到了 r1-1776-distill-llama-70b 模型。
- GRPO 训练:推理需要更多步数?:用户讨论了使用 GRPO 对 Qwen2.5-14B-instruct 进行 LoRA 训练所需的必要训练步数,强调降低 Loss 以获得更好的推理能力。
- 建议包括分配约 24 小时或 700-1200 步,并强调收敛情况取决于模型,如 Unsloth 文档 中所述。
- GCC 编译器导致 VLLM 运行困难:一位用户在本地使用 meta-Llama-3.1-8B-Instruct 运行 GRPO 教程时遇到了与 GCC 编译器 相关的 RuntimeError。
- 尽管尝试通过 conda 安装 GCC,问题依然存在,且由于学校 HPC 的安全原因,该用户被限制使用 apt-get。
- 字符串替换:代码编辑策略的成功?:成员们辩论了使用字符串替换进行代码编辑的有效性,一位成员认为这通常是“垃圾”。
- 然而,另一位成员报告称在针对字符串替换微调 Qwen 2.5 方面取得了成功,特别是当模型在进行替换前可以访问整个文件时。
- Claude 3.5 Sonnet 以 SOTA 成绩横扫基准测试:Anthropic 的 Claude 3.5 Sonnet 在 SWE-bench Verified 上达到了 49%,超过了之前 SOTA 模型的 45%。
- 成员们引用了 Bitter Lesson(惨痛的教训):利用计算能力的通用方法最终是最有效的。
Perplexity AI Discord
- Perplexity Web UI 重写功能故障:用户报告 Perplexity Web UI 的重写功能 已损坏,无论选择什么模型,始终默认为 pplx_pro。
- 一些用户遇到了提示词重复问题,并标记了 <@883069224598257716> 寻求支持,这表明重写工具存在严重问题。
- Claude 3 模型混淆问题持续存在:用户不确定 Perplexity 的模型指示器是否准确反映了正在使用的模型,质疑在选择 Claude 时,接收到的是 Claude 3.7 Sonnet 还是 Claude 3 Opus。
- 一些人注意到 Pro Search 会用 Sonar 覆盖所选模型,导致所选模型与实际使用的模型之间存在差异。
- Perplexity API 困扰 Obsidian Web Clipper:Perplexity API 与 OpenAI 标准的部分不兼容给 Obsidian Web Clipper 等工具带来了问题。
- 该 API 要求在用户消息之间必须有一个 assistant 消息,而 OpenAI 中没有此要求,这阻碍了 Obsidian Web Clipper 发布连续用户消息的能力。
- Deepseek 生成有争议的宣传内容?:用户分享了一张据称由 Deepseek 生成的 图片,社区认为这是具有政治偏见的宣传。
- 另一位成员对该图片不以为然,断言 “你是假的 Deepseek。真正的 Deepseek 不谈论西方事务。”
{kind=link}
HuggingFace Discord
- Phi-3 微调面临障碍:一位成员正在使用配备 A100 的 Colab Pro 对 Phi-3 进行多模态微调,但被提醒此类微调需要 6 台以上的 A100 并运行约 2 周。
- 另一位成员补充说,[只要有积极的态度和可靠的项目,QLora 和 Peft 可以让一切皆有可能]。
- Dataset Viewer 出现错误:用户建议修复 Dataset Viewer 错误,以兼容各种库和 SQL,从而提高数据的可发现性。
- 另一位用户预先表示感谢,并开玩笑地要求额外提供 120 万行 的高质量数据集。
- Hugging Face 通过新 VAE 降低延迟:Hugging Face 在 SD v1、SD XL 和 Flux 的 Remote VAE Decode 端点上部署了代号为 honey 的代码,将延迟降低了高达 10倍,这通过 Hybrid Inference 赋能了本地 AI 构建者。
- Hybrid Inference 是免费的,完全兼容 Diffusers,并且对开发者友好,具有简单的请求和快速的响应,VAE Encode 即将推出。
- Smol Agents 测验引发挫败感:一位成员对 Smol Agents 测验表示挫败,理由是要求不明确,尽管多次尝试,得分仍为 0.0/5,并参考了 测验的 app.py 文件。
- 该成员指出需要“挖掘错误日志”才能了解工具和模型所需的确切提供商。
- Lambda Go Labs:AI 学习与构建:Lambda Go Labs 是一个专注于 AI 学习、构建和研究的社区。
- 该社区提供实践经验、分享作品的机会,并为资深专业人士和新入门者提供支持网络。
aider (Paul Gauthier) Discord
- Aider 排行榜工具对决:Aider leaderboard 现在除了对 AI 模型进行基准测试外,还加入了 Claude Code 等工具,将它们作为主要的编程助手进行评估。
- 一位用户主张建立一个类似于 SWE Benchlets 的工具无关基准测试,以促进编程工具和模型之间更广泛的比较。
- Anon-Kode 修改版 Claude Code:Claude Code 的一个修改版本,被称为 anon-kode,由提取源代码的同一位开发者发布(原推文链接),现在已兼容 OpenAI APIs(推文链接),并可在 GitHub 上获取。
- 虽然有很多需要修复的地方,但你可以使用任何支持 OpenAI 风格 API 的服务。如果你够大胆,可以尝试一下。
- Gemini 2.0 Pro 撞上上下文限制墙?:一位用户报告称,在 Aider 中使用大上下文窗口时,
gemini/gemini-2.0-pro-exp-02-05模型出现了RESOURCE_EXHAUSTED错误。- 相比之下,
gemini-2.0-flash-thinking-exp-01-21模型运行顺畅;该用户询问了如何最大限度地利用 Pro 模型的上下文窗口。
- 相比之下,
- Aider 实现了 Git Diff 愿望:一位用户请求 Aider 直接在文件内部使用 git diff 语法(例如
<<<<<< branch,======,>>>>>>> replace)进行编辑。- 目前,Aider 在终端显示 diff,但用户寻求在接受更改前进行文件内编辑;其他用户指出这可能需要一个 fork,或者使用外部 diff 工具。
- Grok 的调试优势:成员们注意到,虽然 Grok 在调试方面表现出色,但在代码创建任务(如添加新功能)中,O3 mini high sonnet 可能会超越它。
- 他们观察到 Claude 3.7 有时会引入多余的元素,而 deepseek-chat 配合 O1 Pro 已被证明是高度可靠的编辑器,准确率接近 95%。
GPU MODE Discord
- 视觉模型仍青睐 Attention:尽管存在 MLP-Mixer 等替代方案,基于 attention 的 ViTs 仍然是视觉模型的 SOTA 选择。
- 一位成员对 MLP-Mixer 的相对利用不足提出了疑问,详情见 MLP-Mixer: An all-MLP Architecture for Vision。
- SRAM 的缓存特性揭秘:寄存器、共享内存和缓存是基于 SRAM 构建的芯片/软件级属性,未分配的共享内存会变成 L1 cache。
- 虽然在 Triton 中缺乏直接的缓存层级控制(L1/L2),但
tl.load中的cache_modifier可以指定 L1 或 L2 命中,其中cg专门针对 L2。
- 虽然在 Triton 中缺乏直接的缓存层级控制(L1/L2),但
- CUDA 架构查询得到 Torch 解答:为了确定 CUDA 编译的
--arch=参数,建议使用 PyTorch 的torch.cuda.get_device_capability(),另一种替代方案是nvidia-smi --query-gpu=name,compute_cap --format=csv。- 第二种方案避免了对 PyTorch 依赖 的需求,且 CUDA Runtime API 可以根据指定标准以编程方式选择最佳设备,如 文档 所示。
- Tilelang kernel 比 Flash-MLA 运行更快:一位成员夸赞道,80 行 tilelang kernel 代码 即可达到 deepseek flashmla 95% 的性能,在 H100 上比 Triton 快 500%,并附带了 GitHub 仓库 链接。
- 另一位成员表示希望有一个 MLA 排行榜,或许可以从 bitnet 小组 改组而来。
- FA3 需要 Absmax 进行量化:虽然 FA3 现在可以工作,但它表现出的量化误差明显高于基础的 absmax quantization,这表明需要进行策略性调整。
- 提议在 Hada transform 之后应用 absmax quantization,特别是针对 ‘v’,以减轻大激活值带来的分布外(out-of-distribution)问题。
OpenRouter (Alex Atallah) Discord
- 旅游应用兴起,拯救旅游 Reels:一款应用应运而生,旨在解决无休止保存旅游 Reels 视频和数小时手动调研的问题。它使用 AI agents 直接从 https://thatspot.app/ 上的旅游 Reels 中自动提取地点、价格范围、预订要求、预订链接和营业时间等数据。
- 该应用通过利用 AI agents 处理旅游 Reels,自动提取提到的每个地点,从而实现手动调研过程的自动化,简化行程规划。
- Google Flash 2.0 出现 502 错误:一位用户报告在对 Google Flash 2.0 和 Flash 2.0 Light 模型进行推理时出现 502 错误,错误信息为 “Provider returned error”。
- 该错误表明 Google 遇到了内部问题。
- OpenRouter 的 Sonnet 遭遇速率限制:一位用户询问了 Claude 3.7 Sonnet 在 RPM (Requests Per Minute) 和 TPM (Tokens Per Minute) 方面的速率限制(Rate Limits)。
- 一位成员澄清说 OpenRouter 不会对每个用户施加特定的速率限制,并指向了 Anthropic 的速率限制文档和 BYOK 设置(OpenRouter 集成设置)。
- OpenRouter API Key 让 VS Studio 报错:尽管账户资金充足,一位用户在 VS Studio 中通过 RooCode 使用 OpenRouter API Key 时遇到了 401 Authentication Failure。
- 建议包括验证 API Key、在 RooCode 中选择 OpenRouter 作为 API 提供商,并确保 base URL 正确,参考了此教程。
- BYOK Azure 模型期待接入 OpenRouter:一位用户询问在 OpenRouter 中对 Azure 模型使用 BYOK (Bring Your Own Key),寻求为微调模型提供统一的 API。
- 一位成员澄清说,目前仅支持
/models端点中列出的模型,不包括 BYOK 模型,并建议在集成设置中使用 OpenAI API Key 代替。
- 一位成员澄清说,目前仅支持
LM Studio Discord
- LM Studio 发布 Python 和 TypeScript 版 SDK:LM Studio 发布了适用于 Python (
lmstudio-python) 和 TypeScript (lmstudio-js) 的软件开发工具包,采用 MIT 许可证,允许开发者在自己的代码中调用 LM Studio 的 AI 能力。- 这些 SDK 支持 LLMs、embedding 模型以及 agentic 工作流,其特色是提供了用于自主任务执行的
.act()API,相关文档已在其各自页面(lmstudio-python和lmstudio-js)上线。
- 这些 SDK 支持 LLMs、embedding 模型以及 agentic 工作流,其特色是提供了用于自主任务执行的
- LM Studio “设备不支持”错误困扰用户:在 LM Studio 更新后,有用户反映遇到
Failed to load model错误,并提示Unsupported device。建议尝试 调整 GPU offloading 或 线程池大小。- 该错误可能与影响显存占用的 上下文长度(context length) 有关;左侧数字代表模型在 聊天历史 中已使用的 tokens 数量,右侧数字则是 上下文限制。
- Llama.cpp 不支持 Diffusion 模型架构:用户反馈在加载 Diffusion 模型时出现
error loading model architecture: unknown model architecture: 'sd3'错误。官方澄清 llama.cpp 不支持图像/视频/音频生成模型。llama.cpp对视觉模型的支持尚不明确,目前存在缺乏 Llama 3.2 vision 或 Pixtral vision 支持 的担忧,不过一些人认为 UI-TARS 的修复 会有所帮助。
- Pseudollama 填补 OLLAMA 缺口:成员们讨论了 LM Studio 的端点是否与接受 OLLAMA 端点的应用兼容。得到的回答是默认情况下无法直接工作,但 Pseudollama 可以桥接这一差距。
- 作者提到,这完全是凭感觉编写的代码(vibe coded),所以可能到处都是低级问题,但它确实能跑通。
- AMD 需要在 GPU 领域展开竞争:成员们讨论了 AMD 或 Intel 是否能在 ML 流水线和框架中变得可行,从而与 CUDA 竞争。
- 一些成员认为,如果 AMD 提高市场份额,他们会更有动力投资其 GPU 计算部门;而真正的悬念在于 AMD 能否从芯片代工厂争取到产能,因为 Nvidia 目前占据上风。
{kind=link}
{kind=link}
Nous Research AI Discord
- Nous API 定价讨论:成员们讨论了 Nous 可能会为其模型推出 API 以获取收入,推测定价约为 $0.8/M tokens,每天可能产生 $800-1600 的收益。
- 建议包括针对专业模型将定价设为接近 $1/M 输入 tokens 和 $3/M 输出 tokens,目前正在努力实现这一目标。
- LLM 在 CUDA Kernel 生成方面表现不佳:成员们一致认为,虽然 LLM 可以生成正确的 CUDA 语法,但很难独立生成高性能的 CUDA kernels。
- 最佳方案是将 硬件和计算图数据 与 LLM 结合,可能通过 知识图谱或 GNN 实现,并辅以密集的 GPU profiling。
- Logic-RL 通过基于规则的 RL 提升推理能力:Logic-RL 论文 探讨了在大型推理模型中应用 基于规则的强化学习 (RL) 的潜力,灵感源自 DeepSeek-R1。
- 这个 7B 模型 仅在 5K 个逻辑问题 上进行训练,就在 AIME 和 AMC 等具有挑战性的数学基准测试中展现出了泛化能力。
- Runway 发布通用世界模型:Runway 推出了 通用世界模型 (General World Models),旨在创建能够构建环境内部表示以模拟未来事件的 AI 系统。
- 他们的目标是表示和模拟广泛的场景和交互,超越 电子游戏 或 驾驶模拟 等局限的场景。
- Qwen2.5-Math-1.5B 模型在 Longcot 上的困境:一位用户发现 Qwen2.5-Math-1.5B 模型在处理 longcot 示例 时存在困难,在配置数据集结构和 GRPOTrainer 方面需要帮助。
- 他们链接了自己的 Kaggle notebook,寻求解决这些问题的指导。
Interconnects (Nathan Lambert) Discord
- Unitree 发布开源宝库: Unitree Robotics 已开源多个仓库,可通过 其 GitHub 访问。
- 此举为机器人领域的协作开发和创新开启了可能性。
- GPT-4.5 登上 Arena 宝座: GPT-4.5 已夺得 Arena 排行榜所有类别的榜首,包括 Multi-Turn、Hard Prompts、Coding、Math、Creative Writing、Instruction Following 和 Longer Query (来源)。
- 最新的评分巩固了 GPT-4.5 目前作为 State of the Art 的地位。
- Anthropic 的天文级增长仍在继续: Anthropic 以惊人的 615 亿美元 投后估值获得了 35 亿美元 的融资,由 Lightspeed Venture Partners 领投 (来源)。
- 这笔资金旨在推进其 AI 系统的开发,加深对其功能的理解,并推动国际增长。
- Grok3 定价结构浮出水面?: 据 这条推文 报道,潜在泄露的 Grok3 定价 详情显示,输入成本为 $3.50/百万,缓存输入为 $0.875/百万,输出为 $10.50/百万。
- 泄露的定价模型为在各种应用中利用 Grok3 的潜在成本提供了见解。
- 人类数据对于现实世界 AI 仍然至关重要吗?: 一篇博客文章 (https://www.amplifypartners.com/blog-posts/annotation-for-ai-doesnt-scale) 认为,人类数据 对于构建真正有用的 AI 产品仍然必不可少。
- 这一观点挑战了仅靠合成数据就能推动模型性能大幅提升的看法。
Yannick Kilcher Discord
- Claude 攻克编程挑战: 一位成员报告使用 Claude 和 Cursor 完成了 这个 GitHub Pull Request 中 95% 的工作,该 PR 涉及 细粒度配置选项。
- 该成员正在处理
object-property-newline规则,通过添加对细粒度配置选项的支持,允许开发者为不同的节点类型指定不同的行为。
- 该成员正在处理
- 应对棘手的时间段: 一位成员最初考虑就 Joscha Bach 进行演讲,但不确定这是否是最终主题。
- 另一位成员提出,如果没有安排其他演讲,他可以在
<t:1741046400:F>时间段进行演讲,并向感兴趣的人提供进一步建议。
- 另一位成员提出,如果没有安排其他演讲,他可以在
- Elsagate 再次爆发: 一位成员分享了一个名为“Elsagate 3.0 比我们想象的更糟糕”的 YouTube 视频,并警告称该视频 不适合儿童观看。
- 另一位成员回应道:“这太可怕了。”
Notebook LM Discord
- 财务报表进入 NotebookLM: 一位成员询问是否可以将 财务报表 加载到 NotebookLM 中进行分析,以实现财务分析自动化。
- 这表明了将 NotebookLM 用于专业任务的兴趣。
- 播客长度辩论和时间线需求被提出: 成员们对 播客长度 和重要话题的覆盖范围表示担忧,并引用了 此处 发现的 最高法院申请。
- 一位成员要求在播客免费版中添加 时间线,而另一位成员分享了 一个 NotebookLM 播客示例。
- 动态文档,一个缺失的功能: 成员们好奇 NotebookLM 是否可以从 Google Docs 等来源动态更新,用于追踪家具尺寸等用例。
- 由于该功能不是自动的,引发了关于变通方案和功能需求的讨论。
- Notebook 分享故障已解除!: 一位用户报告在与 Gmail 个人账户分享 Notebook 时出现服务器错误,具体为 “You are not allowed to access this notebook”。
- 当用户发现接收者有一部新手机未正确配置其 Gmail 账户时,问题得到了解决。
Stability.ai (Stable Diffusion) Discord
- 脸部复制替代方案出现:成员们讨论了复制脸部的最佳方法,一些人更倾向于使用 ControlNet 中的 reference only,而另一些人则推荐 Reactor Faceswap 作为 IP-Adapter 的更佳替代方案。
- 社区共识似乎更倾向于 ControlNet,因为它具有多功能性。
- Reforge 的 AMDGPU 支持仍不明确:一位用户报告了关于 Reforge 支持 AMDGPU 的矛盾信息,因为它在 Stability Matrix 上被提及,但在 GitHub 页面上却没有。
- 另一位用户尝试使用 Zluda 导致 PC 死机,这引发了对 Stability Matrix 准确性的怀疑,并建议使用 Matrix 之外的 UI。
- DirectML 与 Reforge 不兼容:一名成员在 Zluda 失败后尝试将 Reforge 与 DirectML 结合使用,但未获成功。
- 讨论了 Lshqtiger 可能推出的 Reforge for AMD 分支。
- CivitAI 提供免费图像生成:成员们讨论了将 CivitAI 作为图像生成请求的平台,指出它提供一些初始积分和每日 25 个可累积的免费积分。
- 使用该平台的成本取决于所选的模型。
- 本地图像生成需求详情:一位成员询问了本地创建图像的要求;另一位成员回答建议使用显存 (VRAM) 约为 6-8GB 的 GPU,以及 <#1002602742667280404> 中提到的其他资源。
- 另一位成员分享了 CivitAI 在线生成的链接作为替代方案。
Eleuther Discord
- ReasonableLLAMA-Jr-3b 寻求反馈:一位成员请求对其 ReasonableLLAMA-Jr-3b 模型提供反馈,这是一个基于 Atom of Thoughts (AoT) 论文概念,在 LLAMA 3.2 3B 上使用 GRPO 训练的推理模型。
- 该模型在 Gym 环境中使用 MLX 编写了一个自定义的基于 GRPO 的 Agent,其中推理过程中的每个状态转换都是一个独立的、原子级的问题,如 Atom of Thoughts for Markov LLM Test-Time Scaling 中所述。
- 循环 LLM 推理:代价过高?:成员们辩论了循环 LLM 推理是否实用,因为这种推理需要相当于 32B 参数模型的计算量才能达到 7B 模型的性能。
- 提出的核心问题是:为什么不直接训练一个 32B 参数的模型,并使用 early exit、mixture of depths 或 speculative decoding 来实现更廉价的推理?
- 在 Harness 中排查 ‘trust_remote_code’ 问题:一位用户询问
trust_remote_code是否在lm-evaluation-harness中被无条件设置,并指向了 GitHub 仓库中的特定行。- 一位成员澄清说,只有在提供了
--trust_remote_code参数时才会设置trust_remote_code,并引用了 代码的相关部分。
- 一位成员澄清说,只有在提供了
- 揭秘 Dataset Kwargs 路径:一位用户询问设置
trust_remote_code是否会在加载本地数据集时覆盖dataset_kwargs。- 一位成员澄清说,
dataset_kwargs会被传递给 Harness 内部的datasets.load_dataset(...),并链接到了 代码的相关部分。
- 一位成员澄清说,
- 用户报告数据集生成错误:一位用户报告在运行
lm_eval时遇到 数据集生成错误,其配置指定了dataset_path: json且data_dir包含train.jsonl、validation.jsonl和test.jsonl。- 作为回应,一位成员建议使用
load_dataset手动测试数据集加载,并尝试为数据目录使用绝对路径。
- 作为回应,一位成员建议使用
MCP (Glama) Discord
- MCP Terraform Registry 面临问题:用户报告在启用系统级代理时,terraform-registry-mcp 和 aws-mcp server 无法正常运行,特别是在使用 Claude desktop 和 Cline 时,会导致 mcp-server-fetch 错误。
- 该问题似乎与代理设置干扰了服务器获取必要资源的能力有关。
- 多 Agent MCP 架构兴起:一位成员探索了为多 Agent 系统实现 MCP,引用了 AI Engineering Summit 上的 Anthropic 工作坊,并分享了工作坊中的一张图片。
- 他们正在构建一个让 Agent 跨设备协作的框架,并考虑采用 MCP,灵感来自 BabyAGI 和 Stanford generative agents 等示例。
- Fast Agent 框架备受关注:一位成员分享了他们的项目 fast-agent on GitHub,用于定义、提示和测试支持 MCP 的 Agent 及工作流。
- 该框架允许为每个 Agent 配置一组独立的 MCP server,并可以被其他 Agent 作为 tool 调用。
- Node 版本问题困扰 Claude 用户:用户报告在 Claude desktop 中使用 fastmcp 时遇到 Cannot find package ‘timers’ 错误。
- 问题追溯到 Claude 正在使用的过时的 Node v14 版本。
- MCPHub.nvim 助力 Neovim:新的 MCPHub.nvim 插件 发布,旨在协助在 Neovim 中管理 MCP server,并提供智能服务器生命周期管理以及与 CodeCompanion.nvim 集成进行 AI 聊天等功能。
- 该插件可通过单个命令 (
:MCPHub) 安装,为 MCP server 管理提供了流线化的设置过程。
- 该插件可通过单个命令 (
{kind=link}
DSPy Discord
- Ash 框架生态受到关注:一位成员为一个项目推荐了 Ash 框架,并指向了 ash-project/ash_ai GitHub 仓库。
- 他们强调了 instructor_ex,它为 Elixir 中的 LLM 提供结构化输出,并引导用户前往 Ash Discord 社区寻求指导。
- 异步支持计划启动:一位成员询问了 DSPy 中全异步支持的动机和预期的性能提升,并链接了另一个 Discord 邀请链接。
- 一位核心贡献者宣布了使异步支持成为原生功能的意图,并请求通过 GitHub issues 提交功能需求,以防在 Discord 中被遗漏。
- LangProBe 基准测试程序组合:一篇新论文 LangProBe: a Language Programs Benchmark 评估了 DSPy 程序组合和优化器对不同任务的影响,同时探索了成本/质量的权衡。
- 正如其 X/Twitter 帖子所述,论文表明在优化后的程序中,较小的模型可以以更低的成本超越较大的模型。
- Minions 准备在成本优化方面占据优势:一位成员表示,刚发布的 LangProBe 论文为基准测试他们实现的 minions 功能提供了一个很好的基准,并引用了他们已关闭的 pull request。
- 该成员添加了 MinionsLM 和 StructuredMinionsLM 用于智能 LM 路由,并强调了该论文与成本优化的直接相关性。
LlamaIndex Discord
- AgentWorkflow Context:一位成员询问了 AgentWorkflow 中 Context 与 Chat History 的区别。
- 另一位成员回答道:聊天历史记录包含在 context 之中。
- LlamaIndex 集成 MCP 支持:一位用户询问 LlamaIndex 对 MCP 的支持情况,另一位成员确认已支持并提供了 示例 notebook。
- 该 notebook 演示了如何在 LlamaIndex 中使用 MCP。
- LlamaParse 最新模型支持 Agent 解析:’Parse With Agent’ 模式现在支持 AnthropicAI Claude Sonnet 3.7 和 Google Gemini 2.0 Flash,增强了表格解析和跨页一致性(公告)。
- 这些更新将提高解析复杂文档的准确性和可靠性。
- 需要 PII 处理?咨询 LlamaIndex!:一位成员正在寻求付费和开源方案,用于在将 PDF 和图像发送给 LLM 之前,对其中的个人身份信息 (PII) 进行脱敏处理。
- 这一请求凸显了 LLM 应用中对强大 PII 脱敏工具日益增长的需求。
- 由于缺少 Checkpoint 功能,Windsurf 表现不佳:一位成员指出 Windsurf 缺少 checkpoint 功能,并提到尽管多次尝试编码以及对文件/工作区进行操作,仍无法回滚到之前的状态。
- 该成员附带了一张 图片,展示了他们尝试将文件拖放到标签菜单中以寻求访问之前 checkpoint 的努力。
{kind=link}
Latent Space Discord
- AI 尚未完全取代程序员:一篇 O’Reilly 文章 指出 AI 工具 正在演进编程方式,类似于从早期物理电路编程至今的历史性变革。
- 成员们表示赞同,指出 LLM 加速了学习过程,这与过去人们抱怨从 StackOverflow 复制代码的情况类似。
- 资深工程师主导 AI 输出:资深工程师凭借专业知识有效地引导 AI 的输出,在使用 Cursor 或 Copilot 等工具时,能防止产生不可维护的代码。
- 虽然 AI 加快了实现速度,但资深工程师确保了代码的可维护性,而这通常是初级工程师所缺乏的技能。
- Anthropic 获得巨额融资:Anthropic 获得了 35 亿美元 融资,投后估值达到 615 亿美元,由 Lightspeed Venture Partners 领投。
- 这笔投资将用于支持 AI 系统的推进、增强对其功能的理解以及支持全球扩张。
- Python 开发者寻求 Stagehand 类工具:在听完关于 Browserbase 的 Latent Space 播客后,一位成员在寻找 Python 中类似于 Stagehand 的自修复浏览器工作流工具。
- 另一位成员推荐了 stagehand-py,并指出 “它还在开发中(wip)”。
- 代码对决:Cursor 击败 Claude Code:成员们将 Claude Code 与 Cursor 进行了对比,Cursor 因其回滚能力更受青睐。
- 反馈显示 Claude Code 在专注度方面存在问题,会添加不必要的代码,成本更高,且在代码编辑速度上不如 Cursor。
tinygrad (George Hotz) Discord
- Tinygrad 旨在建立公平的算力市场:George Hotz (@tinygrad) 将 tinygrad 描述为一个形式主义项目,旨在以非泄漏抽象捕获 Software 2.0,目标是建立一个类似于 Linux 和 LLVM 的公平算力市场。
- Hotz 预计到年底,tinygrad 在 NVIDIA 上的速度将在无需 CUDA 的情况下赶上现有的 torch CUDA 后端,并设想建立一个测试云,用于在 lambda 函数中租用 FLOPS。
- Ops.CAT 速度悬赏面临 LLVM 重写问题:一名成员报告了 Ops.CAT 速度悬赏 持续面临的挑战,特别是尽管已在计划中,但在尝试将其重写为 LLVM 时遇到困难。
- 目前的 Ops.CAT 操作 具有由 PAD、RESHAPE 和 BUFFER 操作组成的复杂结构,其中 arg 代表要连接的两个张量。
- RDNA2/RX6000 在 tinygrad 中的可用性咨询:一位用户询问了 RDNA2/RX6000/GFX1030 在 tinygrad 中的可用性,报告在运行
AMD=1时出现OSError: [Errno 22] Invalid argument。- 另一位成员表示它应该可以在 Linux 上运行,并请求获取该操作系统错误的 trace 信息,该信息已在 trace.txt 文件 中提供。
- Intel Arc A770 与 OpenCL 配合良好:一名成员确认 Intel Arc A770 确实可以与 tinygrad 配合使用。
- 建议通过设置
GPU=1来利用 OpenCL 后端。
- 建议通过设置
LLM Agents (Berkeley MOOC) Discord
- Sutton 深入探讨编程 Agent:特邀演讲嘉宾 Charles Sutton 在 第 5 讲 中介绍了“编程 Agent 与用于漏洞检测的 AI”。
- 该讲座探讨了使用 LLM Agent 执行计算机安全任务(如寻找软件漏洞),并讨论了 LLM Agent 的设计问题。
- DeepMind 研究员荣获奖项:Google DeepMind 的研究科学家 Charles Sutton 的机器学习研究主要受代码生成、软件工程、编程语言和计算机安全应用的启发。
- Sutton 在软件工程方面的工作曾获得两项 ACM Distinguished Paper Awards (FSE 2014, ICSE 2020) 和一项 10-year Most Influential Paper award (MSR 2023)。
- 测验发布日期揭晓:一位用户询问每周何时发布测验,另一位用户回答说他们通常尝试在周三或周四发布。
- 该问题是在 mooc-questions 频道中提出的。
- 讲座音频问题困扰:一名成员在 mooc-lecture-discussion 频道报告由于音频问题无法听到讲座中的提问,请求现场人员协助。
- 一名工作人员对讲座期间的音频问题表示歉意,并承诺今后会提醒演讲者重复所有问题。
Cohere Discord
- Cohere 图像嵌入问题消失:一位用户报告了使用 Cohere 嵌入图像时的问题,但随后确认该问题已神秘地自行解决。
- 另一位成员仅确认了问题的解决,未作进一步评论。
- Cohere 调查棘手的 504 错误:一位 Cohere 成员提到,虽然他们没有观察到 504 错误 的激增,但他们注意到极慢的请求可能是潜在原因。
- 该成员计划进一步调查慢请求的来源,并感谢用户的提醒。
Modular (Mojo 🔥) Discord
owned通过 Pull Request 变为own:一名成员提交了一个 pull request,建议将owned重命名为own,以保持与 rest 参数约定的一致性。- 此次重命名旨在与既定的编码实践保持一致,并增强可读性。
- 社区会议征集演讲者:定于一周后举行的下一次社区会议正在征集演讲者进行演讲或展示项目。
- 有意向的个人应联系组织者以在议程中预留位置。
- AWS GenAI Loft 举办 MAX Engine 活动:一场名为 Beyond CUDA: Accelerating GenAI Workloads with Modular’s MAX Engine, Hosted by AWS 的活动将在 AWS GenAI Loft 举行。
- 该活动面向湾区观众,定于明天晚上举行。
- SIMD DType 构造解析:一次讨论澄清了
SIMD[DType.uint8, 1](0).type会在编译时返回 dtype,并以var a = UInt8(0); alias dtype = __typeof(a).type为例。- 一名成员强调
SIMD在其实现中包含了 构造检查,这有助于确保有效性和类型安全。
- 一名成员强调
- 参数注入优于全局变量:针对有关使用全局变量的问题,一名成员断言,如果你有时间的话,注入参数通常是更好的选择。
- 这一偏好符合代码可维护性和可测试性的最佳实践。
Torchtune Discord
- 基于步数的 Checkpointing 减少计算浪费:成员们对基于步数的 Checkpointing (step-based checkpointing) 表示了兴趣,并确认正在实施该功能,以减轻因训练失败导致的计算资源浪费。
- 该功能定期保存进度,减少中断带来的影响。
- Torch 用户使用 Tensorboard 进行 Trace:Torch 用户讨论了可视化 profiler trace 的策略,最初尝试使用 Tensorboard,但注意到 PyTorch 的某些插件功能已被移除。
- 他们推荐使用 PyTorch memory visualizer tool 和 Perfetto 来进行内存和时间 trace,认为这足以追踪相关线索。
- 替代分析工具盛行:讨论强调了 PyTorch memory visualizer tool 和 Perfetto 分别是内存和时间 trace 的可靠替代方案。
- 这些工具在用户反映 Tensorboard 存在问题(特别是缺少某些 PyTorch 插件功能)后被提出。
Nomic.ai (GPT4All) Discord
- Ollama vs GPT4All:哪个 Llama 更胜一筹?:一位用户质疑为什么人们选择 Ollama 或 Llama.cpp 而不是 GPT4All,认为 GPT4All 开箱即用的功能使其成为更好的选择。
- 该用户没有提供具体的比较指标细节,但强调了易用性是其核心优势。
- GPT4All 界面将支持加泰罗尼亚语:一位社区成员请求为 GPT4All 界面添加加泰罗尼亚语 (Catalan) 作为语言选项。
- 该请求强调了社区中存在加泰罗尼亚语使用者,以及本地化支持的潜在益处。
- 发现安全漏洞,GPT4All v3.10.0 面临风险:一位用户报告了 GPT4All v3.10.0 中的一个潜在漏洞,并询问了正确的报告方式。
- 消息中未透露漏洞性质的细节,但建议尽快报告。
MLOps @Chipro Discord 没有新消息。如果该公会长时间保持沉默,请告知我们,我们将将其移除。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该公会长时间保持沉默,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该公会长时间保持沉默,请告知我们,我们将将其移除。
第 2 部分:频道详细摘要与链接
邮件中已截断完整的频道详情。
如果您喜欢 AInews,请分享给朋友!预先感谢!