ainews-not-much-happened-today-7693
今天没什么事发生。
Google DeepMind 宣布了 Gemini 2.0 的更新,包括升级后的 Flash Thinking 模型,该模型具备更强的推理能力和原生图像生成能力。Cohere 推出了 Command A,这是一个拥有 111B(1110 亿)参数的稠密模型,具有 256K 上下文窗口和极具竞争力的定价,已在 Hugging Face 上线。Meta AI 提出了 Dynamic Tanh (DyT) 作为 Transformer 中归一化层的替代方案,并得到了 Yann LeCun 的支持。阿里巴巴发布了 QwQ-32B,这是一个拥有 32.5B 参数的模型,在数学和编程领域表现优异,通过强化学习进行了微调,并根据 Apache 2.0 协议开源。Google DeepMind 还发布了 Gemma 3 系列模型,参数范围从 1B 到 27B,支持 128K token 上下文窗口和 140 多种语言,此外还推出了图像安全检查工具 ShieldGemma 2。基准测试显示,Gemma 3 27B 具有强大的视觉能力和内存效率,但在性能上仍逊于 Llama 3.3 70B 和 DeepSeek V3 671B 等更大规模的模型。@_lewtun 分享了 Hugging Face LLM 排行榜的历史记录。
一个宁静的周五
2025年3月14日至3月15日的 AI 新闻。我们为您检查了 7 个 subreddits、433 个 Twitter 账号 和 28 个 Discord 社区(222 个频道,2399 条消息)。预计节省阅读时间(按 200wpm 计算):240 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
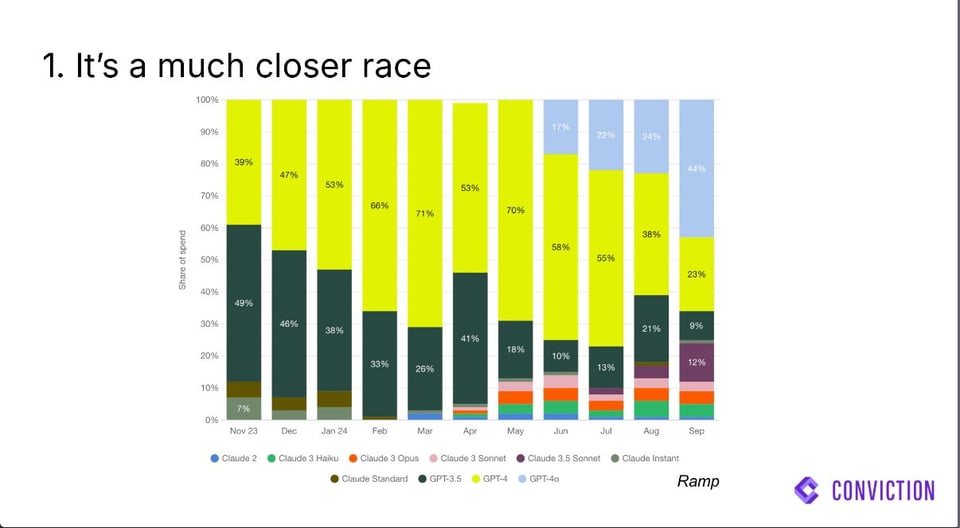
祝 GPT-4 和 Claude 1 两周岁生日快乐。很少有人能预料到过去一年中发生的巨大市场份额变化。
特别说明:我们今天发布了 2025 年 AI 工程现状调查,为 6 月 3 日至 5 日举行的 AI Eng World’s Fair 做准备。请填写调查问卷以表达您的声音!
AI Twitter 综述
语言模型与模型更新
- Google 的 Gemini 2.0 更新与功能:@jack_w_rae 宣布,由于产品开发以及底层模型从 1.5 Pro 更新至 2.0 Flash Thinking,Google Deep Research 得到了改进。Gemini 应用正在推出多项改进,包括具有更强推理能力的升级版 Flash Thinking 模型、更深层次的应用集成、Deep Research 以及个性化功能 @jack_w_rae。此外,@jack_w_rae 指出团队在为 Gemini 2 创建原生图像生成方面取得了进展,强调了其与 text-to-image 模型的区别。
- Cohere 的 Command A 模型:@ArtificialAnlys 报道称,Cohere 推出了 Command A,这是一个拥有 111B 参数的稠密模型,其 Artificial Analysis Intelligence Index 为 40,接近 OpenAI 最新的 GPT-4o。该模型拥有 256K 上下文窗口,速度为 185 tokens/s,定价为每百万输入/输出 token 2.5/10 美元。它可在 Hugging Face 上用于研究,并可通过 Cohere 的许可进行商业使用。
- Meta 的 Dynamic Tanh (DyT):@TheTuringPost 报道称,Meta AI 提议使用 Dynamic Tanh (DyT) 替代 Transformer 中的归一化层,其效果相当或更好,且无需额外的计算或调优,适用于图像、语言、监督学习和自监督学习。Yann LeCun 也在 Twitter 上宣布了同样的消息。
- 阿里巴巴的 QwQ-32B:@DeepLearningAI 重点介绍了阿里巴巴的 QwQ-32B,这是一个拥有 325 亿参数的语言模型,在数学、编程和问题解决方面表现出色。通过强化学习进行微调,它可与 DeepSeek-R1 等大型模型相媲美,并在基准测试中超越了 OpenAI 的 o1-mini。该模型在 Apache 2.0 许可下免费提供。
- Google 的 Gemma 3 模型:@GoogleDeepMind 宣布发布 Gemma 3,提供从 1B 到 27B 的多种尺寸,具有 128K token 上下文窗口,支持超过 140 种语言 @GoogleDeepMind。还宣布了 ShieldGemma 2,这是一个基于 Gemma 3 基础构建的 4B 图像安全检查器 @GoogleDeepMind。@ArtificialAnlys 对 Gemma 3 27B 进行了基准测试,其 Artificial Analysis Intelligence Index 为 38,指出其优势包括宽松的商业许可、视觉能力和内存效率,但在竞争力上不如 Llama 3.3 70B 或 DeepSeek V3 (671B) 等大型模型。@sirbayes 指出,Gemma 3 是能在 1 张 GPU 上运行的最佳 VLM。
模型性能与基准测试
- 排行榜的背景与历史:@_lewtun 分享了 Hugging Face LLM 排行榜 的起源故事,重点介绍了 @edwardbeeching、@AiEleuther、@Thom_Wolf、@ThomasSimonini、@natolambert、@abidlabs 和 @clefourrier 的贡献。该帖子强调了小团队、早期发布以及社区参与的影响。@clefourrier 对此进行了补充,指出在排行榜公开时,@nathanhabib1011 和他们正在开发一套内部评估套件,这促成了代码的工业化。
- GPU 基准测试与 CPU 开销:@dylan522p 表达了对测量 CPU 开销 的 GPU 基准测试(如 vLLM 和 KernelBench)的赞赏。
- 井字游戏作为基准测试:@scaling01 表示在 GPT-5 发布之前他都对 LLM 持悲观态度,理由是 GPT-4.5 和 o1 甚至无法稳定地玩 井字游戏 (tic-tac-toe);@scaling01 认为,如果 LLM 在看过数百万场比赛后仍无法玩好 井字游戏,那么在研究或业务任务中就不应该信任它们。
- 推理模型的评估脚本:@Alibaba_Qwen 宣布了一个 GitHub 仓库,提供用于测试推理模型基准性能并复现 QwQ 报告结果的评估脚本。
AI 应用与工具
- AI 辅助编程与原型设计:@NandoDF 支持现在是学习编程的大好时机的观点,因为 AI copilot 降低了编程门槛,可能引发一波创业浪潮。@AndrewYNg 也表达了同样的看法,指出 AI 和 AI 辅助编程降低了原型设计的成本。
- IDE 中的 Agentic AI:@TheTuringPost 介绍了 Qodo Gen 1.0,这是由 @QodoAI 开发的一款 IDE 插件,它将 Agentic AI 嵌入到 JetBrains 和 VS Code 中,使用了 LangChain 的 LangGraph 和 Anthropic 的 MCP。
- Gemini 2.0 与 OpenAI Agents SDK 的集成:@_philschmid 宣布只需更改一行代码即可在 OpenAI Agents SDK 中使用 Gemini 2.0。
- LangChain 的长期 Agentic Memory 课程:@LangChainAI 和 @DeepLearningAI 宣布了一门关于 使用 LangGraph 构建长期 Agentic Memory 的新 DeepLearningAI 课程,由 @hwchase17 和 @AndrewYNg 授课,重点是构建具有语义、情节和程序记忆的 Agent,以创建一个个人电子邮件助手。
- UnslothAI 更新:@danielhanchen 分享了 UnslothAI 的更新,包括支持全量微调 + 8bit,支持几乎所有模型(如 Mixtral、Cohere、Granite、Gemma 3),视觉微调不再出现 OOM(显存溢出),进一步降低 VRAM 占用,4-bit 速度提升,支持 Windows 等。
- Windows 上的 Perplexity AI:@AravSrinivas 宣布 Perplexity 应用 现已在 Windows 和 Microsoft App Store 上架,语音对语音模式即将推出。
- TestFlight 上的 HuggingSnap:@mervenoyann 宣布 HuggingSnap(由 @pcuenq 和 @cyrilzakka 构建的手机端离线视觉 LM)已在 TestFlight 上线,正寻求反馈以进行进一步开发。
- 机器翻译新趋势:@_akhaliq 重点介绍了一篇关于 大推理模型在现代机器翻译中的新趋势 的论文。
- 微软与 Shopify:@MParakhin 宣布 Shopify 已收购 VantageAI。
AI 与硬件
- AMD 的 Radeon GPU 在 Windows 上的支持:@dylan522p 报道了 AMD 的 @AnushElangovan 在 ROCm 用户见面会上讨论将 Radeon GPU 打造为 Windows 上的“一等公民”,支持多种 GPU 架构,并专注于 CI 和持续交付。
- MLX LM 的新家:@awnihannun 宣布 MLX LM 有了新家。
AI 会议与活动
- AI Dev 25 大会:@AndrewYNg 在旧金山启动了 AI Dev 25,并指出 Agent 是 AI 开发者最兴奋的话题。大会包括来自 Google 的 Bill Jia @AndrewYNg、Meta 的 Chaya Nayak @AndrewYNg 的演讲,以及关于 2025 年构建 AI 应用的小组讨论 @AndrewYNg。@DeepLearningAI 分享了来自 Nebius 的 Roman Chernin 的观点,强调解决现实世界的问题;@AndrewYNg 强调了来自 Replit 的 @mattppal 关于通过理解 LLM 的上下文进行调试的技巧。
- GTC 炉边对话:@ylecun 宣布下周二将在 GTC 与 Nvidia 首席科学家 Bill Dally 进行炉边对话。
- Interrupt 大会:@LangChainAI 宣传了 Interrupt 大会,并列出了其赞助商,包括 CiscoCX、TryArcade、Box 等 @LangChainAI。
- 智利圣地亚哥的 Khipu AI:@sirbayes 在智利圣地亚哥的 @Khipu_AI 上分享了关于使用在线变分贝叶斯(online variational bayes)进行序列决策(Sequential decision making)的演讲。@sarahookr 提到博物馆非常好奇为什么他们最想看的物品是 khipu(奇普)。
其他
- 开源模型的价值:@Teknium1 表达了担忧,认为对美国人禁用中国模型不会减缓其进展,而无法接触到全方位的模型将使美国落后。
- AI 与电影制作:@c_valenzuelab 讨论了 AI 视频生成的发散特性,它允许创意冲动和对意外时刻的探索,不受物理限制的约束。
- 软件的未来:@c_valenzuelab 推测了主要上市软件公司的未来,认为专注于功能和复杂界面的公司面临风险,因为新的软件栈是意图驱动(intention-driven)的。
- 团队规模:@scottastevenson 提出小团队正在获胜,固守旧的大团队文化可能会损害你的职业生涯。
幽默/迷因
- “一切皆 Transformer”:@AravSrinivas 简单地陈述了 “everything is transformer”,并配了一张 Transformer 的图片。
- “Midjourney 最顶尖的技术是域名无法解析”:@DavidSHolz 开玩笑说 Midjourney 最顶尖的技术是 “Domain Not Resolving”,并正在寻找在该领域有至少 6 年经验的人。
- “一百万家初创公司必须消亡”:@andersonbcdefg 说道 “one million startups must perish”。
- “我将在 PlayStation 2 上对人类基因组进行氛围编辑(vibe edit)”:@fabianstelzer 发布了 “I will vibe edit human genome on a PlayStation 2”。
AI Reddit 摘要
/r/LocalLlama 摘要
主题 1. Gemma 3 微调革命:Unsloth 中的性能与效率
- Gemma 3 微调现已支持 Unsloth - 速度提升 1.6 倍,显存占用减少 60% (Score: 172, Comments: 36): Unsloth 现在支持 Gemma 3 (12B) 的微调,与 Hugging Face + FA2 相比,性能提升 1.6 倍,显存占用减少 60%,使得 27B 等模型能够适配 24GB 显存的 GPU。该平台修复了旧款 GPU 上的无限梯度爆炸(infinite exploding gradients)和双 BOS token 等问题,并支持广泛的模型和算法,包括全量微调(full fine-tuning)和动态 4-bit 量化(Dynamic 4-bit quantization)。更多详情请访问其 blog 并通过其 Colab notebook 进行免费微调。
- 用户对 Unsloth 的进展表示热烈欢迎,特别是对全量微调的支持以及 8-bit 微调的潜力。Danielhanchen 确认所有方法(包括 4-bit、8-bit 和全量微调)都将得到优先处理,并提到可能加入 torchao 以支持 float8。
- 用户对更友好的界面感兴趣,有人请求提供本地运行的 webUI 以简化使用。Few_Painter_5588 预测 Unsloth 将成为 LLM 微调的主要工具集。
- FullDeer9001 分享了在 Radeon XTX 上运行 8k 上下文 Gemma3 的正面反馈,强调了显存占用和 prompt 统计数据,并认为其表现优于 Deepseek R1。用户讨论了为 16GB RAM 优化 12B 模型以提升性能的想法。
主题 2. Sesame CSM 1B 声音克隆:预期与现实
- Sesame CSM 1B 声音克隆 (Score: 216, Comments: 30): Sesame CSM 1B 是一款新发布的声音克隆模型。帖子中未提供更多细节。
- 声音克隆模型的许可与使用:讨论涉及 Sesame(Apache 许可)与 F5(Creative Commons Attribution Non Commercial 4.0)之间的许可差异,强调 Sesame 可用于商业用途。用户还提到将声音克隆集成到对话式语音模型(CSM)中是一项潜在的进步。
- 性能与兼容性问题:用户报告该声音克隆模型性能较慢,在 GPU 上处理一整段文字需要长达 50 秒,并指出其可能未针对 Windows 进行优化。有建议称其在 Linux 上可能运行得更好,由于 CPU 的“实验性”triton 后端,在没有独立 GPU 的迷你 PC 上运行可能会面临挑战。
- 技术调整与 API 访问:Chromix_ 分享了通过升级到 torch 2.6 及其他包使模型在 Windows 上运行的步骤,并提到通过从镜像仓库下载文件来绕过对 Hugging Face 账号的需求。他们还提供了声音克隆 API 端点的链接。
- 结论:Sesame 向我们展示了一个 CSM。然后 Sesame 宣布将发布……某些东西。接着 Sesame 发布了一个 TTS,但他们显然具有误导性且虚假地将其称为 CSM。我理解得对吗? (Score: 154, Comments: 51):Sesame 的争议 围绕其误导性的营销策略展开,他们宣布了一个 CSM,但实际发布的却是 TTS,并错误地将其标记为 CSM。如果 Sesame 明确沟通该产品不会 open source,这个问题本可以得到缓解。
- 误导性营销策略:许多用户对 Sesame 的营销手段表示失望,指出该公司通过暗示 open-source 发布来制造巨大的热度,结果却交付了一个平庸的产品。VC-backed 公司经常使用此类策略来衡量产品市场匹配度并吸引投资者兴趣,正如 Sesame 的领投方 a16z 所表现的那样。
- 技术挑战与模型性能:大家一致认为发布的 1B model 性能不尽如人意,尤其是在实时应用中。用户讨论了技术细节,例如 Mimi tokenizer 和模型的架构,这些因素导致其速度缓慢,并建议使用 CUDA graphs 或 exllamav2 等替代模型进行优化以获得更好的性能。
- 不完整的产品发布:讨论强调 Sesame 的发布缺少 demo 流程中的关键组件,如 LLM、STT 和 VAD,迫使用户自行构建这些部分。Demo 令人印象深刻的性能与实际发布的版本形成鲜明对比,引发了人们对 demo 设置可能使用了更大的模型或更强大的硬件(如 8xH100 nodes)的质疑。
主题 3. QwQ 的崛起:统治基准测试并超越预期
- QwQ 在 LiveBench 上的更新 - 优于 DeepSeek R1! (Score: 256, Comments: 117):来自阿里巴巴的 QwQ-32b 在 LiveBench 上超越了 DeepSeek R1,实现了 71.96 的全球平均分,而 DeepSeek R1 为 71.57。如对比表所示,QwQ-32b 在 Reasoning、Coding、Mathematics、Data Analysis、Language 和 IF Average 等子类别中持续表现出色。
- 对于 QwQ-32b 相较于 DeepSeek R1 的性能存在一些怀疑,部分用户指出 Alibaba 倾向于针对 benchmarks 而非真实场景优化模型。QwQ-32b 被强调为一个强大的模型,但与其 R1 相比,其稳定性和现实世界知识仍存疑问。
- Coding 性能 是一个争议点,用户质疑 QwQ-32b 在 coding 能力上如何接近 Claude 3.7。讨论提到 LiveBench 主要测试 Python 和 JavaScript,而 Aider 测试超过 30 种语言,这表明测试环境可能存在差异。
- 一些用户对 QwQ-max 的潜力表示兴奋,期待它可能在规模和性能上都超越 R1。还有关于设置更改对模型性能影响的讨论,并提供了进一步见解的链接(Bindu Reddy 的推文)。
- QwQ-32b 刚刚更新了 Livebench。 (Score: 130, Comments: 73):QwQ 32B 已在 LiveBench 上更新,为其性能提供了新的见解。完整结果可以通过 Livebench 链接访问。
- QwQ 32B 模型因其本地 coding 能力而受到称赞,一些用户注意到它在某些任务上超越了像 R1 这样更大的模型。用户讨论了通过调整 logit bias(针对结束标签)等设置来改变模型的思考时间,一些人还尝试了最近的更新以解决无限循环等问题。
- 讨论强调了像 QwQ 32B 这样的小型模型不断进化的力量,用户注意到与大型旗舰模型相比,它们在本地应用中的潜力日益增加。一些用户对该模型的创造能力及其在 benchmarks 中的出色表现感到惊讶,从而做出了取消 OpenAI 订阅等决定。
- 关于 open-source 模型的意义存在争论,一些用户认为中国的 open-sourcing 策略加速了开发,这与美国专注于企业利润的方法形成对比。人们对未来 open-source 可用性表示担忧,特别是如果竞争优势发生转移。
- 我制作的迷因 (Meme) (评分: 982, 评论: 55): 标题为 “Meme i made” 的帖子缺乏详细内容,仅提到了一个与 QwQ 模型思考过程相关的迷因创作。没有提供关于视频或迷因的其他信息或背景,因此难以提取进一步的技术见解。
- 讨论强调了 QwQ 模型倾向于怀疑自己,导致低效的 Token 使用和响应时间延长。这种行为被比作过度地对自己进行“事实核查”,一些用户认为与传统的 LLM 相比,这种方式效率低下。
- 大家的共识是,目前的推理模型(如 QwQ)仍处于早期阶段,类似于 GPT-3 的初始发布,预计明年其推理能力将有显著提升。用户期待向潜空间 (latent space) 推理的转变,这可能会将效率提高 10 倍。
- 幽默且带有批判性的评论强调了该模型重复提问和自我怀疑的特点,并将其与过时的技术相类比,引发了关于这些模型在处理复杂推理任务时如何改进以避免过度自我质疑的讨论。
{kind=link}
主题 4. 去中心化 LLM 部署:Akash、IPFS 和 Pocket Network 的挑战
- 如何操作:在 Akash、IPFS 和 Pocket Network 上部署去中心化 LLM,这能运行 LLaMA 吗? (评分: 229, 评论: 20): 标题为 “如何在 Akash、IPFS 和 Pocket Network 上部署去中心化 LLM,这能运行 LLaMA 吗?” 的帖子建议使用 Akash、IPFS 和 Pocket Network 部署去中心化大语言模型 (LLM)。它质疑了在这个去中心化基础设施上运行 LLaMA(一种特定的 LLM)的可行性,暗示其重点在于利用去中心化技术进行 AI 模型部署。
- 对安全和隐私的担忧:用户质疑 Pocket Network 的加密验证过程,对确保提供正确的模型以及 Prompt 的隐私表示怀疑。人们担心用户数据(如 IP 地址)是否会被记录,以及网络如何处理匿名化的延迟问题。
- 去中心化基础设施的挑战:评论者强调了以去中心化方式运行 LLM 的技术挑战,特别是节点之间对高带宽和低延迟的需求,这使得目前分布式 LLM 部署的可行性与单机设置相比受到限制。
- 去中心化 vs. 中心化:讨论对比了 Pocket Network 的 API 中继角色与中心化 AI 托管,指出虽然 Pocket 本身不运行模型,但使用 Akash 进行模型托管提供了诸如韧性和潜在成本节约等优势,尽管增加了一个加密层会带来复杂性。
其他 AI 子版块回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding
主题 1. 使用 SDXL、Wan2.1 和长上下文微调的高级 AI 视频生成
- 另一个旨在追求电影级写实感的视频,这次使用了一个难度大得多的角色。SDXL + Wan 2.1 I2V (评分: 1018, 评论: 123): 该帖子讨论了使用 SDXL 和 Wan 2.1 I2V 创建旨在实现电影级写实感 (cinematic realism) 视频的过程。它强调了在这种背景下处理更复杂角色的挑战。
- 技术挑战与技巧: Parallax911 分享了使用 SDXL 和 Wan 2.1 I2V 实现电影级写实感的复杂性,重点介绍了在 Davinci Resolve 中使用 Photopea 进行 Inpainting 和合成。他们提到了实现一致性和写实感的难度,特别是对于复杂的角色设计,以及使用 Blender 为开门等片段制作动画。
- 项目成本与工作流: 该项目使用 RunPod 的 L40S(价格为 $0.84/小时)产生了约 $70 的成本,耗时约 80 小时 的 GPU 时间。Parallax911 使用的工作流涉及 RealVisXL 5.0、Wan 2.1 和用于 Upscaling 的 Topaz Starlight,生成的场景为 61 帧、960x544 分辨率和 25 steps。
- 社区反馈与建议: 社区赞扬了其氛围感叙事和音效设计,并对水滴大小等元素提出了具体反馈,同时表达了对教程的需求。一些用户提出了改进建议,例如更好地整合 AI 和传统技术,并对 Metroid 中 Samus Aran 等角色的更多动作导向场景表示感兴趣。
- Wan2.1 中的视频扩展 - 完全在 ComfyUI 中创建 10 秒以上的高清视频 (评分: 123, 评论: 23): 该帖子讨论了在 Wan2.1 中使用 ComfyUI 创建 Upscaling 视频的高度实验性工作流,成功率约为 25%。该过程涉及从初始视频的最后一帧生成视频、合并、Upscaling 和 Frame Interpolation,具体参数如 Sampler: UniPC、Steps: 18、CFG: 4 和 Shift: 11。更多详情可以在 工作流链接 中找到。
- 用户正在询问工作流中宽高比 (aspect ratio) 的处理方式,质疑它是自动设置的还是需要对输入图像进行手动调整。
- 对该工作流感兴趣的用户给出了积极反馈,表示对这种解决方案的期待。
- 有人提出了对视频片段后半部分模糊问题的担忧,并建议这可能与输入帧的质量有关。
- 使用 WAN 2.1 和 LTX 动画化了我的一些 AI 图片 (评分: 115, 评论: 10): 该帖子讨论了使用 WAN 2.1 和 LTX 创建 AI 动画视频。在没有进一步背景或额外细节的情况下,重点仍然是用于动画的工具。
- 模型使用: LTX 用于第一个片段(跳跃的女人和战斗机),而 WAN 用于奔跑的宇航员、恐怖菲比 (horror furby) 和龙。
- 硬件详情: 视频是使用从 Paperspace 租用的带有 RTX5000 实例的云计算机生成的。
主题 2. OpenAI 的 Sora:将城市景观转变为反乌托邦
- OpenAI 的 Sora 将旧金山的 iPhone 照片变成了反乌托邦噩梦 (评分: 931, 评论: 107): OpenAI 的 Sora 是一款将旧金山的 iPhone 照片转变为具有反乌托邦美感图像的工具。该帖子可能讨论了使用 AI 改变现实世界图像的影响和视觉结果,尽管由于缺乏文本内容,具体细节尚不清楚。
- 几位评论者对 AI 生成的反乌托邦图像的影响表示怀疑,一些人认为旧金山或其他城市的实际地点已经类似于这些反乌托邦视觉效果,质疑 AI 改变的必要性。
- iPhone 作为拍摄原始图像的设备是一个争论点,一些人质疑它与讨论的相关性,而另一些人则强调它在理解图像来源方面的重要性。
- 对话包含了对 AI 能力的钦佩和担忧,用户既对这项技术感到惊讶,又对未来区分 AI 生成和现实世界图像感到焦虑。
- OpenAI 的 Sora 将旧金山的 iPhone 照片变成了反乌托邦地狱景象… (Score: 535, Comments: 58): OpenAI 的 Sora 将 旧金山的 iPhone 照片 变成了反乌托邦的地狱景象,展示了其在改变数字图像以创造未来主义、阴郁美学方面的能力。该帖子除了展示这种转变外,缺乏额外的背景或细节。
- 评论者将 反乌托邦图像 与现实世界的地点进行了类比,提到了 德里、底特律 和 印度街道,突显了 AI 在解释城市环境时被察觉到的偏见。
- 存在对 AI 文本生成能力 的担忧,一位评论者指出,图像中的 标牌文字 是 AI 操纵的明显迹象。
- 用户对 创建此类图像的过程 表示感兴趣,并请求提供 分步说明,以便在自己的照片上复制这种转变。
主题 3. OpenAI 与 DeepSeek:开源大对决
- 我认为太多的不安全感 (Score: 137, Comments: 58): OpenAI 指责 DeepSeek 是“受国家控制的”,并主张禁止中国 AI 模型,突显了对 AI 开发中受国家影响的担忧。图片暗示了地缘政治背景,美国和中国国旗象征着关于 AI 技术中国家控制和安全性的更广泛辩论。
- 讨论突显了对 OpenAI 针对 DeepSeek 指控的怀疑,用户通过指出 DeepSeek 的模型是开源的来挑战国家控制的观点。用户质疑指控的有效性,要求提供证据,并引用了 Sam Altman 过去关于 LLM 缺乏竞争护城河的言论。
- DeepSeek 被视为一个强劲的竞争对手,能够以较低的支出运营,并可能影响 OpenAI 的利润。一些评论建议 DeepSeek 的行为被视为一种经济侵略形式,等同于对美国利益的宣战。
- 存在一股针对 OpenAI 和 Sam Altman 的强烈批评暗流,用户对他们的行为和言论表示不信任和不满。对话包括人身攻击以及对 Altman 公信力的怀疑,并提到了他关于开源模型的承诺尚未兑现。
- 构建了一个 AI Agent 来自动查找并申请工作 (Score: 123, Comments: 22): 一个名为 SimpleApply 的 AI Agent 通过将用户的技能和经验与相关的职位匹配,实现了求职和申请流程的自动化,提供三种使用模式:带职位评分的手动申请、选择性自动申请以及针对匹配度超过 60% 的职位的全自动申请。该工具旨在简化职位申请而不使雇主不堪重负,并因发现了许多用户可能无法发现的远程工作机会而受到称赞。
- 提出了对 数据隐私和合规性 的担忧,涉及 SimpleApply 如何处理 PII 及其对 GDPR 和 CCPA 的遵守。开发者澄清说,他们与合规的第三方安全地存储数据,并正在制定明确的用户协议以实现完全合规。
- 讨论了 申请垃圾邮件风险,并建议避免重复申请同一职位,以防止被 ATS 系统标记。开发者保证,该工具仅申请获得面试可能性较高的职位,以尽量减少垃圾邮件。
- 建议了替代的 定价策略,例如仅在用户通过电子邮件或呼叫转移收到回访时收费。这种方法对于犹豫是否预先花钱的失业用户可能更具吸引力。
{kind=link}
AI Discord 摘要
由 Gemini 2.0 Flash Thinking 提供的摘要之摘要的总结
主题 1. Google 的 Gemma 3 成为各工具关注的焦点
- Unsloth 极大提升 Gemma 3 微调性能,同时支持视觉:Unsloth AI 现在宣布全面支持 Gemma 3。与 48GB GPU 上的标准 Flash Attention 2 设置相比,微调速度提升了 1.6 倍,显存(VRAM)占用降低了 60%,并将上下文长度扩展了 6 倍。针对全量微调、8-bit 和预训练的优化版本已在 Hugging Face 上发布。此外,Gemma 3 vision 的初步支持也已实现,不过 Ollama 用户目前可能会遇到兼容性问题。
- Gemma 3 12B 表现优于 Qwen,尚需 GPT4All 更新支持:用户在个人测试中报告 Gemma 3 12B 的表现优于 Qwen 14B 和 32B,并在多语言问答方面表现出色。然而,由于架构变化和对
mmproj文件的需求,GPT4All 需要更新以全面支持 Gemma 3 12B。在一次基础物理测试中,Gemma-3-12b 正确预测了水结冰时罐子会破碎,而 DeepSeek-R1 则未能做到。 - vLLM 和 LigerKernel 准备集成 Gemma 3:vLLM 正在积极开发 Gemma 3 支持,可在 该 GitHub issue 中跟踪进度。同时,LigerKernel 正在进行 Gemma 3 的草案实现,并指出其与 Gemma 2 架构高度相似,仅有细微的 RMSNorm 调用差异;然而,一些用户报告了 Gemma3 在 TGI 上的上下文窗口大小问题。
主题 2. 新模型涌现:OLMo 2, Command A, Jamba 1.6, PaliGemma 2 Mix
- AI2 的 OLMo 2 32B 闪耀登场,被誉为开源版 GPT-3.5 杀手:AI2 发布了 OLMo 2 32B,这是一个使用 Tulu 3.1 在 6T tokens 上训练的完全开源模型。声称其在学术基准测试中优于 GPT3.5-Turbo 和 GPT-4o mini,而训练成本仅为 Qwen 2.5 32B 的三分之一。该模型提供 7B、13B 和 32B 三种尺寸,现已在 OpenRouter 上线,并在 Yannick Kilcher 的社区中引发了关于其开源性质和性能的讨论。
- Cohere 的 Command A 和 AI21 的 Jamba 1.6 模型发布,具备超大上下文:Cohere 推出了 Command A,这是一个拥有 111B 参数和 256k 上下文窗口的开放权重模型,专为 Agent、多语言和编程任务设计。同时,AI21 发布了 Jamba 1.6 Large(94B 激活参数,256K 上下文)和 Jamba 1.6 Mini(12B 激活参数)。两者现在都支持结构化 JSON 输出和 tool-use(工具调用),所有模型均已在 OpenRouter 上提供。然而,Command A 在质数查询方面表现出一个奇怪的 bug,且据报道在没有特定补丁的情况下,本地 API 性能欠佳。
- Google 的 PaliGemma 2 Mix 系列展现视觉语言通用性:Google 发布了 PaliGemma 2 Mix,这是一个视觉语言模型系列,包含 3B、10B 和 28B 三种尺寸,支持 224 和 448 分辨率,能够处理开放式视觉语言任务和文档理解。同时,Sebastian Raschka 在一篇博客文章中评测了包括 Meta AI 的 Llama 3.2 在内的多模态模型;HuggingFace 的用户也在寻找具有类似图像编辑能力的 Gemini 2.0 Flash 开源替代方案。
主题 3. 编程工具与 IDE 随 AI 集成而演进
- Cursor IDE 用户对性能下降和 Claude 3.7 降级表示不满:Cursor IDE 在 0.47.4 等版本更新后,因在 Linux 和 Windows 上的延迟和卡顿遭到用户抵制;其中 Claude 3.7 被认为“笨拙不堪”且无视规则,同时消耗双倍积分,Cursor agent 也因产生过多终端而受到批评;尽管存在这些问题,v0 在快速 UI 原型设计方面仍广受好评,相比之下,Cursor 的积分系统和创意自由度较 v0 受到更多限制。
- Aider 与 Claude 联手,用户讨论 Rust 移植及 MCP Server 设置:用户盛赞 Claude 与 Aider 的强大组合,并辅以网页搜索和 bash 脚本功能;虽然有关于将 Aider 移植到 Rust 以实现更快文件处理的讨论,但因 LLM API 瓶颈而遭到质疑;针对 Aider MCP Server,出现了用户改进版的 readme,但设置复杂性依然存在,Linux 用户正在寻找运行 Claude Desktop 的变通方法。
- “Vibe Coding” 势头强劲,在游戏开发和资源列表中展露头角:“Vibe Coding”(AI 辅助协作编程)的概念正受到关注,例如一位开发者利用 Cursor 在 20 小时内花费 20 欧元完全使用 AI 开发了一款多人 3D 游戏;此外,精选 AI 编程工具和资源的列表 Awesome Vibe Coding 已在 GitHub 发布,用于自动提交更改的 GitDoc VS Code 扩展 也日益流行,激发了带有可视化变更树的 “Vibe Coding” IDE 的 UI 设计灵感。
Theme 4. 训练与优化技术进展
- Unsloth 开创推理模型的 GRPO 技术,通过动态量化提升速度:Unsloth 推出了 GRPO(指导偏好优化),使推理模型能够以减少 90% VRAM 的代价实现 10 倍长的上下文,并强调动态量化在质量上优于 GGUF(尤其是在 Phi-4 上),相关成果已展示在 Hugging Face 排行榜;同时,Triton bitpacking 实现了比 Pytorch 高达 98 倍的巨幅提速,将 Llama3-8B 的重新打包时间从 49 秒缩短至 1.6 秒。
- DeepSeek 的 Search-R1 利用 RL 实现自主查询生成,IMM 承诺更快的采样:DeepSeek 的 Search-R1 扩展了 DeepSeek-R1,利用强化学习(RL)在推理过程中生成搜索查询,通过检索令牌掩码实现稳定训练并增强 LLM 展开效果;同时,归纳矩匹配(IMM)作为一种新型生成模型类别出现,承诺通过单步或少步采样实现更快的推理,在无需预训练或双网络优化的情况下超越了扩散模型。
- Reasoning-Gym 探索 GRPO、veRL 和复合数据集以增强推理能力:组相对策略优化(GRPO)在 LLM 的 RL 领域日益流行,reasoning-gym 证实了 veRL 训练在 chain_sum 任务上的成功,并探索通过复合数据集提升推理能力,正朝着增强“全方位”模型性能的重构迈进;该项目目前接近 500 stars,版本 0.1.16 已上传至 pypi。
Theme 5. 基础设施与访问:H100、VRAM 与 API 定价
- SF Compute 以低价扰乱 H100 市场,Vultr 进入推理 API 领域:SF Compute 提供了令人惊讶的低 H100 租赁价格,特别是对于短期使用,宣传称每小时有 128 个 H100 可用,并即将推出另外 2,000 个 H100;同时 Vultr 宣布了推理 API 定价,初始阶段 5000 万输出 token 仅需 10 美元,随后为 每百万 token 2 美分,可通过兼容 OpenAI 的端点访问,这源于其大规模采购的 GH200。
- LM Studio 用户深入研究运行时检索和 Snapdragon 兼容性:LM Studio 用户正在对应用程序进行逆向工程,以寻找离线运行时的下载 URL(此前该应用声称可离线运行),并发现了类似 Runtime Vendor 的 CDN ‘API’;同时,LM Studio 对 Snapdragon X Plus GPU 的支持需要直接执行 llama.cpp,且有用户报告 Gemini Vision 的限制可能源于德国/欧盟的地理限制。
- VRAM 消耗担忧上升:讨论 Gemma 3 和 SFT:用户报告在视觉更新后 Gemma 3 的 VRAM 使用量增加,推测 CLIP 集成是原因;关于 Gemma 的 SFT VRAM 需求也引发了争论,认为在类似条件下其要求可能高于 Qwen 2.5;此外,文中还分享了估算 LLM 内存使用的资源,如 Substratus AI 博客和 Hugging Face space。
PART 1: Discord 高层摘要
Unsloth AI (Daniel Han) Discord
- Unsloth 的 Gemma 3 支持势头强劲:Unsloth 现在支持 Gemma 3,包括全量微调和 8-bit,并将 Gemma 3 (12B) 微调优化了 1.6 倍,VRAM 使用量减少了 60%,在 48GB GPU 上与使用 Flash Attention 2 的环境相比,上下文长度扩展了 6 倍。
- 所有 Gemma 3 模型上传均可在 Hugging Face 上找到,包括针对全量微调、8-bit 和预训练优化的版本。
- 动态量化与 GGUF 质量对决:讨论比较了动态量化(dynamic quantization)与 GGUF 模型,特别是尺寸与质量之间的权衡,Unsloth 针对 Phi-4 的动态量化已登上 Hugging Face 排行榜。
- 预计将进行与 GGUF 基准测试的直接对比,以明确不同位宽下的性能,目前的延迟可能是因为 llama-server 尚不支持视觉功能。
- GRPO 将赋予强大的推理能力:GRPO (Guiding Preference Optimization) 将于下周推出并附带新的 notebook,现在支持 10 倍长的上下文且 VRAM 减少 90%,详情见博客文章。
- 团队表示,“只有让你先按照 GRPO 的方式推理规则”,这是专门为推理模型设计的,提供了显著的内存节省和扩展的上下文窗口。
- 视觉模型获得 Unsloth 的视觉支持:Unsloth 实现了 train on completions 功能,并为 Vision Language Models 实现了图像缩放,模型现在可以自动缩放图像,从而防止 OOM 并允许截断序列长度。
- 还分享了一个用于图像处理的 [Qwen2VL Colab notebook](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Qwen2_VL%25287B%2529-Vision.ipynb)。
- QwQ-32B 错误修复增强模型:QwQ-32B 模型已实施错误修复,如博客文章及相应的模型上传所示。
- 这些修复提高了模型的稳定性和性能,确保更流畅的用户体验。
Cursor IDE Discord
- Cursor 在 Linux 和 Windows 上出现性能抖动:用户报告 Cursor 在 Linux 和 Windows 上出现 延迟(lag) 和 冻结,特别是在更新到 0.47.4 版本之后(下载链接)。
- 一位用户详细说明,在 Linux 上仅发送 20-30 条消息 后 UI 就会冻结数秒;另一位用户指出,即使是在运行 3.7 版本的高性能笔记本电脑上,Windows 版也经常出现延迟。
- Claude 3.7 被认为表现不佳且不听指令:用户发现更新到 0.47.4 后,Claude 3.7 变得“笨得要命”,且现在使用它需要消耗双倍额度。
- 成员们提到 Sonnet 3.7 会忽略全局规则,即使被提示输出这些规则时也是如此。根据一条推文,一位用户开玩笑地建议:在你的 Prompt 中加入“做一个乖孩子”,它就能解决任何问题。
- Cursor Agent 触发大量终端窗口:多位用户发现 Cursor Agent 正在生成过量的终端窗口,这令人感到沮丧,尤其是当它重启已经在运行的服务器时。
- 一位成员建议,这种功能要么应该内置化,要么用户应该直接自己编写终端命令。
- V0 因原型开发速度受到称赞:一些用户主张在将设计转移到 Cursor 之前,使用 v0 进行前端原型开发,因为它具有类似 Figma 的子框架 UI 设计能力。
- 一位用户表示:在我看来,先构建原型和布局(更好的前端)然后本地导入到 Cursor 要好得多,尽管其他人因为 v0 的额度系统和有限的创作自主权而更倾向于使用 Cursor。
Eleuther Discord
- LM Studio 用户寻求支持:一位成员建议遇到 LM Studio 问题的用户去专门的 LM Studio Discord 寻求帮助。
- 旨在为 LM Studio 相关问题提供更集中的帮助。
- 为立体异构体寻找 SMILES 字符串编码器:一位成员询问是否有模型或架构可以将 SMILES 字符串 编码为各种 立体异构体(stereoisomers) 或 ChemDraw 输入。
- 目标是从这些编码中提取化学描述符。
- 扩散模型在生成任务中表现出色:分享了一篇 Nature 文章,强调了 扩散模型 (DMs) 在建模复杂数据分布以及为各种媒介生成逼真样本方面的熟练程度。
- 这些模型目前在生成图像、视频、音频和 3D 场景方面处于 SOTA 状态。
- Search-R1 通过 RL 自主进行搜索:介绍了 Search-R1 论文,详细说明了 DeepSeek-R1 模型的扩展,该模型利用强化学习 (RL) 在推理过程中生成搜索查询(参见 论文)。
- 该模型使用检索令牌掩码(retrieved token masking)进行稳定的 RL 训练,通过多轮搜索交互增强了 LLM 的推演(rollouts)能力。
- IMM 声称具有更快的采样时间:分享了一篇关于 Inductive Moment Matching (IMM) 的论文,指出它是一类新型生成模型,承诺通过一步或几步采样实现更快的推理,超越了扩散模型。
- 值得注意的是,与蒸馏方法不同,IMM 不需要预训练初始化或优化两个网络。
HuggingFace Discord
- LLM 对决:Ministral 8B 对比 Exaone 8B:成员们建议在 LLM 任务中使用 4-bit 量化的 Ministral 8B 或 Exaone 8B。
- 一位运行配备 24 GB RAM 的 M4 Mac mini 的用户正试图计算每秒 token 数。
- SmolAgents 在运行 Gemma3 时遇到麻烦:一位用户报告了在 SmolAgents 上运行 Gemma3 时出现的错误,这些错误源于代码解析和正则表达式问题,并指向了 GitHub 上的一个潜在修复方案。
- 该用户通过增加 Ollama 上下文长度解决了这个问题。
- Awesome Vibe Coding 整理资源:一个名为 Awesome Vibe Coding 的精选列表已经发布,其中包含用于 AI 辅助编程的工具、编辑器和资源。
- 该列表包括 AI 驱动的 IDE、基于浏览器的工具、插件、命令行工具以及关于 vibe coding 的最新动态。
- PaliGemma 2 模型发布:Google 发布了 PaliGemma 2 Mix,这是一个视觉语言模型系列,包含三种尺寸(3B、10B 和 28B)以及 224 和 448 两种分辨率,能够通过开放式提示词执行视觉语言任务。
- 欲了解更多信息,请查看博客文章。
- 象棋锦标赛模型下出违规着法?:一位用户分享了一个名为 Chatbot Chess Championship 2025 的 YouTube 播放列表,展示了语言模型或象棋引擎对弈的过程。
- 参与者推测这些模型是真正的语言模型还是仅仅在调用象棋引擎,其中一人注意到某个语言模型下出了违规着法。
Perplexity AI Discord
- Complexity 扩展进入全面维护模式:由于布局更新导致 Complexity 扩展失效,该扩展目前已进入全面维护模式。
- 开发者感谢用户在维护期间的耐心等待。
- 锁定内核以保证安全只是白日梦:在常规频道中,用户们争论锁定内核是否能提高安全性。
- 其他人则认为由于 Linux 的开源特性,这是不可行的,一位用户还开玩笑说不如改用 Windows。
- Perplexity 用户恳求更大的上下文:用户请求在 Perplexity AI 中提供更大的上下文窗口,并愿意为此支付额外费用以避免使用 ChatGPT。
- 一位用户列举了 Perplexity 的功能,如一次对 50 个文件进行无限研究、自定义指令空间以及选择推理模型的能力,作为留下的理由。
- Grok 3 发布即充满 Bug:据报道,新发布的 Grok AI 存在很多 Bug。
- 用户报告说聊天会突然停止工作或在中间断开。
- Gemini Deep Research 并不那么“深度”:测试新的 Gemini Deep Research 功能的用户发现它比 OpenAI 的产品弱。
- 一位用户发现,即使禁用了搜索,它保留的上下文也比普通版 Gemini 少。
aider (Paul Gauthier) Discord
- Claude + Aider = 编程超能力:成员们讨论了将 Claude 与 Aider 结合使用,后者通过网页搜索/URL 抓取和运行 bash 脚本调用来增强功能,从而实现更强大的 Prompting 能力。
- 一位用户强调,添加到 Claude 的每个独特工具所释放的能力远超其各部分之和,尤其是当模型在互联网上搜索 Bug 时。
- Rust 能否提升 Aider 的速度?:一位用户询问是否可以将 Aider 移植到 C++ 或 Rust 以实现更快的文件处理,特别是在为 Gemini 模型加载大型上下文文件时。
- 其他人对此表示怀疑,认为瓶颈仍然在于 LLM API,任何改进可能都无法量化。
- Linux 爱好者启动 Claude Desktop:由于没有官方版本,用户分享了让 Claude Desktop 应用在 Linux 上运行的指南。
- 一位用户引用了一个 GitHub repo,提供了基于 Debian 的安装步骤,而另一位用户分享了他们对 Arch Linux PKGBUILD 的修改。
- Aider MCP Server Readme 获救:用户讨论了 Aider MCP Server,有人提到另一位用户的 Readme 写得“好上 100 倍”,指的是这个仓库。
- 然而,另一位用户幽默地表示,尽管有 Readme,他们仍然无法配置好 MCP。
- DeepSeek 模型话太多:一位用户反映 DeepSeek 模型 生成了过多的输出,大约有 20-30 行 废话,并询问是否可以在配置中设置
thinking-tokens值。- 有人指出,对于 R1 模型 来说,20 行 是非常标准的,一位用户分享说他们曾为了让模型思考一个 5 个单词的 Prompt 而等待了 2 分钟。
Latent Space Discord
- OLMo 2 32B 压倒 GPT 3.5:AI2 发布了 OLMo 2 32B,这是一个使用 Tulu 3.1 训练、数据量高达 6T tokens 的完全开源模型,在学术基准测试中表现优于 GPT3.5-Turbo 和 GPT-4o mini。
- 据称其训练成本仅为 Qwen 2.5 32B 的三分之一,同时达到了类似的性能,并提供 7B、13B 和 32B 参数版本。
- Vibe Coding 利用 AI 创建游戏:一位开发者 100% 利用 AI 创建了一款多人 3D 游戏,耗时 20 小时,花费 20 欧元,并将这一概念称为 vibe coding,同时分享了指南。
- 该游戏具有逼真的元素,如打击反馈、受损时的烟雾以及死亡时的爆炸,全部通过在 Cursor 中输入 Prompt 生成,无需手动编辑代码。
- Levels.io 的 AI 飞行模拟器 ARR 飙升至 100 万美元:一位成员提到了 Levels.io 的飞行模拟器的成功,该模拟器使用 Cursor 构建,通过在游戏中出售广告,迅速达到了 100 万美元的 ARR(年度经常性收入)。
- Levelsio 指出:“AI 对我来说确实是创意和速度的放大器,让我变得更有创意、更高效。”
- GitDoc 扩展自动提交更改:成员们分享了 GitDoc VS Code 扩展,它允许你编辑 Git 仓库并在每次更改时自动提交。
- 一位用户建议增加分支、重启等功能,并表示“存储很便宜,就像在每次更改时自动提交并可视化更改树一样”。
- Latent Space 播客深入探讨 Snipd AI 应用:Latent Space 播客发布了关于 Snipd 的新播客节目,与 Kevin Ben Smith 讨论了用于学习的 AI 播客应用,并在 YouTube 上发布了他们有史以来第一场户外播客。
- 播客内容包括关于 @aidotengineer NYC 的讨论、从金融转向技术领域的经历、AI 如何帮助我们从播客时间中获得更多收获,并透露了 Snipd 应用的技术栈细节。
LM Studio Discord
- 通过逆向工程获取 LM Studio 的运行环境 (Runtimes):一位用户反编译了 LM Studio 以查找供离线使用的下载 URL,发现了 后端主列表 (backends master list) 以及像 Runtime Vendor 这样的 CDN “API”。
- 此举是在另一位用户声称 LM Studio 不需要互联网连接即可运行 之后进行的,显示了对离线运行环境访问的需求。
- Snapdragon 支持需要直接执行 llama.cpp:一位用户报告称 LM Studio 无法检测到其 Snapdragon X Plus GPU,另一位成员回复称 GPU 支持需要直接运行 llama.cpp。
- 他们引导用户参考此 github.com/ggml-org/llama.cpp/pull/10693 Pull Request 以获取更多信息。
- Gemini Vision 受地理限制阻碍:用户报告了在测试 Gemini 2.0 Flash Experimental 的图像处理能力时遇到问题,这可能是由于德国/欧盟的地区限制。
- 一位德国用户怀疑这些限制是由于当地法律引起的,而一位美国用户报告称 AI Studio 中的 Gemini 也未能执行图像处理操作。
- AI 象棋锦标赛凸显模型准确率:举办了一场包含 15 个模型 的 AI 象棋锦标赛,结果可在 dubesor.de/chess/tournament 查看,结果受对局长度和对手走法的影响。
- 虽然 DeepSeek-R1 达到了 92% 的准确率,但组织者澄清说,准确率会根据对局长度和对手走法而变化,且普通的 O1 在锦标赛中运行成本太高。
- 视觉更新后 Gemma 3 的 VRAM 消耗激增:在一次提升视觉速度的更新后,一位用户报告 Gemma 3 的 VRAM 使用量 显著增加。
- 有推测认为,下载体积的增加可能是因为使用了 CLIP 进行视觉处理,且可能由于从独立文件调用,从而增加了整体内存占用 (memory footprint)。
Nous Research AI Discord
- DeepHermes 3 转换为 MLX:模型 mlx-community/DeepHermes-3-Mistral-24B-Preview-4bit 已使用 mlx-lm 0.21.1 版本从 NousResearch/DeepHermes-3-Mistral-24B-Preview 转换为 MLX 格式。
- 此次转换允许在 Apple Silicon 和其他兼容 MLX 的设备上高效使用。
- 深入探讨 Hermes 3 的 vLLM 参数:成员们正在分享不同的配置以使 vllm 正确配合 Hermes-3-Llama-3.1-70B-FP8 运行,包括为 Hermes 3 70B 添加
--enable-auto-tool-choice和--tool-call-parser等建议。- 一位成员指出分词器 (tokenizer) 中需要
<tool_call>和</tool_call>标签,这些标签存在于 Hermes 3 模型 中,但不一定存在于 DeepHermes 中。
- 一位成员指出分词器 (tokenizer) 中需要
- Vultr 公布推理定价:来自 Vultr 的一位成员分享了其推理 API 的官方定价,最初 10 美元可获得 5000 万输出 token,之后为 每百万输出 token 2 美分,可通过位于 https://api.vultrinference.com/ 的 OpenAI 兼容端点访问。
- 据一位成员称,这种定价是因为购买了“多得离谱的 GH200”,并且需要给它们找点活干。
- 动态 LoRA 对接到 vLLM:成员们讨论了使用 vllm 托管动态 LoRA 以应对各种用例(如最新的编码风格)的可能性,并引用了 vLLM 文档。
- 建议允许用户传入其 Hugging Face 仓库 ID 作为 LoRA,并将其提供给 vLLM serve 命令的 CLI 参数。
MCP (Glama) Discord
- Astro 客户端正准备集成 MCP:一位成员计划为其 Astro 客户端使用 MCP,将 AWS API Gateway 与作为 Lambda 函数的每个 MCP 服务器结合使用,并利用带有 SSE gateway 的 MCP 桥接。
- 目标是专门为客户启用 MCP 使用,并探索将 MCP 服务器添加到单个项目中以提高客户端可见性。
- 解码 MCP 服务器架构:一位成员询问像 Cursor 和 Cline 这样将 MCP 服务器保留在客户端的客户端是如何与后端通信的。
- 讨论涉及这些客户端使用的架构和通信方法,但为了获取详细信息,已被重定向到更具体的频道。
- 智能代理服务器转换为 Agentic MCP:一个智能代理 MCP 服务器通过其自身的 LLM,将具有许多工具的标准 MCP 服务器转换为仅具有单个工具的服务器,这实际上是使用 vector tool calling 的子代理(sub-agent)方法。
- OpenAI Swarm framework 遵循类似的过程,将工具子集分配给单个 Agent,现在被 OpenAI 更名为 openai-agents。
- 调试器使用 MCP 服务器调试网页:一位成员分享了一个调试器项目 chrome-debug-mcp (https://github.com/robertheadley/chrome-debug-mcp),该项目使用 MCP 配合 LLMs 调试网页,最初使用 Puppeteer 构建。
- 该项目已移植到 Playwright,更新后的 GitHub 仓库在进一步测试后待发布。
- MCP Hub 概念简化服务器管理:为了增强企业对 MCP 的采用,一位成员创建了一个 MCP Hub 概念,其特点是拥有一个用于简化服务器连接、访问控制和跨 MCP 服务器可见性的仪表板,如此视频中演示的那样。
- 该 Hub 旨在解决企业环境中管理多个 MCP 服务器和权限的担忧。
Interconnects (Nathan Lambert) Discord
- DeepSeek 没收员工护照:据 Twitter 上的 Amir 报道,DeepSeek 的所有者据称要求研发人员上交护照以防止出国旅行。
- 成员们辩论这是否会导致 DeepSeek 开展更多开源工作,或者美国是否可能采取类似措施。
- SF Compute H100 价格震惊市场:一位成员指出 SF Compute 提供的 H100 价格低得令人惊讶,特别是短期租赁,广告称有 128 个 H100 可供按小时使用。
- San Francisco Compute Company 即将推出额外的 2,000 个 H100,并运营一个针对大规模、经过验证的 H100 集群的市场,同时还拥有一个简单但强大的 CLI。
- Gemma 3 许可证引发关注:最近的一篇 TechCrunch 文章强调了对模型许可证的担忧,特别是 Google 的 Gemma 3。
- 文章指出,虽然 Gemma 3 的许可证效率很高,但其限制性和不一致的条款可能会给商业应用带来风险。
- 用户数据隐私受到威胁:一位成员报告了他们对个人在网上发现其电话号码并提出未经请求的要求(如 “hey nato, can you post-train my llama2 model? ty”)的沮丧。
- 他们推测浏览器扩展或付费服务是来源,并正在寻求从 Xeophon 等网站删除其数据的方法。
- Math-500 采样得到验证:针对 Qwen 的 GitHub 仓库 评估脚本中看似随机采样的问题,确认采样显然是随机的。
- 成员们引用了 Lightman et al 2023,并表示长上下文评估和答案提取令人头疼,而 Math 500 的相关性非常好。
{kind=link}
OpenRouter (Alex Atallah) Discord
- Cohere 凭借 111B 模型引发关注:Cohere 发布了 Command A,这是一款全新的 open-weights 111B 参数模型,拥有 256k 上下文窗口,专注于 Agent、多语言和编程应用。
- 该模型旨在为各种用例提供高性能表现。
- AI21 Jamba 推出新模型:AI21 发布了拥有 940 亿激活参数和 256K token 上下文窗口的 Jamba 1.6 Large,以及拥有 120 亿激活参数的 Jamba 1.6 Mini。
- 两款模型现在都支持结构化 JSON 输出和 tool-use。
- Gemma 3 免费开放:Gemma 3 的所有变体均可免费使用:Gemma 3 12B 引入了多模态功能,支持视觉-语言输入和文本输出,并能处理高达 128k tokens 的上下文窗口。
- 该模型理解超过 140 种语言,同时还推出了 Gemma 3 4B 和 Gemma 3 1B 模型。
- Anthropic API 异常已解决:Anthropic 报告了一起针对 Claude 3.7 Sonnet 请求错误率升高的事件,更新已发布在他们的 状态页面。
- 该事件现已解决。
- 象棋锦标赛让 AI 模型同台竞技:一场 AI 象棋锦标赛(可在此处访问:here)让 15 个模型展开对决,使用标准象棋符号表示棋盘状态、游戏历史和合法步法。
- 模型会接收到关于棋盘状态、游戏历史和合法步法列表的信息。
Yannick Kilcher Discord
- Go 在实际移植中胜出:成员们讨论了在移植代码时使用 Go 与 Rust 的实用性,解释说逐个函数地移植到 Go 可以实现精确的行为对等,避免长达数年的代码重写。
- 虽然 Rust 更快且更高效,但有成员指出 Golang 的开发体验非常符合人体工程学 (ergonomic),特别是在分布式、异步或网络应用方面。
- DeepSeek 炒作嫌疑引发讨论:一些成员认为围绕 DeepSeek 的炒作是人为操纵的,且其模型经过了简化,将它们与 frontier AI models 相比就像是拿菠萝比苹果。
- 另一些人则为 DeepSeek 辩护,称其疯狂的工程师开发出了比生命还快的文件系统。
- OLMo 2 32B 完全开源:OLMo 2 32B 作为首个完全开源模型发布,在学术基准测试中超越了 GPT3.5-Turbo 和 GPT-4o mini。
- 据称其性能可与领先的 open-weight 模型媲美,而训练成本仅为 Qwen 2.5 32B 的三分之一。
- ChatGPT 被高估,用户更青睐 Claude:一位成员表示 ChatGPT 被高估了,因为它实际上解决不了我需要解决的问题,他更倾向于 Mistral Small 24B、QwQ 32B 和 Claude 3.7 Sonnet。
- 另一位用户分享道:我用 Claude 得到想要结果的运气更好,而且它似乎出于某种原因更擅长理解意图和动机。
- Grok 3 编写专业级代码:成员们辩论了代码生成的质量,强调 OpenAI 模型经常生成过时的 (legacy) 代码,而 Mistral 可以将其重构为更现代的代码。
- 还有人指出 Grok 3 生成的代码看起来像是专业程序员写的,而在 VSCode 中,一位成员表示相比 Copilot 他更喜欢使用 Amazon Q。
GPU MODE Discord
- Speech-to-Speech 模型引发探索:成员正在积极寻找专注于对话式语音的 speech-to-speech generation 模型,将其与 OpenAI Realtime API 或 Sesame AI 等多模态模型区分开来。
- Block Diffusion 桥接自回归与扩散模型:Block Diffusion 模型在 ICLR 2025 Oral 演讲中进行了详细介绍,它结合了自回归和扩散语言模型的优点,提供高质量、任意长度生成、KV caching 以及可并行化处理。
- 代码可在 GitHub 和 HuggingFace 上找到。
- Triton bitpacking 获得巨大提升:Triton 中的 Bitpacking 相比 4090 上的 Pytorch 实现实现了显著加速,32-bit packing 达到 98x 加速,8-bit packing 达到 26x 加速。
- 使用新的 bitpacking 实现,重新打包 Llama3-8B 模型的时间从 49 秒缩短至 1.6 秒,代码可在 GitHub 获取。
- Gemma3 在 vLLM 和 LigerKernel 中受到关注:成员们讨论了在 vLLM 中增加对 Gemma 3 的支持,引用了这个 GitHub issue;同时一名成员已开始起草将 Gemma3 集成到 LigerKernel 的实现,并分享了 Pull Request 链接。
- 根据 Pull Request,Gemma3 与 Gemma2 高度相似,但在 RMSNorm Calls 方面存在一些差异。
- GRPO 在 LLM 训练中走红:成员们讨论了 Group Relative Policy Optimization (GRPO) 如何在 LLM 的强化学习中变得流行,并引用了 DeepSeek-R1 论文。
- 分享了来自 oxen.ai 关于 GRPO VRAM requirements 的博客文章,指出了其在训练中的有效性。
OpenAI Discord
- 智力下降引发辩论:讨论源于一篇《金融时报》文章,该文章指出发达国家的平均智力正在下降,理由是关于认知挑战以及推理和问题解决能力下降的报告增多。
- 一位成员理论化认为这可能是由于技术(尤其是智能手机和社交媒体)导致思维外包,然而图表显示的年份实际上是在 ChatGPT 问世之前。
- 技术是认知能力下降的罪魁祸首吗?:成员们辩论了认知能力下降的潜在原因,包括技术的影响、移民和氟化水。
- 一位成员指出,认知挑战的比例自 20 世纪 90 年代以来稳步上升,并在 2012 年左右突然加速。
- DeepSeek V3 蒸馏自 OpenAI 模型:讨论提到 Deepseek V3 (instruct 版本) 可能是从 OpenAI 模型中蒸馏出来的。
- 一位成员指出,甚至 OpenAI 也会非正式地支持蒸馏他们的模型,他们只是似乎不喜欢 Deepseek 这么做。
- Claude Sonnet 3.7 在编程任务中占据主导地位:一位成员现在专门使用 Claude Sonnet 3.7 进行编程,发现 ChatGPT 已经落后。
- 在相关新闻中,一位成员表示 o3-mini-high 模型优于 o1。
- 食品添加剂加剧智力衰退:成员们讨论了超加工食品 (UPFs) 的供应和消费在全球范围内有所增加,目前在一些高收入国家占每日能量摄入的 50–60%,并且与认知能力下降有关。
- 另一位成员提到了像雀巢 (Nestlé) 这样在许多国家运营的跨国公司在全球范围内生产和分销,这些公司对产品添加剂的调整或改变可能会产生全球性的影响。
Notebook LM Discord
- Gemini 2.0 Deep Research 加入 NotebookLM?:成员们正在探索将 Gemini 2.0 Deep Research 与 NotebookLM 结合使用,以增强文档处理能力。
- 社区讨论了 Deep Research 在功能上最终是否会取代 NotebookLM。
- NotebookLM 启发非洲项目 Ecokham:一位来自非洲的成员报告称,他使用 NotebookLM 来连接思路、编辑路线图并为他的项目 Ecokham 生成音频。
- 他对 NotebookLM 启发其团队所做的贡献表示感谢。
- NotebookLM 用于 PhytoIntelligence 框架原型设计:一位成员正利用 NotebookLM 整理笔记,并为用于自主营养保健品设计的 PhytoIntelligence 框架 制作原型,旨在缓解诊断挑战。
- 该用户对 Google 提供的这一工具能力表示认可。
- 用户要求 NotebookLM 具备图像和表格识别能力:用户要求 NotebookLM 支持 图像和表格识别,抱怨目前的状态感觉不完整,因为需要不断重新打开源文件并翻阅 Google Sheets;一位用户甚至分享了 相关的猫咪 GIF。
- 社区强调图像胜过“千言万语”,而最清晰的数据通常存在于表格中。
- NotebookLM 移动端 App 仍未上线:用户正积极请求推出 移动端 App 版本 的 NotebookLM,以提高可访问性。
- 社区感觉移动版本“似乎仍遥遥无期”。
LlamaIndex Discord
- Google Gemini 和 Vertex AI 在 LlamaIndex 中合并!:
@googleai集成统一了 Google Gemini 和 Google Vertex AI,支持流式传输、异步、多模态和结构化预测,甚至支持图像,详见 此推文。- 此次集成简化了利用 Google 最新模型构建应用的过程。
- 关于 LlamaIndex 优势的讨论:一位成员寻求了解 LlamaIndex 相比 Langchain 在构建应用方面的优势。
- 在提供的上下文范围内,该询问未得出结论性的讨论。
- 探讨 OpenAI 缺少 Delta 事件的原因:一位成员询问为什么 OpenAI 模型在进行 tool calling 时不发出 delta 事件,观察到事件虽然发出了但内容为空。
- 共识是 tool calling 无法进行流式传输,因为 LLM 需要完整的工具响应才能生成后续响应,因此建议采用自定义(DIY)方法。
- 关于 Agentic RAG 应用 API 的疑问:有人提问是否存在专门用于构建 Agentic RAG 应用 的 API,以简化开发和管理。
- 对话提到 LlamaIndex 中有多种构建模块可用,但缺乏清晰、明确的指南。
Nomic.ai (GPT4All) Discord
- Gemma 3 12B 在智商测试中胜过 Qwen:一位用户报告称,在其个人电脑上,Gemma 3 12B 模型 的智能表现优于 Qwen 14B 和 Qwen 32B。
- 这是通过多语言提问测试的;Gemma 3 和 DeepSeek R1 始终能以与问题相同的语言提供正确答案。
- Gemma 3 需要新的 GPT4All 支持:用户注意到 GPT4All 可能需要更新才能完全支持 Gemma 3 12B,因为其架构与 Gemma 2 不同。
- 具体而言,Gemma 3 需要一个 mmproj 文件才能在 GPT4All 中运行,这凸显了快速适应新 AI 模型开发的挑战。
- 冻水实验测试 AI 知识:当被问及关于冻水的问题时,DeepSeek-R1 错误地预测罐子会破裂,而 Gemma-3-12b 则准确描述了由于水膨胀导致的破碎效应。
- 这展示了模型对基础物理学理解水平的差异,表明了不同架构之间多样化的推理能力。
DSPy Discord
- 显式反馈流入 Refine:一名成员请求在
dspy.Refine中重新引入显式反馈(explicit feedback),类似于dspy.Suggest,以增强调试和理解能力。- 该成员强调了显式反馈对于识别需要改进之处的价值。
- 手动反馈在 Refine 中发挥作用:团队宣布在
Refine中增加了手动反馈功能。- 该实现涉及将反馈作为
dspy.Prediction对象包含在奖励函数(reward function)的返回值中,其中包含分数和反馈。
- 该实现涉及将反馈作为
- 奖励函数返回反馈:一名团队成员询问了将反馈作为 reward_fn 返回值的一部分进行集成的可行性。
- 用户给出了肯定答复,并表达了感谢。
Cohere Discord
- Command A 在 OpenRouter 亮相:Cohere 的 Command A 是一款拥有 111B 参数、256k 上下文窗口的开源权重模型,现已可在 OpenRouter 上访问。
- 该模型旨在在 Agent、多语言和编程应用中提供高性能,为开源权重模型树立了新标准。
- Command A 未能通过质数测试:用户发现 Command A 中存在一个奇特的 Bug:当询问数字之和为 15 的质数时,模型要么提供错误答案,要么陷入死循环。
- 这种意外行为凸显了模型在数学推理能力方面可能存在的缺陷。
- 本地 API 在运行 Command A 时遇到困难:用户在本地运行 Command A 时遇到了性能瓶颈,报告称即使有足够的 VRAM,如果不修补 ITOr 中的建模或使用 APIs,模型也无法达到理想的速度。
- 这表明优化 Command A 的本地部署可能需要进一步工作以提高其效率。
- Cohere 发布兼容性 base_url:一名成员建议使用 Cohere 兼容性 API。
- 他们建议利用 base_url 进行集成。
Modular (Mojo 🔥) Discord
- Discord 账号冒充警报:一名成员报告称收到一个冒充其他用户的诈骗账号发来的消息,被冒充的用户确认:“那不是我。这是我唯一的账号”。
- 虚假账号 caroline_frascaa 已被举报至 Discord,并在用户发布虚假账号截图后被从服务器封禁。
- Mojo 标准库(stdlib)用途讨论:soracc 在 #mojo 中提到了 Mojo 标准库中某些特性的使用。
- 用户提到它被用于
base64。
- 用户提到它被用于
{kind=link}
LLM Agents (Berkeley MOOC) Discord
- 自我反思需要外部评估:一名成员询问了第一节课与第二节课关于自我评估(self-evaluation)的表述,认为在外部反馈的作用方面存在矛盾。
- 第一节课强调自我反思(self-reflection)和自我优化(self-refinement)受益于良好的外部评估,而没有 Oracle 反馈的自我修正(self-correction)可能会降低推理性能。
- 寻求对第 1 课和第 2 课中自我评估的澄清:一名用户正在寻求关于课程中关于自我评估明显矛盾点的澄清。
- 他们注意到第二节课强调了自我评估和改进,而第一节课则强调了外部评估的重要性以及没有 Oracle 反馈的自我修正可能带来的危害。
AI21 Labs (Jamba) Discord
- Vertex 为 1.6 版本做准备:Version 1.6 尚未在 Vertex 上提供,但计划在不久的将来推出。
- 它也将可在 AWS 等其他平台上提供,以实现更广泛的访问。
- AWS 即将托管 1.6 版本:1.6 版本将在不久的将来在 AWS 等平台上提供,从而扩大其覆盖范围。
- 这一进展旨在让 AWS 客户能够访问新功能。
tinygrad (George Hotz) Discord 没有新消息。如果该社区沉寂时间过长,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该社区沉寂时间过长,请告知我们,我们将将其移除。
Torchtune Discord 没有新消息。如果该社区沉寂时间过长,请告知我们,我们将将其移除。
Codeium (Windsurf) Discord 没有新消息。如果该社区沉寂时间过长,请告知我们,我们将将其移除。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该社区沉寂时间过长,请告知我们,我们将将其移除。
第 2 部分:按频道详细摘要和链接
邮件中的各频道详细分析已截断。
如果您喜欢 AInews,请分享给朋友!提前感谢!