ainews-gemma-3-beats-deepseek-v3-in-elo-20-flash
Gemma 3 在 Elo 评分上击败了 DeepSeek V3,2.0 Flash 凭借原生图像生成能力超越了 GPT-4o。
Google DeepMind 发布了 Gemma 3 系列模型,其特点包括 128k 上下文窗口、多模态输入(图像和视频)以及对 140 多种语言的多语言支持。Gemma 3-27B 模型在 LMArena 基准测试中位列顶级开源模型之列,表现优于多个竞争对手,并在基准测试中与 Gemini-1.5-Pro 旗鼓相当。此外,Gemini 2 推出了具有高级图像编辑功能的 Flash 原生图像生成,这一功能 OpenAI 曾进行过预告但尚未正式发布。这些更新突显了在上下文长度、多模态以及通过量化提升模型效率方面的重大进展。
GDM is all you need.
2025年3月12日至3月13日的 AI 新闻。我们为您检查了 7 个 subreddits、433 个 Twitter 账号 和 28 个 Discord 服务区(224 个频道,2511 条消息)。预计节省阅读时间(按每分钟 200 词计算):275 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
今天的 o1-preview(目前唯一在 AINews 任务中能与 Flash Thinking 竞争的模型,而且没错,o1-preview 比 o1-full 或 o3-mini-high 更好)Discord 总结非常精准 —— Google 借在巴黎举办 Gemma Developer Day 的契机,发布了一系列引人注目的更新:

https://www.youtube.com/watch?v=UU13FN2Xpyw
Gemma 3。人们非常喜欢它的 128k 上下文。除了作为一个开放模型在 LMArena 上取得的高分之外:
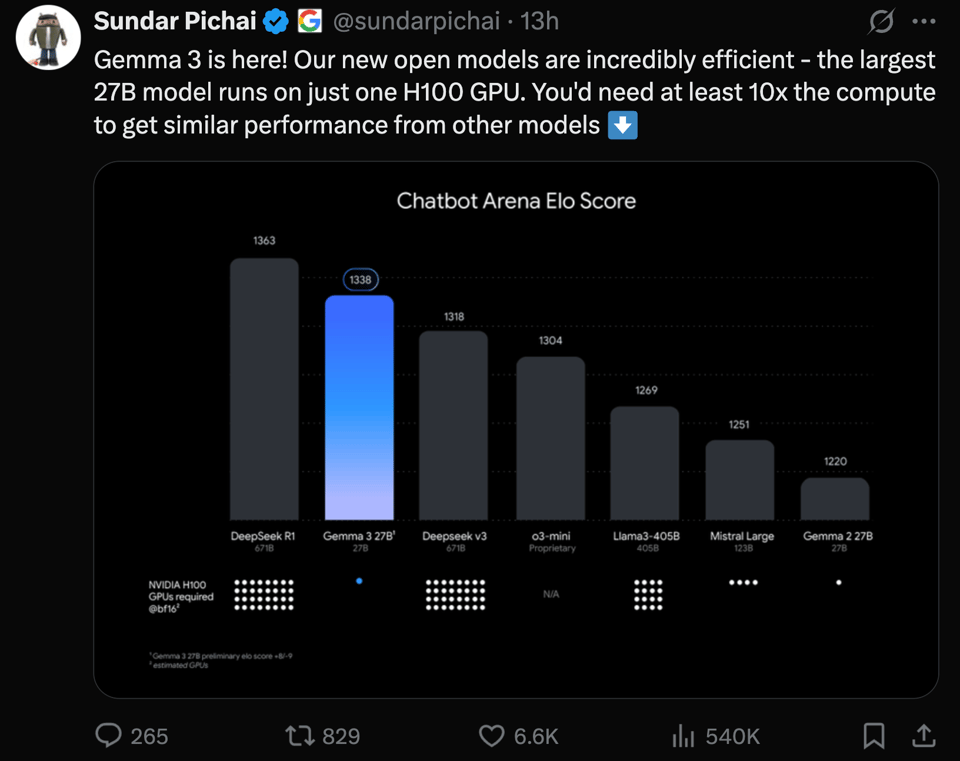
它在同量级模型中也以绝对优势建立了一个新的 Pareto frontier:
它看起来还通过将视觉作为一级能力(first class capability)引入,从而完全取代了 PaliGemma(ShieldGemma 仍然存在)。
Gemini Flash 原生图像生成。
正如在 Gemini 2 发布时所预告的(我们的报道见此),Gemini 2 实际上推出了图像编辑功能,而 OpenAI 预告过却从未发布。其效果非常惊人(如果你能从复杂的 UI 中找到它的话)。图像编辑从未如此简单。
https://x.com/19kaushiks/status/1899856652666568732?s=46
https://x.com/m__dehghani/status/1899854209081868663?s=46
https://x.com/multimodalart/status/1899881757396099231
https://x.com/fofrAI/status/1899927094727000126
AI Twitter 总结
模型发布与更新:Gemma 3 系列
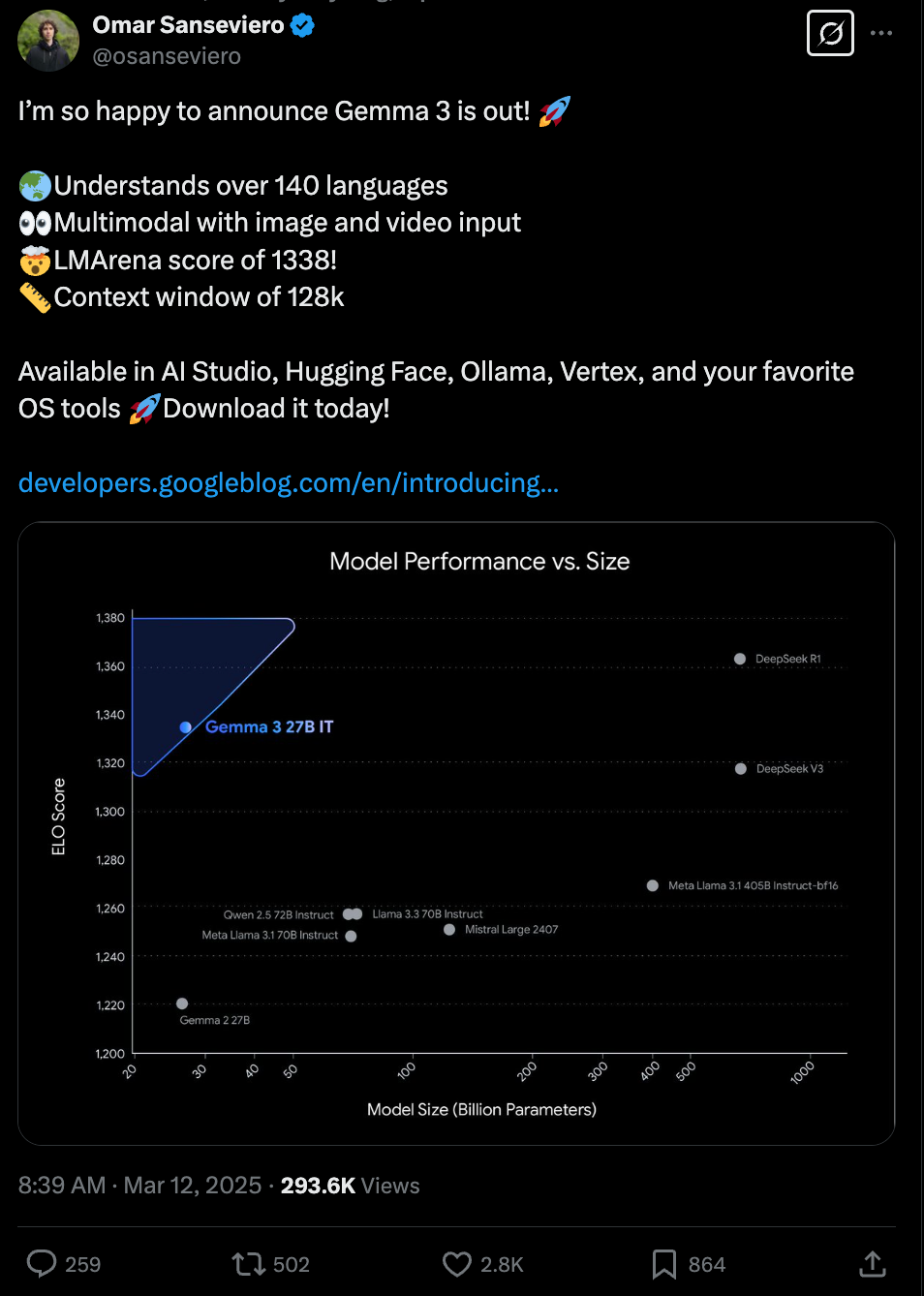
- Gemma 3 系列发布:@osanseviero 宣布发布 Gemma 3,强调了其 多语言能力(支持 140+ 种语言)、多模态输入(图像和视频)、LMArena 评分 1338 以及 128k 上下文窗口。@_philschmid 提供了 Gemma 3 核心特性的摘要,包括 四种尺寸(1B, 4B, 12B, 27B)、在 LMArena 开源非推理模型中排名第一、文本和图像输入、多语言支持、更大的上下文窗口以及 基于 SigLIP 的视觉编码器。@reach_vb 总结了 Gemma 3 的关键特性,指出其 性能媲美 OpenAI 的 o1、多模态和多语言支持、128K 上下文、通过量化实现的内存效率以及 训练细节。@scaling01 详细介绍了 Gemma 3,强调了其 在 LMSLOP arena 的排名、与 Gemma 2 和 Gemini 1.5 Flash 的性能对比、使用 SigLip 的多模态支持、多种模型尺寸、长上下文窗口和 训练方法论。@danielhanchen 同样强调了 Gemma 3 的发布,指出其 多模态能力、多种尺寸(1B 到 27B)、128K 上下文窗口和 多语言支持,并表示 27B 模型在 基准测试上与 Gemini-1.5-Pro 持平。@lmarena_ai 祝贺 Google DeepMind 推出 Gemma-3-27B,认可其为 Arena 总榜前 10 名模型、第 2 优秀的开源模型,并提到了其 128K 上下文窗口。@Google 正式将 Gemma 3 作为其“迄今为止最先进且便携的开源模型”发布,专为智能手机和笔记本电脑等设备设计。
- Gemma 3 性能与基准测试:@iScienceLuvr 关注了 Gemma 3 的性能,强调 27B 模型在 LMArena 排名第 9,超越了 o3-mini, DeepSeek V3, Claude 3.7 Sonnet 和 Qwen2.5-Max。@reach_vb 发现 Gemma3 4B 与 Gemma2 27B 具有竞争力,并强调了“指数级的时间线”。@reach_vb 质疑 Gemma3 27B 是否是最好的非推理 LLM,尤其是在 MATH 领域。@Teknium1 将 Gemma 3 与 Mistral 24B 进行了对比,指出 Mistral 在基准测试上表现更好,但 Gemma 3 拥有 4 倍的上下文和视觉能力。
- Gemma 3 技术细节:@vikhyatk 审阅了 Gemma 3 技术报告,提到模型名称与参数量相匹配,且 4B 以上的模型均为多模态。@nrehiew_ 分享了对 Gemma 3 技术报告 的看法,指出虽然缺乏细节但提供了有趣的信息。@eliebakouch 对 Gemma3 技术报告 进行了详细分析,涵盖了架构、长上下文和蒸馏技术。@danielhanchen 提供了 Gemma-3 分析,详述了架构、训练、聊天模板(chat template)、长上下文和视觉编码器。@giffmana 确认 Gemma3 转向多模态,取代了 PaliGemma,并可与 Gemini 1.5 Pro 媲美。
- Gemma 3 可用性与使用:@ollama 宣布 Gemma 3 在 Ollama 上可用,包括多模态支持和运行不同尺寸模型的命令。@_philschmid 强调了使用
google-genaiSDK 测试 Gemma 3 27B。@_philschmid 分享了一篇关于 Gemma 3 开发者信息 的博客。@_philschmid 分享了在 AI Studio 中试用 Gemma 3 的链接以及 模型链接。@mervenoyann 提供了一个关于 Gemma 3 视频推理 的 Notebook,展示了其视频理解能力。@ggerganov 宣布 Gemma 3 支持已合并至 llama.cpp。@narsilou 指出 Text generation 3.2 已发布并支持 Gemma 3。@reach_vb 提供了一个 体验 Gemma 3 12B 模型 的 Space 空间。
机器人与具身智能 (Robotics and Embodied AI)
- Gemini Robotics 模型:@GoogleDeepMind 推出了 Gemini Robotics,这是基于 Gemini 2.0 的新一代机器人 AI 模型,强调 推理、交互、灵活性和泛化能力。@GoogleDeepMind 宣布与 Apptronik 建立合作伙伴关系,利用 Gemini 2.0 构建人形机器人,并向 Agile Robots、AgilityRobotics、BostonDynamics 和 EnchantedTools 等受信任的测试者开放了 Gemini Robotics-ER 模型。@GoogleDeepMind 表示其目标是开发适用于任何形状或尺寸机器人的 AI,包括 ALOHA 2、Franka 和 Apptronik 的 Apollo 等平台。@GoogleDeepMind 解释说 Gemini Robotics-ER 允许机器人利用 Gemini 的具身推理 (embodied reasoning),实现目标检测、交互识别和避障。@GoogleDeepMind 强调了 Gemini Robotics 的泛化能力,其在基准测试中的表现比最先进的模型(state-of-the-art models)翻了一倍。@GoogleDeepMind 强调了通过 Gemini Robotics 实时调整动作的能力实现无缝的人机交互。@GoogleDeepMind 展示了 Gemini Robotics 将正时皮带绕在齿轮上这一极具挑战性的任务。@GoogleDeepMind 演示了 Gemini Robotics 完成多步骤灵巧任务,如折纸和打包便当盒。
- Figure 机器人与 AGI:@adcock_brett 表示 Figure 将成为 AGI 的最终部署载体。@adcock_brett 分享了机器人技术的更新,指出其在速度提升、处理易变形袋子以及将神经网络权重迁移到新机器人方面的进展,感觉就像“上传到了《黑客帝国》(Matrix)!”。@adcock_brett 将 Helix 描述为解决通用机器人技术的一道微光。@adcock_brett 提到他们的机器人完全嵌入式且离网运行,配备 2 个嵌入式 GPU,目前不需要网络调用。
AI Agent 与工具
- Agent 工作流与框架:@LangChainAI 宣布了一个 Resources Hub,包含构建 AI Agent 的指南,以及关于 AI 趋势和 Replit、Klarna、tryramp 和 LinkedIn 等公司用例的报告。@omarsar0 正在主持一场关于使用 OpenAI 的 Agents SDK 构建高效 Agentic 工作流的免费网络研讨会。@TheTuringPost 列出了 7 个支持 AI Agent 动作的开源框架,包括 LangGraph、AutoGen、CrewAI、Composio、OctoTools、BabyAGI 和 MemGPT,并提到了 OpenAI 的 Swarm 和 HuggingGPT 等新兴方法。@togethercompute 宣布了 5 份关于使用 Together AI 构建 Agent 工作流的详细指南,每份指南都附带深入探讨的 Notebook。
- Model Context Protocol (MCP) 与 API 集成:@llama_index 宣布 LlamaIndex 与 Model Context Protocol (MCP) 集成,支持通过一行代码连接到任何 MCP 服务器并进行工具发现。@PerplexityAI 发布了 Perplexity API Model Context Protocol (MCP),为 Claude 等 AI 助手提供实时网页搜索功能。@AravSrinivas 宣布 Perplexity API 现在支持 MCP,为 Claude 等 AI 提供实时信息。@cognitivecompai 展示了 Dolphin-MCP,这是一个开源且灵活的 MCP 客户端,兼容 Dolphin、ollama、Claude 和 OpenAI 端点。@hwchase17 询问在 IDE 中为了让 LangGraph/LangChain 更易于访问,应该使用 llms.txt 还是 MCP。
- OpenAI API 更新:@LangChainAI 宣布 LangChain 支持 OpenAI 的新 Responses API,包括内置工具和对话状态管理。@sama 称赞 OpenAI 的 API 设计是“有史以来设计最精良、最实用的 API 之一”。@corbtt 发现 OpenAI 的新 API 形式比 Chat Completions API 更好,但希望能够跳过对这两个 API 的同时支持。
AI 性能与优化
- GPU 编程与性能:@hyhieu226 指出 warp divergence 是 GPU 编程中一个微妙的性能 Bug。@awnihannun 发布了编写更快 MLX 并避免性能悬崖的指南。@awnihannun 强调了 MLX 社区对 Gemma 3 的快速支持,涵盖 MLX VLM、MLX LM 和 MLX Swift for iPhone。@tri_dao 将讨论在现代硬件上优化 Attention 以及 Blackwell SASS 技巧。@clattner_llvm 讨论了 TVM 和 XLA 等 AI 编译器,以及为什么 GenAI 仍然使用 CUDA 编写。
- 模型优化与效率:@scaling01 推测 OpenAI 可能很快发布 o1 模型,因为它处理复杂任务的能力优于 o3-mini。@teortaxesTex 质疑 Google 在 Gemma 3 中激进地随模型 N 缩放 D 的逻辑,并询问在 2T 数据上训练的 Gemma-1B 及其对投机采样的适用性。@rsalakhu 分享了关于将优化推理时计算(test-time compute)作为元强化学习问题的新工作,从而产生了 Meta Reinforcement Fine-Tuning (MRT),以提高性能和 Token 效率。@francoisfleuret 询问散热是否是制造更大芯片的关键问题。
AI 研究与论文
- AI 生成科学论文:@SakanaAILabs 宣布 The AI Scientist-v2 的一篇论文通过了 ICLR workshop 的同行评审,声称这是首篇完全由 AI 生成并通过同行评审的论文。@hardmaru 分享了该实验的细节,记录了过程与心得,并在 GitHub 上发布了 AI 生成的论文和人类评审意见。@hardmaru 调侃 The AI Scientist 被 Schmidhubered 了。@hkproj 在一篇 AI Scientist 论文被接收后对 ICLR 的标准提出了质疑。@SakanaAILabs 承认了 The AI Scientist 的引用错误,错误地归属了“一个基于 LSTM 的神经网络”,并记录了人类评审中的错误。
- 扩散模型与图像生成:@iScienceLuvr 重点介绍了一篇关于使用 SoftREPA 改进扩散模型中文本到图像对齐的论文。@iScienceLuvr 分享了一篇关于使用 Latent CLIP 控制 Latent Diffusion 的论文,在潜空间(latent space)中训练 CLIP 模型。@teortaxesTex 称一项新的算法突破是“罕见且令人印象深刻”的进展,可能会终结 Consistency Models 甚至扩散模型。
- 长篇音乐生成:@iScienceLuvr 分享了关于 YuE 的工作,这是一个用于长篇音乐生成的开源基础模型系列,能够生成长达五分钟且歌词对齐的音乐。
- 混合专家模型 (MoE) 的可解释性:@iScienceLuvr 重点介绍了 MoE-X,这是一种重新设计的 MoE 层,旨在提高 LLM 中 MLP 的可解释性。
- Gemini Embedding:@_akhaliq 分享了 Gemini Embedding,即来自 Gemini 的通用嵌入模型。
- 视频创作与编辑 AI:@_akhaliq 展示了阿里巴巴的 VACE,这是一款全能视频创作与编辑 AI。@_akhaliq 分享了一篇关于通过同步耦合采样实现免微调的多事件长视频生成的论文。
- 注意力机制与 Softmax:@torchcompiled 声称注意力机制中 Softmax 的使用是随意的,并且存在一个影响 LLM 的“bug”,并链接到一篇新帖子。@torchcompiled 批评注意力机制缺乏“无操作(do nothing)”选项,并建议温度缩放应取决于序列长度。
行业与商业
- AI 商业与应用:@AravSrinivas 表示 Perplexity API 可以生成 PowerPoint,本质上是通过一次 API 调用取代了顾问的工作。@mustafasuleyman 宣布 GroupMe 集成了 Copilot,为数百万用户(尤其是美国大学生)提供应用内 AI 支持。@yusuf_i_mehdi 强调 GroupMe 中的 Copilot 让群聊不再混乱,并在作业、建议和回复方面提供帮助。@TheTuringPost 讨论了超越基础 AI 技能的必要性,并拥抱合成数据、RAG、多模态 AI 和上下文理解,强调全民 AI 素养。@sarahcat21 指出编程变得更容易,但软件构建仍然很难,原因在于数据管理、状态管理和部署方面的挑战。@mathemagic1an 强调 shadcn/ui 集成是 v0 成功的一部分,并赞扬了 Notion 的 UI 套件在知识工作类应用中的表现。
- AI 市场与竞争:@nearcyan 指出,在 Anthropic 达到 14 万亿美元估值后,Google 的价值预计将翻倍。@mervenoyann 调侃 Google 凭借 Gemma 3 “随手干掉了其他模型”。@scaling01 声称 Google 凭借 Gemini 2.0 Flash 在市场上击败了 OpenAI,并展示了其图像重建能力。@LoubnaBenAllal1 表示 Google 凭借 Gemma3 1B 加入了“小模型俱乐部”,展示了小模型发布加速的时间线以及日益激烈的竞争。@scaling01 预测如果 OpenAI 不尽快发布 GPT-5,o1 将占据主导地位。
- AI 招聘与人才:@fchollet 为垂直整合无人机初创公司 Harmattan 招聘对欧洲国防充满热情的机器学习工程师。@saranormous 在关于初创公司招聘的推文中强调,优先考虑早期招聘以避免恶性循环。@SakanaAILabs 正在为 AI 业务计划招聘一名网络安全工程师。@giffmana 表示在 OpenAI 工作很开心,因为那里有聪明的人、有趣的工作以及“倾向于把事情办成”的氛围。@teortaxesTex 表示中国今年将有数百名高水平的机器学习毕业生。@rsalakhu 祝贺 Murtaza Dalal 博士完成博士学位。
- AI 基础设施与算力:@svpino 推广 Nebius Explorer Tier 以每小时 1.50 美元的价格提供 H100 GPU,强调其价格低廉且可立即配置。@dylan522p 宣布了一场拥有超过 100 块 B200/GB200 GPU 的黑客松,演讲嘉宾来自 OpenAI、Thinking Machines、Together 和 Nvidia。@dylan522p 称赞 Texas Instruments 广州的 IC 零件比美国分销商更便宜。@teortaxesTex 分析了华为 2019 年的数据中心硬件,指出了其性能以及制裁的影响。@cHHillee 将在 GTC 讨论 机器学习系统和 Blackwell GPU。
迷因与幽默
- AI 能力与局限性:@scaling01 开玩笑说要重新发明 Diffusion 模型,并建议 Google 应该在图像生成上训练一个推理模型来修复拼写错误。@scaling01 发现 Gemini 2.0 Flash 通过提示词迭代改进了梗图中难以辨认的文本。@scaling01 发布了一张对比 Google 和 OpenAI 的图片,并配文 “checkmate”(将军)。@goodside 展示了 Gemini 2.0 Flash 在上传图片的 T 恤上将 “BASE” 修改为 “BASED”。@scaling01 使用文生图技术制作了一个 Google vs OpenAI 的梗图。@c_valenzuelab 开玩笑说需要一个 captcha 系统来让 AI 证明你不是人类。@scaling01 幽默地使用了 #savegoogle 标签。@scaling01 在 Google vs OpenAI 的背景下使用了 “checkmate” 梗。
- AI 与社会:@oh_that_hat 建议像你希望 AI 对待你那样对待网上的其他人,因为 AI 会从网络互动中学习。@c_valenzuelab 讨论了关于自动化和真实性的审美价值与实用偏好之间的差距。@jd_pressman 分享了一个想象中的场景:向 2015 年的人展示一张澄清 AI 能力的截图。@jd_pressman 将像 GPT 的 AI 反派(The Master, XERXES, Dagoth Ur, Gravemind)与那些不像的(HAL 9000, GladOS, 343 Guilty Spark, X.A.N.A.)区分开来。@qtnx_ 分享了“我的生活就是这一系列无止尽的 gif”并配上相关 gif。@francoisfleuret 分享了一个关于瑞士和俄罗斯军官及手表的苏联公民笑话。
- 一般幽默与讽刺:@teortaxesTex 发布了“结束了。梗图被反转了。这是我今天读到最搞笑的事”并附带链接。@teortaxesTex 讽刺地说“笑死,美国完全没为那场战争做好准备”。
AI Reddit 摘要
/r/LocalLlama 摘要
主题 1. Gemma 3 多模态发布:视觉、文本及 128K 上下文
- Gemma 3 发布 - Google Collection (Score: 793, Comments: 218):Gemma 3 已作为 Google Collection 发布,尽管该帖子缺乏关于其功能或影响的进一步细节或背景。
- Gemma 3 功能与问题:用户注意到 Gemma 3 不支持 tool calling,并且在 AIstudio 的 gemma-3-27b-it 中存在图像输入问题。模型架构尚未被 Transformers 等平台识别,且尚未在 LM Studio 上运行。
- 性能与对比:4B Gemma 3 模型 超过了 9B Gemma 2,而 12B 模型 因其强大的 vision 能力而受到关注。尽管性能出色,用户报告它在 ollama 上经常崩溃,且缺乏 function calling 等功能。EQ-Bench 结果显示 27b-it 模型在创意写作方面排名第二。
- 模型可用性与技术细节:Gemma 3 模型可在 ollama 和 Hugging Face 等平台获取,并提供了各种资源和技术报告的链接。模型支持高达 128K tokens,并采用 Quantization Aware Training 以减少内存占用,目前正致力于在 Hugging Face 上添加更多版本。
- Gemma 3 27b 现已在 Google AI Studio 上线 (Score: 313, Comments: 61): Gemma 3 27B 现已在 Google AI Studio 上提供,具有 128k 的上下文长度和 8k 的输出长度。更多详情可以在提供的 Google AI Studio 和 Imgur 链接中找到。
- 用户讨论了 system prompt 及其对 Gemma 3 回复的影响,指出它有时能提供超出其所谓截止日期的信息,例如在被问及 2021 年之后的事件时。一些用户在处理逻辑和写作任务的能力方面报告了不同的体验,并将其与 Gemma 2 及其局限性进行了比较。
- 性能问题被重点提及,几位用户表示 Gemma 3 目前运行较慢,尽管与 Gemma 2 相比,它在指令遵循方面有所改进。还有关于其翻译能力的讨论,一些人声称它优于 Google Translate 和 DeepL。
- 分享了 Gemma 3 在 Hugging Face 发布的链接,提供了各种模型版本的访问权限。用户表达了对开放权重和 benchmarks 的期待,以便更好地评估模型的性能和能力。
- Gemma 3 在 Huggingface 上线 (Score: 154, Comments: 27): Google 的 Gemma 3 模型已在 Huggingface 上提供,参数规模包括 1B、4B、12B 和 27B,并提供了每个规模的链接。它们支持文本和图像输入,较大模型的总输入上下文为 128K tokens,1B 模型为 32K tokens,并产生 8192 tokens 的输出上下文。该模型已添加到 Ollama,并在 Chatbot Arena 上拥有 1338 的 ELO 分数,超越了 DeepSeek V3 671B。
- 模型上下文和 VRAM 需求:27B Gemma 3 模型在 128K 上下文下需要高达 45.09GB 的 VRAM,这对于没有像第二块 3090 这样的高端 GPU 的用户来说是一个挑战。8K 指的是输出 token 上下文,而较大模型的输入上下文为 128K。
- 模型性能和特性:用户将 27B Gemma 3 模型与 1.5 Flash 进行了比较,但指出它的行为有所不同,类似于 Sonnet 3.7,会对简单问题提供详尽的回答,暗示其具有作为系统工程师工具的潜力。
- 运行和兼容性问题:由于版本不兼容,一些用户在 Ollama 上运行模型时遇到问题,但更新软件可以解决此问题。GGUFs 和模型版本可在 Huggingface 获取,用户在部署模型时应注意双 BOS tokens 问题。
主题 2. Unsloth 的 GRPO 修改:Llama-8B 的自学习改进
- 我修改了 Unsloth 的 GRPO 代码以支持 Agent 工具使用。在 RTX 4090 上训练 1 小时,Llama-8B 学会了迈向深度研究的第一步!(准确率从 23% 提升至 53%) (Score: 655, Comments: 49): 我修改了 Unsloth 的 GRPO 代码,使 Llama-8B 能够以 Agent 方式使用工具,通过自我对弈 (self-play) 增强其研究技能。仅在 RTX 4090 上训练一小时,该模型就通过生成问题、搜索答案、评估成功与否以及通过强化学习 (reinforcement learning) 完善其研究能力,将准确率从 23% 提高到 53%。你可以在这里找到完整的 代码和说明。
- 用户对 强化学习 (RL) 过程 表现出好奇,特别是数据集的创建和持续的权重调整。作者解释说,他们从 LLM 生成并过滤回复以创建用于微调 (fine-tuning) 的数据集,并迭代重复此过程。
- 将此方法应用于 Llama 70B 和 405B 等更大模型的兴趣非常浓厚,作者提到正在努力设置 FSDP 以进行进一步实验。
- 社区对该项目表现出强烈的支持和兴趣,建议向 Unsloth 仓库贡献代码,并对分享工作表示感谢,强调了其在“Agent 之年”中潜在的行业相关性。
- Gemma 3 - GGUF 及其推荐设置 (Score: 171, Comments: 76): Gemma 3 是 Google 推出的新型多模态模型,目前已在 Hugging Face 上提供 1B、4B、12B 和 27B 尺寸,并上传了 GGUF 和 16-bit 版本。此处提供了运行 Gemma 3 的分步指南,推荐的推理设置包括 temperature 为 1.0、top_k 为 64 以及 top_p 为 0.95。使用 4-bit QLoRA 进行训练目前存在已知 Bug,但预计很快会发布更新。
- 温度与性能问题:用户确认 Gemma 3 在 1.0 的 temperature 下运行,这并不被认为很高,但仍有用户报告了性能问题,例如与 Qwen2.5 32B 等其他模型相比速度较慢。一位使用 RTX 5090 的用户指出 Gemma 3 的性能较慢,其中 4B 模型 的运行速度甚至比 9B 模型 还慢,这引发了 Gemma 团队的进一步调查。
- 系统提示词与推理挑战:讨论强调 Gemma 3 缺乏原生的系统提示词(system prompt),需要用户将系统指令合并到用户提示词中。此外,在 LM Studio 中运行 GGUF 文件 存在问题,建议使用 dynamic 4-bit 推理而非 GGUF,但由于 Transformer 的问题,目前尚未上传。
- 量化与模型兼容性:Gemma2-27B 的 IQ3_XXS 量化版本因其 10.8 GB 的超小体积而受到关注,使其能够在 3060 GPU 上运行。用户对显存(VRAM)需求的准确性展开了辩论,一些人断言 16GB 显存不足以运行 27B 模型,而另一些人则认为配合 Q8 cache quantization 可以有效运行。
主题 3. M3 Ultra 上的 DeepSeek R1:SoC 能力洞察
- M3 Ultra 使用 448GB 统一内存运行 6710 亿参数的 DeepSeek R1,在功耗低于 200W 的情况下提供高带宽性能,无需多 GPU 配置 (Score: 380, Comments: 159): DeepSeek R1 在 M3 Ultra 上以 6710 亿参数运行,使用 448GB 统一内存,在功耗低于 200W 的情况下实现了高带宽性能。该方案消除了对多 GPU 配置的需求。
- 讨论重点集中在 DeepSeek R1 在 M3 Ultra 上的提示词处理速度和上下文大小限制,多位用户对缺乏具体数据表示沮丧。用户强调,即使达到 18 tokens per second,在大上下文尺寸下开始生成内容所需的时间也是不切实际的,通常需要几分钟。
- 对于 Apple Silicon 用于大模型本地推理的实用性存在怀疑,许多用户指出,尽管 M3 Ultra 规格惊人,但其性能并不适合处理复杂的上下文管理或训练任务。用户认为 NVIDIA 和 AMD 的产品虽然功耗更高,但在这些任务上可能更有效。
- 讨论还涉及了 KV Cache 提升 Mac 系统性能的潜力,但用户注意到在处理复杂上下文管理时存在局限性。此外,连接 eGPU 以增强处理能力的可行性也引发了辩论,一些用户指出 macOS 缺乏对 Vulkan 的支持是一个障碍。
- EXO Labs 在两台 M3 Ultra 512GB Mac Studio 上分布式运行了完整的 8-bit DeepSeek R1 - 11 t/s (Score: 143, Comments: 37): EXO Labs 在两台 M3 Ultra 512GB Mac Studio 上执行了完整的 8-bit DeepSeek R1 分布式处理,实现了 11 t/s (每秒 token 数) 的性能。
- 讨论强调了使用 M3 Ultra Mac Studio 与 GPU 等其他硬件相比的成本和性能权衡。虽然 Mac Studio 提供了紧凑且安静的设置,但因其提示词处理速度慢和高昂的费用(尤其是 RAM 和 SSD 的定价)而面临批评,尽管它具有能效高和节省空间的优点。
- 对话强调了批处理 (Batching) 对于在 Mac Studio 等昂贵硬件设置上最大化吞吐量的重要性,并将其与可以并行处理多个请求的 GPU 集群进行了对比。文中还将其与 H200 集群等替代方案进行了比较,后者尽管成本和功耗更高,但在批处理场景下提供了显著更快的性能。
- 用户对提示词处理指标 (prompt processing metrics) 有显著需求,多位用户对 EXO Labs 分享的结果中缺乏这些数据表示失望。短提示词的首个 token 生成时间 (time to first token) 为 0.59 秒,但用户认为这不足以衡量整体性能。
Theme 4. Gemma 3 开源努力:Llama.cpp 及更多
- Gemma 3 - 开源努力 - llama.cpp - MLX 社区 (Score: 160, Comments: 12): Gemma 3 发布并提供开源支持,强调了 ngyson、Google 和 Hugging Face 之间的协作。由 Colin Kealty 和 Awni Hannun 分享的这一公告强调了 MLX 社区内的社区努力,并表彰了主要贡献者,庆祝该模型的进步。
- vLLM 项目正在积极集成 Gemma 3 支持,尽管根据以往的表现,人们对其能否按发布计划完成持怀疑态度。文中分享了相关 GitHub pull requests 的链接以跟踪进度。
- Google 对该项目的贡献因其前所未有的速度和支持而受到称赞,特别是在协助与 llama.cpp 的集成方面。这次协作被视为一次重大的突破,人们对在 LM Studio 中尝试 Gemma 3 27b 感到兴奋。
- Hugging Face、Google 和 llama.cpp 之间的协作被强调为一次成功的努力,使 Gemma 3 能够被迅速使用,并对 Son 的贡献给予了特别认可。
- QwQ 在高思考强度设置下一次性通过弹球示例 (Score: 115, Comments: 18): 该帖子讨论了 Gemma 3 及其与开源 MLX 社区 的兼容性,特别是为了高效执行弹球示例 (bouncing balls example) 所需的高强度设置。
- GPU Offloading 与性能:用户讨论了通过将处理任务卸载到 GPU 来优化弹球示例,其中一名用户使用 Llama 在 40 个 GPU 层上实现了 21,000 个 token。然而,他们遇到了球体消失的问题,需要调整重力和摩擦力等参数以获得更好的表现。
- 思考强度控制 (Thinking Effort Control):ASL_Dev 分享了一种通过调整
</think>token 的 logit 来控制模型思考强度的方法,在思考强度设置为 2.5 时实现了可运行的模拟。他们为该实验性设置提供了一个 GitHub 链接,与常规设置相比,该设置提高了模拟的性能。 - 推理引擎自定义:讨论强调了推理引擎允许手动调整推理强度的潜力,类似于 OpenAI 的模型。用户注意到 openwebui 等平台已经提供了此功能,并且人们对为推理模型添加权重调节器以增强自定义功能表现出兴趣。
{kind=link}
其他 AI 子版块回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding
主题 1. DeepSeek 和 ChatGPT 审查:观察与反弹
- DeepSeek 有那么一瞬间忘记了谁是它的所有者 (Score: 6626, Comments: 100): 该帖子讨论了 DeepSeek,强调了 AI 在识别其所有权时出现的瞬间失误,这引发了对潜在 AI censorship 的担忧。由于帖子缺乏详细的背景或分析,这一事件的具体影响仍有待解读。
- 审查担忧: 用户对 AI 系统生成完整响应后又将其撤回表示沮丧,这表明存在一种在生成后检查“禁忌话题”的内容机制。与 ChatGPT 这种将 guardrails 集成到 AI 逻辑中的系统相比,这种方法被认为不够优雅,凸显了 AI 审查中的透明度问题。
- 中国审查: 有推测认为,这种审查机制可能是针对中国审查政策的一种“恶意合规”,一些用户建议,该系统糟糕的实现是有意为之,旨在突出审查问题。
- 技术建议: 用户建议 AI 系统应该生成完整响应,通过过滤器运行,然后再显示,以避免目前这种可能被撤销的 streaming 答案的做法,因为这被认为效率低下且对用户不友好。
- DeepSeek 忘记了自己的老板…… (Score: 234, Comments: 11): 帖子标题 “DeepSeek Forgot Its Own Owner” 暗示了围绕 DeepSeek 所有权的混乱或争议,可能反映了与 censorship 相关的更广泛问题。在没有额外背景或视频分析的情况下,无法获得进一步的细节。
- 社交媒体评论: 用户对 Reddit 平台表示不满,一条评论讽刺地称其为“有史以来最典型的社交媒体平台之一”,而另一条评论则强调了在媒体化之前对其社交属性的保留。
- 审查与讽刺: 评论影射了审查问题,其中包含涉及 Xi Jinping 的讽刺性言论,以及对视频末尾“社会信用广告”的幽默调侃,表明了对审查或控制机制的批评。
- 技术观察: 一位用户指出了关于 DeepSeek 的一个技术细节,观察到在只剩下三个字母时出现了短暂的停顿,幽默地将其归因于“正对着红色按钮扶额”。
Theme 2. Claude Sonnet 3.7: A Standout in Coding Conversion Tasks
- Claude Sonnet 3.7 的编程能力简直疯狂! (Score: 324, Comments: 126): Claude Sonnet 3.7 在将复杂的 JavaScript 应用程序转换为 Vue 3 方面表现出色,正如它在单个会话中将一个包含 2,000 行 JavaScript 的 4,269 行应用程序重构为 Vue 3 应用程序所证明的那样。它有效地保留了应用程序的功能、用户体验和组件依赖关系,实现了合理的组件结构、Pinia stores、Vue Router 和拖放功能,展示了相比 Claude 3.5 的显著改进。
- 讨论强调了 Claude 3.7 取代传统 BI 工具和分析师的能力,一位用户分享了它如何在几分钟内将 Mixpanel 的 CSV 数据转换为全面的仪表板,节省了与 BI 工具和分析师相关的巨额成本。
- 用户对 Claude 3.7 的评价褒贬不一,一些人称赞其创建无 Bug 复杂应用的能力,而另一些人则批评其过度发挥和产生功能 hallucination 的倾向,反映了关于 AI 在编程中有效性的更广泛辩论。
- 社区对 Claude 3.7 的看法存在两极分化,这是一个幽默的观察,一些用户认为它是革命性的,而另一些人则认为它存在问题,这说明了 AI 工具评估的多样性,有时甚至是矛盾的。
Theme 3. Open-Source Text-to-Video Innovations: New Viral Demos
- 我刚刚开源了另外 8 个病毒式传播的效果!(欢迎在评论区提出更多需求!) (Score: 565, Comments: 41):八种病毒式 AI 文本生成视频效果已开源,并邀请社区在评论中请求更多效果。
- 开源与易用性:这些效果是开源的,允许任何拥有高性能电脑的人免费运行,或者在 Runpod 等平台上以约 每小时 0.70 美元 的价格租赁 GPU。Generative-Explorer 详细解释了如何结合 ComfyUI 和 LoRA 节点设置并使用 Wan 2.1 模型,并为初学者提供了教程链接。
- 效果细节与社区参与:帖子作者 najsonepls 强调了基于 Wan2.1 14B I2V 480p model 训练的效果所取得的病毒式成功,列出的效果包括:挤压 (Squish)、粉碎 (Crush)、蛋糕化 (Cakeify)、充气 (Inflate)、放气 (Deflate)、360 度微波旋转、开枪射击和肌肉展示。社区讨论了诸如“变老”等潜在的新效果,并对开源特性表示出浓厚兴趣,这使得进一步的定制和创新成为可能。
- 担忧与行业影响:用户推测大公司是否会将类似效果限制在付费墙后,但 Generative-Explorer 认为,通过使用少量视频训练 LoRA,开源替代方案可以被迅速开发出来。讨论还涉及了充气和放气等效果对特定利基内容领域(如 NSFW Tumblr 圈子)的影响。
主题 4. 西班牙的 AI 内容标注指令:法律与社会影响
- 西班牙将对未标注 AI 生成内容的行为处以巨额罚款 (Score: 212, Comments: 22):西班牙正在引入一项指令,要求对 AI 生成的内容进行标注,违规者将面临巨额罚款。该法规旨在提高使用 AI 技术时的透明度和问责制。
- 检测挑战:人们对 AI 检测方法的有效性表示担忧,并提到了学校中现有的问题,即 AI 检测软件会产生误报 (false positives)。关于西班牙如何在不冤枉个人的情况下准确识别 AI 生成内容,也引发了疑问。
- 怀疑与批评:舆论对专注于 AI 生成内容标注的做法持怀疑态度,建议优先处理立法过程中的腐败和优待问题,而不是关注交通罚单和学校作业等琐碎事项。
- 监管影响:一些用户表示,该法规可能会导致西班牙境内 AI 使用量的减少,这既可能被视为获得心理安宁的积极举措,也可能被视为阻碍该国 AI 应用的负面后果。
主题 5. ✨ 表情符号的象征意义:作为 AI 图标的兴起
- 星星 ✨ 什么时候成了 AI 生成的象征?它从何而来? (Score: 200, Comments: 42):该帖子询问了 ✨ 表情符号作为 AI 生成内容符号的起源和普及过程,并指出它在新闻文章、社交媒体以及 Notepad 等应用程序中随处可见。配图使用了星星和圆点图形来唤起该表情符号与“闪烁”或“魔法”的关联,但缺乏文字解释。
- Jasper 是早在 2021 年初就采用 ✨ 表情符号来表示 AI 生成内容的先行者之一,早于 Google、Microsoft 和 Adobe 等大公司,后者在 2022-2023 年间开始使用它。到 2023 年中期,设计界开始讨论其作为 AI 非官方标准的地位;到 2023 年底,它已被主流媒体公认为通用的 AI 符号。
- ✨ 表情符号与魔法和自动纠错的概念相关联,让人联想起 Adobe 在 30 多年前使用的魔棒 (magic wand) 图标。这种与魔法和自动改进的关联,促使其被广泛采纳为 AI 生成内容的象征。
- 多个资源探索了该表情符号的历史和采用情况,包括 Wikipedia 条目、一段 YouTube 视频 以及 David Imel 在 Substack 上发表的文章,为它作为 AI 图标的演变提供了见解。
{kind=link}
AI Discord 摘要回顾
由 o1-preview-2024-09-12 生成的摘要之摘要的摘要
主题 1:Google 的多模态新作闪耀 AI 舞台
- Gemma 3 凭借多语言精通成为焦点:Google 发布了 Gemma 3,这是一款参数量从 1B 到 27B 不等的多模态模型,拥有 128K context window,支持超过 140 种语言。社区对其在单个 GPU 或 TPU 上运行的潜力议论纷纷。
- Gemini 2.0 Flash 以词绘图:Gemini 2.0 Flash 现在支持原生图像生成,允许用户直接在模型内创建与上下文相关的图像。开发者可以通过 Google AI Studio 进行体验。
- Gemini Robotics 让 AI 走进现实——字面意义上的!:Google 在 YouTube 视频中展示了 Gemini Robotics,演示了先进的 vision-language-action 模型,使机器人能够与物理世界互动。
主题 2:新型 AI 模型挑战巨头
- OlympicCoder 在编程挑战中超越 Claude 3.7:紧凑的 7B parameter OlympicCoder 模型在奥林匹克级别的编程挑战中超越了 Claude 3.7,证明了在 AI 性能方面,规模并非一切。
- Reka Flash 3 在对话和代码领域加速前进:Reka 发布了 Flash 3,这是一个 21B parameter 的模型,在对话、编程和 function calling 方面表现出色,具有 32K context length,并可免费使用。
- Swallow 70B 在日语领域横扫竞争对手:Llama 3.1 Swallow 70B 是一款具备超快响应速度的日语能力模型,现已加入 OpenRouter,扩展了语言能力并提供极速响应。
主题 3:AI 工具遭遇波折
- Codeium 出现协议错误,开发者大惊失色:用户报告 Codeium 的 VSCode extension 出现 protocol errors,如“invalid_argument: protocol error: incomplete envelope”,导致代码补全功能陷入困境。
- Cursor 更新后运行缓慢,用户纷纷退回旧版本:在更新到 version 0.46.11 后,Cursor IDE 变得反应迟钝,促使用户建议下载 version 0.47.1 以恢复性能。
- Perplexity Windows 应用的 Apple ID 登录出现故障:Perplexity AI 用户在使用 Apple ID 登录时遇到 500 Internal Server Error,而使用 Google 账号的用户则运行顺畅。
主题 4:AI 工具集成迸发创新火花
- OpenAI Agents SDK 与 MCP 挂钩:OpenAI Agents SDK 现在支持 Model Context Protocol (MCP),允许 Agent 无缝聚合来自 MCP server 的工具,以实现更强大的 AI 交互。
- Glama AI 公开所有可用工具详情:Glama AI 的新 API 列出了每个 server 的所有可用工具,以开放的 AI 能力目录令用户感到兴奋。
- LlamaIndex 跨入 MCP 集成行列:LlamaIndex 与 Model Context Protocol 集成,通过接入任何兼容 MCP 的服务所提供的工具来增强其能力。
主题 5:关于 LLM 行为的辩论升温
- “LLM 不会产生幻觉!”怀疑论者惊呼:关于 LLM 是否会产生“幻觉”引发了激烈辩论,一些人认为既然它们不进行“思考”,就不会产生幻觉——这在 AI 社区引发了哲学层面的对决。
- LLM 通过面部记忆系统焕发新颜:一个开源的 LLM Facial Memory System 允许 LLM 根据用户的面部存储记忆和聊天记录,增加了一层新的个性化交互。
- ChatGPT 的伦理提醒令寻求未过滤回复的用户感到恼火:用户对 ChatGPT 在回复中频繁出现的伦理准则表示反感,希望有一个“关闭 AI 保姆”的选项来简化他们的工作流程。
PART 1: 高层级 Discord 摘要
Cursor IDE Discord
- Claude 3.7 遭遇过载:用户报告 Claude 3.7 负载过高,在高峰时段会出现错误和卡顿,建议在夜间编写代码以避开这些问题,并分享了关于该话题的 Cursor 论坛帖子链接。
- ‘diff algorithm stopped early’ 错误是一个频繁报告的问题。
- Cursor 在 0.46 版本变慢:用户观察到在更新到 0.46.11 版本后,Macbook 和 PC 上的 Cursor 变得非常迟钝,建议下载 0.47.1 版本。
- 即使在 CPU 占用率较低的情况下也会出现性能下降,而项目规则的模式匹配问题已在后续版本中修复。
- Manus AI 生成销售线索:成员们讨论了使用 Manus AI 进行线索生成和构建 SaaS 落地页,强调了其获取电话号码的能力,据报道在花费 $600 后获得了 30 个高质量线索。
- OpenManus 尝试复制功能:用户分享称 OpenManus(一个试图复制 Manus AI 的开源项目)展现出了潜力,并提供了 GitHub 仓库链接和展示其能力的 YouTube 视频。
- 一些成员认为它目前还无法与 Manus 媲美。
- Cline 的代码补全成本受到批评:成员们辩论了 Cline 的价值,认为其相对于 Cursor 成本过高。
- 虽然 Cline 提供“全上下文窗口(full context window)”,但一些用户认为 Cursor 的缓存系统允许在单个对话中扩展上下文,并提供 Web 搜索和文档等功能。
LM Studio Discord
- LM Studio 支持 Gemma 3:LM Studio 0.3.13 现在支持 Google 的 Gemma 3 系列,但用户报告 Gemma 3 模型 的运行速度明显变慢,与同类模型相比慢了多达 10 倍。
- 团队还在努力解决一些问题,例如用户难以完全禁用 RAG 以及 Linux 安装程序的问题。
- 关于移除 RAG 的激烈讨论:用户寻求在 LM Studio 中完全关闭 RAG,以便将完整的附件注入上下文中,但目前没有禁用它的 UI 选项。
- 作为权宜之计,用户手动复制粘贴文档,面临着将 PDF 转换为 Markdown 的麻烦。
- AMD GPU 用户的热点温度困扰:用户报告其 7900 XTX 的热点温度达到 110°C,引发了关于 RMA 资格的讨论,并担心 AIB 厂商在散热上偷工减料;有一份报告称 AMD 拒绝 了此类 RMA 请求。
- 有人指出根本原因可能是真空腔(vapour chambers)批次不良,内部水量不足,而 PowerColor 已对 RMA 请求表示同意。
- 矿卡复活作为推理主力:成员们正在讨论复活具有 288 tensor cores 的 CMP-40HX 矿卡用于 AI inference。
- 由于需要对 Nvidia 驱动程序打补丁以启用 3D 加速支持,用户的兴趣受到了一定影响。
- PTM7950 相变材料备受关注:成员们考虑使用 PTM7950(相变材料)代替硅脂,以防止泵出(pump-out)问题并保持稳定的温度。
- 在第一次热循环后,多余的材料会泵出并在芯片周围形成一层厚且粘稠的层,从而防止进一步的泵出。
Nous Research AI Discord
- Nous Research 发布推理 API:Nous Research 发布了其 Inference API,包含 Hermes 3 Llama 70B 和 DeepHermes 3 8B Preview,并为新账户提供 $5.00 的免费额度。
- Nous Portal 已实施候补名单系统,按照先到先得的原则授予访问权限。
- LLM 现在可以识别面部并记住对话:一位成员开源了一个 LLM Facial Memory System,让 LLM 能够根据你的面部存储记忆和聊天记录。
- 成员们讨论了推理 API,包括由于对 API key 安全性的担忧,考虑预充值额度的可能性。
- 利用开源代码构建图推理系统:成员们讨论了目前已有足够的公开信息利用开源代码构建图推理系统 (graph reasoning system),虽然可能不如 Forge,但新 API 提供了 50 欧元的推理额度。
- 提到 Kuzu 非常出色,而对于图数据库,推荐使用 networkx + python。
- Audio-Flamingo-2 调性检测失败:一位用户在 HuggingFace 上测试了 Nvidia 的 Audio-Flamingo-2,用于检测歌曲的调性 (key) 和节拍 (tempo),但结果好坏参半,甚至无法识别简单流行歌曲的调性。
- 例如,当被要求识别 Lorde 的歌曲《Royals》的调性时,Audio-Flamingo-2 错误地猜为 F# Minor,节拍为 150 BPM,引发了社区的哄笑。
Unsloth AI (Daniel Han) Discord
- Gemma 3 获得 GGUF 支持:Gemma 3 的所有 GGUF、4-bit 和 16-bit 版本已上传至 Hugging Face。
- 这些量化版本旨在运行于使用 llama.cpp 的程序中,如 LM Studio 和 GPT4All。
- Transformers 故障阻碍微调:Transformers 中的一个破坏性 Bug 正在阻止 Gemma 3 的微调。根据 Unsloth AI 的博客更新,HF 正在积极修复。
- 建议用户等待官方的 Unsloth notebook,以确保在 Bug 解决后实现兼容性。
- GRPO 泛化效果显著!:讨论涵盖了 RLHF 方法(如 PPO、DPO、GRPO 和 RLOO)的细微差别,一位成员指出 GRPO 的泛化能力更好,并且是 PPO 的直接替代方案。
- RLOO 是 PPO 的更新版本,其优势基于群体响应的归一化奖励分数,由 Cohere AI 开发。
- HackXelerator 登陆伦敦、巴黎、柏林:一位成员宣布了由 Mistral、HF 等支持的伦敦、巴黎、柏林多模态创意 AI HackXelerator。
- 由 Mistral AI、Hugging Face、AMD 等支持的多模态创意 AI HackXelerator 将在伦敦、巴黎和柏林举行,重点关注音乐、艺术、电影、时尚和游戏,将于 2025 年 4 月 5 日开始 (lu.ma/w3mv1c6o)。
- 为 Ollama 调整 Temperature 参数:许多人在使用 1.0 的 temp 设置时遇到问题,建议在 Ollama 中以 0.1 运行。
- 鼓励进行测试,看看在 llama.cpp 和其他程序中是否表现更好。
Perplexity AI Discord
- ANUS AI Agent 引起热议:GitHub 仓库 nikmcfly/ANUS 因其不幸的命名引发了幽默讨论,一位成员开玩笑地建议使用 TWAT (Think, Wait, Act, Talk pipeline) 作为替代缩写。
- 另一位成员提议将 Prostate 作为政府 AI Agent 的名称,进一步延续了这一滑稽的交流。
- Apple ID 登录触发服务器错误:用户报告在尝试为 Perplexity 的新 Windows 应用进行 Apple ID 登录时遇到 500 Internal Server Error。
- 这一问题似乎仅限于 Apple ID,因为部分用户的 Google 登录功能正常。
- 模型选择器忽隐忽现:在新的网页端更新中,模型选择器最初消失了,导致用户因无法选择 R1 等特定模型而感到沮丧。
- 模型选择器随后重新出现,用户建议将模式设置为 “pro” 或使用 “complexity extension” 来解决选择问题。
- Perplexity 搞砸了代码清理:一位用户分享了他们长达 6 小时的惨痛经历,详细描述了 Perplexity 如何未能正确清理一个 875 行的代码文件,导致代码块和链接损坏。
- 尽管受限于消息长度限制,Perplexity 最终返回了原始且未修改的代码。
- MCP Server 连接器发布:API 团队宣布发布其 Model Context Protocol (MCP) server,鼓励社区通过 GitHub 提供反馈和贡献。
- MCP server 作为 Perplexity API 的连接器,支持在 MCP 生态系统中直接进行网页搜索。
aider (Paul Gauthier) Discord
- Gemma 3 登场!:Google 发布了 Gemma 3,这是一款多模态模型,参数范围从 1B 到 27B,拥有 128K 上下文窗口,并根据 Google 博客 兼容 140+ 种语言。
- 这些模型旨在轻量且高效,目标是在单个 GPU 或 TPU 上实现最佳性能。
- OlympicCoder 横扫编程任务!:根据 推文 和 Unsloth.ai 博客文章,OlympicCoder 模型(一个紧凑的 7B 参数模型)在奥林匹克级别的编程挑战中超越了 Claude 3.7。
- 这一壮举强调了高效模型在专业编程领域的潜力。
- Fast Apply 模型加速编辑!:受一篇已删除的 Cursor 博客文章 启发,Fast Apply 模型是一个经过微调的 Qwen2.5 Coder Model,用于快速代码更新,正如在 Reddit 上讨论的那样。
- 该模型解决了在 Aider 等工具中更快应用搜索/替换块的需求,增强了代码编辑工作流。
- Aider 的 Repo Map 被弃用!:用户正选择禁用 Aider 的 repo map,转而手动添加文件以更好地控制上下文,尽管 Aider 的使用技巧建议显式添加文件是最有效的方法,详见 官方使用技巧。
- 目的是防止 LLM 被过多的无关代码分散注意力。
- LLM 极大加速学习:成员们分享说 LLM 大大加速了学习 Python 和 Go 等语言的过程,并提到生产力的提升让他们能够承担以前认为不合理的项目。
- 一位成员指出,这不仅仅是工作变快了,而是让那些原本不可能实现的项目变得可行,并将 AI 描述为 寒武纪大爆发级别 的事件。
OpenAI Discord
- Perplexity 在深度研究方面击败 OpenAI:一位成员认为 Perplexity 在深度研究方面优于 OpenAI 和 SuperGrok,特别是在处理上传文档和互联网搜索时,同时也考虑到了用户的预算问题。
- 用户在寻求如何从 ChatGPT、Perplexity 和 Grok 中做出选择的建议,最终因其研究能力而推荐了 Perplexity。
- Ollama 编排最佳模型部署:当被问及部署 AI Transformer 模型的最佳语言时,一位成员建议将 Ollama 作为服务使用,特别是如果追求更快的推理速度/性能。
- 该用户一直在使用 Python 进行原型设计,并探索 C# 是否能提供更好的性能,从而得到了 Ollama 的推荐。
- 怀疑论者称 LLMs 不会产生幻觉:一位成员认为“幻觉 (hallucination)”一词被错误地应用于 LLM,因为 LLM 不具备思考能力,只是简单地根据概率生成词序。
- 另一位成员补充说,有时它会错误地切换模型,并指向一张附图。
- Gemini 的图像生成能力令人印象深刻:成员们对 Google 发布的 Gemini 原生图像功能赞不绝口,强调其免费可用性,以及能够“看到它生成的图像”以便更好地重新生成。
- 这一功能允许通过文本改进图像的重新生成,并在 Gemini Robotics 公告中进行了展示。
- 伦理化的 ChatGPT 引起反感:用户对 ChatGPT 频繁的伦理提醒表示恼火,认为这些提醒是不必要的、多余的,并且干扰了他们的工作流。
- 一位用户表示,他们希望有一个选项可以禁用这些伦理准则。
{kind=link}
HuggingFace Discord
- HF 课程解释视觉语言模型:Hugging Face 计算机视觉课程包含一个介绍 Vision Language Models (VLMs) 的章节,涵盖了多模态学习策略、常用数据集、下游任务和评估。
- 该课程强调了 VLMs 如何协调来自不同感官的见解,使 AI 能够更全面地理解世界并与之互动,统一了来自不同感官输入的见解。
- 为实现顶级吞吐量而进行的 TensorFlow 调整:一位成员分享了一篇关于 使用 TensorFlow 进行 GPU 配置 的博客文章,涵盖了实验性函数、逻辑设备和物理设备,使用的是 TensorFlow 2.16.1。
- 该成员探索了 GPU 配置的技术和方法,借鉴了使用 NVIDIA GeForce RTX 3050 Laptop GPU 处理 280 万张图像数据集 的经验,利用 TensorFlow API Python Config 来提高执行速度。
- Modal 模块模型可用:一位成员分享了一个 YouTube 教程,关于如何在 Modal 上免费部署 Wan2.1 Image to Video 模型,涵盖了无缝的 Modal 安装和 Python 脚本。
- 提供了关于如何使用 Modelfile 来运行这个 GGUF 格式 的 Gemma 2b 微调模型的说明。
- 本地模型解放语言学习:一位用户分享了在
smolagents中通过litellm和ollama使用本地模型的代码片段,使用LiteLLMModel并指定pip install smolagents[litellm],然后调用localModel = LiteLLMModel(model_id="ollama_chat/qwen2.5:14b", api_key="ollama")。- 用户报告称,使用默认的
hfApiModel在仅调用几次 Qwen 推理 API 后就会产生 需要付费 (payment required) 的错误,但指定本地模型可以绕过这一限制。
- 用户报告称,使用默认的
- Agent 架构的烦恼等待解决:用户们正热切期待 Unit 2.3 的发布,该单元涵盖了 LangGraph,原定于 3 月 11 日发布。
- 一位用户指出,用调用结果覆盖
agent_name变量会导致 Agent 变得无法调用,从而引发了关于预防策略的讨论。
- 一位用户指出,用调用结果覆盖
OpenRouter (Alex Atallah) Discord
- Gemma 3 引入多模态能力:Google 在 OpenRouter 上发布了 Gemma 3,这是一个支持视觉-语言输入和文本输出的多模态模型,具有 128k tokens 的上下文窗口,并支持超过 140 种语言。
- Reka Flash 3 在对话和编程方面表现出色:Reka 发布了 Flash 3,这是一个拥有 210 亿参数的语言模型,在通用对话、编程和 Function Calling 方面表现优异,具有通过强化学习 (RLOO) 优化的 32K 上下文长度。
- 该模型的权重采用 Apache 2.0 许可证,可免费使用,且主要是一个英文模型。
- Swallow 70B 增加日语流利度:一款名为 Llama 3.1 Swallow 70B 的新型超快日语能力模型加入 OpenRouter,扩展了平台的语言能力。
- 这补充了 Reka Flash 3 和 Google Gemma 3 的发布,增强了 OpenRouter 上可用语言处理工具的多样性。
- Gemini 2 Flash 支持原生图像生成:Google 的 Gemini 2.0 Flash 现在支持原生图像输出,供 Google AI Studio 支持的所有地区的开发者进行实验,可通过 Gemini API 和实验版本 (gemini-2.0-flash-exp) 访问。
- 正如 Google Developers Blog 文章中所宣布的,这允许从文本和图像输入创建图像,保持角色一致性并增强叙事能力。
- OpenRouter 的 Chutes 提供商保持免费:Chutes 提供商在准备服务和扩大规模期间,由于尚未完全实现支付系统,目前对 OpenRouter 用户保持免费。
- 虽然数据没有明确用于训练,但由于其去中心化的性质,OpenRouter 无法保证计算主机不会使用这些数据。
Eleuther Discord
- Distill 社区启动每月聚会:在取得成功反响后,Distill 社区正在启动每月聚会,下一次定于 美国东部时间 3 月 14 日上午 11:30 至下午 1:00。
- 详情可以在 Exploring Explainables Reading Group 文档中找到。
- TTT 增强模型引导 (Priming):成员们讨论了 TTT 如何通过执行单次梯度下降过程,加速为给定提示词引导模型的过程,使模型状态更具接收性。
- 模型优化了序列压缩以产生有用的表示,从而通过旨在学习和执行每个 token 的多次梯度下降,增强了 ICL 和 CoT 能力。
- Decoder-Only 架构拥抱动态计算:一项小提议建议将 Decoder 端用于动态计算,通过重新将 Encoder-Decoder 的概念引入 Decoder-Only 架构,利用 类 TTT 层 扩展序列长度以进行内部“思考”。
- 一个挑战是确定额外的采样步数,但测量 TTT 更新损失的增量 (delta) 并在低于中值时停止可能会有所帮助。
- AIME24 实现出现,仍需测试:基于 MATH 实现的 AIME24 实现已出现在 lm-evaluation-harness 中。
- 提交者承认,由于缺乏关于人们运行 AIME24 时具体执行内容的文档,他们还没有时间对其进行测试。
GPU MODE Discord
- Funnel Shift 在 H100 上的性能表现:工程师们惊讶地发现,funnel shift 似乎比 H100 上的等效操作更快,这可能是由于使用了拥堵较少的管道。
- 尽管尝试了
prmt指令,但一致使用断言(predicated)funnel shift 表现更好,最终生成了 4 个shf.r.u32、3 个shf.r.w.u32和 7 个lop3.lutSASS 指令。
- 尽管尝试了
- TensorFlow 的 OpenCL 口水战:一场讨论由 2015 年关于 TensorFlow 中 OpenCL 支持 的 有趣口水战 引发。
- 这场辩论突显了早期对 CUDA 的优先排序以及在集成 OpenCL 支持时遇到的困难。
- Turing 架构获得 FlashAttention 支持:分享了一个针对 Turing 架构的 FlashAttention 前向传递实现,支持
head_dim = 128、原生 attention,且seq_len可被 128 整除。- 在 T4 上测试时,该实现与 Pytorch 的
F.scaled_dot_product_attention相比显示出 2 倍的加速。
- 在 T4 上测试时,该实现与 Pytorch 的
- Modal Runners 征服向量加法:在 T4 GPU 上使用 Modal runners 提交的
vectoradd排行榜测试成功!- ID 为 1946 和 1947 的提交证明了 Modal runners 在 GPU 加速计算中的可靠性。
- H100 内存分配失误:一位成员询问,为什么在 ThunderKittens 的 h100.cu 中修改内存分配以直接为
o_smem分配内存时,会导致 illegal memory access was encountered(遇到非法内存访问)错误。- 他们正试图理解在指定的 H100 GPU kernel 中导致此错误的原因。
Interconnects (Nathan Lambert) Discord
- Gemma 3 夺得第二名:Gemma-3-27b 模型在创意写作中获得第二名,可能成为创意写作和 RP(角色扮演)微调者的首选,详见此推文。
- 像 Gemma 3 这样的开放权重模型也在压缩 API 平台的利润空间,并因 隐私/数据 考量而越来越多地被采用。
- Gemini 2.0 Flash 带来图像生成功能:Gemini 2.0 Flash 现在具备原生图像生成功能,并针对对话迭代进行了优化,允许用户创建与上下文相关的图像并在图像中生成长文本,如此博客文章所述。
- DeepMind 还推出了 Gemini Robotics,这是一个基于 Gemini 2.0 的机器人模型,旨在通过多模态推理解决复杂问题。
- AlphaXiv 创建 ArXiv 论文概览:根据此推文,AlphaXiv 使用 Mistral OCR 配合 Claude 3.7 为 arXiv 论文生成博客风格的概览,只需点击一下即可提供论文中的图表、关键见解和清晰解释。
- 它能生成带有图表、核心见解和清晰解释的精美研究博客。
- ML 模型陷入版权风波:正在进行的法庭案件正在审查 在受版权保护的数据上训练生成式机器学习模型 是否构成版权侵权,详见 Nicholas Carlini 的博客文章。
- 深度学习如同耕作?:一位成员分享了 Arjun Srivastava 撰写的题为《论深度学习与耕作》的文章链接,该文探讨了将概念从一个领域映射到另一个领域。
- 作者将 工程(Engineering)(组件被刻意组装)与 培育(Cultivation)(无法直接构建)进行了对比。培育 就像耕作,而 工程 就像打造一张桌子。
Nomic.ai (GPT4All) Discord
- 更强的大脑,更好的基准测试:一位用户询问了 ChatGPT premium 与 GPT4All 的 LLMs 之间的性能差距,另一位用户将其归因于模型参数量更大。
- 讨论建议在硬件条件允许的情况下,从 Hugging Face 下载更大的模型。
- 服务器解决方案:选择 Ollama 还是 GPT4All?:一位用户质疑 GPT4All 是否适合作为服务器使用,该服务器需要管理多个模型、快速加载/卸载、针对定期更新的文件进行 RAG,以及提供日期/时间/天气的 APIs。
- 该用户提到了 Ollama 的一些问题,并在中低算力的情况下寻求关于其可行性的建议。
- Deepseek 详情:14B 是首选:在寻找 ChatGPT premium 替代方案的咨询中,有人建议使用 Deepseek 14B,前提是拥有 64GB RAM。
- 建议先从 Deepseek 7B 或 Llama 8B 等较小的模型开始,根据系统性能再进行扩展。
- 上下文是关键:4k 还可以:讨论强调了大上下文窗口(超过 4k tokens)的重要性,以便在提示词中容纳更多信息(如文档)。
- 随后一位用户询问他们发布的截图是否属于这些模型之一,并询问其上下文窗口能力。
- Gemma 代际差距:GPT4All 的小故障:一位用户建议使用微型模型测试 GPT4All,以评估加载、卸载和 RAG(配合 LocalDocs)的工作流,并指出 GUI 目前不支持同时运行多个模型。
- 他们指出 Gemma 3 目前与 GPT4All 不兼容,需要更高版本的 llama.cpp,并附上了错误截图。
MCP (Glama) Discord
- Glama API 导出工具数据:一个新的 Glama AI API 端点现在列出了所有可用工具,比 Pulse 提供的每个服务器的数据更多。
- 用户对这些免费提供的信息感到兴奋。
- MCP 日志详情:服务器视角:服务器根据 Model Context Protocol (MCP) 规范 发送日志消息,具体表现为声明
logging能力,并发出带有严重级别和 JSON 可序列化数据的日志消息。- 这允许通过 MCP 控制,实现从服务器到客户端的结构化日志记录。
- Wolfram 助力 Claude 渲染图像:一位成员指向了一个 wolfram 服务器示例,该示例获取渲染的图表,通过对数据进行 base64 编码并设置 mime 类型来返回图像。
- 有人指出 Claude 在工具调用窗口之外进行渲染存在局限性。
- NPM 包位置揭晓:NPM 包存储在
%LOCALAPPDATA%中,具体位于C:\Users\YourUsername\AppData\Local\npm-cache。- 该位置包含 NPM 包和源代码。
- OpenAI Agents SDK 支持 MCP:OpenAI Agents SDK 已添加 MCP 支持,可在 GitHub 上的 fork 版本 中获取,并在 pypi 上作为 openai-agents-mcp 包发布,允许 Agents 聚合来自 MCP 服务器的工具。
- 通过设置
mcp_servers属性,可以通过统一语法无缝集成 MCP 服务器、本地工具和 OpenAI 托管的工具。
- 通过设置
Codeium (Windsurf) Discord
- Codeium 扩展遭遇协议错误:用户报告 VSCode 扩展中出现 协议错误,例如 “invalid_argument: protocol error: incomplete envelope: read tcp… forcibly closed by the remote host”,导致 Codeium 页脚变红。
- 这一问题特别影响了 英国 和 挪威 使用 Hyperoptic 和 Telenor 等运营商的用户。
- Neovim 支持难以跟上进度:一位用户批评了 Neovim 支持 的现状,提到了补全错误(error 500),并担心其落后于 Windsurf。
- 针对批评,一名团队成员回复称团队“正在处理中”。
- 测试修复部署结果不一:团队部署了一个测试修复程序,虽然一些用户报告错误减少,但其他用户仍面临问题,扩展要么“关闭”,要么保持红色状态。
- 这些不一的结果促使团队进行进一步调查。
- 欧盟用户发现 VPN 解决方法:团队确认 欧盟 用户在自动补全时遇到了 “unexpected EOF” 等问题,并且无法在聊天中链接文件。
- 作为临时解决方法,通过 VPN 连接到 洛杉矶 解决了受影响用户的问题。
Yannick Kilcher Discord
- Gemini Robotics 问世:Google 发布了 一段 YouTube 视频 展示 Gemini Robotics,将 Gemini 2.0 作为其最先进的视觉语言动作模型 (vision language action model) 带入物理世界。
- 该模型使机器人能够与物理世界互动,具有增强的物理交互能力。
- Gemma 3 发布,支持 128k 上下文窗口:Gemma 3 正式发布,具备多模态能力和 128k 上下文窗口(1B 模型除外),满足了用户期待。
- 虽然此次发布备受关注,但一位用户评论说它“也就那样” (twas aight)。
- Sakana AI 的论文通过同行评审:由 Sakana AI 生成的一篇 论文 已通过 ICLR workshop 的同行评审。
- 一位用户质疑评审过程的严谨性,暗示该 workshop 可能对作者“比较慷慨”。
- 麦克斯韦妖限制 AI 速度:一位成员分享道,计算机可以通过同时向前和向后运行,以任意低的能量进行计算,但速度限制取决于运行答案的速度和确定性,并引用了 这段 YouTube 视频。
- 他们还链接了 另一段关于“逆转熵”的视频,将计算限制与基础物理学联系起来。
- 欢迎自适应元学习项目:一位成员正在寻找玩具项目来测试 Meta-Transform 和 Adaptive Meta-Learning,从使用 Gymnasium 的小步骤开始。
- 他们还链接了一个用于 Adaptive Meta-Learning (AML) 的 GitHub 仓库。
Latent Space Discord
- Mastra 框架旨在吸引百万 AI 开发者:根据 其博客文章,前 Gatsby/Netlify 的构建者宣布了 Mastra,这是一个全新的 Typescript AI 框架,旨在让玩具项目易于上手,同时对生产环境可靠。
- 该框架面向前端、全栈和后端开发者,创建者旨在提供一个比现有框架更可靠、更简单的替代方案,并鼓励社区为 其 GitHub 项目 做出贡献。
- Cursor 的嵌入模型声称达到 SOTA:根据 一条推文,Cursor 训练了一个专注于语义搜索的 SOTA 嵌入模型,据报道其表现超过了竞争对手的开箱即用嵌入和重排序器 (rerankers)。
- 邀请用户在使用 Agent 时“感受性能差异”。
- Gemini 2.0 Flash 生成原生图像:Google 正在 Gemini 2.0 Flash 中发布原生图像生成功能,供开发者在支持的地区通过 Google AI Studio 进行实验,详情见 博客文章。
- 开发者可以在 Google AI Studio 和 Gemini API 中使用 Gemini 2.0 Flash (gemini-2.0-flash-exp) 的实验版本测试此功能,结合多模态输入、增强推理和自然语言理解来创建图像,如 一条推文 所强调。
- Jina AI 深入探讨 DeepSearch 细节:Jina AI 分享了一篇 博客文章,概述了 DeepSearch/DeepResearch 的实际实现,重点是用于片段选择的延迟分块嵌入 (late-chunking embeddings) 以及在抓取前对 URL 进行优先排序的重排序器 (rerankers)。
- 文章建议通过“阅读-搜索-推理”循环将重点从 QPS 转向深度,以改进答案发现。
Notebook LM Discord
- 研究调查用户移动端习惯:Google 正在招募 NotebookLM 用户进行 60 分钟的访谈,以讨论他们的移动端使用习惯并对新概念提供反馈。参与者将获得 75 美元的感谢礼品,感兴趣的参与者需填写筛选表单(链接)以确认资格。
- Google 将于 2025 年 4 月 2 日和 3 日进行一项可用性研究,以收集对开发中产品的反馈。参与者将获得等值 75 美元的当地货币作为报酬,要求具备高速互联网连接、活跃的 Gmail 账号以及配备摄像头、扬声器和麦克风的电脑。
- NoteBookLM 作为内部 FAQ:一位成员正考虑将 NoteBookLM Plus 用作内部 FAQ,并希望调查未解决问题的具体内容。
- 他们正在寻求建议,了解如何查看用户在聊天中输入但未得到解决的问题。
- NLM+ 生成 API 脚本!:一位成员发现 NLM+ 在利用 API 指令和示例程序生成脚本方面表现出惊人的能力。
- 他们指出,作为非编程人员,通过引用 Notebook 中的材料,获取修改建议变得更加容易。
- RAG 与全上下文窗口(Full Context Window)的对决:一位用户质疑,对于大型数据库,使用带有向量搜索和较小上下文窗口的 RAG 是否优于使用具有全上下文窗口的 Gemini Pro。
- 他们对 RAG 中使用的上下文窗口大小感到好奇,并寻求关于如何通过使用 Gemini Pro 实现“导师型 AI”任务的建议。
- 行内引用得以保留,太棒了!:用户现在可以将聊天回复保存为笔记,并保留原始形式的行内引用(inline citations)。
- 这一增强功能允许用户追溯原始素材,解决了高级用户长期以来的需求;此外,一位用户请求能够将行内引用复制并粘贴到文档中,同时保留链接。
Torchtune Discord
- MPS 设备故障阻碍进展:在最近的一次提交(GitHub commit)后,出现了一个与缺失
torch.mps属性相关的AttributeError,这可能会禁用 MPS 支持。- 通过 PR #2486 提出的修复方案导致随后在 MPS 上运行时出现 torchvision 错误。
- Gemma 3 取得进展:一位成员指出了 Gemma 3 模型的变化,并附上了一张来自 Discord CDN 的截图,详细说明了这些变化。
- 这些变化的性质和影响未在进一步讨论中展开。
- 关于 Pan & Scan 的思考:讨论了 Gemma3 论文中用于增强推理的 Pan & Scan 技术在 torchtune 中实现的必要性。
- 一位成员认为这并非至关重要,建议使用带有 HF ckpt 的 vLLM 可以获得更好的性能,并参考了这个 pull request。
- vLLM 配合 HF ckpt 表现出色:为了提升 Gemma3 的性能,可以使用带有 vLLM 的 HF checkpoint。
- 这通过这个 pull request 得以实现。
{kind=link}
LlamaIndex Discord
- LlamaIndex 连接至 Model Context Protocol:LlamaIndex 现在已与 Model Context Protocol (MCP) 集成,该协议简化了工具的发现和利用,如这条推文所述。
- Model Context Protocol 的集成允许 LlamaIndex 使用任何兼容 MCP 的服务所提供的工具,增强了其功能。
- LlamaExtract 在本地保护敏感数据:LlamaExtract 现在为整个 Llama-Cloud 平台提供本地部署/BYOC(Bring Your Own Cloud)方案,以解决企业对敏感数据的担忧。
- 然而,一位成员指出,这些部署的成本通常比使用 SaaS 解决方案高得多。
- LlamaIndex 关注 Response API:一位用户询问了对新 Response API 的支持情况,认为它有可能通过用户选择加入的搜索工具来丰富结果。
- 一位成员给出了肯定答复,表示他们正尝试在今天完成这项工作。
LLM Agents (Berkeley MOOC) Discord
- 测验截止日期推迟至 5 月:根据最新公告,所有测验截止日期都安排在 5 月。
- 用户被指示查看有关 Lecture 6 的最新邮件以获取更多详情。
- 学习者想要 Lab 和研究机会:一名成员询问了针对 MOOC 学习者的 Labs 计划以及研究机会。
- 目前没有更多可用信息。
Cohere Discord
- Cohere 多语言定价信息缺失?:一名成员询问了 Cohere multilingual embed model 的定价,并指出在文档中很难找到该信息。
- 讨论中未分享有关定价的具体细节或链接。
- OpenAI 的 Responses API 简化了交互:OpenAI 发布了其 Responses API 以及 Agents SDK,强调简单性和表现力,文档见此处。
- 该 API 专为多工具、多轮对话和多模态设计,解决了用户在使用当前 API 时遇到的问题,OpenAI cookbook 中提供了示例。
- Cohere 与 OpenAI API 的兼容性存疑:一名成员询问了 Cohere 与 OpenAI 新发布的 Responses API 兼容的可能性。
- 新 API 旨在作为多轮交互、托管工具和粒度上下文控制的解决方案。
- Chat API Seed 参数出现问题:一位用户注意到 Chat API 似乎忽略了
seed参数,导致即使使用相同的输入和 seed 值,输出也各不相同。- 多位用户报告在使用具有相同
seed值的 Chat API 时输出不一致,这表明可复现性可能存在问题。
- 多位用户报告在使用具有相同
DSPy Discord
- DSPy 缓存机制:一名成员询问了 DSPy 中的缓存工作原理以及缓存行为是否可修改。
- 另一名成员指向了一个正在开发中的可插拔 Cache 模块的 Pull Request,表明未来将具备灵活性。
- 可插拔缓存模块正在开发中:该 Pull Request 引入了一个统一的缓存接口,具有两个缓存级别:内存中的 LRU cache 和 fanout(磁盘上)。
- 此项开发旨在为 DSPy 提供更通用且高效的缓存解决方案。
Modular (Mojo 🔥) Discord
- Modular Max Spawn 更新:一名成员分享了一个 GitHub Pull Request,希望它最终能像他们的项目一样,增加从可执行文件生成和管理进程的功能。
- 然而,首先必须合并 foundations PR,然后还需要解决一些 Linux exec 的问题。
- Linux Exec 阻碍 Modular Max 更新:新功能的发布目前处于停滞状态,正在处理围绕 Linux exec 尚未解决的问题,同时等待 foundations PR 的批准。
- 尽管存在障碍,开发者仍对近期发布表示乐观,并承诺向订阅者更新 PR 的进展。
Gorilla LLM (Berkeley Function Calling) Discord
- 发现追踪评估工具的中心枢纽:一名成员询问是否有中心位置可以追踪 Berkeley Function Calling Leaderboard 背景下使用的所有评估工具。
- 另一名成员建议将目录 gorilla/berkeley-function-call-leaderboard/data/multi_turn_func_doc 作为潜在资源。
- 评估数据集位置已确定:一名成员询问是否所有的评估数据集都可以在
gorilla/berkeley-function-call-leaderboard/data文件夹中找到。- 目前没有进一步的消息确认该文件夹是否包含所有评估数据集。
AI21 Labs (Jamba) Discord
- RAG 放弃 Pinecone:RAG 以前依赖 Pinecone,但由于其性能欠佳且无法支持 VPC deployment,策略转变变得势在必行。
- 这些限制促使团队探索更适合其性能和部署需求的替代方案。
- VPC Deployment 驱动变革:现有 RAG 基础设施中缺乏 VPC deployment 支持,使得重新评估所选技术成为必要。
- 这一限制阻碍了对资源的安全和私密访问,成为决定探索替代方案的关键因素。
tinygrad (George Hotz) Discord 没有新消息。如果该服务器沉寂时间过长,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该服务器沉寂时间过长,请告知我们,我们将将其移除。
第 2 部分:按频道详细摘要和链接
完整的逐频道细分内容已针对电子邮件进行了截断。
如果您喜欢 AInews,请分享给朋友!预先感谢!