ainews-coheres-command-a-claims-3-open-model-spot
Cohere 的 Command A 占据开放模型第三位(仅次于 DeepSeek 和 Gemma)
Cohere 的 Command A 模型巩固了其在 LMArena 排行榜上的地位。该模型拥有 111B 参数并采用开放权重,具备 256K 的超长上下文窗口,且价格极具竞争力。Mistral AI 发布了轻量级、多语言且多模态的 Mistral AI Small 3.1 模型,该模型针对单张 RTX 4090 或 32GB 内存的 Mac 配置进行了优化,在指令遵循和多模态基准测试中表现强劲。新型 OCR 模型 SmolDocling 提供快速的文档读取能力且显存(VRAM)占用较低,性能超越了 Qwen2.5VL 等更大型的模型。相关讨论强调了系统级改进比单纯的 LLM 进步更为重要,同时 MCBench 被推荐为评估模型在代码、审美和意识等方面能力的优选 AI 基准。
为开放权重模型(open weights models)欢呼!
2025年3月14日至2025年3月17日的 AI 新闻。我们为您检查了 7 个 subreddits、433 个 Twitter 账号 和 28 个 Discord 社区(223 个频道,9014 条消息)。预计节省阅读时间(以 200wpm 计算):990 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
我们在上周简要提到了 Cohere 的 Command A 发布,但由于当时的公告中缺乏广泛可比的基准测试(虽然有一些,但那些选择性的、自报的与 DeepSeek V3 和 GPT-4o 的对比,并不能真正将 Command A 置于 SOTA 开源模型或同尺寸 SOTA 模型的大背景下),因此很难判断其长远影响力的排名。
随着今天 LMArena 结果的公布,这一点已不再存疑:
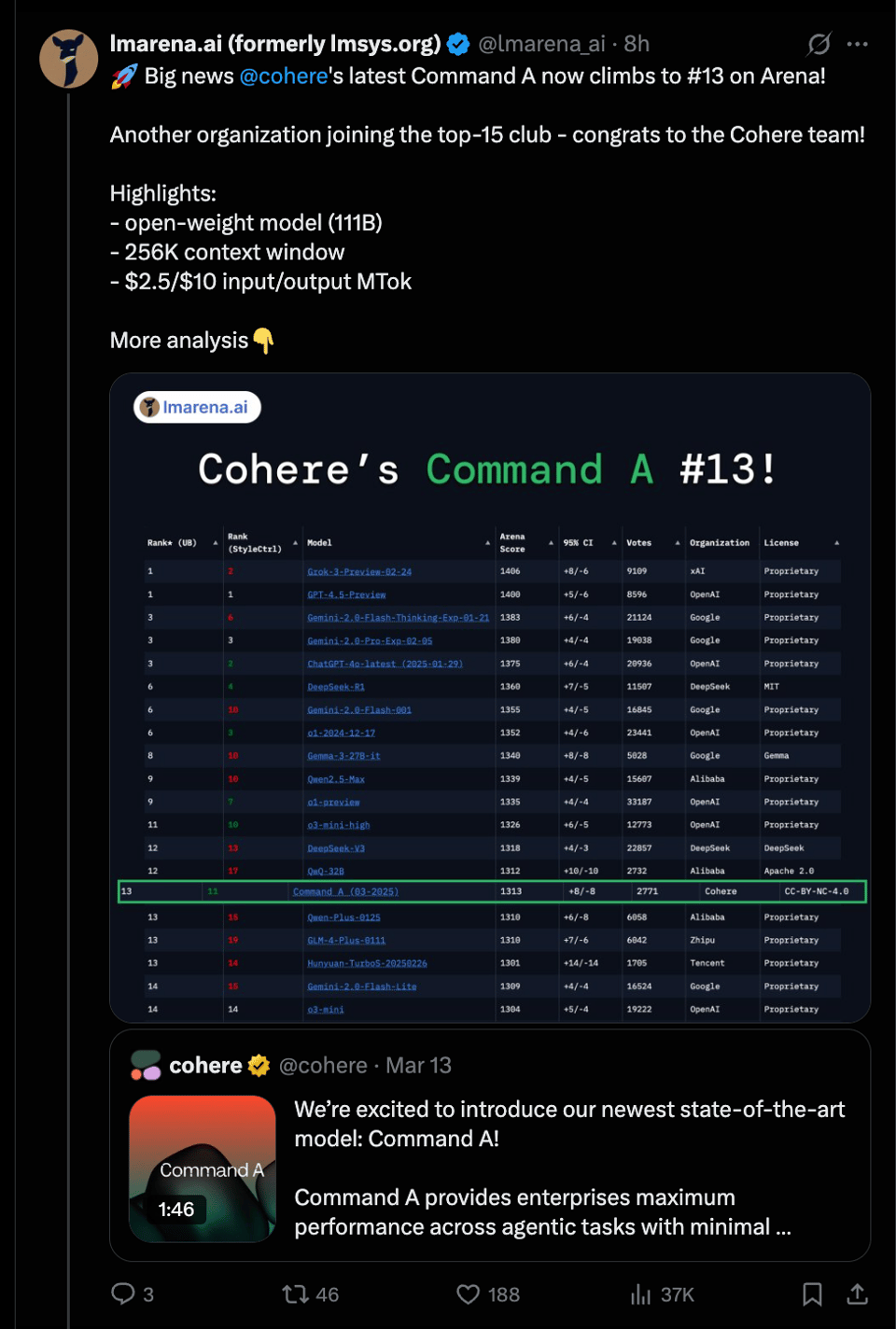
正如 Aidan Gomez 指出的,在使用了 Style Control 修正后,Command A 的排名实际上上升了 2 位(在他们的 LS podcast 中有详细探讨)。
还有许多其他值得注意的细节,使得 Command A 成为开源模型库中极具吸引力的候选者,包括异常长的 256k 上下文窗口(context window)、多语言能力,以及专注于优化 2-H100 推理占用空间(serving footprint)。
AI Twitter 摘要
大语言模型 (LLMs) 与模型发布
- Mistral AI Small 3.1 发布(多模态、多语言、Apache 2.0 许可证):@sophiamyang 宣布发布 Mistral AI Small 3.1,强调其轻量级特性(可在单张 RTX 4090 或 32GB RAM 的 Mac 上运行)、快速响应对话、低延迟函数调用(function calling)、专门的微调以及先进的推理基础。它在指令(instruct)基准测试中优于同类模型 @sophiamyang,在多模态指令基准测试中也表现出色 @sophiamyang,并已在 Hugging Face @sophiamyang、Mistral AI La Plateforme @sophiamyang 以及企业级部署中上线 @sophiamyang。该模型因其多语言和长上下文能力而受到赞誉 @sophiamyang。@reach_vb 强调了其 128K 上下文窗口和 Apache 2.0 许可证。
- SmolDocling:新型 OCR 模型:@mervenoyann 介绍了 SmolDocling,这是一款快速 OCR 模型,使用 0.5GB VRAM 仅需 0.35 秒即可读取单份文档,性能优于包括 Qwen2.5VL 在内的大型模型。它基于 SmolVLM,并在页面和 Docling 转录数据上进行了训练。该模型和演示已在 Hugging Face 上提供 @mervenoyann。
- Cohere Command A 模型:@lmarena_ai 报告称,Cohere 的 Command A 已攀升至 Arena 排行榜第 13 位,突出了其开放权重模型(111B)、256K 上下文窗口以及 $2.5/$10 的输入/输出 MTok 定价。Command A 在风格控制(style control)方面也表现优异 @aidangomez。
- 关于更优 LLM 的讨论:@lateinteraction 表达了一种悲观观点,认为近期 LLM 的进步归功于构建 LLM 系统(CoT),而非 LLM 本身的提升,并质疑更好的 LLM 究竟在哪里。
模型性能、基准测试与评估
- MCBench 作为卓越的 AI 基准测试:@aidan_mclau 推荐 mcbench 为最佳 AI 基准测试,指出其数据易于审计、测试了相关特性(代码、审美、意识),并能区分顶级模型之间的性能差异。该基准测试可以在 https://t.co/YEgzhLotKk 找到 @aidan_mclau
- 用于自主软件任务的 HCAST 基准测试:@idavidrein 分享了关于 HCAST (Human-Calibrated Autonomy Software Tasks) 的细节,这是由 METR 开发的一个基准测试,旨在衡量前沿 AI 系统自主完成多样化软件任务的能力。
- 专利领域的 AI 模型:@casper_hansen_ 测试了模型在专利指令遵循方面的表现,发现 Mistral Small 3 优于 Gemini Flash 2.0,因为 Mistral 模型在更多的专利数据上进行了预训练。
- LLM 中的泛化缺陷:@JJitsev 分享了他们论文的更新,包括关于近期推理模型的部分,质疑它们处理 AIW 问题变体的能力,这些变体揭示了 SOTA LLM 中严重的泛化缺陷。
- 在 OpenRouter 上评估模型:@casper_hansen_ 指出 OpenRouter 是测试新模型的有用工具,但免费额度限制为每天 200 次请求。
AI Agents、工具使用与应用
- AI Agent 与外部工具交互:@TheTuringPost 解释了 AI Agent 如何通过基于 UI 和基于 API 的交互与外部工具或应用进行交互,现代 AI Agent 框架因速度和可靠性而优先考虑基于 API 的工具。
- TxAgent:用于治疗推理的 AI Agent:@iScienceLuvr 介绍了 TXAGENT,这是一个利用多步推理和实时生物医学知识检索的 AI Agent,通过包含 211 个工具的工具箱来分析药物相互作用、禁忌症和针对特定患者的治疗策略。
- Realm-X 助手:@LangChainAI 重点介绍了 AppFolio 的 Realm-X 助手,这是一个由 LangGraph 和 LangSmith 驱动的 AI Copilot,旨在简化物业管理者的日常任务。将 Realm-X 迁移到 LangGraph 使响应准确度提高了 2 倍。
- 用于错误和数据分析的 AI:@gneubig 对 AI Agent 能够比人类更快地执行更细致的错误分析和数据分析的能力表示兴奋。
- 多 Agent 协作结对编程:@karinanguyen_ 分享了一个多 Agent/玩家结对编程的概念草图,设想了一种与 AI 进行实时协作的体验,包括屏幕共享、群聊和 AI 辅助编码。
AI 安全、对齐与审计
- 对齐审计:@iScienceLuvr 重点介绍了 Anthropic 的一篇关于审计语言模型隐藏目标的新论文,详细说明了团队如何利用可解释性、行为攻击和训练数据分析揭示模型的隐藏目标。
- 默认对齐:@jd_pressman 反对“默认对齐”的概念,强调 LLM 的对齐是通过在人类数据上训练实现的,这在 RL 或合成数据方法中可能并不成立。
迷因/幽默
- RLHF 训练:@cto_junior 开玩笑说他们被 RLHF 了,并附上了一个推文链接。
- PyTorch 缓存分配器:@typedfemale 分享了一个关于解释 PyTorch 缓存分配器行为的梗图。
- 可卡因 vs RL:@corbtt 开玩笑说,RL 训练的 Agent 领悟新技能带来的快感比可卡因还要强烈。
AI Reddit 回顾
/r/LocalLlama 回顾
主题 1:使用 SDXL、Wan2.1 和长上下文微调的高级 AI 视频生成
- 另一个旨在追求电影级写实感的视频,这次使用了一个难度大得多的角色。SDXL + Wan 2.1 I2V (评分: 1018, 评论: 123): 该帖子讨论了使用 SDXL 和 Wan 2.1 I2V 创建旨在实现电影级写实感 (cinematic realism) 的视频。它强调了在这种背景下处理更复杂角色的挑战。
- 技术挑战与技巧:Parallax911 分享了使用 SDXL 和 Wan 2.1 I2V 实现电影级写实感的复杂性,重点介绍了如何使用 Photopea 进行 inpainting 以及在 Davinci Resolve 中进行合成。他们提到了在实现一致性和写实感方面的困难,尤其是对于复杂的角色设计,并使用了 Blender 来制作如开门等片段的动画。
- 项目成本与工作流:该项目使用 RunPod 的 L40S(价格为 $0.84/小时),耗时约 80 小时 的 GPU 时间,成本约为 $70。Parallax911 采用的工作流包括 RealVisXL 5.0、Wan 2.1 和用于放大的 Topaz Starlight,生成的场景为 61 帧、960x544 分辨率和 25 steps。
- 社区反馈与建议:社区赞扬了其氛围渲染和声音设计,并对水滴大小等元素提出了具体反馈,同时希望能有教程。一些用户建议改进 AI 与传统技术的结合,并对 Metroid 中的 Samus Aran 等角色的动作场面表现出兴趣。
- Wan2.1 中的视频扩展 - 完全在 ComfyUI 中创建 10 秒以上的高清放大视频 (评分: 123, 评论: 23): 该帖子讨论了在 Wan2.1 中使用 ComfyUI 创建放大视频的高度实验性工作流,成功率约为 25%。该过程涉及从初始视频的最后一帧生成新视频、合并、放大和帧插值,具体参数包括 Sampler: UniPC、Steps: 18、CFG: 4 和 Shift: 11。更多详情可以在 工作流链接 中找到。
- 用户正在询问工作流中的宽高比处理,质疑它是自动设置的还是需要手动调整输入图像。
- 对该工作流感兴趣的用户给出了积极反馈,表示对这种解决方案的期待。
- 用户提出了关于片段后半部分模糊的担忧,并建议这可能与输入帧的质量有关。
- 使用 WAN 2.1 和 LTX 动画化了我的一些 AI 图片 (评分: 115, 评论: 10): 该帖子讨论了使用 WAN 2.1 和 LTX 创建 AI 动画视频。在没有更多背景或额外细节的情况下,重点仍然是用于动画的工具。
- 模型使用:第一个片段(跳跃的女人)和战斗机使用了 LTX,而奔跑的宇航员、恐怖菲比娃娃和龙则使用了 WAN。
- 硬件详情:视频是使用从 Paperspace 租用的带有 RTX5000 实例的云端计算机生成的。
主题 2. OpenAI 的 Sora:将城市景观转变为反乌托邦
- OpenAI 的 Sora 将旧金山的 iPhone 照片变成了反乌托邦噩梦 (评分: 931, 评论: 107): OpenAI 的 Sora 是一款将旧金山的 iPhone 照片转化为具有反乌托邦 (dystopian) 美感图像的工具。尽管由于缺乏文本内容而无法获得具体细节,但该帖子可能讨论了使用 AI 改变现实世界图像的影响和视觉结果。
- 几位评论者对 AI 生成的反乌托邦图像的影响表示怀疑,一些人认为旧金山或其他城市的实际地点已经看起来像这些反乌托邦视觉效果,质疑 AI 改造的必要性。
- 使用 iPhone 作为拍摄原始图像的设备是一个争论点,一些人质疑其与讨论的相关性,而另一些人则强调其在理解图像来源方面的重要性。
- 对话中混杂着对 AI 能力的钦佩和担忧,用户既对技术感到惊讶,又对未来难以区分 AI 生成和现实世界图像感到焦虑。
- OpenAI 的 Sora 将旧金山的 iPhone 照片变成了反乌托邦式的地狱景象…… (Score: 535, Comments: 58): OpenAI 的 Sora 将 旧金山的 iPhone 照片 变成了反乌托邦式的地狱景象,展示了其在改变数字图像以创造未来主义、阴郁美学方面的能力。该帖子除了这一转变外,缺乏额外的背景或细节。
- 评论者将 反乌托邦图像 与现实世界的地点进行了类比,提到了 德里、底特律 和 印度街道,突显了 AI 在解读城市环境时被察觉到的偏见。
- 有人对 AI 的文本生成能力 表示担忧,一位评论者指出,图像中的 标牌文字 是 AI 操纵的明显迹象。
- 用户对 创建此类图像的过程 表现出兴趣,并请求提供 分步说明,以便在自己的照片上复制这种转变。
主题 3. OpenAI 与 DeepSeek:开源对决
- 我认为太多的不安全感 (Score: 137, Comments: 58): OpenAI 指责 DeepSeek 受“国家控制”,并主张禁止中国 AI 模型,突显了对 AI 发展中政府影响的担忧。图片暗示了地缘政治背景,美国和中国国旗象征着关于 AI 技术中国家控制和安全的更广泛辩论。
- 讨论突显了对 OpenAI 针对 DeepSeek 指控的怀疑,用户通过指出 DeepSeek 的模型是开源的来挑战国家控制的观点。用户质疑指控的有效性,要求提供证据,并引用了 Sam Altman 过去关于 LLM 缺乏竞争护城河的言论。
- DeepSeek 被视为一个强劲的竞争对手,能够以较低的支出运营,并可能影响 OpenAI 的利润。一些评论认为 DeepSeek 的行为被视为一种经济侵略,等同于对美国利益的宣战。
- 存在着针对 OpenAI 和 Sam Altman 的强烈批评暗流,用户对他们的行为和言论表示不信任和不满。对话包括人身攻击以及对 Altman 公信力的怀疑,并提到了他关于开源模型的承诺尚未兑现。
- 构建了一个 AI Agent 来自动寻找并申请工作 (Score: 123, Comments: 22): 一个名为 SimpleApply 的 AI Agent 通过将用户的技能和经验与相关的职位匹配,实现了职位搜索和申请流程的自动化,提供三种使用模式:带职位评分的手动申请、选择性自动申请,以及针对匹配度超过 60% 的职位的全自动申请。该工具旨在简化职位申请流程而不至于让雇主应接不暇,并因发现了许多用户可能无法发现的远程工作机会而受到称赞。
- 有人提出了关于 数据隐私和合规性 的担忧,询问 SimpleApply 如何处理 PII 以及是否遵守 GDPR 和 CCPA。开发者澄清说,他们与合规的第三方安全地存储数据,并正在制定明确的用户协议以实现完全合规。
- 讨论了 申请垃圾邮件风险,并建议避免重复申请同一职位,以防止被 ATS 系统标记。开发者保证,该工具仅申请获得面试可能性较高的职位,以尽量减少垃圾邮件。
- 建议了替代的 定价策略,例如仅在用户通过电子邮件或呼叫转移收到回访时收费。这种方法对于犹豫是否要预先花钱的失业用户可能更具吸引力。
{kind=link}
其他 AI Subreddit 综述
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding
主题 1. 对用于确定 LLM 智能的“陷阱”测试的批评
- 当 ChatGPT 成为我的治疗师(得分:172,评论:83):在情绪低落时,作者发现 ChatGPT 出乎意料地令人感到安慰且富有同理心,能提供深思熟虑的提问和自我关怀的提醒。他们承认,虽然 AI 聊天机器人不能替代真实的心理治疗,但它们可以提供宝贵的情感支持,尤其是在应对压力、焦虑和进行自我反思时。
- 许多用户发现 ChatGPT 对情感支持大有裨益,可作为自我反思的工具并提供治疗性引导。一些用户(如 Acrobatic-Deer2891 和 Fair_Cat5629)反馈称,治疗师对 AI 提供的引导给出了正面评价;而另一些用户(如 perplexed_witch)则强调将其用于“引导式自我反思”,而非替代治疗。
- ChatGPT 在危机期间的心理健康管理作用受到称赞,它能提供一个不带偏见的倾诉空间并提供视角,正如 dinosaur_copilot 和 ChampionshipTall5785 的评论所言。用户赞赏它在痛苦时刻提供可操作建议和情感支持的能力。
- 用户也提到了对隐私以及 AI 作为治疗替代品局限性的担忧,例如 acomfysweater 对数据存储表示忧虑。尽管存在这些担忧,包括 Jazzlike-Spare3425 在内的许多人仍看重 AI 提供支持的能力,且不会给人类倾听者带来情感负担。
- 为什么…👀(得分:3810,评论:95):ChatGPT 在治疗角色中的潜力通过一段幽默的对话得到了体现:一名用户要求 ChatGPT 模拟女朋友,引发了一场俏皮的交流,并以一句分手台词结束。这种互动突显了 AI 在聊天界面中进行轻松、类人对话的能力。
- ChatGPT 的效率与能力:用户幽默地评论了 ChatGPT 快速完成请求的能力,有人开玩笑说它的回复是基于 “Andrew Tate Sigma Incel 数据” 训练的,并创造了 “ChadGPT” 一词来描述其高效但生硬的互动风格。
- Prompt Engineering 与个性化:一位具有心理学和技术背景的用户建议,ChatGPT 可以根据它选择保存的记忆形成某种语调,这意味着通过 Prompt Engineering 实现个性化互动是可能的。他们还讨论了神经网络与人类记忆检索系统(如 RAG)的相似性。
- 幽默与讽刺:对话的趣味性在评论中得到体现,有人拿 AI 在人际关系中的角色开玩笑,称其为“高级的单词预测器”,并对其模拟类人互动(包括模拟分手)的能力进行了幽默观察。
{kind=link}
主题 2. 对 Google DeepMind CEO 预测 AGI 将在 5-10 年内实现的反应
- Google DeepMind CEO 表示,能在任何任务上媲美人类的 AI 将在 5 到 10 年内出现(得分:120,评论:65):DeepMind CEO 预测 AI 将在 5-10 年内实现跨任务的人类水平对等,这标志着此前关于明年实现这一里程碑的预期发生了转变。
- 评论者讨论了 AI 实现人类水平对等的时间线预测,一些人对不断变化的时间线表示怀疑,指出 Demis Hassabis 一直在预测 AGI 的时间范围是 5-10 年。人们呼吁对 “AGI” 给出更清晰的定义,以便更好地理解这些预测。
- AI 的大规模普及被比作历史性的技术变革,如从马车到汽车的过渡以及智能手机的普及。这种类比表明,随着时间的推移,AI 将变得无处不在,改变社会规范和期望,而不会立即引起剧烈反应。
- 人们对 AI 的经济和社会影响表示担忧,特别是关于就业和财富集中的问题。一些评论者对 AI 可能加剧职位取代和不平等表示忧虑,而另一些人则质疑 AI 公司在面临潜在风险时仍推动快速发展的动机。
主题 3. OpenAI 关于使用受版权保护内容的争议性请求正由美国政府审议
- OpenAI to U.S. Government - Seeking Permission to Use Copyrighted Content (Score: 506, Comments: 248): OpenAI 正在请求 Trump administration 放宽版权监管,以促进在 AI 开发中使用受保护的内容。该公司强调,此类变革对于维持 America’s leadership 在 AI 领域的地位至关重要。
- 评论者讨论了 copyright law 对 AI 开发的影响,一些人认为 AI 对版权内容的使用应被视为 fair use,类似于人类从现有作品中学习的方式。人们担心 AI 模型可能会绕过个人面临的法律后果,突显了在获取和使用版权材料方面的不平等。
- AI arms race 是一个反复出现的主题,几位用户表示担心 China and other countries 可能不会像美国那样严格遵守版权法,这可能会给他们带来优势。这引发了关于 AI 开发竞争格局和美国公司战略决策的问题。
- 关于版权所有者的 equity and compensation 的讨论提出了替代方案,例如向作品被用于 AI 训练的创作者提供股权。一些评论者建议将大科技公司国有化,以确保 AI 进步带来的利益得到公平分配,反映了对财富分配和 AI 资源控制的更广泛担忧。
- Open AI to U.S. GOVT: Can we Please use copyright content (Score: 398, Comments: 262): OpenAI 请求 Trump administration 放宽 copyright rules,以促进 AI 训练并帮助维持美国在该领域的领导地位。请求随附的图片显示了一个正式场合,演讲者站在讲台上,可能是在 White House,旁边的人包括貌似 Donald Trump 的人士。
- 许多评论者反对 OpenAI 放宽 copyright rules 的请求,强调创作者的作品应该获得报酬,而不是在未经许可的情况下被使用。观点认为版权激励了创造力和创新,放宽这些法律可能会使创作者处于劣势,并使 OpenAI 等大公司获得不公平的利益。
- 评论中反复出现对 OpenAI’s motives 的怀疑,用户暗示 OpenAI 正在寻求利用法律漏洞牟利。人们将其与 China’s approach 对待知识产权的方式进行了比较,一些人担心如果美国严格遵守现行版权法,可能会在 AI 开发方面落后。
- 几位用户提议,如果 OpenAI 或任何公司使用版权材料进行 AI 训练,由此产生的模型或数据应该 open source 并供所有人使用。讨论还涉及 AI 在版权材料上进行训练的更广泛伦理影响,以及可能需要重新评估版权法以应对新的技术现实。
{kind=link}
{kind=link}
Theme 4. ReCamMaster releases new camera angle changing tool
- ReCamMaster - LivePortrait creator has created another winner, it lets you changed the camera angle of any video. (Score: 648, Comments: 46): ReCamMaster 开发了一项技术,允许用户更改任何视频的摄像机角度,这是继其之前的 LivePortrait 取得成功后的又一力作。
- 许多评论者对 ReCamMaster 不是 open source 感到失望,并提到了 TrajectoryCrafter,它是开源的,并允许类似的摄像机操控功能。TrajectoryCrafter 的 GitHub 链接在这里。
- 一些用户预见该技术对视频稳定和沉浸式体验的潜在影响,认为该技术可能会带来更具创新性的电影镜头,并在 Autonomous Driving 等领域得到应用。
- 对于 AI 生成的摄像机角度的真实性存在怀疑,有人建议,要获得更具说服力的结果,需要利用现有的摄像机摇移或源材料中的多个镜头。
- 在一些我父亲在 80 年代拍摄并由我扫描的胶片投影幻灯片上使用了 WAN 2.1 IMG2VID。 (评分: 286, 评论: 24): WAN 2.1 IMG2VID 被用于将 20 世纪 80 年代的扫描胶片投影幻灯片转换为视频格式,展示了视频技术的演进。该帖子缺乏关于具体结果或与 ReCamMaster 等其他技术对比的额外背景或细节。
- 评论者对该项目的技术细节表现出浓厚兴趣,要求提供更多关于创建视频转换所使用的 workflow、hardware 和 prompts 的信息。人们特别好奇如何为个人项目复制这一过程。
- 讨论的很大一部分集中在该项目的情感冲击上,用户分享了个人轶事并表达了希望看到原始幻灯片的愿望。一位评论者确认,幻灯片中出现的人已经看到了视频,并对这项技术感到惊讶。
- 怀旧方面被重点提及,用户回顾了驾驶 Goodyear blimp 等历史内容,并对通过这些转换后的视频“穿越回过去”的能力表示热忱。
AI Discord 摘要
由 Gemini 2.0 Flash Thinking 生成的摘要之摘要之摘要
主题 1. Mistral 与 Google 争夺小模型霸权
- Mistral Small 3.1 展示多模态实力: Mistral AI 推出了 Mistral Small 3.1,这是一款多模态模型,声称在其同参数量级中具有 SOTA 性能,超越了 Gemma 3 和 GPT-4o Mini。该模型以 Apache 2.0 协议发布,拥有 128k context window,推理速度达 每秒 150 tokens,具备处理文本和图像输入的能力。
- Gemma 3 获得视觉、上下文和剪枝功能: Google 的 Gemma 3 模型正在通过新功能突破界限,包括视觉理解、多语言支持以及巨大的 128k token context window。成员们还探索了将 Gemma-3-27b 的词汇量从 260k 剪枝至 40k tokens,以减少 VRAM 占用并提升训练速度。
- 百度的 ERNIE X1 以低成本挑战 DeepSeek R1: 百度发布了新的推理模型 ERNIE X1,声称其性能与 DeepSeek R1 相当,但成本仅为一半。ERNIE Bot 现在对个人用户免费,尽管 X1 推理模型目前仅限中国地区使用。
主题 2. 训练与优化技术趋于白热化
- Unsloth 用户发现梯度步长陷阱: UnslothAI Discord 成员指出,在 fine-tuning 过程中,较小的有效 batch sizes(例如 batch=1, gradient steps = 4)可能导致模型遗忘过多。用户分享了建议的 batch/grad 配置,以便从有限的 VRAM 中榨取性能。
- 深度诅咒困扰 LLM,Pre-LN 是罪魁祸首: 一篇新论文强调了现代 LLM 中的深度诅咒 (Curse of Depth),揭示了 Pre-Layer Normalization (Pre-LN) 使得近一半的模型层效果不如预期。研究人员提出了 LayerNorm Scaling 来缓解这一问题并提高训练效率。
- Block Diffusion 模型融合自回归与扩散模型的优势: 一种新的 Block Diffusion 模型在自回归和扩散语言模型之间进行插值,旨在结合两者的优点。该方法寻求将高质量输出、任意长度生成与 KV caching 以及并行化能力相结合。
主题 3. AI Agent 与 IDE 争夺开发者青睐
- Aider Agent 通过 MCP Server 获得自主性提升: AI 编程助手 Aider 在与 Claude Desktop 和 MCP 配合使用时获得了更强的自主性。用户强调 Claude 现在可以管理 Aider 并发布命令,提升了其引导编程任务的能力,特别是通过 bee 实现的无障碍网页抓取。
- Cursor 用户关注 Windsurf,Claude Max 即将到来: Cursor IDE 面临用户对其性能问题(包括延迟和崩溃)的投诉,促使一些用户转向 Windsurf。然而,Cursor 团队预告 Claude Max 即将登陆该平台,并承诺将提升代码处理能力。
- Awesome Vibe Coding 列表收录 AI 驱动工具: “Awesome Vibe Coding” 列表出现,汇集了旨在增强编程直觉和效率的 AI 辅助编程工具、编辑器和资源。该列表包括 AI 驱动的 IDE、基于浏览器的工具、插件和命令行界面。
Theme 4. 硬件升温:AMD APU 和中国版 RTX 4090 引人关注
- AMD 的 “Strix Halo” APU 剑指 RTX 5080 AI 桂冠: 一篇文章声称 AMD 的 Ryzen AI MAX+ 395 “Strix Halo” APU 在 DeepSeek R1 AI 基准测试中可能比 RTX 5080 强 3 倍以上。这归功于 APU 更大的 VRAM 池,尽管社区仍在等待实际验证。
- OpenCL 后端增强 llama.cpp 中的 Adreno GPU: llama.cpp 引入了针对 Qualcomm Adreno GPU 的实验性 OpenCL 后端,有可能释放移动设备上的巨大计算能力。此更新允许通过 OpenCL 利用移动设备中常见的 Adreno GPU。
- 中国版 48GB RTX 4090 诱惑对 VRAM 渴求的用户: 成员们讨论了从中国采购价格约为 $4500 的 48GB RTX 4090,作为提升 VRAM 的更廉价方式。这些显卡采用涡轮风扇设计,仅占用两个 PCIe 插槽,但与专业卡的驱动兼容性仍是一个担忧。
Theme 5. 版权、社区和 AI 伦理辩论持续升温
- 版权乱局持续:开源模型 vs. Anna’s Archive: 围绕使用受版权保护的数据训练 AI 的争论仍在继续,人们担心完全开源的模型因无法利用 Anna’s Archive 等资源而受到限制。像 LoRA 和合成数据生成等规避策略面临潜在的法律挑战。
- Rust 社区面临毒性指控: 成员们辩论了所谓的 Rust 社区 毒性问题,并将其与 Ruby 社区进行了比较,同时讨论了最近的组织问题。人们对社区在开源项目中的包容性和行为表示担忧。
PART 1: Discord 高层级摘要
Unsloth AI (Daniel Han) Discord
- 梯度累积步数(Gradient Steps)可能会毁掉你的模型:较小的有效 Batch Size(例如 batch=1, gradient steps = 4)会导致模型在训练过程中遗忘过多内容。用户分享了他们建议的 batch/grad 配置。
- 该成员表示,在尝试将更多内容挤进显存较小的设备(vramlet rig)时,“低于这个配置从未有过好运”。
- Gemma 3 的评估故障:数据集导致错误:用户报告在对 Gemma 3 进行微调时添加评估数据集会出现错误,这表明 trl 和 transformers 库中存在问题,潜在的修复方案包括移除评估数据集。
- 发现使用带有 1 个评估样本的 Gemma-3-1B 不会产生错误,完全移除评估(eval)也能解决该错误。
- Unsloth 对速度的追求:优化释放:Unsloth 团队宣布了支持 FFT、8-bit、PT 及所有模型的改进,进一步的优化使 4-bit 模型的 VRAM 占用减少了 +10%,速度提升了 >10%,此外还增加了 Windows 支持、改进了 GGUF 转换、修复了视觉微调,并支持了 4-bit 的非 Unsloth GRPO 模型,但目前尚不支持多 GPU(multigpu)。
- 用户注意到有很多人在协助让 Unsloth 变得更好。
- 细心格式化你的 RAG 数据!:当被问及如何为 RAG 聊天机器人微调模型时,成员建议在数据集中添加示例问题和示例回答,并包含来自文档的上下文,以便为机器人注入新知识。
- 建议聊天机器人数据应遵循
Q: A:格式,并可以使用在用户侧添加文档的 CPT 风格训练。
- 建议聊天机器人数据应遵循
- 剪枝让 Gemma-3-27b 更精简高效:一位成员将 Gemma-3-27b 的词表从原始的 260k 剪枝到了 40k tokens,以减少 VRAM 占用并提高训练速度。
- 该方法涉及基于校准数据的频率计数,并移除那些可以由合并/子词(merge/subword)表示的低频词元。
Cursor IDE Discord
- Windsurf 正在吸走 Cursor 的用户:用户对 Cursor 的性能问题(如延迟和崩溃)表示沮丧,由于可靠性担忧,一些用户正转向 Windsurf。
- 一位用户表示,“该死,Cursor 刚刚失去了他们最重要的客户”,这表明信心严重丧失。
- Cursor 的 Prompt 成本:成员们讨论了 Claude 3.7 的 Prompt 成本:普通 Prompt 为 $0.04,Sonnet Thinking 为 $0.08,Claude Max 每次 Prompt 和工具调用(tool call)为 $0.05。
- 一些用户反映,与直接使用 Claude API 相比,Cursor 的定价太贵了,质疑 Cursor 订阅的价值。
- 在 MCP 配置上 Linux 碾压 Windows:一位用户分享说,在 Linux 上使用 VMware 虚拟机设置 MCP server 比在 Windows 上遇到多个问题要顺畅得多。
- 这引发了一场关于整体开发和 MCP server 设置在 Linux 上是否普遍优于 Windows 的辩论,突出了各自的优缺点。
- Vibe Coding:是福还是祸?:Vibe Coding 的价值引发了辩论,一些人强调扎实编程知识的重要性,而另一些人则断言 AI 使得无需传统技能也能更快地进行创作。
- 这突显了软件开发格局的变化以及对 AI 对行业影响的不同看法。
- Claude Max 即将登陆 Cursor:Cursor 团队的一名成员宣布 Claude Max 即将登陆 Cursor,从而最大化模型的代码处理能力。
- 他们提到,该模型在处理大量输入时比以往的模型表现更好,释放了其全部潜力。
OpenAI Discord
- AI “精通”引发辩论:成员们讨论了熟练使用 AI tools 是否等同于真正的精通,质疑这仅仅是提高了生产力还是有削弱认知能力的风险,同时认为 AI 是一种学习的幻觉。
- 一位成员承认,由于 AI 的辅助,即使在了解某个主题时也会感到像是在“作弊”。
- Gemini 的图像润色:用户探索了 Gemini 的图像生成功能,注意到它编辑上传图像的能力,但也指出了水印和编码错误。
- 一些人称赞 Gemini 的回答非常自然,比起事实的精确性,他们更看重主观上的吸引力。
- GPT-4o 以幽默感给人留下深刻印象:成员们报告了使用 GPT-4o 的积极体验,其中一人表示它用起来最顺手,几乎可以做“任何事情”,还有成员报告说当其他人开始尝试时,出现了“有趣的结果”。
- 这表明 GPT-4o 在创意和多功能应用方面表现出色,提供了有趣的用户体验。
- AI 的自我反思:一位成员创建了一个系统,让 AI 在每次会话后反思其学习内容,存储反思以积累见解,并提出反思性问题。
- 被描述为“下一代未来感”,能够实现模拟中的模拟,以及注入核心特征集的多种人格。
- AI 梦之队指导业务:成员们讨论了组建一个 AI experts 团队来协助任务、规划,并为业务决策提供多样化的视角。
- 该 AI 专家团队将帮助向客户交付更好的产品,并协助处理项目或任务级别的需求。
Nous Research AI Discord
- MoE 模型:伪装的稠密网络?:辩论围绕 Mixture of Experts (MoE) 模型是否仅仅是稠密网络的性能优化,而非根本不同的架构展开,正如这篇论文所强调的。
- 讨论的核心在于 MoEs 是否能像稠密网络一样有效地捕捉复杂性,特别是在避免冗余方面。
- Mistral 的小奇迹:Small 3.1:根据 Mistral AI 博客的详细介绍,以 Apache 2.0 协议发布的 Mistral Small 3.1 是一款多模态模型,具备文本、图像能力,并扩展了 128k token context window。
- 据称其性能优于 Gemma 3 和 GPT-4o Mini 等其他小型模型。
- 版权乱象:开源模型 vs. Anna’s Archive?:关于使用受版权保护的数据训练 AI 的伦理辩论仍在继续,人们担心完全开源的模型会因为无法利用像 Anna’s Archive 这样的资源而受到限制,正如 Annas Archive 的博客文章中所讨论的。
- 规避策略包括使用 LoRAs 或生成合成数据,但这些方法未来可能面临法律挑战。
- 深度之咒再次袭来,这次是在 LLM 上:一篇新论文介绍了深度之咒 (Curse of Depth),揭示了由于 Pre-Layer Normalization (Pre-LN) 的广泛使用,现代 LLMs 中近一半的层效果不如预期,详见这篇 Arxiv 论文。
- 由于 Pre-LN,深层 Transformer 块的导数往往会变成单位矩阵。
- 工具时间:START 长 CoT 推理起飞:根据关于 START 的论文,START 是一种集成工具的长 CoT 推理 LLM,通过代码执行和自我调试等外部工具增强推理能力。
- 一位成员简洁地总结道:RL + tool calling == QwQ 上的数学提升 15% + 编程提升 39%。
aider (Paul Gauthier) Discord
- Aider 通过屏幕录制实现自我改进:Paul Gauthier 在一系列屏幕录制中展示了 aider 如何增强自身,演示了
--auto-accept-architect以及 tree-sitter-language-pack 的集成等功能。- 录制内容说明了 aider 如何编写文件下载脚本并使用 bash 脚本来修改文件集合。
- Claude 3.7 Sonnet 在 API 方面遇到困难:用户报告收到来自 Claude 3.7 Sonnet 的空响应,Anthropic 的状态页面确认了错误率上升。
- 一些成员推测由于这些错误,系统切换回了 Claude 3.5。
- MCP Server 提升 Aider 自主性:成员们强调 Claude Desktop + Aider on MCP 增强了自主性,由 Claude 管理 Aider 并发布命令。
- 一个关键优势是从 Claude Desktop 运行 Aider,提高了 Claude 引导 Aider 的能力,并利用 bee 进行无阻碍的网页抓取。
- 百度发布 ERNIE 4.5 和 X1 推理模型:百度推出了 ERNIE 4.5 和 X1,其中 X1 以一半的成本提供了与 DeepSeek R1 相当的性能,且 ERNIE Bot 现在对个人用户免费。
- 虽然 ERNIE 4.5 可以访问,但 X1 推理模型目前仅限中国境内用户使用。
- Anthropic 准备推出 Claude ‘Harmony’ Agent:Anthropic 正在发布 Harmony,这是 Claude 的一项新功能,赋予其对本地目录的完全访问权限,以便研究和操作其中的内容。
- 这可能是 Anthropic 迈向创建 AI Agent 的第一步。
LM Studio Discord
- Adreno GPU 获得 OpenCL 提升:llama.cpp 为 Qualcomm Adreno GPU 引入了一个实验性的 OpenCL 后端,有可能提升移动设备的计算能力。
- 此更新允许通过 OpenCL 利用移动设备中广泛使用的 Adreno GPU。
- 4070 Ti 用户考虑升级 5090:一位拥有 4070 Ti 的用户考虑升级到 5090,但由于缺货问题,建议等待或考虑二手的 RTX 3090,因为它拥有 36GB VRAM。
- 二手 RTX 3090 将提供足够的 VRAM,以合理的运行速度运行 50B 以下的 Q4 模型。
- Mistral Small 3.1 胜过 Mini:Mistral 发布了 Mistral Small 3.1 模型,声称其性能优于 Gemma 3 和 GPT-4o Mini,但该版本在 llama.cpp 中使用前需要转换为 HF 格式。
- 用户正在等待发布,但承认在开始使用之前需要将其转换为 HF 格式。
- 通过内存调优最大化 M4 Max 性能:用户探索了在 M4 Max 设备上为 LM Studio 优化内存设置,建议使用此脚本调整 ‘wired’ 内存分配,以提高 GPU 性能。
- 该脚本有助于调整 macOS GPU 内存限制,允许用户通过修改 wired 内存设置向 GPU 分配更多内存。
- AMD APU 性能将超越 RTX 5080?:分享了一篇来自 wccftech 的文章,声称 AMD 的 Ryzen AI MAX+ 395 “Strix Halo” APU 由于其更大的 VRAM 池,在 DeepSeek R1 AI 基准测试中可能提供超过 RTX 5080 3 倍的提升。
- 社区保持谨慎乐观,等待实际数据来证实这些性能主张。
OpenRouter (Alex Atallah) Discord
- Anthropic API 故障影响 Claude 3 Sonnet:根据 Anthropic 状态页面 的报告,向 Claude 3.7 Sonnet 发出的请求在大约 30 分钟内出现了错误率上升的情况。
- 该问题随后得到解决,成功率恢复正常,但一些用户反映,尽管回复中没有收到任何文本,但仍被扣费。
- Personality.gg 进入 AI 角色领域:Personality.gg 推出了一个新平台,可以使用 Claude、Gemini 和 Personality-v1 等模型创建 AI 角色、进行聊天和互动,具有自定义主题和完整的聊天控制功能。
- 该平台提供灵活的方案,并鼓励用户加入其 Discord 获取更新,同时宣传允许 NSFW 内容。
- Parasail 计划托管新的 RP 模型:Parasail 正寻求在 OpenRouter 上托管新的 Roleplay (RP) 模型,并正积极与 TheDrummer 等创作者合作,托管 Gemma 3 和 QwQ 等模型的新 fine-tunes 版本。
- 他们正在寻找能够创建强大 RP fine-tunes 的个人,这些模型需具备处理复杂指令和世界观的能力,特别关注针对角色扮演和创意写作进行微调的模型。
- OpenRouter API 速率限制详情:根据 官方文档,OpenRouter 的速率限制取决于用户充值额度,大约 1 USD 对应 1 RPS(每秒请求数)。
- 虽然购买更多额度可以提高速率限制,但用户发现创建额外的账户或 API keys 没有任何区别。
- Mistral Small 3.1 带着视觉能力发布:Mistral Small 3.1 24B Instruct 模型已在 OpenRouter 上线,根据 Mistral 的公告,该模型具备 多模态能力 和 128k 上下文窗口。
- 公告声称其性能优于 Gemma 3 和 GPT-4o Mini 等同类模型,同时推理速度达到每秒 150 tokens。
Perplexity AI Discord
- Perplexity 保证准确性:Perplexity 推出了口号 “当你需要准确无误时,请咨询 Perplexity”,并发布了 一段 Perplexity 视频广告。
- Windows 上的 Perplexity 用户通过 连续 7 天 使用该应用,可以获得 1 个月的 Perplexity Pro。
- Gemini 2 Flash 上下文引发热议:用户正在讨论 Gemini 2 Flash 的上下文保留能力,据称它拥有 1M 上下文窗口,但表现不如常规的 Gemini。
- 一位用户声称,在制作记忆卡片(flashcards)时,它在几条消息后就会 忘记格式。
- Claude 3.7 Sonnet 存在硬性限制:用户澄清,通过 Perplexity Pro 订阅 使用的 Claude 3.7 Sonnet 每天有 500 次查询 的限制,该限制在除 GPT 4.5 以外的模型间共享。
- 他们还指出,上下文限制可能比 Anthropic 官网略多,但响应上下文限制较小,仅为 4000 或 5000 tokens。
- 专家寻求卓越的编程助手:用户正在寻求关于 最佳编程 AI 模型 的指导,建议指向了 Claude 3.7 Reasoning。
- 一位用户报告称 Deepseek R1 的 幻觉率很高,不适合总结文档;但有人分享了 百度 (@Baidu_Inc) 的推文 链接,声称 ERNIE X1 的性能与 DeepSeek R1 相当,而价格仅为一半。
- Sonar Reasoning Pro 存在图片限制:一位用户报告称 sonar-reasoning-pro API 最多返回 5 张图片。
- 该用户正在询问此限制是可配置的还是硬性约束。
Yannick Kilcher Discord
- Rust 社区收到无礼言论:成员们讨论了 Rust 社区 的毒性,有人将其与 Ruby 社区进行比较,并指向了此 Github issue 和 来自 will brown 的推文。
- 一位成员表示:Rust 社区相当毒。该组织最近内部有些崩溃。
- C 语言被称为“古老且破碎”:一位成员将 C 描述为古老、破碎且垃圾,而另一位成员则认为 C 并没有破碎,并通过此 链接 强调了其在国际标准中的应用。
- 一位成员链接到 faultlore.com,认为 C 语言不再是一种编程语言了。
- 优化与搜索,并非一回事?:成员们讨论了 优化(寻找函数的最大值或最小值)与 搜索(寻找集合中的最佳元素)之间的区别,并指向了 重参数化技巧 (Reparameterization trick)。
- 一位成员表示:搜索是探索,不像优化。
- Gemma 3 获得视觉和上下文能力:Gemma 3 集成了 视觉理解、多语言覆盖和扩展的上下文窗口(高达 128K tokens),观看 YouTube 视频。
- 它集成了一个冻结的 SigLIP 视觉编码器,将图像压缩为 256 个软 tokens,并采用了一种新的 Pan & Scan (P&S) 方法。
- Mistral Small 3.1 大放异彩:Mistral AI 宣布发布 Mistral Small 3.1,在 Apache 2.0 许可下,拥有改进的文本性能、多模态理解和 128k token 上下文窗口。
- 该公司声称其性能优于 Gemma 3 和 GPT-4o Mini 等同类模型,推理速度达到 每秒 150 个 tokens。
HuggingFace Discord
- SmolVLM2 缩小了 VLM 的体积:团队发布了 SmolVLM2,这是目前能理解视频的最小 VLM,其 500M 版本 可以在 iPhone 应用上运行。
- 源代码和 TestFlight 测试版已提供参考。
- 简易版新 Gradio 发布!:Gradio Sketch 2.0 现在支持通过事件构建完整的 Gradio 应用,无需编写一行代码。
- 新功能使用户能够通过 GUI 构建应用程序。
- DCLM-Edu 数据集完成清理:发布了一个新数据集 DCLM-Edu;它是使用 FineWeb-Edu 分类器过滤的 DCLM 版本,专门为 SmolLM2 135M/360M 等 smol 模型 进行了优化。
- 其目的是因为 小模型对噪声很敏感,可以从高度精选的数据中受益。
- Coding Vibes 获得 Awesome 列表:公布了一个 “Awesome Vibe Coding” 列表,包含 工具、编辑器和资源,使 AI 辅助编程更加直观和高效。
- 该列表包括 AI 驱动的 IDE 和代码编辑器、基于浏览器的工具、插件和扩展、命令行工具以及最新的新闻和讨论。
- AI Agents 协作正在酝酿中:几位成员表示有兴趣 在 Agentic AI 项目上进行协作,以解决业务问题并增强知识。
- 该行动号召旨在组建团队,为美国消费者构建合格的 AI Agents 并共同学习。
Interconnects (Nathan Lambert) Discord
- Figure 的 BotQ 批量生产人形机器人:Figure 宣布推出 BotQ,这是一个全新的大规模制造设施,其第一代生产线每年可生产多达 12,000 台人形机器人,实现了制造的垂直整合并构建了软件基础设施。
- 该公司旨在控制构建过程和质量,甚至暗示了“机器人制造机器人”的前景。
- 百度 ERNIE X1 媲美 DeepSeek,现已免费!:百度发布了 ERNIE 4.5 和 ERNIE X1,据报道 X1 的性能在价格减半的情况下达到了 DeepSeek R1 的水平。百度还宣布其聊天机器人 ERNIE Bot(文心一言)现对个人用户免费,可在其官网使用。
- 根据这条推文,百度计划在 6 月 30 日开源庞大的 4.5 模型,并在未来逐步向开发者开放。
- Mistral Small 3.1 首次亮相,配备超大上下文窗口:Mistral AI 发布了 Mistral Small 3.1,这是一款提升了文本性能、多模态理解能力并具备 128k token 上下文窗口的新模型。其推理速度达每秒 150 token,表现优于 Gemma 3 和 GPT-4o Mini 等模型,并已根据 Apache 2.0 许可证发布。
- 该模型声称达到了 SOTA 级别,且具备多模态和多语言能力。
- OpenAI 后训练副总裁离职投身材料科学:OpenAI 负责 post-training(后训练)的研究副总裁 Liam Fedus 将离开公司,创办一家材料科学 AI startup。OpenAI 计划投资并与其新公司开展合作。
- 根据这条推文,一位成员将后训练的工作称为“烫手山芋”。
- DAPO 中发现大规模数据集重复:DAPO 的作者意外地将数据集重复了约 100 倍,导致数据集大小达到 310 MB。一名成员通过 HF 的 SQL 控制台创建了一个去重版本,将数据集缩减至 3.17 MB(HuggingFace 数据集)。
- 根据这条推文,作者承认了这一问题,表示他们已知晓但“负担不起重新训练的费用”。
MCP (Glama) Discord
- 多 Agent 拓扑结构引发辩论:成员们就多 Agent 系统的 Swarm、Mesh 和 Sequence 架构展开辩论,寻求关于如何防止子 Agent 偏离轨道的建议,特别是由于“传声筒效应”导致的问题。
- 核心问题可能在于“并行执行”和“无监督自主性”,而在 handoff(移交)过程中 Agent 交换系统指令、可用函数甚至模型,使问题更加复杂。
- OpenSwarm 演变为 OpenAI-Agents:OpenSwarm 项目已被 OpenAI 采纳并更名为 openai-agents,增加了 OpenAI 特有的功能,但一项关于 MCP 支持的 PR 被拒绝了。
- 有传言称 CrewAI(或 PraisonAI?)可能会使用“无状态单线程 Agent 方法”提供类似功能。
- MyCoder.ai 在 Claude-Code 之前抢先亮相:mycoder.ai 的发布恰逢 Claude-code 的发布公告,促使其通过一篇登上首页的 Hacker News 帖子进行适配,详见此处。
- 鉴于 claude-code 仅限 Anthropic 使用,市场对通用替代方案有需求,一名成员使用 litellm proxy 成功解决了这一问题。
- Glama 服务器检查频率引发讨论:成员们询问 Glama 扫描 的频率以及是否可以触发 MCP 服务器的重新扫描;扫描频率与关联 GitHub 仓库的提交频率挂钩。
- 即使在修复了依赖问题后,某些服务器仍无法检查,显示“无法检查服务器”,可在 Glama AI 关注进度。
- Vibe Coders 联合起来!:Awesome Vibe Coding 列表收录了 AI 辅助编码工具、编辑器和资源,旨在增强编码的直观性和效率。
- 该列表包括 AI 驱动的 IDE、基于浏览器的工具、插件和 CLI。甚至有一位 AI 编码员向该仓库提交了 PR,并建议添加 Roo Code。
Latent Space Discord
- GPT-o1 数学技能接近人类水平:GPT-o1 在 Carnegie Mellon 本科数学考试中获得了满分,每道题的解题时间不足一分钟,成本约为 5 美分,详见此推文。
- 讲师对此印象深刻,指出这接近了能够胜任中等难度非例行技术工作的临界点。
- 百度的文心一言(ERNIE)具备成本竞争力:百度发布了 ERNIE 4.5 和 ERNIE X1,据此公告称,后者的性能可与 DeepSeek R1 媲美,但成本仅为一半。
- 值得注意的是,文心一言(ERNIE Bot) 已提前向个人用户免费开放,两款模型均可在官网使用。
- AI 播客应用走向户外:Snipd 发布了由 Kevin Smith 主持的新播客,讨论了用于学习的 AI 播客应用。
- 本期节目是他们的首个“户外”播客,@swyx 和 @KevinBenSmith 聊到了 aidotengineer NYC、从金融转向科技行业的心路历程,以及 @snipd_app 的技术栈。
- 关于 Claude 3.5 与 3.7 优劣的辩论:成员们讨论了使用 Claude 3.5 而非 3.7 的优点,理由是 3.7 过于积极,会在未被要求的情况下执行操作。
- 其他人表示他们在利用 Claude 3.5 时也遇到了 GPU 问题。
Notebook LM Discord
- 用户渴望集成 Gemini 的 Android 体验:多位用户请求提供完整的 Gemini 集成 Android 体验,希望将 Google Assistant/Gemini 与 NotebookLM 结合。
- 一些用户对目前的 Gemini 实现表示失望,正焦急地等待升级。
- Deepseek R1 震撼 AI 市场:一位用户指出,由于 Deepseek R1 的发布,AI 市场发生了剧变,其低成本的推理能力影响了 Gemini 2.0。
- 该用户声称 Deepseek R1 似乎震撼了整个行业,从而促使其他公司发布新模型。
- NotebookLM 音频概览时长增加:一位用户希望增加 NotebookLM 生成的音频概览(Audio Overviews)长度,因为 16,000 字的文件仅生成了 15 分钟的概览。
- 他们明确要求至少 1 小时以上的概览,但目前尚未有解决方案分享。
- NotebookLM 辅助精神科药物减量:一位用户利用 NotebookLM 为某种精神科药物创建了“双曲线减量计划”,并参考相关性研究来指导该计划。
- 另一位用户提醒,在任何平台上基于数据进行减量都不应在没有专业专家意见的情况下独自进行。
- NotebookLM 集成至内部门户/CRM:一位用户希望将 NotebookLM 与包含视频和知识库文章的内部门户/CRM 集成,有人建议使用 Agentspace 作为解决方案。
- 由于 NotebookLM 不支持连接到上述类型的数据源,而 Agentspace 包含并集成了 NotebookLM。
GPU MODE Discord
- Triton-Windows 现已支持 PIP 安装:Triton-windows 已发布至 PyPI,因此你可以通过
pip install -U triton-windows进行安装/升级,不再需要从 GitHub 下载 wheel 文件。- 此前,用户必须手动管理 wheel 文件,使得更新过程更加繁琐。
- Torch Compile 在反向传播中变慢:有成员报告称,虽然 torch.compile 在前向传播中表现良好,但在为自定义 Kernel 使用 torch.autograd.Function 时,反向传播的速度相当慢。
- 使用
torch.compile(compiled_backward_fn)包装反向传播函数可能会解决性能问题。
- 使用
- 分享 NVIDIA SASS 指令历史:一位成员分享了一个 gist,对比了不同架构下的 NVIDIA SASS 指令,这些指令是利用 Python 从 NVIDIA 的 HTML 文档中提取并对比的。
- 这让用户能够追踪 NVIDIA GPU 系列中指令集的演进。
- Reasoning Gym 突破 100 个数据集!:Reasoning Gym 项目现在拥有 101 个数据集,庆祝开发者们的贡献。
- 不断增长的数据集集合将为 LLM 测试提供更全面的支持。
- Jake Cannell 招募 GPU 高手:Jake Cannell 正在招聘 GPU 开发者,以实现他在演讲中提到的想法,同时 nebius.ai 的 GPU 云服务也受到了推崇。
- 这对于那些对 AGI 或类脑硬件(neuromorphic hardware)感兴趣的人来说非常相关。
Eleuther Discord
- EleutherAI 欢迎 Catherine Arnett:EleutherAI 欢迎 Catherine Arnett,她是一位专注于计算社会科学和跨语言 NLP 的 NLP 研究员,致力于确保模型在不同语言间表现“同样出色”。
- 新型 Block Diffusion 模型发布:一篇新论文介绍了 Block Diffusion,这是一种在自回归(autoregressive)和扩散(diffusion)语言模型之间进行插值的方法,结合了两者的优势:高质量、任意长度、KV caching 以及可并行性,详情见论文和代码。
- 它结合了自回归和扩散语言模型的优点。
- VGGT 生成元宇宙 GLB 文件!:一位成员分享了 VGGT,这是一个前馈神经网络,可以从多个视角推断 3D 属性并生成 GLB 文件,这些文件可以直接集成到元宇宙中。
- 该成员表示:“我非常喜欢它能导出 GLB 文件。这意味着我可以原封不动地将它们直接放入我的元宇宙中。”
- Gen Kwargs 完美拥抱 JSON:
--gen_kwargs参数正从逗号分隔的字符串转换为 JSON,从而允许更复杂的配置,例如'{"temperature":0, "stop":["abc"]}'。- 讨论中探讨了同时支持两种格式以方便使用的可能性,特别是对于标量值。
- LLM 排行榜:训练集 vs 验证集划分:旧版 LLM 排行榜的组配置与实际使用的设置之间存在差异,特别是在 arc-challenge 任务方面。
- 已创建一个 PR 来修复此问题,以解决
openllm.yaml配置(指定validation作为 fewshot 划分)与原始排行榜(使用train划分)之间的不一致。
- 已创建一个 PR 来修复此问题,以解决
tinygrad (George Hotz) Discord
- Tinygrad SDXL 性能落后于 Torch:在 7900 XTX 上对 tinygrad 的 SDXL 进行基准测试显示,在 AMD backend 上使用 BEAM=2 时速度为 1.4 it/s,而 torch.compile 使用 FlashAttention 和 TunableOp ROCm 达到了 5.7 it/s。
- George Hotz 建议对比 kernel 以寻找优化机会,目标是在年底前超越 torch。
- Tensor Cat 依然缓慢:一位致力于提高 tensor cat 速度的成员在 X 上分享了白板构思(链接),指出尽管对 devectorizer 进行了更改,速度仍然很慢。
- 他们怀疑生成的 IR 和加载 numpy arrays 存在问题,正考虑通过 ELF 和 LLVM 使用自定义 C/C++ 来克服限制。
- BLAKE3 悬赏细节明朗化:高性能并行 BLAKE3 悬赏的状态已明确,截图(链接)显示了更新后的悬赏状态。
- 该成员更新了电子表格,并指出渐近性能(asymptotic performance)是该悬赏的关键要求。
- WebGPU 集成势头强劲:有成员询问如何发布基于 resnet18 的 electron/photon 分类器的 Tinygrad 实现作为示例,并被引导至一个改进 WebGPU 集成的 PR。
- 建议创建一个托管在 GitHub Pages 上的 WebGPU demo,并将权重放在 Hugging Face 上以供免费访问和测试。
- Tinygrad 在 Lazy Mode 调试中遇到困难:一位成员在 Tinygrad 中通过 print-debugging 中间 tensor 值时遇到了 gradients 的断言错误,尽管由于 lazy computation 的问题使用了
.detach()。- 鉴于 lazy computation 不是幂等的(idempotent),该成员正在寻找比将值线程化输出更好的方法。
{kind=link}
LlamaIndex Discord
- LlamaIndex 展示带有 Corrective RAG 的 Agentic 推理:LlamaIndex 介绍了一个关于使用 corrective RAG 构建用于搜索和检索的 agentic reasoning system 的分步教程,该系统由 LlamaIndex workflows 编排。
- 该教程使用户能够编排复杂的、可定制的、事件驱动的 Agent。
- LlamaExtract 从云端推出:LlamaExtract 解决了从复杂文档中提取结构化数据的问题,目前处于公开测试阶段,可在 cloud.llamaindex.ai 上使用,提供 web UI 和 API。
- 用户可以定义 schema 来自动提取结构化数据;更多详细信息请参见此处。
- 多模态 AI Agent 在 NVIDIA GTC 2025 展开对决:Vertex Ventures US 和 CreatorsCorner 将在 NVIDIA GTC 2025 举办一场 AI hackathon,挑战参与者开发复杂的多模态 AI Agent。
- 该黑客松为能够进行战略决策并与各种工具交互的 Agent 提供 $50k+ 奖金;更多信息可以在此处找到。
- 社区推出视觉语言模型中心:一位社区成员为专注于视觉语言模型 (VLMs) 的多模态研究人员推出了一个社区驱动的中心。
- 创建者正在积极寻求贡献和建议,并计划每周更新该中心。
- Pydantic AI 与 LlamaIndex 的竞争:新用户想知道用于构建 Agent 的 Pydantic AI 和 LlamaIndex 框架之间的区别,尤其是初学者应该使用哪一个。
- LlamaIndex 团队成员表示,最适合你开发思维模型的框架可能就是最好的选择。
Nomic.ai (GPT4All) Discord
- Gemma 的语言能力令人印象深刻:成员们观察到 Gemma、DeepSeek R1 和 Qwen2.5 模型在回答关于“将密封罐子放在零下温度的室外会发生什么”的谜题时,都能以多种语言提供正确答案。
- 虽然其他模型预测罐子会发生灾难性损坏,但 Gemma 提供了更有帮助且更细致的建议。
- Gemma 3 集成遭遇许可障碍:用户正在等待 GPT4All 支持 Gemma 3,但由于 Hugging Face 上的许可协议问题,其集成因等待 Llama.cpp 更新而推迟,详情见 此 GitHub issue。
- 有推测认为 Google 是否会监管那些规避其许可协议的重新分发行为。
- LocalDocs 用户遭遇崩溃困扰:一位新用户报告在崩溃并重新安装后丢失了 LocalDoc 集合,并寻求防止未来崩溃导致数据丢失的建议。
- 资深用户建议定期保存 localdocs 文件并在崩溃后进行恢复,并补充说“有时仅一个损坏的 PDF 就能导致系统崩溃”。
- 通过更好的 Prompt 提升 O3-mini:一位用户分享了一个针对 O3-mini 的 Prompt,用于解释其思考过程,并建议通过要求 thinking(思考)和 reflection(反思)部分(包含逐步推理和错误检查)来改进任何模型的蒸馏(distillation)。
- 现在解释复杂过程变得更加容易。
Cohere Discord
- Cohere 推迟 Command A 的微调(Fine-Tuning):尽管社区充满期待,Cohere 团队成员确认目前尚无计划在平台上启用 Command A 的微调。
- 他们向社区保证会提供更新,但这与部分用户对快速部署功能的预期有所背离。
- Azure Terraform 问题阻碍 Rerank v3:一位用户在使用 Terraform 创建 Azure Cohere Rerank v3 时遇到错误,并分享了代码片段和生成的错误消息。
- 该问题已被重定向至 <#1324436975436038184> 频道,表明需要专门的关注或调试。
- 社区呼吁建立 CMD A 私有频道:一位成员建议创建一个专门讨论 CMD A 私有部署的频道,特别是为了支持客户的本地部署。
- 该提议获得了热烈支持,凸显了社区对本地部署或私有云解决方案的兴趣。
- Vercel SDK 在 Cohere 对象处理上出现失误:一位用户指出 Vercel SDK 错误地认为 Cohere 的 Command A 模型不支持对象生成(object generation)。
- 这种差异可能会影响使用该 SDK 的开发者,需要 Cohere 和 Vercel 团队的关注以确保准确集成。
- 自由职业者提供编程帮助:一位 30 岁的日本男性自由程序员介绍了自己,并表示愿意用他的编程技能帮助社区成员。
- 呼应了“互相帮助是我们生存的支柱”这一情感。
DSPy Discord
- DSPy 考虑集成 MCP:一位成员对集成 dspy/MCP 感兴趣,并链接了一个 GitHub 示例来阐述他们的建议。
- 另一位成员担心添加 MCP 主机、客户端和服务器是否会使过程过于复杂。
- DSPy 弃用 Assertions 和 Suggestions:用户注意到 DSPy 中关于 Assertions / Suggestions 的 文档消失了,并询问它们是否仍受支持。
- 他们希望验证输出(特别是格式),并观察到 LLM 并不总是遵守格式的情况。
- Output Refinement 作为 Assertion 的替代方案登场:在 DSPy 2.6 中,Assertions 被使用
BestOfN和Refine等模块的 Output Refinement 所取代,详见 DSPy 文档。- 这些模块旨在通过使用不同的参数设置进行多次 LM 调用,来增强预测的可靠性和质量。
- QdrantRM 悄然退出 DSPy:用户询问 QdrantRM 是否已在 DSPy 2.6 中被移除。
- 提供的上下文中未给出解释。
LLM Agents (Berkeley MOOC) Discord
- Caiming Xiong 演讲关于 Multimodal Agents:Salesforce 的 Caiming Xiong 讲解了 Multimodal Agents,涵盖了跨多种模态的 perception, grounding, reasoning 和 action 的集成,该演讲在 YouTube 上进行了直播。
- 演讲讨论了在现实环境(OSWorld)中衡量能力以及创建大规模数据集(AgentTrek)的问题,引用了超过 200 篇论文和 >50,000 次引用。
- Self-Reflection 面临二分性:成员们讨论了 Lecture 1 和 Lecture 2 之间关于 LLM 中 self-reflection 和 self-refinement 的明显矛盾。一位用户指出,Lecture 1 提到需要外部评估,而 Lecture 2 则建议 LLM 可以通过奖励自己的输出来改进自身。
- System Prompt 的可靠性受到质疑:一位成员建议,依赖 system prompts 的特定行为可能并不可靠,因为归根结底,所有这些都是文本输入,模型可以处理它,所以你应该能够绕过框架和服务。
- 该成员补充说,训练数据可能包含格式
<system> You are a helpful assistant </system> <user> {{Some example user prompt}} </user> <assistant> {{Expected LLM output}} </assistant>。
- 该成员补充说,训练数据可能包含格式
- 高级 LLM Agent 课程报名仍开放:成员们询问是否仍可以报名 Advanced LLM agent course 并在报名后获得 certificate。
- 工作人员回复说,只需完成 signup form 即可!介绍幻灯片中的大部分信息仅适用于 Berkeley 学生,但任何人都可以参加 MOOC 并在结束时获得 certificate。
{kind=link}
{kind=link}
Modular (Mojo 🔥) Discord
- Modular 因 AI 艺术美学受到赞赏:一位成员对 Modular 在其营销材料中使用的 AI art 表示欣赏。
- 他们表示:“Modular 使用的所有 AI 艺术都很棒!”
- Compact Dict:它过时了吗?:关于 Mojo 中 compact-dict 实现状态的讨论浮出水面。
- 成员们建议,原始版本的功能可能已经集成到 stdlib 的
Dict中。
- 成员们建议,原始版本的功能可能已经集成到 stdlib 的
- SIMD 和 stdlib Dict 性能问题:一位用户在使用 stdlib Dict 处理 SIMD [float64, 1] 类型时遇到了性能瓶颈。
- 瓶颈归因于 hash 库中
hash()函数的缓慢,促使寻找更快的替代方案。
- 瓶颈归因于 hash 库中
- Discord 频道收到垃圾信息:一位成员澄清说,Discord 频道中的某些消息被归类为垃圾信息,另一位成员迅速确认了这一点。
- 未提供有关垃圾信息性质或来源的进一步细节。
MLOps @Chipro Discord
- SVCFA 启动 AI4Legislation 竞赛:硅谷华人协会基金会 (SVCAF) 正在举办 AI4Legislation 竞赛,奖金高达 $3,000,活动持续至 2025 年 7 月 31 日,鼓励用于立法参与的开源 AI 解决方案;竞赛仓库现已上线。
- SVCAF 将于 2025 年 3 月底举行关于该竞赛的在线研讨会;在此处 RSVP。
- Dnipro VC 举办 AI Demo Jam:Dnipro VC 和 Data Phoenix 将于 3 月 20 日在加州 Sunnyvale 举办 AI Demo Jam,届时将有 5 家 AI 初创公司展示其产品。
- 活动将包括来自 Marianna Bonechi (Dnipro VC)、Nick Bilogorskiy (Dnipro VC)、Dmytro Dzhulgakhov (fireworks.ai) 的专家小组讨论、开放式麦克风推介和高能量的社交环节;在此处 注册。
- 成员寻求 MRI Object Detection 帮助:一位成员请求帮助创建一个用于 MRI 图像 object detection 的模型,不提供金钱报酬。
- 未提供关于模型类型、数据可用性或使用场景的具体细节。
AI21 Labs (Jamba) Discord
- Qdrant 请求被断然拒绝:一名成员建议切换到 Qdrant,但另一名成员确认他们目前并未使用它。
- 该建议在没有进一步解释的情况下被否决;不,我们没有使用 Qdrant。
- 用户请求 API 支持重复惩罚(Repetition Penalty):一位用户请求在 API 中增加 repetition penalty 支持,并指出这是阻碍 Jamba 模型更广泛采用的关键功能。
- 该用户表示,缺乏重复惩罚支持是限制他们增加模型使用量的唯一因素。
Torchtune Discord
- Mistral 发布 Small 3-1:Mistral AI 发布了 Mistral Small 3-1,点击此处查看。
- 未提供更多细节。
- 可学习标量(Learnable Scalars)帮助模型收敛:一篇新论文 Mitigating Issues in Models with Learnable Scalars 提出引入 learnable scalar 来帮助模型正常收敛。
- 这为稳定训练提供了一种实用的方法。
Codeium (Windsurf) Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
第 2 部分:频道详细摘要与链接
完整的频道细分内容已在邮件中截断。
如果您喜欢 AInews,请分享给朋友!预先感谢!